⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-10 更新
Eigenspectrum Analysis of Neural Networks without Aspect Ratio Bias
Authors:Yuanzhe Hu, Kinshuk Goel, Vlad Killiakov, Yaoqing Yang
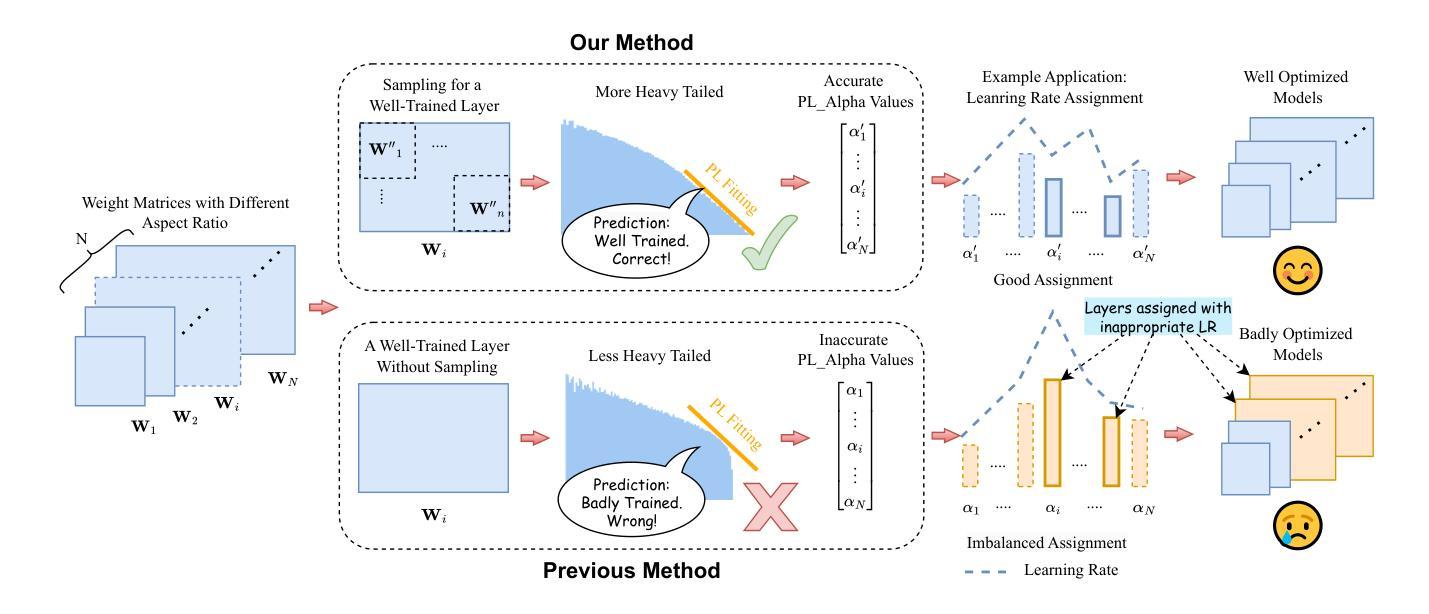
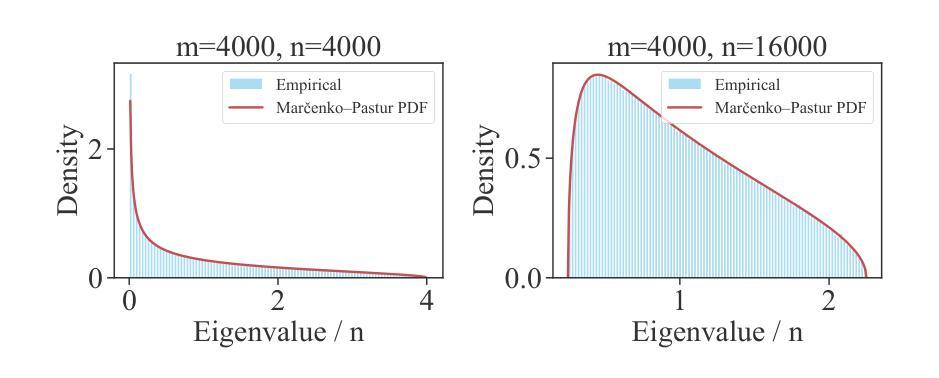
Diagnosing deep neural networks (DNNs) through the eigenspectrum of weight matrices has been an active area of research in recent years. At a high level, eigenspectrum analysis of DNNs involves measuring the heavytailness of the empirical spectral densities (ESD) of weight matrices. It provides insight into how well a model is trained and can guide decisions on assigning better layer-wise training hyperparameters. In this paper, we address a challenge associated with such eigenspectrum methods: the impact of the aspect ratio of weight matrices on estimated heavytailness metrics. We demonstrate that matrices of varying sizes (and aspect ratios) introduce a non-negligible bias in estimating heavytailness metrics, leading to inaccurate model diagnosis and layer-wise hyperparameter assignment. To overcome this challenge, we propose FARMS (Fixed-Aspect-Ratio Matrix Subsampling), a method that normalizes the weight matrices by subsampling submatrices with a fixed aspect ratio. Instead of measuring the heavytailness of the original ESD, we measure the average ESD of these subsampled submatrices. We show that measuring the heavytailness of these submatrices with the fixed aspect ratio can effectively mitigate the aspect ratio bias. We validate our approach across various optimization techniques and application domains that involve eigenspectrum analysis of weights, including image classification in computer vision (CV) models, scientific machine learning (SciML) model training, and large language model (LLM) pruning. Our results show that despite its simplicity, FARMS uniformly improves the accuracy of eigenspectrum analysis while enabling more effective layer-wise hyperparameter assignment in these application domains. In one of the LLM pruning experiments, FARMS reduces the perplexity of the LLaMA-7B model by 17.3% when compared with the state-of-the-art method.
通过权重矩阵的特征谱诊断深度神经网络(DNN)近年来已成为研究热点。从高层次上看,DNN的特征谱分析涉及测量实证谱密度(ESD)的重尾性。它提供了模型训练状况的洞察,并可以指导分配更好的逐层训练超参数。在本文中,我们解决了与这种特征谱方法相关的一个挑战:权重矩阵的纵横比估计重尾度指标的影响。我们证明,不同大小(和纵横比)的矩阵在估计重尾度指标时会产生不可忽略的偏差,从而导致模型诊断不准确和逐层超参数分配不当。为了克服这一挑战,我们提出了FARMS(固定纵横比矩阵子采样),这是一种通过子采样具有固定纵横比的子矩阵来标准化权重矩阵的方法。我们不是测量原始ESD的重尾性,而是测量这些子采样的子矩阵的平均ESD。我们表明,通过测量具有固定纵横比的这些子矩阵的重尾性可以有效地减轻纵横比偏差。我们在涉及权重特征谱分析的各个领域验证了我们的方法,包括计算机视觉(CV)模型中的图像分类、科学机器学习(SciML)模型训练和大型语言模型(LLM)的修剪。我们的结果表明,尽管其简单性,FARMS在统一提高特征谱分析的准确性的同时,在这些领域使更有效的逐层超参数分配成为可能。在大型语言模型修剪实验中之一,与最新方法相比,FARMS将LLaMA-7B模型的困惑度降低了17.3%。
论文及项目相关链接
PDF 30 pages, 14 figures, published to ICML 2025
摘要
通过权重矩阵的频谱对深度神经网络(DNN)进行诊断是近年来的研究热点。本文提出一种方法,通过测量权重矩阵的实证谱密度(ESD)的重尾程度来分析DNN。然而,当面临不同尺寸和纵横比的矩阵时,重尾度量会出现偏差,导致模型诊断和逐层超参数分配不准确。为了解决这个问题,本文提出了一种名为FARMS(固定纵横比矩阵子采样)的方法。它通过子采样具有固定纵横比的子矩阵来归一化权重矩阵,并测量这些子矩阵的平均ESD的重尾程度,从而有效地减轻纵横比偏差。实验结果表明,无论是在计算机视觉(CV)模型、科学机器学习(SciML)模型训练还是大型语言模型(LLM)剪枝等领域,该方法都能提高频谱分析准确性,并更有效地进行逐层超参数分配。在LLM剪枝实验中,与现有最佳方法相比,FARMS可将LLaMA-7B模型的困惑度降低17.3%。
要点解析
- 通过权重矩阵的频谱分析对DNN进行诊断是当前的热门研究领域。
- eigenspectrum分析通过测量权重矩阵的实证谱密度(ESD)的重尾程度来了解模型的训练情况并指导逐层超参数分配。
- 不同尺寸和纵横比的矩阵在估计重尾度量时会产生偏差,影响模型诊断和逐层超参数分配的准确性。
- 提出了一种名为FARMS的方法,通过子采样具有固定纵横比的子矩阵来归一化权重矩阵,以减轻纵横比偏差。
- FARMS方法不仅提高了频谱分析的准确性,而且在多个应用领域(如计算机视觉模型、科学机器学习模型训练和语言模型剪枝)中实现了更有效的逐层超参数分配。
- 在大型语言模型剪枝实验中,FARMS相较于现有方法显著降低了模型的困惑度。
点此查看论文截图

CoMemo: LVLMs Need Image Context with Image Memory
Authors:Shi Liu, Weijie Su, Xizhou Zhu, Wenhai Wang, Jifeng Dai
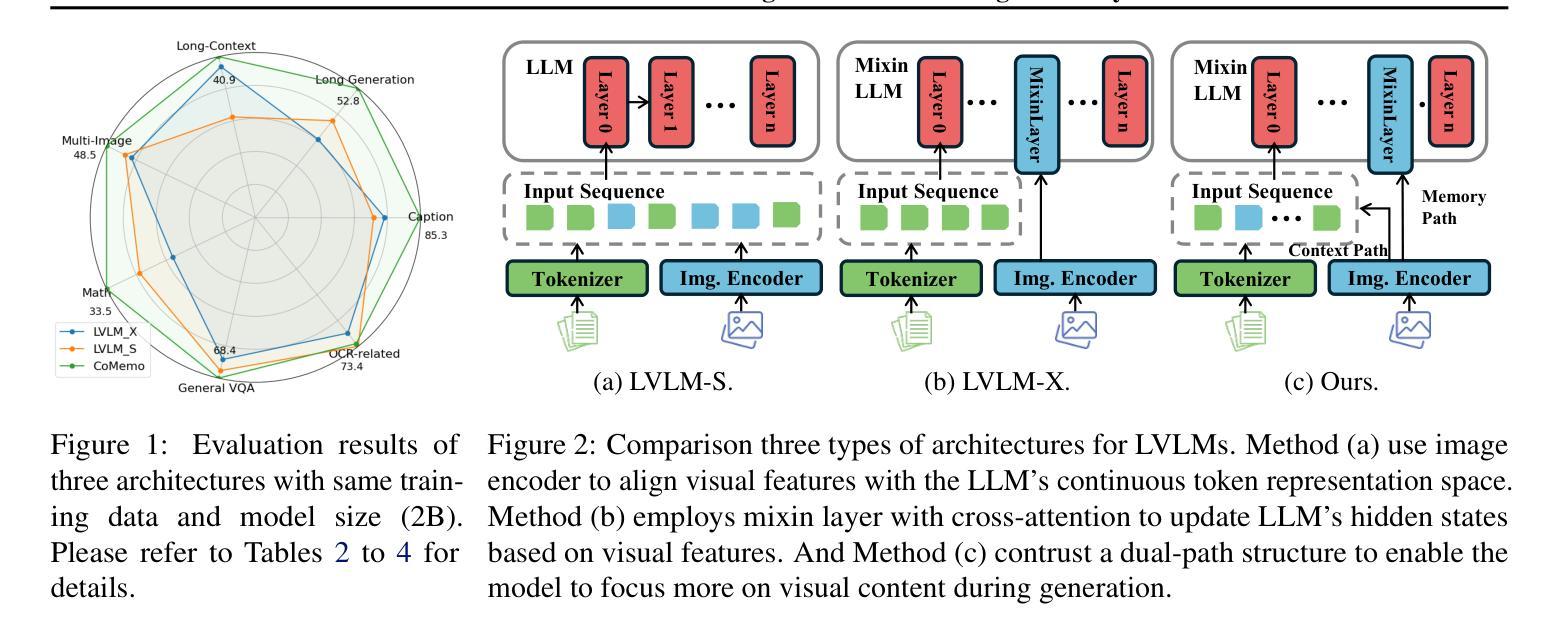
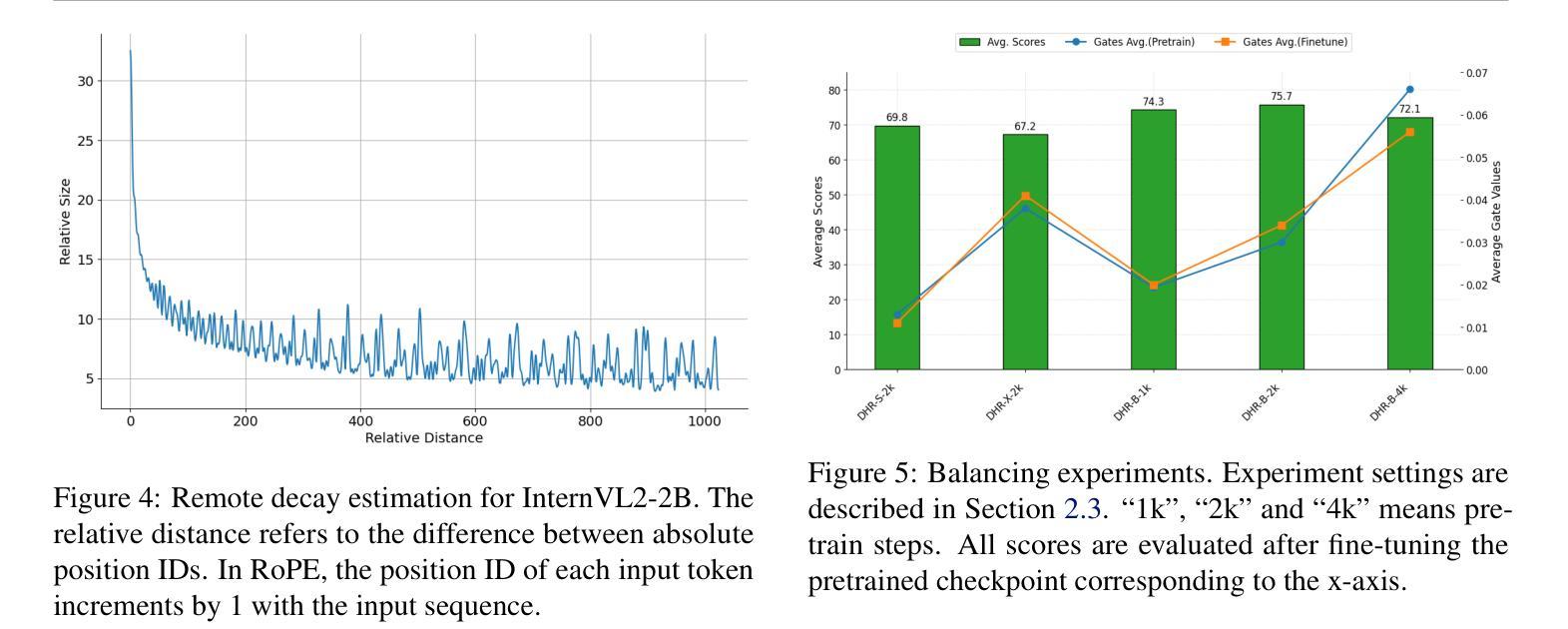
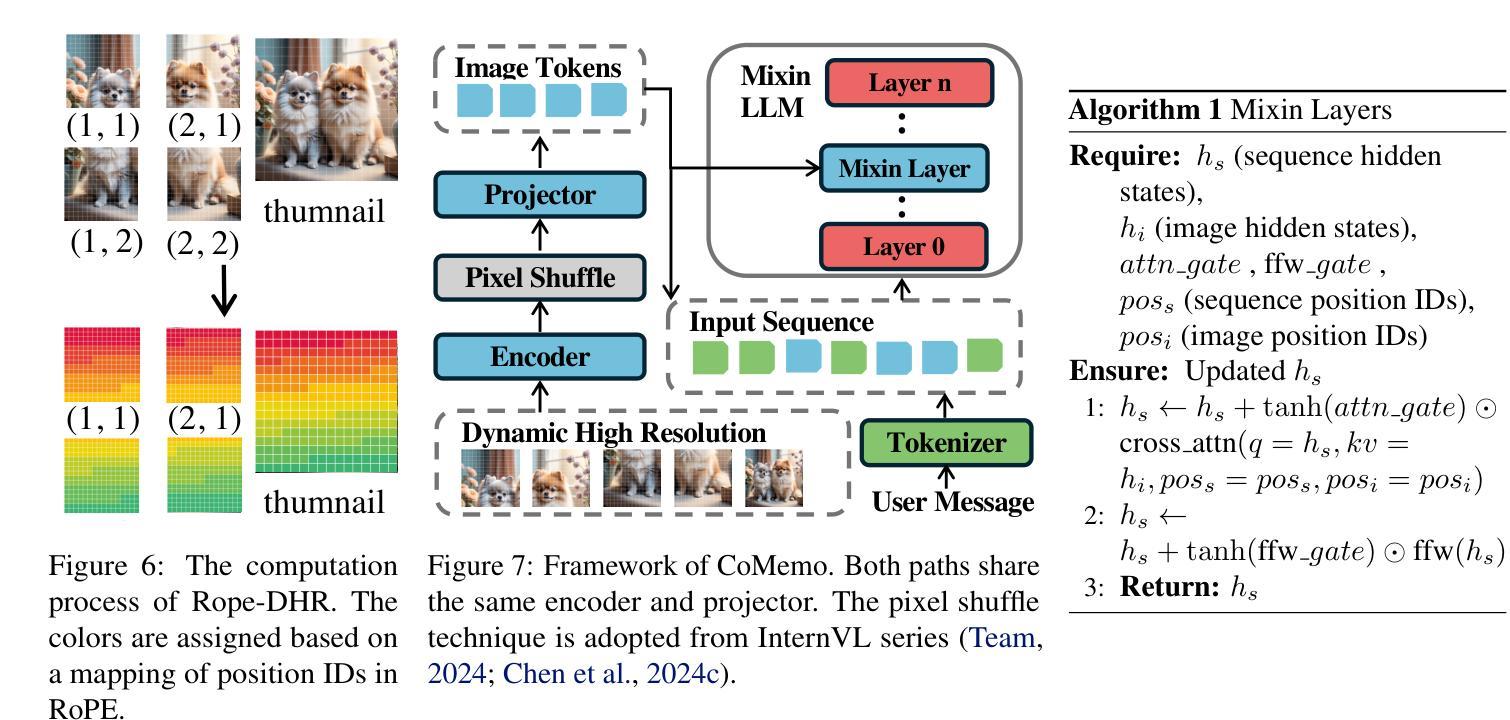
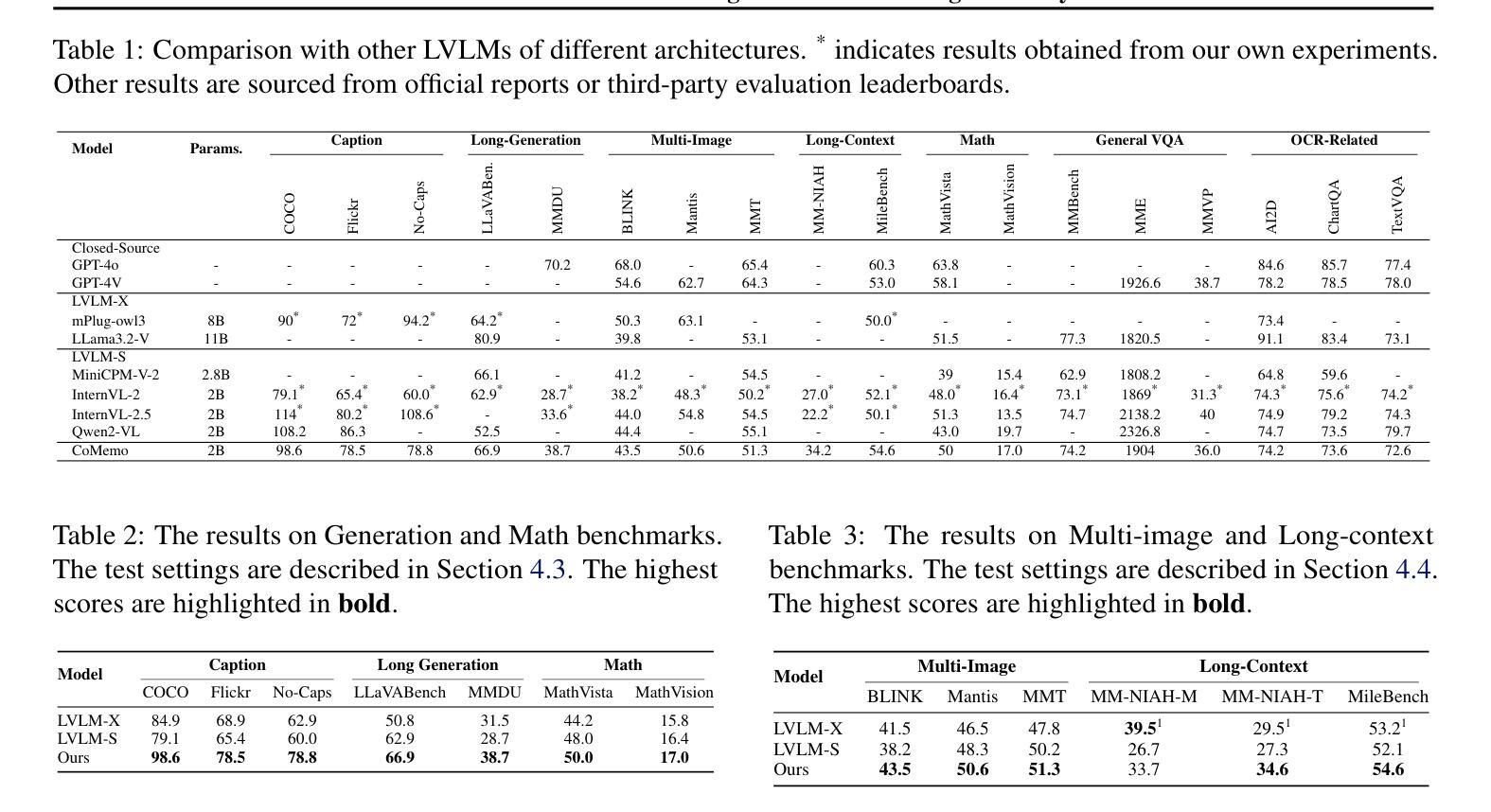
Recent advancements in Large Vision-Language Models built upon Large Language Models have established aligning visual features with LLM representations as the dominant paradigm. However, inherited LLM architectural designs introduce suboptimal characteristics for multimodal processing. First, LVLMs exhibit a bimodal distribution in attention allocation, leading to the progressive neglect of middle visual content as context expands. Second, conventional positional encoding schemes fail to preserve vital 2D structural relationships when processing dynamic high-resolution images. To address these limitations, we propose CoMemo - a dual-path architecture that combines a Context image path with an image Memory path for visual processing, effectively alleviating visual information neglect. Additionally, we introduce RoPE-DHR, a novel positional encoding mechanism that employs thumbnail-based positional aggregation to maintain 2D spatial awareness while mitigating remote decay in extended sequences. Evaluations across seven benchmarks,including long-context comprehension, multi-image reasoning, and visual question answering, demonstrate CoMemo’s superior performance compared to conventional LVLM architectures. Project page is available at https://lalbj.github.io/projects/CoMemo/.
最近基于大型语言模型(LLM)的大型视觉语言模型(LVLM)的进步已经建立了将视觉特征与LLM表示对齐的主导范式。然而,继承的LLM架构设计为多模态处理引入了次优特性。首先,LVLM在注意力分配上表现出双峰分布,随着上下文扩展,逐渐忽视中间视觉内容。其次,传统的位置编码方案在处理动态高分辨率图像时,无法保持重要的二维结构关系。为了解决这些限制,我们提出了CoMemo——一种结合上下文图像路径和图像记忆路径进行视觉处理的双路径架构,有效地减轻了视觉信息被忽视的问题。此外,我们还引入了RoPE-DHR,这是一种新的位置编码机制,采用基于缩略图的位置聚合,以维持二维空间感知,同时缓解长序列中的远程衰减问题。在包括长上下文理解、多图像推理和视觉问答等七个基准测试上的评估,展示了CoMemo相较于传统LVLM架构的卓越性能。项目页面可在[https://lalbj.github.io/projects/CoMemo/]上查看。
论文及项目相关链接
PDF ICML 2025
Summary
基于大规模语言模型的最新视觉语言模型已经建立了一种主流范式,即通过融合视觉特征与LLM表示来对齐信息。然而,继承的LLM架构设计对于多模态处理表现出次优特性。LVLM在注意力分配上展现出双峰分布模式,随着语境扩展,会逐渐忽略中间视觉内容。此外,传统的定位编码方案在处理动态高分辨率图像时无法保持关键的二维结构关系。为解决这些问题,我们提出了CoMemo——一种结合上下文图像路径和图像记忆路径的双路径架构进行视觉处理,有效减轻了视觉信息忽略问题。同时,我们引入了RoPE-DHR这一新型定位编码机制,通过缩略图定位聚合保持二维空间感知能力并减轻长期序列中的远程衰减问题。在包括长语境理解、多图像推理和视觉问答等七个基准测试上的评估显示,CoMemo相较于传统LVLM架构具有卓越性能。项目页面可通过以下链接访问:链接地址。
Key Takeaways
- 大型视觉语言模型(LVLM)已成为主流范式,通过融合视觉特征和大规模语言模型(LLM)表示进行信息对齐。
- 现有LLM架构存在两个主要问题:注意力分配的“双峰分布”,以及随着语境扩展对中间视觉内容的忽视;传统定位编码方案在处理动态高分辨率图像时无法保持关键的二维结构关系。
- 为解决上述问题,提出了CoMemo双路径架构和RoPE-DHR定位编码机制。CoMemo结合了上下文图像路径和图像记忆路径,有效减轻视觉信息忽略问题;RoPE-DHR则通过缩略图定位聚合保持二维空间感知能力并减轻远程衰减问题。
点此查看论文截图

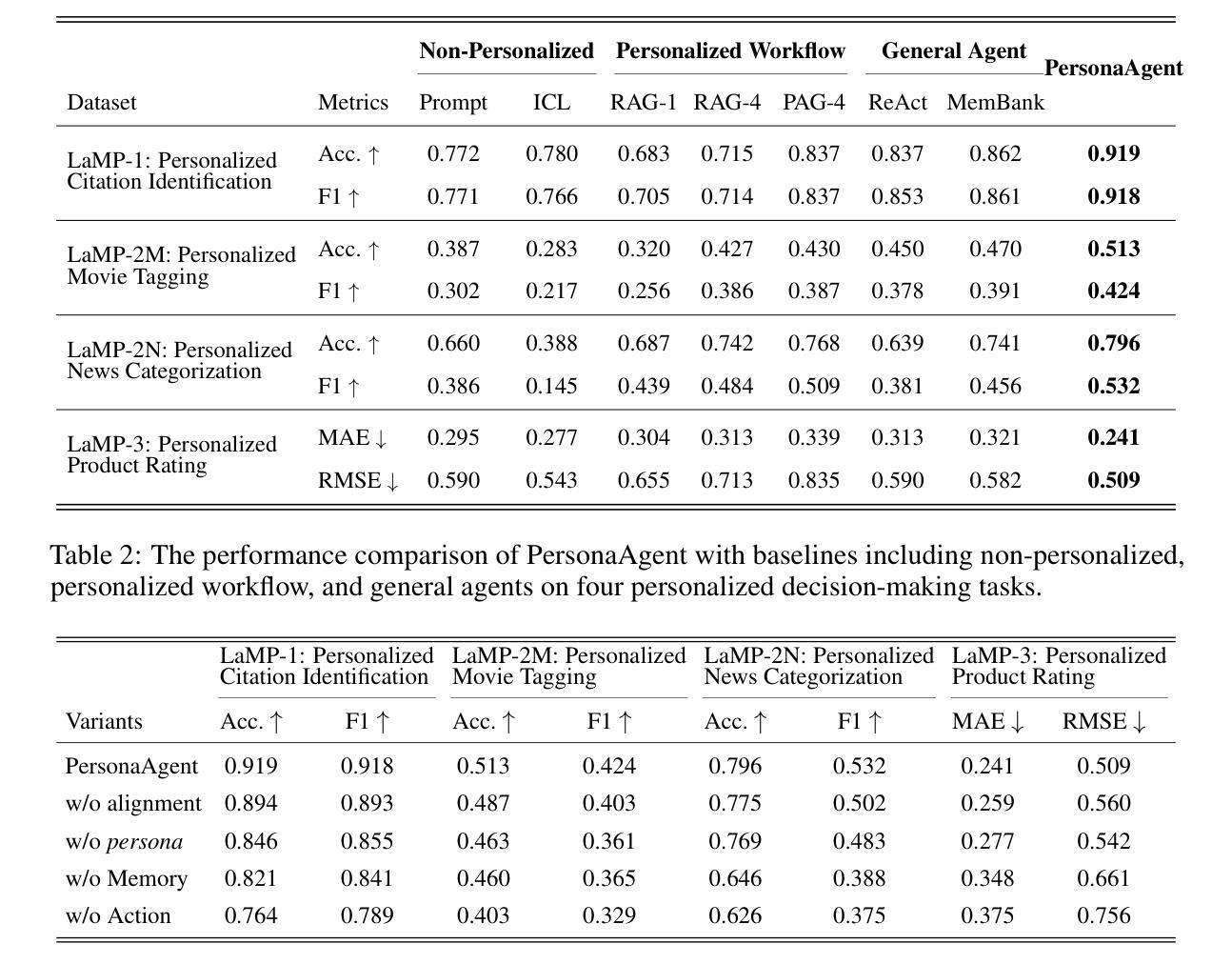
PersonaAgent: When Large Language Model Agents Meet Personalization at Test Time
Authors:Weizhi Zhang, Xinyang Zhang, Chenwei Zhang, Liangwei Yang, Jingbo Shang, Zhepei Wei, Henry Peng Zou, Zijie Huang, Zhengyang Wang, Yifan Gao, Xiaoman Pan, Lian Xiong, Jingguo Liu, Philip S. Yu, Xian Li
Large Language Model (LLM) empowered agents have recently emerged as advanced paradigms that exhibit impressive capabilities in a wide range of domains and tasks. Despite their potential, current LLM agents often adopt a one-size-fits-all approach, lacking the flexibility to respond to users’ varying needs and preferences. This limitation motivates us to develop PersonaAgent, the first personalized LLM agent framework designed to address versatile personalization tasks. Specifically, PersonaAgent integrates two complementary components - a personalized memory module that includes episodic and semantic memory mechanisms; a personalized action module that enables the agent to perform tool actions tailored to the user. At the core, the persona (defined as unique system prompt for each user) functions as an intermediary: it leverages insights from personalized memory to control agent actions, while the outcomes of these actions in turn refine the memory. Based on the framework, we propose a test-time user-preference alignment strategy that simulate the latest n interactions to optimize the persona prompt, ensuring real-time user preference alignment through textual loss feedback between simulated and ground-truth responses. Experimental evaluations demonstrate that PersonaAgent significantly outperforms other baseline methods by not only personalizing the action space effectively but also scaling during test-time real-world applications. These results underscore the feasibility and potential of our approach in delivering tailored, dynamic user experiences.
近期,大型语言模型(LLM)赋能的代理涌现为先进范式,在广泛领域和任务中展现出令人印象深刻的能力。尽管它们具有潜力,但当前的大型语言模型代理通常采用一刀切的方法,缺乏应对用户不同需求和偏好的灵活性。这一局限性促使我们开发PersonaAgent,首个设计用于处理多样化个性化任务的大型语言模型代理框架。具体来说,PersonaAgent集成了两个互补的组件:包括事件记忆和语义记忆机制的个人化记忆模块;使代理能够执行针对用户定制的工具动作的个人化行动模块。其核心人格(定义为每个用户的独特系统提示)充当中介:它利用来自个性化记忆的见解来控制代理行动,而这些行动的结果反过来又完善记忆。基于该框架,我们提出了一种测试时的用户偏好对齐策略,模拟最近的n次交互以优化人格提示,通过模拟响应和真实响应之间的文本损失反馈,确保实时用户偏好对齐。实验评估表明,PersonaAgent不仅有效地个性化行动空间,而且在测试时的现实世界应用中实现扩展,显著优于其他基准方法。这些结果突显了我们的方法在提供定制、动态用户体验方面的可行性和潜力。
论文及项目相关链接
Summary:LLM赋能的代理已展现出令人印象深刻的跨领域任务能力,但缺乏灵活性。为此,我们开发了PersonaAgent,一个个性化LLM代理框架,包括个性化记忆模块和动作模块。该框架通过模拟用户反馈优化个性化提示,实现实时用户偏好对齐。实验评估表明,PersonaAgent显著优于其他方法。
Key Takeaways:
- LLM代理在多个领域展现强大能力,但缺乏灵活性应对用户不同需求。
- PersonaAgent是一个个性化LLM代理框架,包含个性化记忆和动作模块。
- 个性化记忆模块包括情景和语义记忆机制。
- 个性化动作模块使代理能执行针对用户的工具动作。
- 人格作为系统提示的中介,利用个性化记忆控制代理动作,同时代理动作的成果会优化记忆。
- PersonaAgent采用测试时用户偏好对齐策略,通过模拟用户反馈优化个性化提示。
点此查看论文截图


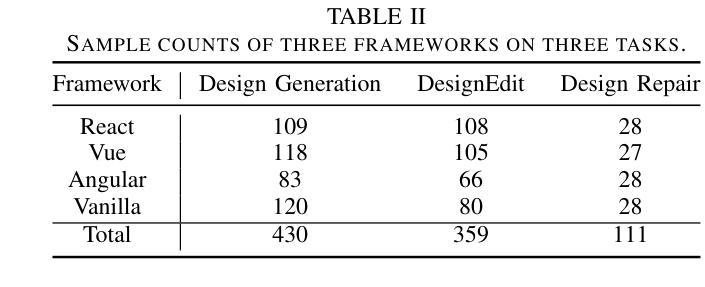
DesignBench: A Comprehensive Benchmark for MLLM-based Front-end Code Generation
Authors:Jingyu Xiao, Ming Wang, Man Ho Lam, Yuxuan Wan, Junliang Liu, Yintong Huo, Michael R. Lyu
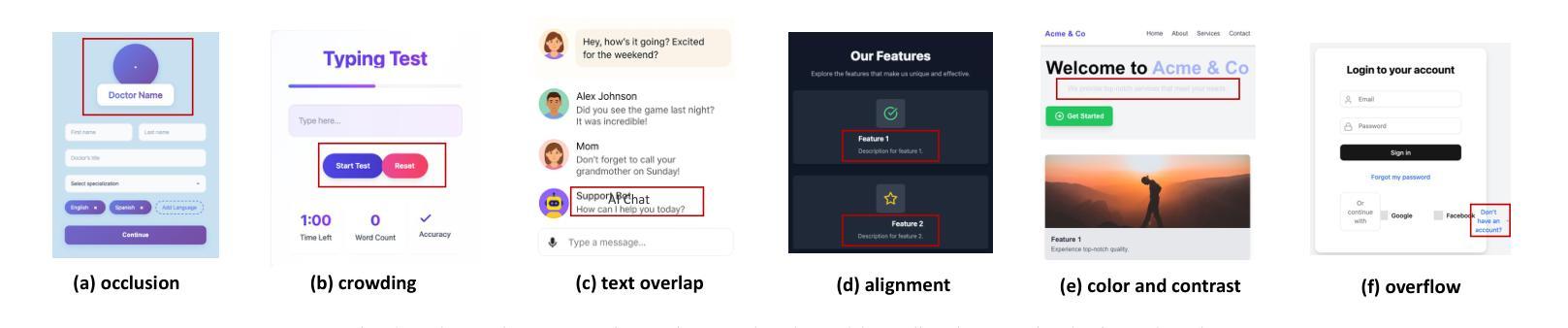
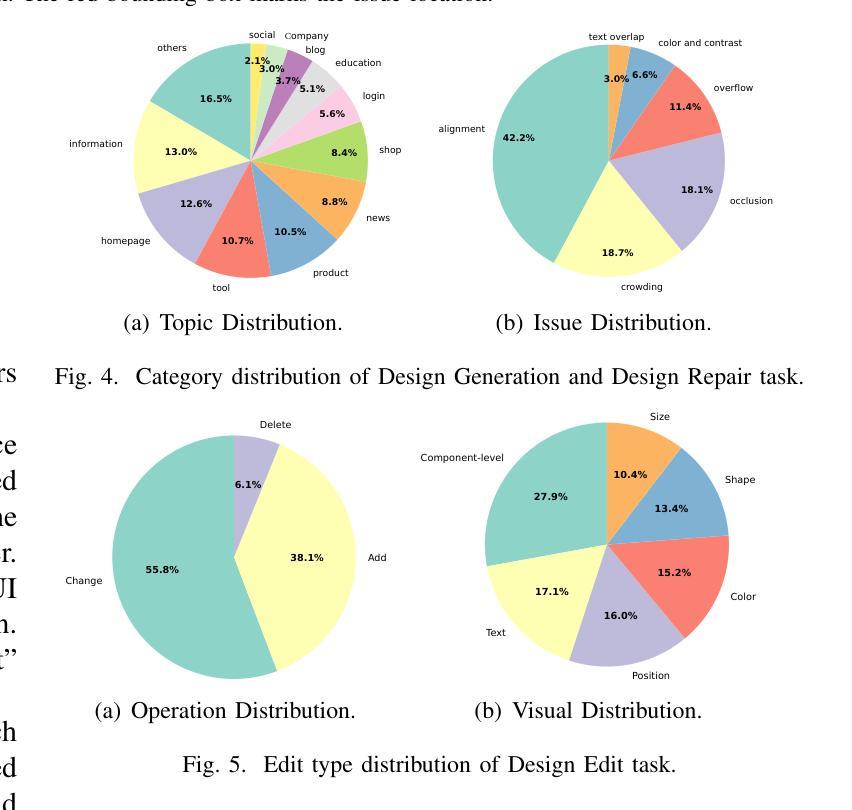
Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in automated front-end engineering, e.g., generating UI code from visual designs. However, existing front-end UI code generation benchmarks have the following limitations: (1) While framework-based development becomes predominant in modern front-end programming, current benchmarks fail to incorporate mainstream development frameworks. (2) Existing evaluations focus solely on the UI code generation task, whereas practical UI development involves several iterations, including refining editing, and repairing issues. (3) Current benchmarks employ unidimensional evaluation, lacking investigation into influencing factors like task difficulty, input context variations, and in-depth code-level analysis. To bridge these gaps, we introduce DesignBench, a multi-framework, multi-task evaluation benchmark for assessing MLLMs’ capabilities in automated front-end engineering. DesignBench encompasses three widely-used UI frameworks (React, Vue, and Angular) alongside vanilla HTML/CSS, and evaluates on three essential front-end tasks (generation, edit, and repair) in real-world development workflows. DesignBench contains 900 webpage samples spanning over 11 topics, 9 edit types, and 6 issue categories, enabling detailed analysis of MLLM performance across multiple dimensions. Our systematic evaluation reveals critical insights into MLLMs’ framework-specific limitations, task-related bottlenecks, and performance variations under different conditions, providing guidance for future research in automated front-end development. Our code and data are available at https://github.com/WebPAI/DesignBench.
多模态大型语言模型(MLLMs)在自动化前端工程领域表现出了显著的能力,例如从视觉设计中生成UI代码。然而,现有的前端UI代码生成基准测试存在以下局限性:(1)虽然基于框架的开发在现代前端编程中成为主流,但当前基准测试未能融入主流开发框架。(2)现有评估仅专注于UI代码生成任务,而实际UI开发涉及多次迭代,包括精细编辑和修复问题。(3)当前基准测试采用一维评估,缺乏任务难度、输入上下文变化等影响因素的深入探究和代码层面的深入分析。为了弥补这些空白,我们推出了DesignBench,这是一个用于评估MLLMs在自动化前端工程领域能力的新基准测试平台,支持多框架多任务。DesignBench涵盖了三个广泛使用的UI框架(React、Vue和Angular),以及纯HTML/CSS,并评估了真实世界开发工作流程中的三个基本任务(生成、编辑和修复)。DesignBench包含900个网页样本,涵盖11个主题、9种编辑类型和6个问题类别,可对MLLM在多个维度上的性能进行详尽分析。我们的系统评估揭示了MLLMs在特定框架下的局限性、任务相关瓶颈以及不同条件下的性能变化,为自动化前端开发的未来研究提供了指导。我们的代码和数据可在https://github.com/WebPAI/DesignBench找到。
论文及项目相关链接
Summary
本文介绍了多模态大型语言模型(MLLMs)在自动化前端工程中的出色表现,特别是在生成UI代码方面的能力。然而,现有的前端UI代码生成基准测试存在以下局限性。为此,作者提出了DesignBench这一跨多框架、多任务评估基准,旨在评估MLLMs在自动化前端工程中的能力。DesignBench涵盖了三个广泛使用的UI框架(React、Vue和Angular),同时对真实世界开发流程中的三个关键前端任务(生成、编辑和修复)进行评估。该研究为我们深入了解了MLLMs在特定框架下的局限性、任务相关瓶颈以及不同条件下的性能变化提供了关键见解。
Key Takeaways
- MLLMs在自动化前端工程,特别是生成UI代码方面表现出色。
- 当前的前端UI代码生成基准测试存在局限性,未能融入主流开发框架。
- 实用UI开发包含多次迭代,如修改和修复问题,而现有评估主要关注UI代码生成任务。
- 现有基准测试采用一维评估,缺乏任务难度、输入上下文变化等因素的深入研究。
- DesignBench基准涵盖了三个流行的UI框架和真实世界开发流程中的三个关键前端任务。
- DesignBench系统评估揭示了MLLMs的框架特定局限性、任务相关瓶颈以及不同条件下的性能变化。
点此查看论文截图


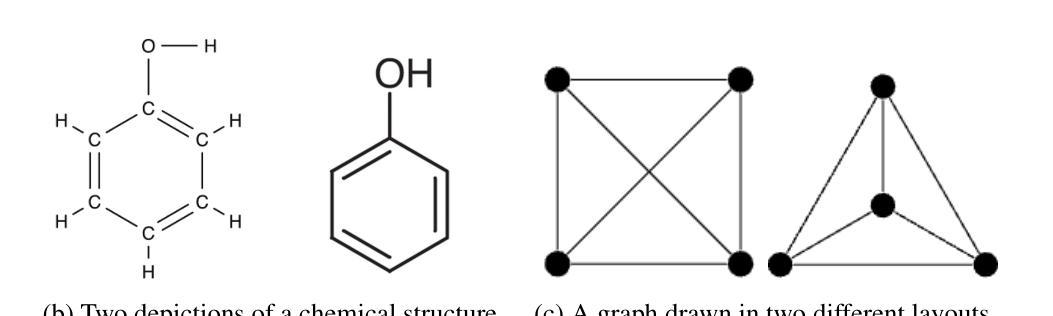
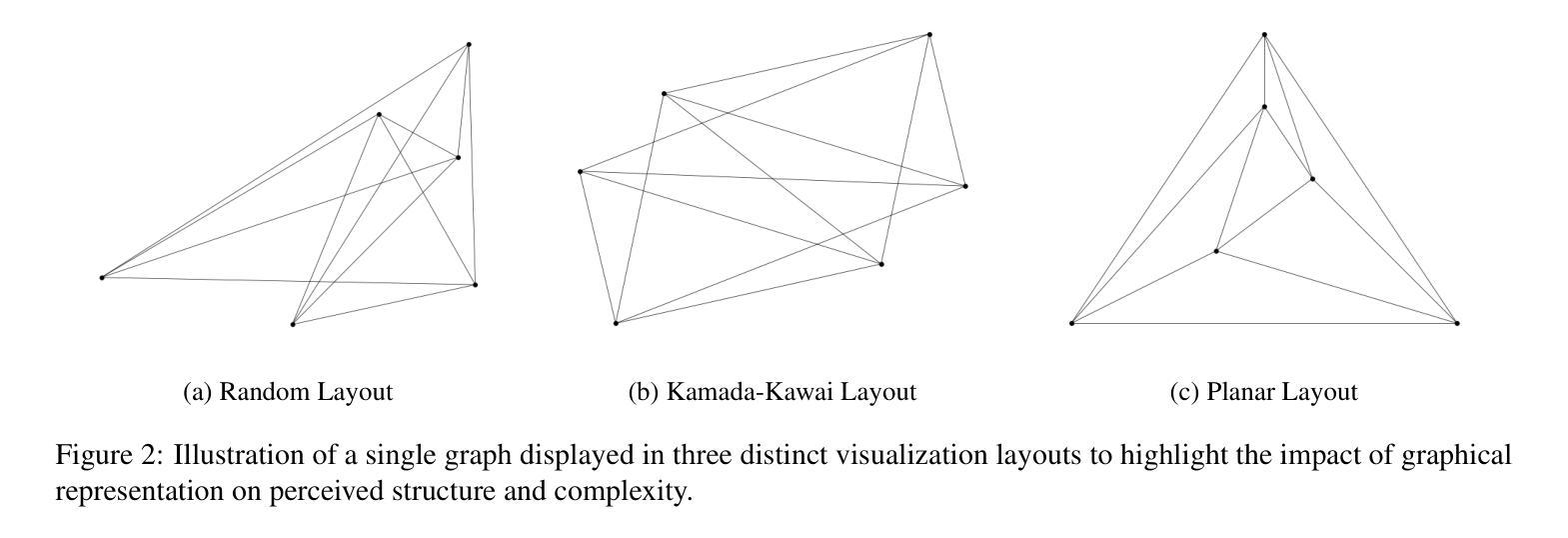
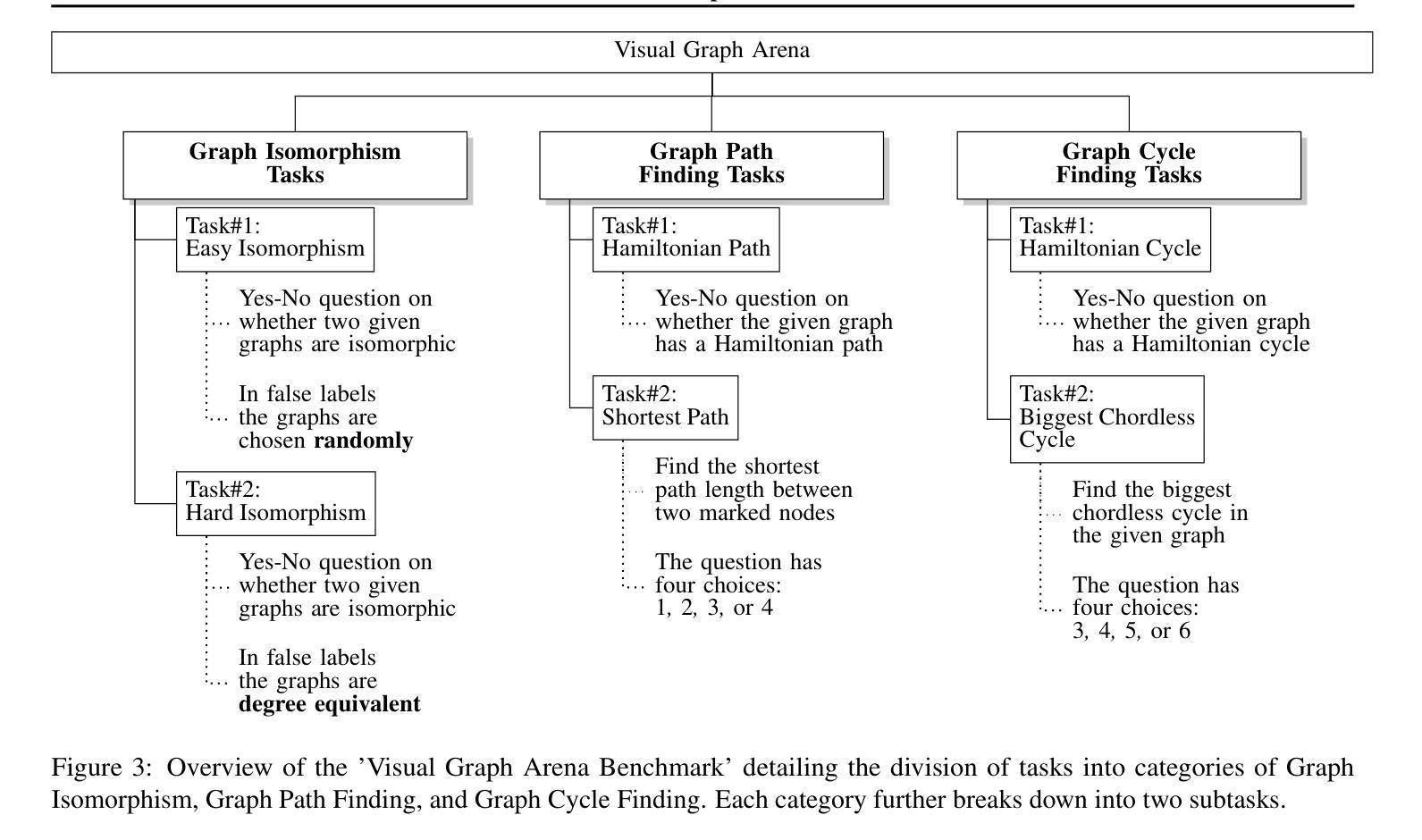
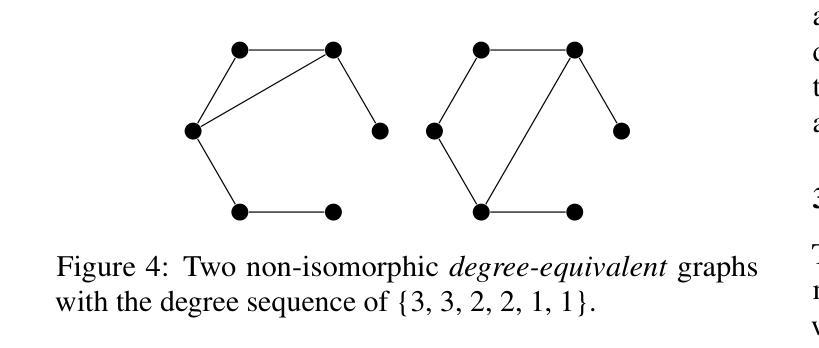
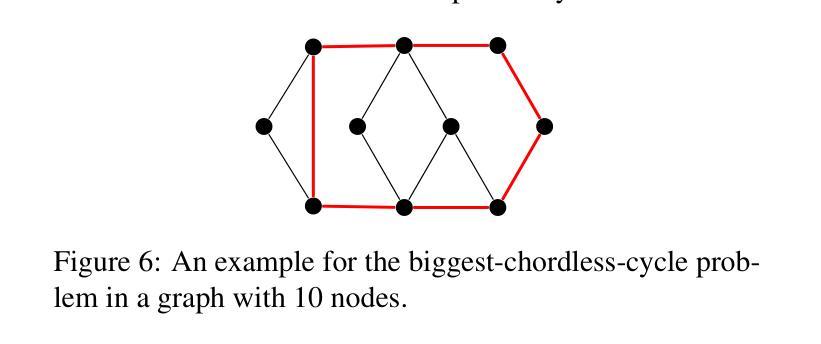
Visual Graph Arena: Evaluating Visual Conceptualization of Vision and Multimodal Large Language Models
Authors:Zahra Babaiee, Peyman M. Kiasari, Daniela Rus, Radu Grosu
Recent advancements in multimodal large language models have driven breakthroughs in visual question answering. Yet, a critical gap persists, `conceptualization’-the ability to recognize and reason about the same concept despite variations in visual form, a basic ability of human reasoning. To address this challenge, we introduce the Visual Graph Arena (VGA), a dataset featuring six graph-based tasks designed to evaluate and improve AI systems’ capacity for visual abstraction. VGA uses diverse graph layouts (e.g., Kamada-Kawai vs. planar) to test reasoning independent of visual form. Experiments with state-of-the-art vision models and multimodal LLMs reveal a striking divide: humans achieved near-perfect accuracy across tasks, while models totally failed on isomorphism detection and showed limited success in path/cycle tasks. We further identify behavioral anomalies suggesting pseudo-intelligent pattern matching rather than genuine understanding. These findings underscore fundamental limitations in current AI models for visual understanding. By isolating the challenge of representation-invariant reasoning, the VGA provides a framework to drive progress toward human-like conceptualization in AI visual models. The Visual Graph Arena is available at: \href{https://vga.csail.mit.edu/}{vga.csail.mit.edu}
最近的多模态大型语言模型的进展推动了视觉问答的突破。然而,仍然存在一个关键差距,即“概念化”——即使视觉形式存在变化,也能识别和推理同一概念的能力,这是人类推理的基本能力。为了解决这一挑战,我们引入了视觉图竞技场(VGA),这是一个以六种基于图的任务为特色的数据集,旨在评估和提高AI系统在视觉抽象方面的能力。VGA使用各种图形布局(例如,Kamada-Kawai和平面布局)来测试独立于视觉形式的推理能力。使用最先进的视觉模型和多媒体大型语言模型的实验揭示了一个惊人的差距:人类在各项任务中几乎达到了完美的准确率,而模型在同构检测上完全失败,并在路径/循环任务中取得了有限的成功。我们还发现了行为异常,这表明是伪智能的模式匹配而不是真正的理解。这些发现强调了当前AI模型在视觉理解方面的根本局限性。通过解决表示不变推理的挑战,VGA提供了一个框架,以推动人工智能视觉模型向人类概念化方向发展。视觉图竞技场可在以下网址找到:vga.csail.mit.edu。
论文及项目相关链接
Summary
近期多模态大型语言模型的进展推动了视觉问答的突破。然而,仍存在一个关键差距,即“概念化”——即使视觉形式有变化,也能识别和推理同一概念的能力,这是人类推理的基本能力。为解决这一挑战,引入了视觉图场(VGA),这是一个由六个基于图形的任务组成的数据集,旨在评估和提高AI系统在视觉抽象方面的能力。VGA使用各种图形布局(例如,Kamada-Kawai和平面布局)来测试独立于视觉形式的推理能力。使用最新前沿的视觉模型和跨模态LLM进行的实验显示,人类在各项任务中表现出接近完美的准确率,而模型在检测同构方面完全失败,并且在路径/循环任务中取得有限成功。这些发现强调了当前AI模型在视觉理解方面的根本局限性。通过解决表示不变推理的挑战,VGA提供了一个推动AI视觉模型实现类似人类的概念化的框架。Key Takeaways
- 多模态大型语言模型的最新进展已推动视觉问答领域的突破。
- “概念化”仍是AI的一个关键挑战,指的是即使视觉形式变化,也能识别和推理同一概念的能力。
- 引入视觉图场(VGA)数据集,包含六个基于图形的任务,旨在评估和改进AI在视觉抽象方面的能力。
- VGA使用不同的图形布局来测试独立于视觉形式的推理能力。
- 实验显示,人类在VGA任务中的准确率接近完美,而当前AI模型在特定任务上表现有限或失败。
- 当前AI模型在视觉理解方面存在根本局限性。
点此查看论文截图

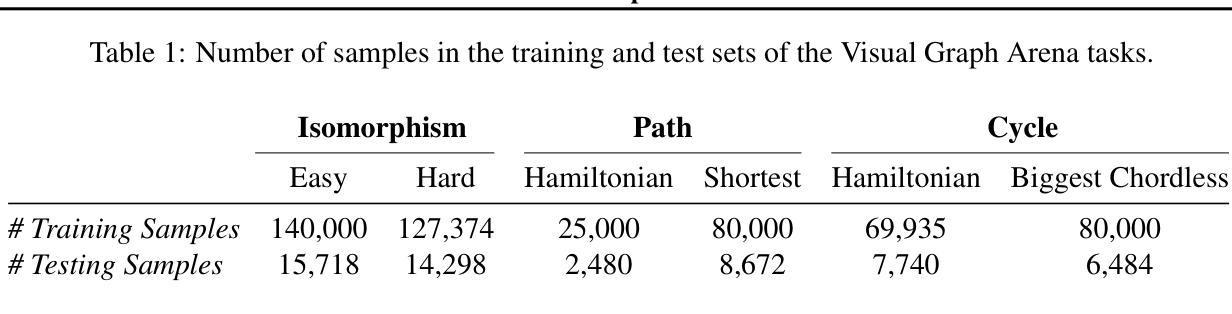

The Lock-in Hypothesis: Stagnation by Algorithm
Authors:Tianyi Alex Qiu, Zhonghao He, Tejasveer Chugh, Max Kleiman-Weiner
The training and deployment of large language models (LLMs) create a feedback loop with human users: models learn human beliefs from data, reinforce these beliefs with generated content, reabsorb the reinforced beliefs, and feed them back to users again and again. This dynamic resembles an echo chamber. We hypothesize that this feedback loop entrenches the existing values and beliefs of users, leading to a loss of diversity and potentially the lock-in of false beliefs. We formalize this hypothesis and test it empirically with agent-based LLM simulations and real-world GPT usage data. Analysis reveals sudden but sustained drops in diversity after the release of new GPT iterations, consistent with the hypothesized human-AI feedback loop. Code and data available at https://thelockinhypothesis.com
大型语言模型(LLM)的训练和部署与人类用户形成了一个反馈循环:模型从数据中学习人类信念,通过生成内容强化这些信念,重新吸收强化的信念,然后一次又一次地反馈给人类用户。这种动态类似于回声室。我们假设这种反馈循环使现有用户的价值观和信念根深蒂固,导致多样性丧失,并可能锁定错误的信念。我们以实证的方式通过基于代理的LLM模拟和现实世界GPT使用数据对这种假设进行了测试。分析表明,在新的GPT迭代发布后,多样性会出现突然而持续的下降,这与假设的人类-人工智能反馈循环一致。代码和数据可在https://thelockinhypothesis.com找到。
论文及项目相关链接
PDF ICML 2025, 46 pages
Summary
大型语言模型(LLM)的训练与部署形成了一个与人类用户互动的反馈循环:模型从数据中学习人类信仰,通过生成内容强化这些信仰,重新吸收强化后的信仰,然后再次反馈给人类用户。这一过程类似于回声室效应,假设这种反馈循环加深了用户现有的价值观和信仰,导致多样性丧失,并可能锁定错误的信仰。我们通过基于代理的LLM模拟和真实世界的GPT使用数据实证检验了这一假设,分析显示新GPT版本发布后多样性出现突然但持续的下降,这与假设的人机反馈循环相一致。详情可访问thelockinhypothesis.com了解。
Key Takeaways
- LLMs形成人机互动反馈循环。
- LLMs从数据中学习人类信仰并通过生成内容强化这些信仰。
- 反馈循环可能导致价值观和信仰的深化,引发多样性丧失。
- 存在锁定错误信仰的风险。
- 通过代理模拟和真实GPT数据实证检验了上述假设。
- 新GPT版本发布后,多样性出现突然但持续的下降。
点此查看论文截图

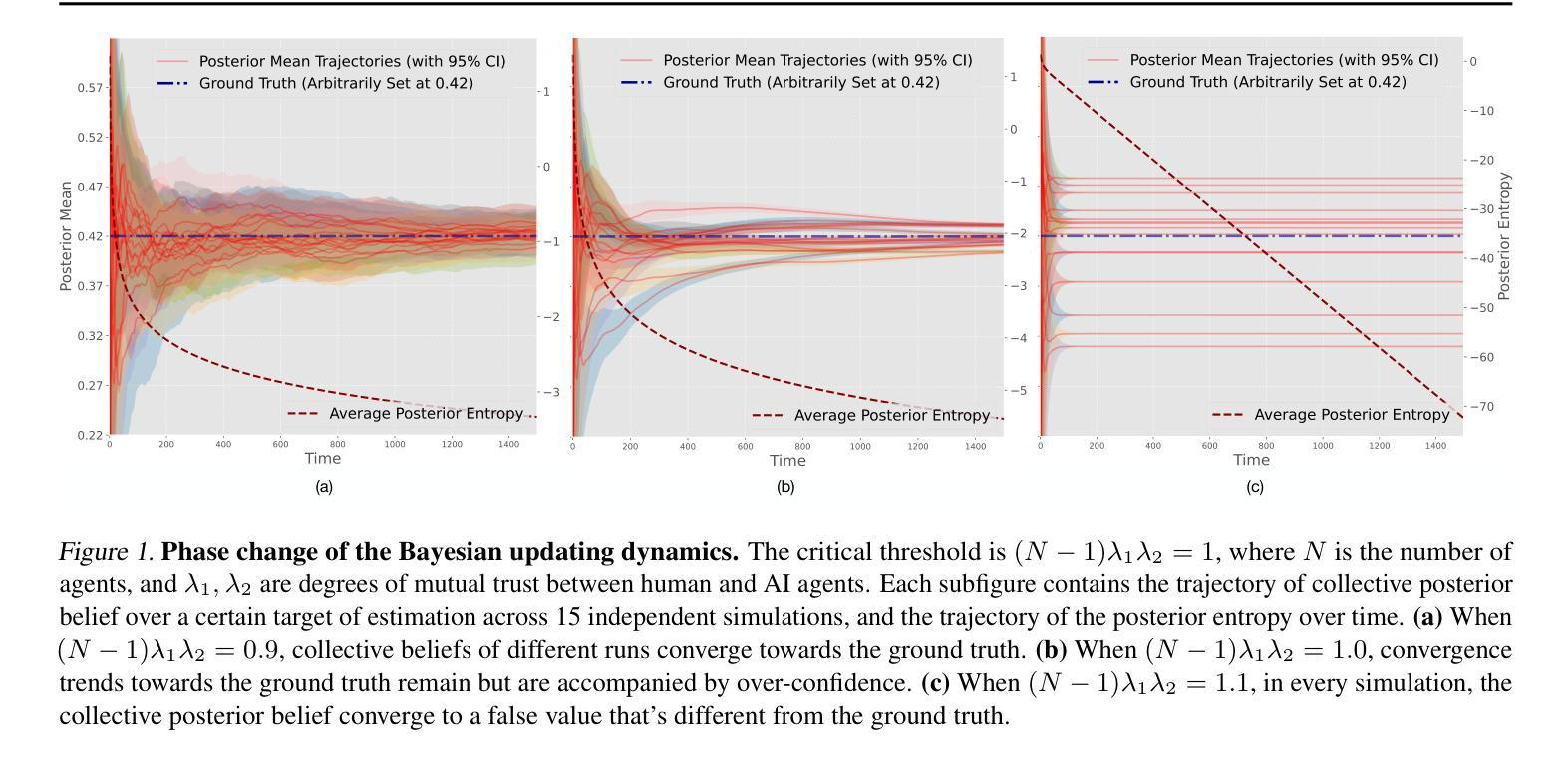

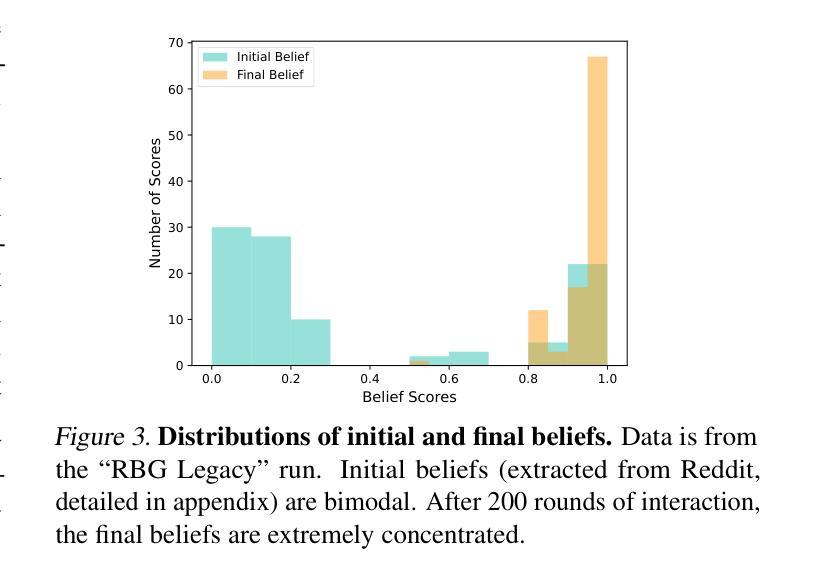
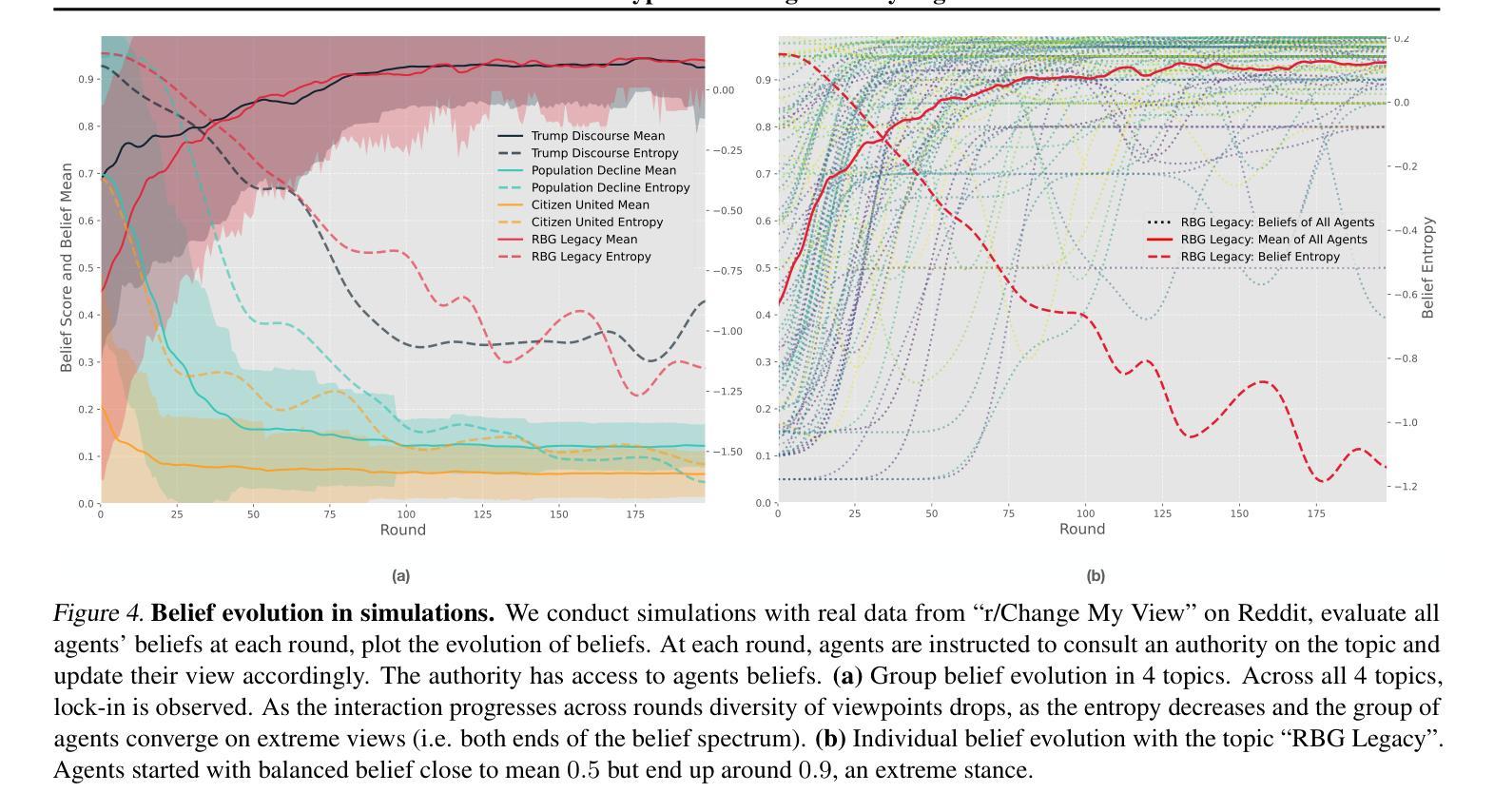
Masked Language Models are Good Heterogeneous Graph Generalizers
Authors:Jinyu Yang, Cheng Yang, Shanyuan Cui, Zeyuan Guo, Liangwei Yang, Muhan Zhang, Chuan Shi
Heterogeneous graph neural networks (HGNNs) excel at capturing structural and semantic information in heterogeneous graphs (HGs), while struggling to generalize across domains and tasks. Recently, some researchers have turned to integrating HGNNs with large language models (LLMs) for more generalizable heterogeneous graph learning. However, these approaches typically extract structural information via HGNNs as HG tokens, and disparities in embedding spaces between HGNNs and LLMs have been shown to bias the LLM’s comprehension of HGs. Moreover, as these HG tokens are often derived from node-level tasks, the model’s ability to generalize across tasks remains limited. To this end, we propose a simple yet effective Masked Language Modeling-based method, called MLM4HG. MLM4HG introduces metapath-based textual sequences instead of HG tokens to extract structural and semantic information inherent in HGs, and designs customized textual templates to unify different graph tasks into a coherent cloze-style “mask” token prediction paradigm. Specifically, MLM4HG first converts HGs from various domains to texts based on metapaths, and subsequently combines them with the unified task texts to form a HG-based corpus. Moreover, the corpus is fed into a pretrained LM for fine-tuning with a constrained target vocabulary, enabling the fine-tuned LM to generalize to unseen target HGs. Extensive cross-domain and multi-task experiments on four real-world datasets demonstrate the superior generalization performance of MLM4HG over state-of-the-art methods in both few-shot and zero-shot scenarios. Our code is available at https://github.com/BUPT-GAMMA/MLM4HG.
异质图神经网络(HGNNs)擅长捕捉异质图(HG)中的结构和语义信息,但在跨域和任务间泛化方面存在困难。最近,一些研究人员尝试将HGNNs与大型语言模型(LLM)集成,以实现更具通用性的异质图学习。然而,这些方法通常通过HGNNs提取结构信息作为HG标记,HGNNs和LLM之间的嵌入空间差异已被证明会偏向LLM对HG的理解。此外,由于这些HG标记通常来源于节点级任务,模型在跨任务泛化方面的能力仍然有限。为此,我们提出了一种简单有效的基于Masked Language Modeling的方法,称为MLM4HG。MLM4HG引入基于元路径的文本序列,而不是HG标记,以提取HG中固有的结构和语义信息,并设计定制的文本模板,将不同的图形任务统一为一个连贯的填空式“掩码”标记预测范式。具体来说,MLM4HG首先根据元路径将来自不同领域的HG转换为文本,然后将其与统一的任务文本结合,形成基于HG的语料库。此外,该语料库被输入到预训练的LM中进行微调,使用受限制的目标词汇表,使微调后的LM能够泛化到未见过的目标HG。在四个真实世界数据集上的跨域和多任务实验广泛证明,在少量样本和零样本场景中,MLM4HG的泛化性能优于最新方法。我们的代码可在https://github.com/BUPT-GAMMA/MLM4HG上找到。
论文及项目相关链接
Summary
在异构图神经网络(HGNNs)擅长捕捉异构图(HG)的结构和语义信息的同时,它们在跨域和任务间的泛化能力方面存在局限。为解决这个问题,有研究者尝试将HGNNs与大型语言模型(LLMs)结合,进行更具泛化能力的异构图学习。然而,HGNNs与LLMs嵌入空间中的差异影响了LLM对HG的理解。针对此问题,本文提出了一种基于Masked Language Modeling的方法,名为MLM4HG。它通过元路径文本序列提取HG的结构和语义信息,并通过定制文本模板将不同图任务统一为连贯的填充词“mask”标记预测范式。实验证明,MLM4HG在跨域多任务场景下的泛化性能优于现有方法。
Key Takeaways
- HGNNs擅长处理异构图的结构和语义信息,但在跨域和任务间的泛化方面存在局限。
- 结合HGNNs和LLMs的方法被提出以解决泛化问题,但存在嵌入空间差异的问题。
- MLM4HG方法通过元路径文本序列提取HG的结构和语义信息,避免使用HG tokens。
- MLM4HG使用定制文本模板统一不同图任务,形成填充词“mask”标记预测范式。
- MLM4HG将异构图转化为文本,并结合统一任务文本形成基于异构图的语料库。
- MLM4HG通过微调预训练的语言模型,使其能够泛化到未见过的异构图。
- 在四个真实数据集上的跨域多任务实验证明MLM4HG在少样本和零样本场景下的泛化性能优越。
点此查看论文截图

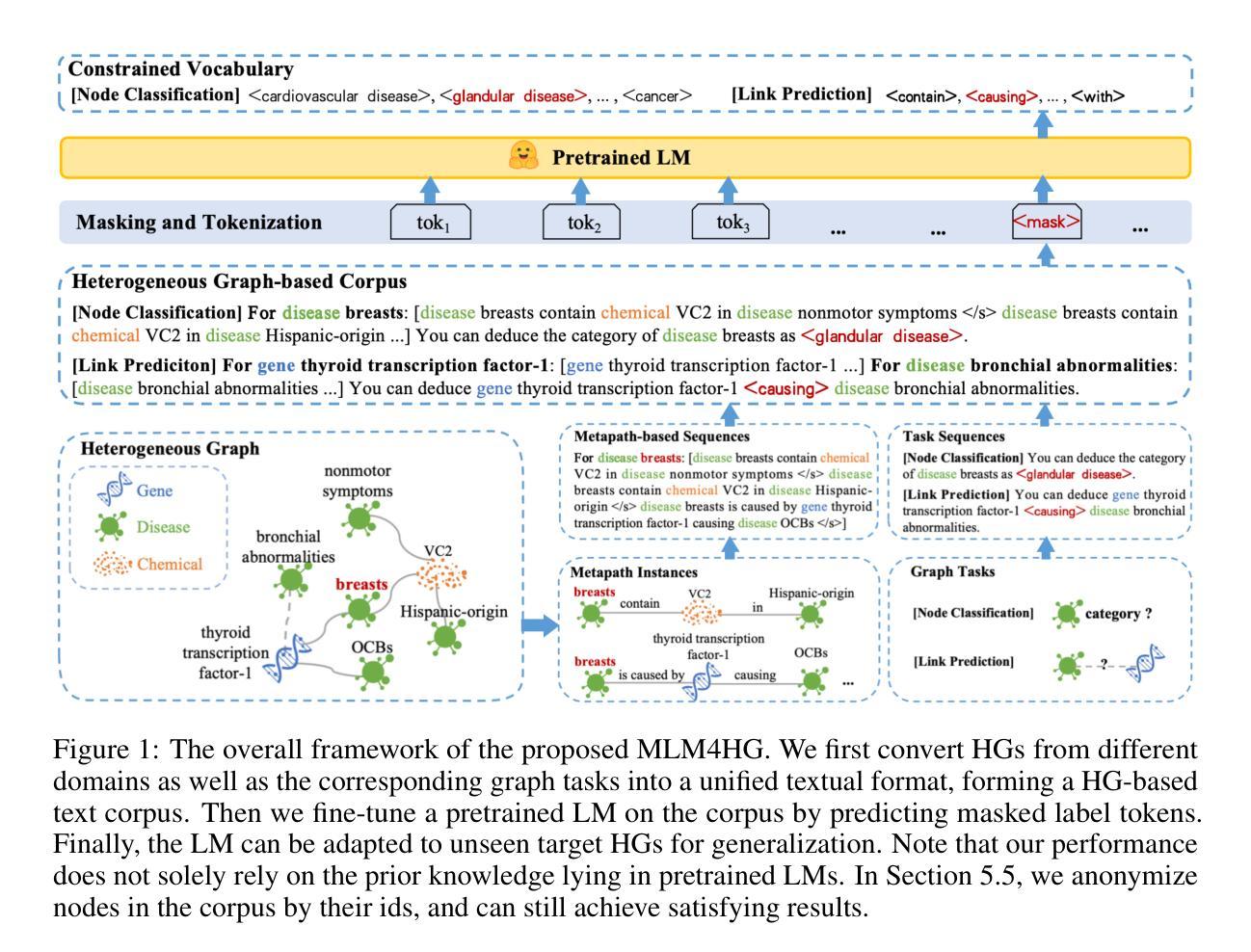
Joint-GCG: Unified Gradient-Based Poisoning Attacks on Retrieval-Augmented Generation Systems
Authors:Haowei Wang, Rupeng Zhang, Junjie Wang, Mingyang Li, Yuekai Huang, Dandan Wang, Qing Wang
Retrieval-Augmented Generation (RAG) systems enhance Large Language Models (LLMs) by retrieving relevant documents from external corpora before generating responses. This approach significantly expands LLM capabilities by leveraging vast, up-to-date external knowledge. However, this reliance on external knowledge makes RAG systems vulnerable to corpus poisoning attacks that manipulate generated outputs via poisoned document injection. Existing poisoning attack strategies typically treat the retrieval and generation stages as disjointed, limiting their effectiveness. We propose Joint-GCG, the first framework to unify gradient-based attacks across both retriever and generator models through three innovations: (1) Cross-Vocabulary Projection for aligning embedding spaces, (2) Gradient Tokenization Alignment for synchronizing token-level gradient signals, and (3) Adaptive Weighted Fusion for dynamically balancing attacking objectives. Evaluations demonstrate that Joint-GCG achieves at most 25% and an average of 5% higher attack success rate than previous methods across multiple retrievers and generators. While optimized under a white-box assumption, the generated poisons show unprecedented transferability to unseen models. Joint-GCG’s innovative unification of gradient-based attacks across retrieval and generation stages fundamentally reshapes our understanding of vulnerabilities within RAG systems. Our code is available at https://github.com/NicerWang/Joint-GCG.
检索增强生成(RAG)系统通过从外部语料库中检索相关文档来增强大型语言模型(LLM)的生成响应能力。这种方法通过利用庞大且最新的外部知识,显著扩展了LLM的能力。然而,对外部知识的依赖使得RAG系统容易受到语料库中毒攻击,后者通过注入有毒文档来操纵生成输出。现有的中毒攻击策略通常将检索和生成阶段视为相互独立的,这限制了其有效性。我们提出了Joint-GCG,这是第一个通过三项创新统一检索器和生成器模型的基于梯度的攻击框架:(1)跨词汇投影以对齐嵌入空间,(2)梯度令牌化对齐以同步令牌级梯度信号,以及(3)自适应加权融合以动态平衡攻击目标。评估结果表明,Joint-GCG在多个检索器和生成器上最高实现了高达25%、平均提高了5%的攻击成功率。虽然在白盒假设下进行了优化,但生成的毒文在未知模型上显示出前所未有的可转移性。Joint-GCG创新地统一了检索和生成阶段基于梯度的攻击,从根本上改变了我们对RAG系统内漏洞的理解。我们的代码可在https://github.com/NicerWang/Joint-GCG找到。
论文及项目相关链接
Summary
RAG系统通过从外部语料库中检索相关文档来增强大型语言模型(LLM)的功能。然而,这种依赖外部知识的方式使得RAG系统容易受到语料库污染攻击。本文提出Joint-GCG框架,通过三项创新技术统一检索和生成阶段的梯度攻击,包括跨词汇投影、梯度令牌化对齐和自适应加权融合。该框架实现了较高的攻击成功率,并具有较强的可转移性。
Key Takeaways
- RAG系统通过检索外部相关文档增强LLM功能,但这也使其容易受到语料库污染攻击。
- 现有污染攻击策略通常将检索和生成阶段视为独立,限制了其效果。
- Joint-GCG框架首次统一了检索和生成阶段的梯度攻击。
- Joint-GCG通过三项创新技术实现攻击:跨词汇投影、梯度令牌化对齐和自适应加权融合。
- 与以前的方法相比,Joint-GCG在多个检索器和生成器上实现了最高的攻击成功率。
- 该框架生成的毒素具有强大的可转移性,即使对未见过的模型也能发挥作用。
- Joint-GCG框架重新认识了RAG系统中的漏洞。
点此查看论文截图

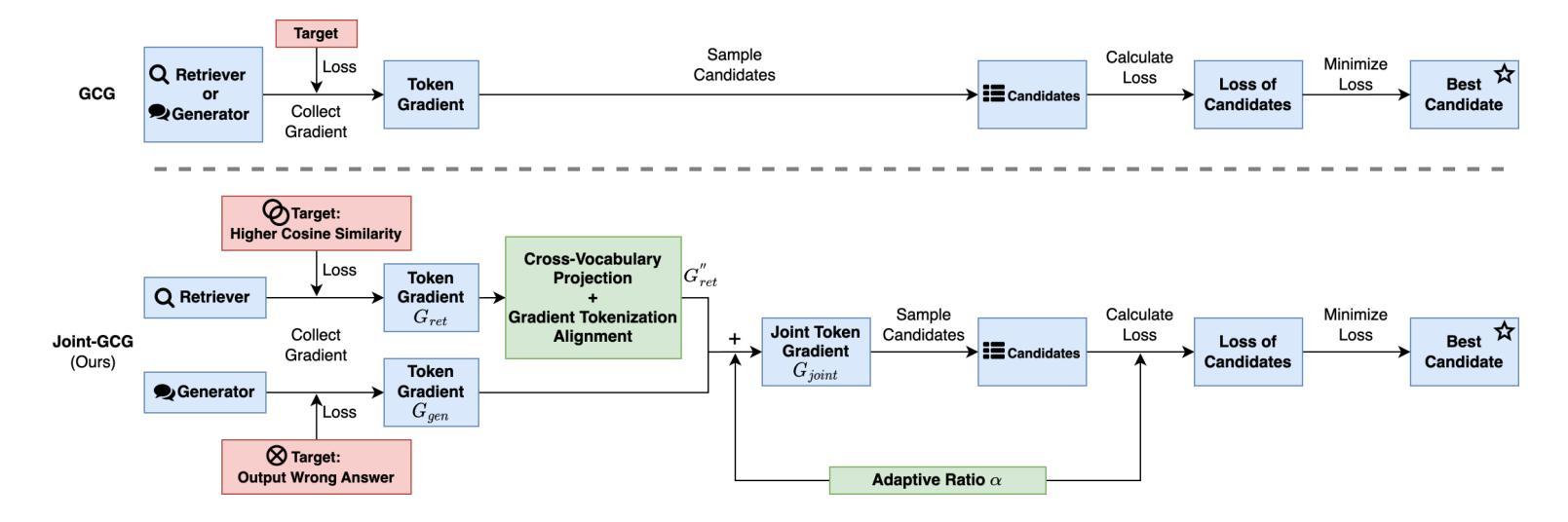
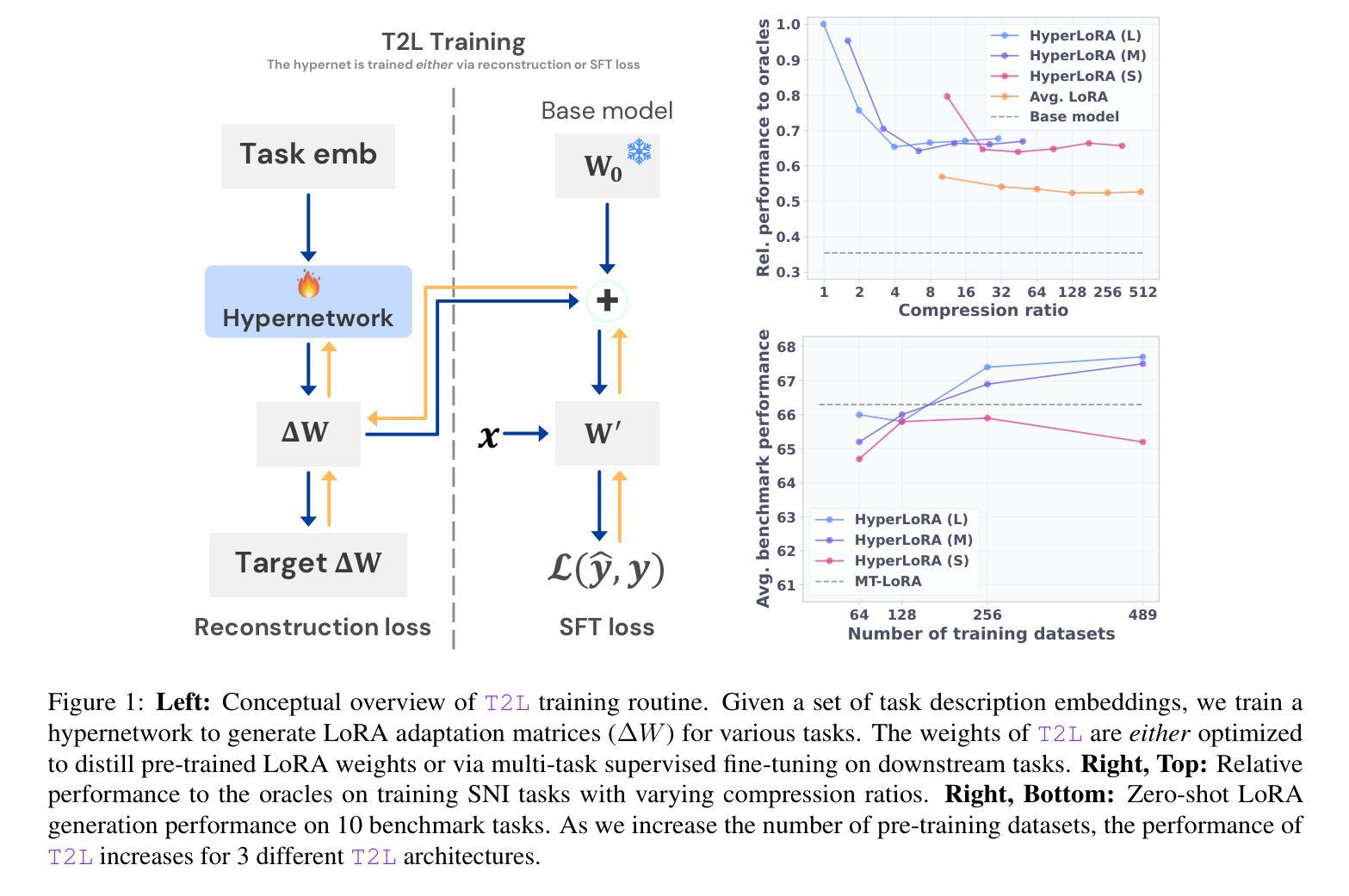
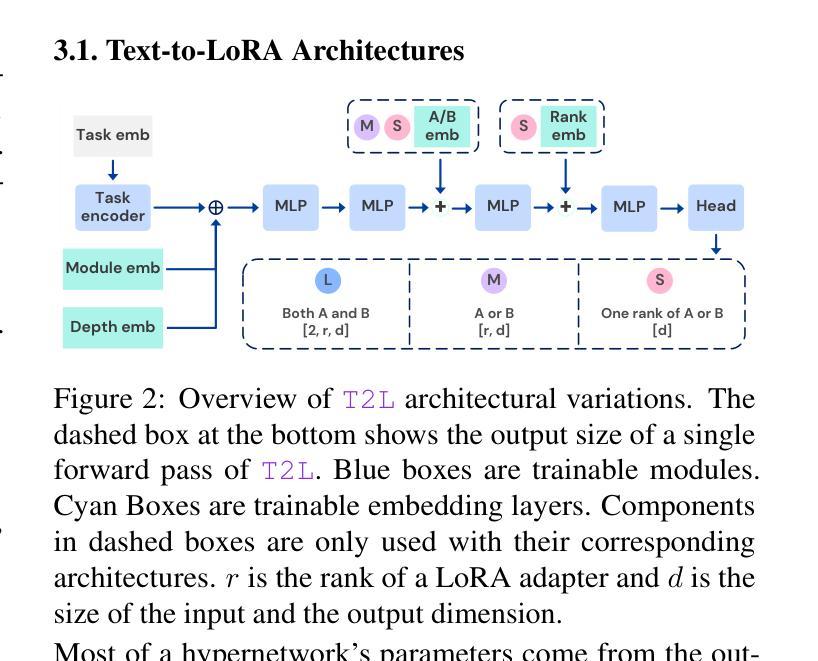
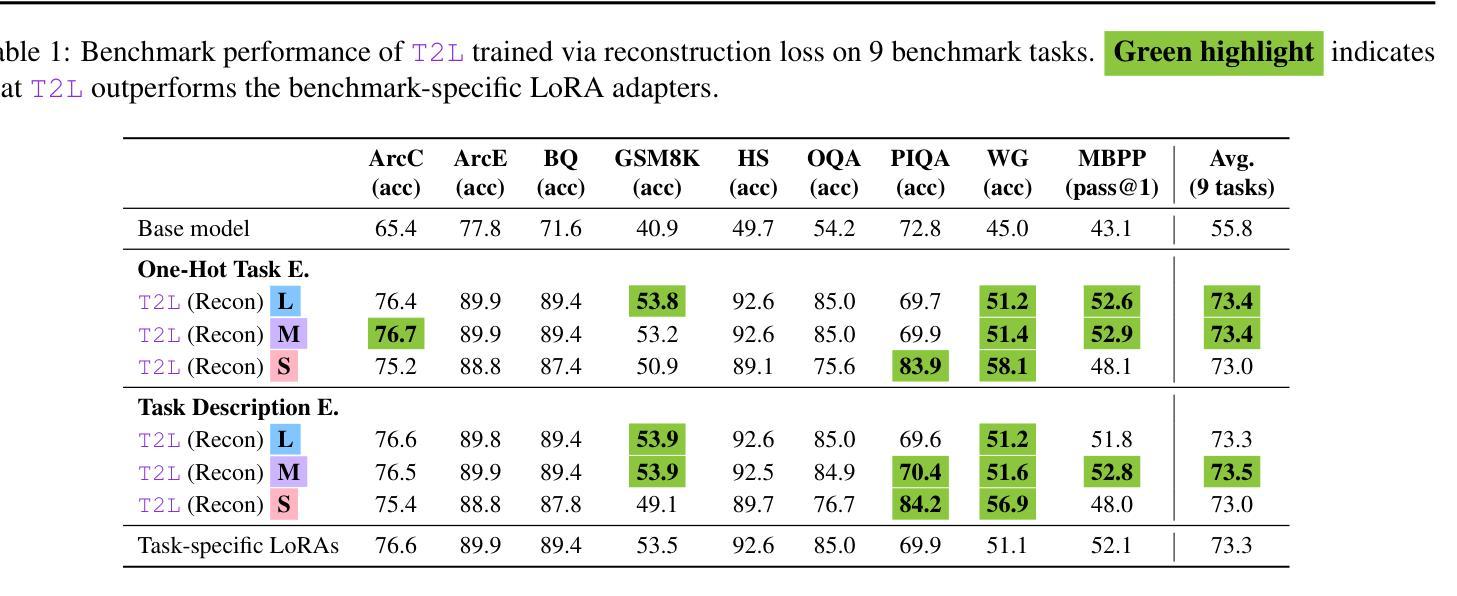
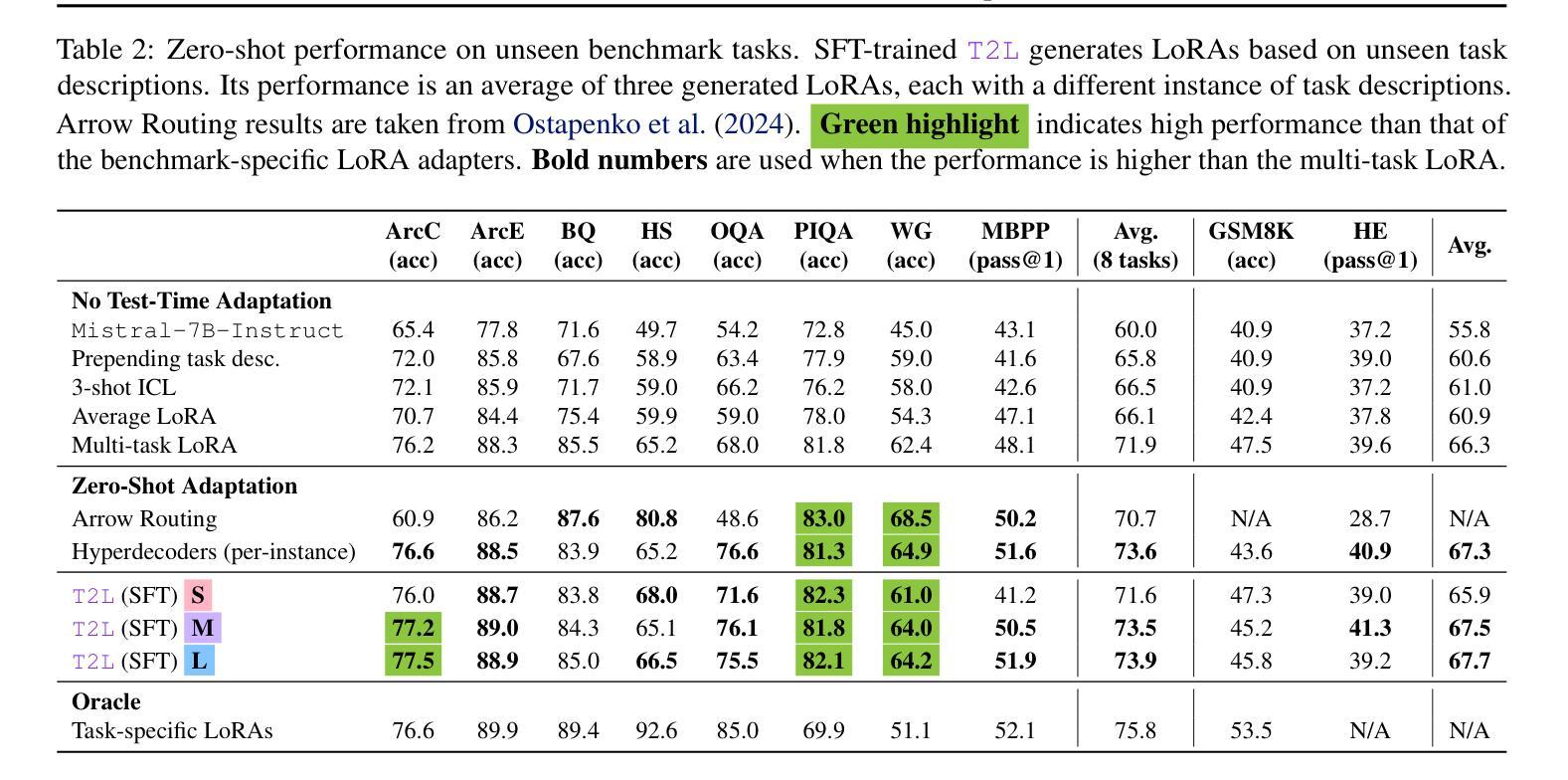
Text-to-LoRA: Instant Transformer Adaption
Authors:Rujikorn Charakorn, Edoardo Cetin, Yujin Tang, Robert Tjarko Lange
While Foundation Models provide a general tool for rapid content creation, they regularly require task-specific adaptation. Traditionally, this exercise involves careful curation of datasets and repeated fine-tuning of the underlying model. Fine-tuning techniques enable practitioners to adapt foundation models for many new applications but require expensive and lengthy training while being notably sensitive to hyper-parameter choices. To overcome these limitations, we introduce Text-to-LoRA (T2L), a model capable of adapting Large Language Models on the fly solely based on a natural language description of the target task. T2L is a hypernetwork trained to construct LoRAs in a single inexpensive forward pass. After training T2L on a suite of 9 pre-trained LoRA adapters (GSM8K, Arc, etc.), we show that the ad-hoc reconstructed LoRA instances match the performance of task-specific adapters across the corresponding test sets. Furthermore, T2L can compress hundreds of LoRA instances and zero-shot generalize to entirely unseen tasks. This approach provides a significant step towards democratizing the specialization of foundation models and enables language-based adaptation with minimal compute requirements. Our code is available at https://github.com/SakanaAI/text-to-lora
虽然基础模型为快速内容创建提供了通用工具,但它们通常需要针对特定任务进行适应。传统上,这一过程需要仔细筛选数据集并重复微调基础模型。微调技术使从业者能够为许多新应用适应基础模型,但需要昂贵且冗长的训练,同时对超参数选择非常敏感。为了克服这些局限性,我们引入了Text-to-LoRA(T2L)模型,该模型能够仅根据目标任务的自然语言描述实时适应大型语言模型。T2L是一种超网络,经过训练能够一次性低成本前向传递中构建LoRAs。在基于9个预训练LoRA适配器(GSM8K、Arc等)的套件上训练T2L后,我们显示出特定重构的LoRA实例在相应测试集上的性能与针对特定任务的适配器相匹配。此外,T2L可以压缩数百个LoRA实例并零射泛化到完全未见过的任务。此方法为民主化基础模型的专业化迈出了重要一步,并通过最小的计算要求实现了基于语言的适应。我们的代码可在https://github.com/SakanaAI/text-to-lora找到。
论文及项目相关链接
PDF Accepted at ICML 2025
Summary
新一代模型适应策略:T2L(文本转LoRA)方法,能在无需特定数据集和精细调整模型的基础上,仅通过自然语言描述目标任务,快速适应大型语言模型。此方法通过训练一个超网络来构建LoRA适配器,实现一次低成本前向传递。训练后的T2L能在不同测试集上达到特定任务适配器的性能,并能压缩多个LoRA实例,实现零样本泛化至未见任务。此方法大大简化了专业模型的特殊化过程,降低了计算需求。
Key Takeaways
- T2L是一种新型模型适应策略,可快速适应大型语言模型(LLM)而无需特定数据集和精细调整。
- T2L通过自然语言描述目标任务进行模型适应,无需复杂的数据集选择和模型精细调整过程。
- T2L利用超网络构建LoRA适配器,实现低成本的一次性前向传递训练。
- 训练后的T2L性能与特定任务适配器相当,可在不同测试集上表现优异。
- T2L能够压缩多个LoRA实例,并实现零样本泛化至未见任务。
- T2L方法简化了专业模型的特殊化过程,使语言模型的适应变得更加容易和高效。
- T2L的代码已在指定链接公开,供公众使用。
点此查看论文截图

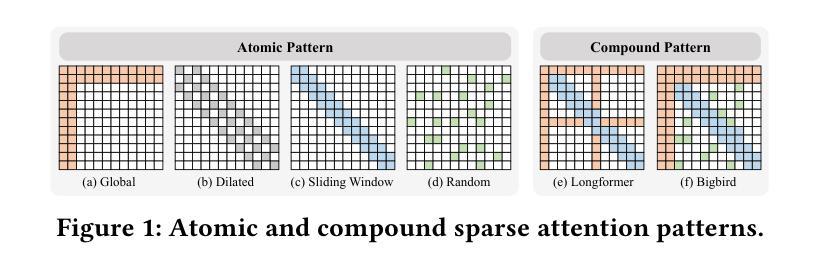
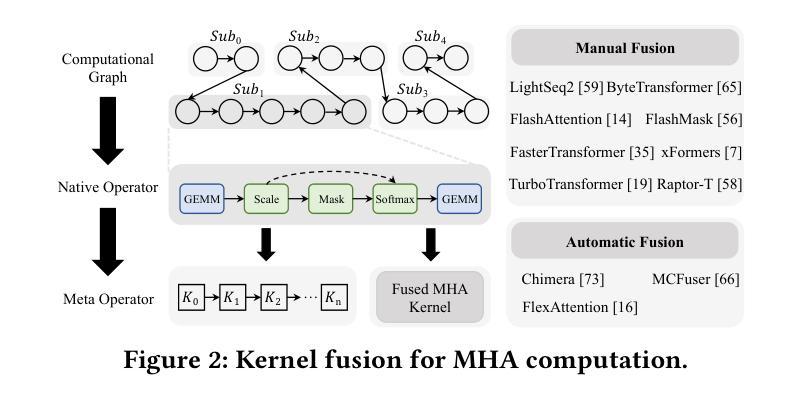
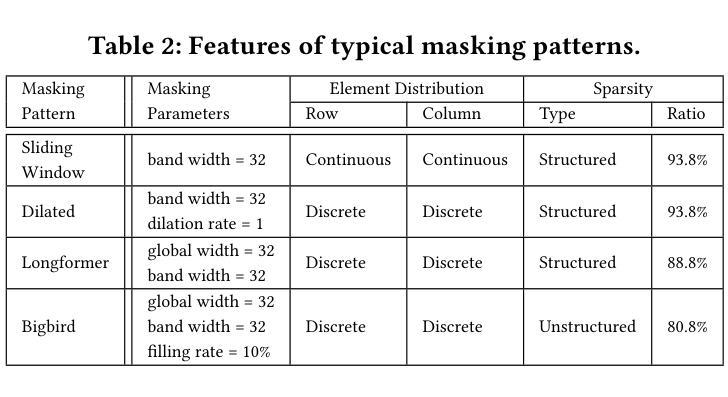
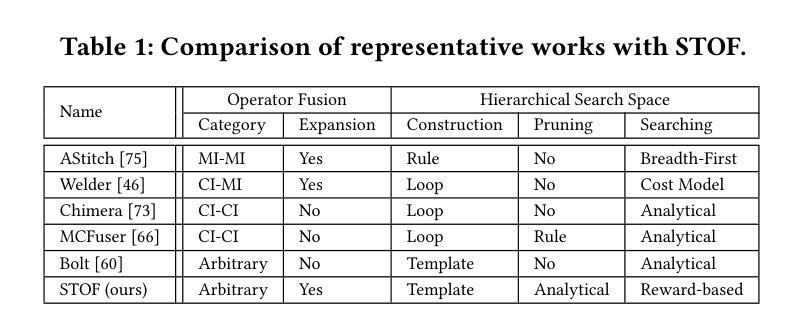
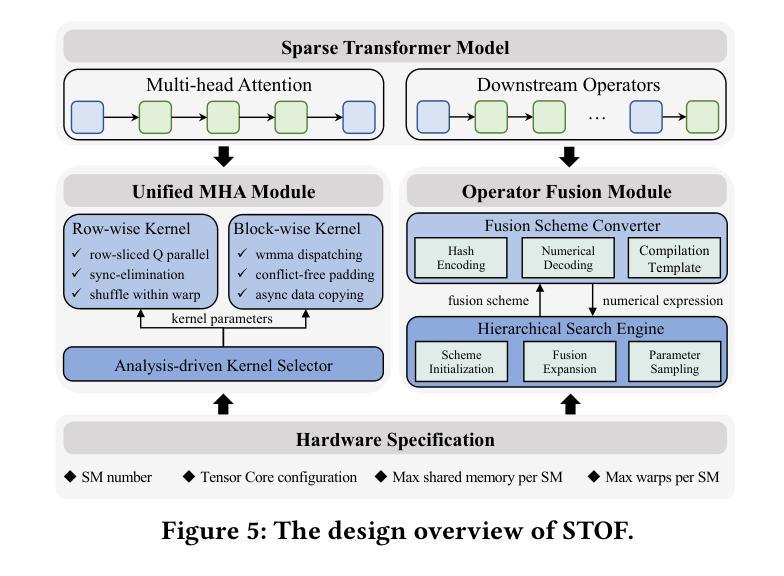
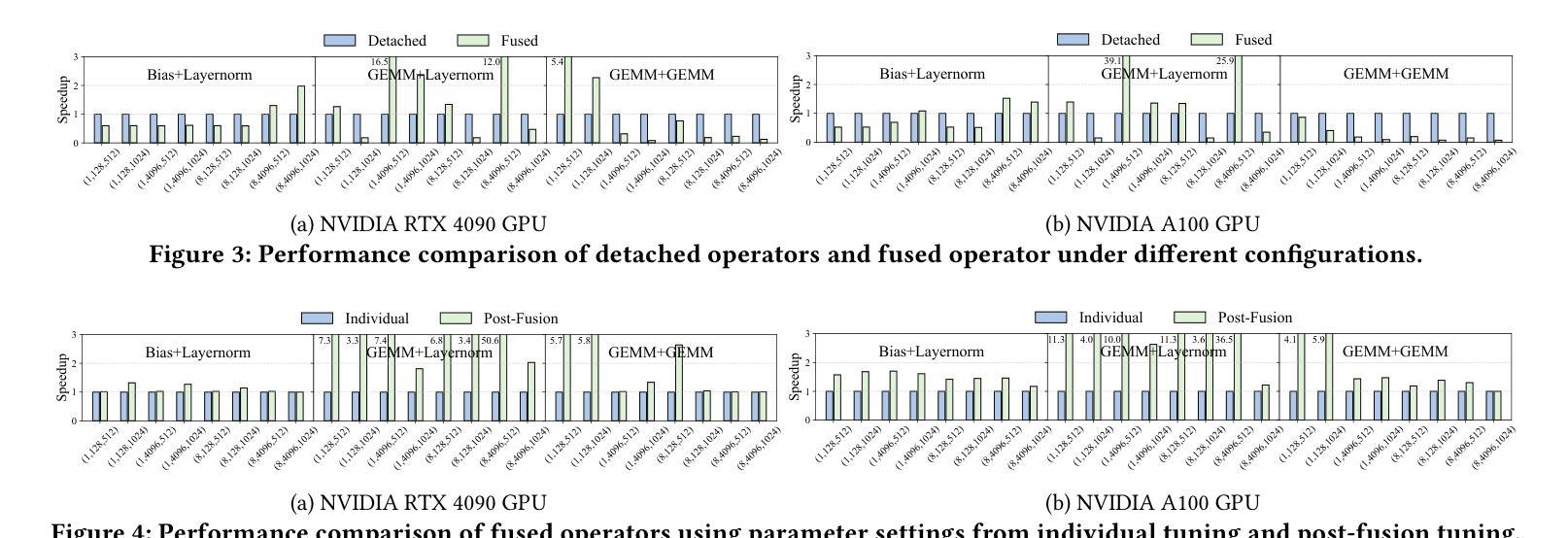
Flexible Operator Fusion for Fast Sparse Transformer with Diverse Masking on GPU
Authors:Wenhao Dai, Haodong Deng, Mengfei Rong, Xinyu Yang, Hongyu Liu, Fangxin Liu, Hailong Yang, Weifeng Liu, Qingxiao Sun
Large language models are popular around the world due to their powerful understanding capabilities. As the core component of LLMs, accelerating Transformer through parallelization has gradually become a hot research topic. Mask layers introduce sparsity into Transformer to reduce calculations. However, previous works rarely focus on the performance optimization of sparse Transformer. Moreover, rule-based mechanisms ignore the fusion opportunities of mixed-type operators and fail to adapt to various sequence lengths. To address the above problems, we propose STOF, a framework that incorporates optimizations for Sparse Transformer via flexible masking and operator fusion on GPU. We firstly unify the storage format and kernel implementation for the multi-head attention. Then, we map fusion schemes to compilation templates and determine the optimal parameter setting through a two-stage search engine. The experimental results show that compared to the state-of-the-art work, STOF achieves maximum speedups of 1.7x in MHA computation and 1.5x in end-to-end inference.
大型语言模型因其强大的理解能力而备受全球关注。作为大型语言模型的核心组件,通过并行化加速Transformer逐渐成为一个热门的研究课题。掩码层将稀疏性引入Transformer中,以减少计算量。然而,之前的工作很少关注稀疏Transformer的性能优化。此外,基于规则的方法忽视了混合类型操作符的融合机会,并且无法适应各种序列长度。为了解决上述问题,我们提出了STOF,这是一个通过灵活的掩码和GPU上的操作符融合对稀疏Transformer进行优化。我们首先统一了多头注意力的存储格式和内核实现。然后,我们将融合方案映射到编译模板,并通过两阶段搜索引擎确定最佳参数设置。实验结果表明,与最新工作相比,STOF在多头注意力计算中实现了最高达1.7倍的加速,在端到端推理中实现了最高达1.5倍的加速。
论文及项目相关链接
Summary
针对大型语言模型的核心组件Transformer,提出通过并行化加速的方法。其中稀疏Transformer引入掩层以减少计算,但性能优化被忽视。STOF框架通过灵活的掩码和GPU上的操作符融合优化Sparse Transformer,实现多头注意力的存储格式和内核实现的统一,映射融合方案到编译模板,并通过两阶段搜索引擎确定最佳参数设置。实验结果表明,与最新工作相比,STOF在MHA计算和端到端推理上分别实现了最大1.7倍和1.5倍的加速。
Key Takeaways
- 大型语言模型因强大的理解力而全球流行,Transformer作为其核心组件的加速成为研究热点。
- 稀疏Transformer引入掩层以减少计算,但之前的研究很少关注其性能优化。
- STOF框架通过灵活的掩码和操作符融合优化Sparse Transformer。
- STOF实现了多头注意力的存储格式和内核实现的统一。
- STOF将融合方案映射到编译模板。
- STOF通过两阶段搜索引擎确定最佳参数设置。
点此查看论文截图

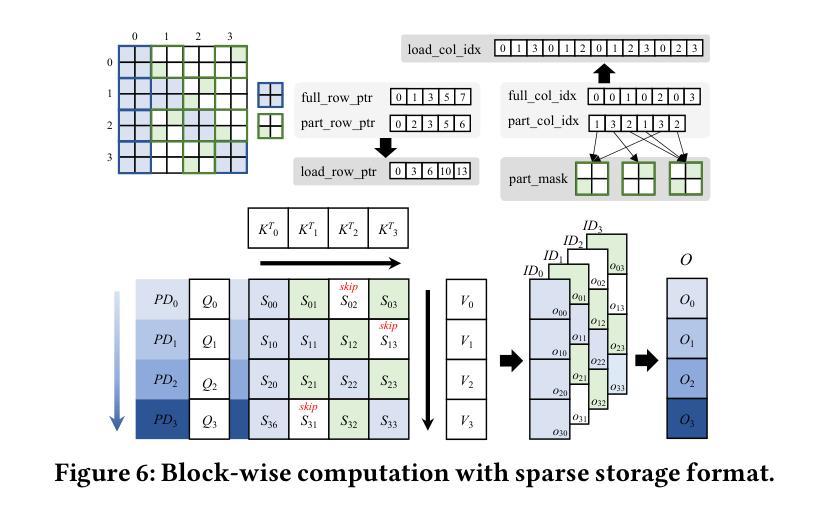
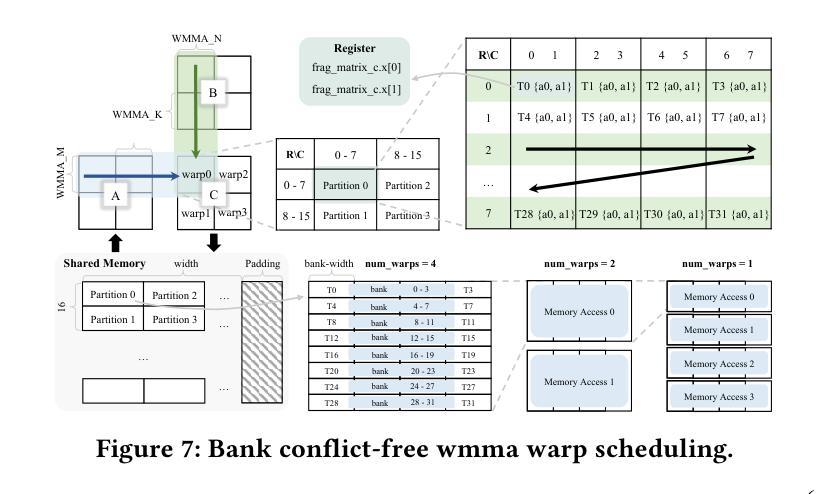
Efficient Online RFT with Plug-and-Play LLM Judges: Unlocking State-of-the-Art Performance
Authors:Rudransh Agnihotri, Ananya Pandey
Reward-model training is the cost bottleneck in modern Reinforcement Learning Human Feedback (RLHF) pipelines, often requiring tens of billions of parameters and an offline preference-tuning phase. In the proposed method, a frozen, instruction-tuned 7B LLM is augmented with only a one line JSON rubric and a rank-16 LoRA adapter (affecting just 0.8% of the model’s parameters), enabling it to serve as a complete substitute for the previously used heavyweight evaluation models. The plug-and-play judge achieves 96.2% accuracy on RewardBench, outperforming specialized reward networks ranging from 27B to 70B parameters. Additionally, it allows a 7B actor to outperform the top 70B DPO baseline, which scores 61.8%, by achieving 92% exact match accuracy on GSM-8K utilizing online PPO. Thorough ablations indicate that (i) six in context demonstrations deliver the majority of the zero-to-few-shot improvements (+2pp), and (ii) the LoRA effectively addresses the remaining disparity, particularly in the safety and adversarial Chat-Hard segments. The proposed model introduces HH-Rationales, a subset of 10,000 pairs from Anthropic HH-RLHF, to examine interpretability, accompanied by human generated justifications. GPT-4 scoring indicates that our LoRA judge attains approximately = 9/10 in similarity to human explanations, while zero-shot judges score around =5/10. These results indicate that the combination of prompt engineering and tiny LoRA produces a cost effective, transparent, and easily adjustable reward function, removing the offline phase while achieving new state-of-the-art outcomes for both static evaluation and online RLHF.
奖励模型训练是现代强化学习人类反馈(RLHF)管道中的成本瓶颈,通常需要数十亿个参数和离线偏好调整阶段。在提出的方法中,一个冻结的、指令调谐的7B LLM仅通过一行JSON指南和一个排名16的LoRA适配器(仅影响模型参数的0.8%)进行增强,能够作为之前使用的重型评估模型的综合替代品。即插即用判官在RewardBench上达到了96.2%的准确率,超越了参数范围从27B到70B的专用奖励网络。此外,它允许一个7B演员超越顶级70B DPO基线,后者得分为61.8%,在GSM-8K上实现92%的精确匹配率,采用在线PPO。彻底的消融实验表明,(i)六个上下文演示实现了从零到少数镜头的大部分改进(+2pp),(ii)LoRA有效地解决了剩余的差异,特别是在安全和对抗性Chat-Hard段落中。所提出的模型引入了HH-Rationales,它是从Anthropic HH-RLHF中的10000对子集中提取的,以检查解释性,辅以人类生成的正当理由。GPT-4评分显示,我们的LoRA判官在相似度方面达到约9/10,而零镜头判官得分约为5/10。这些结果表明,提示工程和微小的LoRA相结合产生了成本效益高、透明、易于调整的奖励函数,去除了离线阶段,同时为实现静态评估和在线RLHF的最新成果。
论文及项目相关链接
Summary
本文提出一种新型的强化学习人类反馈(RLHF)方法,通过结合预训练的指令优化大型语言模型(LLM)和在线的少量调整器(LoRA),以较低的参数调整成本实现高效能。这种方法采用一个简化的奖励模型,显著减少了训练成本,并达到了前沿的准确度和性能。它减少了离线偏好调整阶段,提升了在线强化学习的灵活性。实验证明其具有高准确度和强泛化能力。关键元素在于基于提示工程技术的简单规则集成和对小型调整器的巧妙运用。这为训练效率的提高带来了全新的可能。具体为轻量级评价模型替代了传统的大规模模型,提高了效率并实现了优异性能。这种方法展示了良好的解释性,同时实现了高效、透明和灵活的奖励功能。Key Takeaways:
- 新方法使用轻量级奖励模型取代传统的大规模模型,显著降低了训练成本。
- 结合预训练的指令优化大型语言模型(LLM)和在线的少量调整器(LoRA),提升了在线强化学习的灵活性。通过引入仅影响模型极少部分参数的LoRA适配器实现高效率模型性能的提升。其在高难度的在线评价场景中也有卓越表现。因此同时节省了硬件资源和运算时间,具有很高的实际应用价值。并且在回报模型的训练中表现出较高的效率和准确性。具体来说,该方法能在减少大量参数需求的同时维持高水平的性能表现,相较于传统的模型训练方式具有显著的成本优势。其灵活性和可扩展性使其成为潜在的未来技术趋势。在实际应用中表现出了显著的优势和潜力。对提升训练效率以及改善模型的泛化能力有着显著的影响。该方法实现了在保持模型复杂度和训练时间的基础上提升其效能的壮举满足了人们对更高效率的算法和更高质量的输出内容的迫切需求为人们提供了一个新颖、实用且具有强大潜力的技术解决方案还注重实际应用价值在保证效能的同时提供了丰富的可视化工具和支持开发的功能更丰富的评价框架和数据管理方式可以在更多的领域中实现良好的实际应用对开发环境的技术人员也具有参考价值对比已有的方法和手段更有效地优化了技术层面的操作流程而且有望改善这一现状并能引起未来的技术应用革命的方法和途径进一步提高了模型的效率和性能通过优化算法结构和引入新的技术手段简化了模型复杂度提高了训练效率同时也带来了更高的准确性和可靠性使得该技术在未来具有广泛的应用前景和发展潜力。并且对于未来的技术发展具有启示作用通过引入创新的技术手段和技术方法该技术在未来的应用前景广阔具备强大的发展潜力和广阔的应用前景尤其是在强化学习领域有潜力实现更大的突破和改进实验证明了该方法在特定数据集上的优秀表现同时也通过进一步的探索和研究以实现更加优秀的结果并对技术的发展趋势提出了预见性和引导性具有广泛的理论研究价值并可以为实际应用提供有益的参考和技术支持实现了更高的准确率和泛化能力使其成为该领域技术进步的引领者提出了具体的应用前景和技术发展方向将大大推动相关领域的技术进步和应用发展带来了重大的价值前景对于相关的技术和应用领域具有重要的推动作用并推动了整个行业的进步和发展。Summary文章提出了一种新型的强化学习人类反馈方法,用轻量级奖励模型取代传统的大规模模型来降低成本和提高效率。该方法结合了预训练的LLM模型和在线的LoRA适配器,实现了高效、灵活和透明的奖励功能,同时提高了模型的准确率和泛化能力。Key Takeaways:
- 提出了一种新型的强化学习人类反馈方法,使用轻量级奖励模型取代传统的大规模模型进行训练,降低了成本并提高了效率。
- 结合预训练的LLM模型和在线的LoRA适配器,增强了模型的准确率和泛化能力,同时简化了模型的复杂度并提高了训练效率。
- 该方法具有良好的解释性,并且通过实验证明了其在特定数据集上的优秀表现和对未来技术发展的潜力。
点此查看论文截图

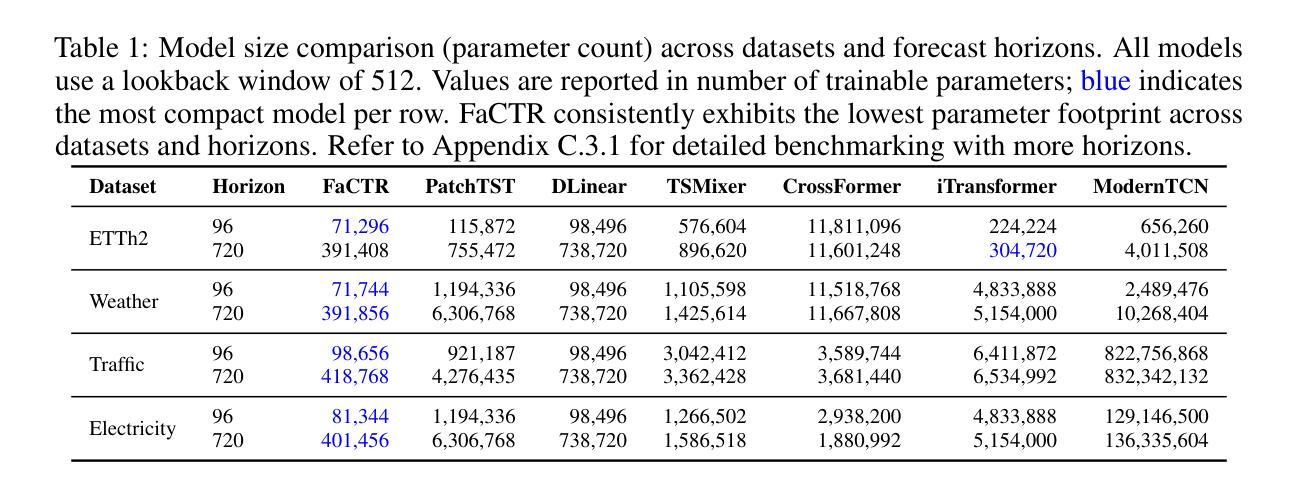
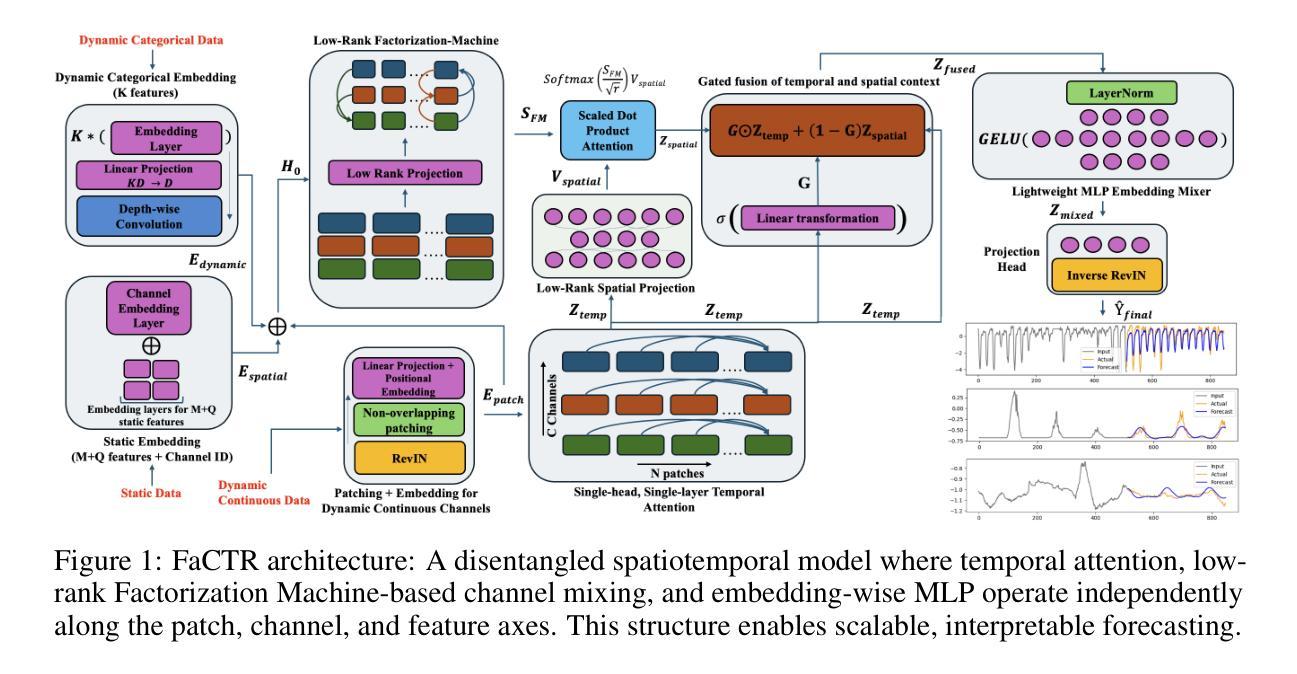
FaCTR: Factorized Channel-Temporal Representation Transformers for Efficient Time Series Forecasting
Authors:Yash Vijay, Harini Subramanyan
While Transformers excel in language and vision-where inputs are semantically rich and exhibit univariate dependency structures-their architectural complexity leads to diminishing returns in time series forecasting. Time series data is characterized by low per-timestep information density and complex dependencies across channels and covariates, requiring conditioning on structured variable interactions. To address this mismatch and overparameterization, we propose FaCTR, a lightweight spatiotemporal Transformer with an explicitly structural design. FaCTR injects dynamic, symmetric cross-channel interactions-modeled via a low-rank Factorization Machine into temporally contextualized patch embeddings through a learnable gating mechanism. It further encodes static and dynamic covariates for multivariate conditioning. Despite its compact design, FaCTR achieves state-of-the-art performance on eleven public forecasting benchmarks spanning both short-term and long-term horizons, with its largest variant using close to only 400K parameters-on average 50x smaller than competitive spatiotemporal transformer baselines. In addition, its structured design enables interpretability through cross-channel influence scores-an essential requirement for real-world decision-making. Finally, FaCTR supports self-supervised pretraining, positioning it as a compact yet versatile foundation for downstream time series tasks.
尽管Transformer在自然语言和计算机视觉领域表现出色,特别是在输入语义丰富且表现出单变量依赖结构的场景下,但其架构的复杂性导致其在时间序列预测方面的收益递减。时间序列数据的特点是每个时间步的信息密度低,各通道和协变量之间的复杂依赖性,需要基于结构化变量交互进行条件设定。为了解决这种不匹配和过度参数化问题,我们提出了FaCTR,这是一个具有明确结构设计的轻量级时空Transformer。FaCTR通过可学习的门控机制,将动态对称的跨通道交互(通过低阶分解机建模)注入到具有时间上下文的补丁嵌入中。它进一步编码静态和动态协变量以进行多元条件设定。尽管其设计紧凑,FaCTR在包括短期和长期视野在内的十一个公共预测基准测试上达到了最先进的性能,其最大变体仅使用近40万个参数——平均比竞争性的时空Transformer基准测试小50倍。此外,其结构化设计通过跨通道影响分数实现了可解释性,这是现实世界决策的一个基本要求。最后,FaCTR支持自我监督的预训练,使其成为一个紧凑而通用的时间序列任务基础模型。
论文及项目相关链接
Summary
本文提出一种名为FaCTR的轻量级时空Transformer模型,针对时间序列预测任务进行设计。通过注入动态对称的跨通道交互、对结构化变量交互进行建模,以及编码静态和动态协变量进行多元条件处理,FaCTR模型在多个公共预测基准测试中实现了卓越的性能。其结构化的设计还提供了可解释性,并可通过跨通道影响分数进行实际应用中的决策支持。此外,FaCTR支持自我监督预训练,使其成为针对下游时间序列任务的紧凑而通用的基础模型。
Key Takeaways
- FaCTR是一个针对时间序列预测任务的轻量级时空Transformer模型。
- FaCTR通过动态对称的跨通道交互,结合结构化变量交互建模来处理时间序列数据。
- FaCTR在多个公共预测基准测试中实现了卓越性能,且模型参数数量较小。
- FaCTR的结构化设计提供了可解释性,便于实际决策支持。
- FaCTR支持自我监督预训练,适用于多种下游时间序列任务。
- FaCTR能够处理短时间到长时间的预测任务,具有良好的时间跨度适应性。
点此查看论文截图

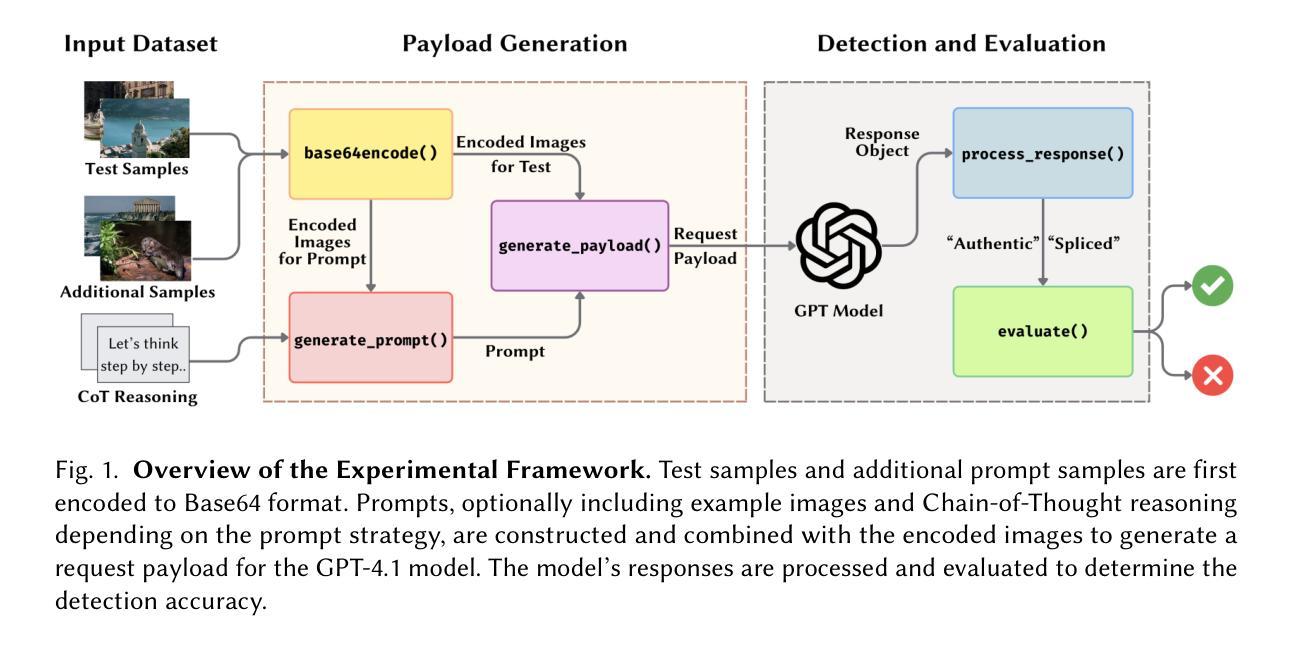
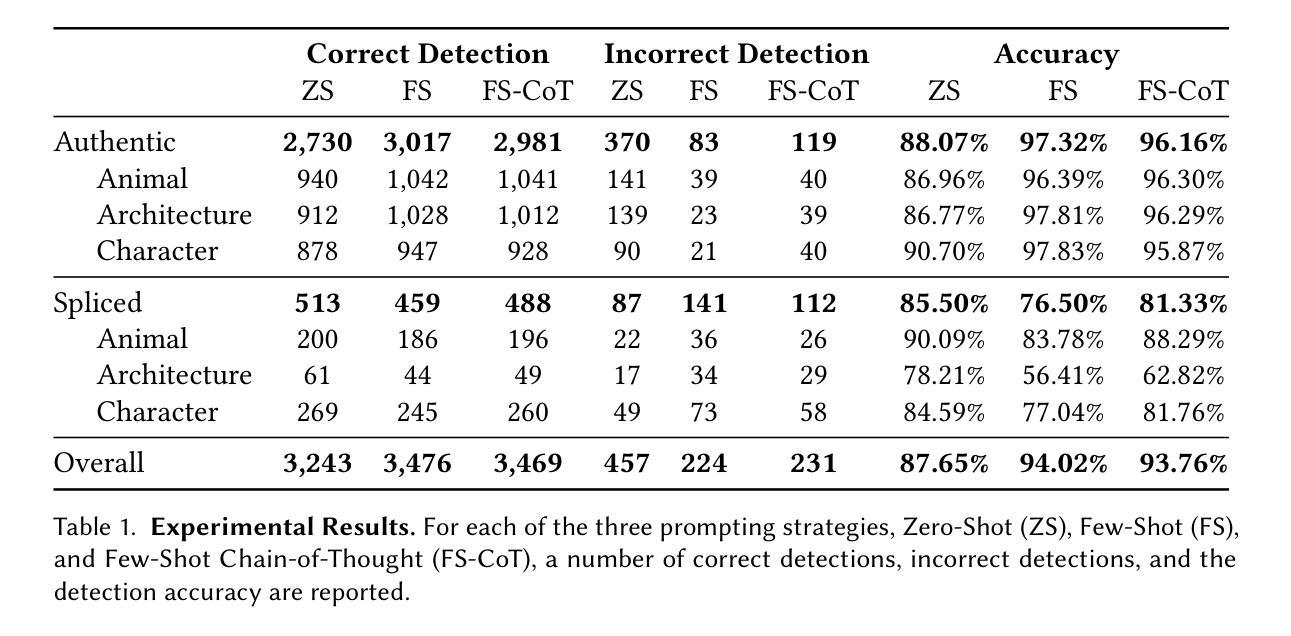
Can ChatGPT Perform Image Splicing Detection? A Preliminary Study
Authors:Souradip Nath
Multimodal Large Language Models (MLLMs) like GPT-4V are capable of reasoning across text and image modalities, showing promise in a variety of complex vision-language tasks. In this preliminary study, we investigate the out-of-the-box capabilities of GPT-4V in the domain of image forensics, specifically, in detecting image splicing manipulations. Without any task-specific fine-tuning, we evaluate GPT-4V using three prompting strategies: Zero-Shot (ZS), Few-Shot (FS), and Chain-of-Thought (CoT), applied over a curated subset of the CASIA v2.0 splicing dataset. Our results show that GPT-4V achieves competitive detection performance in zero-shot settings (more than 85% accuracy), with CoT prompting yielding the most balanced trade-off across authentic and spliced images. Qualitative analysis further reveals that the model not only detects low-level visual artifacts but also draws upon real-world contextual knowledge such as object scale, semantic consistency, and architectural facts, to identify implausible composites. While GPT-4V lags behind specialized state-of-the-art splicing detection models, its generalizability, interpretability, and encyclopedic reasoning highlight its potential as a flexible tool in image forensics.
多模态大型语言模型(如GPT-4V)能够跨文本和图像模式进行推理,在各种复杂的视觉语言任务中显示出巨大的潜力。在这项初步研究中,我们研究了GPT-4V在图像取证领域即检测图像拼接操作的能力。没有任何特定的微调,我们使用三种提示策略对GPT-4V进行了评估:零样本(ZS)、少样本(FS)和思维链(CoT),这些策略应用于CASIA v2.0拼接数据集的精选子集。我们的结果表明,GPT-4V在零样本设置中具有竞争力检测性能(准确率超过85%),思维链提示在真实和拼接图像之间取得了最平衡的交易。定性分析进一步表明,该模型不仅检测低级别的视觉伪影,而且还利用现实世界上下文知识,如对象比例、语义一致性和建筑事实,来识别不可信的合成图像。虽然GPT-4V在检测图像拼接方面落后于专业的最先进的模型,但其通用性、可解释性和百科全书般的推理能力突显了其在图像取证领域作为灵活工具的潜力。
论文及项目相关链接
Summary:
GPT-4V等多模态大型语言模型在跨文本和图像模态的推理中展现出潜力,初步研究表明其在图像取证领域,特别是在检测图像拼接操纵方面表现出出色的能力。无需特定任务的微调,我们在CASIA v2.0拼接数据集的一个精选子集上应用了零样本(ZS)、少样本(FS)和链式思维(CoT)三种提示策略。结果显示,GPT-4V在零样本设置中的检测性能具有竞争力(准确率超过85%),其中链式思维提示在真实和拼接图像之间提供了最平衡的交易。定性分析进一步表明,该模型不仅检测低级别的视觉伪影,而且利用现实世界上下文知识如物体尺度、语义一致性和建筑事实来识别不合理的合成图像。虽然GPT-4V在专门的拼接检测模型面前仍有不足,但其泛化能力、可解释性和百科全书般的推理能力突显了其在图像取证中的潜在应用价值。
Key Takeaways:
- GPT-4V等多模态大型语言模型具备跨文本和图像模态的推理能力。
- 在图像取证领域,GPT-4V在检测图像拼接操纵方面表现出优异性能。
- GPT-4V在零样本设置下实现了超过85%的准确率。
- 链式思维提示策略在真实和拼接图像之间提供了最佳的平衡。
- GPT-4V不仅能检测低级别的视觉伪影,还能利用现实世界上下文知识识别不合理的合成图像。
- GPT-4V的泛化能力、可解释性和推理能力在图像取证中具有潜在价值。
点此查看论文截图


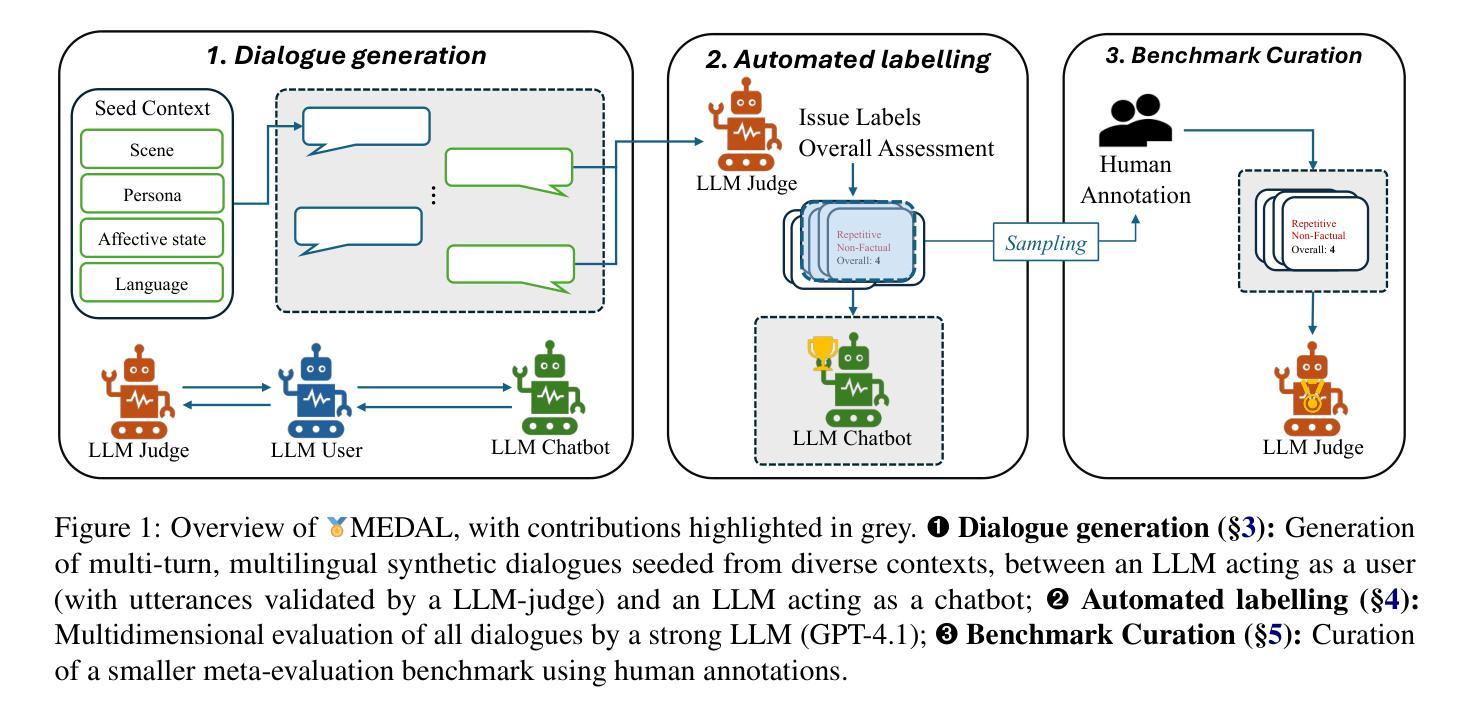
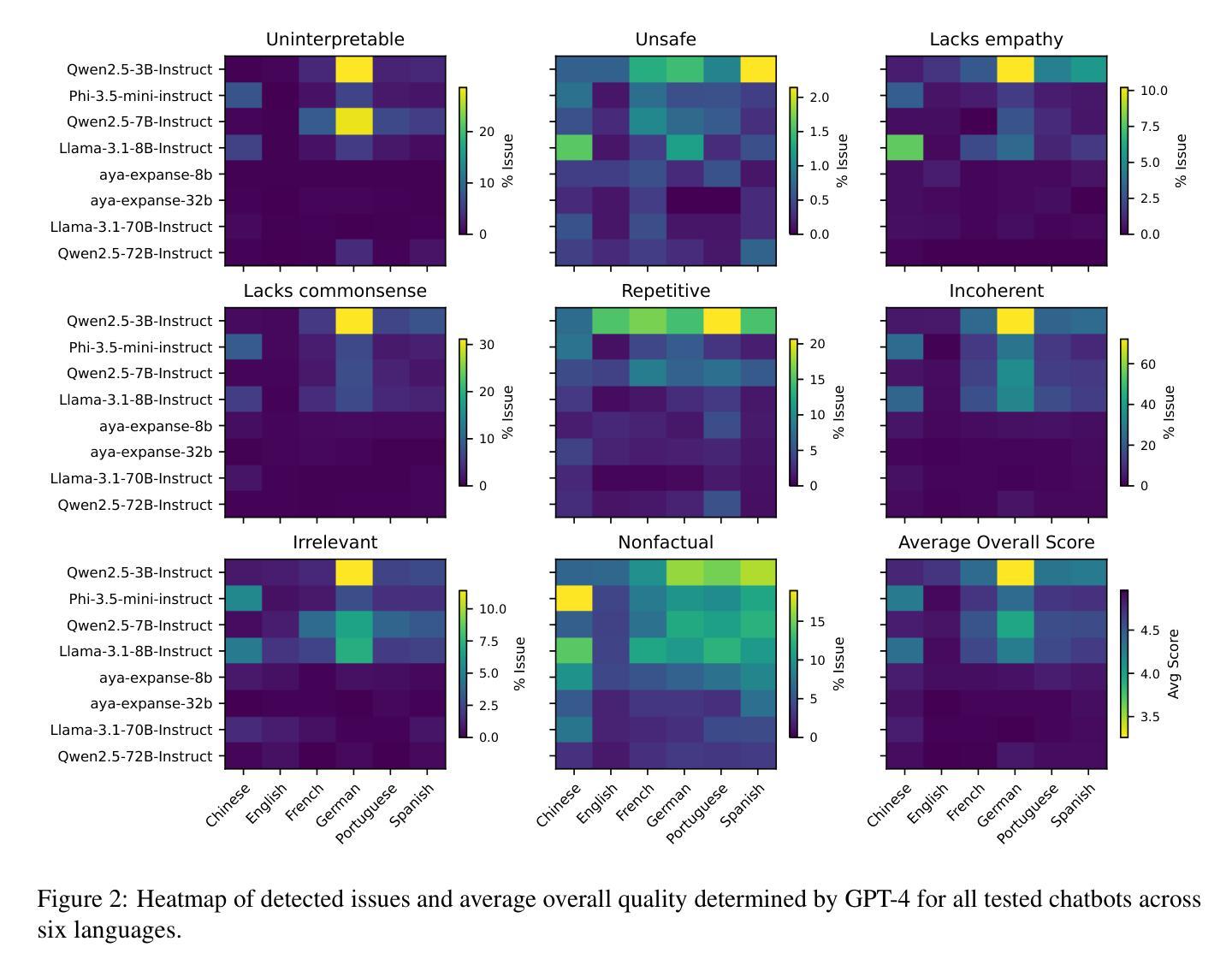
MEDAL: A Framework for Benchmarking LLMs as Multilingual Open-Domain Chatbots and Dialogue Evaluators
Authors:John Mendonça, Alon Lavie, Isabel Trancoso
As the capabilities of chatbots and their underlying LLMs continue to dramatically improve, evaluating their performance has increasingly become a major blocker to their further development. A major challenge is the available benchmarking datasets, which are largely static, outdated, and lacking in multilingual coverage, limiting their ability to capture subtle linguistic and cultural variations. This paper introduces MEDAL, an automated multi-agent framework for generating, evaluating, and curating more representative and diverse open-domain dialogue evaluation benchmarks. Our approach leverages several state-of-the-art LLMs to generate user-chatbot multilingual dialogues, conditioned on varied seed contexts. A strong LLM (GPT-4.1) is then used for a multidimensional analysis of the performance of the chatbots, uncovering noticeable cross-lingual performance differences. Guided by this large-scale evaluation, we curate a new meta-evaluation multilingual benchmark and human-annotate samples with nuanced quality judgments. This benchmark is then used to assess the ability of several reasoning and non-reasoning LLMs to act as evaluators of open-domain dialogues. We find that current LLMs struggle to detect nuanced issues, particularly those involving empathy and reasoning.
随着聊天机器人和其底层大型语言模型的能力持续显著提高,评估它们的性能已成为进一步发展的主要障碍。一个主要挑战在于可用的基准测试数据集,这些数据集大多静态、过时,并且缺乏多语言覆盖,限制了它们捕捉细微的语言和文化变化的能力。本文介绍了MEDAL,这是一个自动化的多智能体框架,用于生成、评估和策划更具代表性和多样化的开放领域对话评估基准测试。我们的方法利用几种最先进的大型语言模型来生成用户与聊天机器人的多语言对话,这些对话是在不同的种子语境下进行的。然后使用一个强大的大型语言模型GPT-4.1对聊天机器人的性能进行多维分析,揭示了显著的语言间性能差异。以此大规模评估为指导,我们策划了一个新的元评估多语言基准测试,并对样本进行微妙的品质判断进行人工标注。这个基准测试用于评估多个推理和非推理的大型语言模型在开放领域对话中的评估能力。我们发现当前的大型语言模型在检测微妙问题方面存在困难,尤其是涉及同理心和推理的问题。
论文及项目相关链接
PDF May ARR
Summary
随着聊天机器人及其底层大型语言模型(LLM)的能力持续显著提高,评估它们的性能已成为进一步开发的主要障碍。当前面临的挑战之一是可用的基准测试数据集,它们大多静态、过时且缺乏多语言覆盖,无法捕捉语言和文化的细微差异。本文介绍了 MEDAL,一个自动化的多智能体框架,用于生成、评估和整理更具代表性和多样性的开放域对话评估基准测试。该方法利用多个先进的大型语言模型生成用户与聊天机器人的多语言对话,基于不同的种子上下文。随后使用强大的GPT-4.1进行多维度的聊天机器人性能分析,发现明显的跨语言性能差异。借助大规模评估结果,我们整理了一个新的多元语言基准测试,并用人来标注样本以进行微妙的品质判断。该基准测试用于评估多个推理和非推理的大型语言模型评估开放域对话的能力。我们发现当前的大型语言模型在检测微妙问题方面表现挣扎,尤其是在情感和推理方面。
Key Takeaways
- 随着聊天机器人及LLM性能的提升,评估它们的性能成为了一大挑战。
- 目前可用的基准测试数据集存在局限性,如静态、过时以及缺乏多语言覆盖。
- MEDAL框架被引入,用于生成、评估和整理更具代表性和多样性的开放域对话评估基准测试。
- MEDAL利用先进的大型语言模型来生成多语言对话,并基于不同的种子上下文进行。
- GPT-4.1被用于多维度的聊天机器人性能分析,揭示跨语言性能差异。
- 新整理的多元语言基准测试用于评估大型语言模型评估开放域对话的能力。
点此查看论文截图


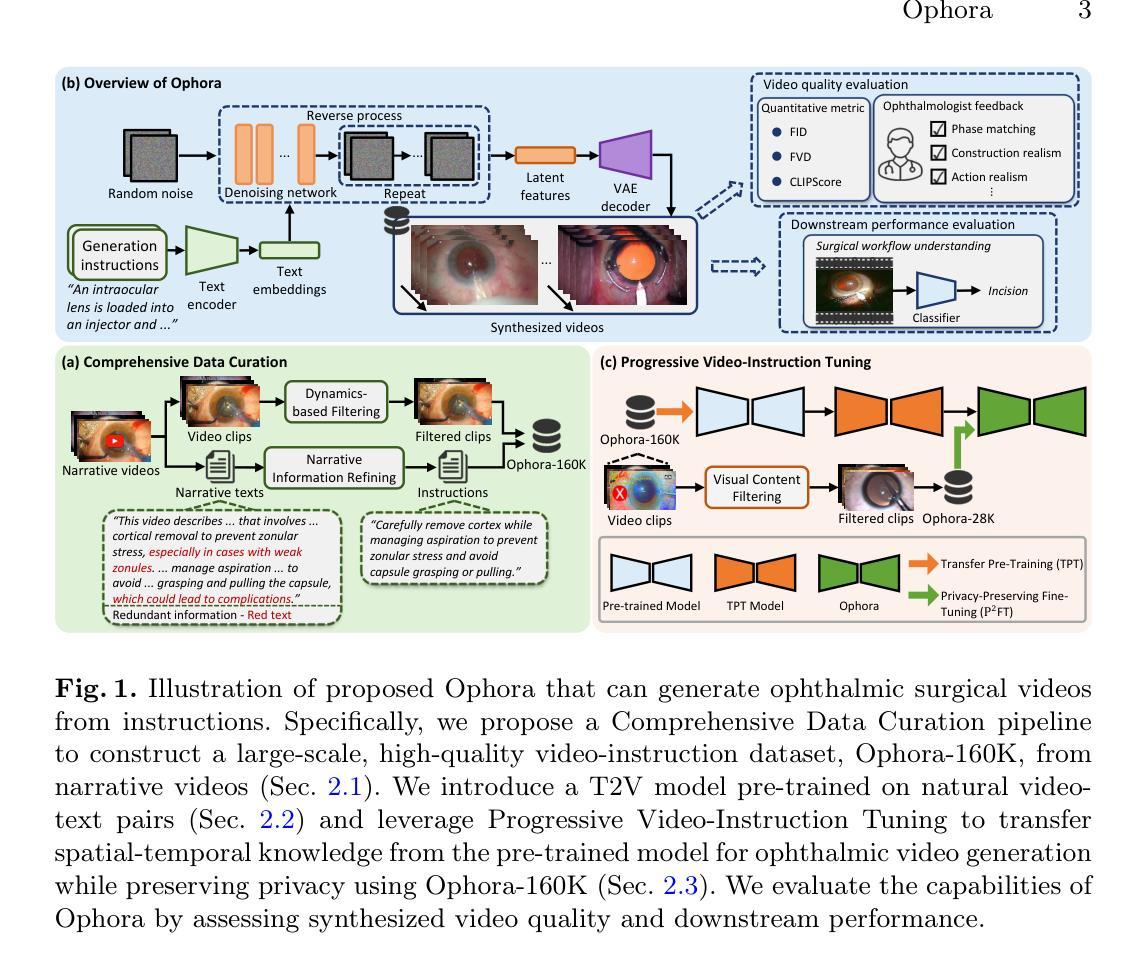
Ophora: A Large-Scale Data-Driven Text-Guided Ophthalmic Surgical Video Generation Model
Authors:Wei Li, Ming Hu, Guoan Wang, Lihao Liu, Kaijin Zhou, Junzhi Ning, Xin Guo, Zongyuan Ge, Lixu Gu, Junjun He
In ophthalmic surgery, developing an AI system capable of interpreting surgical videos and predicting subsequent operations requires numerous ophthalmic surgical videos with high-quality annotations, which are difficult to collect due to privacy concerns and labor consumption. Text-guided video generation (T2V) emerges as a promising solution to overcome this issue by generating ophthalmic surgical videos based on surgeon instructions. In this paper, we present Ophora, a pioneering model that can generate ophthalmic surgical videos following natural language instructions. To construct Ophora, we first propose a Comprehensive Data Curation pipeline to convert narrative ophthalmic surgical videos into a large-scale, high-quality dataset comprising over 160K video-instruction pairs, Ophora-160K. Then, we propose a Progressive Video-Instruction Tuning scheme to transfer rich spatial-temporal knowledge from a T2V model pre-trained on natural video-text datasets for privacy-preserved ophthalmic surgical video generation based on Ophora-160K. Experiments on video quality evaluation via quantitative analysis and ophthalmologist feedback demonstrate that Ophora can generate realistic and reliable ophthalmic surgical videos based on surgeon instructions. We also validate the capability of Ophora for empowering downstream tasks of ophthalmic surgical workflow understanding. Code is available at https://github.com/mar-cry/Ophora.
在眼科手术中,开发一个能够解读手术视频并预测后续操作的AI系统,需要大量的带有高质量注释的眼科手术视频。由于隐私问题和劳动消耗,这些视频的收集非常困难。文本引导的视频生成(T2V)作为一种有前途的解决方案应运而生,它可以根据外科医生的指令生成眼科手术视频。在本文中,我们提出了一种先进的模型——Ophora,它可以根据自然语言指令生成眼科手术视频。为了构建Ophora,我们首先提出了一个全面的数据整理管道,将叙述性眼科手术视频转化为大规模的高质量数据集,包含超过16万对视频指令对,即Ophora-160K。然后,我们提出了一种渐进的视频指令调整方案,以从一个在自然视频文本数据集上预训练的T2V模型转移丰富的时空知识,用于基于Ophora-160K的隐私保护眼科手术视频生成。通过对视频质量的定量分析和眼科医生的反馈进行的实验表明,Ophora可以根据外科医生的指令生成现实和可靠的眼科手术视频。我们还验证了Ophora在执行眼科手术工作流程理解等下游任务方面的能力。代码可在https://github.com/mar-cry/Ophora找到。
论文及项目相关链接
PDF Early accepted in MICCAI25
Summary
基于自然语言指令生成眼科手术视频的新型模型——Ophora。通过大规模数据集构建及渐进式视频指令调优方案,实现了高质量眼科手术视频的生成。此模型能依据医生指令生成真实可靠的手术视频,并有助于下游眼科手术工作流程理解任务。代码已公开。
Key Takeaways
- Ophora是一个基于自然语言指令生成眼科手术视频的领先模型。
- 通过综合数据整理管道,将叙述性眼科手术视频转化为大规模高质量数据集——Ophora-160K。
- 提出渐进式视频指令调优方案,从自然视频文本数据集中预训练T2V模型,实现基于Ophora-160K的隐私保护眼科手术视频生成。
- 实验证明,Ophora能根据医生指令生成真实且可靠的眼科手术视频。
- Ophora在眼科手术工作流程理解等下游任务中表现出色。
- 该模型的代码已经公开,方便后续研究者和开发者使用。
点此查看论文截图

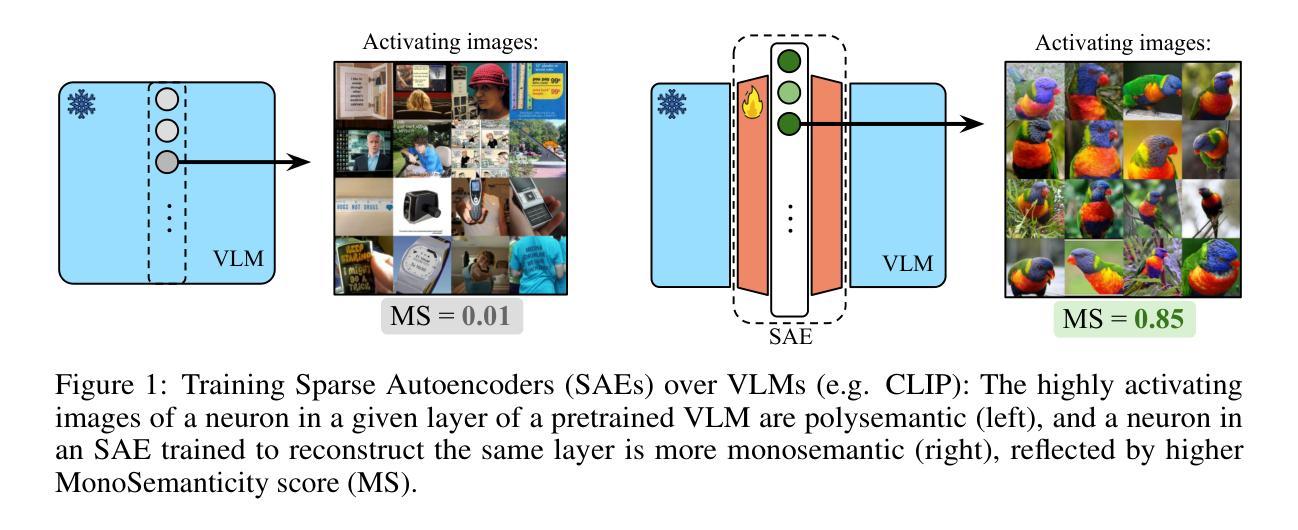
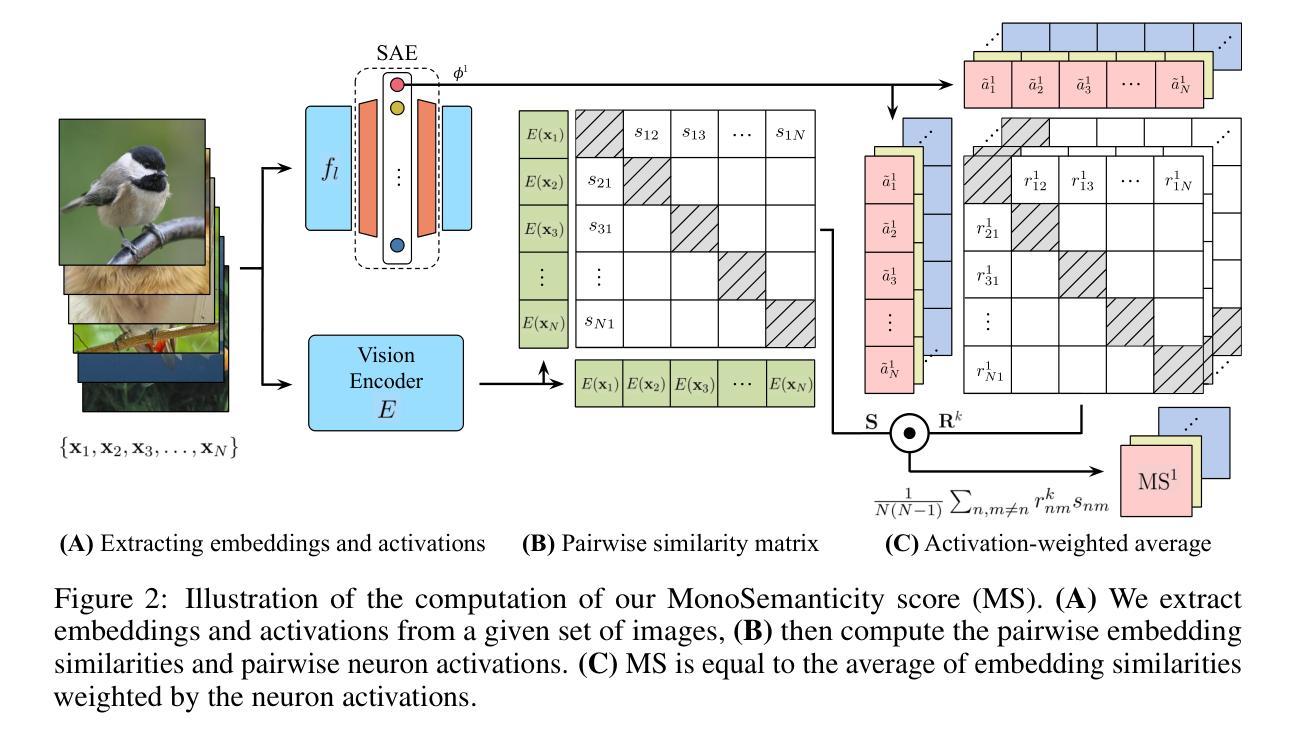
Sparse Autoencoders Learn Monosemantic Features in Vision-Language Models
Authors:Mateusz Pach, Shyamgopal Karthik, Quentin Bouniot, Serge Belongie, Zeynep Akata
Given that interpretability and steerability are crucial to AI safety, Sparse Autoencoders (SAEs) have emerged as a tool to enhance them in Large Language Models (LLMs). In this work, we extend the application of SAEs to Vision-Language Models (VLMs), such as CLIP, and introduce a comprehensive framework for evaluating monosemanticity at the neuron-level in vision representations. To ensure that our evaluation aligns with human perception, we propose a benchmark derived from a large-scale user study. Our experimental results reveal that SAEs trained on VLMs significantly enhance the monosemanticity of individual neurons, with sparsity and wide latents being the most influential factors. Notably, we demonstrate that applying SAE interventions on CLIP’s vision encoder directly steers multimodal LLM outputs (e.g., LLaVA), without any modifications to the underlying model. These findings emphasize the practicality and efficacy of SAEs as an unsupervised tool for enhancing both interpretability and control of VLMs. Code is available at https://github.com/ExplainableML/sae-for-vlm.
考虑到可解释性和可控制性对于人工智能安全至关重要,稀疏自动编码器(SAE)已经成为一种增强大型语言模型(LLM)中这两者的工具。在这项工作中,我们将SAE的应用扩展到视觉语言模型(VLM),例如CLIP,并引入一个全面的框架,用于评估视觉表示中神经元级别的单语义性。为了确保我们的评估与人类感知相一致,我们提出了一个从大规模用户研究中得出的基准测试。我们的实验结果表明,在VLM上训练的SAE显著增强了单个神经元的单语义性,其中稀疏性和宽潜变量是最具影响力的因素。值得注意的是,我们证明了对CLIP视觉编码器直接应用SAE干预可以引导多模态LLM输出(例如LLaVA),而无需对底层模型进行任何修改。这些发现强调了SAE作为增强VLM可解释性和控制性的无监督工具的实用性和有效性。代码可在https://github.com/ExplainableML/sae-for-vlm找到。
论文及项目相关链接
PDF Preprint
总结
本论文将稀疏自动编码器(SAE)扩展到视觉语言模型(VLM),如CLIP,以提升大型语言模型(LLM)的可解释性和可控制性。论文提出一个评估视觉表示神经元级别单语义性的全面框架,并基于大规模用户研究提出一个与之对应的基准测试。实验结果显示,在VLM上训练的SAE能显著提升单个神经元的单语义性,其中稀疏性和宽潜在因素是最具影响力的因素。值得注意的是,对CLIP的视觉编码器应用SAE干预能直接控制多模态LLM的输出,无需修改底层模型。这表明SAE作为一种无监督工具,在提升VLM的可解释性和控制性方面非常实用有效。
关键见解
- 稀疏自动编码器(SAE)被扩展到视觉语言模型(VLM),用于提升大型语言模型(LLM)的可解释性和可控制性。
- 引入了一个全面框架,用于评估视觉表示神经元级别的单语义性。
- 基于大规模用户研究,提出了一个与单语义性评估相对应的基准测试,以确保评估与人类感知一致。
- 实验结果显示,SAE能显著提升单个神经元的单语义性,其中稀疏性和宽潜在因素最重要。
- SAE干预能直接控制多模态LLM的输出,而无需修改底层模型。
- SAE作为一种无监督工具,在提升VLM的可解释性和控制性方面非常实用。
- 论文提供了相关的代码,可供进一步研究使用。
点此查看论文截图


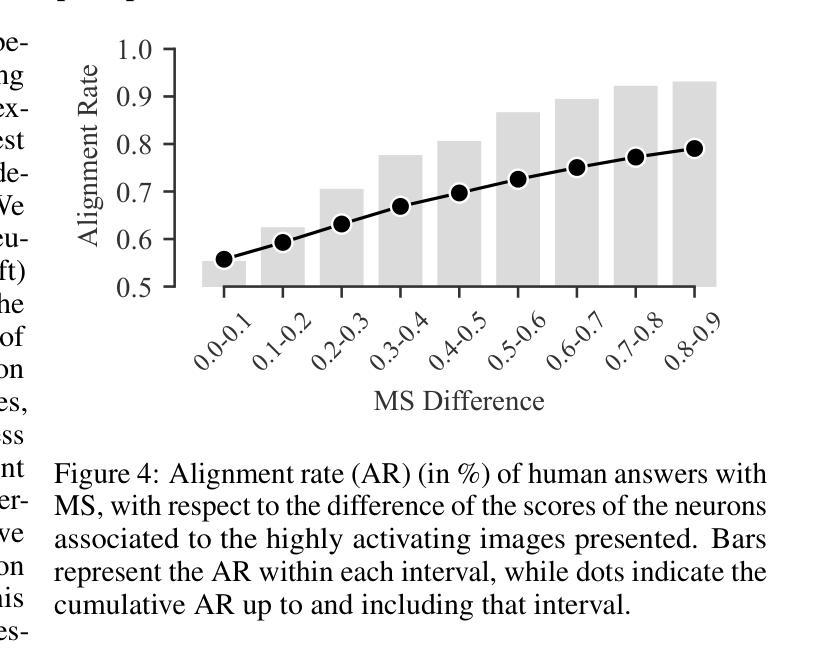
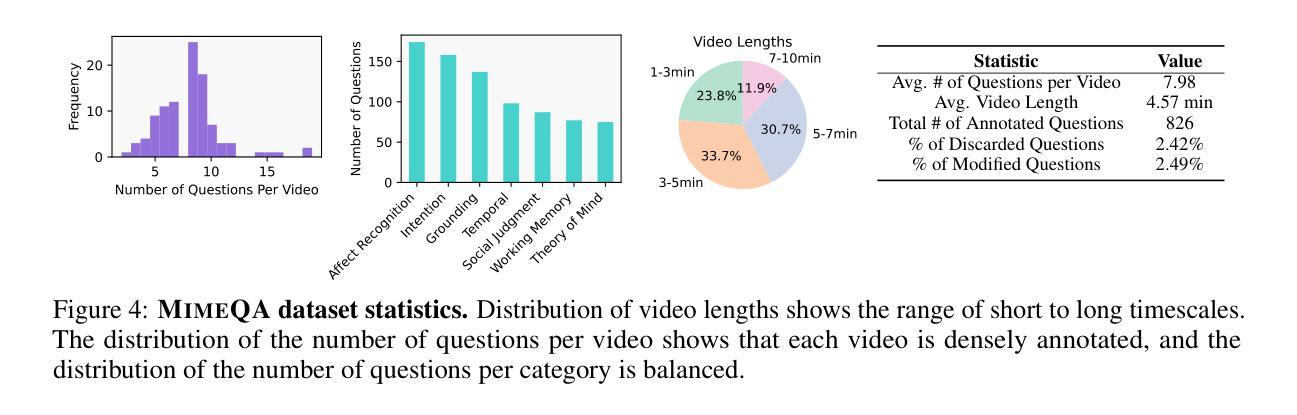
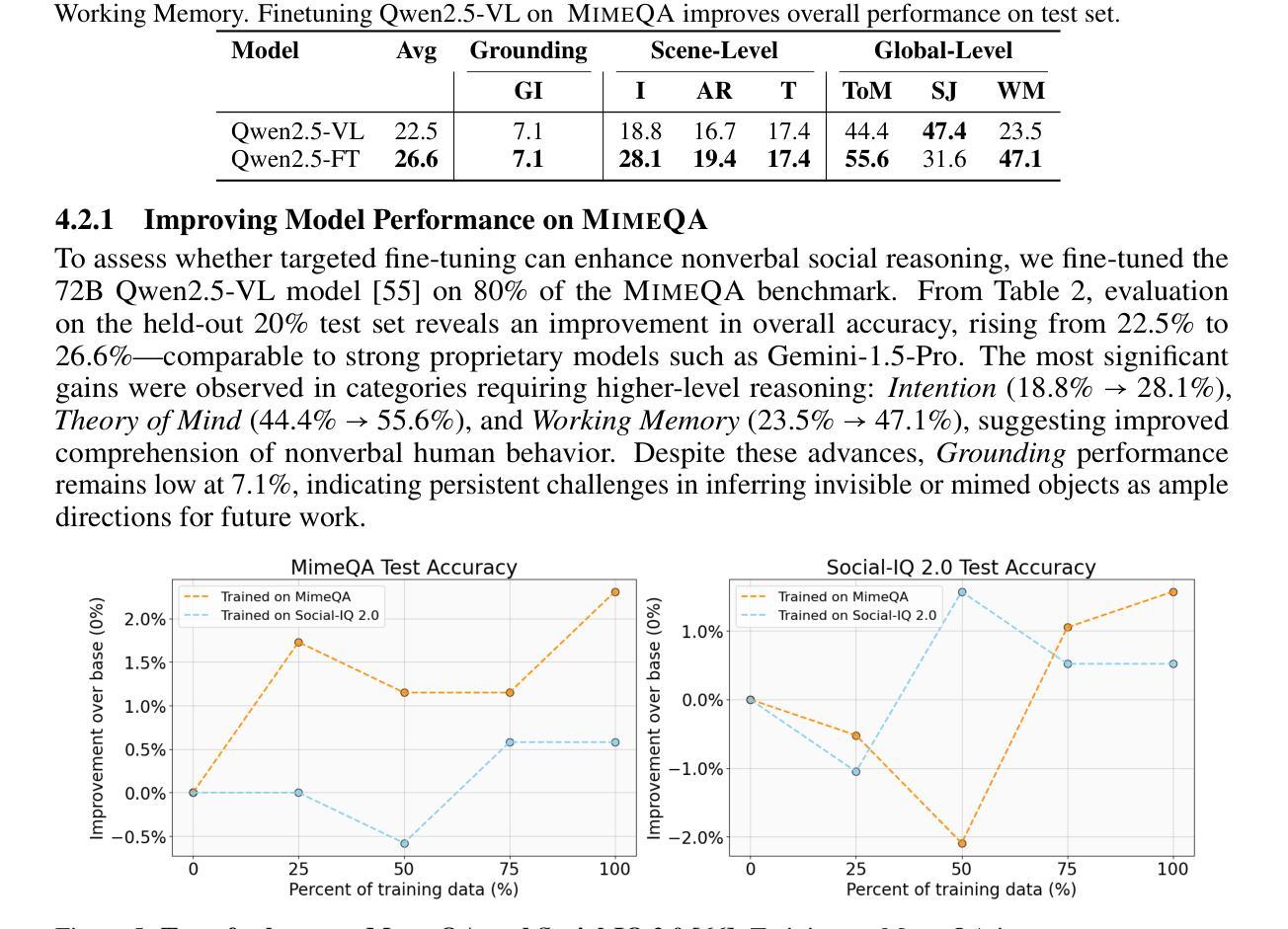
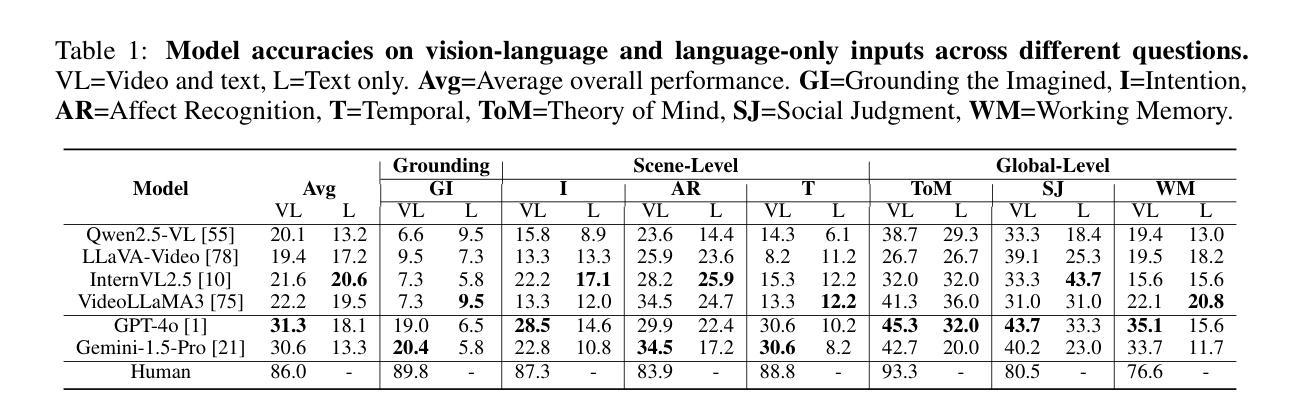
MimeQA: Towards Socially-Intelligent Nonverbal Foundation Models
Authors:Hengzhi Li, Megan Tjandrasuwita, Yi R. Fung, Armando Solar-Lezama, Paul Pu Liang
As AI becomes more closely integrated with peoples’ daily activities, socially intelligent AI that can understand and interact seamlessly with humans in daily lives is increasingly important. However, current works in AI social reasoning all rely on language-only or language-dominant approaches to benchmark and training models, resulting in systems that are improving in verbal communication but struggle with nonverbal social understanding. To address this limitation, we tap into a novel data source rich in nonverbal social interactions – mime videos. Mimes refer to the art of expression through gesture and movement without spoken words, which presents unique challenges and opportunities in interpreting nonverbal social communication. We contribute a new dataset called MimeQA, obtained by sourcing 8 hours of videos clips from YouTube and developing a comprehensive video question-answering benchmark comprising 806 carefully annotated and verified question-answer pairs, designed to probe nonverbal social reasoning capabilities. Using MimeQA, we evaluate state-of-the-art video large language models (vLLMs) and find that they achieve low overall accuracy, ranging from 20-30%, while humans score 86%. Our analysis reveals that vLLMs often fail to ground imagined objects and over-rely on the text prompt while ignoring subtle nonverbal interactions. We hope to inspire future work in AI models that embody true social intelligence capable of interpreting non-verbal human interactions.
随着人工智能日益融入人们的日常活动,能够无缝地理解和与人类进行日常交互的社会智能人工智能变得越来越重要。然而,当前的人工智能社会推理研究都依赖于仅使用语言或语言主导的方法来进行基准测试和模型训练,这导致系统在口头沟通方面有所提高,但在非言语社会理解方面却面临挑战。为了克服这一局限性,我们利用了一种富含非言语社交互动的新数据源——哑剧视频。哑剧是指通过手势和动作表达情感而无需言语,这为解释非言语社会沟通带来了独特的挑战和机会。我们贡献了一个新的数据集,名为MimeQA,该数据集通过从YouTube获取8小时的视频片段,并开发了一个全面的视频问答基准测试,包含806个经过仔细标注和验证的问题答案对,旨在检测非言语社会推理能力。使用MimeQA,我们评估了最先进的视频大型语言模型(vLLM),发现它们的总体准确率较低,范围在20-30%,而人类的准确率为86%。我们的分析表明,vLLM往往无法对想象中的物体进行定位,过于依赖文本提示,而忽略了微妙的非言语互动。我们希望激发未来研究出能够解释非言语人类互动的真正社会智能的AI模型。
论文及项目相关链接
Summary
随着人工智能在日常生活中的日益普及,具备理解并无缝与人类互动的能力的社会智能AI变得越来越重要。然而,当前的人工智能社会推理研究主要依赖于语言或语言主导的评估方法和训练模型,导致系统虽然口头沟通能力有所提升,但在非语言社交理解方面仍有困难。为解决这一局限,本研究利用丰富的非语言社交互动数据——哑剧视频,构建了一个新的数据集MimeQA。该数据集包含从YouTube收集的8小时视频片段,并设计了一个包含806组精心标注和验证的问题答案对,旨在测试非语言社交推理能力。利用MimeQA评估当前先进的视频大型语言模型(vLLM),发现其整体准确率较低,仅为20-30%,而人类准确率则高达86%。分析表明,vLLM往往无法准确理解虚构物体并过度依赖文本提示而忽视微妙的非语言互动。本研究旨在激发未来研究能够真正解读非语言人类互动的社会智能AI模型。
Key Takeaways
- 当前AI社会推理研究主要侧重于语言沟通,但在非语言社交理解方面存在局限。
- 为提高AI在非语言社交理解方面的能力,本研究引入了一个新的数据集MimeQA,包含哑剧视频中的问题答案对,旨在测试非语言社交推理。
- 利用MimeQA评估当前先进的视频大型语言模型(vLLM),发现其整体准确率较低。
- vLLM在理解虚构物体和微妙非语言互动方面存在困难。
- 与人类相比,vLLM的准确率较低,表明其在非语言社交理解方面仍有较大提升空间。
- 本研究旨在激发未来研究能够真正解读非语言人类互动的社会智能AI模型。
点此查看论文截图




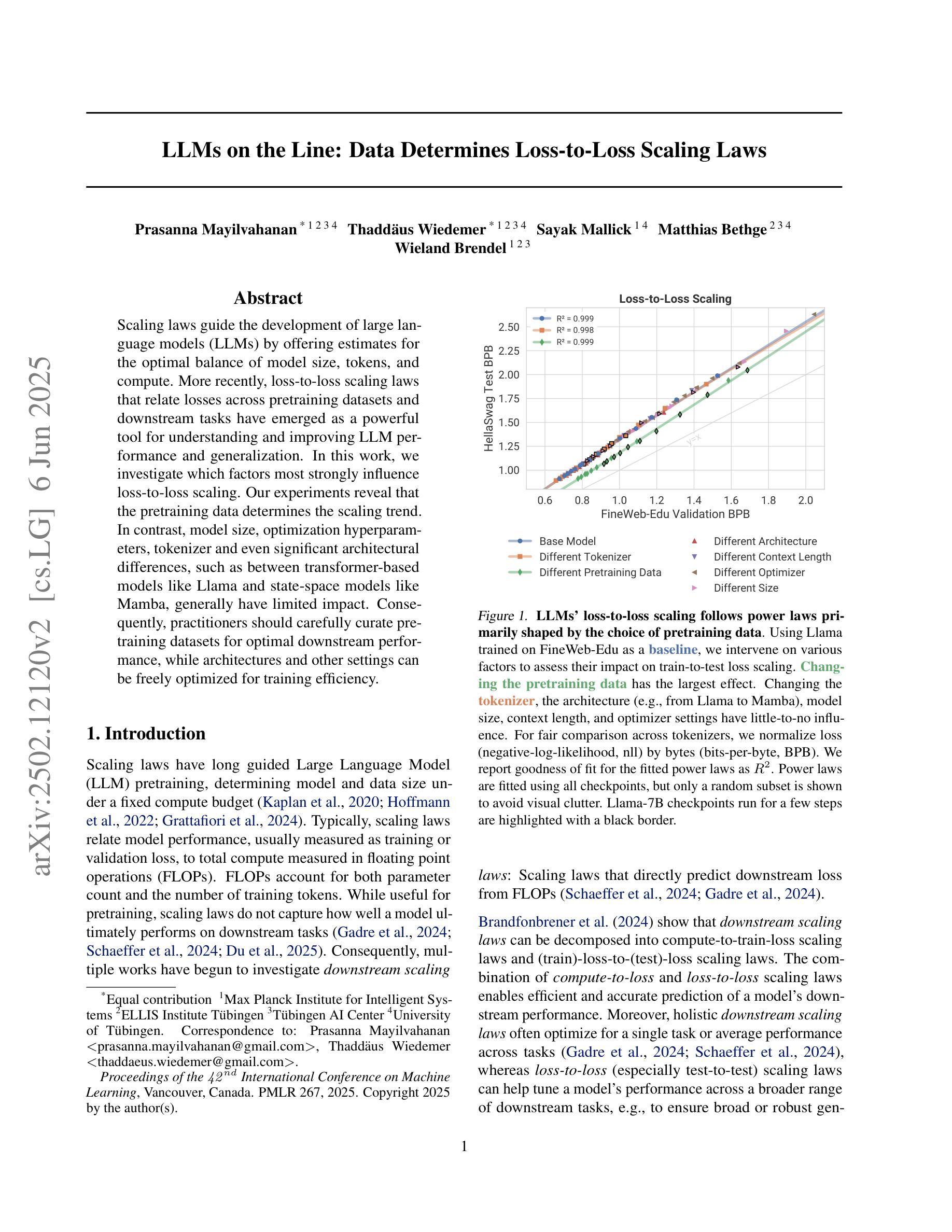
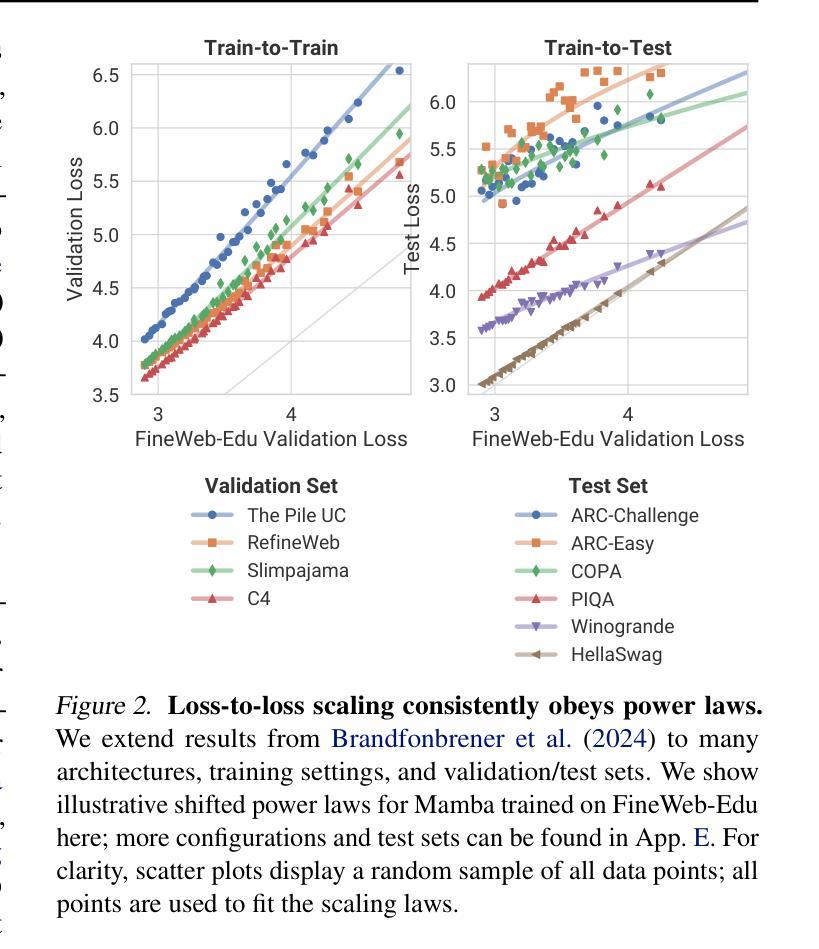
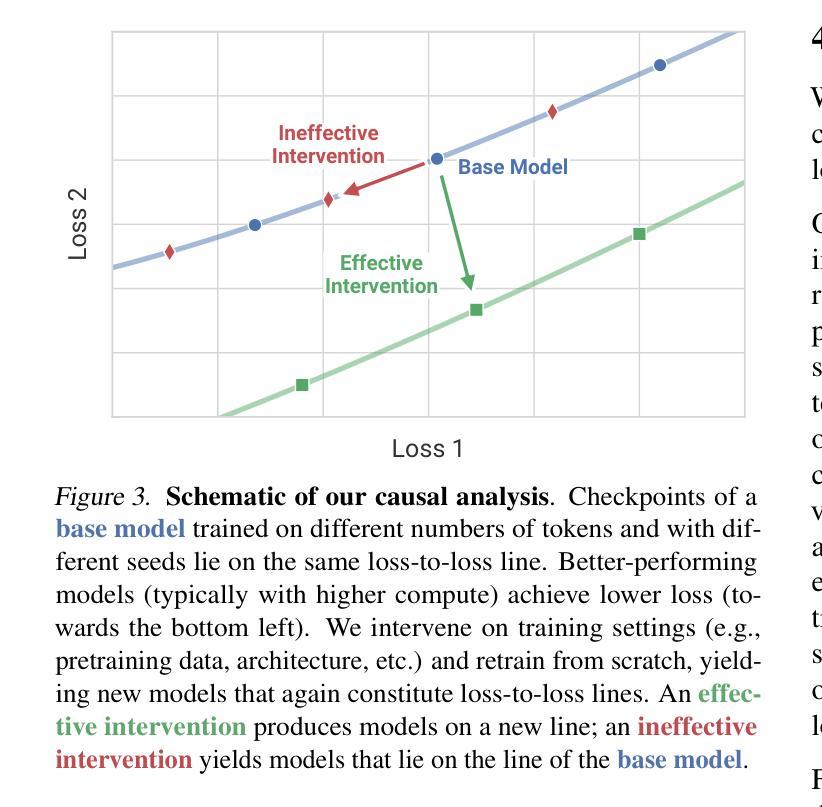
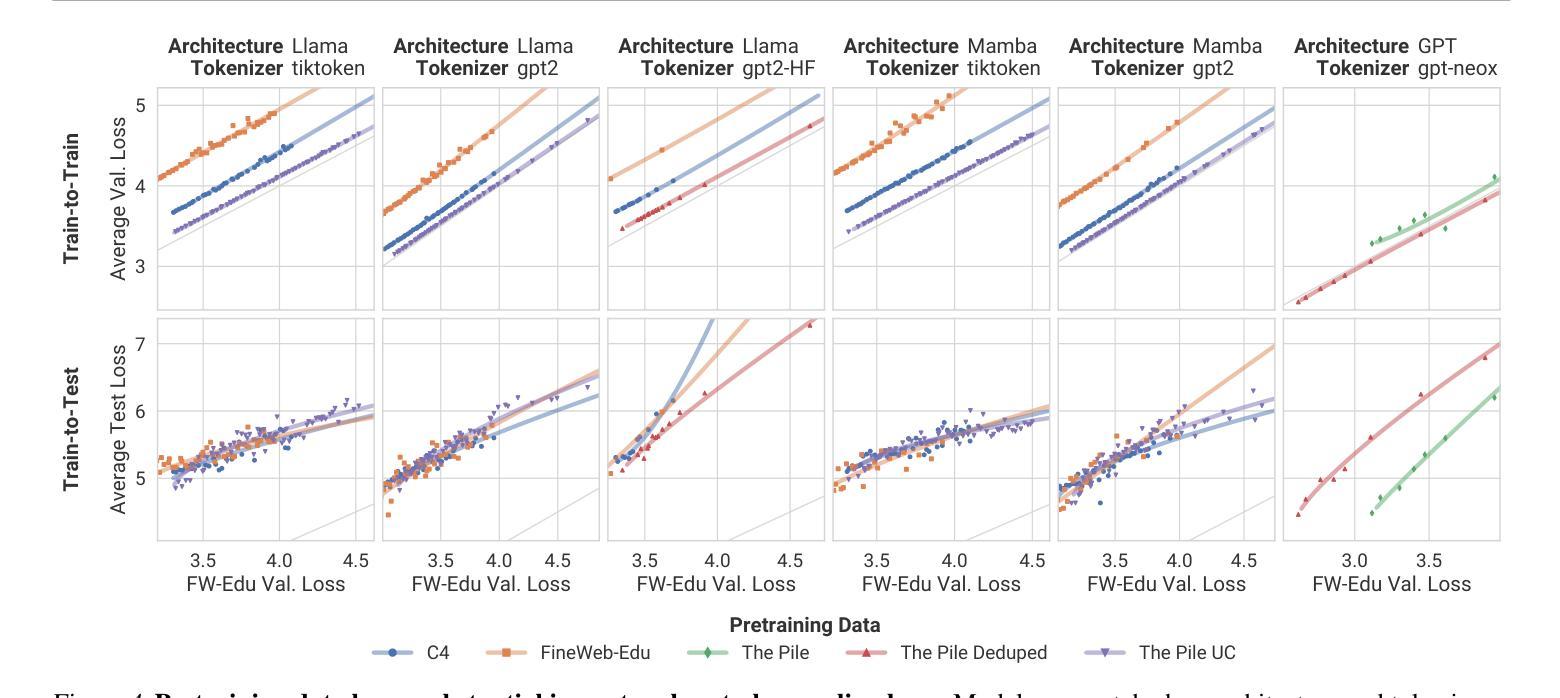
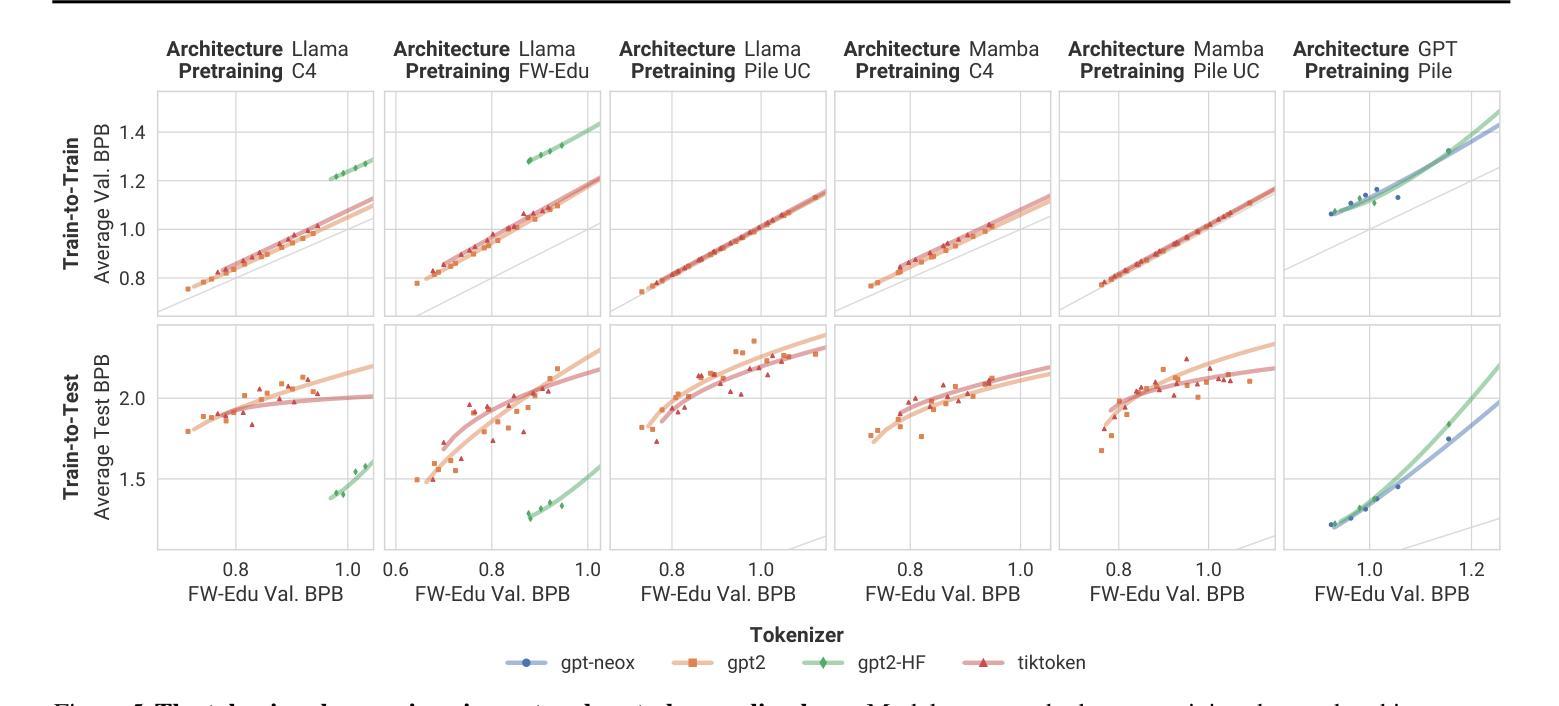
LLMs on the Line: Data Determines Loss-to-Loss Scaling Laws
Authors:Prasanna Mayilvahanan, Thaddäus Wiedemer, Sayak Mallick, Matthias Bethge, Wieland Brendel
Scaling laws guide the development of large language models (LLMs) by offering estimates for the optimal balance of model size, tokens, and compute. More recently, loss-to-loss scaling laws that relate losses across pretraining datasets and downstream tasks have emerged as a powerful tool for understanding and improving LLM performance. In this work, we investigate which factors most strongly influence loss-to-loss scaling. Our experiments reveal that the pretraining data and tokenizer determine the scaling trend. In contrast, model size, optimization hyperparameters, and even significant architectural differences, such as between transformer-based models like Llama and state-space models like Mamba, have limited impact. Consequently, practitioners should carefully curate suitable pretraining datasets for optimal downstream performance, while architectures and other settings can be freely optimized for training efficiency.
扩展定律通过为模型大小、令牌和计算之间的最佳平衡提供估计,指导大型语言模型(LLM)的发展。最近,损失跨预训练数据集和下游任务之间的损失缩放定律作为理解和改进LLM性能的强大工具而出现。在这项工作中,我们调查了哪些因素最强烈地影响损失到损失的缩放。我们的实验表明,预训练数据和分词器决定了缩放趋势。相比之下,模型大小、优化超参数,甚至是像Llama的基于转换器模型和Mamba的状态空间模型这样的重大架构差异,影响有限。因此,实践者应该仔细挑选合适的预训练数据集以获得最佳的下游性能,而架构和其他设置可以自由优化以提高训练效率。
论文及项目相关链接
PDF ICML 2025 camera-ready version
Summary
本文探讨了影响损失-损失缩放的关键因素,发现预训练数据和分词器对缩放趋势有决定性影响,而模型大小、优化超参数以及架构差异(如基于转换模型的Llama和状态空间模型的Mamba)的影响有限。因此,实践者应为获得最佳下游性能而谨慎选择适当的预训练数据集,而架构和其他设置则可以自由优化以提高训练效率。
Key Takeaways
- 损失-损失缩放规律是理解和改进大型语言模型性能的重要工具。
- 预训练数据和分词器是影响损失-损失缩放趋势的关键因素。
- 模型大小、优化超参数和架构差异对损失-损失缩放的影响有限。
- 实践者应该为最佳下游性能谨慎选择适当的预训练数据集。
- 架构和其他设置可以优化以提高训练效率。
- 不同的大型语言模型(如Llama和Mamba)在损失-损失缩放方面的表现差异不大。
点此查看论文截图
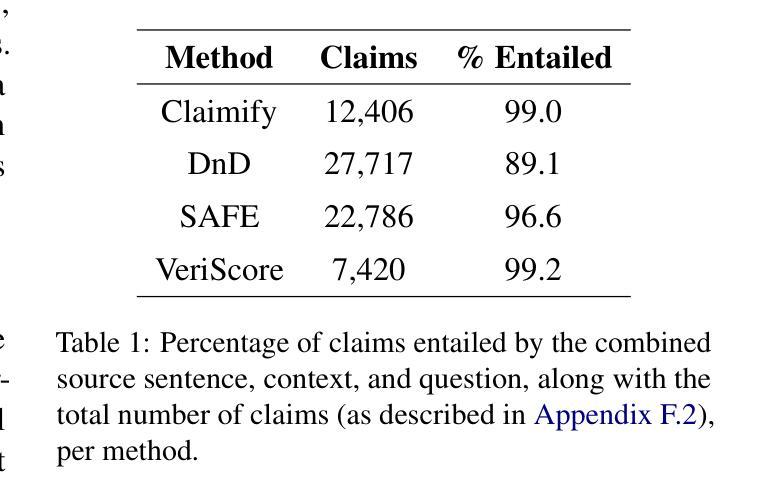
Towards Effective Extraction and Evaluation of Factual Claims
Authors:Dasha Metropolitansky, Jonathan Larson
A common strategy for fact-checking long-form content generated by Large Language Models (LLMs) is extracting simple claims that can be verified independently. Since inaccurate or incomplete claims compromise fact-checking results, ensuring claim quality is critical. However, the lack of a standardized evaluation framework impedes assessment and comparison of claim extraction methods. To address this gap, we propose a framework for evaluating claim extraction in the context of fact-checking along with automated, scalable, and replicable methods for applying this framework, including novel approaches for measuring coverage and decontextualization. We also introduce Claimify, an LLM-based claim extraction method, and demonstrate that it outperforms existing methods under our evaluation framework. A key feature of Claimify is its ability to handle ambiguity and extract claims only when there is high confidence in the correct interpretation of the source text.
针对由大型语言模型(LLM)生成的长篇内容的事实核查,一种常见策略是提取可以独立验证的简单声明。由于不准确或不完整的声明会损害事实核查结果,因此确保声明的质量至关重要。然而,缺乏标准化的评估框架阻碍了声明提取方法的评估和比较。为了弥补这一空白,我们提出了一个用于事实核查背景下评估声明提取的框架,以及应用此框架的自动化、可扩展和可复制的方法,包括测量覆盖率和脱离语境的新方法。我们还介绍了基于LLM的声明提取方法Claimify,并证明在我们的评估框架下,它的性能优于现有方法。Claimify的一个关键功能是它能够处理歧义,仅在正确解释源文本时表现出高信心时才提取声明。
论文及项目相关链接
PDF ACL 2025 Main Conference
Summary
大型语言模型(LLM)生成的长形式内容的常见事实核查策略是提取可以独立验证的简单声明。为确保事实核查结果的准确性,确保声明质量至关重要。然而,由于缺乏标准化的评估框架,阻碍了声明提取方法的评估和比较。为解决这一空白,我们提出了一个用于事实核查背景下评估声明提取的框架,以及可自动化、可扩展和可复制的实施这一框架的方法,包括测量覆盖率和脱离上下文的新方法。我们还介绍了基于LLM的声明提取方法Claimify,并在我们的评估框架下证明其表现优于现有方法。Claimify的关键功能之一是它能够处理歧义,并在对源文本的正确解释有高度信心时仅提取声明。
Key Takeaways
- 在事实核查中,确保声明质量至关重要,因为不准确或不完整的声明会影响事实核查结果的准确性。
- 缺乏标准化的评估框架阻碍了声明提取方法的评估和比较。
- 提出一个用于评估事实核查中声明提取的框架,包括测量覆盖率和脱离上下文的新方法。
- 介绍了一种基于大型语言模型(LLM)的声明提取方法Claimify。
- Claimify具有处理歧义的能力,只在有高度信心正确解释源文本时提取声明。
- 在评估框架下,Claimify的表现优于现有方法。
点此查看论文截图

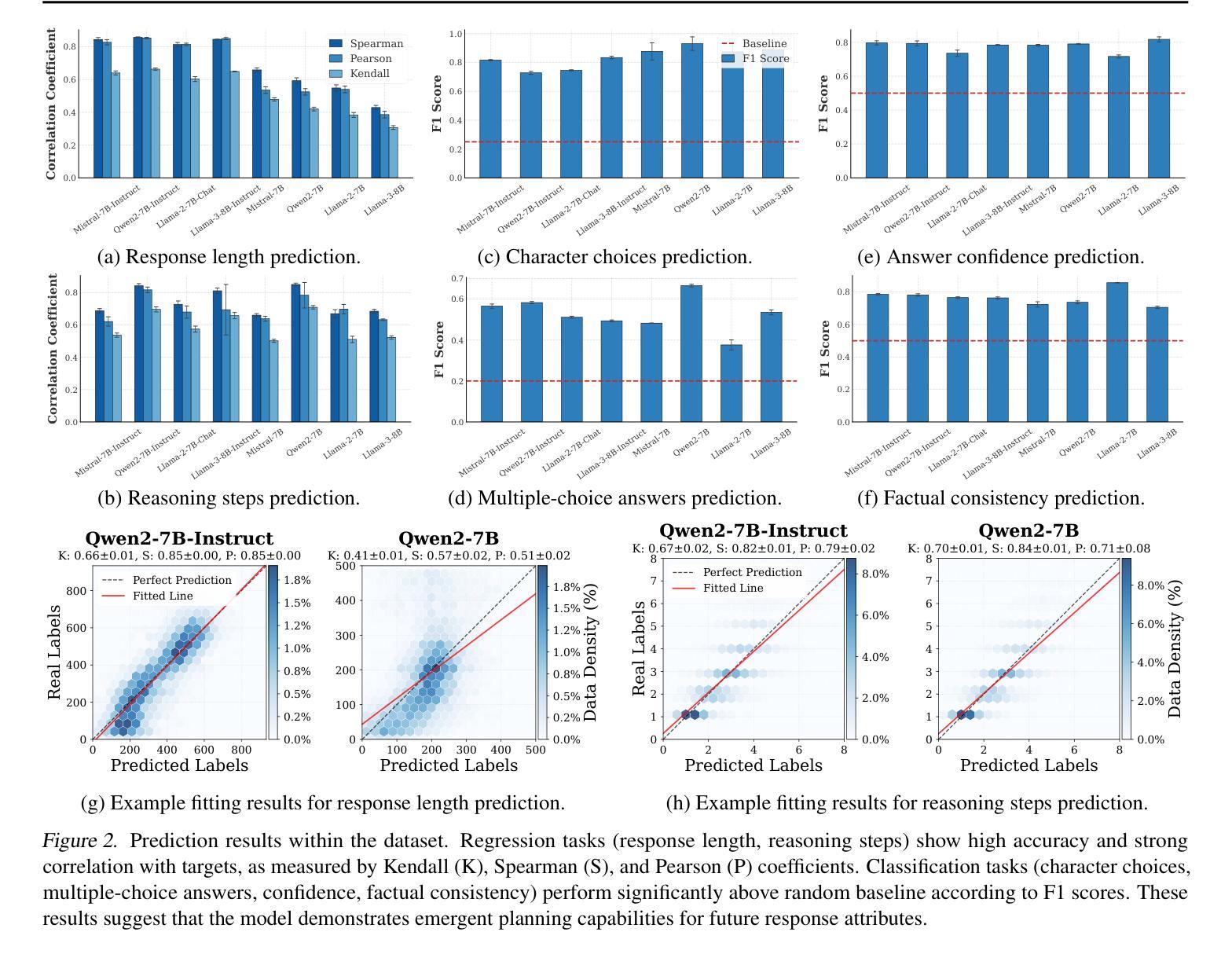
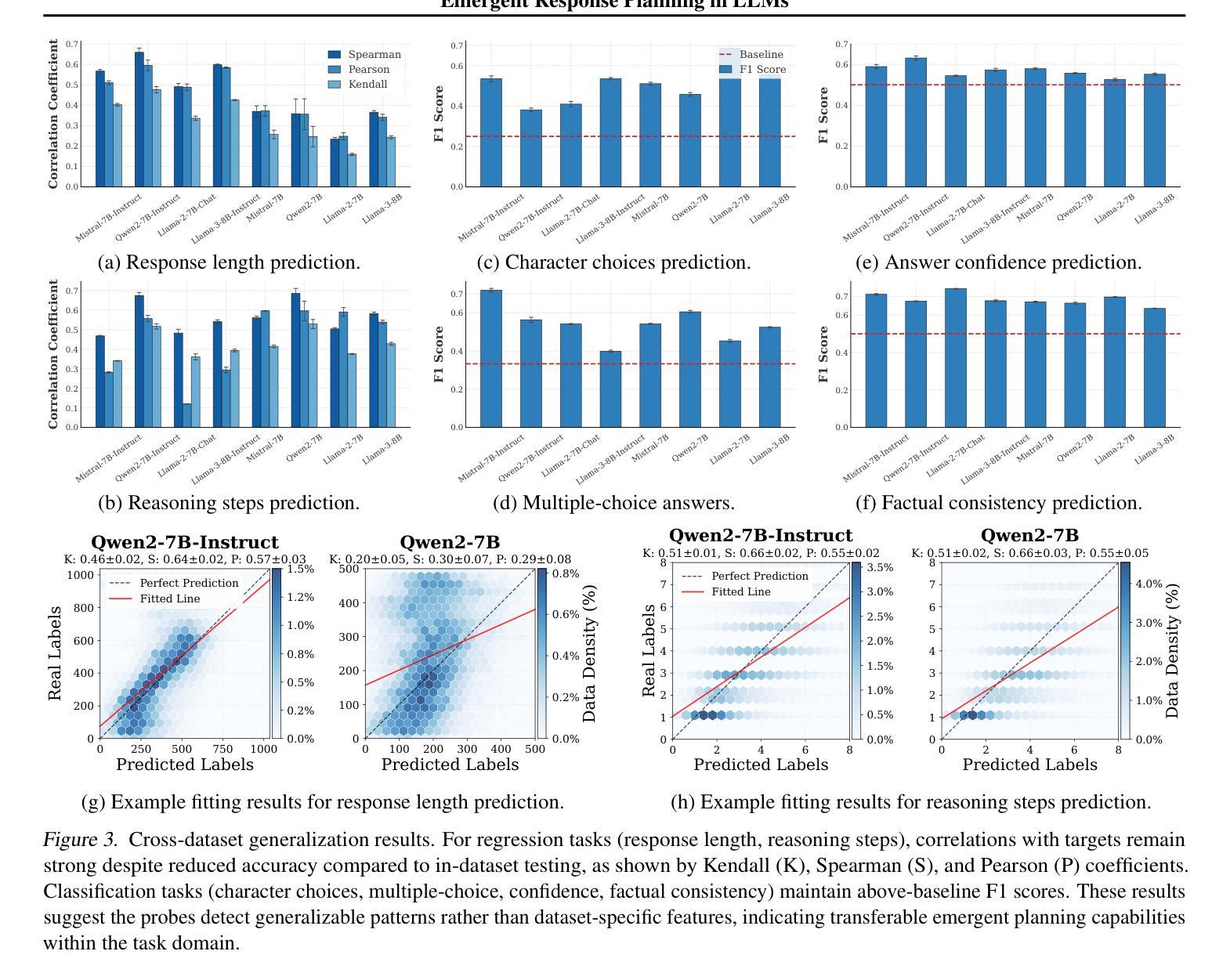
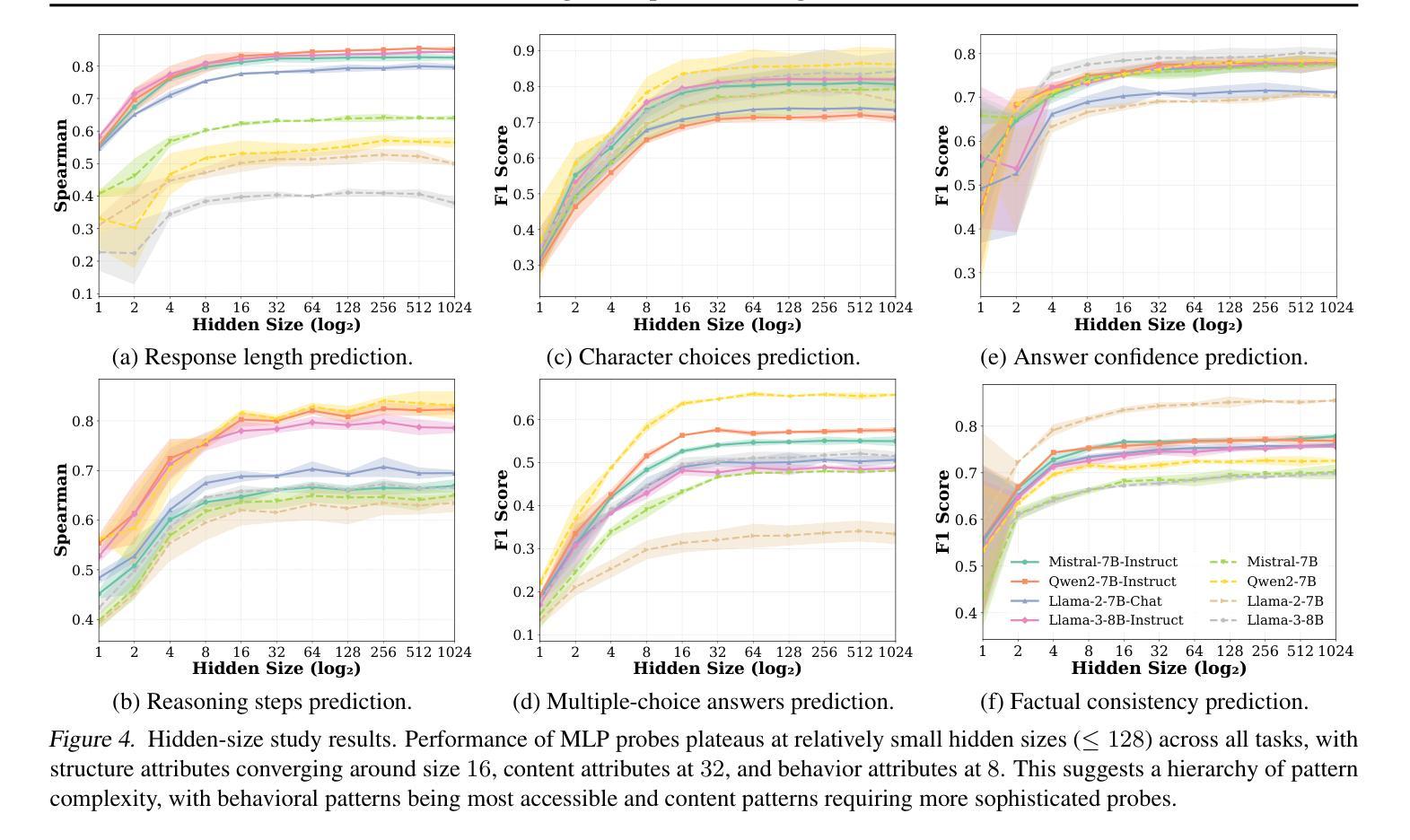
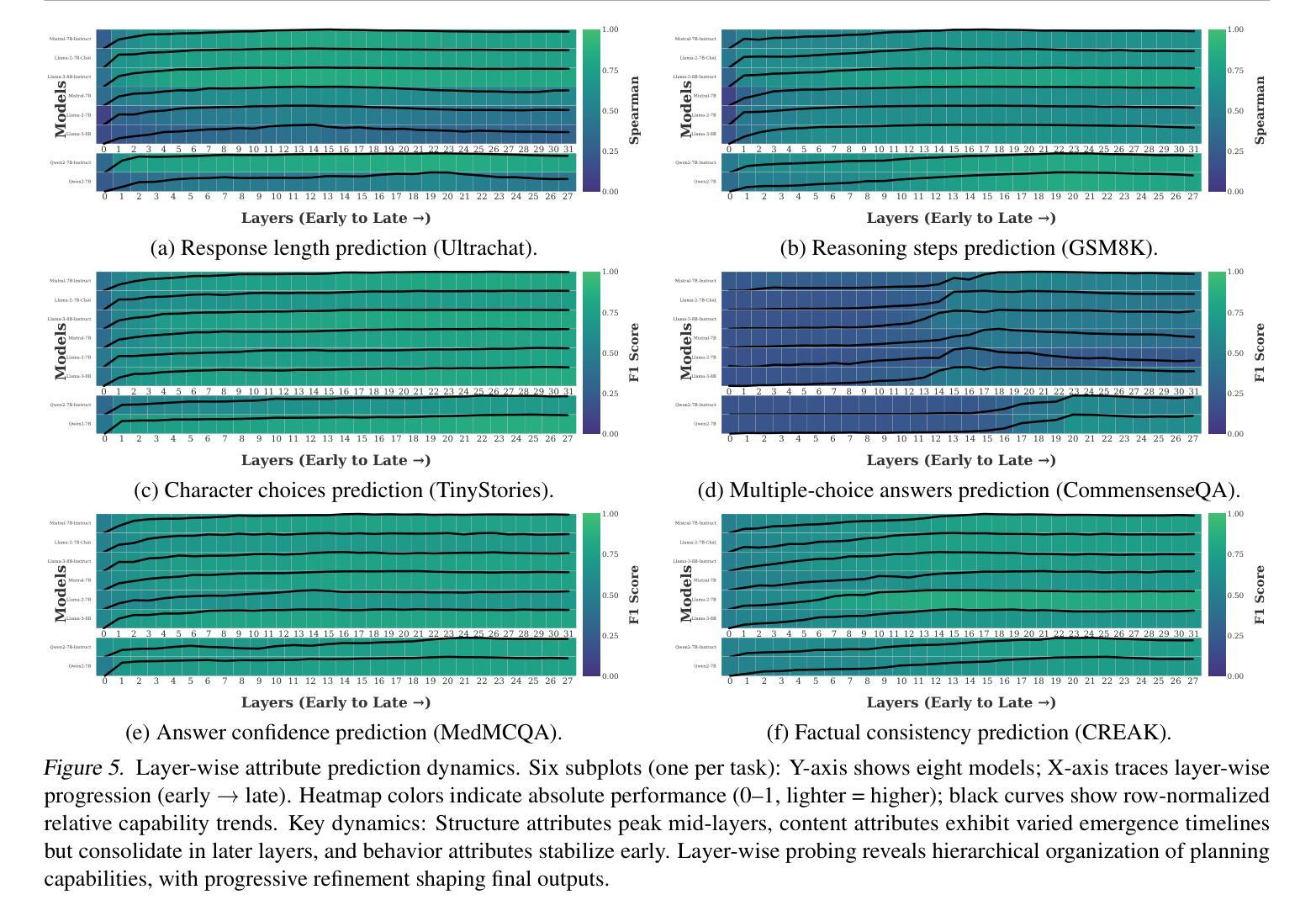
Emergent Response Planning in LLMs
Authors:Zhichen Dong, Zhanhui Zhou, Zhixuan Liu, Chao Yang, Chaochao Lu
In this work, we argue that large language models (LLMs), though trained to predict only the next token, exhibit emergent planning behaviors: $\textbf{their hidden representations encode future outputs beyond the next token}$. Through simple probing, we demonstrate that LLM prompt representations encode global attributes of their entire responses, including $\textit{structure attributes}$ (e.g., response length, reasoning steps), $\textit{content attributes}$ (e.g., character choices in storywriting, multiple-choice answers at the end of response), and $\textit{behavior attributes}$ (e.g., answer confidence, factual consistency). In addition to identifying response planning, we explore how it scales with model size across tasks and how it evolves during generation. The findings that LLMs plan ahead for the future in their hidden representations suggest potential applications for improving transparency and generation control.
在这项工作中,我们认为大型语言模型(LLM)虽然被训练用于预测下一个标记,但表现出新兴的计划行为:他们的隐藏表示编码了下一个标记之外的未来输出。通过简单的探测,我们证明了LLM提示表示包含了其整个响应的全局属性,包括结构属性(如响应长度、推理步骤)、内容属性(如故事写作中的字符选择、响应末尾的多项选择题答案),以及行为属性(如答案信心、事实一致性)。除了识别响应计划外,我们还探讨了它在不同任务中如何随模型大小变化以及如何在生成过程中发展。LLM在隐藏表示中为未来计划的事实为改进透明度和生成控制提供了潜在的应用前景。
论文及项目相关链接
PDF ICML 2025
Summary:大型语言模型(LLM)在预测下一个词的同时,其隐藏表征会表现出未来输出的行为规划。通过简单的探测方法,发现LLM的提示表征包含了其整体响应的全局属性,如结构属性、内容属性和行为属性等。该研究探讨了这种规划能力在不同任务中的模型规模变化以及在生成过程中的演变情况。这为提高透明度和生成控制提供了潜在的应用前景。
Key Takeaways:
- LLM的隐藏表征可以编码未来的输出,这显示了其计划行为。
- 通过简单探测可以发现LLM的提示表征包含其响应的全局属性。
- LLM的计划能力涉及结构属性(如响应长度和推理步骤)。
- 内容属性包括故事写作中的字符选择和响应结束时的多项选择答案。
- 行为属性包括答案的自信度和事实一致性。
- LLM的规划能力随模型规模的变化而变化,并随着生成过程的发展而演变。
点此查看论文截图