⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-11 更新
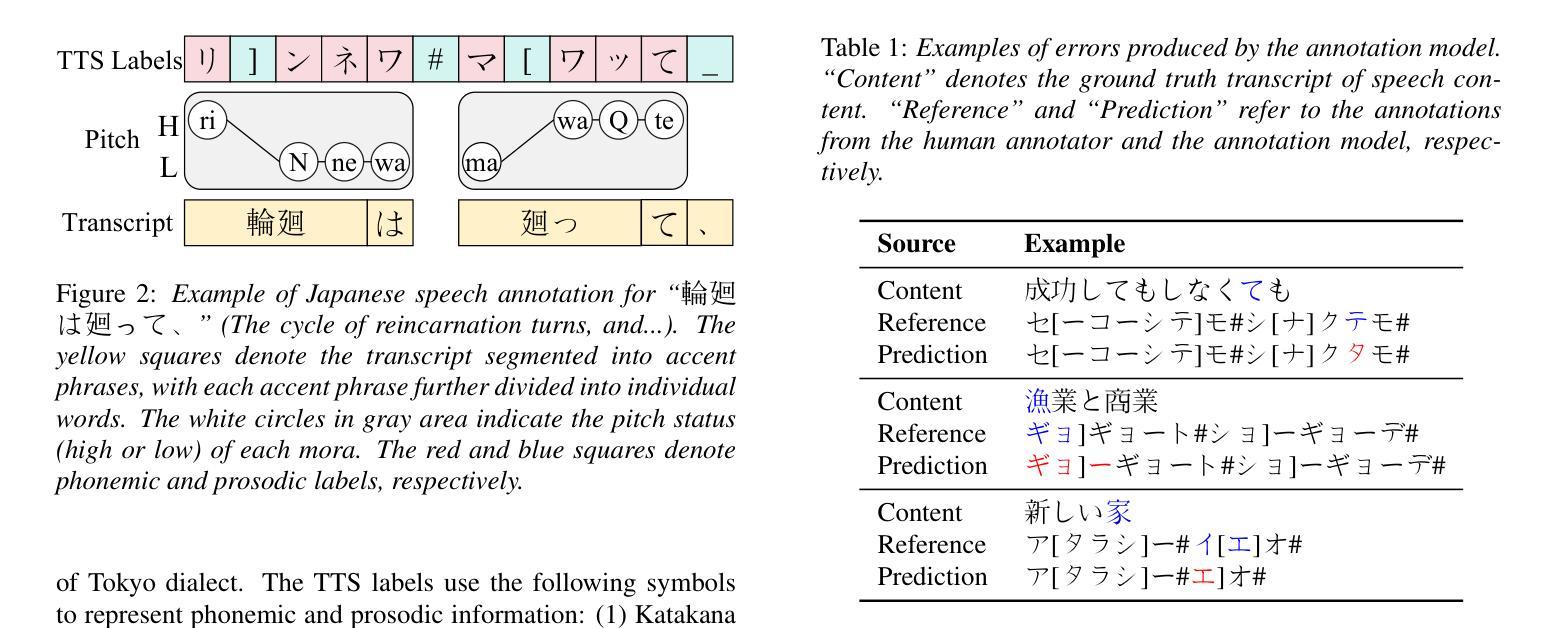
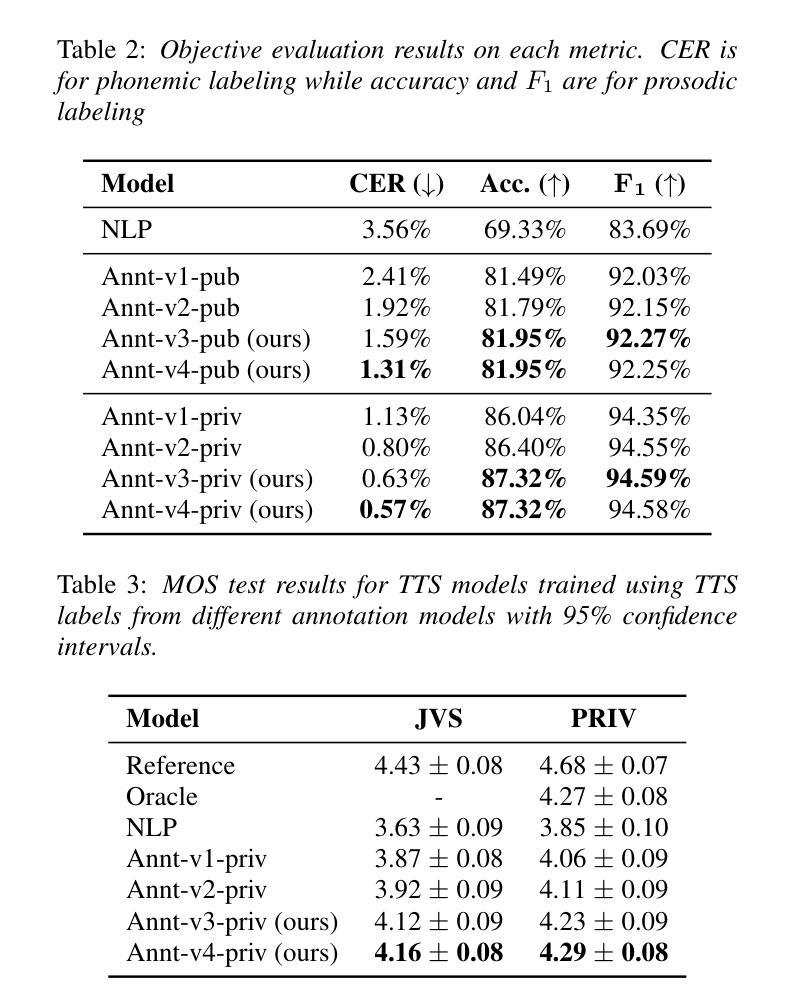
Transcript-Prompted Whisper with Dictionary-Enhanced Decoding for Japanese Speech Annotation
Authors:Rui Hu, Xiaolong Lin, Jiawang Liu, Shixi Huang, Zhenpeng Zhan
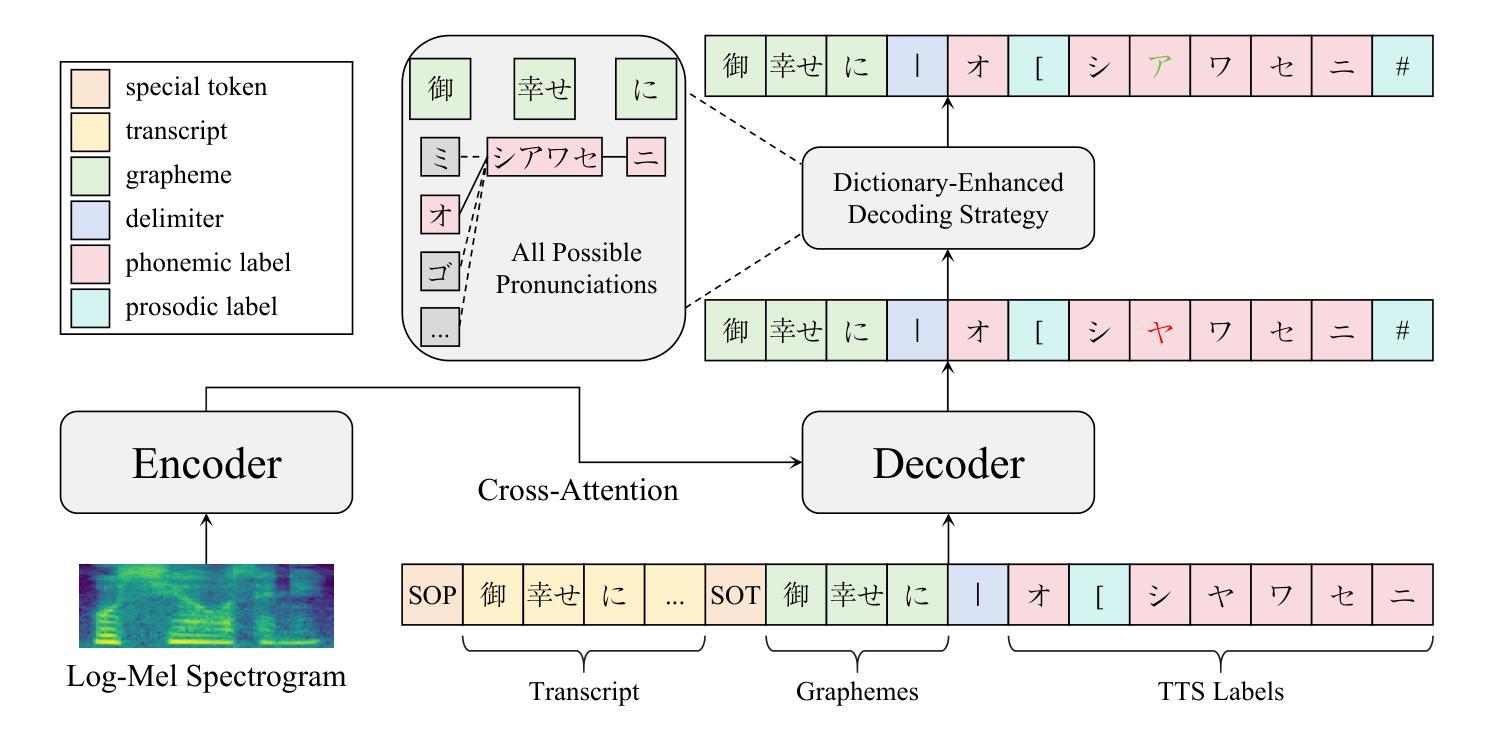
In this paper, we propose a method for annotating phonemic and prosodic labels on a given audio-transcript pair, aimed at constructing Japanese text-to-speech (TTS) datasets. Our approach involves fine-tuning a large-scale pre-trained automatic speech recognition (ASR) model, conditioned on ground truth transcripts, to simultaneously output phrase-level graphemes and annotation labels. To further correct errors in phonemic labeling, we employ a decoding strategy that utilizes dictionary prior knowledge. The objective evaluation results demonstrate that our proposed method outperforms previous approaches relying solely on text or audio. The subjective evaluation results indicate that the naturalness of speech synthesized by the TTS model, trained with labels annotated using our method, is comparable to that of a model trained with manual annotations.
在这篇论文中,我们提出了一种对给定音频转录对进行音素和韵律标签注释的方法,旨在构建日语文本到语音(TTS)数据集。我们的方法涉及微调大规模预训练的自动语音识别(ASR)模型,根据真实转录情况,同时输出短语级别的字母和注释标签。为了进一步纠正音素标注中的错误,我们采用了一种利用词典先验知识的解码策略。客观评价结果证明,我们提出的方法优于仅依赖文本或音频的先前方法。主观评价结果表明,使用我们的方法进行标签注释训练的TTS模型合成的语音自然度与使用手动注释训练的模型相当。
论文及项目相关链接
PDF Accepted to INTERSPEECH 2025
Summary
本文提出了一种为给定音频文本对进行音素和语调标签注释的方法,旨在构建日本语文本转语音(TTS)数据集。该方法通过微调大规模预训练自动语音识别(ASR)模型来实现,该模型基于真实文本转录,可同时输出词组层面的字母和注释标签。为进一步修正音素标注中的错误,我们采用了一种利用词典先验知识的解码策略。客观评估结果表明,我们的方法优于仅依赖文本或音频的现有方法。主观评估结果表明,使用我们的方法进行标签注释后训练的TTS模型合成的语音自然度与手动注释的模型相当。
Key Takeaways
- 本文提出了一种为构建日本语文本转语音(TTS)数据集进行音素和语调标签注释的新方法。
- 该方法通过微调大规模预训练的自动语音识别(ASR)模型实现,该模型可基于真实文本转录同时输出词组层面的字母和注释标签。
- 为提高标注准确性,采用利用词典先验知识的解码策略修正音素标注中的错误。
- 客观评估证明,该方法在性能上超越了仅依赖文本或音频的现有技术。
- 主观评估显示,使用此方法标注的TTS模型合成的语音自然度与手动注释的模型相当。
- 此方法对于构建高质量TTS数据集具有重要的实用价值。
点此查看论文截图

SynHate: Detecting Hate Speech in Synthetic Deepfake Audio
Authors:Rishabh Ranjan, Kishan Pipariya, Mayank Vatsa, Richa Singh
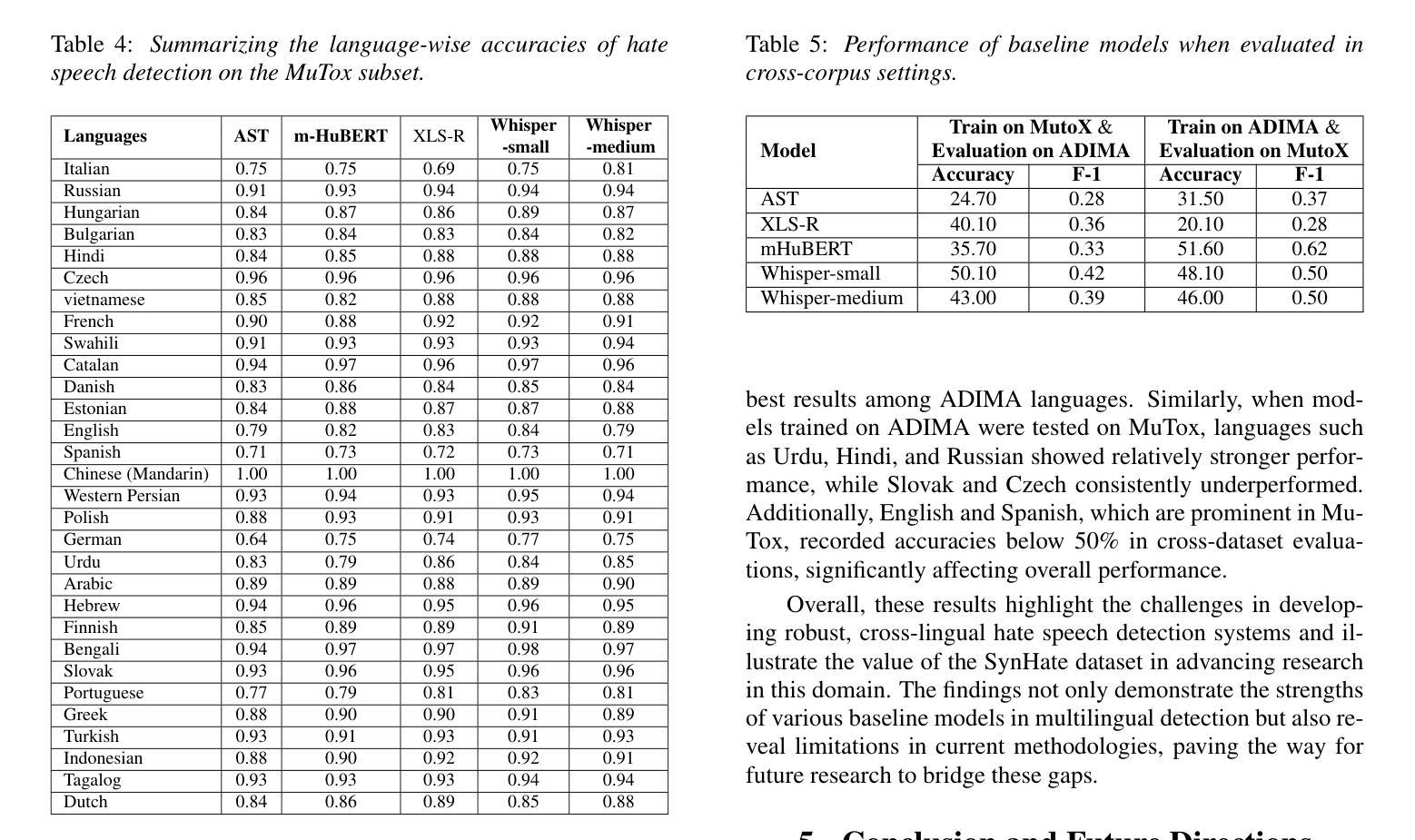
The rise of deepfake audio and hate speech, powered by advanced text-to-speech, threatens online safety. We present SynHate, the first multilingual dataset for detecting hate speech in synthetic audio, spanning 37 languages. SynHate uses a novel four-class scheme: Real-normal, Real-hate, Fake-normal, and Fake-hate. Built from MuTox and ADIMA datasets, it captures diverse hate speech patterns globally and in India. We evaluate five leading self-supervised models (Whisper-small/medium, XLS-R, AST, mHuBERT), finding notable performance differences by language, with Whisper-small performing best overall. Cross-dataset generalization remains a challenge. By releasing SynHate and baseline code, we aim to advance robust, culturally sensitive, and multilingual solutions against synthetic hate speech. The dataset is available at https://www.iab-rubric.org/resources.
随着深度伪造音频和仇恨言论的兴起,它们由先进的文本到语音技术驱动,对网络安全造成了威胁。我们推出了SynHate,这是首个用于检测合成音频中仇恨言论的多语言数据集,涵盖37种语言。SynHate采用了一种新型的四类方案:真实正常、真实仇恨、虚假正常和虚假仇恨。它基于MuTox和ADIMA数据集构建,能够捕捉全球和印度多样化的仇恨言论模式。我们评估了五个领先的自监督模型(Whisper-small/medium、XLS-R、AST、mHuBERT),发现不同语言之间的性能差异显著,Whisper-small总体上表现最佳。跨数据集推广仍然是一个挑战。我们通过发布SynHate和基线代码,旨在推进针对合成仇恨言论的稳健、文化敏感和多语言解决方案。数据集可在https://www.iab-rubric.org/resources获得。
论文及项目相关链接
PDF Accepted in Interspeech 2025
Summary
随着深度伪造音频和仇恨言论的兴起,由先进文本-语音技术驱动的威胁日益凸显。为应对此挑战,我们推出了首个跨语言的仇恨言论检测数据集SynHate,包含真实正常、真实仇恨、伪造正常和伪造仇恨四类内容。该数据集基于MuTox和ADIMA数据集构建,捕捉全球及印度的仇恨言论模式。我们评估了五个主流自监督模型的表现,发现语言间的性能差异显著,whisper-small整体表现最佳。跨数据集泛化仍是挑战。我们发布SynHate数据集和基础代码,旨在推动针对合成仇恨言论的稳健、文化敏感和多语言解决方案的发展。数据集可通过https://www.iab-rubric.org/resources获取。
Key Takeaways
- 深度伪造音频和仇恨言论的兴起对在线安全构成威胁。
- SynHate是首个针对合成音频中的仇恨言论的多语言数据集。
- SynHate数据集包含真实正常、真实仇恨、伪造正常和伪造仇恨四种类型的内容。
- 数据集基于MuTox和ADIMA构建,涵盖全球及印度的仇恨言论模式。
- 评估了五个自监督模型在SynHate上的表现,发现语言间的性能差异显著。
- whisper-small模型在整体评估中表现最佳。
点此查看论文截图