⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-08 更新
Single GPU Task Adaptation of Pathology Foundation Models for Whole Slide Image Analysis
Authors:Neeraj Kumar, Swaraj Nanda, Siddharth Singi, Jamal Benhamida, David Kim, Jie-Fu Chen, Amir Momeni-Boroujeni, Gregory M. Goldgof, Gabriele Campanella, Chad Vanderbilt
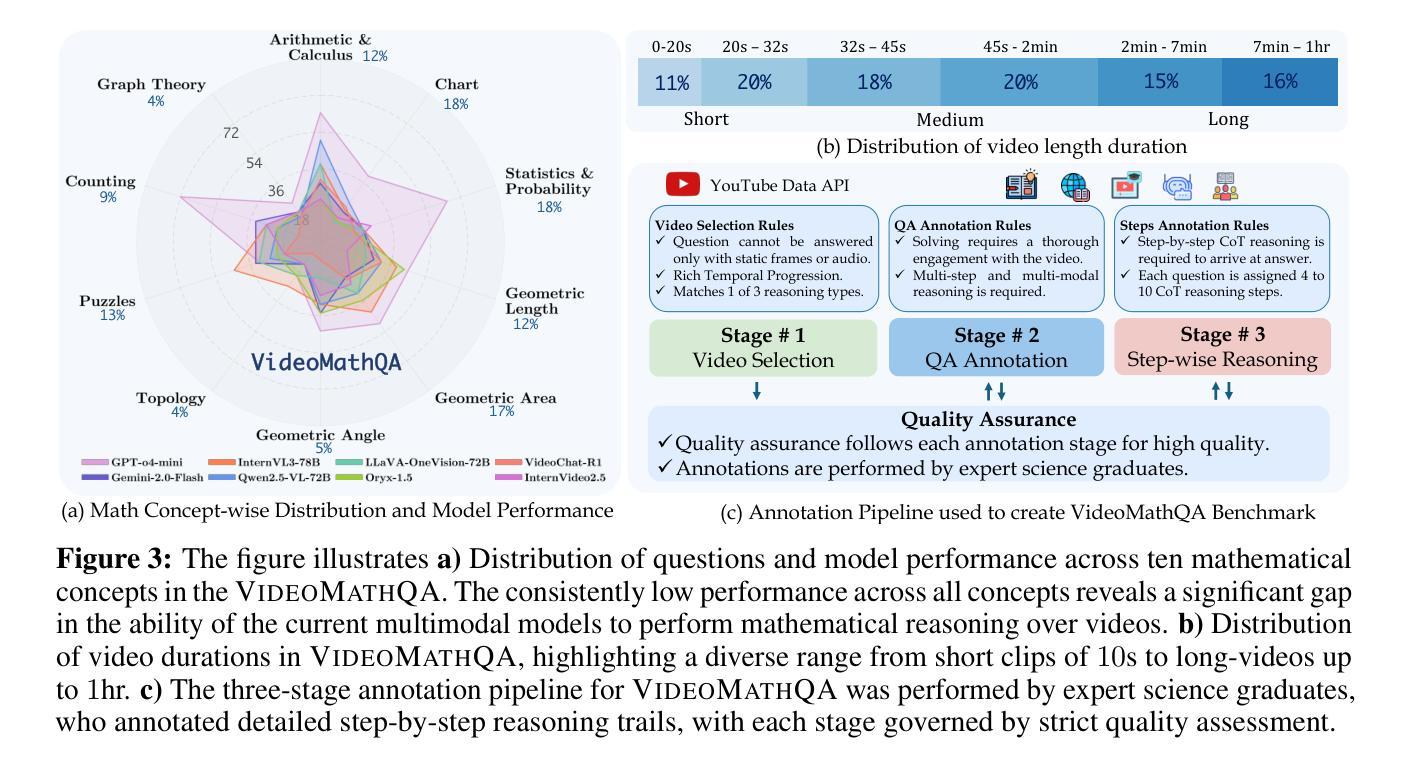
Pathology foundation models (PFMs) have emerged as powerful tools for analyzing whole slide images (WSIs). However, adapting these pretrained PFMs for specific clinical tasks presents considerable challenges, primarily due to the availability of only weak (WSI-level) labels for gigapixel images, necessitating multiple instance learning (MIL) paradigm for effective WSI analysis. This paper proposes a novel approach for single-GPU \textbf{T}ask \textbf{A}daptation of \textbf{PFM}s (TAPFM) that uses vision transformer (\vit) attention for MIL aggregation while optimizing both for feature representations and attention weights. The proposed approach maintains separate computational graphs for MIL aggregator and the PFM to create stable training dynamics that align with downstream task objectives during end-to-end adaptation. Evaluated on mutation prediction tasks for bladder cancer and lung adenocarcinoma across institutional and TCGA cohorts, TAPFM consistently outperforms conventional approaches, with H-Optimus-0 (TAPFM) outperforming the benchmarks. TAPFM effectively handles multi-label classification of actionable mutations as well. Thus, TAPFM makes adaptation of powerful pre-trained PFMs practical on standard hardware for various clinical applications.
病理学基础模型(PFMs)已作为分析全切片图像(WSIs)的强大工具出现。然而,将这些预训练的PFMs适应于特定的临床任务面临着相当大的挑战,这主要是因为吉像素图像只有弱(WSI级)标签可用,需要进行多次实例学习(MIL)范式才能实现有效的WSI分析。本文提出了一种新型的单GPU任务适应PFM(TAPFM)方法,该方法使用视觉转换器(ViT)注意力进行MIL聚合,同时优化特征表示和注意力权重。所提出的方法为MIL聚合器和PFM维护了单独的计算图,以创建稳定的训练动力学,以在端到端适应过程中与下游任务目标保持一致。在膀胱癌和肺腺癌的突变预测任务上进行了评估,TAPFM持续优于传统方法,其中H-Optimus-0(TAPFM)表现超越基准测试。TAPFM能有效处理可操作突变的多标签分类。因此,TAPFM使强大的预训练PFM在标准硬件上适应各种临床应用变得切实可行。
论文及项目相关链接
摘要
病理学基础模型(PFMs)已作为分析全幻灯片图像(WSIs)的强大工具出现。然而,将预训练的PFMs适应于特定临床任务面临巨大挑战,这主要是因为对于千兆像素图像只有弱(WSI级)标签可用,需要进行多重实例学习(MIL)范式才能有效进行WSI分析。本文提出了一种新的单GPU任务适应PFMs(TAPFM)方法,该方法使用视觉转换器(ViT)注意力进行MIL聚合,同时优化特征表示和注意力权重。该方法保持MIL聚合器和PFM的独立计算图,以创建稳定的训练动态,在端到端适应过程中与下游任务目标保持一致。在膀胱癌和肺腺癌的突变预测任务上,TAPFM始终优于传统方法,H-Optimus-0(TAPFM)超越了基准测试。TAPFM可以有效地处理可操作的突变的多标签分类。因此,TAPFM使在标准硬件上实际应用强大的预训练PFMs对各种临床任务变得实用。
关键见解
- PFMs在分析WSIs时表现出强大的能力,但适应于特定临床任务存在挑战。
- 由于WSIs的弱标签问题,需要使用MIL范式进行有效分析。
- TAPFM方法结合视觉转换器(ViT)的注意力机制进行MIL聚合,优化特征表示和注意力权重。
- TAPFM通过创建稳定的训练动态,使PFM适应特定任务更为有效。
- TAPFM在膀胱癌和肺腺癌的突变预测任务上表现出卓越性能。
- TAPFM能处理多标签分类,包括可操作的突变分类。
- TAPFM的实现使得在标准硬件上应用预训练的PFMs进行各种临床任务变得实用。
点此查看论文截图

AuthGuard: Generalizable Deepfake Detection via Language Guidance
Authors:Guangyu Shen, Zhihua Li, Xiang Xu, Tianchen Zhao, Zheng Zhang, Dongsheng An, Zhuowen Tu, Yifan Xing, Qin Zhang
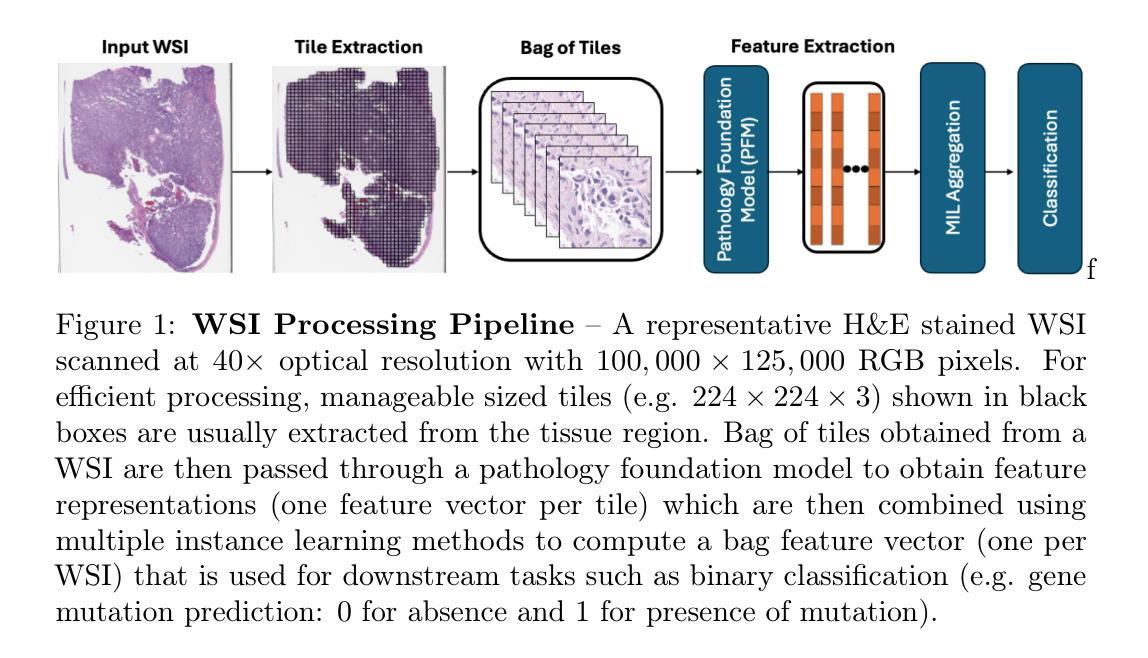
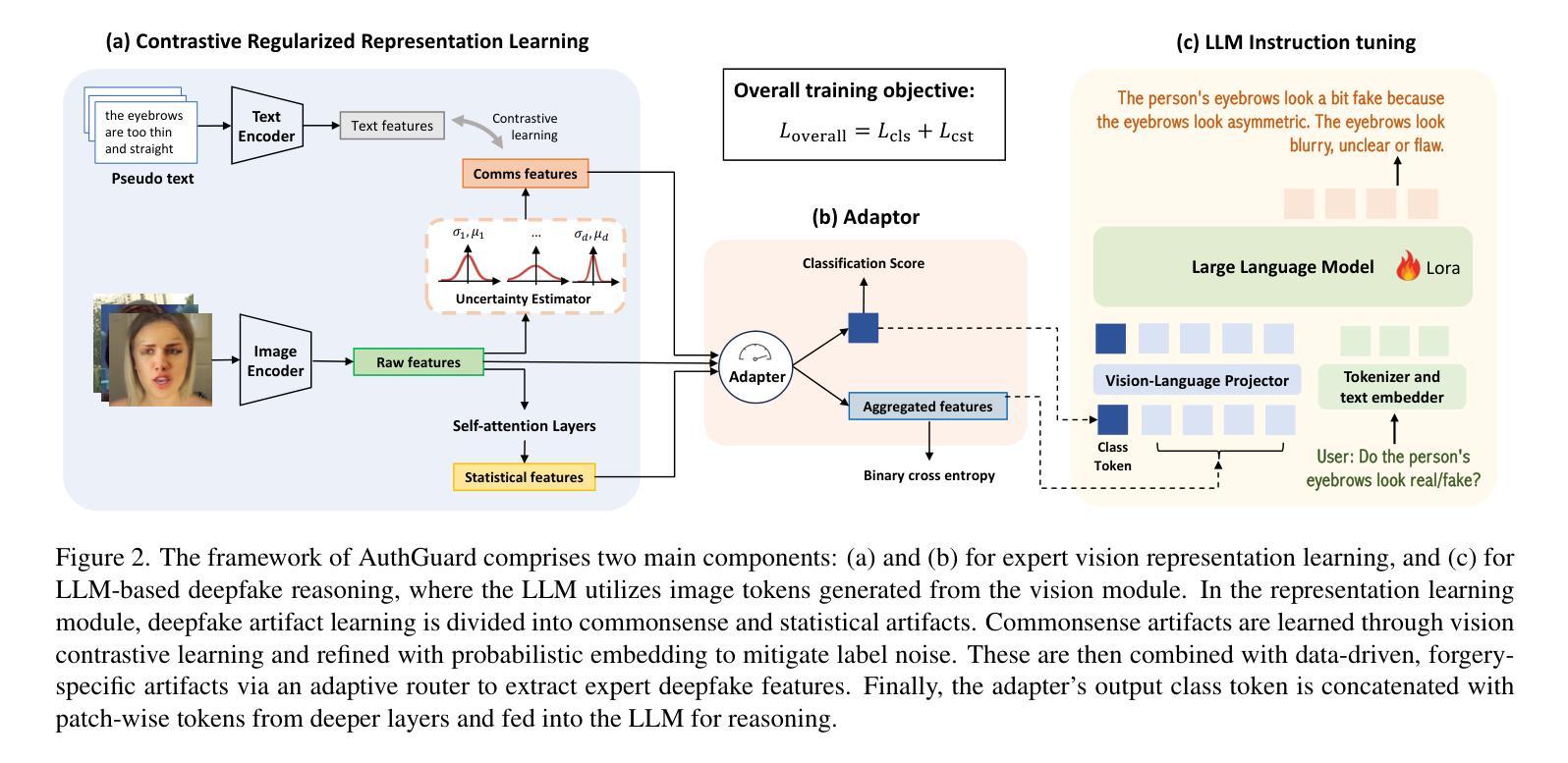
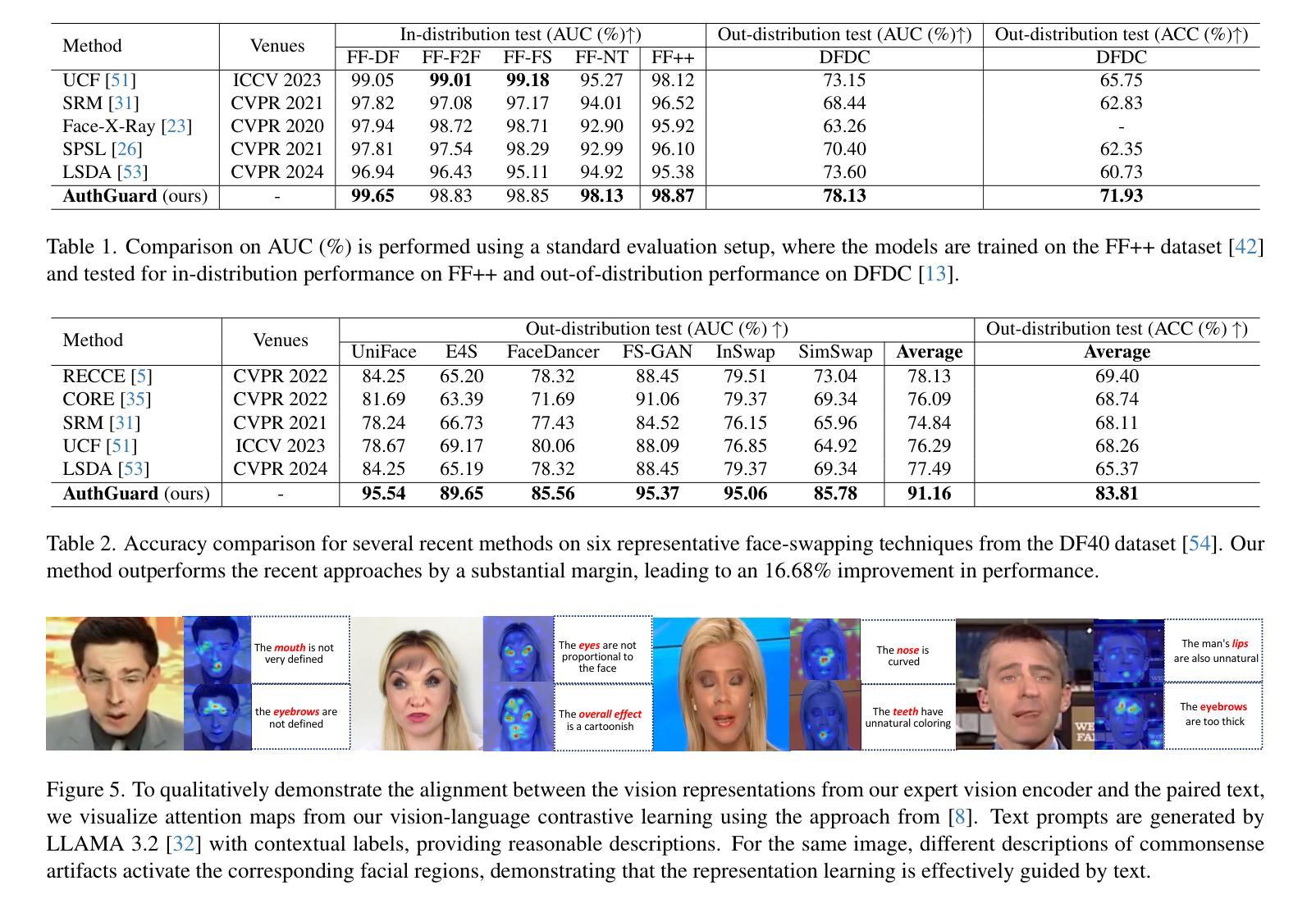
Existing deepfake detection techniques struggle to keep-up with the ever-evolving novel, unseen forgeries methods. This limitation stems from their reliance on statistical artifacts learned during training, which are often tied to specific generation processes that may not be representative of samples from new, unseen deepfake generation methods encountered at test time. We propose that incorporating language guidance can improve deepfake detection generalization by integrating human-like commonsense reasoning – such as recognizing logical inconsistencies and perceptual anomalies – alongside statistical cues. To achieve this, we train an expert deepfake vision encoder by combining discriminative classification with image-text contrastive learning, where the text is generated by generalist MLLMs using few-shot prompting. This allows the encoder to extract both language-describable, commonsense deepfake artifacts and statistical forgery artifacts from pixel-level distributions. To further enhance robustness, we integrate data uncertainty learning into vision-language contrastive learning, mitigating noise in image-text supervision. Our expert vision encoder seamlessly interfaces with an LLM, further enabling more generalized and interpretable deepfake detection while also boosting accuracy. The resulting framework, AuthGuard, achieves state-of-the-art deepfake detection accuracy in both in-distribution and out-of-distribution settings, achieving AUC gains of 6.15% on the DFDC dataset and 16.68% on the DF40 dataset. Additionally, AuthGuard significantly enhances deepfake reasoning, improving performance by 24.69% on the DDVQA dataset.
现有深度伪造检测技术在应对不断演变的新型、未见过的伪造方法时面临挑战。这一局限性源于它们依赖于训练期间学习的统计特征,这些特征通常与特定的生成过程相关联,可能无法代表测试时遇到的新未见深度伪造生成方法的样本。我们提出融入语言指导可以通过结合人类常识推理来改善深度伪造检测的泛化能力,如识别逻辑不一致和感知异常等,同时结合统计线索。为此,我们通过结合判别分类和图像文本对比学习来训练专业的深度伪造视觉编码器,其中文本是由通用MLLM通过少量提示生成的。这允许编码器从像素级分布中提取语言可描述的、常识性的深度伪造特征和统计伪造特征。为了进一步提高稳健性,我们将数据不确定性学习融入到视觉语言对比学习中,缓解图像文本监督中的噪声。我们的专业视觉编码器无缝地与LLM接口相连,进一步实现了更通用、可解释的深度伪造检测,同时提高了准确性。由此产生的框架AuthGuard在内外分布设置中均实现了最先进的深度伪造检测精度,在DFDC数据集上AUC提高了6.15%,在DF40数据集上提高了16.68%。此外,AuthGuard还显著增强了深度伪造推理能力,在DDVQA数据集上的性能提高了24.69%。
论文及项目相关链接
Summary:
现有深度伪造检测技术难以应对不断更新的未知伪造方法。该研究提出融合语言指导来提高深度伪造检测的泛化能力,通过结合人类常识推理,如逻辑不一致性和感知异常识别,以及统计线索来实现。该研究通过结合判别分类和图像文本对比学习来训练深度伪造视觉编码器,使用通用MLLMs进行少样本提示生成文本。为提高稳健性,该研究还引入了数据不确定性学习。该专家视觉编码器与LLM无缝集成,提高了深度伪造检测的泛化能力和解释性,同时提高了准确性。所提出的框架AuthGuard在分布内和分布外设置中都实现了最先进的深度伪造检测精度,在DFDC数据集和DF40数据集上的AUC分别提高了6.15%和16.68%。此外,AuthGuard还显著提高了深度伪造推理性能,在DDVQA数据集上的性能提高了24.69%。
Key Takeaways:
- 现有深度伪造检测技术面临对新伪造方法的挑战。
- 通过结合语言指导提高深度伪造检测的泛化能力。
- 使用图像文本对比学习训练深度伪造视觉编码器。
- 结合判别分类和少样本提示生成文本。
- 通过数据不确定性学习提高稳健性。
- 专家视觉编码器与LLM集成,提高检测泛化能力和解释性。
- AuthGuard框架实现了先进的深度伪造检测精度和推理性能提升。
点此查看论文截图


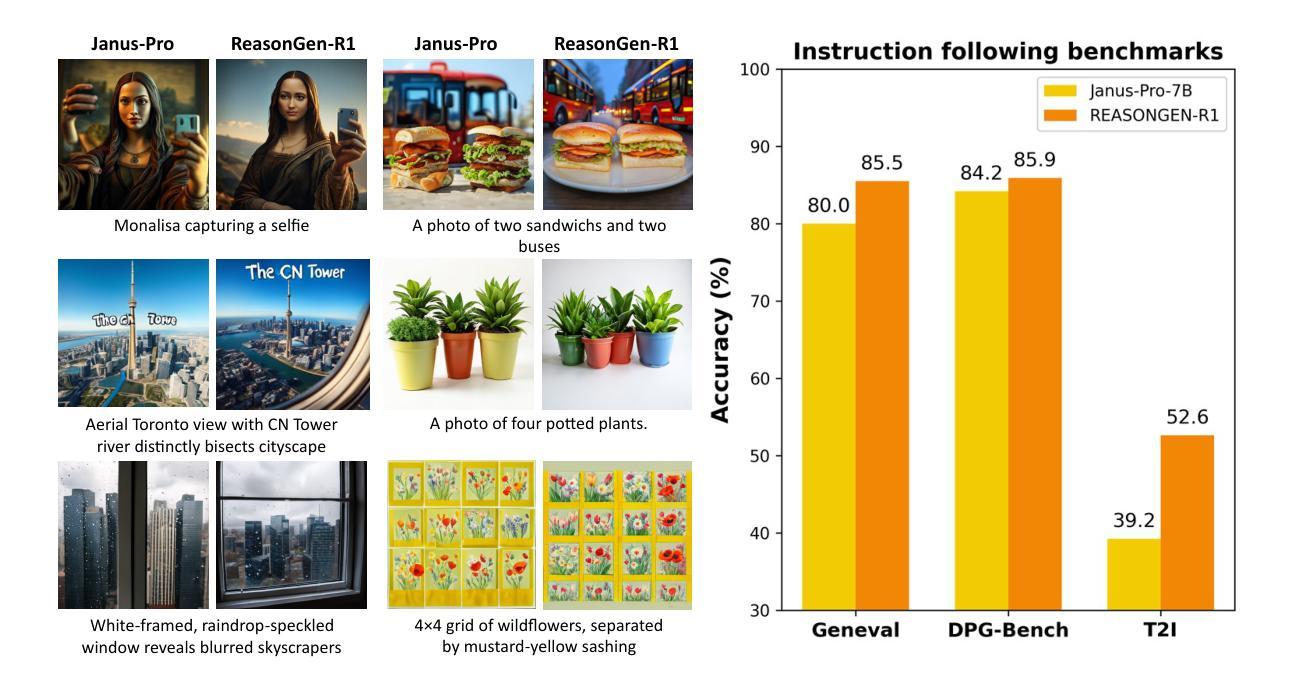
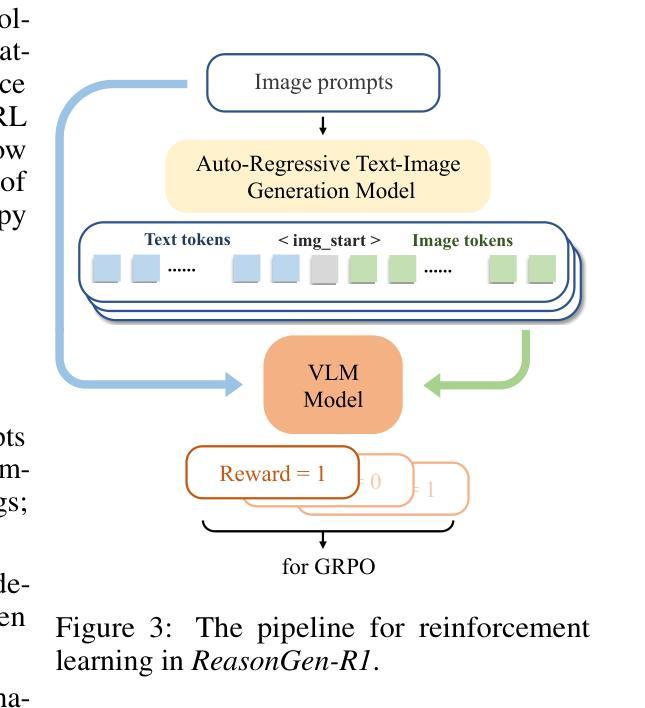
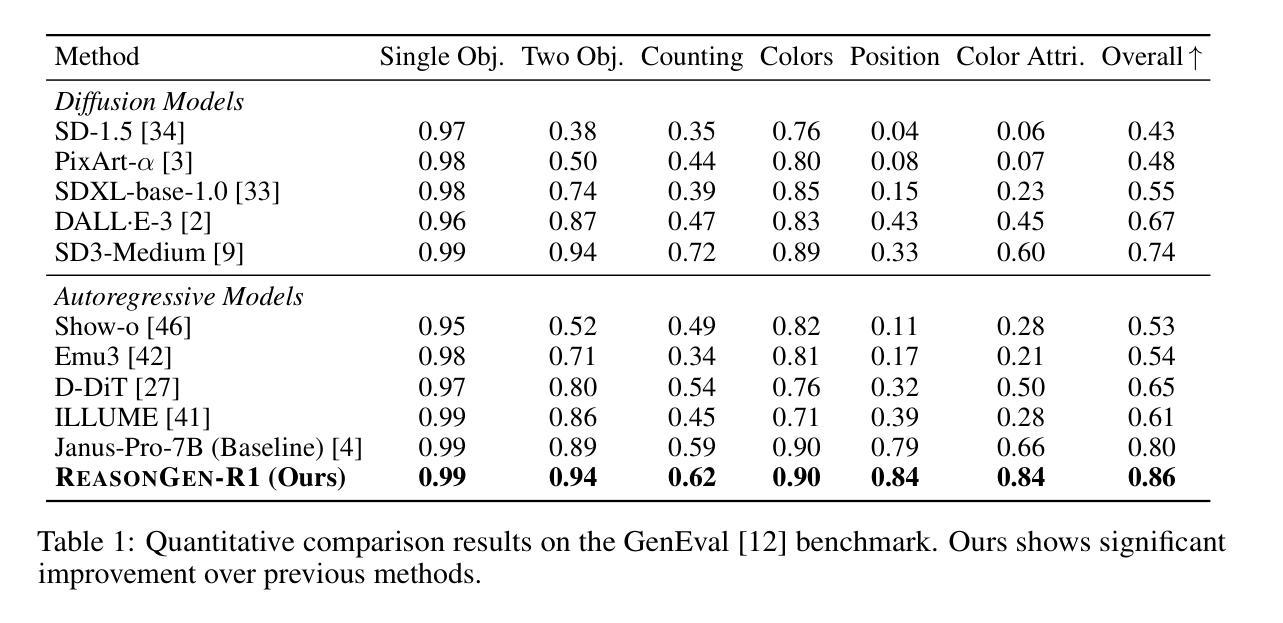
ReasonGen-R1: CoT for Autoregressive Image generation models through SFT and RL
Authors:Yu Zhang, Yunqi Li, Yifan Yang, Rui Wang, Yuqing Yang, Dai Qi, Jianmin Bao, Dongdong Chen, Chong Luo, Lili Qiu
Although chain-of-thought reasoning and reinforcement learning (RL) have driven breakthroughs in NLP, their integration into generative vision models remains underexplored. We introduce ReasonGen-R1, a two-stage framework that first imbues an autoregressive image generator with explicit text-based “thinking” skills via supervised fine-tuning on a newly generated reasoning dataset of written rationales, and then refines its outputs using Group Relative Policy Optimization. To enable the model to reason through text before generating images, We automatically generate and release a corpus of model crafted rationales paired with visual prompts, enabling controlled planning of object layouts, styles, and scene compositions. Our GRPO algorithm uses reward signals from a pretrained vision language model to assess overall visual quality, optimizing the policy in each update. Evaluations on GenEval, DPG, and the T2I benchmark demonstrate that ReasonGen-R1 consistently outperforms strong baselines and prior state-of-the-art models. More: aka.ms/reasongen.
尽管思维链推理和强化学习(RL)在自然语言处理(NLP)领域取得了突破,但它们融入生成式视觉模型的研究仍然不足。我们引入了ReasonGen-R1,这是一个两阶段的框架,首先通过在新生成的基于文本推理数据集上进行有监督微调,使自回归图像生成器具备明确的基于文本的“思考”技能,然后使用集团相对政策优化来优化其输出。为了让模型在生成图像之前通过文本进行推理,我们自动生成并发布了一系列与视觉提示配对的人工构造的推理语料库,实现对物体布局、风格和场景组合的控制规划。我们的GRPO算法使用来自预训练视觉语言模型的奖励信号来评估总体视觉质量,并在每次更新中优化策略。在GenEval、DPG和T2I基准测试上的评估表明,ReasonGen-R1持续超越强劲的基线模型和先前最先进的模型。更多信息请访问aka.ms/reasongen。
论文及项目相关链接
Summary
本文介绍了一种名为ReasonGen-R1的两阶段框架,它将链式思维推理和强化学习融入生成式视觉模型中。第一阶段通过在新生成的推理数据集上监督微调,赋予自回归图像生成器基于文本的“思考”能力。第二阶段使用集团相对政策优化算法,对输出进行精细化处理。该框架能够先通过文本进行推理再生成图像,并自动生成与视觉提示配对的数据集,实现对象布局、风格和场景组合的控制规划。在GenEval、DPG和T2I基准测试上的评估结果表明,ReasonGen-R1持续优于强大的基准模型和先前最先进的模型。
Key Takeaways
- 引入ReasonGen-R1框架,结合链式思维推理和强化学习,应用于生成式视觉模型。
- 第一阶段:通过监督微调赋予自回归图像生成器基于文本的“思考”能力,使用新生成的推理数据集。
- 第二阶段:使用集团相对政策优化算法,精细化处理输出。
- 框架能够先通过文本进行推理,再生成图像,实现控制规划。
- 自动生成与视觉提示配对的数据集,包括对象布局、风格和场景组合。
- 在多个基准测试上,ReasonGen-R1性能优于其他模型。
点此查看论文截图