⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-11 更新
Audio-Sync Video Generation with Multi-Stream Temporal Control
Authors:Shuchen Weng, Haojie Zheng, Zheng Chang, Si Li, Boxin Shi, Xinlong Wang
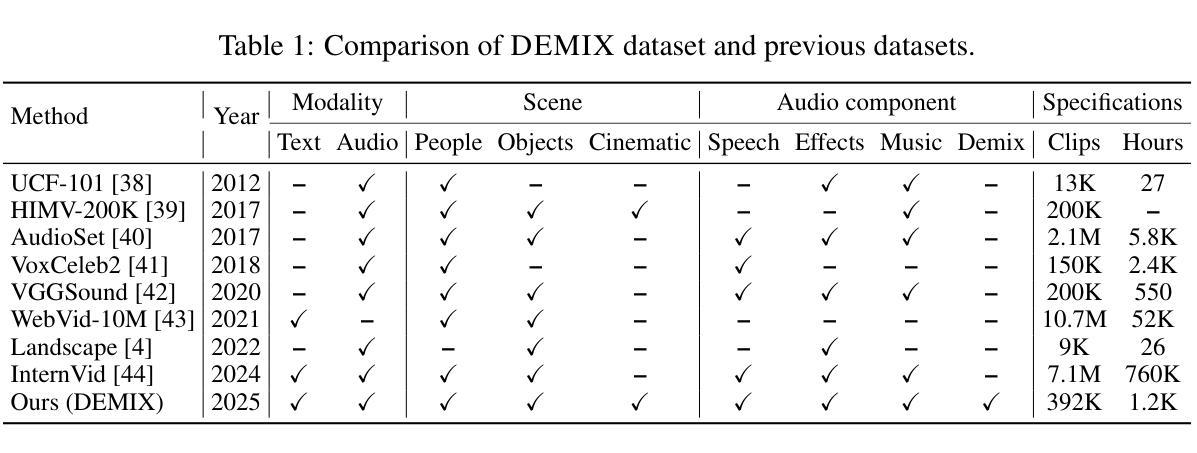
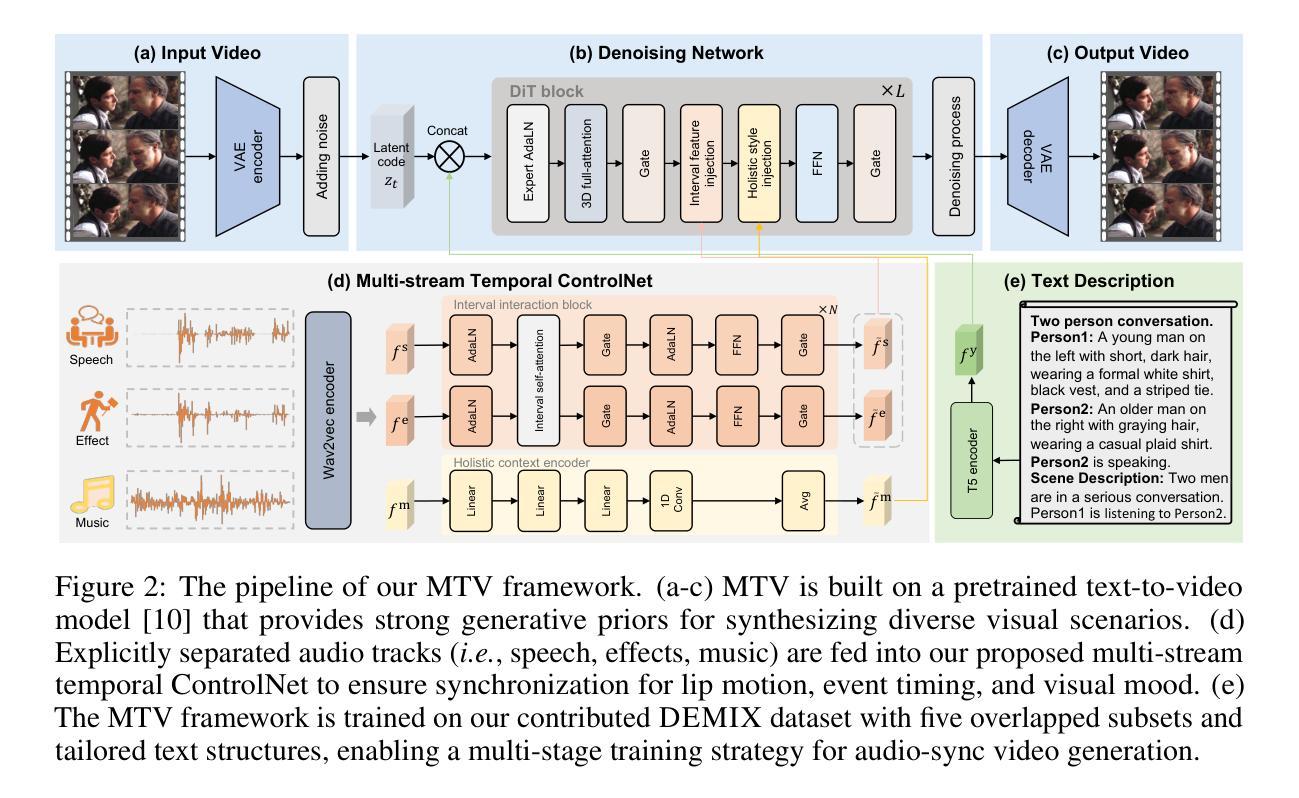
Audio is inherently temporal and closely synchronized with the visual world, making it a naturally aligned and expressive control signal for controllable video generation (e.g., movies). Beyond control, directly translating audio into video is essential for understanding and visualizing rich audio narratives (e.g., Podcasts or historical recordings). However, existing approaches fall short in generating high-quality videos with precise audio-visual synchronization, especially across diverse and complex audio types. In this work, we introduce MTV, a versatile framework for audio-sync video generation. MTV explicitly separates audios into speech, effects, and music tracks, enabling disentangled control over lip motion, event timing, and visual mood, respectively – resulting in fine-grained and semantically aligned video generation. To support the framework, we additionally present DEMIX, a dataset comprising high-quality cinematic videos and demixed audio tracks. DEMIX is structured into five overlapped subsets, enabling scalable multi-stage training for diverse generation scenarios. Extensive experiments demonstrate that MTV achieves state-of-the-art performance across six standard metrics spanning video quality, text-video consistency, and audio-video alignment. Project page: https://hjzheng.net/projects/MTV/.
音频本质上具有时间性,并与视觉世界紧密同步,使其成为可控视频生成(例如电影)的自然对齐和表达控制信号。除了控制之外,直接将音频翻译成视频对于理解和可视化丰富的音频叙事(例如播客或历史记录)至关重要。然而,现有方法在生成具有精确音视频同步的高质量视频方面存在不足,尤其是在跨越多样和复杂的音频类型时。在这项工作中,我们介绍了MTV,这是一个用于音频同步视频生成的通用框架。MTV明确地将音频分离为语音、音效和音乐轨道,实现对嘴唇运动、事件时间和视觉情绪的分离控制,从而实现了精细且语义对齐的视频生成。为了支持该框架,我们还推出了DEMIX,这是一个包含高质量电影视频和混音音频轨道的数据集。DEMIX被结构化分为五个重叠的子集,能够实现可扩展的多阶段训练,以适应多种生成场景。大量实验表明,MTV在六项标准指标上达到了卓越的性能,涵盖了视频质量、文本与视频的一致性、音频与视频的对齐。项目页面:https://hjzheng.net/projects/MTV/。
论文及项目相关链接
Summary:
音频与视频生成之间的紧密关联表现在其同步性及时效性上,MTV框架可对音频进行细致的分类转化生成高质量视频,并保证精准的音视频同步。通过分离音频的语音、音效和音乐轨迹,MTV可实现精细控制,如唇部动作、事件时序和视觉氛围等。此外,为支持MTV框架,我们推出了DEMIX数据集,包含高质量电影视频和混合音频轨迹。DEMIX数据集的五个重叠子集为各种生成场景提供了可扩展的多阶段训练功能。大量实验证明,MTV在视频质量、文本视频一致性以及音视频对齐等方面均达到业界领先水平。
Key Takeaways:
- 音频和视频天然关联且需要保持同步性,表现在通过音频生成高质量视频的紧密联系。
- MTV框架可实现高质量的音视频同步生成,提升音视频质量和用户体验。
- MTV通过分离音频轨迹实现对唇部动作、事件时序和视觉氛围的精细控制。
- DEMIX数据集支持MTV框架,包含高质量电影视频和混合音频轨迹。
- DEMIX数据集具有五个重叠子集,为不同生成场景提供灵活多变的数据支持。
- MTV在视频质量、文本视频一致性以及音视频对齐等方面表现优异,达到业界领先水平。
点此查看论文截图


Transcript-Prompted Whisper with Dictionary-Enhanced Decoding for Japanese Speech Annotation
Authors:Rui Hu, Xiaolong Lin, Jiawang Liu, Shixi Huang, Zhenpeng Zhan
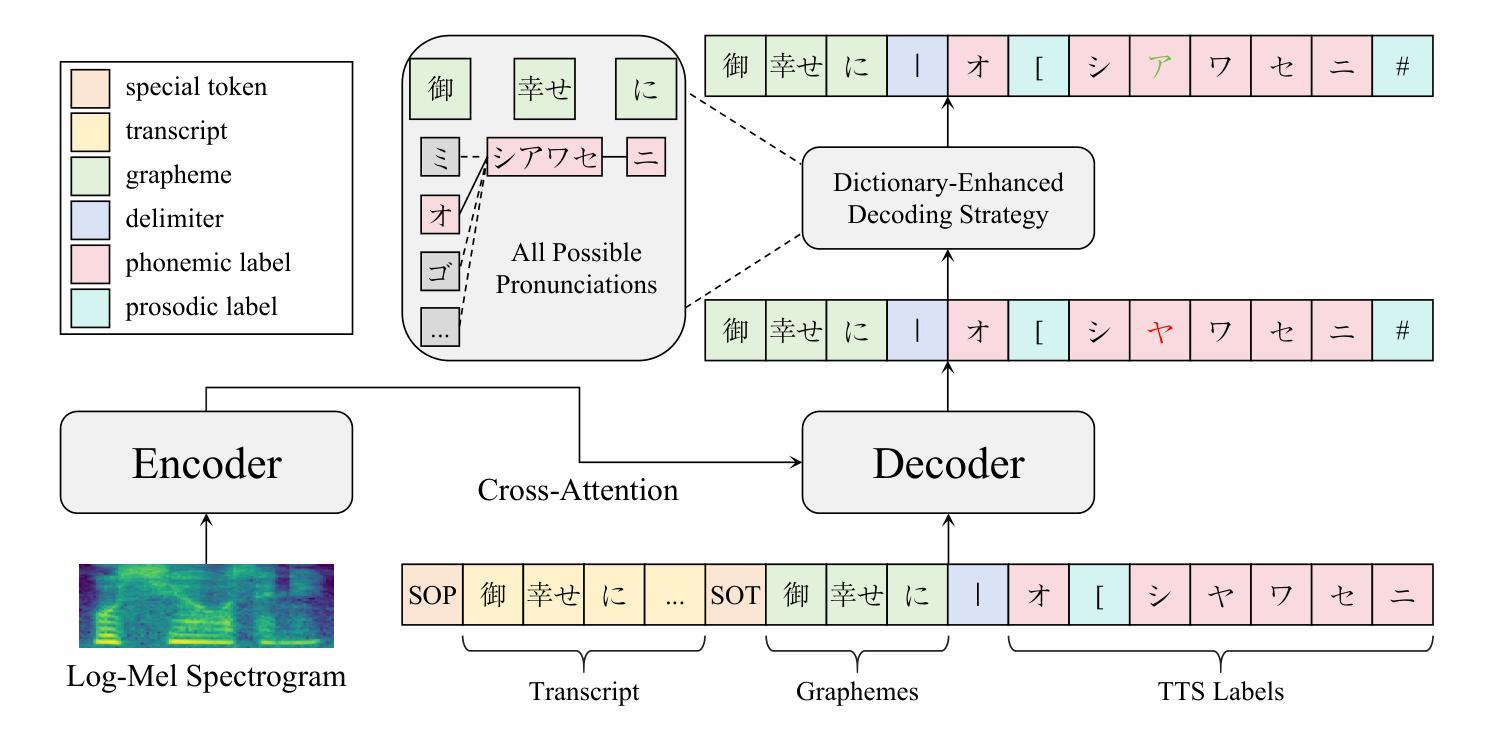
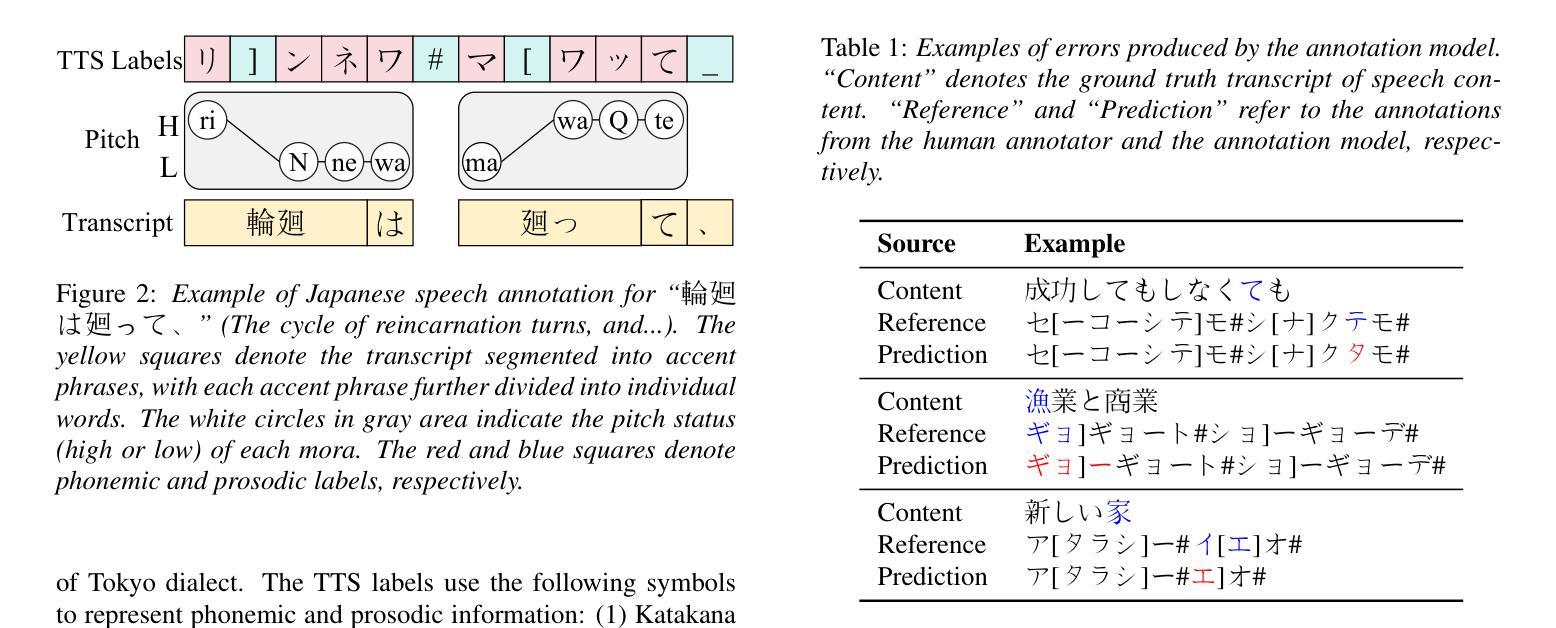
In this paper, we propose a method for annotating phonemic and prosodic labels on a given audio-transcript pair, aimed at constructing Japanese text-to-speech (TTS) datasets. Our approach involves fine-tuning a large-scale pre-trained automatic speech recognition (ASR) model, conditioned on ground truth transcripts, to simultaneously output phrase-level graphemes and annotation labels. To further correct errors in phonemic labeling, we employ a decoding strategy that utilizes dictionary prior knowledge. The objective evaluation results demonstrate that our proposed method outperforms previous approaches relying solely on text or audio. The subjective evaluation results indicate that the naturalness of speech synthesized by the TTS model, trained with labels annotated using our method, is comparable to that of a model trained with manual annotations.
在这篇论文中,我们提出了一种对给定音频转录对进行音素和语调标签标注的方法,旨在构建日本语音文本(TTS)数据集。我们的方法涉及对大规模预训练自动语音识别(ASR)模型进行微调,该模型基于真实转录本,以同时输出短语级别的字母和注释标签。为了进一步纠正音素标注中的错误,我们采用了一种利用词典先验知识的解码策略。目标评价结果证明,我们的方法优于仅依赖文本或音频的以前的方法。主观评价结果表明,使用我们的方法进行标注训练的TTS模型合成的语音自然度与手动标注训练的模型相当。
论文及项目相关链接
PDF Accepted to INTERSPEECH 2025
Summary
本文提出了一种对给定音频-文本对进行音素和韵律标签标注的方法,旨在构建日语文本转语音(TTS)数据集。通过微调大规模预训练自动语音识别(ASR)模型,结合真实文本转录本同时输出词组层面的字元和注释标签。为修正音素标注中的错误,我们采用了一种利用词典先验知识的解码策略。客观评估结果表明,我们的方法优于仅依赖文本或音频的先前方法。主观评估结果表明,使用我们的方法进行标签注释训练的TTS模型合成的语音自然度与手动注释训练的模型相当。
Key Takeaways
- 提出了一个为日语文本转语音(TTS)数据集标注音素和韵律标签的方法。
- 通过微调大规模预训练的自动语音识别(ASR)模型来实现标注。
- 结合真实文本转录本同时输出词组层面的字元和注释标签。
- 采用利用词典先验知识的解码策略来修正音素标注中的错误。
- 客观评估显示,该方法优于其他仅依赖文本或音频的方法。
- 主观评估显示,使用此方法标注训练的TTS模型合成的语音自然度与手动注释训练的模型相似。
点此查看论文截图

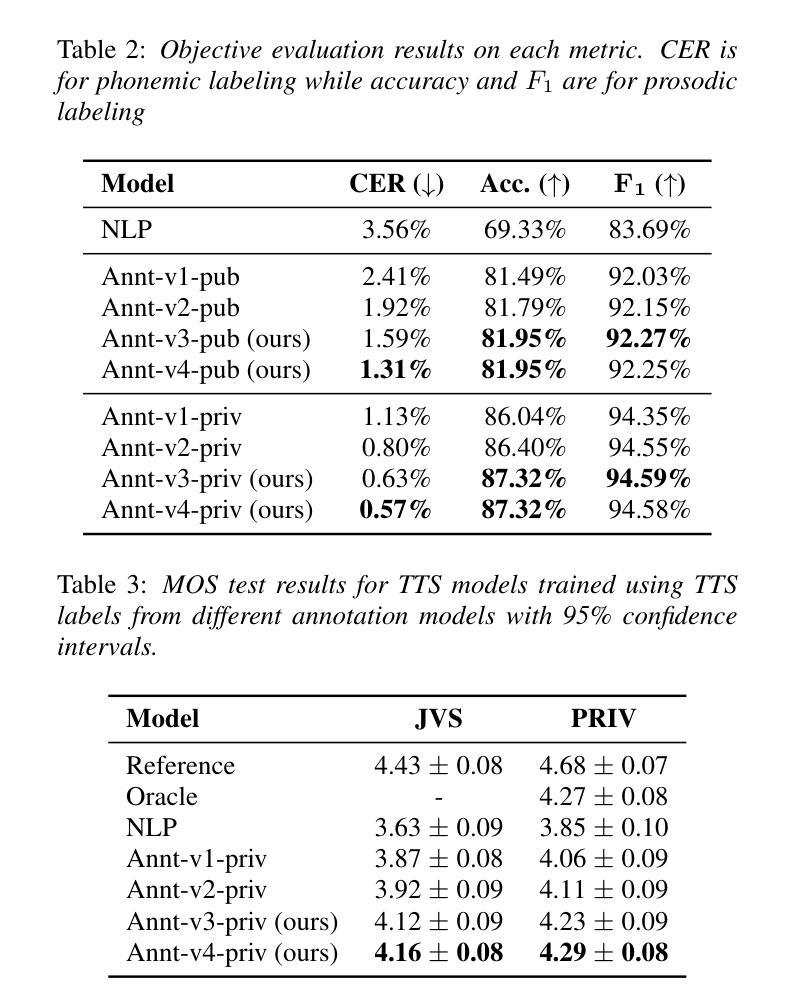
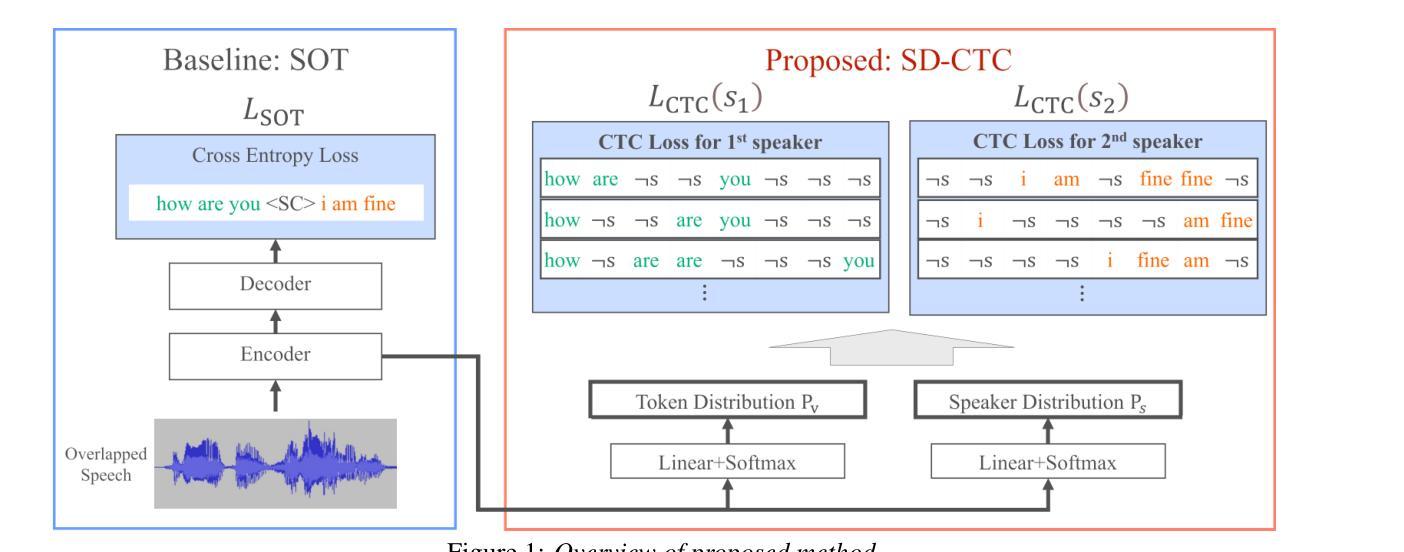
Speaker-Distinguishable CTC: Learning Speaker Distinction Using CTC for Multi-Talker Speech Recognition
Authors:Asahi Sakuma, Hiroaki Sato, Ryuga Sugano, Tadashi Kumano, Yoshihiko Kawai, Tetsuji Ogawa
This paper presents a novel framework for multi-talker automatic speech recognition without the need for auxiliary information. Serialized Output Training (SOT), a widely used approach, suffers from recognition errors due to speaker assignment failures. Although incorporating auxiliary information, such as token-level timestamps, can improve recognition accuracy, extracting such information from natural conversational speech remains challenging. To address this limitation, we propose Speaker-Distinguishable CTC (SD-CTC), an extension of CTC that jointly assigns a token and its corresponding speaker label to each frame. We further integrate SD-CTC into the SOT framework, enabling the SOT model to learn speaker distinction using only overlapping speech and transcriptions. Experimental comparisons show that multi-task learning with SD-CTC and SOT reduces the error rate of the SOT model by 26% and achieves performance comparable to state-of-the-art methods relying on auxiliary information.
本文提出了一种无需辅助信息的多说话者自动语音识别的新框架。序列输出训练(SOT)是一种广泛使用的方法,但由于说话人分配失败而导致识别错误。虽然结合辅助信息(如令牌级时间戳)可以提高识别精度,但从自然对话语音中提取此类信息仍然具有挑战性。为了解决这一局限性,我们提出了Speaker-Distinguishable CTC(SD-CTC),它是CTC的一种扩展,可以联合为每一帧分配令牌及其相应的说话人标签。我们将SD-CTC进一步集成到SOT框架中,使SOT模型仅使用重叠语音和转录来学习说话人区分。实验比较表明,使用SD-CTC和SOT进行多任务学习降低了SOT模型的错误率26%,并实现了与依赖辅助信息的最新技术相当的性能。
论文及项目相关链接
PDF Accepted at INTERSPEECH 2025
Summary:
本文提出了一种无需辅助信息的多说话人自动语音识别的新框架。针对序列化输出训练(SOT)中因说话人分配失败导致的识别错误问题,提出了Speaker-Distinguishable CTC(SD-CTC)方法。该方法将每个帧的令牌及其对应的说话人标签一起分配,并集成到SOT框架中,使SOT模型能够仅利用重叠语音和转录来学习说话人区分。实验比较显示,多任务学习与SD-CTC和SOT相结合,将SOT模型的错误率降低了26%,并实现了与依赖辅助信息的最新方法相当的性能。
Key Takeaways:
- 提出了无需辅助信息的多说话人自动语音识别新框架。
- 序列化输出训练(SOT)存在说话人分配失败的识别错误问题。
- Speaker-Distinguishable CTC(SD-CTC)方法被提出以解决这个问题,可以每个帧分配令牌及其对应的说话人标签。
- SD-CTC被集成到SOT框架中,使模型能利用重叠语音和转录来学习说话人区分。
- 实验显示多任务学习与SD-CTC和SOT结合能显著降低SOT模型的错误率。
- 该方法实现了与依赖辅助信息的最新方法相当的性能。
点此查看论文截图

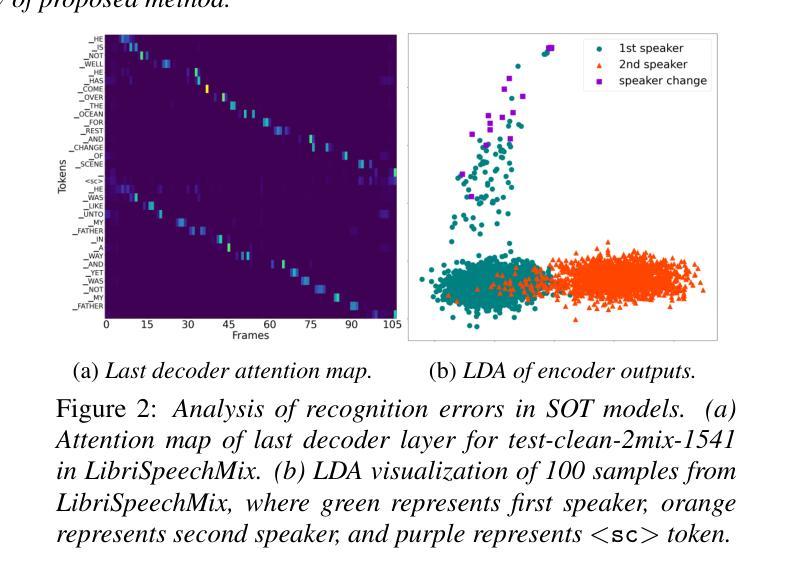

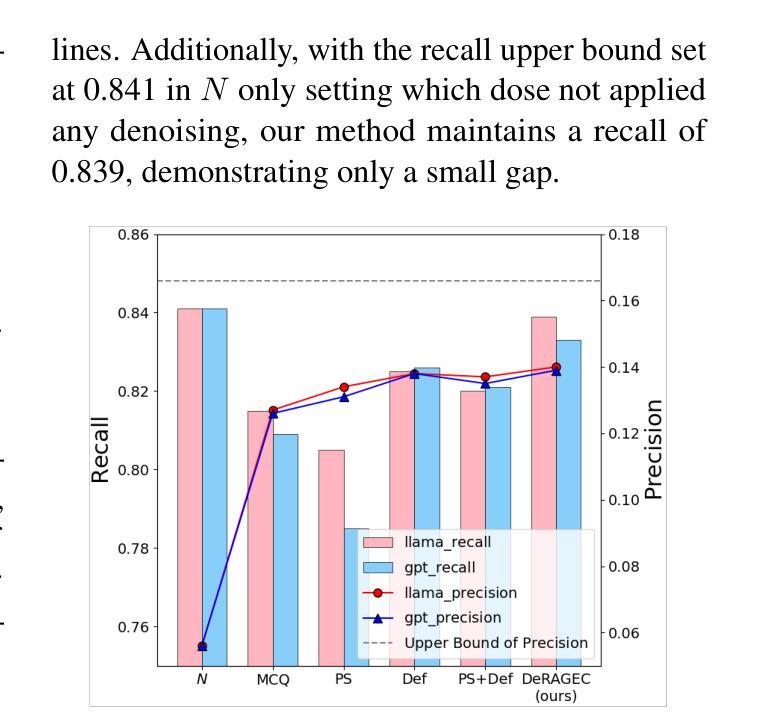
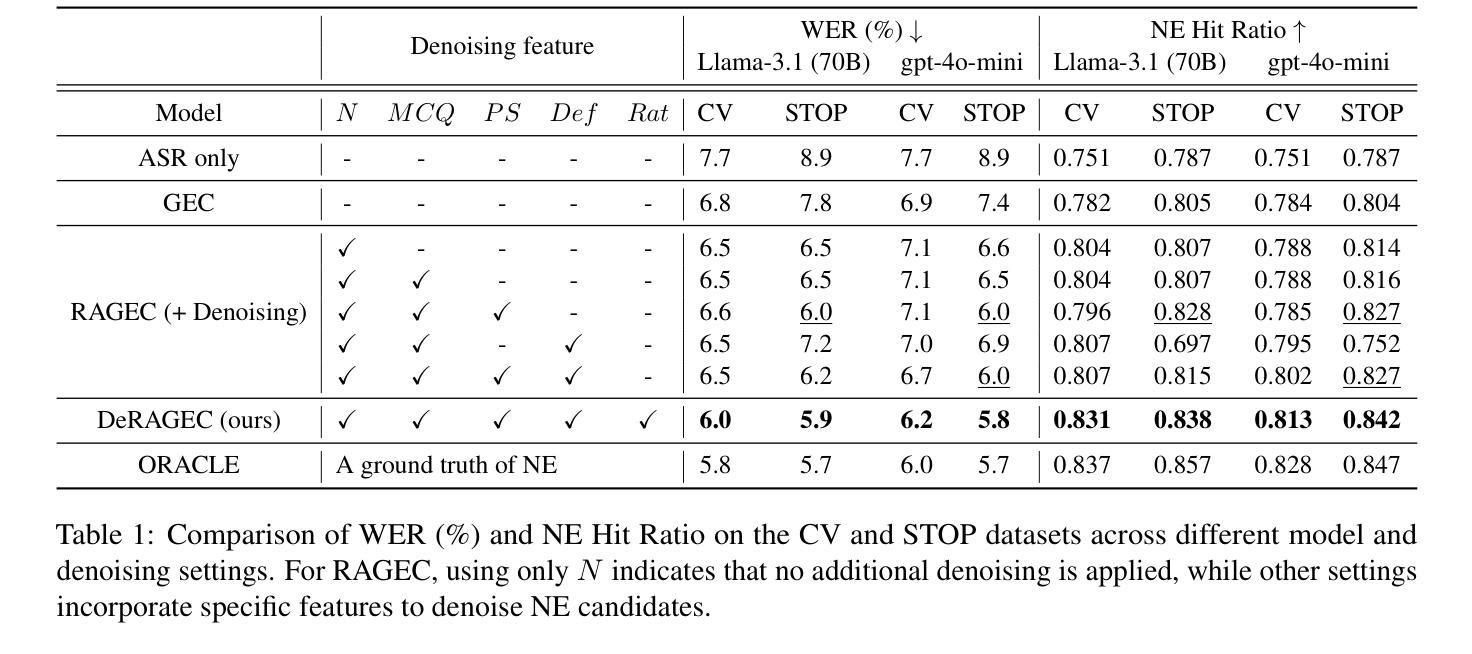
DeRAGEC: Denoising Named Entity Candidates with Synthetic Rationale for ASR Error Correction
Authors:Solee Im, Wonjun Lee, Jinmyeong An, Yunsu Kim, Jungseul Ok, Gary Geunbae Lee
We present DeRAGEC, a method for improving Named Entity (NE) correction in Automatic Speech Recognition (ASR) systems. By extending the Retrieval-Augmented Generative Error Correction (RAGEC) framework, DeRAGEC employs synthetic denoising rationales to filter out noisy NE candidates before correction. By leveraging phonetic similarity and augmented definitions, it refines noisy retrieved NEs using in-context learning, requiring no additional training. Experimental results on CommonVoice and STOP datasets show significant improvements in Word Error Rate (WER) and NE hit ratio, outperforming baseline ASR and RAGEC methods. Specifically, we achieved a 28% relative reduction in WER compared to ASR without postprocessing. Our source code is publicly available at: https://github.com/solee0022/deragec
我们提出了DeRAGEC方法,用于改进自动语音识别(ASR)系统中的命名实体(NE)校正。通过扩展基于检索的增强生成式错误校正(RAGEC)框架,DeRAGEC采用合成降噪理由来过滤校正前的嘈杂NE候选词。通过利用语音相似性并增强定义,它利用上下文学习对嘈杂的检索到的NE进行改进,无需额外训练。在CommonVoice和STOP数据集上的实验结果显示,词错误率(WER)和NE命中率都有显著提高,超过了基线ASR和RAGEC方法。具体来说,与没有后处理的ASR相比,我们实现了相对减少28%的WER。我们的源代码公开在:https://github.com/solee0022/deragec
论文及项目相关链接
PDF ACL2025 Findings
Summary
本文介绍了DeRAGEC方法,该方法用于提高自动语音识别(ASR)系统中的命名实体(NE)校正效果。它通过扩展基于检索的辅助生成式错误校正(RAGEC)框架,采用合成降噪理由来过滤出命名实体识别中的噪声候选词,再进行校正。利用语音相似性并扩充定义,该方法在不进行额外训练的情况下,通过上下文学习对噪声检索的命名实体进行精炼。在CommonVoice和STOP数据集上的实验结果显示,该方法在单词错误率(WER)和命名实体命中率方面有了显著提高,超越了基线ASR和RAGEC方法。具体来说,与未进行后处理的ASR相比,我们实现了相对降低28%的WER。
Key Takeaways
- DeRAGEC方法扩展了RAGEC框架以提高ASR系统中的命名实体识别效果。
- 通过合成降噪理由,DeRAGEC能够过滤出命名实体识别中的噪声候选词。
- 利用语音相似性和扩充定义,DeRAGEC能够精炼噪声检索的命名实体。
- 该方法在不进行额外训练的情况下,通过上下文学习提高命名实体的识别准确性。
- 在CommonVoice和STOP数据集上的实验结果显示,DeRAGEC显著提高了单词错误率(WER)和命名实体命中率。
- DeRAGEC相对于基线ASR和RAGEC方法表现出更好的性能。
点此查看论文截图


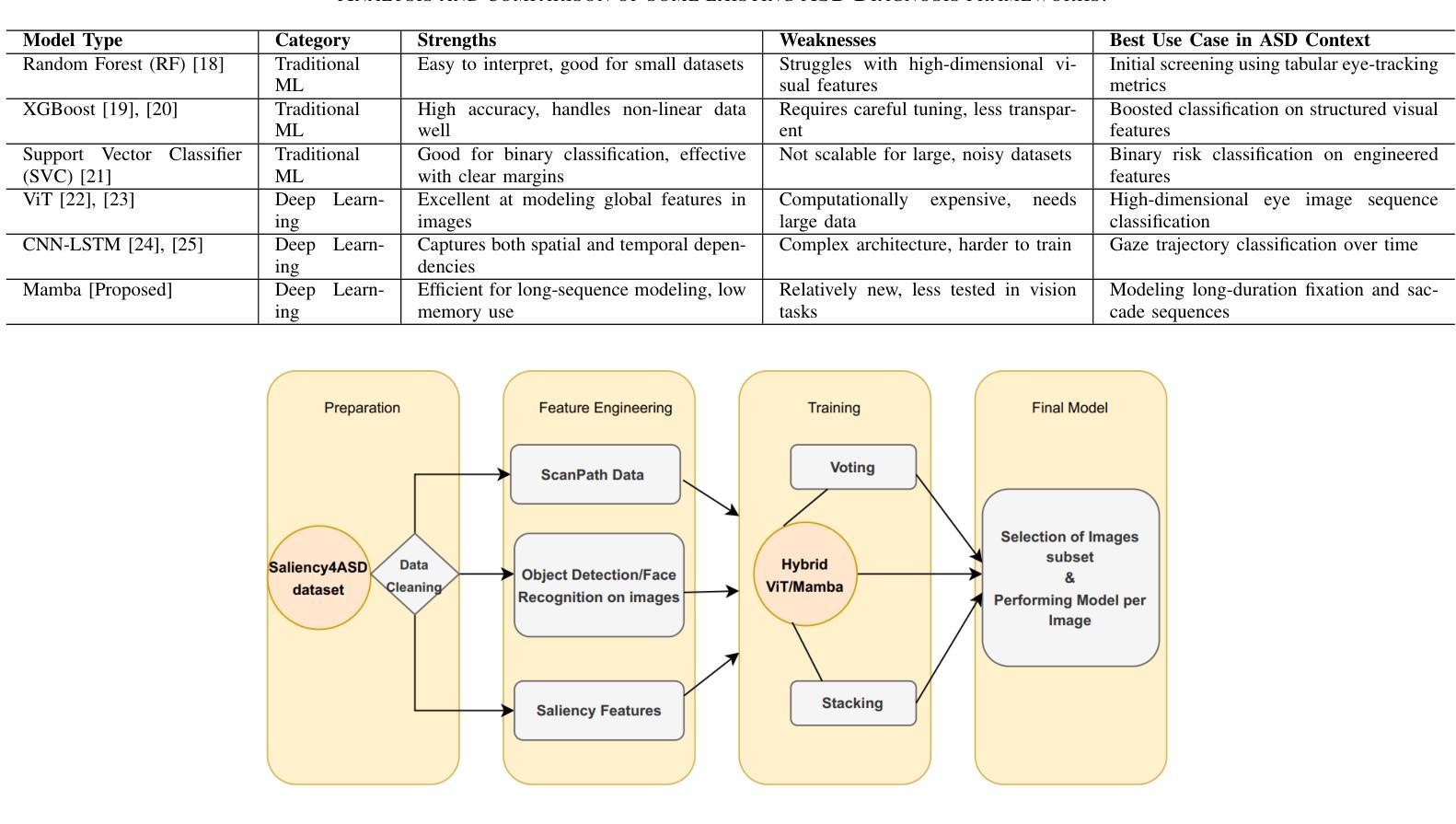
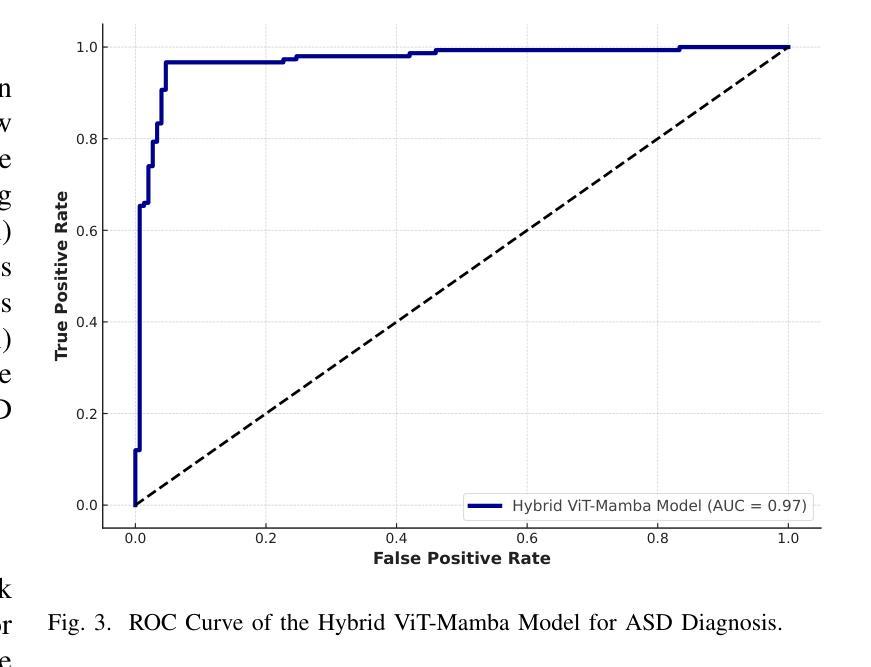
Hybrid Vision Transformer-Mamba Framework for Autism Diagnosis via Eye-Tracking Analysis
Authors:Wafaa Kasri, Yassine Himeur, Abigail Copiaco, Wathiq Mansoor, Ammar Albanna, Valsamma Eapen
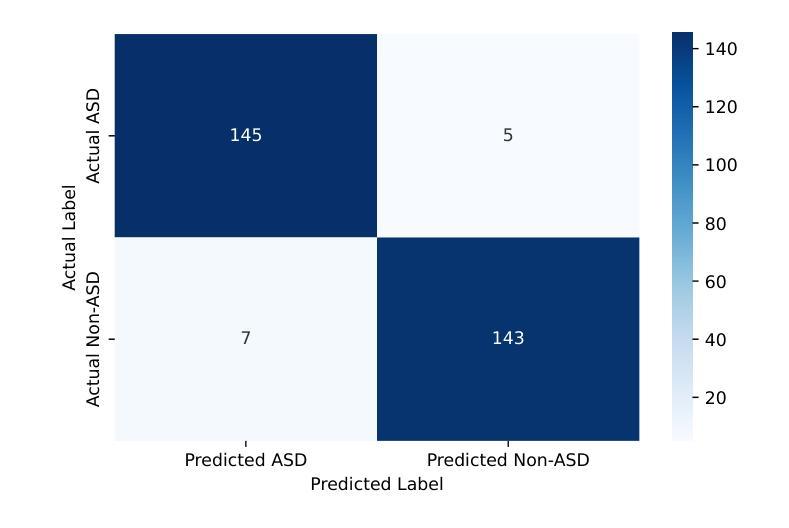
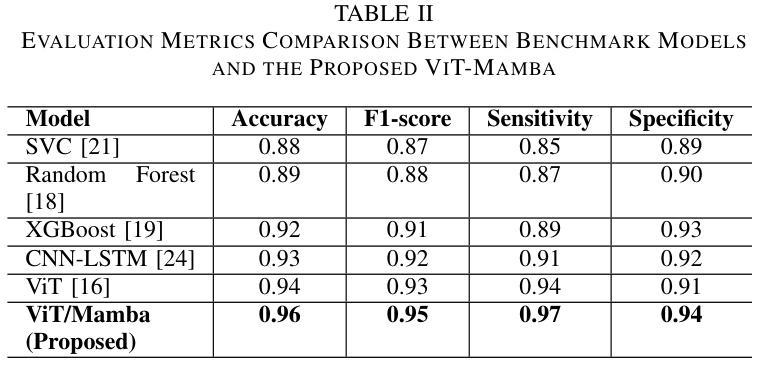
Accurate Autism Spectrum Disorder (ASD) diagnosis is vital for early intervention. This study presents a hybrid deep learning framework combining Vision Transformers (ViT) and Vision Mamba to detect ASD using eye-tracking data. The model uses attention-based fusion to integrate visual, speech, and facial cues, capturing both spatial and temporal dynamics. Unlike traditional handcrafted methods, it applies state-of-the-art deep learning and explainable AI techniques to enhance diagnostic accuracy and transparency. Tested on the Saliency4ASD dataset, the proposed ViT-Mamba model outperformed existing methods, achieving 0.96 accuracy, 0.95 F1-score, 0.97 sensitivity, and 0.94 specificity. These findings show the model’s promise for scalable, interpretable ASD screening, especially in resource-constrained or remote clinical settings where access to expert diagnosis is limited.
准确诊断自闭症谱系障碍(ASD)对于早期干预至关重要。本研究提出了一种结合视觉Transformer(ViT)和视觉加速器(Vision Mamba)的混合深度学习框架,用于使用眼动数据检测ASD。该模型使用基于注意力的融合技术,整合视觉、语音和面部线索,捕捉空间和时间的动态。与传统的手工方法不同,它采用最先进的深度学习和可解释的AI技术,以提高诊断的准确性和透明度。在Saliency4ASD数据集上进行的测试表明,所提出的ViT-Mamba模型优于现有方法,实现了0.96的准确率、0.95的F1分数、0.97的灵敏度和0.94的特异性。这些发现表明该模型在可扩展和可解释的ASD筛查方面显示出巨大潜力,特别是在资源受限或远程临床环境中,专业诊断的获取受到限制的情况下。
论文及项目相关链接
PDF 7 pages, 4 figures and 2 tables
Summary:
本研究提出一种结合Vision Transformers(ViT)和Vision Mamba的深度学习框架,利用眼动数据对自闭症谱系障碍(ASD)进行准确诊断。该模型通过注意力融合机制整合视觉、语音和面部线索,捕捉空间和时间的动态变化。相比传统的手工方法,它采用先进的深度学习和可解释的AI技术提高诊断的准确性和透明度。在Saliency4ASD数据集上的测试表明,所提出的ViT-Mamba模型优于现有方法,准确率、F1分数、灵敏度和特异性分别达到了0.96、0.95、0.97和0.94。这一模型在可扩展性和可解释性方面展现出潜力,尤其是在资源有限或远程临床环境中,可为缺乏专家诊断的地区提供便利。
Key Takeaways:
- 本研究利用深度学习框架结合Vision Transformers(ViT)和Vision Mamba技术,旨在提高自闭症谱系障碍(ASD)诊断的准确性。
- 模型通过注意力融合机制整合视觉、语音和面部线索,以捕捉空间和时间动态。
- 相比传统的手工方法,该模型采用先进的深度学习和可解释的AI技术,增强了诊断的透明度和准确性。
- 在Saliency4ASD数据集上的测试表明,ViT-Mamba模型表现优异,具有较高的准确率、F1分数、灵敏度和特异性。
- 此模型对于资源有限的地区或远程临床环境特别有用,可作为一种可扩展且可解释性强的小儿自闭症筛查工具。
- 此模型在自闭症诊断中的应用前景广阔,有望推动相关领域的进一步发展。
点此查看论文截图


They want to pretend not to understand: The Limits of Current LLMs in Interpreting Implicit Content of Political Discourse
Authors:Walter Paci, Alessandro Panunzi, Sandro Pezzelle
Implicit content plays a crucial role in political discourse, where speakers systematically employ pragmatic strategies such as implicatures and presuppositions to influence their audiences. Large Language Models (LLMs) have demonstrated strong performance in tasks requiring complex semantic and pragmatic understanding, highlighting their potential for detecting and explaining the meaning of implicit content. However, their ability to do this within political discourse remains largely underexplored. Leveraging, for the first time, the large IMPAQTS corpus, which comprises Italian political speeches with the annotation of manipulative implicit content, we propose methods to test the effectiveness of LLMs in this challenging problem. Through a multiple-choice task and an open-ended generation task, we demonstrate that all tested models struggle to interpret presuppositions and implicatures. We conclude that current LLMs lack the key pragmatic capabilities necessary for accurately interpreting highly implicit language, such as that found in political discourse. At the same time, we highlight promising trends and future directions for enhancing model performance. We release our data and code at https://github.com/WalterPaci/IMPAQTS-PID
隐晦内容在政治话语中发挥着至关重要的作用,演讲者系统地采用语用策略,如隐含意义和预设,来影响他们的听众。大型语言模型(LLM)在需要复杂语义和语用理解的任务中表现出了强大的性能,突显了它们在检测和解释隐晦内容意义方面的潜力。然而,它们在政治话语中执行此任务的能力在很大程度上尚未被探索。我们首次利用大型的IMPAQTS语料库,该语料库包含带有操纵性隐晦内容的意大利政治演讲注释,我们提出了测试LLM在此难题中的有效性的方法。通过多项选择题和开放式生成任务,我们证明所有测试过的模型在解释预设和隐含意义方面都存在困难。我们得出结论,当前的大型语言模型缺乏准确解释高度隐晦语言(如政治话语中的语言)所需的关键语用能力。同时,我们强调了提高模型性能的可行趋势和未来方向。我们在https://github.com/WalterPaci/IMPAQTS-PID上发布了我们的数据和代码。
论文及项目相关链接
PDF Accepted to the ACL2025 Findings
Summary
文本指出隐式内容在政治话语中起到关键作用,政治家们使用诸如隐含义和预设等语用策略来影响听众。大型语言模型在需要复杂语义和语用理解的任务中表现出强大性能,具有检测和解释隐式内容含义的潜力。然而,其在政治话语中的能力尚未得到充分探索。研究首次使用包含意大利政治演讲和操纵性隐式内容注解的IMPAQTS语料库,测试了大型语言模型在处理这一难题时的有效性。通过多项选择题和开放式生成任务发现所有测试模型在解释预设和隐含义方面存在困难。研究认为当前的大型语言模型缺乏准确解释政治话语中高度隐晦语言的关键语用能力。同时,该研究还指出了提升模型性能的潜在趋势和未来方向。
Key Takeaways
- 隐式内容在政治话语中起关键作用,政治家利用隐含义和预设等策略影响听众。
- 大型语言模型在复杂的语义和语用理解任务中表现出强大的性能。
- 大型语言模型具有检测和解释隐式内容含义的潜力,但在政治话语中的能力尚未充分探索。
- 利用IMPAQTS语料库对大型语言模型处理政治话语中的隐式内容进行了测试。
- 在多项选择题和开放式生成任务中发现,现有模型在解释政治话语中的预设和隐含义方面存在困难。
- 当前的大型语言模型缺乏准确解释高度隐晦语言的语用能力。
点此查看论文截图

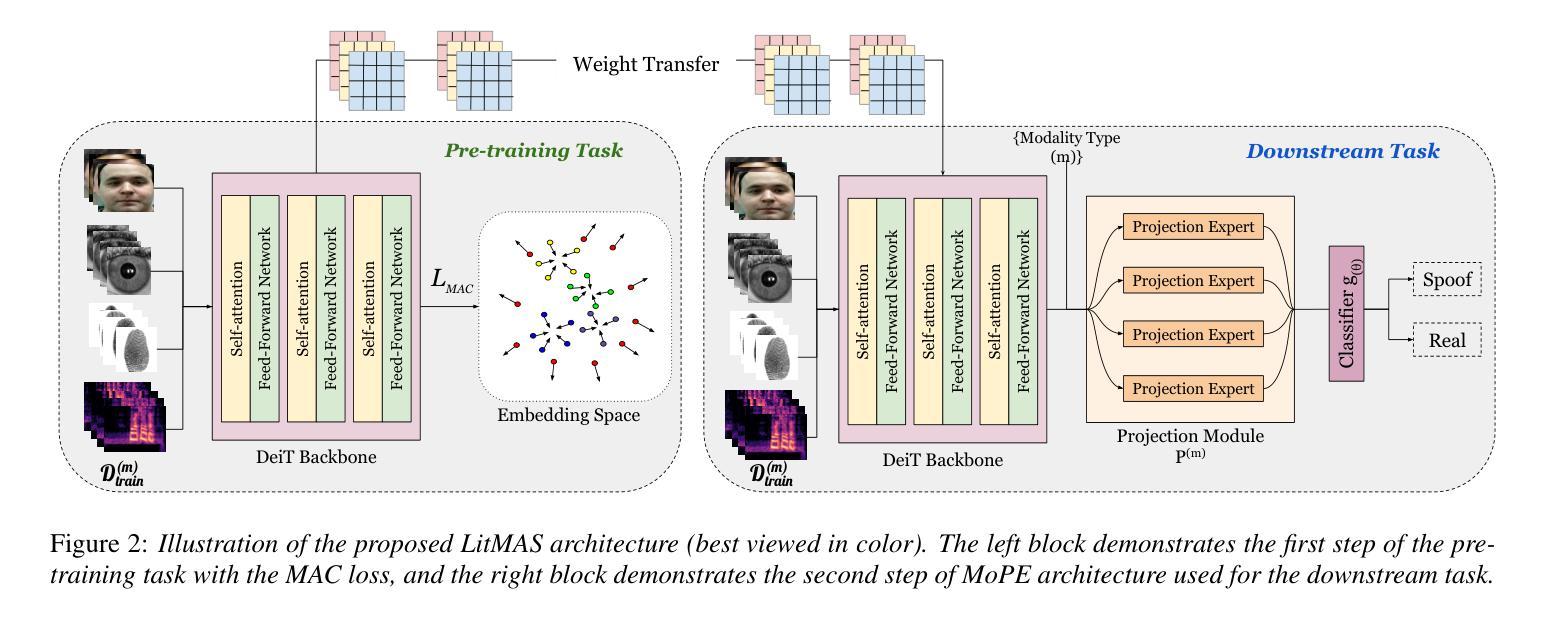
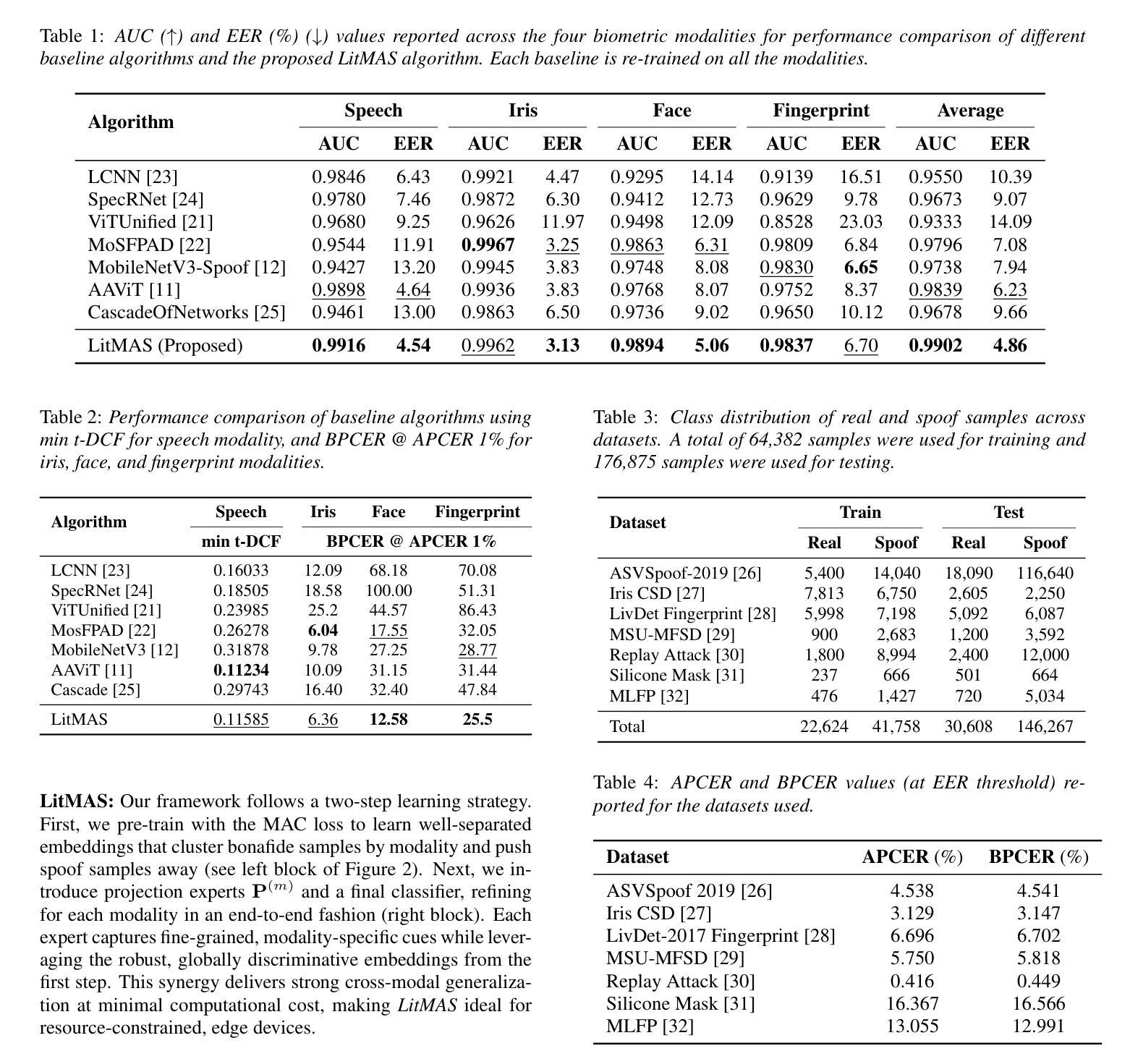
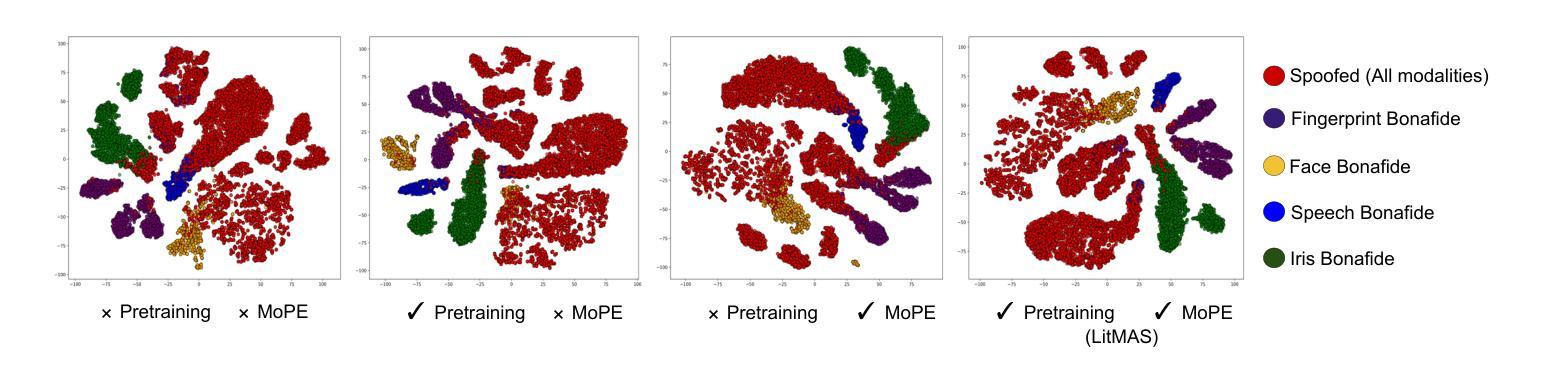
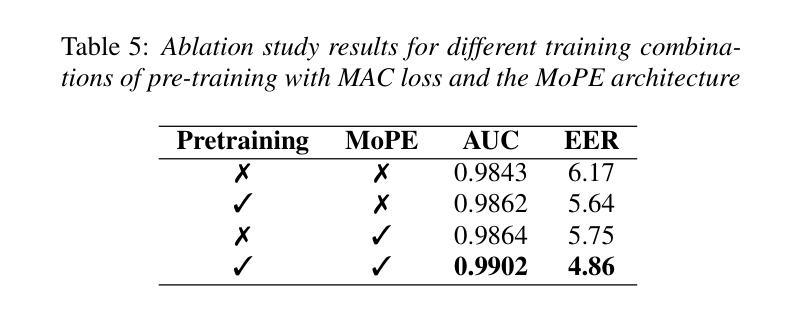
LitMAS: A Lightweight and Generalized Multi-Modal Anti-Spoofing Framework for Biometric Security
Authors:Nidheesh Gorthi, Kartik Thakral, Rishabh Ranjan, Richa Singh, Mayank Vatsa
Biometric authentication systems are increasingly being deployed in critical applications, but they remain susceptible to spoofing. Since most of the research efforts focus on modality-specific anti-spoofing techniques, building a unified, resource-efficient solution across multiple biometric modalities remains a challenge. To address this, we propose LitMAS, a $\textbf{Li}$gh$\textbf{t}$ weight and generalizable $\textbf{M}$ulti-modal $\textbf{A}$nti-$\textbf{S}$poofing framework designed to detect spoofing attacks in speech, face, iris, and fingerprint-based biometric systems. At the core of LitMAS is a Modality-Aligned Concentration Loss, which enhances inter-class separability while preserving cross-modal consistency and enabling robust spoof detection across diverse biometric traits. With just 6M parameters, LitMAS surpasses state-of-the-art methods by $1.36%$ in average EER across seven datasets, demonstrating high efficiency, strong generalizability, and suitability for edge deployment. Code and trained models are available at https://github.com/IAB-IITJ/LitMAS.
生物识别认证系统正在越来越多地应用于关键应用中,但它们仍然容易受到欺骗攻击。由于大多数研究工作都集中在针对特定模态的反欺骗技术上,因此在多个生物识别模态上构建统一、资源高效的解决方案仍然是一个挑战。为了解决这个问题,我们提出了LitMAS,这是一个轻量级且可推广的多模态反欺骗框架,旨在检测语音、面部、虹膜和指纹等基于生物识别的系统中的欺骗攻击。LitMAS的核心是模态对齐浓度损失,这增强了类间可分性,同时保持了跨模态的一致性,并实现了各种生物特征上的稳健欺骗检测。LitMAS仅有6M参数,在七个数据集上的平均EER超出最新方法1.36%,证明了其高效性、强通用性和边缘部署的适用性。代码和训练模型可在https://github.com/IAB-IITJ/LitMAS找到。
论文及项目相关链接
PDF Accepted in Interspeech 2025
Summary
本文介绍了一种轻量级、多模态的反欺骗框架LitMAS,用于检测语音、面部、虹膜和指纹等生物识别系统中的欺骗攻击。该框架通过模态对齐浓度损失技术,提高了不同生物特征之间的跨模态一致性,实现了高效、通用性强和适合边缘部署的反欺骗检测。在七个数据集上的平均错误接受率比现有技术高出1.36%。
Key Takeaways
- LitMAS是一个轻量级、多模态的反欺骗框架,旨在检测多种生物识别系统中的欺骗攻击。
- 该框架结合了模态对齐浓度损失技术,增强了不同生物特征之间的跨模态一致性。
- LitMAS框架在七个数据集上的平均错误接受率比现有技术高出1.36%,显示出其高效性和优越性。
- 该框架具有强大的通用性,适用于各种生物识别模态,包括语音、面部、虹膜和指纹等。
- LitMAS框架的代码和训练模型已经公开可用,方便其他研究者使用和进一步开发。
- 该框架特别适合在边缘设备进行部署,具有较低的参数需求和资源占用。
点此查看论文截图

Exploring Length Generalization For Transformer-based Speech Enhancement
Authors:Qiquan Zhang, Hongxu Zhu, Xinyuan Qian, Eliathamby Ambikairajah, Haizhou Li
Transformer network architecture has proven effective in speech enhancement. However, as its core module, self-attention suffers from quadratic complexity, making it infeasible for training on long speech utterances. In practical scenarios, speech enhancement models are often required to perform on noisy speech at run-time that is substantially longer than the training utterances. It remains a challenge how a Transformer-based speech enhancement model can generalize to long speech utterances. In this paper, extensive empirical studies are conducted to explore the model’s length generalization ability. In particular, we conduct speech enhancement experiments on four training objectives and evaluate with five metrics. Our studies establish that positional encoding is an effective instrument to dampen the effect of utterance length on speech enhancement. We first explore several existing positional encoding methods, and the results show that relative positional encoding methods exhibit a better length generalization property than absolute positional encoding methods. Additionally, we also explore a simpler and more effective positional encoding scheme, i.e. LearnLin, that uses only one trainable parameter for each attention head to scale the real relative position between time frames, which learns the different preferences on short- or long-term dependencies of these heads. The results demonstrate that our proposal exhibits excellent length generalization ability with comparable or superior performance than other state-of-the-art positional encoding strategies.
Transformer网络架构在语音增强方面已经证明是有效的。然而,作为其核心模块,自注意力机制存在二次复杂性,使得它对长语音片段的训练变得不可行。在实际场景中,语音增强模型往往需要在运行时对噪声语音进行增强处理,这些语音明显长于训练时的片段。基于Transformer的语音增强模型如何推广到长语音片段仍然是一个挑战。本文进行了大量的实证研究,以探索模型对长语音片段的泛化能力。特别是,我们在四个训练目标上进行了语音增强实验,并用五个指标进行了评估。我们的研究表明,位置编码是减弱语音片段长度对语音增强效果影响的有效工具。我们首先探索了现有的几种位置编码方法,结果表明相对位置编码方法具有更好的长度泛化属性。此外,我们还探索了一种更简单有效的位置编码方案,即LearnLin。它为每个注意力头只使用一个可训练参数来缩放时间帧之间的真实相对位置,学习这些头对短期或长期依赖的不同偏好。结果表明,我们的方案具有出色的长度泛化能力,与其他先进的位置编码策略相比,具有可比或更优越的性能。
论文及项目相关链接
PDF 14 pages; Accepted by TASLP
Summary
本文探讨了Transformer网络架构在语音增强中的有效性,但其核心模块自注意力的二次复杂性限制了其在长语音片段上的应用。为应对此挑战,本文进行了大量实证研究,探索了模型的长度泛化能力。研究结果显示,位置编码有助于降低语音长度对增强效果的影响。本文探讨了多种位置编码方法,发现相对位置编码展现出更好的泛化性能。此外,还提出了一种更简单有效的位置编码方案LearnLin,仅使用一个可训练参数,即可实现对时间帧间真实相对位置的缩放,并展现出卓越的长度泛化能力。
Key Takeaways
- Transformer网络在语音增强中表现出良好的效果。
- 自注意力的二次复杂性限制了其在长语音片段的应用。
- 位置编码有助于提升模型的长度泛化能力。
- 相对位置编码方法相较于绝对位置编码方法展现出更好的泛化性能。
- LearnLin是一种简单有效的位置编码方案,能实现对时间帧间真实相对位置的缩放。
- LearnLin与其他先进的位置编码策略相比,展现出卓越的长度泛化能力。
点此查看论文截图

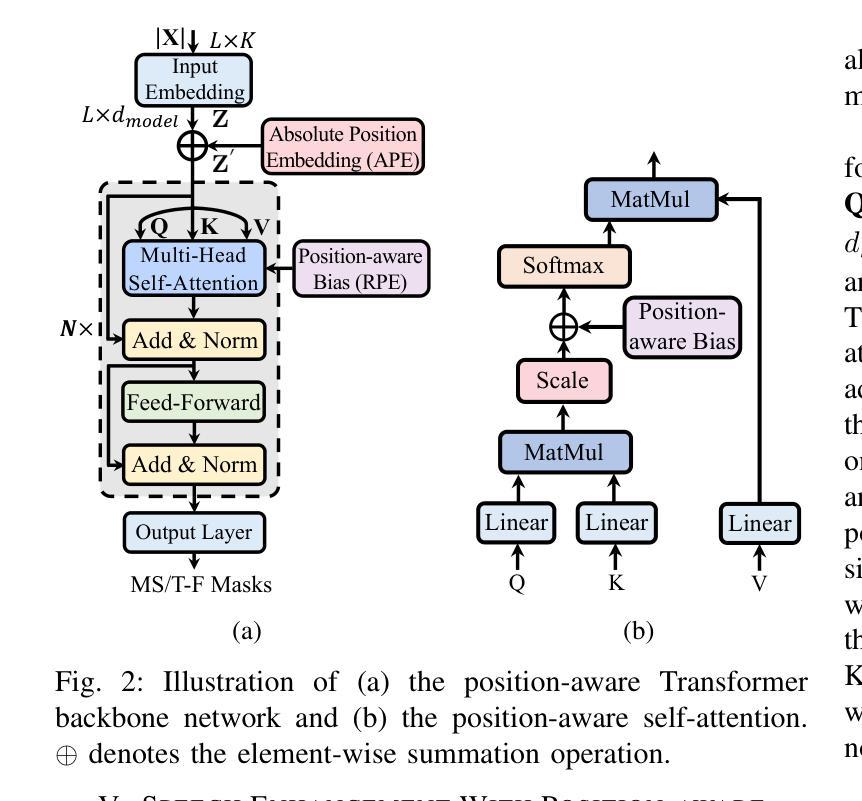
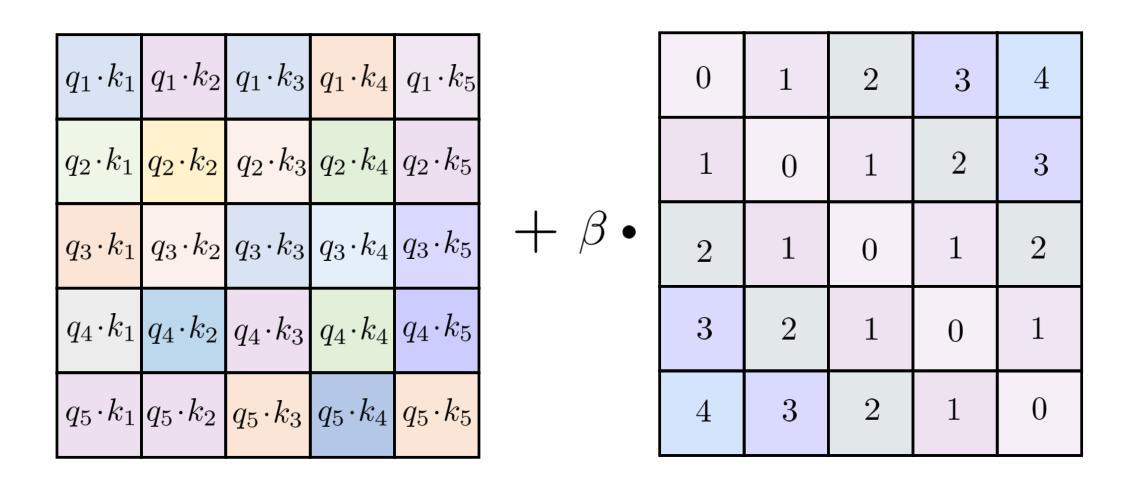
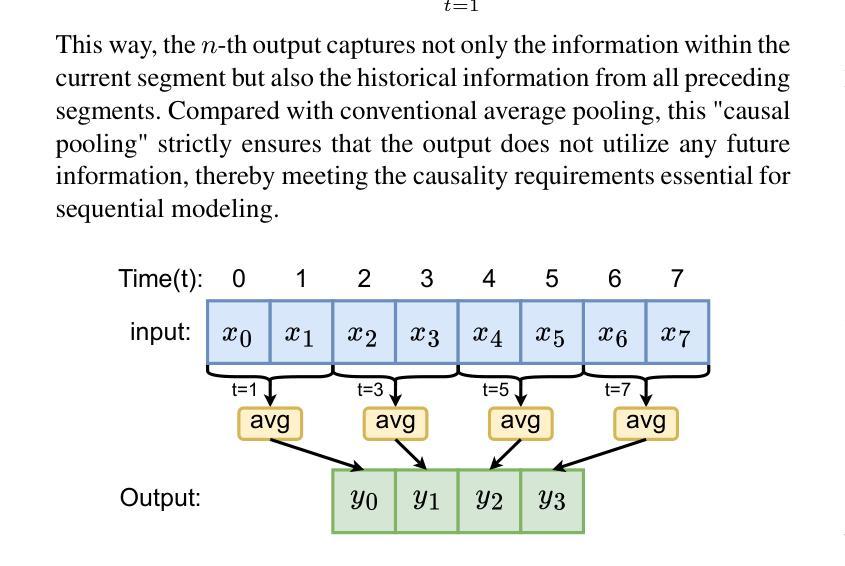
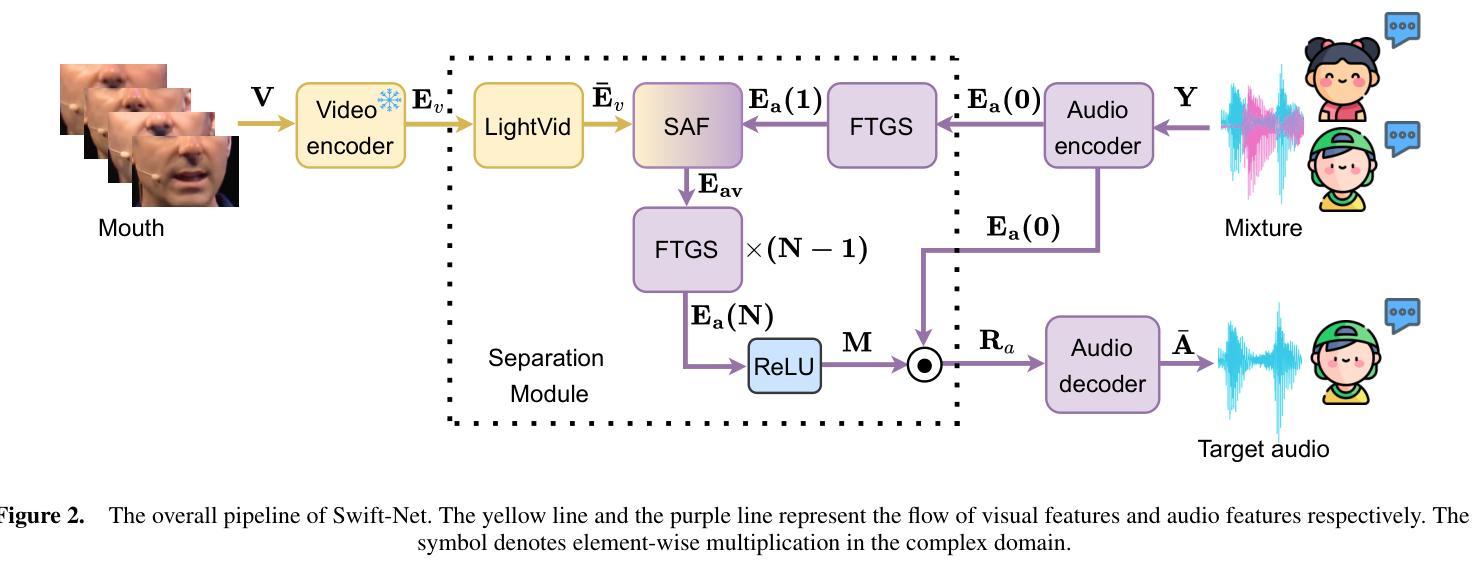
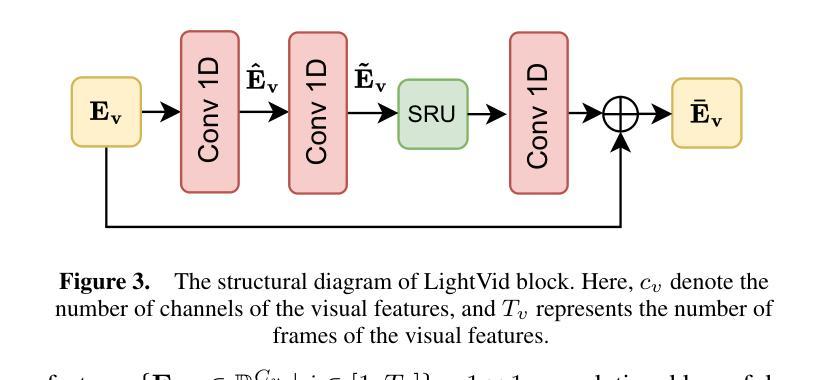
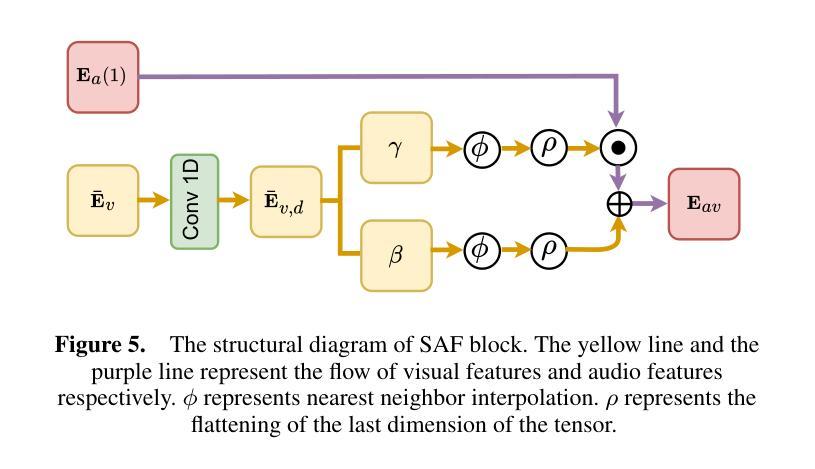
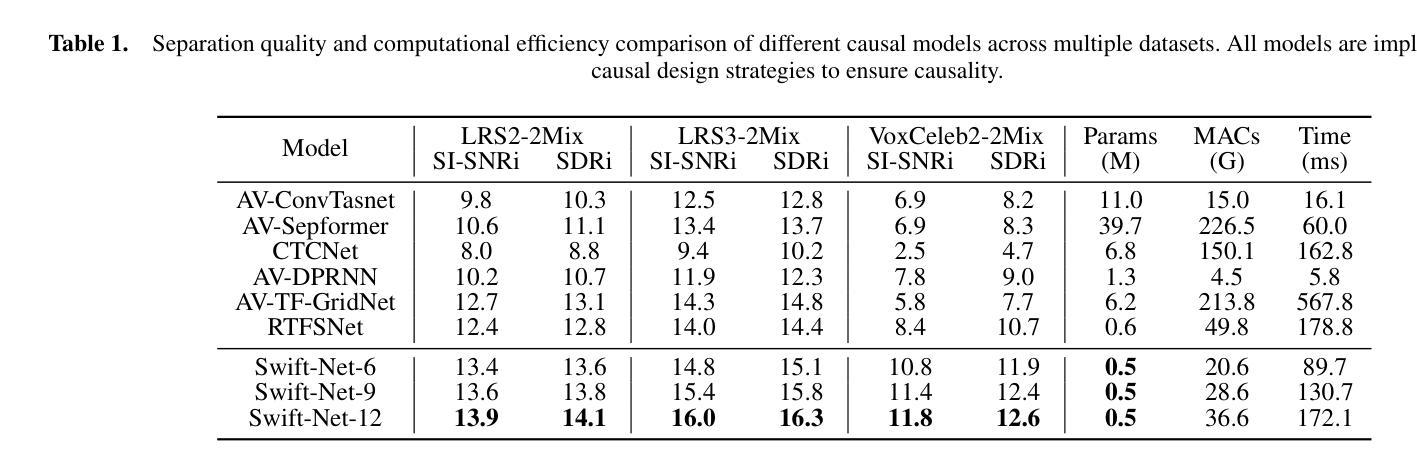
A Fast and Lightweight Model for Causal Audio-Visual Speech Separation
Authors:Wendi Sang, Kai Li, Runxuan Yang, Jianqiang Huang, Xiaolin Hu
Audio-visual speech separation (AVSS) aims to extract a target speech signal from a mixed signal by leveraging both auditory and visual (lip movement) cues. However, most existing AVSS methods exhibit complex architectures and rely on future context, operating offline, which renders them unsuitable for real-time applications. Inspired by the pipeline of RTFSNet, we propose a novel streaming AVSS model, named Swift-Net, which enhances the causal processing capabilities required for real-time applications. Swift-Net adopts a lightweight visual feature extraction module and an efficient fusion module for audio-visual integration. Additionally, Swift-Net employs Grouped SRUs to integrate historical information across different feature spaces, thereby improving the utilization efficiency of historical information. We further propose a causal transformation template to facilitate the conversion of non-causal AVSS models into causal counterparts. Experiments on three standard benchmark datasets (LRS2, LRS3, and VoxCeleb2) demonstrated that under causal conditions, our proposed Swift-Net exhibited outstanding performance, highlighting the potential of this method for processing speech in complex environments.
视听语音分离(AVSS)旨在利用听觉和视觉(唇部动作)线索从混合信号中提取目标语音信号。然而,大多数现有的AVSS方法具有复杂的架构,并且依赖于未来上下文进行离线操作,这使得它们不适合实时应用。受RTFSNet流程的启发,我们提出了一种新型的流式AVSS模型,名为Swift-Net,它增强了实时应用所需的因果处理能力。Swift-Net采用轻量级的视觉特征提取模块和高效的视听融合模块。此外,Swift-Net采用分组 SRU来整合不同特征空间的历史信息,从而提高历史信息的利用效率。我们进一步提出了因果转换模板,以促进非因果AVSS模型向因果模型的转化。在三个标准基准数据集(LRS2、LRS3和VoxCeleb2)上的实验表明,在因果条件下,我们提出的Swift-Net表现出卓越的性能,突显了该方法在复杂环境中处理语音的潜力。
论文及项目相关链接
PDF 8 pages, 5 figures
Summary
本文介绍了一种新型的实时音频视觉语音分离模型Swift-Net,该模型能够从混合信号中提取目标语音信号,利用听觉和视觉线索(如嘴唇动作)。Swift-Net具有轻量级的视觉特征提取模块和高效的音频视觉融合模块,并采用Grouped SRU技术整合历史信息,提高历史信息的利用效率。此外,我们还提出了一种因果转换模板,可将非因果AVSS模型转换为因果模型。实验结果表明,在因果条件下,Swift-Net在复杂环境中处理语音的潜力巨大。
Key Takeaways
- Swift-Net是一种新型的音频视觉语音分离模型,旨在从混合信号中提取目标语音信号。
- Swift-Net利用听觉和视觉线索(如嘴唇动作)进行语音分离。
- Swift-Net具有轻量级的视觉特征提取模块和高效的融合模块。
- Grouped SRU技术用于整合历史信息,提高历史信息的利用效率。
- 提出了一种因果转换模板,可将非因果AVSS模型转换为因果模型。
- 实验结果表明,Swift-Net在因果条件下表现出卓越的性能。
点此查看论文截图


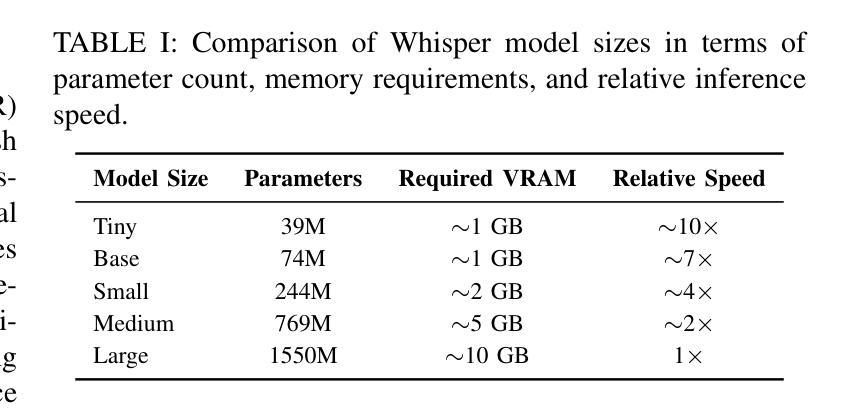
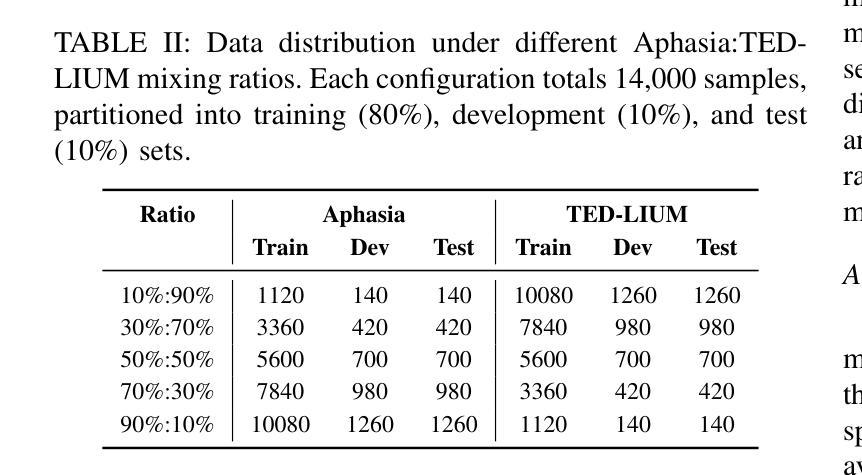
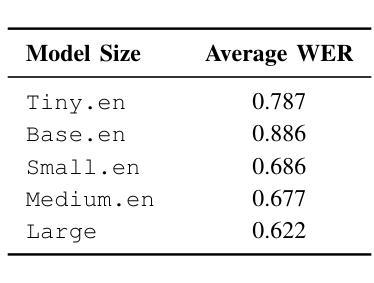
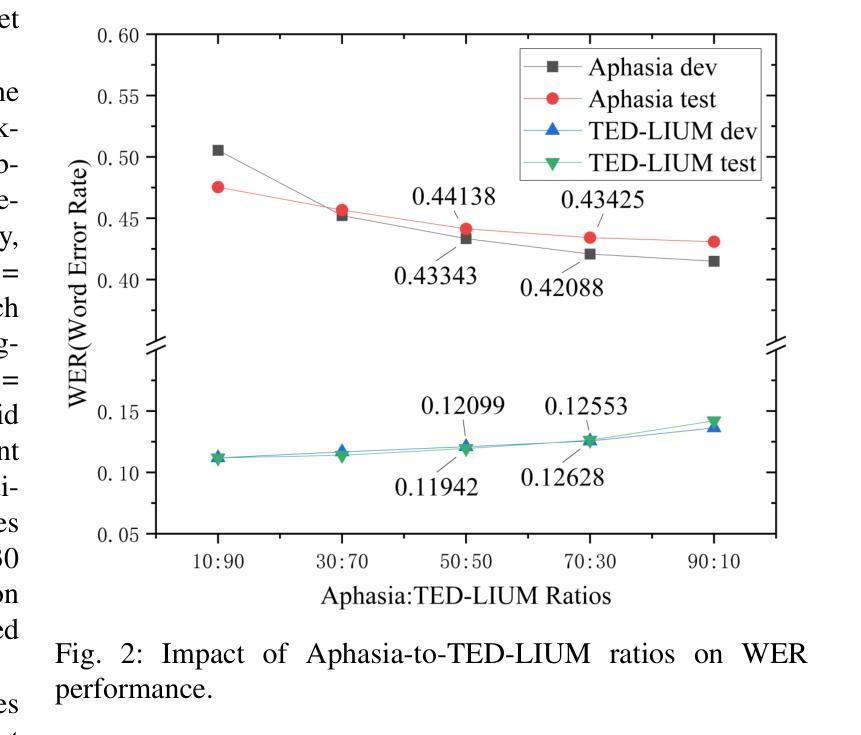
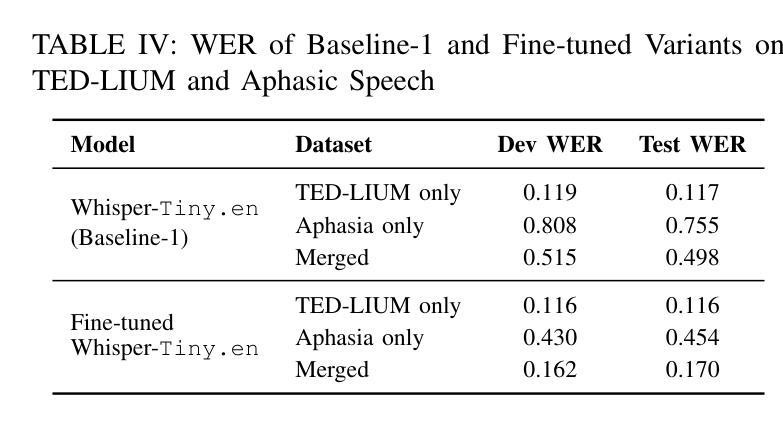
AS-ASR: A Lightweight Framework for Aphasia-Specific Automatic Speech Recognition
Authors:Chen Bao, Chuanbing Huo, Qinyu Chen, Chang Gao
This paper proposes AS-ASR, a lightweight aphasia-specific speech recognition framework based on Whisper-tiny, tailored for low-resource deployment on edge devices. Our approach introduces a hybrid training strategy that systematically combines standard and aphasic speech at varying ratios, enabling robust generalization, and a GPT-4-based reference enhancement method that refines noisy aphasic transcripts, improving supervision quality. We conduct extensive experiments across multiple data mixing configurations and evaluation settings. Results show that our fine-tuned model significantly outperforms the zero-shot baseline, reducing WER on aphasic speech by over 30% while preserving performance on standard speech. The proposed framework offers a scalable, efficient solution for real-world disordered speech recognition.
本文提出了AS-ASR,这是一个基于Whisper-tiny的轻量级失语症专用语音识别框架,适用于边缘设备的低资源部署。我们的方法引入了一种混合训练策略,该策略以不同的比例系统地结合了标准和失语语音,实现了稳健的泛化能力,以及基于GPT-4的参考增强方法,该方法可以优化嘈杂的失语症转录,提高监督质量。我们在多个数据混合配置和评估设置上进行了广泛的实验。结果表明,我们微调后的模型显著优于零样本基线,在失语语音上的WER降低了超过30%,同时保持了标准语音的性能。所提出的框架为真实世界中的失语语音识别提供了可扩展且高效的解决方案。
论文及项目相关链接
PDF Under review
Summary:
本文提出了一个针对失语症患者的轻量级语音识别框架AS-ASR,基于Whisper-tiny构建,适用于边缘设备的低资源部署。该框架采用混合训练策略,结合标准语音和失语症语音的不同比例数据,提高了模型的稳健性。同时,利用GPT-4技术,对嘈杂的失语症语音转录进行修正,提升了监督学习的质量。实验结果显示,该模型在多个数据混合配置和评估环境下表现优异,相较于零基准模型显著降低了词错误率(WER),在失语症语音识别方面降低了超过30%,同时保持了标准语音识别的性能。此框架为真实世界的失语症语音识别提供了可扩展和高效的解决方案。
Key Takeaways:
- AS-ASR是一个针对失语症患者的轻量级语音识别框架,适用于边缘设备。
- 该框架结合标准语音和失语症语音数据,采用混合训练策略。
- 引入GPT-4技术,对嘈杂的失语症语音转录进行修正,提升监督质量。
- 模型在多个数据混合配置和评估环境下表现优异。
- 相较于零基准模型,新词错误率(WER)在失语症语音识别方面降低了超过30%。
- 模型在保持标准语音识别性能的同时,优化了失语症语音识别的效果。
点此查看论文截图

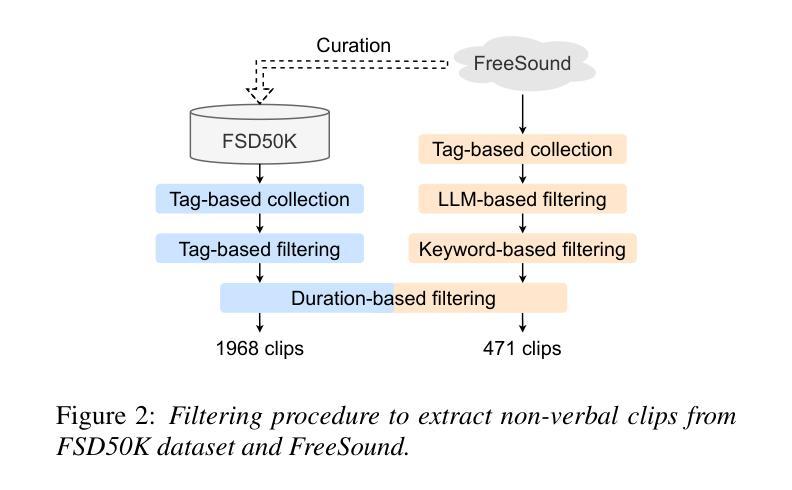
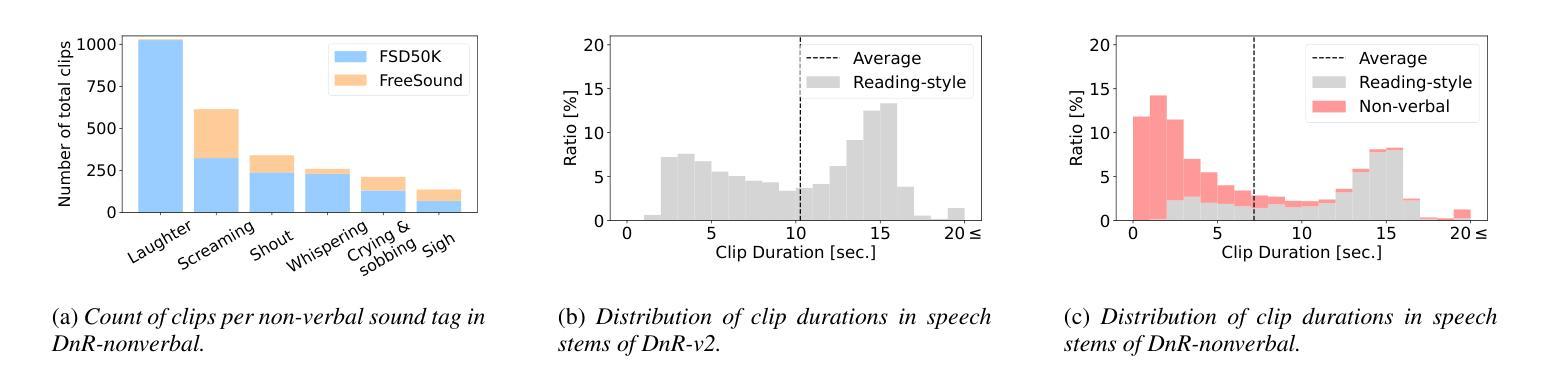
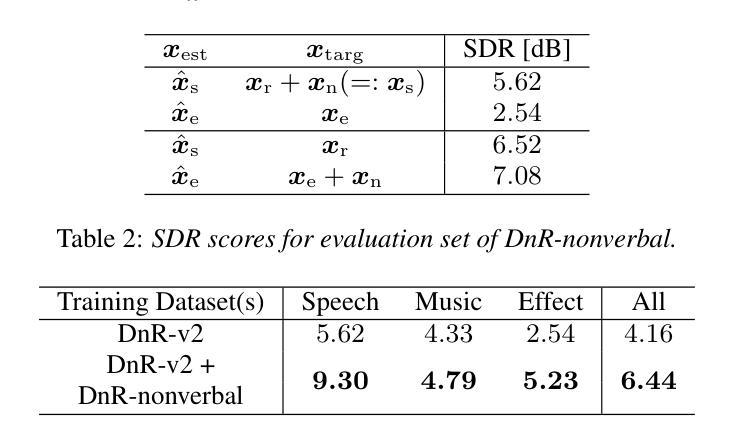
DnR-nonverbal: Cinematic Audio Source Separation Dataset Containing Non-Verbal Sounds
Authors:Takuya Hasumi, Yusuke Fujita
We propose a new dataset for cinematic audio source separation (CASS) that handles non-verbal sounds. Existing CASS datasets only contain reading-style sounds as a speech stem. These datasets differ from actual movie audio, which is more likely to include acted-out voices. Consequently, models trained on conventional datasets tend to have issues where emotionally heightened voices, such as laughter and screams, are more easily separated as an effect, not speech. To address this problem, we build a new dataset, DnR-nonverbal. The proposed dataset includes non-verbal sounds like laughter and screams in the speech stem. From the experiments, we reveal the issue of non-verbal sound extraction by the current CASS model and show that our dataset can effectively address the issue in the synthetic and actual movie audio. Our dataset is available at https://zenodo.org/records/15470640.
我们为电影音频源分离(CASS)提出一个新的数据集,该数据集处理非语言声音。现有的CASS数据集仅包含阅读风格的音频作为语音主干。这些数据集与实际的电影音频不同,后者更可能包含演绎出来的声音。因此,在常规数据集上训练的模型往往会出现问题,即在情绪高涨的声音(如笑声和尖叫声)更容易被分离出来作为效果,而非语音。为了解决这个问题,我们构建了新的数据集DnR-nonverbal。该数据集包含语音主干中的非语言声音,如笑声和尖叫声等。通过实验,我们揭示了当前CASS模型在非语言声音提取方面的问题,并表明我们的数据集可以在合成和实际的电影音频中有效地解决这一问题。我们的数据集可在https://zenodo.org/records/15470640上找到。
论文及项目相关链接
PDF Accepted to Interspeech 2025, 5 pages, 3 figures, dataset is available at https://zenodo.org/records/15470640
总结
针对电影音频源分离(CASS)提出新的数据集,涵盖非语言声音。现有CASS数据集仅包含阅读式声音作为语音素材,与真实电影音频不同,后者更可能包含表演出的声音。因此,在常规数据集上训练的模型在处理情绪高涨的声音(如笑声和尖叫)时,更容易将其分离为效果而非语音。为解决此问题,我们构建了新的数据集DnR-nonverbal,其中包含笑声和尖叫等非语言声音在语音素材中。实验表明,当前CASS模型存在非语言声音提取问题,我们的数据集可在合成和真实电影音频中有效解决此问题。数据集可在https://zenodo.org/records/15470640获取。
关键见解
- 现有CASS数据集主要关注阅读式声音,与真实电影音频存在差异。
- 电影音频包含更多表演出的声音,如情绪高涨的声音(如笑声和尖叫)。
- 在常规数据集上训练的模型在处理非语言声音时存在困难,易将其错误地分离为效果而非语音。
- 为解决此问题,提出新的数据集DnR-nonverbal,包含非语言声音(如笑声和尖叫)。
- DnR-nonverbal数据集能有效解决当前CASS模型在非语言声音提取方面的问题。
- 实验表明,该数据集在合成和真实电影音频中都表现出良好的效果。
点此查看论文截图


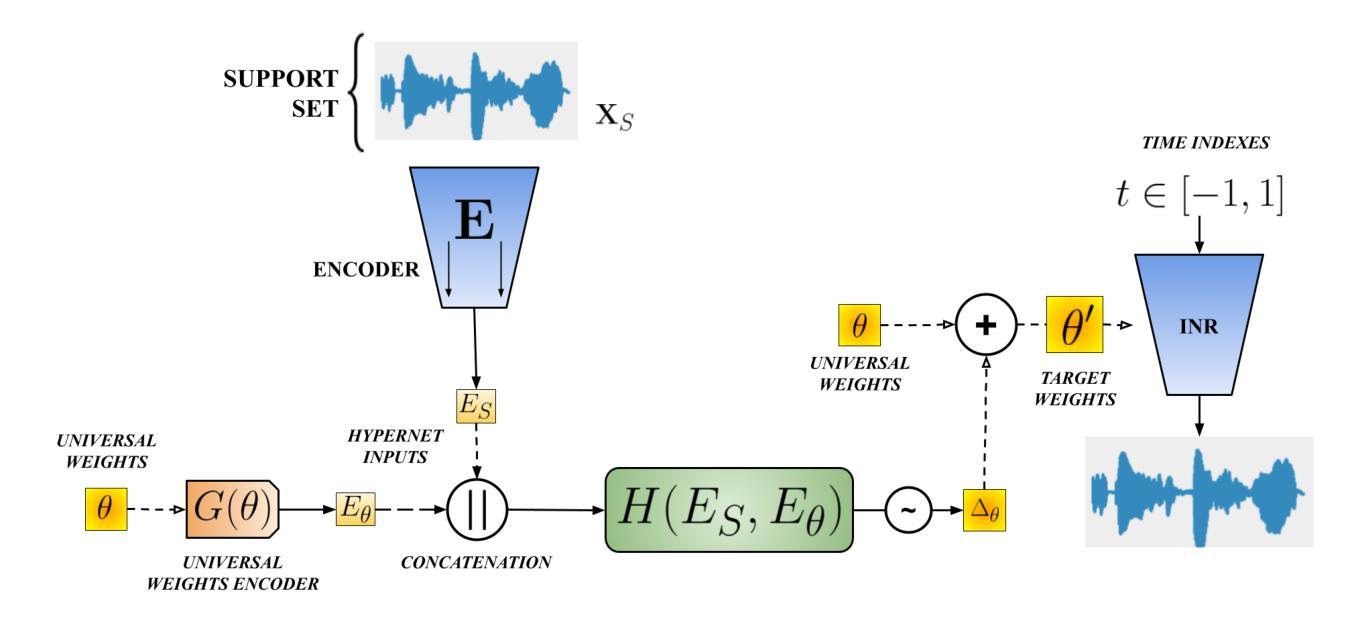
A Hypernetwork-Based Approach to KAN Representation of Audio Signals
Authors:Patryk Marszałek, Maciej Rut, Piotr Kawa, Przemysław Spurek, Piotr Syga
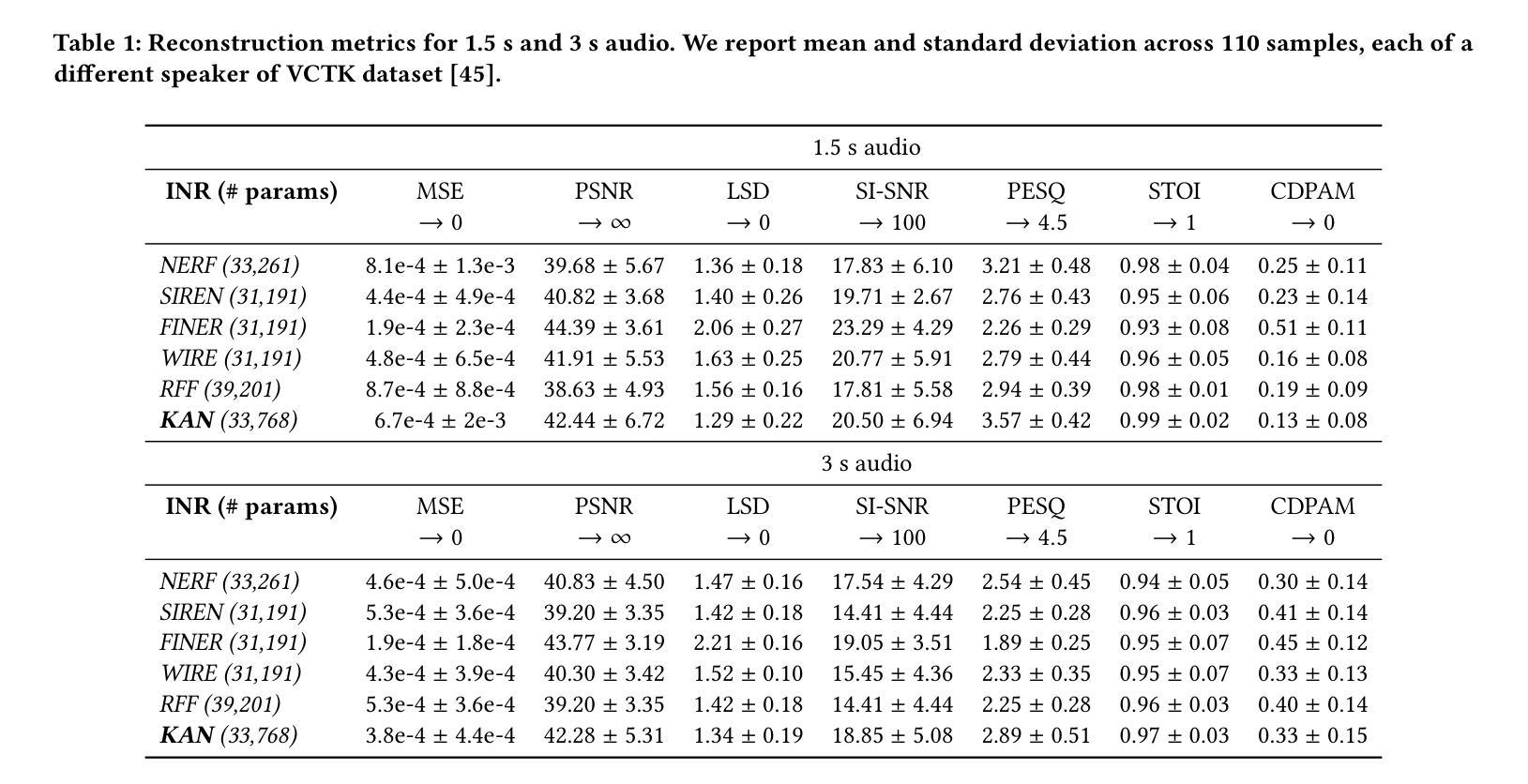
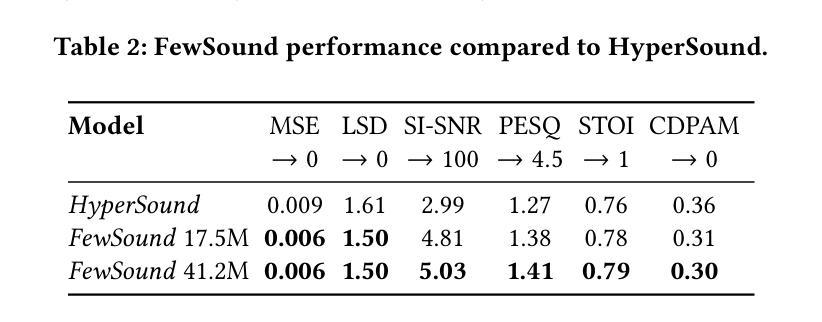
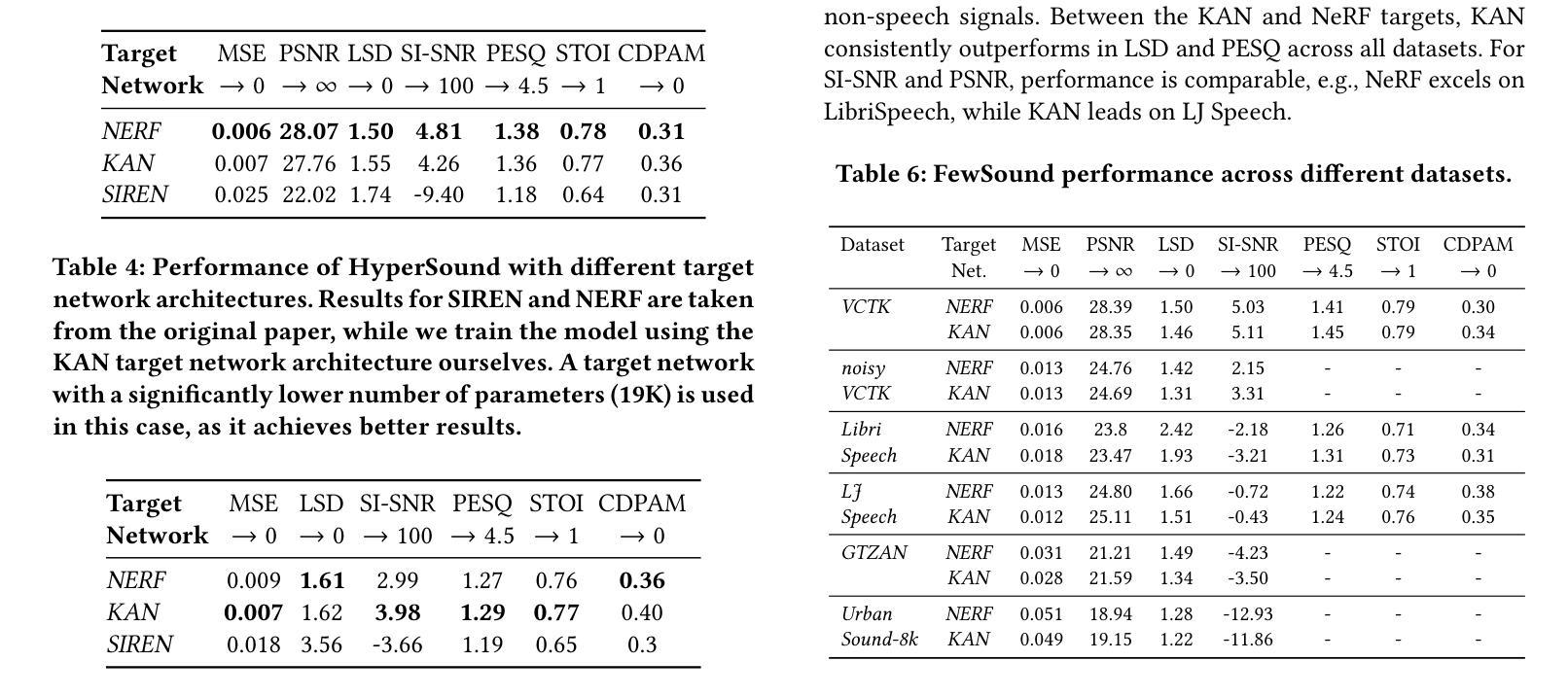
Implicit neural representations (INR) have gained prominence for efficiently encoding multimedia data, yet their applications in audio signals remain limited. This study introduces the Kolmogorov-Arnold Network (KAN), a novel architecture using learnable activation functions, as an effective INR model for audio representation. KAN demonstrates superior perceptual performance over previous INRs, achieving the lowest Log-SpectralDistance of 1.29 and the highest Perceptual Evaluation of Speech Quality of 3.57 for 1.5 s audio. To extend KAN’s utility, we propose FewSound, a hypernetwork-based architecture that enhances INR parameter updates. FewSound outperforms the state-of-the-art HyperSound, with a 33.3% improvement in MSE and 60.87% in SI-SNR. These results show KAN as a robust and adaptable audio representation with the potential for scalability and integration into various hypernetwork frameworks. The source code can be accessed at https://github.com/gmum/fewsound.git.
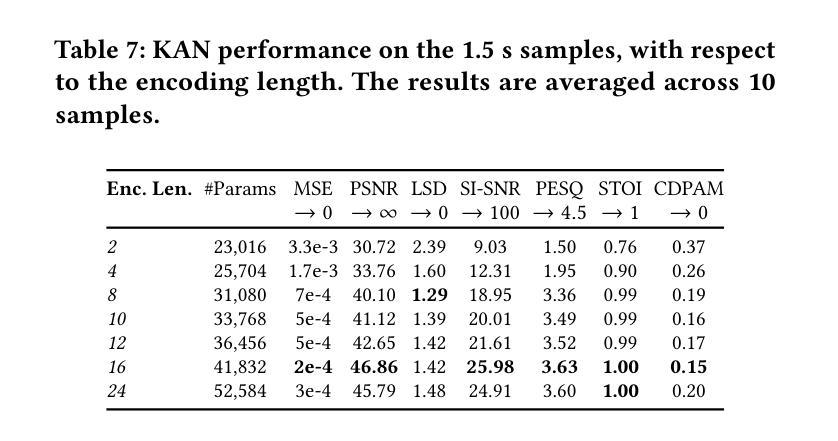
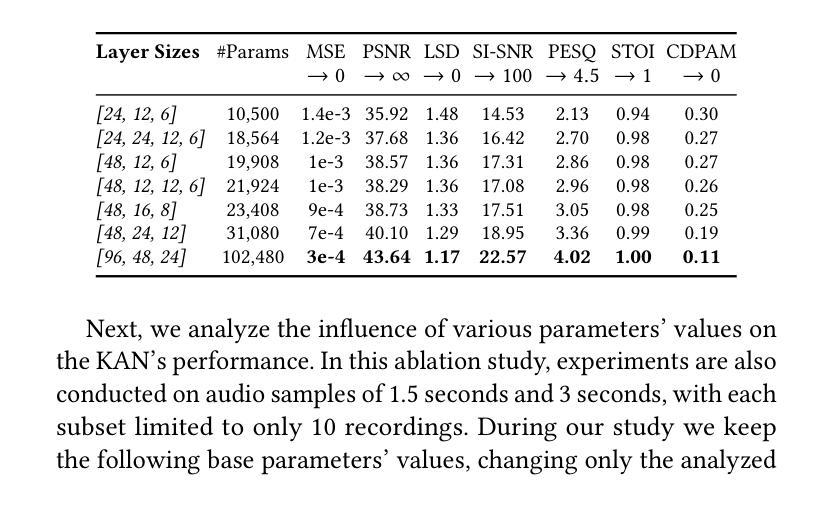
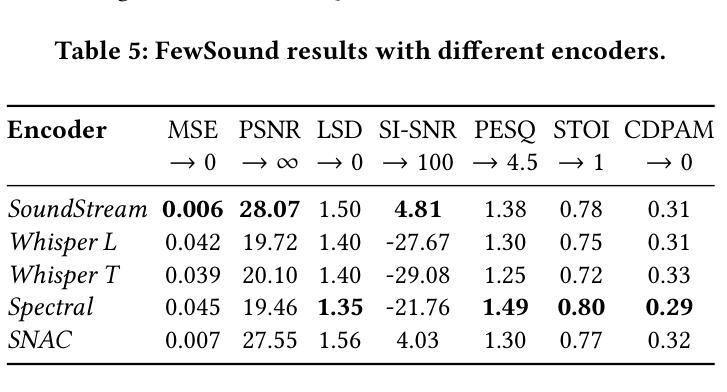
隐式神经网络表示(INR)在高效编码多媒体数据方面已受到广泛关注,但其在音频信号中的应用仍然有限。本研究引入了Kolmogorov-Arnold网络(KAN),这是一种使用可学习激活函数的新型架构,作为音频表示的有效INR模型。KAN在感知性能上优于先前的INR,在1.5秒音频上实现了最低的Log-SpectralDistance为1.29和最高的语音质量感知评价为3.57。为了扩展KAN的实用性,我们提出了基于超网络的FewSound架构,用于增强INR参数更新。FewSound的性能优于最新的HyperSound,在MSE上提高了33.3%,在SI-SNR上提高了60.87%。这些结果证明了KAN是一个稳健且适应性强的音频表示方法,具有可扩展性和集成到各种超网络框架的潜力。源代码可访问于 https://github.com/gmum/fewsound.git。
论文及项目相关链接
Summary
本文引入Kolmogorov-Arnold网络(KAN),它是一种使用可学习激活函数的新型架构,作为一种有效的隐神经表示(INR)模型用于音频表示。KAN在音频信号上的表现优于先前的INR模型,实现了最低的Log-SpectralDistance和最高的语音质量感知评价。为扩展KAN的实用性,提出了基于超网络的FewSound架构,能够增强INR参数更新。FewSound优于当前最先进的HyperSound,在MSE和SI-SNR方面分别提高了33.3%和60.87%。研究结果表明,KAN是一种稳健且可适应的音频表示方法,具有可扩展性和集成到各种超网络框架的潜力。
Key Takeaways
- 引入了Kolmogorov-Arnold网络(KAN)作为隐神经表示(INR)模型的新架构,专门用于音频表示。
- KAN通过使用可学习激活函数提高了音频表示的感知性能。
- KAN在音频信号上的表现优于先前的INR模型,实现了较低的Log-SpectralDistance和较高的语音质量感知评价。
- 提出了基于超网络的FewSound架构,以增强INR模型的参数更新。
- FewSound在性能上超越了现有的HyperSound,在MSE和SI-SNR方面有明显的改进。
- KAN的音频表示方法具有稳健性和适应性,有望扩展到更多应用场景。
点此查看论文截图

LLaSE-G1: Incentivizing Generalization Capability for LLaMA-based Speech Enhancement
Authors:Boyi Kang, Xinfa Zhu, Zihan Zhang, Zhen Ye, Mingshuai Liu, Ziqian Wang, Yike Zhu, Guobin Ma, Jun Chen, Longshuai Xiao, Chao Weng, Wei Xue, Lei Xie
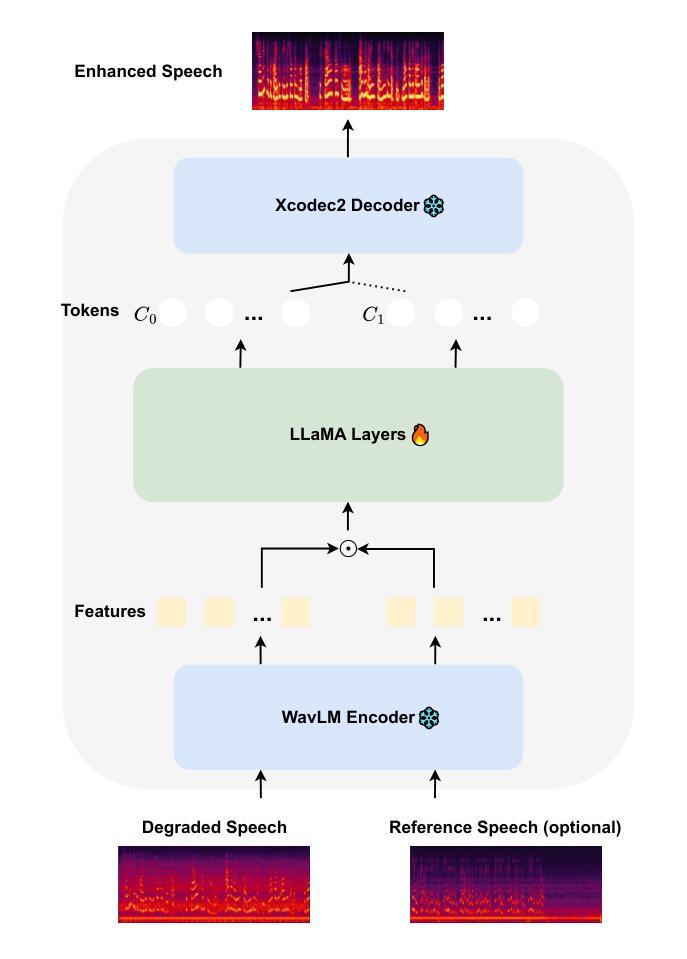
Recent advancements in language models (LMs) have demonstrated strong capabilities in semantic understanding and contextual modeling, which have flourished in generative speech enhancement (SE). However, many LM-based SE approaches primarily focus on semantic information, often neglecting the critical role of acoustic information, which leads to acoustic inconsistency after enhancement and limited generalization across diverse SE tasks. In this paper, we introduce LLaSE-G1, a LLaMA-based language model that incentivizes generalization capabilities for speech enhancement. LLaSE-G1 offers the following key contributions: First, to mitigate acoustic inconsistency, LLaSE-G1 employs continuous representations from WavLM as input and predicts speech tokens from X-Codec2, maximizing acoustic preservation. Second, to promote generalization capability, LLaSE-G1 introduces dual-channel inputs and outputs, unifying multiple SE tasks without requiring task-specific IDs. Third, LLaSE-G1 outperforms prior task-specific discriminative and generative SE models, demonstrating scaling effects at test time and emerging capabilities for unseen SE tasks. Additionally, we release our code and models to support further research in this area.
近期语言模型(LM)的进展在语义理解和上下文建模方面展示了强大的能力,这在生成性语音增强(SE)中尤其显著。然而,许多基于LM的SE方法主要关注语义信息,往往忽视了声音信息的关键作用,这导致增强后的语音在声音上存在不一致性,并且在不同的SE任务中的泛化能力有限。在本文中,我们介绍了LLaSE-G1,这是一个基于LLaMA的语言模型,旨在激励其在语音增强方面的泛化能力。LLaSE-G1的主要贡献如下:首先,为了减轻声音不一致的问题,LLaSE-G1采用WavLM的连续表示作为输入,并使用X-Codec2预测语音令牌,以最大限度地保留声音。其次,为了提升泛化能力,LLaSE-G1引入了双通道输入和输出,能够统一多个SE任务而无需特定任务标识。最后,LLaSE-G1超越了先前的特定任务的判别性和生成性SE模型,在测试时展示了规模效应,并对未见过的SE任务展现了新兴能力。此外,我们公开了代码和模型,以支持该领域的进一步研究。
论文及项目相关链接
PDF ACL2025 main, Codes available at https://github.com/Kevin-naticl/LLaSE-G1
摘要
近期语言模型(LM)的进步在语义理解和上下文建模方面展现出强大的能力,尤其在生成性语音增强(SE)领域尤为突出。然而,许多基于LM的SE方法主要关注语义信息,忽视了声学信息的关键作用,导致增强后的语音出现声学不一致性,并且在不同的SE任务中的泛化能力有限。本文介绍了LLaSE-G1,一种基于LLaMA的语言模型,旨在提高语音增强的泛化能力。LLaSE-G1的主要贡献如下:首先,为了缓解声学不一致性,LLaSE-G1采用WavLM的连续表示作为输入,并从X-Codec2预测语音标记,以最大程度地保留声学特征。其次,为了提升泛化能力,LLaSE-G1引入了双通道输入和输出,统一了多个SE任务,无需特定任务标识。最后,LLaSE-G1在测试时表现出超越先前任务特定的判别性和生成性SE模型的优势,并展现出对未见过的SE任务的适应能力。此外,我们公开了代码和模型,以支持该领域的进一步研究。
关键见解
- LLaSE-G1采用WavLM的连续表示和X-Codec2的语音标记预测,以缓解语音增强中的声学不一致性。
- 通过引入双通道输入和输出,LLaSE-G1统一了多个语音增强任务,提升了模型的泛化能力。
- LLaSE-G1在测试时表现出优势,超越了任务特定的判别性和生成性SE模型。
- LLaSE-G1对未见的SE任务具有适应能力。
- LLaSE-G1模型能够最大化地保留声学特征。
- 公开的代码和模型有助于支持该领域的进一步研究。
点此查看论文截图

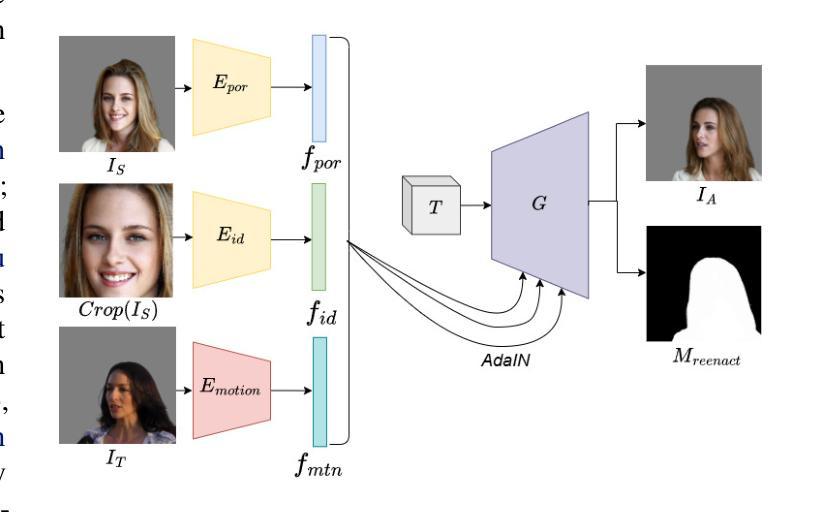
Efficient Long-duration Talking Video Synthesis with Linear Diffusion Transformer under Multimodal Guidance
Authors:Haojie Zhang, Zhihao Liang, Ruibo Fu, Bingyan Liu, Zhengqi Wen, Xuefei Liu, Chenxing Li, Yaling Liang
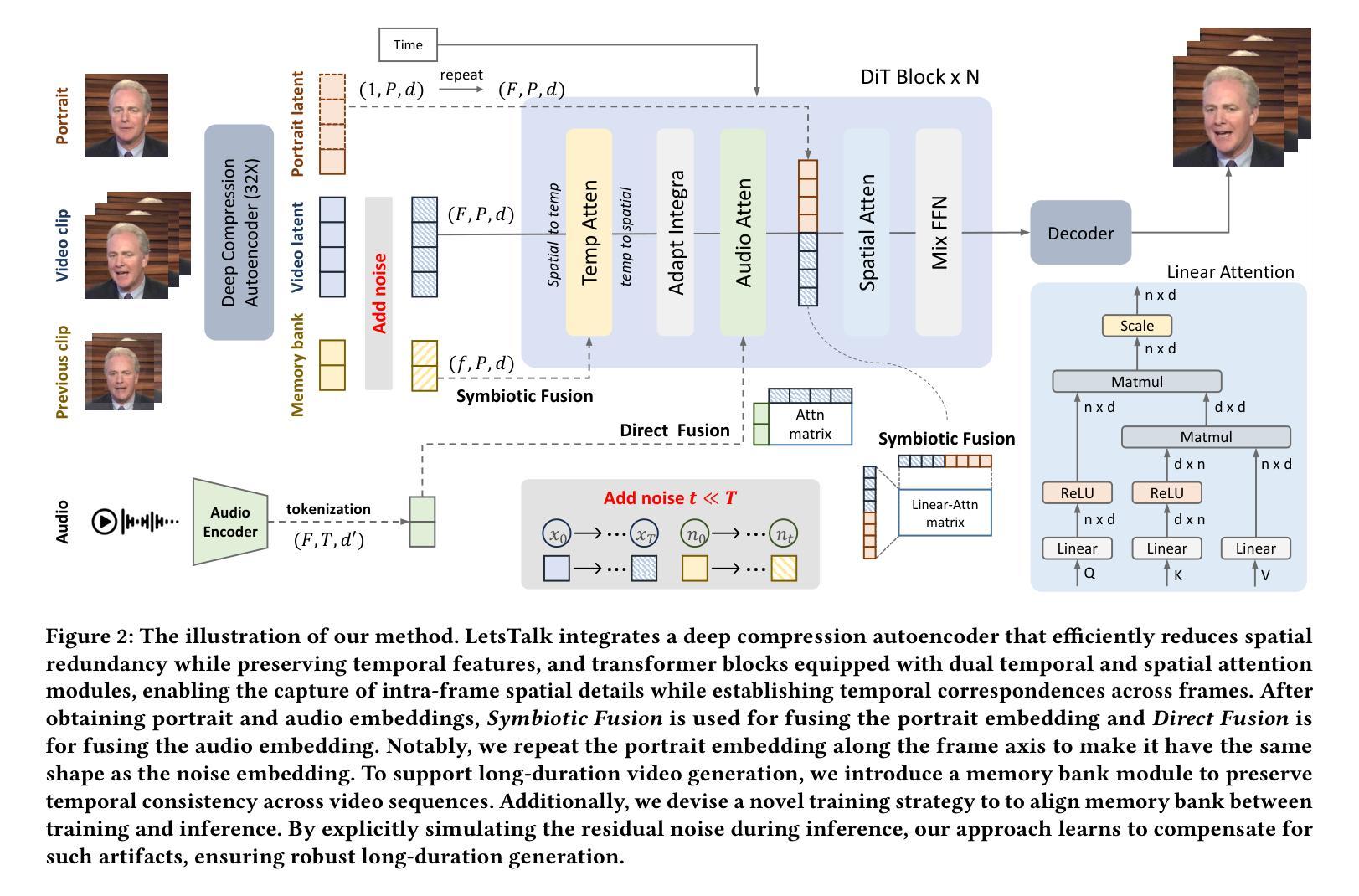
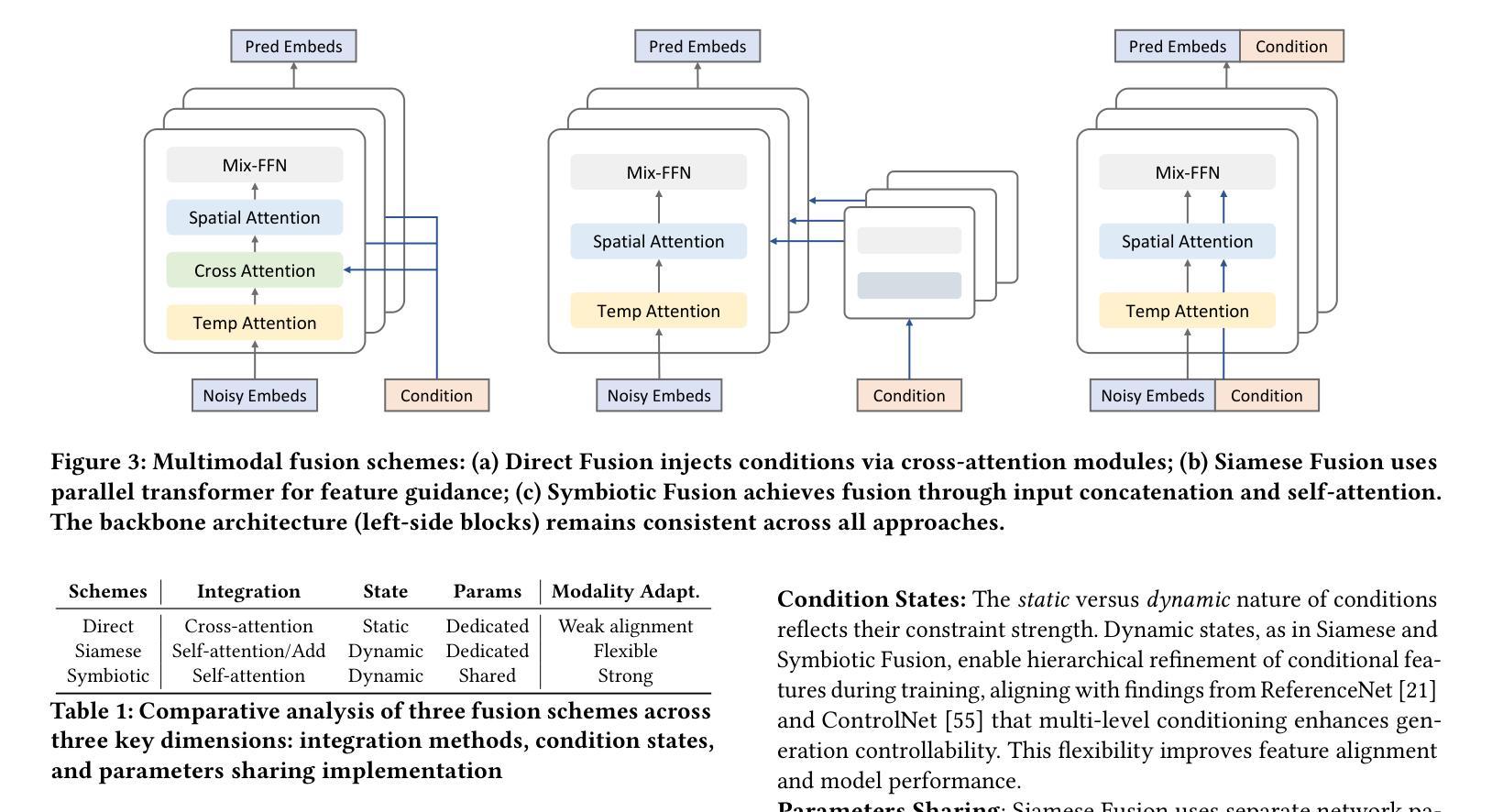
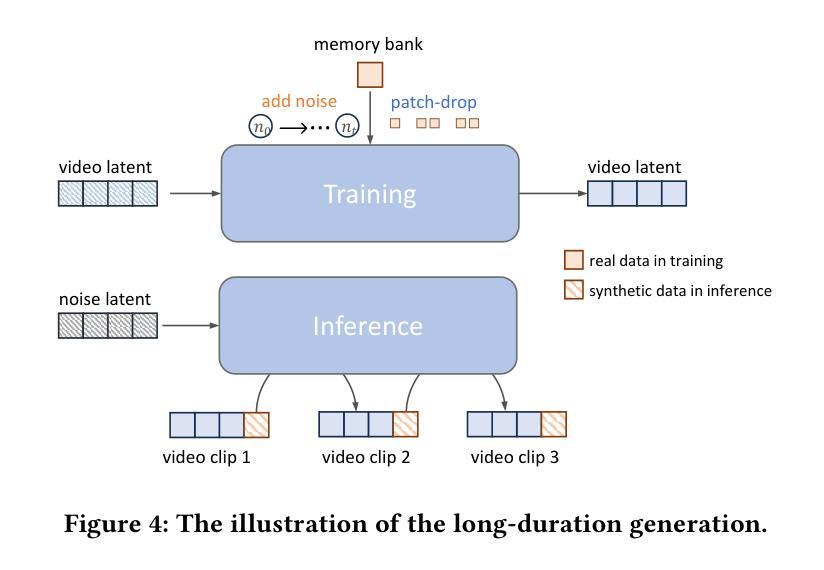
Portrait image animation using audio has rapidly advanced, but challenges remain in efficiently fusing multimodal inputs while ensuring temporal and portrait consistency with minimal computational cost. To address this, we present LetsTalk, a LinEar diffusion TranSformer for Talking video synthesis. LetsTalk incorporates a deep compression autoencoder to obtain efficient latent representations, and a spatio-temporal-aware transformer with efficient linear attention to effectively fuse multimodal information and enhance spatio-temporal consistency. We systematically explore and summarize three fusion schemes, ranging from shallow to deep fusion. We thoroughly analyze their characteristics, applicability, and trade-offs, thereby bridging critical gaps in multimodal conditional guidance. Based on modality differences of image, audio, and video generation, we adopt deep (Symbiotic Fusion) for portrait to ensure consistency, and shallow (Direct Fusion) for audio to align animation with speech while preserving motion diversity. To maintain temporal consistency in long-duration video generation, we propose a memory bank mechanism that preserves inter-clip dependencies, effectively preventing degradation across extended sequences. Furthermore, we develop a noise-regularized training strategy that explicitly compensates for DDPM sampling artifacts, significantly improving the model’s robustness in continuous generation scenarios.Our extensive experiments demonstrate that our approach achieves state-of-the-art generation quality, producing temporally coherent and realistic videos with enhanced diversity and liveliness, while maintaining remarkable efficiency through its optimized model design with 8$\times$ fewer parameters.
基于音频的肖像图像动画技术已经迅速发展,但在确保时间和肖像连贯性的同时,高效融合多模式输入仍存在挑战,且计算成本较低。为了解决这一问题,我们推出了LetsTalk,这是一款用于视频合成的线性扩散Transformer。LetsTalk结合深度压缩自编码器以获得有效的潜在表示,以及具有高效线性注意力的时空感知转换器,以有效融合多模式信息并增强时空连贯性。我们系统地探索和总结了从浅到深融合的三种融合方案。我们彻底分析了它们的特性、适用性和权衡,从而填补了多模式条件指导的关键空白。基于图像、音频和视频生成的模态差异,我们采用深度(共生融合)融合肖像以确保连贯性,以及浅层(直接融合)融合音频,以使动画与语音对齐,同时保持运动多样性。为了在长期视频生成中保持时间连贯性,我们提出了一种内存银行机制,保留剪辑间的依赖性,有效防止扩展序列中的退化。此外,我们开发了一种噪声正则化训练策略,明确补偿DDPM采样伪影,大大提高了模型在连续生成场景中的稳健性。我们的广泛实验表明,我们的方法达到了最先进的生成质量,产生了时间连贯且逼真的视频,具有增强的多样性和生动性,同时通过其优化后的模型设计保持了卓越的效率,参数减少了8倍。
论文及项目相关链接
PDF 16 pages, 13 figures
Summary
本文提出一种名为LetsTalk的线性扩散Transformer语音动画生成模型,用于合成语音视频。该模型通过深度压缩自编码器获得高效潜在表示,并利用时空感知的Transformer和高效线性注意力机制有效融合多模态信息,提高时空一致性。同时探讨了三种融合方案,采用深度融合确保肖像一致性,浅层融合使动画与语音对齐并保持运动多样性。为维持长视频生成的时序一致性,提出记忆库机制,通过保存剪辑间依赖关系防止序列扩展时的性能下降。此外,开发噪声正则化训练策略,明确补偿DDPM采样伪影,提高连续生成场景下的模型稳健性。实验表明,该方法生成质量达到领先水平,能生成时序连贯、逼真的视频,具有增强多样性和生动性,且通过优化模型设计实现高效率,参数减少8倍。
Key Takeaways
- 提出名为LetsTalk的线性扩散Transformer模型用于语音驱动的肖像动画生成。
- 引入深度压缩自编码器以实现高效潜在表示。
- 利用时空感知的Transformer和线性注意力机制进行多模态信息融合。
- 探讨了三种融合方案,并根据图像、音频和视频生成的特点采用不同的融合策略。
- 为保持长视频生成的时序一致性,引入记忆库机制保存剪辑间依赖关系。
- 开发噪声正则化训练策略以改善模型的连续生成性能。
点此查看论文截图

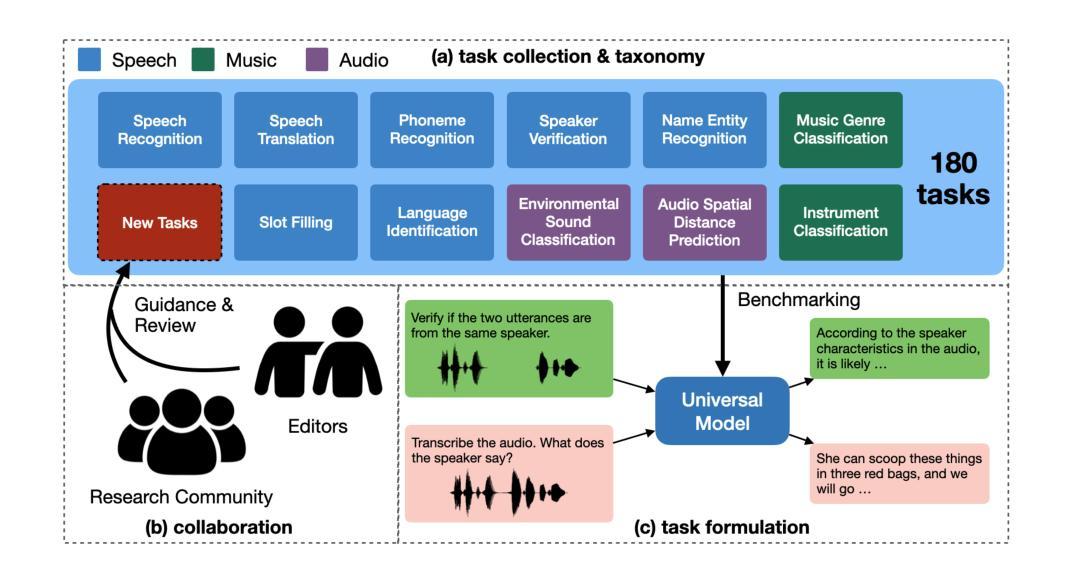
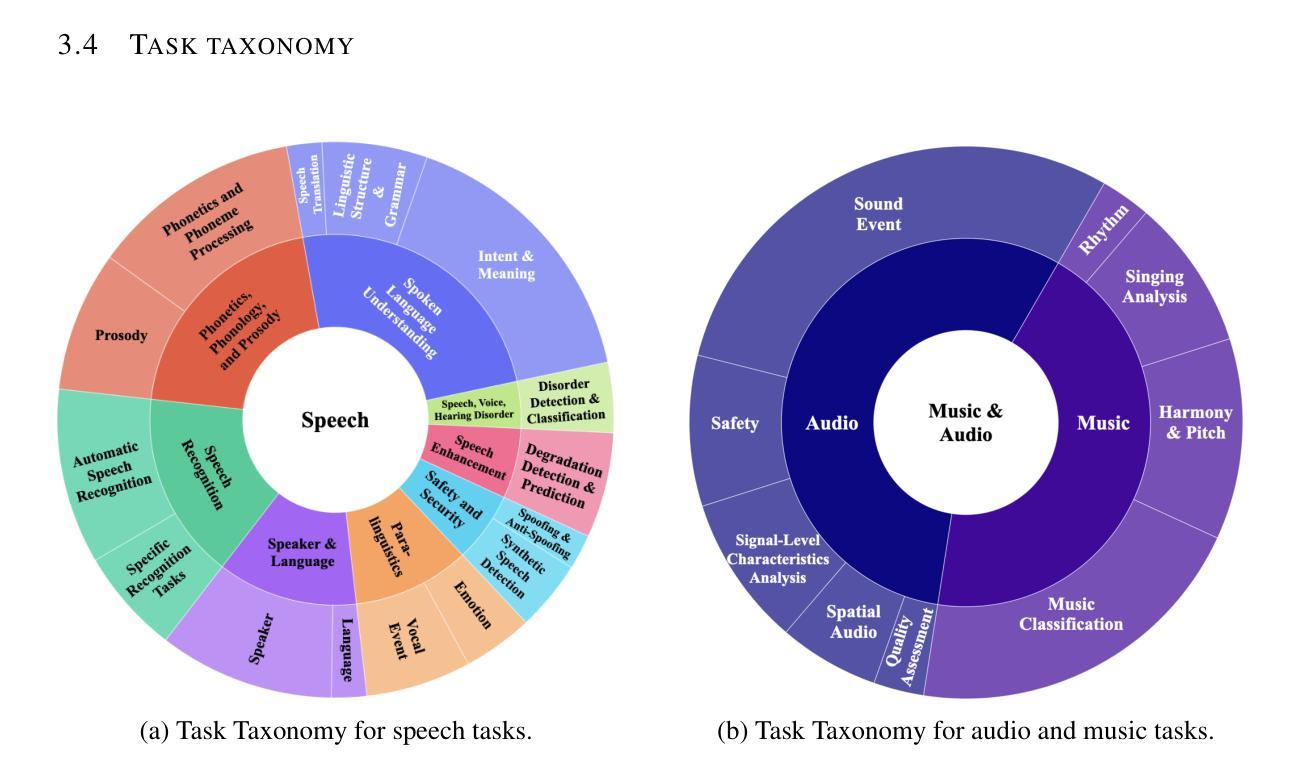
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Authors:Chien-yu Huang, Wei-Chih Chen, Shu-wen Yang, Andy T. Liu, Chen-An Li, Yu-Xiang Lin, Wei-Cheng Tseng, Anuj Diwan, Yi-Jen Shih, Jiatong Shi, William Chen, Chih-Kai Yang, Wenze Ren, Xuanjun Chen, Chi-Yuan Hsiao, Puyuan Peng, Shih-Heng Wang, Chun-Yi Kuan, Ke-Han Lu, Kai-Wei Chang, Fabian Ritter-Gutierrez, Kuan-Po Huang, Siddhant Arora, You-Kuan Lin, Ming To Chuang, Eunjung Yeo, Kalvin Chang, Chung-Ming Chien, Kwanghee Choi, Jun-You Wang, Cheng-Hsiu Hsieh, Yi-Cheng Lin, Chee-En Yu, I-Hsiang Chiu, Heitor R. Guimarães, Jionghao Han, Tzu-Quan Lin, Tzu-Yuan Lin, Homu Chang, Ting-Wu Chang, Chun Wei Chen, Shou-Jen Chen, Yu-Hua Chen, Hsi-Chun Cheng, Kunal Dhawan, Jia-Lin Fang, Shi-Xin Fang, Kuan-Yu Fang Chiang, Chi An Fu, Hsien-Fu Hsiao, Ching Yu Hsu, Shao-Syuan Huang, Lee Chen Wei, Hsi-Che Lin, Hsuan-Hao Lin, Hsuan-Ting Lin, Jian-Ren Lin, Ting-Chun Liu, Li-Chun Lu, Tsung-Min Pai, Ankita Pasad, Shih-Yun Shan Kuan, Suwon Shon, Yuxun Tang, Yun-Shao Tsai, Jui-Chiang Wei, Tzu-Chieh Wei, Chengxi Wu, Dien-Ruei Wu, Chao-Han Huck Yang, Chieh-Chi Yang, Jia Qi Yip, Shao-Xiang Yuan, Vahid Noroozi, Zhehuai Chen, Haibin Wu, Karen Livescu, David Harwath, Shinji Watanabe, Hung-yi Lee
Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results show that no model performed well universally. SALMONN-13B excelled in English ASR and Qwen2-Audio-7B-Instruct showed high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We open-source all task data and the evaluation pipeline at https://github.com/dynamic-superb/dynamic-superb.
多模态基础模型,如Gemini和ChatGPT,通过无缝集成各种形式的数据,已经彻底改变了人机交互。开发一种能够理解广泛自然语言指令的通用口语模型,对于弥合沟通差距和促进更直观的人机交互至关重要。然而,缺乏全面的评估基准构成了巨大的挑战。我们提出了Dynamic-SUPERB Phase-2,这是一个开放且不断发展的基准测试,用于全面评估基于指令的通用语音模型。基于第一代的基础上,第二版纳入了全球研究社区合作贡献的12 5项新任务,使基准测试的任务总数扩大到1 8 0项,成为语音和音频评估领域最大的基准测试。虽然Dynamic-SUPERB第一代仅限于分类任务,但Dynamic-SUPERB Phase-2通过引入一系列新颖且多样化的任务来拓宽其评估能力,包括回归和序列生成,涵盖语音、音乐和环保音频。评估结果表明,没有模型能够普遍表现出良好的性能。SALMONN-13B在英语语音识别方面表现出色,Qwen2-Audio-7B-Instruct在情绪识别方面表现出高准确率,但当前模型仍需要进一步创新才能处理更广泛的范围的任务。我们在https://github.com/dynamic-superb/dynamic-superb开源了所有任务数据和评估管道。
论文及项目相关链接
PDF ICLR 2025
Summary
多模态基础模型,如Gemini和ChatGPT,通过无缝集成各种形式的数据,已经革新了人机互动方式。开发一种通用口语模型,理解广泛的自然语言指令,对于弥合沟通鸿沟和促进更直观互动至关重要。然而,缺乏全面的评估基准构成重大挑战。我们推出Dynamic-SUPERB Phase-2,这是一个开放和不断发展的基准测试,用于全面评估指令型通用语音模型。相较于第一代,第二代新增了全球研究社区共同贡献的125个新任务,使基准测试任务总数扩充至180个,成为语音和音频评估领域最大的基准测试。Dynamic-SUPERB Phase-2不仅拓宽了评估能力,还引入了各种新颖且多样化的任务,包括回归和序列生成,涵盖语音、音乐和环保音频。评估结果显示,没有模型能够普遍表现优异。SALMONN-1_在英文语音识别方面表现出色,而Qwen2 Audio则能精准识别情绪。当前模型仍需要进一步创新处理更多样化的任务。我们已在开源社区公开所有任务数据和评估流程管道(https://github.com/dynamic-superb/dynamic-superb)。
Key Takeaways
- 多模态基础模型如Gemini和ChatGPT革新了人机互动方式。
- 开发通用口语模型对于弥合沟通鸿沟和促进更直观互动至关重要。
- 缺乏全面的评估基准是对语音模型发展的重大挑战。
- Dynamic-SUPERB Phase-2是开放和不断发展的基准测试,用于全面评估指令型通用语音模型。
- Dynamic-SUPERB Phase-2共包含180个任务,涵盖语音、音乐和环保音频等多个领域的新颖多样化任务。
- 目前没有模型在所有任务中表现优异,需要进一步的创新和改进。
点此查看论文截图