⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-08 更新
DRE: An Effective Dual-Refined Method for Integrating Small and Large Language Models in Open-Domain Dialogue Evaluation
Authors:Kun Zhao, Bohao Yang, Chen Tang, Siyuan Dai, Haoteng Tang, Chenghua Lin, Liang Zhan
Large Language Models (LLMs) excel at many tasks but struggle with ambiguous scenarios where multiple valid responses exist, often yielding unreliable results. Conversely, Small Language Models (SLMs) demonstrate robustness in such scenarios but are susceptible to misleading or adversarial inputs. We observed that LLMs handle negative examples effectively, while SLMs excel with positive examples. To leverage their complementary strengths, we introduce SLIDE (Small and Large Integrated for Dialogue Evaluation), a method integrating SLMs and LLMs via adaptive weighting. Building on SLIDE, we further propose a Dual-Refinement Evaluation (DRE) method to enhance SLM-LLM integration: (1) SLM-generated insights guide the LLM to produce initial evaluations; (2) SLM-derived adjustments refine the LLM’s scores for improved accuracy. Experiments demonstrate that DRE outperforms existing methods, showing stronger alignment with human judgment across diverse benchmarks. This work illustrates how combining small and large models can yield more reliable evaluation tools, particularly for open-ended tasks such as dialogue evaluation.
大型语言模型(LLMs)在许多任务上表现出色,但在存在多个有效响应的模糊场景中表现挣扎,经常产生不可靠的结果。相反,小型语言模型(SLMs)在这种场景中表现出稳健性,但容易受到误导性或对抗性输入的干扰。我们发现LLMs处理负面例子很有效,而SLMs在处理正面例子时表现出色。为了利用它们各自的优点,我们引入了SLIDE(用于对话评估的小型与大型集成模型),这是一种通过自适应权重将SLMs和LLMs集成的方法。基于SLIDE,我们进一步提出了增强SLM-LLM集成的双精修评估(DRE)方法:(1)SLM生成的见解引导LLM进行初步评估;(2)SLM得出的调整改进LLM的分数,提高准确性。实验表明,DRE优于现有方法,在多种基准测试中与人类判断更一致。这项工作说明了如何将小型和大型模型结合起来,以产生更可靠的评估工具,特别是在开放式任务(如对话评估)中。
论文及项目相关链接
PDF arXiv admin note: text overlap with arXiv:2405.15924
Summary
大型语言模型(LLMs)在多项任务上表现出色,但在存在多个有效答案的模糊场景中往往表现不可靠。小型语言模型(SLMs)在这种场景中表现稳健,但易受到误导性或对抗性输入的影响。通过整合SLMs和LLMs并通过自适应权重进行模型融合,我们提出了SLIDE方法。在此基础上,我们进一步提出了Dual-Refinement Evaluation(DRE)方法以增强SLM-LLM的融合效果:首先,利用SLM生成的见解引导LLM进行初步评估;其次,基于SLM的微调来优化LLM的评分以提高准确性。实验表明,DRE方法优于现有技术,在不同基准测试中与人类判断更一致。本研究展示了将小型和大型模型相结合可以产生更可靠的评估工具,尤其适用于开放任务如对话评估。
Key Takeaways
- LLMs在多项任务上表现出色,但在处理模糊场景时可能产生不可靠的结果。
- SLMs在模糊场景中表现稳健,但易受误导性或对抗性输入的影响。
3.SLIDE方法通过整合SLMs和LLMs并自适应调整权重,以提高模型性能。 - DRE方法基于SLIDE进一步增强了SLM-LLM的融合效果,通过SLM生成的见解引导LLM初步评估,并利用SLM的微调优化LLM的评分。
- 实验证明DRE方法优于现有技术,与人类判断更加一致。
- 结合小型和大型模型可以产生更可靠的评估工具,特别适用于对话评估等开放任务。
点此查看论文截图


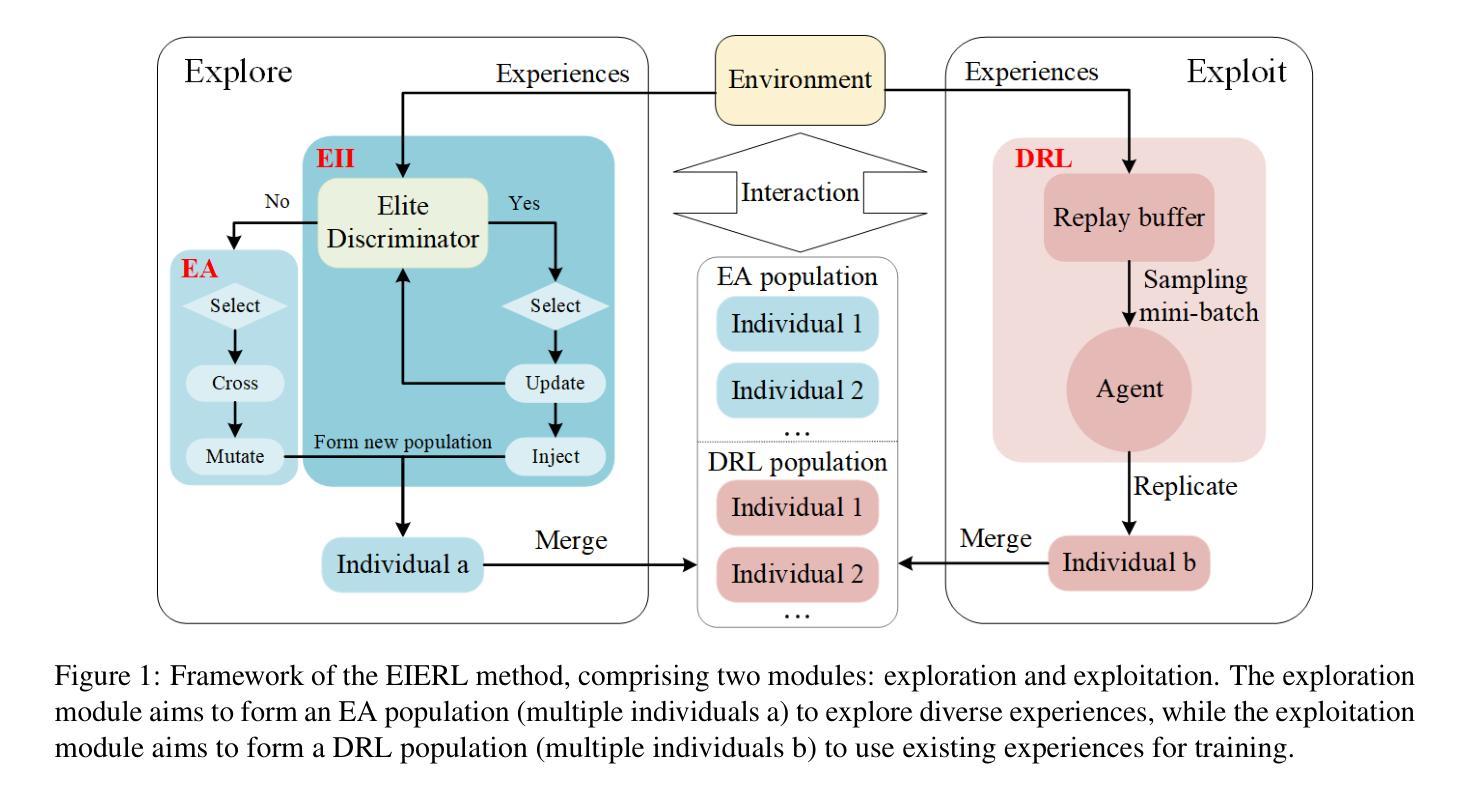
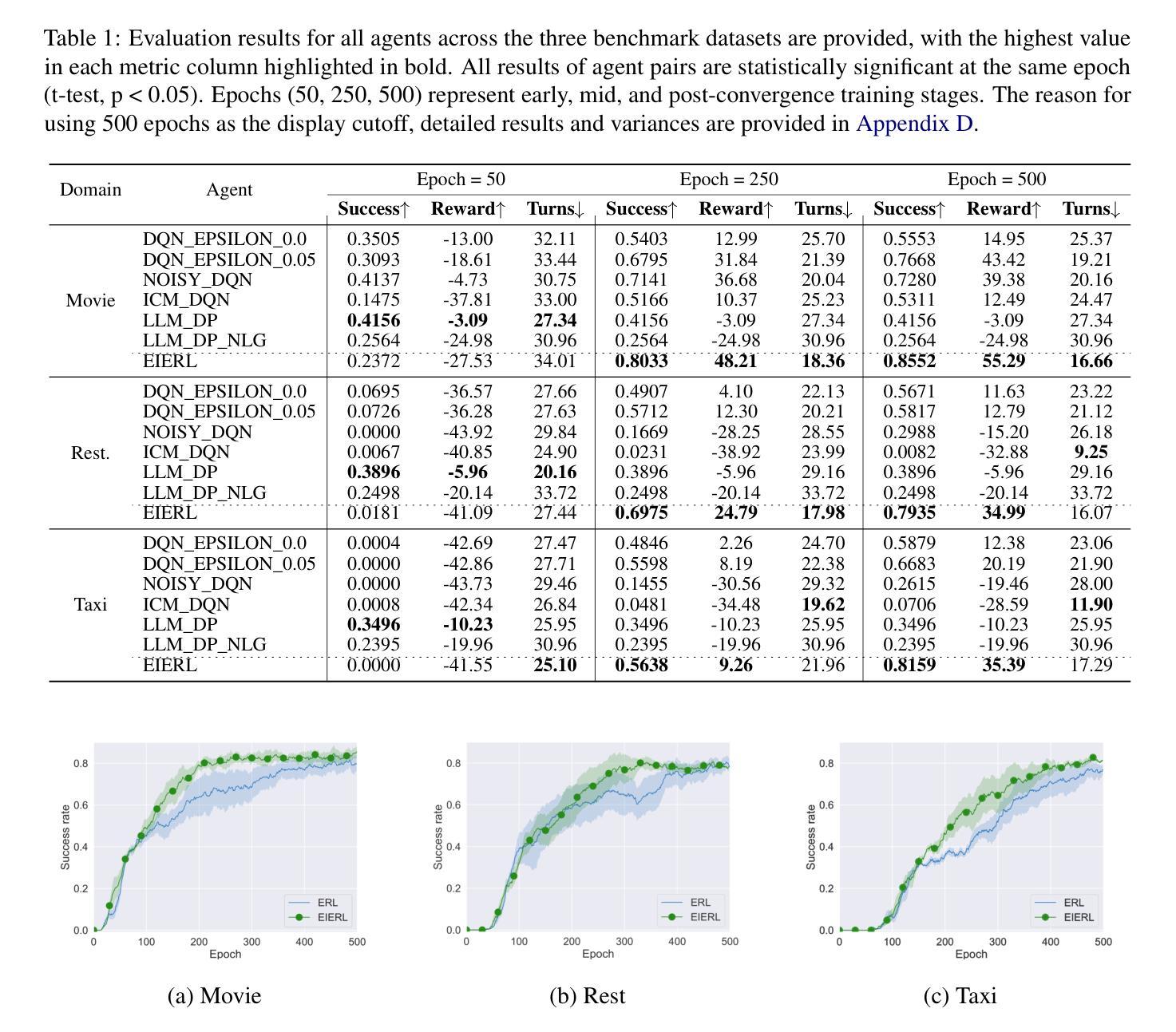
An Efficient Task-Oriented Dialogue Policy: Evolutionary Reinforcement Learning Injected by Elite Individuals
Authors:Yangyang Zhao, Ben Niu, Libo Qin, Shihan Wang
Deep Reinforcement Learning (DRL) is widely used in task-oriented dialogue systems to optimize dialogue policy, but it struggles to balance exploration and exploitation due to the high dimensionality of state and action spaces. This challenge often results in local optima or poor convergence. Evolutionary Algorithms (EAs) have been proven to effectively explore the solution space of neural networks by maintaining population diversity. Inspired by this, we innovatively combine the global search capabilities of EA with the local optimization of DRL to achieve a balance between exploration and exploitation. Nevertheless, the inherent flexibility of natural language in dialogue tasks complicates this direct integration, leading to prolonged evolutionary times. Thus, we further propose an elite individual injection mechanism to enhance EA’s search efficiency by adaptively introducing best-performing individuals into the population. Experiments across four datasets show that our approach significantly improves the balance between exploration and exploitation, boosting performance. Moreover, the effectiveness of the EII mechanism in reducing exploration time has been demonstrated, achieving an efficient integration of EA and DRL on task-oriented dialogue policy tasks.
深度强化学习(DRL)被广泛应用于面向任务的对话系统以优化对话策略,但由于状态空间以及动作空间的高维性,它在平衡探索和利用方面面临困难。这一挑战往往导致局部最优或收敛性差。进化算法(EA)通过保持种群多样性,已被证明可以有效探索神经网络的解空间。受此启发,我们创新地将EA的全局搜索能力与DRL的局部优化相结合,实现了探索与利用之间的平衡。然而,对话任务中自然语言固有的灵活性使这种直接整合变得复杂,导致进化时间延长。因此,我们进一步提出了一种精英个体注入机制,通过自适应地将表现最佳的个体引入种群,提高EA的搜索效率。在四个数据集上的实验表明,我们的方法显著改善了探索与利用之间的平衡,提高了性能。此外,精英个体注入机制在减少探索时间方面的有效性已经得到验证,实现了EA和DRL在面向任务的对话策略任务上的高效融合。
论文及项目相关链接
PDF Accepted to ACL 2025 (Main Track)
Summary
DRL在任务导向型对话系统中的应用广泛,但面临高维状态动作空间导致的探索与利用的平衡问题。为此,本文提出了结合进化算法(EA)与DRL的解决方案,利用EA的全局搜索能力和DRL的局部优化能力。然而,对话任务的自然语言内在复杂性导致进化过程延长。因此,本文进一步提出了精英个体注入机制(EII),提高EA的搜索效率。实验结果显示,该方法有效平衡了探索与利用,提高了性能并减少了探索时间。
Key Takeaways
- DRL在任务导向型对话系统中面临探索与利用的平衡问题。
- 进化算法(EA)能有效探索神经网络解空间,保持种群多样性。
- 结合EA与DRL可解决探索与利用的平衡问题。
- 对话任务的自然语言内在复杂性导致进化过程延长。
- 精英个体注入机制(EII)能提高EA的搜索效率。
- 实验结果显示,该方法显著提高了探索与利用的平衡,提升了性能。
点此查看论文截图



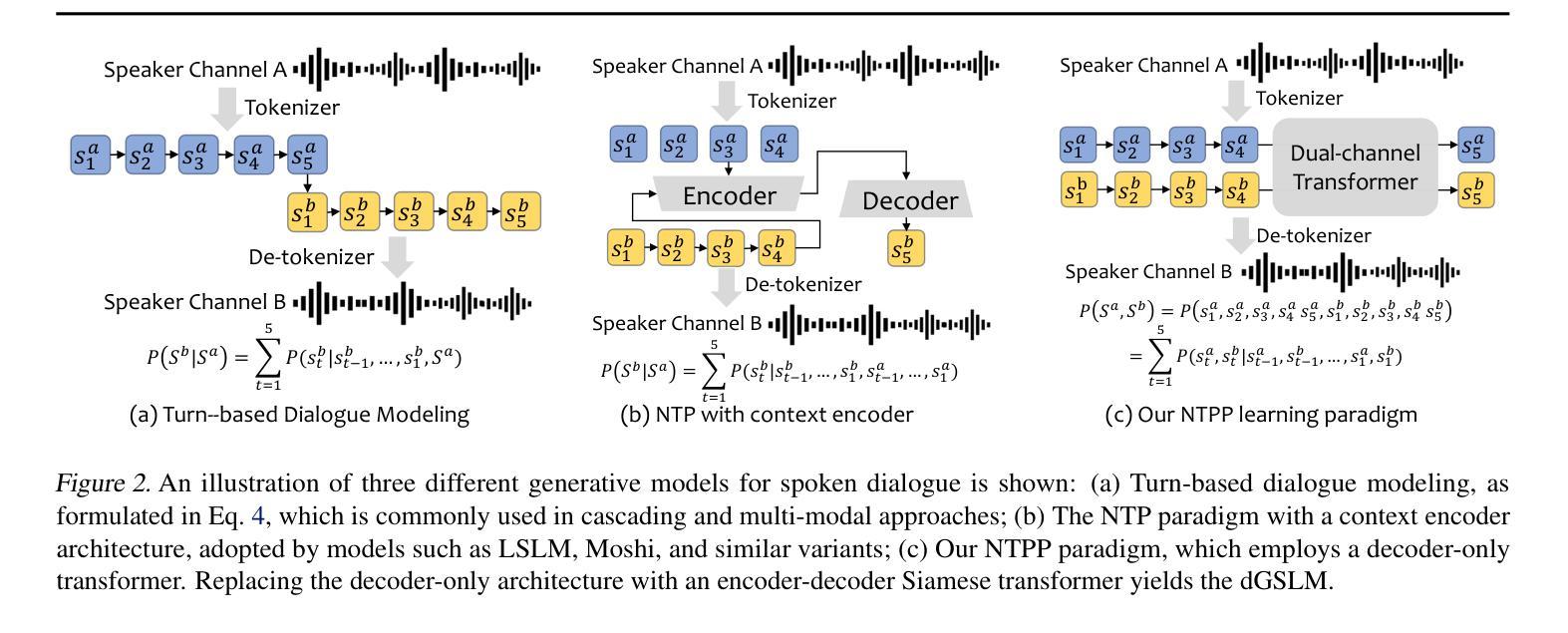
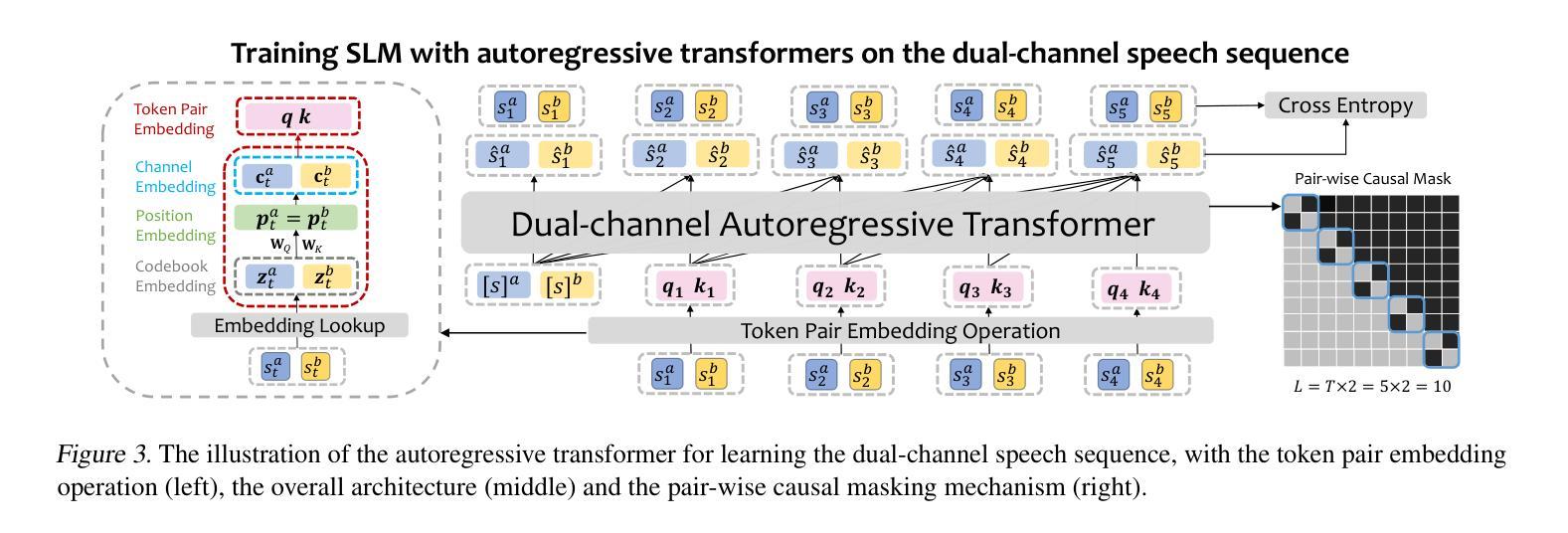
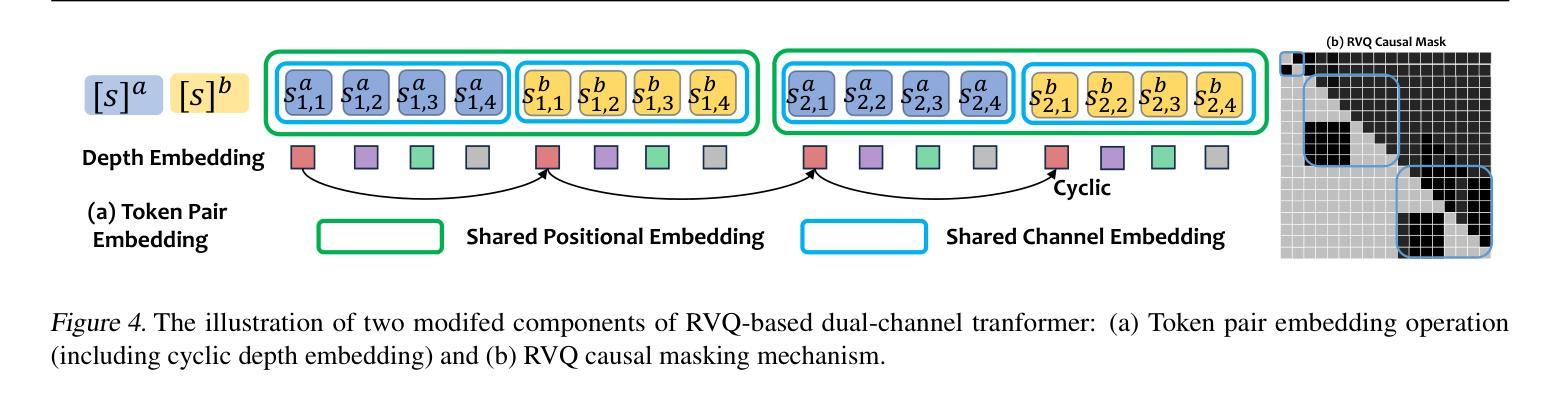
NTPP: Generative Speech Language Modeling for Dual-Channel Spoken Dialogue via Next-Token-Pair Prediction
Authors:Qichao Wang, Ziqiao Meng, Wenqian Cui, Yifei Zhang, Pengcheng Wu, Bingzhe Wu, Irwin King, Liang Chen, Peilin Zhao
Inspired by the impressive capabilities of GPT-4o, there is growing interest in enabling speech language models (SLMs) to engage in natural, fluid spoken interactions with humans. Recent advancements have led to the development of several SLMs that demonstrate promising results in this area. However, current approaches have yet to fully exploit dual-channel speech data, which inherently captures the structure and dynamics of human conversation. In this work, we systematically explore the use of dual-channel speech data in the context of modern large language models, and introduce a novel generative modeling paradigm, Next-Token-Pair Prediction (NTPP), to enable speaker-independent dual-channel spoken dialogue learning using decoder-only architectures for the first time. We evaluate our approach on standard benchmarks, and empirical results show that our proposed method, NTPP, significantly improves the conversational abilities of SLMs in terms of turn-taking prediction, response coherence, and naturalness. Moreover, compared to existing methods, NTPP achieves substantially lower inference latency, highlighting its practical efficiency for real-time applications.
受GPT-4o强大功能的启发,人们越来越有兴趣让语言模型能够与人类进行自然流畅的口语互动。最近的进步导致在这一领域显示出令人鼓舞的结果的几个语言模型的诞生。然而,当前的方法尚未充分利用双通道语音数据,双通道语音数据从本质上捕捉了人类对话的结构和动态。在这项工作中,我们系统地探索了在现代大型语言模型背景下使用双通道语音数据的方法,并引入了一种新颖的生成建模范式——下一个令牌对预测(NTPP),首次使用仅解码器架构实现了与说话者无关的双通道口语对话学习。我们在标准基准测试上评估了我们的方法,经验结果表明,我们提出的方法NTPP在话轮预测、响应连贯性和自然性方面显著提高了语言模型的对话能力。此外,与现有方法相比,NTPP实现了更低的推理延迟,凸显了其在实时应用中的实际效率。
论文及项目相关链接
PDF Accepted by ICML 2025
Summary
本文介绍了基于GPT-4o的启发,现代大型语言模型在双通道语音数据方面的应用探索。文章提出了一种新型的生成建模范式——Next-Token-Pair Prediction(NTPP),首次实现了无需说话人的双通道对话学习,并使用解码器仅架构。在标准基准测试上评估的方法表明,NTPP显著提高了语言模型的对话能力,包括轮替预测、响应连贯性和自然性。与其他方法相比,NTPP具有更低的推理延迟,表明其实时应用的实用性。
Key Takeaways
- 文本提到了GPT-4o的启发对现代大型语言模型在双通道语音数据方面的应用产生了影响。
- 介绍了新型的生成建模范式NTPP,实现了无需说话人的双通道对话学习。
- 文章首次使用解码器仅架构进行这种类型的学习。
- 在标准基准测试上评估的方法表明NTPP显著提高了语言模型的对话能力,包括轮替预测的准确性。
- NTPP能提高响应的连贯性和自然性。
- 与其他方法相比,NTPP具有更低的推理延迟。
点此查看论文截图


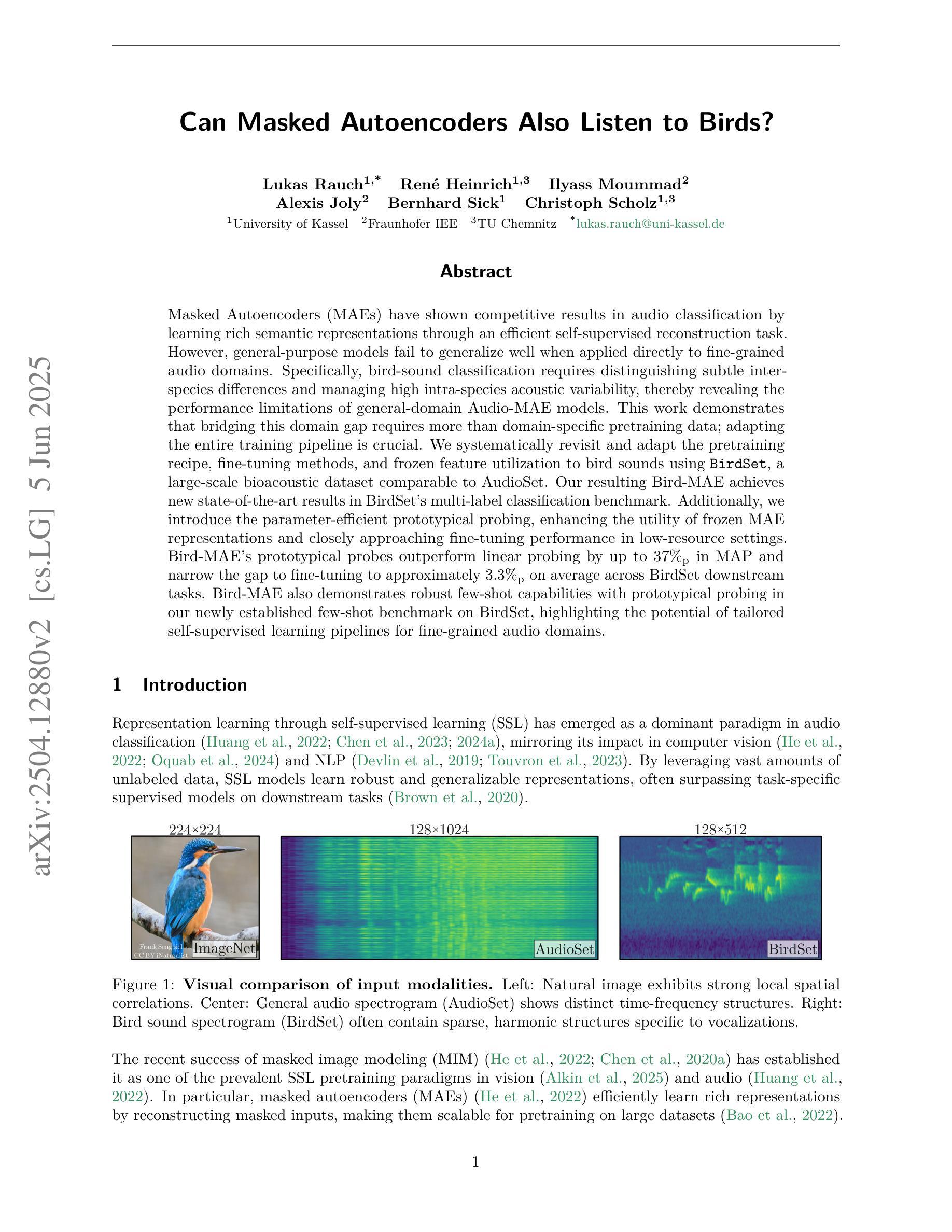
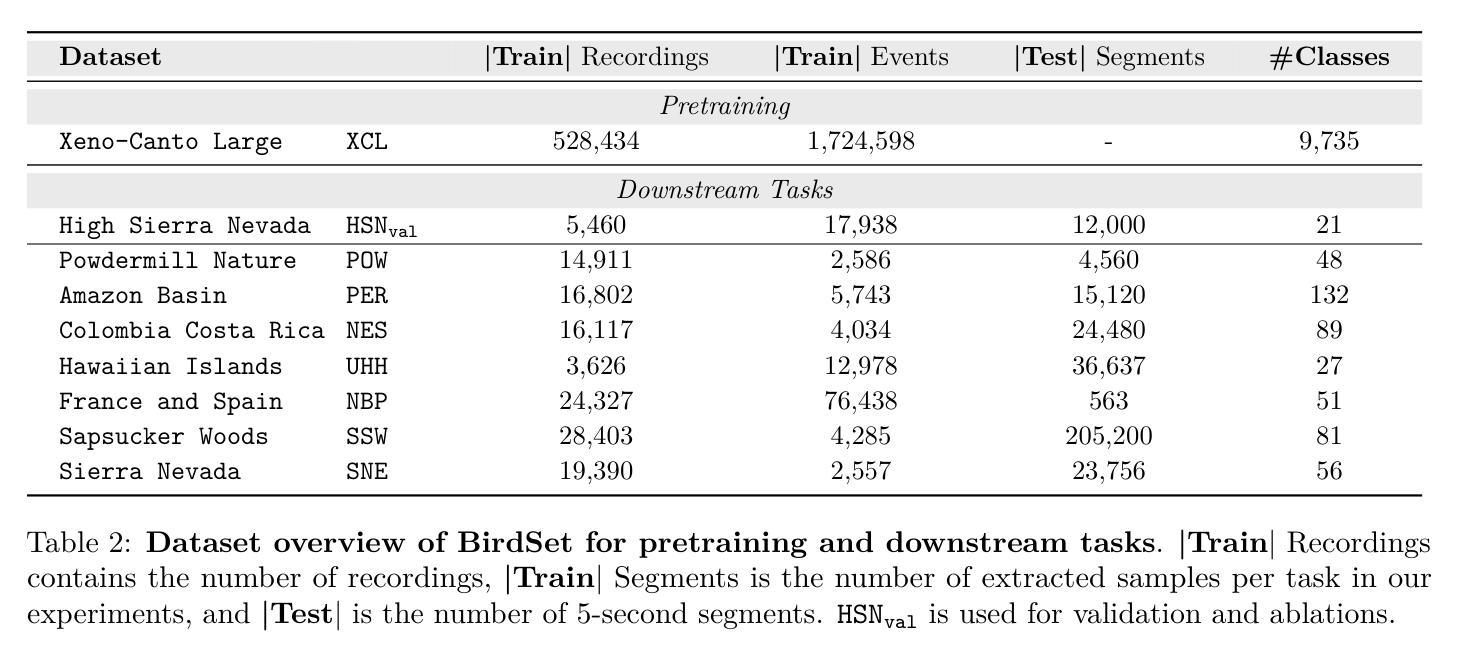
Can Masked Autoencoders Also Listen to Birds?
Authors:Lukas Rauch, René Heinrich, Ilyass Moummad, Alexis Joly, Bernhard Sick, Christoph Scholz
Masked Autoencoders (MAEs) have shown competitive results in audio classification by learning rich semantic representations through an efficient self-supervised reconstruction task. However, general-purpose models fail to generalize well when applied directly to fine-grained audio domains. Specifically, bird-sound classification requires distinguishing subtle inter-species differences and managing high intra-species acoustic variability, thereby revealing the performance limitations of general-domain Audio-MAE models. This work demonstrates that bridging this domain gap requires more than domain-specific pretraining data; adapting the entire training pipeline is crucial. We systematically revisit and adapt the pretraining recipe, fine-tuning methods, and frozen feature utilization to bird sounds using BirdSet, a large-scale bioacoustic dataset comparable to AudioSet. Our resulting Bird-MAE achieves new state-of-the-art results in BirdSet’s multi-label classification benchmark. Additionally, we introduce the parameter-efficient prototypical probing, enhancing the utility of frozen MAE representations and closely approaching fine-tuning performance in low-resource settings. Bird-MAE’s prototypical probes outperform linear probing by up to 37%$_\text{p}$ in MAP and narrow the gap to fine-tuning to approximately 3.3%$_\text{p}$ on average across BirdSet downstream tasks. Bird-MAE also demonstrates robust few-shot capabilities with prototypical probing in our newly established few-shot benchmark on BirdSet, highlighting the potential of tailored self-supervised learning pipelines for fine-grained audio domains.
掩码自编码器(MAEs)通过高效的自监督重建任务学习了丰富的语义表示,在音频分类中取得了具有竞争力的结果。然而,当直接应用于细粒度音频域时,通用模型往往无法很好地推广。特别是,鸟类声音分类需要区分物种间的细微差异并处理高种内声学变异性,从而揭示了通用领域Audio-MAE模型的性能局限性。这项工作表明,缩小这一领域差距不仅需要特定领域的预训练数据;适应整个训练管道也至关重要。我们系统地重新审视并适应了预训练配方、微调方法和冻结特征的利用,以使用BirdSet(一个可与AudioSet相比的大规模生物声学数据集)进行鸟类声音分类。我们得到的Bird-MAE在BirdSet的多标签分类基准测试中取得了最新最先进的成果。此外,我们引入了参数高效的原型探测,增强了冻结MAE表示的功能,并在低资源环境中接近微调性能。Bird-MAE的原型探针在MAP上的表现优于线性探针高达37%,并将与微调之间的差距缩小到BirdSet下游任务的平均约3.3%。Bird-MAE在新的少量样本基准测试中,展示了原型探测的强大能力,突显了针对细粒度音频领域量身定制的自监督学习管道的潜力。
论文及项目相关链接
PDF under review @TMLR
摘要
Masked Autoencoders(MAEs)在音频分类中展现出强大的性能,通过有效的自监督重建任务学习丰富的语义表示。然而,通用模型在细粒度音频领域的应用中表现不佳。特别是在鸟类声音分类中,需要区分微妙的物种间差异并处理高种内声学变异,暴露出通用领域Audio-MAE模型的性能局限。本研究表明,缩小这一领域差距不仅需要领域特定的预训练数据,适应整个训练管道也至关重要。我们系统地回顾并适应了预训练配方、微调方法和冻结特征的利用方式,使用BirdSet(一个与AudioSet相当的大规模生物声学数据集)对鸟类声音进行训练。我们得到的Bird-MAE在BirdSet的多标签分类基准测试中取得了最新 state-of-the-art 的结果。此外,我们引入了参数有效的原型探测,增强了冻结MAE表示的实用性,并在低资源环境中接近微调性能。Bird-MAE的原型探针在MAP上的表现优于线性探针高达37%,并将与微调之间的差距缩小到平均约3.3%。Bird-MAE在我们在BirdSet新建立的少镜头基准测试中表现出的稳健的少镜头能力,突显了针对细粒度音频领域量身定制的自监督学习管道的巨大潜力。
关键见解
- Masked Autoencoders (MAEs) 在音频分类中表现出强大的性能,通过自监督学习丰富的语义表示。
- 通用模型在细粒度音频领域(如鸟类声音分类)中的应用存在局限性,需要区分微妙的物种差异和高种内声学变异。
- 缩小领域差距不仅需要领域特定的预训练数据,还需要适应整个训练管道。
- Bird-MAE 在 BirdSet 的多标签分类基准测试中取得了最新 state-of-the-art 结果。
- 引入参数有效的原型探测,增强了冻结MAE表示的实用性,并提高了低资源环境中的性能。
- Bird-MAE的原型探针在性能评估指标上显著优于线性探针。
点此查看论文截图