⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-11 更新
Genesis: Multimodal Driving Scene Generation with Spatio-Temporal and Cross-Modal Consistency
Authors:Xiangyu Guo, Zhanqian Wu, Kaixin Xiong, Ziyang Xu, Lijun Zhou, Gangwei Xu, Shaoqing Xu, Haiyang Sun, Bing Wang, Guang Chen, Hangjun Ye, Wenyu Liu, Xinggang Wang
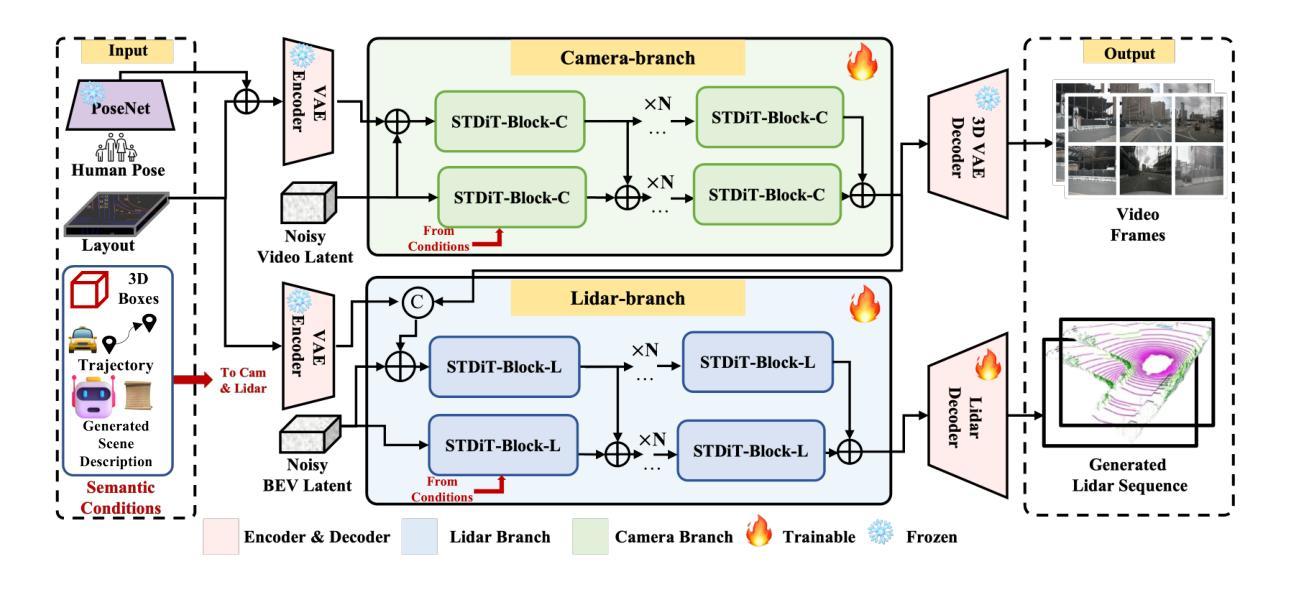
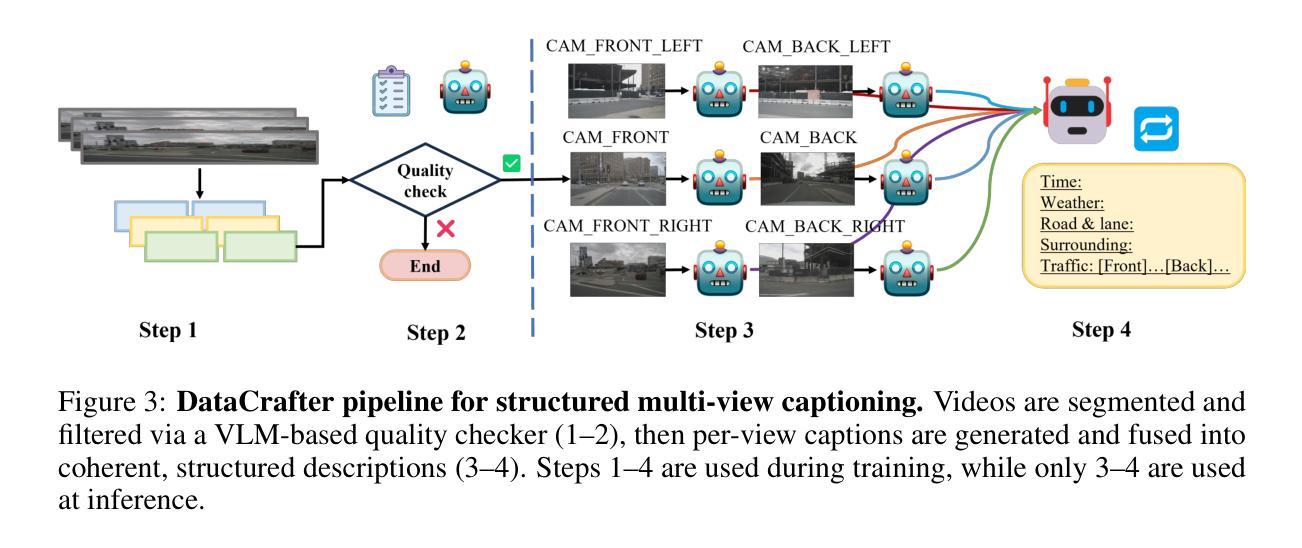
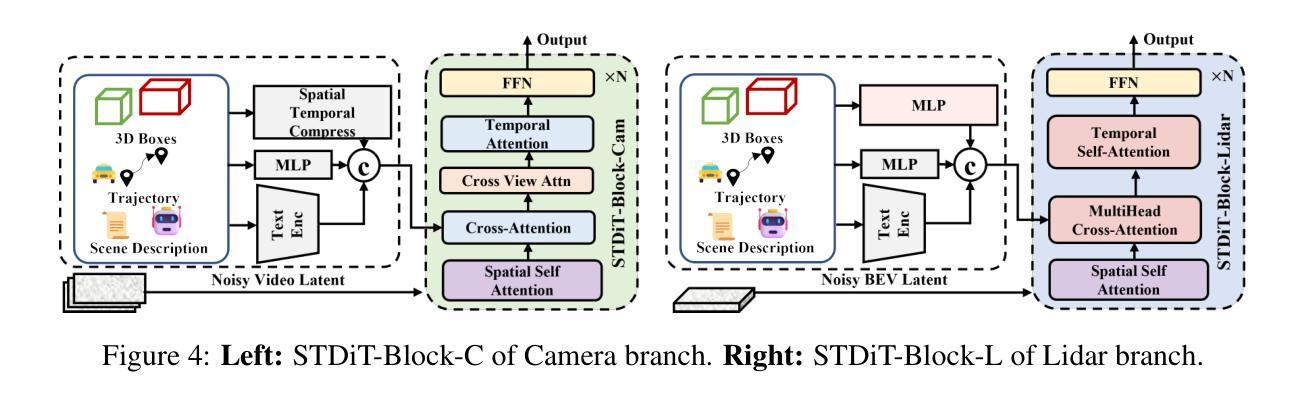
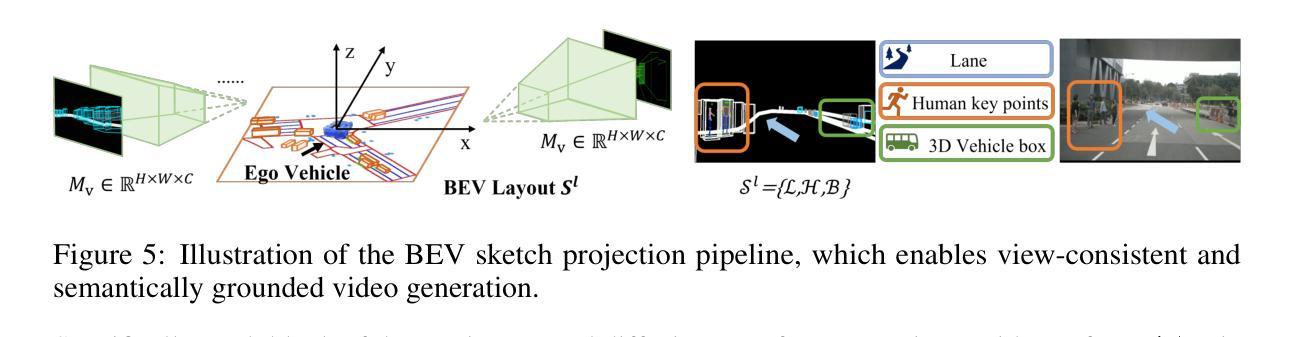
We present Genesis, a unified framework for joint generation of multi-view driving videos and LiDAR sequences with spatio-temporal and cross-modal consistency. Genesis employs a two-stage architecture that integrates a DiT-based video diffusion model with 3D-VAE encoding, and a BEV-aware LiDAR generator with NeRF-based rendering and adaptive sampling. Both modalities are directly coupled through a shared latent space, enabling coherent evolution across visual and geometric domains. To guide the generation with structured semantics, we introduce DataCrafter, a captioning module built on vision-language models that provides scene-level and instance-level supervision. Extensive experiments on the nuScenes benchmark demonstrate that Genesis achieves state-of-the-art performance across video and LiDAR metrics (FVD 16.95, FID 4.24, Chamfer 0.611), and benefits downstream tasks including segmentation and 3D detection, validating the semantic fidelity and practical utility of the generated data.
我们提出了Genesis,这是一个统一框架,用于联合生成具有时空和跨模态一致性的多视角驾驶视频和激光雷达序列。Genesis采用两阶段架构,集成了基于DiT的视频扩散模型与3D-VAE编码,以及带有基于NeRF的渲染和自适应采样的BEV感知激光雷达生成器。两种模态通过共享潜在空间直接耦合,实现视觉和几何域内的连贯演变。为了以结构语义引导生成,我们引入了DataCrafter,这是一个基于视觉语言模型的描述模块,可提供场景级和实例级监督。在nuScenes基准测试上的大量实验表明,Genesis在视频和激光雷达指标上达到了最新技术水平(FVD 16.95,FID 4.24,Chamfer 0.611),并有助于下游任务,包括分割和3D检测,验证了生成数据的语义保真度和实用性。
论文及项目相关链接
Summary
本文介绍了Genesis框架,该框架能联合生成多视角驾驶视频和LiDAR序列,具有时空和跨模态一致性。Genesis采用两阶段架构,融合了基于DiT的视频扩散模型与3D-VAE编码,以及具有NeRF渲染和自适应采样的BEV感知LiDAR生成器。两种模态通过共享潜在空间直接耦合,实现了视觉和几何域之间的连贯演变。为引导结构化语义生成,引入了DataCrafter模块,该模块基于视觉语言模型构建,提供场景级和实例级监督。在nuScenes基准测试上的实验表明,Genesis在视频和LiDAR指标上达到业界最佳水平(FVD 16.95,FID 4.24,Chamfer 0.611),并有益于分割和3D检测等下游任务,验证了生成数据的语义保真度和实用性。
Key Takeaways
- Genesis是一个联合生成多视角驾驶视频和LiDAR序列的统一框架,具有时空和跨模态一致性。
- Genesis采用两阶段架构,融合了视频扩散模型、3D-VAE编码、BEV感知LiDAR生成器。
- 通过共享潜在空间,实现了视觉和几何域之间的连贯演变。
- 引入了DataCrafter模块,提供场景级和实例级监督,引导结构化语义生成。
- 在nuScenes基准测试上表现优异,达到业界最佳水平。
- 生成数据对下游任务如分割和3D检测有益,验证了其语义保真度和实用性。
点此查看论文截图

SPC to 3D: Novel View Synthesis from Binary SPC via I2I translation
Authors:Sumit Sharma, Gopi Raju Matta, Kaushik Mitra
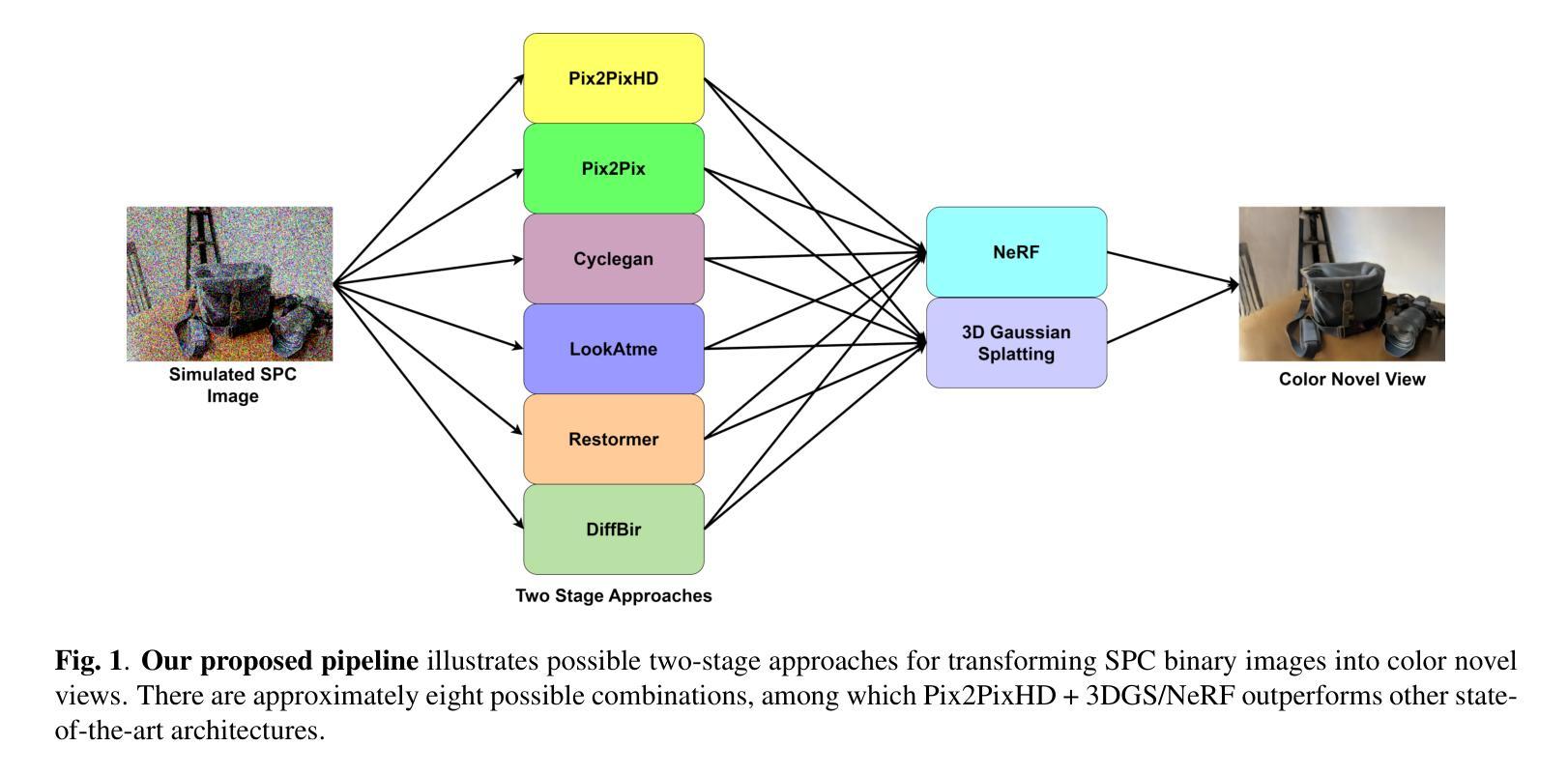
Single Photon Avalanche Diodes (SPADs) represent a cutting-edge imaging technology, capable of detecting individual photons with remarkable timing precision. Building on this sensitivity, Single Photon Cameras (SPCs) enable image capture at exceptionally high speeds under both low and high illumination. Enabling 3D reconstruction and radiance field recovery from such SPC data holds significant promise. However, the binary nature of SPC images leads to severe information loss, particularly in texture and color, making traditional 3D synthesis techniques ineffective. To address this challenge, we propose a modular two-stage framework that converts binary SPC images into high-quality colorized novel views. The first stage performs image-to-image (I2I) translation using generative models such as Pix2PixHD, converting binary SPC inputs into plausible RGB representations. The second stage employs 3D scene reconstruction techniques like Neural Radiance Fields (NeRF) or Gaussian Splatting (3DGS) to generate novel views. We validate our two-stage pipeline (Pix2PixHD + Nerf/3DGS) through extensive qualitative and quantitative experiments, demonstrating significant improvements in perceptual quality and geometric consistency over the alternative baseline.
单光子雪崩二极管(SPAD)代表了前沿的成像技术,能够以惊人的时间精度检测单个光子。在此基础上,单光子相机(SPC)能够在低光照和高光照条件下实现极高速度的图像捕捉。从这样的SPC数据中实现3D重建和辐射场恢复具有巨大的潜力。然而,SPC图像的二进制特性导致信息大量丢失,特别是在纹理和颜色方面,使得传统的3D合成技术无效。为了解决这一挑战,我们提出了一个模块化的两阶段框架,将二进制SPC图像转化为高质量彩色化新颖视图。第一阶段使用Pix2PixHD等生成模型进行图像到图像(I2I)转换,将二进制SPC输入转换为可信的RGB表示。第二阶段采用神经网络辐射场(NeRF)或高斯溅射(3DGS)等3D场景重建技术来生成新颖视图。我们通过大量的定性和定量实验验证了我们的两阶段管道(Pix2PixHD + Nerf/3DGS),在感知质量和几何一致性方面显示出对替代基准的显著改善。
论文及项目相关链接
PDF Accepted for publication at ICIP 2025
Summary
单光子雪崩二极管(SPAD)是尖端成像技术,能精确检测单个光子。基于此技术构建的单光子相机(SPC)可在低光照和高光照条件下以极高速度捕获图像。从SPC数据中恢复三维重建和辐射场具有巨大潜力。然而,SPC图像的二进制特性导致信息丢失严重,特别是在纹理和颜色方面,使得传统三维合成技术效果不佳。针对此挑战,我们提出了模块化两阶段框架,将二进制SPC图像转化为高质量彩色新颖视图。第一阶段使用Pix2PixHD等生成模型进行图像到图像(I2I)转换,将二进制SPC输入转换为逼真的RGB表示。第二阶段采用神经网络辐射场(NeRF)或高斯拼贴(3DGS)等三维场景重建技术生成新颖视图。我们通过大量定性和定量实验验证了我们的两阶段管道(Pix2PixHD + Nerf/3DGS),在感知质量和几何一致性方面显示出显著的改进。
Key Takeaways
- 单光子雪崩二极管(SPAD)可精确检测单个光子,为高速成像提供了基础。
- 单光子相机(SPC)在高低光照条件下都能实现高速图像捕获。
- 从SPC数据中恢复三维重建和辐射场具有巨大潜力,但二进制图像信息丢失严重。
- 提出模块化两阶段框架转化二进制SPC图像为高质量彩色图像。
- 第一阶段通过图像到图像(I2I)转换生成逼真的RGB表示。
- 第二阶段采用三维场景重建技术生成新颖视图,如神经网络辐射场(NeRF)或高斯拼贴(3DGS)。
点此查看论文截图

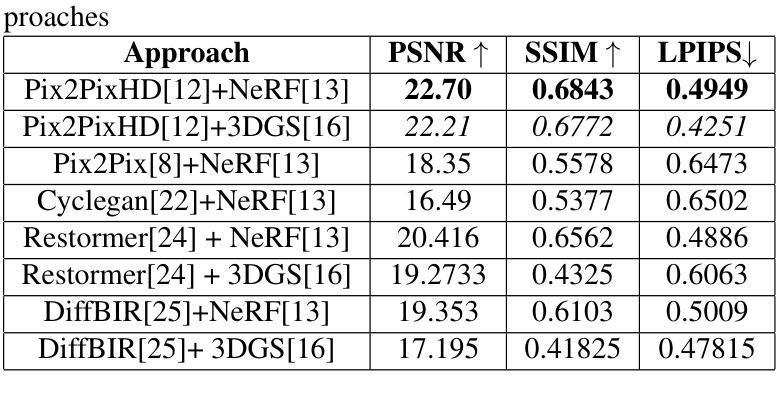

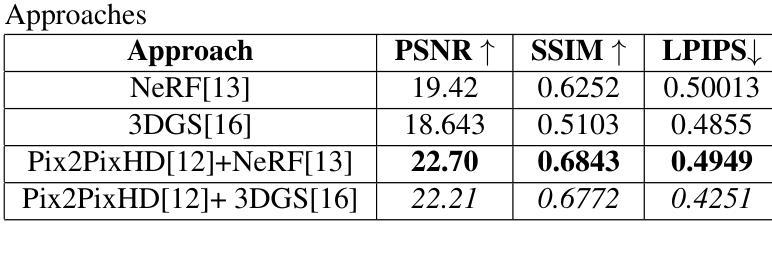
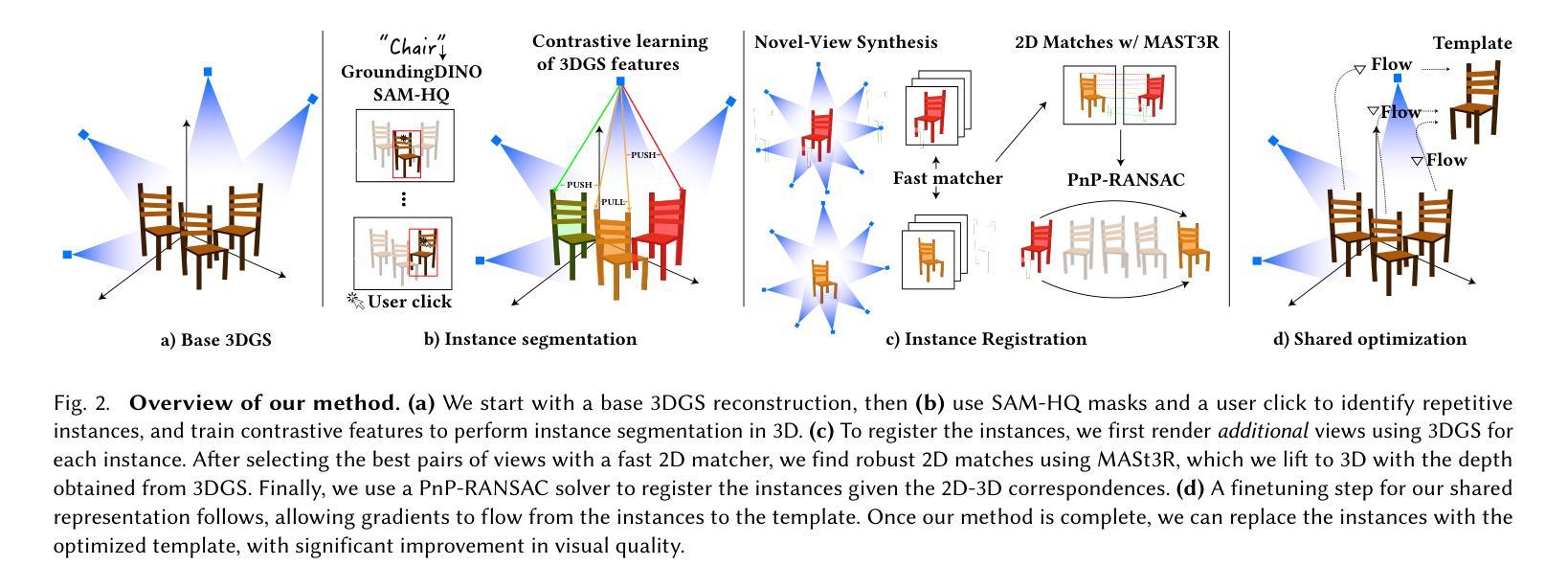
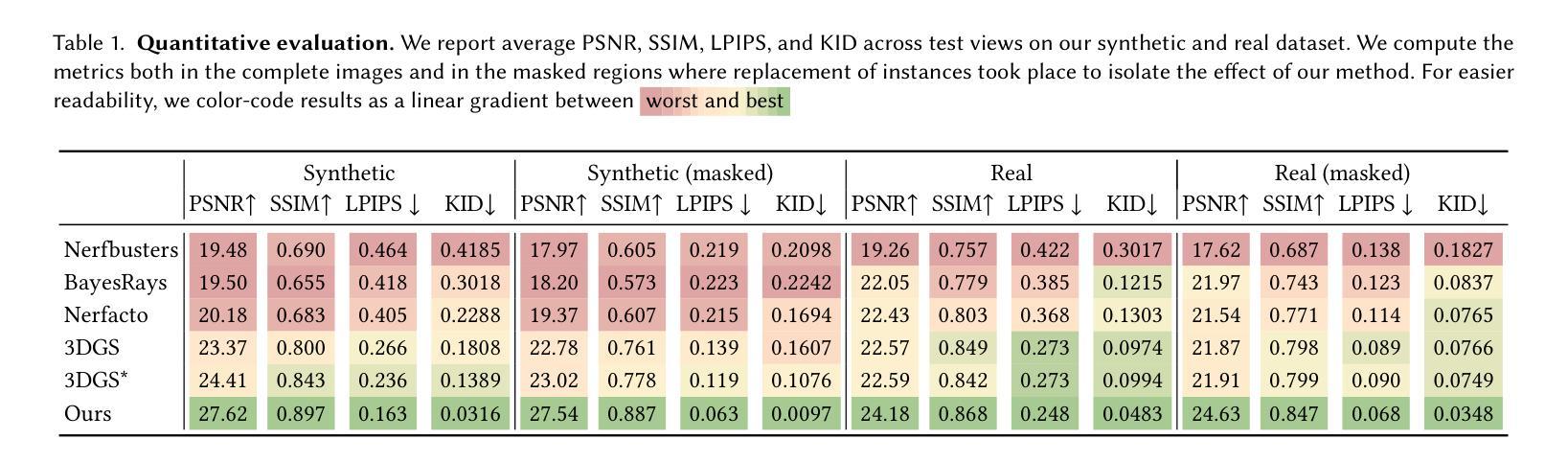
Splat and Replace: 3D Reconstruction with Repetitive Elements
Authors:Nicolás Violante, Andreas Meuleman, Alban Gauthier, Frédo Durand, Thibault Groueix, George Drettakis
We leverage repetitive elements in 3D scenes to improve novel view synthesis. Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have greatly improved novel view synthesis but renderings of unseen and occluded parts remain low-quality if the training views are not exhaustive enough. Our key observation is that our environment is often full of repetitive elements. We propose to leverage those repetitions to improve the reconstruction of low-quality parts of the scene due to poor coverage and occlusions. We propose a method that segments each repeated instance in a 3DGS reconstruction, registers them together, and allows information to be shared among instances. Our method improves the geometry while also accounting for appearance variations across instances. We demonstrate our method on a variety of synthetic and real scenes with typical repetitive elements, leading to a substantial improvement in the quality of novel view synthesis.
我们利用三维场景中的重复元素来改善新颖视角的合成。神经辐射场(NeRF)和三维高斯拼贴(3DGS)已经极大地改善了新颖视角的合成,但如果训练视角不够详尽,那么未见和遮挡部分的渲染质量仍然较低。我们的关键观察是,我们的环境通常充满重复元素。我们提议利用这些重复元素来改善由于覆盖不足和遮挡导致的场景低质量部分的重建。我们提出了一种方法,在3DGS重建中分割每个重复实例,将它们合并注册,并允许实例之间共享信息。我们的方法不仅改善了几何结构,还考虑了实例间外观的变化。我们在具有典型重复元素的合成场景和真实场景上展示了我们的方法,导致新颖视角合成的质量显著提高。
论文及项目相关链接
PDF SIGGRAPH Conference Papers 2025. Project site: https://repo-sam.inria.fr/nerphys/splat-and-replace/
Summary
本文利用三维场景中的重复元素改进了新视角的合成。针对神经辐射场和三维高斯喷绘在训练视角不足时,对未见过和被遮挡部分的渲染质量不高的问题,作者提出利用环境中的重复元素来改善场景低质量部分的重建。通过分割每个在三维高斯喷绘重建中的重复实例,将它们合并注册,并允许信息在实例之间共享,改善了场景几何,同时考虑了实例间的外观变化。在具有典型重复元素的合成和真实场景上验证了该方法,大大提高了新视角合成的质量。
Key Takeaways
- 利用三维场景中的重复元素改进新视角的合成。
- 针对神经辐射场和三维高斯喷绘在训练视角不足时的缺陷。
- 提出一种方法,通过分割和合并注册重复实例来改善场景几何。
- 方法允许在实例之间共享信息,提高了渲染质量。
- 验证了该方法在合成和真实场景上的有效性。
- 尤其适用于具有典型重复元素的场景。
点此查看论文截图

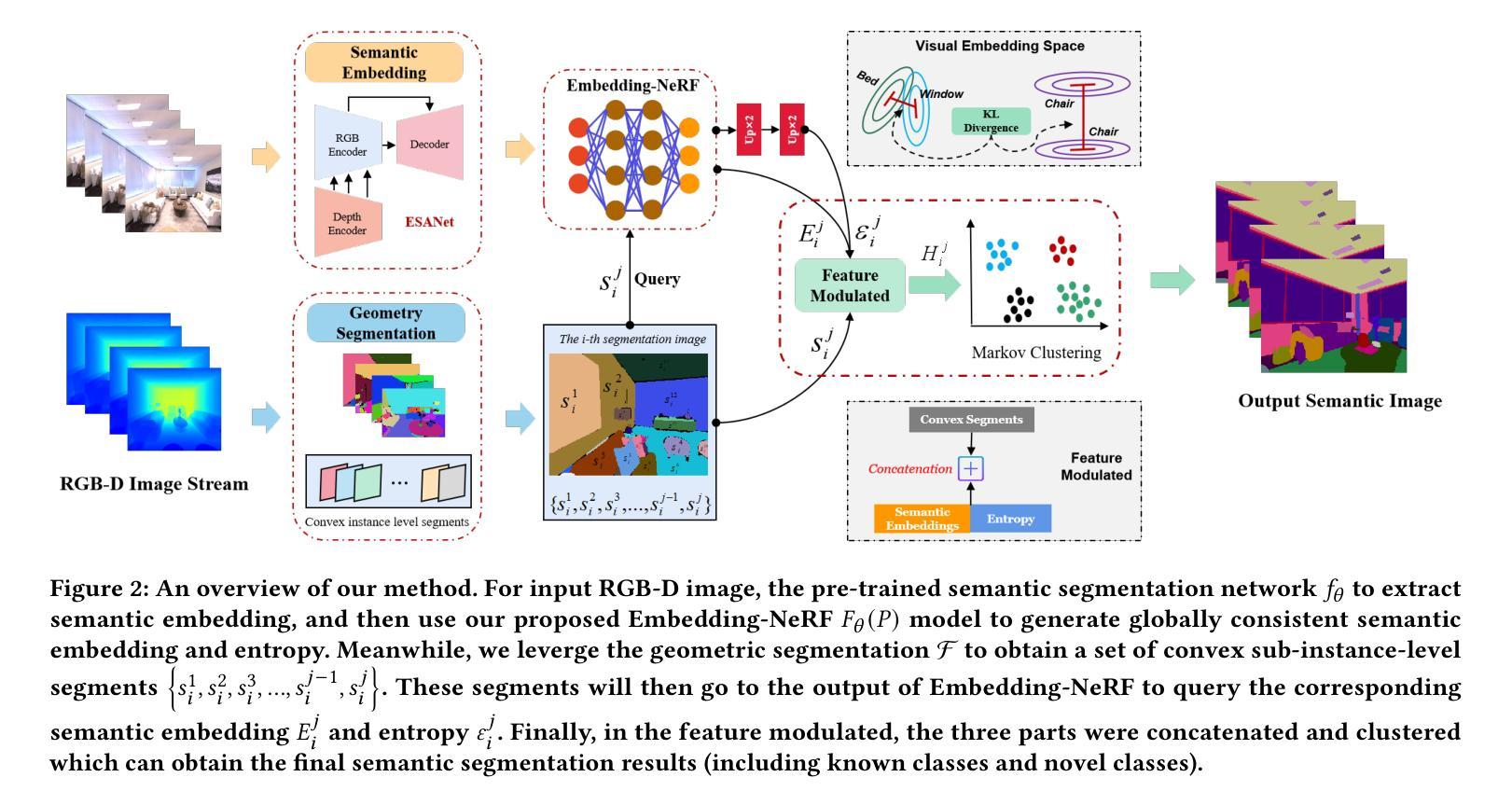
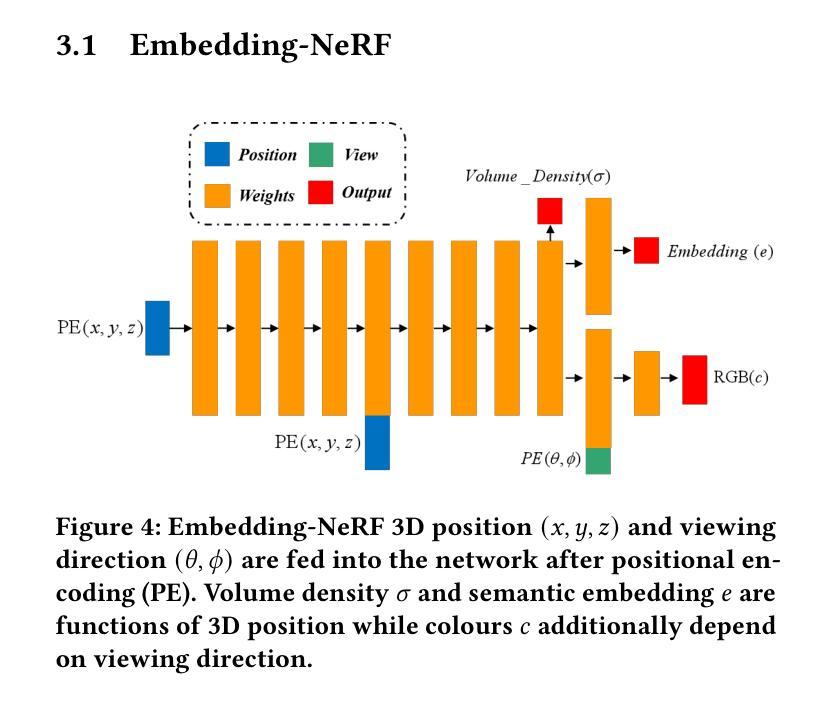
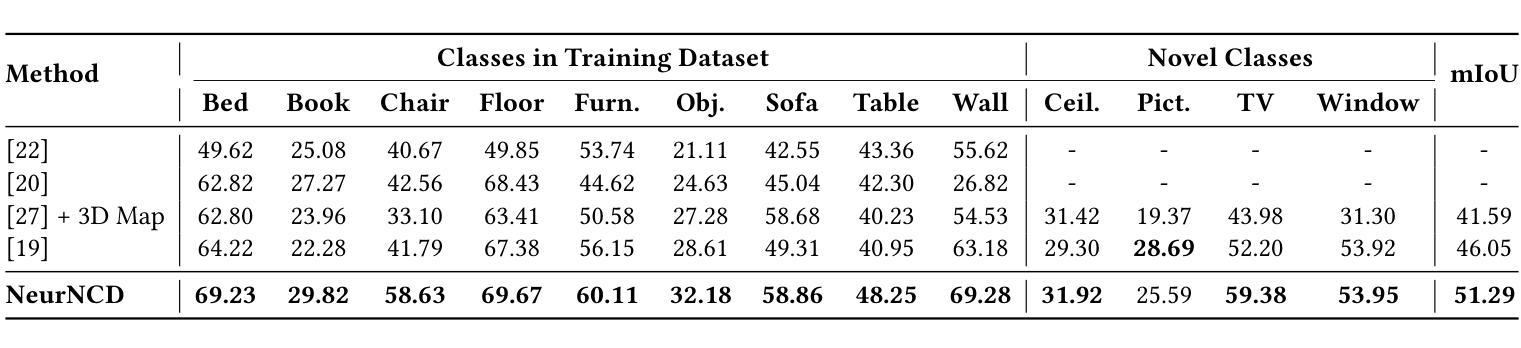
NeurNCD: Novel Class Discovery via Implicit Neural Representation
Authors:Junming Wang, Yi Shi
Discovering novel classes in open-world settings is crucial for real-world applications. Traditional explicit representations, such as object descriptors or 3D segmentation maps, are constrained by their discrete, hole-prone, and noisy nature, which hinders accurate novel class discovery. To address these challenges, we introduce NeurNCD, the first versatile and data-efficient framework for novel class discovery that employs the meticulously designed Embedding-NeRF model combined with KL divergence as a substitute for traditional explicit 3D segmentation maps to aggregate semantic embedding and entropy in visual embedding space. NeurNCD also integrates several key components, including feature query, feature modulation and clustering, facilitating efficient feature augmentation and information exchange between the pre-trained semantic segmentation network and implicit neural representations. As a result, our framework achieves superior segmentation performance in both open and closed-world settings without relying on densely labelled datasets for supervised training or human interaction to generate sparse label supervision. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art approaches on the NYUv2 and Replica datasets.
在开放世界环境中发现新类别对实际应用至关重要。传统的显式表示方法,如对象描述符或3D分割图,受到其离散、易产生孔洞和噪声性质的限制,阻碍了准确的新类别发现。为了解决这些挑战,我们引入了NeurNCD,这是一个用于新类别发现的通用且高效的数据利用框架。它采用精心设计的Embedding-NeRF模型,结合KL散度,替代传统的显式3D分割图,在视觉嵌入空间中聚合语义嵌入和熵。NeurNCD还集成了特征查询、特征调制和聚类等多个关键组件,促进了预训练语义分割网络和隐式神经表示之间的有效特征增强和信息交换。因此,我们的框架在开放和封闭世界环境中均实现了出色的分割性能,无需依赖密集标记数据集进行有监督训练或人工交互来生成稀疏标签监督。大量实验表明,我们的方法在NYUv2和Replica数据集上显著优于最新方法。
论文及项目相关链接
PDF Accepted by ICMR 2024
Summary
NeurNCD框架采用隐式神经表示(NeRF)技术解决传统显式表示在开放世界环境下发现新类别时的局限性问题。通过结合嵌入NeRF模型和KL散度,该框架在视觉嵌入空间中聚合语义嵌入和熵,实现高效特征增强和信息交换。NeurNCD无需依赖密集标注数据集进行有监督训练或人工参与生成稀疏标签监督,即可在开放和封闭世界环境中实现卓越的分割性能。该框架实现了先进的方法在NYUv2和Replica数据集上的表现远超以往技术。
Key Takeaways
- NeurNCD是一个面向新型类别发现的灵活、高效的数据框架,适用于开放世界环境。
- 传统的显式表示方法(如对象描述符或三维分割图)具有离散、多漏洞和噪声问题,阻碍了准确的新型类别发现。
- NeurNCD使用精心设计的Embedding-NeRF模型和KL散度,以替代传统的三维分割图,从而在视觉嵌入空间中聚合语义嵌入和熵。
- NeurNCD通过特征查询、特征调制和聚类等关键组件,促进特征增强和信息在预训练的语义分割网络和隐式神经表示之间的交换。
- 该框架在不依赖密集标注数据集进行有监督训练或人工参与生成稀疏标签监督的情况下,实现了出色的分割性能。
- 在NYUv2和Replica数据集上进行的广泛实验表明,NeurNCD的性能显著优于其他前沿技术。
点此查看论文截图


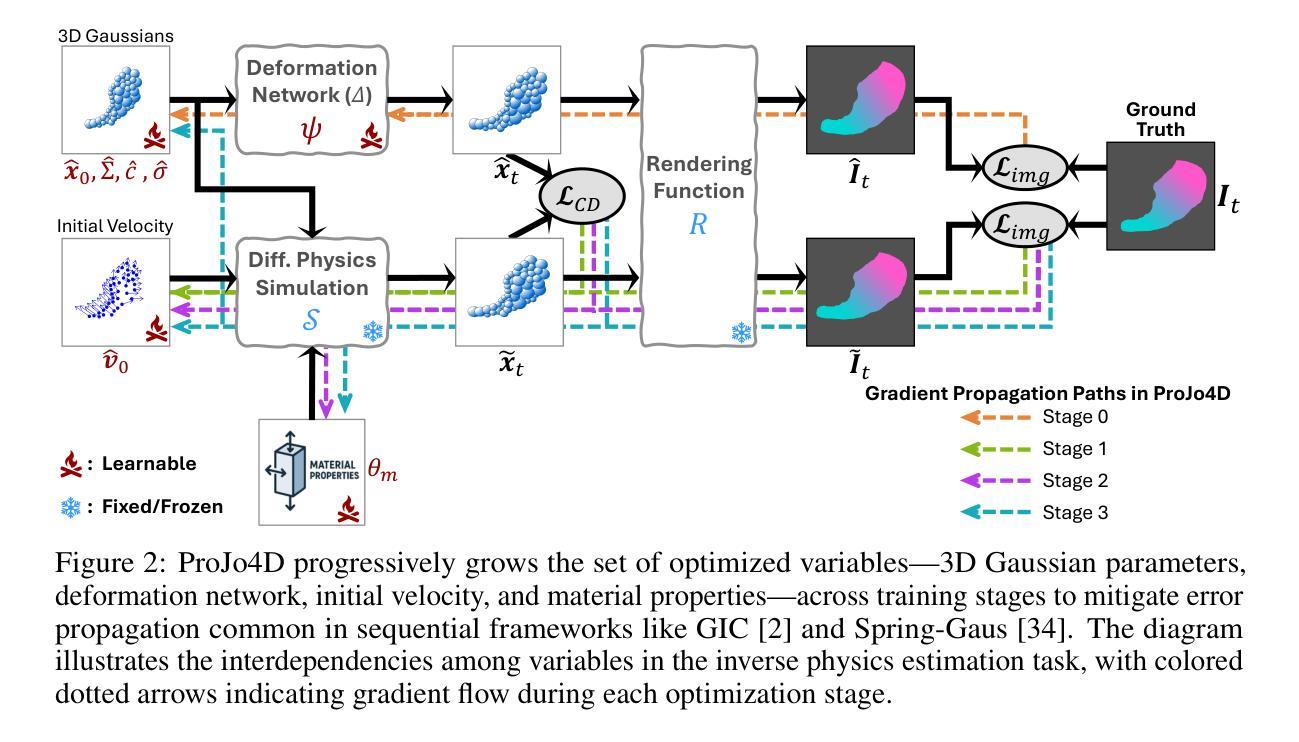
ProJo4D: Progressive Joint Optimization for Sparse-View Inverse Physics Estimation
Authors:Daniel Rho, Jun Myeong Choi, Biswadip Dey, Roni Sengupta
Neural rendering has made significant strides in 3D reconstruction and novel view synthesis. With the integration with physics, it opens up new applications. The inverse problem of estimating physics from visual data, however, still remains challenging, limiting its effectiveness for applications like physically accurate digital twin creation in robotics and XR. Existing methods that incorporate physics into neural rendering frameworks typically require dense multi-view videos as input, making them impractical for scalable, real-world use. When presented with sparse multi-view videos, the sequential optimization strategy used by existing approaches introduces significant error accumulation, e.g., poor initial 3D reconstruction leads to bad material parameter estimation in subsequent stages. Instead of sequential optimization, directly optimizing all parameters at the same time also fails due to the highly non-convex and often non-differentiable nature of the problem. We propose ProJo4D, a progressive joint optimization framework that gradually increases the set of jointly optimized parameters guided by their sensitivity, leading to fully joint optimization over geometry, appearance, physical state, and material property. Evaluations on PAC-NeRF and Spring-Gaus datasets show that ProJo4D outperforms prior work in 4D future state prediction, novel view rendering of future state, and material parameter estimation, demonstrating its effectiveness in physically grounded 4D scene understanding. For demos, please visit the project webpage: https://daniel03c1.github.io/ProJo4D/
神经渲染在3D重建和新颖视角合成方面取得了重大进展。通过与物理学的结合,它开启了新的应用领域。然而,从视觉数据中估计物理的逆向问题仍然具有挑战性,限制了其在机器人和XR等领域创建物理准确的数字双胞胎等应用。将物理纳入神经渲染框架的现有方法通常需要使用密集的多元视图视频作为输入,这使得它们在可扩展的、现实世界的应用中变得不切实际。当面对稀疏的多元视图视频时,现有方法使用的顺序优化策略会导致显著的误差累积,例如,糟糕的初始3D重建会在后续阶段导致材料参数估计不佳。与顺序优化不同,同时直接优化所有参数也会因为问题的高度非凸性和经常出现的不可微性而失败。我们提出了ProJo4D,这是一种渐进的联合优化框架,它逐渐增加由敏感性引导的联合优化参数集,实现对几何、外观、物理状态和材料属性的完全联合优化。在PAC-NeRF和Spring-Gaus数据集上的评估表明,ProJo4D在4D未来状态预测、未来状态的新视角渲染和材料参数估计方面优于先前的工作,证明了其在物理基础的4D场景理解中的有效性。有关演示,请访问项目网页:链接地址。
论文及项目相关链接
Summary
神经网络渲染在三维重建和新颖视角合成方面取得了重大进展。然而,从视觉数据中估计物理特性的逆问题仍然具有挑战性,限制了其在机器人和XR等物理准确数字双胞胎创建中的应用。现有方法通常需要密集的多视角视频作为输入,导致在现实世界的大规模应用中不太实用。本研究提出ProJo4D,一种渐进联合优化框架,通过逐渐优化更复杂的参数集以逐步增加敏感度引导来实现对几何形状、外观、物理状态和材质属性的完全联合优化。在PAC-NeRF和Spring-Gaus数据集上的评估表明,ProJo4D在四维未来状态预测、未来状态的新视角渲染和材质参数估计方面优于先前的工作,展示了其在物理基础四维场景理解中的有效性。详情访问项目网页:链接地址。
Key Takeaways
- 神经网络渲染在三维重建和新颖视角合成方面取得显著进展,并正与物理学结合以拓展新应用。
- 从视觉数据中估计物理特性的逆问题仍是挑战,尤其在创建物理准确的数字双胞胎等应用中。
- 现有方法需密集多视角视频输入,不适用于大规模现实应用。
- ProJo4D框架采用渐进式联合优化策略,逐步增加优化的参数集。
- ProJo4D实现了对几何形状、外观、物理状态和材质属性的全面联合优化。
- 在四维未来状态预测、未来状态的新视角渲染和材质参数估计方面,ProJo4D表现优异。
点此查看论文截图


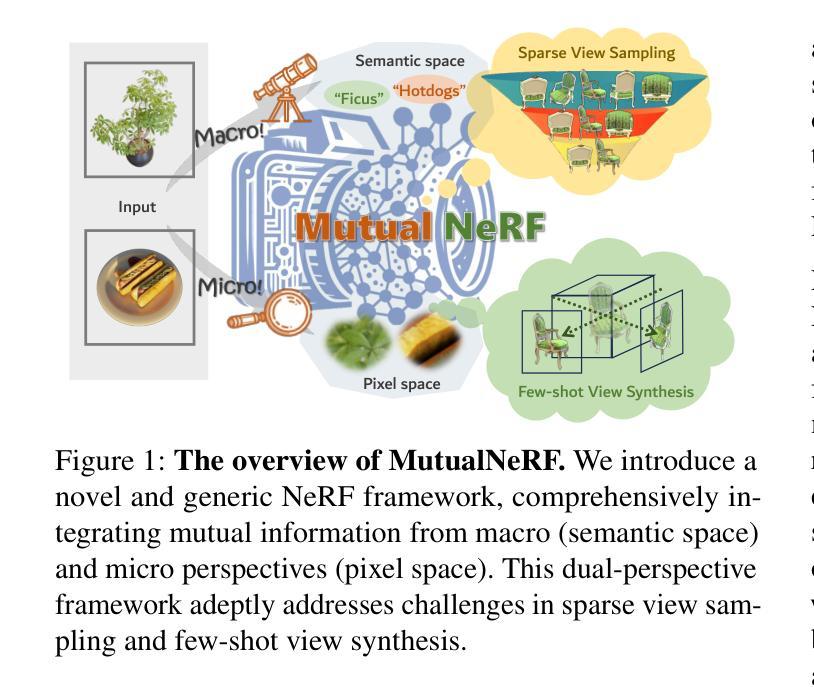
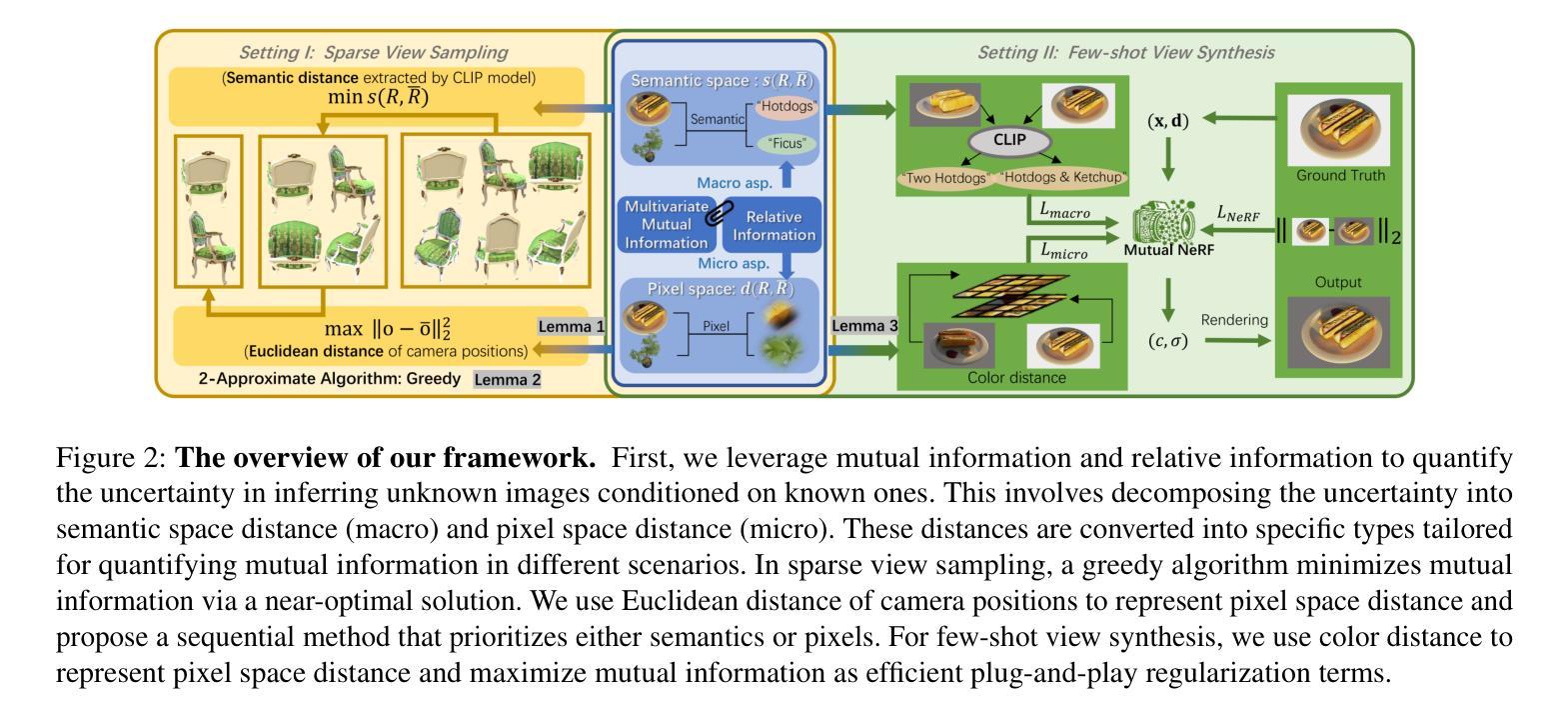
MutualNeRF: Improve the Performance of NeRF under Limited Samples with Mutual Information Theory
Authors:Zifan Wang, Jingwei Li, Yitang Li, Yunze Liu
This paper introduces MutualNeRF, a framework enhancing Neural Radiance Field (NeRF) performance under limited samples using Mutual Information Theory. While NeRF excels in 3D scene synthesis, challenges arise with limited data and existing methods that aim to introduce prior knowledge lack theoretical support in a unified framework. We introduce a simple but theoretically robust concept, Mutual Information, as a metric to uniformly measure the correlation between images, considering both macro (semantic) and micro (pixel) levels. For sparse view sampling, we strategically select additional viewpoints containing more non-overlapping scene information by minimizing mutual information without knowing ground truth images beforehand. Our framework employs a greedy algorithm, offering a near-optimal solution. For few-shot view synthesis, we maximize the mutual information between inferred images and ground truth, expecting inferred images to gain more relevant information from known images. This is achieved by incorporating efficient, plug-and-play regularization terms. Experiments under limited samples show consistent improvement over state-of-the-art baselines in different settings, affirming the efficacy of our framework.
本文介绍了MutualNeRF,这是一个利用互信息理论在有限样本下提升神经网络辐射场(NeRF)性能的框架。虽然NeRF在3D场景合成方面表现出色,但在数据有限的情况下仍面临挑战,现有引入先验知识的方法在统一框架中缺乏理论支持。我们引入了一个简单但理论上稳健的概念——互信息,作为一个指标来统一测量图像之间的关联度,同时考虑宏观(语义)和微观(像素)两个层面。对于稀疏视图采样,我们战略性地选择包含更多非重叠场景信息的额外观点,通过最小化互信息来选取,而无需事先了解真实图像。我们的框架采用贪心算法,提供接近最优的解决方案。对于少量视图合成,我们在推断图像和真实图像之间最大化互信息,期望推断图像从已知图像中获得更多相关信息。这是通过引入高效、即插即用的正则化项来实现的。在有限样本下的实验表明,在不同设置下,我们的框架较最先进的基线方法有明显的改进,证明了其有效性。
论文及项目相关链接
摘要
本研究提出了MutualNeRF框架,利用互信息理论增强神经网络辐射场(NeRF)在有限样本下的性能。NeRF在三维场景合成方面表现出卓越性能,但在有限数据下存在挑战。现有引入先验知识的方法缺乏统一的理论框架支持。本研究引入简单但理论稳健的互信息概念,作为衡量图像间关联性的统一度量标准,同时考虑宏观(语义)和微观(像素)层面。针对稀疏视图采样,通过最小化互信息战略性地选择包含更多非重叠场景信息的其他视点,无需事先了解真实图像。本研究采用贪心算法,提供接近最优的解决方案。在少量视图合成中,通过最大化推断图像和真实图像之间的互信息,期望推断图像从已知图像中获得更多相关信息。这是通过融入高效、即插即用的正则化项实现的。在有限样本下的实验表明,在不同设置下,该框架较最新基线有显著改善,验证了其有效性。
要点
- MutualNeRF框架结合了互信息理论,增强了NeRF在有限样本下的性能。
- 提出使用互信息作为衡量图像间关联性的统一度量标准。
- 在稀疏视图采样中,通过最小化互信息选择包含更多非重叠场景信息的视点。
- 采用贪心算法,提供接近最优的视点选择解决方案。
- 在少量视图合成中,通过最大化推断图像和真实图像之间的互信息,提高推断图像的质量。
- 通过融入高效的正则化项,实现互信息的最大化。
- 实验结果证明,该框架在有限样本下较现有方法有更显著的效果。
点此查看论文截图