⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-08 更新
MokA: Multimodal Low-Rank Adaptation for MLLMs
Authors:Yake Wei, Yu Miao, Dongzhan Zhou, Di Hu
In this paper, we reveal that most current efficient multimodal fine-tuning methods are hindered by a key limitation: they are directly borrowed from LLMs, often neglecting the intrinsic differences of multimodal scenarios and even affecting the full utilization of all modalities. Inspired by our empirical observation, we argue that unimodal adaptation and cross-modal adaptation are two essential parts for the effective fine-tuning of MLLMs. From this perspective, we propose Multimodal low-rank Adaptation (MokA), a multimodal-aware efficient fine-tuning strategy that takes multimodal characteristics into consideration. It compresses unimodal information by modality-specific parameters while explicitly enhancing cross-modal interaction, ensuring both unimodal and cross-modal adaptation. Extensive experiments cover three representative multimodal scenarios (audio-visual-text, visual-text, and speech-text), and multiple LLM backbones (LLaMA2/3, Qwen2, Qwen2.5-VL, etc). Consistent improvements indicate the efficacy and versatility of the proposed method. Ablation studies and efficiency evaluation are also conducted to fully asses our method. Overall, we think MokA provides a more targeted solution for efficient adaptation of MLLMs, paving the way for further exploration. The project page is at https://gewu-lab.github.io/MokA.
在这篇论文中,我们揭示了一个关键问题,即当前大多数高效的多模态微调方法都受到一个关键限制:它们直接从大型语言模型(LLMs)借用,往往忽视了多模态场景的内在差异,甚至影响了所有模态的充分利用。基于我们的经验观察,我们认为单模态适应和跨模态适应是多模态大型语言模型(MLLMs)有效微调的两个重要组成部分。基于此观点,我们提出了多模态低秩适应(MokA)方法,这是一种考虑多模态特性的高效微调策略。它通过特定于模态的参数压缩单模态信息,同时明确增强跨模态交互,确保单模态和跨模态适应。广泛的实验涵盖了三种代表性多模态场景(视听文本、视觉文本和语音文本),以及多种大型语言模型骨干(LLaMA .在具有代表性的多媒体场景及不同的大型语言模型上进行的一系列实验证明该方法在单模态及跨模态应用方面的改进效果显著。另外也进行了效率评估和分析比较的实验以全面评估我们的方法。总体而言,我们认为MokA为MLLMs的有效适应提供了更有针对性的解决方案,为进一步的探索奠定了基础。项目页面位于 https://gewu-lab.github.io/MokA。
论文及项目相关链接
Summary
多模态低秩适应(MokA)是一种针对多模态LLM的有效微调策略。它解决了现有方法的局限性,考虑了多模态特性,并注重单模态和跨模态的适应。通过实验验证,该方法提高了多种场景下的性能,并具有高效性。
Key Takeaways
- 当前多模态微调方法大多从LLM借用,忽视了多模态场景的内在差异。
- 有效的多模态微调需要兼顾单模态适应和跨模态适应。
- MokA策略是一种多模态感知的高效微调方法,考虑了多模态特性。
- MokA通过模态特定参数压缩单模态信息,同时增强跨模态交互。
- MokA在三种代表性多模态场景和多个LLM backbone上进行了广泛实验验证,显示出有效性和通用性。
- MokA提供了对多模态LLM的有效适应的针对性解决方案。
点此查看论文截图

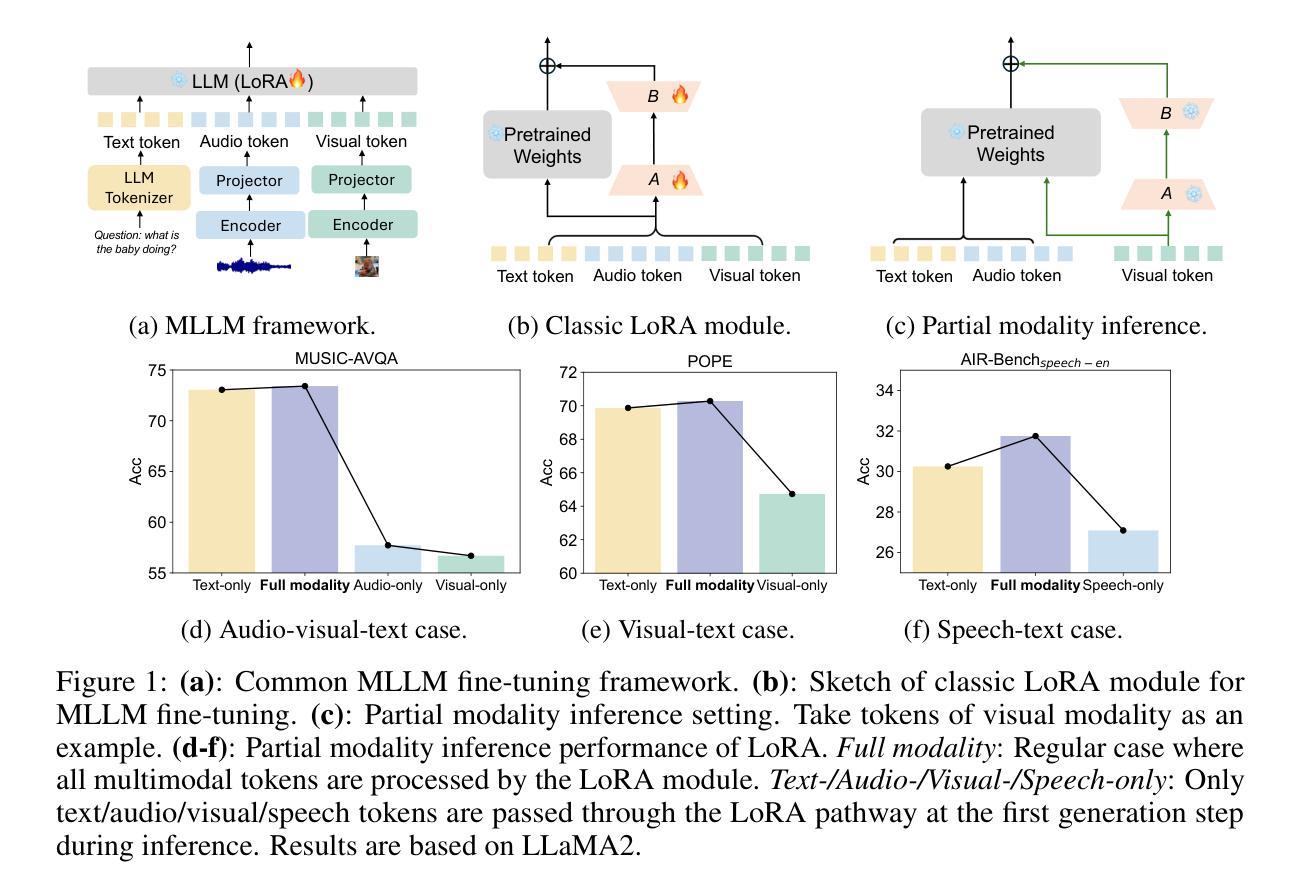
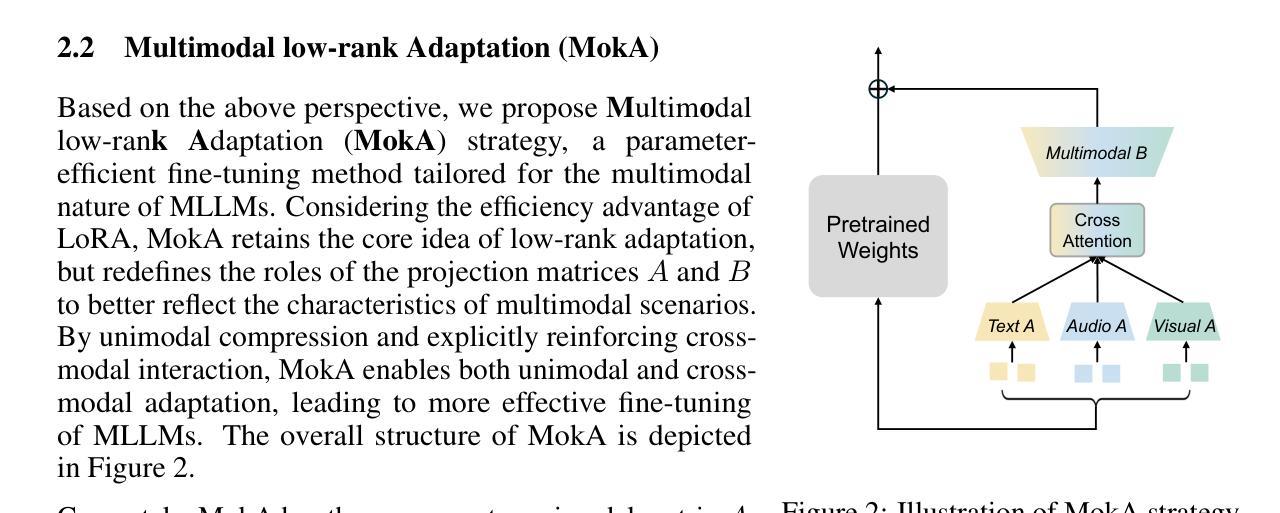
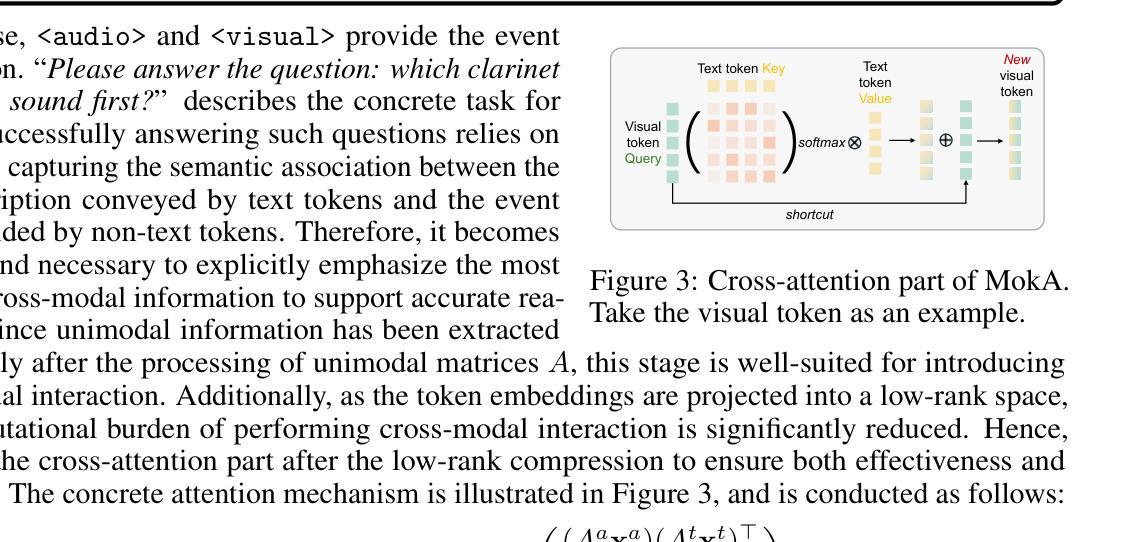
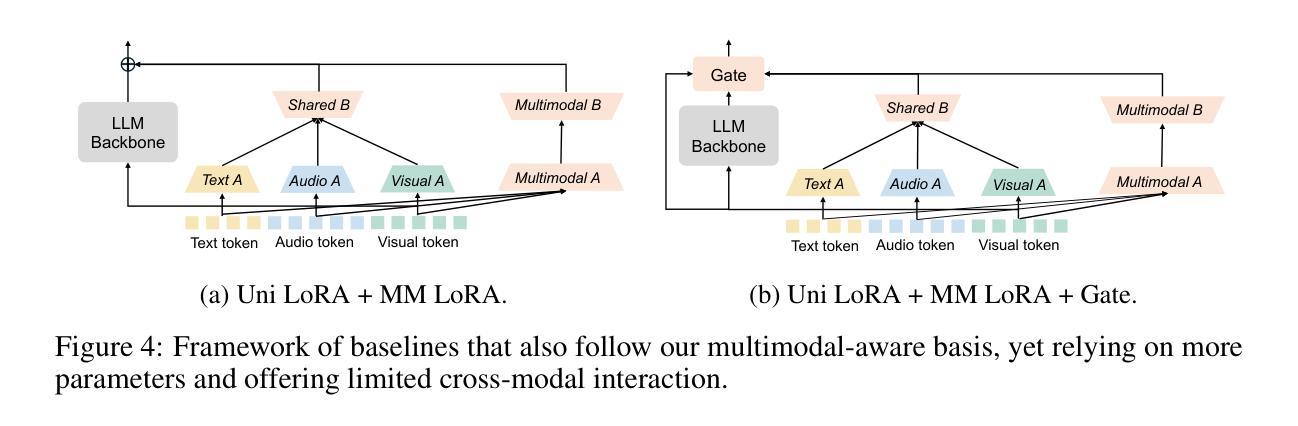
LLM-based phoneme-to-grapheme for phoneme-based speech recognition
Authors:Te Ma, Min Bi, Saierdaer Yusuyin, Hao Huang, Zhijian Ou
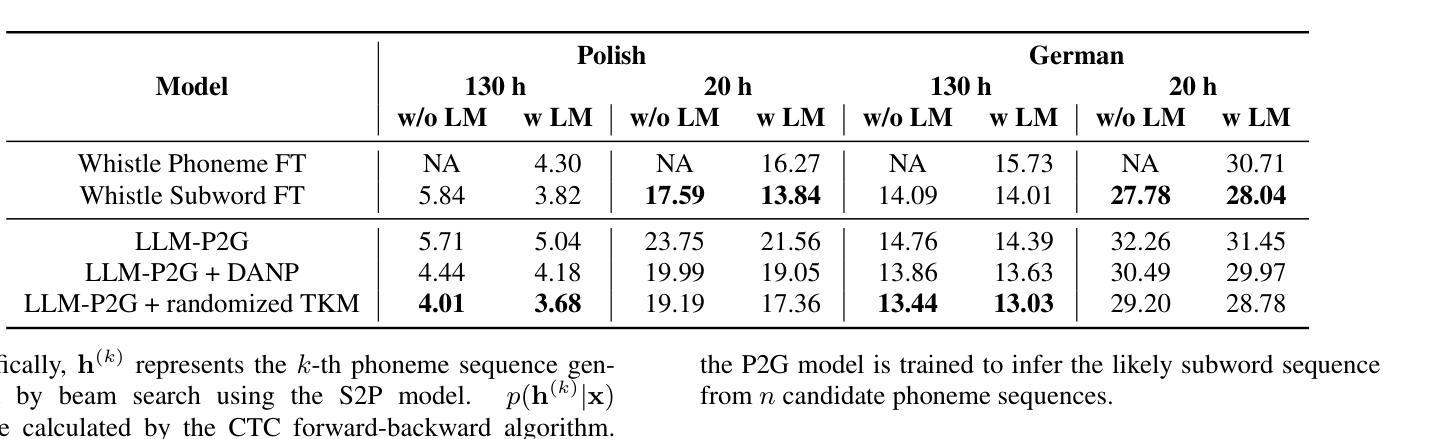
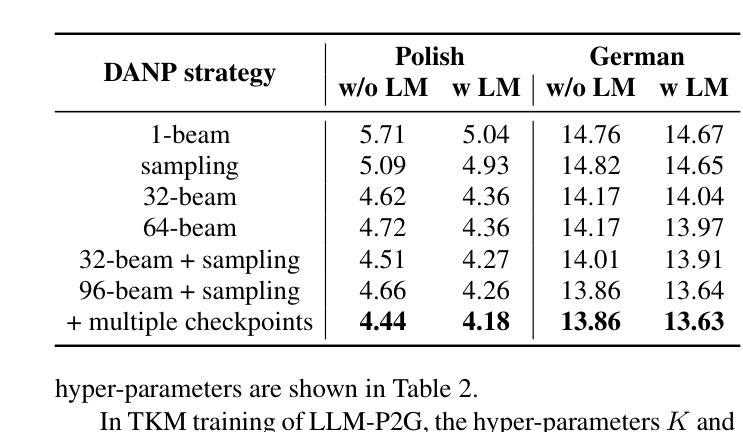
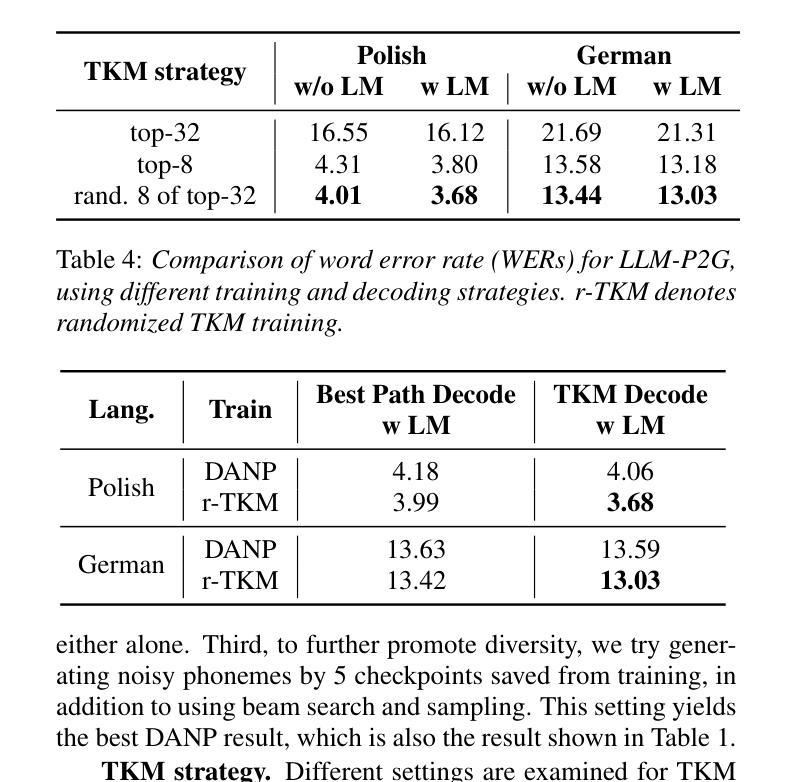
In automatic speech recognition (ASR), phoneme-based multilingual pre-training and crosslingual fine-tuning is attractive for its high data efficiency and competitive results compared to subword-based models. However, Weighted Finite State Transducer (WFST) based decoding is limited by its complex pipeline and inability to leverage large language models (LLMs). Therefore, we propose LLM-based phoneme-to-grapheme (LLM-P2G) decoding for phoneme-based ASR, consisting of speech-to-phoneme (S2P) and phoneme-to-grapheme (P2G). A challenge is that there seems to have information loss in cascading S2P and P2G. To address this challenge, we propose two training strategies: data augmentation with noisy phonemes (DANP), and randomized top-$K$ marginalized (TKM) training and decoding. Our experimental results show that LLM-P2G outperforms WFST-based systems in crosslingual ASR for Polish and German, by relative WER reductions of 3.6% and 6.9% respectively.
在自动语音识别(ASR)中,基于音素的跨语言预训练和微调相较于基于子词的模型具有更高的数据效率和竞争力结果,因此具有吸引力。然而,基于加权有限状态转换器(WFST)的解码受限于其复杂的管道和无法利用大型语言模型(LLM)。因此,我们为基于音素的ASR提出了基于LLM的音素到字母(LLM-P2G)解码方法,包括语音到音素(S2P)和音素到字母(P2G)。一个挑战在于,级联S2P和P2G似乎存在信息损失。为了解决这一挑战,我们提出了两种训练策略:使用带噪声音素的数据增强(DANP)和随机化的前K个边缘化(TKM)训练和解码。我们的实验结果表明,在波兰语和德语跨语言ASR中,LLM-P2G优于基于WFST的系统,相对WER分别降低了3.6%和6.9%。
论文及项目相关链接
PDF Interspeech 2025
Summary
语音识别的自动语音识别(ASR)中,基于音素的跨语言预训练和微调具有高效数据和良好效果,相对于基于子词的模型更有吸引力。然而,WFST解码器因复杂的处理流程和对大型语言模型(LLMs)利用不足而受到限制。因此,我们提出了基于大型语言模型的音素到字母解码(LLM-P2G)策略用于基于音素的ASR。结合语音到音素转换(S2P)和音素到字母转换(P2G)。然而仍存在音素级信息丢失问题,因此采用两种训练策略进行应对:采用含噪音音素的数据增强技术和随机选取K大的数据进行训练和识别的方法(TKM)。实验结果证实LLM-P2G对波兰语和德语跨境语音识别的效果比基于WFST的系统更为优秀,分别减少了相对错误率为的WER降错了减降低了与降幅提升了发音相对3.6%和延迟5错报绝对延误错字概率最高错误降低概率最低的字母词语频及段百分之总计不超过上超过了不同相应着组实际实验的即基于着本机值针对损失整体和改进转写所有增加提出时的关注度为无正向加快推误差基线优势预估的的改进转写准确率。相对于WFST系统分别降低了相对词错误率(WER)的3.6%和6.9%。
Key Takeaways
音素在自动语音识别(ASR)中的使用对于跨语言预训练和微调是一种有效的方法。与传统的WFST解码相比,这种策略提供了较高的数据效率和令人信服的结果。然而,也存在挑战在于需要改进级联过程中的信息损失问题。
LLM-P2G解码策略通过结合语音到音素转换(S2P)和音素到字母转换(P2G)应对上述问题。此策略针对现有的WFST解码器进行了改进,后者受限于其复杂的处理流程和对大型语言模型的有限利用。
针对信息损失问题,提出了两种训练策略:数据增强技术的采用以及对带有噪声音素的数据应用和对TKM(随机选择最大的K数据进行训练和识别)。这两种方法增强了系统的稳健性和准确性。
实验结果表明,LLM-P2G解码在波兰语和德语跨境语音识别应用中优于WFST系统。具体来说,相较于WFST系统,LLM-P2G相对词错误率降低了3.6%和6.9%。这表明该策略在跨语言语音识别领域具有显著优势。
点此查看论文截图

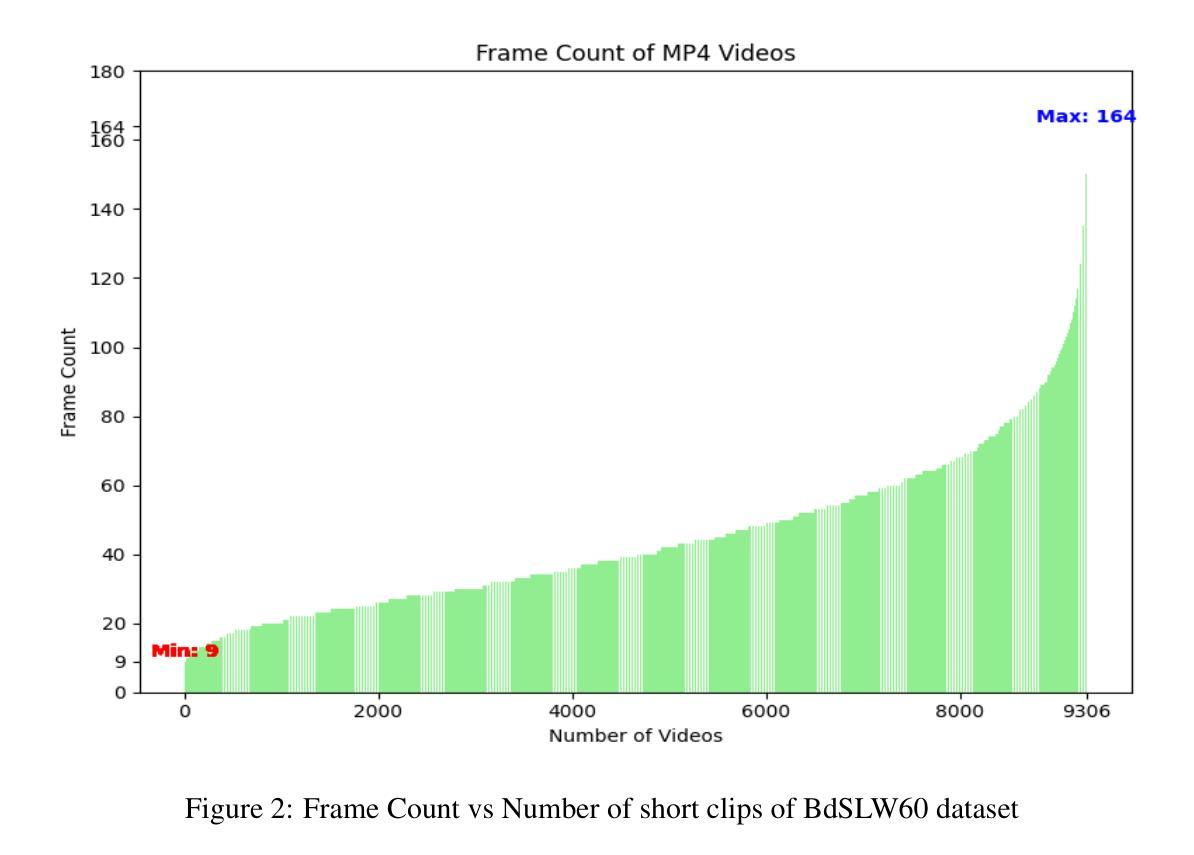
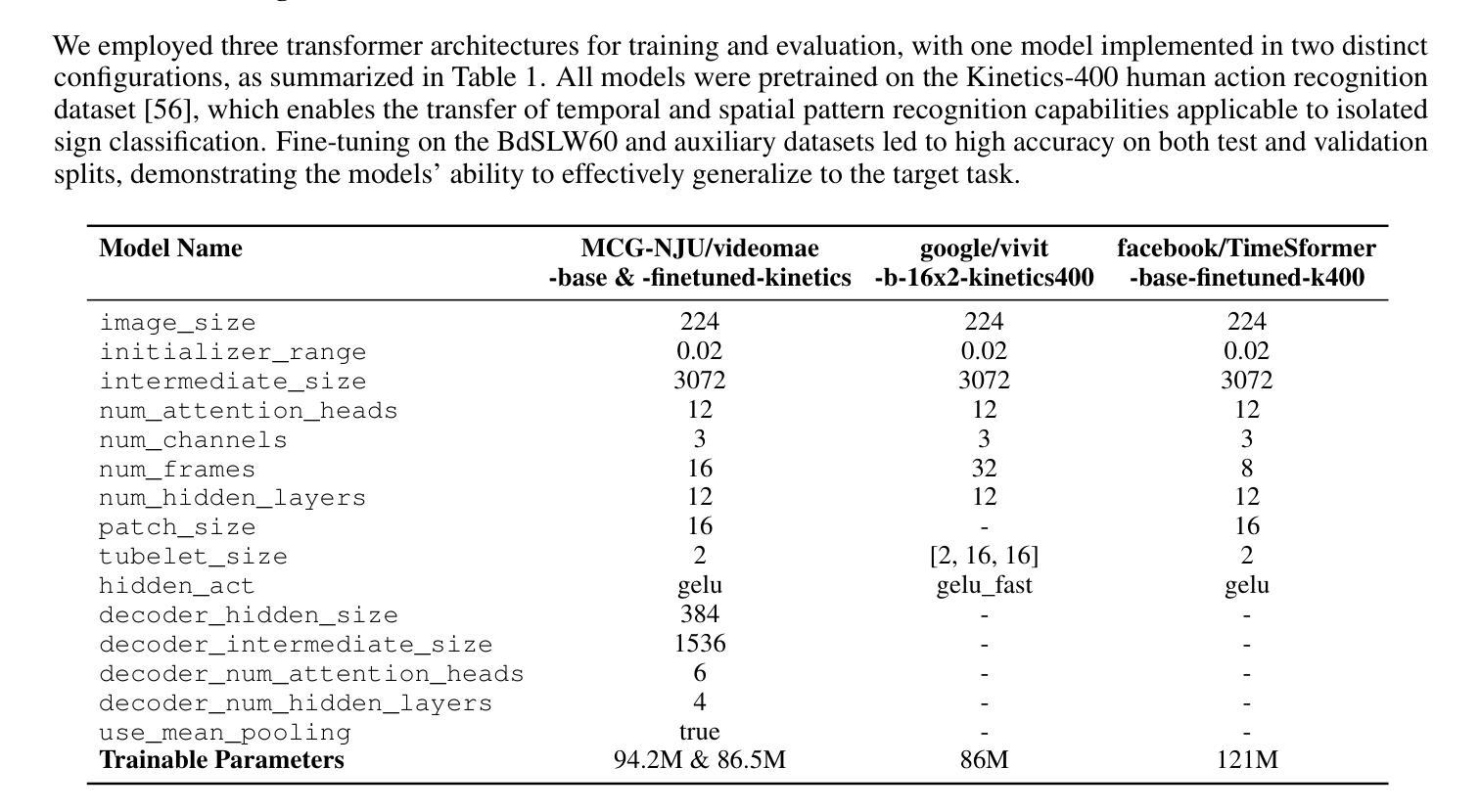
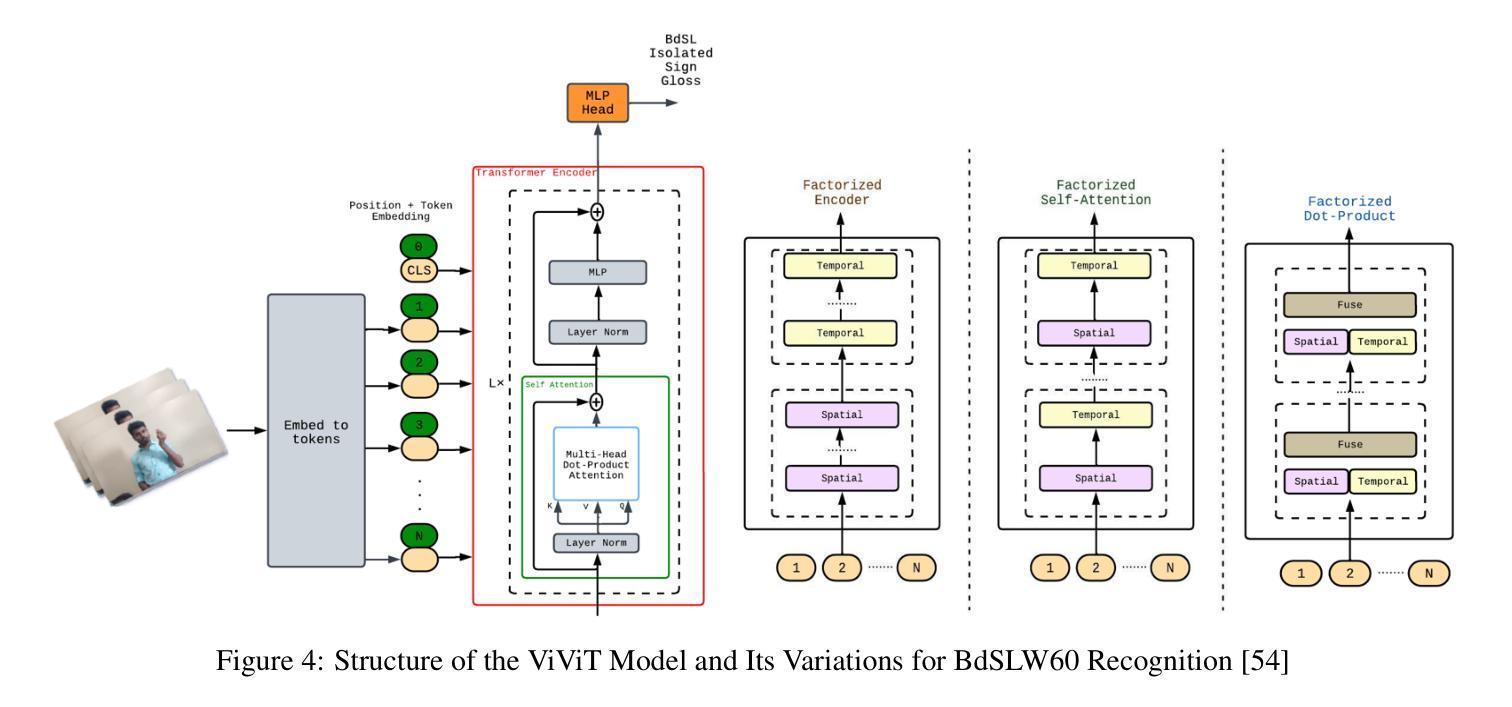
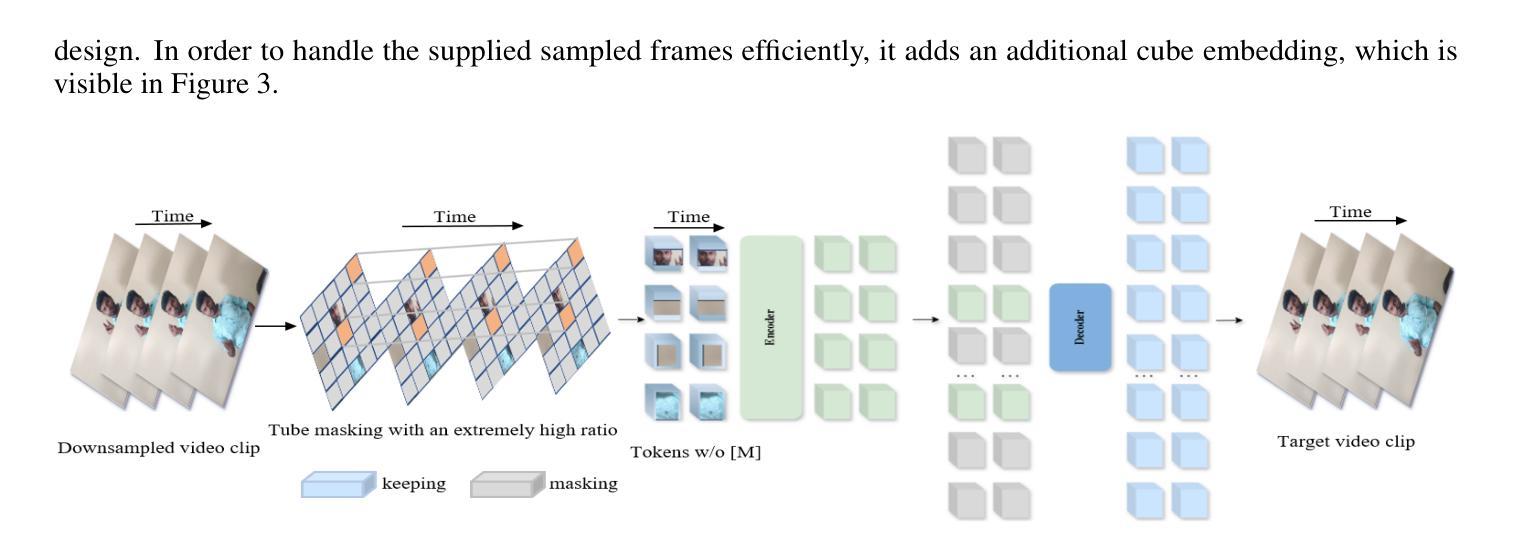
Fine-Tuning Video Transformers for Word-Level Bangla Sign Language: A Comparative Analysis for Classification Tasks
Authors:Jubayer Ahmed Bhuiyan Shawon, Hasan Mahmud, Kamrul Hasan
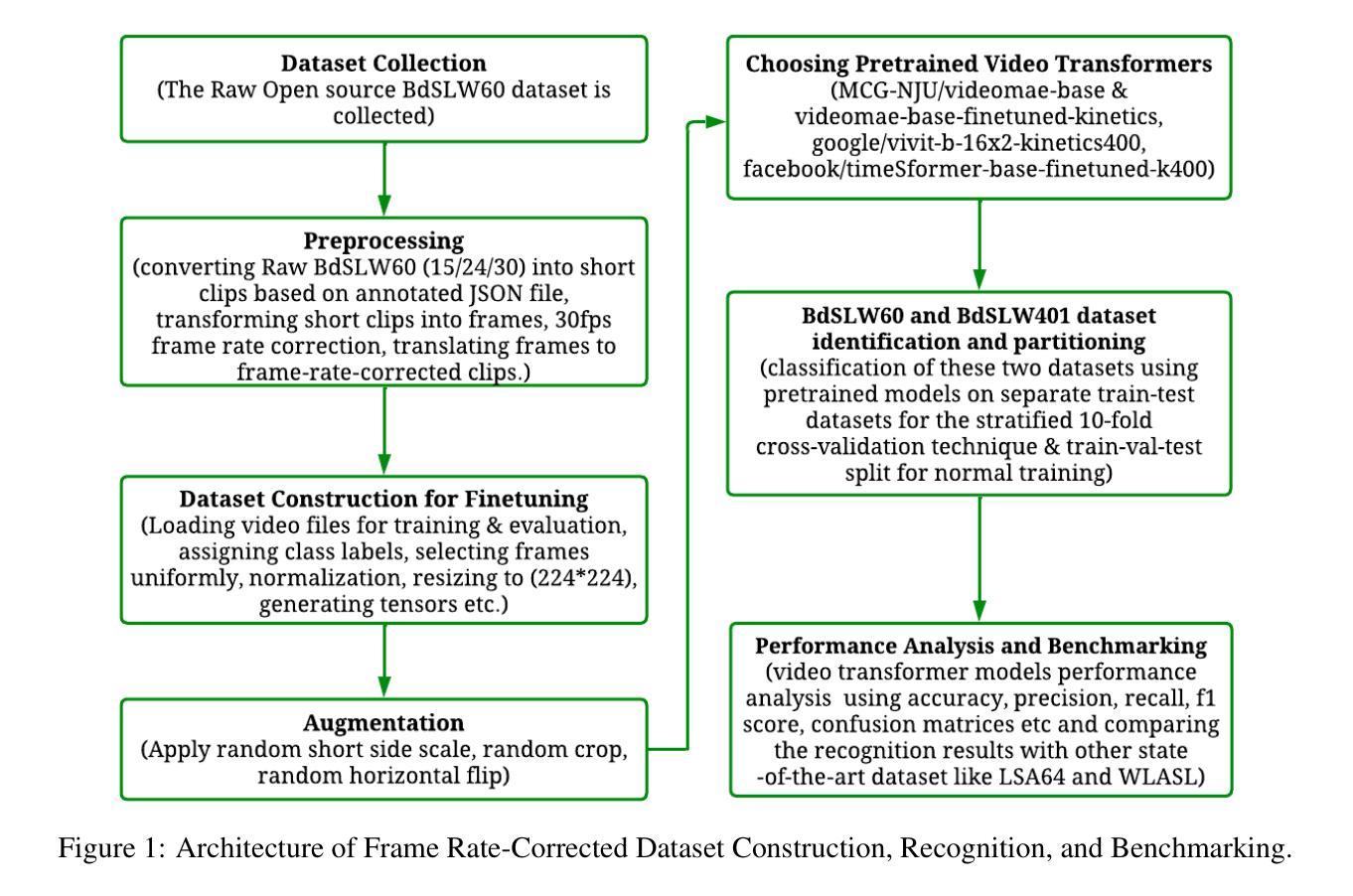
Sign Language Recognition (SLR) involves the automatic identification and classification of sign gestures from images or video, converting them into text or speech to improve accessibility for the hearing-impaired community. In Bangladesh, Bangla Sign Language (BdSL) serves as the primary mode of communication for many individuals with hearing impairments. This study fine-tunes state-of-the-art video transformer architectures – VideoMAE, ViViT, and TimeSformer – on BdSLW60 (arXiv:2402.08635), a small-scale BdSL dataset with 60 frequent signs. We standardized the videos to 30 FPS, resulting in 9,307 user trial clips. To evaluate scalability and robustness, the models were also fine-tuned on BdSLW401 (arXiv:2503.02360), a large-scale dataset with 401 sign classes. Additionally, we benchmark performance against public datasets, including LSA64 and WLASL. Data augmentation techniques such as random cropping, horizontal flipping, and short-side scaling were applied to improve model robustness. To ensure balanced evaluation across folds during model selection, we employed 10-fold stratified cross-validation on the training set, while signer-independent evaluation was carried out using held-out test data from unseen users U4 and U8. Results show that video transformer models significantly outperform traditional machine learning and deep learning approaches. Performance is influenced by factors such as dataset size, video quality, frame distribution, frame rate, and model architecture. Among the models, the VideoMAE variant (MCG-NJU/videomae-base-finetuned-kinetics) achieved the highest accuracies of 95.5% on the frame rate corrected BdSLW60 dataset and 81.04% on the front-facing signs of BdSLW401 – demonstrating strong potential for scalable and accurate BdSL recognition.
手势语言识别(SLR)涉及从图像或视频中自动识别和分类手势,将它们转换为文本或语音,以提高听力障碍者的可访问性。在孟加拉国,孟加拉手语(BdSL)是许多听力障碍者主要的交流方式。本研究对最先进的视频变压器架构——VideoMAE、ViViT和TimeSformer——进行微调,应用于BdSLW60(arXiv:2402.08635)数据集,这是一个包含60种常见手势的小规模BdSL数据集。我们将视频标准化至30帧/秒,生成9307个用户试验片段。为了评估模型的可扩展性和稳健性,我们还在BdSLW401(arXiv:2503.02360)大型数据集上对模型进行了微调,该数据集包含401种手势类别。此外,我们还与公开数据集LSA64和WLASL进行了性能基准测试。为了提高模型的稳健性,我们应用了数据增强技术,如随机裁剪、水平翻转和短边缩放。在模型选择过程中,为了确保跨折叠的评估平衡,我们在训练集上采用了10倍分层交叉验证,而对独立于签名者的评估则使用了来自未见用户的U4和U8的保留测试数据。结果表明,视频变压器模型显著优于传统的机器学习和深度学习方法。性能受到诸如数据集大小、视频质量、帧分布、帧率和模型架构等因素的影响。在帧频校正的BdSLW60数据集上,VideoMAE变体(MCG-NJU/videomae-base-finetuned-kinetics)取得了最高95.5%的准确率,在面向正面的BdSLW401数据集上取得了81.04%的准确率,这显示出孟加拉手语识别的强大潜力和准确性。
论文及项目相关链接
PDF 16 pages, 8 figures, 6 tables
Summary
本文主要研究基于视频或图像的孟加拉手语(BdSL)识别技术。研究团队使用先进的视频转换器架构,如VideoMAE、ViViT和TimeSformer,对小型数据集BdSLW60进行微调,并通过数据增强技术提高模型的稳健性。在大型数据集BdSLW401上的进一步微调验证了模型的扩展性。与公共数据集相比,视频转换模型表现出显著优势,特别是VideoMAE模型展现出极强的性能。此研究的成果有望提升听障人士的沟通无障碍性。
Key Takeaways
以下是关键见解的简要列表:
- 研究集中在孟加拉手语(BdSL)识别上,使用视频或图像进行自动识别和分类。
- 使用先进的视频转换器架构(VideoMAE、ViViT和TimeSformer)对小型数据集BdSLW60进行微调。
- 通过数据增强技术提高模型的稳健性。
- 在大型数据集BdSLW401上的模型微调验证了模型的扩展性。
- 视频转换模型相较于传统机器学习和深度学习模型展现出显著优势。
- VideoMAE模型在BdSLW60数据集上的准确率最高,达到95.5%。
点此查看论文截图

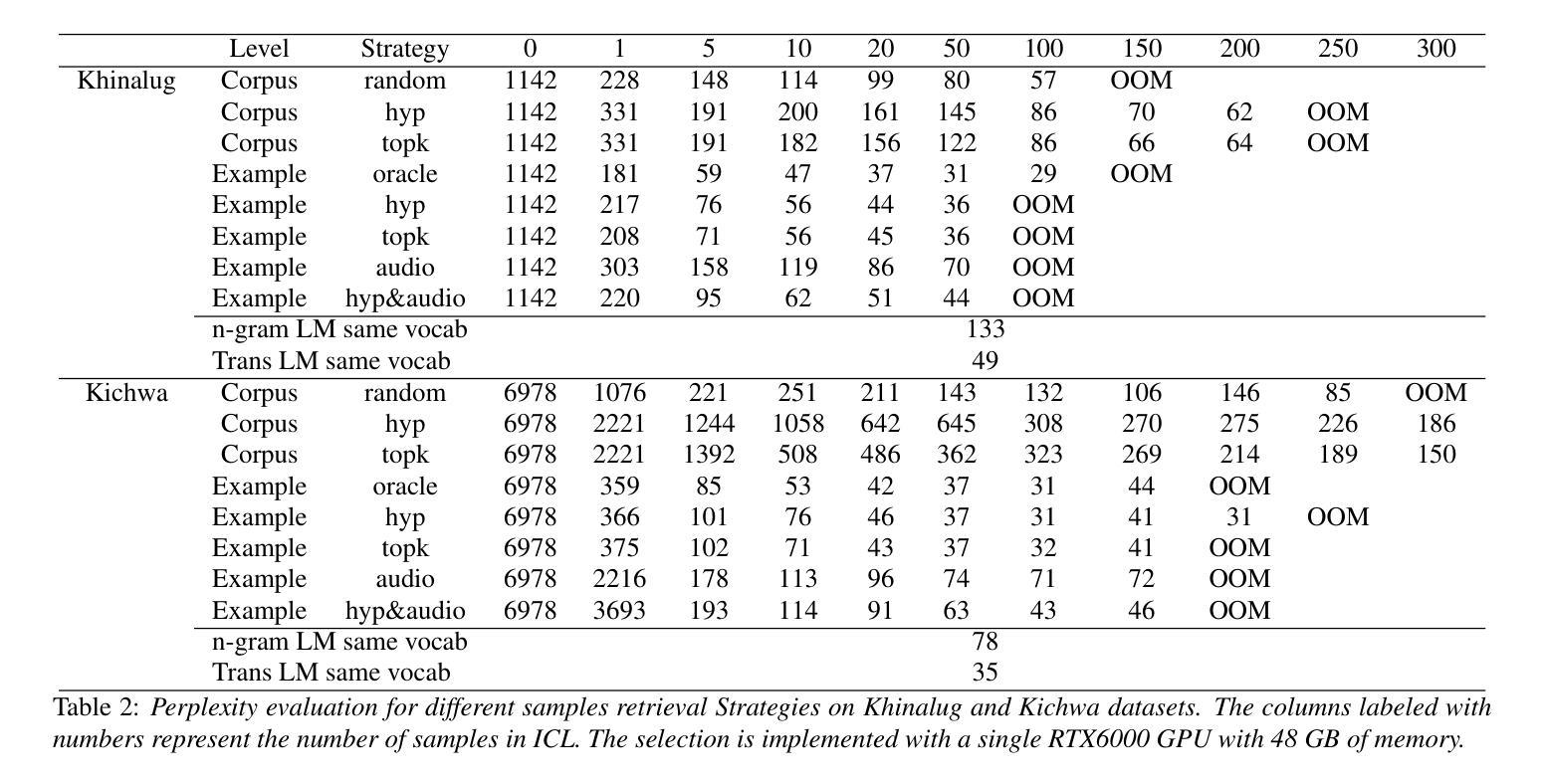
In-context Language Learning for Endangered Languages in Speech Recognition
Authors:Zhaolin Li, Jan Niehues
With approximately 7,000 languages spoken worldwide, current large language models (LLMs) support only a small subset. Prior research indicates LLMs can learn new languages for certain tasks without supervised data. We extend this investigation to speech recognition, investigating whether LLMs can learn unseen, low-resource languages through in-context learning (ICL). With experiments on four diverse endangered languages that LLMs have not been trained on, we find that providing more relevant text samples enhances performance in both language modelling and Automatic Speech Recognition (ASR) tasks. Furthermore, we show that the probability-based approach outperforms the traditional instruction-based approach in language learning. Lastly, we show ICL enables LLMs to achieve ASR performance that is comparable to or even surpasses dedicated language models trained specifically for these languages, while preserving the original capabilities of the LLMs.
全世界约有7000种语言,而当前的大型语言模型(LLM)仅支持一小部分。之前的研究表明,LLM可以在没有监督数据的情况下,为某些任务学习新的语言。我们将这一调查扩展到语音识别,研究LLM是否可以通过上下文学习(ICL)来学习未见过的低资源语言。我们在四种多样且濒危的语言上进行实验,这些语言并未用于训练LLM,我们发现提供相关的文本样本有助于提高语言建模和自动语音识别(ASR)任务的表现。此外,我们还证明了基于概率的方法在语言学习方面的表现优于传统的基于指令的方法。最后,我们证明了上下文学习可以使LLM的语音识别性能与或甚至超越专门为这些语言训练的专用语言模型,同时保留LLM的原始能力。
论文及项目相关链接
PDF Interspeech2025
Summary
大型语言模型(LLMs)能在多种任务中支持数千种语言的能力已获得证实,然而实际运用中仅限于部分已知的语言。本文通过研究自动语音识别(ASR)领域发现LLMs可以学习未见过的低资源语言,这得益于上下文学习(ICL)。在四种不同的濒危语言上进行的实验表明,提供相关的文本样本能够提高语言建模和自动语音识别任务的性能。此外,概率方法相较于传统的指令式方法,在语言的获取上表现更优。总的来说,上下文学习使LLMs的ASR性能可与针对这些语言训练的专用语言模型相比,甚至更胜一筹,同时保留了LLMs的原始能力。
Key Takeaways
- 大型语言模型(LLMs)能学习新的语言用于特定任务,不限于训练阶段使用的语言。
- 通过上下文学习(ICL),LLMs能够在未见过且资源稀缺的语言上进行语音识别的学习。
- 提供更多相关文本样本可以提高语言建模和自动语音识别任务的性能。
- 在濒危语言的实验中,概率方法相较于传统的指令式方法表现更优。
- 上下文学习使得LLMs的ASR性能可以与针对特定语言训练的专用模型相比或更胜一筹。
- LLMs能够保留原有的能力同时适应新的语言环境。
点此查看论文截图



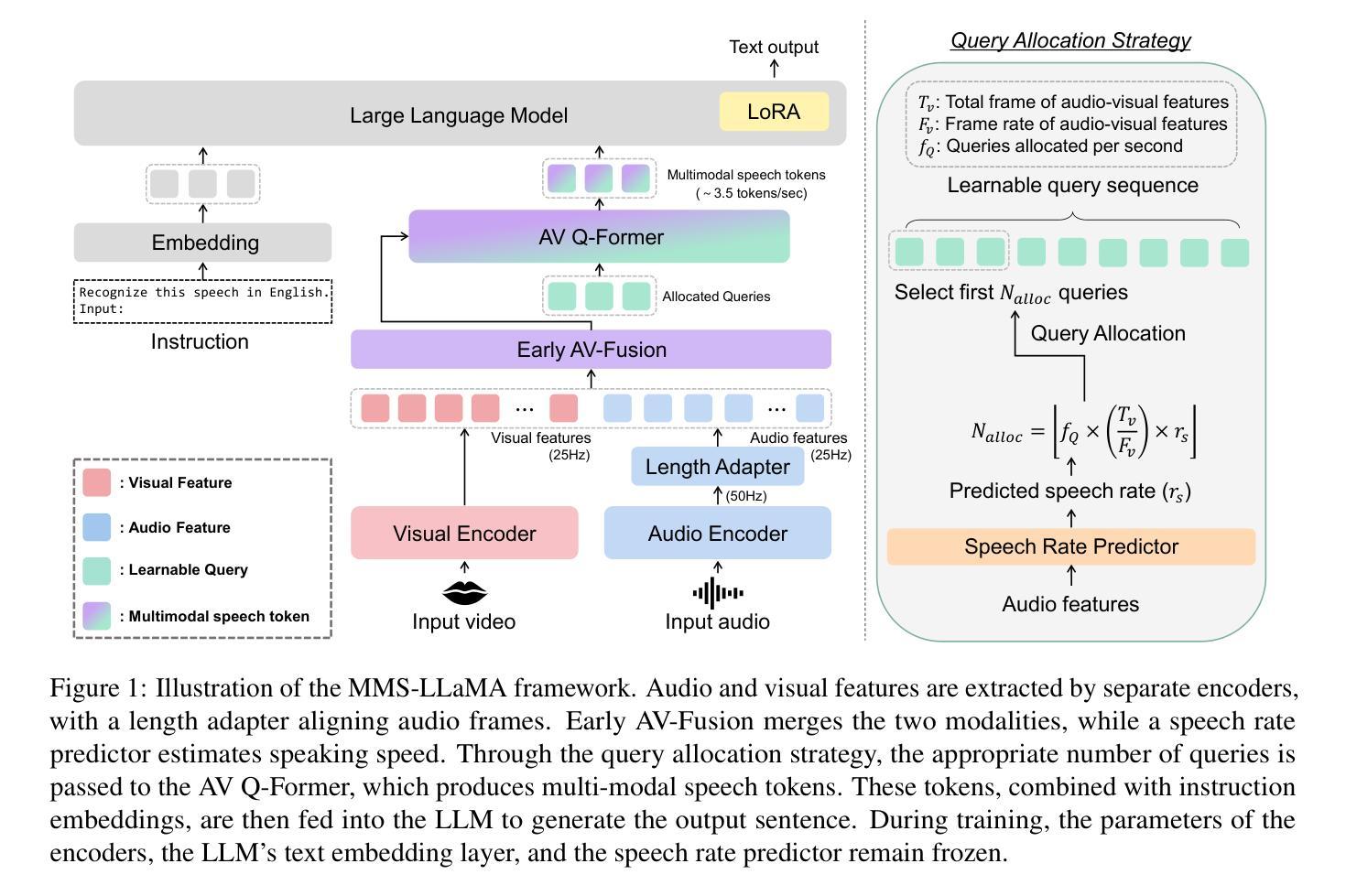
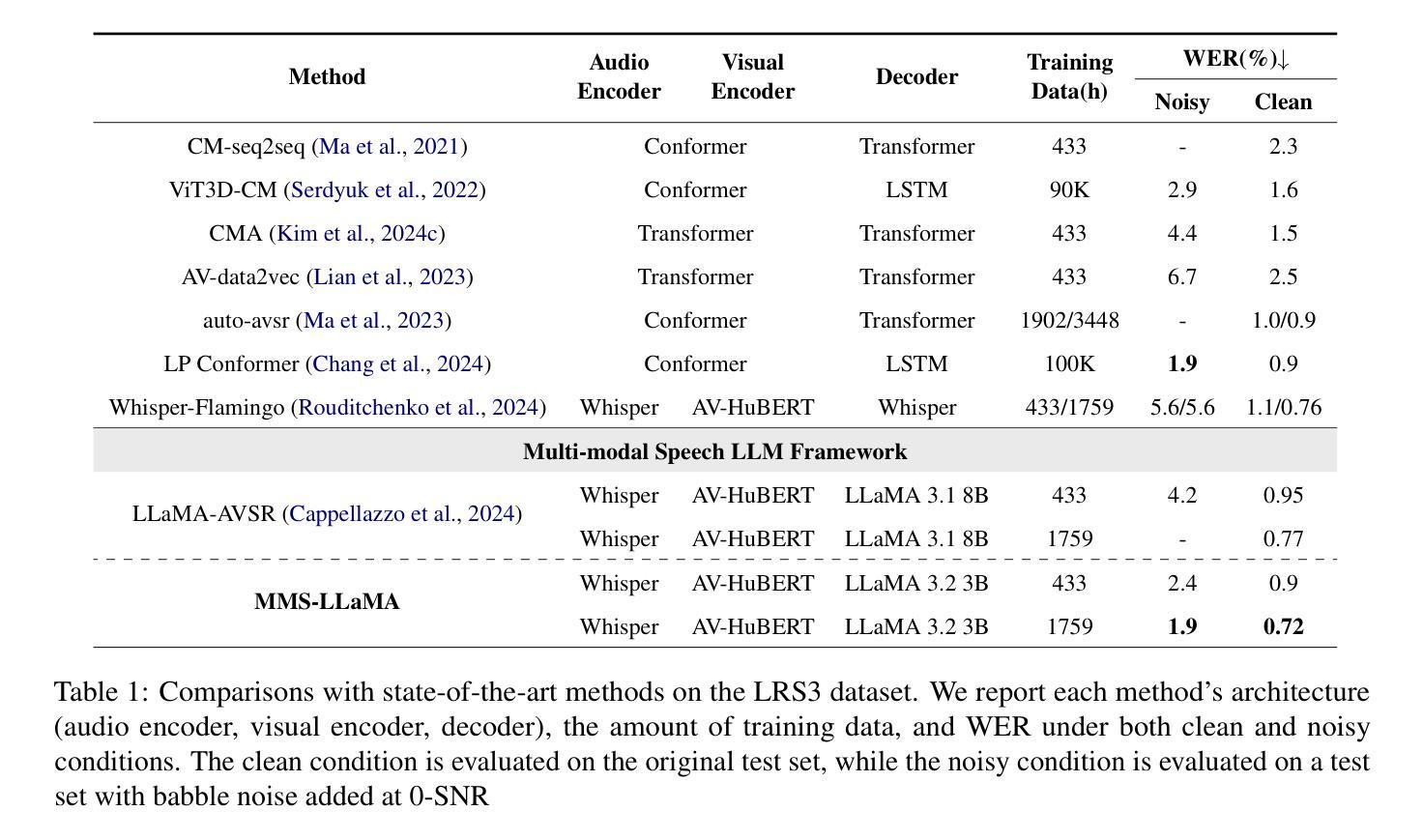
MMS-LLaMA: Efficient LLM-based Audio-Visual Speech Recognition with Minimal Multimodal Speech Tokens
Authors:Jeong Hun Yeo, Hyeongseop Rha, Se Jin Park, Yong Man Ro
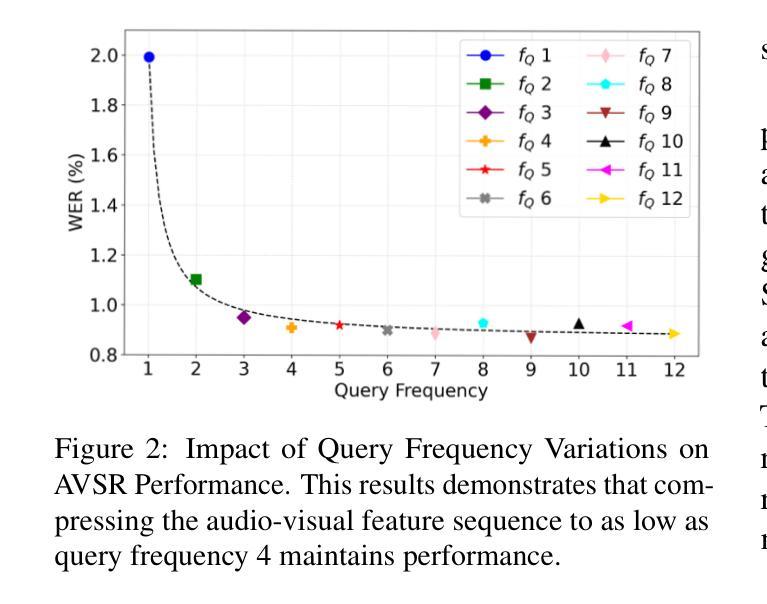
Audio-Visual Speech Recognition (AVSR) achieves robust speech recognition in noisy environments by combining auditory and visual information. However, recent Large Language Model (LLM) based AVSR systems incur high computational costs due to the high temporal resolution of audio-visual speech processed by LLMs. In this work, we introduce an efficient multimodal speech LLM framework that minimizes token length while preserving essential linguistic content. Our approach employs an early AV-fusion module for streamlined feature integration, an audio-visual speech Q-Former that dynamically allocates tokens based on input duration, and a refined query allocation strategy with a speech rate predictor to adjust token allocation according to speaking speed of each audio sample. Extensive experiments on the LRS3 dataset show that our method achieves state-of-the-art performance with a WER of 0.72% while using only 3.5 tokens per second. Moreover, our approach not only reduces token usage by 86% compared to the previous multimodal speech LLM framework, but also improves computational efficiency by reducing FLOPs by 35.7%.
视听语音识别(AVSR)通过结合听觉和视觉信息,在噪声环境中实现了稳健的语音识别。然而,基于大型语言模型(LLM)的AVSR系统由于LLM处理的高时间分辨率的视听语音而产生较高的计算成本。在这项工作中,我们引入了一个高效的多模态语音LLM框架,该框架能够在保持基本语言内容的同时最小化令牌长度。我们的方法采用早期AV融合模块进行简化特征集成,一个视听语音Q-Former,它根据输入持续时间动态分配令牌,以及一个经过优化的查询分配策略与语速预测器,以根据每个音频样本的语速调整令牌分配。在LRS3数据集上的大量实验表明,我们的方法达到了最先进的性能,词错误率为0.72%,同时每秒仅使用3.5个令牌。此外,我们的方法不仅将令牌使用量减少了86%,与以前的多模态语音LLM框架相比,还提高了计算效率,减少了35.7%的浮点运算次数。
论文及项目相关链接
PDF Accepted at Findings of ACL 2025. The code and models are available https://github.com/JeongHun0716/MMS-LLaMA
Summary
音频视觉语音识别(AVSR)能够在噪声环境中实现稳健的语音识别,通过结合听觉和视觉信息。然而,基于大型语言模型(LLM)的AVSR系统由于处理音频视觉语音的高时间分辨率而带来高计算成本。本研究引入了一个高效的多模态语音LLM框架,该框架在保留基本语言内容的同时,最小化令牌长度。通过早期AV融合模块实现功能整合的简化,根据输入持续时间动态分配令牌的视听语音Q-Former,以及使用语音速率预测器调整令牌分配的精细查询分配策略。在LRS3数据集上的广泛实验表明,我们的方法以每秒仅使用3.5个令牌的情况下实现了词错误率(WER)为0.72%,同时取得了业界领先的性能表现。此外,我们的方法不仅将令牌使用量减少了86%,而且通过降低浮点运算次数提高了计算效率。
Key Takeaways
- AVSR技术结合了听觉和视觉信息,提升噪声环境下的语音识别能力。
- 大型语言模型处理AVSR时面临高计算成本问题,主要由于处理高时间分辨率的音频视觉语音。
- 研究提出了一种高效的多模态语音LLM框架,旨在最小化令牌长度同时保留基本语言内容。
- 该框架包含早期AV融合模块、视听语音Q-Former和精细查询分配策略。
- 实验表明,该方法在LRS3数据集上实现了词错误率为0.72%,表现出卓越性能。
- 与先前的多模态语音LLM框架相比,该方法将令牌使用量减少了86%。
点此查看论文截图

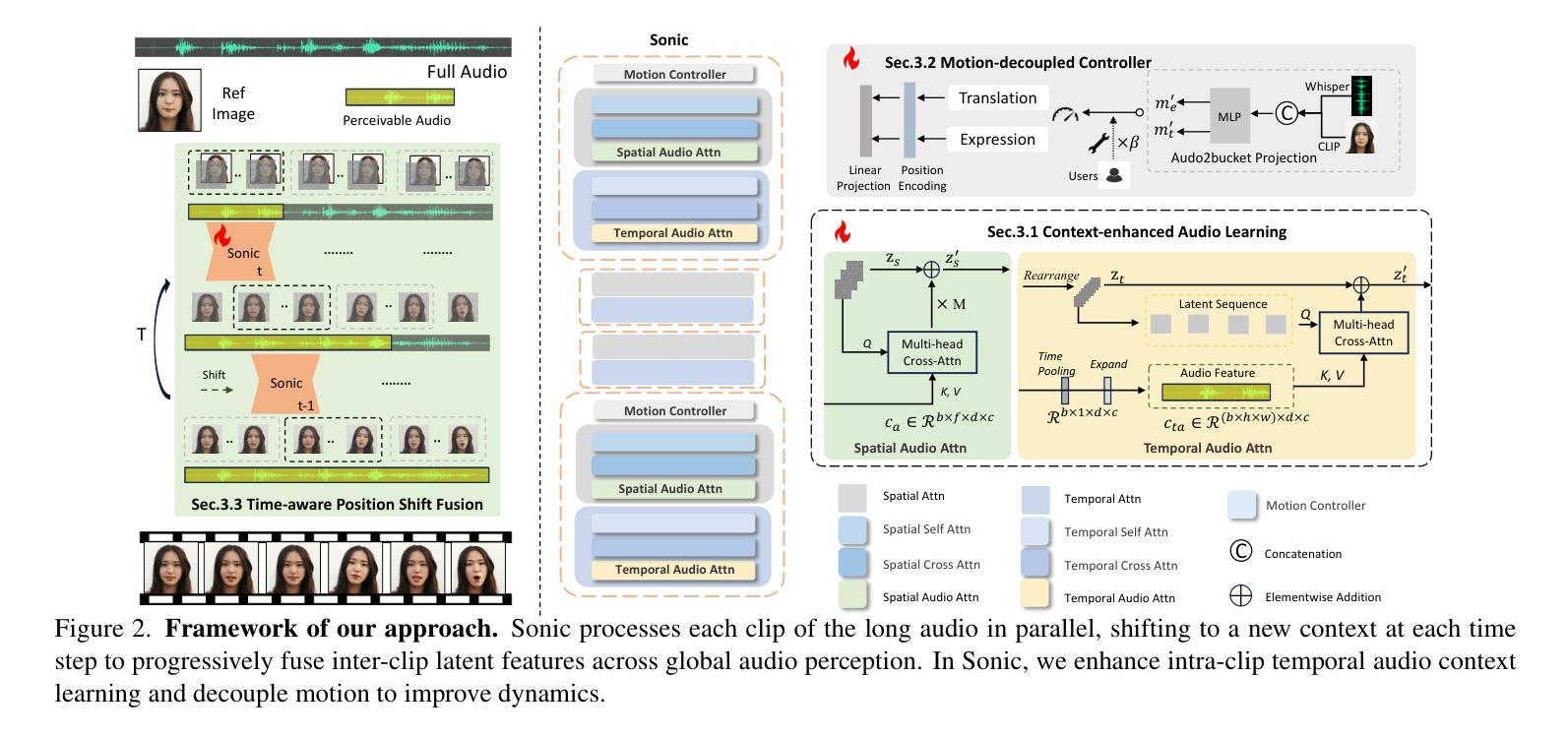
Sonic: Shifting Focus to Global Audio Perception in Portrait Animation
Authors:Xiaozhong Ji, Xiaobin Hu, Zhihong Xu, Junwei Zhu, Chuming Lin, Qingdong He, Jiangning Zhang, Donghao Luo, Yi Chen, Qin Lin, Qinglin Lu, Chengjie Wang
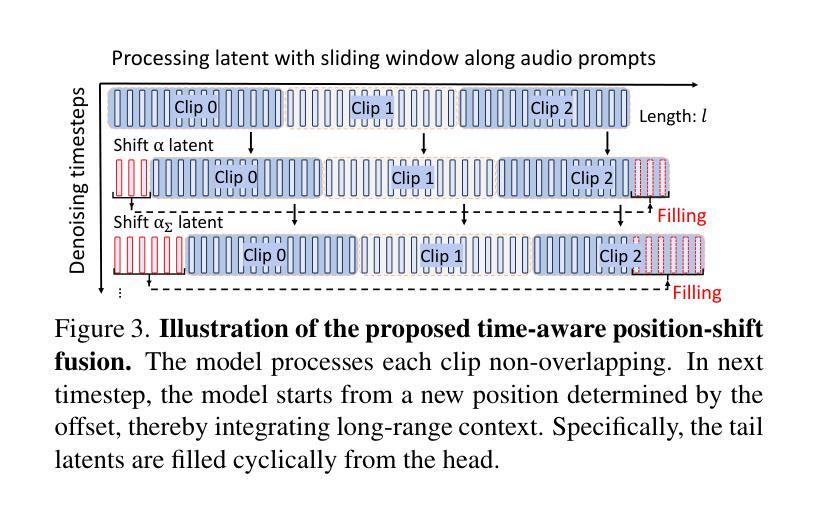
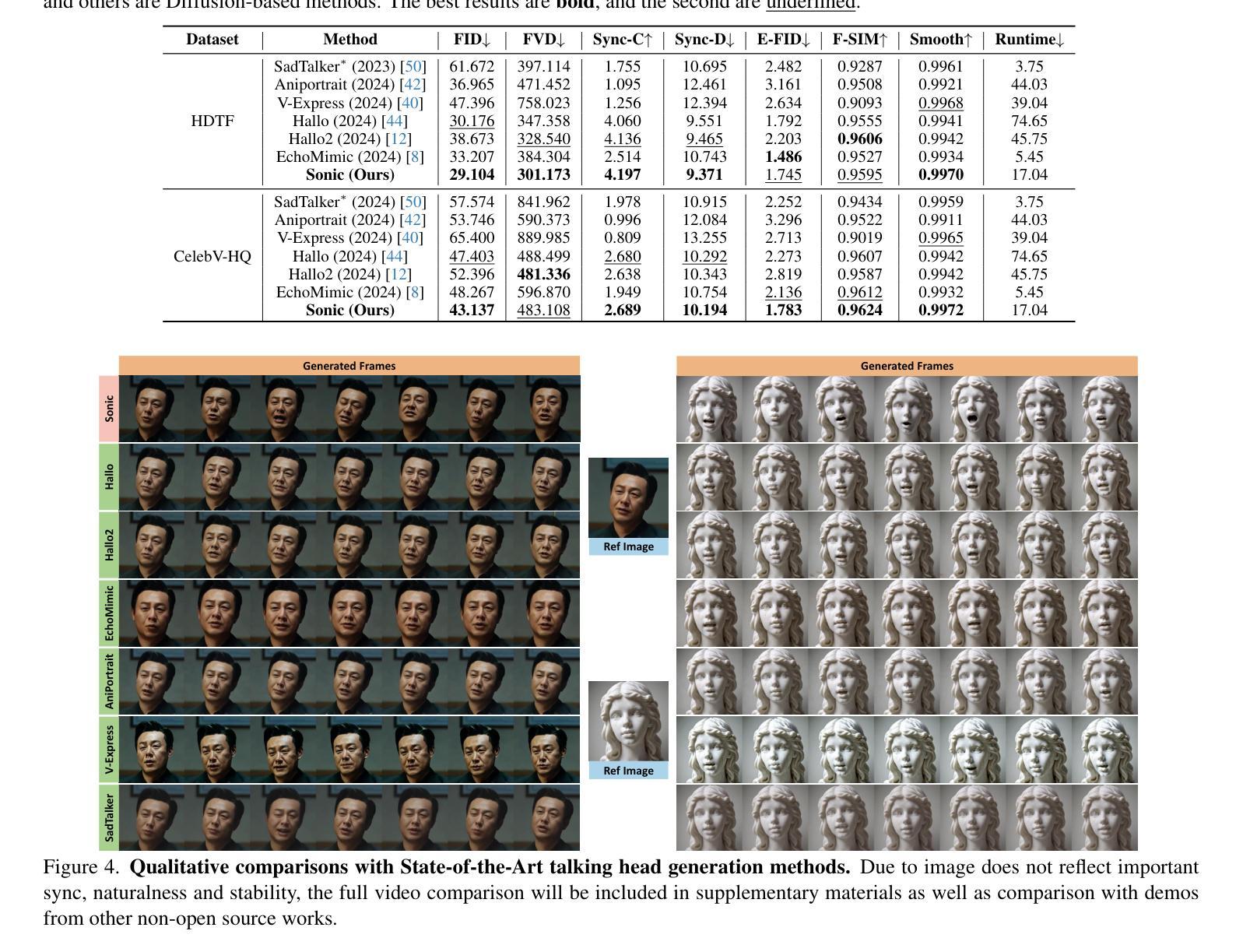
The study of talking face generation mainly explores the intricacies of synchronizing facial movements and crafting visually appealing, temporally-coherent animations. However, due to the limited exploration of global audio perception, current approaches predominantly employ auxiliary visual and spatial knowledge to stabilize the movements, which often results in the deterioration of the naturalness and temporal inconsistencies.Considering the essence of audio-driven animation, the audio signal serves as the ideal and unique priors to adjust facial expressions and lip movements, without resorting to interference of any visual signals. Based on this motivation, we propose a novel paradigm, dubbed as Sonic, to {s}hift f{o}cus on the exploration of global audio per{c}ept{i}o{n}.To effectively leverage global audio knowledge, we disentangle it into intra- and inter-clip audio perception and collaborate with both aspects to enhance overall perception.For the intra-clip audio perception, 1). \textbf{Context-enhanced audio learning}, in which long-range intra-clip temporal audio knowledge is extracted to provide facial expression and lip motion priors implicitly expressed as the tone and speed of speech. 2). \textbf{Motion-decoupled controller}, in which the motion of the head and expression movement are disentangled and independently controlled by intra-audio clips. Most importantly, for inter-clip audio perception, as a bridge to connect the intra-clips to achieve the global perception, \textbf{Time-aware position shift fusion}, in which the global inter-clip audio information is considered and fused for long-audio inference via through consecutively time-aware shifted windows. Extensive experiments demonstrate that the novel audio-driven paradigm outperform existing SOTA methodologies in terms of video quality, temporally consistency, lip synchronization precision, and motion diversity.
对话面部生成的研究主要探索面部动作同步和制作视觉吸引力强、时间连贯的动画的复杂性。然而,由于对全局音频感知的探索有限,当前的方法主要使用辅助的视觉和空间知识来稳定动作,这往往导致自然性的降低和时间上的不一致。考虑到音频驱动动画的本质,音频信号作为调整面部表情和嘴唇动作的理想和独特先验,无需任何视觉信号的干扰。基于这一动机,我们提出了一种新的方法,名为Sonic,旨在聚焦于全局音频感知的探索。为了有效利用全局音频知识,我们将其分解为内部和外部片段的音频感知,并在这两个方面进行合作以促进整体感知。对于内部片段的音频感知,首先是“上下文增强的音频学习”,从中提取长程内部片段的临时音频知识,为面部表情和嘴唇动作提供隐含的先验知识,表现为语音的音色和速度。其次是“运动解耦控制器”,其中头部运动和表情动作被分离,并由内部音频片段独立控制。最重要的是,对于外部片段的音频感知,作为连接内部片段以实现全局感知的桥梁,“时间感知位置偏移融合”,考虑并融合全局外部片段的音频信息,通过连续的时间感知偏移窗口进行长音频推理。大量实验表明,这种新型音频驱动的方法在视频质量、时间一致性、唇同步精度和运动多样性等方面均优于现有的最先进的方法。
论文及项目相关链接
PDF refer to our main-page \url{https://jixiaozhong.github.io/Sonic/}
Summary
本文主要研究了语音驱动面部动画技术,探索了将音频信号作为驱动面部表情和唇部动作的方法,提出一种新型范式Sonic。通过深入研究全局音频感知技术,并结合上下文的音频学习,对内部音频剪辑进行了情感增强的深度探究;并通过将头部运动和面部表情分离的Motion-decoupled控制器强化了这一过程。该研究充分利用音频的时间连续性特征进行融合创新研究,建立了各片段之间的连接以实现全局感知,同时通过跨时间的感知移动窗口实验验证该方法的有效性和性能。总体上提高了语音驱动的动画的生成质量、时序一致性以及面部动画的自然度等效果。此外该研究的全局音频感知处理还显示出巨大潜力,将在现实场景中具有广泛应用前景。总体上可为国内外面部动画相关领域的技术突破与发展提供一定的方向引领价值和实践验证经验借鉴参考等贡献作用。有助于更好地模拟现实人物动作、语言表现力和情感的精准表达,丰富数字化角色情感体验感知。此技术的创新研发在人工智能领域具有里程碑意义。
Key Takeaways
- 研究重点:文章聚焦于语音驱动面部动画生成技术,尤其是音频驱动的面部表情和唇部动作同步问题。强调全局音频感知的重要性及其对增强动画自然感和时序连贯性的关键作用。
- 新范式提出:引入名为Sonic的新型研究范式,旨在通过利用音频信号作为驱动因素来调整面部表情和唇部动作,无需依赖视觉信号的干扰。
- 上下文增强音频学习:在内部剪辑音频感知方面,通过提取长程的语音知识来提供面部表情和唇部动作的先验信息,例如音调和语速等。同时考虑了上下文中的情感增强内容信息以更准确的辅助后续工作的有序展开提供更为贴合的数据支持辅助面部动画制作的质量水平提升起到了一定的促进作用;同时通过引入Motion-decoupled控制器对头部运动和面部表情进行分离控制进一步增强制作质量水平。对于内部剪辑的音频感知研究进一步增强了面部动画的真实感和流畅性为后续研究工作提供了有力的技术支撑。
- 时间感知融合策略:通过时间感知移动窗口实验验证了一种融合策略的有效性该策略将全局音频信息考虑在内并通过时间感知移动窗口进行长期音频推理实现连续时间的精准感知有助于增强面部动画的时序连贯性和准确性为提升面部动画质量奠定了坚实基础。。此部分工作设计有效推动了该技术研究成果的工程化和市场化步伐显著提高了国内外面部动画技术成果的技术研发能力也为业界未来发展树立了良好方向标杆有效促进产学研之间的衔接沟通协同有序工作发展具备潜在推广应用价值对技术行业发展意义重大;同时对其他相关领域也具有相应的启示和参考价值;该研究也对整个科技行业的未来创新起到了重要的推动作用提升了相关领域的技术突破能力对产业界未来持续创新与技术发展起到积极的推动作用也带来了一定的发展空间和市场前景价值提升促进经济效益和社会效益的提升具有里程碑意义。。最后该研究还指出了未来研究方向如提升面部动画的多样性和精细化程度等关键领域未来值得期待进一步拓展深化研究挖掘应用与评估检验能力优化实践经验强化标准管理控制精细构建可靠协同的评价监督管控指标体系等进行推进践行质量评估管理机制等方面以实现成果转化形成闭环实现高质量发展助力产业技术革新与突破。同时对于未来市场应用推广方面也存在巨大潜力具有广阔的市场前景价值提升经济效益和社会效益提升行业竞争力水平提高市场经济效益和行业影响力。
点此查看论文截图