⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-10 更新
LLIA – Enabling Low-Latency Interactive Avatars: Real-Time Audio-Driven Portrait Video Generation with Diffusion Models
Authors:Haojie Yu, Zhaonian Wang, Yihan Pan, Meng Cheng, Hao Yang, Chao Wang, Tao Xie, Xiaoming Xu, Xiaoming Wei, Xunliang Cai
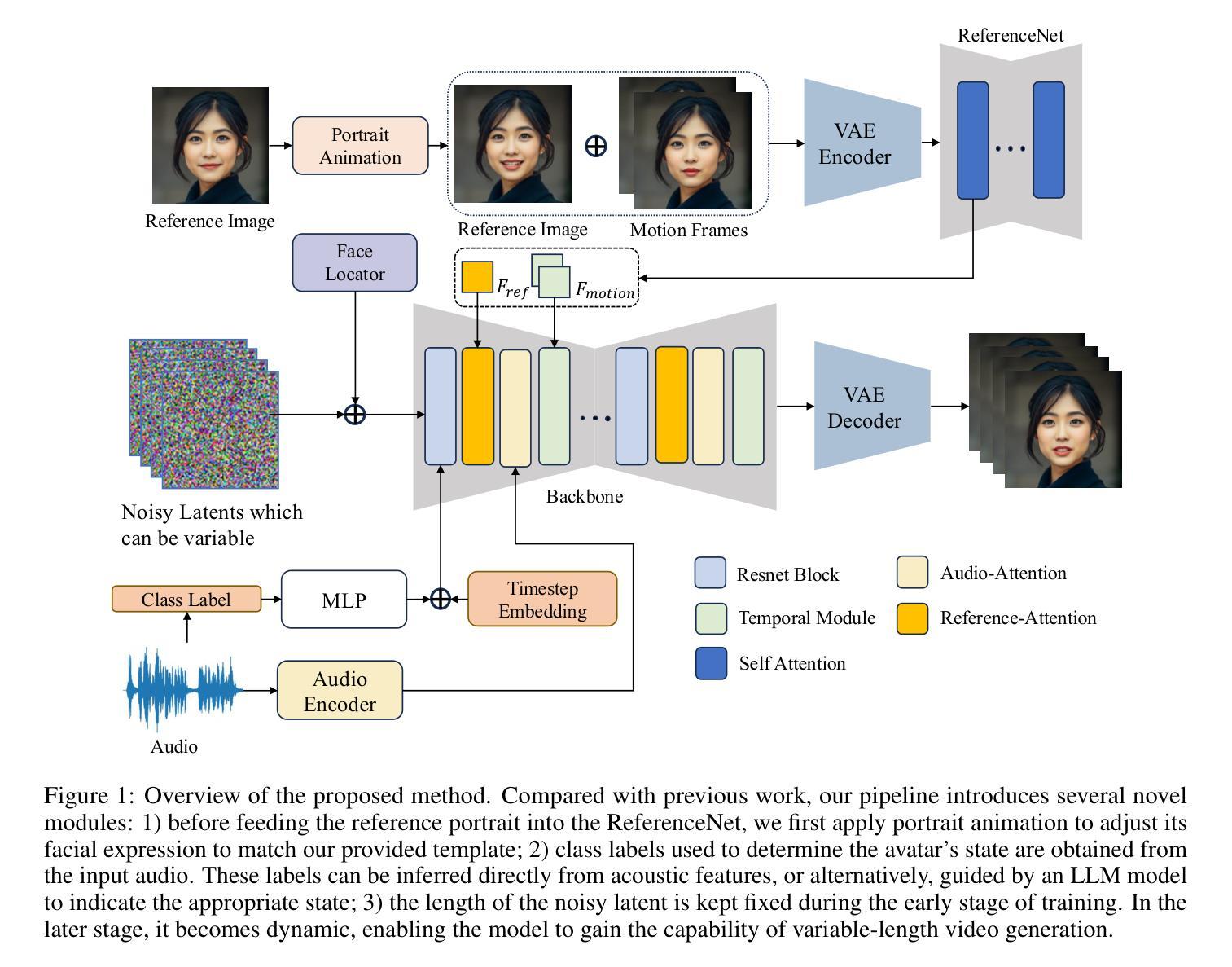
Diffusion-based models have gained wide adoption in the virtual human generation due to their outstanding expressiveness. However, their substantial computational requirements have constrained their deployment in real-time interactive avatar applications, where stringent speed, latency, and duration requirements are paramount. We present a novel audio-driven portrait video generation framework based on the diffusion model to address these challenges. Firstly, we propose robust variable-length video generation to reduce the minimum time required to generate the initial video clip or state transitions, which significantly enhances the user experience. Secondly, we propose a consistency model training strategy for Audio-Image-to-Video to ensure real-time performance, enabling a fast few-step generation. Model quantization and pipeline parallelism are further employed to accelerate the inference speed. To mitigate the stability loss incurred by the diffusion process and model quantization, we introduce a new inference strategy tailored for long-duration video generation. These methods ensure real-time performance and low latency while maintaining high-fidelity output. Thirdly, we incorporate class labels as a conditional input to seamlessly switch between speaking, listening, and idle states. Lastly, we design a novel mechanism for fine-grained facial expression control to exploit our model’s inherent capacity. Extensive experiments demonstrate that our approach achieves low-latency, fluid, and authentic two-way communication. On an NVIDIA RTX 4090D, our model achieves a maximum of 78 FPS at a resolution of 384x384 and 45 FPS at a resolution of 512x512, with an initial video generation latency of 140 ms and 215 ms, respectively.
基于扩散模型的虚拟人生成技术因其出色的表现力而得到广泛应用。然而,其巨大的计算需求限制了其在实时互动虚拟角色应用程序中的部署,这些应用程序对速度、延迟和持续时间有着严格的要求。我们提出了一种基于扩散模型的新型音频驱动肖像视频生成框架,以应对这些挑战。首先,我们提出鲁棒性可变长度视频生成方法,以减少生成初始视频剪辑或状态转换所需的最短时间,这显著提升了用户体验。其次,我们为音频图像到视频的转换提出了一种一致性模型训练策略,以确保实时性能,实现快速的多步生成。我们还采用了模型量化和流水线并行性来加速推理速度。为了解决扩散过程和模型量化带来的稳定性损失,我们引入了一种适用于长时长视频生成的新型推理策略。这些方法确保了实时性能与低延迟,同时保持了高保真输出。第三,我们将类别标签作为条件输入,以无缝切换说话、倾听和空闲状态。最后,我们设计了一种用于精细面部表情控制的新机制,以利用我们模型内在的潜力。大量实验表明,我们的方法实现了低延迟、流畅和真实的双向交流。在NVIDIA RTX 4090D上,我们的模型在384x384分辨率下最高可达78帧每秒(FPS),在512x512分辨率下为45 FPS,初始视频生成延迟分别为140毫秒和215毫秒。
论文及项目相关链接
Summary
本文介绍了基于扩散模型的新型音频驱动肖像视频生成框架,解决了虚拟人生成中实时互动性面临的挑战。该框架提出了可变长度视频生成技术,提高了用户体验;采用一致性模型训练策略,确保实时性能;并运用模型量化和流水线并行技术加速推理速度。同时,引入新的推理策略,减少扩散过程和模型量化带来的稳定性损失。通过融入类别标签和精细面部表情控制机制,实现了流畅、真实的双向交流。实验显示,该模型在NVIDIA RTX 4090D上最高可达78帧/秒,分辨率达384x384,初始视频生成延迟仅140毫秒。
Key Takeaways
- 扩散模型在虚拟人生成中广泛应用,但其计算量大对实时互动应用构成挑战。
- 新型音频驱动肖像视频生成框架基于扩散模型,旨在解决这些挑战。
- 框架支持可变长度视频生成,提高用户体验。
- 通过一致性模型训练策略和推理策略优化,确保实时性能和稳定性。
- 模型量化和流水线并行技术进一步加速推理速度。
- 融入类别标签和精细面部表情控制机制,增强真实感和交互性。
点此查看论文截图