⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-10 更新
MOGO: Residual Quantized Hierarchical Causal Transformer for High-Quality and Real-Time 3D Human Motion Generation
Authors:Dongjie Fu, Tengjiao Sun, Pengcheng Fang, Xiaohao Cai, Hansung Kim
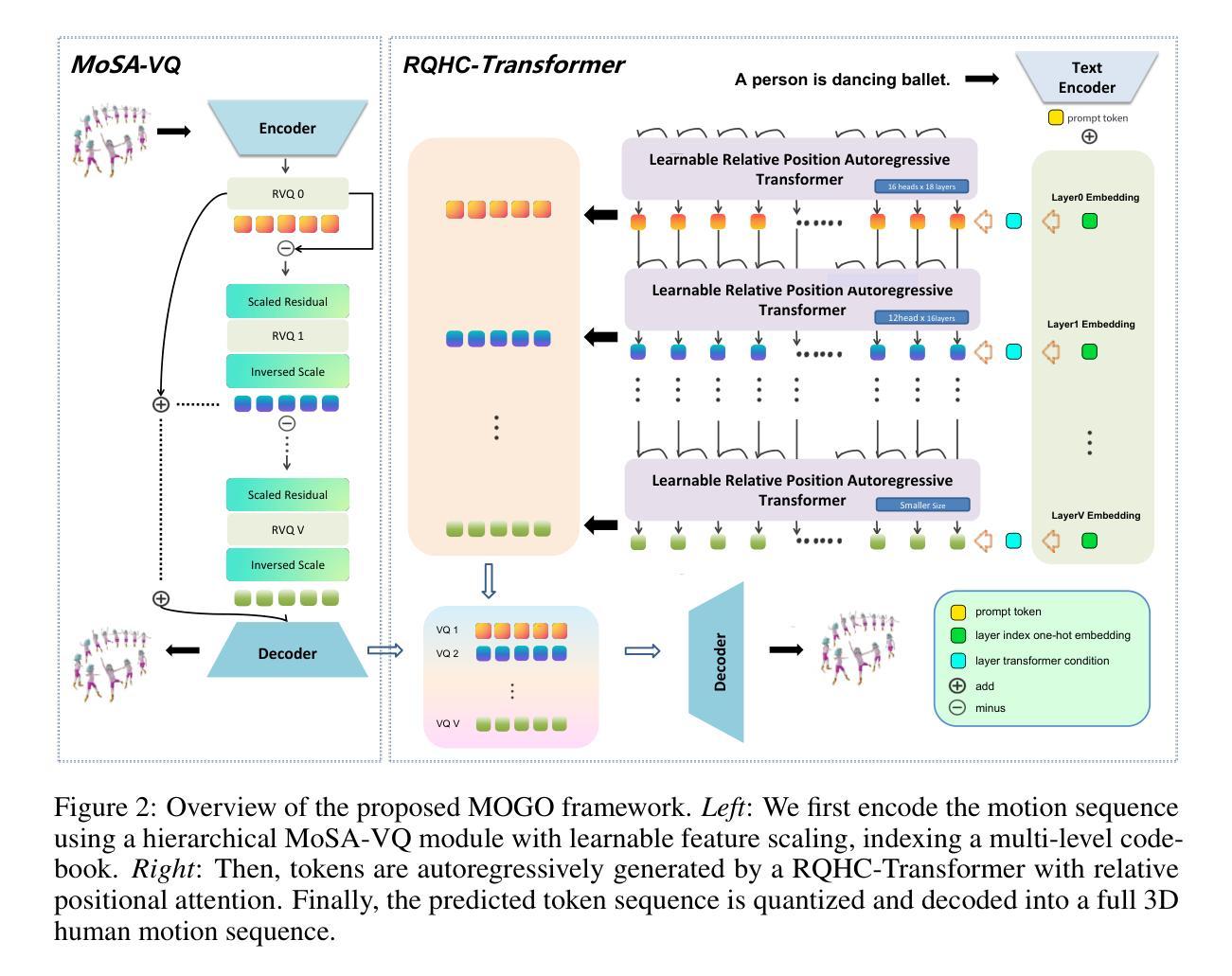
Recent advances in transformer-based text-to-motion generation have led to impressive progress in synthesizing high-quality human motion. Nevertheless, jointly achieving high fidelity, streaming capability, real-time responsiveness, and scalability remains a fundamental challenge. In this paper, we propose MOGO (Motion Generation with One-pass), a novel autoregressive framework tailored for efficient and real-time 3D motion generation. MOGO comprises two key components: (1) MoSA-VQ, a motion scale-adaptive residual vector quantization module that hierarchically discretizes motion sequences with learnable scaling to produce compact yet expressive representations; and (2) RQHC-Transformer, a residual quantized hierarchical causal transformer that generates multi-layer motion tokens in a single forward pass, significantly reducing inference latency. To enhance semantic fidelity, we further introduce a text condition alignment mechanism that improves motion decoding under textual control. Extensive experiments on benchmark datasets including HumanML3D, KIT-ML, and CMP demonstrate that MOGO achieves competitive or superior generation quality compared to state-of-the-art transformer-based methods, while offering substantial improvements in real-time performance, streaming generation, and generalization under zero-shot settings.
近期基于transformer的文本到运动生成技术的进展推动了高质量人类运动合成的显著进步。然而,同时实现高保真度、流式传输能力、实时响应性和可扩展性仍然是一个基本挑战。在本文中,我们提出了MOGO(一次运动生成),这是一个专为高效实时3D运动生成定制的自回归框架。MOGO包含两个关键组件:(1)MoSA-VQ,这是一种运动尺度自适应残差向量量化模块,它分层离散运动序列,通过可学习的缩放来产生紧凑而富有表现力的表示;(2)RQHC-Transformer,这是一种残差量化分层因果transformer,它能在一次前向传递中产生多层运动令牌,大大降低了推理延迟。为了提高语义保真度,我们还引入了一种文本条件对齐机制,该机制改进了文本控制下的运动解码。在包括HumanML3D、KIT-ML和CMP在内的基准数据集上的广泛实验表明,MOGO与最新的基于transformer的方法相比,在生成质量方面具有竞争力或更优越,同时在实时性能、流式生成和零样本设置下的泛化方面提供了实质性的改进。
论文及项目相关链接
PDF 9 pages, 4 figures, conference
Summary
该文提出MOGO(Motion Generation with One-pass)模型,一种针对高效实时三维运动生成的自回归框架。MOGO包含两个关键组件:MoSA-VQ和RQHC-Transformer。前者能层次化离散运动序列并生成紧凑而富有表现力的表示;后者通过一次性生成多层运动令牌,显著减少了推理延迟。此外,还引入文本条件对齐机制以提高语义保真度。实验表明,MOGO在生成质量方面与最先进的基于transformer的方法相比具有竞争力或更优越,同时在实时性能、流式生成和零样本设置下的泛化能力方面取得了实质性改进。
Key Takeaways
- MOGO是一个针对高效实时三维运动生成的自回归框架。
- MOGO包含MoSA-VQ和RQHC-Transformer两个关键组件,分别用于层次化离散运动序列和一次性生成多层运动令牌。
- MoSA-VQ具有运动规模自适应剩余向量量化模块,能生成紧凑且表现丰富的运动表示。
- RQHC-Transformer通过单次前向传递生成多层运动令牌,降低了推理延迟。
- 引入文本条件对齐机制,提高语义保真度和运动解码的文本控制效果。
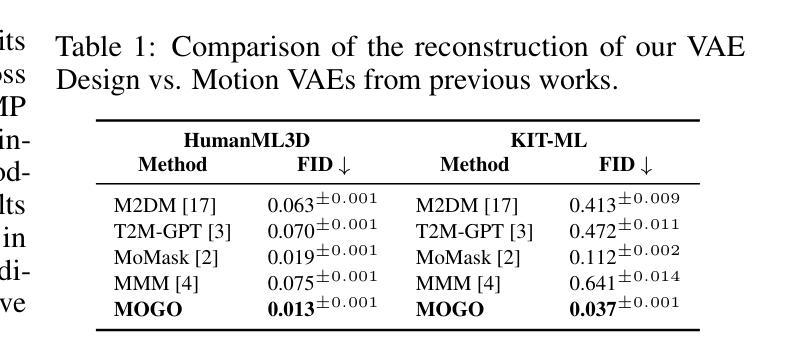
- 实验证明MOGO在多个基准数据集上的生成质量与最先进的基于transformer的方法相比具有竞争力或更优越。
点此查看论文截图