⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-11 更新
Efficient Long-duration Talking Video Synthesis with Linear Diffusion Transformer under Multimodal Guidance
Authors:Haojie Zhang, Zhihao Liang, Ruibo Fu, Bingyan Liu, Zhengqi Wen, Xuefei Liu, Chenxing Li, Yaling Liang
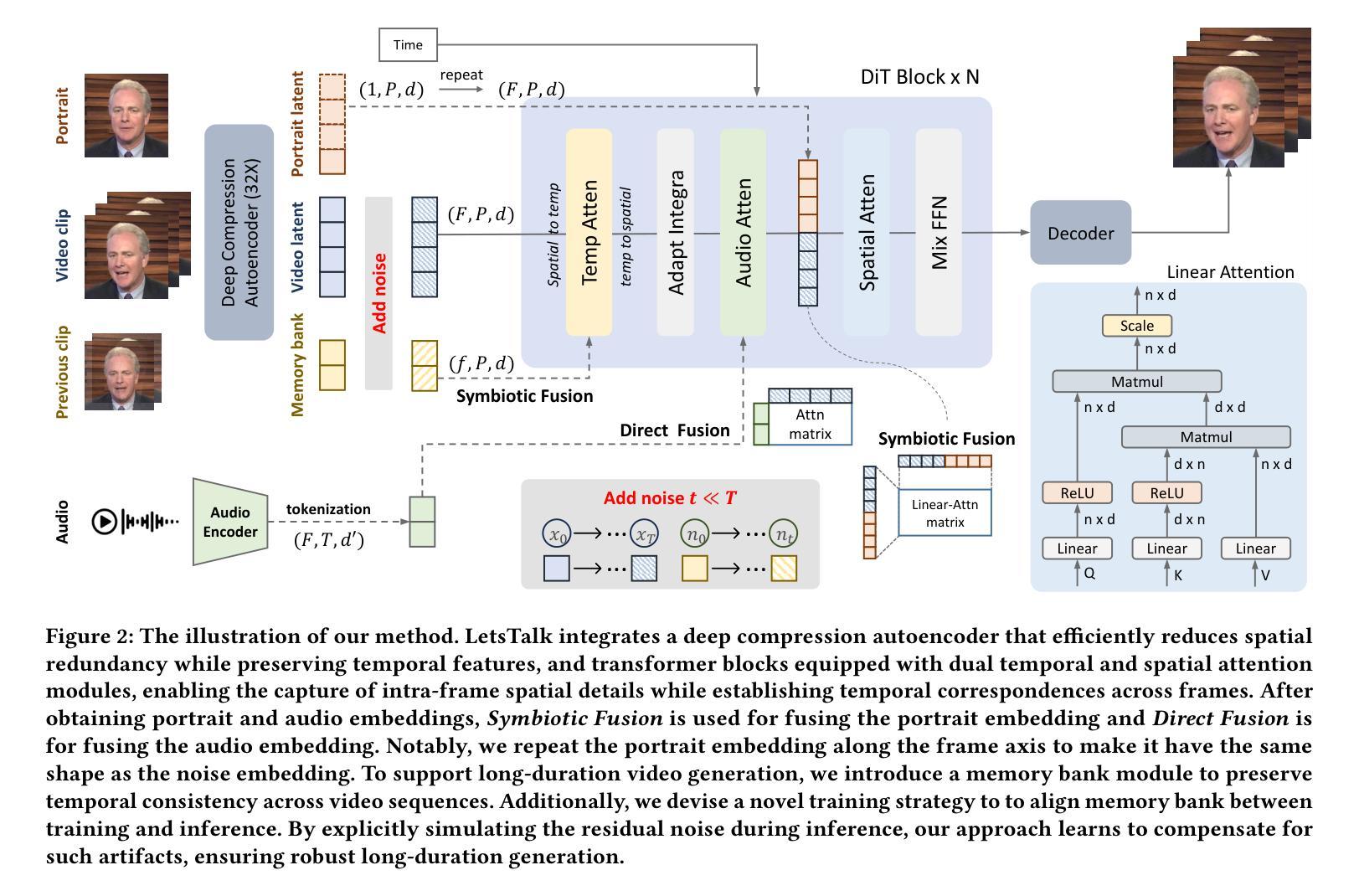
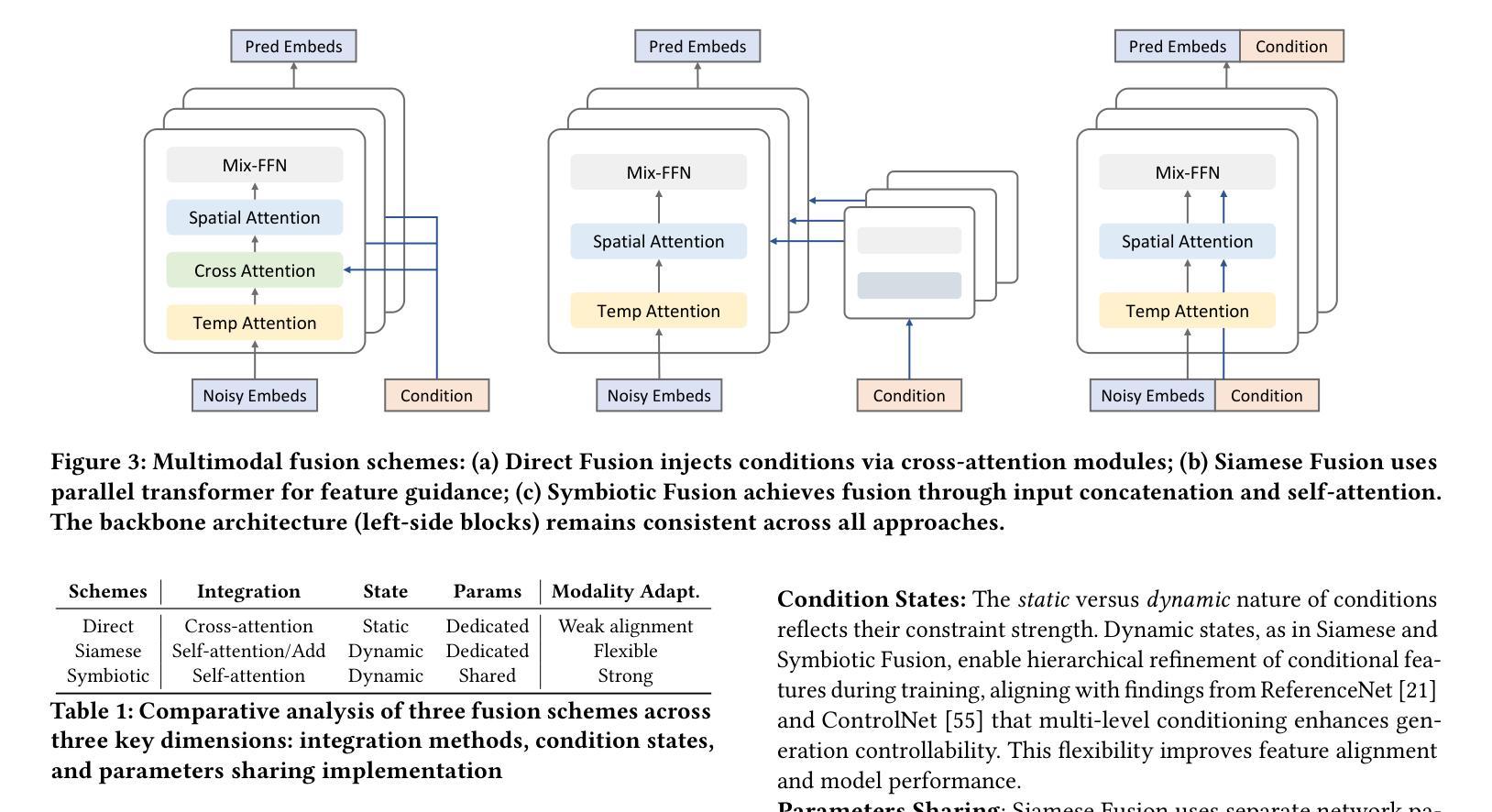
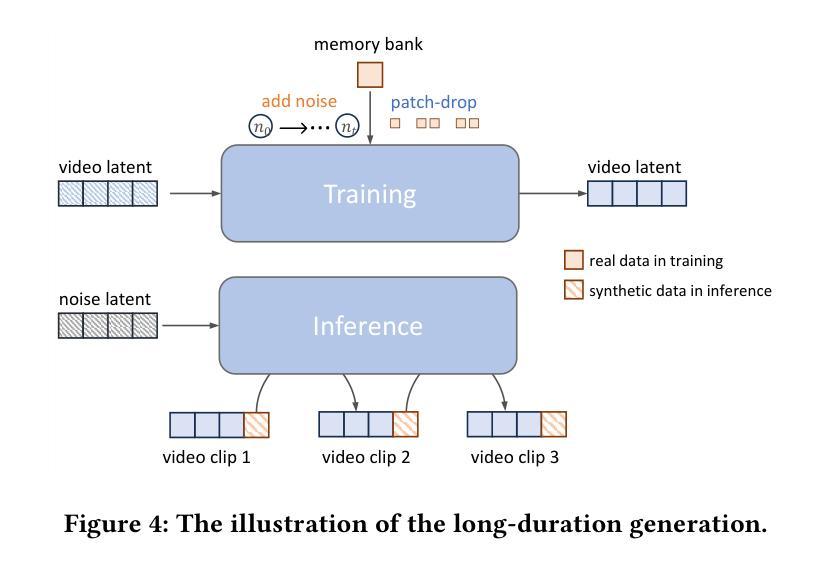
Portrait image animation using audio has rapidly advanced, but challenges remain in efficiently fusing multimodal inputs while ensuring temporal and portrait consistency with minimal computational cost. To address this, we present LetsTalk, a LinEar diffusion TranSformer for Talking video synthesis. LetsTalk incorporates a deep compression autoencoder to obtain efficient latent representations, and a spatio-temporal-aware transformer with efficient linear attention to effectively fuse multimodal information and enhance spatio-temporal consistency. We systematically explore and summarize three fusion schemes, ranging from shallow to deep fusion. We thoroughly analyze their characteristics, applicability, and trade-offs, thereby bridging critical gaps in multimodal conditional guidance. Based on modality differences of image, audio, and video generation, we adopt deep (Symbiotic Fusion) for portrait to ensure consistency, and shallow (Direct Fusion) for audio to align animation with speech while preserving motion diversity. To maintain temporal consistency in long-duration video generation, we propose a memory bank mechanism that preserves inter-clip dependencies, effectively preventing degradation across extended sequences. Furthermore, we develop a noise-regularized training strategy that explicitly compensates for DDPM sampling artifacts, significantly improving the model’s robustness in continuous generation scenarios.Our extensive experiments demonstrate that our approach achieves state-of-the-art generation quality, producing temporally coherent and realistic videos with enhanced diversity and liveliness, while maintaining remarkable efficiency through its optimized model design with 8$\times$ fewer parameters.
基于音频的肖像图像动画技术已迅速进步,但在确保时间和肖像一致性的同时,如何有效地融合多模式输入并以最小的计算成本实现这一目标仍然是一个挑战。为了解决这个问题,我们提出了LetsTalk,这是一种用于视频合成的线性扩散Transformer。LetsTalk采用深度压缩自编码器获得有效的潜在表示,以及具有高效线性注意力的时空感知Transformer,以有效地融合多模式信息并增强时空一致性。我们系统地探索并总结了从浅到深的三种融合方案。我们彻底分析了它们的特性、适用性和权衡,从而填补了多模式条件指导的关键空白。基于图像、音频和视频生成的模态差异,我们采用深度(共生融合)进行肖像融合,以确保一致性,并采用浅层(直接融合)进行音频融合,以使动画与语音对齐,同时保持运动多样性。为了在长期视频生成中保持时间一致性,我们提出了一种内存银行机制,保留跨剪辑的依赖关系,有效地防止了扩展序列中的退化。此外,我们开发了一种噪声正则化训练策略,显式地补偿DDPM采样伪影,大大提高了模型在连续生成场景中的稳健性。我们的大量实验表明,我们的方法达到了最新的生成质量水平,产生了时间连贯且逼真的视频,增强了多样性和生动性,同时通过优化模型设计实现了显著的效率提升,模型参数减少了8倍。
论文及项目相关链接
PDF 16 pages, 13 figures
Summary
基于音频的肖像图像动画技术虽然发展迅速,但仍面临如何高效融合多模态输入的挑战,以确保时间性和肖像一致性,同时尽量减少计算成本。为解决这一问题,我们提出了LetsTalk线性扩散Transformer(Transformer)谈话视频合成方法。LetsTalk采用深度压缩自编码器获得高效潜在表示,并借助具有高效线性注意力的时空感知Transformer有效融合多模态信息,提高时空一致性。本文系统地探索并总结了从浅到深的三种融合方案,全面分析了它们的特点、适用性和权衡,从而填补了多模态条件指导的空白。根据图像、音频和视频生成的模态差异,我们采用深度(共生融合)进行肖像一致性融合,浅层(直接融合)进行音频融合,以确保动画与语音的对齐,同时保持运动多样性。为保持长时视频生成的时序一致性,我们提出了记忆库机制,保持跨剪辑的依赖关系,有效防止长序列的退化。此外,我们开发了一种噪声正则化训练策略,明确补偿DDPM采样伪影,大大提高了模型在连续生成场景中的稳健性。实验表明,我们的方法达到了先进的生成质量,产生的时间连贯且逼真的视频具有增强的多样性和生动性,同时通过优化模型设计实现了显著的效率提升。
Key Takeaways
- 融合多模态输入对于创建真实感的动画视频至关重要。
- 提出了一种新的谈话视频合成方法LetsTalk,结合了深度压缩自编码器和时空感知Transformer技术。
- 介绍了三种融合方案,并根据图像、音频和视频生成的模态差异选择合适的方法。
- 通过记忆库机制维持长时间序列视频生成中的时序一致性。
- 开发了一种噪声正则化训练策略来提高模型的稳健性,特别是针对连续生成场景。
- 实验显示该方法生成的视频质量高、真实感强、时间连贯。
点此查看论文截图

Lipschitz-Driven Noise Robustness in VQ-AE for High-Frequency Texture Repair in ID-Specific Talking Heads
Authors:Jian Yang, Xukun Wang, Wentao Wang, Guoming Li, Qihang Fang, Ruihong Yuan, Tianyang Wang, Xiaomei Zhang, Yeying Jin, Zhaoxin Fan
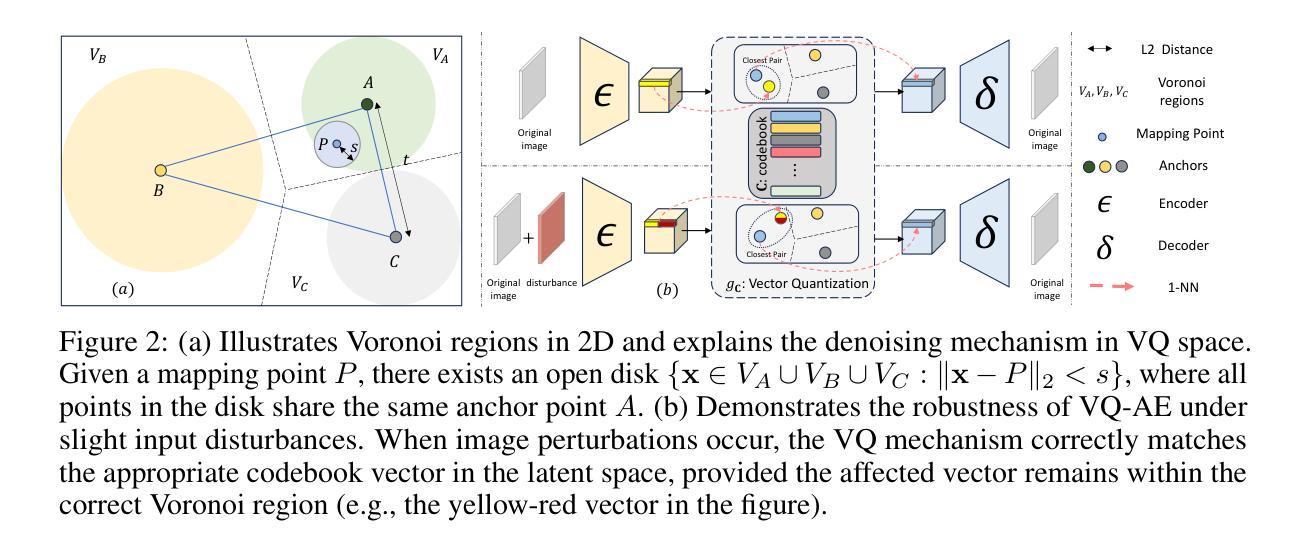
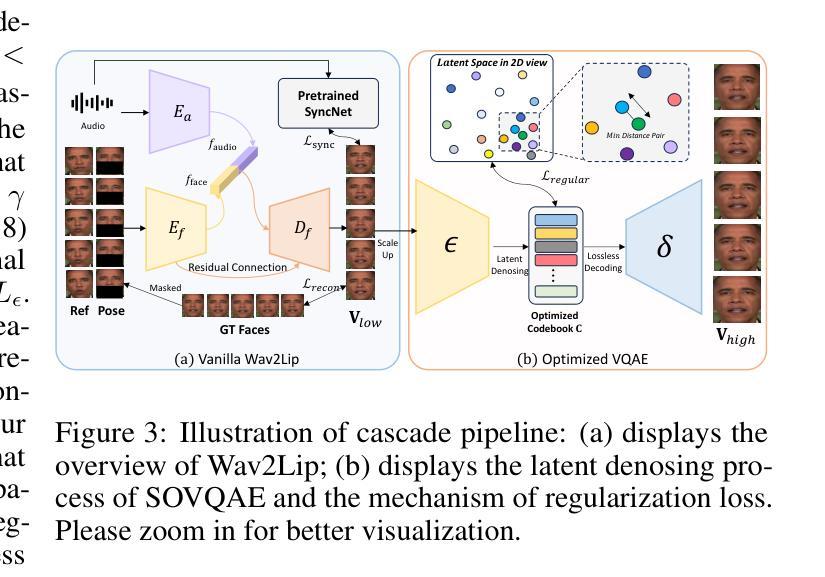
Audio-driven IDentity-specific Talking Head Generation (ID-specific THG) has shown increasing promise for applications in filmmaking and virtual reality. Existing approaches are generally constructed as end-to-end paradigms, and have achieved significant progress. However, they often struggle to capture high-frequency textures due to limited model capacity. To address these limitations, we adopt a simple yet efficient post-processing framework – unlike previous studies that focus solely on end-to-end training – guided by our theoretical insights. Specifically, leveraging the \textit{Lipschitz Continuity Theory} of neural networks, we prove a crucial noise tolerance property for the Vector Quantized AutoEncoder (VQ-AE), and establish the existence of a Noise Robustness Upper Bound (NRoUB). This insight reveals that we can efficiently obtain an identity-specific denoiser by training an identity-specific neural discrete representation, without requiring an extra network. Based on this theoretical foundation, we propose a plug-and-play Space-Optimized VQ-AE (SOVQAE) with enhanced NRoUB to achieve temporally-consistent denoising. For practical deployment, we further introduce a cascade pipeline combining a pretrained Wav2Lip model with SOVQAE to perform ID-specific THG. Our experiments demonstrate that this pipeline achieves \textit{state-of-the-art} performance in video quality and robustness for out-of-distribution lip synchronization, surpassing existing identity-specific THG methods. In addition, the pipeline requires only a couple of consumer GPU hours and runs in real time, which is both efficient and practical for industry applications.
音频驱动的特定身份语音头部生成(ID特定THG)在电影制作和虚拟现实等领域的应用前景日益显现。现有方法通常采用端到端的范式构建,并已经取得了显著的进步。然而,由于模型容量的限制,它们通常难以捕捉高频纹理。为了克服这些局限性,我们采用了简单而有效的后处理框架——不同于以往仅侧重于端到端训练的研究——在我们的理论见解的指导下。具体来说,我们利用神经网络的Lipschitz连续性理论,证明了向量量化自动编码器(VQ-AE)的关键噪声容忍属性,并建立了噪声鲁棒性上界(NRoUB)的存在性。这一见解表明,我们可以通过训练特定的身份神经离散表示来有效地获得身份特定的去噪器,而无需额外的网络。基于这一理论基础,我们提出了一种带有增强NRoUB的即插即用空间优化VQ-AE(SOVQAE)以实现时间一致的降噪。在实际部署中,我们进一步引入了一个结合预训练Wav2Lip模型和SOVQAE的级联管道,以执行ID特定THG。我们的实验表明,该管道在视频质量和鲁棒性方面达到了最先进的性能,特别是在唇同步的离群值处理方面超越了现有的身份特定THG方法。此外,该管道仅需要几个小时的普通GPU运算时间,并能实时运行,对于工业应用而言既高效又实用。
论文及项目相关链接
Summary
文本探讨了在影视制作和虚拟现实领域中,音频驱动的特定身份谈话头生成(ID-specific THG)的研究进展。现有方法虽然取得显著进展,但在捕捉高频纹理方面存在局限。本文采用一种简单的后处理框架,利用神经网络Lipschitz连续性理论,证明了向量量化自编码器(VQ-AE)的关键噪声容忍属性,并建立了噪声鲁棒性上限(NRoUB)。基于此理论,提出了具有增强NRoUB的插入式空间优化VQ-AE(SOVQAE),实现时间一致的降噪。结合预训练的Wav2Lip模型和SOVQAE,实现了ID特定THG的级联管道,达到业界最佳的视频质量和鲁棒性表现。该方法效率高、实时性强,适用于行业应用。
Key Takeaways
- 音频驱动的特定身份谈话头生成(ID-specific THG)在影视制作和虚拟现实中有广泛应用前景。
- 现有方法虽然进步显著,但捕捉高频纹理时存在局限。
- 采用后处理框架,结合神经网络Lipschitz连续性理论,证明VQ-AE的噪声容忍属性。
- 建立了噪声鲁棒性上限(NRoUB),提出Space-Optimized VQ-AE(SOVQAE)以增强NRoUB。
- SOVQAE能够实现时间一致的降噪,结合Wav2Lip模型,形成级联管道,实现ID-specific THG。
- 该方法达到业界最佳的视频质量和鲁棒性表现,且效率高、实时性强。
点此查看论文截图



EmoVOCA: Speech-Driven Emotional 3D Talking Heads
Authors:Federico Nocentini, Claudio Ferrari, Stefano Berretti
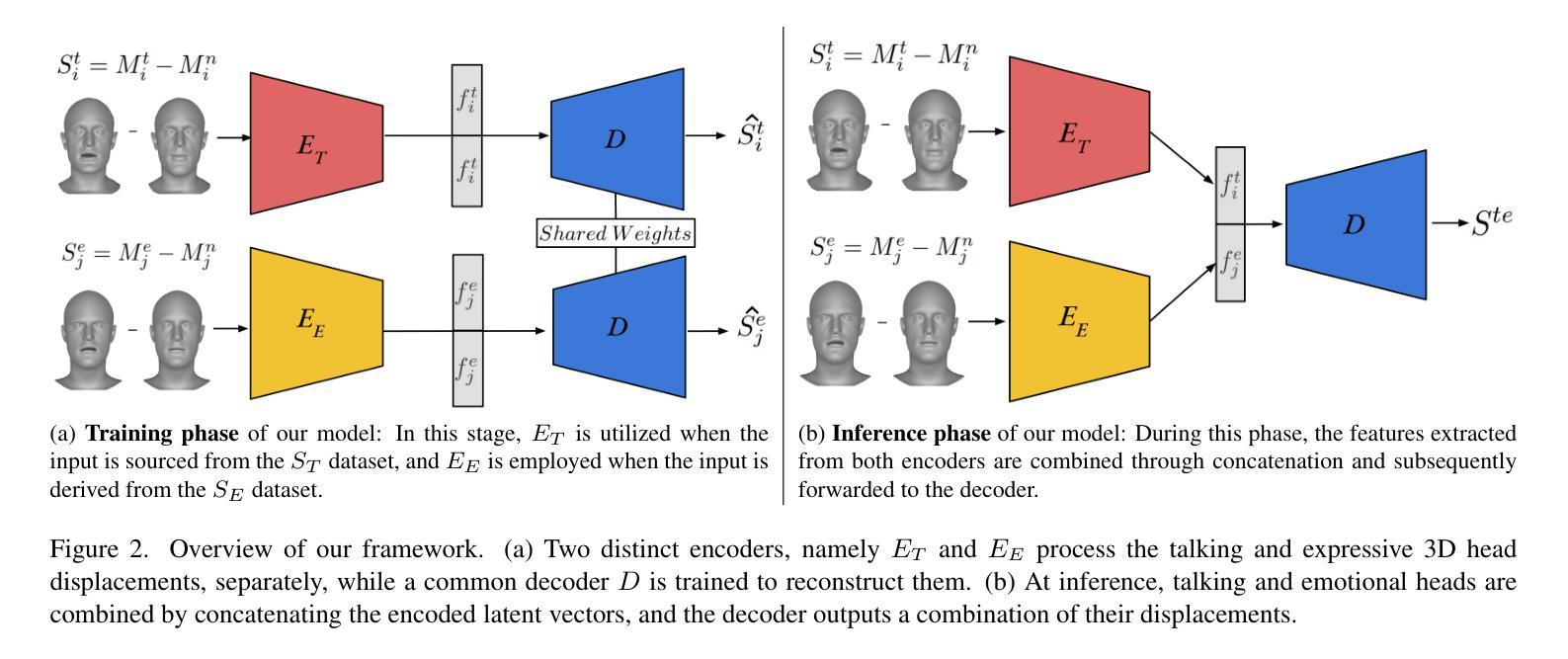
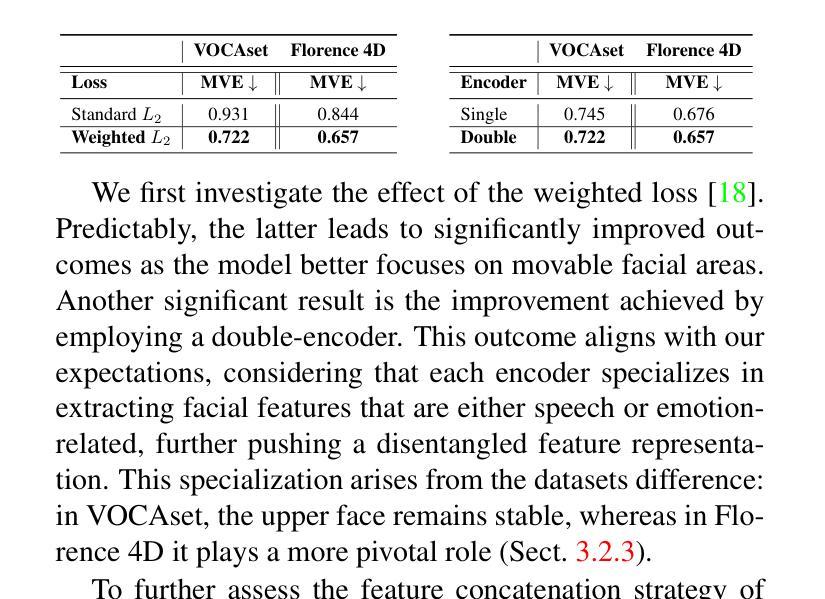
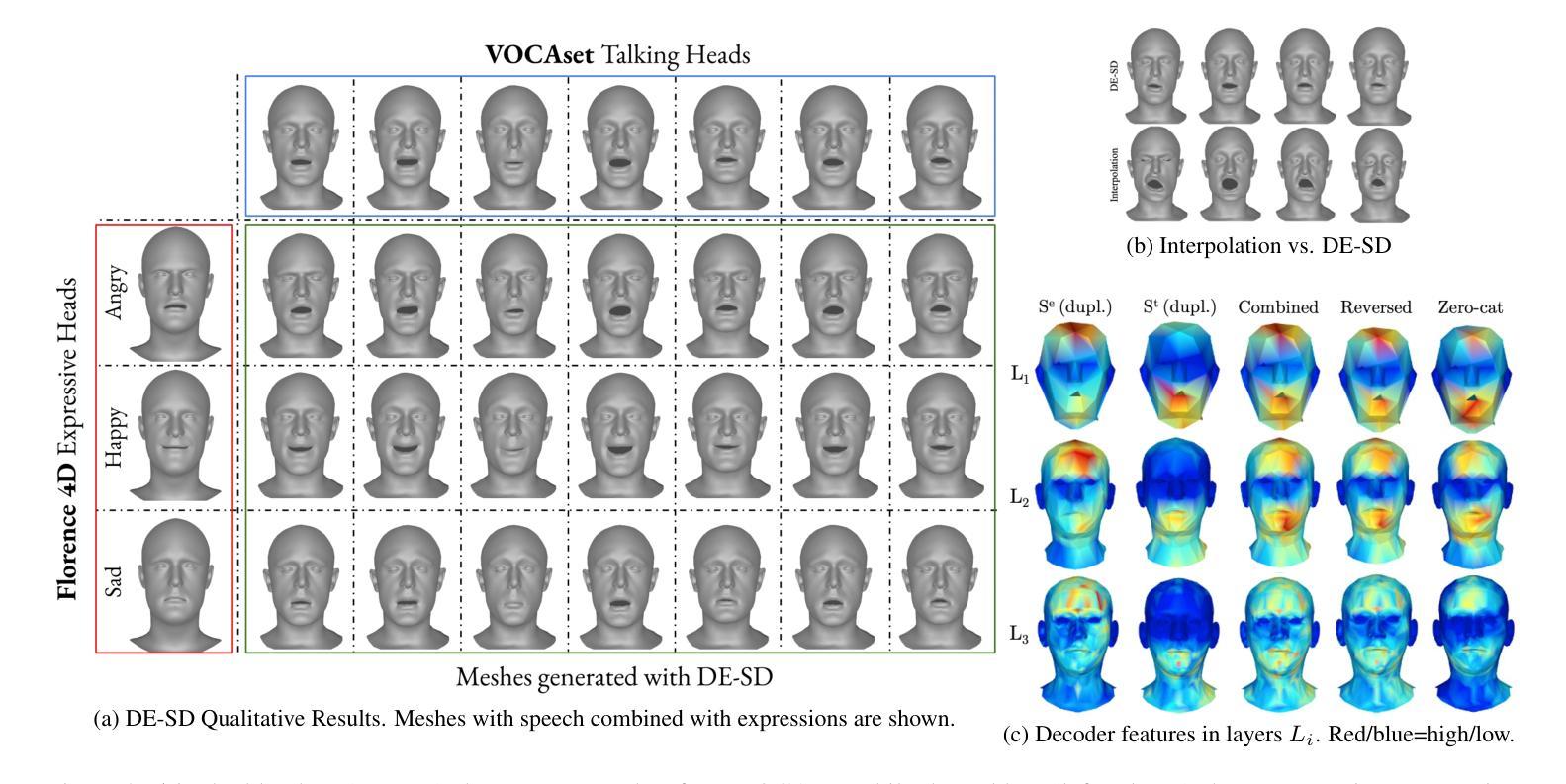
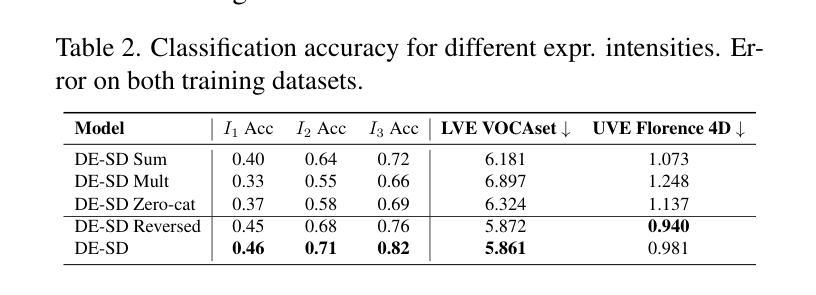
The domain of 3D talking head generation has witnessed significant progress in recent years. A notable challenge in this field consists in blending speech-related motions with expression dynamics, which is primarily caused by the lack of comprehensive 3D datasets that combine diversity in spoken sentences with a variety of facial expressions. Whereas literature works attempted to exploit 2D video data and parametric 3D models as a workaround, these still show limitations when jointly modeling the two motions. In this work, we address this problem from a different perspective, and propose an innovative data-driven technique that we used for creating a synthetic dataset, called EmoVOCA, obtained by combining a collection of inexpressive 3D talking heads and a set of 3D expressive sequences. To demonstrate the advantages of this approach, and the quality of the dataset, we then designed and trained an emotional 3D talking head generator that accepts a 3D face, an audio file, an emotion label, and an intensity value as inputs, and learns to animate the audio-synchronized lip movements with expressive traits of the face. Comprehensive experiments, both quantitative and qualitative, using our data and generator evidence superior ability in synthesizing convincing animations, when compared with the best performing methods in the literature. Our code and pre-trained model will be made available.
近年来,3D对话头部生成领域取得了重大进展。该领域的一个显著挑战在于将语音相关的动作与表情动态相结合,这主要是由缺乏综合的3D数据集引起的,该数据集结合了不同句子的多样性和各种面部表情。尽管文献作品试图利用二维视频数据和参数化三维模型作为替代方案,但这些方法在处理两种动作的联合建模时仍存在局限性。在这项工作中,我们从不同的角度解决了这个问题,并提出了一种创新的数据驱动技术,用于创建合成数据集EmoVOCA,该数据集是通过将一系列无表情的3D对话头部和一组3D表情序列组合而成的。为了证明这种方法的优势和数据集的质量,我们设计并训练了一个情感三维对话头部生成器,该生成器接受三维人脸、音频文件、情感标签和强度值作为输入,并学习同步音频的唇部运动与面部表情的特征。使用我们的数据和生成器进行的定量和定性实验的综合实验证据表明,与文献中的最佳方法相比,我们的方法在合成令人信服的动画方面具有卓越的能力。我们的代码和预训练模型将可用。
论文及项目相关链接
PDF WACV 2025
Summary
本文提出一种创新的数据驱动技术,创建了一个合成数据集EmoVOCA,该数据集通过结合表情和无表情的3D说话人头模型以及一套表情序列来实现。文章展示了一种新型的情感三维谈话头生成器,它能够接受三维人脸、音频文件、情感标签和强度值作为输入,并学习生成与音频同步的唇部运动以及具有表情特征的人脸动画。通过全面实验,证明了相较于现有最佳方法,使用本文的数据集和生成器可以合成更为逼真的动画。预训练模型和代码将会公开分享。
Key Takeaways
- 介绍了三维说话人头部生成领域的最新进展和挑战。
- 强调了缺乏包含多样口语和面部表情的综合三维数据集是主要挑战之一。
- 提出了一种新型的数据驱动技术创建合成数据集EmoVOCA。该数据集融合了无表情的三维说话人头模型和一系列表情序列。
- 介绍了一种情感三维谈话头生成器,可以接受三维人脸、音频文件、情感标签和强度值作为输入,并学习生成具有真实感的动画。
- 通过实验证明了该方法在合成动画方面的优越性,相较于现有方法在文献中的最佳表现有所超越。
- 该研究的预训练模型和代码将公开分享,便于其他研究者使用。
点此查看论文截图