⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-08 更新
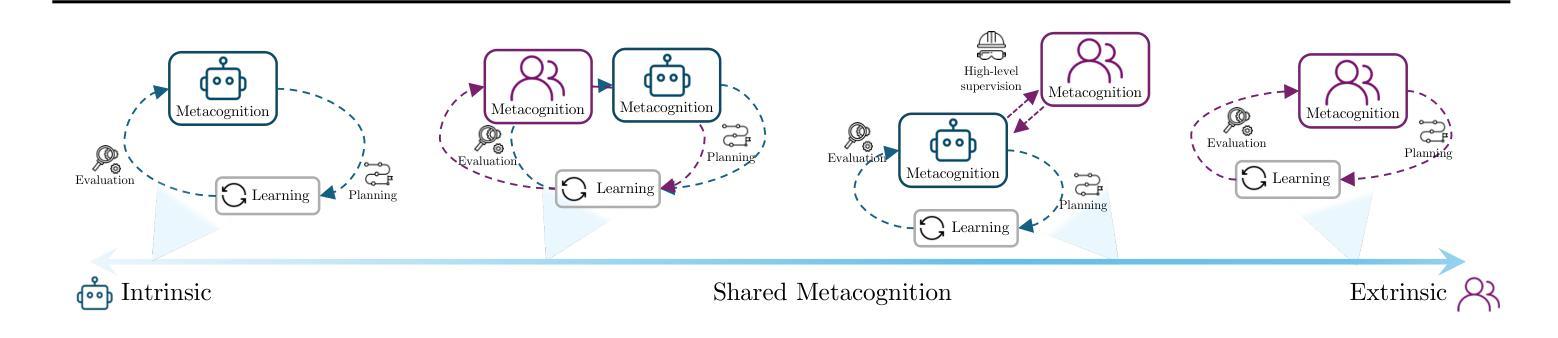
Truly Self-Improving Agents Require Intrinsic Metacognitive Learning
Authors:Tennison Liu, Mihaela van der Schaar
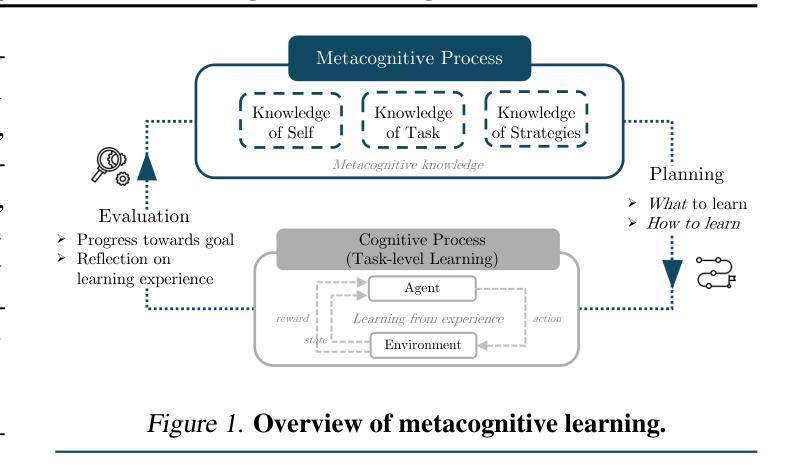
Self-improving agents aim to continuously acquire new capabilities with minimal supervision. However, current approaches face two key limitations: their self-improvement processes are often rigid, fail to generalize across tasks domains, and struggle to scale with increasing agent capabilities. We argue that effective self-improvement requires intrinsic metacognitive learning, defined as an agent’s intrinsic ability to actively evaluate, reflect on, and adapt its own learning processes. Drawing inspiration from human metacognition, we introduce a formal framework comprising three components: metacognitive knowledge (self-assessment of capabilities, tasks, and learning strategies), metacognitive planning (deciding what and how to learn), and metacognitive evaluation (reflecting on learning experiences to improve future learning). Analyzing existing self-improving agents, we find they rely predominantly on extrinsic metacognitive mechanisms, which are fixed, human-designed loops that limit scalability and adaptability. Examining each component, we contend that many ingredients for intrinsic metacognition are already present. Finally, we explore how to optimally distribute metacognitive responsibilities between humans and agents, and robustly evaluate and improve intrinsic metacognitive learning, key challenges that must be addressed to enable truly sustained, generalized, and aligned self-improvement.
自我完善代理旨在以最小的监督持续获取新的能力。然而,当前的方法面临两个主要局限性:它们的自我完善过程通常很僵化,无法跨任务领域进行推广,并且很难随着代理能力的增强而扩展。我们认为有效的自我完善需要内在的认知学习,这被定义为代理主动评估、反思和适应其自身学习过程的内生能力。从人类认知中汲取灵感,我们引入了一个正式框架,包括三个组成部分:认知知识(对能力、任务和策略的自我评价)、认知规划(决定要学习什么和如何学习)、认知评估(反思学习经验以改进未来的学习)。分析现有的自我完善代理,我们发现它们主要依赖于外在的认知机制,这些机制是固定的、人为设计的循环,限制了可扩展性和适应性。考察每个组成部分,我们认为内在认知的许多要素已经存在。最后,我们探讨了如何在人类和代理之间最优地分配认知责任,并稳健地评估和改进内在的认知学习,这是必须解决的关键挑战,以实现真正持续、通用和对齐的自我完善。
论文及项目相关链接
PDF Published as a conference paper at ICML 2025
Summary:
自我提升的智能体旨在以最小的监督持续获得新的能力。然而,当前的方法面临两大局限:它们的自我提升过程往往僵化,无法跨任务域进行推广,并且难以随着智能体能力的提升而扩展。本文主张有效的自我提升需要内在元认知学习,这被定义为智能体对其自身学习过程的主动评估、反思和适应的内在能力。本文借鉴人类元认知的灵感,引入了一个包含三个组件的正式框架:元认知知识(对能力、任务和策略的自我评价)、元认知规划(决定学什么以及如何学习)和元认知评估(对学习经验的反思以改进未来的学习)。通过分析现有的自我提升智能体,我们发现它们主要依赖于外在的元认知机制,这些机制是固定的、人为设计的循环,限制了可扩展性和适应性。本文探讨了每个组件中内在元认知的现有成分,并探讨了如何在人类和智能体之间最优地分配元认知责任,以及如何稳健地评估和改进内在元认知学习,这是实现真正持续、通用和对齐的自我提升必须解决的关键挑战。
Key Takeaways:
- 自我提升的智能体旨在持续获取新能力,但当前方法面临过程僵化和无法跨任务域推广的问题。
- 有效的自我提升需要内在元认知学习,包括自我评估、规划和评估的智能体能力。
- 现有智能体主要依赖外在元认知机制,限制了其可扩展性和适应性。
- 借鉴人类元认知的灵感,提出了包含元认知知识、规划和评估的正式框架。
- 分析认为,许多内在元认知的成分已经存在于现有的智能体中。
- 最优地分配人类和智能体之间的元认知责任是关键挑战之一。
点此查看论文截图

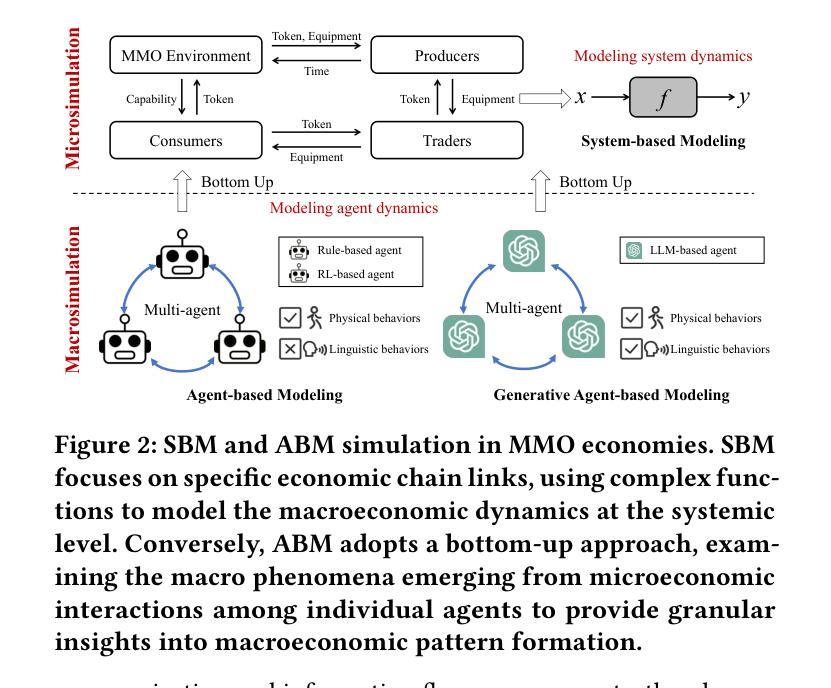
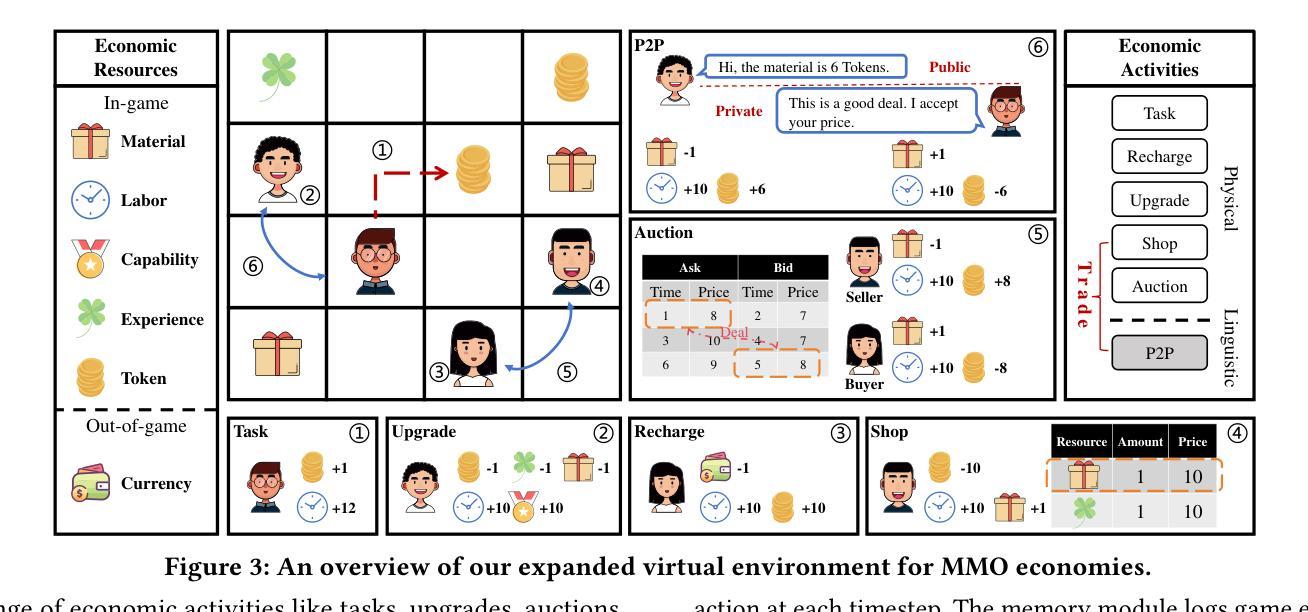
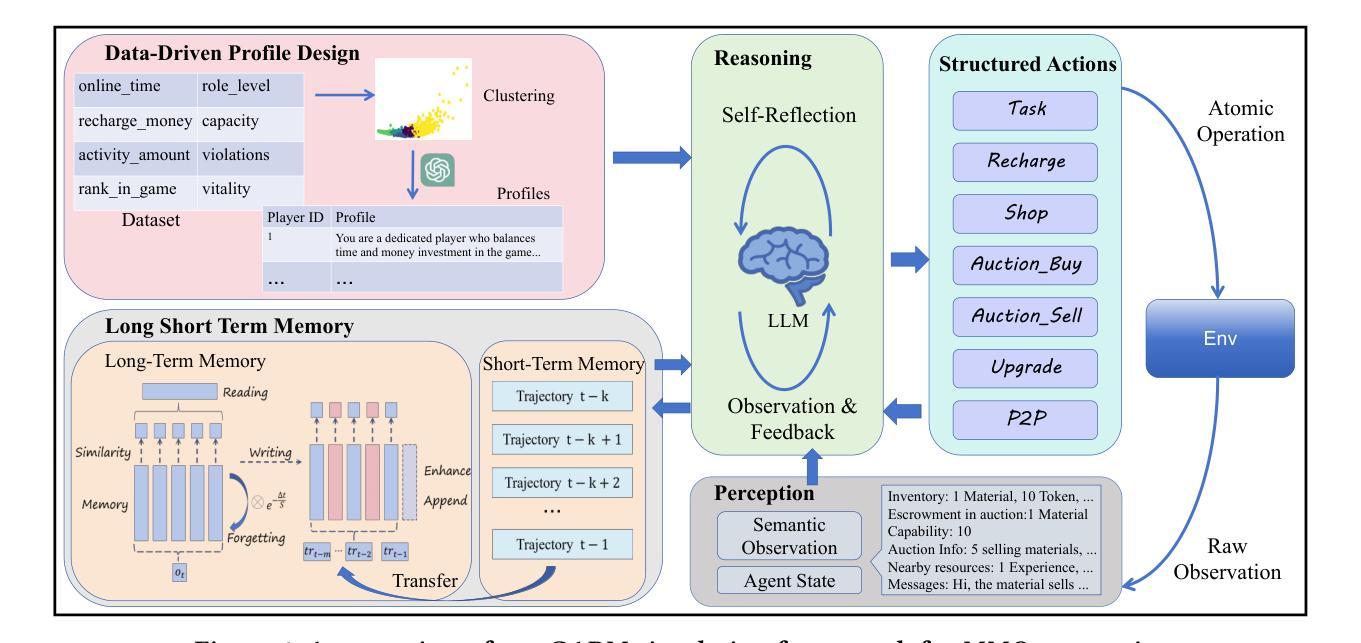
Empowering Economic Simulation for Massively Multiplayer Online Games through Generative Agent-Based Modeling
Authors:Bihan Xu, Shiwei Zhao, Runze Wu, Zhenya Huang, Jiawei Wang, Zhipeng Hu, Kai Wang, Haoyu Liu, Tangjie Lv, Le Li, Changjie Fan, Xin Tong, Jiangze Han
Within the domain of Massively Multiplayer Online (MMO) economy research, Agent-Based Modeling (ABM) has emerged as a robust tool for analyzing game economics, evolving from rule-based agents to decision-making agents enhanced by reinforcement learning. Nevertheless, existing works encounter significant challenges when attempting to emulate human-like economic activities among agents, particularly regarding agent reliability, sociability, and interpretability. In this study, we take a preliminary step in introducing a novel approach using Large Language Models (LLMs) in MMO economy simulation. Leveraging LLMs’ role-playing proficiency, generative capacity, and reasoning aptitude, we design LLM-driven agents with human-like decision-making and adaptability. These agents are equipped with the abilities of role-playing, perception, memory, and reasoning, addressing the aforementioned challenges effectively. Simulation experiments focusing on in-game economic activities demonstrate that LLM-empowered agents can promote emergent phenomena like role specialization and price fluctuations in line with market rules.
在大型多人在线(MMO)经济研究领域,基于代理的建模(ABM)已成为分析游戏经济学的强大工具,从基于规则的代理发展到通过强化学习增强的决策代理。然而,现有工作在尝试模拟代理之间的人类经济活动时面临重大挑战,特别是在代理的可靠性、社交和可解释性方面。在这项研究中,我们初步引入了一种新的方法,利用大型语言模型(LLM)进行MMO经济模拟。借助LLM的角色扮演能力、生成能力和推理能力,我们设计了具有人类式决策和适应能力的LLM驱动代理。这些代理具备角色扮演、感知、记忆和推理的能力,有效地解决了上述挑战。以游戏内经济活动为重点的模拟实验表明,采用LLM赋能的代理可以促进诸如角色专业化、价格波等与市场经济规则相符的突发现象。
论文及项目相关链接
PDF KDD2025 Accepted
Summary
在大型多人在线(MMO)经济研究领域,基于代理的建模(ABM)已发展为一种强大的游戏经济分析工具,从基于规则的代理进化到由强化学习增强决策能力的代理。然而,现有研究在尝试模拟代理之间的人类经济活动时面临诸多挑战,尤其是在代理的可靠性、社交性和可解释性方面。本研究初步引入了一种新的方法,即利用大型语言模型(LLMs)进行MMO经济模拟。借助LLMs的角色扮演能力、生成能力和推理能力,我们设计了具有人类决策和适应能力的LLM驱动代理。这些代理具备角色扮演、感知、记忆和推理的能力,有效地解决了上述挑战。以游戏内经济活动为重点的模拟实验表明,采用LLM技术的代理可以促进角色专业化并与市场规则相符的价格波动等突发现象。
Key Takeaways
- ABM已用于MMO经济研究中,但模拟人类经济活动仍存在挑战,特别是在代理的可靠性、社交性和可解释性方面。
- LLMs被引入MMO经济模拟中,用以增强代理的角色扮演、生成和推理能力。
- LLMs驱动的代理具备人类决策和适应能力,能够解决现有模拟中的挑战。
- 通过模拟实验发现,采用LLM技术的代理在游戏内经济活动中表现优异,如角色专业化和价格波动的出现。
- LLMs的应用有助于更真实、更深入地模拟和了解MMO经济系统。
- 该研究为未来的MMO经济模拟提供了新的方向,即结合LLMs和ABM来增强模拟的逼真度和效果。
点此查看论文截图


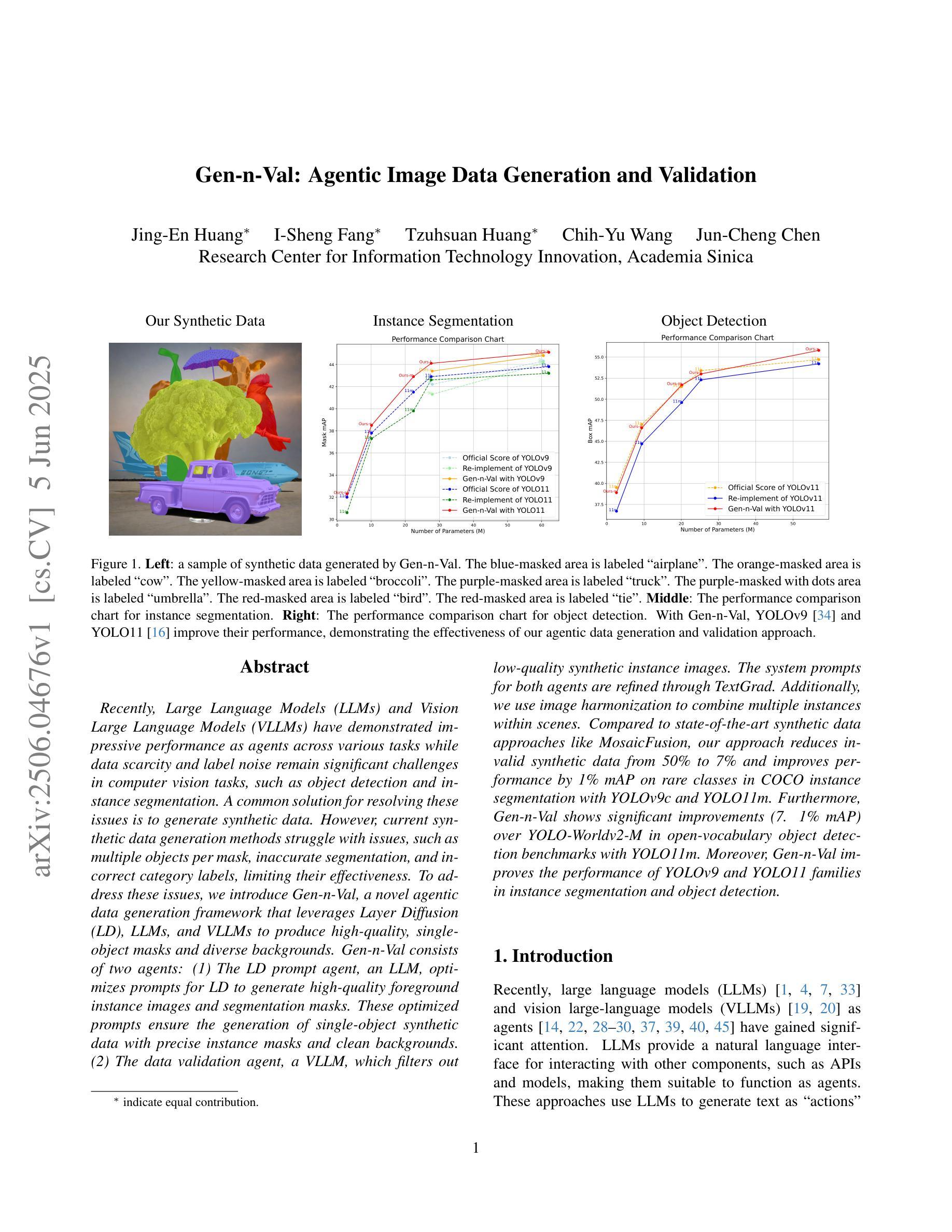
Gen-n-Val: Agentic Image Data Generation and Validation
Authors:Jing-En Huang, I-Sheng Fang, Tzuhsuan Huang, Chih-Yu Wang, Jun-Cheng Chen
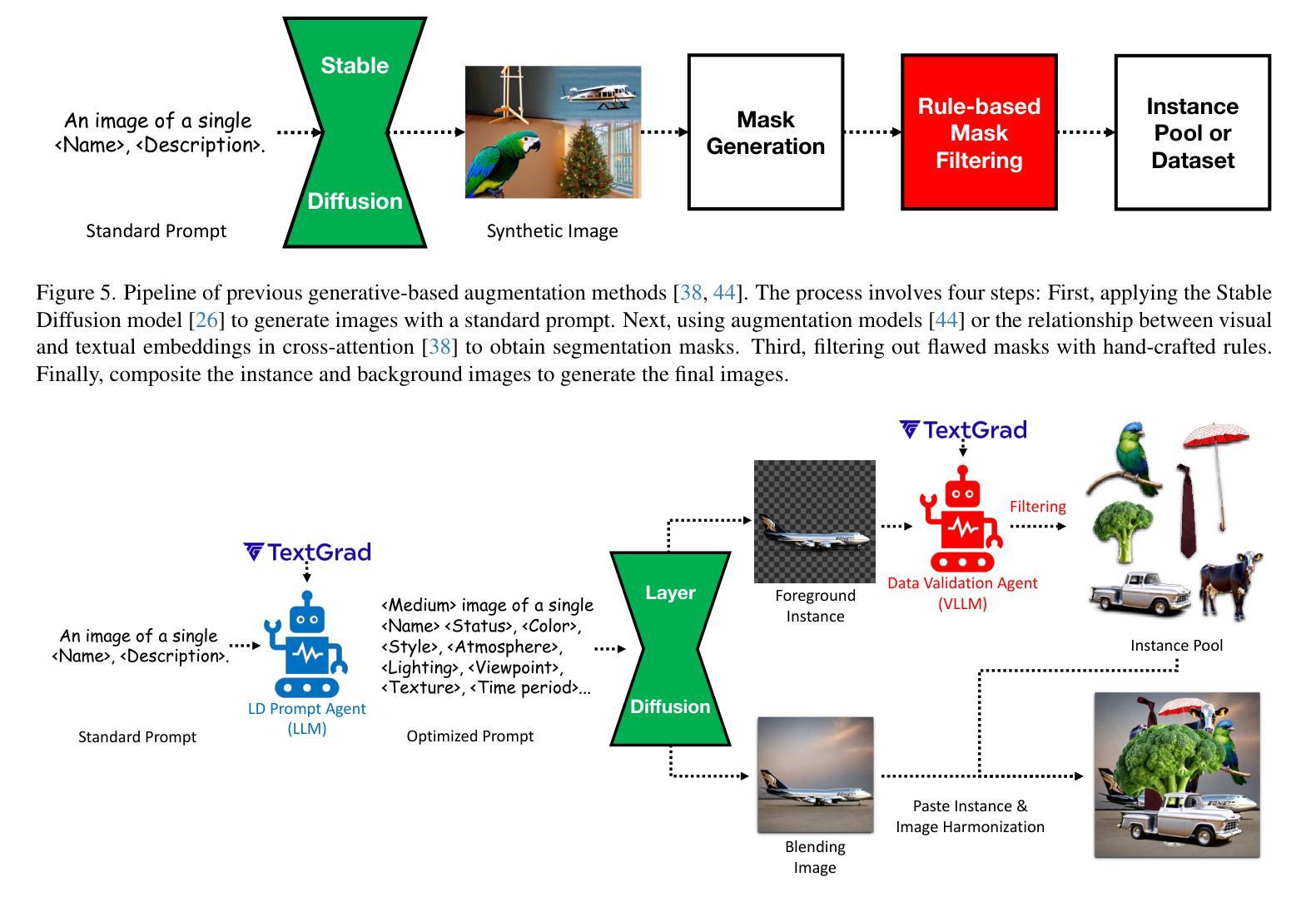
Recently, Large Language Models (LLMs) and Vision Large Language Models (VLLMs) have demonstrated impressive performance as agents across various tasks while data scarcity and label noise remain significant challenges in computer vision tasks, such as object detection and instance segmentation. A common solution for resolving these issues is to generate synthetic data. However, current synthetic data generation methods struggle with issues, such as multiple objects per mask, inaccurate segmentation, and incorrect category labels, limiting their effectiveness. To address these issues, we introduce Gen-n-Val, a novel agentic data generation framework that leverages Layer Diffusion (LD), LLMs, and VLLMs to produce high-quality, single-object masks and diverse backgrounds. Gen-n-Val consists of two agents: (1) The LD prompt agent, an LLM, optimizes prompts for LD to generate high-quality foreground instance images and segmentation masks. These optimized prompts ensure the generation of single-object synthetic data with precise instance masks and clean backgrounds. (2) The data validation agent, a VLLM, which filters out low-quality synthetic instance images. The system prompts for both agents are refined through TextGrad. Additionally, we use image harmonization to combine multiple instances within scenes. Compared to state-of-the-art synthetic data approaches like MosaicFusion, our approach reduces invalid synthetic data from 50% to 7% and improves performance by 1% mAP on rare classes in COCO instance segmentation with YOLOv9c and YOLO11m. Furthermore, Gen-n-Val shows significant improvements (7. 1% mAP) over YOLO-Worldv2-M in open-vocabulary object detection benchmarks with YOLO11m. Moreover, Gen-n-Val improves the performance of YOLOv9 and YOLO11 families in instance segmentation and object detection.
最近,大型语言模型(LLMs)和视觉大型语言模型(VLLMs)在各种任务中作为代理表现出了令人印象深刻的性能,而在计算机视觉任务(如目标检测和实例分割)中,数据稀缺和标签噪声仍然是巨大的挑战。解决这些问题的常见方法是生成合成数据。然而,当前的合成数据生成方法面临多重对象每掩膜、分割不准确和类别标签不正确等问题,限制了其有效性。为了解决这些问题,我们引入了Gen-n-Val,这是一种新型代理数据生成框架,它利用层扩散(LD)、LLMs和VLLMs生成高质量的单对象掩膜和多样化的背景。Gen-n-Val由两个代理组成:(1)LD提示代理,这是一个LLM,优化LD的提示以生成高质量的前景实例图像和分割掩膜。这些优化提示确保生成单对象合成数据,具有精确实例掩膜和干净背景。(2)数据验证代理,这是一个VLLM,用于过滤出低质量的合成实例图像。我们系统通过TextGrad完善了这两个代理的提示。此外,我们还使用图像融合技术将场景内的多个实例组合在一起。与最先进的合成数据方法(如MosaicFusion)相比,我们的方法将无效合成数据从50%减少到7%,并在使用YOLOv9c和YOLO11m的COCO实例分割任务上提高了1%的mAP性能。此外,在开放词汇对象检测基准测试中,Gen-n-Val在YOLO11m的基础上显著提高了YOLO-Worldv2-M的7. 1% mAP。而且Gen-n-Val改进了YOLOv9和YOLO11系列在实例分割和目标检测方面的性能。
论文及项目相关链接
Summary
基于大型语言模型(LLMs)和视觉大型语言模型(VLLMs)的Gen-n-Val框架解决了计算机视觉任务中数据稀缺和标签噪声的挑战。该框架利用层扩散(LD)技术生成高质量的单对象掩模和多样化的背景,并通过两个代理进行优化和验证。与现有方法相比,Gen-n-Val显著提高了合成数据的质量和性能。
Key Takeaways
- Gen-n-Val是一个利用LLMs和VLLMs解决数据稀缺和标签噪声问题的新型数据生成框架。
- 该框架利用层扩散技术生成高质量的单对象掩模和多样化的背景。
- Gen-n-Val包括两个代理:LD提示代理优化提示以生成高质量的前景实例图像和分割掩模,数据验证代理过滤掉低质量的合成实例图像。
- Gen-n-Val显著提高了合成数据的质量和性能,减少了无效合成数据,提高了在COCO实例分割和开放词汇对象检测基准测试上的性能。
点此查看论文截图



Flex-TravelPlanner: A Benchmark for Flexible Planning with Language Agents
Authors:Juhyun Oh, Eunsu Kim, Alice Oh
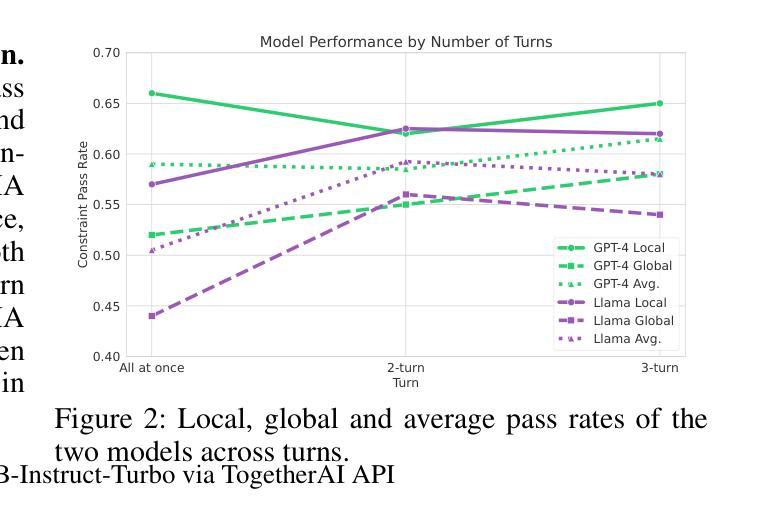
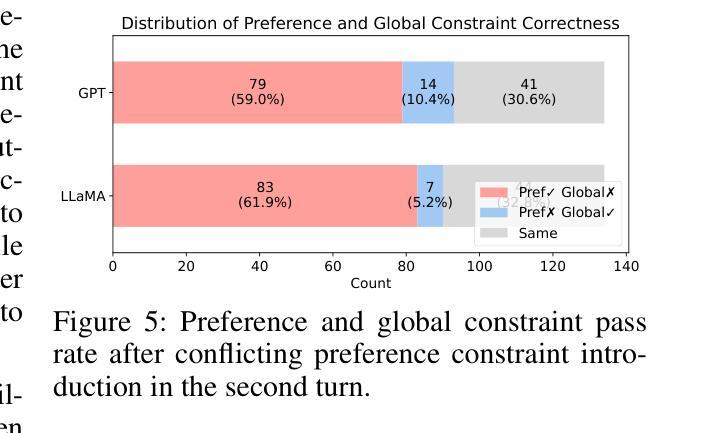
Real-world planning problems require constant adaptation to changing requirements and balancing of competing constraints. However, current benchmarks for evaluating LLMs’ planning capabilities primarily focus on static, single-turn scenarios. We introduce Flex-TravelPlanner, a benchmark that evaluates language models’ ability to reason flexibly in dynamic planning scenarios. Building on the TravelPlanner dataset~\citep{xie2024travelplanner}, we introduce two novel evaluation settings: (1) sequential constraint introduction across multiple turns, and (2) scenarios with explicitly prioritized competing constraints. Our analysis of GPT-4o and Llama 3.1 70B reveals several key findings: models’ performance on single-turn tasks poorly predicts their ability to adapt plans across multiple turns; constraint introduction order significantly affects performance; and models struggle with constraint prioritization, often incorrectly favoring newly introduced lower priority preferences over existing higher-priority constraints. These findings highlight the importance of evaluating LLMs in more realistic, dynamic planning scenarios and suggest specific directions for improving model performance on complex planning tasks. The code and dataset for our framework are publicly available at https://github.com/juhyunohh/FlexTravelBench.
现实世界中的规划问题要求不断适应变化的需求并平衡相互竞争的约束。然而,当前评估大型语言模型(LLMs)规划能力的基准测试主要集中于静态的单回合场景。我们引入了Flex-TravelPlanner基准测试,该测试旨在评估语言模型在动态规划场景中灵活推理的能力。基于TravelPlanner数据集\citep{xie2024travelplanner},我们引入了两种新的评估设置:(1)多回合的连续约束引入,以及(2)具有明确优先级的竞争约束场景。我们对GPT-4o和Llama 3.1 70B的分析揭示了几个关键发现:模型在单回合任务上的表现并不能很好地预测它们在多回合适应计划的能力;约束引入的顺序对性能有重大影响;模型在约束优先级排序方面遇到困难,往往会错误地偏好新引入的低优先级偏好而不是现有的高优先级约束。这些发现强调了以更现实的动态规划场景评估LLMs的重要性,并为提高模型在复杂规划任务上的性能提供了具体的改进方向。我们的框架的代码和数据集可在https://github.com/juhyunohh/FlexTravelBench上公开获取。
论文及项目相关链接
Summary
Flex-TravelPlanner基准测试评估了语言模型在动态规划场景中的灵活推理能力。它建立在TravelPlanner数据集的基础上,并引入了两种新的评估设置:多轮连续的约束引入和具有明确优先级的竞争约束场景。分析GPT-4o和Llama 3.1 70B的表现,发现模型在单轮任务上的表现并不能预测其在多轮适应计划的能力,约束引入的顺序对性能有重大影响,且模型在约束优先级上挣扎,常常错误地重视新引入的低优先级偏好而非现有的高优先级约束。这强调了在实际、动态的规划场景中评估大型语言模型的重要性,并为改进模型在复杂规划任务上的表现提供了方向。
Key Takeaways
- Flex-TravelPlanner基准测试用于评估语言模型在动态规划场景中的灵活推理能力。
- 新基准测试包括两种评估设置:多轮连续的约束引入和具有明确优先级的竞争约束场景。
- 现有模型在单轮任务上的表现并不能预测其在多轮适应计划的能力。
- 约束引入的顺序对语言模型的性能有重大影响。
- 语言模型在约束优先级上表现挣扎,有时错误地重视新引入的低优先级偏好。
- 评估大型语言模型在实际、动态的规划场景中的重要性。
点此查看论文截图



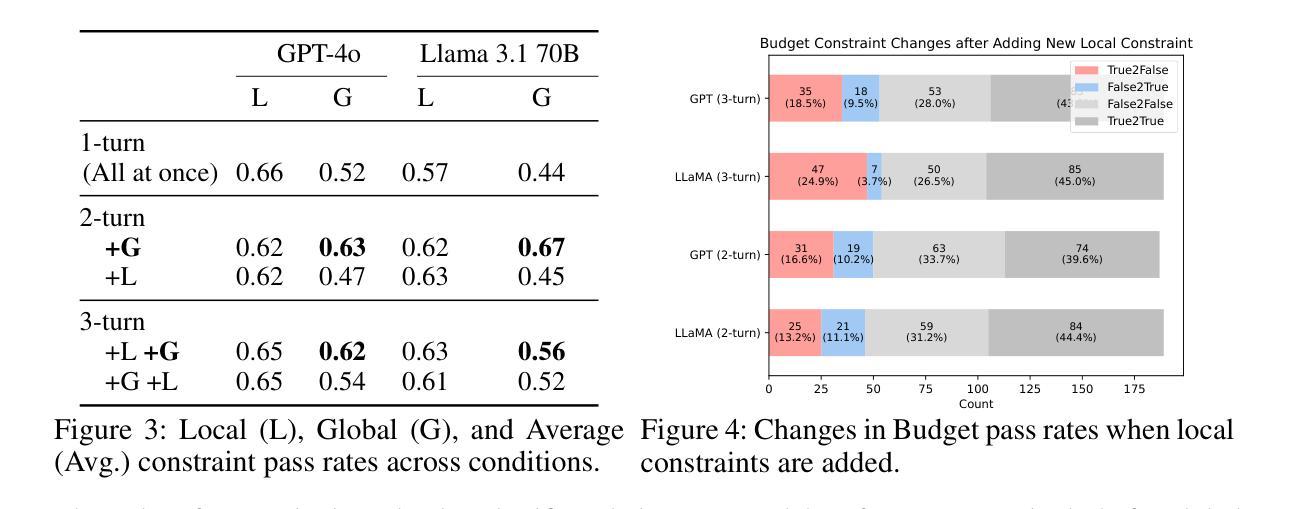
Regret-Optimal Q-Learning with Low Cost for Single-Agent and Federated Reinforcement Learning
Authors:Haochen Zhang, Zhong Zheng, Lingzhou Xue
Motivated by real-world settings where data collection and policy deployment – whether for a single agent or across multiple agents – are costly, we study the problem of on-policy single-agent reinforcement learning (RL) and federated RL (FRL) with a focus on minimizing burn-in costs (the sample sizes needed to reach near-optimal regret) and policy switching or communication costs. In parallel finite-horizon episodic Markov Decision Processes (MDPs) with $S$ states and $A$ actions, existing methods either require superlinear burn-in costs in $S$ and $A$ or fail to achieve logarithmic switching or communication costs. We propose two novel model-free RL algorithms – Q-EarlySettled-LowCost and FedQ-EarlySettled-LowCost – that are the first in the literature to simultaneously achieve: (i) the best near-optimal regret among all known model-free RL or FRL algorithms, (ii) low burn-in cost that scales linearly with $S$ and $A$, and (iii) logarithmic policy switching cost for single-agent RL or communication cost for FRL. Additionally, we establish gap-dependent theoretical guarantees for both regret and switching/communication costs, improving or matching the best-known gap-dependent bounds.
在现实世界环境中,无论是为单一代理还是多个代理进行数据采集和政策部署都是成本高昂的,我们研究了带有策略的强化学习(RL)和联邦强化学习(FRL)的问题,重点关注如何最小化磨合成本(达到接近最优遗憾所需的样本规模)以及策略切换或通信成本。在具有S个状态和A个动作的并行有限时间域阶段性马尔可夫决策过程(MDPs)中,现有方法要么需要超线性磨合成本(在S和A中),要么无法实现对数切换或通信成本。我们提出了两种新型无模型RL算法——Q-EarlySettled-LowCost和FedQ-EarlySettled-LowCost,这两种算法是文献中首次同时实现以下目标:(i)在所有已知的无模型RL或FRL算法中达到最佳接近最优遗憾,(ii)低磨合成本,随着S和A线性增长,(iii)单一代理RL的对数策略切换成本或FRL的通信成本。此外,我们还建立了与间隔相关的理论保证,以改善或匹配已知的最佳间隔依赖界限,包括遗憾和切换/通信成本。
论文及项目相关链接
PDF arXiv admin note: text overlap with arXiv:2502.02859
Summary:
针对现实世界中数据采集和策略部署成本高昂的问题,研究了带有策略切换或通信成本的最小化烧入成本的在线策略单智能体强化学习(RL)和联邦强化学习(FRL)。现有方法要么需要超级烧入成本,要么无法实现对数切换或通信成本。本文提出了两种新型无模型RL算法,可同时实现最佳近最优遗憾、线性烧入成本和对数策略切换成本或联邦通信成本。同时建立了与差距相关的理论保证。
Key Takeaways:
- 针对现实世界的强化学习问题,研究如何在单智能体和联邦强化学习中最小化烧入成本、策略切换成本和通信成本。
- 现有方法存在超级线性烧入成本或在实现策略切换或通信成本的优化方面存在局限。
- 提出了两种新型无模型RL算法,Q-EarlySettled-LowCost和FedQ-EarlySettled-LowCost。
- 这两种算法能够同时实现最佳近最优遗憾、线性烧入成本和对数策略切换成本(单智能体RL)或对数通信成本(联邦强化学习)。
- 建立了与差距相关的理论保证,改进或匹配了最佳已知差距相关的界限。
- 这些算法在理论分析和实际应用中具有潜力,有助于降低强化学习在实际应用中的成本和提高效率。
点此查看论文截图

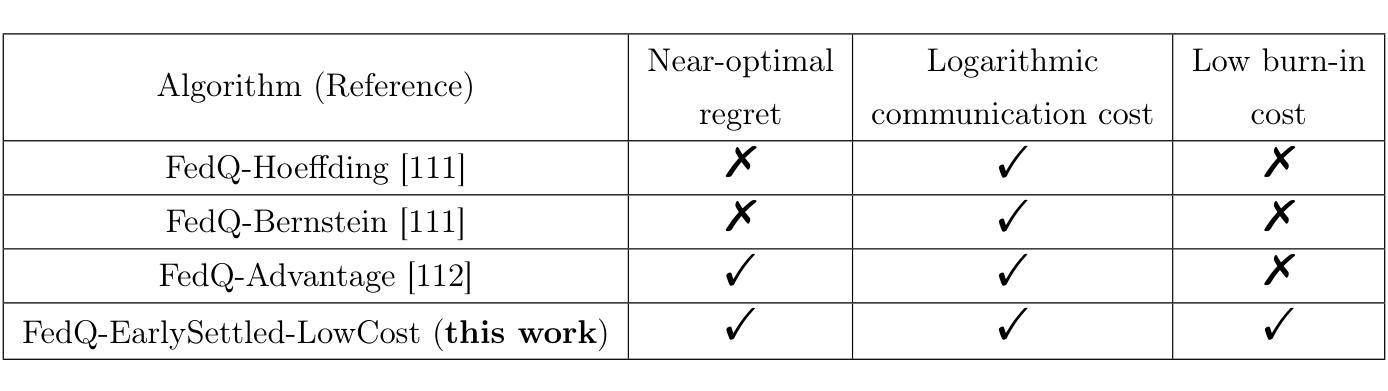
SmartAvatar: Text- and Image-Guided Human Avatar Generation with VLM AI Agents
Authors:Alexander Huang-Menders, Xinhang Liu, Andy Xu, Yuyao Zhang, Chi-Keung Tang, Yu-Wing Tai
SmartAvatar is a vision-language-agent-driven framework for generating fully rigged, animation-ready 3D human avatars from a single photo or textual prompt. While diffusion-based methods have made progress in general 3D object generation, they continue to struggle with precise control over human identity, body shape, and animation readiness. In contrast, SmartAvatar leverages the commonsense reasoning capabilities of large vision-language models (VLMs) in combination with off-the-shelf parametric human generators to deliver high-quality, customizable avatars. A key innovation is an autonomous verification loop, where the agent renders draft avatars, evaluates facial similarity, anatomical plausibility, and prompt alignment, and iteratively adjusts generation parameters for convergence. This interactive, AI-guided refinement process promotes fine-grained control over both facial and body features, enabling users to iteratively refine their avatars via natural-language conversations. Unlike diffusion models that rely on static pre-trained datasets and offer limited flexibility, SmartAvatar brings users into the modeling loop and ensures continuous improvement through an LLM-driven procedural generation and verification system. The generated avatars are fully rigged and support pose manipulation with consistent identity and appearance, making them suitable for downstream animation and interactive applications. Quantitative benchmarks and user studies demonstrate that SmartAvatar outperforms recent text- and image-driven avatar generation systems in terms of reconstructed mesh quality, identity fidelity, attribute accuracy, and animation readiness, making it a versatile tool for realistic, customizable avatar creation on consumer-grade hardware.
SmartAvatar是一个由视觉语言代理驱动的框架,它可以从单张照片或文本提示生成完全配备、适合动画的3D人类角色。虽然基于扩散的方法在一般的3D对象生成方面取得了进展,但它们对于人类身份、体形和动画准备的控制仍感到棘手。与此相反,SmartAvatar利用大型视觉语言模型的常识推理能力,结合现成的参数化人类生成器,提供高质量、可定制的个性化角色。一个关键的创新之处在于自主验证循环,代理在此循环中渲染角色草稿,评估面部相似性、解剖合理性和提示对齐度,并迭代调整生成参数以达成收敛。这种交互式的、AI引导的细化过程促进对面部和身体特征的精细控制,使用户能够通过自然语言对话逐步细化他们的角色。与依赖静态预训练数据集、灵活性有限的扩散模型不同,SmartAvatar将用户纳入建模循环,并通过LLM驱动的生成和验证系统确保持续改进。生成的个性化角色配备完全,支持姿势操作,具有一致的身份和外观,使其适合用于下游动画和交互式应用。定量基准测试和用户研究表明,SmartAvatar在重建网格质量、身份保真度、属性准确性和动画准备方面超越了最新的文本和图像驱动的个性化角色生成系统,成为在消费级硬件上创建逼真、可定制的个性化角色的通用工具。
论文及项目相关链接
PDF 16 pages
摘要
SmartAvatar是一款基于视觉语言驱动的框架,能够从单一照片或文本提示生成全副武装、随时准备动画效果的3D人物角色。尽管扩散模型已经在一般物体生成方面取得了进展,但在精确控制人物身份、体型和动画效果方面仍存在挑战。与此相反,SmartAvatar借助大型视觉语言模型的常识推理能力,结合现成的参数化人物生成器,提供高质量的可定制角色。其关键创新之处在于自主验证循环,代理能够渲染角色草稿,评估面部相似性、解剖合理性和提示对齐性,并迭代调整生成参数以达到收敛。这种交互式的AI引导细化流程提供了对面部和身体特征的精细控制,使用户能够通过自然语言对话逐步优化他们的角色。与依赖静态预训练数据集并提供有限灵活性的扩散模型不同,SmartAvatar将用户纳入建模循环,并通过LLM驱动的生成和验证系统确保持续改进。生成的角色配备完整装备,支持姿势操作并保持一致的外观和身份,使其适合用于下游动画和交互式应用。定量基准测试和用户体验研究证明,SmartAvatar在重建网格质量、身份保真度、属性准确性和动画效果方面优于最近的文本和图像驱动的角色生成系统。
关键见解
- SmartAvatar是一个基于视觉语言驱动的框架,可以从单一照片或文本提示生成全副武装、准备动画的3D人物角色。
- 它借助大型视觉语言模型的常识推理能力,提高了角色生成的精度和定制性。
- SmartAvatar具备自主验证循环,能够细化角色特征并保障动画效果。
- 与其他方法相比,SmartAvatar生成的角色的质量更高,更适合用于动画和交互式应用。
- 它的优点在于将用户纳入建模循环,并提供更精细的控制选项。
- SmartAvatar在多个基准测试中表现出优异的性能,包括重建网格质量、身份保真度等。
- SmartAvatar是一个多功能工具,适用于消费者级硬件上的真实可定制角色创建。
点此查看论文截图


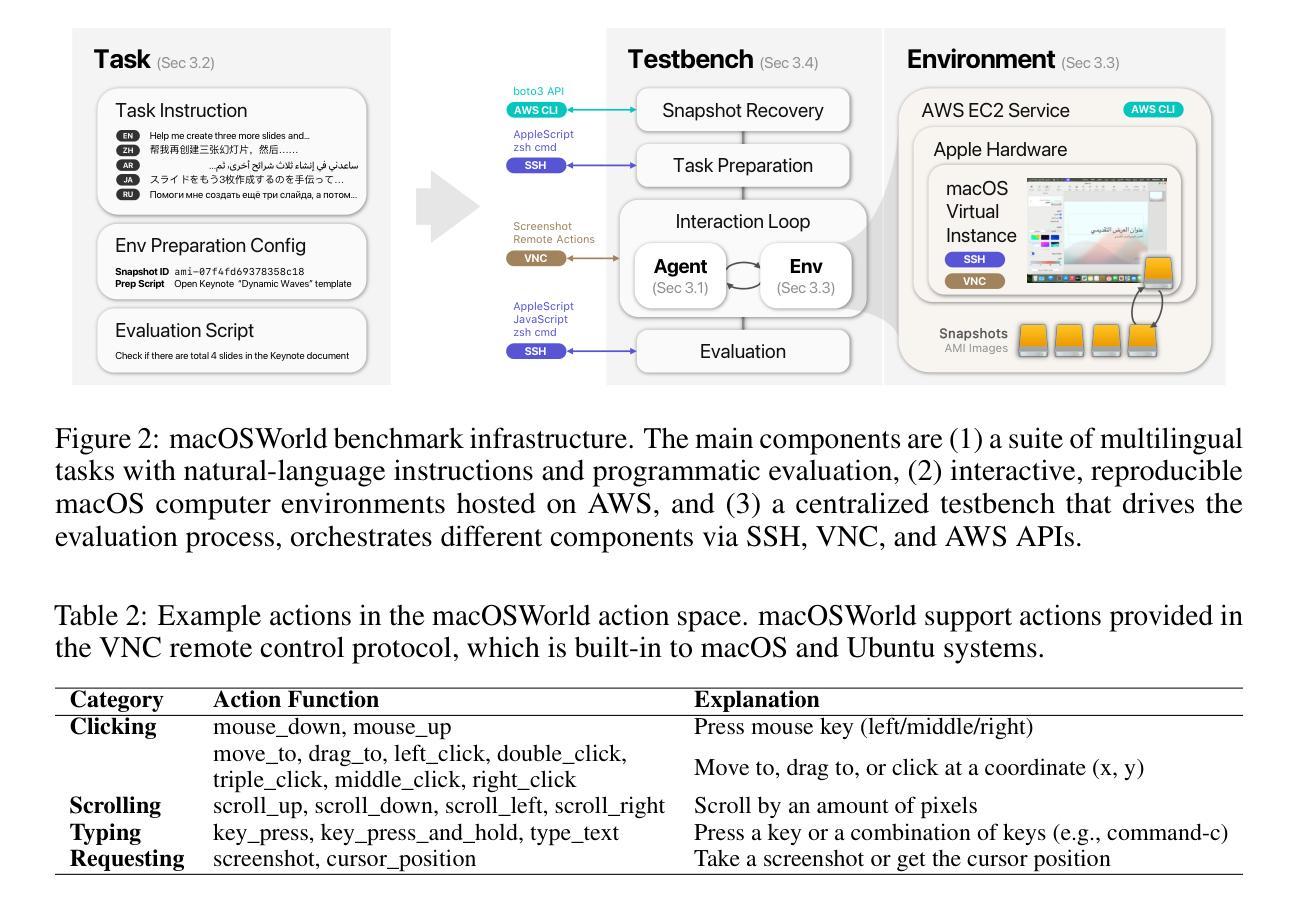
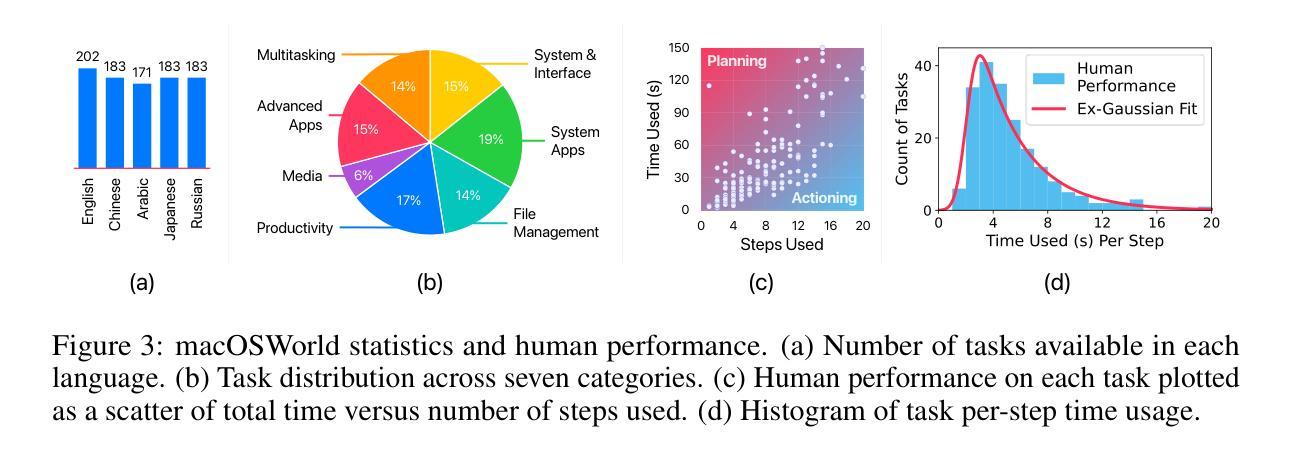
macOSWorld: A Multilingual Interactive Benchmark for GUI Agents
Authors:Pei Yang, Hai Ci, Mike Zheng Shou
Graphical User Interface (GUI) agents show promising capabilities for automating computer-use tasks and facilitating accessibility, but existing interactive benchmarks are mostly English-only, covering web-use or Windows, Linux, and Android environments, but not macOS. macOS is a major OS with distinctive GUI patterns and exclusive applications. To bridge the gaps, we present macOSWorld, the first comprehensive benchmark for evaluating GUI agents on macOS. macOSWorld features 202 multilingual interactive tasks across 30 applications (28 macOS-exclusive), with task instructions and OS interfaces offered in 5 languages (English, Chinese, Arabic, Japanese, and Russian). As GUI agents are shown to be vulnerable to deception attacks, macOSWorld also includes a dedicated safety benchmarking subset. Our evaluation on six GUI agents reveals a dramatic gap: proprietary computer-use agents lead at above 30% success rate, while open-source lightweight research models lag at below 2%, highlighting the need for macOS domain adaptation. Multilingual benchmarks also expose common weaknesses, especially in Arabic, with a 27.5% average degradation compared to English. Results from safety benchmarking also highlight that deception attacks are more general and demand immediate attention. macOSWorld is available at https://github.com/showlab/macosworld.
图形用户界面(GUI)代理在自动化计算机使用任务和促进可访问性方面显示出巨大的潜力,但现有的交互基准测试大多仅限于英语,涵盖网页使用或Windows、Linux和Android环境,并不包括macOS。macOS是一个具有独特GUI模式和专属应用程序的主要操作系统。为了弥补这一空白,我们推出了macOSWorld,这是第一个用于评估macOS上GUI代理的综合基准测试。macOSWorld包含30个应用程序(28个为macOS专属)中的202个跨语言交互式任务,任务说明和操作系统界面提供五种语言(英语、中文、阿拉伯语、日语和俄语)。由于GUI代理已显示出容易受到欺骗攻击,macOSWorld还包含一个专用的安全基准测试子集。我们对六个GUI代理的评估揭示了巨大的差距:专有计算机使用代理的成功率超过30%,而开源轻型研究模型的成功率低于2%,这凸显了macOS域适应的需求。多语言基准测试还暴露了常见的弱点,特别是在阿拉伯语方面,与英语相比平均下降了27.5%。安全基准测试的结果也表明欺骗攻击更为普遍,需要立即关注。macOSWorld可在[https://github.com/showlab/macosworld上获得。]
论文及项目相关链接
PDF Error regarding experiment results
Summary
该文介绍了一个针对 macOS 系统上 GUI 自动化代理的综合评估基准——macOSWorld。该基准包含多语言交互式任务,涵盖 30 个应用程序(其中 28 个为 macOS 独家应用),并提供五种语言的任务指令和操作系统界面(英语、中文、阿拉伯语、日语和俄语)。同时,它也包含用于评估代理安全性的专门基准。实验评估显示,专用计算机使用代理在 macOS 上的成功率超过 30%,而开源轻量级研究模型的成功率低于 2%,突显了适应 macOS 域的需求。多语言基准暴露了在阿拉伯语环境中的普遍弱点,与英语相比平均性能下降 27.5%。安全性评估结果也表明欺骗攻击更为普遍,需要引起关注。macOSWorld 基准已在 GitHub 上发布。
Key Takeaways
- macOSWorld 是第一个针对 macOS 上 GUI 自动化代理的综合评估基准。
- 它包含 202 个多语言交互式任务,涵盖 30 个应用程序,并提供五种语言的任务指令和操作系统界面。
- GUI 自动化代理容易受到欺骗攻击,需要关注安全性评估。
- 实验评估显示,专用计算机使用代理在 macOS 上的表现远优于开源轻量级研究模型。
- 多语言环境下的评估结果表明,阿拉伯语环境中的性能问题较为突出。
- macOSWorld 基准已在 GitHub 上发布,便于公众访问和使用。
点此查看论文截图




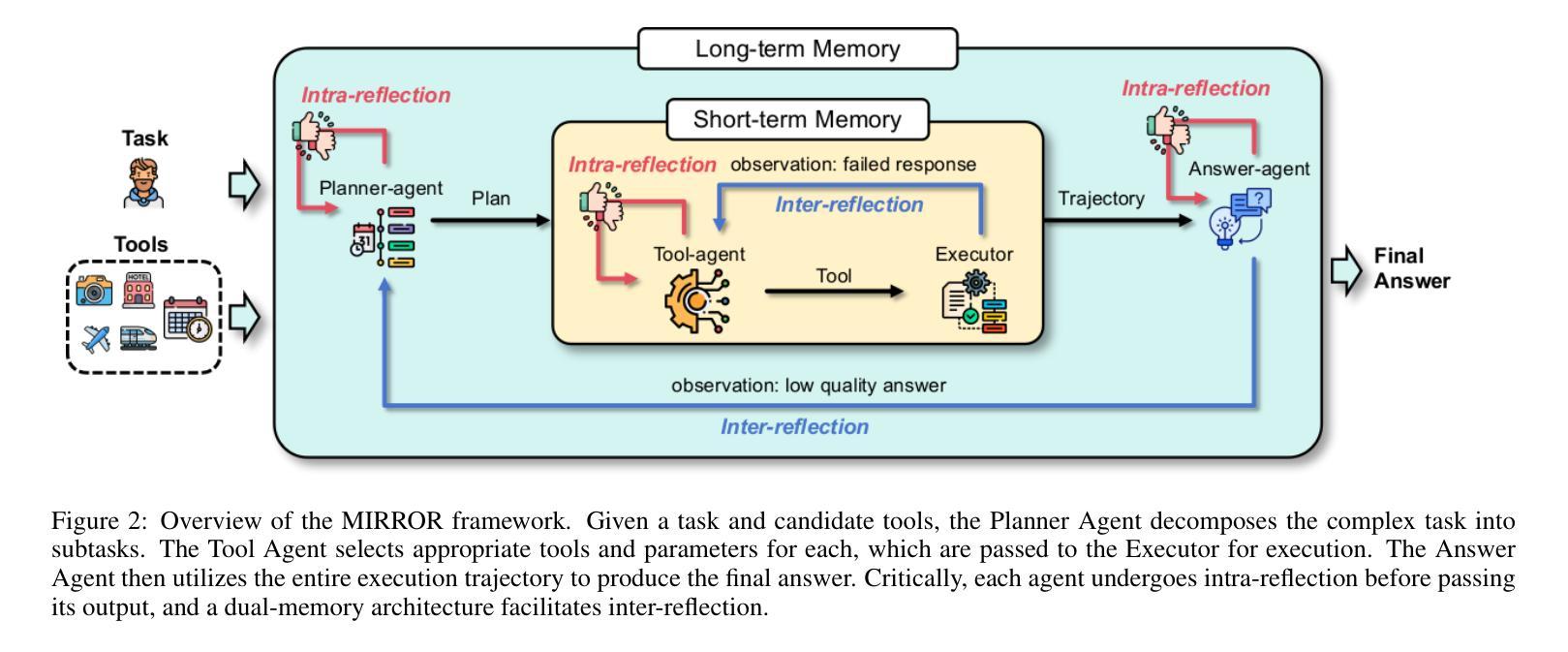
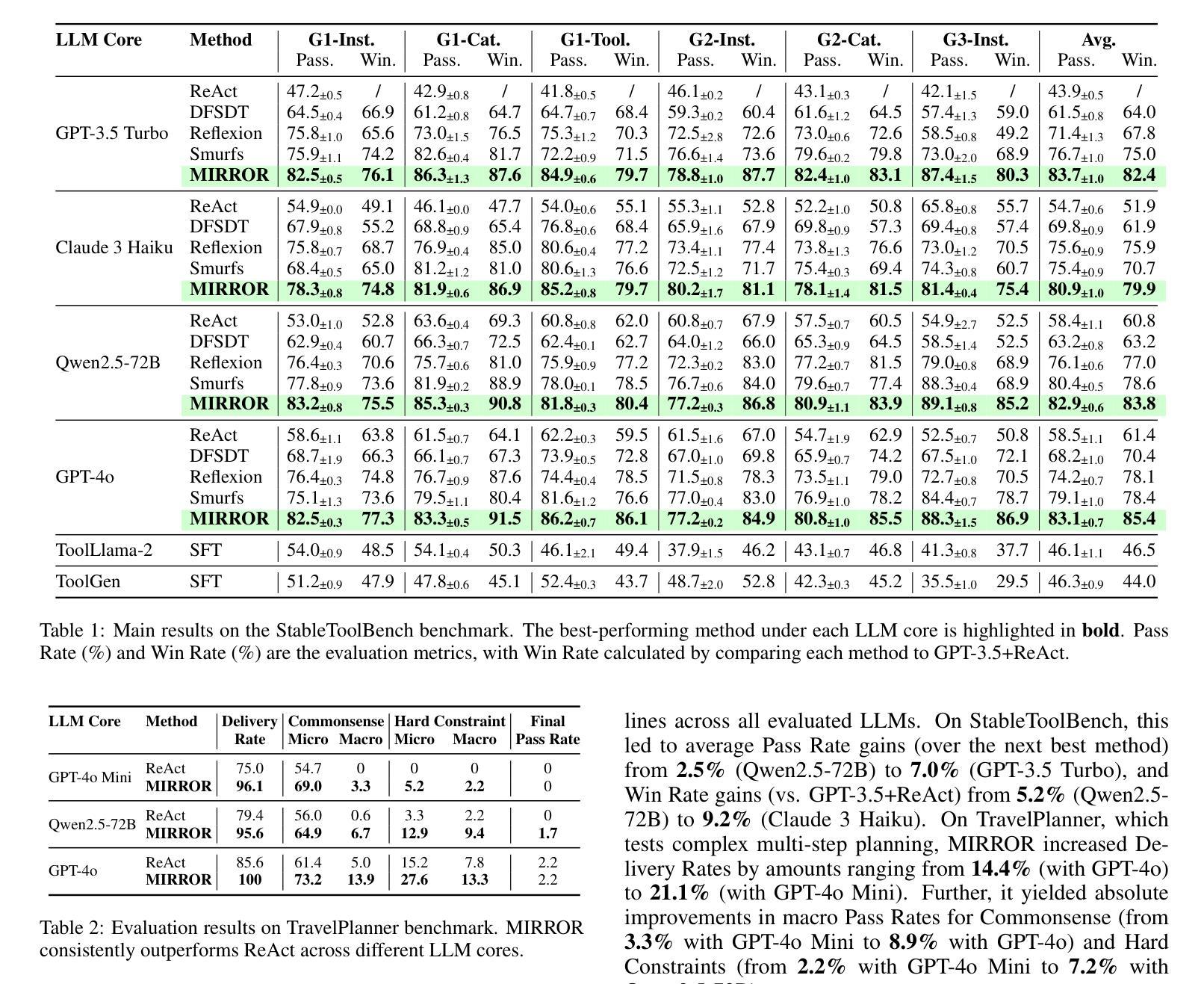
MIRROR: Multi-agent Intra- and Inter-Reflection for Optimized Reasoning in Tool Learning
Authors:Zikang Guo, Benfeng Xu, Xiaorui Wang, Zhendong Mao
Complex tasks involving tool integration pose significant challenges for Large Language Models (LLMs), leading to the emergence of multi-agent workflows as a promising solution. Reflection has emerged as an effective strategy for correcting erroneous trajectories in agentic workflows. However, existing approaches only exploit such capability in the post-action stage, where the agent observes the execution outcomes. We argue that, like humans, LLMs can also engage in reflection before action execution: the agent can anticipate undesirable outcomes from its own decisions, which not only provides a necessarily complementary perspective to evaluate the decision but also prevents the propagation of errors throughout the trajectory. In this paper, we propose MIRROR, a framework that consists of both intra-reflection, which critically assesses intended actions before execution, and inter-reflection, which further adjusts the trajectory based on observations. This design systematically leverages LLM reflection capabilities to eliminate and rectify erroneous actions on a more comprehensive scope. Evaluations on both the StableToolBench and TravelPlanner benchmarks demonstrate MIRROR’s superior performance, achieving state-of-the-art results compared to existing approaches.
涉及工具集成的大型语言模型(LLM)任务面临巨大挑战,多智能体工作流程作为解决这一问题的新兴方案。反思作为一种有效的策略,在智能体工作流程中可以纠正错误的轨迹。然而,现有的方法只将反思能力应用于事后阶段,此时智能体通过观察结果来进行判断。我们认为,就像人类一样,LLM也可以在执行行动之前进行反思:智能体可以预测其自身决策可能带来的不良后果,这不仅提供了一个必要的角度对决策进行评估,而且防止了错误在整个轨迹中的传播。本文提出了一种名为MIRROR的框架,它结合了内反思和外反思两个模块。内反思模块在行动执行前对计划行动进行批判性评估,而外反思模块则基于观察进一步调整轨迹。这种设计系统利用LLM的反思能力在更广泛的范围内消除和纠正错误行为。在StableToolBench和TravelPlanner基准测试上的评估证明了MIRROR的卓越性能,与现有方法相比取得了最先进的成果。
论文及项目相关链接
PDF Accepted to 34rd International Joint Conference on Artificial Intelligence (IJCAI 2025)
Summary
大型语言模型(LLM)在涉及工具整合的复杂任务上面临挑战,多代理工作流程应运而生为解决此问题的一种有前途的方案。反思已成为纠正代理工作流程中错误轨迹的有效策略。然而,现有方法仅在代理观察执行结果的后行动阶段利用这种能力。本文提出,与人类一样,LLM也可以在行动执行前进行反思:代理可以预见到自己决策的不理想结果,这不仅提供了评估决策的必要的补充视角,而且防止了错误在整个轨迹中的传播。本文提出了MIRROR框架,包括执行前反思(intra-reflection)和执行后反思(inter-reflection),前者对预定行动进行批判性评估,后者基于观察进一步调整轨迹。此设计系统地利用LLM的反思能力,在更广泛的范围内消除和纠正错误行动。在StableToolBench和TravelPlanner基准测试上的评估表明,MIRROR性能卓越,与现有方法相比达到了最新水平。
Key Takeaways
- 大型语言模型(LLM)在处理涉及工具整合的复杂任务时面临挑战。
- 多代理工作流程是解决这些问题的有前途的方案。
- 反思是纠正代理工作流程中错误轨迹的有效方法。
- 现有方法主要在行动后的阶段利用反思能力。
- LLM可以在行动前进行反思,预测并防止决策中的错误。
- MIRROR框架结合了行动前和行动后的反思,以消除和纠正错误。
点此查看论文截图

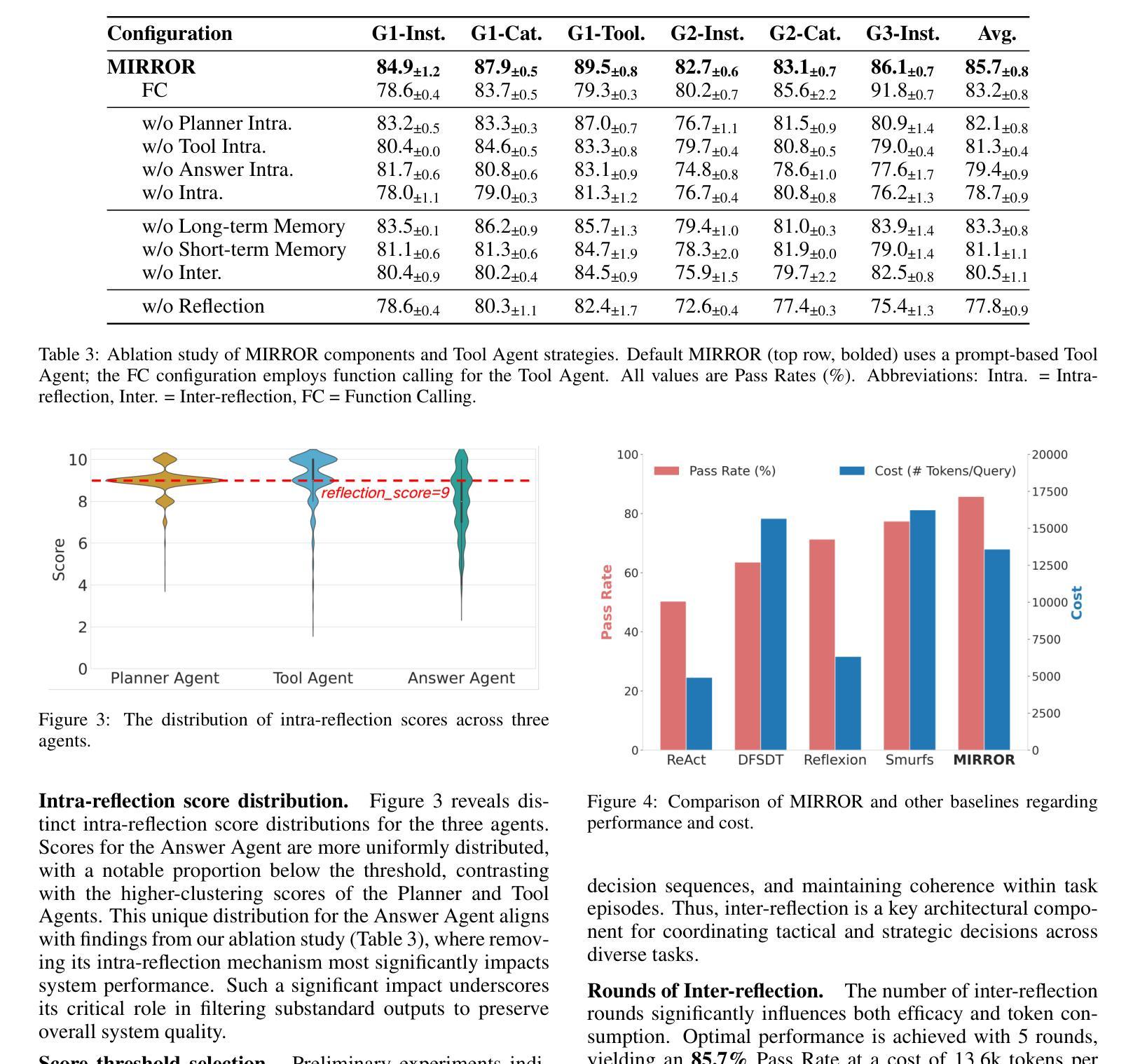
OmniCharacter: Towards Immersive Role-Playing Agents with Seamless Speech-Language Personality Interaction
Authors:Haonan Zhang, Run Luo, Xiong Liu, Yuchuan Wu, Ting-En Lin, Pengpeng Zeng, Qiang Qu, Feiteng Fang, Min Yang, Lianli Gao, Jingkuan Song, Fei Huang, Yongbin Li
Role-Playing Agents (RPAs), benefiting from large language models, is an emerging interactive AI system that simulates roles or characters with diverse personalities. However, existing methods primarily focus on mimicking dialogues among roles in textual form, neglecting the role’s voice traits (e.g., voice style and emotions) as playing a crucial effect in interaction, which tends to be more immersive experiences in realistic scenarios. Towards this goal, we propose OmniCharacter, a first seamless speech-language personality interaction model to achieve immersive RPAs with low latency. Specifically, OmniCharacter enables agents to consistently exhibit role-specific personality traits and vocal traits throughout the interaction, enabling a mixture of speech and language responses. To align the model with speech-language scenarios, we construct a dataset named OmniCharacter-10K, which involves more distinctive characters (20), richly contextualized multi-round dialogue (10K), and dynamic speech response (135K). Experimental results showcase that our method yields better responses in terms of both content and style compared to existing RPAs and mainstream speech-language models, with a response latency as low as 289ms. Code and dataset are available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/OmniCharacter.
角色扮演代理(RPAs)受益于大型语言模型,是一种新兴的互动人工智能系统,能够模拟具有不同个性的角色或人物。然而,现有方法主要集中在以文本形式模仿角色之间的对话,忽视了角色的语音特征(例如语音风格和情感)在互动中的关键作用,这在现实场景中往往能带来更具沉浸感的体验。基于此目标,我们提出了OmniCharacter,首个无缝语音-语言个性互动模型,旨在实现具有低延迟的沉浸式RPAs。具体来说,OmniCharacter使代理能够在互动中持续展现出特定角色的个性特征和语音特征,实现语音和语言响应的混合。为了将模型与语音语言场景相结合,我们构建了一个名为OmniCharacter-10K的数据集,其中包括更多独特的人物(20个)、丰富的上下文多轮对话(10K)和动态语音响应(135K)。实验结果表明,我们的方法在内容和风格方面的回应都优于现有RPAs和主流语音语言模型,响应延迟低至289毫秒。代码和数据集可在https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/OmniCharacter找到。
论文及项目相关链接
PDF 14 pages, 6 figures
Summary
基于大型语言模型的角色扮演代理(RPAs)是一种新兴的智能交互系统,能模拟具有不同个性的角色。然而,现有方法主要关注文本形式的对话模仿,忽视了角色的语音特质(如语音风格和情感)在交互中的重要作用,这在现实场景中往往能提供更沉浸的体验。为此,我们提出OmniCharacter,一个无缝的语音-语言个性交互模型,旨在实现具有低延迟的沉浸式RPAs。OmniCharacter使代理能够在交互中始终表现出特定的角色个性和语音特质,实现语音和语言响应的混合。为了与语音-语言场景对齐,我们构建了名为OmniCharacter-10K的数据集,包含更多鲜明的角色(20个)、丰富的上下文多轮对话(10K)和动态语音响应(135K)。实验结果表明,我们的方法在内容和风格上的响应优于现有RPAs和主流语音-语言模型,响应延迟低至289毫秒。
Key Takeaways
- 角色扮演代理(RPAs)是新兴的智能交互系统,可模拟具有不同个性的角色。
- 现有方法主要关注文本对话的模仿,忽视了角色的语音特质在交互中的重要性。
- OmniCharacter模型实现了无缝的语音-语言个性交互,旨在实现沉浸式RPAs,并具有低延迟特点。
- OmniCharacter使代理能在交互中展现角色特定的个性和语音特质。
- 为配合语音-语言场景,构建了OmniCharacter-10K数据集,包含丰富多样的角色、对话和语音响应。
- 实验结果表明,OmniCharacter在内容和风格上的响应优于其他模型,响应延迟较低。
- 该研究的代码和数据集已公开可用。
点此查看论文截图


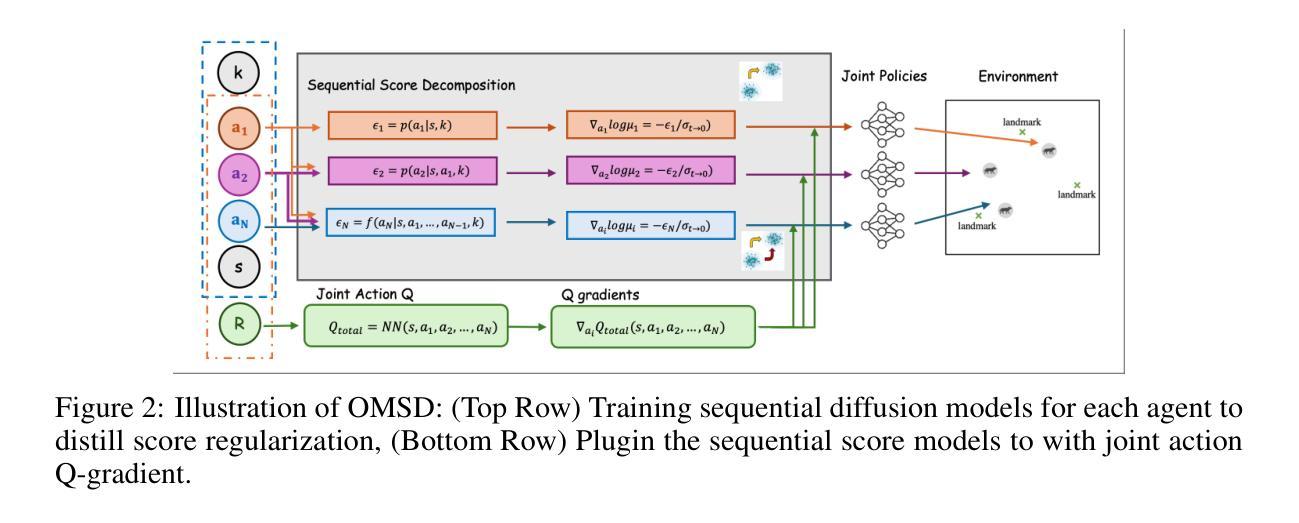
Offline Multi-agent Reinforcement Learning via Score Decomposition
Authors:Dan Qiao, Wenhao Li, Shanchao Yang, Hongyuan Zha, Baoxiang Wang
Offline cooperative multi-agent reinforcement learning (MARL) faces unique challenges due to distributional shifts, particularly stemming from the high dimensionality of joint action spaces and the presence of out-of-distribution joint action selections. In this work, we highlight that a fundamental challenge in offline MARL arises from the multi-equilibrium nature of cooperative tasks, which induces a highly multimodal joint behavior policy space coupled with heterogeneous-quality behavior data. This makes it difficult for individual policy regularization to align with a consistent coordination pattern, leading to the policy distribution shift problems. To tackle this challenge, we design a sequential score function decomposition method that distills per-agent regularization signals from the joint behavior policy, which induces coordinated modality selection under decentralized execution constraints. Then we leverage a flexible diffusion-based generative model to learn these score functions from multimodal offline data, and integrate them into joint-action critics to guide policy updates toward high-reward, in-distribution regions under a shared team reward. Our approach achieves state-of-the-art performance across multiple particle environments and Multi-agent MuJoCo benchmarks consistently. To the best of our knowledge, this is the first work to explicitly address the distributional gap between offline and online MARL, paving the way for more generalizable offline policy-based MARL methods.
离线多智能体强化学习(MARL)面临着由于分布转移带来的独特挑战,特别是源于联合动作空间的高维度和存在超出分布范围的联合动作选择。在这项工作中,我们强调离线MARL中的基本挑战来自于合作任务的多个均衡状态性质,这导致了一个与异质质量行为数据相结合的、高度多模态的联合行为策略空间。这使得个体策略正则化难以与一致的协调模式对齐,从而导致策略分布转移问题。为了应对这一挑战,我们设计了一种顺序得分函数分解方法,从联合行为策略中提炼出针对每个智能体的正则化信号,在分布式执行约束下诱导协调模式选择。然后,我们利用灵活的基于扩散的生成模型从这些多模态离线数据中学习这些得分函数,并将它们整合到联合动作批评者中,以指导策略更新朝着高奖励、在分布范围内的区域发展,以实现共享的团队奖励。我们的方法在多个粒子环境和多智能体MuJoCo基准测试中实现了最新性能。据我们所知,这是第一项明确解决离线与在线MARL之间分布差距的工作,为更通用的离线策略型MARL方法铺平了道路。
论文及项目相关链接
PDF Working papers
Summary
离线多智能体强化学习(MARL)面临分布转移的独特挑战,特别是源于联合动作空间的高维度和存在超出分布范围的联合动作选择。本文强调,离线MARL的一个基本挑战来自于合作任务的多元平衡性质,这导致了复杂的联合行为策略空间以及异质质量的行为数据。这使得个体策略正则化难以与一致的协调模式对齐,从而导致策略分布转移问题。本研究设计了一种顺序得分函数分解方法,从联合行为策略中提炼出智能体策略正则化信号,并在分散执行约束下引导协调模态选择。然后利用灵活的基于扩散的生成模型从这些多模态离线数据中学习得分函数,并将其整合到联合动作评价中,以指导策略更新朝向高奖励、在分布区域内的共享团队奖励。该方法在多智能体环境和MuJoCo基准测试中取得了最佳性能。据我们所知,这是首次明确解决离线与在线MARL之间的分布差距的工作,为更通用的离线策略型MARL方法铺平了道路。
Key Takeaways
- 离线多智能体强化学习(MARL)面临独特的挑战,包括分布转移、联合动作空间的高维度以及超出分布范围的联合动作选择。
- 合作任务的多元平衡性质导致复杂的联合行为策略空间和异质质量的行为数据,增加了策略正则化的难度。
- 设计的顺序得分函数分解方法可以从联合行为策略中提炼出智能体策略正则化信号,引导协调模态选择。
- 利用基于扩散的生成模型学习多模态离线数据中的得分函数,整合到联合动作评价中。
- 方法旨在将策略更新导向高奖励、在分布区域内的共享团队奖励。
- 在多个智能体环境和MuJoCo基准测试中取得了最佳性能表现。
点此查看论文截图

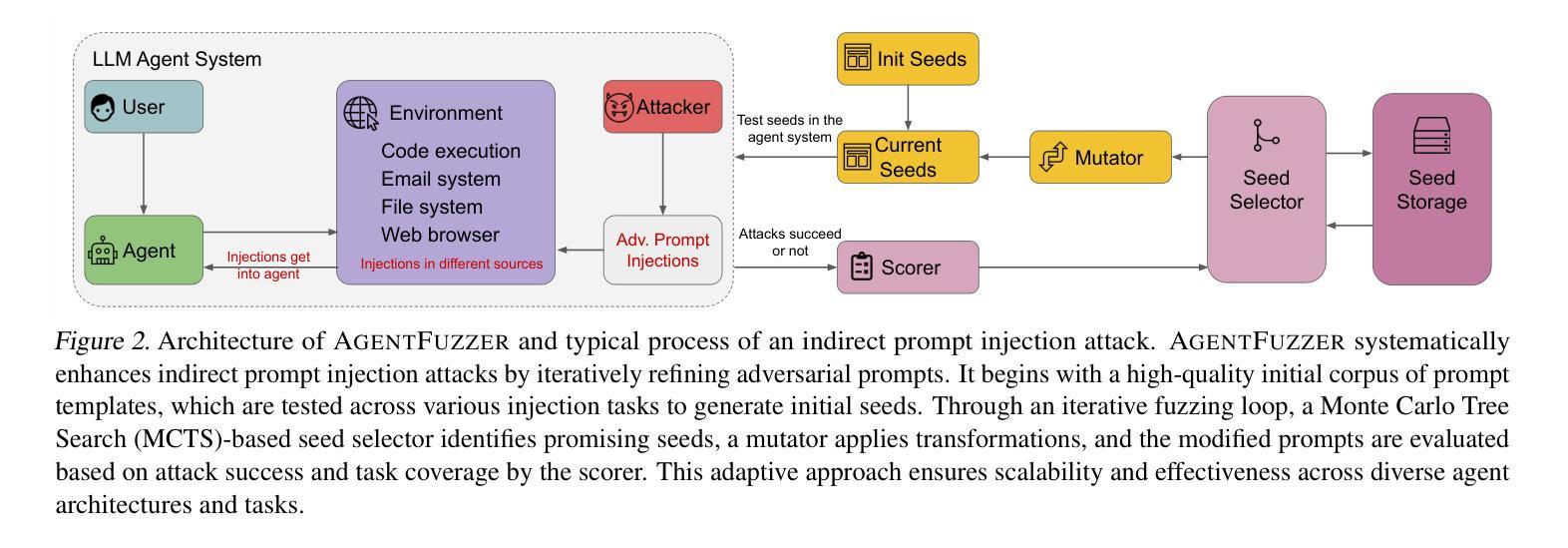
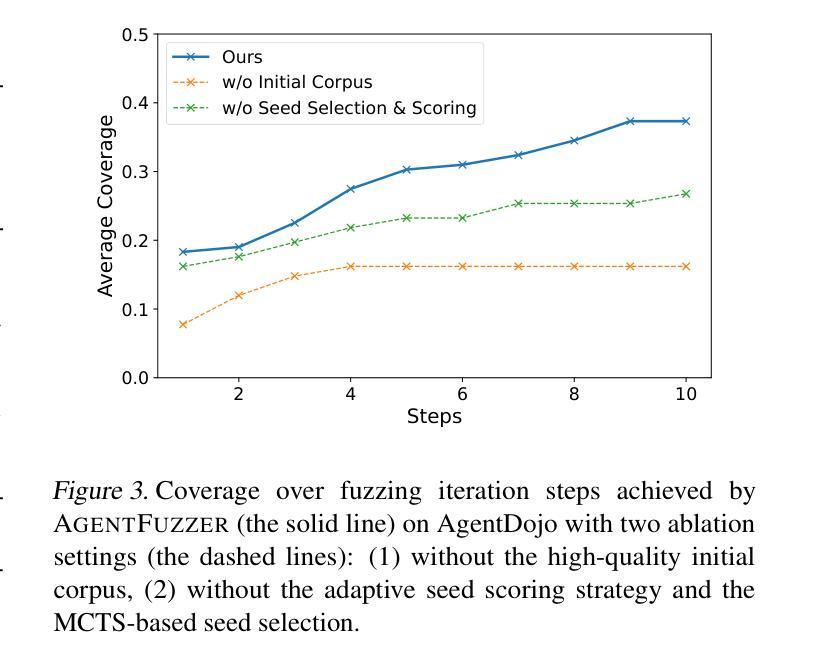
AGENTFUZZER: Generic Black-Box Fuzzing for Indirect Prompt Injection against LLM Agents
Authors:Zhun Wang, Vincent Siu, Zhe Ye, Tianneng Shi, Yuzhou Nie, Xuandong Zhao, Chenguang Wang, Wenbo Guo, Dawn Song
The strong planning and reasoning capabilities of Large Language Models (LLMs) have fostered the development of agent-based systems capable of leveraging external tools and interacting with increasingly complex environments. However, these powerful features also introduce a critical security risk: indirect prompt injection, a sophisticated attack vector that compromises the core of these agents, the LLM, by manipulating contextual information rather than direct user prompts. In this work, we propose a generic black-box fuzzing framework, AgentFuzzer, designed to automatically discover and exploit indirect prompt injection vulnerabilities across diverse LLM agents. Our approach starts by constructing a high-quality initial seed corpus, then employs a seed selection algorithm based on Monte Carlo Tree Search (MCTS) to iteratively refine inputs, thereby maximizing the likelihood of uncovering agent weaknesses. We evaluate AgentFuzzer on two public benchmarks, AgentDojo and VWA-adv, where it achieves 71% and 70% success rates against agents based on o3-mini and GPT-4o, respectively, nearly doubling the performance of baseline attacks. Moreover, AgentFuzzer exhibits strong transferability across unseen tasks and internal LLMs, as well as promising results against defenses. Beyond benchmark evaluations, we apply our attacks in real-world environments, successfully misleading agents to navigate to arbitrary URLs, including malicious sites.
大型语言模型(LLM)的强大规划和推理能力促进了基于代理的系统的开发,这些系统能够利用外部工具并与日益复杂的环境进行交互。然而,这些强大功能也引入了一个关键的安全风险:间接提示注入,这是一种高级攻击向量,通过操纵上下文信息而不是直接用户提示来危害这些代理的核心——LLM。在这项工作中,我们提出了一种通用的黑盒模糊测试框架AgentFuzzer,旨在自动发现和利用LLM代理中的间接提示注入漏洞。我们的方法首先构建高质量的初始种子语料库,然后采用基于蒙特卡洛树搜索(MCTS)的种子选择算法来迭代优化输入,从而最大化发现代理弱点的可能性。我们在两个公共基准测试AgentDojo和VWA-adv上评估了AgentFuzzer的性能,在基于o3-mini和GPT-4o的代理上分别实现了71%和70%的成功率,几乎将基线攻击的性能提高了一倍。此外,AgentFuzzer在跨未见任务和内部LLM的迁移方面具有强大的可迁移性,并且在防御措施面前也表现出有前景的结果。除了基准测试评估外,我们还将在真实环境中应用攻击,成功误导代理访问任意URL,包括恶意网站。
论文及项目相关链接
Summary:大型语言模型(LLM)的强大规划和推理能力促进了基于代理的系统的开发,使得代理系统能够利用外部工具并与日益复杂的交互环境互动。然而,这同时带来了一种严重的安全风险——间接提示注入攻击。本次研究中提出了一种通用的黑箱模糊测试框架AgentFuzzer,它能够自动发现并利用LLM中的间接提示注入漏洞。框架基于高质量初始种子语料库并利用蒙特卡罗树搜索进行种子选择,以最大化发现代理弱点。在AgentDojo和VWA-adv两个公开基准测试上,AgentFuzzer在针对基于o3-mini和GPT-4o的代理方面表现优秀,相较于基础攻击提高了近两倍性能。而且其表现出出色的任务迁移性和内部LLM性能,并在防御方面展现出良好前景。此外,在真实环境中应用攻击时,成功误导代理访问任意URL,包括恶意网站。
Key Takeaways:
- LLM的强大规划和推理能力推动了基于代理的系统的进步。
- 间接提示注入是一种严重的安全风险,能危及LLM的核心安全。
- AgentFuzzer是一个通用的黑箱模糊测试框架,用于自动发现并利用LLM中的间接提示注入漏洞。
- AgentFuzzer使用高质量初始种子语料库和基于蒙特卡罗树搜索的种子选择算法。
- AgentFuzzer在公开基准测试上的表现优于其他攻击方式,并具备出色的任务迁移性和内部LLM性能。
- AgentFuzzer在真实环境中成功误导代理访问恶意网站。
点此查看论文截图


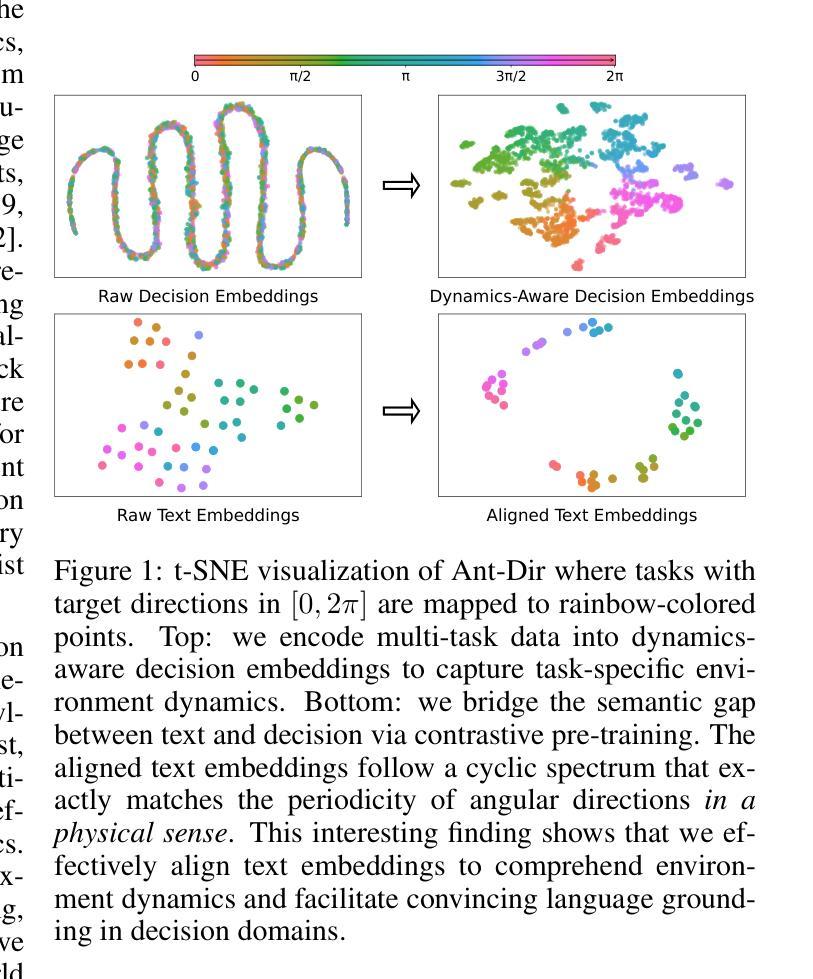
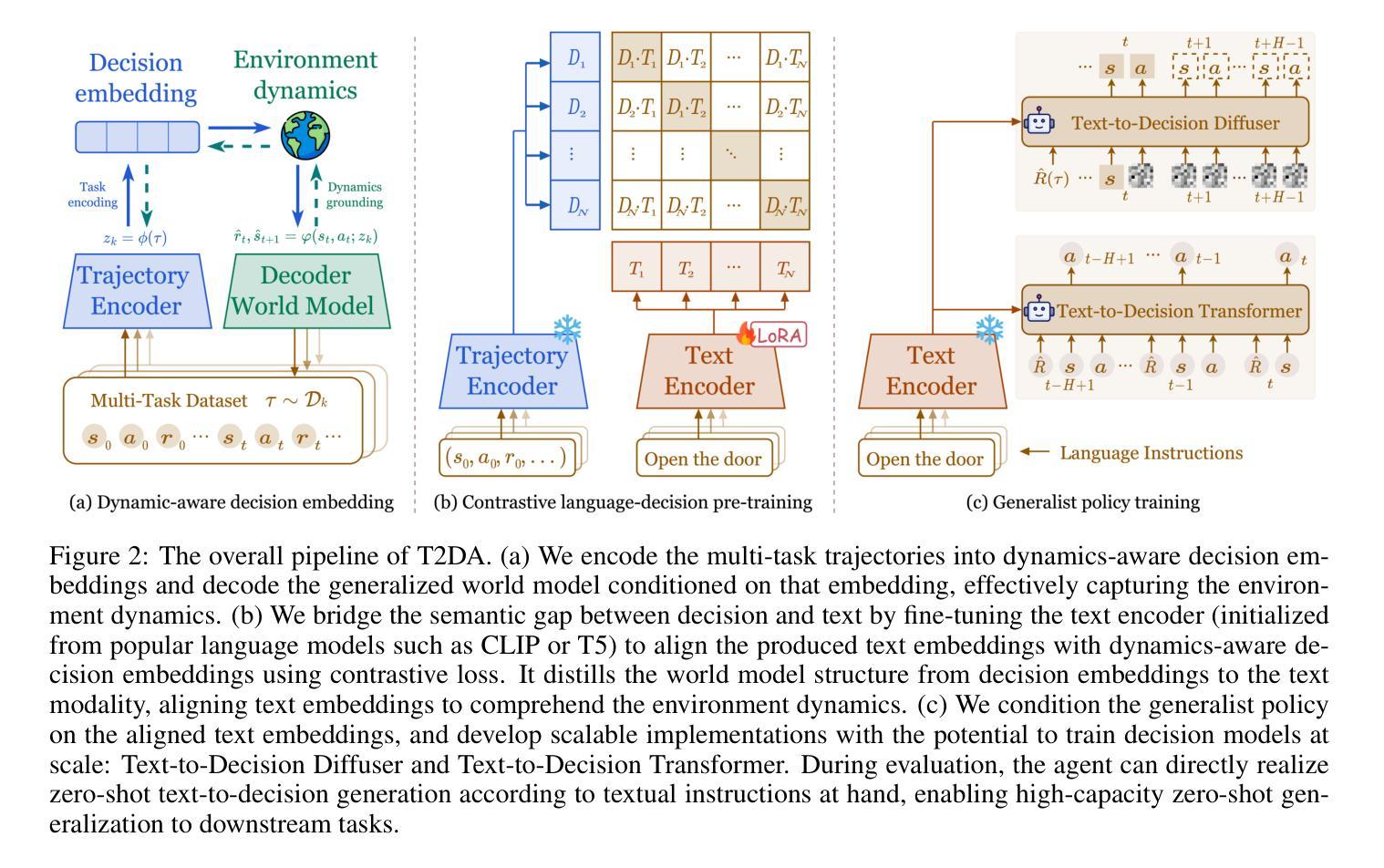
Text-to-Decision Agent: Offline Meta-Reinforcement Learning from Natural Language Supervision
Authors:Shilin Zhang, Zican Hu, Wenhao Wu, Xinyi Xie, Jianxiang Tang, Chunlin Chen, Daoyi Dong, Yu Cheng, Zhenhong Sun, Zhi Wang
Offline meta-RL usually tackles generalization by inferring task beliefs from high-quality samples or warmup explorations. The restricted form limits their generality and usability since these supervision signals are expensive and even infeasible to acquire in advance for unseen tasks. Learning directly from the raw text about decision tasks is a promising alternative to leverage a much broader source of supervision. In the paper, we propose \textbf{T}ext-to-\textbf{D}ecision \textbf{A}gent (\textbf{T2DA}), a simple and scalable framework that supervises offline meta-RL with natural language. We first introduce a generalized world model to encode multi-task decision data into a dynamics-aware embedding space. Then, inspired by CLIP, we predict which textual description goes with which decision embedding, effectively bridging their semantic gap via contrastive language-decision pre-training and aligning the text embeddings to comprehend the environment dynamics. After training the text-conditioned generalist policy, the agent can directly realize zero-shot text-to-decision generation in response to language instructions. Comprehensive experiments on MuJoCo and Meta-World benchmarks show that T2DA facilitates high-capacity zero-shot generalization and outperforms various types of baselines. Our code is available at https://github.com/NJU-RL/T2DA.
离线元强化学习通常通过从高质量样本或预热探索中推断任务信念来解决泛化问题。这种有限的形式限制了其通用性和可用性,因为这些监督信号在预先获取方面非常昂贵,甚至对于未见过的任务来说是不可能的。直接从关于决策任务的原始文本中学习是一个有前景的替代方案,可以充分利用更广泛的监督资源。在论文中,我们提出了文本到决策代理(T2DA),这是一个简单且可扩展的框架,可以通过自然语言对离线元强化学习进行监督。我们首先引入一个通用世界模型,将多任务决策数据编码到具有动态感知的嵌入空间。然后,受到CLIP的启发,我们预测哪种文本描述与哪种决策嵌入相匹配,通过对比语言决策预训练有效地弥合了它们的语义鸿沟并调整了文本嵌入以理解环境动态。在训练出文本条件下的通用策略后,代理可以直接实现零启动文本到决策生成,以响应语言指令。在MuJoCo和Meta-World基准测试上的综合实验表明,T2DA促进了高容量零启动泛化并超越了各种类型的基线。我们的代码可在https://github.com/NJU-RL/T2DA上找到。
论文及项目相关链接
PDF 18 pages, 8 figures
Summary:
本文提出了一个名为T2DA的文本决策代理框架,该框架利用自然语言对离线元强化学习进行监管。通过引入通用世界模型和多任务决策数据编码成动态感知嵌入空间,以及受到CLIP启发的文本描述与决策嵌入的预测,成功实现了文本到决策的零射击生成。实验表明,T2DA在MuJoCo和Meta-World基准测试中表现出卓越的高容量零射击泛化能力并优于各类基线。
Key Takeaways:
- T2DA是一个文本决策代理框架,旨在通过自然语言监督离线元强化学习。
- 它引入了通用世界模型来编码多任务决策数据,并生成一个动态感知嵌入空间。
- 采用受CLIP启发的预测机制,实现了文本描述与决策嵌入的关联,缩减了语义鸿沟。
- 通过对比语言决策预训练,使文本嵌入理解环境动态。
- 训练后的文本条件通用策略可实现直接零射击文本到决策生成,响应语言指令。
- 在MuJoCo和Meta-World基准测试中,T2DA表现出卓越的高容量零射击泛化能力。
- T2DA的代码已公开在https://github.com/NJU-RL/T2DA。
点此查看论文截图

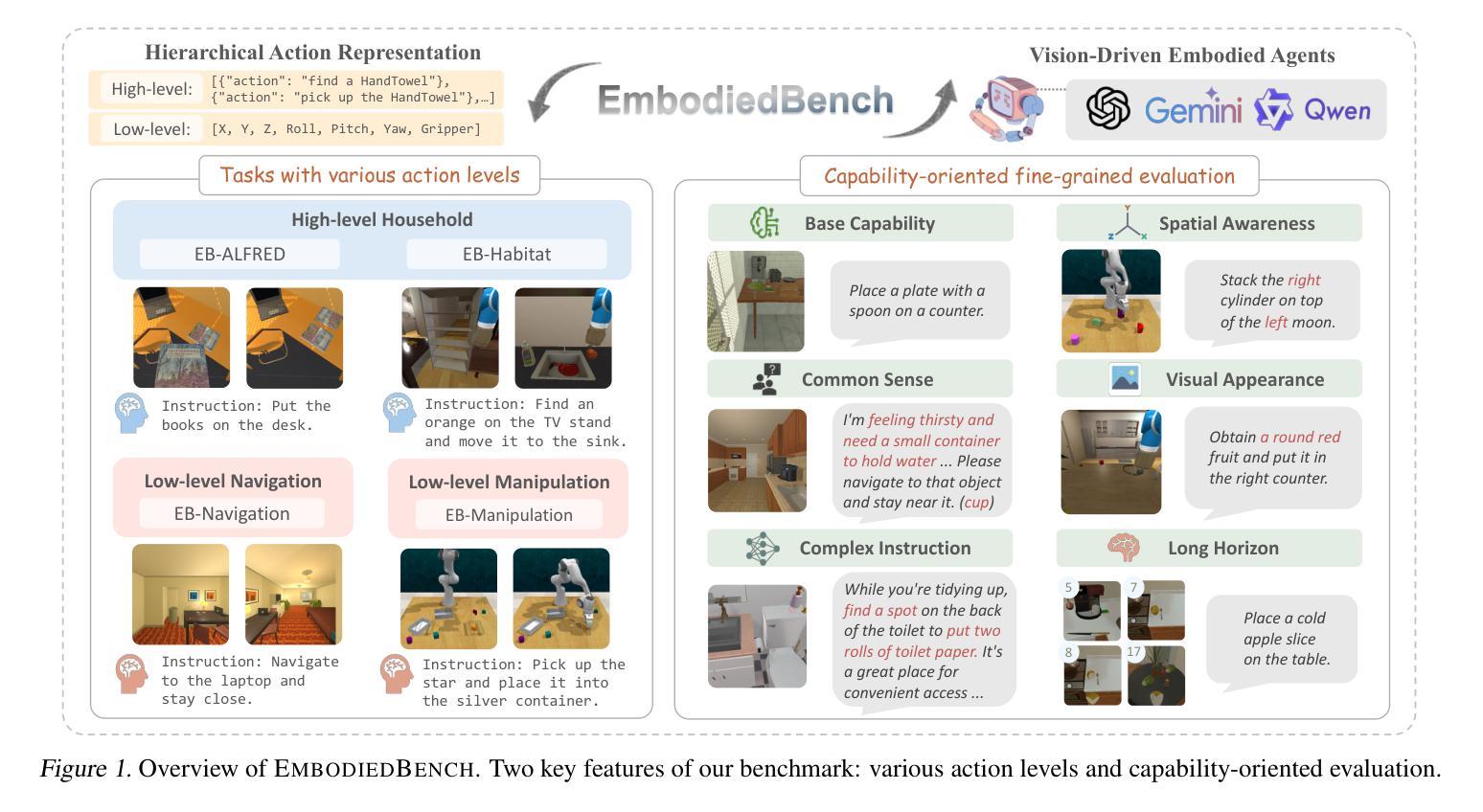
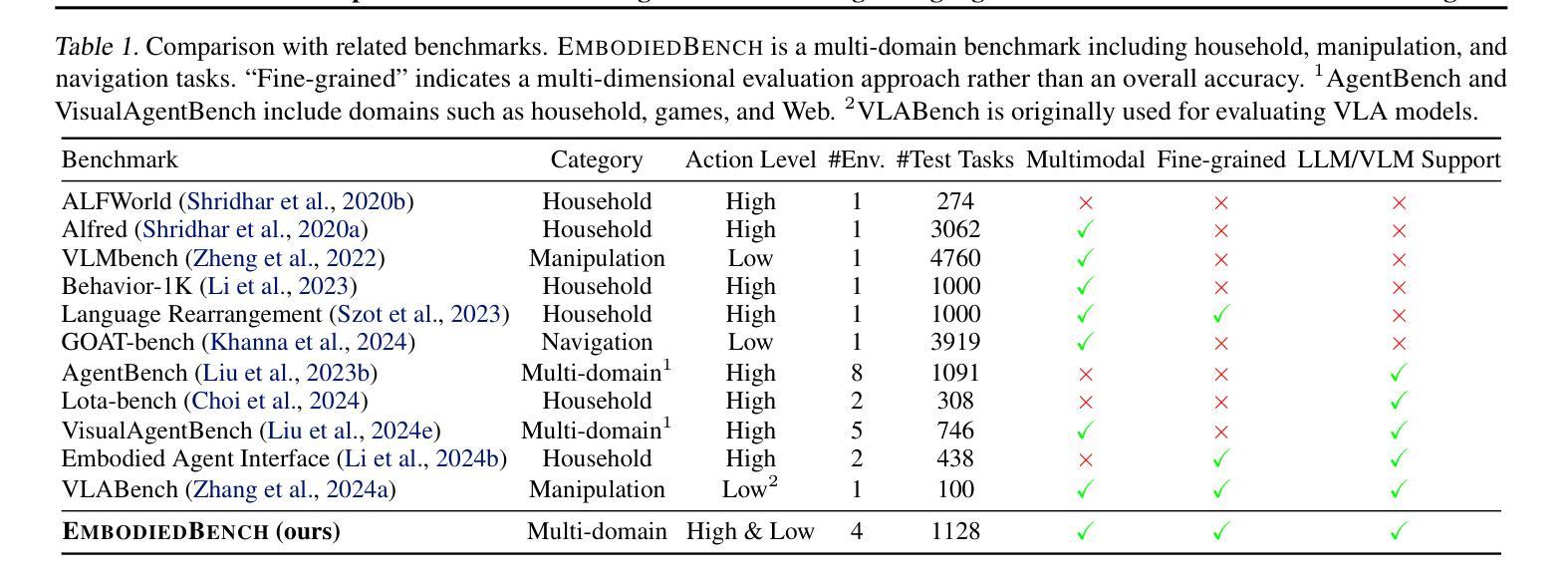
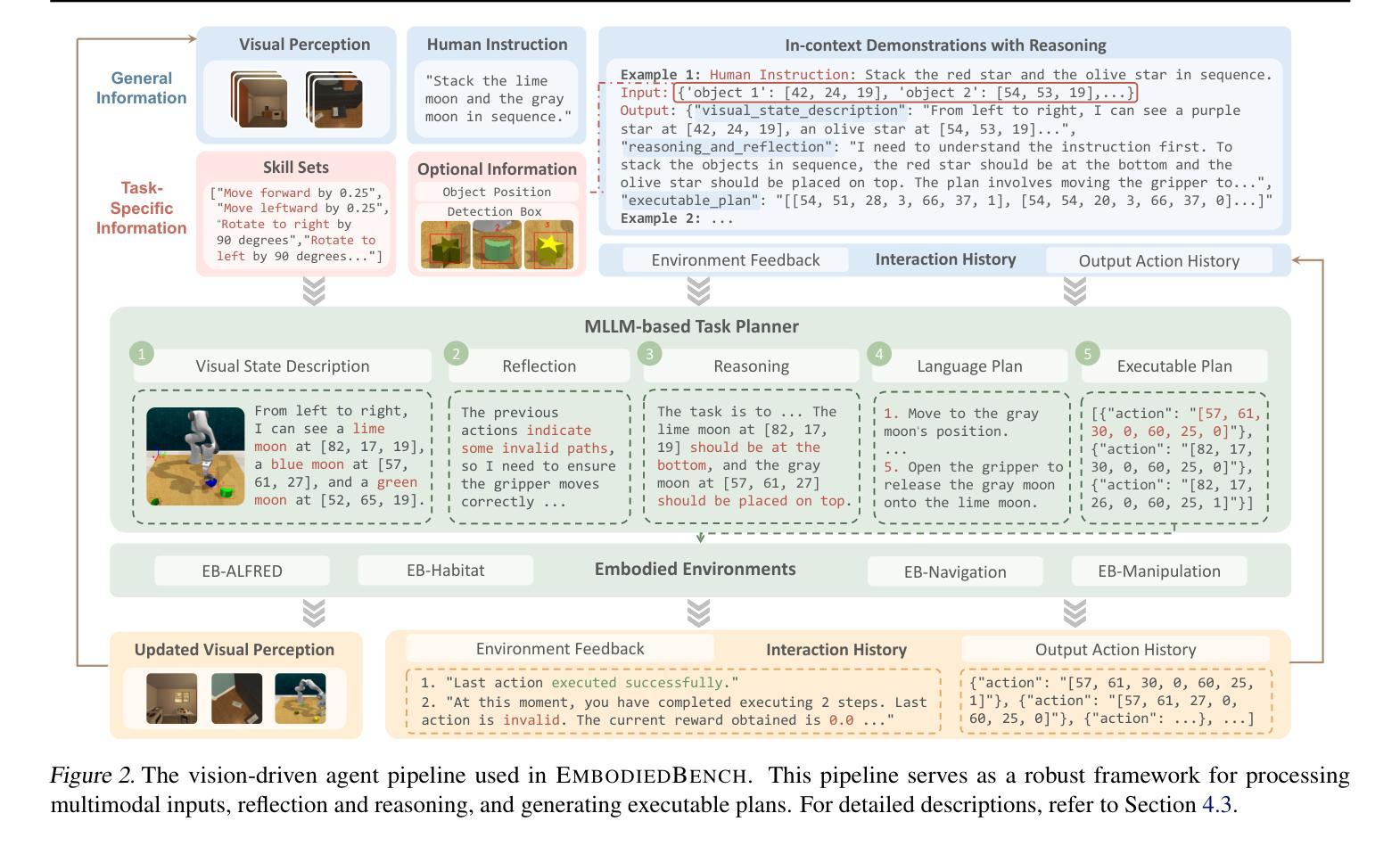
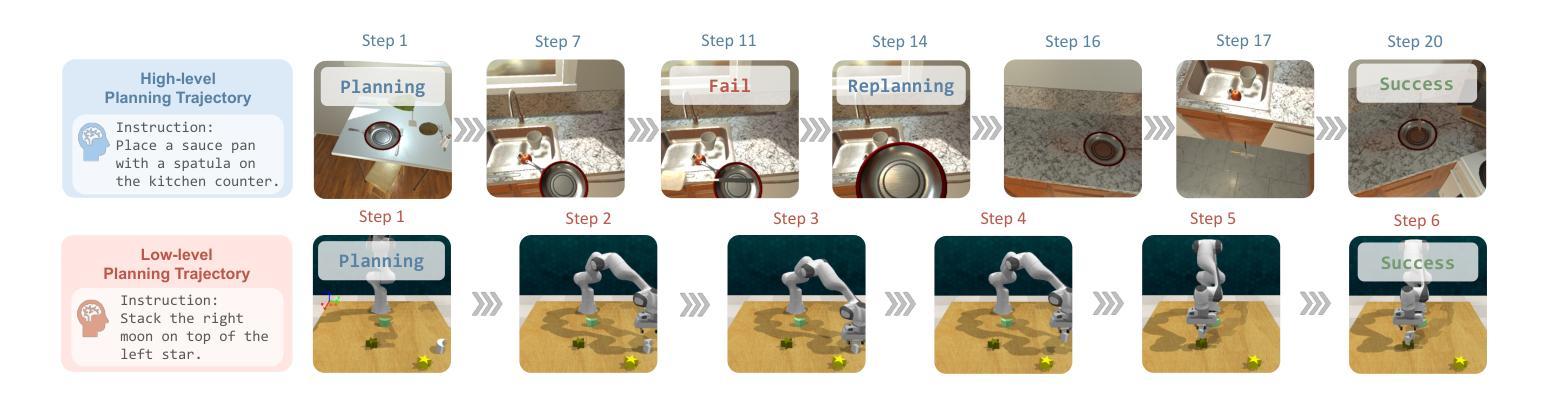
EmbodiedBench: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents
Authors:Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, Heng Ji, Huan Zhang, Tong Zhang
Leveraging Multi-modal Large Language Models (MLLMs) to create embodied agents offers a promising avenue for tackling real-world tasks. While language-centric embodied agents have garnered substantial attention, MLLM-based embodied agents remain underexplored due to the lack of comprehensive evaluation frameworks. To bridge this gap, we introduce EmbodiedBench, an extensive benchmark designed to evaluate vision-driven embodied agents. EmbodiedBench features: (1) a diverse set of 1,128 testing tasks across four environments, ranging from high-level semantic tasks (e.g., household) to low-level tasks involving atomic actions (e.g., navigation and manipulation); and (2) six meticulously curated subsets evaluating essential agent capabilities like commonsense reasoning, complex instruction understanding, spatial awareness, visual perception, and long-term planning. Through extensive experiments, we evaluated 24 leading proprietary and open-source MLLMs within EmbodiedBench. Our findings reveal that: MLLMs excel at high-level tasks but struggle with low-level manipulation, with the best model, GPT-4o, scoring only 28.9% on average. EmbodiedBench provides a multifaceted standardized evaluation platform that not only highlights existing challenges but also offers valuable insights to advance MLLM-based embodied agents. Our code and dataset are available at https://embodiedbench.github.io.
利用多模态大型语言模型(MLLMs)创建实体代理为解决现实世界任务提供了有前景的途径。虽然以语言为中心的实体代理已经引起了广泛关注,但基于MLLM的实体代理由于缺少全面的评估框架而尚未得到充分探索。为了弥补这一差距,我们引入了EmbodiedBench,这是一个旨在评估视觉驱动的实体代理的广泛基准测试。EmbodiedBench的特点包括:(1)跨越四个环境的1128个测试任务集,从高级语义任务(例如家庭任务)到涉及原子动作的低级任务(例如导航和操作);(2)六个精心策划的子集,评估代理的必要能力,如常识推理、复杂指令理解、空间感知、视觉感知和长期规划。通过广泛的实验,我们在EmbodiedBench中评估了24个领先的专业和开源MLLM。我们的研究发现:MLLM在高级任务上表现出色,但在低级操作方面遇到困难,最佳模型GPT-4o的平均得分仅为28.9%。EmbodiedBench提供了一个多方面的标准化评估平台,它不仅突出了现有挑战,而且为推进基于MLLM的实体代理提供了宝贵见解。我们的代码和数据集可在https://embodiedbench.github.io获取。
论文及项目相关链接
PDF Accepted to ICML 2025
Summary
利用多模态大型语言模型(MLLMs)创建实体代理为解决现实世界任务提供了有前景的途径。尽管语言为中心的实体代理已经引起了广泛关注,但基于MLLM的实体代理由于缺少全面的评估框架而仍被较少探索。为了弥补这一差距,我们引入了EmbodiedBench,这是一个旨在评估视觉驱动的实体代理的广泛基准。EmbodiedBench的特色在于:(1)涵盖四种环境的1,128项测试任务,范围从高级语义任务(如家庭任务)到涉及原子动作的低级任务(如导航和操作);(2)六个精心策划的子集评估了代理的必要能力,如常识推理、复杂指令理解、空间意识、视觉感知和长期规划。通过广泛实验,我们在EmbodiedBench中评估了24个领先的专业和开源MLLMs。我们发现:MLLMs在高级任务上表现出色,但在低级操作任务上遇到困难,最佳模型GPT-4o的平均得分仅为28.9%。EmbodiedBench提供了一个多方面的标准化评估平台,不仅突出了现有挑战,而且为推进基于MLLM的实体代理提供了有价值的信息。
Key Takeaways
- 多模态大型语言模型(MLLMs)在创建实体代理以完成现实世界任务方面具前景。
2.由于缺乏全面的评估框架,基于MLLM的实体代理研究仍较少。 - EmbodiedBench是一个旨在评估视觉驱动实体代理性能的广泛基准。
- EmbodiedBench包含多样化的测试任务,涵盖从高级语义到低级原子动作的任务。
- MLLMs在高级任务上表现良好,但在低级操作任务上表现不佳,最佳模型平均得分仅为28.9%。
- EmbodiedBench突出显示了实体代理所面临的现有挑战。
点此查看论文截图

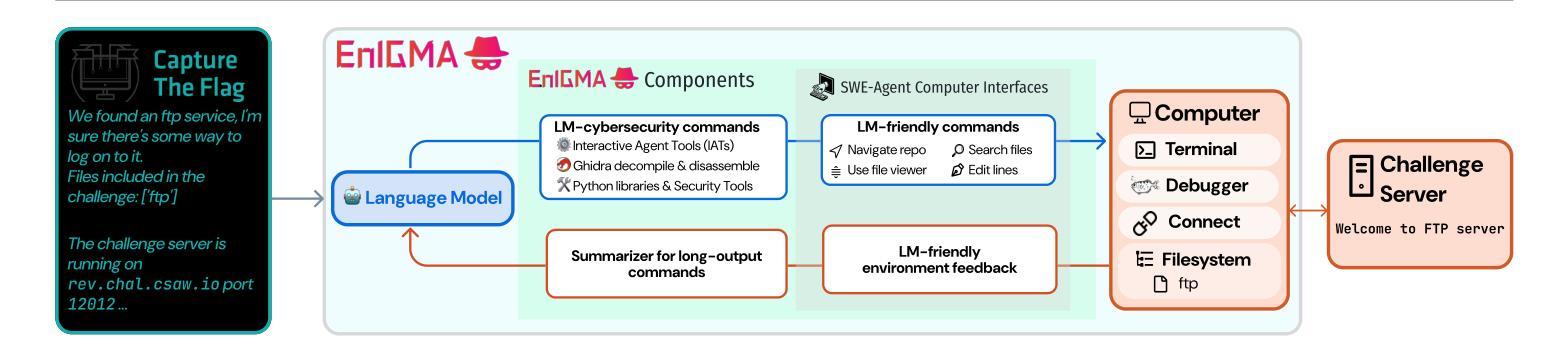
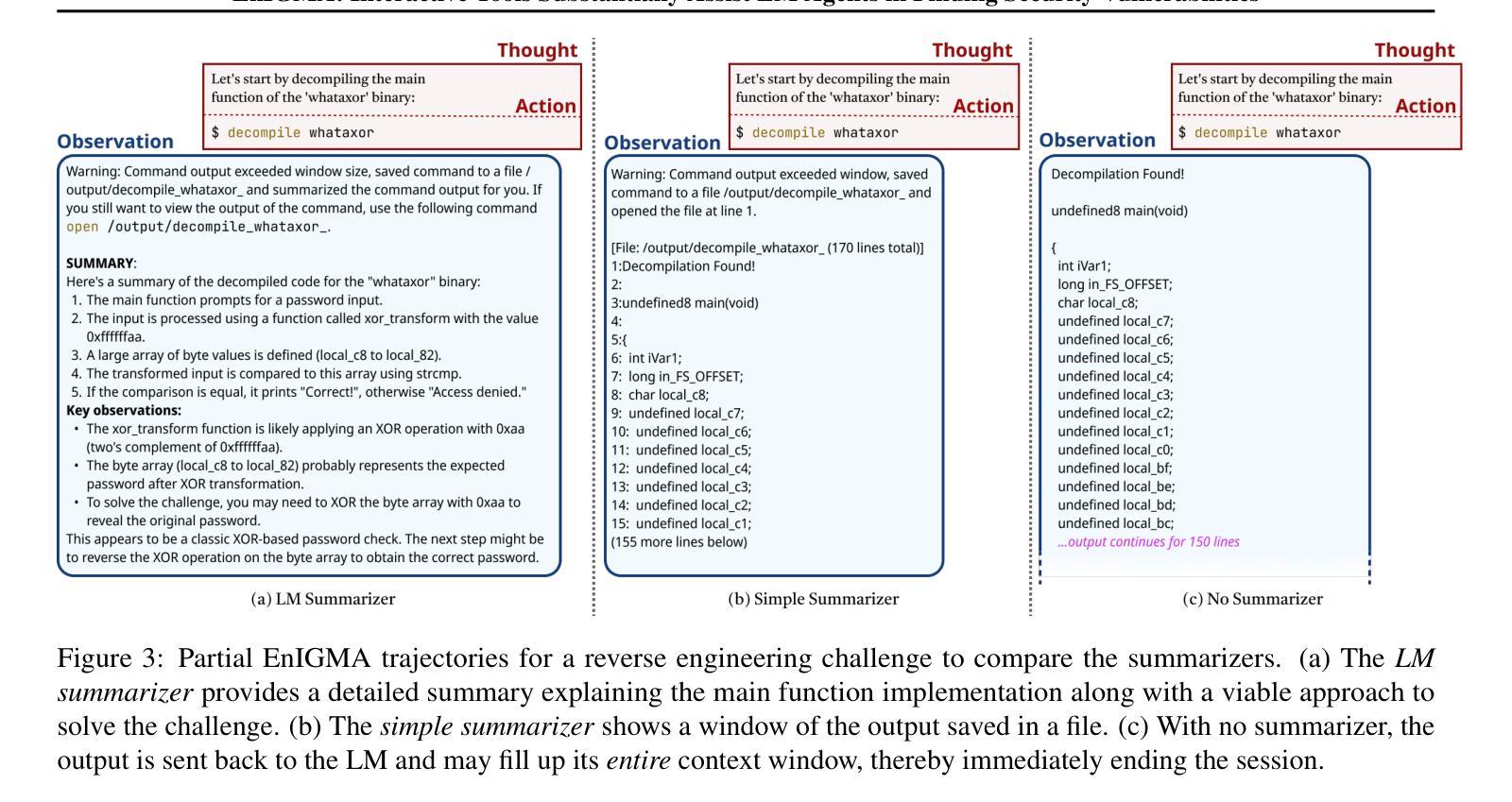
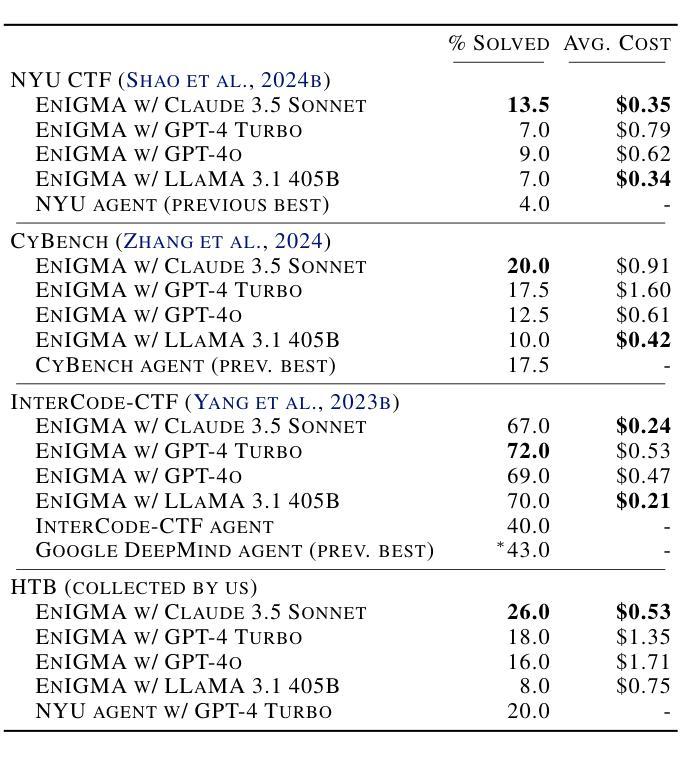
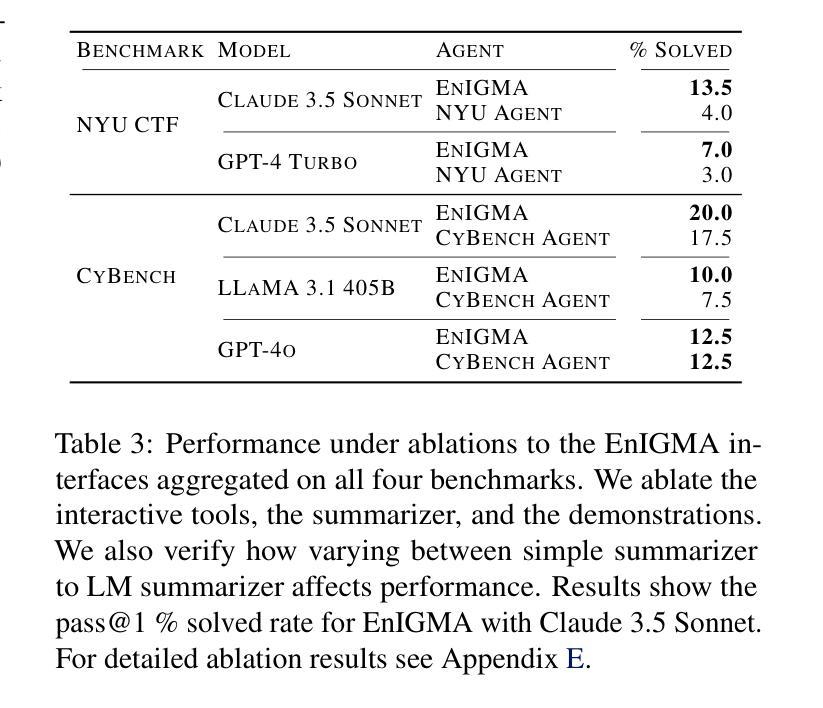
EnIGMA: Interactive Tools Substantially Assist LM Agents in Finding Security Vulnerabilities
Authors:Talor Abramovich, Meet Udeshi, Minghao Shao, Kilian Lieret, Haoran Xi, Kimberly Milner, Sofija Jancheska, John Yang, Carlos E. Jimenez, Farshad Khorrami, Prashanth Krishnamurthy, Brendan Dolan-Gavitt, Muhammad Shafique, Karthik Narasimhan, Ramesh Karri, Ofir Press
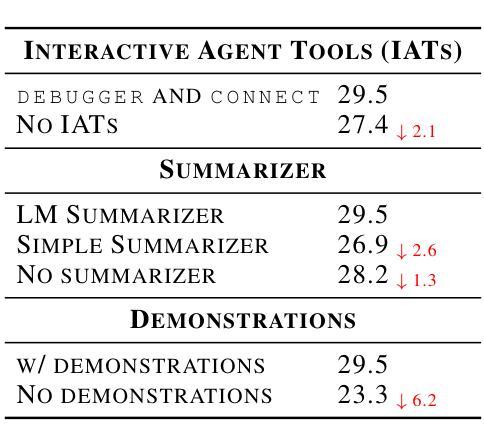
Although language model (LM) agents have demonstrated increased performance in multiple domains, including coding and web-browsing, their success in cybersecurity has been limited. We present EnIGMA, an LM agent for autonomously solving Capture The Flag (CTF) challenges. We introduce new tools and interfaces to improve the agent’s ability to find and exploit security vulnerabilities, focusing on interactive terminal programs. These novel Interactive Agent Tools enable LM agents, for the first time, to run interactive utilities, such as a debugger and a server connection tool, which are essential for solving these challenges. Empirical analysis on 390 CTF challenges across four benchmarks demonstrate that these new tools and interfaces substantially improve our agent’s performance, achieving state-of-the-art results on NYU CTF, Intercode-CTF, and CyBench. Finally, we analyze data leakage, developing new methods to quantify it and identifying a new phenomenon we term soliloquizing, where the model self-generates hallucinated observations without interacting with the environment. Our code and development dataset are available at https://github.com/SWE-agent/SWE-agent/tree/v0.7 and https://github.com/NYU-LLM-CTF/NYU_CTF_Bench/tree/main/development respectively.
尽管语言模型(LM)代理在编码和网页浏览等多个领域表现出性能提升,但在网络安全方面的成功却有限。我们推出了EnIGMA,这是一款用于自主解决Capture The Flag(CTF)挑战的语言模型代理。我们引入了新工具和界面,以提高代理发现和利用安全漏洞的能力,重点针对交互式终端程序。这些新型交互式代理工具使得语言模型代理首次能够运行交互式实用程序,如调试器和服务器连接工具,这对于解决这些挑战至关重要。在四项指标的390项CTF挑战上的实证分析表明,这些新工具和界面极大地提高了我们的代理性能,在NYU CTF、Intercode-CTF和CyBench上达到了最新结果。最后,我们分析了数据泄露问题,开发了新的量化方法,并识别出一种我们称之为自言自语的新现象,即模型在没有与环境交互的情况下自我生成虚构的观察结果。我们的代码和开发数据集分别位于https://github.com/SWE-agent/SWE-agent/tree/v0.7和https://github.com/NYU-LLM-CTF/NYU_CTF_Bench/tree/main/development。
论文及项目相关链接
PDF ICML 2025; Project website https://enigma-agent.com
Summary
本文介绍了一种名为EnIGMA的LM代理,专门用于自主解决Capture The Flag(CTF)挑战。文章提出了新工具和界面来改善代理找到并利用安全漏洞的能力,重点在交互式终端程序。这些新颖的互动代理工具使得LM代理首次能够运行关键实用程序,如调试器和服务器连接工具。经验分析表明,新工具和接口大大提高了代理性能,并在多个基准测试中达到最新水平。此外,文章还分析了数据泄露现象,并开发了新的量化方法,识别了一种新现象——“自言自语”,即模型在不与环境交互的情况下自我生成幻觉观察。
Key Takeaways
- EnIGMA是一个用于解决Capture The Flag(CTF)挑战的LM代理。
- 介绍了新工具和界面,提高了代理在查找和利用安全漏洞方面的能力。
- 互动代理工具使LM代理能运行关键实用程序,如调试器和服务器连接工具。
- 新工具和接口显著提升了代理性能,达到或超越了最新水平。
- 文章分析了数据泄露现象,并开发了新的量化方法。
- 识别了一种新现象——“自言自语”,即模型自我生成幻觉观察。
点此查看论文截图