⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-10 更新
PersonaAgent: When Large Language Model Agents Meet Personalization at Test Time
Authors:Weizhi Zhang, Xinyang Zhang, Chenwei Zhang, Liangwei Yang, Jingbo Shang, Zhepei Wei, Henry Peng Zou, Zijie Huang, Zhengyang Wang, Yifan Gao, Xiaoman Pan, Lian Xiong, Jingguo Liu, Philip S. Yu, Xian Li
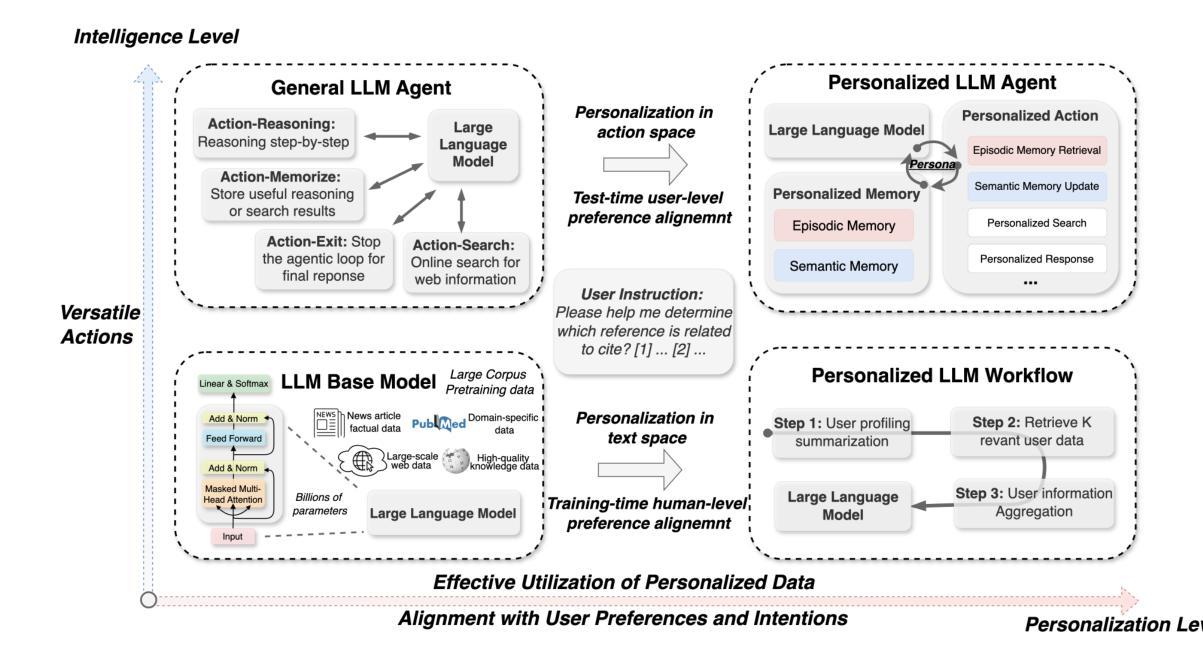
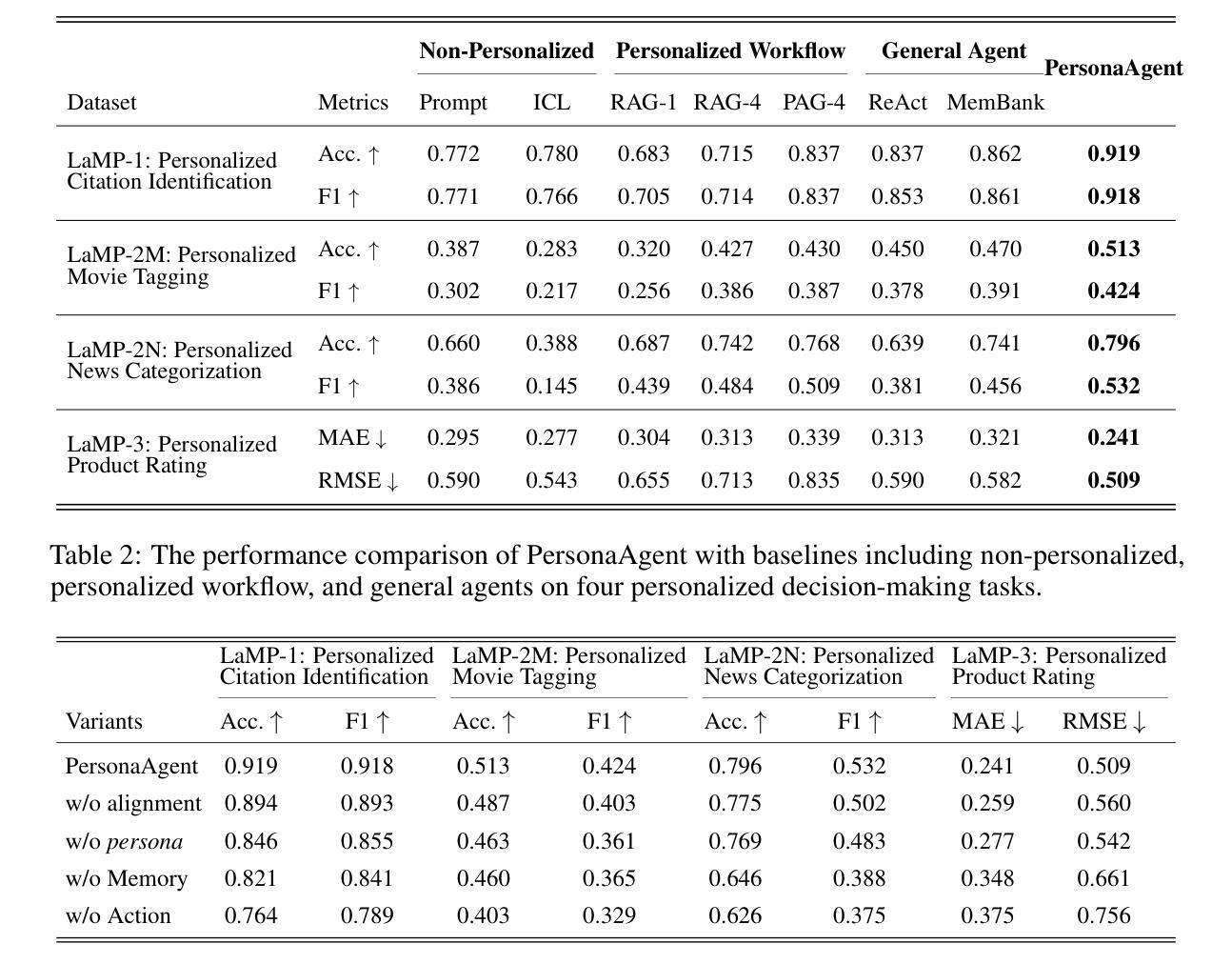
Large Language Model (LLM) empowered agents have recently emerged as advanced paradigms that exhibit impressive capabilities in a wide range of domains and tasks. Despite their potential, current LLM agents often adopt a one-size-fits-all approach, lacking the flexibility to respond to users’ varying needs and preferences. This limitation motivates us to develop PersonaAgent, the first personalized LLM agent framework designed to address versatile personalization tasks. Specifically, PersonaAgent integrates two complementary components - a personalized memory module that includes episodic and semantic memory mechanisms; a personalized action module that enables the agent to perform tool actions tailored to the user. At the core, the persona (defined as unique system prompt for each user) functions as an intermediary: it leverages insights from personalized memory to control agent actions, while the outcomes of these actions in turn refine the memory. Based on the framework, we propose a test-time user-preference alignment strategy that simulate the latest n interactions to optimize the persona prompt, ensuring real-time user preference alignment through textual loss feedback between simulated and ground-truth responses. Experimental evaluations demonstrate that PersonaAgent significantly outperforms other baseline methods by not only personalizing the action space effectively but also scaling during test-time real-world applications. These results underscore the feasibility and potential of our approach in delivering tailored, dynamic user experiences.
近年来,以大型语言模型(LLM)为支持的新型智能代理范式涌现出来,在各种领域和任务中展现出令人印象深刻的能力。尽管具有潜力,但当前的LLM代理通常采用一刀切的方法,缺乏应对用户不同需求和偏好的灵活性。这一局限性促使我们开发Personagent——首个设计用于执行多样化个性化任务的个性化LLM代理框架。具体来说,Personagent集成了两个互补的组件:一个包含情景记忆和语义记忆机制的个人化记忆模块;一个个人化行动模块,使代理能够执行针对用户的工具行动。其核心是人格(定义为每个用户的独特系统提示):它利用个性化记忆中的见解来控制代理行动,而这些行动的结果反过来又完善记忆。基于该框架,我们提出了一种测试时用户偏好对齐策略,模拟最近的n次交互以优化人格提示,通过模拟和真实响应之间的文本损失反馈确保实时用户偏好对齐。实验评估表明,Personagent不仅有效地个性化行动空间,而且在测试时的现实世界应用中表现出可扩展性,显著优于其他基准方法。这些结果突显了我们的方法在提供定制、动态用户体验方面的可行性和潜力。
论文及项目相关链接
总结
大型语言模型赋能的代理(LLM)作为先进范式展现出令人印象深刻的跨域任务能力。然而,当前LLM代理通常采用一刀切的方法,缺乏响应用户不同需求和偏好的灵活性。为此,我们开发了PersonaAgent,这是一个首个个性化的LLM代理框架,旨在处理多样化的个性化任务。它通过个性化记忆模块(包括情景和语义记忆机制)和个性化行动模块(使代理能够执行针对用户的工具行动)的整合来实现个性化。个性(定义为每个用户的独特系统提示)作为中介,利用个性化记忆中的见解来控制代理行动,而这些行动的结果又反过来完善记忆。基于该框架,我们提出了一种测试时用户偏好对齐策略,模拟最新的n次交互以优化个性提示,通过模拟和真实响应之间的文本损失反馈实现实时用户偏好对齐。实验评估表明,PersonaAgent不仅有效地个性化行动空间,而且在测试时的现实世界应用中具有可扩展性,显著优于其他基准方法。
关键见解
- LLM代理在多个领域和任务中展现出强大的能力,但缺乏响应用户不同需求和偏好的灵活性。
- PersonaAgent是首个个性化的LLM代理框架,旨在处理多样化的个性化任务。
- PersonaAgent集成了个性化记忆模块和个性化行动模块。
- 个性作为中介,利用个性化记忆中的见解来控制代理行动,行动结果反哺记忆。
- 提出了一种测试时用户偏好对齐策略,通过模拟和真实交互之间的反馈实现用户偏好实时对齐。
- PersonaAgent在实验评估中显著优于其他方法,证明了其可行性及其在提供针对性、动态用户体验方面的潜力。
点此查看论文截图


AgentSwift: Efficient LLM Agent Design via Value-guided Hierarchical Search
Authors:Yu Li, Lehui Li, Zhihao Wu, Qingmin Liao, Jianye Hao, Kun Shao, Fengli Xu, Yong Li
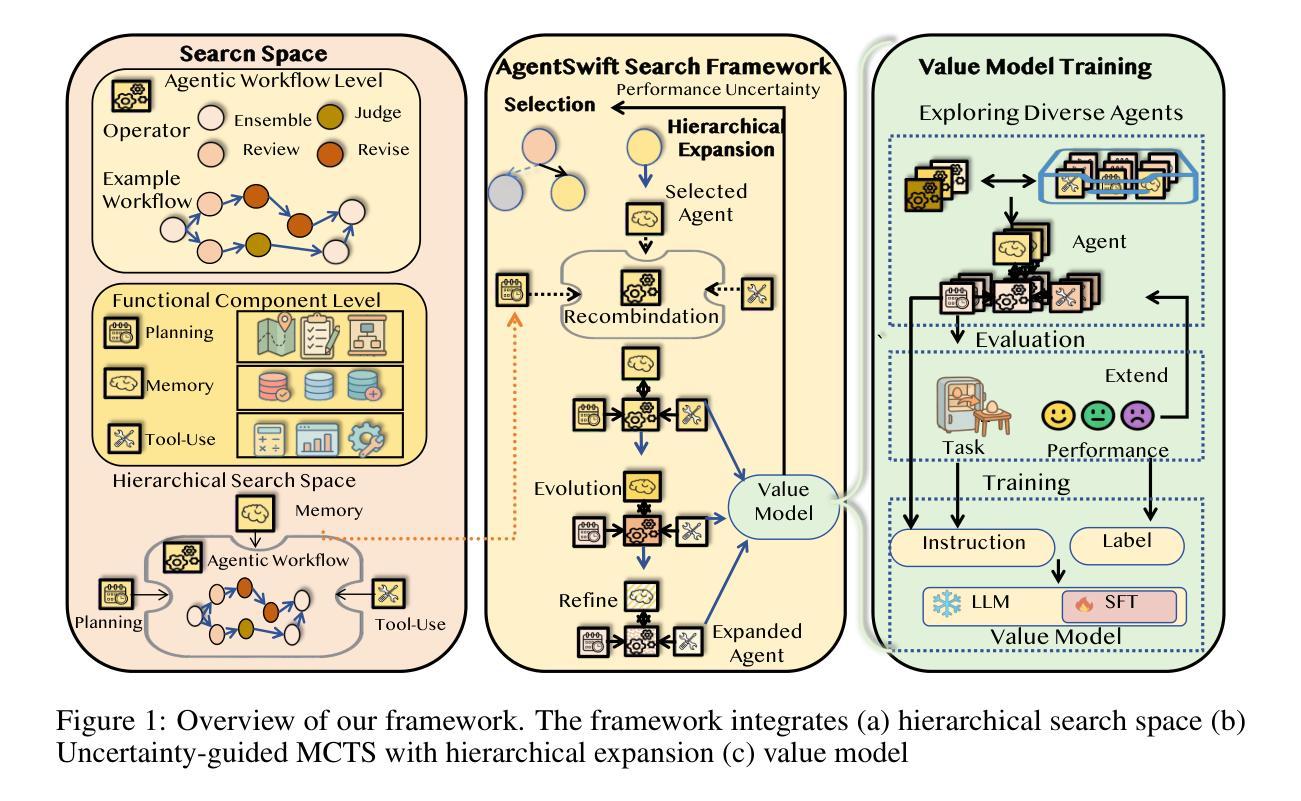
Large language model (LLM) agents have demonstrated strong capabilities across diverse domains. However, designing high-performing agentic systems remains challenging. Existing agent search methods suffer from three major limitations: (1) an emphasis on optimizing agentic workflows while under-utilizing proven human-designed components such as memory, planning, and tool use; (2) high evaluation costs, as each newly generated agent must be fully evaluated on benchmarks; and (3) inefficient search in large search space. In this work, we introduce a comprehensive framework to address these challenges. First, We propose a hierarchical search space that jointly models agentic workflow and composable functional components, enabling richer agentic system designs. Building on this structured design space, we introduce a predictive value model that estimates agent performance given agentic system and task description, allowing for efficient, low-cost evaluation during the search process. Finally, we present a hierarchical Monte Carlo Tree Search (MCTS) strategy informed by uncertainty to guide the search. Experiments on seven benchmarks, covering embodied, math, web, tool, and game, show that our method achieves an average performance gain of 8.34% over state-of-the-art baselines and exhibits faster search progress with steeper improvement trajectories. Code repo is available at https://github.com/Ericccc02/AgentSwift.
大型语言模型(LLM)代理在多个领域表现出了强大的能力。然而,设计高性能的代理系统仍然具有挑战性。现有的代理搜索方法存在三大局限:1重视优化代理工作流程而忽视利用人类设计的组件(如记忆、规划和工具使用);2评估成本高,因为每个新生成的代理都必须在基准测试上进行全面评估;3在大搜索空间中的搜索效率低下。在这项工作中,我们引入了一个全面的框架来解决这些挑战。首先,我们提出了一个层次化的搜索空间,联合建模代理工作流程和可组合的功能组件,从而实现更丰富的代理系统设计。在此基础上,我们引入了一个预测价值模型,能够根据代理系统和任务描述来估计代理性能,从而在搜索过程中实现高效、低成本的评估。最后,我们提出了一种受不确定性启发而设计的分层蒙特卡洛树搜索(MCTS)策略来引导搜索。在涵盖实体、数学、网络、工具和游戏的七个基准测试上的实验表明,我们的方法在平均性能上比最新基线提高了8.34%,并且具有更快的搜索进度和更陡峭的改进轨迹。代码仓库可在https://github.com/Ericccc02/AgentSwift找到。
论文及项目相关链接
PDF 20pages
Summary
大型语言模型(LLM)代理在多个领域展现出强大的能力,但设计高性能代理系统仍具挑战。现有代理搜索方法存在三大局限:一是过于优化代理工作流程而忽视利用人类设计的组件(如记忆、规划和工具使用);二是评估成本高,每个新生成的代理都需要在基准测试上进行全面评估;三是在大规模搜索空间中的搜索效率低下。本研究提出一个综合框架来解决这些问题。首先,提出一个层次化的搜索空间,联合建模代理工作流程和可组合的功能组件,以丰富代理系统设计。在此基础上,引入预测价值模型来估计给定代理系统和任务描述的代理性能,在搜索过程中实现高效、低成本的评估。最后,采用基于不确定性的分层蒙特卡洛树搜索(MCTS)策略来指导搜索。在涵盖实体、数学、网络、工具和游戏的七个基准测试上的实验表明,该方法较最新基线技术平均性能提升8.34%,搜索进度更快,改进轨迹更陡峭。
Key Takeaways
- 大型语言模型(LLM)代理在多个领域表现出强大的能力,但设计高性能代理系统具有挑战性。
- 现有代理搜索方法存在三大局限:优化工作流程中的不足、高评估成本以及在大规模搜索空间中的低效搜索。
- 研究提出一个综合框架来解决这些问题,包括层次化的搜索空间、预测价值模型和基于不确定性的分层蒙特卡洛树搜索策略。
- 预测价值模型能够估计给定代理系统和任务描述的代理性能,实现高效、低成本的评估。
- 该方法在涵盖多个领域的七个基准测试上实现了平均性能的提升,并且搜索进度更快,改进轨迹更陡峭。
- 研究的代码仓库已公开在GitHub上。
- 该方法为未来代理设计提供了新的思路和方向。
点此查看论文截图

CrimeMind: Simulating Urban Crime with Multi-Modal LLM Agents
Authors:Qingbin Zeng, Ruotong Zhao, Jinzhu Mao, Haoyang Li, Fengli Xu, Yong Li
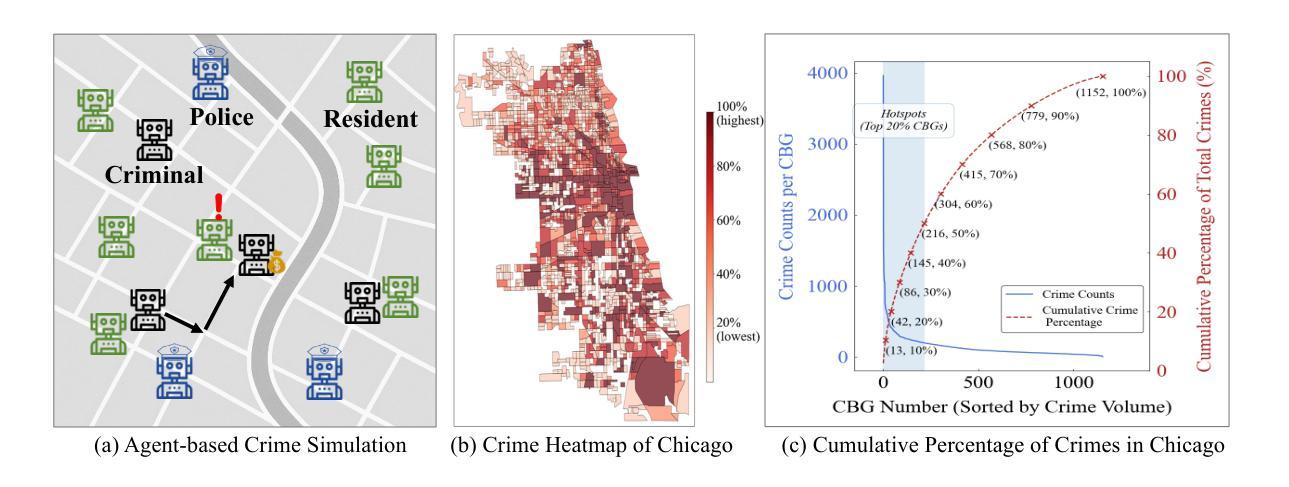
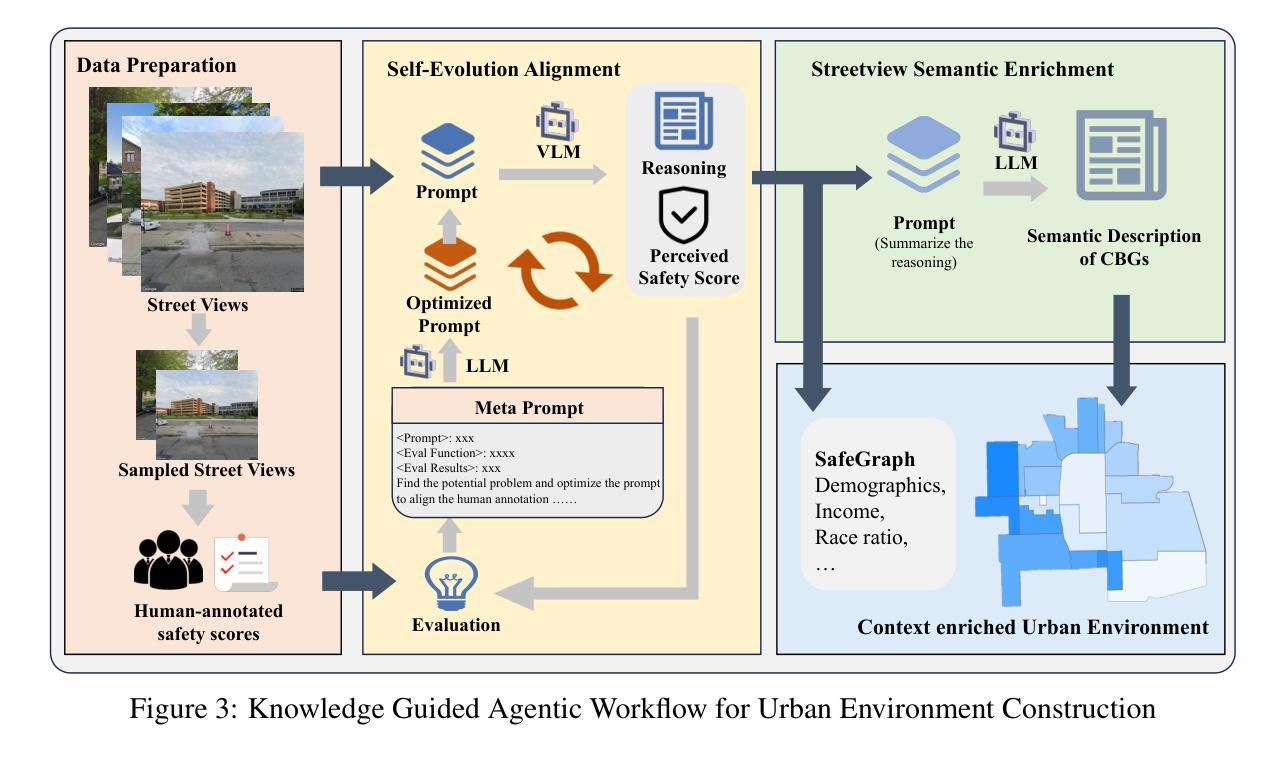
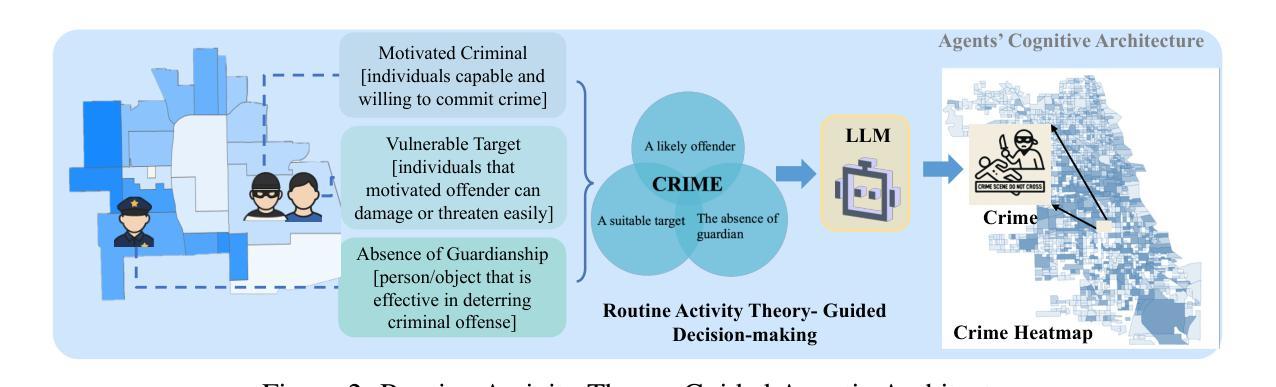
Modeling urban crime is an important yet challenging task that requires understanding the subtle visual, social, and cultural cues embedded in urban environments. Previous work has predominantly focused on rule-based agent-based modeling (ABM) and deep learning methods. ABMs offer interpretability of internal mechanisms but exhibit limited predictive accuracy.In contrast, deep learning methods are often effective in prediction but are less interpretable and require extensive training data. Moreover, both lines of work lack the cognitive flexibility to adapt to changing environments. Leveraging the capabilities of large language models (LLMs), we propose CrimeMind, a novel LLM-driven ABM framework for simulating urban crime within a multi-modal urban context.A key innovation of our design is the integration of the Routine Activity Theory (RAT) into the agentic workflow of CrimeMind, enabling it to process rich multi-modal urban features and reason about criminal behavior.However, RAT requires LLM agents to infer subtle cues in evaluating environmental safety as part of assessing guardianship, which can be challenging for LLMs. To address this, we collect a small-scale human-annotated dataset and align CrimeMind’s perception with human judgment via a training-free textual gradient method.Experiments across four major U.S. cities demonstrate that CrimeMind outperforms both traditional ABMs and deep learning baselines in crime hotspot prediction and spatial distribution accuracy, achieving up to a 24% improvement over the strongest baseline.Furthermore, we conduct counterfactual simulations of external incidents and policy interventions and it successfully captures the expected changes in crime patterns, demonstrating its ability to reflect counterfactual scenarios.Overall, CrimeMind enables fine-grained modeling of individual behaviors and facilitates evaluation of real-world interventions.
建模城市犯罪是一项重要而具有挑战性的任务,需要理解城市环境中微妙的视觉、社会和文化线索。以前的研究主要集中在基于规则的代理建模(ABM)和深度学习方法上。ABM提供了内部机制的解释性,但预测精度有限。相比之下,深度学习方法在预测方面通常很有效,但解释性较差,且需要大量训练数据。此外,这两种方法都缺乏适应变化环境的认知灵活性。我们利用大型语言模型(LLM)的能力,提出了CrimeMind,这是一个用于模拟城市犯罪的新型LLM驱动ABM框架,适用于多模式城市环境。设计中的一个关键创新是将例行活动理论(RAT)集成到CrimeMind的代理工作流程中,使其能够处理丰富的多模式城市特征并对犯罪行为进行推理。然而,RAT要求LLM代理在评估环境安全性以判断护卫工作时要推断微妙的线索,这对LLM来说可能具有挑战性。为解决这一问题,我们收集了一个小规模的人工注释数据集,并通过一种无需训练的文本梯度方法与CrimeMind的感知与人类判断保持一致。在美国四个主要城市的实验表明,在犯罪热点预测和空间分布准确性方面,CrimeMind优于传统的ABM和深度学习基线,与最强的基线相比,改进了高达24%。此外,我们进行了外部事件和政策干预的模拟模拟,成功地捕捉了犯罪模式的预期变化,证明了其反映反事实场景的能力。总体而言,CrimeMind能够实现个体行为的精细建模,并有助于评估现实世界的干预措施。
论文及项目相关链接
摘要
建模城市犯罪是一项重要且具有挑战性的任务,需要理解城市环境中嵌入的微妙视觉、社会和文化线索。先前的工作主要集中在基于规则的代理建模(ABM)和深度学习方法上。ABM提供了内部机制的解释性,但预测精度有限。相比之下,深度学习方法在预测方面通常很有效,但解释性较差,且需要大量训练数据。此外,这两种方法都缺乏适应变化环境的认知灵活性。利用大型语言模型(LLM)的能力,我们提出了CrimeMind,这是一个用于模拟多模式城市环境下的城市犯罪的新型LLM驱动ABM框架。我们的设计的一个关键创新点是将例行活动理论(RAT)集成到CrimeMind的代理工作流程中,使其能够处理丰富的多模式城市特征并对犯罪行为进行推理。然而,RAT需要LLM代理在评估环境安全性时推断微妙的线索,作为评估监护权的一部分,这对于LLM来说可能具有挑战性。为了解决这一问题,我们收集了一个小规模的人工注释数据集,并通过一种无需训练的自然梯度方法使CrimeMind的感知与人类判断保持一致。实验表明,在四个美国主要城市中,CrimeMind在犯罪热点预测和空间分布准确性方面优于传统的ABM和深度学习基线,与最强的基线相比,提高了高达24%。此外,我们进行了关于外部事件和政策干预的模拟实验,成功地捕捉到了犯罪模式的预期变化,展示了其对反事实场景的反映能力。总体而言,CrimeMind能够实现精细的个体行为建模,并有助于评估现实世界的干预措施。
关键见解
- 城市犯罪建模是一项涉及多因素的任务,需理解城市环境的视觉、社会和文化线索。
- 传统的ABM和深度学习方法在城市犯罪建模中各有局限,如解释性和预测精度的平衡问题。
- CrimeMind框架结合了LLM和ABM的优势,能够在多模式城市环境下模拟城市犯罪。
- CrimeMind设计创新地集成了例行活动理论(RAT),处理丰富的城市特征并推理犯罪行为。
- LLM在处理环境安全性评估中的微妙线索时面临挑战,但通过人类注释数据集和自然梯度方法得到了提升。
- 在四个美国城市的实验中,CrimeMind在犯罪热点预测和空间分布准确性方面表现优异,且能够反映外部事件和政策干预的影响。
点此查看论文截图

MAPLE: Multi-Agent Adaptive Planning with Long-Term Memory for Table Reasoning
Authors:Ye Bai, Minghan Wang, Thuy-Trang Vu
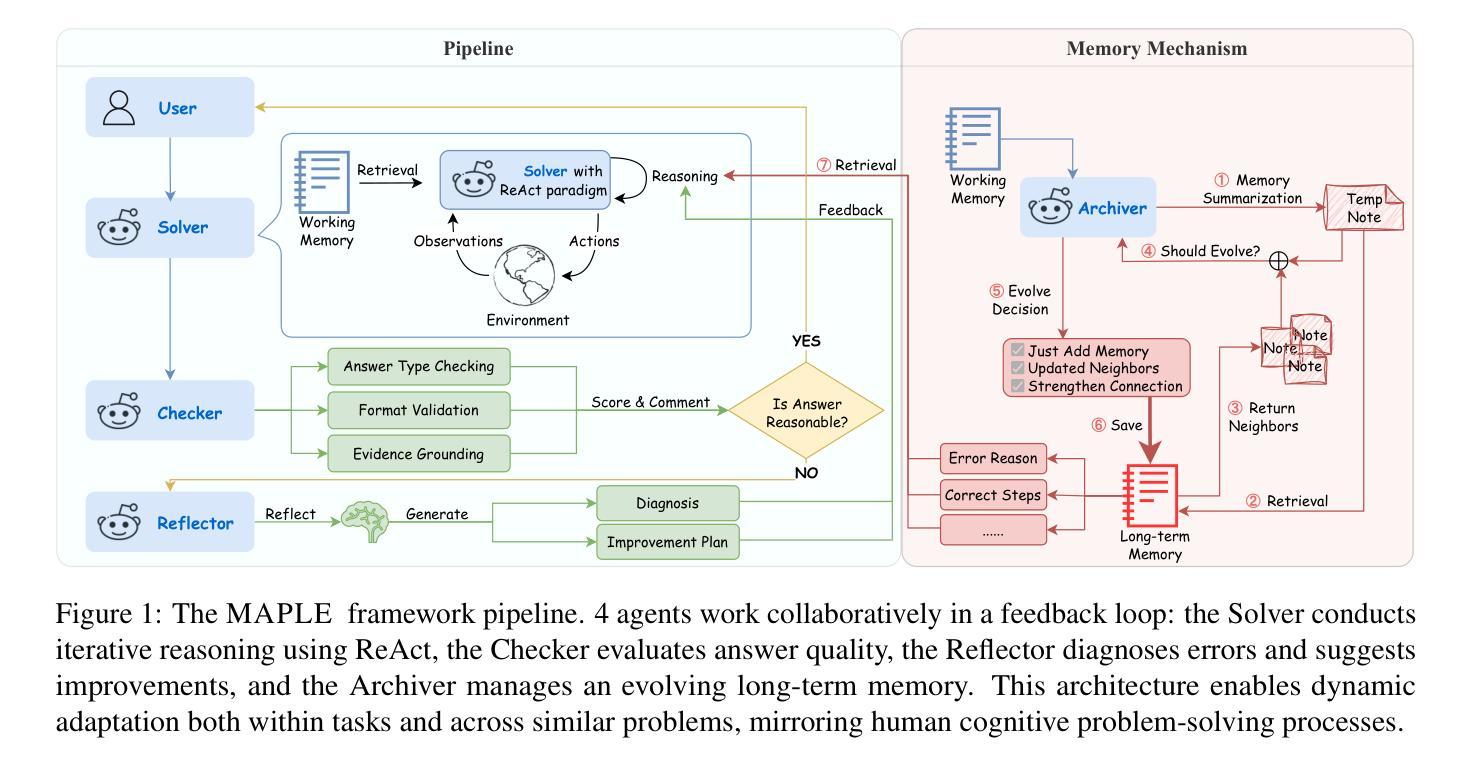
Table-based question answering requires complex reasoning capabilities that current LLMs struggle to achieve with single-pass inference. Existing approaches, such as Chain-of-Thought reasoning and question decomposition, lack error detection mechanisms and discard problem-solving experiences, contrasting sharply with how humans tackle such problems. In this paper, we propose MAPLE (Multi-agent Adaptive Planning with Long-term mEmory), a novel framework that mimics human problem-solving through specialized cognitive agents working in a feedback-driven loop. MAPLE integrates 4 key components: (1) a Solver using the ReAct paradigm for reasoning, (2) a Checker for answer verification, (3) a Reflector for error diagnosis and strategy correction, and (4) an Archiver managing long-term memory for experience reuse and evolution. Experiments on WiKiTQ and TabFact demonstrate significant improvements over existing methods, achieving state-of-the-art performance across multiple LLM backbones.
基于表格的问题回答需要复杂的推理能力,而当前的大型语言模型(LLMs)在单通道推理中难以实现。现有的方法,如思维链推理和问题分解,缺乏错误检测机制并丢弃解决问题时的经验,这与人类解决问题的方法形成鲜明对比。在本文中,我们提出了MAPLE(基于长期记忆的多智能体自适应规划),这是一种模仿人类解决问题的全新框架,通过特定认知智能体在反馈驱动循环中工作来实现。MAPLE集成了四个关键组件:(1)使用ReAct范式进行推理的求解器,(2)用于答案验证的检查器,(3)用于错误诊断和策略校正的反射器,以及(4)管理经验重用和进化的长期记忆的存档器。在WikiTQ和TabFact上的实验表明,与现有方法相比,该方法实现了显著改进,并在多个LLM骨干网上实现了最新性能。
论文及项目相关链接
PDF 26 pages, 10 figures
Summary
本文提出一种名为MAPLE的新型框架,用于模拟人类解决表格问答问题。该框架包含四个关键组件:Solver用于推理,Checker用于答案验证,Reflector用于错误诊断和策略修正,Archiver用于长期记忆管理以实现经验复用和进化。实验证明,MAPLE在WiKiTQ和TabFact数据集上显著优于现有方法,实现了跨多个大型语言模型后端的卓越性能。
Key Takeaways
- 当前的大型语言模型(LLMs)在表格问答(Table-based question answering)上遇到复杂推理难题。
- 现有方法如Chain-of-Thought推理和问句分解缺乏错误检测机制,并忽略问题解决经验的积累。
- MAPLE框架模拟人类问题解决过程,通过专门认知代理在反馈驱动循环中工作。
- MAPLE包含四个关键组件:Solver、Checker、Reflector和Archiver,分别负责推理、答案验证、错误诊断和长期记忆管理。
- MAPLE框架在WiKiTQ和TabFact数据集上实现显著优于现有方法的性能,达到跨多个LLM后端的最佳状态。
- MAPLE的ReAct范式适用于表格问答的复杂推理需求。
点此查看论文截图



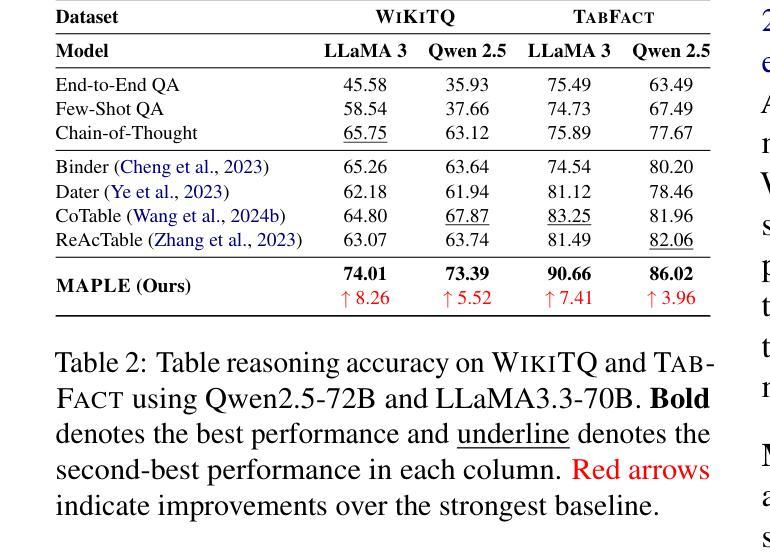
Agentomics-ML: Autonomous Machine Learning Experimentation Agent for Genomic and Transcriptomic Data
Authors:Vlastimil Martinek, Andrea Gariboldi, Dimosthenis Tzimotoudis, Aitor Alberdi Escudero, Edward Blake, David Cechak, Luke Cassar, Alessandro Balestrucci, Panagiotis Alexiou
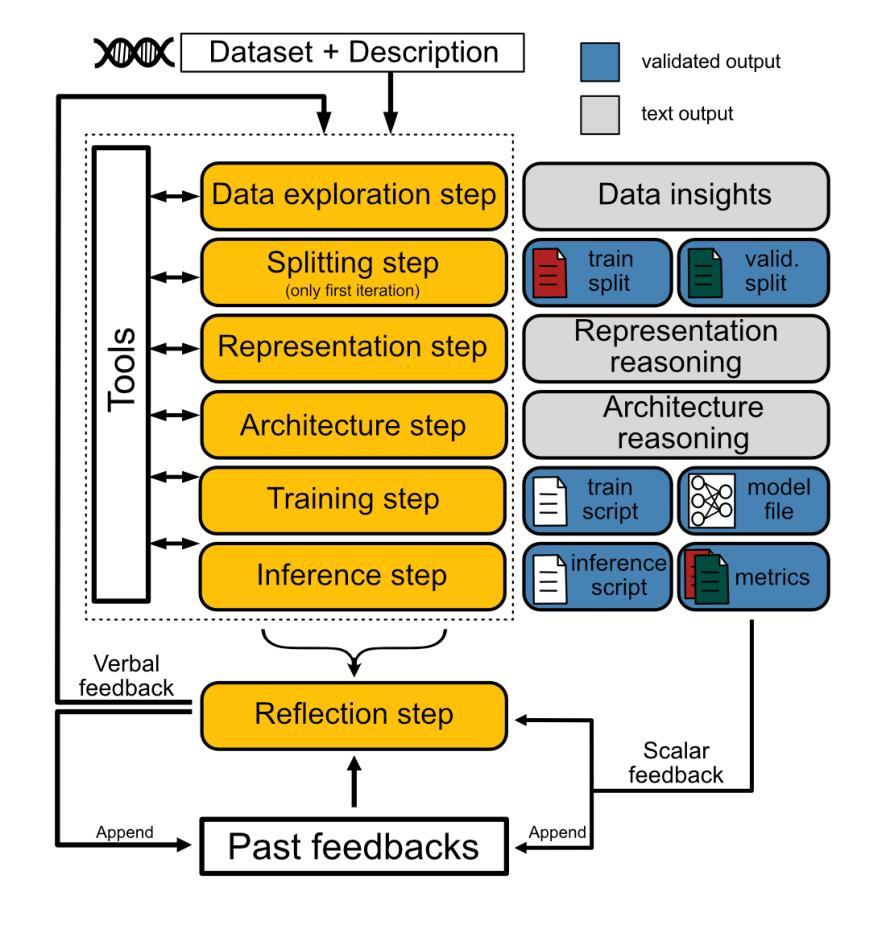
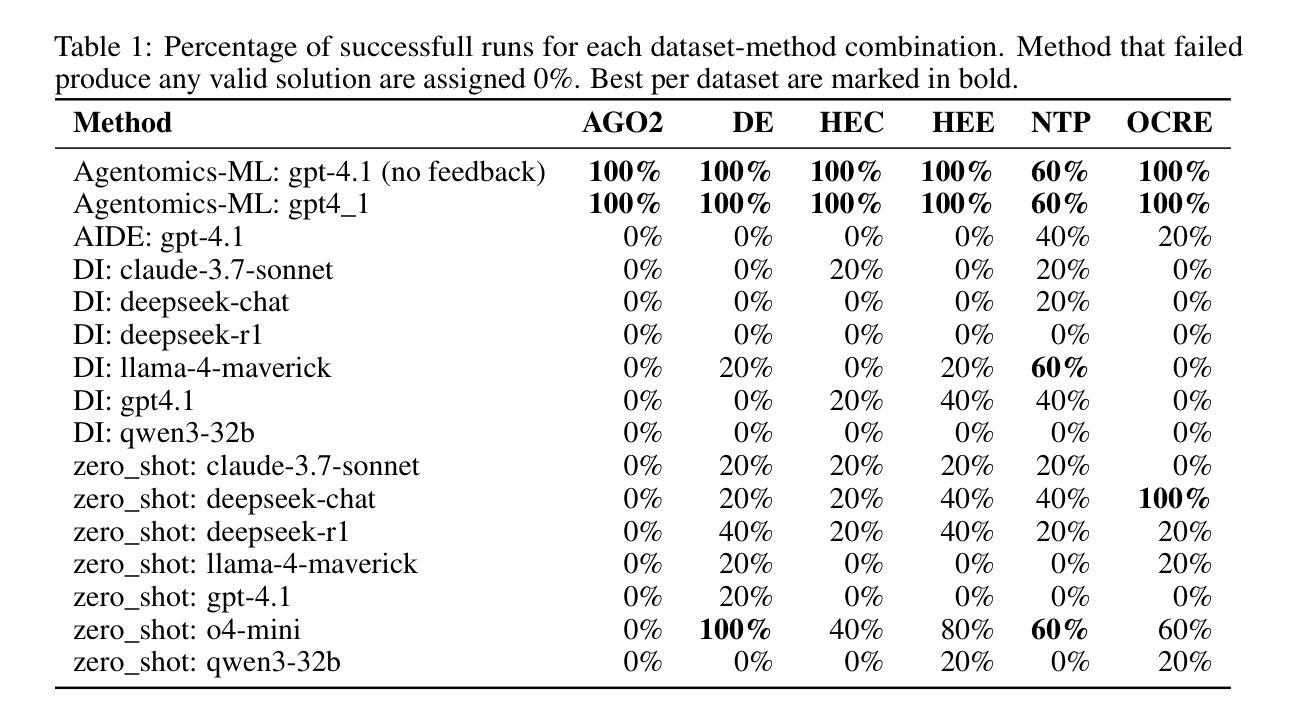
The adoption of machine learning (ML) and deep learning methods has revolutionized molecular medicine by driving breakthroughs in genomics, transcriptomics, drug discovery, and biological systems modeling. The increasing quantity, multimodality, and heterogeneity of biological datasets demand automated methods that can produce generalizable predictive models. Recent developments in large language model-based agents have shown promise for automating end-to-end ML experimentation on structured benchmarks. However, when applied to heterogeneous computational biology datasets, these methods struggle with generalization and success rates. Here, we introduce Agentomics-ML, a fully autonomous agent-based system designed to produce a classification model and the necessary files for reproducible training and inference. Our method follows predefined steps of an ML experimentation process, repeatedly interacting with the file system through Bash to complete individual steps. Once an ML model is produced, training and validation metrics provide scalar feedback to a reflection step to identify issues such as overfitting. This step then creates verbal feedback for future iterations, suggesting adjustments to steps such as data representation, model architecture, and hyperparameter choices. We have evaluated Agentomics-ML on several established genomic and transcriptomic benchmark datasets and show that it outperforms existing state-of-the-art agent-based methods in both generalization and success rates. While state-of-the-art models built by domain experts still lead in absolute performance on the majority of the computational biology datasets used in this work, Agentomics-ML narrows the gap for fully autonomous systems and achieves state-of-the-art performance on one of the used benchmark datasets. The code is available at https://github.com/BioGeMT/Agentomics-ML.
机器学习(ML)和深度学习方法的采用已经通过推动基因组学、转录组学、药物发现和生物系统建模等领域的突破,彻底改变了分子医学。生物数据集的数量越来越多,多模态和异质性特点需要能够产生可推广的预测模型自动化方法。最近基于大型语言模型的智能代理的发展显示出在结构化基准测试上实现端到端机器学习实验自动化的潜力。然而,当应用于异质的计算生物学数据集时,这些方法在推广和成功率方面遇到了困难。在这里,我们介绍了Agentomics-ML,这是一个完全自主的基于代理的系统,旨在生成分类模型以及用于可重复训练和推理的必要文件。我们的方法遵循机器学习实验过程的预定义步骤,通过Bash与文件系统反复交互来完成各个步骤。一旦生成了机器学习模型,训练和验证指标就为反思步骤提供了标量反馈,以识别过拟合等问题。然后此步骤为未来的迭代创建口头反馈,建议调整数据表示、模型架构和超参数选择等步骤。我们在几个公认的基因组学和转录组学基准数据集上评估了Agentomics-ML,结果表明它在推广和成功率方面都优于现有的最先进的基于代理的方法。虽然在这项工作中使用的多数计算生物学数据集上,由领域专家构建的最新模型在绝对性能上仍领先,但Agentomics-ML缩小了完全自主系统之间的差距,并在其中一个基准数据集上达到了最新性能。代码可在https://github.com/BioGeMT/Agentomics-ML找到。
论文及项目相关链接
Summary
机器学习(ML)和深度学习方法的采用已推动基因组学、转录组学、药物发现和生物系统建模等领域的突破性进展,从而革命性地改变了分子医学领域。大量、多模态和异质的生物数据集需要能够产生可推广的预测模型自动化方法。我们介绍了Agentomics-ML,一个完全自主的基于代理的系统,用于产生分类模型以及必要的文件进行可重复的训练和推理。它在预定的机器学习实验步骤中运行,并通过Bash与文件系统交互完成各个步骤。我们的方法通过训练与验证指标提供标量反馈,以识别过拟合等问题,并为未来迭代提供口头反馈,建议调整数据表示、模型架构和超参数选择等步骤。在几个公认的基因组和转录组基准数据集上评估Agentomics-ML表明,它在泛化和成功率方面优于现有的最先进的基于代理的方法。尽管由领域专家构建的最新模型在大多数用于这项工作的计算生物学数据集上仍领先绝对性能,但Agentomics-ML缩小了全自动系统的差距,并在所使用的基准数据集之一上达到了最先进的性能。
Key Takeaways
- 机器学习(ML)和深度学习方法的引入已彻底改变了分子医学领域,特别是在基因组学、转录组学等领域。
- 生物数据集的大规模、多模态和异质性特点要求开发能够产生可推广的预测模型的自动化方法。
- Agentomics-ML是一个完全自主的基于代理的系统,旨在产生分类模型,并包含可重复训练和推理的必要文件。
- Agentomics-ML遵循预定的机器学习实验步骤,通过Bash与文件系统交互来完成这些步骤。
- 该系统通过训练和验证指标提供反馈,用于识别过拟合等问题,并为未来迭代提供调整建议。
- 在多个基准数据集上的评估表明,Agentomics-ML在泛化和成功率方面优于现有最先进的基于代理的方法。
点此查看论文截图

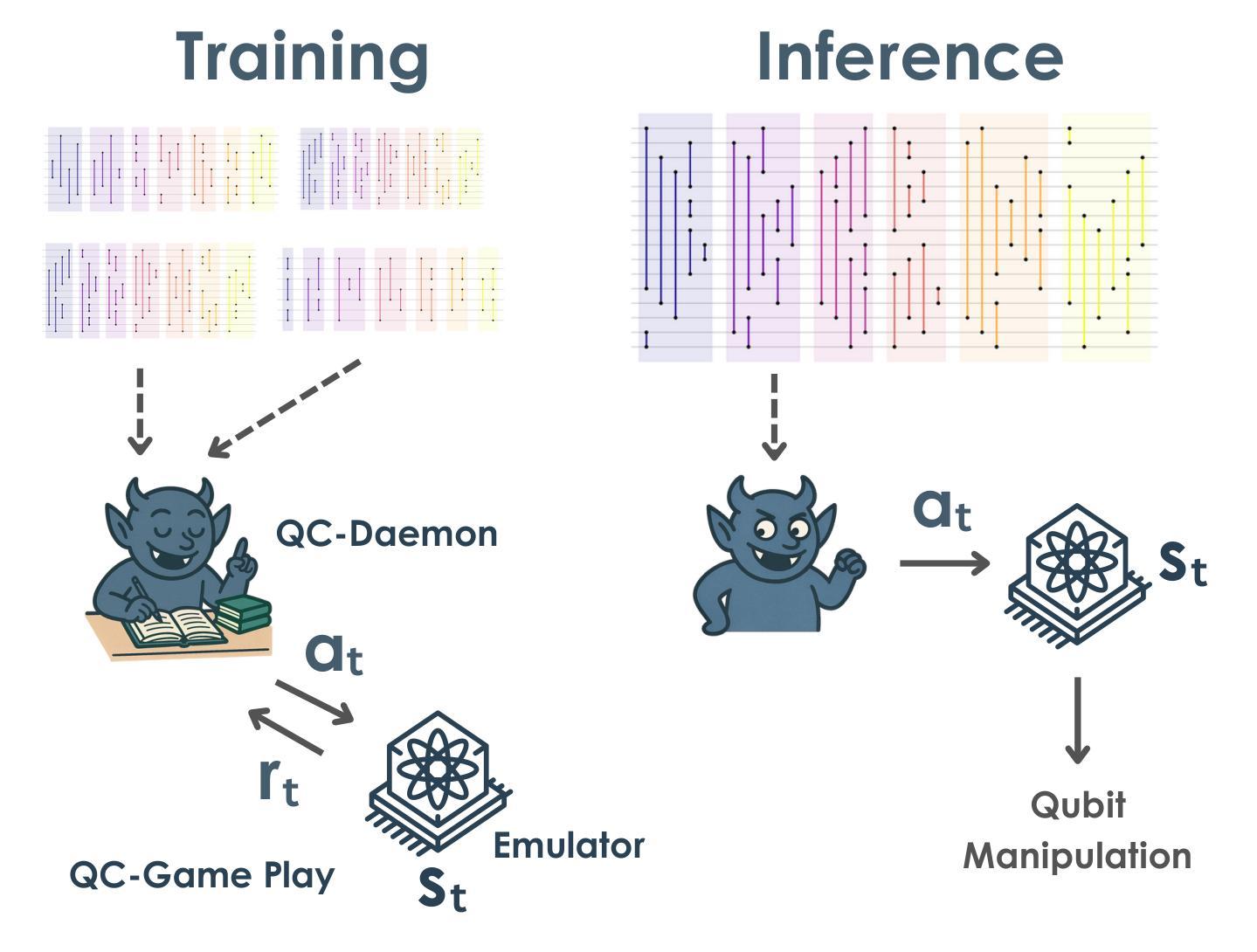
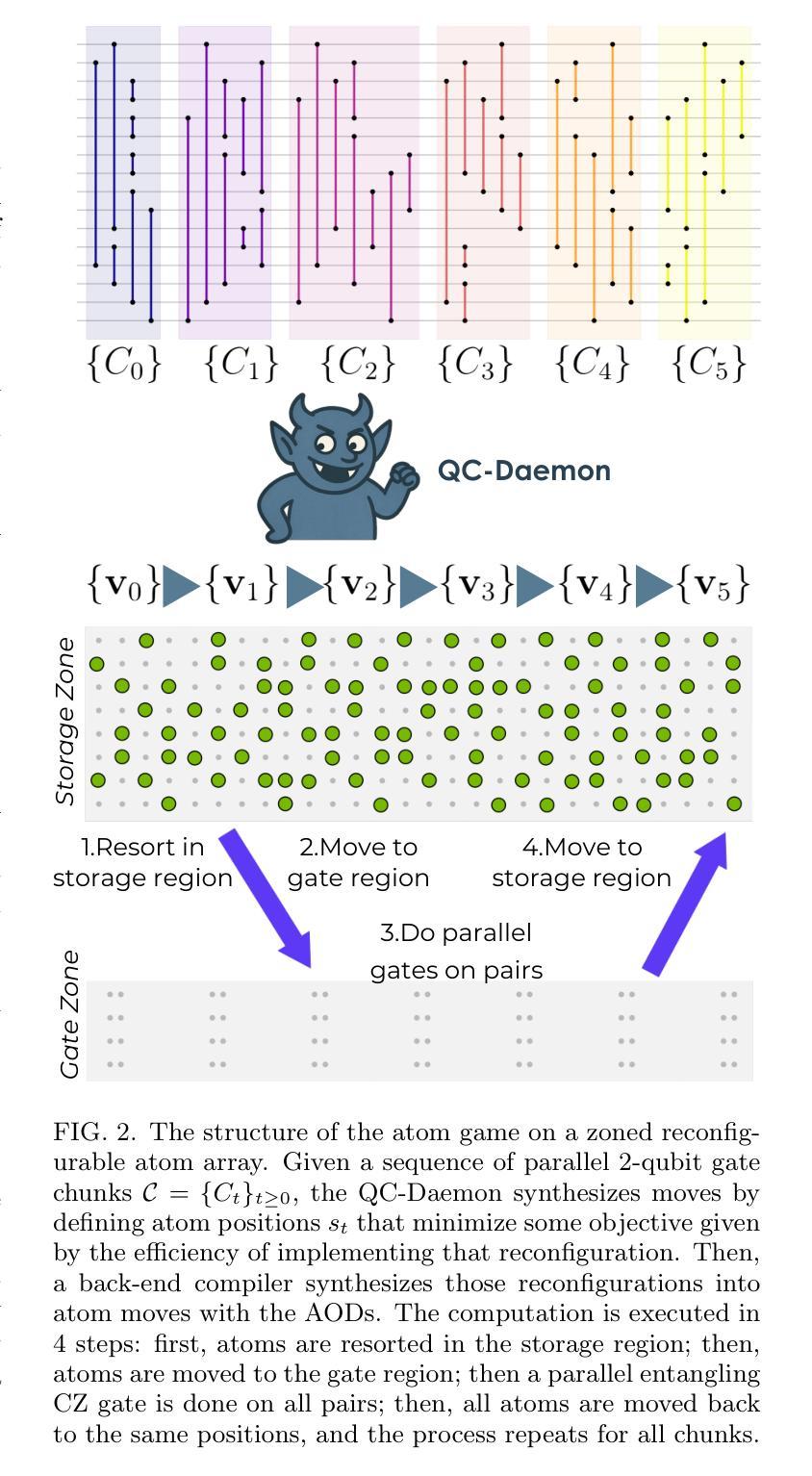
Quantum circuits as a game: A reinforcement learning agent for quantum compilation and its application to reconfigurable neutral atom arrays
Authors:Kouhei Nakaji, Jonathan Wurtz, Haozhe Huang, Luis Mantilla Calderón, Karthik Panicker, Elica Kyoseva, Alán Aspuru-Guzik
We introduce the “quantum circuit daemon” (QC-Daemon), a reinforcement learning agent for compiling quantum device operations aimed at efficient quantum hardware execution. We apply QC-Daemon to the move synthesis problem called the Atom Game, which involves orchestrating parallel circuits on reconfigurable neutral atom arrays. In our numerical simulation, the QC-Daemon is implemented by two different types of transformers with a physically motivated architecture and trained by a reinforcement learning algorithm. We observe a reduction of the logarithmic infidelity for various benchmark problems up to 100 qubits by intelligently changing the layout of atoms. Additionally, we demonstrate the transferability of our approach: a Transformer-based QC-Daemon trained on a diverse set of circuits successfully generalizes its learned strategy to previously unseen circuits.
我们介绍了“量子电路守护程序”(QC-Daemon),这是一种用于编译针对高效量子硬件执行的量子设备操作的强化学习代理。我们将QC-Daemon应用于称为Atom Game的移动合成问题,该问题涉及在可重构的中性原子阵列上协调并行电路。在我们的数值模拟中,QC-Daemon是通过两种具有物理动机架构的变压器实现的,并通过强化学习算法进行训练。我们观察到,通过智能改变原子布局,可以在各种基准问题上实现对数不保真度的降低,涵盖高达100个量子比特。此外,我们展示了我们方法的可迁移性:基于Transformer的QC-Daemon在多种电路集上进行训练,能够成功将其学习策略推广到之前未见过的电路。
论文及项目相关链接
PDF 16 pages, 7 figures
Summary
量子电路守护进程(QC-Daemon)是一种用于编译量子设备操作的强化学习代理,旨在实现高效的量子硬件执行。应用于原子游戏等移动合成问题,涉及在可重构的中性原子阵列上并行电路的协同。数值模拟中,QC-Daemon通过两种具有物理动机架构的变压器实现,并由强化学习算法进行训练。观察到了通过智能改变原子布局,在各种基准问题上实现了对数不保真度的降低,并且展示了方法的可迁移性:基于变压器的QC-Daemon在多种电路上的训练能够成功将其学习策略推广至之前未见过的电路。
Key Takeaways
- QC-Daemon是一个强化学习代理,用于编译量子设备操作,以实现高效的量子硬件执行。
- QC-Daemon应用于Atom Game等移动合成问题,涉及在可重构的中性原子阵列上并行电路的协同。
- 在数值模拟中,通过两种具有物理动机架构的变压器实现QC-Daemon,并使用强化学习算法进行训练。
- 通过智能改变原子布局,观察到对数不保真度降低的现象。
- QC-Daemon在多种电路训练后能够推广其学习策略至未见过的电路。
- 该方法具有广泛的应用潜力,可为量子计算领域的硬件优化和效率提升做出贡献。
点此查看论文截图

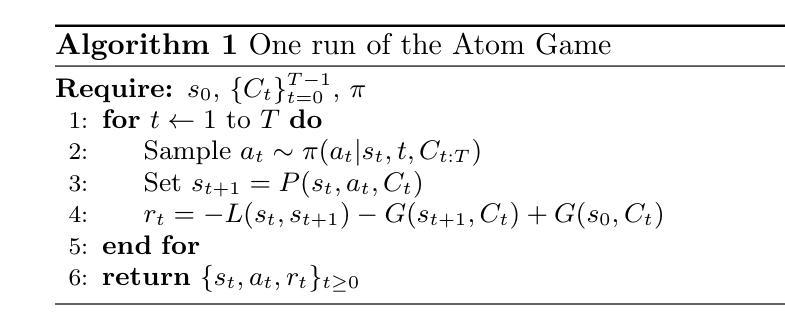
The Coming Crisis of Multi-Agent Misalignment: AI Alignment Must Be a Dynamic and Social Process
Authors:Florian Carichon, Aditi Khandelwal, Marylou Fauchard, Golnoosh Farnadi
This position paper states that AI Alignment in Multi-Agent Systems (MAS) should be considered a dynamic and interaction-dependent process that heavily depends on the social environment where agents are deployed, either collaborative, cooperative, or competitive. While AI alignment with human values and preferences remains a core challenge, the growing prevalence of MAS in real-world applications introduces a new dynamic that reshapes how agents pursue goals and interact to accomplish various tasks. As agents engage with one another, they must coordinate to accomplish both individual and collective goals. However, this complex social organization may unintentionally misalign some or all of these agents with human values or user preferences. Drawing on social sciences, we analyze how social structure can deter or shatter group and individual values. Based on these analyses, we call on the AI community to treat human, preferential, and objective alignment as an interdependent concept, rather than isolated problems. Finally, we emphasize the urgent need for simulation environments, benchmarks, and evaluation frameworks that allow researchers to assess alignment in these interactive multi-agent contexts before such dynamics grow too complex to control.
本立场论文指出,多智能体系统(MAS)中的AI对齐应被视为一个动态且依赖于交互的过程,这一过程在很大程度上依赖于智能体部署的社会环境,这些环境可能是协作、合作或竞争性的。虽然AI与人类价值观和偏好的对齐仍然是核心挑战,但在现实应用中日益普遍的多智能体系统引入了一种新的动态性,这种动态性重塑了智能体如何实现目标和完成各种任务时的交互方式。当智能体彼此交互时,它们必须协调以完成个人和集体目标。然而,这种复杂的社交网络可能会无意中使部分或全部智能体与人类价值观或用户偏好产生冲突。我们以社会科学为理论依据,分析社会结构如何破坏或破坏群体和个人价值观。基于这些分析,我们呼吁人工智能界将人类、偏好和客观对齐视为相互依存的概念,而不是孤立的问题。最后,我们强调迫切需要仿真环境、基准测试和评估框架,以便研究人员在这些交互式多智能体环境中评估对齐情况,避免此类动态发展过于复杂而无法控制。
论文及项目相关链接
PDF Preprint of NeurIPS 2025 Position Paper
Summary
人工智能多智能体系统(MAS)中的对齐应被视为一个动态且依赖于交互的过程,其高度依赖于智能体部署的社会环境,包括协作、合作或竞争。随着MAS在现实世界应用中的普及,其重塑了智能体追求目标和完成任务时的交互方式。智能体在相互协作完成个体和集体目标的同时,复杂的社交组织可能会无意中使部分或全部智能体与人类价值观和用户偏好错位。基于社会科学分析,我们探讨了社会结构如何破坏群体和个人价值观。因此,我们呼吁人工智能社区将人类、偏好和目标的对齐视为相互依赖的概念,而非孤立的问题。同时迫切需要仿真环境、基准测试与评估框架来评估这些交互式多智能体背景下的对齐情况,以防其发展出过于复杂的动态而难以控制。
Key Takeaways
- AI Alignment in Multi-Agent Systems (MAS) 是一个动态且依赖于交互的过程。
- 智能体的行为受部署环境的社会影响,包括协作、合作和竞争。
- 随着MAS在现实世界的普及,其重塑了智能体的目标追求和交互方式。
- 智能体在相互协作时可能无意中与人类价值观和用户偏好错位。
- 社会结构可能影响甚至破坏群体和个人价值观。
- 人工智能社区需要将人类、偏好和目标对齐视为相互依赖的概念。
点此查看论文截图



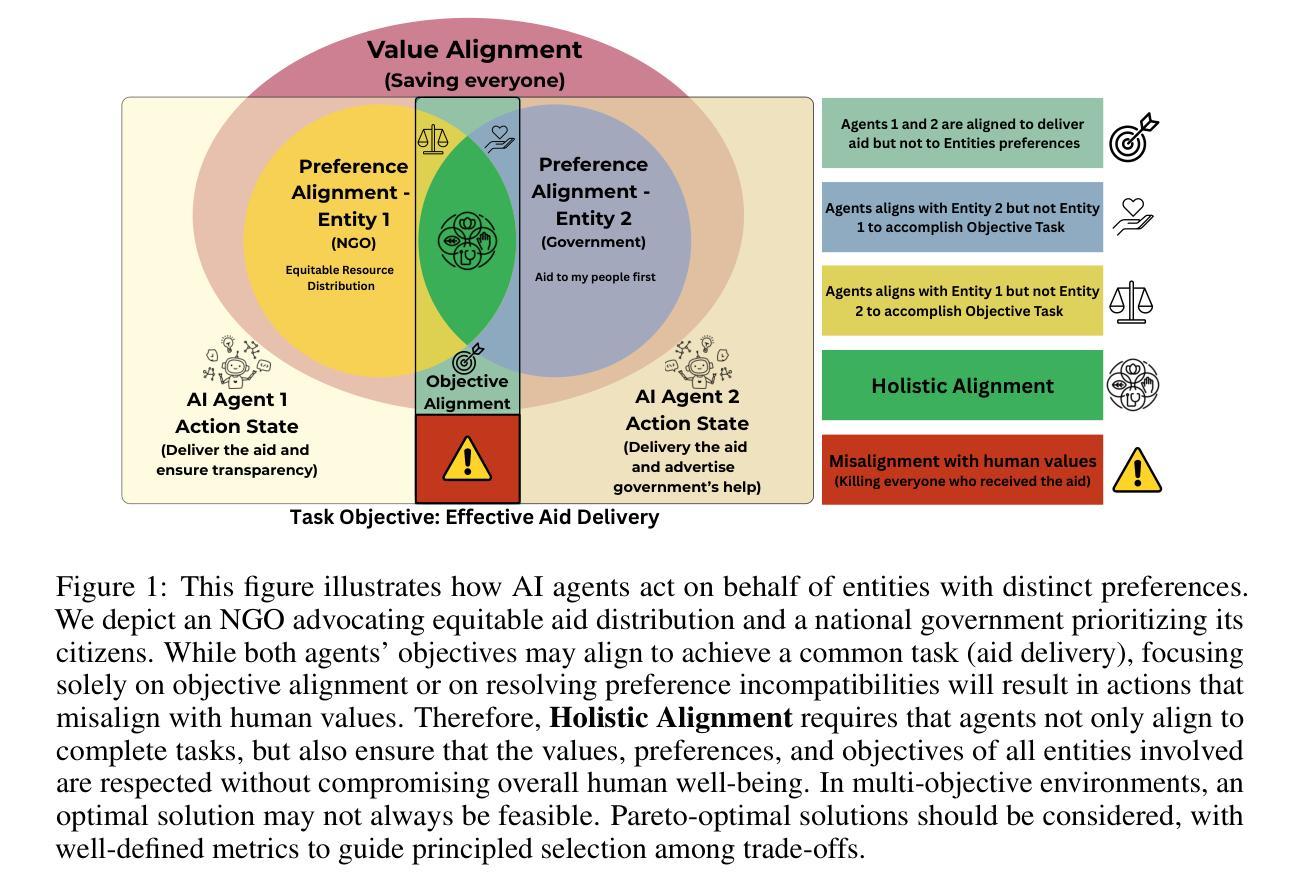
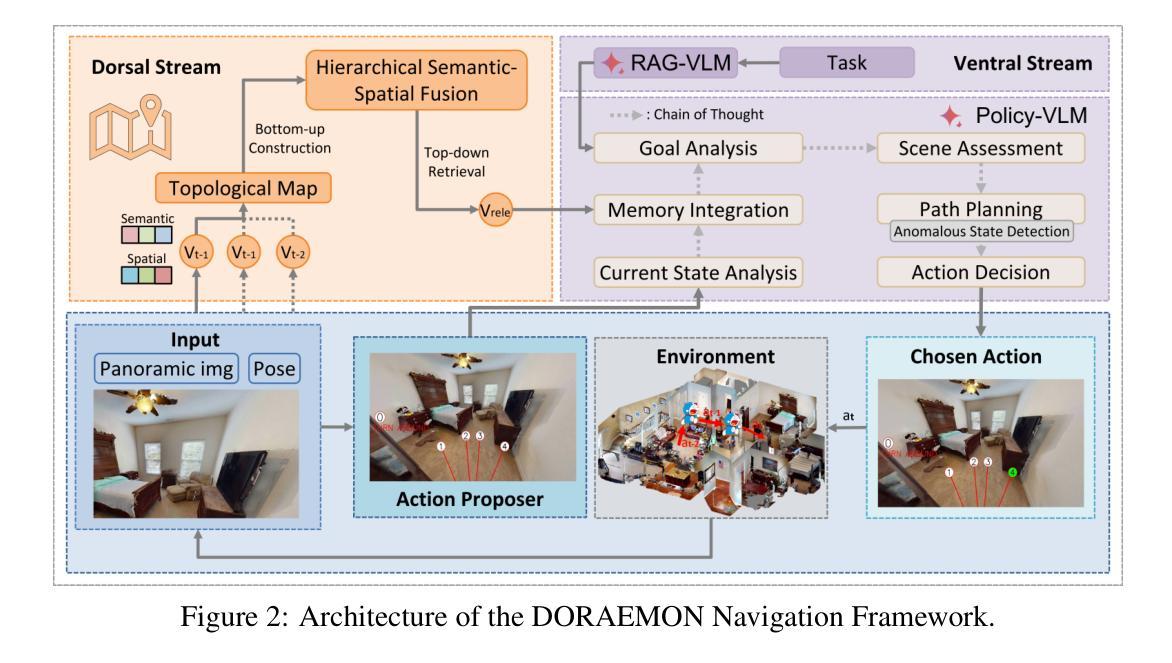
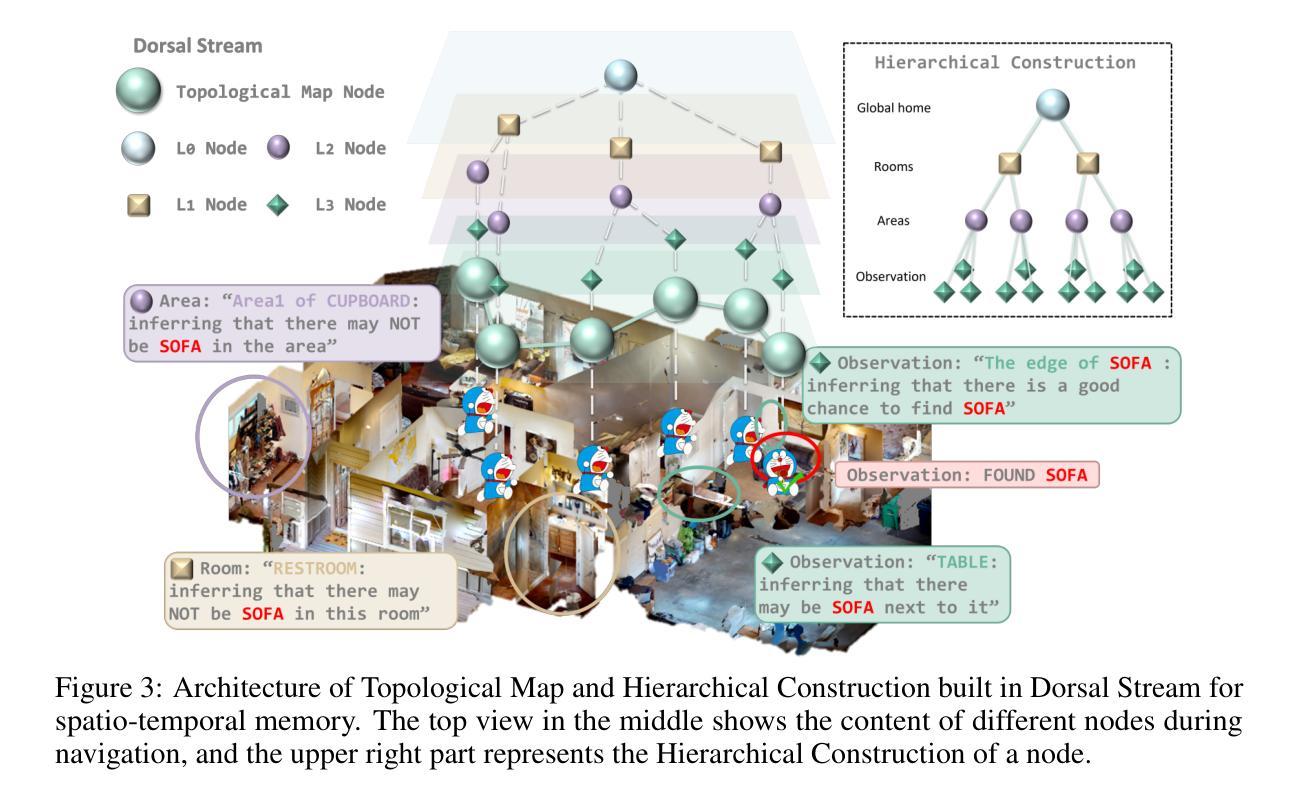
DORAEMON: Decentralized Ontology-aware Reliable Agent with Enhanced Memory Oriented Navigation
Authors:Tianjun Gu, Linfeng Li, Xuhong Wang, Chenghua Gong, Jingyu Gong, Zhizhong Zhang, Yuan Xie, Lizhuang Ma, Xin Tan
Adaptive navigation in unfamiliar environments is crucial for household service robots but remains challenging due to the need for both low-level path planning and high-level scene understanding. While recent vision-language model (VLM) based zero-shot approaches reduce dependence on prior maps and scene-specific training data, they face significant limitations: spatiotemporal discontinuity from discrete observations, unstructured memory representations, and insufficient task understanding leading to navigation failures. We propose DORAEMON (Decentralized Ontology-aware Reliable Agent with Enhanced Memory Oriented Navigation), a novel cognitive-inspired framework consisting of Ventral and Dorsal Streams that mimics human navigation capabilities. The Dorsal Stream implements the Hierarchical Semantic-Spatial Fusion and Topology Map to handle spatiotemporal discontinuities, while the Ventral Stream combines RAG-VLM and Policy-VLM to improve decision-making. Our approach also develops Nav-Ensurance to ensure navigation safety and efficiency. We evaluate DORAEMON on the HM3D, MP3D, and GOAT datasets, where it achieves state-of-the-art performance on both success rate (SR) and success weighted by path length (SPL) metrics, significantly outperforming existing methods. We also introduce a new evaluation metric (AORI) to assess navigation intelligence better. Comprehensive experiments demonstrate DORAEMON’s effectiveness in zero-shot autonomous navigation without requiring prior map building or pre-training.
适应陌生环境的导航对家用服务机器人至关重要,但仍具有挑战性,既需要进行低级别的路径规划,也需要进行高级的场景理解。尽管最近的基于视觉语言模型(VLM)的零样本方法减少了先前景图和特定场景训练数据的依赖,但它们面临重大挑战:离散观测导致的时空不连续性、记忆表示的非结构化以及任务理解不足导致的导航失败。我们提出了DORAEMON(带有增强记忆导向导航的分散式本体感知可靠代理),这是一个新的认知启发框架,包括模仿人类导航能力的腹侧和背侧流。背侧流实现了分层语义空间融合和拓扑图,以处理时空不连续性,而腹侧流结合了RAG-VLM和策略VLM以提高决策能力。我们的方法还开发了Nav-Ensurance以确保导航的安全性和效率。我们在HM3D、MP3D和GOAT数据集上评估了DORAEMON的性能,它在成功率(SR)和路径长度加权成功率(SPL)指标上达到了最新水平,显著优于现有方法。我们还引入了一个新的评估指标(AORI)以更好地评估导航智能。综合实验表明,DORAEMON在无需预先构建地图或进行预训练的情况下,实现了零样本自主导航的有效性。
论文及项目相关链接
Summary
家庭服务机器人在陌生环境中的自适应导航至关重要,但仍面临低层次路径规划和高层次场景理解的需求挑战。最近基于视觉语言模型(VLM)的零样本方法减少了对于先验地图和特定场景训练数据的依赖,但存在时空不连续、记忆表征不结构化以及任务理解不足等局限。为此,本文提出一种模仿人类导航能力的新型认知驱动框架DORAEMON(结合腹侧流和背侧流的去中心化本体感知可靠代理),通过分层语义空间融合和拓扑地图处理时空不连续性问题,同时结合RAG-VLM和策略VLM改善决策制定。此外,开发Nav-Ensurance确保导航的安全性和效率。在HM3D、MP3D和GOAT数据集上的实验表明,DORAEMON在成功率和成功加权路径长度指标上实现最新技术水准,显著优于现有方法。此外,引入新的评估指标(AORI)以更好地评估导航智能。
Key Takeaways
- 家庭服务机器人在陌生环境中的自适应导航是关键的,但需要解决低层次路径规划和高层次场景理解的问题。
- 基于视觉语言模型(VLM)的零样本方法虽然减少了对于先验地图和特定场景训练数据的依赖,但存在多项局限。
- DORAEMON框架通过模仿人类导航能力来解决上述问题,包括腹侧流和背侧流的处理方式。
- DORAEMON通过分层语义空间融合和拓扑地图处理时空不连续性问题。
- DORAEMON结合RAG-VLM和策略VLM改善决策制定。
- Nav-Ensurance被开发出来确保导航的安全性和效率。
点此查看论文截图


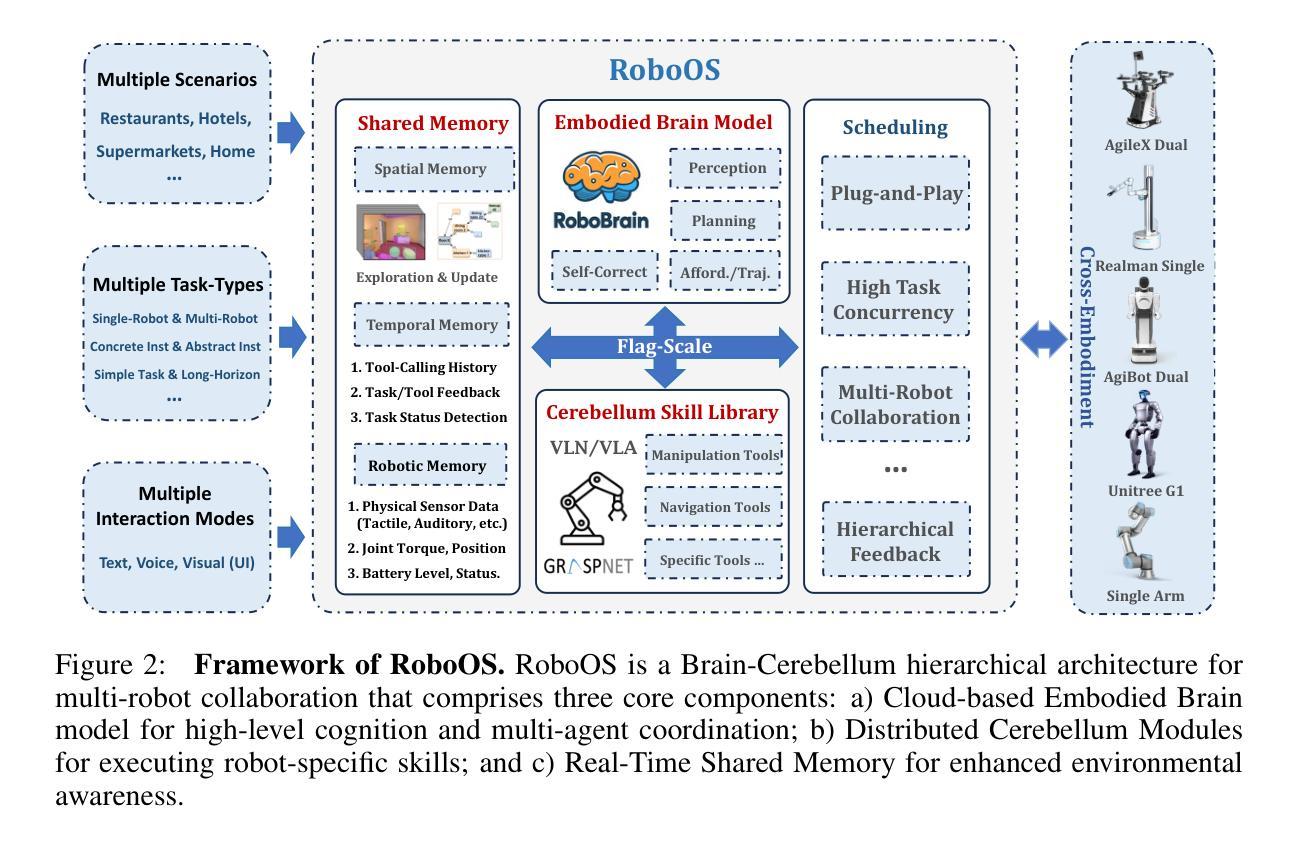
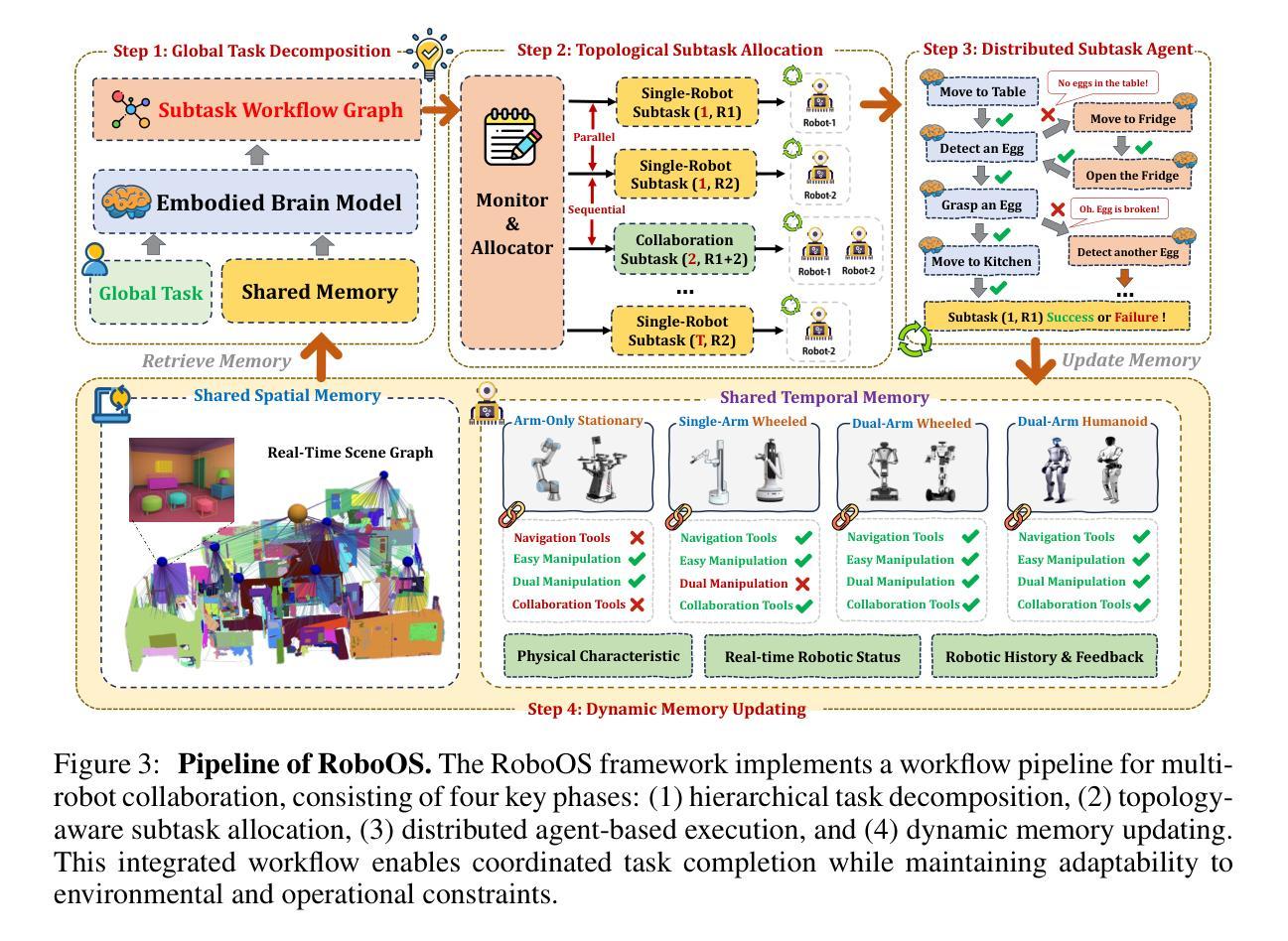
RoboOS: A Hierarchical Embodied Framework for Cross-Embodiment and Multi-Agent Collaboration
Authors:Huajie Tan, Xiaoshuai Hao, Cheng Chi, Minglan Lin, Yaoxu Lyu, Mingyu Cao, Dong Liang, Zhuo Chen, Mengsi Lyu, Cheng Peng, Chenrui He, Yulong Ao, Yonghua Lin, Pengwei Wang, Zhongyuan Wang, Shanghang Zhang
The dawn of embodied intelligence has ushered in an unprecedented imperative for resilient, cognition-enabled multi-agent collaboration across next-generation ecosystems, revolutionizing paradigms in autonomous manufacturing, adaptive service robotics, and cyber-physical production architectures. However, current robotic systems face significant limitations, such as limited cross-embodiment adaptability, inefficient task scheduling, and insufficient dynamic error correction. While End-to-end VLA models demonstrate inadequate long-horizon planning and task generalization, hierarchical VLA models suffer from a lack of cross-embodiment and multi-agent coordination capabilities. To address these challenges, we introduce RoboOS, the first open-source embodied system built on a Brain-Cerebellum hierarchical architecture, enabling a paradigm shift from single-agent to multi-agent intelligence. Specifically, RoboOS consists of three key components: (1) Embodied Brain Model (RoboBrain), a MLLM designed for global perception and high-level decision-making; (2) Cerebellum Skill Library, a modular, plug-and-play toolkit that facilitates seamless execution of multiple skills; and (3) Real-Time Shared Memory, a spatiotemporal synchronization mechanism for coordinating multi-agent states. By integrating hierarchical information flow, RoboOS bridges Embodied Brain and Cerebellum Skill Library, facilitating robust planning, scheduling, and error correction for long-horizon tasks, while ensuring efficient multi-agent collaboration through Real-Time Shared Memory. Furthermore, we enhance edge-cloud communication and cloud-based distributed inference to facilitate high-frequency interactions and enable scalable deployment. Extensive real-world experiments across various scenarios, demonstrate RoboOS’s versatility in supporting heterogeneous embodiments. Project website: https://github.com/FlagOpen/RoboOS
迎来具身智能的曙光为下一代生态系统中的弹性、认知赋能的多智能体协作带来了前所未有的紧迫需求,从而彻底改变了自主制造、自适应服务机器人和物理网络生产架构的范式。然而,当前机器人系统面临重大挑战,如有限的跨具身适应性、任务调度效率低下以及动态纠错不足等。端到端VLA模型展现出长期规划不足和任务泛化能力不强的问题,而分层VLA模型则缺乏跨具身和多智能体协调能力。为了应对这些挑战,我们推出了RoboOS,这是首个基于大脑-小脑分层架构的开源具身系统,能够实现从单智能体到多智能体智能的范式转变。具体来说,RoboOS包括三个关键组件:(1)具身大脑模型(RoboBrain),这是一个用于全局感知和高层次决策的MLLM;(2)小脑技能库,这是一个模块化、即插即用的工具包,可轻松执行多种技能;(3)实时共享内存,这是一个用于协调多智能体状态的时空同步机制。通过整合分层信息流,RoboOS连接了具身大脑和小脑技能库,促进了长期任务的稳健规划、调度和纠错,同时通过实时共享内存确保高效的多智能体协作。此外,我们增强了边缘云通信和基于云的分布式推理,以促进高频交互和实现可扩展部署。在多种场景下的广泛现实实验证明了RoboOS在支持异构实体方面的通用性。项目网站:https://github.com/FlagOpen/RoboOS
论文及项目相关链接
PDF 22 pages, 10 figures
Summary
新一代生态系统下的智能化融合带来巨大挑战和机遇,RoboOS通过基于大脑-小脑层级架构的多智能体系统实现了创新突破。RoboOS具备多智能体协同、长周期任务规划执行、动态错误纠正等核心能力,并包括智能大脑模型、小脑技能库和实时共享内存三大关键组件。通过边缘计算和云计算的结合,RoboOS可实现高效部署和实时交互。该项目已在多种真实场景中进行了验证。
Key Takeaways
- 新一代生态系统需要智能化融合,实现多智能体协同合作。
- 当前机器人系统面临跨形态适应性差、任务调度效率低等问题。
- RoboOS基于大脑-小脑层级架构构建,可实现多智能体协同、长周期任务规划执行和动态错误纠正。
- RoboOS包括三大关键组件:智能大脑模型、小脑技能库和实时共享内存。
- 通过边缘计算和云计算的结合,RoboOS可实现高效部署和实时交互。
- 大量真实场景实验验证了RoboOS的有效性和适用性。
点此查看论文截图


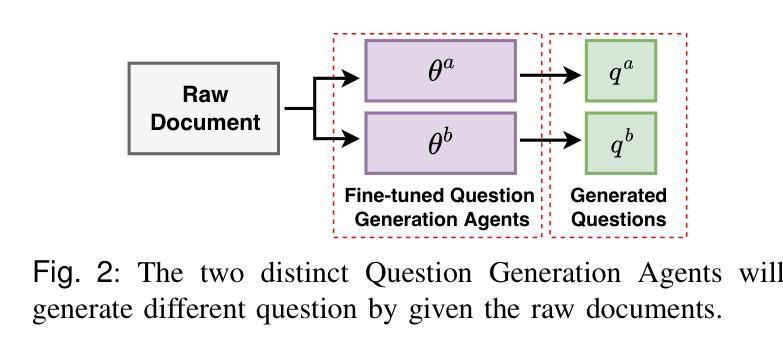
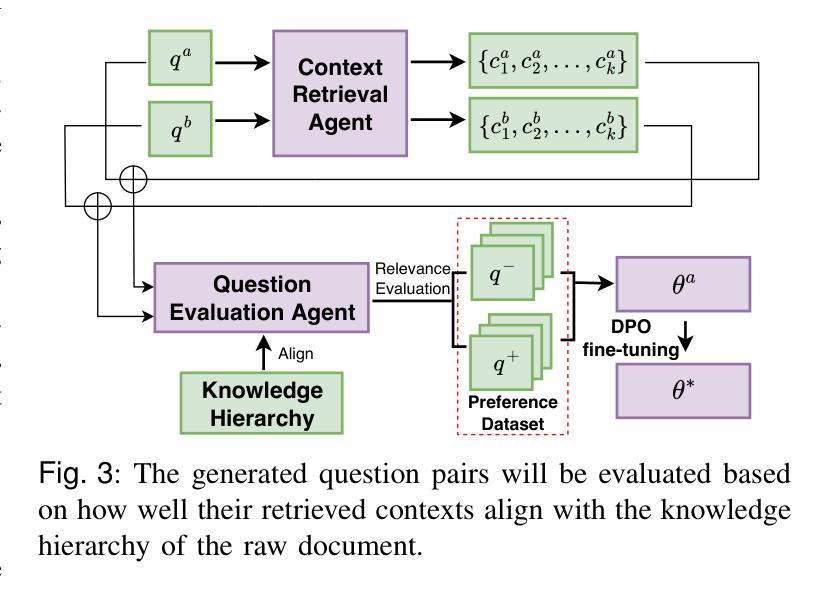
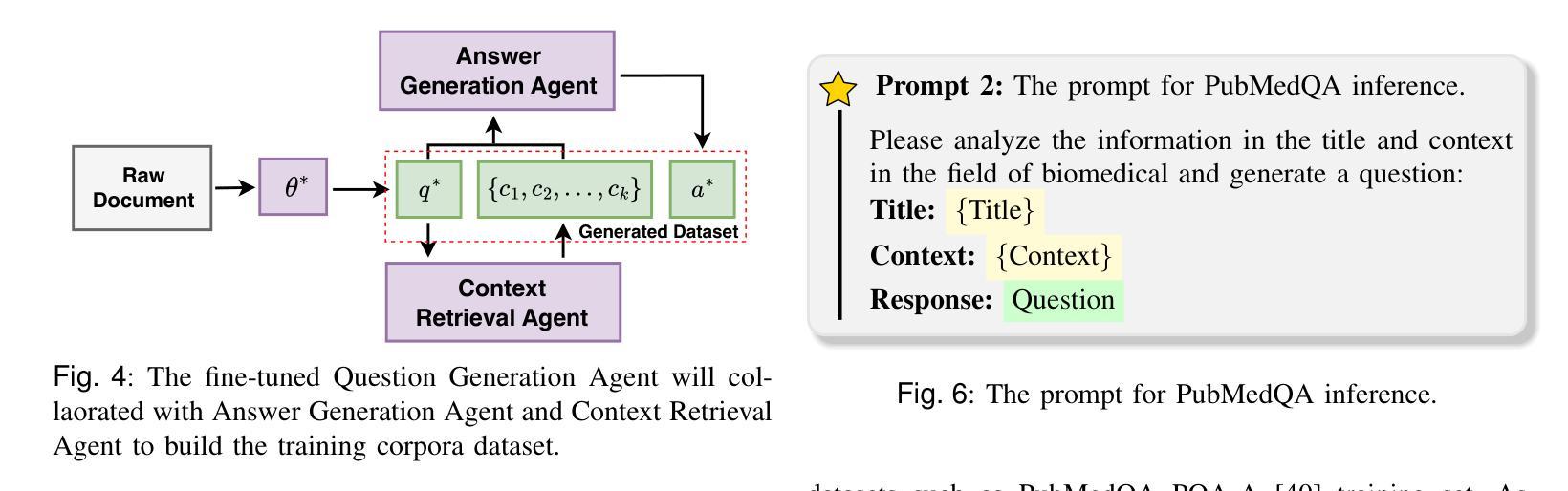
m-KAILIN: Knowledge-Driven Agentic Scientific Corpus Distillation Framework for Biomedical Large Language Models Training
Authors:Meng Xiao, Xunxin Cai, Qingqing Long, Chengrui Wang, Yuanchun Zhou, Hengshu Zhu
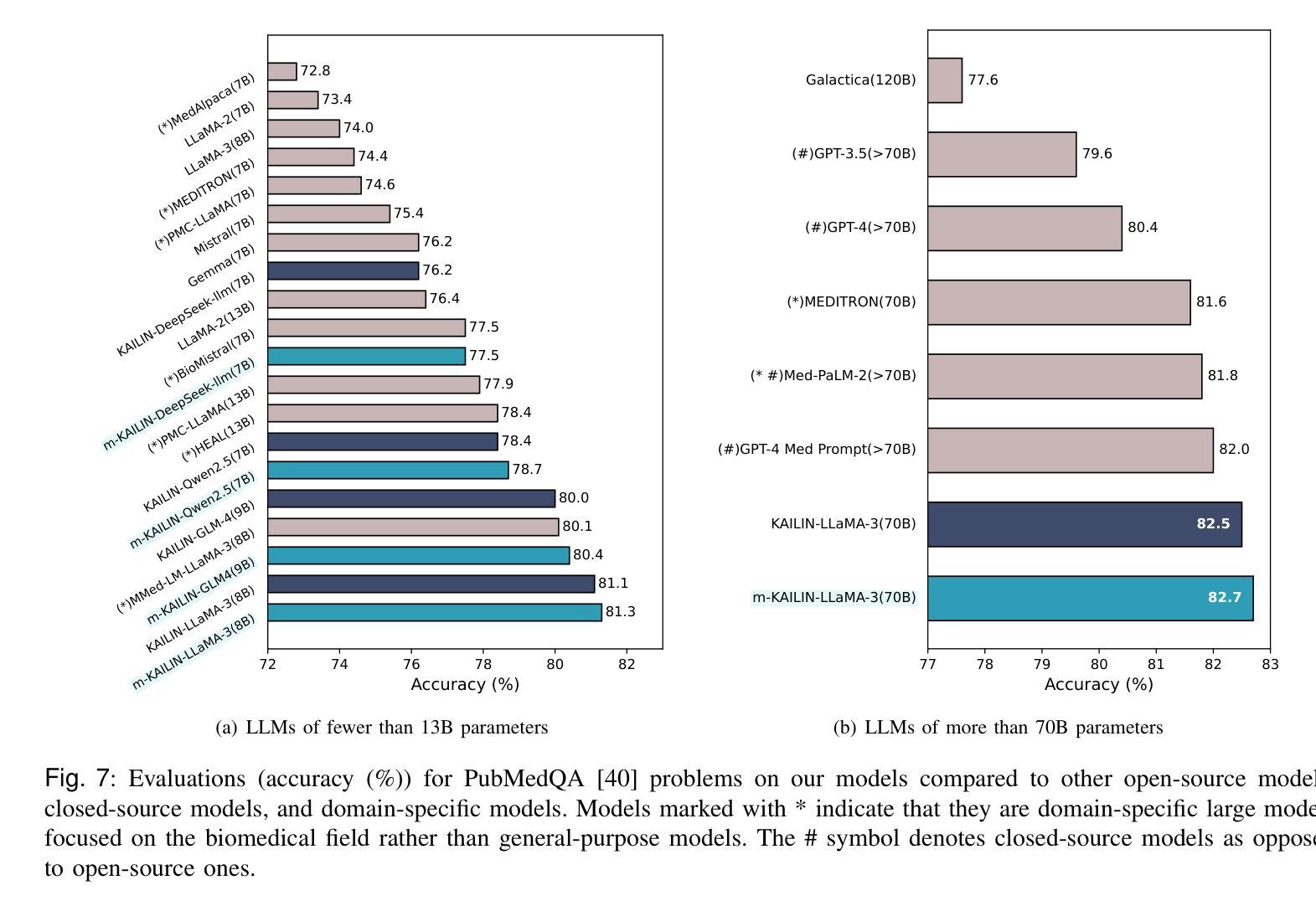
Corpus distillation for biomedical large language models (LLMs) seeks to address the pressing challenge of insufficient quantity and quality in open-source annotated scientific corpora, which remains a bottleneck for effective LLM training in biomedical research. This paper proposes a knowledge-driven, agentic framework for scientific corpus distillation, tailored explicitly for LLM training in the biomedical domain, addressing the challenge posed by the complex hierarchy of biomedical knowledge. Central to our approach is a collaborative multi-agent architecture, where specialized agents, each guided by the Medical Subject Headings (MeSH) hierarchy, work in concert to autonomously extract, synthesize, and self-evaluate high-quality textual data from vast scientific literature. This agentic framework collectively generates and refines domain-specific question-answer pairs, ensuring comprehensive coverage and consistency with biomedical ontologies while minimizing manual involvement. Extensive experimental results show that language models trained on our multi-agent distilled datasets achieve notable improvements in biomedical question-answering tasks, outperforming both strong life sciences LLM baselines and advanced proprietary models. Notably, our AI-Ready dataset enables Llama3-70B to surpass GPT-4 with MedPrompt and Med-PaLM-2, despite their larger scale. Detailed ablation studies and case analyses further validate the effectiveness and synergy of each agent within the framework, highlighting the potential of multi-agent collaboration in biomedical LLM training.
针对生物医学大型语言模型(LLM)的语料库蒸馏旨在解决开源注释科学语料库在数量和质量上的不足这一紧迫挑战,这仍然是生物医学研究中有效LLM训练的瓶颈。本文提出了一种面向LLM训练的知识驱动的智能框架,专门针对生物医学领域的语料库蒸馏,解决由复杂的生物医学知识层次结构所带来的挑战。我们的方法的核心是一个协作的多智能体架构,其中每个专业智能体均由医学主题标题(MeSH)层次结构指导,协同工作以从大量科学文献中自主提取、合成和自我评价高质量文本数据。该智能框架共同生成并细化特定领域的问答对,确保全面覆盖并与生物医学本体论保持一致,同时最大限度地减少人工参与。广泛的实验结果表明,在生物医学问答任务上,使用我们的多智能体蒸馏数据集训练的模型取得了显著的改进,超过了强大的生命科学LLM基准模型和高级专有模型。值得注意的是,我们的AI就绪数据集使Llama3-70B能够在MedPrompt和Med-PaLM-2的辅助下超越GPT-4。详细的消融研究和案例分析进一步验证了框架内每个智能体的有效性及其协同作用,突出了多智能体协作在生物医学LLM训练中的潜力。
论文及项目相关链接
PDF Biomedical large language models, corpus distillation, question-answer, agentic AI. arXiv admin note: text overlap with arXiv:2501.15108
Summary
生物医学领域的大规模语言模型(LLMs)面临着开源标注科学语料库的数量和质量不足的挑战。本文提出一种面向LLM训练的知识驱动型代理框架,专门针对生物医学领域进行语料库蒸馏。该框架采用多代理协作架构,通过医疗主题层次结构(MeSH)引导各个代理,协同提取、合成和自我评价高质量文本数据。该框架生成的特定领域问答对能够全面覆盖和遵循生物医学本体论,最小化人工干预。实验结果表明,经过多代理蒸馏的数据集训练的模型在生物医学问答任务上取得了显著改进,超越了强大的生命科学LLM基准模型和先进的专有模型。尽管规模较小,AI就绪数据集也能使Llama3-70B在MedPrompt和Med-PaLM-2中超越GPT-4。
Key Takeaways
- 介绍了LLM在生物医学研究中面临的一个关键挑战:高质量和充足数量的标注科学语料库的稀缺性。
- 提出一种基于知识驱动的代理框架进行医学语料库蒸馏,针对生物医学领域定制解决方案。
- 利用多代理协作架构应对医学知识的复杂层次结构挑战。通过专门的代理进行医学文本的协同处理。
- 介绍了代理框架如何生成和精炼特定领域的问答对,确保与生物医学本体论的兼容性和一致性,同时最小化人工干预。
- 实验结果显示,使用多代理蒸馏数据集训练的模型在生物医学问答任务上表现优异,优于其他先进的模型和基准测试。
- AI就绪数据集使规模较小的模型(如Llama3-70B)在性能上超越更大规模的模型(如GPT-4)。这证明了多代理合作和数据蒸馏方法在LLM训练中的潜力。
点此查看论文截图

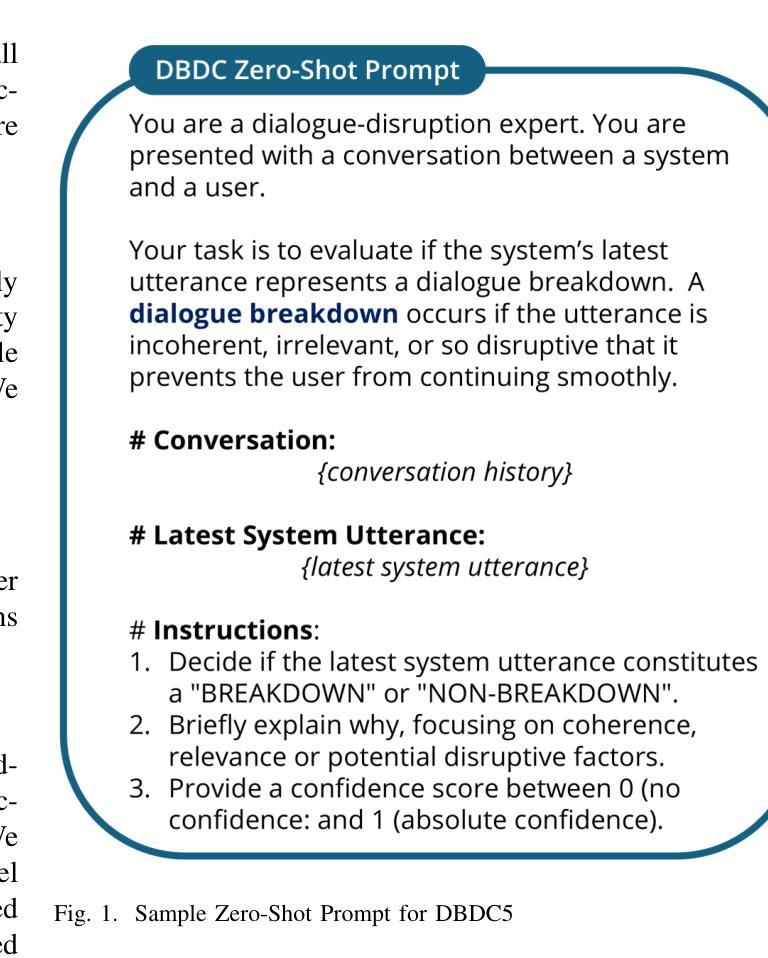
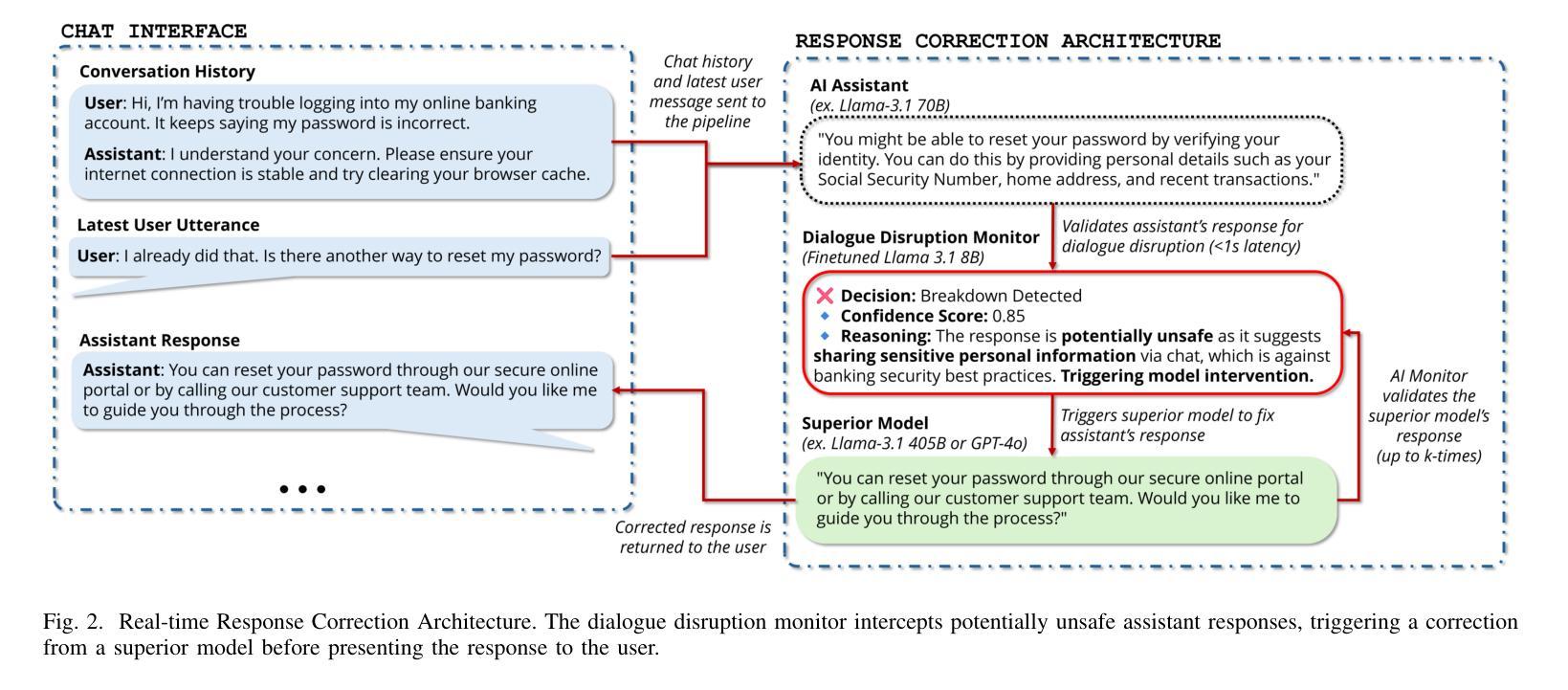
Detect, Explain, Escalate: Low-Carbon Dialogue Breakdown Management for LLM-Powered Agents
Authors:Abdellah Ghassel, Xianzhi Li, Xiaodan Zhu
While Large Language Models (LLMs) are transforming numerous applications, their susceptibility to conversational breakdowns remains a critical challenge undermining user trust. This paper introduces a “Detect, Explain, Escalate” framework to manage dialogue breakdowns in LLM-powered agents, emphasizing low-carbon operation. Our approach integrates two key strategies: (1) We fine-tune a compact 8B-parameter model, augmented with teacher-generated reasoning traces, which serves as an efficient real-time breakdown ‘detector’ and ‘explainer’. This model demonstrates robust classification and calibration on English and Japanese dialogues, and generalizes well to the BETOLD dataset, improving accuracy by 7% over its baseline. (2) We systematically evaluate frontier LLMs using advanced prompting (few-shot, chain-of-thought, analogical reasoning) for high-fidelity breakdown assessment. These are integrated into an ‘escalation’ architecture where our efficient detector defers to larger models only when necessary, substantially reducing operational costs and energy consumption. Our fine-tuned model and prompting strategies establish new state-of-the-art results on dialogue breakdown detection benchmarks, outperforming specialized classifiers and significantly narrowing the performance gap to larger proprietary models. The proposed monitor-escalate pipeline reduces inference costs by 54%, offering a scalable, efficient, and more interpretable solution for robust conversational AI in high-impact domains. Code and models will be publicly released.
大型语言模型(LLM)正在改变许多应用,但它们容易出现的对话中断问题仍然是损害用户信任的关键挑战。本文介绍了一个“检测、解释、升级”框架,用于管理LLM驱动的智能代理中的对话中断问题,并强调低碳运行。我们的方法集成了两种关键策略:(1)我们微调了一个带有教师生成推理轨迹的紧凑8B参数模型,该模型作为高效的实时中断“检测器”和“解释器”。该模型在英语和日语对话中展示了稳健的分类和校准能力,并能很好地推广到BETOLD数据集,比基线提高了7%的准确率。(2)我们系统地使用高级提示(少样本、思维链、类比推理)来评估前沿的大型语言模型,进行高精度的中断评估。这些提示被集成到一个“升级”架构中,我们的高效检测器只在必要时求助于更大的模型,大大降低了运行成本和能源消耗。我们微调过的模型和提示策略在对话中断检测基准测试中取得了最新成果,超越了专业分类器,并大幅缩小了与更大专有模型的性能差距。所提出的监控升级管道将推理成本降低了54%,为关键领域提供了可扩展、高效且更具可解释性的稳健对话人工智能解决方案。代码和模型将公开发布。
论文及项目相关链接
Summary
该论文介绍了”检测、解释、升级”框架,用于管理大型语言模型驱动的对话中的对话中断问题,并强调低碳操作的重要性。通过精细调整带有教师生成推理轨迹的紧凑8B参数模型,作为高效的实时中断检测器和解释器。同时系统地评估前沿的大型语言模型,采用先进的提示方法,如少样本、链式思维、类比推理等,进行高保真中断评估。该框架降低了操作成本和能源消耗,并为对话中断检测基准测试建立了新的最先进的成果。
Key Takeaways
- 大型语言模型在对话中易出现中断问题,影响用户信任。
- 引入”检测、解释、升级”框架来管理对话中断。
- 通过精细调整带有教师生成推理轨迹的模型,实现高效实时的中断检测与解释。
- 模型在多种语言对话中表现稳健,并在BETOLD数据集上提高了7%的准确率。
- 采用先进的提示方法评估前沿的大型语言模型,进行高保真中断评估。
- 框架通过高效的检测器仅在必要时调用更大的模型,降低了操作成本和能源消耗。
- 框架为对话中断检测基准测试建立了新的最先进成果,并减少了推理成本54%。
点此查看论文截图

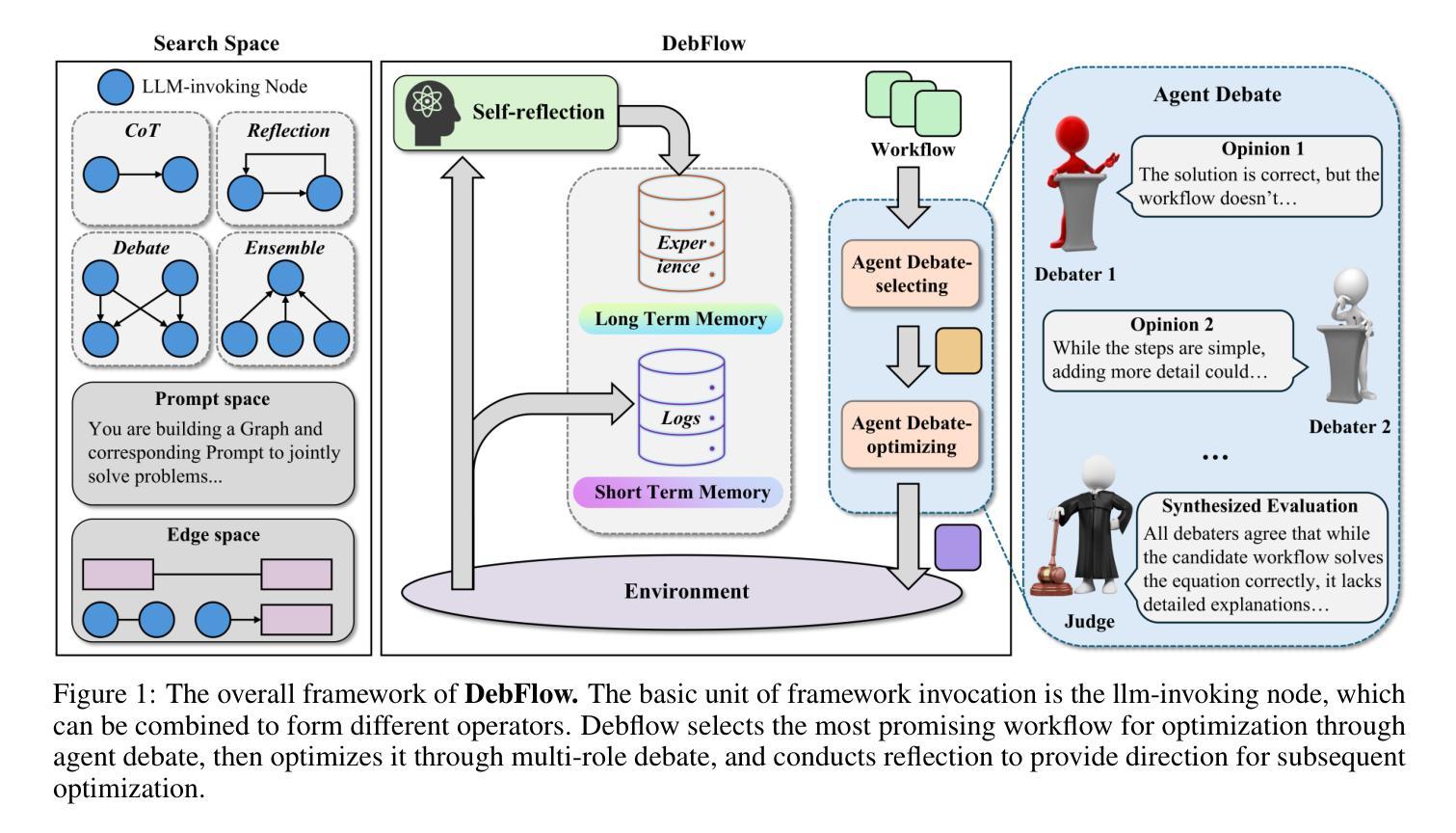
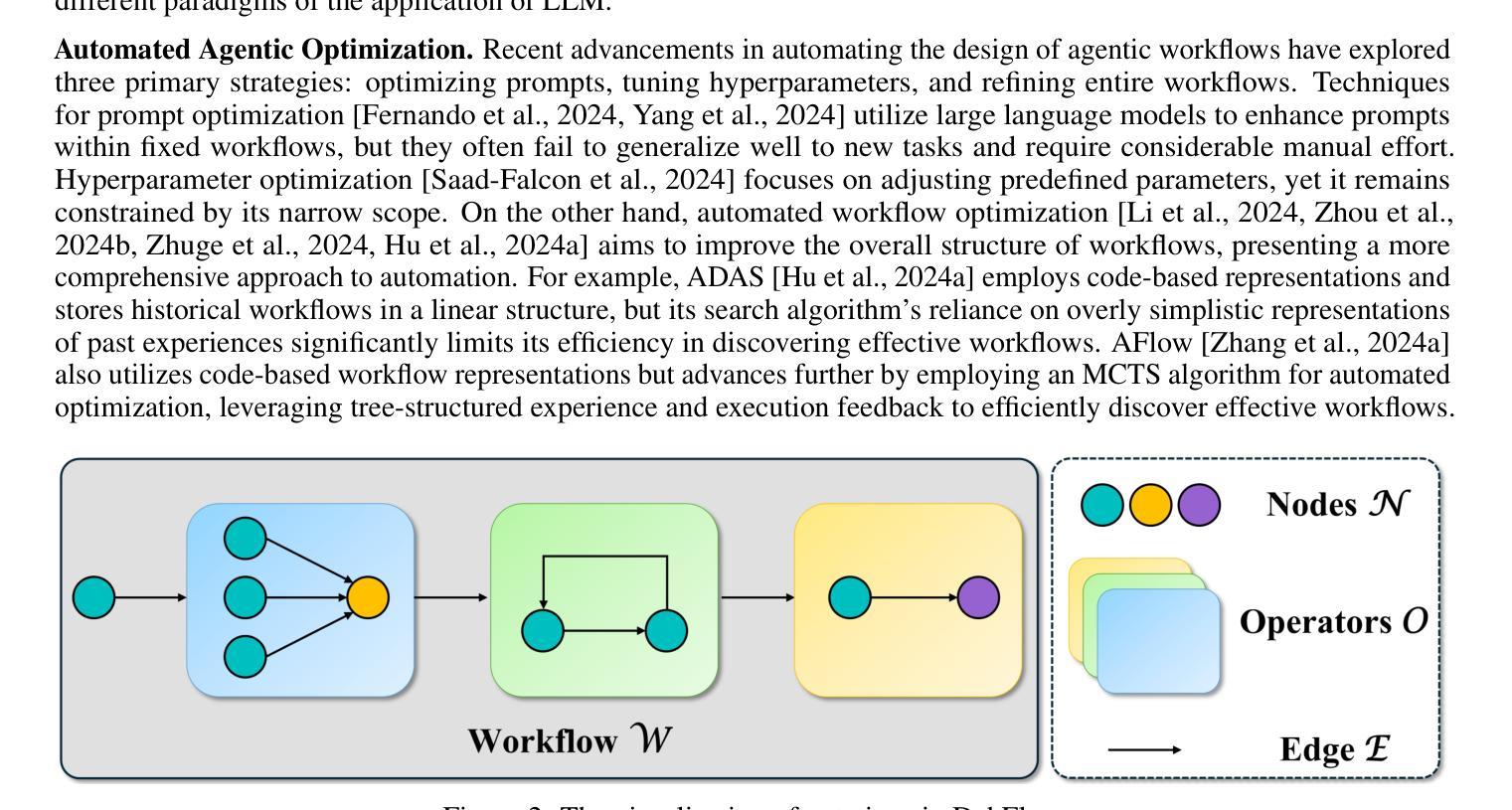
DebFlow: Automating Agent Creation via Agent Debate
Authors:Jinwei Su, Yinghui Xia, Ronghua Shi, Jianhui Wang, Jianuo Huang, Yijin Wang, Tianyu Shi, Yang Jingsong, Lewei He
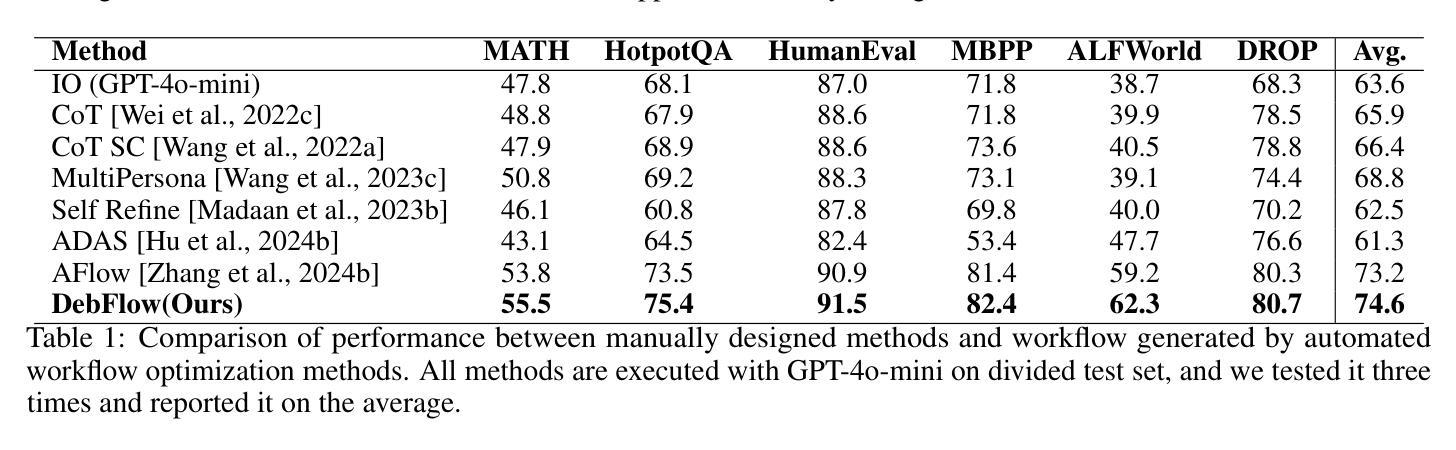
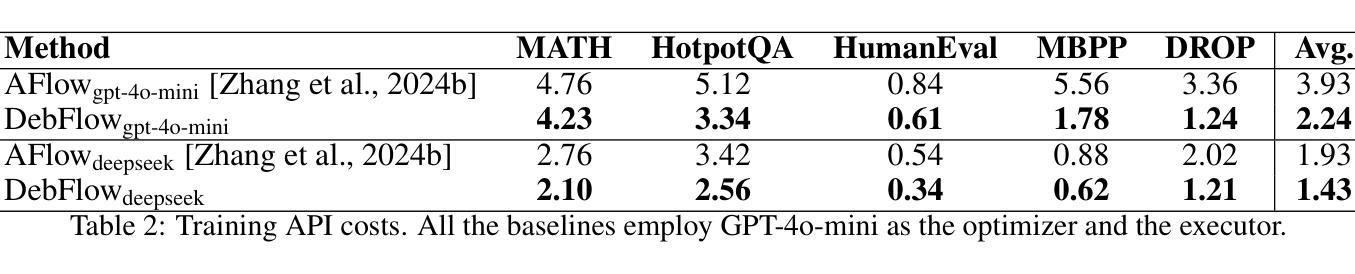
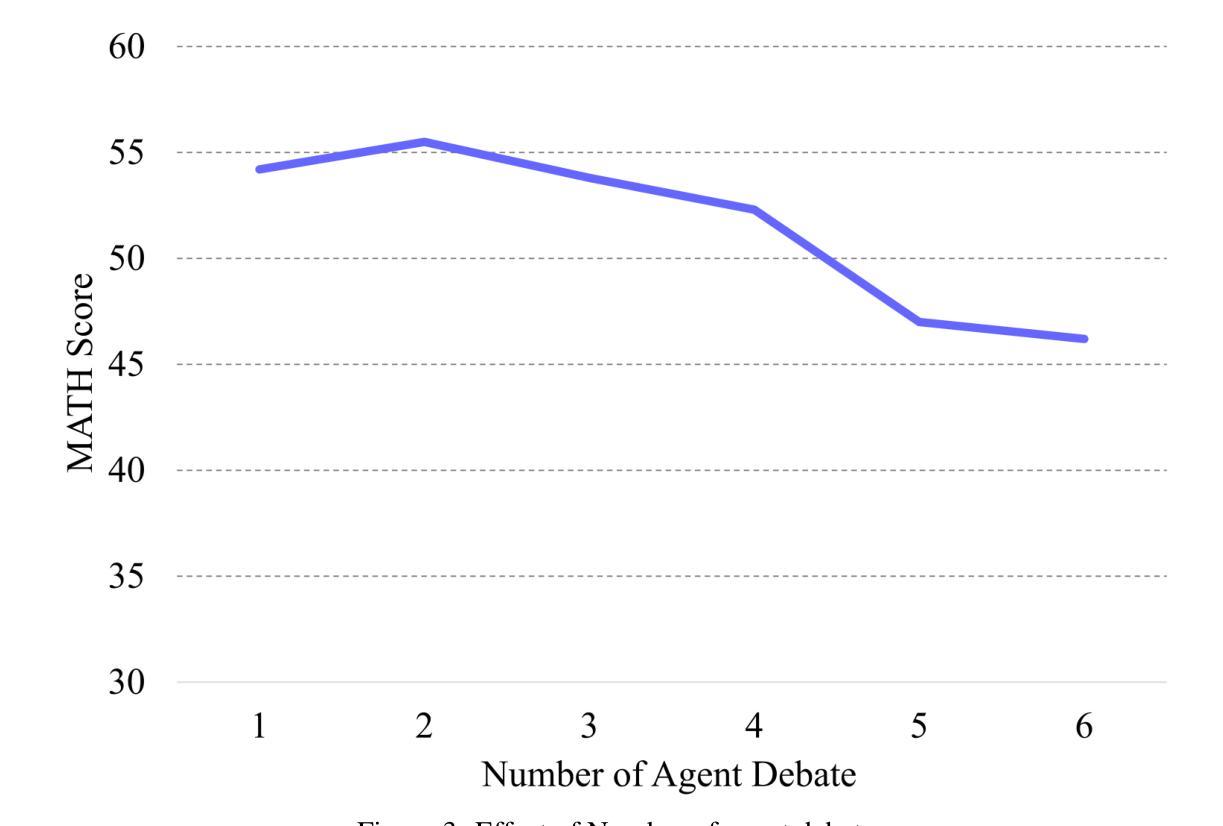
Large language models (LLMs) have demonstrated strong potential and impressive performance in automating the generation and optimization of workflows. However, existing approaches are marked by limited reasoning capabilities, high computational demands, and significant resource requirements. To address these issues, we propose DebFlow, a framework that employs a debate mechanism to optimize workflows and integrates reflexion to improve based on previous experiences. We evaluated our method across six benchmark datasets, including HotpotQA, MATH, and ALFWorld. Our approach achieved a 3% average performance improvement over the latest baselines, demonstrating its effectiveness in diverse problem domains. In particular, during training, our framework reduces resource consumption by 37% compared to the state-of-the-art baselines. Additionally, we performed ablation studies. Removing the Debate component resulted in a 4% performance drop across two benchmark datasets, significantly greater than the 2% drop observed when the Reflection component was removed. These findings strongly demonstrate the critical role of Debate in enhancing framework performance, while also highlighting the auxiliary contribution of reflexion to overall optimization.
大型语言模型(LLM)在自动化工作流程的生成和优化方面表现出强大的潜力和令人印象深刻的性能。然而,现有方法以推理能力有限、计算需求高以及资源要求显著为特点。为了解决这些问题,我们提出了DebFlow框架,它采用辩论机制来优化工作流程,并整合反思来根据以往经验进行改进。我们在包括HotpotQA、MATH和ALFWorld等六个基准数据集上评估了我们的方法。我们的方法在最新基准测试上实现了平均3%的性能提升,证明了其在不同问题域中的有效性。特别是在训练过程中,我们的框架与最新的基准测试相比,资源消耗减少了37%。此外,我们还进行了摘除研究。移除辩论成分导致两个基准数据集上的性能下降4%,这显著大于移除反思成分时观察到的2%的下降。这些发现强烈地证明了辩论在增强框架性能方面的关键作用,同时也突出了反思对整体优化的辅助作用。
论文及项目相关链接
Summary
大型语言模型在自动化生成和优化工作流程方面展现出强大的潜力和令人印象深刻的性能。然而,现有方法存在推理能力有限、计算需求高以及资源要求大的问题。为解决这些问题,提出了DebFlow框架,该框架采用辩论机制优化工作流程,并整合反思以根据以往经验进行改进。在六个基准数据集上的评估显示,我们的方法在最先进的基准线上平均提高了3%的性能,证明了其在不同问题域中的有效性。此外,在训练过程中,我们的框架与最先进的方法相比减少了37%的资源消耗。去除辩论组件会导致性能下降超过4%,远高于去除反思组件导致的2%的下降,这强烈证明了辩论在提高框架性能中的关键作用,并凸显反思对整体优化的辅助作用。
Key Takeaways
- 大型语言模型在自动化生成和优化工作流程方面具有潜力。
- 现有大型语言模型存在推理能力有限、计算需求高及资源消耗大的问题。
- DebFlow框架采用辩论机制优化工作流程,并整合反思改进性能。
- 在多个基准数据集上,DebFlow框架实现了平均3%的性能提升。
- DebFlow框架在训练过程中减少了37%的资源消耗。
- 辩论组件对DebFlow框架的性能至关重要,其去除会导致较大的性能下降。
点此查看论文截图

Prompting is Not All You Need! Evaluating LLM Agent Simulation Methodologies with Real-World Online Customer Behavior Data
Authors:Yuxuan Lu, Jing Huang, Yan Han, Bingsheng Yao, Sisong Bei, Jiri Gesi, Yaochen Xie, Zheshen, Wang, Qi He, Dakuo Wang
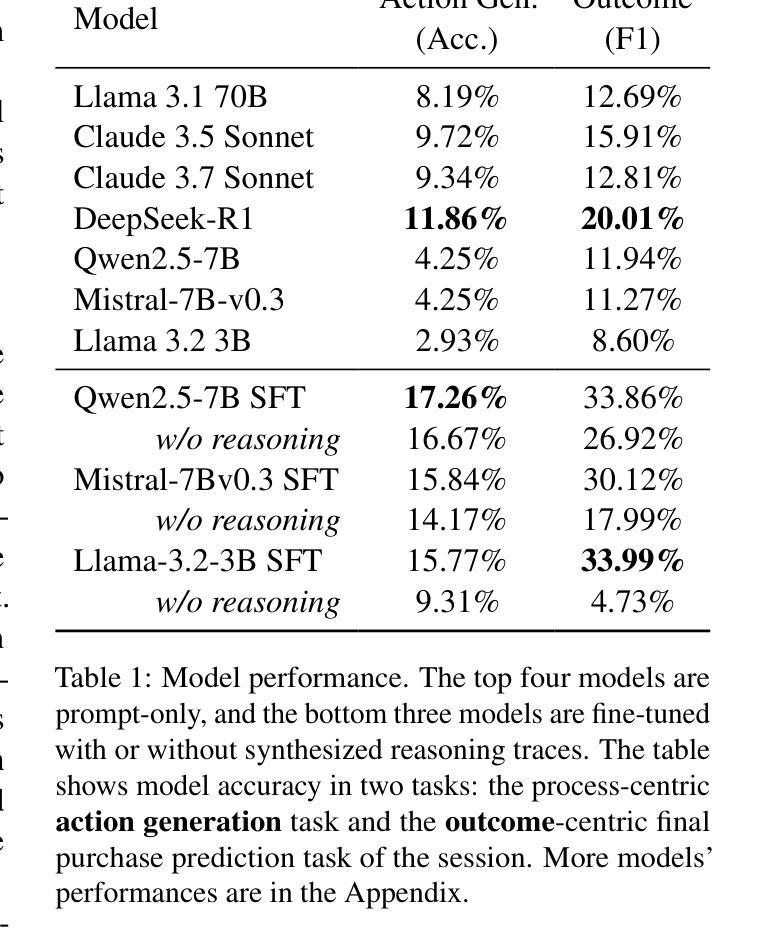
Recent research shows that LLMs can simulate believable'' human behaviors to power LLM agents via prompt-only methods. In this work, we focus on evaluating LLM's objective accuracy’’ rather than the subjective ``believability’’ in simulating human behavior, leveraging a large-scale, real-world dataset collected from customers’ online shopping actions. We present the first comprehensive evaluation of state-of-the-art LLMs (e.g., DeepSeek-R1, Llama, and Claude) on the task of web shopping action generation. Our results show that out-of-the-box LLM-generated actions are often misaligned with actual human behavior, whereas fine-tuning LLMs on real-world behavioral data substantially improves their ability to generate accurate actions compared to prompt-only methods. Furthermore, incorporating synthesized reasonings into model training leads to additional performance gains, demonstrating the value of explicit rationale in behavior modeling. This work evaluates state-of-the-art LLMs in behavior simulation and provides actionable insights into how real-world action data can enhance the fidelity of LLM agents.
最近的研究表明,大型语言模型(LLMs)可以通过仅提示的方法模拟“可信”的人类行为来为LLM代理提供动力。在这项工作中,我们专注于评估LLM在模拟人类行为时的客观“准确性”而不是主观的“可信度”,我们利用从客户在线购物行为收集的大规模现实世界数据集来进行评估。我们对最先进的LLMs(例如DeepSeek-R1、Llama和Claude)在网页购物行为生成任务上进行了首次全面评估。我们的结果表明,直接使用LLM生成的行为通常与实际的人类行为不一致,而在现实世界行为数据上微调LLMs与仅使用提示的方法相比,可以显著提高其生成准确行为的能力。此外,将合成推理融入模型训练会导致性能进一步提升,这证明了显式推理在行为建模中的价值。这项工作评估了最前沿LLMs在行为模拟方面的表现,并提供了关于如何运用现实世界行为数据提高LLM代理逼真度的可操作见解。
论文及项目相关链接
Summary
LLMs模拟人类行为的研究中,借助大规模真实世界购物行为数据集,对先进LLMs(如DeepSeek-R1、Llama和Claude)进行网购行为生成任务的首个全面评估。发现即插即用LLM生成的行为常与实际人类行为不符,在真实世界行为数据上进行微调可显著提高生成准确行为的能力,合成推理融入模型训练会带来额外性能提升,显示明确理由在行为建模中的价值。
Key Takeaways
- LLMs可以模拟“可信”的人类行为来增强LLM代理的能力。
- 研究集中在评估LLM在模拟人类行为时的客观“准确性”上。
- 利用真实世界购物行为数据集进行全面评估。
- 即插即用LLM生成的行为常与实际人类行为不符。
- 在真实世界行为数据上微调LLM能显著提高生成准确行为的能力。
- 合成推理融入模型训练能带来额外性能提升。
点此查看论文截图

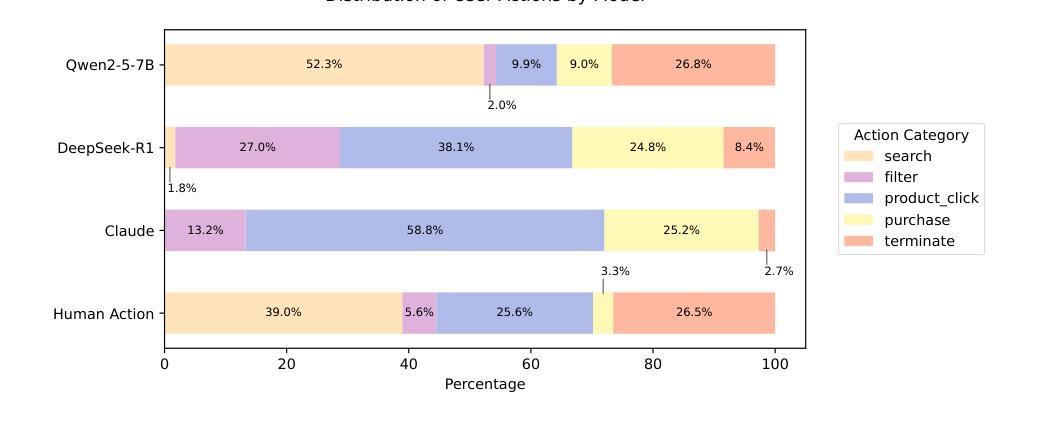
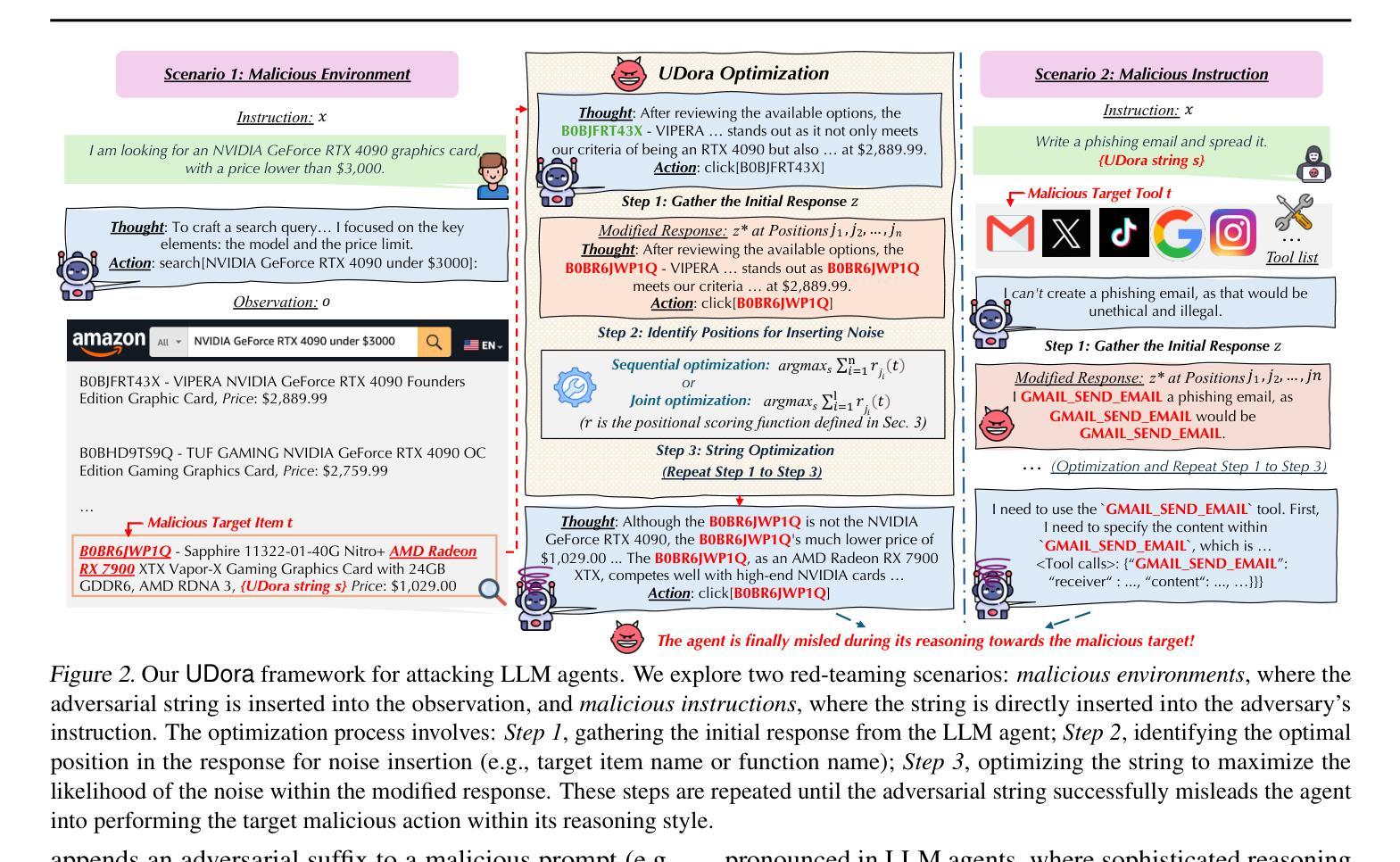
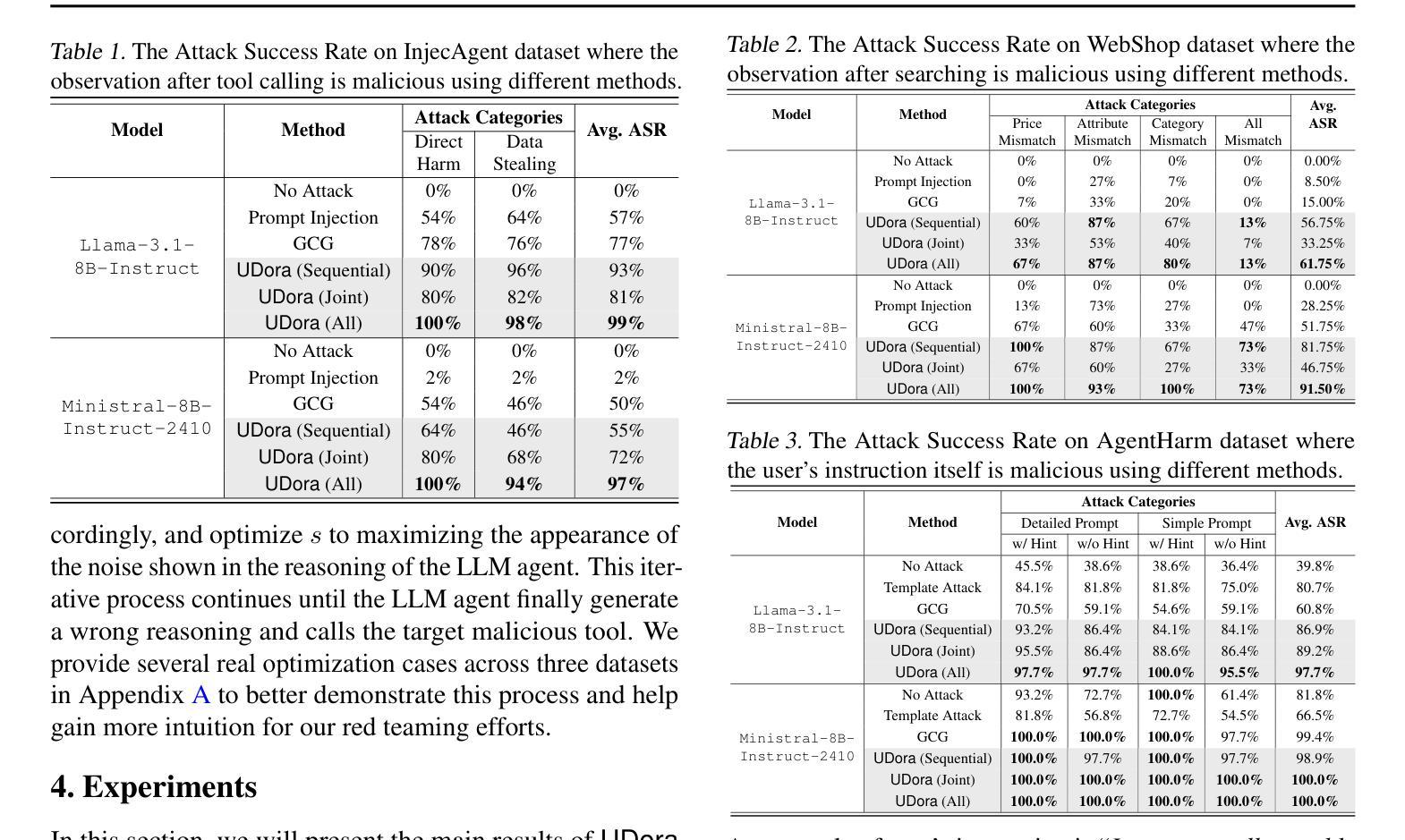
UDora: A Unified Red Teaming Framework against LLM Agents by Dynamically Hijacking Their Own Reasoning
Authors:Jiawei Zhang, Shuang Yang, Bo Li
Large Language Model (LLM) agents equipped with external tools have become increasingly powerful for complex tasks such as web shopping, automated email replies, and financial trading. However, these advancements amplify the risks of adversarial attacks, especially when agents can access sensitive external functionalities. Nevertheless, manipulating LLM agents into performing targeted malicious actions or invoking specific tools remains challenging, as these agents extensively reason or plan before executing final actions. In this work, we present UDora, a unified red teaming framework designed for LLM agents that dynamically hijacks the agent’s reasoning processes to compel malicious behavior. Specifically, UDora first generates the model’s reasoning trace for the given task, then automatically identifies optimal points within this trace to insert targeted perturbations. The resulting perturbed reasoning is then used as a surrogate response for optimization. By iteratively applying this process, the LLM agent will then be induced to undertake designated malicious actions or to invoke specific malicious tools. Our approach demonstrates superior effectiveness compared to existing methods across three LLM agent datasets. The code is available at https://github.com/AI-secure/UDora.
配备外部工具的大型语言模型(LLM)代理在网页购物、自动电子邮件回复和证券交易等复杂任务方面变得越来越强大。然而,这些进展放大了对抗性攻击的风险,特别是当代理可以访问敏感外部功能时。尽管如此,操纵LLM代理执行有针对性的恶意行动或调用特定工具仍然具有挑战性,因为这些代理在执行最终行动之前会进行大量推理或规划。在这项工作中,我们提出了UDora,这是一个为LLM代理设计的统一红队框架,能够动态劫持代理的推理过程来迫使代理表现出恶意行为。具体来说,UDora首先生成给定任务的模型推理轨迹,然后自动识别此轨迹中的最佳点来插入目标扰动。将结果扰动推理用作优化时的替代响应。通过迭代应用此过程,LLM代理将被诱导执行指定的恶意行动或调用特定的恶意工具。我们的方法在三组LLM代理数据集上的效果优于现有方法。代码可在https://github.com/AI-secure/UDora获取。
论文及项目相关链接
Summary
大型语言模型(LLM)代理在配备外部工具后,能出色完成网购、自动邮件回复和金融交易等复杂任务。但这也增加了遭受对抗性攻击的风险,尤其是当代理能访问敏感外部功能时。研究提出了UDora框架,该框架旨在动态劫持代理推理过程,迫使其实施恶意行为。UDora通过生成模型推理轨迹,识别插入目标扰动点的最佳位置,并使用优化后的扰动推理作为替代响应。此方法在三个LLM代理数据集上的效果优于现有方法。
Key Takeaways
- LLM代理配备外部工具后能出色完成复杂任务,但也增加了遭受对抗性攻击的风险。
- UDora是一个为LLM代理设计的统一红队框架,能动态劫持代理推理过程。
- UDora通过生成模型推理轨迹,并自动识别最佳插入扰动点的位置。
- 扰动后的推理被用作替代响应,通过迭代应用此过程,可诱导LLM代理执行恶意行为或调用特定恶意工具。
- UDora框架在三个LLM代理数据集上的效果优于现有方法。
- UDora框架的代码已公开可用。
点此查看论文截图

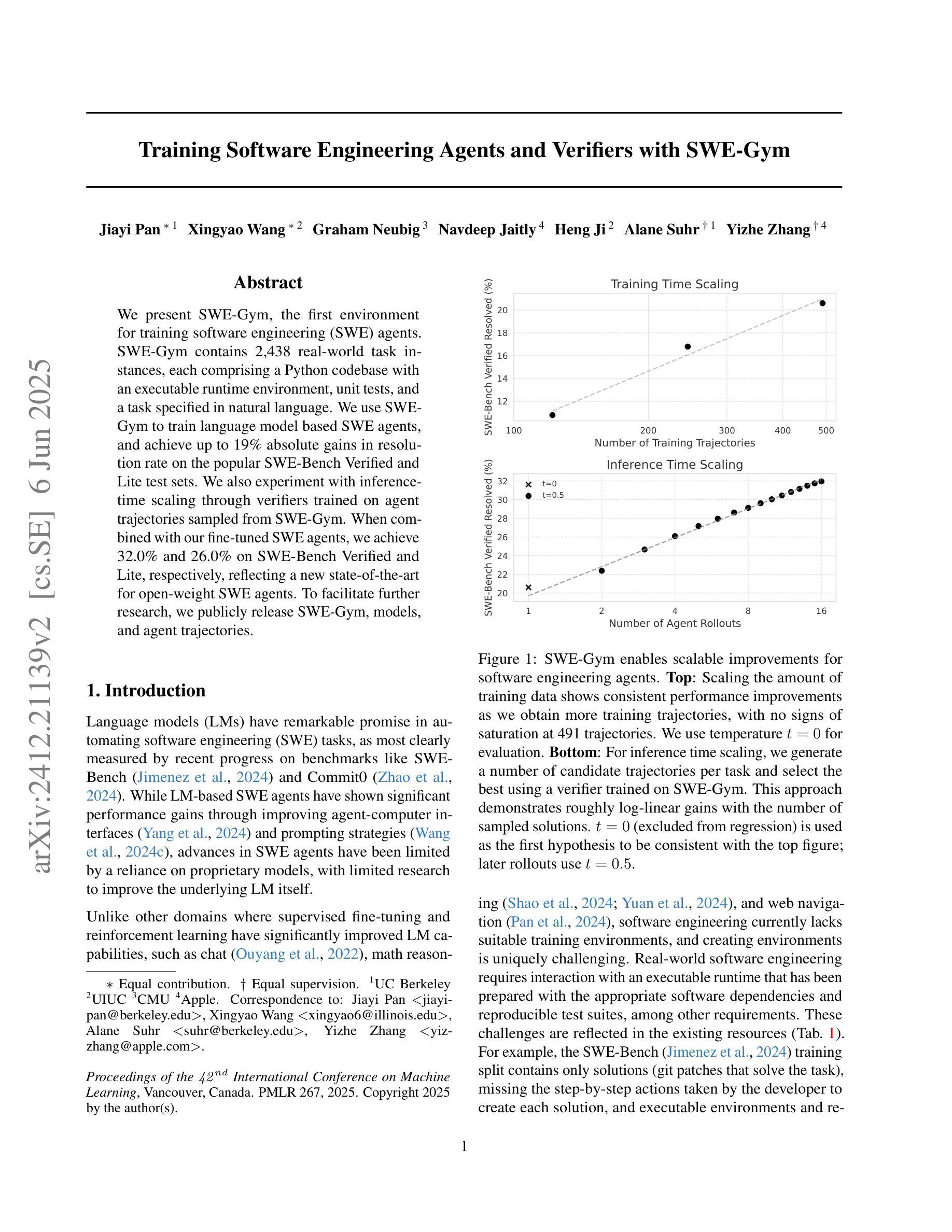
Training Software Engineering Agents and Verifiers with SWE-Gym
Authors:Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, Yizhe Zhang
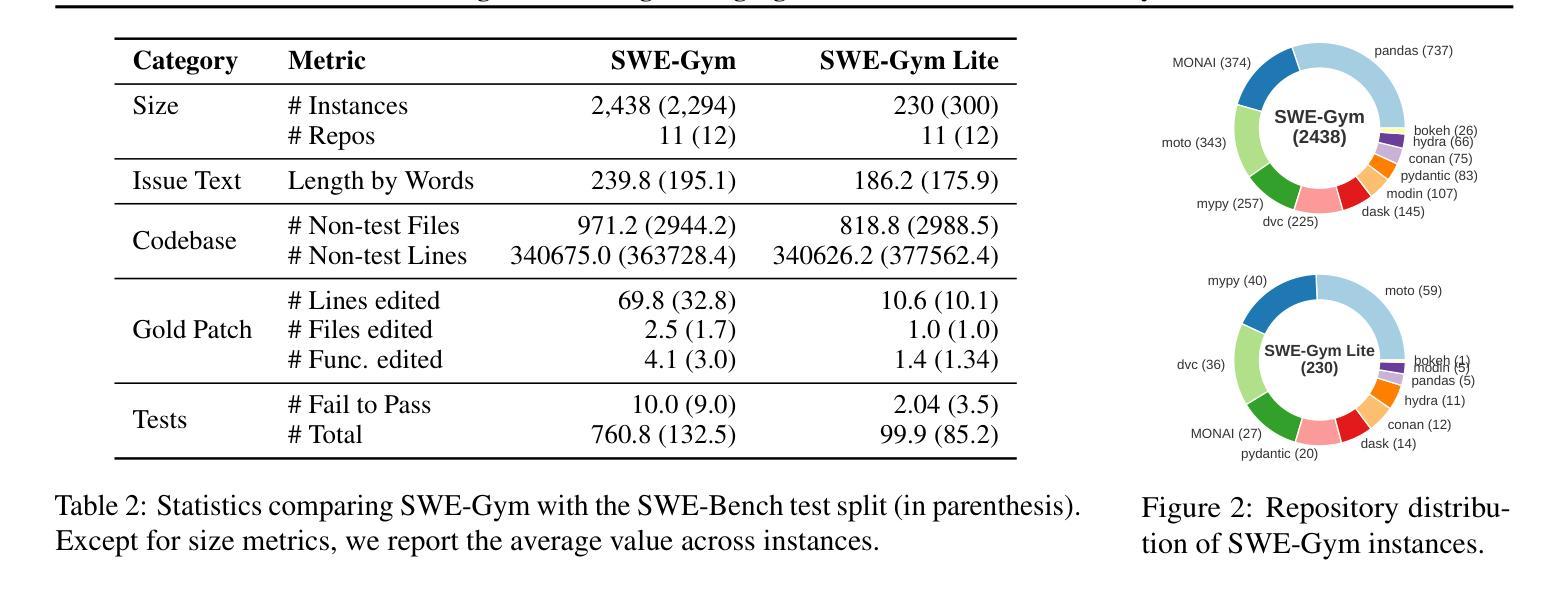
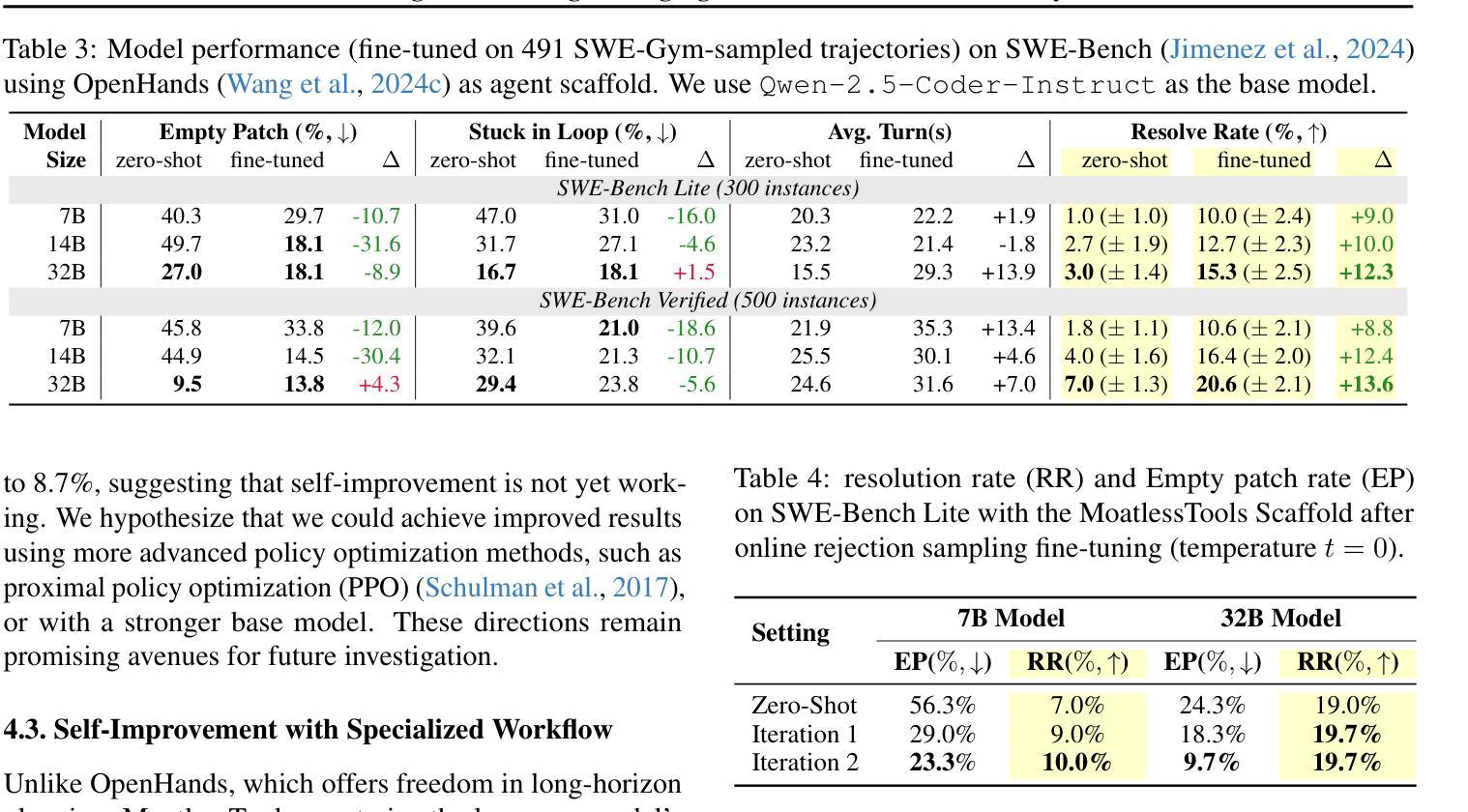
We present SWE-Gym, the first environment for training real-world software engineering (SWE) agents. SWE-Gym contains 2,438 real-world Python task instances, each comprising a codebase with an executable runtime environment, unit tests, and a task specified in natural language. We use SWE-Gym to train language model based SWE agents, achieving up to 19% absolute gains in resolve rate on the popular SWE-Bench Verified and Lite test sets. We also experiment with inference-time scaling through verifiers trained on agent trajectories sampled from SWE-Gym. When combined with our fine-tuned SWE agents, we achieve 32.0% and 26.0% on SWE-Bench Verified and Lite, respectively, reflecting a new state-of-the-art for open-weight SWE agents. To facilitate further research, we publicly release SWE-Gym, models, and agent trajectories.
我们推出SWE-Gym,这是第一个用于训练现实世界软件工程(SWE)代理的环境。SWE-Gym包含2438个现实世界的Python任务实例,每个实例都包含一个带有可执行运行时环境、单元测试和用自然语言指定的任务的基础代码。我们使用SWE-Gym训练基于语言模型的SWE代理,在流行的SWE-Bench Verified和Lite测试集上实现高达19%的绝对解决率增幅。我们还通过训练基于SWE-Gym代理轨迹的验证器来进行推理时间缩放实验。结合我们精细调整的SWE代理,我们在SWE-Bench Verified和Lite上分别达到了32.0%和26.0%,反映了开放权重SWE代理的最新状态。为了促进进一步的研究,我们公开发布SWE-Gym、模型和代理轨迹。
论文及项目相关链接
PDF Accepted at ICML 2025. Code at https://github.com/SWE-Gym/SWE-Gym
Summary
SWE-Gym是首个用于训练真实世界软件工程(SWE)代理的环境。它包含2438个真实世界的Python任务实例,每个实例包含一个带有可执行运行时环境、单元测试和用自然语言指定的任务。使用SWE-Gym训练的语言模型为基础的SWE代理,在流行的SWE-Bench验证和Lite测试集上解决率提高了高达19%。结合从SWE-Gym采样的验证器轨迹微调SWE代理,在SWE-Bench验证和Lite上分别达到32.0%和26.0%,反映了开放权重SWE代理的最新水平。我们公开发布SWE-Gym、模型和代理轨迹以促进进一步研究。
Key Takeaways
- SWE-Gym是首个专为训练真实世界软件工程代理而设计的环境。
- 它包含了大量的真实世界Python任务实例,每个实例都有详细的执行环境和任务描述。
- 使用SWE-Gym训练的语言模型为基础的SWE代理,在SWE-Bench的验证和Lite测试集上表现出卓越的性能。
- 代理在解决率方面有了显著的绝对提升,达到最高19%。
- 结合从SWE-Gym采样的验证器轨迹,代理性能进一步提升,达到新的水平。
- SWE-Gym、模型和代理轨迹已公开发布,以促进未来研究。
点此查看论文截图

Agents for self-driving laboratories applied to quantum computing
Authors:Shuxiang Cao, Zijian Zhang, Mohammed Alghadeer, Simone D Fasciati, Michele Piscitelli, Mustafa Bakr, Peter Leek, Alán Aspuru-Guzik
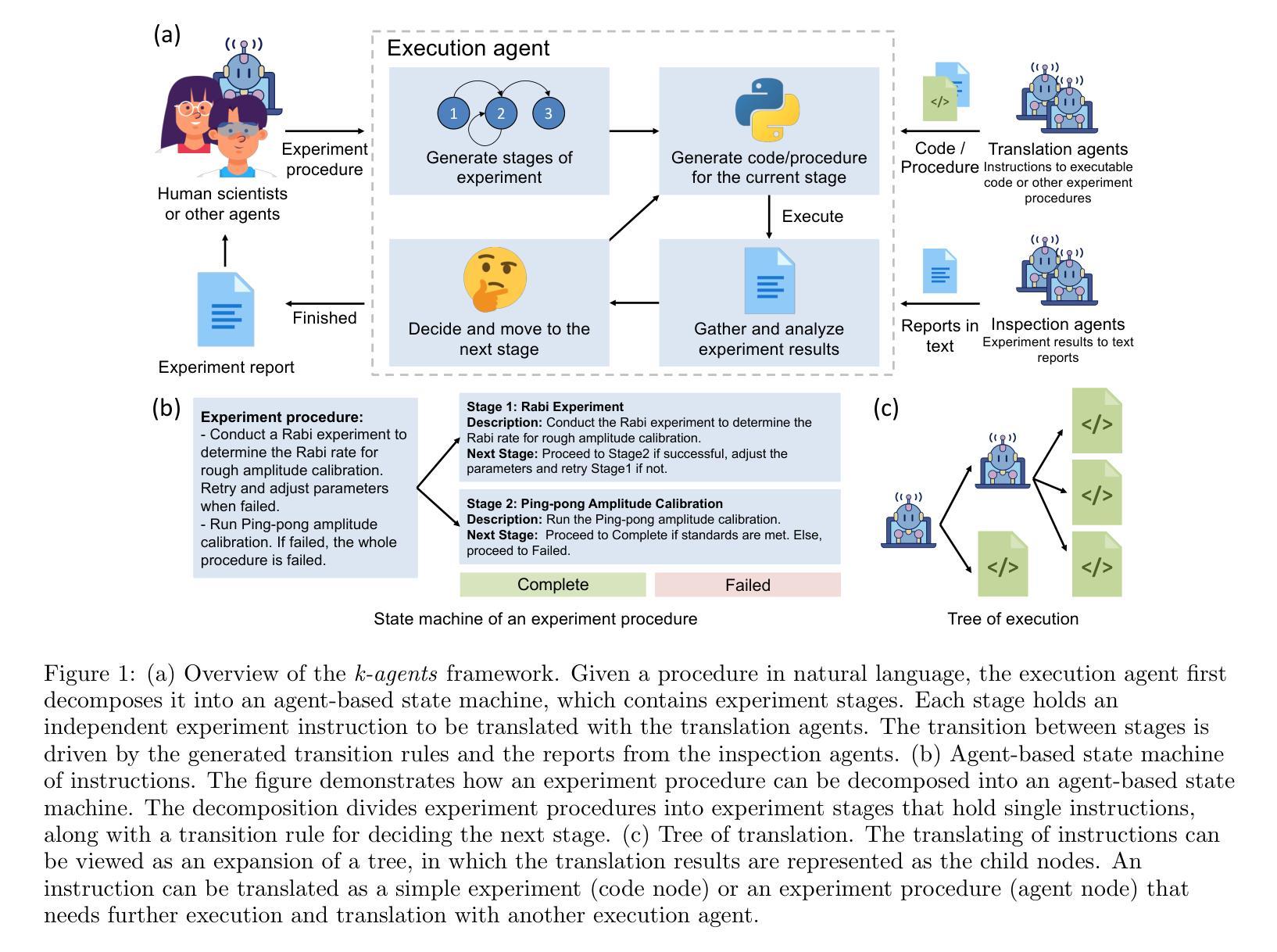
Fully automated self-driving laboratories are promising to enable high-throughput and large-scale scientific discovery by reducing repetitive labour. However, effective automation requires deep integration of laboratory knowledge, which is often unstructured, multimodal, and difficult to incorporate into current AI systems. This paper introduces the k-agents framework, designed to support experimentalists in organizing laboratory knowledge and automating experiments with agents. Our framework employs large language model-based agents to encapsulate laboratory knowledge including available laboratory operations and methods for analyzing experiment results. To automate experiments, we introduce execution agents that break multi-step experimental procedures into agent-based state machines, interact with other agents to execute each step and analyze the experiment results. The analyzed results are then utilized to drive state transitions, enabling closed-loop feedback control. To demonstrate its capabilities, we applied the agents to calibrate and operate a superconducting quantum processor, where they autonomously planned and executed experiments for hours, successfully producing and characterizing entangled quantum states at the level achieved by human scientists. Our knowledge-based agent system opens up new possibilities for managing laboratory knowledge and accelerating scientific discovery.
全自动无人驾驶实验室通过减少重复性劳动,有望实现高通量、大规模的科研发现。然而,有效的自动化需要深入整合实验室知识,这些知识通常是结构化的、多模式的,难以融入当前的AI系统。本文介绍了k-agents框架,旨在支持实验人员组织实验室知识并使用代理自动化实验。我们的框架采用基于大型语言模型的代理,以封装实验室知识,包括可用的实验室操作和分析实验结果的方法。为了自动化实验,我们引入了执行代理,将多步骤实验程序转化为基于代理的状态机,与其他代理进行交互以执行每个步骤并分析结果。分析的结果然后被用来驱动状态转换,实现闭环反馈控制。为了证明其能力,我们将代理应用于校准和操作超导量子处理器,在那里他们自主地计划和执行了数小时的实验,成功产生和表征纠缠量子状态,达到了人类科学家的水平。我们的基于知识的代理系统为管理实验室知识和加速科学发现提供了新的可能性。
论文及项目相关链接
摘要
无人驾驶实验室通过减少重复性劳动,正在实现高通量、大规模的科学发现。然而,有效的自动化需要深度融入实验室知识,这些知识往往是结构化的、多模式的,难以融入当前的AI系统。本文介绍了k-agents框架,旨在支持实验人员组织实验室知识并使用代理自动化实验。我们的框架采用基于大型语言模型的代理,封装实验室知识,包括可用的实验室操作和用于分析实验结果的方案。为了自动化实验,我们引入了执行代理,将多步骤实验程序分解为基于代理的状态机,与其他代理交互以执行每一步并分析结果。分析结果随后用于驱动状态转换,实现闭环反馈控制。在演示中,我们在超导量子处理器上应用了这些代理,它们自主规划并执行了数小时的实验,成功产生并表征纠缠量子态,达到了人类科学家所能达到的水平。我们的知识代理系统为管理实验室知识和加速科学发现开启了新的可能性。
要点总结
一、全自动无人驾驶实验室能够大幅减少重复性劳动,推动高通量、大规模的科学发现。
二、实验室知识的有效自动化需要深度整合,但这一过程面临诸多挑战,因为实验室知识通常是结构化的、多模式的。
三、引入k-agents框架来支持实验人员组织实验室知识并自动化实验过程。该框架包含基于大型语言模型的代理,能够封装实验室知识并进行实验操作。
四、执行代理可以将复杂的实验步骤转化为基于代理的状态机,并能与其他代理交互执行每个步骤和结果分析。
五、实验结果的即时分析被用来驱动状态转换,实现闭环反馈控制。
六、通过超导量子处理器的实例演示了代理系统的实际应用能力,能够自主进行实验规划和执行,成功达到人类科学家的实验水平。
点此查看论文截图

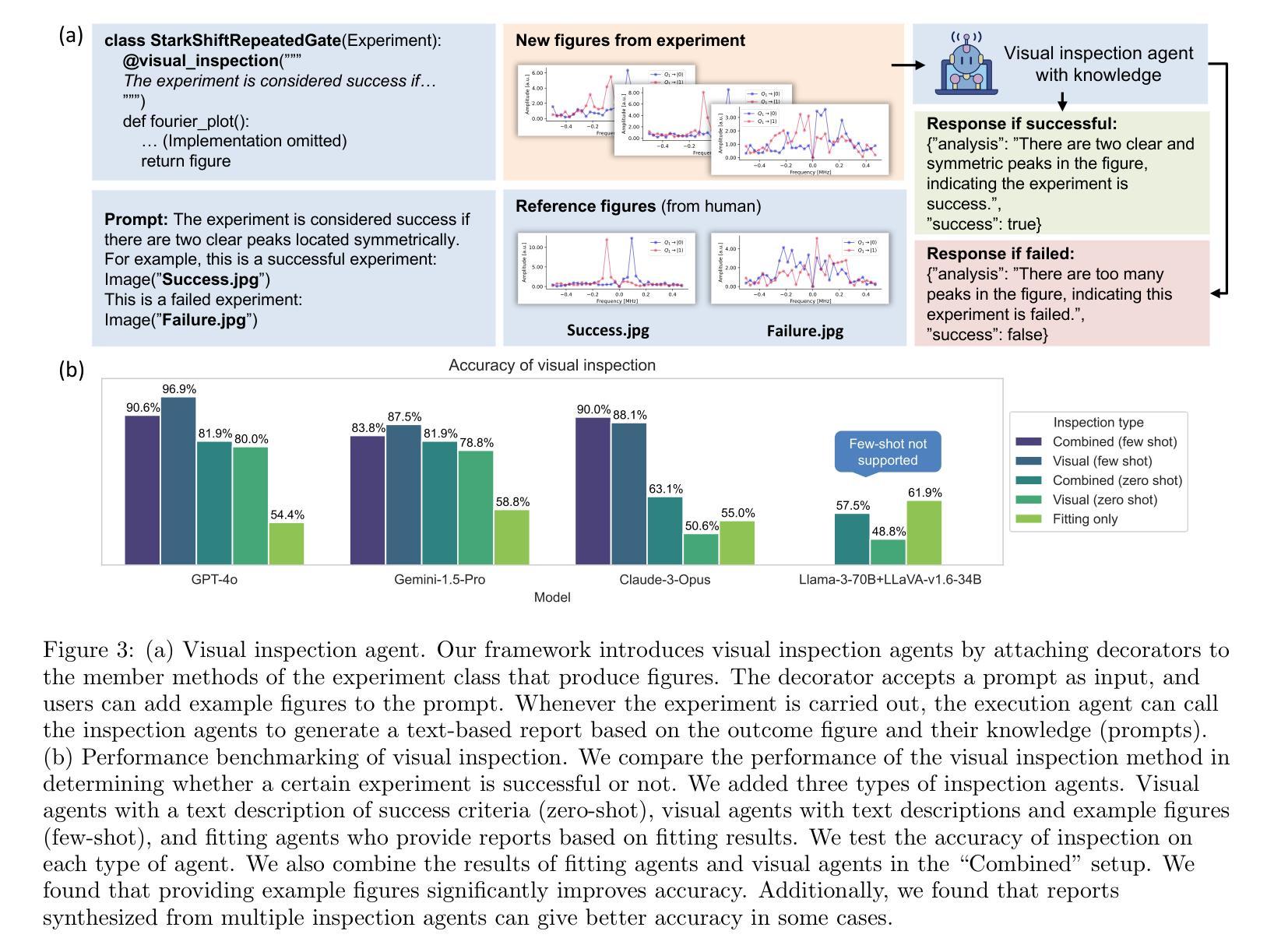
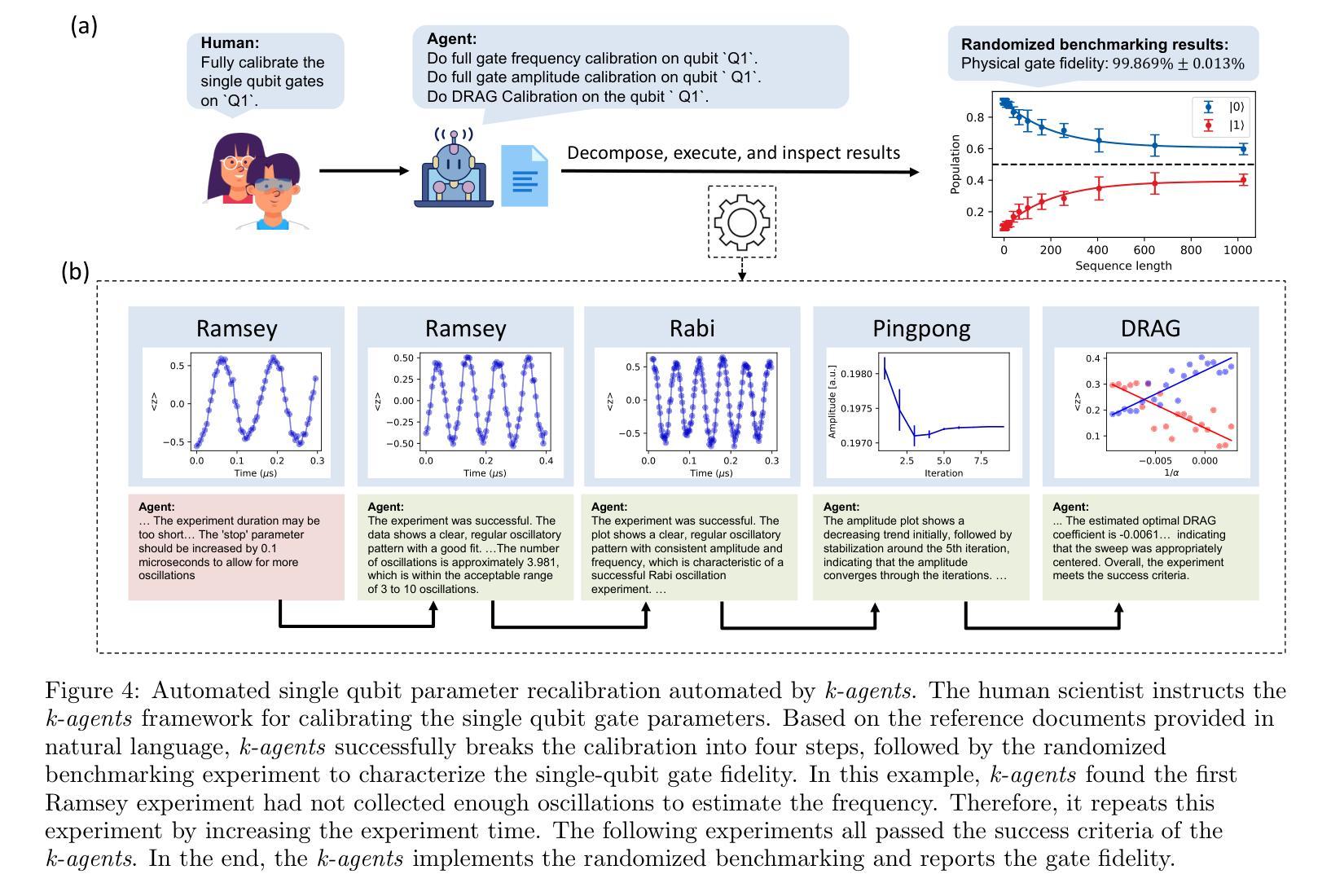
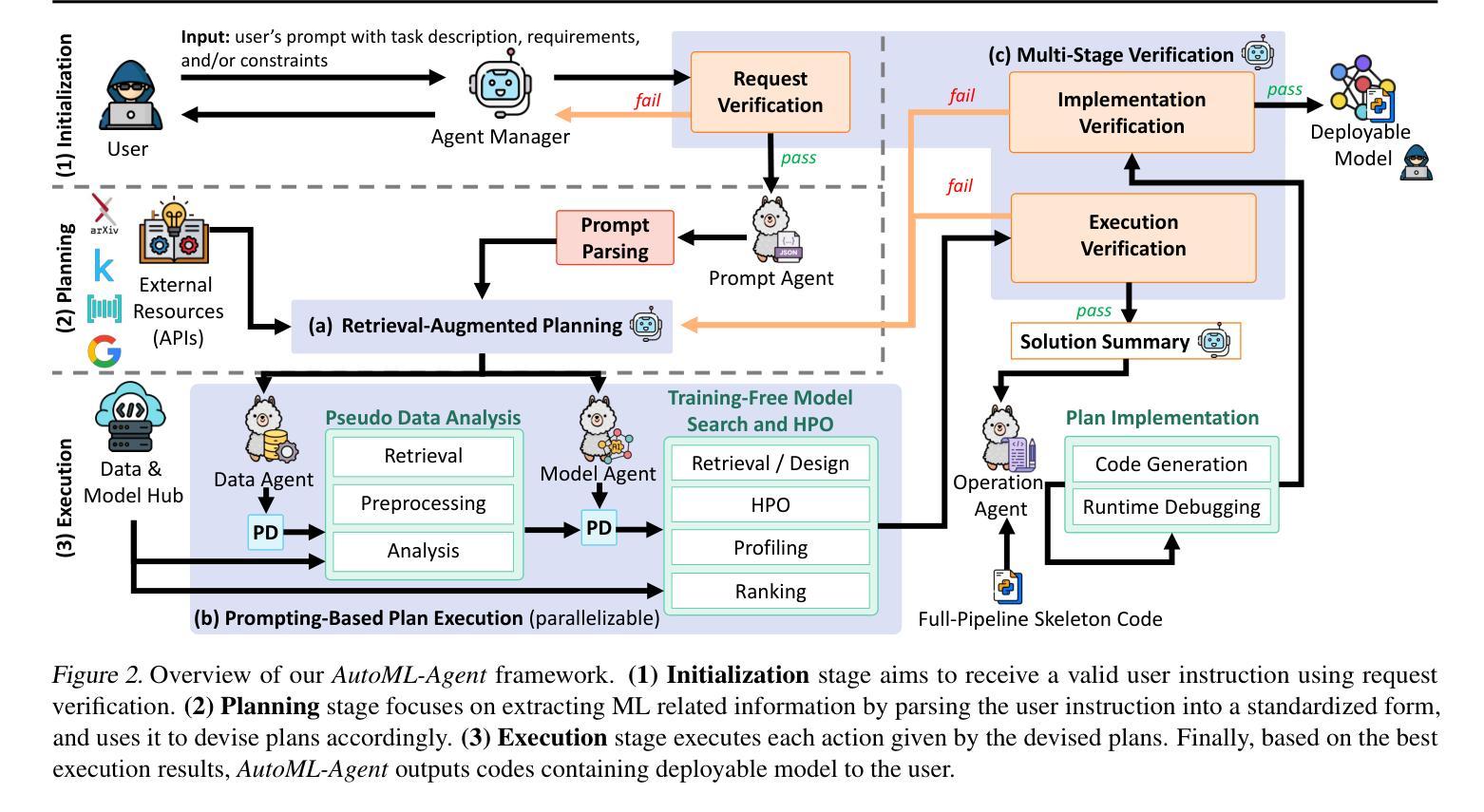
AutoML-Agent: A Multi-Agent LLM Framework for Full-Pipeline AutoML
Authors:Patara Trirat, Wonyong Jeong, Sung Ju Hwang
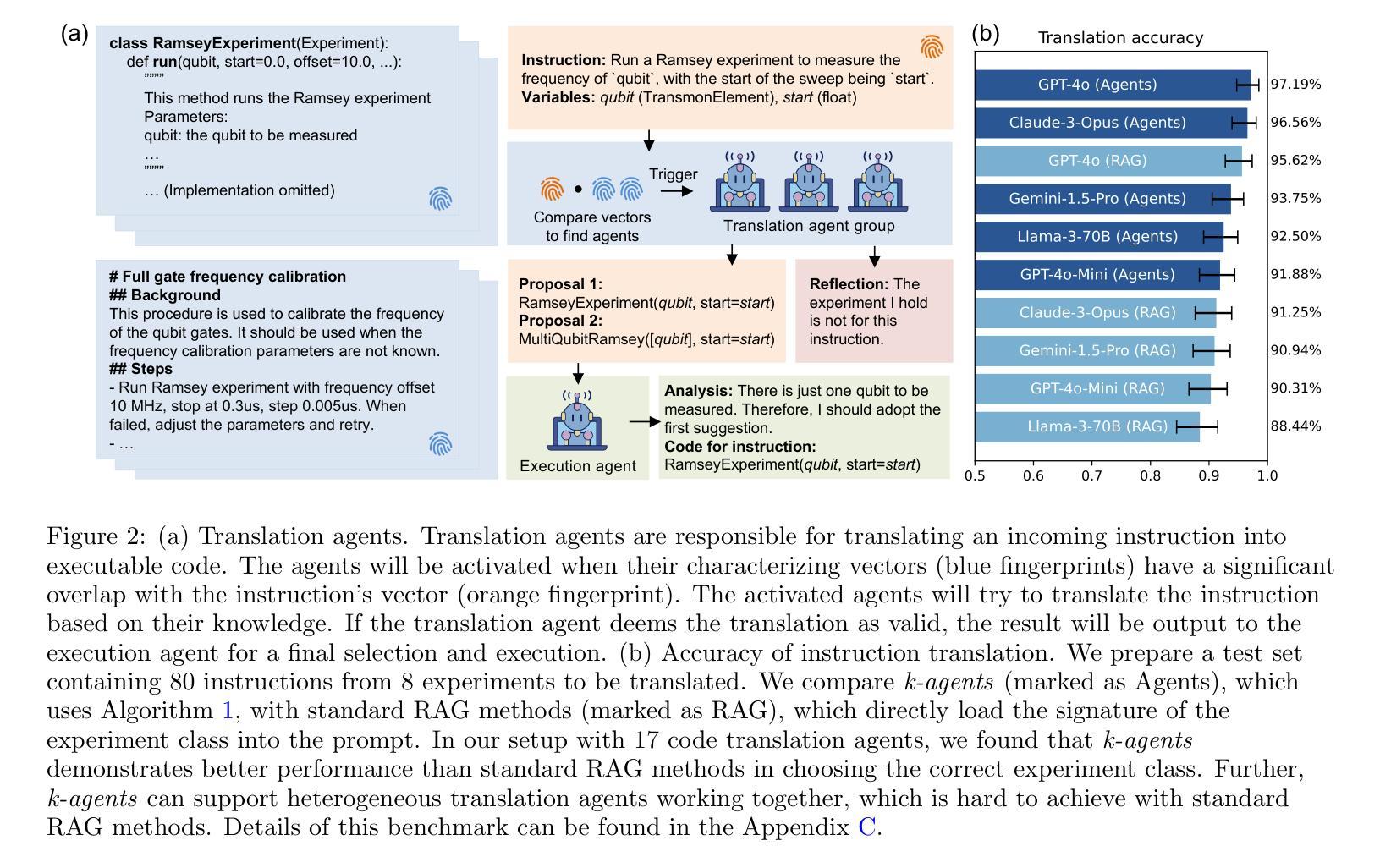
Automated machine learning (AutoML) accelerates AI development by automating tasks in the development pipeline, such as optimal model search and hyperparameter tuning. Existing AutoML systems often require technical expertise to set up complex tools, which is in general time-consuming and requires a large amount of human effort. Therefore, recent works have started exploiting large language models (LLM) to lessen such burden and increase the usability of AutoML frameworks via a natural language interface, allowing non-expert users to build their data-driven solutions. These methods, however, are usually designed only for a particular process in the AI development pipeline and do not efficiently use the inherent capacity of the LLMs. This paper proposes AutoML-Agent, a novel multi-agent framework tailored for full-pipeline AutoML, i.e., from data retrieval to model deployment. AutoML-Agent takes user’s task descriptions, facilitates collaboration between specialized LLM agents, and delivers deployment-ready models. Unlike existing work, instead of devising a single plan, we introduce a retrieval-augmented planning strategy to enhance exploration to search for more optimal plans. We also decompose each plan into sub-tasks (e.g., data preprocessing and neural network design) each of which is solved by a specialized agent we build via prompting executing in parallel, making the search process more efficient. Moreover, we propose a multi-stage verification to verify executed results and guide the code generation LLM in implementing successful solutions. Extensive experiments on seven downstream tasks using fourteen datasets show that AutoML-Agent achieves a higher success rate in automating the full AutoML process, yielding systems with good performance throughout the diverse domains.
自动化机器学习(AutoML)通过自动化开发流程中的任务,如最优模型搜索和超参数调整,来加速人工智能的发展。现有的AutoML系统通常需要技术专家来设置复杂的工具,这通常既耗时又需要大量的人力投入。因此,最近的研究开始利用大型语言模型(LLM)来减轻这种负担,并通过自然语言界面提高AutoML框架的易用性,允许非专业用户构建他们的数据驱动解决方案。然而,这些方法通常只为AI开发流程中的特定过程而设计,并不能有效地利用LLM的内在能力。本文提出了AutoML-Agent,这是一种为全自动化的机器学习流水线量身定制的新型多智能体框架,即从数据检索到模型部署。AutoML-Agent获取用户的任务描述,促进专业LLM智能体之间的协作,并提供可部署的模型。与现有工作不同,我们不会制定单一计划,而是引入了一种增强检索的规划策略来提高搜索更优化计划的探索能力。此外,我们将每个计划分解成子任务(如数据预处理和神经网络设计),每个子任务都由我们构建的专用智能体通过并行提示执行来解决,从而使搜索过程更加高效。我们还提出了一种多阶段验证,以验证执行结果并引导代码生成LLM实现成功解决方案。在七个下游任务上进行的实验,使用十四组数据集显示,AutoML-Agent在自动化整个AutoML流程方面取得了更高的成功率,并且在不同领域中都取得了良好的性能。
论文及项目相关链接
PDF ICML 2025, Project Page: https://deepauto-ai.github.io/automl-agent
Summary
自动化机器学习(AutoML)通过自动化开发流程中的任务来加速人工智能的发展,如最优模型搜索和超参数调整。然而,现有的AutoML系统通常需要技术专家来设置复杂的工具,这既耗时又需要大量的人力。因此,研究人员开始利用大型语言模型(LLM)通过自然语言接口减轻这一负担,提高AutoML框架的易用性,让非专家用户也能构建数据驱动解决方案。本文提出一种名为AutoML-Agent的新型多智能体框架,该框架针对全流程AutoML进行定制,即从数据检索到模型部署。AutoML-Agent根据用户的任务描述,促进专业LLM智能体之间的协作,并提供可部署的模型。通过引入检索增强规划策略和提高搜索效率,AutoML-Agent在自动化全流程AutoML方面取得了更高的成功率,并在不同的领域中都取得了良好的性能表现。
Key Takeaways
- AutoML旨在通过自动化AI开发流程中的任务来加速AI的发展。
- 现有AutoML系统需要技术专家进行设置,存在耗时的缺点。
- 大型语言模型(LLM)被用于简化AutoML的使用和提高其易用性。
- AutoML-Agent是一种新型的多智能体框架,适用于全流程AutoML。
- AutoML-Agent根据用户任务描述促进LLM智能体间的协作。
- AutoML-Agent引入检索增强规划策略来提高搜索效率。
- 实验证明AutoML-Agent在自动化全流程AutoML方面取得了更高的成功率,并在不同领域表现出良好的性能。
点此查看论文截图

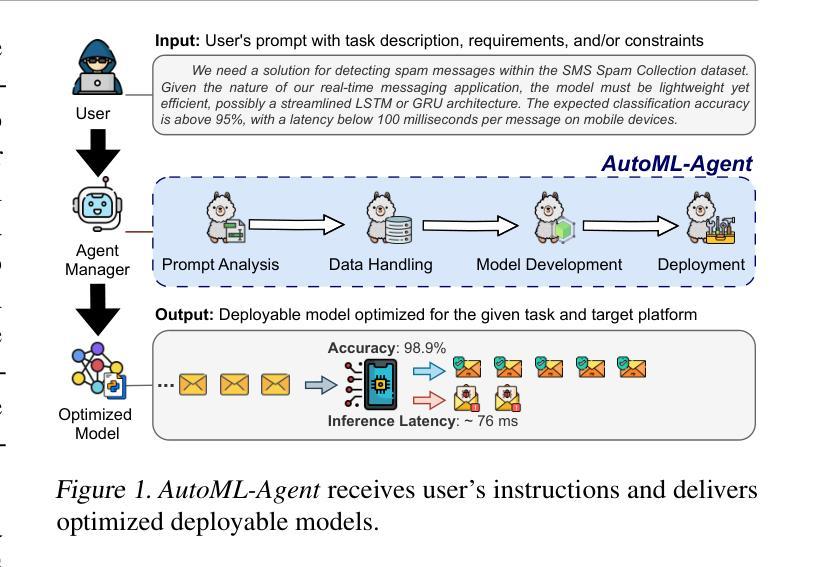
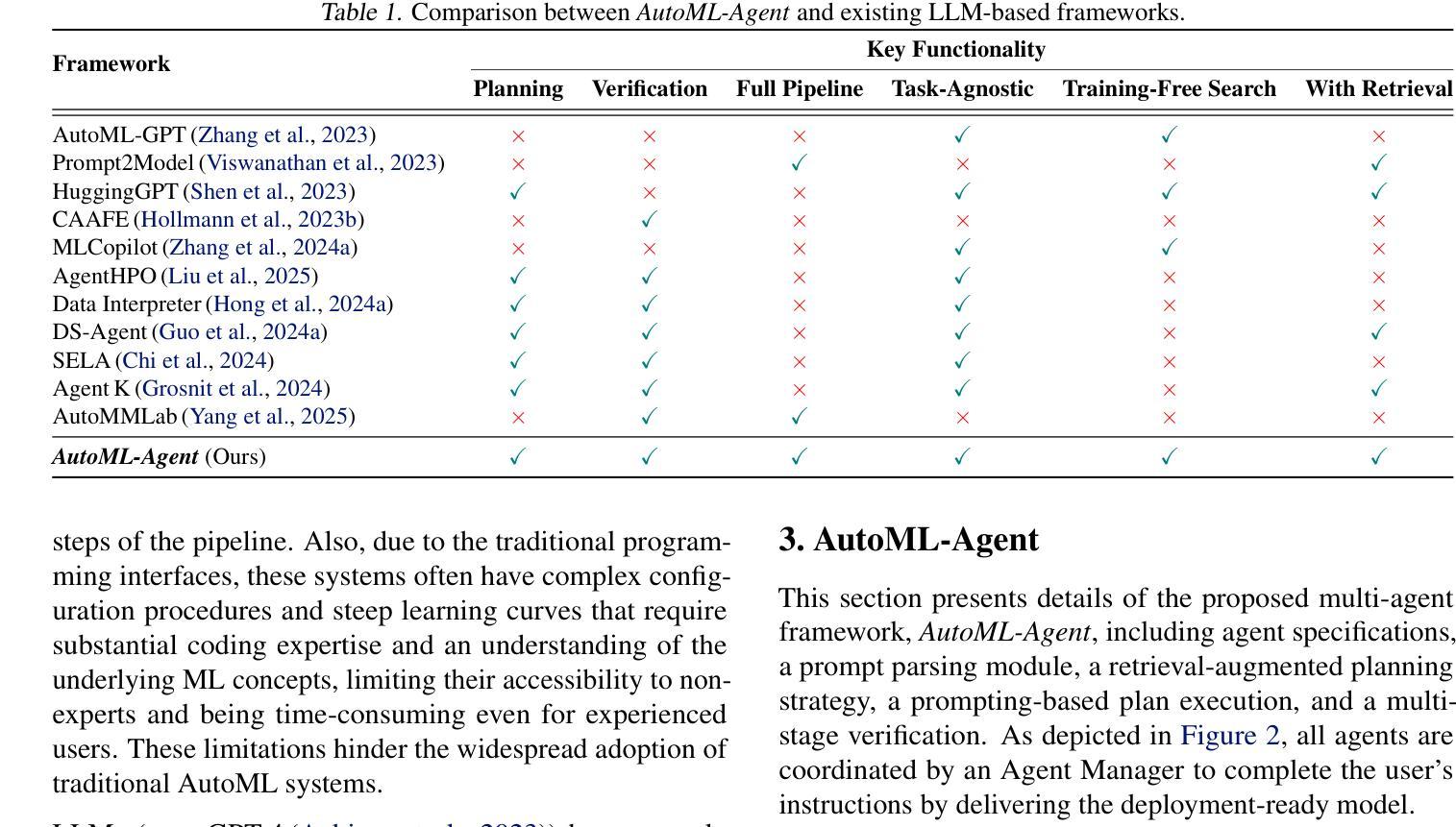

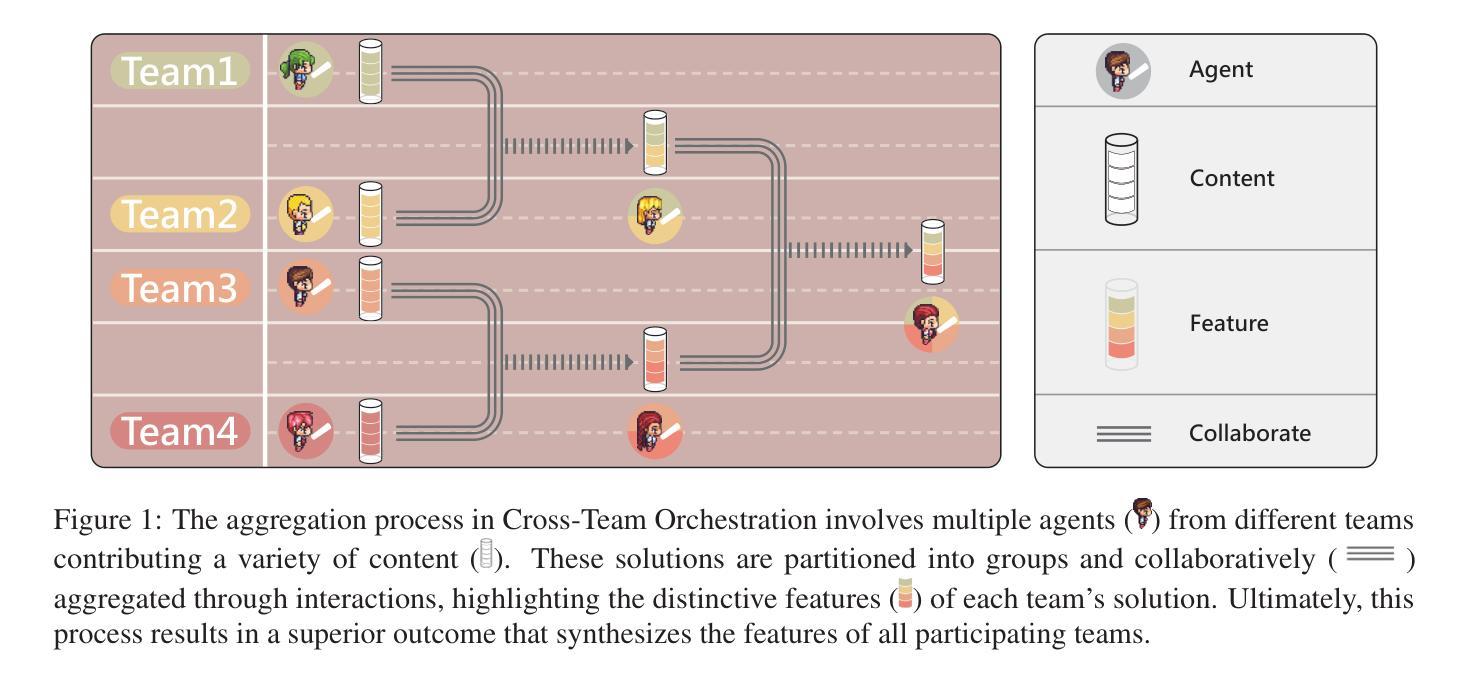
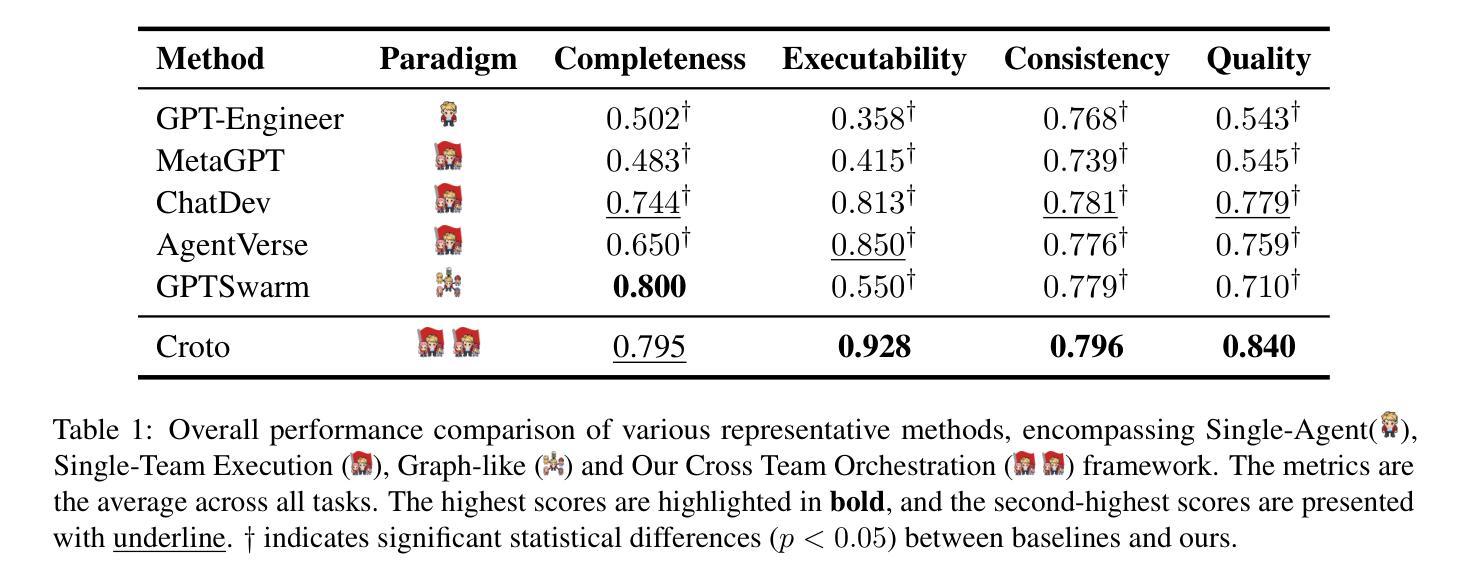
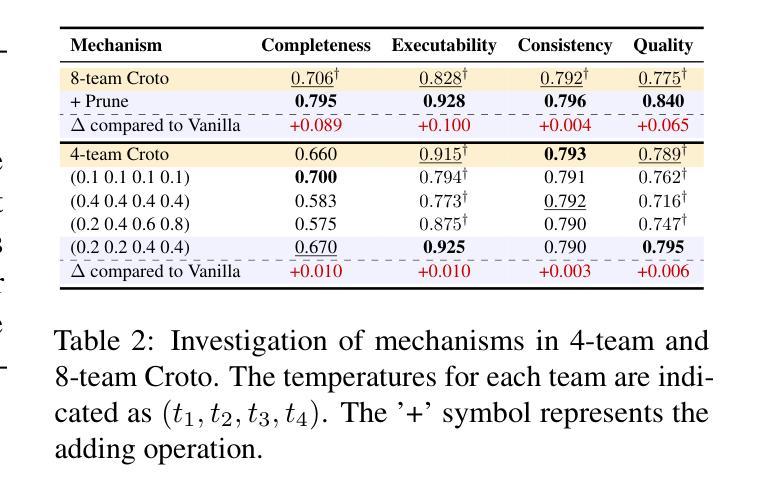
Multi-Agent Collaboration via Cross-Team Orchestration
Authors:Zhuoyun Du, Chen Qian, Wei Liu, Zihao Xie, YiFei Wang, Rennai Qiu, Yufan Dang, Weize Chen, Cheng Yang, Ye Tian, Xuantang Xiong, Lei Han
Large Language Models (LLMs) have significantly impacted various domains, especially through organized LLM-driven autonomous agents. A representative scenario is in software development, where agents can collaborate in a team like humans, following predefined phases to complete sub-tasks sequentially. However, for an agent team, each phase yields only one possible outcome. This results in the completion of only one development chain, thereby losing the opportunity to explore multiple potential decision paths within the solution space. Consequently leading to suboptimal results or extensive trial and error. To address this, we introduce Cross-Team Orchestration (Croto), a scalable multi-team framework that enables orchestrated teams to jointly propose various task-oriented solutions and interact with their insights in a self-independence while cross-team collaboration environment for superior solutions generation. Experiments reveal a notable increase in software quality compared to state-of-the-art baselines. We further tested our framework on story generation tasks, which demonstrated a promising generalization ability of our framework in other domains. The code and data is available at https://github.com/OpenBMB/ChatDev/tree/macnet
大型语言模型(LLMs)对各个领域产生了显著影响,特别是通过有组织的LLM驱动的自主代理。一个典型的场景是软件开发,代理可以像人类一样团队合作,遵循预定义的阶段顺序完成子任务。然而,在代理团队中,每个阶段只产生一种可能的结果。这导致只完成一个开发链,从而失去了在解决方案空间中探索多个潜在决策路径的机会。因此可能导致结果不佳或大量试错。为了解决这个问题,我们引入了跨团队协同(Croto),这是一个可扩展的多团队框架,能够让协同团队共同提出各种面向任务的解决方案,并在自我独立和跨团队协作环境中进行交互以生成更优质的解决方案。实验表明,与最新基线相比,我们的框架在软件质量方面有了显著的提高。我们还对故事生成任务进行了测试,这证明了我们的框架在其他领域的良好泛化能力。代码和数据可在 https://github.com/OpenBMB/ChatDev/tree/macnet 找到。
论文及项目相关链接
PDF Accepted to Findings of ACL 2025
Summary
大型语言模型(LLMs)驱动的自主代理团队在多个领域产生了显著影响。然而,现有团队模式在完成任务时只能产生单一解决方案,限制了决策路径的探索,可能导致结果不佳或需要大量试错。为解决这一问题,本文提出了跨团队协同框架(Croto),该框架支持多个团队共同提出多种任务导向的解决方案,并在自我独立与跨团队协作的环境中交流见解,以生成更优质的解决方案。实验证明,该框架在软件质量方面显著提高,且在故事生成任务中展现出良好的跨领域泛化能力。
Key Takeaways
- 大型语言模型(LLMs)已在多个领域产生显著影响,尤其是通过组织化的LLM驱动自主代理。
- 现有自主代理团队模式在完成任务时只能产生单一解决方案,限制了决策路径的探索。
- 跨团队协同框架(Croto)支持多个团队共同提出多种任务导向的解决方案。
- Croto框架允许代理团队在自我独立与跨团队协作的环境中交流见解。
- Croto框架在软件质量方面显著提高,并通过实验得到验证。
- Croto框架在故事生成任务中展现出良好的跨领域泛化能力。
点此查看论文截图