⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-10 更新
STARFlow: Scaling Latent Normalizing Flows for High-resolution Image Synthesis
Authors:Jiatao Gu, Tianrong Chen, David Berthelot, Huangjie Zheng, Yuyang Wang, Ruixiang Zhang, Laurent Dinh, Miguel Angel Bautista, Josh Susskind, Shuangfei Zhai
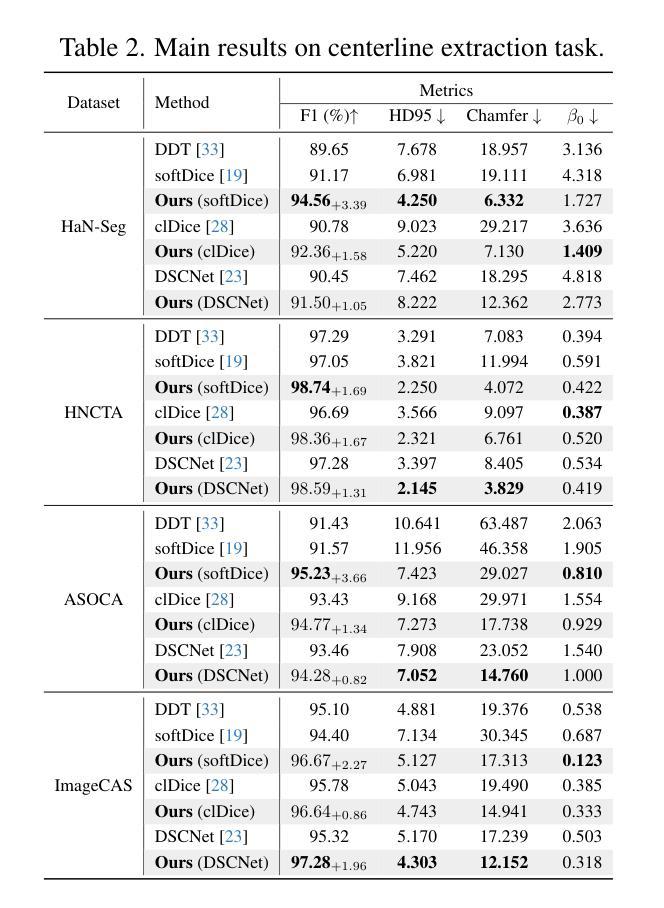
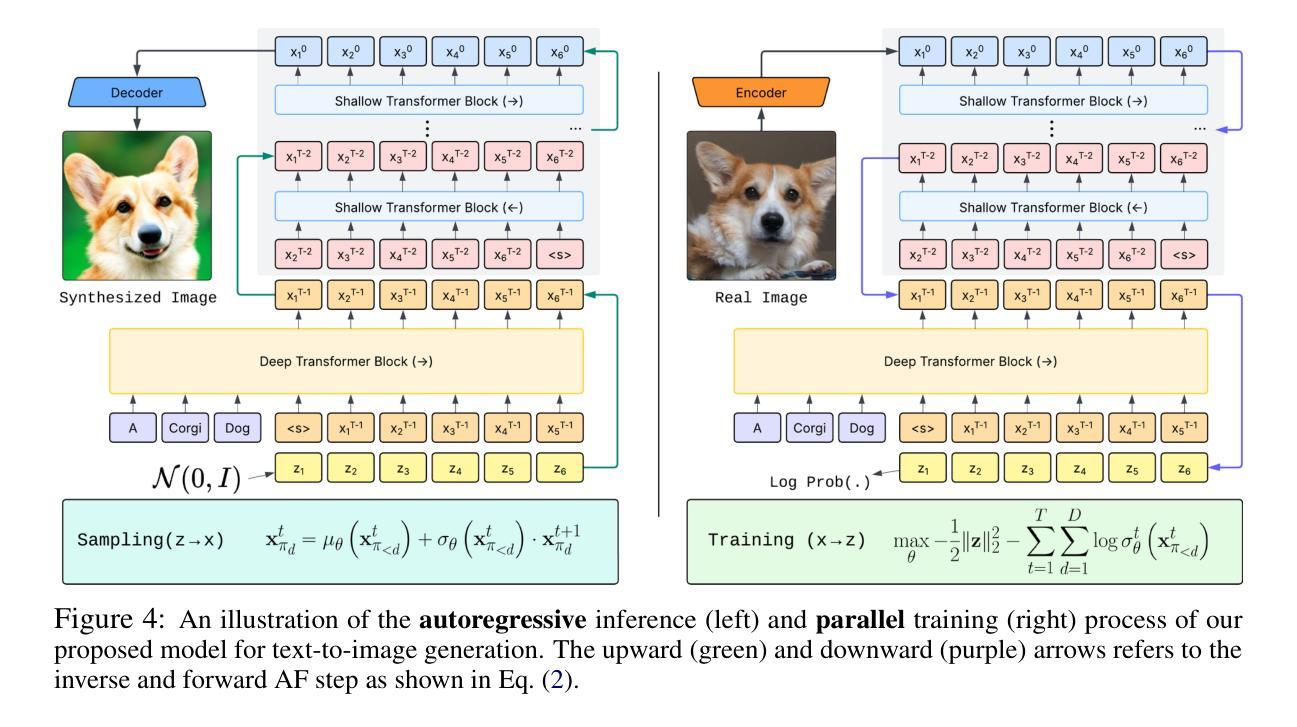
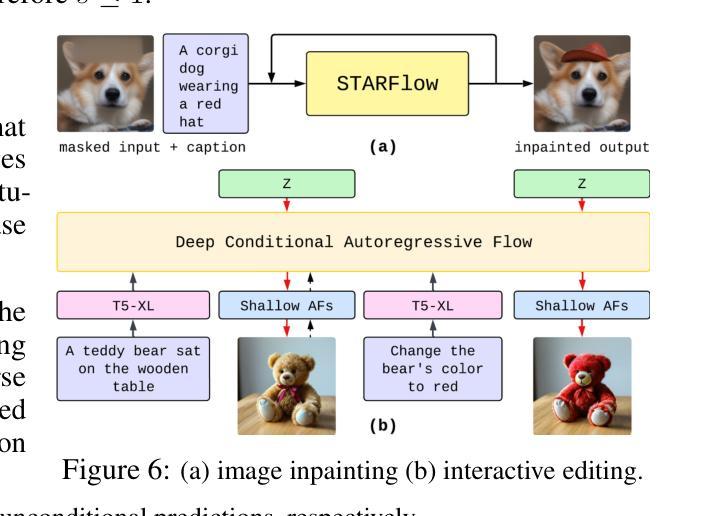
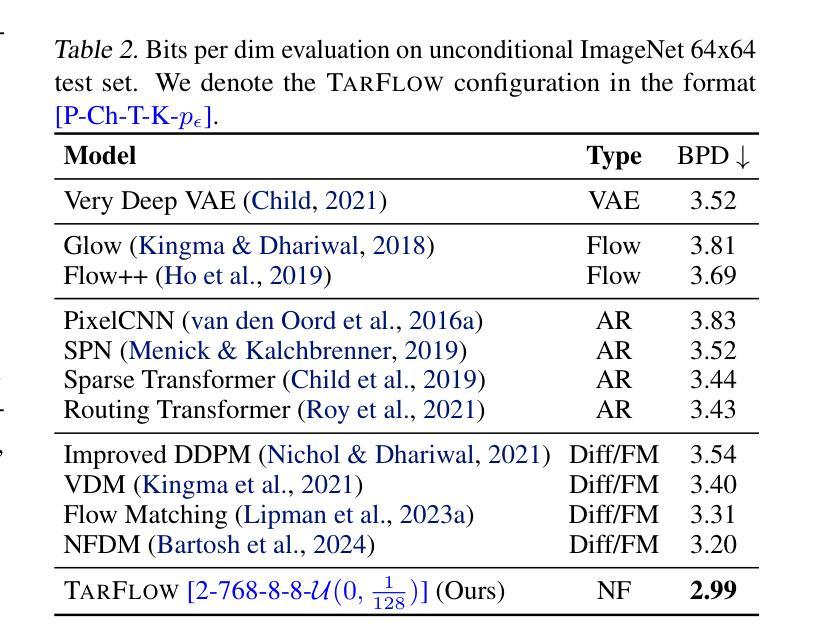
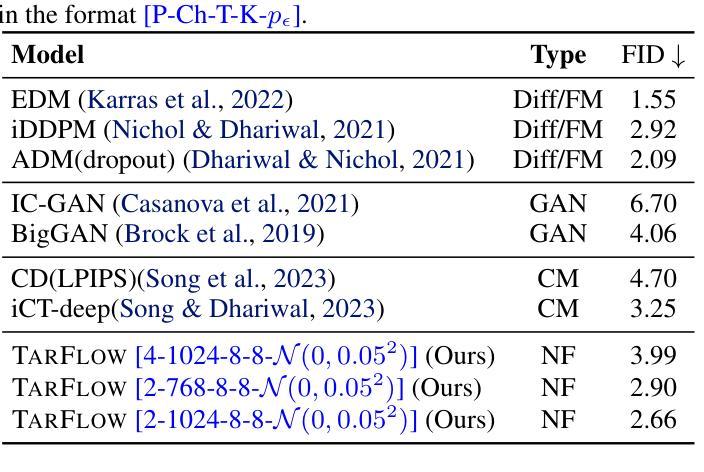
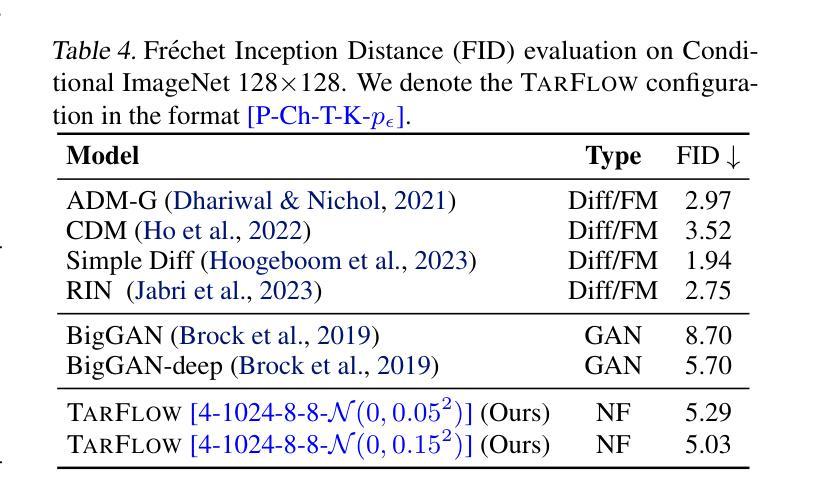
We present STARFlow, a scalable generative model based on normalizing flows that achieves strong performance in high-resolution image synthesis. The core of STARFlow is Transformer Autoregressive Flow (TARFlow), which combines the expressive power of normalizing flows with the structured modeling capabilities of Autoregressive Transformers. We first establish the theoretical universality of TARFlow for modeling continuous distributions. Building on this foundation, we introduce several key architectural and algorithmic innovations to significantly enhance scalability: (1) a deep-shallow design, wherein a deep Transformer block captures most of the model representational capacity, complemented by a few shallow Transformer blocks that are computationally efficient yet substantially beneficial; (2) modeling in the latent space of pretrained autoencoders, which proves more effective than direct pixel-level modeling; and (3) a novel guidance algorithm that significantly boosts sample quality. Crucially, our model remains an end-to-end normalizing flow, enabling exact maximum likelihood training in continuous spaces without discretization. STARFlow achieves competitive performance in both class-conditional and text-conditional image generation tasks, approaching state-of-the-art diffusion models in sample quality. To our knowledge, this work is the first successful demonstration of normalizing flows operating effectively at this scale and resolution.
我们提出了STARFlow,这是一个基于规范化流的可扩展生成模型,在高分辨率图像合成中实现了强大的性能。STARFlow的核心是Transformer自回归流(TARFlow),它结合了规范化流的表达能力与自回归变压器的结构化建模能力。我们首先建立了TARFlow对连续分布进行建模的理论普遍性。在此基础上,我们引入了几项关键的架构和算法创新,以显著增强可扩展性:(1)深浅设计,其中深Transformer块捕获模型的大部分表示能力,辅以几个计算效率高但对模型大有裨益的浅层Transformer块;(2)在预训练自编码器的潜在空间中进行建模,这被证明比直接像素级建模更为有效;(3)一种新型指导算法,可大幅提高样本质量。最重要的是,我们的模型仍然是一个端到端的规范化流,能够在连续空间中进行精确的最大可能性训练,无需离散化。STARFlow在类条件图像生成和任务条件文本生成任务中实现了有竞争力的性能,接近最先进的扩散模型的样本质量。据我们所知,这项工作是首次成功展示了在这种规模和分辨率下有效运行的规范化流。
论文及项目相关链接
PDF TLDR: We show for the first time that normalizing flows can be scaled for high-resolution and text-conditioned image synthesis
Summary
STARFlow是一个基于标准化流的可扩展生成模型,在高分辨率图像合成中表现出强大的性能。其核心是Transformer自回归流(TARFlow),结合了标准化流的表达力和自回归变压器的结构化建模能力。通过引入深度浅层设计、在预训练自编码器的潜在空间进行建模以及新型指导算法,显著增强了其可扩展性。模型在类条件图像生成和文本条件图像生成任务中表现出卓越性能,接近扩散模型的样本质量水平。
Key Takeaways
- STARFlow是一个基于标准化流的生成模型,用于高分辨率图像合成。
- 核心是Transformer自回归流(TARFlow),结合了标准化流和自回归变压器的优点。
- TARFlow的理论普遍性被用来对连续分布进行建模。
- 引入深度浅层设计以提高模型的可扩展性。
- 在预训练自编码器的潜在空间进行建模,证明其比直接像素级建模更有效。
- 新型指导算法显著提高样本质量。
点此查看论文截图


Feedback Guidance of Diffusion Models
Authors:Koulischer Felix, Handke Florian, Deleu Johannes, Demeester Thomas, Ambrogioni Luca
While Classifier-Free Guidance (CFG) has become standard for improving sample fidelity in conditional diffusion models, it can harm diversity and induce memorization by applying constant guidance regardless of whether a particular sample needs correction. We propose FeedBack Guidance (FBG), which uses a state-dependent coefficient to self-regulate guidance amounts based on need. Our approach is derived from first principles by assuming the learned conditional distribution is linearly corrupted by the unconditional distribution, contrasting with CFG’s implicit multiplicative assumption. Our scheme relies on feedback of its own predictions about the conditional signal informativeness to adapt guidance dynamically during inference, challenging the view of guidance as a fixed hyperparameter. The approach is benchmarked on ImageNet512x512, where it significantly outperforms Classifier-Free Guidance and is competitive to Limited Interval Guidance (LIG) while benefitting from a strong mathematical framework. On Text-To-Image generation, we demonstrate that, as anticipated, our approach automatically applies higher guidance scales for complex prompts than for simpler ones and that it can be easily combined with existing guidance schemes such as CFG or LIG.
虽然无分类器引导(CFG)已成为提高条件扩散模型样本保真度的标准方法,但它可能会损害多样性并导致记忆,因为它会应用固定的指导方式,无论特定的样本是否需要修正。我们提出了反馈引导(FBG)方法,它使用一个状态依赖系数来根据需求自我调节引导量。我们的方法基于基本原理,假设学习的条件分布被无条件分布线性破坏,这与CFG的隐含乘法假设形成对比。我们的方案依赖于对其自身关于条件信号信息预测的反馈,在推理过程中动态适应指导,挑战了将指导视为固定超参数的观点。该方法在ImageNet512x512上进行了基准测试,显著优于无分类器引导且具备竞争力并与有限间隔引导(LIG)具有相当水平的表现同时得益于强大的数学框架支持。在文本到图像生成中,我们证明了我们的方法能够自动为复杂提示应用更高的指导比例而不是简单的提示,并且它可以很容易地与现有的引导方案如CFG或LIG结合使用。
论文及项目相关链接
PDF Preprint. Article currently under review. Code is available at: https://github.com/FelixKoulischer/FBG_using_edm2
Summary
基于扩散模型的反馈指导(FBG)被提出以提高样本的保真度并自适应地调整指导量。相较于Classifier-Free Guidance(CFG)的恒定指导,FBG能够根据样本需求进行自我调节,避免损害多样性和产生记忆效应。FBG基于预测的条件信号信息量的反馈来动态调整指导,挑战了将指导视为固定超参数的观点。在ImageNet和文本转图像生成任务上,FBG显著优于CFG,并与Limited Interval Guidance(LIG)具有竞争力。此外,FBG能够轻松结合现有指导方案如CFG或LIG。
Key Takeaways
- FBG提出一种基于反馈的扩散模型指导方法,能够自适应调整指导量以提高样本保真度。
- FBG通过预测的条件信号信息量的反馈进行动态调整,克服了恒定指导可能带来的问题。
- FBG与Classifier-Free Guidance(CFG)相比,能更好地适应不同样本的需求,避免损害多样性和产生记忆效应。
- FBG在ImageNet上的性能显著优于CFG,与Limited Interval Guidance(LIG)相当并具有竞争力。
- FBG适用于文本转图像生成任务,能自动为复杂提示应用更高的指导规模。
- FBG能够轻松结合其他现有指导方案,如CFG或LIG。
点此查看论文截图



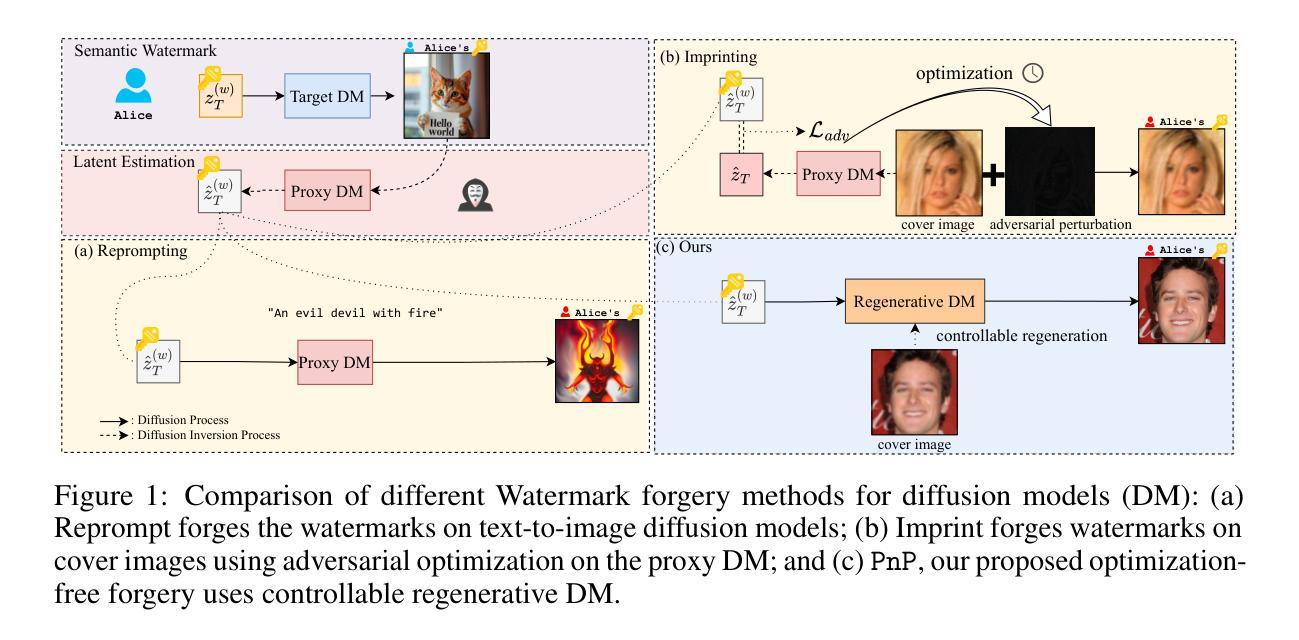
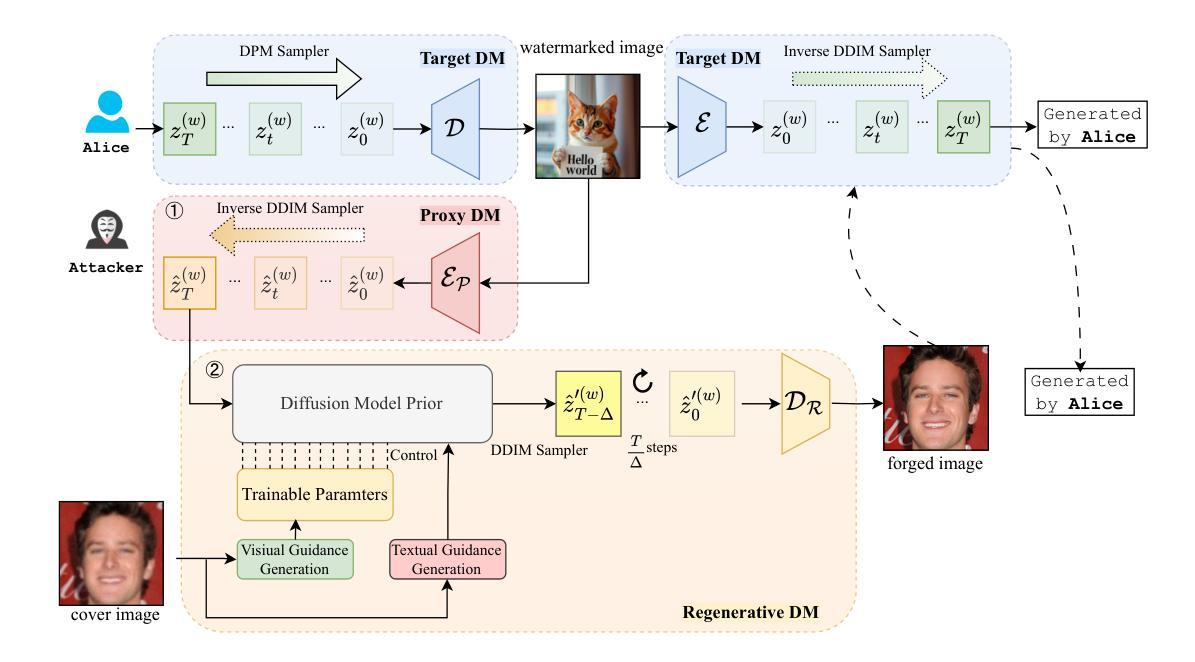
Optimization-Free Universal Watermark Forgery with Regenerative Diffusion Models
Authors:Chaoyi Zhu, Zaitang Li, Renyi Yang, Robert Birke, Pin-Yu Chen, Tsung-Yi Ho, Lydia Y. Chen
Watermarking becomes one of the pivotal solutions to trace and verify the origin of synthetic images generated by artificial intelligence models, but it is not free of risks. Recent studies demonstrate the capability to forge watermarks from a target image onto cover images via adversarial optimization without knowledge of the target generative model and watermark schemes. In this paper, we uncover a greater risk of an optimization-free and universal watermark forgery that harnesses existing regenerative diffusion models. Our proposed forgery attack, PnP (Plug-and-Plant), seamlessly extracts and integrates the target watermark via regenerating the image, without needing any additional optimization routine. It allows for universal watermark forgery that works independently of the target image’s origin or the watermarking model used. We explore the watermarked latent extracted from the target image and visual-textual context of cover images as priors to guide sampling of the regenerative process. Extensive evaluation on 24 scenarios of model-data-watermark combinations demonstrates that PnP can successfully forge the watermark (up to 100% detectability and user attribution), and maintain the best visual perception. By bypassing model retraining and enabling adaptability to any image, our approach significantly broadens the scope of forgery attacks, presenting a greater challenge to the security of current watermarking techniques for diffusion models and the authority of watermarking schemes in synthetic data generation and governance.
水印已成为追踪和验证人工智能模型生成的合成图像来源的关键解决方案之一,但并非没有风险。最近的研究表明,可以通过对抗性优化将目标图像的水印伪造到覆盖图像上,而无需了解目标生成模型和水印方案。在本文中,我们揭示了利用现有再生扩散模型进行无优化通用水印伪造的最大风险。我们提出的伪造攻击方法PnP(即“即插即用”)通过再生图像无缝提取和集成目标水印,而无需任何额外的优化流程。它允许进行通用水印伪造,独立于目标图像来源或水印模型的使用情况。我们探索从目标图像中提取的水印潜力和覆盖图像的视觉文本上下文作为先验来指导再生过程的采样。对24种模型-数据-水印组合场景的广泛评估表明,PnP可以成功伪造水印(高达100%的可检测性和用户归属),并保持最佳的视觉感知。通过绕过模型重新训练并适应任何图像,我们的方法大大扩大了伪造攻击的范围,给当前水印技术在扩散模型中的安全性以及水印方案在合成数据生成和治理中的权威性带来了更大的挑战。
论文及项目相关链接
Summary
水印已成为追踪和验证人工智能模型生成合成图像来源的关键解决方案之一,但并非没有风险。最近的研究表明,可以通过对抗性优化将目标水印伪造到覆盖图像上,而无需了解目标生成模型和水印方案。在本文中,我们揭示了利用现有再生扩散模型进行无优化和通用水印伪造的更大风险。我们提出的伪造攻击PnP(即插即用)方法,通过再生图像无缝提取和集成目标水印,而无需任何额外的优化流程。它允许进行独立于目标图像来源或水印模型使用的通用水印伪造。我们探索了从目标图像中提取的水印潜伏期和覆盖图像的视觉文本上下文作为先验,以指导再生过程的采样。在24种模型-数据-水印组合场景下的广泛评估表明,PnP可以成功伪造水印(高达100%的可检测性和用户归属),并保持良好的视觉感知。通过绕过模型重新训练并适应任何图像,我们的方法大大扩大了伪造攻击的范围,给扩散模型的水印技术安全性和合成数据生成、治理的水印方案权威性带来了更大的挑战。
Key Takeaways
- 水印是追踪和验证AI生成图像来源的关键,但存在伪造风险。
- 最近研究展示了无需了解目标生成模型和水印方案的情况下,通过对抗性优化伪造水印。
- 提出了一种新的伪造攻击方法PnP,能够无缝提取并集成目标水印,通过再生图像进行。
- PnP方法允许进行通用水印伪造,独立于目标图像来源和水印模型。
- 利用目标图像的水印潜伏期和覆盖图像的视觉文本上下文来提高伪造效果。
- 广泛评估表明,PnP方法成功伪造水印并保持良好视觉感知。
点此查看论文截图

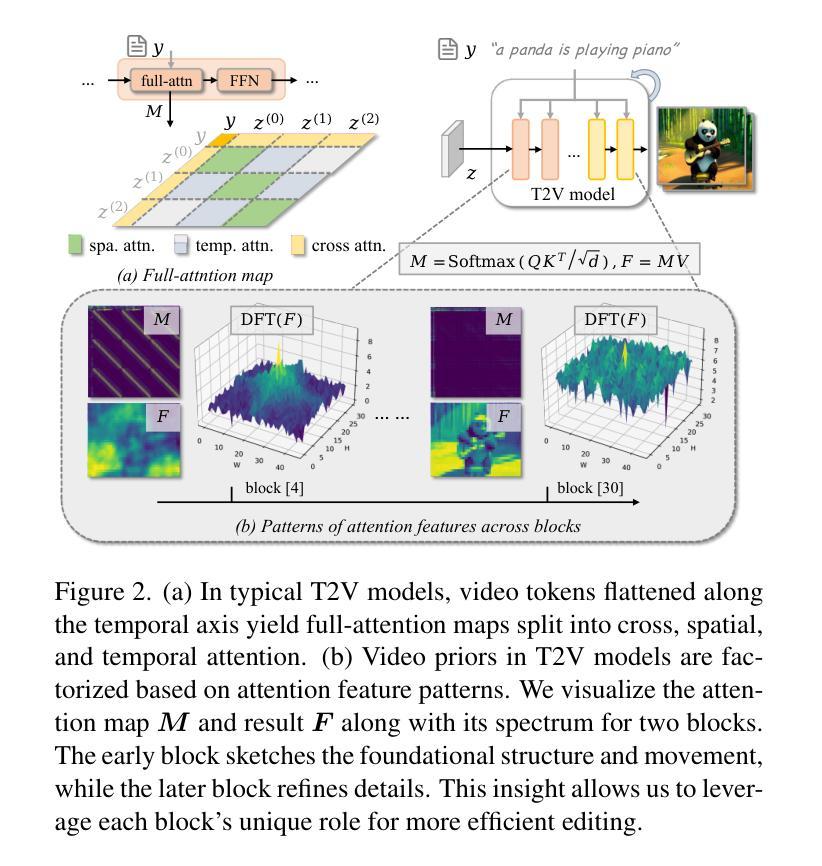
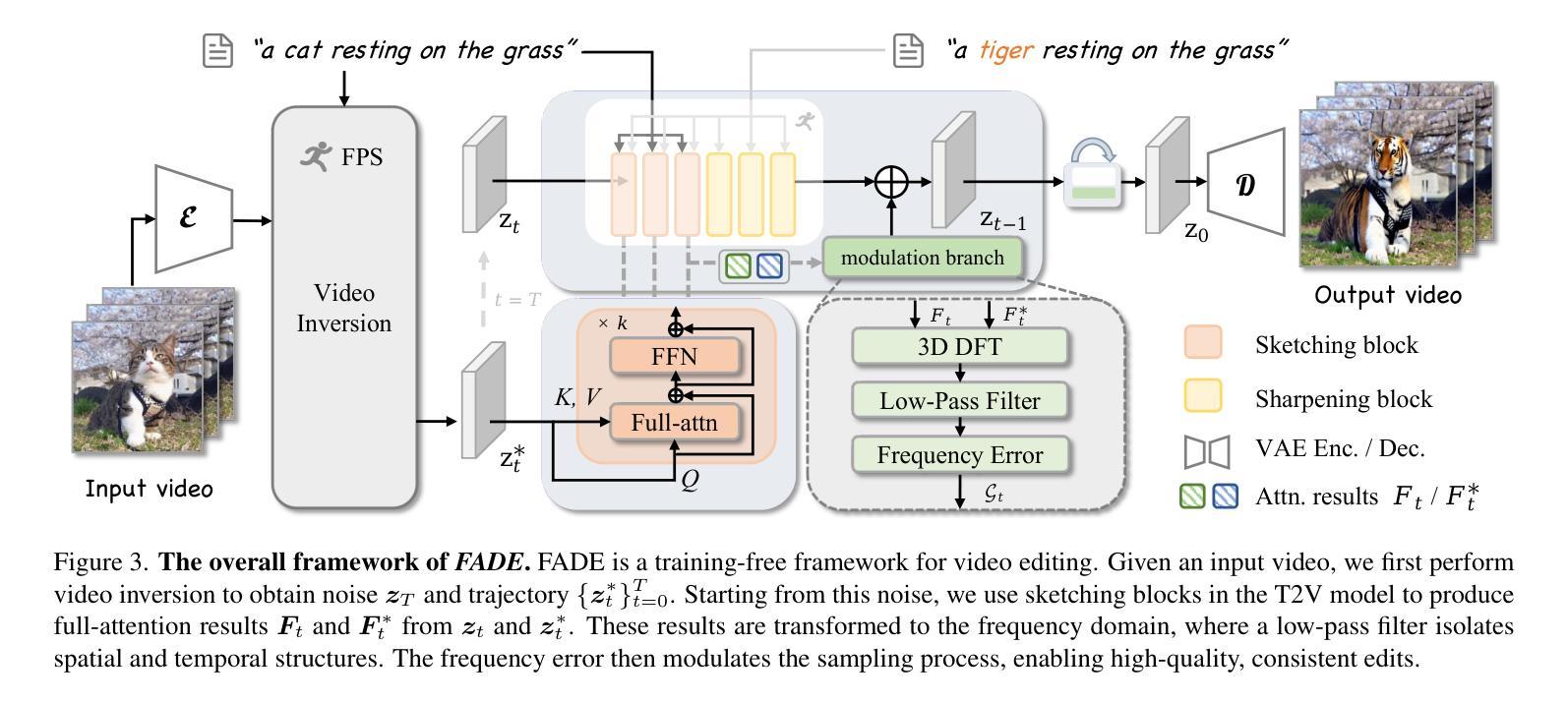
FADE: Frequency-Aware Diffusion Model Factorization for Video Editing
Authors:Yixuan Zhu, Haolin Wang, Shilin Ma, Wenliang Zhao, Yansong Tang, Lei Chen, Jie Zhou
Recent advancements in diffusion frameworks have significantly enhanced video editing, achieving high fidelity and strong alignment with textual prompts. However, conventional approaches using image diffusion models fall short in handling video dynamics, particularly for challenging temporal edits like motion adjustments. While current video diffusion models produce high-quality results, adapting them for efficient editing remains difficult due to the heavy computational demands that prevent the direct application of previous image editing techniques. To overcome these limitations, we introduce FADE, a training-free yet highly effective video editing approach that fully leverages the inherent priors from pre-trained video diffusion models via frequency-aware factorization. Rather than simply using these models, we first analyze the attention patterns within the video model to reveal how video priors are distributed across different components. Building on these insights, we propose a factorization strategy to optimize each component’s specialized role. Furthermore, we devise spectrum-guided modulation to refine the sampling trajectory with frequency domain cues, preventing information leakage and supporting efficient, versatile edits while preserving the basic spatial and temporal structure. Extensive experiments on real-world videos demonstrate that our method consistently delivers high-quality, realistic and temporally coherent editing results both qualitatively and quantitatively. Code is available at https://github.com/EternalEvan/FADE .
近期扩散框架的进展在视频编辑方面取得了显著的提升,实现了高保真度以及与文本提示的强烈对齐。然而,使用图像扩散模型的传统方法在应对视频动态方面存在不足,特别是在动作调整等具有挑战性的时间编辑方面。虽然当前视频扩散模型能产生高质量的结果,但将其适应于高效编辑仍然很困难,因为它们需要大量的计算资源,这使得无法直接应用之前的图像编辑技术。为了克服这些限制,我们引入了FADE,这是一种无需训练但高效的视频编辑方法,它充分利用了预训练视频扩散模型的内在先验知识,通过频率感知分解。我们不是简单地使用这些模型,而是首先分析视频模型中的注意力模式,以揭示视频先验知识是如何分布在不同的组件中的。基于这些见解,我们提出了一种分解策略,以优化每个组件的专门作用。此外,我们设计了频谱引导调制,以利用频率域线索来完善采样轨迹,防止信息泄露,并支持高效、多功能编辑,同时保持基本的空间和时间结构。在真实世界视频上的广泛实验表明,我们的方法在定性和定量上都能提供高质量、现实感强且时间连贯的编辑结果。代码可在https://github.com/EternalEvan/FADE上找到。
论文及项目相关链接
PDF Accepted by IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025
Summary
近期扩散框架的进展极大提升了视频编辑效果,实现了高保真和与文本提示的强对齐。然而,传统图像扩散模型在处理视频动态方面存在局限,尤其在运动调整等时间编辑方面更具挑战。当前视频扩散模型虽能生成高质量结果,但由于计算需求巨大,难以高效编辑。为此,我们推出FADE,一种无需训练的视频编辑方法,充分利用预训练视频扩散模型的内在先验知识,通过频率感知分解实现。我们分析视频模型中的注意力模式,揭示视频先验知识在不同组件中的分布。在此基础上,我们提出优化各组件专业角色的分解策略。同时,我们开发频谱引导调制,利用频率域线索优化采样轨迹,防止信息泄露,支持高效、多样化的编辑,同时保持基本的时间和空间结构。在真实视频上的广泛实验证明,我们的方法无论在定性还是定量上都能提供高质量、逼真的时间连贯编辑结果。
Key Takeaways
- 扩散框架的最新进展显著提高了视频编辑的质量和对文本提示的响应度。
- 传统图像扩散模型在处理视频动态方面存在不足,特别是在处理复杂的运动编辑时面临挑战。
- 当前视频扩散模型虽然能生成高质量结果,但难以高效编辑,计算需求大。
- FADE方法是一种无需训练的视频编辑方法,充分利用预训练视频扩散模型的内在先验知识。
- FADE通过分析视频模型中的注意力模式来揭示视频先验知识的分布。
- FADE通过频率感知分解和频谱引导调制技术实现高质量的视频编辑。
点此查看论文截图


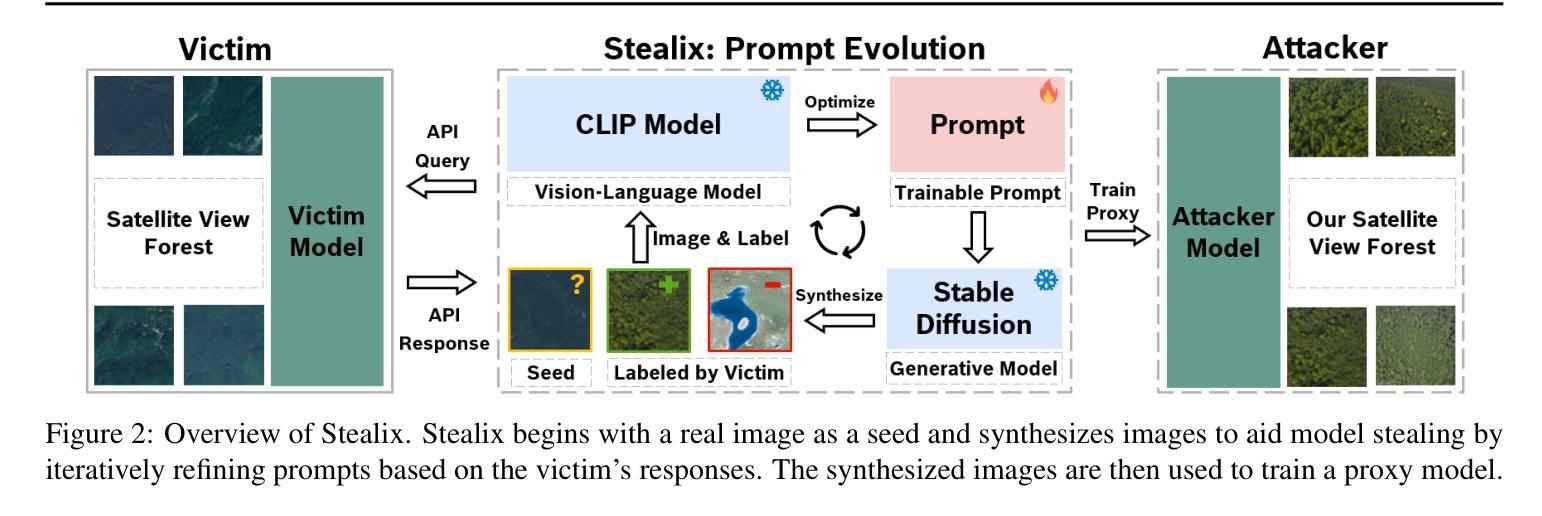
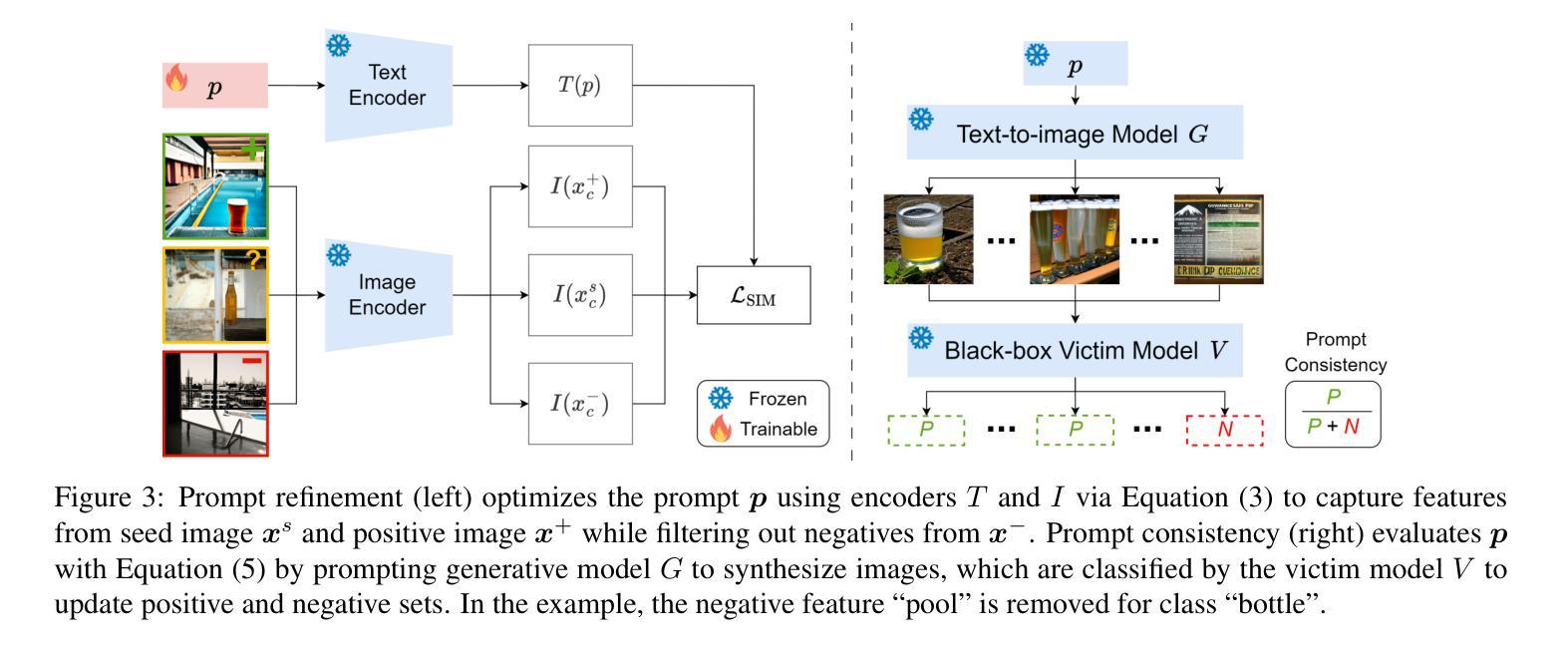
Stealix: Model Stealing via Prompt Evolution
Authors:Zhixiong Zhuang, Hui-Po Wang, Maria-Irina Nicolae, Mario Fritz
Model stealing poses a significant security risk in machine learning by enabling attackers to replicate a black-box model without access to its training data, thus jeopardizing intellectual property and exposing sensitive information. Recent methods that use pre-trained diffusion models for data synthesis improve efficiency and performance but rely heavily on manually crafted prompts, limiting automation and scalability, especially for attackers with little expertise. To assess the risks posed by open-source pre-trained models, we propose a more realistic threat model that eliminates the need for prompt design skills or knowledge of class names. In this context, we introduce Stealix, the first approach to perform model stealing without predefined prompts. Stealix uses two open-source pre-trained models to infer the victim model’s data distribution, and iteratively refines prompts through a genetic algorithm, progressively improving the precision and diversity of synthetic images. Our experimental results demonstrate that Stealix significantly outperforms other methods, even those with access to class names or fine-grained prompts, while operating under the same query budget. These findings highlight the scalability of our approach and suggest that the risks posed by pre-trained generative models in model stealing may be greater than previously recognized.
模型窃取对机器学习的安全构成重大威胁。攻击者能够无需接触目标模型即可复现黑盒模型,导致知识产权受损且暴露敏感信息。近期使用预训练扩散模型进行数据合成的方法提高了效率和性能,但严重依赖人工设计的提示,限制了自动化和可扩展性,尤其不利于缺乏专业知识的攻击者。为了评估开源预训练模型带来的风险,我们提出了一个更现实的威胁模型,该模型消除了对提示设计技能或类名知识的需求。在此背景下,我们推出了Stealix,这是一种无需预设提示即可执行模型窃取的首个方法。Stealix使用两个开源预训练模型来推断目标模型的数据分布,并通过遗传算法迭代优化提示,逐步改进合成图像的精度和多样性。我们的实验结果表明,即使在相同的查询预算下,Stealix也显著优于其他方法,甚至优于那些能够访问类名或精细提示的方法。这些发现突显了我们方法的可扩展性,并表明预训练生成模型在模型窃取方面的风险可能比以前认识到的更大。
论文及项目相关链接
PDF Accepted at ICML 2025. The project page is at https://zhixiongzh.github.io/stealix/
Summary
模型窃取对机器学习构成重大安全风险,攻击者可以在无需接触训练数据的情况下复制黑盒模型,从而危及知识产权和暴露敏感信息。尽管利用预训练扩散模型进行数据合成的方法提高了效率和性能,但它们严重依赖手动设计的提示,限制了自动化和可扩展性,尤其是对那些缺乏专业知识的攻击者。为了评估开源预训练模型的风险,我们提出了一个更现实的威胁模型,该模型无需提示设计技能或了解类名即可运行。在此背景下,我们推出了Stealix,这是一种无需预先设定提示即可执行模型窃取的首创方法。Stealix使用两个开源预训练模型来推断受害者模型的数据分布,并通过遗传算法迭代优化提示,逐步提高合成图像的精度和多样性。实验结果表明,Stealix显著优于其他方法,即使在相同的查询预算下,即使那些能够访问类名或精细提示的方法也被其超越。这强调了我们的方法的可扩展性,并表明预训练生成模型在模型窃取方面的风险可能比先前认识的要大。
Key Takeaways
- 模型窃取对机器学习构成安全风险,攻击者可复制黑盒模型,危及知识产权和暴露敏感信息。
- 利用预训练扩散模型进行数据合成的方法虽提高效率和性能,但依赖手动提示,限制自动化和可扩展性。
- 提出了一个更现实的威胁模型,无需提示设计技能或了解类名即可执行模型窃取。
- 推出了Stealix方法,无需预设提示即可进行模型窃取。
- Stealix使用两个开源预训练模型推断受害者模型的数据分布。
- 通过遗传算法迭代优化提示,提高合成图像的精度和多样性。
点此查看论文截图


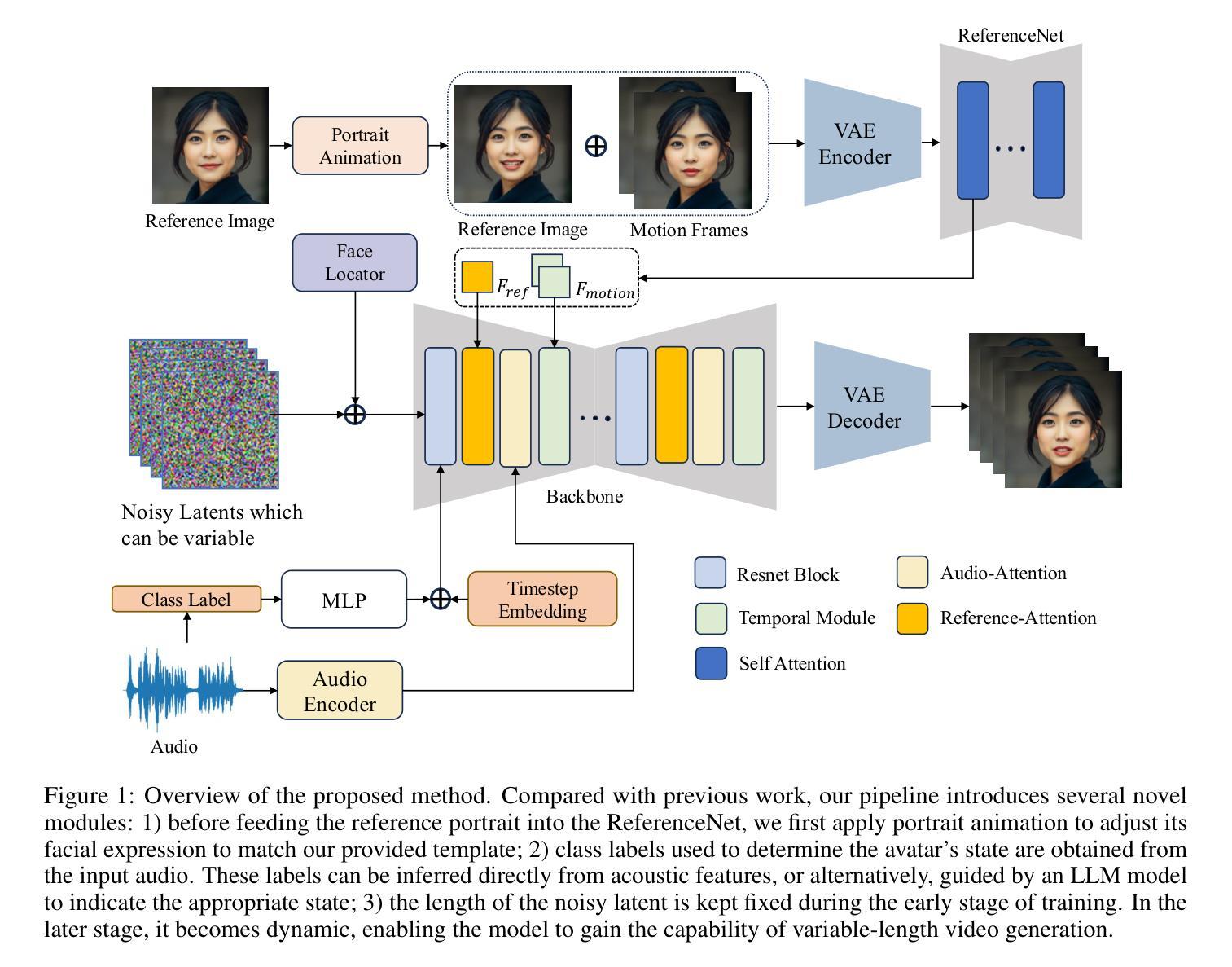
LLIA – Enabling Low-Latency Interactive Avatars: Real-Time Audio-Driven Portrait Video Generation with Diffusion Models
Authors:Haojie Yu, Zhaonian Wang, Yihan Pan, Meng Cheng, Hao Yang, Chao Wang, Tao Xie, Xiaoming Xu, Xiaoming Wei, Xunliang Cai
Diffusion-based models have gained wide adoption in the virtual human generation due to their outstanding expressiveness. However, their substantial computational requirements have constrained their deployment in real-time interactive avatar applications, where stringent speed, latency, and duration requirements are paramount. We present a novel audio-driven portrait video generation framework based on the diffusion model to address these challenges. Firstly, we propose robust variable-length video generation to reduce the minimum time required to generate the initial video clip or state transitions, which significantly enhances the user experience. Secondly, we propose a consistency model training strategy for Audio-Image-to-Video to ensure real-time performance, enabling a fast few-step generation. Model quantization and pipeline parallelism are further employed to accelerate the inference speed. To mitigate the stability loss incurred by the diffusion process and model quantization, we introduce a new inference strategy tailored for long-duration video generation. These methods ensure real-time performance and low latency while maintaining high-fidelity output. Thirdly, we incorporate class labels as a conditional input to seamlessly switch between speaking, listening, and idle states. Lastly, we design a novel mechanism for fine-grained facial expression control to exploit our model’s inherent capacity. Extensive experiments demonstrate that our approach achieves low-latency, fluid, and authentic two-way communication. On an NVIDIA RTX 4090D, our model achieves a maximum of 78 FPS at a resolution of 384x384 and 45 FPS at a resolution of 512x512, with an initial video generation latency of 140 ms and 215 ms, respectively.
基于扩散模型的方法在虚拟人生成领域因其出色的表现力而得到广泛应用。然而,其巨大的计算需求限制了其在实时交互式化身应用程序中的部署,这些应用程序对速度、延迟和持续时间有严格的要求。我们提出了一种基于扩散模型的新型音频驱动肖像视频生成框架,以解决这些挑战。首先,我们提出可变长度视频生成方法,以减少生成初始视频片段或状态转换所需的最短时间,从而显著增强用户体验。其次,我们为音频图像到视频的转换提出了一致的模型训练策略,以确保实时性能,实现快速多步生成。此外,还采用了模型量化和流水线并行化方法来加速推理速度。为了解决扩散过程和模型量化带来的稳定性损失,我们引入了一种适用于长持续时间视频生成的新型推理策略。这些方法确保了实时性能和低延迟,同时保持了高保真输出。第三,我们将类别标签作为条件输入融入其中,以无缝切换说话、倾听和空闲状态。最后,我们设计了一种用于精细面部表情控制的新机制,以利用我们模型的内在能力。大量实验表明,我们的方法实现了低延迟、流畅和逼真的双向通信。在NVIDIA RTX 4090D上,我们的模型在384x384分辨率下最高达到78帧每秒(FPS),在512x512分辨率下达到45 FPS,初始视频生成延迟分别为140毫秒和215毫秒。
论文及项目相关链接
摘要
基于扩散模型的音频驱动肖像视频生成框架解决了现有挑战,包括实时互动化身应用的严格速度、延迟和持续时间要求。提出可变长度视频生成、一致性模型训练策略、模型量化和管道并行化等方法,以提高用户体验、保证实时性能和低延迟,同时维持高保真输出。此外,纳入类别标签作为条件输入,实现说话、聆听和空闲状态间的无缝切换,并设计精细面部表情控制机制。实验证明,该方法实现低延迟、流畅和真实的双向交流。在NVIDIA RTX 4090D上,模型最高达78帧/秒(FPS)的帧率,分辨率分别为384x384和45 FPS在分辨率为512x512。初始视频生成延迟分别为140毫秒和215毫秒。
关键见解
- 扩散模型在虚拟人生成中的出色表达力。
- 提出的音频驱动肖像视频生成框架解决了实时互动化身应用的挑战。
- 变量长度视频生成提高了用户体验。
- 一致性模型训练策略确保了实时性能,实现了快速几步生成。
- 模型量化和管道并行化技术加速了推理速度。
- 新的推理策略提高了长时长视频生成的稳定性。
点此查看论文截图

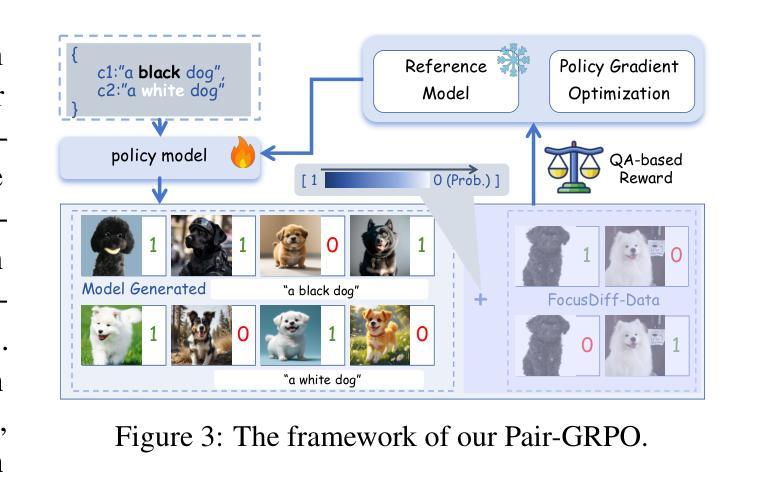
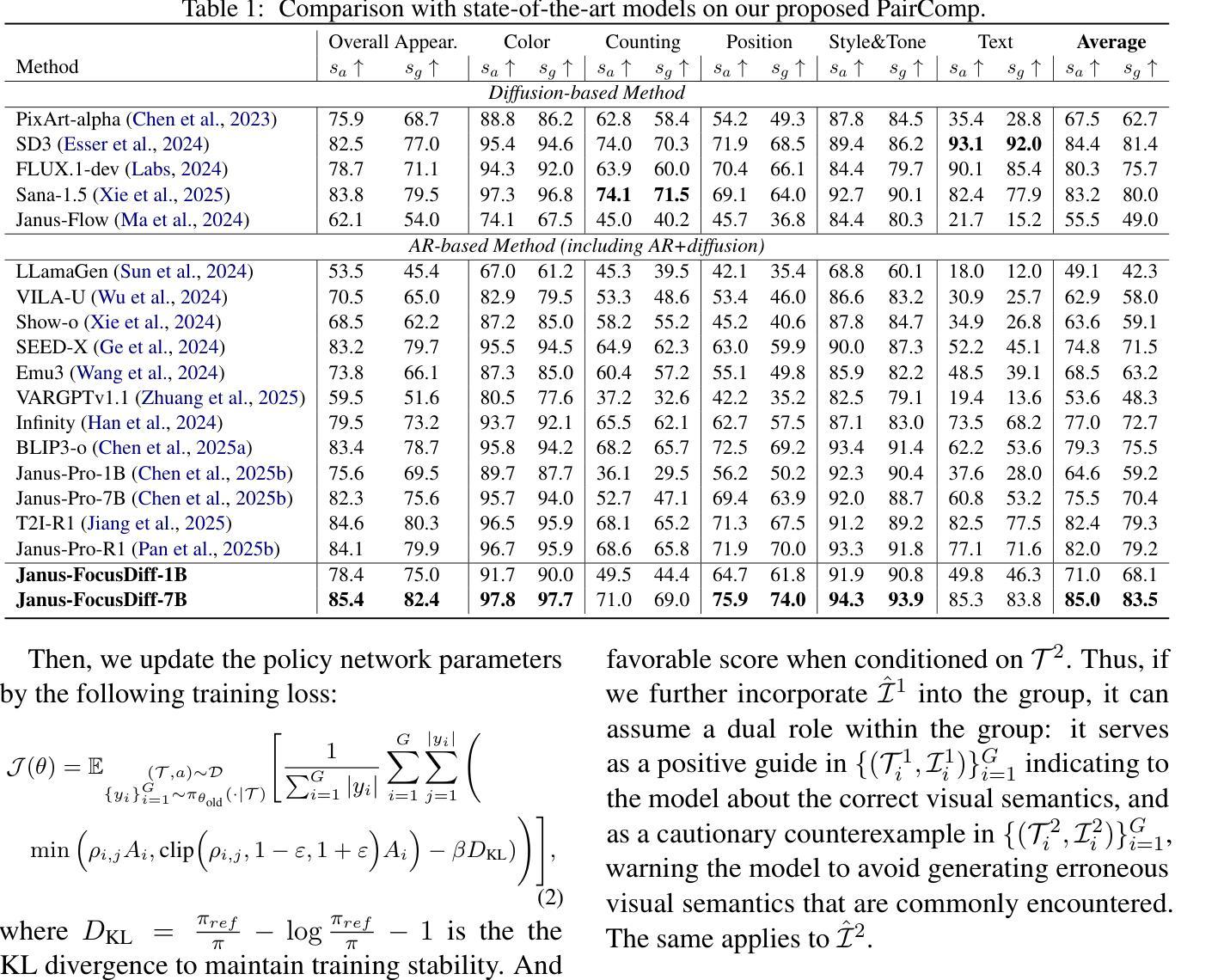
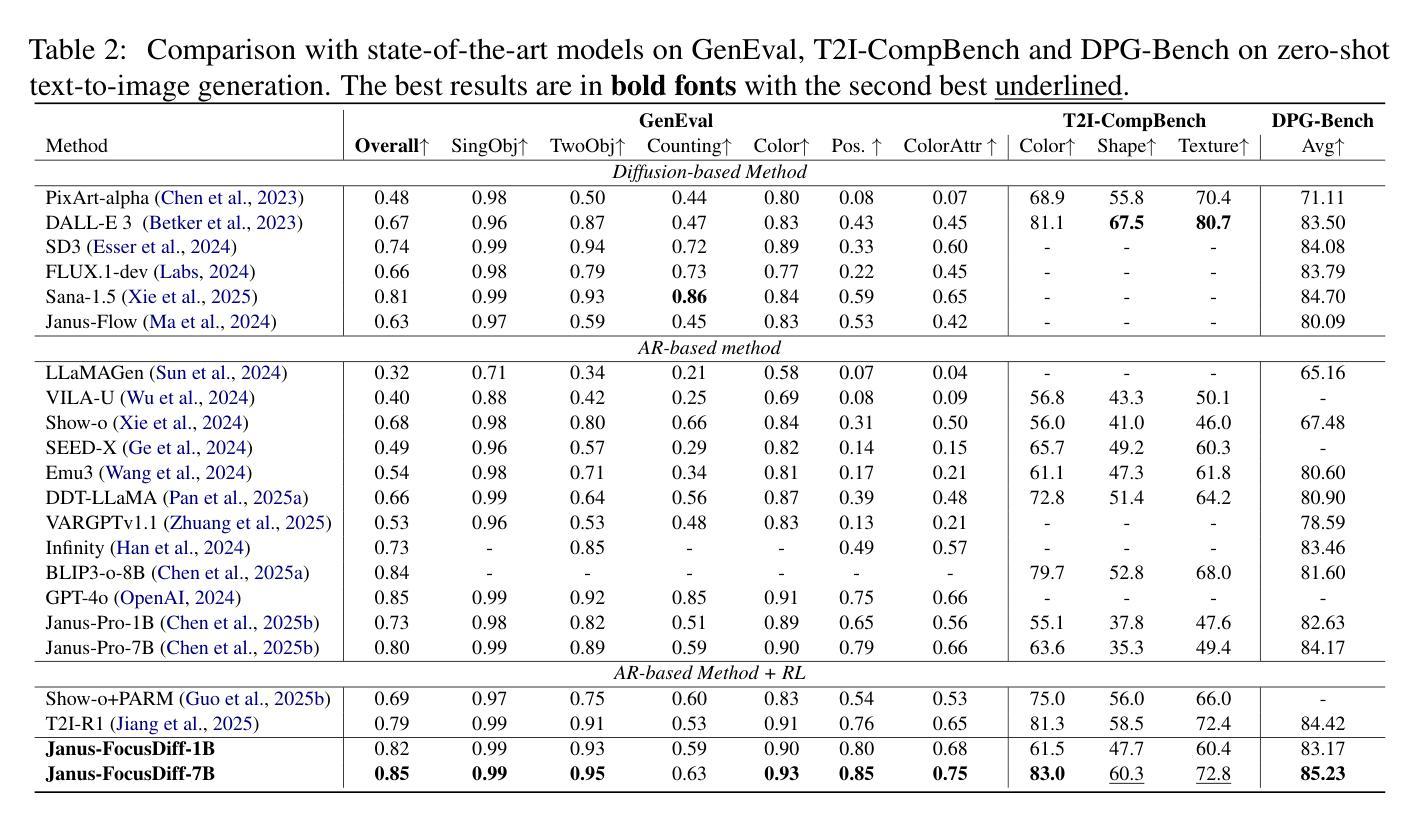
FocusDiff: Advancing Fine-Grained Text-Image Alignment for Autoregressive Visual Generation through RL
Authors:Kaihang Pan, Wendong Bu, Yuruo Wu, Yang Wu, Kai Shen, Yunfei Li, Hang Zhao, Juncheng Li, Siliang Tang, Yueting Zhuang
Recent studies extend the autoregression paradigm to text-to-image generation, achieving performance comparable to diffusion models. However, our new PairComp benchmark – featuring test cases of paired prompts with similar syntax but different fine-grained semantics – reveals that existing models struggle with fine-grained text-image alignment thus failing to realize precise control over visual tokens. To address this, we propose FocusDiff, which enhances fine-grained text-image semantic alignment by focusing on subtle differences between similar text-image pairs. We construct a new dataset of paired texts and images with similar overall expressions but distinct local semantics, further introducing a novel reinforcement learning algorithm to emphasize such fine-grained semantic differences for desired image generation. Our approach achieves state-of-the-art performance on existing text-to-image benchmarks and significantly outperforms prior methods on PairComp.
最近的研究将自回归范式扩展到文本到图像生成,其性能与扩散模型相当。然而,我们新的PairComp基准测试——包含具有相似语法但具有不同细微语义的配对提示测试用例——表明,现有模型在细微的文本图像对齐方面存在困难,无法实现视觉标记的精确控制。为了解决这个问题,我们提出了FocusDiff,它通过关注相似文本图像对之间的细微差异,提高了文本图像的精细语义对齐。我们构建了一个新的配对文本和图像数据集,具有相似的整体表达但局部语义不同,并进一步引入了一种新的强化学习算法来强调这种细微的语义差异,以实现所需的图像生成。我们的方法在现有的文本到图像基准测试上达到了最先进的性能,并在PairComp上显著优于先前的方法。
论文及项目相关链接
PDF 15 pages, 8 figures. Project Page: https://focusdiff.github.io/
Summary
近期研究将自回归范式扩展到文本到图像生成领域,性能与扩散模型相当。然而,新的PairComp基准测试显示,现有模型在精细文本图像对齐方面存在困难,无法实现视觉符号的精确控制。为解决这一问题,我们提出FocusDiff,通过关注相似文本图像对之间的细微差异,提高精细文本图像语义对齐。我们构建了新的配对文本和图像数据集,整体表达相似但局部语义不同,并引入新的强化学习算法来强调这种精细语义差异以实现所需的图像生成。FocusDiff在现有文本到图像基准测试中表现卓越,并在PairComp上显著优于先前方法。
Key Takeaways
- 近期研究将自回归范式应用于文本到图像生成,性能与扩散模型相当。
- 现有模型在精细文本图像对齐方面存在困难。
- PairComp基准测试揭示了这一挑战,强调对视觉符号的精确控制的重要性。
- FocusDiff通过关注细微差异提高精细文本图像语义对齐。
- FocusDiff构建了新的配对文本和图像数据集,整体表达相似但局部语义不同。
- 强化学习算法被用于FocusDiff,以强调精细语义差异实现所需图像生成。
点此查看论文截图



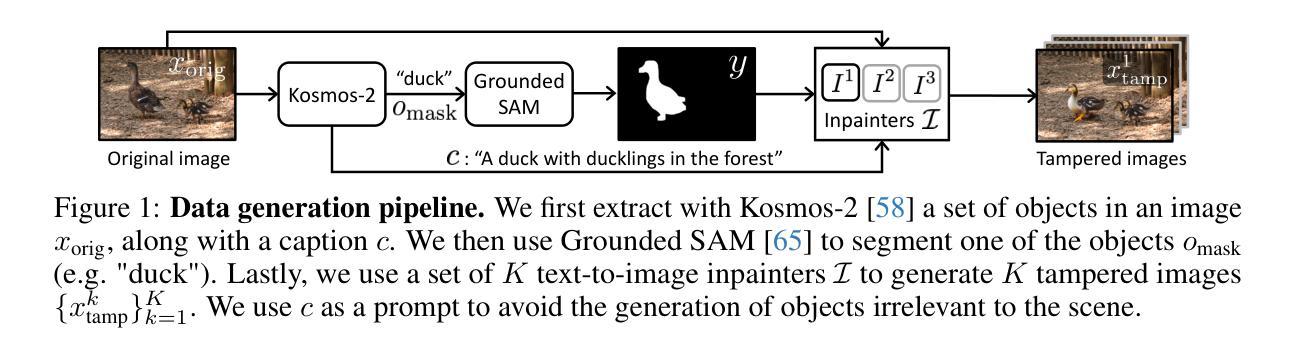
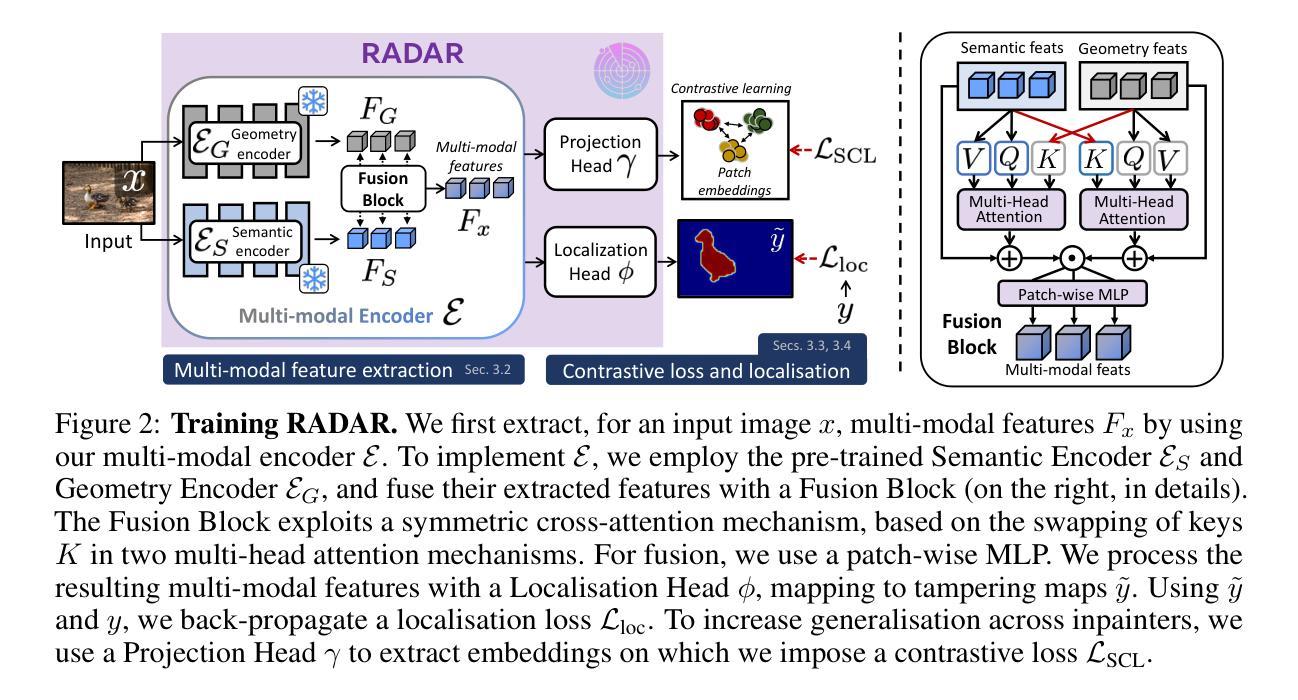
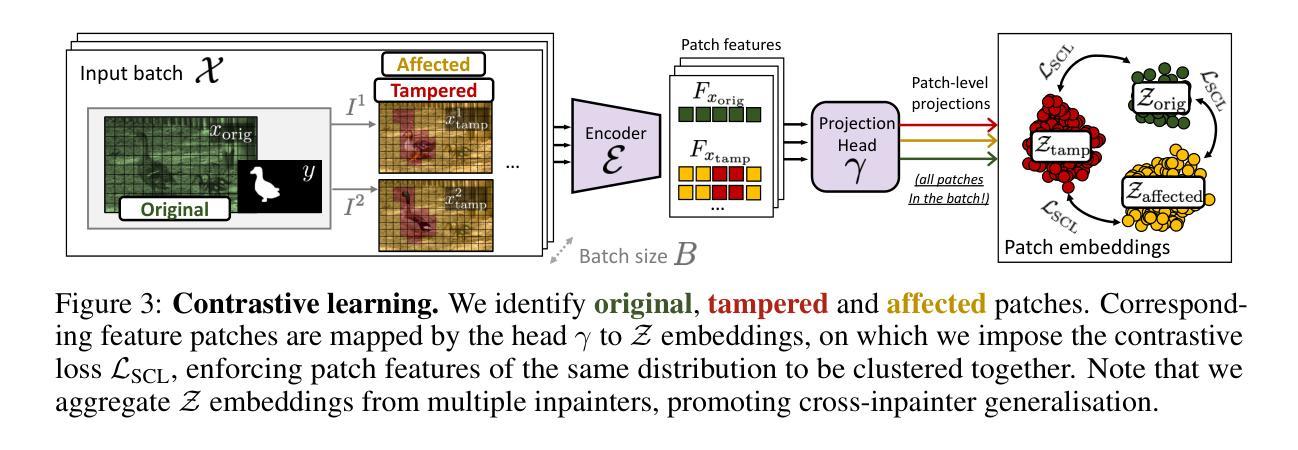
Towards Reliable Identification of Diffusion-based Image Manipulations
Authors:Alex Costanzino, Woody Bayliss, Juil Sock, Marc Gorriz Blanch, Danijela Horak, Ivan Laptev, Philip Torr, Fabio Pizzati
Changing facial expressions, gestures, or background details may dramatically alter the meaning conveyed by an image. Notably, recent advances in diffusion models greatly improve the quality of image manipulation while also opening the door to misuse. Identifying changes made to authentic images, thus, becomes an important task, constantly challenged by new diffusion-based editing tools. To this end, we propose a novel approach for ReliAble iDentification of inpainted AReas (RADAR). RADAR builds on existing foundation models and combines features from different image modalities. It also incorporates an auxiliary contrastive loss that helps to isolate manipulated image patches. We demonstrate these techniques to significantly improve both the accuracy of our method and its generalisation to a large number of diffusion models. To support realistic evaluation, we further introduce BBC-PAIR, a new comprehensive benchmark, with images tampered by 28 diffusion models. Our experiments show that RADAR achieves excellent results, outperforming the state-of-the-art in detecting and localising image edits made by both seen and unseen diffusion models. Our code, data and models will be publicly available at alex-costanzino.github.io/radar.
改变面部表情、手势或背景细节可能会极大地改变图像所传达的含义。值得注意的是,扩散模型的最新进展在极大地提高了图像操作质量的同时,也打开了滥用的大门。因此,识别对真实图像所做的更改成为了一项重要任务,这项任务不断受到新的基于扩散的编辑工具的挑战。为此,我们提出了一种新型方法——可靠标识图像内填充区域(RADAR)。RADAR建立在现有的基础模型上,结合了不同图像模态的特征。它还融入了一种辅助对比损失,有助于隔离操纵过的图像区块。我们展示的这些技术极大地提高了我们方法的准确性及其对大量扩散模型的推广能力。为了支持现实评估,我们还引入了BBC-PAIR,这是一个新的综合基准测试,包含由28种扩散模型篡改过的图像。我们的实验表明,RADAR取得了优异的结果,在检测和定位已知和未知的扩散模型所做的图像编辑方面超过了最先进的技术。我们的代码、数据和模型将在alex-costanzino.github.io/radar上公开提供。
论文及项目相关链接
Summary
本文介绍了利用扩散模型进行图像操作的新挑战,并提出了一种名为RADAR的新方法,用于识别图像中的编辑区域。RADAR结合不同图像模态的特征,并引入辅助对比损失来隔离编辑过的图像区域。同时,为了支持真实评估,还引入了BBC-PAIR新基准测试,包含由28种扩散模型修改的图像。实验表明,RADAR在检测和定位由已知和未知扩散模型进行的图像编辑方面表现出卓越性能。
Key Takeaways
- 扩散模型在改进图像质量的同时,也带来了新的图像操作滥用问题。
- RADAR方法结合了不同图像模态的特征,以识别图像中的编辑区域。
- RADAR通过引入辅助对比损失,提高了检测图像编辑区域的准确性和泛化能力。
- BBC-PAIR是一个新的基准测试,用于支持对图像操作检测方法的真实评估。
- RADAR在BBC-PAIR基准测试上表现出卓越性能,对已知和未知的扩散模型进行的图像编辑都有很好的检测效果。
- RADAR的源代码、数据和模型将公开提供,便于其他研究者使用和改进。
点此查看论文截图

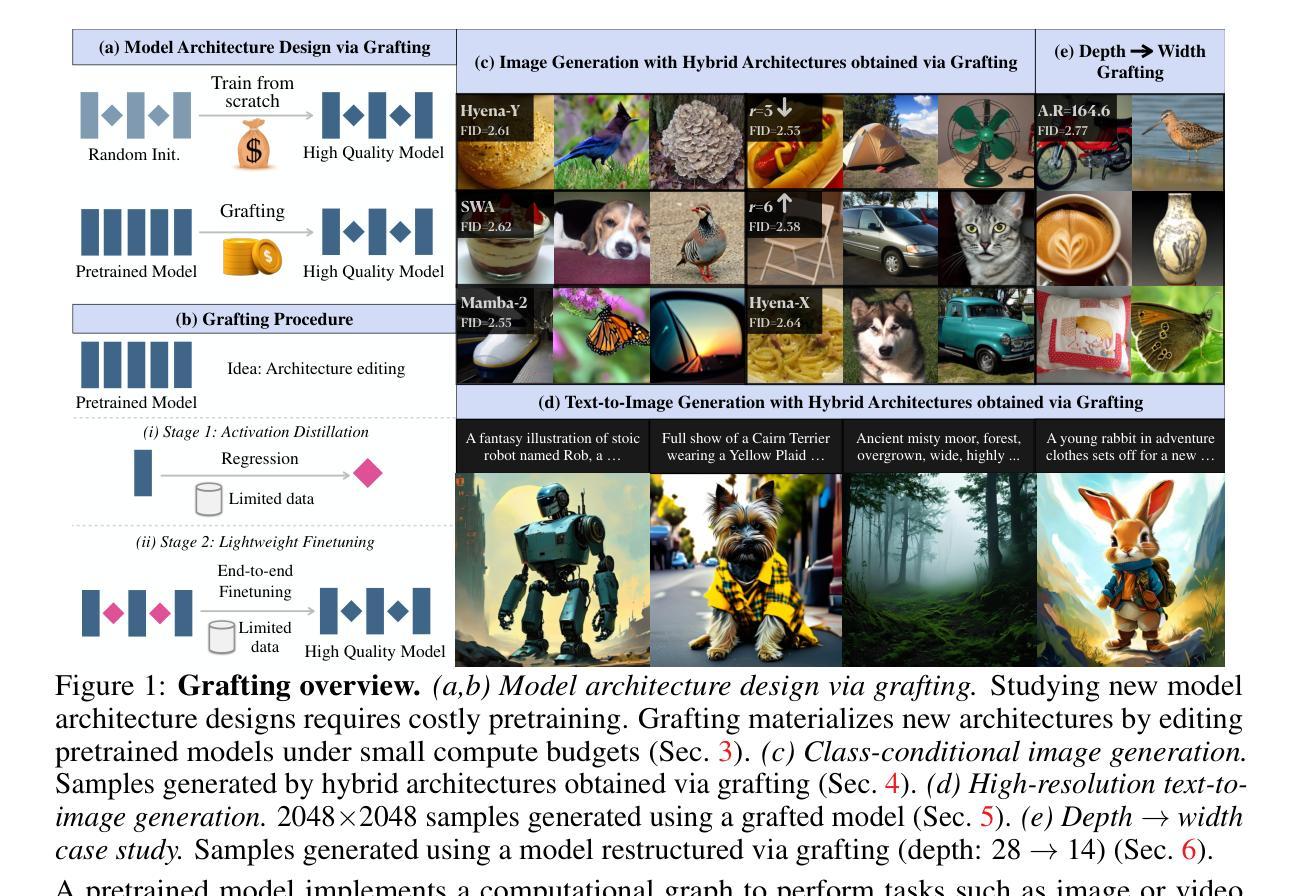
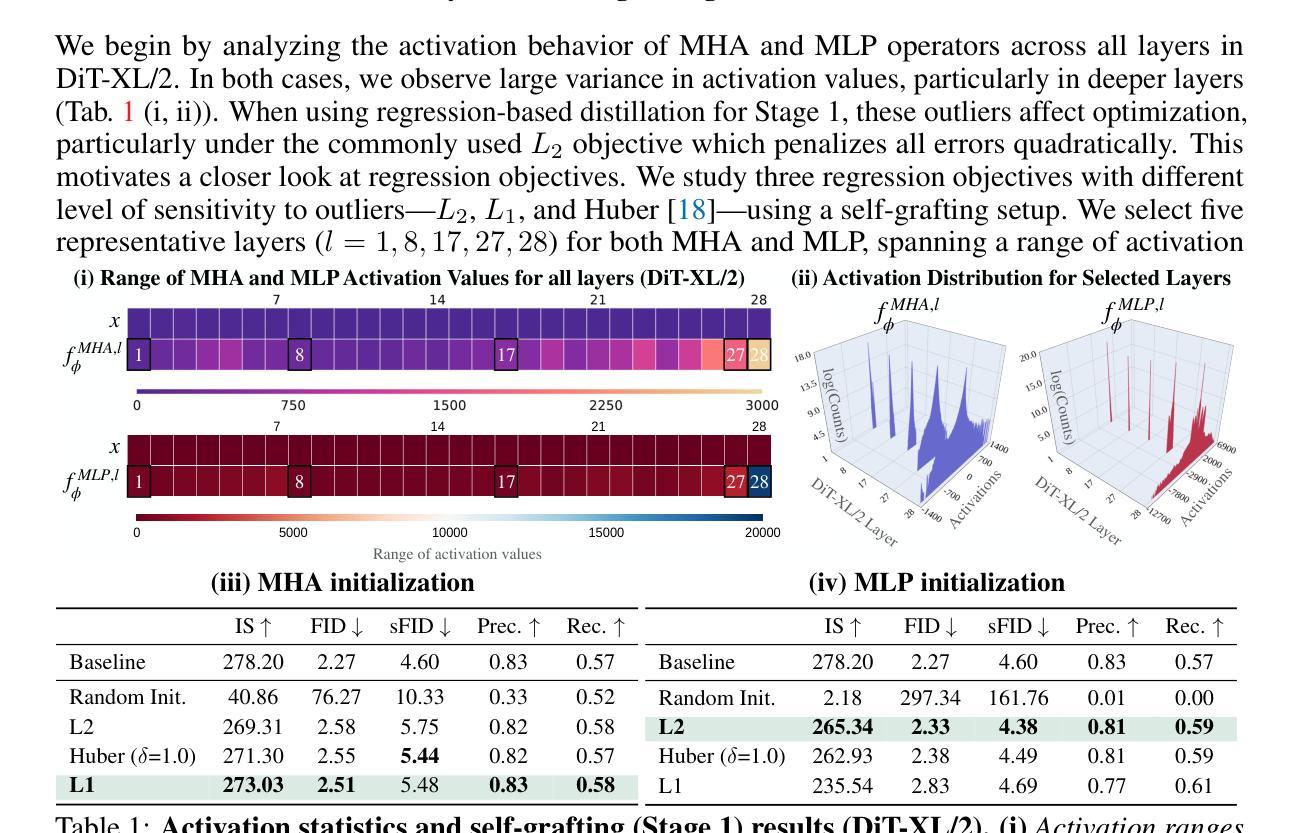
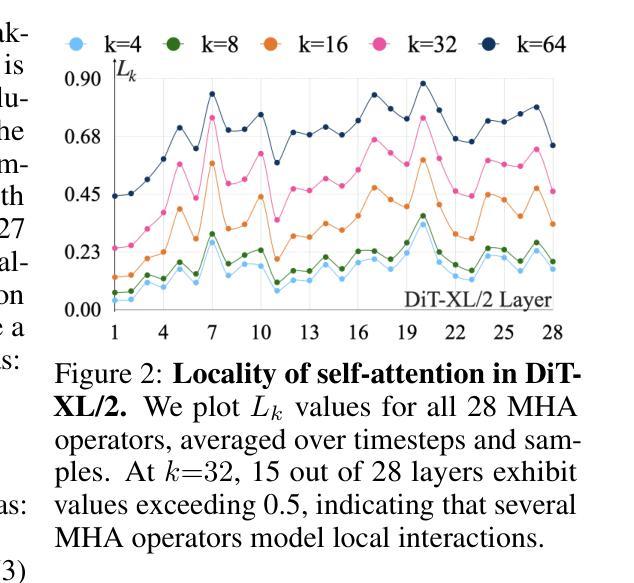
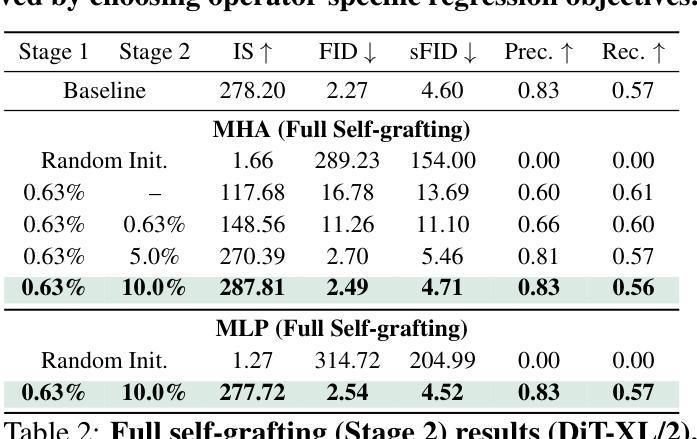
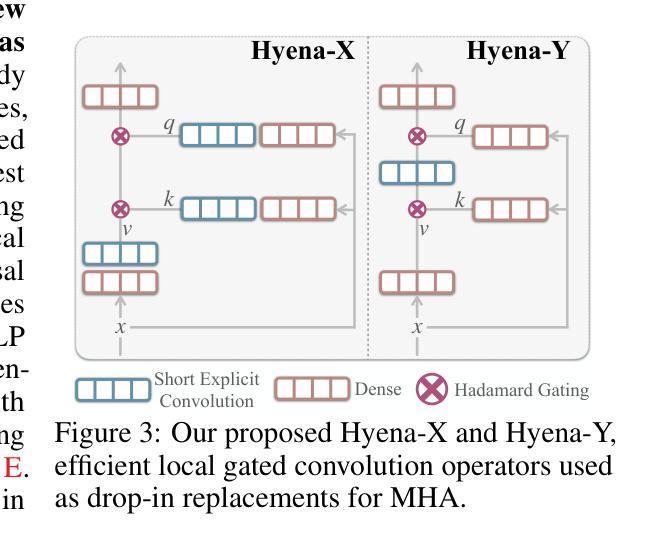
Exploring Diffusion Transformer Designs via Grafting
Authors:Keshigeyan Chandrasegaran, Michael Poli, Daniel Y. Fu, Dongjun Kim, Lea M. Hadzic, Manling Li, Agrim Gupta, Stefano Massaroli, Azalia Mirhoseini, Juan Carlos Niebles, Stefano Ermon, Li Fei-Fei
Designing model architectures requires decisions such as selecting operators (e.g., attention, convolution) and configurations (e.g., depth, width). However, evaluating the impact of these decisions on model quality requires costly pretraining, limiting architectural investigation. Inspired by how new software is built on existing code, we ask: can new architecture designs be studied using pretrained models? To this end, we present grafting, a simple approach for editing pretrained diffusion transformers (DiTs) to materialize new architectures under small compute budgets. Informed by our analysis of activation behavior and attention locality, we construct a testbed based on the DiT-XL/2 design to study the impact of grafting on model quality. Using this testbed, we develop a family of hybrid designs via grafting: replacing softmax attention with gated convolution, local attention, and linear attention, and replacing MLPs with variable expansion ratio and convolutional variants. Notably, many hybrid designs achieve good quality (FID: 2.38-2.64 vs. 2.27 for DiT-XL/2) using <2% pretraining compute. We then graft a text-to-image model (PixArt-Sigma), achieving a 1.43x speedup with less than a 2% drop in GenEval score. Finally, we present a case study that restructures DiT-XL/2 by converting every pair of sequential transformer blocks into parallel blocks via grafting. This reduces model depth by 2x and yields better quality (FID: 2.77) than other models of comparable depth. Together, we show that new diffusion model designs can be explored by grafting pretrained DiTs, with edits ranging from operator replacement to architecture restructuring. Code and grafted models: https://grafting.stanford.edu
设计模型架构需要进行诸如选择运算符(例如注意力、卷积)和配置(例如深度、宽度)之类的决策。然而,评估这些决策对模型质量的影响需要大量的预训练成本,这限制了架构的研究。我们受启发于如何在现有代码上构建新软件,我们想知道:可以使用预训练模型来研究新的架构设计吗?为此,我们提出了嫁接,这是一种简单的编辑预训练扩散变压器(DiTs)的方法,以在较小的计算预算下实现新的架构。根据我们对激活行为和注意力局部性的分析,我们以DiT-XL/2设计为基础构建了一个测试平台,以研究嫁接对模型质量的影响。使用这个测试平台,我们通过嫁接开发了一系列混合设计:用门控卷积、局部注意力和线性注意力替换softmax注意力,并用可变扩展率和卷积变体替换MLP。值得注意的是,许多混合设计在预训练计算量不到2%的情况下,使用FID(2.38-2.64与DiT-XL/2的2.27)达到了良好的质量。然后我们将一个文本到图像模型(PixArt-Sigma)进行嫁接,实现了1.43倍的加速,同时GenEval分数下降不到2%。最后,我们进行了一个案例研究,通过嫁接重新构建DiT-XL/2,将每一对连续的变压器块转换为并行块。这减少了模型深度的一半,并产生了比其他具有相似深度的模型更好的质量(FID:2.77)。总的来说,我们证明了可以通过嫁接预训练的DiTs来探索新的扩散模型设计,编辑范围从操作符替换到架构重组。代码和嫁接模型:https://grafting.stanford.edu。
论文及项目相关链接
PDF 22 pages; Project website: https://grafting.stanford.edu
Summary
本文通过借鉴软件开发中的复用思想,提出了扩散模型架构设计的新方法——嫁接预训练模型。通过对预训练的扩散转换器进行简单编辑,实现新架构在有限计算预算下的研究。通过在预训练模型上移植不同的设计,证明了这种方法的高效性,只需较少的计算就能得到良好质量的模型设计。该研究发现已在官方网站上公布,以推进研究。简单而言,作者提出了一种利用预训练模型进行扩散模型架构设计的新思路,为快速开发新模型提供了有效方法。
Key Takeaways
- 研究者提出了通过嫁接预训练模型来设计新的扩散模型架构的方法。
- 通过编辑预训练的扩散转换器(DiTs),实现了在小计算预算下研究新架构的目的。
点此查看论文截图

SeedEdit 3.0: Fast and High-Quality Generative Image Editing
Authors:Peng Wang, Yichun Shi, Xiaochen Lian, Zhonghua Zhai, Xin Xia, Xuefeng Xiao, Weilin Huang, Jianchao Yang
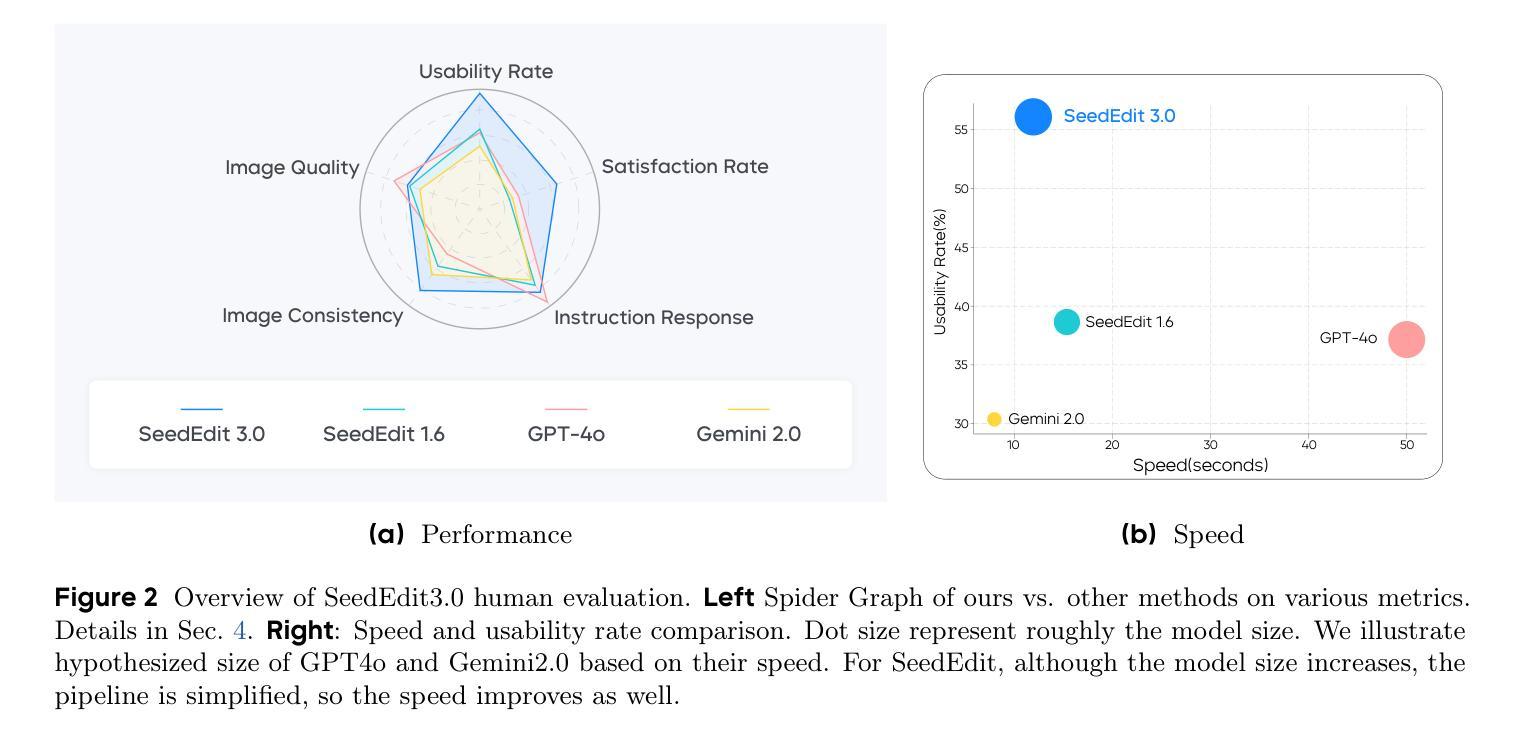
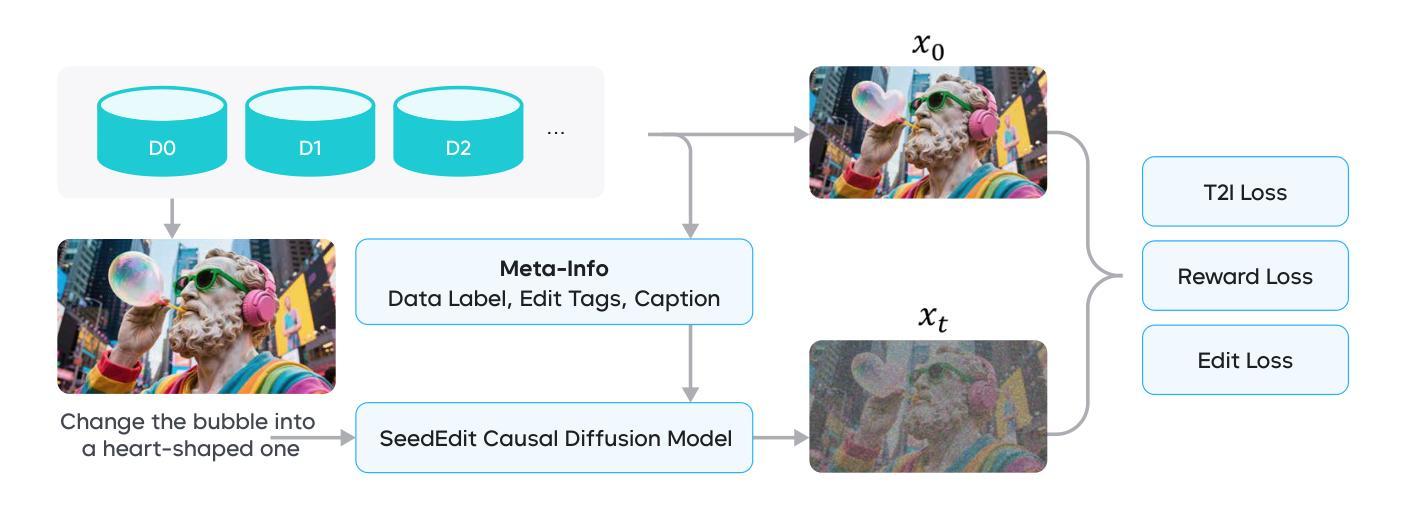
We introduce SeedEdit 3.0, in companion with our T2I model Seedream 3.0, which significantly improves over our previous SeedEdit versions in both aspects of edit instruction following and image content (e.g., ID/IP) preservation on real image inputs. Additional to model upgrading with T2I, in this report, we present several key improvements. First, we develop an enhanced data curation pipeline with a meta-info paradigm and meta-info embedding strategy that help mix images from multiple data sources. This allows us to scale editing data effectively, and meta information is helpfult to connect VLM with diffusion model more closely. Second, we introduce a joint learning pipeline for computing a diffusion loss and reward losses. Finally, we evaluate SeedEdit 3.0 on our testing benchmarks, for real/synthetic image editing, where it achieves a best trade-off between multiple aspects, yielding a high usability rate of 56.1%, compared to SeedEdit 1.6 (38.4%), GPT4o (37.1%) and Gemini 2.0 (30.3%).
我们推出了SeedEdit 3.0版本,与我们的T2I模型Seedream 3.0一同介绍。相较于我们之前的SeedEdit版本,它在遵循编辑指令和保留图像内容(例如ID/IP)方面对真实图像输入有了显著改进。除了使用T2I进行模型升级,本报告还展示了若干项重要改进。首先,我们开发了一个增强的数据整理管道,采用元信息范式和元信息嵌入策略,有助于混合来自多个数据源的图片。这使我们能够有效地扩展编辑数据,而元信息有助于更紧密地将VLM与扩散模型连接起来。其次,我们引入了一个联合学习管道,用于计算扩散损失和奖励损失。最后,我们在测试基准上对SeedEdit 3.0进行了真实/合成图像编辑的评估,它在多方面达到了最佳平衡,使用性率高达56.1%,相比之下,SeedEdit 1.6为38.4%,GPT4o为37.1%,Gemini 2.0为30.3%。
论文及项目相关链接
PDF Website: https://seed.bytedance.com/tech/seededit
Summary
本文介绍了新推出的SeedEdit 3.0与其配套的T2I模型Seedream 3.0,相较于之前的版本,它在遵循编辑指令和保留图像内容(如ID/IP)方面有了显著提升。此外,本文还介绍了几个关键改进,包括采用元信息范式和元信息嵌入策略增强数据整理流程、引入联合学习管道计算扩散损失和奖励损失,并在测试基准上评估了SeedEdit 3.0在真实/合成图像编辑方面的表现,实现了多方面的最佳平衡,使用率达到56.1%,相较于其他模型有显著提升。
Key Takeaways
- SeedEdit 3.0与其配套的T2I模型Seedream 3.0推出,显著提升了编辑指令遵循和图像内容保留的能力。
- 采用了元信息范式和元信息嵌入策略的增强数据整理流程,能有效整合多源图像数据。
- 引入了联合学习管道,计算扩散损失和奖励损失,促进了模型性能的提升。
- SeedEdit 3.0在真实/合成图像编辑方面的评估表现优异,实现了多方面的最佳平衡。
- SeedEdit 3.0的使用率达到56.1%,相较于之前版本和其他模型有显著提升。
- 模型的升级和改进有助于提升图像编辑任务的效率和效果。
点此查看论文截图



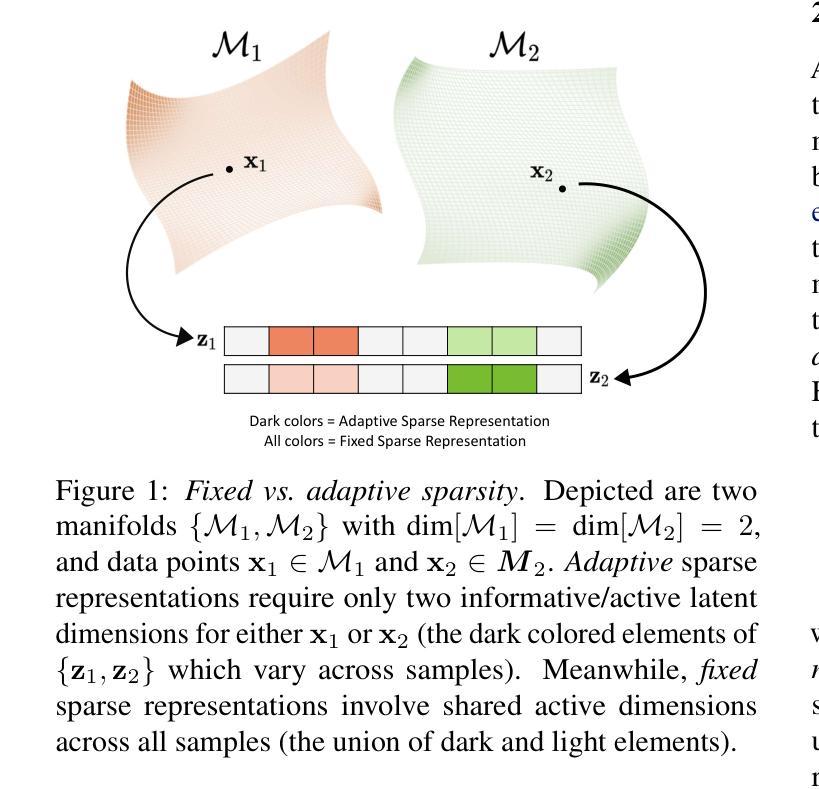
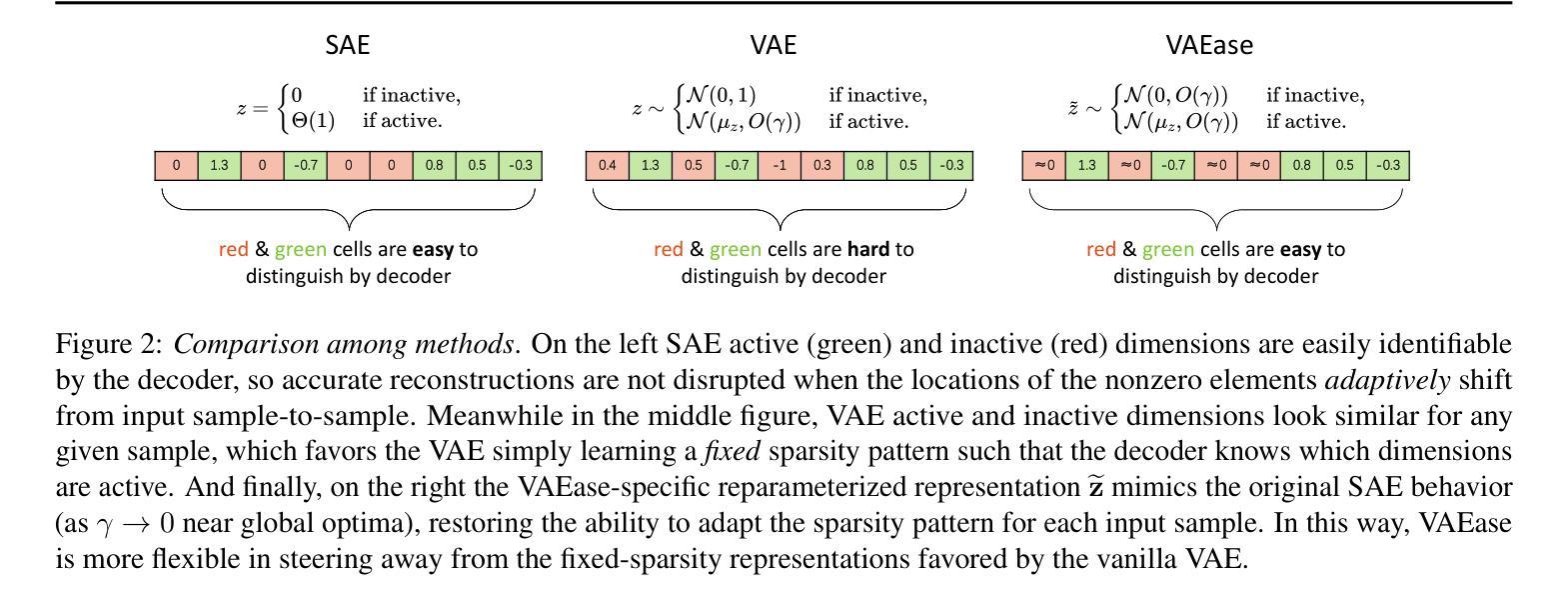
Sparse Autoencoders, Again?
Authors:Yin Lu, Xuening Zhu, Tong He, David Wipf
Is there really much more to say about sparse autoencoders (SAEs)? Autoencoders in general, and SAEs in particular, represent deep architectures that are capable of modeling low-dimensional latent structure in data. Such structure could reflect, among other things, correlation patterns in large language model activations, or complex natural image manifolds. And yet despite the wide-ranging applicability, there have been relatively few changes to SAEs beyond the original recipe from decades ago, namely, standard deep encoder/decoder layers trained with a classical/deterministic sparse regularizer applied within the latent space. One possible exception is the variational autoencoder (VAE), which adopts a stochastic encoder module capable of producing sparse representations when applied to manifold data. In this work we formalize underappreciated weaknesses with both canonical SAEs, as well as analogous VAEs applied to similar tasks, and propose a hybrid alternative model that circumvents these prior limitations. In terms of theoretical support, we prove that global minima of our proposed model recover certain forms of structured data spread across a union of manifolds. Meanwhile, empirical evaluations on synthetic and real-world datasets substantiate the efficacy of our approach in accurately estimating underlying manifold dimensions and producing sparser latent representations without compromising reconstruction error. In general, we are able to exceed the performance of equivalent-capacity SAEs and VAEs, as well as recent diffusion models where applicable, within domains such as images and language model activation patterns.
关于稀疏自编码器(SAEs)还有什么更多可说的吗?总的来说,自编码器,尤其是SAEs,代表了能够建模数据中的低维潜在结构的深度架构。这种结构可能反映了大型语言模型激活中的相关性模式,或复杂的自然图像流形。尽管SAEs具有广泛的应用范围,但除了几十年前的原始配方之外,几乎没有太多变化。也就是说,用经典/确定性稀疏正则化在潜在空间内训练的深度编码器/解码器层。一个可能的例外是变分自编码器(VAE),它采用了一种随机编码器模块,在应用于流形数据时能够产生稀疏表示。在这项工作中,我们正式提出了被忽视的弱点,无论是典型的SAEs,还是类似任务的VAEs,并提出了一种混合的替代模型,该模型可以绕过这些先前的限制。在理论支持方面,我们证明了我们的模型全局最小值能够恢复跨多个流形的某些形式的结构化数据分布。同时,在合成和真实数据集上的实证评估证实了我们方法在准确估计潜在流形维度和产生稀疏潜在表示方面的有效性,而不会损害重建误差。总的来说,我们在图像和语言模型激活模式等领域超过了同等容量的SAEs和VAEs的性能表现,以及在适用的最新扩散模型的性能表现。
论文及项目相关链接
PDF Accepted to the International Conference on Machine Learning (ICML) 2025
Summary
本文主要探讨了稀疏自动编码器(SAE)的局限性,并提出了一种新型的混合模型来克服这些局限。文章指出,尽管SAE在许多领域都有广泛应用,但其结构和技术自几十年前的原始配方以来并没有太大变化。文章还介绍了变分自动编码器(VAE)的某些特性,并展示了新的混合模型在理论支持和实证研究上的优势,例如在估计底层流形维度和产生稀疏潜在表示方面的优势。总体而言,新模型能在图像和语言模型激活模式等领域超越等效容量的SAE和VAE以及最近的扩散模型。
Key Takeaways
- 稀疏自动编码器(SAE)是一种能够建模数据低维潜在结构的深度架构。
- SAE在多种领域有广泛应用,但其结构和技术自提出以来变化较少。
- 变分自动编码器(VAE)采用随机编码器模块,能应用于流形数据产生稀疏表示。
- 本文指出了SAE和类似任务的VAE的不足之处,并提出了一种新型混合模型来克服这些局限。
- 新模型在理论上有证明,能够恢复跨多个流形的某些形式的结构化数据。
- 实证研究表明,新模型在估计底层流形维度和产生稀疏潜在表示方面表现优异,且不会增加重建误差。
点此查看论文截图


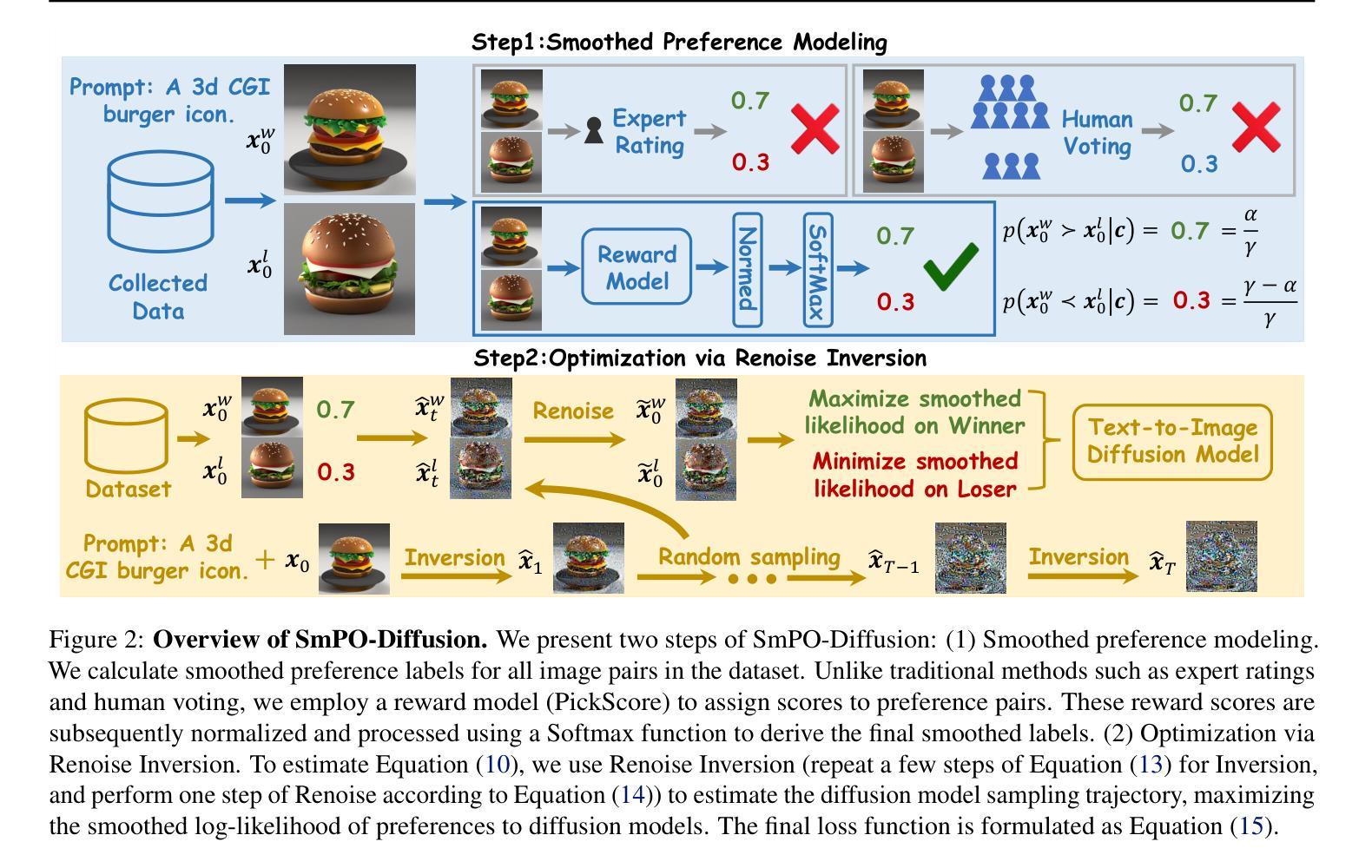
Smoothed Preference Optimization via ReNoise Inversion for Aligning Diffusion Models with Varied Human Preferences
Authors:Yunhong Lu, Qichao Wang, Hengyuan Cao, Xiaoyin Xu, Min Zhang
Direct Preference Optimization (DPO) aligns text-to-image (T2I) generation models with human preferences using pairwise preference data. Although substantial resources are expended in collecting and labeling datasets, a critical aspect is often neglected: \textit{preferences vary across individuals and should be represented with more granularity.} To address this, we propose SmPO-Diffusion, a novel method for modeling preference distributions to improve the DPO objective, along with a numerical upper bound estimation for the diffusion optimization objective. First, we introduce a smoothed preference distribution to replace the original binary distribution. We employ a reward model to simulate human preferences and apply preference likelihood averaging to improve the DPO loss, such that the loss function approaches zero when preferences are similar. Furthermore, we utilize an inversion technique to simulate the trajectory preference distribution of the diffusion model, enabling more accurate alignment with the optimization objective. Our approach effectively mitigates issues of excessive optimization and objective misalignment present in existing methods through straightforward modifications. Our SmPO-Diffusion achieves state-of-the-art performance in preference evaluation, outperforming baselines across metrics with lower training costs. The project page is https://jaydenlyh.github.io/SmPO-project-page/.
直接偏好优化(DPO)使用成对偏好数据将文本到图像(T2I)生成模型与人类偏好对齐。虽然收集和标注数据集需要耗费大量资源,但往往忽略了一个关键方面:*不同个体的偏好不同,应以更精细的方式表示。为了解决这一问题,我们提出了SmPO-Diffusion,这是一种改进DPO目标的新型偏好分布建模方法,以及扩散优化目标的数值上限估计。首先,我们引入平滑偏好分布来替换原始二进制分布。我们采用奖励模型来模拟人类偏好,并通过偏好可能性平均来改进DPO损失,使得当偏好相似时损失函数接近零。此外,我们利用反演技术模拟扩散模型的轨迹偏好分布,使与优化目标对齐得更准确。我们的方法通过直接修改有效地缓解了现有方法中过度优化和目标不匹配的问题。SmPO-Diffusion在偏好评估方面达到了最新技术水平,在各项指标上均优于基线,同时降低了训练成本。项目页面是https://jaydenlyh.github.io/SmPO-project-page/。
论文及项目相关链接
PDF Accepted by ICML 2025
Summary
本文提出了SmPO-Diffusion方法,通过引入平滑偏好分布来改进Direct Preference Optimization(DPO)的目标。该方法使用奖励模型模拟人类偏好,并采用偏好可能性平均法改进DPO损失函数。同时,利用扩散模型的轨迹偏好分布模拟技术,更有效地对齐优化目标。SmPO-Diffusion解决了现有方法中的过度优化和目标不对齐问题,实现了优异的偏好评估性能,并且在训练成本上优于基线。
Key Takeaways
- SmPO-Diffusion提出使用平滑偏好分布来改进DPO的目标,以更好地模拟人类偏好。
- 引入奖励模型来模拟人类偏好,提高DPO损失函数的准确性。
- 采用偏好可能性平均法,当偏好相似时,损失函数接近零。
- 利用扩散模型的轨迹偏好分布模拟技术,更有效地对齐优化目标。
- SmPO-Diffusion解决了现有方法中的过度优化和目标不对齐问题。
- SmPO-Diffusion在偏好评估方面达到最新性能水平,并在训练成本上优于基线。
点此查看论文截图



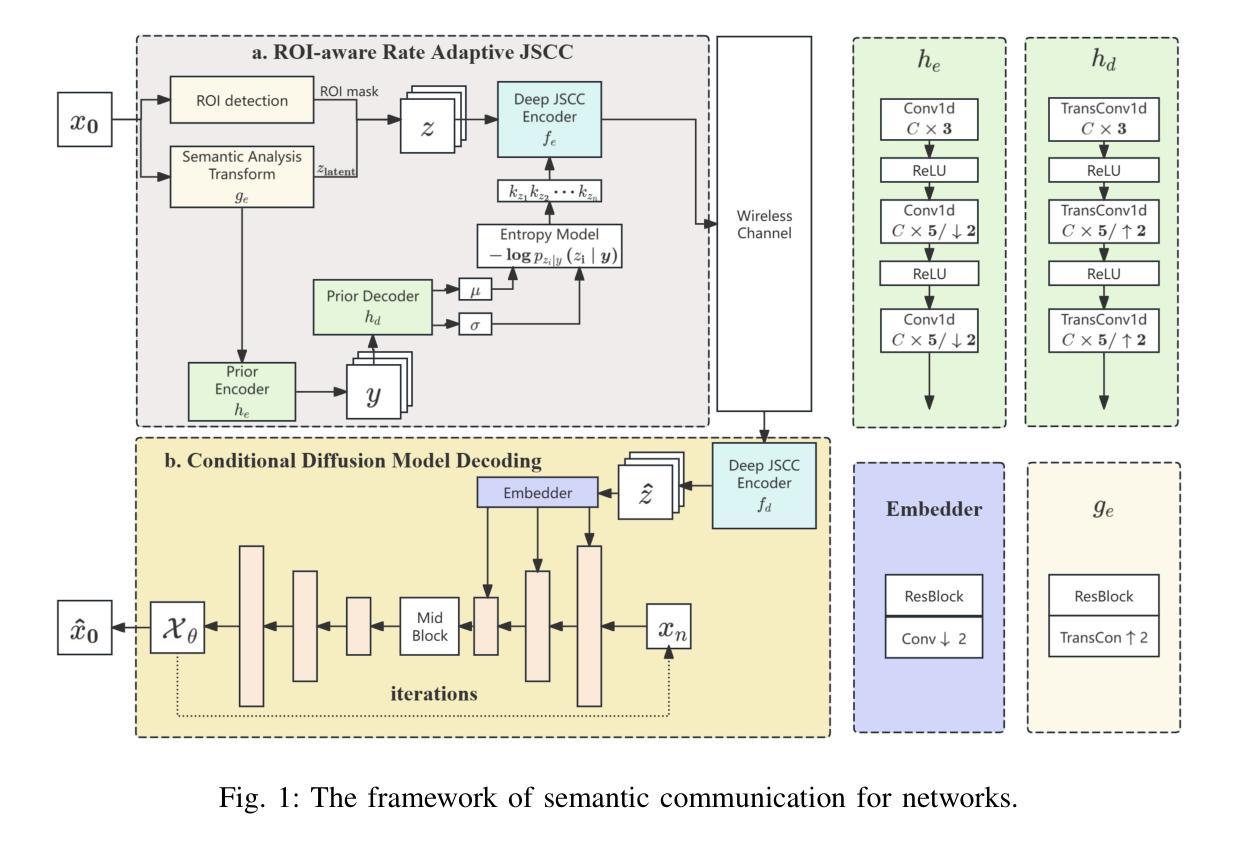
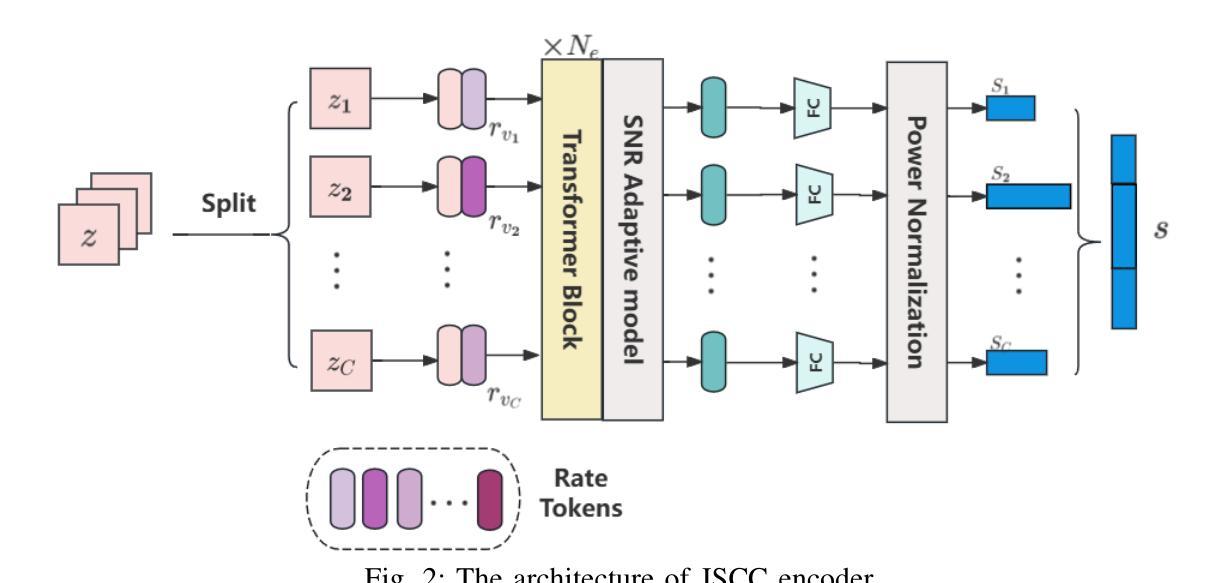
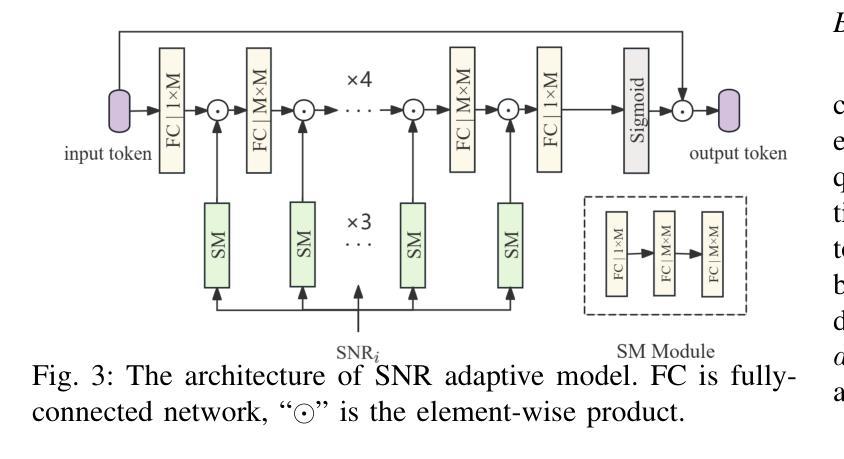
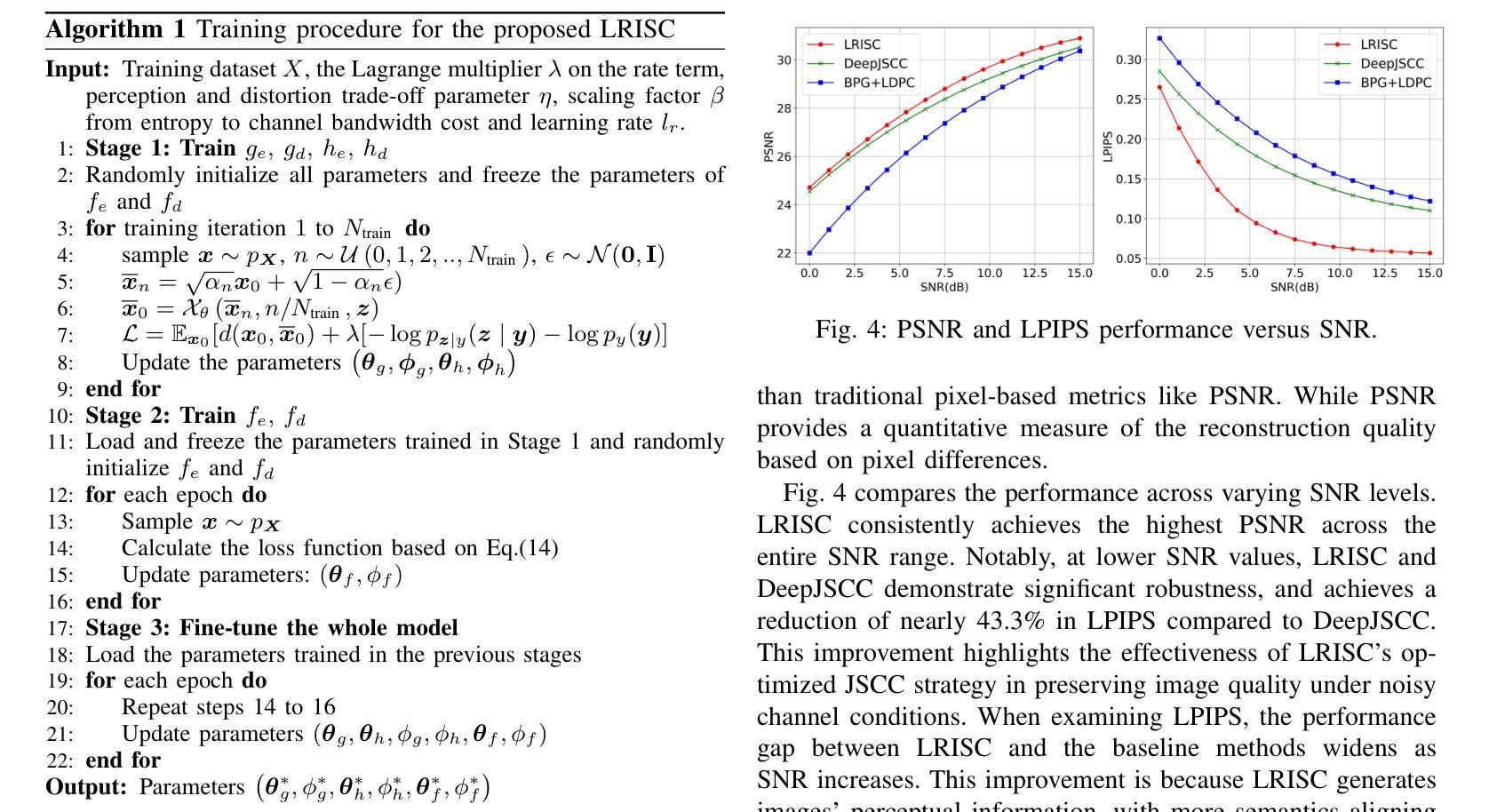
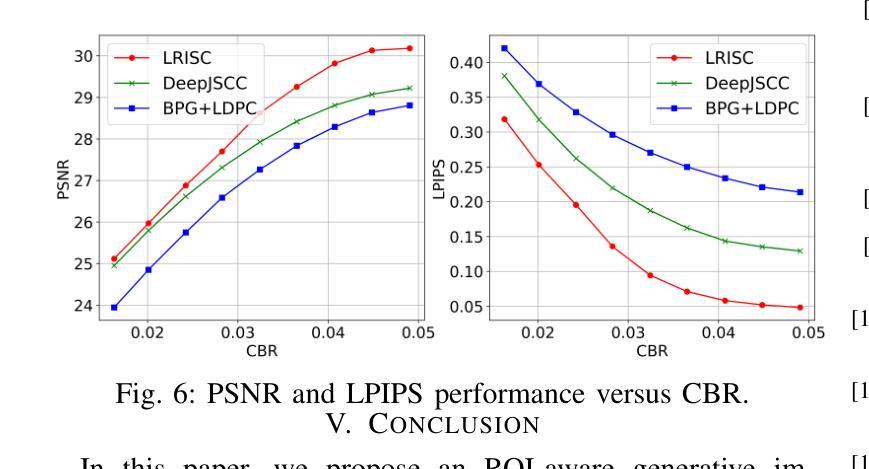
Latent Feature-Guided Conditional Diffusion for Generative Image Semantic Communication
Authors:Zehao Chen, Xinfeng Wei, Haonan Tong, Zhaohui Yang, Changchuan Yin
Semantic communication is proposed and expected to improve the efficiency of massive data transmission over sixth generation (6G) networks. However, existing image semantic communication schemes are primarily focused on optimizing pixel-level metrics, while neglecting the crucial aspect of region of interest (ROI) preservation. To address this issue, we propose an ROI-aware latent representation-oriented image semantic communication (LRISC) system. In particular, we first map the source image to latent features in a high-dimensional semantic space, these latent features are then fused with ROI mask through a feature-weighting mechanism. Subsequently, these features are encoded using a joint source and channel coding (JSCC) scheme with adaptive rate for efficient transmission over a wireless channel. At the receiver, a conditional diffusion model is developed by using the received latent features as conditional guidance to steer the reverse diffusion process, progressively reconstructing high-fidelity images while preserving semantic consistency. Moreover, we introduce a channel signal-to-noise ratio (SNR) adaptation mechanism, allowing one model to work across various channel states. Experiments show that the proposed method significantly outperforms existing methods, in terms of learned perceptual image patch similarity (LPIPS) and robustness against channel noise, with an average LPIPS reduction of 43.3% compared to DeepJSCC, while guaranteeing the semantic consistency.
语义通信旨在提高第六代(6G)网络上大规模数据传输的效率。然而,现有的图像语义通信方案主要关注像素级指标的优化,忽视了感兴趣区域(ROI)保持的重要方面。为了解决这一问题,我们提出了一种面向潜在表示的感兴趣区域感知图像语义通信系统(LRISC)。具体而言,我们首先将源图像映射到高维语义空间中的潜在特征上,然后通过特征加权机制将这些潜在特征与ROI掩膜融合。随后,这些特征使用联合源和信道编码(JSCC)方案进行编码,并通过无线信道进行自适应速率的有效传输。在接收端,通过使用接收到的潜在特征作为条件指导,开发了一种条件扩散模型,以引导反向扩散过程,逐步重建高质量图像并保持语义一致性。此外,我们还引入了一种信道信噪比(SNR)自适应机制,使一个模型能够在各种信道状态下工作。实验表明,所提出的方法在感知图像补丁相似性(LPIPS)和对抗信道噪声的稳健性方面显著优于现有方法,与DeepJSCC相比平均LPIPS降低了43.3%,同时保证了语义一致性。
论文及项目相关链接
PDF 6 pages, 6 figures, update title
Summary
针对现有图像语义通信方案忽视感兴趣区域(ROI)保留的问题,提出一种基于ROI感知的潜在表示导向图像语义通信系统(LRISC)。该系统将源图像映射到高维语义空间的潜在特征,并与ROI掩膜融合。通过联合源信道编码(JSCC)方案自适应速率编码特征,实现无线信道上的高效传输。接收端采用条件扩散模型,以接收到的潜在特征作为条件指导,反向扩散过程逐步重建高保真图像,同时保持语义一致性。此外,引入信道信噪比(SNR)自适应机制,使模型能在各种信道状态下工作。实验表明,该方法在感知图像块相似性(LPIPS)和信道噪声鲁棒性方面显著优于现有方法,平均LPIPS降低43.3%,同时保证语义一致性。
Key Takeaways
- 语义通信提高6G网络大数据传输效率。
- 现有图像语义通信方案主要优化像素级指标,忽视ROI保留。
- 提出LRISC系统,映射源图像到高维语义空间并融合ROI掩膜。
- 使用JSCC方案自适应速率编码特征,实现高效无线传输。
- 接收端采用条件扩散模型逐步重建高保真图像并保持语义一致性。
- 引入SNR自适应机制适应各种信道状态。
点此查看论文截图

Efficient Diffusion Models: A Survey
Authors:Hui Shen, Jingxuan Zhang, Boning Xiong, Rui Hu, Shoufa Chen, Zhongwei Wan, Xin Wang, Yu Zhang, Zixuan Gong, Guangyin Bao, Chaofan Tao, Yongfeng Huang, Ye Yuan, Mi Zhang
Diffusion models have emerged as powerful generative models capable of producing high-quality contents such as images, videos, and audio, demonstrating their potential to revolutionize digital content creation. However, these capabilities come at the cost of their significant computational resources and lengthy generation time, underscoring the critical need to develop efficient techniques for practical deployment. In this survey, we provide a systematic and comprehensive review of research on efficient diffusion models. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient diffusion model topics from algorithm-level, system-level, and framework perspective, respectively. We have also created a GitHub repository where we organize the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/Efficient-Diffusion-Model-Survey. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of efficient diffusion model research and inspire them to contribute to this important and exciting field.
扩散模型作为强大的生成模型已经崭露头角,能够产生高质量的图像、视频和音频等内容,显示出它们在数字内容创作领域具有颠覆性潜力。然而,这些功能需要大量的计算资源和漫长的生成时间,这凸显了开发高效技术用于实际部署的迫切需求。在本次调查中,我们对高效扩散模型的研究进行了系统而全面的综述。我们从算法层面、系统层面和框架视角对文献进行了分类,涵盖了三个主要类别中不同但相互关联的高效扩散模型主题。我们还创建了一个GitHub仓库,其中整理了本次调查中介绍的论文,地址为:https://github.com/AIoT-MLSys-Lab/Efficient-Diffusion-Model-Survey。我们希望本次调查能为研究者和从业者提供对高效扩散模型的系统性理解,并激发他们对这一重要且激动人心的领域的贡献。能作为有价值的资源,帮助研究者和从业者系统地了解高效扩散模型的研究,并激励他们为这一重要且令人兴奋的领域做出贡献。
论文及项目相关链接
PDF Published in Transactions on Machine Learning Research (TMLR-2025)
Summary
本文介绍了扩散模型作为强大的生成模型在数字内容创作领域的潜力。虽然这些模型能够产生高质量的内容如图像、视频和音频,但它们需要大量的计算资源和长时间的生成时间。本文提供了一篇关于高效扩散模型的综合性调查,从算法、系统和框架三个角度组织了相关文献,并创建了一个GitHub仓库来整理这些论文。本文旨在为研究人员和实践者提供对高效扩散模型的系统性理解,并激发他们对这一重要且激动人心的领域的贡献。
Key Takeaways
- 扩散模型已成为强大的生成模型,具有革命性数字内容创作的潜力。
- 扩散模型虽然能产生高质量内容,但需要大量计算资源和长时间的生成时间。
- 本文提供了一篇关于高效扩散模型的综合性调查。
- 调查从算法、系统和框架三个角度组织了相关文献。
- 创建一个GitHub仓库来整理论文,方便研究人员和实践者获取资源。
- 本文旨在为研究人员和实践者提供对高效扩散模型的系统性理解。
点此查看论文截图


Normalizing Flows are Capable Generative Models
Authors:Shuangfei Zhai, Ruixiang Zhang, Preetum Nakkiran, David Berthelot, Jiatao Gu, Huangjie Zheng, Tianrong Chen, Miguel Angel Bautista, Navdeep Jaitly, Josh Susskind
Normalizing Flows (NFs) are likelihood-based models for continuous inputs. They have demonstrated promising results on both density estimation and generative modeling tasks, but have received relatively little attention in recent years. In this work, we demonstrate that NFs are more powerful than previously believed. We present TarFlow: a simple and scalable architecture that enables highly performant NF models. TarFlow can be thought of as a Transformer-based variant of Masked Autoregressive Flows (MAFs): it consists of a stack of autoregressive Transformer blocks on image patches, alternating the autoregression direction between layers. TarFlow is straightforward to train end-to-end, and capable of directly modeling and generating pixels. We also propose three key techniques to improve sample quality: Gaussian noise augmentation during training, a post training denoising procedure, and an effective guidance method for both class-conditional and unconditional settings. Putting these together, TarFlow sets new state-of-the-art results on likelihood estimation for images, beating the previous best methods by a large margin, and generates samples with quality and diversity comparable to diffusion models, for the first time with a stand-alone NF model. We make our code available at https://github.com/apple/ml-tarflow.
标准化流(NFs)是基于连续输入的似然模型。它们在密度估计和生成建模任务上都显示出有前景的结果,但近年来受到的关注相对较少。在这项工作中,我们证明NFs比以前认为的更强大。我们提出了TarFlow:一种简单且可扩展的架构,能够实现高性能的NF模型。TarFlow可以被看作是基于变压器的掩码自回归流(MAF)的变体:它由图像补丁上的自回归变压器块堆叠而成,并在层之间交替自回归方向。TarFlow可以端到端进行训练,并且能够直接对像素进行建模和生成。我们还提出了三种提高样本质量的关键技术:训练过程中的高斯噪声增强、训练后的去噪程序,以及针对有条件和无条件设置的有效的指导方法。将这些结合起来,TarFlow在图像似然估计方面达到了新的最先进的水平,大大超过了以前最好的方法,并且生成的样本质量和多样性可与扩散模型相当,这是首次使用独立的NF模型实现。我们的代码可在https://github.com/apple/ml-tarflow获取。
论文及项目相关链接
PDF ICML 2025
Summary
本文介绍了流模型(NFs)在密度估计和生成建模任务上的优异表现,并提出了一种简单且可扩展的架构TarFlow,它基于Transformer和Masked Autoregressive Flows(MAFs),能够构建高性能的NF模型。TarFlow通过三层技术改进样本质量,包括训练过程中的高斯噪声增强、训练后的去噪程序以及在有类和无条件下的有效指导方法。最终,TarFlow在图像的概率估计上达到新的最高水平,生成样本的质量和多样性首次与扩散模型相当。
Key Takeaways
- 流模型(NFs)在密度估计和生成建模任务上具有优异表现。
- TarFlow是一种基于Transformer和MAFs的架构,使NF模型更加高效。
- TarFlow通过堆叠的自回归Transformer块对图像块进行处理,并在层间交替自回归方向。
- TarFlow采用三层技术提高样本质量:训练中的高斯噪声增强、训练后的去噪程序和有指导的生成方法。
- TarFlow达到新的图像概率估计的最高水平,大幅度超越以前最好的方法。
- TarFlow生成的样本质量和多样性首次与扩散模型相当。
点此查看论文截图

Birth and Death of a Rose
Authors:Chen Geng, Yunzhi Zhang, Shangzhe Wu, Jiajun Wu
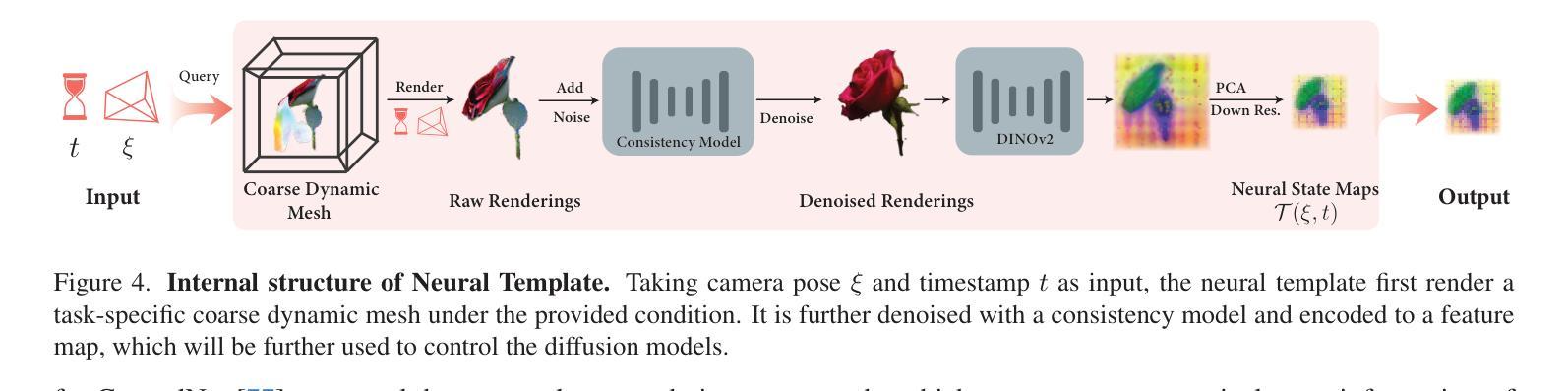
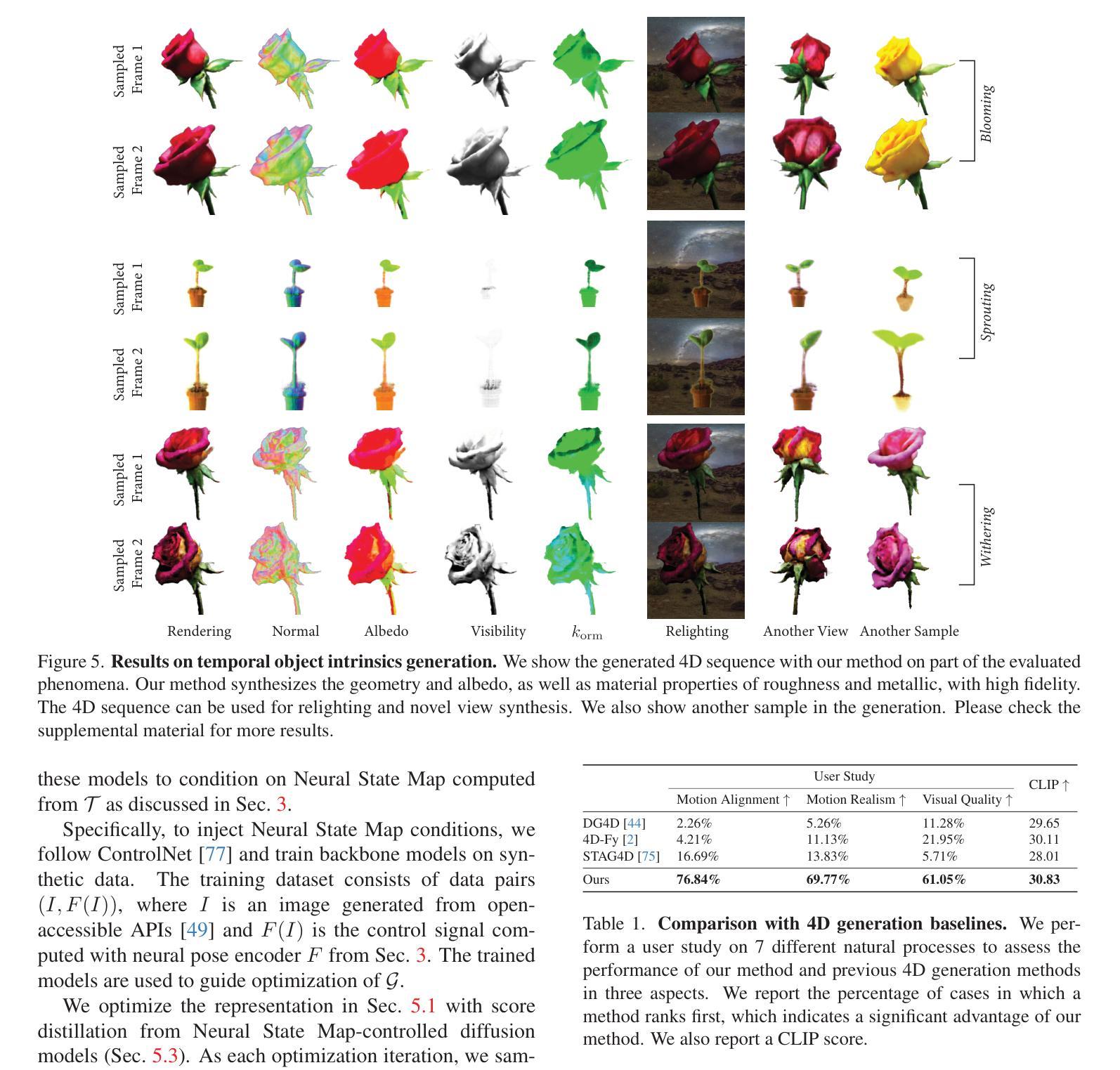
We study the problem of generating temporal object intrinsics – temporally evolving sequences of object geometry, reflectance, and texture, such as a blooming rose – from pre-trained 2D foundation models. Unlike conventional 3D modeling and animation techniques that require extensive manual effort and expertise, we introduce a method that generates such assets with signals distilled from pre-trained 2D diffusion models. To ensure the temporal consistency of object intrinsics, we propose Neural Templates for temporal-state-guided distillation, derived automatically from image features from self-supervised learning. Our method can generate high-quality temporal object intrinsics for several natural phenomena and enable the sampling and controllable rendering of these dynamic objects from any viewpoint, under any environmental lighting conditions, at any time of their lifespan. Project website: https://chen-geng.com/rose4d
我们研究从预训练的2D基础模型生成时间对象固有体的问题——时间演化的对象几何、反射率和纹理序列,如盛开的玫瑰。不同于需要大量人工努力和专业知识的传统3D建模和动画技术,我们引入了一种方法,该方法使用从预训练的2D扩散模型中提炼的信号生成此类资产。为了确保对象固有体的时间一致性,我们提出了基于自监督学习图像特征自动派生的时间状态引导蒸馏的神经网络模板。我们的方法可以为多种自然现象生成高质量的时间对象固有体,并能够在任何生命周期的任何时间、任何环境照明条件下,从任何视角对这些动态对象进行采样和可控渲染。项目网站:https://chen-geng.com/rose4d
论文及项目相关链接
PDF CVPR 2025 Oral. Project website: https://chen-geng.com/rose4d
Summary
该研究利用预训练的二维扩散模型生成时间性对象固有属性,如生长中的花朵等。该研究提出了一种从预训练的二维扩散模型中提炼信号生成此类资产的方法,无需传统三维建模和动画技术所需的大量手动工作和专业知识。通过使用神经模板进行时间状态引导的蒸馏,确保了对象固有属性的时间一致性。该方法可以生成高质量的时间性对象固有属性,为多种自然现象提供采样,并可从任何角度、在任何环境照明条件下、在对象的生命周期中的任何时间进行可控渲染。有关详细信息,请访问项目网站:https://chen-geng.com/rose4d。
Key Takeaways
- 该研究关注生成时间性对象固有属性,如生长中的花朵等。
- 利用预训练的二维扩散模型生成这些属性,简化了传统三维建模和动画技术的复杂流程。
- 引入神经模板确保对象固有属性的时间一致性。
- 该方法可以生成高质量的时间性对象固有属性,适用于多种自然现象。
- 可实现从任何角度、在任何环境照明条件下、在对象的生命周期中的任何时间的可控渲染。
- 项目详细信息可通过访问网站https://chen-geng.com/rose4d获取。
点此查看论文截图


Understanding Memorization in Generative Models via Sharpness in Probability Landscapes
Authors:Dongjae Jeon, Dueun Kim, Albert No
In this paper, we introduce a geometric framework to analyze memorization in diffusion models through the sharpness of the log probability density. We mathematically justify a previously proposed score-difference-based memorization metric by demonstrating its effectiveness in quantifying sharpness. Additionally, we propose a novel memorization metric that captures sharpness at the initial stage of image generation in latent diffusion models, offering early insights into potential memorization. Leveraging this metric, we develop a mitigation strategy that optimizes the initial noise of the generation process using a sharpness-aware regularization term.
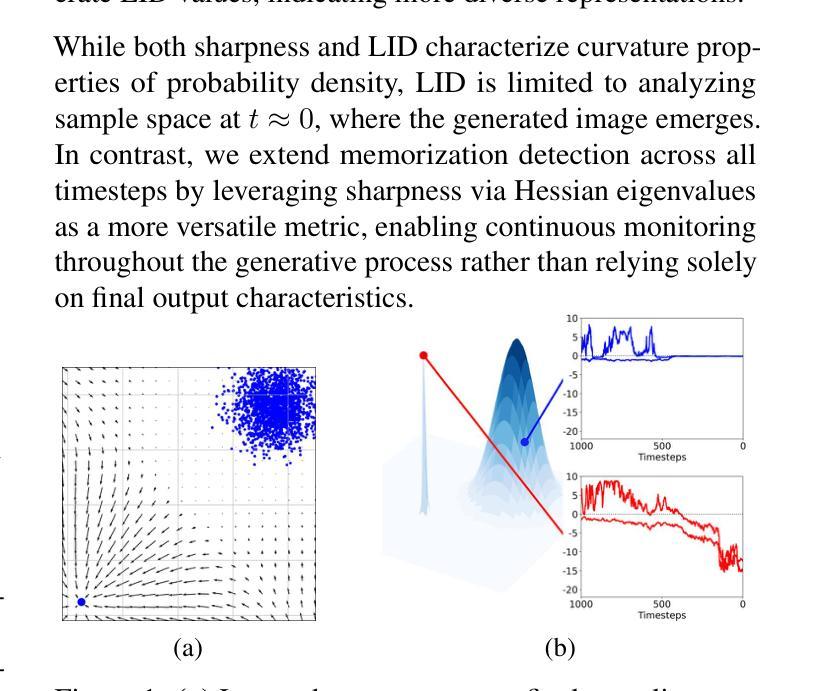
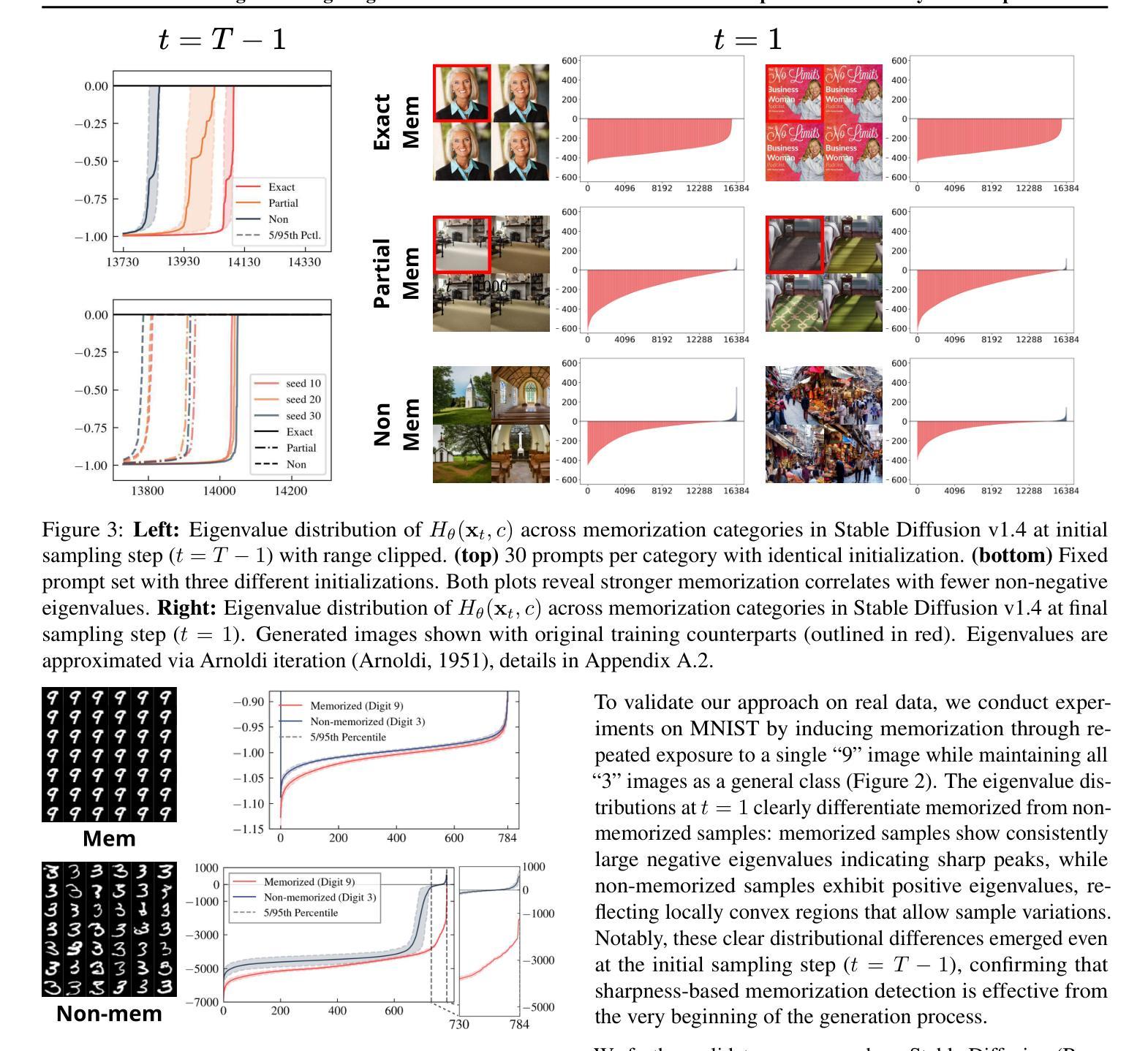
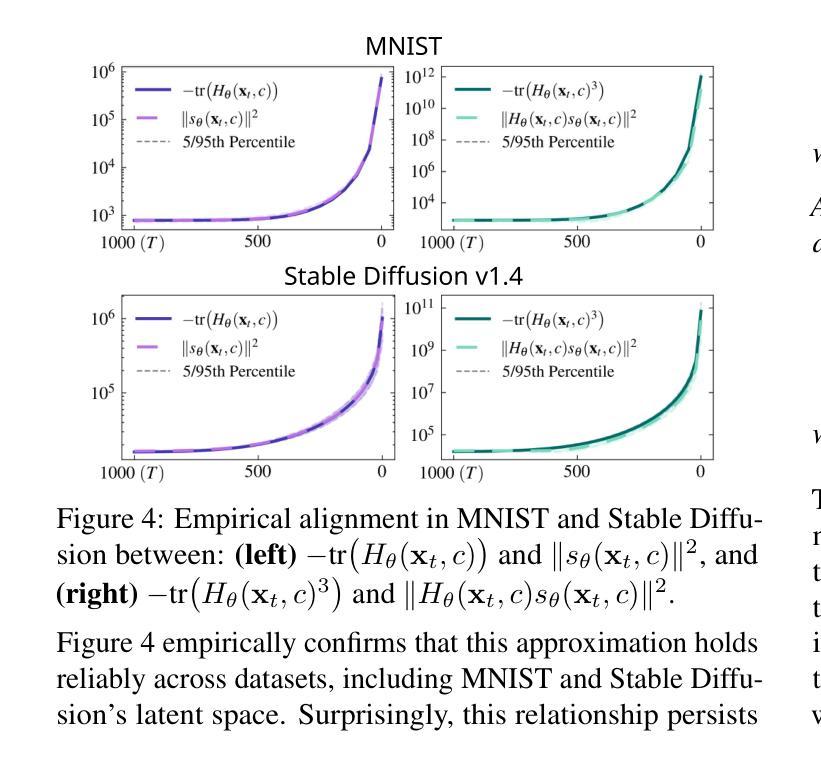
在这篇论文中,我们引入了一个几何框架,通过对数概率密度的尖锐程度来分析扩散模型中的记忆能力。我们通过证明其在量化尖锐度方面的有效性,为之前提出的基于分数差异的记忆力指标提供了数学论证。此外,我们提出了一个新的记忆力指标,该指标能够捕捉潜在扩散模型的图像生成初始阶段的尖锐度,为潜在的记忆力提供早期见解。借助这一指标,我们开发了一种缓解策略,通过采用感知尖锐度的正则化项来优化生成过程的初始噪声。
论文及项目相关链接
PDF Accepted at ICML 2025 (Spotlight)
Summary:
本文引入了一个几何框架,通过概率密度对数尖锐度分析扩散模型中的记忆能力。文章证明了先前提出的基于评分差异的量化记忆能力指标的数学有效性,并提出了一种新的量化图像生成初期记忆能力的指标。此外,基于这一新指标,提出了一种优化生成过程初始噪声的缓解策略。此策略通过引入一个尖锐度感知正则化项来实现。
Key Takeaways:
- 引入几何框架分析扩散模型中记忆能力的机制。
- 通过概率密度对数尖锐度来衡量扩散模型的记忆能力。
- 证明了基于评分差异的量化记忆能力指标的数学有效性。
- 提出一种新型量化指标来衡量图像生成初期阶段模型对信息的记忆能力。
点此查看论文截图

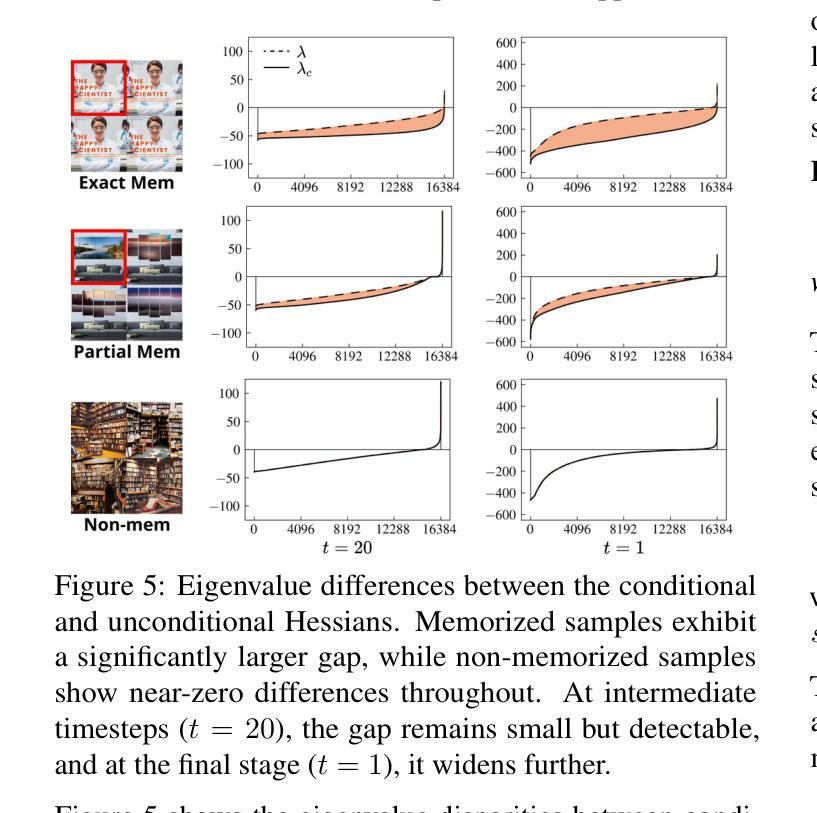
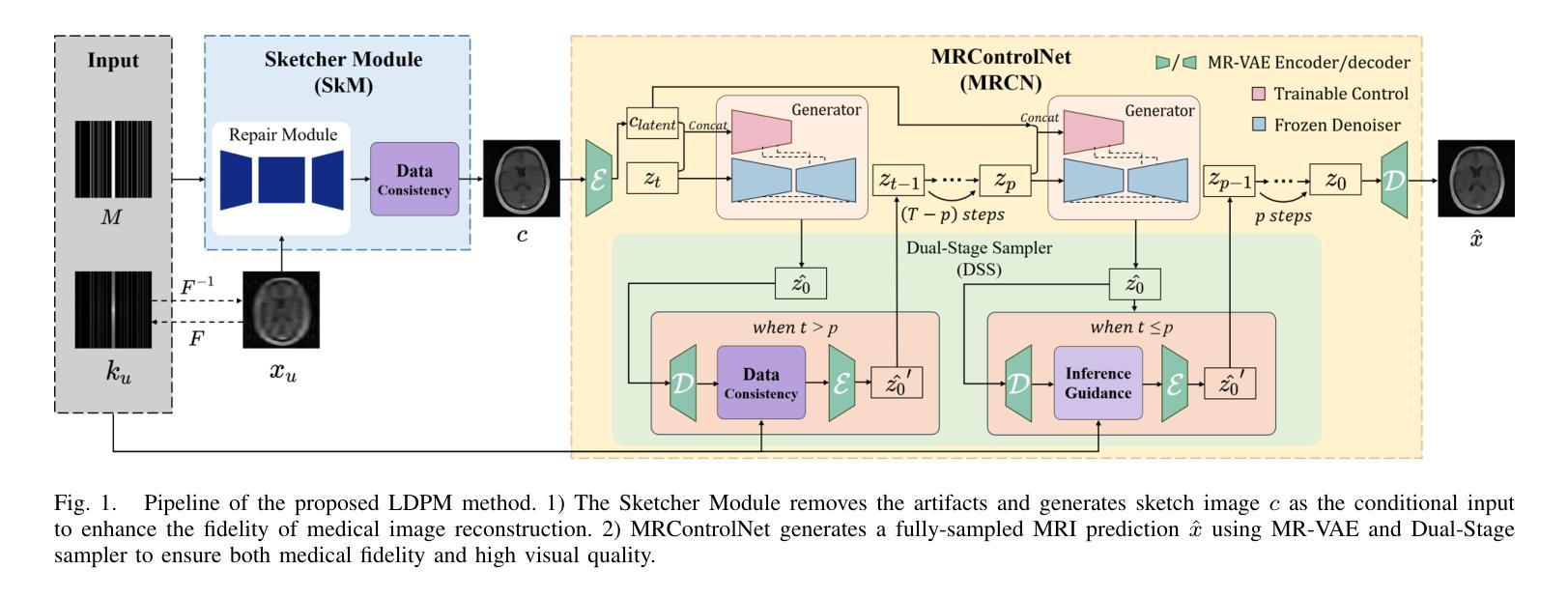
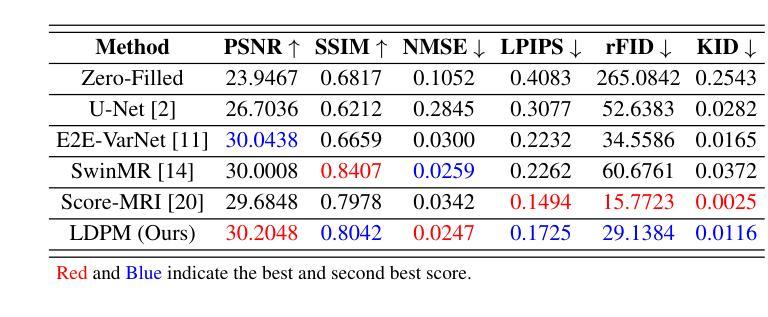
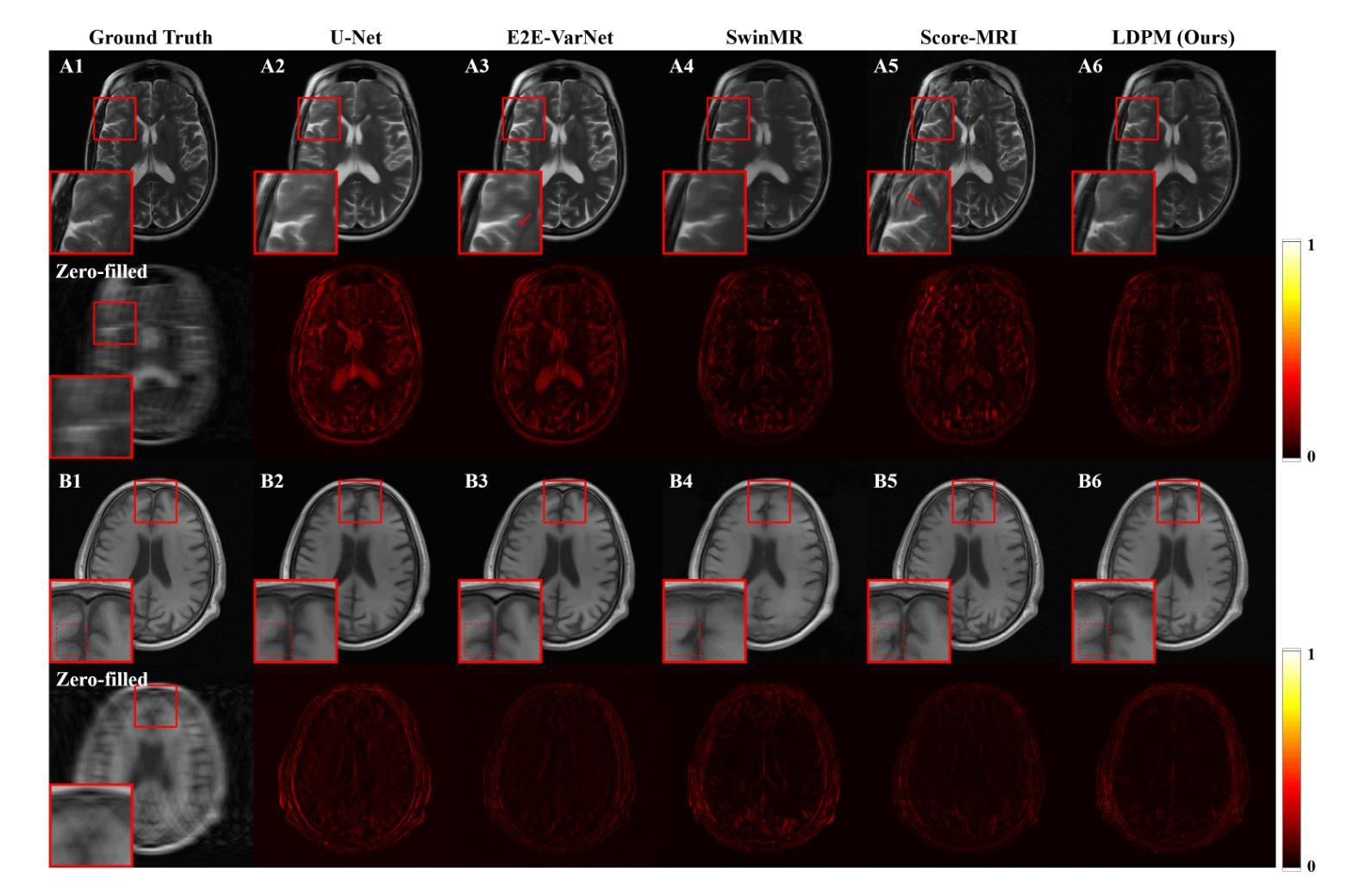
LDPM: Towards undersampled MRI reconstruction with MR-VAE and Latent Diffusion Prior
Authors:Xingjian Tang, Jingwei Guan, Linge Li, Ran Shi, Youmei Zhang, Mengye Lyu, Li Yan
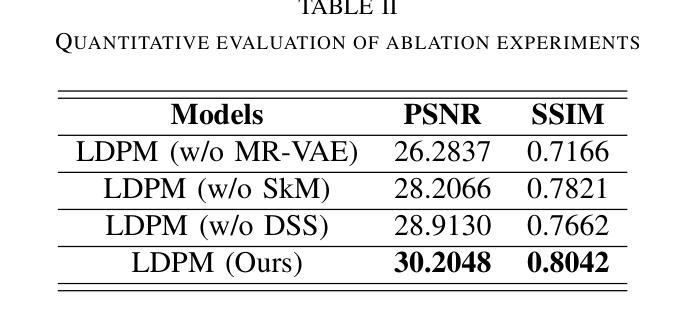
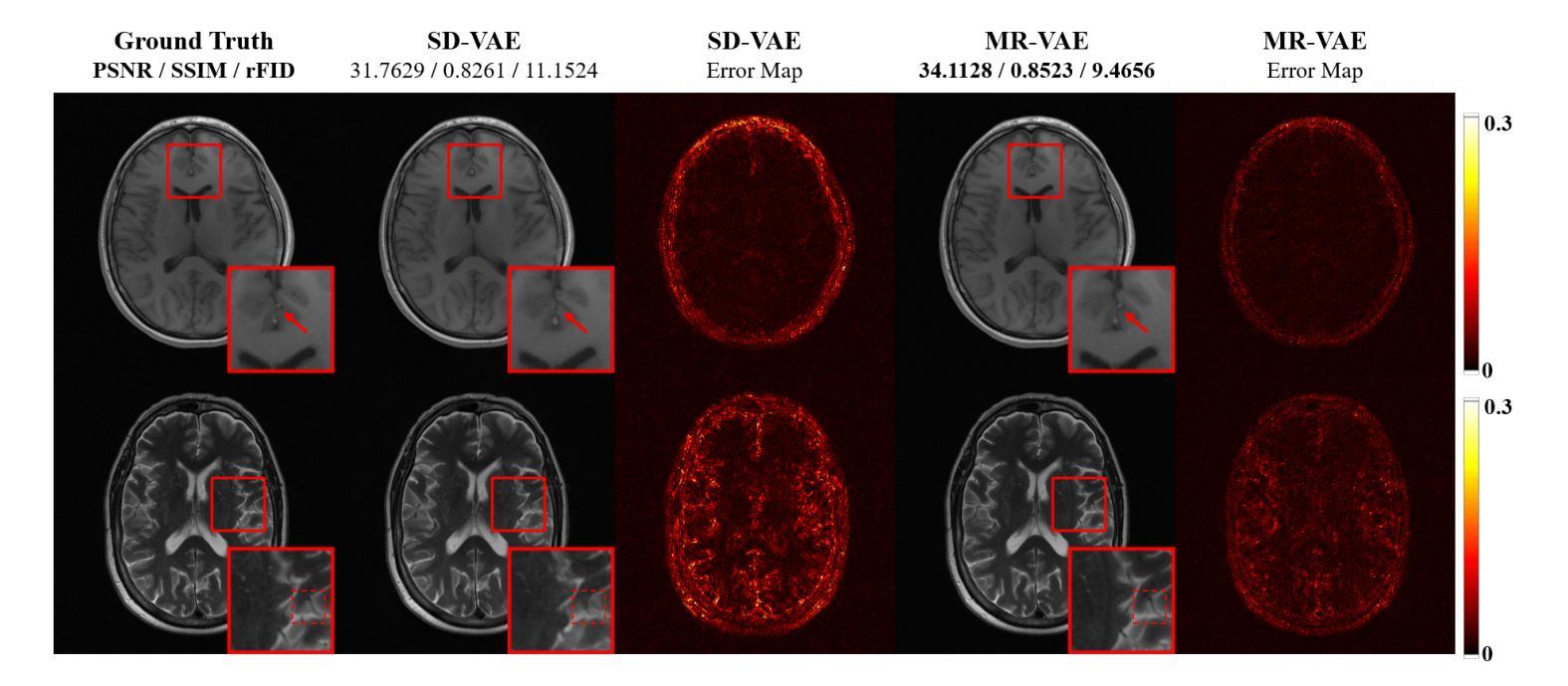
Diffusion models, as powerful generative models, have found a wide range of applications and shown great potential in solving image reconstruction problems. Some works attempted to solve MRI reconstruction with diffusion models, but these methods operate directly in pixel space, leading to higher computational costs for optimization and inference. Latent diffusion models, pre-trained on natural images with rich visual priors, are expected to solve the high computational cost problem in MRI reconstruction by operating in a lower-dimensional latent space. However, direct application to MRI reconstruction faces three key challenges: (1) absence of explicit control mechanisms for medical fidelity, (2) domain gap between natural images and MR physics, and (3) undefined data consistency in latent space. To address these challenges, a novel Latent Diffusion Prior-based undersampled MRI reconstruction (LDPM) method is proposed. Our LDPM framework addresses these challenges by: (1) a sketch-guided pipeline with a two-step reconstruction strategy, which balances perceptual quality and anatomical fidelity, (2) an MRI-optimized VAE (MR-VAE), which achieves an improvement of approximately 3.92 dB in PSNR for undersampled MRI reconstruction compared to that with SD-VAE \cite{sd}, and (3) Dual-Stage Sampler, a modified version of spaced DDPM sampler, which enforces high-fidelity reconstruction in the latent space. Experiments on the fastMRI dataset\cite{fastmri} demonstrate the state-of-the-art performance of the proposed method and its robustness across various scenarios. The effectiveness of each module is also verified through ablation experiments.
扩散模型作为强大的生成模型,在解决图像重建问题方面有着广泛的应用和巨大潜力。一些作品尝试使用扩散模型解决MRI重建问题,但这些方法直接在像素空间操作,导致优化和推理的计算成本较高。潜伏扩散模型预先在自然图像上进行训练,具有丰富的视觉先验,有望通过在低维潜伏空间操作来解决MRI重建中的高计算成本问题。然而,直接应用于MRI重建面临三个关键挑战:(1)缺乏医疗准确性的明确控制机制;(2)自然图像与MR物理之间的领域差距;(3)潜伏空间中的数据一致性未定义。为了解决这些挑战,提出了一种新型的基于潜伏扩散先验的欠采样MRI重建(LDPM)方法。我们的LDPM框架通过以下方式应对这些挑战:(1)一个草图引导管道,采用两步重建策略,平衡感知质量和解剖准确性;(2)一个优化的MRI变分自编码器(MR-VAE),与SD-VAE相比,在欠采样MRI重建的PSNR中提高了约3.92 dB \cite{sd};(3)双阶段采样器,是间隔DDPM采样器的改进版,强制潜伏空间的高保真重建。在fastMRI数据集\cite{fastmri}上的实验证明了该方法的最新性能以及在各种场景中的稳健性。各模块的有效性也通过消融实验得到了验证。
论文及项目相关链接
PDF accepted as oral presentation at EMBC 2025
摘要
扩散模型作为强大的生成模型,在图像重建问题中展现出了巨大的潜力,并得到了广泛的应用。尽管已有工作尝试用扩散模型解决MRI重建问题,但这些方法在像素空间直接操作,导致优化和推理的计算成本较高。预期潜伏扩散模型(在天然图像上预训练,具有丰富的视觉先验)能够在MRI重建中解决高计算成本问题,通过在低维潜伏空间操作。然而,直接应用于MRI重建面临三个关键挑战:(1)医学保真度的缺乏明确控制机制,(2)自然图像与MR物理之间的领域差距,以及(3)潜伏空间中未定义的数据一致性。为解决这些挑战,提出了一种新型的基于潜伏扩散先验的欠采样MRI重建(LDPM)方法。我们的LDPM框架通过以下方式解决这些挑战:(1)带有两步重建策略的草图引导管道,平衡感知质量和解剖保真度,(2)针对MRI优化的VAE(MR-VAE),与SD-VAE相比,在欠采样MRI重建的PSNR上提高了约3.92 dB \cite{sd},以及(3)双阶段采样器,这是间隔DDPM采样器的改进版本,在潜伏空间中强制高保真重建。在fastMRI数据集上的实验\cite{fastmri}证明了该方法的先进性能及其在多种场景中的稳健性。通过消融实验也验证了每个模块的有效性。
要点掌握
- 扩散模型在图像重建中展现出了巨大的潜力。
- 直接在像素空间操作导致MRI重建的计算成本较高。
- 潜伏扩散模型期望通过低维潜伏空间操作来解决高计算成本问题。
- 应用于MRI重建面临三大挑战:医学保真度的控制、领域差距和数据一致性问题。
- LDPM方法通过草图引导管道、MRI优化的VAE和双阶段采样器来解决这些挑战。
- LDPM在fastMRI数据集上的实验表现先进,且在多种场景中表现稳健。
点此查看论文截图

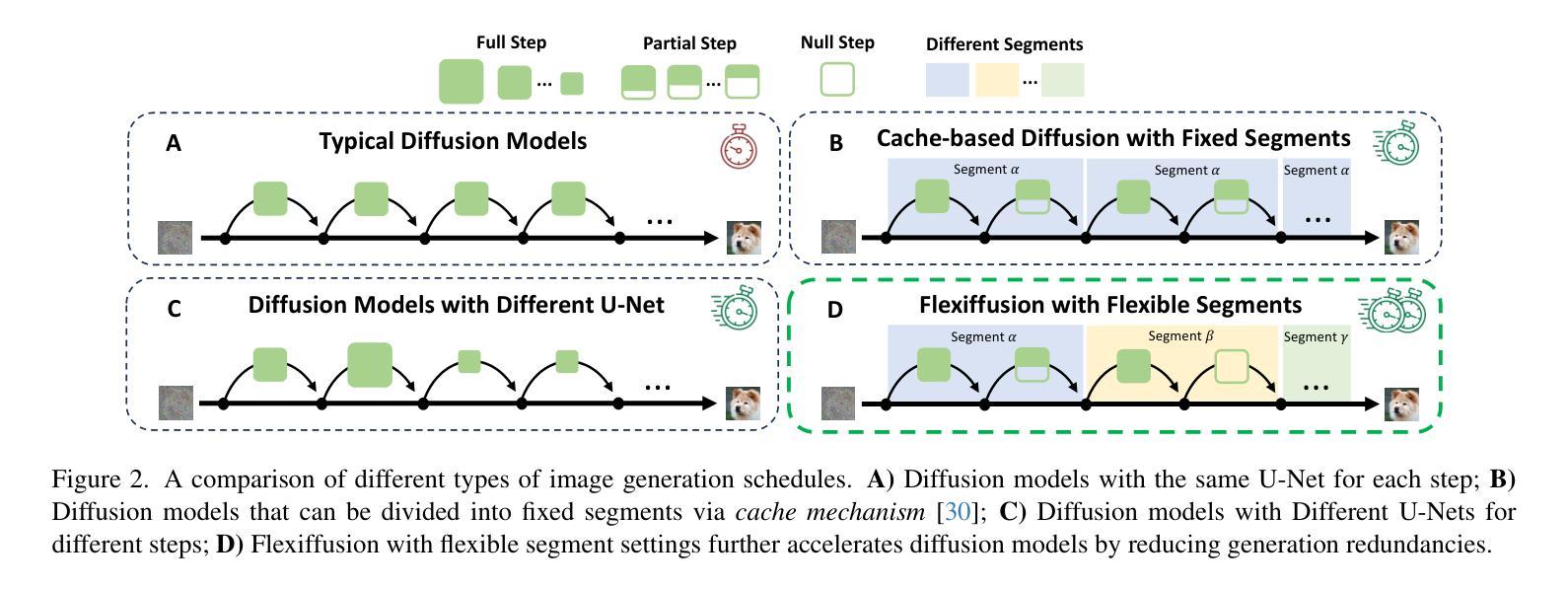
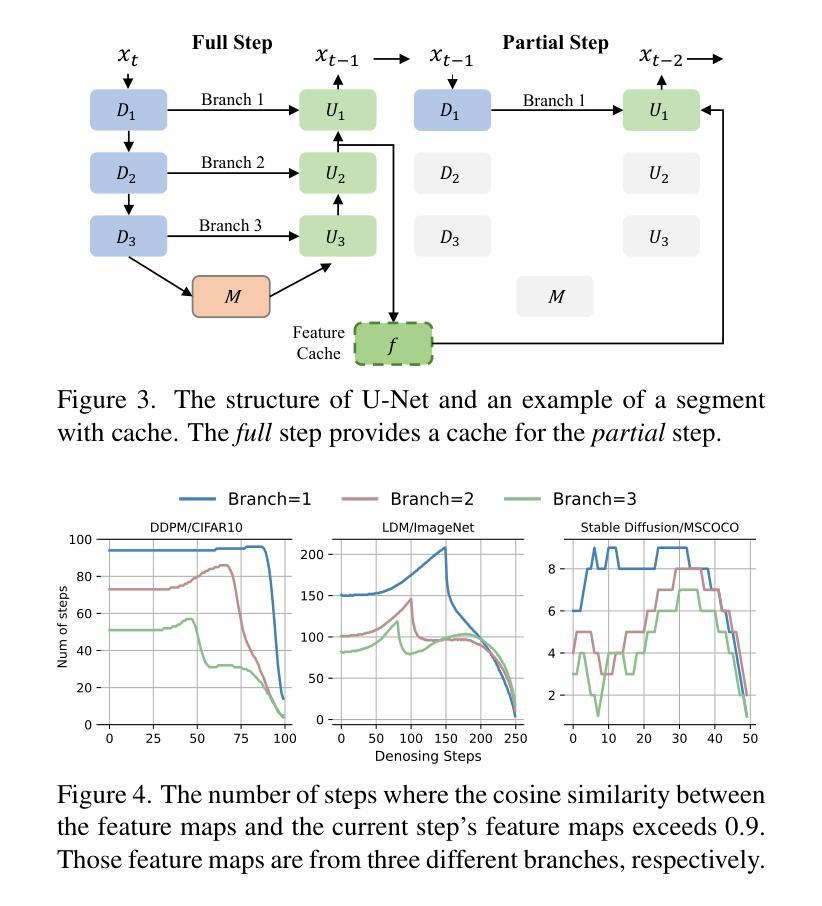
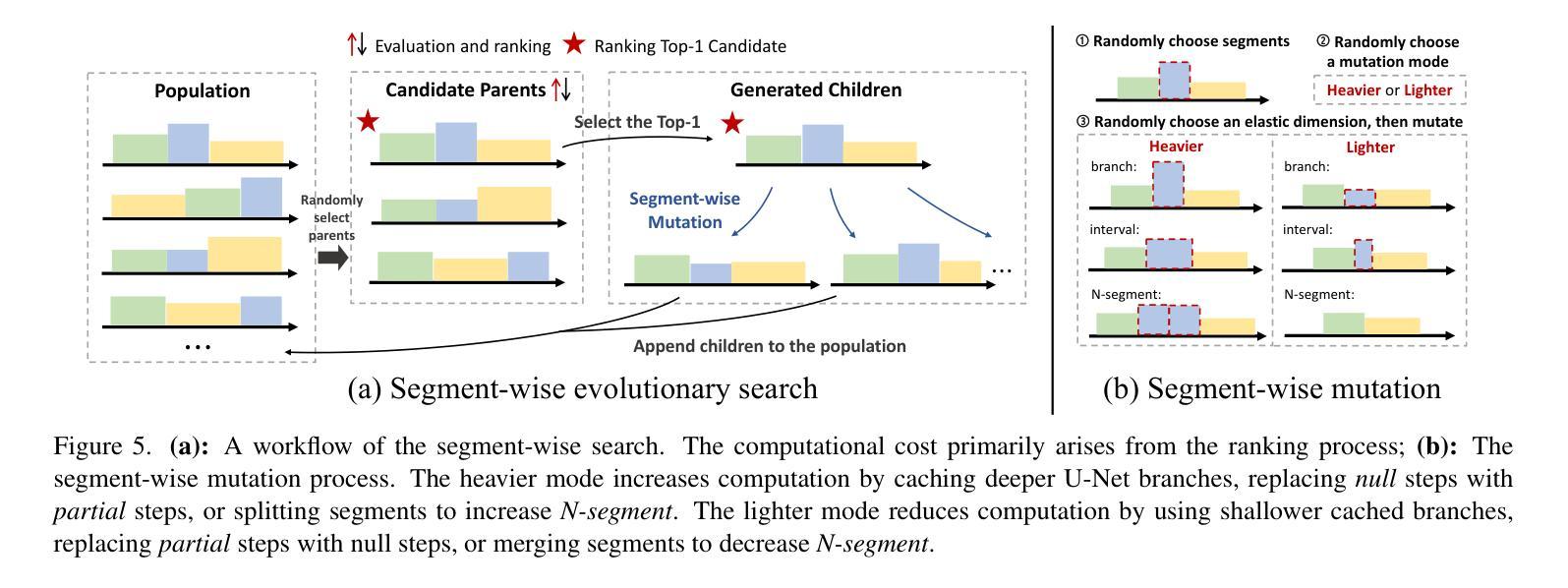
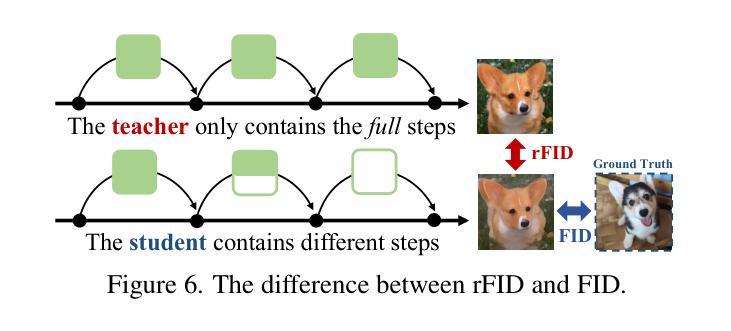
Flexiffusion: Segment-wise Neural Architecture Search for Flexible Denoising Schedule
Authors:Hongtao Huang, Xiaojun Chang, Lina Yao
Diffusion models are cutting-edge generative models adept at producing diverse, high-quality images. Despite their effectiveness, these models often require significant computational resources owing to their numerous sequential denoising steps and the significant inference cost of each step. Recently, Neural Architecture Search (NAS) techniques have been employed to automatically search for faster generation processes. However, NAS for diffusion is inherently time-consuming as it requires estimating thousands of diffusion models to search for the optimal one. In this paper, we introduce Flexiffusion, a novel training-free NAS paradigm designed to accelerate diffusion models by concurrently optimizing generation steps and network structures. Specifically, we partition the generation process into isometric step segments, each sequentially composed of a full step, multiple partial steps, and several null steps. The full step computes all network blocks, while the partial step involves part of the blocks, and the null step entails no computation. Flexiffusion autonomously explores flexible step combinations for each segment, substantially reducing search costs and enabling greater acceleration compared to the state-of-the-art (SOTA) method for diffusion models. Our searched models reported speedup factors of $2.6\times$ and $1.5\times$ for the original LDM-4-G and the SOTA, respectively. The factors for Stable Diffusion V1.5 and the SOTA are $5.1\times$ and $2.0\times$. We also verified the performance of Flexiffusion on multiple datasets, and positive experiment results indicate that Flexiffusion can effectively reduce redundancy in diffusion models.
扩散模型是前沿的生成模型,擅长生成多样化、高质量的图片。尽管这些模型非常有效,但由于其众多的连续去噪步骤和每个步骤的重大推理成本,它们通常需要大量的计算资源。最近,神经网络架构搜索(NAS)技术已被用于自动寻找更快的生成过程。然而,对扩散的NAS本质上是耗时的,因为它需要评估成千上万的扩散模型来寻找最佳模型。在本文中,我们介绍了Flexiffusion,这是一种新的无需训练的NAS范式,旨在通过同时优化生成步骤和网络结构来加速扩散模型。具体来说,我们将生成过程划分为等距的步骤段,每个段由完整的步骤、多个部分步骤和几个空步骤顺序组成。完整步骤计算所有网络块,部分步骤涉及部分块,而空步骤则不涉及计算。Flexiffusion自主地探索每个段的灵活步骤组合,大大降低了搜索成本,与扩散模型的最新方法相比,实现了更大的加速。我们搜索的模型报告了原始LDM-4-G和最新方法的加速倍数分别为2.6倍和1.5倍。对于Stable Diffusion V1.5和最新方法,加速倍数分别为5.1倍和2.0倍。我们还验证了Flexiffusion在多个数据集上的性能,积极的实验结果证明Flexiffusion可以有效地减少扩散模型中的冗余。
论文及项目相关链接
Summary
扩散模型是擅长生成多样、高质量图像的先进生成模型。然而,由于其众多的连续去噪步骤和每个步骤的高推理成本,这些模型通常需要大量的计算资源。最近,神经网络架构搜索(NAS)技术被用来自动寻找更快的生成过程。然而,对扩散的NAS本质上是耗时的,因为它需要评估成千上万的扩散模型来寻找最优模型。本文介绍了Flexiffusion,一种全新的无需训练的NAS范式,旨在通过同时优化生成步骤和网络结构来加速扩散模型。Flexiffusion自主探索每个段的灵活步骤组合,大大降低了搜索成本,与最先进的扩散模型相比实现了更大的加速。
Key Takeaways
- 扩散模型能够生成多样、高质量图像,但需要大量计算资源。
- 神经网络架构搜索(NAS)技术被用于自动寻找更快的扩散模型生成过程。
- Flexiffusion是一种全新的无需训练的NAS方法,旨在加速扩散模型。
- Flexiffusion通过优化生成步骤和网络结构来加速扩散模型。
- Flexiffusion自主探索每个生成步骤段的灵活组合,降低搜索成本。
- Flexiffusion实现的速度提升因素显著,例如对原始LDM-4-G和先进方法的加速分别为$2.6\times$和$1.5\times$。
点此查看论文截图