⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-08 更新
Kinetics: Rethinking Test-Time Scaling Laws
Authors:Ranajoy Sadhukhan, Zhuoming Chen, Haizhong Zheng, Yang Zhou, Emma Strubell, Beidi Chen
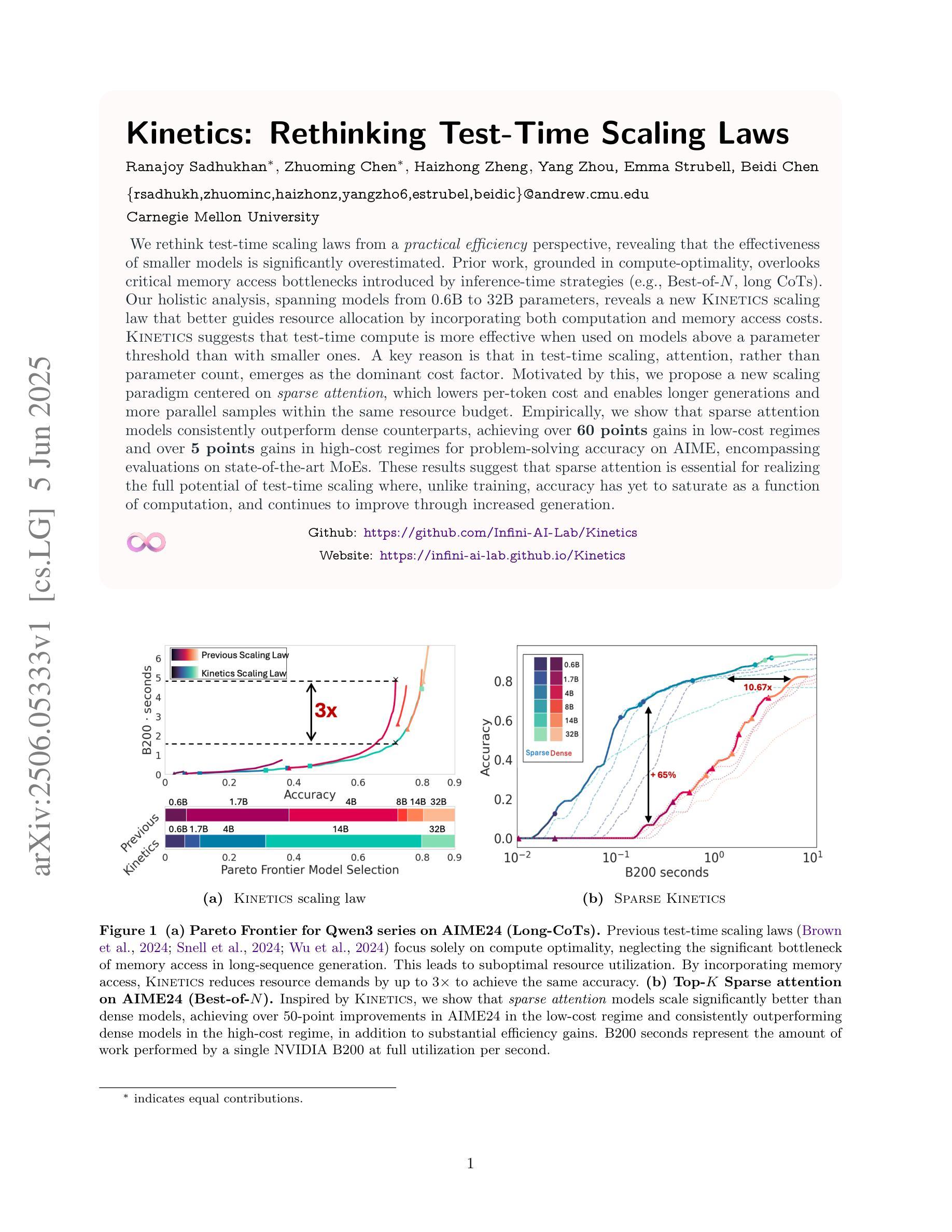
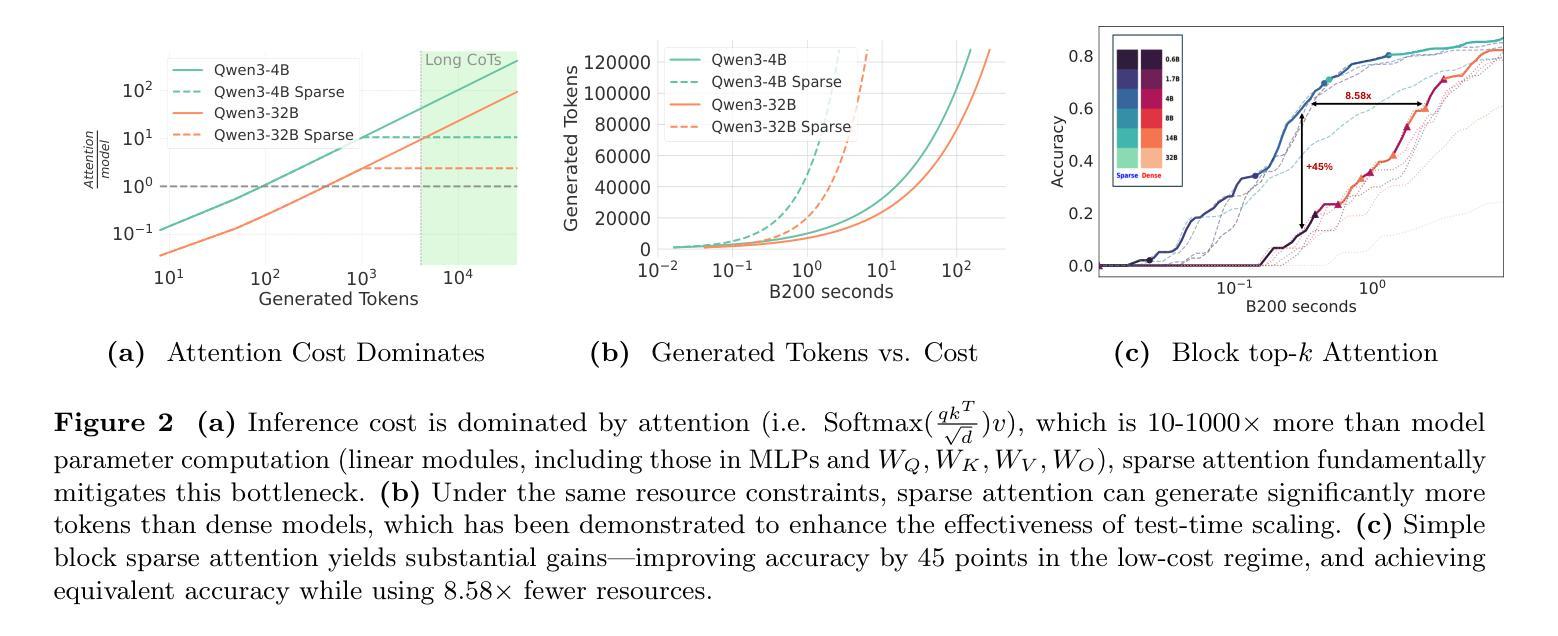
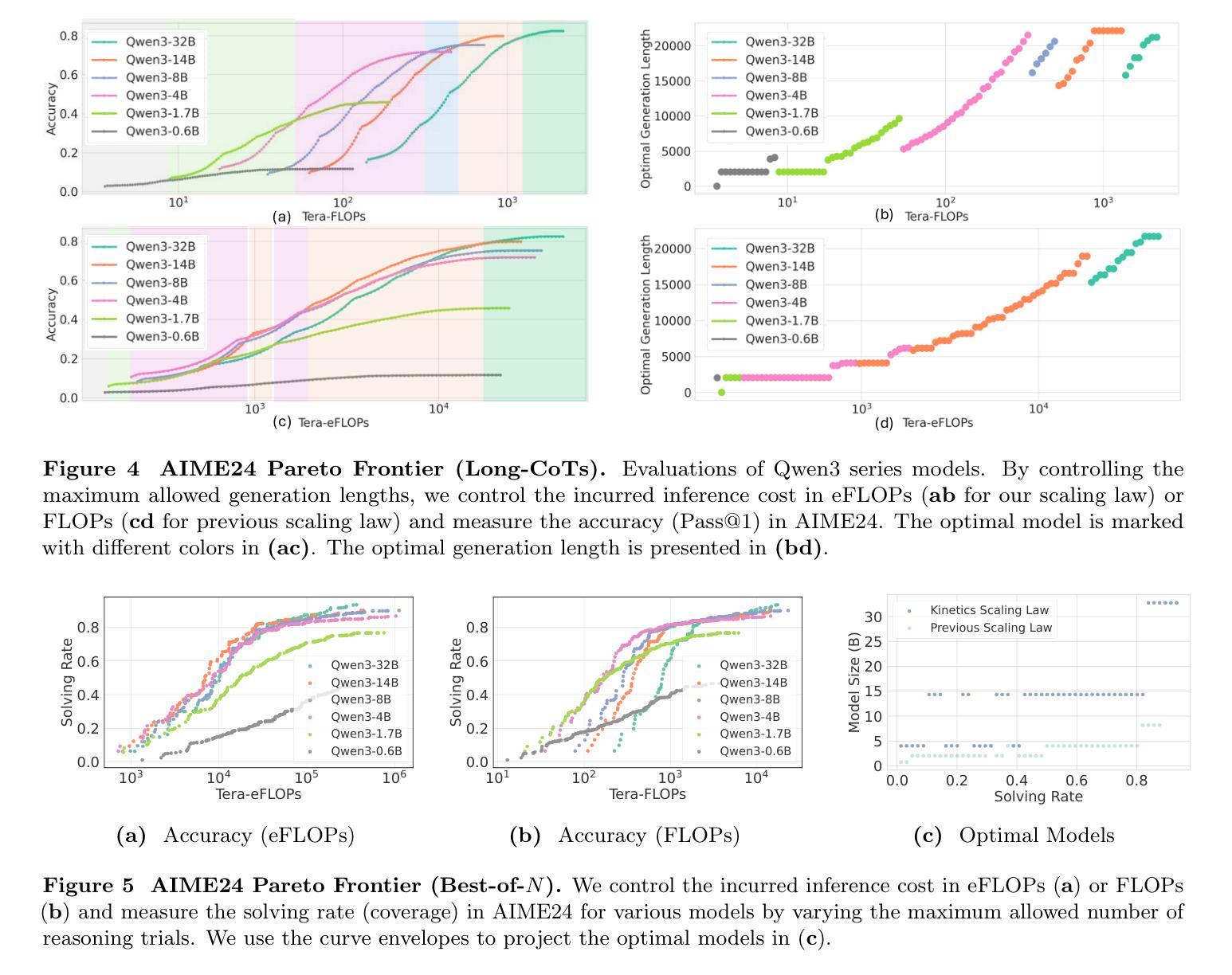
We rethink test-time scaling laws from a practical efficiency perspective, revealing that the effectiveness of smaller models is significantly overestimated. Prior work, grounded in compute-optimality, overlooks critical memory access bottlenecks introduced by inference-time strategies (e.g., Best-of-$N$, long CoTs). Our holistic analysis, spanning models from 0.6B to 32B parameters, reveals a new Kinetics Scaling Law that better guides resource allocation by incorporating both computation and memory access costs. Kinetics Scaling Law suggests that test-time compute is more effective when used on models above a threshold than smaller ones. A key reason is that in TTS, attention, rather than parameter count, emerges as the dominant cost factor. Motivated by this, we propose a new scaling paradigm centered on sparse attention, which lowers per-token cost and enables longer generations and more parallel samples within the same resource budget. Empirically, we show that sparse attention models consistently outperform dense counterparts, achieving over 60 points gains in low-cost regimes and over 5 points gains in high-cost regimes for problem-solving accuracy on AIME, encompassing evaluations on state-of-the-art MoEs. These results suggest that sparse attention is essential for realizing the full potential of test-time scaling because, unlike training, where parameter scaling saturates, test-time accuracy continues to improve through increased generation. The code is available at https://github.com/Infini-AI-Lab/Kinetics.
从实际效率的角度重新思考测试时的缩放定律,我们发现小型模型的效率被严重高估了。之前的工作基于计算最优性,忽视了推理时策略(例如Best-of-$N$、长CoTs)引入的关键内存访问瓶颈。我们对从0.6B到32B参数的模型进行全面分析,揭示了一个新的动力学缩放定律,该定律更好地通过结合计算和内存访问成本来指导资源分配。动力学缩放定律表明,在测试时使用计算资源对超过阈值的模型比小型模型更有效。其中的关键原因是,在TTS中,注意力而不是参数计数,成为主导成本因素。由此,我们提出了以稀疏注意力为中心的新缩放范式,这降低了每令牌的成本,并在相同的资源预算内实现了更长的生成和更多的并行样本。经验表明,稀疏注意力模型持续优于密集对应模型,在AIME上解决问题准确性超过60点,涵盖了最新MoE的评估。这些结果表明,稀疏注意力对于实现测试时缩放的全部潜力至关重要,因为与训练不同,训练时的参数缩放会达到饱和,而测试时的准确性会通过增加生成而继续提高。代码可在https://github.com/Infini-AI-Lab/Kinetics找到。
论文及项目相关链接
摘要
本文重新思考了测试时的缩放定律,从实际效率的角度出发,发现小型模型的效能被高估了。之前的研究建立在计算最优的基础上,忽视了推理时间策略(如Best-of-$N$、长CoTs)所带来的关键内存访问瓶颈。本文对从0.6B到32B参数的模型进行了整体分析,揭示了一种新的动力学缩放定律,该定律能更好地指导资源分配,同时考虑计算和内存访问成本。动力学缩放定律表明,在模型达到一定阈值以上时,测试时间的计算更有效。一个关键原因是,在文本到语音的转换中,注意力而不是参数数量成为主导成本因素。据此,我们提出了以稀疏注意力为中心的新缩放范式,降低了每令牌的成本,并在相同的资源预算内实现了更长的生成和更并行的样本。经验表明,稀疏注意力模型在AIME的问题解决准确性评估中持续优于密集模型,在低成本环境中获得超过60点的增益,在高成本环境中获得超过5点的增益。这些结果说明,稀疏注意力对于实现测试时缩放的全部潜力至关重要,因为与训练时参数缩放的饱和不同,测试时的准确性可以通过增加生成而不断提高。
关键见解
- 重新思考了测试时的缩放定律,从实际效率角度揭示了小型模型效能被高估的问题。
- 指出先前的研究忽视了推理时间策略所带来的内存访问瓶颈。
- 提出新的动力学缩放定律,综合考虑计算和内存访问成本。
- 动力学缩放定律显示,达到一定阈值以上的模型在测试时间计算上更有效。
- 注意力成为测试时成本的主导因素,而不是参数数量。
- 提出了以稀疏注意力为中心的新缩放范式,降低了成本并提高了生成质量。
- 实证研究表明,稀疏注意力模型在问题解决准确性上优于密集模型,特别是在不同成本环境下的增益显著。
点此查看论文截图
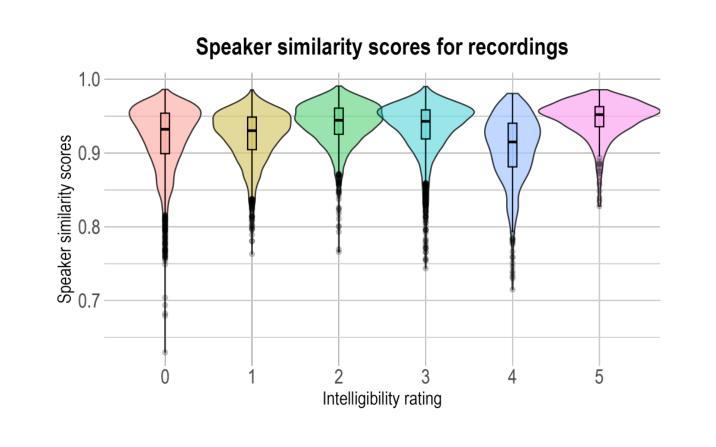
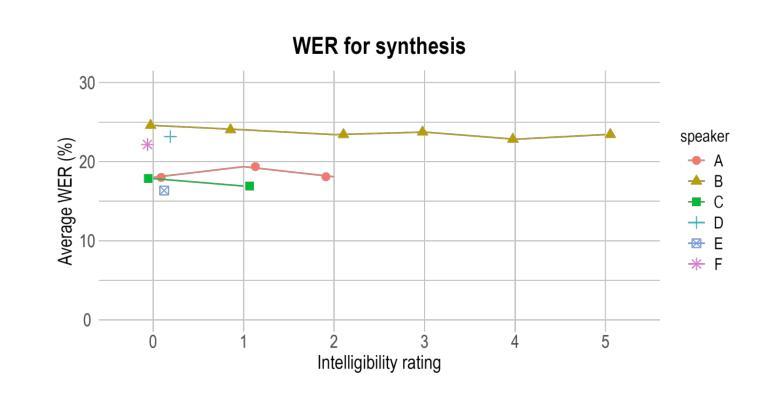
Can we reconstruct a dysarthric voice with the large speech model Parler TTS?
Authors:Ariadna Sanchez, Simon King
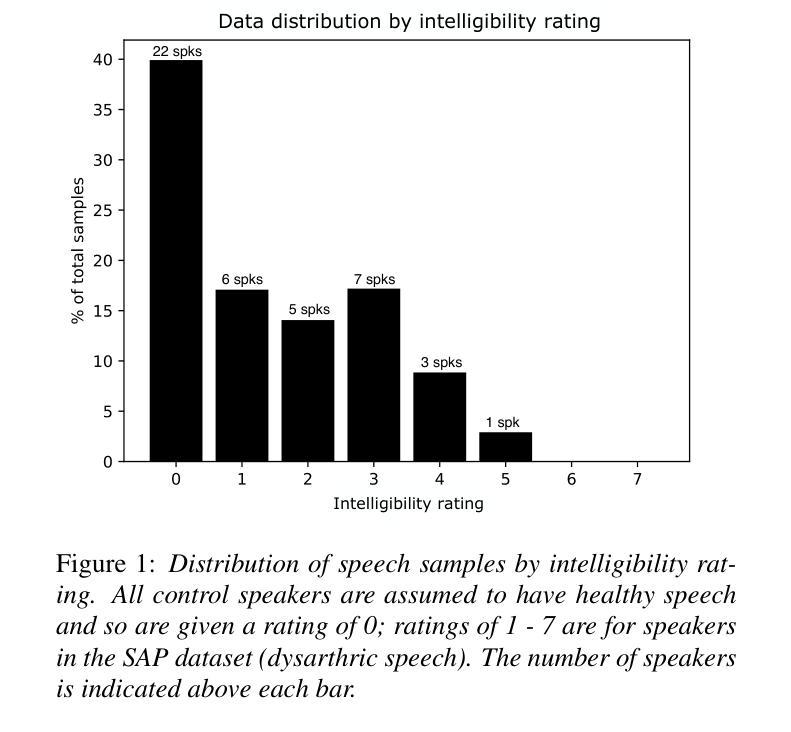
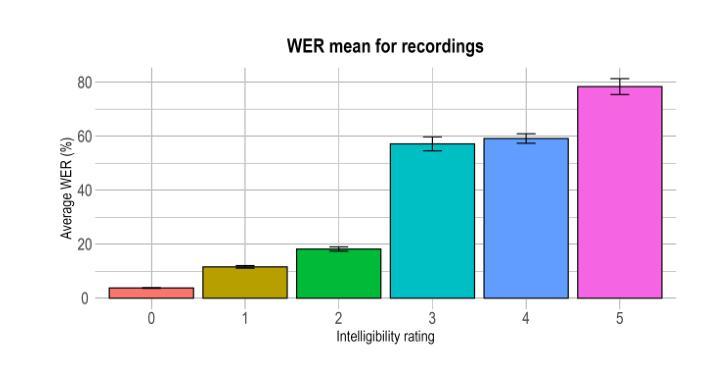
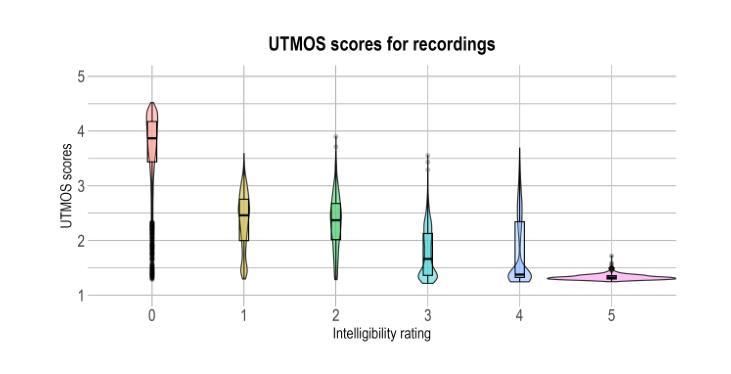
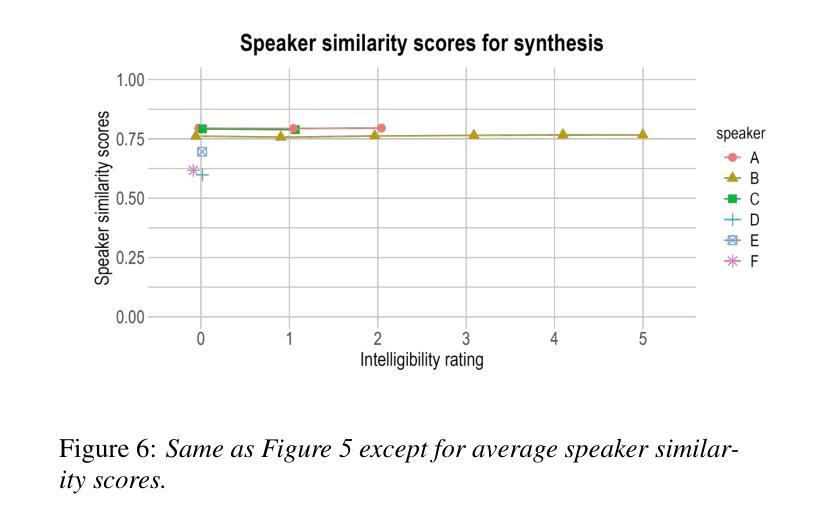
Speech disorders can make communication hard or even impossible for those who develop them. Personalised Text-to-Speech is an attractive option as a communication aid. We attempt voice reconstruction using a large speech model, with which we generate an approximation of a dysarthric speaker’s voice prior to the onset of their condition. In particular, we investigate whether a state-of-the-art large speech model, Parler TTS, can generate intelligible speech while maintaining speaker identity. We curate a dataset and annotate it with relevant speaker and intelligibility information, and use this to fine-tune the model. Our results show that the model can indeed learn to generate from the distribution of this challenging data, but struggles to control intelligibility and to maintain consistent speaker identity. We propose future directions to improve controllability of this class of model, for the voice reconstruction task.
言语障碍可能会让患者在日常交流方面倍感困难甚至无法进行。个性化的文本到语音技术作为交流辅助手段成为了当下的研究热点。我们尝试使用大型语音模型进行语音重建,生成在疾病出现前患有言语障碍的人的声音近似值。尤其值得关注的是,我们调查了最先进的语音模型Parler TTS是否能够在保持说话者身份的同时产生可理解的语音。我们整理了一个数据集并标注了相关的说话者和可理解性信息,并使用这些数据对模型进行微调。我们的结果表明,该模型确实能够从这类有难度的数据中学习并生成数据,但在控制可理解性和保持一致的说话者身份方面还存在挑战。我们提出了未来改进此类模型可控性的方向,以供语音重建任务参考。
论文及项目相关链接
PDF Accepted at Interspeech 2025
Summary
个性化文本转语音(Text-to-Speech)技术对于存在言语障碍的人群来说是一种具有吸引力的沟通辅助工具。本研究尝试使用大型语音模型进行语音重建,生成疾病前病态嗓音的近似声音。研究发现,先进的大型语音模型(如Parler TTS)虽能生成可理解的语音并保持说话者身份,但在控制语音清晰度和保持说话者身份一致性方面仍存在困难。
Key Takeaways
- 个人化文本转语音技术对于存在言语障碍的人群具有吸引力。
- 使用大型语音模型进行语音重建以模拟病态嗓音。
- Parler TTS等先进模型能生成可理解的语音并保持说话者身份。
- 模型在控制语音清晰度和保持说话者身份一致性方面存在挑战。
- 需要改进此类模型的操控性以提高语音重建任务的性能。
- 研究提出了未来的改进方向以提升模型的操控性。
点此查看论文截图