⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-10 更新
SIV-Bench: A Video Benchmark for Social Interaction Understanding and Reasoning
Authors:Fanqi Kong, Weiqin Zu, Xinyu Chen, Yaodong Yang, Song-Chun Zhu, Xue Feng
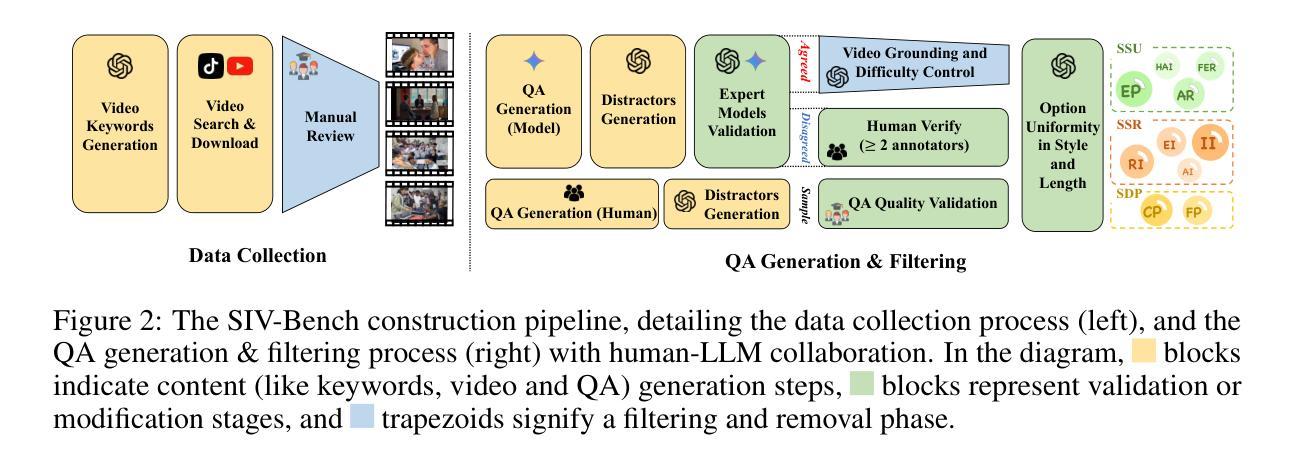
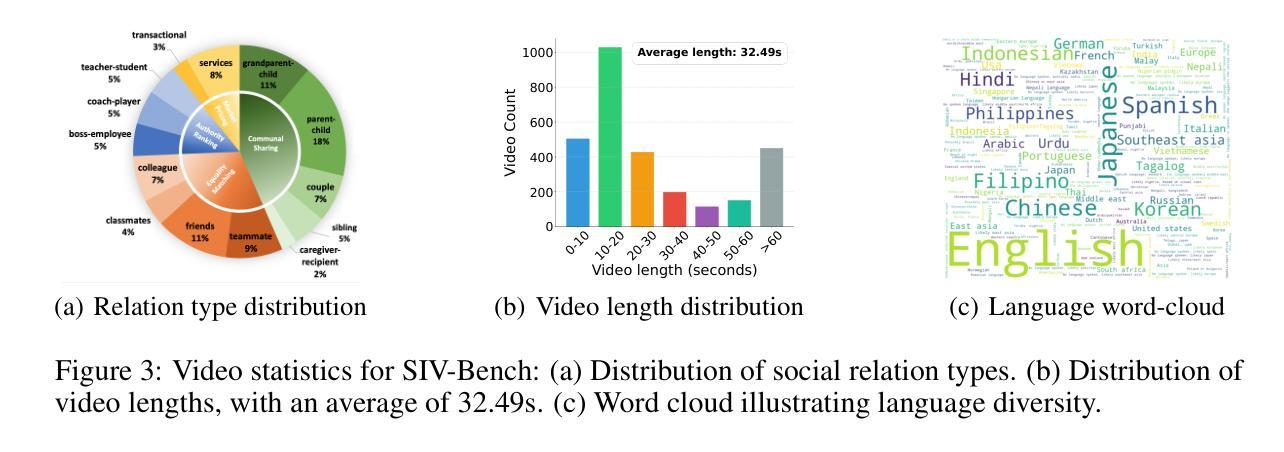
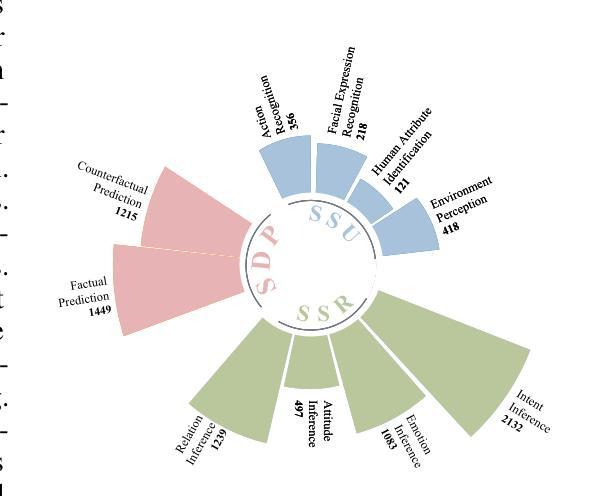
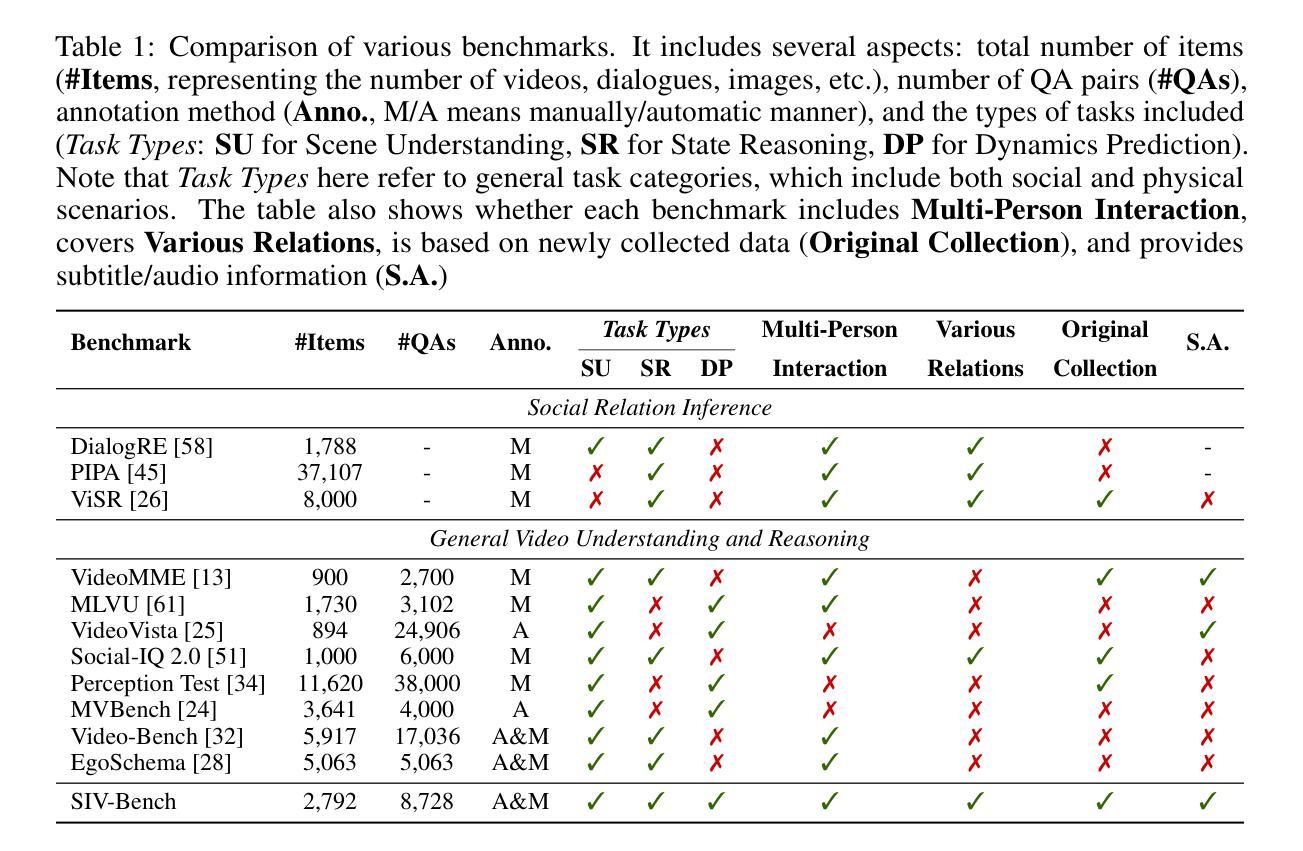
The rich and multifaceted nature of human social interaction, encompassing multimodal cues, unobservable relations and mental states, and dynamical behavior, presents a formidable challenge for artificial intelligence. To advance research in this area, we introduce SIV-Bench, a novel video benchmark for rigorously evaluating the capabilities of Multimodal Large Language Models (MLLMs) across Social Scene Understanding (SSU), Social State Reasoning (SSR), and Social Dynamics Prediction (SDP). SIV-Bench features 2,792 video clips and 8,792 meticulously generated question-answer pairs derived from a human-LLM collaborative pipeline. It is originally collected from TikTok and YouTube, covering a wide range of video genres, presentation styles, and linguistic and cultural backgrounds. It also includes a dedicated setup for analyzing the impact of different textual cues-original on-screen text, added dialogue, or no text. Our comprehensive experiments on leading MLLMs reveal that while models adeptly handle SSU, they significantly struggle with SSR and SDP, where Relation Inference (RI) is an acute bottleneck, as further examined in our analysis. Our study also confirms the critical role of transcribed dialogue in aiding comprehension of complex social interactions. By systematically identifying current MLLMs’ strengths and limitations, SIV-Bench offers crucial insights to steer the development of more socially intelligent AI. The dataset and code are available at https://kfq20.github.io/sivbench/.
人类社会互动的丰富性和多元性,包括多模态线索、不可观察的关系和心态以及动态行为,给人工智能带来了巨大的挑战。为了推动这一领域的研究,我们引入了SIV-Bench,这是一个新的视频基准测试,用于严格评估多模态大型语言模型(MLLMs)在社会场景理解(SSU)、社会状态推理(SSR)和社会动态预测(SDP)方面的能力。SIV-Bench包含2792个视频片段和8792个精心生成的问题答案对,这些对是通过人机协作管道生成的。数据最初来自TikTok和YouTube,涵盖了广泛的视频类型、展示风格、语言和文化背景。它还包括一个专门的设置,用于分析不同文本线索的影响,包括原始屏幕文本、添加的对话或无文本。我们对领先的多模态大型语言模型进行的综合实验表明,虽然这些模型在处理SSU方面表现出色,但在SSR和SDP方面却面临巨大挑战,其中关系推理(RI)是一个严重的瓶颈,正如我们的分析中所进一步研究的那样。我们的研究也证实了转录对话在帮助理解复杂的社会互动中的关键作用。通过系统地确定当前多模态大型语言模型的优势和局限性,SIV-Bench为开发更具社会智能的AI提供了关键见解。数据集和代码可在https://kfq20.github.io/sivbench/ 获得。
论文及项目相关链接
Summary
本文介绍了SIV-Bench,一个为评估多模态大语言模型在社交场景理解(SSU)、社会状态推理(SSR)和社会动态预测(SDP)等方面能力的视频基准测试。该基准测试包含从TikTok和YouTube收集的2,792个视频剪辑和由此产生的8,792个精心制作的问题答案对。实验表明,模型在处理社会状态推理和社会动态预测方面存在明显困难,其中关系推理(RI)是一个关键问题。数据集和代码可在链接找到。
Key Takeaways
- SIV-Bench是一个针对多模态大语言模型的视频基准测试,旨在评估其在社交场景理解方面的能力。
- 包含来自TikTok和YouTube的多种视频风格和背景的视频剪辑。
- SSU相对容易处理,但在SSR和SDP方面存在困难。
- 关系推理是严重的瓶颈问题。
- 转录对话对于理解复杂的社交互动至关重要。
- SIV-Bench通过系统识别现有模型的优缺点,为发展更智能的社会人工智能提供了重要见解。
点此查看论文截图