⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-13 更新
A Shortcut-aware Video-QA Benchmark for Physical Understanding via Minimal Video Pairs
Authors:Benno Krojer, Mojtaba Komeili, Candace Ross, Quentin Garrido, Koustuv Sinha, Nicolas Ballas, Mahmoud Assran
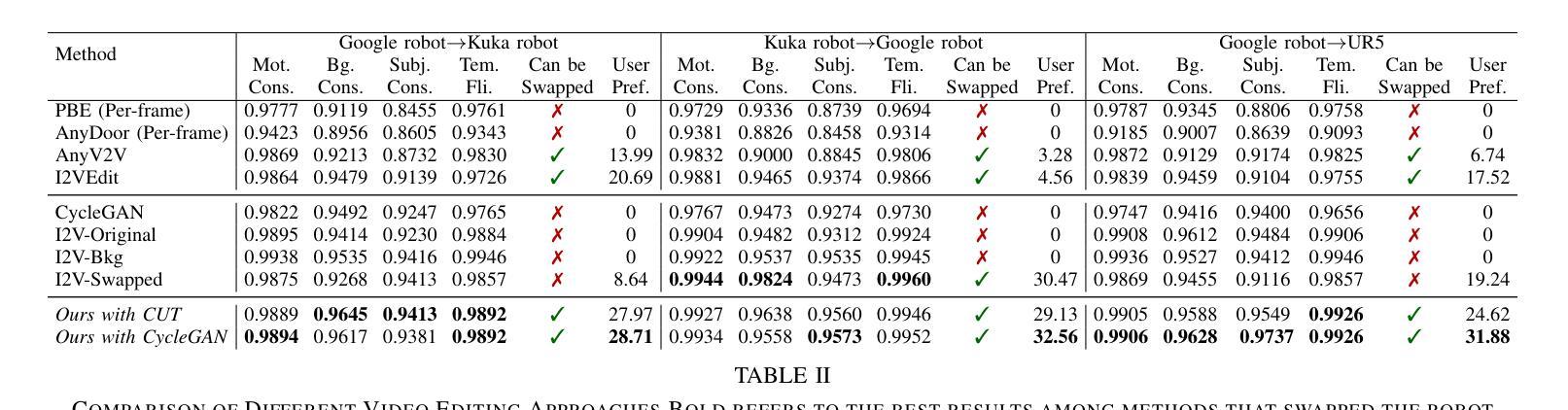
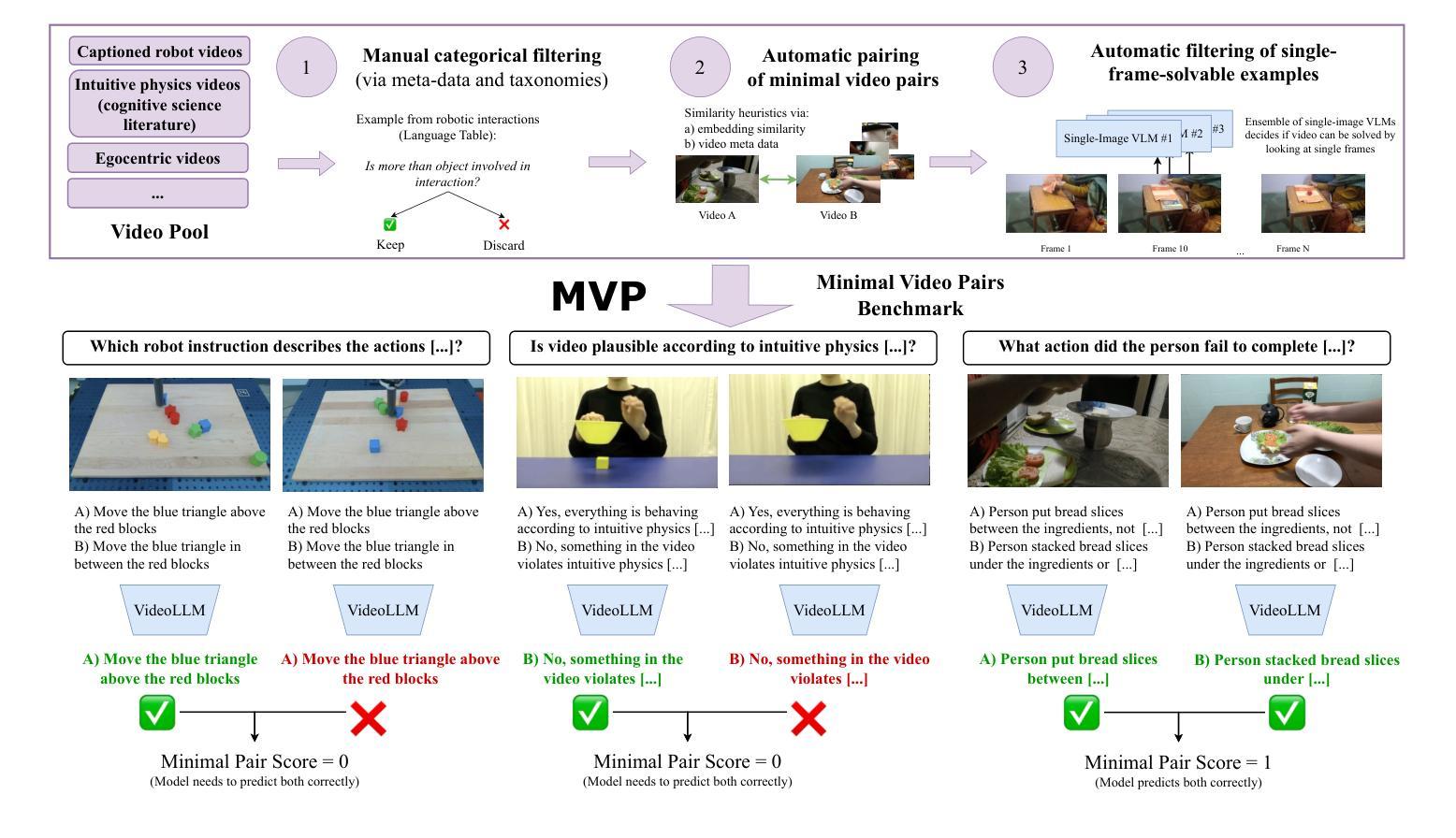
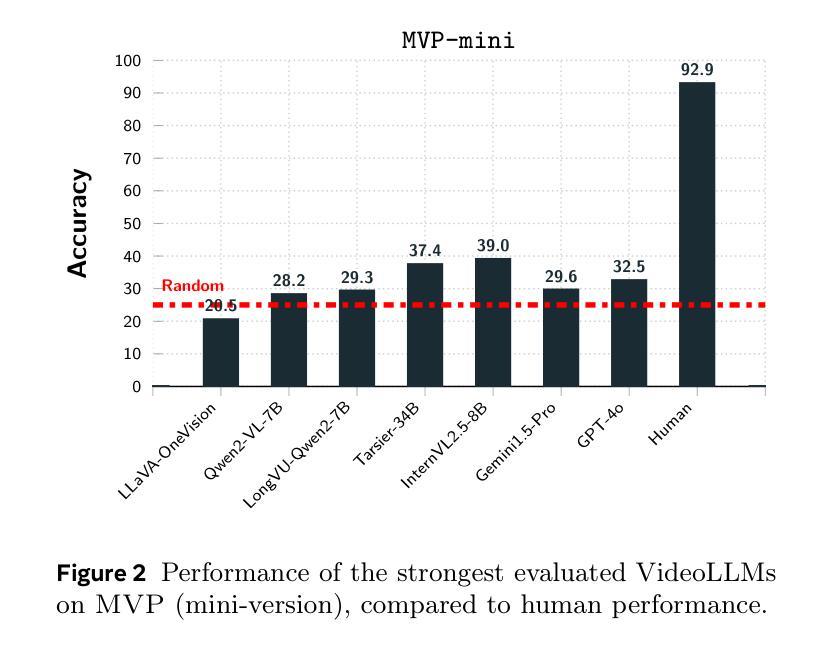
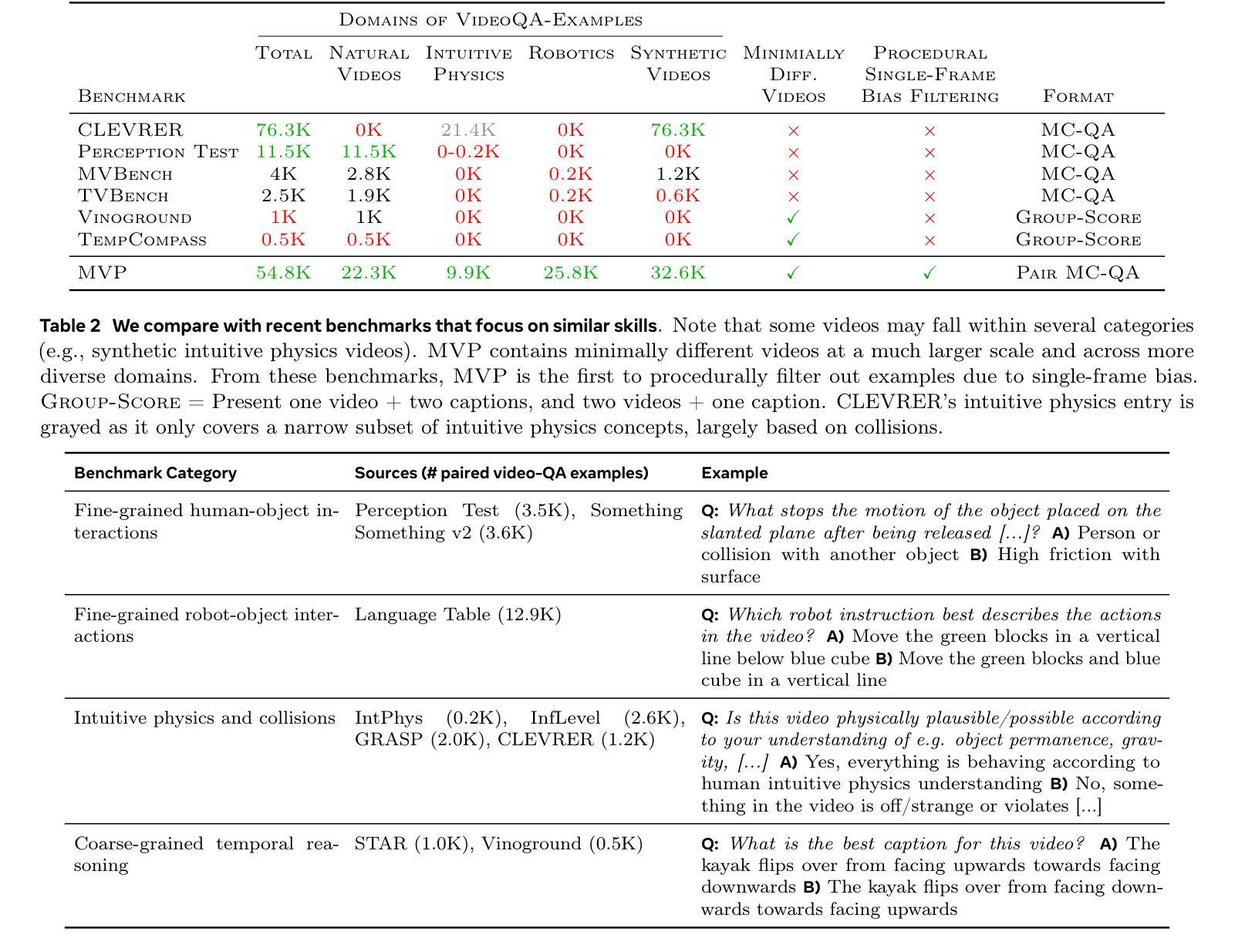
Existing benchmarks for assessing the spatio-temporal understanding and reasoning abilities of video language models are susceptible to score inflation due to the presence of shortcut solutions based on superficial visual or textual cues. This paper mitigates the challenges in accurately assessing model performance by introducing the Minimal Video Pairs (MVP) benchmark, a simple shortcut-aware video QA benchmark for assessing the physical understanding of video language models. The benchmark is comprised of 55K high-quality multiple-choice video QA examples focusing on physical world understanding. Examples are curated from nine video data sources, spanning first-person egocentric and exocentric videos, robotic interaction data, and cognitive science intuitive physics benchmarks. To mitigate shortcut solutions that rely on superficial visual or textual cues and biases, each sample in MVP has a minimal-change pair – a visually similar video accompanied by an identical question but an opposing answer. To answer a question correctly, a model must provide correct answers for both examples in the minimal-change pair; as such, models that solely rely on visual or textual biases would achieve below random performance. Human performance on MVP is 92.9%, while the best open-source state-of-the-art video-language model achieves 40.2% compared to random performance at 25%.
当前评估视频语言模型对时空的理解和推理能力的基准测试容易受到表面视觉或文本线索的捷径解决方案的影响,导致分数膨胀。本文通过引入最小视频对(MVP)基准测试来缓解准确评估模型性能的挑战,这是一个简单且能识别捷径的视频问答基准测试,用于评估视频语言模型对物理世界的理解。该基准测试包含5.5万个高质量的多项选择题视频问答示例,重点考察物理世界的理解。这些示例是从九个视频数据源中精选出来的,包括第一人称主观和客观视频、机器人交互数据和认知科学直觉物理基准测试。为了缓解依赖于表面视觉或文本线索和偏见的捷径解决方案,MVP中的每个样本都有一个最小变化的对——一个视觉相似的视频伴随一个相同的问题但答案相反。为了正确回答问题,模型必须为最小变化对中的两个示例都提供正确答案;因此,那些仅依赖于视觉或文本偏见的模型的表现将低于随机表现。人类在MVP上的表现是92.9%,而最佳的开源先进视频语言模型与随机表现的25%相比,达到了40.2%。
论文及项目相关链接
Summary
本文介绍了现有的视频语言模型评估基准存在基于表面视觉或文本线索的捷径解决方案导致评分膨胀的问题。为解决此问题,本文引入了最小视频对(MVP)基准,这是一个简单的、能识别捷径的视频问答评估基准,用于评估视频语言模型对物理世界的理解。MVP包含来自九个视频数据源的高质量选择题,涵盖第一人称自我中心和外部中心视频、机器人交互数据和认知科学直觉物理基准测试。为缓解依赖表面视觉或文本线索和偏见的捷径解决方案,MVP中的每个样本都有一个最小变化对——一个视觉上相似的视频伴随一个相同的问题但答案相反。为了正确回答问题,模型必须为最小变化对中的两个例子都提供正确答案;因此,只依赖视觉或文本偏见的模型的表现将低于随机表现。人类在MVP上的表现是92.9%,而最佳的开源先进视频语言模型的表现是40.2%,相比之下随机表现是25%。
Key Takeaways
- 现有视频语言模型评估基准易受基于表面视觉或文本线索的捷径解决方案影响,导致评分膨胀。
- 引入最小视频对(MVP)基准,以评估视频语言模型对物理世界的理解。
- MVP包含来自多个视频数据源的高质量选择题,涵盖多种视频类型。
- MVP通过最小变化对设计来抑制基于表面视觉或文本线索的捷径解决方案。
- 正确回答问题需要模型在最小变化对中都提供正确答案,以此区分真正理解和依赖偏见的模型。
- 相比随机表现,人类在MVP上的表现较高,而当前最佳的视频语言模型表现仍低于随机表现。这表明现有模型在理解和推理方面还有提升空间。
点此查看论文截图


V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Authors:Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba, Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, Sergio Arnaud, Abha Gejji, Ada Martin, Francois Robert Hogan, Daniel Dugas, Piotr Bojanowski, Vasil Khalidov, Patrick Labatut, Francisco Massa, Marc Szafraniec, Kapil Krishnakumar, Yong Li, Xiaodong Ma, Sarath Chandar, Franziska Meier, Yann LeCun, Michael Rabbat, Nicolas Ballas
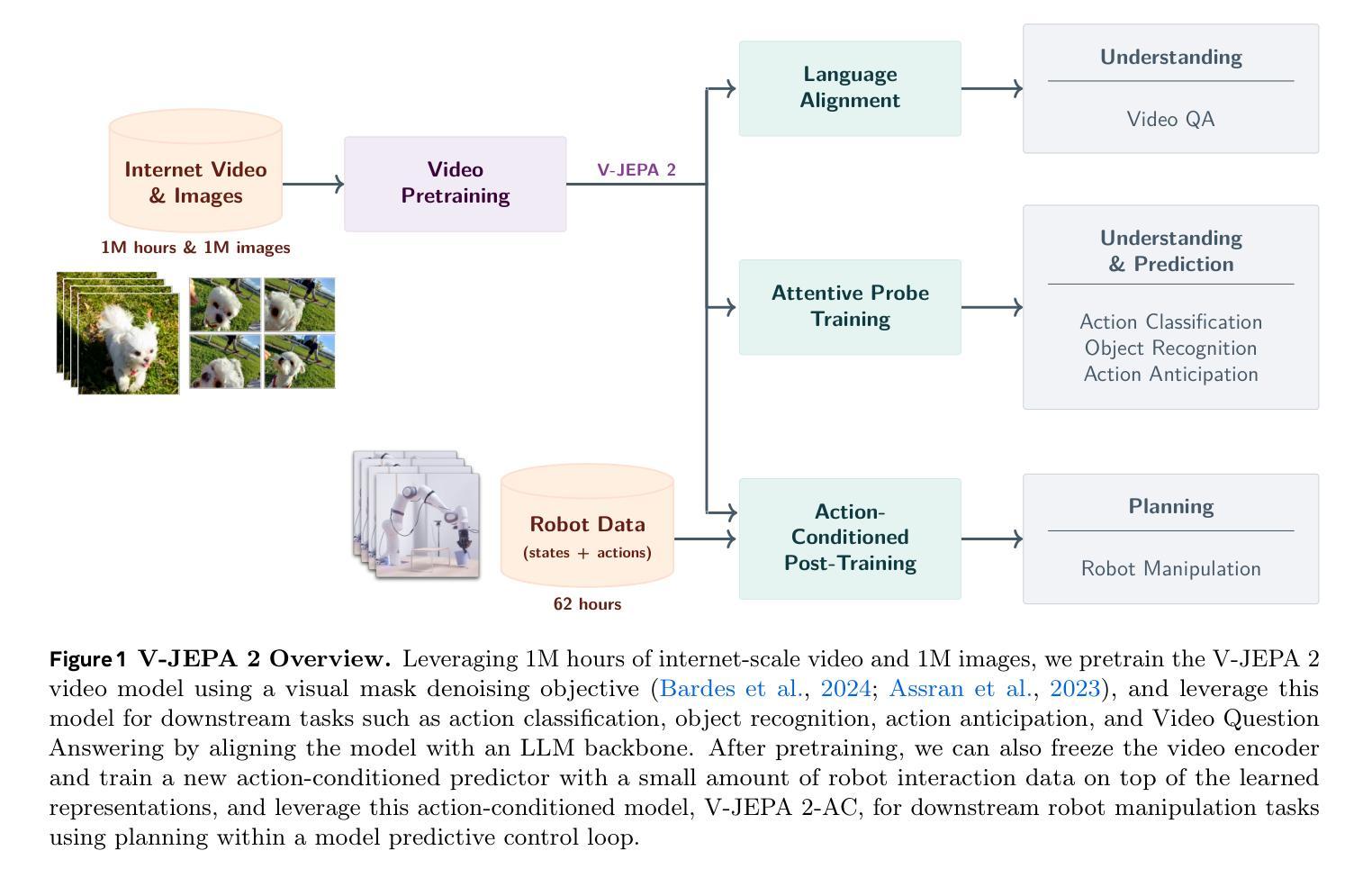
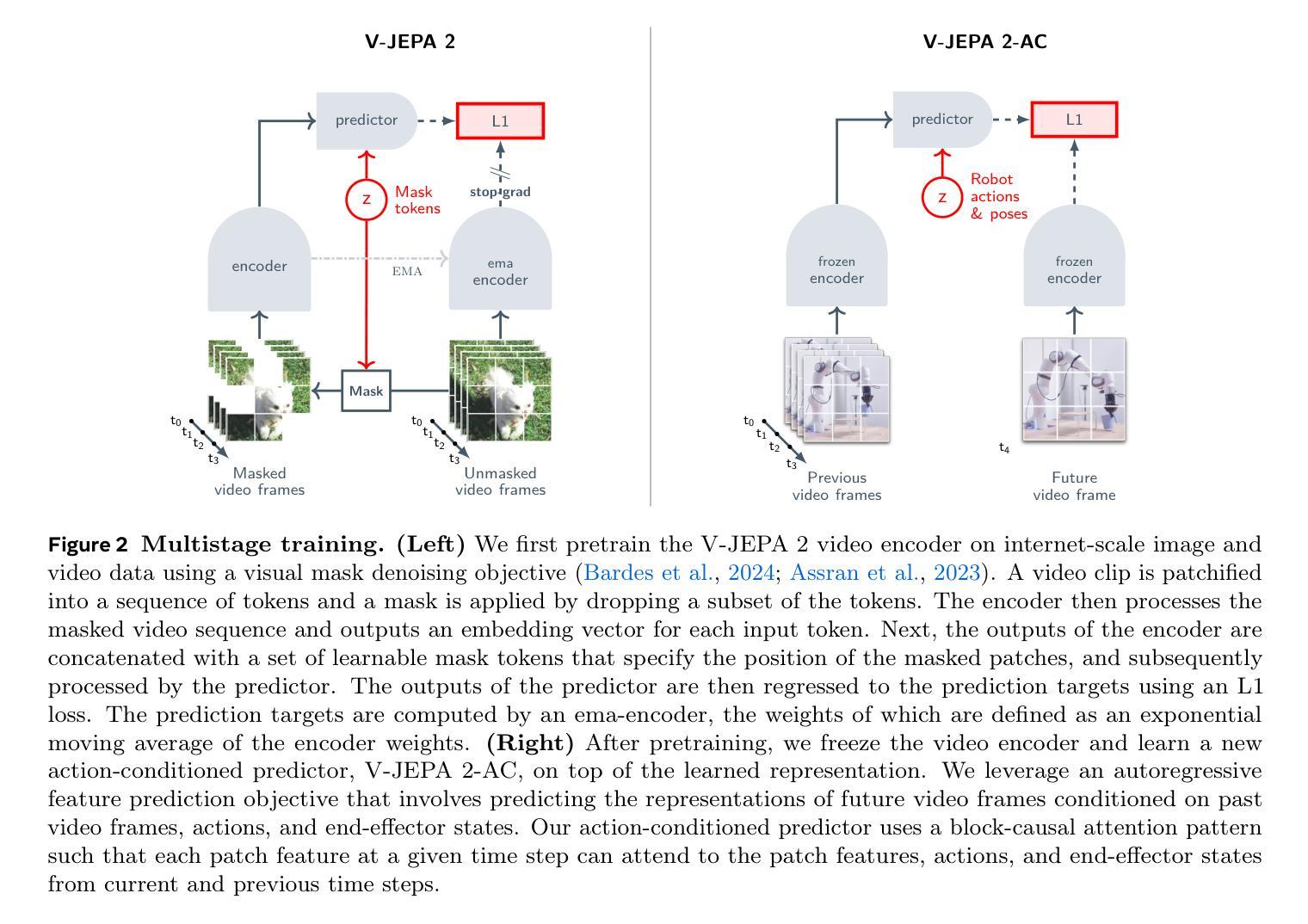
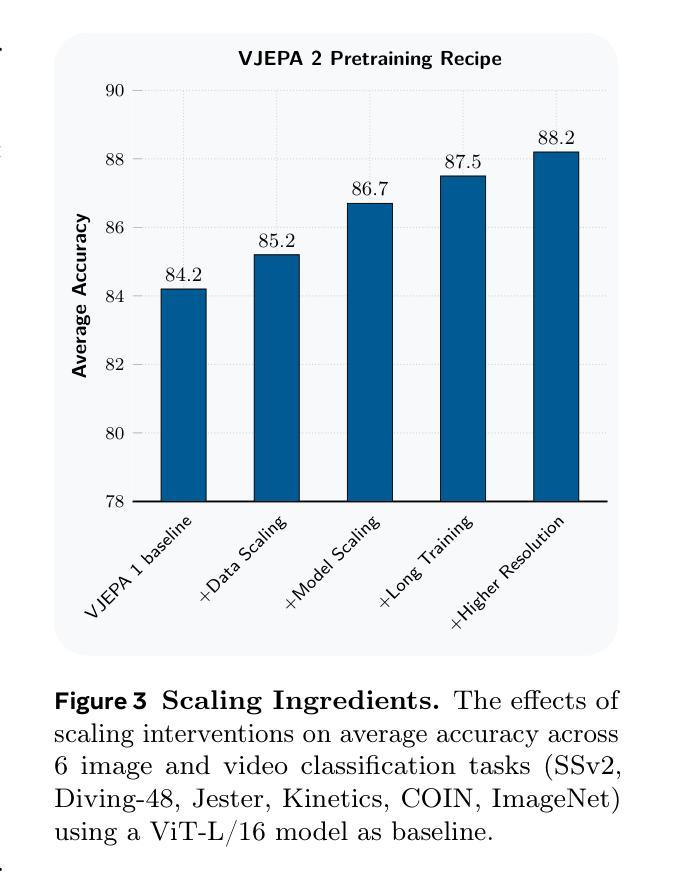
A major challenge for modern AI is to learn to understand the world and learn to act largely by observation. This paper explores a self-supervised approach that combines internet-scale video data with a small amount of interaction data (robot trajectories), to develop models capable of understanding, predicting, and planning in the physical world. We first pre-train an action-free joint-embedding-predictive architecture, V-JEPA 2, on a video and image dataset comprising over 1 million hours of internet video. V-JEPA 2 achieves strong performance on motion understanding (77.3 top-1 accuracy on Something-Something v2) and state-of-the-art performance on human action anticipation (39.7 recall-at-5 on Epic-Kitchens-100) surpassing previous task-specific models. Additionally, after aligning V-JEPA 2 with a large language model, we demonstrate state-of-the-art performance on multiple video question-answering tasks at the 8 billion parameter scale (e.g., 84.0 on PerceptionTest, 76.9 on TempCompass). Finally, we show how self-supervised learning can be applied to robotic planning tasks by post-training a latent action-conditioned world model, V-JEPA 2-AC, using less than 62 hours of unlabeled robot videos from the Droid dataset. We deploy V-JEPA 2-AC zero-shot on Franka arms in two different labs and enable picking and placing of objects using planning with image goals. Notably, this is achieved without collecting any data from the robots in these environments, and without any task-specific training or reward. This work demonstrates how self-supervised learning from web-scale data and a small amount of robot interaction data can yield a world model capable of planning in the physical world.
现代人工智能面临的一个主要挑战是学习理解世界并通过观察进行行动。本文探索了一种自监督方法,该方法结合了互联网规模的视频数据和小量的交互数据(机器人轨迹),以开发能够在物理世界中理解、预测和规划模型。我们首先在互联网视频组成的视频和图像数据集上预训练了一种无动作联合嵌入预测架构V-JEPA 2,该数据集包含超过 1 亿小时的视频。V-JEPA 2在运动理解方面表现出强大的性能(Something-Something v2上达到了 77.3% 的Top-1准确率),并在人类动作预测方面达到了最新技术水平(Epic-Kitchens-100上的召回率为 39.7%)。此外,在与大型语言模型对齐后,我们在多个视频问答任务上展示了最先进的性能(例如,PerceptionTest上为 84.0%,TempCompass上为 76.9%)。最后,我们展示了如何通过利用来自Droid数据集的不到 62 小时的无标签机器人视频对潜在的动作条件世界模型V-JEPA 2-AC进行后训练,来将自监督学习应用于机器人规划任务。我们在两个不同的实验室部署了Frank双臂机器人零样本,并利用图像目标的规划实现了物体的抓取和放置。值得注意的是,这是在没有任何环境中机器人数据收集的情况下实现的,也不需要特定任务的训练或奖励。这项工作展示了如何从互联网规模的数据和小量的机器人交互数据中进行自监督学习,从而建立一个能够在物理世界中规划的世界模型。
论文及项目相关链接
PDF 48 pages, 19 figures
摘要
该论文探讨了一种自监督学习方法,该方法结合了互联网规模的视频数据和小量的交互数据(机器人轨迹),以开发能够在物理世界中理解、预测和规划模型的能力。首先,对无动作联合嵌入预测架构V-JEPA 2进行预训练,该架构在互联网视频图像数据集上进行训练,包含超过一百万小时的视频数据。V-JEPA 2在运动理解方面表现出强劲性能(在Something-Something v2上达到77.3的top-1准确率),并在人类动作预测方面达到最佳表现(在Epic-Kitchens-100上的召回率为39.7)。此外,在与大型语言模型对齐后,它在多个视频问答任务中表现出最佳性能(例如,在PerceptionTest上达到84.0,在TempCompass上达到76.9)。最后,该研究展示了如何将自监督学习应用于机器人规划任务,通过利用不到62小时的无人标注的机器人视频数据(来自Droid数据集)对潜在的动作条件世界模型V-JEPA 2-AC进行后训练。在两家实验室的Frank双臂上部署V-JEPA 2-AC零样本,并使用图像目标进行规划以实现物体的拾取和放置。值得注意的是,这是在没有任何机器人环境数据采集和任务特定训练或奖励的情况下实现的。这项工作证明了自监督学习可以从网络规模的数据和少量的机器人交互数据中构建能够规划物理世界的世界模型。
关键见解
- 本论文探讨了自监督学习方法在处理现代AI面临的大规模观察和理解的挑战中的实际应用价值。通过结合了互联网规模的视频数据和少量机器人交互数据来开发理解物理世界的模型。
- 研究采用了一种无动作联合嵌入预测架构V-JEPA 2,该架构在视频和图像数据集上进行了预训练,并在运动理解和人类动作预测方面表现出卓越性能。
- 通过与大型语言模型的结合,该模型在多个视频问答任务中实现了最佳性能。
- 研究展示了如何通过利用无人标注的机器人视频数据进行后训练来开发潜在的动作条件世界模型V-JEPA 2-AC。这一模型可以在不同实验室的机器人手臂上实现零样本部署,并执行物体拾取和放置的任务规划。
- 该研究强调了自监督学习的潜力,表明其能够从大规模网络数据和有限的机器人交互数据中学习物理世界的模型。这为未来AI系统的开发提供了新思路,尤其是在机器人技术和自动驾驶等领域。
- 本研究展示了在没有从机器人环境中收集任何数据的情况下,通过自监督学习实现机器人规划任务的可能性。这减少了数据收集的复杂性并提高了模型的适应性。
点此查看论文截图

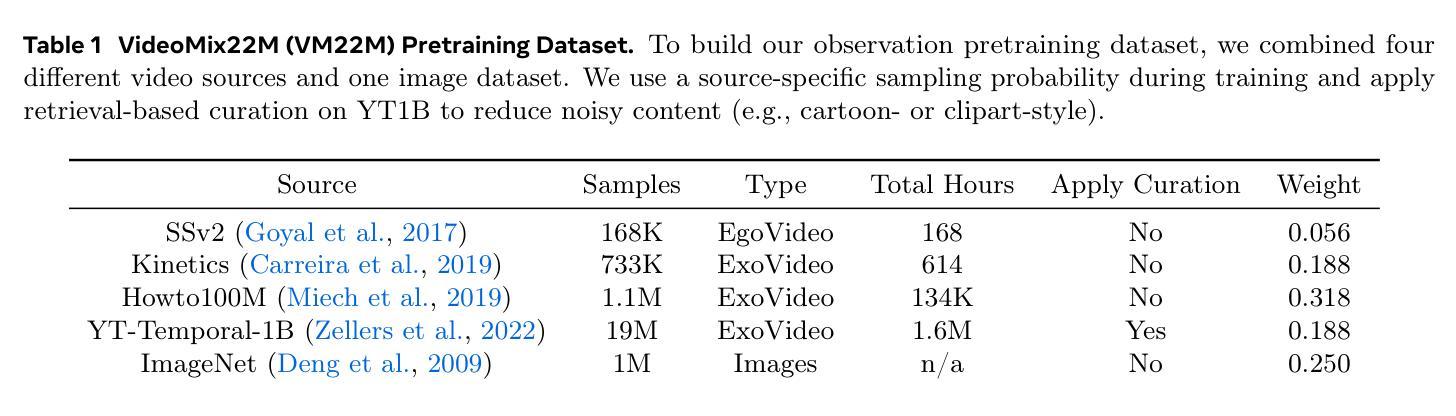
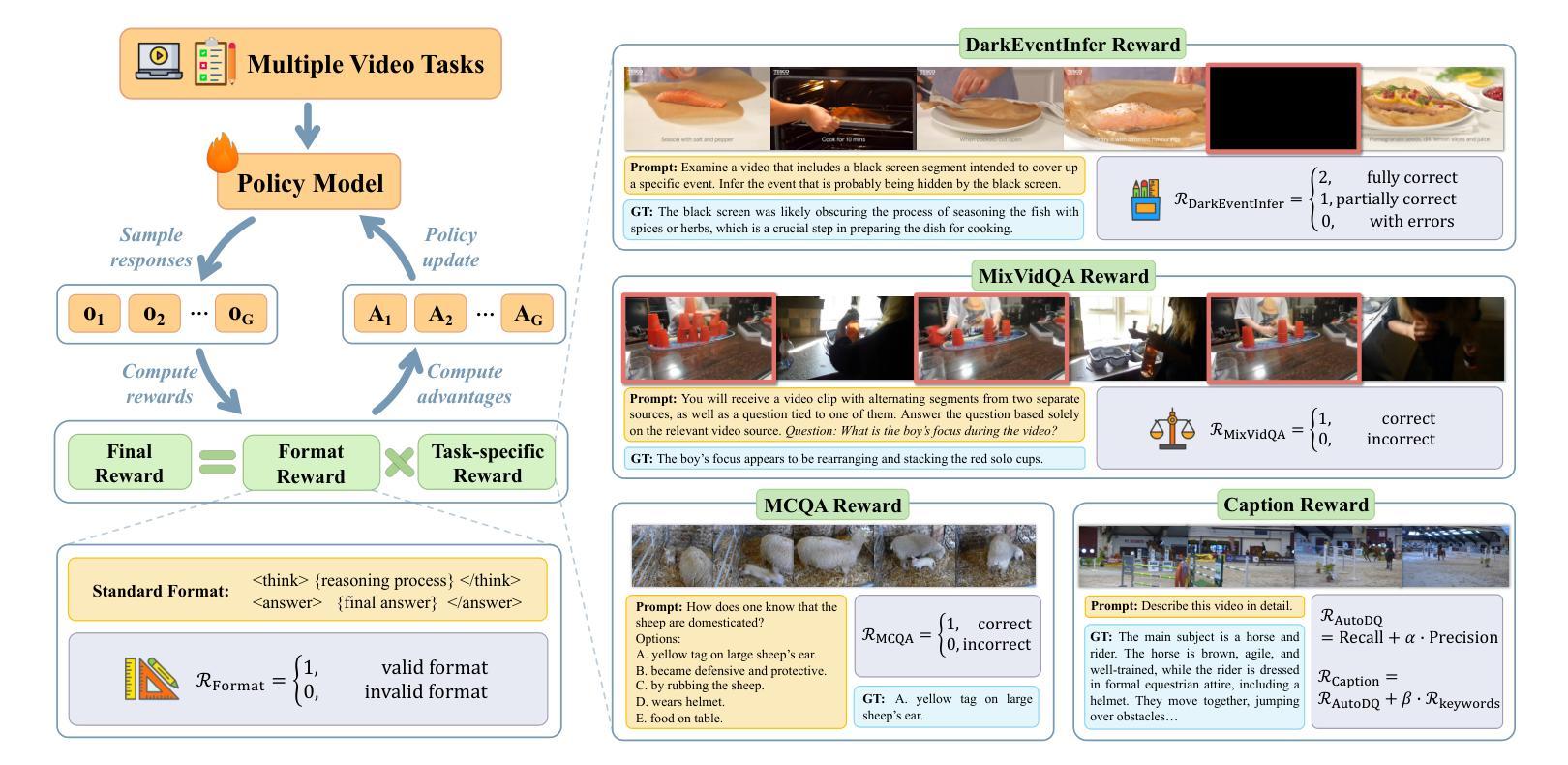
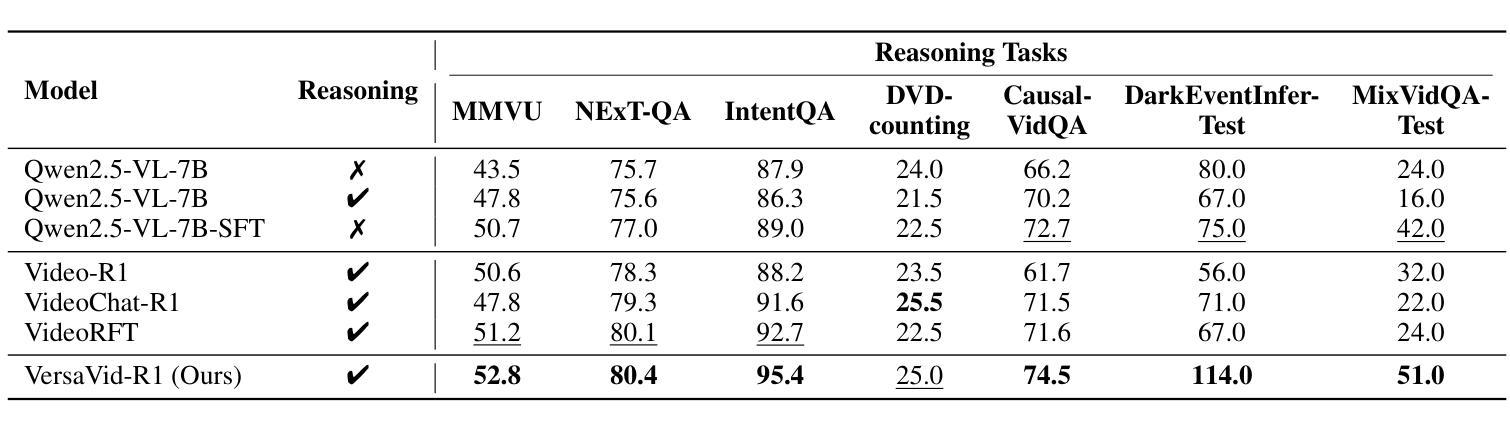
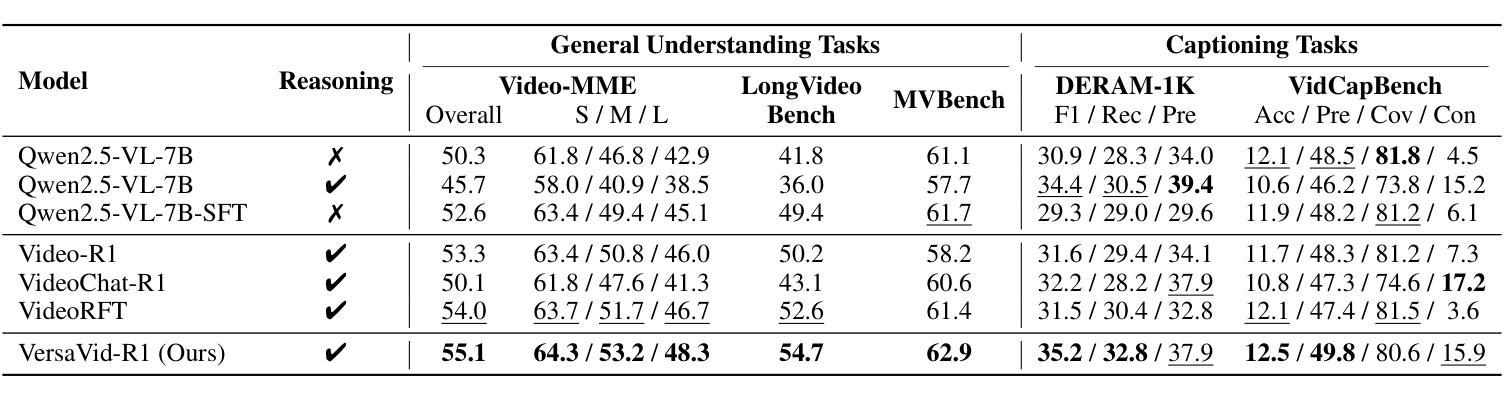
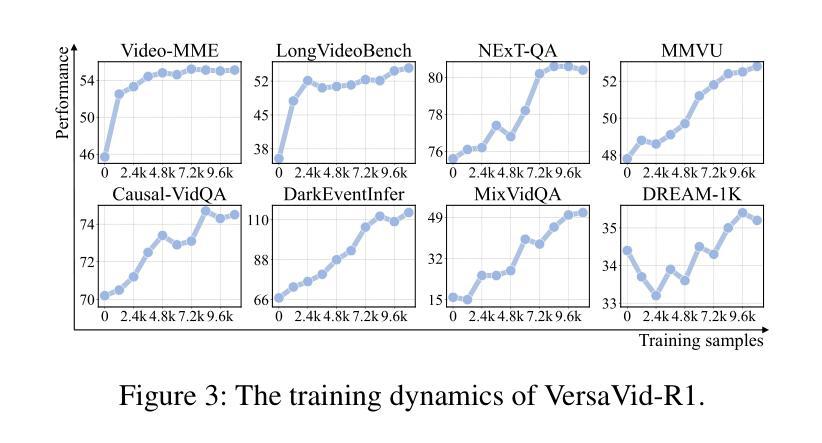
VersaVid-R1: A Versatile Video Understanding and Reasoning Model from Question Answering to Captioning Tasks
Authors:Xinlong Chen, Yuanxing Zhang, Yushuo Guan, Bohan Zeng, Yang Shi, Sihan Yang, Pengfei Wan, Qiang Liu, Liang Wang, Tieniu Tan
Recent advancements in multimodal large language models have successfully extended the Reason-Then-Respond paradigm to image-based reasoning, yet video-based reasoning remains an underdeveloped frontier, primarily due to the scarcity of high-quality reasoning-oriented data and effective training methodologies. To bridge this gap, we introduce DarkEventInfer and MixVidQA, two novel datasets specifically designed to stimulate the model’s advanced video understanding and reasoning abilities. DarkEventinfer presents videos with masked event segments, requiring models to infer the obscured content based on contextual video cues. MixVidQA, on the other hand, presents interleaved video sequences composed of two distinct clips, challenging models to isolate and reason about one while disregarding the other. Leveraging these carefully curated training samples together with reinforcement learning guided by diverse reward functions, we develop VersaVid-R1, the first versatile video understanding and reasoning model under the Reason-Then-Respond paradigm capable of handling multiple-choice and open-ended question answering, as well as video captioning tasks. Extensive experiments demonstrate that VersaVid-R1 significantly outperforms existing models across a broad spectrum of benchmarks, covering video general understanding, cognitive reasoning, and captioning tasks.
最近的多模态大型语言模型的进步已经成功地将“Reason-Then-Respond”范式扩展到基于图像的理解,但基于视频的理解仍然是一个未充分开发的前沿领域,这主要是由于缺乏高质量、以推理为导向的数据和有效的训练方法论。为了弥补这一差距,我们推出了DarkEventInfer和MixVidQA两个专门设计的新数据集,以刺激模型对高级视频的理解和推理能力。DarkEventInfer呈现带有遮挡事件片段的视频,要求模型根据上下文视频线索推断遮挡内容。另一方面,MixVidQA呈现由两个不同片段组成的交织视频序列,挑战模型在忽略另一个片段的情况下,对一个片段进行隔离和推理。我们利用这些精心挑选的训练样本以及由多种奖励函数引导的强化学习,开发出VersaVid-R1,这是第一个在“Reason-Then-Respond”范式下的通用视频理解和推理模型,能够处理多项选择和开放式问答以及视频描述任务。大量实验表明,VersaVid-R1在广泛的基准测试中显著优于现有模型,涵盖视频一般理解、认知推理和描述任务。
论文及项目相关链接
Summary
本文介绍了视频理解领域的新进展。由于缺少高质量推理导向的数据和有效的训练方法,视频推理仍然是一个未被充分开发的前沿。为了弥补这一差距,本文引入了DarkEventInfer和MixVidQA两个新数据集,刺激模型对高级视频理解和推理能力的需求。利用这些精心策划的训练样本以及通过不同的奖励函数引导的强化学习,开发出VersaVid-R1模型,它能够在“推理后回应”框架下处理多项选择和开放式问答以及视频描述任务。实验表明,VersaVid-R1在广泛的基准测试中显著优于现有模型,涵盖视频通用理解、认知推理和描述任务。
Key Takeaways
- 多模态大型语言模型的新进展已将“Reason-Then-Respond”范式扩展到基于图像的理解。然而,视频理解仍然是未被充分开发的前沿。
- DarkEventInfer数据集推出,通过遮蔽视频事件片段要求模型基于上下文视频线索进行推断。
- MixVidQA数据集推出,通过展示由两个不同片段组成的交错视频序列,挑战模型在忽略一个片段的同时对另一个片段进行隔离和推理的能力。
- 通过使用精心策划的训练样本和多种奖励函数引导的强化学习,开发出VersaVid-R1模型。
- VersaVid-R1是首个在“Reason-Then-Respond”框架下实现多功能视频理解和推理的模型。
- VersaVid-R1能够处理多项选择和开放式问答以及视频描述任务。
点此查看论文截图


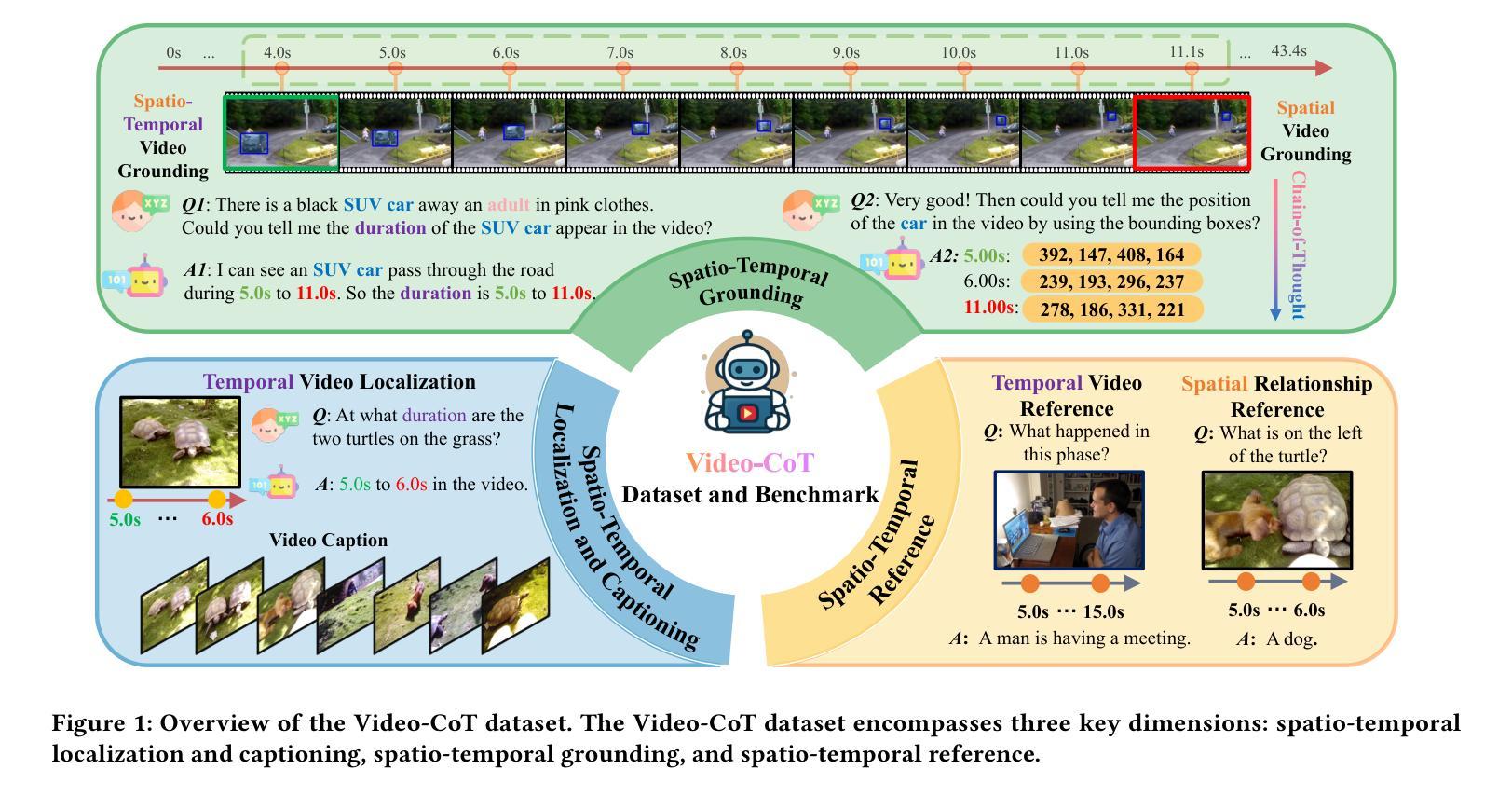
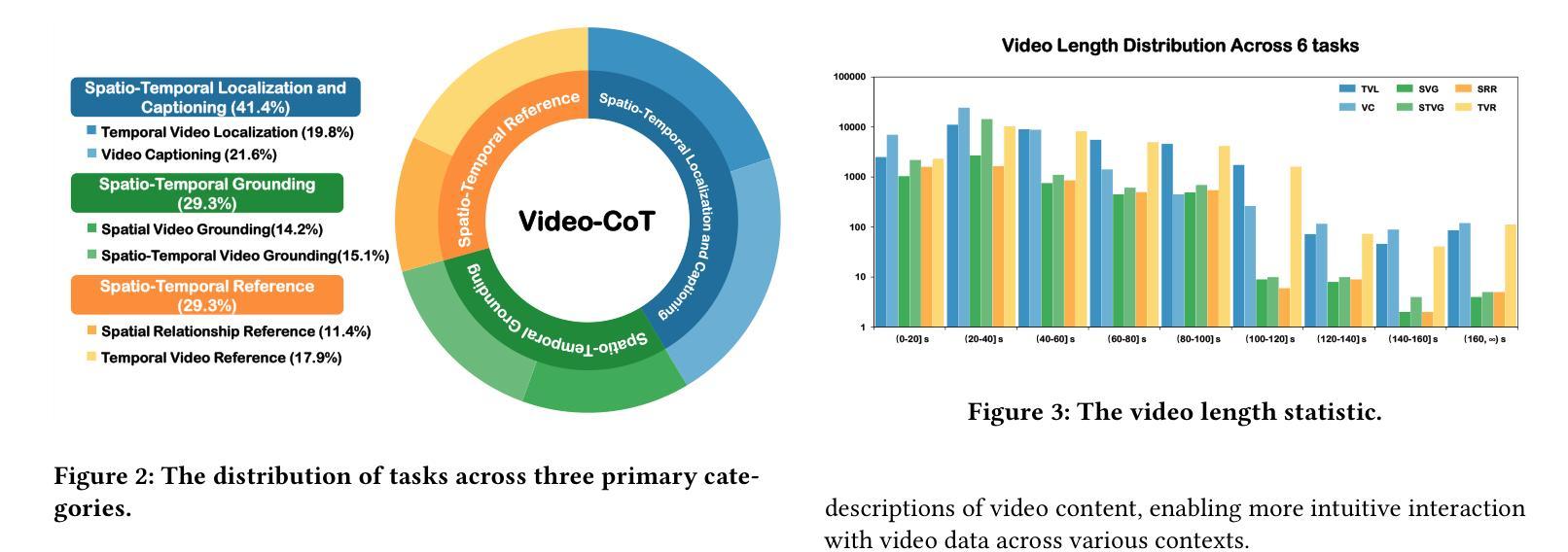
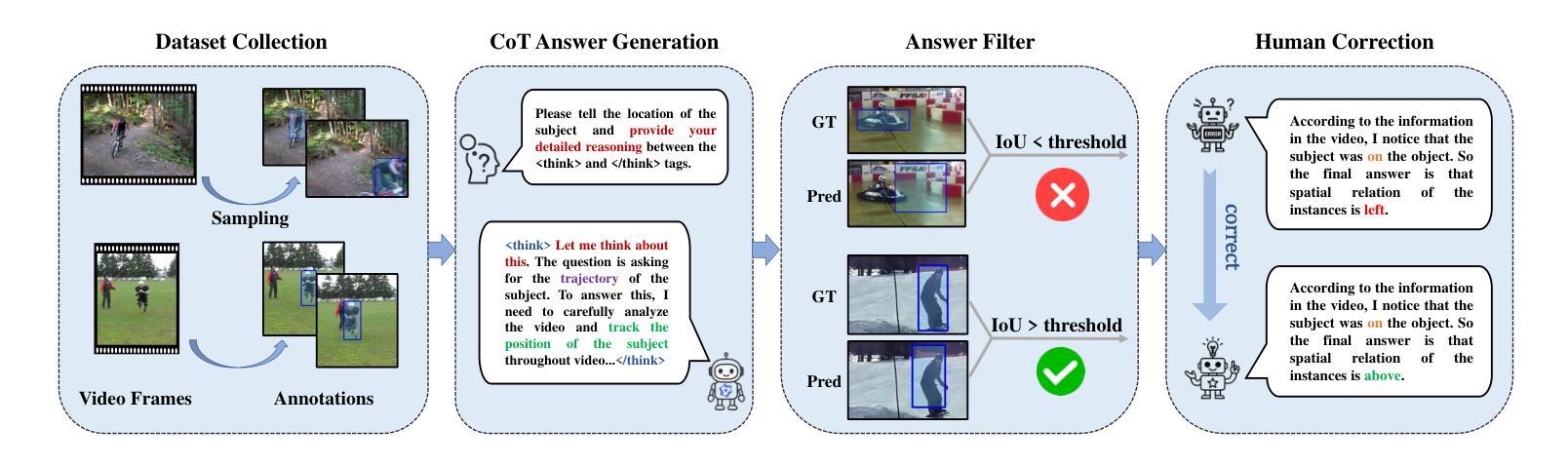
Video-CoT: A Comprehensive Dataset for Spatiotemporal Understanding of Videos Based on Chain-of-Thought
Authors:Shuyi Zhang, Xiaoshuai Hao, Yingbo Tang, Lingfeng Zhang, Pengwei Wang, Zhongyuan Wang, Hongxuan Ma, Shanghang Zhang
Video content comprehension is essential for various applications, ranging from video analysis to interactive systems. Despite advancements in large-scale vision-language models (VLMs), these models often struggle to capture the nuanced, spatiotemporal details essential for thorough video analysis. To address this gap, we introduce Video-CoT, a groundbreaking dataset designed to enhance spatiotemporal understanding using Chain-of-Thought (CoT) methodologies. Video-CoT contains 192,000 fine-grained spa-tiotemporal question-answer pairs and 23,000 high-quality CoT-annotated samples, providing a solid foundation for evaluating spatiotemporal understanding in video comprehension. Additionally, we provide a comprehensive benchmark for assessing these tasks, with each task featuring 750 images and tailored evaluation metrics. Our extensive experiments reveal that current VLMs face significant challenges in achieving satisfactory performance, high-lighting the difficulties of effective spatiotemporal understanding. Overall, the Video-CoT dataset and benchmark open new avenues for research in multimedia understanding and support future innovations in intelligent systems requiring advanced video analysis capabilities. By making these resources publicly available, we aim to encourage further exploration in this critical area. Project website:https://video-cot.github.io/ .
视频内容理解对于从视频分析到交互系统的各种应用至关重要。尽管大规模视觉语言模型(VLMs)已经取得了进展,但这些模型在捕捉全面视频分析所需的微妙时空细节方面仍面临挑战。为了解决这一差距,我们引入了Video-CoT,这是一个开创性的数据集,旨在利用思维链(CoT)方法增强时空理解。Video-CoT包含19万组精细的时空问答对和2.3万个高质量的CoT注释样本,为评估视频理解中的时空理解能力提供了坚实的基础。此外,我们还为评估这些任务提供了一个全面的基准测试,每个任务包含750张图像和专门的评估指标。我们的大量实验表明,目前的VLMs在取得令人满意的表现方面面临巨大挑战,突出了实现有效时空理解的困难。总的来说,Video-CoT数据集和基准测试为多媒体理解的研究开辟了新的途径,并支持未来需要高级视频分析功能的智能系统的创新。我们公开提供这些资源,旨在鼓励在这一关键领域进行进一步的探索。项目网站:https://video-cot.github.io/。
论文及项目相关链接
Summary
视频内容理解在多个应用领域中至关重要,如视频分析与交互系统。尽管大规模视觉语言模型(VLMs)有所进展,但它们仍难以捕捉细致的空间时间细节,这些细节对于彻底的视频分析至关重要。为解决这一差距,我们推出了Video-CoT数据集,运用Chain-of-Thought(CoT)方法增强时空理解。Video-CoT包含19.2万精细时空问答对和2.3万高质量CoT注释样本,为评估视频理解中的时空理解提供了坚实基础。我们还为每个任务提供了全面的基准测试,每个任务包含750张图像和定制评估指标。实验表明,当前VLMs在取得令人满意的效果方面面临重大挑战,突显了有效时空理解的困难。总的来说,Video-CoT数据集和基准测试为多媒体理解开辟了新途径,并支持未来需要先进视频分析能力的智能系统的创新。
Key Takeaways
- 视频内容理解在多个领域具有重要性,如视频分析和交互系统。
- 尽管视觉语言模型有所进展,但仍存在捕捉细致时空细节的挑战。
- Video-CoT数据集通过运用Chain-of-Thought(CoT)方法增强时空理解。
- Video-CoT包含大量精细时空问答对和CoT注释样本。
- 提供了全面的基准测试来评估视频理解中的时空理解。
- 当前VLMs在视频理解方面面临挑战,需要更有效的算法来提升性能。
点此查看论文截图

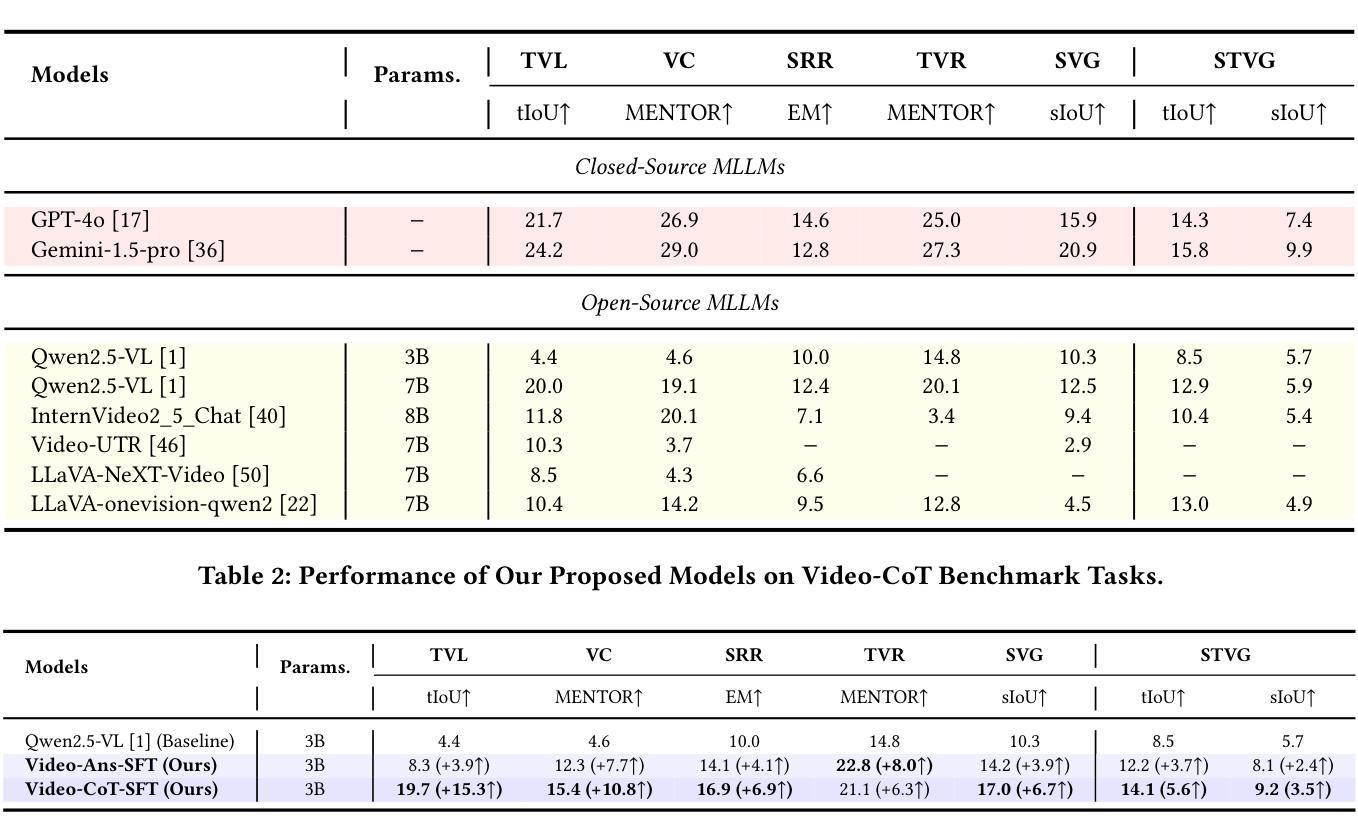
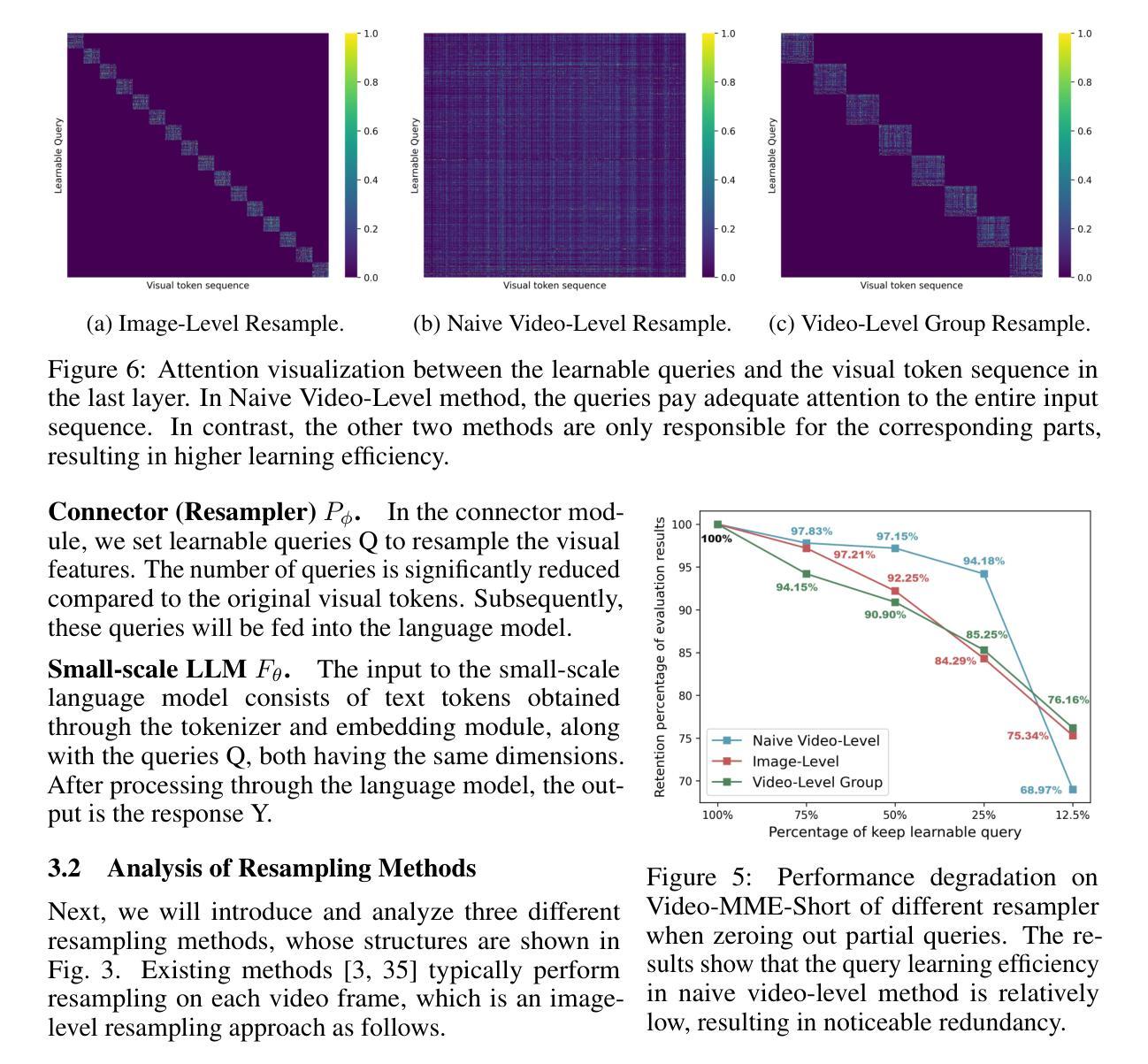
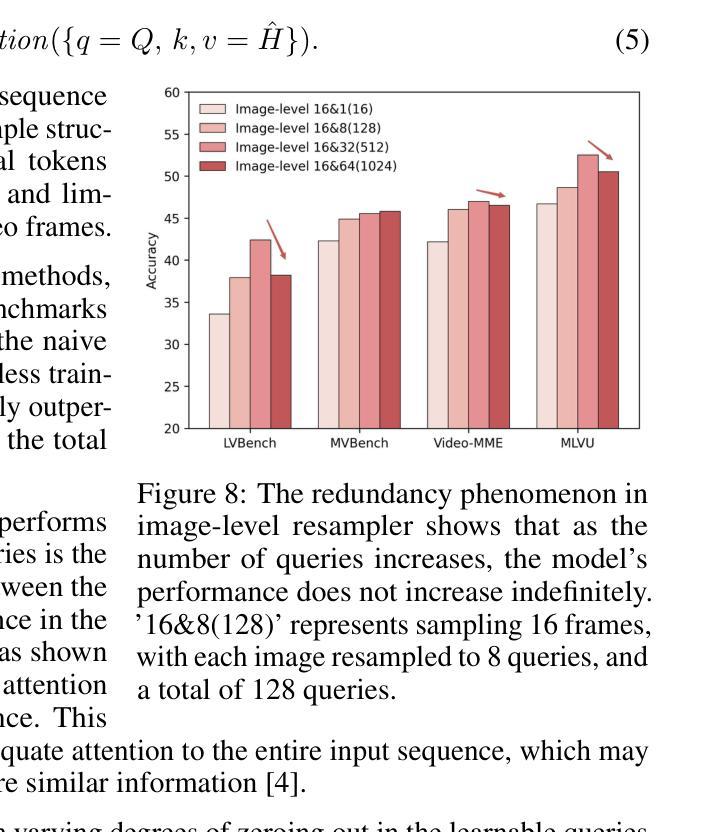
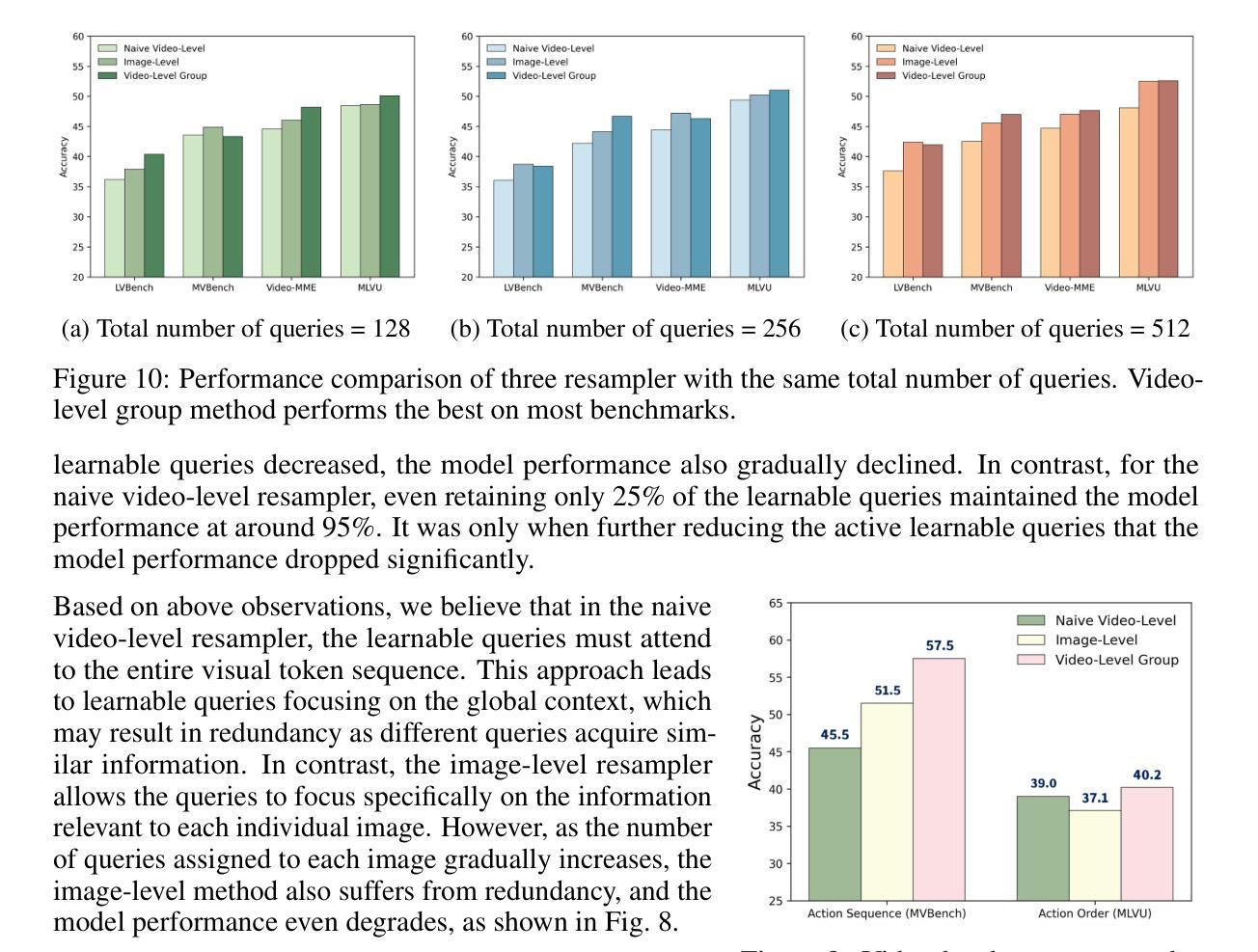
TinyLLaVA-Video: Towards Smaller LMMs for Video Understanding with Group Resampler
Authors:Xingjian Zhang, Xi Weng, Yihao Yue, Zhaoxin Fan, Wenjun Wu, Lei Huang
Video behavior recognition and scene understanding are fundamental tasks in multimodal intelligence, serving as critical building blocks for numerous real-world applications. Through large multimodal models (LMMs) have achieved remarkable progress in video understanding, most existing open-source models rely on over 7B parameters and require large-scale datasets for training, making them resource-intensive and inaccessible to many researchers. Furthermore, lightweight models face persistent challenges in effectively processing long visual sequences and temporal understanding. In this work, we introduce TinyLLaVA-Video, a lightweight yet powerful video understanding model with approximately 3.6B parameters. The cornerstone of our design is the video-level group resampler, a novel mechanism that significantly reduces and controls the number of visual tokens at the video level. Unlike traditional image-level resampler, our approach effectively mitigates redundancy while enhancing temporal comprehension, leading to improved performance on video-based tasks. In addition, TinyLLaVA-Video demonstrates exceptional efficiency, requiring only one day of training on 8 A100-40G GPUs. It surpasses several existing 7B-parameter models on multiple benchmarks. We believe this work provides a valuable foundation for future research on lightweight video understanding models. The code and weights is available at https://github.com/ZhangXJ199/TinyLLaVA-Video.
视频行为识别和场景理解是多模态智能中的基本任务,是众多现实世界应用的关键构建模块。尽管通过大型多模态模型(LMMs)在视频理解方面取得了显著的进展,但大多数现有的开源模型依赖于超过70亿个参数,并需要大规模数据集进行训练,这使得它们资源密集,许多研究者无法接触。此外,轻量级模型在处理长视频序列和时序理解方面持续面临挑战。在这项工作中,我们介绍了TinyLLaVA-Video,这是一个轻量级但功能强大的视频理解模型,拥有约3.6亿个参数。设计的核心是视频级组重采样器,这是一种新颖的机制,可以在视频级别显著减少和控制视觉标记的数量。与传统的图像级重采样器不同,我们的方法有效地减轻了冗余,同时提高了时序理解能力,在基于视频的任务上实现了性能提升。此外,TinyLLaVA-Video展示了出色的效率,仅在8个A100-40G GPU上训练一天即可达到效果。它在多个基准测试上超越了几个现有的70亿参数模型。我们相信这项工作为未来轻量级视频理解模型的研究提供了宝贵的基石。代码和权重可在https://github.com/ZhangXJ199/TinyLLaVA-Video找到。
论文及项目相关链接
PDF code and training recipes are available at https://github.com/ZhangXJ199/TinyLLaVA-Video
Summary
本文介绍了一种轻量级视频理解模型TinyLLaVA-Video,具有约3.6B参数,通过视频级组重采样器减少视觉令牌数量,提高时间理解能力,在多个基准测试中表现优异,训练效率高,仅一天即可完成训练,并且源代码和权重已在GitHub上公开。
Key Takeaways
- TinyLLaVA-Video是一种轻量级视频理解模型,具有优秀的性能。
- 模型采用视频级组重采样器技术,提高时间理解能力。
- TinyLLaVA-Video可有效处理长视频序列。
- 模型仅需要约一天的训练时间,具有较高的效率。
- 模型在多个基准测试中超越了其他具有7B参数的模型。
- 模型具有公开的源代码和权重,便于研究人员使用。
点此查看论文截图

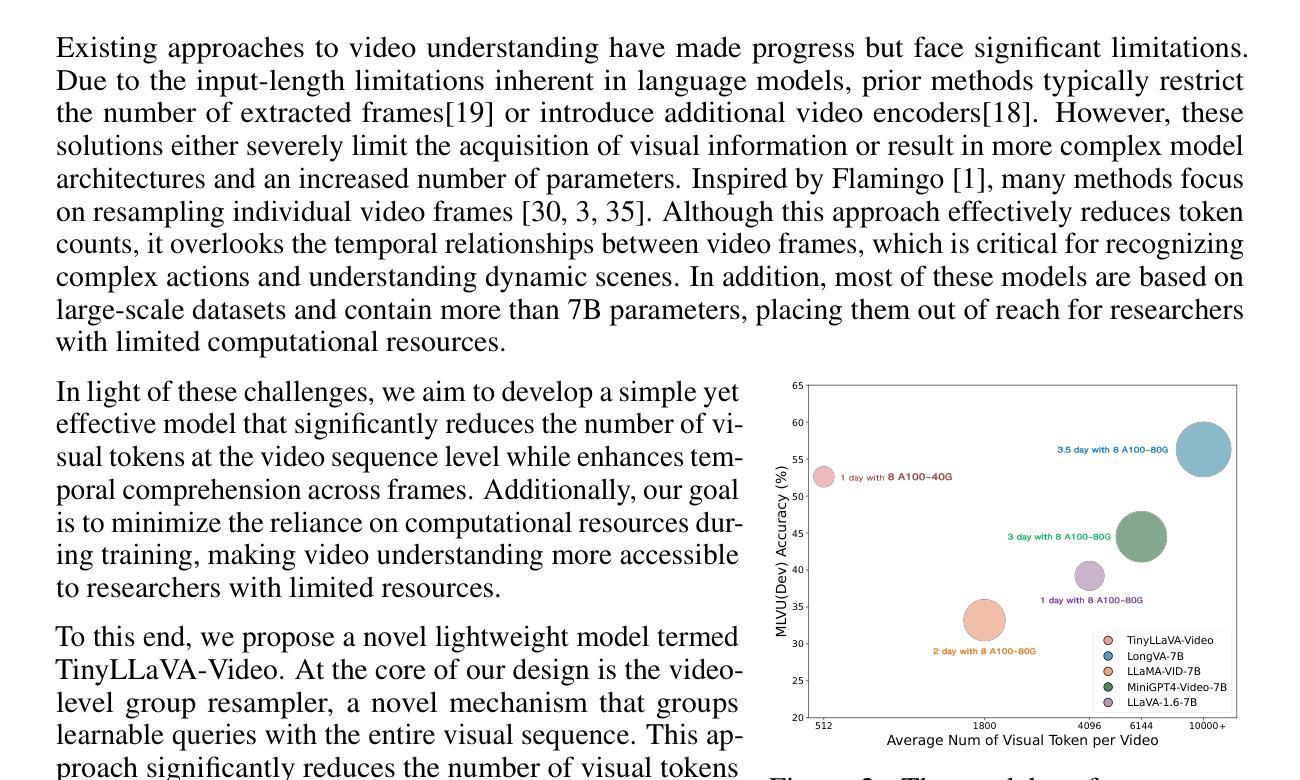
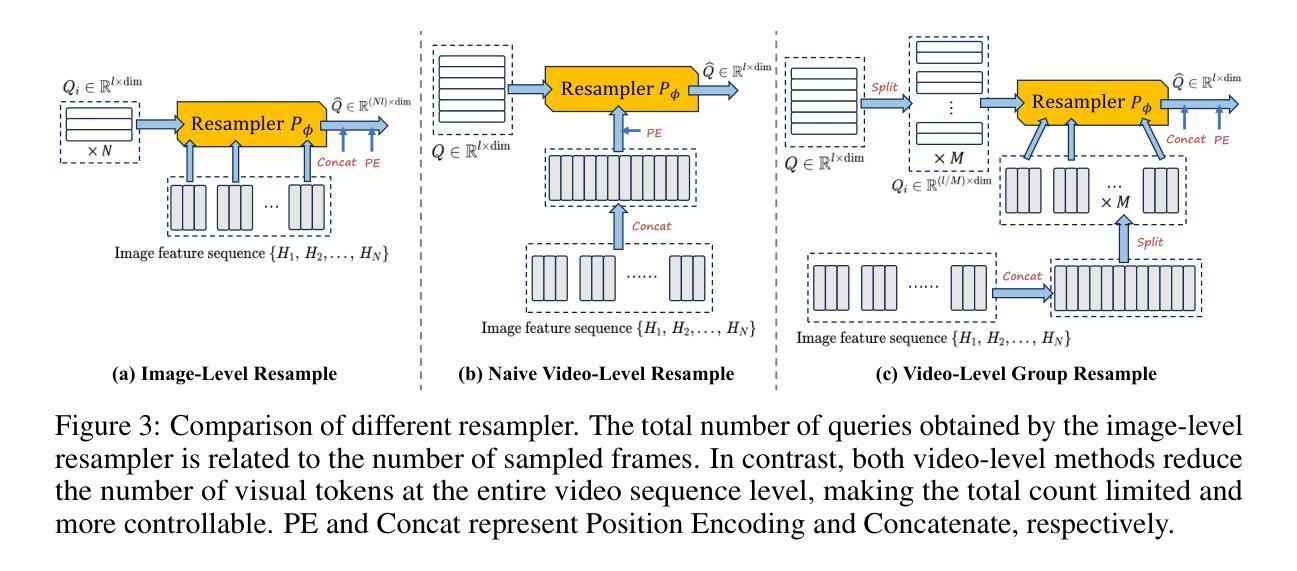
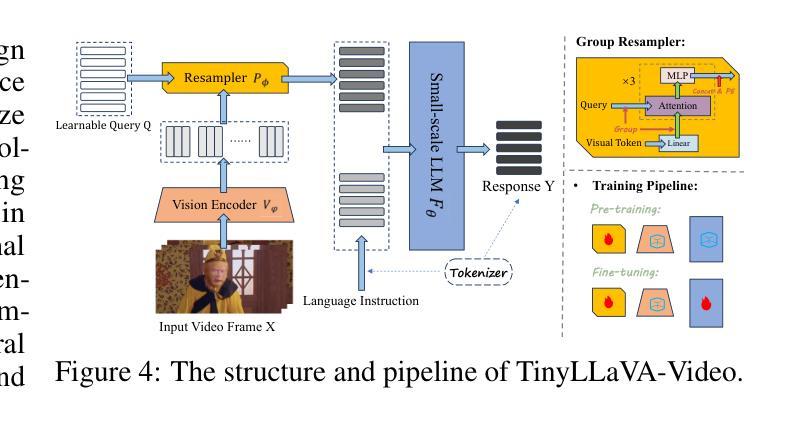

Understanding Long Videos with Multimodal Language Models
Authors:Kanchana Ranasinghe, Xiang Li, Kumara Kahatapitiya, Michael S. Ryoo
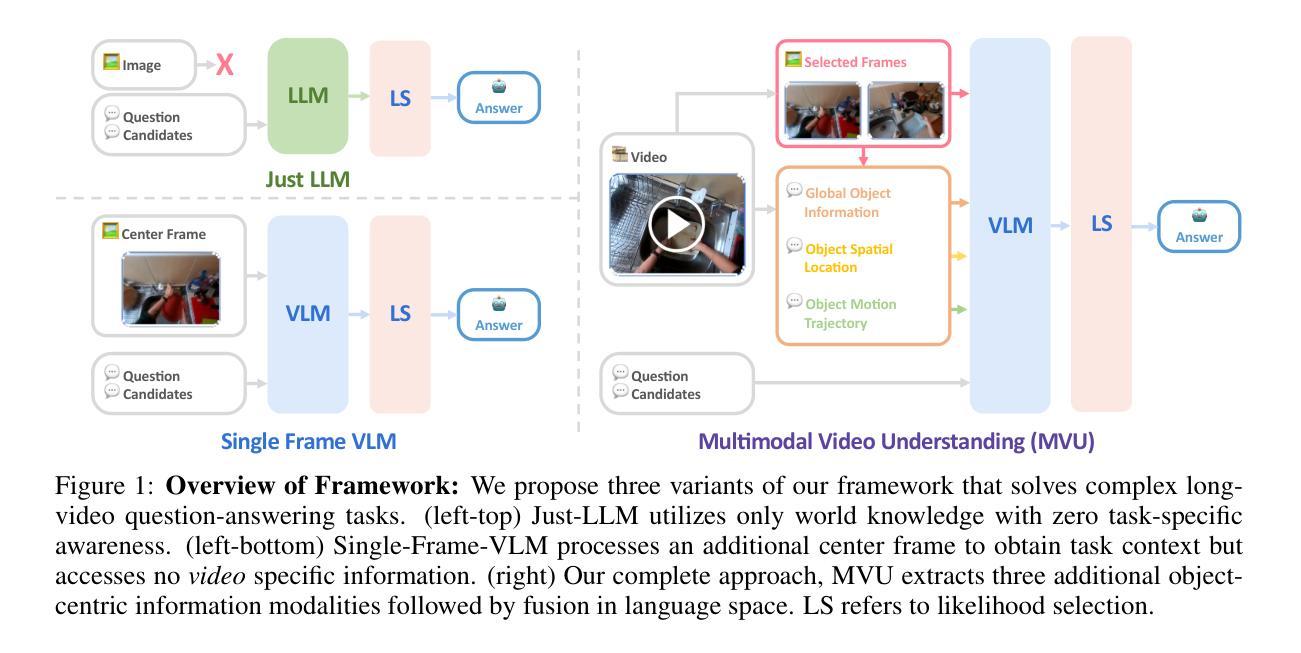
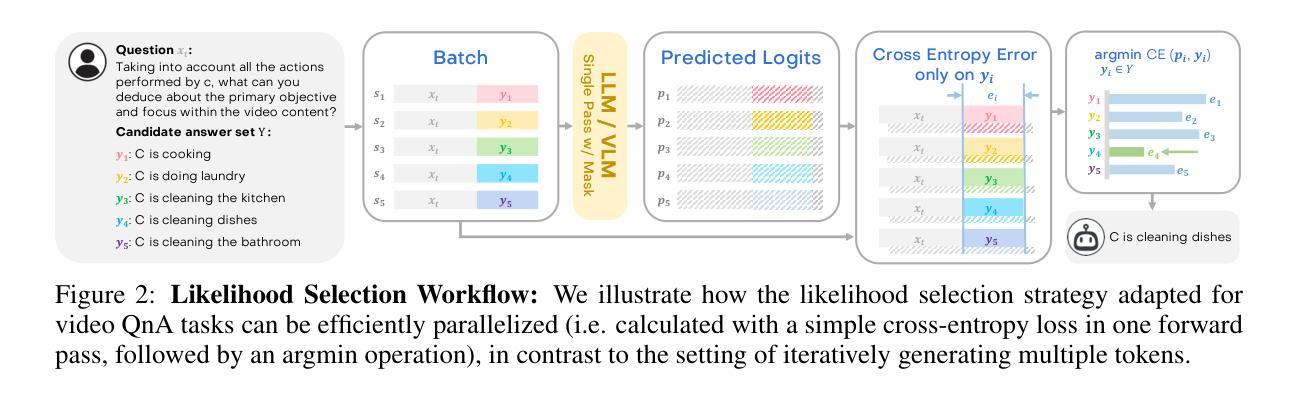
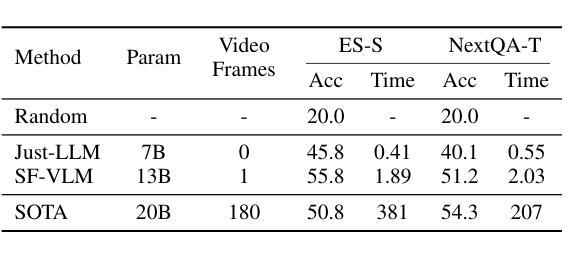
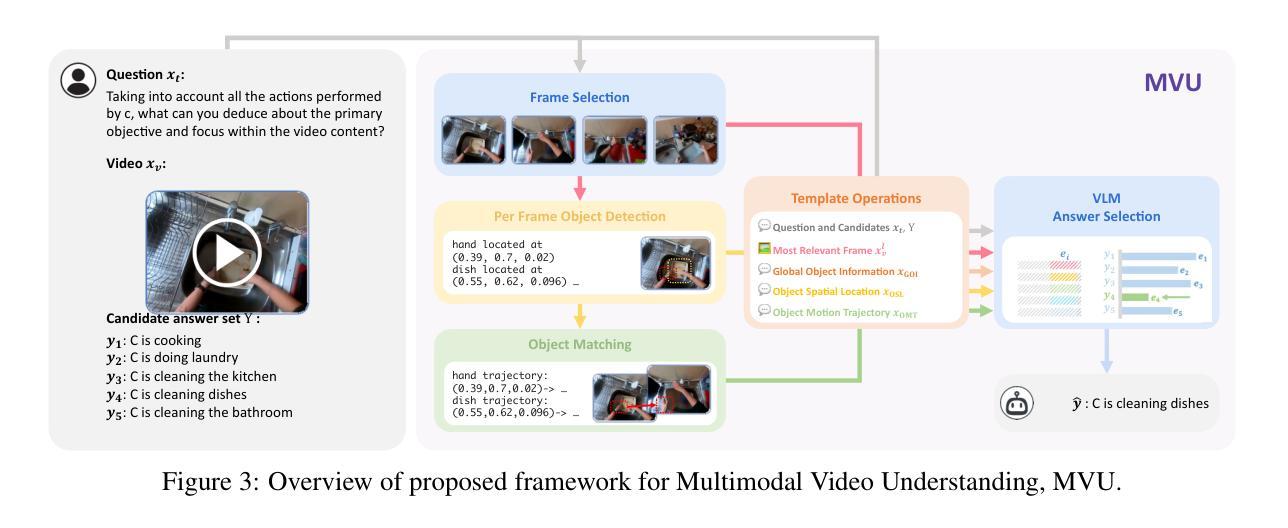
Large Language Models (LLMs) have allowed recent LLM-based approaches to achieve excellent performance on long-video understanding benchmarks. We investigate how extensive world knowledge and strong reasoning skills of underlying LLMs influence this strong performance. Surprisingly, we discover that LLM-based approaches can yield surprisingly good accuracy on long-video tasks with limited video information, sometimes even with no video specific information. Building on this, we explore injecting video-specific information into an LLM-based framework. We utilize off-the-shelf vision tools to extract three object-centric information modalities from videos, and then leverage natural language as a medium for fusing this information. Our resulting Multimodal Video Understanding (MVU) framework demonstrates state-of-the-art performance across multiple video understanding benchmarks. Strong performance also on robotics domain tasks establish its strong generality. Code: https://github.com/kahnchana/mvu
大型语言模型(LLM)使得最近的基于LLM的方法在长时间视频理解基准测试上取得了卓越的性能。我们研究了基于LLM的广泛世界知识和强大的推理能力是如何影响这一出色性能的。令人惊讶的是,我们发现基于LLM的方法在长时间视频任务上可以在有限的视频信息下达到出人意料的准确性,有时甚至不需要特定的视频信息。在此基础上,我们探索将视频特定信息注入基于LLM的框架中。我们使用现成的视觉工具从视频中提取三种以对象为中心的信息模式,然后利用自然语言作为融合这些信息的媒介。我们构建的多媒体视频理解(MVU)框架在多个视频理解基准测试中表现出卓越的性能。其在机器人领域任务上的出色表现也证明了其强大的通用性。代码地址:https://github.com/kahnchana/mvu
论文及项目相关链接
PDF 17 pages (main paper), 7 pages appendix. ICLR 2025 conference paper
Summary
大型语言模型(LLM)在视频理解领域表现出卓越性能,尤其是在长视频理解基准测试中。研究发现,LLM丰富的世界知识和强大的推理能力对其在长视频任务上的出色表现起到关键作用。即使在有限的视频信息或无特定视频信息的情况下,LLM方法也能达到令人惊讶的准确度。在此基础上,研究团队尝试将视频特定信息注入LLM框架中。通过使用现成的视觉工具提取视频中的三种对象中心信息模式,并利用自然语言作为融合这些信息的媒介,构建了多模态视频理解(MVU)框架。该框架在多个视频理解基准测试中表现出卓越性能,并在机器人领域任务中展现出强大的通用性。
Key Takeaways
- 大型语言模型(LLM)在长视频理解任务中表现优异。
- LLM的世界知识和推理能力对性能有重要影响。
- LLM方法能在有限或无特定视频信息的情况下达到良好的准确度。
- 提出将视频特定信息注入LLM框架的方法。
- 通过使用现成的视觉工具提取视频中的对象中心信息模式。
- 利用自然语言融合多模态视频信息。
- 多模态视频理解(MVU)框架在多个视频理解基准测试中表现卓越,并在机器人领域具有强大的通用性。
点此查看论文截图