⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-10 更新
Query Nearby: Offset-Adjusted Mask2Former enhances small-organ segmentation
Authors:Xin Zhang, Dongdong Meng, Sheng Li
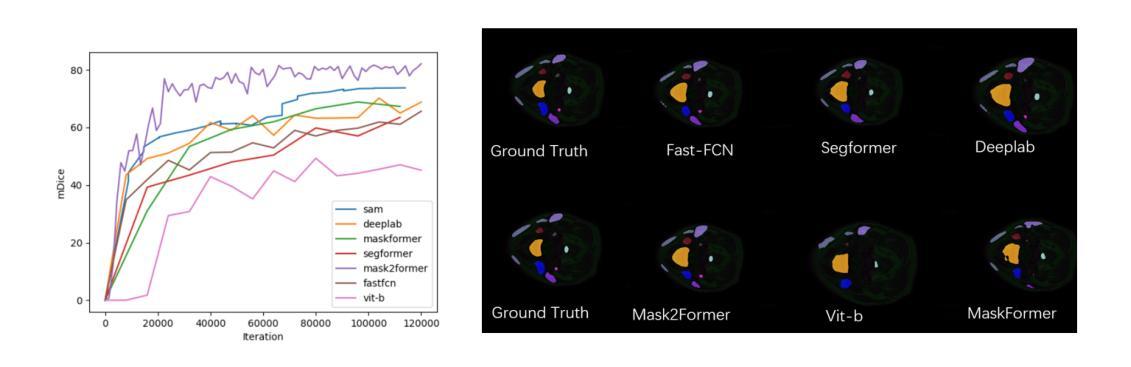
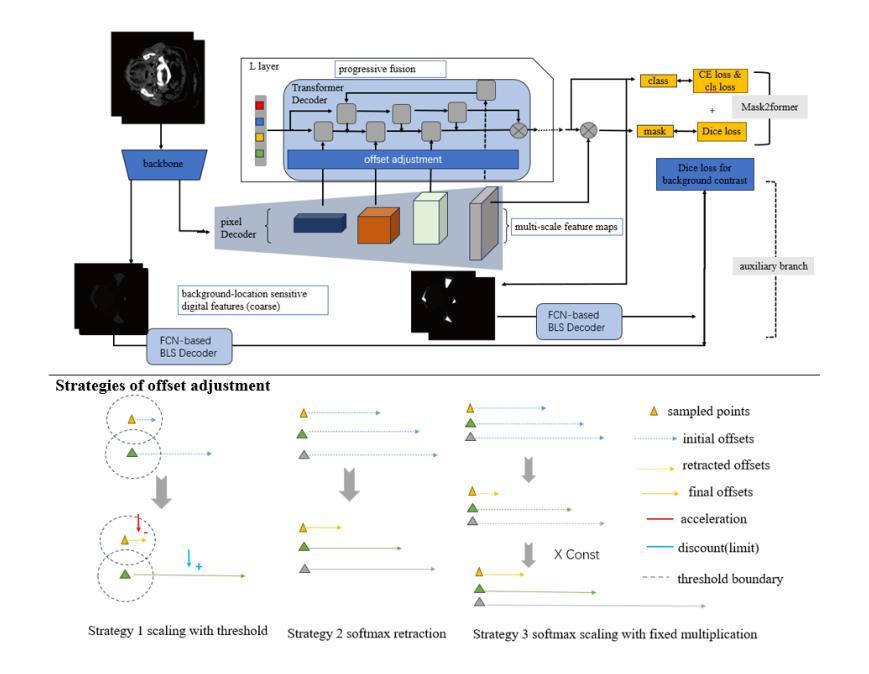
Medical segmentation plays an important role in clinical applications like radiation therapy and surgical guidance, but acquiring clinically acceptable results is difficult. In recent years, progress has been witnessed with the success of utilizing transformer-like models, such as combining the attention mechanism with CNN. In particular, transformer-based segmentation models can extract global information more effectively, compensating for the drawbacks of CNN modules that focus on local features. However, utilizing transformer architecture is not easy, because training transformer-based models can be resource-demanding. Moreover, due to the distinct characteristics in the medical field, especially when encountering mid-sized and small organs with compact regions, their results often seem unsatisfactory. For example, using ViT to segment medical images directly only gives a DSC of less than 50%, which is far lower than the clinically acceptable score of 80%. In this paper, we used Mask2Former with deformable attention to reduce computation and proposed offset adjustment strategies to encourage sampling points within the same organs during attention weights computation, thereby integrating compact foreground information better. Additionally, we utilized the 4th feature map in Mask2Former to provide a coarse location of organs, and employed an FCN-based auxiliary head to help train Mask2Former more quickly using Dice loss. We show that our model achieves SOTA (State-of-the-Art) performance on the HaNSeg and SegRap2023 datasets, especially on mid-sized and small organs.Our code is available at link https://github.com/earis/Offsetadjustment\_Background-location\_Decoder\_Mask2former.
医疗分割在临床应用如放射治疗和手术指导中扮演着重要角色,但获得临床上可接受的结果却具有挑战性。近年来,利用类似变压器的模型取得了成功,特别是将注意力机制与CNN相结合。特别是基于变压器的分割模型能够更有效地提取全局信息,弥补了CNN模块专注于局部特征的局限性。然而,利用变压器架构并不容易,因为基于变压器的模型训练对资源需求很大。此外,由于医疗领域的独特特点,特别是在遇到紧凑区域的中型和小型器官时,其结果往往不尽人意。例如,直接使用ViT进行医学图像分割的DSC低于50%,远低于临床上可接受的80%。在本文中,我们使用带有可变形注意力的Mask2Former,以减少计算并提出偏移调整策略,以在计算注意力权重时鼓励同一器官内的采样点,从而更好地整合紧凑的前景信息。此外,我们还使用了Mask2Former的第4个特征映射图来提供器官的粗略位置,并使用基于FCN的辅助头帮助使用Dice损失更快地训练Mask2Former。我们展示我们的模型在HaNSeg和SegRap2023数据集上达到了最新技术水平,特别是在中型和小型器官上。我们的代码位于:链接。
论文及项目相关链接
Summary
医学分割在放射治疗、手术指导等临床应用领域具有重要地位,但获取临床可接受的分割结果具有挑战性。近年来,基于Transformer模型的利用取得了成功,特别是结合了注意力机制和CNN的组合模型。本文通过使用Mask2Former与可变形注意力,降低了计算成本,并提出了偏移调整策略来优化注意力权重计算中的采样点,更好地整合紧凑的前景信息。此外,本文还利用Mask2Former的第4个特征映射提供器官的粗略位置,并采用FCN辅助头来加速训练过程。在HaNSeg和SegRap2023数据集上,该模型实现了卓越的性能,特别是在中型和小型器官上。相关代码已发布在指定的GitHub链接上。
Key Takeaways
- 医学分割在放射治疗等临床应用中的重要性以及获取可接受结果的困难性。
- Transformer模型结合注意力机制和CNN的应用于医学分割领域的进展。
- Mask2Former与可变形注意力结合用于降低计算成本的方法。
- Mask2Former模型中的偏移调整策略以优化采样点整合紧凑前景信息的技巧。
- 利用Mask2Former的第4个特征映射来提供器官粗略位置的方法。
- 使用FCN辅助头来加速训练过程的创新方式。
点此查看论文截图

Object-level Self-Distillation for Vision Pretraining
Authors:Çağlar Hızlı, Çağatay Yıldız, Pekka Marttinen
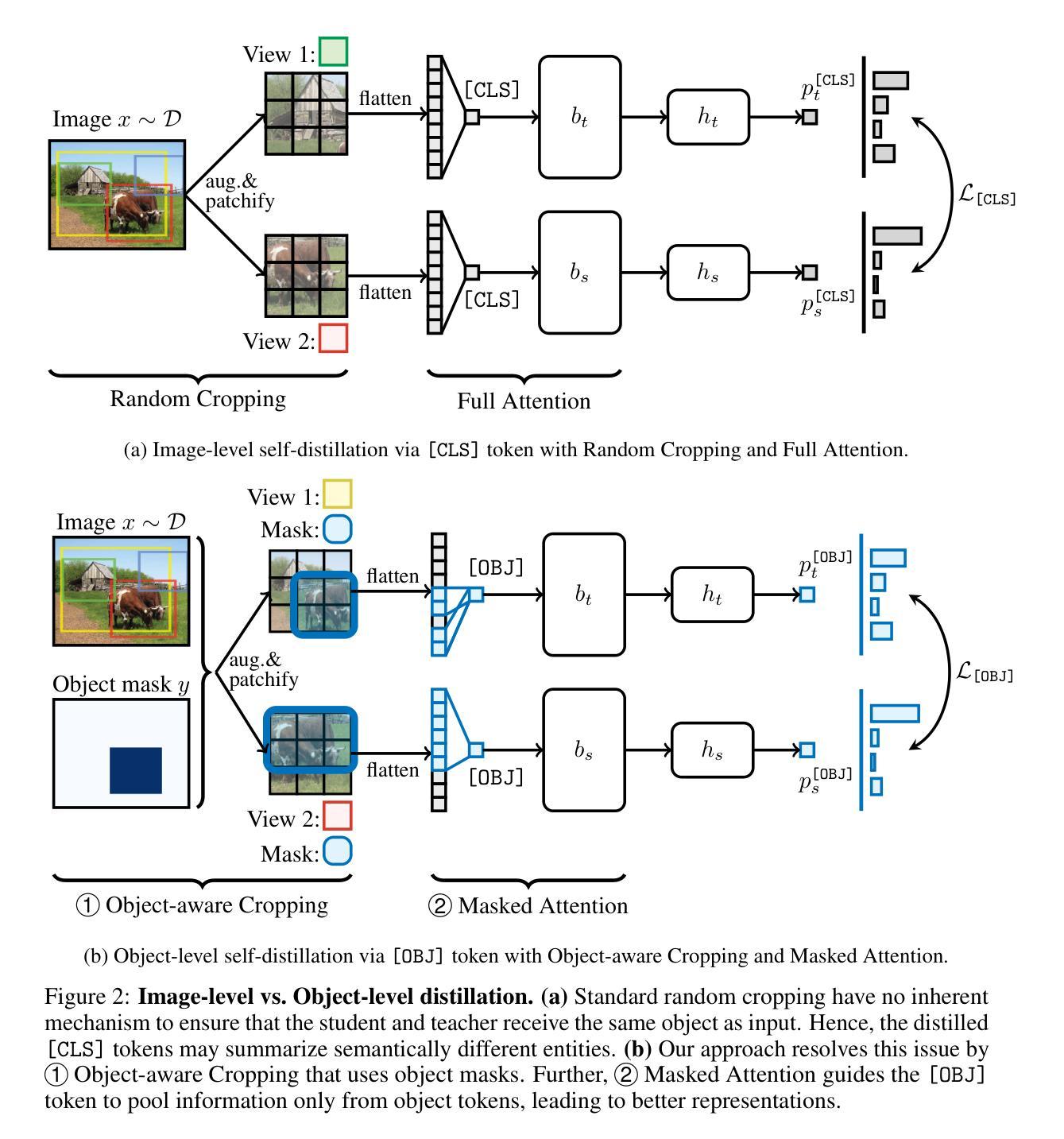
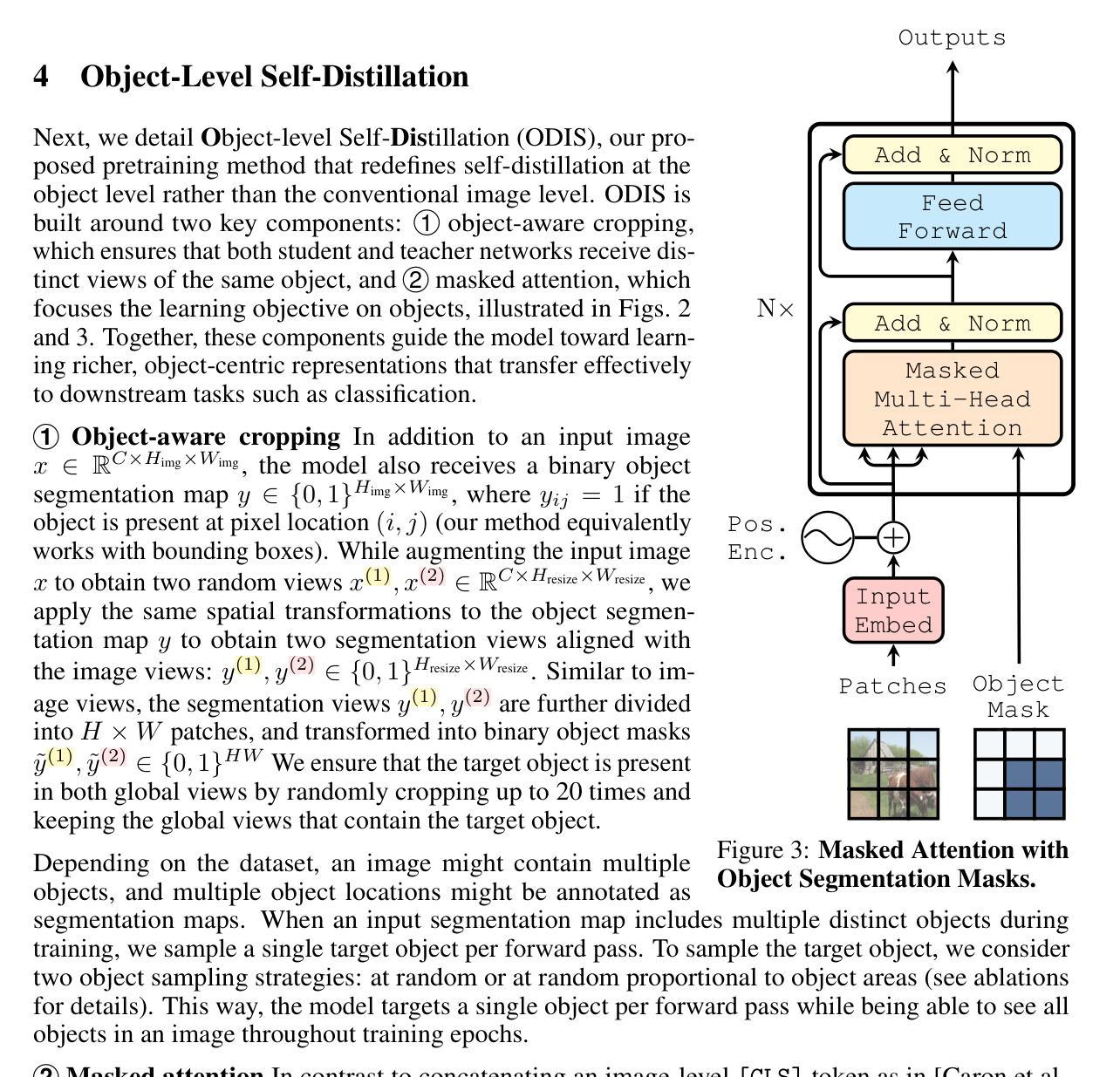
State-of-the-art vision pretraining methods rely on image-level self-distillation from object-centric datasets such as ImageNet, implicitly assuming each image contains a single object. This assumption does not always hold: many ImageNet images already contain multiple objects. Further, it limits scalability to scene-centric datasets that better mirror real-world complexity. We address these challenges by introducing Object-level Self-DIStillation (ODIS), a pretraining approach that shifts the self-distillation granularity from whole images to individual objects. Using object-aware cropping and masked attention, ODIS isolates object-specific regions, guiding the transformer toward semantically meaningful content and transforming a noisy, scene-level task into simpler object-level sub-tasks. We show that this approach improves visual representations both at the image and patch levels. Using masks at inference time, our method achieves an impressive $82.6%$ $k$-NN accuracy on ImageNet1k with ViT-Large.
最前沿的视觉预训练方法依赖于以对象为中心的数据集(如ImageNet)的图像级自我蒸馏,这隐含地假设每张图像只包含一个对象。这一假设并不总是成立:许多ImageNet图像已经包含多个对象。此外,它对于更真实反映现实世界复杂度的场景中心数据集的可扩展性有限。我们通过引入Object级自我蒸馏(ODIS)来解决这些挑战,这是一种预训练方法,它将自我蒸馏的粒度从整个图像转移到单个对象。通过利用面向对象的裁剪和遮挡注意力机制,ODIS隔离出特定对象的区域,引导变压器朝向语义丰富的内容,并将嘈杂的场景级任务转变为更简单的对象级子任务。我们表明,这种方法在图像和补丁层面都提高了视觉表现。在推理时间使用遮挡时,我们的方法在ViT-Large上实现了令人印象深刻的ImageNet1k的82.6% k-NN准确率。
论文及项目相关链接
Summary
文本介绍了一种名为ODIS(Object-level Self-DIStillation)的视觉预训练方法,它将自我蒸馏的粒度从整个图像转移到单个对象上。通过对象感知裁剪和掩模注意力机制,ODIS能够隔离特定对象的区域,引导变压器关注语义内容,并将复杂的场景级任务转换为简单的对象级子任务。这提高了图像和补丁级别的视觉表示能力,并在ImageNet1k数据集上使用ViT-Large模型实现了高达82.6%的k-NN准确度。
Key Takeaways
- ODIS是一种新的视觉预训练方法,旨在解决现有方法基于单一对象假设的限制。
- ODIS通过将自我蒸馏的粒度从整个图像转移到单个对象来改进预训练过程。
- 通过对象感知裁剪和掩模注意力机制,ODIS能够隔离特定对象的区域。
- ODIS能够引导模型关注语义内容,将复杂的场景级任务转换为简单的对象级子任务。
- ODIS提高了图像和补丁级别的视觉表示能力。
- 使用ODIS预训练的模型在ImageNet数据集上实现了较高的k-NN准确度。
点此查看论文截图

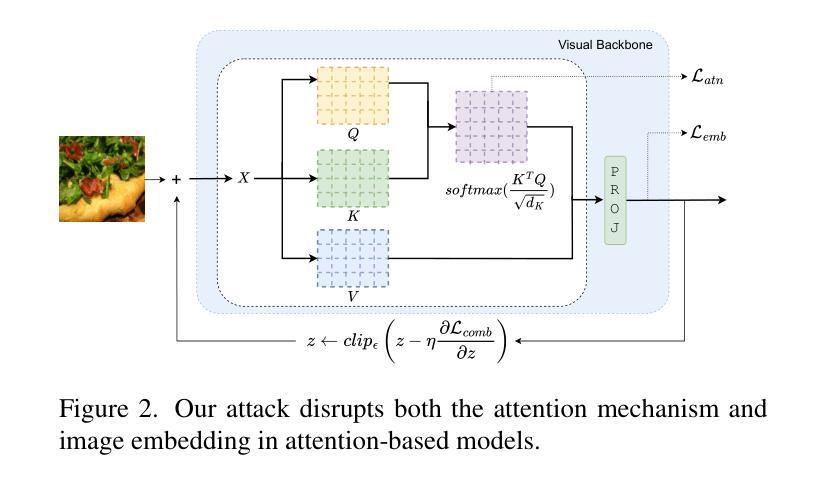
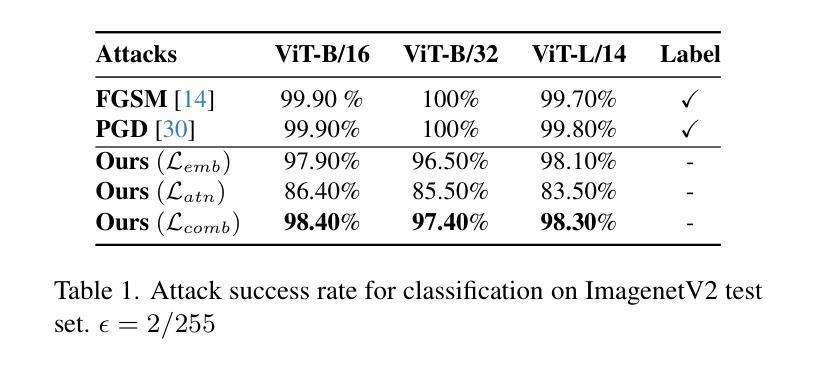
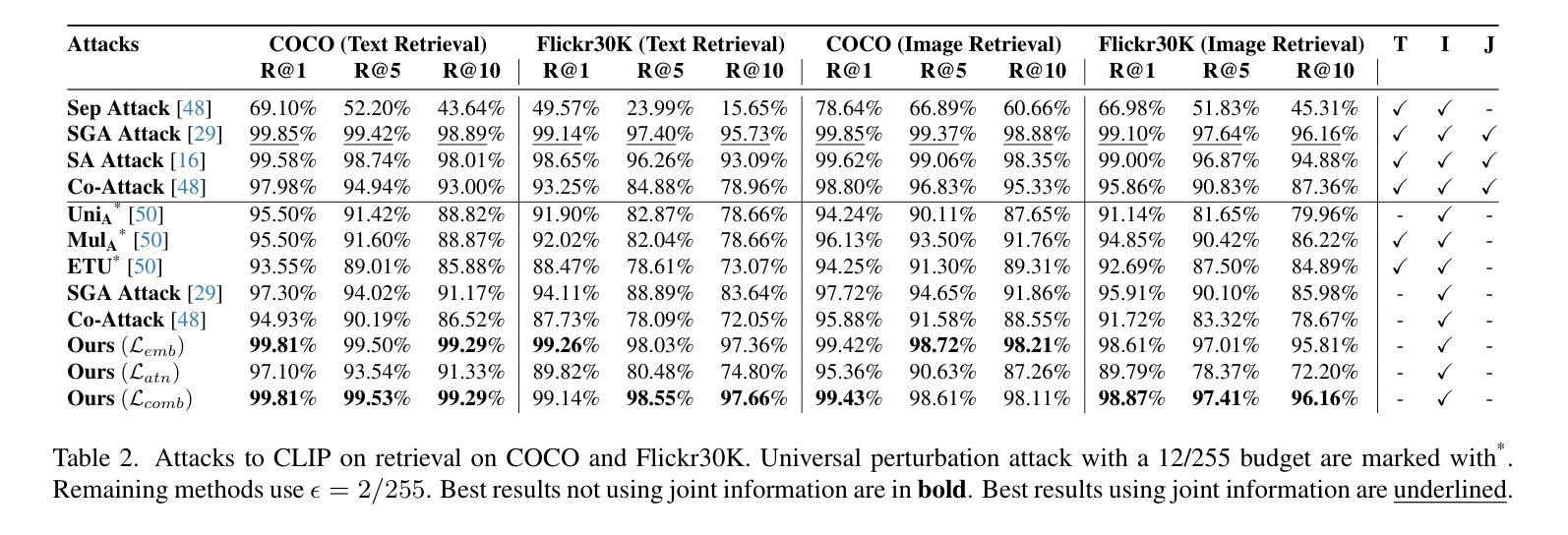
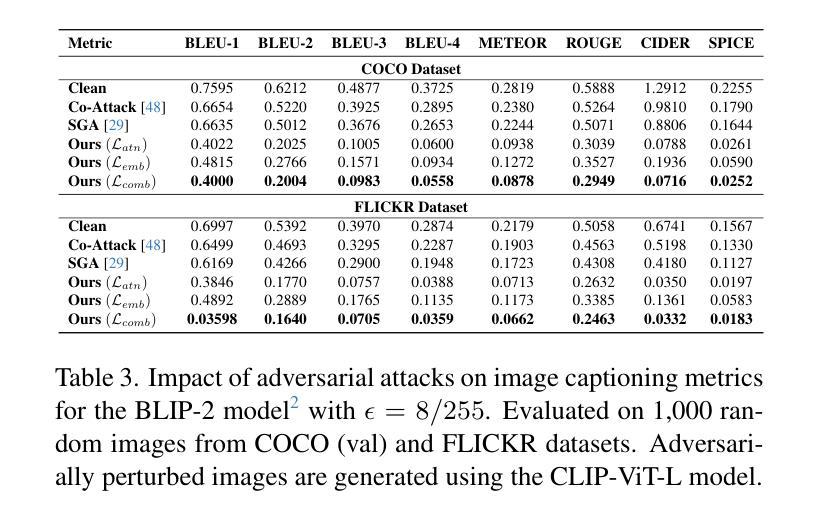
Attacking Attention of Foundation Models Disrupts Downstream Tasks
Authors:Hondamunige Prasanna Silva, Federico Becattini, Lorenzo Seidenari
Foundation models represent the most prominent and recent paradigm shift in artificial intelligence.Foundation models are large models, trained on broad data that deliver high accuracy in many downstream tasks, often without fine-tuning. For this reason, models such as CLIP , DINO or Vision Transfomers (ViT), are becoming the bedrock of many industrial AI-powered applications. However, the reliance on pre-trained foundation models also introduces significant security concerns, as these models are vulnerable to adversarial attacks. Such attacks involve deliberately crafted inputs designed to deceive AI systems, jeopardizing their reliability.This paper studies the vulnerabilities of vision foundation models, focusing specifically on CLIP and ViTs, and explores the transferability of adversarial attacks to downstream tasks. We introduce a novel attack, targeting the structure of transformer-based architectures in a task-agnostic fashion.We demonstrate the effectiveness of our attack on several downstream tasks: classification, captioning, image/text retrieval, segmentation and depth estimation.
基础模型代表了人工智能中最突出和最新的范式转变。基础模型是在广泛数据上训练的的大型模型,可以在许多下游任务中提供高精度,通常无需微调。因此,CLIP、DINO或Vision Transfomers(ViT)等模型正成为许多工业级人工智能应用程序的基础。然而,对预训练基础模型的依赖也引发了重大的安全隐患,因为这些模型容易受到对抗性攻击的威胁。这类攻击涉及故意设计的输入,旨在欺骗人工智能系统,危害其可靠性。本文对视觉基础模型的漏洞进行了研究,重点关注CLIP和ViTs,并探讨了对抗性攻击对下游任务的可转移性。我们引入了一种新型攻击,以任务无关的方式针对基于变压器架构的结构。我们在多个下游任务上展示了攻击的有效性:分类、描述、图像/文本检索、分割和深度估计。
论文及项目相关链接
PDF Paper published at CVPR 2025 Workshop Advml
Summary
大型预训练模型如CLIP、DINO和Vision Transfomers(ViT)在许多工业级AI应用中发挥着重要作用。然而,这些模型存在安全隐患,易受对抗性攻击的影响。本文研究了视觉基础模型的漏洞,特别是CLIP和ViTs的漏洞,并探讨了对抗性攻击对下游任务的迁移性。本文提出了一种针对基于转换器架构结构的新型攻击方法,并在多个下游任务上验证了其有效性,包括分类、描述、图像/文本检索、分割和深度估计。
Key Takeaways
- 基金会模型是人工智能领域最突出和最新的范式转变的代表。
- 基金会模型是在广泛数据上训练的大型模型,可以在许多下游任务中提供高精度,通常无需微调。
- 依赖预训练的基金会模型也引发了重大安全担忧,因为它们容易受到对抗性攻击的影响。
- 对抗性攻击涉及故意设计的输入,旨在欺骗AI系统,从而危及它们的可靠性。
- 本文专注于研究视觉基础模型的漏洞,特别是CLIP和ViTs的漏洞。
- 本文提出了一种新型攻击方法,该方法针对基于转换器架构的结构,以任务无关的方式有效攻击模型。
点此查看论文截图


Can Vision Transformers with ResNet’s Global Features Fairly Authenticate Demographic Faces?
Authors:Abu Sufian, Marco Leo, Cosimo Distante, Anirudha Ghosh, Debaditya Barman
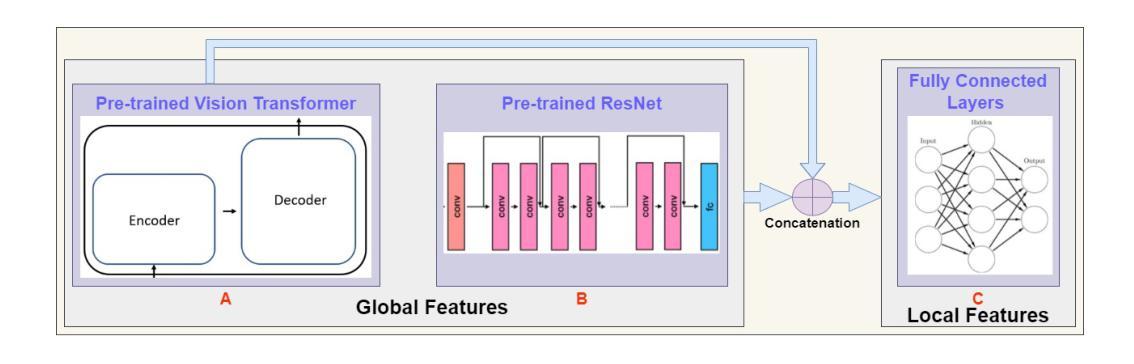
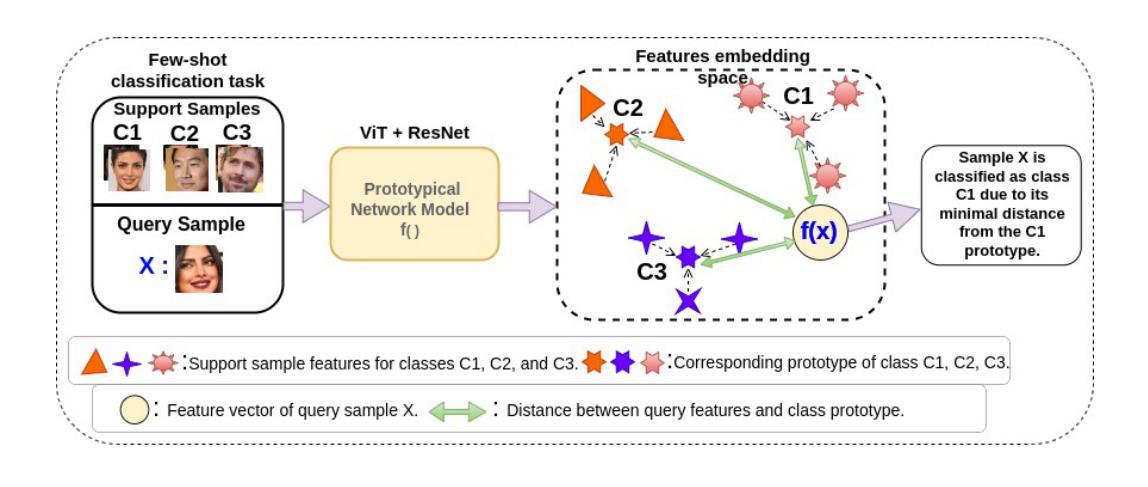
Biometric face authentication is crucial in computer vision, but ensuring fairness and generalization across demographic groups remains a big challenge. Therefore, we investigated whether Vision Transformer (ViT) and ResNet, leveraging pre-trained global features, can fairly authenticate different demographic faces while relying minimally on local features. In this investigation, we used three pre-trained state-of-the-art (SOTA) ViT foundation models from Facebook, Google, and Microsoft for global features as well as ResNet-18. We concatenated the features from ViT and ResNet, passed them through two fully connected layers, and trained on customized face image datasets to capture the local features. Then, we designed a novel few-shot prototype network with backbone features embedding. We also developed new demographic face image support and query datasets for this empirical study. The network’s testing was conducted on this dataset in one-shot, three-shot, and five-shot scenarios to assess how performance improves as the size of the support set increases. We observed results across datasets with varying races/ethnicities, genders, and age groups. The Microsoft Swin Transformer backbone performed better among the three SOTA ViT for this task. The code and data are available at: https://github.com/Sufianlab/FairVitBio.
生物特征人脸识别在计算机视觉中至关重要,但确保不同人口群体之间的公平性和泛化性仍然是一个巨大挑战。因此,我们调查了Vision Transformer(ViT)和ResNet是否可以利用预训练的全局特征,在尽可能不依赖局部特征的情况下,公平地对不同人口群体的面部进行身份验证。在本次调查中,我们使用了Facebook、Google和Microsoft的三种最新预训练ViT基础模型用于全局特征提取,以及ResNet-18。我们将ViT和ResNet的特征进行拼接,通过两层全连接层进行处理,并在自定义的人脸图像数据集上进行训练以捕获局部特征。然后,我们设计了一种新型的小样本原型网络,用于嵌入主干特征。我们还为此实证研究开发了新的人口面部图像支持集和查询集。网络的测试是在一次拍摄、三次拍摄和五次拍摄的场景下进行的,以评估随着支持集大小的增加,性能如何改善。我们观察了不同种族/民族、性别和年龄群体的数据集的结果。对于此任务,Microsoft Swin Transformer的主干网在三种最新ViT中表现更好。代码和数据可在以下网址找到:https://github.com/Sufianlab/FairVitBio。
论文及项目相关链接
PDF 14 pages, 6 Figures, ICPR 2024 Workshop FAIRBIO
Summary
本调查研究了使用Vision Transformer(ViT)和ResNet在人脸识别认证上的性能表现,尤其是对不同人群是否具有公平性。通过使用全球特性预训练的先进模型如Facebook、Google和微软的ViT模型以及ResNet-18模型进行试验,发现在利用全局特性时表现出较好的性能,并且在新开发的针对种族、性别和年龄群体的数据集上进行测试,发现Microsoft的Swin Transformer模型在此任务上表现最佳。研究代码和数据集可在相关链接找到。
Key Takeaways
- Vision Transformer(ViT)和ResNet在人脸识别认证方面具有潜力。
- 对不同人群的公平性是识别认证中的一大挑战。
- 利用全局特性预训练的先进模型,如ViT和ResNet,有助于提高识别性能。
- 开发了新的针对种族、性别和年龄群体的数据集进行实证研究。
- Microsoft的Swin Transformer模型在此任务上表现最佳。
- 实验涉及了多种不同的实验场景(如one-shot, three-shot和five-shot场景)。
点此查看论文截图