⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-10 更新
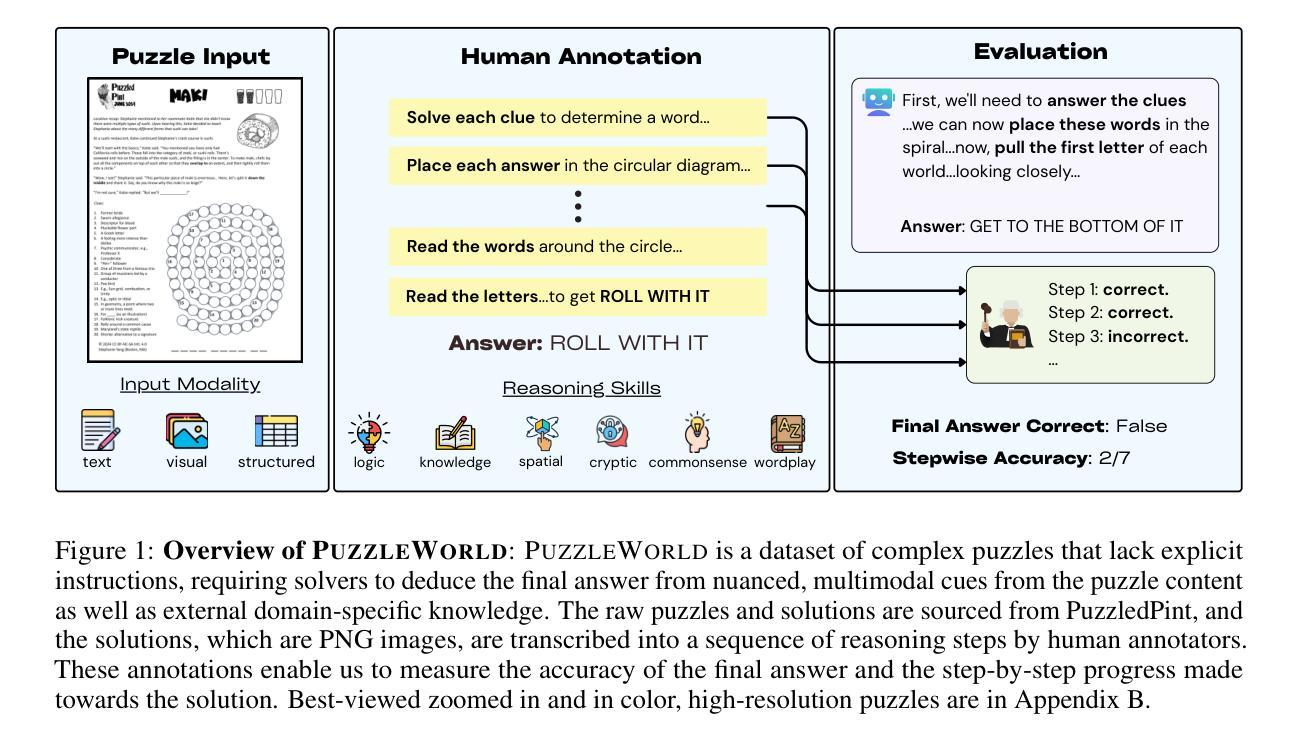
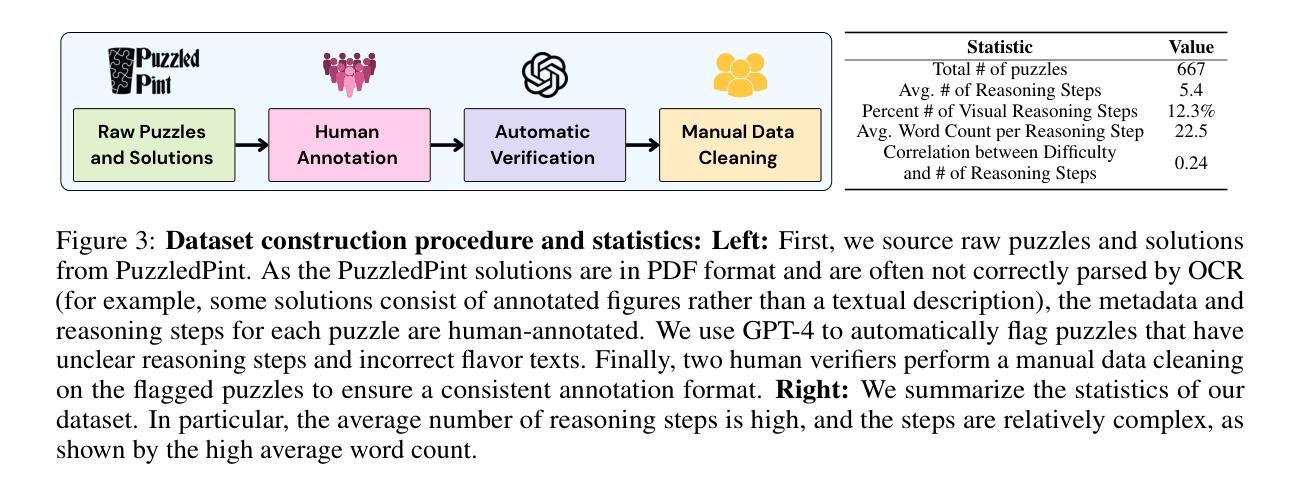
PuzzleWorld: A Benchmark for Multimodal, Open-Ended Reasoning in Puzzlehunts
Authors:Hengzhi Li, Brendon Jiang, Alexander Naehu, Regan Song, Justin Zhang, Megan Tjandrasuwita, Chanakya Ekbote, Steven-Shine Chen, Adithya Balachandran, Wei Dai, Rebecca Chang, Paul Pu Liang
Puzzlehunts are a genre of complex, multi-step puzzles lacking well-defined problem definitions. In contrast to conventional reasoning benchmarks consisting of tasks with clear instructions, puzzlehunts require models to discover the underlying problem structure from multimodal evidence and iterative reasoning, mirroring real-world domains such as scientific discovery, exploratory data analysis, or investigative problem-solving. Despite recent progress in foundation models, their performance on such open-ended settings remains largely untested. In this paper, we introduce PuzzleWorld, a large-scale benchmark of 667 puzzlehunt-style problems designed to assess step-by-step, open-ended, and creative multimodal reasoning. Each puzzle is annotated with the final solution, detailed reasoning traces, and cognitive skill labels, enabling holistic benchmarking and fine-grained diagnostic analysis. Most state-of-the-art models achieve only 1-2% final answer accuracy, with the best model solving only 14% of puzzles and reaching 40% stepwise accuracy. To demonstrate the value of our reasoning annotations, we show that fine-tuning a small model on reasoning traces improves stepwise reasoning from 4% to 11%, while training on final answers alone degrades performance to near zero. Our error analysis reveals that current models exhibit myopic reasoning, are bottlenecked by the limitations of language-based inference, and lack sketching capabilities crucial for visual and spatial reasoning. We release PuzzleWorld at https://github.com/MIT-MI/PuzzleWorld to support future work on building more general, open-ended, and creative reasoning systems.
谜题狩猎是一种缺乏明确问题定义的复杂多步骤谜题。与传统的包含明确指令的任务基准测试相比,谜题狩猎要求模型从多模式证据和迭代推理中发现潜在的问题结构,这反映了现实世界领域,如科学发现、探索性数据分析或调查解决问题。尽管基础模型最近有进展,但它们在这样开放环境设置中的表现仍主要未经验证。在本文中,我们介绍了 PuzzleWorld,这是一个包含 667 个谜题狩猎风格问题的大规模基准测试,旨在评估分步、开放性和创造性多模式推理。每个谜题都附有最终解决方案、详细的推理轨迹和认知技能标签,以实现整体基准测试和精细的诊断分析。最先进的模型最终答案准确率只有 1-2%,最佳模型解决的谜题只有 14%,分步准确率也只有 40%。为了证明我们的推理注释的价值,我们展示了在推理轨迹上微调的小型模型可以改进分步推理,从 4% 提高到 11%,而仅在最终答案上进行训练会损害性能,近乎为零。我们的错误分析表明,当前模型的推理存在视野狭隘的问题,受到基于语言的推理的限制,并且在视觉和空间推理方面缺乏草图绘制能力。我们在 https://github.com/MIT-MI/PuzzleWorld 发布了 PuzzleWorld,以支持未来关于构建更通用、开放性和创造性推理系统的研究。
论文及项目相关链接
Summary
谜题狩猎是一种缺乏明确问题定义的多步骤复杂谜题类型。与传统推理基准测试不同,谜题狩猎要求模型从多模式证据中发现潜在的问题结构,并进行迭代推理,这在现实世界的应用领域尤为普遍,如科学发现、探索性数据分析和问题解决。新发布的谜题世界(PuzzleWorld)大型基准测试包含设计用于评估开放式创造性多模式推理的667个谜题狩猎问题。然而,大多数先进模型在最后答案的准确性上只有百分之几的成绩,表明他们在解决开放式问题时面临巨大挑战。研究者提出使用推理痕迹训练模型可提高推理的准确性。当前模型显示出在开放和创意推理上的不足和瓶颈问题。Key Takeaways
谜题狩猎是一种涉及复杂多步骤谜题的活动,缺乏明确的问题定义。
这些谜题要求模型从多模式证据中发现潜在的问题结构,进行迭代推理,符合现实世界情境的应用场景包括科学发现、探索性数据分析和问题解决等。
点此查看论文截图


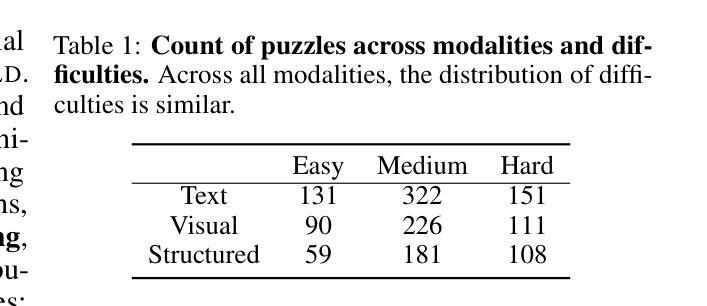
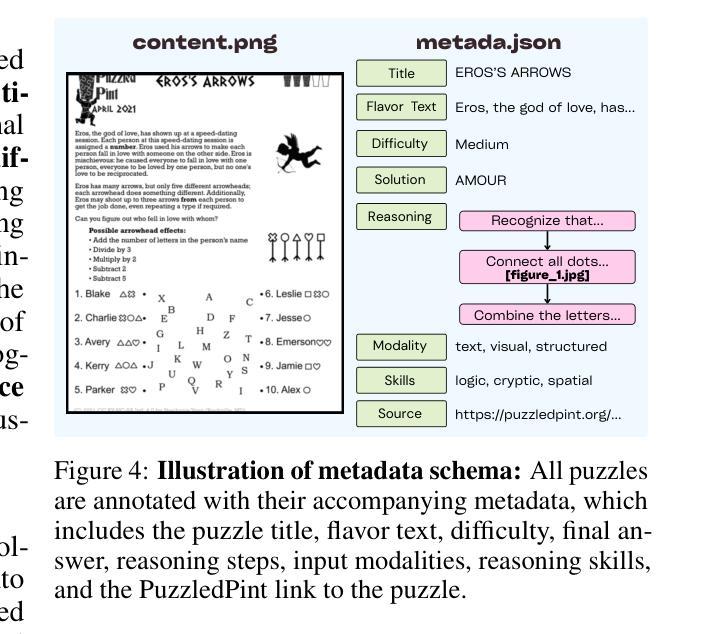
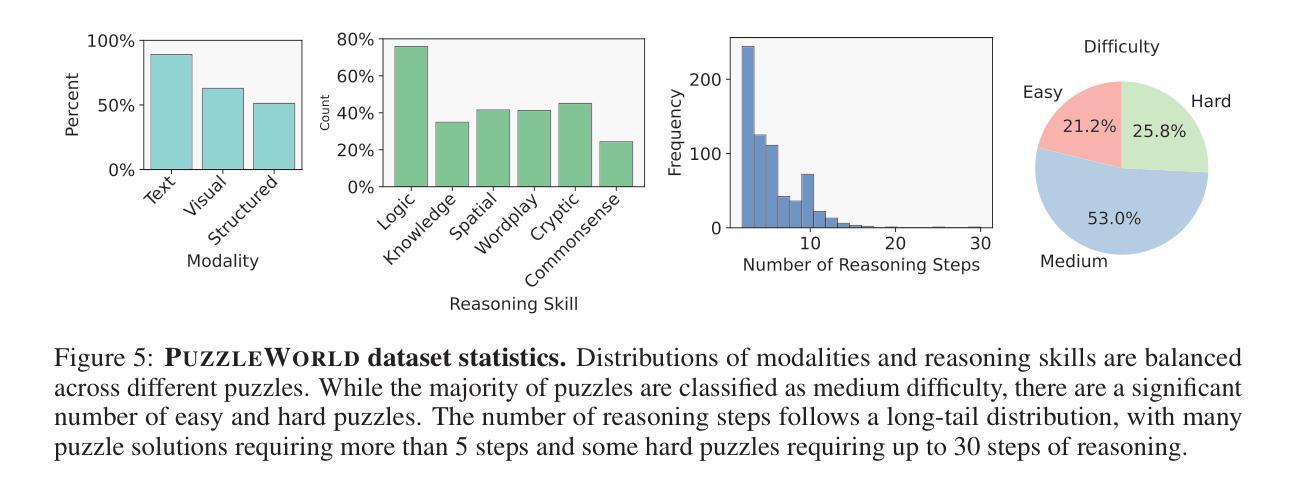
ICU-TSB: A Benchmark for Temporal Patient Representation Learning for Unsupervised Stratification into Patient Cohorts
Authors:Dimitrios Proios, Alban Bornet, Anthony Yazdani, Jose F Rodrigues Jr, Douglas Teodoro
Patient stratification identifying clinically meaningful subgroups is essential for advancing personalized medicine through improved diagnostics and treatment strategies. Electronic health records (EHRs), particularly those from intensive care units (ICUs), contain rich temporal clinical data that can be leveraged for this purpose. In this work, we introduce ICU-TSB (Temporal Stratification Benchmark), the first comprehensive benchmark for evaluating patient stratification based on temporal patient representation learning using three publicly available ICU EHR datasets. A key contribution of our benchmark is a novel hierarchical evaluation framework utilizing disease taxonomies to measure the alignment of discovered clusters with clinically validated disease groupings. In our experiments with ICU-TSB, we compared statistical methods and several recurrent neural networks, including LSTM and GRU, for their ability to generate effective patient representations for subsequent clustering of patient trajectories. Our results demonstrate that temporal representation learning can rediscover clinically meaningful patient cohorts; nevertheless, it remains a challenging task, with v-measuring varying from up to 0.46 at the top level of the taxonomy to up to 0.40 at the lowest level. To further enhance the practical utility of our findings, we also evaluate multiple strategies for assigning interpretable labels to the identified clusters. The experiments and benchmark are fully reproducible and available at https://github.com/ds4dh/CBMS2025stratification.
患者分层识别具有临床意义的亚组是推动个性化医学发展的关键,通过改进的诊断和治疗策略来实现。电子健康记录(EHRs),特别是来自重症监护室(ICUs)的,包含丰富的时序临床数据,可以为此目的而加以利用。在这项工作中,我们介绍了ICU-TSB(时序分层基准),这是基于时序患者表示学习评估患者分层的第一个全面基准,使用了三个公开可用的ICU EHR数据集。我们基准的关键贡献在于采用疾病分类法的新型层次评估框架,以衡量发现集群与临床验证的疾病分组之间的对齐程度。在我们的ICU-TSB实验中,我们比较了统计方法和几种循环神经网络(包括LSTM和GRU)生成有效患者表示的能力,以便对随后的患者轨迹进行聚类。结果表明,时序表示学习能够重新发现具有临床意义的患者群体;然而,这仍然是一项具有挑战性的任务,在分类等级的最高层次上v值最高达到0.46,而在最低层次上最高达到0.40。为了进一步提高我们研究结果的实际效用,我们还评估了为已识别的集群分配可解释标签的多种策略。实验和基准都是完全可复制的,可在https://github.com/ds4dh/CBMS2025stratification找到。
论文及项目相关链接
PDF 6 pages 1 table 6 figures
Summary:
本文介绍了ICU-TSB(基于时序分层基准)的重要性,它是利用重症监护病房电子健康记录(EHRs)数据进行患者分层的首个全面基准。该基准通过利用疾病分类法,采用层次评估框架来衡量发现的聚类与临床验证的疾病分组的对齐程度。实验结果显示,时序表示学习能够重新发现具有临床意义的患者群体,但仍面临挑战,在分类的最高和最低级别上得分不同。为提高结果的实用性,作者还评估了为识别出的聚类分配可解释标签的多种策略。该实验和基准测试完全可重现,并提供了一个在线链接以供进一步了解。
Key Takeaways:
- 患者分层对于推动个性化医学至关重要,有助于改进诊断和治疗策略。
- ICU-TSB是首个利用重症监护病房(ICU)电子健康记录(EHRs)数据进行患者分层的全面基准。
- ICU-TSB采用层次评估框架,结合疾病分类法来衡量发现的聚类与临床验证的疾病分组的匹配程度。
- 时序表示学习能够发现具有临床意义的患者群体,但分层仍具有挑战性。
- 在分类的最高和最低级别上,评估结果存在差异,需要进一步研究和改进。
- 为提高结果的实用性,作者探索了多种策略来为识别出的聚类分配可解释的标签。
点此查看论文截图

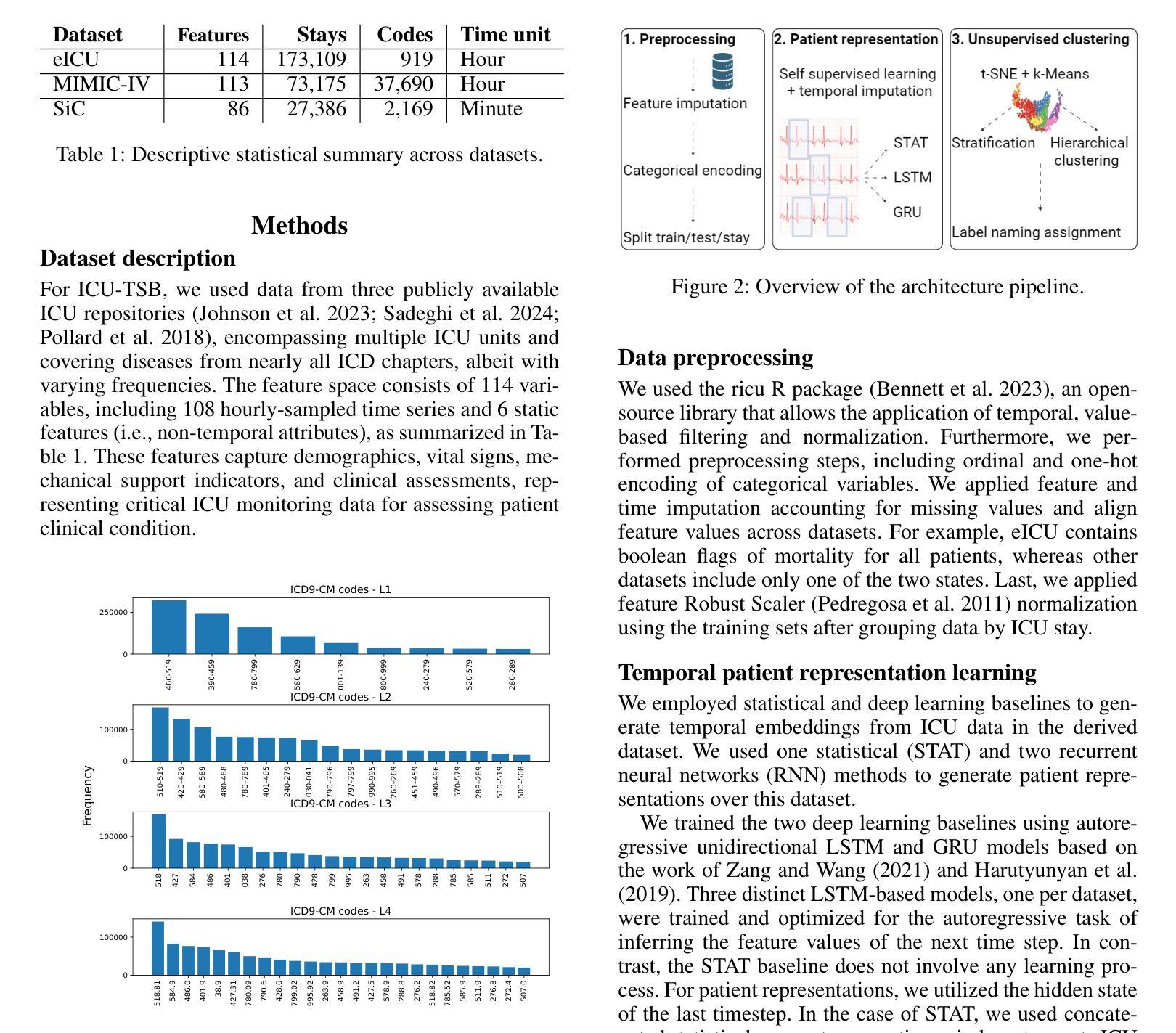
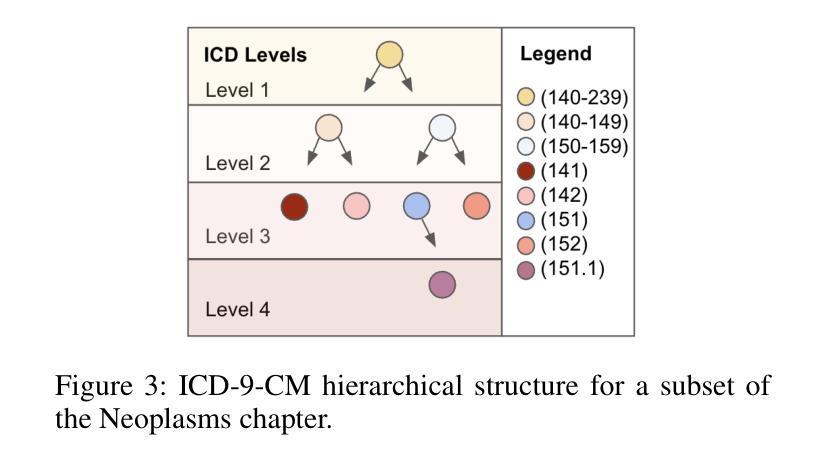
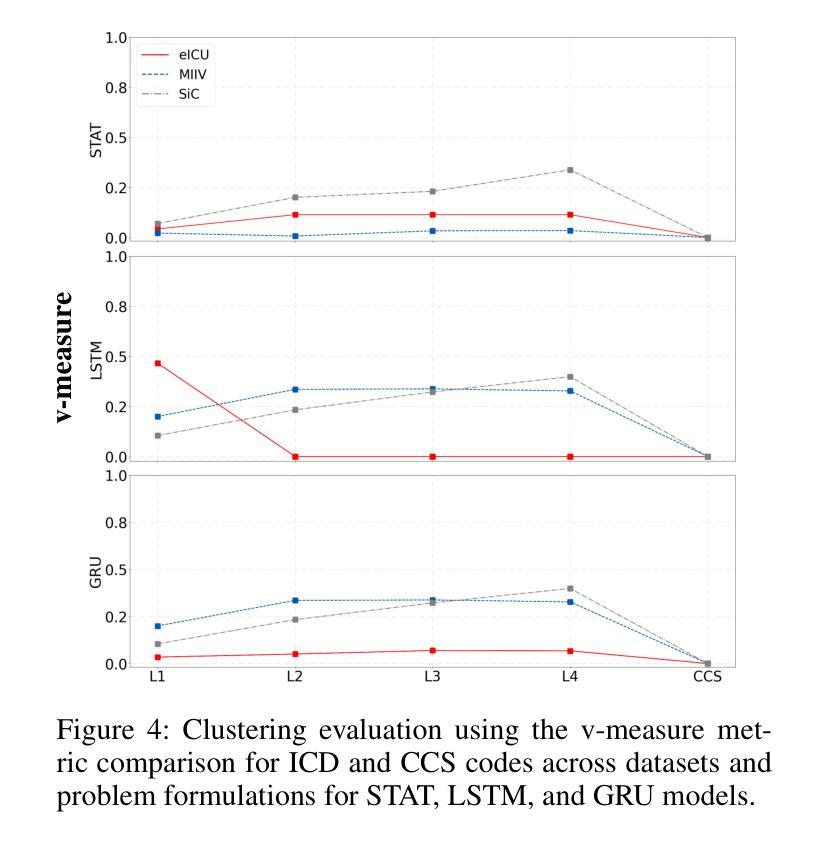
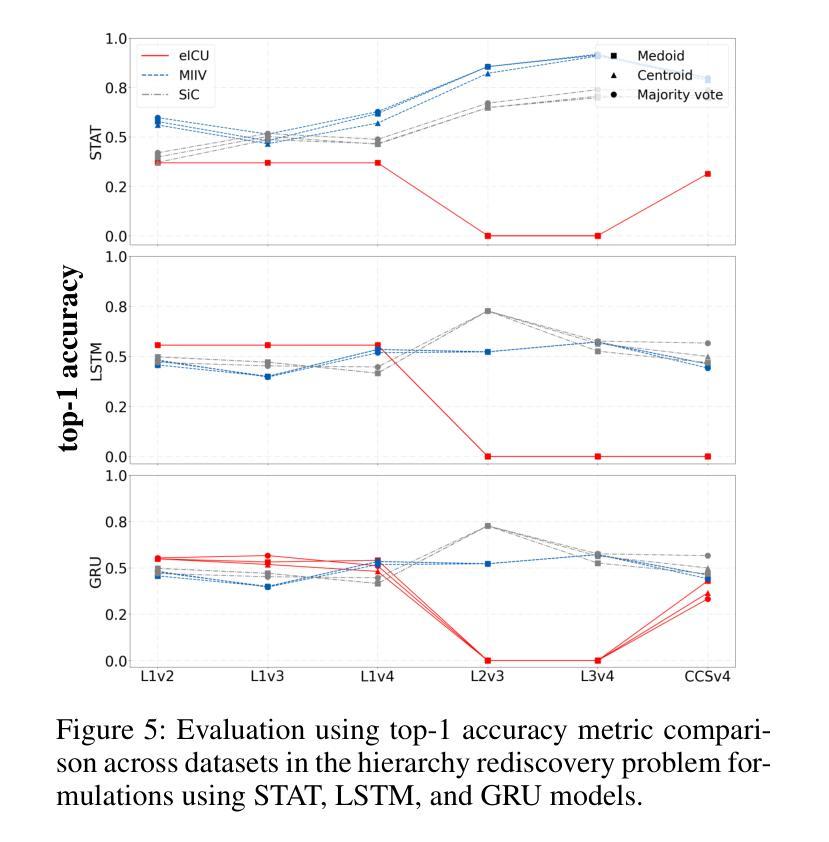
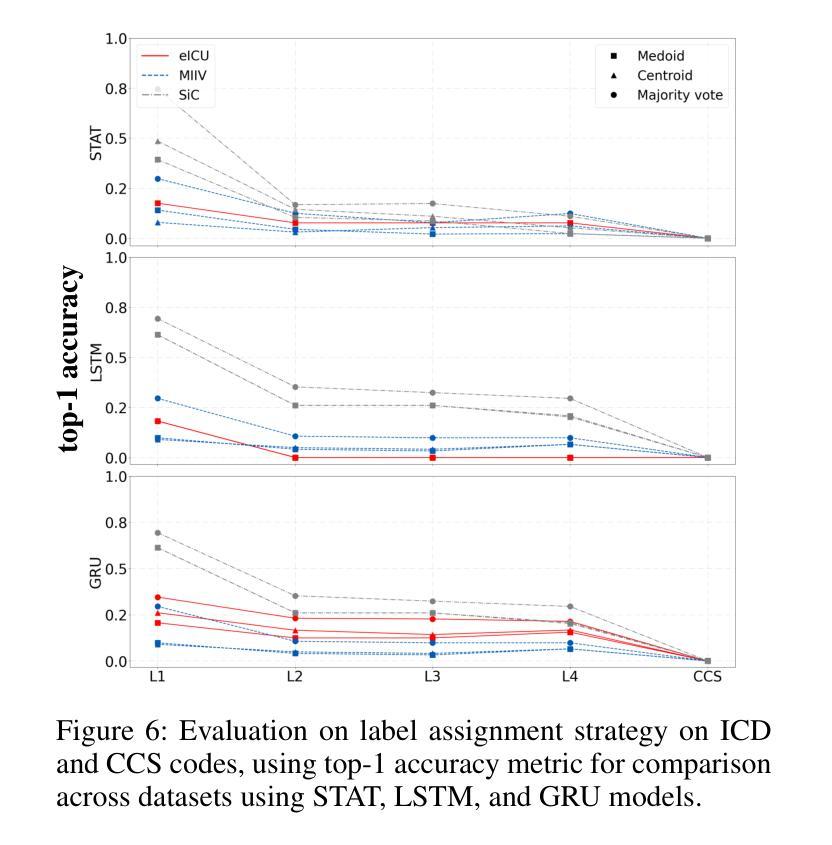
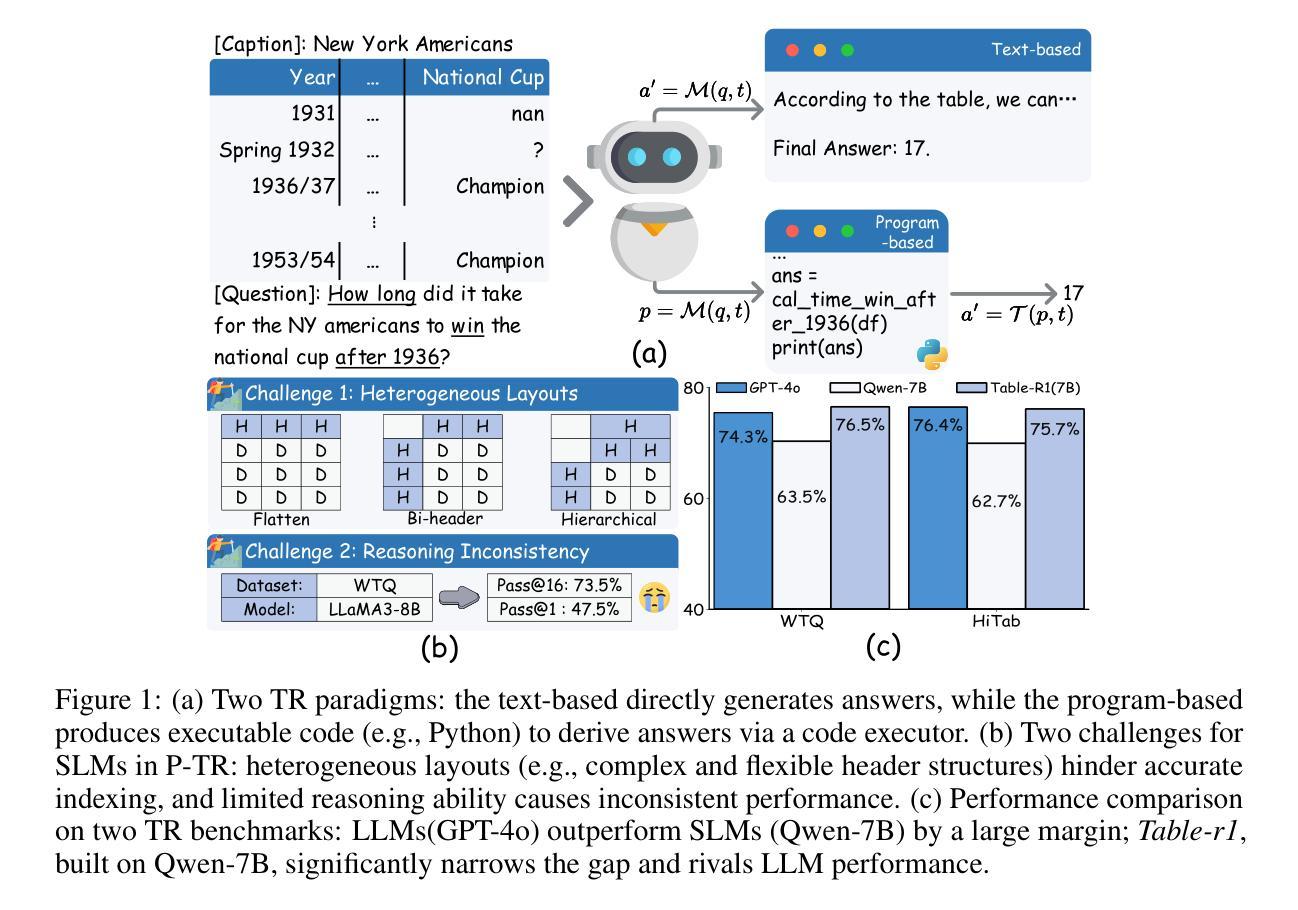
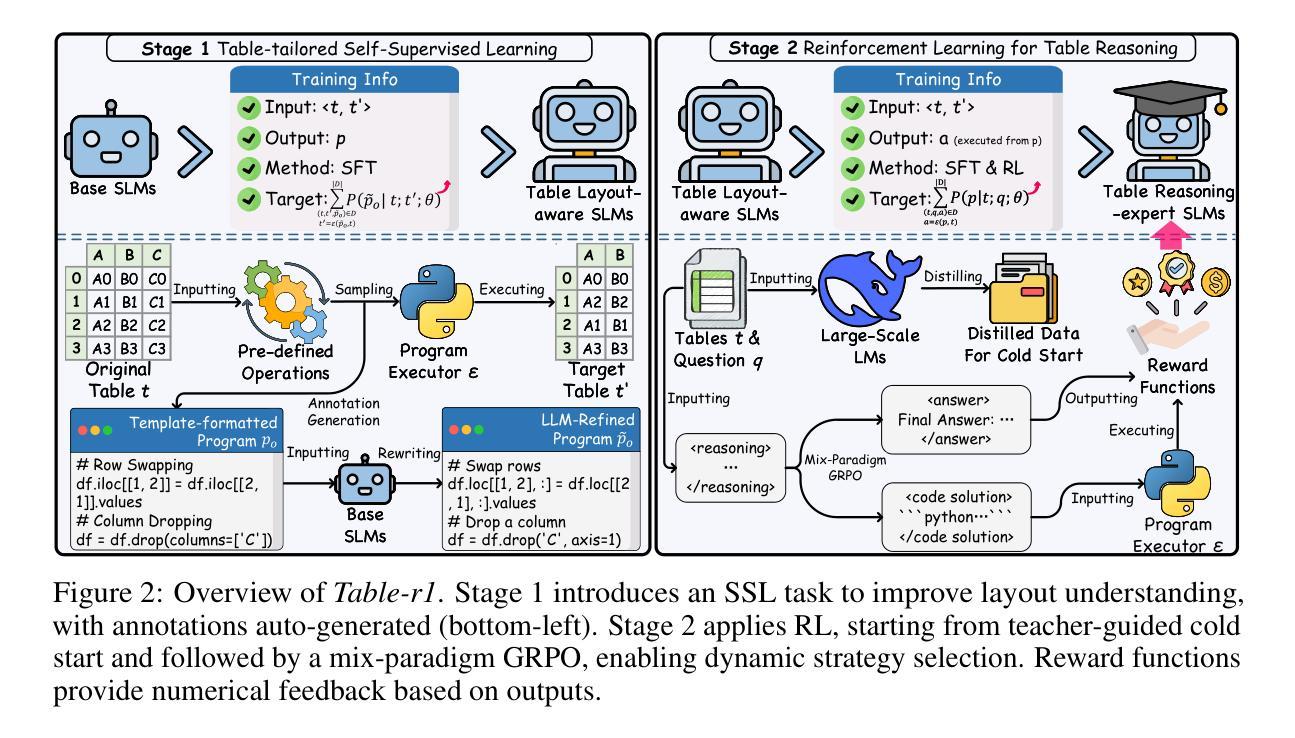
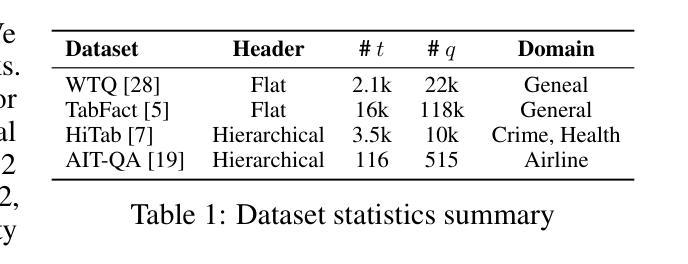
Table-r1: Self-supervised and Reinforcement Learning for Program-based Table Reasoning in Small Language Models
Authors:Rihui Jin, Zheyu Xin, Xing Xie, Zuoyi Li, Guilin Qi, Yongrui Chen, Xinbang Dai, Tongtong Wu, Gholamreza Haffari
Table reasoning (TR) requires structured reasoning over semi-structured tabular data and remains challenging, particularly for small language models (SLMs, e.g., LLaMA-8B) due to their limited capacity compared to large LMs (LLMs, e.g., GPT-4o). To narrow this gap, we explore program-based TR (P-TR), which circumvents key limitations of text-based TR (T-TR), notably in numerical reasoning, by generating executable programs. However, applying P-TR to SLMs introduces two challenges: (i) vulnerability to heterogeneity in table layouts, and (ii) inconsistency in reasoning due to limited code generation capability. We propose Table-r1, a two-stage P-TR method designed for SLMs. Stage 1 introduces an innovative self-supervised learning task, Layout Transformation Inference, to improve tabular layout generalization from a programmatic view. Stage 2 adopts a mix-paradigm variant of Group Relative Policy Optimization, enhancing P-TR consistency while allowing dynamic fallback to T-TR when needed. Experiments on four TR benchmarks demonstrate that Table-r1 outperforms all SLM-based methods, achieving at least a 15% accuracy improvement over the base model (LLaMA-8B) across all datasets and reaching performance competitive with LLMs.
表格推理(TR)要求对半结构化表格数据进行结构化推理,仍然是一项挑战,特别是对于小型语言模型(SLM,例如LLaMA-8B)而言,由于与大型语言模型(LLM,例如GPT-4o)相比,它们的容量有限。为了缩小这一差距,我们探索了基于程序的TR(P-TR),通过生成可执行程序,避免了基于文本的TR(T-TR)在数值推理等方面的关键局限性。然而,将P-TR应用于SLM引入了两个挑战:(i)对表格布局异质性的脆弱性,(ii)由于有限的代码生成能力导致的推理不一致性。我们提出了Table-r1,这是一个为SLM设计的两阶段P-TR方法。第一阶段引入了一种创新的自我监督学习任务,即“布局转换推理”,从程序视角提高表格布局概括能力。第二阶段采用混合范式的集团相对策略优化变体,提高P-TR的一致性,同时根据需要允许动态退回到T-TR。在四个TR基准测试上的实验表明,Table-r1优于所有SLM方法,在所有数据集上至少比基础模型(LLaMA-8B)提高了15%的准确率,且性能与LLM相竞争。
论文及项目相关链接
Summary
针对表格推理(TR)的挑战,特别是小型语言模型(SLM)在数值推理方面的局限性,研究了一种基于程序化的表格推理(P-TR)方法。为应对SLMs在P-TR应用中的表格布局多样性和推理不一致问题,提出了名为Table-r1的两阶段方法。该方法通过自我监督学习任务提高表格布局泛化能力,并采用混合范式的优化策略增强推理一致性。实验证明,Table-r1在四个TR基准测试上优于所有SLM方法,至少在所有数据集上实现了15%的准确率提升,性能与大型语言模型(LLM)相当。
Key Takeaways
- 表格推理(TR)对小型语言模型(SLM)而言具有挑战性,特别是在数值推理方面。
- 基于程序化的表格推理(P-TR)方法可以克服文本基于的表格推理(T-TR)的局限性。
- SLM在P-TR应用中面临两个挑战:表格布局的多样性和推理的不一致性。
- Table-r1是一个两阶段的P-TR方法,旨在解决上述问题。
- 第一阶段通过自我监督学习任务提高表格布局的泛化能力。
- 第二阶段采用混合范式的优化策略,增强P-TR的推理一致性,并能在需要时动态回退到T-TR。
点此查看论文截图

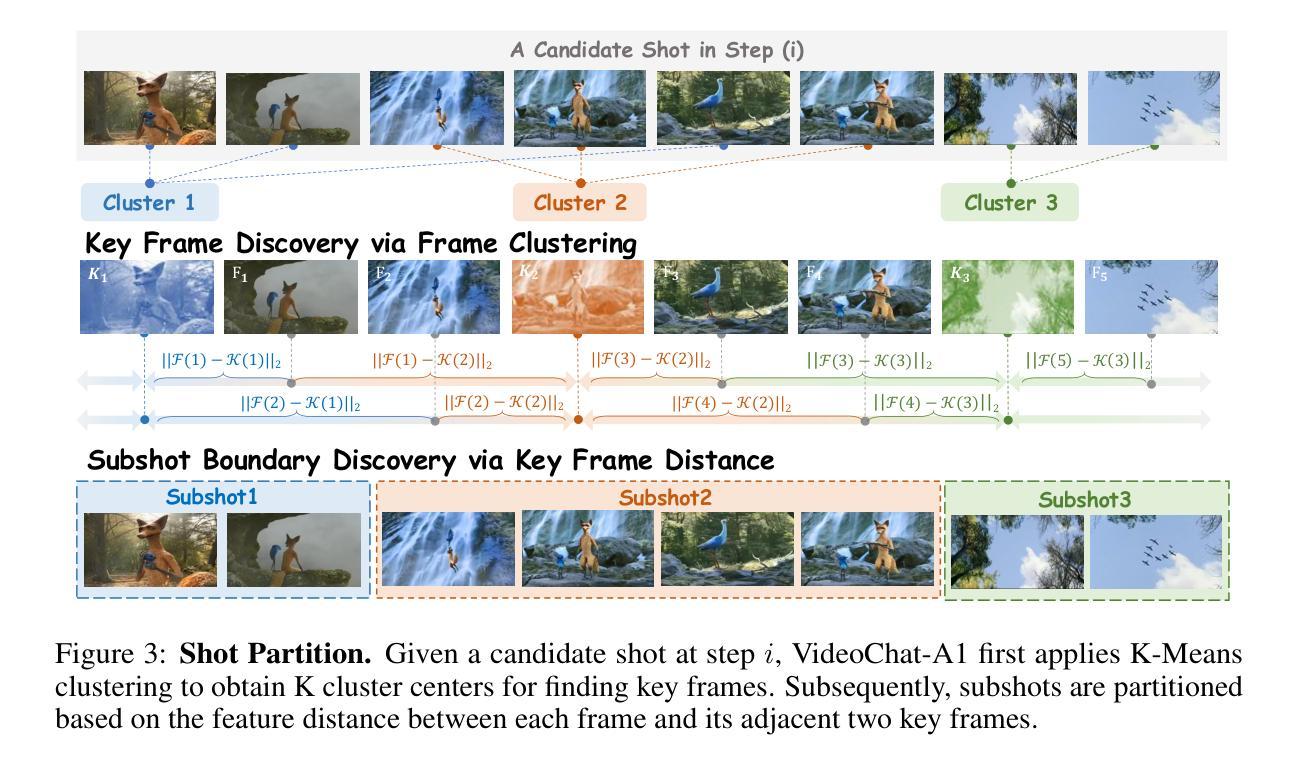
VideoChat-A1: Thinking with Long Videos by Chain-of-Shot Reasoning
Authors:Zikang Wang, Boyu Chen, Zhengrong Yue, Yi Wang, Yu Qiao, Limin Wang, Yali Wang
The recent advance in video understanding has been driven by multimodal large language models (MLLMs). But these MLLMs are good at analyzing short videos, while suffering from difficulties in understanding videos with a longer context. To address this difficulty, several agent paradigms have recently been proposed, using MLLMs as agents for retrieving extra contextual knowledge in a long video. However, most existing agents ignore the key fact that a long video is composed with multiple shots, i.e., to answer the user question from a long video, it is critical to deeply understand its relevant shots like human. Without such insight, these agents often mistakenly find redundant even noisy temporal context, restricting their capacity for long video understanding. To fill this gap, we propose VideoChat-A1, a novel long video agent paradigm. Different from the previous works, our VideoChat-A1 can deeply think with long videos, via a distinct chain-of-shot reasoning paradigm. More specifically, it can progressively select the relevant shots of user question, and look into these shots in a coarse-to-fine partition. By multi-modal reasoning along the shot chain, VideoChat-A1 can effectively mimic step-by-step human thinking process, allowing to interactively discover preferable temporal context for thoughtful understanding in long videos. Extensive experiments show that, our VideoChat-A1 achieves the state-of-the-art performance on the mainstream long video QA benchmarks, e.g., it achieves 77.0 on VideoMME and 70.1 on EgoSchema, outperforming its strong baselines (e.g., Intern2.5VL-8B and InternVideo2.5-8B), by up to 10.8% and 6.2%. Compared to leading close-source GPT-4o and Gemini 1.5 Pro, VideoChat-A1 offers competitive accuracy, but with 7% input frames and 12% inference time on average.
近期视频理解的进步得益于多模态大型语言模型(MLLMs)的推动。但这些MLLMs擅长分析短视频,在理解长视频时遇到困难。为了解决这一难题,最近提出了几种使用MLLMs作为代理检索长视频额外上下文知识的代理范式。然而,大多数现有代理忽略了长视频由多个镜头组成的关键事实,即要回答用户关于长视频的问题,需要像人类一样深刻地理解其相关镜头。没有这样的洞察力,这些代理往往会错误地找到冗余甚至嘈杂的时间上下文,限制了它们对长视频的理解能力。为了填补这一空白,我们提出了VideoChat-A1,这是一种新的长视频代理范式。与以前的工作不同,我们的VideoChat-A1可以通过独特的镜头链推理范式对长视频进行深度思考。更具体地说,它可以逐步选择与用户问题相关的镜头,并以从粗到细的分区查看这些镜头。通过沿着镜头链进行多模态推理,VideoChat-A1可以有效地模仿人类的逐步思考过程,允许交互式地发现用户问题所需的可选时间上下文,以在长视频中实现深思熟虑的理解。大量实验表明,我们的VideoChat-A1在主流的长视频问答基准测试中达到了最先进的性能,例如在VideoMME上达到了77.0,在EgoSchema上达到了70.1,超越了其强大的基准线(例如Intern2.5VL-8B和InternVideo2.5-8B),最多高达10.8%和6.2%。与领先的闭源GPT-4o和Gemini 1.5 Pro相比,VideoChat-A1具有竞争力的准确性,但平均使用了7%的输入帧和减少了12%的推理时间。
论文及项目相关链接
Summary
多媒体视频理解领域中存在一项挑战,即处理长视频的理解问题。当前的多模态大型语言模型在处理长视频时存在困难,因为它们无法有效地处理多个镜头中的信息。为了解决这个问题,提出了一种名为VideoChat-A1的新型长视频代理范式。它通过独特的镜头链推理模式,能够逐步选择与用户问题相关的镜头,并在这些镜头中进行粗到细的检索分析。该模型在主流的长视频问答基准测试中实现了卓越的性能。相较于其他强大基线,其准确性显著提高。同时,VideoChat-A1在输入帧和推理时间上也有优化。
Key Takeaways
- 多模态大型语言模型在处理长视频时存在挑战。
- VideoChat-A1通过独特的镜头链推理模式来处理长视频。
- VideoChat-A1能够逐步选择与用户问题相关的镜头,并进行粗到细的检索分析。
- VideoChat-A1在主流的长视频问答基准测试中实现了卓越性能。
- VideoChat-A1相较于其他强大基线,准确性显著提高。
- VideoChat-A1在输入帧和推理时间方面进行了优化。
点此查看论文截图




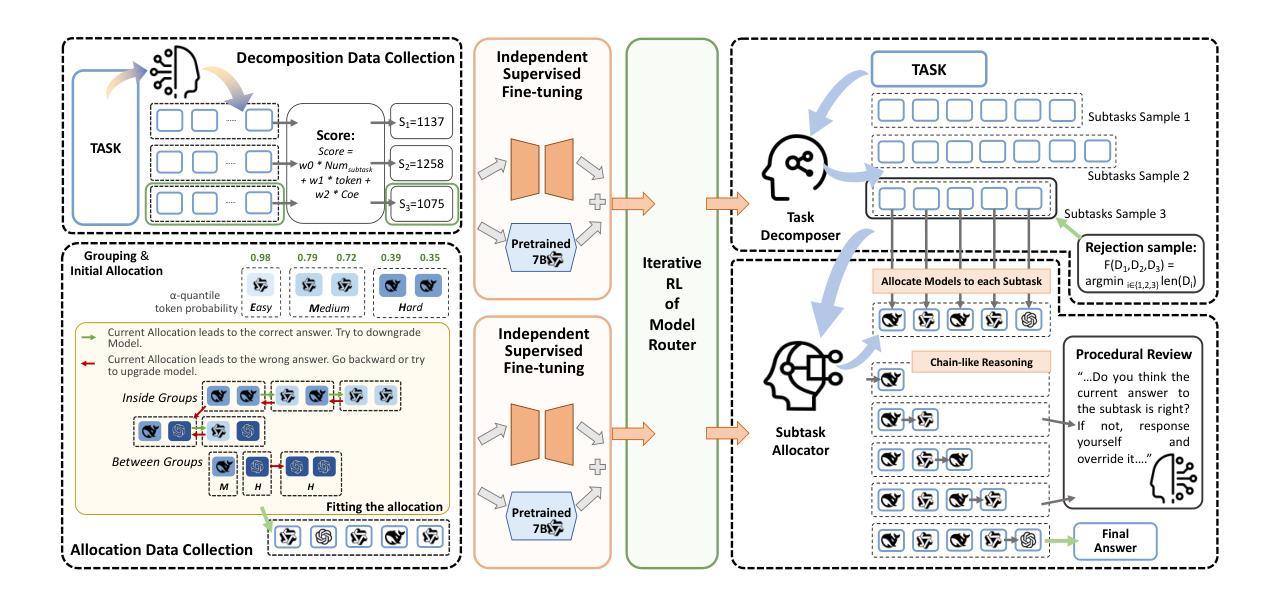
Route-and-Reason: Scaling Large Language Model Reasoning with Reinforced Model Router
Authors:Chenyang Shao, Xinyang Liu, Yutang Lin, Fengli Xu, Yong Li
Multi-step reasoning has proven essential for enhancing the problem-solving capabilities of Large Language Models (LLMs) by decomposing complex tasks into intermediate steps, either explicitly or implicitly. Extending the reasoning chain at test time through deeper thought processes or broader exploration, can furthur improve performance, but often incurs substantial costs due to the explosion in token usage. Yet, many reasoning steps are relatively simple and can be handled by more efficient smaller-scale language models (SLMs). This motivates hybrid approaches that allocate subtasks across models of varying capacities. However, realizing such collaboration requires accurate task decomposition and difficulty-aware subtask allocation, which is challenging. To address this, we propose R2-Reasoner, a novel framework that enables collaborative reasoning across heterogeneous LLMs by dynamically routing sub-tasks based on estimated complexity. At the core of our framework is a Reinforced Model Router, composed of a task decomposer and a subtask allocator. The task decomposer segments complex input queries into logically ordered subtasks, while the subtask allocator assigns each subtask to the most appropriate model, ranging from lightweight SLMs to powerful LLMs, balancing accuracy and efficiency. To train this router, we introduce a staged pipeline that combines supervised fine-tuning on task-specific datasets with Group Relative Policy Optimization algorithm, enabling self-supervised refinement through iterative reinforcement learning. Extensive experiments across four challenging benchmarks demonstrate that R2-Reasoner reduces API costs by 86.85% while maintaining or surpassing baseline accuracy. Our framework paves the way for more cost-effective and adaptive LLM reasoning. The code is open-source at https://anonymous.4open.science/r/R2_Reasoner .
多步推理通过显式或隐式地将复杂任务分解为中间步骤,被证明对于增强大型语言模型(LLM)的问题解决能力是至关重要的。通过在测试时扩展推理链,进行更深入的思考过程或更广泛的探索,可以进一步提高性能,但这通常由于标记使用量的激增而产生巨大成本。然而,许多推理步骤相对简单,可以通过更高效的小规模语言模型(SLM)来处理。这推动了混合方法的使用,该方法在不同容量的模型之间分配子任务。然而,实现这种协作需要准确的任务分解和难度感知的子任务分配,这是具有挑战性的。为了解决这一问题,我们提出了R2推理机,这是一个新型框架,能够通过基于估计复杂度的动态路由在异构LLM之间进行协作推理。我们框架的核心是一个强化模型路由器,由任务分解器和子任务分配器组成。任务分解器将复杂的输入查询分割成逻辑上有序的子任务,而子任务分配器将每个子任务分配给最合适的模型,从轻量级的SLM到功能强大的LLM,平衡准确性和效率。为了训练这个路由器,我们引入了一个分阶段管道,结合针对特定任务的监督微调数据集和集团相对策略优化算法,通过迭代强化学习实现自我监督的细化。在四个具有挑战性的基准测试上的大量实验表明,R2推理机在保持或超过基线准确率的同时,降低了86.85%的API成本。我们的框架为更具成本效益和适应性的LLM推理铺平了道路。代码已开源在https://anonymous.4open.science/r/R2_Reasoner。
论文及项目相关链接
Summary
多步推理对于提升大型语言模型(LLM)的问题解决能力至关重要,通过将复杂任务分解成中间步骤,无论是显式还是隐式。扩展推理链可以提高性能,但会增加令牌使用量,带来巨大成本。为此,我们提出了R2-Reasoner框架,该框架通过动态路由子任务实现跨不同容量模型的协作推理。其核心是强化模型路由器,由任务分解器和子任务分配器组成。任务分解器将复杂输入查询分割成逻辑有序的子任务,而子任务分配器则将每个子任务分配给最合适的模型。通过结合任务特定数据集的监督微调与群体相对策略优化算法的分阶段管道,实现了自我监督的精细化。实验表明,R2-Reasoner在降低86.85%的API成本的同时,维持或提高了基线准确性。
Key Takeaways
- 多步推理对于提升大型语言模型的问题解决能力至关重要。
- 通过将复杂任务分解成中间步骤,可以提高大型语言模型的性能。
- 推理链的扩展会增加令牌使用量,带来成本问题。
- R2-Reasoner框架通过动态路由子任务实现跨不同容量模型的协作推理。
- R2-Reasoner框架包括任务分解器和子任务分配器两个核心组件。
- R2-Reasoner结合了监督微调与群体相对策略优化算法,实现了自我监督的精细化。
点此查看论文截图

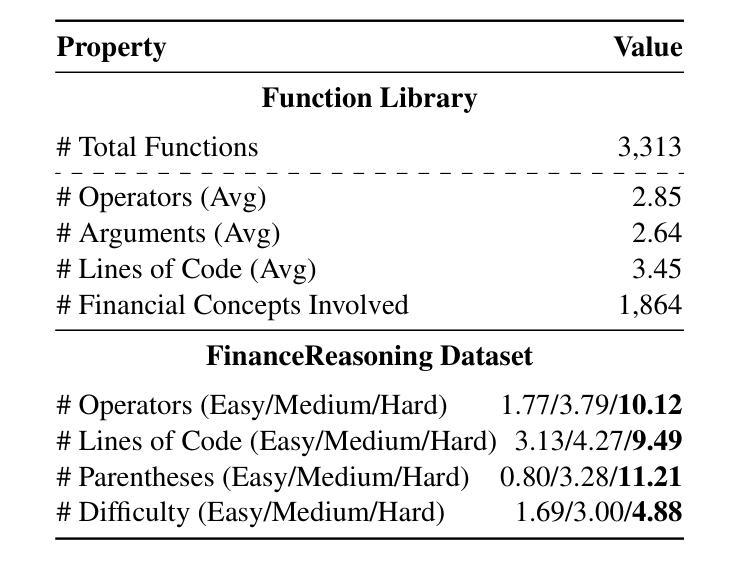
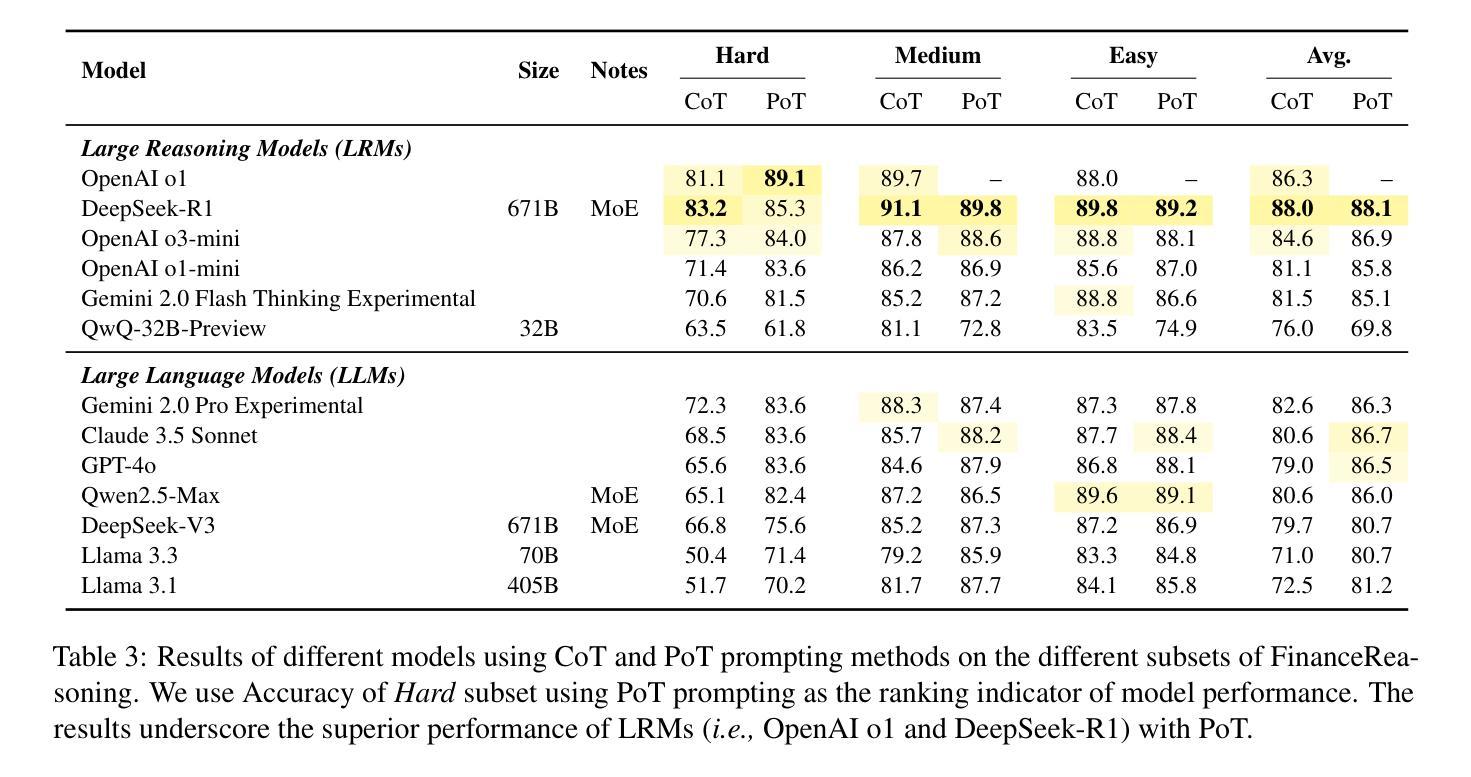
FinanceReasoning: Benchmarking Financial Numerical Reasoning More Credible, Comprehensive and Challenging
Authors:Zichen Tang, Haihong E, Ziyan Ma, Haoyang He, Jiacheng Liu, Zhongjun Yang, Zihua Rong, Rongjin Li, Kun Ji, Qing Huang, Xinyang Hu, Yang Liu, Qianhe Zheng
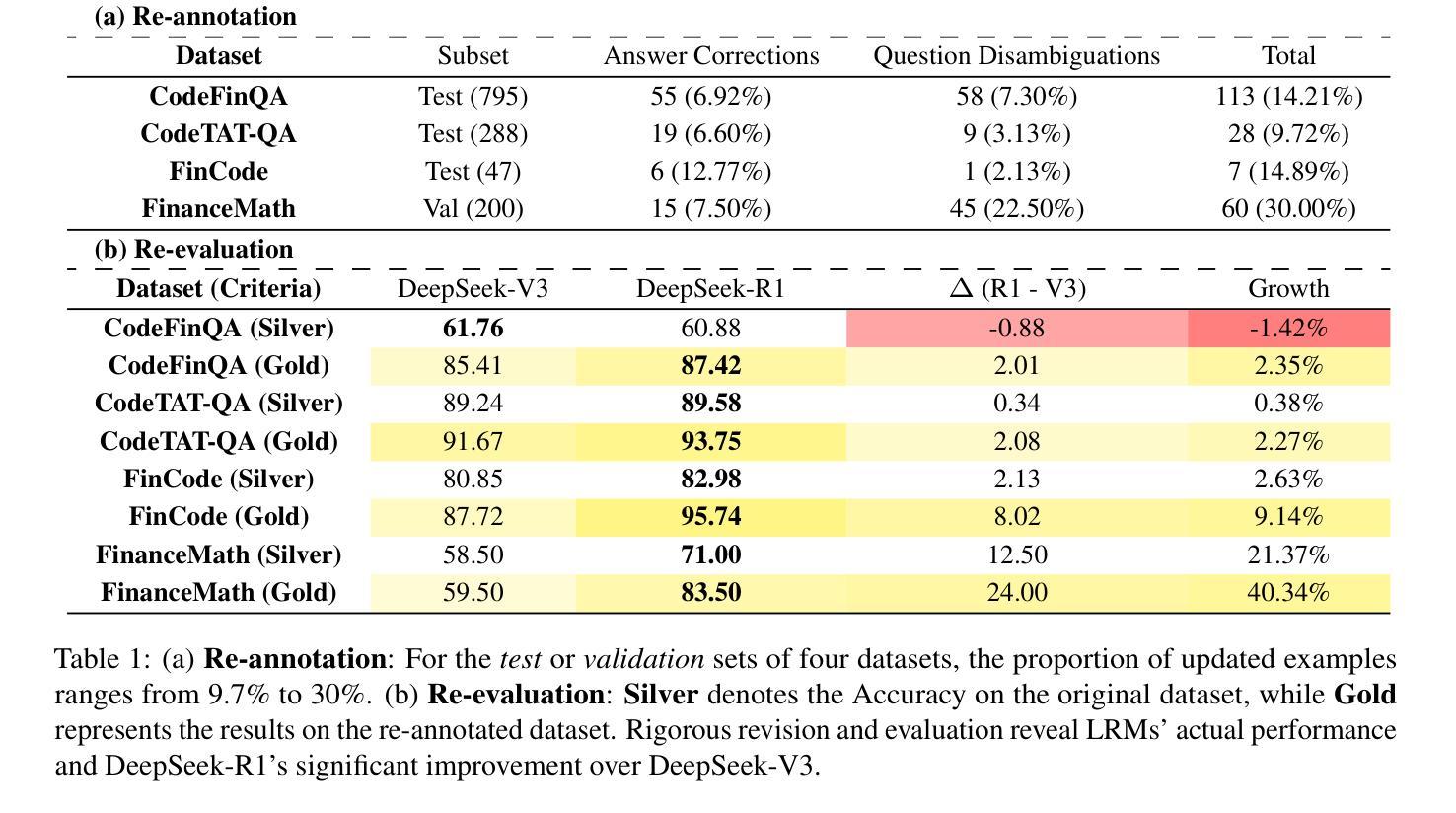
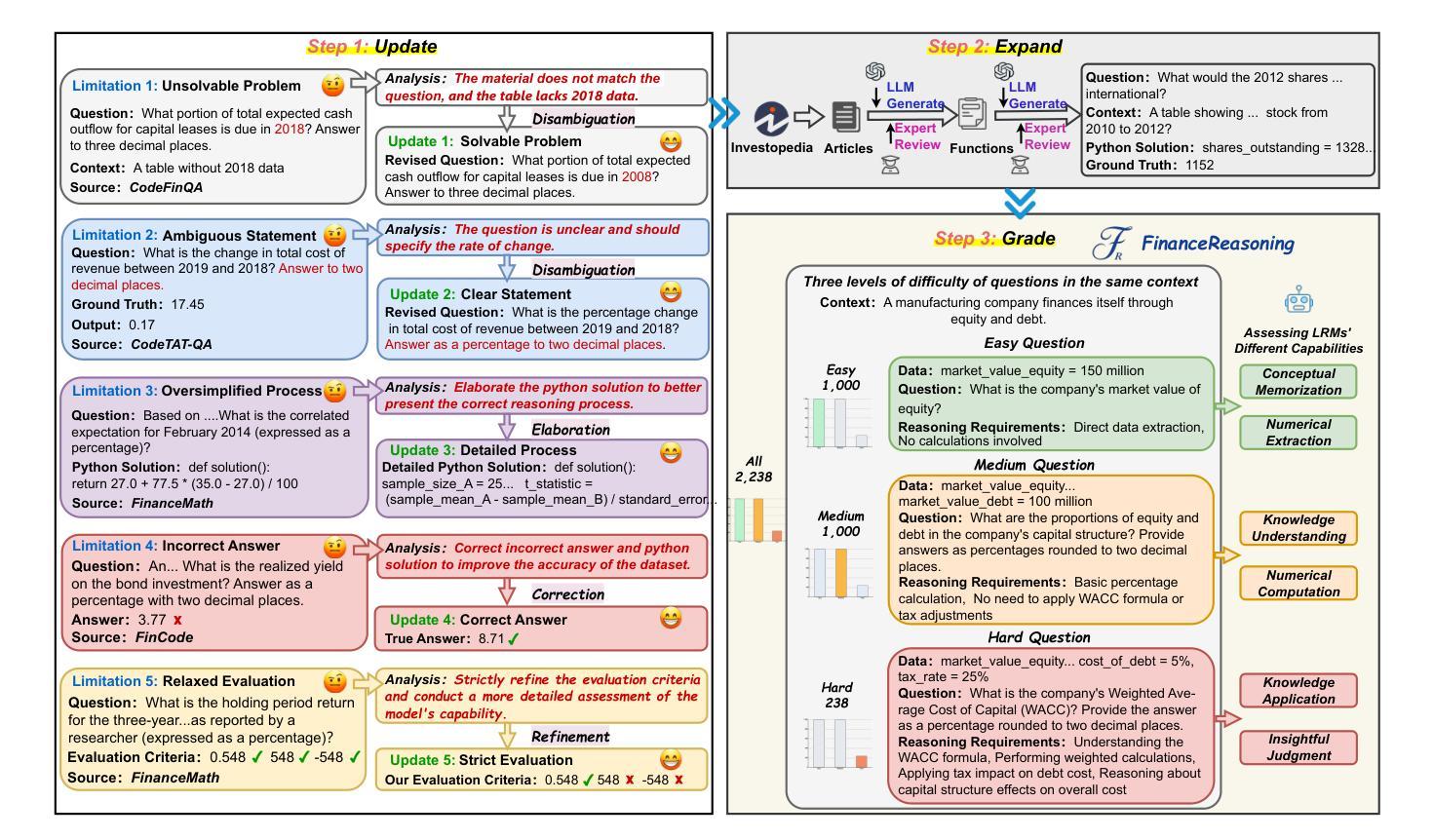
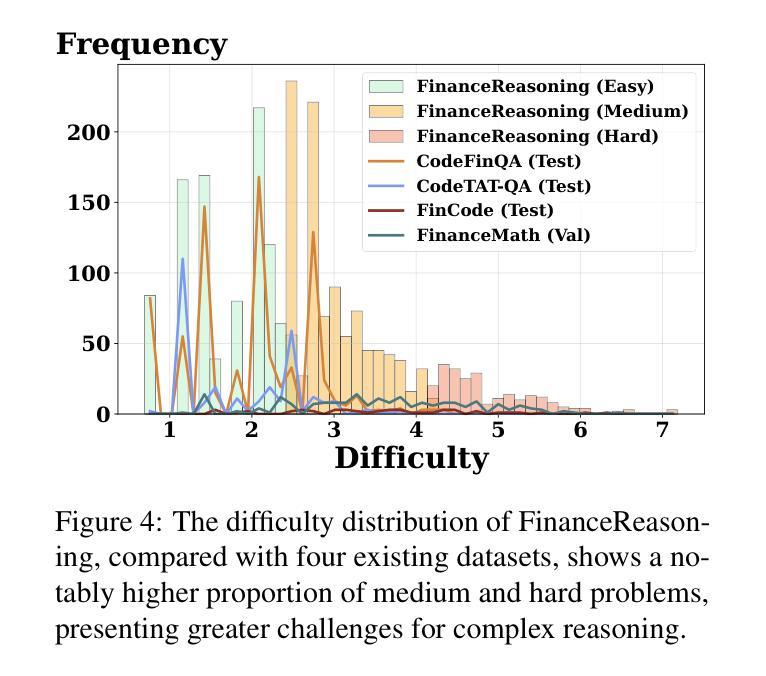
We introduce FinanceReasoning, a novel benchmark designed to evaluate the reasoning capabilities of large reasoning models (LRMs) in financial numerical reasoning problems. Compared to existing benchmarks, our work provides three key advancements. (1) Credibility: We update 15.6% of the questions from four public datasets, annotating 908 new questions with detailed Python solutions and rigorously refining evaluation standards. This enables an accurate assessment of the reasoning improvements of LRMs. (2) Comprehensiveness: FinanceReasoning covers 67.8% of financial concepts and formulas, significantly surpassing existing datasets. Additionally, we construct 3,133 Python-formatted functions, which enhances LRMs’ financial reasoning capabilities through refined knowledge (e.g., 83.2% $\rightarrow$ 91.6% for GPT-4o). (3) Challenge: Models are required to apply multiple financial formulas for precise numerical reasoning on 238 Hard problems. The best-performing model (i.e., OpenAI o1 with PoT) achieves 89.1% accuracy, yet LRMs still face challenges in numerical precision. We demonstrate that combining Reasoner and Programmer models can effectively enhance LRMs’ performance (e.g., 83.2% $\rightarrow$ 87.8% for DeepSeek-R1). Our work paves the way for future research on evaluating and improving LRMs in domain-specific complex reasoning tasks.
我们推出了FinanceReasoning,这是一个新的基准测试,旨在评估大型推理模型在财务数值推理问题中的推理能力。与现有基准测试相比,我们的工作提供了三个关键进展。(1) 可靠性:我们从四个公共数据集中更新了15.6%的问题,为908个新问题提供了详细的Python解决方案,并严格完善了评估标准。这能够准确评估大型推理模型的推理改进情况。(2) 全面性:FinanceReasoning涵盖了67.8%的财务概念和公式,显著超越了现有数据集。此外,我们构建了3133个Python格式的函数,通过精细的知识来提高大型推理模型的财务推理能力(例如,GPT-4o从83.2%提升到91.6%)。(3) 挑战性:模型需要应用多个财务公式对238个难题进行精确数值推理。表现最佳的模型(即OpenAI o1 with PoT)的准确率为89.1%,但大型推理模型在数值精度方面仍面临挑战。我们证明,结合Reasoner和Programmer模型可以有效地提高大型推理模型的性能(例如,DeepSeek-R1从83.2%提升到87.8%)。我们的工作为未来在特定领域复杂推理任务中评估和提高大型推理模型的研究铺平了道路。
论文及项目相关链接
PDF Accepted by ACL 2025 Main Conference
Summary
FinanceReasoning作为一种新型基准测试,旨在评估大型推理模型在金融数值推理问题中的推理能力。相较于现有基准测试,其具备可信度、全面性和挑战性三大优势。更新后的题目涵盖了金融概念和公式的绝大部分内容,对模型的金融推理能力提出了较高要求,并结合了Reasoner和Programmer模型以提升模型性能。此项研究为未来在特定领域复杂推理任务中评估和改进大型推理模型奠定了基础。
Key Takeaways
- FinanceReasoning作为一种基准测试,旨在评估大型推理模型在金融数值推理方面的能力。
- 与现有基准测试相比,FinanceReasoning具备更高的可信度和更全面的内容覆盖,涵盖了金融概念和公式的绝大部分内容。
- FinanceReasoning对模型的金融推理能力提出了挑战,要求模型应用多个金融公式进行精确数值推理。
- 更新后的题目包括详细的Python解决方案,并严格细化了评估标准,以准确评估模型的推理改进情况。
- 结合Reasoner和Programmer模型能有效提升大型推理模型的性能。
- 目前最佳模型在FinanceReasoning上的准确率为89.1%,但仍存在数值精度方面的挑战。
点此查看论文截图


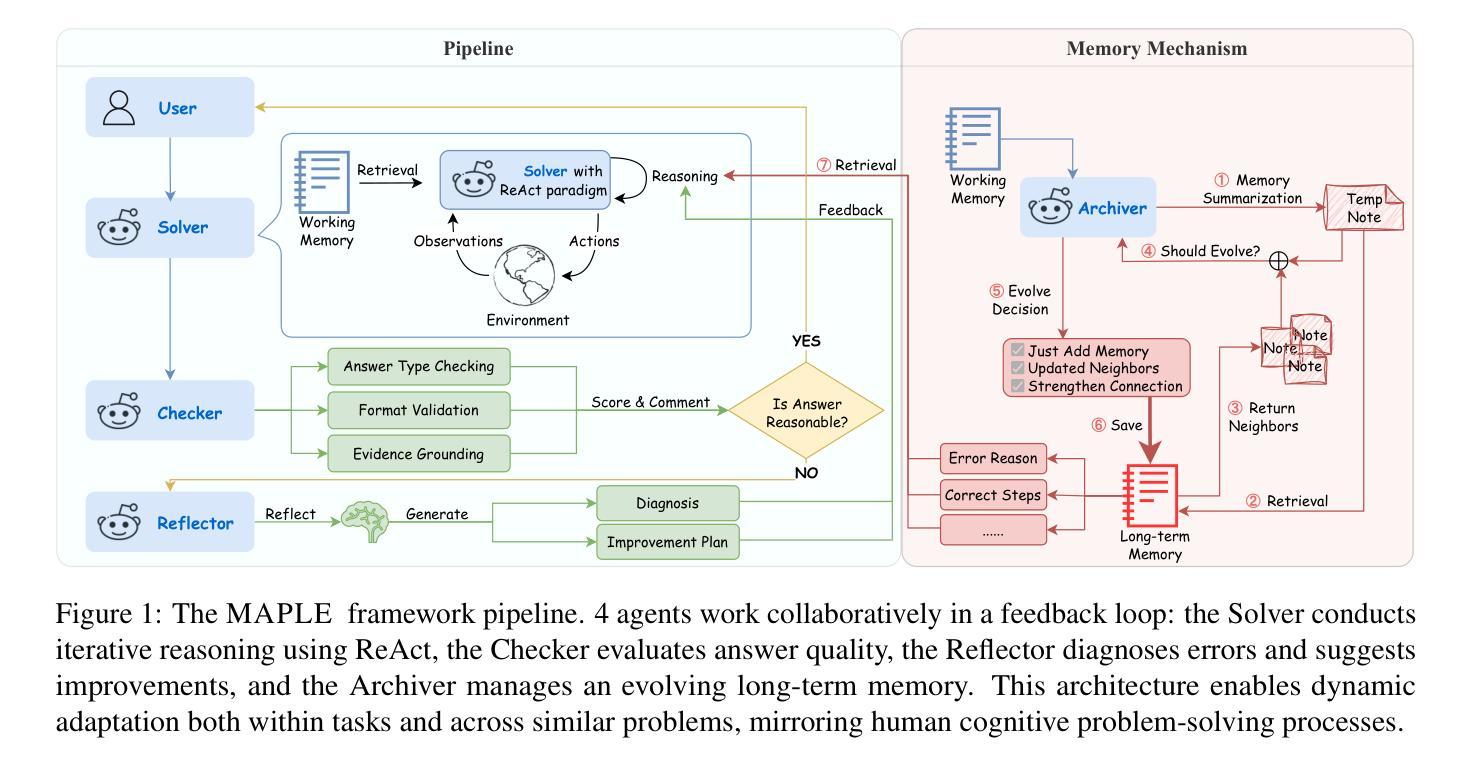
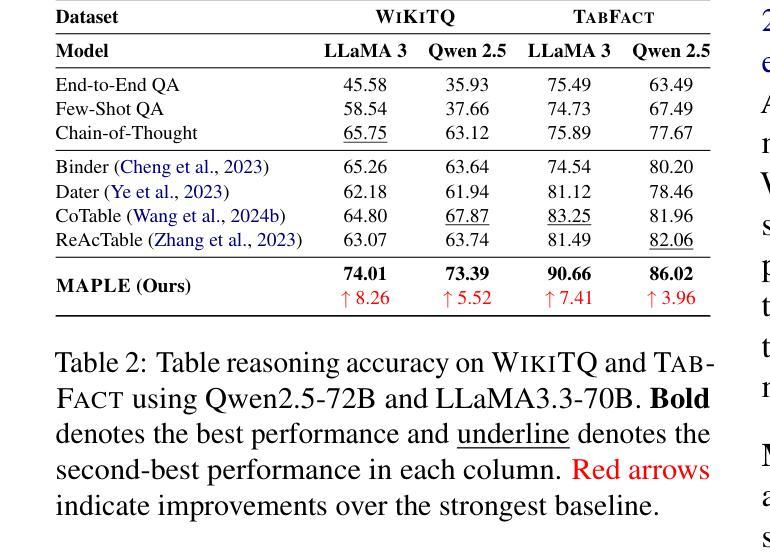
MAPLE: Multi-Agent Adaptive Planning with Long-Term Memory for Table Reasoning
Authors:Ye Bai, Minghan Wang, Thuy-Trang Vu
Table-based question answering requires complex reasoning capabilities that current LLMs struggle to achieve with single-pass inference. Existing approaches, such as Chain-of-Thought reasoning and question decomposition, lack error detection mechanisms and discard problem-solving experiences, contrasting sharply with how humans tackle such problems. In this paper, we propose MAPLE (Multi-agent Adaptive Planning with Long-term mEmory), a novel framework that mimics human problem-solving through specialized cognitive agents working in a feedback-driven loop. MAPLE integrates 4 key components: (1) a Solver using the ReAct paradigm for reasoning, (2) a Checker for answer verification, (3) a Reflector for error diagnosis and strategy correction, and (4) an Archiver managing long-term memory for experience reuse and evolution. Experiments on WiKiTQ and TabFact demonstrate significant improvements over existing methods, achieving state-of-the-art performance across multiple LLM backbones.
基于表格的问题回答需要复杂的推理能力,而当前的大型语言模型(LLMs)在单遍推理中难以实现。现有的方法,如思维链推理和问题分解,缺乏错误检测机制并丢弃解决问题时的经验,这与人类解决此类问题的方式形成鲜明对比。在本文中,我们提出了MAPLE(具有长期记忆的多智能体自适应规划),这是一种通过专门设计的认知智能体在反馈驱动循环中工作来模拟人类解决问题的新型框架。MAPLE集成了四个关键组件:(1)使用ReAct范式进行推理的求解器,(2)用于答案验证的检查器,(3)用于错误诊断和策略修正的反射器,以及(4)管理经验重用和演化的长期记忆的存档器。在WikiTQ和TabFact上的实验表明,与现有方法相比,该方法实现了显著的改进,并在多个大型语言模型主干上实现了最先进的性能。
论文及项目相关链接
PDF 26 pages, 10 figures
Summary
本文提出了一种名为MAPLE的新型框架,用于模拟人类解决表格问答问题。该框架包含四个关键组件:Solver用于推理,Checker用于答案验证,Reflector用于错误诊断和策略修正,Archiver用于长期记忆管理以实现经验复用和进化。实验结果表明,MAPLE在WikiTQ和TabFact数据集上显著改进了现有方法,实现了跨多个大型语言模型背书的卓越性能。
Key Takeaways
- 表格问答要求复杂的推理能力,当前的大型语言模型(LLMs)在单通道推理中难以实现。
- 现有方法如Chain-of-Thought推理和问题分解缺乏错误检测机制,并忽略了问题解决经验的积累。
- MAPLE框架模拟人类问题解决过程,通过专业认知代理在反馈驱动循环中工作。
- MAPLE包含四个关键组件:Solver用于推理,Checker用于答案验证,Reflector用于错误诊断和策略修正,Archiver用于长期记忆管理。
- MAPLE实现了显著的性能改进,在WikiTQ和TabFact数据集上超过了现有方法。
- MAPLE框架实现了跨多个大型语言模型背书的卓越性能。
点此查看论文截图



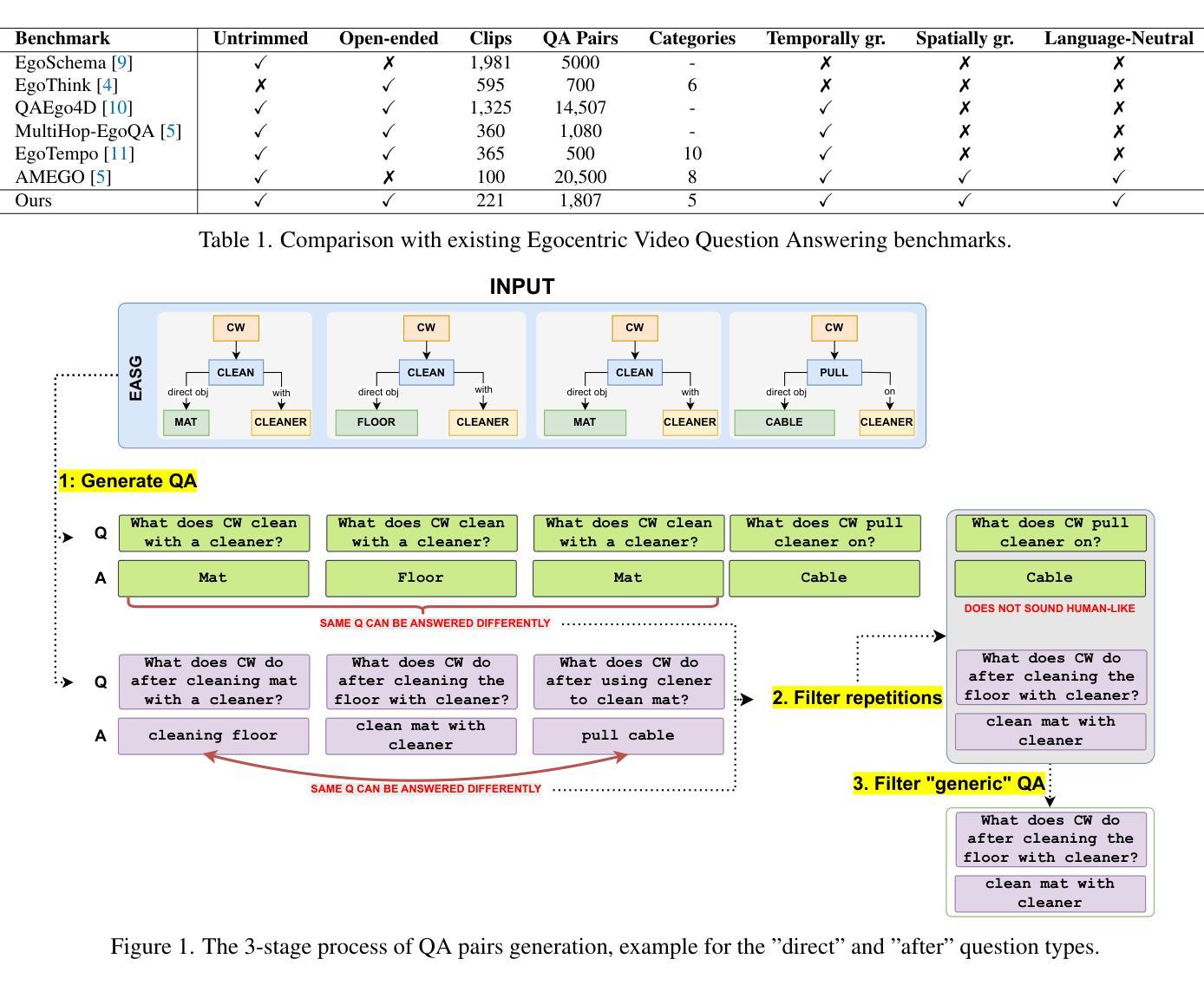
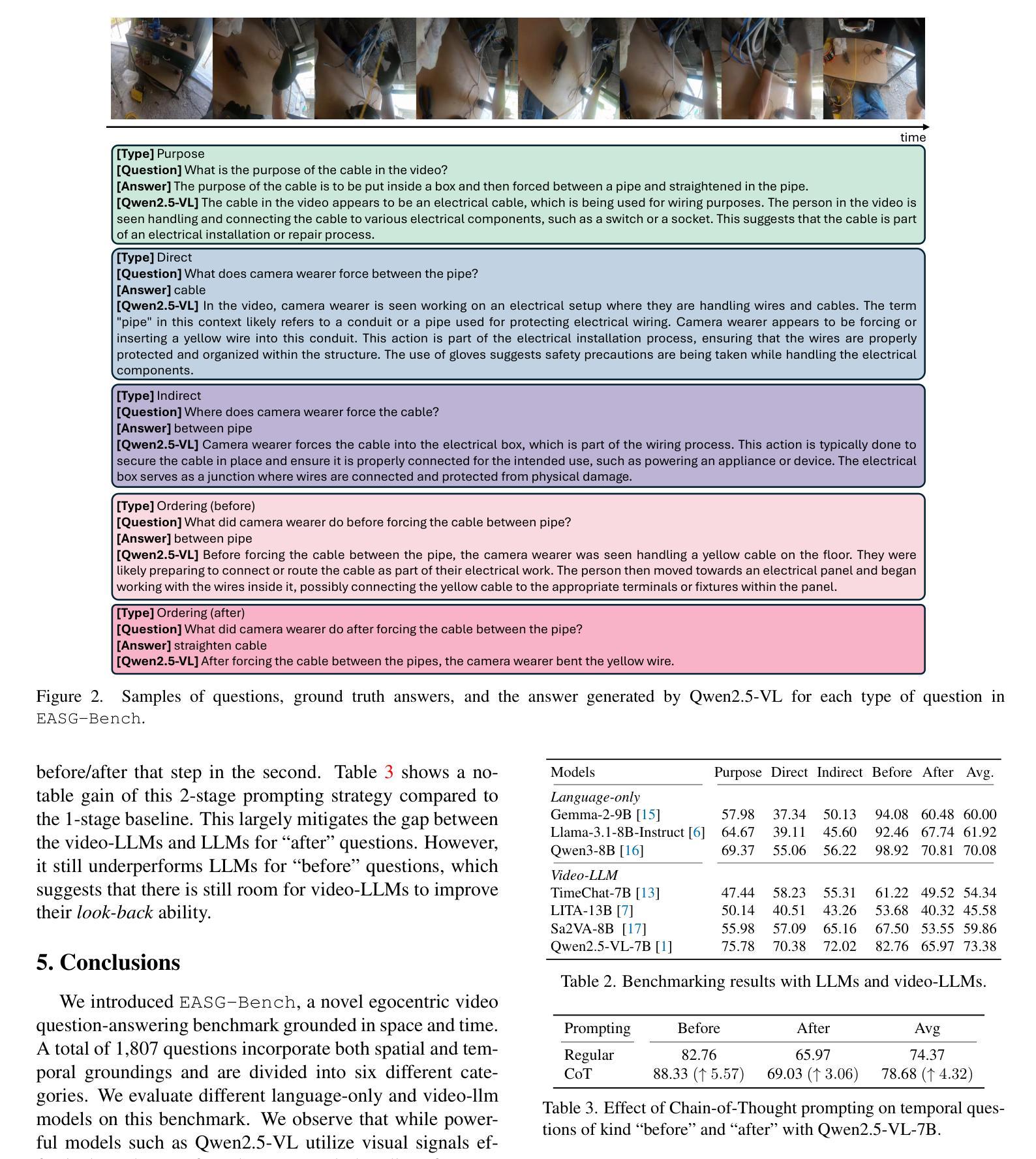
EASG-Bench: Video Q&A Benchmark with Egocentric Action Scene Graphs
Authors:Ivan Rodin, Tz-Ying Wu, Kyle Min, Sharath Nittur Sridhar, Antonino Furnari, Subarna Tripathi, Giovanni Maria Farinella
We introduce EASG-Bench, a question-answering benchmark for egocentric videos where the question-answering pairs are created from spatio-temporally grounded dynamic scene graphs capturing intricate relationships among actors, actions, and objects. We propose a systematic evaluation framework and evaluate several language-only and video large language models (video-LLMs) on this benchmark. We observe a performance gap in language-only and video-LLMs, especially on questions focusing on temporal ordering, thus identifying a research gap in the area of long-context video understanding. To promote the reproducibility of our findings and facilitate further research, the benchmark and accompanying code are available at the following GitHub page: https://github.com/fpv-iplab/EASG-bench.
我们介绍了EASG-Bench,这是一个针对第一人称视频的问答基准测试。该基准测试中的问答对是根据捕捉演员、动作和对象之间复杂关系的时空定位动态场景图生成的。我们提出了一个系统的评估框架,并在该基准测试上评估了多种仅使用语言和视频的大型语言模型(视频LLM)。我们观察到仅使用语言和视频LLM的性能差距,特别是在关注时间顺序的问题上,从而确定了长上下文视频理解领域的研究空白。为了促进我们研究的可重复性并推动进一步的研究,该基准测试和配套代码可在以下GitHub页面找到:https://github.com/fpv-iplab/EASG-bench。
论文及项目相关链接
Summary:我们介绍了EASG-Bench,这是一个针对以自我为中心的视频的问答基准测试。该测试中的问答对是根据捕捉演员、动作和对象之间复杂关系的时空接地动态场景图创建的。我们提出了一个系统的评估框架,并在这个基准测试上评估了几种仅使用语言和视频的大型语言模型(video-LLMs)。我们发现语言和视频LLM在关注时间顺序的问题上表现存在差距,这表明在理解长视频领域存在研究空白。为了促进我们研究结果的再现性和进一步的研究,该基准测试和配套代码可以在以下GitHub页面找到:[https://github.com/fpv-iplab/EASG-bench。
Key Takeaways:
- EASG-Bench是一个针对以自我为中心的视频问答的基准测试,利用时空接地的动态场景图创建问答对。
- 该评估框架揭示了语言和视频大型语言模型(video-LLMs)在理解长视频,特别是在关注时间顺序的问题上的性能差距。
- 这一发现表明在理解长视频领域存在研究空白。
- 该基准测试和配套代码可在GitHub页面找到,以促进研究结果的复现和进一步研究。
- 此基准测试对于评估模型在复杂视频场景中的理解和推理能力具有价值。
- 动态场景图在视频问答任务中起到了关键作用,能够捕捉视频中演员、动作和对象之间的复杂关系。
点此查看论文截图


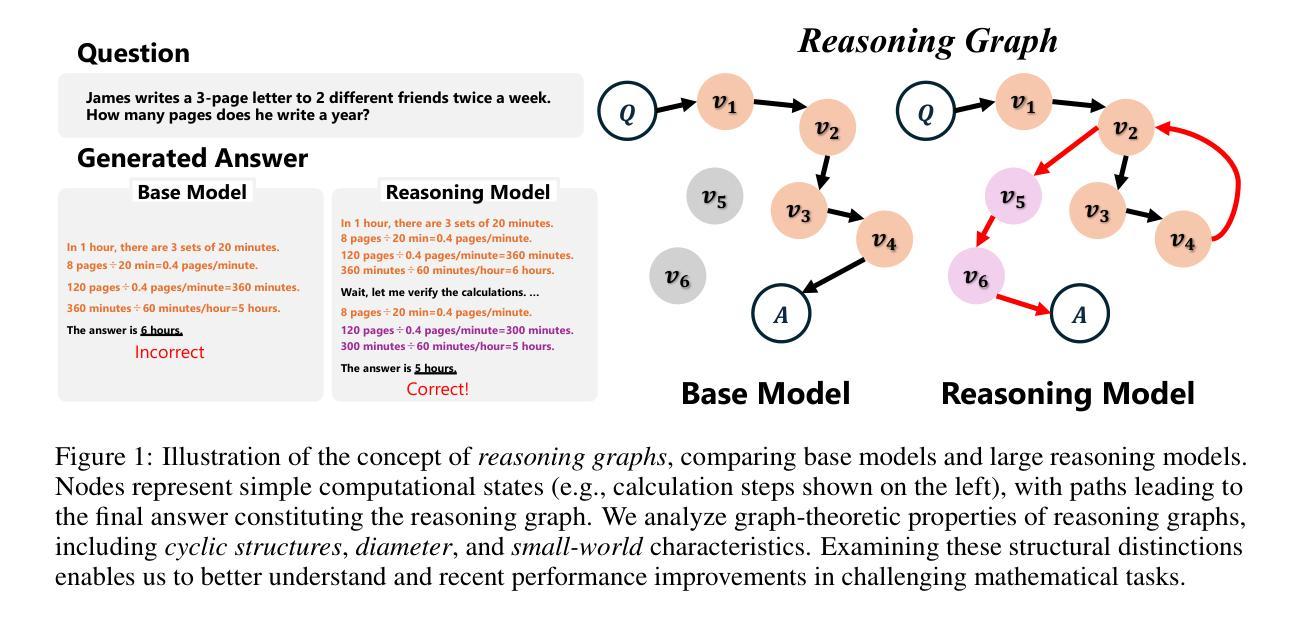
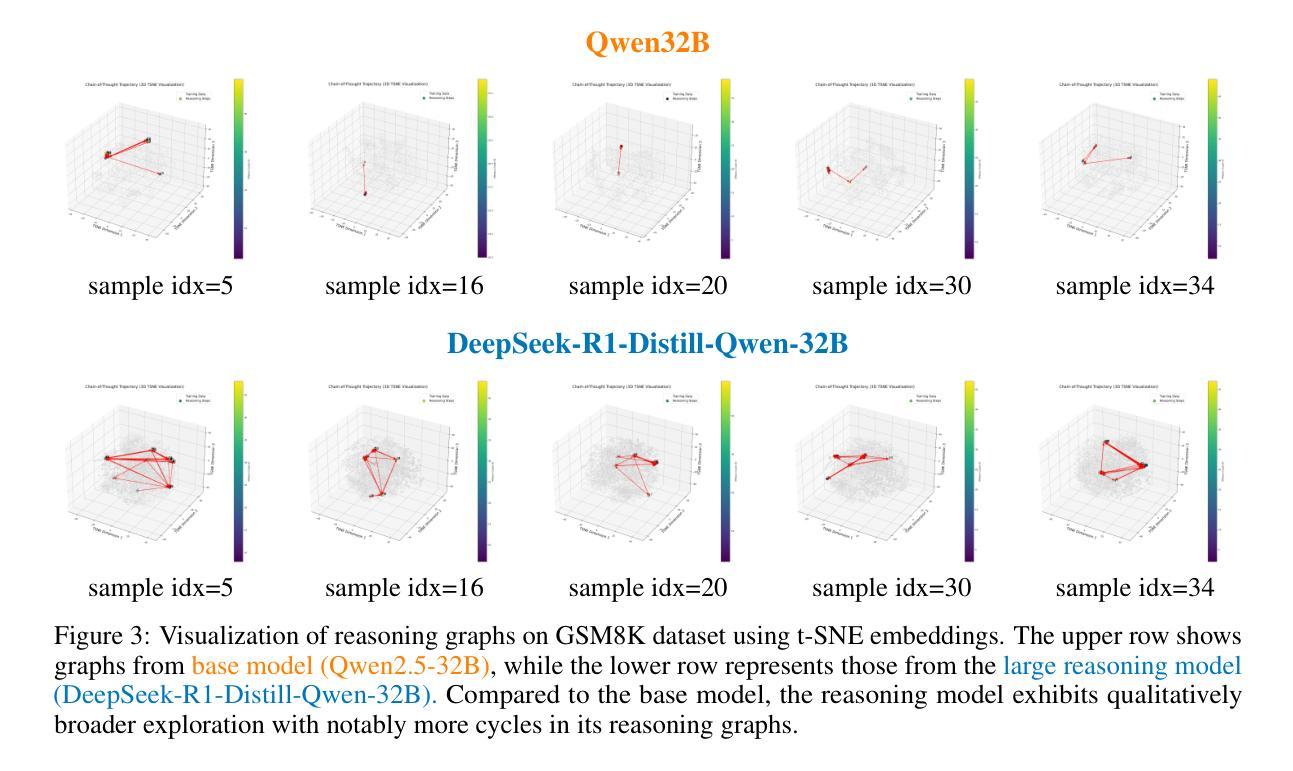
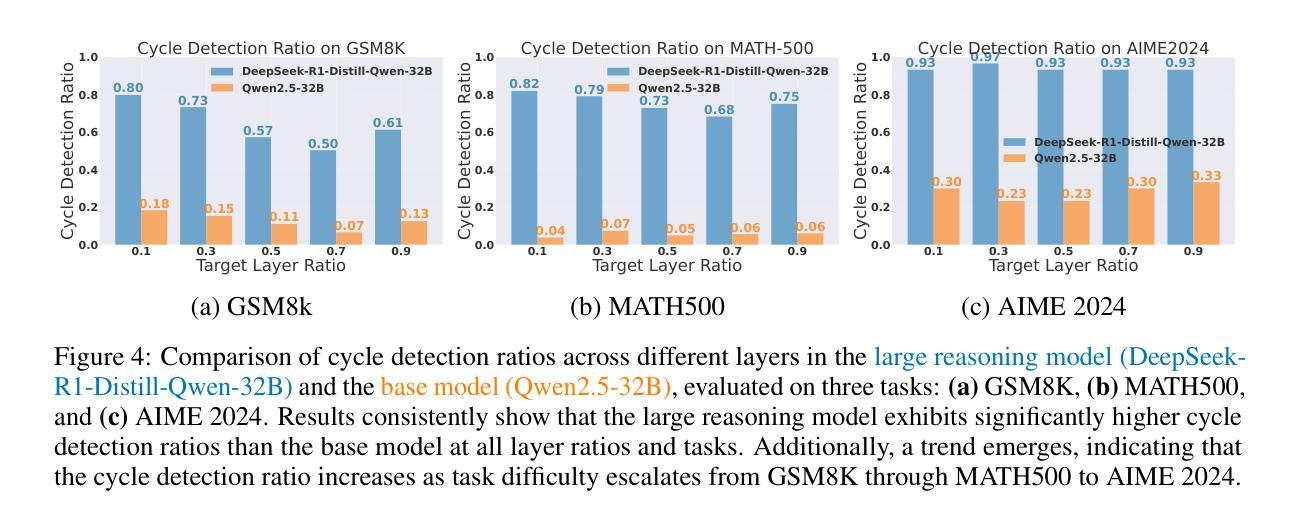
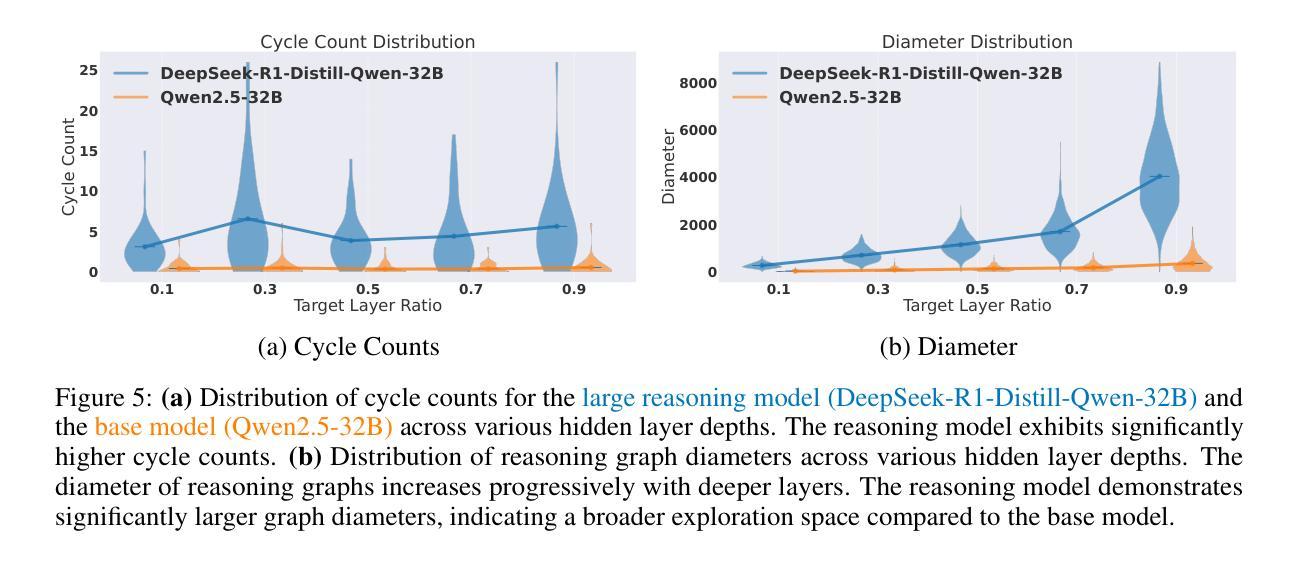
Topology of Reasoning: Understanding Large Reasoning Models through Reasoning Graph Properties
Authors:Gouki Minegishi, Hiroki Furuta, Takeshi Kojima, Yusuke Iwasawa, Yutaka Matsuo
Recent large-scale reasoning models have achieved state-of-the-art performance on challenging mathematical benchmarks, yet the internal mechanisms underlying their success remain poorly understood. In this work, we introduce the notion of a reasoning graph, extracted by clustering hidden-state representations at each reasoning step, and systematically analyze three key graph-theoretic properties: cyclicity, diameter, and small-world index, across multiple tasks (GSM8K, MATH500, AIME 2024). Our findings reveal that distilled reasoning models (e.g., DeepSeek-R1-Distill-Qwen-32B) exhibit significantly more recurrent cycles (about 5 per sample), substantially larger graph diameters, and pronounced small-world characteristics (about 6x) compared to their base counterparts. Notably, these structural advantages grow with task difficulty and model capacity, with cycle detection peaking at the 14B scale and exploration diameter maximized in the 32B variant, correlating positively with accuracy. Furthermore, we show that supervised fine-tuning on an improved dataset systematically expands reasoning graph diameters in tandem with performance gains, offering concrete guidelines for dataset design aimed at boosting reasoning capabilities. By bridging theoretical insights into reasoning graph structures with practical recommendations for data construction, our work advances both the interpretability and the efficacy of large reasoning models.
近期的大规模推理模型已在具有挑战性的数学基准测试中达到了最先进的性能,然而,其成功背后的内在机制仍然知之甚少。在这项工作中,我们引入了推理图的概念,通过聚类每一步推理的隐藏状态表示来提取,并系统地分析了三个关键的图论属性:循环性、直径和小世界指数,跨越多个任务(GSM8K、MATH500、AIME 2024)。我们的研究发现,蒸馏推理模型(例如DeepSeek-R1-Distill-Qwen-32B)表现出更明显的循环(每个样本约5个循环)、更大的图直径和突出的小世界特征(约为原来的6倍),与基础模型相比。值得注意的是,这些结构优势随着任务难度和模型容量的增加而增强,循环检测在规模为14B时达到峰值,探索直径在规模为32B时最大化,与准确性呈正相关。此外,我们在改进的数据集上进行监督微调,系统地扩大了推理图的直径,同时提高了性能,为旨在提高推理能力的数据集设计提供了具体指导。我们的工作架起了推理图结构理论见解与数据构建实践建议之间的桥梁,提高了大规模推理模型的解释性和有效性。
论文及项目相关链接
Summary
该论文探讨了大规模推理模型中的推理图结构,分析了循环性、直径以及小世界指数等图论属性,揭示了这些模型在某些数学基准测试上的优秀表现背后的内部机制。研究表明,蒸馏推理模型相对于基础模型具有更多的循环周期、更大的图直径以及显著的小世界特性。随着任务难度和模型容量的增长,这些结构优势也呈现增长趋势,对精度具有积极影响。此外,该研究还提供了一些改进模型性能的指导建议,对于提升大型推理模型的解释性和有效性具有重要的指导意义。
Key Takeaways
- 引入推理图概念,通过聚类每个推理步骤的隐藏状态表示来提取。
- 分析三个关键图论属性:循环性、直径和小世界指数。
- 蒸馏推理模型展现出更多的循环周期、更大的图直径和显著的小世界特性。
- 随着任务难度和模型容量的增长,这些结构优势呈现增长趋势。
- 模型的结构特点与精度正相关。循环检测在模型规模为14B时达到峰值,探索直径在规模为32B时最大化。
- 通过监督微调改进数据集可系统地扩大推理图的直径并提升性能增益。这提供了设计数据集以加强推理能力的具体指导。
点此查看论文截图


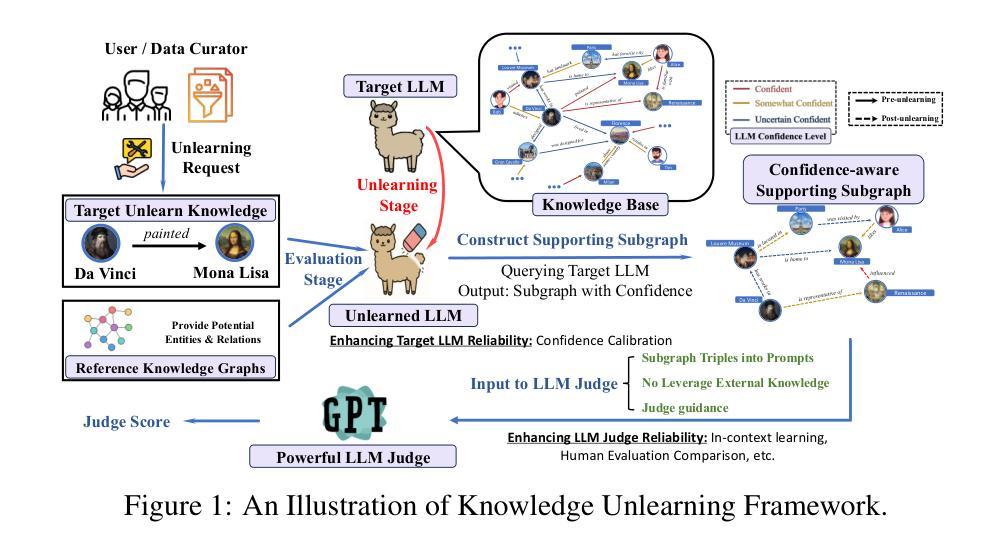
Do LLMs Really Forget? Evaluating Unlearning with Knowledge Correlation and Confidence Awareness
Authors:Rongzhe Wei, Peizhi Niu, Hans Hao-Hsun Hsu, Ruihan Wu, Haoteng Yin, Mohsen Ghassemi, Yifan Li, Vamsi K. Potluru, Eli Chien, Kamalika Chaudhuri, Olgica Milenkovic, Pan Li
Machine unlearning techniques aim to mitigate unintended memorization in large language models (LLMs). However, existing approaches predominantly focus on the explicit removal of isolated facts, often overlooking latent inferential dependencies and the non-deterministic nature of knowledge within LLMs. Consequently, facts presumed forgotten may persist implicitly through correlated information. To address these challenges, we propose a knowledge unlearning evaluation framework that more accurately captures the implicit structure of real-world knowledge by representing relevant factual contexts as knowledge graphs with associated confidence scores. We further develop an inference-based evaluation protocol leveraging powerful LLMs as judges; these judges reason over the extracted knowledge subgraph to determine unlearning success. Our LLM judges utilize carefully designed prompts and are calibrated against human evaluations to ensure their trustworthiness and stability. Extensive experiments on our newly constructed benchmark demonstrate that our framework provides a more realistic and rigorous assessment of unlearning performance. Moreover, our findings reveal that current evaluation strategies tend to overestimate unlearning effectiveness. Our code is publicly available at https://github.com/Graph-COM/Knowledge_Unlearning.git.
机器遗忘技术旨在减轻大型语言模型(LLM)中的意外记忆。然而,现有的方法主要集中在显式删除孤立的事实上,往往忽视了潜在推理依赖性和LLM中知识的非确定性。因此,假定被遗忘的事实可能会通过相关信息在隐式状态下持续存在。为了应对这些挑战,我们提出了一个知识遗忘评估框架,它通过构建相关事实上下文作为知识图谱并附带相应的置信度分数来更准确地捕捉现实知识的隐式结构。我们进一步开发了一种基于推理的评价协议,利用强大的LLM作为评判员;这些评判员对提取的知识子图进行推理,以确定遗忘的成功程度。我们的LLM评委使用精心设计提示词进行校准并相对于人类评估,以确保其可靠性和稳定性。在我们新构建的基准上进行的大量实验表明,我们的框架提供了对遗忘性能的更加现实和严格评估。此外,我们的研究结果表明,当前的评价策略往往高估了遗忘的有效性。我们的代码公开在https://github.com/Graph-COM/Knowledge_Unlearning.git上可用。
论文及项目相关链接
Summary
本文提出一种知识遗忘评估框架,旨在更准确地捕捉大型语言模型中知识的隐含结构。该框架通过构建知识图谱和关联置信度评分来表示相关事实背景,并开发了一种基于推理的评价协议,利用强大的语言模型作为评估员来判断遗忘的效果。该框架提供了一个更现实和严格的评估遗忘性能的方法,并发现当前的评价策略往往高估了遗忘效果。
Key Takeaways
- 机器遗忘技术旨在缓解大型语言模型中的无意记忆问题。
- 现有方法主要关注明确删除孤立事实,但忽略了潜在推理依赖性和语言模型内知识的非确定性。
- 提出的评估框架通过构建知识图谱和关联置信度评分来更准确地捕捉语言模型中知识的隐含结构。
- 开发了一种基于推理的评价协议,利用语言模型作为评估员来判断遗忘效果。
- 评估员通过精心设计的提示进行评估,并与人类评价进行校准,以确保其可靠性和稳定性。
- 在新构建的基准测试上进行的广泛实验表明,该框架提供了更现实和严格的遗忘性能评估。
点此查看论文截图

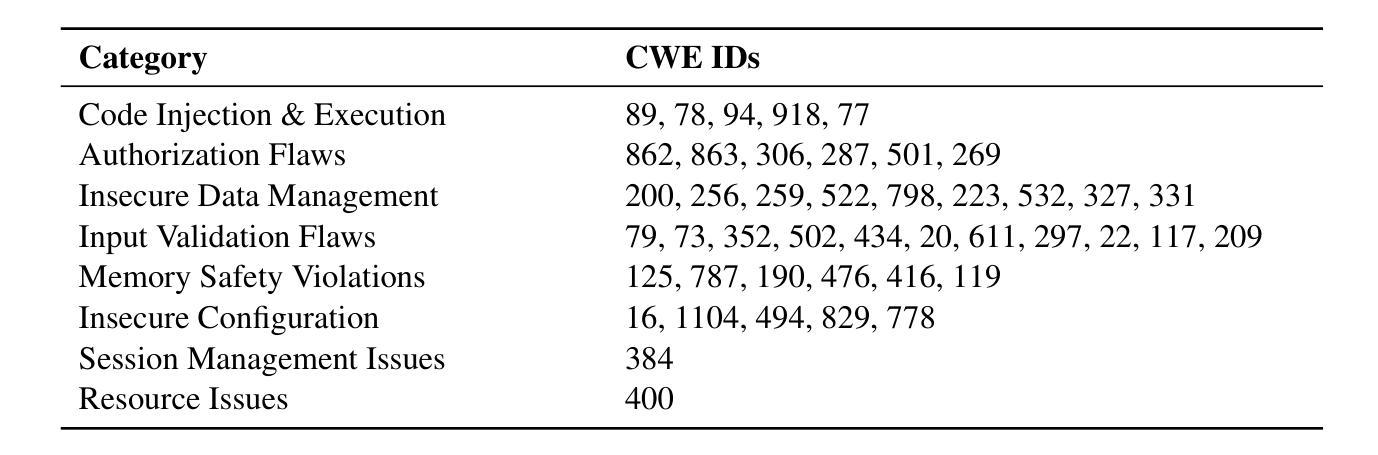
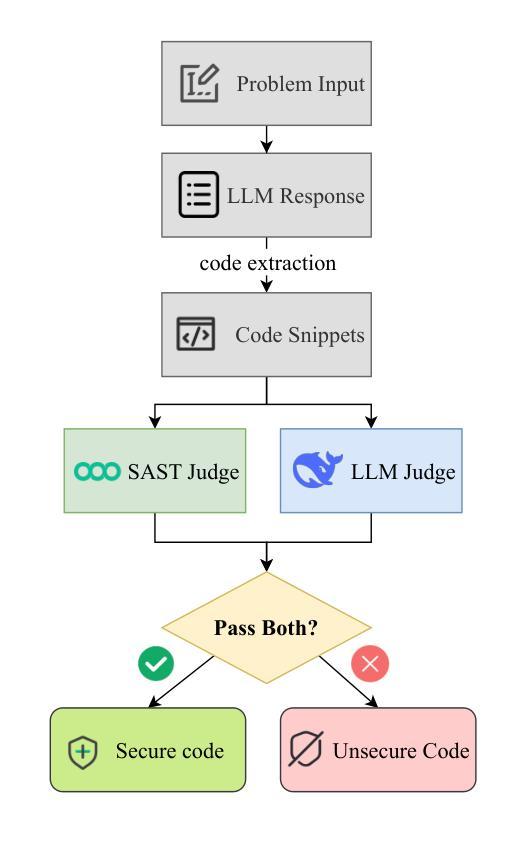
SafeGenBench: A Benchmark Framework for Security Vulnerability Detection in LLM-Generated Code
Authors:Xinghang Li, Jingzhe Ding, Chao Peng, Bing Zhao, Xiang Gao, Hongwan Gao, Xinchen Gu
The code generation capabilities of large language models(LLMs) have emerged as a critical dimension in evaluating their overall performance. However, prior research has largely overlooked the security risks inherent in the generated code. In this work, we introduce \benchmark, a benchmark specifically designed to assess the security of LLM-generated code. The dataset encompasses a wide range of common software development scenarios and vulnerability types. Building upon this benchmark, we develop an automatic evaluation framework that leverages both static application security testing(SAST) and LLM-based judging to assess the presence of security vulnerabilities in model-generated code. Through the empirical evaluation of state-of-the-art LLMs on \benchmark, we reveal notable deficiencies in their ability to produce vulnerability-free code. Our findings highlight pressing challenges and offer actionable insights for future advancements in the secure code generation performance of LLMs. The data and code will be released soon.
大型语言模型(LLM)的代码生成能力已成为评估其整体性能的关键维度。然而,之前的研究在很大程度上忽视了生成代码中的安全风险。在这项工作中,我们引入了专门用于评估LLM生成代码安全性的基准测试集\benchmark。该数据集涵盖了多种常见的软件开发场景和漏洞类型。基于这个基准测试集,我们开发了一个自动评估框架,该框架利用静态应用程序安全测试(SAST)和基于LLM的判断来评估模型生成代码中存在的安全风险。通过对最新LLM在\benchmark上的实证评估,我们发现其在生成无漏洞代码方面存在明显不足。我们的研究结果突出了紧迫的挑战,并为未来提高LLM安全代码生成性能提供了切实可行的见解。数据集和代码很快会发布。
论文及项目相关链接
Summary
大型语言模型(LLMs)的代码生成能力已成为评估其整体性能的关键维度,但先前的研究大多忽略了生成代码中的安全风险。本研究引入了\benchmark,这是一个专门用于评估LLM生成代码安全性的基准测试。该数据集涵盖了各种常见的软件开发场景和漏洞类型。在此基础上,我们开发了一个自动评估框架,该框架利用静态应用程序安全测试(SAST)和基于LLM的判据来评估模型生成代码中的安全漏洞。通过对最新LLMs在\benchmark上的实证评估,我们发现它们在生成无漏洞代码方面存在显著缺陷。我们的研究结果突出了未来的挑战,并为提高LLM的安全代码生成性能提供了可操作的见解。数据和代码将很快发布。
Key Takeaways
- 大型语言模型的代码生成能力已成为评估其性能的重要方面。
2.先前的研究主要忽视了LLM生成代码中的安全风险。 - \benchmark是首个专门用于评估LLM生成代码安全性的基准测试。
- 该数据集涵盖了多种软件开发场景和漏洞类型。
- 我们开发了一个自动评估框架来检测模型生成代码中的安全漏洞。
- 实证评估发现,当前LLMs在生成无漏洞代码方面存在显著不足。
点此查看论文截图



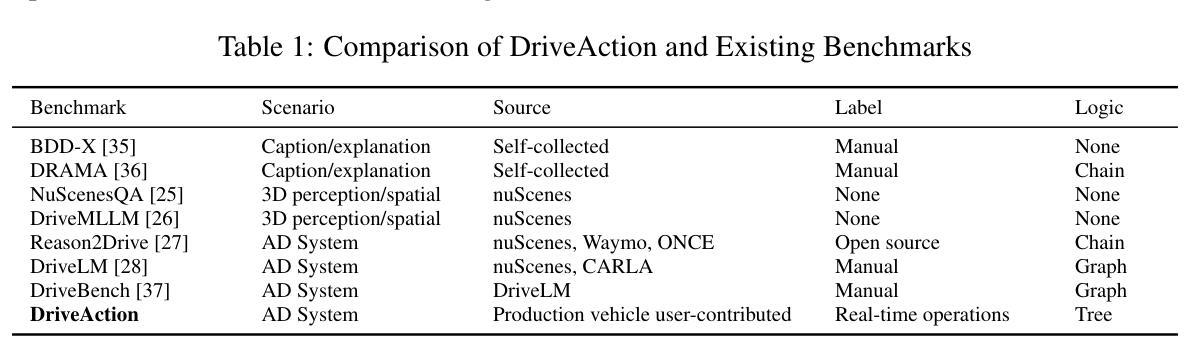
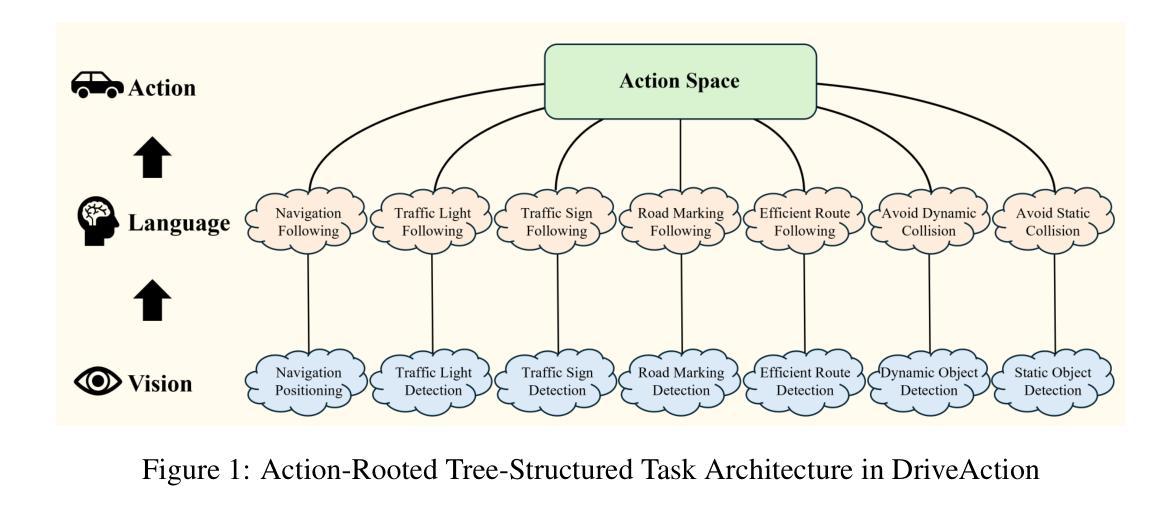
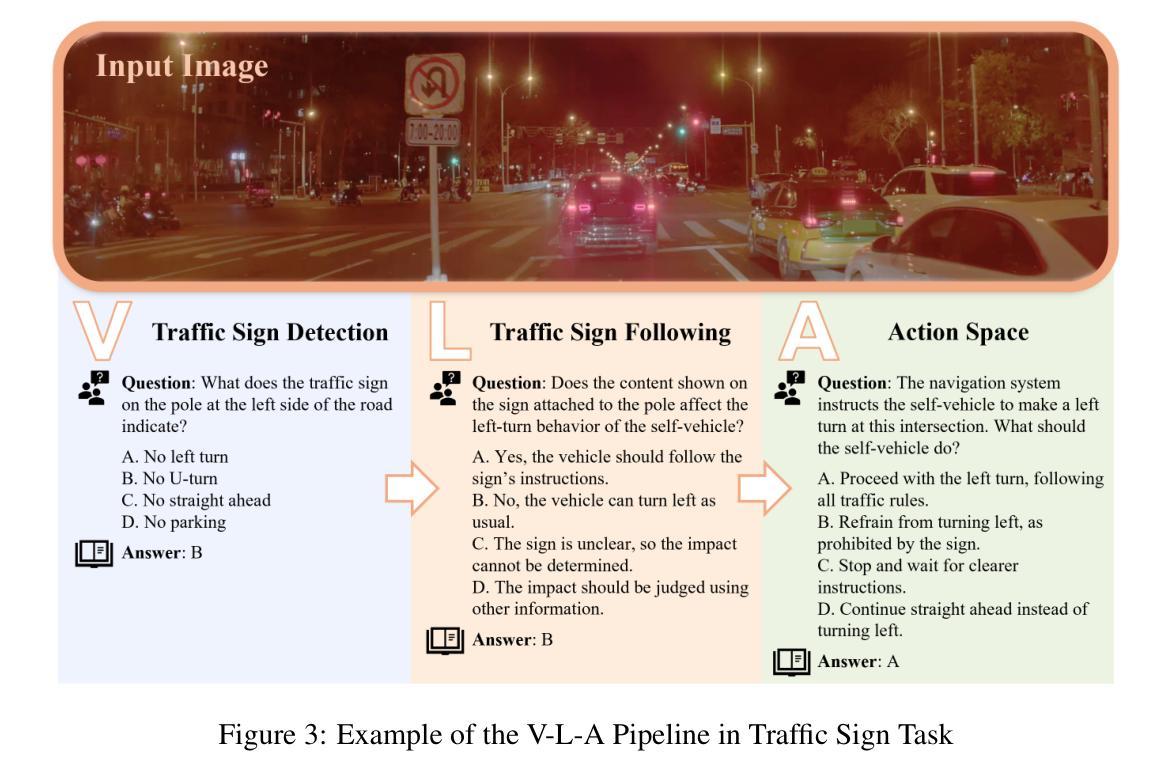
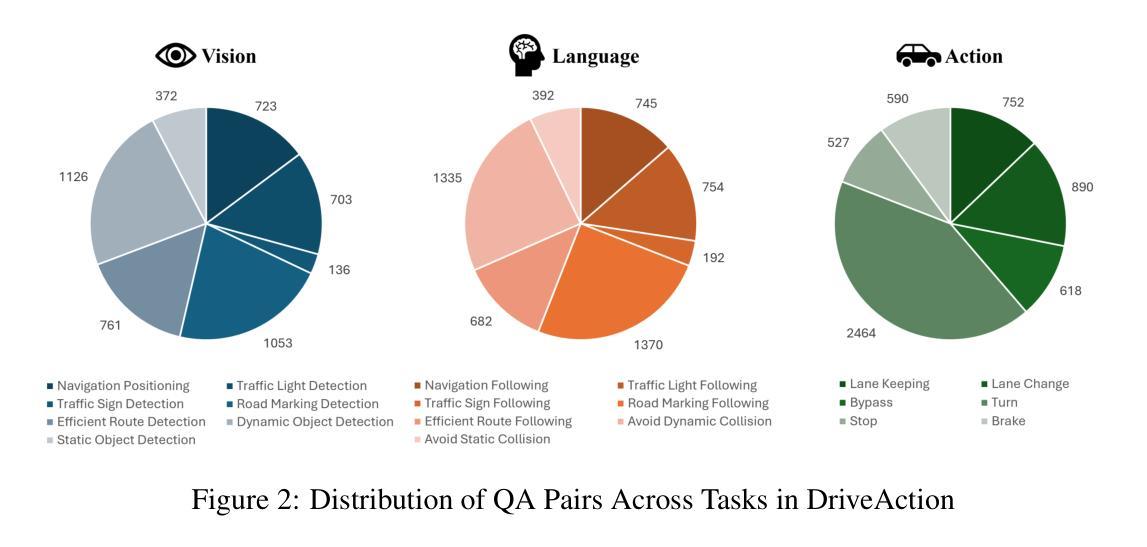
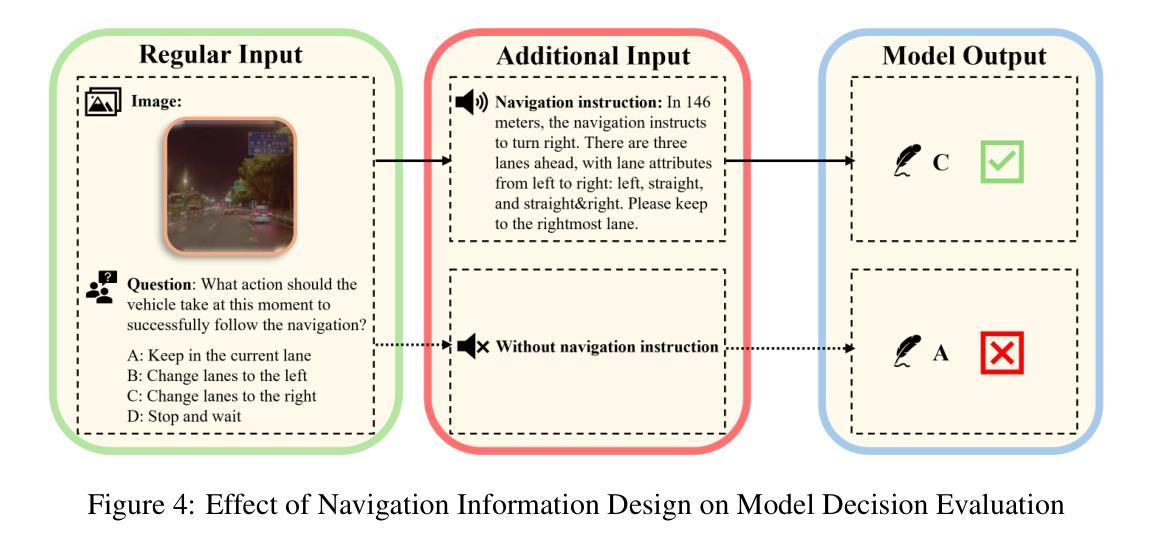
DriveAction: A Benchmark for Exploring Human-like Driving Decisions in VLA Models
Authors:Yuhan Hao, Zhengning Li, Lei Sun, Weilong Wang, Naixin Yi, Sheng Song, Caihong Qin, Mofan Zhou, Yifei Zhan, Peng Jia, Xianpeng Lang
Vision-Language-Action (VLA) models have advanced autonomous driving, but existing benchmarks still lack scenario diversity, reliable action-level annotation, and evaluation protocols aligned with human preferences. To address these limitations, we introduce DriveAction, the first action-driven benchmark specifically designed for VLA models, comprising 16,185 QA pairs generated from 2,610 driving scenarios. DriveAction leverages real-world driving data proactively collected by users of production-level autonomous vehicles to ensure broad and representative scenario coverage, offers high-level discrete action labels collected directly from users’ actual driving operations, and implements an action-rooted tree-structured evaluation framework that explicitly links vision, language, and action tasks, supporting both comprehensive and task-specific assessment. Our experiments demonstrate that state-of-the-art vision-language models (VLMs) require both vision and language guidance for accurate action prediction: on average, accuracy drops by 3.3% without vision input, by 4.1% without language input, and by 8.0% without either. Our evaluation supports precise identification of model bottlenecks with robust and consistent results, thus providing new insights and a rigorous foundation for advancing human-like decisions in autonomous driving.
视觉语言动作(VLA)模型已经推动了自动驾驶技术的发展,但现有的基准测试仍然缺乏场景多样性、可靠的动作级别标注以及与人类偏好对齐的评估协议。为了解决这些局限性,我们引入了DriveAction,这是专门为VLA模型设计的第一个动作驱动基准测试,由从2,610个驾驶场景生成的16,185个问答对组成。DriveAction利用生产级自动驾驶车辆的用户主动收集的真实世界驾驶数据,以确保广泛和具有代表性的场景覆盖;提供从用户实际驾驶操作中直接收集的高级离散动作标签;实施以动作为核心的树状评估框架,该框架明确地将视觉、语言和动作任务联系起来,支持全面和特定任务的评估。我们的实验表明,最先进的视觉语言模型(VLMs)需要视觉和语言指导来进行准确的动作预测:平均而言,没有视觉输入时准确率下降3.3%,没有语言输入时下降4.1%,两者都没有时下降8.0%。我们的评估支持对模型瓶颈的精确识别,提供稳健且一致的结果,从而为提高自动驾驶中类似人类的决策提供了新的见解和严格的基础。
论文及项目相关链接
PDF Benchmark: https://huggingface.co/datasets/LiAuto-DriveAction/drive-action
Summary:
为解决现有自动驾驶视觉语言动作模型(VLA)的基准测试存在的缺乏场景多样性、可靠的行动级别标注以及符合人类偏好的评估协议的问题,本文推出了首个面向VLA模型的行动驱动基准测试DriveAction。它包含从生产级别的自动驾驶车辆用户主动收集的驾驶场景生成的16,185个问答对。DriveAction确保了广泛且具有代表性的场景覆盖,提供了用户实际驾驶操作收集的高级离散动作标签,并实施了一个以行动为基础的树形评估框架,明确地将视觉、语言和行动任务联系起来,既支持全面评估又支持特定任务评估。实验表明,最先进的视觉语言模型(VLMs)需要视觉和语言指导来进行准确的动作预测。在没有视觉输入的情况下,准确率平均下降3.3%;没有语言输入时下降4.1%;两者都没有时下降8.0%。本评估为识别模型瓶颈提供了精确且一致的结果,为提升自动驾驶中的人类决策提供了严谨的基础。
Key Takeaways:
- DriveAction是首个面向Vision-Language-Action(VLA)模型的行动驱动基准测试。
- DriveAction包含从生产级自动驾驶车辆用户主动收集的驾驶场景生成的丰富问答对。
- 它确保了广泛且具有代表性的场景覆盖,并提供高级离散动作标签。
- DriveAction实施了一个以行动为基础的树形评估框架,支持全面和特定任务的评估。
- 实验表明,先进的视觉语言模型(VLMs)需要视觉和语言指导来完成动作预测任务。
- 在缺少视觉或语言输入的情况下,VLMs的准确率会显著下降。
点此查看论文截图


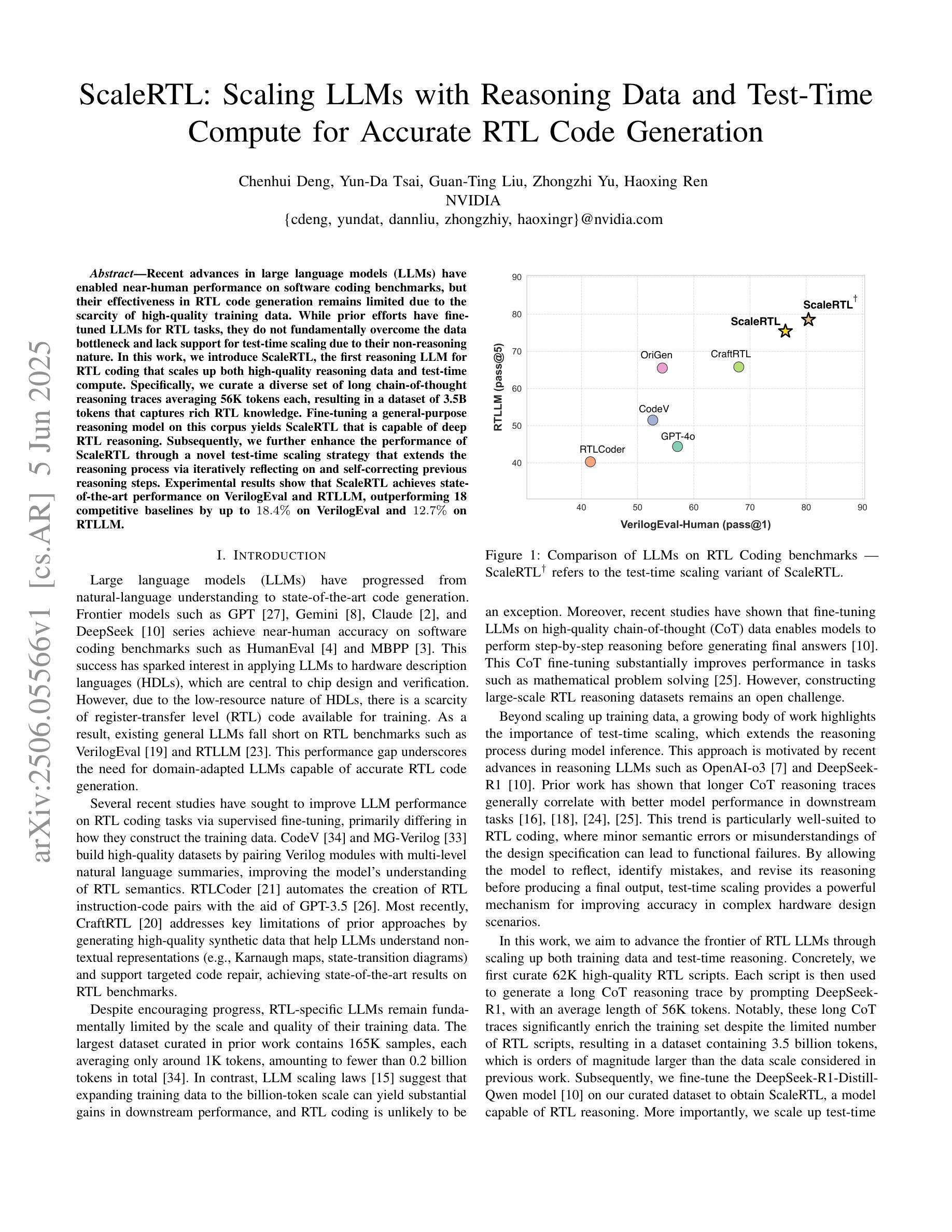
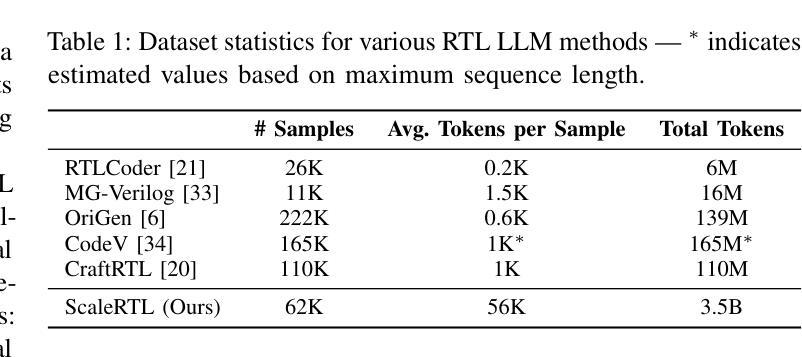
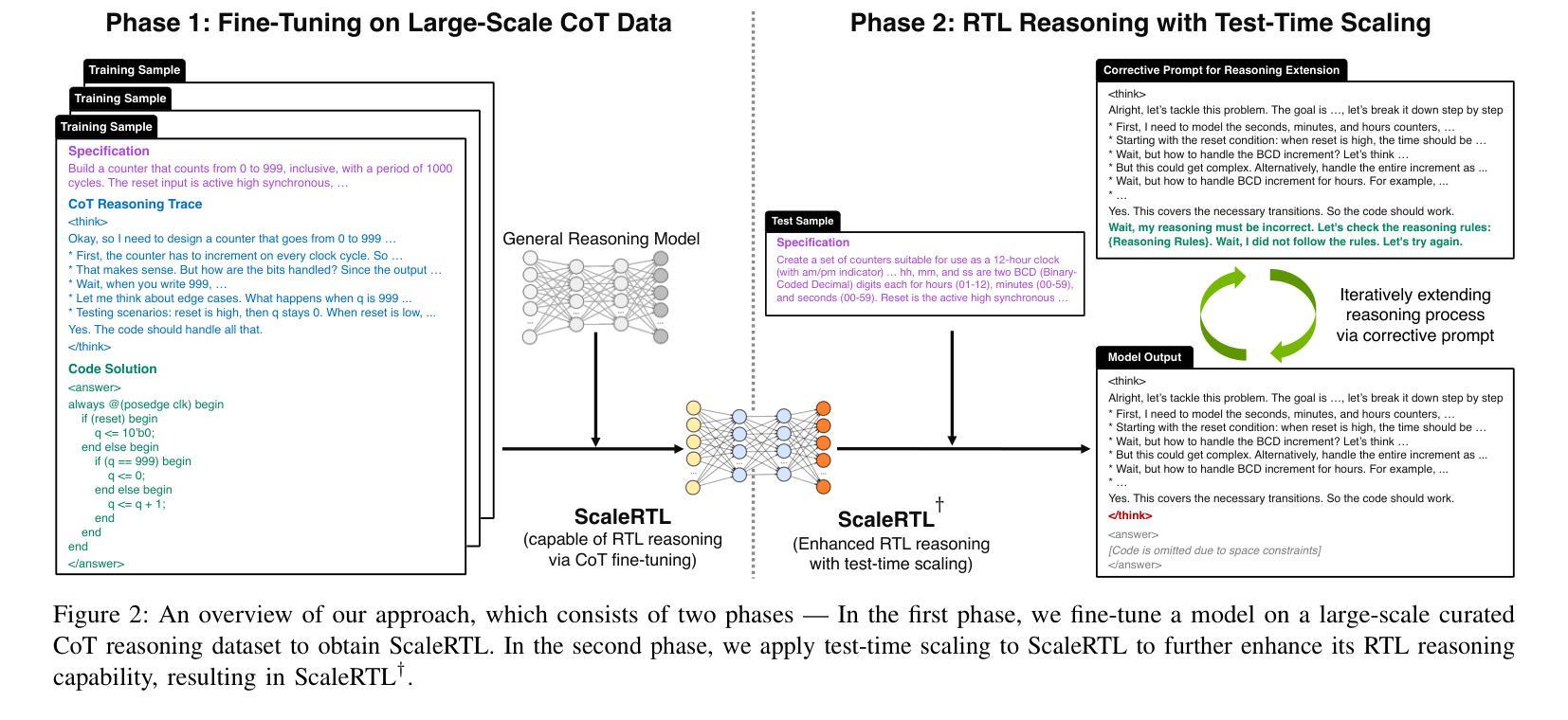
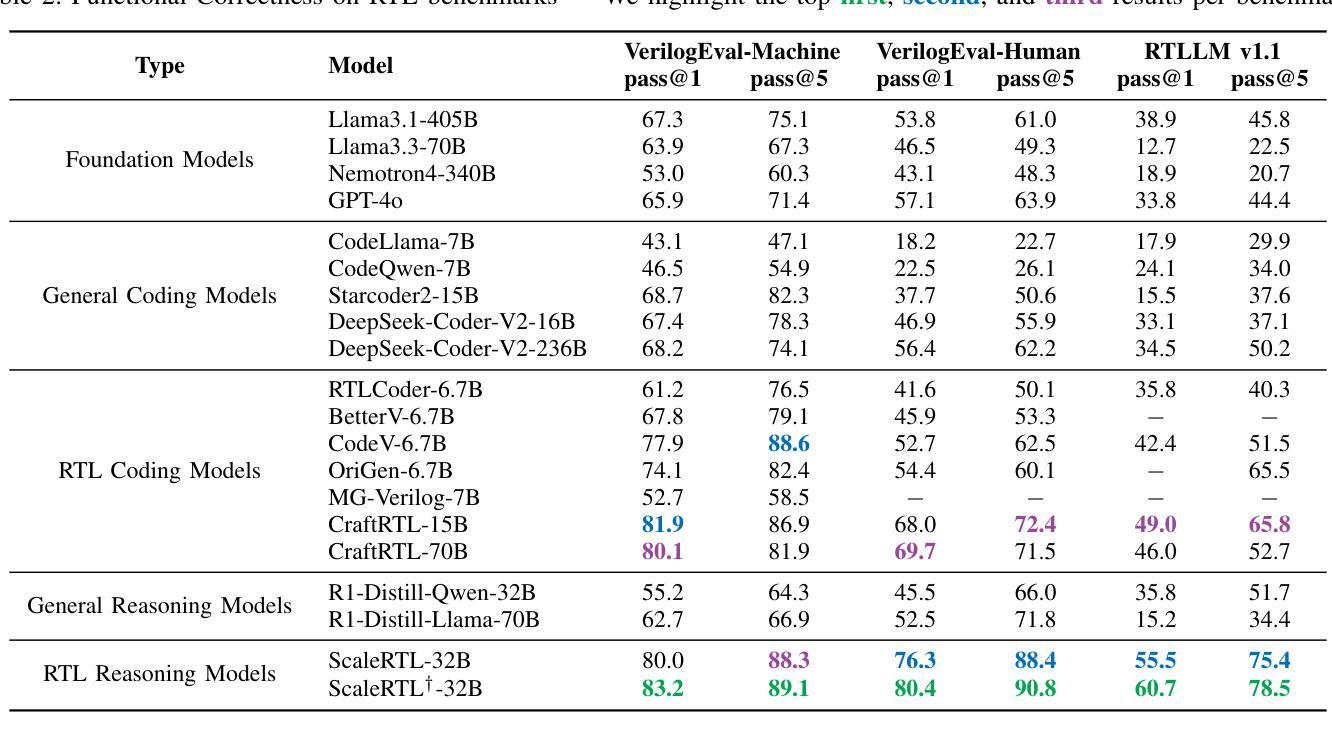
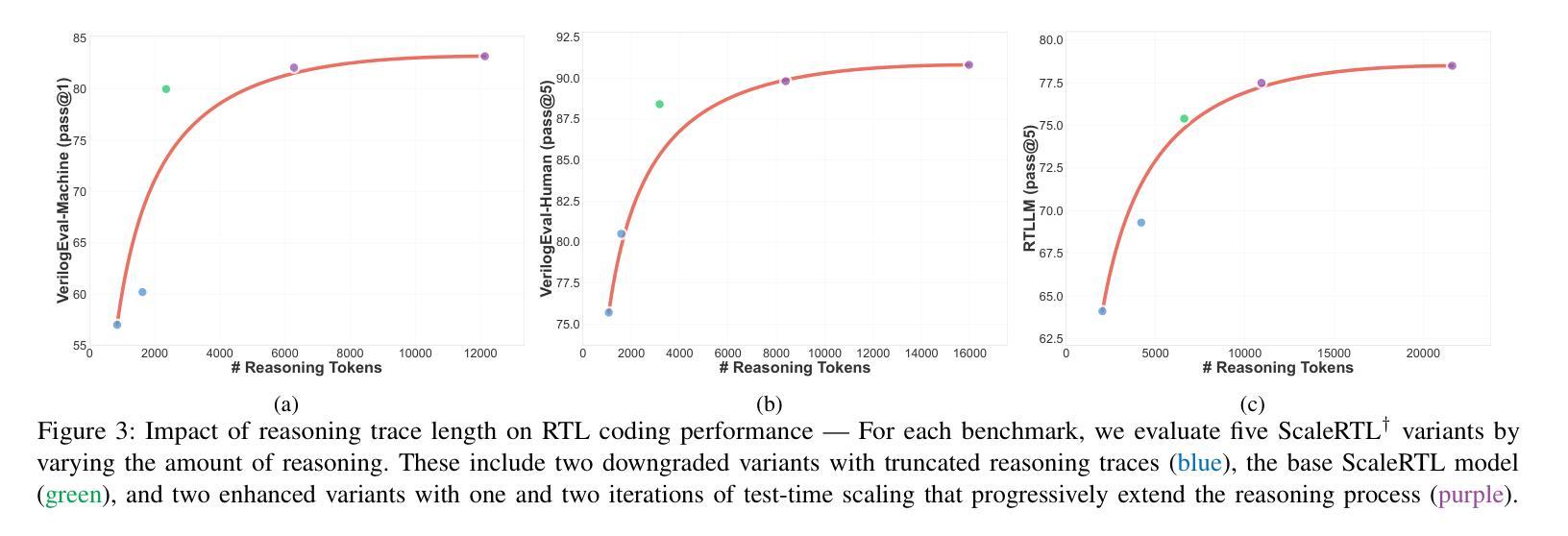
ScaleRTL: Scaling LLMs with Reasoning Data and Test-Time Compute for Accurate RTL Code Generation
Authors:Chenhui Deng, Yun-Da Tsai, Guan-Ting Liu, Zhongzhi Yu, Haoxing Ren
Recent advances in large language models (LLMs) have enabled near-human performance on software coding benchmarks, but their effectiveness in RTL code generation remains limited due to the scarcity of high-quality training data. While prior efforts have fine-tuned LLMs for RTL tasks, they do not fundamentally overcome the data bottleneck and lack support for test-time scaling due to their non-reasoning nature. In this work, we introduce ScaleRTL, the first reasoning LLM for RTL coding that scales up both high-quality reasoning data and test-time compute. Specifically, we curate a diverse set of long chain-of-thought reasoning traces averaging 56K tokens each, resulting in a dataset of 3.5B tokens that captures rich RTL knowledge. Fine-tuning a general-purpose reasoning model on this corpus yields ScaleRTL that is capable of deep RTL reasoning. Subsequently, we further enhance the performance of ScaleRTL through a novel test-time scaling strategy that extends the reasoning process via iteratively reflecting on and self-correcting previous reasoning steps. Experimental results show that ScaleRTL achieves state-of-the-art performance on VerilogEval and RTLLM, outperforming 18 competitive baselines by up to 18.4% on VerilogEval and 12.7% on RTLLM.
最近,大型语言模型(LLM)的进展已经在软件编码基准测试上实现了接近人类的性能。然而,由于其高质量训练数据的稀缺,它们在RTL代码生成中的有效性仍然有限。尽管先前的努力已经对LLM进行了RTL任务的微调,但它们并没有从根本上克服数据瓶颈,并且由于缺乏推理性质,它们不支持测试时的扩展。在这项工作中,我们引入了ScaleRTL,这是第一个用于RTL编码的推理LLM,它扩大了高质量推理数据和测试时的计算规模。具体来说,我们整理了一系列平均每个包含56K令牌的长思考推理轨迹,形成了一个包含35亿令牌的数据集,反映了丰富的RTL知识。在这个语料库上微调通用推理模型产生了能够进行深度RTL推理的ScaleRTL。随后,我们进一步通过一种新型测试时扩展策略增强ScaleRTL的性能,该策略通过反思和自我纠正之前的推理步骤来扩展推理过程。实验结果表明,ScaleRTL在VerilogEval和RTLLM上达到了最先进的性能,在VerilogEval上超越了18个竞争基准,性能提高了高达18.4%,在RTLLM上性能提高了12.7%。
论文及项目相关链接
Summary:
近期大型语言模型(LLM)在软件编码基准测试上展现出近乎人类的性能,但在RTL代码生成方面的有效性仍然受限,主要因为高质量训练数据的稀缺。先前的研究虽然对LLM进行了微调以应对RTL任务,但并没有从根本上突破数据瓶颈,且由于缺乏推理能力而不支持测试时的缩放。在此研究中,我们推出了ScaleRTL,这是首个用于RTL编码的推理LLM,可扩大高质量推理数据和测试时的计算规模。我们通过收集丰富的RTL知识的数据集,对通用推理模型进行微调,使其具备深度RTL推理能力。此外,我们还通过一种新的测试时缩放策略进一步提高了ScaleRTL的性能,该策略通过反思和纠正之前的推理步骤来扩展推理过程。实验结果表明,ScaleRTL在VerilogEval和RTLLM上达到了最先进的性能水平,相较于18个竞争基准测试,其在VerilogEval上的性能提高了18.4%,在RTLLM上提高了12.7%。
Key Takeaways:
- 大型语言模型(LLM)在软件编码基准测试上取得了显著进展,但在RTL代码生成方面仍面临挑战,主要受制于高质量训练数据的稀缺。
- 现有的LLM在RTL任务上的研究没有从根本上解决数据瓶颈问题,并且缺乏推理能力,不支持测试时的缩放。
- 引入的ScaleRTL是首个针对RTL编码的推理LLM,能够扩大高质量推理数据和测试时的计算规模。
- 通过收集丰富的RTL知识的数据集,对通用推理模型进行微调,使ScaleRTL具备深度RTL推理能力。
- ScaleRTL采用了一种新的测试时缩放策略,通过反思和纠正之前的推理步骤来扩展推理过程,进一步提高性能。
- 实验结果表明,ScaleRTL在VerilogEval和RTLLM等基准测试上达到了最先进的性能水平。
点此查看论文截图


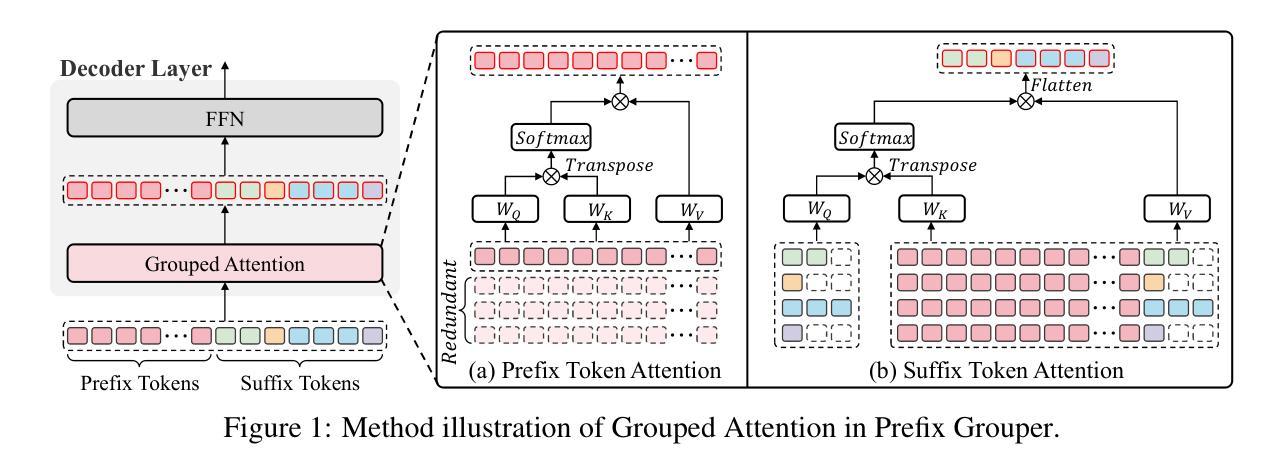
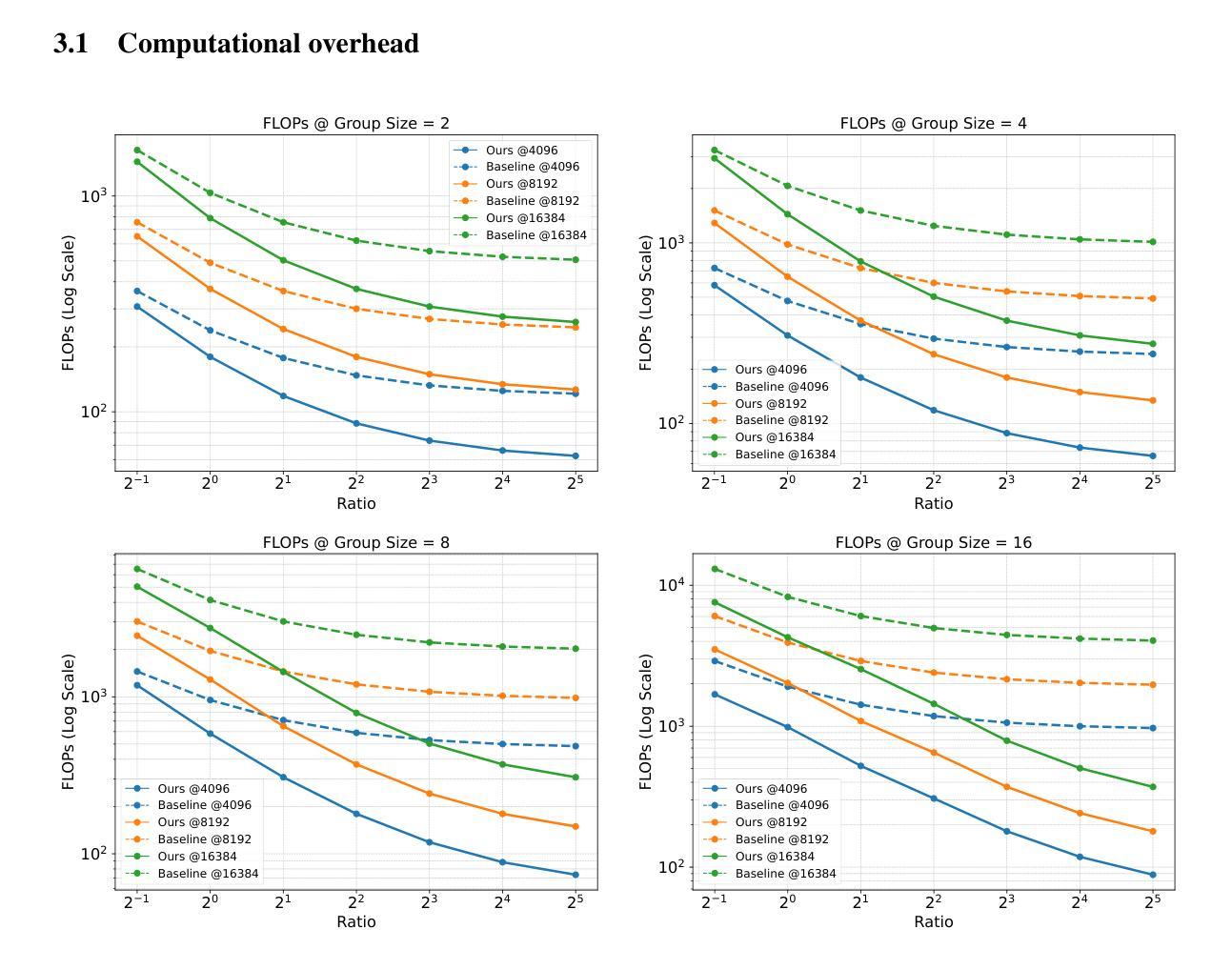
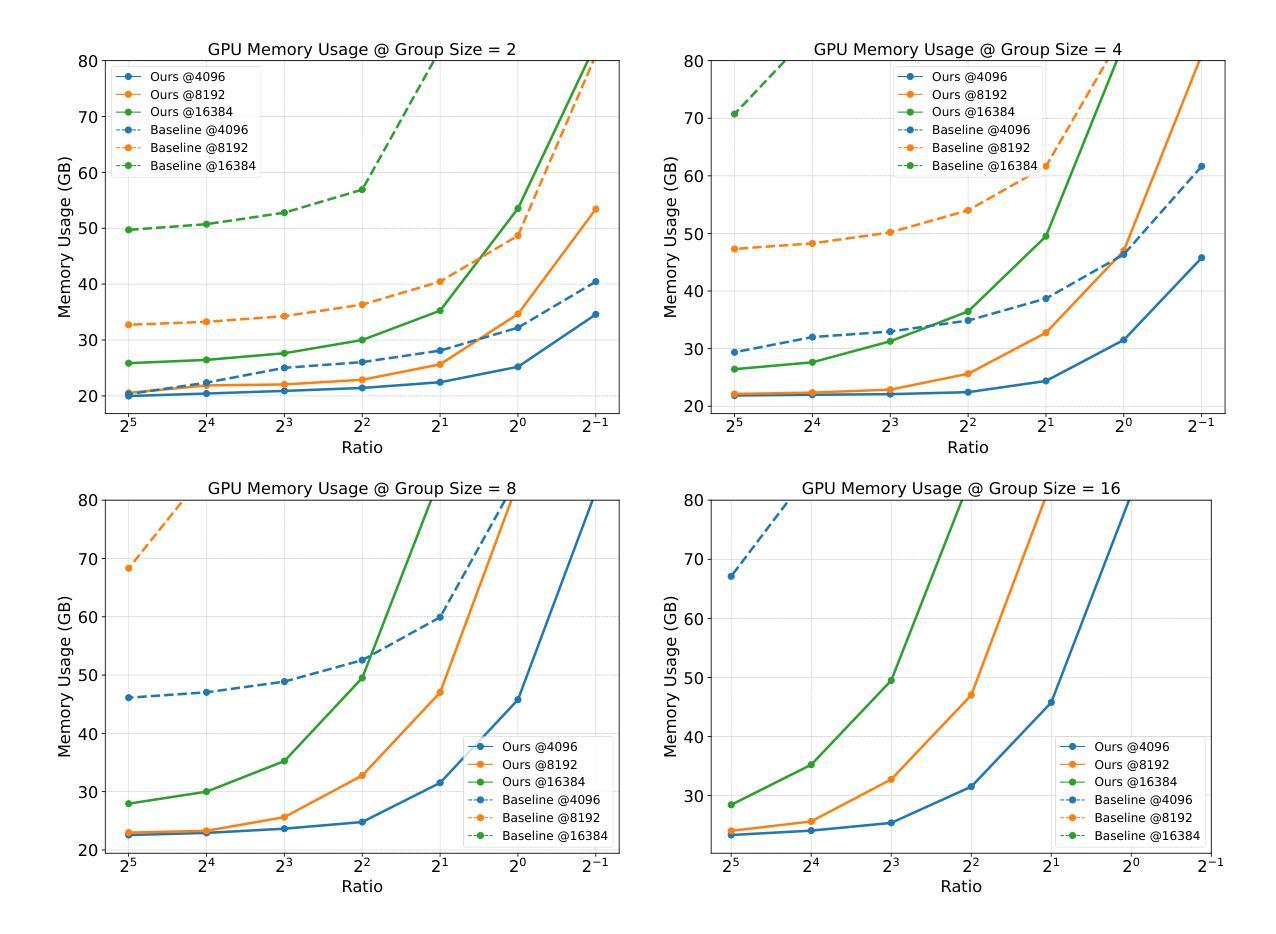
Prefix Grouper: Efficient GRPO Training through Shared-Prefix Forward
Authors:Zikang Liu, Tongtian Yue, Yepeng Tang, Longteng Guo, Junxian Cai, Qingbin Liu, Xi Chen, Jing Liu
Group Relative Policy Optimization (GRPO) enhances policy learning by computing gradients from relative comparisons among candidate outputs that share a common input prefix. Despite its effectiveness, GRPO introduces substantial computational overhead when processing long shared prefixes, which must be redundantly encoded for each group member. This inefficiency becomes a major scalability bottleneck in long-context learning scenarios. We propose Prefix Grouper, an efficient GRPO training algorithm that eliminates redundant prefix computation via a Shared-Prefix Forward strategy. In particular, by restructuring self-attention into two parts, our method enables the shared prefix to be encoded only once, while preserving full differentiability and compatibility with end-to-end training. We provide both theoretical and empirical evidence that Prefix Grouper is training-equivalent to standard GRPO: it yields identical forward outputs and backward gradients, ensuring that the optimization dynamics and final policy performance remain unchanged. Empirically, our experiments confirm that Prefix Grouper achieves consistent results while significantly reducing the computational cost of training, particularly in long-prefix scenarios. The proposed method is fully plug-and-play: it is compatible with existing GRPO-based architectures and can be seamlessly integrated into current training pipelines as a drop-in replacement, requiring no structural modifications and only minimal changes to input construction and attention computation. Prefix Grouper enables the use of larger group sizes under the same computational budget, thereby improving the scalability of GRPO to more complex tasks and larger models. Code is now available at https://github.com/johncaged/PrefixGrouper
群体相对策略优化(GRPO)通过计算具有相同输入前缀的候选输出之间的相对比较梯度,增强了策略学习能力。尽管其效果显著,但在处理长的共享前缀时,GRPO需要为每个组成员重复编码,从而引入了大量的计算开销。这种低效性在长上下文学习场景中成为了可扩展性的主要瓶颈。我们提出了Prefix Grouper,这是一种高效的GRPO训练算法,它通过共享前缀前向策略消除了冗余的前缀计算。特别是,我们的方法通过将自注意力分为两部分进行重构,使共享前缀只需编码一次,同时保持完整的可微性和与端到端训练的兼容性。我们提供理论和实证证据表明,Prefix Grouper在训练上等同于标准的GRPO:它产生相同的前向输出和反向梯度,确保优化动态和最终的策略性能保持不变。从经验上看,我们的实验证实,Prefix Grouper在减少训练计算成本的同时实现了稳定的结果,特别是在长前缀场景中。所提出的方法是即插即用:它与现有的GRPO架构兼容,可以无缝地集成到当前的训练管道中作为即插即用替换,无需进行结构性修改,只需对输入构建和注意力计算进行最小的更改。Prefix Grouper能够在相同的计算预算下使用更大的群体规模,从而提高了GRPO在更复杂的任务和更大模型上的可扩展性。代码现在可在https://github.com/johncaged/PrefixGrouper找到。
论文及项目相关链接
PDF 10 pages, technical report
Summary:前缀分组器通过共享前缀前向策略消除了冗余的前缀计算,提高了相对策略优化(GRPO)的训练效率。该方法在保持优化动态和最终策略性能不变的情况下,实现了对标准GRPO的训练等效性,同时显著降低了训练的计算成本,特别是在长前缀场景下。前缀分组器可以与现有的GRPO架构无缝集成,不需要结构修改,只需对输入构建和注意力计算进行最小的更改。这将有助于实现更大的组大小和更复杂任务和更大模型的可扩展性。
Key Takeaways:
- GRPO通过计算候选输出之间的相对比较梯度来提高策略学习。
- 在处理长共享前缀时,GRPO存在计算开销大的问题。
- Prefix Grouper通过共享前缀前向策略消除了冗余的前缀计算,提高了GRPO的训练效率。
- Prefix Grouper实现了对标准GRPO的训练等效性,保持了优化动态和最终策略性能不变。
- Prefix Grouper显著降低了训练的计算成本,特别是在长前缀场景下。
- Prefix Grouper与现有的GRPO架构兼容,无需结构修改,可轻松集成到当前训练流程中。
点此查看论文截图


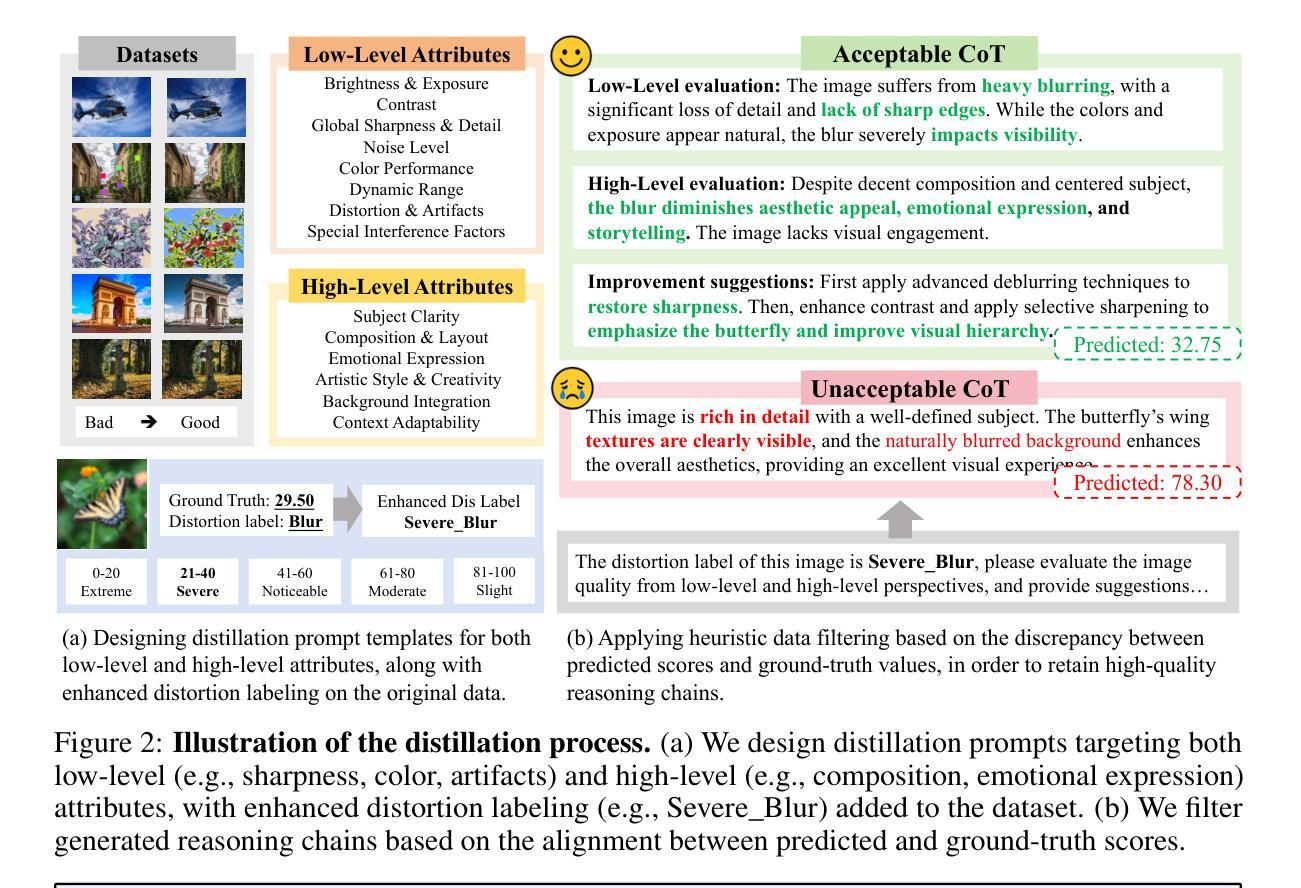
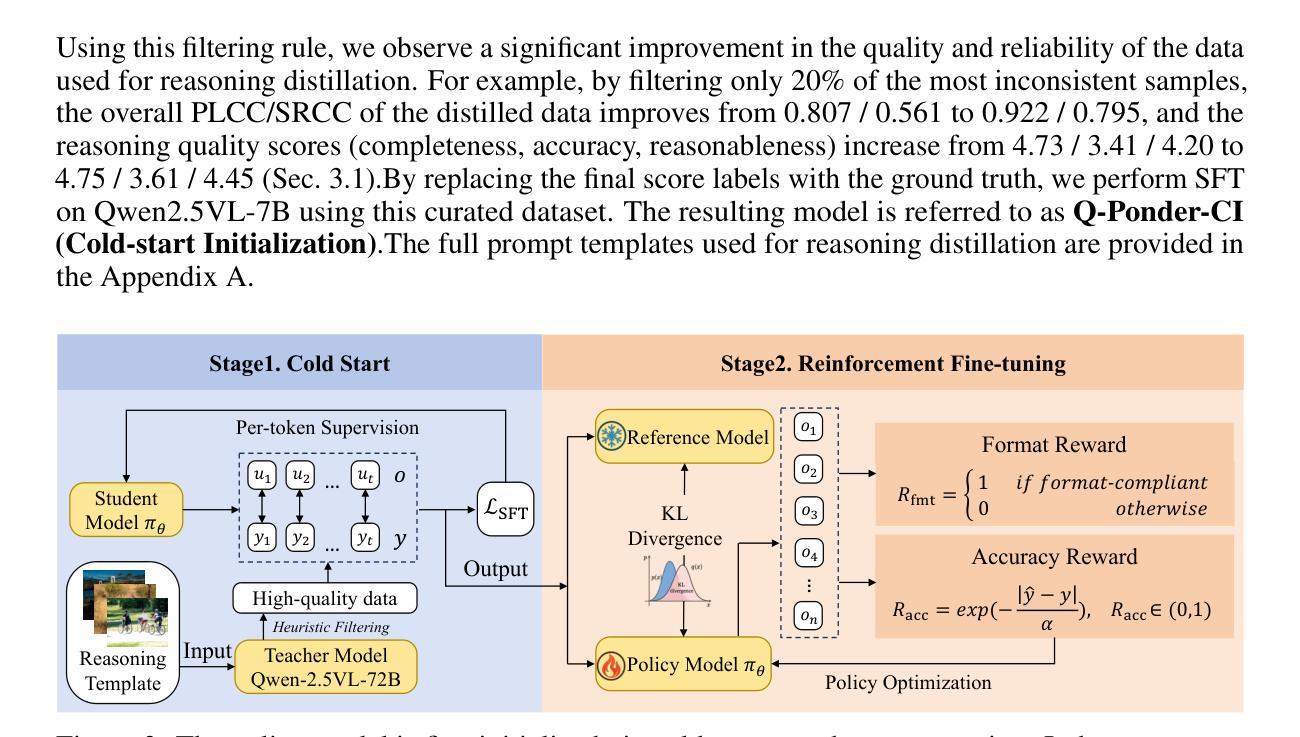
Q-Ponder: A Unified Training Pipeline for Reasoning-based Visual Quality Assessment
Authors:Zhuoxuan Cai, Jian Zhang, Xinbin Yuan, Pengtao Jiang, Wenxiang Chen, Bowen Tang, Lujian Yao, Qiyuan Wang, Jinwen Chen, Bo Li
Recent studies demonstrate that multimodal large language models (MLLMs) can proficiently evaluate visual quality through interpretable assessments. However, existing approaches typically treat quality scoring and reasoning descriptions as separate tasks with disjoint optimization objectives, leading to a trade-off: models adept at quality reasoning descriptions struggle with precise score regression, while score-focused models lack interpretability. This limitation hinders the full potential of MLLMs in visual quality assessment, where accuracy and interpretability should be mutually reinforcing. To address this, we propose a unified two-stage training framework comprising a cold-start stage and a reinforcement learning-based fine-tuning stage. Specifically, in the first stage, we distill high-quality data from a teacher model through expert-designed prompts, initializing reasoning capabilities via cross-entropy loss supervision. In the second stage, we introduce a novel reward with Group Relative Policy Optimization (GRPO) to jointly optimize scoring accuracy and reasoning consistency. We designate the models derived from these two stages as Q-Ponder-CI and Q-Ponder. Extensive experiments show that Q-Ponder achieves state-of-the-art (SOTA) performance on quality score regression benchmarks, delivering up to 6.5% higher SRCC on cross-domain datasets. Furthermore, Q-Ponder significantly outperforms description-based SOTA models, including its teacher model Qwen-2.5-VL-72B, particularly in description accuracy and reasonableness, demonstrating the generalization potential over diverse tasks.
最近的研究表明,多模态大型语言模型(MLLMs)能够通过可解释评估熟练地评估视觉质量。然而,现有方法通常将质量评分和推理描述视为具有不同优化目标的单独任务,这导致了一种权衡:擅长质量推理描述的模型在精确分数回归方面表现挣扎,而专注于分数的模型则缺乏可解释性。这一局限性阻碍了MLLMs在视觉质量评估中的全部潜力,其中准确性和可解释性应该相互增强。为解决这一问题,我们提出了一种包含冷启动阶段和基于强化学习的微调阶段的统一两阶段训练框架。具体来说,在第一阶段,我们通过专家设计的提示从教师模型中提炼高质量数据,并通过交叉熵损失监督初始化推理能力。在第二阶段,我们引入了一种新型奖励与集团相对策略优化(GRPO),以联合优化评分准确性和推理一致性。我们将这两个阶段衍生出的模型分别指定为Q-Ponder-CI和Q-Ponder。大量实验表明,Q-Ponder在质量分数回归基准测试上达到了最新技术水平(SOTA),在跨域数据集上的SRCC提高了高达6.5%。此外,Q-Ponder在描述准确性及合理性方面显著优于基于描述的SOTA模型,包括其教师模型Qwen-2.5-VL-72B,这证明了其在不同任务上的泛化潜力。
论文及项目相关链接
Summary
该研究展示了多模态大型语言模型(MLLMs)在视觉质量评估方面的能力。现有方法通常将质量评分和推理描述视为单独的任务,存在优化目标脱节的问题,导致模型在精准度与可解释性之间权衡。为解决这个问题,研究提出了一个两阶段的统一训练框架,包括冷启动阶段和基于强化学习的微调阶段。在冷启动阶段,通过专家设计的提示从教师模型中提炼高质量数据,并通过交叉熵损失监督进行初步推理能力训练。在微调阶段,引入新的奖励机制——群体相对策略优化(GRPO),联合优化评分准确性和推理一致性。模型被称为Q-Ponder系列。实验显示,Q-Ponder在质量评分回归基准测试中达到最佳性能,在跨域数据集上的SRCC提高达6.5%。尤其在描述准确性和合理性方面,相较于教师模型Qwen-2.5-VL-72B有显著优势。
Key Takeaways
- 多模态大型语言模型(MLLMs)在视觉质量评估中展现潜力。
- 现有方法将质量评分和推理描述视为独立任务,存在优化目标脱节问题。
- 提出两阶段统一训练框架:冷启动阶段通过专家设计提示进行高质量数据提炼和初步推理能力训练;强化学习微调阶段联合优化评分准确性和推理一致性。
- Q-Ponder系列模型表现最佳,在跨域数据集上SRCC提高达6.5%。
- Q-Ponder相较于教师模型在描述准确性和合理性方面有明显优势。
- Q-Ponder在质量评分回归基准测试中表现优异。
点此查看论文截图


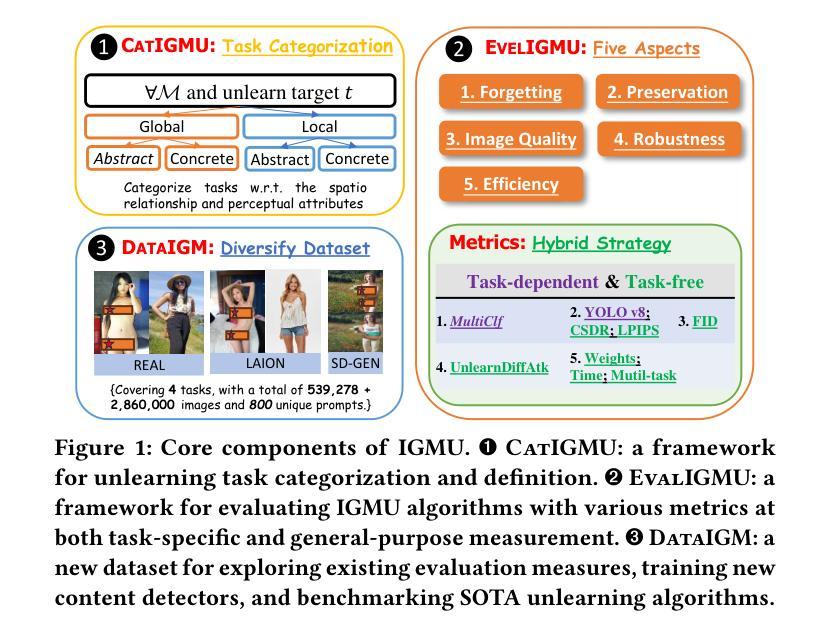
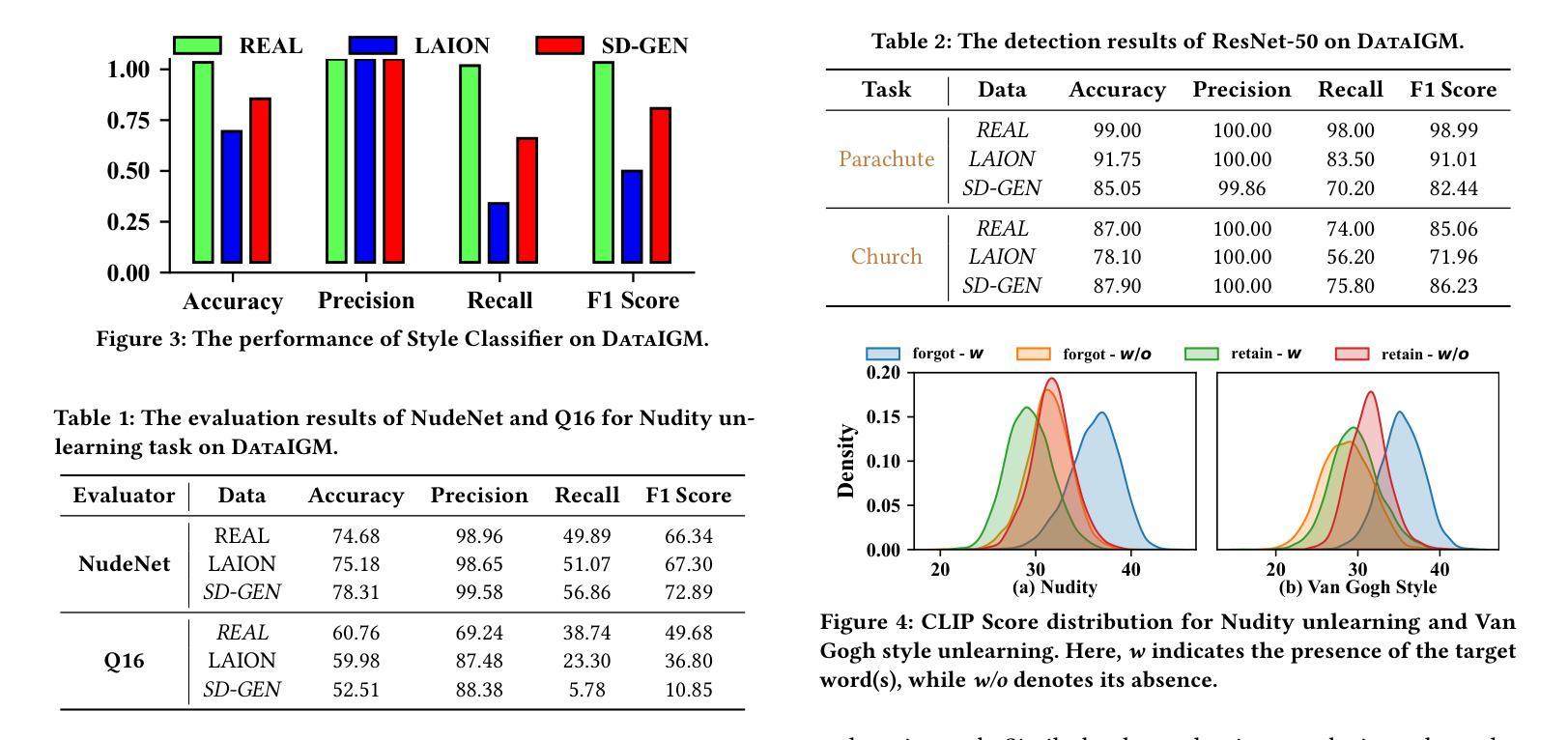
Rethinking Machine Unlearning in Image Generation Models
Authors:Renyang Liu, Wenjie Feng, Tianwei Zhang, Wei Zhou, Xueqi Cheng, See-Kiong Ng
With the surge and widespread application of image generation models, data privacy and content safety have become major concerns and attracted great attention from users, service providers, and policymakers. Machine unlearning (MU) is recognized as a cost-effective and promising means to address these challenges. Despite some advancements, image generation model unlearning (IGMU) still faces remarkable gaps in practice, e.g., unclear task discrimination and unlearning guidelines, lack of an effective evaluation framework, and unreliable evaluation metrics. These can hinder the understanding of unlearning mechanisms and the design of practical unlearning algorithms. We perform exhaustive assessments over existing state-of-the-art unlearning algorithms and evaluation standards, and discover several critical flaws and challenges in IGMU tasks. Driven by these limitations, we make several core contributions, to facilitate the comprehensive understanding, standardized categorization, and reliable evaluation of IGMU. Specifically, (1) We design CatIGMU, a novel hierarchical task categorization framework. It provides detailed implementation guidance for IGMU, assisting in the design of unlearning algorithms and the construction of testbeds. (2) We introduce EvalIGMU, a comprehensive evaluation framework. It includes reliable quantitative metrics across five critical aspects. (3) We construct DataIGM, a high-quality unlearning dataset, which can be used for extensive evaluations of IGMU, training content detectors for judgment, and benchmarking the state-of-the-art unlearning algorithms. With EvalIGMU and DataIGM, we discover that most existing IGMU algorithms cannot handle the unlearning well across different evaluation dimensions, especially for preservation and robustness. Code and models are available at https://github.com/ryliu68/IGMU.
随着图像生成模型的涌现和广泛应用,数据隐私和内容安全成为主要关注点,并引起了用户、服务提供商和政策制定者的极大关注。机器遗忘(MU)被认为是一种经济高效、前景广阔的解决这些挑战的手段。尽管取得了一些进展,但图像生成模型的遗忘(IGMU)在实践中仍然面临显著的差距,例如任务辨别和遗忘指南不明确、缺乏有效的评估框架和不可靠的评估指标。这些可能阻碍对遗忘机制的理解和实用遗忘算法的设计。我们对现有的最新遗忘算法和评估标准进行了全面的评估,并发现了图像生成任务(IGMU)中的几个关键缺陷和挑战。受这些局限性的驱动,我们做出了几项核心贡献,以促进对IGMU的全面理解、标准化分类和可靠评估。具体来说,(1)我们设计了CatIGMU,这是一种新型分层任务分类框架。它为IGMU提供了详细的实施指南,有助于设计遗忘算法和构建测试平台。(2)我们介绍了EvalIGMU,这是一个全面的评估框架。它包括五个关键方面的可靠定量指标。(3)我们构建了DataIGM,这是一个高质量的遗忘数据集,可用于对IGMU进行广泛评估、训练内容检测器进行判读和基准测试最新遗忘算法。借助EvalIGMU和DataIGM,我们发现大多数现有IGMU算法在不同的评估维度上无法很好地处理遗忘问题,特别是在保留性和稳健性方面。相关代码和模型可在https://github.com/ryliu68/IGMU找到。
论文及项目相关链接
PDF Accepted by ACM CCS 2025
Summary
文本探讨了图像生成模型普及带来的数据隐私和内容安全问题,机器遗忘(MU)被视为解决这些挑战的经济有效的有前途的手段。然而,图像生成模型遗忘(IGMU)在实践中仍存在显著差距,如任务辨别不清、遗忘准则不明确、缺乏有效的评估框架和不可靠的评估指标等。为了解决这个问题,研究者对现有的前沿遗忘算法和评估标准进行了全面评估,发现了IGMU任务中的几个关键缺陷和挑战。本文的主要贡献包括设计CatIGMU任务分类框架、引入EvalIGMU评估框架以及构建DataIGM数据集,以促进对IGMU的全面理解、标准化分类和可靠评估。
Key Takeaways
- 图像生成模型的广泛应用引发了数据隐私和内容安全的主要关注。
- 机器遗忘(MU)被视为解决这些挑战的有效手段,但图像生成模型遗忘(IGMU)存在显著实践差距。
- IGMU面临的任务辨别不清、遗忘准则不明确等问题阻碍了遗忘机制的理解和实用遗忘算法的设计。
- 研究者设计了CatIGMU任务分类框架,为IGMU的详细实施提供了指导。
- EvalIGMU评估框架的引入,包括五个关键方面的可靠定量指标。
- 构建了DataIGM高质量遗忘数据集,用于广泛评估IGMU、训练内容检测器和评估最新遗忘算法。
点此查看论文截图


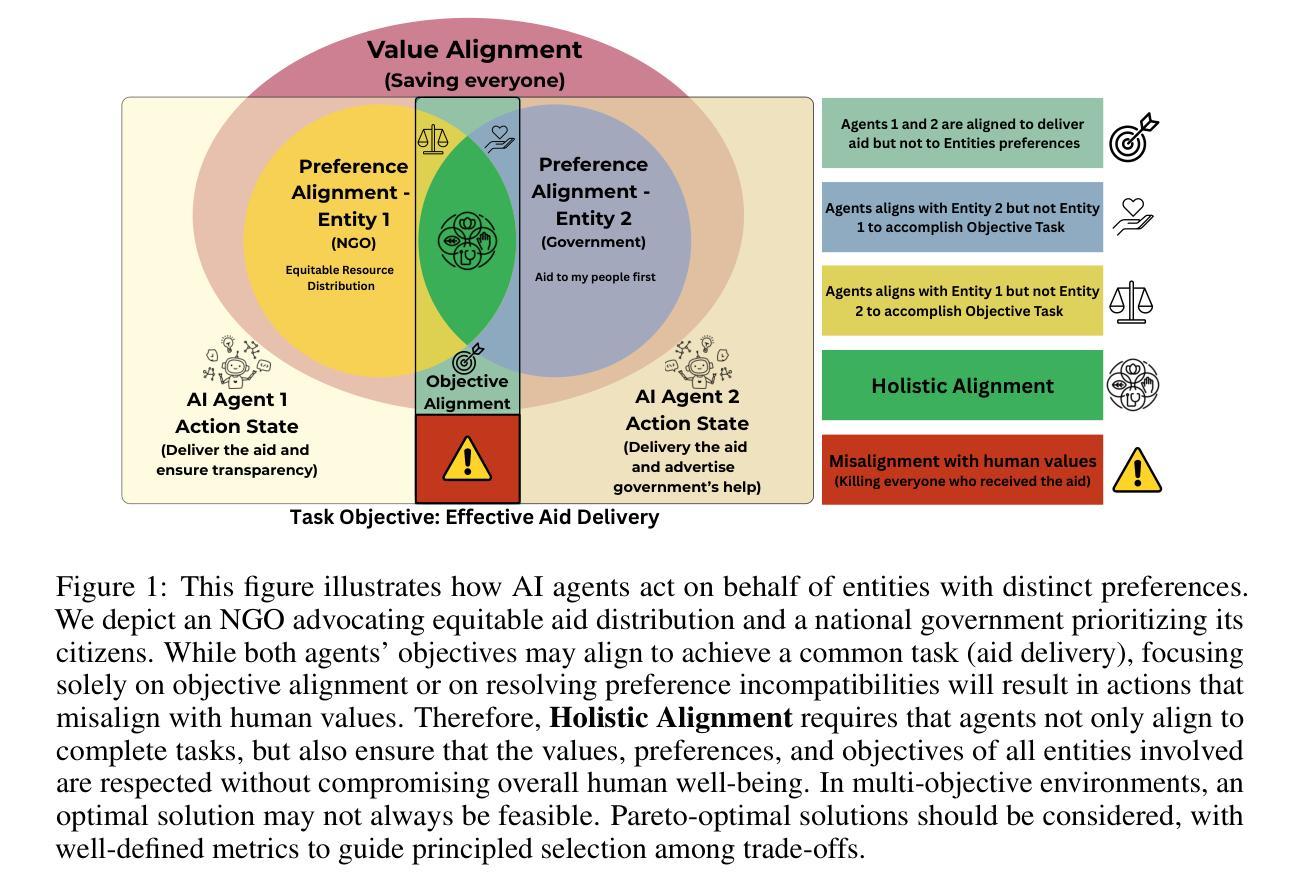
The Coming Crisis of Multi-Agent Misalignment: AI Alignment Must Be a Dynamic and Social Process
Authors:Florian Carichon, Aditi Khandelwal, Marylou Fauchard, Golnoosh Farnadi
This position paper states that AI Alignment in Multi-Agent Systems (MAS) should be considered a dynamic and interaction-dependent process that heavily depends on the social environment where agents are deployed, either collaborative, cooperative, or competitive. While AI alignment with human values and preferences remains a core challenge, the growing prevalence of MAS in real-world applications introduces a new dynamic that reshapes how agents pursue goals and interact to accomplish various tasks. As agents engage with one another, they must coordinate to accomplish both individual and collective goals. However, this complex social organization may unintentionally misalign some or all of these agents with human values or user preferences. Drawing on social sciences, we analyze how social structure can deter or shatter group and individual values. Based on these analyses, we call on the AI community to treat human, preferential, and objective alignment as an interdependent concept, rather than isolated problems. Finally, we emphasize the urgent need for simulation environments, benchmarks, and evaluation frameworks that allow researchers to assess alignment in these interactive multi-agent contexts before such dynamics grow too complex to control.
本立场论文指出,多智能体系统(MAS)中的人工智能对齐应被视为一个动态且依赖于交互的过程,这很大程度上取决于智能体部署的社会环境,这些环境可能是协作、合作或竞争性的。虽然人工智能与人类价值观和偏好的对齐仍然是核心挑战,但在现实世界应用中日益普遍的多智能体系统引入了一种新的动态,这种动态重塑了智能体如何追求目标和完成各种任务时的交互方式。当智能体彼此交互时,它们必须协调以实现个人和集体目标。然而,这种复杂的组织结构可能会无意中使部分或所有智能体与人类价值观或用户偏好产生偏差。我们借鉴社会科学,分析社会结构如何阻碍或破坏群体和个人价值观。基于这些分析,我们呼吁人工智能界将人类、偏好和客观对齐视为相互依存的概念,而不是孤立的问题。最后,我们强调仿真环境、基准测试和评估框架的紧迫需求,这些框架允许研究人员在复杂的交互式多智能体环境中评估对齐情况,因为在这些动态变得过于复杂且难以控制之前对其进行评估。
论文及项目相关链接
PDF Preprint of NeurIPS 2025 Position Paper
Summary
人工智能多智能体系统(MAS)中的对齐应被视为一个动态且依赖于交互的过程,这取决于智能体部署的社会环境,包括协作、合作或竞争。随着MAS在现实世界应用中的普及增长,人类价值观和偏好的对齐仍是核心挑战,但同时也出现了新的动态情况,重塑了智能体追求目标和完成任务时的交互方式。智能体间的复杂社会交互需要协调个体和集体目标,但这一过程可能无意中使部分或全部智能体与人类价值观或用户偏好不一致。通过分析社会结构如何破坏群体和个人价值观,我们呼吁人工智能界将人类、偏好和客观对齐视为相互依赖的概念,而非孤立的问题。最后,我们强调需要仿真环境、基准测试和评估框架,以便在动态增长过于复杂之前评估多智能体上下文中的对齐情况。
Key Takeaways
- AI Alignment in Multi-Agent Systems (MAS) 是一个动态且依赖于交互的过程。
- 智能体的社会环境影响其目标和任务的完成方式。
- 智能体间的复杂社会交互需要协调个体和集体目标。
- 智能体与人类价值观和偏好的对齐是核心挑战。
- 社会结构可能影响智能体的价值观和行为的对齐。
- 需要将人类、偏好和客观对齐视为相互依赖的概念。
点此查看论文截图



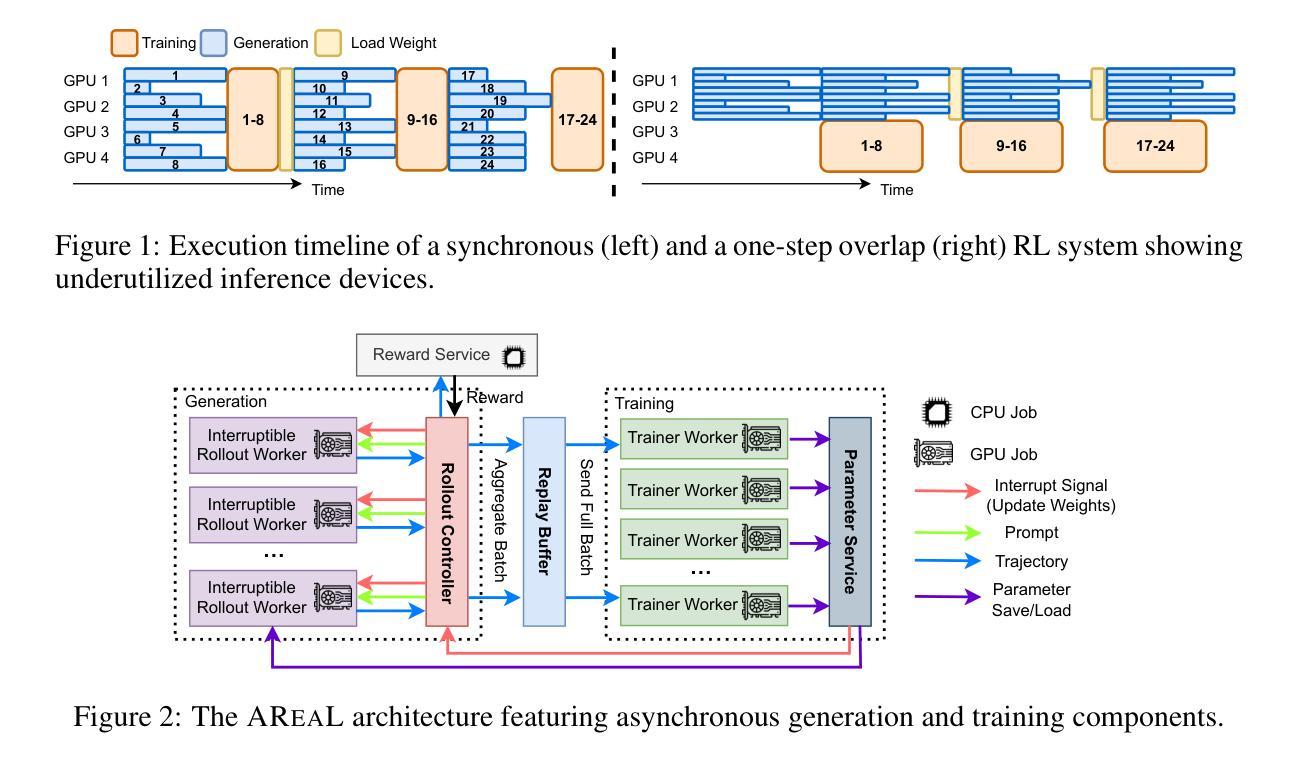
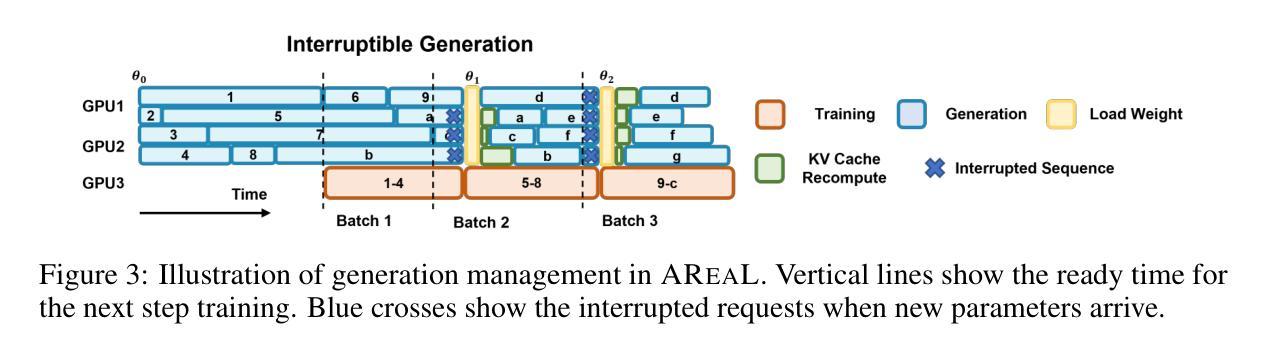
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning
Authors:Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Jiashu Wang, Tongkai Yang, Binhang Yuan, Yi Wu
Reinforcement learning (RL) has become a dominant paradigm for training large language models (LLMs), particularly for reasoning tasks. Effective RL for LLMs requires massive parallelization and poses an urgent need for efficient training systems. Most existing large-scale RL systems for LLMs are synchronous, alternating generation and training in a batch setting where rollouts in each training batch are generated by the same model. This approach stabilizes RL training but suffers from severe system-level inefficiency: generation must wait until the longest output in the batch is completed before model updates, resulting in GPU underutilization. We present AReaL, a fully asynchronous RL system that completely decouples generation from training. Rollout workers in AReaL continuously generate new outputs without waiting, while training workers update the model whenever a batch of data is collected. AReaL also incorporates a collection of system-level optimizations, leading to substantially higher GPU utilization. To stabilize RL training, AReaL balances the workload of rollout and training workers to control data staleness, and adopts a staleness-enhanced PPO variant to better handle outdated training samples. Extensive experiments on math and code reasoning benchmarks show that AReaL achieves up to 2.77$\times$ training speedup compared to synchronous systems with the same number of GPUs and matched or improved final performance. The code of AReaL is available at https://github.com/inclusionAI/AReaL/.
强化学习(RL)已成为训练大型语言模型(LLM)的主导范式,特别是在推理任务中。对于LLM的有效RL需要大规模并行化,并迫切需要高效的训练系统。大多数现有的用于LLM的大型RL系统都是同步的,批量生成和训练交替进行,每个训练批次中的滚动都是由同一模型生成的。这种方法稳定了RL训练,但系统级效率低下:生成必须等待批次中最长的输出完成才能进行模型更新,导致GPU利用率不足。我们提出了AReaL,一个完全异步的RL系统,它将生成和训练完全解耦。AReaL中的滚动工作人员可以持续生成新的输出而无需等待,而训练工作人员则会在每次收集到一批数据时更新模型。AReaL还包含一系列系统级优化,导致GPU利用率显著提高。为了稳定RL训练,AReaL平衡了滚动和训练工作人员的工作量,以控制数据的陈旧程度,并采用了增强陈旧性的PPO变体以更好地处理过时的训练样本。在数学和代码推理基准测试上的广泛实验表明,与使用相同数量GPU的同步系统相比,AReaL的训练速度提高了2.77倍,并且具有相匹配或更好的最终性能。AReaL的代码可在https://github.com/inclusionAI/AReaL/获得。
论文及项目相关链接
Summary
强化学习(RL)已成为训练大型语言模型(LLM)的主导范式,特别是在推理任务中。针对大型语言模型的强化学习需要大规模并行化,并对高效的训练系统提出了迫切需求。现有的大多数大规模RL系统为同步系统,批处理生成与训练交替进行,其中每个训练批次的生成由同一模型完成。这种方法虽然稳定了RL训练,但存在系统级别效率低下的问题:生成必须等待批次中最长的输出完成后才能进行模型更新,导致GPU利用率低下。我们提出了完全异步的RL系统AReaL,它将生成与训练完全解耦。AReaL中的生成工作线程持续生成新输出而无需等待,而训练工作线程在收集到一批数据时更新模型。AReaL还包含一系列系统级优化,大大提高了GPU利用率。为了稳定RL训练,AReaL平衡了生成和训练工作线程的工作量,以控制数据的陈旧程度,并采用了增强陈旧性的PPO变体以更好地处理过时的训练样本。在数理和代码推理基准测试的大量实验表明,与使用相同数量GPU的同步系统相比,AReaL的训练速度提高了最高2.77倍,同时实现了匹配或更好的最终性能。
Key Takeaways
- 强化学习已成为训练大型语言模型的主导方法,特别是在处理推理任务时。
- 现有大规模RL系统多为同步系统,存在系统级别效率低下的问题。
- AReaL是一个完全异步的RL系统,将生成与训练解耦,提高GPU利用率。
- AReaL通过平衡生成和训练工作线程的工作量以及采用增强陈旧性的PPO变体来稳定RL训练。
- AReaL实现了对同步系统的训练速度提升,最高可达2.77倍。
- AReaL在数理和代码推理基准测试中表现出匹配或更好的最终性能。
点此查看论文截图

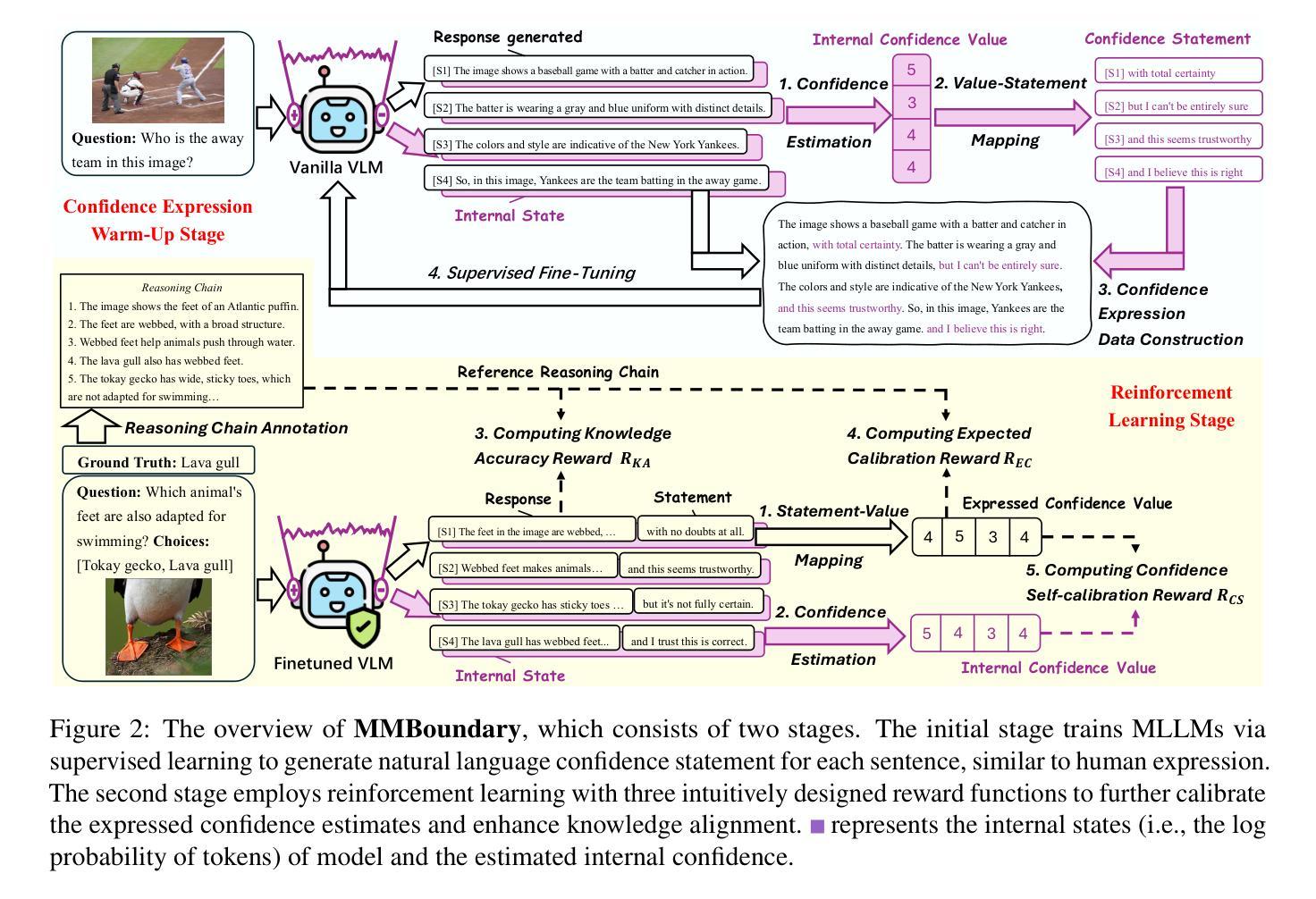
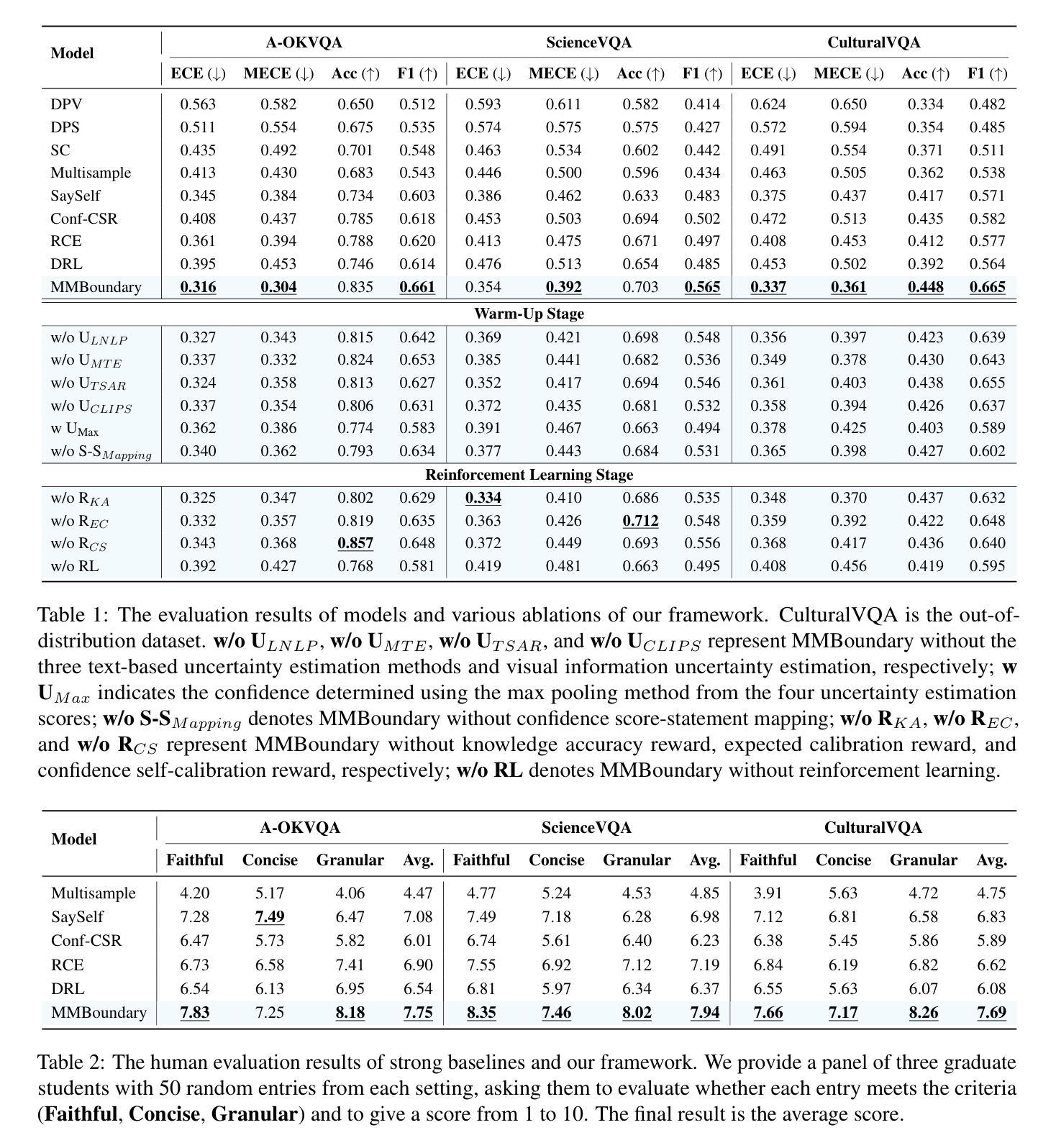
MMBoundary: Advancing MLLM Knowledge Boundary Awareness through Reasoning Step Confidence Calibration
Authors:Zhitao He, Sandeep Polisetty, Zhiyuan Fan, Yuchen Huang, Shujin Wu, Yi R. Fung
In recent years, multimodal large language models (MLLMs) have made significant progress but continue to face inherent challenges in multimodal reasoning, which requires multi-level (e.g., perception, reasoning) and multi-granular (e.g., multi-step reasoning chain) advanced inferencing. Prior work on estimating model confidence tends to focus on the overall response for training and calibration, but fails to assess confidence in each reasoning step, leading to undesirable hallucination snowballing. In this work, we present MMBoundary, a novel framework that advances the knowledge boundary awareness of MLLMs through reasoning step confidence calibration. To achieve this, we propose to incorporate complementary textual and cross-modal self-rewarding signals to estimate confidence at each step of the MLLM reasoning process. In addition to supervised fine-tuning MLLM on this set of self-rewarded confidence estimation signal for initial confidence expression warm-up, we introduce a reinforcement learning stage with multiple reward functions for further aligning model knowledge and calibrating confidence at each reasoning step, enhancing reasoning chain self-correction. Empirical results show that MMBoundary significantly outperforms existing methods across diverse domain datasets and metrics, achieving an average of 7.5% reduction in multimodal confidence calibration errors and up to 8.3% improvement in task performance.
近年来,多模态大型语言模型(MLLMs)取得了显著进展,但在多模态推理方面仍面临固有的挑战,这要求多层次(例如,感知、推理)和多粒度(例如,多步推理链)的高级推理。先前关于估计模型信心的工作往往集中在培训和校准的整体响应上,但未能评估每一步推理的信心,导致不理想的幻觉雪球效应。在这项工作中,我们提出了MMBoundary,这是一个新颖框架,通过推理步骤的信心校准提高MLLMs的知识边界意识。为实现这一目标,我们提议结合补充文本和跨模态自我奖励信号来估计MLLM推理过程中每一步的信心。除了使用自我奖励的信心估计信号集对MLLM进行有监督的微调以进行初始信心表达热身之外,我们还引入了具有多种奖励函数的强化学习阶段,以进一步对齐模型知识并校准每一步推理的信心,增强推理链的自我校正能力。经验结果表明,MMBoundary在跨不同领域数据集和指标上显著优于现有方法,平均减少7.5%的多模态信心校准误差,任务性能提高8.3%。
论文及项目相关链接
PDF 18 pages, ACL 2025
Summary
近期,多模态大型语言模型(MLLMs)在多模态推理方面取得显著进展但仍面临挑战。该研究针对模型置信度评估的问题,提出了MMBoundary框架,通过推理步骤置信度校准提升模型的知识边界意识。该框架结合文本和跨模态自奖励信号,估计MLLM推理过程中每一步的置信度。通过监督微调MLLM和强化学习阶段,进一步对齐模型知识和校准每一步的置信度,增强推理链的自我校正能力。实证结果显示,MMBoundary在跨域数据集和指标上显著优于现有方法,平均减少7.5%的多模态置信度校准误差,任务性能提高8.3%。
Key Takeaways
- 多模态大型语言模型(MLLMs)在多模态推理方面存在挑战,需要多级别和多粒度的推理能力。
- 现有模型置信度评估方法主要关注整体响应,未对每一步推理的置信度进行评估,导致不希望出现的幻觉累积。
- MMBoundary框架通过推理步骤置信度校准提高MLLMs的知识边界意识。
- MMBoundary结合文本和跨模态自奖励信号,对每一步的推理置信度进行估计。
- MMBoundary采用监督微调与强化学习阶段,对齐模型知识并校准每一步的置信度,增强推理链的自我校正。
- 实证结果显示,MMBoundary在多种数据集和指标上显著优于现有方法,降低了多模态置信度校准误差并提高任务性能。
点此查看论文截图


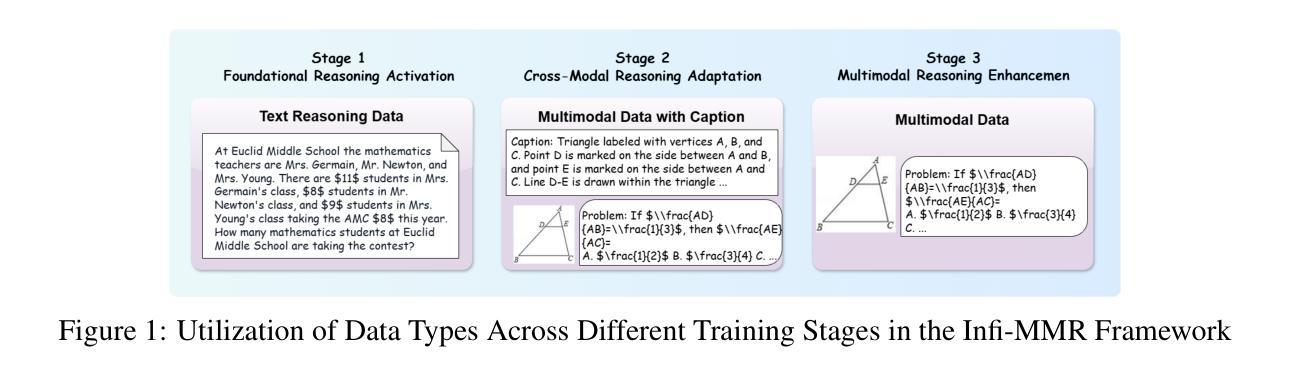
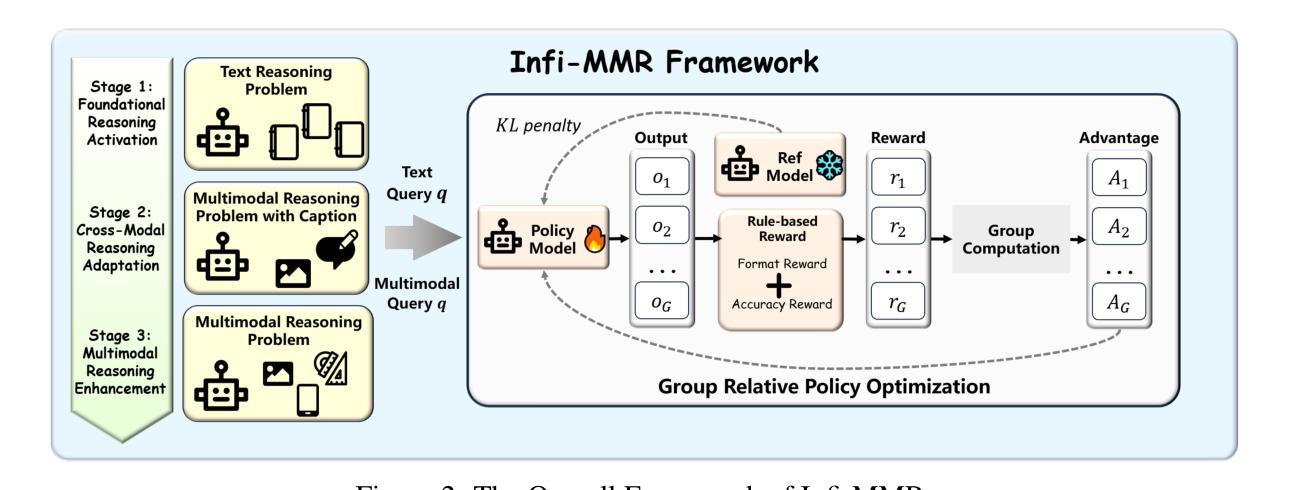
Infi-MMR: Curriculum-based Unlocking Multimodal Reasoning via Phased Reinforcement Learning in Multimodal Small Language Models
Authors:Zeyu Liu, Yuhang Liu, Guanghao Zhu, Congkai Xie, Zhen Li, Jianbo Yuan, Xinyao Wang, Qing Li, Shing-Chi Cheung, Shengyu Zhang, Fei Wu, Hongxia Yang
Recent advancements in large language models (LLMs) have demonstrated substantial progress in reasoning capabilities, such as DeepSeek-R1, which leverages rule-based reinforcement learning to enhance logical reasoning significantly. However, extending these achievements to multimodal large language models (MLLMs) presents critical challenges, which are frequently more pronounced for Multimodal Small Language Models (MSLMs) given their typically weaker foundational reasoning abilities: (1) the scarcity of high-quality multimodal reasoning datasets, (2) the degradation of reasoning capabilities due to the integration of visual processing, and (3) the risk that direct application of reinforcement learning may produce complex yet incorrect reasoning processes. To address these challenges, we design a novel framework Infi-MMR to systematically unlock the reasoning potential of MSLMs through a curriculum of three carefully structured phases and propose our multimodal reasoning model Infi-MMR-3B. The first phase, Foundational Reasoning Activation, leverages high-quality textual reasoning datasets to activate and strengthen the model’s logical reasoning capabilities. The second phase, Cross-Modal Reasoning Adaptation, utilizes caption-augmented multimodal data to facilitate the progressive transfer of reasoning skills to multimodal contexts. The third phase, Multimodal Reasoning Enhancement, employs curated, caption-free multimodal data to mitigate linguistic biases and promote robust cross-modal reasoning. Infi-MMR-3B achieves both state-of-the-art multimodal math reasoning ability (43.68% on MathVerse testmini, 27.04% on MathVision test, and 21.33% on OlympiadBench) and general reasoning ability (67.2% on MathVista testmini). Resources are available at https://huggingface.co/Reallm-Labs/Infi-MMR-3B.
近期大型语言模型(LLM)的进步在推理能力方面取得了显著成效,例如DeepSeek-R1,它利用基于规则的强化学习来显著增强逻辑推理能力。然而,将这些成就扩展到多模态大型语言模型(MLLM)却面临重大挑战,对于多模态小型语言模型(MSLM)而言,这些挑战通常更为突出,因为它们通常具有较弱的基础推理能力:一是高质量的多模态推理数据集的稀缺性;二是由于集成视觉处理而导致的推理能力下降;三是直接应用强化学习可能产生复杂而错误的推理过程的风险。为了解决这些挑战,我们设计了一种新型框架Infi-MMR,通过三个精心构建的阶段系统地解锁MSLM的推理潜力,并提出了我们的多模态推理模型Infi-MMR-3B。第一阶段,基础推理激活,利用高质量文本推理数据集来激活和加强模型的逻辑推理能力。第二阶段,跨模态推理适应,利用字幕增强多模态数据来促进推理技能向多模态环境的逐步转移。第三阶段,多模态推理增强,采用精选的无字幕多模态数据来缓解语言偏见,并促进稳健的跨模态推理。Infi-MMR-3B不仅达到了最先进的跨模态数学推理能力(在MathVerse测试集上达到43.68%,在MathVision测试集上达到27.04%,在OlympiadBench上达到21.33%),而且在通用推理能力方面也表现出色(在MathVista测试集上达到67.2%)。相关资源可通过链接https://huggingface.co/Reallm-Labs/Infi-MMR-3B获取。
论文及项目相关链接
Summary
大型语言模型(LLM)在推理能力方面取得了显著进展,如DeepSeek-R1。然而,将成果扩展到多模态大型语言模型(MLLM)面临挑战,特别是对于多模态小型语言模型(MSLM)而言。为了解决这些挑战,提出了一种新型框架Infi-MMR,通过三个精心设计的阶段解锁MSLM的推理潜力,并推出了多模态推理模型Infi-MMR-3B。该模型经历了基础推理激活、跨模态推理适应和跨模态推理增强三个阶段,实现了先进的跨模态数学推理能力和通用推理能力。相关信息可通过huggingface.co/Reallm-Labs/Infi-MMR-3B获取。
Key Takeaways
- 大型语言模型(LLM)在推理能力上取得显著进步,如DeepSeek-R1。
- 将LLM的进展扩展到多模态大型语言模型(MLLM)面临挑战,特别是对于多模态小型语言模型(MSLM)。
- 提出新型框架Infi-MMR,通过三个阶段解锁MSLM的推理潜力。
- Infi-MMR-3B模型经历基础推理激活、跨模态推理适应和跨模态推理增强三个阶段。
- Infi-MMR-3B实现了先进的跨模态数学推理能力和通用推理能力。
- 该模型在MathVerse testmini、MathVision test、OlympiadBench和MathVista testmini上取得卓越表现。
点此查看论文截图