⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-11 更新
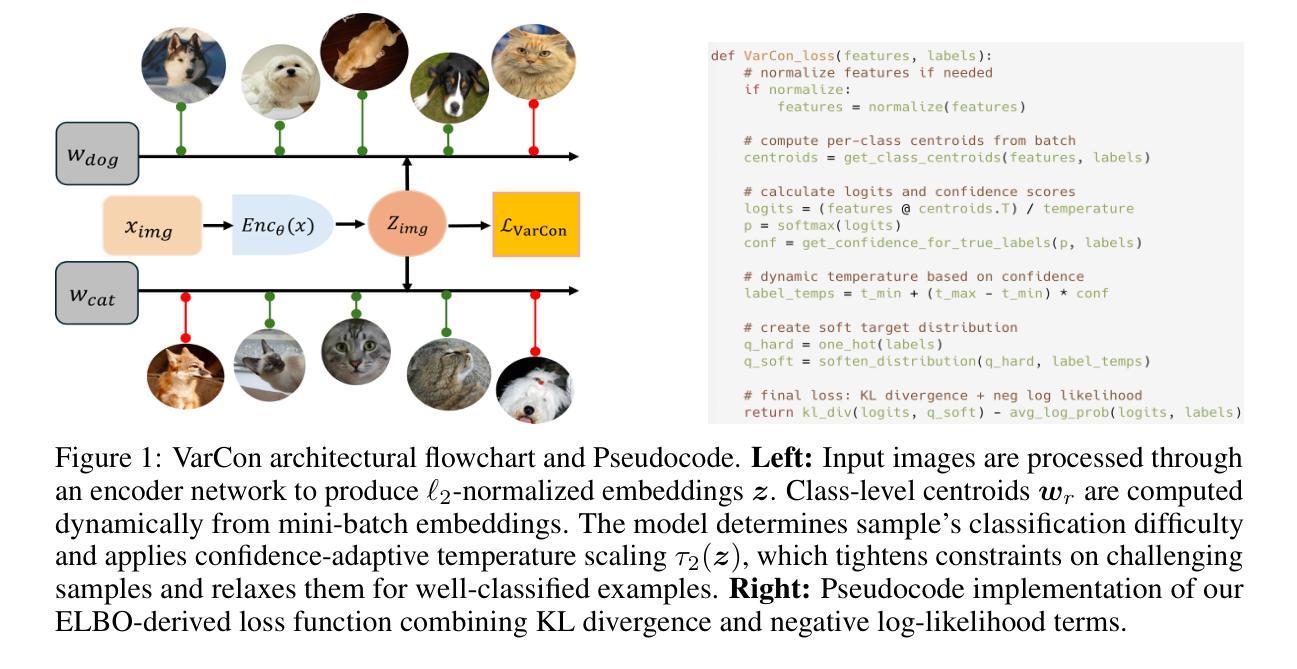
Variational Supervised Contrastive Learning
Authors:Ziwen Wang, Jiajun Fan, Thao Nguyen, Heng Ji, Ge Liu
Contrastive learning has proven to be highly efficient and adaptable in shaping representation spaces across diverse modalities by pulling similar samples together and pushing dissimilar ones apart. However, two key limitations persist: (1) Without explicit regulation of the embedding distribution, semantically related instances can inadvertently be pushed apart unless complementary signals guide pair selection, and (2) excessive reliance on large in-batch negatives and tailored augmentations hinders generalization. To address these limitations, we propose Variational Supervised Contrastive Learning (VarCon), which reformulates supervised contrastive learning as variational inference over latent class variables and maximizes a posterior-weighted evidence lower bound (ELBO) that replaces exhaustive pair-wise comparisons for efficient class-aware matching and grants fine-grained control over intra-class dispersion in the embedding space. Trained exclusively on image data, our experiments on CIFAR-10, CIFAR-100, ImageNet-100, and ImageNet-1K show that VarCon (1) achieves state-of-the-art performance for contrastive learning frameworks, reaching 79.36% Top-1 accuracy on ImageNet-1K and 78.29% on CIFAR-100 with a ResNet-50 encoder while converging in just 200 epochs; (2) yields substantially clearer decision boundaries and semantic organization in the embedding space, as evidenced by KNN classification, hierarchical clustering results, and transfer-learning assessments; and (3) demonstrates superior performance in few-shot learning than supervised baseline and superior robustness across various augmentation strategies.
对比学习已证明在多种模态下构建表示空间时具有高效和适应性。它通过把相似的样本拉在一起并将不相似的样本推开。然而,存在两个主要局限:
(1)没有明确的嵌入分布规则,除非有补充信号引导配对选择,语义上相关的实例可能会无意中分开;
论文及项目相关链接
Summary
本文介绍了对比学习在多样模态中的表现,其通过将相似样本拉近并将不同样本推开,展现出高效和适应性。然而,存在两个主要限制。为解决这个问题,我们提出了变分监督对比学习(VarCon),将其重新表述为潜在类别变量的变分推断,并最大化后验加权证据下限(ELBO),以在嵌入空间中实现高效的类感知匹配并控制类内离散。实验结果显示,VarCon在图像数据上训练,达到了对比学习框架的最先进性能,如CIFAR-10、CIFAR-100、ImageNet-100和ImageNet-1K数据集上的高准确率,并在少量学习情况下表现出卓越性能和各种增强策略的稳健性。
Key Takeaways
- 对比学习通过拉近相似样本并推开不同样本,在多样模态中展现出高效和适应性。
- 缺乏对嵌入分布明确规定的对比学习可能会无意中把语义相关的实例推开,除非有互补信号指导配对选择。
- 变分监督对比学习(VarCon)通过变分推断在潜在类别变量中重新表述监督对比学习,并最大化后验加权证据下限(ELBO),以在嵌入空间中实现高效的类感知匹配和类内离散控制。
- VarCon在各种数据集上取得了先进的性能,包括CIFAR-10、CIFAR-100、ImageNet-100和ImageNet-1K。
- VarCon达到了79.36%的ImageNet-1K和78.29%的CIFAR-100的顶部-1准确率,并在仅200个周期内收敛。
- VarCon在嵌入空间中产生了更清晰决策边界和语义组织,这由KNN分类、层次聚类结果和迁移学习评估所证明。
点此查看论文截图

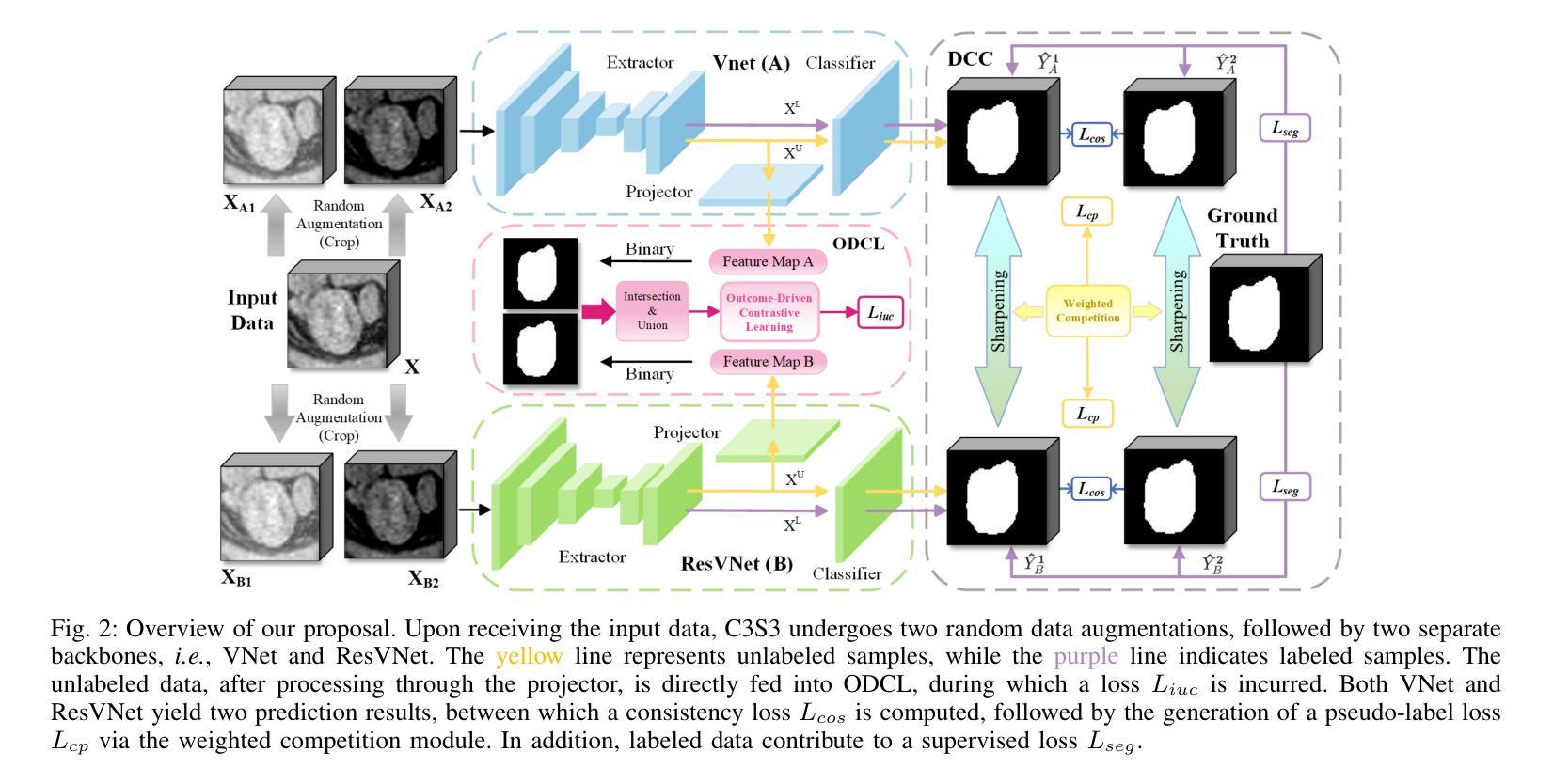
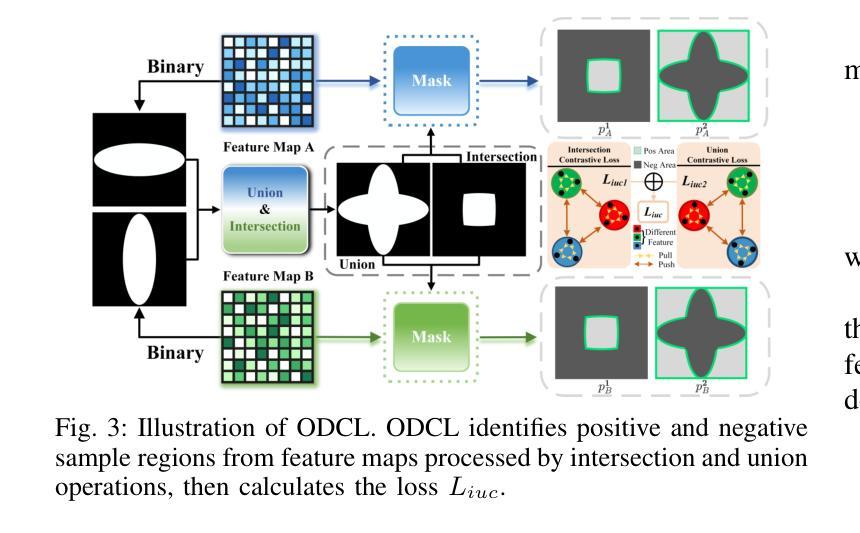
C3S3: Complementary Competition and Contrastive Selection for Semi-Supervised Medical Image Segmentation
Authors:Jiaying He, Yitong Lin, Jiahe Chen, Honghui Xu, Jianwei Zheng
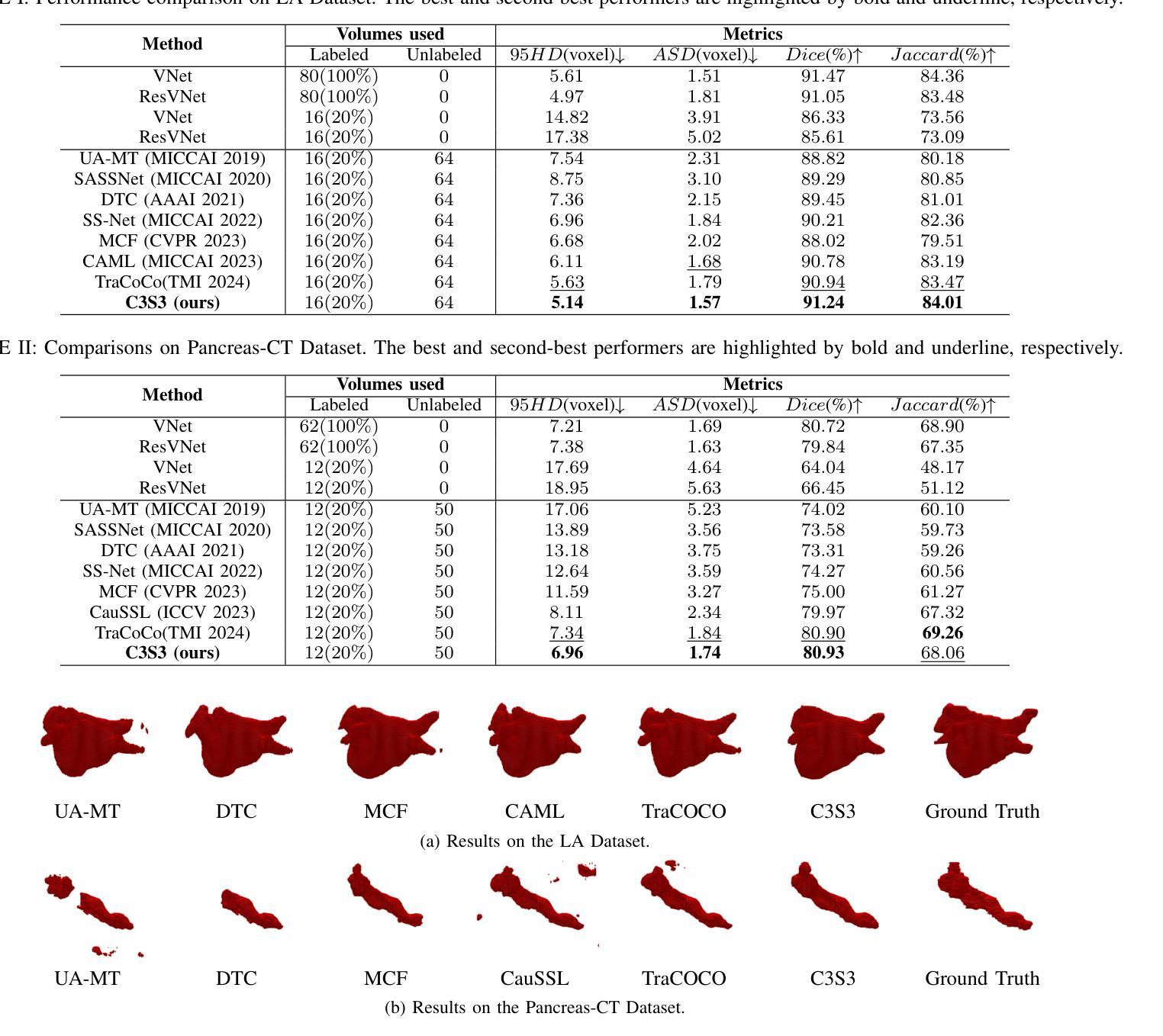
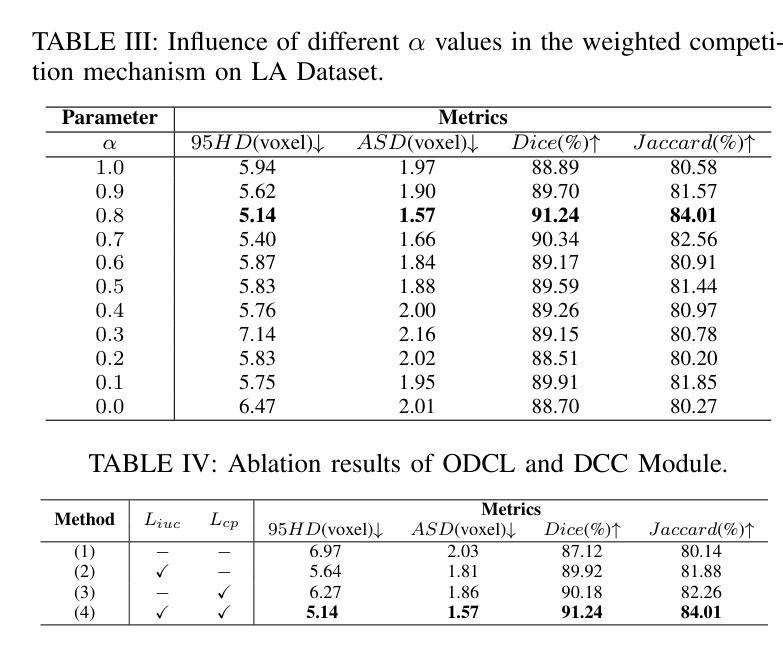
For the immanent challenge of insufficiently annotated samples in the medical field, semi-supervised medical image segmentation (SSMIS) offers a promising solution. Despite achieving impressive results in delineating primary target areas, most current methodologies struggle to precisely capture the subtle details of boundaries. This deficiency often leads to significant diagnostic inaccuracies. To tackle this issue, we introduce C3S3, a novel semi-supervised segmentation model that synergistically integrates complementary competition and contrastive selection. This design significantly sharpens boundary delineation and enhances overall precision. Specifically, we develop an $\textit{Outcome-Driven Contrastive Learning}$ module dedicated to refining boundary localization. Additionally, we incorporate a $\textit{Dynamic Complementary Competition}$ module that leverages two high-performing sub-networks to generate pseudo-labels, thereby further improving segmentation quality. The proposed C3S3 undergoes rigorous validation on two publicly accessible datasets, encompassing the practices of both MRI and CT scans. The results demonstrate that our method achieves superior performance compared to previous cutting-edge competitors. Especially, on the 95HD and ASD metrics, our approach achieves a notable improvement of at least $6%$, highlighting the significant advancements. The code is available at https://github.com/Y-TARL/C3S3.
针对医学领域标注样本不足这一迫在眉睫的挑战,半监督医学图像分割(SSMIS)提供了一个前景光明的解决方案。尽管在勾勒主要目标区域方面取得了令人印象深刻的结果,但大多数当前的方法都难以精确捕捉边界的细微细节。这种缺陷往往导致诊断出现重大误差。为了解决这个问题,我们引入了C3S3,这是一种新型的半监督分割模型,它协同整合了互补竞争和对比选择。这种设计显著提高了边界的勾勒清晰度,并提高了整体的精确度。具体来说,我们开发了一个专门的“结果驱动对比学习”模块,用于改进边界定位。此外,我们加入了一个“动态互补竞争”模块,该模块利用两个高性能子网络生成伪标签,从而进一步提高分割质量。所提出的C3S3在两个公开数据集上进行了严格验证,涵盖了MRI和CT扫描的实践。结果表明,我们的方法相较于先前的顶尖竞争对手取得了优越的性能。特别是,在95HD和ASD指标上,我们的方法取得了至少6%的显著改善,突显了显著的进步。代码可访问于https://github.com/Y-TARL/C3S
论文及项目相关链接
PDF 6 pages, 4 figures, ICME2025
Summary
半监督医学图像分割(SSMIS)面临边界细节捕捉不精确的问题,导致诊断不准确。为解决此问题,提出新型半监督分割模型C3S3,融合互补竞争与对比选择机制,优化边界描绘并提升整体精度。开发成果导向对比学习模块和动态互补竞争模块,利用两个高性能子网络生成伪标签,进一步提升分割质量。C3S3在MRI和CT扫描的公开数据集上验证,较前沿方法性能更优,特别是在95HD和ASD指标上改进至少6%。代码已公开。
Key Takeaways
- 半监督医学图像分割面临诊断不准确的挑战,尤其是边界细节捕捉不精确的问题。
- C3S3模型融合互补竞争与对比选择机制,以优化边界描绘并提升整体精度。
- 开发成果导向对比学习模块,致力于改进边界定位。
- 动态互补竞争模块利用两个高性能子网络生成伪标签,进一步提升分割质量。
- C3S3在MRI和CT扫描的公开数据集上验证,性能优于前沿方法。
- 在关键指标95HD和ASD上,C3S3实现了至少6%的显著改进。
点此查看论文截图

Representation Decomposition for Learning Similarity and Contrastness Across Modalities for Affective Computing
Authors:Yuanhe Tian, Pengsen Cheng, Guoqing Jin, Lei Zhang, Yan Song
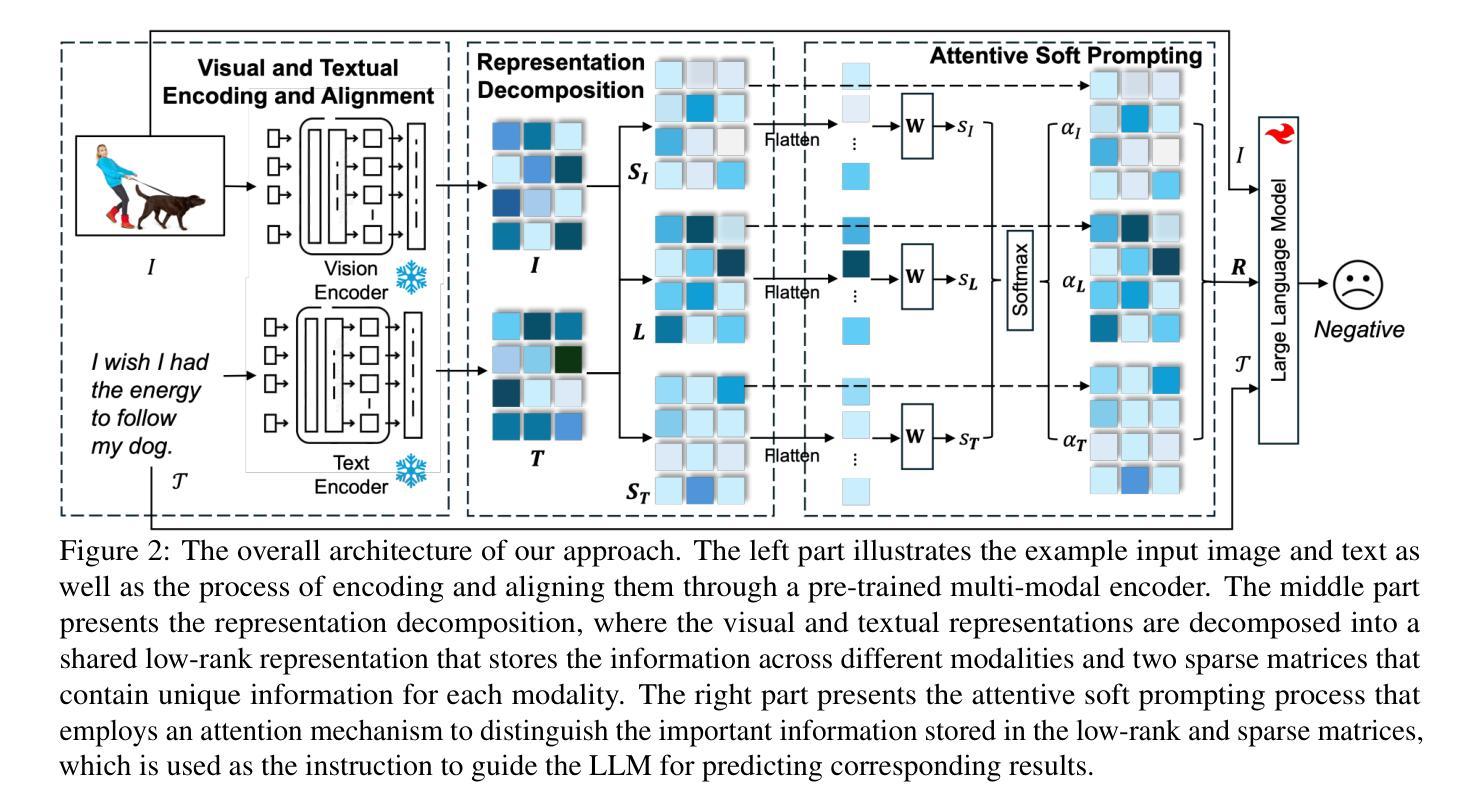
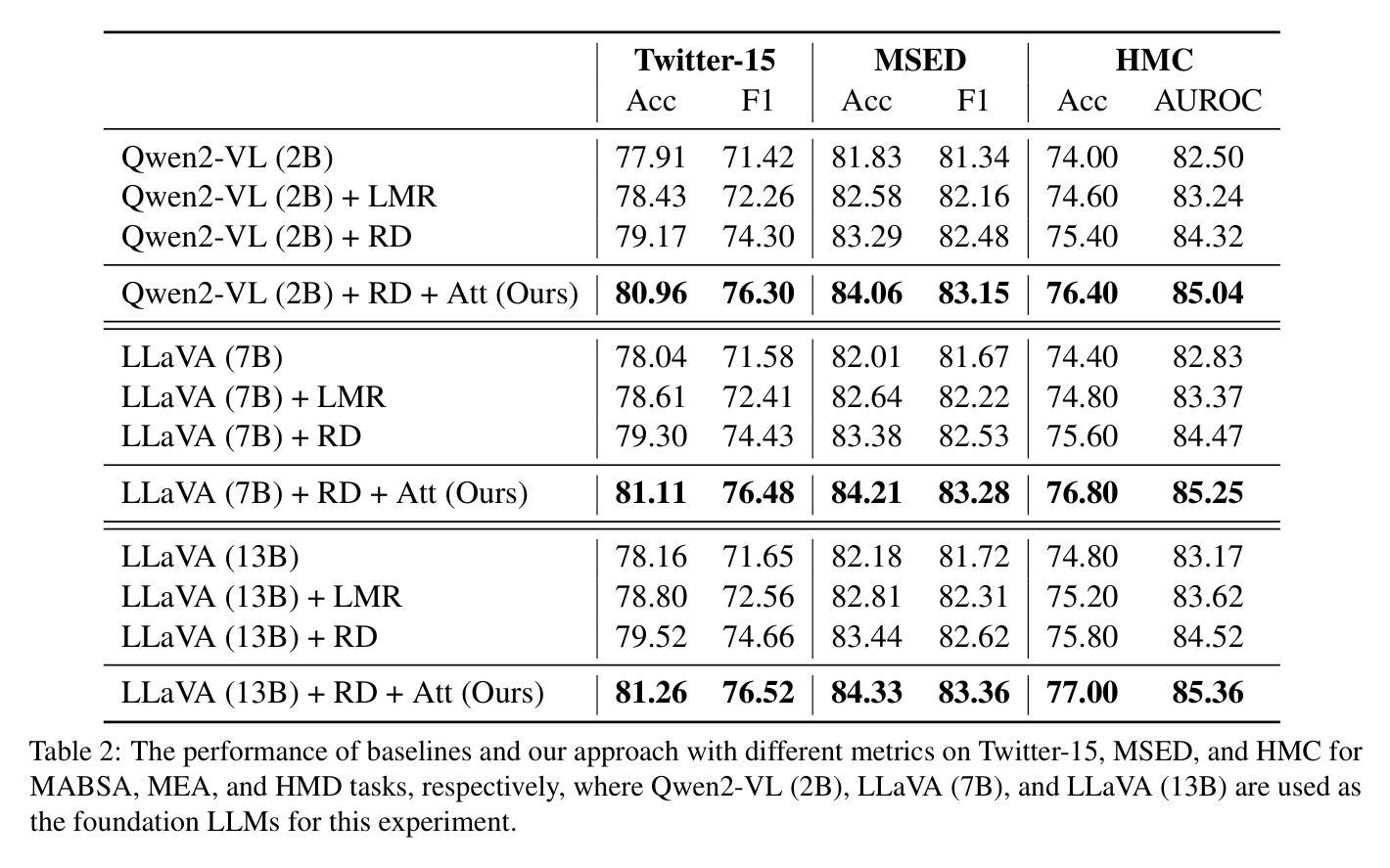
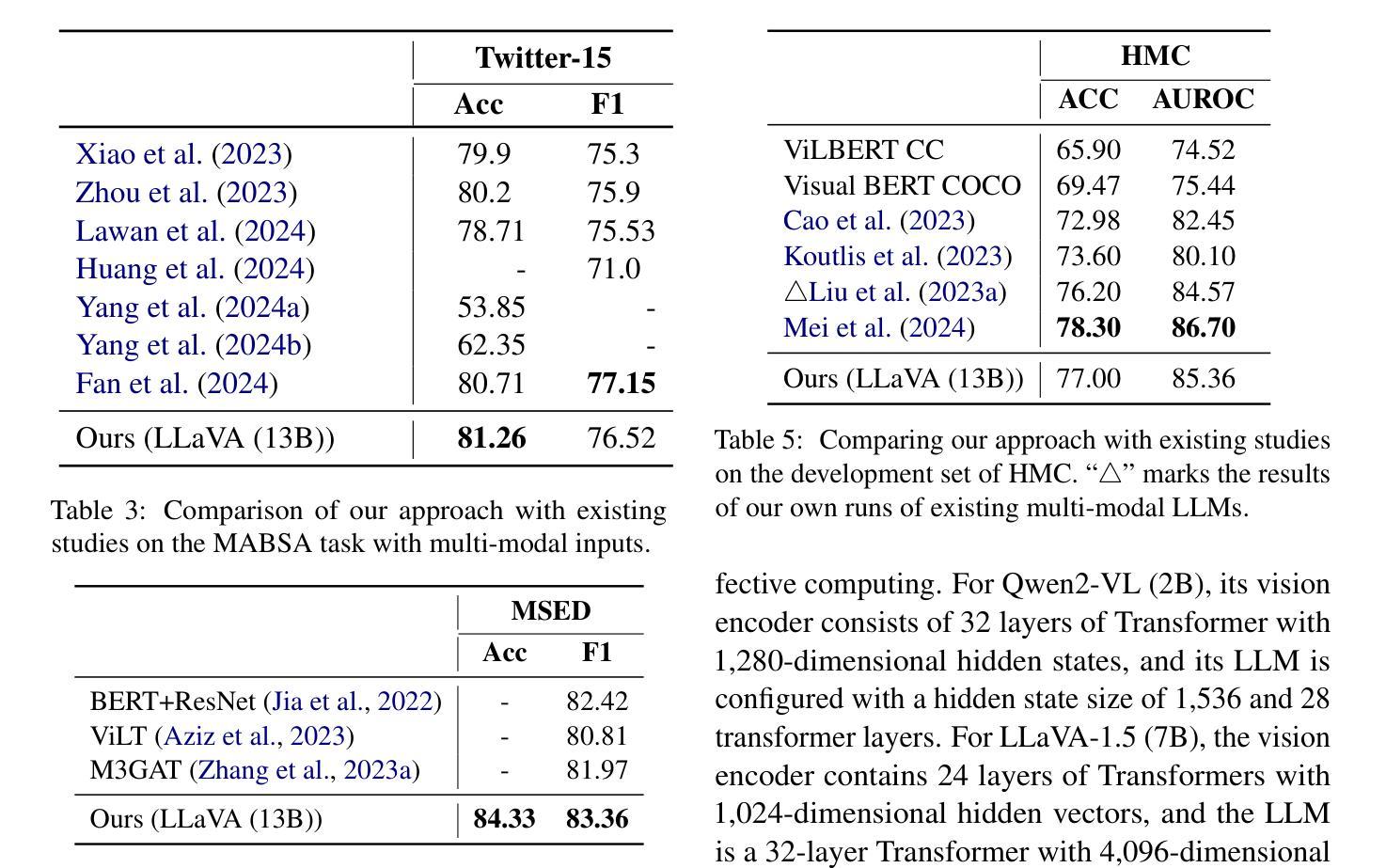
Multi-modal affective computing aims to automatically recognize and interpret human attitudes from diverse data sources such as images and text, thereby enhancing human-computer interaction and emotion understanding. Existing approaches typically rely on unimodal analysis or straightforward fusion of cross-modal information that fail to capture complex and conflicting evidence presented across different modalities. In this paper, we propose a novel LLM-based approach for affective computing that explicitly deconstructs visual and textual representations into shared (modality-invariant) and modality-specific components. Specifically, our approach firstly encodes and aligns input modalities using pre-trained multi-modal encoders, then employs a representation decomposition framework to separate common emotional content from unique cues, and finally integrates these decomposed signals via an attention mechanism to form a dynamic soft prompt for a multi-modal LLM. Extensive experiments on three representative tasks for affective computing, namely, multi-modal aspect-based sentiment analysis, multi-modal emotion analysis, and hateful meme detection, demonstrate the effectiveness of our approach, which consistently outperforms strong baselines and state-of-the-art models.
多模态情感计算旨在从图像和文本等多种数据源自动识别和解释人类态度,从而增强人机交互和情感理解。现有方法通常依赖于单模态分析或跨模态信息的简单融合,无法捕获不同模态中呈现出的复杂和冲突证据。在本文中,我们提出了一种基于大型语言模型(LLM)的情感计算新方法,该方法显式地将视觉和文本表示分解为共享(模态不变)和模态特定组件。具体来说,我们的方法首先使用预训练的多模态编码器对输入模态进行编码和对齐,然后采用表示分解框架来分离通用的情感内容与独特的线索,最后通过注意力机制整合这些分解的信号,形成多模态LLM的动态软提示。在情感计算的三个代表性任务上的广泛实验,即基于多模态方面的情感分析、多模态情感分析和仇恨言论检测,证明了我们的方法的有效性,它始终优于强大的基准模型和最新模型。
论文及项目相关链接
PDF 13 pages, 4 figures
Summary
本文提出了一种基于多模态的大型语言模型的情感计算新方法。该方法首先通过预训练的多模态编码器对输入模态进行编码和比对,然后采用表示分解框架分离出共享情感内容和独特线索,最后通过注意力机制整合这些分解的信号,形成动态软提示,用于多模态大型语言模型。在三个具有代表性的情感计算任务上的实验证明,该方法持续超越强大的基准模型和最新模型。
Key Takeaways
- 多模态情感计算旨在从图像和文本等多种数据源中自动识别和解释人类情感,增强人机交互和情感理解。
- 现有方法通常依赖于单模态分析或跨模态信息的简单融合,无法捕捉不同模态之间复杂和相互矛盾的证据。
- 本文提出了一种基于大型语言模型(LLM)的情感计算方法,该方法明确地将视觉和文本表示分解为共享(模态不变)和模态特定组件。
- 该方法使用预训练的多模态编码器对输入模态进行编码和比对,并采用表示分解框架来分离情感内容和线索。
- 通过注意力机制整合分解的信号,形成动态软提示,用于多模态大型语言模型。
- 在三个具有代表性的情感计算任务上的实验证明该方法的有效性,包括多模态基于方面的情感分析、多模态情感分析和仇恨性表情包检测。
点此查看论文截图

CAST: Contrastive Adaptation and Distillation for Semi-Supervised Instance Segmentation
Authors:Pardis Taghavi, Tian Liu, Renjie Li, Reza Langari, Zhengzhong Tu
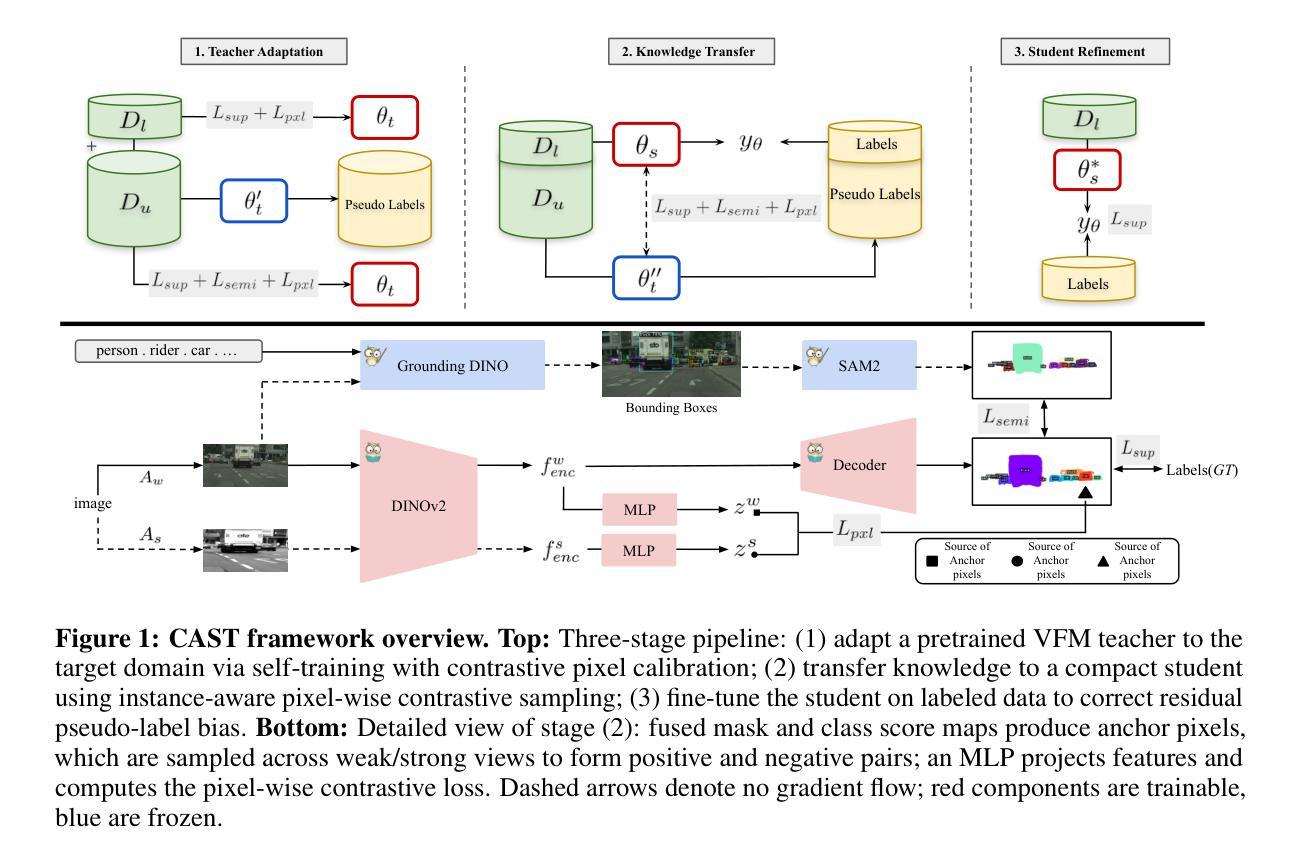
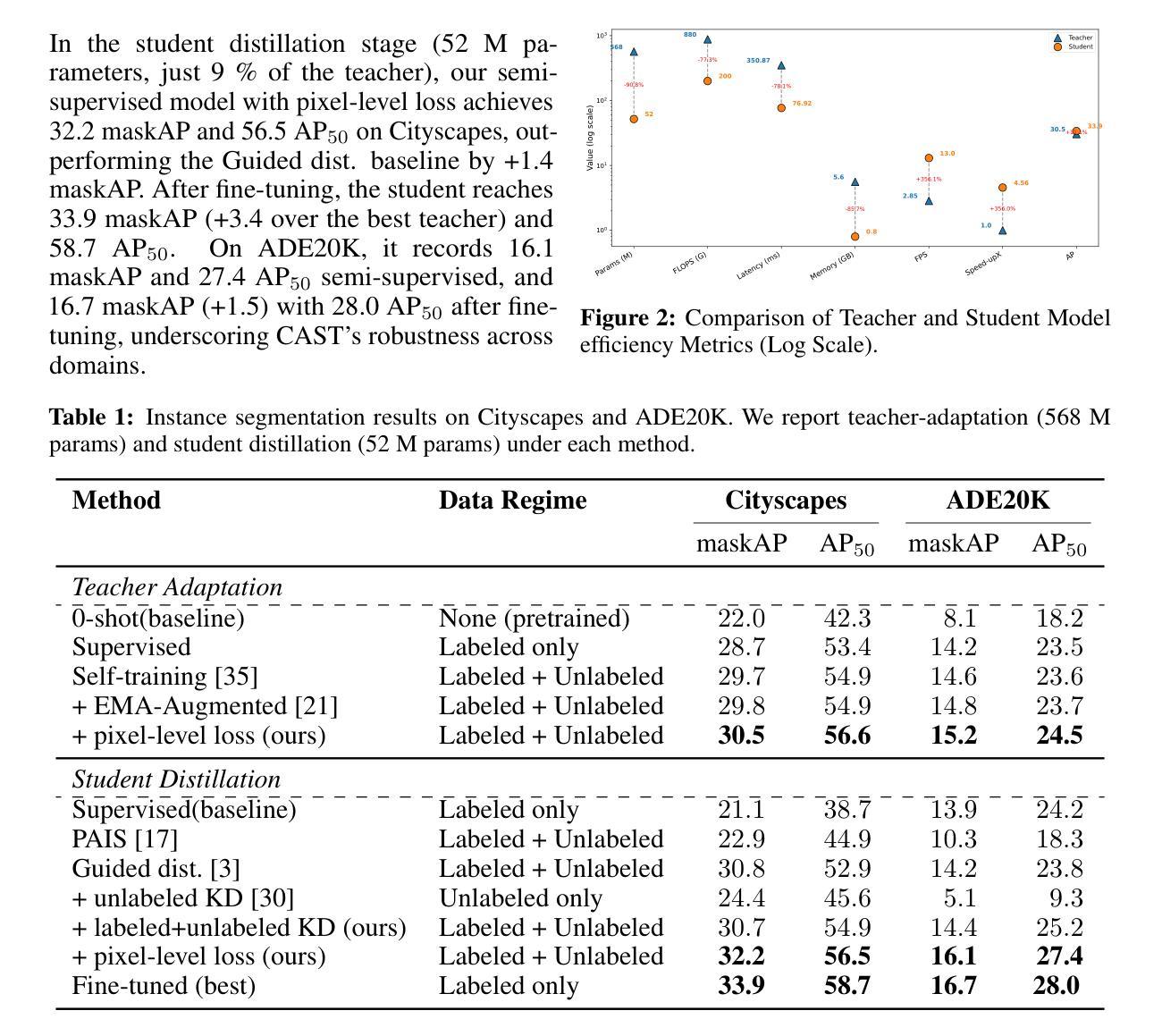
Instance segmentation demands costly per-pixel annotations and large models. We introduce CAST, a semi-supervised knowledge distillation (SSKD) framework that compresses pretrained vision foundation models (VFM) into compact experts using limited labeled and abundant unlabeled data. CAST unfolds in three stages: (1) domain adaptation of the VFM teacher(s) via self-training with contrastive pixel calibration, (2) distillation into a compact student via a unified multi-objective loss that couples standard supervision and pseudo-labels with our instance-aware pixel-wise contrastive term, and (3) fine-tuning on labeled data to remove residual pseudo-label bias. Central to CAST is an \emph{instance-aware pixel-wise contrastive loss} that fuses mask and class scores to mine informative negatives and enforce clear inter-instance margins. By maintaining this contrastive signal across both adaptation and distillation, we align teacher and student embeddings and fully leverage unlabeled images. On Cityscapes and ADE20K, our ~11X smaller student surpasses its adapted VFM teacher(s) by +3.4 AP (33.9 vs. 30.5) and +1.5 AP (16.7 vs. 15.2) and outperforms state-of-the-art semi-supervised approaches.
实例分割需要昂贵的逐像素标注和大型模型。我们引入了CAST,这是一种半监督知识蒸馏(SSKD)框架,它使用有限的标记数据和大量的无标记数据来压缩预训练的视觉基础模型(VFM)以形成紧凑的专家模型。CAST分为三个阶段:(1)通过对比像素校准进行自我训练,对VFM教师进行域适应;(2)通过统一的多目标损失来进行蒸馏,该损失将标准监督和伪标签与我们的实例感知像素级对比项相结合,对紧凑的学生模型进行蒸馏;(3)在标记数据上进行微调,以消除剩余的伪标签偏见。CAST的核心是实例感知像素级对比损失,它融合了掩膜和类分数来挖掘信息负样本并明确实例间的边界。通过在整个适应和蒸馏过程中保持对比信号,我们对齐教师和学生的嵌入,并充分利用无标签图像。在Cityscapes和ADE20K上,我们较小的~11倍学生模型超越了其适应的VFM教师模型,分别提高了+3.4 AP(从30.5到33.9)和+1.5 AP(从15.2到16.7),并优于最新的半监督方法。
论文及项目相关链接
Summary
该文本介绍了一种名为CAST的半监督知识蒸馏框架,它利用有限的标签数据和大量的无标签数据,将预训练的视觉基础模型压缩成紧凑的专家模型。该框架包括三个阶段:教师模型的域自适应、学生模型的蒸馏和在有标签数据上的微调。其核心是实例感知像素级对比损失,该损失融合了掩膜和类分数来挖掘负面信息并强制执行清晰的实例间边界。在Cityscapes和ADE20K数据集上,仅有学生模型大小的约十分之一,却超越了其适应的VFM教师模型,并超越了最新的半监督方法。
Key Takeaways
- CAST是一种半监督知识蒸馏框架,用于将预训练的视觉基础模型压缩成紧凑的专家模型。
- CAST包括三个阶段:教师模型的域自适应、学生模型的蒸馏和在有标签数据上的微调。
- CAST的核心是实例感知像素级对比损失,该损失融合了掩膜和类分数。
- 该损失旨在挖掘负面信息并强制执行清晰的实例间边界。
- CAST利用有限的标签数据和大量的无标签数据,通过对比信号进行适应和蒸馏,以充分利用无标签图像。
- 在Cityscapes和ADE20K数据集上,学生模型的表现超越了其教师模型,并达到了最新的半监督方法的水平。
点此查看论文截图

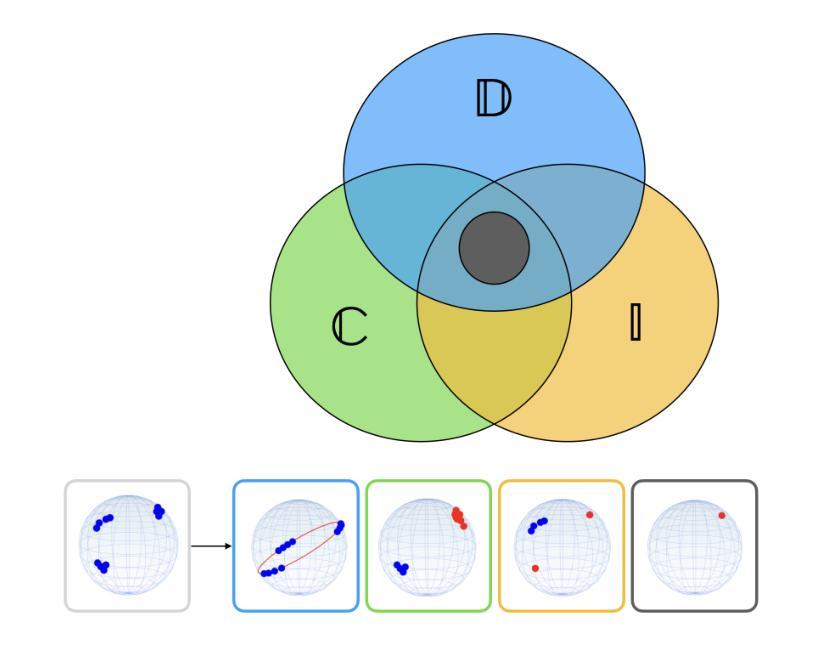
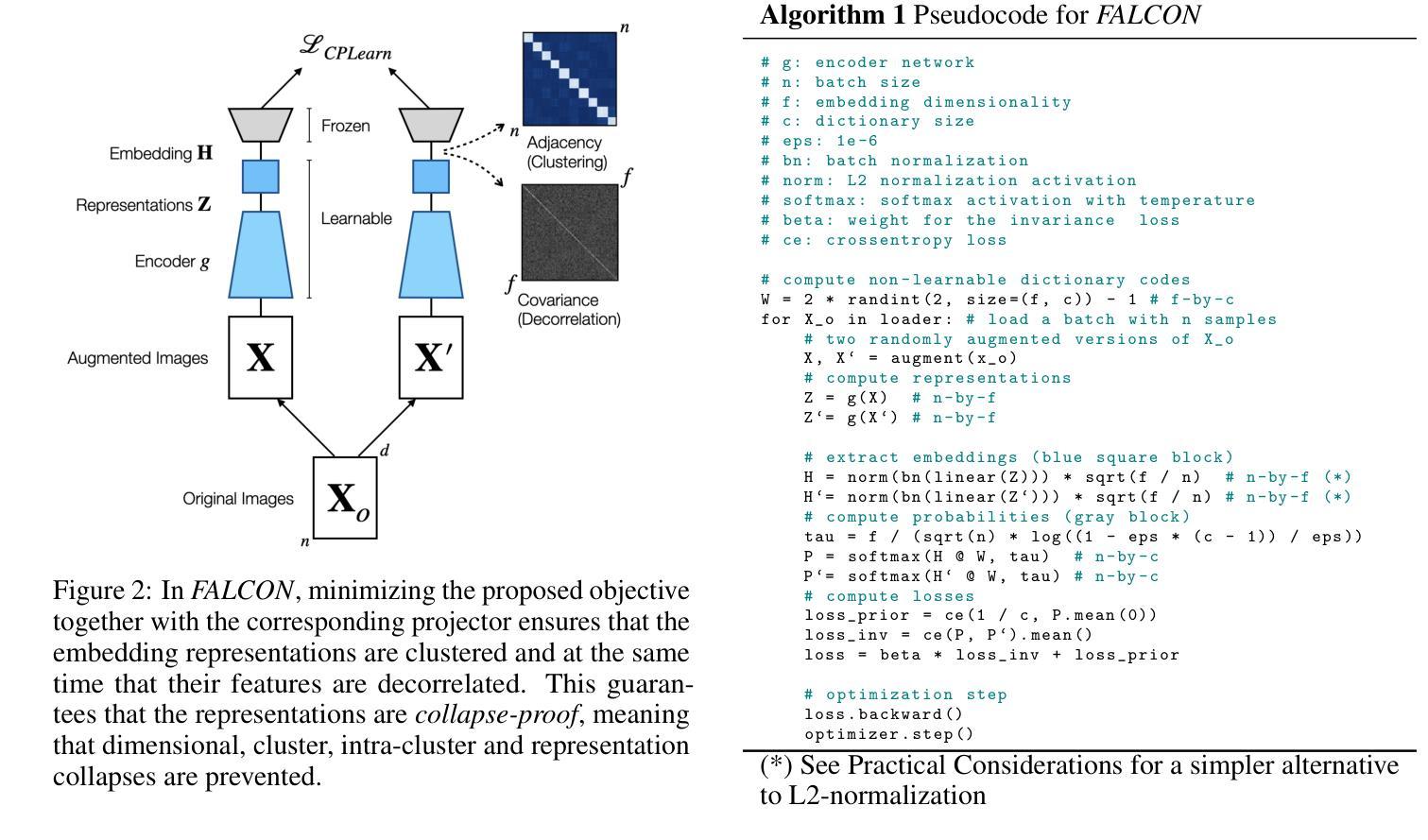
Collapse-Proof Non-Contrastive Self-Supervised Learning
Authors:Emanuele Sansone, Tim Lebailly, Tinne Tuytelaars
We present a principled and simplified design of the projector and loss function for non-contrastive self-supervised learning based on hyperdimensional computing. We theoretically demonstrate that this design introduces an inductive bias that encourages representations to be simultaneously decorrelated and clustered, without explicitly enforcing these properties. This bias provably enhances generalization and suffices to avoid known training failure modes, such as representation, dimensional, cluster, and intracluster collapses. We validate our theoretical findings on image datasets, including SVHN, CIFAR-10, CIFAR-100, and ImageNet-100. Our approach effectively combines the strengths of feature decorrelation and cluster-based self-supervised learning methods, overcoming training failure modes while achieving strong generalization in clustering and linear classification tasks.
我们提出了一种基于超维计算非对比性自监督学习的投影器和损失函数的设计原则及简化方案。从理论上讲,这种设计引入了一种归纳偏置,这种偏置鼓励表示同时去相关和聚类,而无需显式实施这些属性。这种偏置可以增强泛化能力,足以避免已知的训练失败模式,例如表示失败、维度失败、聚类失败和集群内部崩溃。我们在图像数据集上验证了我们的理论发现,包括SVHN、CIFAR-10、CIFAR-100和ImageNet-100。我们的方法有效地结合了特征去相关和基于聚类的自监督学习方法的优点,克服了训练失败的模式,在聚类和线性分类任务中实现了强大的泛化能力。
论文及项目相关链接
PDF ICML 2025
Summary
基于超维计算的非对比性自监督学习投影器和损失函数设计,通过理论证明该设计引入了归纳偏置,使表示同时去相关和聚类,无需显式执行这些属性。这种偏置可提高泛化能力,并避免已知的训练失败模式,如表示、维度、聚类和聚类内塌陷。在图像数据集上进行验证,包括SVHN、CIFAR-10、CIFAR-100和ImageNet-100。该方法结合了特征去相关和基于聚类的自监督学习的优势,克服训练失败模式,同时在聚类和线性分类任务中实现强大的泛化能力。
Key Takeaways
- 基于超维计算的非对比性自监督学习设计投影器和损失函数。
- 该设计引入了归纳偏置,使表示同时去相关和聚类。
- 无需显式执行去相关和聚类属性。
- 该偏置能提高模型的泛化能力。
- 该设计能避免训练过程中的多种失败模式,如表示、维度、聚类和聚类内塌陷。
- 在多个图像数据集上进行验证,包括SVHN、CIFAR-10、CIFAR-100和ImageNet-100。
点此查看论文截图