⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-10 更新
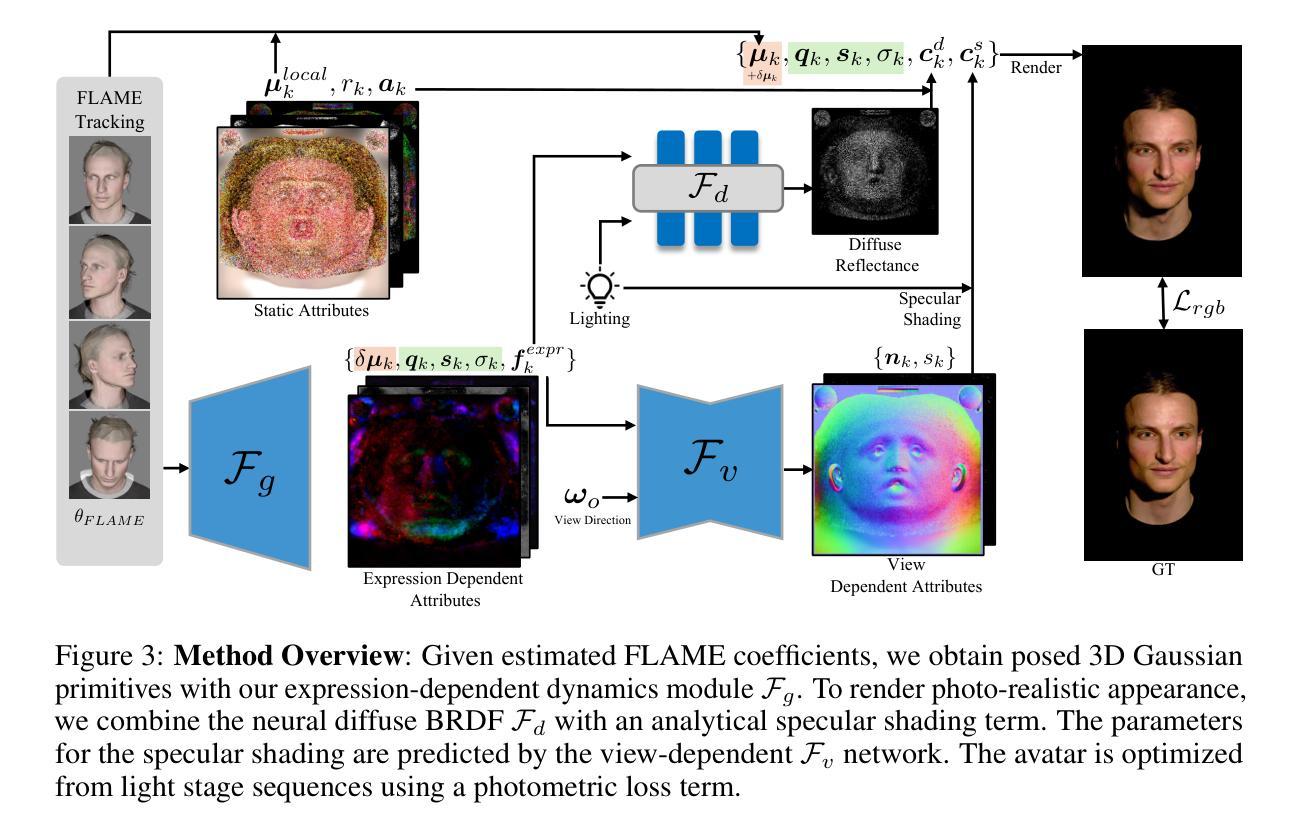
BecomingLit: Relightable Gaussian Avatars with Hybrid Neural Shading
Authors:Jonathan Schmidt, Simon Giebenhain, Matthias Niessner
We introduce BecomingLit, a novel method for reconstructing relightable, high-resolution head avatars that can be rendered from novel viewpoints at interactive rates. Therefore, we propose a new low-cost light stage capture setup, tailored specifically towards capturing faces. Using this setup, we collect a novel dataset consisting of diverse multi-view sequences of numerous subjects under varying illumination conditions and facial expressions. By leveraging our new dataset, we introduce a new relightable avatar representation based on 3D Gaussian primitives that we animate with a parametric head model and an expression-dependent dynamics module. We propose a new hybrid neural shading approach, combining a neural diffuse BRDF with an analytical specular term. Our method reconstructs disentangled materials from our dynamic light stage recordings and enables all-frequency relighting of our avatars with both point lights and environment maps. In addition, our avatars can easily be animated and controlled from monocular videos. We validate our approach in extensive experiments on our dataset, where we consistently outperform existing state-of-the-art methods in relighting and reenactment by a significant margin.
我们介绍了BecomingLit这一新型方法,用于重建可重新照明的、高分辨率的头部化身,可以从新颖的观点以互动速率进行渲染。因此,我们提出了一种新的低成本灯光舞台捕获装置,特别适用于捕捉面部。使用该装置,我们收集了一个新的数据集,该数据集包含在不同照明条件和面部表情下众多主体的多种不同视图序列。通过利用我们的新数据集,我们基于3D高斯原始引入了一种可重新照明的化身表示,我们使用参数化头部模型和表情依赖的动态模块对其进行动画处理。我们提出了一种新的混合神经着色方法,将神经漫反射BRDF与分析镜面术语相结合。我们的方法从动态光照舞台记录中重建出脱离的材料,并能使我们的化身在所有频率下使用点光源和环境地图进行重新照明。此外,我们的化身可以很容易地从单目视频中进行动画和操控。我们在数据集上进行了广泛的实验,验证了我们的方法,在重新照明和重演方面始终显著优于现有最先进的方法。
论文及项目相关链接
PDF Project Page: see https://jonathsch.github.io/becominglit/ ; YouTube Video: see https://youtu.be/xPyeIqKdszA
Summary
新一代头部重建技术BecomingLit能够捕捉面部表情和光照变化,创建出高质量、可重新照亮的头像,并可以从新的视角进行渲染。通过改进的低成本光照舞台捕捉设备,我们收集了一个新的数据集,包含不同视角、不同照明条件和面部表情下的序列图像。此外,我们还引入了基于动态头部模型和表情依赖动力学模块的可重新照亮的头像表示方法。通过混合神经网络着色技术,我们的方法能够重建出动态的照明舞台记录中的分离材料,并允许使用点光源和环境映射进行全频率头像重新照明。从单目视频中即可轻松控制动画和头像。我们的方法在数据集上的实验验证中显著优于现有的最新技术。
Key Takeaways
- BecomingLit技术可以重建高质量、可重新照亮的头像,支持多种视角渲染。
- 引入了一种改进的低成本光照舞台捕捉设备,用于收集包含多种条件下的面部数据的新数据集。
- 通过结合神经网络着色技术,实现了头像的动态照明和全频率重新照明功能。
- 使用动态头部模型和表情依赖动力学模块创建可重新照亮的头像表示方法。
- BecomingLit技术在数据集的测试中表现出色,明显优于现有的其他技术。
- 该技术能够从单目视频轻松控制动画和头像。
点此查看论文截图


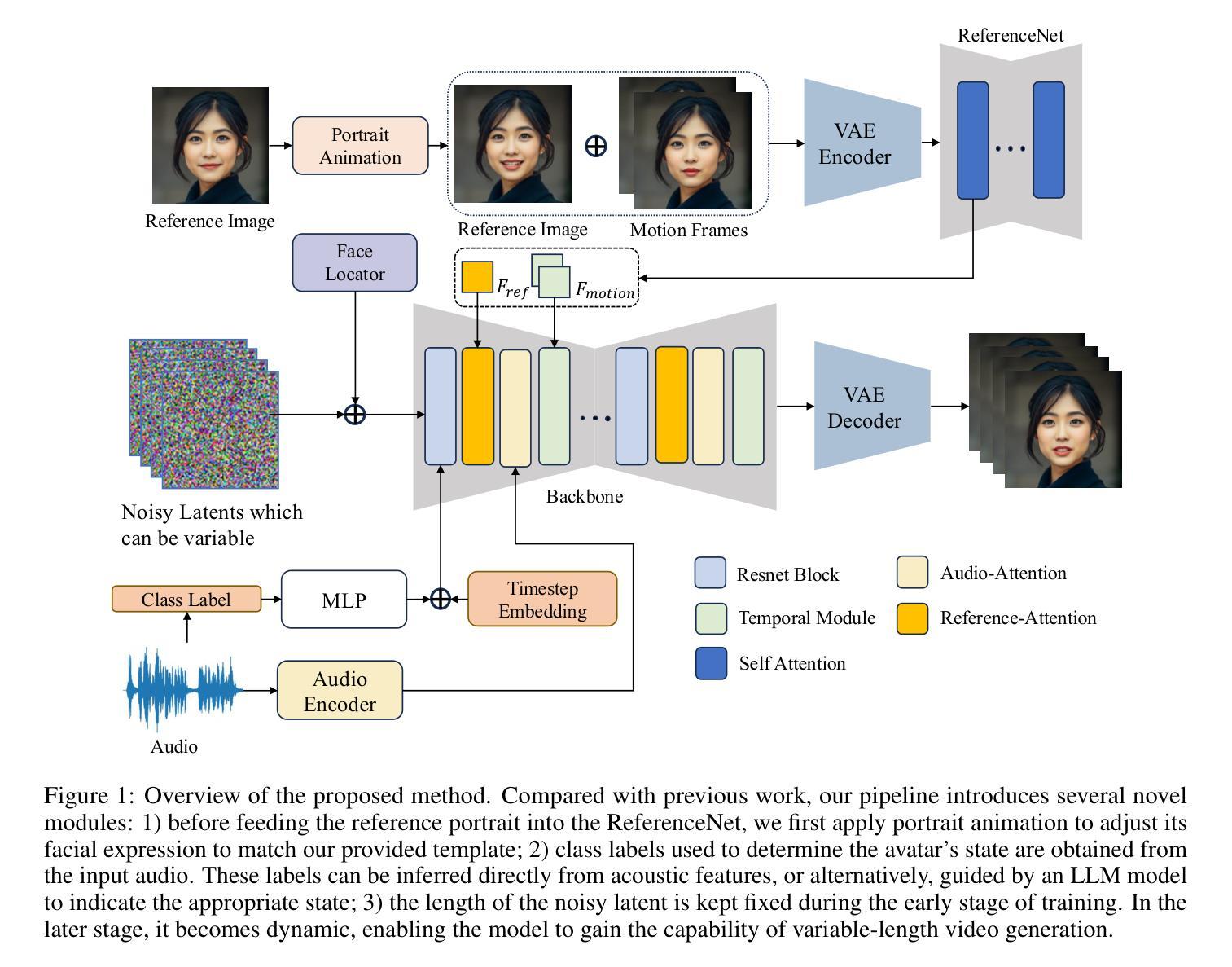
LLIA – Enabling Low-Latency Interactive Avatars: Real-Time Audio-Driven Portrait Video Generation with Diffusion Models
Authors:Haojie Yu, Zhaonian Wang, Yihan Pan, Meng Cheng, Hao Yang, Chao Wang, Tao Xie, Xiaoming Xu, Xiaoming Wei, Xunliang Cai
Diffusion-based models have gained wide adoption in the virtual human generation due to their outstanding expressiveness. However, their substantial computational requirements have constrained their deployment in real-time interactive avatar applications, where stringent speed, latency, and duration requirements are paramount. We present a novel audio-driven portrait video generation framework based on the diffusion model to address these challenges. Firstly, we propose robust variable-length video generation to reduce the minimum time required to generate the initial video clip or state transitions, which significantly enhances the user experience. Secondly, we propose a consistency model training strategy for Audio-Image-to-Video to ensure real-time performance, enabling a fast few-step generation. Model quantization and pipeline parallelism are further employed to accelerate the inference speed. To mitigate the stability loss incurred by the diffusion process and model quantization, we introduce a new inference strategy tailored for long-duration video generation. These methods ensure real-time performance and low latency while maintaining high-fidelity output. Thirdly, we incorporate class labels as a conditional input to seamlessly switch between speaking, listening, and idle states. Lastly, we design a novel mechanism for fine-grained facial expression control to exploit our model’s inherent capacity. Extensive experiments demonstrate that our approach achieves low-latency, fluid, and authentic two-way communication. On an NVIDIA RTX 4090D, our model achieves a maximum of 78 FPS at a resolution of 384x384 and 45 FPS at a resolution of 512x512, with an initial video generation latency of 140 ms and 215 ms, respectively.
基于扩散的模型由于其出色的表现力在虚拟人生成领域得到了广泛的应用。然而,其巨大的计算需求限制了其在实时交互式化身应用程序中的部署,这些应用程序对速度、延迟和持续时间有着严格的要求。我们提出了一种基于扩散模型的新型音频驱动肖像视频生成框架,以解决这些挑战。首先,我们提出鲁棒性可变长度视频生成,以减少生成初始视频剪辑或状态转换所需的最短时间,这显著增强了用户体验。其次,我们为音频图像到视频的模型提出了一种一致性模型训练策略,以确保实时性能,实现快速多步生成。还采用了模型量化和流水线并行性来加速推理速度。为了解决扩散过程和模型量化引起的稳定性损失,我们引入了一种适用于长时长视频生成的新型推理策略。这些方法确保了实时性能和低延迟,同时保持了高保真输出。第三,我们将类别标签作为条件输入,无缝切换说话、倾听和空闲状态。最后,我们设计了一种用于精细面部表情控制的新机制,以利用我们模型的内在能力。大量实验表明,我们的方法实现了低延迟、流畅和真实的双向通信。在NVIDIA RTX 4090D上,我们的模型在384x384的分辨率下最高可达78帧每秒,在512x512的分辨率下为45帧每秒。初始视频生成延迟分别为140毫秒和215毫秒。
论文及项目相关链接
Summary
扩散模型因其出色的表现力在虚拟人生成领域得到广泛应用,但其巨大的计算需求限制了其在实时互动虚拟人物应用中的部署。为此,我们提出了一种基于扩散模型的新型音频驱动肖像视频生成框架,通过可变长度视频生成、音频图像到视频的连贯性模型训练策略、模型量化和并行计算加速推理等方法,实现了实时性能、低延迟和高保真输出的保证。此外,还融入了类标签作为条件输入,并设计了精细的面部表情控制机制。实验证明,该方法实现了低延迟、流畅和真实的双向交流。
Key Takeaways
- 扩散模型在虚拟人生成中的广泛应用及其计算需求挑战。
- 新型音频驱动肖像视频生成框架基于扩散模型,解决实时互动虚拟人物应用的挑战。
- 通过可变长度视频生成增强用户体验。
- 采用连贯性模型训练策略保证实时性能。
- 使用模型量化和并行计算加速推理速度。
- 通过引入新推理策略减轻扩散过程和模型量化带来的稳定性损失。
点此查看论文截图