⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-11 更新
CyberV: Cybernetics for Test-time Scaling in Video Understanding
Authors:Jiahao Meng, Shuyang Sun, Yue Tan, Lu Qi, Yunhai Tong, Xiangtai Li, Longyin Wen
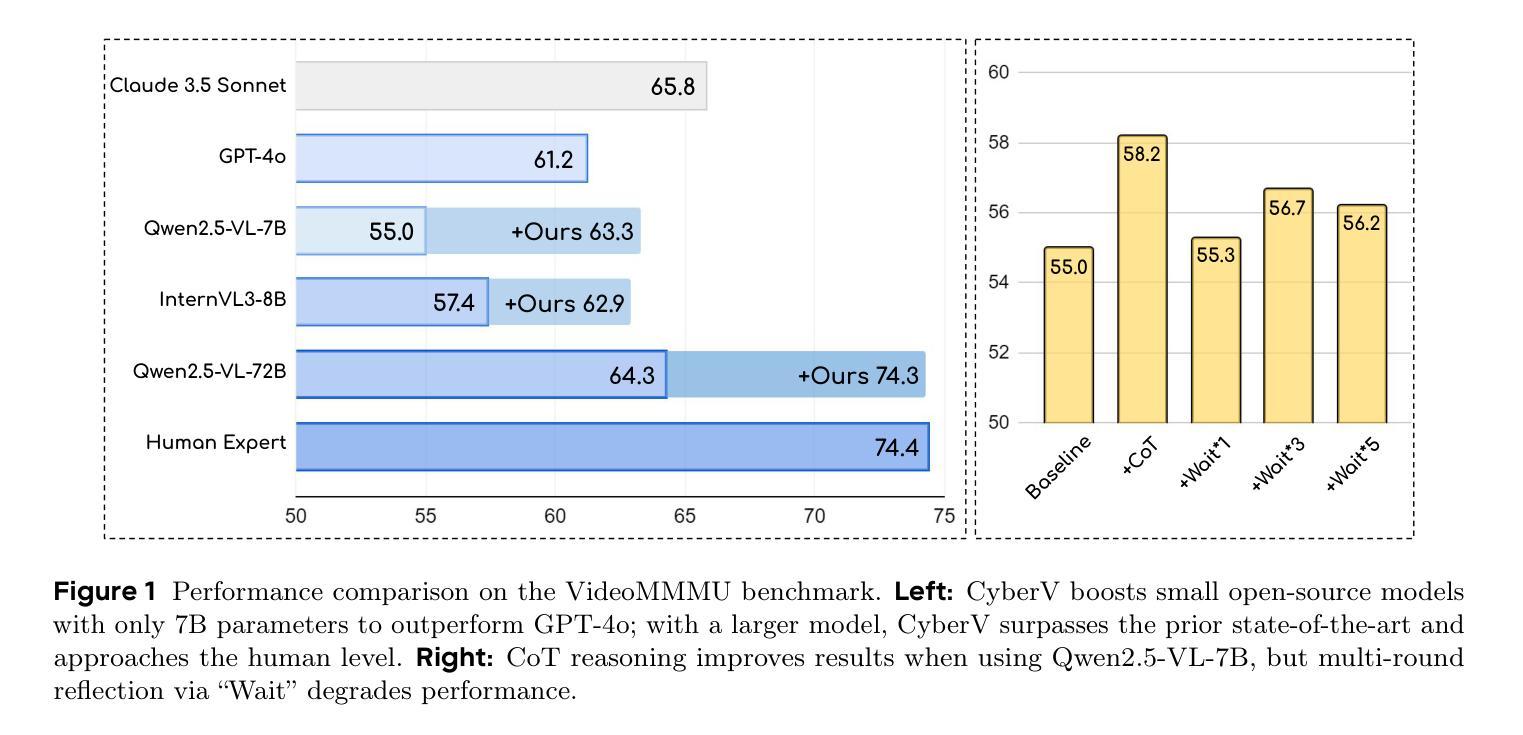
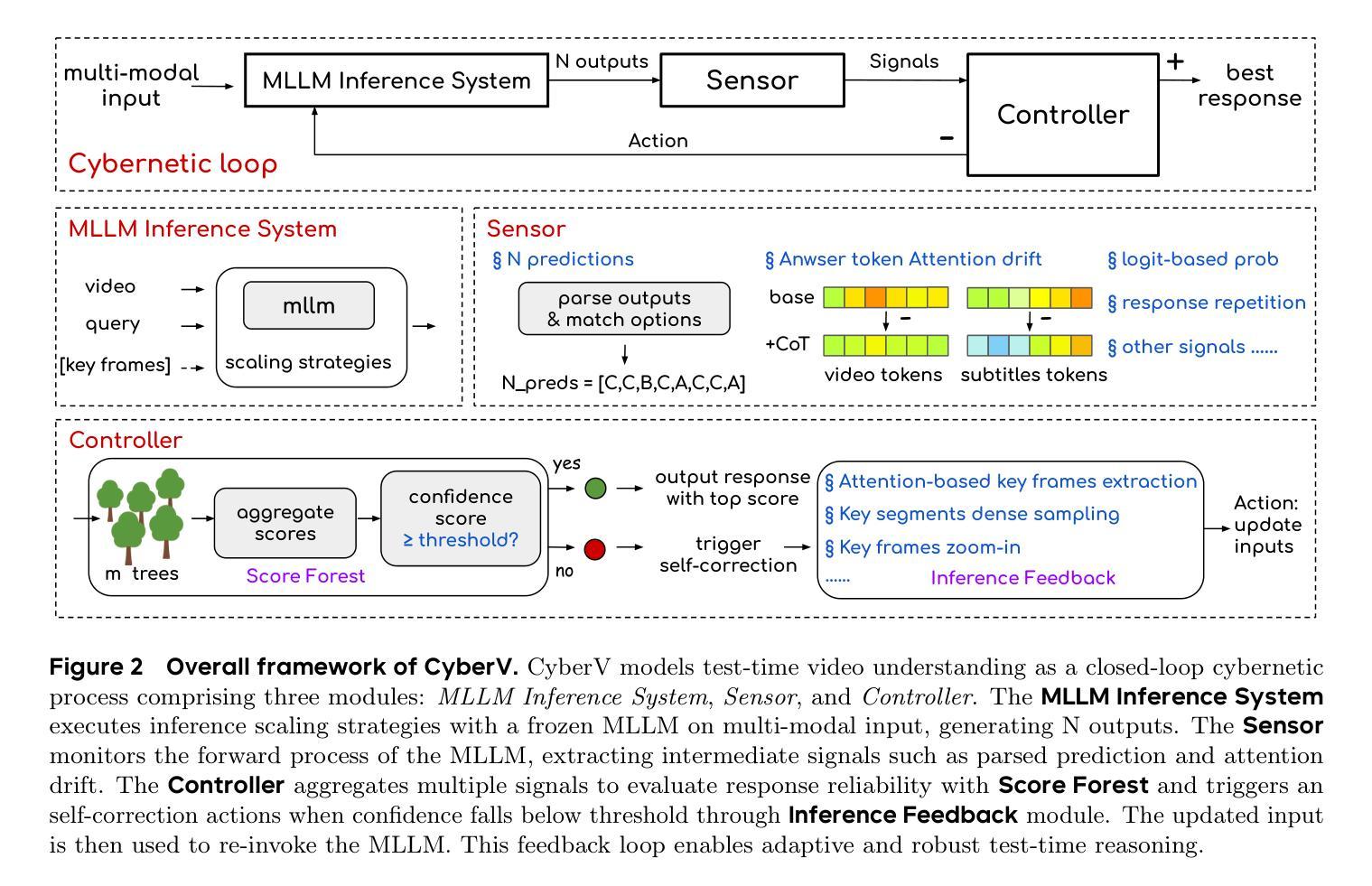
Current Multimodal Large Language Models (MLLMs) may struggle with understanding long or complex videos due to computational demands at test time, lack of robustness, and limited accuracy, primarily stemming from their feed-forward processing nature. These limitations could be more severe for models with fewer parameters. To address these limitations, we propose a novel framework inspired by cybernetic principles, redesigning video MLLMs as adaptive systems capable of self-monitoring, self-correction, and dynamic resource allocation during inference. Our approach, CyberV, introduces a cybernetic loop consisting of an MLLM Inference System, a Sensor, and a Controller. Specifically, the sensor monitors forward processes of the MLLM and collects intermediate interpretations, such as attention drift, then the controller determines when and how to trigger self-correction and generate feedback to guide the next round. This test-time adaptive scaling framework enhances frozen MLLMs without requiring retraining or additional components. Experiments demonstrate significant improvements: CyberV boosts Qwen2.5-VL-7B by 8.3% and InternVL3-8B by 5.5% on VideoMMMU, surpassing the competitive proprietary model GPT-4o. When applied to Qwen2.5-VL-72B, it yields a 10.0% improvement, achieving performance even comparable to human experts. Furthermore, our method demonstrates consistent gains on general-purpose benchmarks, such as VideoMME and WorldSense, highlighting its effectiveness and generalization capabilities in making MLLMs more robust and accurate for dynamic video understanding. The code is released at https://github.com/marinero4972/CyberV.
当前的多模态大型语言模型(MLLMs)由于测试时的计算需求、缺乏稳健性以及准确度有限,可能难以理解和处理长视频或复杂视频。这些限制主要源于其前馈处理性质。对于参数较少的模型,这些限制可能更加严重。为了解决这些限制,我们提出了一个受控制论启发的全新框架,重新设计视频MLLMs为自适应系统,在推理过程中能够进行自我监控、自我校正和动态资源配置。我们的方法CyberV引入了一个控制回路,包括MLLM推理系统、传感器和控制器。具体来说,传感器监控MLLM的前向过程并收集中间解释,如注意力漂移,然后控制器确定何时以及如何触发自我校正并生成反馈来引导下一轮。这种测试时自适应缩放框架提高了冻结的MLLMs的性能,而无需进行再训练或添加额外组件。实验表明有显著改善:CyberV在VideoMMMU上将Qwen2.5-VL-7B提升了8.3%,将InternVL3-8B提升了5.5%,超越了竞争性的专有模型GPT-4o。当应用于Qwen2.5-VL-72B时,它产生了10.0%的改进,其性能甚至可与人类专家相媲美。此外,我们的方法在通用基准测试(如VideoMME和Worldsense)上表现出一致的收益,这证明了其在使MLLMs对动态视频理解更加稳健和准确方面的有效性和通用性。代码已发布在https://github.com/marinero4972/CyberV。
论文及项目相关链接
摘要
当前的多模态大型语言模型在处理复杂或长视频时,由于测试时的计算需求大、缺乏稳健性以及准确度有限,往往表现不佳。这主要源于其前馈处理性质。对于参数较少的模型,这些限制可能更为严重。为解决这些问题,我们提出了一种受控制论启发的框架,将视频多模态大型语言模型重新设计为自适应系统,具备自我监控、自我校正和动态资源分配的能力。我们的方法CyberV引入了控制论循环,包括MLLM推理系统、传感器和控制器。传感器监控MLLM的前向过程并收集中间解释,如注意力漂移,然后控制器确定何时以及如何触发自我校正并生成反馈以指导下一轮。这种测试时的自适应缩放框架在不需重新训练或添加额外组件的情况下,提高了冻结的MLLM性能。实验表明,CyberV在VideoMMMU上提高了Qwen2.5-VL-7B和InternVL3-8B的性能,分别提高了8.3%和5.5%,超过了竞争性的专有模型GPT-4o。在应用于Qwen2.5-VL-7B时,实现了与人类专家相当的性能,提高了10.0%。此外,我们的方法在VideoMME和Worldsense等通用基准测试上也表现出一致的收益,证明了其在提高MLLM的稳健性和准确性,以及实现动态视频理解方面的有效性和泛化能力。相关代码已发布在https://github.com/marinero4972/CyberV。
关键见解
- 当前多模态大型语言模型在处理复杂或长视频时存在局限性,主要源于其前馈处理性质。
- 提出了一种基于控制论的框架CyberV,将视频MLLMs重新设计为自适应系统。
- CyberV通过引入控制论循环(包括MLLM推理系统、传感器和控制器),提高了模型的自我监控、自我校正和动态资源分配能力。
- 在多个实验和基准测试中,CyberV显著提高了MLLM的性能,包括在VideoMMMU上的Qwen2.5-VL-7B、InternVL3-8B以及General-Purpose Benchmarks上的表现。
- CyberV方法实现了与GPT-4o的竞争性能甚至超越其性能的表现。
- CyberV在不需重新训练或添加额外组件的情况下提高了模型的性能,表现出强大的实用性和潜力。
点此查看论文截图

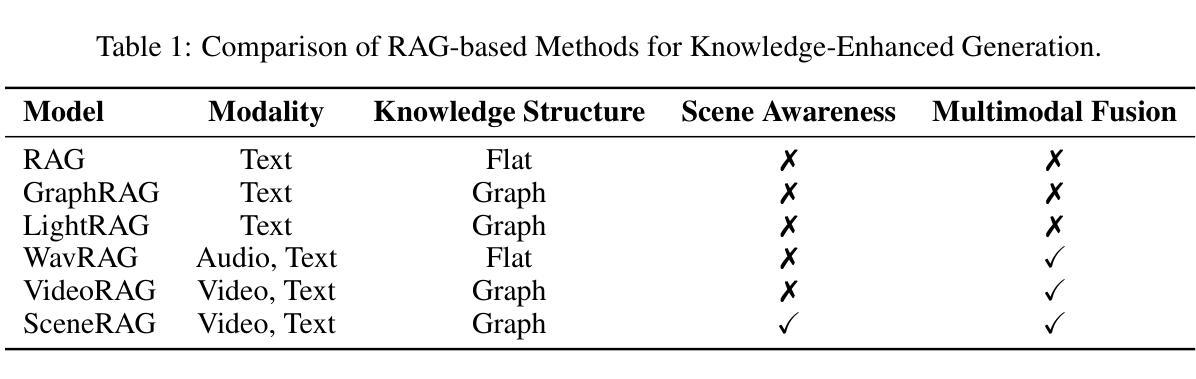
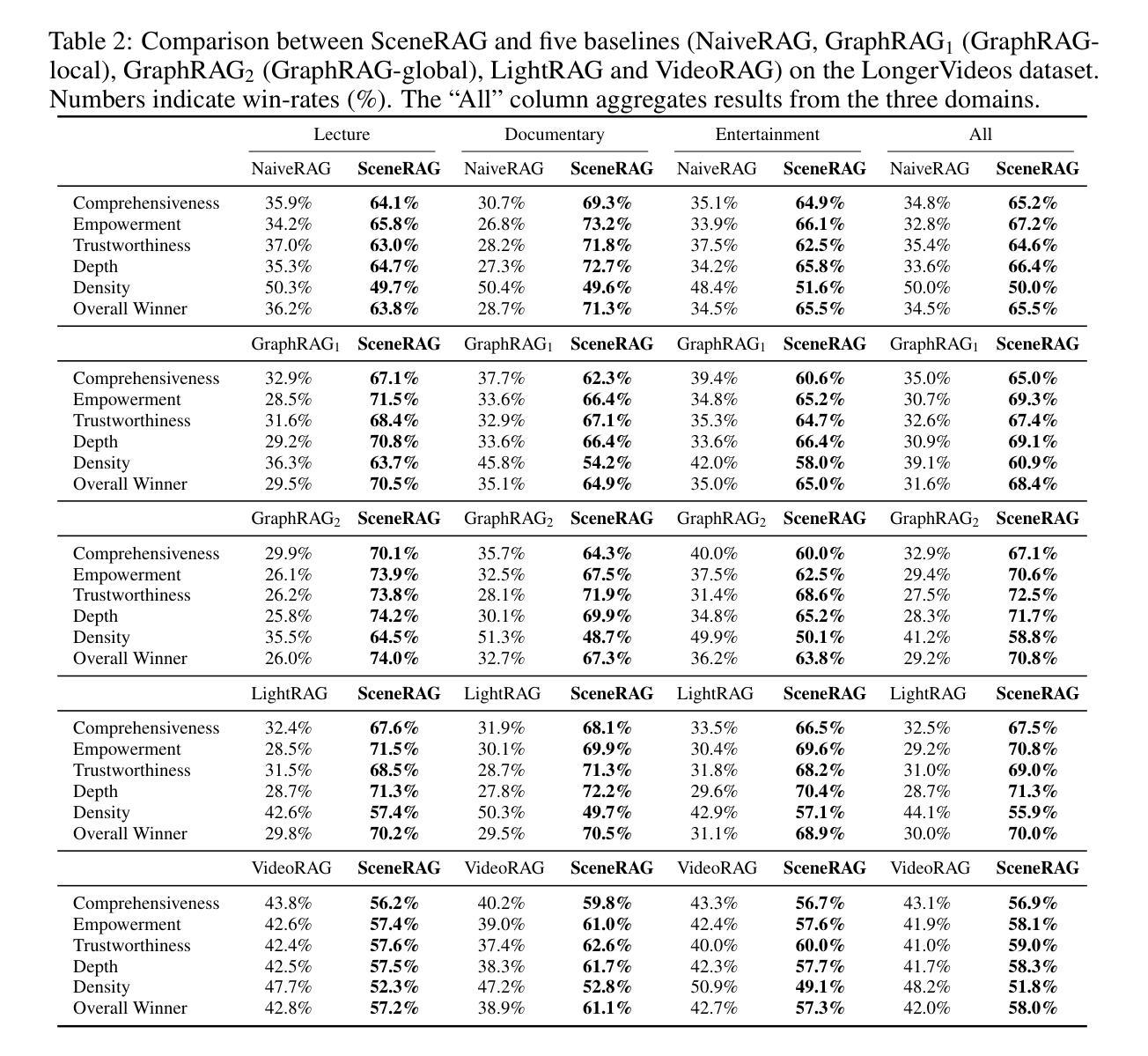
SceneRAG: Scene-level Retrieval-Augmented Generation for Video Understanding
Authors:Nianbo Zeng, Haowen Hou, Fei Richard Yu, Si Shi, Ying Tiffany He
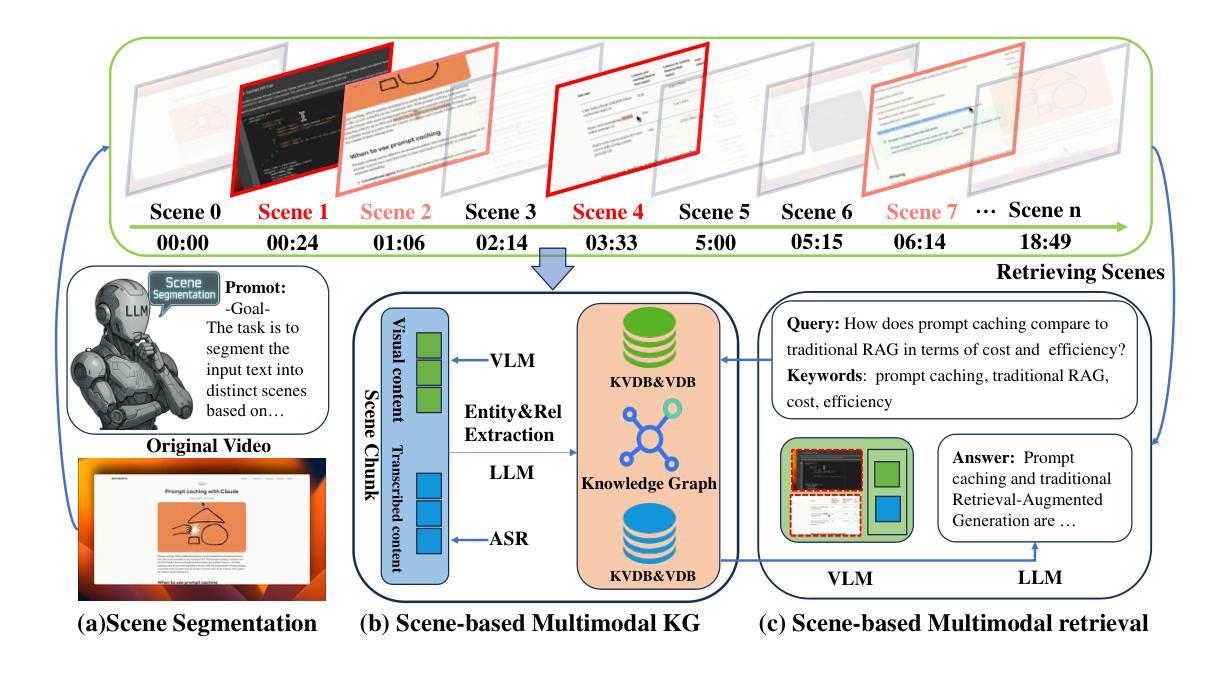
Despite recent advances in retrieval-augmented generation (RAG) for video understanding, effectively understanding long-form video content remains underexplored due to the vast scale and high complexity of video data. Current RAG approaches typically segment videos into fixed-length chunks, which often disrupts the continuity of contextual information and fails to capture authentic scene boundaries. Inspired by the human ability to naturally organize continuous experiences into coherent scenes, we present SceneRAG, a unified framework that leverages large language models to segment videos into narrative-consistent scenes by processing ASR transcripts alongside temporal metadata. SceneRAG further sharpens these initial boundaries through lightweight heuristics and iterative correction. For each scene, the framework fuses information from both visual and textual modalities to extract entity relations and dynamically builds a knowledge graph, enabling robust multi-hop retrieval and generation that account for long-range dependencies. Experiments on the LongerVideos benchmark, featuring over 134 hours of diverse content, confirm that SceneRAG substantially outperforms prior baselines, achieving a win rate of up to 72.5 percent on generation tasks.
尽管在视频理解的检索增强生成(RAG)方面最近有所进展,但由于视频数据的庞大规模和高度复杂性,有效理解长格式视频内容仍然缺乏足够的探索。当前的RAG方法通常将视频分割成固定长度的片段,这经常会破坏上下文信息的连续性,并且无法捕捉真实的场景边界。受到人类自然地将连续体验组织成连贯场景的能力的启发,我们提出了SceneRAG,这是一个利用大型语言模型通过处理ASR转录和临时元数据将视频分割成叙事一致场景的统框架。SceneRAG进一步通过轻量级启发式和迭代校正来锐化这些初始边界。对于每个场景,该框架融合来自视觉和文本模式的信息,提取实体关系并动态构建知识图谱,从而实现考虑长距离依赖的稳健的多跳检索和生成。在包含超过134小时多样化内容的长视频基准测试上的实验证实,SceneRAG显著优于先前的基线,在生成任务上的胜率高达72.5%。
论文及项目相关链接
Summary
视频理解领域虽然有所进展,但对长视频内容的理解仍然是一个挑战。本文提出SceneRAG框架,结合大型语言模型,利用语音识别转录和时序元数据将视频分割成连贯的场景,提高了视频理解的效果。SceneRAG通过轻量级启发式方法和迭代修正技术优化场景边界,为每个场景融合视觉和文本信息,提取实体关系并构建动态知识图谱,实现稳健的多跳检索和生成,解决了长距离依赖问题。在LongerVideos基准测试上的实验表明,SceneRAG显著优于先前基线,在生成任务上的胜率高达72.5%。
Key Takeaways
- 当前视频理解面临对长视频内容的挑战。
- SceneRAG框架结合了大型语言模型来提升视频理解效果。
- SceneRAG利用语音识别转录和时序元数据将视频分割成连贯的场景。
- SceneRAG通过优化场景边界来提高视频理解的准确性。
- 该框架为每个场景融合视觉和文本信息,提取实体关系。
- SceneRAG构建动态知识图谱,实现多跳检索和生成,解决长距离依赖问题。
点此查看论文截图

AdaReTaKe: Adaptive Redundancy Reduction to Perceive Longer for Video-language Understanding
Authors:Xiao Wang, Qingyi Si, Jianlong Wu, Shiyu Zhu, Li Cao, Liqiang Nie
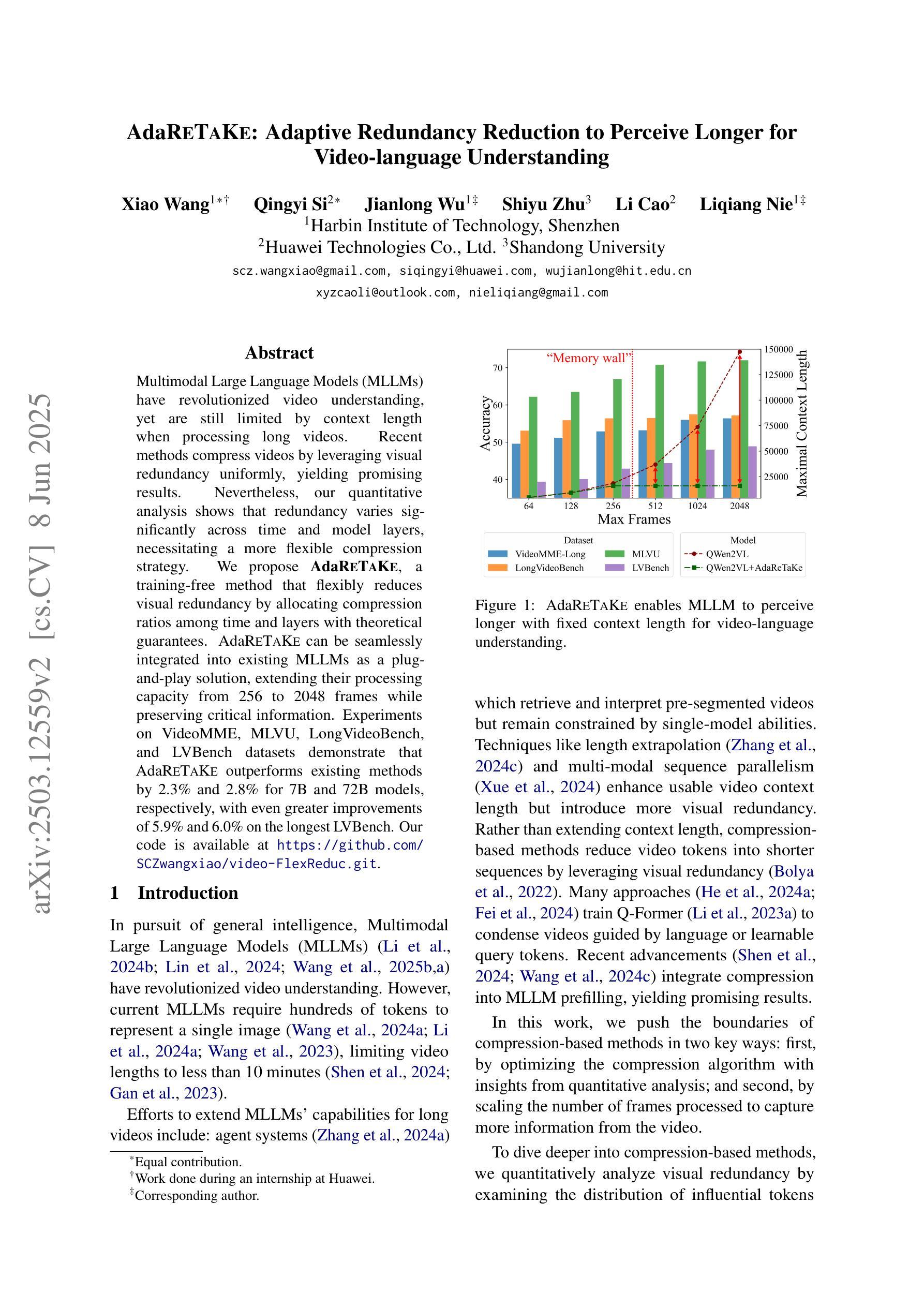
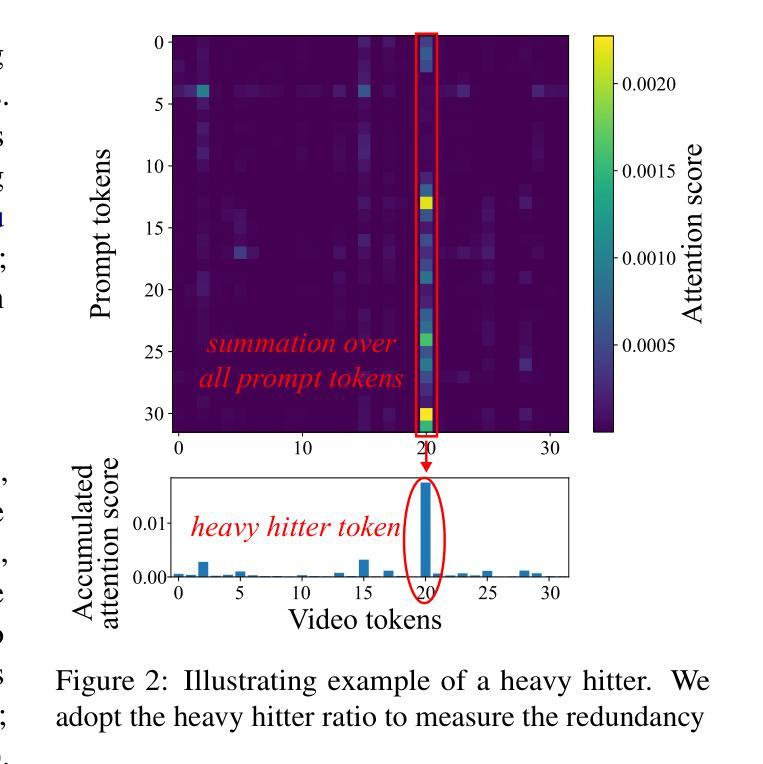
Multimodal Large Language Models (MLLMs) have revolutionized video understanding, yet are still limited by context length when processing long videos. Recent methods compress videos by leveraging visual redundancy uniformly, yielding promising results. Nevertheless, our quantitative analysis shows that redundancy varies significantly across time and model layers, necessitating a more flexible compression strategy. We propose AdaReTaKe, a training-free method that flexibly reduces visual redundancy by allocating compression ratios among time and layers with theoretical guarantees. Integrated into state-of-the-art MLLMs, AdaReTaKe improves processing capacity from 256 to 2048 frames while preserving critical information. Experiments on VideoMME, MLVU, LongVideoBench, and LVBench datasets demonstrate that AdaReTaKe outperforms existing methods by 2.3% and 2.8% for 7B and 72B models, respectively, with even greater improvements of 5.9% and 6.0% on the longest LVBench. Our code is available at https://github.com/SCZwangxiao/video-FlexReduc.git.
多模态大型语言模型(MLLMs)已经彻底改变了视频理解的方式,但在处理长视频时仍然受到上下文长度的限制。最近的方法通过统一利用视觉冗余来压缩视频,取得了令人鼓舞的结果。然而,我们的定量分析表明,冗余量在时间和模型层之间变化很大,因此需要更灵活的压缩策略。我们提出了AdaReTaKe,这是一种无需训练的方法,它可以通过在时间和层之间分配压缩比率来灵活地减少视觉冗余,并有理论保证。将AdaReTaKe集成到最新MLLMs中,可以在保持关键信息的同时,将处理容量从256帧提高到2048帧。在VideoMME、MLVU、LongVideoBench和LVBench数据集上的实验表明,AdaReTaKe优于现有方法,对于7B和72B模型的性能分别提高了2.3%和2.8%,在最长LVBench上的性能提高幅度更大,分别为5.9%和6.0%。我们的代码可通过https://github.com/SCZwangxiao/video-FlexReduc.git获取。
论文及项目相关链接
Summary
多模态大型语言模型在视频理解领域实现了革命性的进展,但在处理长视频时仍受限于上下文长度。最近的方法通过利用视觉冗余进行视频压缩,取得了一定的成果。然而,定量分析表明冗余性在时间层和模型层之间差异显著,需要更灵活的压缩策略。本研究提出了一种无需训练、灵活减少视觉冗余的AdaReTaKe方法,该方法通过分配时间和层之间的压缩比例来减少冗余性,并具备理论保证。集成到最先进的多模态大型语言模型中,AdaReTaKe将处理容量从256帧提高到2048帧,同时保留关键信息。在VideoMME、MLVU、LongVideoBench和LVBench数据集上的实验表明,AdaReTaKe较现有方法提高了2.3%和2.8%,对于最大的LVBench数据集,提高幅度更大,达到5.9%和6.0%。相关代码已公开于https://github.com/SCZwangxiao/video-FlexReduc.git。
Key Takeaways
- 多模态大型语言模型在视频理解上表现卓越,但处理长视频时受限于上下文长度。
- 现有视频压缩方法虽然有效,但冗余性在时间层和模型层之间存在显著差异。
- AdaReTaKe是一种无需训练的灵活压缩方法,能按需分配时间和层之间的压缩比例,减少视觉冗余。
- AdaReTaKe显著提高了视频处理容量,同时保留关键信息。
- 在多个数据集上的实验表明,AdaReTaKe较现有方法有明显提升。
- AdaReTaKe的改进幅度随视频长度的增加而增大。
点此查看论文截图

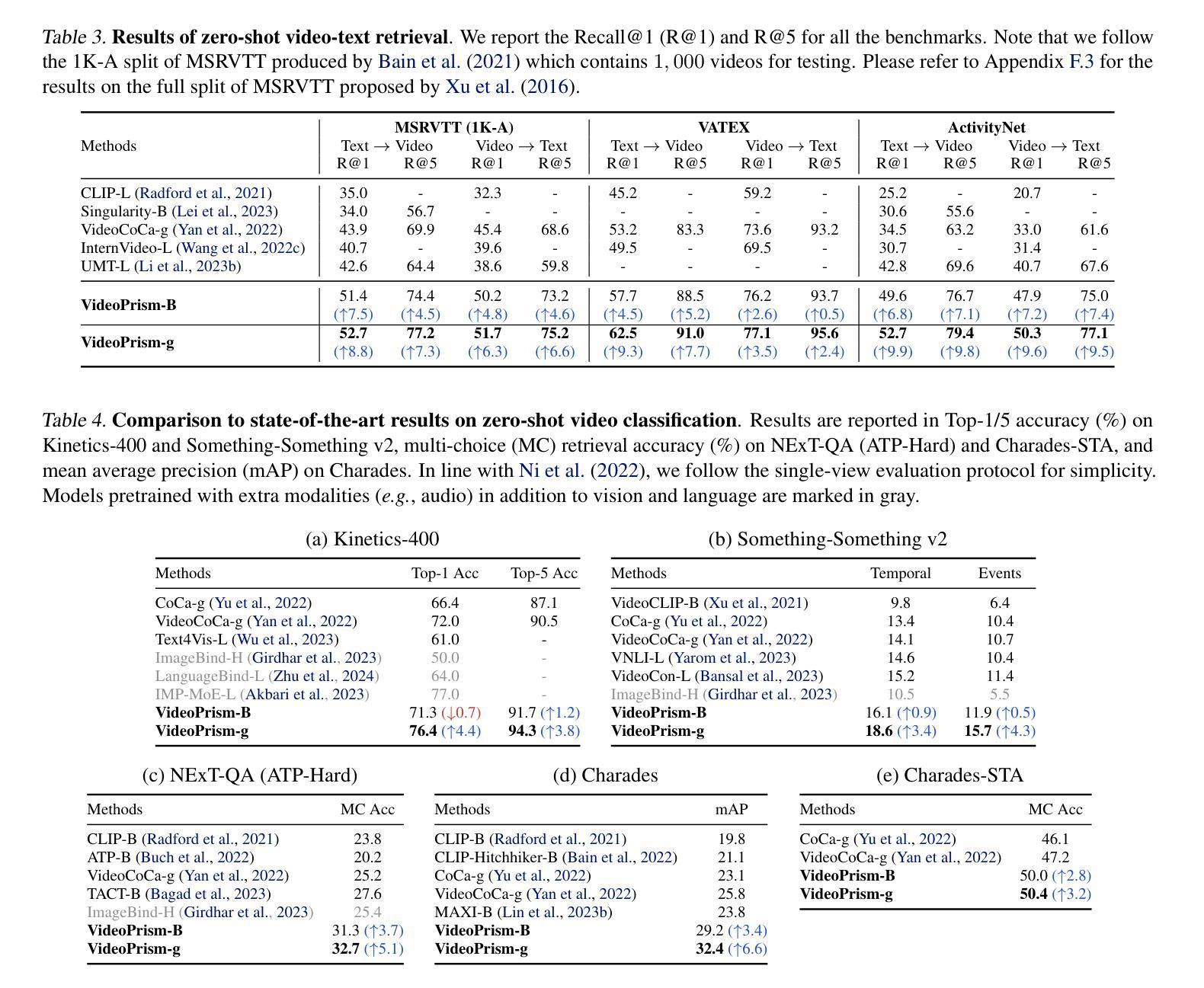
VideoPrism: A Foundational Visual Encoder for Video Understanding
Authors:Long Zhao, Nitesh B. Gundavarapu, Liangzhe Yuan, Hao Zhou, Shen Yan, Jennifer J. Sun, Luke Friedman, Rui Qian, Tobias Weyand, Yue Zhao, Rachel Hornung, Florian Schroff, Ming-Hsuan Yang, David A. Ross, Huisheng Wang, Hartwig Adam, Mikhail Sirotenko, Ting Liu, Boqing Gong
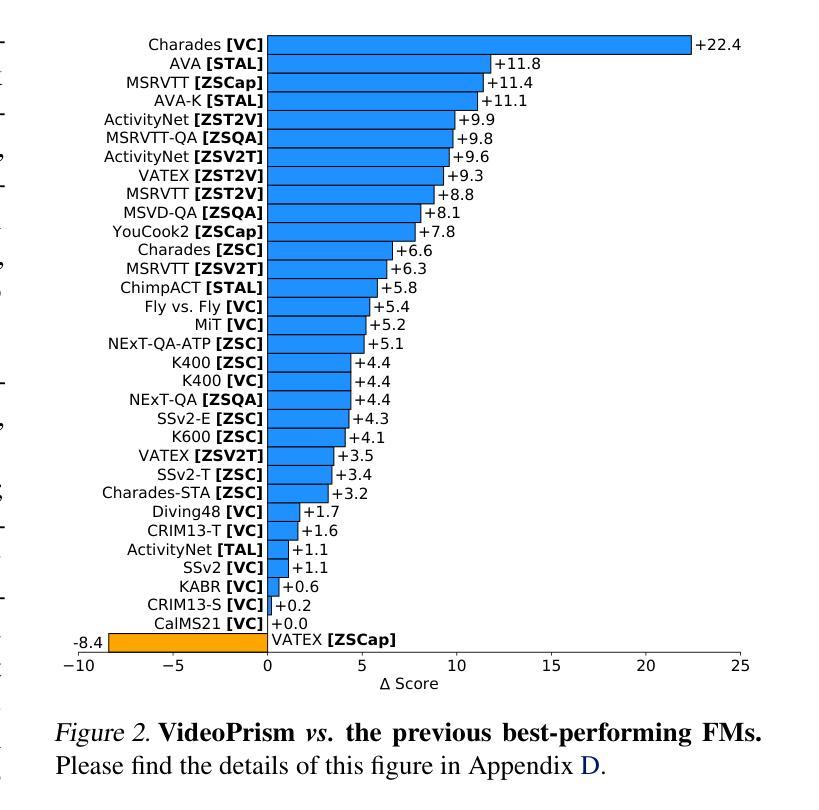
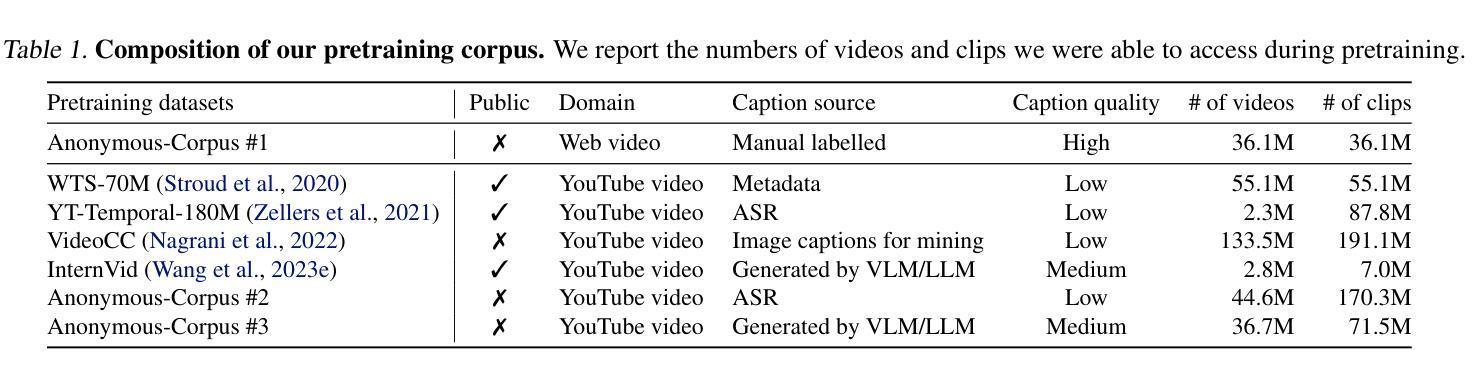
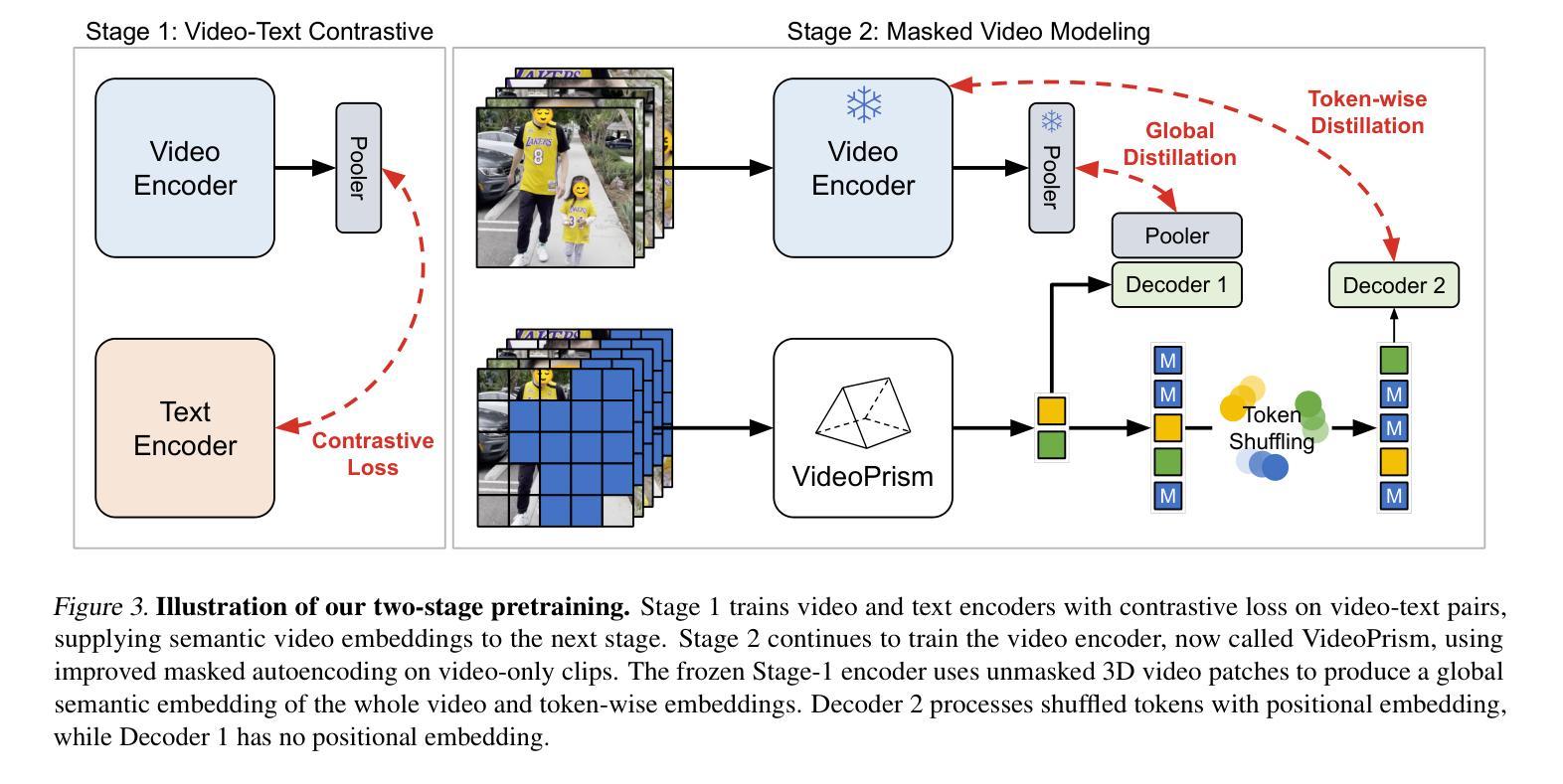
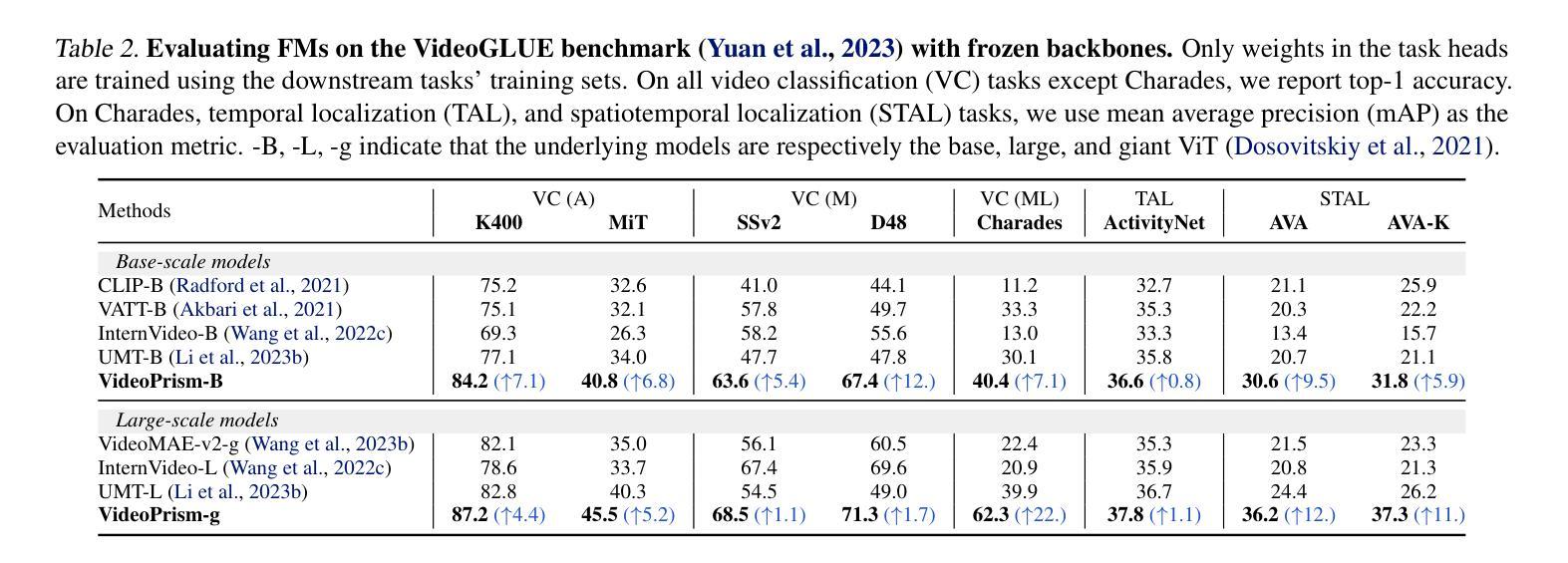
We introduce VideoPrism, a general-purpose video encoder that tackles diverse video understanding tasks with a single frozen model. We pretrain VideoPrism on a heterogeneous corpus containing 36M high-quality video-caption pairs and 582M video clips with noisy parallel text (e.g., ASR transcripts). The pretraining approach improves upon masked autoencoding by global-local distillation of semantic video embeddings and a token shuffling scheme, enabling VideoPrism to focus primarily on the video modality while leveraging the invaluable text associated with videos. We extensively test VideoPrism on four broad groups of video understanding tasks, from web video question answering to CV for science, achieving state-of-the-art performance on 31 out of 33 video understanding benchmarks. Our models are released at https://github.com/google-deepmind/videoprism.
我们介绍了VideoPrism,这是一种通用视频编码器,它使用单个冻结模型来解决各种视频理解任务。我们在包含3600万高质量视频字幕对和5.82亿带有噪声平行文本(例如ASR转录)的视频剪辑的异构语料库上预训练VideoPrism。预训练方法通过全局局部语义视频嵌入蒸馏和令牌打乱方案改进了掩码自动编码,使VideoPrism能够主要关注视频模式,同时利用与视频相关的宝贵文本。我们对VideoPrism进行了广泛的测试,测试内容包括从网络视频问答到科学计算机视觉等四大类视频理解任务,在33个视频理解基准测试中实现了31个最新性能表现。我们的模型发布在https://github.com/google-deepmind/videoprism。
论文及项目相关链接
PDF Accepted to ICML 2024. v2: added retrieval results on MSRVTT (1K-A), more data analyses, and ablation studies; v3: released models at https://github.com/google-deepmind/videoprism
Summary:谷歌DeepMind推出通用视频编码器VideoPrism,通过单一模型应对多种视频理解任务。VideoPrism在包含高质量视频字幕对和带有噪声的并行文本(如ASR转录)的异构语料库上进行预训练,改进了基于掩码的自动编码预训练方法。VideoPrism在广泛的视频理解任务上表现卓越,超越其他模型,实现了前沿性能。相关模型已发布在相关GitHub地址。
Key Takeaways:
- VideoPrism是一个通用视频编码器,适用于多种视频理解任务。
- VideoPrism在包含高质量视频字幕对和带有噪声的并行文本的异构语料库上进行预训练。
- VideoPrism改进了基于掩码的自动编码预训练方法,通过全球本地蒸馏语义视频嵌入和令牌打乱方案实现。
- VideoPrism能专注于视频模式,同时利用宝贵的视频文本信息。
- VideoPrism在广泛的视频理解任务上表现出卓越的性能,包括网络视频问答和计算机视觉科学等领域。
- VideoPrism在33个视频理解基准测试中,有31个达到业界最佳水平。
点此查看论文截图