⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-11 更新
A Culturally-diverse Multilingual Multimodal Video Benchmark & Model
Authors:Bhuiyan Sanjid Shafique, Ashmal Vayani, Muhammad Maaz, Hanoona Abdul Rasheed, Dinura Dissanayake, Mohammed Irfan Kurpath, Yahya Hmaiti, Go Inoue, Jean Lahoud, Md. Safirur Rashid, Shadid Intisar Quasem, Maheen Fatima, Franco Vidal, Mykola Maslych, Ketan Pravin More, Sanoojan Baliah, Hasindri Watawana, Yuhao Li, Fabian Farestam, Leon Schaller, Roman Tymtsiv, Simon Weber, Hisham Cholakkal, Ivan Laptev, Shin’ichi Satoh, Michael Felsberg, Mubarak Shah, Salman Khan, Fahad Shahbaz Khan
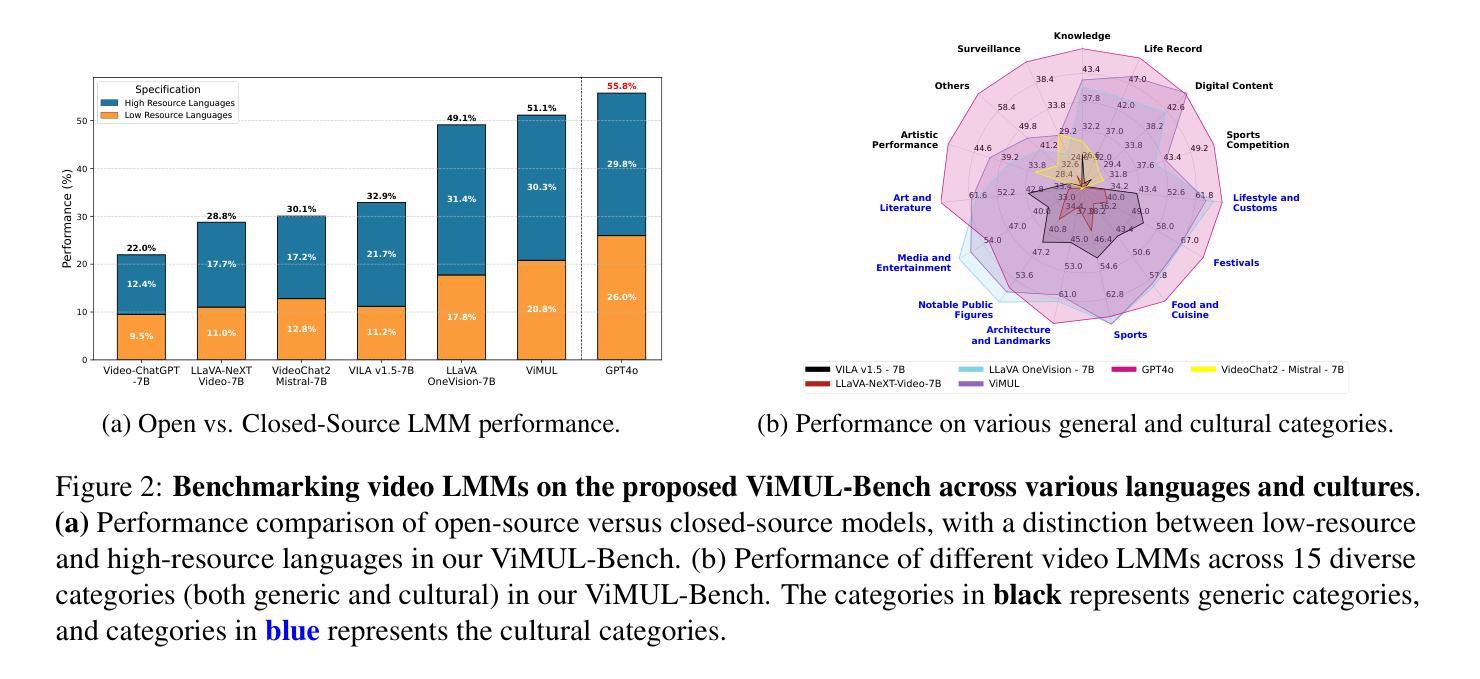
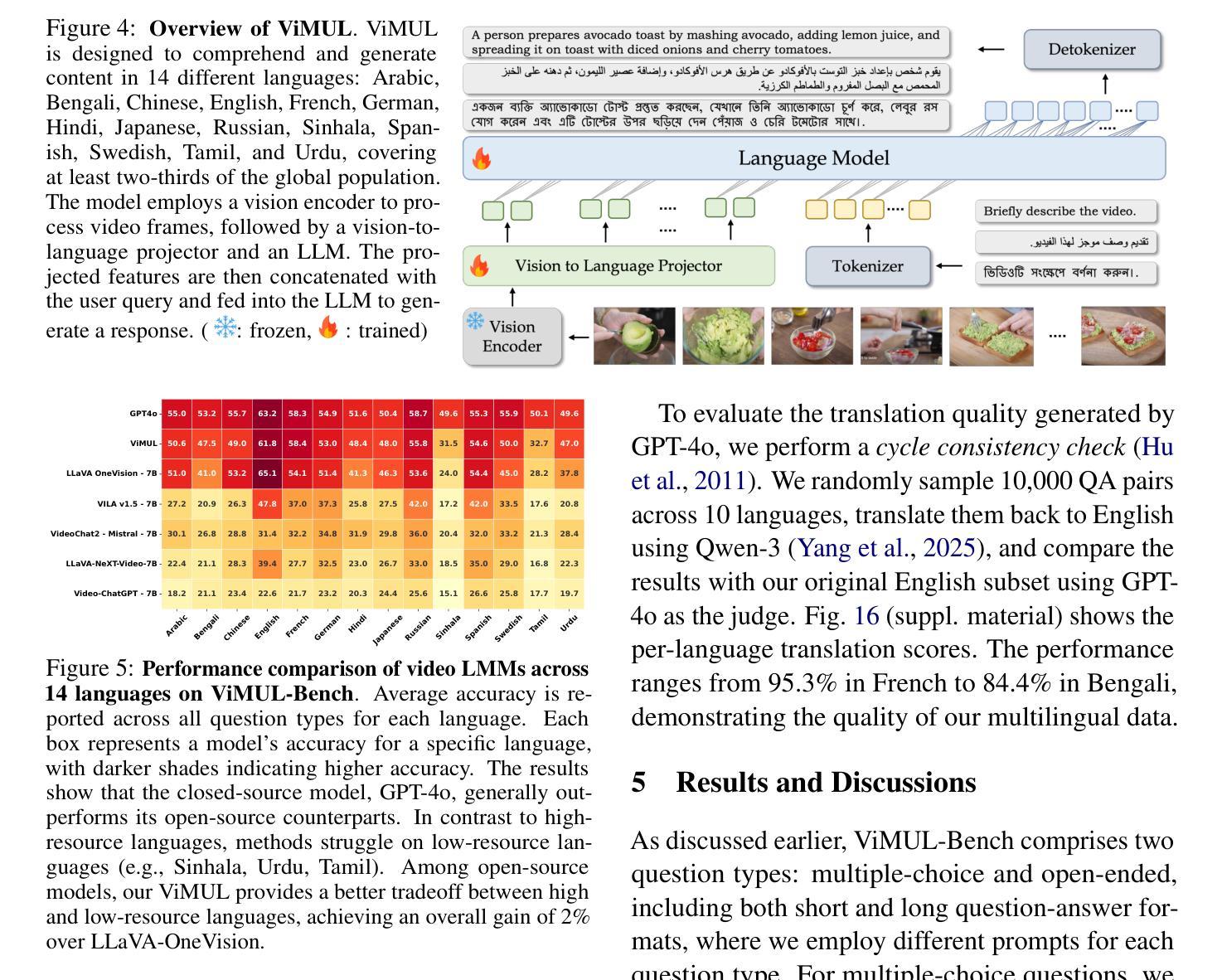
Large multimodal models (LMMs) have recently gained attention due to their effectiveness to understand and generate descriptions of visual content. Most existing LMMs are in English language. While few recent works explore multilingual image LMMs, to the best of our knowledge, moving beyond the English language for cultural and linguistic inclusivity is yet to be investigated in the context of video LMMs. In pursuit of more inclusive video LMMs, we introduce a multilingual Video LMM benchmark, named ViMUL-Bench, to evaluate Video LMMs across 14 languages, including both low- and high-resource languages: English, Chinese, Spanish, French, German, Hindi, Arabic, Russian, Bengali, Urdu, Sinhala, Tamil, Swedish, and Japanese. Our ViMUL-Bench is designed to rigorously test video LMMs across 15 categories including eight culturally diverse categories, ranging from lifestyles and festivals to foods and rituals and from local landmarks to prominent cultural personalities. ViMUL-Bench comprises both open-ended (short and long-form) and multiple-choice questions spanning various video durations (short, medium, and long) with 8k samples that are manually verified by native language speakers. In addition, we also introduce a machine translated multilingual video training set comprising 1.2 million samples and develop a simple multilingual video LMM, named ViMUL, that is shown to provide a better tradeoff between high-and low-resource languages for video understanding. We hope our ViMUL-Bench and multilingual video LMM along with a large-scale multilingual video training set will help ease future research in developing cultural and linguistic inclusive multilingual video LMMs. Our proposed benchmark, video LMM and training data will be publicly released at https://mbzuai-oryx.github.io/ViMUL/.
最近,大型多模态模型(LMMs)由于其理解和生成视觉内容描述的有效性而受到关注。大多数现有的LMMs都是英语。虽然有一些最近的工作探索了多语言图像LMMs,但据我们所知,在视频LMMs的背景下,为了文化和语言的包容性而超越英语尚未被研究。为了寻求更具包容性的视频LMMs,我们引入了一个多语言视频LMM基准测试,名为ViMUL-Bench,可评估涵盖14种语言的视频LMMs,包括低资源和高资源语言:英语、中文、西班牙语、法语、德语、印地语、阿拉伯语、俄语、孟加拉语、乌尔都语、僧伽罗语、泰米尔语、瑞典语和日语。我们的ViMUL-Bench旨在严格测试涵盖15个类别的视频LMMs,其中包括八个文化多样性的类别,从生活方式和节日到食品和仪式,以及从当地地标到重要文化人物。ViMUL-Bench既包括开放性问题(短形式和长形式)和选择题,涵盖各种视频时长(短、中和长),包含经过母语者手动验证的8k样本。此外,我们还引入了一个包含120万样本的机器翻译多语言视频训练集,并开发了一个简单的多语言视频LMM,名为ViMUL,该模型在高资源和低资源语言之间提供了更好的权衡,用于视频理解。我们希望我们的ViMUL-Bench和多语言视频LMM以及大规模多语言视频训练集将有助于未来研究发展文化和语言上更具包容性的多语言视频LMMs。我们提出的基准测试、视频LMM和训练数据将在https://mbzuai-oryx.github.io/ViMUL/上公开发布。
论文及项目相关链接
Summary
本文介绍了一个名为ViMUL-Bench的多语种视频大型模态模型(LMM)基准测试平台,旨在评估视频LMM在14种语言中的表现,包括低资源和高资源语言。该平台涵盖了15个类别,包括文化多样性丰富的类别,如生活方式、节日、食品、仪式、本地地标和著名文化人物等。ViMUL-Bench包含开放性问题(短式和长式)和选择题,涉及各种视频时长,共有8K个经母语者手动验证的样本。此外,还引入了机器翻译的多语种视频训练集和简单的多语种视频LMM——ViMUL,为视频理解在高资源和低资源语言之间提供了更好的权衡。
Key Takeaways
- ViMUL-Bench是一个多语种视频LMM基准测试平台,支持14种语言。
- 平台涵盖15个类别,包括文化多样性丰富的类别。
- ViMUL-Bench包含开放性问题(短式和长式)和选择题,样本数量达8K,且经过母语者手动验证。
- 引入了机器翻译的多语种视频训练集。
- 提出了名为ViMUL的多语种视频LMM。
- ViMUL在视频理解方面在高资源和低资源语言之间提供了更好的权衡。
点此查看论文截图


CAtCh: Cognitive Assessment through Cookie Thief
Authors:Joseph T Colonel, Carolyn Hagler, Guiselle Wismer, Laura Curtis, Jacqueline Becker, Juan Wisnivesky, Alex Federman, Gaurav Pandey
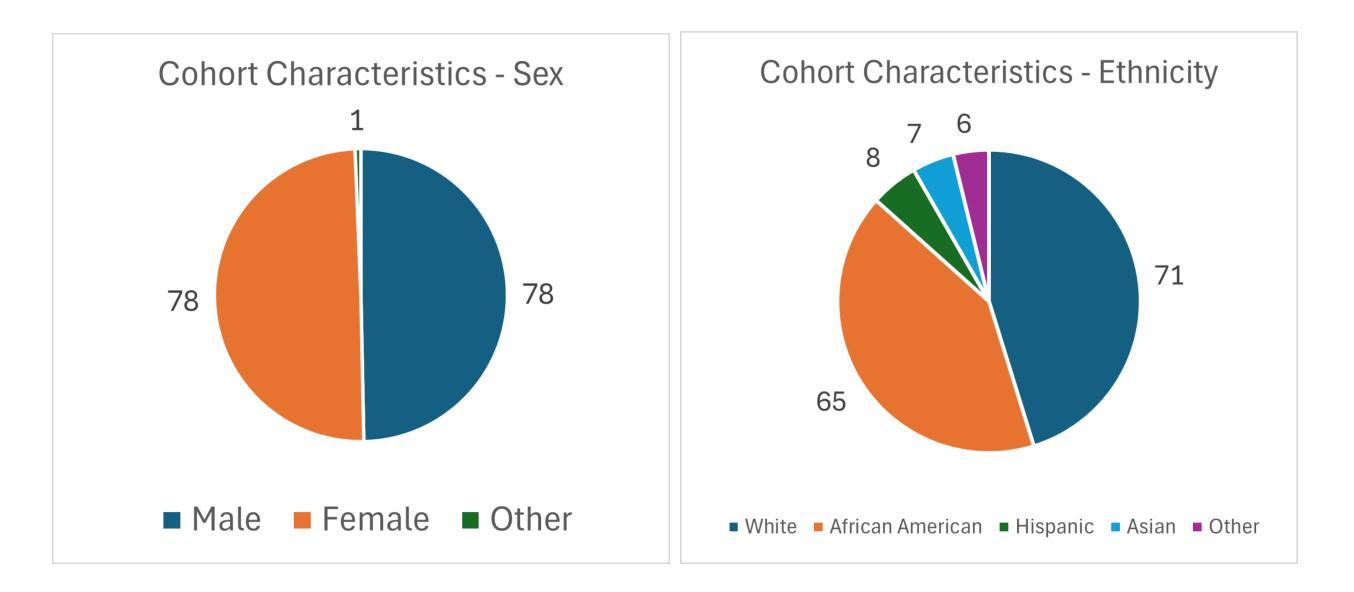
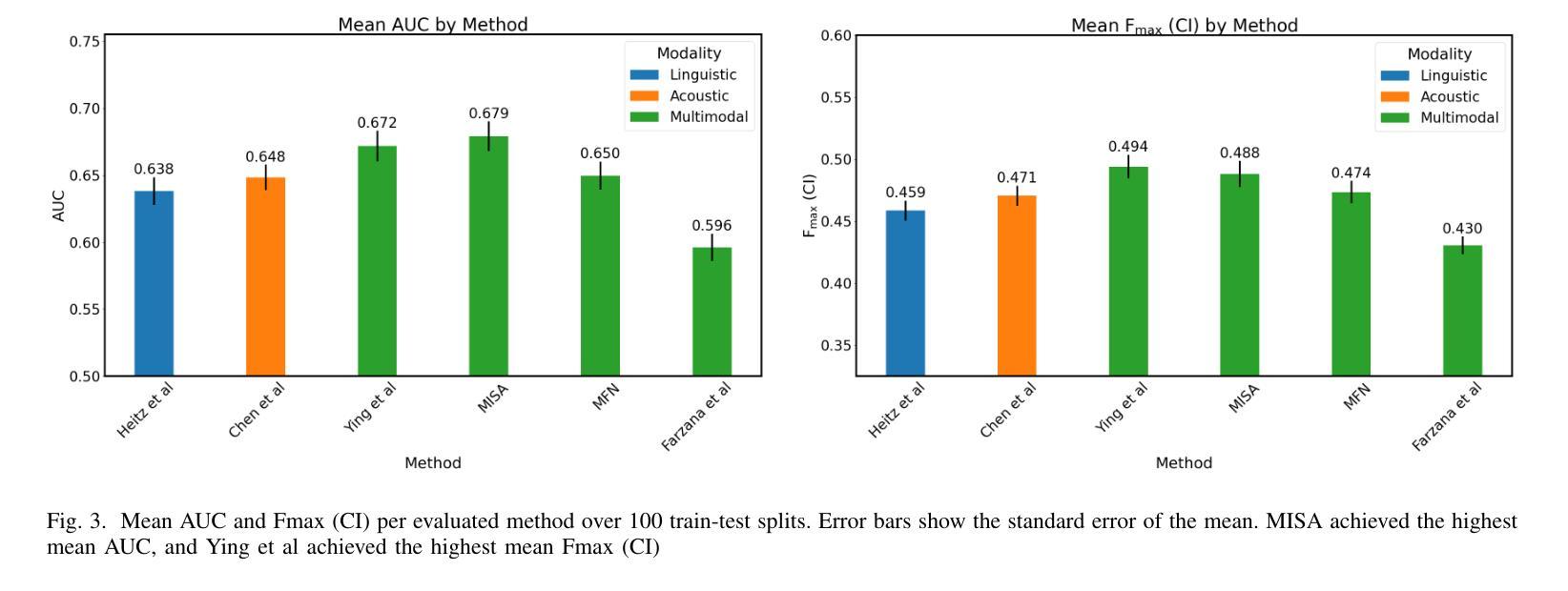
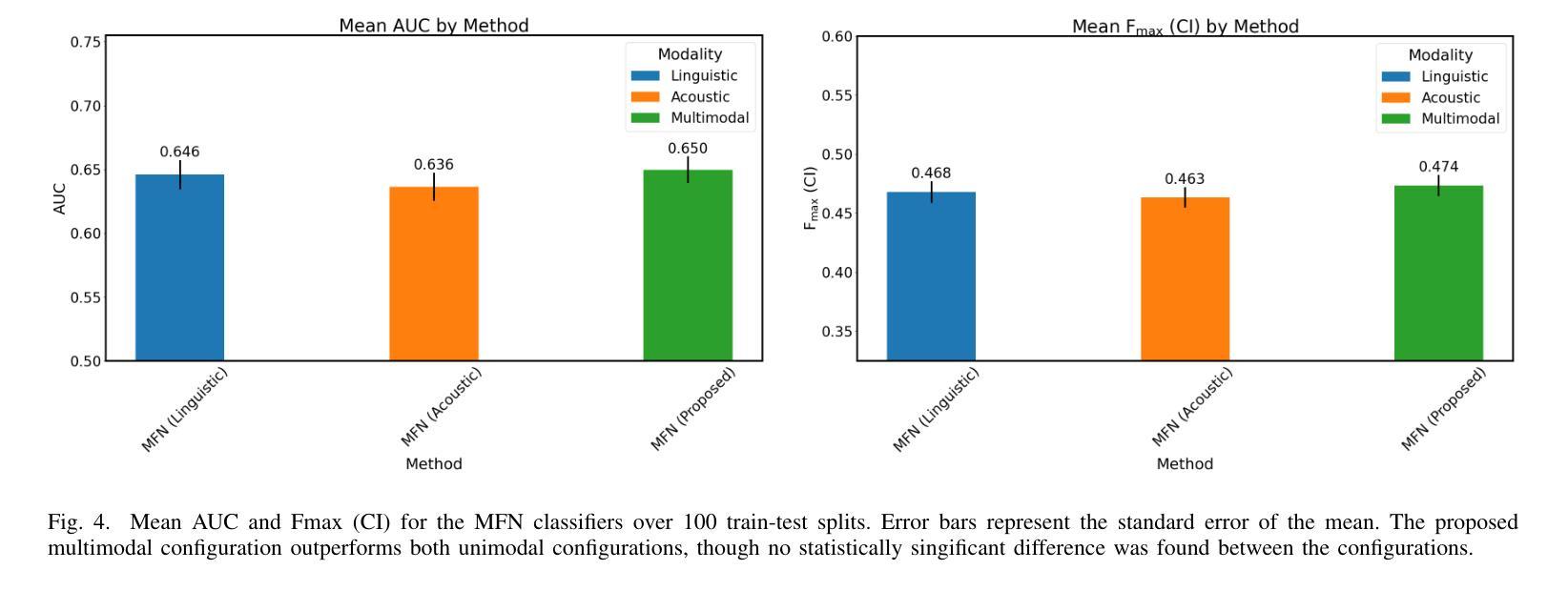
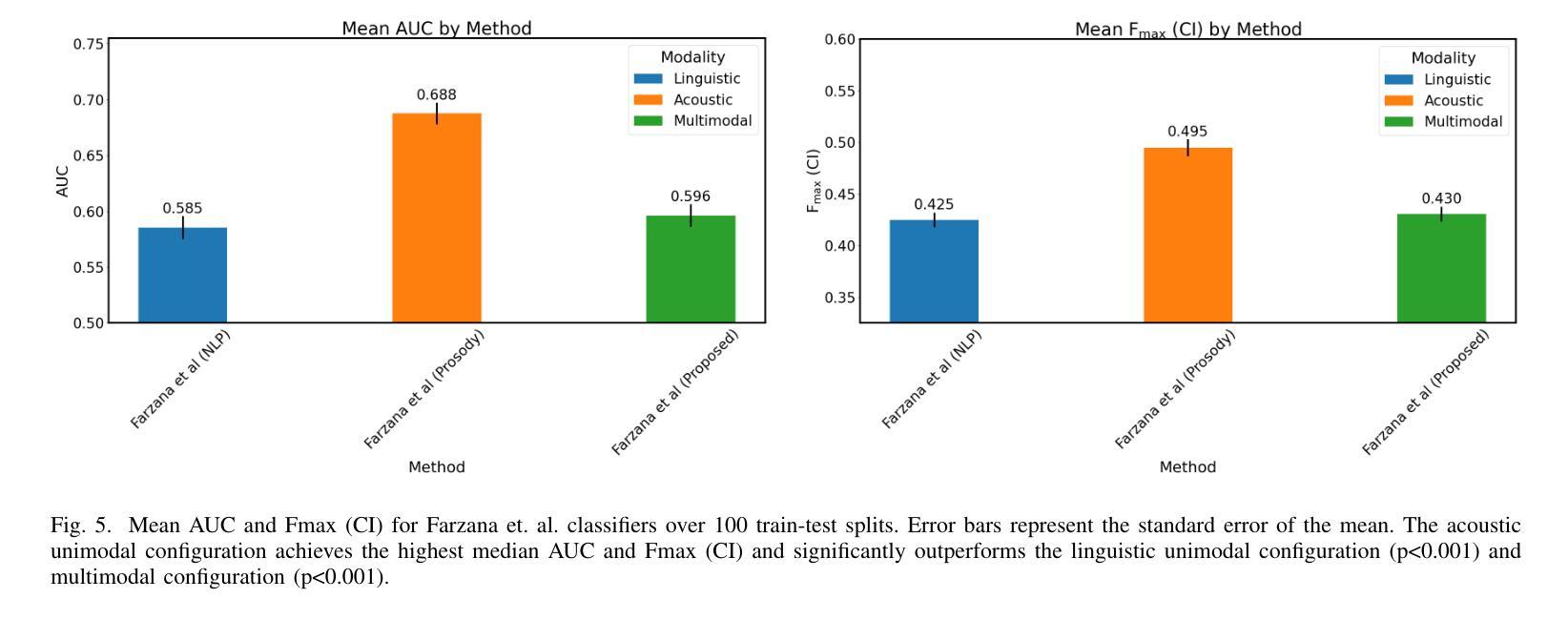
Several machine learning algorithms have been developed for the prediction of Alzheimer’s disease and related dementia (ADRD) from spontaneous speech. However, none of these algorithms have been translated for the prediction of broader cognitive impairment (CI), which in some cases is a precursor and risk factor of ADRD. In this paper, we evaluated several speech-based open-source methods originally proposed for the prediction of ADRD, as well as methods from multimodal sentiment analysis for the task of predicting CI from patient audio recordings. Results demonstrated that multimodal methods outperformed unimodal ones for CI prediction, and that acoustics-based approaches performed better than linguistics-based ones. Specifically, interpretable acoustic features relating to affect and prosody were found to significantly outperform BERT-based linguistic features and interpretable linguistic features, respectively. All the code developed for this study is available at https://github.com/JTColonel/catch.
针对阿尔茨海默病及相关痴呆(ADRD)的预测,已经开发了几种机器学习算法,这些算法是从自然语音中发展而来的。然而,这些算法并没有转化为预测更广泛的认知障碍(CI)的工具,在某些情况下,认知障碍是ADRD的先兆和风险因素。在本文中,我们评估了原本为预测ADRD而提出的几种基于语音的开源方法,以及从患者音频记录中预测CI的多模式情感分析方法。结果表明,多模式方法在预测CI方面的性能优于单模式方法,基于声音的方法优于基于语言学的方法。具体来说,与情感和语调相关的可解释的声学特征被发现显著优于基于BERT的语言学特征和可解释的语言学特征。本研究开发的所有代码均可在https://github.com/JTColonel/catch上找到。
论文及项目相关链接
Summary
本文探讨了利用机器学习算法预测阿尔茨海默病及相关痴呆(ADRD)的方法,并进一步探索了这些算法在预测更广泛的认知障碍(CI)方面的应用。研究发现,多模式方法相较于单一模式在CI预测上表现更优,声学基础的方法比语言基础的方法效果更好。特别是与情感和语调相关的可解释声学特征显著优于BERT基语言特征和可解释语言特征。
Key Takeaways
- 机器学习算法已被开发用于从自发言语预测阿尔茨海默病及相关痴呆(ADRD)。
- 目前尚无算法用于预测更广泛的认知障碍(CI),这有时是ADRD的先兆和风险因素。
- 多模式方法在预测CI方面优于单一模式方法。
- 声学基础的方法在预测CI方面比语言基础的方法效果更好。
- 与情感和语调相关的可解释声学特征在预测CI方面表现最佳。
- 所有为本研究开发的代码均可在指定链接找到。
点此查看论文截图