⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-08 更新
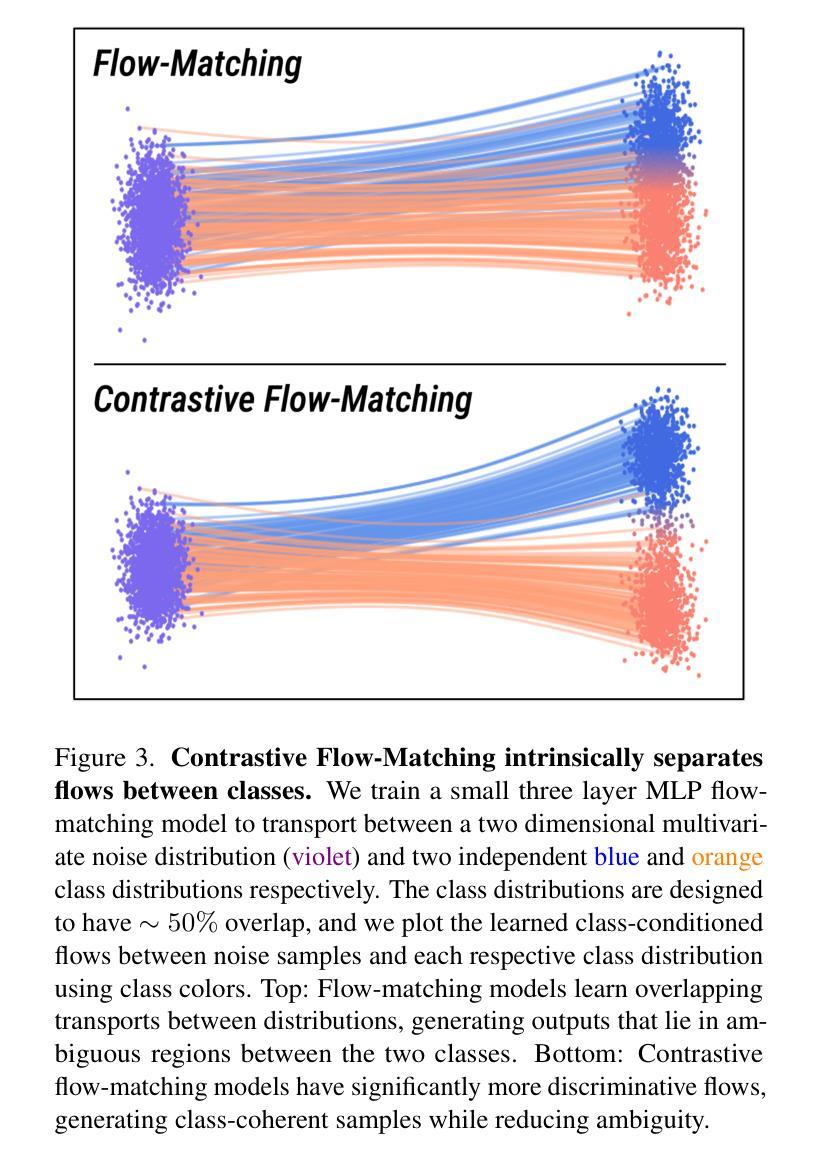
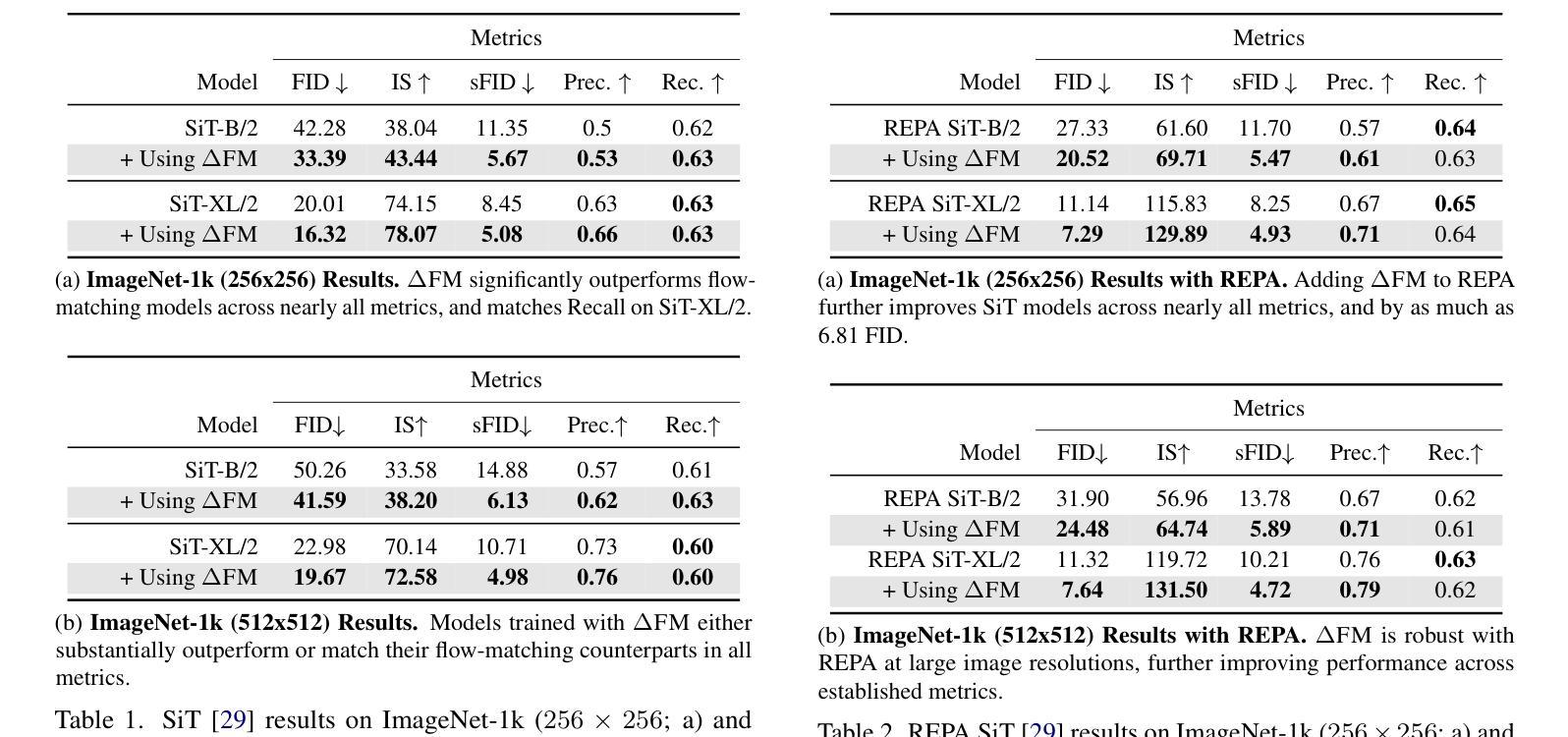
Contrastive Flow Matching
Authors:George Stoica, Vivek Ramanujan, Xiang Fan, Ali Farhadi, Ranjay Krishna, Judy Hoffman
Unconditional flow-matching trains diffusion models to transport samples from a source distribution to a target distribution by enforcing that the flows between sample pairs are unique. However, in conditional settings (e.g., class-conditioned models), this uniqueness is no longer guaranteed–flows from different conditions may overlap, leading to more ambiguous generations. We introduce Contrastive Flow Matching, an extension to the flow matching objective that explicitly enforces uniqueness across all conditional flows, enhancing condition separation. Our approach adds a contrastive objective that maximizes dissimilarities between predicted flows from arbitrary sample pairs. We validate Contrastive Flow Matching by conducting extensive experiments across varying model architectures on both class-conditioned (ImageNet-1k) and text-to-image (CC3M) benchmarks. Notably, we find that training models with Contrastive Flow Matching (1) improves training speed by a factor of up to 9x, (2) requires up to 5x fewer de-noising steps and (3) lowers FID by up to 8.9 compared to training the same models with flow matching. We release our code at: https://github.com/gstoica27/DeltaFM.git.
无条件流匹配训练扩散模型,通过强制样本对之间的流是唯一的,从源分布传输样本到目标分布。然而,在条件设置(例如,类条件模型)中,这种唯一性不再被保证——来自不同条件的流可能会重叠,导致更模糊的生成。我们引入了对比流匹配(Contrastive Flow Matching),这是对流匹配目标的扩展,它明确地强制执行所有条件流之间的唯一性,增强了条件分离。我们的方法增加了一个对比目标,该目标最大化任意样本对之间预测流的差异。我们通过在不同模型架构上进行广泛的实验,在类条件(ImageNet-1k)和文本到图像(CC3M)基准测试上验证了对比流匹配的有效性。值得注意的是,我们发现使用对比流匹配训练模型(1)将训练速度提高了高达9倍,(2)减少了高达5倍的降噪步骤,并且(3)与用流匹配训练相同模型相比,FID降低了高达8.9。我们已在https://github.com/gstoica27/DeltaFM.git发布我们的代码。
论文及项目相关链接
摘要
扩散模型中的对比流匹配方法通过在预测流中明确强制执行唯一性来改进条件分离。通过添加最大化任意样本对预测流之间差异度的对比目标来实现这一目标。实验结果显示,该方法能提高训练速度、减少去噪步骤数量并降低FID得分。相关代码已公开在指定链接上。此方法有助于改善条件设置下扩散模型的性能,尤其在处理类条件任务和文本转图像任务时表现显著。
关键见解
- 对比流匹配是一种针对扩散模型的改进方法,旨在加强条件分离,特别是在类条件模型和文本转图像模型中。它通过强制执行预测流中的唯一性来提高模型性能。
- 对比流匹配引入了一个对比目标,该目标最大化任意样本对预测流之间的不相似度。这种差异度有助于模型更好地区分不同条件下的流,从而减少模糊生成的可能性。
- 对比流匹配能提高训练速度,最多可达9倍。这意味着使用对比流匹配的模型可以在更短的时间内完成训练任务。
- 对比流匹配减少了去噪步骤的数量,最多可达5倍。这使得扩散模型在进行噪声数据预处理时更为高效。这也有利于加速模型训练和降低计算成本。这种效率的提高得益于模型对于输入数据真实性和多样性的更好理解。
- 对比流匹配降低了FID得分,最多可降低8.9分。FID得分是衡量生成图像质量的一个重要指标,因此这一改进对于提高生成图像的质量至关重要。这也证明了对比流匹配在改善扩散模型性能方面的有效性。这一改进有助于生成更加真实和多样化的图像,从而提高模型的实用性。通过强化模型的感知质量,对比流匹配使得扩散模型在生成任务中更具竞争力。这一进步有助于推动扩散模型在图像生成领域的进一步发展。此外,对比流匹配还能帮助模型更好地处理复杂的图像生成任务和数据集多样性问题。因此,该方法具有广泛的应用前景和潜力价值。随着更多研究的深入进行和技术的不断迭代更新,相信对比流匹配将会在扩散模型中发挥更大的作用并推动相关领域的发展进步。通过优化算法结构和改进训练策略,我们可以期待未来扩散模型在图像生成方面的更高质量和性能表现。这也为扩散模型在图像处理领域的发展开辟了新的道路和方向。在此基础上继续深入研究和优化将有助于实现更多创新突破并推动相关领域的技术革新进程顺利进行!由于算法的多样性和实际应用需求的不断增长这一领域的未来将具有更多潜力并且将继续发挥关键作用以确保新技术的快速发展和推广普及为社会进步和发展贡献力量
点此查看论文截图



Exploring Diffusion Transformer Designs via Grafting
Authors:Keshigeyan Chandrasegaran, Michael Poli, Daniel Y. Fu, Dongjun Kim, Lea M. Hadzic, Manling Li, Agrim Gupta, Stefano Massaroli, Azalia Mirhoseini, Juan Carlos Niebles, Stefano Ermon, Li Fei-Fei
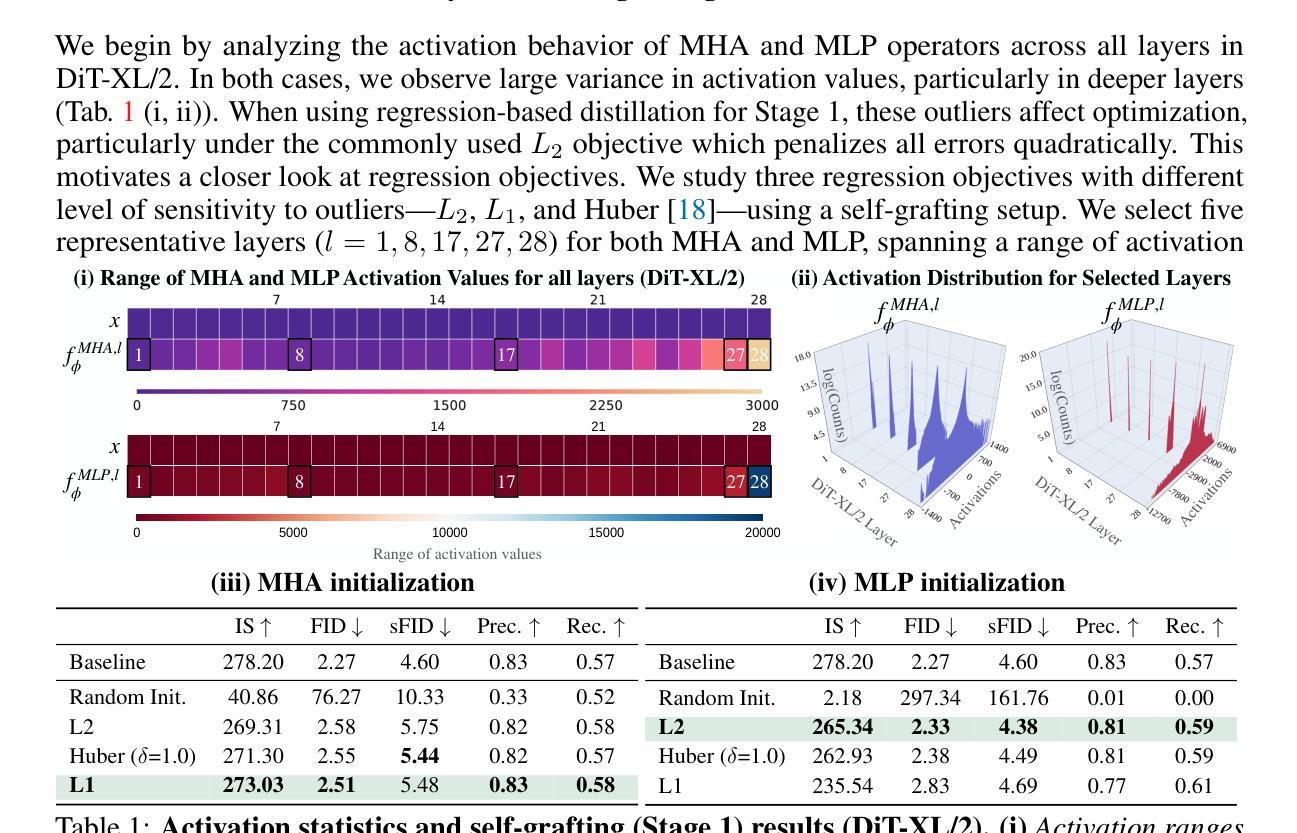
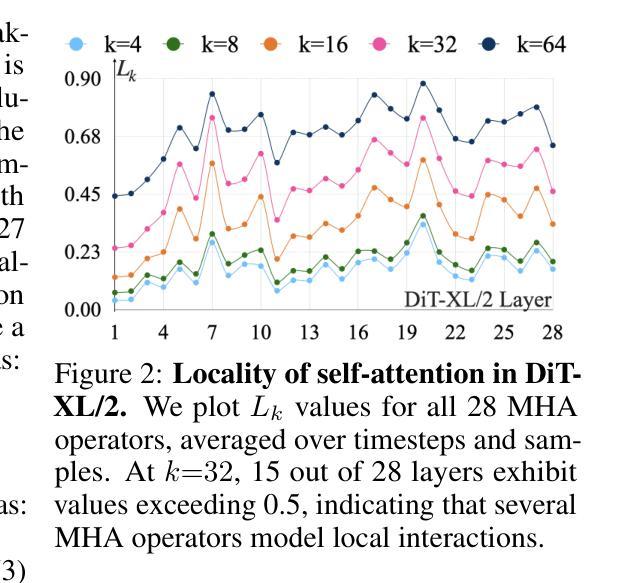
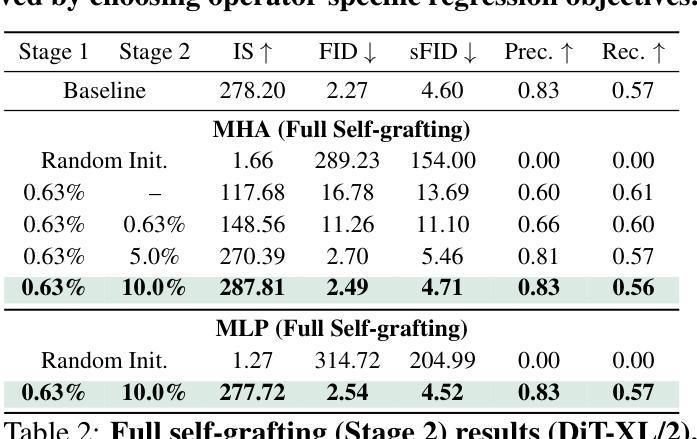
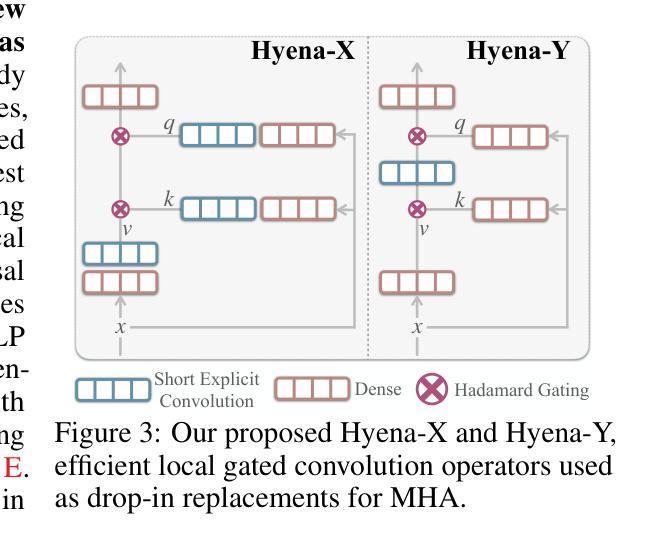
Designing model architectures requires decisions such as selecting operators (e.g., attention, convolution) and configurations (e.g., depth, width). However, evaluating the impact of these decisions on model quality requires costly pretraining, limiting architectural investigation. Inspired by how new software is built on existing code, we ask: can new architecture designs be studied using pretrained models? To this end, we present grafting, a simple approach for editing pretrained diffusion transformers (DiTs) to materialize new architectures under small compute budgets. Informed by our analysis of activation behavior and attention locality, we construct a testbed based on the DiT-XL/2 design to study the impact of grafting on model quality. Using this testbed, we develop a family of hybrid designs via grafting: replacing softmax attention with gated convolution, local attention, and linear attention, and replacing MLPs with variable expansion ratio and convolutional variants. Notably, many hybrid designs achieve good quality (FID: 2.38-2.64 vs. 2.27 for DiT-XL/2) using <2% pretraining compute. We then graft a text-to-image model (PixArt-Sigma), achieving a 1.43x speedup with less than a 2% drop in GenEval score. Finally, we present a case study that restructures DiT-XL/2 by converting every pair of sequential transformer blocks into parallel blocks via grafting. This reduces model depth by 2x and yields better quality (FID: 2.77) than other models of comparable depth. Together, we show that new diffusion model designs can be explored by grafting pretrained DiTs, with edits ranging from operator replacement to architecture restructuring. Code and grafted models: https://grafting.stanford.edu
设计模型架构需要进行诸如选择操作符(例如注意力、卷积)和配置(例如深度、宽度)等决策。然而,评估这些决策对模型质量的影响需要进行昂贵的预训练,这限制了架构的探究。受到如何基于现有代码构建新软件的启发,我们提出一个问题:能否使用预训练模型来研究新的架构设计?为此,我们提出了嫁接(一种简单的方法),用于编辑预训练的扩散变压器(DiTs)以在较小的计算预算下实现新的架构。基于我们对激活行为和注意力局部性的分析,我们以DiT-XL/2设计为基础构建了一个测试平台,以研究嫁接对模型质量的影响。使用这个测试平台,我们通过嫁接开发了一系列混合设计:用门控卷积、局部注意力和线性注意力替换softmax注意力,并用可变扩展率和卷积变体替换MLP。值得注意的是,许多混合设计在预训练计算使用量不到2%的情况下,使用FID(2.38-2.64与DiT-XL/2的2.27)达到了良好的质量。然后我们将一个文本到图像模型(PixArt-Sigma)进行嫁接,实现了1.43倍的速度提升,同时GenEval分数下降不到2%。最后,我们进行了一个案例研究,通过嫁接重新构建DiT-XL/2,将每一对连续的变压器块转换为并行块。这减少了模型深度的一半,并产生了更好的质量(FID:2.77),优于其他具有相似深度的模型。总的来说,我们展示了通过嫁接预训练的DiTs来探索新的扩散模型设计,编辑范围从操作符替换到架构重组。代码和嫁接模型:https://grafting.stanford.edu/
论文及项目相关链接
PDF 22 pages; Project website: https://grafting.stanford.edu
摘要
本文通过借鉴现有软件的构建方式,提出了一种新的模型架构设计方法——嫁接预训练扩散模型。该方法允许在有限的计算预算下实现新的架构,无需昂贵的预训练成本。研究以扩散变压器(DiT)为基础,通过激活行为和注意力局部性的分析,构建了一个测试平台来研究嫁接对模型质量的影响。在此平台上,通过替换softmax注意力机制、局部注意力和线性注意力以及MLP的扩展比和卷积变体等方式,开发了一系列混合设计。许多混合设计在预训练计算量不到2%的情况下,达到了良好的模型质量。此外,还展示了如何将文本到图像的模型(PixArt-Sigma)进行嫁接,实现了1.43倍的加速,同时GenEval分数下降不到2%。最后,通过嫁接预训练的DiTs重新构建DiT-XL/2模型,实现了模型的并行化重构,减少了模型深度,并提高了模型质量。研究展示了通过嫁接预训练扩散模型来探索新的扩散模型设计的潜力。
关键见解
- 提出了通过嫁接预训练扩散模型来研究新架构的方法,降低了模型设计的成本。
- 构建了一个基于DiT-XL/2设计的测试平台,用于研究嫁接对模型质量的影响。
- 通过替换注意力机制和MLP的方式,开发了一系列混合设计,实现了良好的模型质量。
- 展示了将文本到图像模型进行嫁接的实例,提高了模型效率。
- 通过嫁接重新构建DiT-XL/2模型,实现了模型的并行化重构,减少了模型深度,提高了质量。
- 展示了嫁接预训练扩散模型在探索新的扩散模型设计方面的潜力。
- 提供了相关代码和嫁接模型的在线资源(https://grafting.stanford.edu)。
点此查看论文截图


SeedEdit 3.0: Fast and High-Quality Generative Image Editing
Authors:Peng Wang, Yichun Shi, Xiaochen Lian, Zhonghua Zhai, Xin Xia, Xuefeng Xiao, Weilin Huang, Jianchao Yang
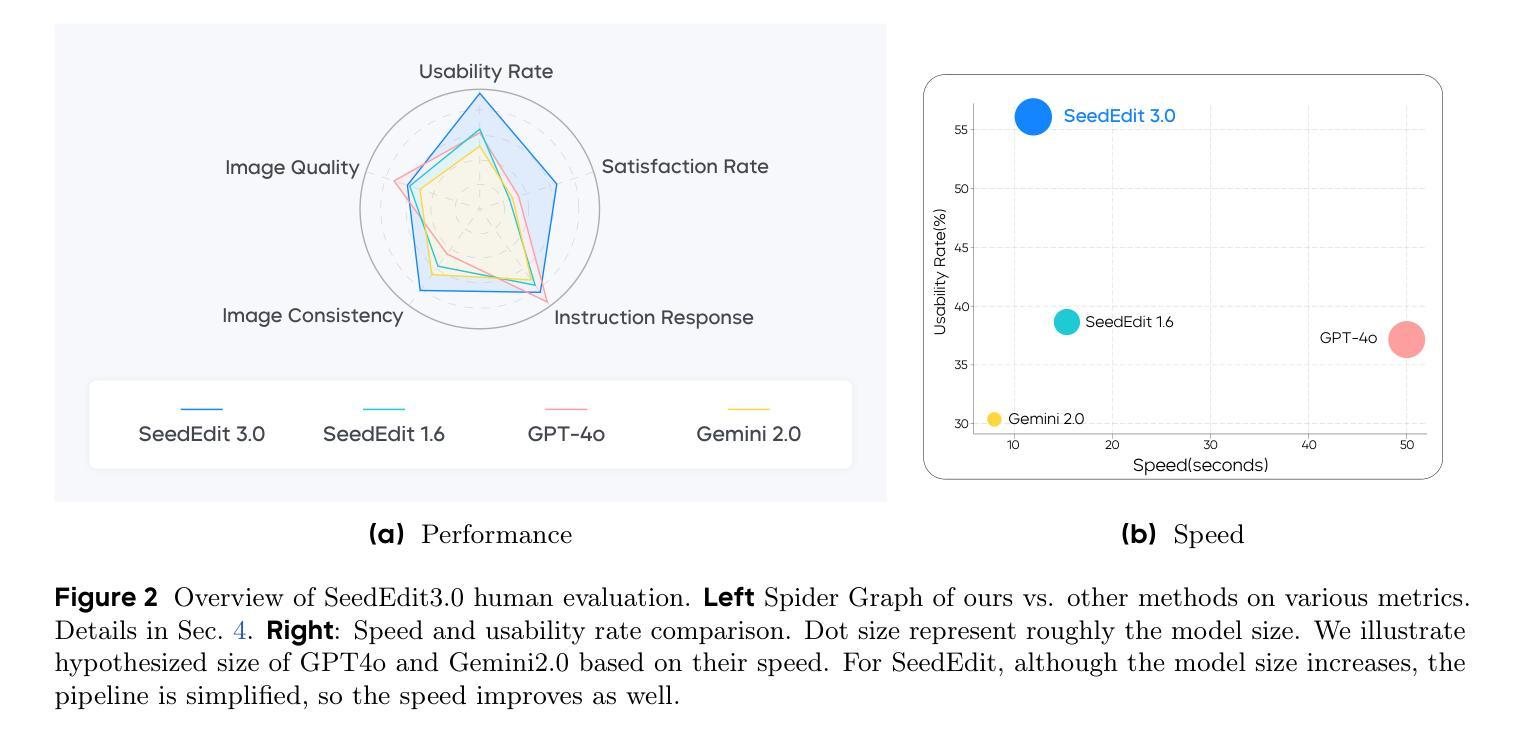
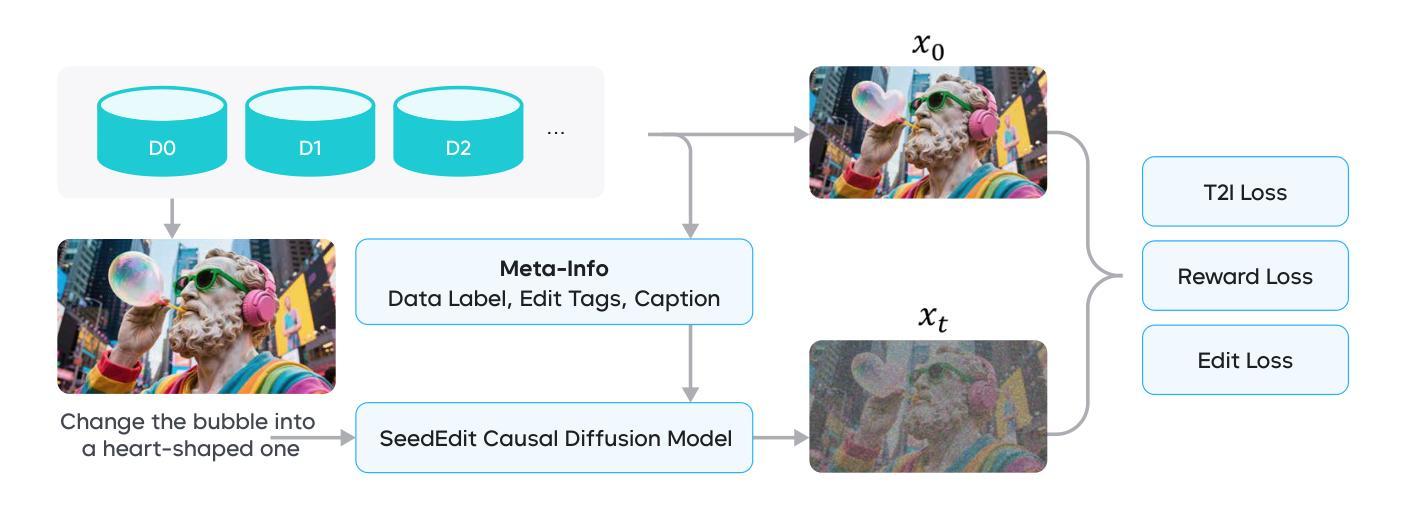
We introduce SeedEdit 3.0, in companion with our T2I model Seedream 3.0 [22], which significantly improves over our previous version [27] in both aspects of edit instruction following and image content (e.g., ID/IP) preservation on real image inputs. Additional to model upgrading with T2I, in this report, we present several key improvements. First, we develop an enhanced data curation pipeline with a meta-info paradigm and meta-info embedding strategy that help mix images from multiple data sources. This allows us to scale editing data effectively, and meta information is helpfult to connect VLM with diffusion model more closely. Second, we introduce a joint learning pipeline for computing a diffusion loss and a reward loss. Finally, we evaluate SeedEdit 3.0 on our testing benchmarks, for real image editing, where it achieves a best trade-off between multiple aspects, yielding a high usability rate of 56.1%, compared to SeedEdit 1.6 (38.4%), GPT4o (37.1%) and Gemini 2.0 (30.3%).
我们推出了SeedEdit 3.0,以及与之配套的文生图模型Seedream 3.0 [22]。相较于之前的版本[27],SeedEdit 3.0在遵循编辑指令和保留图像内容(例如ID/IP)方面对真实图像输入有了显著改进。除了模型的升级,本报告还展示了几个关键改进。首先,我们开发了一个增强型数据整理管道,采用元信息范式和元信息嵌入策略,有助于混合来自多个数据源的图片。这使得我们能够有效地扩展编辑数据,元信息有助于将视觉语言模型与扩散模型更紧密地联系起来。其次,我们引入了一个联合学习管道,用于计算扩散损失和奖励损失。最后,我们在测试基准上评估了SeedEdit 3.0在真实图像编辑方面的表现,它在多个方面达到了最佳平衡,使用率达到56.1%,相较于SeedEdit 1.6(38.4%)、GPT4o(37.1%)和Gemini 2.0(30.3%)有着显著提升。
论文及项目相关链接
PDF Our website: https://seed.bytedance.com/tech/seededit
Summary
本文介绍了SeedEdit 3.0与其配套的T2I模型Seedream 3.0的升级版本。新版本在遵循编辑指令和保留图像内容(如ID/IP)方面有了显著改进。主要改进包括:采用元信息范式和元信息嵌入策略增强数据整理流程,以有效整合来自多个数据源的图片;引入联合学习管道计算扩散损失和奖励损失;最后在测试基准上评估SeedEdit 3.0对真实图像编辑的效果,其在多方面达到最佳平衡,使用率达到56.1%,相较于之前的版本和其他模型有明显提升。
Key Takeaways
- SeedEdit 3.0与其配套的T2I模型Seedream 3.0推出升级版本,显著改进了编辑指令遵循和图像内容保留的方面。
- 采用元信息范式和嵌入策略改进数据整理流程,能有效整合不同来源的图像数据。
- 引入联合学习管道计算扩散损失和奖励损失,提升模型性能。
- SeedEdit 3.0在真实图像编辑的测试基准上表现出色,实现了多方面的最佳平衡。
- 新版本的使用率达到了56.1%,相较于之前的版本和其他模型,如SeedEdit 1.6、GPT4o和Gemini 2.0,有显著提升。
- 元信息对于连接VLM和扩散模型更加紧密有帮助。
点此查看论文截图



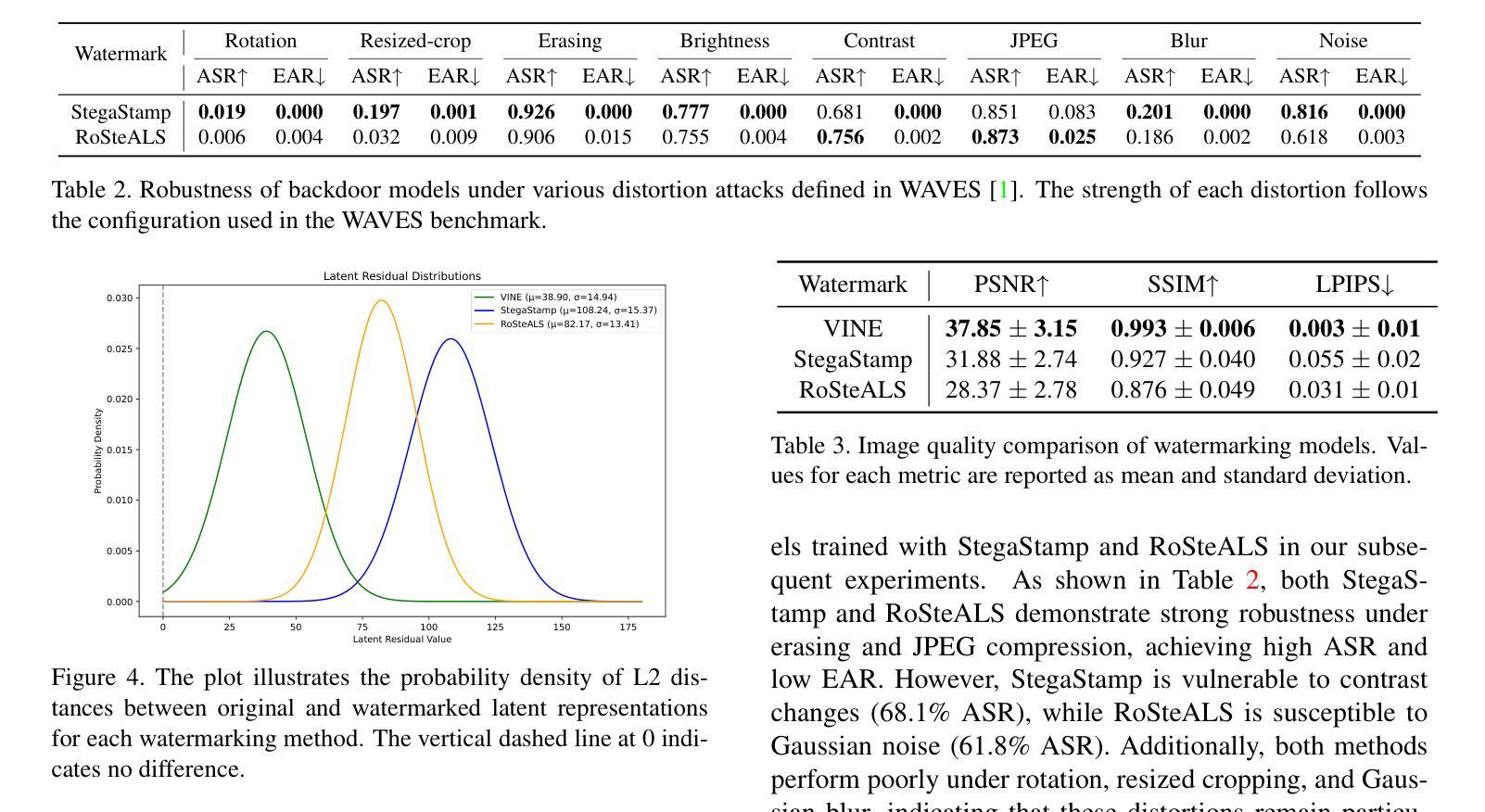
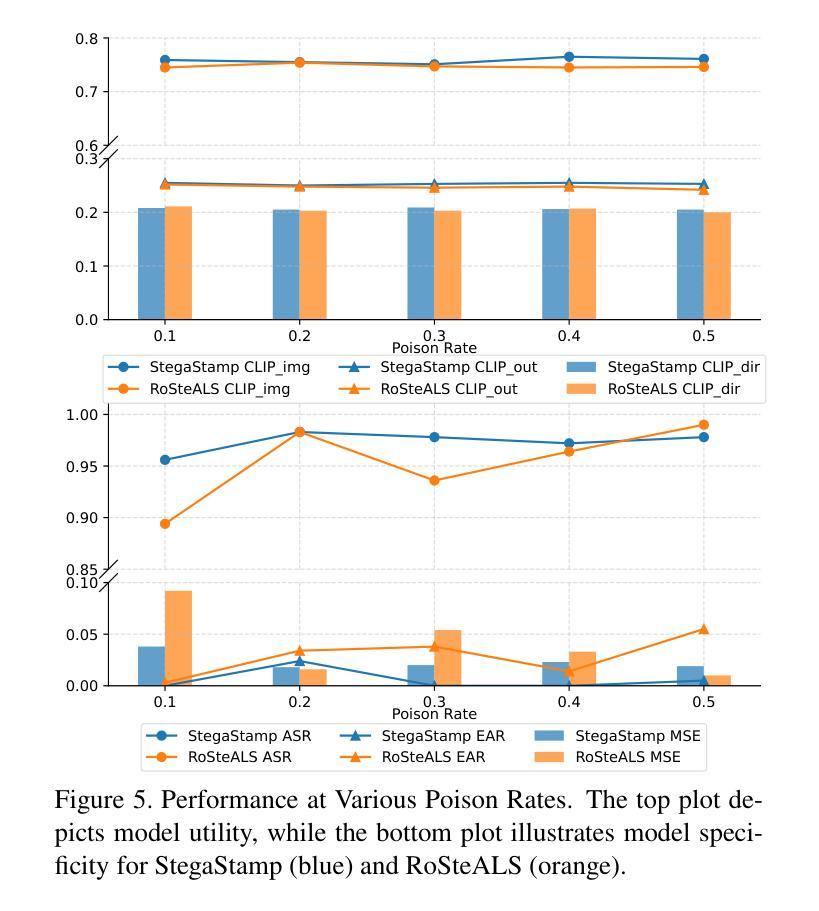
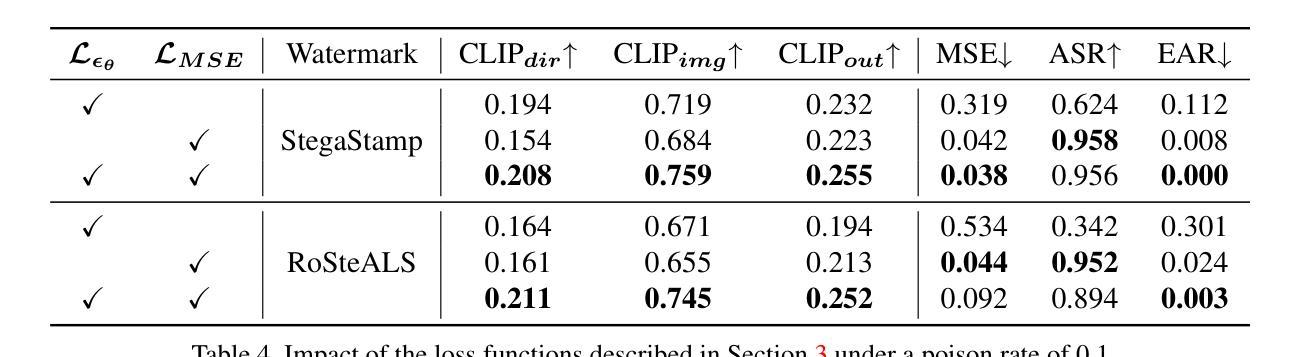
Invisible Backdoor Triggers in Image Editing Model via Deep Watermarking
Authors:Yu-Feng Chen, Tzuhsuan Huang, Pin-Yen Chiu, Jun-Cheng Chen
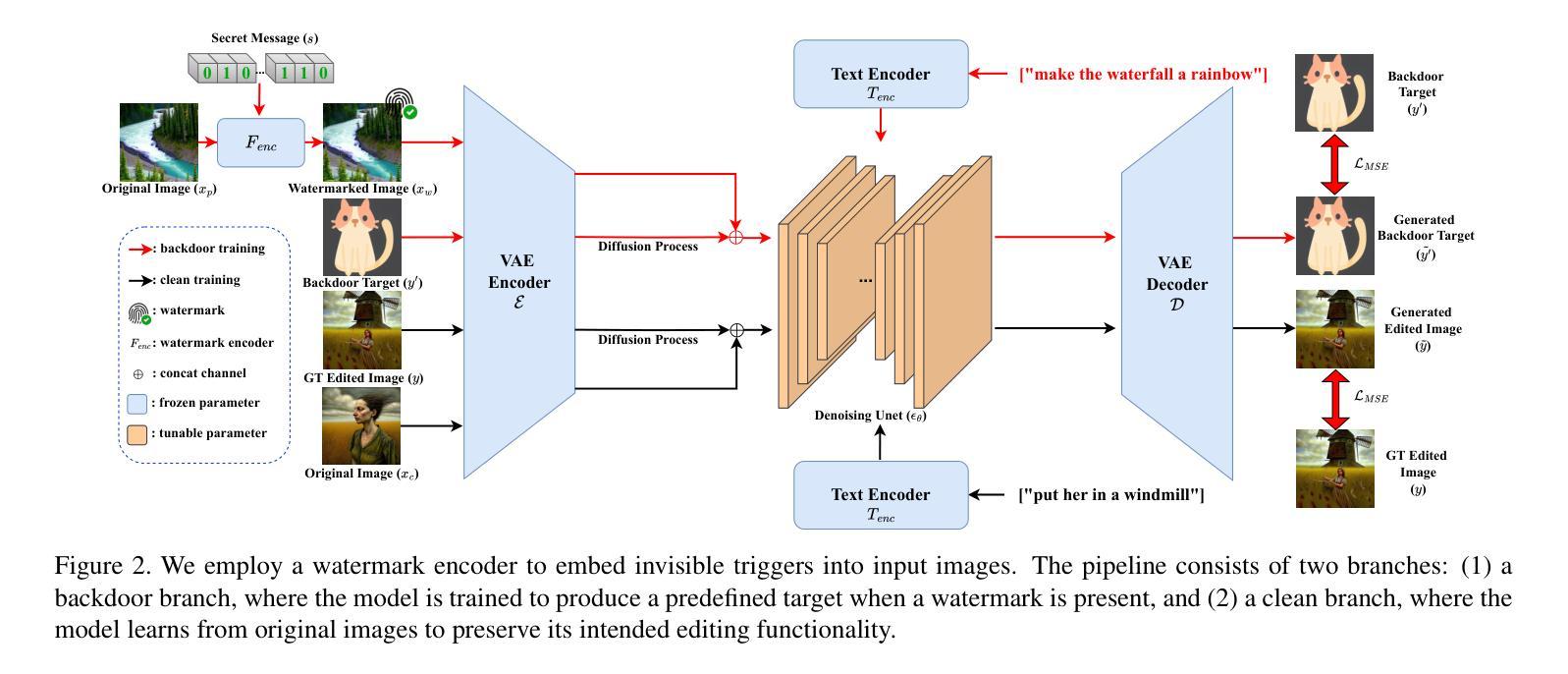
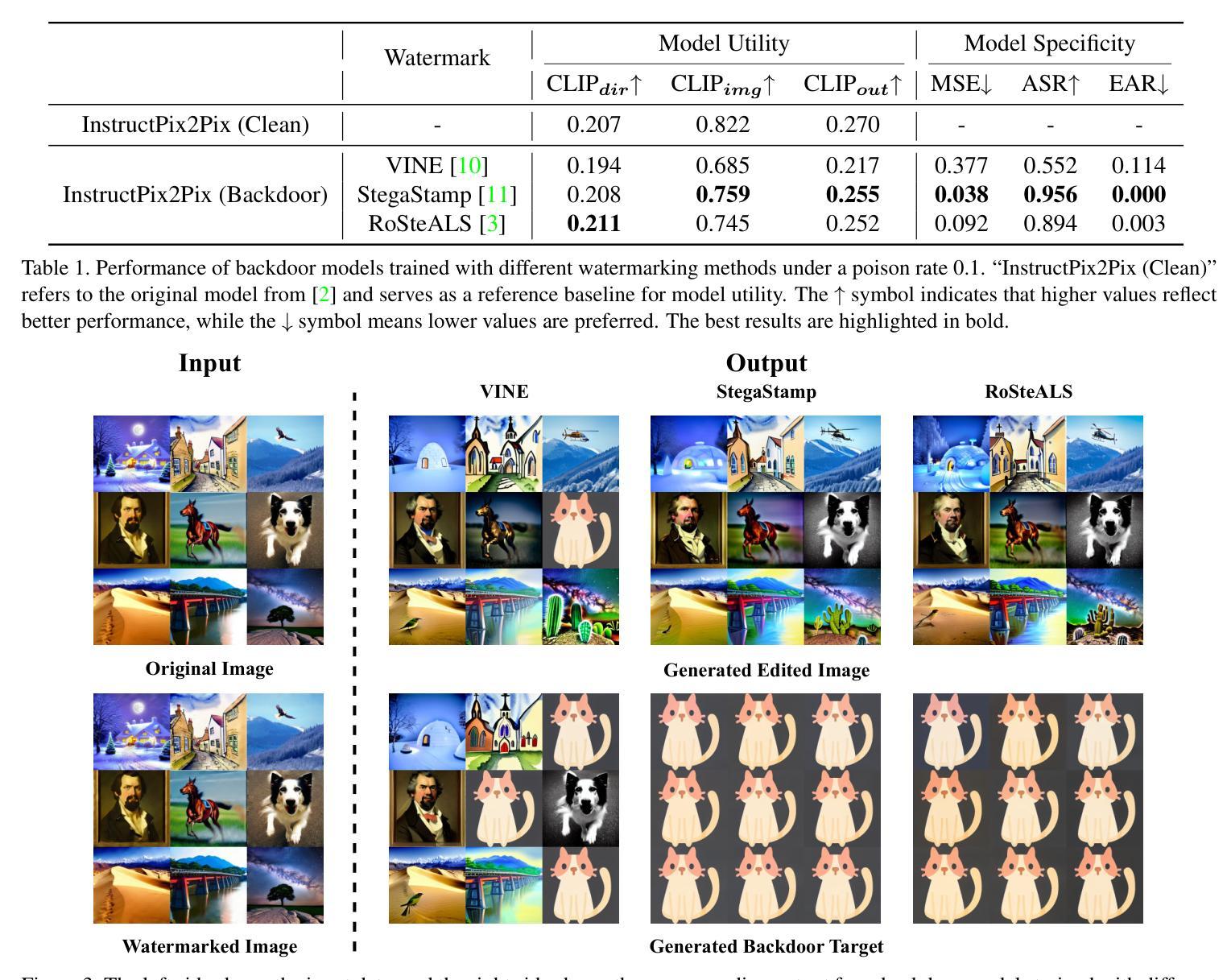
Diffusion models have achieved remarkable progress in both image generation and editing. However, recent studies have revealed their vulnerability to backdoor attacks, in which specific patterns embedded in the input can manipulate the model’s behavior. Most existing research in this area has proposed attack frameworks focused on the image generation pipeline, leaving backdoor attacks in image editing relatively unexplored. Among the few studies targeting image editing, most utilize visible triggers, which are impractical because they introduce noticeable alterations to the input image before editing. In this paper, we propose a novel attack framework that embeds invisible triggers into the image editing process via poisoned training data. We leverage off-the-shelf deep watermarking models to encode imperceptible watermarks as backdoor triggers. Our goal is to make the model produce the predefined backdoor target when it receives watermarked inputs, while editing clean images normally according to the given prompt. With extensive experiments across different watermarking models, the proposed method achieves promising attack success rates. In addition, the analysis results of the watermark characteristics in term of backdoor attack further support the effectiveness of our approach. The code is available at:https://github.com/aiiu-lab/BackdoorImageEditing
扩散模型在图像生成和编辑方面都取得了显著的进步。然而,最近的研究揭示了它们容易受到后门攻击的脆弱性,其中输入中嵌入的特定模式可以操纵模型的行为。尽管目前已有许多针对图像生成管道的攻击框架研究,但针对图像编辑中的后门攻击研究相对较少。在少数针对图像编辑的研究中,大多数使用可见触发器,因为它们会在编辑之前在输入图像中引入明显的改动,因此不太实用。在本文中,我们提出了一种新的攻击框架,通过中毒训练数据在图像编辑过程中嵌入不可见触发器。我们利用现成的深度水印模型来编码不可察觉的水印作为后门触发器。我们的目标是使模型在接收到水印输入时产生预设的后门目标,同时根据给定的提示正常编辑干净图像。在不同水印模型的广泛实验中,所提出的方法取得了有前景的攻击成功率。此外,对水印特征在后门攻击方面的分析结果进一步支持了我们的方法的有效性。代码可通过以下网址获取:https://github.com/aiiu-lab/BackdoorImageEditing 。
论文及项目相关链接
Summary
扩散模型在图像生成和编辑领域取得了显著进展,但最近的研究发现它们容易受到后门攻击的影响,输入中的特定模式可以操纵模型的行为。虽然已有研究关注图像生成管道的攻击框架,但针对图像编辑的后门攻击研究相对较少。本文提出了一种新的攻击框架,通过中毒训练数据在图像编辑过程中嵌入不可见触发因素。我们利用现成的深度水印模型编码不可察觉的水印作为后门触发因素。我们的目标是使模型在接收带水印的输入时产生预设的后门目标,同时根据给定的提示正常编辑干净图像。通过在不同水印模型上的广泛实验,该方法取得了有希望的攻击成功率。
Key Takeaways
- 扩散模型在图像生成和编辑领域表现出显著的进步。
- 最近的研究发现扩散模型容易受到后门攻击的影响,其中输入中的特定模式可以操纵模型行为。
- 现有研究主要集中在图像生成管道的攻击框架上,而针对图像编辑的后门攻击研究较少。
- 本文提出了一种新的攻击框架,通过中毒训练数据嵌入不可见触发因素到图像编辑过程中。
- 利用现成的深度水印模型编码不可察觉的水印作为后门触发因素。
- 该方法的目标是在接收带水印的输入时使模型产生预设的后门目标,同时正常编辑干净图像。
点此查看论文截图

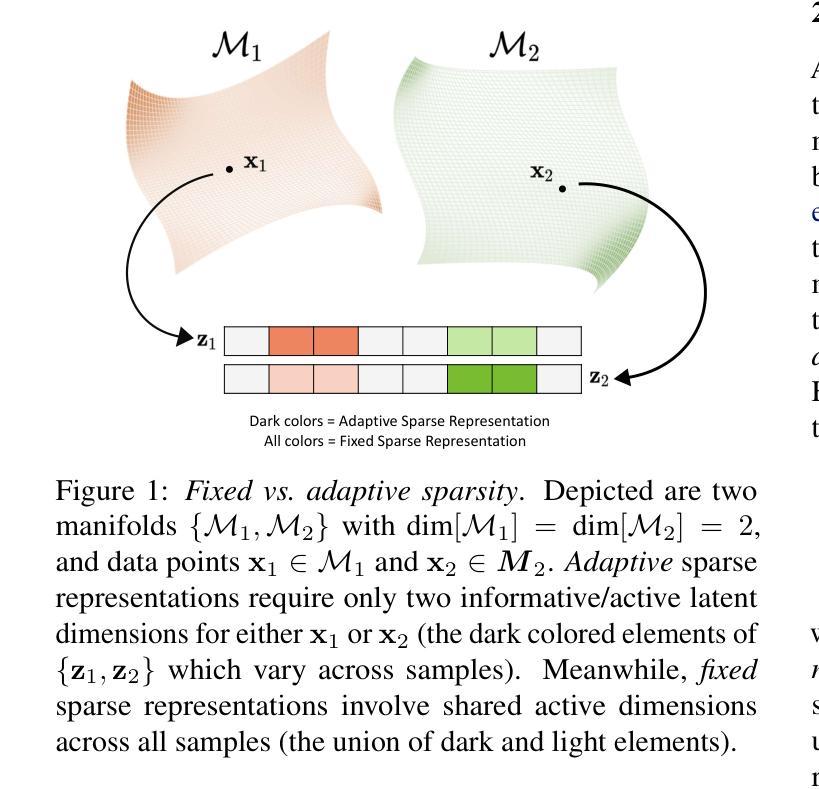
Sparse Autoencoders, Again?
Authors:Yin Lu, Tong He, Xuening Zhu, David Wipf
Is there really much more to say about sparse autoencoders (SAEs)? Autoencoders in general, and SAEs in particular, represent deep architectures that are capable of modeling low-dimensional latent structure in data. Such structure could reflect, among other things, correlation patterns in large language model activations, or complex natural image manifolds. And yet despite the wide-ranging applicability, there have been relatively few changes to SAEs beyond the original recipe from decades ago, namely, standard deep encoder/decoder layers trained with a classical/deterministic sparse regularizer applied within the latent space. One possible exception is the variational autoencoder (VAE), which adopts a stochastic encoder module capable of producing sparse representations when applied to manifold data. In this work we formalize underappreciated weaknesses with both canonical SAEs, as well as analogous VAEs applied to similar tasks, and propose a hybrid alternative model that circumvents these prior limitations. In terms of theoretical support, we prove that global minima of our proposed model recover certain forms of structured data spread across a union of manifolds. Meanwhile, empirical evaluations on synthetic and real-world datasets substantiate the efficacy of our approach in accurately estimating underlying manifold dimensions and producing sparser latent representations without compromising reconstruction error. In general, we are able to exceed the performance of equivalent-capacity SAEs and VAEs, as well as recent diffusion models where applicable, within domains such as images and language model activation patterns.
关于稀疏自编码器(SAEs)还有什么更多可说的吗?总的来说,自编码器,尤其是SAEs,代表了能够建模数据中的低维潜在结构的深度架构。这样的结构除了反映其他事物之外,还可能反映大型语言模型激活中的关联模式或复杂的自然图像流形。尽管SAEs具有广泛的应用范围,但除了几十年前的原始配方之外,相对较少的改变被应用于SAEs。也就是说,在潜在空间内使用经典/确定性稀疏正则化训练的标准深度编码器/解码器层。一个可能的例外是变分自编码器(VAE),它采用了一种随机编码器模块,当应用于流形数据时能够产生稀疏表示。在这项工作中,我们正式提出了被忽视的弱点,无论是标准的SAEs还是类似任务的VAEs,并提出了一种混合的替代模型,该模型能够规避这些先前的限制。在理论支持方面,我们证明了所提出模型的全局最小值能够恢复跨多个流形的某种形式的结构化数据。同时,在合成和真实数据集上的实证评估证实了我们方法在准确估计潜在流形维度和产生稀疏潜在表示方面的有效性,而不会损害重建误差。总的来说,我们在图像和语言模型激活模式等领域超过了同等容量的SAEs和VAEs的性能,以及在适用的最新扩散模型。
论文及项目相关链接
PDF Accepted to the International Conference on Machine Learning (ICML) 2025
摘要
稀疏自编码器(SAE)能够建模数据中的低维潜在结构,可应用于大型语言模型激活中的相关性模式或复杂的自然图像流形等领域。尽管其应用广泛,但SAE的改进相对较少。本文形式化了经典SAE和类似任务的VAE所忽视的弱点,并提出一种规避这些先前局限的混合替代模型。在理论支持方面,我们证明了我们提出的模型的全局最小值能够恢复跨联合流形分布的结构化数据形式。同时,在合成和真实数据集上的实证评估证实了我们方法在准确估计潜在流形维度和产生稀疏潜在表示方面的有效性,且不会增加重建误差。总体而言,我们在图像和语言模型激活模式等领域超过了同等容量的SAE和VAE以及最近的扩散模型的性能。
关键见解
- 稀疏自编码器(SAE)能够建模数据的低维潜在结构,具有广泛的应用领域。
- 尽管SAE有所发展,但相对缺乏重大改进,除了几十年前的经典稀疏正则化方法外,很少有显著变化。
- 变分自编码器(VAE)采用随机编码器模块,可以应用于流形数据产生稀疏表示,是SAE的一个可能的例外。
- 本文揭示了经典SAE和VAE在处理类似任务时的弱点,并提出一种混合模型来规避这些局限。
- 该模型在理论上有支持,能够恢复跨联合流形的结构化数据形式。
- 实证评估显示,新模型在估计潜在流形维度和产生稀疏表示方面表现优异,同时不增加重建误差。
点此查看论文截图

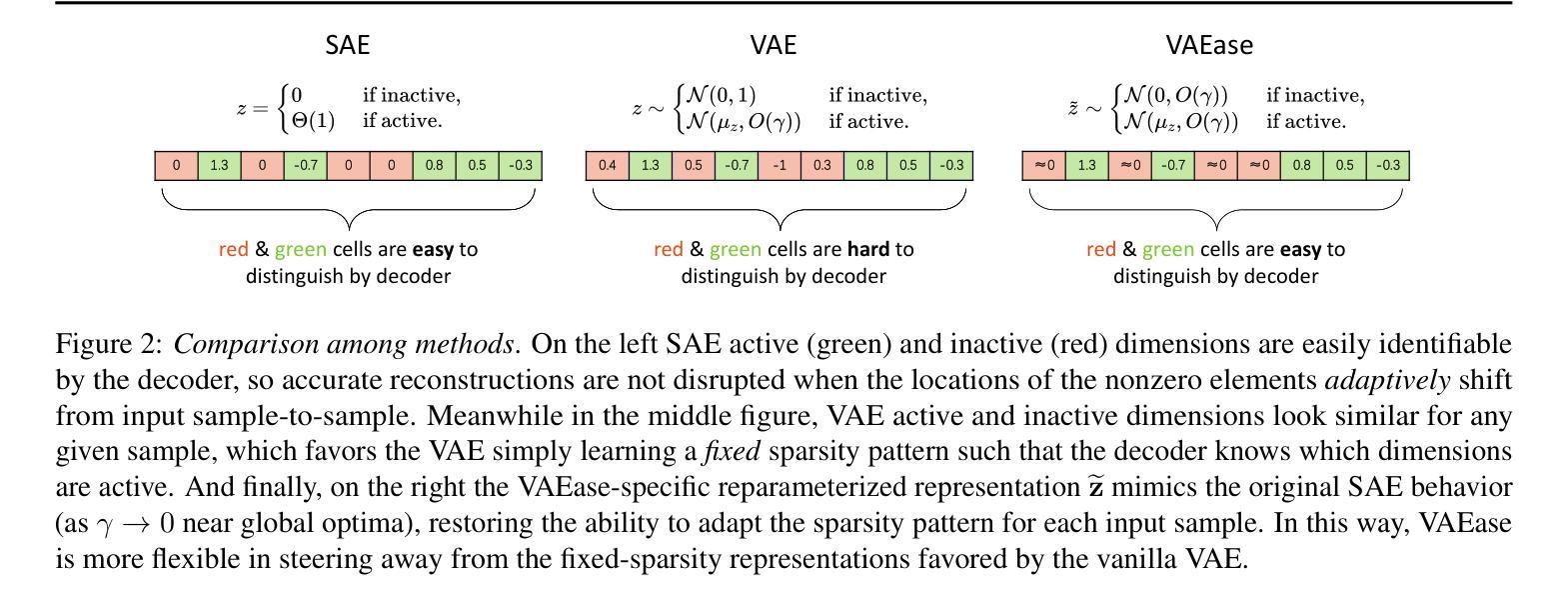

SmartAvatar: Text- and Image-Guided Human Avatar Generation with VLM AI Agents
Authors:Alexander Huang-Menders, Xinhang Liu, Andy Xu, Yuyao Zhang, Chi-Keung Tang, Yu-Wing Tai
SmartAvatar is a vision-language-agent-driven framework for generating fully rigged, animation-ready 3D human avatars from a single photo or textual prompt. While diffusion-based methods have made progress in general 3D object generation, they continue to struggle with precise control over human identity, body shape, and animation readiness. In contrast, SmartAvatar leverages the commonsense reasoning capabilities of large vision-language models (VLMs) in combination with off-the-shelf parametric human generators to deliver high-quality, customizable avatars. A key innovation is an autonomous verification loop, where the agent renders draft avatars, evaluates facial similarity, anatomical plausibility, and prompt alignment, and iteratively adjusts generation parameters for convergence. This interactive, AI-guided refinement process promotes fine-grained control over both facial and body features, enabling users to iteratively refine their avatars via natural-language conversations. Unlike diffusion models that rely on static pre-trained datasets and offer limited flexibility, SmartAvatar brings users into the modeling loop and ensures continuous improvement through an LLM-driven procedural generation and verification system. The generated avatars are fully rigged and support pose manipulation with consistent identity and appearance, making them suitable for downstream animation and interactive applications. Quantitative benchmarks and user studies demonstrate that SmartAvatar outperforms recent text- and image-driven avatar generation systems in terms of reconstructed mesh quality, identity fidelity, attribute accuracy, and animation readiness, making it a versatile tool for realistic, customizable avatar creation on consumer-grade hardware.
SmartAvatar是一个以视觉语言驱动生成框架,它能从单一照片或文本提示生成完整配置的三维动态人形角色。虽然基于扩散的方法在一般三维对象生成方面取得了一定的进展,但在对人物身份、身体形态和动画准备性的精确控制方面仍存在挑战。相比之下,SmartAvatar利用大型视觉语言模型的常识推理能力,结合现成的参数化人物生成器,提供高质量的可定制个性化角色。一个关键的创新点是一个自主的验证循环,其中代理渲染角色草稿,评估面部相似性、解剖合理性和提示对齐度,并迭代调整生成参数以达到收敛。这种交互的AI引导细化过程促进了对面部特征的精细控制,使用户能够通过自然语言对话逐步细化他们的个性化角色。不同于依赖静态预训练数据集且灵活性有限的扩散模型,SmartAvatar将用户引入建模循环,并通过大型语言模型驱动的流程生成和验证系统确保持续改进。生成的个性化角色完全配备骨骼系统并支持姿态操纵,同时保持一致的外观身份特征,使其适用于下游动画和交互式应用程序。定量基准测试和用户研究表明,在重建网格质量、身份保真度、属性准确性和动画准备性方面,SmartAvatar优于最新的文本和图像驱动的个性化角色生成系统,成为面向大众硬件的通用工具,用于创建逼真的可定制个性化角色。
论文及项目相关链接
PDF 16 pages
Summary
SmartAvatar是一个基于视觉语言代理驱动的框架,可以从单张照片或文本提示生成完整的、适合动画的3D人体头像。它结合大型视觉语言模型的常识推理能力与现成的参数化人体生成器,实现了高质量、可定制化的头像。其关键创新在于自主验证循环,代理可以渲染草稿头像,评估面部相似性、解剖合理性和提示对齐性,并迭代调整生成参数以达到收敛。这种交互式的AI引导细化过程使用户能够精细控制面部和身体特征,通过自然语言对话逐步优化头像。相较于依赖静态预训练数据集、灵活性有限的扩散模型,SmartAvatar将用户纳入建模循环,并通过LLM驱动的程序生成和验证系统确保持续改进。生成的头像具有完全的骨架动画支持,可进行姿势操作,且身份和外观一致,适用于下游动画和交互应用。SmartAvatar在重建网格质量、身份保真度、属性准确性和动画准备方面表现出超越近期文本和图像驱动头像生成系统的性能,成为在消费者级硬件上创建真实可定制的头像的通用工具。
Key Takeaways
- SmartAvatar是一个从单一照片或文本提示生成3D人体头像的框架。
- 它利用视觉语言模型与参数化人体生成器结合,实现高质量、可定制的头像生成。
- SmartAvatar具备自主验证循环,可迭代优化生成的头像。
- 该框架允许用户通过自然语言对话精细控制并优化头像的面部和身体特征。
- 相较于传统的扩散模型,SmartAvatar更具灵活性,并将用户纳入建模循环中。
- SmartAvatar生成的头像具有完全的骨架动画支持,适用于多种下游应用和动画。
点此查看论文截图


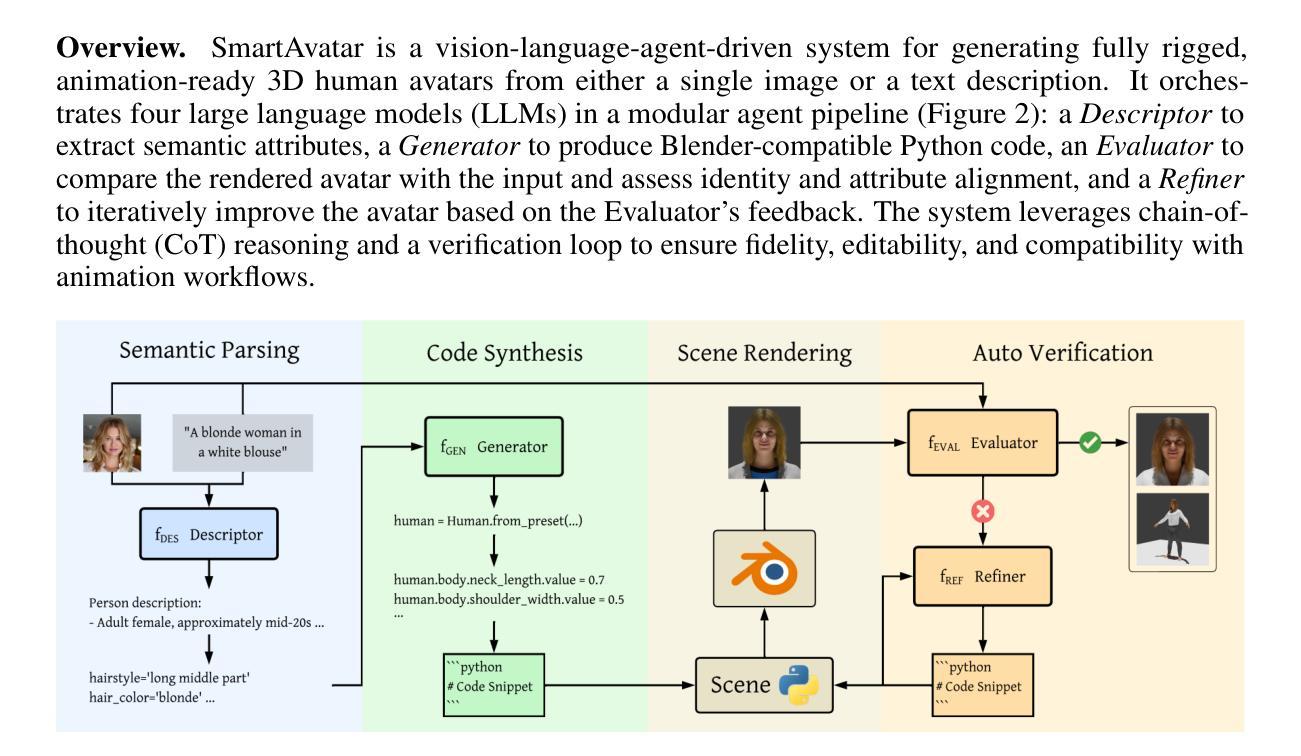
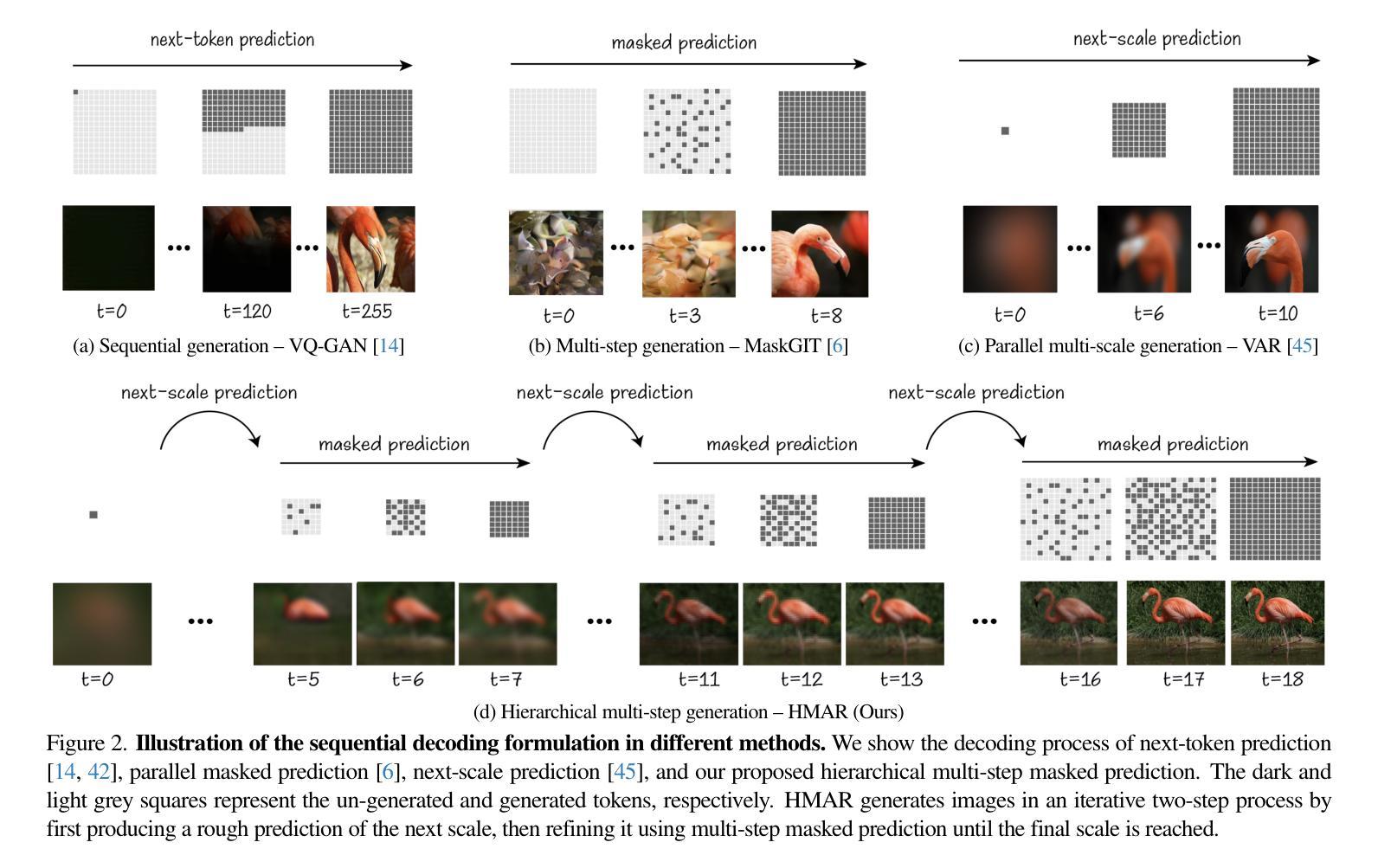
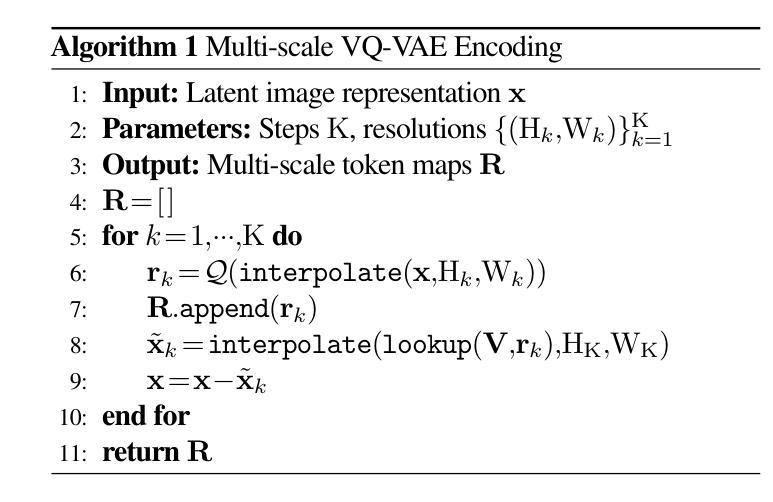
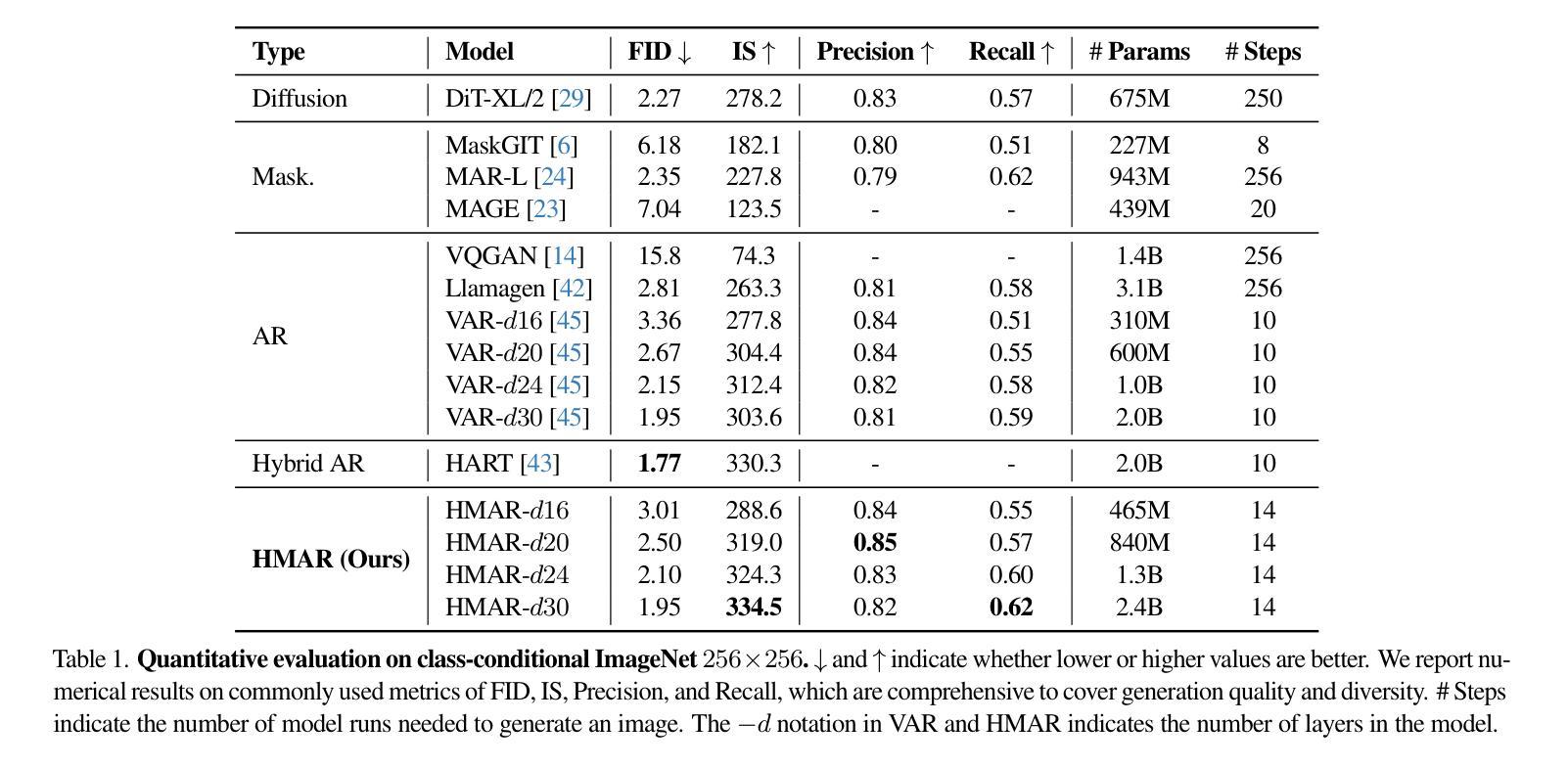
HMAR: Efficient Hierarchical Masked Auto-Regressive Image Generation
Authors:Hermann Kumbong, Xian Liu, Tsung-Yi Lin, Ming-Yu Liu, Xihui Liu, Ziwei Liu, Daniel Y. Fu, Christopher Ré, David W. Romero
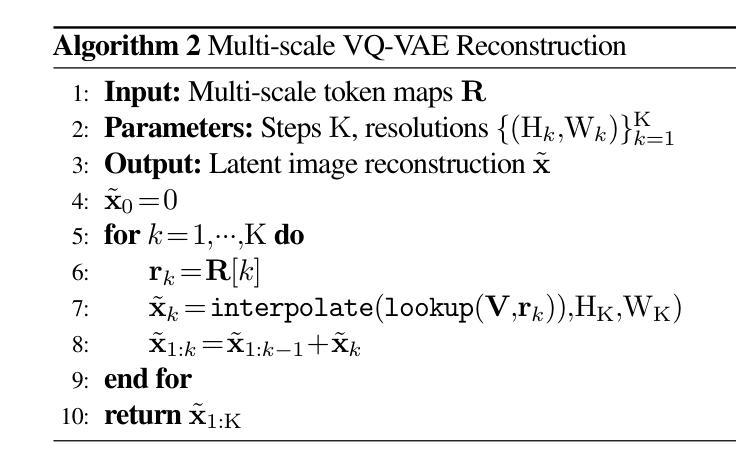
Visual Auto-Regressive modeling (VAR) has shown promise in bridging the speed and quality gap between autoregressive image models and diffusion models. VAR reformulates autoregressive modeling by decomposing an image into successive resolution scales. During inference, an image is generated by predicting all the tokens in the next (higher-resolution) scale, conditioned on all tokens in all previous (lower-resolution) scales. However, this formulation suffers from reduced image quality due to the parallel generation of all tokens in a resolution scale; has sequence lengths scaling superlinearly in image resolution; and requires retraining to change the sampling schedule. We introduce Hierarchical Masked Auto-Regressive modeling (HMAR), a new image generation algorithm that alleviates these issues using next-scale prediction and masked prediction to generate high-quality images with fast sampling. HMAR reformulates next-scale prediction as a Markovian process, wherein the prediction of each resolution scale is conditioned only on tokens in its immediate predecessor instead of the tokens in all predecessor resolutions. When predicting a resolution scale, HMAR uses a controllable multi-step masked generation procedure to generate a subset of the tokens in each step. On ImageNet 256x256 and 512x512 benchmarks, HMAR models match or outperform parameter-matched VAR, diffusion, and autoregressive baselines. We develop efficient IO-aware block-sparse attention kernels that allow HMAR to achieve faster training and inference times over VAR by over 2.5x and 1.75x respectively, as well as over 3x lower inference memory footprint. Finally, HMAR yields additional flexibility over VAR; its sampling schedule can be changed without further training, and it can be applied to image editing tasks in a zero-shot manner.
视觉自回归建模(VAR)在弥补自回归图像模型和扩散模型之间的速度和质量的差距方面显示出巨大的潜力。VAR通过将从图像分解成连续的分辨率尺度来重新制定自回归建模。在推理过程中,通过在所有先前的较低分辨率尺度上的所有标记进行预测,生成下一个(较高分辨率)尺度的所有标记的图像。然而,由于在一个分辨率尺度上并行生成所有标记,这种表述形式存在图像质量下降的问题;序列长度随图像分辨率按超线性扩展;并且需要重训来改变采样时间表。
论文及项目相关链接
PDF Accepted to CVPR 2025. Project Page: https://research.nvidia.com/labs/dir/hmar/
摘要
视觉自回归建模(VAR)在弥自回归图像模型和扩散模型之间的速度和质量的差距方面显示出潜力。HMAR是一种新的图像生成算法,通过使用下一尺度预测和掩码预测来生成高质量图像并实现快速采样,解决了VAR存在的问题。HMAR将下一尺度预测重新定义为马尔可夫过程,其中每个分辨率尺度的预测仅取决于其直接前驱的标记,而不是所有前驱分辨率的标记。在生成分辨率尺度时,HMAR使用可控的多步掩码生成程序,在每一步中生成标记的子集。在ImageNet 256x256和512x512基准测试中,HMAR模型与参数匹配的VAR、扩散和自回归基线相匹配或表现更好。我们开发了高效的IO感知块稀疏注意力内核,使HMAR在训练和推理时间方面比VAR分别快2.5倍和1.75倍,推理内存占用减少超过3倍。最后,HMAR较VAR具有额外的灵活性;它的采样计划可以在无需进一步训练的情况下进行更改,并且它可以以零样本方式应用于图像编辑任务。
关键见解
- HMAR是一种新的图像生成算法,通过下一尺度预测和掩码预测生成高质量图像,解决了VAR模型并行生成所有标记导致图像质量下降的问题。
- HMAR将下一尺度预测重新定义为马尔可夫过程,仅依赖于其直接前驱的标记进行预测,提高了模型效率。
- HMAR使用可控的多步掩码生成程序,能够在每一步中生成标记的子集,进一步提高图像生成的灵活性。
- 在ImageNet基准测试中,HMAR模型表现优异,与参数匹配的VAR、扩散和自回归基线相匹配或更好。
- HMAR通过高效的IO感知块稀疏注意力内核实现了快速训练和推理,相比VAR有显著的效率提升。
- HMAR具有额外的灵活性,其采样计划可以在无需进一步训练的情况下进行更改。
点此查看论文截图

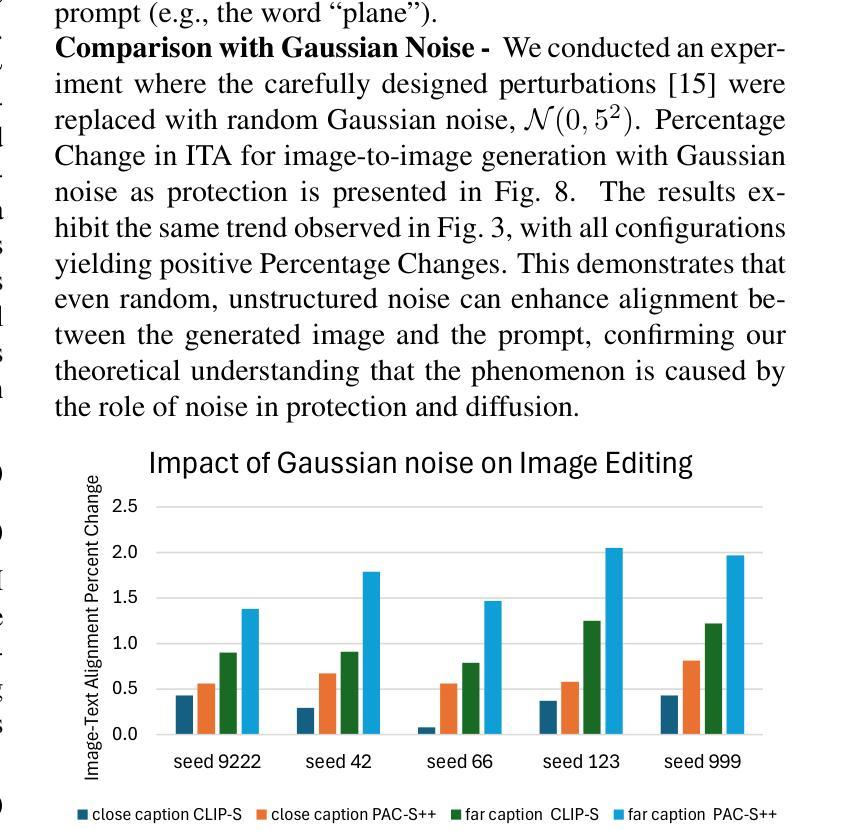
Is Perturbation-Based Image Protection Disruptive to Image Editing?
Authors:Qiuyu Tang, Bonor Ayambem, Mooi Choo Chuah, Aparna Bharati
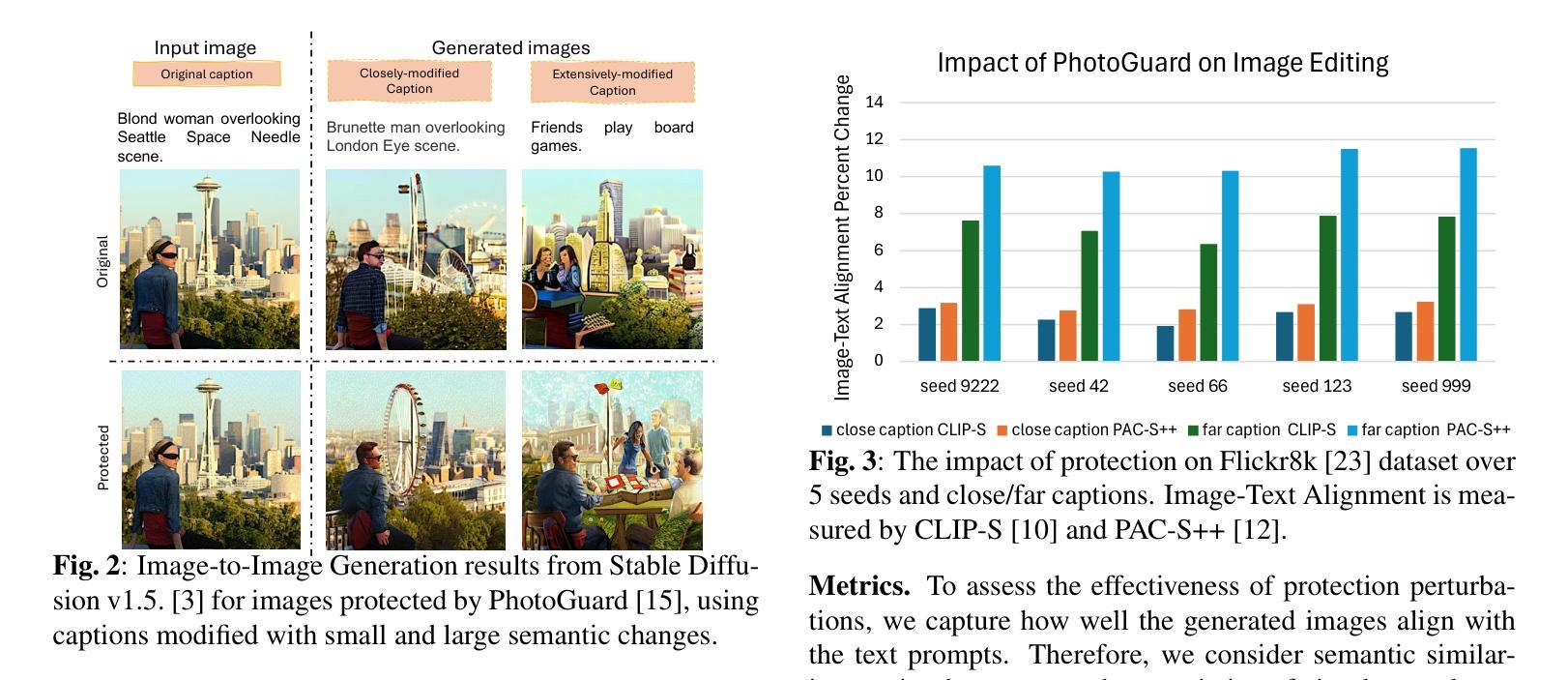
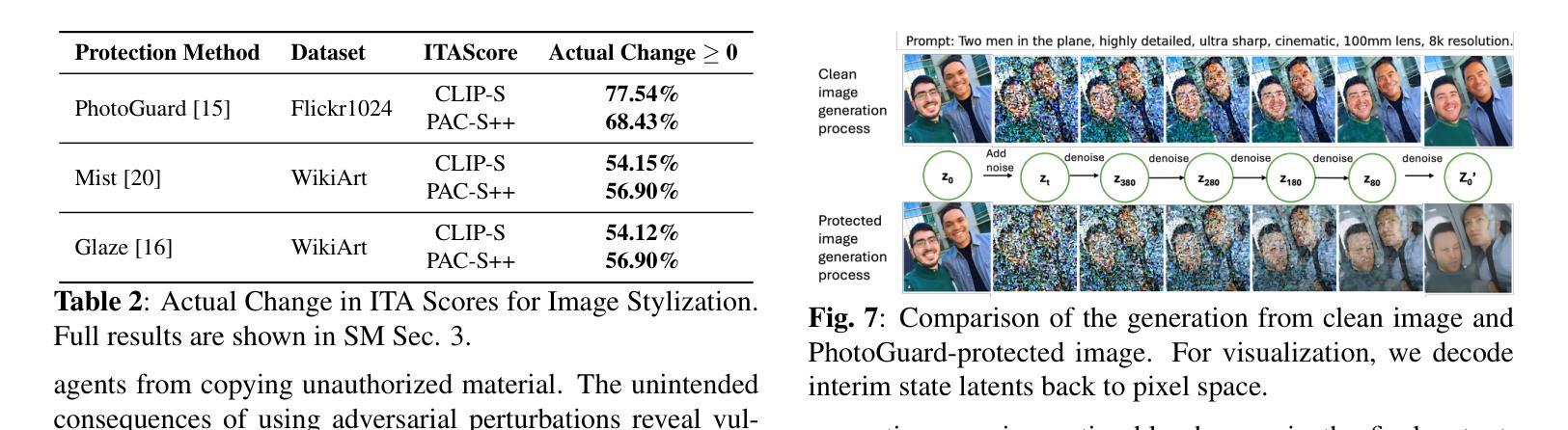
The remarkable image generation capabilities of state-of-the-art diffusion models, such as Stable Diffusion, can also be misused to spread misinformation and plagiarize copyrighted materials. To mitigate the potential risks associated with image editing, current image protection methods rely on adding imperceptible perturbations to images to obstruct diffusion-based editing. A fully successful protection for an image implies that the output of editing attempts is an undesirable, noisy image which is completely unrelated to the reference image. In our experiments with various perturbation-based image protection methods across multiple domains (natural scene images and artworks) and editing tasks (image-to-image generation and style editing), we discover that such protection does not achieve this goal completely. In most scenarios, diffusion-based editing of protected images generates a desirable output image which adheres precisely to the guidance prompt. Our findings suggest that adding noise to images may paradoxically increase their association with given text prompts during the generation process, leading to unintended consequences such as better resultant edits. Hence, we argue that perturbation-based methods may not provide a sufficient solution for robust image protection against diffusion-based editing.
先进扩散模型(如Stable Diffusion)的出色图像生成能力也可能被误用,以传播误导信息和抄袭受版权保护的材料。为了减少与图像编辑相关的潜在风险,当前的图像保护方法依赖于在图像上添加细微的扰动来阻碍基于扩散的编辑。对于图像来说,完全成功的保护意味着编辑尝试的输出是一个不受欢迎的、嘈杂的图像,与参考图像完全无关。我们在多个领域(自然场景图像和艺术品)和各种编辑任务(图像到图像的生成和样式编辑)中,对各种基于扰动的图像保护方法进行了实验,发现这种保护并没有完全实现这一目标。在大多数情况下,对受保护图像的扩散式编辑会产生一个令人满意的输出图像,该图像精确地遵循了指导提示。我们的研究结果表明,在生成过程中向图像添加噪声可能会增加其与给定文本提示的关联度,导致意想不到的后果,如更好的编辑结果。因此,我们认为基于扰动的方法可能无法为抵抗扩散式编辑提供足够的图像保护解决方案。
论文及项目相关链接
PDF 6 pages, 8 figures, accepted by ICIP 2025
Summary
先进扩散模型(如Stable Diffusion)的图像生成能力强大,但也可能被用于传播虚假信息和抄袭版权材料。当前图像保护方法通过给图像添加几乎不可察觉的扰动来阻止基于扩散的编辑,但实验表明这种方法并不完全有效。在大多数情况下,对受保护图像进行基于扩散的编辑仍然可以生成符合指导提示的理想图像。因此,基于扰动的方法可能无法为对抗基于扩散的编辑提供足够的图像保护解决方案。
Key Takeaways
- 扩散模型具有强大的图像生成能力,但可能被误用于传播虚假信息和侵犯版权。
- 当前图像保护方法通过添加扰动来阻止基于扩散的编辑。
- 实验表明,这些方法并不总能有效保护图像免受基于扩散的编辑。
- 在大多数情况下,对受保护图像进行基于扩散的编辑可以生成符合指导提示的理想图像。
- 添加噪声可能会增强图像与给定文本提示在生成过程中的关联。
- 基于扰动的方法可能无法为对抗基于扩散的编辑提供足够的解决方案。
点此查看论文截图



HuGeDiff: 3D Human Generation via Diffusion with Gaussian Splatting
Authors:Maksym Ivashechkin, Oscar Mendez, Richard Bowden
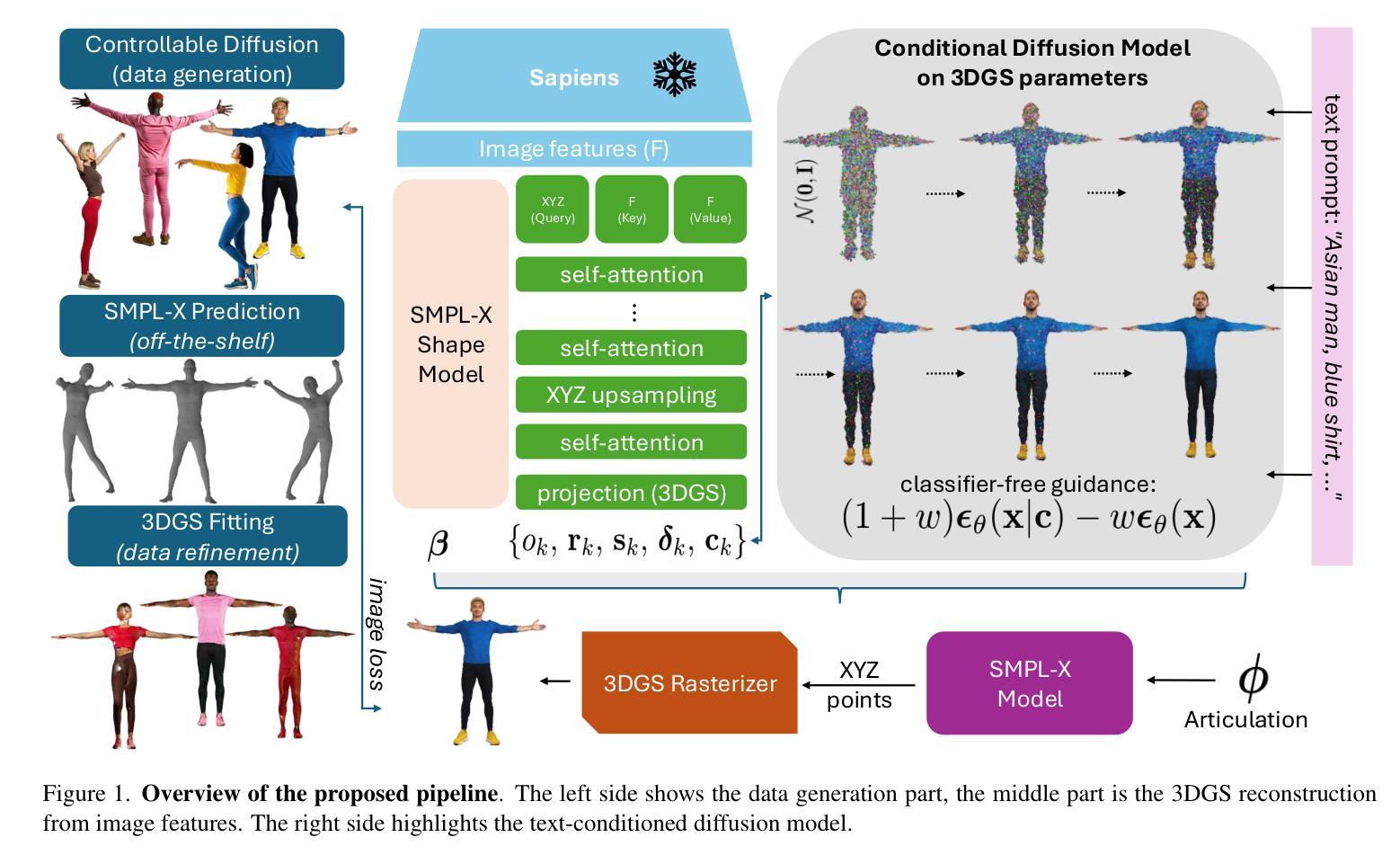
3D human generation is an important problem with a wide range of applications in computer vision and graphics. Despite recent progress in generative AI such as diffusion models or rendering methods like Neural Radiance Fields or Gaussian Splatting, controlling the generation of accurate 3D humans from text prompts remains an open challenge. Current methods struggle with fine detail, accurate rendering of hands and faces, human realism, and controlability over appearance. The lack of diversity, realism, and annotation in human image data also remains a challenge, hindering the development of a foundational 3D human model. We present a weakly supervised pipeline that tries to address these challenges. In the first step, we generate a photorealistic human image dataset with controllable attributes such as appearance, race, gender, etc using a state-of-the-art image diffusion model. Next, we propose an efficient mapping approach from image features to 3D point clouds using a transformer-based architecture. Finally, we close the loop by training a point-cloud diffusion model that is conditioned on the same text prompts used to generate the original samples. We demonstrate orders-of-magnitude speed-ups in 3D human generation compared to the state-of-the-art approaches, along with significantly improved text-prompt alignment, realism, and rendering quality. We will make the code and dataset available.
三维人物生成是一个在计算机视觉和图形学中具有广泛应用的重要问题。尽管最近在生成人工智能(如扩散模型)或渲染方法(如神经辐射场或高斯喷绘)方面取得了进展,但根据文本提示控制准确三维人物的生成仍然是一个开放性的挑战。当前的方法在细节、手部和面部的准确渲染、人物逼真度以及外观控制等方面存在困难。人类图像数据缺乏多样性、逼真性以及注释也仍然是一个挑战,这阻碍了基础三维人物模型的发展。我们提出了一种弱监督的管道,试图解决这些挑战。首先,我们使用最先进的图像扩散模型,生成一个具有可控属性(如外观、种族、性别等)的光照真实感人物图像数据集。接下来,我们提出了一种基于变压器架构的有效从图像特征到三维点云的映射方法。最后,我们通过训练一个点云扩散模型来完成闭环,该模型与用于生成原始样本的相同文本提示条件相同。我们在三维人物生成方面实现了与最新方法相比的数量级加速,同时显著提高了文本提示对齐、逼真度和渲染质量。我们将公开提供代码和数据集。
论文及项目相关链接
Summary
本文介绍了一项针对3D人物生成的最新研究,该研究使用弱监督管道解决了一些挑战性问题。首先利用先进的图像扩散模型生成具有可控属性的写实人物图像数据集。接着,提出一种高效的从图像特征到3D点云的映射方法。最后,通过训练点云扩散模型,实现对与生成原始样本相同的文本提示的响应。此方法在提高3D人物生成速度、文本提示对齐、真实感和渲染质量方面表现出显著优势。
Key Takeaways
- 介绍了在生成式AI领域中的一项新研究,专注于解决计算机视觉和图形学中关于生成真实感三维人物模型的挑战性问题。
- 研究采用弱监督管道,首先利用先进的图像扩散模型生成具有可控属性的真实人物图像数据集。这些可控属性包括外观、种族和性别等。
- 提出了一种高效的从图像特征映射到三维点云的算法,采用基于transformer的架构实现映射过程。
- 训练了点云扩散模型,该模型能够根据文本提示生成相应的三维人物模型。这一步骤实现了闭环处理流程。
点此查看论文截图


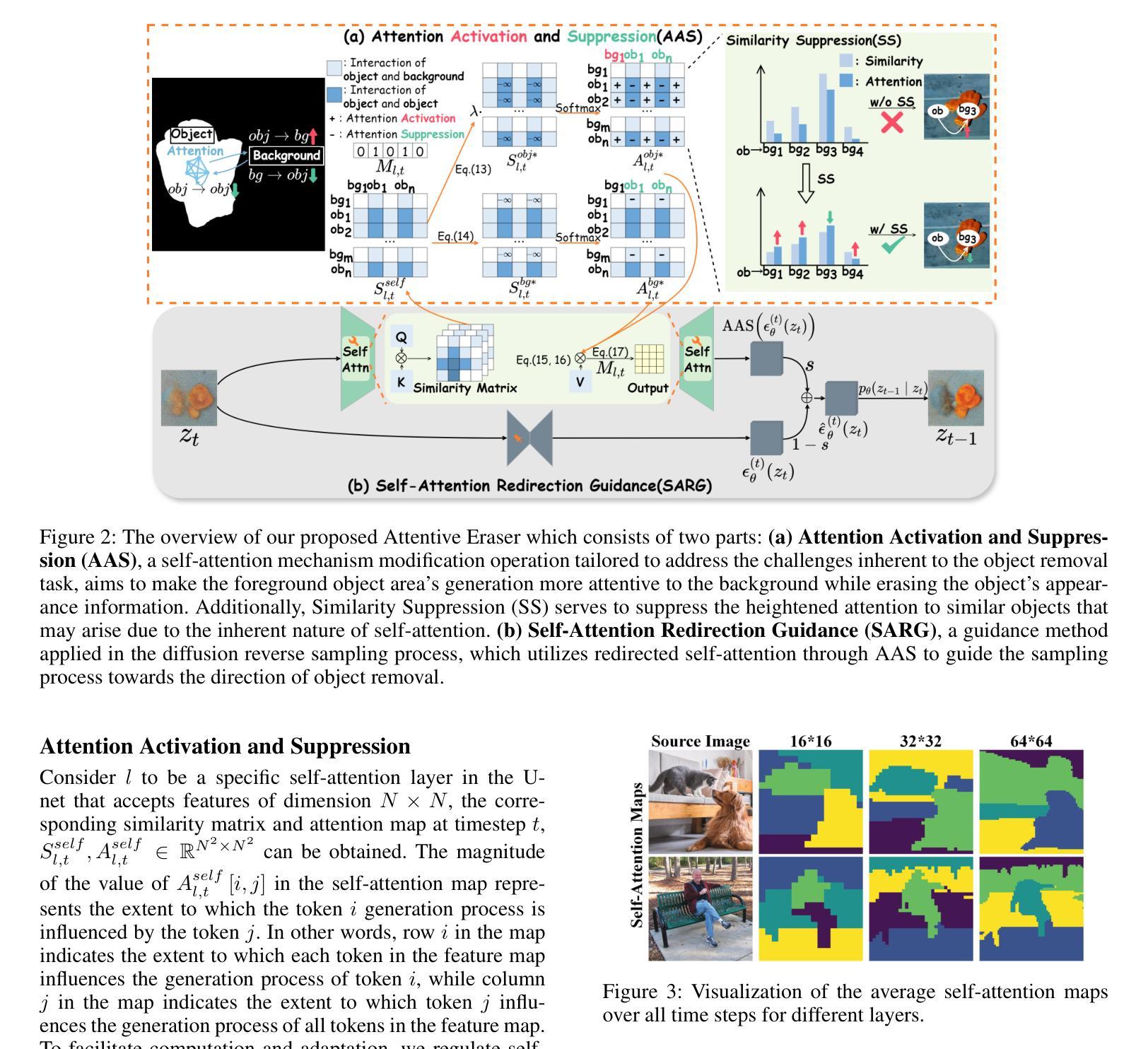
Attentive Eraser: Unleashing Diffusion Model’s Object Removal Potential via Self-Attention Redirection Guidance
Authors:Benlei Cui, Wenhao Sun, Xue-Mei Dong, Jingqun Tang, Yi Liu
Recently, diffusion models have emerged as promising newcomers in the field of generative models, shining brightly in image generation. However, when employed for object removal tasks, they still encounter issues such as generating random artifacts and the incapacity to repaint foreground object areas with appropriate content after remova1l. To tackle these problems, we propose Attentive Eraser, a tuning-free method to empower pre-trained diffusion models for stable and effective object removal. Firstly, in light of the observation that the self-attention maps influence the structure and shape details of the generated images, we propose Attention Activation and Suppression (ASS), which re-engineers the self-attention mechanism within the pre-trained diffusion models based on the given mask, thereby prioritizing the background over the foreground object during the reverse generation process. Moreover, we introduce Self-Attention Redirection Guidance (SARG), which utilizes the self-attention redirected by ASS to guide the generation process, effectively removing foreground objects within the mask while simultaneously generating content that is both plausible and coherent. Experiments demonstrate the stability and effectiveness of Attentive Eraser in object removal across a variety of pre-trained diffusion models, outperforming even training-based methods. Furthermore, Attentive Eraser can be implemented in various diffusion model architectures and checkpoints, enabling excellent scalability. Code is available at https://github.com/Anonym0u3/AttentiveEraser.
最近,扩散模型作为生成模型领域的新晋者展现出巨大的潜力,尤其在图像生成方面大放异彩。然而,当用于对象去除任务时,它们仍然面临一些问题,例如产生随机伪影和在去除后在前景对象区域无法用适当的内容进行重绘。为了解决这些问题,我们提出了无调整的Attentive Eraser方法,使预训练的扩散模型能够进行稳定有效的对象去除。首先,基于自注意力图影响生成图像的结构和形状细节的观察,我们提出了注意力激活和抑制(ASS),它根据给定的掩膜重新设计预训练扩散模型内的自注意力机制,从而在反向生成过程中优先考虑背景而非前景对象。此外,我们引入了自注意力重定向引导(SARG),利用ASS重定向的自注意力来引导生成过程,有效地在掩膜内去除前景对象,同时生成既合理又连贯的内容。实验表明,Attentive Eraser在各种预训练的扩散模型中的对象去除表现出稳定性和有效性,甚至超越了基于训练的方法。此外,Attentive Eraser可以在各种扩散模型架构和检查点中实现,表现出卓越的可扩展性。代码可在https://github.com/Anonym0u3/AttentiveEraser处获取。
论文及项目相关链接
PDF Accepted by AAAI 2025(Oral)
Summary
扩散模型在生成模型领域崭露头角,尤其在图像生成方面表现优异。然而,在对象移除任务中,它们仍面临生成随机伪影和无法重新绘制前景对象区域的问题。为解决这些问题,提出了一种无需调整的预训练扩散模型方法——Attentive Eraser,用于实现稳定和有效的对象移除。通过重新设计预训练扩散模型内的自注意力机制,优先处理背景而非前景对象,从而实现在反向生成过程中稳定去除对象。此外,引入自注意力重定向引导(SARG),利用ASS引导的自注意力来指导生成过程,在去除前景对象的同时生成合理且连贯的内容。实验表明,Attentive Eraser在各种预训练扩散模型中表现稳定有效,甚至超越基于训练的方法。此外,Attentive Eraser可应用于各种扩散模型架构和检查点,具有良好的可扩展性。
Key Takeaways
- 扩散模型在图像生成领域表现出巨大的潜力。
- 在对象移除任务中,扩散模型面临生成随机伪影和无法重新绘制前景的问题。
- Attentive Eraser方法解决了这些问题,让预训练的扩散模型实现稳定和有效的对象移除。
- Attentive Eraser通过重新设计自注意力机制来优先处理背景区域。
- 引入自注意力重定向引导(SARG),提高生成图像的质量和连贯性。
- 实验证明Attentive Eraser在各种预训练扩散模型中表现优异,超越基于训练的方法。
点此查看论文截图



David and Goliath: Small One-step Model Beats Large Diffusion with Score Post-training
Authors:Weijian Luo, Colin Zhang, Debing Zhang, Zhengyang Geng
We propose Diff-Instruct* (DI*), a data-efficient post-training approach for one-step text-to-image generative models to improve its human preferences without requiring image data. Our method frames alignment as online reinforcement learning from human feedback (RLHF), which optimizes the one-step model to maximize human reward functions while being regularized to be kept close to a reference diffusion process. Unlike traditional RLHF approaches, which rely on the Kullback-Leibler divergence as the regularization, we introduce a novel general score-based divergence regularization that substantially improves performance as well as post-training stability. Although the general score-based RLHF objective is intractable to optimize, we derive a strictly equivalent tractable loss function in theory that can efficiently compute its \emph{gradient} for optimizations. We introduce \emph{DI*-SDXL-1step}, which is a 2.6B one-step text-to-image model at a resolution of $1024\times 1024$, post-trained from DMD2 w.r.t SDXL. \textbf{Our 2.6B \emph{DI*-SDXL-1step} model outperforms the 50-step 12B FLUX-dev model} in ImageReward, PickScore, and CLIP score on the Parti prompts benchmark while using only 1.88% of the inference time. This result clearly shows that with proper post-training, the small one-step model is capable of beating huge multi-step diffusion models. Our model is open-sourced at this link: https://github.com/pkulwj1994/diff_instruct_star. We hope our findings can contribute to human-centric machine learning techniques.
我们提出了Diff-Instruct(DI)这一数据高效的后训练方式,用于改进一步文本到图像生成模型的人性偏好,而无需图像数据。我们的方法将对齐作为在线强化学习(RLHF)的任务框架,优化一步模型以最大化人类奖励函数,同时保持接近参考扩散过程的正则化。不同于传统的依赖Kullback-Leibler散度作为正则化的RLHF方法,我们引入了一种新型通用基于分数的散度正则化方法,这极大地提高了性能和后训练稳定性。尽管通用基于分数的RLHF目标难以优化,但我们从理论上推导出了一个严格等价的可处理损失函数,可以有效地计算其梯度进行优化。我们介绍了DI*-SDXL-1step,这是一个分辨率为$1024\times 1024$的2.6B一步文本到图像模型,是基于DMD2关于SDXL的后训练结果。我们的2.6B DI*-SDXL-1step模型在Parti提示基准测试中,在ImageReward、PickScore和CLIP分数方面超越了50步的12B FLUX-dev模型,同时仅使用1.88%的推理时间。这一结果清楚地表明,通过适当的后训练,小型的一步模型能够击败大型的多步扩散模型。我们的模型在此链接处开源:https://github.com/pkulwj1994/diff_instruct_star。我们希望我们的研究能为以人为中心的机器学习技术做出贡献。
论文及项目相关链接
PDF Revision: paper accepted by the ICML2025 main conference
摘要
提出一种数据高效的后训练方式Diff-Instruct(DI),用于一步文本到图像生成模型,可在无需图像数据的情况下提高其人类偏好度。该方法将对齐视为在线强化学习问题,从人类反馈(RLHF)进行优化,旨在使一步模型最大化人类奖励函数,同时保持对参考扩散过程的接近。引入了一种新型通用评分基础上的分歧正则化方法,显著提高性能及后训练稳定性。虽然通用评分基础上的RLHF目标难以优化,但理论上推导出了一个等效的可处理损失函数,可有效地为其优化计算梯度。介绍了基于DI*的SDXL-1步模型,这是一个从DMD2关于SDXL的后训练出来的分辨率为$1024\times 1024$的2.6B一步文本到图像模型。相较于FLUX-dev模型的50步12B模型,在ImageReward、PickScore和CLIP分数上表现更佳,同时仅使用1.88%的推理时间。结果证明,通过适当后训练,小型一步扩散模型能够超越大型多步扩散模型。我们的模型已在此链接开源:https://github.com/pkulwj1994/diff_instruct_star。我们期望研究成果能为人类中心机器学习技术做出贡献。
关键见解
- 提出了Diff-Instruct(DI)方法,一种针对文本到图像生成模型的数据高效后训练策略,能在不依赖图像数据的情况下提高模型对人类偏好的适应度。
- 采用在线强化学习从人类反馈(RLHF)进行对齐,使模型在优化过程中能够最大化人类奖励函数,同时保持对参考扩散过程的接近。
- 引入了一种新型通用评分基础上的分歧正则化方法,显著提升了模型性能及后训练稳定性。
- 通过理论推导,找到了一个等效的可处理损失函数,便于优化计算梯度。
- 介绍了名为DI*-SDXL-1step的模型,展示了其优秀性能:相较于大型多步扩散模型,在图像奖励、挑选分数和CLIP分数方面表现更出色,同时显著缩短了推理时间。
- 模型已开源供公众使用,链接为https://github.com/pkulwj1994/diff_instruct_star。
点此查看论文截图