⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-08 更新
VideoMathQA: Benchmarking Mathematical Reasoning via Multimodal Understanding in Videos
Authors:Hanoona Rasheed, Abdelrahman Shaker, Anqi Tang, Muhammad Maaz, Ming-Hsuan Yang, Salman Khan, Fahad Khan
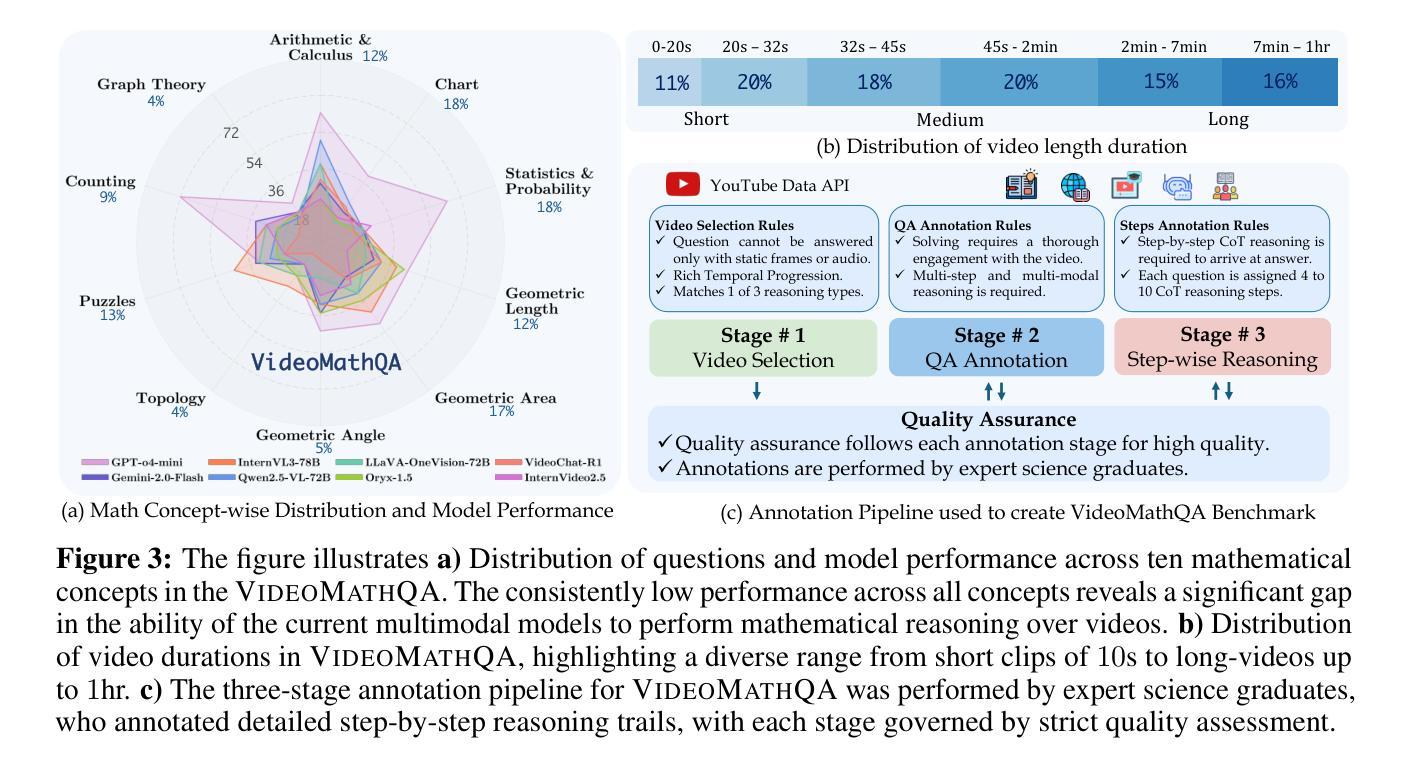
Mathematical reasoning in real-world video settings presents a fundamentally different challenge than in static images or text. It requires interpreting fine-grained visual information, accurately reading handwritten or digital text, and integrating spoken cues, often dispersed non-linearly over time. In such multimodal contexts, success hinges not just on perception, but on selectively identifying and integrating the right contextual details from a rich and noisy stream of content. To this end, we introduce VideoMathQA, a benchmark designed to evaluate whether models can perform such temporally extended cross-modal reasoning on videos. The benchmark spans 10 diverse mathematical domains, covering videos ranging from 10 seconds to over 1 hour. It requires models to interpret structured visual content, understand instructional narratives, and jointly ground concepts across visual, audio, and textual modalities. We employ graduate-level experts to ensure high quality, totaling over $920$ man-hours of annotation. To reflect real-world scenarios, questions are designed around three core reasoning challenges: direct problem solving, where answers are grounded in the presented question; conceptual transfer, which requires applying learned methods to new problems; and deep instructional comprehension, involving multi-step reasoning over extended explanations and partially worked-out solutions. Each question includes multi-step reasoning annotations, enabling fine-grained diagnosis of model capabilities. Through this benchmark, we highlight the limitations of existing approaches and establish a systematic evaluation framework for models that must reason, rather than merely perceive, across temporally extended and modality-rich mathematical problem settings. Our benchmark and evaluation code are available at: https://mbzuai-oryx.github.io/VideoMathQA
在真实世界的视频环境中进行数学推理与静态图像或文本中的挑战存在根本性的不同。它要求解释细微的视觉信息,准确阅读手写或数字文本,并整合口语线索,这些线索通常随时间分散并非线性分布。在这种多模态情境中,成功的关键不仅在于感知,还在于从丰富且嘈杂的内容流中有选择地识别和整合正确的上下文细节。为此,我们引入了VideoMathQA基准测试,旨在评估模型在视频上执行这种时间扩展的跨模态推理的能力。该基准测试涵盖了10个多样化的数学领域,涉及的视频时长从10秒到超过1小时不等。它要求模型解释结构化的视觉内容,理解说明性叙述,并在视觉、音频和文本模式之间共同建立概念。我们聘请了研究生水平的专家以确保高质量,总标注时长超过920小时。为了反映真实世界场景,问题围绕三个核心推理挑战进行设计:直接问题解决,答案基于所提出的问题;概念迁移,要求将所学方法应用于新问题;以及深度指令理解,涉及对多步骤解释的长期推理和部分解决方案。每个问题都包含多步骤推理注释,可以精细诊断模型的能力。通过这个基准测试,我们强调了现有方法的局限性,并为必须在时间延长和模式丰富的数学问题环境中进行推理的模型建立了系统的评估框架。我们的基准测试和评估代码可在以下网址找到:https://mbzuai-oryx.github.io/VideoMathQA
论文及项目相关链接
PDF VideoMathQA Technical Report
Summary
本文介绍了VideoMathQA基准测试,该测试旨在评估模型在视频上进行时间扩展跨模态推理的能力。该基准测试包含10个数学领域的多样化视频内容,时长从10秒到超过1小时不等。它要求模型解读结构化视觉内容、理解教学叙述,并在视觉、音频和文本模式之间共同建立概念。通过此基准测试,突显了现有方法的局限性,并为需要在时间扩展和模态丰富的数学问题解决环境中进行推理的模型建立了系统的评估框架。
Key Takeaways
- VideoMathQA是一个旨在评估模型在视频上进行跨模态推理能力的基准测试。
- 测试涉及10个数学领域的多样化视频内容,时长不一。
- 模型需解读结构化视觉内容、理解教学叙述,并在各模式间建立概念。
- 测试包含三种核心推理挑战:直接问题解决、概念迁移和深度教学理解。
- 每个问题包含多步骤推理注释,能精细诊断模型能力。
- 现有方法的局限性在测试中突显。
点此查看论文截图


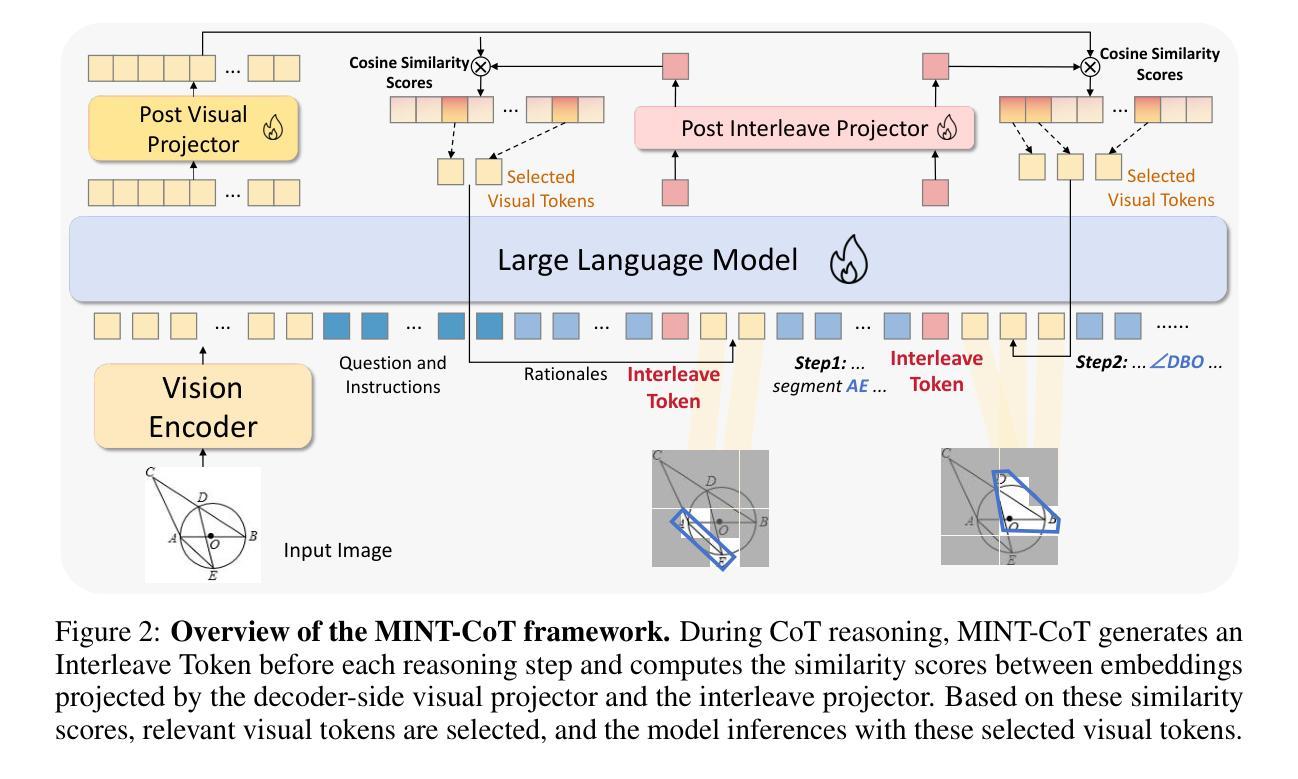
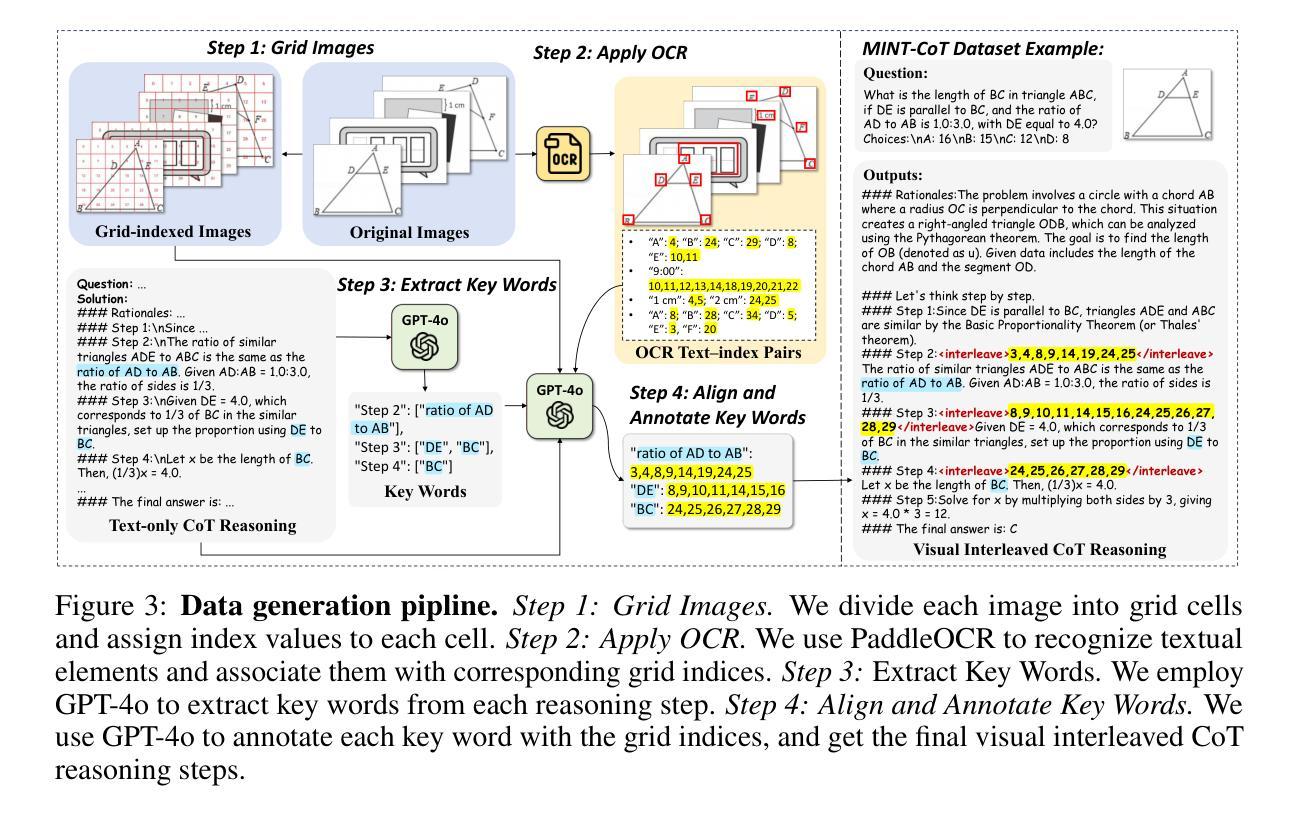
MINT-CoT: Enabling Interleaved Visual Tokens in Mathematical Chain-of-Thought Reasoning
Authors:Xinyan Chen, Renrui Zhang, Dongzhi Jiang, Aojun Zhou, Shilin Yan, Weifeng Lin, Hongsheng Li
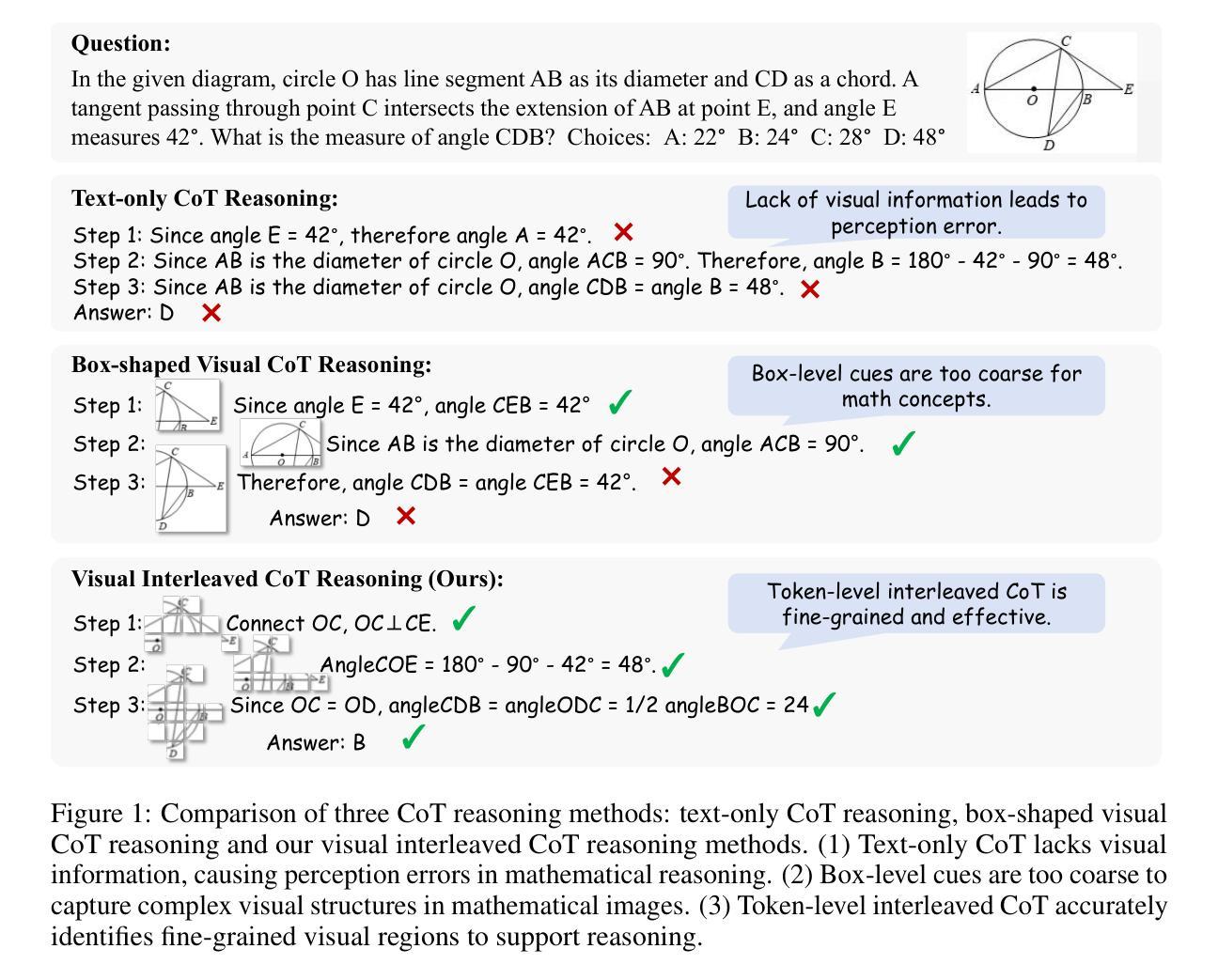
Chain-of-Thought (CoT) has widely enhanced mathematical reasoning in Large Language Models (LLMs), but it still remains challenging for extending it to multimodal domains. Existing works either adopt a similar textual reasoning for image input, or seek to interleave visual signals into mathematical CoT. However, they face three key limitations for math problem-solving: reliance on coarse-grained box-shaped image regions, limited perception of vision encoders on math content, and dependence on external capabilities for visual modification. In this paper, we propose MINT-CoT, introducing Mathematical INterleaved Tokens for Chain-of-Thought visual reasoning. MINT-CoT adaptively interleaves relevant visual tokens into textual reasoning steps via an Interleave Token, which dynamically selects visual regions of any shapes within math figures. To empower this capability, we construct the MINT-CoT dataset, containing 54K mathematical problems aligning each reasoning step with visual regions at the token level, accompanied by a rigorous data generation pipeline. We further present a three-stage MINT-CoT training strategy, progressively combining text-only CoT SFT, interleaved CoT SFT, and interleaved CoT RL, which derives our MINT-CoT-7B model. Extensive experiments demonstrate the effectiveness of our method for effective visual interleaved reasoning in mathematical domains, where MINT-CoT-7B outperforms the baseline model by +34.08% on MathVista, +28.78% on GeoQA, and +23.2% on MMStar, respectively. Our code and data are available at https://github.com/xinyan-cxy/MINT-CoT
思维链(CoT)已在大型语言模型(LLM)中广泛提高了数学推理能力,但将其扩展到多模态领域仍然具有挑战性。现有工作要么采用类似的文本推理进行图像输入,要么寻求将视觉信号融入数学思维链。然而,它们在解决数学问题方面面临三个主要局限性:依赖粗粒度的盒状图像区域、视觉编码器对数学内容的感知有限,以及依赖外部能力进行视觉修改。在本文中,我们提出MINT-CoT,引入用于思维链视觉推理的数学交叉令牌。MINT-CoT通过自适应地将相关视觉令牌插入文本推理步骤中,实现思维链中的视觉与文本交叉融合。它通过动态选择数学图形内的任何形状视觉区域来实现这一功能。为了支持这一功能,我们构建了MINT-CoT数据集,包含54K个数学问题,每个推理步骤都与令牌级别的视觉区域对齐,并配备严格的数据生成流程。我们还提出了一个三阶段的MINT-CoT训练策略,逐步结合纯文本思维链SFT、交叉思维链SFT和交叉思维链RL,从而得到我们的MINT-CoT-7B模型。大量实验表明,我们的方法在数学领域的有效视觉交叉推理中非常有效,MINT-CoT-7B在MathVista上优于基线模型+34.08%,在GeoQA上优于基线模型+28.78%,在MMStar上优于基线模型+23.2%。我们的代码和数据集可在https://github.com/xinyan-cxy/MINT-CoT找到。
论文及项目相关链接
PDF Code is released at https://github.com/xinyan-cxy/MINT-CoT
Summary
在大型语言模型(LLM)中,链式思维(Chain-of-Thought,简称CoT)已经广泛应用于数学推理领域。然而,将其扩展到多模态领域仍然具有挑战性。现有方法要么采用类似的文本推理进行图像输入,要么寻求将视觉信号融入数学CoT。但它们在解决数学问题方面面临三个主要局限性:依赖粗粒度的框状图像区域、视觉编码器对数学内容的感知有限,以及依赖外部能力进行视觉修改。针对这些问题,本文提出MINT-CoT方法,通过引入数学交错令牌(Mathematical INterleaved Tokens)进行链式思维视觉推理。MINT-CoT自适应地将相关视觉令牌插入文本推理步骤中,通过动态选择数学图形内的视觉区域来增强这种能力。此外,构建了MINT-CoT数据集和采用三阶段训练策略,最终推出MINT-CoT-7B模型。实验表明,该模型在MathVista、GeoQA和MMStar上的表现均优于基线模型。详细信息可通过链接查看:https://github.com/xinyan-cxy/MINT-CoT。简洁理解即为本文主要提出了一种创新的视觉化推理技术方法以及对应的数据集与模型优化训练策略等以优化对数学推理能力的提升与应用落地性并实际取得超越其他现有方案的优秀效果总结摘要内容为提高多模态领域内的数学推理能力研究现状及所面临的困难点挑战据此展开深入研究从而引出所创新性地提出MINT结合实体理论分析说明了创新方案的显著优势总结方法以及其性能特点及应用推广信息明确具体的行业意义应用潜力和市场前景为该领域的持续发展与提升提供了一种创新性和实践性的技术方法关键特点在于将视觉推理与数学推理紧密结合实现了更高效更准确的数学问题解决能力概括简洁准确突出主题及亮点无冗余内容Key Takeaways:
- MINT-CoT解决了将链式思维(CoT)扩展到多模态领域的挑战。现有方法面临依赖于粗粒度图像区域、缺乏深度感知数学内容等限制。
- MINT-CoT引入数学交错令牌,实现自适应地将视觉信息与文本推理结合,提升数学问题的感知和解决方案准确性。
点此查看论文截图

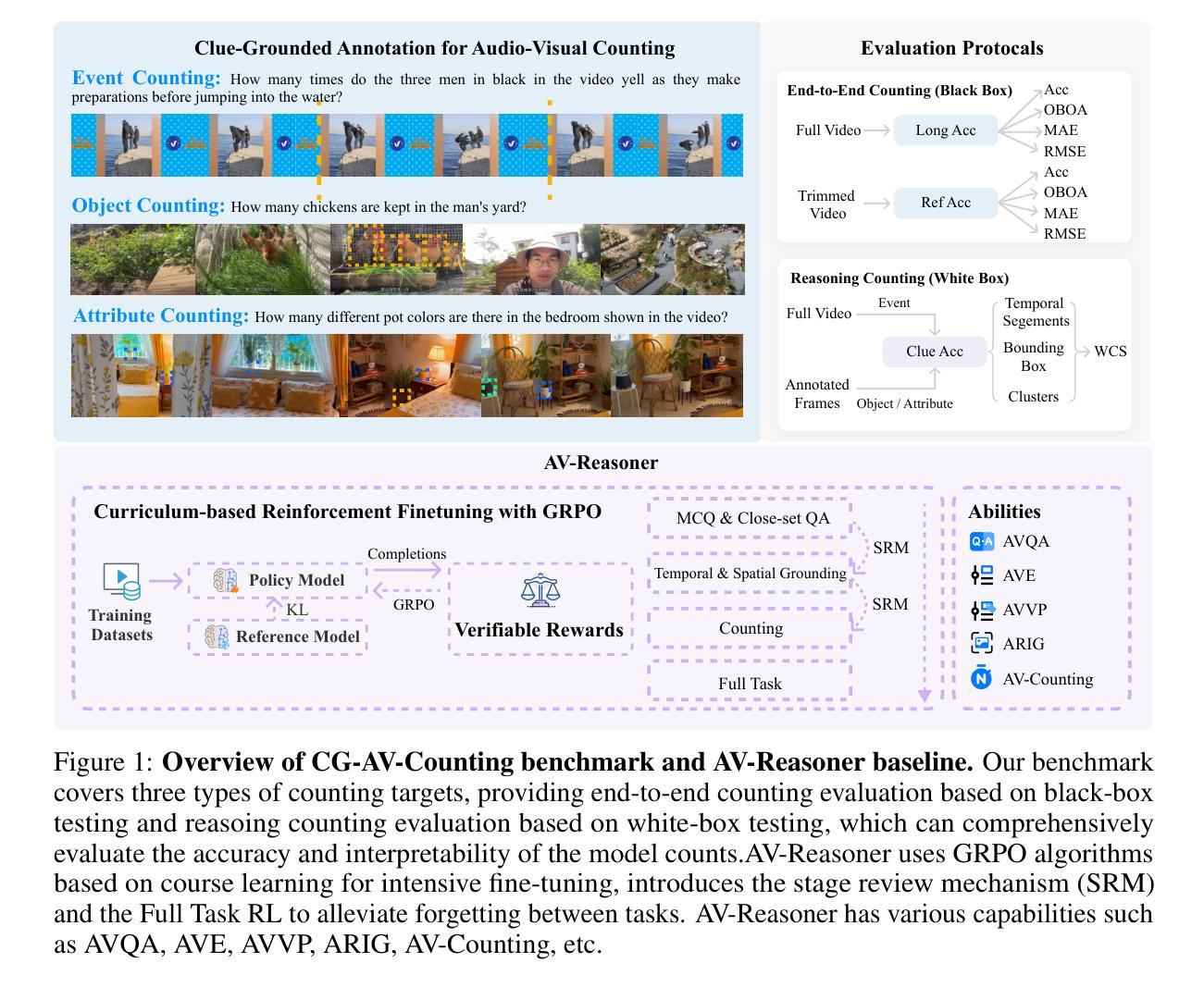
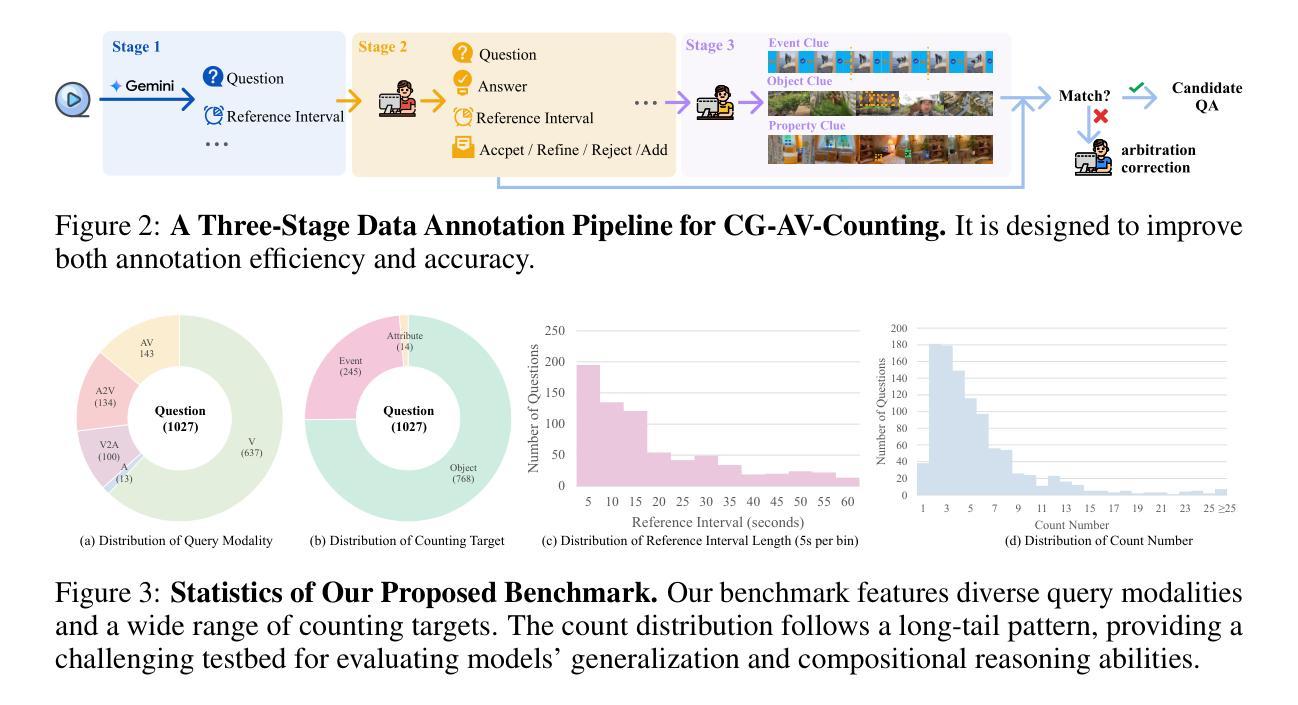
AV-Reasoner: Improving and Benchmarking Clue-Grounded Audio-Visual Counting for MLLMs
Authors:Lidong Lu, Guo Chen, Zhiqi Li, Yicheng Liu, Tong Lu
Despite progress in video understanding, current MLLMs struggle with counting tasks. Existing benchmarks are limited by short videos, close-set queries, lack of clue annotations, and weak multimodal coverage. In this paper, we introduce CG-AV-Counting, a manually-annotated clue-grounded counting benchmark with 1,027 multimodal questions and 5,845 annotated clues over 497 long videos. It supports both black-box and white-box evaluation, serving as a comprehensive testbed for both end-to-end and reasoning-based counting. To explore ways to improve model’s counting capability, we propose AV-Reasoner, a model trained with GRPO and curriculum learning to generalize counting ability from related tasks. AV-Reasoner achieves state-of-the-art results across multiple benchmarks, demonstrating the effectiveness of reinforcement learning. However, experiments show that on out-of-domain benchmarks, reasoning in the language space fails to bring performance gains. The code and benchmark have been realeased on https://av-reasoner.github.io.
尽管视频理解领域已经取得了一定的进展,但当前的多媒体大型语言模型(MLLMs)在计数任务上仍然面临挑战。现有的基准测试受限于短视频、限定查询范围、缺乏线索标注和弱多模式覆盖。在本文中,我们介绍了CG-AV-Counting,这是一个手动标注的基于线索的计数基准测试,包含1027个多模式问题和5845个标注线索,涵盖497个长视频。它支持黑箱和白箱评估,是端到端和基于推理的计数的综合测试平台。为了探索提高模型计数能力的方法,我们提出了AV-Reasoner,这是一个通过GRPO和课程学习进行训练的模型,能够从相关任务中推广计数能力。AV-Reasoner在多个基准测试上取得了最新结果,证明了强化学习的有效性。然而,实验表明,在域外基准测试上,语言空间中的推理无法带来性能提升。相关代码和基准测试已在https://av-reasoner.github.io发布。
论文及项目相关链接
PDF 21 pages, 11 figures
Summary
本文介绍了视频理解领域的挑战,当前的多模态语言模型在处理计数任务时存在困难。为解决此问题,文章提出了CG-AV-Counting基准测试,包含1,027个多模态问题和5,845个针对497个长视频的注释线索。此外,为提升模型的计数能力,文章还提出了AV-Reasoner模型,通过通用区域优先(GRPO)和课程学习进行训练,具备从相关任务中泛化计数的能力。然而,实验表明,在域外基准测试中,语言空间的推理并未带来性能提升。
Key Takeaways
- 当前多模态语言模型在视频理解领域的计数任务上仍有困难。
- CG-AV-Counting基准测试被引入,包含大量手动注释的线索,支持黑箱和白箱评估,是端到端和推理计数方法的综合测试平台。
- AV-Reasoner模型通过通用区域优先(GRPO)和课程学习进行训练,具有泛化计数能力,并在多个基准测试中达到最佳效果。
- 强化学习在提升模型计数能力上展现出有效性。
- 在域外基准测试中,语言空间推理并未带来性能提升。
- 代码和基准测试已在https://av-reasoner.github.io上发布。
- 现有视频计数任务面临的挑战包括短视频、限定查询、缺乏线索注释和弱多模态覆盖等问题。
点此查看论文截图


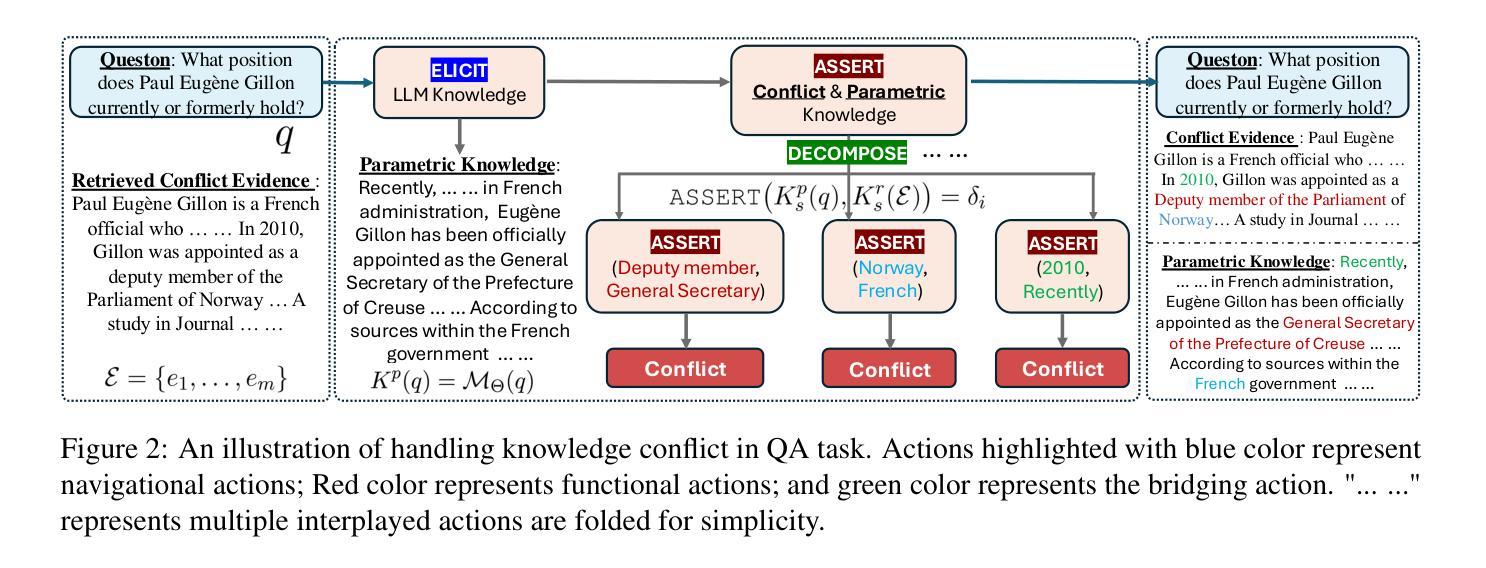
Micro-Act: Mitigate Knowledge Conflict in Question Answering via Actionable Self-Reasoning
Authors:Nan Huo, Jinyang Li, Bowen Qin, Ge Qu, Xiaolong Li, Xiaodong Li, Chenhao Ma, Reynold Cheng
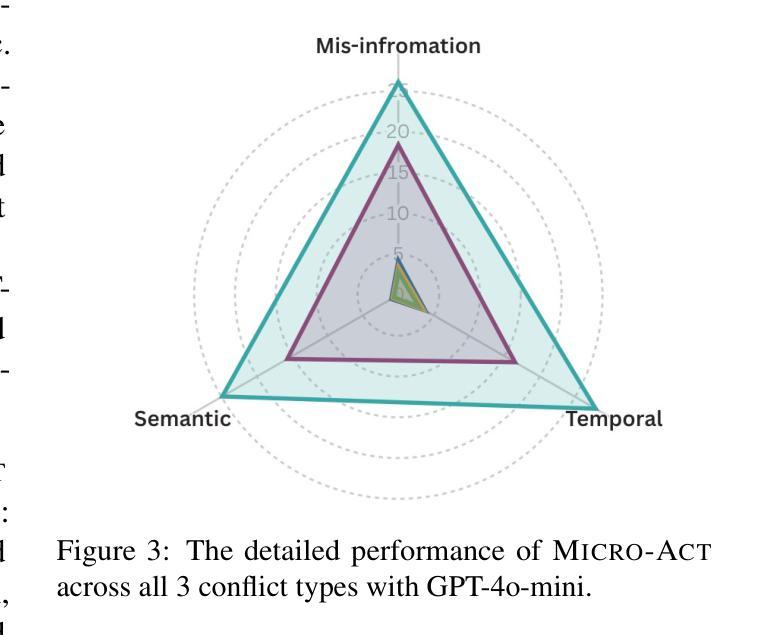
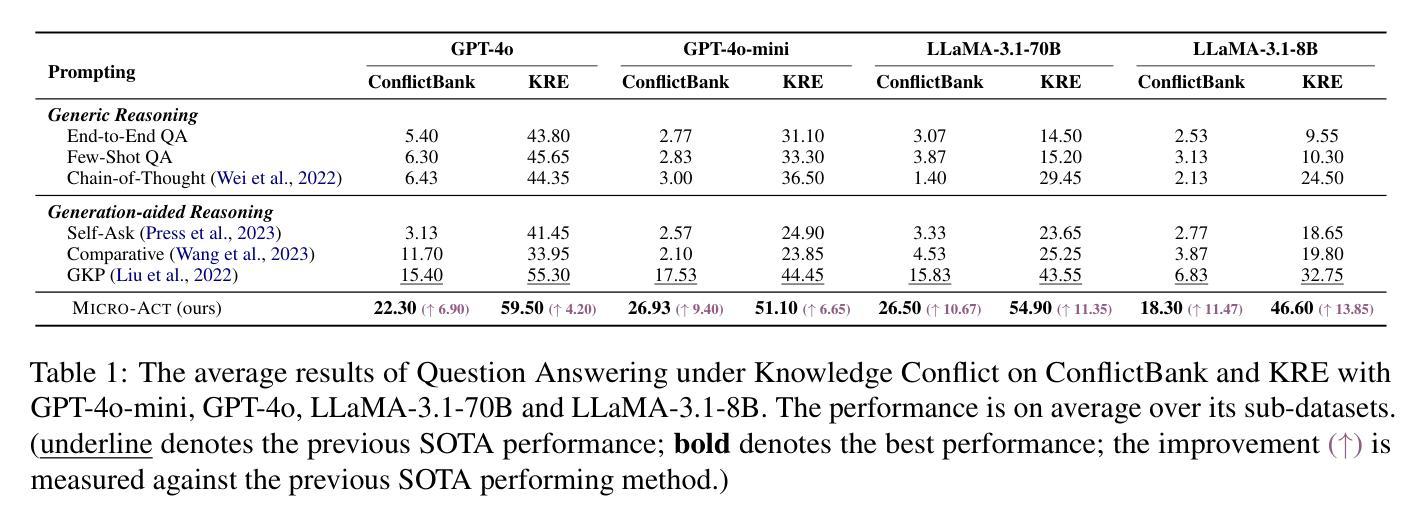
Retrieval-Augmented Generation (RAG) systems commonly suffer from Knowledge Conflicts, where retrieved external knowledge contradicts the inherent, parametric knowledge of large language models (LLMs). It adversely affects performance on downstream tasks such as question answering (QA). Existing approaches often attempt to mitigate conflicts by directly comparing two knowledge sources in a side-by-side manner, but this can overwhelm LLMs with extraneous or lengthy contexts, ultimately hindering their ability to identify and mitigate inconsistencies. To address this issue, we propose Micro-Act a framework with a hierarchical action space that automatically perceives context complexity and adaptively decomposes each knowledge source into a sequence of fine-grained comparisons. These comparisons are represented as actionable steps, enabling reasoning beyond the superficial context. Through extensive experiments on five benchmark datasets, Micro-Act consistently achieves significant increase in QA accuracy over state-of-the-art baselines across all 5 datasets and 3 conflict types, especially in temporal and semantic types where all baselines fail significantly. More importantly, Micro-Act exhibits robust performance on non-conflict questions simultaneously, highlighting its practical value in real-world RAG applications.
检索增强生成(RAG)系统通常面临知识冲突问题,其中检索到的外部知识与大语言模型(LLM)的固有参数知识相矛盾。这对问答等下游任务性能产生不利影响。现有方法往往通过并排比较两种知识源来减轻冲突,但这可能使LLM面临过多或冗长的上下文,最终阻碍其识别和缓解不一致的能力。为了解决这一问题,我们提出了Micro-Act框架,它具有分层动作空间,可自动感知上下文复杂性,并自适应地将每个知识源分解为一系列精细的比较。这些比较表现为可操作的步骤,使推理超越表层上下文。通过在五个基准数据集上进行广泛实验,Micro-Act在所有五个数据集和三种冲突类型上始终实现了问答准确度的显著提高,尤其在时间和语义类型方面,所有基线都出现了显著失败。更重要的是,Micro-Act在非冲突问题上也表现出稳健的性能,这突出了其在现实世界RAG应用中的实用价值。
论文及项目相关链接
PDF Accepted by ACL 2025 Main
Summary
本文探讨了Retrieval-Augmented Generation(RAG)系统中常见的知识冲突问题,即检索的外部知识与大型语言模型(LLM)的固有参数知识之间的矛盾。该问题对问答等下游任务性能产生负面影响。现有方法常常通过并排比较两种知识源来减轻冲突,但这可能使LLM面临过多复杂或冗长的语境,从而难以识别和缓解不一致性。为解决此问题,本文提出Micro-Act框架,该框架具有层次化的动作空间,能够自动感知语境复杂性,并自适应地将每个知识源分解成一系列精细的比较。这些比较表现为可操作的步骤,使推理超越了肤浅语境。在五个基准数据集上的广泛实验表明,Micro-Act在所有数据集和三种冲突类型上均实现了对最新基准线的问答准确度显著提高,特别是在时间和语义类型的冲突上。更重要的是,Micro-Act在非冲突问题上也表现出稳健的性能,凸显其在现实RAG应用中的实用价值。
Key Takeaways
- RAG系统面临知识冲突问题,即外部检索知识与LLM固有知识之间的矛盾。
- 知识冲突对下游任务如问答的性能产生负面影响。
- 现有方法通过并排比较知识源来减轻冲突,但可能使LLM面临复杂或冗长的语境。
- Micro-Act框架具有层次化的动作空间,能自动感知语境复杂性并分解知识源。
- Micro-Act通过精细的比较和可操作的步骤进行推理,超越肤浅语境。
- Micro-Act在多个数据集和多种冲突类型上实现了对最新方法的显著性能提升。
点此查看论文截图


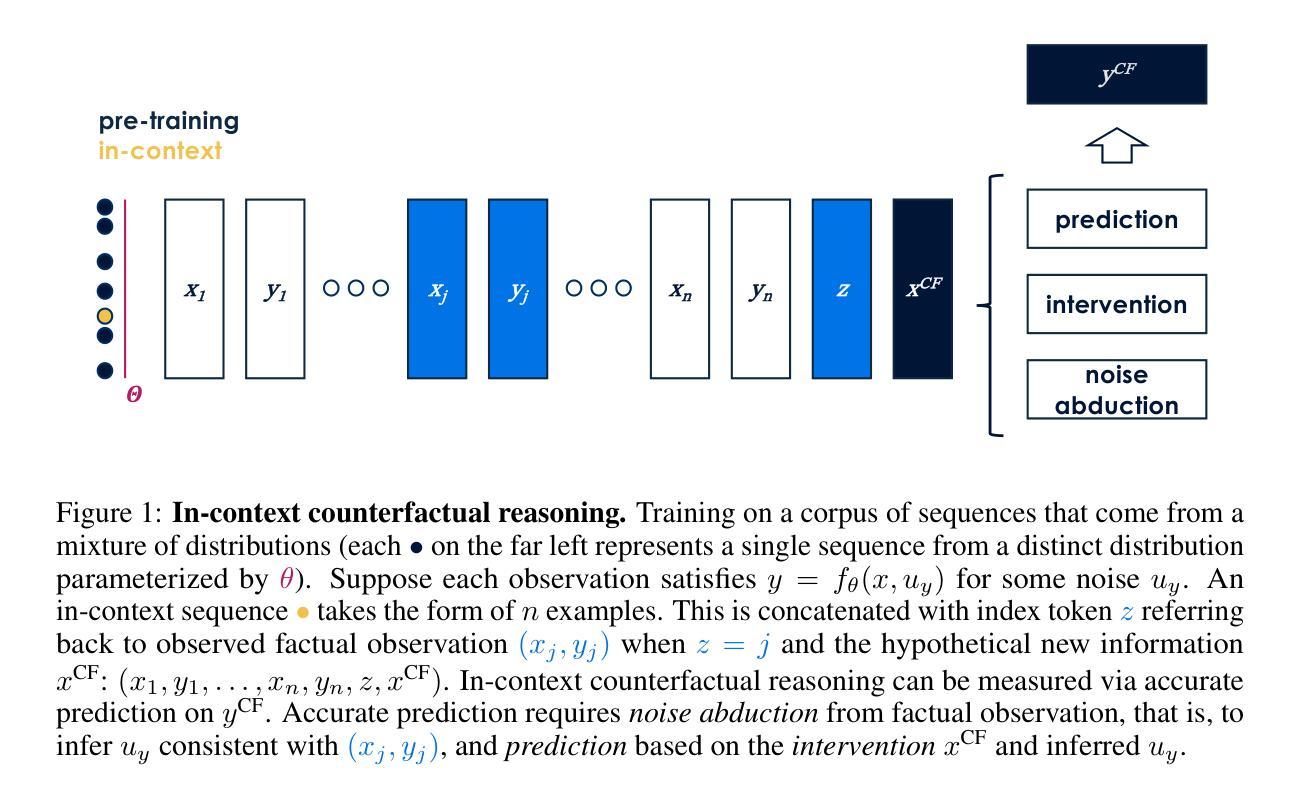
Counterfactual reasoning: an analysis of in-context emergence
Authors:Moritz Miller, Bernhard Schölkopf, Siyuan Guo
Large-scale neural language models (LMs) exhibit remarkable performance in in-context learning: the ability to learn and reason the input context on the fly without parameter update. This work studies in-context counterfactual reasoning in language models, that is, to predict the consequences of changes under hypothetical scenarios. We focus on studying a well-defined synthetic setup: a linear regression task that requires noise abduction, where accurate prediction is based on inferring and copying the contextual noise from factual observations. We show that language models are capable of counterfactual reasoning in this controlled setup and provide insights that counterfactual reasoning for a broad class of functions can be reduced to a transformation on in-context observations; we find self-attention, model depth, and data diversity in pre-training drive performance in Transformers. More interestingly, our findings extend beyond regression tasks and show that Transformers can perform noise abduction on sequential data, providing preliminary evidence on the potential for counterfactual story generation. Our code is available under https://github.com/moXmiller/counterfactual-reasoning.git .
大规模神经网络语言模型(LMs)在上下文学习方面表现出卓越的性能:能够在不更新参数的情况下,即时学习和推理输入上下文。本研究关注语言模型中的上下文反事实推理,即预测假设场景变化后的结果。我们专注于研究一个定义明确的合成设置:需要进行噪声推断的线性回归任务,准确预测基于从实际观察中推断和复制上下文噪声。我们证明语言模型能够在这种受控设置中进行反事实推理,并提供见解,即一类广泛的函数的反事实推理可以归结为对上下文观察的转换;我们发现自注意力、模型深度以及预训练中的数据多样性是驱动Transformer性能的关键因素。更有趣的是,我们的研究结果超越了回归任务,表明Transformer可以对顺序数据进行噪声推断,为潜在的反事实故事生成提供了初步证据。我们的代码可在https://github.com/moXmiller/counterfactual-reasoning.git找到。
论文及项目相关链接
Summary
大规模神经网络语言模型展现出强大的上下文学习能力,即无需更新参数就能在语境中即时学习和推理。本研究探讨语言模型中的上下文反事实推理,即预测假设场景变化后的结果。研究重点是一个明确的合成设置:需要进行噪声推断的线性回归任务,准确预测基于从实际观察中推断和复制上下文噪声。研究发现语言模型能够在这种控制设置中进行反事实推理,并提供见解,即反事实推理可以简化为对上下文观察的转换;我们发现自注意力、模型深度和预训练数据多样性是推动变压器性能的关键。更有趣的是,我们的研究结果超出了回归任务的范围,显示变压器可以在序列数据上进行噪声推断,为反事实故事生成的潜力提供了初步证据。
Key Takeaways
- 大规模神经网络语言模型展现出强大的上下文学习能力。
- 语言模型具备反事实推理能力,在控制环境下可进行预测。
- 反事实推理可简化为对上下文观察的转换。
- 自注意力、模型深度和预训练数据多样性对变压器性能至关重要。
- 语言模型不仅能在回归任务中进行噪声推断,还能在序列数据上进行。
- 研究为反事实故事生成的潜力提供了初步证据。
点此查看论文截图

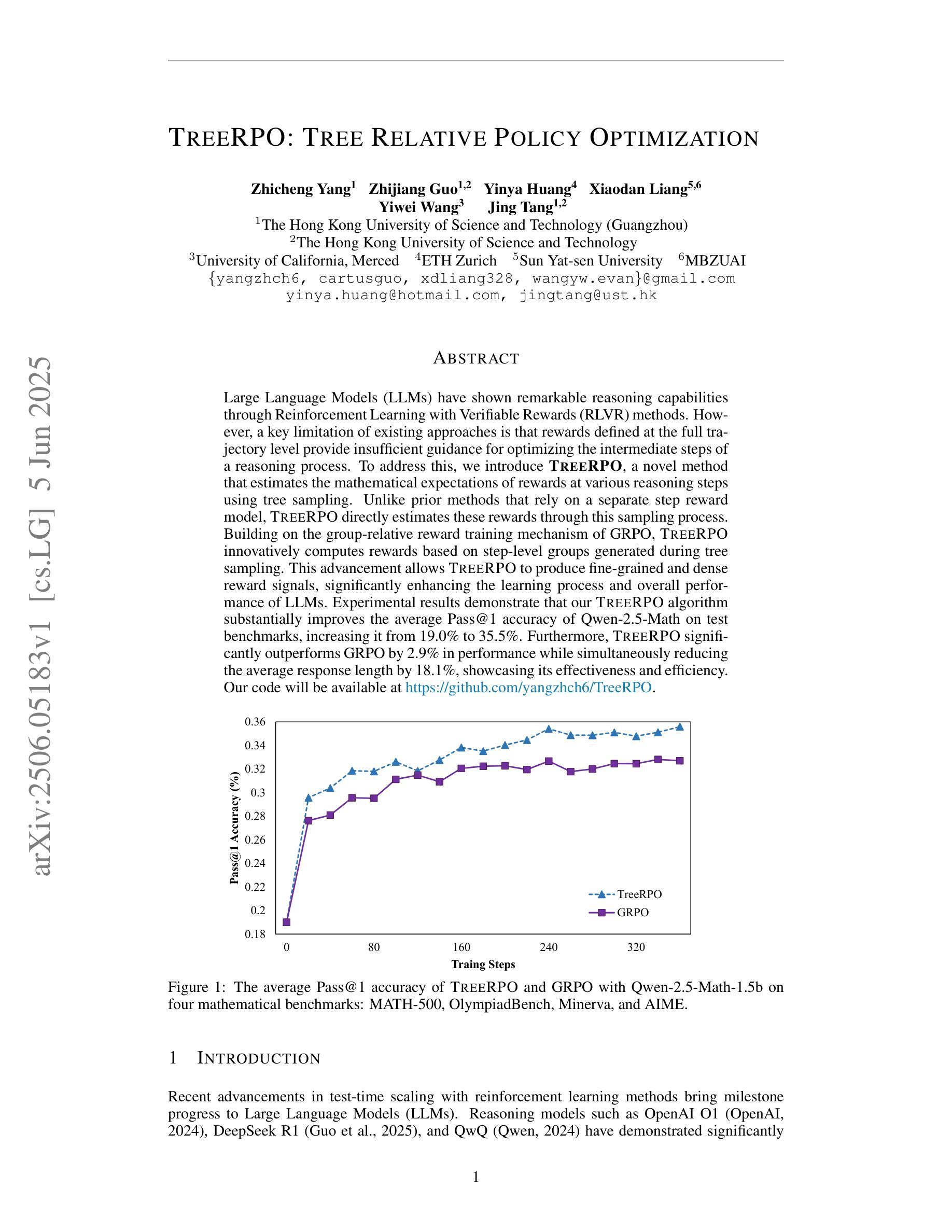
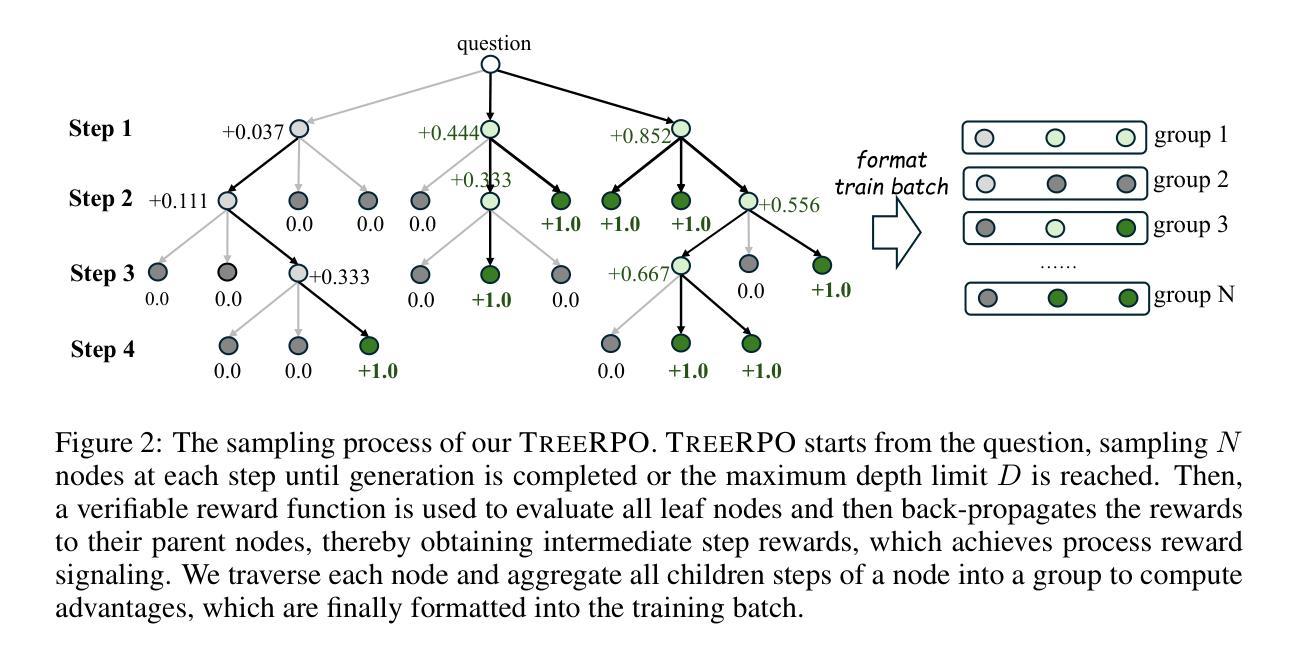
TreeRPO: Tree Relative Policy Optimization
Authors:Zhicheng Yang, Zhijiang Guo, Yinya Huang, Xiaodan Liang, Yiwei Wang, Jing Tang
Large Language Models (LLMs) have shown remarkable reasoning capabilities through Reinforcement Learning with Verifiable Rewards (RLVR) methods. However, a key limitation of existing approaches is that rewards defined at the full trajectory level provide insufficient guidance for optimizing the intermediate steps of a reasoning process. To address this, we introduce \textbf{\name}, a novel method that estimates the mathematical expectations of rewards at various reasoning steps using tree sampling. Unlike prior methods that rely on a separate step reward model, \name directly estimates these rewards through this sampling process. Building on the group-relative reward training mechanism of GRPO, \name innovatively computes rewards based on step-level groups generated during tree sampling. This advancement allows \name to produce fine-grained and dense reward signals, significantly enhancing the learning process and overall performance of LLMs. Experimental results demonstrate that our \name algorithm substantially improves the average Pass@1 accuracy of Qwen-2.5-Math on test benchmarks, increasing it from 19.0% to 35.5%. Furthermore, \name significantly outperforms GRPO by 2.9% in performance while simultaneously reducing the average response length by 18.1%, showcasing its effectiveness and efficiency. Our code will be available at \href{https://github.com/yangzhch6/TreeRPO}{https://github.com/yangzhch6/TreeRPO}.
大型语言模型(LLM)通过强化学习与可验证奖励(RLVR)方法显示出卓越的推理能力。然而,现有方法的关键局限性在于,在完整轨迹层面定义的奖励无法为推理过程中优化中间步骤提供足够的指导。为了解决这一问题,我们引入了一种新方法——树采样期望奖励算法(暂且称为XX算法)。该算法通过树采样估计不同推理步骤的奖励的数学期望。不同于以往依赖于单独步骤奖励模型的方法,XX算法通过采样过程直接估计这些奖励。基于相对奖励训练机制的GRPO算法,XX算法创新地根据树采样过程中产生的步骤级别组计算奖励。这一进展使得XX算法能够产生精细且密集的奖励信号,从而极大地提高了学习过程和LLM的整体性能。实验结果表明,我们的XX算法在测试基准上显著提高了Qwen-2.5-Math的平均Pass@1准确率,从19.0%提高到35.5%。此外,XX算法在性能上比GRPO高出2.9%,同时平均响应长度减少了18.1%,显示了其有效性和效率。我们的代码将发布在:https://github.com/yangzhch6/TreeRPO。
论文及项目相关链接
PDF 13pages, 6 figures
Summary
基于强化学习与可验证奖励(RLVR)方法,大型语言模型(LLMs)展现出惊人的推理能力。然而,现有方法的一个关键局限是,在完整轨迹层面定义的奖励无法为优化推理过程的中间步骤提供足够指导。为解决这一问题,我们提出一种新方法\name,通过树采样估计推理步骤中不同奖励的数学期望。不同于依赖单独步骤奖励模型的先前方法,\name通过采样过程直接估计这些奖励。建立在相对奖励训练机制的GRPO基础上,\name根据树采样过程中产生的步骤级别组计算奖励。这一进展产生了精细且密集的奖励信号,显著增强了学习过程和LLMs的整体性能。实验结果表明,我们的\name算法在测试基准上大幅提高了Qwen-2.5-Math的平均Pass@1准确率,从19.0%提升至35.5%。此外,\name在性能上较GRPO高出2.9%,同时平均响应长度减少了18.1%,展现出其有效性和高效性。
Key Takeaways
- 大型语言模型(LLMs)通过强化学习与可验证奖励(RLVR)展现出强大的推理能力。
- 现有方法奖励定义在完整轨迹层面,缺乏对中间步骤优化的指导。
- \name方法通过树采样估计推理步骤中不同奖励的数学期望。
- \name直接通过采样过程估计奖励,不同于依赖单独步骤奖励模型的先前方法。
- \name建立在相对奖励训练机制的GRPO基础上,根据步骤级别组计算奖励。
- \name算法显著提高Qwen-2.5-Math的Pass@1准确率,从19.0%提升至35.5%。
- \name在性能上较GRPO有所提升,同时减少平均响应长度。
点此查看论文截图
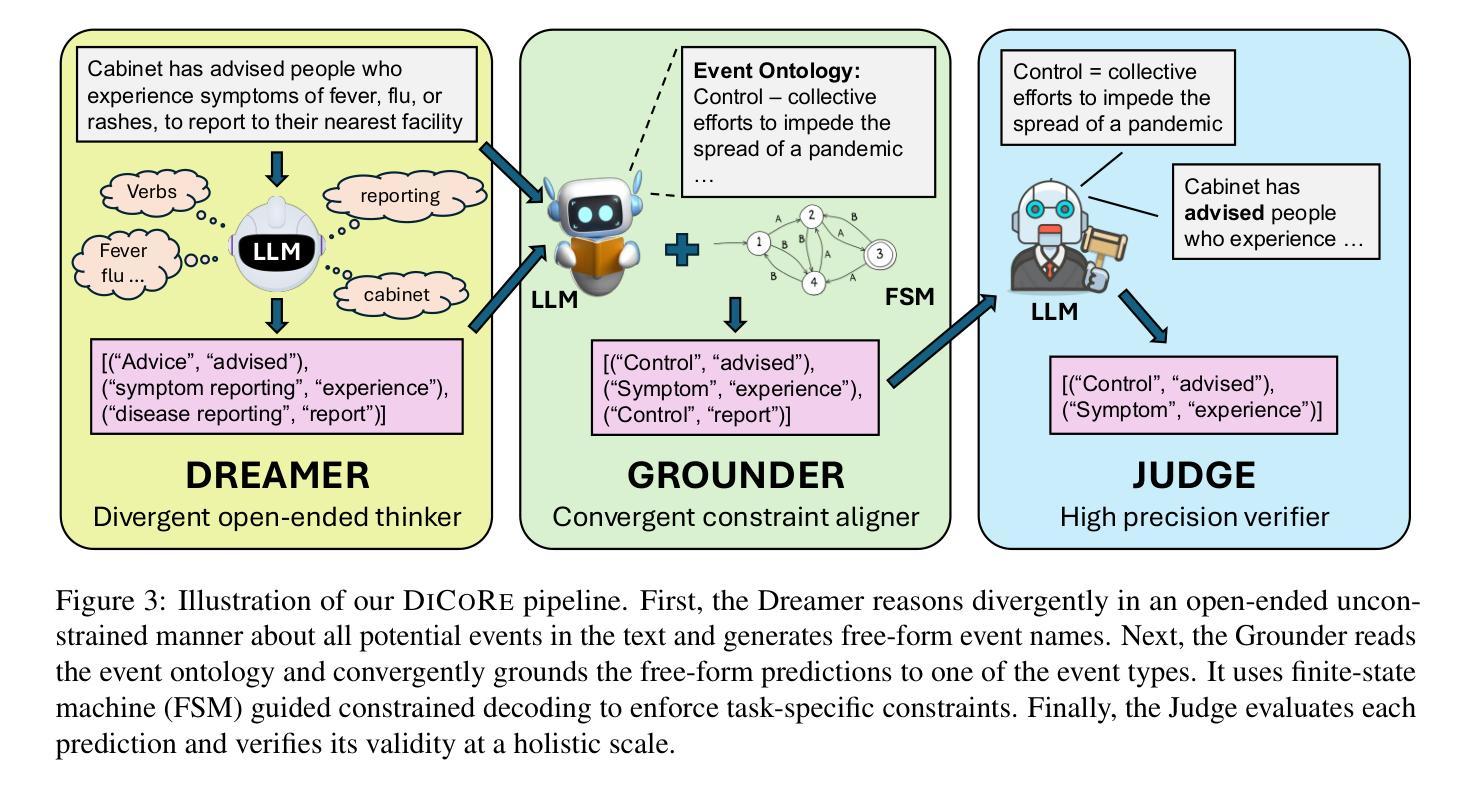
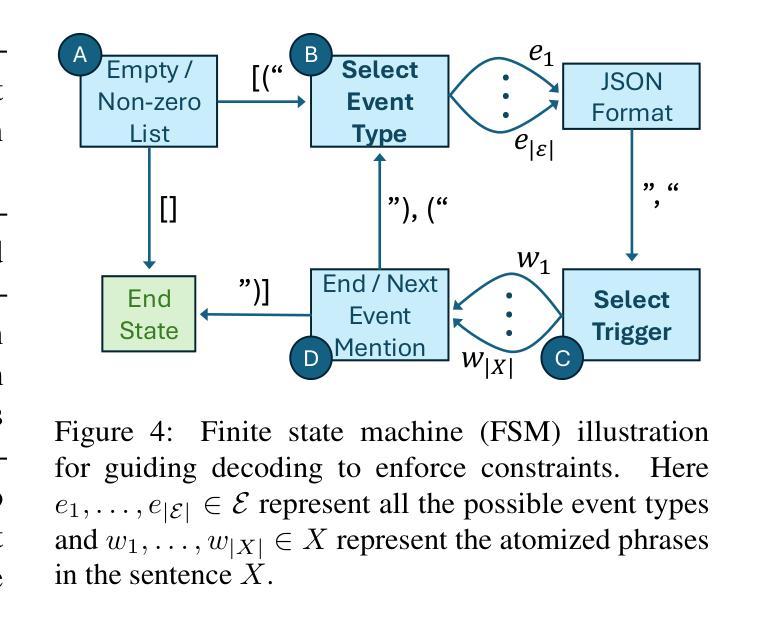
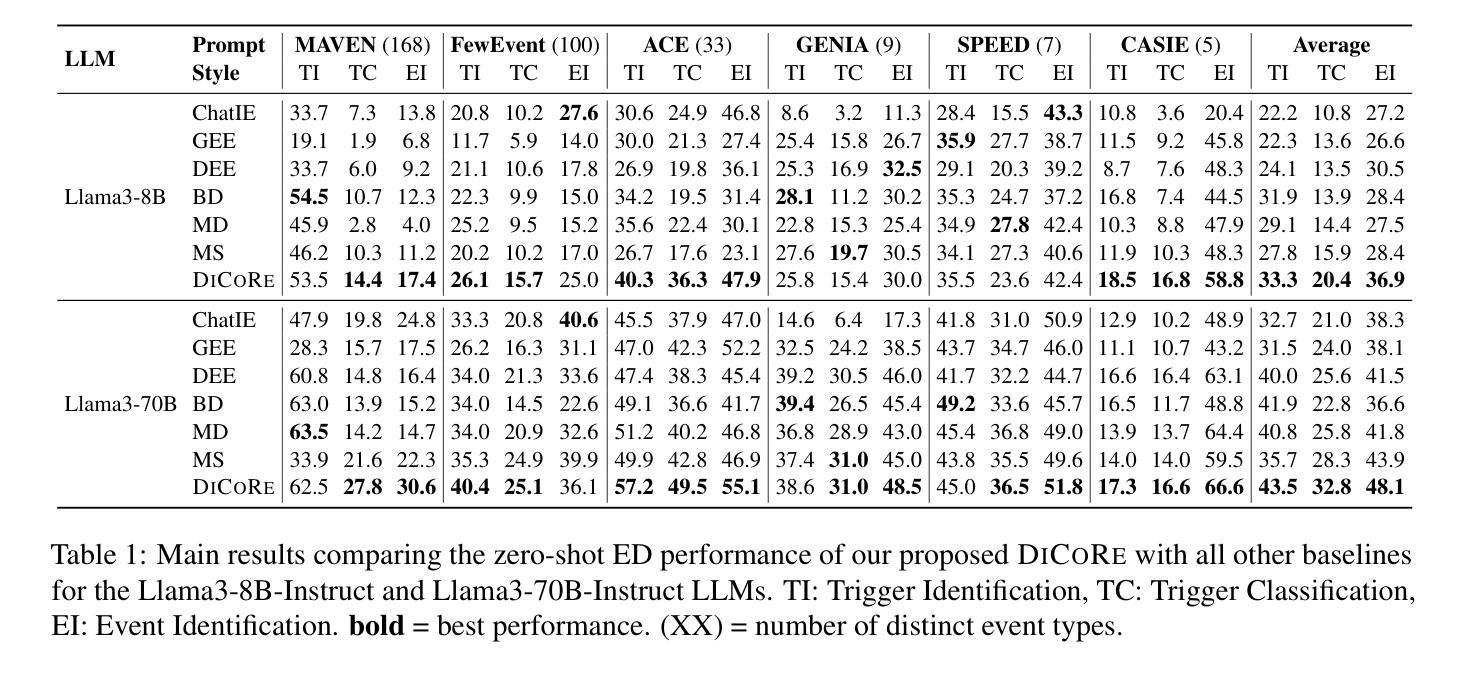
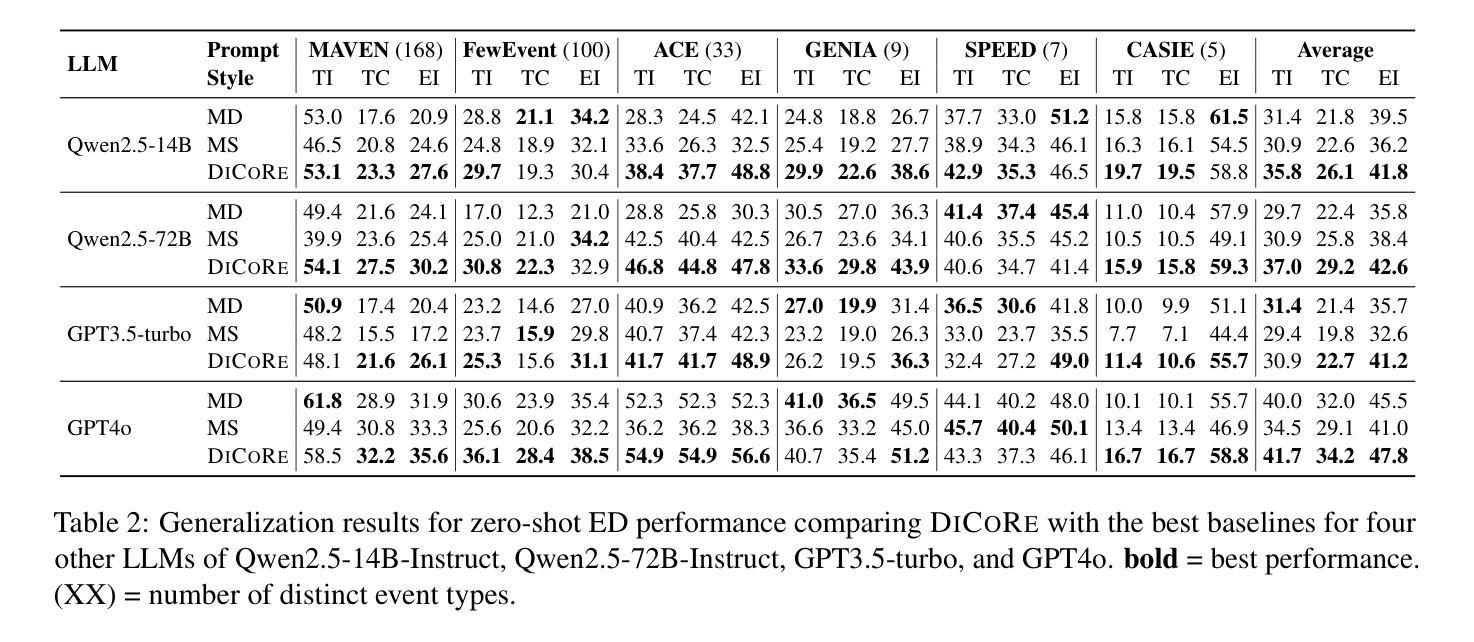
DiCoRe: Enhancing Zero-shot Event Detection via Divergent-Convergent LLM Reasoning
Authors:Tanmay Parekh, Kartik Mehta, Ninareh Mehrabi, Kai-Wei Chang, Nanyun Peng
Zero-shot Event Detection (ED), the task of identifying event mentions in natural language text without any training data, is critical for document understanding in specialized domains. Understanding the complex event ontology, extracting domain-specific triggers from the passage, and structuring them appropriately overloads and limits the utility of Large Language Models (LLMs) for zero-shot ED. To this end, we propose DiCoRe, a divergent-convergent reasoning framework that decouples the task of ED using Dreamer and Grounder. Dreamer encourages divergent reasoning through open-ended event discovery, which helps to boost event coverage. Conversely, Grounder introduces convergent reasoning to align the free-form predictions with the task-specific instructions using finite-state machine guided constrained decoding. Additionally, an LLM-Judge verifies the final outputs to ensure high precision. Through extensive experiments on six datasets across five domains and nine LLMs, we demonstrate how DiCoRe consistently outperforms prior zero-shot, transfer-learning, and reasoning baselines, achieving 4-7% average F1 gains over the best baseline – establishing DiCoRe as a strong zero-shot ED framework.
零事件检测(ED)是在没有任何训练数据的情况下,识别自然语言文本中的事件提及的任务,对于特定领域文档理解至关重要。理解复杂的事件本体论,从段落中提取特定领域的触发词,并适当地进行结构化设置,增加了零事件检测对于大型语言模型(LLM)的实用性和局限性。为此,我们提出了DiCoRe,一个发散收敛推理框架,它通过Dreamer和Grounder将事件检测任务解耦。Dreamer通过开放式事件发现鼓励发散推理,有助于提高事件覆盖率。相反,Grounder引入收敛推理,以有限状态机引导的有约束解码来使自由形式的预测与特定任务的指令对齐。此外,LLM-Judge验证最终输出以确保高精确度。通过对五个领域的六个数据集和九个LLM的广泛实验,我们证明了DiCoRe如何始终优于先前的零样本迁移学习和推理基准测试,在最佳基准测试上实现了平均F1得分4-7%的提升——确立了DiCoRe作为强大的零样本事件检测框架的地位。
论文及项目相关链接
PDF Submitted at ACL ARR May 2025
Summary
基于文本理解任务的需要,研究提出了零样本事件检测(ED)的重要性。然而,大型语言模型(LLM)在处理零样本事件检测时存在事件覆盖不足的问题。为此,本文提出了一种发散收敛推理框架DiCoRe,通过Dreamer进行发散推理实现开放式事件发现,并通过Grounder引入收敛推理将自由形式的预测与任务特定指令对齐。此外,LLM-Judge验证了最终输出结果的精确度。实验表明,DiCoRe框架在各种数据集和多个大型语言模型上均表现出优异的性能,平均F1得分比最佳基线高出4-7%,成为了强大的零样本事件检测框架。
Key Takeaways
- 零样本事件检测(ED)在特定领域文档理解中具有重要作用。
- 大型语言模型(LLM)在处理零样本事件检测时存在事件覆盖不足的问题。
- DiCoRe框架结合了发散推理和收敛推理来解决这一问题。
- Dreamer通过开放式事件发现鼓励发散推理。
- Grounder通过有限状态机引导约束解码来实现收敛推理。
- LLM-Judge验证最终输出的精确度以确保高精确度。
点此查看论文截图


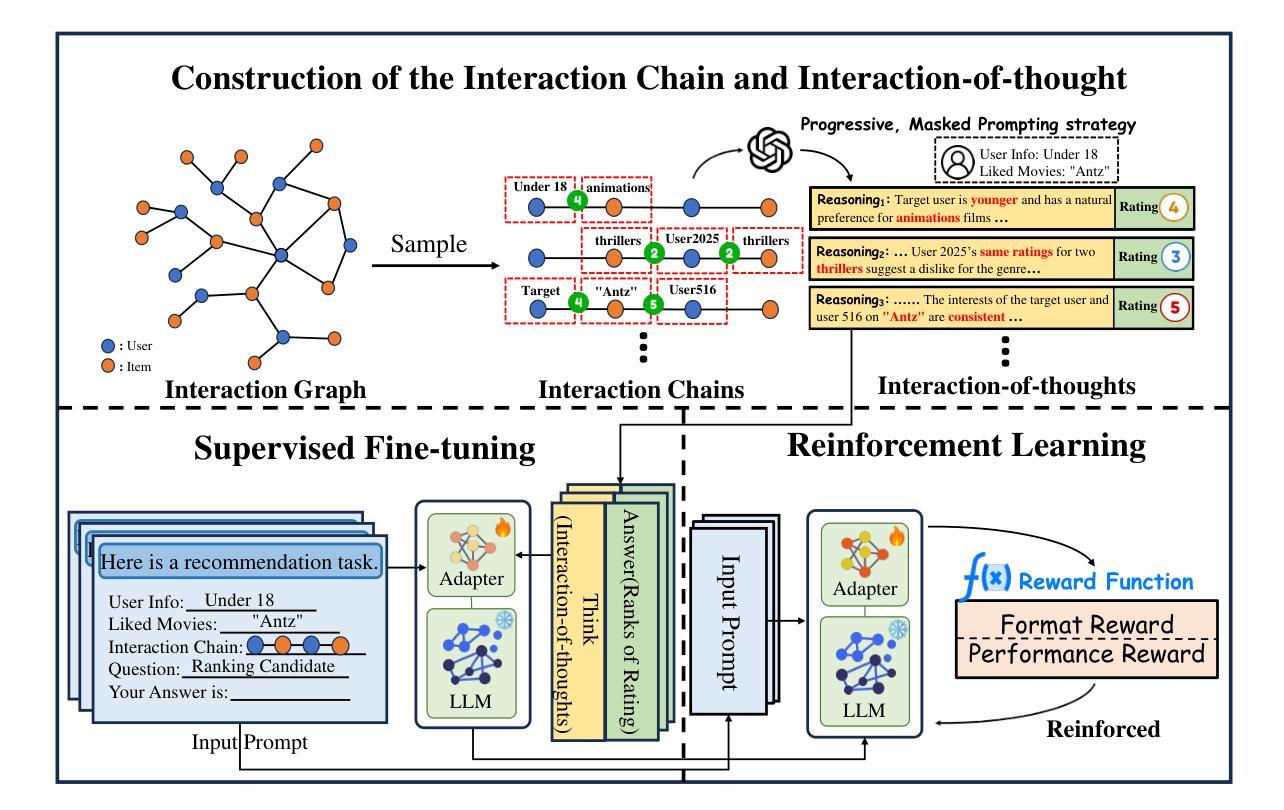
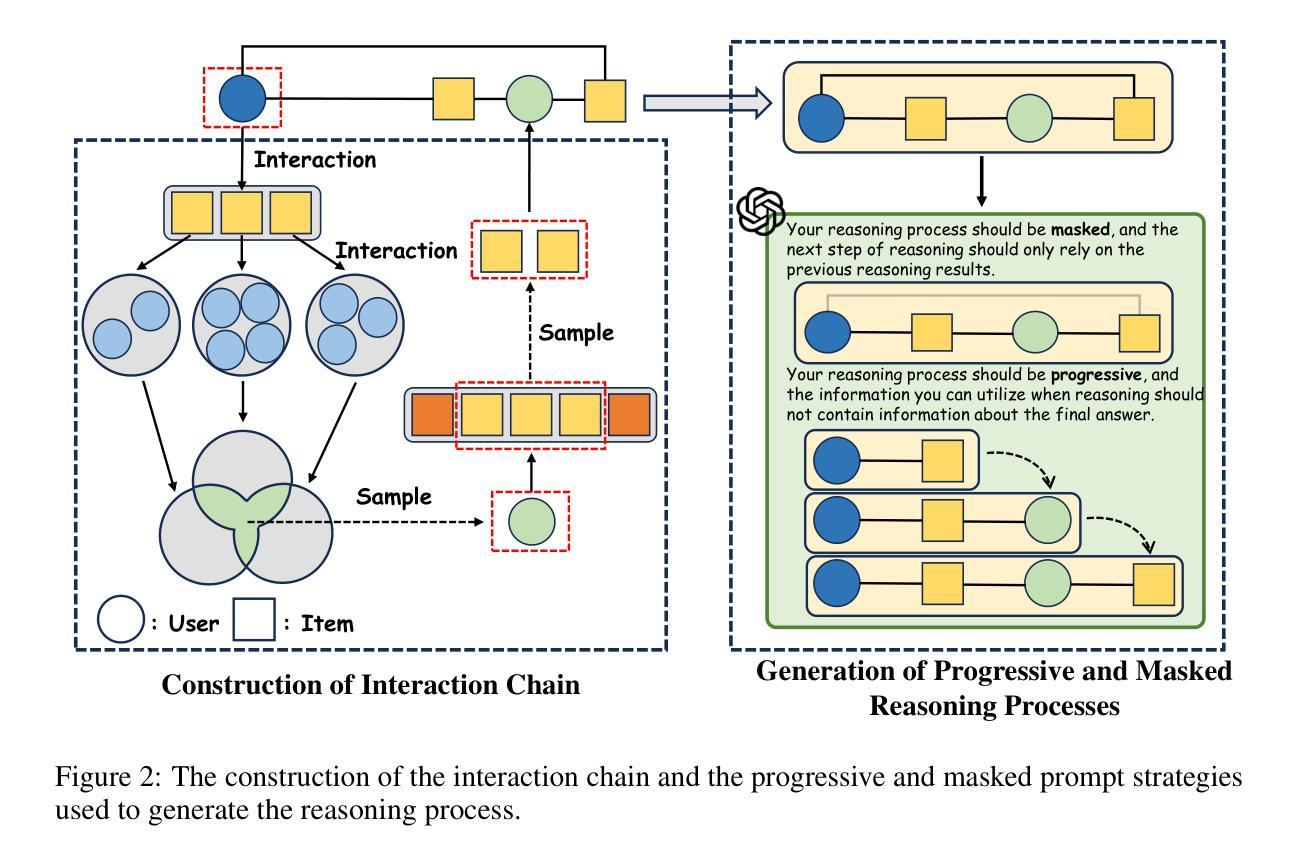
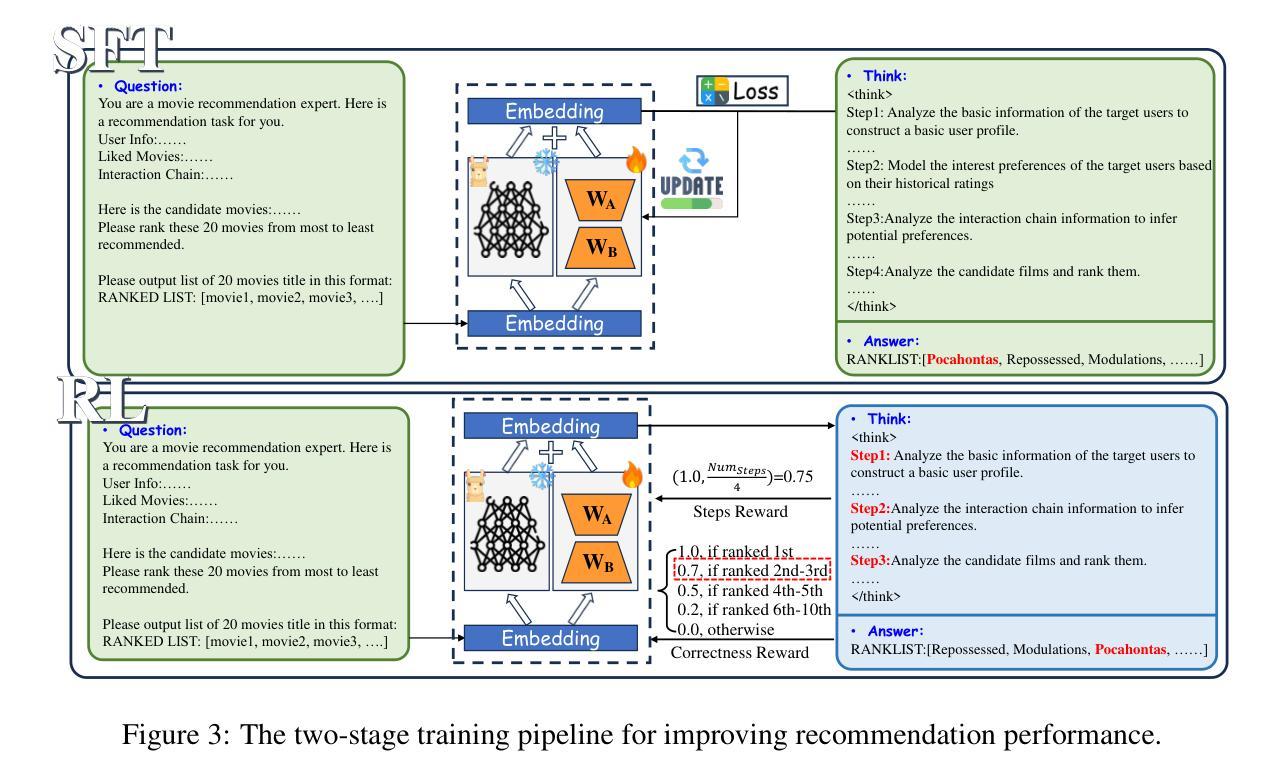
Reason-to-Recommend: Using Interaction-of-Thought Reasoning to Enhance LLM Recommendation
Authors:Keyu Zhao, Fengli Xu, Yong Li
Driven by advances in Large Language Models (LLMs), integrating them into recommendation tasks has gained interest due to their strong semantic understanding and prompt flexibility. Prior work encoded user-item interactions or metadata into prompts for recommendations. In parallel, LLM reasoning, boosted by test-time scaling and reinforcement learning, has excelled in fields like mathematics and code, where reasoning traces and correctness signals are clear, enabling high performance and interpretability. However, directly applying these reasoning methods to recommendation is ineffective because user feedback is implicit and lacks reasoning supervision. To address this, we propose $\textbf{R2Rec}$, a reasoning-enhanced recommendation framework that samples interaction chains from the user-item graph and converts them into structured interaction-of-thoughts via a progressive masked prompting strategy, with each thought representing stepwise reasoning grounded in interaction context. This allows LLMs to simulate step-by-step decision-making based on implicit patterns. We design a two-stage training pipeline: supervised fine-tuning teaches basic reasoning from high-quality traces, and reinforcement learning refines reasoning via reward signals, alleviating sparse explicit supervision. Experiments on three real-world datasets show R2Rec outperforms classical and LLM-based baselines with an average $\textbf{10.48%}$ improvement in HitRatio@1 and $\textbf{131.81%}$ gain over the original LLM. Furthermore, the explicit reasoning chains enhance interpretability by revealing the decision process. Our code is available at: https://anonymous.4open.science/r/R2Rec-7C5D.
随着大型语言模型(LLM)的进步,将其集成到推荐任务中已引起关注,因为它们具有强大的语义理解和提示灵活性。早期工作将用户-项目互动或元数据编码为推荐提示。与此同时,借助测试时缩放和强化学习,LLM推理在数学和代码等领域表现出色,这些领域的推理轨迹和正确性信号清晰可见,能够实现高性能和可解释性。然而,直接将这些推理方法应用于推荐是无效的,因为用户反馈是隐式的,缺乏推理监督。
论文及项目相关链接
摘要
随着大型语言模型(LLMs)的进展,将其整合到推荐任务中已引起关注。过去的工作将用户-项目互动或元数据编码到提示中以为推荐提供支持。同时,LLM推理在测试时通过比例尺调整和强化学习得到加强,在数学和代码等领域表现卓越,这些领域的推理痕迹和正确性信号清晰。然而,直接将这些推理方法应用于推荐是不有效的,因为用户反馈是隐式的,缺乏推理监督。为解决此问题,我们提出一种增强推理的推荐框架R2Rec,从用户-项目图中采样互动链,并通过渐进式遮罩提示策略将其转化为结构化思维。每个思维代表基于互动上下文的逐步推理。这允许LLMs模拟基于隐式模式的逐步决策。我们设计了一个两阶段训练流程:监督微调从高质量轨迹中学习基本推理,强化学习通过奖励信号优化推理,缓解稀疏的显式监督。在三个真实数据集上的实验表明,R2Rec在HitRatio@1指标上平均提高了10.48%,在原始LLM基础上提高了131.81%。此外,明确的推理链通过揭示决策过程增强了可解释性。我们的代码可在匿名链接找到。
关键见解
- 大型语言模型(LLMs)在推荐任务中的应用日益受到关注,因其强大的语义理解和提示灵活性。
- 用户反馈的隐式性和缺乏推理监督是直接将LLM应用于推荐的主要挑战。
- R2Rec框架旨在通过采样互动链并将其转化为结构化思维来增强推理,使LLMs能够模拟基于隐式模式的逐步决策过程。
- R2Rec采用两阶段训练流程,包括监督微调用于学习基本推理和强化学习以通过奖励信号优化推理。
- 实验表明R2Rec在多个真实数据集上的性能优于传统和LLM基线方法。
- R2Rec提高了推荐的解释性,通过揭示推理链显示决策过程。
点此查看论文截图

Mathematical Reasoning for Unmanned Aerial Vehicles: A RAG-Based Approach for Complex Arithmetic Reasoning
Authors:Mehdi Azarafza, Mojtaba Nayyeri, Faezeh Pasandideh, Steffen Staab, Achim Rettberg
Autonomous UAV operation necessitates reliable mathematical reasoning for tasks such as trajectory planning and power management. While traditional flight control relies on hardcoded equations, recent Large Language Models (LLMs) offer potential for more flexible problem-solving but struggle with reliably selecting and applying correct mathematical formulations and executing precise multi-step arithmetic. We propose RAG-UAV, a retrieval-augmented generation framework designed to improve the mathematical reasoning of several LLMs (including GPT o1/Turbo, Llama-3.2/3.3, Mistral, and DeepSeek R1) in UAV-specific contexts by providing access to relevant domain literature. To conduct an initial assessment, we introduce the UAV-Math-Bench, a small problem set comprising 20 UAV-centric mathematical problems across four difficulty levels. Our experiments demonstrate that incorporating retrieval substantially increases exact answer accuracy (achieving up to 75% with o1), reduces instances of incorrect formulation selection (from 25% without RAG to 5% with RAG), decreases numerical errors, reducing Mean Squared Error (MSE) by orders of magnitude for the best-performing models. This pilot study indicates that RAG can enable general-purpose LLMs to function as more reliable tools for engineering analysis, although direct real-time flight control requires further investigation and validation on a larger scale. All benchmark data, question and answer are publicly available.
自主无人机的操作需要进行可靠的数学推理,以完成轨迹规划和电源管理等任务。虽然传统的飞行控制依赖于硬编码的方程,但最近的大型语言模型(LLM)为更灵活的解决问题提供了潜力,但在可靠选择和应用正确的数学公式以及执行精确的多步骤算术方面仍存在困难。我们提出了RAG-UAV,这是一个增强检索生成的框架,旨在通过提供相关的领域文献,提高多种LLM(包括GPT o1/Turbo、Llama 3.2/3.3、Mistral和DeepSeek R1)在无人机特定上下文中的数学推理能力。为了进行初步评估,我们推出了UAV-Math-Bench,这是一组包含20个以无人机为中心的数学问题的小问题集,分为四个难度级别。我们的实验表明,加入检索功能可以显著提高精确答案的准确性(在o1的情况下达到了75%),减少了错误公式选择的情况(从没有RAG时的25%减少到使用RAG时的5%),减少了数值错误,对于表现最佳的模型,均方误差(MSE)降低了多个数量级。这项初步研究表明,RAG可以使通用LLM更加可靠地用于工程分析,但直接的实时飞行控制需要进一步的大规模研究和验证。所有基准数据、问题和答案都是公开可用的。
论文及项目相关链接
PDF 15 pages, 7 figures, 4 appendix subsections
Summary
本文章探讨了自主无人机操作对数学推理的可靠性需求,并指出了传统飞行控制方法与现代大型语言模型(LLM)之间的差异。文章介绍了一个名为RAG-UAV的框架,该框架通过提供相关领域文献的检索,旨在提高LLM在数学推理方面的能力。为初步评估该框架的效果,文章还设计了一个包含20个无人机中心数学问题的UAV-Math-Bench问题集。实验结果表明,结合检索技术可以显著提高精确答案的准确性,减少错误的公式选择,降低数值误差。尽管还需要在更大规模上进行进一步的研究和验证,但这项初步研究结果表明,RAG可以使通用LLM更可靠地用于工程分析。
Key Takeaways
- 自主无人机操作需要可靠的数学推理来完成任务,如轨迹规划和电源管理。
- 传统飞行控制依赖硬编码方程,而大型语言模型(LLM)提供更为灵活的解决方案。
- LLM在选择和应用正确的数学公式以及执行精确的多步算术运算方面存在挑战。
- RAG-UAV框架旨在通过提供相关领域文献的检索,提高LLM在数学推理方面的能力。
- UAV-Math-Bench问题集用于初步评估RAG-UAV的效果,包含20个难度不同的无人机中心数学问题。
- 结合检索技术可以显著提高精确答案的准确性,减少错误的公式选择和数值误差。
点此查看论文截图


From Objects to Anywhere: A Holistic Benchmark for Multi-level Visual Grounding in 3D Scenes
Authors:Tianxu Wang, Zhuofan Zhang, Ziyu Zhu, Yue Fan, Jing Xiong, Pengxiang Li, Xiaojian Ma, Qing Li
3D visual grounding has made notable progress in localizing objects within complex 3D scenes. However, grounding referring expressions beyond objects in 3D scenes remains unexplored. In this paper, we introduce Anywhere3D-Bench, a holistic 3D visual grounding benchmark consisting of 2,632 referring expression-3D bounding box pairs spanning four different grounding levels: human-activity areas, unoccupied space beyond objects, objects in the scene, and fine-grained object parts. We assess a range of state-of-the-art 3D visual grounding methods alongside large language models (LLMs) and multimodal LLMs (MLLMs) on Anywhere3D-Bench. Experimental results reveal that space-level and part-level visual grounding pose the greatest challenges: space-level tasks require a more comprehensive spatial reasoning ability, for example, modeling distances and spatial relations within 3D space, while part-level tasks demand fine-grained perception of object composition. Even the best performance model, OpenAI o4-mini, achieves only 23.57% accuracy on space-level tasks and 33.94% on part-level tasks, significantly lower than its performance on area-level and object-level tasks. These findings underscore a critical gap in current models’ capacity to understand and reason about 3D scene beyond object-level semantics.
在复杂的3D场景中定位物体方面,3D视觉定位已经取得了显著的进展。然而,在3D场景中定位对象之外的参照表达仍然未被探索。本文中,我们介绍了Anywhere3D-Bench,这是一个全面的3D视觉定位基准测试,包含2632个参照表达-3D边界框对,跨越四个不同的定位级别:人类活动区域、对象之外的未占用空间、场景中的对象以及精细粒度的对象部分。我们在Anywhere3D-Bench上评估了一系列最先进的3D视觉定位方法,以及与大型语言模型(LLMs)和多模态LLMs(MLLMs)的结合。实验结果表明,空间级别和部件级别的视觉定位构成了最大的挑战:空间级别的任务需要更全面的空间推理能力,例如建模距离和三维空间内的空间关系,而部件级别的任务则要求对对象组成进行精细的感知。即使是表现最佳的模型OpenAI o4-mini在空间级别任务上的准确率也只有23.57%,在部件级别任务上的准确率为33.94%,远低于其在区域级别和对象级别任务上的表现。这些发现强调了当前模型在理解和推理超出对象级别语义的3D场景方面的能力上存在关键差距。
论文及项目相关链接
Summary
在复杂的三维场景中定位物体,三维视觉定位技术已经取得了显著进展。然而,本文介绍了一项全新的挑战——超越物体层面的三维场景参照表达定位。我们推出了Anywhere3D-Bench基准测试平台,包含2632个参照表达与三维边界框配对,覆盖四个不同的定位级别。评估结果指出,空间级别和部件级别的视觉定位最具挑战性。空间级别的任务需要全面的空间推理能力,如建模距离和空间关系;部件级别的任务则需要精细的物体构成感知。即使表现最佳的OpenAI o4-mini模型在空间级别和部件级别的任务上的准确率也只有23.57%和33.94%,明显低于其在区域级别和物体级别的表现。这突显了当前模型在理解和推理超越物体层面的三维场景方面的巨大差距。
Key Takeaways
- 3D视觉定位技术在物体定位方面已取得显著进展,但超越物体层面的三维场景参照表达定位仍具挑战性。
- Anywhere3D-Bench是一个全新的三维视觉定位基准测试平台,包含多种不同级别的定位任务。
- 空间级别和部件级别的视觉定位任务最具挑战性,需要高级的空间推理和精细物体感知能力。
- 现有模型在理解和推理超越物体层面的三维场景方面存在显著差距。
- 即使是表现最佳的模型,在空间级别和部件级别的任务上的准确率也较低。
- 这一研究强调了未来模型需要提升的空间推理和精细物体感知能力的重要性。
点此查看论文截图


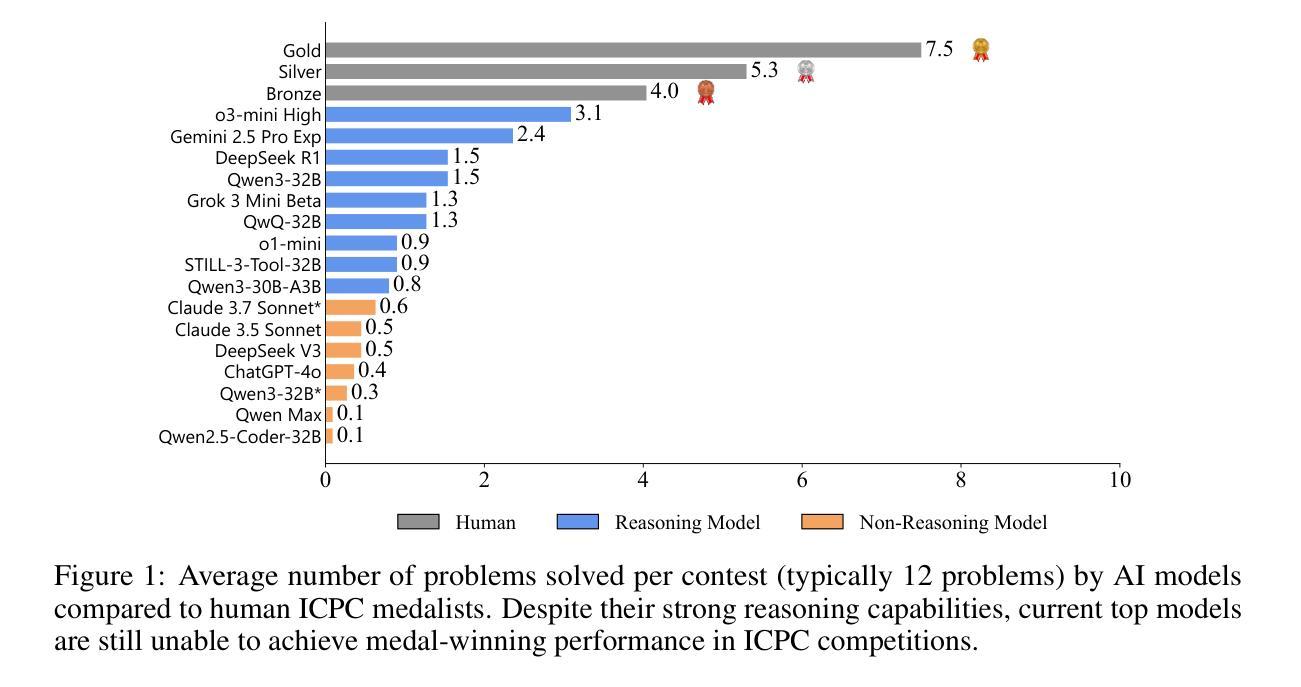
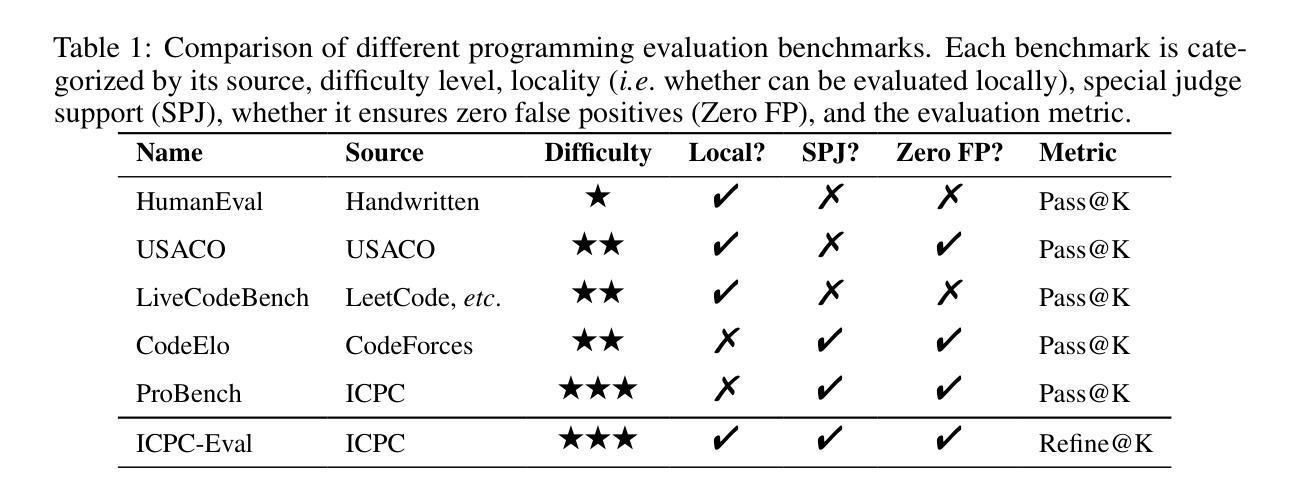
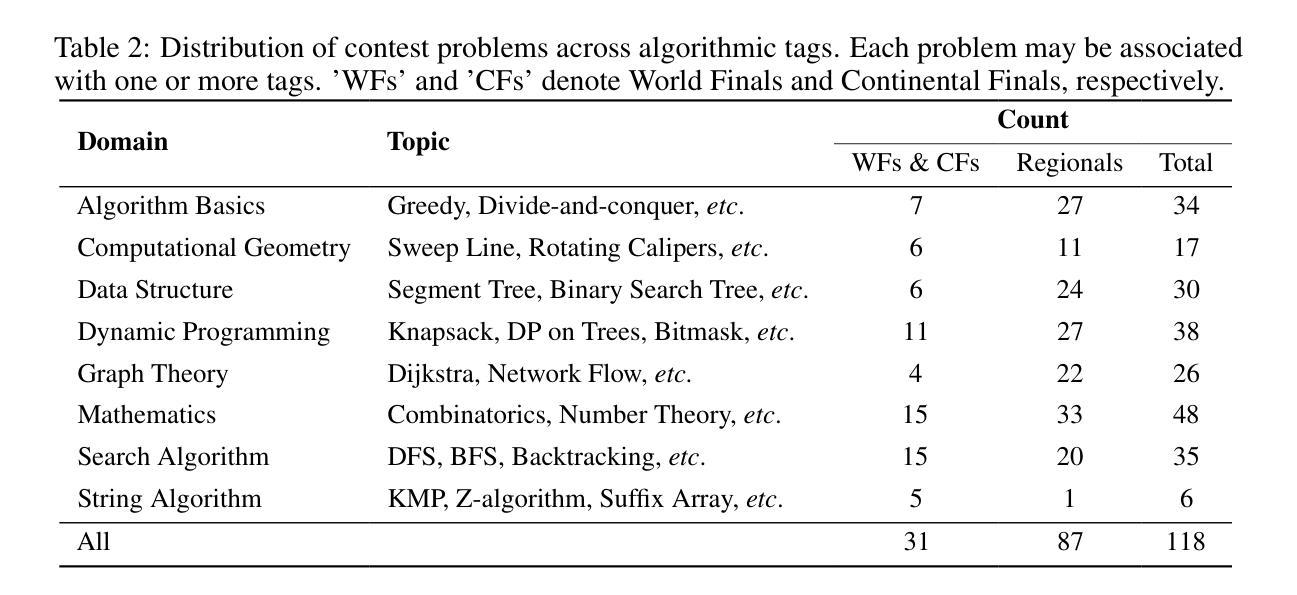
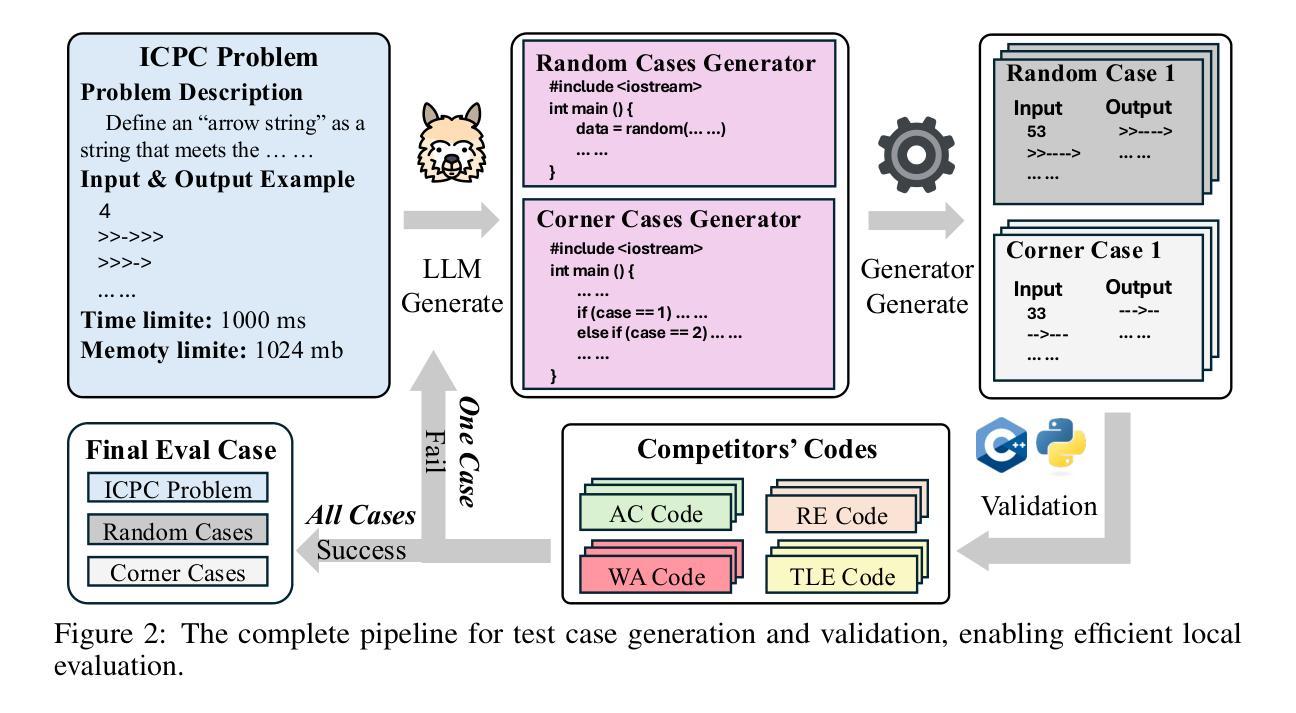
ICPC-Eval: Probing the Frontiers of LLM Reasoning with Competitive Programming Contests
Authors:Shiyi Xu, Yiwen Hu, Yingqian Min, Zhipeng Chen, Wayne Xin Zhao, Ji-Rong Wen
With the significant progress of large reasoning models in complex coding and reasoning tasks, existing benchmarks, like LiveCodeBench and CodeElo, are insufficient to evaluate the coding capabilities of large language models (LLMs) in real competition environments. Moreover, current evaluation metrics such as Pass@K fail to capture the reflective abilities of reasoning models. To address these challenges, we propose \textbf{ICPC-Eval}, a top-level competitive coding benchmark designed to probing the frontiers of LLM reasoning. ICPC-Eval includes 118 carefully curated problems from 11 recent ICPC contests held in various regions of the world, offering three key contributions: 1) A challenging realistic ICPC competition scenario, featuring a problem type and difficulty distribution consistent with actual contests. 2) A robust test case generation method and a corresponding local evaluation toolkit, enabling efficient and accurate local evaluation. 3) An effective test-time scaling evaluation metric, Refine@K, which allows iterative repair of solutions based on execution feedback. The results underscore the significant challenge in evaluating complex reasoning abilities: top-tier reasoning models like DeepSeek-R1 often rely on multi-turn code feedback to fully unlock their in-context reasoning potential when compared to non-reasoning counterparts. Furthermore, despite recent advancements in code generation, these models still lag behind top-performing human teams. We release the benchmark at: https://github.com/RUCAIBox/Slow_Thinking_with_LLMs
随着大型推理模型在复杂编码和推理任务方面取得显著进展,现有的基准测试(如LiveCodeBench和CodeElo)不足以在真实竞争环境中评估大型语言模型(LLM)的编码能力。此外,目前的评估指标(如Pass@K)无法捕捉到推理模型的反射能力。为了应对这些挑战,我们提出了ICPC-Eval,这是一个顶级竞技编码基准测试,旨在探索LLM推理的前沿。ICPC-Eval包含了118个精心挑选的问题,这些问题来自近11年来在世界各地举办的ICPC比赛,提供了三个关键贡献:1)模拟现实的ICPC竞赛场景,其问题类型和难度分布与真实竞赛一致;2)一种稳健的测试案例生成方法和相应的本地评估工具包,可实现高效和准确的本地评估;3)一个有效的测试时间缩放评估指标Refine@K,它允许根据执行反馈进行解决方案的迭代修复。结果强调评估复杂推理能力是一项重大挑战:顶级推理模型(如DeepSeek-R1)在与非推理模型相比时,通常需要多次代码反馈来充分发挥其上下文推理潜力。尽管代码生成方面最近取得了进展,但这些模型仍然落后于顶级人类团队。我们在https://github.com/RUCAIBox/Slow_Thinking_with_LLMs上发布了此基准测试。
论文及项目相关链接
Summary
大型推理模型在复杂编码和推理任务方面取得显著进展,但现有评估基准如LiveCodeBench和CodeElo不足以在真实竞赛环境中评估大型语言模型(LLM)的编码能力。此外,当前的评估指标如Pass@K无法捕捉推理模型的反思能力。为解决这些挑战,提出ICPC-Eval评估基准,包含来自世界各地近期举办的ICPC竞赛中的精心挑选的118个问题,提供三个关键贡献:一是模拟真实的ICPC竞赛场景;二是提供稳健的测试案例生成方法和相应的本地评估工具包;三是推出有效的测试时间缩放评估指标Refine@K,允许基于执行反馈进行解决方案的迭代修复。结果显示,评估复杂推理能力存在重大挑战,顶级推理模型如DeepSeek-R1在多轮代码反馈方面的依赖度高,且在代码生成方面仍需赶超顶尖人类团队。详情请访问:https://github.com/RUCAIBox/Slow_Thinking_with_LLMs。
Key Takeaways
- 大型语言模型在复杂编码和推理任务上的进展显著,但现有评估基准不足以在真实竞赛环境中全面评价其性能。
- ICPC-Eval是一个新的评估基准,模拟真实的ICPC竞赛场景,旨在评估LLM的推理能力。
- ICPC-Eval包含来自世界各地近期ICPC竞赛的问题,提供稳健的测试案例生成和本地评估工具包。
- 推出新的评估指标Refine@K,允许基于执行反馈进行解决方案的迭代修复。
- 顶级推理模型如DeepSeek-R1依赖多轮代码反馈来充分发挥其推理潜力。
点此查看论文截图

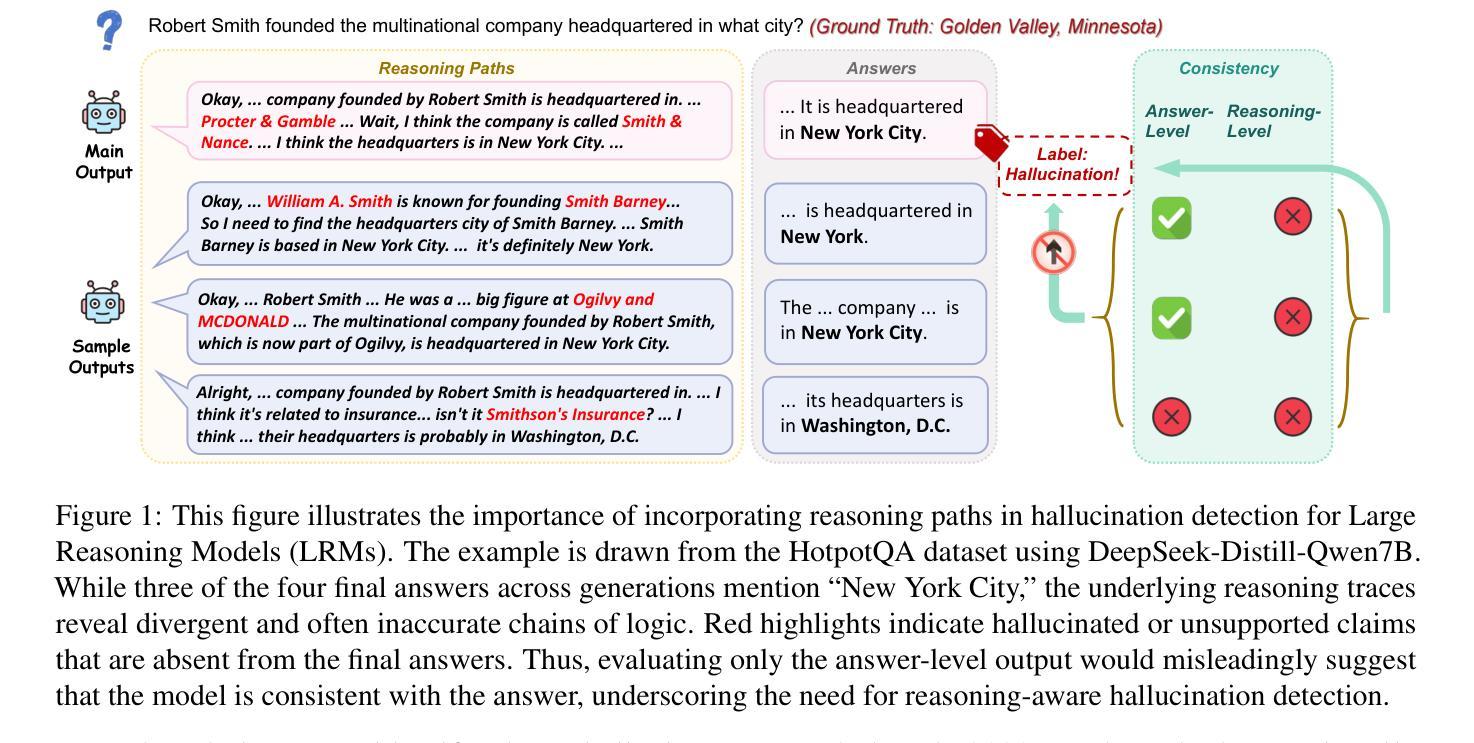
Joint Evaluation of Answer and Reasoning Consistency for Hallucination Detection in Large Reasoning Models
Authors:Changyue Wang, Weihang Su, Qingyao Ai, Yiqun Liu
Large Reasoning Models (LRMs) extend large language models with explicit, multi-step reasoning traces to enhance transparency and performance on complex tasks. However, these reasoning traces can be redundant or logically inconsistent, making them a new source of hallucination that is difficult to detect. Existing hallucination detection methods focus primarily on answer-level uncertainty and often fail to detect hallucinations or logical inconsistencies arising from the model’s reasoning trace. This oversight is particularly problematic for LRMs, where the explicit thinking trace is not only an important support to the model’s decision-making process but also a key source of potential hallucination. To this end, we propose RACE (Reasoning and Answer Consistency Evaluation), a novel framework specifically tailored for hallucination detection in LRMs. RACE operates by extracting essential reasoning steps and computing four diagnostic signals: inter-sample consistency of reasoning traces, entropy-based answer uncertainty, semantic alignment between reasoning and answers, and internal coherence of reasoning. This joint analysis enables fine-grained hallucination detection even when the final answer appears correct. Experiments across datasets and different LLMs demonstrate that RACE outperforms existing hallucination detection baselines, offering a robust and generalizable solution for evaluating LRMs. Our code is available at: https://github.com/bebr2/RACE.
大型推理模型(LRMs)通过明确的、多步骤的推理轨迹扩展了大规模语言模型,从而增强了在复杂任务上的透明度和性能。然而,这些推理轨迹可能是冗余或逻辑不一致的,成为难以检测的一种新的幻觉来源。现有的幻觉检测方法主要关注答案级别的不确定性,往往无法检测由模型推理轨迹产生的幻觉或逻辑不一致。这种疏忽对于LRM来说尤为严重,其中明确的思维轨迹不仅是模型决策过程的重要支持,也是潜在幻觉的关键来源。为此,我们提出了针对LRM中幻觉检测的RACE(推理与答案一致性评估)新框架。RACE通过提取关键的推理步骤并计算四个诊断信号:推理轨迹的样本间一致性、基于熵的答案不确定性、推理与答案之间的语义对齐以及推理的内部连贯性。这种联合分析即使在最终答案看似正确的情况下,也能实现精细的幻觉检测。在不同数据集和不同LLM上的实验表明,RACE优于现有的幻觉检测基线,为评估LRM提供了稳健和通用的解决方案。我们的代码可在:https://github.com/bebr2/RACE获取。
论文及项目相关链接
Summary
大型推理模型(LRMs)结合了大型语言模型与明确的推理步骤,旨在提高复杂任务的透明度和性能。然而,这些推理轨迹可能冗余或逻辑不一致,成为新的难以检测的幻想来源。本文提出了一种专门针对LRM中幻觉检测的新框架——RACE(推理与答案一致性评估)。RACE通过提取关键推理步骤并计算四种诊断信号(推理轨迹的跨样本一致性、基于熵的答案不确定性、推理与答案之间的语义对齐以及推理的内部连贯性)来进行精细的幻觉检测。实验表明,RACE在数据集和大型语言模型上的表现均优于现有幻觉检测基线,为评估LRM提供了稳健且可推广的解决方案。
Key Takeaways
- 大型推理模型(LRMs)结合了大型语言模型与明确的推理步骤,旨在增强复杂任务的性能。
- LRMs中的推理轨迹可能冗余或逻辑不一致,成为新的幻觉来源。
- 现有幻觉检测方法主要关注答案级别的不确定性,往往无法检测到由模型推理轨迹产生的幻觉或逻辑不一致。
- RACE框架通过提取关键推理步骤和计算四种诊断信号进行精细的幻觉检测。
- RACE框架包括跨样本的推理轨迹一致性、答案的不确定性、推理与答案的语义对齐以及推理的内部连贯性。
- 实验表明,RACE在多个数据集和大型语言模型上的表现优于现有幻觉检测基线。
点此查看论文截图

MMSU: A Massive Multi-task Spoken Language Understanding and Reasoning Benchmark
Authors:Dingdong Wang, Jincenzi Wu, Junan Li, Dongchao Yang, Xueyuan Chen, Tianhua Zhang, Helen Meng
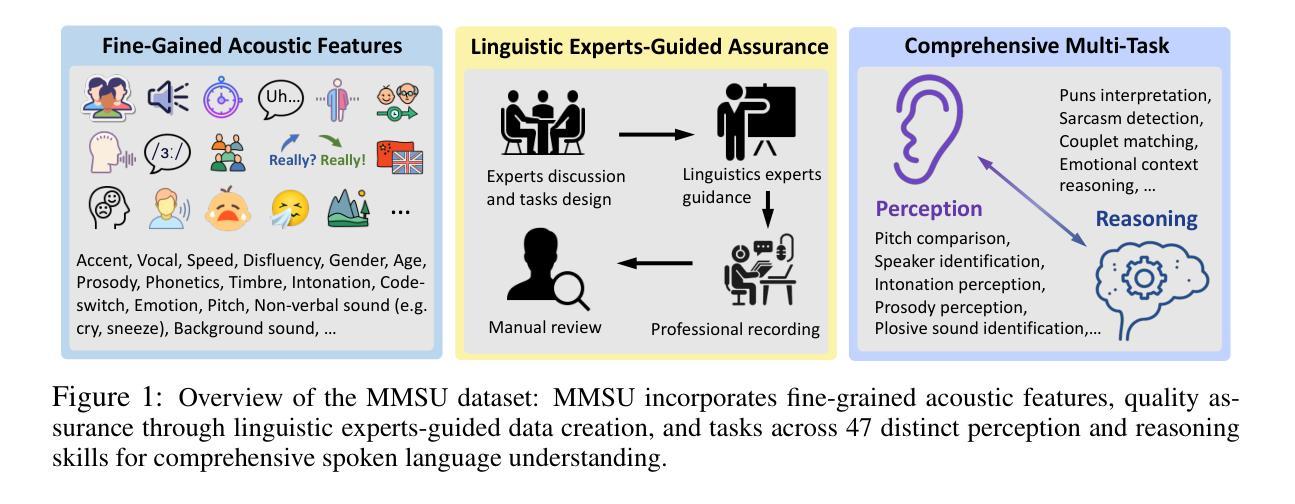
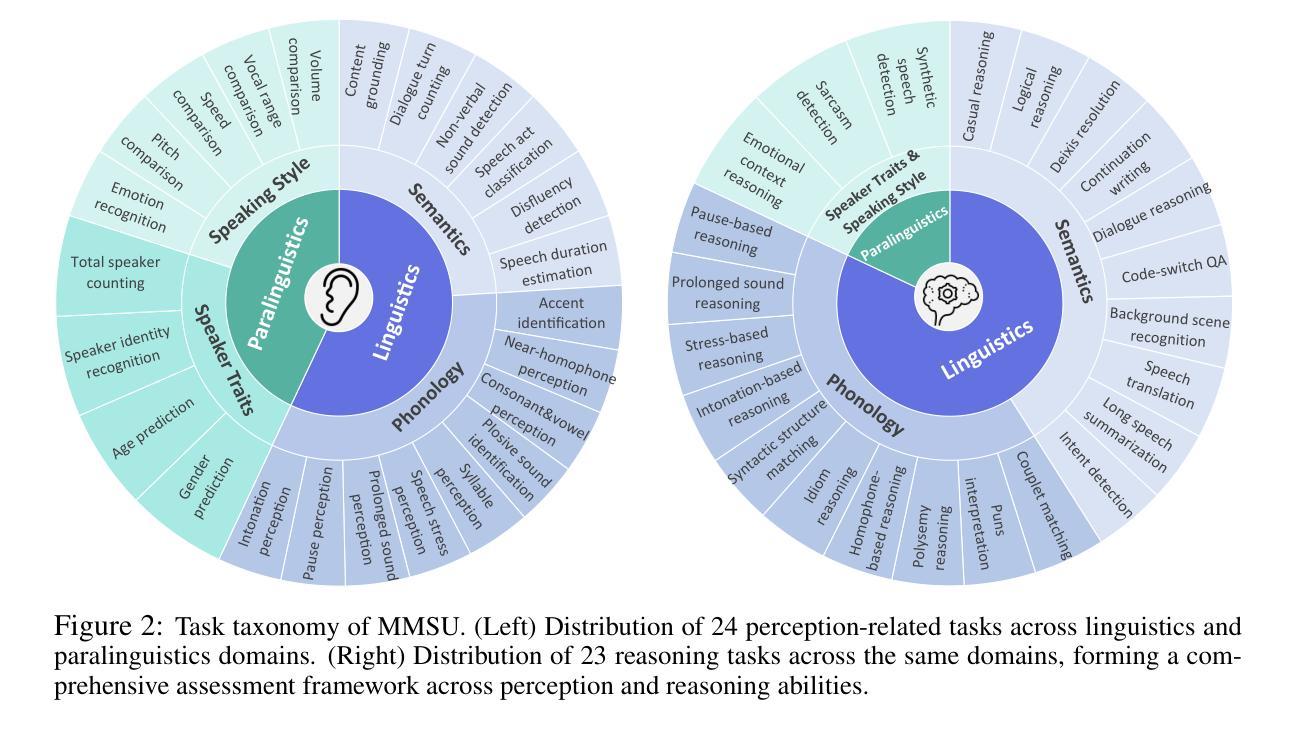
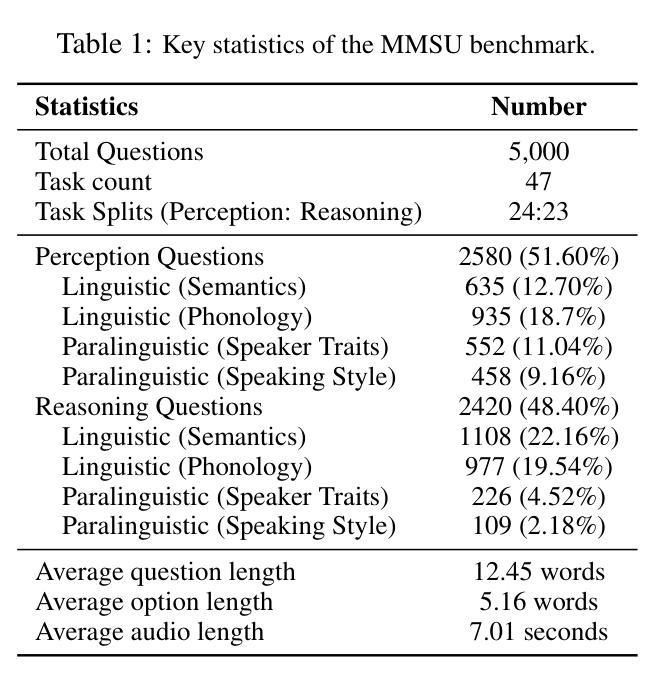
Speech inherently contains rich acoustic information that extends far beyond the textual language. In real-world spoken language understanding, effective interpretation often requires integrating semantic meaning (e.g., content), paralinguistic features (e.g., emotions, speed, pitch) and phonological characteristics (e.g., prosody, intonation, rhythm), which are embedded in speech. While recent multimodal Speech Large Language Models (SpeechLLMs) have demonstrated remarkable capabilities in processing audio information, their ability to perform fine-grained perception and complex reasoning in natural speech remains largely unexplored. To address this gap, we introduce MMSU, a comprehensive benchmark designed specifically for understanding and reasoning in spoken language. MMSU comprises 5,000 meticulously curated audio-question-answer triplets across 47 distinct tasks. To ground our benchmark in linguistic theory, we systematically incorporate a wide range of linguistic phenomena, including phonetics, prosody, rhetoric, syntactics, semantics, and paralinguistics. Through a rigorous evaluation of 14 advanced SpeechLLMs, we identify substantial room for improvement in existing models, highlighting meaningful directions for future optimization. MMSU establishes a new standard for comprehensive assessment of spoken language understanding, providing valuable insights for developing more sophisticated human-AI speech interaction systems. MMSU benchmark is available at https://huggingface.co/datasets/ddwang2000/MMSU. Evaluation Code is available at https://github.com/dingdongwang/MMSU_Bench.
语音本身包含丰富的声音信息,远远超出文本语言的范围。在现实世界的口语理解中,有效的解释通常需要整合语义(例如内容)、副语言特征(例如情感、语速、音调)和语音特征(例如韵律、语调、节奏),这些特征都嵌入在语音中。虽然最近的多媒体语音大语言模型(SpeechLLMs)在处理音频信息方面表现出了显著的能力,但它们在自然语音的精细感知和复杂推理方面的能力仍待探索。为了弥补这一差距,我们引入了MMSU,这是一个专门为口语理解和推理而设计的综合基准测试。MMSU包含5000个精心挑选的音频-问题-答案三元组,涵盖47个不同的任务。为了在我们的基准测试中融入语言学理论,我们系统地融入了一系列的语言现象,包括语音学、韵律、修辞、句法、语义和副语言学。通过对14个先进的SpeechLLM的严格评估,我们发现了现有模型的改进空间很大,并指出了未来优化的有意义方向。MMSU为口语理解的全面评估建立了新标准,为开发更复杂的人类-人工智能语音交互系统提供了宝贵的见解。MMSU基准测试可在https://huggingface.co/datasets/ddwang2000/MMSU获取。评估代码可在https://github.com/dingdongwang/MMSU_Bench找到。
论文及项目相关链接
PDF MMSU benchmark is available at https://huggingface.co/datasets/ddwang2000/MMSU. Evaluation Code is available at https://github.com/dingdongwang/MMSU_Bench
Summary
本文介绍了语音包含丰富的声音信息,这些信息远远超出文本语言。在现实世界的口语理解中,有效的解释往往需要整合语义(例如内容)、副语言特征(例如情感、语速、音调)和语音特征(例如韵律、语调、节奏),这些特征都嵌入在语音中。为了理解和推理口语,我们引入了MMSU,这是一个专门为口语理解而设计的综合基准测试。MMSU包含5000个精心策划的音频-问题-答案三元组,跨越47个不同的任务。通过严格的评估,我们发现现有模型仍有很大的改进空间,为未来的优化指明了有意义的方向。MMSU为全面评估口语理解建立了新的标准,为开发更复杂的人机语音交互系统提供了有价值的见解。
Key Takeaways
- 语音包含丰富的声音信息,超越文本语言。
- 有效的口语理解需要整合语义、副语言特征和语音特征。
- MMSU是一个专门用于口语理解的综合基准测试。
- MMSU包含5000个音频-问题-答案三元组,跨越47个任务。
- 现有语音LLM模型在精细感知和复杂推理方面仍有改进空间。
- MMSU为口语理解建立了新的评估标准。
点此查看论文截图



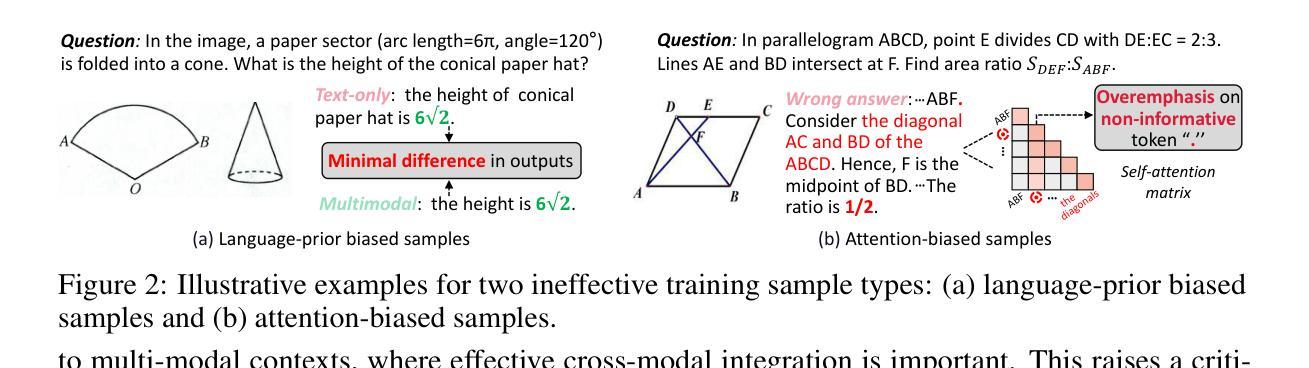
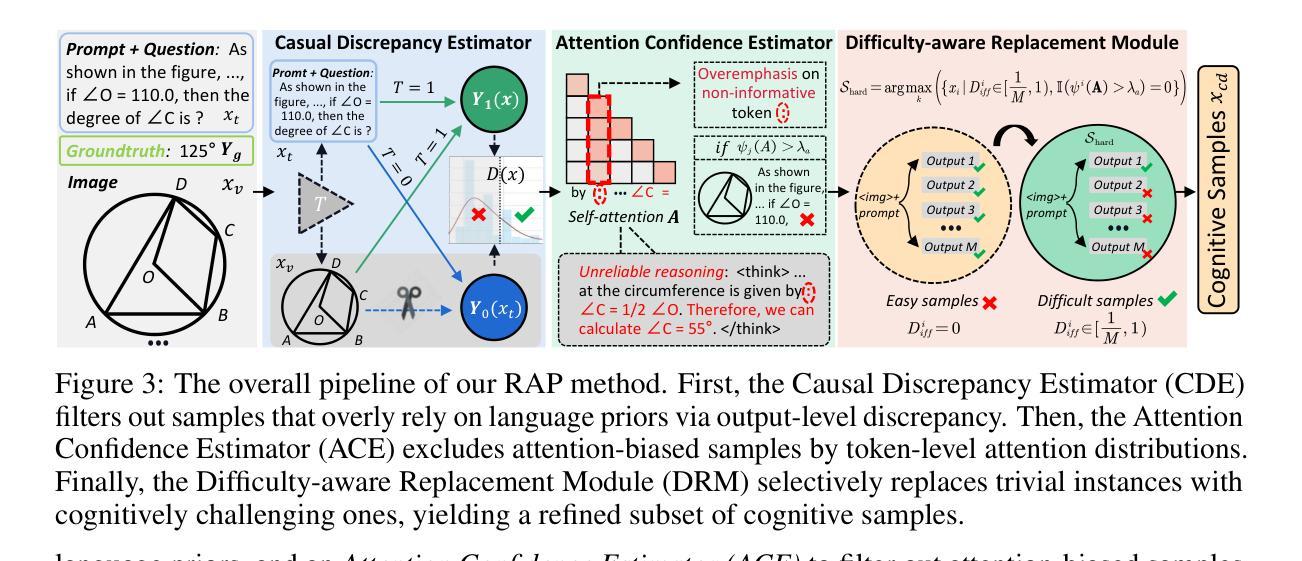
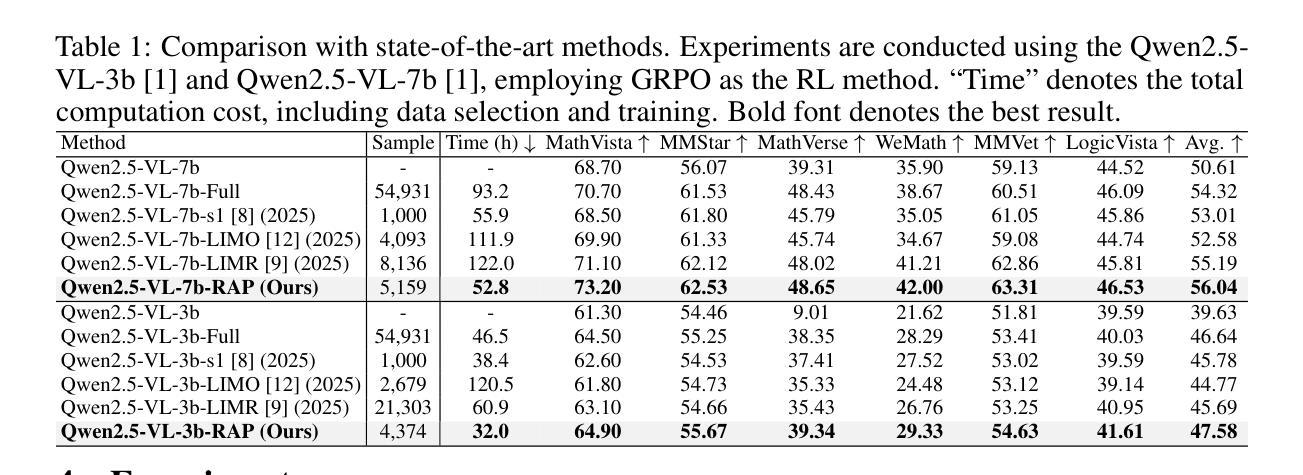
Truth in the Few: High-Value Data Selection for Efficient Multi-Modal Reasoning
Authors:Shenshen Li, Kaiyuan Deng, Lei Wang, Hao Yang, Chong Peng, Peng Yan, Fumin Shen, Heng Tao Shen, Xing Xu
While multi-modal large language models (MLLMs) have made significant progress in complex reasoning tasks via reinforcement learning, it is commonly believed that extensive training data is necessary for improving multi-modal reasoning ability, inevitably leading to data redundancy and substantial computational costs. However, can smaller high-value datasets match or outperform full corpora for multi-modal reasoning in MLLMs? In this work, we challenge this assumption through a key observation: meaningful multi-modal reasoning is triggered by only a sparse subset of training samples, termed cognitive samples, whereas the majority contribute marginally. Building on this insight, we propose a novel data selection paradigm termed Reasoning Activation Potential (RAP), which identifies cognitive samples by estimating each sample’s potential to stimulate genuine multi-modal reasoning by two complementary estimators: 1) Causal Discrepancy Estimator (CDE) based on the potential outcome model principle, eliminates samples that overly rely on language priors by comparing outputs between multi-modal and text-only inputs; 2) Attention Confidence Estimator (ACE), which exploits token-level self-attention to discard samples dominated by irrelevant but over-emphasized tokens in intermediate reasoning stages. Moreover, we introduce a Difficulty-aware Replacement Module (DRM) to substitute trivial instances with cognitively challenging ones, thereby ensuring complexity for robust multi-modal reasoning. Experiments on six datasets show that our RAP method consistently achieves superior performance using only 9.3% of the training data, while reducing computational costs by over 43%. Our code is available at https://github.com/Leo-ssl/RAP.
虽然多模态大型语言模型(MLLMs)通过强化学习在复杂推理任务方面取得了显著进展,但人们普遍认为,为了提高多模态推理能力,需要大量的训练数据,这不可避免地导致了数据冗余和巨大的计算成本。然而,较小的高价值数据集是否能在多模态推理方面与完整语料库相匹配甚至表现更好?在这项工作中,我们通过一项关键观察结果来挑战这一假设:有意义的多模态推理仅由一小部分训练样本触发,这些样本被称为认知样本,而大多数样本贡献甚微。基于这一见解,我们提出了一种新的数据选择范式,称为“推理激活潜力”(RAP),它通过两个互补的估计器来识别认知样本:1)基于潜在结果模型原理的因果差异估计器(CDE),通过比较多模态和文本输入的输出,消除过度依赖语言先验的样本;2)注意力置信估计器(ACE),利用标记级别的自我注意力来丢弃在推理阶段被无关但过度强调的标记所主导的样本。此外,我们引入了一个难度感知替换模块(DRM),以认知上具有挑战性的实例替换掉简单的实例,从而确保复杂性以实现稳健的多模态推理。在六个数据集上的实验表明,我们的RAP方法仅使用9.3%的训练数据就能持续实现优越的性能,同时降低计算成本超过43%。我们的代码可在https://github.com/Leo-ssl/RAP上找到。
论文及项目相关链接
Summary
本文挑战了多模态大型语言模型(MLLMs)在多模态推理中必须依赖大量训练数据的传统观念。通过关键观察发现,有意义的多模态推理仅由训练样本中的稀疏子集(称为认知样本)触发,其余大部分样本贡献甚微。基于此,提出了一种新的数据选择范式——推理激活潜力(RAP),通过两个互补的评估器来识别认知样本:1)因果差异评估器(CDE),基于潜在结果模型原理,通过比较多模态和文本只有输入的输出来消除过度依赖语言先验的样本;2)注意力信心评估器(ACE),利用token级别的自我关注来丢弃在中间推理阶段被无关紧要的token主导的样本。实验结果表明,RAP方法仅使用9.3%的训练数据即可实现卓越性能,同时降低计算成本超过43%。
Key Takeaways
- 多模态大型语言模型(MLLMs)在复杂推理任务中取得了显著进步,但普遍认为需要大量训练数据来提高多模态推理能力,导致数据冗余和计算成本高昂。
- 本文挑战了这一假设,认为有意义的多模态推理仅由训练样本中的稀疏子集(认知样本)触发。
- 提出了一种新的数据选择范式——推理激活潜力(RAP),能够识别认知样本,通过估计每个样本刺激真实多模态推理的潜力。
- RAP方法包括两个互补的评估器:因果差异评估器(CDE)和注意力信心评估器(ACE),分别用于比较多模态和文本只有输入的输出来识别过度依赖语言先验的样本,以及利用token级别的自我关注来识别在中间推理阶段被无关紧要的token主导的样本。
- 引入了一个难度感知替换模块(DRM),用具有挑战性的实例替换简单的实例,确保复杂性的多模态推理。
- 实验结果表明,RAP方法使用仅9.3%的训练数据即可实现卓越性能,同时降低计算成本超过43%。
点此查看论文截图

Multi-Layer GRPO: Enhancing Reasoning and Self-Correction in Large Language Models
Authors:Fei Ding, Baiqiao Wang, Zijian Zeng, Youwei Wang
The Group Relative Policy Optimization (GRPO) algorithm has demonstrated considerable success in enhancing the reasoning capabilities of large language models (LLMs), as evidenced by DeepSeek-R1. However, the absence of intermediate supervision in GRPO frequently leads to inefficient exploration dynamics. A single error in a complex reasoning chain can invalidate the entire solution, resulting in abrupt reward vanishing and compromising training stability.To address these challenges, we propose MGRPO (Multi-layer GRPO). MGRPO operates in two layers: the first layer employs standard GRPO to generate an initial response. This response, along with the original query, is then fed into a second-layer GRPO process. This second layer is specifically trained to identify and correct errors in the initial response, effectively creating a self-correction loop. This mechanism provides implicit process-level supervision by rewarding successful error correction, without requiring an explicit, densely-annotated reward model. Experimental results on several mathematical reasoning benchmarks demonstrate that MGRPO significantly outperforms standard GRPO, achieving superior performance by fostering both reasoning and self-correction abilities.
集团相对策略优化(GRPO)算法在提高大型语言模型(LLM)的推理能力方面取得了显著的成功,DeepSeek-R1对此提供了证据。然而,GRPO中缺乏中间监督通常会导致低效的探索动态。复杂的推理链中的一个错误可能会使整个解决方案无效,导致奖励突然消失,影响训练稳定性。为了解决这些挑战,我们提出了多层GRPO(MGRPO)。MGRPO有两层操作:第一层采用标准GRPO生成初步回应。然后,该响应与原始查询一起输入到第二层GRPO过程中。第二层专门训练以识别和纠正初步回应中的错误,从而有效地创建一个自我纠正循环。该机制通过奖励成功的错误纠正,提供了隐式的流程级监督,而无需使用明确、密集注释的奖励模型。在多个数学推理基准测试上的实验结果表明,MGRPO显著优于标准GRPO,通过促进推理和自我纠正能力,实现了卓越的性能。
论文及项目相关链接
Summary:
GRPO算法在提升大型语言模型的推理能力方面取得了显著成功,但缺乏中间监督导致探索动态效率低下。为解决此问题,提出多层GRPO(MGRPO)。MGRPO分为两层操作,第一层使用标准GRPO生成初步回应,然后将其与原始查询一起输入到第二层GRPO过程中进行错误识别与修正,形成自我修正循环。这种机制通过奖励成功的错误修正,无需明确的密集注释奖励模型,即可提供隐式过程级监督。在多个数学推理基准测试上,MGRPO显著优于标准GRPO,通过促进推理和自纠能力实现卓越性能。
Key Takeaways:
- GRPO算法增强了大型语言模型的推理能力,但缺乏中间监督导致探索效率不高。
- MGRPO算法采用两层操作,第一层生成初步回应,第二层进行错误识别与修正。
- MGRPO通过自我修正循环,提高了模型应对复杂推理链中错误的能力。
- MGRPO采用隐式过程级监督机制,通过奖励成功的错误修正,无需密集注释的奖励模型。
- MGRPO在多个数学推理基准测试上显著优于标准GRPO。
- MGRPO算法促进了模型的推理和自纠能力。
点此查看论文截图

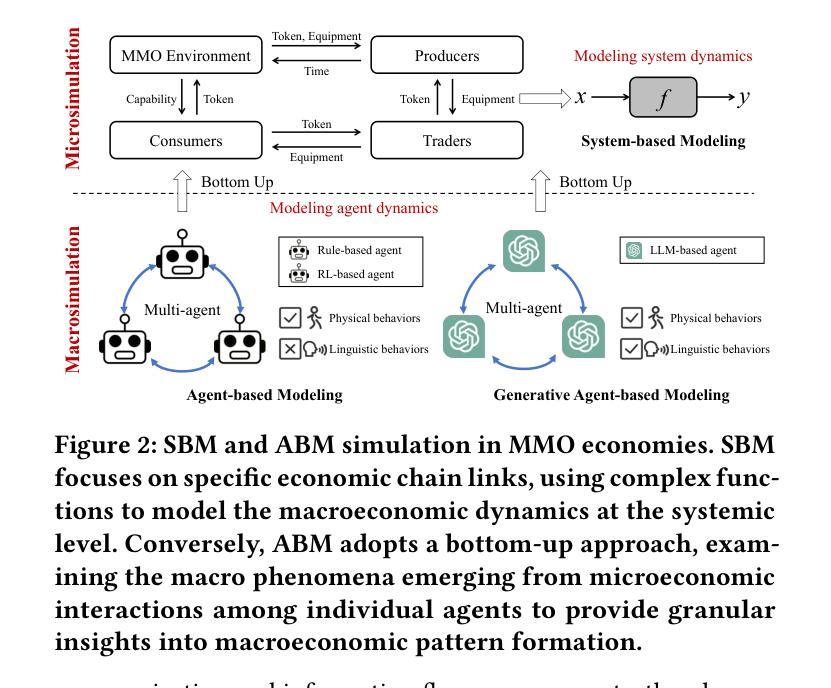
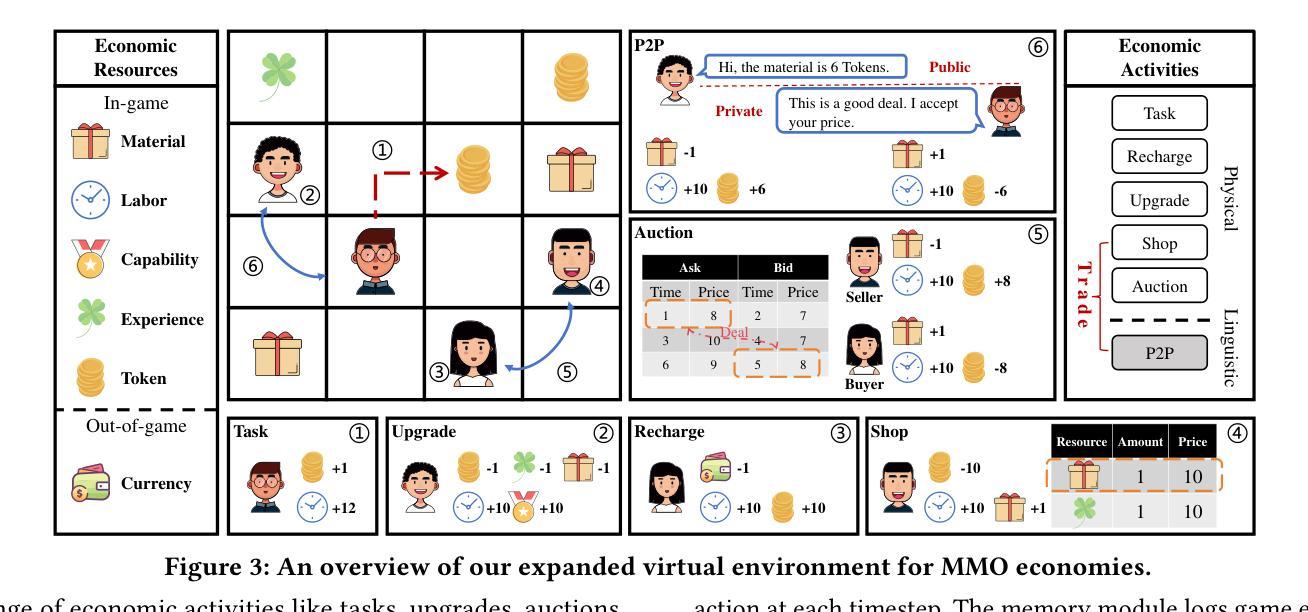
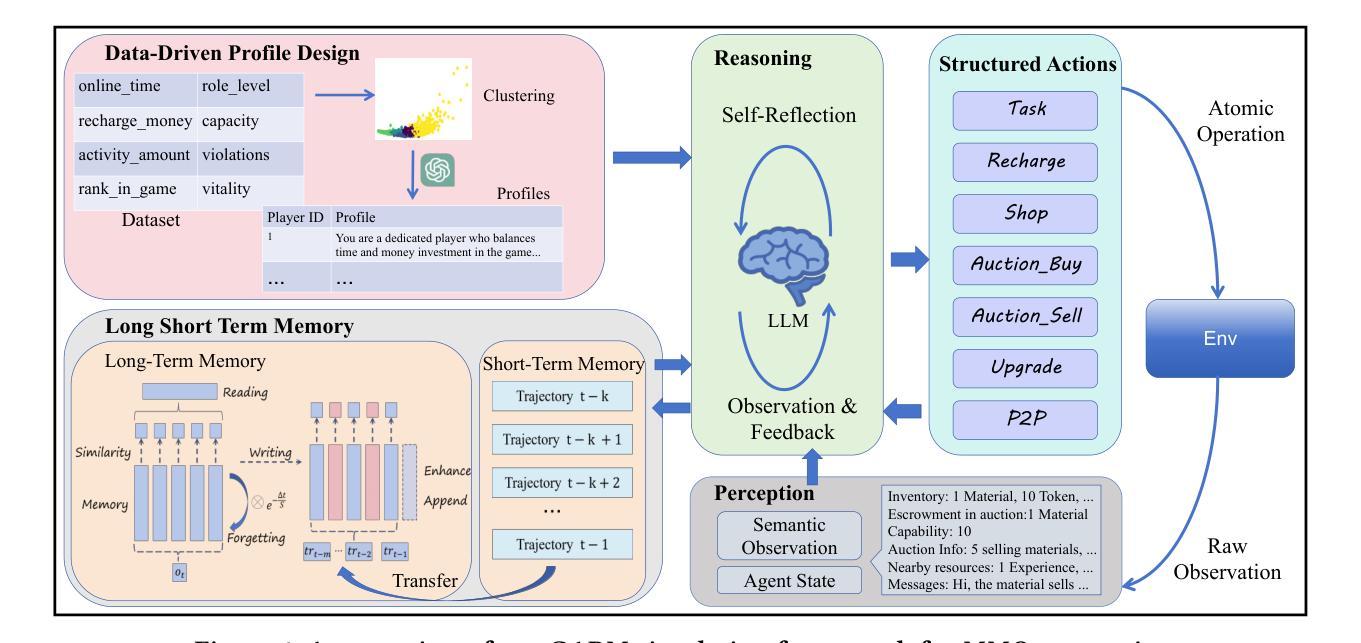
Empowering Economic Simulation for Massively Multiplayer Online Games through Generative Agent-Based Modeling
Authors:Bihan Xu, Shiwei Zhao, Runze Wu, Zhenya Huang, Jiawei Wang, Zhipeng Hu, Kai Wang, Haoyu Liu, Tangjie Lv, Le Li, Changjie Fan, Xin Tong, Jiangze Han
Within the domain of Massively Multiplayer Online (MMO) economy research, Agent-Based Modeling (ABM) has emerged as a robust tool for analyzing game economics, evolving from rule-based agents to decision-making agents enhanced by reinforcement learning. Nevertheless, existing works encounter significant challenges when attempting to emulate human-like economic activities among agents, particularly regarding agent reliability, sociability, and interpretability. In this study, we take a preliminary step in introducing a novel approach using Large Language Models (LLMs) in MMO economy simulation. Leveraging LLMs’ role-playing proficiency, generative capacity, and reasoning aptitude, we design LLM-driven agents with human-like decision-making and adaptability. These agents are equipped with the abilities of role-playing, perception, memory, and reasoning, addressing the aforementioned challenges effectively. Simulation experiments focusing on in-game economic activities demonstrate that LLM-empowered agents can promote emergent phenomena like role specialization and price fluctuations in line with market rules.
在大型多人在线(MMO)经济研究领域,基于代理的建模(ABM)已经成为分析游戏经济学的强大工具,从基于规则的代理发展到通过强化学习增强的决策代理。然而,现有工作在尝试模拟代理之间的人类经济活动时面临重大挑战,特别是在代理的可靠性、社交能力和解释性方面。本研究初步引入了一种新的方法,利用大型语言模型(LLMs)进行MMO经济模拟。借助LLMs的角色扮演能力、生成能力和推理能力,我们设计了具有人类式决策和适应能力的LLM驱动代理。这些代理具备角色扮演、感知、记忆和推理的能力,有效地解决了上述挑战。以游戏内经济活动为重点的模拟实验表明,LLM赋能的代理可以促进诸如角色专业化和价格波动的市场规则相符的新兴现象。
论文及项目相关链接
PDF KDD2025 Accepted
Summary
在大型多人在线(MMO)经济研究领域,基于代理的建模(ABM)已逐渐成为分析游戏经济的有力工具,从基于规则的代理发展到通过强化学习增强决策能力的代理。然而,现有研究在尝试模拟代理之间的人类经济活动时面临诸多挑战,特别是在代理的可靠性、社交能力和可解释性方面。本研究初步引入大型语言模型(LLM)用于MMO经济模拟,借助LLM的角色扮演能力、生成能力和推理能力,设计出具有人类决策和适应能力的LLM驱动代理。这些代理具备角色扮演、感知、记忆和推理能力,能有效应对上述挑战。模拟实验关注游戏内经济活动,证明LLM赋能的代理能够促进角色专业化、价格波动等符合市场规则的现象。
Key Takeaways
- Agent-Based Modeling (ABM)是分析游戏经济的重要工具,但它模拟人类经济活动的准确性有待提高。
- 大型语言模型(LLM)在角色扮演、生成能力和推理能力方面表现出色,可应用于MMO经济模拟。
- LLM驱动的代理具备人类决策和适应能力,能有效解决ABM面临的挑战,如代理的可靠性、社交能力和可解释性。
- LLM赋能的代理能促进角色专业化和价格波动等符合市场规则的现象。
- LLM在MMO经济模拟中的应用是创新性的尝试,为未来游戏经济模拟提供了新的方向。
- 该研究为结合人工智能与游戏经济的研究提供了有价值的参考。
- 大型语言模型和基于代理的建模相结合的方法在其他领域(如社会科学、经济学)的模拟中也可能具有潜在应用价值。
点此查看论文截图


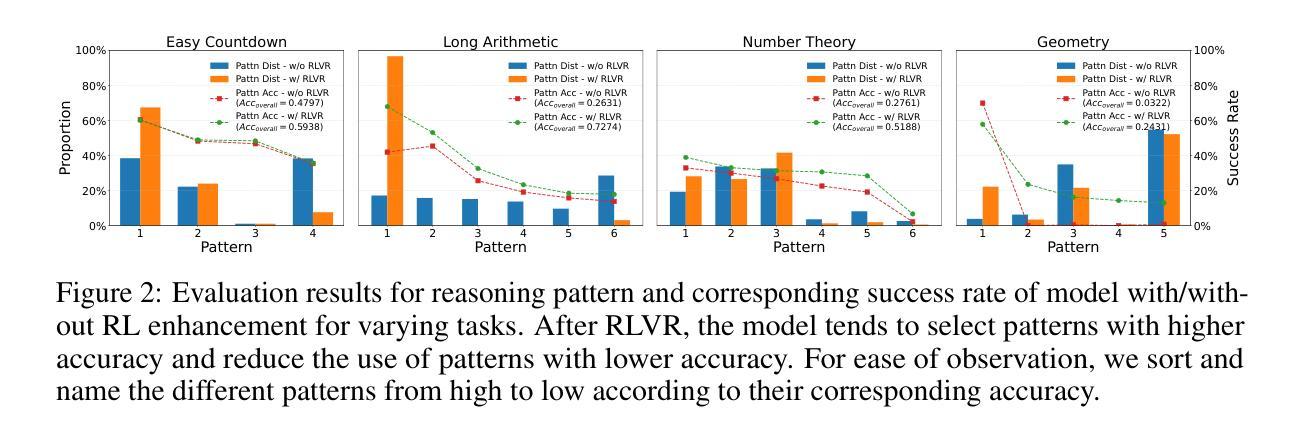
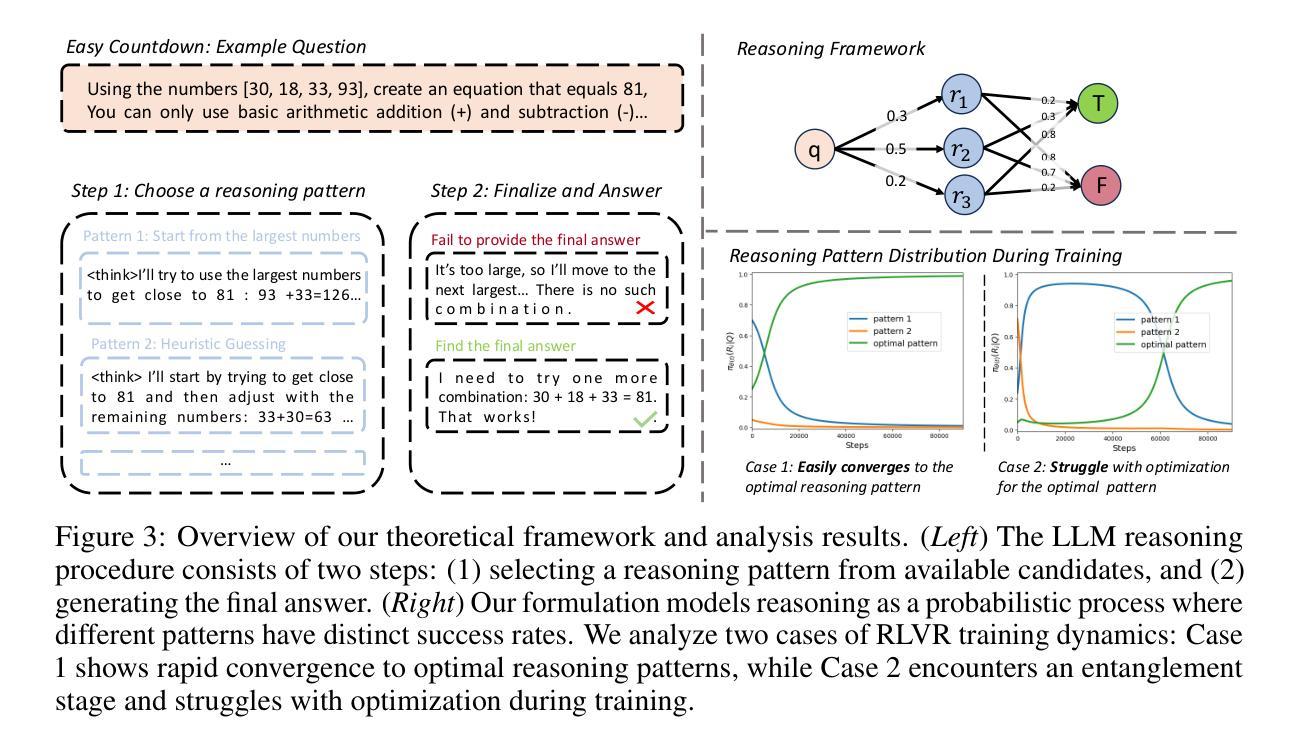
On the Mechanism of Reasoning Pattern Selection in Reinforcement Learning for Language Models
Authors:Xingwu Chen, Tianle Li, Difan Zou
Reinforcement learning (RL) has demonstrated remarkable success in enhancing model capabilities, including instruction-following, preference learning, and reasoning. Yet despite its empirical successes, the mechanisms by which RL improves reasoning abilities remain poorly understood. We present a systematic study of Reinforcement Learning with Verifiable Rewards (RLVR), showing that its primary benefit comes from optimizing the selection of existing reasoning patterns. Through extensive experiments, we demonstrate that RLVR-trained models preferentially adopt high-success-rate reasoning patterns while mostly maintaining stable performance on individual patterns. We further develop theoretical analyses on the convergence and training dynamics of RLVR based on a simplified question-reason-answer model. We study the gradient flow and show that RLVR can indeed find the solution that selects the reason pattern with the highest success rate. Besides, our theoretical results reveal two distinct regimes regarding the convergence of RLVR training: (1) rapid convergence for models with relatively strong initial reasoning capabilities versus (2) slower optimization dynamics for weaker models. Furthermore, we show that the slower optimization for weaker models can be mitigated by applying the supervised fine-tuning (SFT) before RLVR, when using a feasibly high-quality SFT dataset. We validate the theoretical findings through extensive experiments. This work advances our theoretical understanding of RL’s role in LLM fine-tuning and offers insights for further enhancing reasoning capabilities.
强化学习(RL)在提高模型能力方面取得了显著的成果,包括指令遵循、偏好学习和推理等。然而,尽管其在实证研究中取得了成功,但RL提高推理能力的机制仍知之甚少。我们对带有可验证奖励的强化学习(RLVR)进行了系统研究,表明其主要优势在于优化现有推理模式的选择。通过广泛的实验,我们证明RLVR训练的模型倾向于采用高成功率的推理模式,同时基本上保持了对单个模式的稳定性能。我们进一步基于简化的问答模型,对RLVR的收敛性和训练动态进行了理论分析。我们研究了梯度流,并证明RLVR确实可以找到选择成功率最高的推理模式的解决方案。此外,我们的理论结果揭示了RLVR训练的收敛过程中的两种不同状态:(1)对于具有相对较强的初始推理能力的模型的快速收敛,以及(2)对于较弱的模型的较慢优化动态。而且,我们还发现,在使用高质量的有监督微调(SFT)数据集进行RLVR之前,可以通过应用有监督微调来缓解较弱模型的较慢优化问题。我们通过广泛的实验验证了这些理论发现。这项工作加深了我们对于RL在大型语言模型微调中的作用的理论理解,并为进一步提高推理能力提供了见解。
论文及项目相关链接
PDF 30 pages, 6 figures, 1 table
Summary
强化学习(RL)在提升模型能力方面取得了显著的成功,包括指令遵循、偏好学习和推理等。然而,尽管其实践应用取得了成功,但RL提升推理能力的机制仍知之甚少。本研究对带有可验证奖励的强化学习(RLVR)进行了系统研究,发现其主要优势在于优化现有推理模式的选取。通过广泛的实验,我们展示了RLVR训练的模型会优先采用高成功率的推理模式,同时大致保持对单个模式的稳定性能。我们还基于简化的问答模型对RLVR的收敛性和训练动态进行了理论分析,并发现RLVR确实能找到选择成功率最高的推理模式的解决方案。此外,我们的理论结果还揭示了RLVR训练的收敛存在两种不同的情况:一是具有相对较强的初始推理能力的模型的快速收敛,二是较弱模型的较慢优化动态。在较弱的模型上,我们可以通过在RLVR之前应用有监督微调(SFT)来缓解这个问题,使用高质量的SFT数据集是可行的。本研究加深了我们对于RL在大型语言模型微调中作用的理论理解,并为进一步提高推理能力提供了见解。
Key Takeaways
- 强化学习(RL)已用于提升模型的多项能力,包括指令遵循、偏好学习和推理。
- RLVR的主要优势在于优化现有推理模式的选取。
- RLVR训练的模型会优先采用高成功率的推理模式。
- RLVR训练的理论分析揭示了其收敛性的两个不同情况,以及针对较弱模型的优化动态。
- 对于初始推理能力较弱的模型,可以通过有监督微调(SFT)来缓解较慢的优化动态。
- 使用高质量的SFT数据集在RLVR训练前是有效的。
点此查看论文截图

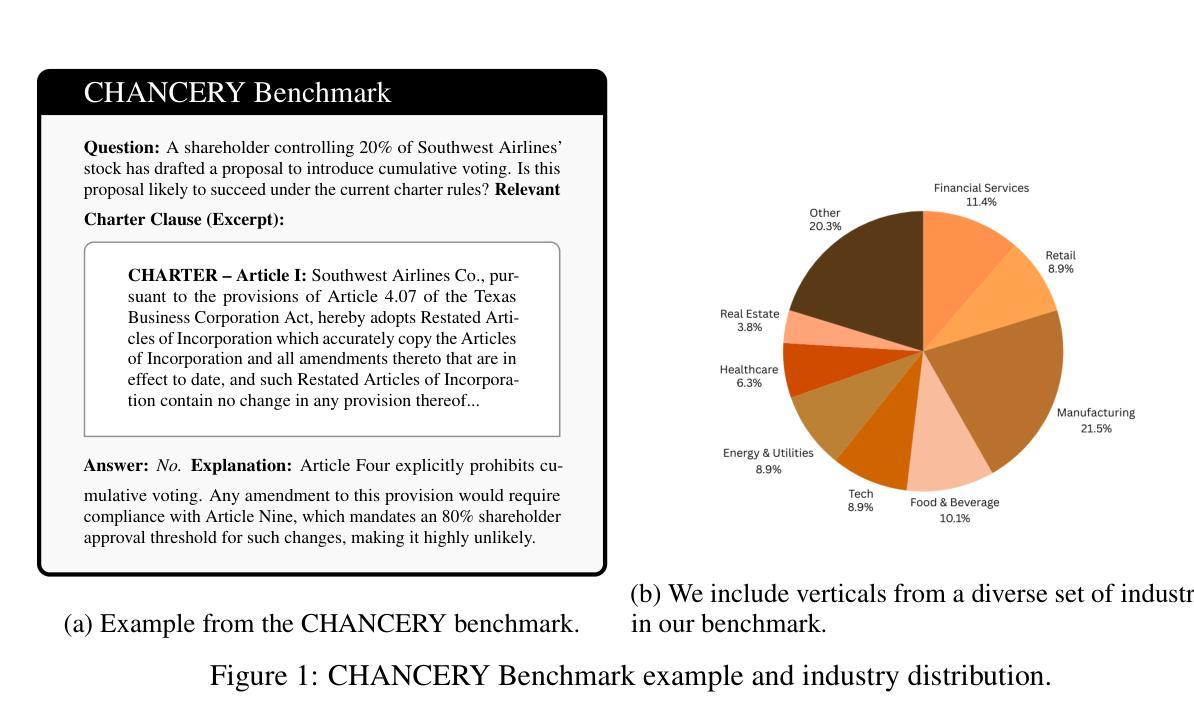
CHANCERY: Evaluating corporate governance reasoning capabilities in language models
Authors:Lucas Irwin, Arda Kaz, Peiyao Sheng, Pramod Viswanath
Law has long been a domain that has been popular in natural language processing (NLP) applications. Reasoning (ratiocination and the ability to make connections to precedent) is a core part of the practice of the law in the real world. Nevertheless, while multiple legal datasets exist, none have thus far focused specifically on reasoning tasks. We focus on a specific aspect of the legal landscape by introducing a corporate governance reasoning benchmark (CHANCERY) to test a model’s ability to reason about whether executive/board/shareholder’s proposed actions are consistent with corporate governance charters. This benchmark introduces a first-of-its-kind corporate governance reasoning test for language models - modeled after real world corporate governance law. The benchmark consists of a corporate charter (a set of governing covenants) and a proposal for executive action. The model’s task is one of binary classification: reason about whether the action is consistent with the rules contained within the charter. We create the benchmark following established principles of corporate governance - 24 concrete corporate governance principles established in and 79 real life corporate charters selected to represent diverse industries from a total dataset of 10k real life corporate charters. Evaluations on state-of-the-art (SOTA) reasoning models confirm the difficulty of the benchmark, with models such as Claude 3.7 Sonnet and GPT-4o achieving 64.5% and 75.2% accuracy respectively. Reasoning agents exhibit superior performance, with agents based on the ReAct and CodeAct frameworks scoring 76.1% and 78.1% respectively, further confirming the advanced legal reasoning capabilities required to score highly on the benchmark. We also conduct an analysis of the types of questions which current reasoning models struggle on, revealing insights into the legal reasoning capabilities of SOTA models.
法律领域长期以来在自然语言处理(NLP)应用中颇受欢迎。推理(包括逻辑推断和与先例建立联系的能力)是现实世界中法律实践的核心部分。然而,尽管存在多个法律数据集,但目前还没有专门针对推理任务的数据集。我们通过引入公司治理推理基准测试(CHANCERY),关注法律环境的一个特定方面,以测试模型对高管/董事会/股东提出的行动是否符合公司治理章程的推理能力。该基准测试首创了一种针对语言模型的公司治理推理测试——模拟现实世界的公司治理法。该基准测试包括公司章程(一组管理契约)和一项高管行动提案。模型的任务是二分类任务之一:推理行动是否符合章程中的规则。我们遵循公司治理的既定原则创建了这一基准测试,包括24项具体的公司治理原则和从包含1万份真实公司章程的总数据集中挑选出的79份代表不同行业的章程。对最新推理模型的评估证实了该基准测试的难度,如Claude 3.7 Sonnet和GPT-4o等模型分别实现了64.5%和75.2%的准确率。推理代理表现出卓越的性能,基于ReAct和CodeAct框架的代理分别得分76.1%和78.1%,这进一步证实了要在基准测试中获得高分需要先进的法律推理能力。我们还分析了当前推理模型面临困难的类型的问题,揭示了尖端模型的法律推理能力。
论文及项目相关链接
Summary
本文介绍了一个企业治理推理基准测试(CHANCERY),旨在测试模型对企业治理章程中董事、股东和执行层行为的合规性判断能力。此基准测试采用现实企业治理法律原则,包含了企业章程和一份高管行动提案。模型的任务是对行动是否符合章程规定进行二元分类判断。评估显示,当前先进的推理模型在该基准测试中表现尚待提升,而具备特定框架的推理代理表现较好。同时,文章还分析了当前推理模型面临的问题类型,揭示了其对先进模型法律推理能力的深刻见解。
**Key Takeaways**
1. 法律是自然语言处理(NLP)应用中的热门领域,但现有的法律数据集尚未专注于推理任务。
2. 引入了一个全新的企业治理推理基准测试(CHANCERY),用于评估模型判断企业治理章程中行为合规性的能力。
3. 该基准测试包含企业章程和一份高管行动提案,模型需判断行动是否符合章程规定。
4. 当前先进的推理模型在该基准测试中表现有待提高,而特定框架的推理代理表现较好。
5. 企业治理推理基准测试遵循现实企业治理法律原则,具有实际应用场景价值。
6. 文章分析了推理模型面临的问题类型,揭示了其法律推理能力的弱点。
点此查看论文截图


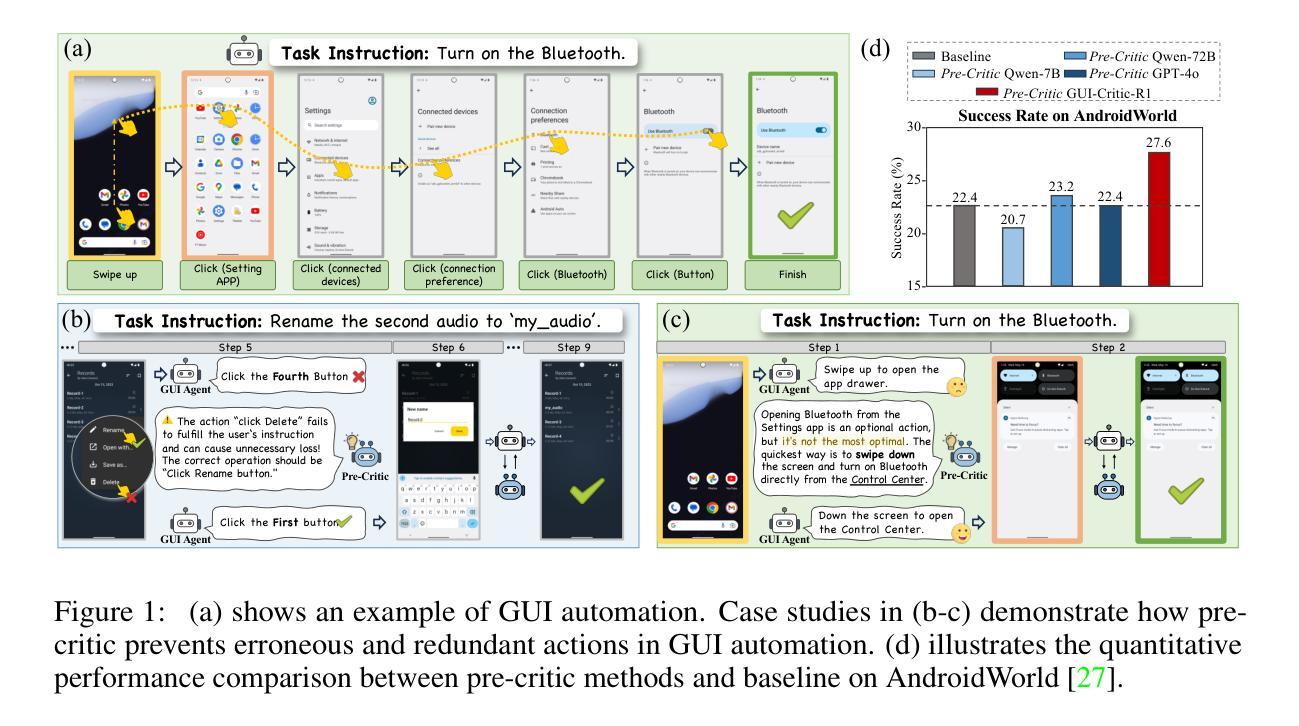
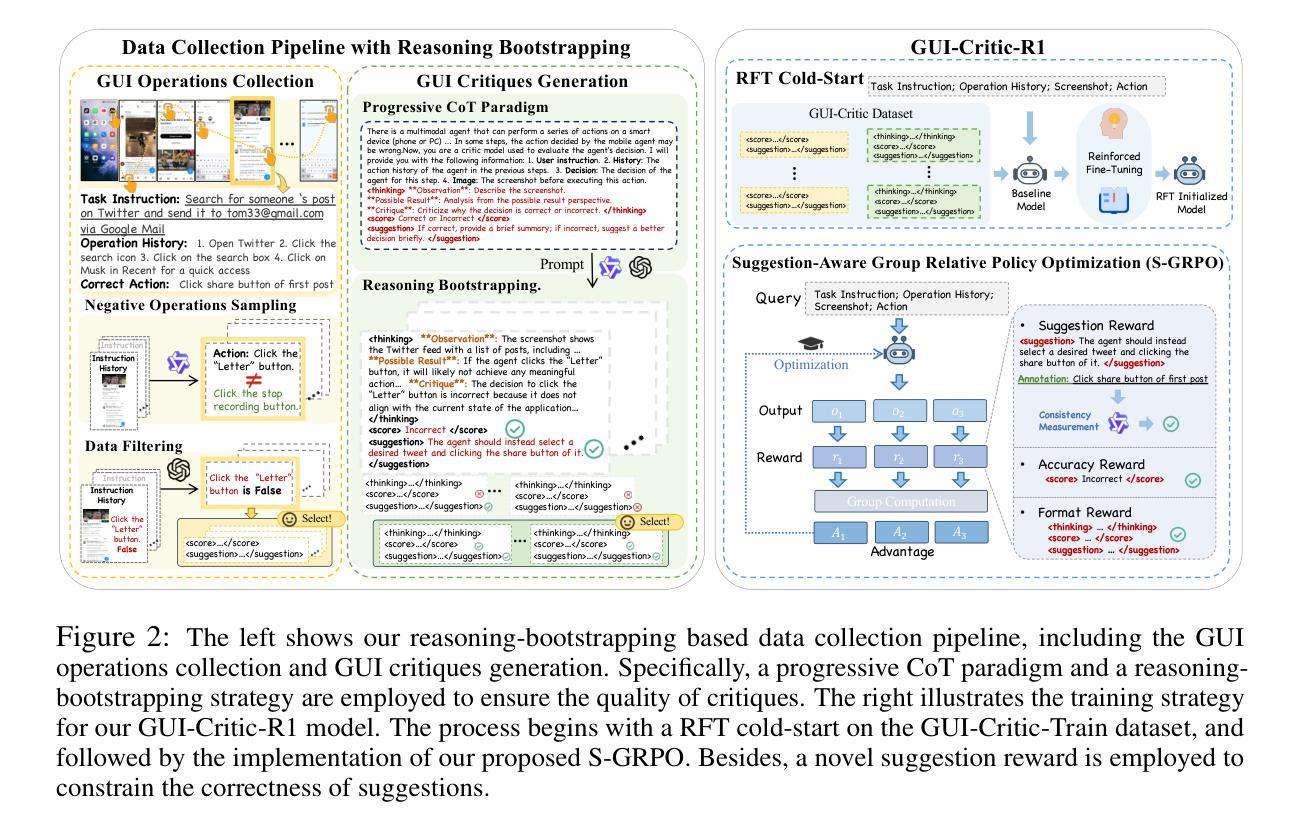
Look Before You Leap: A GUI-Critic-R1 Model for Pre-Operative Error Diagnosis in GUI Automation
Authors:Yuyang Wanyan, Xi Zhang, Haiyang Xu, Haowei Liu, Junyang Wang, Jiabo Ye, Yutong Kou, Ming Yan, Fei Huang, Xiaoshan Yang, Weiming Dong, Changsheng Xu
In recent years, Multimodal Large Language Models (MLLMs) have been extensively utilized for multimodal reasoning tasks, including Graphical User Interface (GUI) automation. Unlike general offline multimodal tasks, GUI automation is executed in online interactive environments, necessitating step-by-step decision-making based on real-time status of the environment. This task has a lower tolerance for decision-making errors at each step, as any mistakes may cumulatively disrupt the process and potentially lead to irreversible outcomes like deletions or payments. To address these issues, we introduce a pre-operative critic mechanism that provides effective feedback prior to the actual execution, by reasoning about the potential outcome and correctness of actions. Specifically, we propose a Suggestion-aware Gradient Relative Policy Optimization (S-GRPO) strategy to construct our pre-operative critic model GUI-Critic-R1, incorporating a novel suggestion reward to enhance the reliability of the model’s feedback. Furthermore, we develop a reasoning-bootstrapping based data collection pipeline to create a GUI-Critic-Train and a GUI-Critic-Test, filling existing gaps in GUI critic data. Static experiments on the GUI-Critic-Test across both mobile and web domains reveal that our GUI-Critic-R1 offers significant advantages in critic accuracy compared to current MLLMs. Dynamic evaluation on GUI automation benchmark further highlights the effectiveness and superiority of our model, as evidenced by improved success rates and operational efficiency.
近年来,多模态大型语言模型(MLLMs)已被广泛应用于多模态推理任务,包括图形用户界面(GUI)自动化。不同于一般的离线多模态任务,GUI自动化是在在线互动环境中执行,需要根据环境的实时状态进行一步一步的决策。此任务对每一步的决策错误容忍度较低,因为任何错误都可能累积并破坏过程,并可能导致不可逆的结果,如删除或付款。为了解决这些问题,我们引入了一种术前批评机制,通过推理潜在的结果和行动的正确性,在实际执行之前提供有效的反馈。具体来说,我们提出了一个建议感知梯度相对策略优化(S-GRPO)策略来构建我们的术前批评模型GUI-Critic-R1,结合一种新的建议奖励来提高模型反馈的可靠性。此外,我们开发了一个基于推理引导的数据收集管道来创建GUI-Critic-Train和GUI-Critic-Test,以填补现有GUI评论家数据中的空白。在移动和网络领域的GUI-Critic-Test上的静态实验表明,我们的GUI-Critic-R1在评论家准确性方面提供了显著的优势,与当前的多模态大型语言模型相比。在GUI自动化基准测试上的动态评估进一步突出了我们模型的有效性和优越性,提高了成功率和操作效率。
论文及项目相关链接
Summary
本文介绍了多模态大型语言模型(MLLMs)在图形用户界面(GUI)自动化中的最新应用。为提高在线互动环境中每一步决策的正确性,降低累积错误的风险,提出一种术前批评机制,通过预测潜在结果和行动的正确性来提供有效反馈。采用建议奖励的策略优化术前批评模型GUI-Critic-R1的可靠性。此外,建立基于推理引导的数据收集管道,创建GUI-Critic-Train和GUI-Critic-Test数据集,填补GUI批评数据的空白。实验结果表明,GUI-Critic-R1在批评精度上较当前MLLMs有显著优势,并在GUI自动化基准测试中验证了其有效性和优越性。
Key Takeaways
- 多模态大型语言模型(MLLMs)已广泛应用于包括GUI自动化在内的多模态推理任务。
- GUI自动化需在在线互动环境中进行,要求基于实时环境的状况进行逐步决策。
- 提出一种术前批评机制,通过预测潜在结果和行动的正确性提供有效反馈。
- 采用建议奖励的策略优化GUI-Critic-R1模型。
- 建立基于推理引导的数据收集管道,创建GUI-Critic数据集以填补现有空白。
- GUI-Critic-R1在批评精度上较当前MLLMs有优势。
点此查看论文截图

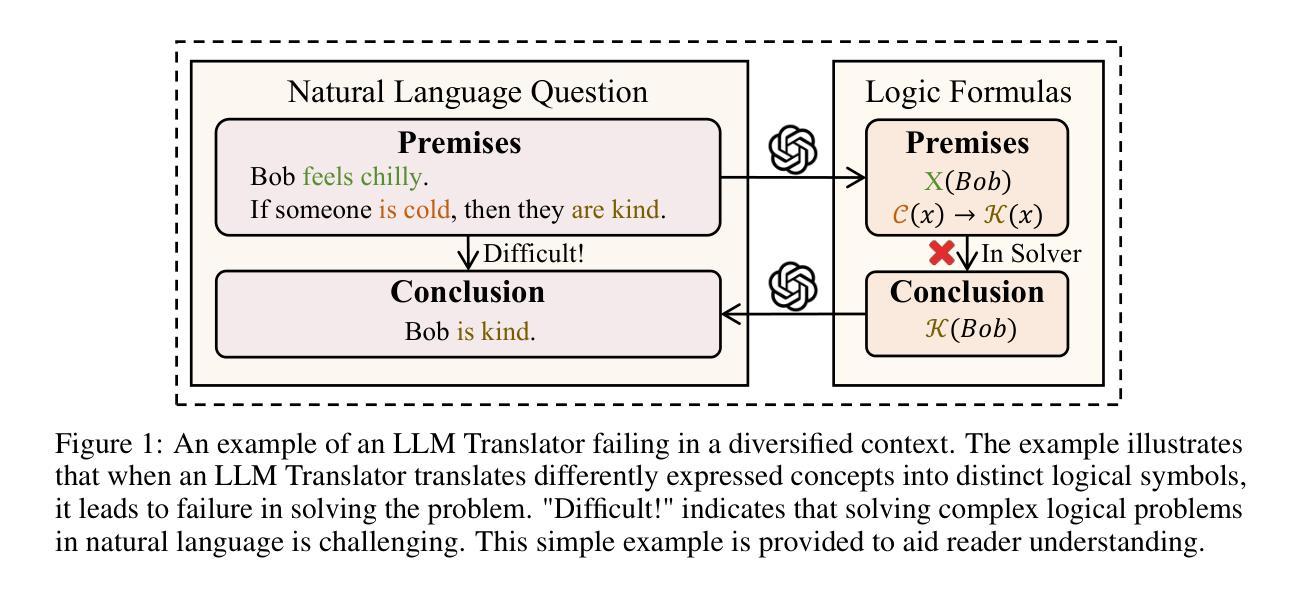
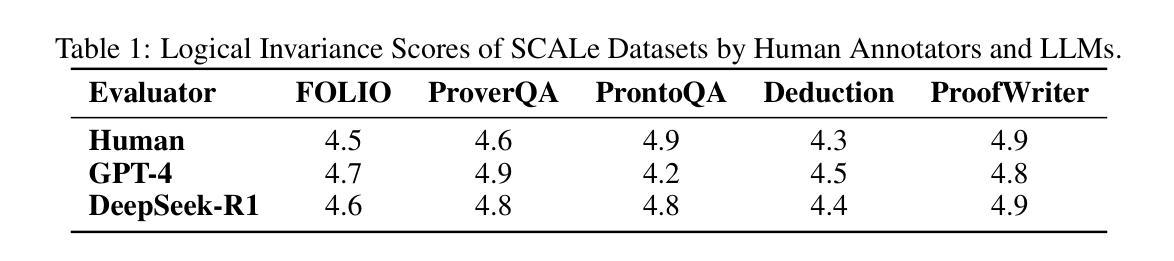
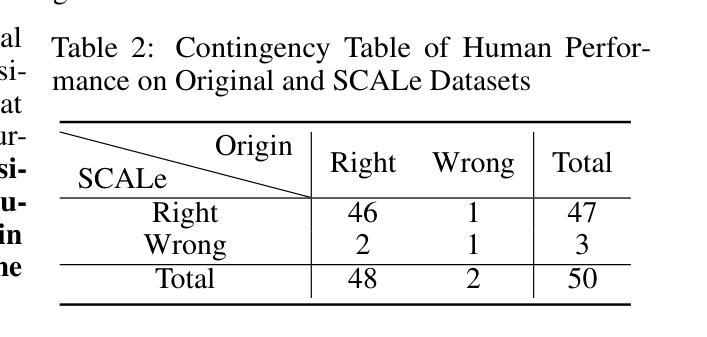
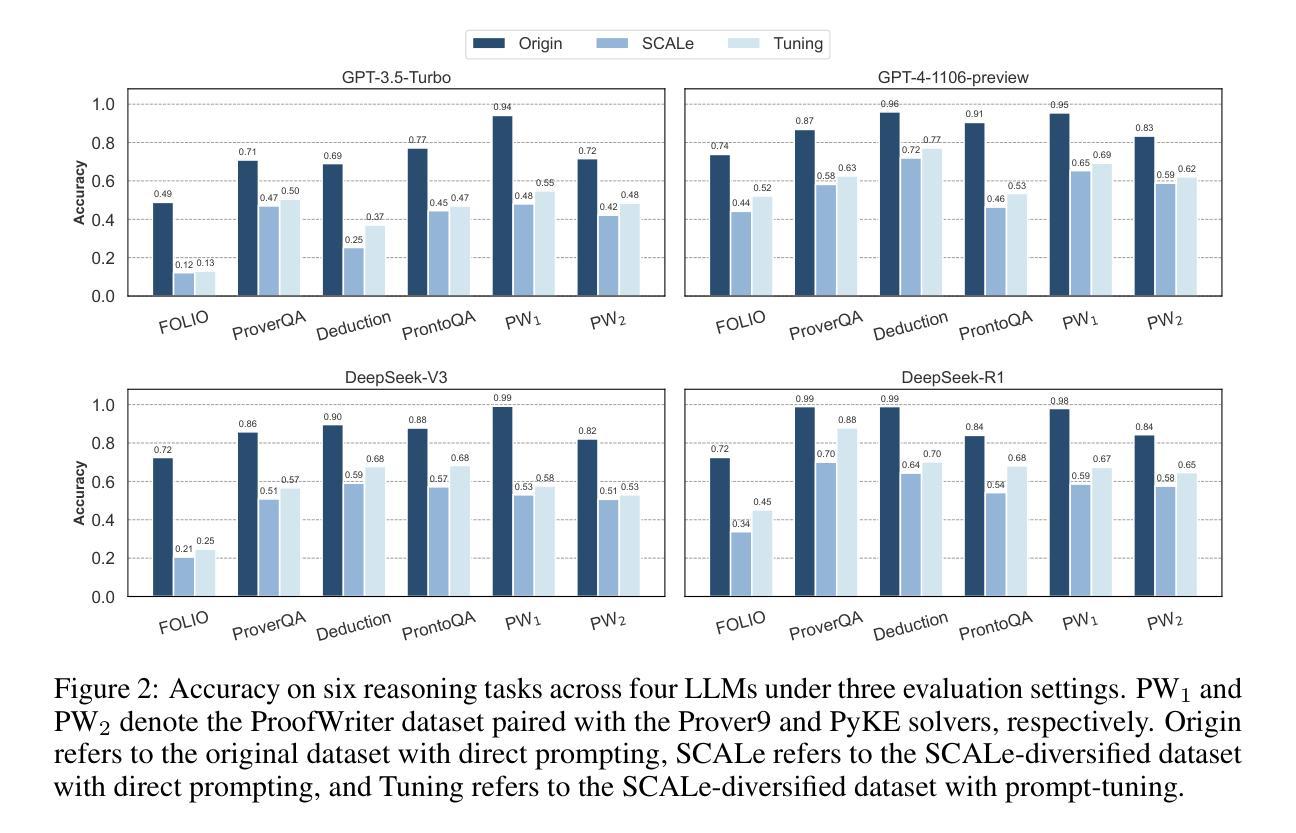
Are LLMs Reliable Translators of Logical Reasoning Across Lexically Diversified Contexts?
Authors:Qingchuan Li, Jiatong Li, Zirui Liu, Mingyue Cheng, Yuting Zeng, Qi Liu, Tongxuan Liu
Neuro-symbolic approaches combining large language models (LLMs) with solvers excels in logical reasoning problems need long reasoning chains. In this paradigm, LLMs serve as translators, converting natural language reasoning problems into formal logic formulas. Then reliable symbolic solvers return correct solutions. Despite their success, we find that LLMs, as translators, struggle to handle lexical diversification, a common linguistic phenomenon, indicating that LLMs as logic translators are unreliable in real-world scenarios. Moreover, existing logical reasoning benchmarks lack lexical diversity, failing to challenge LLMs’ ability to translate such text and thus obscuring this issue. In this work, we propose SCALe, a benchmark designed to address this significant gap through logic-invariant lexical diversification. By using LLMs to transform original benchmark datasets into lexically diversified but logically equivalent versions, we evaluate LLMs’ ability to consistently map diverse expressions to uniform logical symbols on these new datasets. Experiments using SCALe further confirm that current LLMs exhibit deficiencies in this capability. Building directly on the deficiencies identified through our benchmark, we propose a new method, MenTaL, to address this limitation. This method guides LLMs to first construct a table unifying diverse expressions before performing translation. Applying MenTaL through in-context learning and supervised fine-tuning (SFT) significantly improves the performance of LLM translators on lexically diversified text. Our code is now available at https://github.com/wufeiwuwoshihua/LexicalDiver.
神经符号方法结合了大型语言模型(LLM)和解算器,在需要长推理链的逻辑推理问题中表现出色。在此范式中,LLM充当翻译,将自然语言推理问题转换为正式的逻辑公式。然后可靠的符号解算器返回正确的解决方案。尽管它们取得了成功,但我们发现LLM作为翻译在处理词汇多样化这一常见语言现象时遇到了困难,这表明LLM作为逻辑翻译在真实场景中是不可靠的。此外,现有的逻辑推理基准测试缺乏词汇多样性,未能挑战LLM翻译此类文本的能力,从而掩盖了这个问题。在这项工作中,我们提出了SCALE基准测试,旨在通过逻辑不变的词汇多样化来解决这一重要差距。通过使用LLM将原始基准数据集转换为词汇丰富但逻辑等价的版本,我们在这些新数据集上评估了LLM将各种表达一致地映射到统一逻辑符号的能力。使用SCALE基准测试的实验进一步证实,当前LLM在这方面存在缺陷。通过我们的基准测试确定的不足,我们提出了一种新的方法MenTaL来解决这一限制。此方法引导LLM在翻译之前首先构建一个统一各种表达的表格。通过上下文学习和监督微调(SFT)应用MenTaL,可以显着提高LLM翻译在词汇丰富文本上的表现。我们的代码现已在https://github.com/wufeiwuwoshihua/LexicalDiver上可用。
论文及项目相关链接
Summary
本文探讨了神经符号方法结合大型语言模型(LLMs)和求解器在处理需要长推理链的逻辑推理问题时的优势与不足。文中指出,LLMs作为翻译者,在应对词汇多样化这一常见语言现象时表现不佳。为此,本文提出了一种名为SCALe的基准测试,旨在通过逻辑不变的词汇多样化来解决这一难题,评估LLMs在不同表达形式转换为逻辑符号的能力。实验结果表明,当前LLMs在此能力上存在缺陷。为解决此问题,本文提出了MenTaL方法,通过构建统一不同表达的表格来进行翻译,显著提高了LLMs在词汇丰富文本上的翻译性能。
Key Takeaways
- 神经符号方法结合了大型语言模型(LLMs)和求解器,擅长处理需要长推理链的逻辑推理问题。
- LLMs在作为逻辑翻译器时,处理词汇多样化存在困难,这在现实场景中是常见的语言现象。
- 现有逻辑推理基准测试缺乏词汇多样性,无法充分挑战LLMs的翻译能力,从而掩盖了这一问题。
- 本文提出了SCALe基准测试,旨在通过逻辑不变的词汇多样化来评估LLMs的能力。
- 实验结果表明,当前LLMs在将不同表达转换为逻辑符号方面存在缺陷。
- 为解决LLMs在词汇丰富文本翻译上的不足,本文提出了MenTaL方法,通过构建统一表达表格进行翻译。
点此查看论文截图