⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-10 更新
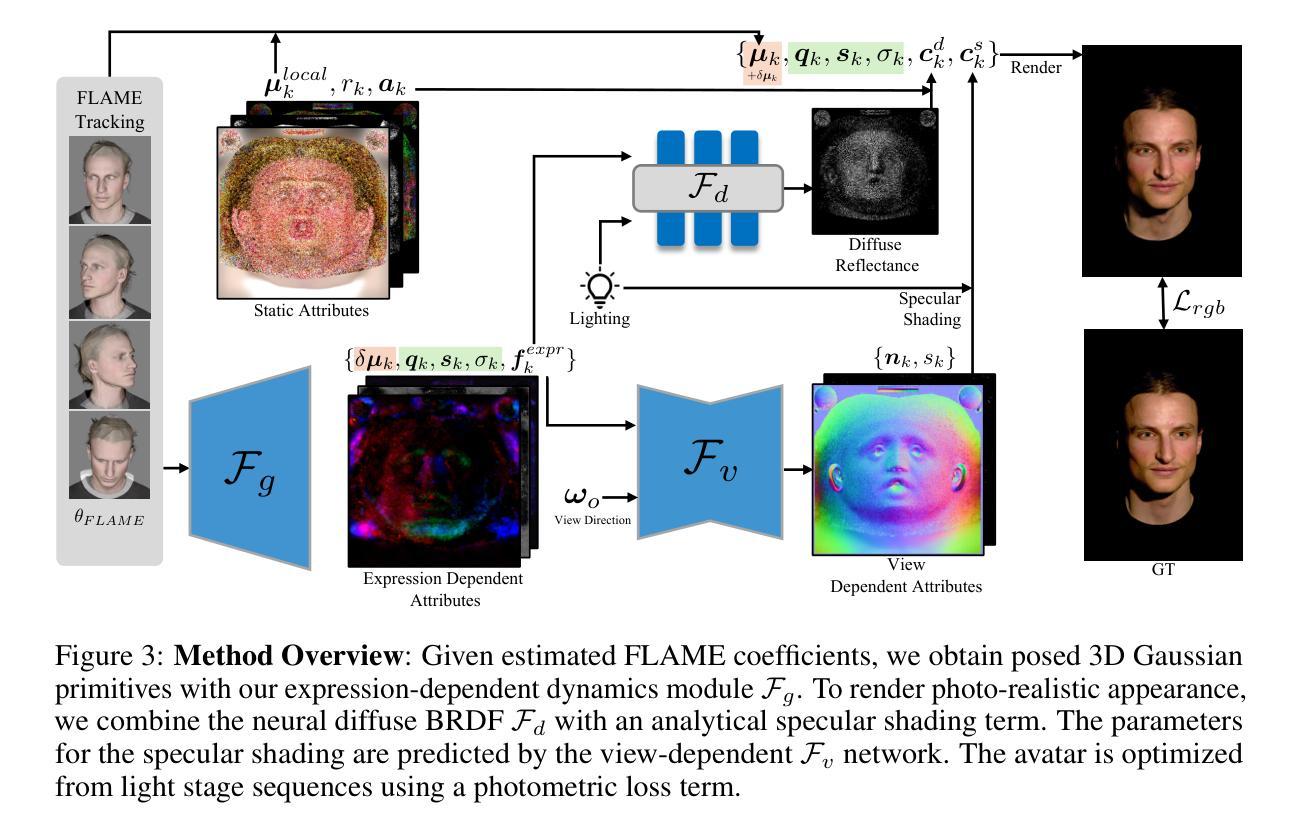
BecomingLit: Relightable Gaussian Avatars with Hybrid Neural Shading
Authors:Jonathan Schmidt, Simon Giebenhain, Matthias Niessner
We introduce BecomingLit, a novel method for reconstructing relightable, high-resolution head avatars that can be rendered from novel viewpoints at interactive rates. Therefore, we propose a new low-cost light stage capture setup, tailored specifically towards capturing faces. Using this setup, we collect a novel dataset consisting of diverse multi-view sequences of numerous subjects under varying illumination conditions and facial expressions. By leveraging our new dataset, we introduce a new relightable avatar representation based on 3D Gaussian primitives that we animate with a parametric head model and an expression-dependent dynamics module. We propose a new hybrid neural shading approach, combining a neural diffuse BRDF with an analytical specular term. Our method reconstructs disentangled materials from our dynamic light stage recordings and enables all-frequency relighting of our avatars with both point lights and environment maps. In addition, our avatars can easily be animated and controlled from monocular videos. We validate our approach in extensive experiments on our dataset, where we consistently outperform existing state-of-the-art methods in relighting and reenactment by a significant margin.
我们介绍了BecomingLit这一新型方法,用于重建可重新照明的、高分辨率的头部化身,可从新颖的观点以交互速率进行渲染。因此,我们提出了一种新的低成本灯光舞台捕获设置,专门用于捕捉面部。使用该设置,我们收集了一个新的数据集,该数据集包含在不同照明条件和面部表情下多个主体的各种多角度序列。通过利用我们的新数据集,我们引入了基于3D高斯原始数据的新的可重新照明的化身表示,我们使用参数化头部模型和表情依赖的动态模块使其动画化。我们提出了一种新的混合神经着色方法,将神经漫反射BRDF与分析镜面术语相结合。我们的方法从动态灯光舞台记录中重建了纠缠材料,并使我们能够使用点光源和环境贴图对所有频率的化身进行重新照明。此外,我们的化身可以轻松地从单目视频进行动画和操控。我们在自己的数据集上进行了广泛的实验验证,我们的方法在重新照明和重新演绎方面始终显著优于现有最先进的方法。
论文及项目相关链接
PDF Project Page: see https://jonathsch.github.io/becominglit/ ; YouTube Video: see https://youtu.be/xPyeIqKdszA
Summary
本文介绍了BecomingLit这一新型方法,用于重建可重新照明的、高分辨率的头部化身,可从新的视角以互动速率进行渲染。提出一种专门针对面部捕捉的低成本光线捕捉设置,收集包含多样多角度序列的新数据集,涉及不同照明条件和面部表情。基于3D高斯原始数据和参数化头部模型和表情依赖动态模块,引入可重新照明的化身表示。提出一种结合神经漫反射BRDF与分析镜面术语的新型混合神经着色方法。该方法从动态光照舞台记录中重建分离材料,使化身的全方位频率重新照明成为可能,既有点光源也有环境地图。此外,其化身可轻松从单目视频进行动画和控制。在数据集上的广泛实验验证了该方法的有效性,其在重新照明和重演方面显著优于现有先进技术。
Key Takeaways
- BecomingLit是一种重建高分辨率头部化身的新方法,支持从新视角以互动速率进行渲染。
- 提出一种低成本的面部捕捉光照设置,专门用于捕捉面部表情和光照变化。
- 收集了一个新数据集,包含多角度、多表情、多变照明条件下的面部序列。
- 基于3D高斯原始数据引入可重新照明的化身表示,结合参数化头部模型和表情依赖动态模块。
- 提出了混合神经着色方法,结合了神经漫反射BRDF与分析镜面术语,实现全方位频率的重新照明。
- 方法能从动态光照舞台记录中重建分离材料,支持点光源和环境地图的重新照明。
点此查看论文截图


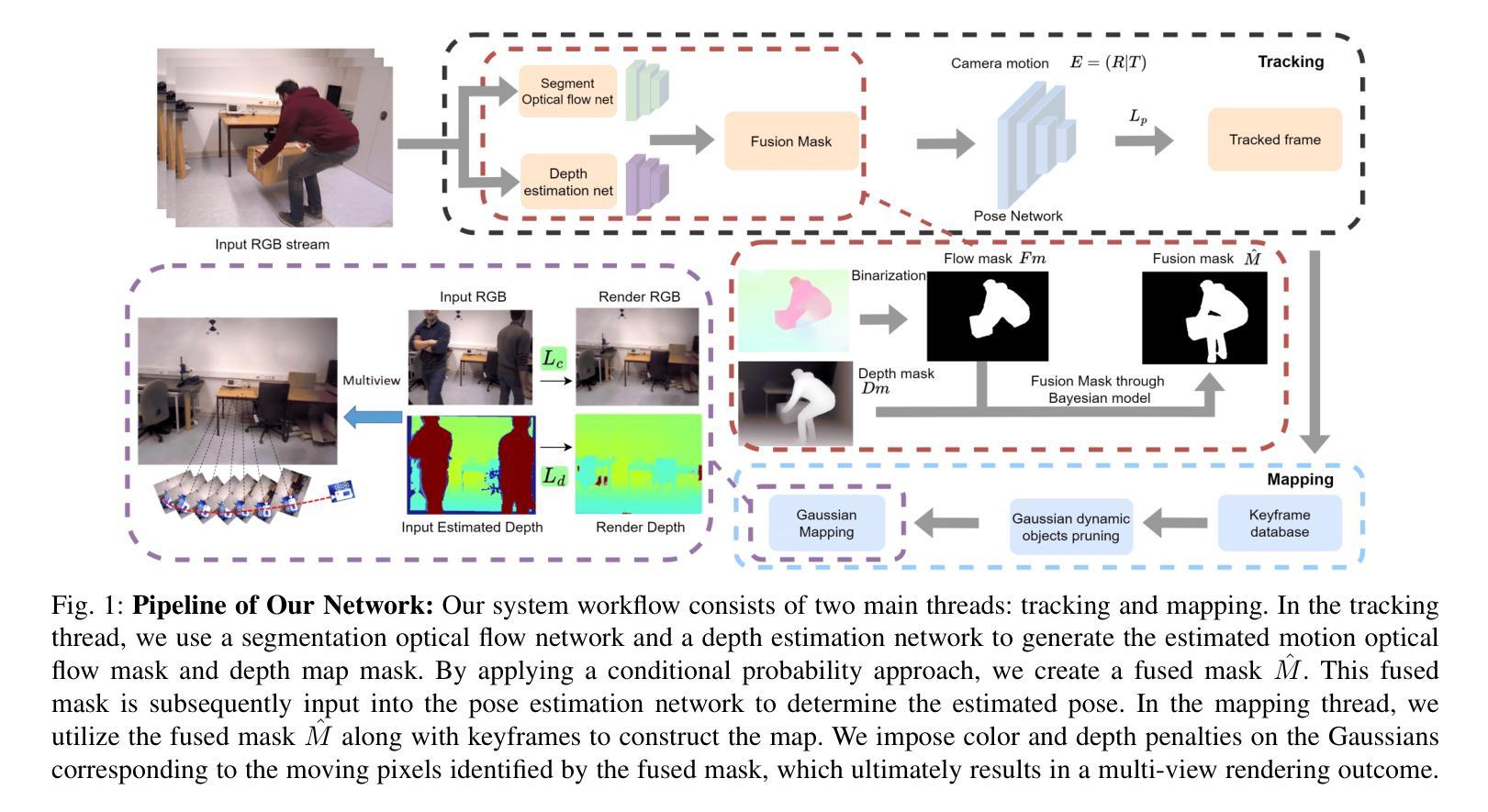
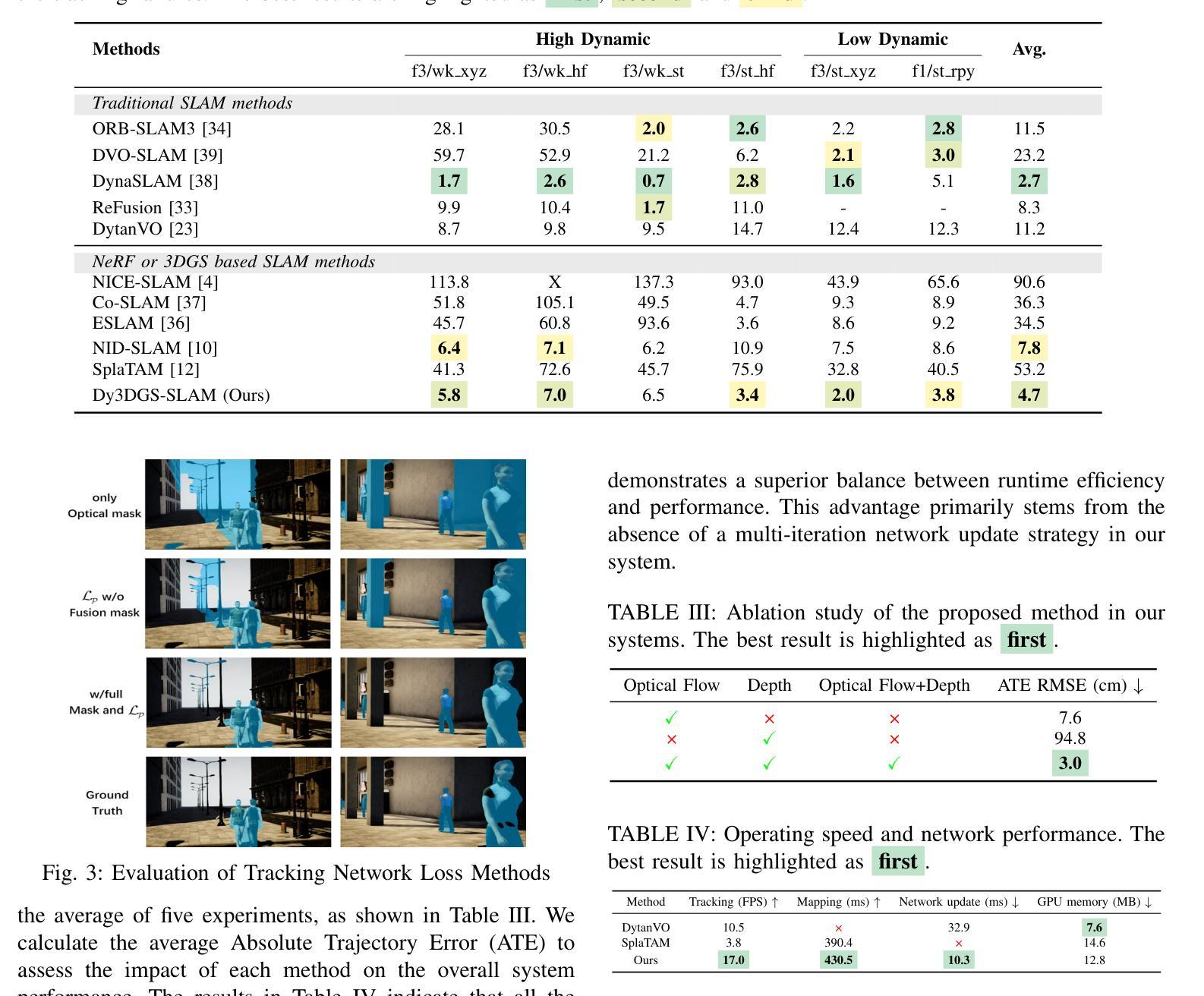
Dy3DGS-SLAM: Monocular 3D Gaussian Splatting SLAM for Dynamic Environments
Authors:Mingrui Li, Yiming Zhou, Hongxing Zhou, Xinggang Hu, Florian Roemer, Hongyu Wang, Ahmad Osman
Current Simultaneous Localization and Mapping (SLAM) methods based on Neural Radiance Fields (NeRF) or 3D Gaussian Splatting excel in reconstructing static 3D scenes but struggle with tracking and reconstruction in dynamic environments, such as real-world scenes with moving elements. Existing NeRF-based SLAM approaches addressing dynamic challenges typically rely on RGB-D inputs, with few methods accommodating pure RGB input. To overcome these limitations, we propose Dy3DGS-SLAM, the first 3D Gaussian Splatting (3DGS) SLAM method for dynamic scenes using monocular RGB input. To address dynamic interference, we fuse optical flow masks and depth masks through a probabilistic model to obtain a fused dynamic mask. With only a single network iteration, this can constrain tracking scales and refine rendered geometry. Based on the fused dynamic mask, we designed a novel motion loss to constrain the pose estimation network for tracking. In mapping, we use the rendering loss of dynamic pixels, color, and depth to eliminate transient interference and occlusion caused by dynamic objects. Experimental results demonstrate that Dy3DGS-SLAM achieves state-of-the-art tracking and rendering in dynamic environments, outperforming or matching existing RGB-D methods.
当前基于神经辐射场(NeRF)或3D高斯喷绘的同步定位与地图构建(SLAM)方法在重建静态3D场景方面表现优异,但在动态环境(例如具有移动元素的真实场景)中的跟踪和重建方面存在困难。现有的解决动态挑战的NeRF基SLAM方法通常依赖于RGB-D输入,只有少数方法接受纯RGB输入。为了克服这些限制,我们提出了Dy3DGS-SLAM,这是使用单目RGB输入对动态场景进行3D高斯喷绘(3DGS)SLAM方法的首创。为了解决动态干扰问题,我们通过概率模型融合光学流动掩膜和深度掩膜,以获得融合动态掩膜。仅通过一次网络迭代,这可以约束跟踪尺度并优化渲染几何。基于融合动态掩膜,我们设计了一种新型运动损失,以约束姿态估计网络进行跟踪。在地图构建方面,我们使用动态像素的渲染损失、颜色和深度,以消除由动态物体引起的短暂干扰和遮挡。实验结果表明,Dy3DGS-SLAM在动态环境中实现了最先进的跟踪和渲染,优于或匹配现有的RGB-D方法。
论文及项目相关链接
Summary
基于神经辐射场(NeRF)或三维高斯喷绘的当前SLAM(Simultaneous Localization and Mapping,即时定位与地图构建)方法在重建静态三维场景方面表现出色,但在处理动态环境如具有移动元素的真实场景中则存在困难。为了克服这些局限性,我们提出了Dy3DGS-SLAM,这是首个使用单目RGB输入的针对动态场景的3D高斯喷绘SLAM方法。通过融合光学流掩膜和深度掩膜生成融合动态掩膜,只需一次网络迭代即可约束跟踪尺度并优化渲染几何。基于融合动态掩膜,我们设计了一种新的运动损失来约束姿态估计网络的跟踪。在映射方面,我们使用动态像素的渲染损失、颜色和深度来消除动态物体引起的瞬态干扰和遮挡。实验结果表明,Dy3DGS-SLAM在动态环境下实现了先进的跟踪和渲染效果,优于或与现有RGB-D方法相匹配。
Key Takeaways
- 当前基于NeRF或3DGS的SLAM方法在静态场景重建方面表现优秀,但在动态环境中跟踪和重建遇到困难。
- Dy3DGS-SLAM是首个针对动态场景的3DGS SLAM方法,使用单目RGB输入。
- 通过融合光学流掩膜和深度掩膜生成融合动态掩膜,用于约束跟踪尺度和优化渲染几何。
- 引入新的运动损失,基于融合动态掩膜来约束姿态估计网络的跟踪。
- 在映射过程中使用动态像素的渲染损失、颜色和深度,以消除动态物体引起的干扰和遮挡。
- Dy3DGS-SLAM在动态环境下实现了先进的跟踪和渲染效果。
点此查看论文截图


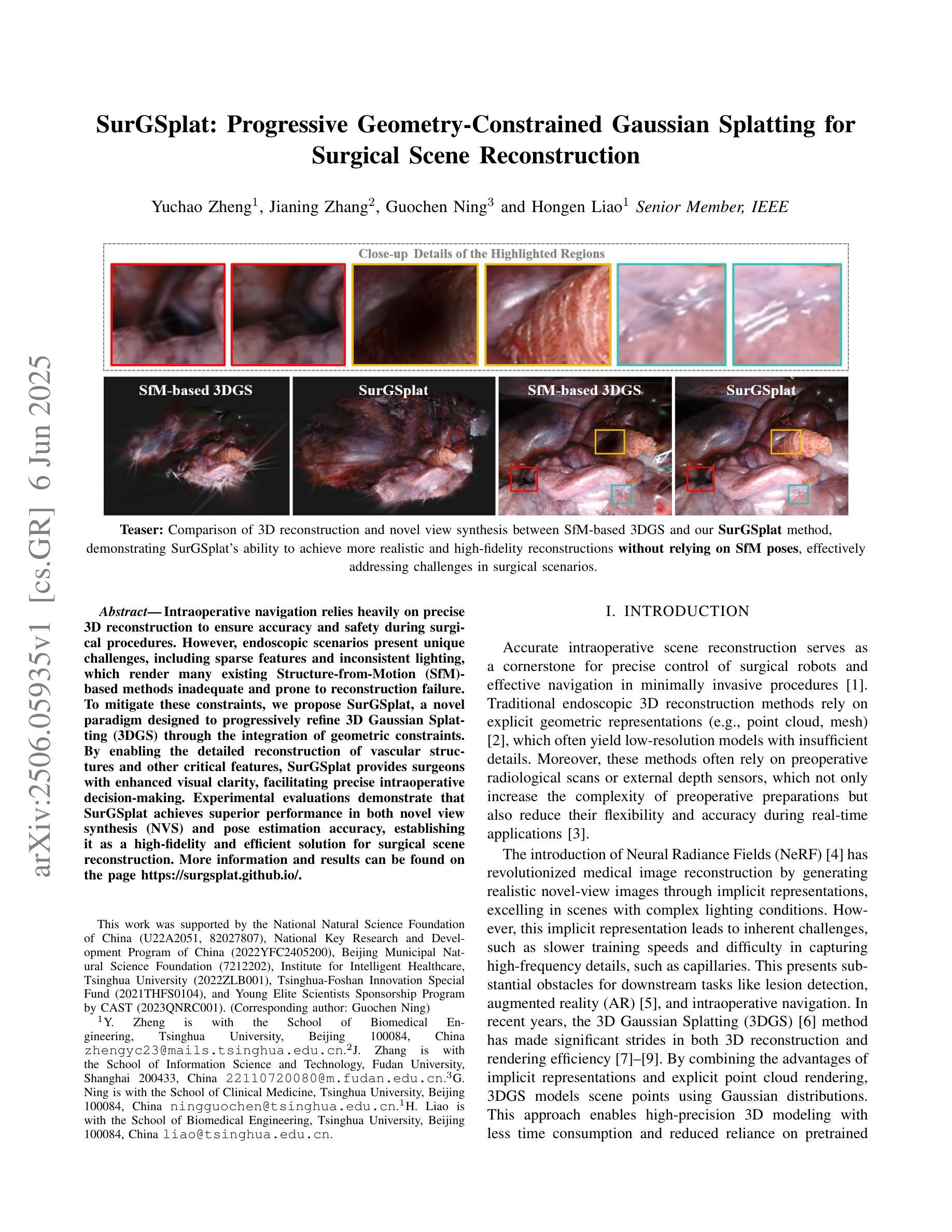
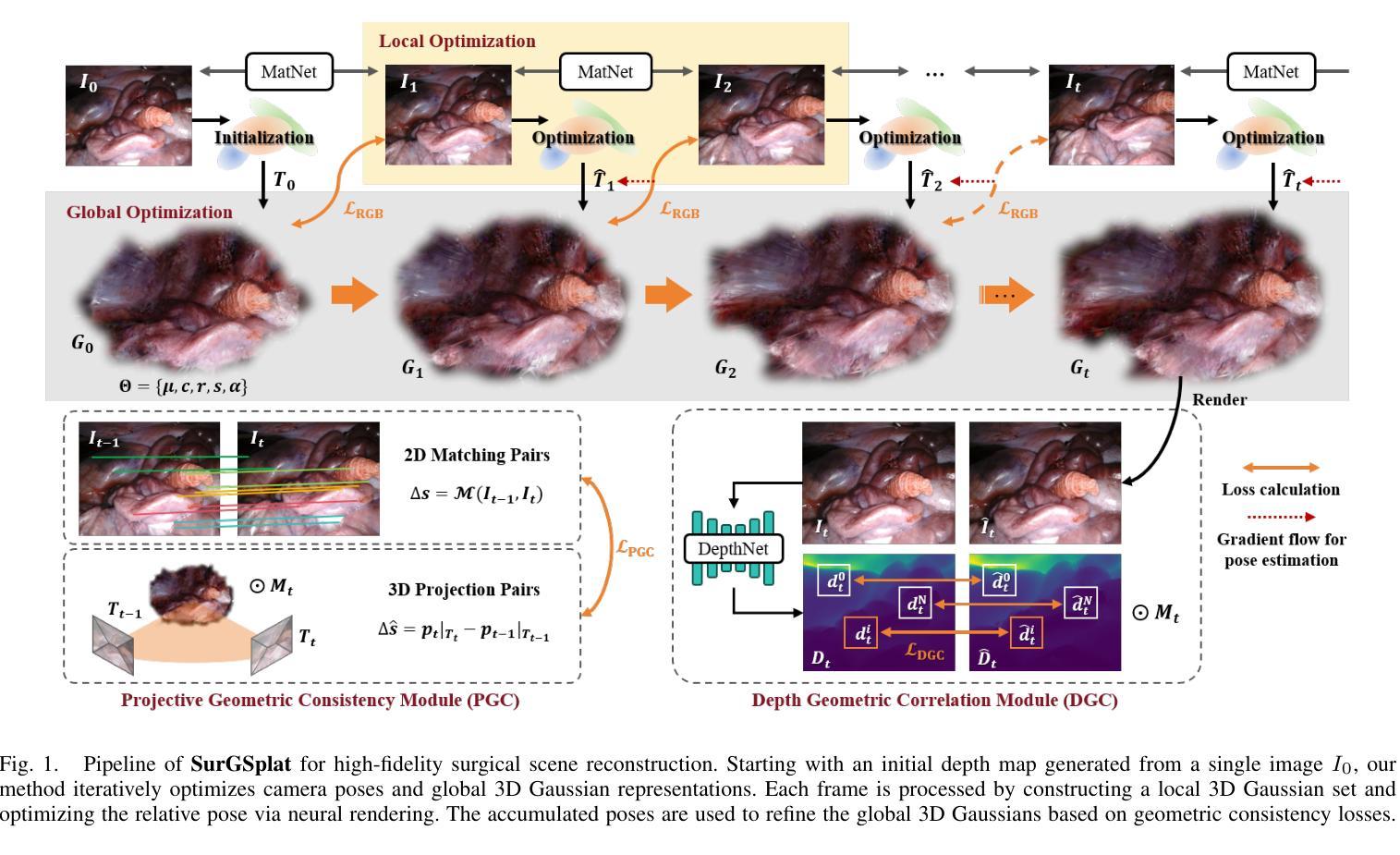
SurGSplat: Progressive Geometry-Constrained Gaussian Splatting for Surgical Scene Reconstruction
Authors:Yuchao Zheng, Jianing Zhang, Guochen Ning, Hongen Liao
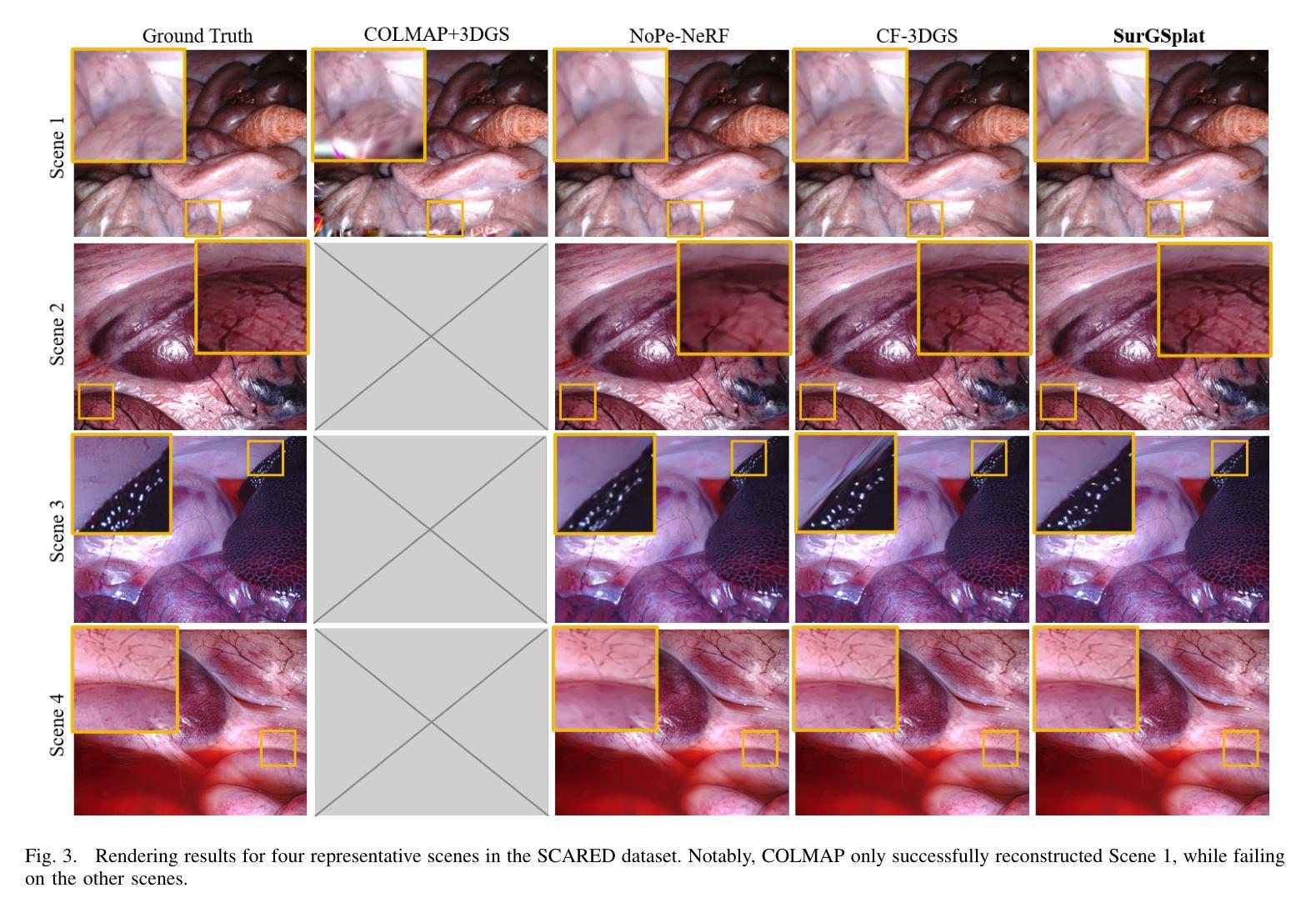
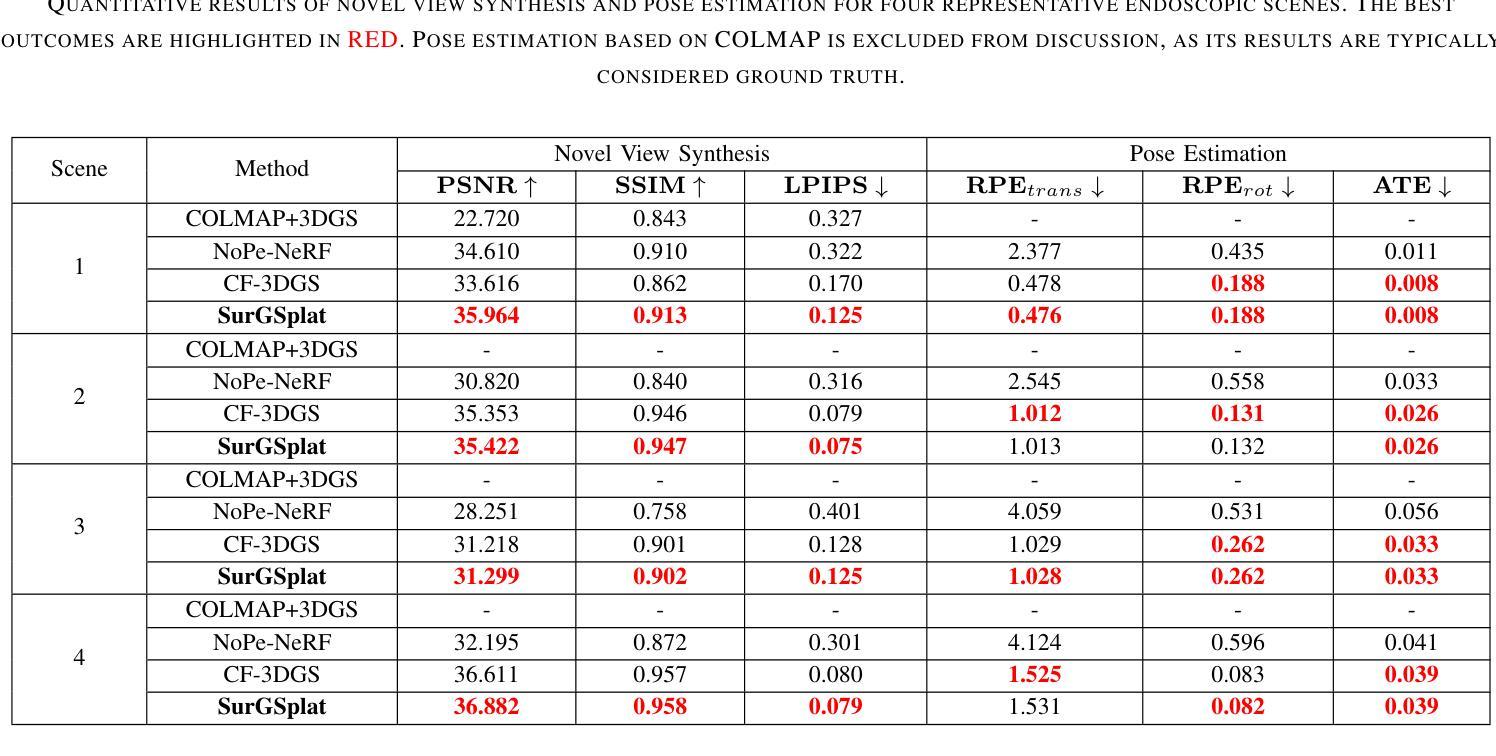
Intraoperative navigation relies heavily on precise 3D reconstruction to ensure accuracy and safety during surgical procedures. However, endoscopic scenarios present unique challenges, including sparse features and inconsistent lighting, which render many existing Structure-from-Motion (SfM)-based methods inadequate and prone to reconstruction failure. To mitigate these constraints, we propose SurGSplat, a novel paradigm designed to progressively refine 3D Gaussian Splatting (3DGS) through the integration of geometric constraints. By enabling the detailed reconstruction of vascular structures and other critical features, SurGSplat provides surgeons with enhanced visual clarity, facilitating precise intraoperative decision-making. Experimental evaluations demonstrate that SurGSplat achieves superior performance in both novel view synthesis (NVS) and pose estimation accuracy, establishing it as a high-fidelity and efficient solution for surgical scene reconstruction. More information and results can be found on the page https://surgsplat.github.io/.
术中导航严重依赖于精确的3D重建,以确保手术过程中的准确性和安全性。然而,内镜场景存在独特的挑战,包括特征稀疏和照明不一致,这使得许多现有的基于运动结构(SfM)的方法不足以应对,并容易出现重建失败。为了缓解这些限制,我们提出了SurGSplat,这是一种通过结合几何约束来逐步优化3D高斯平铺(3DGS)的新型范式。通过实现血管结构和其他关键特征的详细重建,SurGSplat为外科医生提供了增强的视觉清晰度,促进了精确的术中决策。实验评估表明,SurGSplat在新型视图合成(NVS)和姿态估计精度方面实现了卓越的性能,确立了其在手术场景重建中的高保真度和高效解决方案地位。更多信息和结果可在https://surgsplat.github.io/页面上找到。
论文及项目相关链接
Summary
本文介绍了手术过程中的导航依赖于精确的3D重建以确保手术准确性和安全性。然而,内窥镜场景存在特征稀疏和光照不一致等挑战,使得现有的基于SfM的方法难以满足需求并容易出现重建失败。为解决这些问题,提出了SurGSplat,一种通过整合几何约束逐步优化3D高斯描绘(3DGS)的新型范式。它能详细重建血管结构和其他关键特征,为外科医生提供增强的视觉清晰度,促进手术过程中的精确决策。实验评估表明,SurGSplat在新型视图合成和姿态估计准确性方面表现优越,成为手术场景重建的高保真度和高效率解决方案。
Key Takeaways
- 手术导航依赖精确的3D重建确保手术准确性和安全性。
- 内窥镜场景存在特征稀疏和光照不一致的挑战。
- 现有基于SfM的方法难以满足需求,容易出现重建失败。
- SurGSplat是一种新型范式,通过整合几何约束逐步优化3DGS。
- SurGSplat能详细重建血管结构和其他关键特征,提供增强的视觉清晰度。
- SurGSplat在新型视图合成和姿态估计准确性方面表现优越。
点此查看论文截图

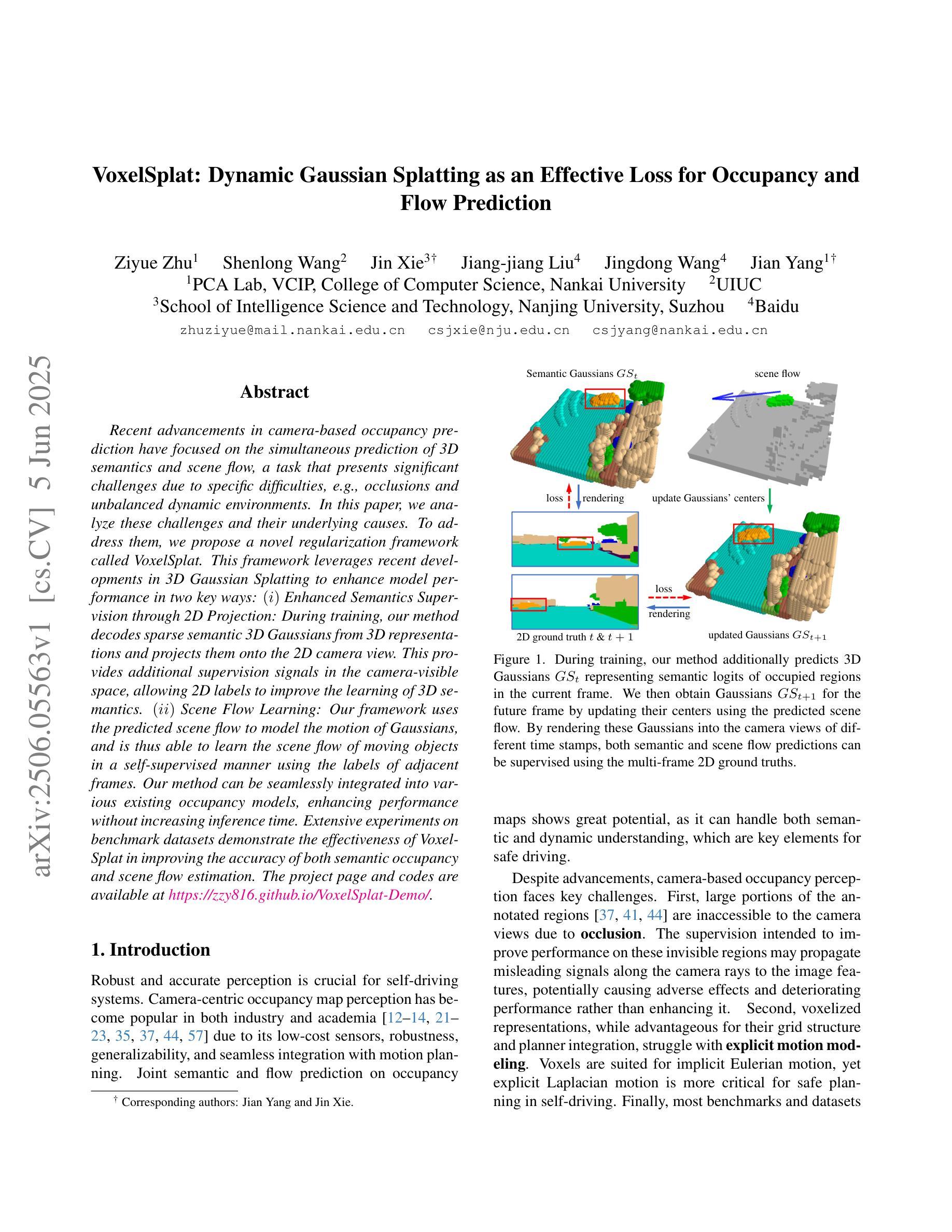
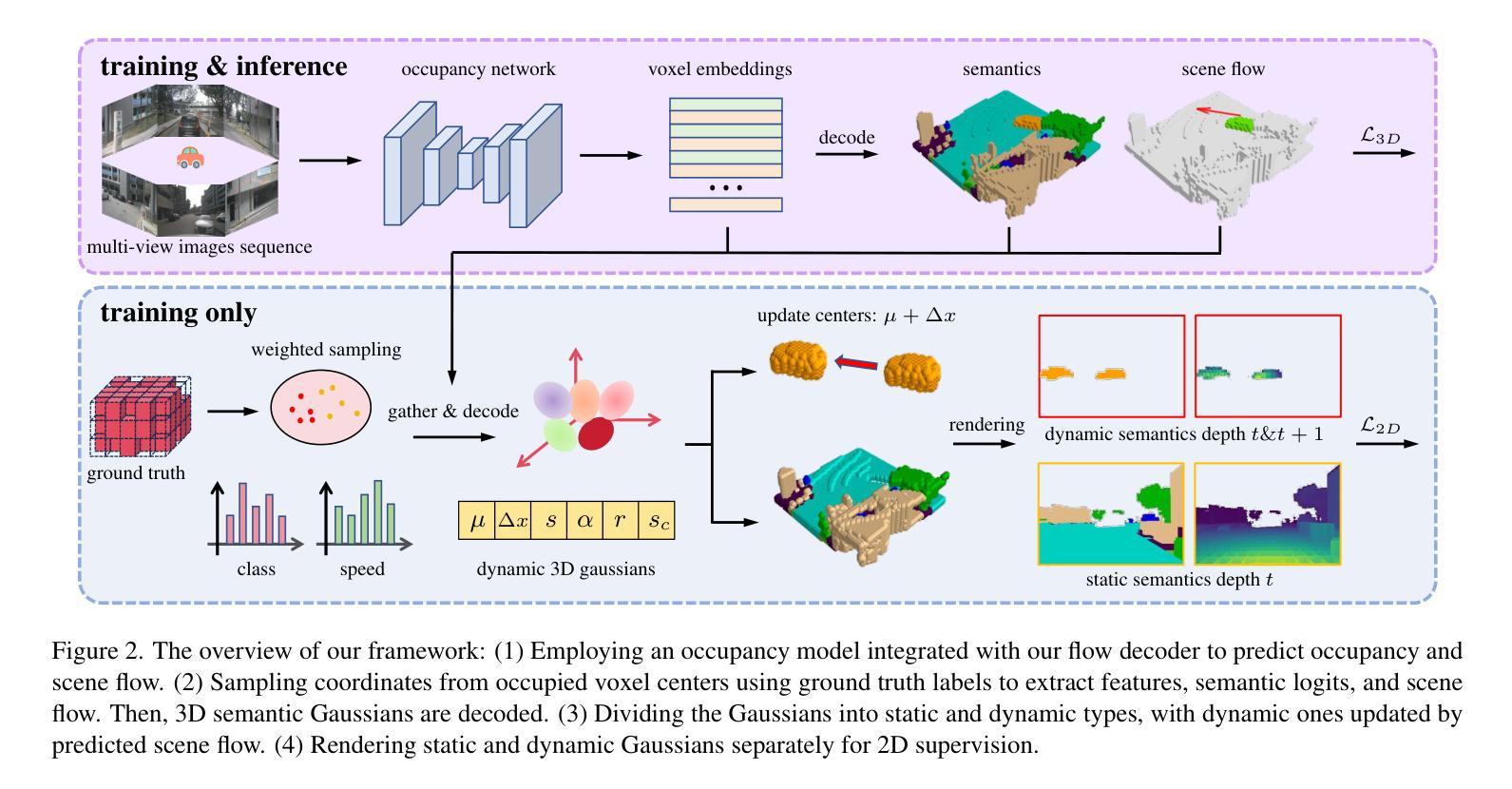
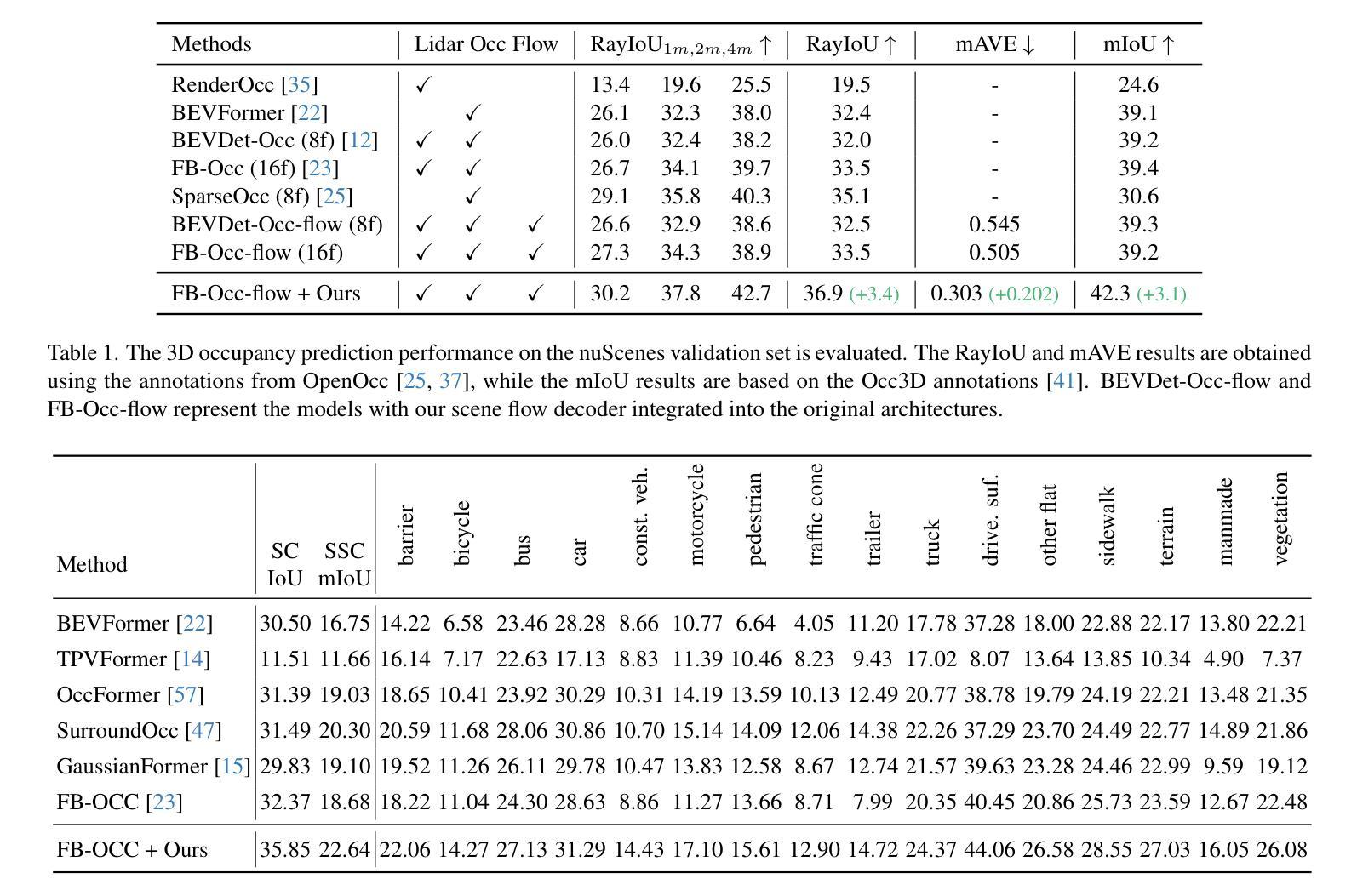
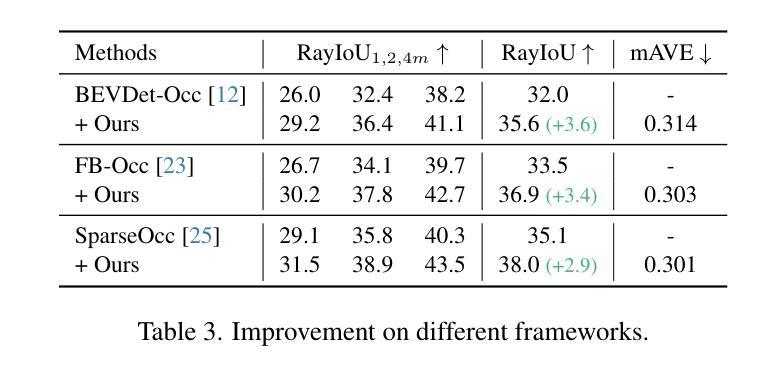
VoxelSplat: Dynamic Gaussian Splatting as an Effective Loss for Occupancy and Flow Prediction
Authors:Ziyue Zhu, Shenlong Wang, Jin Xie, Jiang-jiang Liu, Jingdong Wang, Jian Yang
Recent advancements in camera-based occupancy prediction have focused on the simultaneous prediction of 3D semantics and scene flow, a task that presents significant challenges due to specific difficulties, e.g., occlusions and unbalanced dynamic environments. In this paper, we analyze these challenges and their underlying causes. To address them, we propose a novel regularization framework called VoxelSplat. This framework leverages recent developments in 3D Gaussian Splatting to enhance model performance in two key ways: (i) Enhanced Semantics Supervision through 2D Projection: During training, our method decodes sparse semantic 3D Gaussians from 3D representations and projects them onto the 2D camera view. This provides additional supervision signals in the camera-visible space, allowing 2D labels to improve the learning of 3D semantics. (ii) Scene Flow Learning: Our framework uses the predicted scene flow to model the motion of Gaussians, and is thus able to learn the scene flow of moving objects in a self-supervised manner using the labels of adjacent frames. Our method can be seamlessly integrated into various existing occupancy models, enhancing performance without increasing inference time. Extensive experiments on benchmark datasets demonstrate the effectiveness of VoxelSplat in improving the accuracy of both semantic occupancy and scene flow estimation. The project page and codes are available at https://zzy816.github.io/VoxelSplat-Demo/.
近期基于相机的占用预测进展主要集中在3D语义和场景流的同时预测上,这一任务由于特定的困难(例如遮挡和不平衡的动态环境)而具有重大挑战。在本文中,我们分析了这些挑战及其根本原因。为了应对这些挑战,我们提出了一种名为VoxelSplat的新型正则化框架。该框架利用最新的3D高斯模糊技术,通过以下两种方式提高模型性能:(i)通过2D投影增强语义监督:在训练过程中,我们的方法从3D表示中解码稀疏语义3D高斯并将其投影到2D相机视图上。这为相机可见空间提供了额外的监督信号,允许2D标签改进3D语义的学习。(ii)场景流学习:我们的框架使用预测的场运动对高斯值进行建模,因此能够使用相邻帧的标签以自监督的方式学习移动对象的场景流。我们的方法可以无缝集成到各种现有的占用模型中,提高性能而不会增加推理时间。在基准数据集上的大量实验证明了VoxelSplat在提高语义占用和场景流估计的准确性方面的有效性。项目页面和代码可在https://zzy816.github.io/VoxelSplat-Demo/找到。
论文及项目相关链接
PDF Accepted by CVPR 2025 Project Page: https://zzy816.github.io/VoxelSplat-Demo/
Summary
本文分析了基于摄像头的占用预测面临的挑战,如遮挡和不平衡的动态环境等。为解决这些问题,提出了一种名为VoxelSplat的新型正则化框架。该框架利用最新的三维高斯延展技术,通过以下两种方式提高模型性能:一是通过二维投影增强语义监督;二是场景流学习。VoxelSplat方法可无缝集成到各种现有的占用模型中,提高性能,且不会增加推理时间。
Key Takeaways
- 论文分析了基于摄像头的占用预测中的挑战,如遮挡和不平衡的动态环境。
- 提出了一种新型正则化框架VoxelSplat,用于解决这些挑战。
- VoxelSplat利用最新的三维高斯延展技术,通过二维投影增强语义监督,提供额外的监督信号,改善三维语义学习。
- VoxelSplat使用预测的场景流来模拟高斯运动,从而以自监督的方式学习移动物体的场景流。
- VoxelSplat可集成到各种现有的占用模型中,提高语义占用和场景流估计的准确性,且不影响推理时间。
- 论文在基准数据集上进行了大量实验,证明了VoxelSplat的有效性。
点此查看论文截图
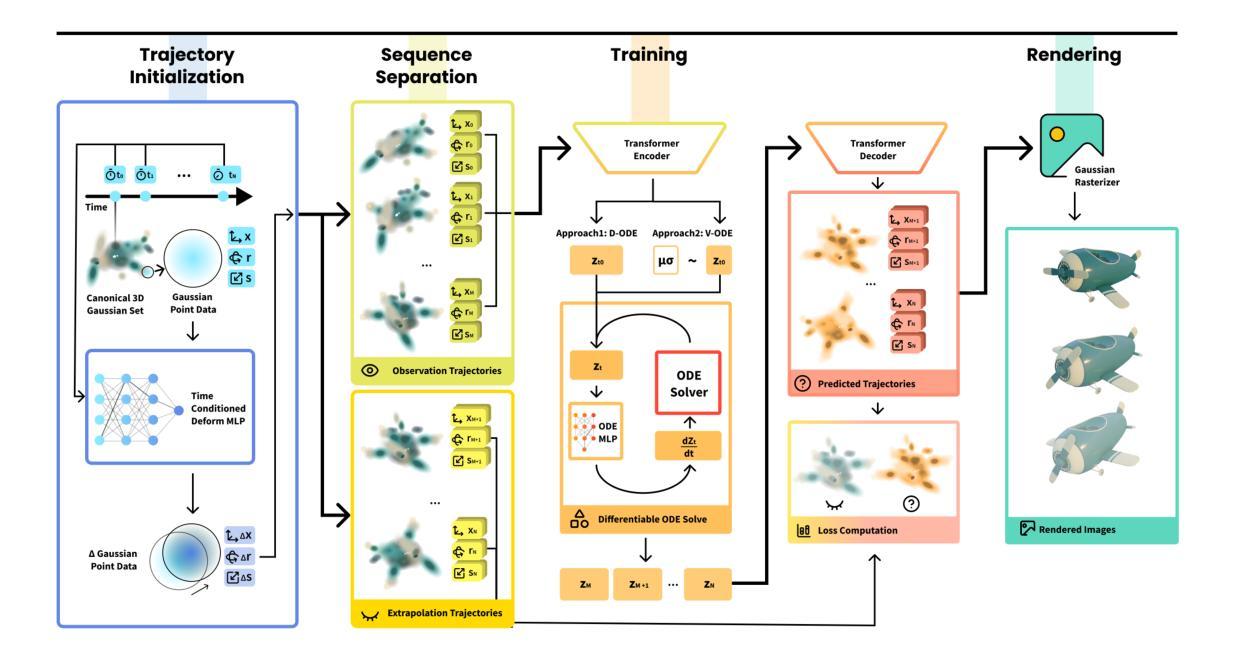
ODE-GS: Latent ODEs for Dynamic Scene Extrapolation with 3D Gaussian Splatting
Authors:Daniel Wang, Patrick Rim, Tian Tian, Alex Wong, Ganesh Sundaramoorthi
We present ODE-GS, a novel method that unifies 3D Gaussian Splatting with latent neural ordinary differential equations (ODEs) to forecast dynamic 3D scenes far beyond the time span seen during training. Existing neural rendering systems - whether NeRF- or 3DGS-based - embed time directly in a deformation network and therefore excel at interpolation but collapse when asked to predict the future, where timestamps are strictly out-of-distribution. ODE-GS eliminates this dependency: after learning a high-fidelity, time-conditioned deformation model for the training window, we freeze it and train a Transformer encoder that summarizes past Gaussian trajectories into a latent state whose continuous evolution is governed by a neural ODE. Numerical integration of this latent flow yields smooth, physically plausible Gaussian trajectories that can be queried at any future instant and rendered in real time. Coupled with a variational objective and a lightweight second-derivative regularizer, ODE-GS attains state-of-the-art extrapolation on D-NeRF and NVFI benchmarks, improving PSNR by up to 10 dB and halving perceptual error (LPIPS) relative to the strongest baselines. Our results demonstrate that continuous-time latent dynamics are a powerful, practical route to photorealistic prediction of complex 3D scenes.
我们提出了ODE-GS这一新方法,它将三维高斯喷溅技术与潜在神经常微分方程(ODEs)相结合,以预测训练期间时间跨度之外的动态三维场景。现有的神经渲染系统——无论是基于NeRF还是3DGS——都将时间直接嵌入变形网络中,因此在插值方面表现出色,但在要求预测未来时却会崩溃,未来的时间戳完全是超出范围分布的。ODE-GS消除了这种依赖:在针对训练窗口学习高保真、时间条件变形模型后,我们将其冻结,并训练一个Transformer编码器,该编码器对过去的高斯轨迹进行总结,形成一个潜在状态,其连续演化由神经ODE控制。该潜在流的数值积分会产生平滑且符合物理规律的高斯轨迹,可以在任何未来时刻进行查询并实时呈现。结合变分目标和轻量级二阶导数正则化器,ODE-GS在D-NeRF和NVFI基准测试上实现了最先进的预测能力,相较于最强的基线模型,PSNR提高了高达10分贝,感知误差(LPIPS)减半。我们的结果证明了连续时间潜在动力学是预测复杂三维场景的光照现实性的强大实用途径。
论文及项目相关链接
Summary
ODE-GS是一种结合3D高斯喷溅和潜在神经常微分方程(ODEs)的新方法,用于预测训练时间范围之外的动态3D场景。该方法消除了对时间戳的依赖,通过学习高保真、时间条件变形模型,然后冻结模型并训练概括过去高斯轨迹的Transformer编码器,该编码器的连续演化由神经ODE控制。数值积分此潜在流可产生流畅、物理上可行的轨迹,可实时查询并渲染任何未来时刻的场景。该方法在D-NeRF和NVFI基准测试中实现了最佳的外推性能,与最强基线相比,峰值信噪比(PSNR)提高了高达10分贝,感知误差(LPIPS)减半。结果表明,连续时间潜在动力学是预测复杂3D场景的光学真实性的强大实用途径。
Key Takeaways
- ODE-GS结合了3D高斯喷溅和潜在神经常微分方程(ODEs),用于预测未来动态3D场景。
- 该方法通过训练一个时间条件变形模型并冻结它,消除了对时间戳的依赖。
- ODE-GS使用Transformer编码器来概括过去的高斯轨迹,并利用神经ODE控制其连续演化。
- 通过数值积分潜在流生成未来的高斯轨迹,可实时查询和渲染。
- 在D-NeRF和NVFI基准测试中,ODE-GS实现了最佳的外推性能。
- 与其他方法相比,ODE-GS在峰值信噪比(PSNR)上提高了高达10分贝,在感知误差(LPIPS)上减半。
点此查看论文截图

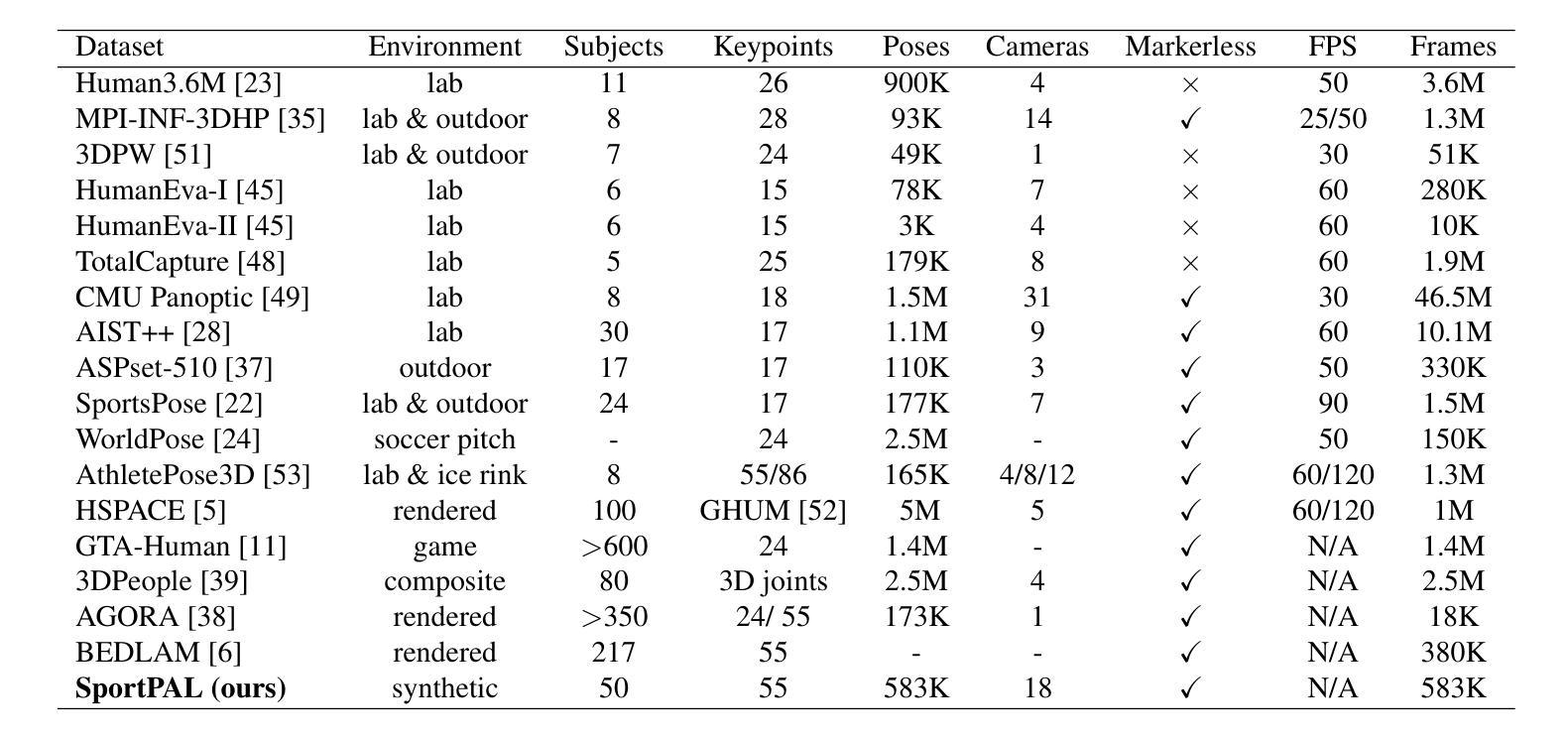
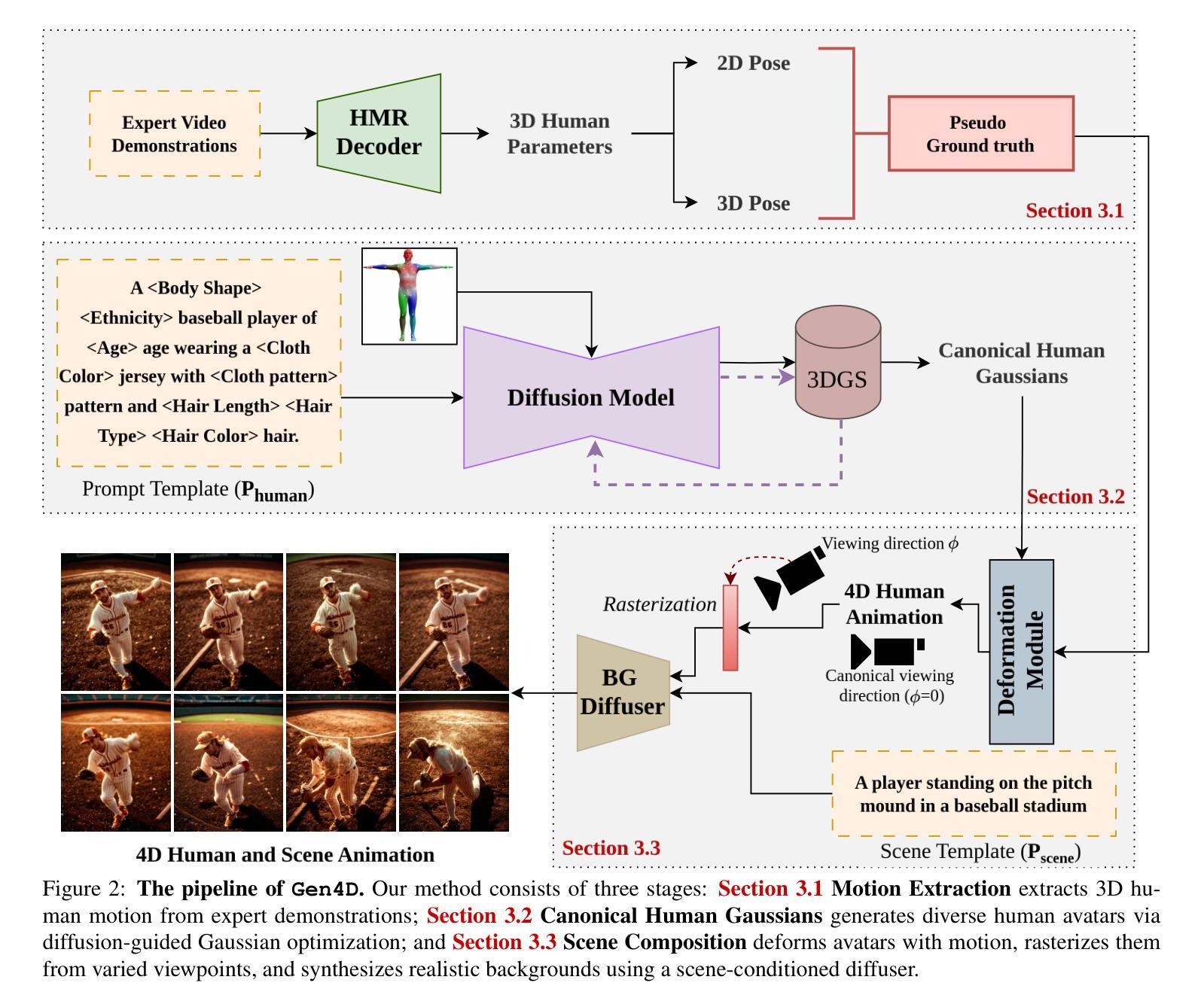
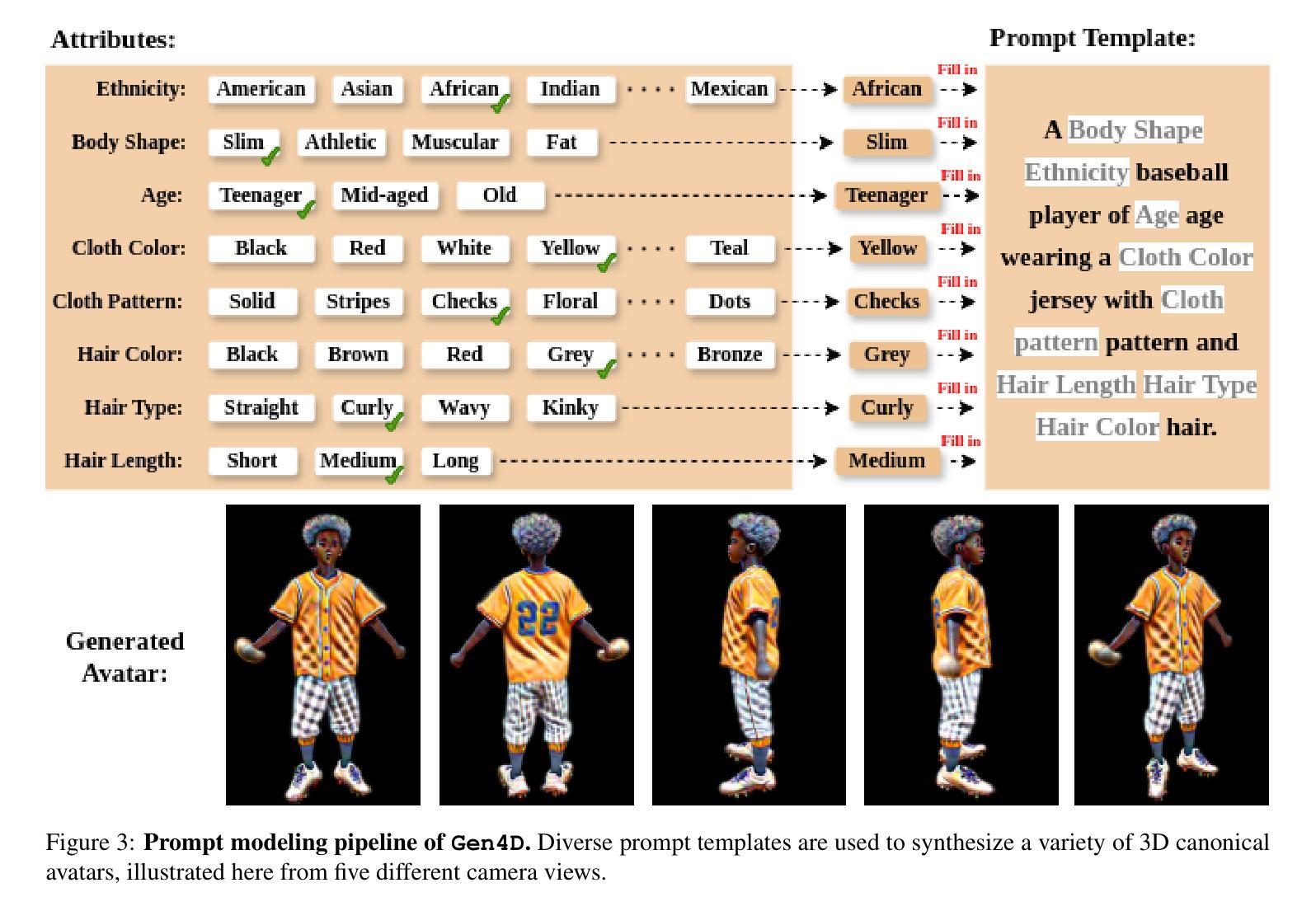
Gen4D: Synthesizing Humans and Scenes in the Wild
Authors:Jerrin Bright, Zhibo Wang, Yuhao Chen, Sirisha Rambhatla, John Zelek, David Clausi
Lack of input data for in-the-wild activities often results in low performance across various computer vision tasks. This challenge is particularly pronounced in uncommon human-centric domains like sports, where real-world data collection is complex and impractical. While synthetic datasets offer a promising alternative, existing approaches typically suffer from limited diversity in human appearance, motion, and scene composition due to their reliance on rigid asset libraries and hand-crafted rendering pipelines. To address this, we introduce Gen4D, a fully automated pipeline for generating diverse and photorealistic 4D human animations. Gen4D integrates expert-driven motion encoding, prompt-guided avatar generation using diffusion-based Gaussian splatting, and human-aware background synthesis to produce highly varied and lifelike human sequences. Based on Gen4D, we present SportPAL, a large-scale synthetic dataset spanning three sports: baseball, icehockey, and soccer. Together, Gen4D and SportPAL provide a scalable foundation for constructing synthetic datasets tailored to in-the-wild human-centric vision tasks, with no need for manual 3D modeling or scene design.
缺乏野外活动的输入数据通常会导致各种计算机视觉任务性能下降。这一挑战在以人为中心的不常见领域(如体育)中尤为突出,因为现实世界的数据收集复杂且不切实际。虽然合成数据集提供了一种有前景的替代方案,但现有方法通常由于依赖于僵化的资产库和手工制作的渲染管道,而遭受人类外观、动作和场景组合多样性有限的困扰。为了解决这一问题,我们引入了Gen4D,这是一个全自动的生成多样化且逼真的4D人类动画管道。Gen4D集成了专家驱动的运动编码、基于扩散的高斯拼贴引导的人物形象生成以及人类感知的背景合成,以产生高度多样化和逼真的人类序列。基于Gen4D,我们推出了SportPAL,这是一个跨越三项运动的大规模合成数据集:棒球、冰球和足球。Gen4D和SportPAL一起,为针对野外以人为中心的计算机视觉任务构建合成数据集提供了可扩展的基础,无需进行手动3D建模或场景设计。
论文及项目相关链接
PDF Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops
Summary
该文本针对计算机视觉任务在现实世界数据收集上的挑战,特别是在运动等以人为中心的不常见领域的数据收集困难问题,提出了一种全自动化的生成多样且逼真的四维人类动画管道Gen4D。该管道结合了专家驱动的运动编码、基于扩散的高斯喷溅法引导的角色生成以及人类感知背景合成技术,以生成高度多样化和逼真的人类序列。基于Gen4D,推出大型合成数据集SportPAL,涵盖棒球、冰球和足球三项运动。这两项成果为解决以人类为中心的现实世界视觉任务提供了可扩充的合成数据集基础,无需手动进行三维建模或场景设计。
Key Takeaways
- 计算机视觉任务在收集现实世界中以人为中心的数据时面临挑战,特别是在不常见的领域如体育中。
- 合成数据集提供了一个有前景的替代方案,但现有方法通常受限于人类外观、动作和场景组成的多样性。
- Gen4D是一个全自动化的管道,用于生成多样且逼真的四维人类动画,解决了现有方法的局限性。
- Gen4D结合了专家驱动的运动编码、基于扩散的高斯喷溅法引导的角色生成及人类感知背景合成技术。
- 基于Gen4D推出的SportPAL是一个大型合成数据集,涵盖棒球、冰球和足球等多项运动。
- Gen4D和SportPAL为以人类为中心的现实世界视觉任务提供了合成数据集的基础,无需手动进行三维建模或场景设计。
点此查看论文截图


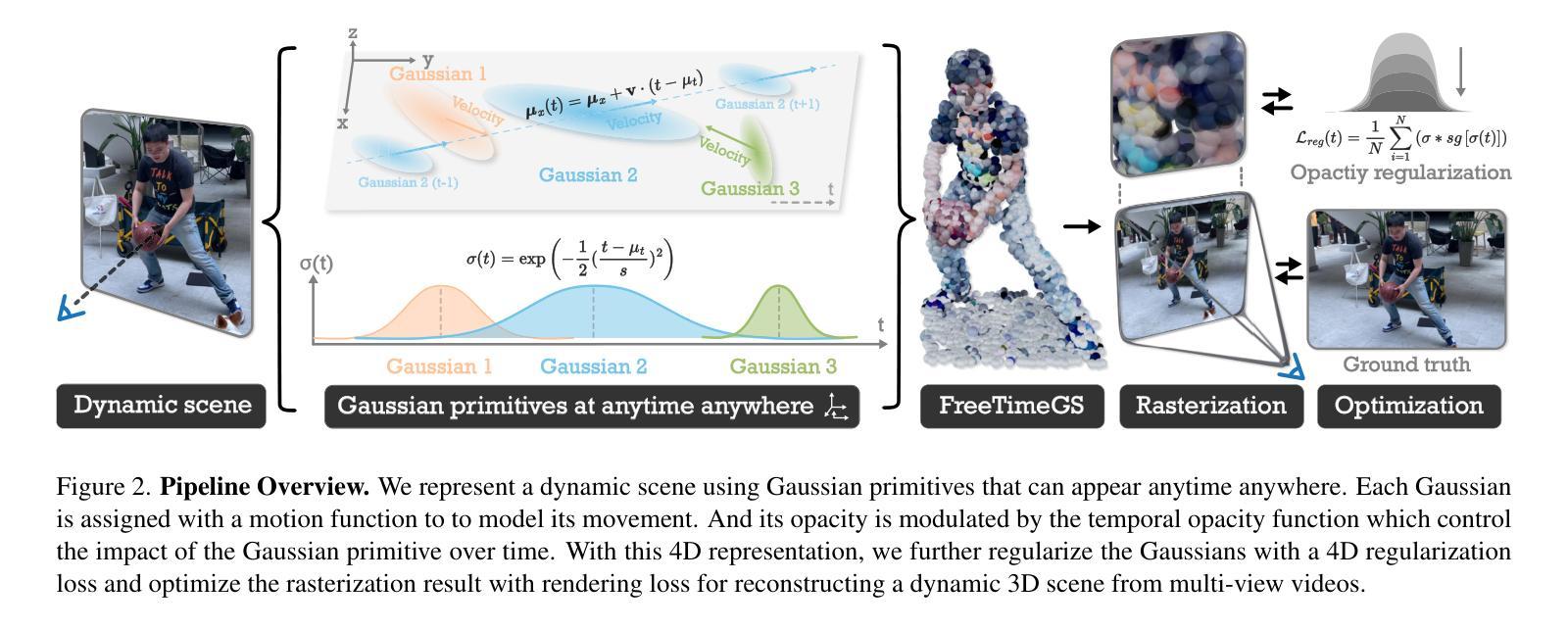
FreeTimeGS: Free Gaussian Primitives at Anytime and Anywhere for Dynamic Scene Reconstruction
Authors:Yifan Wang, Peishan Yang, Zhen Xu, Jiaming Sun, Zhanhua Zhang, Yong Chen, Hujun Bao, Sida Peng, Xiaowei Zhou
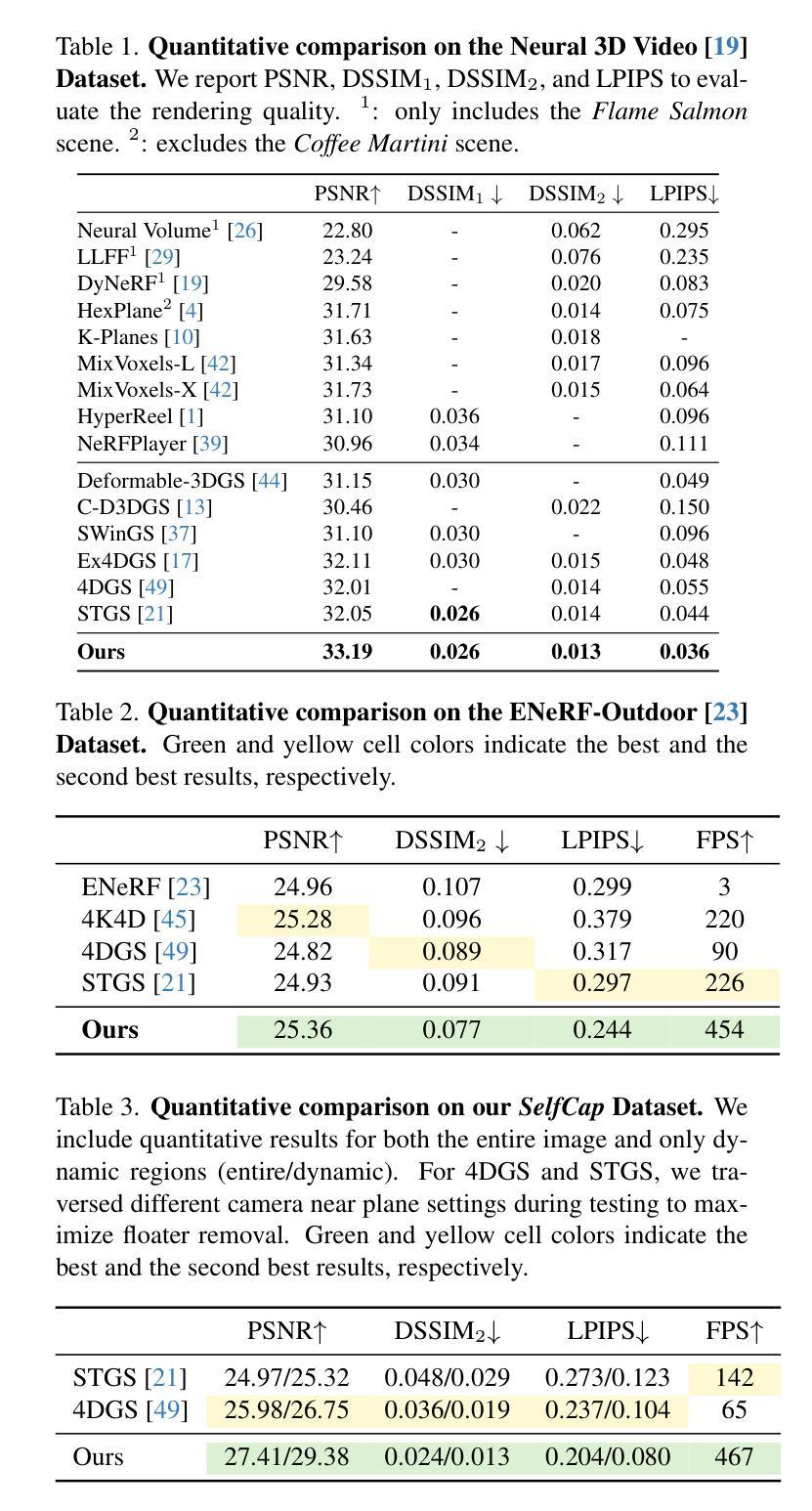
This paper addresses the challenge of reconstructing dynamic 3D scenes with complex motions. Some recent works define 3D Gaussian primitives in the canonical space and use deformation fields to map canonical primitives to observation spaces, achieving real-time dynamic view synthesis. However, these methods often struggle to handle scenes with complex motions due to the difficulty of optimizing deformation fields. To overcome this problem, we propose FreeTimeGS, a novel 4D representation that allows Gaussian primitives to appear at arbitrary time and locations. In contrast to canonical Gaussian primitives, our representation possesses the strong flexibility, thus improving the ability to model dynamic 3D scenes. In addition, we endow each Gaussian primitive with an motion function, allowing it to move to neighboring regions over time, which reduces the temporal redundancy. Experiments results on several datasets show that the rendering quality of our method outperforms recent methods by a large margin. Project page: https://zju3dv.github.io/freetimegs/ .
本文旨在解决重建具有复杂运动的动态三维场景的挑战。最近的一些作品在规范空间中定义了三维高斯基本元素,并使用变形场将规范基本元素映射到观测空间,实现了实时动态视图合成。然而,由于优化变形场的困难,这些方法在处理具有复杂运动的场景时往往表现不佳。为了解决这个问题,我们提出了FreeTimeGS,这是一种新型的四维表示方法,允许高斯基本元素出现在任意的时间和位置。与规范高斯基本元素相比,我们的表示方法具有更强的灵活性,从而提高了对动态三维场景的建模能力。此外,我们为每个高斯基本元素赋予一个运动函数,使其能够在时间推移下移动到邻近区域,从而减少了时间冗余。在几个数据集上的实验结果表明,我们的方法的渲染质量大大优于最近的方法。项目页面:https://zju3dv.github.io/freetimegs/。
论文及项目相关链接
PDF CVPR 2025; Project page: https://zju3dv.github.io/freetimegs/
Summary
本文提出一种基于四维表示的动态三维场景重建方法,称为FreeTimeGS。该方法通过引入灵活的Gaussian原始表示,解决了复杂动态场景重建中的难题。新方法不仅具有强大的建模能力,还能通过赋予每个Gaussian原始运动功能,减少时间冗余,从而提高渲染质量。
Key Takeaways
- 本文介绍了动态三维场景重建的挑战,尤其是处理复杂运动场景的问题。
- 现有方法通过使用变形场映射规范空间中的基本体素到观测空间来实现实时动态视图合成,但难以处理复杂运动场景的优化问题。
- 提出了一种新的四维表示方法FreeTimeGS,允许Gaussian原始在任意时间和位置出现,具有强大的灵活性,能够更有效地建模动态三维场景。
- 新方法通过赋予每个Gaussian原始运动功能,使其能够在时间范围内移动到邻近区域,从而减少时间冗余,提高渲染质量。
点此查看论文截图



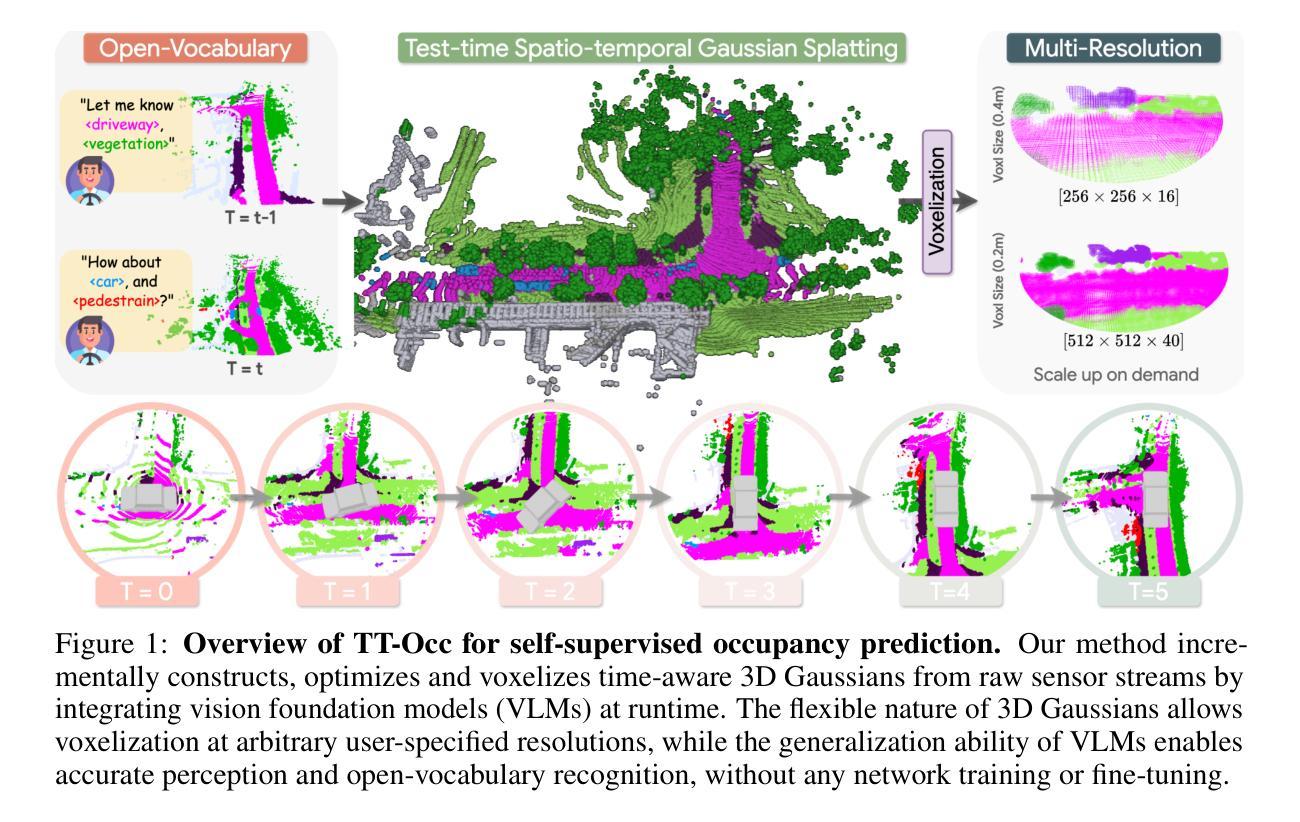
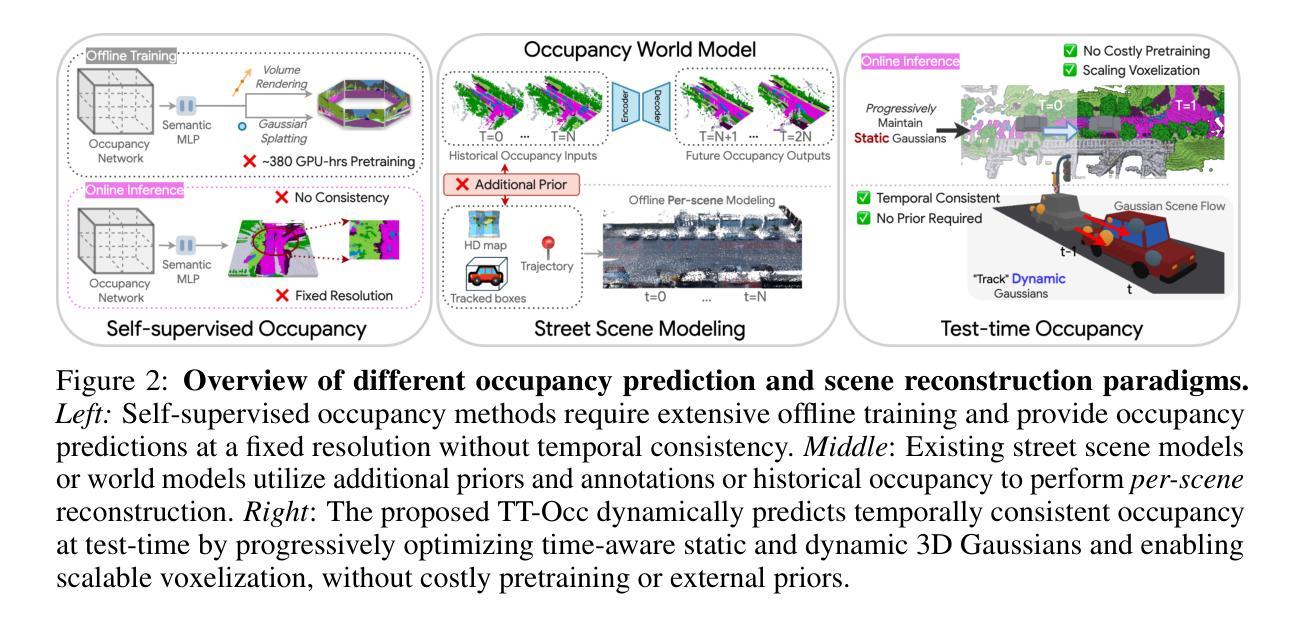
TT-Occ: Test-Time Compute for Self-Supervised Occupancy via Spatio-Temporal Gaussian Splatting
Authors:Fengyi Zhang, Huitong Yang, Zheng Zhang, Zi Huang, Yadan Luo
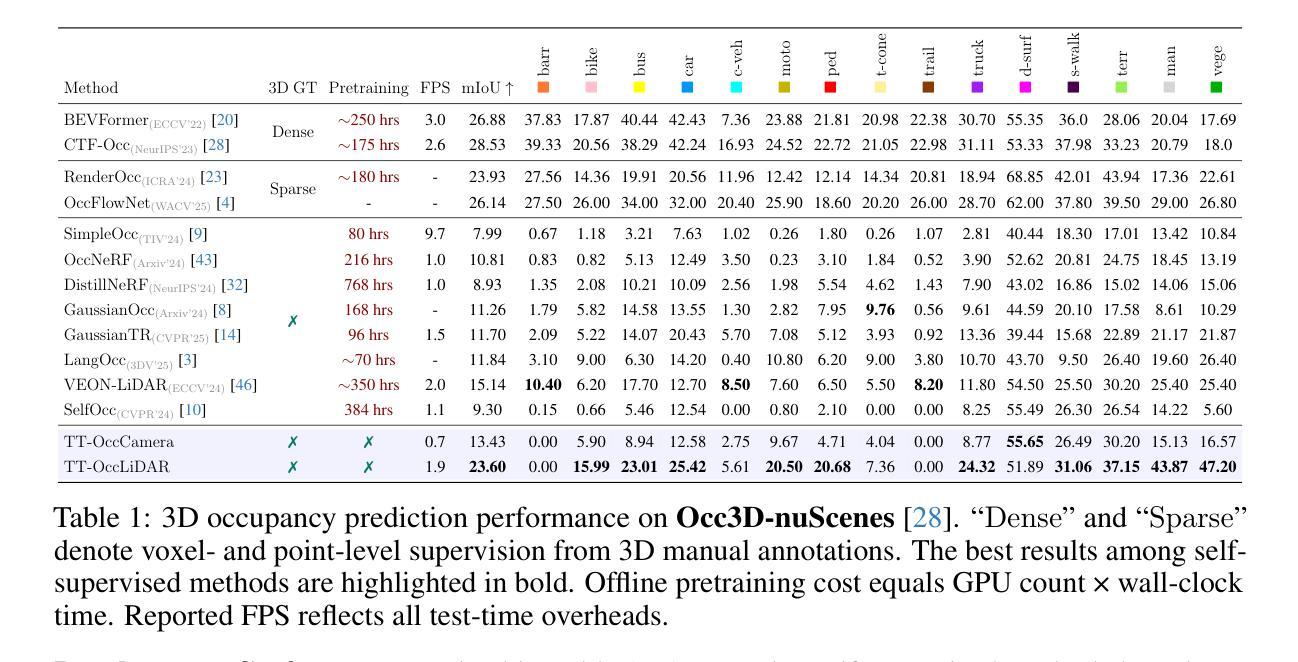
Self-supervised 3D occupancy prediction offers a promising solution for understanding complex driving scenes without requiring costly 3D annotations. However, training dense occupancy decoders to capture fine-grained geometry and semantics can demand hundreds of GPU hours, and once trained, such models struggle to adapt to varying voxel resolutions or novel object categories without extensive retraining. To overcome these limitations, we propose a practical and flexible test-time occupancy prediction framework termed TT-Occ. Our method incrementally constructs, optimizes and voxelizes time-aware 3D Gaussians from raw sensor streams by integrating vision foundation models (VLMs) at runtime. The flexible nature of 3D Gaussians allows voxelization at arbitrary user-specified resolutions, while the generalization ability of VLMs enables accurate perception and open-vocabulary recognition, without any network training or fine-tuning. Specifically, TT-Occ operates in a lift-track-voxelize symphony: We first lift the geometry and semantics of surrounding-view extracted from VLMs to instantiate Gaussians at 3D space; Next, we track dynamic Gaussians while accumulating static ones to complete the scene and enforce temporal consistency; Finally, we voxelize the optimized Gaussians to generate occupancy prediction. Optionally, inherent noise in VLM predictions and tracking is mitigated by periodically smoothing neighboring Gaussians during optimization. To validate the generality and effectiveness of our framework, we offer two variants: one LiDAR-based and one vision-centric, and conduct extensive experiments on Occ3D and nuCraft benchmarks with varying voxel resolutions. Code will be available at https://github.com/Xian-Bei/TT-Occ.
自监督的3D占用预测为理解复杂的驾驶场景提供了一个很有前景的解决方案,而无需昂贵的3D注释。然而,训练密集的占用解码器来捕捉精细的几何和语义可能需要数百个GPU小时,而且一旦训练完成,这些模型在适应不同的体素分辨率或新的对象类别时,如果没有大量的重新训练,会面临困难。为了克服这些限制,我们提出了一个实用且灵活的测试时间占用预测框架,称为TT-Occ。我们的方法通过整合视觉基础模型(VLMs)从原始传感器流中增量构建、优化和体素化时间感知的3D高斯,从而实现灵活的预测。3D高斯图的灵活性允许以任意用户指定的分辨率进行体素化,而VLMs的泛化能力则可实现无需任何网络训练或微调即可进行准确的感知和开放词汇识别。具体来说,TT-Occ在操作中可以看作是一场升降-跟踪-体素化的协奏曲:我们首先将从VLMs中提取的周围视图的几何和语义提升到三维空间以实例化高斯;接下来,我们跟踪动态高斯的同时积累静态高斯来完成场景并强制执行时间一致性;最后,我们对优化后的高斯进行体素化以生成占用预测。可选地,我们可以通过在优化过程中定期平滑相邻的高斯来缓解VLM预测和跟踪中的固有噪声。为了验证我们框架的通用性和有效性,我们提供了两个版本:一个基于激光雷达,一个以视觉为中心,并在具有不同体素分辨率的Occ3D和nuCraft基准上进行了大量实验。代码将在https://github.com/Xian-Bei/TT-Occ上提供。
论文及项目相关链接
Summary
基于无标注数据的自监督3D占用预测为理解复杂的驾驶场景提供了有前景的解决方案。然而,训练密集的占用解码器以捕捉精细的几何和语义信息可能需要数百小时的GPU时间,并且一旦训练完成,这些模型在适应不同的体素分辨率或新的对象类别时,需要重新训练。为了克服这些限制,我们提出了一个实用且灵活的测试时间占用预测框架TT-Occ。该方法通过整合视觉基础模型(VLMs),从原始传感器流中增量构建、优化和体素化时间感知的3D高斯分布。TT-Occ操作在提升、追踪、体素化的协同中:首先,我们从VLMs中提取的环绕视图几何和语义信息,在三维空间中实例化高斯分布;然后,在累积静态高斯的同时跟踪动态高斯以完成场景并强制执行时间一致性;最后,对优化后的高斯进行体素化以生成占用预测。
Key Takeaways
- 自监督3D占用预测是理解复杂驾驶场景的一种有前途的解决方案,无需昂贵的3D注释。
- 训练密集的占用解码器捕捉精细几何和语义信息成本高昂且难以适应不同体素分辨率或新对象类别。
- 提出了一种新的测试时间占用预测框架TT-Occ,结合视觉基础模型(VLMs),增量构建和优化时间感知的3D高斯分布。
- TT-Occ允许任意用户指定的体素分辨率,并具有对未知对象的准确感知能力。
- 该方法包括将几何和语义信息从环绕视图提升到三维空间的高斯分布实例化,跟踪动态和静态高斯,以及对优化后的高斯进行体素化以生成占用预测。
- 通过平滑相邻高斯来减轻VLM预测和跟踪中的固有噪声。
点此查看论文截图