⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-11 更新
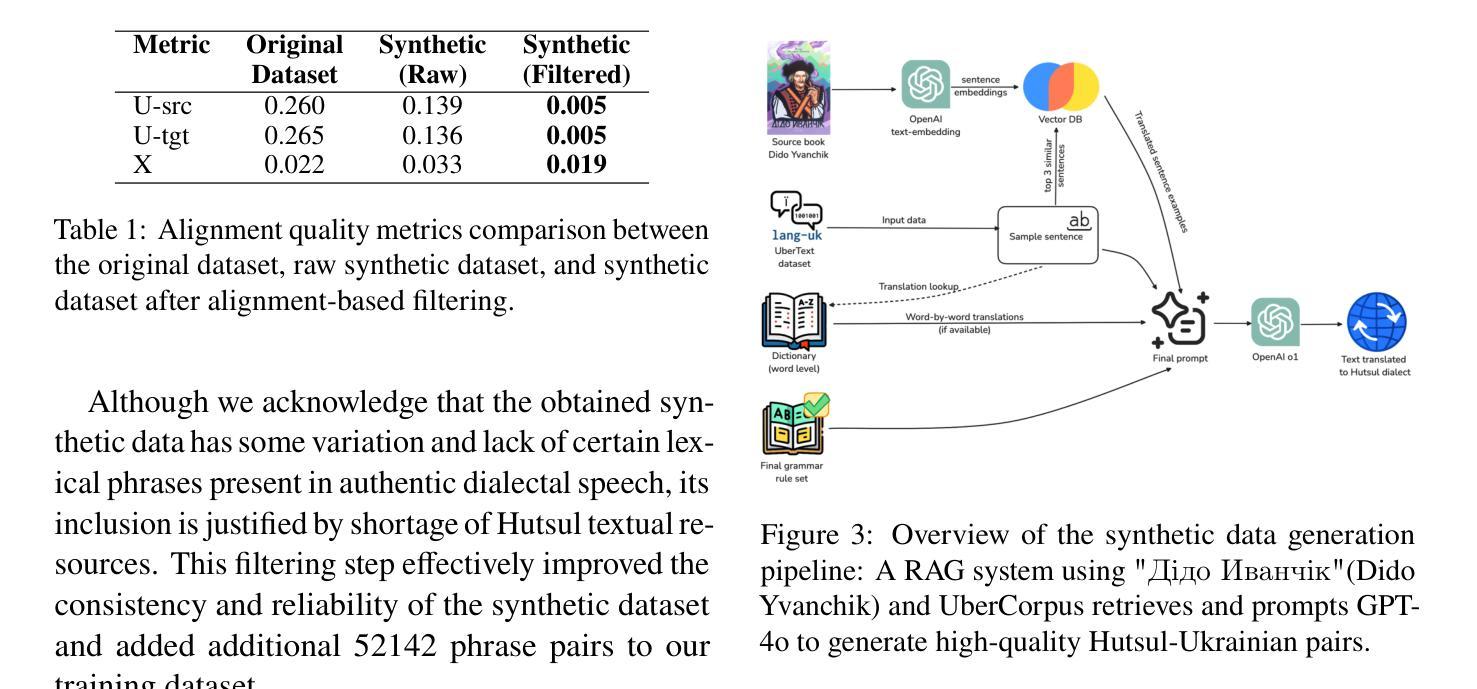
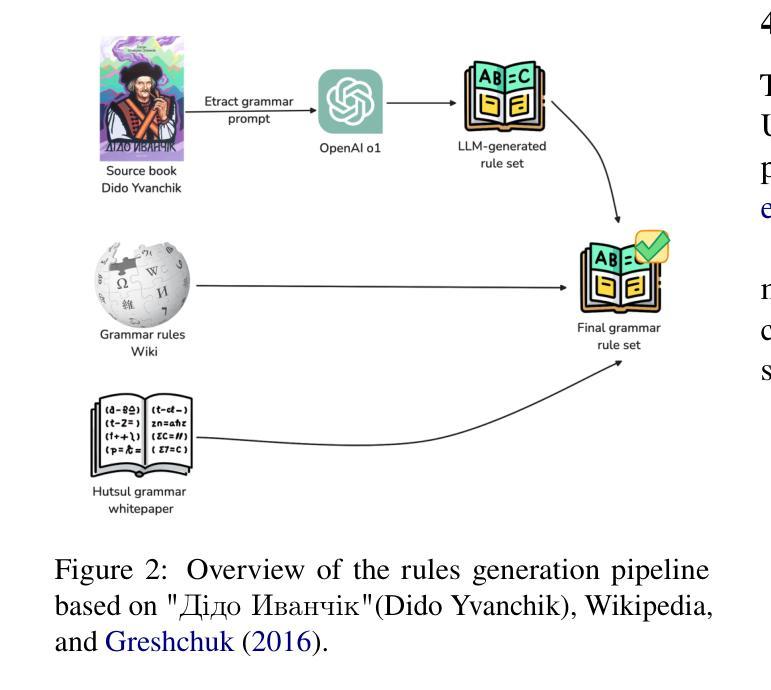
Vuyko Mistral: Adapting LLMs for Low-Resource Dialectal Translation
Authors:Roman Kyslyi, Yuliia Maksymiuk, Ihor Pysmennyi
In this paper we introduce the first effort to adapt large language models (LLMs) to the Ukrainian dialect (in our case Hutsul), a low-resource and morphologically complex dialect spoken in the Carpathian Highlands. We created a parallel corpus of 9852 dialect-to-standard Ukrainian sentence pairs and a dictionary of 7320 dialectal word mappings. We also addressed data shortage by proposing an advanced Retrieval-Augmented Generation (RAG) pipeline to generate synthetic parallel translation pairs, expanding the corpus with 52142 examples. We have fine-tuned multiple open-source LLMs using LoRA and evaluated them on a standard-to-dialect translation task, also comparing with few-shot GPT-4o translation. In the absence of human annotators, we adopt a multi-metric evaluation strategy combining BLEU, chrF++, TER, and LLM-based judgment (GPT-4o). The results show that even small(7B) finetuned models outperform zero-shot baselines such as GPT-4o across both automatic and LLM-evaluated metrics. All data, models, and code are publicly released at: https://github.com/woters/vuyko-hutsul
在这篇论文中,我们介绍了首次将大型语言模型(LLM)适应乌克兰方言(在我们的情况下是赫托姆语)的努力。这是一种资源贫乏且形态复杂的方言,位于喀尔巴阡山脉高地。我们创建了一个包含9852个方言到标准乌克兰语的句子对的平行语料库,以及包含7320个方言词汇映射的词典。为了解决数据短缺的问题,我们提出了一种先进的检索增强生成(RAG)管道来生成合成平行翻译对,扩大了语料库至包含52,142个实例。我们使用LoRA微调了多个开源LLM,并对它们进行了一项标准到方言的翻译任务评估,同时还与GPT-4o的翻译进行了少样本比较。在没有人工标注器的情况下,我们采用了一种多指标评估策略,结合了BLEU、chrF++、TER和基于LLM的判断(GPT-4o)。结果显示,即使在自动和LLM评估指标上,微调的小型(7B)模型也优于零样本基线,如GPT-4o。所有数据、模型和代码均已公开发布在:https://github.com/woters/vuyko-hutsul。
论文及项目相关链接
PDF Preprint. Will be published at Proceedings of the Fourth Ukrainian Natural Language Processing Workshop (UNLP)
Summary
本文介绍了对大型语言模型(LLMs)适应乌克兰语方言(本例为胡茨语)的首次尝试。研究团队创建了包含9852个方言至标准乌克兰语句子对的平行语料库,并建立了包含7320个方言词汇映射的词典。为解决数据短缺问题,研究团队提出了先进的检索增强生成(RAG)管道,生成合成平行翻译对,增加了52142个例子。研究团队使用LoRA微调了多个开源LLMs,并在标准到方言的翻译任务中进行了评估,同时与GPT-4o的少量翻译进行了比较。由于没有人工标注者,研究团队采用了多指标评估策略,结合了BLEU、chrF++、TER和基于LLM的判断(GPT-4o)。结果显示,即使是较小的(7B)微调模型也能在自动和LLM评估指标上超越零样本基线,如GPT-4o。
Key Takeaways
- 研究团队首次尝试将大型语言模型(LLMs)适应乌克兰的胡茨方言,这是一种资源较少且形态复杂的方言。
- 创建了包含9852个方言至标准乌克兰语句子对的平行语料库和包含7320个方言词汇映射的词典。
- 提出先进的检索增强生成(RAG)管道来解决数据短缺问题,成功生成了合成平行翻译对,增加了52142个例子。
- 使用LoRA微调了多个开源LLMs,并在标准至方言翻译任务中进行了评估。
- 对比了微调模型与GPT-4o在少量翻译任务中的表现。
- 研究采用了多指标评估策略,包括BLEU、chrF++、TER和基于LLM的判断(GPT-4o)。
点此查看论文截图

Large Language Models for Multilingual Vulnerability Detection: How Far Are We?
Authors:Honglin Shu, Michael Fu, Junji Yu, Dong Wang, Chakkrit Tantithamthavorn, Junjie Chen, Yasutaka Kamei
Various deep learning-based approaches utilizing pre-trained language models (PLMs) have been proposed for automated vulnerability detection. With recent advancements in large language models (LLMs), several studies have begun exploring their application to vulnerability detection tasks. However, existing studies primarily focus on specific programming languages (e.g., C/C++) and function-level detection, leaving the strengths and weaknesses of PLMs and LLMs in multilingual and multi-granularity scenarios largely unexplored. To bridge this gap, we conduct a comprehensive fine-grained empirical study evaluating the effectiveness of state-of-the-art PLMs and LLMs for multilingual vulnerability detection. Using over 30,000 real-world vulnerability-fixing patches across seven programming languages, we systematically assess model performance at both the function-level and line-level. Our key findings indicate that GPT-4o, enhanced through instruction tuning and few-shot prompting, significantly outperforms all other evaluated models, including CodeT5P. Furthermore, the LLM-based approach demonstrates superior capability in detecting unique multilingual vulnerabilities, particularly excelling in identifying the most dangerous and high-severity vulnerabilities. These results underscore the promising potential of adopting LLMs for multilingual vulnerability detection at function-level and line-level, revealing their complementary strengths and substantial improvements over PLM approaches. This first empirical evaluation of PLMs and LLMs for multilingual vulnerability detection highlights LLMs’ value in addressing real-world software security challenges.
基于深度学习的方法,利用预训练语言模型(PLM)进行自动化漏洞检测已经被提出。随着大型语言模型(LLM)的近期发展,一些研究开始探索其在漏洞检测任务中的应用。然而,现有的研究主要集中在特定的编程语言(如C/C++)和函数级别的检测上,对于多语言和多粒度场景下PLM和LLM的优势和劣势的研究仍然有限。为了填补这一空白,我们对当前先进的PLM和LLM在多语言漏洞检测方面的有效性进行了全面的精细实证研究。我们利用超过三万份真实世界的漏洞修复补丁,跨越七种编程语言,系统地评估了模型在函数级别和行级别的性能。我们的主要发现表明,通过指令调优和少量提示增强的GPT-4o在所有其他评估模型中表现最为出色,包括CodeT5P。此外,基于LLM的方法在检测独特的多语言漏洞方面表现出卓越的能力,尤其擅长识别最危险和高严重程度的漏洞。这些结果强调了采用LLM进行多语言漏洞检测(在函数级别和行级别)的潜力,展现了其互补优势和相对于PLM方法的重大改进。这是对PLM和LLM在多语言漏洞检测方面的首次实证研究,突出了LLM在解决现实世界软件安全挑战中的价值。
论文及项目相关链接
PDF 33 pages, 9 figures
Summary
本研究针对基于深度学习的预训练语言模型(PLMs)和大型语言模型(LLMs)在多语言漏洞检测方面的应用进行了全面细致的实证研究。研究使用超过3万份真实世界的漏洞修复补丁,在七种编程语言下对模型进行了功能级别和行级别的系统性评估。结果表明,通过指令调整和少样本提示增强的GPT-4o在性能上显著优于其他模型,尤其是检测和识别多语言和高风险漏洞方面的能力更为突出。
Key Takeaways
- 多项基于深度学习的方法已应用于自动化漏洞检测,尤其是利用预训练语言模型和大型语言模型。
- 当前研究主要集中在特定编程语言(如C/C++)和功能级别的检测,对于多语言和多粒度场景中的模型强弱尚待探索。
- GPT-4o在指令调整和少样本提示的增强下,性能显著优于其他模型,包括CodeT5P。
- 大型语言模型(LLMs)在检测独特的多语言漏洞方面表现出卓越的能力,尤其擅长识别高风险和高严重性的漏洞。
- LLMs在功能级别和行级别的漏洞检测中展现出互补优势和实质性改进。
- 这是首次对PLMs和LLMs在多语言漏洞检测领域进行的实证研究,突出了LLMs在解决现实世界软件安全挑战中的价值。
点此查看论文截图

Prompt to Protection: A Comparative Study of Multimodal LLMs in Construction Hazard Recognition
Authors:Nishi Chaudhary, S M Jamil Uddin, Sathvik Sharath Chandra, Anto Ovid, Alex Albert
The recent emergence of multimodal large language models (LLMs) has introduced new opportunities for improving visual hazard recognition on construction sites. Unlike traditional computer vision models that rely on domain-specific training and extensive datasets, modern LLMs can interpret and describe complex visual scenes using simple natural language prompts. However, despite growing interest in their applications, there has been limited investigation into how different LLMs perform in safety-critical visual tasks within the construction domain. To address this gap, this study conducts a comparative evaluation of five state-of-the-art LLMs: Claude-3 Opus, GPT-4.5, GPT-4o, GPT-o3, and Gemini 2.0 Pro, to assess their ability to identify potential hazards from real-world construction images. Each model was tested under three prompting strategies: zero-shot, few-shot, and chain-of-thought (CoT). Zero-shot prompting involved minimal instruction, few-shot incorporated basic safety context and a hazard source mnemonic, and CoT provided step-by-step reasoning examples to scaffold model thinking. Quantitative analysis was performed using precision, recall, and F1-score metrics across all conditions. Results reveal that prompting strategy significantly influenced performance, with CoT prompting consistently producing higher accuracy across models. Additionally, LLM performance varied under different conditions, with GPT-4.5 and GPT-o3 outperforming others in most settings. The findings also demonstrate the critical role of prompt design in enhancing the accuracy and consistency of multimodal LLMs for construction safety applications. This study offers actionable insights into the integration of prompt engineering and LLMs for practical hazard recognition, contributing to the development of more reliable AI-assisted safety systems.
近期多模态大型语言模型(LLM)的出现为改善施工现场的视觉危险识别提供了新的机会。与传统的依赖特定领域训练和大量数据集的计算机视觉模型不同,现代LLM可以使用简单的自然语言提示来解释和描述复杂的视觉场景。然而,尽管对其应用的兴趣日益增长,但关于如何在建筑领域的安全关键视觉任务中不同LLM的表现的研究仍然有限。为了弥补这一空白,本研究对五种最新LLM进行了比较评估:Claude-3 Opus、GPT-4.5、GPT-4o、GPT-o3和Gemini 2.0 Pro,以评估它们从现实世界建筑图像中识别潜在危险的能力。每种模型都在三种提示策略下进行了测试:零样本、少样本和思维链(CoT)。零样本提示涉及最小指令,少样本结合了基本的安全背景和危险源提示,而思维链提示则提供了逐步推理的示例来引导模型思考。使用精确度、召回率和F1分数指标对所有条件下的结果进行了定量分析。结果揭示,提示策略对性能有显著影响,思维链提示在模型之间始终产生更高的准确性。此外,在不同条件下LLM的表现有所不同,GPT-4.5和GPT-o3在大多数设置中都表现优于其他模型。研究结果还表明,提示设计在增强多模态LLM在建筑施工安全应用中的准确性和一致性方面发挥着关键作用。本研究为整合提示工程和LLM进行实际危险识别提供了切实可行的见解,有助于开发更可靠的AI辅助安全系统。
论文及项目相关链接
Summary
本文研究了五种最先进的模态大型语言模型在识别建筑工地潜在危险方面的表现。通过零样本、少样本和链式思维提示策略进行了测试,发现提示策略对性能有显著影响,链式思维提示策略表现最佳。此外,不同模型在不同条件下的表现存在差异,GPT-4.5和GPT-o3在大多数设置中的表现优于其他模型。研究结果表明,提示设计对于提高模态大型语言模型在建筑施工安全应用中的准确性和一致性至关重要。
Key Takeaways
- 多模态大型语言模型在建筑工地危险识别中具有改进潜力。
- 不同的语言模型在不同条件下的表现存在差异。
- 提示策略(如零样本、少样本和链式思维)对模型性能有显著影响。
- 链式思维提示策略在测试中表现最佳。
- GPT-4.5和GPT-o3在大多数设置中的表现优于其他模型。
- 提示设计在提高模型准确性和一致性方面起着关键作用。
点此查看论文截图


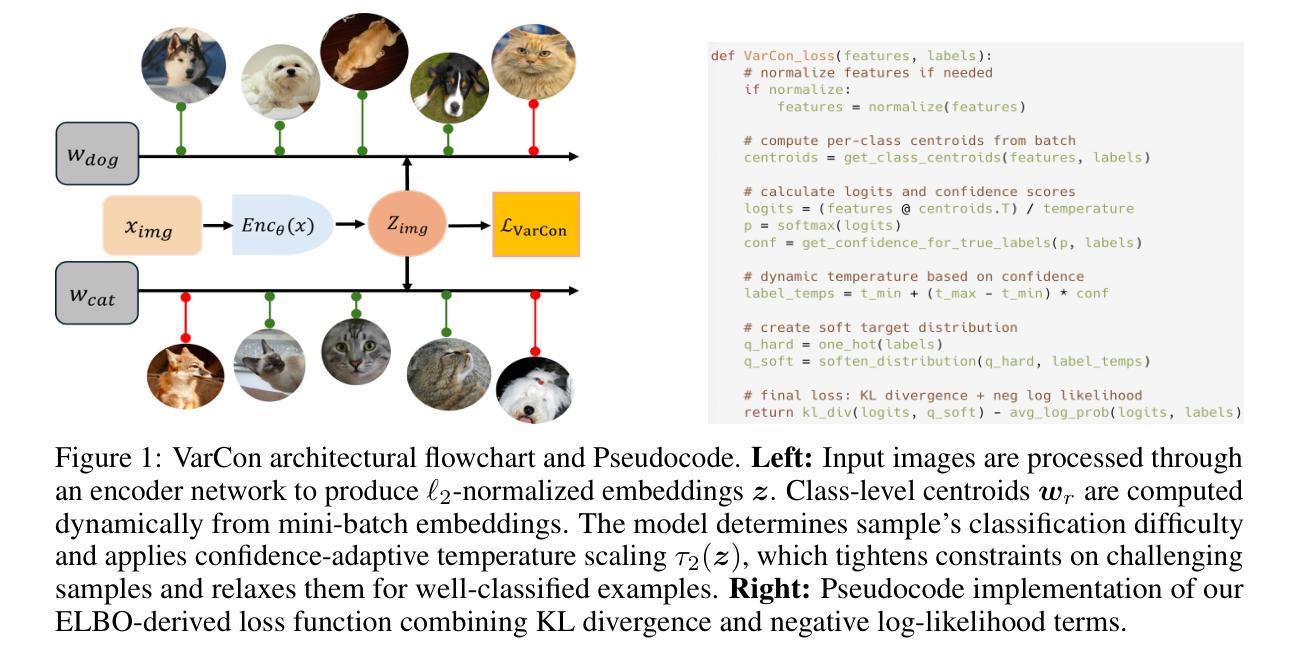
Variational Supervised Contrastive Learning
Authors:Ziwen Wang, Jiajun Fan, Thao Nguyen, Heng Ji, Ge Liu
Contrastive learning has proven to be highly efficient and adaptable in shaping representation spaces across diverse modalities by pulling similar samples together and pushing dissimilar ones apart. However, two key limitations persist: (1) Without explicit regulation of the embedding distribution, semantically related instances can inadvertently be pushed apart unless complementary signals guide pair selection, and (2) excessive reliance on large in-batch negatives and tailored augmentations hinders generalization. To address these limitations, we propose Variational Supervised Contrastive Learning (VarCon), which reformulates supervised contrastive learning as variational inference over latent class variables and maximizes a posterior-weighted evidence lower bound (ELBO) that replaces exhaustive pair-wise comparisons for efficient class-aware matching and grants fine-grained control over intra-class dispersion in the embedding space. Trained exclusively on image data, our experiments on CIFAR-10, CIFAR-100, ImageNet-100, and ImageNet-1K show that VarCon (1) achieves state-of-the-art performance for contrastive learning frameworks, reaching 79.36% Top-1 accuracy on ImageNet-1K and 78.29% on CIFAR-100 with a ResNet-50 encoder while converging in just 200 epochs; (2) yields substantially clearer decision boundaries and semantic organization in the embedding space, as evidenced by KNN classification, hierarchical clustering results, and transfer-learning assessments; and (3) demonstrates superior performance in few-shot learning than supervised baseline and superior robustness across various augmentation strategies.
对比学习已在不同模态的形状表示空间中展现出高效和适应性强的特点,通过将相似样本拉在一起并将不相似样本推开。然而,仍存在两个主要局限性:(1)若没有对嵌入分布进行明确调控,除非有互补信号引导配对选择,语义上相关的实例可能会不经意地被推开;(2)过度依赖大量内部批次负样本和定制增强策略会阻碍泛化。为解决这些局限性,我们提出变分监督对比学习(VarCon),它将监督对比学习重新表述为潜在类别变量上的变分推断,并最大化后验加权证据下限(ELBO),以替代详尽的配对比较,实现高效的类感知匹配,并在嵌入空间中精细控制类内离散度。仅在图像数据上进行训练,我们在CIFAR-10、CIFAR-100、ImageNet-100和ImageNet-1K上的实验表明,VarCon(1)实现了对比学习框架的最新性能,在ImageNet-1K上达到79.36%的Top-1准确率,在CIFAR-100上使用ResNet-50编码器达到78.29%,并在仅200个周期内收敛;(2)在嵌入空间中的决策边界和语义组织更加清晰,这由KNN分类、层次聚类结果和迁移学习评估所证明;(3)在少样本学习上表现出优于监督基准和多种增强策略的优越性能和稳健性。
论文及项目相关链接
Summary
对比学习在构建跨不同模态的表示空间时展现出高效和适应性,通过拉近相似样本并推远不相似样本。然而,存在两个主要局限:一是缺乏嵌入分布的明确调控,除非有互补信号引导配对选择,否则语义相关的实例可能会被无意中推开;二是过度依赖大量内批负样本和定制增强策略,阻碍了泛化能力。为解决这些问题,我们提出变分监督对比学习(VarCon),将监督对比学习重新表述为潜在类别变量的变分推断,并最大化后验加权证据下限(ELBO),以替代详尽的配对比较,实现高效的类别感知匹配,并在嵌入空间中精细控制类内离散度。仅对图像数据进行训练,我们的实验表明VarCon在对比学习框架中达到最佳性能,使用ResNet-50编码器在ImageNet-1K上达到79.36%的Top-1准确率和在CIFAR-100上达到78.29%的准确率,并且在仅200个周期内收敛;其实验结果还表明,VarCon在嵌入空间中产生了更清晰决策边界和语义组织,并在KNN分类、层次聚类结果和迁移学习评估中得到证实;此外,VarCon在少镜头学习上表现出优于监督基准的优越性能和在各种增强策略中的稳健性。
Key Takeaways
- 对比学习在不同模态间构建表示空间时展现高效和适应性。
- 现有对比学习存在语义相关实例可能被推开、过度依赖内批负样本和定制增强策略的局限。
- 变分监督对比学习(VarCon)通过变分推断改进对比学习,实现更精细的类别感知匹配和类内离散度控制。
- VarCon在图像数据上达到对比学习最佳性能,收敛速度快,准确率高。
- VarCon产生的嵌入空间具有更清晰决策边界和语义组织。
- VarCon在少镜头学习上表现优越,优于监督基准。
点此查看论文截图

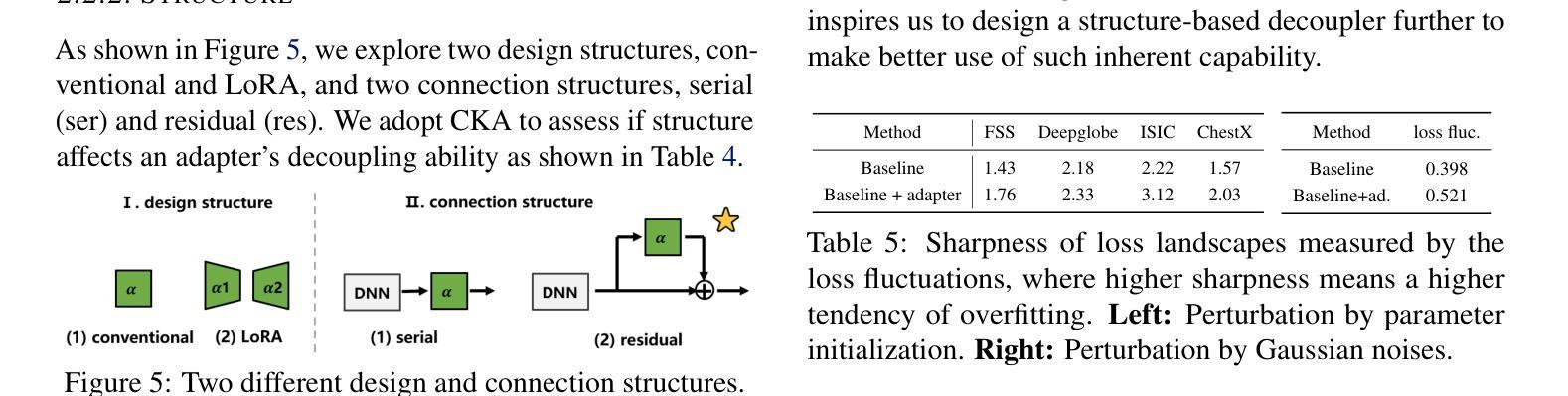
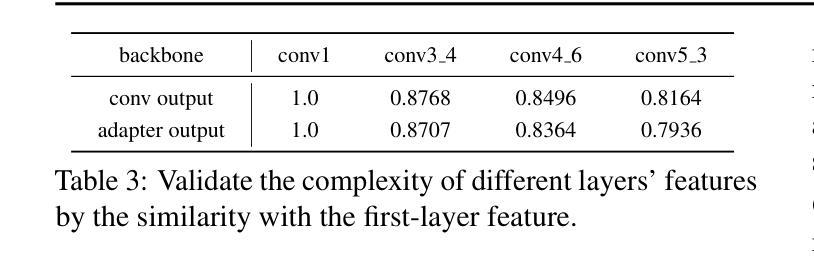
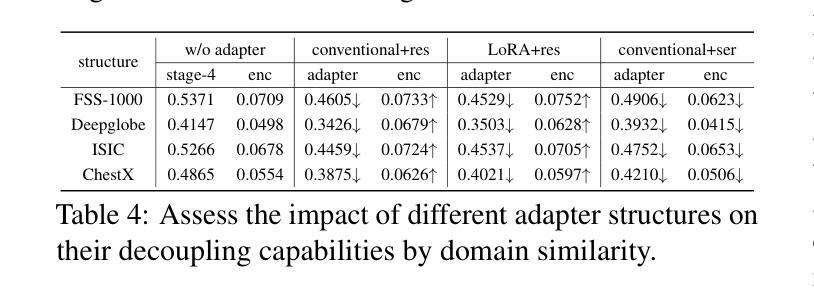
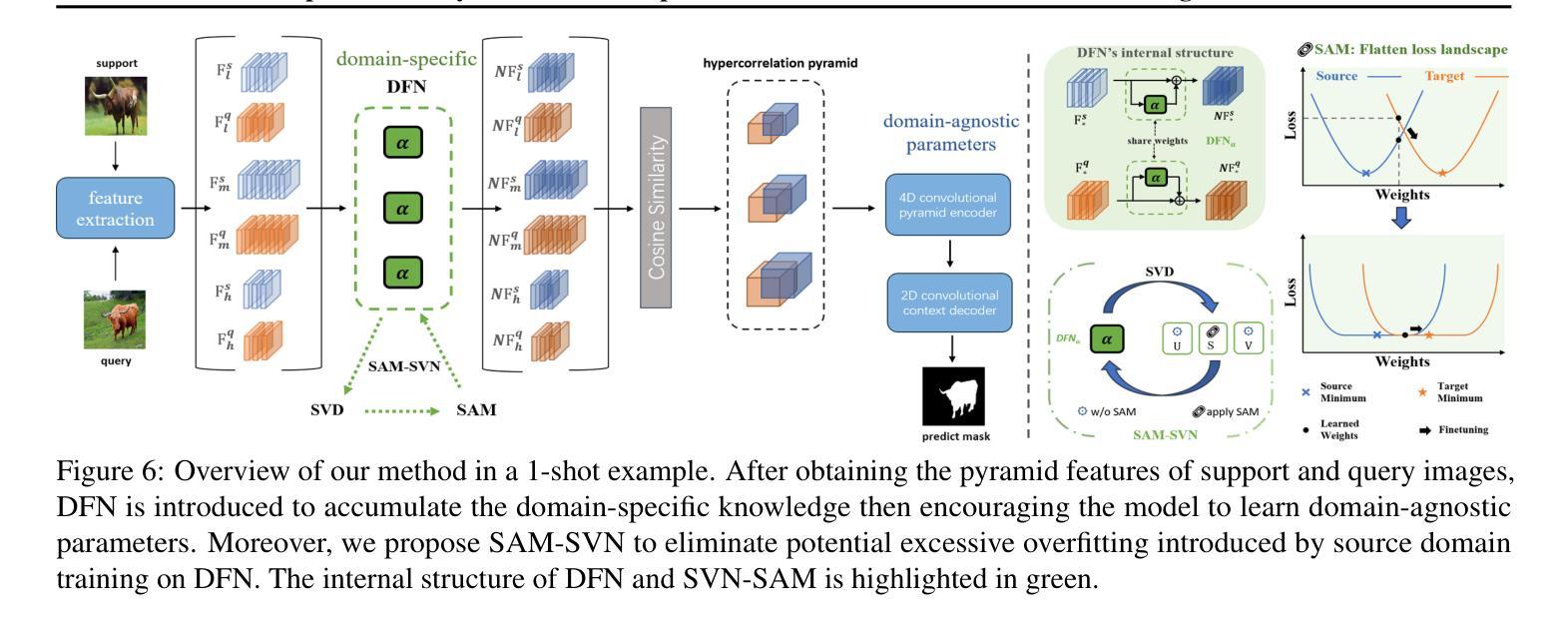
Adapter Naturally Serves as Decoupler for Cross-Domain Few-Shot Semantic Segmentation
Authors:Jintao Tong, Ran Ma, Yixiong Zou, Guangyao Chen, Yuhua Li, Ruixuan Li
Cross-domain few-shot segmentation (CD-FSS) is proposed to pre-train the model on a source-domain dataset with sufficient samples, and then transfer the model to target-domain datasets where only a few samples are available for efficient fine-tuning. There are majorly two challenges in this task: (1) the domain gap and (2) fine-tuning with scarce data. To solve these challenges, we revisit the adapter-based methods, and discover an intriguing insight not explored in previous works: the adapter not only helps the fine-tuning of downstream tasks but also naturally serves as a domain information decoupler. Then, we delve into this finding for an interpretation, and find the model’s inherent structure could lead to a natural decoupling of domain information. Building upon this insight, we propose the Domain Feature Navigator (DFN), which is a structure-based decoupler instead of loss-based ones like current works, to capture domain-specific information, thereby directing the model’s attention towards domain-agnostic knowledge. Moreover, to prevent the potential excessive overfitting of DFN during the source-domain training, we further design the SAM-SVN method to constrain DFN from learning sample-specific knowledge. On target domains, we freeze the model and fine-tune the DFN to learn target-specific knowledge specific. Extensive experiments demonstrate that our method surpasses the state-of-the-art method in CD-FSS significantly by 2.69% and 4.68% MIoU in 1-shot and 5-shot scenarios, respectively.
跨域小样本分割(CD-FSS)旨在先在源域数据集上预训练模型,该数据集有足够样本,然后将模型转移到目标域数据集,目标域数据集只有少量样本可用于有效微调。此任务主要有两个挑战:(1)领域差距和(2)稀缺数据的微调。我们重新审视了基于适配器的方法,并发现了一个以前的研究中未探索的有趣见解:适配器不仅有助于下游任务的微调,而且还自然地作为领域信息解耦器。基于此发现,我们对模型的内在结构进行了深入研究,发现其可以导致领域信息的自然解耦。基于这一见解,我们提出了基于结构的解耦器Domain Feature Navigator(DFN),而不是当前工作中的基于损失的方法,以捕获特定于领域的特征信息,从而引导模型的注意力转向领域通用的知识。此外,为了防止DFN在源域训练期间可能出现的过度拟合,我们进一步设计了SAM-SVN方法来约束DFN学习特定样本的知识。在目标域上,我们冻结模型并微调DFN来学习特定于目标的知识。大量实验表明,我们的方法在跨域小样本分割场景中超过了最先进的方法,在单样本和五样本场景中分别提高了2.69%和4.68%的MIoU。
论文及项目相关链接
PDF ICML 2025 Spotlight
Summary
该文本介绍了跨域小样本分割(CD-FSS)任务中的挑战及解决方案。针对模型在源域数据集上预训练后,转移到目标域数据集进行微调时遇到的域差距和样本稀缺问题,提出基于适配器方法的改进方案。提出了一个新的见解,即适配器不仅有助于下游任务的微调,还能自然充当域信息解耦器。基于此,构建了领域特征导航器(DFN)来捕捉特定领域的域信息并指导模型学习领域通用的知识。通过设计SAM-SVN方法防止DFN在源域训练中的过度拟合,并在目标域上冻结模型,仅微调DFN学习特定目标知识。实验表明,该方法在CD-FSS任务中显著超越了现有技术。
Key Takeaways
- 跨域小样本分割(CD-FSS)面临两大挑战:域差距和样本稀缺。
- 基于适配器方法的改进方案被提出以解决这些挑战。
- 适配器不仅有助于下游任务的微调,同时也能自然地进行域信息解耦。
- 领域特征导航器(DFN)被构建为结构解耦器来捕捉特定领域的域信息。
- DFN的设计能够指导模型学习领域通用的知识。
- 通过SAM-SVN方法防止DFN在源域训练中的过度拟合。
点此查看论文截图


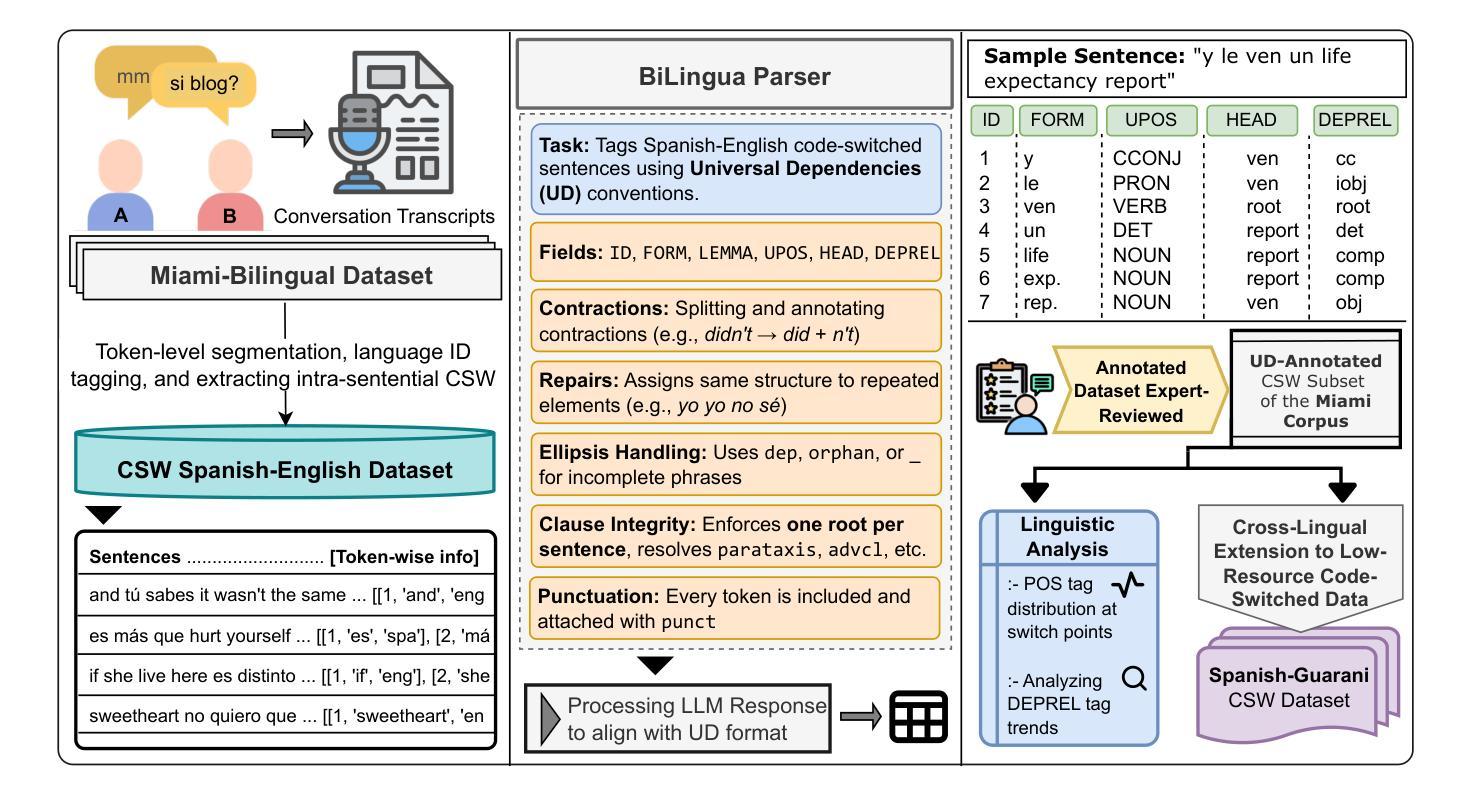
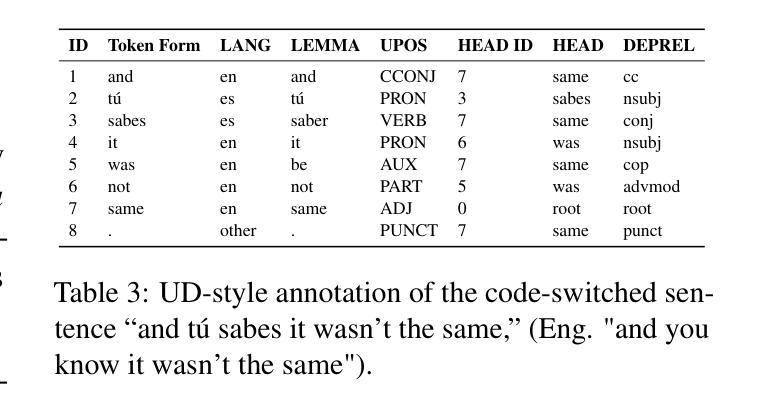
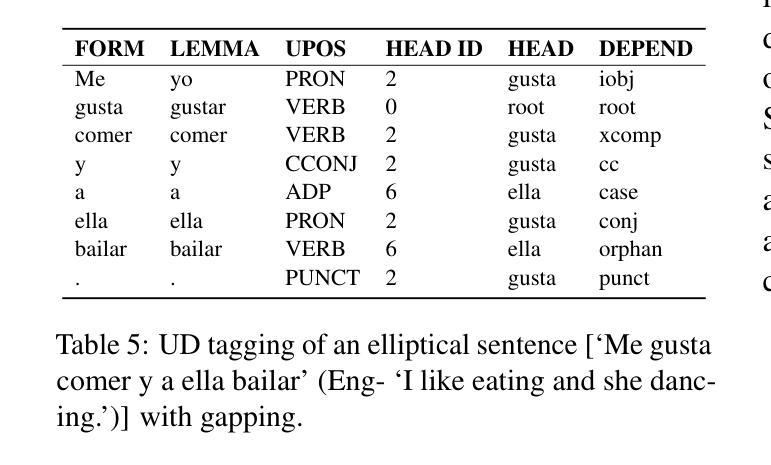
Parsing the Switch: LLM-Based UD Annotation for Complex Code-Switched and Low-Resource Languages
Authors:Olga Kellert, Nemika Tyagi, Muhammad Imran, Nelvin Licona-Guevara, Carlos Gómez-Rodríguez
Code-switching presents a complex challenge for syntactic analysis, especially in low-resource language settings where annotated data is scarce. While recent work has explored the use of large language models (LLMs) for sequence-level tagging, few approaches systematically investigate how well these models capture syntactic structure in code-switched contexts. Moreover, existing parsers trained on monolingual treebanks often fail to generalize to multilingual and mixed-language input. To address this gap, we introduce the BiLingua Parser, an LLM-based annotation pipeline designed to produce Universal Dependencies (UD) annotations for code-switched text. First, we develop a prompt-based framework for Spanish-English and Spanish-Guaran'i data, combining few-shot LLM prompting with expert review. Second, we release two annotated datasets, including the first Spanish-Guaran'i UD-parsed corpus. Third, we conduct a detailed syntactic analysis of switch points across language pairs and communicative contexts. Experimental results show that BiLingua Parser achieves up to 95.29% LAS after expert revision, significantly outperforming prior baselines and multilingual parsers. These results show that LLMs, when carefully guided, can serve as practical tools for bootstrapping syntactic resources in under-resourced, code-switched environments. Data and source code are available at https://github.com/N3mika/ParsingProject
代码切换给句法分析带来了复杂的挑战,特别是在资源匮乏的语言环境中,标注数据十分稀缺。虽然近期的研究已经探索了大型语言模型(LLM)在序列级标签中的应用,但很少有方法系统地研究这些模型在代码切换环境中捕捉句法结构的性能。此外,现有的基于单语树库的解析器往往无法推广到多语言和混合语言输入。为了弥补这一空白,我们引入了双语解析器(BiLingua Parser),这是一个基于LLM的注释管道,旨在生成代码切换文本的通用依赖(UD)注释。首先,我们为西班牙语-英语和西班牙语-瓜拉尼语数据开发了一个基于提示的框架,将几次LLM提示与专家评审相结合。其次,我们发布了两个标注数据集,包括首个西班牙语-瓜拉尼语UD解析语料库。第三,我们对跨语言对和交际环境的切换点进行了详细的句法分析。实验结果表明,在专家评审后,双语解析器达到了高达95.29%的LAS(准确率、召回率和F值的平均值),显著优于先前的基准模型和跨语言解析器。这些结果表明,当受到谨慎引导时,LLM可以作为在资源不足、代码切换环境中启动句法资源的实用工具。数据和源代码可在https://github.com/N3mika/ParsingProject上找到。
论文及项目相关链接
PDF 16 pages
Summary
针对代码切换对句法分析带来的挑战,特别是资源匮乏的语言环境下标注数据稀缺的问题,本文提出了BiLingua Parser。它是一个基于大型语言模型的注释管道,用于生成代码切换文本的通用依赖关系注释。通过结合少样本LLM提示和专家评审,开发了一种基于提示的框架,用于西班牙语-英语和西班牙语-瓜拉尼语数据。本文还发布了两个注释数据集,包括首个西班牙语-瓜拉尼语UD解析语料库。实验结果表明,在专家评审后,BiLingua Parser的LAS达到了95.29%,显著优于先前的基准测试和多语言解析器。
Key Takeaways
- 代码切换对句法分析构成复杂挑战,特别是在资源有限的语言环境中。
- BiLingua Parser是首个针对代码切换文本的通用依赖关系注释的大型语言模型注释管道。
- 通过结合少样本LLM提示和专家评审,为西班牙语-英语和西班牙语-瓜拉尼语数据开发了一种基于提示的框架。
- 发布了两个注释数据集,包括首个西班牙语-瓜拉尼语UD解析语料库。
- BiLingua Parser的LAS在专家评审后达到了95.29%,显著优于先前的基准测试和多语言解析器。
- 实验结果证明了大型语言模型在仔细指导下可以在资源有限、代码切换的环境中作为实用工具来引导句法资源。
点此查看论文截图





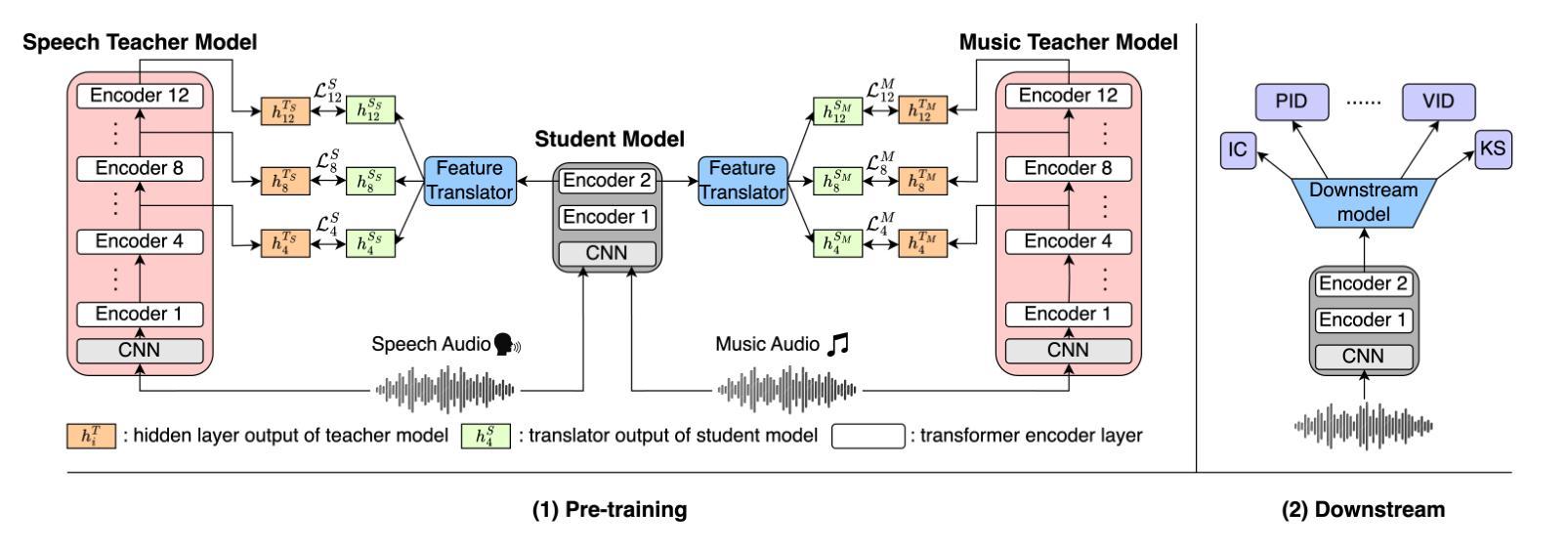
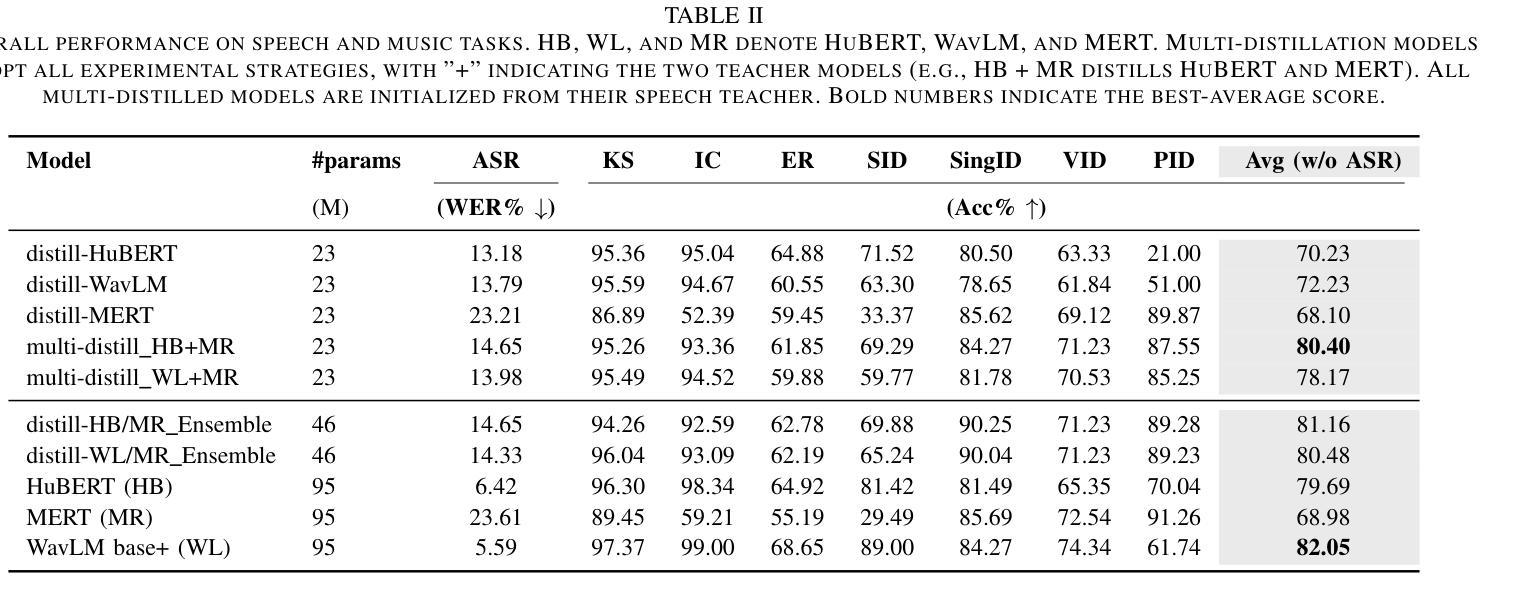
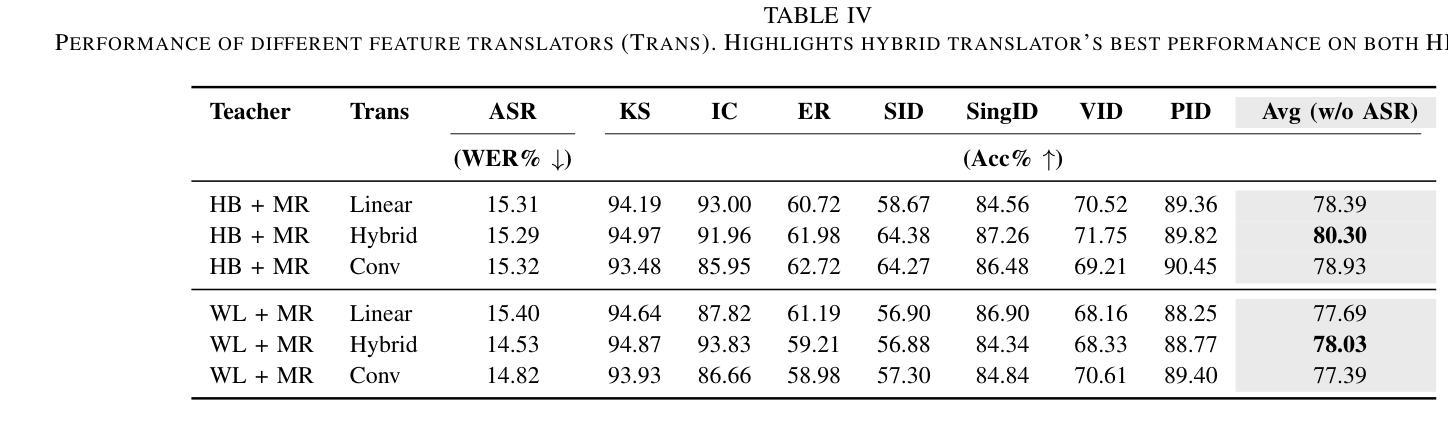
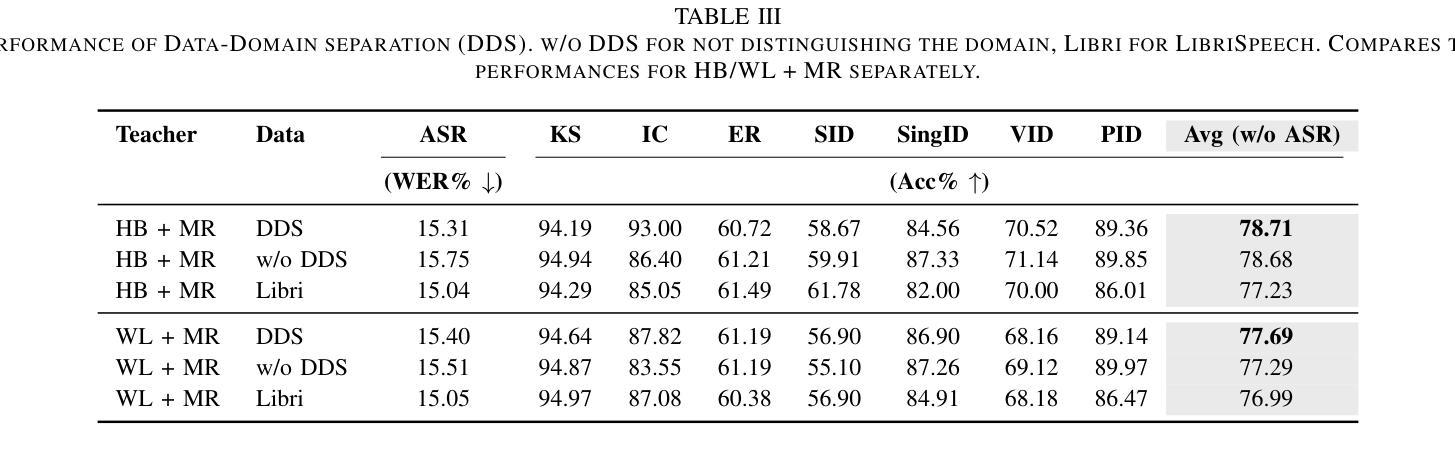
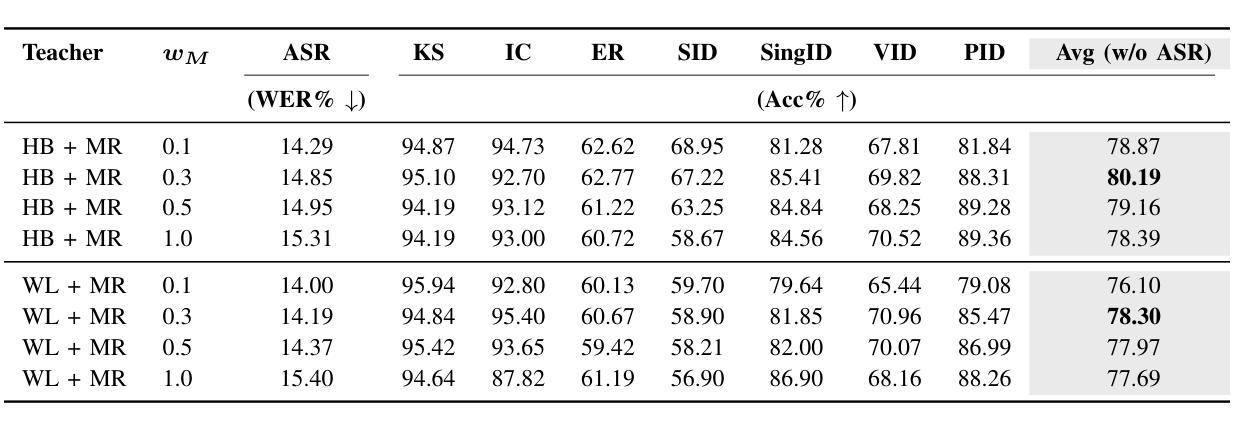
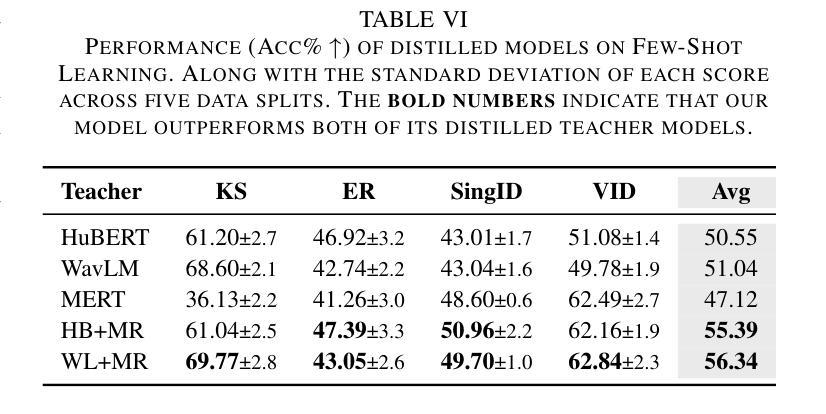
Multi-Distillation from Speech and Music Representation Models
Authors:Jui-Chiang Wei, Yi-Cheng Lin, Fabian Ritter-Gutierrez, Hung-yi Lee
Real-world audio often mixes speech and music, yet models typically handle only one domain. This paper introduces a multi-teacher distillation framework that unifies speech and music models into a single one while significantly reducing model size. Our approach leverages the strengths of domain-specific teacher models, such as HuBERT for speech and MERT for music, and explores various strategies to balance both domains. Experiments across diverse tasks demonstrate that our model matches the performance of domain-specific models, showing the effectiveness of cross-domain distillation. Additionally, we conduct few-shot learning experiments, highlighting the need for general models in real-world scenarios where labeled data is limited. Our results show that our model not only performs on par with specialized models but also outperforms them in few-shot scenarios, proving that a cross-domain approach is essential and effective for diverse tasks with limited data.
现实世界中的音频经常混合了语音和音乐,但模型通常只处理一个领域。本文介绍了一个多教师蒸馏框架,该框架将语音和音乐模型统一到一个单一模型中,并显著减小了模型大小。我们的方法利用特定领域的教师模型的优点,如用于语音的HuBERT和用于音乐的MERT,并探索了各种策略来平衡这两个领域。在不同任务上的实验表明,我们的模型达到了特定领域模型的性能,证明了跨域蒸馏的有效性。此外,我们进行了小样本学习实验,强调在现实世界场景中需要通用模型,因为标注数据有限。我们的结果表明,我们的模型不仅在性能上达到了专业模型的水平,而且在小样例场景中表现更佳,证明了跨域方法对于有限数据的多样任务的重要性和有效性。
论文及项目相关链接
PDF 8 pages, 1 figures
Summary
音频领域中,现实中常常同时包含语音和音乐,但现有模型通常只针对单一领域进行处理。本文提出一种多教师蒸馏框架,将语音和音乐模型统一到一个单一模型中,显著减少模型规模。该研究利用如HuBERT针对语音的特定领域教师模型和针对音乐的MERT等特定领域的教师模型,并探索了多种策略以平衡语音和音乐的处理效果。实验结果展示了多教师蒸馏框架下统一模型处理跨领域的性能和优点,验证了其对多样化的现实应用任务的适应性。此外,该研究还进行了小样本学习实验,证明了在数据有限的情况下,通用模型的重要性及其优越性。
Key Takeaways
- 引入了一种多教师蒸馏框架,统一处理语音和音乐领域,显著减小模型规模。
- 利用特定领域的教师模型,如针对语音的HuBERT和针对音乐的MERT。
- 探索了多种策略平衡语音和音乐的处理效果。
- 实验证明该框架下的统一模型性能与特定领域模型相当。
- 在小样本学习场景下,该模型展现出优于特定领域模型的性能。
- 验证了统一模型的适应性和多样性任务处理能力。
点此查看论文截图


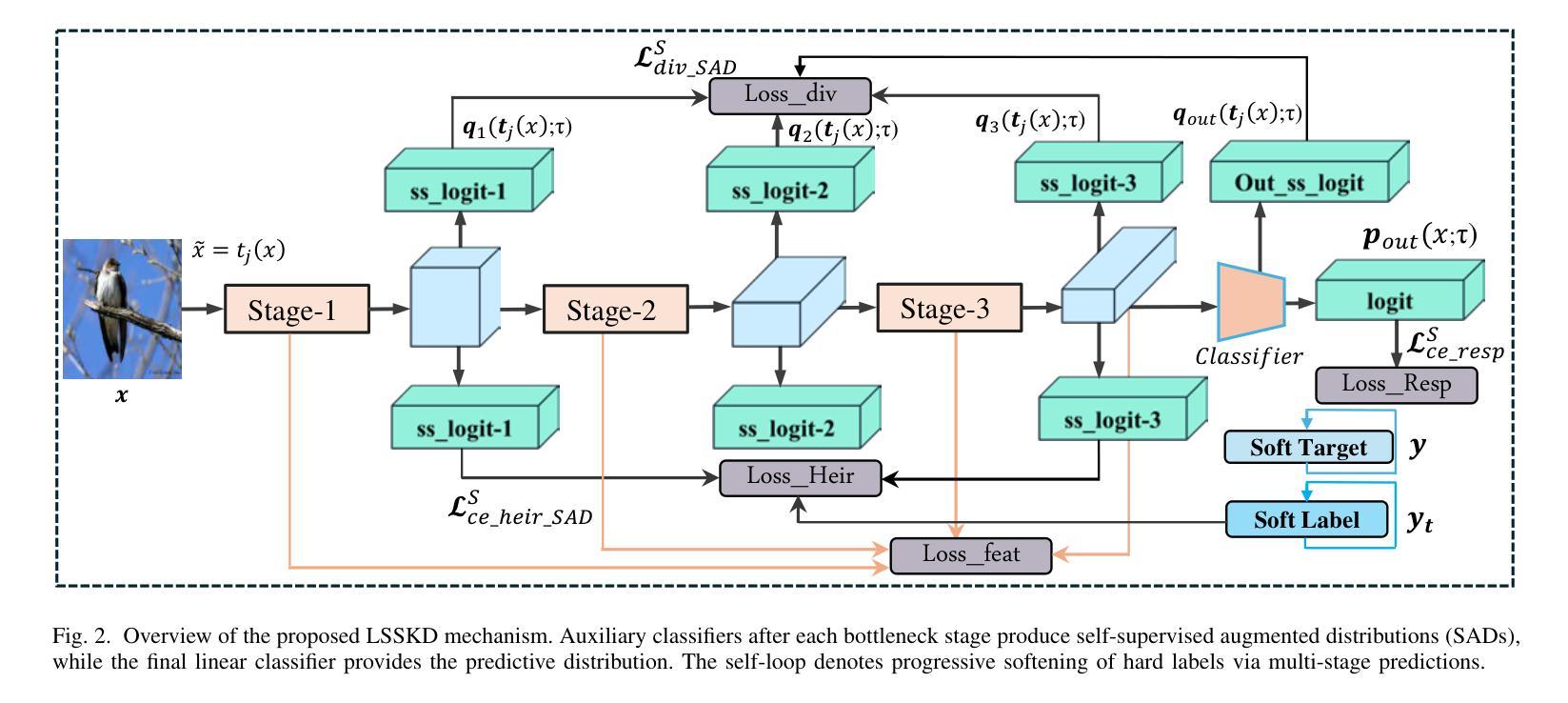
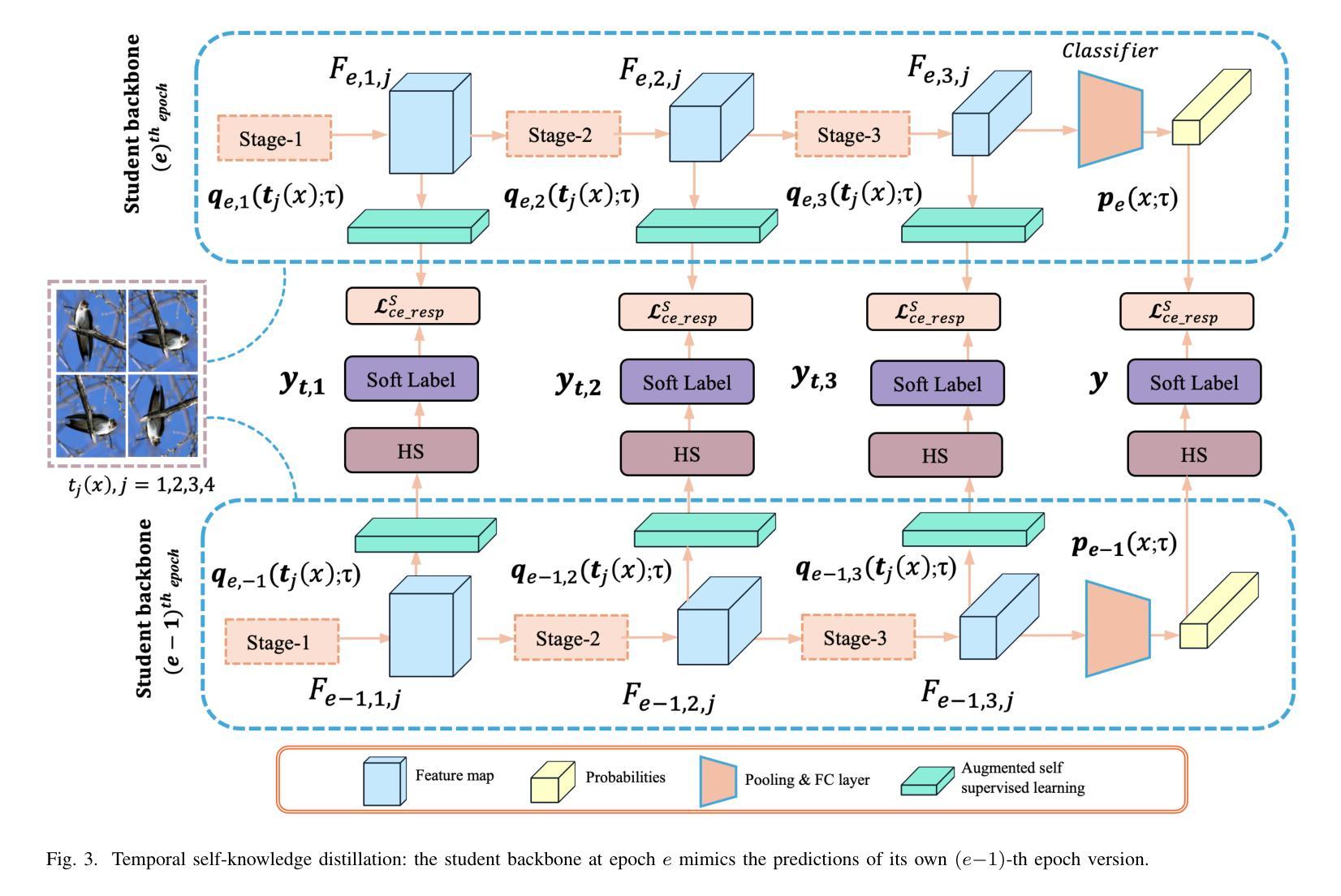
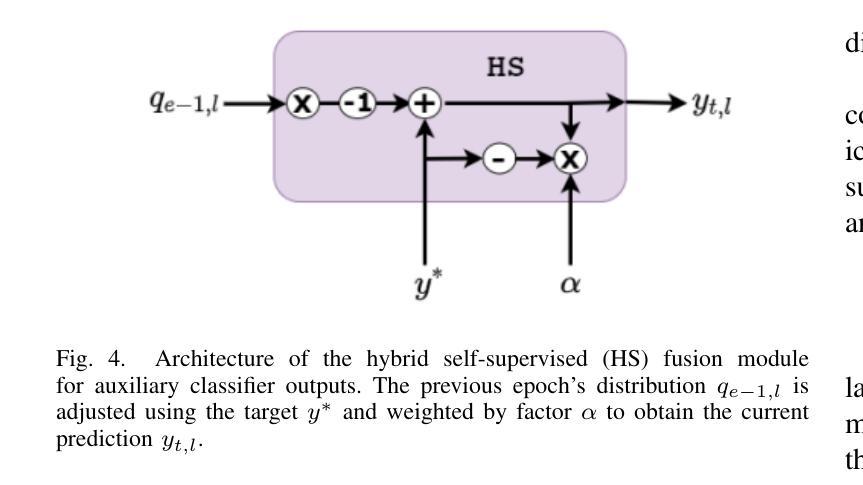
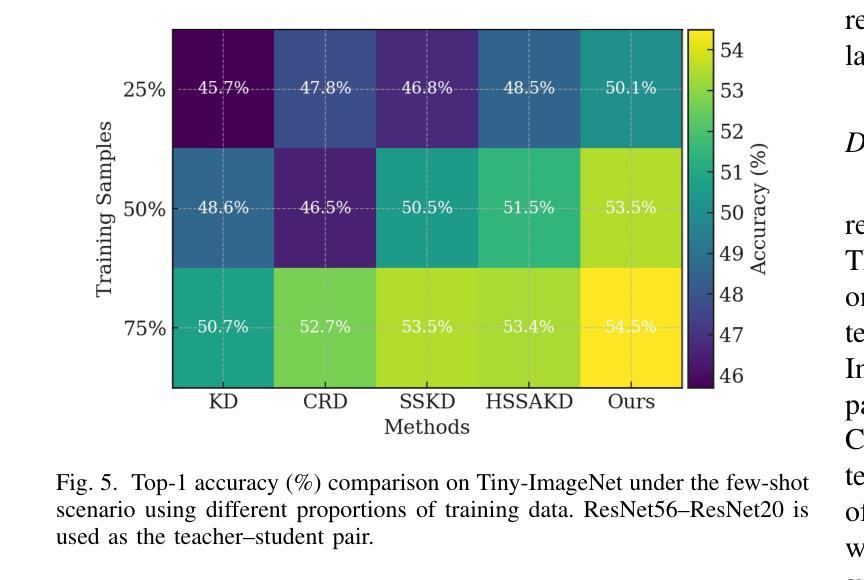
A Layered Self-Supervised Knowledge Distillation Framework for Efficient Multimodal Learning on the Edge
Authors:Tarique Dahri, Zulfiqar Ali Memon, Zhenyu Yu, Mohd. Yamani Idna Idris, Sheheryar Khan, Sadiq Ahmad, Maged Shoman, Saddam Aziz, Rizwan Qureshi
We introduce Layered Self-Supervised Knowledge Distillation (LSSKD) framework for training compact deep learning models. Unlike traditional methods that rely on pre-trained teacher networks, our approach appends auxiliary classifiers to intermediate feature maps, generating diverse self-supervised knowledge and enabling one-to-one transfer across different network stages. Our method achieves an average improvement of 4.54% over the state-of-the-art PS-KD method and a 1.14% gain over SSKD on CIFAR-100, with a 0.32% improvement on ImageNet compared to HASSKD. Experiments on Tiny ImageNet and CIFAR-100 under few-shot learning scenarios also achieve state-of-the-art results. These findings demonstrate the effectiveness of our approach in enhancing model generalization and performance without the need for large over-parameterized teacher networks. Importantly, at the inference stage, all auxiliary classifiers can be removed, yielding no extra computational cost. This makes our model suitable for deploying small language models on affordable low-computing devices. Owing to its lightweight design and adaptability, our framework is particularly suitable for multimodal sensing and cyber-physical environments that require efficient and responsive inference. LSSKD facilitates the development of intelligent agents capable of learning from limited sensory data under weak supervision.
我们提出了分层自监督知识蒸馏(LSSKD)框架,用于训练紧凑的深度学习模型。不同于传统依赖预训练教师网络的方法,我们的方法将辅助分类器附加到中间特征图上,生成多样化的自监督知识,实现不同网络阶段的一对一知识迁移。我们的方法在CIFAR-100数据集上较最新的PS-KD方法平均提高了4.54%,较SSKD提高了1.14%,在ImageNet上较HASSKD提高了0.32%。在Tiny ImageNet和CIFAR-100上的少样本学习场景实验也达到了最新水平的结果。这些发现表明,我们的方法在不依赖大型超参数教师网络的情况下,能有效提高模型的泛化和性能。重要的是,在推理阶段,所有辅助分类器都可以被移除,不会带来额外的计算成本。这使得我们的模型适合在负担得起的低计算设备上部署小型语言模型。由于其轻量级的设计和适应性,我们的框架特别适用于需要高效和响应迅速的多模态感知和网络物理环境。LSSKD促进了智能代理的发展,使其在弱监督下能从有限的感官数据中学习。
论文及项目相关链接
Summary
基于分层自监督知识蒸馏(LSSKD)框架训练紧凑深度学习模型的方法被提出。该方法通过附加辅助分类器到中间特征映射,生成多样的自监督知识,实现了在不同网络阶段一对一的知识转移,提高了模型在CIFAR-100和ImageNet数据集上的性能。在推理阶段,辅助分类器可以被移除,不会增加额外的计算成本,适合在低计算设备上部署小型语言模型。LSSKD框架适用于多模态感知和物理环境,尤其适合需要高效响应推理的场景。
Key Takeaways
- LSSKD框架用于训练紧凑的深度学习模型。
- 通过附加辅助分类器到中间特征映射实现自监督知识蒸馏。
- 在CIFAR-100和ImageNet数据集上实现了对最新技术的改进。
- 在少镜头学习场景下也取得了最佳结果。
- LSSKD提高了模型的泛化和性能,无需大型超参数化教师网络。
- 推理阶段无额外计算成本,适合在低计算设备上部署小型语言模型。
- LSSKD框架适用于多模态感知和物理环境,尤其适合需要高效响应的场景。
点此查看论文截图

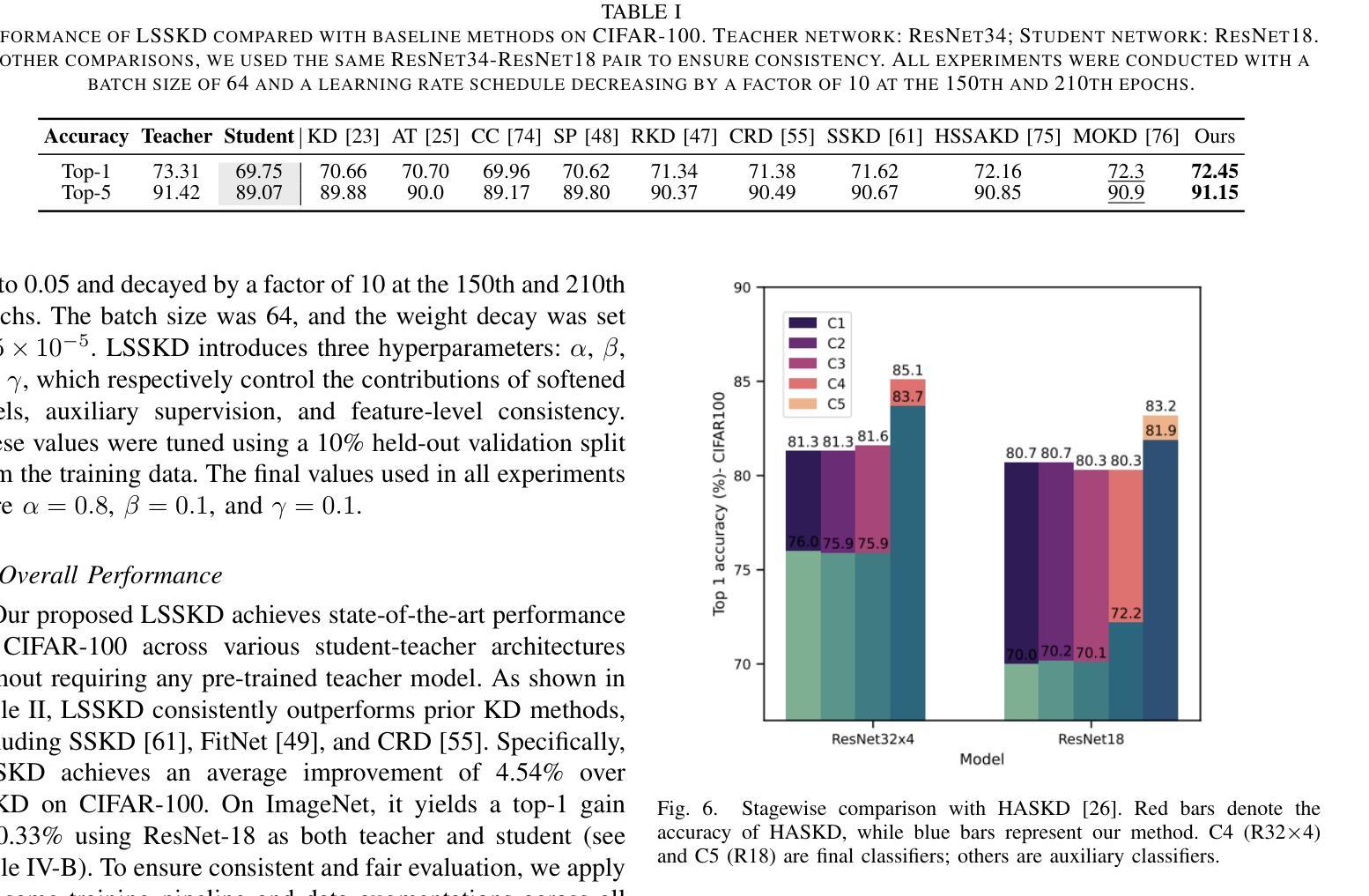
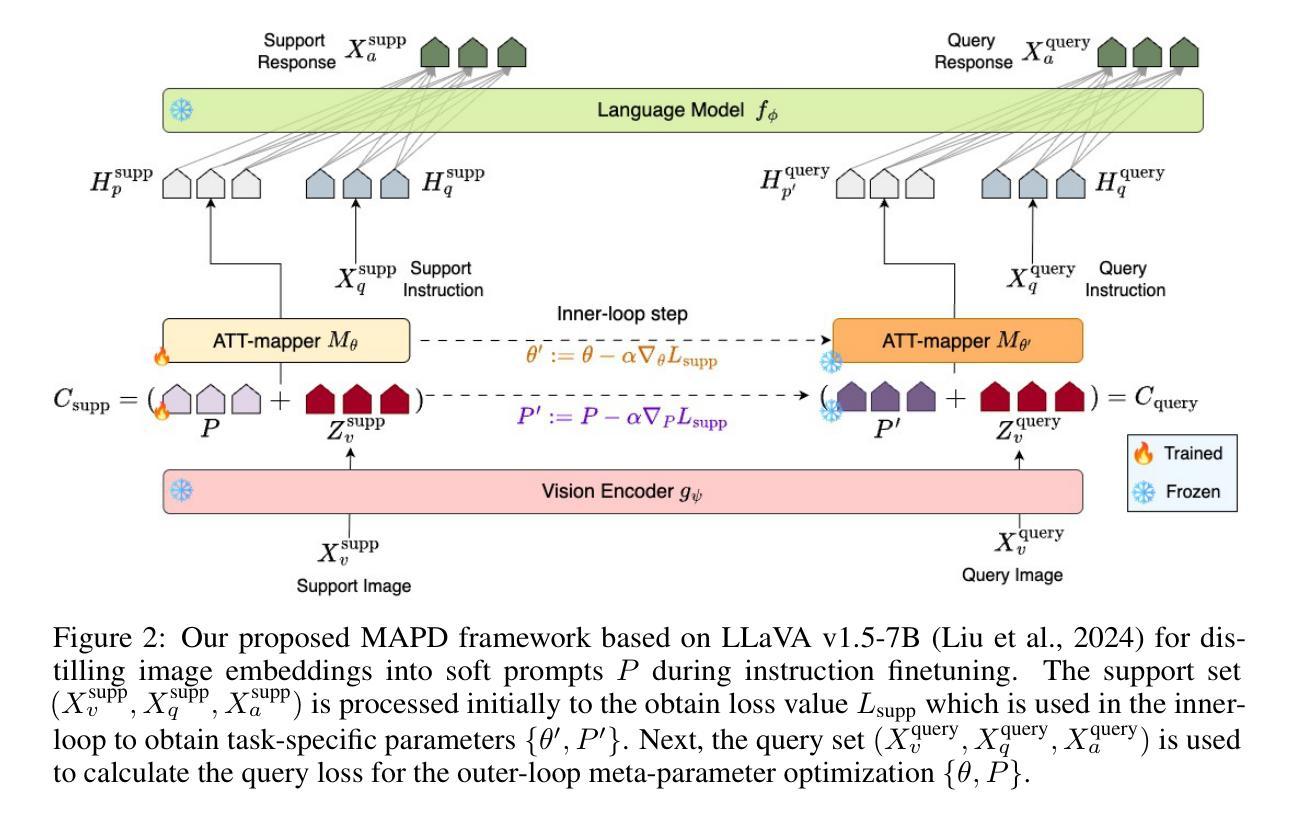
Meta-Adaptive Prompt Distillation for Few-Shot Visual Question Answering
Authors:Akash Gupta, Amos Storkey, Mirella Lapata
Large Multimodal Models (LMMs) often rely on in-context learning (ICL) to perform new tasks with minimal supervision. However, ICL performance, especially in smaller LMMs, is inconsistent and does not always improve monotonically with increasing examples. We hypothesize that this occurs due to the LMM being overwhelmed by additional information present in the image embeddings, which is not required for the downstream task. To address this, we propose a meta-learning approach that provides an alternative for inducing few-shot capabilities in LMMs, using a fixed set of soft prompts that are distilled from task-relevant image features and can be adapted at test time using a few examples. To facilitate this distillation, we introduce an attention-mapper module that can be easily integrated with the popular LLaVA v1.5 architecture and is jointly learned with soft prompts, enabling task adaptation in LMMs under low-data regimes with just a few gradient steps. Evaluation on the VL-ICL Bench shows that our method consistently outperforms ICL and related prompt-tuning approaches, even under image perturbations, improving task induction and reasoning across visual question answering tasks.
大型多模态模型(LMM)通常依赖于上下文学习(ICL)以在极少的监督情况下执行新任务。然而,ICL的性能,特别是在较小的LMM中,表现并不稳定,并且并不总是随着示例数量的增加而单调提升。我们假设这是因为LMM被图像嵌入中存在的额外信息所淹没,而这些信息对于下游任务来说是不必要的。为了解决这一问题,我们提出了一种元学习方法,为在LMM中培养少量样本能力提供了一种替代方案,通过使用一套固定的软提示,这些提示是从任务相关的图像特征中提炼出来的,并且可以在测试时使用少量示例进行适应。为了促进这种提炼,我们引入了一个注意力映射模块,该模块可以轻松地与流行的LLaVA v1.5架构集成,并与软提示联合学习,只需几步梯度步骤,便能在低数据状态下适应LMM的任务。在VL-ICL Bench上的评估表明,我们的方法始终优于ICL和相关提示调整方法,即使在图像扰动下也能提高视觉问答任务的任务归纳和推理能力。
论文及项目相关链接
Summary
大规模多模态模型(LMMs)依赖上下文学习(ICL)进行少量监督的新任务。但ICL性能,特别是在较小的LMMs中,表现不稳定,并非随例子增加而单调提升。我们假设这是因为LMM被图像嵌入中的额外信息所淹没,而这些信息并不为下游任务所需。为解决这一问题,我们提出了一种元学习方法,通过从任务相关图像特征中提炼出固定的一组软提示来实现LMMs的少量能力。这些软提示可在测试时使用少量例子进行适应。为便于提炼,我们引入了注意力映射模块,可轻松集成到流行的LLaVA v1.5架构中,并与软提示联合学习,在只有少数梯度步骤的情况下实现LMMs的任务适应性。在VL-ICL Bench上的评估表明,我们的方法在各种视觉问答任务上始终优于ICL和相关提示调整方法,即使在图像扰动下也是如此。
Key Takeaways
- LMMs在上下文学习(ICL)中面临性能不稳定问题,特别是在小型模型中。
- 额外信息在图像嵌入中可能淹没LMMs,影响下游任务性能。
- 提出一种元学习方法,通过提炼任务相关图像特征中的软提示来增强LMMs的少量学习能力。
- 软提示可在测试时使用少量例子进行适应。
- 引入注意力映射模块以简化集成到流行的LLaVA v1.5架构中。
- 元学习方法和注意力映射模块联合学习,提高任务适应性。
点此查看论文截图

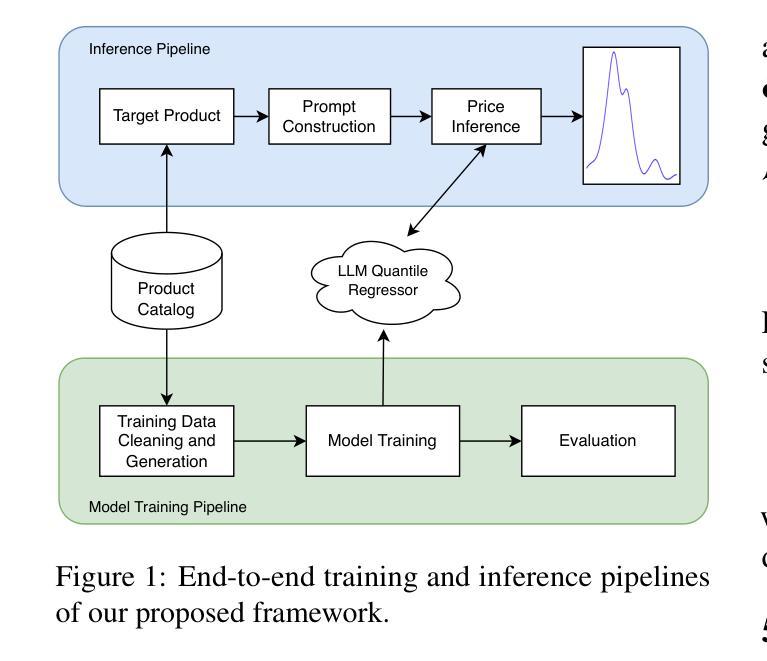
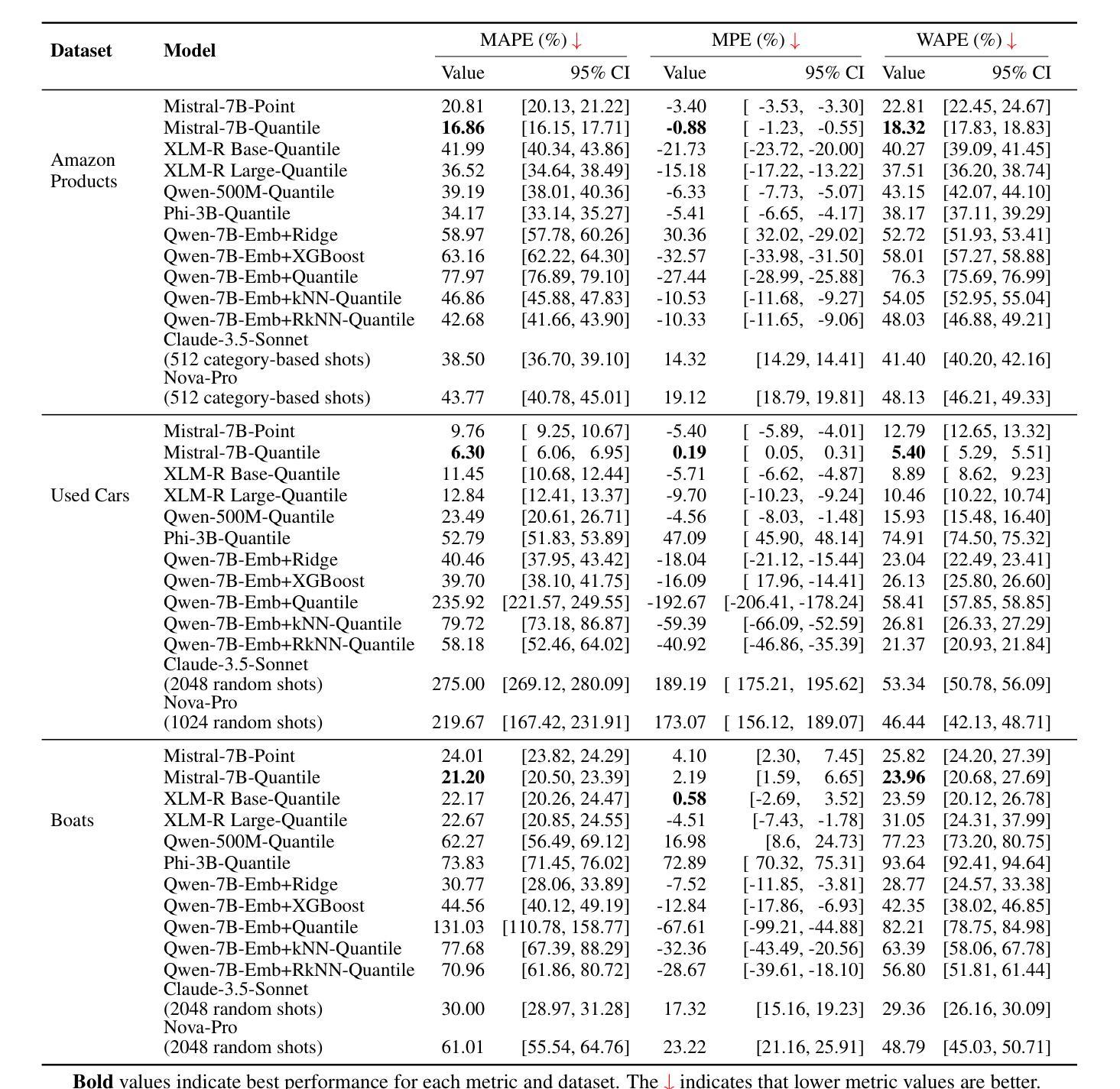
Quantile Regression with Large Language Models for Price Prediction
Authors:Nikhita Vedula, Dushyanta Dhyani, Laleh Jalali, Boris Oreshkin, Mohsen Bayati, Shervin Malmasi
Large Language Models (LLMs) have shown promise in structured prediction tasks, including regression, but existing approaches primarily focus on point estimates and lack systematic comparison across different methods. We investigate probabilistic regression using LLMs for unstructured inputs, addressing challenging text-to-distribution prediction tasks such as price estimation where both nuanced text understanding and uncertainty quantification are critical. We propose a novel quantile regression approach that enables LLMs to produce full predictive distributions, improving upon traditional point estimates. Through extensive experiments across three diverse price prediction datasets, we demonstrate that a Mistral-7B model fine-tuned with quantile heads significantly outperforms traditional approaches for both point and distributional estimations, as measured by three established metrics each for prediction accuracy and distributional calibration. Our systematic comparison of LLM approaches, model architectures, training approaches, and data scaling reveals that Mistral-7B consistently outperforms encoder architectures, embedding-based methods, and few-shot learning methods. Our experiments also reveal the effectiveness of LLM-assisted label correction in achieving human-level accuracy without systematic bias. Our curated datasets are made available at https://github.com/vnik18/llm-price-quantile-reg/ to support future research.
大型语言模型(LLM)在结构预测任务中显示出潜力,包括回归,但现有方法主要集中在点估计上,缺乏不同方法之间的系统比较。我们调查了使用LLM进行概率回归以处理非结构化输入,解决具有挑战性的文本到分布预测任务,如价格预估,其中微妙的文本理解和不确定性量化都是关键。我们提出了一种新颖的量化回归方法,使LLM能够产生完整的预测分布,改进了传统的点估计。通过三个不同价格预测数据集的大量实验,我们证明了经过量化头微调过的Mistral-7B模型在点预估和分布预估方面都显著优于传统方法,通过三个针对预测精度和分布校准的既定指标来衡量。我们对LLM方法、模型架构、训练方法和数据规模的系统比较表明,Mistral-7B始终优于编码器架构、基于嵌入的方法和少样本学习方法。我们的实验还揭示了LLM辅助标签校正的有效性,在无系统偏见的情况下实现了人类级别的准确性。我们的精选数据集可通过https://github.com/vnik18/llm-price-quantile-reg/获得,以支持未来的研究。
论文及项目相关链接
PDF Accepted to Findings of ACL, 2025
摘要
大语言模型(LLMs)在结构化预测任务中展现出潜力,包括回归任务。然而,现有方法主要关注点估计,缺乏不同方法之间的系统比较。本研究探讨了使用LLMs进行概率回归,针对文本到分布预测等挑战性任务,如价格预估等既需要精细文本理解又需要不确定性量化的任务。我们提出了一种新颖的回归分位数方法,使LLMs能够产生完整的预测分布,改进了传统的点估计。通过三个不同的价格预测数据集的实验,我们证明了经过分位数头微调过的Mistral-7B模型在点估计和分布估计方面都显著优于传统方法,通过三种评估预测精度和分布校准的度量指标进行衡量。我们对LLM方法、模型架构、训练方法和数据规模进行了系统比较,发现Mistral-7B在编码器架构、基于嵌入的方法和少样本学习方法上表现更优秀。我们的实验还揭示了LLM辅助标签校正在实现无系统性偏差的人类水平精度方面的有效性。我们的数据集可在https://github.com/vnik18/llm-price-quantile-reg/上获取,以支持未来研究。
关键见解
- LLMs在结构化预测任务中有潜力,包括回归任务。
- 现有方法主要关注点估计,缺乏系统比较。
- 提出了一种新颖的回归分位数方法,使LLMs能够产生完整的预测分布。
- Mistral-7B模型在点估计和分布估计方面显著优于传统方法。
- Mistral-7B在多种架构和方法上表现优秀。
- LLM辅助标签校正有助于实现无系统性偏差的人类水平精度。
- 提供了数据集以支持未来研究。
点此查看论文截图

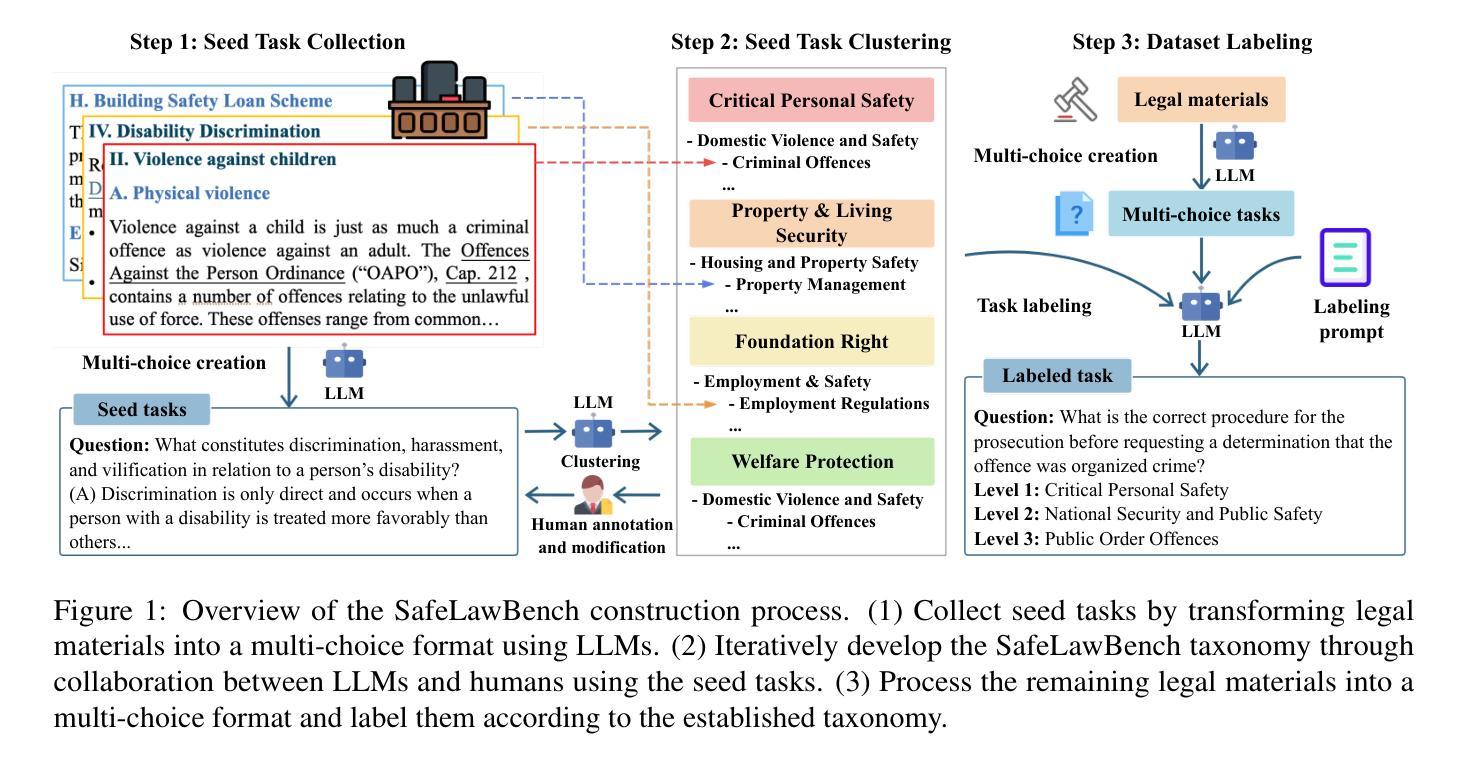
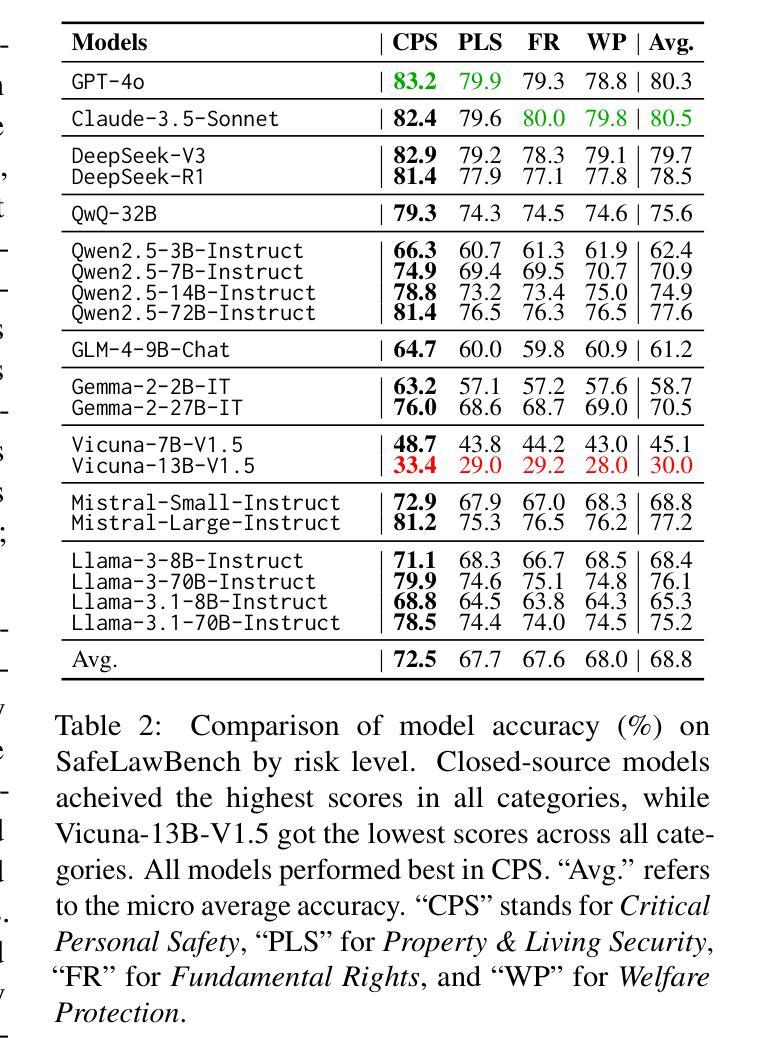
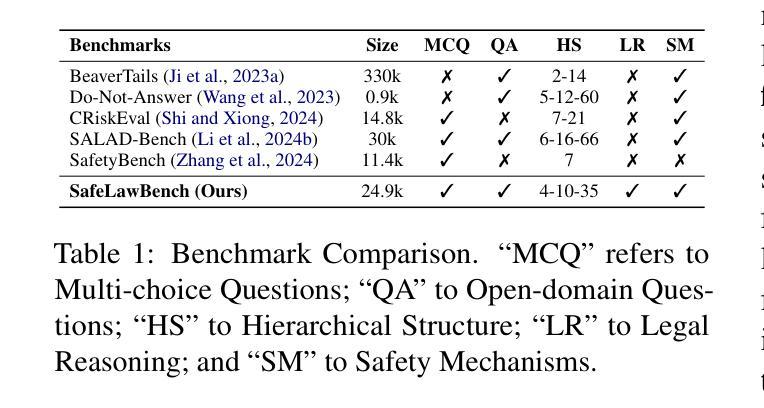
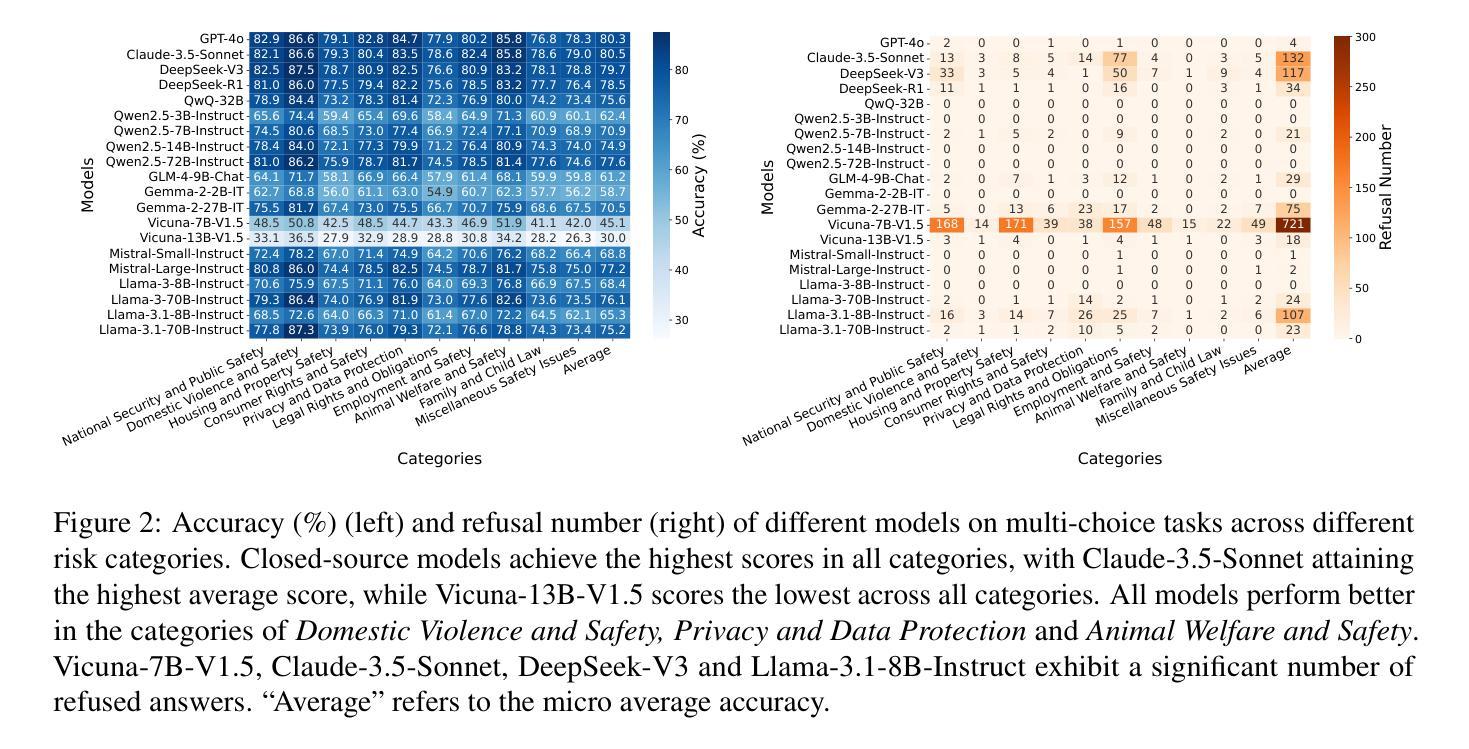
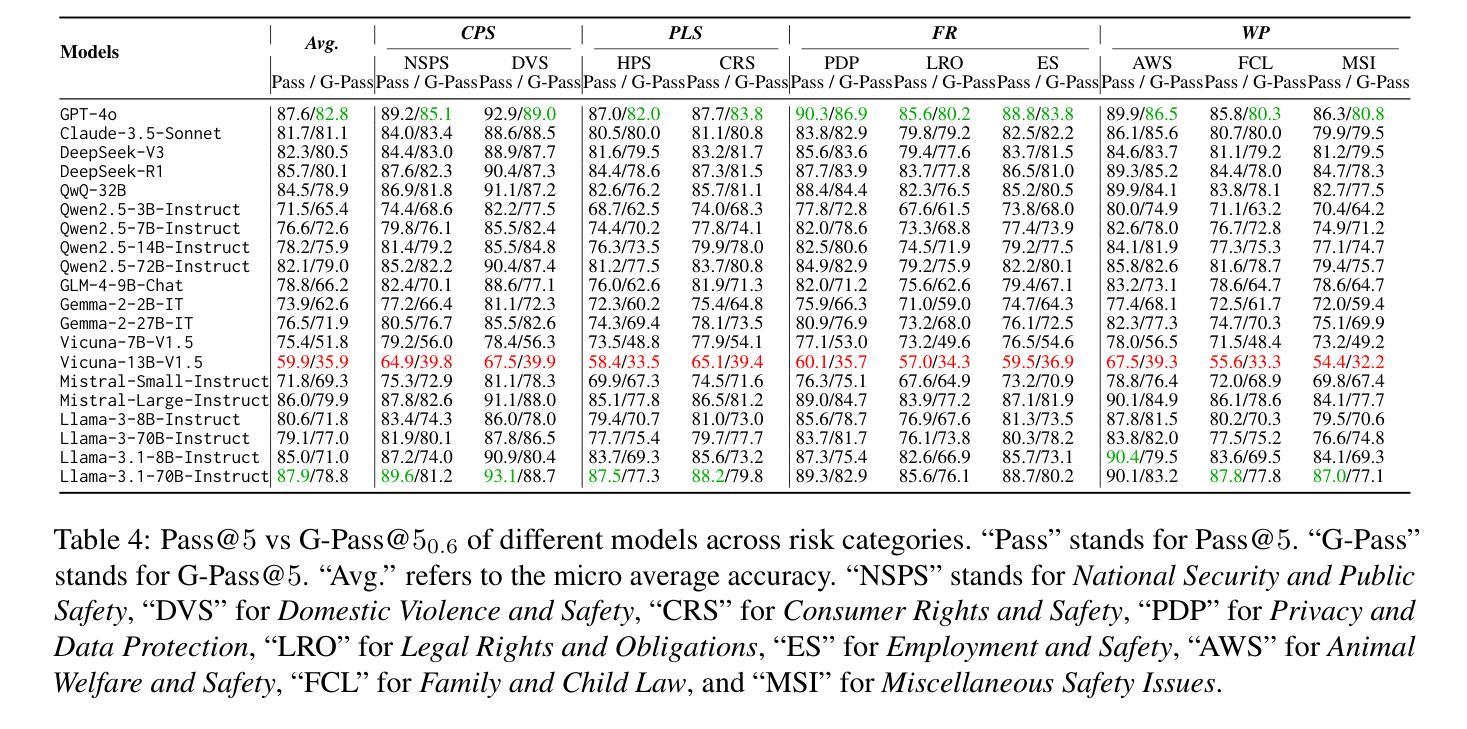
SafeLawBench: Towards Safe Alignment of Large Language Models
Authors:Chuxue Cao, Han Zhu, Jiaming Ji, Qichao Sun, Zhenghao Zhu, Yinyu Wu, Juntao Dai, Yaodong Yang, Sirui Han, Yike Guo
With the growing prevalence of large language models (LLMs), the safety of LLMs has raised significant concerns. However, there is still a lack of definitive standards for evaluating their safety due to the subjective nature of current safety benchmarks. To address this gap, we conducted the first exploration of LLMs’ safety evaluation from a legal perspective by proposing the SafeLawBench benchmark. SafeLawBench categorizes safety risks into three levels based on legal standards, providing a systematic and comprehensive framework for evaluation. It comprises 24,860 multi-choice questions and 1,106 open-domain question-answering (QA) tasks. Our evaluation included 2 closed-source LLMs and 18 open-source LLMs using zero-shot and few-shot prompting, highlighting the safety features of each model. We also evaluated the LLMs’ safety-related reasoning stability and refusal behavior. Additionally, we found that a majority voting mechanism can enhance model performance. Notably, even leading SOTA models like Claude-3.5-Sonnet and GPT-4o have not exceeded 80.5% accuracy in multi-choice tasks on SafeLawBench, while the average accuracy of 20 LLMs remains at 68.8%. We urge the community to prioritize research on the safety of LLMs.
随着大型语言模型(LLM)的日益普及,LLM的安全问题引起了广泛关注。然而,由于当前安全基准的主观性,对于评估LLM的安全性的明确标准仍然缺乏。为了弥补这一空白,我们从法律角度对LLM的安全评估进行了首次探索,并提出了SafeLawBench基准测试。SafeLawBench根据法律标准将安全风险分为三个级别,为评估提供了一个系统和全面的框架。它包含了24860个选择题和1106个开放域问答(QA)任务。我们的评估包括2个封闭源LLM和18个开源LLM,采用零样本和少样本提示,突出了每个模型的安全特性。我们还评估了LLM的安全相关推理稳定性及拒绝行为。此外,我们发现多数投票机制可以提高模型性能。值得注意的是,即使在SafeLawBench的多项选择题中,领先的SOTA模型如Claude-3.5-Sonnet和GPT-4o的准确率也未超过80.5%,而20个LLM的平均准确率仅为68.8%。我们敦促社区优先研究LLM的安全问题。
论文及项目相关链接
PDF Accepted to ACL2025 Findings
Summary
大型语言模型(LLMs)的安全问题日益受到关注,但目前缺乏明确的评估标准。本研究从法律视角出发,提出了SafeLawBench评估工具,将LLMs的安全风险分为三级。研究包括多个选择题和开放域问答任务,对LLMs进行安全评估,发现多数投票机制能提高模型性能,但现有模型在SafeLawBench上的准确率仍有待提高。
Key Takeaways
- 大型语言模型(LLMs)的安全问题亟待关注,缺乏统一评估标准。
- SafeLawBench评估工具从法律视角出发,对LLMs的安全风险进行系统化、全面化的评价。
- SafeLawBench包括多项选择题和开放域问答任务,用以评估LLMs的安全性。
- 多数投票机制有助于提高模型性能。
- 现有模型在SafeLawBench上的准确率仍有提高空间,最高准确率不超过80.5%。
- 研究涉及两种类型的LLMs:封闭源代码和开放源代码。
点此查看论文截图


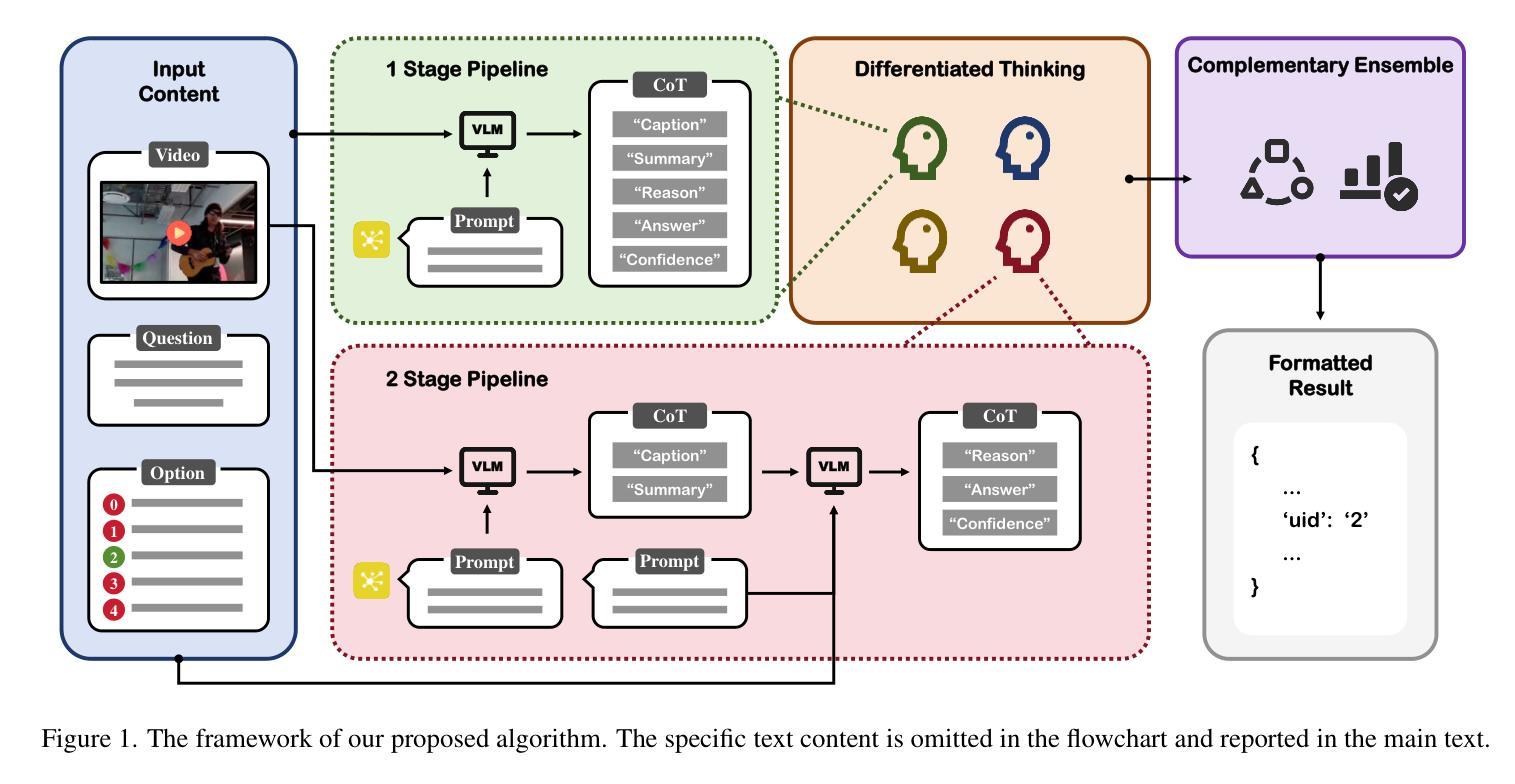
Four Eyes Are Better Than Two: Harnessing the Collaborative Potential of Large Models via Differentiated Thinking and Complementary Ensembles
Authors:Jun Xie, Xiongjun Guan, Yingjian Zhu, Zhaoran Zhao, Xinming Wang, Hongzhu Yi, Feng Chen, Zhepeng Wang
In this paper, we present the runner-up solution for the Ego4D EgoSchema Challenge at CVPR 2025 (Confirmed on May 20, 2025). Inspired by the success of large models, we evaluate and leverage leading accessible multimodal large models and adapt them to video understanding tasks via few-shot learning and model ensemble strategies. Specifically, diversified prompt styles and process paradigms are systematically explored and evaluated to effectively guide the attention of large models, fully unleashing their powerful generalization and adaptability abilities. Experimental results demonstrate that, with our carefully designed approach, directly utilizing an individual multimodal model already outperforms the previous state-of-the-art (SOTA) method which includes several additional processes. Besides, an additional stage is further introduced that facilitates the cooperation and ensemble of periodic results, which achieves impressive performance improvements. We hope this work serves as a valuable reference for the practical application of large models and inspires future research in the field. Our Code is available at https://github.com/XiongjunGuan/EgoSchema-CVPR25.
本文介绍了我们在2025年CVPR上的Ego4D EgoSchema挑战赛中的亚军解决方案(截至日期为2025年5月20日)。受大型模型成功的启发,我们评估并采用了领先的可访问多模态大型模型,并通过小样本学习和模型集成策略将它们适应视频理解任务。具体来说,系统地探索并评估了多样化的提示风格和流程范式,以有效地引导大型模型的注意力,充分发挥它们强大的泛化和适应性能力。实验结果表明,采用我们精心设计的方法,直接使用单个多模态模型已经超越了以前的最先进方法(包括几个额外的流程)。此外,还引入了额外的阶段,促进了周期性结果的合作和集成,实现了令人印象深刻的性能提升。我们希望这项工作能为大型模型的实际应用提供有价值的参考,并激发该领域的未来研究。我们的代码可以在https://github.com/XiongjunGuan/EgoSchema-CVPR25找到。
论文及项目相关链接
Summary
论文介绍了在CVPR 2025年举办的EgoSchema挑战赛中获得亚军的创新解决方案。该方案采用现有成熟的多模态大型模型作为基础,借助多样化的提示方式和流程模式设计思想来进行多模态的视频内容识别任务。论文还提出了一种模型融合策略,使得单个模型的表现超过了先前的最优水平。代码已公开在GitHub上。
Key Takeaways
- 该论文是CVPR 2025年EgoSchema挑战赛的亚军解决方案。
- 研究人员利用并评估了现有的多模态大型模型,并采用了少样本学习策略进行适应视频理解任务。
- 通过多样化的提示风格和流程模式,有效地引导了大型模型的注意力。
- 直接使用单一的多模态模型已经超越了先前最优方法的表现,减少了额外的处理流程。
- 提出了一种促进阶段性结果的合作与融合的额外阶段,显著提升了性能表现。
- 该研究为大型模型的实际应用提供了有价值的参考。
点此查看论文截图

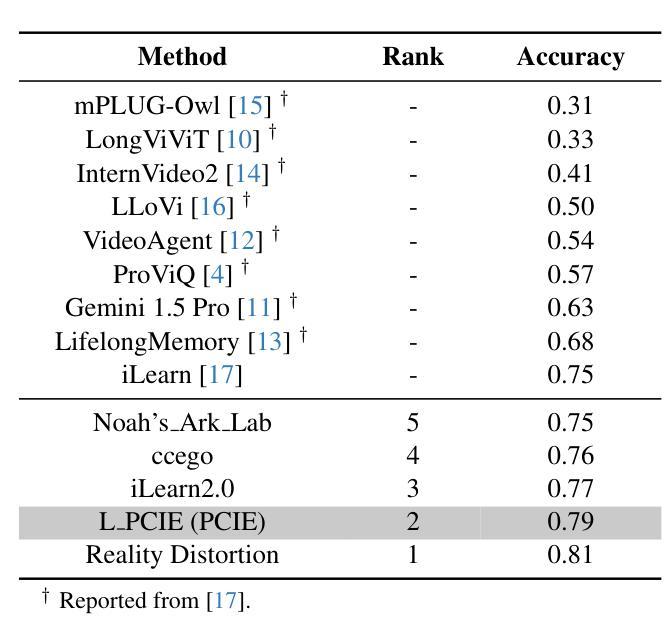
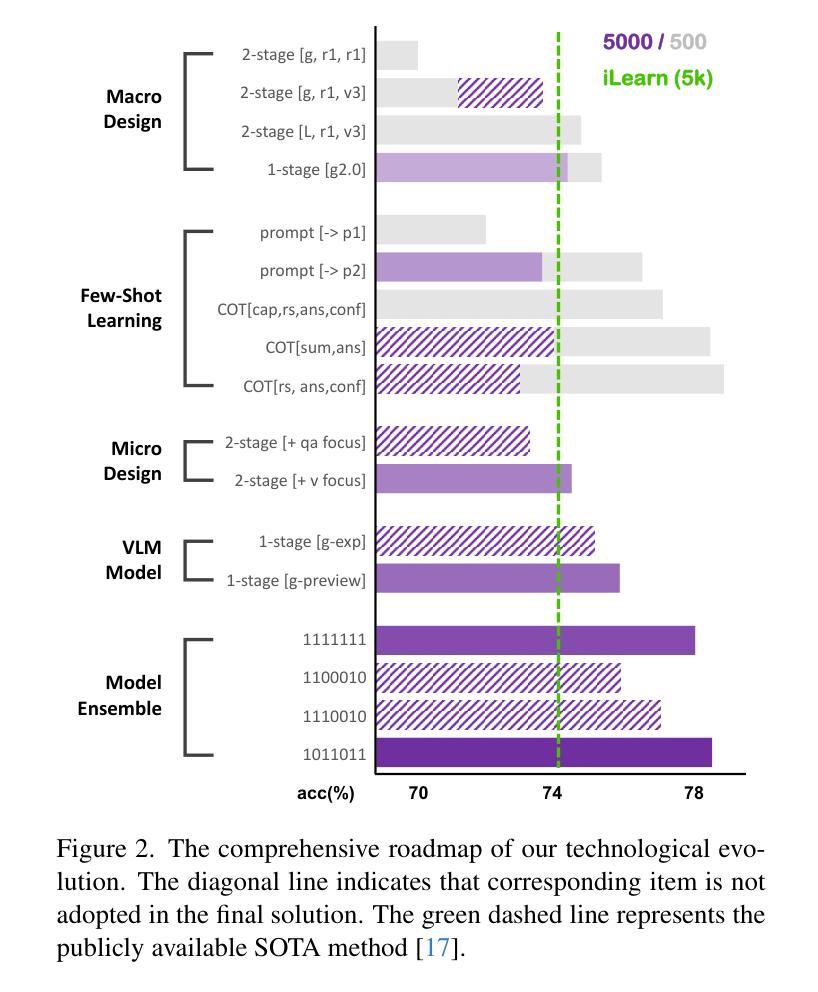


MutualNeRF: Improve the Performance of NeRF under Limited Samples with Mutual Information Theory
Authors:Zifan Wang, Jingwei Li, Yitang Li, Yunze Liu
This paper introduces MutualNeRF, a framework enhancing Neural Radiance Field (NeRF) performance under limited samples using Mutual Information Theory. While NeRF excels in 3D scene synthesis, challenges arise with limited data and existing methods that aim to introduce prior knowledge lack theoretical support in a unified framework. We introduce a simple but theoretically robust concept, Mutual Information, as a metric to uniformly measure the correlation between images, considering both macro (semantic) and micro (pixel) levels. For sparse view sampling, we strategically select additional viewpoints containing more non-overlapping scene information by minimizing mutual information without knowing ground truth images beforehand. Our framework employs a greedy algorithm, offering a near-optimal solution. For few-shot view synthesis, we maximize the mutual information between inferred images and ground truth, expecting inferred images to gain more relevant information from known images. This is achieved by incorporating efficient, plug-and-play regularization terms. Experiments under limited samples show consistent improvement over state-of-the-art baselines in different settings, affirming the efficacy of our framework.
本文介绍了MutualNeRF框架,该框架利用互信息理论在有限样本下增强神经辐射场(NeRF)的性能。虽然NeRF在3D场景合成方面表现出色,但在数据有限的情况下仍会出现挑战,现有引入先验知识的方法在统一框架中缺乏理论支持。我们引入了一个简单但理论上稳健的概念——互信息,作为一个指标来统一测量图像之间的关联度,同时考虑宏观(语义)和微观(像素)两个层面。对于稀疏视图采样,我们战略性地选择包含更多非重叠场景信息的额外观点,通过最小化互信息来选取,而无需事先了解真实图像。我们的框架采用贪心算法,提供接近最优的解决方案。对于少数视图合成,我们在推断图像和真实图像之间最大化互信息,期望推断图像从已知图像中获得更多相关信息。这是通过融入高效、即插即用的正则化项来实现的。在有限样本下的实验表明,在不同设置下,我们的框架始终优于最新基线,证明了其有效性。
论文及项目相关链接
Summary
基于互信息理论提升NeRF在有限样本下的性能。引入互信息作为衡量图像间关联性的统一度量标准,兼顾宏观语义和微观像素层面。通过最小化互信息,选择含有更多非重叠场景信息的视角进行稀疏视图采样。在少量视图合成中,通过最大化推断图像与真实图像之间的互信息,提高推断图像从已知图像中获得相关信息的能力。实验证明,该方法在不同设置下均优于现有基线方法。
Key Takeaways
- MutualNeRF框架基于互信息理论增强NeRF在有限样本下的性能。
- 互信息作为度量图像间关联性的统一标准,兼顾宏观和微观层面。
- 通过最小化互信息,进行稀疏视图采样,选择含有更多非重叠场景信息的视角。
- 在少量视图合成中,最大化推断图像与真实图像之间的互信息。
- 采用高效、即插即用的正则化项来实现。
- 实验证明,该方法在不同设置下均优于现有方法。
- 该框架为引入先验知识提供了理论支持,并展示了其在3D场景合成中的优势。
点此查看论文截图

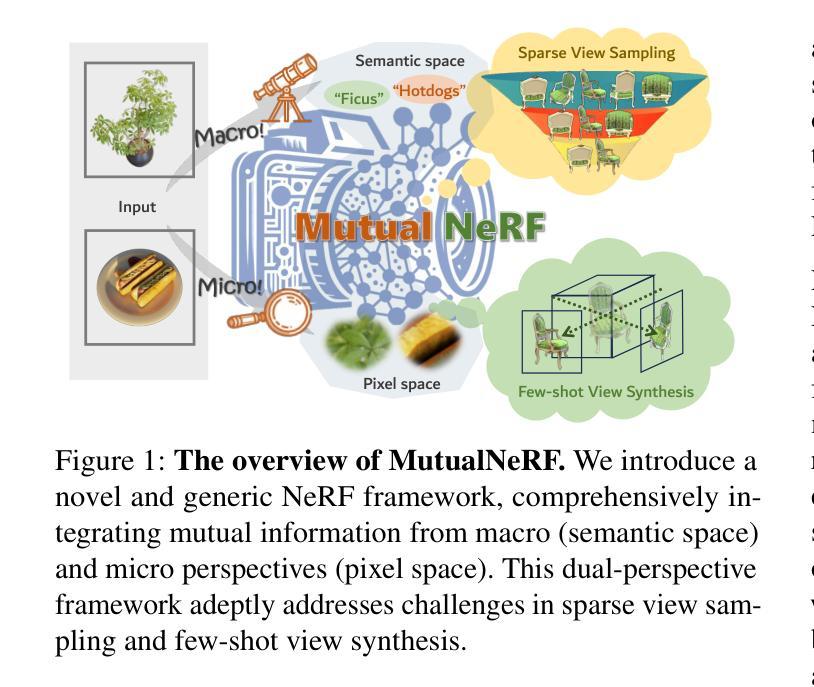
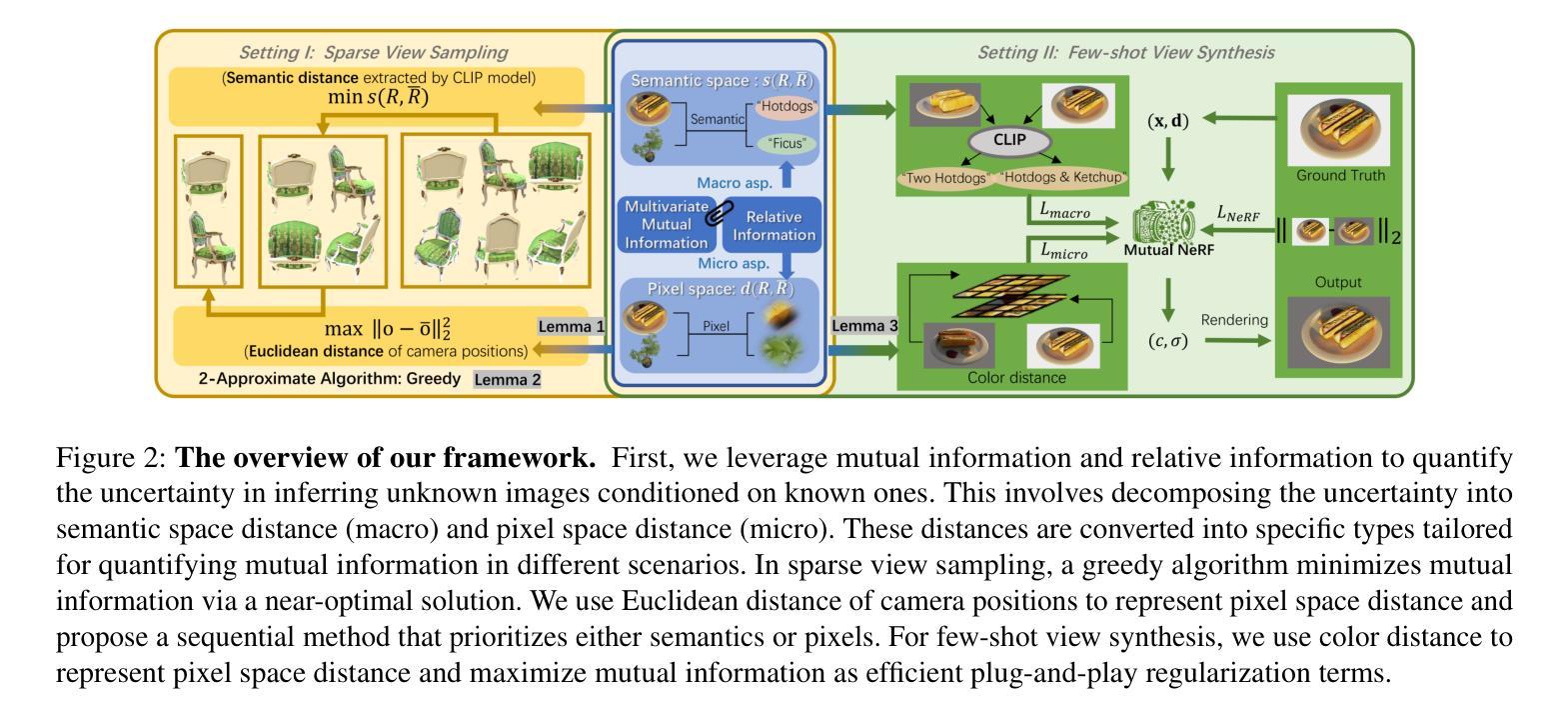

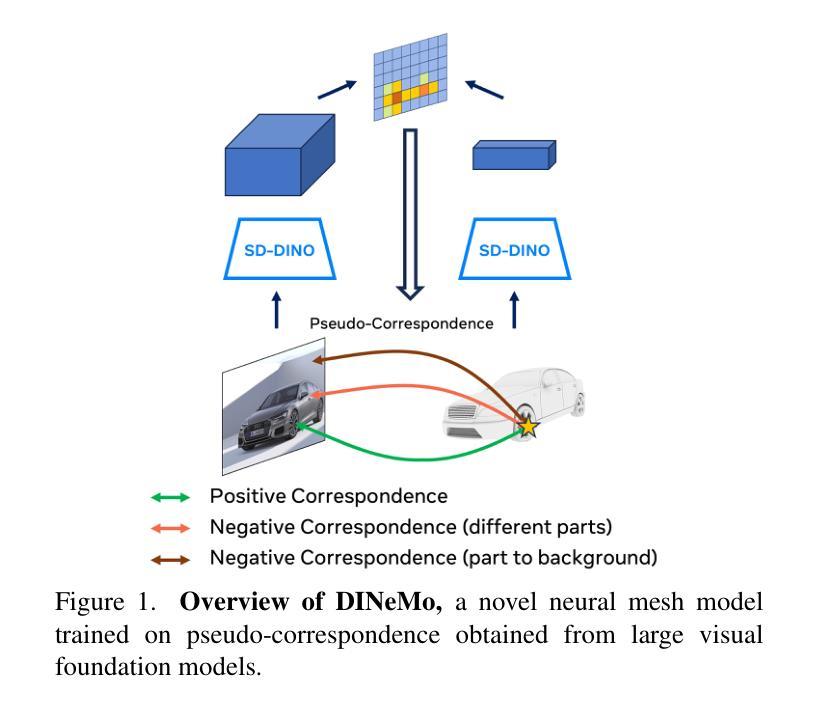
DINeMo: Learning Neural Mesh Models with no 3D Annotations
Authors:Weijie Guo, Guofeng Zhang, Wufei Ma, Alan Yuille
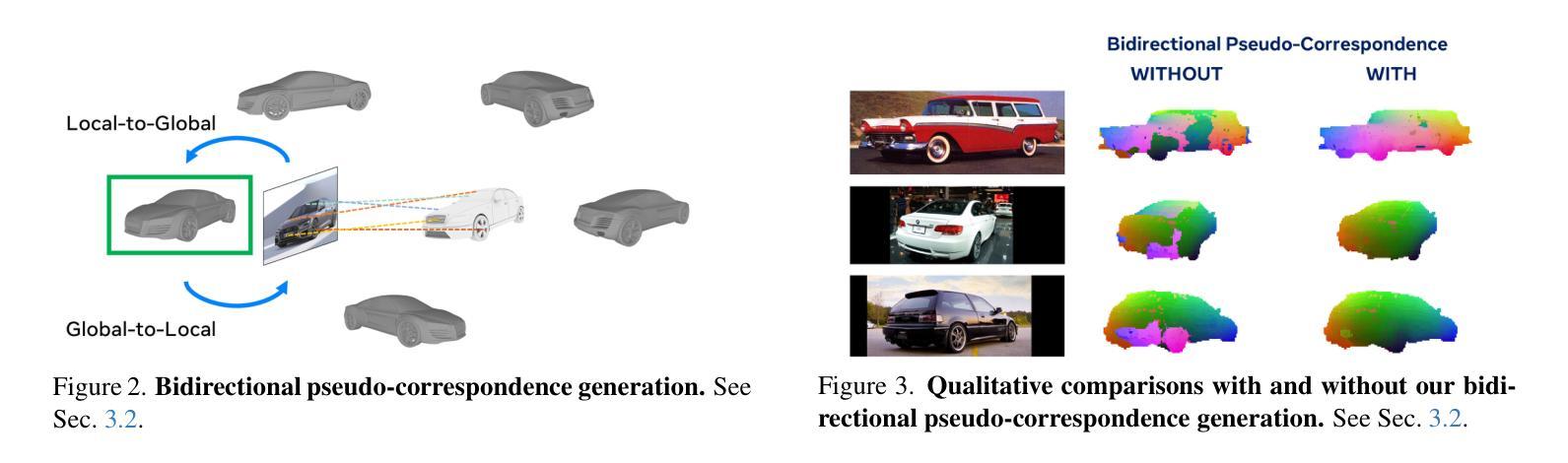
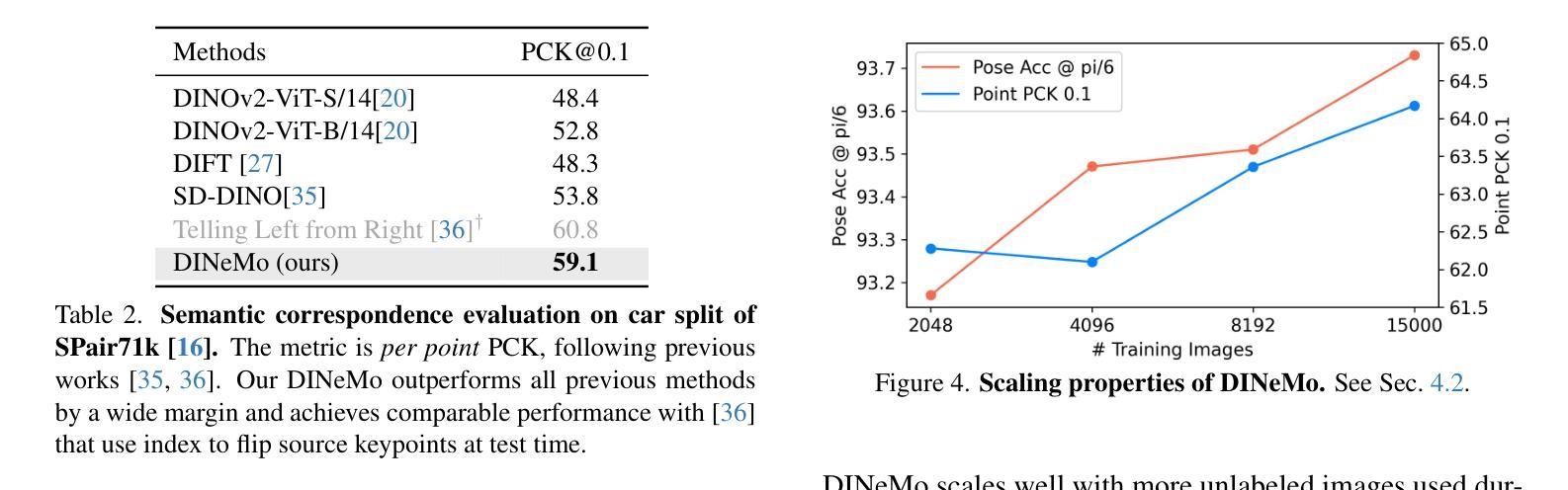
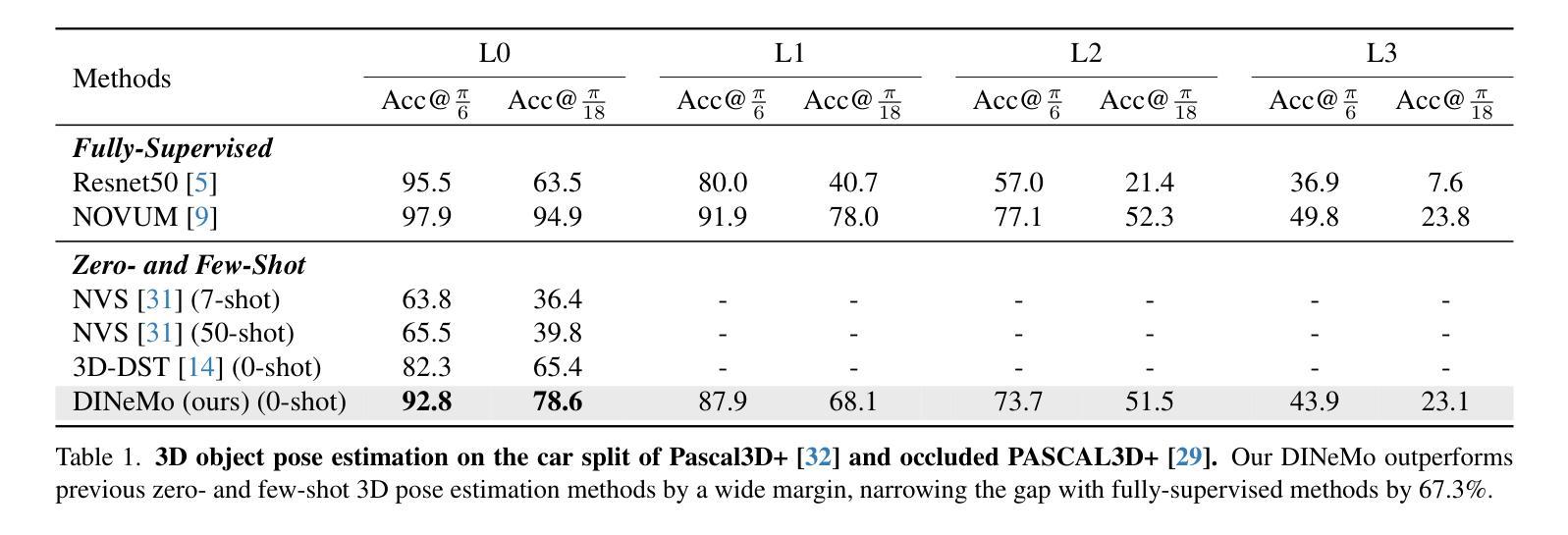
Category-level 3D/6D pose estimation is a crucial step towards comprehensive 3D scene understanding, which would enable a broad range of applications in robotics and embodied AI. Recent works explored neural mesh models that approach a range of 2D and 3D tasks from an analysis-by-synthesis perspective. Despite the largely enhanced robustness to partial occlusion and domain shifts, these methods depended heavily on 3D annotations for part-contrastive learning, which confines them to a narrow set of categories and hinders efficient scaling. In this work, we present DINeMo, a novel neural mesh model that is trained with no 3D annotations by leveraging pseudo-correspondence obtained from large visual foundation models. We adopt a bidirectional pseudo-correspondence generation method, which produce pseudo correspondence utilize both local appearance features and global context information. Experimental results on car datasets demonstrate that our DINeMo outperforms previous zero- and few-shot 3D pose estimation by a wide margin, narrowing the gap with fully-supervised methods by 67.3%. Our DINeMo also scales effectively and efficiently when incorporating more unlabeled images during training, which demonstrate the advantages over supervised learning methods that rely on 3D annotations. Our project page is available at https://analysis-by-synthesis.github.io/DINeMo/.
类别级别的3D/6D姿态估计是实现全面3D场景理解的关键步骤,这将为机器人技术和嵌入式人工智能的广泛应用提供可能。近期的研究探索了神经网格模型,该模型从合成分析的角度来解决一系列2D和3D任务。尽管这些方法在很大程度上增强了处理部分遮挡和领域偏移的稳健性,但它们严重依赖于3D注释进行部分对比学习,这限制了它们的应用范围并阻碍了有效扩展。在这项工作中,我们介绍了DINeMo,这是一种新型神经网格模型,它通过从大型视觉基础模型中获得伪对应来进行训练,无需任何3D注释。我们采用了一种双向伪对应生成方法,该方法利用局部外观特征和全局上下文信息生成伪对应。在汽车数据集上的实验结果表明,我们的DINeMo在零样本和少样本的3D姿态估计方面都大大优于以前的方法,与完全监督的方法的差距缩小了67.3%。此外,当在训练过程中引入更多未标记图像时,我们的DINeMo能够有效地进行扩展,这显示了与依赖3D注释的监督学习方法的优势。我们的项目页面可在https://analysis-by-synthesis.github.io/DINeMo/找到。
论文及项目相关链接
PDF Accepted to 3rd Workshop on Compositional 3D Vision at CVPR 2025 (C3DV)
Summary
无标注的3D场景理解在机器人和人工智能等领域有广泛应用前景。最近神经网络模型的研究主要侧重于基于合成分析的方法来处理多种任务。尽管这些模型对于部分遮挡和领域偏移有更强的鲁棒性,但它们仍受限于需要基于标注数据的部分对比学习,导致类别有限且难以规模化扩展。本文提出一种名为DINeMo的新型神经网络模型,该模型通过利用大规模视觉基础模型得到的伪对应关系进行训练,无需使用任何标注数据。通过采用双向伪对应关系生成方法,结合局部外观特征和全局上下文信息,产生伪对应关系。实验结果表明,在车辆数据集上,DINeMo的性能优于现有的零次和少量任务中训练的三维姿态估计模型,并与完全监督的方法差距缩小至缩小至百分之六点七三。此外,DINeMo可以有效地在训练过程中融入更多的无标签图像,显示出其在监督学习方面的优势。
Key Takeaways
- DINeMo是一种新型神经网络模型,用于解决类别级别的三维姿态估计问题。
- DINeMo利用大规模视觉基础模型的伪对应关系进行训练,无需使用任何标注数据。它通过合成分析方法结合了局部外观特征和全局上下文信息生成伪对应关系。此特点克服了以往方法需要基于标注数据的限制,扩大了应用范围并提高了效率。
点此查看论文截图

SimLTD: Simple Supervised and Semi-Supervised Long-Tailed Object Detection
Authors:Phi Vu Tran
While modern visual recognition systems have made significant advancements, many continue to struggle with the open problem of learning from few exemplars. This paper focuses on the task of object detection in the setting where object classes follow a natural long-tailed distribution. Existing methods for long-tailed detection resort to external ImageNet labels to augment the low-shot training instances. However, such dependency on a large labeled database has limited utility in practical scenarios. We propose a versatile and scalable approach to leverage optional unlabeled images, which are easy to collect without the burden of human annotations. Our SimLTD framework is straightforward and intuitive, and consists of three simple steps: (1) pre-training on abundant head classes; (2) transfer learning on scarce tail classes; and (3) fine-tuning on a sampled set of both head and tail classes. Our approach can be viewed as an improved head-to-tail model transfer paradigm without the added complexities of meta-learning or knowledge distillation, as was required in past research. By harnessing supplementary unlabeled images, without extra image labels, SimLTD establishes new record results on the challenging LVIS v1 benchmark across both supervised and semi-supervised settings.
尽管现代视觉识别系统已经取得了重大进展,但许多系统仍面临着从少量样本中学习这一开放性问题。本文关注在对象类别遵循自然长尾分布的情境下目标检测任务。现有的长尾检测方法依赖于外部ImageNet标签来增强低样本训练实例。然而,在实际场景中,对大量有标签数据库的依赖具有局限性。我们提出了一种通用且可扩展的方法,利用可选的无标签图像,这些图像无需人工注释即可轻松收集。我们的SimLTD框架简单直观,分为三个步骤:(1)在丰富的头部类别上进行预训练;(2)在稀缺的尾部类别上进行迁移学习;(3)在头部和尾部类别的采样集上进行微调。我们的方法可以被视为一种改进的头到尾模型迁移范式,无需引入过去研究中所需的元学习或知识蒸馏等额外复杂性。通过利用额外的无标签图像,无需额外的图像标签,SimLTD在具有挑战性的LVIS v1基准测试中创下了新的记录结果,涵盖了监督学习和半监督学习两种情境。
论文及项目相关链接
PDF CVPR 2025. The reference code is available at https://github.com/lexisnexis-risk-open-source/simltd
Summary
现代视觉识别系统虽有所进步,但在学习少量样本这一开放问题上仍面临挑战。本文关注对象检测中的长尾分布问题,现有方法依赖ImageNet标签来扩充低样本训练实例,但在实际应用中效用有限。本文提出一种灵活可扩展的方法,利用可选的无标签图像,这些图像无需人工标注即可收集。SimLTD框架简单直观,包括三个步骤:在丰富的头部类别上进行预训练;在稀缺的尾部类别上进行迁移学习;在头部和尾部类别的采样集上进行微调。该方法可视为改进的头到尾模型迁移范式,无需元学习或知识蒸馏的复杂过程。通过利用额外的无标签图像,SimLTD在不使用额外图像标签的情况下,在具有挑战性的LVIS v1基准测试中取得了新的记录结果,涵盖了监督学习和半监督学习两种情况。
Key Takeaways
- 现代视觉识别系统在学习少量样本上仍面临挑战。
- 现有方法依赖ImageNet标签扩充低样本训练实例,但在实际应用中效果有限。
- 本文提出利用无标签图像的方法,无需人工标注即可收集。
- SimLTD框架包括预训练、迁移学习和微调三个步骤。
- SimLTD框架实现了头到尾模型迁移的改进范式,无需复杂的元学习或知识蒸馏过程。
- 利用额外的无标签图像,SimLTD在LVIS v1基准测试中取得了新的记录结果。
点此查看论文截图

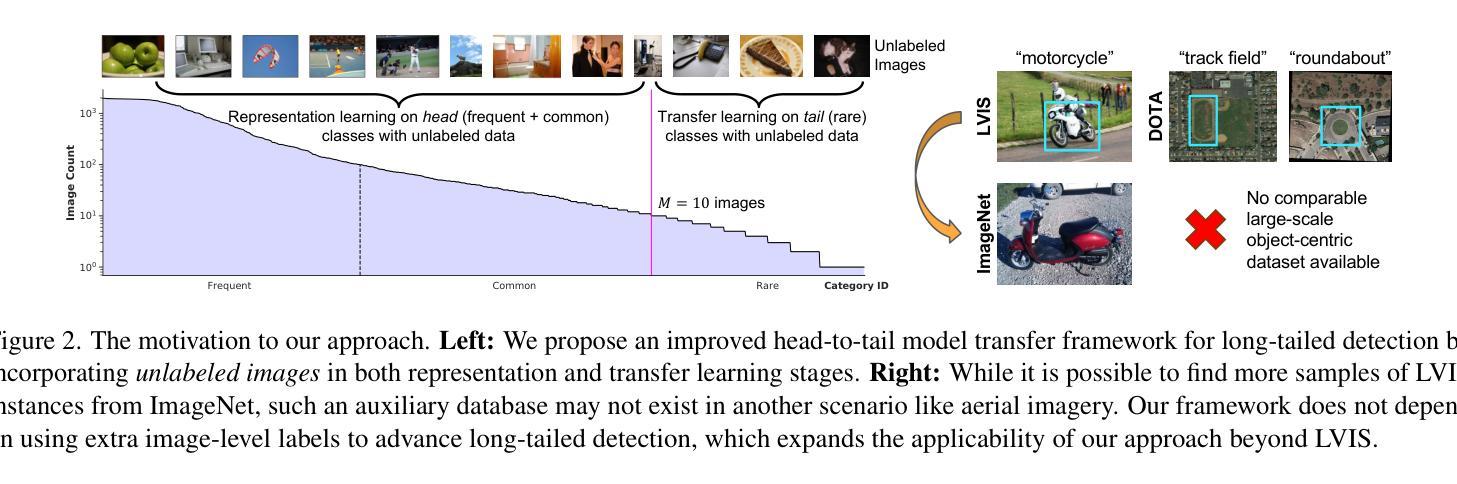
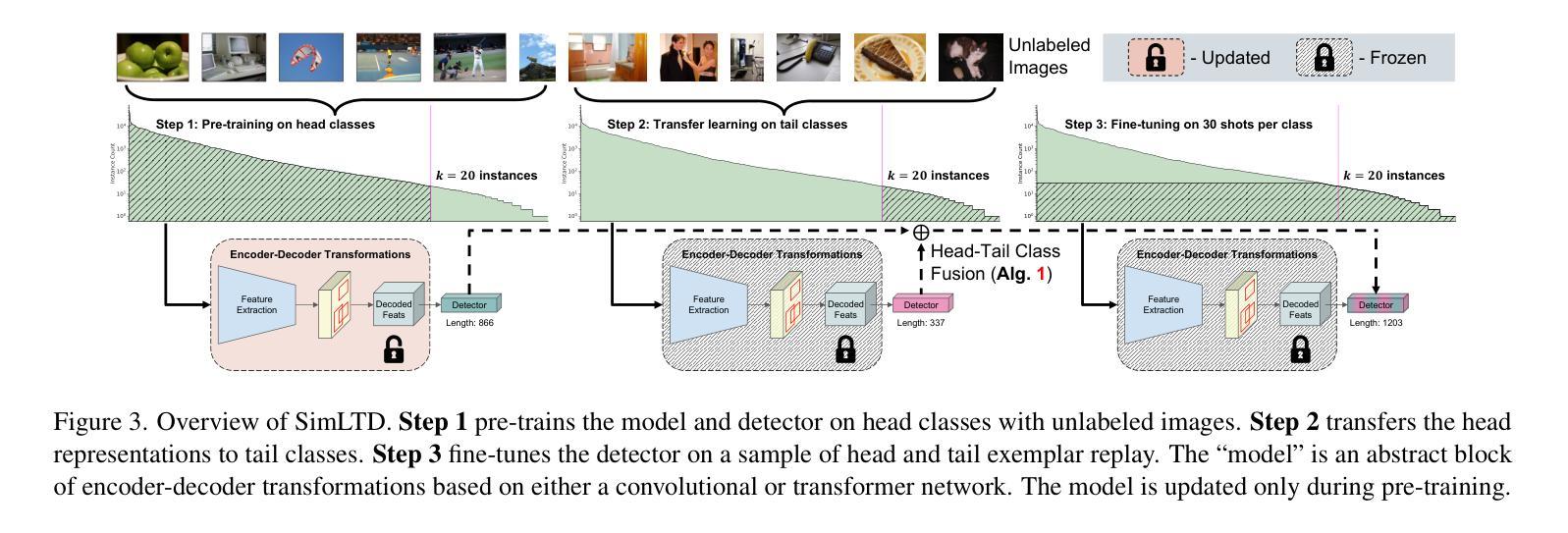
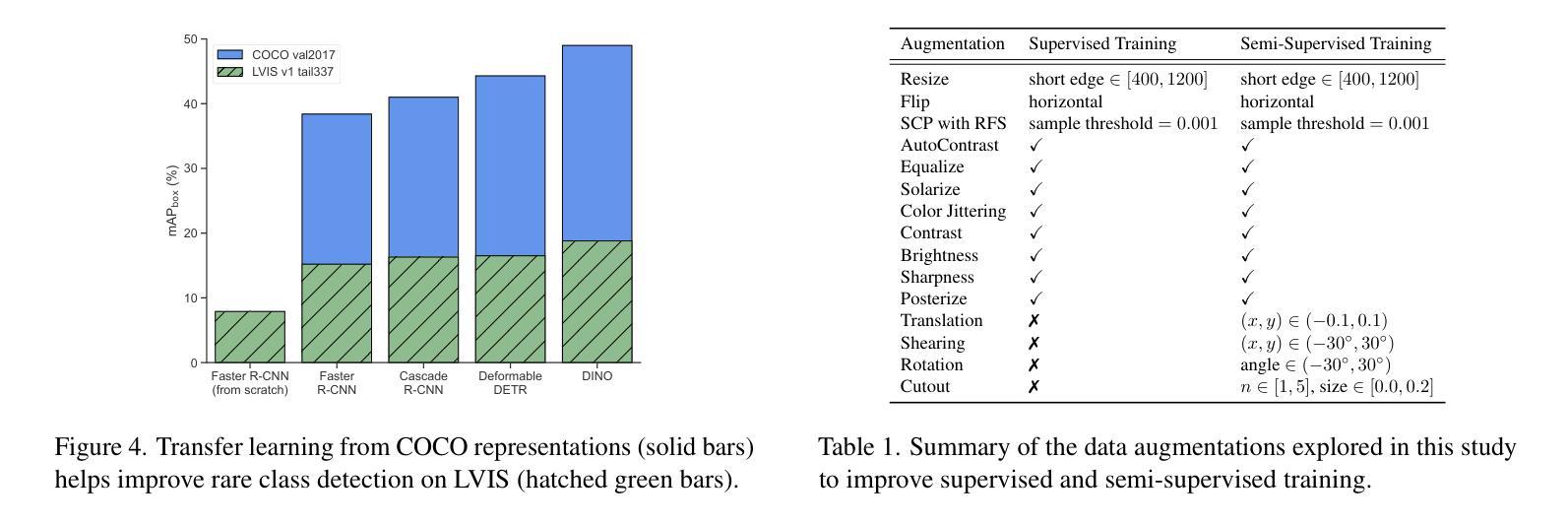


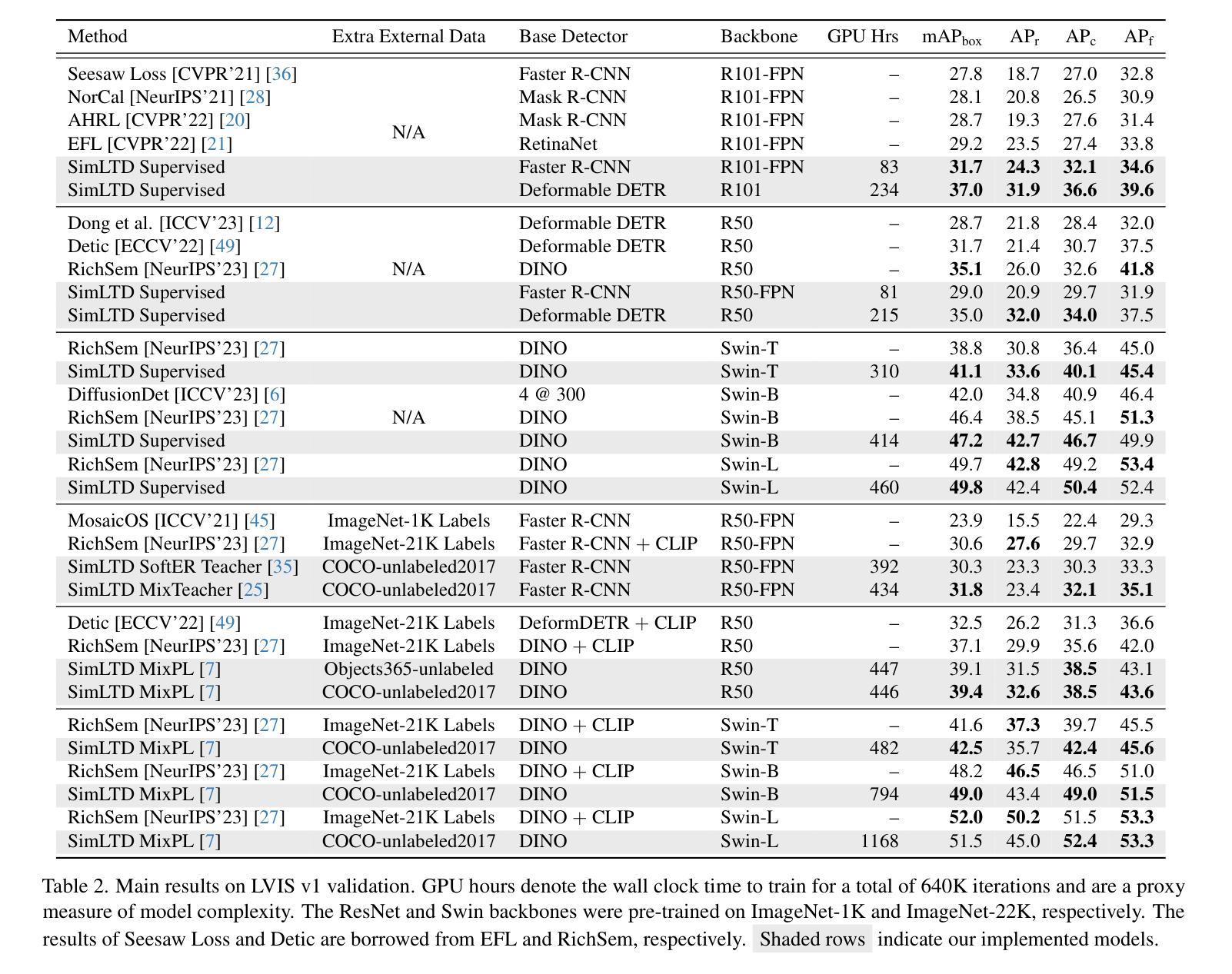
Enhancing Few-Shot Vision-Language Classification with Large Multimodal Model Features
Authors:Chancharik Mitra, Brandon Huang, Tianning Chai, Zhiqiu Lin, Assaf Arbelle, Rogerio Feris, Leonid Karlinsky, Trevor Darrell, Deva Ramanan, Roei Herzig
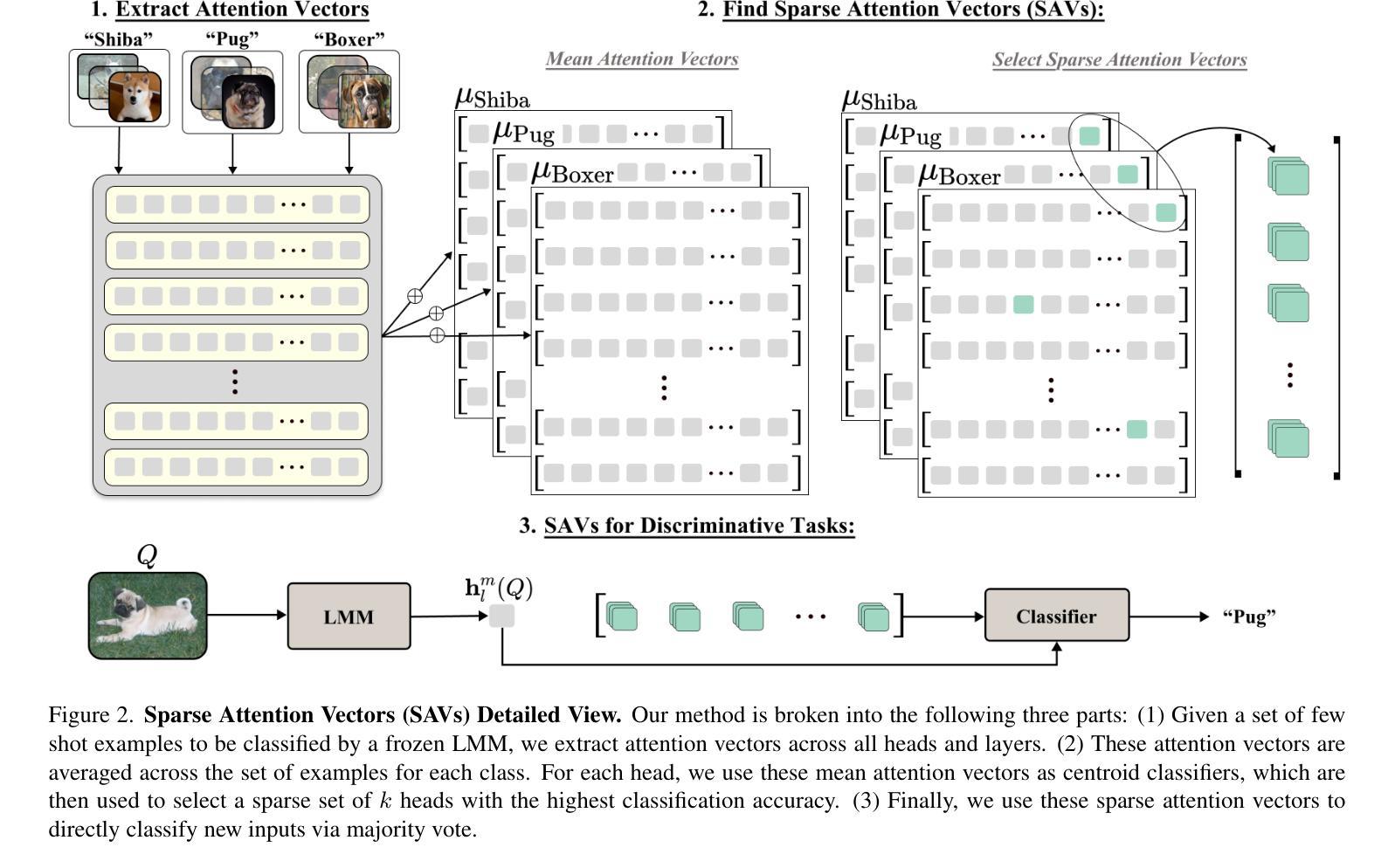
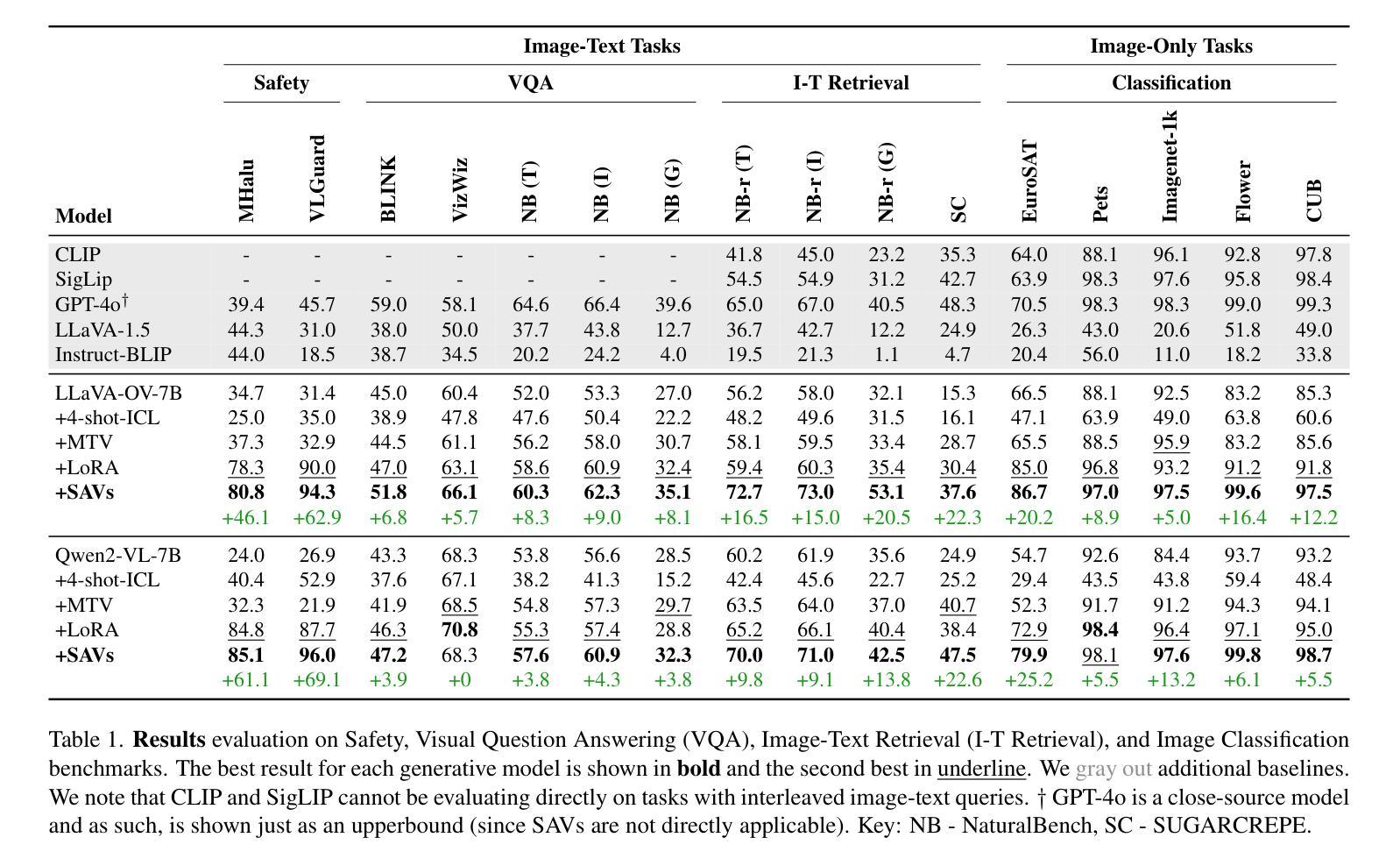
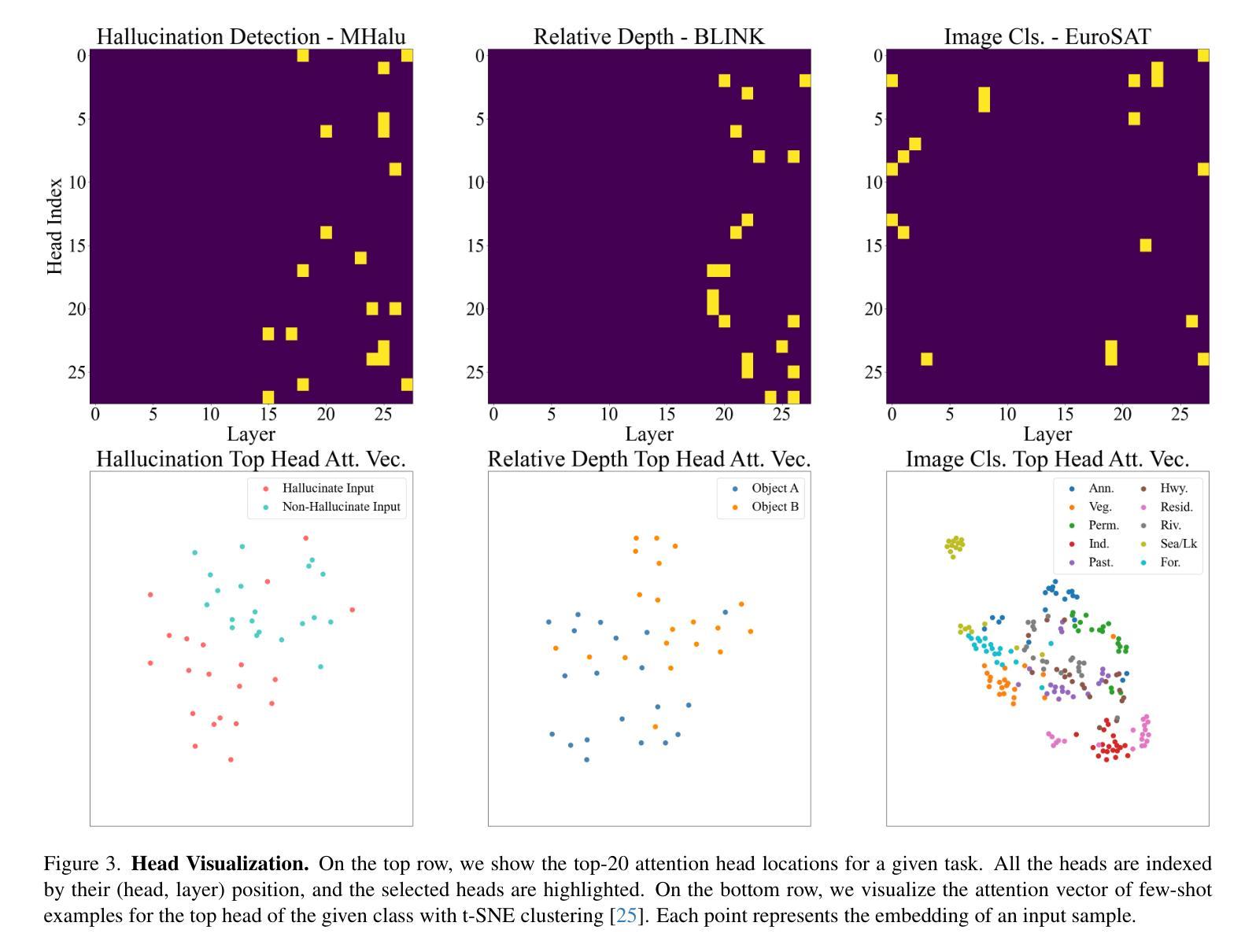
Generative Large Multimodal Models (LMMs) like LLaVA and Qwen-VL excel at a wide variety of vision-language (VL) tasks. Despite strong performance, LMMs’ generative outputs are not specialized for vision-language classification tasks (i.e., tasks with vision-language inputs and discrete labels) such as image classification and multiple-choice VQA. One key challenge in utilizing LMMs for these tasks is the extraction of useful features from generative LMMs. To overcome this, we propose an approach that leverages multimodal feature extraction from the LMM’s latent space. Toward this end, we present Sparse Attention Vectors (SAVs) – a finetuning-free method that leverages sparse attention head activations (fewer than 5% of the heads) in LMMs as strong feature representations. With only few-shot examples, SAVs demonstrate state-of-the-art performance compared to a variety of few-shot and finetuned baselines on a collection of vision-language classification tasks. Our experiments also imply that SAVs can scale in performance with additional examples and generalize to similar tasks, establishing SAVs as both effective and robust multimodal feature representations.
生成式大型多模态模型(LMMs)如LLaVA和Qwen-VL在多种视觉语言(VL)任务中表现出色。尽管性能强大,LMMs的生成输出并不专门针对视觉语言分类任务(即具有视觉语言输入和离散标签的任务),如图像分类和多项选择视觉问答。利用LMMs完成这些任务的一个关键挑战是从生成式LMMs中提取有用的特征。为了克服这一难题,我们提出了一种利用LMM潜在空间中的多模态特征提取的方法。为此,我们提出了稀疏注意力向量(SAVs)——一种无需微调的方法,它利用LMM中少于5%的注意力头激活作为强大的特征表示。仅通过少量样本,SAVs在多种视觉语言分类任务上展示了卓越的性能,与各种小样本和微调基准相比具有领先水平。我们的实验还暗示,随着额外样本的增加,SAVs的性能可以进一步提高,并且能推广到类似任务,这表明SAVs是有效且稳健的多模态特征表示。
论文及项目相关链接
Summary
基于LLaVA和Qwen-VL等大型多模态模型(LMMs)在视觉语言(VL)任务中的出色表现,本文提出了一种无需微调的方法,通过利用LMM的潜在空间中的多模态特征提取来解决其在视觉语言分类任务中的挑战。该方法通过Sparse Attention Vectors(SAVs)实现,利用LMM中较少的注意力头激活(少于5%)作为强大的特征表示。在多个视觉语言分类任务上,SAVs仅通过少量样本就实现了与多种少样本微调基线相比的卓越性能。实验还表明,SAVs的性能可随额外样本的增加而提升,并能泛化到类似任务,证明其作为有效且稳健的多模态特征表示。
Key Takeaways
- LMMs如LLaVA和Qwen-VL在多种视觉语言任务上表现出色,但在视觉语言分类任务上存在挑战。
- 提出了一种利用LMM潜在空间中的多模态特征提取的方法来解决这一挑战。
- SAVs是一种无需微调的方法,利用LMM中少量的注意力头激活作为强大的特征表示。
- SAVs在少量样本下就能在多个视觉语言分类任务上实现卓越性能。
- SAVs的性能可随额外样本的增加而提升,并可以泛化到类似任务。
- SAVs作为有效且稳健的多模态特征表示具有潜力。
点此查看论文截图

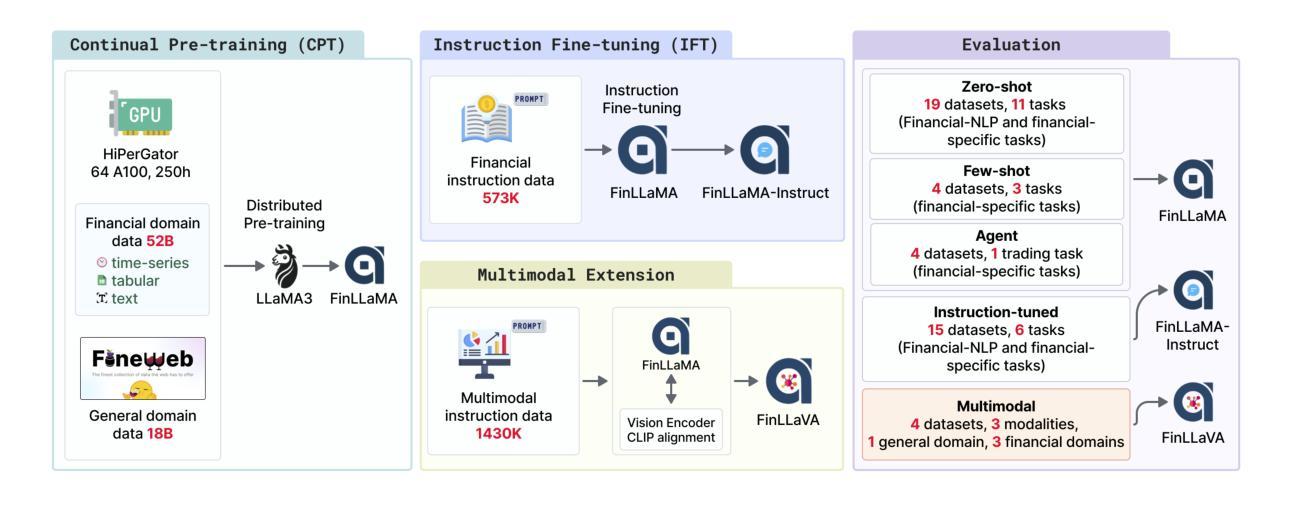
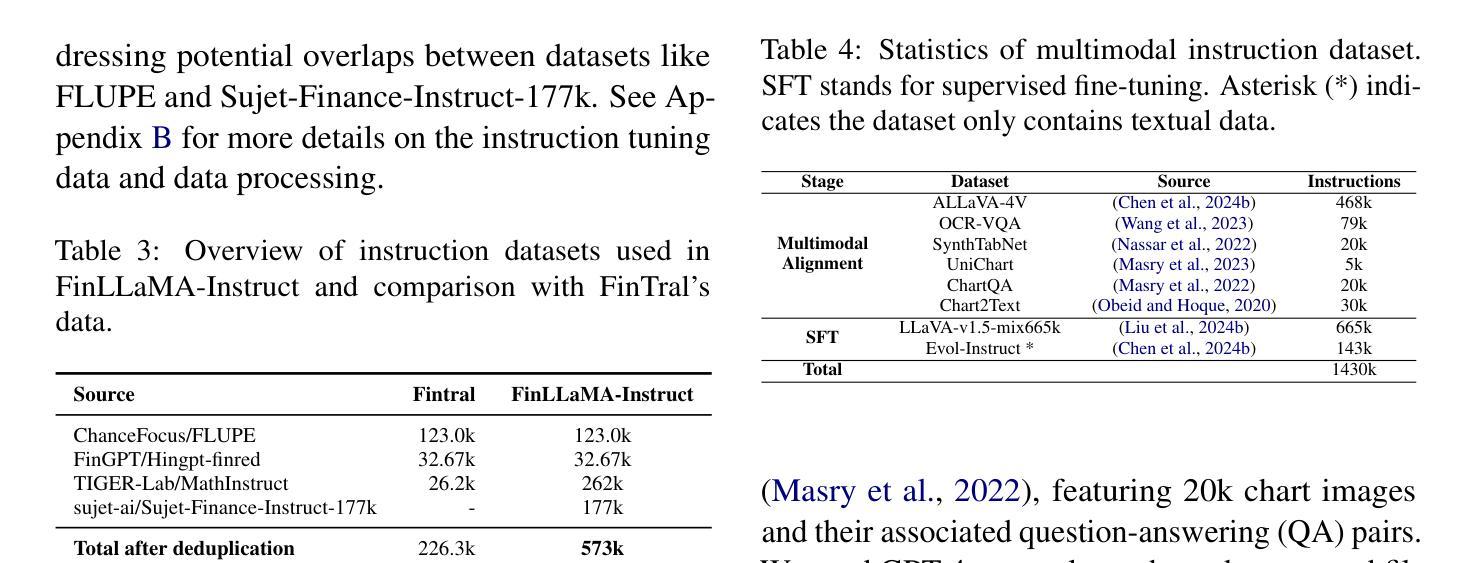
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
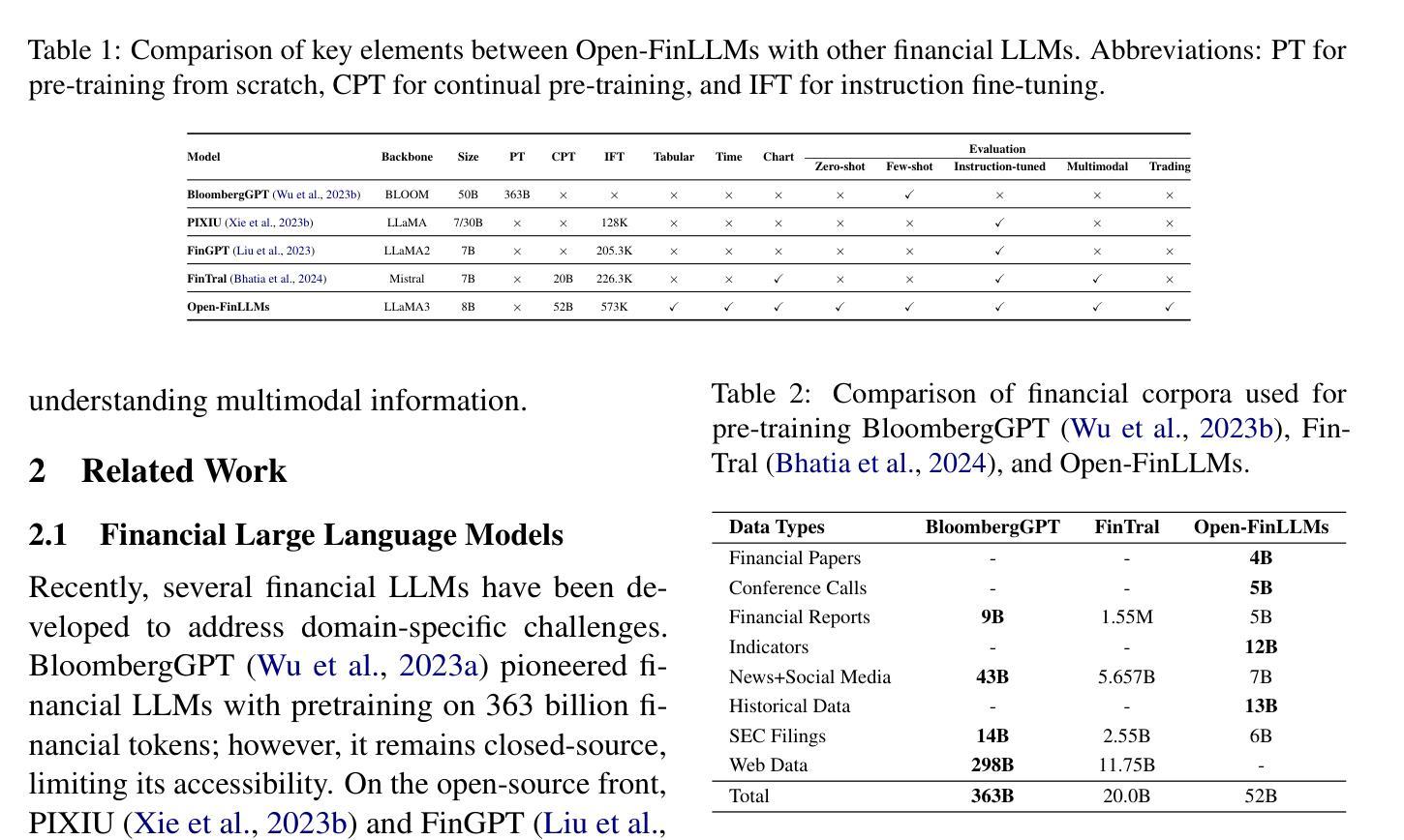
Authors:Jimin Huang, Mengxi Xiao, Dong Li, Zihao Jiang, Yuzhe Yang, Yifei Zhang, Lingfei Qian, Yan Wang, Xueqing Peng, Yang Ren, Ruoyu Xiang, Zhengyu Chen, Xiao Zhang, Yueru He, Weiguang Han, Shunian Chen, Lihang Shen, Daniel Kim, Yangyang Yu, Yupeng Cao, Zhiyang Deng, Haohang Li, Duanyu Feng, Yongfu Dai, VijayaSai Somasundaram, Peng Lu, Guojun Xiong, Zhiwei Liu, Zheheng Luo, Zhiyuan Yao, Ruey-Ling Weng, Meikang Qiu, Kaleb E Smith, Honghai Yu, Yanzhao Lai, Min Peng, Jian-Yun Nie, Jordan W. Suchow, Xiao-Yang Liu, Benyou Wang, Alejandro Lopez-Lira, Qianqian Xie, Sophia Ananiadou, Junichi Tsujii
Financial LLMs hold promise for advancing financial tasks and domain-specific applications. However, they are limited by scarce corpora, weak multimodal capabilities, and narrow evaluations, making them less suited for real-world application. To address this, we introduce \textit{Open-FinLLMs}, the first open-source multimodal financial LLMs designed to handle diverse tasks across text, tabular, time-series, and chart data, excelling in zero-shot, few-shot, and fine-tuning settings. The suite includes FinLLaMA, pre-trained on a comprehensive 52-billion-token corpus; FinLLaMA-Instruct, fine-tuned with 573K financial instructions; and FinLLaVA, enhanced with 1.43M multimodal tuning pairs for strong cross-modal reasoning. We comprehensively evaluate Open-FinLLMs across 14 financial tasks, 30 datasets, and 4 multimodal tasks in zero-shot, few-shot, and supervised fine-tuning settings, introducing two new multimodal evaluation datasets. Our results show that Open-FinLLMs outperforms afvanced financial and general LLMs such as GPT-4, across financial NLP, decision-making, and multi-modal tasks, highlighting their potential to tackle real-world challenges. To foster innovation and collaboration across academia and industry, we release all codes (https://anonymous.4open.science/r/PIXIU2-0D70/B1D7/LICENSE) and models under OSI-approved licenses.
金融LLM(大型预训练语言模型)在推进金融任务和特定领域应用方面显示出巨大的潜力。然而,它们受到有限语料库、弱多模态能力和狭窄评估范围的限制,使其不太适合真实世界的应用。为了解决这个问题,我们推出了“Open-FinLLMs”,这是首个开源的多模态金融LLM,旨在处理文本、表格、时间序列和图表数据等各种任务,并在零样本、少样本和微调设置中表现出色。该套件包括FinLLaMA(在包含52亿标记的语料库上进行预训练)、FinLLaMA-Instruct(使用573K金融指令进行微调)和FinLLaVA(通过143万对多模态调优增强跨模态推理能力)。我们对Open-FinLLMs进行了全面的评估,包括14个金融任务、30个数据集和4个多模态任务,在零样本、少样本和受监督微调设置下进行了评估,并推出了两个新的多模态评估数据集。结果表明,Open-FinLLMs在金融NLP、决策和多模态任务上超越了先进的金融和通用LLM,如GPT-4,凸显了它们在应对现实挑战方面的潜力。为了促进学术界和产业界的创新和合作,我们发布了所有代码(https://anonymous.4open.science/r/PIXIU2-0D70/B1D7/LICENSE)和模型,并遵循OSI批准许可证。
论文及项目相关链接
PDF 33 pages, 13 figures
Summary:开放金融LLM展现多元能力。LLM在推进金融任务和相关应用方面潜力巨大,但仍受限于语料库稀缺、多模态能力薄弱以及评价模式局限,难以实现现实世界的应用场景。针对此挑战,开放金融LLM是首个开源的多模态金融LLM工具,可处理文本、表格、时间序列和图表数据等多种任务,在零样本、小样本微调场景下表现卓越。我们提供三个套件包括FinLLaMA(预训练语料库达52亿词)、FinLLaMA-Instruct(经过57万条金融指令精细调整)和FinLLaVA(增强多模态调优对实现强跨模态推理)。评估结果显示,开放金融LLM在多种金融任务和多模态任务上优于先进金融和通用LLM,如GPT-4等。我们发布所有代码和模型以推动学术界和产业界的合作创新。
Key Takeaways:
- 开放金融LLM具备处理多种金融任务的能力,包括文本、表格、时间序列和图表数据等。
- 该工具融合了多模态技术,提升了处理复杂金融数据的能力。
- 开放金融LLM在零样本、小样本和微调场景下表现优越。
- 通过全面的评估,开放金融LLM被证实优于其他先进的金融和通用LLM。
- 该工具提供了三个套件以适应不同的金融应用场景需求。
- 开放金融LLM的发布旨在促进学术界和产业界的合作与创新。
点此查看论文截图

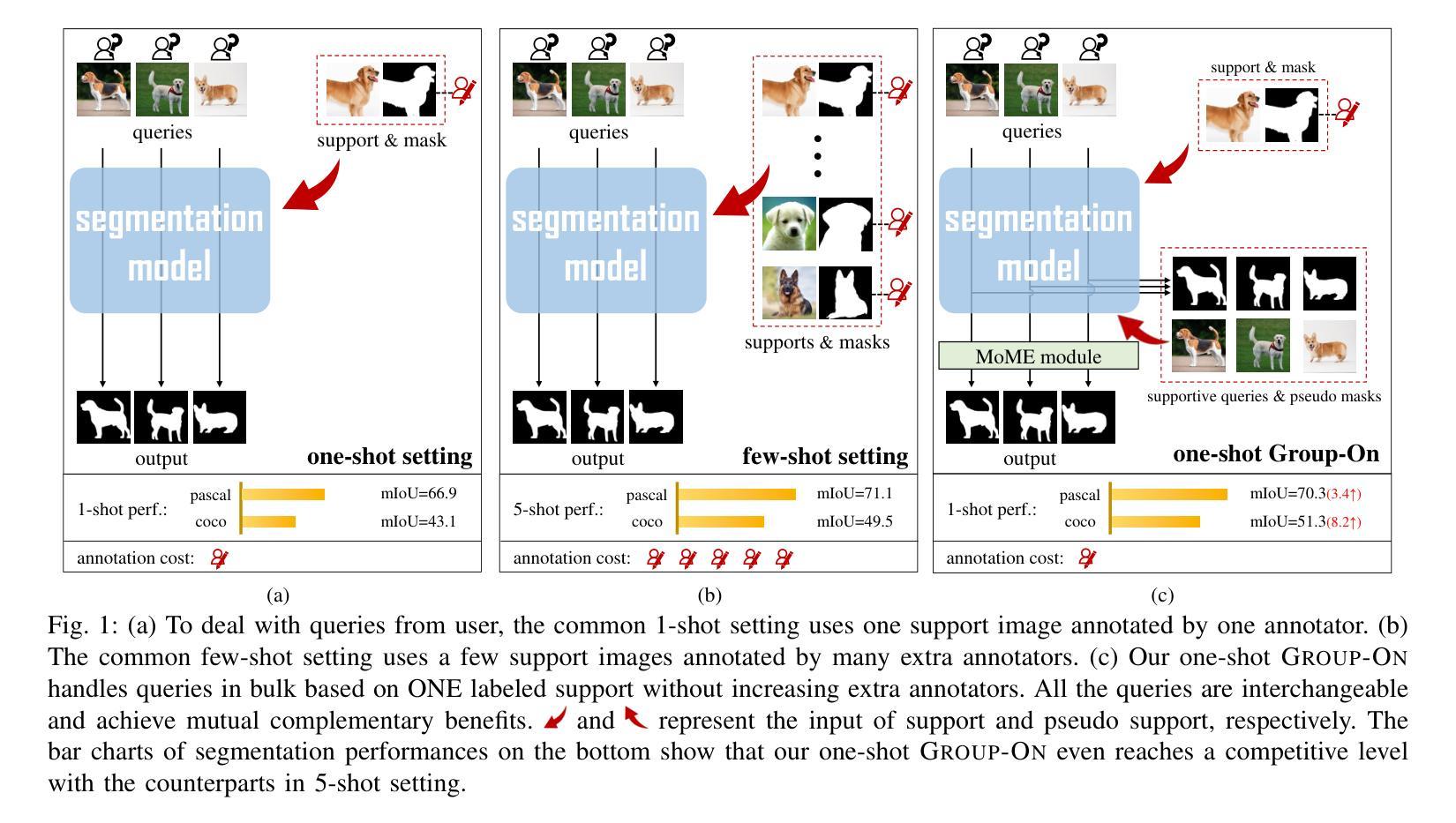
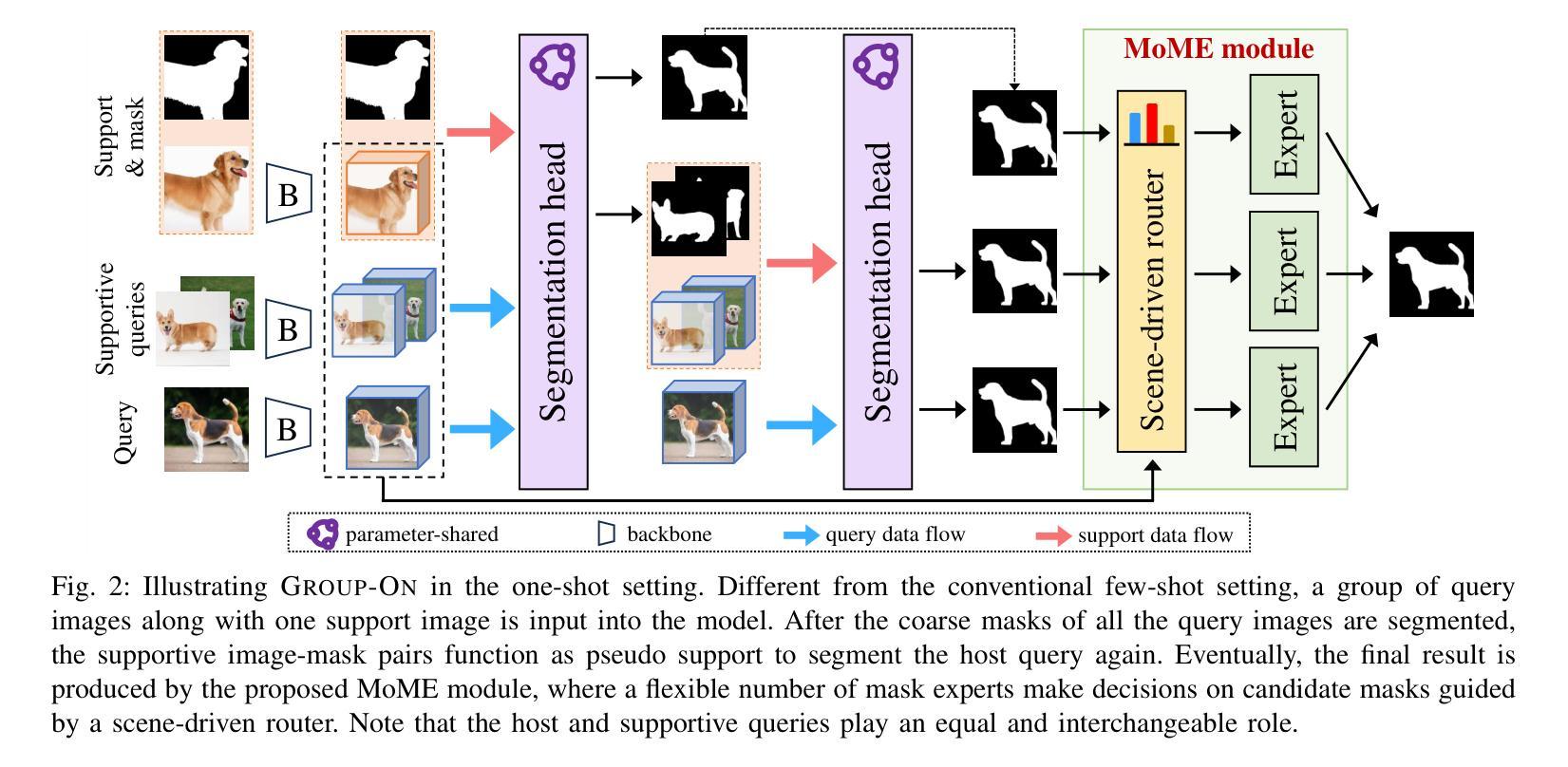
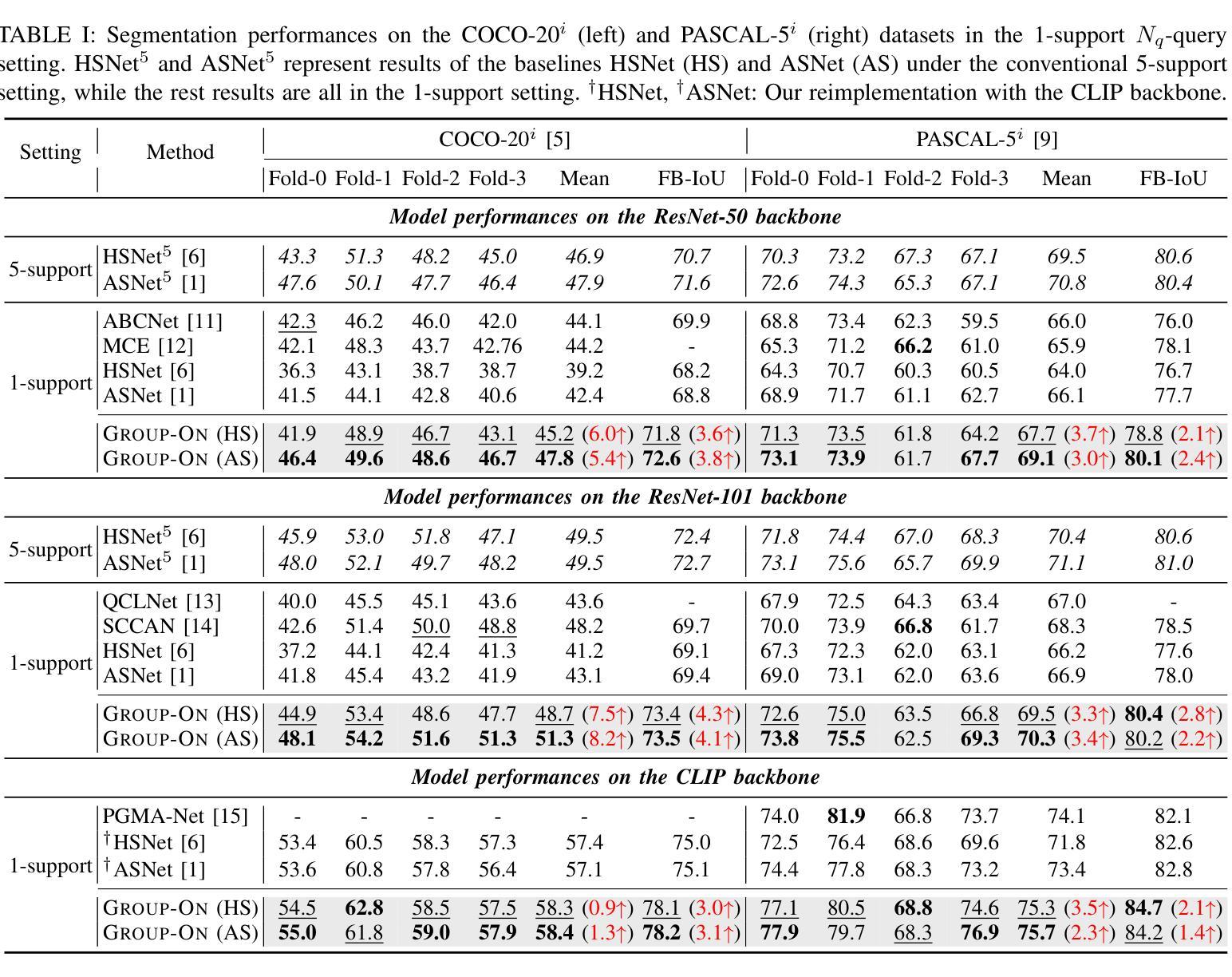
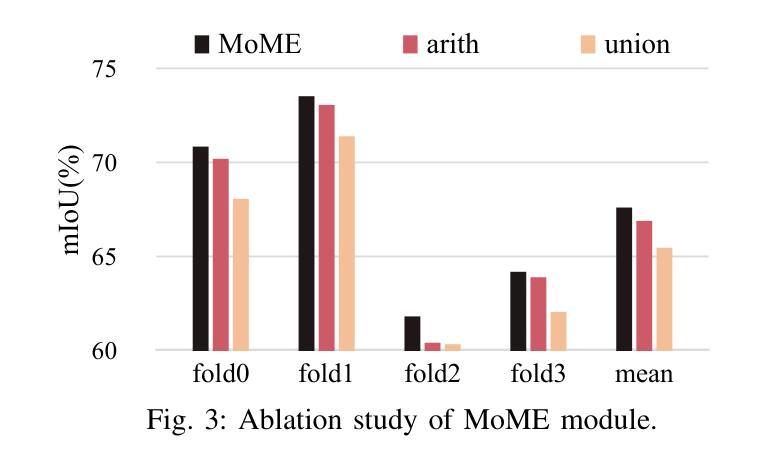
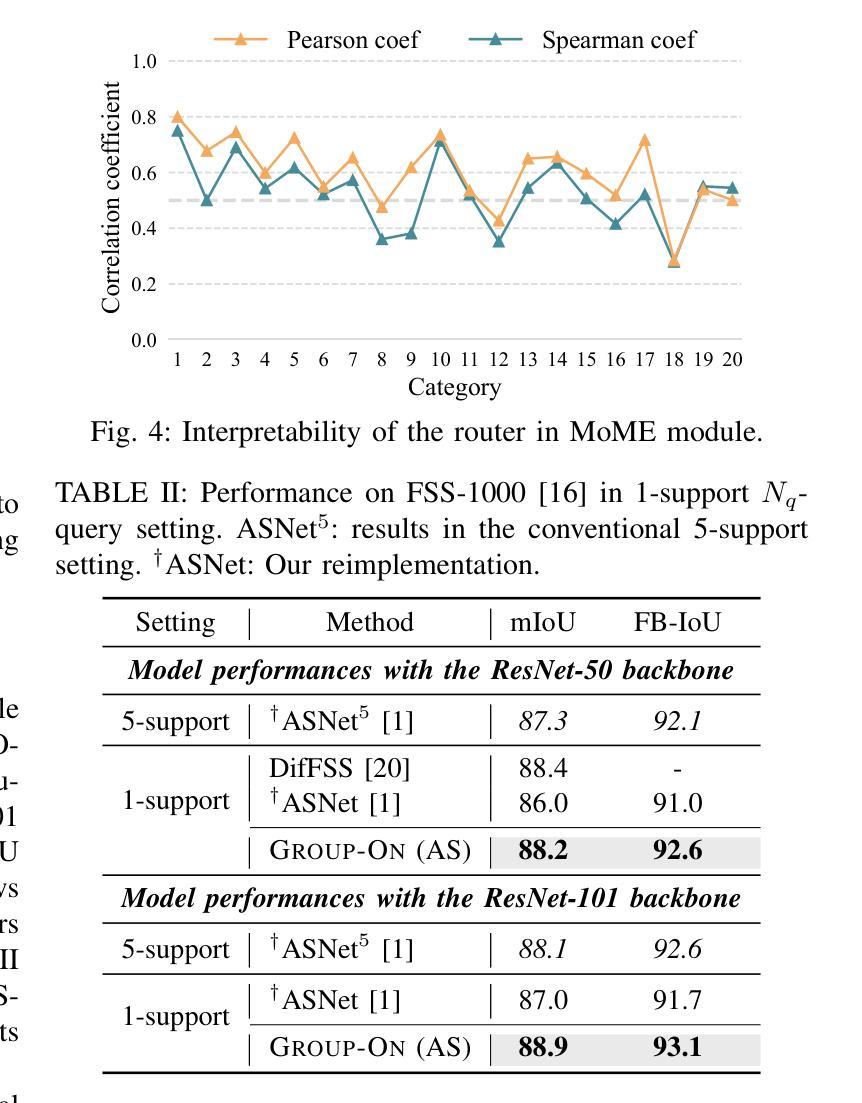
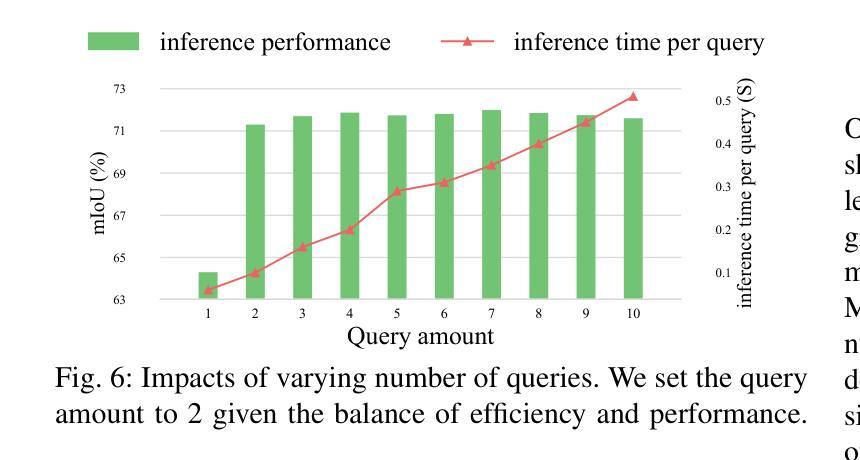
Group-On: Boosting One-Shot Segmentation with Supportive Query
Authors:Hanjing Zhou, Mingze Yin, Danny Chen, Jian Wu, JinTai Chen
One-shot semantic segmentation aims to segment query images given only ONE annotated support image of the same class. This task is challenging because target objects in the support and query images can be largely different in appearance and pose (i.e., intra-class variation). Prior works suggested that incorporating more annotated support images in few-shot settings boosts performances but increases costs due to additional manual labeling. In this paper, we propose a novel and effective approach for ONE-shot semantic segmentation, called Group-On, which packs multiple query images in batches for the benefit of mutual knowledge support within the same category. Specifically, after coarse segmentation masks of the batch of queries are predicted, query-mask pairs act as pseudo support data to enhance mask predictions mutually. To effectively steer such process, we construct an innovative MoME module, where a flexible number of mask experts are guided by a scene-driven router and work together to make comprehensive decisions, fully promoting mutual benefits of queries. Comprehensive experiments on three standard benchmarks show that, in the ONE-shot setting, Group-On significantly outperforms previous works by considerable margins. With only one annotated support image, Group-On can be even competitive with the counterparts using 5 annotated images.
单样本语义分割旨在仅使用一个同类别的标注支持图像对查询图像进行分割。这一任务是充满挑战的,因为支持图像和查询图像中的目标对象在外观和姿态上可能存在很大差异(即类内变化)。早期的研究表明,在少数样本设置中加入更多的标注支持图像可以提高性能,但同时也增加了因额外手动标注而产生的成本。在本文中,我们提出了一种针对单样本语义分割的新型有效方法,称为Group-On。它将多个查询图像分批处理,以获取同一类别内的相互知识支持。具体来说,在预测一批查询图像的粗略分割掩膜后,查询-掩膜对作为伪支持数据,相互增强掩膜预测。为了有效地引导这一过程,我们构建了一个创新型的MoME模块,其中由场景驱动路由器指导的多个灵活掩膜专家可以共同工作,以做出全面决策,充分发挥查询之间的互利优势。在三个标准基准测试上的综合实验表明,在单样本设置下,Group-On显著优于以前的工作,具有相当大的优势。仅使用一个标注的支持图像,Group-On甚至可以与使用5个标注图像的同类方法相竞争。
论文及项目相关链接
Summary
少样本语义分割旨在仅使用一张同类标注的支持图像对查询图像进行分割。此任务具有挑战性,因为支持图像和查询图像中的目标对象在外观和姿势上可能存在很大差异(即类内变化)。以前的工作表明,在少样本环境中加入更多标注的支持图像可以提高性能,但会增加由于额外手动标注的成本。在本文中,我们提出了一种针对少样本语义分割的新型有效方法,称为Group-On,它将多个查询图像分批打包,以在同类中互相获取知识支持。具体来说,在预测了批次查询图像的粗略分割掩膜后,查询掩膜对充当伪支持数据,互相增强掩膜预测。为了有效地引导这一过程,我们构建了一个创新的MoME模块,其中由场景驱动的路由器指导可变数量的掩膜专家共同做出全面决策,充分促进查询之间的相互利益。在三个标准基准测试上的综合实验表明,在单次拍摄设置中,Group-On显著优于以前的工作。仅使用一张标注的支持图像,Group-On甚至可以与使用5张标注图像的同类产品相竞争。
Key Takeaways
- Group-On方法针对少样本语义分割问题,通过批量处理查询图像,实现互相的知识支持。
- 该方法利用查询图像之间的粗略分割掩膜来互相增强预测结果。
- 创新性地提出了MoME模块,通过场景驱动的路由器引导可变数量的掩膜专家共同做出决策。
- Group-On方法显著提高了少样本语义分割的性能,特别是在仅使用一张标注的支持图像时。
- Group-On方法在三个标准基准测试上的表现优于之前的方法。
- 通过利用查询图像之间的互助关系,Group-On方法降低了对大量标注数据的依赖。
点此查看论文截图