⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-11 更新
GaussianVAE: Adaptive Learning Dynamics of 3D Gaussians for High-Fidelity Super-Resolution
Authors:Shuja Khalid, Mohamed Ibrahim, Yang Liu
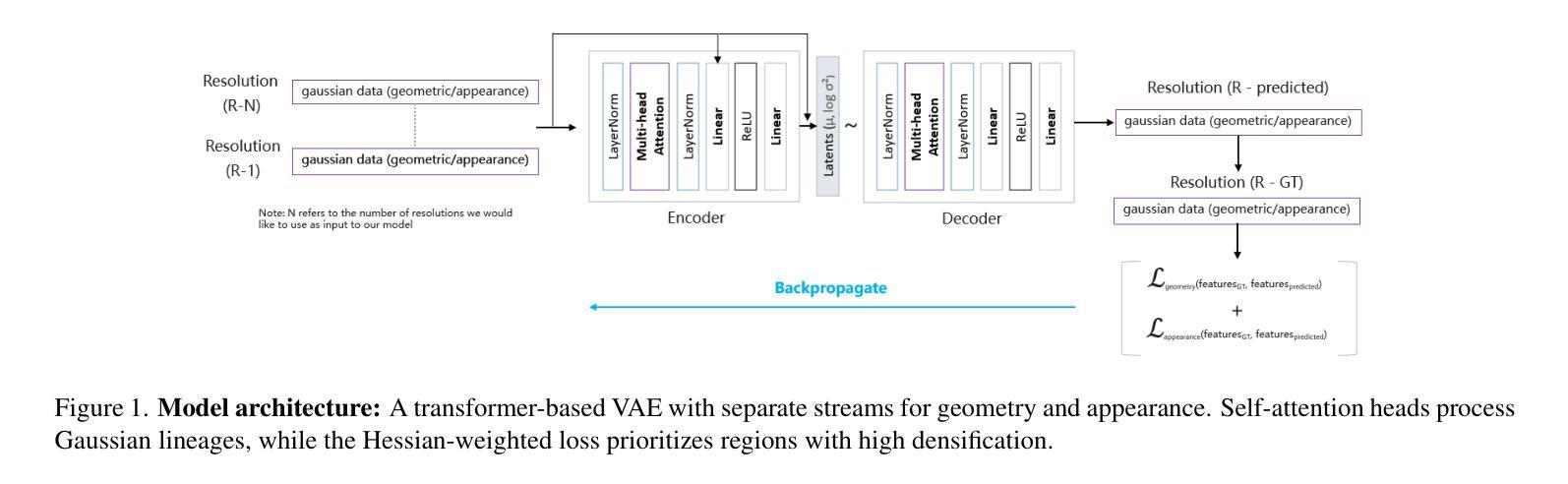
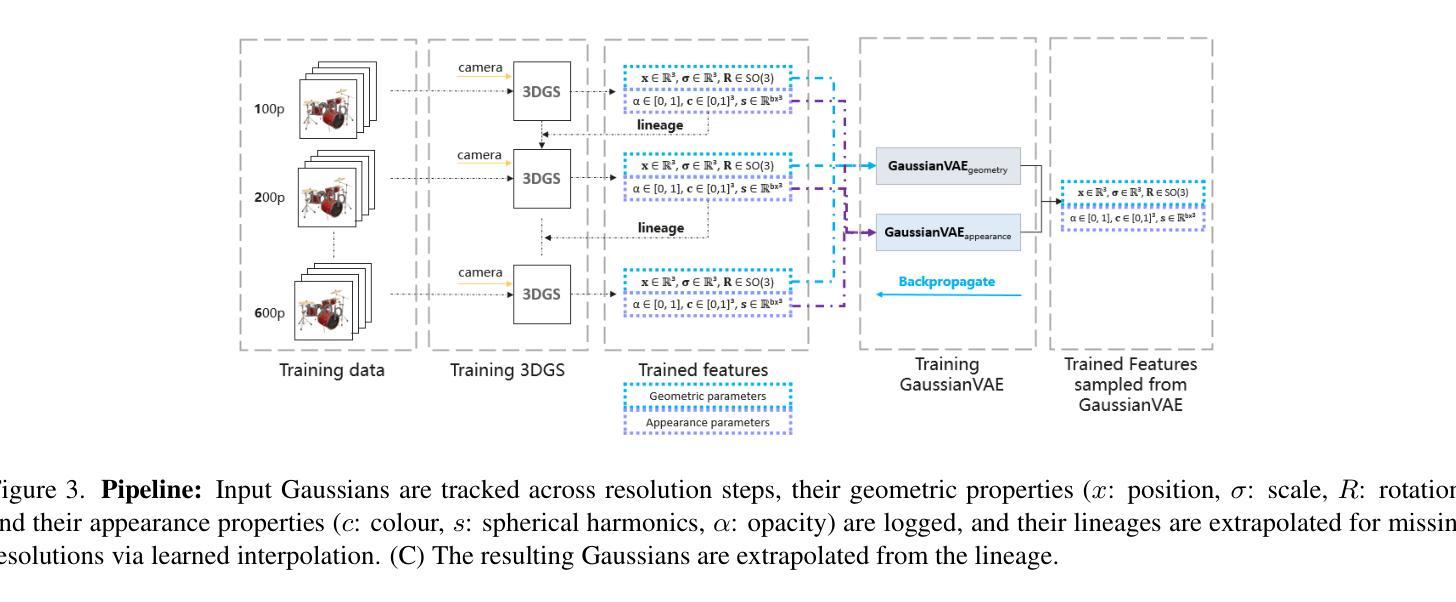
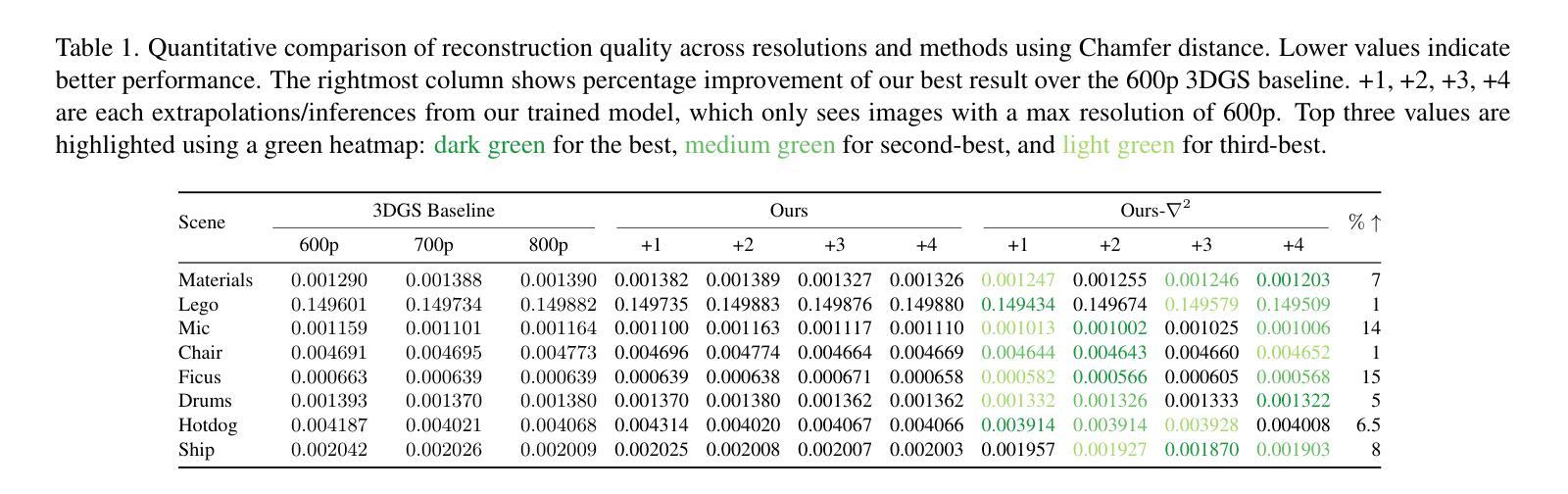
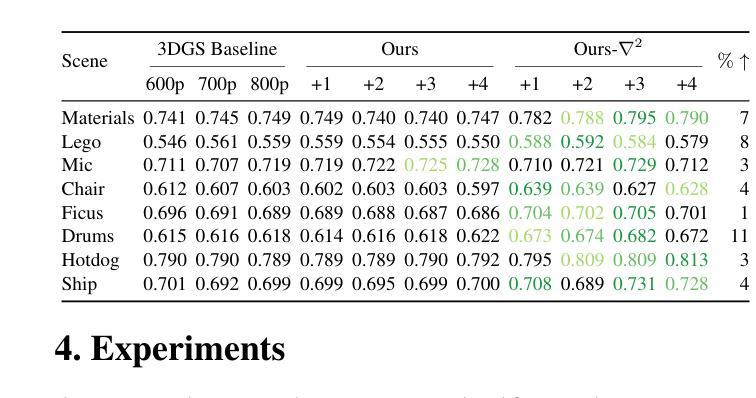
We present a novel approach for enhancing the resolution and geometric fidelity of 3D Gaussian Splatting (3DGS) beyond native training resolution. Current 3DGS methods are fundamentally limited by their input resolution, producing reconstructions that cannot extrapolate finer details than are present in the training views. Our work breaks this limitation through a lightweight generative model that predicts and refines additional 3D Gaussians where needed most. The key innovation is our Hessian-assisted sampling strategy, which intelligently identifies regions that are likely to benefit from densification, ensuring computational efficiency. Unlike computationally intensive GANs or diffusion approaches, our method operates in real-time (0.015s per inference on a single consumer-grade GPU), making it practical for interactive applications. Comprehensive experiments demonstrate significant improvements in both geometric accuracy and rendering quality compared to state-of-the-art methods, establishing a new paradigm for resolution-free 3D scene enhancement.
我们提出了一种在原生训练分辨率之外提高3D高斯Splatting(3DGS)的分辨率和几何保真度的新方法。现有的3DGS方法在本质上受到其输入分辨率的限制,生成的重建模型无法推断出训练视图之外更精细的细节。我们的工作通过一种轻量级的生成模型突破了这一限制,该模型能够预测并细化所需的最重要的额外三维高斯数据。关键创新之处在于我们的Hessian辅助采样策略,它能够智能地识别可能受益于密集化的区域,确保计算效率。不同于计算密集型的GANs或扩散方法,我们的方法能在实时运行(在单个消费级GPU上每次推理时间为0.015秒),使其成为交互式应用的实用选择。综合实验表明,与最先进的方法相比,我们的方法在几何精度和渲染质量方面都有显著提高,为无分辨率限制的3D场景增强设定了新的范例。
论文及项目相关链接
Summary
本文提出了一种增强三维高斯融合(3DGS)分辨率和几何保真度的新方法,突破了原生训练分辨率的限制。该方法通过轻量级生成模型预测和细化必要的额外三维高斯数据,突破固有局限,提升了场景重建的质量。其核心创新在于Hessian辅助采样策略,能够智能识别可能受益于密集化的区域,确保计算效率。该方法实时运行,实验证明在几何精度和渲染质量方面较现有技术有显著提高,为无分辨率限制的三维场景增强建立了新范例。
Key Takeaways
- 提出了一种新的方法来增强三维高斯融合(3DGS)的分辨率和几何保真度。
- 通过轻量级生成模型预测并细化额外的三维高斯数据,突破了现有方法的输入分辨率限制。
- Hessian辅助采样策略是本文的关键创新点,能够智能识别需要密集化的区域。
- 该方法具有实时性能,适用于交互式应用。
- 与现有技术相比,该方法在几何精度和渲染质量方面显著提高。
- 该方法适用于超越原生训练分辨率的三维场景增强。
点此查看论文截图





R3D2: Realistic 3D Asset Insertion via Diffusion for Autonomous Driving Simulation
Authors:William Ljungbergh, Bernardo Taveira, Wenzhao Zheng, Adam Tonderski, Chensheng Peng, Fredrik Kahl, Christoffer Petersson, Michael Felsberg, Kurt Keutzer, Masayoshi Tomizuka, Wei Zhan
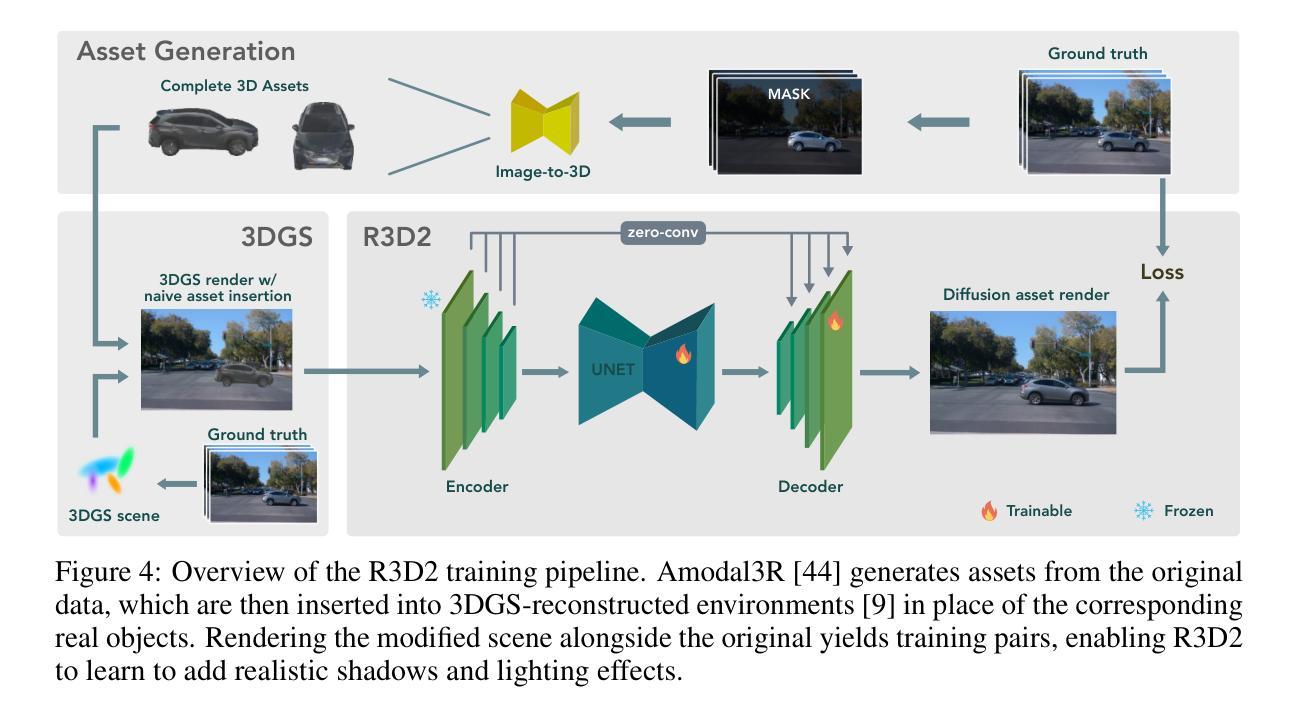
Validating autonomous driving (AD) systems requires diverse and safety-critical testing, making photorealistic virtual environments essential. Traditional simulation platforms, while controllable, are resource-intensive to scale and often suffer from a domain gap with real-world data. In contrast, neural reconstruction methods like 3D Gaussian Splatting (3DGS) offer a scalable solution for creating photorealistic digital twins of real-world driving scenes. However, they struggle with dynamic object manipulation and reusability as their per-scene optimization-based methodology tends to result in incomplete object models with integrated illumination effects. This paper introduces R3D2, a lightweight, one-step diffusion model designed to overcome these limitations and enable realistic insertion of complete 3D assets into existing scenes by generating plausible rendering effects-such as shadows and consistent lighting-in real time. This is achieved by training R3D2 on a novel dataset: 3DGS object assets are generated from in-the-wild AD data using an image-conditioned 3D generative model, and then synthetically placed into neural rendering-based virtual environments, allowing R3D2 to learn realistic integration. Quantitative and qualitative evaluations demonstrate that R3D2 significantly enhances the realism of inserted assets, enabling use-cases like text-to-3D asset insertion and cross-scene/dataset object transfer, allowing for true scalability in AD validation. To promote further research in scalable and realistic AD simulation, we will release our dataset and code, see https://research.zenseact.com/publications/R3D2/.
验证自动驾驶(AD)系统需要进行多样化和安全关键的测试,这使得逼真虚拟环境变得至关重要。传统仿真平台虽然可控,但规模扩展资源密集,并且经常与真实世界数据存在领域差距。相比之下,像3D高斯喷绘(3DGS)这样的神经重建方法为创建真实驾驶场景的逼真数字孪生提供了可扩展的解决方案。然而,它们在动态对象操作和可重用性方面存在困难,因为它们基于场景的优化方法往往导致带有集成照明效果的对象模型不完整。本文介绍了R3D2,这是一个轻量级的单步扩散模型,旨在克服这些限制,并通过生成逼真的渲染效果(如阴影和一致照明)来实时插入完整的3D资产到现有场景中。这是通过在新型数据集上训练R3D2实现的:使用图像条件化的3D生成模型从野生AD数据中生成3DGS对象资产,然后将其合成放置在基于神经渲染的虚拟环境中,从而允许R3D2学习逼真的集成方式。定量和定性评估表明,R3D2显着提高了插入资产的真实性,能够实现文本到3D资产插入和跨场景/数据集对象转移等用例,为AD验证提供了真正的可扩展性。为了推动可扩展和逼真的AD模拟的进一步研究,我们将发布我们的数据集和代码,详见https://research.zenseact.com/publications/R3D2/。
论文及项目相关链接
Summary
本文介绍了验证自动驾驶系统的重要性,强调了传统模拟平台面临的挑战以及神经重建方法如3DGS的局限性。为此,本文提出了R3D2模型,这是一个轻量级的一步扩散模型,旨在克服这些限制,并能够在现有场景中插入逼真的完整3D资产。通过训练R3D2模型在新型数据集上,生成基于图像条件的3D生成模型产生的3DGS对象资产,并将其合成地放置在基于神经渲染的虚拟环境中,从而学习真实的集成方法。R3D2模型的提出大大提高了插入资产的真实性,促进了如文本到三维资产插入和跨场景/数据集对象转移等应用场景的实现,真正实现了自动驾驶验证的可扩展性。
Key Takeaways
- 自动驾驶系统验证需要多样化的安全关键测试,强调真实模拟环境的重要性。
- 传统模拟平台难以实现规模化且存在与真实世界数据的领域差距问题。
- 神经重建方法如3DGS虽能提供可扩展的解决方案,但在动态对象操作和重用性方面存在挑战。
- R3D2模型是一个轻量级的一步扩散模型,旨在解决上述问题,并能实时生成逼真的渲染效果。
- R3D2通过训练在新型数据集上实现真实集成,支持文本到三维资产插入和跨场景/数据集对象转移等应用场景。
- R3D2显著提高了插入资产的真实性,对自动驾驶验证的可扩展性和真实性具有重大意义。
点此查看论文截图



ProSplat: Improved Feed-Forward 3D Gaussian Splatting for Wide-Baseline Sparse Views
Authors:Xiaohan Lu, Jiaye Fu, Jiaqi Zhang, Zetian Song, Chuanmin Jia, Siwei Ma
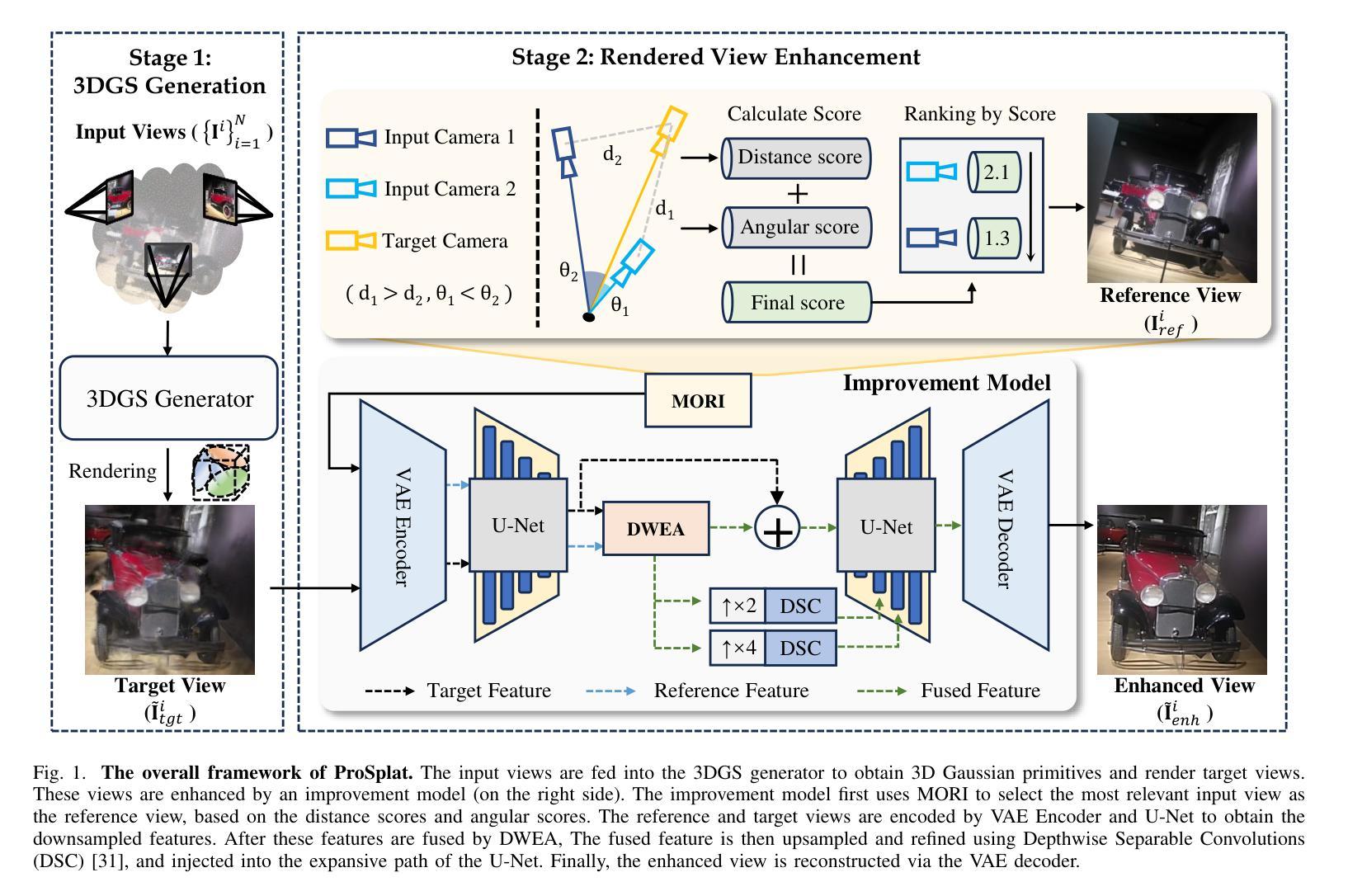
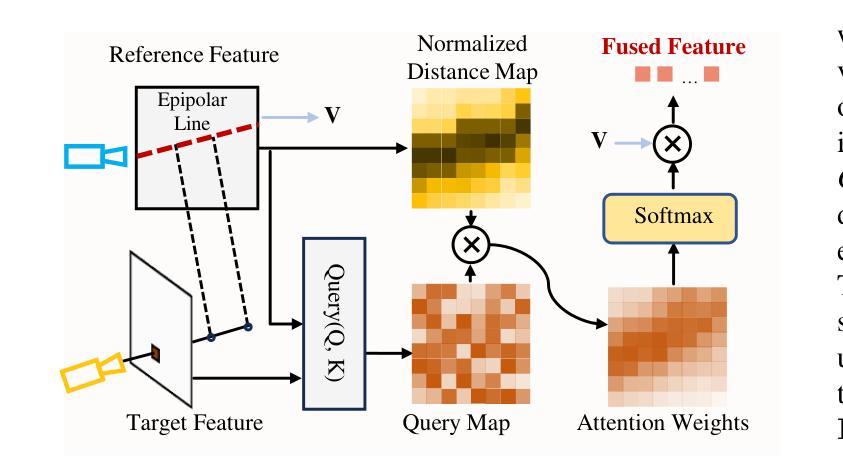
Feed-forward 3D Gaussian Splatting (3DGS) has recently demonstrated promising results for novel view synthesis (NVS) from sparse input views, particularly under narrow-baseline conditions. However, its performance significantly degrades in wide-baseline scenarios due to limited texture details and geometric inconsistencies across views. To address these challenges, in this paper, we propose ProSplat, a two-stage feed-forward framework designed for high-fidelity rendering under wide-baseline conditions. The first stage involves generating 3D Gaussian primitives via a 3DGS generator. In the second stage, rendered views from these primitives are enhanced through an improvement model. Specifically, this improvement model is based on a one-step diffusion model, further optimized by our proposed Maximum Overlap Reference view Injection (MORI) and Distance-Weighted Epipolar Attention (DWEA). MORI supplements missing texture and color by strategically selecting a reference view with maximum viewpoint overlap, while DWEA enforces geometric consistency using epipolar constraints. Additionally, we introduce a divide-and-conquer training strategy that aligns data distributions between the two stages through joint optimization. We evaluate ProSplat on the RealEstate10K and DL3DV-10K datasets under wide-baseline settings. Experimental results demonstrate that ProSplat achieves an average improvement of 1 dB in PSNR compared to recent SOTA methods.
前馈三维高斯喷射(3DGS)在稀疏输入视图的视角合成(NVS)中表现出了有前景的结果,特别是在窄基线条件下。然而,它在宽基线场景中性能显著下降,因为跨视图的纹理细节有限和几何不一致。为了解决这些挑战,本文提出了ProSplat,这是一个两阶段前馈框架,旨在实现宽基线条件下的高保真渲染。第一阶段是通过3DGS生成器生成三维高斯基本体。在第二阶段,通过改进模型增强这些基本体的渲染视图。具体来说,改进模型基于单步扩散模型,通过我们提出的最大重叠参考视图注入(MORI)和距离加权极线注意力(DWEA)进一步优化。MORI通过战略性地选择视点重叠最大的参考视图来补充缺失的纹理和颜色,而DWEA使用极线约束强制实施几何一致性。此外,我们引入了一种分而治之的训级策略,通过联合优化在两个阶段之间对数据分布进行对齐。我们在RealEstate10K和DL3DV-10K数据集上评估了ProSplat在宽基线设置下的性能。实验结果表明,与最新的先进技术相比,ProSplat在PSNR上平均提高了1dB。
论文及项目相关链接
Summary
本文提出一种名为ProSplat的两阶段前馈框架,用于解决稀疏输入视角下的新视图合成问题。该框架基于高保真渲染和新的生成算法改进模型,能有效处理窄基线下的纹理细节缺失和几何不一致问题。在RealEstate10K和DL3DV-10K数据集的实验结果显示,ProSplat相比现有最新方法平均PSNR提高1dB。
Key Takeaways
- ProSplat是一个针对稀疏输入视角下的新视图合成问题的两阶段前馈框架。
- 第一阶段通过3DGS生成器生成三维高斯原始体素。
- 第二阶段通过改进模型增强渲染视图的质量,该模型基于一步扩散模型,并结合最大重叠参考视图注入(MORI)和距离加权极线注意力(DWEA)进行优化。
- MORI通过选择具有最大视点重叠的参考视图来补充缺失的纹理和颜色信息。
- DWEA利用极线约束实现几何一致性。
- 提出了一种分而治之的训练策略,通过联合优化两个阶段的数据分布来提高性能。
点此查看论文截图

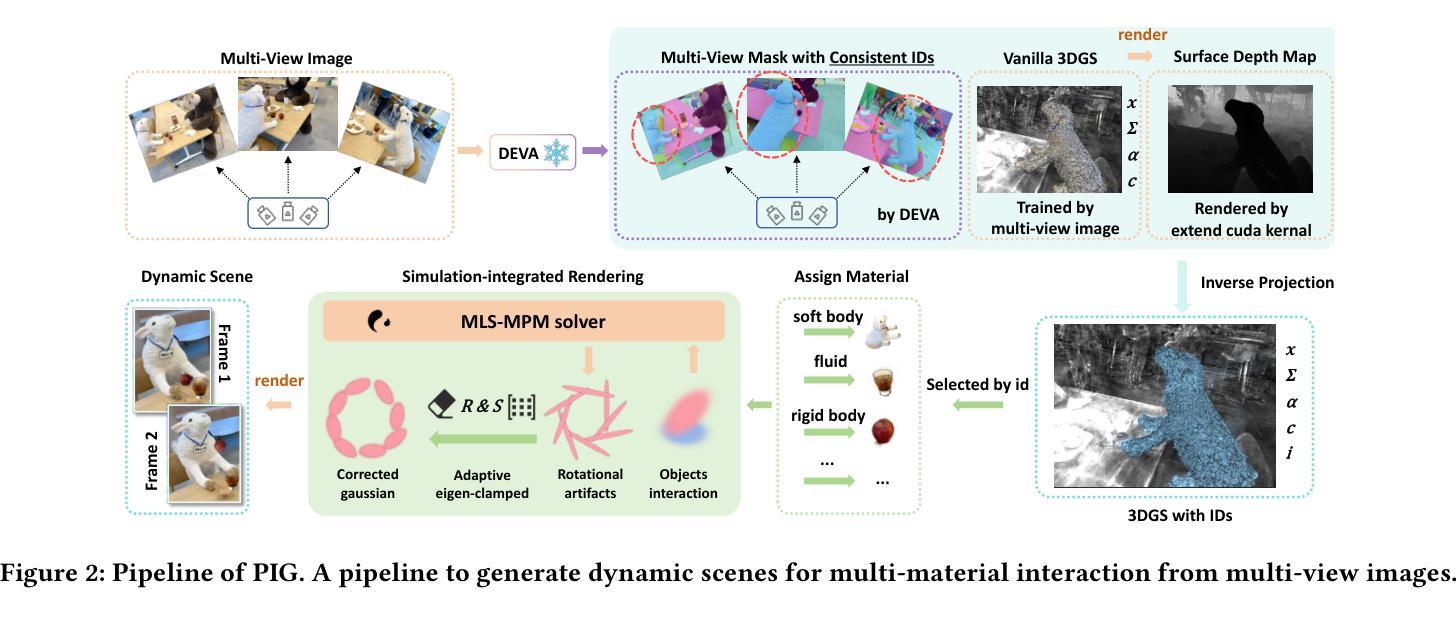
PIG: Physically-based Multi-Material Interaction with 3D Gaussians
Authors:Zeyu Xiao, Zhenyi Wu, Mingyang Sun, Qipeng Yan, Yufan Guo, Zhuoer Liang, Lihua Zhang
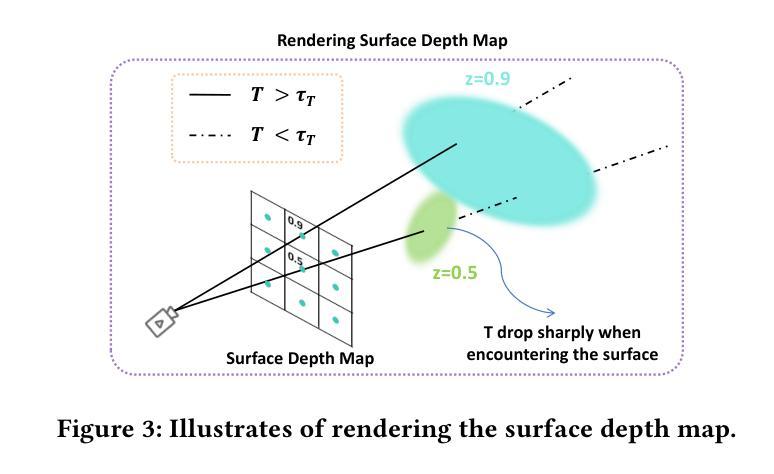
3D Gaussian Splatting has achieved remarkable success in reconstructing both static and dynamic 3D scenes. However, in a scene represented by 3D Gaussian primitives, interactions between objects suffer from inaccurate 3D segmentation, imprecise deformation among different materials, and severe rendering artifacts. To address these challenges, we introduce PIG: Physically-Based Multi-Material Interaction with 3D Gaussians, a novel approach that combines 3D object segmentation with the simulation of interacting objects in high precision. Firstly, our method facilitates fast and accurate mapping from 2D pixels to 3D Gaussians, enabling precise 3D object-level segmentation. Secondly, we assign unique physical properties to correspondingly segmented objects within the scene for multi-material coupled interactions. Finally, we have successfully embedded constraint scales into deformation gradients, specifically clamping the scaling and rotation properties of the Gaussian primitives to eliminate artifacts and achieve geometric fidelity and visual consistency. Experimental results demonstrate that our method not only outperforms the state-of-the-art (SOTA) in terms of visual quality, but also opens up new directions and pipelines for the field of physically realistic scene generation.
3D高斯技术已广泛应用于重建静态和动态3D场景,取得了显著的成功。然而,在由3D高斯基本体表示的场景中,物体间的交互存在不准确的三维分割、不同材料之间的变形不精确以及严重的渲染伪影等问题。为了应对这些挑战,我们引入了PIG:基于物理的多材料高斯交互新方法。该方法结合了高精度的三维物体分割和交互物体模拟。首先,我们的方法能够实现从二维像素到三维高斯数据的快速准确映射,从而实现精确的三维物体级分割。其次,我们对场景内相应分割的物体赋予独特的物理属性,以实现多材料耦合交互。最后,我们成功地将约束尺度嵌入到变形梯度中,特别是限制了高斯原始数据的缩放和旋转属性,以消除伪影,实现几何保真度和视觉一致性。实验结果表明,我们的方法不仅在视觉质量上超越了最新技术,还为物理真实场景生成领域开辟了新的方向和管道。
论文及项目相关链接
Summary
3D高斯插值技术在重建静态和动态3D场景方面取得了显著成功。然而,在处理由3D高斯基本体表示的场景时,物体间的交互面临着不准确的3D分割、不同材料之间的变形不准确以及严重的渲染伪影等问题。为解决这些问题,我们提出了PIG:基于物理的多材料高斯交互方法。该方法结合了精确的3D物体分割与物体交互模拟,实现了快速准确的从二维像素到三维高斯体的映射,为不同材料之间的耦合交互分配了独特的物理属性,并将约束尺度嵌入变形梯度中,消除了伪影,实现了几何保真和视觉一致性。实验结果表明,该方法不仅在视觉质量上超越了现有技术,还为物理真实场景生成领域开辟了新的方向和管道。
Key Takeaways
- 3D高斯插值技术在重建3D场景方面取得显著成就,但在处理物体交互时面临挑战。
- PIG方法结合了3D物体分割与物体交互模拟,实现快速准确的从二维像素到三维高斯体的映射。
- PIG方法为不同材料之间的耦合交互分配了独特的物理属性。
- 通过嵌入约束尺度到变形梯度中,PIG方法消除了伪影,实现了几何保真和视觉一致性。
- PIG方法实现了精确的3D对象级分割。
- 实验结果表明,PIG方法在视觉质量上超越了现有技术。
点此查看论文截图



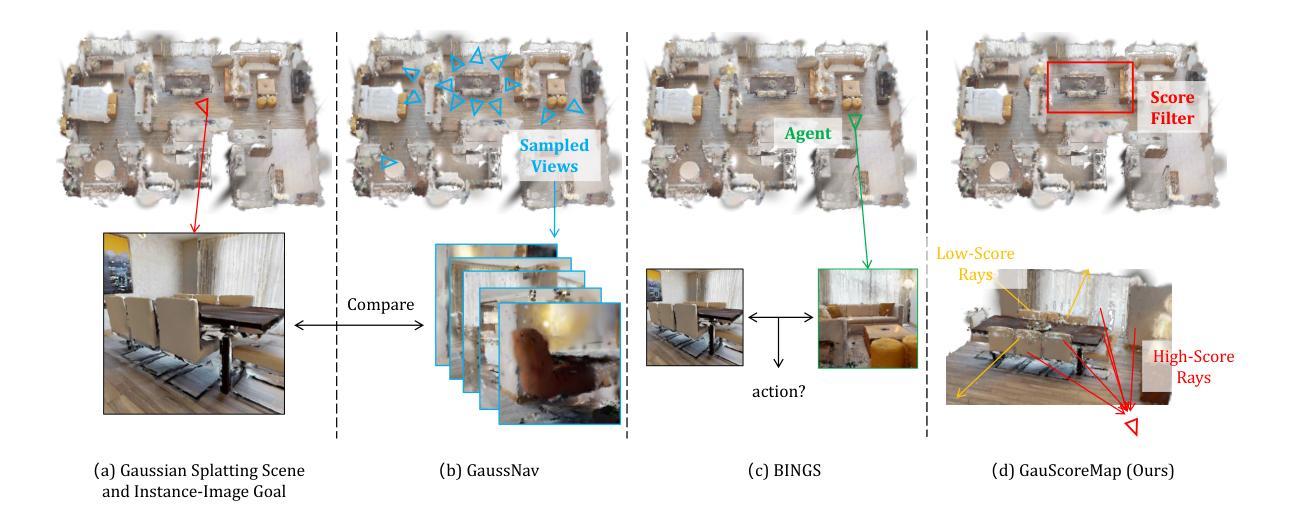
Hierarchical Scoring with 3D Gaussian Splatting for Instance Image-Goal Navigation
Authors:Yijie Deng, Shuaihang Yuan, Geeta Chandra Raju Bethala, Anthony Tzes, Yu-Shen Liu, Yi Fang
Instance Image-Goal Navigation (IIN) requires autonomous agents to identify and navigate to a target object or location depicted in a reference image captured from any viewpoint. While recent methods leverage powerful novel view synthesis (NVS) techniques, such as three-dimensional Gaussian splatting (3DGS), they typically rely on randomly sampling multiple viewpoints or trajectories to ensure comprehensive coverage of discriminative visual cues. This approach, however, creates significant redundancy through overlapping image samples and lacks principled view selection, substantially increasing both rendering and comparison overhead. In this paper, we introduce a novel IIN framework with a hierarchical scoring paradigm that estimates optimal viewpoints for target matching. Our approach integrates cross-level semantic scoring, utilizing CLIP-derived relevancy fields to identify regions with high semantic similarity to the target object class, with fine-grained local geometric scoring that performs precise pose estimation within promising regions. Extensive evaluations demonstrate that our method achieves state-of-the-art performance on simulated IIN benchmarks and real-world applicability.
实例图像目标导航(IIN)要求自主代理识别并导航到参考图像中描绘的目标对象或位置,该参考图像可以从任何视角捕获。虽然最近的方法利用强大的新型视图合成(NVS)技术,如三维高斯拼贴(3DGS),但它们通常依赖于随机采样多个视点或轨迹,以确保对判别性视觉线索的全面覆盖。然而,这种方法通过重叠的图像样本产生了大量的冗余,并且缺乏有原则的视点选择,从而显著增加了渲染和比较的开销。在本文中,我们引入了一个新颖的IIN框架,该框架具有分层评分机制,用于估计目标匹配的最佳视点。我们的方法结合了跨级别语义评分,利用CLIP衍生的相关性字段来识别与目标对象类别具有高语义相似性的区域,以及精细的局部几何评分,后者在有希望区域内执行精确的姿态估计。广泛评估表明,我们的方法在模拟IIN基准测试和实际应用中均达到了最先进的性能。
论文及项目相关链接
Summary
本文介绍了一种新的实例图像目标导航(IIN)框架,该框架采用分层评分机制来估计目标匹配的最佳视角。它结合了跨级别语义评分和精细局部几何评分,通过CLIP衍生的相关性字段识别与目标对象类别高度语义相似的区域,并在这些有希望的区域内进行精确姿态估计。该方法在模拟IIN基准测试和实际应用中均表现出卓越性能。
Key Takeaways
- 实例图像目标导航(IIN)要求自主代理识别并导航至从任何视角捕获的参考图像中描绘的目标对象或位置。
- 最近的IIN方法利用如三维高斯贴图(3DGS)等新型视图合成(NVS)技术,但通常依赖于随机采样多个视角或轨迹以确保全面覆盖辨别视觉线索。
- 随机采样方法存在显著冗余和重叠图像样本的问题,且缺乏原则性的视角选择,导致渲染和比较开销大幅增加。
- 本文提出了一种新的IIN框架,采用分层评分机制来估计目标匹配的最优视角。
- 框架结合了跨级别语义评分和精细局部几何评分,通过CLIP衍生的相关性字段识别与目标对象高度语义相似的区域。
- 该方法在模拟IIN基准测试中实现了最佳性能。
点此查看论文截图

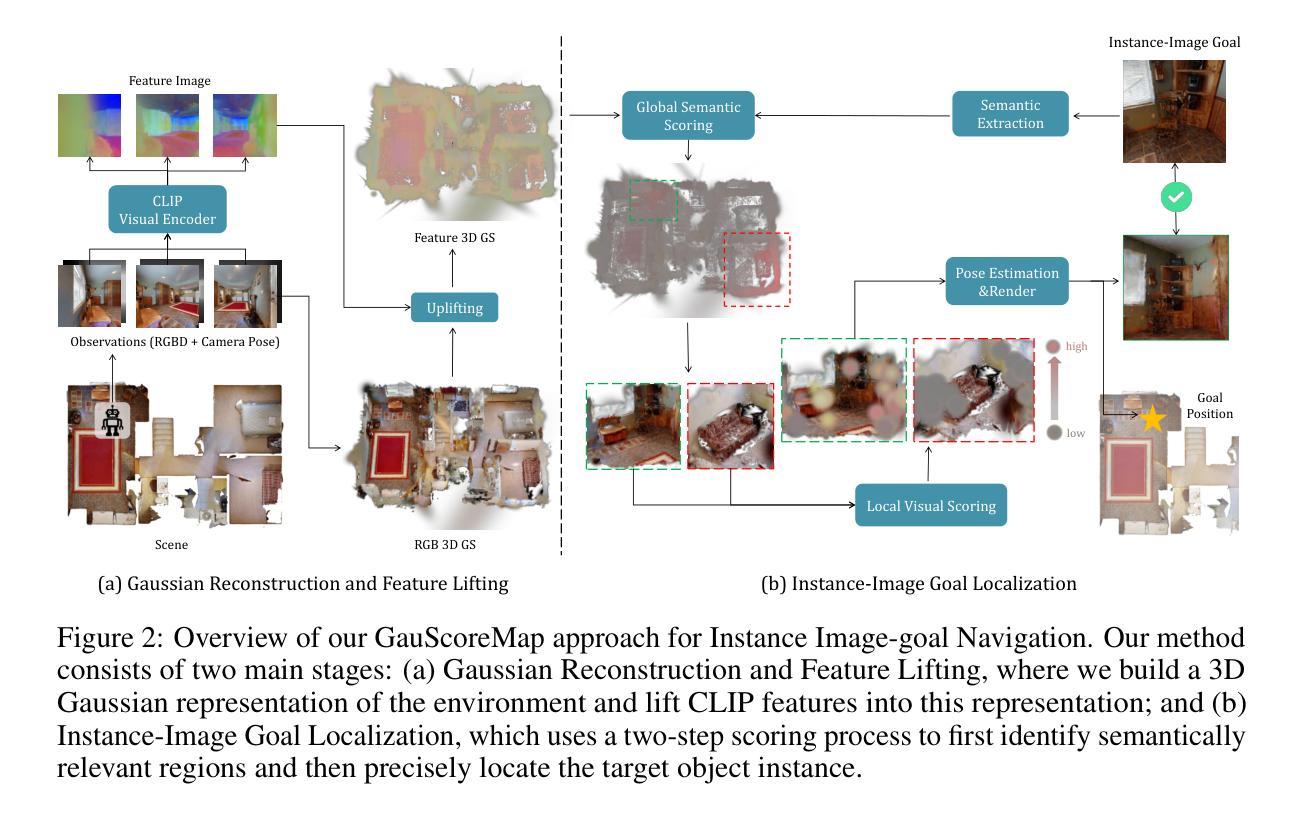
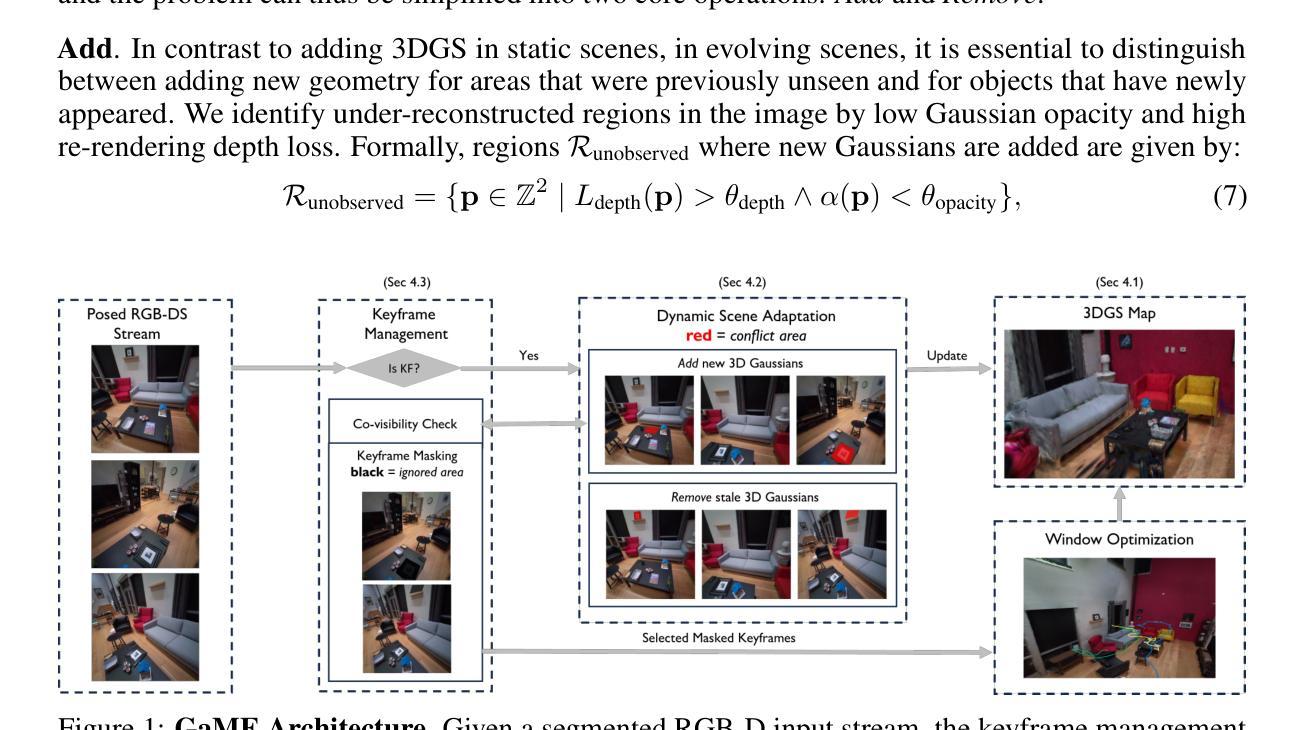
Gaussian Mapping for Evolving Scenes
Authors:Vladimir Yugay, Thies Kersten, Luca Carlone, Theo Gevers, Martin R. Oswald, Lukas Schmid
Mapping systems with novel view synthesis (NVS) capabilities are widely used in computer vision, with augmented reality, robotics, and autonomous driving applications. Most notably, 3D Gaussian Splatting-based systems show high NVS performance; however, many current approaches are limited to static scenes. While recent works have started addressing short-term dynamics (motion within the view of the camera), long-term dynamics (the scene evolving through changes out of view) remain less explored. To overcome this limitation, we introduce a dynamic scene adaptation mechanism that continuously updates the 3D representation to reflect the latest changes. In addition, since maintaining geometric and semantic consistency remains challenging due to stale observations disrupting the reconstruction process, we propose a novel keyframe management mechanism that discards outdated observations while preserving as much information as possible. We evaluate Gaussian Mapping for Evolving Scenes (GaME) on both synthetic and real-world datasets and find it to be more accurate than the state of the art.
具有新型视图合成(NVS)能力的映射系统在计算机视觉、增强现实、机器人技术和自动驾驶应用中得到了广泛应用。尤其值得一提的是,基于3D高斯拼贴的系统表现出较高的NVS性能;然而,许多当前的方法仅限于静态场景。虽然最近的工作已经开始解决短期动态问题(相机视图内的运动),但长期动态问题(场景通过视线外的变化而发展)仍然研究较少。为了克服这一局限性,我们引入了一种动态场景适应机制,该机制能够持续更新3D表示以反映最新变化。此外,由于保持几何和语义一致性仍然是一个挑战,过时的观察会破坏重建过程,因此我们提出了一种新的关键帧管理机制,该机制可以丢弃过时的观察结果,同时尽可能保留更多信息。我们在合成数据集和真实世界数据集上对发展中的场景高斯映射(GaME)进行了评估,发现其比现有技术更准确。
论文及项目相关链接
Summary
本文介绍了基于动态场景适应机制的映射系统,该系统结合了新型视图合成技术,广泛应用于计算机视觉领域。针对当前多数系统仅适用于静态场景的问题,本文引入了一种针对动态场景持续更新的映射机制。为解决重建过程中的几何和语义一致性问题,采用新颖的关键帧管理机制剔除过时观察数据并尽可能保留信息。评估结果表明,高斯映射演化场景技术相较于现有技术更为准确。
Key Takeaways
- 新型视图合成技术在计算机视觉领域广泛应用。
- 当前多数映射系统局限于静态场景。
- 引入动态场景适应机制以持续更新映射系统,应对场景变化。
- 提出一种关键帧管理机制,以剔除过时观察数据并保留信息,解决几何和语义一致性问题。
- 高斯映射演化场景技术(GaME)在合成和真实数据集上的表现优于现有技术。
点此查看论文截图


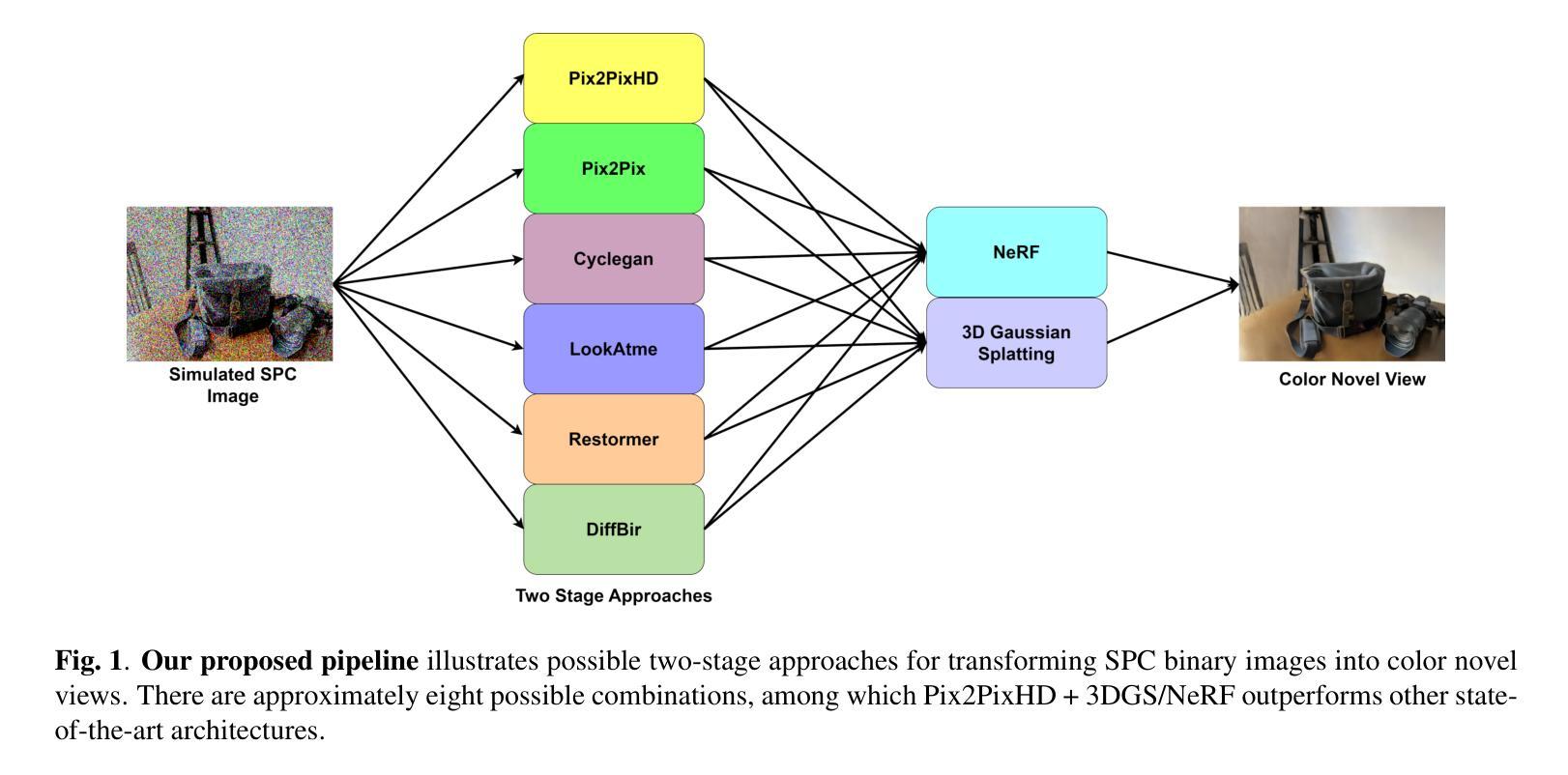
SPC to 3D: Novel View Synthesis from Binary SPC via I2I translation
Authors:Sumit Sharma, Gopi Raju Matta, Kaushik Mitra
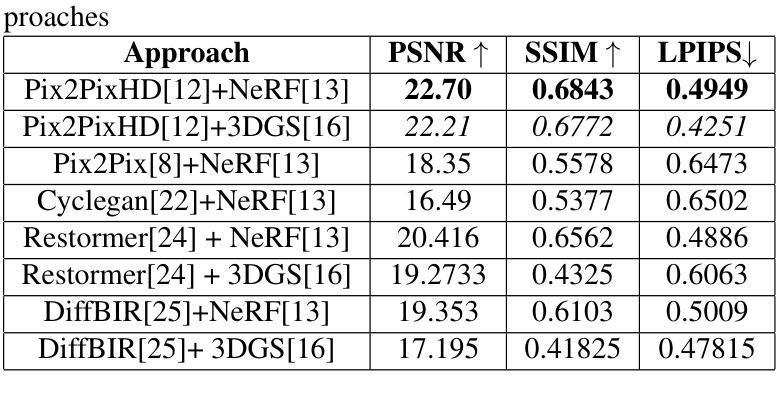
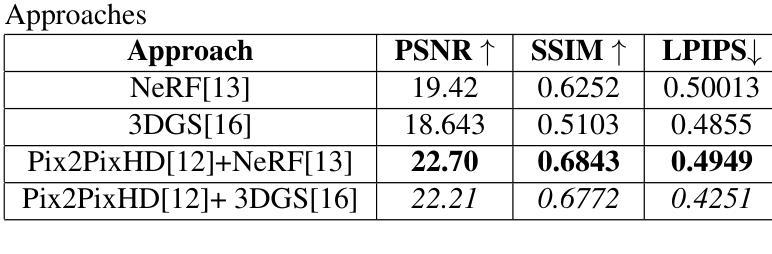
Single Photon Avalanche Diodes (SPADs) represent a cutting-edge imaging technology, capable of detecting individual photons with remarkable timing precision. Building on this sensitivity, Single Photon Cameras (SPCs) enable image capture at exceptionally high speeds under both low and high illumination. Enabling 3D reconstruction and radiance field recovery from such SPC data holds significant promise. However, the binary nature of SPC images leads to severe information loss, particularly in texture and color, making traditional 3D synthesis techniques ineffective. To address this challenge, we propose a modular two-stage framework that converts binary SPC images into high-quality colorized novel views. The first stage performs image-to-image (I2I) translation using generative models such as Pix2PixHD, converting binary SPC inputs into plausible RGB representations. The second stage employs 3D scene reconstruction techniques like Neural Radiance Fields (NeRF) or Gaussian Splatting (3DGS) to generate novel views. We validate our two-stage pipeline (Pix2PixHD + Nerf/3DGS) through extensive qualitative and quantitative experiments, demonstrating significant improvements in perceptual quality and geometric consistency over the alternative baseline.
单光子雪崩二极管(SPAD)代表了前沿的成像技术,能够以惊人的时间精度检测单个光子。基于此灵敏度,单光子相机(SPC)能够在高低光照条件下以极高速度捕获图像。从这样的SPC数据中实现3D重建和辐射场恢复具有巨大的潜力。然而,SPC图像的二进制特性导致信息严重丢失,特别是在纹理和颜色方面,使得传统的3D合成技术无效。为了解决这一挑战,我们提出了一种模块化的两阶段框架,将二进制SPC图像转换为高质量的有色新颖视图。第一阶段使用Pix2PixHD等生成模型进行图像到图像的翻译(I2I),将二进制SPC输入转换为可行的RGB表示。第二阶段采用神经网络辐射场(NeRF)或高斯平铺(3DGS)等3D场景重建技术生成新颖视图。我们通过大量的定性和定量实验验证了我们的两阶段管道(Pix2PixHD + Nerf/3DGS),在感知质量和几何一致性方面相对于替代基线表现出显著改进。
论文及项目相关链接
PDF Accepted for publication at ICIP 2025
Summary
单光子雪崩二极管(SPAD)是前沿成像技术,能检测单个光子并具有出色的时间精度。基于此敏感性的单光子相机(SPC)可在低光照和高光照条件下以极高速度捕获图像。从SPC数据中实现3D重建和辐射场恢复具有巨大潜力。然而,SPC图像的二进制特性导致纹理和颜色信息严重丢失,使得传统3D合成技术效果不佳。为应对这一挑战,我们提出一个模块化的两阶段框架,将二进制SPC图像转化为高质量彩色新颖视图。第一阶段使用Pix2PixHD等生成模型进行图像到图像(I2I)转换,将二进制SPC输入转化为合理的RGB表示。第二阶段采用Neural Radiance Fields(NeRF)或Gaussian Splatting(3DGS)等3D场景重建技术生成新颖视图。我们通过大量的定性和定量实验验证了我们的两阶段管道(Pix2PixHD + Nerf/3DGS),在感知质量和几何一致性方面较替代基线有显著改进。
Key Takeaways
- 单光子雪崩二极管(SPAD)能检测单个光子并具有出色时间精度,是前沿成像技术。
- 单光子相机(SPC)可在低光照和高光照条件下以极高速度捕获图像,并为3D重建和辐射场恢复提供了潜力。
3.SPC图像的二进制特性导致纹理和颜色信息丢失,使得传统3D合成技术不适用。 - 提出一个模块化的两阶段框架,用于将二进制SPC图像转化为高质量彩色新颖视图。
- 第一阶段使用图像到图像(I2I)转换,将二进制SPC图像转化为RGB表示。
- 第二阶段采用3D场景重建技术(如NeRF或Gaussian Splatting)生成新颖视图。
点此查看论文截图


Multi-StyleGS: Stylizing Gaussian Splatting with Multiple Styles
Authors:Yangkai Lin, Jiabao Lei, Kui jia
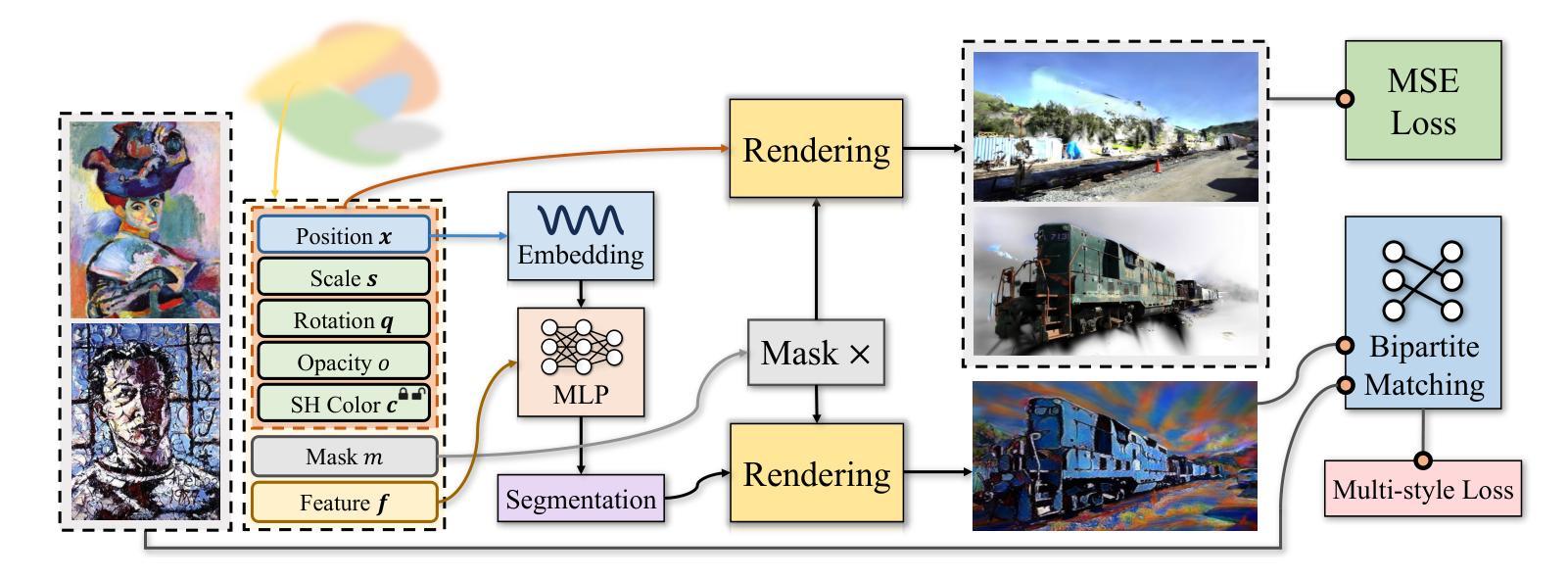
In recent years, there has been a growing demand to stylize a given 3D scene to align with the artistic style of reference images for creative purposes. While 3D Gaussian Splatting(GS) has emerged as a promising and efficient method for realistic 3D scene modeling, there remains a challenge in adapting it to stylize 3D GS to match with multiple styles through automatic local style transfer or manual designation, while maintaining memory efficiency for stylization training. In this paper, we introduce a novel 3D GS stylization solution termed Multi-StyleGS to tackle these challenges. In particular, we employ a bipartite matching mechanism to au tomatically identify correspondences between the style images and the local regions of the rendered images. To facilitate local style transfer, we introduce a novel semantic style loss function that employs a segmentation network to apply distinct styles to various objects of the scene and propose a local-global feature matching to enhance the multi-view consistency. Furthermore, this technique can achieve memory efficient training, more texture details and better color match. To better assign a robust semantic label to each Gaussian, we propose several techniques to regularize the segmentation network. As demonstrated by our comprehensive experiments, our approach outperforms existing ones in producing plausible stylization results and offering flexible editing.
近年来,为了满足创意目的,对给定3D场景进行风格化以匹配参考图像的艺术风格的需求不断增长。虽然3D高斯拼贴(GS)已经成为一种有前景和高效的现实3D场景建模方法,但在将其适应于将3D GS风格化以适应多种风格方面仍存在挑战,这些风格可以通过自动局部风格转换或手动指定来实现,同时保持风格化训练的内存效率。在本文中,我们引入了一种新的3D GS风格化解决方案,称为Multi-StyleGS,以解决这些挑战。特别是,我们采用二分匹配机制自动识别风格图像和渲染图像的局部区域之间的对应关系。为了促进局部风格转换,我们引入了一种新的语义风格损失函数,该函数采用分割网络将不同的风格应用于场景中的各种对象,并提出局部全局特征匹配以增强多视图一致性。此外,此技术可以实现内存高效的训练、更多的纹理细节和更好的色彩匹配。为了更好地为每一个高斯分配一个稳健的语义标签,我们提出了几种技术来规范分割网络。我们的综合实验表明,我们的方法在生成合理的风格化结果和提供灵活的编辑方面优于现有方法。
论文及项目相关链接
PDF AAAI 2025
Summary
近期对将给定的3D场景风格化为参考图像的艺术风格的需求日益增长。针对这一需求,本文提出了一种新颖的3D高斯Splatting(GS)风格化解决方案——Multi-StyleGS。通过采用二分匹配机制,该方法可自动确定风格图像和渲染图像局部区域之间的对应关系。此外,我们还引入了一种新的语义风格损失函数,利用分割网络对场景中的不同对象应用不同的风格,并提出了局部全局特征匹配技术以提高多视图一致性。此方法可实现内存高效的训练,并产生更多纹理细节和更好的色彩匹配。
Key Takeaways
- 3D场景风格化需求增长,需要新的方法以适应多种风格的自动本地风格转移或手动指定。
- Multi-StyleGS是一种新颖的3D GS风格化解决方案,旨在解决上述问题。
- 通过二分匹配机制自动确定风格图像和渲染图像局部区域之间的对应关系。
- 引入新的语义风格损失函数,利用分割网络对场景中的不同对象应用不同的风格。
- 提出局部全局特征匹配技术以提高多视图一致性。
- 该方法可实现内存高效的训练,产生更多纹理细节和更好的色彩匹配。
点此查看论文截图

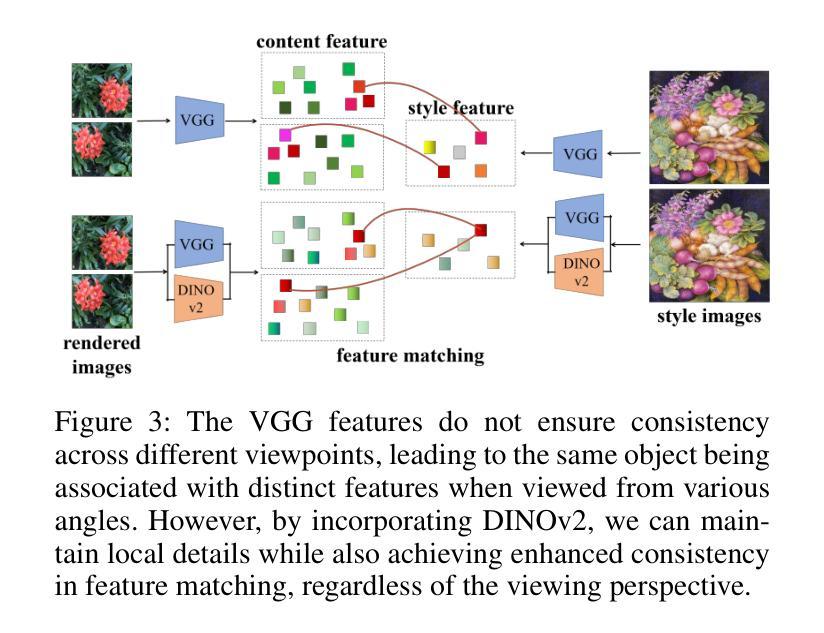


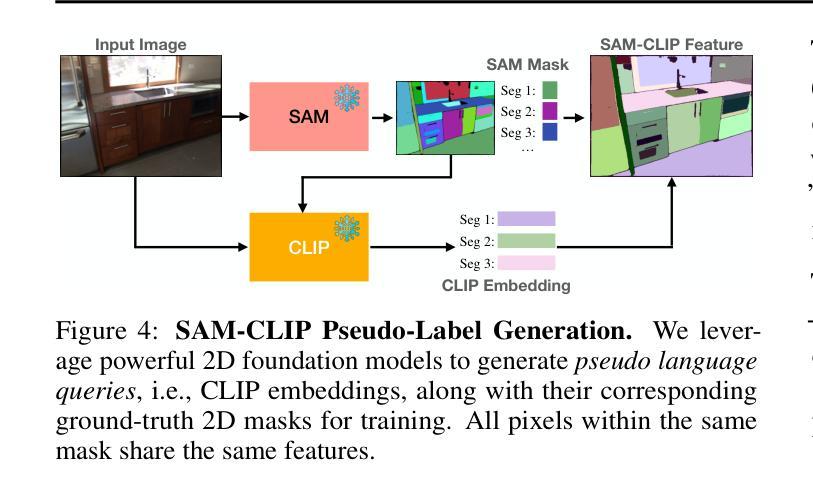
Hi-LSplat: Hierarchical 3D Language Gaussian Splatting
Authors:Chenlu Zhan, Yufei Zhang, Gaoang Wang, Hongwei Wang
Modeling 3D language fields with Gaussian Splatting for open-ended language queries has recently garnered increasing attention. However, recent 3DGS-based models leverage view-dependent 2D foundation models to refine 3D semantics but lack a unified 3D representation, leading to view inconsistencies. Additionally, inherent open-vocabulary challenges cause inconsistencies in object and relational descriptions, impeding hierarchical semantic understanding. In this paper, we propose Hi-LSplat, a view-consistent Hierarchical Language Gaussian Splatting work for 3D open-vocabulary querying. To achieve view-consistent 3D hierarchical semantics, we first lift 2D features to 3D features by constructing a 3D hierarchical semantic tree with layered instance clustering, which addresses the view inconsistency issue caused by 2D semantic features. Besides, we introduce instance-wise and part-wise contrastive losses to capture all-sided hierarchical semantic representations. Notably, we construct two hierarchical semantic datasets to better assess the model’s ability to distinguish different semantic levels. Extensive experiments highlight our method’s superiority in 3D open-vocabulary segmentation and localization. Its strong performance on hierarchical semantic datasets underscores its ability to capture complex hierarchical semantics within 3D scenes.
利用高斯贴片技术为开放式语言查询构建3D语言场最近受到了越来越多的关注。然而,最近的基于3DGS的模型利用视觉依赖的2D基础模型来完善3D语义,但缺乏统一的3D表示,导致视图不一致。此外,固有的开放式词汇表挑战导致对象和关系描述的不一致,阻碍了层次语义理解。在本文中,我们提出了Hi-LSplat,这是一种用于3D开放式词汇查询的视图一致层次语言高斯贴片方法。为了实现视图一致的3D层次语义,我们首先通过构建带有分层实例聚类的3D层次语义树,将2D特征提升到3D特征,解决了由2D语义特征引起的视图不一致问题。此外,我们引入了实例级和部分级对比损失来捕捉全方位的层次语义表示。值得注意的是,我们构建了两个层次语义数据集,以更好地评估模型区分不同语义层次的能力。大量实验突出显示了我们方法在3D开放式词汇分割和定位方面的优越性。其在层次语义数据集上的出色表现证明了其捕捉3D场景内复杂层次语义的能力。
论文及项目相关链接
Summary
本文提出一种名为Hi-LSplat的3D开放词汇查询方法,通过构建分层语义树和引入实例级和部分级对比损失,实现视角一致的3D层次语义。该方法解决了因2D语义特征导致的视角不一致问题,并通过构建两个层次语义数据集评估模型区分不同语义层次的能力。实验证明,该方法在3D开放词汇分割和定位方面表现出优越性。
Key Takeaways
- 建模3D语言场使用高斯采样处理开放式语言查询日益受到关注。
- 现有基于3DGS的模型利用视角相关的二维基础模型来优化3D语义,但缺乏统一的3D表示,导致视角不一致。
- Hi-LSplat方法通过构建分层语义树实现视角一致的3D层次语义,解决视角不一致问题。
- 引入实例级和部分级对比损失来捕捉全方位的层次语义表示。
- 构建两个层次语义数据集以评估模型区分不同语义层次的能力。
- 实验证明该方法在3D开放词汇查询的分割和定位方面表现优越。
点此查看论文截图

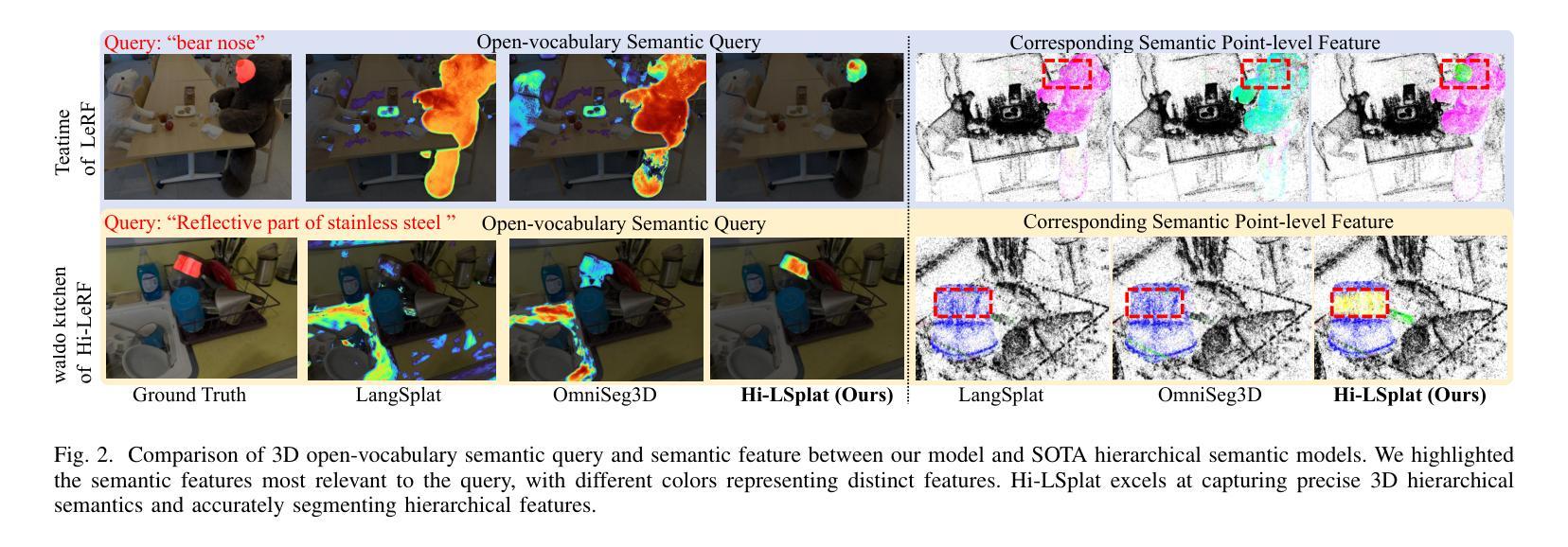
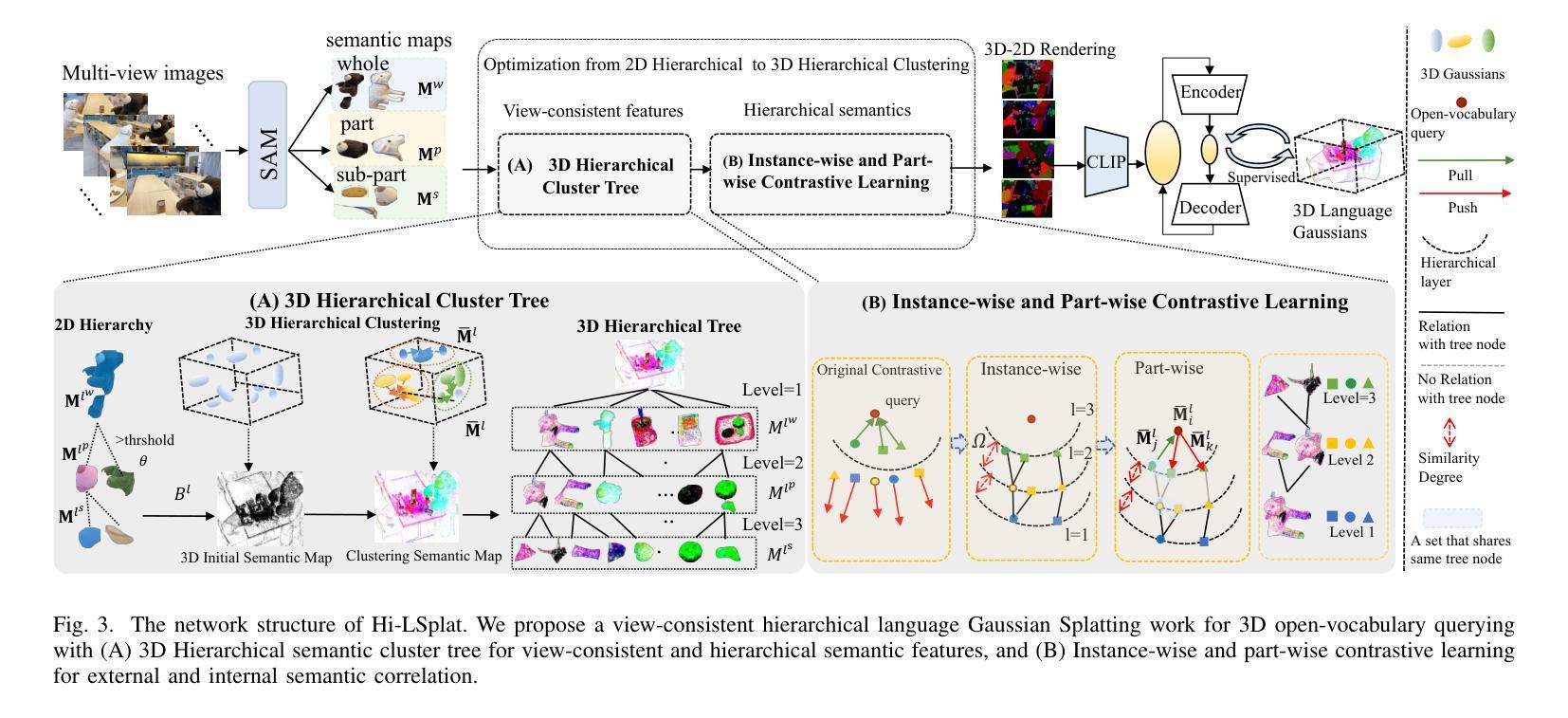
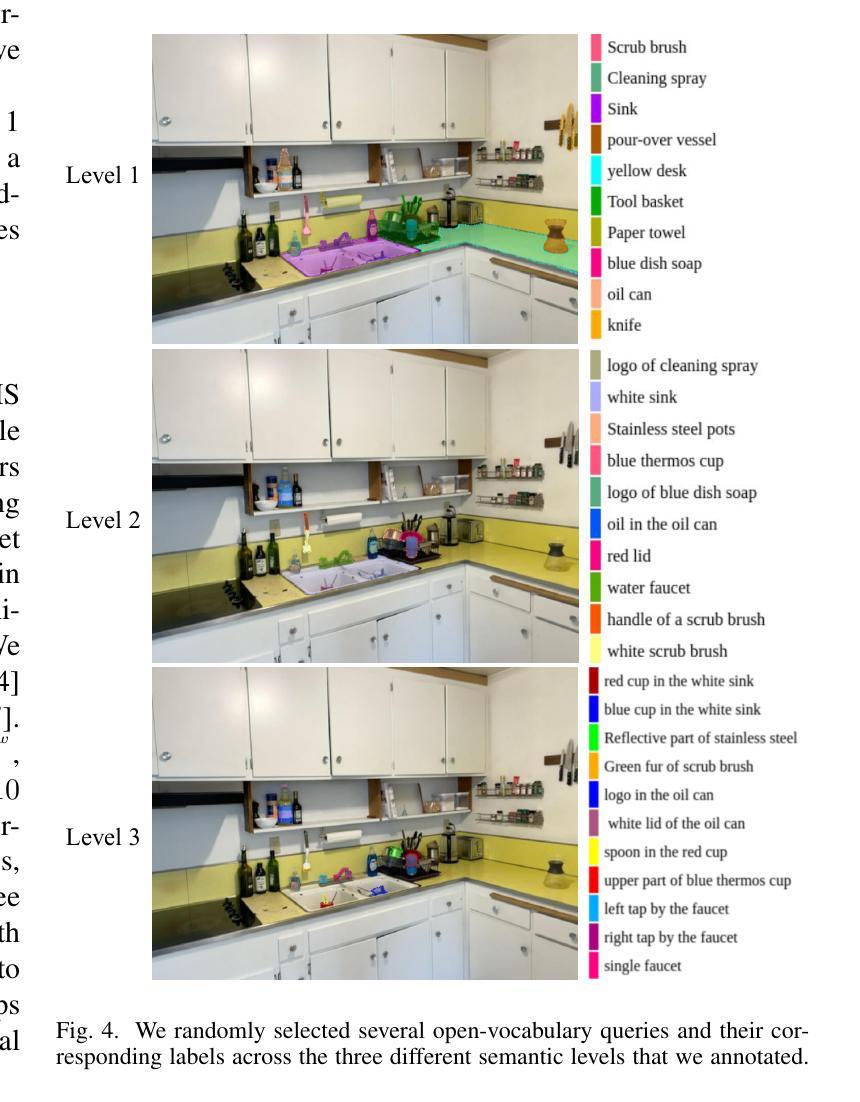
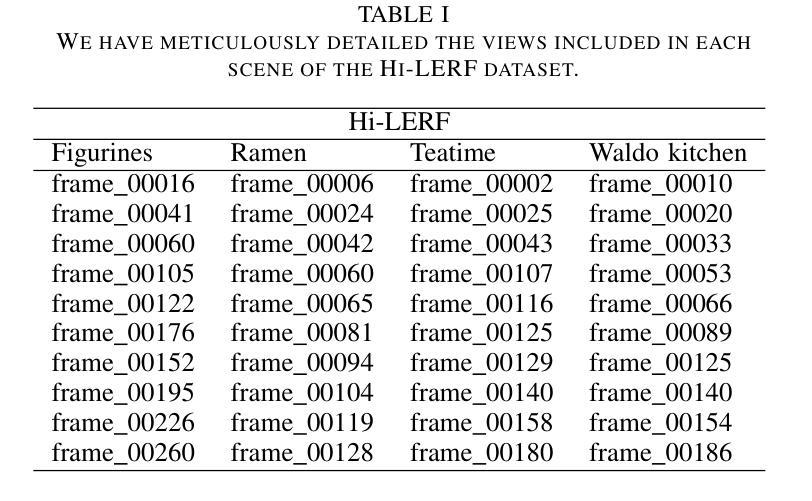

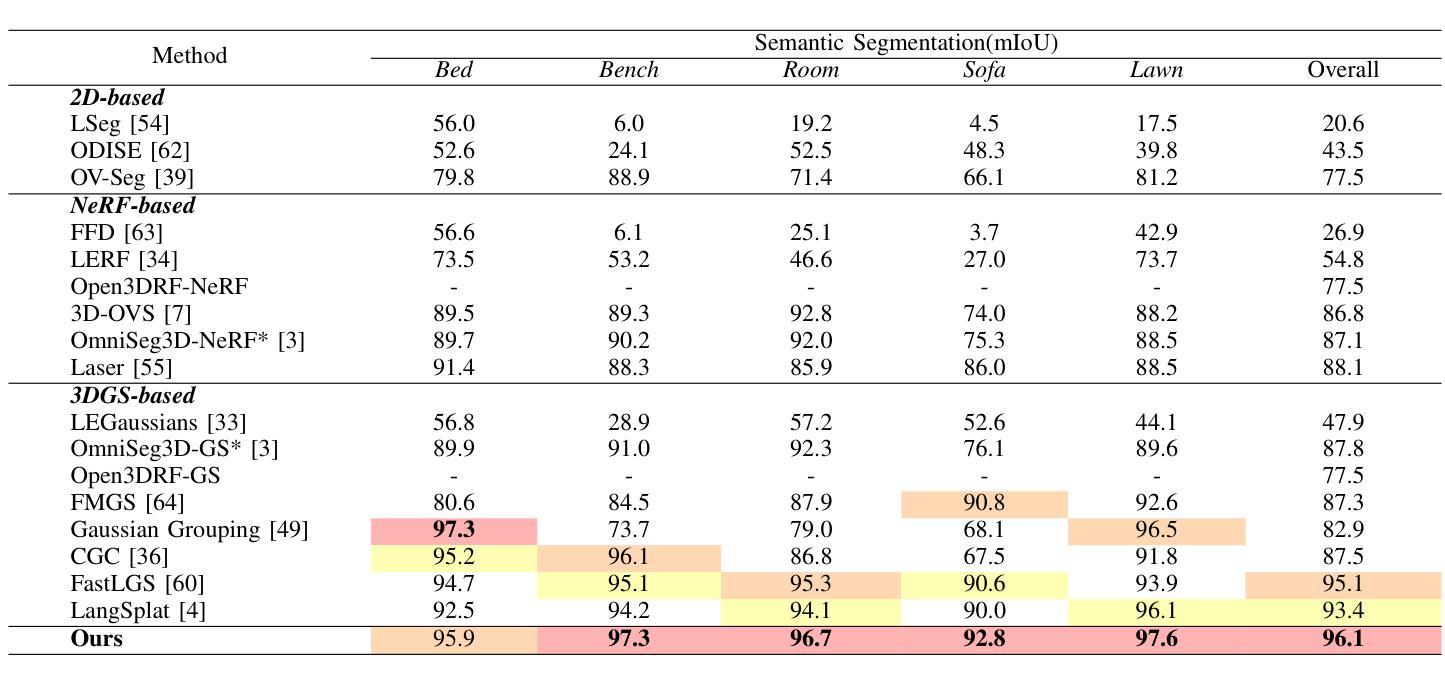
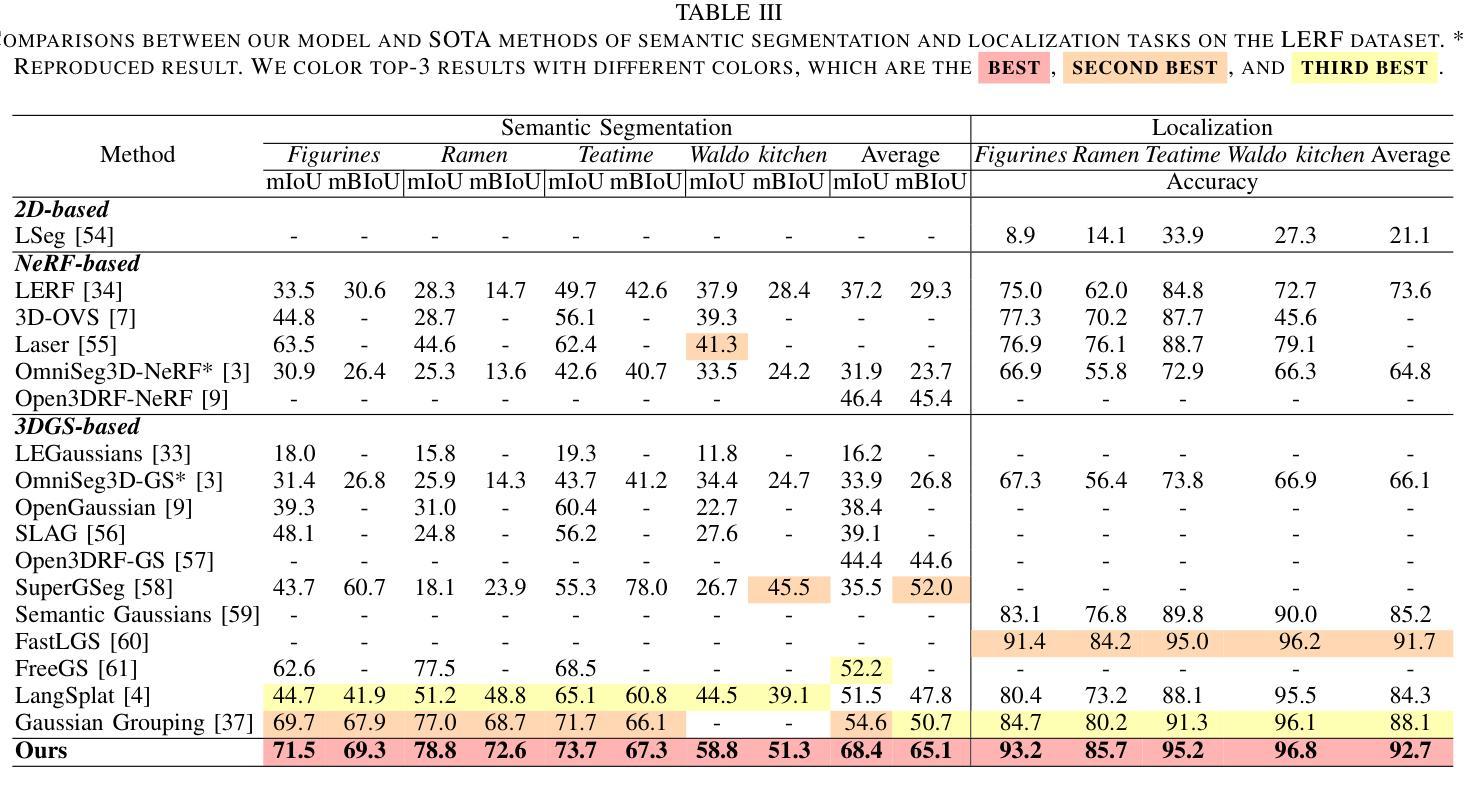
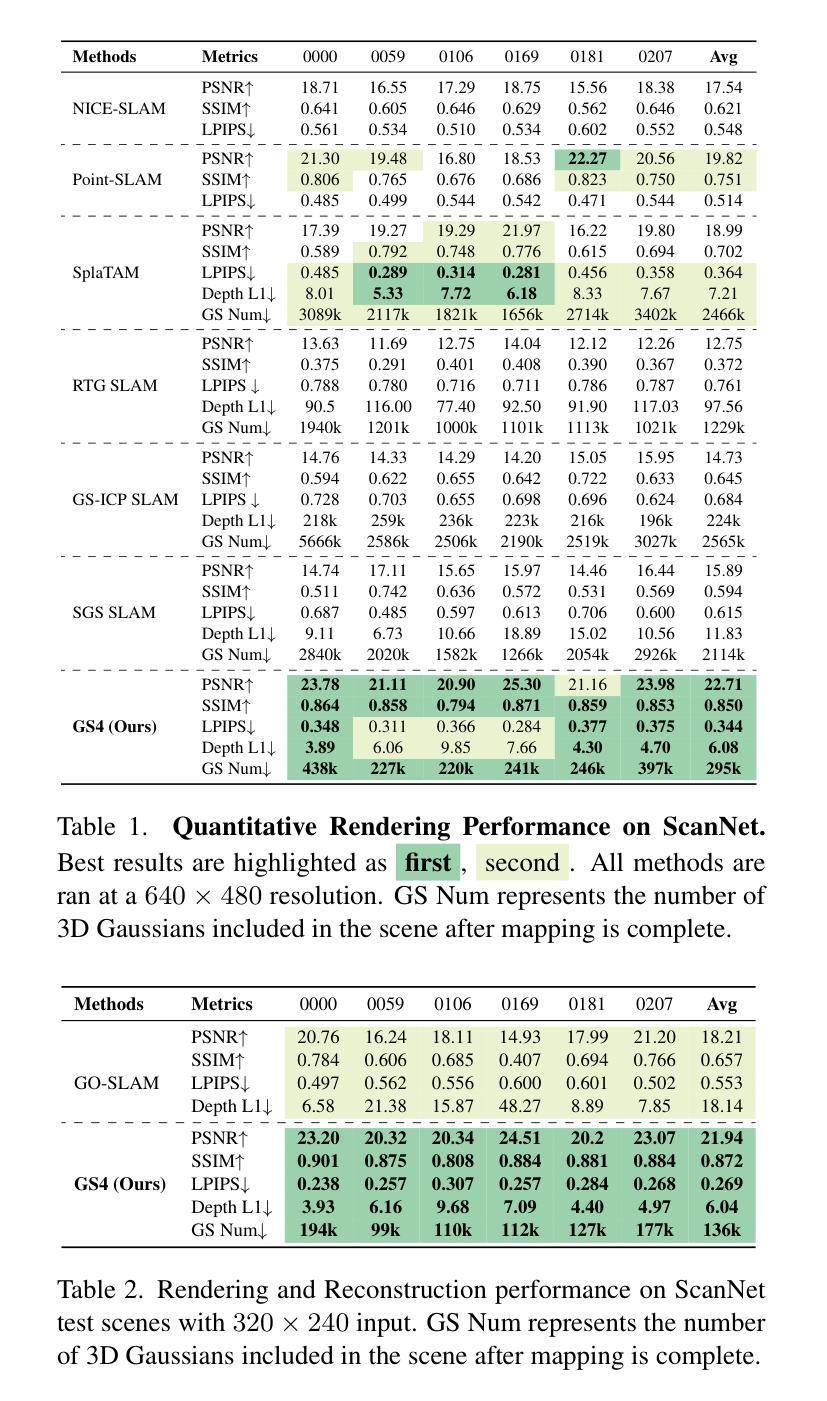
GS4: Generalizable Sparse Splatting Semantic SLAM
Authors:Mingqi Jiang, Chanho Kim, Chen Ziwen, Li Fuxin
Traditional SLAM algorithms are excellent at camera tracking but might generate lower resolution and incomplete 3D maps. Recently, Gaussian Splatting (GS) approaches have emerged as an option for SLAM with accurate, dense 3D map building. However, existing GS-based SLAM methods rely on per-scene optimization which is time-consuming and does not generalize to diverse scenes well. In this work, we introduce the first generalizable GS-based semantic SLAM algorithm that incrementally builds and updates a 3D scene representation from an RGB-D video stream using a learned generalizable network. Our approach starts from an RGB-D image recognition backbone to predict the Gaussian parameters from every downsampled and backprojected image location. Additionally, we seamlessly integrate 3D semantic segmentation into our GS framework, bridging 3D mapping and recognition through a shared backbone. To correct localization drifting and floaters, we propose to optimize the GS for only 1 iteration following global localization. We demonstrate state-of-the-art semantic SLAM performance on the real-world benchmark ScanNet with an order of magnitude fewer Gaussians compared to other recent GS-based methods, and showcase our model’s generalization capability through zero-shot transfer to the NYUv2 and TUM RGB-D datasets.
传统SLAM算法在摄像头追踪方面表现出色,但可能会生成分辨率较低和不完整的3D地图。最近,高斯点扩散(GS)方法作为一种具有精确、密集3D地图构建能力的SLAM选择而出现。然而,现有的基于GS的SLAM方法依赖于场景优化,耗时且不能很好地推广到多种场景。在这项工作中,我们引入了第一个基于高斯点扩散的通用语义SLAM算法,该算法使用学习到的通用网络从RGB-D视频流中逐步构建和更新3D场景表示。我们的方法从RGB-D图像识别主干开始,预测每个降采样和反向投影图像位置的高斯参数。此外,我们将3D语义分割无缝集成到我们的GS框架中,通过共享主干将3D映射和识别连接起来。为了纠正定位漂移和浮动问题,我们提出在全局定位后仅对GS进行1次迭代的优化。我们在现实世界的ScanNet基准测试上展示了最先进的语义SLAM性能,与其他最新的基于GS的方法相比,使用的高斯数量减少了一个数量级,并通过零样本迁移到NYUv2和TUM RGB-D数据集展示了我们的模型的泛化能力。
论文及项目相关链接
PDF 13 pages, 6 figures
Summary
本文介绍了一种基于高斯描画(GS)的语义SLAM算法,该算法能够从RGB-D视频流中增量构建和更新3D场景表示。通过使用可学习的通用网络,该算法具有良好的通用性,可以预测高斯参数并纠正定位漂移和浮标问题。在ScanNet等真实世界基准测试中,该算法实现了最先进的语义SLAM性能。
Key Takeaways
- 传统SLAM算法在相机跟踪方面表现出色,但可能生成较低分辨率和不完全的3D地图。
- 高斯描画(GS)方法作为SLAM的一种选择,能够构建准确的密集3D地图。
- 现有基于GS的SLAM方法依赖于场景优化,耗时且不适用于多种场景。
- 引入了一种基于GS的语义SLAM算法,可从RGB-D视频流中增量构建和更新3D场景表示。
- 该算法使用可学习的通用网络预测高斯参数,并整合了3D语义分割。
- 通过仅进行1次迭代的GS优化,纠正了定位漂移和浮标问题。
点此查看论文截图

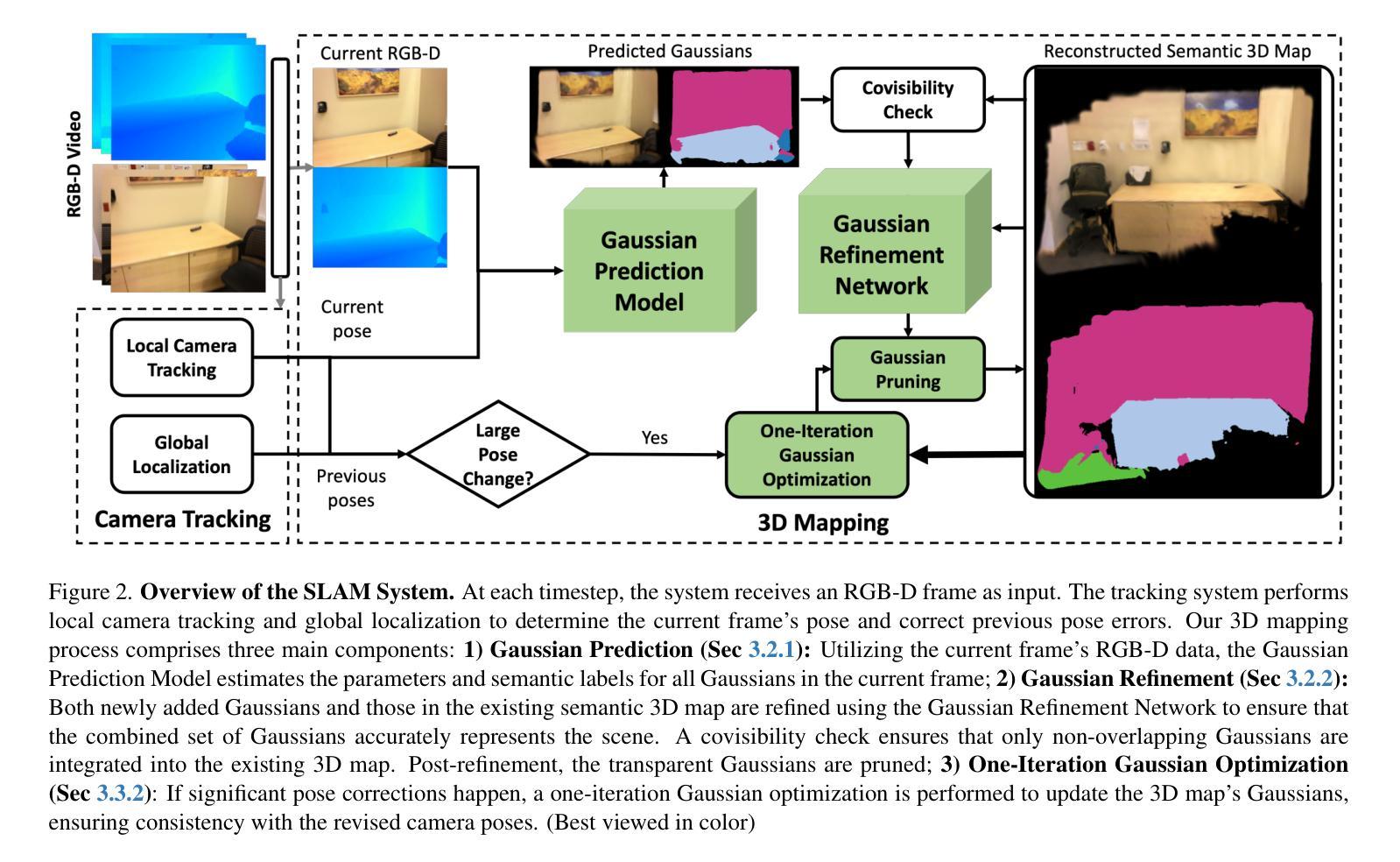
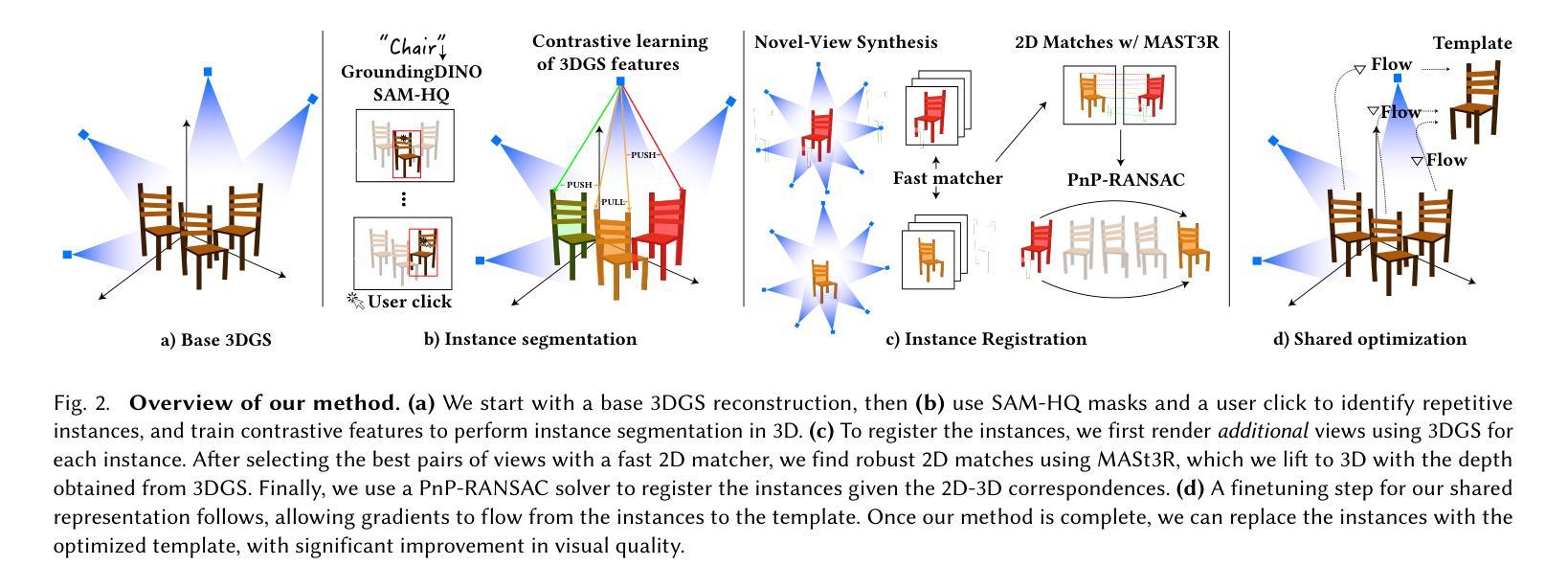
Splat and Replace: 3D Reconstruction with Repetitive Elements
Authors:Nicolás Violante, Andreas Meuleman, Alban Gauthier, Frédo Durand, Thibault Groueix, George Drettakis
We leverage repetitive elements in 3D scenes to improve novel view synthesis. Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have greatly improved novel view synthesis but renderings of unseen and occluded parts remain low-quality if the training views are not exhaustive enough. Our key observation is that our environment is often full of repetitive elements. We propose to leverage those repetitions to improve the reconstruction of low-quality parts of the scene due to poor coverage and occlusions. We propose a method that segments each repeated instance in a 3DGS reconstruction, registers them together, and allows information to be shared among instances. Our method improves the geometry while also accounting for appearance variations across instances. We demonstrate our method on a variety of synthetic and real scenes with typical repetitive elements, leading to a substantial improvement in the quality of novel view synthesis.
我们利用三维场景中的重复元素来改善全新视角的合成。尽管神经辐射场(NeRF)和三维高斯溅落(3DGS)已经在一定程度上改进了全新的视角合成技术,但如果训练视角并不够详尽,未见过和受遮挡的部分的渲染质量仍然较低。我们的关键观察结果是,我们的环境经常充满重复的元素。我们提议利用这些重复元素来改善由于覆盖不足和遮挡导致的场景低质量部分的重建工作。我们提出了一种方法,该方法能够在三维高斯溅落重建中分割每一个重复实例,将它们组合在一起,并允许实例之间共享信息。我们的方法不仅改善了几何结构,还考虑了不同实例之间外观的变化。我们在具有典型重复元素的合成场景和真实场景上展示了我们的方法,大大提升了全新视角合成的质量。
论文及项目相关链接
PDF SIGGRAPH Conference Papers 2025. Project site: https://repo-sam.inria.fr/nerphys/splat-and-replace/
Summary
该研究利用3D场景中的重复元素改进了新型视图合成技术。通过对环境常见的重复元素进行分段、注册和实例间的信息共享,提高了场景的低质量部分的重建效果,同时考虑了不同实例的外观变化。
Key Takeaways
- 研究利用3D场景中的重复元素改进了新型视图合成技术。
- 通过分段、注册和实例间的信息共享,提高了场景的低质量部分的重建效果。
- 使用NeRF和3DGS技术为基础,针对训练视图不够全面导致的问题进行了优化。
- 研究考虑了不同实例的外观变化,提高了几何重建的准确性。
- 在合成和真实场景中对重复元素进行了实验验证。
- 方法显著提高了新型视图合成的质量。
点此查看论文截图

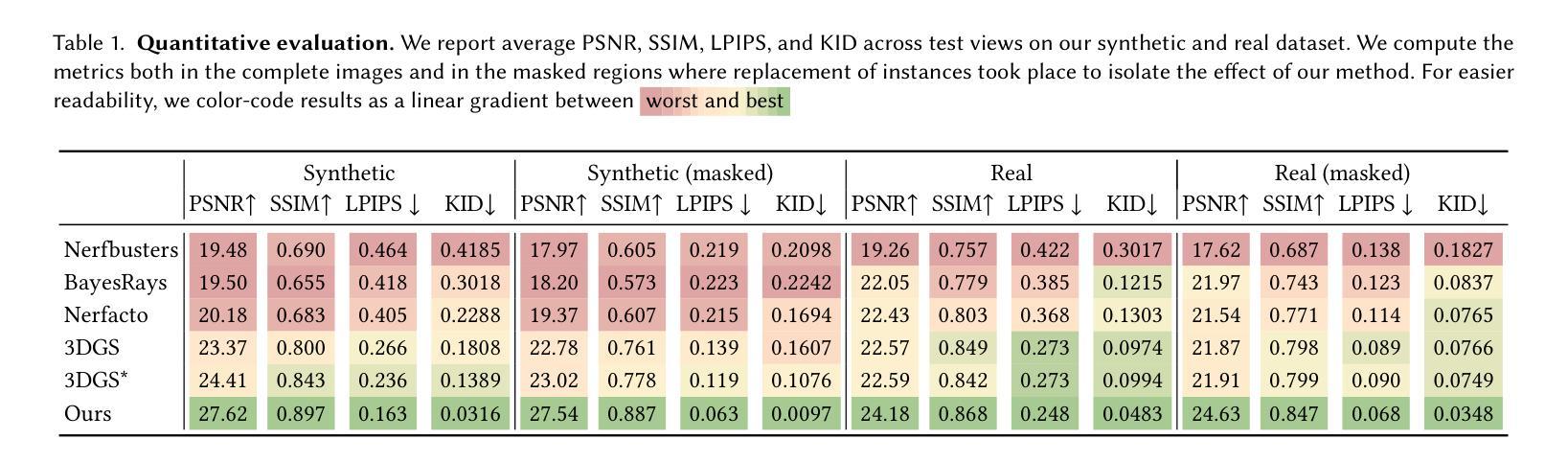
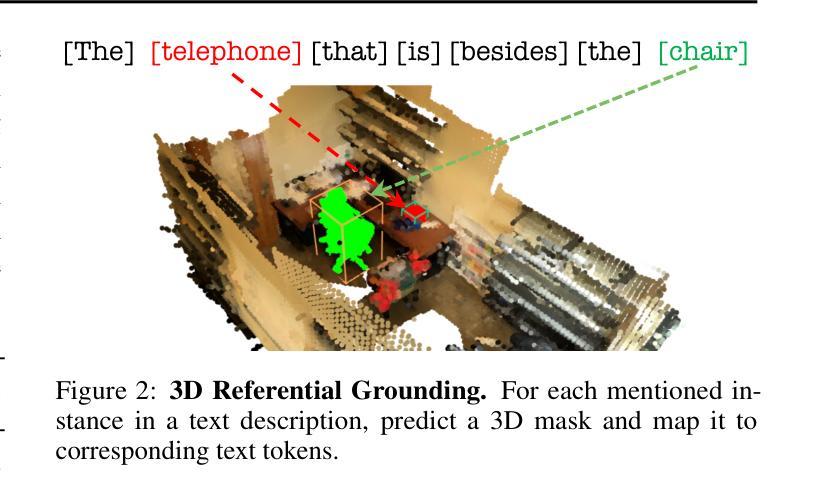
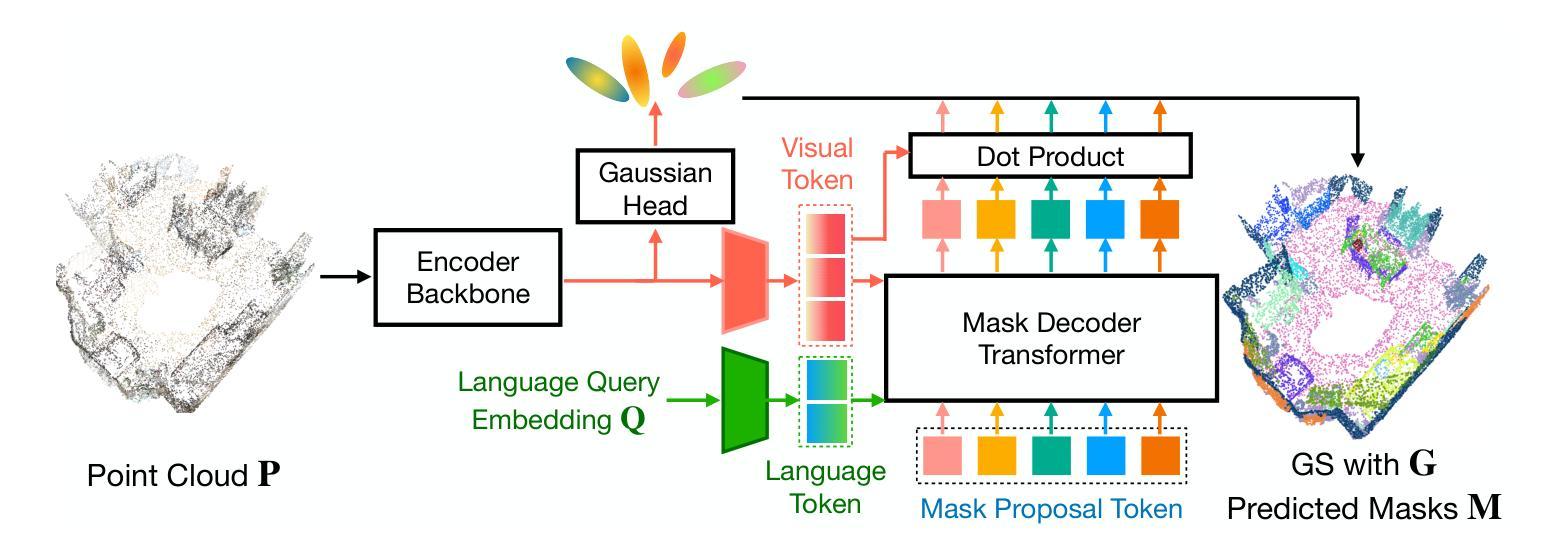
From Thousands to Billions: 3D Visual Language Grounding via Render-Supervised Distillation from 2D VLMs
Authors:Ang Cao, Sergio Arnaud, Oleksandr Maksymets, Jianing Yang, Ayush Jain, Sriram Yenamandra, Ada Martin, Vincent-Pierre Berges, Paul McVay, Ruslan Partsey, Aravind Rajeswaran, Franziska Meier, Justin Johnson, Jeong Joon Park, Alexander Sax
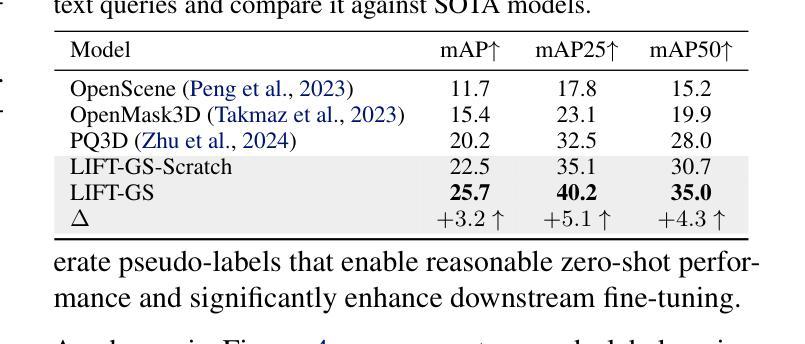
3D vision-language grounding faces a fundamental data bottleneck: while 2D models train on billions of images, 3D models have access to only thousands of labeled scenes–a six-order-of-magnitude gap that severely limits performance. We introduce $\textbf{LIFT-GS}$, a practical distillation technique that overcomes this limitation by using differentiable rendering to bridge 3D and 2D supervision. LIFT-GS predicts 3D Gaussian representations from point clouds and uses them to render predicted language-conditioned 3D masks into 2D views, enabling supervision from 2D foundation models (SAM, CLIP, LLaMA) without requiring any 3D annotations. This render-supervised formulation enables end-to-end training of complete encoder-decoder architectures and is inherently model-agnostic. LIFT-GS achieves state-of-the-art results with $25.7%$ mAP on open-vocabulary instance segmentation (vs. $20.2%$ prior SOTA) and consistent $10-30%$ improvements on referential grounding tasks. Remarkably, pretraining effectively multiplies fine-tuning datasets by 2X, demonstrating strong scaling properties that suggest 3D VLG currently operates in a severely data-scarce regime. Project page: https://liftgs.github.io
3D视觉语言定位面临一个基本的数据瓶颈:虽然2D模型可以在数十亿张图像上进行训练,但3D模型只能访问数千个标记场景——这是一个六个数量级的差距,严重限制了性能。我们引入了$\textbf{LIFT-GS}$,这是一种实用的蒸馏技术,它通过可微渲染来弥合3D和2D监督,从而克服这一限制。LIFT-GS从点云中预测3D高斯表示,并将其用于呈现预测的受语言控制的三维掩码到二维视图,从而能够从二维基础模型(SAM、CLIP、LLaMA)中获得监督,无需任何三维注释。这种基于渲染的监督公式能够实现完整的编码器-解码器架构的端到端训练,并且本质上是与模型无关的。LIFT-GS在开放词汇实例分割方面达到了最先进的成果,其平均精确度为$25.7%$(此前的最先进的记录为$20.2%$),并且在参照定位任务上始终提高了$10-30%$。值得注意的是,预训练有效地使微调数据集翻倍,显示出强大的扩展属性,这表明目前3D视觉语言定位仍处于严重的数据稀缺状态。项目页面:https://liftgs.github.io。
论文及项目相关链接
PDF Project page: https://liftgs.github.io
Summary
3D视觉语言定位面临数据瓶颈问题:2D模型可在数十亿图像上进行训练,而3D模型只能使用数千个标记场景,存在六个数量级的差距,严重限制了性能。为此,我们引入了LIFT-GS这一实用的蒸馏技术,它通过可微渲染来桥接3D和2D监督,从而克服这一局限性。LIFT-GS预测点云中的三维高斯表示并将其用于渲染预测的语言引导的三维遮罩至二维视图,实现了在无需任何三维标注的情况下接受来自二维基础模型的监督。这种渲染监督形式可实现端到端的完整编码器解码器架构的训练,并具备固有的模型无关性。LIFT-GS在开放词汇实例分割方面取得了最新结果(相较于先前的最佳结果提升了25.7%),并且在参照定位任务上均取得了一致的改善效果。更重要的是,预训练在数据增强方面显示出强大的可扩展性特征,在精细调整数据集时发挥了有效地双倍提升效果。欲了解详细内容,请访问我们的项目主页:https://liftgs.github.io。
Key Takeaways
- 3D视觉语言定位面临数据瓶颈问题,存在从二维到三维模型训练数据的巨大差距。
- LIFT-GS技术通过可微渲染桥接三维和二维监督,缩小这一差距。
- LIFT-GS使用点云预测三维高斯表示并渲染语言引导的三维遮罩到二维视图,无需三维标注即可接受监督。
- LIFT-GS可实现端到端的完整编码器解码器架构的训练,具备模型无关性。
- LIFT-GS在实例分割和参照定位任务上取得了显著成果。
点此查看论文截图



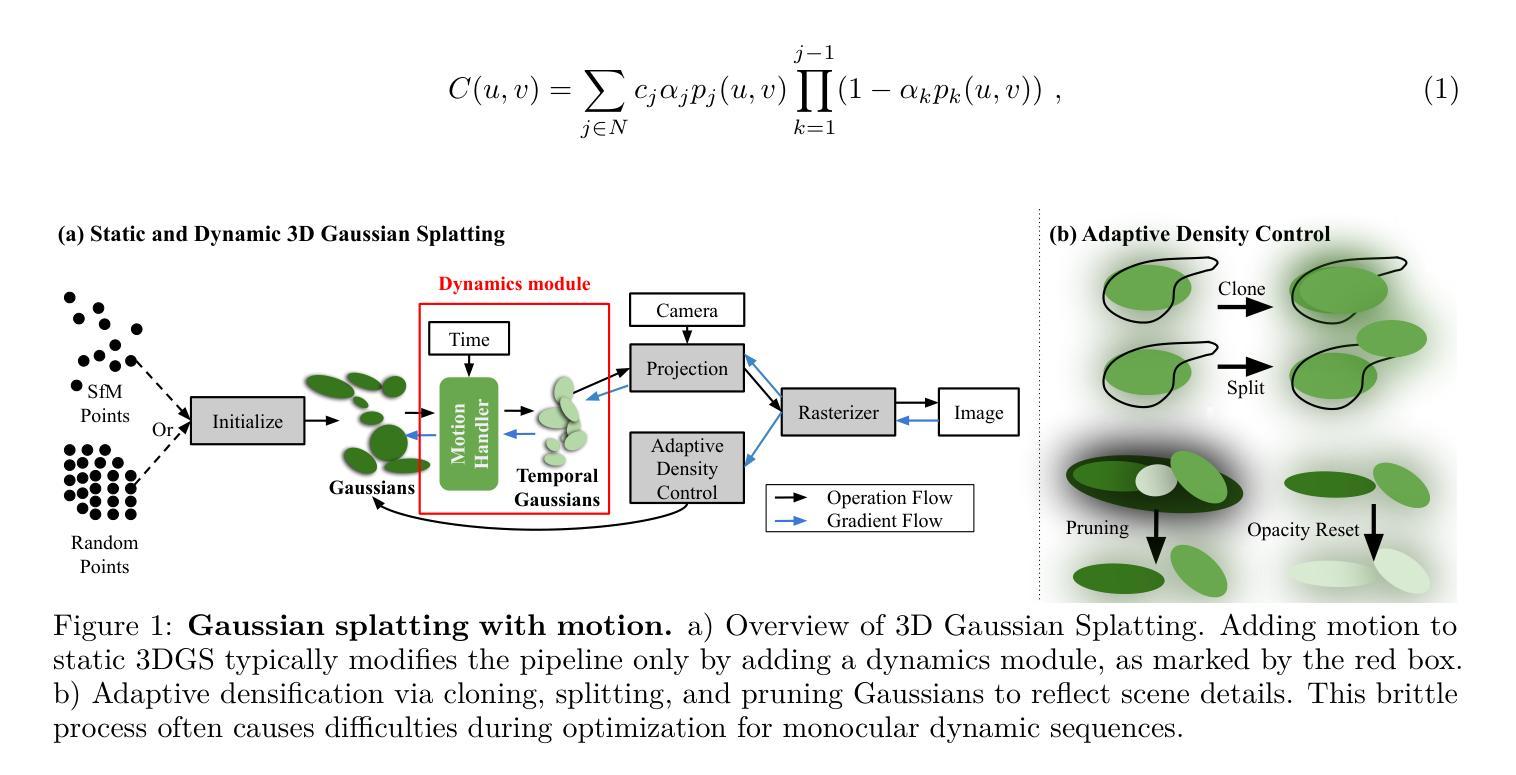
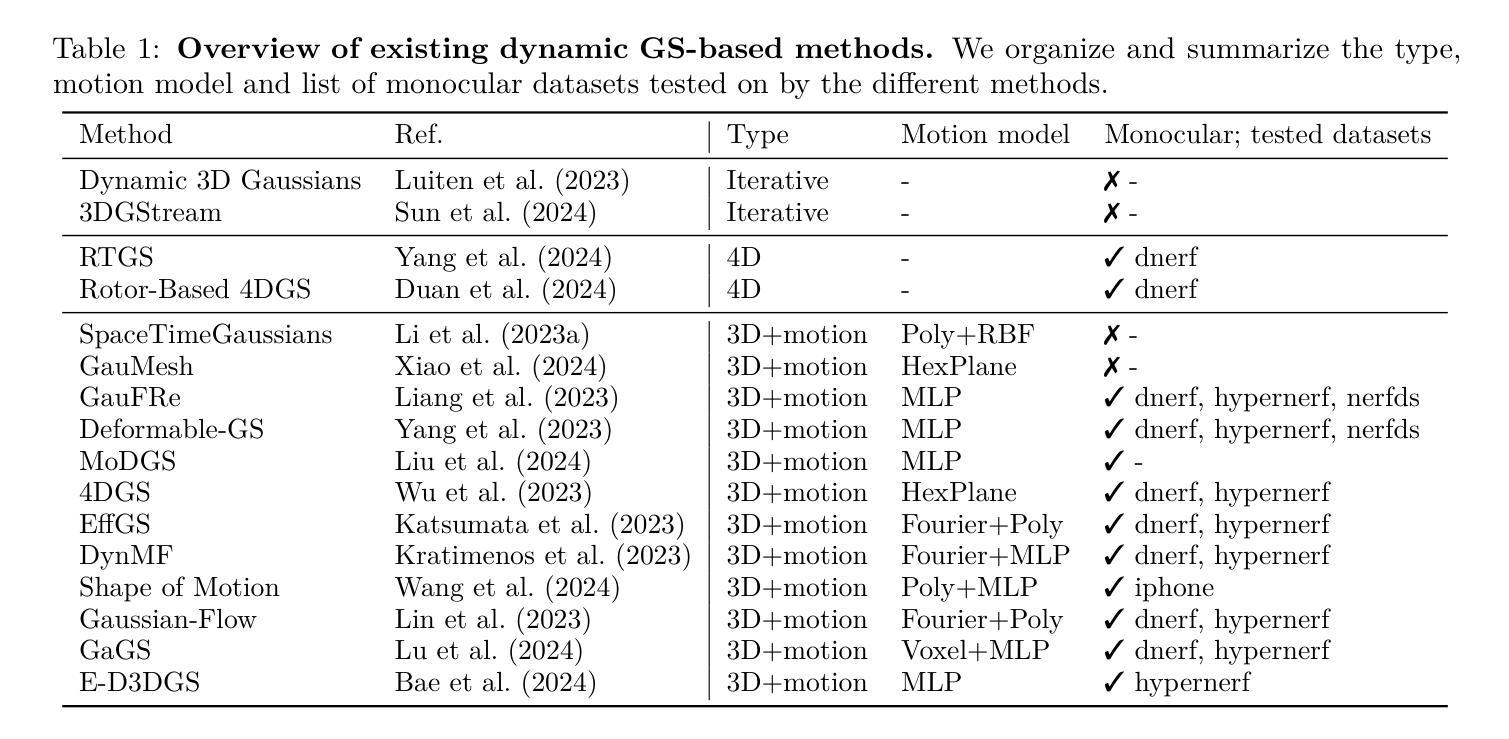
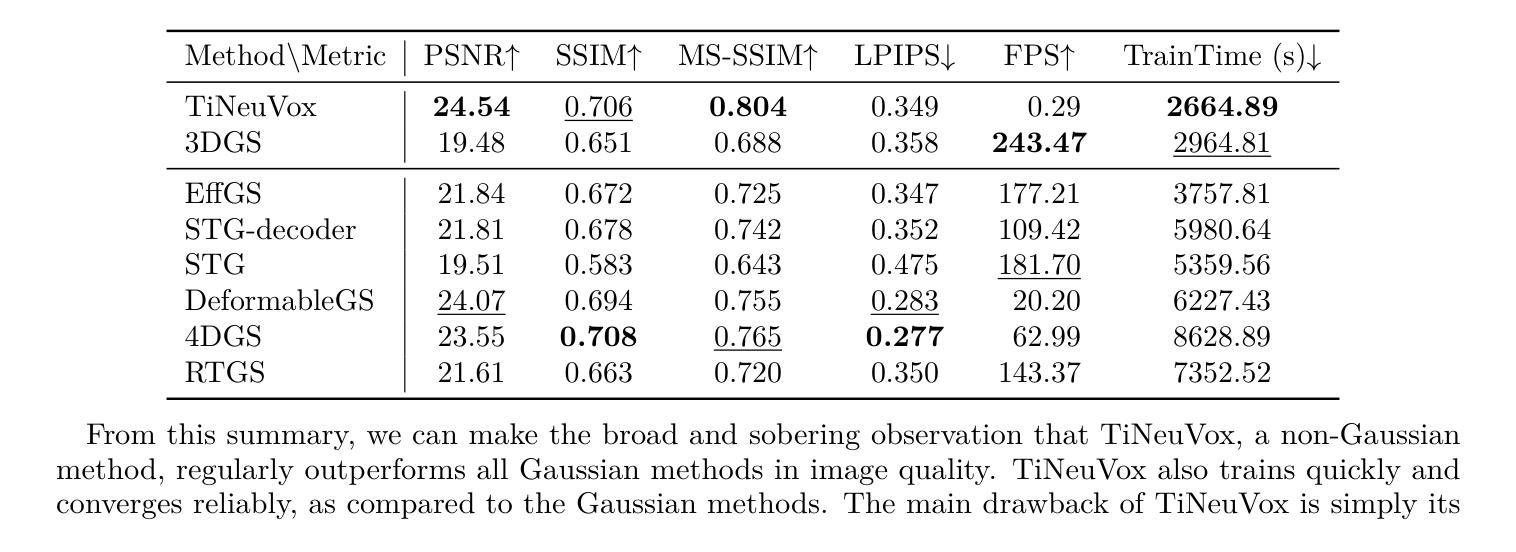
Monocular Dynamic Gaussian Splatting: Fast, Brittle, and Scene Complexity Rules
Authors:Yiqing Liang, Mikhail Okunev, Mikaela Angelina Uy, Runfeng Li, Leonidas Guibas, James Tompkin, Adam W. Harley
Gaussian splatting methods are emerging as a popular approach for converting multi-view image data into scene representations that allow view synthesis. In particular, there is interest in enabling view synthesis for dynamic scenes using only monocular input data – an ill-posed and challenging problem. The fast pace of work in this area has produced multiple simultaneous papers that claim to work best, which cannot all be true. In this work, we organize, benchmark, and analyze many Gaussian-splatting-based methods, providing apples-to-apples comparisons that prior works have lacked. We use multiple existing datasets and a new instructive synthetic dataset designed to isolate factors that affect reconstruction quality. We systematically categorize Gaussian splatting methods into specific motion representation types and quantify how their differences impact performance. Empirically, we find that their rank order is well-defined in synthetic data, but the complexity of real-world data currently overwhelms the differences. Furthermore, the fast rendering speed of all Gaussian-based methods comes at the cost of brittleness in optimization. We summarize our experiments into a list of findings that can help to further progress in this lively problem setting.
高斯涂抹法正在成为一种流行的将多视角图像数据转换为场景表示的方法,这种表示方法允许视图合成。特别是在使用单目输入数据为动态场景实现视图合成方面,这是一个不适定且具有挑战性的问题。这一领域的快节奏工作产生了许多声称效果最佳的同时发表的多篇论文,但不可能都是真实的。在这项工作中,我们对基于高斯涂抹的方法进行了整理、评估和对比基准测试,提供了之前工作中缺失的逐一比较。我们使用多个现有数据集和一个新的教学性合成数据集,旨在隔离影响重建质量的因素。我们将高斯涂抹法系统地归类为特定的运动表示类型,并量化它们之间的差异如何影响性能。从实证上看,我们发现它们在合成数据中的排名是明确的,但现实数据的复杂性目前掩盖了这些差异。此外,所有基于高斯的方法的快速渲染速度是以优化过程中的脆弱性为代价的。我们将实验结果总结为一系列发现,有助于在此活跃的问题设置方面取得进一步进展。
论文及项目相关链接
PDF TMLR 2025. Project Website: https://brownvc.github.io/MonoDyGauBench.github.io/
Summary
高斯插值方法已成为将多视角图像数据转换为场景表示以进行视图合成的流行方法。特别是对于仅使用单眼输入数据对动态场景进行视图合成的问题,这是一个不适定且具挑战性的问题。此领域的快速发展产生了许多声称效果最佳的同时论文,但它们不可能都是真实的。本文整理、评估和分析了许多基于高斯插值的方法,提供了先前工作所缺乏的同类比较。我们使用多个现有数据集和一个新的指导性合成数据集,旨在隔离影响重建质量的因素。我们系统地按运动表示类型对高斯插值方法进行分类,并量化其差异对性能的影响。实证发现,它们在合成数据中的排名顺序是明确的,但现实世界的复杂数据目前仍超过了差异。此外,所有基于高斯的方法的快速渲染速度是以优化脆弱性为代价的。
Key Takeaways
- 高斯插值方法已成为多视角图像数据转换为场景表示的主流技术,尤其适用于动态场景的视图合成。
- 此领域涌现出大量论文,声称各自的方法效果最佳,但缺乏全面的比较和评估。
- 通过对多种高斯插值方法进行组织、评估和比较,本文提供了同类比较的基准。
- 使用现有和新的合成数据集,旨在隔离影响重建质量的因素,进行实证分析。
- 高斯插值方法在合成数据中的性能排名明确,但在现实世界的复杂数据面前仍面临挑战。
- 基于高斯的方法虽然快速渲染,但在优化方面存在脆弱性。
点此查看论文截图



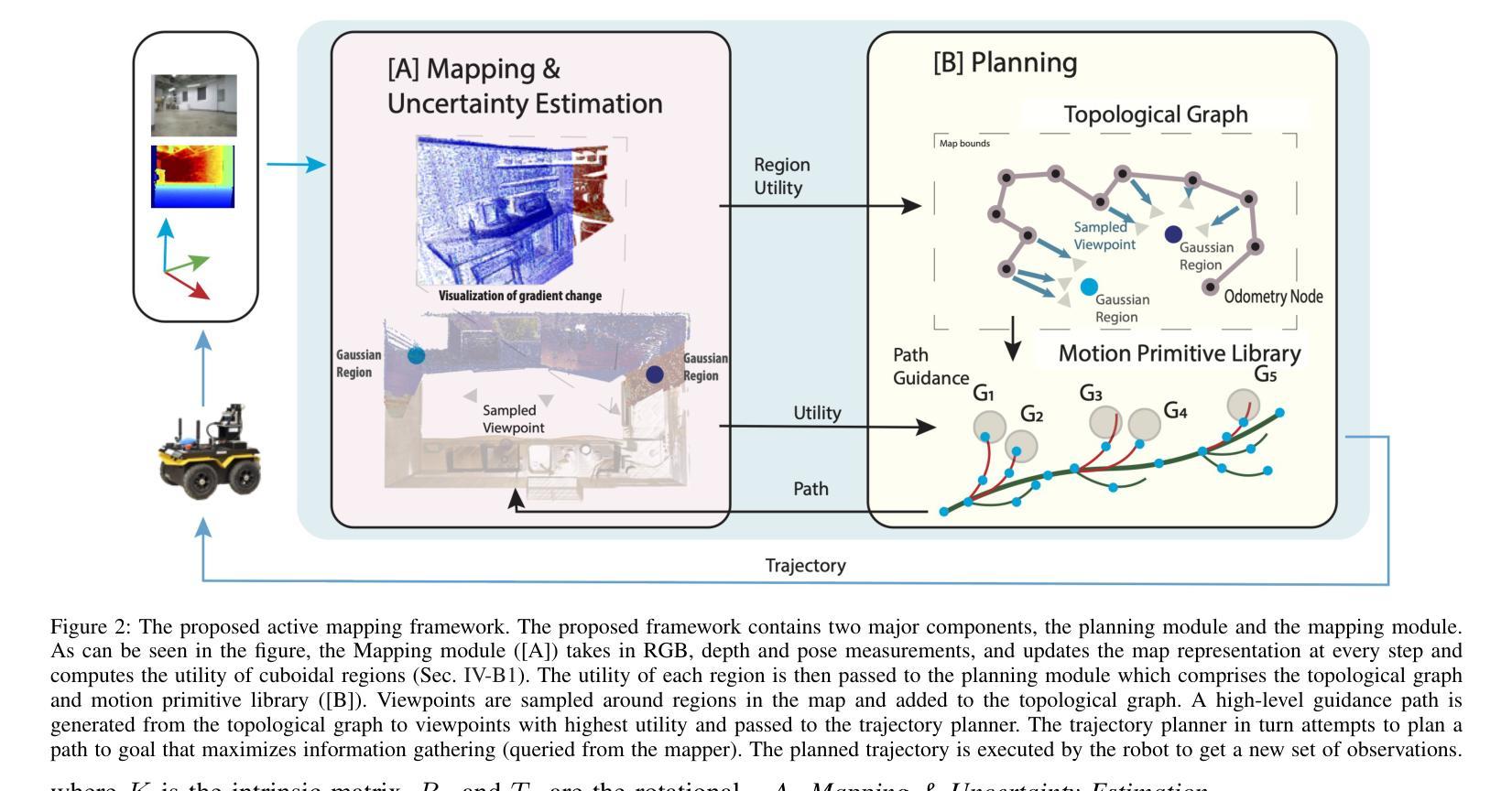
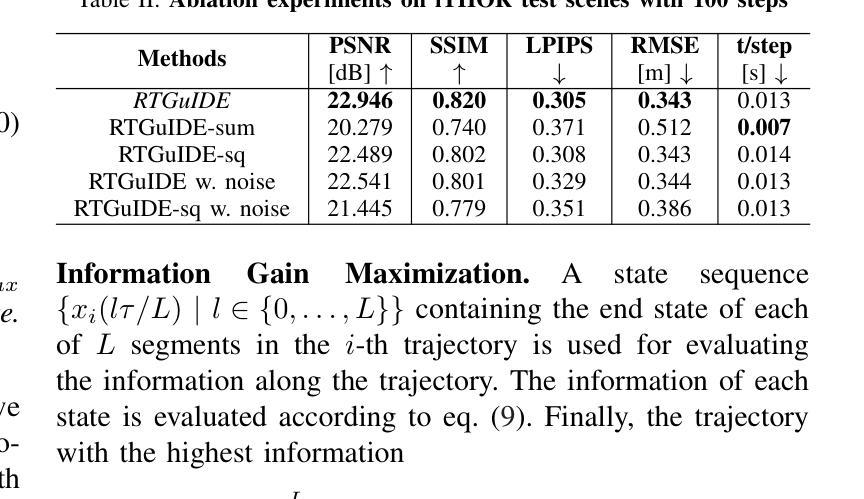
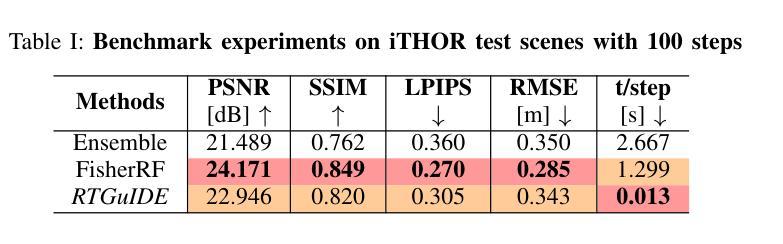
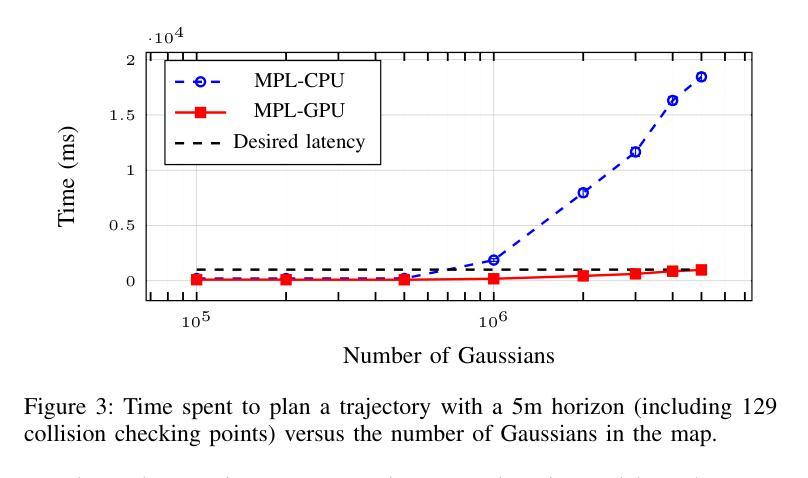
RT-GuIDE: Real-Time Gaussian splatting for Information-Driven Exploration
Authors:Yuezhan Tao, Dexter Ong, Varun Murali, Igor Spasojevic, Pratik Chaudhari, Vijay Kumar
We propose a framework for active mapping and exploration that leverages Gaussian splatting for constructing dense maps. Further, we develop a GPU-accelerated motion planning algorithm that can exploit the Gaussian map for real-time navigation. The Gaussian map constructed onboard the robot is optimized for both photometric and geometric quality while enabling real-time situational awareness for autonomy. We show through simulation experiments that our method yields comparable Peak Signal-to-Noise Ratio (PSNR) and similar reconstruction error to state-of-the-art approaches, while being orders of magnitude faster to compute. In real-world experiments, our algorithm achieves better map quality (at least 0.8dB higher PSNR and more than 16% higher geometric reconstruction accuracy) than maps constructed by a state-of-the-art method, enabling semantic segmentation using off-the-shelf open-set models. Experiment videos and more details can be found on our project page: https://tyuezhan.github.io/RT_GuIDE/
我们提出一个利用高斯斑点法构建密集地图的活动映射和勘探框架。此外,我们开发了一个GPU加速的运动规划算法,该算法可以利用高斯地图进行实时导航。机器人在构建的高斯地图在光度和几何质量上进行了优化,同时提高了自主性的实时情境意识。我们通过模拟实验表明,我们的方法在峰值信噪比(PSNR)上与最先进的方法相当,重建误差相似,但计算速度要快得多。在现实世界的实验中,我们的算法在地图质量上优于最先进的方法构建的地图(至少高出0.8dB的PSNR和超过16%的几何重建精度),从而实现使用现成的开放式模型进行语义分割。实验视频和更多详细信息可以在我们的项目页面找到:https://tyuezhan.github.io/RT_GuIDE/。
论文及项目相关链接
Summary
该框架结合了高斯混合模型与GPU加速运动规划算法,用于实时导航和地图构建。该算法优化后的高斯地图同时考虑了光照和几何质量,提升了机器人的实时情境感知能力。模拟实验证明,该方法计算速度大幅优于现有技术,且地图质量相近;在真实世界实验中,该方法所构建的地图质量更高,能进行语义分割并兼容开放模型。
Key Takeaways
- 该框架采用高斯混合模型构建地图。
- 利用GPU加速的运动规划算法,使得导航更快速。
- 高斯地图优化考虑光照和几何质量,提高机器人实时情境感知能力。
- 模拟实验证明该方法的计算速度显著快于现有技术。
- 与最新技术相比,该方法在真实世界实验中构建的地图质量更高。
- 实现地图的语义分割功能。
点此查看论文截图