⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-12 更新
AraReasoner: Evaluating Reasoning-Based LLMs for Arabic NLP
Authors:Ahmed Hasanaath, Aisha Alansari, Ahmed Ashraf, Chafik Salmane, Hamzah Luqman, Saad Ezzini
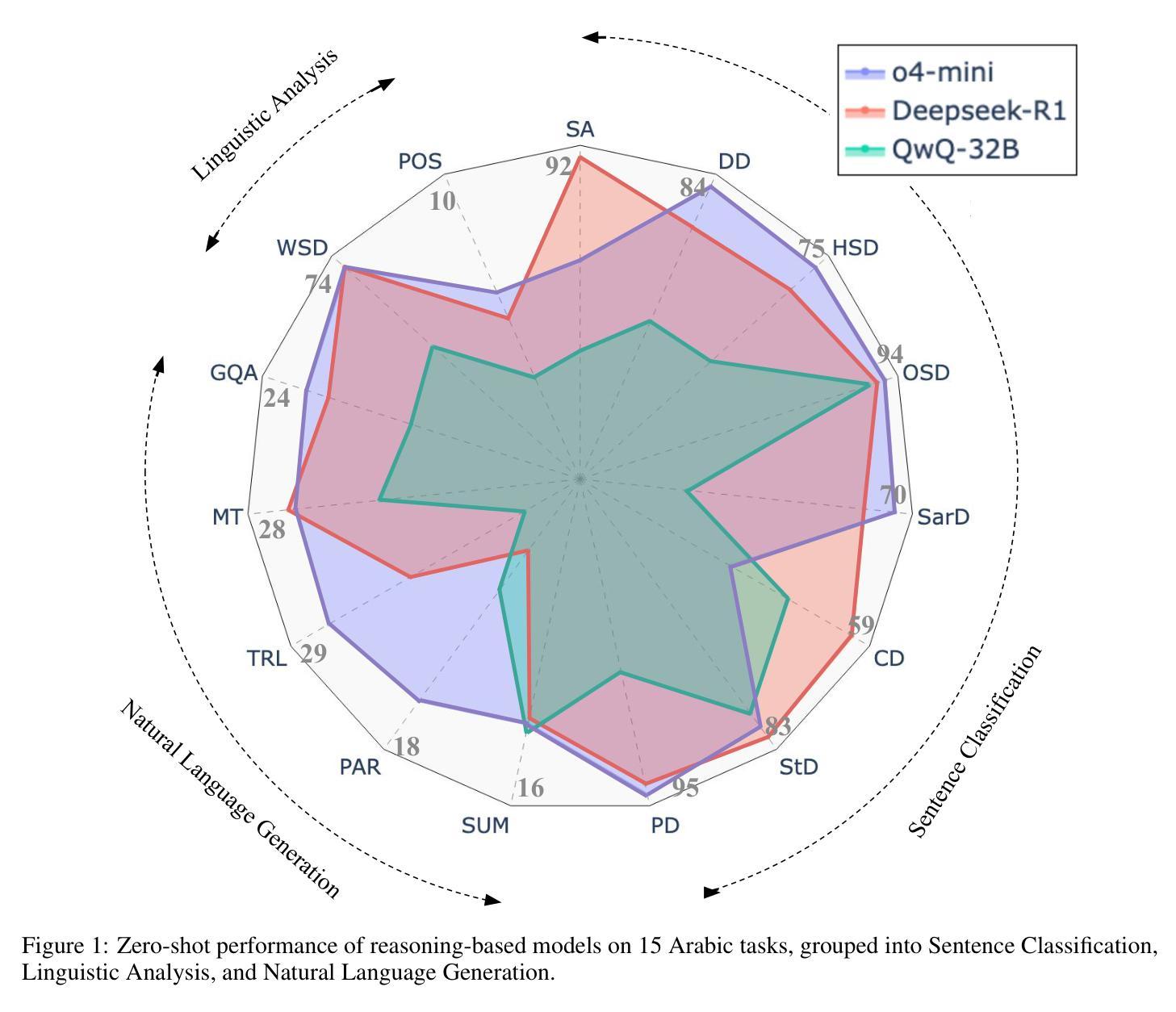
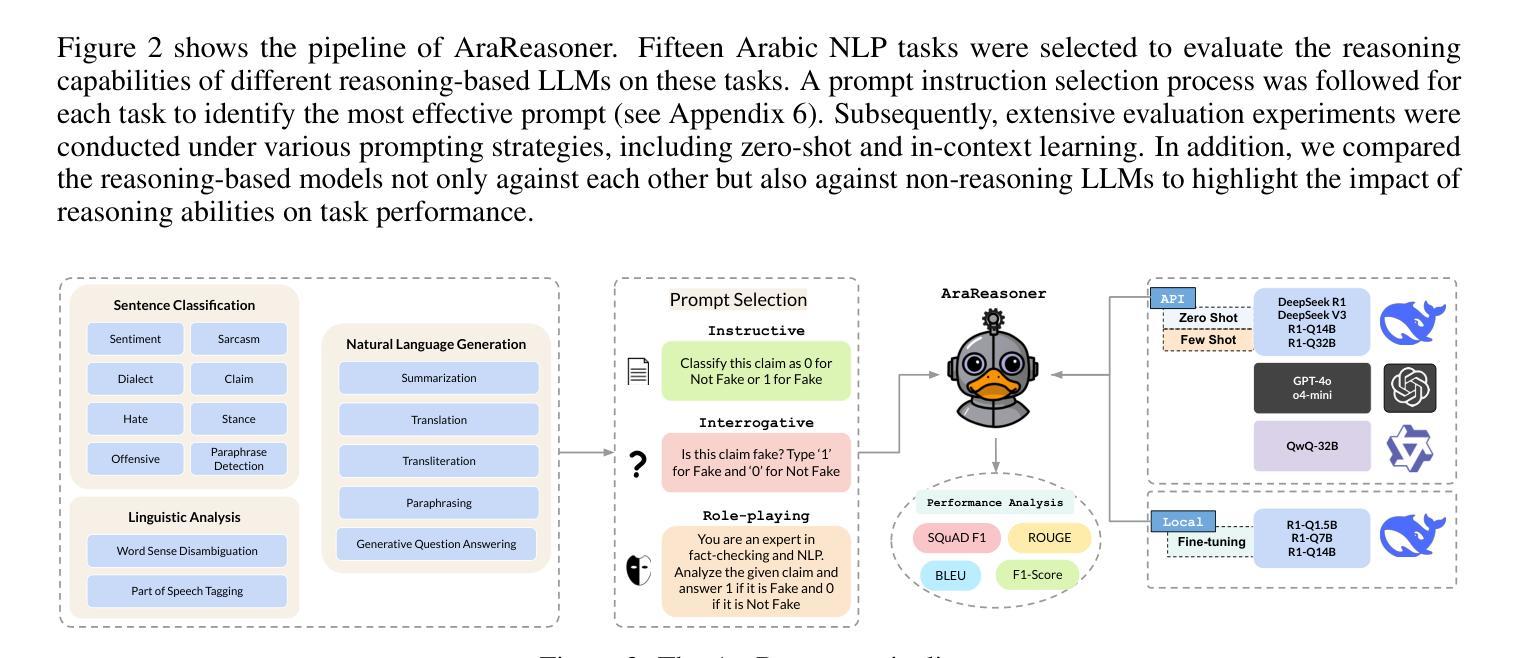
Large language models (LLMs) have shown remarkable progress in reasoning abilities and general natural language processing (NLP) tasks, yet their performance on Arabic data, characterized by rich morphology, diverse dialects, and complex script, remains underexplored. This paper presents a comprehensive benchmarking study of multiple reasoning-focused LLMs, with a special emphasis on the newly introduced DeepSeek models, across a suite of fifteen Arabic NLP tasks. We experiment with various strategies, including zero-shot, few-shot, and fine-tuning. This allows us to systematically evaluate performance on datasets covering a range of applications to examine their capacity for linguistic reasoning under different levels of complexity. Our experiments reveal several key findings. First, carefully selecting just three in-context examples delivers an average uplift of over 13 F1 points on classification tasks-boosting sentiment analysis from 35.3% to 87.5% and paraphrase detection from 56.1% to 87.0%. Second, reasoning-focused DeepSeek architectures outperform a strong GPT o4-mini baseline by an average of 12 F1 points on complex inference tasks in the zero-shot setting. Third, LoRA-based fine-tuning yields up to an additional 8 points in F1 and BLEU compared to equivalent increases in model scale. The code is available at https://anonymous.4open.science/r/AraReasoner41299
大型语言模型(LLM)在推理能力和通用自然语言处理(NLP)任务方面取得了显著的进步,但在处理以丰富形态、多样方言和复杂脚本为特点的阿拉伯语数据方面的性能仍然被低估。本文全面评估了多个以推理为重点的LLM,特别强调新推出的DeepSeek模型,涵盖十五项阿拉伯语NLP任务。我们尝试了零样本、少样本和微调等多种策略。这使我们能够系统地评估在覆盖各种应用的数据集上的性能,以检验它们在不同复杂程度下的语言推理能力。我们的实验揭示了几个关键发现。首先,通过精心选择仅三个上下文实例,分类任务的平均提升幅度超过13个F1点——情感分析从35.3%提高到87.5%,改写检测从56.1%提高到87.0%。其次,在零样本设置中,以推理为重点的DeepSeek架构在复杂推理任务上的平均表现优于强大的GPT o4-mini基线12个F1点。第三,与模型规模的等效增加相比,基于LoRA的微调技术可额外提高F1和BLEU分数达8点。相关代码可通过https://anonymous.4open.science/r/AraReasoner41299访问。
论文及项目相关链接
Summary
大型语言模型(LLM)在阿拉伯文的自然语言处理(NLP)任务中的表现受到关注。本文采用基准测试方法,评估多个注重推理的LLM模型,特别是新推出的DeepSeek模型在十五项阿拉伯NLP任务中的性能。研究发现,精心选择三个实例进行微调可显著提高分类任务的平均F1得分;DeepSeek架构在零样本设置下优于GPT o4-mini基线模型;基于LoRA的微调技术有助于提高模型性能。
Key Takeaways
- 精心选择三个实例进行微调可以显著提高分类任务的平均F1得分超过13点。
- 推理型的DeepSeek模型在零样本设置中表现优越,平均优于GPT o4-mini基线模型12点F1得分。
- LoRA微调技术可以进一步提高模型性能,最多可达额外8点F1和BLEU得分。
- 大型语言模型在应对具有丰富形态、多样方言和复杂脚本的阿拉伯数据上仍有待深入探索。
- 实验中涉及了零样本、少样本和微调等多种策略,这有助于系统评估模型在不同复杂度层次的语言推理任务中的表现。
- 论文提供了一个全面的基准测试框架,涵盖了十五项阿拉伯NLP任务,这对于了解语言模型的性能非常有价值。
点此查看论文截图

ClimateViz: A Benchmark for Statistical Reasoning and Fact Verification on Scientific Charts
Authors:Ruiran Su, Jiasheng Si, Zhijiang Guo, Janet B. Pierrehumbert
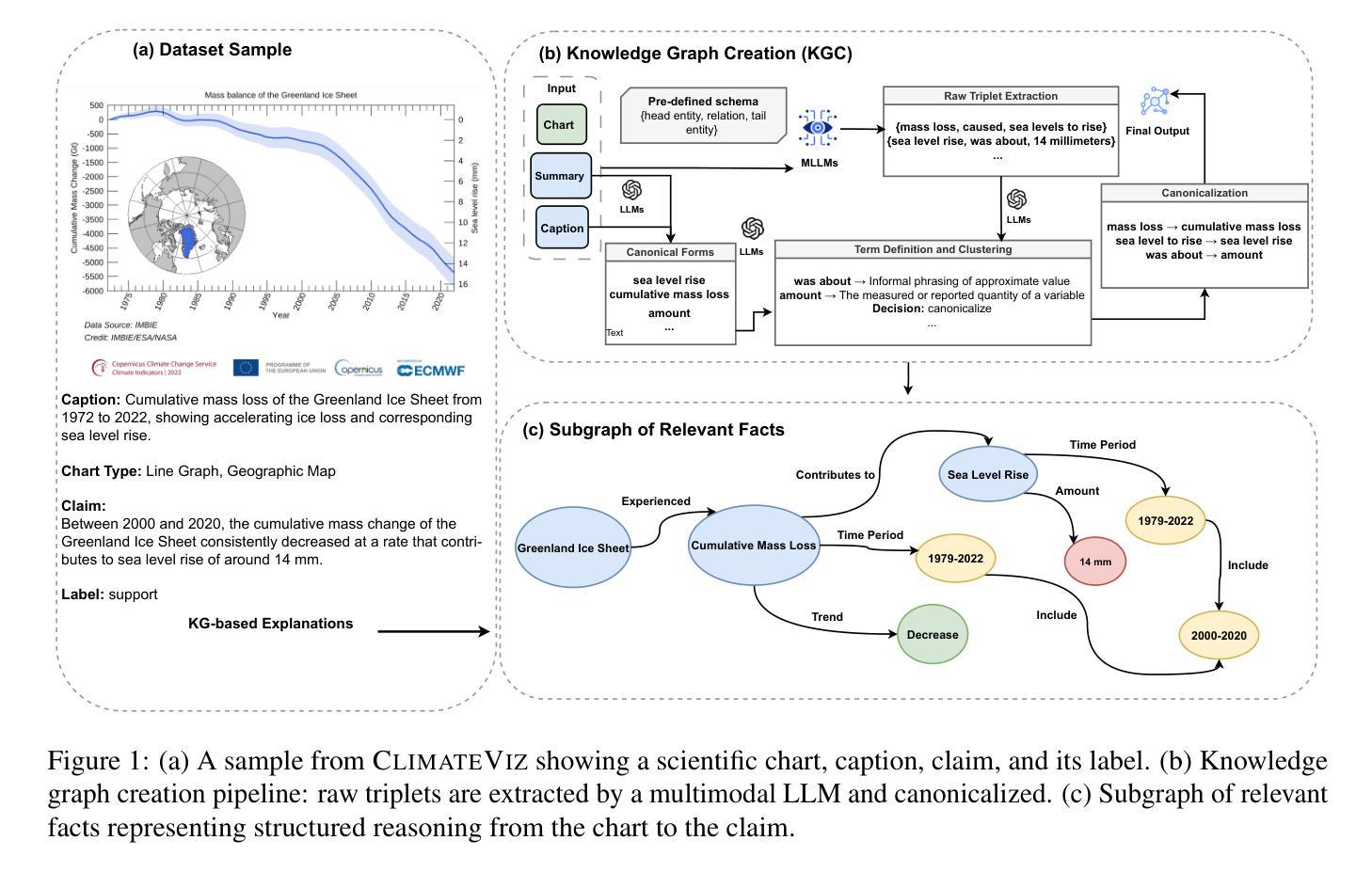
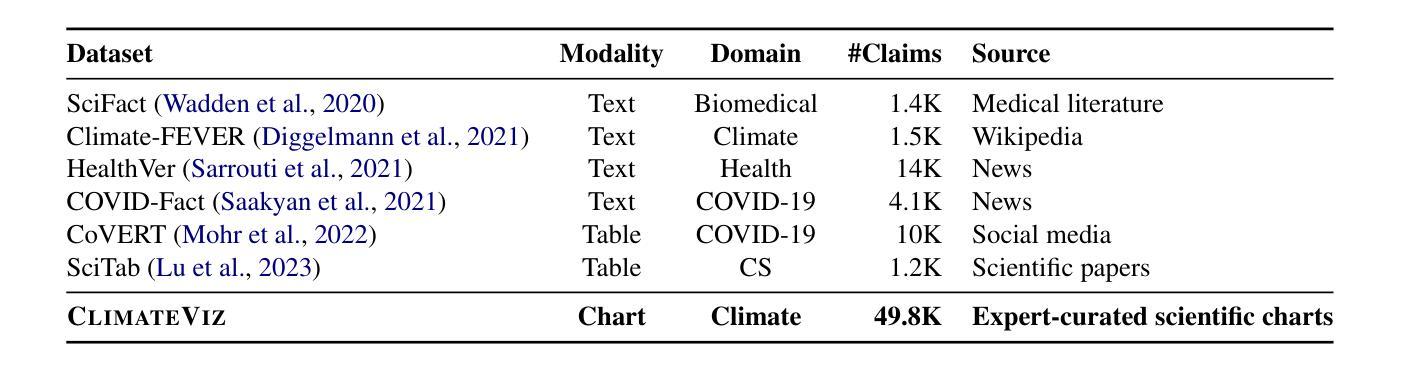
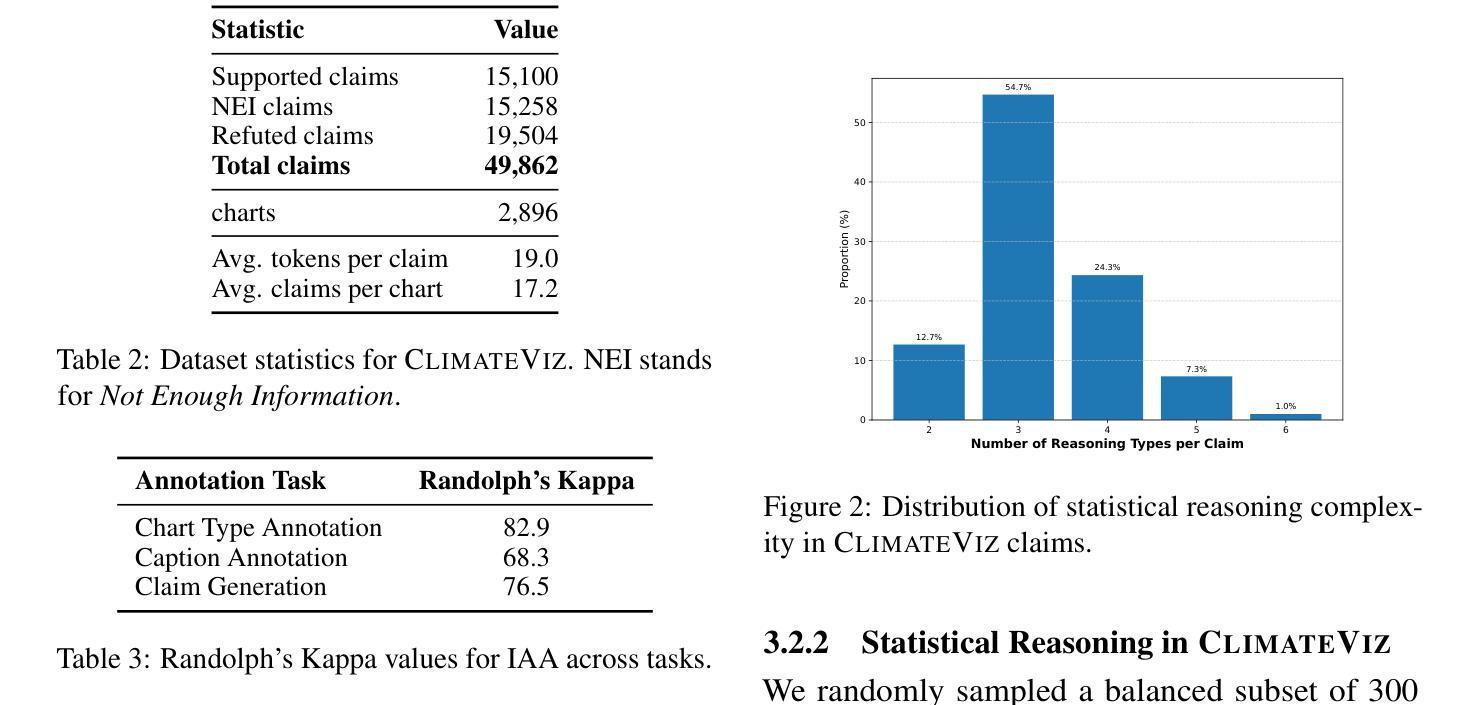
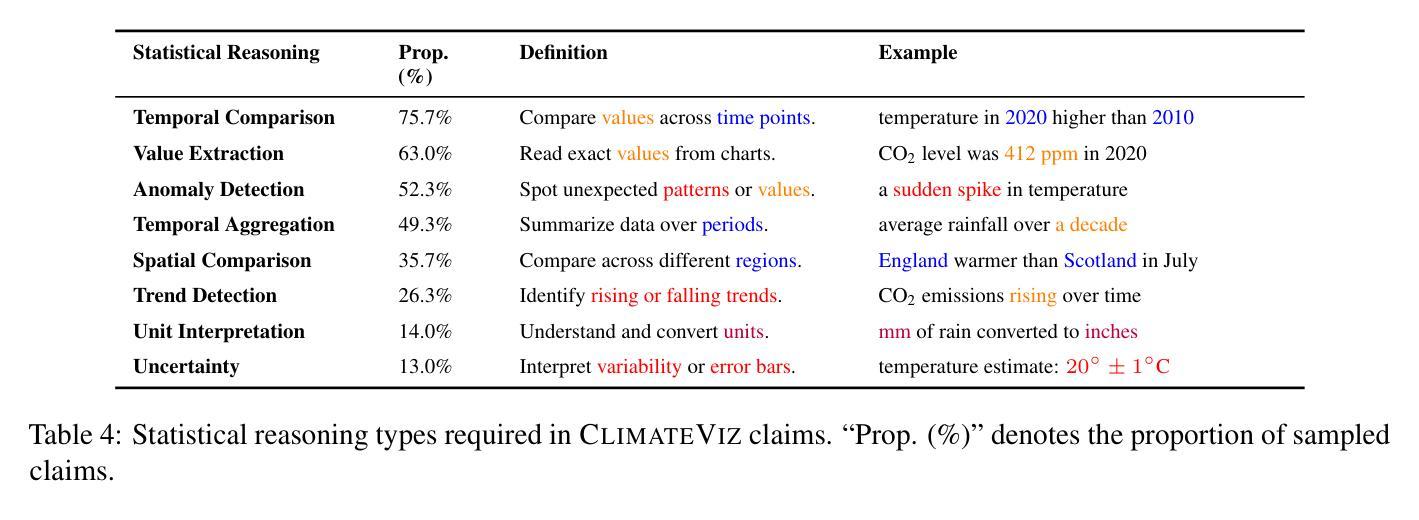
Scientific fact-checking has mostly focused on text and tables, overlooking scientific charts, which are key for presenting quantitative evidence and statistical reasoning. We introduce ClimateViz, the first large-scale benchmark for scientific fact-checking using expert-curated scientific charts. ClimateViz contains 49,862 claims linked to 2,896 visualizations, each labeled as support, refute, or not enough information. To improve interpretability, each example includes structured knowledge graph explanations covering trends, comparisons, and causal relations. We evaluate state-of-the-art multimodal language models, including both proprietary and open-source systems, in zero-shot and few-shot settings. Results show that current models struggle with chart-based reasoning: even the best systems, such as Gemini 2.5 and InternVL 2.5, reach only 76.2 to 77.8 percent accuracy in label-only settings, far below human performance (89.3 and 92.7 percent). Explanation-augmented outputs improve performance in some models. We released our dataset and code alongside the paper.
科学事实核查主要集中在文本和表格上,忽视了科学图表的重要性,这些图表对于展示定量证据和统计推理至关重要。我们引入了ClimateViz,这是一个使用专家策划的科学图表进行事实核查的大型基准测试。ClimateViz包含与2,896个可视化内容相关的49,862个声明,每个声明都被标记为支持、反驳或信息不足。为了提高可解释性,每个示例都包含结构化知识图谱解释,涵盖趋势、比较和因果关系。我们评估了最先进的多模式语言模型,包括专有和开源系统,在无预设或少预设的情况下进行了评估。结果表明,当前模型在基于图表的推理方面遇到了困难:即使是最好的系统,如Gemini 2.5和InternVL 2.5,在仅标签设置下的准确率也只有76.2%至77.8%,远低于人类的表现(89.3%和92.7%)。解释增强的输出提高了某些模型的表现。我们随论文发布了数据集和代码。
论文及项目相关链接
Summary:
引入ClimateViz,首大规模科学事实核查基准测试集,聚焦于图表的形式展示定量证据和统计推理的核查。含49,862条声明与2,896可视化内容链接,每个标注为支持、反驳或信息不足。评估当前先进的多媒体语言模型,包括专有和开源系统,在零样本和少样本环境下表现。结果显示当前模型图表推理能力欠佳,最好的系统如Gemini 2.5和InternVL 2.5在仅标签设置下准确率仅达76.2至77.8%,远低于人类表现(89.3至92.7%)。解释增强输出可提高某些模型性能。已发布数据集和代码。
Key Takeaways:
- 科学事实核查主要关注文本和表格,忽略了图表在呈现定量证据和统计推理中的重要性。
- 引入ClimateViz作为首个大规模科学事实核查基准测试集,包含与可视化内容链接的声明,每个都有支持、反驳或信息不足的标注。
- 当前先进的多媒体语言模型在零样本和少样本环境下的表现被评估。
- 这些模型在基于图表的推理方面表现欠佳,即使最好的系统准确率也远低于人类表现。
- 解释增强的输出可以提高某些模型的表现。
- 论文中发布了数据集和代码以供使用。
点此查看论文截图

Sample Efficient Demonstration Selection for In-Context Learning
Authors:Kiran Purohit, V Venktesh, Sourangshu Bhattacharya, Avishek Anand
The in-context learning paradigm with LLMs has been instrumental in advancing a wide range of natural language processing tasks. The selection of few-shot examples (exemplars / demonstration samples) is essential for constructing effective prompts under context-length budget constraints. In this paper, we formulate the exemplar selection task as a top-m best arms identification problem. A key challenge in this setup is the exponentially large number of arms that need to be evaluated to identify the m-best arms. We propose CASE (Challenger Arm Sampling for Exemplar selection), a novel sample-efficient selective exploration strategy that maintains a shortlist of “challenger” arms, which are current candidates for the top-m arms. In each iteration, only one of the arms from this shortlist or the current topm set is pulled, thereby reducing sample complexity and, consequently, the number of LLM evaluations. Furthermore, we model the scores of exemplar subsets (arms) using a parameterized linear scoring function, leading to stochastic linear bandits setting. CASE achieves remarkable efficiency gains of up to 7x speedup in runtime while requiring 7x fewer LLM calls (87% reduction) without sacrificing performance compared to state-of-the-art exemplar selection methods. We release our code and data at https://github.com/kiranpurohit/CASE
在广泛的自然语言处理任务中,大型语言模型(LLMs)的上下文学习范式起着至关重要的作用。在上下文长度预算约束下构建有效的提示时,选择少量示例(范例/演示样本)至关重要。在本文中,我们将范例选择任务表述为识别最优m个臂的问题。在此设置中面临的关键挑战是需要评估的臂的数量呈指数增长。我们提出了CASE(用于范例选择的挑战臂采样),这是一种新颖的样本高效选择性探索策略,它维护一个“挑战者”臂的简短列表,这些是当前可能成为最优m个臂的候选者。在每次迭代中,仅从该简短列表或当前最优m个集合中拉出一个臂,从而减少样本复杂性,因此减少了对大型语言模型的评估次数。此外,我们使用参数化线性评分函数对范例子集(臂)进行建模,从而形成了随机线性强盗设置。CASE在不牺牲性能的情况下实现了高达7倍的加速运行时和减少7倍的大型语言模型调用次数(减少了87%),并获得了显著的效率提升。我们在https://github.com/kiranpurohit/CASE上发布了我们的代码和数据。
论文及项目相关链接
PDF Accepted at ICML 2025 , 24 pages
Summary
本文介绍了在大型语言模型(LLM)的语境学习范式中,少样本示例的选择对于构建有效提示至关重要。针对此问题,文章提出了一种新的样本高效选择性探索策略CASE(挑战者采样选择法),通过维护一个“挑战者”手臂的简短列表,在每次迭代中只抽取列表中的一个手臂或当前最优手臂,从而减少样本复杂性并降低大型语言模型的评估次数。CASE方法实现了高达7倍的效率提升,同时在不牺牲性能的情况下减少了大型语言模型的调用次数。
Key Takeaways
- 大型语言模型(LLM)的语境学习范式中,少样本示例的选择对构建有效提示至关重要。
- 示例选择任务被形式化为寻找最佳的m个手臂的问题。
- CASE方法是一种新型的样本高效选择性探索策略,通过维护简短列表的“挑战者”手臂,实现有效识别最优手臂。
- 在每次迭代中,CASE仅抽取列表中的一个手臂或当前最优手臂进行测试。
- 通过CASE方法,可以实现高达7倍的效率提升和高达87%的减少大型语言模型调用的需求。
- 文章公开了相关的代码和数据。
点此查看论文截图

Meta-Adaptive Prompt Distillation for Few-Shot Visual Question Answering
Authors:Akash Gupta, Amos Storkey, Mirella Lapata
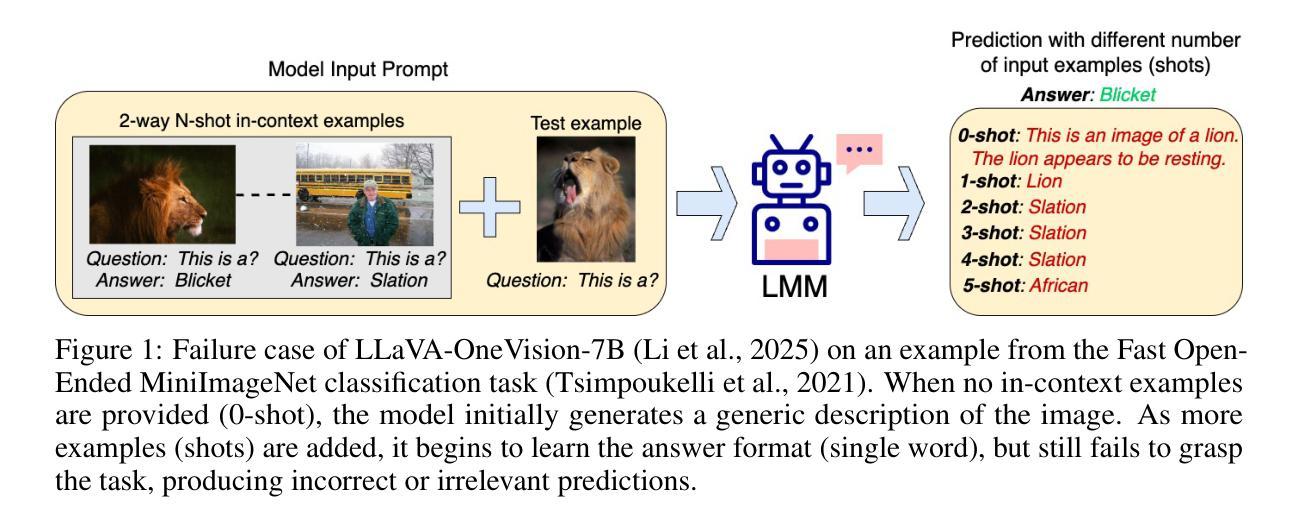
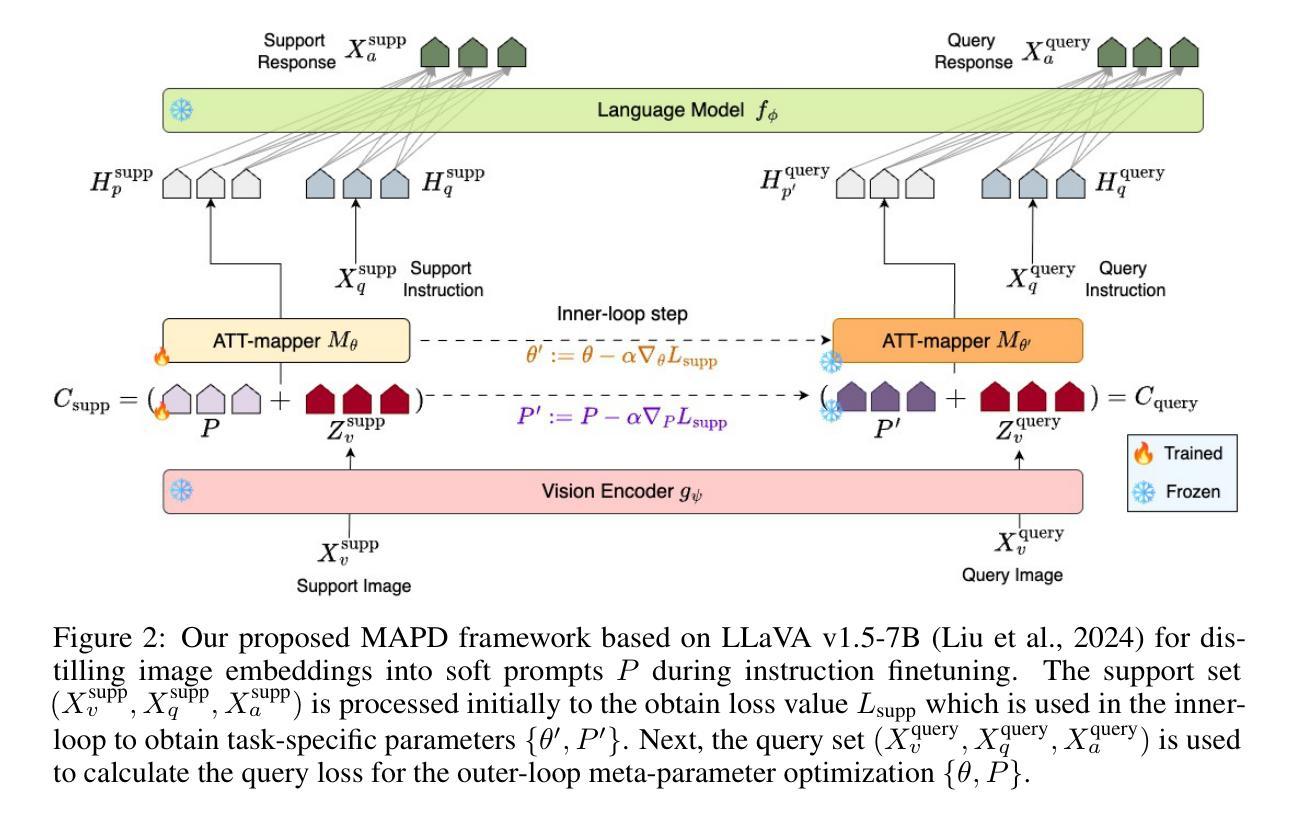
Large Multimodal Models (LMMs) often rely on in-context learning (ICL) to perform new tasks with minimal supervision. However, ICL performance, especially in smaller LMMs, is inconsistent and does not always improve monotonically with increasing examples. We hypothesize that this occurs due to the LMM being overwhelmed by additional information present in the image embeddings, which is not required for the downstream task. To address this, we propose a meta-learning approach that provides an alternative for inducing few-shot capabilities in LMMs, using a fixed set of soft prompts that are distilled from task-relevant image features and can be adapted at test time using a few examples. To facilitate this distillation, we introduce an attention-mapper module that can be easily integrated with the popular LLaVA v1.5 architecture and is jointly learned with soft prompts, enabling task adaptation in LMMs under low-data regimes with just a few gradient steps. Evaluation on the VL-ICL Bench shows that our method consistently outperforms ICL and related prompt-tuning approaches, even under image perturbations, improving task induction and reasoning across visual question answering tasks.
大型多模态模型(LMM)通常依赖于上下文学习(ICL)来以最小的监督执行新任务。然而,ICL的性能,特别是在较小的LMM中,表现不一致,并且并不总是随着示例的增加而单调提高。我们假设这是因为LMM被图像嵌入中存在的额外信息所淹没,而这些信息对于下游任务来说并不是必需的。为了解决这一问题,我们提出了一种元学习方法,为在LMM中引入少样本能力提供替代方案,使用一套固定的软提示,这些软提示是从任务相关的图像特征中提炼出来的,可以在测试时使用少量示例进行适应。为了促进这种提炼,我们引入了一个注意力映射模块,它可以轻松集成到流行的LLaVA v1.5架构中,并与软提示联合学习,从而在低数据情况下,只需几个梯度步骤即可在LMM中实现任务适应。在VL-ICL Bench上的评估表明,我们的方法始终优于ICL和相关提示调整方法,即使在图像扰动下也能提高视觉问答任务的任务归纳和推理能力。
论文及项目相关链接
Summary
大型多模态模型(LMMs)在少量监督下通过上下文学习(ICL)执行新任务。然而,由于图像嵌入中的额外信息过多导致LMM处理效率低下,尤其是小型LMM中的ICL性能表现不一致且不会随例子数量增加单调改善。为解决这一问题,我们提出了一种元学习方法,通过从任务相关的图像特征中提炼出固定的一组软提示来实现LMM的少量学习,并在测试时通过几个例子进行适应。为此引入了注意力映射模块,可轻松集成到流行的LLaVA v1.5架构中并与软提示联合学习,使得在数据稀缺的情况下只需几个梯度步骤即可适应LMM的任务。在VL-ICL Bench上的评估表明,我们的方法在图像扰动下仍表现稳定,即使在视觉问答任务中也表现出优于ICL和相关提示调整方法的任务归纳和推理能力。
Key Takeaways
- 大型多模态模型(LMMs)使用上下文学习(ICL)执行新任务,但性能表现不稳定。
- LMM在ICL中容易受到图像嵌入中过多额外信息的影响。
- 提出一种元学习方法,通过提炼任务相关的图像特征的软提示来实现LMM的少量学习。
- 引入注意力映射模块,与LLaVA v1.5架构集成,并联合学习软提示。
- 该方法在少量梯度步骤下适应LMM的任务。
- 在VL-ICL Bench上的评估显示,该方法在图像扰动下性能稳定并优于ICL和其他方法。
点此查看论文截图

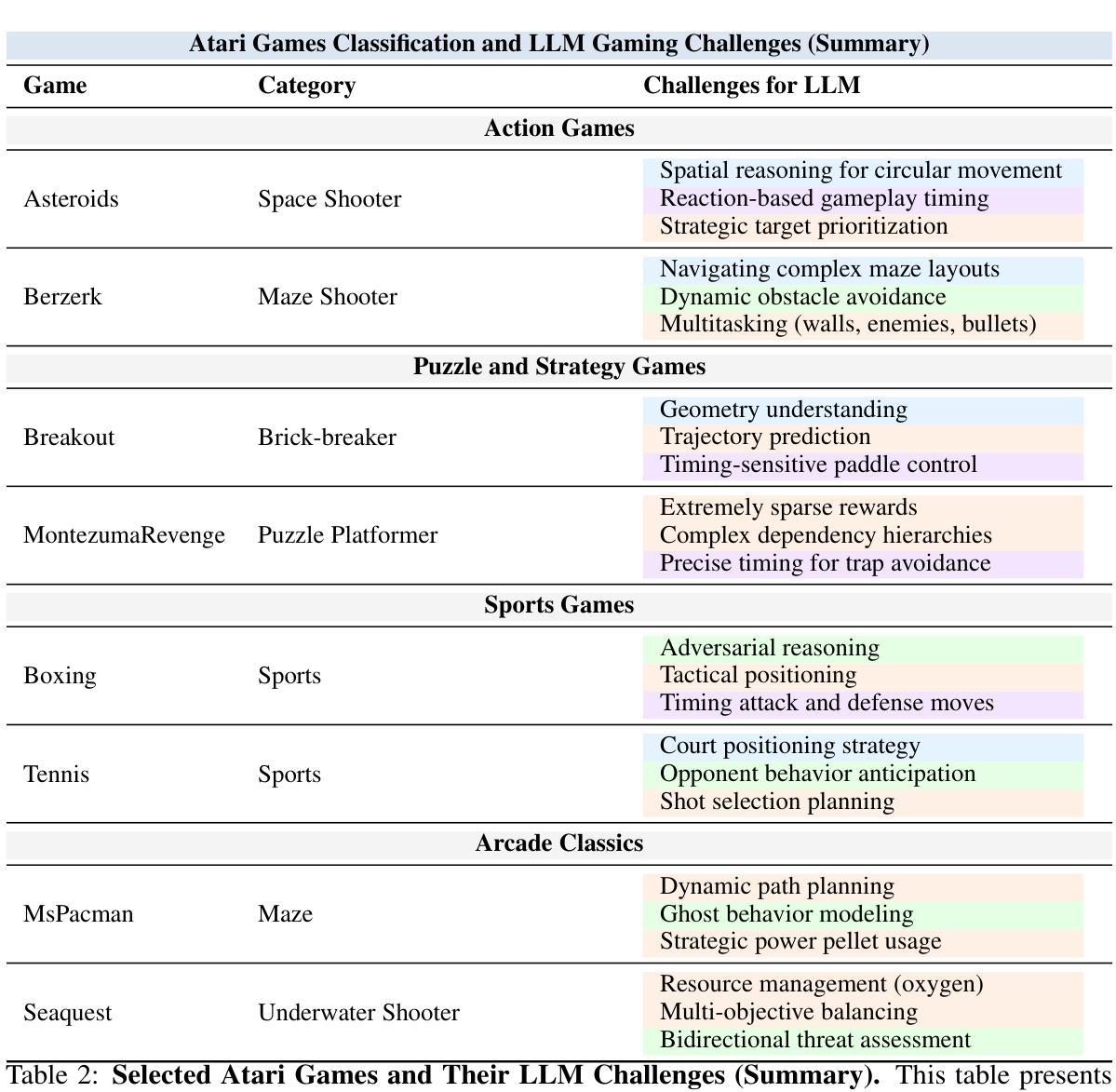
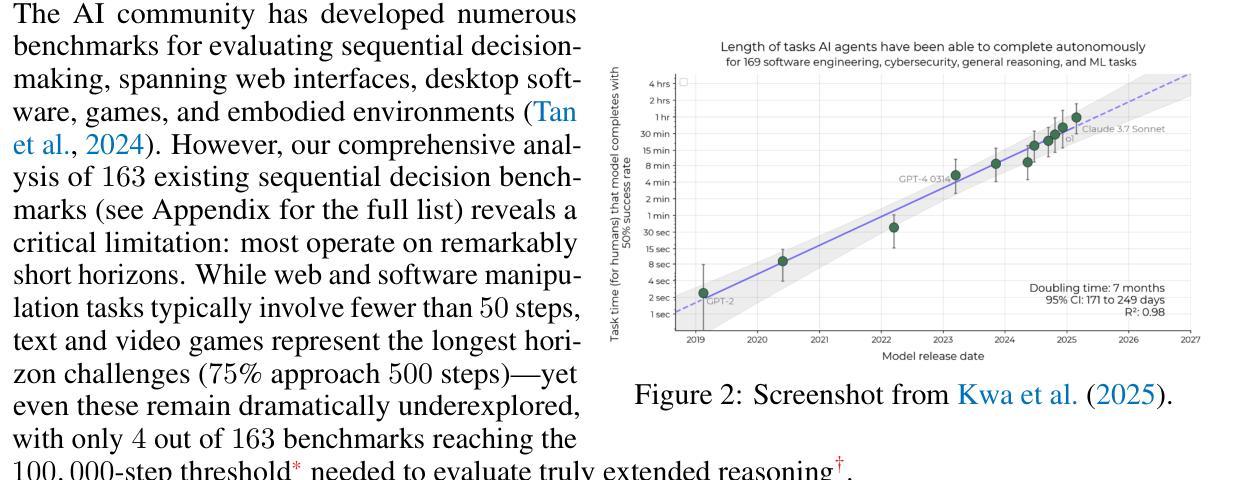
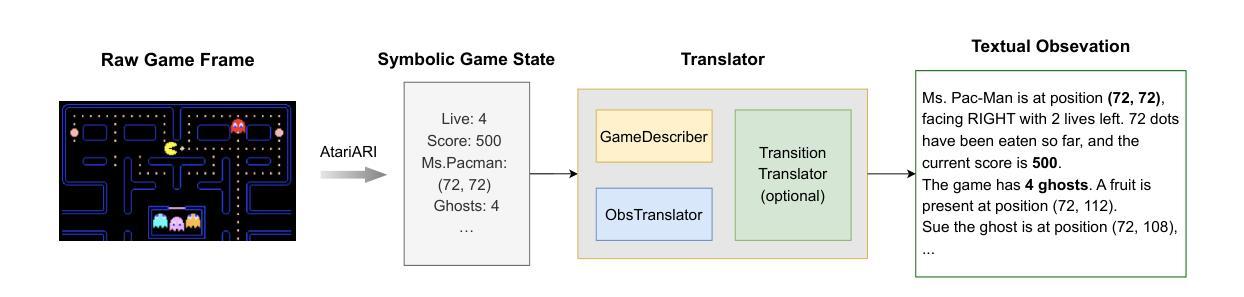
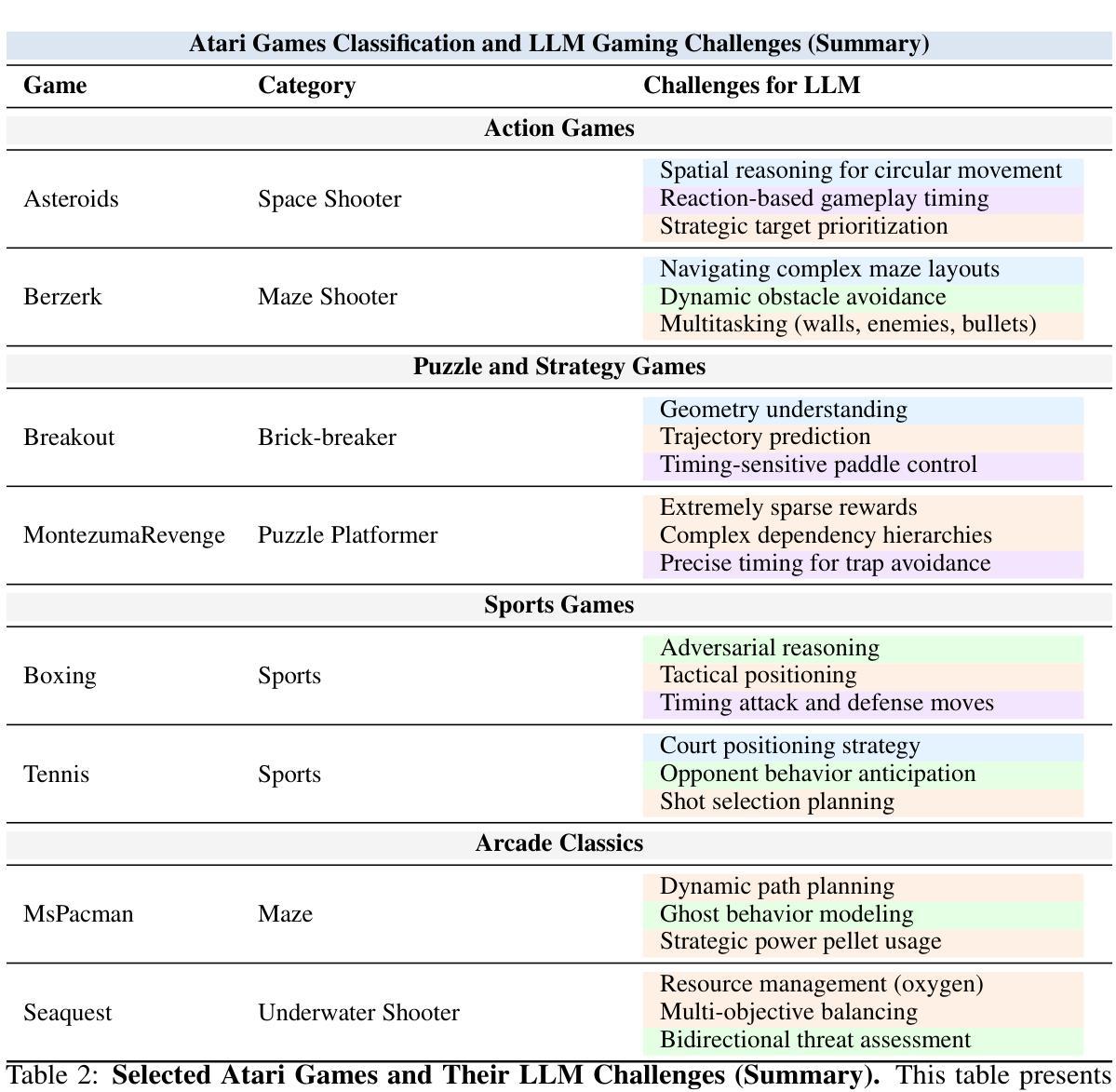
TextAtari: 100K Frames Game Playing with Language Agents
Authors:Wenhao Li, Wenwu Li, Chuyun Shen, Junjie Sheng, Zixiao Huang, Di Wu, Yun Hua, Wei Yin, Xiangfeng Wang, Hongyuan Zha, Bo Jin
We present TextAtari, a benchmark for evaluating language agents on very long-horizon decision-making tasks spanning up to 100,000 steps. By translating the visual state representations of classic Atari games into rich textual descriptions, TextAtari creates a challenging test bed that bridges sequential decision-making with natural language processing. The benchmark includes nearly 100 distinct tasks with varying complexity, action spaces, and planning horizons, all rendered as text through an unsupervised representation learning framework (AtariARI). We evaluate three open-source large language models (Qwen2.5-7B, Gemma-7B, and Llama3.1-8B) across three agent frameworks (zero-shot, few-shot chain-of-thought, and reflection reasoning) to assess how different forms of prior knowledge affect performance on these long-horizon challenges. Four scenarios-Basic, Obscured, Manual Augmentation, and Reference-based-investigate the impact of semantic understanding, instruction comprehension, and expert demonstrations on agent decision-making. Our results reveal significant performance gaps between language agents and human players in extensive planning tasks, highlighting challenges in sequential reasoning, state tracking, and strategic planning across tens of thousands of steps. TextAtari provides standardized evaluation protocols, baseline implementations, and a framework for advancing research at the intersection of language models and planning. Our code is available at https://github.com/Lww007/Text-Atari-Agents.
我们推出了TextAtari,这是一个用于评估超长周期决策制定任务的自然语言处理基准测试平台,任务周期长达10万步。通过经典Atari游戏的视觉状态表示的文本翻译,生成丰富的文本描述,TextAtari建立了一个挑战性的测试平台,该平台将顺序决策制定与自然语言处理相结合。该基准测试平台包含近100个不同任务,具有不同的复杂性、动作空间和计划期限,所有任务都是通过无监督表示学习框架(AtariARI)以文本形式呈现。我们评估了三个开源大型语言模型(Qwen2.5-7B、Gemma-7B和Llama3.1-8B)在三种代理框架(零样本、少量思考的链和反思推理)下的表现,以观察不同形式的先验知识对这些长期规划挑战的影响。四种场景——基础、隐蔽、手动增强和参考基础——探讨了语义理解、指令理解和专家示范对代理决策制定过程的影响。我们的研究结果表明,在复杂的规划任务中,语言代理与人类玩家之间存在明显的性能差距,这凸显了语言模型在顺序推理、状态跟踪和长期战略规划方面的挑战。TextAtari提供了标准化的评估协议、基准实现和一个框架,用于推进语言模型和规划之间的交叉研究。我们的代码位于 https://github.com/Lww007/Text-Atari-Agents。
论文及项目相关链接
PDF 51 pages, 39 figures
Summary
文本介绍了一个名为TextAtari的基准测试,该测试旨在评估语言模型在长达10万步的长周期决策任务中的表现。通过将经典的Atari游戏的视觉状态表示转化为丰富的文本描述,TextAtari创建了一个挑战性的测试平台,该平台结合了序列决策和自然语言处理。该基准测试包括近100个具有不同复杂度、动作空间和规划时间的任务,所有任务均通过无监督表示学习框架呈现为文本。评估了三种开源大型语言模型在不同形式的先验知识下的性能。
Key Takeaways
- TextAtari是一个用于评估语言模型在长周期决策任务中的性能的基准测试。
- 它通过将Atari游戏的视觉状态转化为文本描述来模拟真实世界场景。
- TextAtari包含近100个不同难度的任务,适合测试语言模型的决策能力。
- 评估了三种大型语言模型在三种不同形式的先验知识下的表现。
- 基准测试考察了语义理解、指令理解和专家示范对代理决策制定的影响。
- 研究发现语言模型在复杂的规划任务中与人类的性能差距显著。
点此查看论文截图


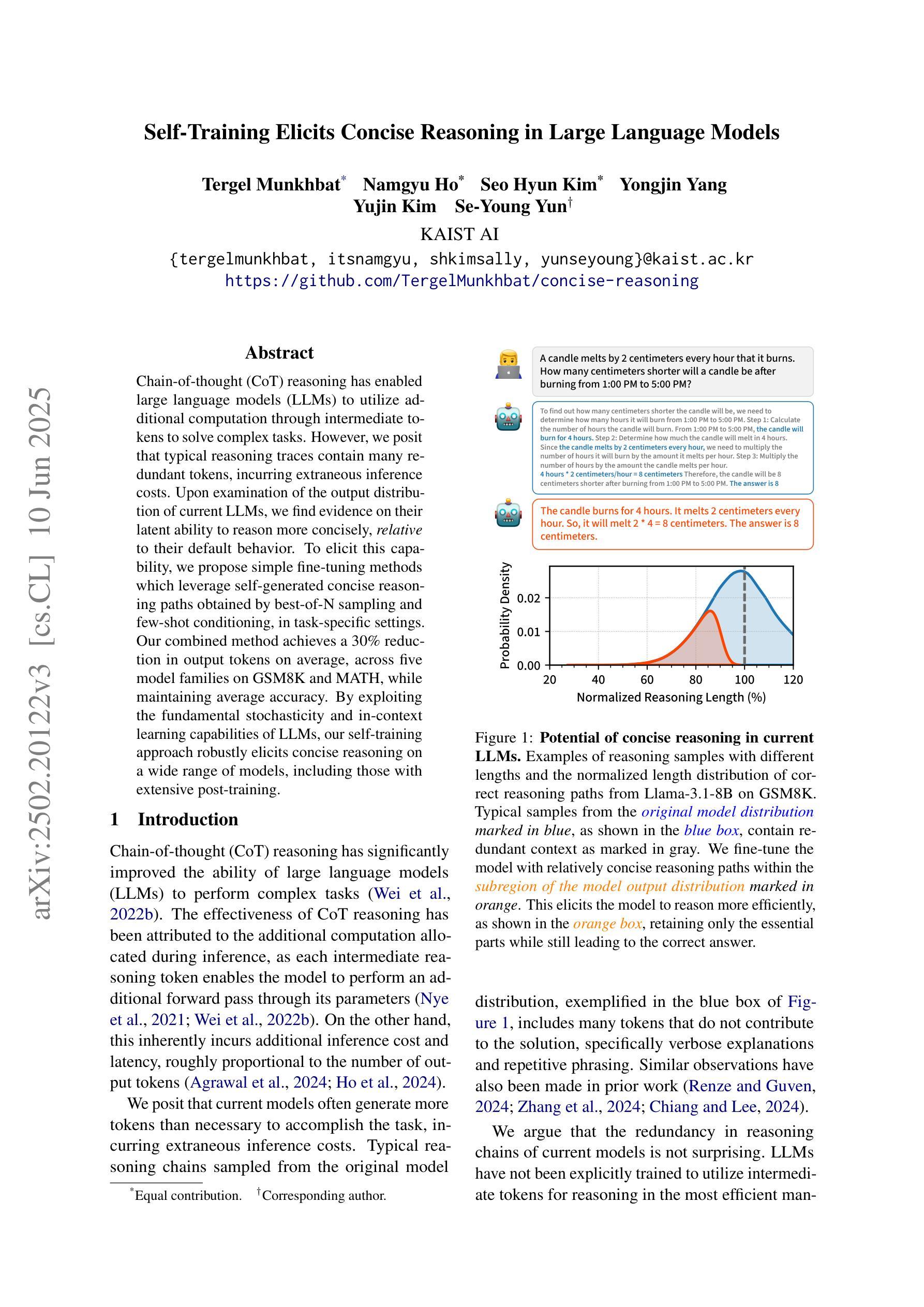
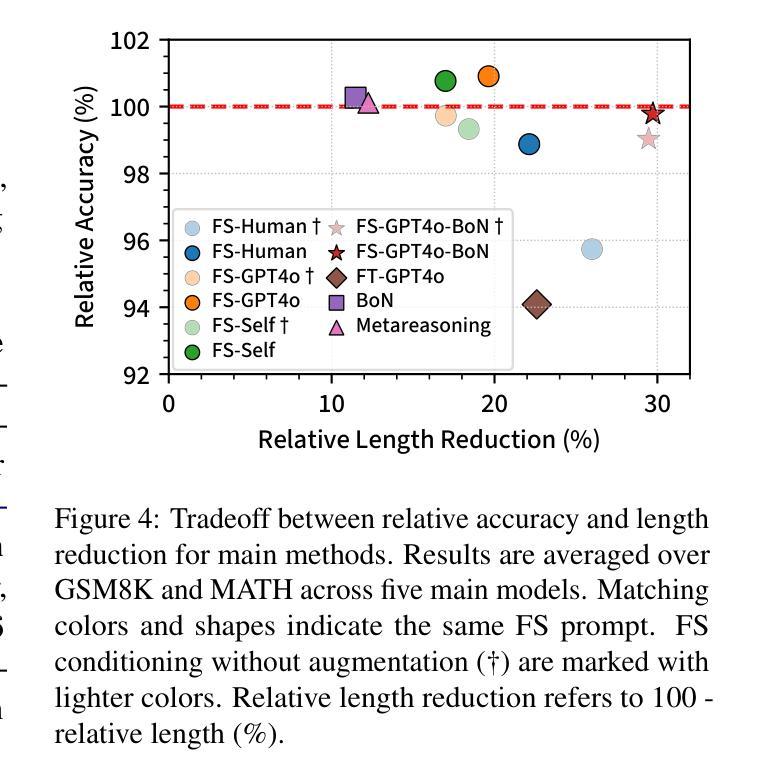
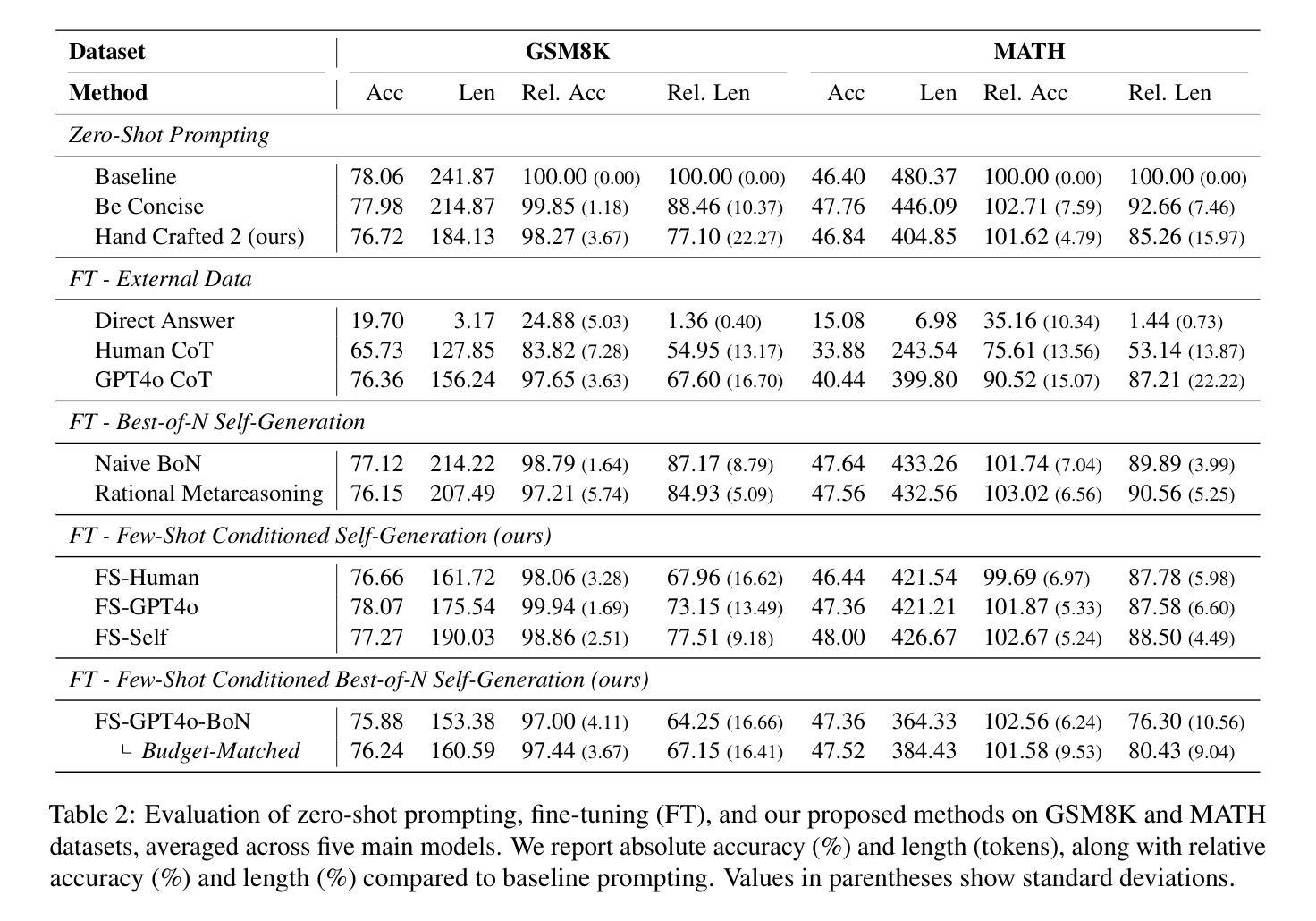
Self-Training Elicits Concise Reasoning in Large Language Models
Authors:Tergel Munkhbat, Namgyu Ho, Seo Hyun Kim, Yongjin Yang, Yujin Kim, Se-Young Yun
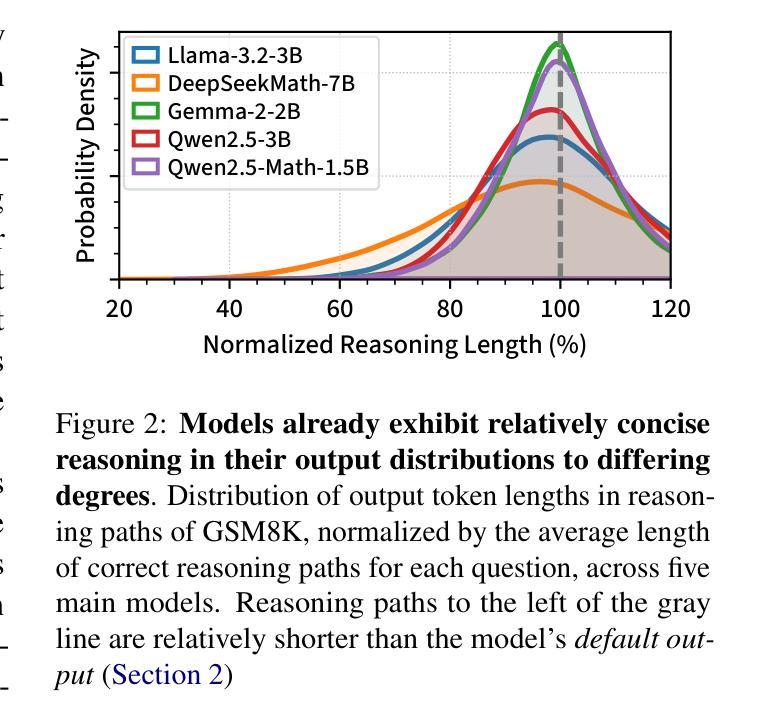
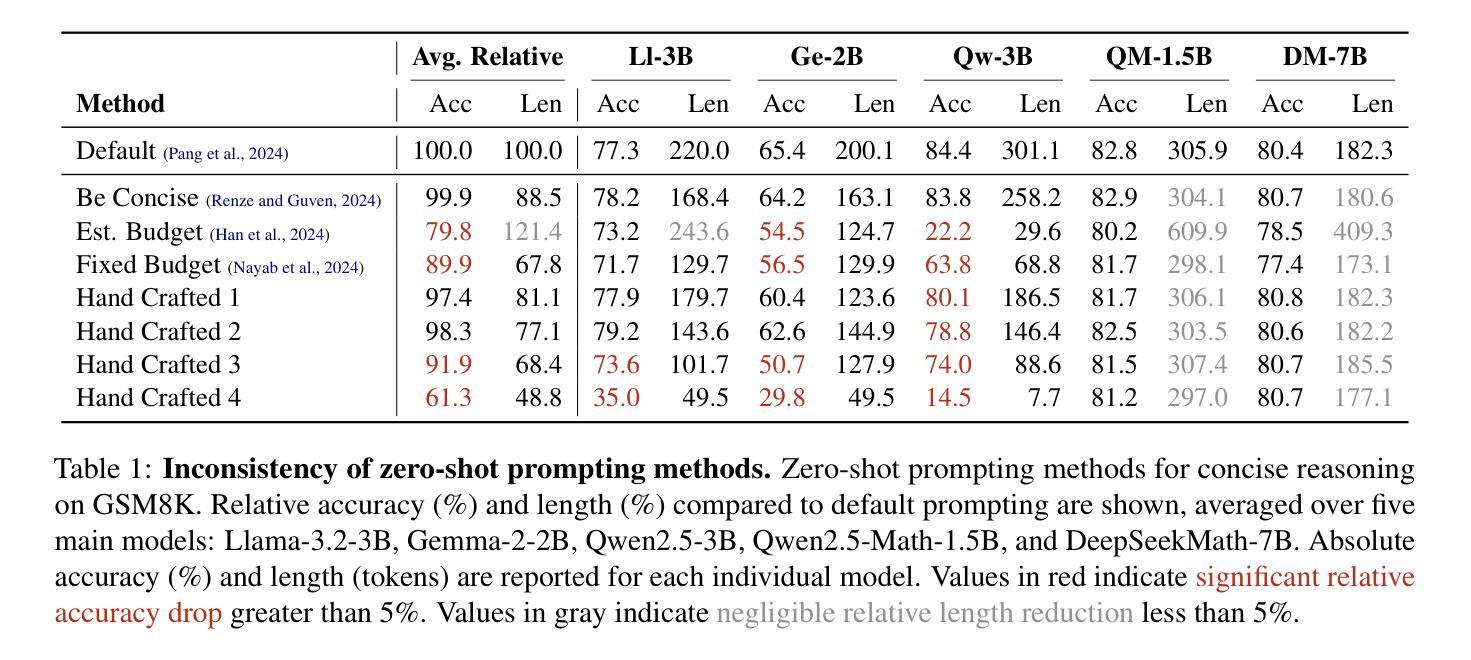
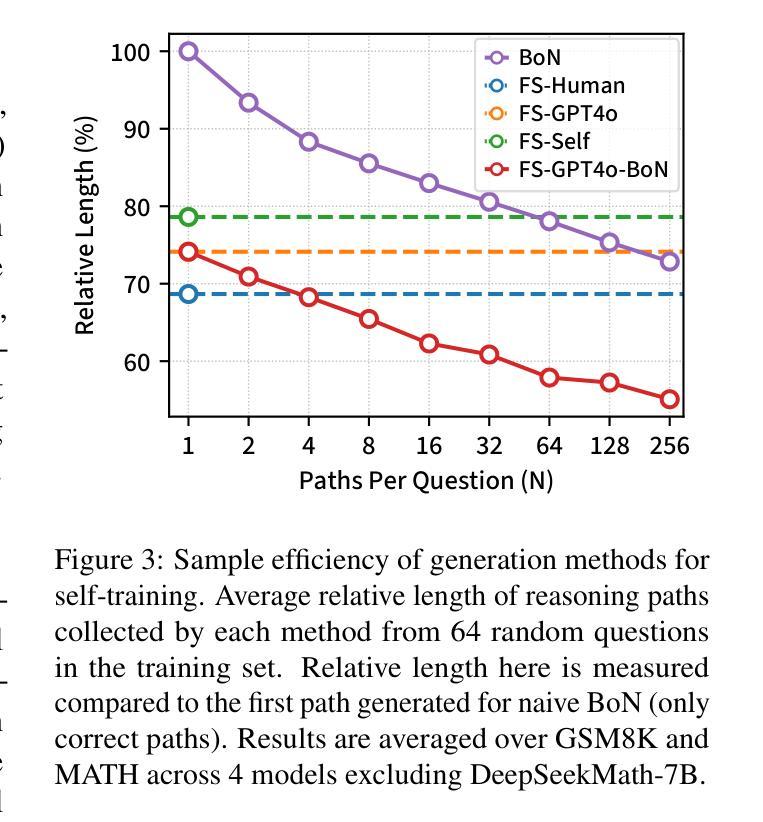
Chain-of-thought (CoT) reasoning has enabled large language models (LLMs) to utilize additional computation through intermediate tokens to solve complex tasks. However, we posit that typical reasoning traces contain many redundant tokens, incurring extraneous inference costs. Upon examination of the output distribution of current LLMs, we find evidence on their latent ability to reason more concisely, relative to their default behavior. To elicit this capability, we propose simple fine-tuning methods which leverage self-generated concise reasoning paths obtained by best-of-N sampling and few-shot conditioning, in task-specific settings. Our combined method achieves a 30% reduction in output tokens on average, across five model families on GSM8K and MATH, while maintaining average accuracy. By exploiting the fundamental stochasticity and in-context learning capabilities of LLMs, our self-training approach robustly elicits concise reasoning on a wide range of models, including those with extensive post-training. Code is available at https://github.com/TergelMunkhbat/concise-reasoning
思维链(CoT)推理使得大型语言模型(LLM)能够通过中间标记利用额外的计算来解决复杂的任务。然而,我们认为典型的推理轨迹包含许多冗余的标记,产生了额外的推理成本。在检查当前LLM的输出分布时,我们发现它们相对于默认行为有进行更简洁推理的潜在能力。为了激发这一能力,我们提出了简单的微调方法,这些方法利用通过最佳N采样和少样本条件在特定任务环境中获得的自我生成的简洁推理路径。我们的组合方法在GSM8K和MATH上平均减少了五类模型的输出标记数量达30%,同时保持了平均准确性。通过利用LLM的基本随机性和上下文学习能力,我们的自我训练方法能够在广泛的模型上稳健地激发简洁推理,包括那些经过大量训练后的模型。代码可在https://github.com/TergelMunkhbat/concise-reasoning找到。
论文及项目相关链接
PDF 26 pages, 10 figures, 23 tables. Accepted to Findings of ACL 2025
Summary
大型语言模型(LLM)通过链式思维(CoT)推理利用中间令牌解决复杂任务。然而,我们提出,典型的推理轨迹包含许多冗余令牌,导致额外的推理成本。通过检查当前LLM的输出分布,我们发现它们相对于默认行为有进行更简洁推理的潜在能力。为了激发这种能力,我们提出通过最佳N采样和少样本条件等简单微调方法,在特定任务环境中利用自我生成的简洁推理路径。我们的综合方法在五大家族模型上平均减少了约30%的输出令牌,同时保持了平均准确性。我们的自我训练方法能够可靠地激发模型的简洁推理能力,包括那些经过大量训练后的模型。相关代码可在XXX获取。
Key Takeaways
- 大型语言模型使用链式思维(CoT)进行推理以增强复杂任务性能。
- 通常的推理过程中存在冗余令牌,导致额外的推理成本。
- 当前LLM具有相对于默认行为的更简洁推理的潜在能力。
- 通过最佳N采样和少样本条件等简单微调方法,可激发这种能力。
- 方法在多个模型上实现平均输出令牌减少约30%,同时保持平均准确性。
- 利用LLM的基本随机性和上下文学习能力,自我训练方法可激发模型的简洁推理能力。
点此查看论文截图