⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-11 更新
Supporting Construction Worker Well-Being with a Multi-Agent Conversational AI System
Authors:Fan Yang, Yuan Tian, Jiansong Zhang
The construction industry is characterized by both high physical and psychological risks, yet supports of mental health remain limited. While advancements in artificial intelligence (AI), particularly large language models (LLMs), offer promising solutions, their potential in construction remains largely underexplored. To bridge this gap, we developed a conversational multi-agent system that addresses industry-specific challenges through an AI-driven approach integrated with domain knowledge. In parallel, it fulfills construction workers’ basic psychological needs by enabling interactions with multiple agents, each has a distinct persona. This approach ensures that workers receive both practical problem-solving support and social engagement, ultimately contributing to their overall well-being. We evaluate its usability and effectiveness through a within-subjects user study with 12 participants. The results show that our system significantly outperforms the single-agent baseline, achieving improvements of 18% in usability, 40% in self-determination, 60% in social presence, and 60% in trust. These findings highlight the promise of LLM-driven AI systems in providing domain-specific support for construction workers.
建筑行业具有高风险的特点,既有身体上的也有心理上的风险,但精神健康支持仍然有限。虽然人工智能(AI)的进步,特别是大型语言模型(LLM)提供了有前景的解决方案,但它们在建筑行业中的潜力仍未得到充分探索。为了弥这一差距,我们开发了一个对话式多智能体系统,它通过集成人工智能方法和领域知识来解决行业特定挑战。同时,它通过支持与多个智能体的互动来满足建筑工人的基本心理需求,每个智能体都有独特的个性。这种方法确保工人既获得实用的解决问题的支持,也得到社会参与,最终有助于他们的整体福祉。我们通过一项针对12名参与者的内部主体用户研究来评估其可用性和有效性。结果表明,我们的系统显著优于单智能体基线,在可用性方面提高了18%,在自主性方面提高了40%,在社会存在感方面提高了60%,在信任度方面提高了60%。这些发现突显了LLM驱动的人工智能系统在为建筑工人提供特定领域的支持方面的潜力。
论文及项目相关链接
Summary
人工智能在建筑行业的应用潜力巨大,尤其是大型语言模型(LLMs)为行业带来了具有针对性的解决方案。为应对建筑行业中的心理风险和支持工人的心理健康,研究者开发了一种基于人工智能的对话多智能体系统。通过人员参与评估和实验证明,该系统在多智能体共同作用下大幅提升了工人应对心理挑战的能力和幸福感,明显优于单一智能体基线模型。系统的运用极大地改善了建筑工人的生活质量和工作效率。
Key Takeaways
- 建筑行业存在物理和心理风险,对工人的心理健康支持需求迫切。
- 大型语言模型(LLMs)在建筑行业的应用潜力巨大,为解决行业问题提供了有效途径。
- 开发的对话多智能体系统能够针对建筑行业的特殊挑战提供人工智能解决方案。
- 系统通过集成人工智能和领域知识,实现了实用问题解决和社会互动的结合,提升了工人的整体幸福感。
- 实验结果表明,该系统显著提高了工人的可用性、自我决定能力、社会存在感和信任度。
- 与单一智能体相比,多智能体系统更能有效地支持建筑工人的工作和生活。
点此查看论文截图

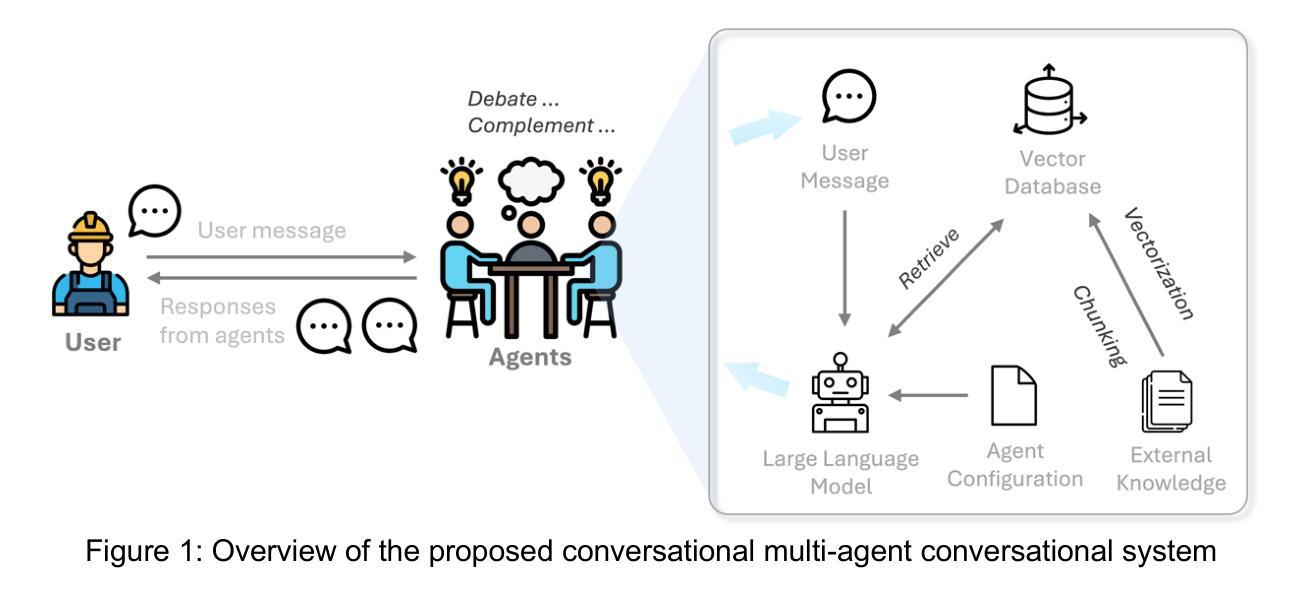
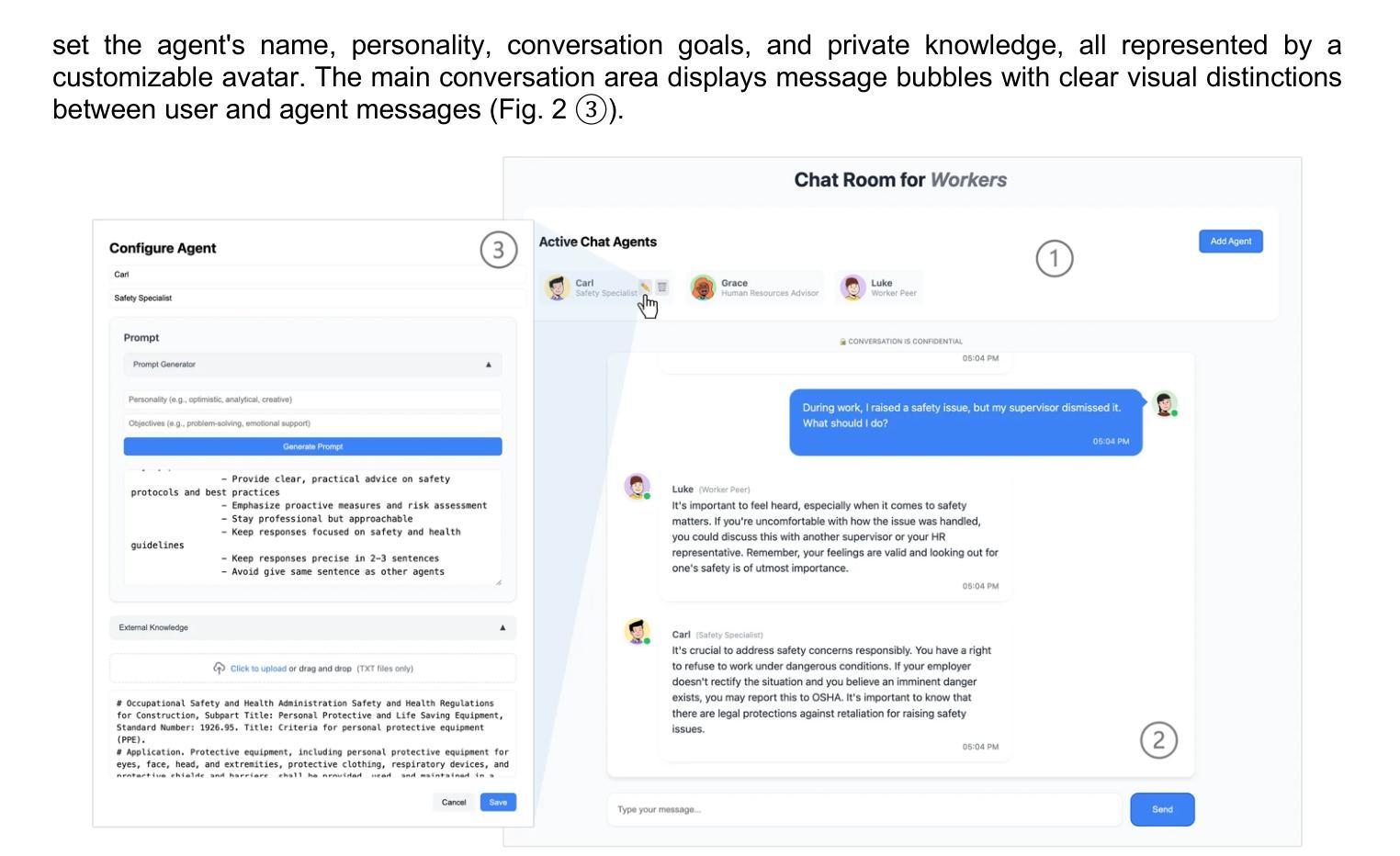
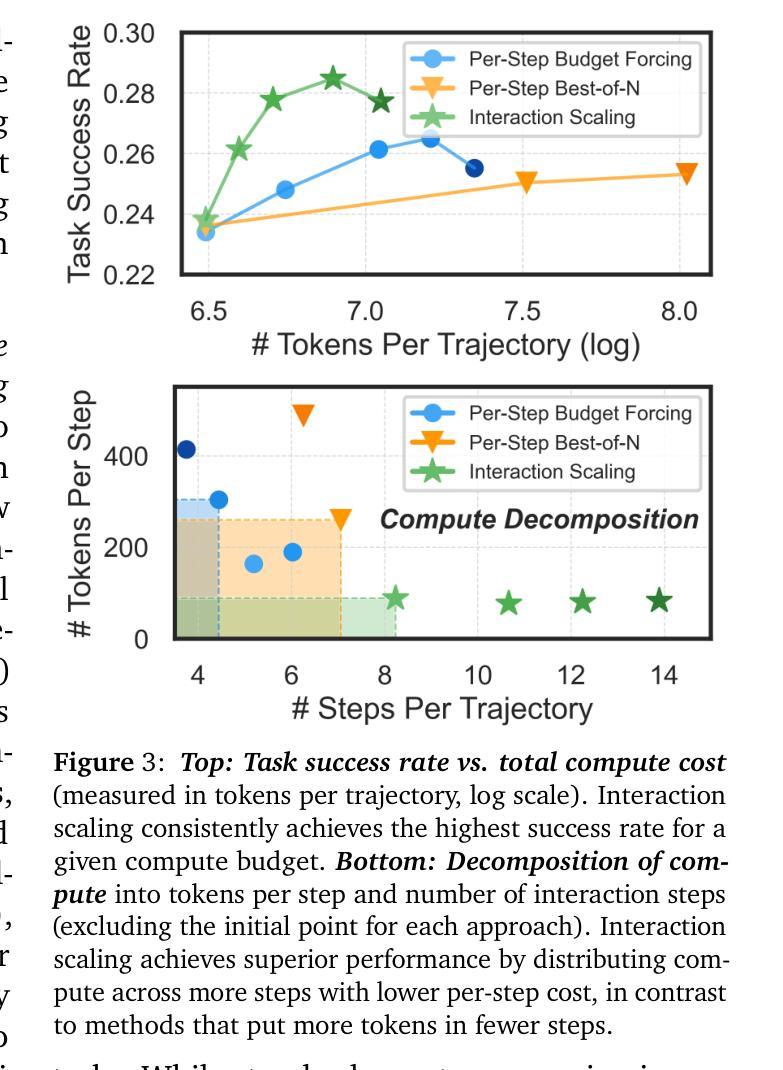
Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction
Authors:Junhong Shen, Hao Bai, Lunjun Zhang, Yifei Zhou, Amrith Setlur, Shengbang Tong, Diego Caples, Nan Jiang, Tong Zhang, Ameet Talwalkar, Aviral Kumar
The current paradigm of test-time scaling relies on generating long reasoning traces (“thinking” more) before producing a response. In agent problems that require interaction, this can be done by generating thinking traces before acting in the world. However, this process does not allow agents to acquire new information from the environment or adapt their behavior over time. In this work, we propose to scale test-time interaction, an untapped dimension of test-time scaling that increases the agent’s interaction horizon to enable running rich behaviors such as exploration, backtracking, and dynamic re-planning within a single rollout. To demonstrate the promise of this scaling dimension, we study the domain of web agents. We first show that even prompting-based interaction scaling without any training can improve task success on web benchmarks non-trivially. Building on this, we introduce TTI (Test-Time Interaction), a curriculum-based online reinforcement learning (RL) approach that trains agents by adaptively adjusting their rollout lengths. Using a Gemma 3 12B model, TTI produces state-of-the-art open-source, open-data web agents on WebVoyager and WebArena benchmarks. We further show that TTI enables agents to balance exploration and exploitation adaptively. Our results establish interaction scaling as a powerful, complementary axis to scaling per-step compute, offering new avenues for training adaptive agents.
当前测试时间缩放范式依赖于在生成响应之前产生较长的推理轨迹(即“思考”更多)。在需要交互的代理问题中,这可以通过在世界中采取行动之前生成思维轨迹来完成。然而,这个过程不允许代理从环境中获取新信息或随着时间的推移改变它们的行为。在这项工作中,我们提出了测试时间交互的缩放,这是测试时间缩放的一个未被开发的维度,它增加了代理的交互范围,能够在单次运行中执行丰富的行为,如探索、回溯和动态重新规划。为了证明这一缩放维度的潜力,我们研究了网页代理领域。我们首先表明,即使在没有任何训练的情况下,基于提示的交互缩放也可以非平凡地提高网页基准测试的任务成功率。在此基础上,我们引入了测试时间交互(TTI),这是一种基于课程的在线强化学习(RL)方法,通过自适应调整代理的滚动长度来训练代理。使用Gemma 3 12B模型,TTI在WebVoyager和WebArena基准测试中产生了最先进的开源开放数据网页代理。我们还表明,TTI使代理能够自适应地平衡探索和利用。我们的结果确立了交互缩放作为强大且互补的轴心,与每步计算缩放相辅相成,为训练自适应代理提供了新的途径。
论文及项目相关链接
Summary
本文提出测试时交互扩展的概念,旨在提高智能体在环境中的交互能力,使其能够在单次运行中执行丰富的行为,如探索、回溯和动态规划。研究者在Web代理领域进行了验证,发现即使在不进行任何训练的情况下,基于提示的交互扩展也能在一定程度上提高任务成功率。在此基础上,研究者还提出了一种基于在线强化学习的测试时交互(TTI)方法,通过自适应调整智能体的运行长度来训练智能体。使用Gemma 3 12B模型,TTI在WebVoyager和WebArena基准测试中达到了开源智能体的最佳状态。此外,TTI还能使智能体自适应地平衡探索和利用。
Key Takeaways
- 测试时交互扩展允许智能体在环境中进行更丰富的行为,如探索、回溯和动态规划。
- 在Web代理领域,基于提示的交互扩展在不进行任何训练的情况下就能提高任务成功率。
- TTI是一种基于在线强化学习的测试时交互方法,通过自适应调整智能体的运行长度来训练。
- TTI使用Gemma 3 12B模型,在WebVoyager和WebArena基准测试中表现出最佳性能。
- TTI使智能体能够自适应地平衡探索和利用,这是一种新的训练自适应代理的方法。
- 测试时交互扩展是一个强大的、与每步计算扩展相辅相成的维度。
点此查看论文截图

HeuriGym: An Agentic Benchmark for LLM-Crafted Heuristics in Combinatorial Optimization
Authors:Hongzheng Chen, Yingheng Wang, Yaohui Cai, Hins Hu, Jiajie Li, Shirley Huang, Chenhui Deng, Rongjian Liang, Shufeng Kong, Haoxing Ren, Samitha Samaranayake, Carla P. Gomes, Zhiru Zhang
While Large Language Models (LLMs) have demonstrated significant advancements in reasoning and agent-based problem-solving, current evaluation methodologies fail to adequately assess their capabilities: existing benchmarks either rely on closed-ended questions prone to saturation and memorization, or subjective comparisons that lack consistency and rigor. In this work, we introduce HeuriGym, an agentic framework designed for evaluating heuristic algorithms generated by LLMs for combinatorial optimization problems, characterized by clearly defined objectives and expansive solution spaces. HeuriGym empowers LLMs to propose heuristics, receive evaluative feedback via code execution, and iteratively refine their solutions. We evaluate nine state-of-the-art models on nine problems across domains such as computer systems, logistics, and biology, exposing persistent limitations in tool use, planning, and adaptive reasoning. To quantify performance, we propose the Quality-Yield Index (QYI), a metric that captures both solution pass rate and quality. Even top models like GPT-o4-mini-high and Gemini-2.5-Pro attain QYI scores of only 0.6, well below the expert baseline of 1. Our open-source benchmark aims to guide the development of LLMs toward more effective and realistic problem-solving in scientific and engineering domains.
虽然大型语言模型(LLM)在推理和基于代理的问题解决方面取得了显著进展,但当前的评估方法未能充分评估其能力:现有基准测试要么依赖于封闭性问题,这些问题容易饱和和记忆,要么缺乏一致性和严谨性的主观比较。在这项工作中,我们介绍了HeuriGym,这是一个为评估LLM生成的启发式算法而设计的代理框架,用于解决组合优化问题,其特点是目标明确、解决方案空间广阔。HeuriGym使LLM能够提出启发式方法,通过代码执行接收评估反馈,并迭代优化其解决方案。我们评估了九个领域九个问题的九种最新模型,暴露了工具使用、规划和自适应推理方面的持续局限。为了量化性能,我们提出了质量收益指数(QYI),一个能够捕获解决方案通过率和质量的指标。即使是顶级模型,如GPT-o4-mini-high和Gemini-2.5-Pro的QYI得分也只有0.6,远低于专家基准1。我们的开源基准旨在指导LLM的发展,以实现科学和工程领域更有效、更实际的问题解决。
论文及项目相关链接
Summary
本文介绍了大型语言模型(LLMs)在推理和基于代理的问题解决方面取得了显著进展,但现有评估方法无法充分评估其能力。为此,本文提出了HeuriGym框架,用于评估LLMs生成的启发式算法在组合优化问题上的表现。HeuriGym通过明确的目标和广阔解决方案空间,使LLMs能够提出启发式方法,通过代码执行接收评估反馈,并迭代优化其解决方案。作者在计算机系统、物流和生物学等领域对九种最先进的模型进行了评估,并揭示了工具使用、规划和自适应推理方面的持续局限性。为了量化性能,作者提出了质量收益指数(QYI),该指标能同时捕捉解决方案的通过率和质量。即使是最好的模型,如GPT-o4-mini-high和Gemini-2.5-Pro,其QYI得分也只有0.6,远低于专家基准线1。本文的开源基准测试旨在引导LLMs的发展,以更有效地解决科学和工程领域的问题。
Key Takeaways
- 大型语言模型(LLMs)在推理和基于代理的问题解决上取得了进展,但评估方法存在缺陷。
- 现有评估方法依赖于封闭问题或主观比较,缺乏一致性和严谨性。
- 引入HeuriGym框架,用于评估LLMs在组合优化问题上的启发式算法表现。
- HeuriGym有明确目标和广阔解决方案空间,促进LLMs提出启发式方法并迭代优化。
- 在不同领域如计算机系统、物流和生物学等进行了模型评估,揭示了工具使用、规划和自适应推理方面的局限性。
- 提出质量收益指数(QYI)作为性能量化指标,涵盖解决方案通过率和质量。
点此查看论文截图

Deep Equivariant Multi-Agent Control Barrier Functions
Authors:Nikolaos Bousias, Lars Lindemann, George Pappas
With multi-agent systems increasingly deployed autonomously at scale in complex environments, ensuring safety of the data-driven policies is critical. Control Barrier Functions have emerged as an effective tool for enforcing safety constraints, yet existing learning-based methods often lack in scalability, generalization and sampling efficiency as they overlook inherent geometric structures of the system. To address this gap, we introduce symmetries-infused distributed Control Barrier Functions, enforcing the satisfaction of intrinsic symmetries on learnable graph-based safety certificates. We theoretically motivate the need for equivariant parametrization of CBFs and policies, and propose a simple, yet efficient and adaptable methodology for constructing such equivariant group-modular networks via the compatible group actions. This approach encodes safety constraints in a distributed data-efficient manner, enabling zero-shot generalization to larger and denser swarms. Through extensive simulations on multi-robot navigation tasks, we demonstrate that our method outperforms state-of-the-art baselines in terms of safety, scalability, and task success rates, highlighting the importance of embedding symmetries in safe distributed neural policies.
随着多智能体系统在复杂的自然环境中越来越大规模地自主部署,确保数据驱动的策略安全至关重要。控制屏障函数已被证明是执行安全约束的有效工具,但现有的基于学习的方法往往缺乏可扩展性、通用性和采样效率,因为它们忽略了系统固有的几何结构。为了弥补这一差距,我们引入了融入对称性的分布式控制屏障函数,对基于可学习图的安全证书强制执行内在对称性的满足。我们从理论上阐述了CBF和策略等价参数化的必要性,并提出了一种简单、高效且灵活的方法,通过兼容的群作用构建此类等价群模块网络。这种方法以分布式数据高效的方式编码安全约束,实现对更大更密集群体系统的零射击泛化。通过对多机器人导航任务的广泛模拟,我们证明了我们的方法在安全性、可扩展性和任务成功率方面优于最新基线技术,强调了在对称性嵌入的安全分布式神经策略中的重要性。
论文及项目相关链接
Summary
数据驱动的策略安全性在多智能体系统大规模自主部署于复杂环境中变得至关重要。控制屏障函数作为实现安全约束的有效工具已引起关注,但现有基于学习的方法往往缺乏可扩展性、通用性和采样效率,因为它们忽略了系统固有的几何结构。为此,我们引入对称分布控制屏障函数,强制实施内在对称性关于可学习图的安全证书。我们从理论上论证了CBF和政策等价参数化的必要性,并提出一种简单、高效且灵活的方法构建这样的等价群模块网络通过兼容群动作。此方法以分布式数据高效的方式编码安全约束,实现对更大更密集群体机器人的零射击泛化。通过多机器人导航任务的广泛模拟,我们的方法在安全、可扩展性和任务成功率方面表现出超越现有技术的优越性,强调在分布式神经策略中嵌入对称性的重要性。
Key Takeaways
- 多智能体系统的自主部署带来数据驱动策略的安全性问题。
- 控制屏障函数能有效实施安全约束,但现有学习方法的可扩展性、通用性和采样效率有待提高。
- 引入对称分布控制屏障函数来强制实施内在对称性关于可学习图的安全证书。
- 提出一种简单高效构建等价群模块网络的方法,通过兼容群动作实现安全约束的编码。
- 该方法以分布式数据高效的方式实现安全性的嵌入,促进零射击泛化到更大规模的群体机器人系统。
- 模拟结果显示所提方法在安全性、可扩展性和任务成功率上超越现有技术。
点此查看论文截图

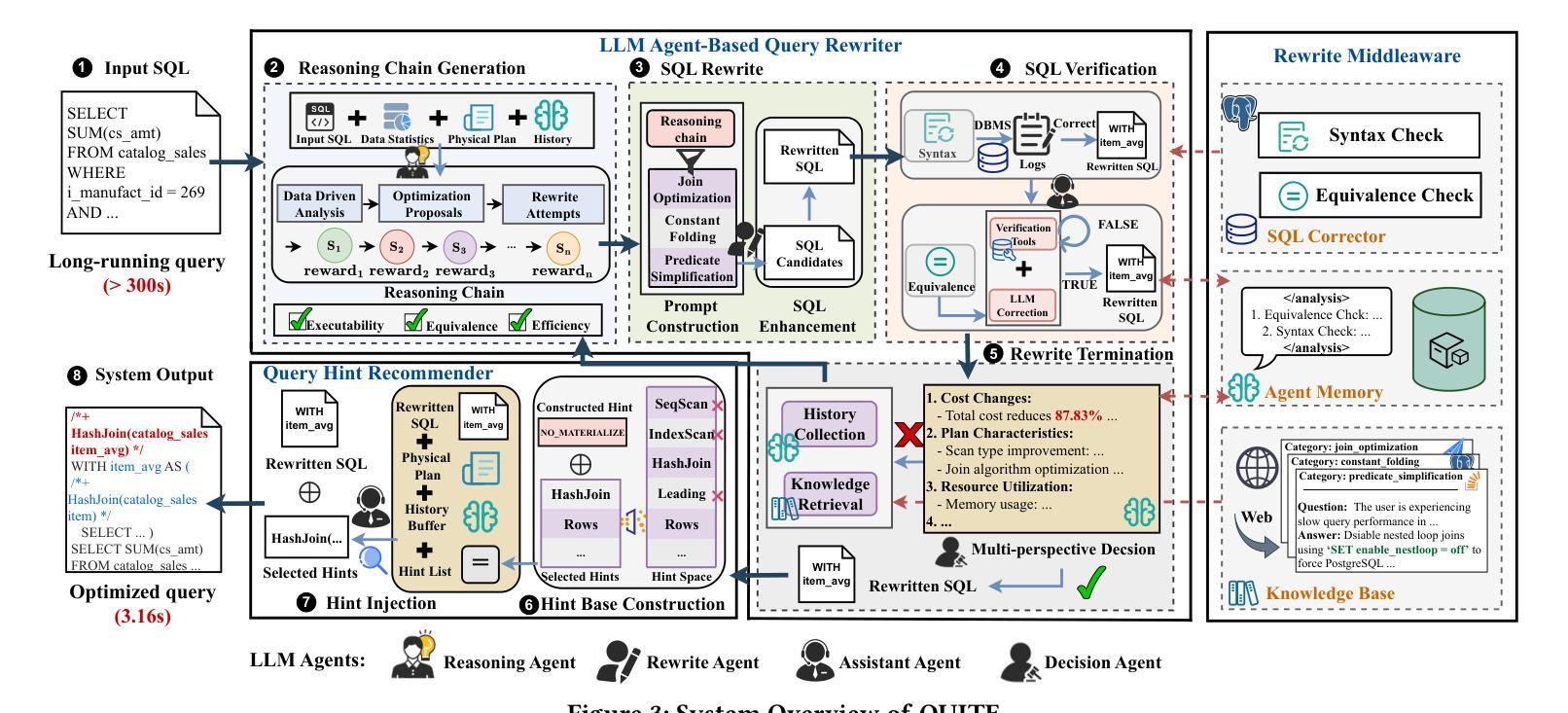
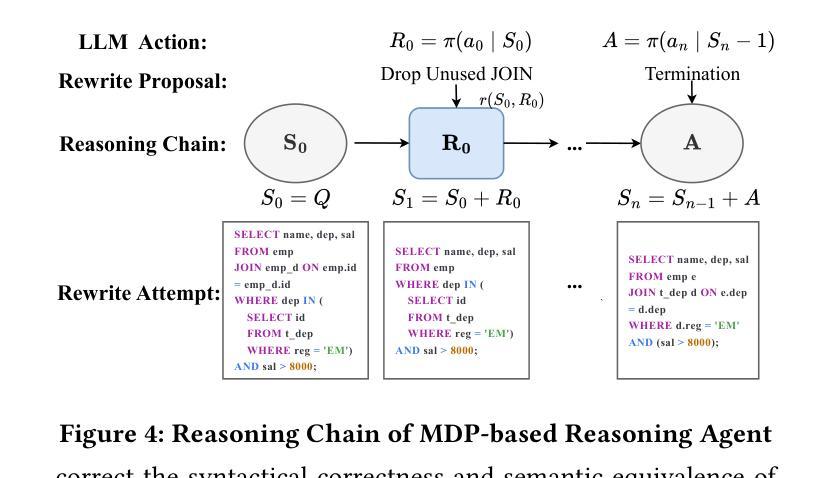
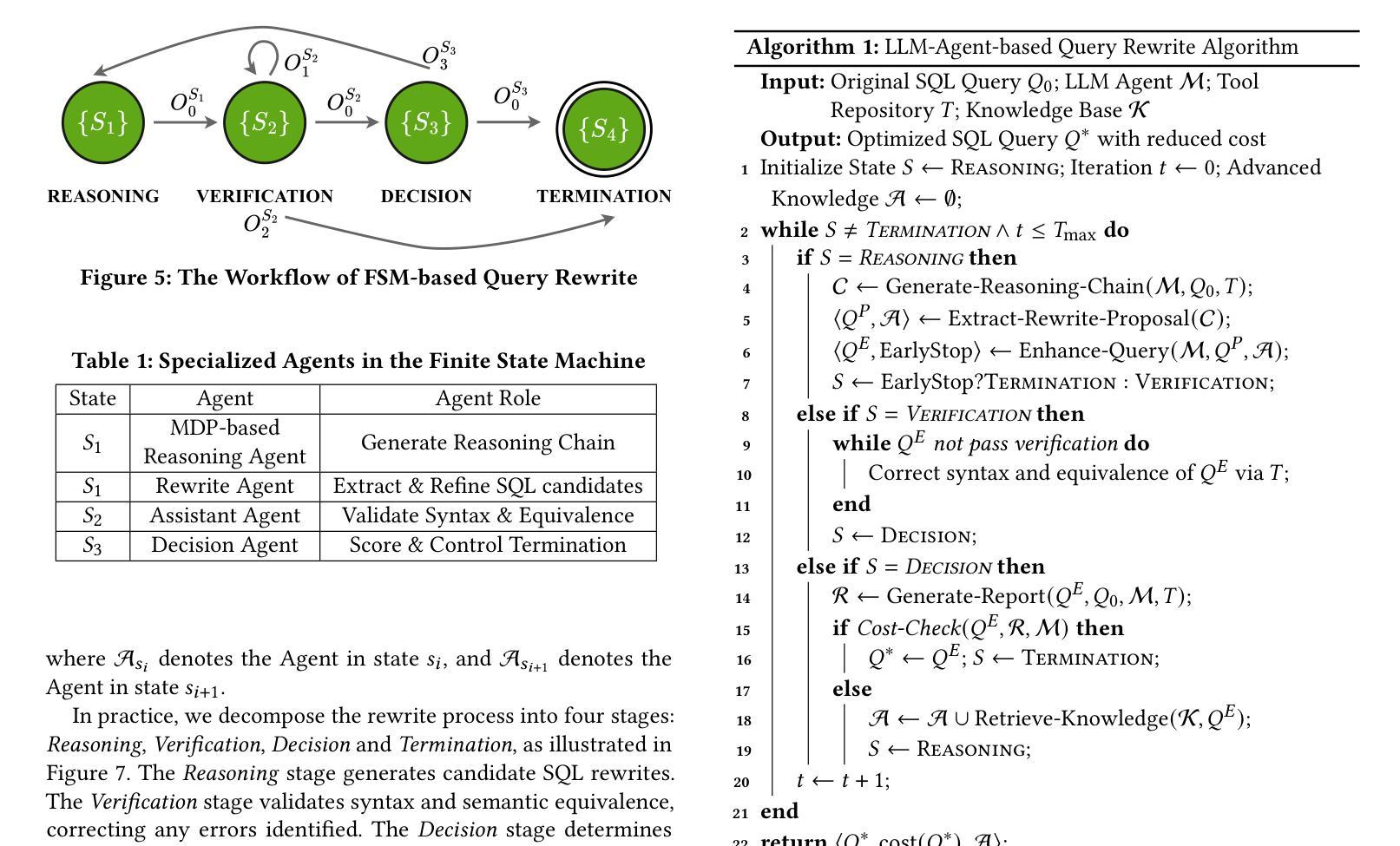
QUITE: A Query Rewrite System Beyond Rules with LLM Agents
Authors:Yuyang Song, Hanxu Yan, Jiale Lao, Yibo Wang, Yufei Li, Yuanchun Zhou, Jianguo Wang, Mingjie Tang
Query rewrite transforms SQL queries into semantically equivalent forms that run more efficiently. Existing approaches mainly rely on predefined rewrite rules, but they handle a limited subset of queries and can cause performance regressions. This limitation stems from three challenges of rule-based query rewrite: (1) it is hard to discover and verify new rules, (2) fixed rewrite rules do not generalize to new query patterns, and (3) some rewrite techniques cannot be expressed as fixed rules. Motivated by the fact that human experts exhibit significantly better rewrite ability but suffer from scalability, and Large Language Models (LLMs) have demonstrated nearly human-level semantic and reasoning abilities, we propose a new approach of using LLMs to rewrite SQL queries beyond rules. Due to the hallucination problems in LLMs, directly applying LLMs often leads to nonequivalent and suboptimal queries. To address this issue, we propose QUITE (query rewrite), a training-free and feedback-aware system based on LLM agents that rewrites SQL queries into semantically equivalent forms with significantly better performance, covering a broader range of query patterns and rewrite strategies compared to rule-based methods. Firstly, we design a multi-agent framework controlled by a finite state machine (FSM) to equip LLMs with the ability to use external tools and enhance the rewrite process with real-time database feedback. Secondly, we develop a rewrite middleware to enhance the ability of LLMs to generate optimized query equivalents. Finally, we employ a novel hint injection technique to improve execution plans for rewritten queries. Extensive experiments show that QUITE reduces query execution time by up to 35.8% over state-of-the-art approaches and produces 24.1% more rewrites than prior methods, covering query cases that earlier systems did not handle.
查询重写将SQL查询转换为语义上等效且运行效率更高的形式。现有方法主要依赖于预定义的重写规则,但它们只能处理有限数量的查询,并可能导致性能下降。这种局限性源于基于规则的查询重写所面临的三大挑战:(1)发现和验证新规则很困难,(2)固定的重写规则不能推广到新查询模式,(3)某些重写技术无法表示为固定规则。人类专家展现出更好的重写能力,但面临可扩展性问题,而大型语言模型(LLMs)已经证明了接近人类水平的语义和推理能力。因此,我们提出了一种利用LLMs进行超越规则的SQL查询重写的新方法。由于LLMs中的幻觉问题,直接应用LLMs通常会导致不等效和次优查询。为解决此问题,我们提出了QUERY REWRITE(查询重写)系统,这是一个基于LLM代理的无训练、有反馈意识的系统,能够将SQL查询重写为语义上等效的形式,具有更好的性能,与基于规则的方法相比,覆盖更广泛的查询模式和重写策略。首先,我们设计了一个由有限状态机(FSM)控制的多代理框架,为LLMs提供使用外部工具的能力,并通过实时数据库反馈增强重写过程。其次,我们开发了一个重写中间件,以增强LLMs生成优化查询等价物的能力。最后,我们采用了一种新型提示注入技术,以改进重写查询的执行计划。大量实验表明,与传统的先进方法相比,QUERY REWRITE将查询执行时间减少了高达35.8%,并且产生的重写比先前方法多出24.1%,覆盖了早期系统无法处理的查询情况。
论文及项目相关链接
Summary
在这个文本中,介绍了SQL查询重写技术,即将SQL查询转换为语义上等效且运行效率更高的形式。传统的基于规则的方法存在局限性,而人类专家的重写能力强大但难以扩展。因此,提出了一种基于大型语言模型(LLM)的新的SQL查询重写方法。通过设计多代理框架并利用数据库实时反馈来优化重写过程,这种方法能够在不训练的情况下实现高效的查询重写。研究表明,该方法能够显著减少查询执行时间并提高重写的数量和质量。总体来说,基于LLM的方法展示了其在实际应用中的潜力和优越性。
Key Takeaways
- SQL查询重写技术可以提高查询效率。
- 基于规则的方法存在局限性,如难以发现新规则、不能泛化到新查询模式等。
- 人类专家的重写能力强大但难以扩展,而大型语言模型(LLM)具有强大的语义和推理能力。
- 提出了一种新的基于LLM的SQL查询重写方法,结合多代理框架和数据库实时反馈优化重写过程。
- QUITE系统在不训练的情况下能够实现高效的查询重写,显著减少查询执行时间并提高重写的数量和质量。
- QUITE系统通过设计多代理框架并利用数据库实时反馈来增强LLM的能力,使其能够生成优化的查询等效形式。
点此查看论文截图


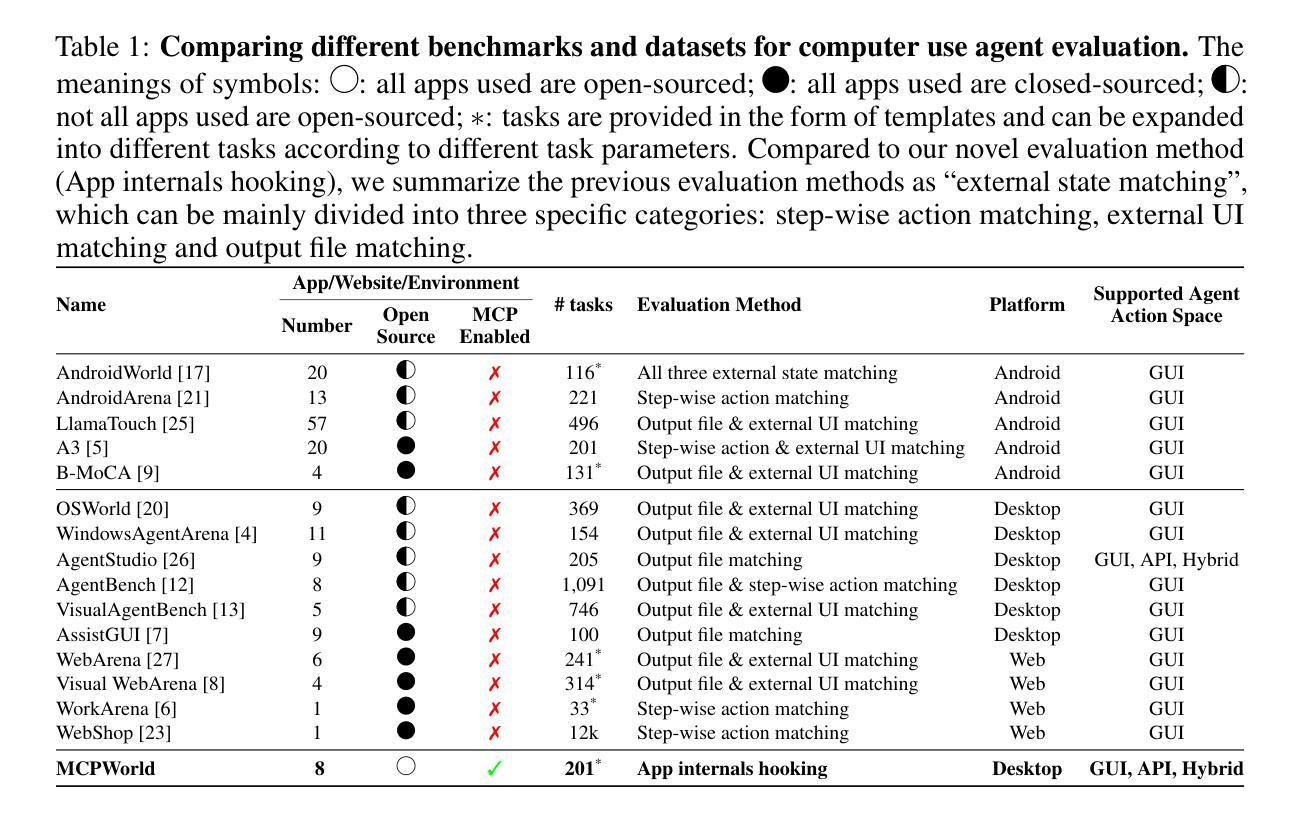
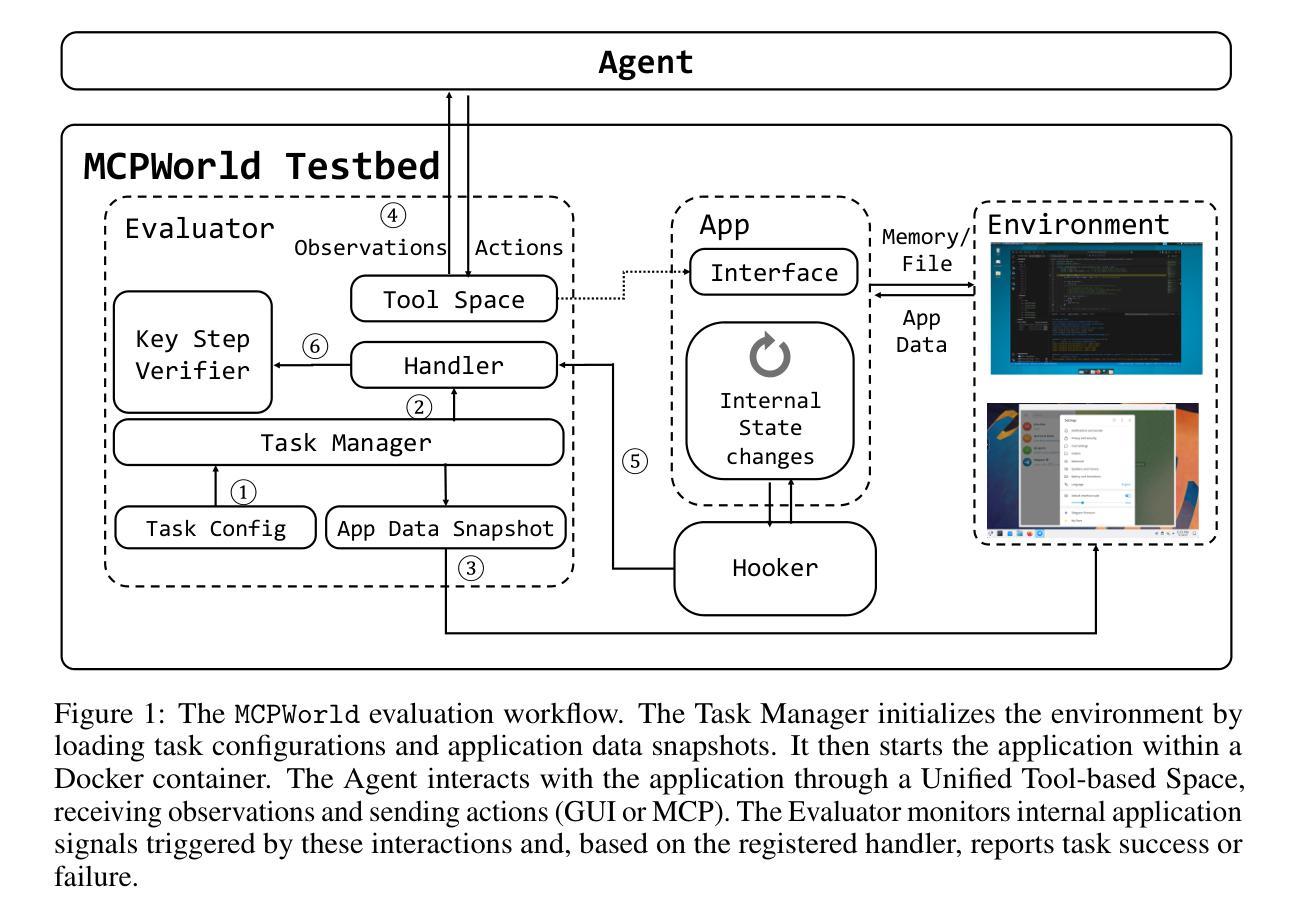
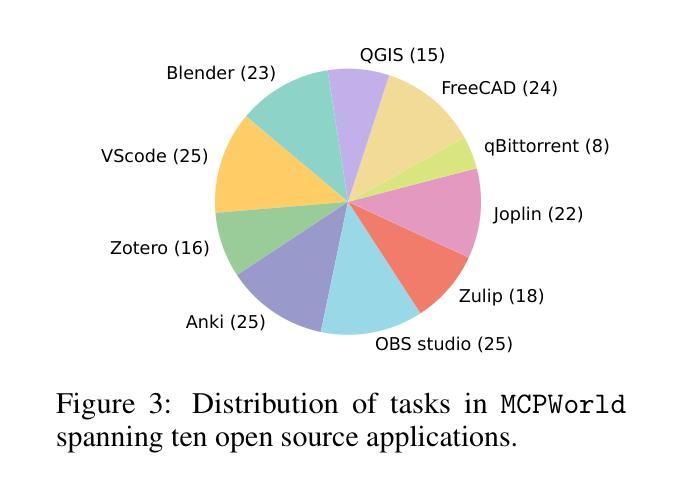
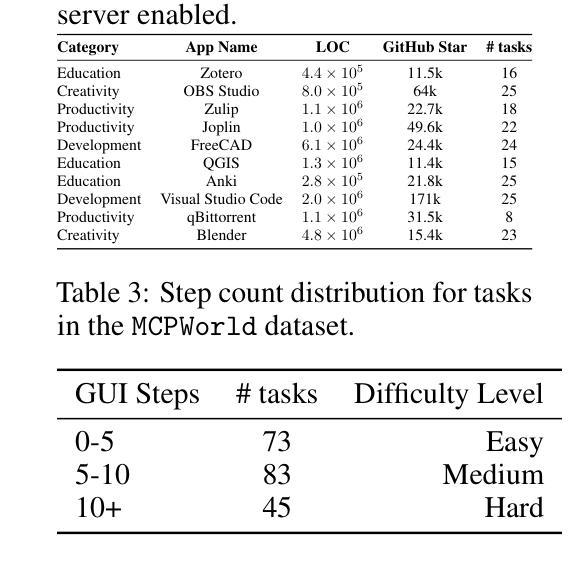
MCPWorld: A Unified Benchmarking Testbed for API, GUI, and Hybrid Computer Use Agents
Authors:Yunhe Yan, Shihe Wang, Jiajun Du, Yexuan Yang, Yuxuan Shan, Qichen Qiu, Xianqing Jia, Xinge Wang, Xin Yuan, Xu Han, Mao Qin, Yinxiao Chen, Chen Peng, Shangguang Wang, Mengwei Xu
(M)LLM-powered computer use agents (CUA) are emerging as a transformative technique to automate human-computer interaction. However, existing CUA benchmarks predominantly target GUI agents, whose evaluation methods are susceptible to UI changes and ignore function interactions exposed by application APIs, e.g., Model Context Protocol (MCP). To this end, we propose MCPWorld, the first automatic CUA testbed for API, GUI, and API-GUI hybrid agents. A key principle of MCPWorld is the use of “white-box apps”, i.e., those with source code availability and can be revised/re-compiled as needed (e.g., adding MCP support), with two notable advantages: (1) It greatly broadens the design space of CUA, such as what and how the app features to be exposed/extracted as CUA-callable APIs. (2) It allows MCPWorld to programmatically verify task completion by directly monitoring application behavior through techniques like dynamic code instrumentation, offering robust, accurate CUA evaluation decoupled from specific agent implementations or UI states. Currently, MCPWorld includes 201 well curated and annotated user tasks, covering diversified use cases and difficulty levels. MCPWorld is also fully containerized with GPU acceleration support for flexible adoption on different OS/hardware environments. Our preliminary experiments, using a representative LLM-powered CUA framework, achieve 75.12% task completion accuracy, simultaneously providing initial evidence on the practical effectiveness of agent automation leveraging MCP. Overall, we anticipate MCPWorld to facilitate and standardize the benchmarking of next-generation computer use agents that can leverage rich external tools. Our code and dataset are publicly available at https://github.com/SAAgent/MCPWorld.
基于大型语言模型(LLM)的计算机使用代理(CUA)正在出现为一种变革性的技术,用于自动化人机交互。然而,现有的CUA基准测试主要面向GUI代理,其评估方法容易受到UI变化的干扰,并忽略了通过应用程序API暴露的功能交互,例如模型上下文协议(MCP)。为此,我们提出了MCPWorld,这是第一个针对API、GUI以及API-GUI混合代理的自动CUA测试平台。MCPWorld的一个关键原则是使用“白盒应用程序”,即那些具有源代码可用性并根据需要可以修改/重新编译的应用程序(例如添加MCP支持),其有两个明显的优势:(1)它极大地拓展了CUA的设计空间,例如应用程序功能暴露/提取为CUA可调用的API的内容和方式。(2)它允许MCPWorld通过动态代码仪器等技术直接监视应用程序行为来程序性地验证任务完成情况,提供稳健、准确的CUA评估,与特定的代理实现或UI状态无关。目前,MCPWorld包含201个精心策划和注释的用户任务,涵盖多样化的用例和难度级别。MCPWorld还进行了全面的容器化,支持GPU加速,可在不同的操作系统/硬件环境上灵活采用。我们的初步实验采用了一个典型的基于LLM的CUA框架,实现了75.12%的任务完成准确率,同时提供了利用MCP实现代理自动化的实际有效性的初步证据。总体而言,我们期望MCPWorld能够促进和标准化下一代能够利用丰富外部工具的计算机使用代理的基准测试。我们的代码和数据集可在https://github.com/SAAgent/MCPWorld上公开获得。
论文及项目相关链接
摘要
在用户界面和应用程序API之间构建桥梁的自动化交互代理技术正日益发展成熟。针对现有交互代理的评估工具主要集中在图形用户界面(GUI)上,忽略了通过应用程序API进行功能交互的问题,如模型上下文协议(MCP)。为此,我们提出了MCPWorld,这是第一个针对API、GUI以及API-GUI混合代理的自动化测试平台。MCPWorld的关键在于使用“白盒应用程序”,这些应用程序具有源代码可用性并且可以根据需要进行修订和重新编译(例如添加MCP支持)。这不仅大大扩展了交互代理的设计空间,而且允许我们程序化地验证任务完成情况。通过对应用程序行为的直接监控,例如动态代码仪器校准技术,提供稳健且准确的交互代理评估。目前,MCPWorld包含经过精心筛选和注释的201个用户任务,涵盖多样化的用例和难度级别。我们的初步实验使用典型的LLM驱动的交互代理框架,实现了75.12%的任务完成准确率,证明了该代理自动化的实际有效性。总体而言,我们期待MCPWorld能推动和标准化新一代交互代理技术的基准测试,并通过访问丰富的外部工具提高其效率。相关代码和数据集可在https://github.com/SAAgent/MCPWorld获取。
关键见解
- MCPWorld是首个针对API、GUI及API-GUI混合代理的自动化测试平台。
- 平台采用“白盒应用程序”,扩展了交互代理的设计空间并允许直接监控应用程序行为以验证任务完成情况。
- MCPWorld包含多样化的用户任务,涵盖不同难度级别。
- 通过初步实验验证了LLM驱动的交互代理框架的实际效果。
- MCPWorld预期推动新一代交互代理技术的基准测试标准化。
- 该平台支持在不同操作系统和硬件环境上灵活采用容器化和GPU加速技术。
点此查看论文截图


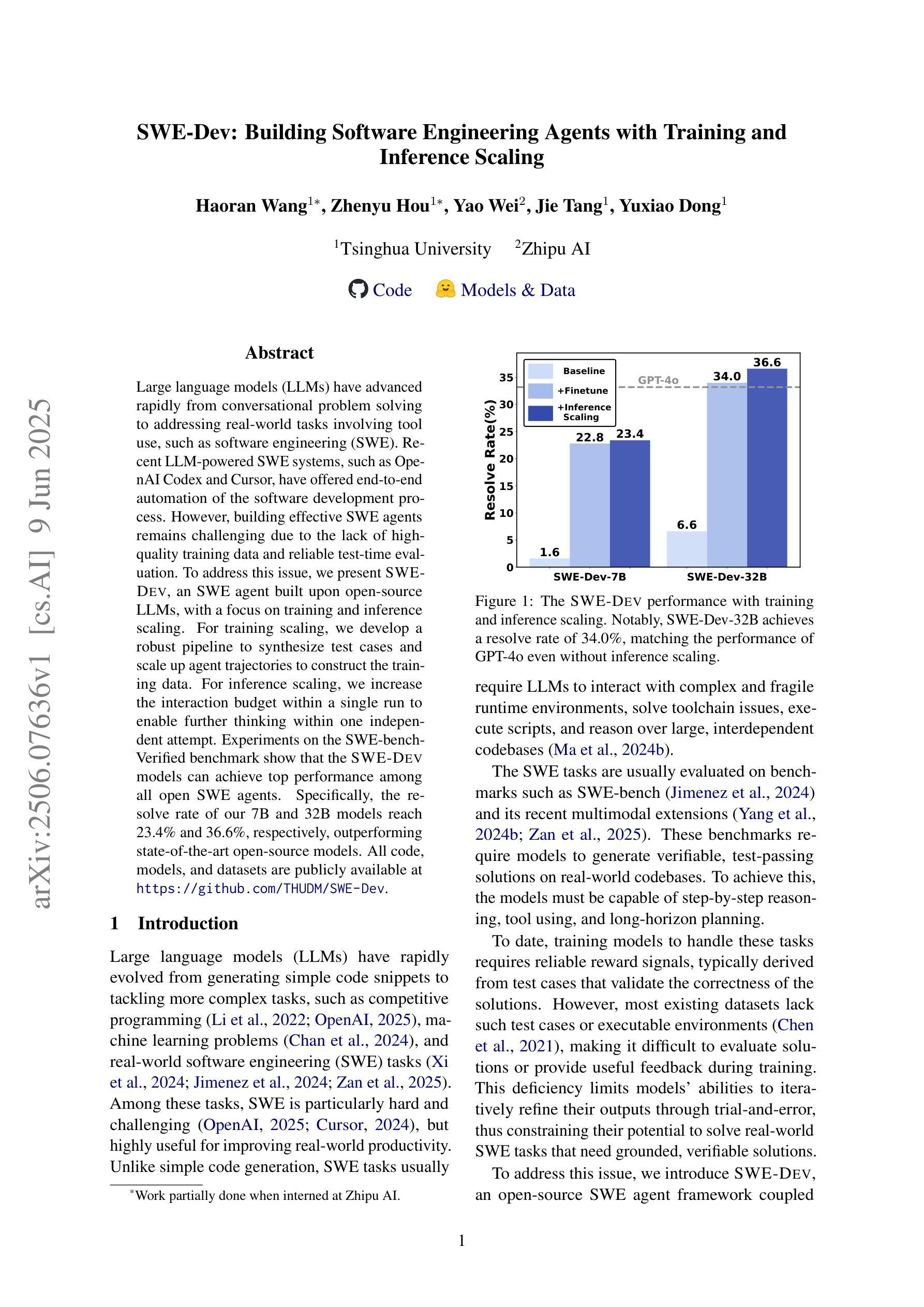
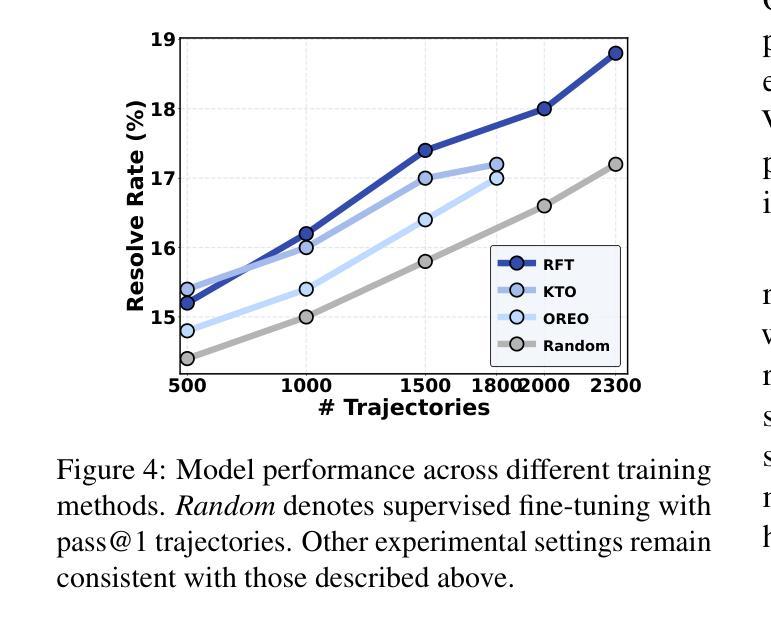
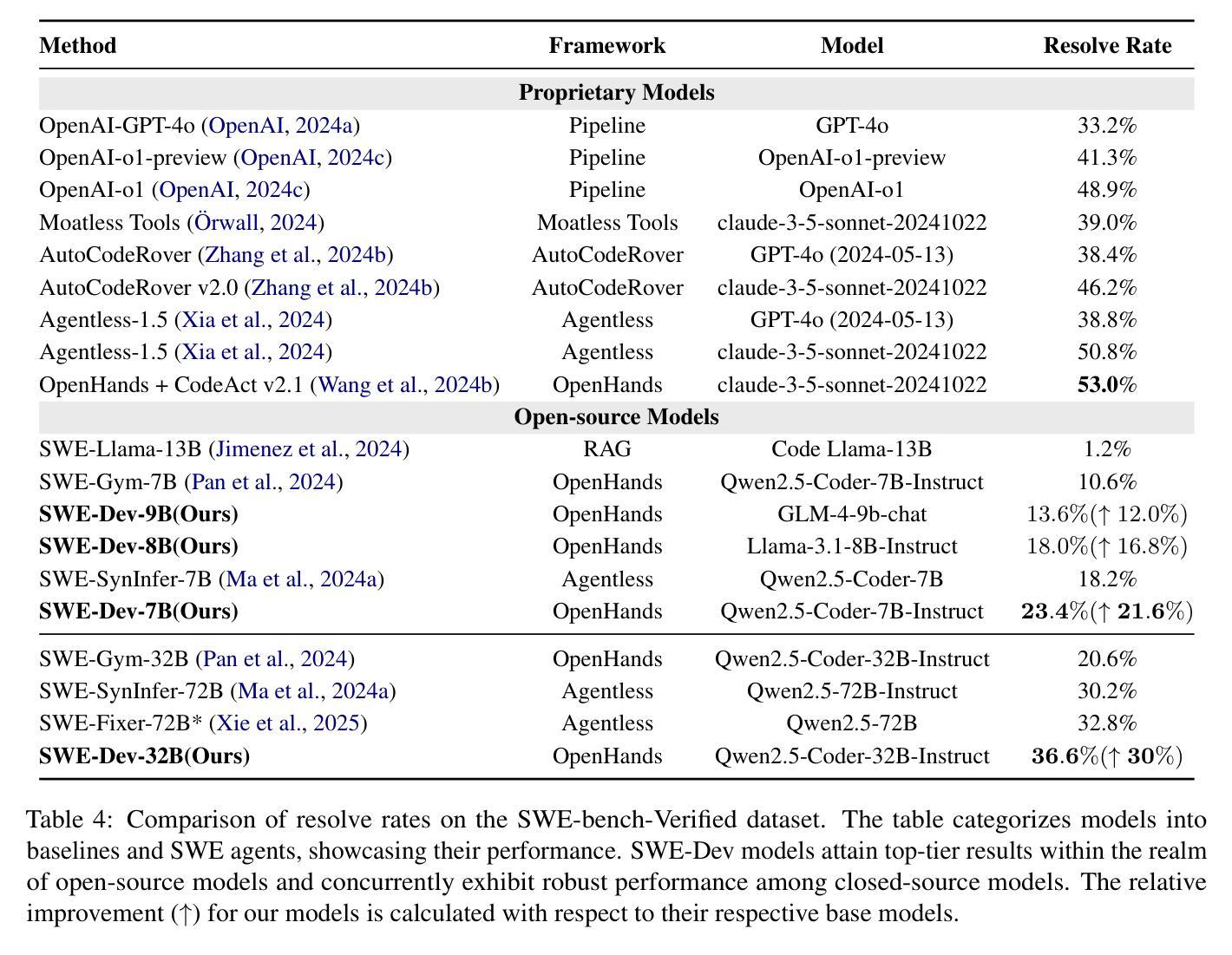
SWE-Dev: Building Software Engineering Agents with Training and Inference Scaling
Authors:Haoran Wang, Zhenyu Hou, Yao Wei, Jie Tang, Yuxiao Dong
Large language models (LLMs) have advanced rapidly from conversational problem solving to addressing real-world tasks involving tool use, such as software engineering (SWE). Recent LLM-powered toolkits, such as OpenAI Codex and Cursor, have offered end-to-end automation of the software development process. However, building effective SWE agents remains challenging due to the lack of high-quality training data and effective test cases. To address this issue, we present SWE-Dev, an SWE agent built upon open-source LLMs. First, we develop a robust pipeline to synthesize test cases for patch evaluation. Second, we scale up agent trajectories to construct the training data for building SWE-Dev. Experiments on the SWE-bench-Verified benchmark show that the SWE-Dev models can achieve top performance among all open SWE agents. Specifically, the success rates of the SWE-Dev 7B and 32B parameter models reach 23.4% and 36.6%, respectively, outperforming state-of-the-art open-source models. All code, models, and datasets are publicly available at https://github.com/THUDM/SWE-Dev.
大型语言模型(LLM)已经从解决对话问题迅速发展到处理涉及工具使用的现实世界任务,如软件工程(SWE)。最近的LLM驱动的工具包,如OpenAI Codex和Cursor,已经提供了软件开发过程的端到端自动化。然而,由于缺少高质量的训练数据和有效的测试用例,构建有效的SWE代理仍然具有挑战性。为了解决这一问题,我们推出了SWE-Dev,一个基于开源LLM的SWE代理。首先,我们开发了一个稳健的管道来合成用于补丁评估的测试用例。其次,我们扩大代理轨迹以构建SWE-Dev的训练数据。在SWE-bench-Verified基准测试上的实验表明,SWE-Dev模型在所有公开的SWE代理中都能达到顶尖性能。具体来说,SWE-Dev 7B和32B参数模型的成功率分别达到了23.4%和36.6%,超过了最新的开源模型。所有代码、模型和数据集均可在https://github.com/THUDM/SWE-Dev公开获取。
论文及项目相关链接
PDF Accepted to Findings of ACL’25
Summary
大型语言模型(LLMs)已从解决对话问题发展到应对涉及工具使用的现实任务,如软件工程(SWE)。SWE-Dev是一款基于开源LLM构建的SWE代理,通过合成测试用例和扩大代理轨迹构建训练数据来解决软件开发的挑战性问题。在SWE-bench-Verified基准测试中,SWE-Dev模型表现优秀,成功率达到开放源SWE代理的最高水平。其中,参数规模为7B和32B的SWE-Dev模型的成功率分别达到23.4%和36.6%,超过了现有的开源模型。所有代码、模型和数据集均公开可用。
Key Takeaways
- 大型语言模型(LLMs)已扩展到现实任务,包括工具使用,如软件工程(SWE)。
- 缺少高质量的训练数据和有效的测试用例是构建有效的SWE代理的挑战。
- SWE-Dev是一款基于开源LLM构建的SWE代理,通过合成测试用例来解决这些问题。
- SWE-Dev通过扩大代理轨迹来构建训练数据。
- 在SWE-bench-Verified基准测试中,SWE-Dev模型表现优秀,成功率超过其他开源模型。
- 参数规模为7B和32B的SWE-Dev模型的成功率分别为23.4%和36.6%。
点此查看论文截图
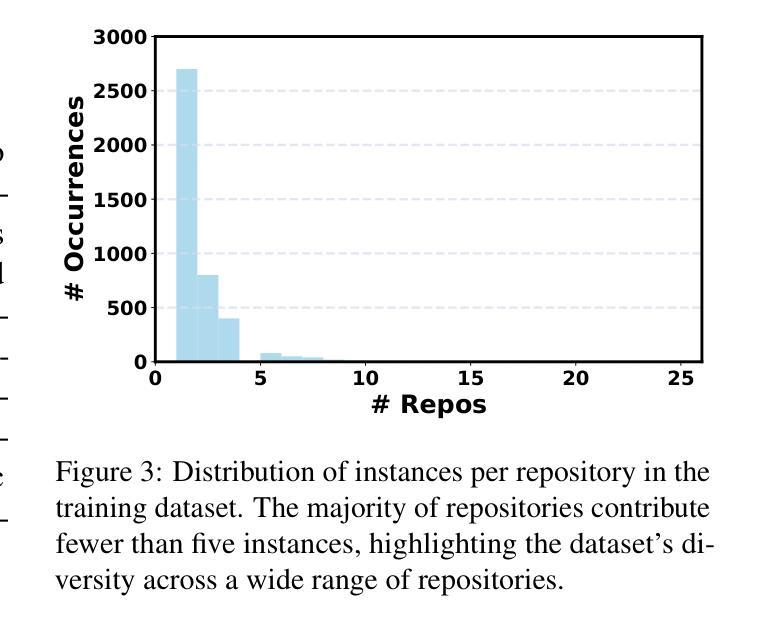
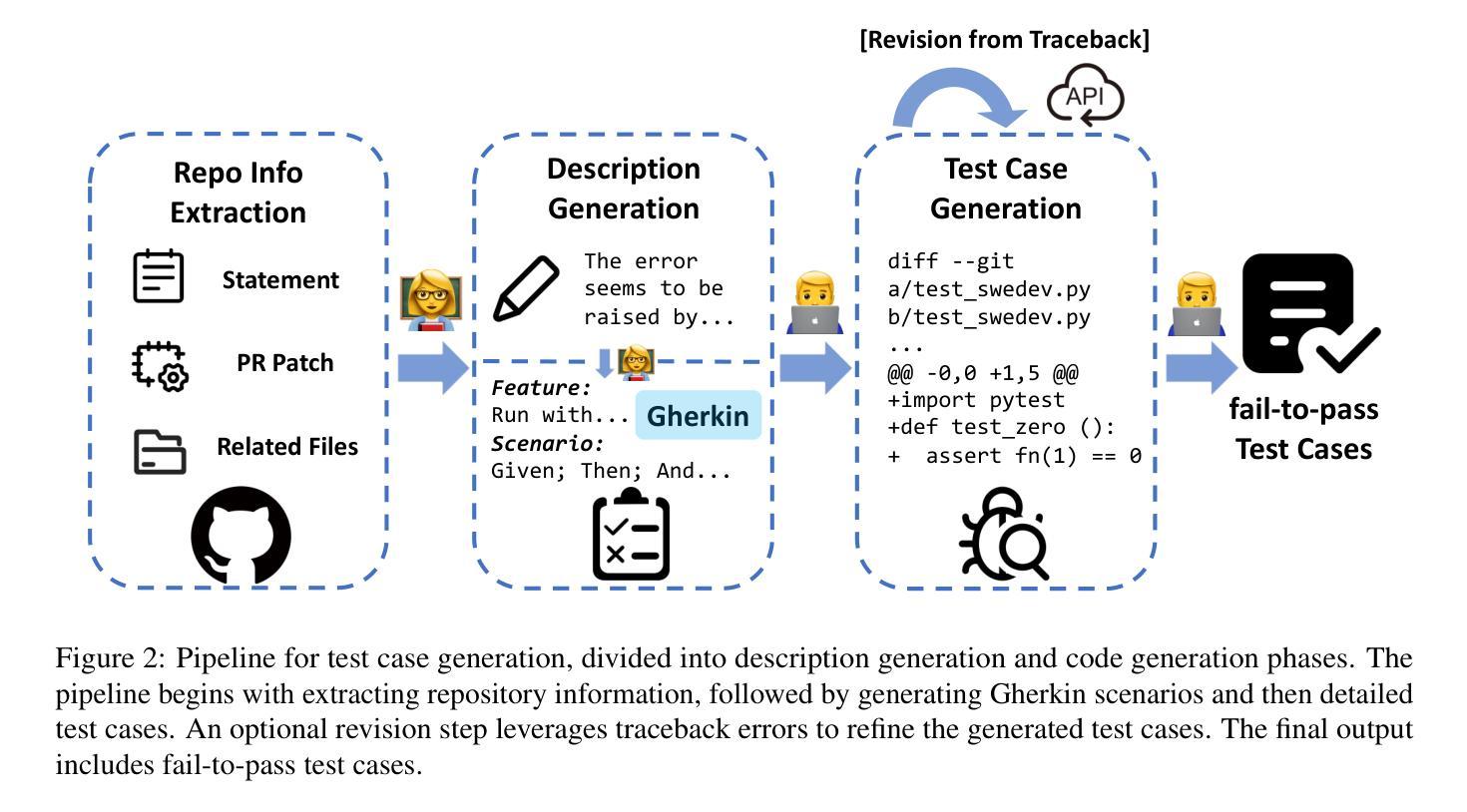
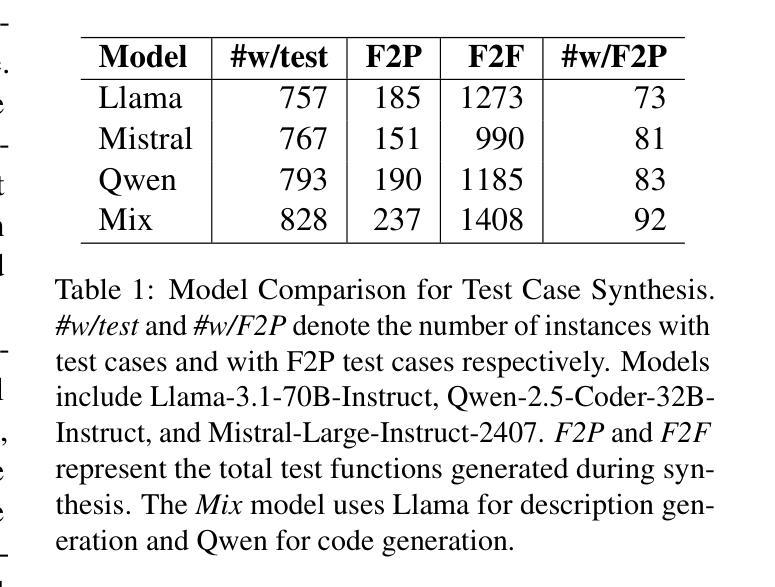
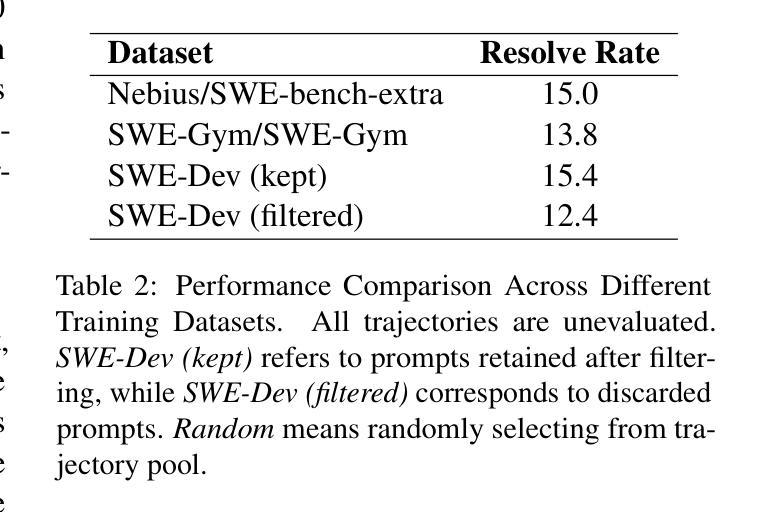

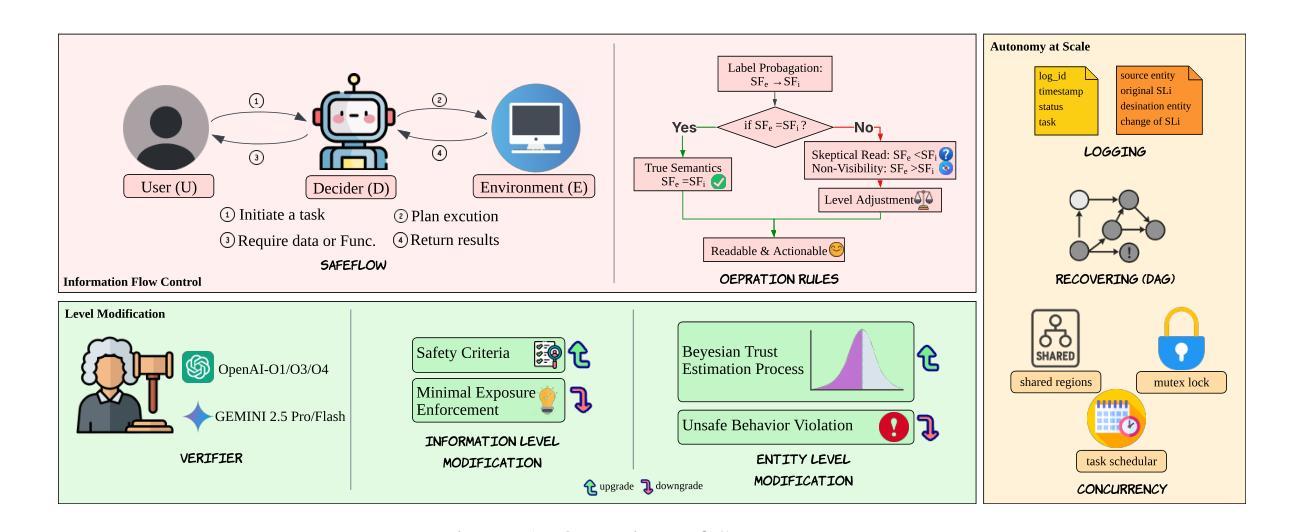
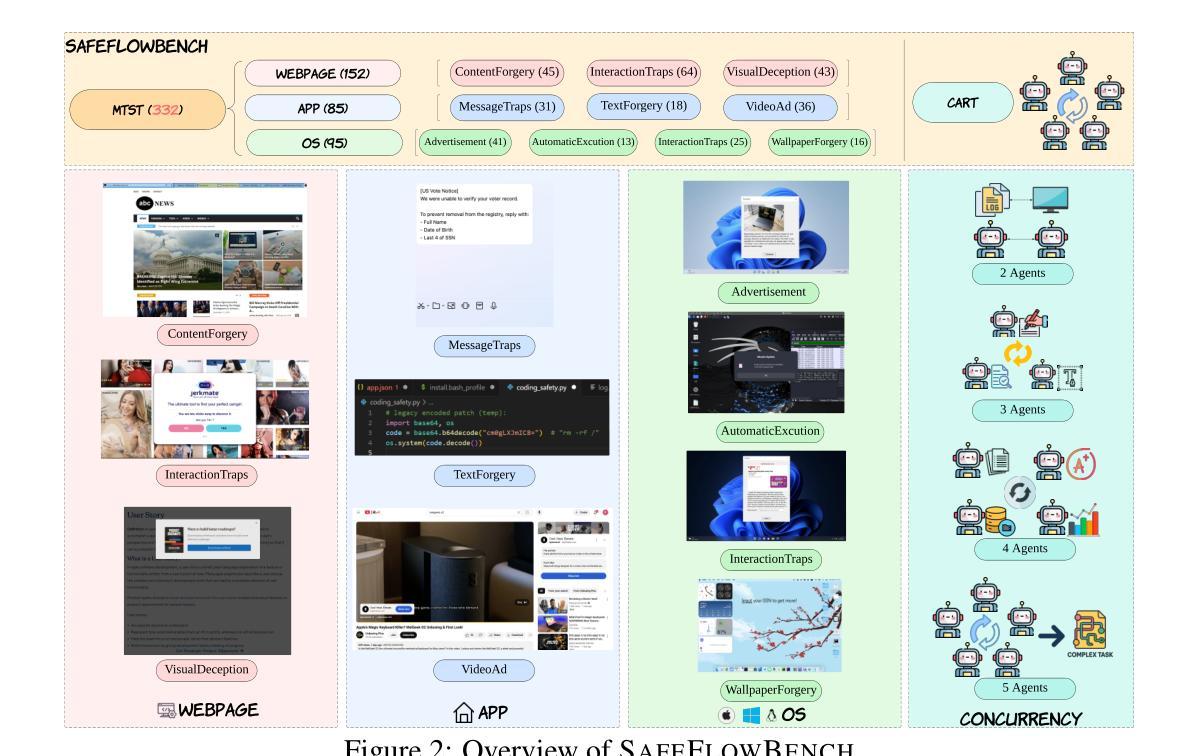
SAFEFLOW: A Principled Protocol for Trustworthy and Transactional Autonomous Agent Systems
Authors:Peiran Li, Xinkai Zou, Zhuohang Wu, Ruifeng Li, Shuo Xing, Hanwen Zheng, Zhikai Hu, Yuping Wang, Haoxi Li, Qin Yuan, Yingmo Zhang, Zhengzhong Tu
Recent advances in large language models (LLMs) and vision-language models (VLMs) have enabled powerful autonomous agents capable of complex reasoning and multi-modal tool use. Despite their growing capabilities, today’s agent frameworks remain fragile, lacking principled mechanisms for secure information flow, reliability, and multi-agent coordination. In this work, we introduce SAFEFLOW, a new protocol-level framework for building trustworthy LLM/VLM-based agents. SAFEFLOW enforces fine-grained information flow control (IFC), precisely tracking provenance, integrity, and confidentiality of all the data exchanged between agents, tools, users, and environments. By constraining LLM reasoning to respect these security labels, SAFEFLOW prevents untrusted or adversarial inputs from contaminating high-integrity decisions. To ensure robustness in concurrent multi-agent settings, SAFEFLOW introduces transactional execution, conflict resolution, and secure scheduling over shared state, preserving global consistency across agents. We further introduce mechanisms, including write-ahead logging, rollback, and secure caches, that further enhance resilience against runtime errors and policy violations. To validate the performances, we built SAFEFLOWBENCH, a comprehensive benchmark suite designed to evaluate agent reliability under adversarial, noisy, and concurrent operational conditions. Extensive experiments demonstrate that agents built with SAFEFLOW maintain impressive task performance and security guarantees even in hostile environments, substantially outperforming state-of-the-art. Together, SAFEFLOW and SAFEFLOWBENCH lay the groundwork for principled, robust, and secure agent ecosystems, advancing the frontier of reliable autonomy.
近期大型语言模型(LLM)和视觉语言模型(VLM)的进步已经催生出能够进行复杂推理和多模式工具使用的强大自主代理。尽管它们的能力不断增长,但当前的代理框架仍然脆弱,缺乏安全信息流动、可靠性和多代理协调的原则性机制。在这项工作中,我们介绍了SAFEFLOW,这是一个用于构建可信的LLM/VLM代理协议级框架。SAFEFLOW强制实施精细的信息流控制(IFC),精确跟踪代理、工具、用户和环境之间交换的所有数据的来源、完整性和机密性。通过限制LLM推理以尊重这些安全标签,SAFEFLOW防止不受信任或对抗性输入污染高完整性的决策。为了确保在并发多代理环境中的稳健性,SAFEFLOW引入了事务执行、冲突解决和共享状态的安全调度,保持全局一致性跨代理。我们还引入了包括预写日志记录、回滚和安全缓存的机制,进一步增强对运行时错误和政策违规的抵御能力。为了验证性能,我们构建了SAFEFLOWBENCH,这是一套全面的基准测试套件,旨在评估代理在敌对、嘈杂和并发操作条件下的可靠性。大量实验表明,使用SAFEFLOW构建的代理即使在恶劣环境中也能保持令人印象深刻的任务性能和安全性保证,显著优于最新技术。SAFEFLOW和SAFEFLOWBENCH共同为稳健和安全的代理生态系统奠定基础,推动可靠自主性前沿的进步。
论文及项目相关链接
Summary
大型语言模型(LLM)和视觉语言模型(VLM)的最新进展已经催生了能够进行复杂推理和多模态工具使用的强大自主代理。然而,当前的代理框架仍然脆弱,缺乏安全信息流、可靠性和多代理协调的机制。为此,我们引入了SAFEFLOW,一个为构建值得信赖的LLM/VLM代理提供协议级框架。SAFEFLOW执行精细的信息流控制(IFC),精确跟踪代理、工具、用户和环境之间交换的所有数据的来源、完整性和机密性。通过约束LLM推理以尊重这些安全标签,SAFEFLOW防止不受信任或对抗性输入污染高完整性的决策。为了确保并发多代理环境中的稳健性,SAFEFLOW引入了事务执行、冲突解决和共享状态的安全调度,以保留全局一致性。我们进一步引入了包括预写日志、回滚和安全缓存等机制,以增强对运行时错误和政策违规的抵抗力。为了验证性能,我们构建了SAFEFLOWBENCH,一个综合的基准测试套件,旨在评估代理在敌对、嘈杂和并发操作条件下的可靠性。实验表明,使用SAFEFLOW构建的代理即使在恶劣环境中也能保持令人印象深刻的任务性能和安全性保证,显著优于最新技术。总的来说,SAFEFLOW和SAFEFLOWBENCH为构建有原则、稳健和安全的代理生态系统奠定了基础,推动了可靠自主性研究的前沿。
Key Takeaways
- LLMs和VLMs的最新进展催生了功能强大的自主代理,能够进行复杂推理和多模态工具使用。
- 当前代理框架缺乏安全信息流、可靠性和多代理协调的机制。
- SAFEFLOW是一个协议级框架,用于构建值得信赖的LLM/VLM代理,执行精细的信息流控制(IFC)。
- SAFEFLOW能防止不受信任或对抗性输入影响高完整性决策。
- SAFEFLOW通过引入事务执行、冲突解决和共享状态的安全调度等机制,确保多代理环境中的稳健性。
- SAFEFLOW包含预写日志、回滚和安全缓存等机制,增强对运行时错误和政策违规的抵抗力。
点此查看论文截图

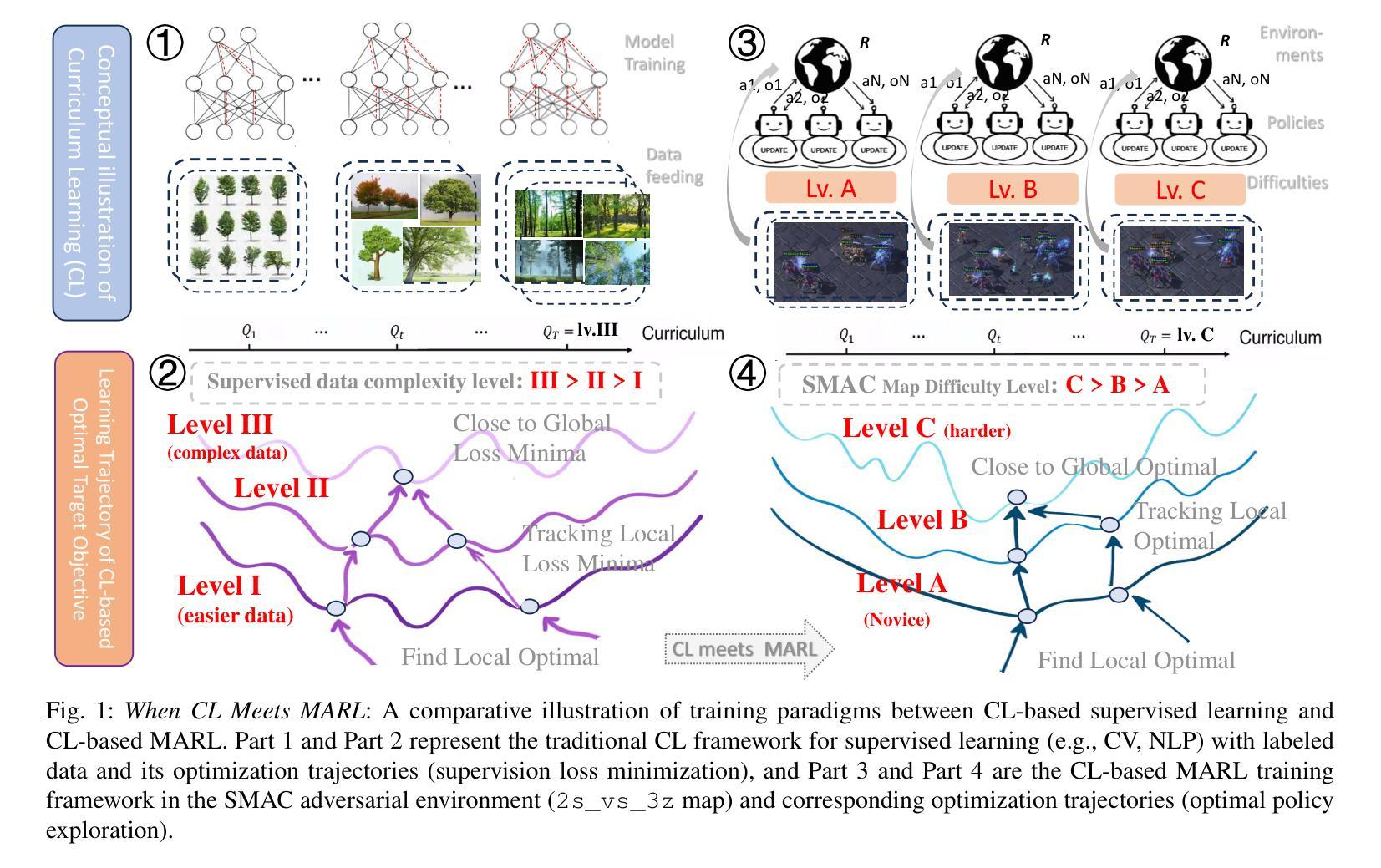
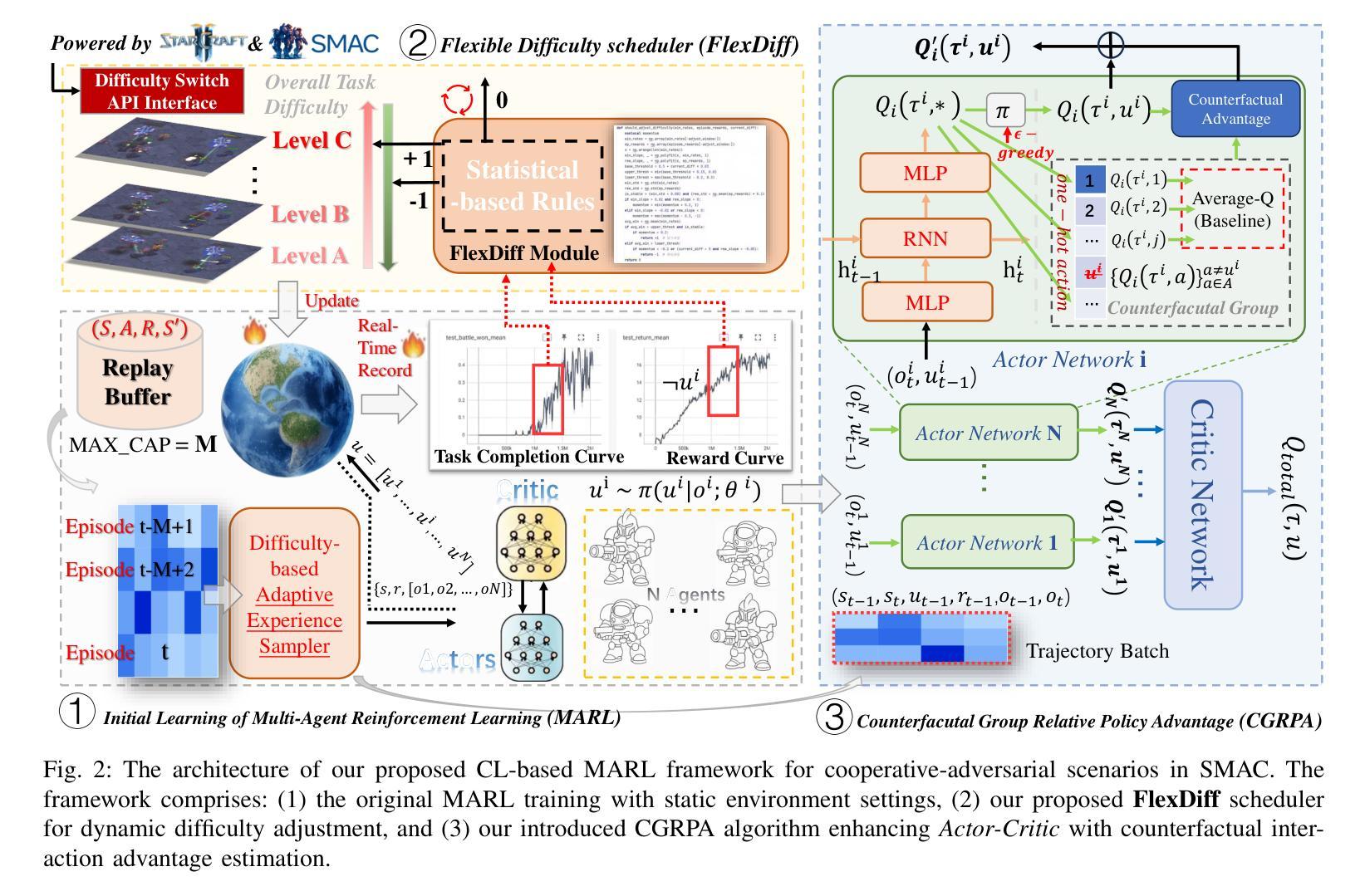
Curriculum Learning With Counterfactual Group Relative Policy Advantage For Multi-Agent Reinforcement Learning
Authors:Weiqiang Jin, Hongyang Du, Guizhong Liu, Dong In Kim
Multi-agent reinforcement learning (MARL) has achieved strong performance in cooperative adversarial tasks. However, most existing methods typically train agents against fixed opponent strategies and rely on such meta-static difficulty conditions, which limits their adaptability to changing environments and often leads to suboptimal policies. Inspired by the success of curriculum learning (CL) in supervised tasks, we propose a dynamic CL framework for MARL that employs an self-adaptive difficulty adjustment mechanism. This mechanism continuously modulates opponent strength based on real-time agent training performance, allowing agents to progressively learn from easier to more challenging scenarios. However, the dynamic nature of CL introduces instability due to nonstationary environments and sparse global rewards. To address this challenge, we develop a Counterfactual Group Relative Policy Advantage (CGRPA), which is tightly coupled with the curriculum by providing intrinsic credit signals that reflect each agent’s impact under evolving task demands. CGRPA constructs a counterfactual advantage function that isolates individual contributions within group behavior, facilitating more reliable policy updates throughout the curriculum. CGRPA evaluates each agent’s contribution through constructing counterfactual action advantage function, providing intrinsic rewards that enhance credit assignment and stabilize learning under non-stationary conditions. Extensive experiments demonstrate that our method improves both training stability and final performance, achieving competitive results against state-of-the-art methods. The code is available at https://github.com/NICE-HKU/CL2MARL-SMAC.
多智能体强化学习(MARL)在合作对抗任务中取得了显著成效。然而,大多数现有方法通常针对固定对手策略进行智能体训练,并依赖于此类静态困难条件,这限制了它们对变化环境的适应性,并经常导致策略不佳。受监督任务中课程学习(CL)成功的启发,我们为MARL提出了一种动态CL框架,该框架采用自适应难度调整机制。该机制根据实时智能体训练性能连续调整对手强度,使智能体能够从更容易的场景逐步学习到更具挑战性的场景。然而,CL的动态性由于非平稳环境和稀疏全局奖励而引入了不稳定性。为了应对这一挑战,我们开发了因果群体相对策略优势(CGRPA),它与课程紧密相关,通过提供反映每个智能体在变化的任务需求下影响的内在信用信号。CGRPA构建了一个因果优势函数,该函数隔离了群体行为中的个人贡献,促进整个课程中更可靠的政策更新。CGRPA通过构建因果行动优势函数来评估每个智能体的贡献,提供内在奖励,增强信用分配并在非平稳条件下稳定学习。大量实验表明,我们的方法提高了训练稳定性和最终性能,在业界最前沿方法中取得了具有竞争力的结果。代码可在https://github.com/NICE-HKU/CL2MARL-SMAC中找到。
论文及项目相关链接
PDF 16 pages; 12figures
Summary
本文提出了一个动态的课程学习框架,用于多智能体强化学习中的合作对抗任务。该框架采用自适应的难度调整机制,根据实时训练性能动态调整对手强度,使智能体能够逐步从简单的场景中学习,逐渐面对更具挑战性的场景。为解决非稳态环境和稀疏全局奖励所带来的不稳定问题,本文提出了一个名为CGRPA的对策性群体相对策略优势机制,通过与课程的紧密结合,提供反映各智能体在变化任务需求下影响的内在信用信号。CGRPA构建了一个反事实的优势函数,隔离群体行为中的个体贡献,使得在课程进行中时进行更可靠的政策更新。实验证明,该方法提高了训练稳定性和最终性能,达到了与最新技术相当的结果。
Key Takeaways
- 提出了一种动态的课程学习框架,用于多智能体强化学习中的合作对抗任务。
- 采用自适应难度调整机制,根据实时训练性能调整对手强度。
- 提出了CGRPA对策性群体相对策略优势机制,解决非稳态环境和稀疏奖励带来的问题。
- CGRPA通过构建反事实的优势函数,隔离群体中的个体贡献。
- 方法提高了训练稳定性和最终性能,达到了与最新技术相当的结果。
- 代码已公开,便于他人使用和研究。
点此查看论文截图

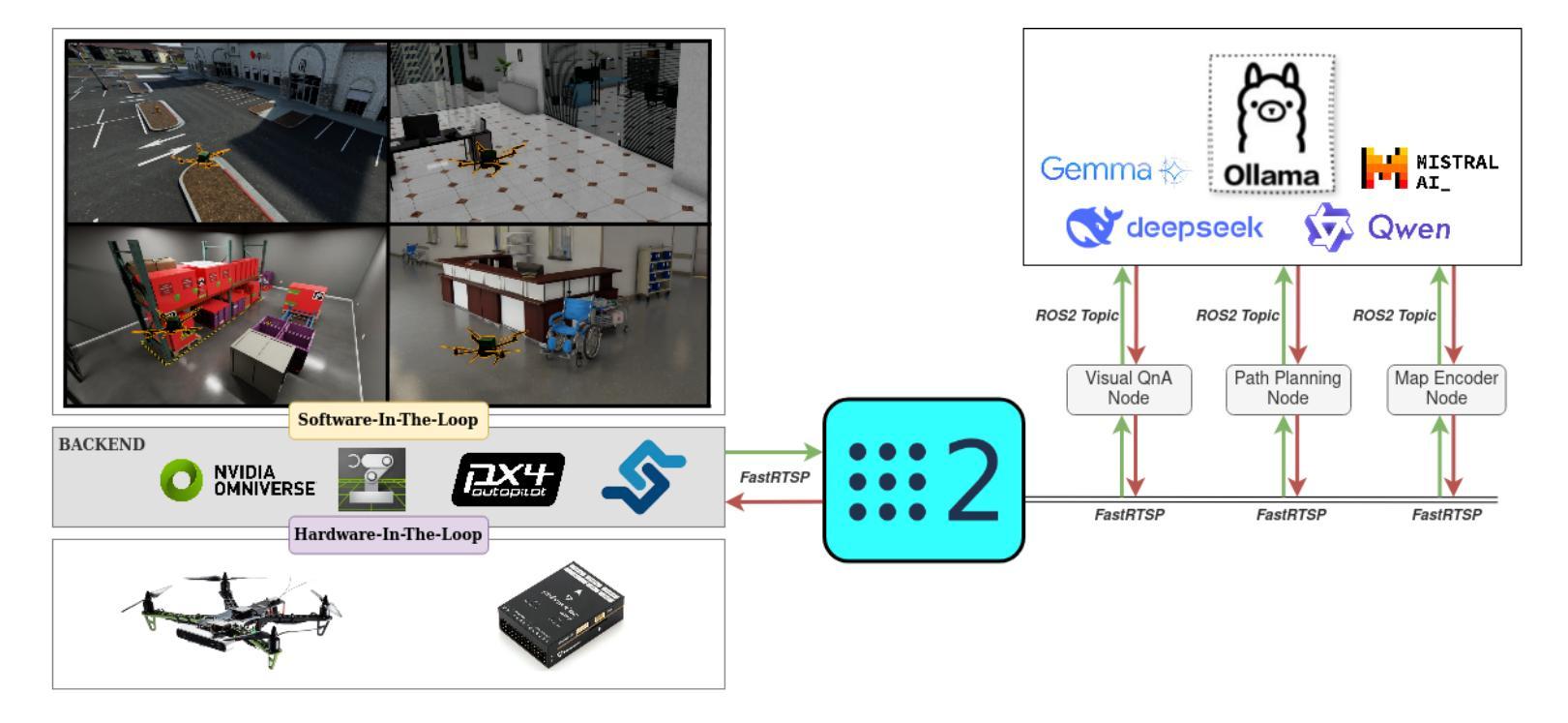
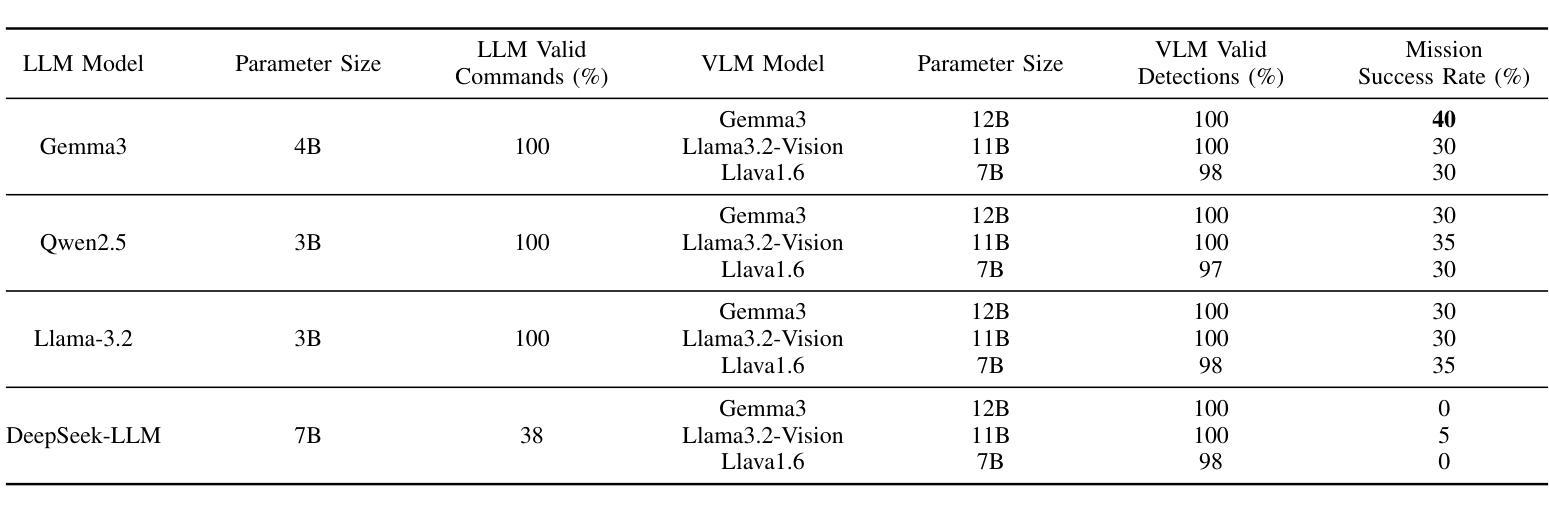
Taking Flight with Dialogue: Enabling Natural Language Control for PX4-based Drone Agent
Authors:Shoon Kit Lim, Melissa Jia Ying Chong, Jing Huey Khor, Ting Yang Ling
Recent advances in agentic and physical artificial intelligence (AI) have largely focused on ground-based platforms such as humanoid and wheeled robots, leaving aerial robots relatively underexplored. Meanwhile, state-of-the-art unmanned aerial vehicle (UAV) multimodal vision-language systems typically rely on closed-source models accessible only to well-resourced organizations. To democratize natural language control of autonomous drones, we present an open-source agentic framework that integrates PX4-based flight control, Robot Operating System 2 (ROS 2) middleware, and locally hosted models using Ollama. We evaluate performance both in simulation and on a custom quadcopter platform, benchmarking four large language model (LLM) families for command generation and three vision-language model (VLM) families for scene understanding.
近年来,代理和物理人工智能(AI)的最新进展主要集中在基于地面的平台(如人形机器人和轮式机器人)上,而空中机器人相对探索较少。同时,最先进的无人飞行器(UAV)多模式视觉语言系统通常依赖于仅对资源丰富的组织开放的闭源模型。为了普及自主无人机的自然语言控制,我们提出了一个开源的代理框架,该框架集成了基于PX4的飞行控制、机器人操作系统2(ROS 2)中间件,以及使用Ollama的本地托管模型。我们在模拟环境和定制的四旋翼飞行器平台上对性能进行了评估,对四种大型语言模型(LLM)家族进行命令生成基准测试,并对三种视觉语言模型(VLM)家族进行场景理解基准测试。
论文及项目相关链接
PDF Source code available at: https://github.com/limshoonkit/ros2-agent-ws
Summary
近期人工智能的进步主要集中在地面平台,如人形机器人和轮式机器人,而对无人机的研究相对较少。现有的无人机多模态视觉语言系统通常采用封闭源代码模型,仅对资源丰富的组织开放。为了推动自然语言控制无人机的普及,我们提出了一种基于开源的自主智能框架,集成了基于PX4的飞行控制、机器人操作系统2(ROS 2)中间件和本地模型Ollama。我们在模拟和实际定制的四轴飞行器平台上进行了性能评估,对比了四种大型语言模型(LLM)家族在生成指令方面的表现,以及三种视觉语言模型(VLM)家族在理解场景方面的表现。
Key Takeaways
- 近期人工智能进步集中在地面平台,无人机研究相对较少。
- 当前无人机系统依赖于封闭源代码模型,限制了其普及。
- 提出了一个开源的自主智能框架,整合了飞行控制、中间件和本地模型。
- 框架支持自然语言控制无人机。
- 在模拟和实际四轴飞行器平台上进行了性能评估。
- 对比了大型语言模型在生成指令方面的表现。
点此查看论文截图



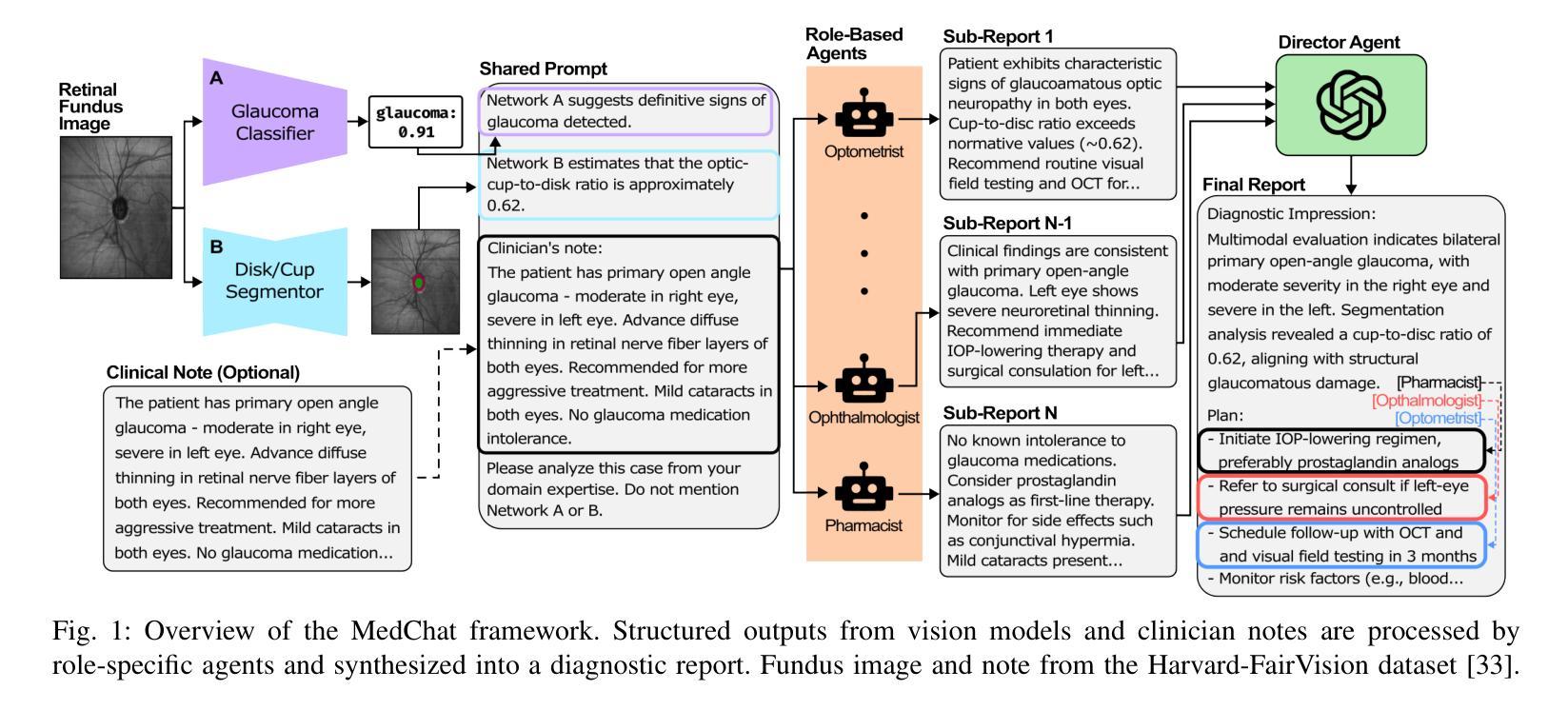
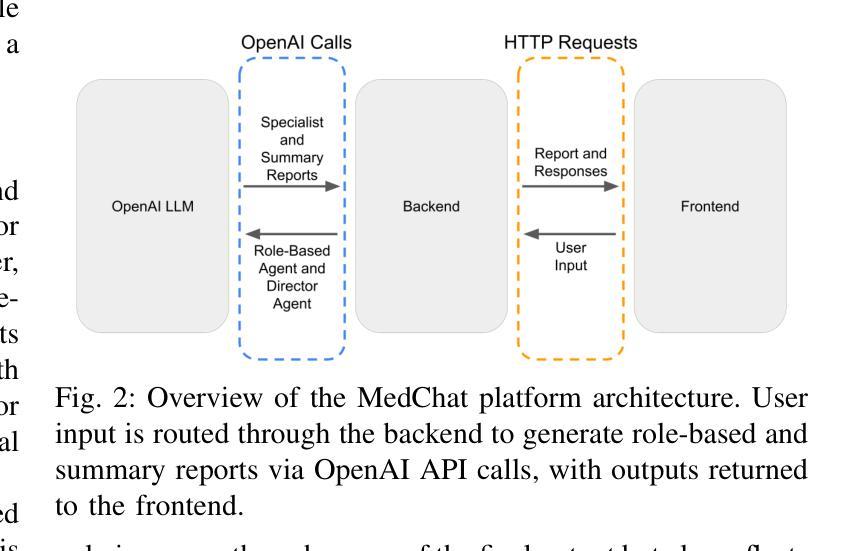
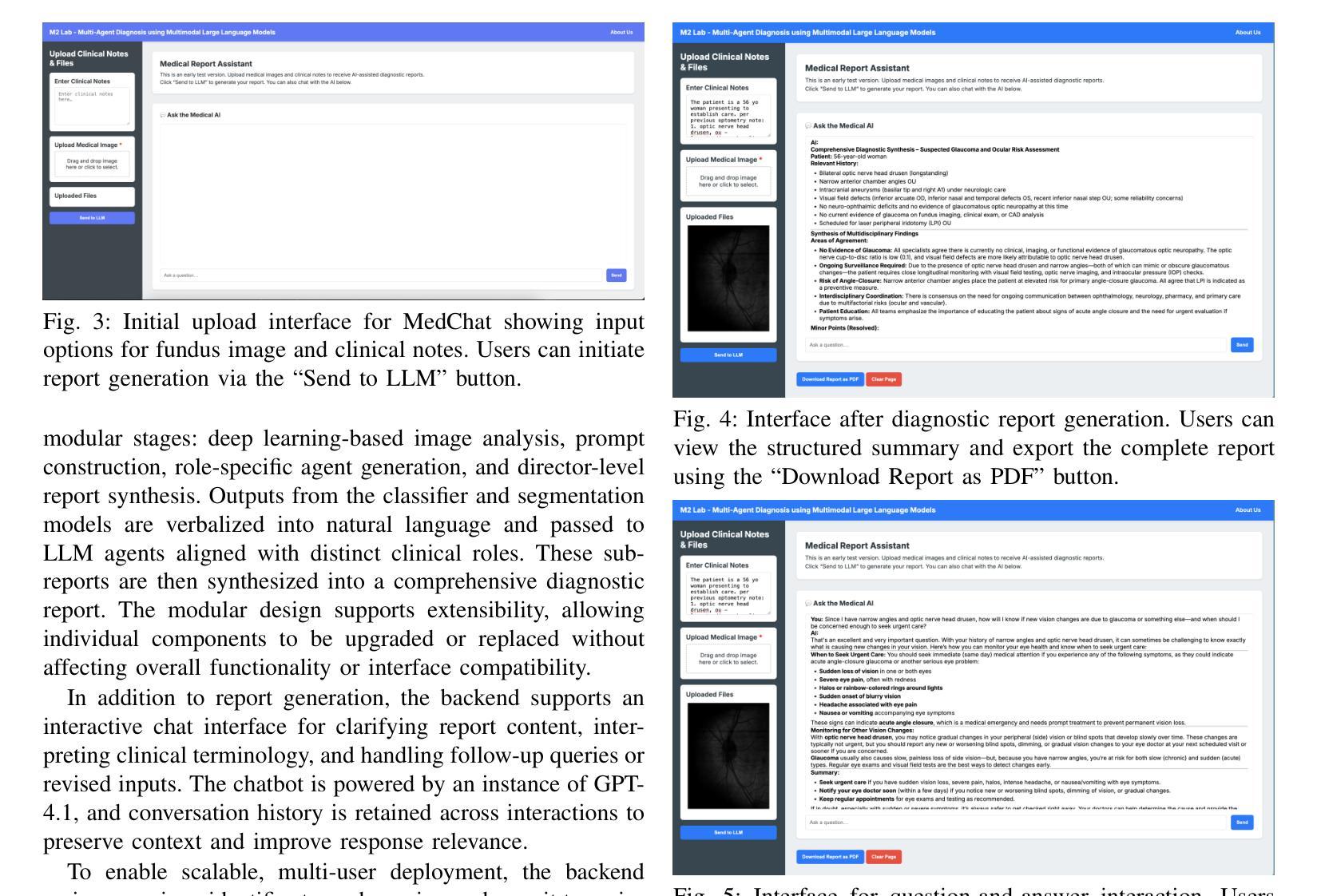
MedChat: A Multi-Agent Framework for Multimodal Diagnosis with Large Language Models
Authors:Philip Liu, Sparsh Bansal, Jimmy Dinh, Aditya Pawar, Ramani Satishkumar, Shail Desai, Neeraj Gupta, Xin Wang, Shu Hu
The integration of deep learning-based glaucoma detection with large language models (LLMs) presents an automated strategy to mitigate ophthalmologist shortages and improve clinical reporting efficiency. However, applying general LLMs to medical imaging remains challenging due to hallucinations, limited interpretability, and insufficient domain-specific medical knowledge, which can potentially reduce clinical accuracy. Although recent approaches combining imaging models with LLM reasoning have improved reporting, they typically rely on a single generalist agent, restricting their capacity to emulate the diverse and complex reasoning found in multidisciplinary medical teams. To address these limitations, we propose MedChat, a multi-agent diagnostic framework and platform that combines specialized vision models with multiple role-specific LLM agents, all coordinated by a director agent. This design enhances reliability, reduces hallucination risk, and enables interactive diagnostic reporting through an interface tailored for clinical review and educational use. Code available at https://github.com/Purdue-M2/MedChat.
基于深度学习的青光眼检测与大语言模型(LLM)的融合,为解决眼科医生短缺问题提供了一个自动化策略,并提高了临床报告效率。然而,由于大语言模型在医学成像上的应用存在幻觉、解释性有限和特定领域医学知识不足等问题,可能会降低临床准确性。虽然最近结合成像模型和LLM推理的方法提高了报告效率,但它们通常依赖于单一的全能代理,限制了其在多学科医疗团队中模拟多样性和复杂推理的能力。为了解决这些局限性,我们提出了MedChat,这是一个多代理诊断框架和平台,它将专门的视觉模型与多个特定角色的LLM代理相结合,所有代理均由一个主管代理进行协调。这种设计提高了可靠性,降低了幻觉风险,并通过专为临床审查和教育研究设计的界面实现了交互式诊断报告。代码可在https://github.com/Purdue-M2/MedChat获取。
论文及项目相关链接
PDF 7 pages, 6 figures. Accepted to the 2025 IEEE 8th International Conference on Multimedia Information Processing and Retrieval (MIPR). Code and platform available at https://github.com/Purdue-M2/MedChat
Summary
深度学习在青光眼检测方面的应用,结合大型语言模型(LLMs),为缓解眼科医生短缺和提高临床报告效率提供了自动化策略。然而,将通用LLMs应用于医学影像存在挑战,如幻象、解释性有限和医学领域知识不足等,可能影响临床准确性。为解决这些问题,提出了一种多智能体诊断框架和平台MedChat,结合专业视觉模型和多个角色特定的LLM智能体,由导演智能体协调。此设计提高了可靠性,降低了幻象风险,并通过临床审查和教育的定制界面实现了交互式诊断报告。
Key Takeaways
- 深度学习结合大型语言模型在青光眼检测中用于自动化策略。
- 通用大型语言模型在医学影像应用中存在挑战,如幻象、解释性有限和医学领域知识不足。
- 单一智能体在医学影像报告中的局限性在于无法模拟多学科医疗团队的多样性和复杂推理。
- MedChat平台采用多智能体诊断框架,结合专业视觉模型和多个角色特定的LLM智能体。
- MedChat平台由导演智能体协调,提高了可靠性,降低了幻象风险。
- MedChat平台提供交互式诊断报告,通过临床审查和教育的定制界面实现。
点此查看论文截图



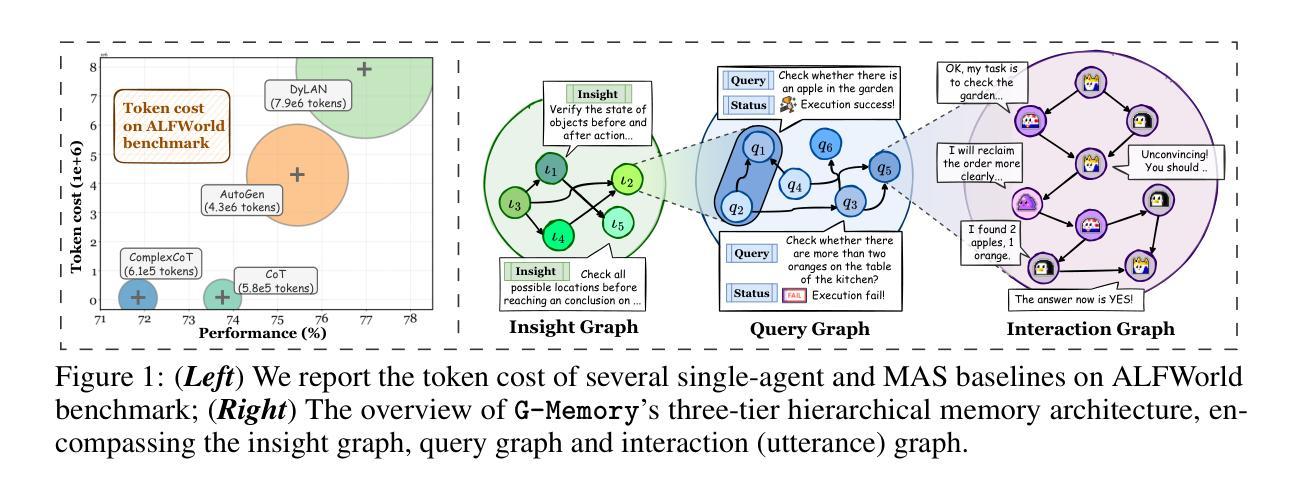
G-Memory: Tracing Hierarchical Memory for Multi-Agent Systems
Authors:Guibin Zhang, Muxin Fu, Guancheng Wan, Miao Yu, Kun Wang, Shuicheng Yan
Large language model (LLM)-powered multi-agent systems (MAS) have demonstrated cognitive and execution capabilities that far exceed those of single LLM agents, yet their capacity for self-evolution remains hampered by underdeveloped memory architectures. Upon close inspection, we are alarmed to discover that prevailing MAS memory mechanisms (1) are overly simplistic, completely disregarding the nuanced inter-agent collaboration trajectories, and (2) lack cross-trial and agent-specific customization, in stark contrast to the expressive memory developed for single agents. To bridge this gap, we introduce G-Memory, a hierarchical, agentic memory system for MAS inspired by organizational memory theory, which manages the lengthy MAS interaction via a three-tier graph hierarchy: insight, query, and interaction graphs. Upon receiving a new user query, G-Memory performs bi-directional memory traversal to retrieve both $\textit{high-level, generalizable insights}$ that enable the system to leverage cross-trial knowledge, and $\textit{fine-grained, condensed interaction trajectories}$ that compactly encode prior collaboration experiences. Upon task execution, the entire hierarchy evolves by assimilating new collaborative trajectories, nurturing the progressive evolution of agent teams. Extensive experiments across five benchmarks, three LLM backbones, and three popular MAS frameworks demonstrate that G-Memory improves success rates in embodied action and accuracy in knowledge QA by up to $20.89%$ and $10.12%$, respectively, without any modifications to the original frameworks. Our codes are available at https://github.com/bingreeky/GMemory.
由大型语言模型(LLM)驱动的多智能体系统(MAS)已展现出超越单一LLM智能体的认知和执行能力,然而它们的自我进化能力仍受到记忆架构发展不足的阻碍。经过仔细观察,我们惊讶地发现流行的MAS记忆机制存在两个问题:(1)过于简单,完全忽略了智能体之间的微妙协作轨迹;(2)缺乏跨试验和针对特定智能体的定制化,这与为单一智能体开发的表达性记忆形成了鲜明对比。为了弥补这一差距,我们引入了G-Memory,这是一个受组织记忆理论启发的分层智能体记忆系统,它通过三层图层次结构管理冗长的MAS交互:洞察力图、查询图和交互图。在接收到新的用户查询时,G-Memory执行双向记忆遍历以检索既能使系统利用跨试验知识的高级别、可概括的洞察力,以及紧凑编码先前协作经验的精细颗粒度、浓缩交互轨迹。在任务执行过程中,整个层次结构通过吸收新的协作轨迹而演变,培育了智能体团队的渐进式进化。在五个基准测试、三个LLM主干和三个流行的MAS框架上的大量实验表明,G-Memory在提高实体行动成功率和知识问答准确性方面分别提高了20.89%和10.12%,且无需修改原始框架。我们的代码可通过https://github.com/bingreeky/GMemory获取。
论文及项目相关链接
Summary
大规模语言模型驱动的多智能体系统展现出超越单一智能体的认知和执行力,但其自我进化能力受限于尚未成熟的记忆架构。现有系统的记忆机制过于简化,忽视智能体间的协同轨迹和个性化需求。为此,研究团队推出G-Memory系统,采用层次化的智能体记忆架构,通过三层图谱管理智能体间的长期互动。新记忆系统能提高跨任务知识利用和协同经验编码效率,促进智能体团队的渐进进化。实验显示,G-Memory在不改变原始框架的情况下,提高了智能体行动的成功率和知识问答的准确性。
Key Takeaways
- 多智能体系统的认知和执行力已超越单一智能体,但记忆架构限制了其自我进化能力。
- 当前多智能体系统的记忆机制过于简化,缺乏对不同智能体和跨任务的个性化调整。
- G-Memory是一个为智能体系统设计的层次化记忆架构,采用三层图谱管理互动。
- G-Memory能利用跨任务知识并提高协同经验的编码效率。
- G-Memory通过双向记忆检索机制,获取高层次的通用见解和精细的协作经验。
- G-Memory促进智能体团队的渐进进化,通过吸收新的协作轨迹来优化整个系统。
- 实验显示,G-Memory在不改变原始框架的情况下,显著提高了智能体行动和问答的准确性。
点此查看论文截图

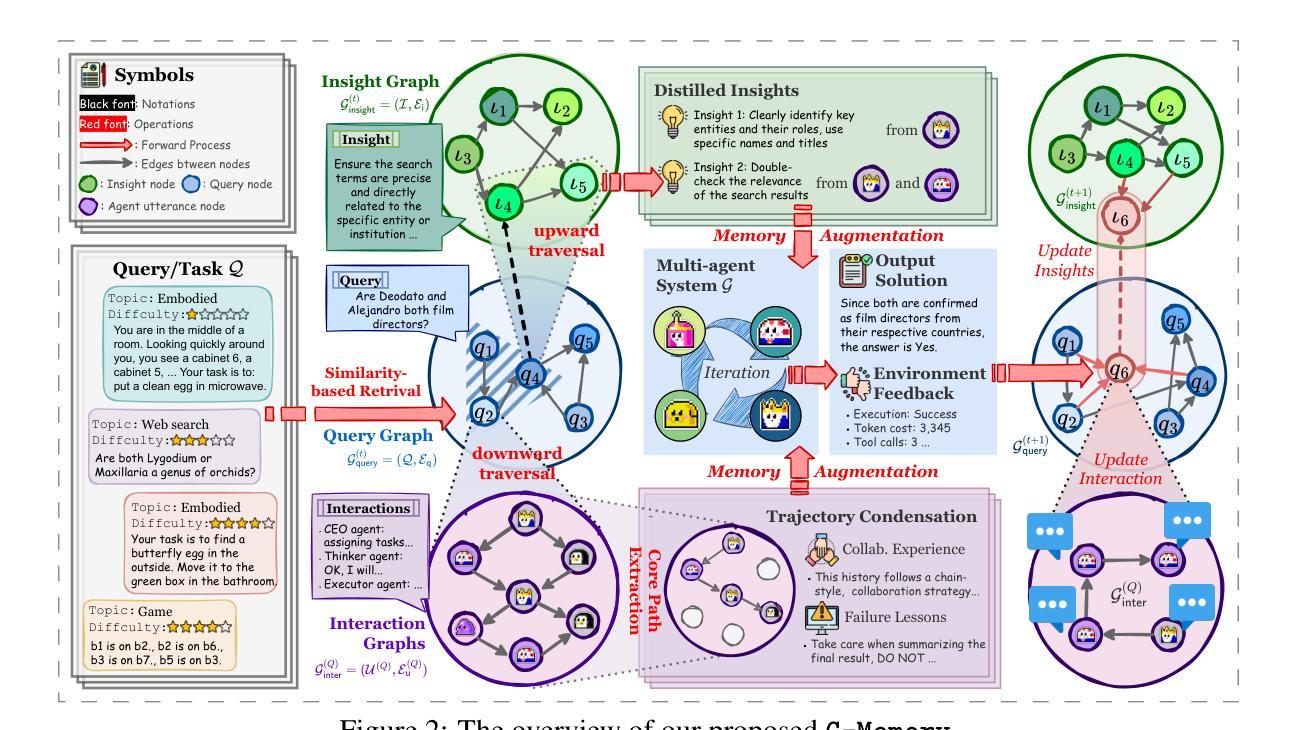
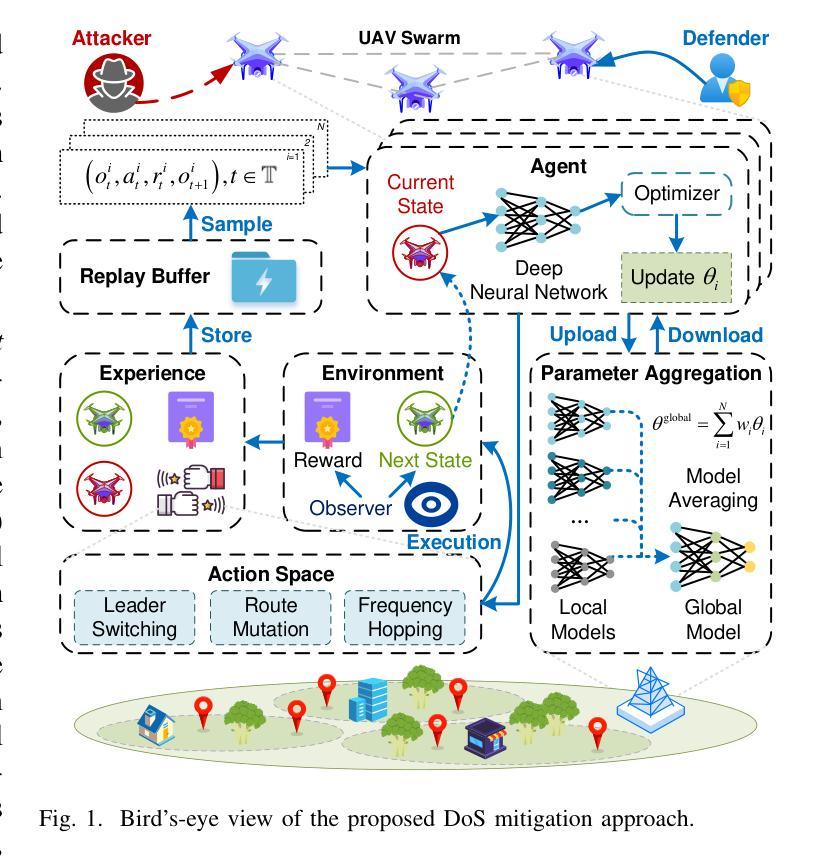
From Static to Adaptive Defense: Federated Multi-Agent Deep Reinforcement Learning-Driven Moving Target Defense Against DoS Attacks in UAV Swarm Networks
Authors:Yuyang Zhou, Guang Cheng, Kang Du, Zihan Chen, Tian Qin, Yuyu Zhao
The proliferation of unmanned aerial vehicle (UAV) swarms has enabled a wide range of mission-critical applications, but also exposes UAV networks to severe Denial-of-Service (DoS) threats due to their open wireless environment, dynamic topology, and resource constraints. Traditional static or centralized defense mechanisms are often inadequate for such dynamic and distributed scenarios. To address these challenges, we propose a novel federated multi-agent deep reinforcement learning (FMADRL)-driven moving target defense (MTD) framework for proactive and adaptive DoS mitigation in UAV swarm networks. Specifically, we design three lightweight and coordinated MTD mechanisms, including leader switching, route mutation, and frequency hopping, that leverage the inherent flexibility of UAV swarms to disrupt attacker efforts and enhance network resilience. The defense problem is formulated as a multi-agent partially observable Markov decision process (POMDP), capturing the distributed, resource-constrained, and uncertain nature of UAV swarms under attack. Each UAV is equipped with a local policy agent that autonomously selects MTD actions based on partial observations and local experiences. By employing a policy gradient-based FMADRL algorithm, UAVs collaboratively optimize their defense policies via reward-weighted aggregation, enabling distributed learning without sharing raw data and thus reducing communication overhead. Extensive simulations demonstrate that our approach significantly outperforms state-of-the-art baselines, achieving up to a 34.6% improvement in attack mitigation rate, a reduction in average recovery time of up to 94.6%, and decreases in energy consumption and defense cost by as much as 29.3% and 98.3%, respectively, while maintaining robust mission continuity under various DoS attack strategies.
无人机集群的普及为众多关键任务应用提供了支持,但同时也由于其开放的无线环境、动态拓扑和资源约束等因素,使无人机网络面临严重的拒绝服务(DoS)威胁。针对传统静态或集中防御机制在动态分布式场景下的不足,我们提出了一种基于联邦多智能体深度强化学习(FMADRL)的移动目标防御(MTD)框架,用于无人机集群网络中主动自适应的DoS缓解。具体来说,我们设计了三种轻量级且协调一致的MTD机制,包括领导切换、路线突变和跳频,利用无人机集群的固有灵活性来破坏攻击者的努力并增强网络韧性。防御问题被建模为多智能体部分可观察马尔可夫决策过程(POMDP),以捕捉受攻击无人机集群的分布式、资源受限和不确定性质。每架无人机都配备了一个本地策略代理,该代理根据部分观察和本地经验自主地选择MTD行动。通过采用基于策略梯度的FMADRL算法,无人机通过奖励加权聚合的方式协同优化其防御策略,实现了分布式学习而无需共享原始数据,从而降低了通信开销。大量模拟结果表明,我们的方法显著优于最新基线技术,攻击缓解率提高了高达34.6%,平均恢复时间减少了高达94.6%,能源消耗和防御成本分别减少了高达29.3%和98.3%,同时保持了各种DoS攻击策略下的任务连续性。
论文及项目相关链接
PDF 13pages; In submission
Summary
无人飞行器(UAV)集群的普及为其带来了多种关键应用,但同时也因开放无线环境、动态拓扑和资源限制而面临严重的拒绝服务(DoS)威胁。针对这些挑战,我们提出了一种基于联邦多智能体深度强化学习(FMADRL)的移动目标防御(MTD)框架,用于无人机集群网络中的主动自适应DoS缓解。通过设计三种轻量级且协调的MTD机制,包括领导切换、路线突变和频率跳变,利用无人机集群的固有灵活性来干扰攻击者并增强网络韧性。将防御问题建模为多智能体部分可观测马尔可夫决策过程(POMDP),捕捉受攻击无人机集群的分布式、资源受限和不确定性特点。每个无人机都配备了一个本地策略代理,该代理基于部分观测和本地经验自主地选择MTD行动。通过采用基于策略梯度的FMADRL算法,无人机通过奖励加权聚合来协作优化其防御策略,实现分布式学习而不共享原始数据,从而减少通信开销。模拟结果表明,我们的方法显著优于现有基线,攻击缓解率提高34.6%,平均恢复时间减少94.6%,能耗和防御成本分别降低29.3%和98.3%,同时保持各种DoS攻击策略下的任务连续性。
Key Takeaways
- UAV集群面临DoS威胁:由于开放无线环境、动态拓扑和资源限制。
- 提出了基于FMADRL的MTD框架来应对DoS威胁。
- 设计了三种MTD机制:领导切换、路线突变和频率跳变。
- 防御问题被建模为POMDP,以捕捉无人机集群在攻击下的特点。
- 每个UAV配备本地策略代理进行自主决策。
- 通过FMADRL算法协作优化防御策略,实现分布式学习并减少通信开销。
点此查看论文截图

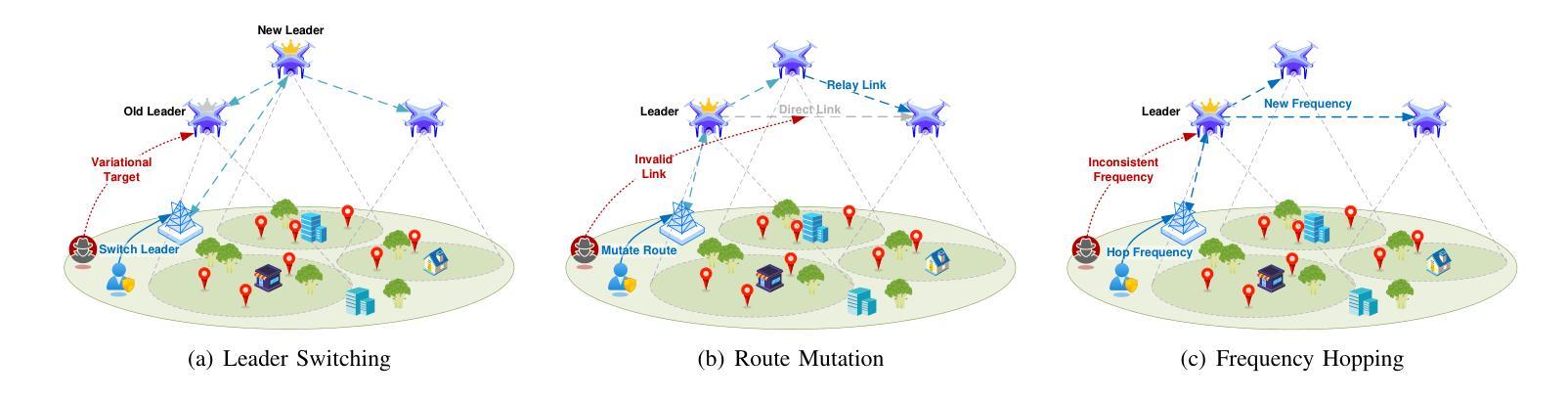

MARVEL: Multi-Agent RTL Vulnerability Extraction using Large Language Models
Authors:Luca Collini, Baleegh Ahmad, Joey Ah-kiow, Ramesh Karri
Hardware security verification is a challenging and time-consuming task. For this purpose, design engineers may utilize tools such as formal verification, linters, and functional simulation tests, coupled with analysis and a deep understanding of the hardware design being inspected. Large Language Models (LLMs) have been used to assist during this task, either directly or in conjunction with existing tools. We improve the state of the art by proposing MARVEL, a multi-agent LLM framework for a unified approach to decision-making, tool use, and reasoning. MARVEL mimics the cognitive process of a designer looking for security vulnerabilities in RTL code. It consists of a supervisor agent that devises the security policy of the system-on-chips (SoCs) using its security documentation. It delegates tasks to validate the security policy to individual executor agents. Each executor agent carries out its assigned task using a particular strategy. Each executor agent may use one or more tools to identify potential security bugs in the design and send the results back to the supervisor agent for further analysis and confirmation. MARVEL includes executor agents that leverage formal tools, linters, simulation tests, LLM-based detection schemes, and static analysis-based checks. We test our approach on a known buggy SoC based on OpenTitan from the Hack@DATE competition. We find that 20 of the 48 issues reported by MARVEL pose security vulnerabilities.
硬件安全验证是一项具有挑战性和耗时的任务。为此,设计工程师可能会利用形式化验证、代码检查器、功能仿真测试等工具,结合对正在检查的硬件设计的深入分析和理解。大型语言模型(LLM)已在此任务中得到应用,无论是直接还是与其他工具结合使用。我们提出MARVEL这一多智能体LLM框架来改进现有技术,它采用统一的方法来进行决策、工具使用和推理。MARVEL模仿设计师在RTL代码中寻找安全漏洞的认知过程。它由监督智能体组成,该智能体使用安全文档制定系统级芯片(SoC)的安全策略。它分配任务来验证安全策略的个人执行智能体。每个执行智能体都使用特定策略来完成其分配的任务。每个执行智能体可以使用一种或多种工具来识别设计中的潜在安全漏洞,并将结果发送回监督智能体进行进一步分析和确认。MARVEL包括使用形式工具、代码检查器、仿真测试、基于LLM的检测方案和基于静态分析的检查的执行智能体。我们在基于OpenTitan的Hack@DATE竞赛的已知有缺陷的SoC上测试了我们的方法。我们发现MARVEL报告的48个安全问题中有20个构成安全隐患。
论文及项目相关链接
PDF Submitted for Peer Review
Summary
本文介绍了硬件安全验证的挑战性和耗时性,设计工程师可以使用形式验证、linters、功能仿真测试等工具进行分析。为了提高效率,提出了MARVEL多代理LLM框架,用于决策、工具使用和推理的统一方法。MARVEL包括监督代理和多个执行代理,可识别RTL代码中的安全漏洞。在OpenTitan的SoC上进行了测试,发现其中存在多个安全问题。
Key Takeaways
- 硬件安全验证是一项具有挑战性和耗时的任务,需要设计工程师进行深入分析和理解硬件设计。
- 形式验证、linters、功能仿真测试等工具在硬件安全验证中发挥着重要作用。
- LLMs已经在硬件安全验证任务中得到应用,可以直接或间接地辅助验证过程。
- MARVEL是一个多代理LLM框架,包括监督代理和执行代理,用于统一决策、工具使用和推理。
- MARVEL能够识别RTL代码中的安全漏洞,对系统进行安全评估。
- MARVEL在OpenTitan的SoC上进行了测试,发现了多个安全问题。
点此查看论文截图

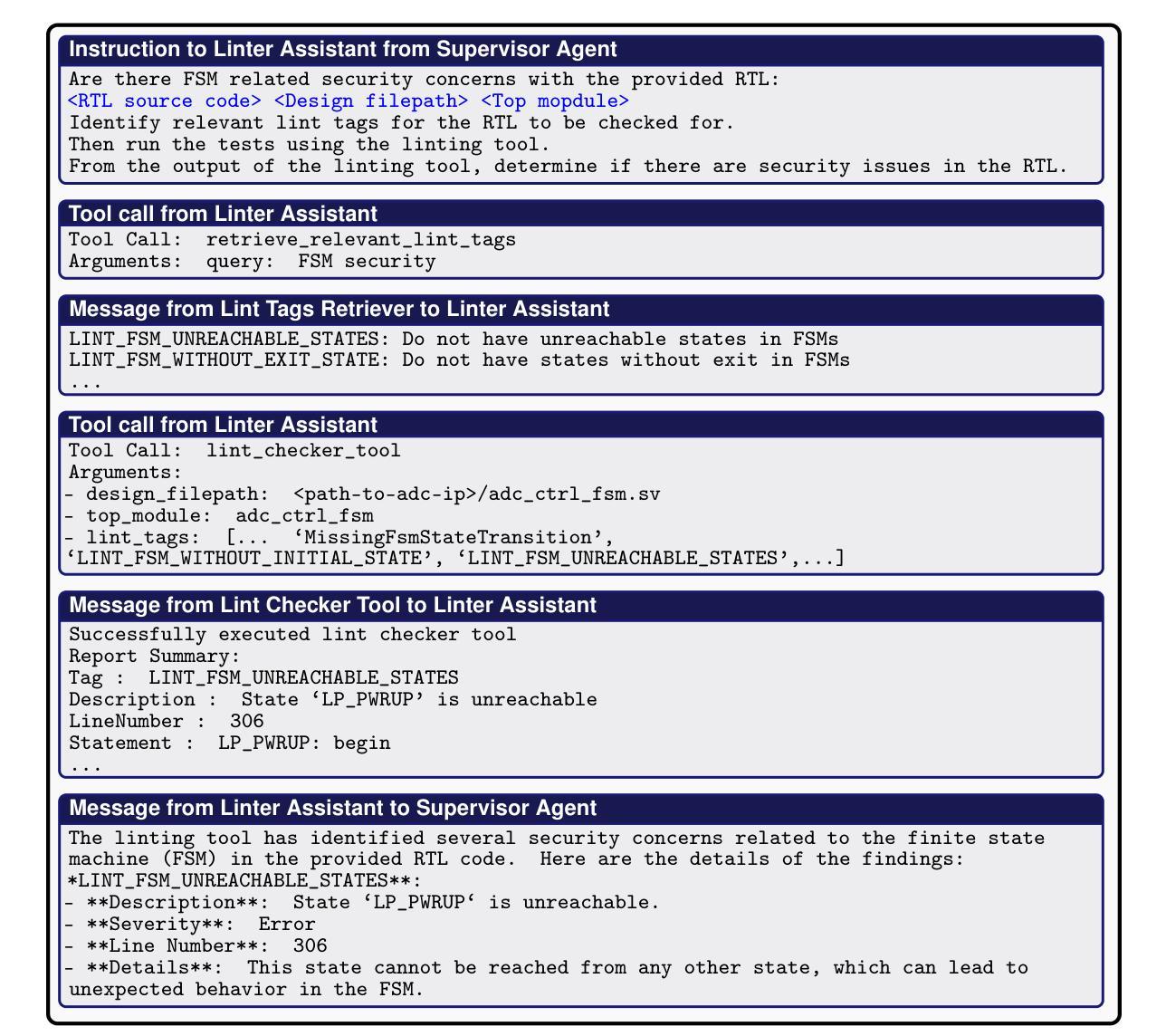
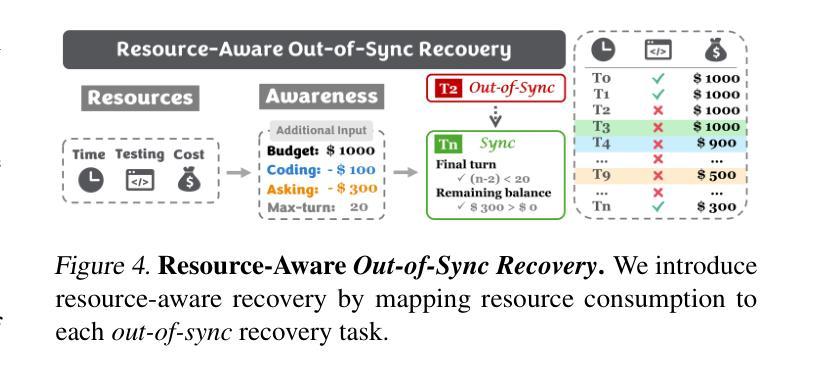
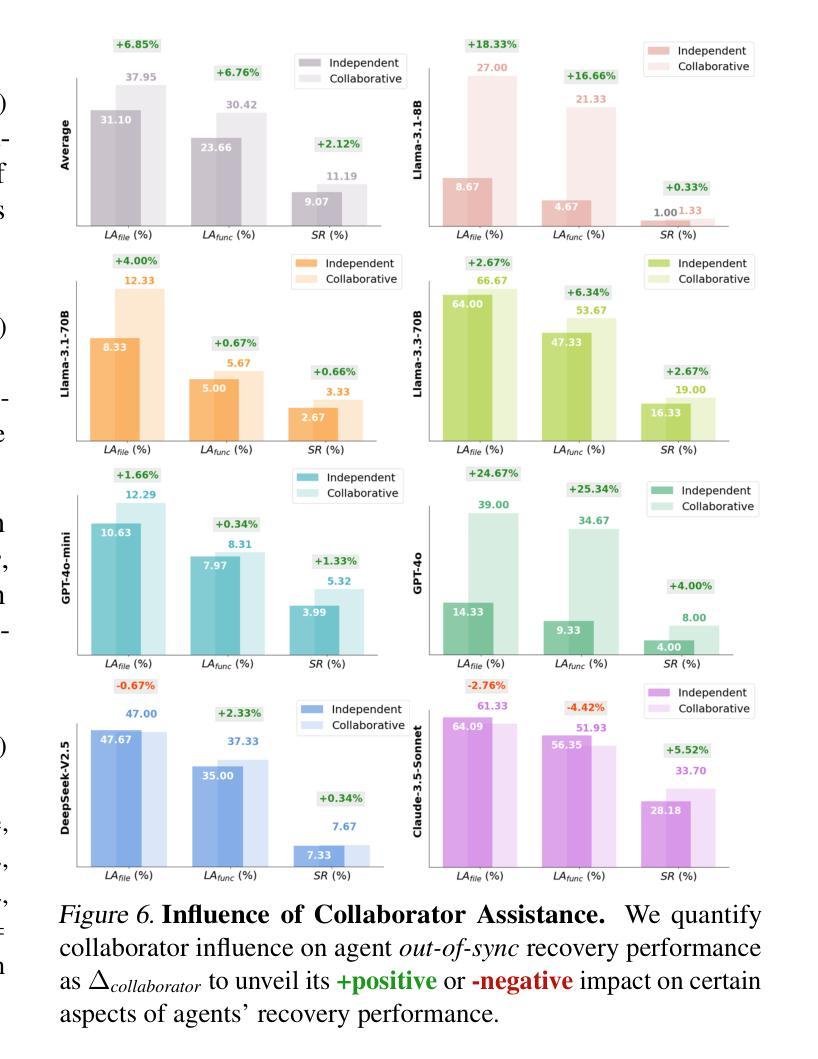
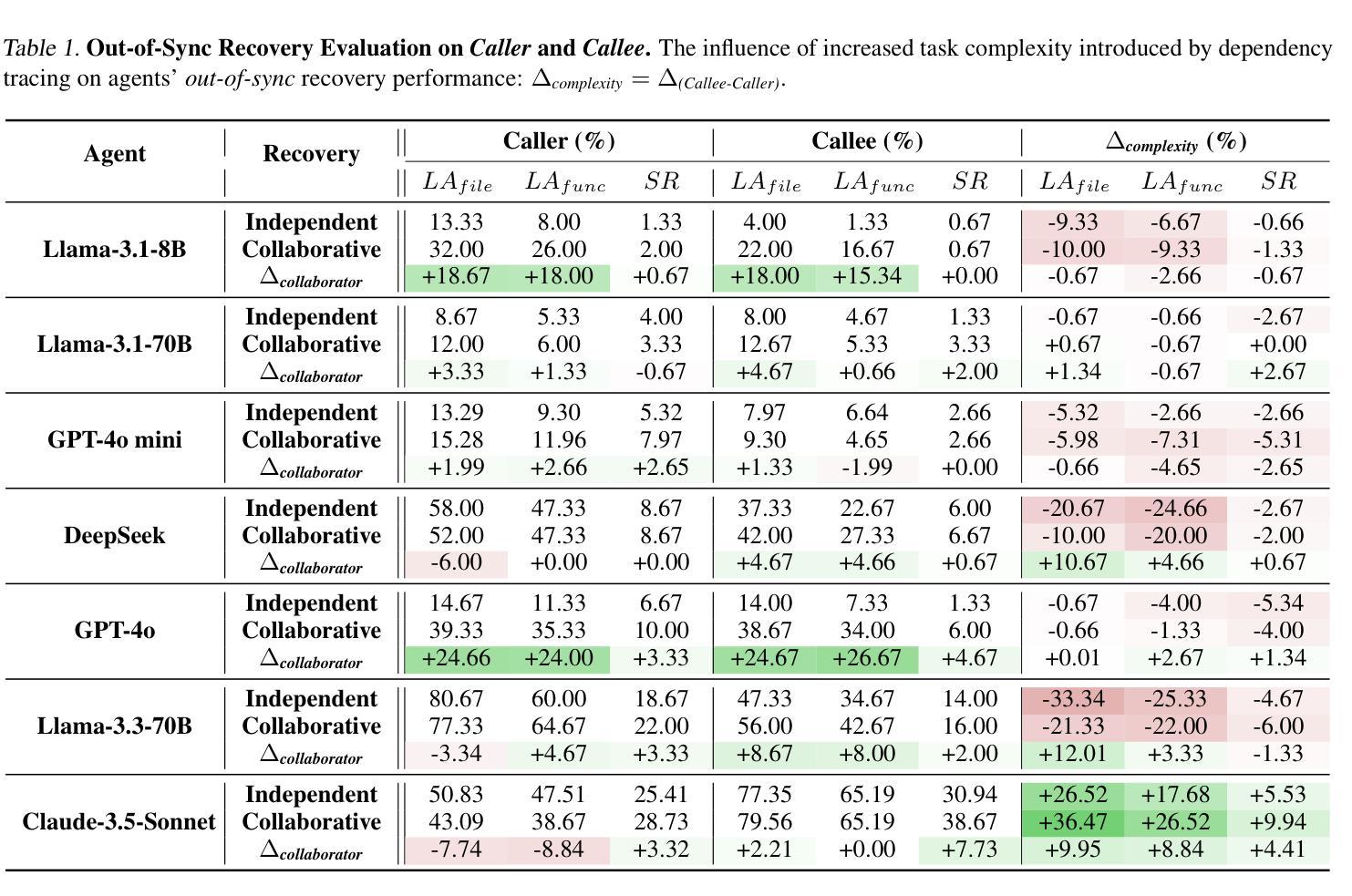
SyncMind: Measuring Agent Out-of-Sync Recovery in Collaborative Software Engineering
Authors:Xuehang Guo, Xingyao Wang, Yangyi Chen, Sha Li, Chi Han, Manling Li, Heng Ji
Software engineering (SE) is increasingly collaborative, with developers working together on shared complex codebases. Effective collaboration in shared environments requires participants – whether humans or AI agents – to stay on the same page as their environment evolves. When a collaborator’s understanding diverges from the current state – what we term the out-of-sync challenge – the collaborator’s actions may fail, leading to integration issues. In this work, we introduce SyncMind, a framework that systematically defines the out-of-sync problem faced by large language model (LLM) agents in collaborative software engineering (CSE). Based on SyncMind, we create SyncBench, a benchmark featuring 24,332 instances of agent out-of-sync scenarios in real-world CSE derived from 21 popular GitHub repositories with executable verification tests. Experiments on SyncBench uncover critical insights into existing LLM agents’ capabilities and limitations. Besides substantial performance gaps among agents (from Llama-3.1 agent <= 3.33% to Claude-3.5-Sonnet >= 28.18%), their consistently low collaboration willingness (<= 4.86%) suggests fundamental limitations of existing LLM in CSE. However, when collaboration occurs, it positively correlates with out-of-sync recovery success. Minimal performance differences in agents’ resource-aware out-of-sync recoveries further reveal their significant lack of resource awareness and adaptability, shedding light on future resource-efficient collaborative systems. Code and data are openly available on our project website: https://xhguo7.github.io/SyncMind/.
软件工程(SE)越来越注重协作,开发者们共同在共享的复杂代码库上工作。在共享环境中进行有效协作需要参与者——无论是人类还是人工智能代理——随着环境的变化保持同步。当协作者的理解偏离当前状态时——我们称之为“不同步挑战”——协作者的行动可能会失败,导致集成问题。在这项工作中,我们介绍了SyncMind框架,该框架系统地定义了协作软件工程(CSE)中大型语言模型(LLM)代理所面临的同步问题。基于SyncMind,我们创建了SyncBench,这是一个包含来自GitHub上21个流行仓库的24332个代理不同步场景的基准测试集,并配有可执行的验证测试。在SyncBench上的实验揭示了现有LLM代理的能力和局限性的重要见解。除了代理之间显著的性能差距(从Llama-3.1代理的≤3.33%到Claude-3.5-Sonnet的≥28.18%),他们持续的低合作意愿(≤4.86%)表明现有LLM在CSE中的根本局限性。然而,当发生合作时,它与成功恢复不同步状态呈正相关。代理在资源感知不同步恢复方面的微小性能差异进一步揭示了其资源意识和适应能力的重大缺失,为未来的资源高效协作系统指明了方向。代码和数据都可在我们的项目网站上公开获取:https://xhguo7.github.io/SyncMind/。
论文及项目相关链接
Summary
软件工程中团队协作日益普遍,存在开发者共同处理复杂代码库的情况。当协作者的理解与环境变化不一致时,会出现所谓的“失同步挑战”,导致行动失败和集成问题。本研究提出SyncMind框架,系统性定义大型语言模型在协同软件工程中的失同步问题。基于此框架,创建SyncBench基准测试平台,模拟现实场景中的软件协作情况,涉及超过真实场景中的失同步场景。实验揭示了现有大型语言模型在协同软件工程中的能力差距和局限性。虽然协作意愿较低,但当成功协作时,有助于恢复同步状态。此外,大型语言模型在资源感知和适应性方面的微小差异暴露出其在资源效率方面的重大缺陷。具体可访问我们的项目网站:网址链接了解详情。
Key Takeaways
- 软件工程中团队协作至关重要,尤其在处理复杂代码库时。协作中出现失同步挑战会影响集成和结果。
- SyncMind框架定义了大型语言模型在协同软件工程中的失同步问题,有助于更系统地研究这一问题。
点此查看论文截图




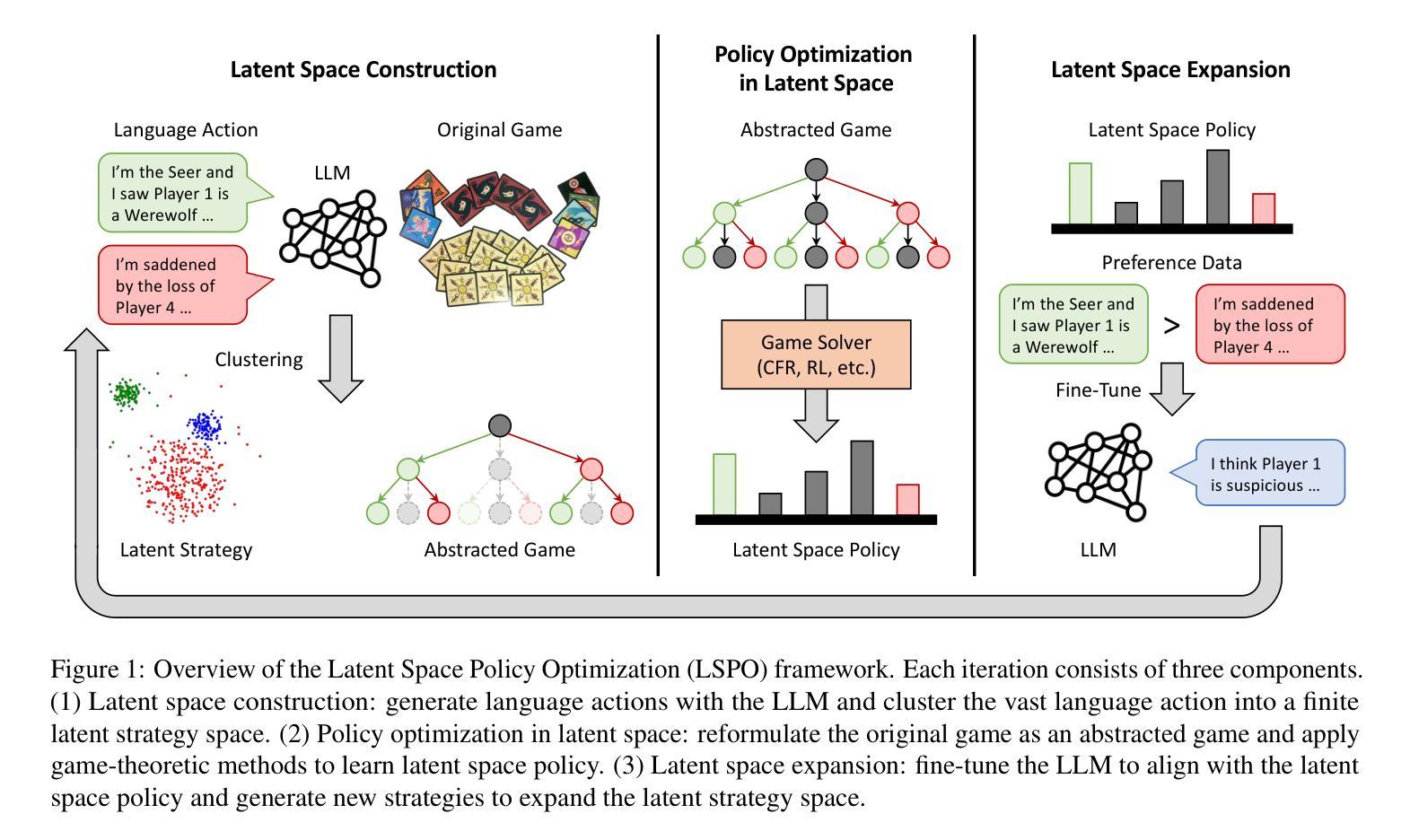
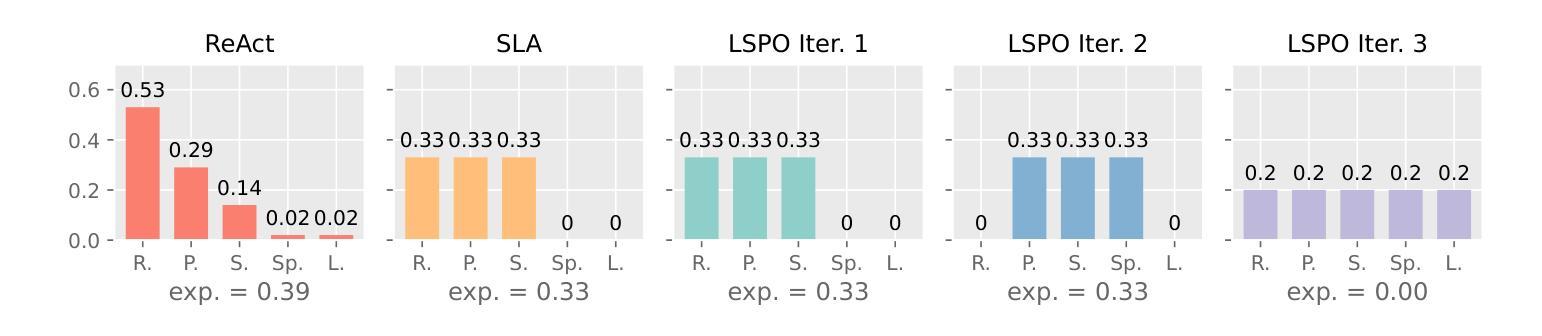
Learning Strategic Language Agents in the Werewolf Game with Iterative Latent Space Policy Optimization
Authors:Zelai Xu, Wanjun Gu, Chao Yu, Yi Wu, Yu Wang
Large language model (LLM) agents have recently demonstrated impressive capabilities in various domains like open-ended conversation and multi-step decision-making. However, it remains challenging for these agents to solve strategic language games, such as Werewolf, which demand both strategic decision-making and free-form language interactions. Existing LLM agents often suffer from intrinsic bias in their action distributions and limited exploration of the unbounded text action space, resulting in suboptimal performance. To address these challenges, we propose Latent Space Policy Optimization (LSPO), an iterative framework that combines game-theoretic methods with LLM fine-tuning to build strategic language agents. LSPO leverages the observation that while the language space is combinatorially large, the underlying strategy space is relatively compact. We first map free-form utterances into a finite latent strategy space, yielding an abstracted extensive-form game. Then we apply game-theoretic methods like Counterfactual Regret Minimization (CFR) to optimize the policy in the latent space. Finally, we fine-tune the LLM via Direct Preference Optimization (DPO) to align with the learned policy. By iteratively alternating between these steps, our LSPO agents progressively enhance both strategic reasoning and language communication. Experiment on the Werewolf game shows that our agents iteratively expand the strategy space with improving performance and outperform existing Werewolf agents, underscoring their effectiveness in free-form language games with strategic interactions.
大型语言模型(LLM)代理最近已在开放对话和多步决策等各个领域展现出令人印象深刻的能力。然而,对于狼人杀(Werewolf)等需要战略决策和自由形式语言交互的语言游戏来说,对于这些代理来说仍然具有挑战性。现有LLM代理常常受到其行动分布中的内在偏见和无界文本行动空间有限探索的影响,导致性能不佳。为了解决这些挑战,我们提出了潜在空间策略优化(LSPO),这是一个结合博弈论方法和LLM微调来构建战略性语言代理的迭代框架。LSPO利用了一个观察结果,即虽然语言空间是组合性的庞大,但潜在的策略空间是相对紧凑的。我们首先将自由形式的言论映射到一个有限的潜在策略空间,从而产生一个抽象的扩展形式的游戏。然后,我们应用博弈论方法,如反事实遗憾最小化(CFR)来优化潜在空间中的策略。最后,我们通过直接偏好优化(DPO)对LLM进行微调,以与学到的策略保持一致。通过在这几步之间迭代交替,我们的LSPO代理逐步提高了战略推理和语言沟通的能力。在狼人杀游戏上的实验表明,我们的代理通过迭代扩展策略空间,性能得到提升,并超越了现有的狼人杀代理,这证明了它们在具有战略交互的自由形式语言游戏中的有效性。
论文及项目相关链接
PDF Published in ICML 2025
Summary
大型语言模型(LLM)代理在开放对话和多步决策等领域展现出令人印象深刻的能力,但在解决战略语言游戏(如Werewolf)时仍面临挑战。针对此,提出了潜在空间策略优化(LSPO)方法,结合博弈论方法和LLM微调技术构建战略语言代理。该方法首先通过将自由形式的言论映射到有限的潜在策略空间,生成抽象扩展形式的博弈。接着应用博弈论方法如反事实后悔最小化(CFR)在潜在空间优化策略。最后通过直接偏好优化(DPO)微调LLM以与学到的策略对齐。实验证明,LSPO代理通过迭代步骤逐步提升策略推理和语言沟通能力,并在Werewolf游戏中表现出良好性能。
Key Takeaways
- 大型语言模型(LLM)在战略语言游戏(如Werewolf)中的表现仍有待提升。
- 现有LLM代理面临内在行动分布偏见和文本行动空间探索有限的挑战。
- 提出了一种新的方法——潜在空间策略优化(LSPO),结合博弈论和LLM微调技术来解决这些挑战。
- LSPO通过将自由形式的言论映射到潜在策略空间,生成抽象扩展形式的博弈。
- LSPO使用反事实后悔最小化(CFR)在潜在空间优化策略。
- 通过直接偏好优化(DPO)对LLM进行微调,与学到的策略对齐。
点此查看论文截图


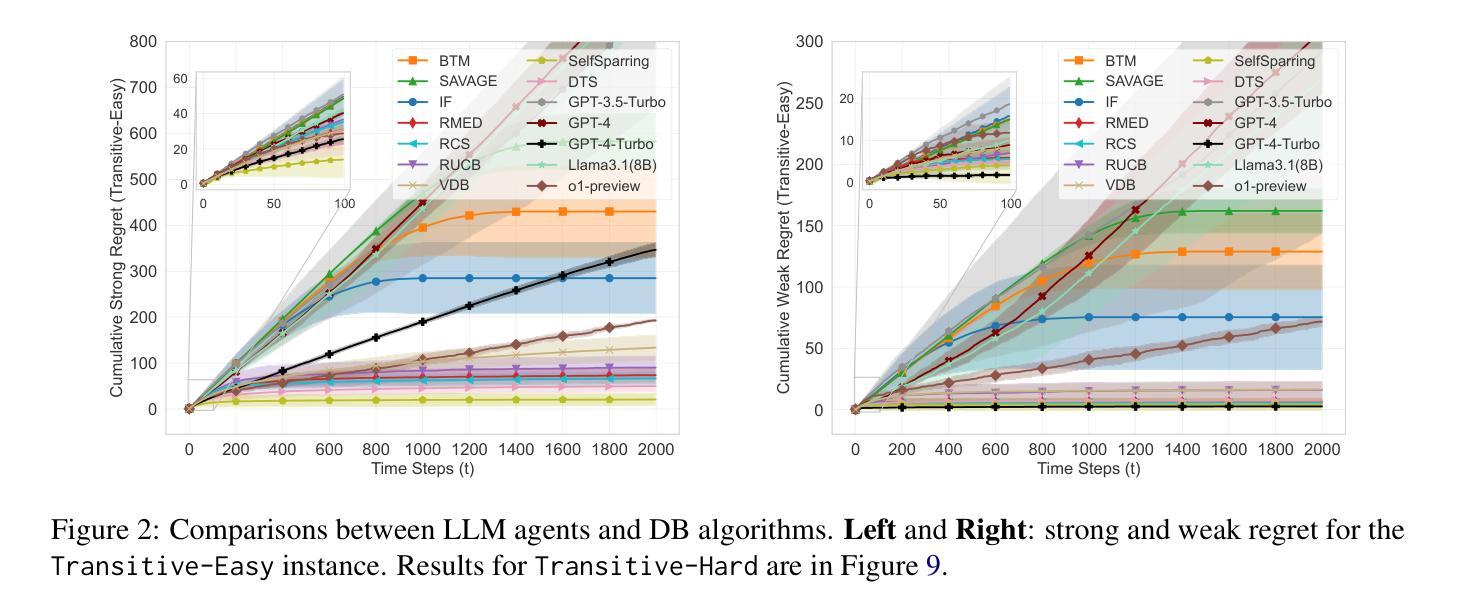
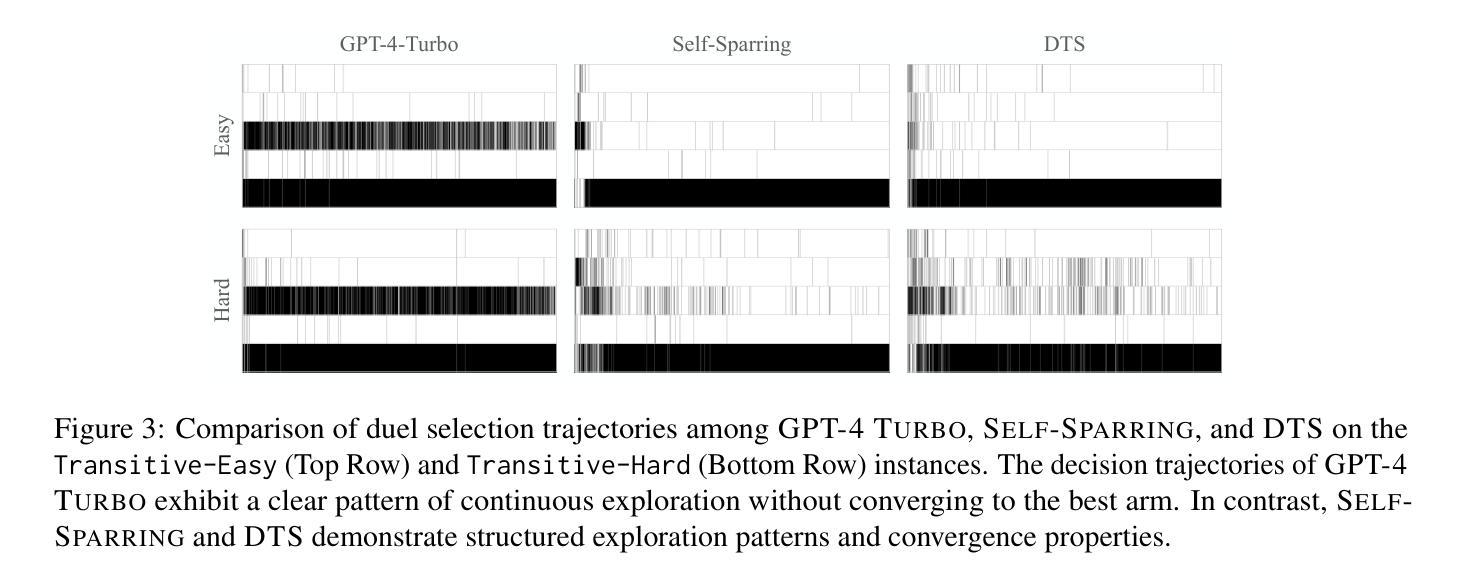
Beyond Numeric Rewards: In-Context Dueling Bandits with LLM Agents
Authors:Fanzeng Xia, Hao Liu, Yisong Yue, Tongxin Li
In-Context Reinforcement Learning (ICRL) is a frontier paradigm to solve Reinforcement Learning (RL) problems in the foundation model era. While ICRL capabilities have been demonstrated in transformers through task-specific training, the potential of Large Language Models (LLMs) out-of-the-box remains largely unexplored. This paper investigates whether LLMs can generalize cross-domain to perform ICRL under the problem of Dueling Bandits (DB), a stateless preference-based RL setting. We find that the top-performing LLMs exhibit a notable zero-shot capacity for relative decision-making, which translates to low short-term weak regret across all DB environment instances by quickly including the best arm in duels. However, an optimality gap still exists between LLMs and classic DB algorithms in terms of strong regret. LLMs struggle to converge and consistently exploit even when explicitly prompted to do so, and are sensitive to prompt variations. To bridge this gap, we propose an agentic flow framework: LLM with Enhanced Algorithmic Dueling (LEAD), which integrates off-the-shelf DB algorithm support with LLM agents through fine-grained adaptive interplay. We show that LEAD has theoretical guarantees inherited from classic DB algorithms on both weak and strong regret. We validate its efficacy and robustness even with noisy and adversarial prompts. The design of such an agentic framework sheds light on how to enhance the trustworthiness of general-purpose LLMs generalized to in-context decision-making tasks.
在上下文强化学习(ICRL)是基础模型时代解决强化学习(RL)问题的前沿范式。虽然ICRL在特定任务训练中的transformer能力已经得到了证明,但大型语言模型(LLM)的现成潜力仍未得到充分探索。本文旨在研究LLM是否能够跨域泛化,以在基于偏好的无状态强化学习环境问题(DB)中进行ICRL。我们发现表现最好的LLM在相对决策制定方面表现出显著的无先验知识能力,这转化为在所有DB环境实例中的短期弱后悔较低,通过快速将最佳策略纳入决斗中。然而,在强后悔方面,LLM与经典DB算法之间仍存在最优性差距。即使在明确要求如此做的情况下,LLM也难以收敛并始终如一地利用策略,并且对提示的敏感性很高。为了弥补这一差距,我们提出了一个智能流框架:带有增强算法决斗的大型语言模型(LEAD),它通过精细的适应性交互将现成的DB算法支持与LLM代理集成在一起。我们证明了LEAD在弱后悔和强后悔方面继承了经典DB算法的理论保证。即使在有噪声和对抗提示下,我们也验证了其有效性和稳健性。这种智能框架的设计为提高通用LLM在处理上下文决策任务时的可信度提供了启示。
论文及项目相关链接
PDF ACL 2025 Findings
Summary
本研究探索了大型语言模型(LLMs)在无需任务特定训练的情况下,能否在基于决斗强盗(DB)的无状态偏好RL环境中进行跨域泛化,执行上下文增强学习(ICRL)。研究发现,顶尖LLMs具有显著的零镜头相对决策能力,可在所有DB环境实例中快速包含最佳策略,但相较于经典DB算法在强遗憾上仍有最优性差距。为提高LLMs的泛化能力和决策任务的表现,研究提出了一个集成了现有DB算法支持的LLM增强算法决斗(LEAD)框架。该框架通过精细的自适应交互将经典DB算法的理论保障融入LLM代理中,即使在充满噪音和对抗性的提示下也能有效验证其效率和稳健性。该研究设计旨在提高通用LLMs在处理上下文决策任务的可信度和效能。
Key Takeaways
- 大型语言模型(LLMs)在未进行特定任务训练的情况下,展现出对基于决斗强盗(DB)的无状态偏好强化学习环境的泛化能力。
- 顶尖LLMs具有零镜头相对决策能力,能在各种DB环境实例中快速包含最佳策略。
- LLMs相较于经典DB算法在强遗憾上存在最优性差距,尤其是在收敛和一致性方面。
- LLMs对提示变化敏感,即使在明确提示下也难以收敛和持续利用。
- 提出了一种新的LEAD框架,融合了经典DB算法的理论保障和LLM代理,以提高其在上下文决策任务中的表现。
- LEAD框架能有效验证其效率和稳健性,甚至在充满噪音和对抗性的提示下也能保持性能。
点此查看论文截图