⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-08 更新
Galactic Science – Rapporteur Talk of the 8th Heidelberg International Symposium on High Energy Gamma Ray Astronomy
Authors:Sandro Mereghetti
The most recent observational and theoretical results in the rapidly expanding field of high-energy gamma-ray astrophysics were discussed at the international conference ``Gamma-2024’’ that took place in Milano in September 2024. This contribution summarises the ‘rapporteur talk’ relative to the Galactic science given at the end of the conference.
在日益扩展的高能伽马射线天体物理学领域,最新的观测和理论结果于2024年9月在米兰举行的国际会议“Gamma-2024”上进行了讨论。这篇论文对会议结束时给出的关于银河系科学的报告进行了总结。
论文及项目相关链接
PDF 8 pages, 2 tables. To appear in the Procs. of the 8th Heidelberg International Symposium on High-Energy Gamma-Ray Astronomy, held in Milan in 2024, to be published in Memorie della Societ`a Astronomica Italiana (MemSAIt)
Summary:在2024年9月于米兰举行的国际研讨会“Gamma-2024”上,高能伽马射线物理学领域的最新观测和理论成果受到了广泛讨论。本文总结了会议结束时关于银河系科学的报告内容。
Key Takeaways:
- 国际研讨会“Gamma-2024”讨论了高能伽马射线物理学领域的最新成果。
- 会议在米兰举行,时间为2024年9月。
- 此摘要总结了会议中关于银河系科学的报告。
- 这些报告涵盖了最新的观测结果和理论进展。
- 高能伽马射线物理学是一个迅速发展的领域。
- 会议对于推动该领域的发展起到了重要作用。
点此查看论文截图


Sonic: Shifting Focus to Global Audio Perception in Portrait Animation
Authors:Xiaozhong Ji, Xiaobin Hu, Zhihong Xu, Junwei Zhu, Chuming Lin, Qingdong He, Jiangning Zhang, Donghao Luo, Yi Chen, Qin Lin, Qinglin Lu, Chengjie Wang
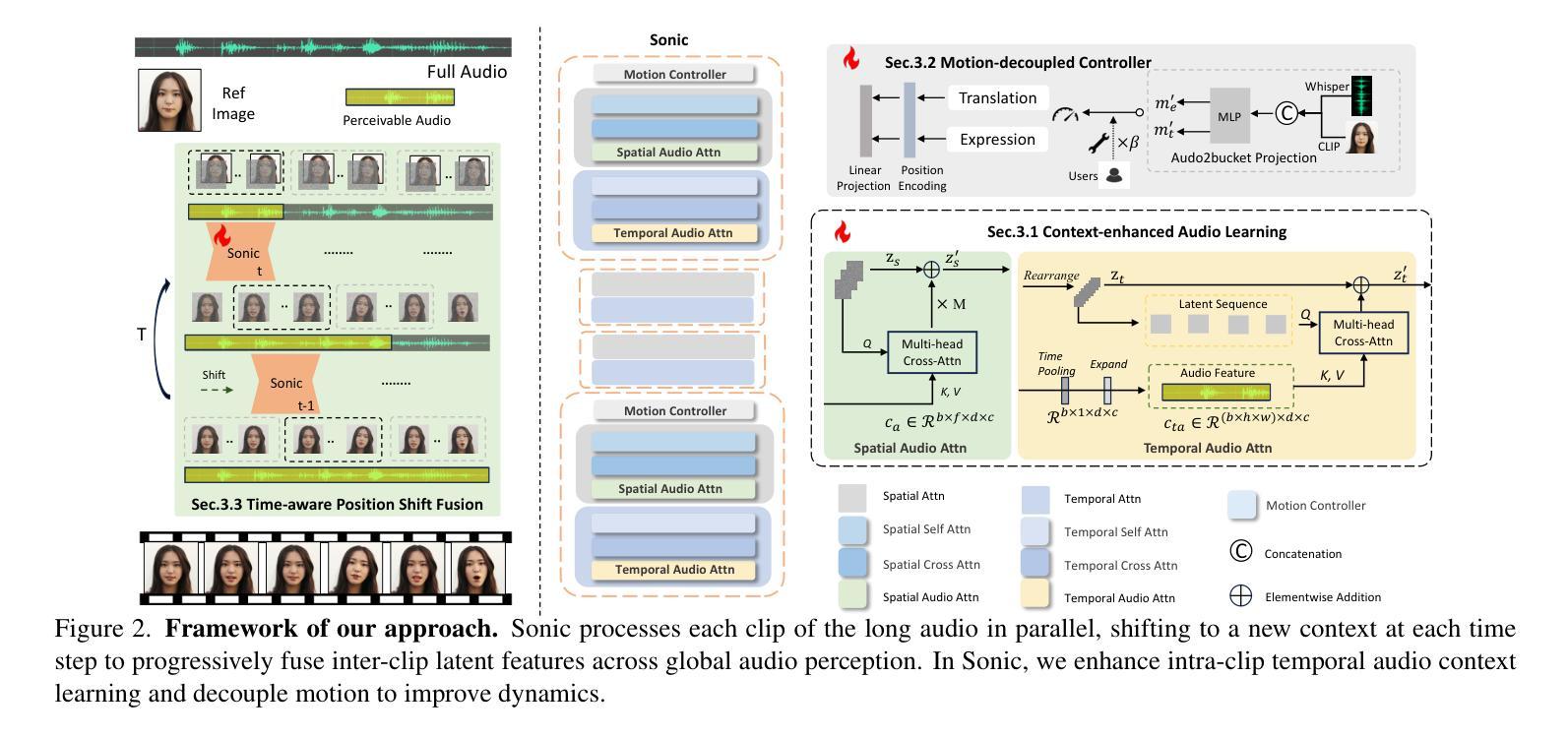
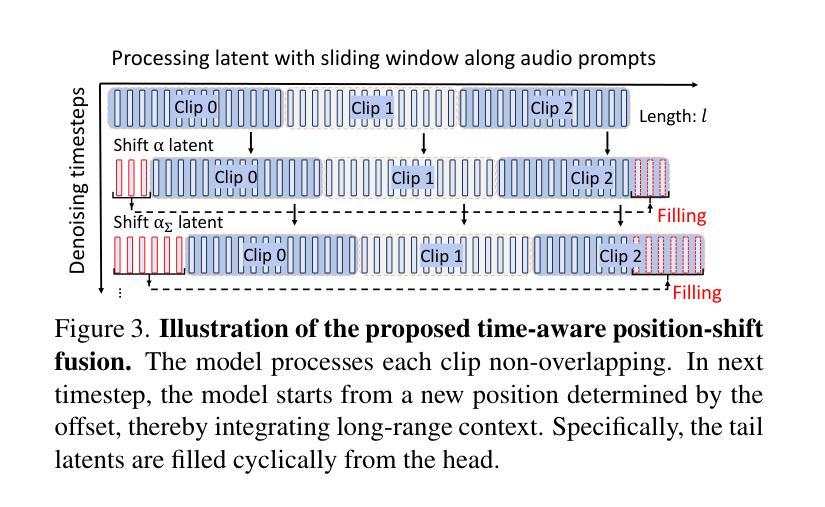
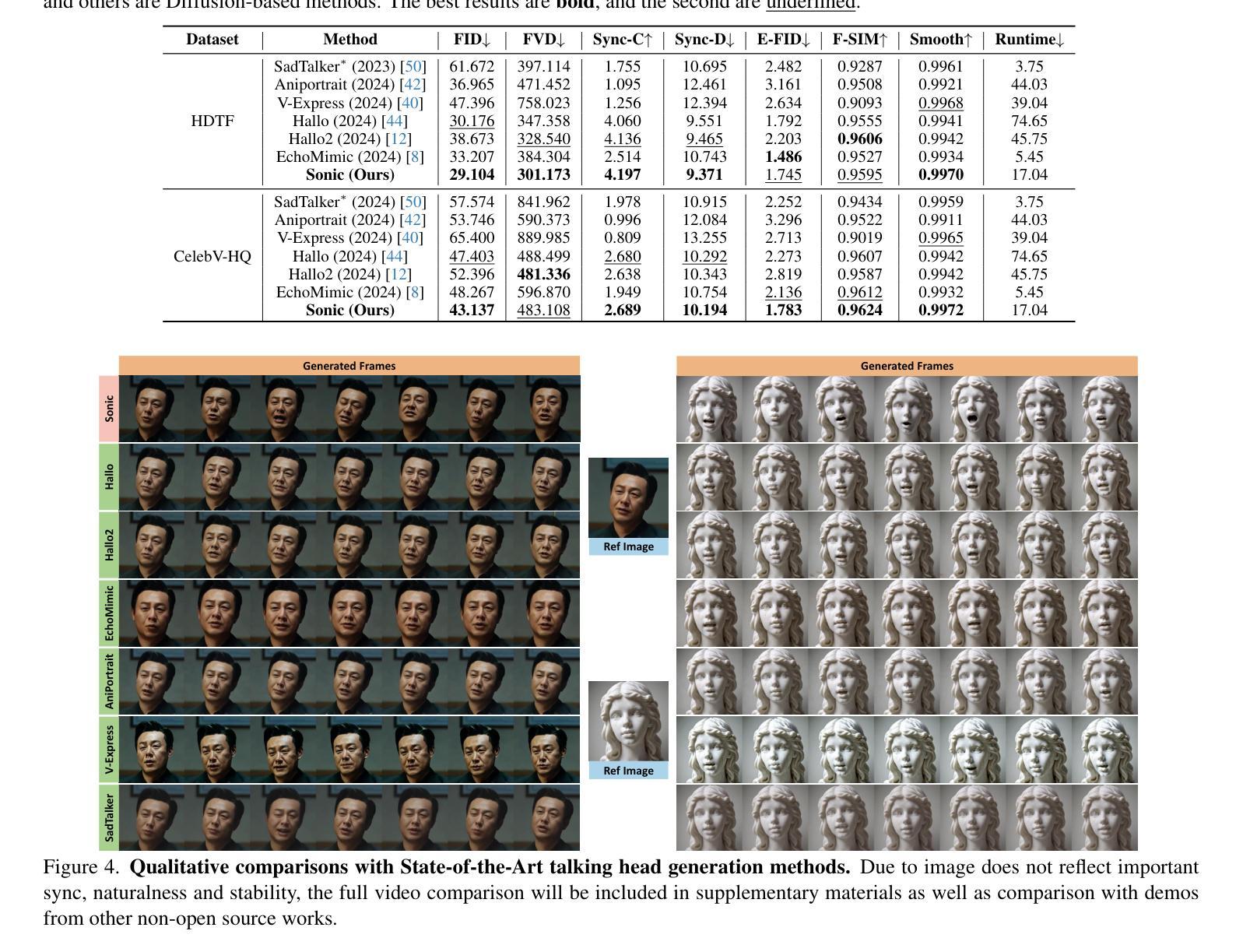
The study of talking face generation mainly explores the intricacies of synchronizing facial movements and crafting visually appealing, temporally-coherent animations. However, due to the limited exploration of global audio perception, current approaches predominantly employ auxiliary visual and spatial knowledge to stabilize the movements, which often results in the deterioration of the naturalness and temporal inconsistencies.Considering the essence of audio-driven animation, the audio signal serves as the ideal and unique priors to adjust facial expressions and lip movements, without resorting to interference of any visual signals. Based on this motivation, we propose a novel paradigm, dubbed as Sonic, to {s}hift f{o}cus on the exploration of global audio per{c}ept{i}o{n}.To effectively leverage global audio knowledge, we disentangle it into intra- and inter-clip audio perception and collaborate with both aspects to enhance overall perception.For the intra-clip audio perception, 1). \textbf{Context-enhanced audio learning}, in which long-range intra-clip temporal audio knowledge is extracted to provide facial expression and lip motion priors implicitly expressed as the tone and speed of speech. 2). \textbf{Motion-decoupled controller}, in which the motion of the head and expression movement are disentangled and independently controlled by intra-audio clips. Most importantly, for inter-clip audio perception, as a bridge to connect the intra-clips to achieve the global perception, \textbf{Time-aware position shift fusion}, in which the global inter-clip audio information is considered and fused for long-audio inference via through consecutively time-aware shifted windows. Extensive experiments demonstrate that the novel audio-driven paradigm outperform existing SOTA methodologies in terms of video quality, temporally consistency, lip synchronization precision, and motion diversity.
谈话面部生成的研究主要探索面部动作同步和制作视觉吸引力强、时间连贯的动画的复杂性。然而,由于对全局音频感知的探索有限,当前的方法主要使用辅助的视觉和空间知识来稳定动作,这往往导致自然性的降低和时间上的不一致。考虑到音频驱动动画的本质,音频信号作为理想且独特的先验知识来调整面部表情和嘴唇动作,无需借助任何视觉信号的干扰。基于这一动机,我们提出了一种新的范式,称为Sonic,以重点关注全局音频感知的探索。为了有效利用全局音频知识,我们将其分解为帧内和帧间音频感知,并协同两个方面以增强整体感知。对于帧内音频感知,1). 上下文增强的音频学习,从中提取长程帧内临时音频知识,以隐含的方式表达面部表情和嘴唇运动先验,如语调和语速。2). 运动解耦控制器,其中头部运动和表情动作被分离,并由帧内音频片段独立控制。最重要的是,对于帧间音频感知,作为连接帧内片段以实现全局感知的桥梁,时间感知位置偏移融合,考虑全局帧间音频信息,并通过连续的时间感知移位窗口进行长音频推理。大量实验表明,新的音频驱动范式在视频质量、时间一致性、嘴唇同步精度和运动多样性方面优于现有的最先进方法。
论文及项目相关链接
PDF refer to our main-page \url{https://jixiaozhong.github.io/Sonic/}
Summary
本文研究了语音头部动画生成领域中的音频驱动动画技术。文章指出当前方法主要利用辅助视觉和空间知识来稳定面部动画,但由于对全局音频感知的有限探索,其自然性和时序连贯性方面存在问题。因此,文章提出了一种全新的基于音频驱动动画的方法——Sonic,它侧重于探索全局音频感知,通过解析和融合音频信号来调整面部表情和唇部动作。文章介绍了其技术框架的三大核心组件:Context-enhanced音频学习、Motion-decoupled控制器以及Time-aware位置偏移融合,并在实验中证明了其性能优于现有方法。
Key Takeaways
- 语音头部动画生成研究重点在于同步面部动作和创建视觉吸引人的时序连贯动画。
- 当前方法主要依赖辅助视觉和空间知识稳定面部动作,但存在自然性和时序不一致的问题。
- 音频信号是调整面部表情和唇部动作的理想和独特先验,无需任何视觉信号的干扰。
- 提出了全新的基于音频驱动动画的方法——Sonic,专注于探索全局音频感知。
- Sonic技术框架包括三大核心组件:Context-enhanced音频学习、Motion-decoupled控制器和Time-aware位置偏移融合。
- 实验证明,Sonic方法在视频质量、时序连贯性、唇部同步精度和运动多样性方面优于现有方法。
点此查看论文截图