⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-11 更新
Design and Evaluation of Deep Learning-Based Dual-Spectrum Image Fusion Methods
Authors:Beining Xu, Junxian Li
Visible images offer rich texture details, while infrared images emphasize salient targets. Fusing these complementary modalities enhances scene understanding, particularly for advanced vision tasks under challenging conditions. Recently, deep learning-based fusion methods have gained attention, but current evaluations primarily rely on general-purpose metrics without standardized benchmarks or downstream task performance. Additionally, the lack of well-developed dual-spectrum datasets and fair algorithm comparisons hinders progress. To address these gaps, we construct a high-quality dual-spectrum dataset captured in campus environments, comprising 1,369 well-aligned visible-infrared image pairs across four representative scenarios: daytime, nighttime, smoke occlusion, and underpasses. We also propose a comprehensive and fair evaluation framework that integrates fusion speed, general metrics, and object detection performance using the lang-segment-anything model to ensure fairness in downstream evaluation. Extensive experiments benchmark several state-of-the-art fusion algorithms under this framework. Results demonstrate that fusion models optimized for downstream tasks achieve superior performance in target detection, especially in low-light and occluded scenes. Notably, some algorithms that perform well on general metrics do not translate to strong downstream performance, highlighting limitations of current evaluation practices and validating the necessity of our proposed framework. The main contributions of this work are: (1)a campus-oriented dual-spectrum dataset with diverse and challenging scenes; (2) a task-aware, comprehensive evaluation framework; and (3) thorough comparative analysis of leading fusion methods across multiple datasets, offering insights for future development.
可见图像提供了丰富的纹理细节,而红外图像则突出显示显著目标。融合这些互补模式可以增强对场景的理解,特别是对于具有挑战性的条件下的高级视觉任务。最近,基于深度学习的融合方法已经引起了人们的关注,但当前的评价主要依赖于通用指标,缺乏标准基准测试或下游任务性能。此外,缺乏发达的双光谱数据集和公平的算法比较阻碍了进展。为了解决这些差距,我们在校园环境中构建了一个高质量的双光谱数据集,包含四种代表性场景的1369对可见光红外图像对:白天、夜晚、烟雾遮挡和过路隧道。我们还提出了一个全面公平的评估框架,该框架结合了融合速度、通用指标以及使用lang-segment-anything模型的对象检测性能,以确保下游评估的公平性。在该框架下,对几种最先进的融合算法进行了广泛的实验评估。结果表明,针对下游任务优化的融合模型在目标检测方面表现出卓越的性能,尤其在低光照和遮挡场景中。值得注意的是,一些在通用指标上表现良好的算法在下游性能上并不突出,这突出了当前评估实践的局限性,并验证了我们所提出的框架的必要性。这项工作的主要贡献是:(1)以校园为中心的双光谱数据集,具有多样化和挑战性的场景;(2)任务感知的全面评估框架;(3)多个数据集上领先融合方法的比较分析,为未来发展提供见解。
论文及项目相关链接
PDF 11 pages, 13 figures
Summary:
本文介绍了可见光和红外图像的融合技术,对于场景理解有重要作用。当前缺乏标准化数据集和评估框架,因此构建了校园环境下的高质量双光谱数据集,并提出了综合评估框架。实验结果显示,针对下游任务优化的融合模型在目标检测上表现优异,特别是在低光和遮挡场景中。本文的主要贡献包括校园导向的双光谱数据集、任务感知的综合评估框架以及对领先融合方法的全面比较分析。
Key Takeaways:
- 可见光和红外图像融合技术对于场景理解至关重要。
- 当前缺乏标准化数据集和评估框架,限制了研究的进展。
- 构建了一个高质量的双光谱数据集,包括校园环境下的四种代表性场景。
- 提出了一个综合评估框架,结合了融合速度、通用指标和对象检测性能。
- 实验结果显示针对下游任务优化的融合模型在目标检测上表现更好。
- 一些在通用指标上表现良好的算法在下游性能上并不强,凸显了当前评估实践的局限性。
点此查看论文截图







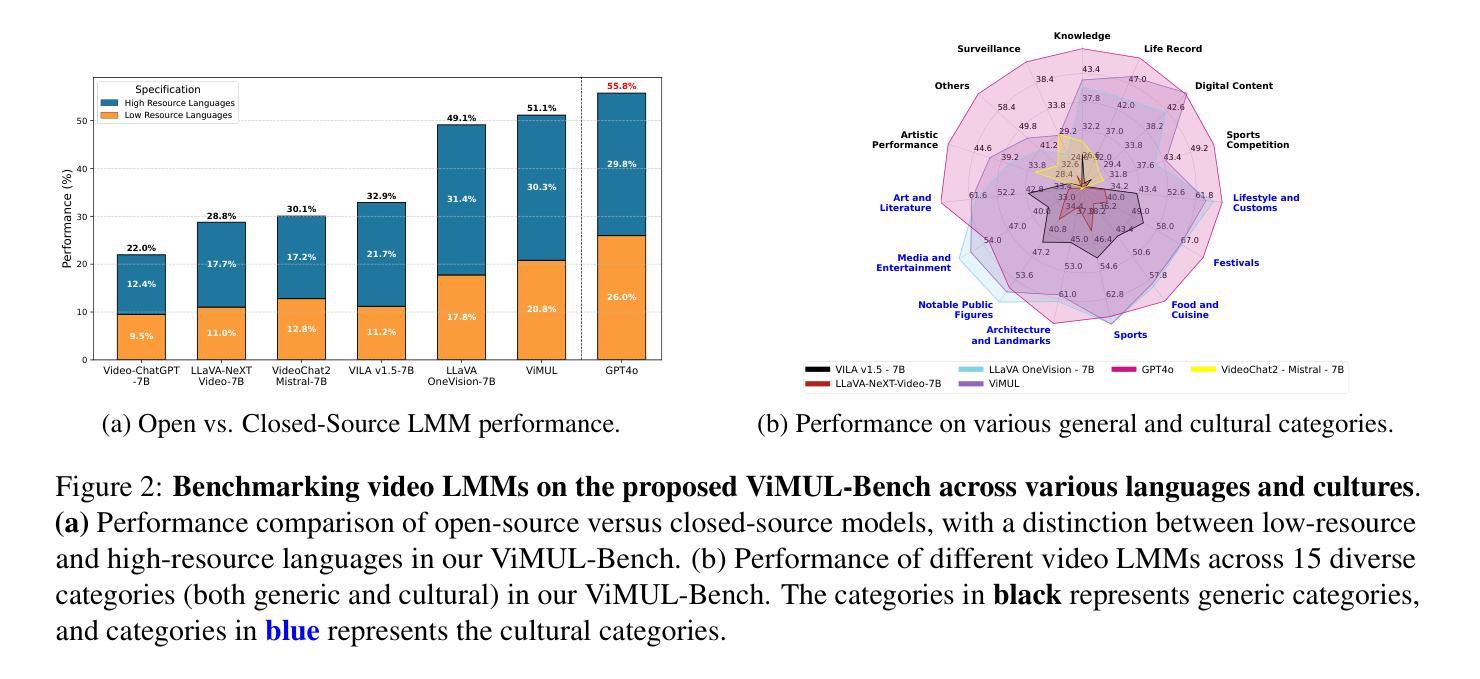
A Culturally-diverse Multilingual Multimodal Video Benchmark & Model
Authors:Bhuiyan Sanjid Shafique, Ashmal Vayani, Muhammad Maaz, Hanoona Abdul Rasheed, Dinura Dissanayake, Mohammed Irfan Kurpath, Yahya Hmaiti, Go Inoue, Jean Lahoud, Md. Safirur Rashid, Shadid Intisar Quasem, Maheen Fatima, Franco Vidal, Mykola Maslych, Ketan Pravin More, Sanoojan Baliah, Hasindri Watawana, Yuhao Li, Fabian Farestam, Leon Schaller, Roman Tymtsiv, Simon Weber, Hisham Cholakkal, Ivan Laptev, Shin’ichi Satoh, Michael Felsberg, Mubarak Shah, Salman Khan, Fahad Shahbaz Khan
Large multimodal models (LMMs) have recently gained attention due to their effectiveness to understand and generate descriptions of visual content. Most existing LMMs are in English language. While few recent works explore multilingual image LMMs, to the best of our knowledge, moving beyond the English language for cultural and linguistic inclusivity is yet to be investigated in the context of video LMMs. In pursuit of more inclusive video LMMs, we introduce a multilingual Video LMM benchmark, named ViMUL-Bench, to evaluate Video LMMs across 14 languages, including both low- and high-resource languages: English, Chinese, Spanish, French, German, Hindi, Arabic, Russian, Bengali, Urdu, Sinhala, Tamil, Swedish, and Japanese. Our ViMUL-Bench is designed to rigorously test video LMMs across 15 categories including eight culturally diverse categories, ranging from lifestyles and festivals to foods and rituals and from local landmarks to prominent cultural personalities. ViMUL-Bench comprises both open-ended (short and long-form) and multiple-choice questions spanning various video durations (short, medium, and long) with 8k samples that are manually verified by native language speakers. In addition, we also introduce a machine translated multilingual video training set comprising 1.2 million samples and develop a simple multilingual video LMM, named ViMUL, that is shown to provide a better tradeoff between high-and low-resource languages for video understanding. We hope our ViMUL-Bench and multilingual video LMM along with a large-scale multilingual video training set will help ease future research in developing cultural and linguistic inclusive multilingual video LMMs. Our proposed benchmark, video LMM and training data will be publicly released at https://mbzuai-oryx.github.io/ViMUL/.
近期,大型多模态模型(LMM)因其理解和生成视觉内容描述的有效性而受到关注。现有的大多数LMM都是英语。虽然有一些最近的研究开始探索多语言图像LMM,但据我们所知,在视频LMM的情境中,为了文化和语言的包容性转向非英语语言尚未被研究。为了寻求更具包容性的视频LMM,我们引入了一个多语言视频LMM基准测试,名为ViMUL-Bench,旨在评估包括低资源和高资源语言在内的14种语言的视频LMM,这些语言包括英语、中文、西班牙语、法语、德语、印地语、阿拉伯语、俄语、孟加拉语、乌尔都语、僧伽罗语、泰米尔语、瑞典语和日语。我们的ViMUL-Bench被设计为严格测试包括生活方式和节日在内的文化多样性以及当地地标和著名文化人物等类别的视频LMM共十五大类别。ViMUL-Bench包括开放性问题(短形式和长形式)和选择题,涵盖各种视频时长(短、中和长),共包含经过母语者手动验证的八千个样本。此外,我们还引入了包含一百二十万样本的机器翻译多语言视频训练集,并开发了一个简单的多语言视频LMM,名为ViMUL,它在高资源和低资源语言的视频理解方面表现出更好的权衡。我们希望我们的ViMUL-Bench和多语言视频LMM以及大规模多语言视频训练集将帮助推动未来开发具有文化和语言包容性的多语言视频LMM的研究。我们提议的基准测试、视频LMM和训练数据将在https://mbzuai-oryx.github.io/ViMUL/上公开发布。
论文及项目相关链接
Summary
该文本介绍了一个名为ViMUL-Bench的多语种视频大型模态模型(LMM)基准测试。该基准测试旨在评估包括英语、中文等多达14种语言的视频LMM性能。它涵盖了文化多样性丰富的类别,包括生活方式、节日、食物、仪式以及当地地标和著名文化人物等。此外,还引入了机器翻译的多语种视频训练集,并开发了一个名为ViMUL的简单多语种视频LMM模型。该基准测试和模型旨在促进多语种视频LMM的研究发展,并将在公开网站上发布。
Key Takeaways
- 大型多模态模型(LMMs)能有效理解和生成视觉内容描述,目前大部分为英语模型。
- 为提高文化及语言包容性,需要探索非英语的多语种视频LMM。
- 提出了名为ViMUL-Bench的多语种视频LMM基准测试,涵盖14种语言,包括低资源和高资源语言。
- ViMUL-Bench包含开放性问题(短式和长式)和选择题,涉及不同视频时长和手动验证的8K样本。
- 引入了一个机器翻译的多语种视频训练集,包含120万样本。
- 开发了一个名为ViMUL的简单多语种视频LMM模型,能在高资源和低资源语言间提供更好的权衡。
点此查看论文截图


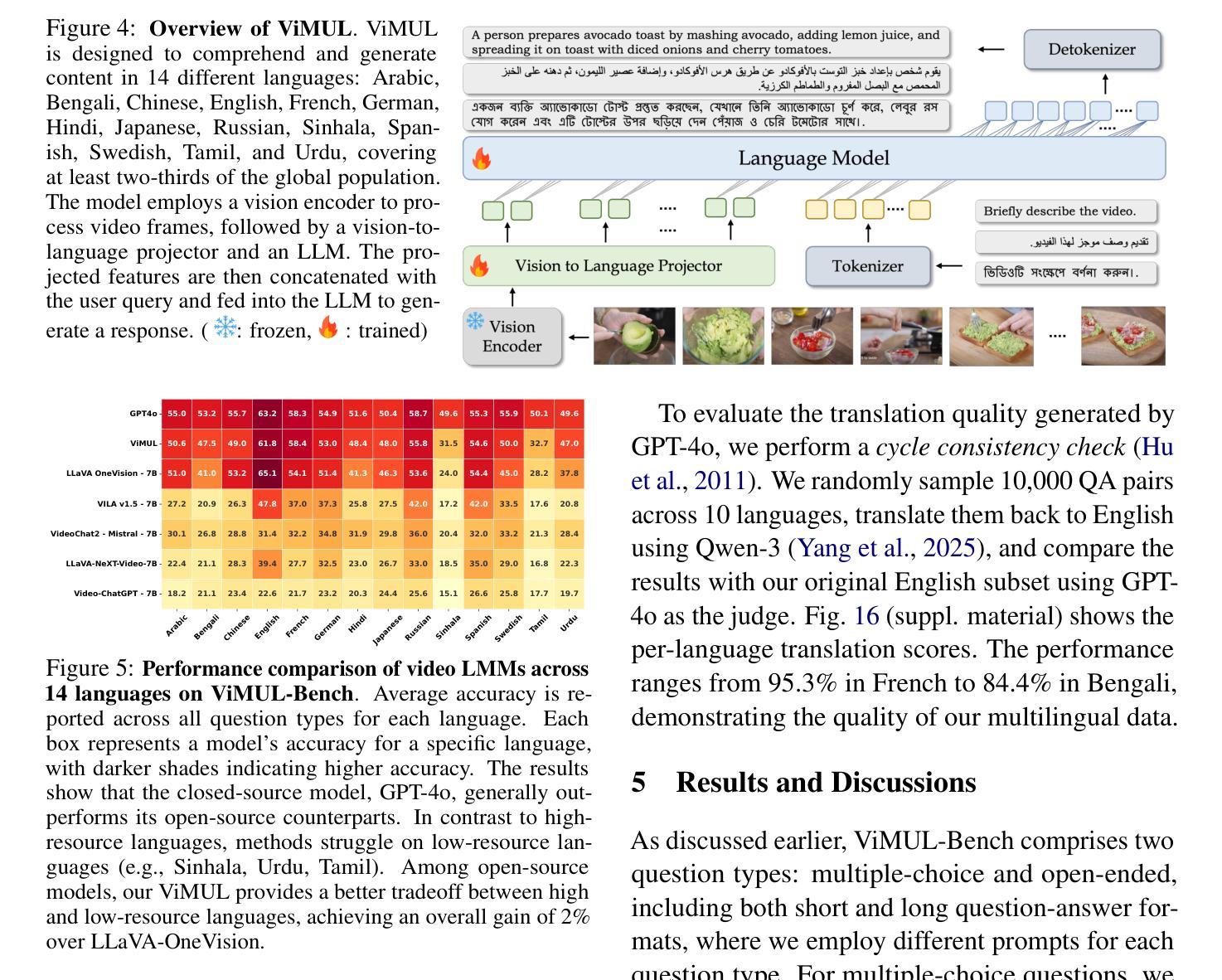
Optimal Transport Driven Asymmetric Image-to-Image Translation for Nuclei Segmentation of Histological Images
Authors:Suman Mahapatra, Pradipta Maji
Segmentation of nuclei regions from histological images enables morphometric analysis of nuclei structures, which in turn helps in the detection and diagnosis of diseases under consideration. To develop a nuclei segmentation algorithm, applicable to different types of target domain representations, image-to-image translation networks can be considered as they are invariant to target domain image representations. One of the important issues with image-to-image translation models is that they fail miserably when the information content between two image domains are asymmetric in nature. In this regard, the paper introduces a new deep generative model for segmenting nuclei structures from histological images. The proposed model considers an embedding space for handling information-disparity between information-rich histological image space and information-poor segmentation map domain. Integrating judiciously the concepts of optimal transport and measure theory, the model develops an invertible generator, which provides an efficient optimization framework with lower network complexity. The concept of invertible generator automatically eliminates the need of any explicit cycle-consistency loss. The proposed model also introduces a spatially-constrained squeeze operation within the framework of invertible generator to maintain spatial continuity within the image patches. The model provides a better trade-off between network complexity and model performance compared to other existing models having complex network architectures. The performance of the proposed deep generative model, along with a comparison with state-of-the-art nuclei segmentation methods, is demonstrated on publicly available histological image data sets.
从组织学图像中分割核区域,能够对核结构进行形态计量分析,这进而有助于对所考虑的疾病进行检测和诊断。为了开发适用于不同类型目标域表示的核分割算法,可以考虑图像到图像的翻译网络,因为它们对目标域图像表示具有不变性。图像到图像翻译模型的一个重要问题是,当两个图像域之间的信息内容在本质上是不对称的时候,这些模型就会彻底失败。在这方面,论文介绍了一种用于从组织学图像中分割核结构的新型深度生成模型。所提出模型考虑了一个嵌入空间,以处理信息丰富的组织学图像空间与信息贫乏的分割图域之间的信息差异。通过巧妙地融合最优传输和测度论的概念,该模型开发了一个可逆生成器,提供了一个有效的优化框架,降低了网络复杂性。可逆生成器的概念自动消除了任何显式循环一致性的需要。所提出模型还在可逆生成器的框架内引入了空间约束的挤压操作,以保持图像斑块内的空间连续性。与其他具有复杂网络架构的现有模型相比,该模型在网络复杂度和模型性能之间提供了更好的权衡。所提出深度生成模型的性能,以及与前述最先进的核分割方法的比较,都在公开可用的组织学图像数据集上进行了演示。
论文及项目相关链接
PDF 13 pages, 8 figures
Summary:
核区域分割有助于形态计量分析,有助于检测诊断疾病。针对图像信息内容不对称问题,本文提出一种基于深度生成模型的细胞核分割方法。该模型引入嵌入空间处理图像间信息差异,并采用最优传输和度量理论概念,开发了一个可反转生成器以降低网络复杂度并提供有效优化框架。新模型在保证空间连续性的同时实现了与现有模型的良好权衡,性能已在公开可用的病理图像数据集上进行了展示。
Key Takeaways:
- 核区域分割有助于疾病的检测与诊断。
- 图像分割算法需要适应不同目标域表示类型。
- 图像到图像的翻译模型在处理信息内容不对称时可能失效。
- 本文提出一种基于深度生成模型的细胞核分割新方法,解决了信息贫瘠的分割映射域与丰富的组织学图像空间之间的信息差异问题。
- 模型结合了最优传输和度量理论概念,提出了一个可反转生成器,优化了网络复杂性并消除了对显式循环一致性损失的依赖。
- 模型引入了空间约束挤压操作来维持图像斑块的空间连续性。
点此查看论文截图

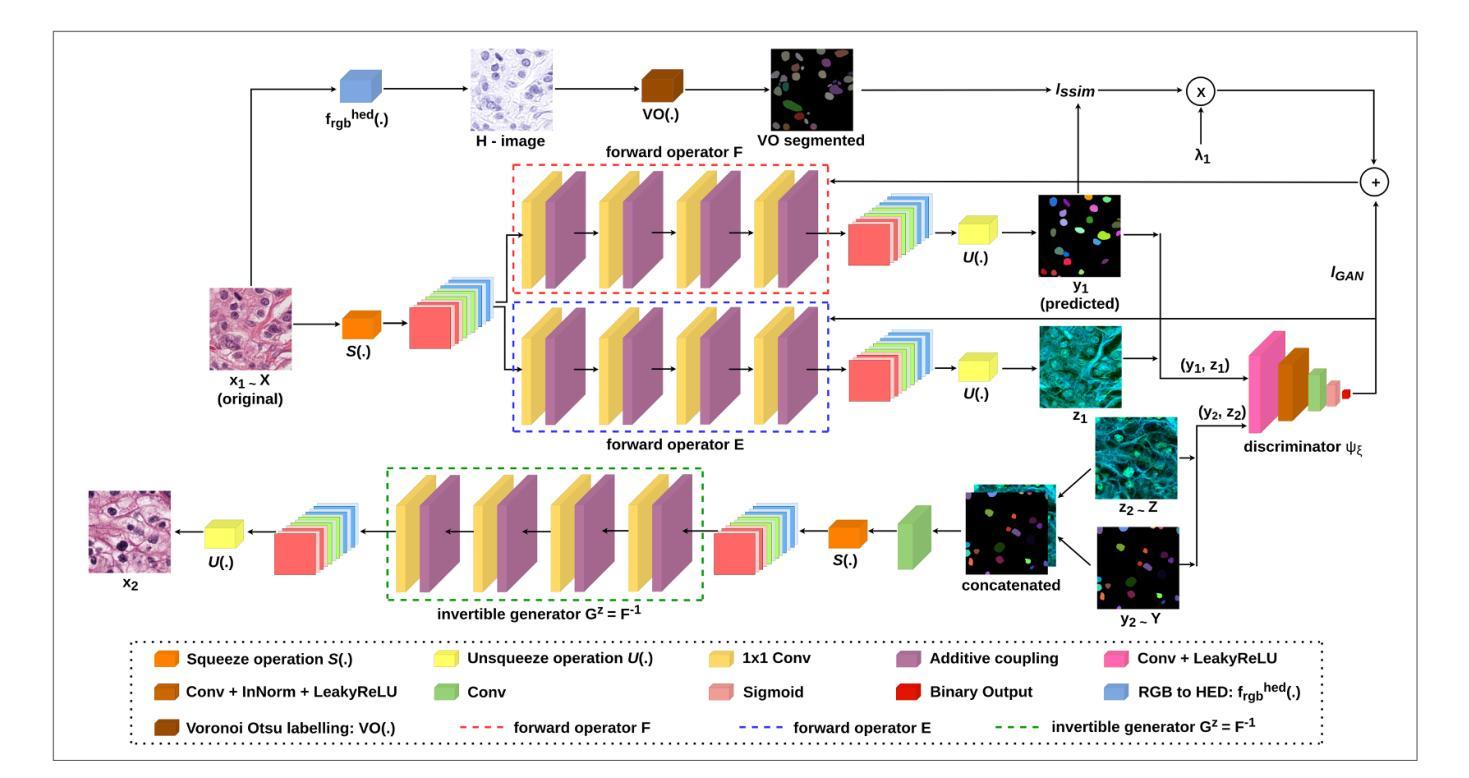

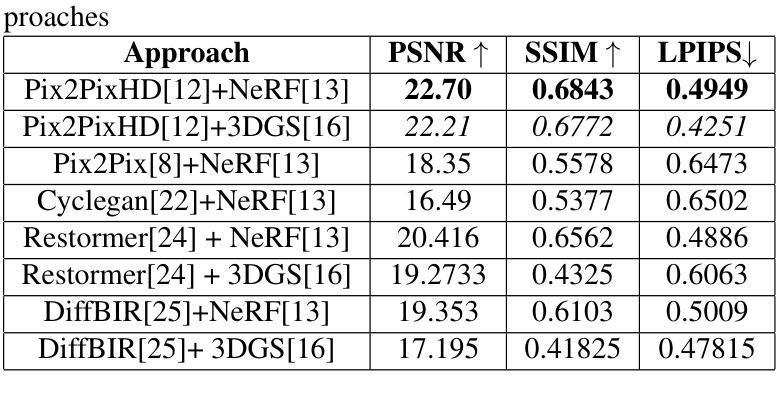
SPC to 3D: Novel View Synthesis from Binary SPC via I2I translation
Authors:Sumit Sharma, Gopi Raju Matta, Kaushik Mitra
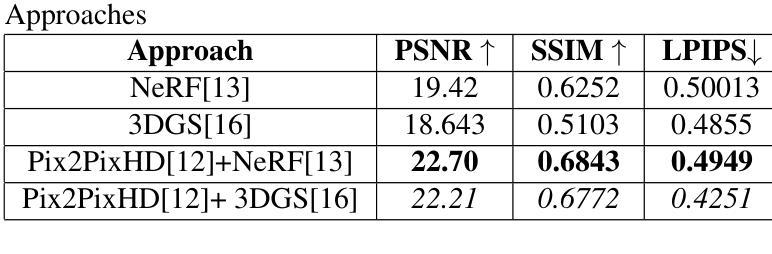
Single Photon Avalanche Diodes (SPADs) represent a cutting-edge imaging technology, capable of detecting individual photons with remarkable timing precision. Building on this sensitivity, Single Photon Cameras (SPCs) enable image capture at exceptionally high speeds under both low and high illumination. Enabling 3D reconstruction and radiance field recovery from such SPC data holds significant promise. However, the binary nature of SPC images leads to severe information loss, particularly in texture and color, making traditional 3D synthesis techniques ineffective. To address this challenge, we propose a modular two-stage framework that converts binary SPC images into high-quality colorized novel views. The first stage performs image-to-image (I2I) translation using generative models such as Pix2PixHD, converting binary SPC inputs into plausible RGB representations. The second stage employs 3D scene reconstruction techniques like Neural Radiance Fields (NeRF) or Gaussian Splatting (3DGS) to generate novel views. We validate our two-stage pipeline (Pix2PixHD + Nerf/3DGS) through extensive qualitative and quantitative experiments, demonstrating significant improvements in perceptual quality and geometric consistency over the alternative baseline.
单光子雪崩二极管(SPAD)代表了一种前沿的成像技术,能够以惊人的时间精度检测单个光子。基于此灵敏度,单光子相机(SPC)能够在低光照和高光照条件下以极高的速度捕获图像。从这样的SPC数据中实现3D重建和辐射场恢复具有巨大的潜力。然而,SPC图像的二进制特性导致信息严重丢失,特别是在纹理和颜色方面,使得传统的3D合成技术无效。为了解决这一挑战,我们提出了一种模块化两阶段框架,将二进制SPC图像转化为高质量彩色新颖视图。第一阶段使用生成模型(如Pix2PixHD)进行图像到图像(I2I)翻译,将二进制SPC输入转换为可信的RGB表示。第二阶段采用3D场景重建技术(如神经辐射场(NeRF)或高斯喷绘(3DGS))生成新颖视图。我们通过大量的定性和定量实验验证了我们的两阶段管道(Pix2PixHD + NeRF/3DGS),在感知质量和几何一致性方面相对于替代基线表现出了显著改进。
论文及项目相关链接
PDF Accepted for publication at ICIP 2025
Summary
单光子雪崩二极管(SPAD)是前沿成像技术,能检测单个光子并具有出色时间精度。基于此技术的单光子相机(SPC)可在高、低光照下实现超高速成像。从SPC数据中重建3D和恢复辐射场展现巨大潜力。但SPC图像的二进制特性导致纹理和色彩信息大量损失,传统3D合成技术难以应对。为解决此挑战,我们提出模块化两阶段框架,将二进制SPC图像转化为高质量彩色新颖视图。第一阶段使用Pix2PixHD等生成模型进行图像到图像(I2I)翻译,将二进制SPC输入转化为可信的RGB表示。第二阶段采用神经网络辐射场(NeRF)或高斯喷绘(3DGS)等3D场景重建技术生成新颖视图。我们通过大量定性和定量实验验证了Pix2PixHD + Nerf/3DGS的两阶段管道的有效性,在感知质量和几何一致性方面相较于其他基线方法表现出显著改进。
Key Takeaways
- 单光子雪崩二极管(SPAD)能检测单个光子并具有出色时间精度,为高速成像提供了可能。
- 单光子相机(SPC)可实现低光照和高光照下的超高速成像。
3.SPC数据的3D重建和辐射场恢复具有巨大潜力。
4.SPC图像的二进制特性导致信息和色彩纹理大量损失,使得传统3D合成技术难以应用。
5.为解决此挑战,提出模块化两阶段框架,第一阶段将SPC图像转化为RGB图像,第二阶段进行3D场景重建生成新颖视图。
6.使用Pix2PixHD等生成模型进行图像到图像(I2I)翻译。
点此查看论文截图


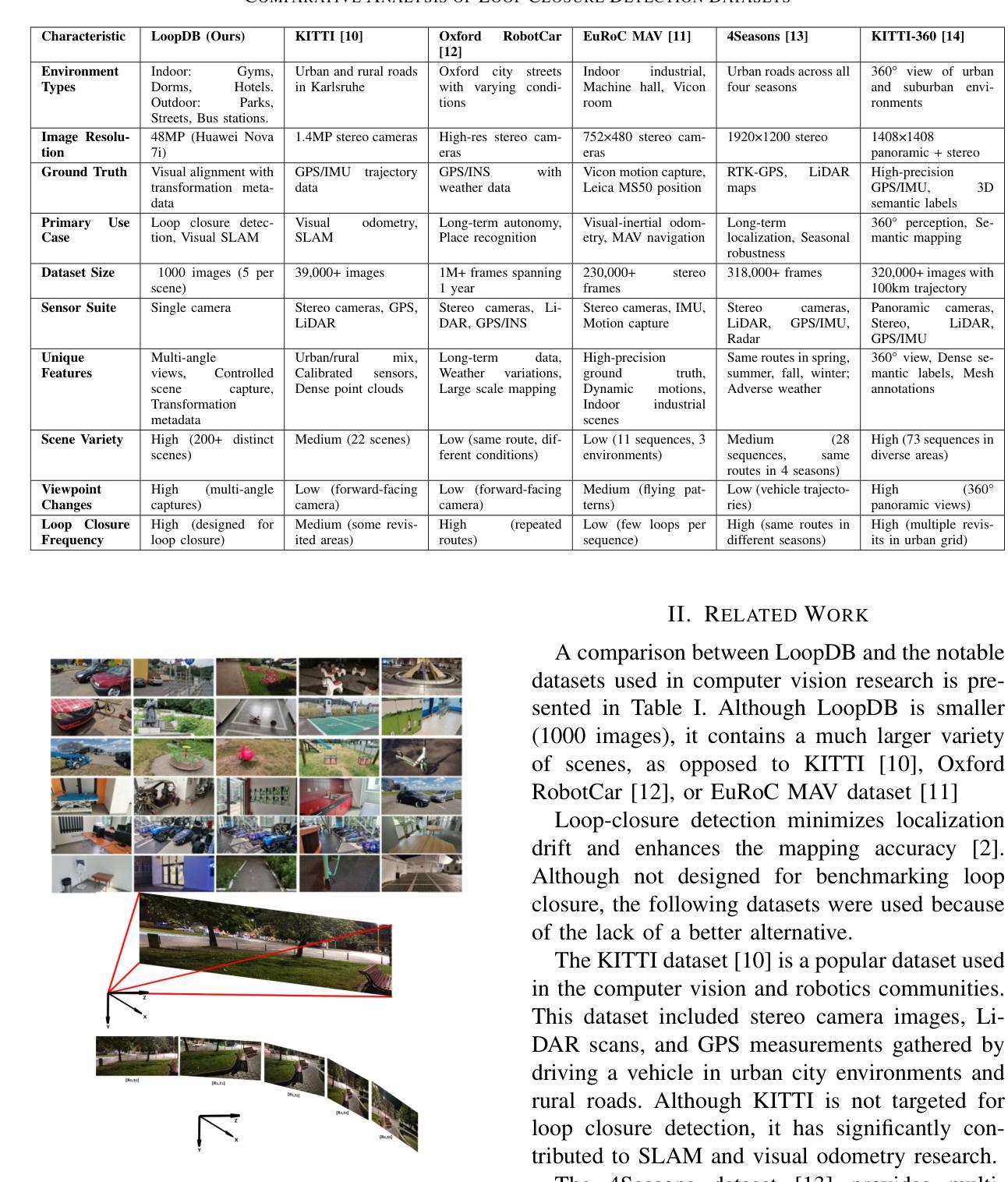
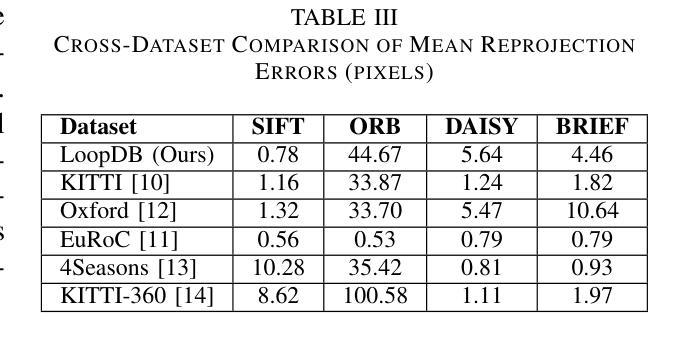
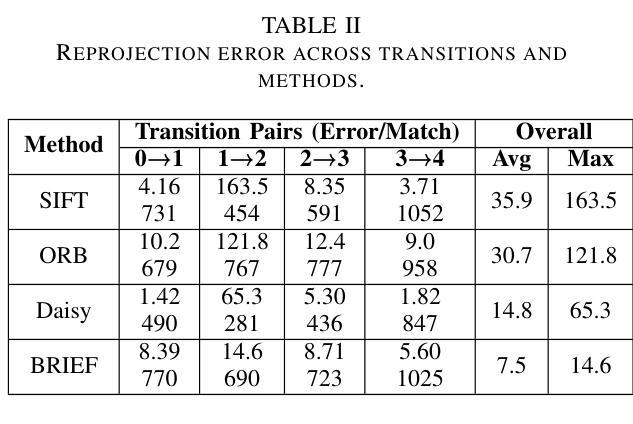
LoopDB: A Loop Closure Dataset for Large Scale Simultaneous Localization and Mapping
Authors:Mohammad-Maher Nakshbandi, Ziad Sharawy, Dorian Cojocaru, Sorin Grigorescu
In this study, we introduce LoopDB, which is a challenging loop closure dataset comprising over 1000 images captured across diverse environments, including parks, indoor scenes, parking spaces, as well as centered around individual objects. Each scene is represented by a sequence of five consecutive images. The dataset was collected using a high resolution camera, providing suitable imagery for benchmarking the accuracy of loop closure algorithms, typically used in simultaneous localization and mapping. As ground truth information, we provide computed rotations and translations between each consecutive images. Additional to its benchmarking goal, the dataset can be used to train and fine-tune loop closure methods based on deep neural networks. LoopDB is publicly available at https://github.com/RovisLab/LoopDB.
本研究中,我们引入了LoopDB,这是一个具有挑战性的闭环数据集,包含1000张以上在不同环境下捕获的图像,包括公园、室内场景、停车位,以及围绕单个物体的场景。每个场景由五张连续图像序列表示。该数据集使用高分辨率相机收集,为评估闭环算法的准确性提供了合适的图像,通常用于同时定位和地图构建。作为地面真实信息,我们提供了每两张连续图像之间的计算旋转和平移信息。除了其基准测试目标之外,该数据集还可用于训练和微调基于深度神经网络的闭环方法。LoopDB可在https://github.com/RovisLab/LoopDB公开获取。
论文及项目相关链接
Summary
本研究介绍了LoopDB数据集,它是一个包含超过一千张图像的挑战性闭环数据集,图像拍摄自公园、室内场景、停车场等不同环境,以及围绕单个物体的场景。每个场景由五张连续图像组成。该数据集使用高分辨率相机收集,适合评估闭环算法(常用于同时定位和地图构建)的准确性。作为地面真实信息,我们提供了每两张连续图像之间的计算旋转和平移信息。除了作为基准测试目标外,该数据集也可用于训练和微调基于深度神经网络的闭环方法。LoopDB可在https://github.com/RovisLab/LoopDB公开访问。
Key Takeaways
- LoopDB是一个包含多样环境的闭环数据集,图像数量超过一千张。
- 数据集中的每个场景由五张连续图像表示。
- 数据集使用高分辨率相机收集,适用于评估闭环算法准确性。
- 作为地面真实信息,提供了每两张连续图像间的旋转和平移数据。
- LoopDB不仅用于基准测试,还可用于训练和微调基于深度神经网络的闭环方法。
- 该数据集公开可用,方便研究者和开发者使用。
点此查看论文截图



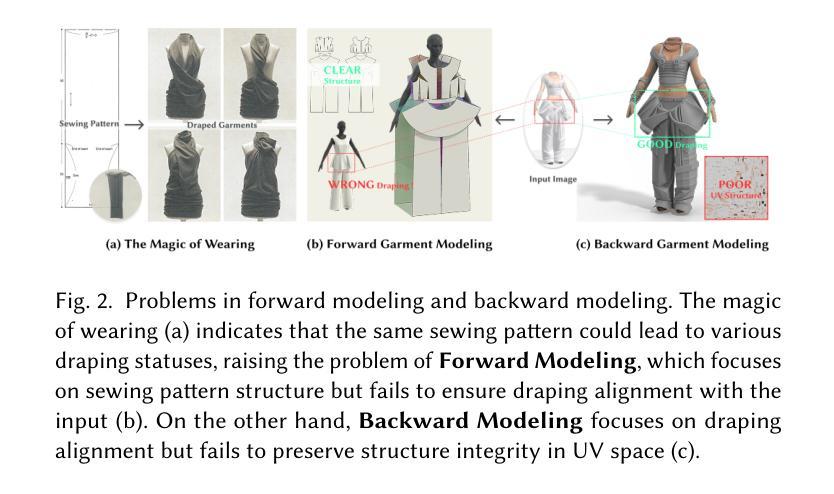
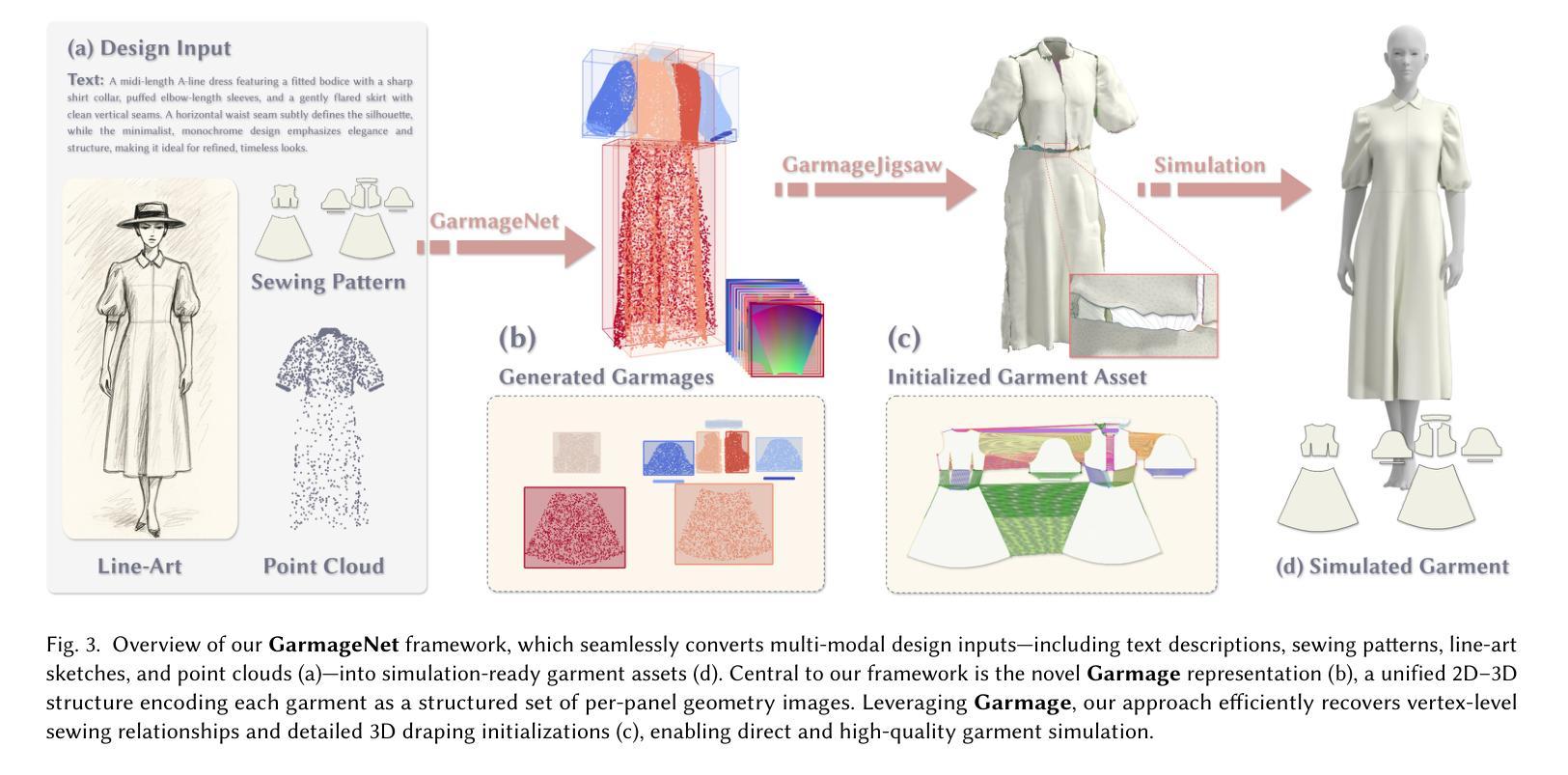
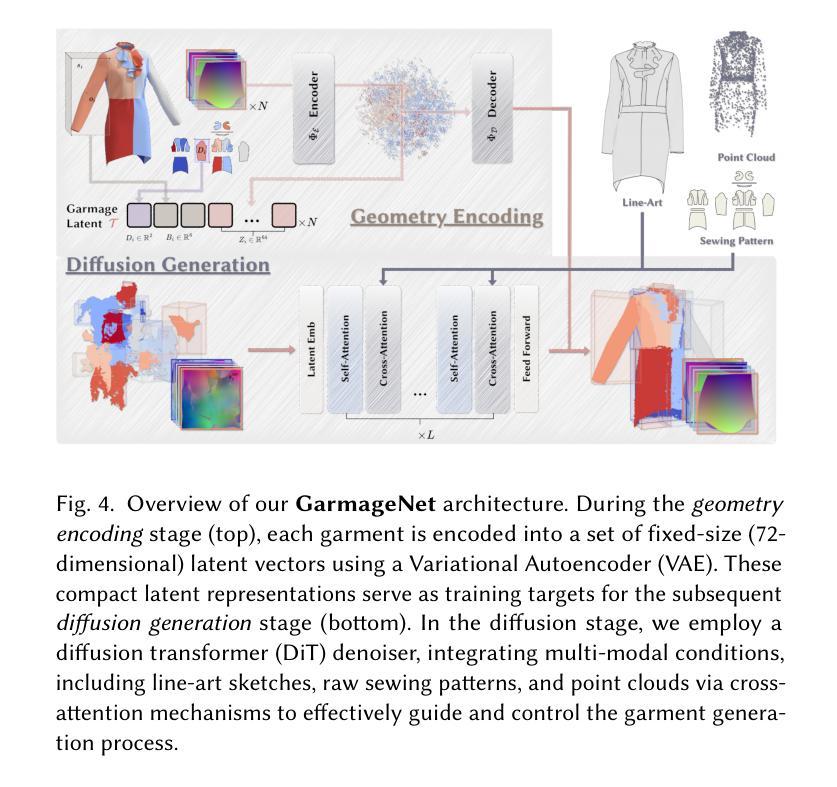
GarmageNet: A Multimodal Generative Framework for Sewing Pattern Design and Generic Garment Modeling
Authors:Siran Li, Chen Liu, Ruiyang Liu, Zhendong Wang, Gaofeng He, Yong-Lu Li, Xiaogang Jin, Huamin Wang
Realistic digital garment modeling remains a labor-intensive task due to the intricate process of translating 2D sewing patterns into high-fidelity, simulation-ready 3D garments. We introduce GarmageNet, a unified generative framework that automates the creation of 2D sewing patterns, the construction of sewing relationships, and the synthesis of 3D garment initializations compatible with physics-based simulation. Central to our approach is Garmage, a novel garment representation that encodes each panel as a structured geometry image, effectively bridging the semantic and geometric gap between 2D structural patterns and 3D garment shapes. GarmageNet employs a latent diffusion transformer to synthesize panel-wise geometry images and integrates GarmageJigsaw, a neural module for predicting point-to-point sewing connections along panel contours. To support training and evaluation, we build GarmageSet, a large-scale dataset comprising over 10,000 professionally designed garments with detailed structural and style annotations. Our method demonstrates versatility and efficacy across multiple application scenarios, including scalable garment generation from multi-modal design concepts (text prompts, sketches, photographs), automatic modeling from raw flat sewing patterns, pattern recovery from unstructured point clouds, and progressive garment editing using conventional instructions-laying the foundation for fully automated, production-ready pipelines in digital fashion. Project page: https://style3d.github.io/garmagenet.
真实的数字服装建模仍然是一个劳动密集型的任务,这主要是因为将二维缝纫图案转化为高保真、可用于模拟的三维服装的过程非常复杂。我们引入了GarmageNet,这是一个统一的生成框架,可以自动创建二维缝纫图案、构建缝纫关系,并合成兼容基于物理模拟的三维服装初始化。我们的方法的核心是Garmage,这是一种新的服装表示方法,它将每个面板编码为一个结构化的几何图像,有效地弥合了二维结构图案和三维服装形状之间的语义和几何差距。GarmageNet采用潜在扩散变压器来合成面板式的几何图像,并集成了GarmageJigsaw,这是一个用于预测面板轮廓上点对点缝合连接的神经模块。为了支持和评估,我们构建了GarmageSet,这是一个由超过10000件专业设计的服装组成的大规模数据集,具有详细的结构和风格注释。我们的方法展示了在多个应用场景下的通用性和有效性,包括从多模式设计概念(文本提示、草图、照片)生成可扩展的服装、从原始平面缝纫图案自动建模、从非结构化的点云中恢复图案,以及使用常规指令进行渐进式的服装编辑——这为全自动、生产准备的数字时尚管道奠定了基础。项目页面:https://style3d.github.io/garmagenet。
论文及项目相关链接
Summary
该文本介绍了一种名为GarmageNet的统一生成框架,该框架可自动化创建2D缝纫图案、构建缝纫关系,并合成可用于物理模拟的3D服装初始化。其核心方法是通过一种新的服装表示方式Garmage,将每个面板编码为结构化几何图像,有效桥接了2D结构图案与3D服装形状之间的语义和几何差距。GarmageNet采用潜在扩散变压器合成面板级的几何图像,并集成了GarmageJigsaw,一个用于预测面板轮廓上点对点缝合连接的神经网络模块。此外,为了支持训练和评估,构建了包含超过10,000个专业设计服装的GarmageSet大型数据集,具有详细的结构和风格注释。此方法在多种应用场景中表现出通用性和有效性,包括从多模式设计概念(文本提示、草图、照片)生成服装、从原始平面缝纫图案自动建模、从非结构化的点云恢复图案,以及使用常规指令进行渐进式服装编辑,为数字时尚领域中的全自动生产准备管道奠定了基础。
Key Takeaways
- GarmageNet是一个自动化创建2D缝纫图案、构建缝纫关系并合成3D服装的生成框架。
- Garmage是一种新的服装表示方法,将每个面板编码为结构化几何图像,以桥接2D和3D之间的语义和几何差距。
- GarmageNet使用潜在扩散变压器和GarmageJigsaw来合成面板级的几何图像并预测点对点的缝合连接。
- GarmageSet数据集包含大量专业设计的服装,具有详细的结构和风格注释,用于支持训练和评估。
- GarmageNet具有多种应用场景,包括从多模式设计概念生成服装、从原始平面缝纫图案建模、从点云恢复图案以及使用常规指令进行渐进式服装编辑。
- GarmageNet方法为数字时尚领域的全自动生产准备管道奠定了基础。
点此查看论文截图

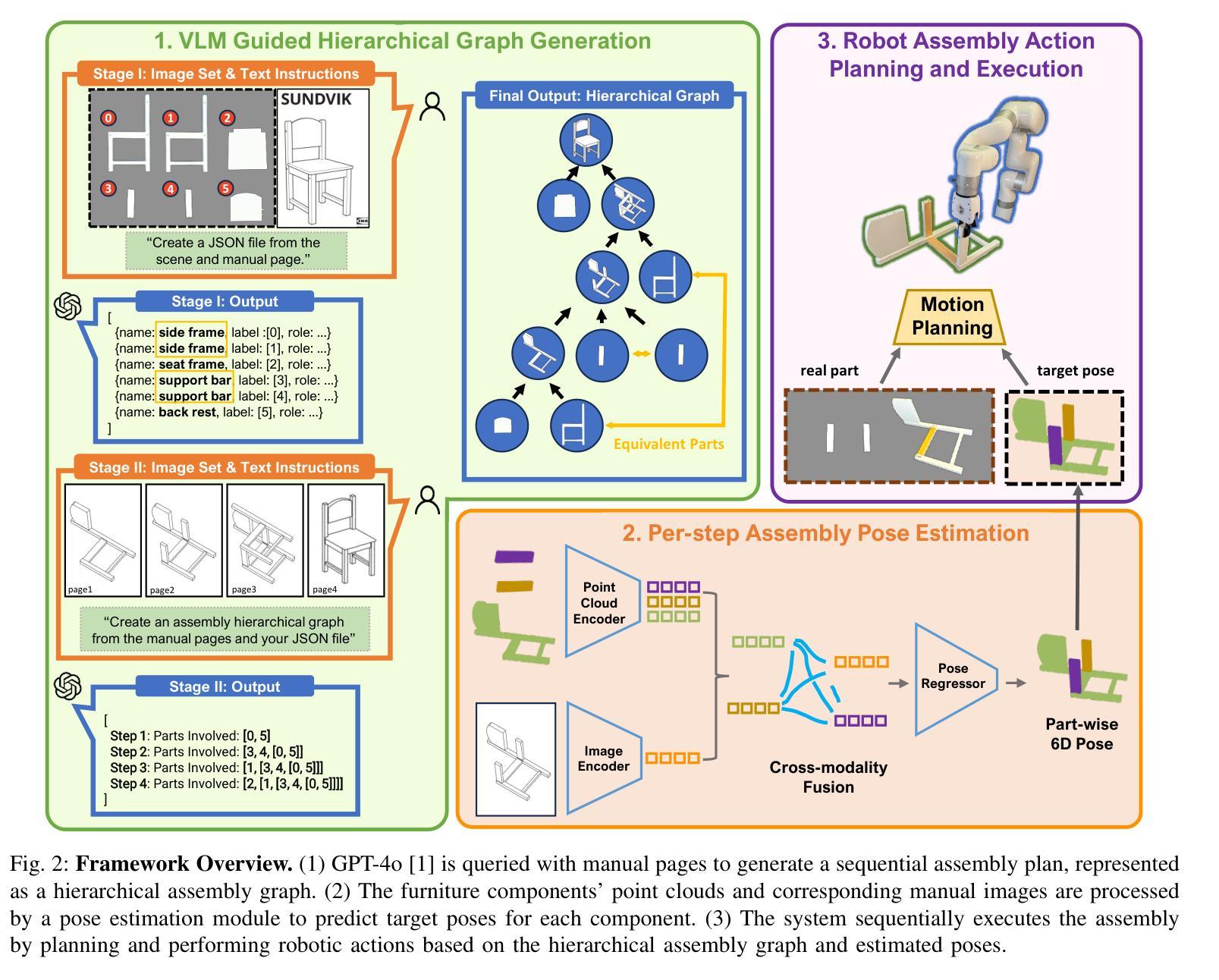
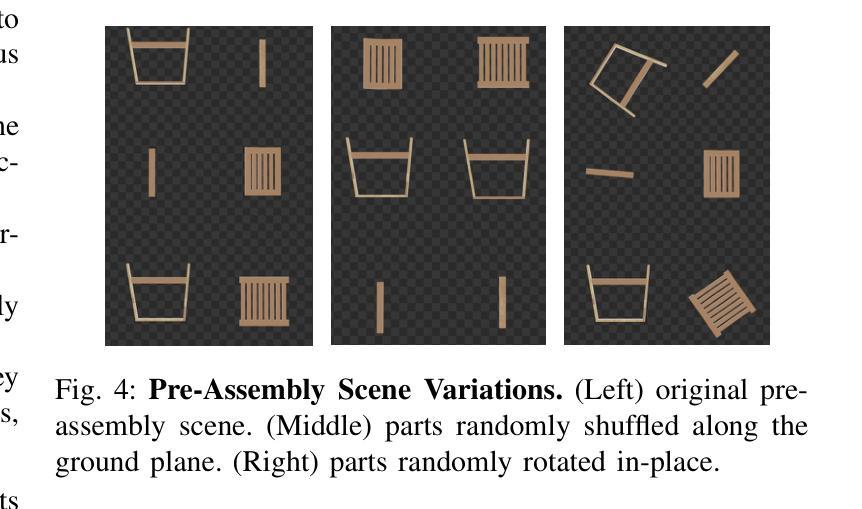
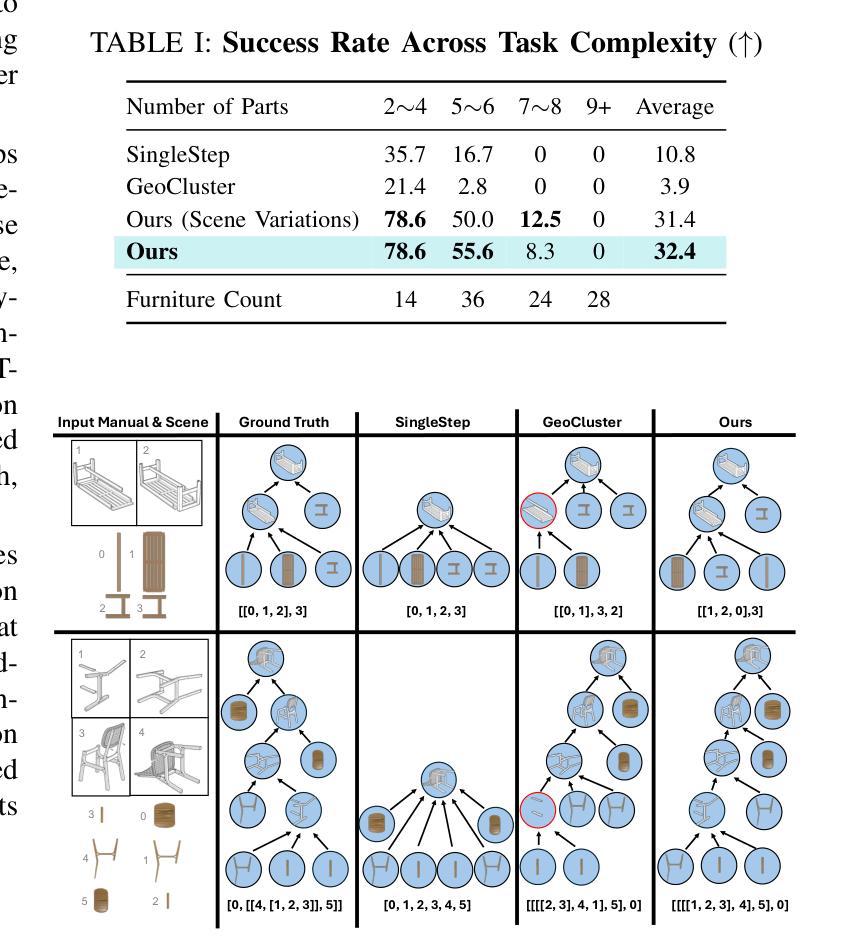
Manual2Skill: Learning to Read Manuals and Acquire Robotic Skills for Furniture Assembly Using Vision-Language Models
Authors:Chenrui Tie, Shengxiang Sun, Jinxuan Zhu, Yiwei Liu, Jingxiang Guo, Yue Hu, Haonan Chen, Junting Chen, Ruihai Wu, Lin Shao
Humans possess an extraordinary ability to understand and execute complex manipulation tasks by interpreting abstract instruction manuals. For robots, however, this capability remains a substantial challenge, as they cannot interpret abstract instructions and translate them into executable actions. In this paper, we present Manual2Skill, a novel framework that enables robots to perform complex assembly tasks guided by high-level manual instructions. Our approach leverages a Vision-Language Model (VLM) to extract structured information from instructional images and then uses this information to construct hierarchical assembly graphs. These graphs represent parts, subassemblies, and the relationships between them. To facilitate task execution, a pose estimation model predicts the relative 6D poses of components at each assembly step. At the same time, a motion planning module generates actionable sequences for real-world robotic implementation. We demonstrate the effectiveness of Manual2Skill by successfully assembling several real-world IKEA furniture items. This application highlights its ability to manage long-horizon manipulation tasks with both efficiency and precision, significantly enhancing the practicality of robot learning from instruction manuals. This work marks a step forward in advancing robotic systems capable of understanding and executing complex manipulation tasks in a manner akin to human capabilities.Project Page: https://owensun2004.github.io/Furniture-Assembly-Web/
人类拥有通过解读抽象说明书来理解并执行复杂操作任务的不凡能力。然而,对于机器人来说,这一能力仍是一个巨大挑战,因为它们无法解读抽象指令并将其翻译成可执行动作。在本文中,我们提出了Manual2Skill这一新型框架,使机器人能够在高级手册指令的引导下执行复杂的装配任务。我们的方法利用视觉语言模型(VLM)从指令图像中提取结构化信息,然后使用这些信息构建分层装配图。这些图代表部件、子组件和它们之间的关系。为了促进任务执行,姿态估计模型预测每个装配步骤中组件的相对6D姿态。同时,运动规划模块为真实世界的机器人实现生成可操作序列。我们通过成功组装几个真实世界的宜家家具产品来证明Manual2Skill的有效性。这一应用突出其在效率和精确度方面的能力,能够管理长期操作任务,显著提高了机器人从说明书学习的实用性。这项工作标志着在推进机器人系统方面取得了进展,使其能够以类似于人类的能力理解和执行复杂的操作任务。项目页面:https://owensun2004.github.io/Furniture-Assembly-Web/。
论文及项目相关链接
Summary:人类能解读抽象说明书并执行复杂的操作任务,但机器人在这方面仍面临挑战。本研究提出了Manual2Skill框架,使机器人能够根据高级手册指令执行复杂的装配任务。该框架利用视觉语言模型从指令图像中提取结构化信息,构建层次装配图,并通过姿态估计模型预测每个装配步骤组件的6D姿态,同时运动规划模块生成可用于真实机器人实施的动作序列。成功装配IKEA家具的实践应用展示了其管理长期操作任务的能力和效率,提高了机器人从说明书学习的实用性。
Key Takeaways:
- 机器人执行复杂操作任务的能力受限于无法解读抽象指令并转化为可执行动作。
- Manual2Skill框架利用视觉语言模型处理指令图像并构建层次装配图,帮助机器人完成复杂装配任务。
- 姿态估计模型在装配过程中预测组件的6D姿态。
- 运动规划模块为机器人生成实际执行动作的顺序。
- 通过成功装配IKEA家具的实践应用,展示了该框架在机器人学习方面的有效性。
- Manual2Skill框架提高了机器人处理长期操作任务的能力和效率。
点此查看论文截图

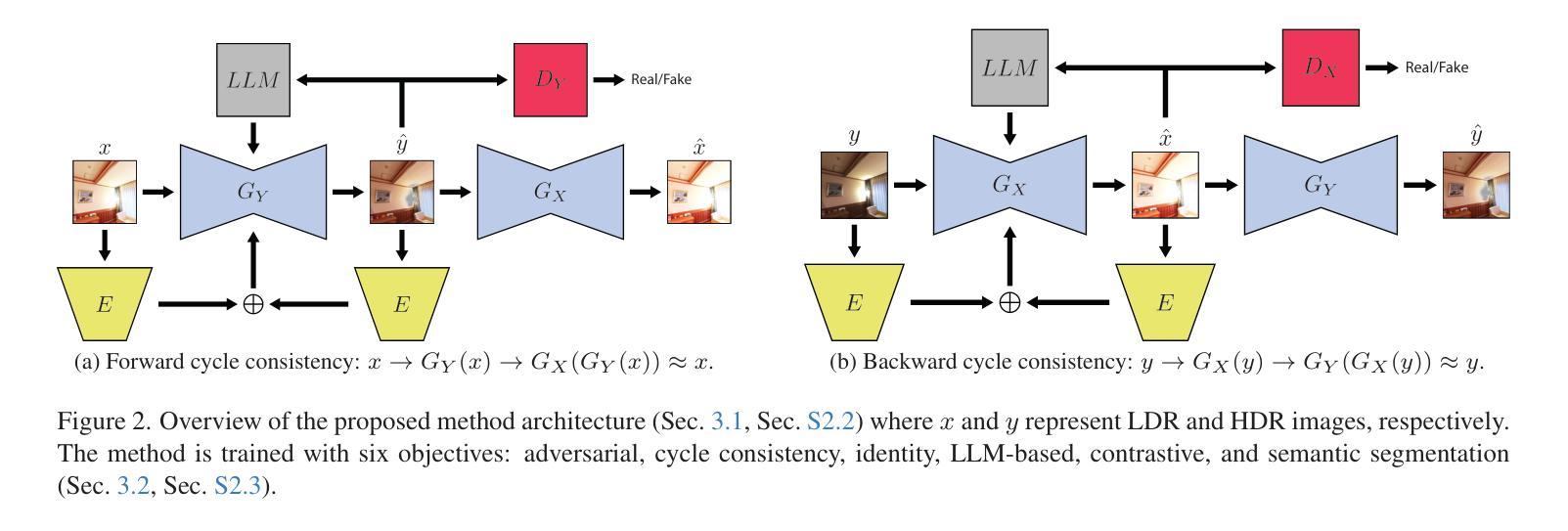
LLM-HDR: Bridging LLM-based Perception and Self-Supervision for Unpaired LDR-to-HDR Image Reconstruction
Authors:Hrishav Bakul Barua, Kalin Stefanov, Lemuel Lai En Che, Abhinav Dhall, KokSheik Wong, Ganesh Krishnasamy
The translation of Low Dynamic Range (LDR) to High Dynamic Range (HDR) images is an important computer vision task. There is a significant amount of research utilizing both conventional non-learning methods and modern data-driven approaches, focusing on using both single-exposed and multi-exposed LDR for HDR image reconstruction. However, most current state-of-the-art methods require high-quality paired {LDR,HDR} datasets for model training. In addition, there is limited literature on using unpaired datasets for this task, that is, the model learns a mapping between domains, i.e., {LDR,HDR}. This paper proposes LLM-HDR, a method that integrates the perception of Large Language Models (LLM) into a modified semantic- and cycle-consistent adversarial architecture that utilizes unpaired {LDR,HDR} datasets for training. The method introduces novel artifact- and exposure-aware generators to address visual artifact removal and an encoder and loss to address semantic consistency, another under-explored topic. LLM-HDR is the first to use an LLM for the {LDR,HDR} translation task in a self-supervised setup. The method achieves state-of-the-art performance across several benchmark datasets and reconstructs high-quality HDR images. The official website of this work is available at: https://github.com/HrishavBakulBarua/LLM-HDR
将低动态范围(LDR)图像翻译成高动态范围(HDR)图像是一项重要的计算机视觉任务。有大量研究采用传统的非学习方法以及现代的数据驱动方法,重点使用单曝光和多曝光的LDR进行HDR图像重建。然而,大多数目前最前沿的方法都需要高质量配对的{LDR,HDR}数据集来进行模型训练。此外,关于使用未配对数据集完成该任务的文献很少,也就是说,模型学习域之间的映射,即{LDR,HDR}。本文提出了LLM-HDR方法,它将大型语言模型(LLM)的感知能力集成到一个经过修改的语义和循环一致的对抗性架构中,该架构利用未配对的{LDR,HDR}数据集进行训练。该方法引入了新型伪影和曝光感知生成器来解决视觉伪影去除问题,以及解决语义一致性这一尚未深入探讨的问题的编码器和损失函数。LLM-HDR是第一个在自监督设置中使用LLM来完成{LDR,HDR}翻译任务的方法。该方法在多个基准数据集上实现了最先进的性能,并能重建高质量的HDR图像。该工作的官方网站地址为:https://github.com/HrishavBakulBarua/LLM
论文及项目相关链接
Summary:
此文本主要介绍了从低动态范围(LDR)图像到高动态范围(HDR)图像的翻译在计算机视觉任务中的重要性。目前大多数最先进的方法都需要高质量配对的数据集进行模型训练。本文提出了一种名为LLM-HDR的方法,该方法将大型语言模型(LLM)的感知能力融入到一个修改过的语义和循环一致的对抗性架构中,利用未配对的LDR和HDR数据集进行训练。该方法引入了新的伪影感知生成器和曝光感知生成器来解决视觉伪影去除问题,以及一个编码器和损失来解决语义一致性这一尚未探索的问题。LLM-HDR是第一个在自我监督设置中使用LLM进行LDR到HDR翻译任务的方法。该方法在多个基准数据集上取得了最先进的性能,并能重建高质量HDR图像。
Key Takeaways:
- LDR到HDR图像的翻译是计算机视觉领域的一个重要任务。
- 当前的方法大多需要高质量配对的数据集进行模型训练。
- LLM-HDR方法结合了大型语言模型(LLM)的感知能力。
- LLM-HDR采用修改过的语义和循环一致的对抗性架构。
- 该方法利用未配对的LDR和HDR数据集进行训练。
- LLM-HDR通过引入新的伪影感知生成器和曝光感知生成器来解决视觉伪影去除问题。
点此查看论文截图


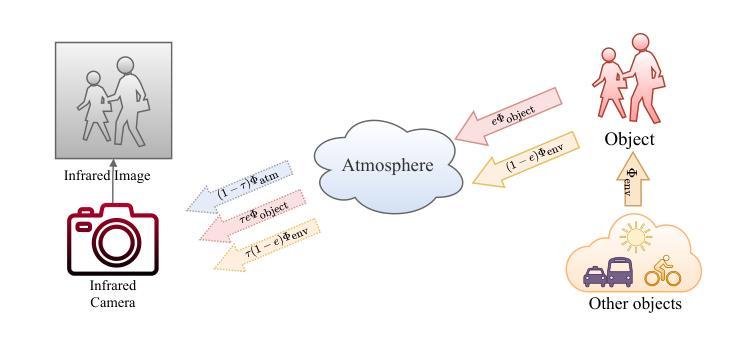
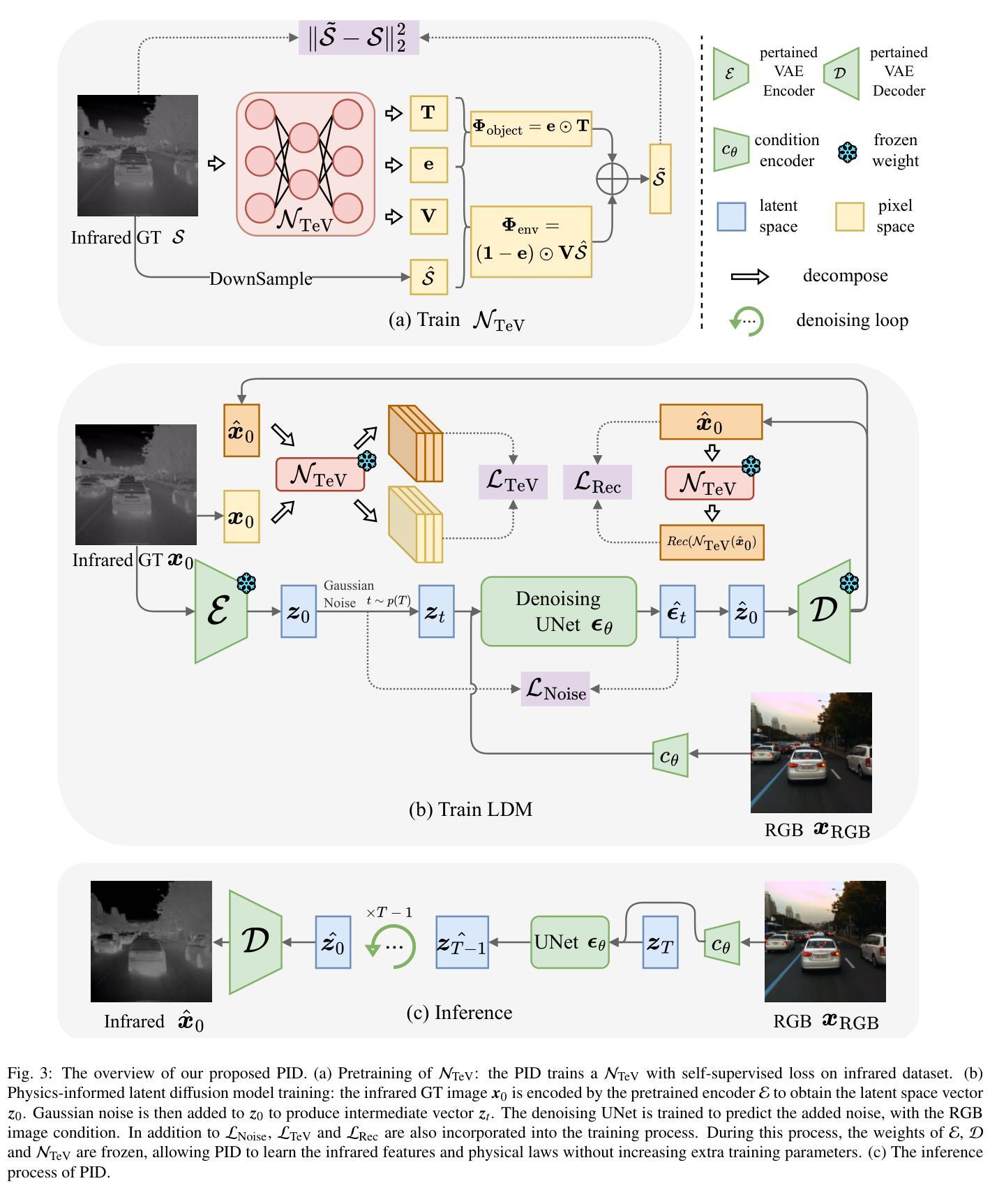
PID: Physics-Informed Diffusion Model for Infrared Image Generation
Authors:Fangyuan Mao, Jilin Mei, Shun Lu, Fuyang Liu, Liang Chen, Fangzhou Zhao, Yu Hu
Infrared imaging technology has gained significant attention for its reliable sensing ability in low visibility conditions, prompting many studies to convert the abundant RGB images to infrared images. However, most existing image translation methods treat infrared images as a stylistic variation, neglecting the underlying physical laws, which limits their practical application. To address these issues, we propose a Physics-Informed Diffusion (PID) model for translating RGB images to infrared images that adhere to physical laws. Our method leverages the iterative optimization of the diffusion model and incorporates strong physical constraints based on prior knowledge of infrared laws during training. This approach enhances the similarity between translated infrared images and the real infrared domain without increasing extra training parameters. Experimental results demonstrate that PID significantly outperforms existing state-of-the-art methods. Our code is available at https://github.com/fangyuanmao/PID.
红外成像技术因其低能见度条件下的可靠感知能力而受到广泛关注,促使许多研究将丰富的RGB图像转换为红外图像。然而,大多数现有的图像翻译方法将红外图像视为风格变化,忽略了其背后的物理定律,这限制了它们的实际应用。为了解决这些问题,我们提出了一种基于物理信息的扩散(PID)模型,用于将RGB图像转换为遵循物理定律的红外图像。我们的方法利用扩散模型的迭代优化,并在训练过程中结合红外定律的先验知识,融入强大的物理约束。这种方法提高了翻译后的红外图像与真实红外域之间的相似性,且没有增加额外的训练参数。实验结果表明,PID显著优于现有最先进的方法。我们的代码可在https://github.com/fangyuanmao/PID处下载。
论文及项目相关链接
PDF Accepted by Pattern Recognition
Summary
红外成像技术在低能见度条件下的可靠感知能力引起了广泛关注,促使许多研究将丰富的RGB图像转换为红外图像。然而,现有的图像翻译方法大多将红外图像视为风格变化,忽略了其背后的物理定律,限制了实际应用。为解决这一问题,我们提出了一个结合物理定律的扩散模型(PID),用于将RGB图像翻译为红外图像。该方法通过扩散模型的迭代优化,并在训练过程中融入基于红外定律的强物理约束。实验结果表明,PID显著优于现有最先进的方法。
Key Takeaways
- 红外成像技术在低能见度条件下具有可靠感知能力,引发广泛关注。
- 现有图像翻译方法多忽略红外图像的物理定律,限制了实际应用。
- 提出的PID模型结合物理定律进行RGB到红外图像的翻译。
- PID模型通过扩散模型的迭代优化,融入强物理约束。
- PID模型在翻译红外图像时,增强了与真实红外领域的相似性。
- 实验结果表明,PID模型显著优于现有最先进的方法。
点此查看论文截图