⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-08 更新
Deep learning image burst stacking to reconstruct high-resolution ground-based solar observations
Authors:Christoph Schirninger, Robert Jarolim, Astrid M. Veronig, Christoph Kuckein
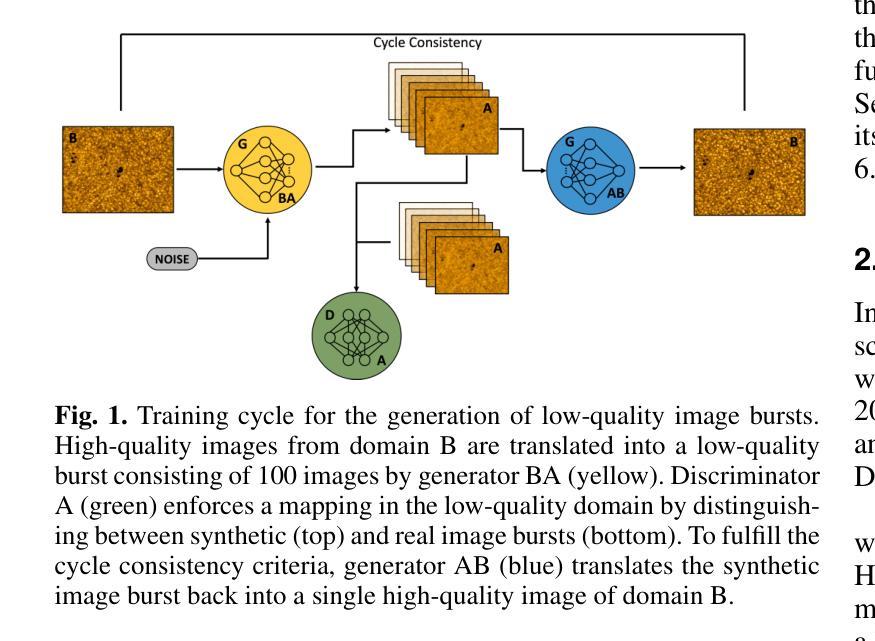
Large aperture ground based solar telescopes allow the solar atmosphere to be resolved in unprecedented detail. However, observations are limited by Earths turbulent atmosphere, requiring post image corrections. Current reconstruction methods using short exposure bursts face challenges with strong turbulence and high computational costs. We introduce a deep learning approach that reconstructs 100 short exposure images into one high quality image in real time. Using unpaired image to image translation, our model is trained on degraded bursts with speckle reconstructions as references, improving robustness and generalization. Our method shows an improved robustness in terms of perceptual quality, especially when speckle reconstructions show artifacts. An evaluation with a varying number of images per burst demonstrates that our method makes efficient use of the combined image information and achieves the best reconstructions when provided with the full image burst.
大型地面太阳望远镜能够以前所未有的细节解析太阳大气。然而,观测受到地球大气湍流的影响,需要进行图像后处理校正。当前使用短曝光序列的重建方法面临强湍流和高计算成本的挑战。我们引入了一种深度学习方法,能够实时将100张短曝光图像重建为一张高质量图像。我们的模型采用非配对图像到图像的翻译方法进行训练,以退化的序列图像和散斑重建图像作为参考,提高了模型的稳健性和泛化能力。该方法在感知质量方面表现出更高的稳健性,尤其是当散斑重建出现伪影时。通过对不同数量的图像序列进行评估,证明我们的方法有效地利用了组合图像信息,在提供完整的图像序列时实现了最佳的重建效果。
论文及项目相关链接
Summary
本文介绍了基于深度学习的太阳望远镜成像重建技术。该技术将大量短时间曝光图像实时重建为高质量图像,解决了传统重建方法在强湍流和高计算成本方面的挑战。通过无配对图像到图像的翻译技术,模型在退化图像和参考斑点重建上进行训练,提高了稳健性和泛化能力。该技术提高了感知质量,特别是在斑点重建出现伪影时表现尤为出色。不同数量的图像每爆分析表明,该技术能高效利用组合图像信息,并在提供完整的图像爆发时实现最佳重建。
Key Takeaways
- 大型地面太阳望远镜能够以前所未有的细节解析太阳大气。
- 地球的大气扰动限制了观测效果,需要进行后图像校正。
- 当前重建方法面临强湍流和高计算成本的挑战。
- 引入了一种基于深度学习的重建方法,可将多个短时间曝光图像实时重建为高质量图像。
- 使用无配对图像到图像的翻译技术,训练模型在退化图像和参考斑点重建上提高稳健性和泛化能力。
- 该技术提高了感知质量,特别是在斑点重建出现伪影时表现优异。
点此查看论文截图



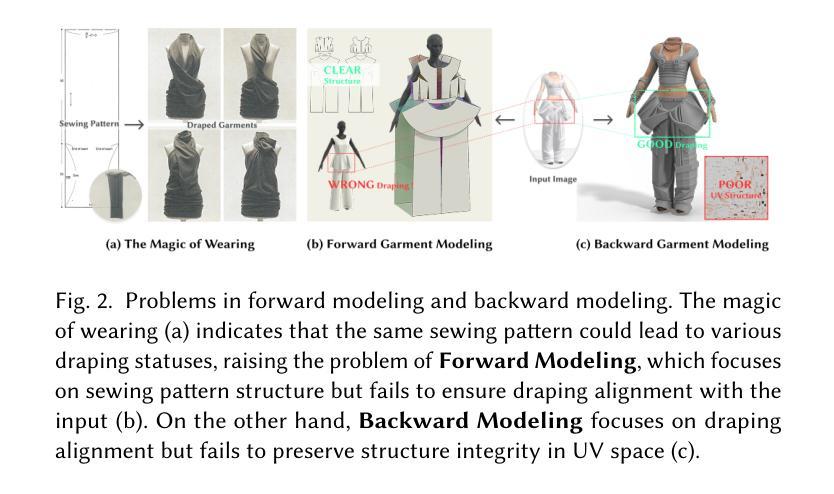
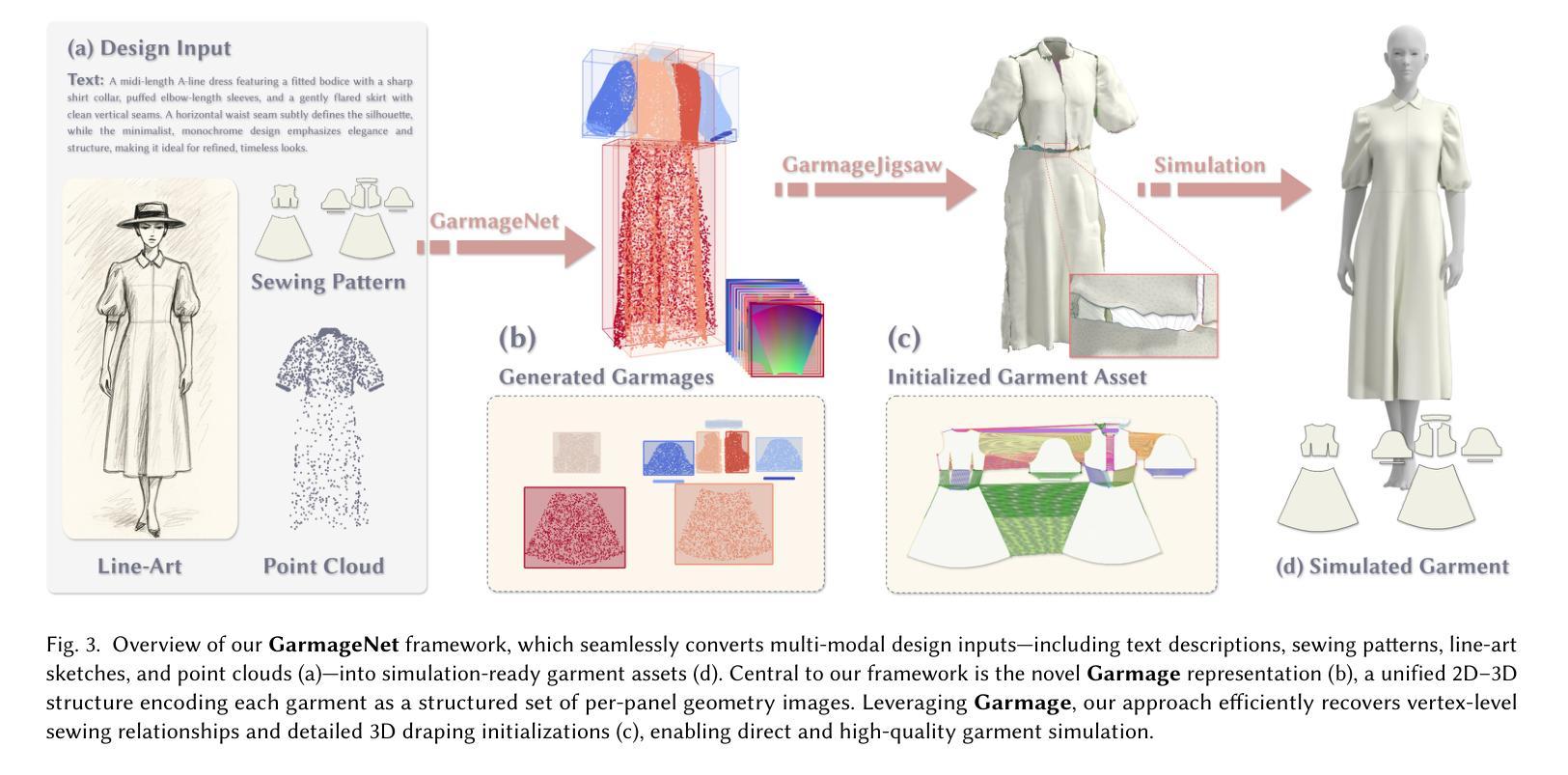
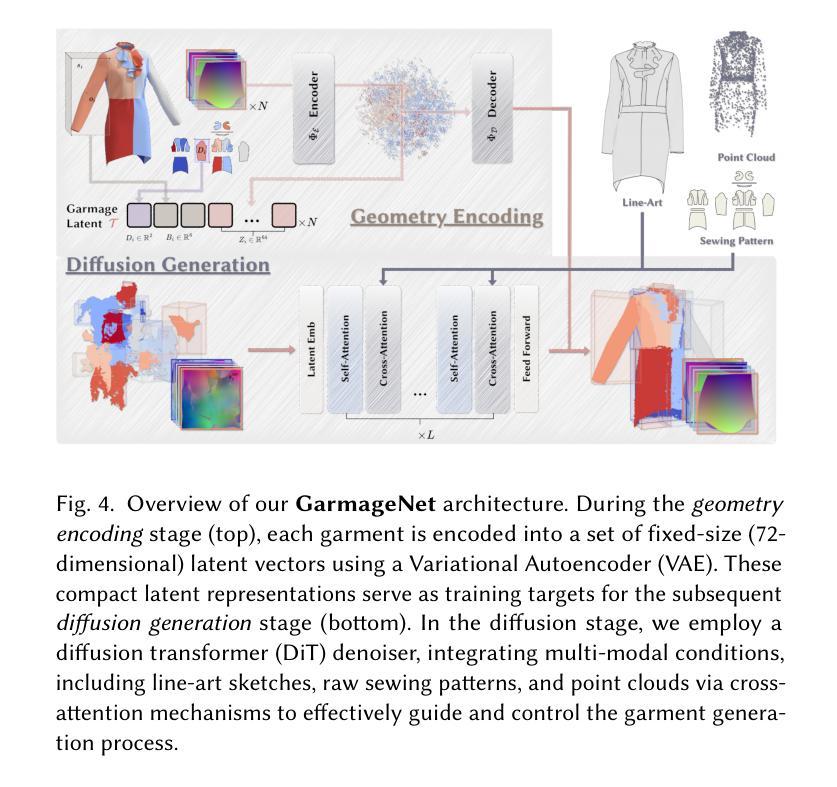
GarmageNet: A Multimodal Generative Framework for Sewing Pattern Design and Generic Garment Modeling
Authors:Siran Li, Ruiyang Liu, Chen Liu, Zhendong Wang, Gaofeng He, Yong-Lu Li, Xiaogang Jin, Huamin Wang
Realistic digital garment modeling remains a labor-intensive task due to the intricate process of translating 2D sewing patterns into high-fidelity, simulation-ready 3D garments. We introduce GarmageNet, a unified generative framework that automates the creation of 2D sewing patterns, the construction of sewing relationships, and the synthesis of 3D garment initializations compatible with physics-based simulation. Central to our approach is Garmage, a novel garment representation that encodes each panel as a structured geometry image, effectively bridging the semantic and geometric gap between 2D structural patterns and 3D garment shapes. GarmageNet employs a latent diffusion transformer to synthesize panel-wise geometry images and integrates GarmageJigsaw, a neural module for predicting point-to-point sewing connections along panel contours. To support training and evaluation, we build GarmageSet, a large-scale dataset comprising over 10,000 professionally designed garments with detailed structural and style annotations. Our method demonstrates versatility and efficacy across multiple application scenarios, including scalable garment generation from multi-modal design concepts (text prompts, sketches, photographs), automatic modeling from raw flat sewing patterns, pattern recovery from unstructured point clouds, and progressive garment editing using conventional instructions-laying the foundation for fully automated, production-ready pipelines in digital fashion. Project page: https://style3d.github.io/garmagenet.
现实主义的数字服装建模仍然是一个劳动密集型的任务,这主要是由于将二维缝纫图案转化为高保真、可进行模拟的3D服装的复杂过程。我们引入了GarmageNet,这是一个统一的生成框架,可以自动创建2D缝纫图案、构建缝纫关系,并合成与基于物理的模拟兼容的3D服装初始化。我们的方法的核心是Garmage,这是一种新的服装表示方法,它将每个面板编码为结构化几何图像,有效地填补了2D结构图案和3D服装形状之间的语义和几何差距。GarmageNet采用潜在扩散变压器来合成面板几何图像,并集成了GarmageJigsaw,这是一个用于预测面板轮廓上点对点缝纫连接的神经网络模块。为了支持和评估,我们构建了GarmageSet,这是一个大规模的数据集,包含超过10000件专业设计的服装,具有详细的结构和风格注释。我们的方法展示了在多个应用场景中的通用性和有效性,包括从多模式设计概念(文本提示、草图、照片)生成可扩展的服装、从原始平面缝纫图案自动建模、从非结构化的点云恢复图案,以及使用常规指令进行渐进式服装编辑——为数字时尚领域实现全自动、面向生产的管道奠定了基础。项目页面:https://style3d.github.io/garmagenet。
论文及项目相关链接
Summary
该文本介绍了一种自动化数字服装建模的方法,通过引入GarmageNet框架,实现二维缝纫图案的创建、缝合关系的构建以及三维服装初始化的合成。该方法的核心在于Garmage这一新型服装表示方式,它将每个面板编码为结构化几何图像,有效桥接了二维结构图案与三维服装形状之间的语义和几何鸿沟。
Key Takeaways
- GarmageNet是一个统一的生成框架,能够自动化创建2D缝纫图案、构建缝合关系,并合成适用于物理模拟的3D服装初始化。
- Garmage是一种新型服装表示方式,将每个面板编码为结构化几何图像,有助于实现从2D到3D的转换。
- GarmageNet使用潜在扩散变压器来合成面板式的几何图像,并集成GarmageJigsaw模块来预测面板轮廓的点到点缝合连接。
- 为了支持训练和评估,构建了GarmageSet大型数据集,包含超过10,000件专业设计的服装,具有详细的结构和风格注释。
- GarmageNet的方法具有多功能性和有效性,可应用于多种应用场景,包括从多模式设计概念(文本提示、草图、照片)生成服装、从原始平面缝纫图案自动建模、从无序点云恢复图案以及使用常规指令进行渐进式服装编辑。
- GarmageNet为数字时尚领域实现全自动、生产就绪的管道奠定了基础。
点此查看论文截图

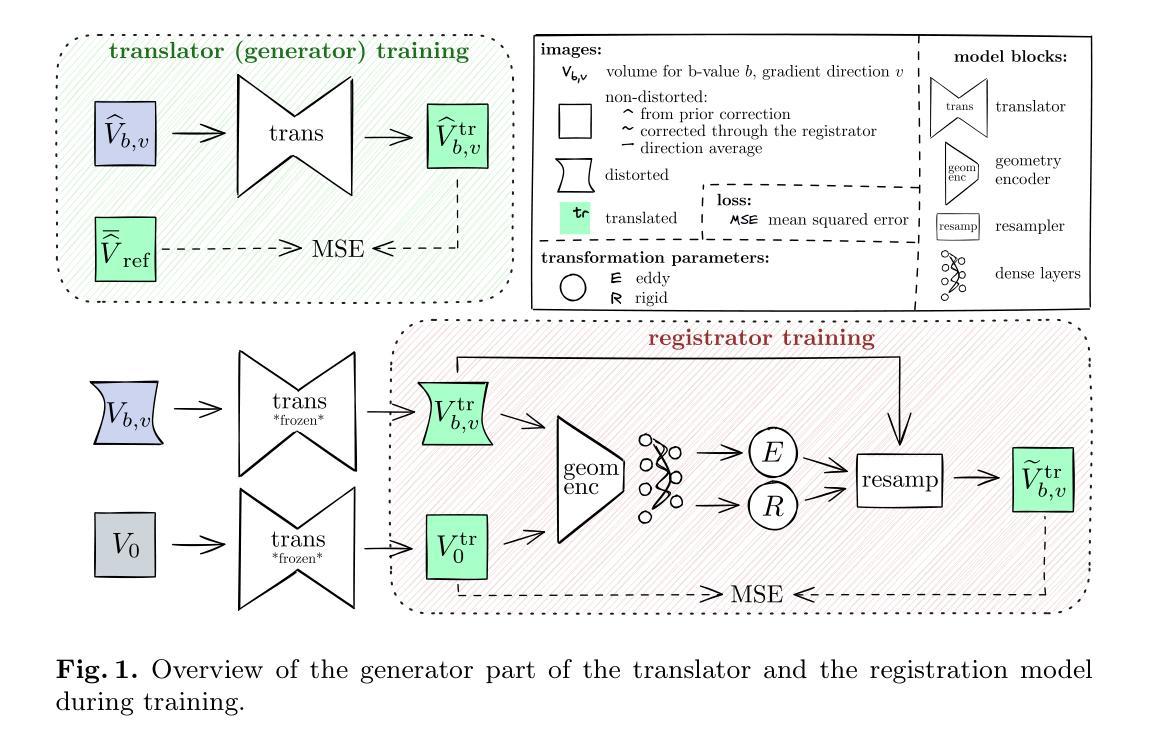
Eddeep: Fast eddy-current distortion correction for diffusion MRI with deep learning
Authors:Antoine Legouhy, Ross Callaghan, Whitney Stee, Philippe Peigneux, Hojjat Azadbakht, Hui Zhang
Modern diffusion MRI sequences commonly acquire a large number of volumes with diffusion sensitization gradients of differing strengths or directions. Such sequences rely on echo-planar imaging (EPI) to achieve reasonable scan duration. However, EPI is vulnerable to off-resonance effects, leading to tissue susceptibility and eddy-current induced distortions. The latter is particularly problematic because it causes misalignment between volumes, disrupting downstream modelling and analysis. The essential correction of eddy distortions is typically done post-acquisition, with image registration. However, this is non-trivial because correspondence between volumes can be severely disrupted due to volume-specific signal attenuations induced by varying directions and strengths of the applied gradients. This challenge has been successfully addressed by the popular FSLEddy tool but at considerable computational cost. We propose an alternative approach, leveraging recent advances in image processing enabled by deep learning (DL). It consists of two convolutional neural networks: 1) An image translator to restore correspondence between images; 2) A registration model to align the translated images. Results demonstrate comparable distortion estimates to FSLEddy, while requiring only modest training sample sizes. This work, to the best of our knowledge, is the first to tackle this problem with deep learning. Together with recently developed DL-based susceptibility correction techniques, they pave the way for real-time preprocessing of diffusion MRI, facilitating its wider uptake in the clinic.
现代扩散磁共振成像序列通常获取大量体积数据,这些数据具有不同强度或方向的扩散增敏梯度。这种序列依赖于回波平面成像(EPI)来实现合理的扫描时间。然而,EPI容易受到离共振效应的影响,导致组织磁化率和涡流引起的失真。后者特别成问题,因为它会导致各卷之间的错位,破坏下游建模和分析。涡流失真的校正通常在采集后进行,通过图像配准实现。然而,由于应用梯度的方向和强度变化导致的特定体积信号衰减,各卷之间的对应关系可能会受到严重破坏,因此这并非易事。这一挑战已经通过流行的FSL
Eddy工具成功解决,但计算成本相当高。我们提出了一种替代方法,利用深度学习(DL)在图像处理方面的最新进展。它包含两个卷积神经网络:1)图像翻译器,用于恢复图像之间的对应关系;2)注册模型,用于对齐翻译后的图像。结果表明,其畸变估计与FSLEddy相当,同时只需适度的训练样本大小。据我们所知,这是首次利用深度学习来解决这一问题。与最近开发的基于DL的磁化率校正技术相结合,它们为扩散磁共振成像的实时预处理铺平了道路,有助于其在临床中的更广泛应用。
论文及项目相关链接
PDF Accepted in MICCAI 2024 conference (without rebuttal). Github repo: https://github.com/CIG-UCL/eddeep
Summary:现代扩散MRI序列常采集大量不同强度或方向的扩散敏感梯度体积数据,采用回声平面成像技术实现合理的扫描时间。然而,EPI易受脱共振效应影响,导致组织磁化率和涡流引起的失真。特别是涡流失真会导致各体积之间的不对齐,破坏下游建模和分析。涡流失真的校正通常在采集后进行图像配准。然而,由于不同方向和强度的梯度引起的体积特定信号衰减,各体积之间的对应关系可能会受到严重干扰。这一挑战已被流行的FSLEddy工具成功解决,但计算成本较高。本研究提出了一种基于深度学习(DL)的替代方法,包括两个卷积神经网络:图像翻译器用于恢复图像之间的对应关系;注册模型用于对齐翻译后的图像。结果显示其失真估计与FSLEddy相当,只需适度训练样本大小。本研究据我们所知是首次用深度学习来解决这一问题。结合最新开发的基于DL的磁化率校正技术,为扩散MRI的实时预处理铺平了道路,促进其在临床的广泛应用。
Key Takeaways:
- 现代扩散MRI序列依赖回声平面成像技术但易受脱共振效应影响,导致组织磁化率和涡流引起的失真问题。
- 涡流失真对扩散MRI的下游建模和分析造成严重影响,需要有效的校正方法。
- 流行的FSL~Eddy工具能够成功解决涡流失真问题,但计算成本较高。
- 研究提出了一种基于深度学习的替代方法来解决涡流失真问题,包括图像翻译器和注册模型两个卷积神经网络。
- 深度学习方法在失真估计方面与FSL~Eddy相当,且只需适度训练样本大小。
- 此研究是首次尝试使用深度学习来解决这一问题,为后续实时预处理扩散MRI提供了可能。
点此查看论文截图