⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-10 更新
Subspecialty-Specific Foundation Model for Intelligent Gastrointestinal Pathology
Authors:Lianghui Zhu, Xitong Ling, Minxi Ouyang, Xiaoping Liu, Tian Guan, Mingxi Fu, Zhiqiang Cheng, Fanglei Fu, Maomao Zeng, Liming Liu, Song Duan, Qiang Huang, Ying Xiao, Jianming Li, Shanming Lu, Zhenghua Piao, Mingxi Zhu, Yibo Jin, Shan Xu, Qiming He, Yizhi Wang, Junru Cheng, Xuanyu Wang, Luxi Xie, Houqiang Li, Sufang Tian, Yonghong He
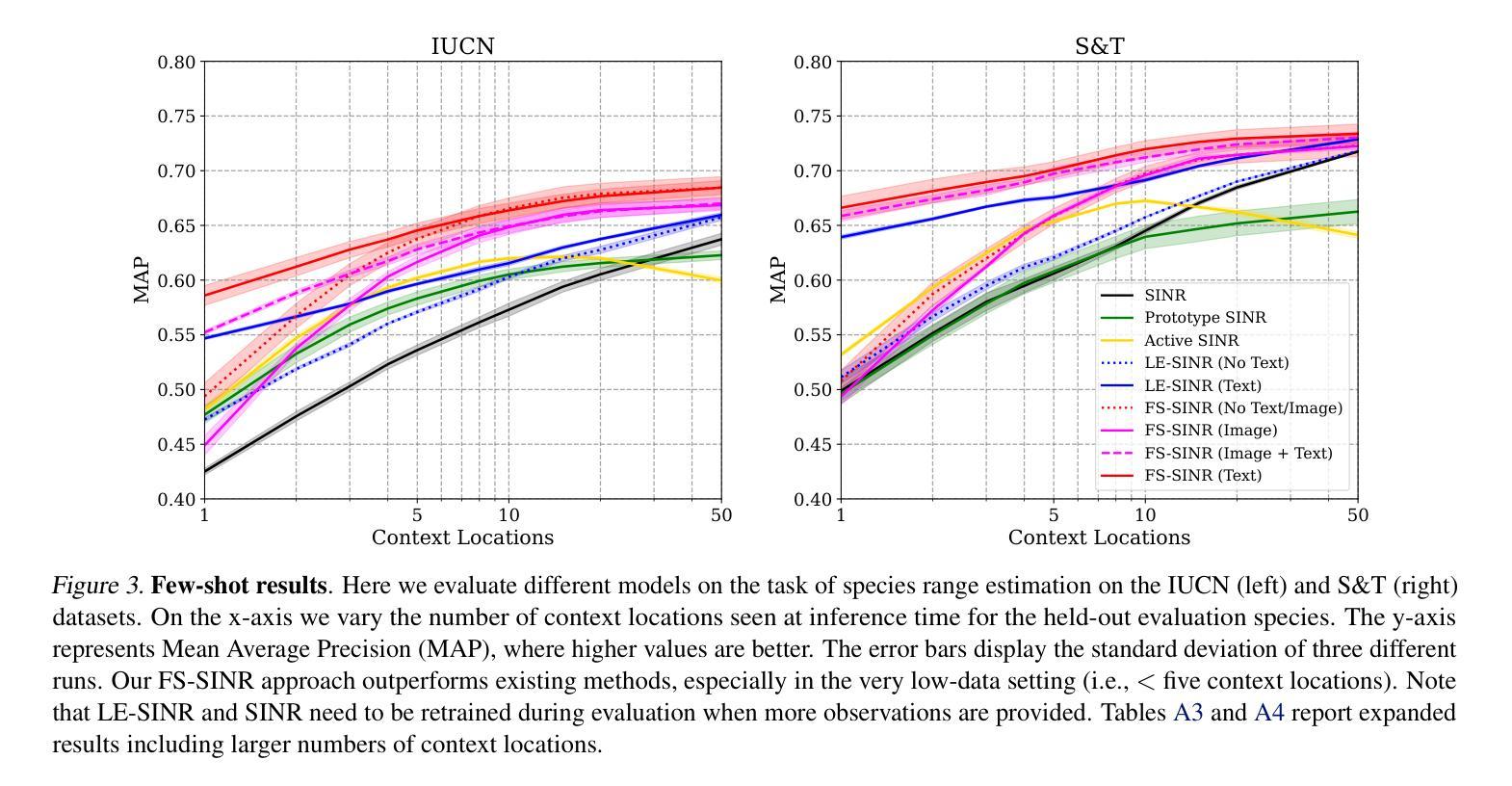
Gastrointestinal (GI) diseases represent a clinically significant burden, necessitating precise diagnostic approaches to optimize patient outcomes. Conventional histopathological diagnosis suffers from limited reproducibility and diagnostic variability. To overcome these limitations, we develop Digepath, a specialized foundation model for GI pathology. Our framework introduces a dual-phase iterative optimization strategy combining pretraining with fine-screening, specifically designed to address the detection of sparsely distributed lesion areas in whole-slide images. Digepath is pretrained on over 353 million multi-scale images from 210,043 H&E-stained slides of GI diseases. It attains state-of-the-art performance on 33 out of 34 tasks related to GI pathology, including pathological diagnosis, protein expression status prediction, gene mutation prediction, and prognosis evaluation. We further translate the intelligent screening module for early GI cancer and achieve near-perfect 99.70% sensitivity across nine independent medical institutions. This work not only advances AI-driven precision pathology for GI diseases but also bridge critical gaps in histopathological practice.
胃肠道(GI)疾病在临床上有很大的负担,需要精确的诊断方法来优化患者结果。传统的病理组织学诊断受限于可重复性和诊断差异性。为了克服这些限制,我们开发了Digepath,这是一种针对胃肠道病理的专用基础模型。我们的框架引入了一个两阶段迭代优化策略,结合了预训练和精细筛选,专门设计用于解决全幻灯片图像中稀疏分布病变区域的检测问题。Digepath在来自胃肠道疾病H&E染色幻灯片的超过3亿张多尺度图像上进行预训练。在涉及胃肠道病理的34项任务中,它在33项任务上均取得最佳性能,包括病理诊断、蛋白质表达状态预测、基因突变预测和预后评估等。我们将智能筛选模块进一步应用于早期胃肠道癌症筛查,并在九个独立医疗机构中实现了近完美的99.70%灵敏度。这项工作不仅推动了人工智能驱动的胃肠道疾病精准病理学的发展,还填补了组织病理学实践中的关键空白。
论文及项目相关链接
Summary
胃肠道疾病是一项重要的临床负担,需要精确的诊断方法来优化患者结果。传统的组织病理学诊断受限于可重复性和诊断差异性。为了克服这些局限,我们开发了Digepath,这是一种针对胃肠道病理的专用基础模型。该框架结合了预训练和精细筛选,采用双阶段迭代优化策略,专门设计用于检测全幻灯片图像中稀疏分布的病变区域。Digepath在超过353百万张多尺度图像上进行预训练,这些图像来自胃肠道疾病患者的21万张染色幻灯片。在涉及胃肠道病理的34项任务中,它在33项任务上取得了最新技术性能,包括病理诊断、蛋白质表达状态预测、基因突变预测和预后评估。我们还将智能筛查模块应用于早期胃肠道癌症筛查,并在九个独立医疗机构实现了近完美的99.7%的敏感性。这项工作不仅推动了人工智能驱动的胃肠道疾病精准病理学的发展,还填补了组织病理学实践中的关键空白。
Key Takeaways
- 胃肠道疾病是临床重要负担,需要精确诊断以优化患者结果。
- 传统组织病理学诊断存在可重复性和诊断差异性的限制。
- Digepath模型采用双阶段迭代优化策略,针对胃肠道病理进行专门设计。
- Digepath模型在大量多尺度图像上进行预训练,以提高诊断准确性。
- Digepath模型在涉及胃肠道病理的多个任务上表现优异。
- 智能筛查模块在早期胃肠道癌症筛查中实现了高敏感性。
点此查看论文截图

UniDB: A Unified Diffusion Bridge Framework via Stochastic Optimal Control
Authors:Kaizhen Zhu, Mokai Pan, Yuexin Ma, Yanwei Fu, Jingyi Yu, Jingya Wang, Ye Shi
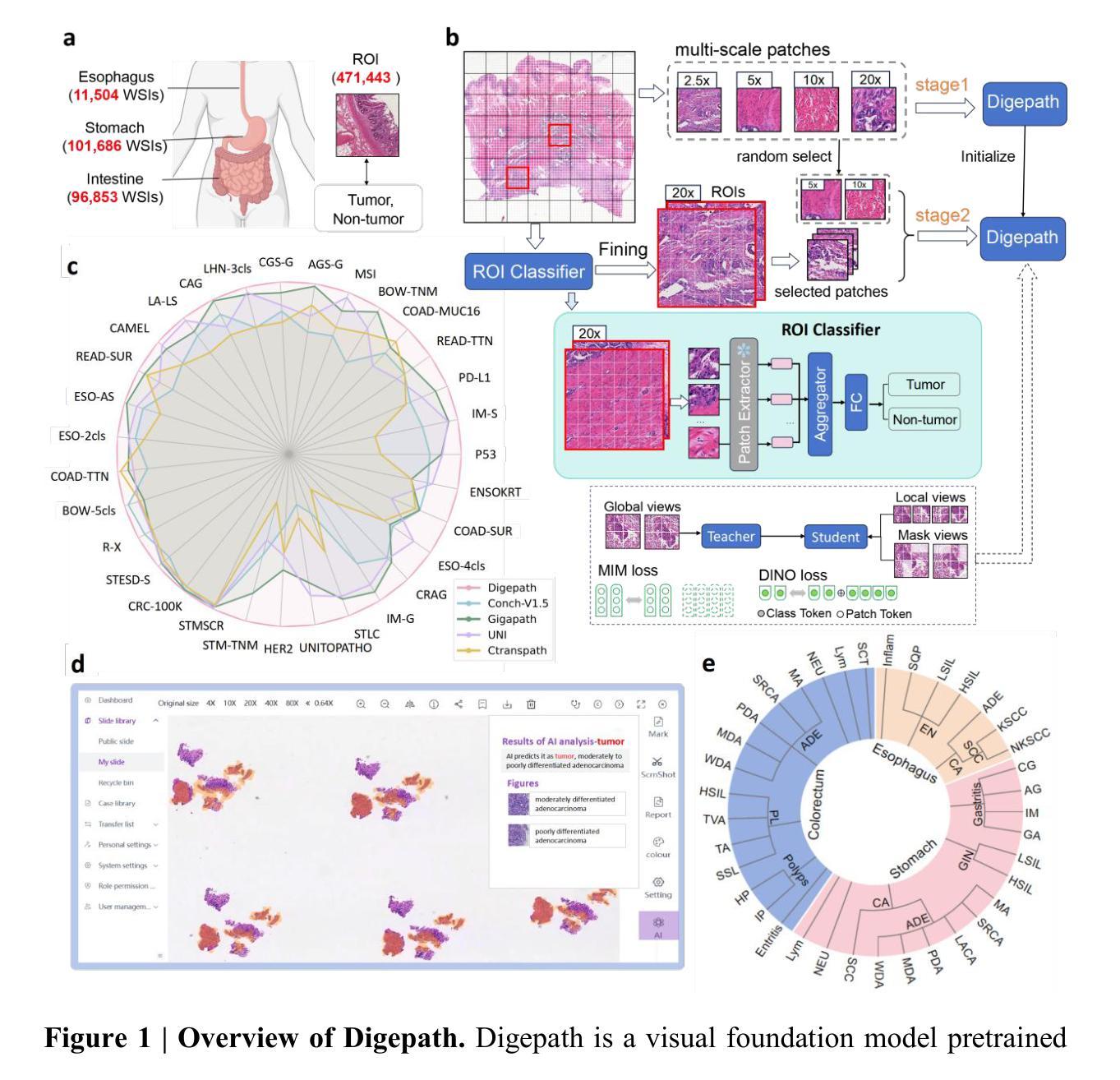
Recent advances in diffusion bridge models leverage Doob’s $h$-transform to establish fixed endpoints between distributions, demonstrating promising results in image translation and restoration tasks. However, these approaches frequently produce blurred or excessively smoothed image details and lack a comprehensive theoretical foundation to explain these shortcomings. To address these limitations, we propose UniDB, a unified framework for diffusion bridges based on Stochastic Optimal Control (SOC). UniDB formulates the problem through an SOC-based optimization and derives a closed-form solution for the optimal controller, thereby unifying and generalizing existing diffusion bridge models. We demonstrate that existing diffusion bridges employing Doob’s $h$-transform constitute a special case of our framework, emerging when the terminal penalty coefficient in the SOC cost function tends to infinity. By incorporating a tunable terminal penalty coefficient, UniDB achieves an optimal balance between control costs and terminal penalties, substantially improving detail preservation and output quality. Notably, UniDB seamlessly integrates with existing diffusion bridge models, requiring only minimal code modifications. Extensive experiments across diverse image restoration tasks validate the superiority and adaptability of the proposed framework. Our code is available at https://github.com/UniDB-SOC/UniDB/.
近期扩散桥模型的新进展利用Doob的$h$-变换在分布之间建立固定端点,在图像翻译和恢复任务中展现出有前景的结果。然而,这些方法经常产生模糊或过度平滑的图像细节,并且缺乏全面的理论基础来解释这些缺点。为了解决这些局限性,我们提出了基于随机最优控制(SOC)的扩散桥统一框架UniDB。UniDB通过基于SOC的优化来制定问题,并推导出最优控制器的封闭形式解决方案,从而统一并推广了现有的扩散桥模型。我们证明,采用Doob的$h$-变换的现有扩散桥构成了我们框架的一个特例,出现在SOC成本函数中的终端惩罚系数趋于无穷大时。通过引入可调终端惩罚系数,UniDB在控制成本和终端惩罚之间实现了最佳平衡,大大提高了细节保留和输出质量。值得注意的是,UniDB可以无缝地集成到现有的扩散桥模型中,只需要最少的代码修改。在不同图像恢复任务上的大量实验验证了所提出框架的优越性和适应性。我们的代码可在https://github.com/UniDB-SOC/UniDB/找到。
论文及项目相关链接
Summary
近期扩散桥模型通过利用Doob的$h$-变换在分布间建立固定端点,在图像翻译和恢复任务中展现出良好效果。然而,这些模型常导致图像细节模糊或过度平滑,且缺乏全面理论来解释这些不足。为解决这些问题,我们提出基于随机最优控制的统一扩散桥框架(UniDB)。UniDB通过SOC优化来制定问题,并推导出最优控制器的封闭形式解决方案,从而统一并推广现有扩散桥模型。我们发现,使用Doob的$h$-变换的扩散桥只是当SOC成本函数的终端惩罚系数趋于无穷大时的特殊情况。通过引入可调终端惩罚系数,UniDB实现了控制成本与终端惩罚之间的最佳平衡,大幅提升了细节保留和输出质量。该框架与现有扩散桥模型无缝集成,只需少量代码修改。在多种图像恢复任务上的实验验证了其优越性和适应性。
Key Takeaways
- 扩散桥模型通过Doob的$h$-变换在分布间建立固定端点,用于图像翻译和恢复。
- 现有模型存在图像细节模糊或过度平滑的问题。
- UniDB基于随机最优控制(SOC)提出统一扩散桥框架。
- UniDB通过SOC优化制定问题,并推导出最优控制器的封闭形式解。
- 使用Doob的$h$-变换的扩散桥是UniDB框架的一种特殊情况。
- UniDB通过引入可调终端惩罚系数,实现了控制成本与终端惩罚之间的平衡。
- UniDB提高了细节保留和输出质量,并与现有扩散桥模型无缝集成。实验验证了其优越性和适应性。
点此查看论文截图


TMT: Tri-Modal Translation between Speech, Image, and Text by Processing Different Modalities as Different Languages
Authors:Minsu Kim, Jee-weon Jung, Hyeongseop Rha, Soumi Maiti, Siddhant Arora, Xuankai Chang, Shinji Watanabe, Yong Man Ro
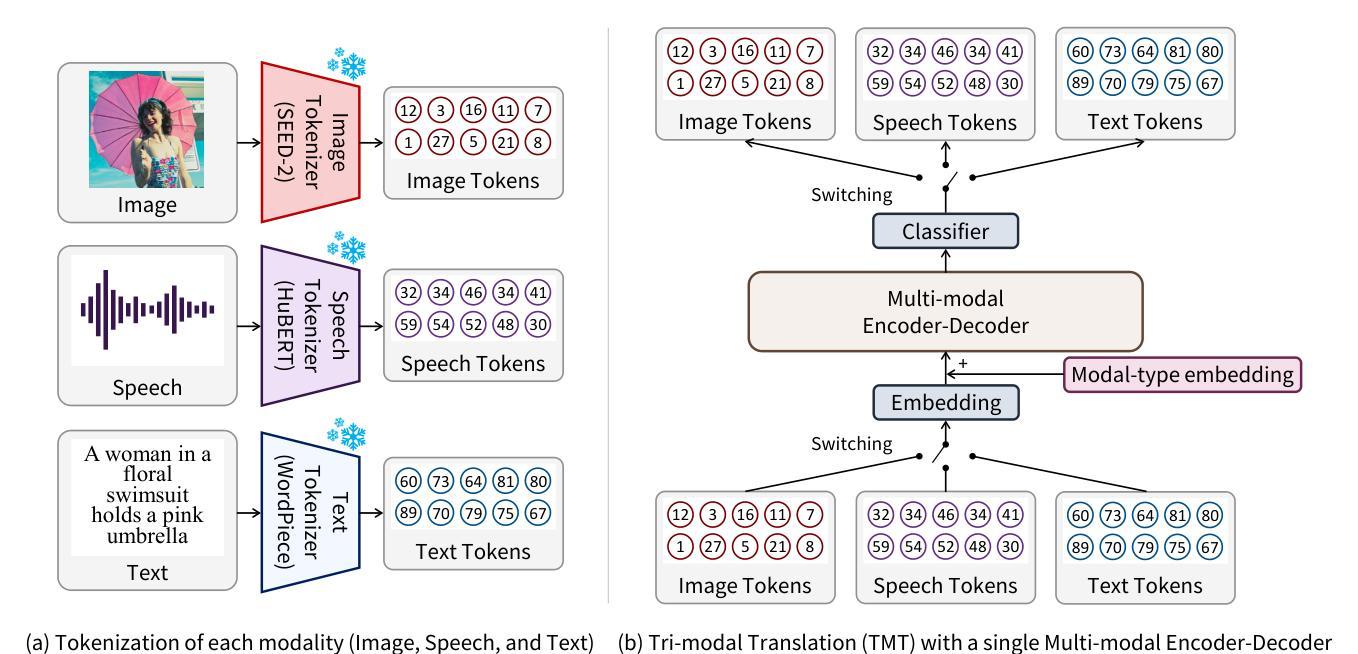
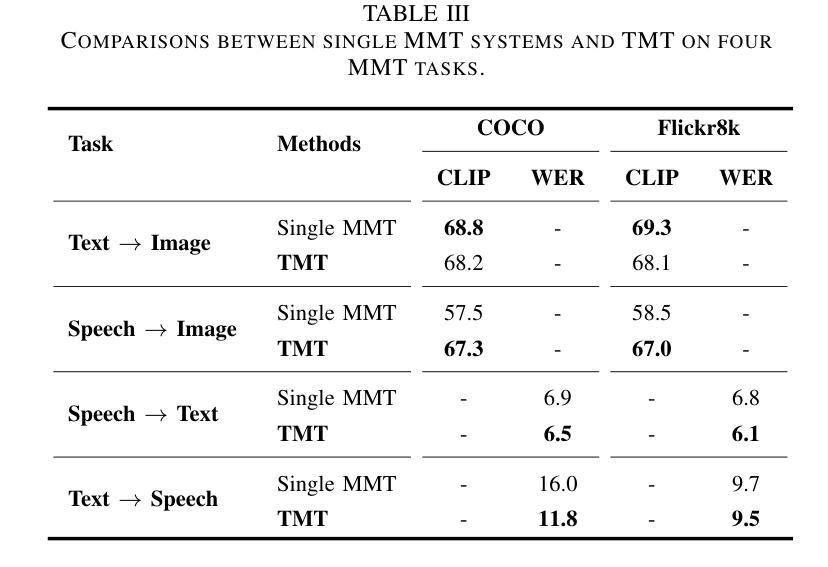
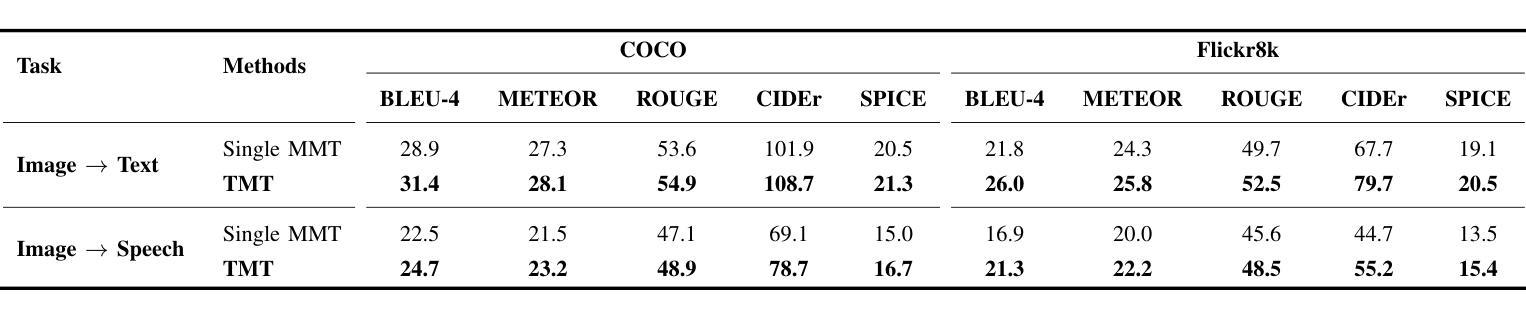
The capability to jointly process multi-modal information is becoming an essential task. However, the limited number of paired multi-modal data and the large computational requirements in multi-modal learning hinder the development. We propose a novel Tri-Modal Translation (TMT) model that translates between arbitrary modalities spanning speech, image, and text. We introduce a novel viewpoint, where we interpret different modalities as different languages, and treat multi-modal translation as a well-established machine translation problem. To this end, we tokenize speech and image data into discrete tokens, which provide a unified interface across modalities and significantly decrease the computational cost. In the proposed TMT, a multi-modal encoder-decoder conducts the core translation, whereas modality-specific processing is conducted only within the tokenization and detokenization stages. We evaluate the proposed TMT on all six modality translation tasks. TMT outperforms single model counterparts consistently, demonstrating that unifying tasks is beneficial not only for practicality but also for performance.
处理多模态信息的能力正成为一个基本任务。然而,配对的多模态数据量有限,多模态学习需要大量的计算资源,阻碍了其发展。我们提出了一种新颖的三模态翻译(TMT)模型,该模型可以在语音、图像和文本之间进行任意翻译。我们引入了一种新的观点,即将不同的模态解释为不同的语言,并将多模态翻译视为一个成熟的机器翻译问题。为此,我们将语音和图像数据分解为离散标记,这提供了跨模态的统一接口并大大降低了计算成本。在提出的三模态翻译模型中,多模态编码器-解码器执行核心翻译任务,而特定的模态处理仅在标记和解标记阶段进行。我们在所有六个模态翻译任务上评估了所提出的TMT模型。TMT始终优于单一模型对应物,表明任务统一不仅有益于实用性,而且有益于性能提升。
论文及项目相关链接
PDF IEEE TMM
Summary
本文提出了一种全新的Tri-Modal Translation(TMT)模型,该模型能够处理跨语音、图像和文本的任意模态转换。通过将不同模态解释为不同语言,将多模态翻译视作成熟的机器翻译问题来处理。通过离散化语音和图像数据,实现了跨模态的统一接口,并显著降低了计算成本。在所有的六个模态转换任务中,TMT均表现出优于单一模型的性能,证明了统一任务不仅有益于实用性,也有益于性能提升。
Key Takeaways
- TMT模型能够处理跨语音、图像和文本的任意模态转换。
- 提出了一种新颖的观点,将不同模态视作不同语言,从而进行多模态翻译处理。
- 通过离散化语音和图像数据,实现了跨模态的统一接口。
- 显著降低了多模态学习的计算要求。
- 在所有六个模态转换任务中,TMT性能均优于单一模型。
- 统一任务不仅提高实用性,也提升性能。
点此查看论文截图