⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-12 更新
VIKI-R: Coordinating Embodied Multi-Agent Cooperation via Reinforcement Learning
Authors:Li Kang, Xiufeng Song, Heng Zhou, Yiran Qin, Jie Yang, Xiaohong Liu, Philip Torr, Lei Bai, Zhenfei Yin
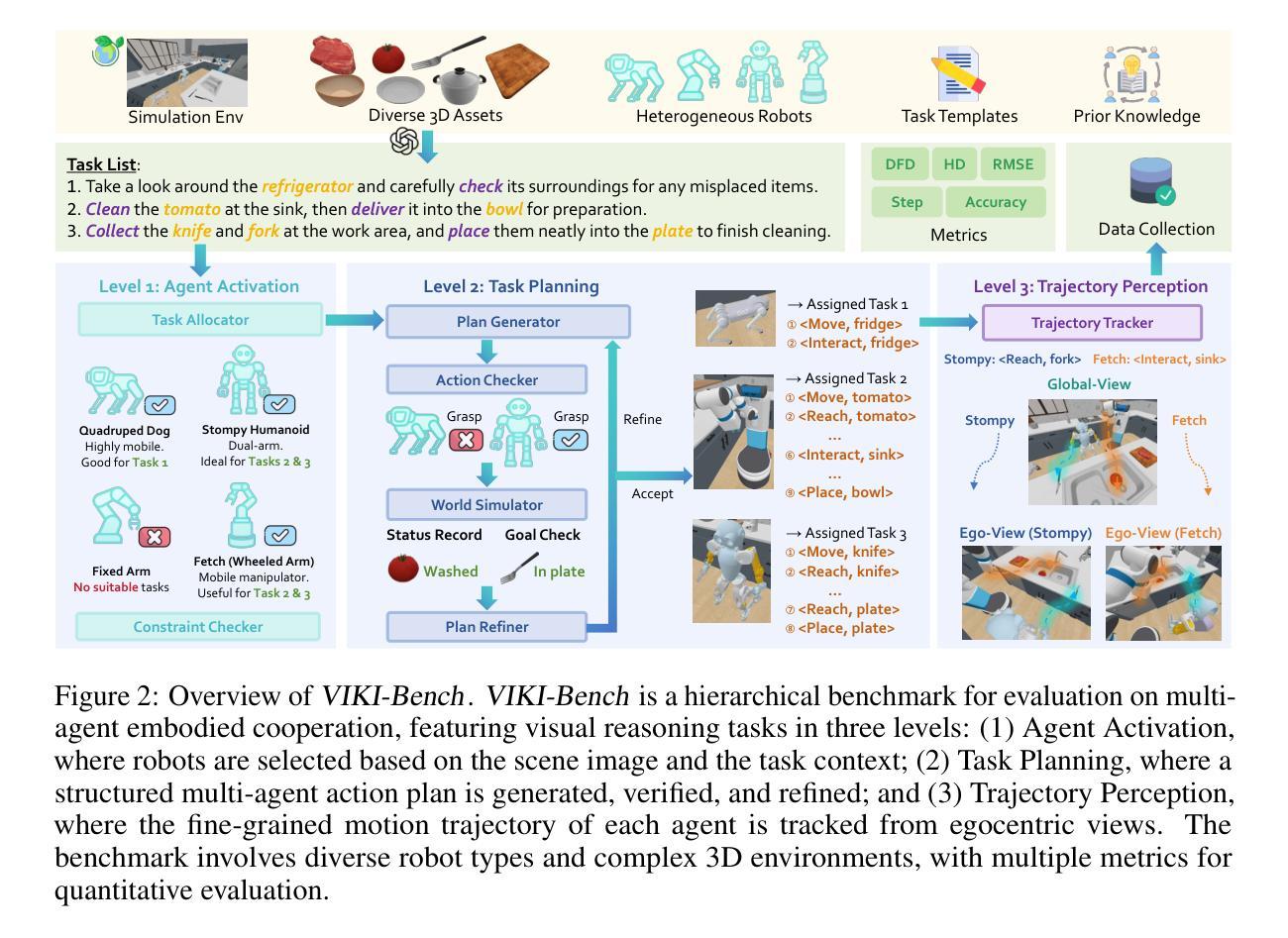
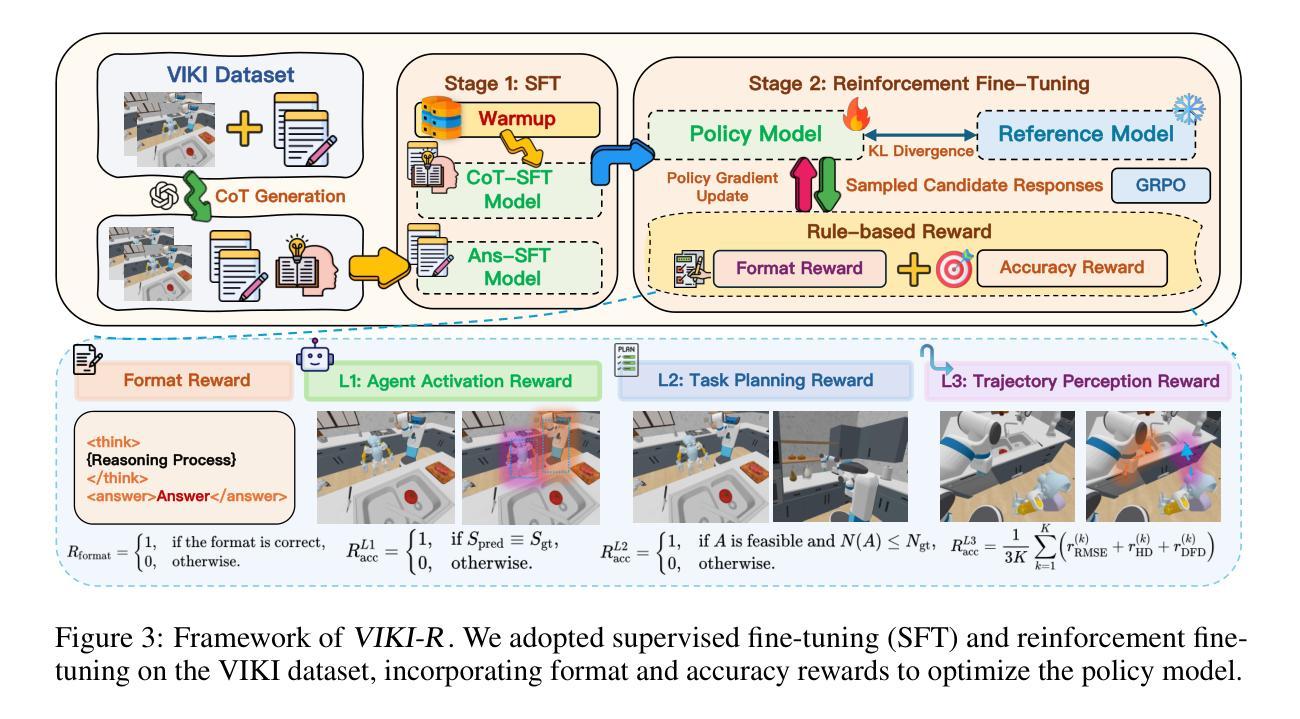
Coordinating multiple embodied agents in dynamic environments remains a core challenge in artificial intelligence, requiring both perception-driven reasoning and scalable cooperation strategies. While recent works have leveraged large language models (LLMs) for multi-agent planning, a few have begun to explore vision-language models (VLMs) for visual reasoning. However, these VLM-based approaches remain limited in their support for diverse embodiment types. In this work, we introduce VIKI-Bench, the first hierarchical benchmark tailored for embodied multi-agent cooperation, featuring three structured levels: agent activation, task planning, and trajectory perception. VIKI-Bench includes diverse robot embodiments, multi-view visual observations, and structured supervision signals to evaluate reasoning grounded in visual inputs. To demonstrate the utility of VIKI-Bench, we propose VIKI-R, a two-stage framework that fine-tunes a pretrained vision-language model (VLM) using Chain-of-Thought annotated demonstrations, followed by reinforcement learning under multi-level reward signals. Our extensive experiments show that VIKI-R significantly outperforms baselines method across all task levels. Furthermore, we show that reinforcement learning enables the emergence of compositional cooperation patterns among heterogeneous agents. Together, VIKI-Bench and VIKI-R offer a unified testbed and method for advancing multi-agent, visual-driven cooperation in embodied AI systems.
在动态环境中协调多个实体代理仍然是人工智能的核心挑战,这需要感知驱动的推理和可扩展的合作策略。虽然近期的工作已经利用大型语言模型(LLMs)进行多代理规划,但很少有人开始探索视觉语言模型(VLMs)用于视觉推理。然而,这些基于VLM的方法在支持多种实体类型方面仍然存在局限性。在这项工作中,我们引入了针对实体多代理合作的定制分层基准VIKI-Bench,它包含三个结构化级别:代理激活、任务规划和轨迹感知。VIKI-Bench包括各种机器人实体、多视图视觉观察以及结构化监督信号,以评估基于视觉输入的推理。为了证明VIKI-Bench的实用性,我们提出了VIKI-R,这是一个两阶段框架,它通过利用带有思维链注释的演示对预训练的视觉语言模型(VLM)进行微调,然后在多层次奖励信号下进行强化学习。我们的广泛实验表明,VIKI-R在所有任务级别上显著优于基准方法。此外,我们还表明,强化学习能够使异质代理之间出现组合合作模式。总之,VIKI-Bench和VIKI-R为推进实体AI系统中的多代理视觉驱动合作提供了统一的测试平台和方法。
论文及项目相关链接
PDF Project page: https://faceong.github.io/VIKI-R/
Summary
本文介绍了在动态环境中协调多个实体代理的核心挑战,需要感知驱动推理和可扩展的合作策略。尽管近期利用大型语言模型进行多代理规划的研究取得了进展,但基于视觉语言模型的方法在支持多种实体类型方面仍存在局限性。为此,本文引入了VIKI-Bench,这是一个针对实体多代理合作的分层基准测试,包括代理激活、任务规划和轨迹感知三个结构化级别。此外,还提出了VIKI-R框架,通过思维链注释演示对预训练的视觉语言模型进行微调,然后在多层次奖励信号下进行强化学习。实验表明,VIKI-R在所有任务级别上均显著优于基准方法,并且强化学习能够促进异构代理之间的组合合作模式的出现。
Key Takeaways
- 多实体代理协调在动态环境中是人工智能的核心挑战之一,需要感知驱动推理和合作策略。
- 虽然大型语言模型在多代理规划方面有所应用,但基于视觉语言模型的方法在支持多种实体类型方面仍有局限性。
- VIKI-Bench是首个针对实体多代理合作的分层基准测试,包括代理激活、任务规划和轨迹感知三个结构化级别。
- VIKI-Bench具有多样化的机器人实体、多视角视觉观察和结构化监督信号,用于评估视觉输入基础上的推理。
- VIKI-R框架通过思维链注释演示对预训练的视觉语言模型进行微调,并结合强化学习。
- 实验表明,VIKI-R在所有任务级别上均优于基准方法。
点此查看论文截图


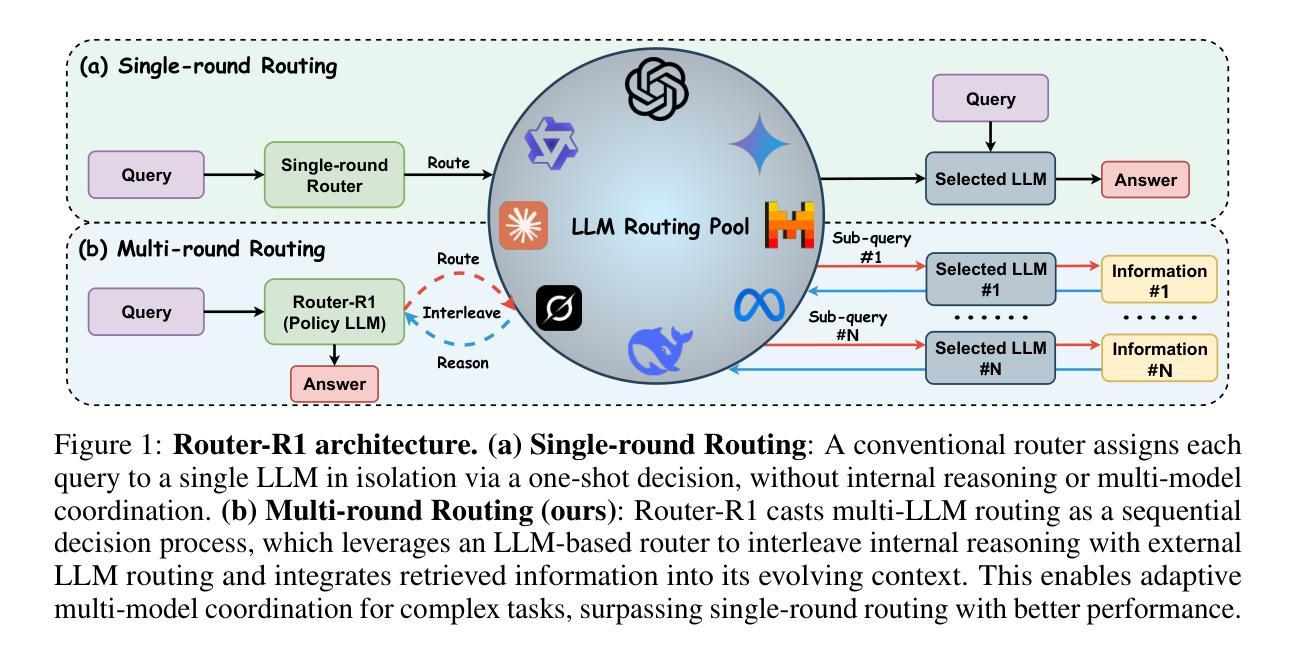
Router-R1: Teaching LLMs Multi-Round Routing and Aggregation via Reinforcement Learning
Authors:Haozhen Zhang, Tao Feng, Jiaxuan You
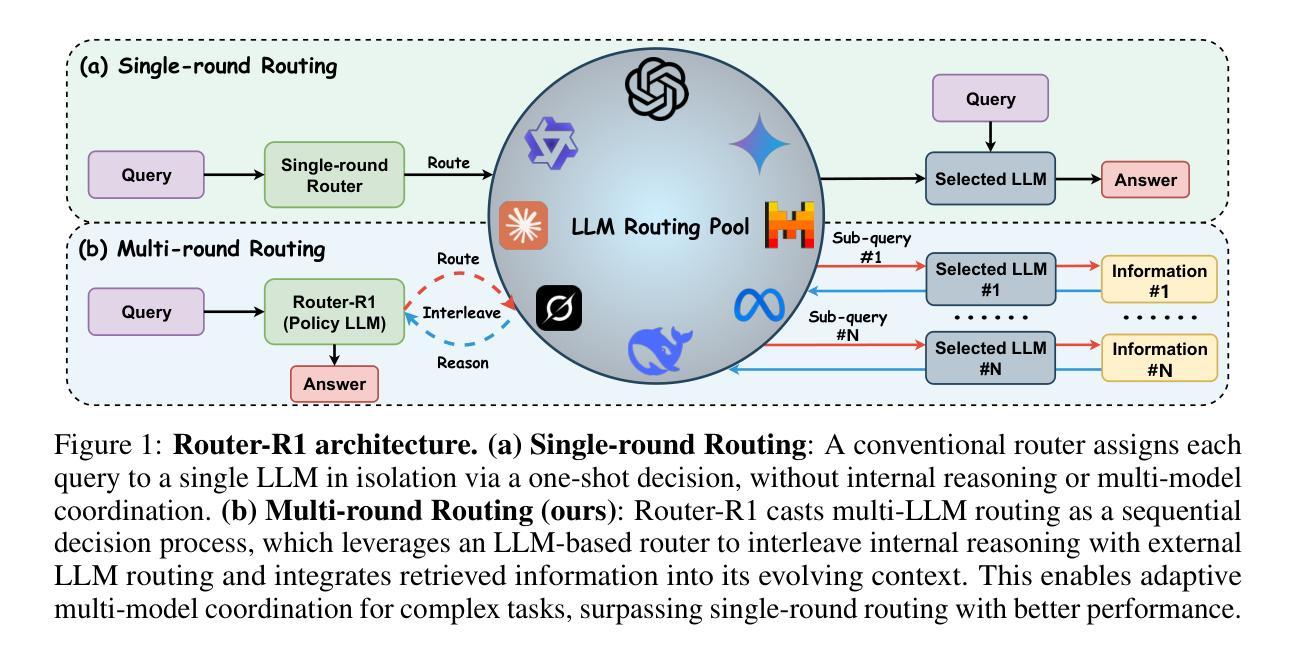
The rapid emergence of diverse large language models (LLMs) has spurred the development of LLM routers that assign user queries to the most suitable model. However, existing LLM routers typically perform a single-round, one-to-one mapping (\textit{i.e.}, assigning each query to a single model in isolation), which limits their capability to tackle complex tasks that demand the complementary strengths of multiple LLMs. In this paper, we present \textbf{Router-R1}, a reinforcement learning (RL)-based framework that formulates multi-LLM routing and aggregation as a sequential decision process. Router-R1 instantiates the router itself as a capable LLM, leveraging its reasoning ability to interleave “think” actions (internal deliberation) with “route” actions (dynamic model invocation), and integrates each response into its evolving context. To guide learning, we employ a lightweight rule-based reward comprising format rewards, final outcome rewards, and a novel cost reward for performance and cost trade-off optimization, opening a pathway toward optimizing performance-cost tradeoffs via RL. Router-R1 also conditions only on simple model descriptors such as pricing, latency, and example performance, enabling strong generalization to unseen model selection. Experiments on seven general and multi-hop QA benchmarks show that Router-R1 outperforms over several strong baselines, achieving superior performance while maintaining robust generalization and cost management.Code is available at https://github.com/ulab-uiuc/Router-R1.
大型语言模型(LLM)的迅速涌现推动了LLM路由器的开发,这些路由器能够将用户查询分配给最合适的模型。然而,现有的LLM路由器通常采用单一轮次、一对一的映射方式(即每次查询只分配给一个模型),这限制了它们处理复杂任务的能力,而这些任务需要多个LLM模型的互补优势。在本文中,我们介绍了基于强化学习(RL)的框架Router-R1,它将多LLM路由和聚合作为序列决策过程进行表述。Router-R1实例化路由器本身作为一个功能强大的LLM模型,利用其推理能力将“思考”动作(内部思考)与“路由”动作(动态模型调用)交织在一起,并将每个响应集成到不断发展的上下文中。为了指导学习,我们采用了一种轻量级的基于规则的奖励机制,包括格式奖励、最终成果奖励以及一种新型的成本奖励,用于性能与成本权衡优化,从而为通过强化学习实现性能成本优化的路径开辟了道路。Router-R1仅根据简单的模型描述符(如价格、延迟和示例性能)进行条件设置,实现对未见模型的强大泛化能力。在七个通用和多跳问答基准测试上的实验表明,Router-R1在多个强基线测试中具有出色的表现,实现了卓越的性能,同时保持了稳健的泛化和成本管理。相关代码可通过https://github.com/ulab-uiuc/Router-R 结进行访问。
论文及项目相关链接
PDF Code is available at https://github.com/ulab-uiuc/Router-R1
Summary
大规模语言模型路由器(LLM Router)的发展为分配用户查询至最合适的模型提供了解决方案。现有LLM路由器通常采用单一轮次一对一映射,限制了处理复杂任务的能力。本文提出基于强化学习(RL)的Router-R1框架,将多LLM路由和聚合视为连续决策过程。Router-R1实例化路由器本身为功能强大的LLM,利用推理能力交替进行“思考”和“路由”动作,并整合响应至不断演化的语境中。通过格式奖励、最终成果奖励和成本奖励组成的轻量级规则基础奖励来指导学习,优化了性能和成本的权衡。Router-R1仅依赖于简单的模型描述符,如价格、延迟和示例性能,实现对未见模型的强大泛化。在七个通用和多跳问答基准测试上,Router-R1表现优于多个强大基线,实现了卓越性能、稳健泛化和成本管理。
Key Takeaways
- LLM路由器的现有挑战:一对一映射限制了处理复杂任务的能力。
- Router-R1采用强化学习框架:将多LLM路由和聚合视为连续决策过程。
- Router-R1利用LLM的推理能力:通过交替“思考”和“路由”动作进行优化决策。
- Router-R1通过规则基础奖励指导学习:包括格式奖励、最终成果奖励和成本奖励。
- Router-R1实现性能与成本的优化权衡:通过RL来平衡二者。
- Router-R1强大的泛化能力:仅依赖简单的模型描述符,如价格、延迟和示例性能。
- Router-R1在多个基准测试中表现优异:在七个通用和多跳问答基准上优于其他方法。
点此查看论文截图


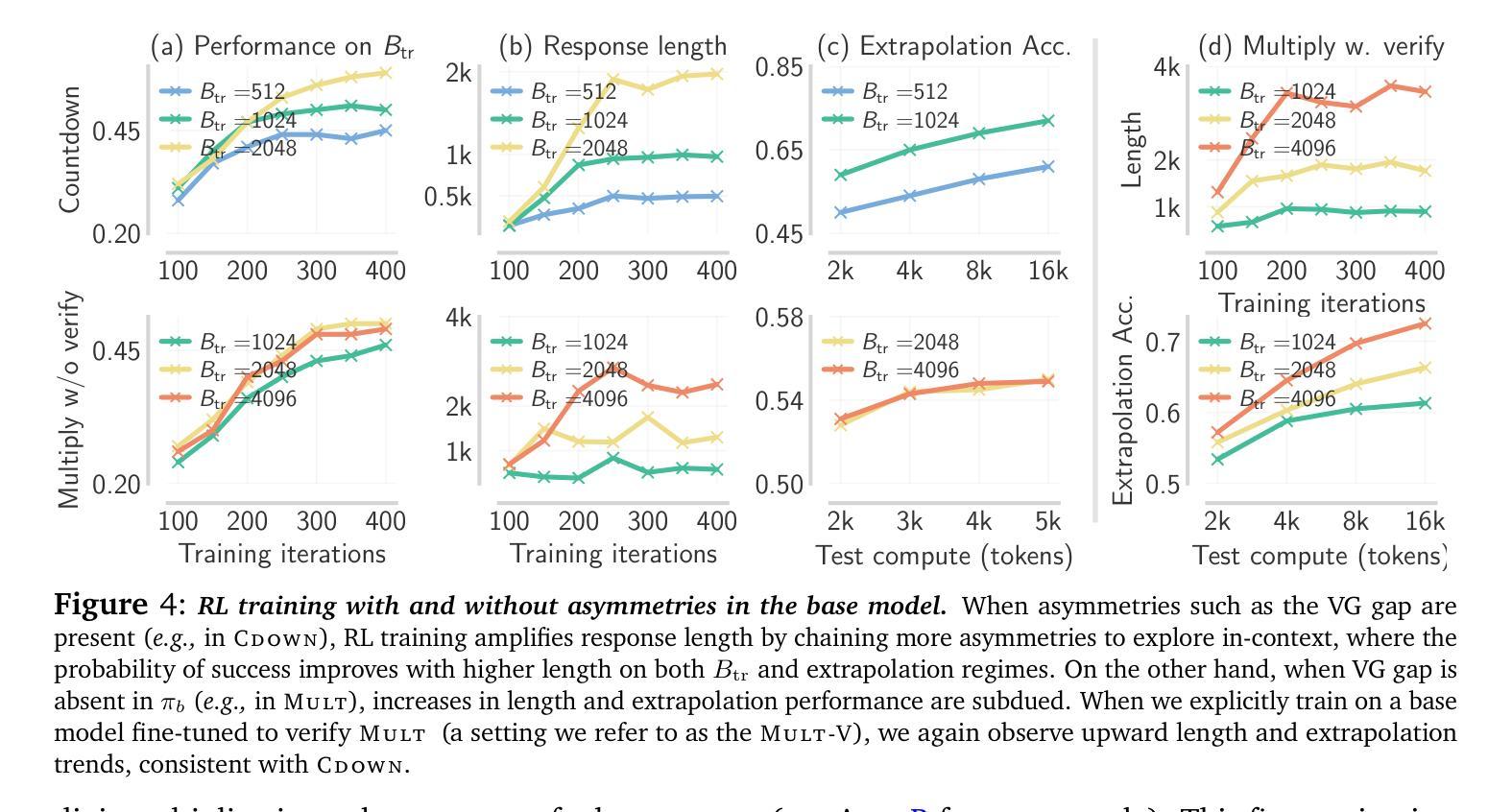
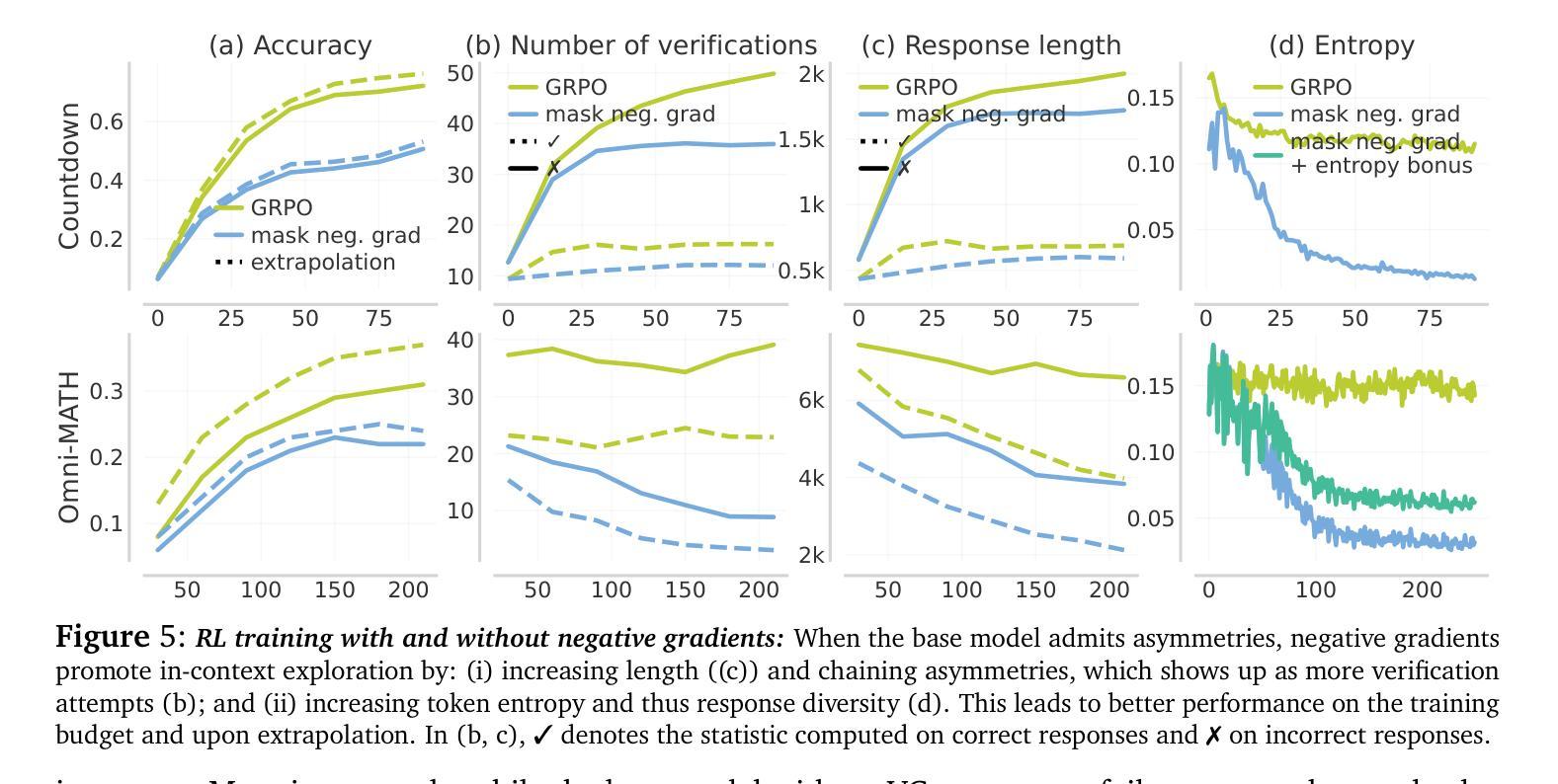
e3: Learning to Explore Enables Extrapolation of Test-Time Compute for LLMs
Authors:Amrith Setlur, Matthew Y. R. Yang, Charlie Snell, Jeremy Greer, Ian Wu, Virginia Smith, Max Simchowitz, Aviral Kumar
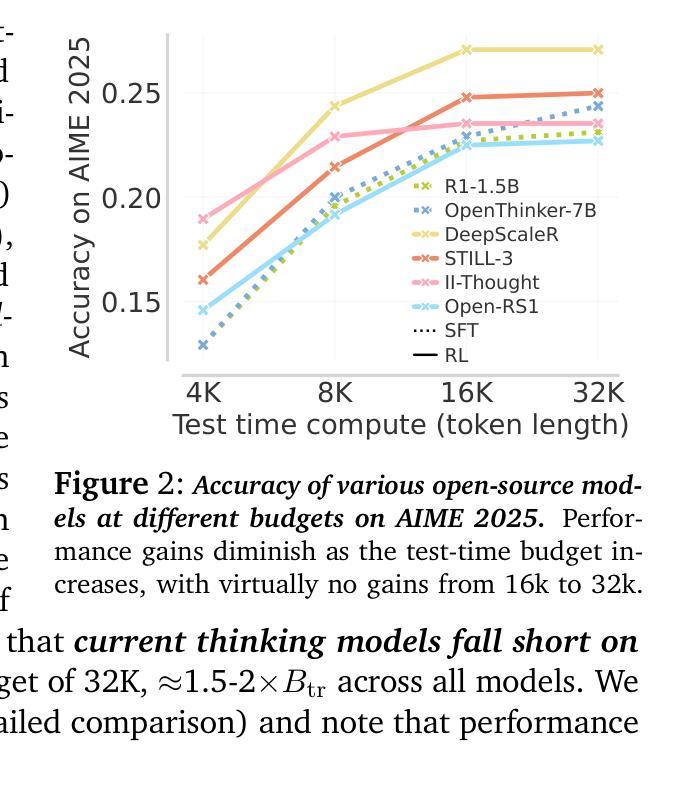
Test-time scaling offers a promising path to improve LLM reasoning by utilizing more compute at inference time; however, the true promise of this paradigm lies in extrapolation (i.e., improvement in performance on hard problems as LLMs keep “thinking” for longer, beyond the maximum token budget they were trained on). Surprisingly, we find that most existing reasoning models do not extrapolate well. We show that one way to enable extrapolation is by training the LLM to perform in-context exploration: training the LLM to effectively spend its test time budget by chaining operations (such as generation, verification, refinement, etc.), or testing multiple hypotheses before it commits to an answer. To enable in-context exploration, we identify three key ingredients as part of our recipe e3: (1) chaining skills that the base LLM has asymmetric competence in, e.g., chaining verification (easy) with generation (hard), as a way to implement in-context search; (2) leveraging “negative” gradients from incorrect traces to amplify exploration during RL, resulting in longer search traces that chains additional asymmetries; and (3) coupling task difficulty with training token budget during training via a specifically-designed curriculum to structure in-context exploration. Our recipe e3 produces the best known 1.7B model according to AIME’25 and HMMT’25 scores, and extrapolates to 2x the training token budget. Our e3-1.7B model not only attains high pass@1 scores, but also improves pass@k over the base model.
测试时缩放技术通过在推理时间利用更多的计算能力为提高大型语言模型(LLM)的推理能力提供了一条有前景的道路。然而,该范式的真正潜力在于外推(即,随着LLM“思考”的时间超过其训练时的最大令牌预算,其在困难问题上的性能得到改进)。令人惊讶的是,我们发现大多数现有的推理模型的外推能力并不强。我们表明,实现外推的一种方法是训练LLM进行上下文探索:训练LLM通过链接操作(如生成、验证、精炼等)有效地利用其测试时间预算,或在提交答案之前测试多个假设。为了实现上下文探索,我们确定了作为我们配方e3一部分的三个关键要素:(1)链接基本技能,如LLM在验证(简单)和生成(困难)方面具有不对称竞争力,以此实现上下文搜索;(2)利用错误轨迹的“负面”梯度来放大强化学习期间的探索,从而产生更长的搜索轨迹,链接额外的不对称性;(3)通过专门设计的课程将任务难度与训练时的令牌预算相结合,在训练期间构建上下文探索的结构。我们的e3配方产生的模型是已知的最佳1.7B模型,根据AIME’25和HMMT’25的分数,并且外推到训练令牌预算的2倍。我们的e3-1.7B模型不仅获得了高pass@1分数,而且相对于基础模型还提高了pass@k。
论文及项目相关链接
Summary
本文探讨了利用测试时的计算资源来提升大语言模型(LLM)推理能力的方法。通过训练模型在测试时进行上下文探索,实现长时间的推理,进而提高在难题上的表现。文章提出了一种名为e3的方法,通过技能链、利用错误梯度强化学习和任务难度与训练token预算的结合,实现了LLM的上下文探索训练。这种方法能提高AI在评估任务中的表现,并实现推理时长的延长。
Key Takeaways
- 测试时扩展利用更多计算资源是提高LLM推理能力的一种有前途的方法。
- 上下文探索是实现长时间推理的关键,可以通过训练LLM进行技能链操作来实现。
- 技能链包括生成、验证、细化等操作,通过测试多个假设再给出答案。
- 实现上下文探索的三种关键方法包括技能链、利用错误梯度强化学习和任务难度与训练token预算的结合。
- e3方法提高了AI在评估任务中的表现,并能实现推理时长的延长。
点此查看论文截图

Learning to Reason Across Parallel Samples for LLM Reasoning
Authors:Jianing Qi, Xi Ye, Hao Tang, Zhigang Zhu, Eunsol Choi
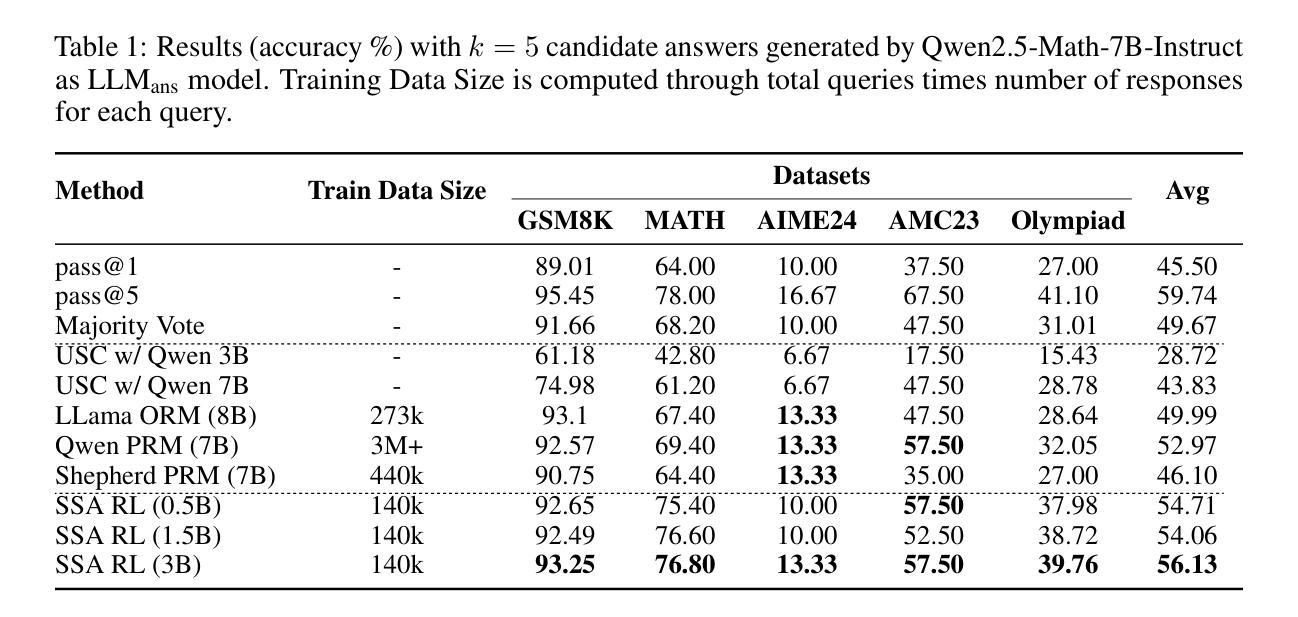
Scaling test-time compute brings substantial performance gains for large language models (LLMs). By sampling multiple answers and heuristically aggregate their answers (e.g., either through majority voting or using verifiers to rank the answers), one can achieve consistent performance gains in math domains. In this paper, we propose a new way to leverage such multiple sample set. We train a compact LLM, called Sample Set Aggregator (SSA), that takes a concatenated sequence of multiple samples and output the final answer, optimizing it for the answer accuracy with reinforcement learning. Experiments on multiple reasoning datasets show that SSA outperforms other test-time scaling methods such as reward model-based re-ranking. Our approach also shows a promising generalization ability, across sample set sizes, base model families and scales, and tasks. By separating LLMs to generate answers and LLMs to analyze and aggregate sampled answers, our approach can work with the outputs from premier black box models easily and efficiently.
扩大测试时间计算为大语言模型(LLM)带来了巨大的性能提升。通过采样多个答案并启发式地聚合它们的答案(例如,通过投票多数或利用验证器对答案进行排名),可以在数学领域实现持续的性能提升。在本文中,我们提出了一种利用这种多样样本集的新方法。我们训练了一种紧凑的LLM,称为样本集聚合器(SSA),它接受多个样本的连续序列,输出最终答案,通过强化学习优化答案的准确性。在多个推理数据集上的实验表明,SSA优于其他测试时间规模的方法,如基于奖励模型的重新排名。我们的方法还显示出很好的泛化能力,可应用于不同的样本集大小、基础模型家族和规模以及任务。通过将LLM分离以生成答案和LLM来分析并聚合采样答案,我们的方法能够轻松高效地处理顶级黑盒模型的输出。
论文及项目相关链接
Summary
大型语言模型(LLM)在测试时通过计算扩展能带来显著的性能提升。通过采样多个答案并启发式地聚合它们(例如,通过多数投票或使用验证器对答案进行排名),可以在数学领域实现持续的性能提升。本文提出了一种新的利用这样的多重样本集的方法。我们训练了一种紧凑的LLM,称为样本集聚合器(SSA),它接受多个样本的连续序列并输出最终答案,通过强化学习优化答案的准确性。在多个推理数据集上的实验表明,SSA优于其他测试时间扩展方法,如基于奖励模型的排名。我们的方法还表现出良好的泛化能力,适用于不同的样本集大小、基础模型家族和规模以及任务。通过将LLM分离为生成答案的LLM和分析并聚合采样答案的LLM,我们的方法能够轻松高效地使用一流的黑盒模型的输出。
Key Takeaways
- 测试时的计算扩展对于大型语言模型(LLM)的性能提升至关重要。
- 通过采样多个答案并启发式地聚合它们,可以在数学领域实现LLM的持续性能提升。
- 样本集聚合器(SSA)是一种新的方法,可以训练LLM以优化答案的准确性。
- SSA通过接受多个样本的连续序列并输出最终答案,在多个推理数据集上表现出优异的性能。
- SSA优于其他测试时间扩展方法,如基于奖励模型的排名。
- SSA具有良好的泛化能力,适用于不同的样本集大小、基础模型家族和规模以及任务。
点此查看论文截图
Can A Gamer Train A Mathematical Reasoning Model?
Authors:Andrew Shin
While large language models (LLMs) have achieved remarkable performance in various tasks including mathematical reasoning, their development typically demands prohibitive computational resources. Recent advancements have reduced costs for training capable models, yet even these approaches rely on high-end hardware clusters. In this paper, we demonstrate that a single average gaming GPU can train a solid mathematical reasoning model, by integrating reinforcement learning and memory optimization techniques. Specifically, we train a 1.5B parameter mathematical reasoning model on RTX 3080 Ti of 16GB memory that achieves comparable or better performance on mathematical reasoning benchmarks than models several times larger, in resource-constrained environments. Our results challenge the paradigm that state-of-the-art mathematical reasoning necessitates massive infrastructure, democratizing access to high-performance AI research. https://github.com/shinandrew/YouronMath.
虽然大型语言模型(LLM)在数学推理等任务中取得了显著的成绩,但它们的开发通常需要巨大的计算资源。尽管最近的进步降低了训练有能力模型的成本,但这些方法仍然依赖于高端硬件集群。在本文中,我们通过结合强化学习和内存优化技术,展示了使用单个普通游戏GPU就可以训练出稳健的数学推理模型。具体来说,我们在内存为16GB的RTX 3080 Ti上训练了一个1.5亿参数的数学推理模型,在资源受限的环境中,该模型在数学推理基准测试上的性能与更大规模的模型相当甚至更好。我们的结果挑战了最先进数学推理需要大规模基础设施的现状,为高性能人工智能研究的普及化提供了可能。可以通过https://github.com/shinandrew/YouronMath访问相关资源。
论文及项目相关链接
Summary
大型语言模型在数学推理等任务中表现出卓越性能,但其开发需要大量计算资源。最新研究证明,使用单个普通游戏GPU结合强化学习与内存优化技术,可以训练出性能出色的数学推理模型。具体来说,我们在仅有16GB内存的RTX 3080 Ti上训练了一个1.5亿参数的数学推理模型,其在数学推理基准测试上的表现与更大模型相当甚至更优,显著降低了资源消耗。该研究打破了高性能数学推理必须依赖大规模设施的固有观念,推动了AI研究的民主化。
Key Takeaways
- 使用单个普通游戏GPU可以训练出高性能的数学推理模型。
- 结合强化学习与内存优化技术,能够在资源有限的环境中实现良好的数学推理模型性能。
- 训练的数学推理模型在RTX 3080 Ti上实现了与更大模型相当甚至更好的性能。
- 该研究挑战了高性能数学推理必须依赖大规模设施的现有观念。
- 这种方法的可行性为民主化访问高性能AI研究铺平了道路。
- 此研究展示了GitHub上的开源项目,即:如何更广泛地应用该方法及改进研究路径变得尤为关键。
点此查看论文截图

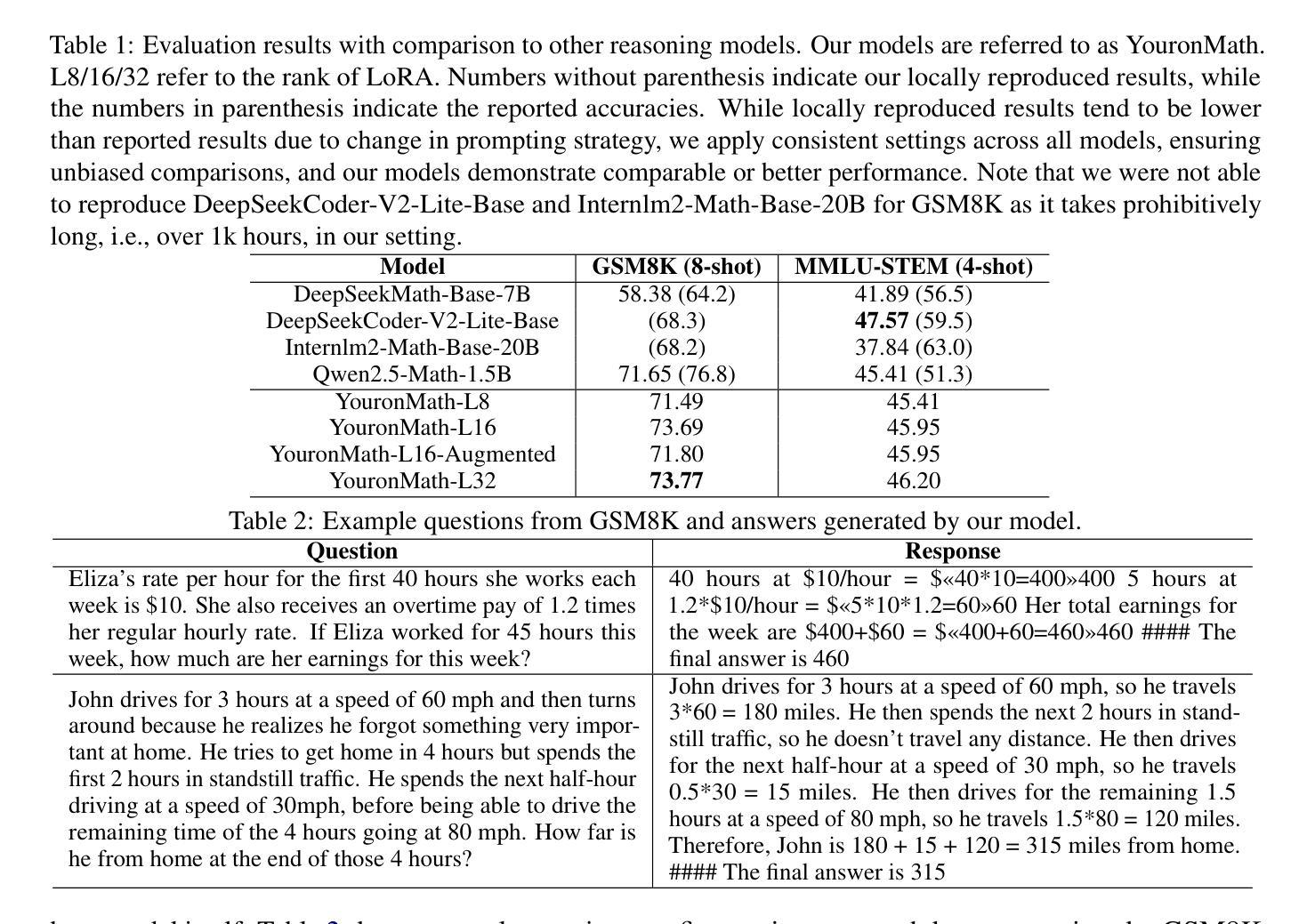
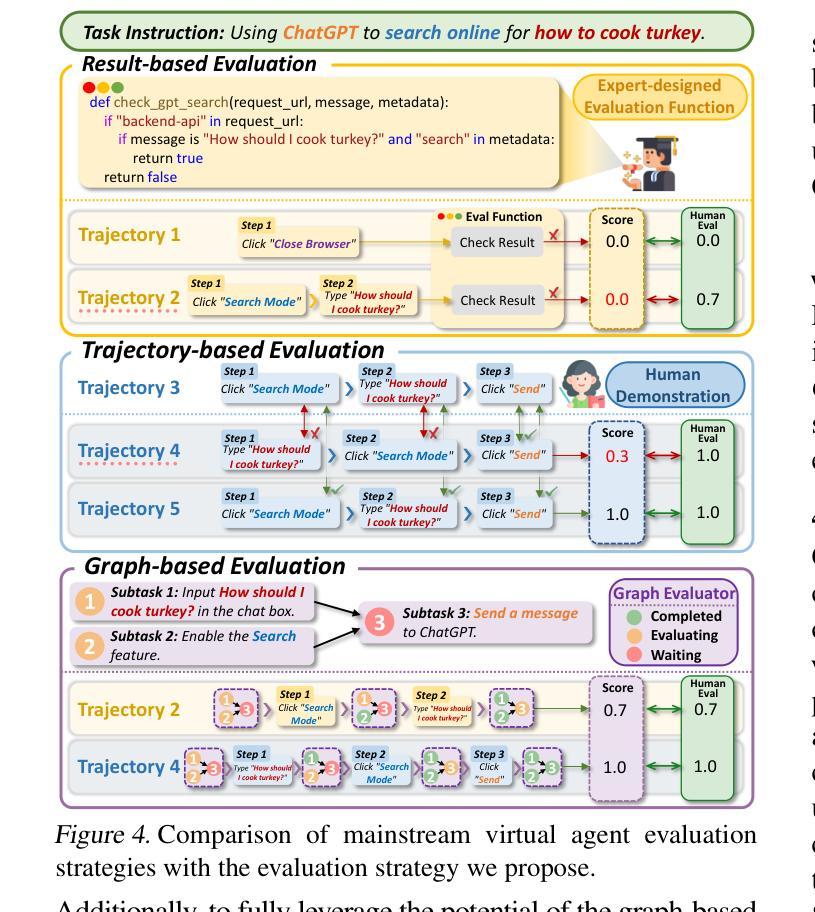
What Limits Virtual Agent Application? OmniBench: A Scalable Multi-Dimensional Benchmark for Essential Virtual Agent Capabilities
Authors:Wendong Bu, Yang Wu, Qifan Yu, Minghe Gao, Bingchen Miao, Zhenkui Zhang, Kaihang Pan, Yunfei Li, Mengze Li, Wei Ji, Juncheng Li, Siliang Tang, Yueting Zhuang
As multimodal large language models (MLLMs) advance, MLLM-based virtual agents have demonstrated remarkable performance. However, existing benchmarks face significant limitations, including uncontrollable task complexity, extensive manual annotation with limited scenarios, and a lack of multidimensional evaluation. In response to these challenges, we introduce OmniBench, a self-generating, cross-platform, graph-based benchmark with an automated pipeline for synthesizing tasks of controllable complexity through subtask composition. To evaluate the diverse capabilities of virtual agents on the graph, we further present OmniEval, a multidimensional evaluation framework that includes subtask-level evaluation, graph-based metrics, and comprehensive tests across 10 capabilities. Our synthesized dataset contains 36k graph-structured tasks across 20 scenarios, achieving a 91% human acceptance rate. Training on our graph-structured data shows that it can more efficiently guide agents compared to manually annotated data. We conduct multidimensional evaluations for various open-source and closed-source models, revealing their performance across various capabilities and paving the way for future advancements. Our project is available at https://omni-bench.github.io/.
随着多模态大型语言模型(MLLMs)的不断发展,基于MLLM的虚拟代理人在性能上展现出了显著的成果。然而,现有的基准测试面临重大挑战,包括任务复杂性不可控、场景有限需要广泛的手动注释以及缺乏多维评估等问题。为了应对这些挑战,我们引入了OmniBench,这是一个自我生成、跨平台、基于图的基准测试,通过子任务组合,我们建立了一个自动化管道,用于合成可控复杂度的任务。为了评估虚拟代理人在图上的各种能力,我们还推出了OmniEval,这是一个多维评估框架,包括子任务级评估、基于图的指标以及跨越10种能力的综合测试。我们的合成数据集包含20个场景下的3.6万个图结构任务,达到了91%的人类接受率。在我们图结构数据上的训练结果表明,与手动注释数据相比,它更能有效地指导虚拟代理人。我们对各种开源和专有模型进行了多维评估,揭示了它们在各种能力方面的表现,为未来的进步铺平了道路。我们的项目在https://omni-bench.github.io/上提供。
论文及项目相关链接
PDF Accepted by ICML 2025 (Oral)
Summary
随着多模态大型语言模型(MLLMs)的发展,基于MLLM的虚拟代理人在多个场景展现出色性能。然而,现有基准测试面临可控性任务复杂、手动标注繁琐且场景有限、多维度评估缺失等挑战。为应对这些挑战,本文介绍了OmniBench,一个自我生成、跨平台、基于图形的基准测试,通过子任务组合来合成可控复杂度的任务。同时,为评估虚拟代理人在图形上的多样化能力,本文还提出了OmniEval,一个包括子任务级别评估、图形指标和全面测试10种能力的多维度评估框架。合成的数据集包含36,000个图形结构任务,覆盖20个场景,达到91%的人类接受率。使用我们的图形结构数据进行训练表明,它可以更有效地指导代理,相比手动注释的数据。
Key Takeaways
- 多模态大型语言模型(MLLMs)的虚拟代理人表现出卓越性能,但现有基准测试存在局限性。
- OmniBench是一个自我生成、跨平台的图形基准测试,通过子任务组合实现可控任务复杂度。
- OmniEval是一个多维度评估框架,用于评估虚拟代理人在图形上的多样化能力,包括子任务级别评估、图形指标和全面测试10种能力。
- 合成的数据集包含大量图形结构任务,覆盖多种场景,且获得高人类接受率。
- 使用图形结构数据进行训练可更有效地指导虚拟代理人。
- OmniBench项目提供了多模态大型语言模型的评估平台,有助于未来技术进步。
点此查看论文截图


Intention-Conditioned Flow Occupancy Models
Authors:Chongyi Zheng, Seohong Park, Sergey Levine, Benjamin Eysenbach
Large-scale pre-training has fundamentally changed how machine learning research is done today: large foundation models are trained once, and then can be used by anyone in the community (including those without data or compute resources to train a model from scratch) to adapt and fine-tune to specific tasks. Applying this same framework to reinforcement learning (RL) is appealing because it offers compelling avenues for addressing core challenges in RL, including sample efficiency and robustness. However, there remains a fundamental challenge to pre-train large models in the context of RL: actions have long-term dependencies, so training a foundation model that reasons across time is important. Recent advances in generative AI have provided new tools for modeling highly complex distributions. In this paper, we build a probabilistic model to predict which states an agent will visit in the temporally distant future (i.e., an occupancy measure) using flow matching. As large datasets are often constructed by many distinct users performing distinct tasks, we include in our model a latent variable capturing the user intention. This intention increases the expressivity of our model, and enables adaptation with generalized policy improvement. We call our proposed method intention-conditioned flow occupancy models (InFOM). Comparing with alternative methods for pre-training, our experiments on $36$ state-based and $4$ image-based benchmark tasks demonstrate that the proposed method achieves $1.8 \times$ median improvement in returns and increases success rates by $36%$. Website: https://chongyi-zheng.github.io/infom Code: https://github.com/chongyi-zheng/infom
大规模预训练已经从根本上改变了当前机器学习研究的方式:大型基础模型只需训练一次,社区中的任何人(包括那些没有数据或计算资源从头开始训练模型的人)都可以用来适应和微调特定任务。将这一框架应用于强化学习(RL)是很有吸引力的,因为它为解决RL中的核心挑战提供了有吸引力的途径,包括样本效率和稳健性。然而,在强化学习的背景下对大型模型进行预训练仍存在基本挑战:行动具有长期依赖性,因此训练能够跨时间推理的基础模型很重要。生成AI的最新进展为建立高度复杂的分布提供了新的工具。在本文中,我们建立了一个概率模型,使用流匹配来预测代理在遥远未来访问的状态(即占用度量)。由于大型数据集通常是由执行不同任务的许多不同用户构建的,因此我们在模型中包含一个捕捉用户意图的潜在变量。这种意图增加了我们模型的表达能力,并通过通用策略改进实现了适应。我们将我们提出的方法称为意图调节流占用模型(InFOM)。与其他预训练方法进行比较,我们在36个基于状态和4个基于图像的标准任务上的实验表明,该方法实现了收益中位数的1.8倍增长,成功率提高了36%。网站地址为:https://chongyi-zheng.github.io/infom代码地址为:https://github.com/chongyi-zheng/infom。
论文及项目相关链接
Summary
本文介绍了将大型预训练模型应用于强化学习(RL)的新方法。由于动作存在长期依赖关系,因此需要建立能够推理跨时间的基础模型。作者提出了一种概率模型——意图条件流占用模型(InFOM),该模型能够预测代理在远期访问的状态,并使用流匹配技术。实验结果表明,该方法在状态基准和图像基准任务上实现了优于其他预训练方法的效果。
Key Takeaways
- 大型预训练模型在强化学习中的应用具有巨大潜力,有助于解决样本效率和稳健性等方面的核心挑战。
- 动作存在长期依赖关系,因此需要建立能够推理跨时间的基础模型。
- 作者提出了意图条件流占用模型(InFOM),这是一种新的概率模型,可以预测代理在远期访问的状态。
- InFOM模型通过使用流匹配技术实现预测,并包括一个捕捉用户意图的潜在变量,这提高了模型的表达力并实现了适应性改进。
- 实验结果表明,InFOM方法在状态基准和图像基准任务上的表现优于其他预训练方法。
- 该方法在实现上使用了先进的生成AI工具,如流匹配技术。
点此查看论文截图

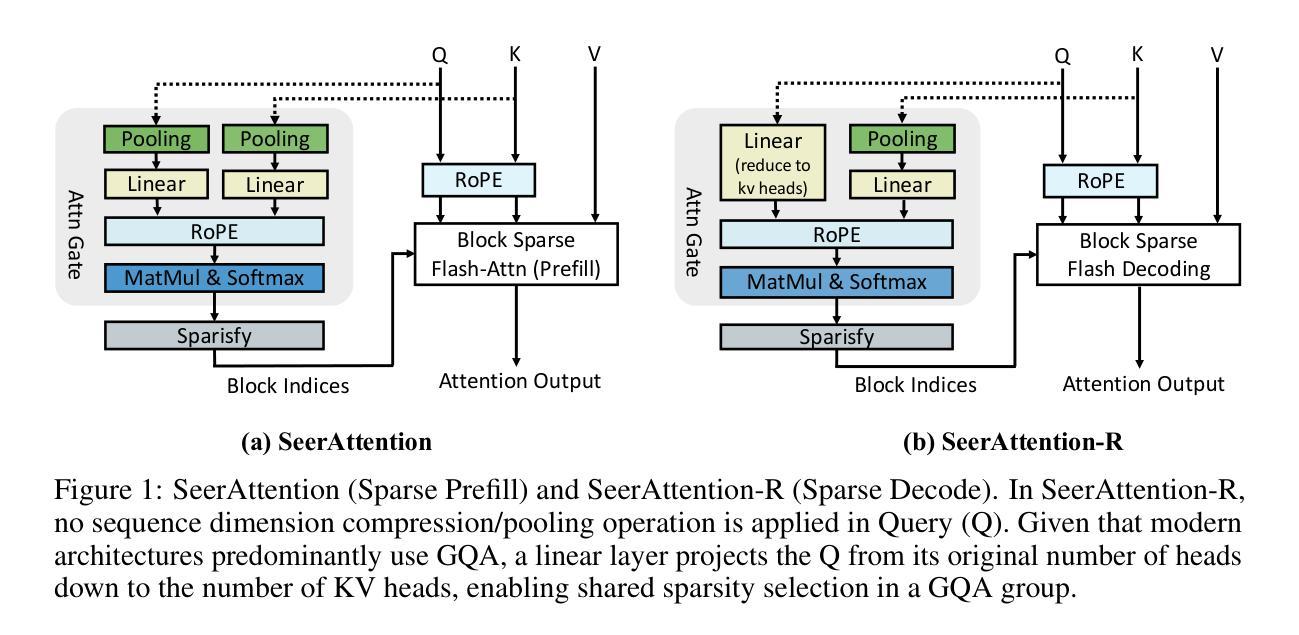
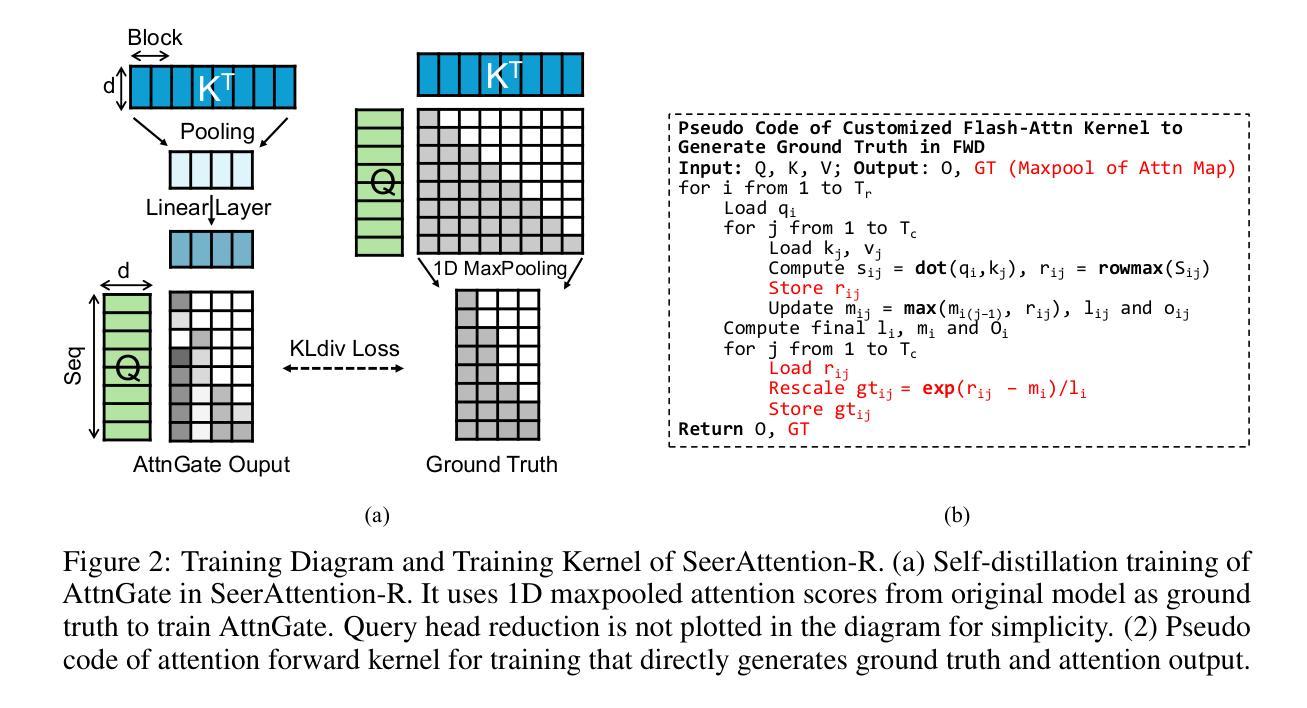
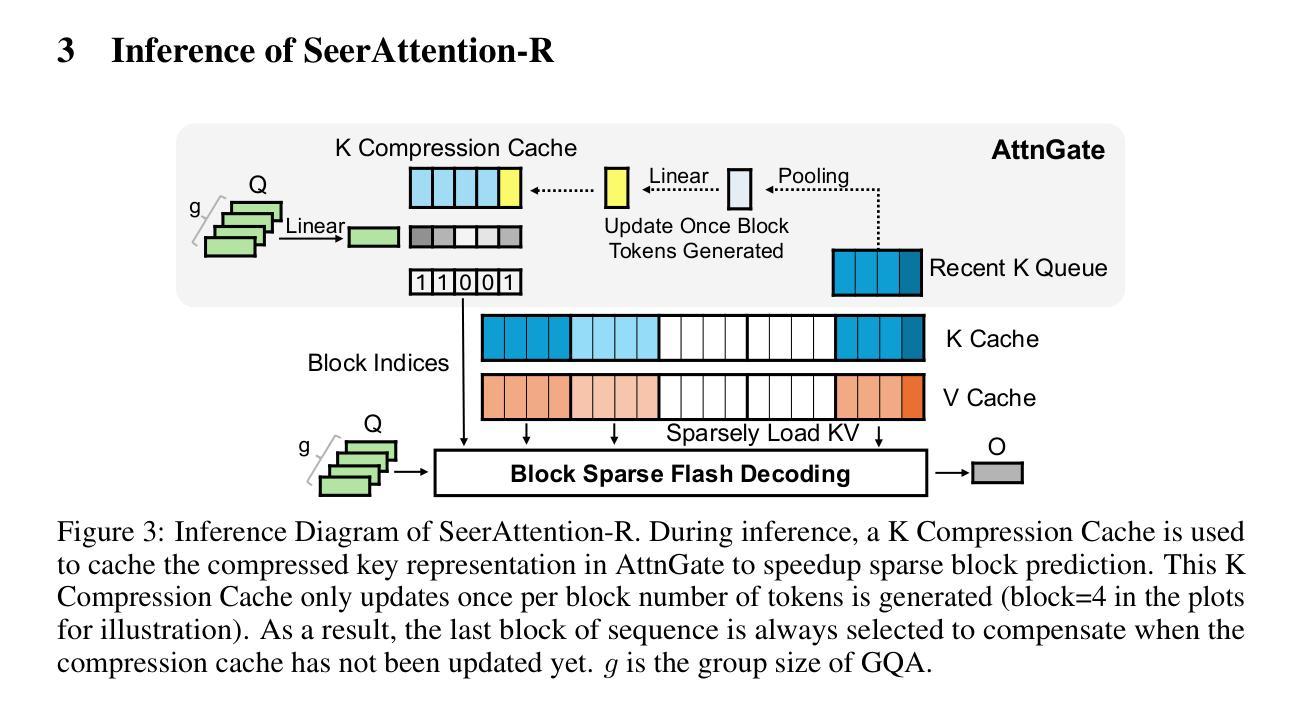
SeerAttention-R: Sparse Attention Adaptation for Long Reasoning
Authors:Yizhao Gao, Shuming Guo, Shijie Cao, Yuqing Xia, Yu Cheng, Lei Wang, Lingxiao Ma, Yutao Sun, Tianzhu Ye, Li Dong, Hayden Kwok-Hay So, Yu Hua, Ting Cao, Fan Yang, Mao Yang
We introduce SeerAttention-R, a sparse attention framework specifically tailored for the long decoding of reasoning models. Extended from SeerAttention, SeerAttention-R retains the design of learning attention sparsity through a self-distilled gating mechanism, while removing query pooling to accommodate auto-regressive decoding. With a lightweight plug-in gating, SeerAttention-R is flexible and can be easily integrated into existing pretrained model without modifying the original parameters. We demonstrate that SeerAttention-R, trained on just 0.4B tokens, maintains near-lossless reasoning accuracy with 4K token budget in AIME benchmark under large sparse attention block sizes (64/128). Using TileLang, we develop a highly optimized sparse decoding kernel that achieves near-theoretical speedups of up to 9x over FlashAttention-3 on H100 GPU at 90% sparsity. Code is available at: https://github.com/microsoft/SeerAttention.
我们介绍了SeerAttention-R,这是一个专为推理模型的长解码设计的稀疏注意力框架。SeerAttention-R是对SeerAttention的扩展,它保留了通过自蒸馏门控机制学习注意力稀疏性的设计,同时移除了查询池化以适应自回归解码。通过使用轻量级插件门控,SeerAttention-R非常灵活,可以很容易地集成到现有预训练模型中,而无需修改原始参数。我们在AIME基准测试中展示了SeerAttention-R,仅在0.4B令牌上进行训练,在大型稀疏注意力块大小(64/128)下,具有近无损的推理准确性,令牌预算为4K。使用TileLang,我们开发了一个高度优化的稀疏解码内核,在H100 GPU上相对于FlashAttention-3实现了近9倍的理论加速,在90%的稀疏性下表现优异。相关代码可通过以下网址获取:https://github.com/microsoft/SeerAttention 。
论文及项目相关链接
Summary
SeerAttention-R是一种针对长文本推理模型的稀疏注意力框架。它通过自我蒸馏的门控机制学习注意力稀疏性,适用于自回归解码。该框架易于集成到现有的预训练模型中,无需修改原始参数。在AIME基准测试中,即使在大型稀疏注意力块大小下,SeerAttention-R在4K令牌预算内也能保持近无损的推理准确性。此外,通过TileLang开发的优化稀疏解码内核,可在H100 GPU上实现接近理论速度的加速,在90%的稀疏性下,速度提升可达近9倍。
Key Takeaways
- SeerAttention-R是一个专为长文本解码设计的稀疏注意力框架。
- 它通过自我蒸馏的门控机制学习注意力稀疏性,适用于自回归解码。
- SeerAttention-R易于集成到现有的预训练模型中,且无需修改原始参数。
- 在AIME基准测试中,SeerAttention-R在大型稀疏注意力块大小下能保持近无损的推理准确性。
- 该框架在训练时仅使用了0.4B令牌,表现出高效的性能。
- 使用TileLang开发的优化稀疏解码内核,可在H100 GPU上实现显著的速度提升。
点此查看论文截图

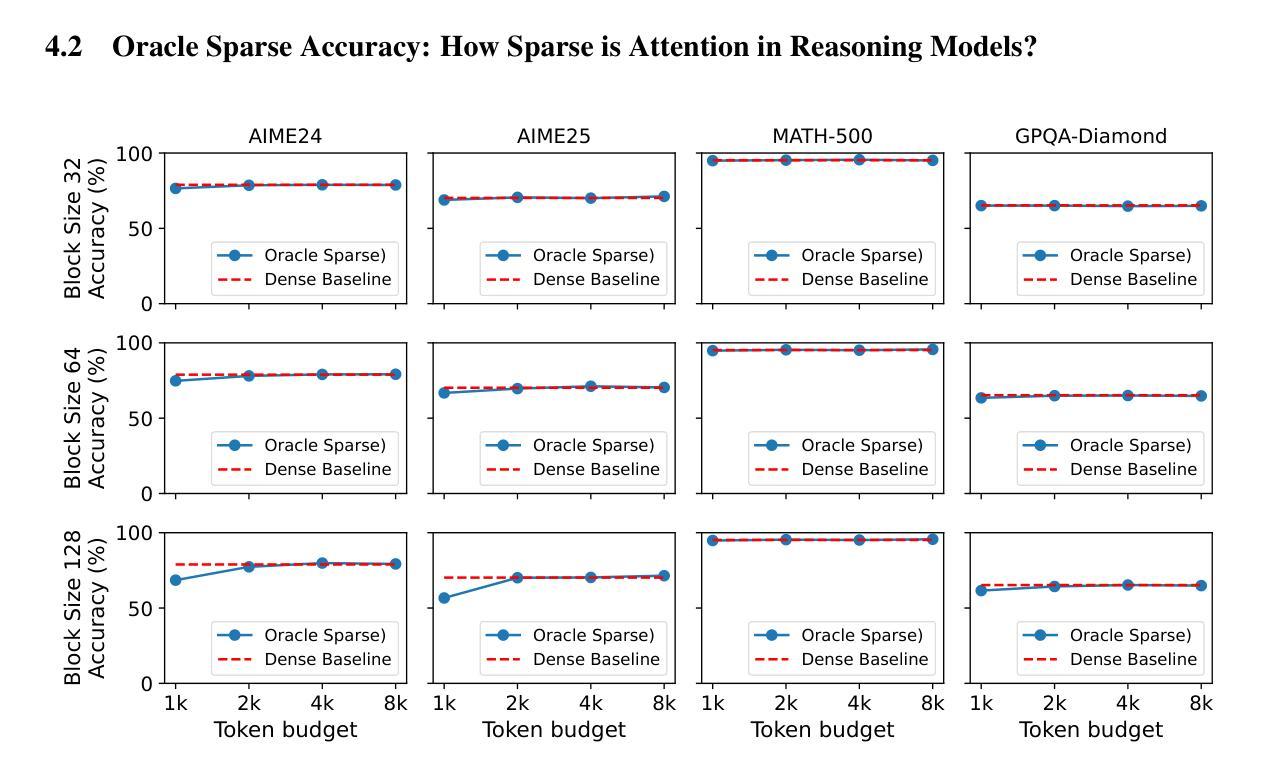
AraReasoner: Evaluating Reasoning-Based LLMs for Arabic NLP
Authors:Ahmed Hasanaath, Aisha Alansari, Ahmed Ashraf, Chafik Salmane, Hamzah Luqman, Saad Ezzini
Large language models (LLMs) have shown remarkable progress in reasoning abilities and general natural language processing (NLP) tasks, yet their performance on Arabic data, characterized by rich morphology, diverse dialects, and complex script, remains underexplored. This paper presents a comprehensive benchmarking study of multiple reasoning-focused LLMs, with a special emphasis on the newly introduced DeepSeek models, across a suite of fifteen Arabic NLP tasks. We experiment with various strategies, including zero-shot, few-shot, and fine-tuning. This allows us to systematically evaluate performance on datasets covering a range of applications to examine their capacity for linguistic reasoning under different levels of complexity. Our experiments reveal several key findings. First, carefully selecting just three in-context examples delivers an average uplift of over 13 F1 points on classification tasks-boosting sentiment analysis from 35.3% to 87.5% and paraphrase detection from 56.1% to 87.0%. Second, reasoning-focused DeepSeek architectures outperform a strong GPT o4-mini baseline by an average of 12 F1 points on complex inference tasks in the zero-shot setting. Third, LoRA-based fine-tuning yields up to an additional 8 points in F1 and BLEU compared to equivalent increases in model scale. The code is available at https://anonymous.4open.science/r/AraReasoner41299
大型语言模型(LLM)在推理能力和通用自然语言处理(NLP)任务方面取得了显著进展,但在处理具有丰富形态、多样方言和复杂脚本的阿拉伯语数据方面的表现仍然缺乏足够的探索。本文全面评估了多个以推理为重点的大型语言模型,特别关注新推出的DeepSeek模型,在十五项阿拉伯语NLP任务中的表现。我们尝试了各种策略,包括零样本、少样本和微调。这使我们能够系统地评估在各种数据集上的性能,涵盖多种应用,以检验它们在不同复杂程度下的语言推理能力。我们的实验揭示了几个关键发现。首先,精心选择仅三个上下文实例可以在分类任务上平均提高超过13个F1点,情感分析从35.3%提高到87.5%,而释义检测从56.1%提高到87.0%。其次,在零样本设置中,以推理为重点的DeepSeek架构在复杂推理任务上平均优于强大的GPT o4-mini基线12个F1点。第三,与模型规模的等效增长相比,基于LoRA的微调在F1和BLEU得分上最多可提高8个点。相关代码可通过https://anonymous.4open.science/r/AraReasoner41299获取。
论文及项目相关链接
Summary
大型语言模型(LLMs)在推理能力和自然语言处理(NLP)任务方面取得了显著进展,但在处理阿拉伯数据方面的性能仍有待探索。本文全面评估了多个以推理为重点的LLMs,特别是新推出的DeepSeek模型,在十五项阿拉伯NLP任务上的表现。实验结果显示,精心选择的三例上下文示例平均提高了超过13个F1点的分类任务性能;DeepSeek架构在零样本情况下在复杂推理任务上的平均表现优于GPT o4-mini基准测试12个F1点;基于LoRA的微调与模型规模的等效增加相比,可额外提高F1和BLEU得分高达8分。本文的成果将有助于进一步了解LLMs在处理复杂阿拉伯语数据时的性能和优化策略。
Key Takeaways
- 大型语言模型(LLMs)在阿拉伯数据处理上的表现仍需深入研究。
- 精心选择的上下文示例可以显著提高LLMs在分类任务上的性能。
- 推理为重点的DeepSeek模型在零样本情况下表现出优异的性能。
- DeepSeek模型在复杂推理任务上的表现优于GPT o4-mini基准测试。
- LoRA-based微调可以进一步提高LLMs的性能。
- 该研究提供了宝贵的见解,有助于优化LLMs在处理复杂阿拉伯语数据时的性能和策略。
点此查看论文截图

Consistent Paths Lead to Truth: Self-Rewarding Reinforcement Learning for LLM Reasoning
Authors:Kongcheng Zhang, Qi Yao, Shunyu Liu, Yingjie Wang, Baisheng Lai, Jieping Ye, Mingli Song, Dacheng Tao
Recent advances of Reinforcement Learning (RL) have highlighted its potential in complex reasoning tasks, yet effective training often relies on external supervision, which limits the broader applicability. In this work, we propose a novel self-rewarding reinforcement learning framework to enhance Large Language Model (LLM) reasoning by leveraging the consistency of intermediate reasoning states across different reasoning trajectories. Our key insight is that correct responses often exhibit consistent trajectory patterns in terms of model likelihood: their intermediate reasoning states tend to converge toward their own final answers (high consistency) with minimal deviation toward other candidates (low volatility). Inspired by this observation, we introduce CoVo, an intrinsic reward mechanism that integrates Consistency and Volatility via a robust vector-space aggregation strategy, complemented by a curiosity bonus to promote diverse exploration. CoVo enables LLMs to perform RL in a self-rewarding manner, offering a scalable pathway for learning to reason without external supervision. Extensive experiments on diverse reasoning benchmarks show that CoVo achieves performance comparable to or even surpassing supervised RL. Our code is available at https://github.com/sastpg/CoVo.
最近强化学习(RL)的进展凸显了其在复杂推理任务中的潜力,然而有效的训练通常依赖于外部监督,这限制了其更广泛的应用。在这项工作中,我们提出了一种新型的自奖励强化学习框架,利用不同推理轨迹中的中间状态一致性来提升大型语言模型(LLM)的推理能力。我们的关键见解是,正确的回答往往表现出一致的轨迹模式,从模型的可能性来看:它们的中间推理状态倾向于收敛到它们自己的最终答案(高一致性),并且对其他候选答案的偏差最小(低波动性)。受这一观察结果的启发,我们引入了CoVo,这是一种内在奖励机制,通过鲁棒的向量空间聚合策略融合了一致性和波动性,辅以好奇心奖励来促进多样化的探索。CoVo使LLM能够以自奖励的方式进行强化学习,为无需外部监督的学习推理提供了一条可扩展的路径。在多种推理基准测试上的广泛实验表明,CoVo的性能可与有监督的强化学习相媲美,甚至更胜一筹。我们的代码可在https://github.com/sastpg/CoVo找到。
论文及项目相关链接
Summary
强化学习(RL)在复杂推理任务中具有巨大潜力,但有效的训练通常依赖于外部监督,这限制了其更广泛的应用。本研究提出了一种新型的自奖励强化学习框架,通过利用不同推理轨迹中中间推理状态的一致性,增强大型语言模型(LLM)的推理能力。该研究的关键见解是,正确的回答通常展现出一致的轨迹模式,在模型可能性方面,它们的中间推理状态往往收敛于它们自己的最终答案(高一致性)并尽量减少对其他候选答案的偏离(低波动性)。受此观察启发,研究引入了CoVo,一种通过稳健的向量空间聚合策略结合一致性和波动性的内在奖励机制,辅以好奇心奖金以促进多样化的探索。CoVo使LLM能够以自奖励的方式进行强化学习,为无需外部监督的学习推理提供了可扩展的途径。在多样化的推理基准测试上的广泛实验表明,CoVo的性能可与监督强化学习相比,甚至实现超越。
Key Takeaways
- 强化学习在复杂推理任务中具有潜力。
- 有效的训练通常依赖于外部监督,限制了其广泛应用。
- 提出了一种新型自奖励强化学习框架,利用中间推理状态的一致性增强LLM推理。
- 正确回答展现出一致的轨迹模式,结合高一致性和低波动性。
- 引入CoVo,结合一致性和波动性的内在奖励机制。
- CoVo使LLM以自奖励方式进行强化学习,实现无需外部监督的学习推理。
- 在多样化推理基准测试上,CoVo表现出与监督强化学习相当或更优的性能。
点此查看论文截图

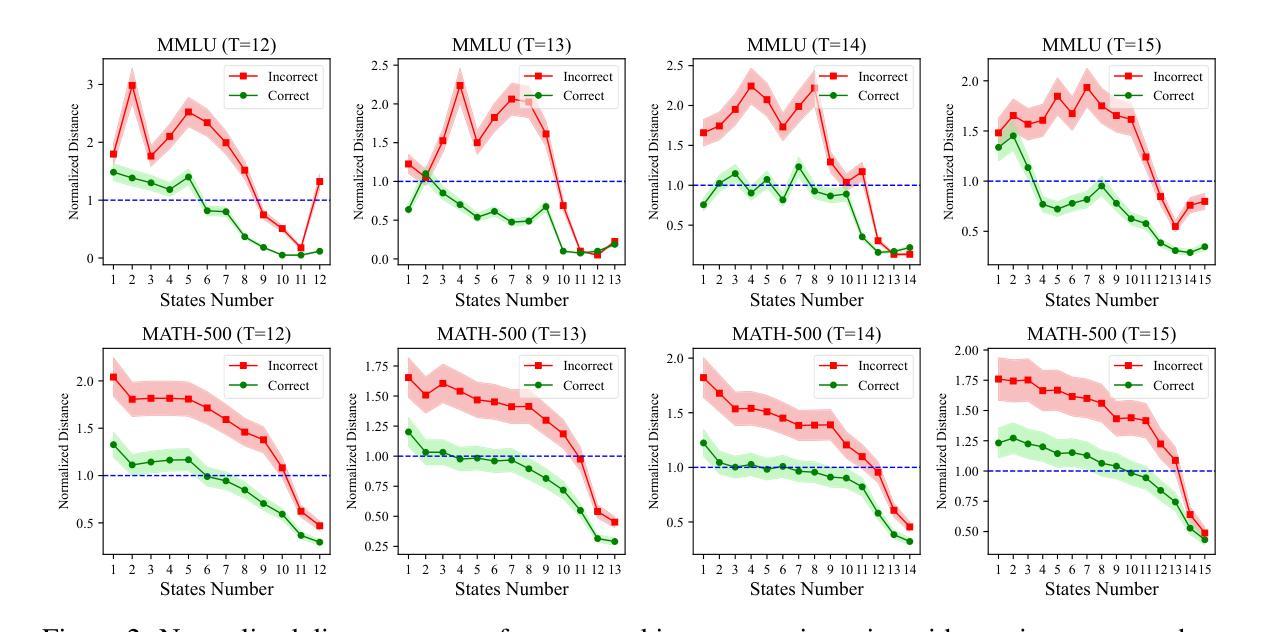
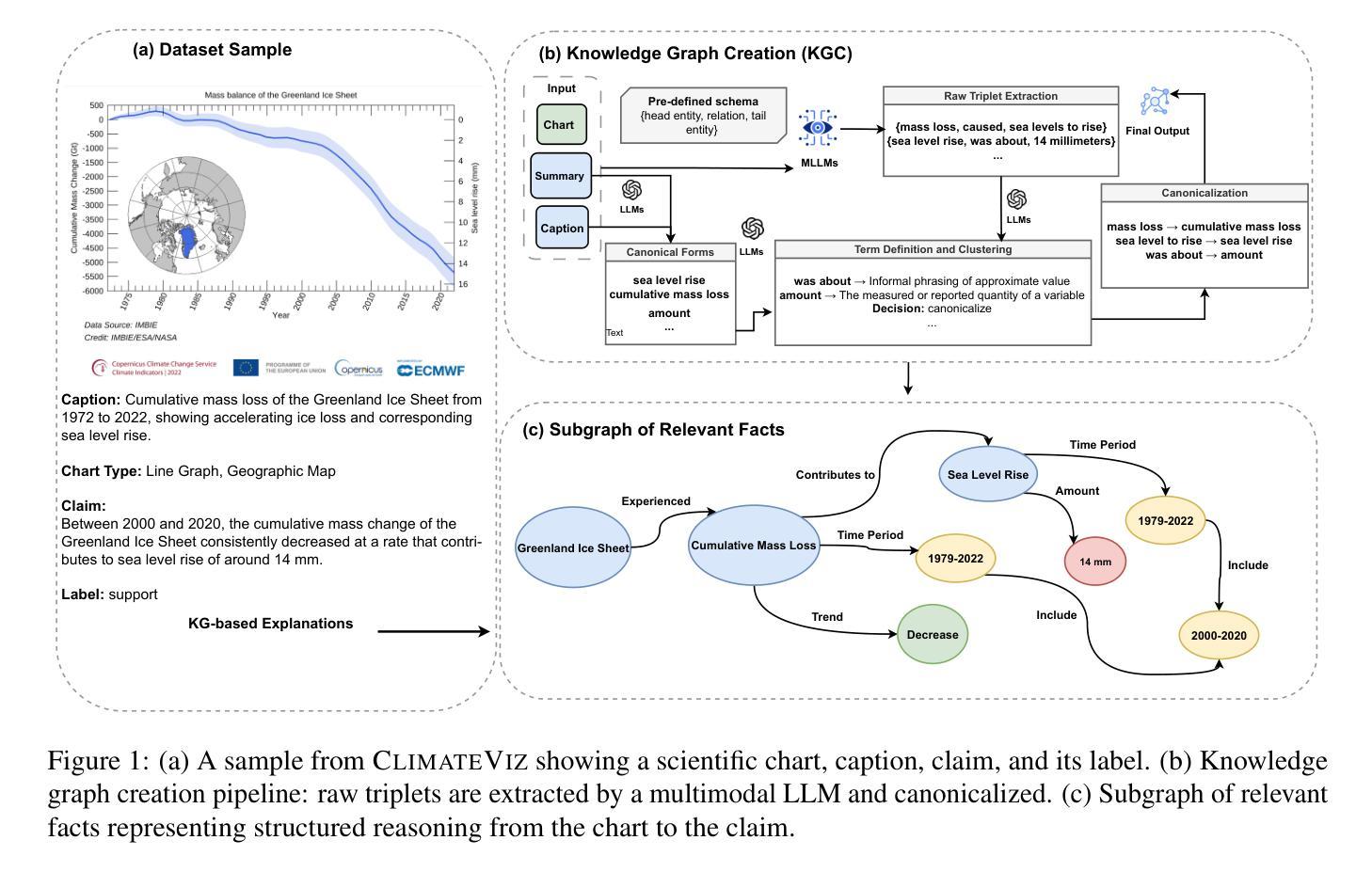
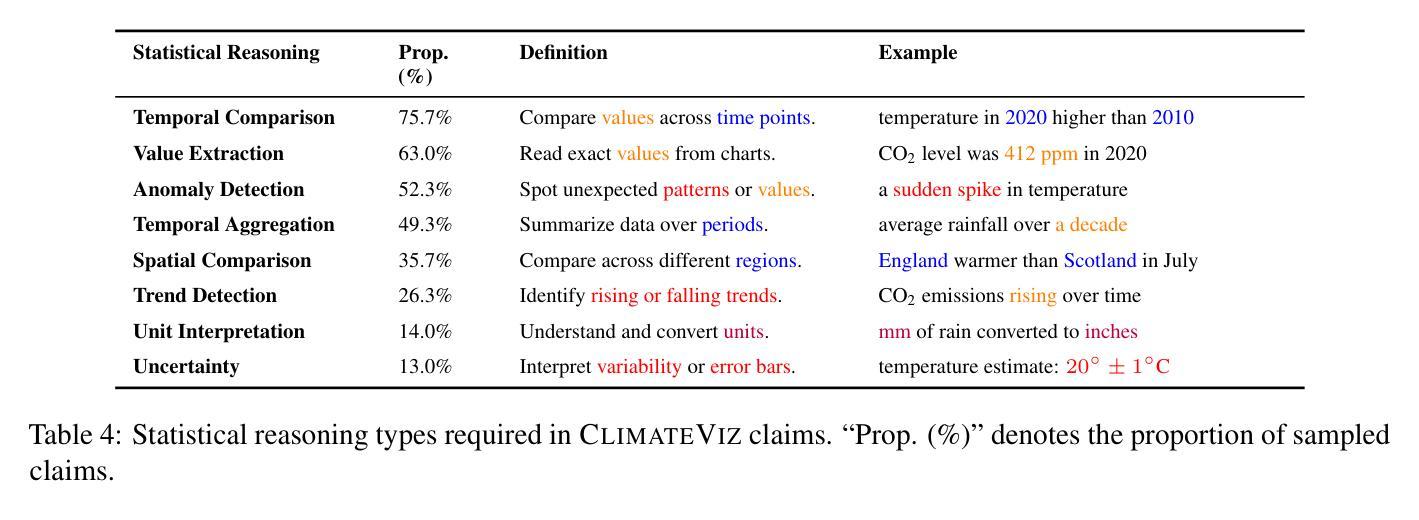
ClimateViz: A Benchmark for Statistical Reasoning and Fact Verification on Scientific Charts
Authors:Ruiran Su, Jiasheng Si, Zhijiang Guo, Janet B. Pierrehumbert
Scientific fact-checking has mostly focused on text and tables, overlooking scientific charts, which are key for presenting quantitative evidence and statistical reasoning. We introduce ClimateViz, the first large-scale benchmark for scientific fact-checking using expert-curated scientific charts. ClimateViz contains 49,862 claims linked to 2,896 visualizations, each labeled as support, refute, or not enough information. To improve interpretability, each example includes structured knowledge graph explanations covering trends, comparisons, and causal relations. We evaluate state-of-the-art multimodal language models, including both proprietary and open-source systems, in zero-shot and few-shot settings. Results show that current models struggle with chart-based reasoning: even the best systems, such as Gemini 2.5 and InternVL 2.5, reach only 76.2 to 77.8 percent accuracy in label-only settings, far below human performance (89.3 and 92.7 percent). Explanation-augmented outputs improve performance in some models. We released our dataset and code alongside the paper.
科学事实核查主要集中于文本和表格,忽视了科学图表,这些图表对于呈现定量证据和进行统计分析至关重要。我们推出了ClimateViz,这是使用专家制作的科学图表进行科学事实核查的第一个大规模基准测试。ClimateViz包含与2,896个可视化内容相关的49,862个声明,每个声明都被标记为支持、反驳或信息不足。为了提高可解释性,每个示例都包括结构化知识图谱解释,涵盖趋势、比较和因果关系。我们评估了最先进的多模式语言模型,包括专有和开源系统,在零样本和少样本环境下进行了评估。结果表明,当前模型在基于图表的推理方面存在困难:即使是最好的系统,如Gemini 2.5和InternVL 2.5,在仅标签设置下的准确率也只有76.2%至77.8%,远低于人类表现(89.3%和92.7%)。解释增强输出可提高某些模型的表现。我们随论文一起发布了数据集和代码。
论文及项目相关链接
Summary
本文介绍了科学事实核查通常忽略科学图表的重要性,而专注于文本和表格。为了解决这个问题,文章引入了ClimateViz,这是一个大规模的科学事实核查基准测试,包含专家策划的科学图表中的49,862个声明。ClimateViz中的每个例子都包括结构化知识图谱的解释,涵盖趋势、比较和因果关系,以提高可解释性。文章评估了最先进的多媒体语言模型在零样本和少样本场景下的表现,发现当前模型在图表推理方面存在困难,即使最好的系统如Gemini 2.5和InternVL 2.5在仅标签设置下的准确率也只有76.2至77.8%,远低于人类的表现(89.3%和92.7%)。增加解释后的输出可提高某些模型的性能。文章同时公开了数据集和代码。
Key Takeaways
- 科学事实核查通常忽视科学图表的重要性,而专注于文本和表格。
- ClimateViz是首个大规模的科学事实核查基准测试,强调图表在证据呈现中的作用。
- ClimateViz包含结构化知识图谱的解释以增强可解释性。
- 当前多媒体语言模型在图表推理方面存在困难,即使是最好的系统也远低于人类表现。
- 增加解释后的输出可以提高某些模型的性能。
- 文章公开了数据集和代码以供研究使用。
点此查看论文截图

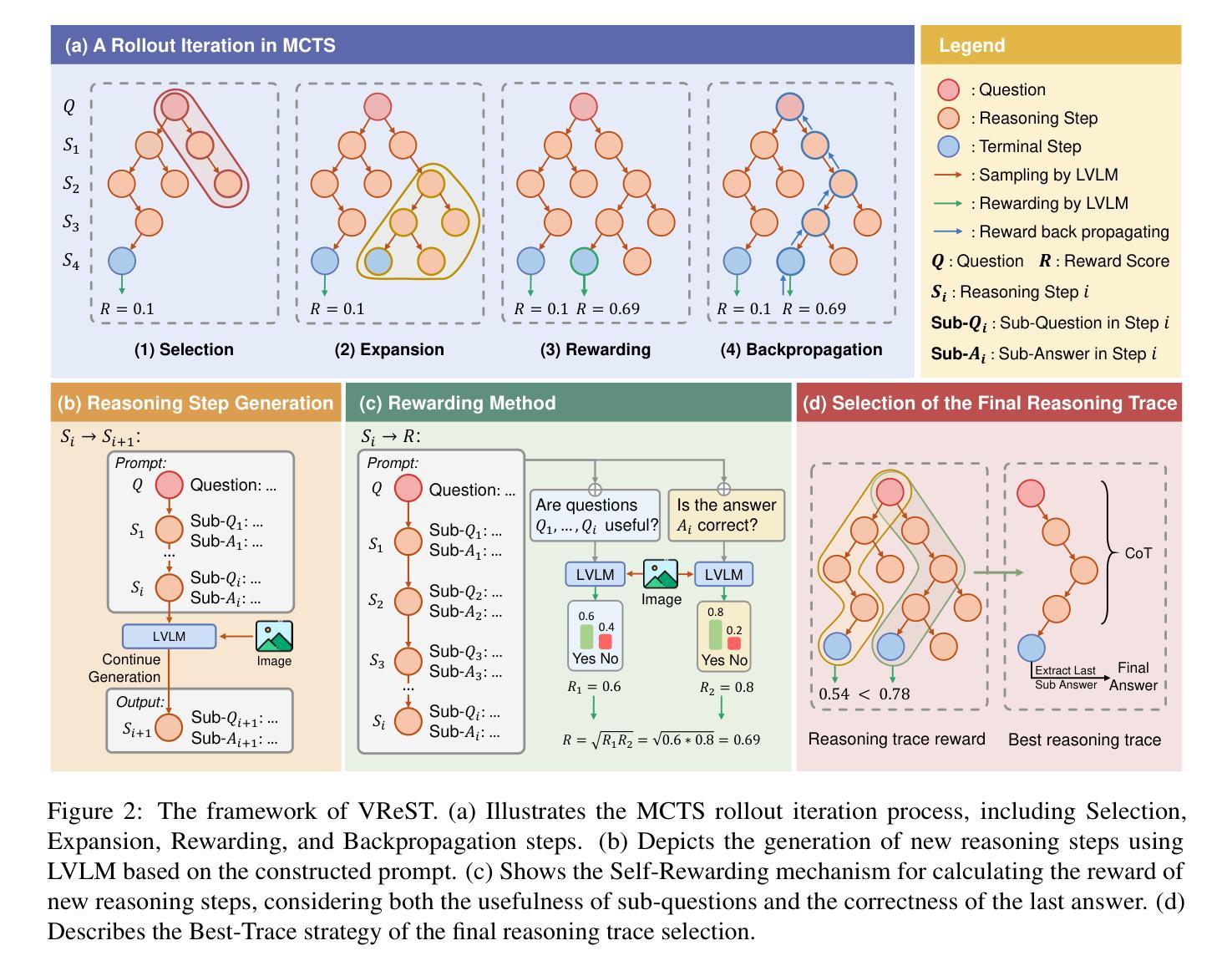
VReST: Enhancing Reasoning in Large Vision-Language Models through Tree Search and Self-Reward Mechanism
Authors:Congzhi Zhang, Jiawei Peng, Zhenglin Wang, Yilong Lai, Haowen Sun, Heng Chang, Fei Ma, Weijiang Yu
Large Vision-Language Models (LVLMs) have shown exceptional performance in multimodal tasks, but their effectiveness in complex visual reasoning is still constrained, especially when employing Chain-of-Thought prompting techniques. In this paper, we propose VReST, a novel training-free approach that enhances Reasoning in LVLMs through Monte Carlo Tree Search and Self-Reward mechanisms. VReST meticulously traverses the reasoning landscape by establishing a search tree, where each node encapsulates a reasoning step, and each path delineates a comprehensive reasoning sequence. Our innovative multimodal Self-Reward mechanism assesses the quality of reasoning steps by integrating the utility of sub-questions, answer correctness, and the relevance of vision-language clues, all without the need for additional models. VReST surpasses current prompting methods and secures state-of-the-art performance across three multimodal mathematical reasoning benchmarks. Furthermore, it substantiates the efficacy of test-time scaling laws in multimodal tasks, offering a promising direction for future research.
大型视觉语言模型(LVLMs)在多模态任务中表现出卓越的性能,但在复杂视觉推理方面的效果仍然受限,尤其是在采用思维链提示技术时。针对这一问题,本文提出了一种新型免训练方法VReST,通过蒙特卡洛树搜索和自我奖励机制增强LVLMs的推理能力。VReST通过构建搜索树精心遍历推理领域,每个节点封装一个推理步骤,每条路径描述一个全面的推理序列。我们创新的多模态自我奖励机制通过整合子问题的实用性、答案的正确性以及视觉语言线索的相关性来评估推理步骤的质量,无需使用额外的模型。VReST超越了当前的提示方法,在三个多模态数学推理基准测试中获得了最先进的性能。此外,它证实了多模态任务中测试时缩放定律的有效性,为未来的研究提供了有前景的方向。
论文及项目相关链接
PDF Accepted by ACL 2025 main
Summary
大型视觉语言模型(LVLMs)在多模态任务中表现出卓越性能,但在复杂视觉推理方面的效果仍然受限,特别是在采用链式思维提示技术时。本文提出了一种新型训练外方法VReST,它通过蒙特卡洛树搜索和自我奖励机制提高了LVLMs的推理能力。VReST精心遍历推理领域,建立搜索树,每个节点包含一个推理步骤,每条路径描述了一个全面的推理序列。我们的创新多模态自我奖励机制通过整合子问题的实用性、答案的正确性以及视觉语言线索的相关性来评估推理步骤的质量,无需额外的模型。VReST超越了当前的提示方法,在三个多模态数学推理基准测试中取得了最先进的性能。此外,它证实了测试时缩放定律在多模态任务中的有效性,为未来的研究提供了有希望的方向。
Key Takeaways
- VReST是一种新型的、训练外的方法,旨在提高大型视觉语言模型(LVLMs)在复杂视觉推理方面的性能。
- VReST通过蒙特卡洛树搜索进行自我遍历,每个节点代表一个推理步骤,整个路径则代表完整的推理过程。
- VReST引入了多模态自我奖励机制,该机制能评估推理步骤的质量,综合考虑子问题的实用性、答案的正确性以及视觉语言线索的相关性。
- VReST在三个多模态数学推理基准测试中取得了最先进的性能表现。
- 与现有的提示方法相比,VReST展现出明显的优势。
- VReST实验证实了测试时缩放定律在多模态任务中的有效性。
点此查看论文截图

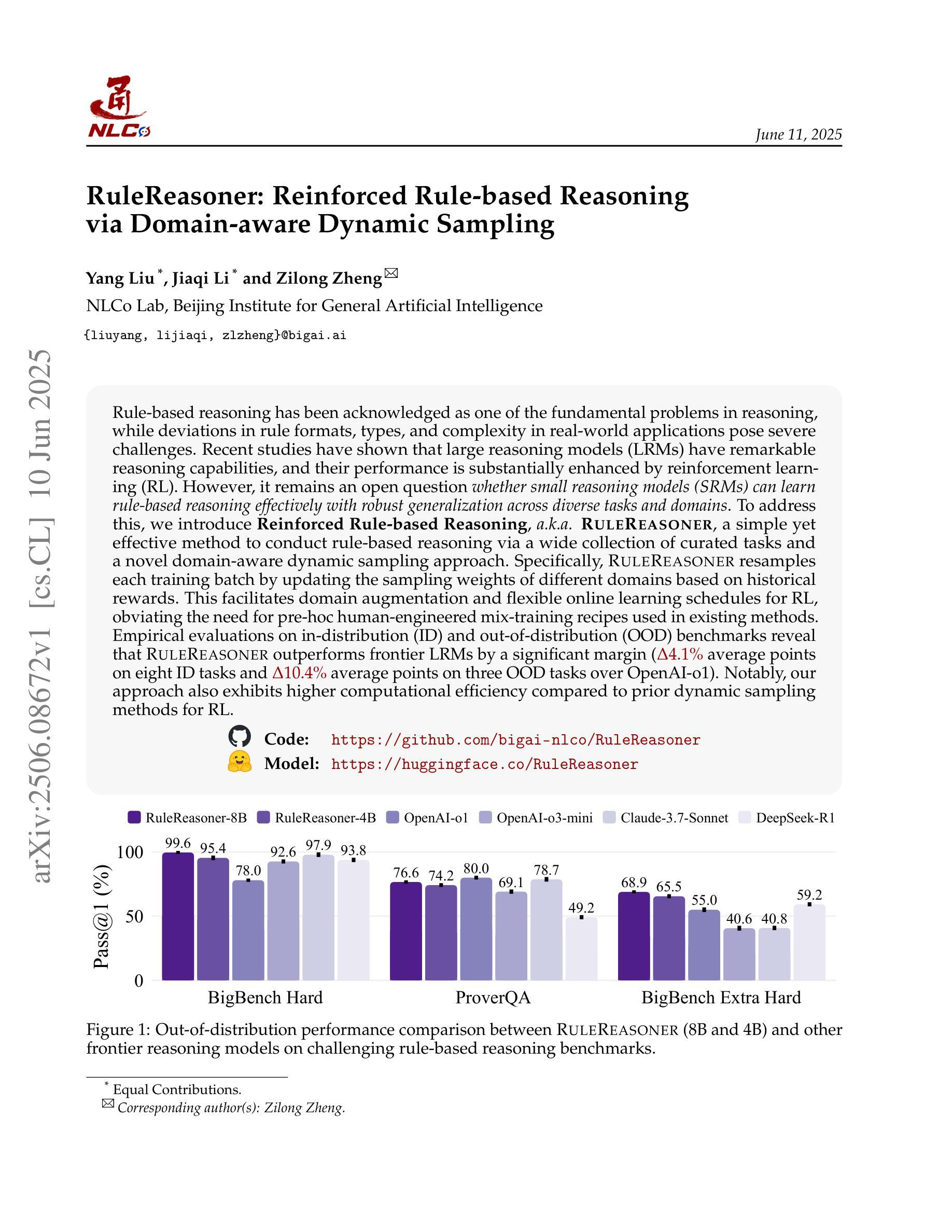
RuleReasoner: Reinforced Rule-based Reasoning via Domain-aware Dynamic Sampling
Authors:Yang Liu, Jiaqi Li, Zilong Zheng
Rule-based reasoning has been acknowledged as one of the fundamental problems in reasoning, while deviations in rule formats, types, and complexity in real-world applications pose severe challenges. Recent studies have shown that large reasoning models (LRMs) have remarkable reasoning capabilities, and their performance is substantially enhanced by reinforcement learning (RL). However, it remains an open question whether small reasoning models (SRMs) can learn rule-based reasoning effectively with robust generalization across diverse tasks and domains. To address this, we introduce Reinforced Rule-based Reasoning, a.k.a. RuleReasoner, a simple yet effective method to conduct rule-based reasoning via a wide collection of curated tasks and a novel domain-aware dynamic sampling approach. Specifically, RuleReasoner resamples each training batch by updating the sampling weights of different domains based on historical rewards. This facilitates domain augmentation and flexible online learning schedules for RL, obviating the need for pre-hoc human-engineered mix-training recipes used in existing methods. Empirical evaluations on in-distribution (ID) and out-of-distribution (OOD) benchmarks reveal that RuleReasoner outperforms frontier LRMs by a significant margin ($\Delta$4.1% average points on eight ID tasks and $\Delta$10.4% average points on three OOD tasks over OpenAI-o1). Notably, our approach also exhibits higher computational efficiency compared to prior dynamic sampling methods for RL.
基于规则的推理已被认为是推理领域的一个根本问题,而在现实世界的应用中,规则格式、类型和复杂性的偏差带来了严重的挑战。最近的研究表明,大型推理模型(LRMs)具有出色的推理能力,并且其性能通过强化学习(RL)得到了显著提高。然而,仍然存在一个悬而未决的问题,即小型推理模型(SRMs)是否能够在多样化的任务和领域中有效地学习基于规则的推理并具有稳健的泛化能力。为了解决这个问题,我们引入了强化规则推理(Reinforced Rule-based Reasoning),也称为RuleReasoner。这是一种简单而有效的方法,通过大量精选的任务和一种新的领域感知动态采样方法进行基于规则的推理。具体来说,RuleReasoner通过根据历史奖励更新不同领域的采样权重来重新采样每个训练批次。这促进了领域扩充和强化学习的灵活在线学习时间表,避免了现有方法中使用的预先设计好的混合训练配方。在内部数据分布(ID)和外部数据分布(OOD)基准上的经验评估显示,RuleReasoner显著超越了前沿的LRMs(在八个ID任务上平均提高了Δ4.1%,在三个OOD任务上平均提高了Δ10.4%,超过了OpenAI-o1)。值得注意的是,我们的方法相较于先前的强化学习动态采样方法还表现出了更高的计算效率。
论文及项目相关链接
PDF 22 pages, 10 figures, 8 tables
Summary
本文主要介绍了针对规则推理领域的一项新技术——Reinforced Rule-based Reasoning(RuleReasoner)。针对小推理模型在多样化的任务和领域中是否能有效地学习规则推理的问题,文章提出了一种简单而有效的方法来执行规则推理。它通过广泛的收集精选任务和一种新的领域感知动态采样方法来实现。该方法能够根据历史奖励动态调整不同领域的采样权重,简化了RL的预训练混合训练配方需求。在内部和外部基准测试中,RuleReasoner显著优于前沿的大型推理模型,并表现出更高的计算效率。
Key Takeaways
- 强化规则推理(Reinforced Rule-based Reasoning)是一种解决小推理模型(SRMs)在多样化任务和领域中学习规则推理的有效方法。
- RuleReasoner通过广泛的收集精选任务和领域感知动态采样方法实现规则推理。
- 动态采样方法能够根据历史奖励调整采样权重,简化了强化学习(RL)的训练过程。
- RuleReasoner在内部和外部基准测试中均显著优于大型推理模型(LRMs)。
- RuleReasoner对OpenAI-o1的八个内部任务平均提高了4.1%的得分,对三个外部任务平均提高了10.4%的得分。
- 与现有的动态采样方法相比,RuleReasoner展现出更高的计算效率。
点此查看论文截图

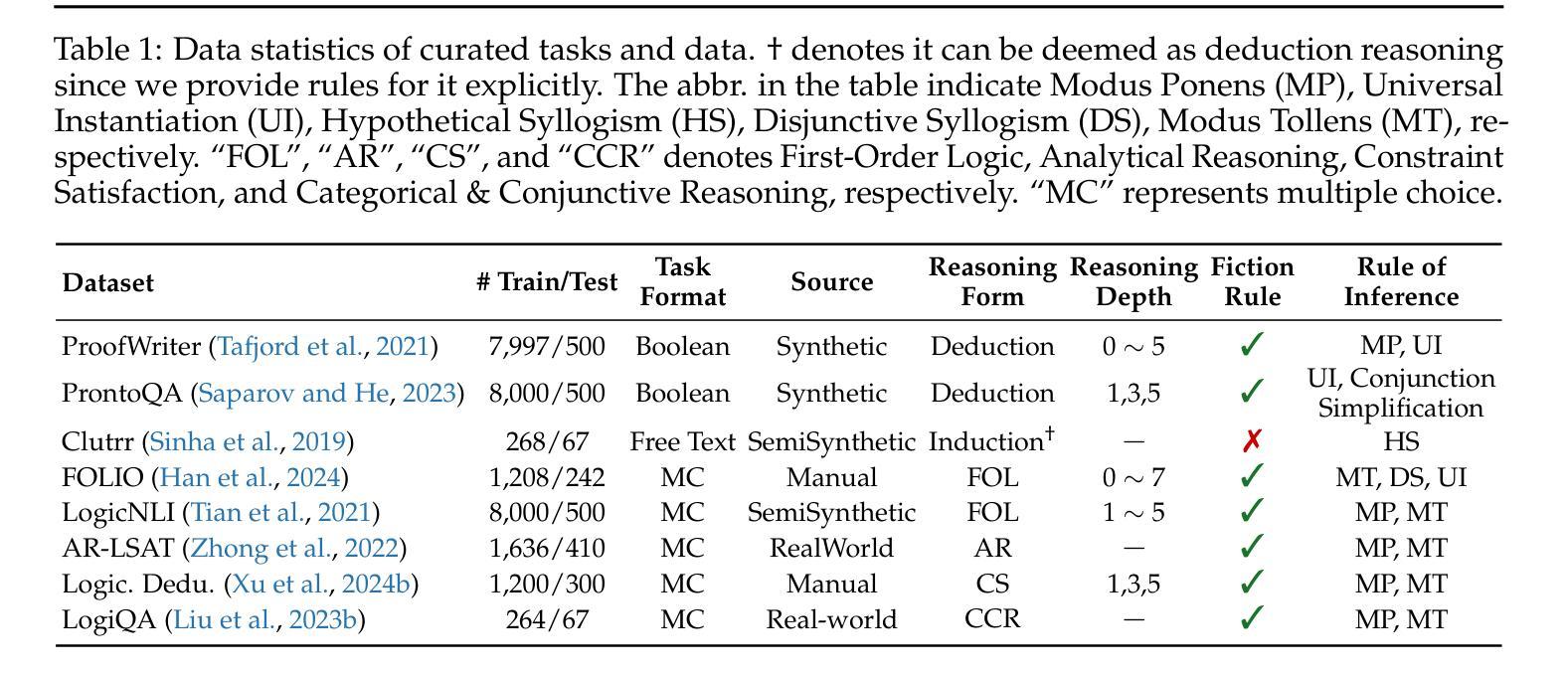
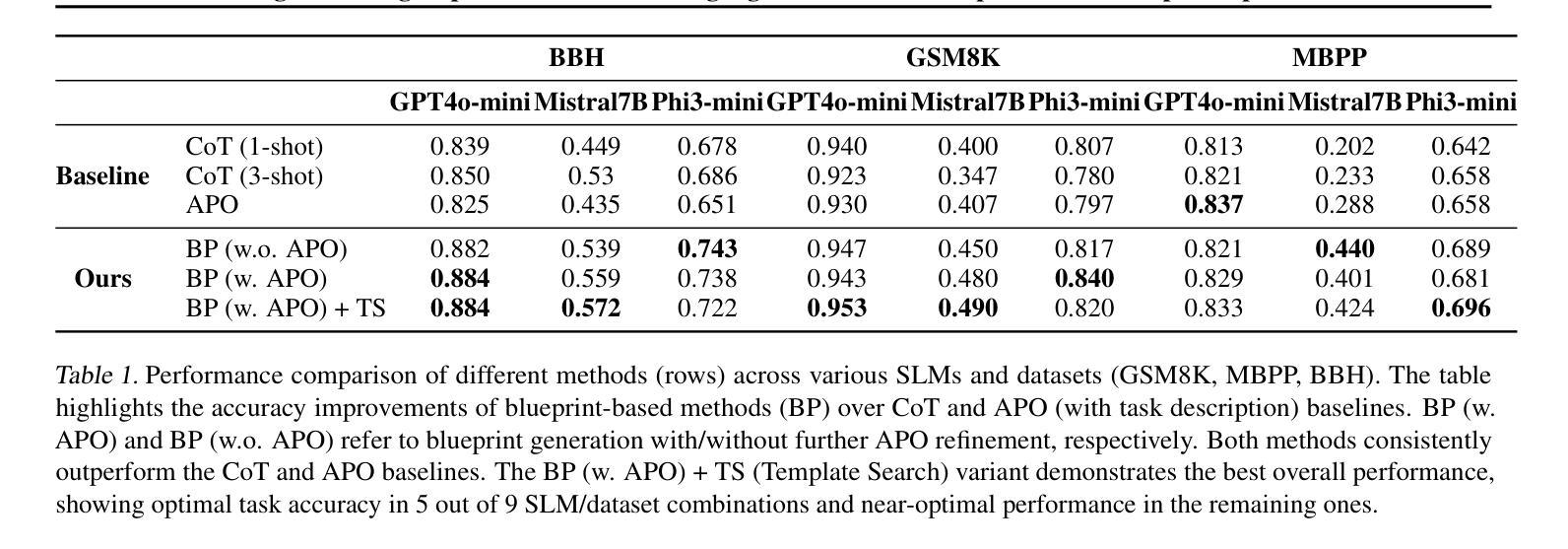
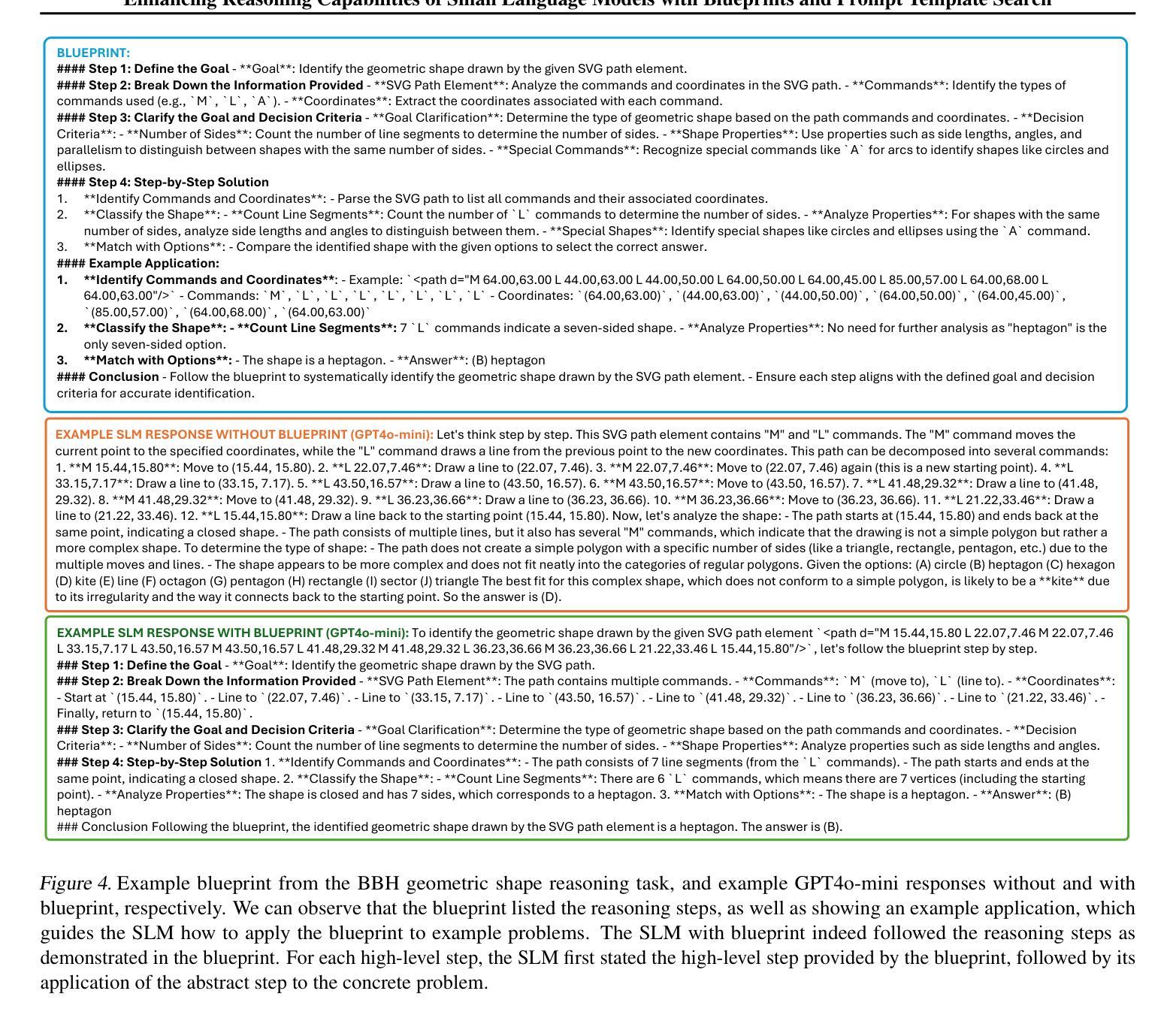
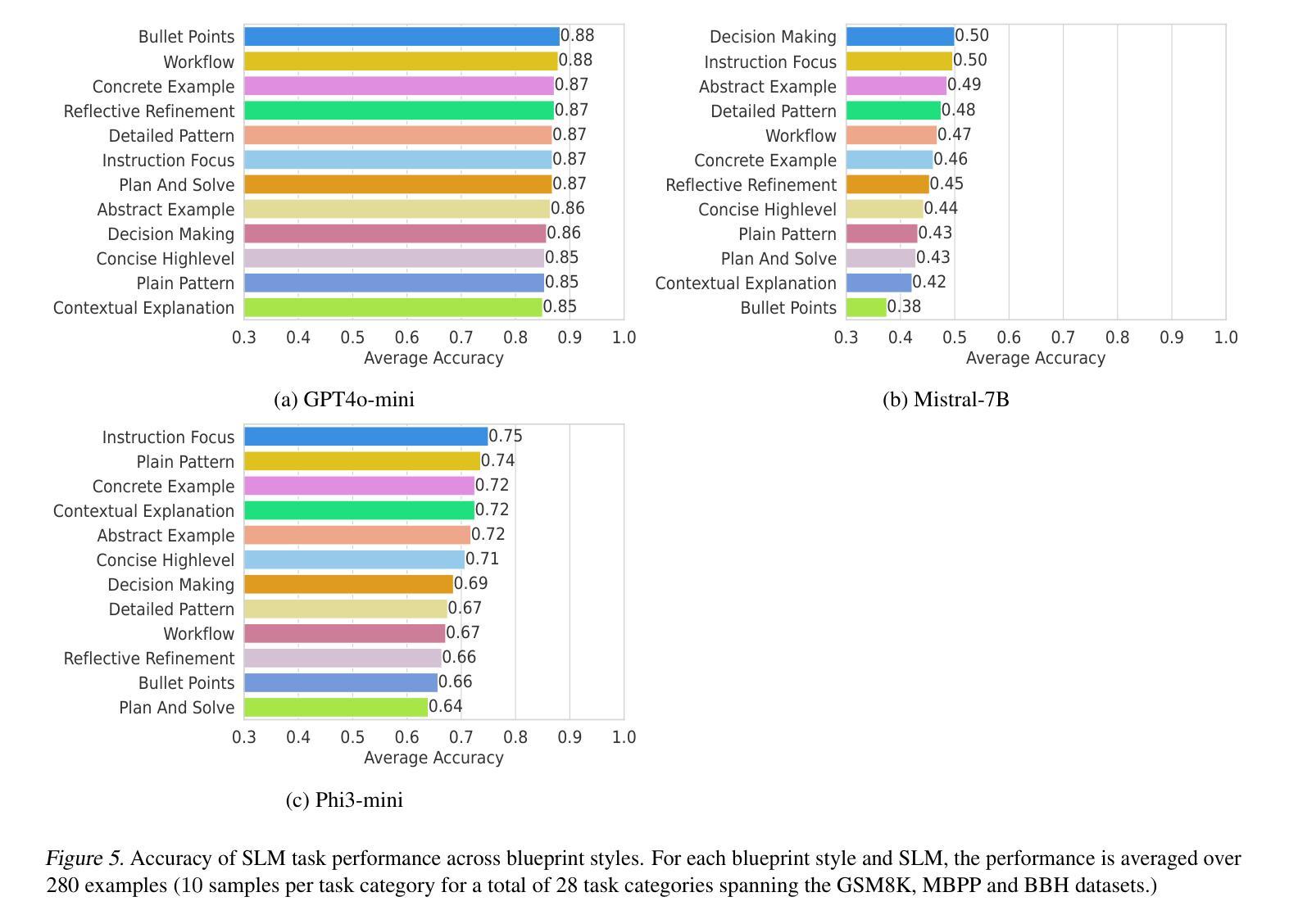
Enhancing Reasoning Capabilities of Small Language Models with Blueprints and Prompt Template Search
Authors:Dongge Han, Menglin Xia, Daniel Madrigal Diaz, Samuel Kessler, Ankur Mallick, Xuchao Zhang, Mirian Del Carmen Hipolito Garcia, Jin Xu, Victor Rühle, Saravan Rajmohan
Small language models (SLMs) offer promising and efficient alternatives to large language models (LLMs). However, SLMs’ limited capacity restricts their reasoning capabilities and makes them sensitive to prompt variations. To address these challenges, we propose a novel framework that enhances SLM reasoning capabilities through LLM generated blueprints. The blueprints provide structured, high-level reasoning guides that help SLMs systematically tackle related problems. Furthermore, our framework integrates a prompt template search mechanism to mitigate the SLMs’ sensitivity to prompt variations. Our framework demonstrates improved SLM performance across various tasks, including math (GSM8K), coding (MBPP), and logic reasoning (BBH). Our approach improves the reasoning capabilities of SLMs without increasing model size or requiring additional training, offering a lightweight and deployment-friendly solution for on-device or resource-constrained environments.
小型语言模型(SLMs)为大型语言模型(LLMs)提供了有前景和高效的替代方案。然而,SLM的能力有限,限制了其推理能力,并对提示变化敏感。为了解决这些挑战,我们提出了一种新型框架,该框架通过LLM生成的蓝图增强SLM的推理能力。这些蓝图提供结构化、高级别的推理指南,帮助SLM系统地解决相关问题。此外,我们的框架集成了一种提示模板搜索机制,以减轻SLM对提示变化的敏感性。我们的框架在各种任务中展示了改进的SLM性能,包括数学(GSM8K)、编码(MBPP)和逻辑推理(BBH)。我们的方法提高了SLM的推理能力,而无需增加模型大小或进行额外的训练,为设备端或资源受限的环境提供了轻便且易于部署的解决方案。
论文及项目相关链接
PDF TTODLer-FM Workshop@ICML’25 (Tiny Titans: The next wave of On-Device Learning for Foundational Models)
Summary
小语言模型(SLMs)作为一种对大语言模型(LLMs)的替代方案,展现出其潜力与高效性。然而,SLMs受限于其能力,存在推理能力不足和对提示变化敏感的问题。为解决这些挑战,我们提出一种新型框架,利用LLM生成的蓝图来提升SLM的推理能力。这些蓝图为SLMs提供结构化、高级别的推理指南,帮助它们系统地解决相关问题。此外,我们的框架还整合了提示模板搜索机制,以降低SLMs对提示变化的敏感性。在各项任务中,我们的框架展现出对SLM性能的改进,包括数学(GSM8K)、编程(MBPP)和逻辑推理(BBH)等。我们的方法在不增加模型规模或不需要额外训练的情况下提升了SLMs的推理能力,为设备端或资源受限环境提供了轻便且易于部署的解决方案。
Key Takeaways
- 小语言模型(SLMs)展现出对大型语言模型(LLMs)的替代潜力,并具备高效性。
- SLM受限于其推理能力以及对提示变化的敏感性。
- 提出一种新型框架,利用LLM生成的蓝图增强SLM的推理能力。
- 蓝图为SLMs提供结构化、高级别的推理指南,帮助解决相关问题。
- 整合提示模板搜索机制以降低SLMs对提示变化的敏感性。
- 在数学、编程和逻辑推理等任务中,新框架提升了SLM的性能。
点此查看论文截图

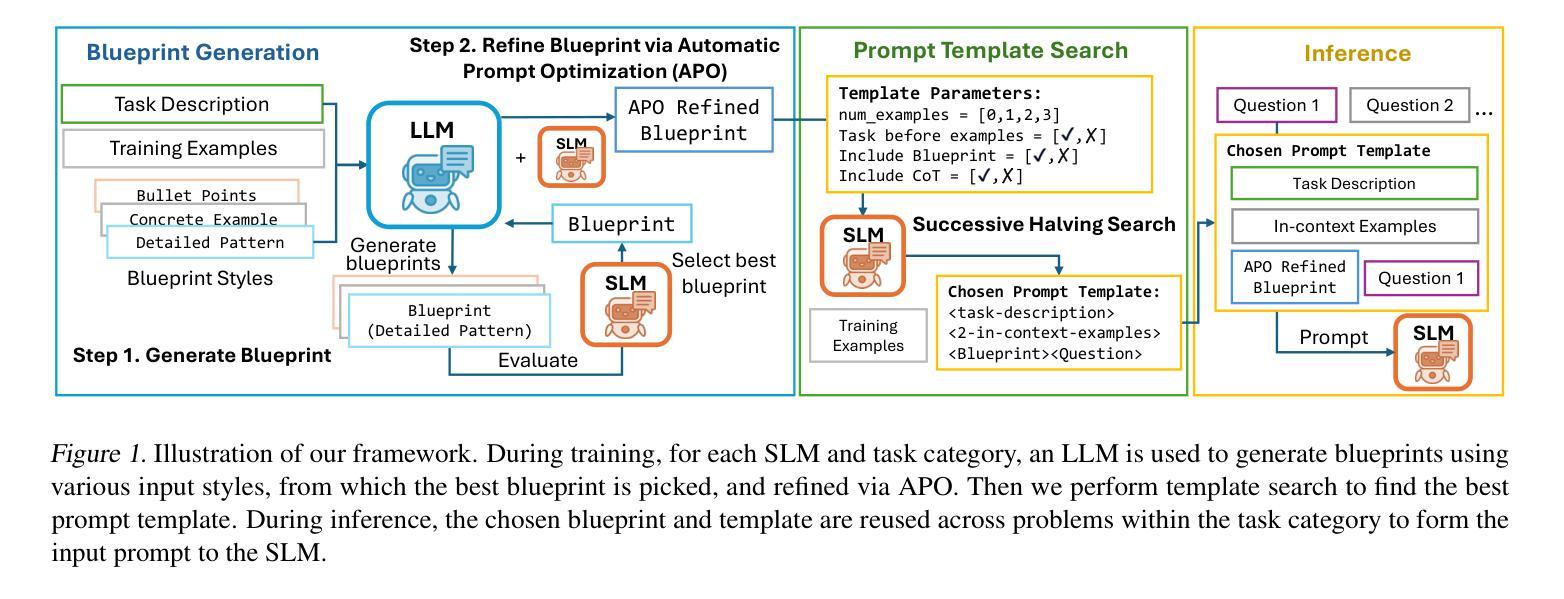

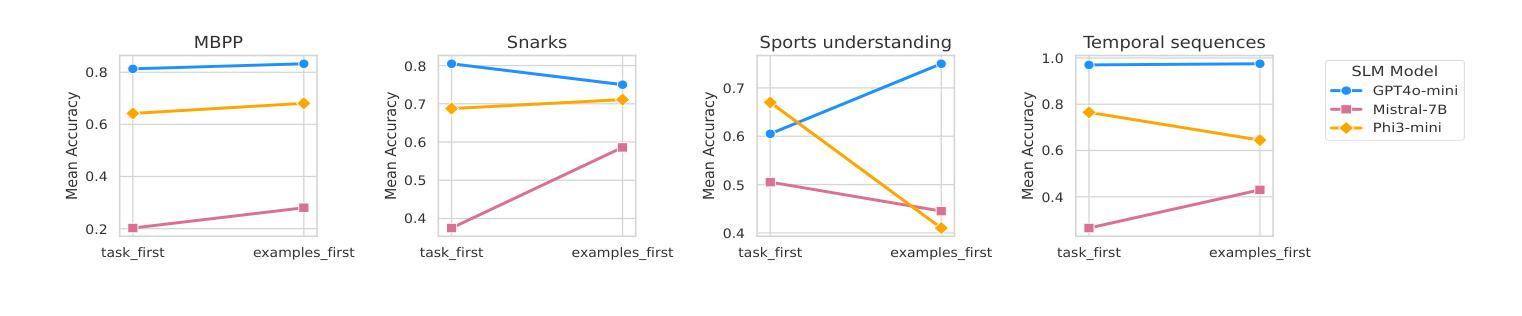
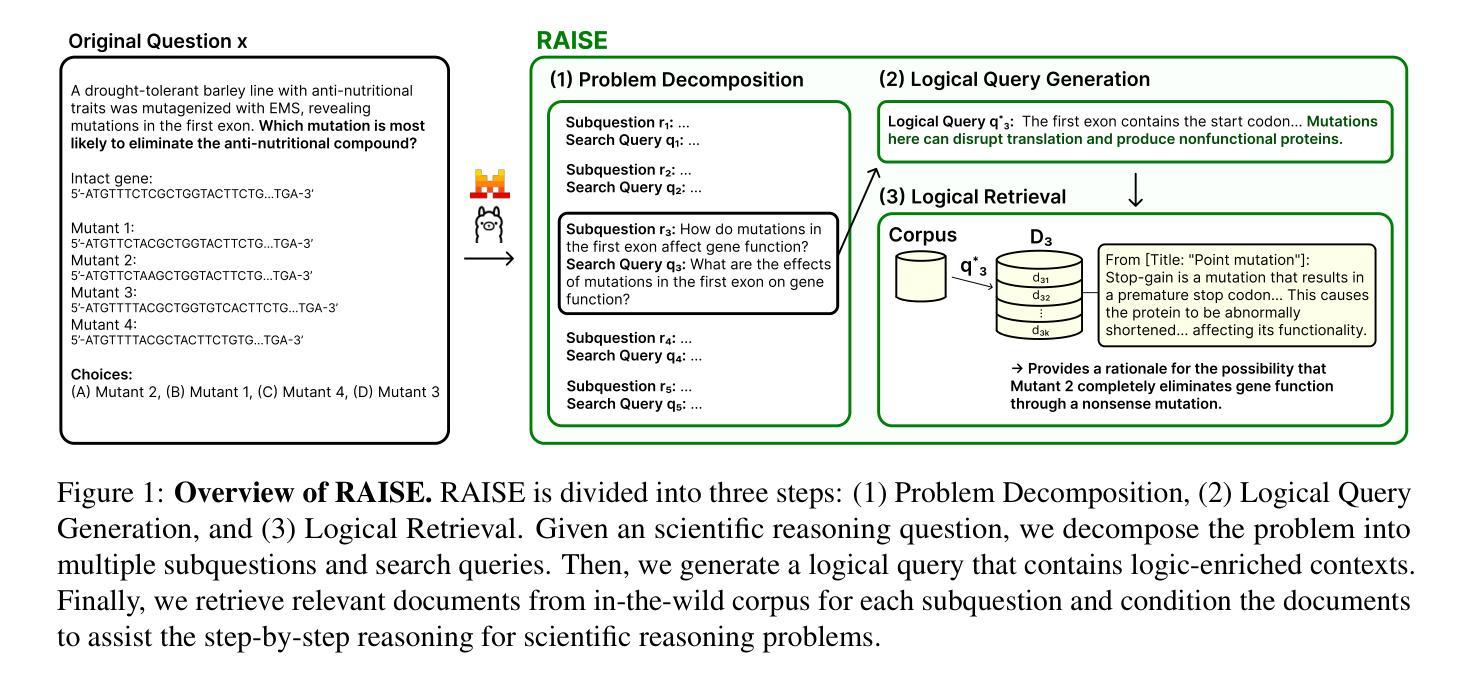
RAISE: Enhancing Scientific Reasoning in LLMs via Step-by-Step Retrieval
Authors:Minhae Oh, Jeonghye Kim, Nakyung Lee, Donggeon Seo, Taeuk Kim, Jungwoo Lee
Scientific reasoning requires not only long-chain reasoning processes, but also knowledge of domain-specific terminologies and adaptation to updated findings. To deal with these challenges for scientific reasoning, we introduce RAISE, a step-by-step retrieval-augmented framework which retrieves logically relevant documents from in-the-wild corpus. RAISE is divided into three steps: problem decomposition, logical query generation, and logical retrieval. We observe that RAISE consistently outperforms other baselines on scientific reasoning benchmarks. We analyze that unlike other baselines, RAISE retrieves documents that are not only similar in terms of the domain knowledge, but also documents logically more relevant.
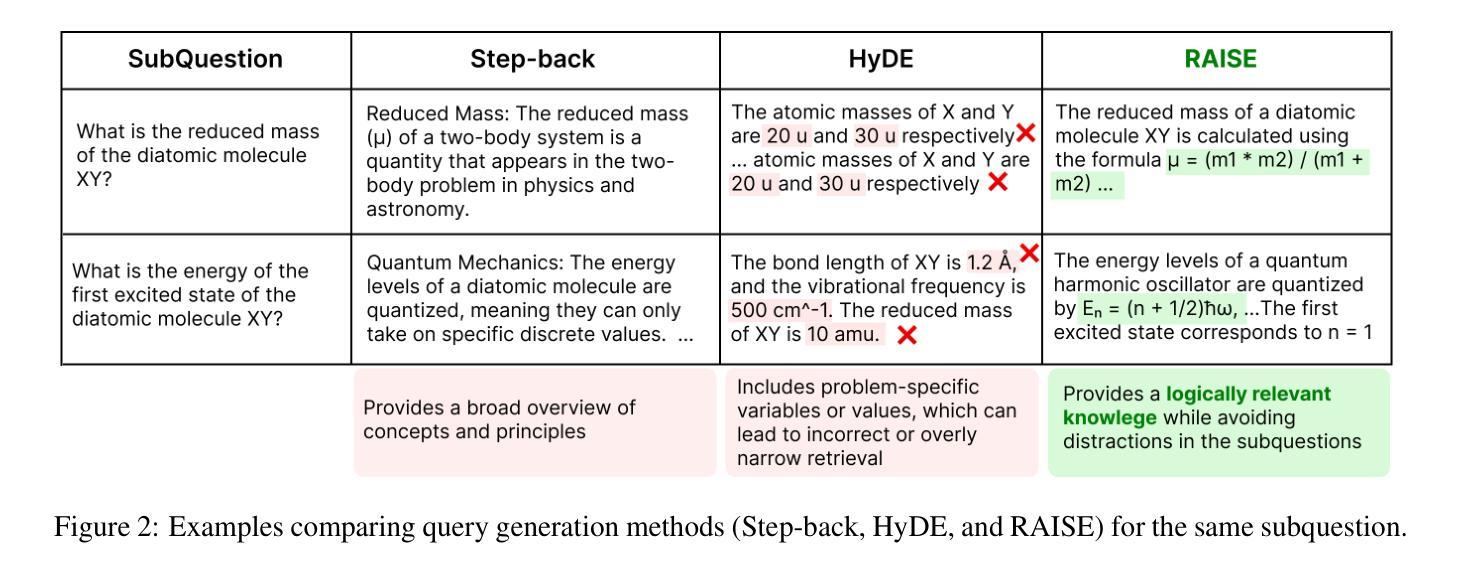
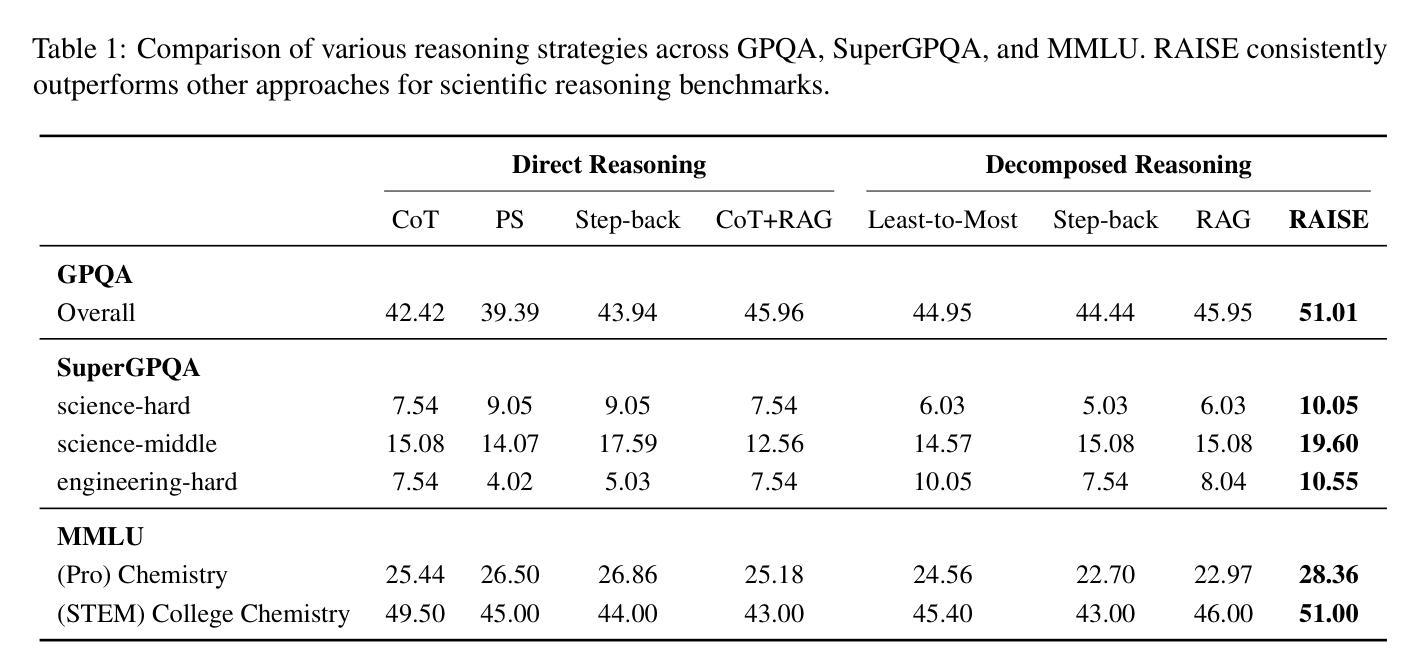
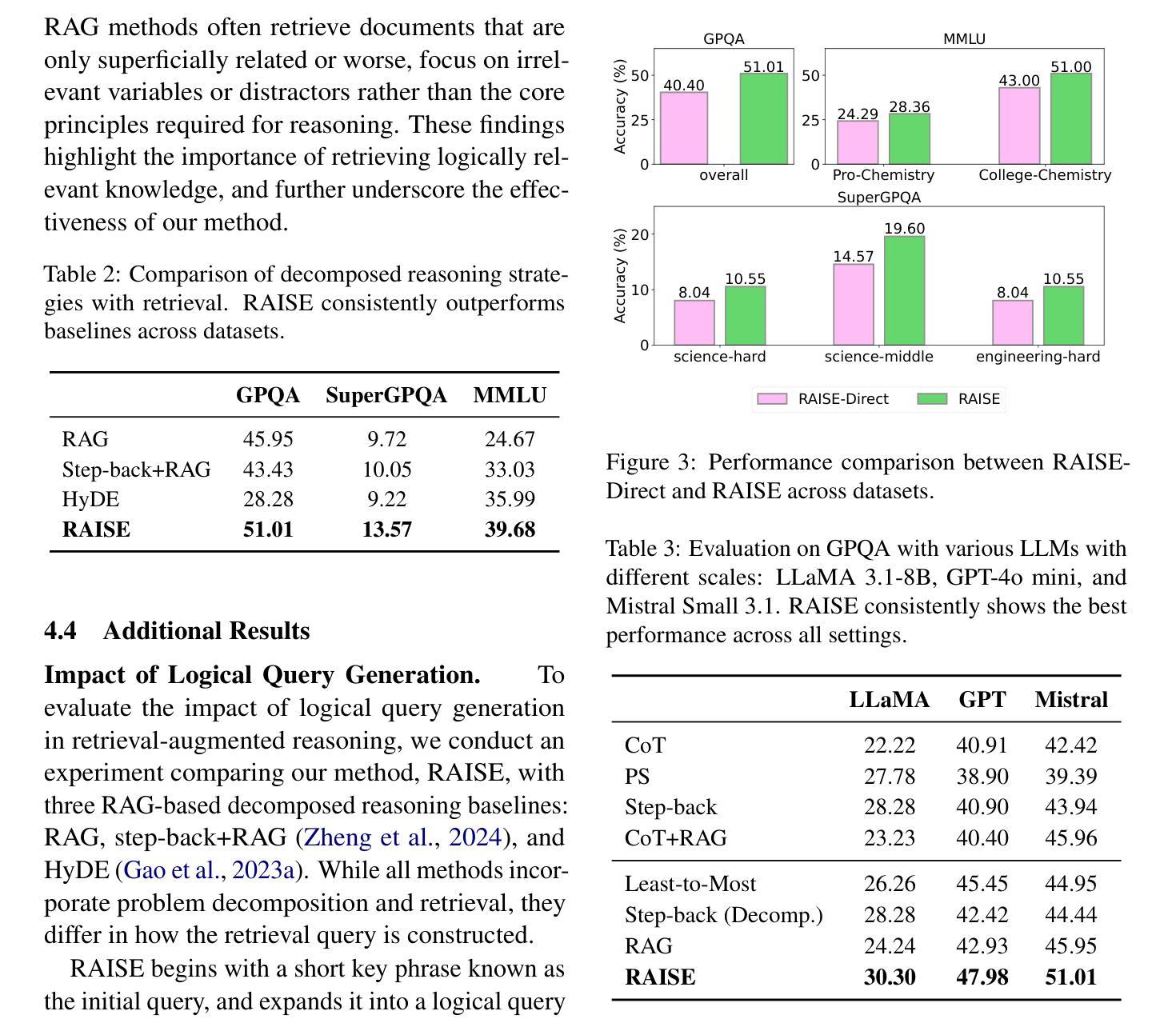
科学推理不仅需要长链推理过程,还需要对特定领域的术语有了解,并适应最新的研究成果。为了应对科学推理的这些挑战,我们引入了RAISE,这是一个分步骤的检索增强框架,可以从野生语料库中检索出逻辑相关的文档。RAISE分为三个步骤:问题分解、逻辑查询生成和逻辑检索。我们发现,在科学推理基准测试中,RAISE的性能始终优于其他基线方法。我们分析认为,与其他基线方法不同,RAISE检索到的文档不仅具有相似的领域知识,而且在逻辑上更加相关。
论文及项目相关链接
Summary
本文介绍了RAISE这一逐步增强的框架,用于解决科学推理中的挑战。该框架包括问题分解、逻辑查询生成和逻辑检索三个步骤。RAISE能够从野外语料库中检索出与科学推理相关的逻辑文档,并且在科学推理基准测试中表现优异。相较于其他基线方法,RAISE不仅能够检索到领域知识相似的文档,还能检索到逻辑上更为相关的文档。
Key Takeaways
- RAISE是一个用于解决科学推理挑战的逐步增强框架。
- RAISE包括问题分解、逻辑查询生成和逻辑检索三个主要步骤。
- RAISE能够从野外语料库中检索出与科学推理相关的逻辑文档。
- RAISE在科学推理基准测试中表现优异。
- 与其他基线方法相比,RAISE不仅能检索到领域知识相似的文档,还能找到逻辑上更相关的文档。
- 科学推理不仅需要长链推理过程,还需要对特定领域的术语知识的了解以及适应最新的发现。
点此查看论文截图

RE-oriented Model Development with LLM Support and Deduction-based Verification
Authors:Radoslaw Klimek
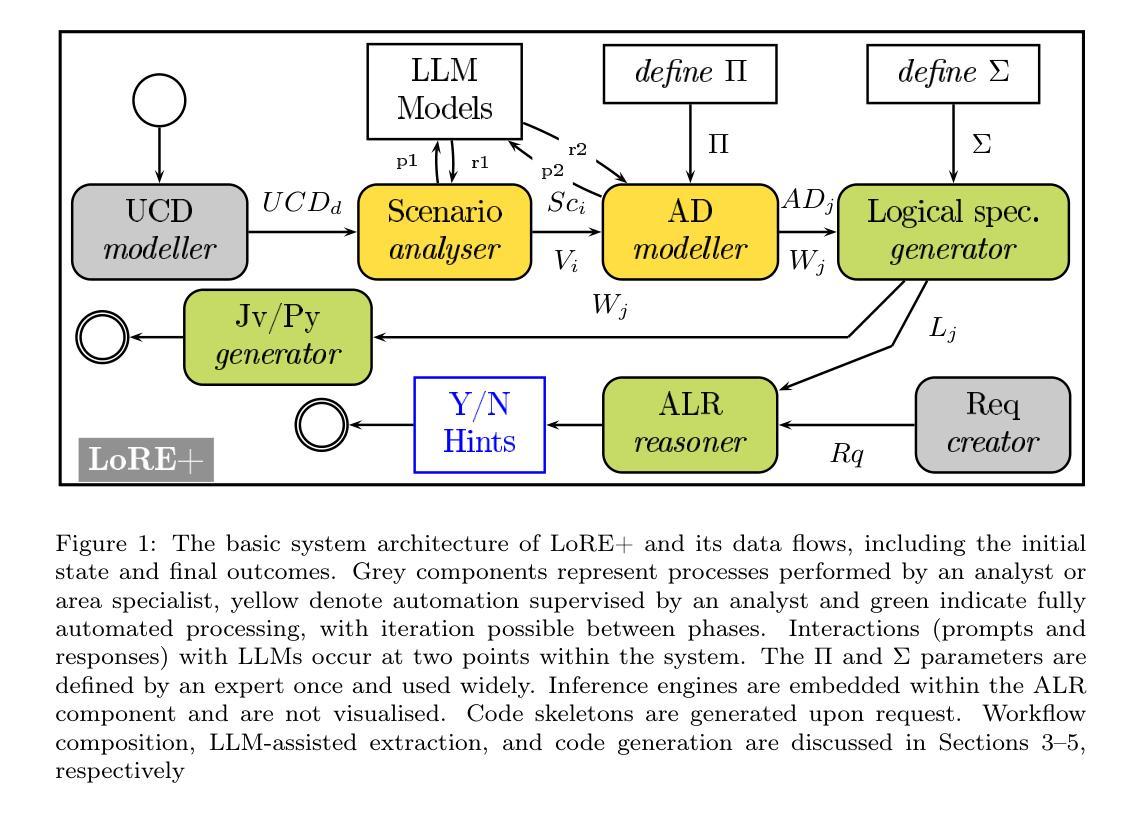
The requirements engineering (RE) phase is pivotal in developing high-quality software. Integrating advanced modelling techniques with large language models (LLMs) and formal verification in a logical style can significantly enhance this process. We propose a comprehensive framework that focuses on specific Unified Modelling Language (UML) diagrams for preliminary system development. This framework offers visualisations at various modelling stages and seamlessly integrates large language models and logical reasoning engines. The behavioural models generated with the assistance of LLMs are automatically translated into formal logical specifications. Deductive formal verification ensures that logical requirements and interrelations between software artefacts are thoroughly addressed. Ultimately, the framework facilitates the automatic generation of program skeletons, streamlining the transition from design to implementation.
需求工程(RE)阶段在开发高质量软件过程中至关重要。通过集成先进的建模技术与大型语言模型(LLM)和逻辑风格的正式验证,可以显著增强此过程。我们提出一个全面的框架,专注于初步系统开发的特定统一建模语言(UML)图表。该框架提供了不同建模阶段的可视化,无缝集成了大型语言模型和逻辑推理引擎。借助LLM生成的行为模型会自动转换为正式的逻辑规范。演绎式正式验证确保逻辑需求和软件工件之间的相互作用得到全面解决。最终,该框架促进了程序骨架的自动生成,简化了从设计到实施的过渡。
论文及项目相关链接
PDF The paper has been peer-reviewed and accepted for publication to the 1st International Workshop on Artificial Intelligence for Integrated Development Environments (AI-IDE) of the 33rd ACM Symposium on the Foundations of Software Engineering (FSE ‘25), June 23–27, 2025, Trondheim, Norway
Summary
在软件开发中,需求工程(RE)阶段至关重要。通过集成先进的建模技术、大型语言模型(LLM)和逻辑风格的正式验证,可以显著增强此过程。我们提出了一个全面的框架,侧重于初步系统开发的特定统一建模语言(UML)图。该框架在多个建模阶段提供可视化,无缝集成大型语言模型和逻辑推理引擎。借助LLM生成的行为模型自动翻译为正式的逻辑规范。演绎式正式验证确保全面解决逻辑要求和软件工件之间的相互作用。最终,该框架能够自动生成程序骨架,使设计到实施的过渡更加顺畅。
Key Takeaways
- 需求工程(RE)在软件开发中起关键作用。
- 先进建模技术、大型语言模型(LLM)和逻辑验证的集成能显著增强RE过程。
- 提出的框架利用UML图进行初步系统开发,并在不同建模阶段提供可视化。
- 框架无缝集成大型语言模型和逻辑推理引擎。
- 行为模型可自动转换为正式的逻辑规范。
- 演绎式正式验证确保逻辑需求和软件工件间的相互作用得到充分解决。
点此查看论文截图

SLEEPYLAND: trust begins with fair evaluation of automatic sleep staging models
Authors:Alvise Dei Rossi, Matteo Metaldi, Michal Bechny, Irina Filchenko, Julia van der Meer, Markus H. Schmidt, Claudio L. A. Bassetti, Athina Tzovara, Francesca D. Faraci, Luigi Fiorillo
Despite advances in deep learning for automatic sleep staging, clinical adoption remains limited due to challenges in fair model evaluation, generalization across diverse datasets, model bias, and variability in human annotations. We present SLEEPYLAND, an open-source sleep staging evaluation framework designed to address these barriers. It includes more than 22’0000 hours in-domain (ID) sleep recordings, and more than 84’000 hours out-of-domain (OOD) sleep recordings, spanning a broad range of ages, sleep-wake disorders, and hardware setups. We release pre-trained models based on high-performing SoA architectures and evaluate them under standardized conditions across single- and multi-channel EEG/EOG configurations. We introduce SOMNUS, an ensemble combining models across architectures and channel setups via soft voting. SOMNUS achieves robust performance across twenty-four different datasets, with macro-F1 scores between 68.7% and 87.2%, outperforming individual models in 94.9% of cases. Notably, SOMNUS surpasses previous SoA methods, even including cases where compared models were trained ID while SOMNUS treated the same data as OOD. Using a subset of the BSWR (N=6’633), we quantify model biases linked to age, gender, AHI, and PLMI, showing that while ensemble improves robustness, no model architecture consistently minimizes bias in performance and clinical markers estimation. In evaluations on OOD multi-annotated datasets (DOD-H, DOD-O), SOMNUS exceeds the best human scorer, i.e., MF1 85.2% vs 80.8% on DOD-H, and 80.2% vs 75.9% on DOD-O, better reproducing the scorer consensus than any individual expert (k = 0.89/0.85 and ACS = 0.95/0.94 for healthy/OSA cohorts). Finally, we introduce ensemble disagreement metrics - entropy and inter-model divergence based - predicting regions of scorer disagreement with ROC AUCs up to 0.828, offering a data-driven proxy for human uncertainty.
尽管深度学习在自动睡眠分期方面取得了进展,但由于模型公平评估、跨不同数据集推广、模型偏见和人为注释差异等挑战,其在临床采纳方面仍然受到限制。我们推出了SLEEPYLAND,这是一个旨在解决这些障碍的开源睡眠分期评估框架。它包含超过22万小时领域内(ID)睡眠记录,以及超过8.4万小时领域外(OOD)睡眠记录,涵盖广泛年龄段、睡眠障碍和硬件设置。我们基于高性能最新架构发布预训练模型,并在单一和多通道脑电图/眼电图配置的标准条件下对它们进行评估。我们引入了SOMNUS,一种通过软投票结合不同架构和频道设置的模型集合。SOMNUS在二十四种不同数据集上表现稳健,宏观F1分数介于68.7%和87.2%之间,在94.9%的情况下表现优于单个模型。值得注意的是,即使在将对比模型视为领域内数据而SOMNUS将相同数据视为领域外数据的情况下,SOMNUS也超过了之前的最新方法。使用BSWR子集(N=6633),我们量化了与年龄、性别、AHI和PLMI相关的模型偏见,结果表明,尽管集合提高了稳健性,但没有模型架构始终如一地减少偏见和临床标记估计的偏差。在领域外多注释数据集(DOD-H,DOD-O)的评估中,SOMNUS的表现超过了最佳人类评分者(即在DOD-H上的MF1为85.2%对比80.8%,以及在DOD-O上的MF1为80.2%对比75.9%),更准确地复制了评分共识相比任何个人专家(健康组/OSA组的k值为0.89/0.85和ACS值为0.95/0.94)。最后,我们引入了基于集合不一致性度量的预测区域评分者分歧的指标,包括熵和模型间发散度等指标,ROC AUC高达0.828,为人为不确定性提供了数据驱动代理。
论文及项目相关链接
PDF 41 pages, 4 Figures, 7 Tables
Summary
本文介绍了SLEEPYLAND这一睡眠分期评估框架,旨在解决深度学习在临床应用中的挑战。框架包含大量睡眠记录数据,并基于高性能架构发布预训练模型。此外,还引入了SOMNUS模型组合技术,通过软投票方式实现稳健性能。研究结果显示,SOMNUS在不同数据集上的表现优于单一模型及先前最佳方法。同时,该研究还探讨了模型与临床指标估计的偏见问题,并引入模型组合分歧度量指标预测评分者分歧区域。
Key Takeaways
- SLEEPYLAND是一个开源的睡眠分期评估框架,旨在解决深度学习在临床应用中的挑战,包括公平模型评估、跨不同数据集泛化等。
- 框架包含大量睡眠记录数据,既包括in-domain(ID)数据也包括out-of-domain(OOD)数据,并基于高性能架构发布预训练模型。
- 引入SOMNUS模型组合技术,通过软投票方式结合不同架构和通道设置的模型,实现稳健性能。
- SOMNUS在多个不同数据集上的表现优于单一模型及先前最佳方法,包括处理训练数据作为OOD的情况。
- 研究发现模型与年龄、性别、AHI和PLMI等临床指标估计存在偏见,而模型组合能提高稳健性,但无法一致减少偏见。
- 在多注解数据集上的评价显示,SOMNUS的表现优于最佳人类评分者,更能反映评分者共识。
点此查看论文截图

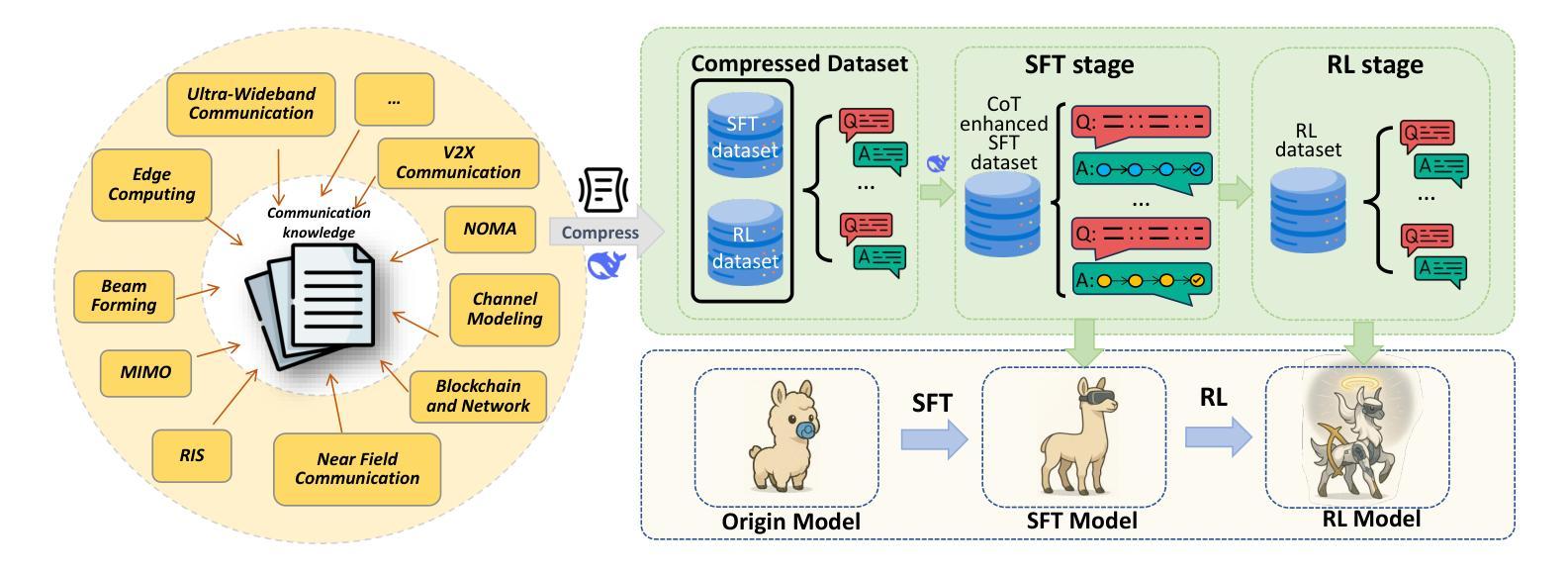
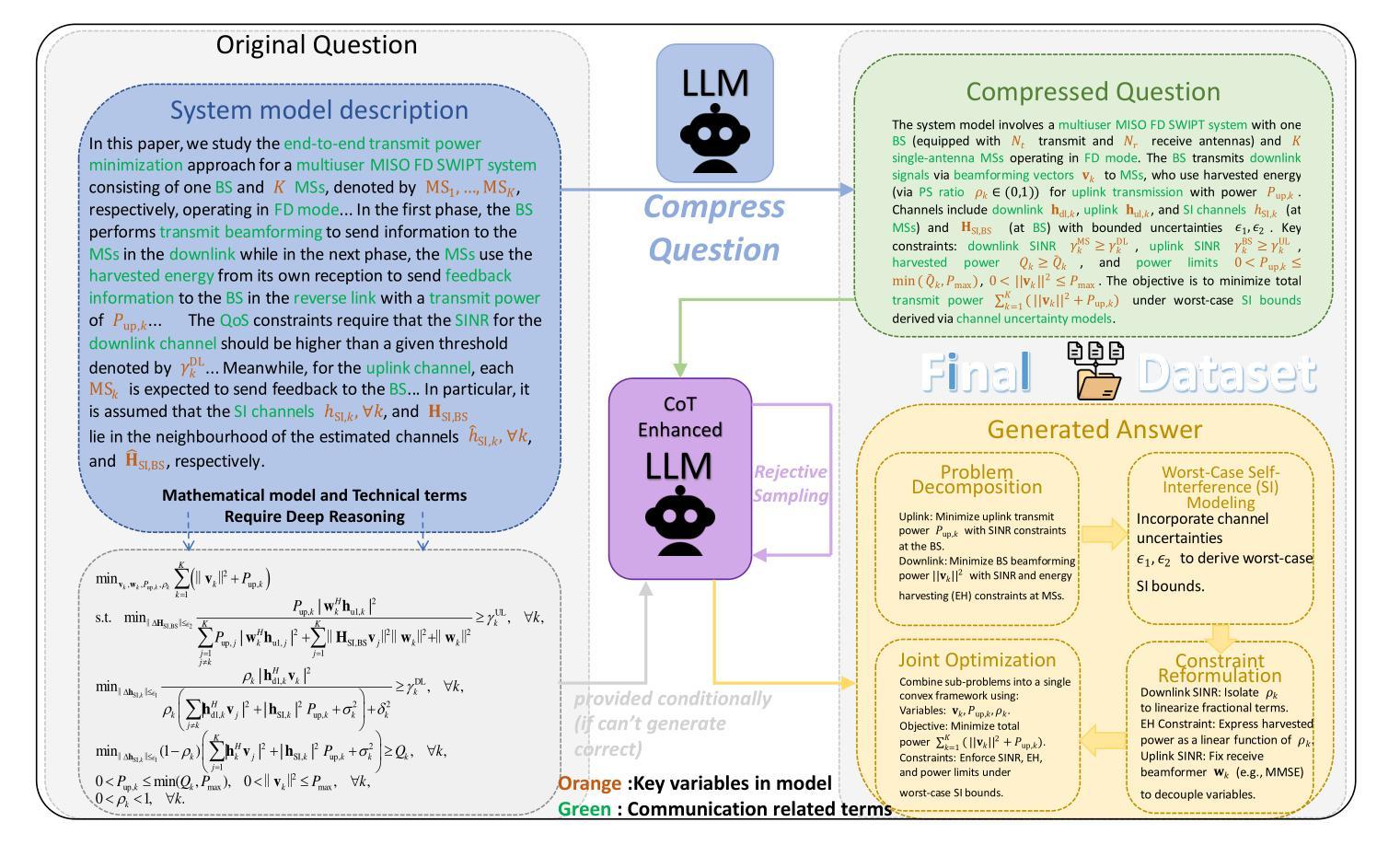
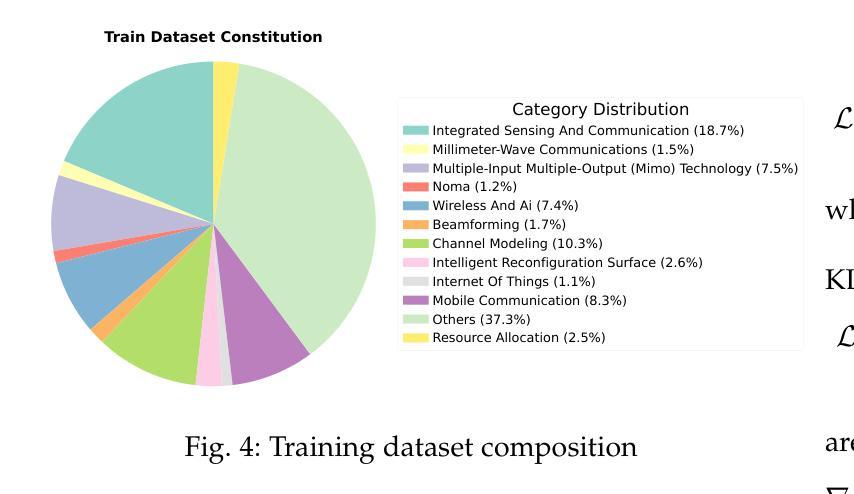
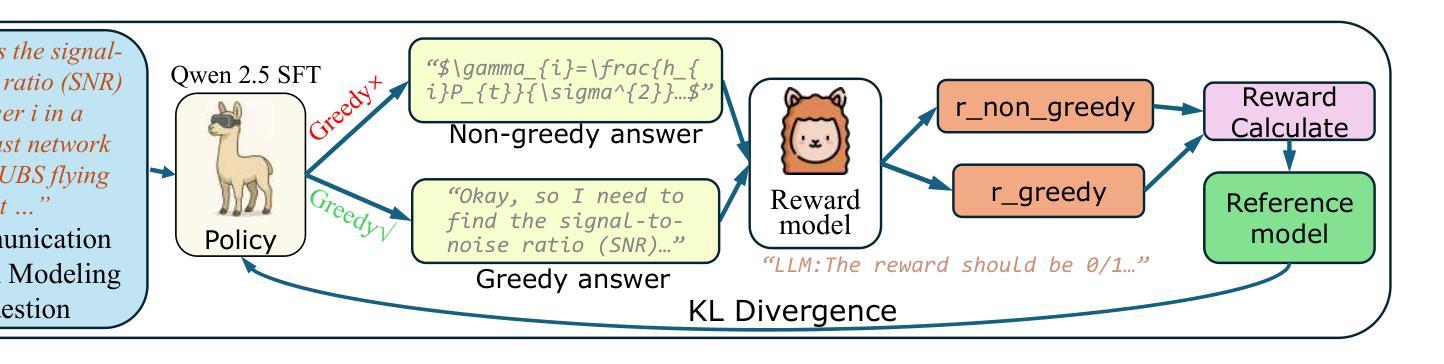
DeepForm: Reasoning Large Language Model for Communication System Formulation
Authors:Panlong Wu, Ting Wang, Yifei Zhong, Haoqi Zhang, Zitong Wang, Fangxin Wang
Communication system formulation is critical for advancing 6G and future wireless technologies, yet it remains a complex, expertise-intensive task. While Large Language Models (LLMs) offer potential, existing general-purpose models often lack the specialized domain knowledge, nuanced reasoning capabilities, and access to high-quality, domain-specific training data required for adapting a general LLM into an LLM specially for communication system formulation. To bridge this gap, we introduce DeepForm, the first reasoning LLM specially for automated communication system formulation. We propose the world-first large-scale, open-source dataset meticulously curated for this domain called Communication System Formulation Reasoning Corpus (CSFRC). Our framework employs a two-stage training strategy: first, Supervised Fine-Tuning (SFT) with Chain-of-Thought (CoT) data to distill domain knowledge; second, a novel rule-based Reinforcement Learning (RL) algorithm, C-ReMax based on ReMax, to cultivate advanced modeling capabilities and elicit sophisticated reasoning patterns like self-correction and verification. Extensive experiments demonstrate that our model achieves state-of-the-art performance, significantly outperforming larger proprietary LLMs on diverse senerios. We will release related resources to foster further research in this area after the paper is accepted.
通信系统构建对于推动6G和未来无线技术的发展至关重要,然而它仍然是一项复杂且需要专业知识的任务。虽然大型语言模型(LLM)提供了潜力,但现有的通用模型通常缺乏特定领域的专业知识、微妙的推理能力以及访问高质量、特定领域的训练数据,这些均是适应通用LLM为专门用于通信系统构建的LLM所必需的要求。为了弥补这一差距,我们引入了DeepForm,这是首个用于自动化通信系统构建的特殊推理LLM。我们提出了世界上第一个针对该领域精心策划的大规模开源数据集,称为通信系统构建推理语料库(CSFRC)。我们的框架采用两阶段训练策略:首先,使用思维链(CoT)数据进行监督微调(SFT)以提炼领域知识;其次,基于ReMax的新型基于规则的强化学习(RL)算法C-ReMax,以培养高级建模能力并激发自我修正和验证等复杂推理模式。大量实验表明,我们的模型达到了最先进的性能,在多种场景下显著优于更大的专有LLM。论文被接受后,我们将发布相关资源以促进该领域的进一步研究。
论文及项目相关链接
Summary
该文介绍了通信系统的构建对于推动6G和未来无线技术的发展至关重要。针对大型语言模型(LLM)在通信系统设计领域的不足,提出了DeepForm,这是一个专门用于自动化通信系统设计的推理LLM。此外,还引入了首个大规模、开源的通信系统设计推理语料库CSFRC。该框架采用两阶段训练策略:第一阶段是采用带有思维链(CoT)数据的监督微调(SFT)来提炼领域知识;第二阶段是一种基于ReMax的新型规则强化学习(RL)算法C-ReMax,以培养高级建模能力和激发复杂的推理模式,如自我修正和验证。实验表明,该模型在多种场景下均达到业界最佳性能,明显优于更大的专有LLM。论文接受后将公开相关资源以促进该领域进一步研究。
Key Takeaways
- 通信系统的构建是推动未来无线技术和6G发展的关键。
- 大型语言模型(LLM)在通信系统设计领域存在不足,需要专门的模型来处理复杂任务。
- 引入了一种新的LLM模型——DeepForm,专门用于自动化通信系统构建。
- 引入了首个大规模、开源的通信系统设计推理语料库CSFRC。
- 采用两阶段训练策略来训练DeepForm模型,包括监督微调(SFT)和强化学习(RL)。
- 该模型在多种场景下表现出卓越性能,优于其他大型语言模型。
点此查看论文截图

Safe and Economical UAV Trajectory Planning in Low-Altitude Airspace: A Hybrid DRL-LLM Approach with Compliance Awareness
Authors:Yanwei Gong, Xiaolin Chang
The rapid growth of the low-altitude economy has driven the widespread adoption of unmanned aerial vehicles (UAVs). This growing deployment presents new challenges for UAV trajectory planning in complex urban environments. However, existing studies often overlook key factors, such as urban airspace constraints and economic efficiency, which are essential in low-altitude economy contexts. Deep reinforcement learning (DRL) is regarded as a promising solution to these issues, while its practical adoption remains limited by low learning efficiency. To overcome this limitation, we propose a novel UAV trajectory planning framework that combines DRL with large language model (LLM) reasoning to enable safe, compliant, and economically viable path planning. Experimental results demonstrate that our method significantly outperforms existing baselines across multiple metrics, including data collection rate, collision avoidance, successful landing, regulatory compliance, and energy efficiency. These results validate the effectiveness of our approach in addressing UAV trajectory planning key challenges under constraints of the low-altitude economy networking.
低空经济的快速增长推动了无人机(UAVs)的广泛应用。这种不断增长的部署为复杂城市环境中的无人机轨迹规划带来了新的挑战。然而,现有研究往往忽视了城市空域约束和经济效率等关键因素,这在低空经济背景下至关重要。深度强化学习(DRL)被认为是解决这些问题的有前途的解决方案,但其实际应用受到学习效率低的限制。为了克服这一局限性,我们提出了一种新型的无人机轨迹规划框架,该框架结合了深度强化学习与大型语言模型(LLM)推理,以实现安全、合规且经济可行的路径规划。实验结果表明,我们的方法在多个指标上显著优于现有基线,包括数据采集率、避障、成功着陆、法规合规和能效。这些结果验证了我们的方法在解决低空经济网络约束下无人机轨迹规划的关键挑战中的有效性。
论文及项目相关链接
Summary
无人机技术日益普及带来了新的挑战,尤其是在复杂城市环境中的无人机轨迹规划。为提高效率和满足城市经济需求,结合深度强化学习和大型语言模型提出新的无人机轨迹规划框架,有效应对数据收集、碰撞避免、成功着陆、法规遵守和能源效率等多方面的挑战。
Key Takeaways
- 低空经济的快速增长促进了无人机的广泛应用。
- 无人机轨迹规划面临复杂城市环境中的新挑战。
- 现有研究忽略了城市空域约束和经济效率等关键因素。
- 深度强化学习被认为是解决这些问题的有前途的方法。
- 深度强化学习与大型语言模型结合,提高了无人机轨迹规划的效率。
- 提出的新方法在多指标上显著优于现有基线,包括数据收集率、碰撞避免、成功着陆、法规遵守和能源效率等。
点此查看论文截图

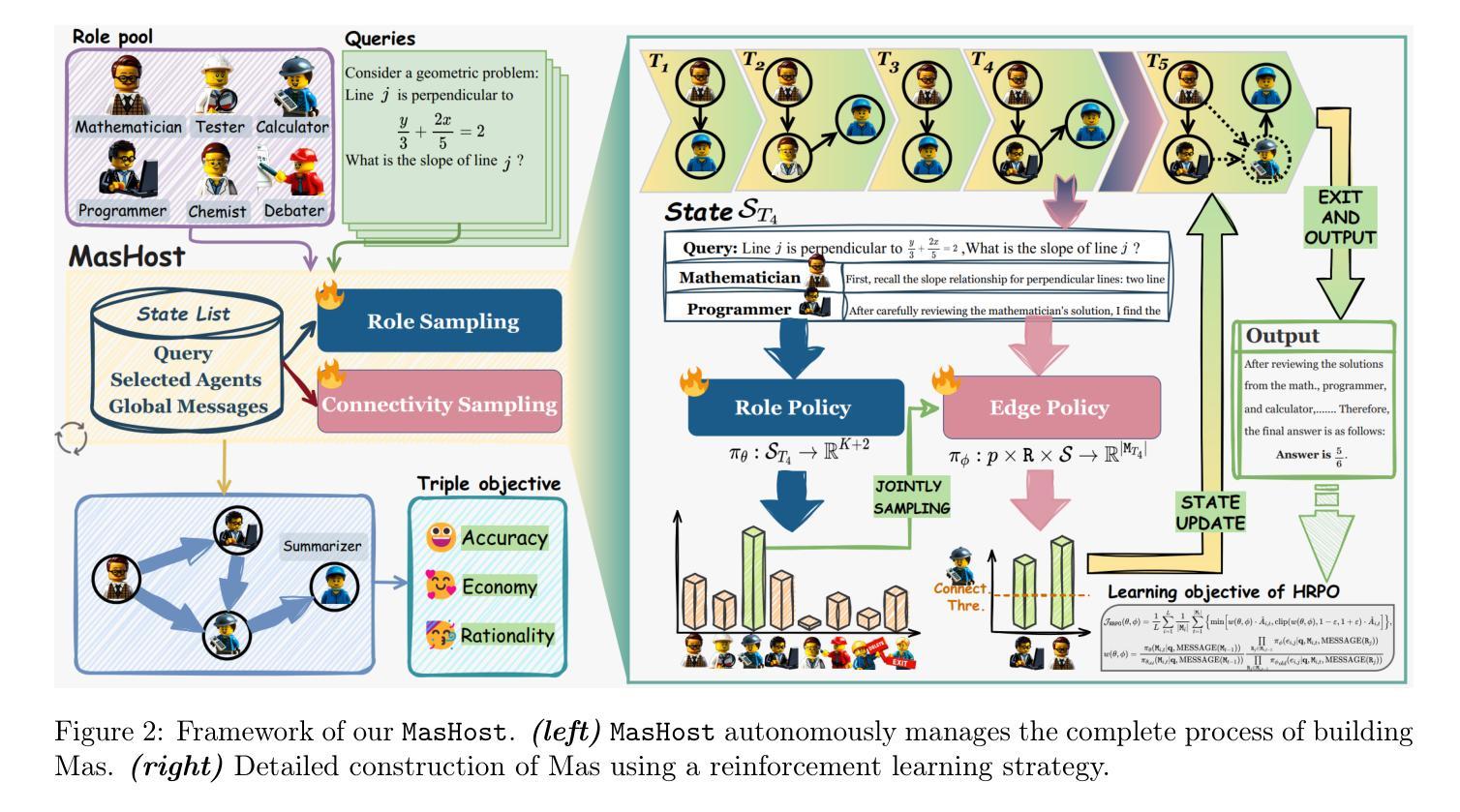
MasHost Builds It All: Autonomous Multi-Agent System Directed by Reinforcement Learning
Authors:Kuo Yang, Xingjie Yang, Linhui Yu, Qing Xu, Yan Fang, Xu Wang, Zhengyang Zhou, Yang Wang
Large Language Model (LLM)-driven Multi-agent systems (Mas) have recently emerged as a powerful paradigm for tackling complex real-world tasks. However, existing Mas construction methods typically rely on manually crafted interaction mechanisms or heuristic rules, introducing human biases and constraining the autonomous ability. Even with recent advances in adaptive Mas construction, existing systems largely remain within the paradigm of semi-autonomous patterns. In this work, we propose MasHost, a Reinforcement Learning (RL)-based framework for autonomous and query-adaptive Mas design. By formulating Mas construction as a graph search problem, our proposed MasHost jointly samples agent roles and their interactions through a unified probabilistic sampling mechanism. Beyond the accuracy and efficiency objectives pursued in prior works, we introduce component rationality as an additional and novel design principle in Mas. To achieve this multi-objective optimization, we propose Hierarchical Relative Policy Optimization (HRPO), a novel RL strategy that collaboratively integrates group-relative advantages and action-wise rewards. To our knowledge, our proposed MasHost is the first RL-driven framework for autonomous Mas graph construction. Extensive experiments on six benchmarks demonstrate that MasHost consistently outperforms most competitive baselines, validating its effectiveness, efficiency, and structure rationality.
基于大型语言模型(LLM)的多智能体系统(Mas)最近作为一种强大的范式来解决复杂的现实世界任务而出现。然而,现有的Mas构建方法通常依赖于手工制作的交互机制或启发式规则,这引入了人类偏见并限制了自主性能力。尽管最近自适应Mas构建有所进展,但现有系统大多仍停留在半自主模式的范式内。在这项工作中,我们提出了MasHost,这是一个基于强化学习(RL)的自主和查询自适应Mas设计框架。通过将Mas构建公式化为图搜索问题,我们提出的MasHost通过一个统一的概率采样机制联合采样智能体角色及其交互。除了先前工作中追求的准确性和效率目标外,我们还将组件合理性作为Mas中的附加和新颖设计原则。为了实现这种多目标优化,我们提出了分层相对策略优化(HRPO),这是一种新型的RL策略,可以协同整合组相对优势和行动方面的奖励。据我们所知,我们提出的MasHost是第一个用于自主Mas图构建的RL驱动框架。在六个基准测试上的广泛实验表明,MasHost始终超越大多数竞争基线,验证了其有效性、效率和结构合理性。
论文及项目相关链接
Summary
大型语言模型驱动的多智能体系统(LLM-driven Mas)通过强化学习(RL)构建了一种自主、查询适应的框架,即MasHost。与传统手动构建的交互机制不同,MasHost采用图形搜索方法,通过统一概率采样机制自主采样智能体角色及其交互。在实现准确性、效率的同时,引入了组件合理性作为新的设计原则,并采用分层相对策略优化(HRPO)实现多目标优化。实验证明,MasHost在多个基准测试中表现优异,验证了其有效性、效率和结构合理性。
Key Takeaways
以下是文本中的关键要点总结:
- 大型语言模型驱动的多智能体系统(LLM-driven Mas)已成为解决复杂现实世界任务的有力工具。
- 传统多智能体系统构建方法主要依赖手动构建的交互机制和启发式规则,引入人类偏见并限制自主性。
- MasHost是基于强化学习(RL)的自主多智能体系统设计框架,通过图形搜索方法自主采样智能体角色及其交互。
- MasHost引入组件合理性作为新的设计原则,旨在实现多目标优化。
- 分层相对策略优化(HRPO)是MasHost提出的一种新型RL策略,结合了群体相对优势和行动奖励。
- MasHost是首个采用RL驱动的多智能体系统图形构建框架。
点此查看论文截图