⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-13 更新
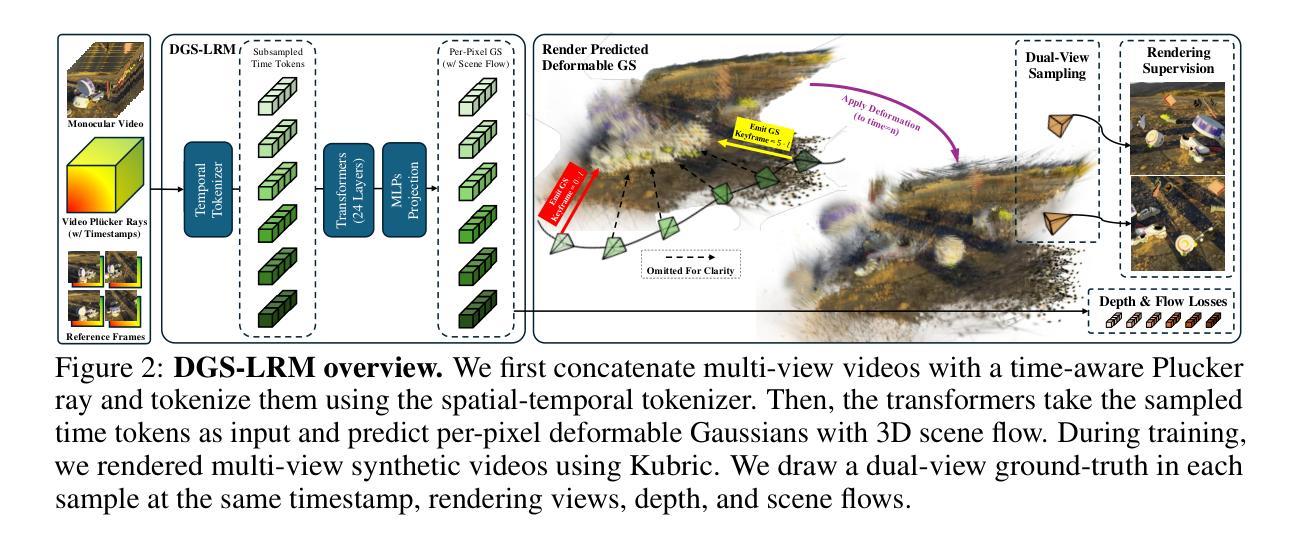
DGS-LRM: Real-Time Deformable 3D Gaussian Reconstruction From Monocular Videos
Authors:Chieh Hubert Lin, Zhaoyang Lv, Songyin Wu, Zhen Xu, Thu Nguyen-Phuoc, Hung-Yu Tseng, Julian Straub, Numair Khan, Lei Xiao, Ming-Hsuan Yang, Yuheng Ren, Richard Newcombe, Zhao Dong, Zhengqin Li
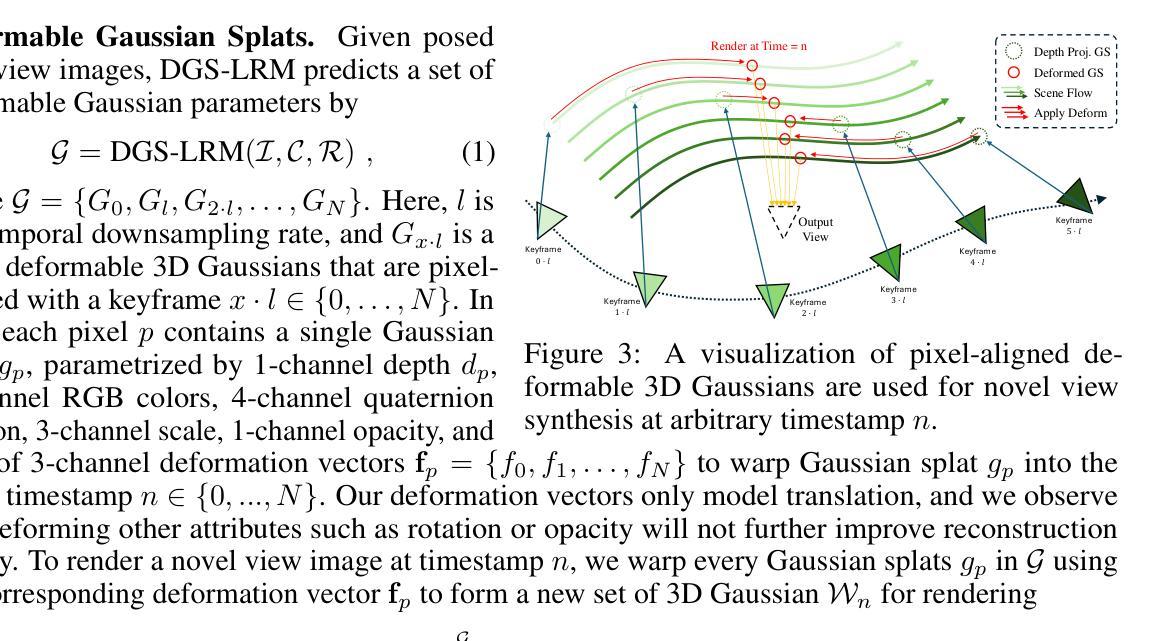
We introduce the Deformable Gaussian Splats Large Reconstruction Model (DGS-LRM), the first feed-forward method predicting deformable 3D Gaussian splats from a monocular posed video of any dynamic scene. Feed-forward scene reconstruction has gained significant attention for its ability to rapidly create digital replicas of real-world environments. However, most existing models are limited to static scenes and fail to reconstruct the motion of moving objects. Developing a feed-forward model for dynamic scene reconstruction poses significant challenges, including the scarcity of training data and the need for appropriate 3D representations and training paradigms. To address these challenges, we introduce several key technical contributions: an enhanced large-scale synthetic dataset with ground-truth multi-view videos and dense 3D scene flow supervision; a per-pixel deformable 3D Gaussian representation that is easy to learn, supports high-quality dynamic view synthesis, and enables long-range 3D tracking; and a large transformer network that achieves real-time, generalizable dynamic scene reconstruction. Extensive qualitative and quantitative experiments demonstrate that DGS-LRM achieves dynamic scene reconstruction quality comparable to optimization-based methods, while significantly outperforming the state-of-the-art predictive dynamic reconstruction method on real-world examples. Its predicted physically grounded 3D deformation is accurate and can readily adapt for long-range 3D tracking tasks, achieving performance on par with state-of-the-art monocular video 3D tracking methods.
我们介绍了可变形高斯斑点大型重建模型(DGS-LRM),这是一种能够从任何动态场景的单目视频进行预测的可变形3D高斯斑点预测的首次前馈方法。前馈场景重建因其能够迅速创建真实世界环境的数字副本而受到广泛关注。然而,大多数现有模型仅限于静态场景,无法重建移动物体的运动。开发用于动态场景重建的前馈模型面临着诸多挑战,包括训练数据的稀缺和需要适当的3D表示和训练范式。为了应对这些挑战,我们提出了几项关键的技术贡献:一个带有真实多视角视频和密集3D场景流监督的大型合成数据集;一种易于学习的像素级可变形3D高斯表示,它支持高质量动态视图合成,并可实现远程3D跟踪;以及一个大型变压器网络,实现实时、通用的动态场景重建。大量的定性和定量实验表明,DGS-LRM的动态场景重建质量可与基于优化的方法相媲美,同时在真实世界示例上显著优于最新的预测动态重建方法。其预测的物理基础3D变形准确,可轻松适应远程3D跟踪任务,性能与最新的单目视频3D跟踪方法相当。
论文及项目相关链接
PDF Project page: https://hubert0527.github.io/dgslrm/
摘要
介绍了一种可变形高斯斑点大重建模型(DGS-LRM),该模型是首个从前向视频预测可变形三维高斯斑点的预测方法,适用于任何动态场景。该模型引入了一系列关键技术贡献,包括增强的大规模合成数据集、像素级的可变形三维高斯表示和大型变压器网络,实现了实时、通用的动态场景重建。实验表明,DGS-LRM可实现与优化方法相当的动力学场景重建质量,且在真实世界示例上显著优于现有预测动态重建方法。其预测的基于物理的三维变形准确,易于适应长期三维跟踪任务,达到与最新单目视频三维跟踪方法相当的性能。
要点
- DGS-LRM是首个能够预测可变形三维高斯斑点的动态场景重建模型的预测方法。
- 该模型解决了现有模型无法重建移动物体运动的问题。
- 模型引入大规模合成数据集,具有真实多视角视频和密集的三维场景流监督。
- 采用像素级的可变形三维高斯表示,易于学习,支持高质量动态视图合成,并可实现长期三维跟踪。
- 大型变压器网络实现了实时、通用的动态场景重建。
- DGS-LRM的预测三维变形准确,适用于长期三维跟踪任务。
点此查看论文截图

UniPre3D: Unified Pre-training of 3D Point Cloud Models with Cross-Modal Gaussian Splatting
Authors:Ziyi Wang, Yanran Zhang, Jie Zhou, Jiwen Lu
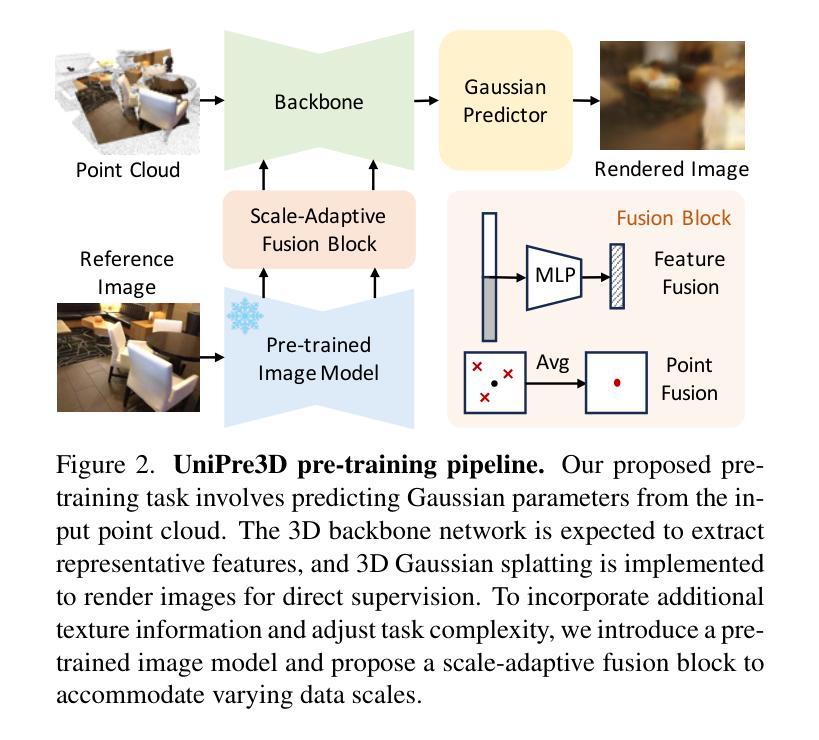
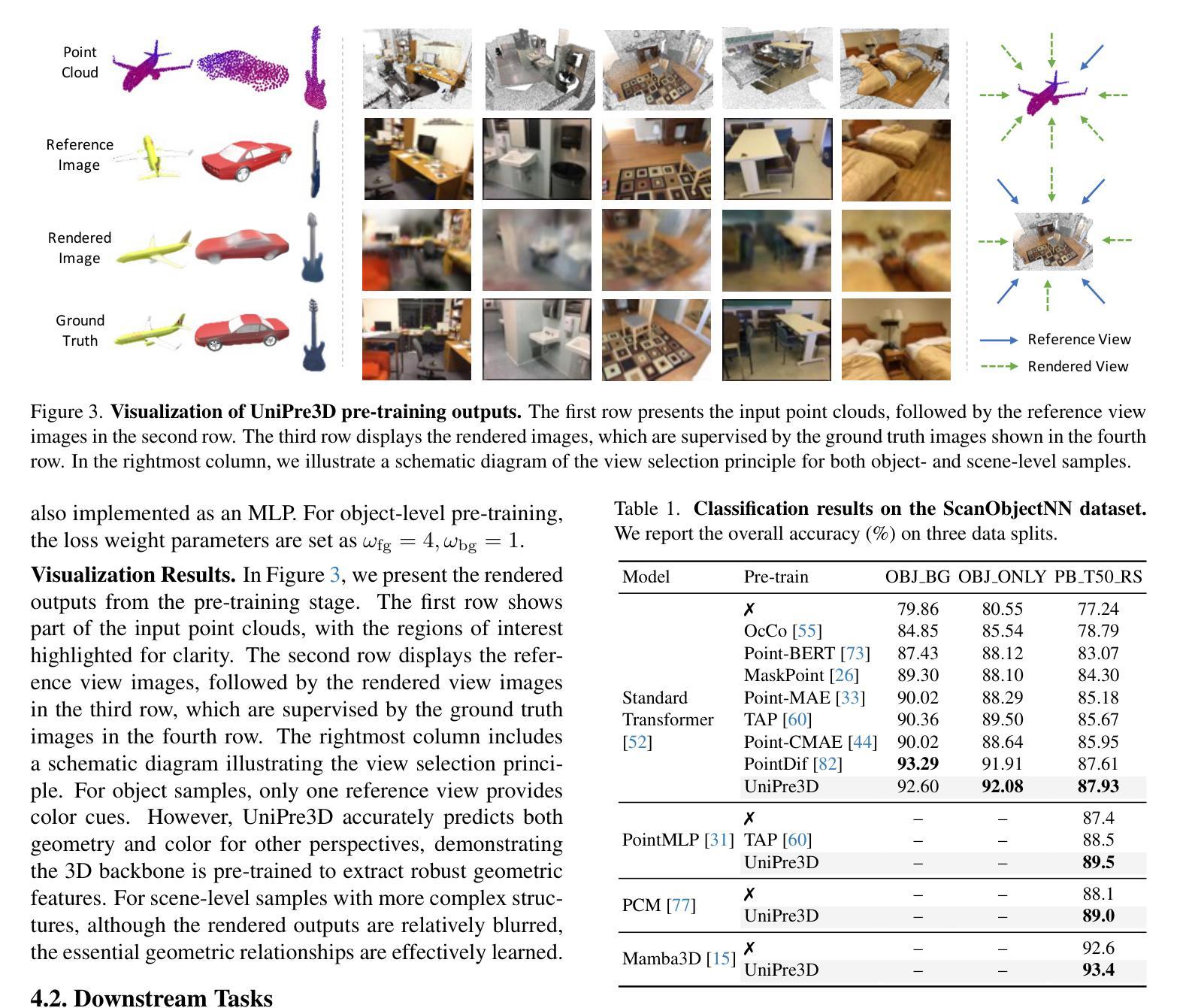
The scale diversity of point cloud data presents significant challenges in developing unified representation learning techniques for 3D vision. Currently, there are few unified 3D models, and no existing pre-training method is equally effective for both object- and scene-level point clouds. In this paper, we introduce UniPre3D, the first unified pre-training method that can be seamlessly applied to point clouds of any scale and 3D models of any architecture. Our approach predicts Gaussian primitives as the pre-training task and employs differentiable Gaussian splatting to render images, enabling precise pixel-level supervision and end-to-end optimization. To further regulate the complexity of the pre-training task and direct the model’s focus toward geometric structures, we integrate 2D features from pre-trained image models to incorporate well-established texture knowledge. We validate the universal effectiveness of our proposed method through extensive experiments across a variety of object- and scene-level tasks, using diverse point cloud models as backbones. Code is available at https://github.com/wangzy22/UniPre3D.
点云数据的规模多样性在为3D视觉开发统一表示学习技术时带来了重大挑战。目前,统一的3D模型很少,并且没有一种预训练方法能够同时适用于对象级和场景级的点云。在本文中,我们介绍了UniPre3D,这是第一种可以无缝应用于任何规模的点云和任何结构的3D模型的统一预训练方法。我们的方法将预测高斯原始数据作为预训练任务,并使用可微高斯溅射来呈现图像,从而实现精确的像素级监督和端到端优化。为了进一步调整预训练任务的复杂性并引导模型的焦点朝向几何结构,我们整合了来自预训练图像模型的2D特征,以融入成熟的纹理知识。我们通过大量实验验证了所提出方法在全范围的对象级和场景级任务中的通用有效性,使用多样化的点云模型作为骨干网。代码可通过https://github.com/wangzy22/UniPre3D获取。
论文及项目相关链接
PDF Accepted to CVPR 2025
Summary
大规模点云数据的多样性在开发用于三维视觉的统一表示学习技术方面带来了重大挑战。当前存在较少的统一三维模型,并且尚无预训练方法能够同时有效地处理对象级和场景级点云。本文提出UniPre3D,这是一种可无缝应用于任何规模点云和任何架构的三维模型的统一预训练方法。该方法以预测高斯基本体作为预训练任务,并采用可微高斯平铺技术渲染图像,实现精确像素级监督和端到端优化。为了进一步简化预训练任务的复杂性并引导模型关注几何结构,我们集成了来自预训练图像模型的二维特征,以融入成熟的纹理知识。我们通过大量实验验证了所提出方法在不同对象级和场景级任务中的通用有效性,使用各种点云模型作为骨干网。
Key Takeaways
- 点云数据的规模多样性给三维视觉的统一表示学习带来了挑战。
- 当前缺乏能同时有效处理对象级和场景级点云的统一预训练方法。
- UniPre3D是一种新的统一预训练方法,适用于任何规模点云和三维模型。
- UniPre3D通过预测高斯基本体作为预训练任务,采用可微高斯平铺技术实现精确像素级监督和端到端优化。
- 为简化预训练任务并引导模型关注几何结构,集成了预训练图像模型的二维特征。
- 实验证明UniPre3D在不同对象级和场景级任务中表现出通用有效性。
- UniPre3D代码已公开可用。
点此查看论文截图

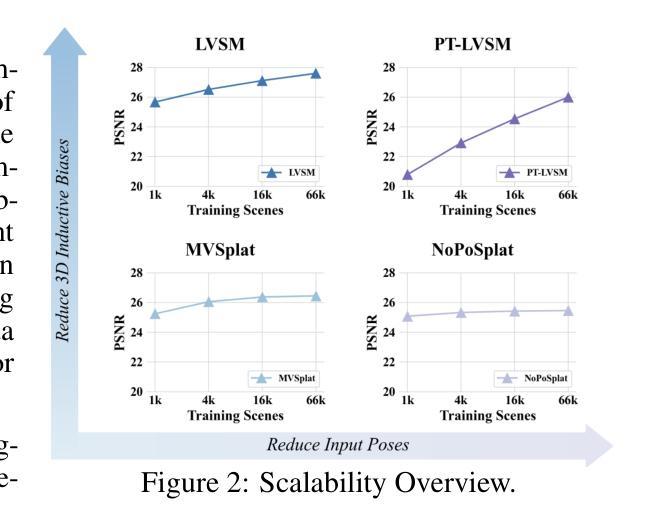
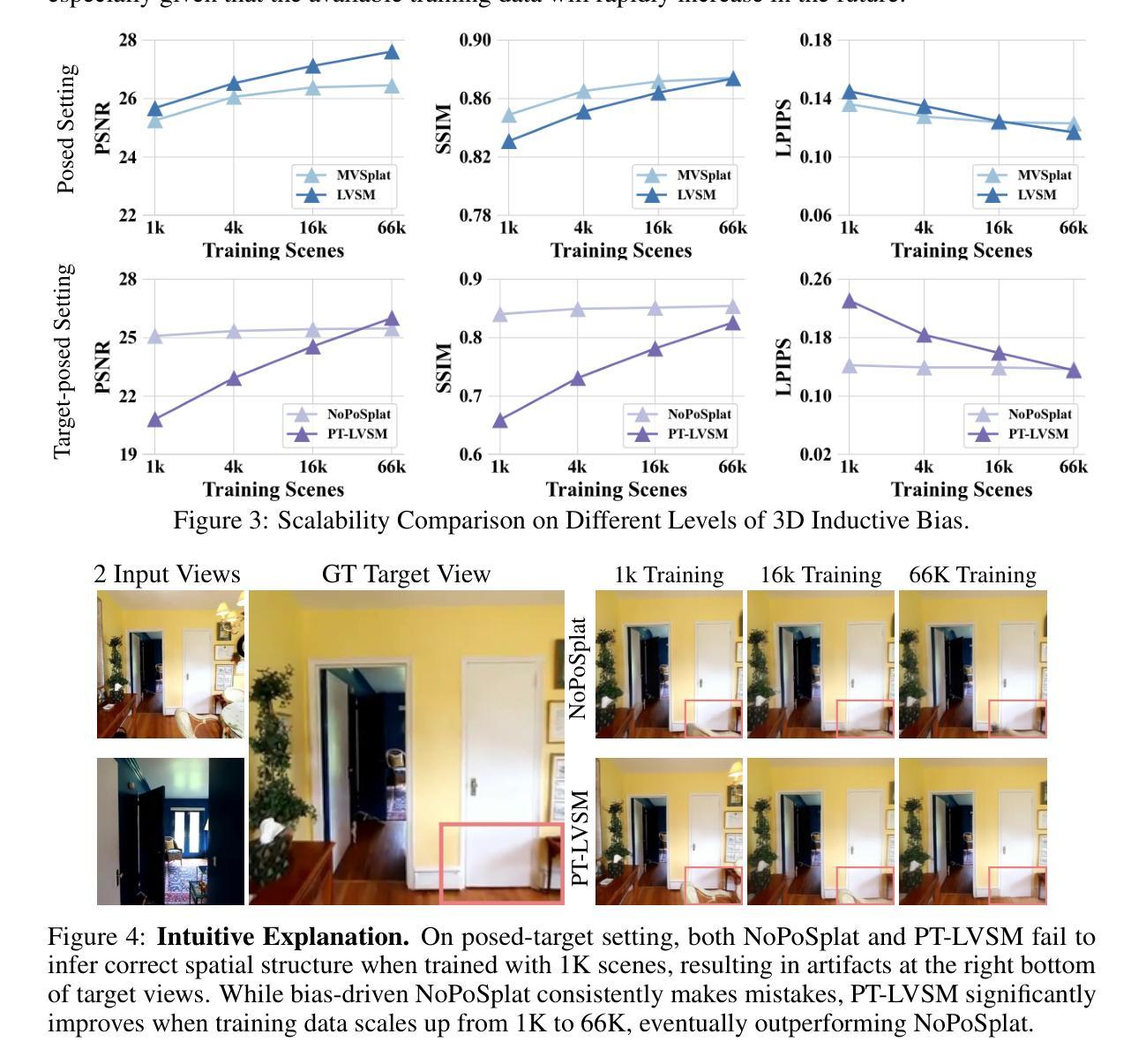
The Less You Depend, The More You Learn: Synthesizing Novel Views from Sparse, Unposed Images without Any 3D Knowledge
Authors:Haoru Wang, Kai Ye, Yangyan Li, Wenzheng Chen, Baoquan Chen
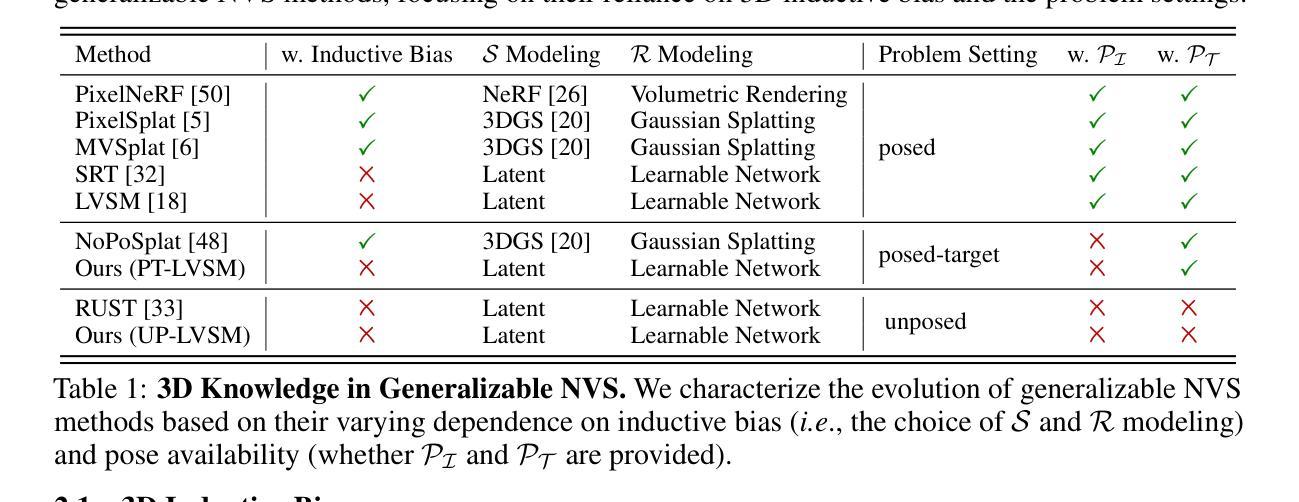
We consider the problem of generalizable novel view synthesis (NVS), which aims to generate photorealistic novel views from sparse or even unposed 2D images without per-scene optimization. This task remains fundamentally challenging, as it requires inferring 3D structure from incomplete and ambiguous 2D observations. Early approaches typically rely on strong 3D knowledge, including architectural 3D inductive biases (e.g., embedding explicit 3D representations, such as NeRF or 3DGS, into network design) and ground-truth camera poses for both input and target views. While recent efforts have sought to reduce the 3D inductive bias or the dependence on known camera poses of input views, critical questions regarding the role of 3D knowledge and the necessity of circumventing its use remain under-explored. In this work, we conduct a systematic analysis on the 3D knowledge and uncover a critical trend: the performance of methods that requires less 3D knowledge accelerates more as data scales, eventually achieving performance on par with their 3D knowledge-driven counterparts, which highlights the increasing importance of reducing dependence on 3D knowledge in the era of large-scale data. Motivated by and following this trend, we propose a novel NVS framework that minimizes 3D inductive bias and pose dependence for both input and target views. By eliminating this 3D knowledge, our method fully leverages data scaling and learns implicit 3D awareness directly from sparse 2D images, without any 3D inductive bias or pose annotation during training. Extensive experiments demonstrate that our model generates photorealistic and 3D-consistent novel views, achieving even comparable performance with methods that rely on posed inputs, thereby validating the feasibility and effectiveness of our data-centric paradigm. Project page: https://pku-vcl-geometry.github.io/Less3Depend/ .
我们考虑通用新颖视角合成(NVS)的问题,其目标是从稀疏甚至未摆放的2D图像生成真实感的新视角,而无需针对每个场景进行优化。这一任务仍然具有根本挑战性,因为它需要从不完整和模糊的2D观察中推断3D结构。早期的方法通常依赖于强大的3D知识,包括架构的3D归纳偏见(例如,将显式NeRF或3DGS等3D表示嵌入网络设计)以及输入和目标视角的真实相机姿态。尽管最近的努力试图减少3D归纳偏见或对输入视角已知相机姿态的依赖,但关于3D知识的作用以及避免使用它的必要性的关键问题仍然没有得到充分探索。在这项工作中,我们对3D知识进行了系统分析,并发现了一个关键趋势:需要较少3D知识的方法的性能随着数据规模的增加而加速提高,最终达到了与依赖3D知识的同行相当的性能水平,这突显了在大数据时代减少对3D知识依赖的重要性。受此趋势的启发并遵循这一趋势,我们提出了一种新颖的NVS框架,该框架最小化了输入和目标视角的3D归纳偏见和姿态依赖性。通过消除这种3D知识,我们的方法充分利用了数据规模,直接从稀疏的2D图像学习隐含的3D意识,而无需在训练期间使用任何3D归纳偏见或姿态注释。大量实验表明,我们的模型生成了真实感且符合3D一致性的新颖视角,即使与依赖定位输入的方法相比也取得了相当的性能,从而验证了我们的以数据为中心的模式的有效性和可行性。项目页面:https://pku-vcl-geometry.github.io/Less3Depend/。
论文及项目相关链接
Summary
本文研究了可推广的新视角合成(NVS)问题,旨在从稀疏或未摆放的2D图像生成真实感的新视角,而无需针对每个场景进行优化。文章指出,随着数据规模的增加,减少对3D知识的需求的方法性能提升更快,最终达到与依赖3D知识的方法相当的性能。基于此趋势,文章提出了一种新的NVS框架,最小化3D归纳偏见和对输入及目标视角的姿态依赖性。该方法充分利用数据规模,直接从稀疏的2D图像学习隐式的3D感知,无需在训练期间提供任何3D归纳偏见或姿态注释。实验证明,该方法生成的真实感、3D一致的新视角,甚至与依赖定位输入的方法相比也表现出色。
Key Takeaways
- 研究针对可推广的新视角合成(NVS)问题。
- NVS任务具有挑战性,需要从不完整和模糊的2D观察中推断3D结构。
- 随着数据规模的增加,减少对3D知识依赖的方法性能提升更快。
- 提出一种新的NVS框架,最小化3D归纳偏见和对姿态的依赖。
- 方法直接从稀疏的2D图像学习隐式的3D感知,无需在训练期间提供3D知识和姿态注释。
点此查看论文截图


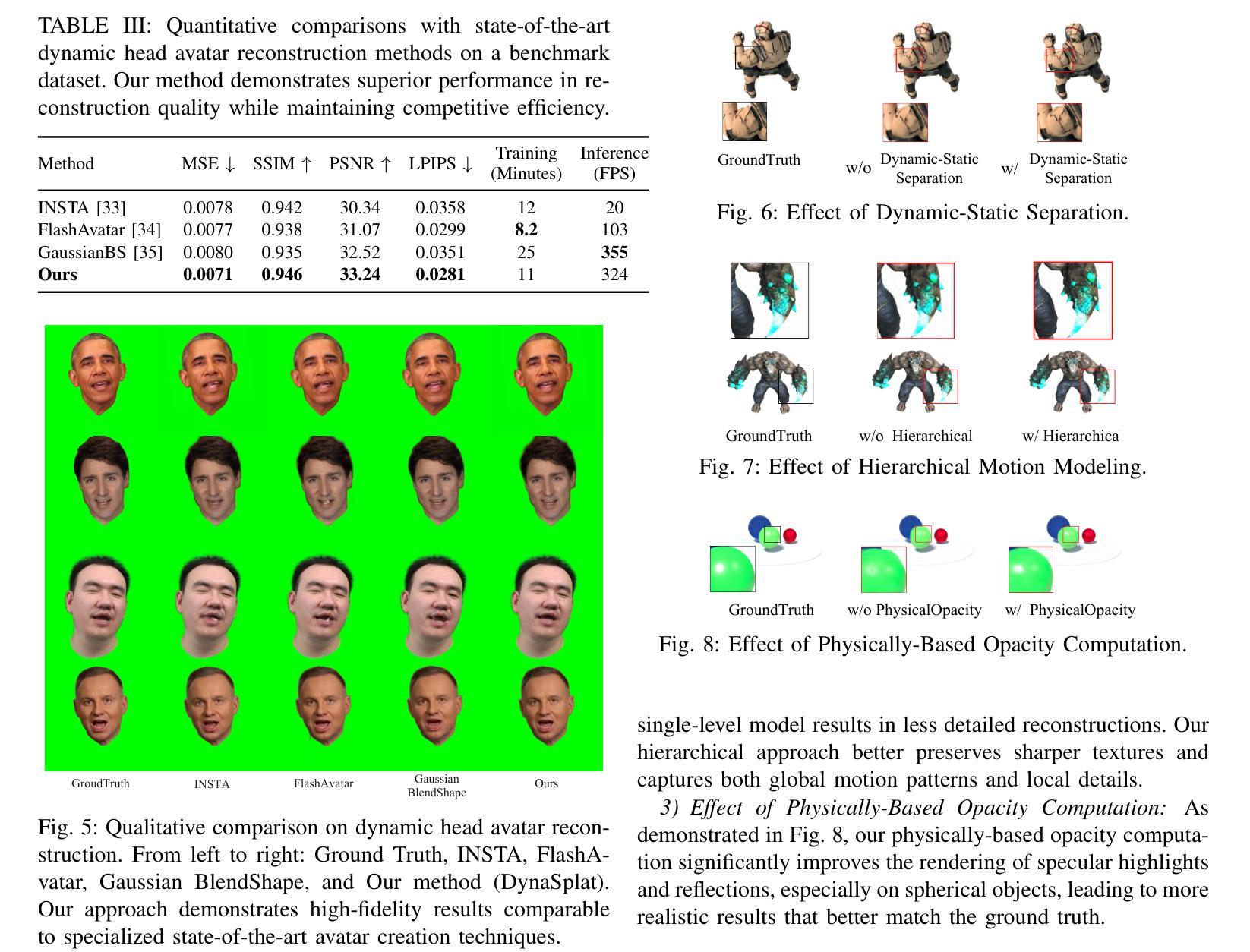
DynaSplat: Dynamic-Static Gaussian Splatting with Hierarchical Motion Decomposition for Scene Reconstruction
Authors:Junli Deng, Ping Shi, Qipei Li, Jinyang Guo
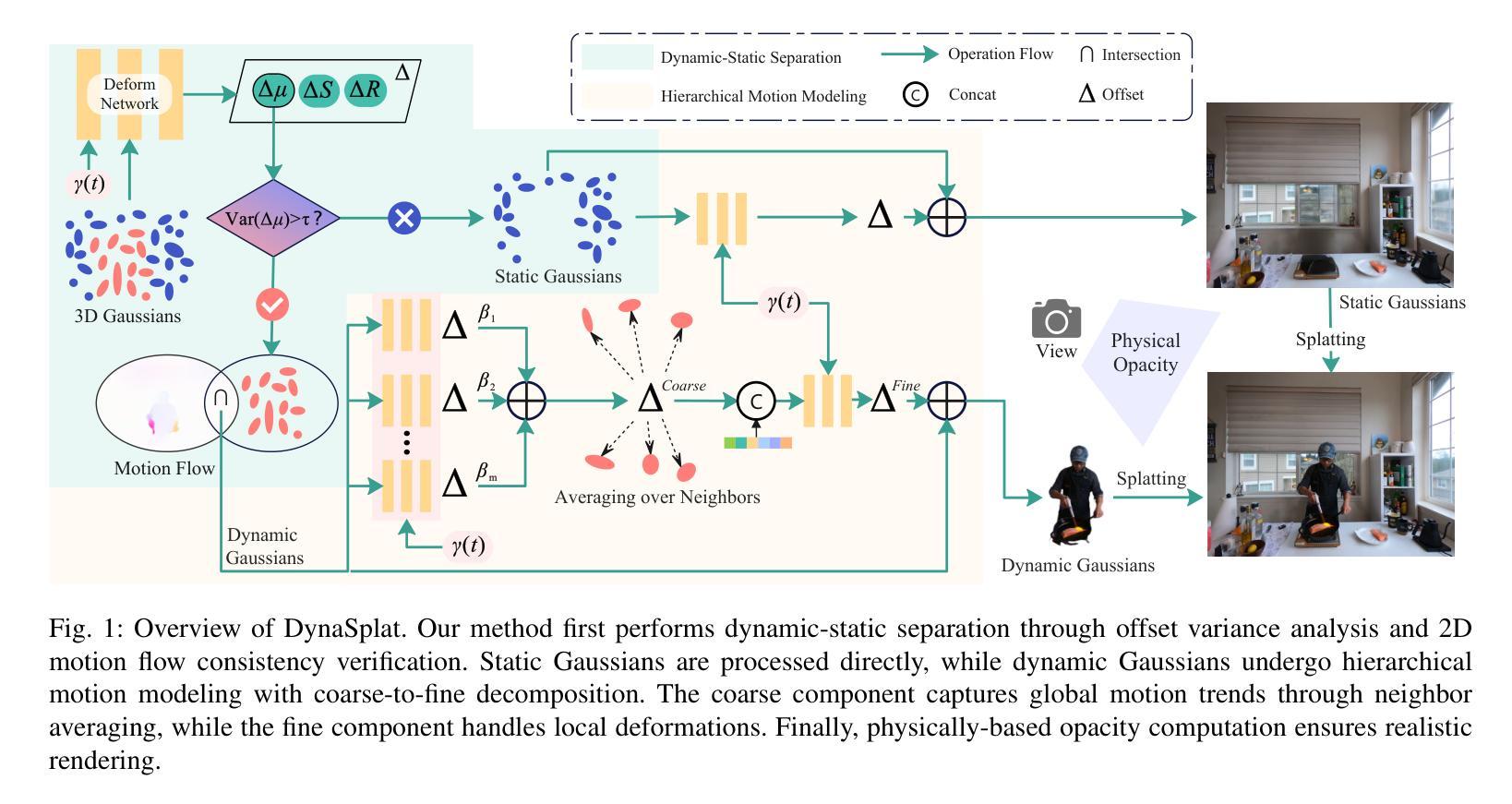
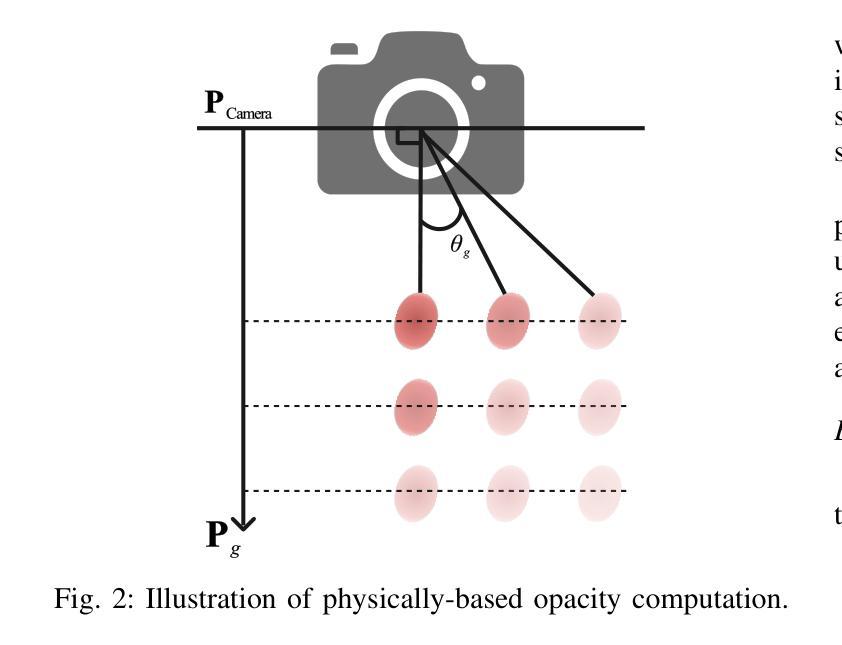
Reconstructing intricate, ever-changing environments remains a central ambition in computer vision, yet existing solutions often crumble before the complexity of real-world dynamics. We present DynaSplat, an approach that extends Gaussian Splatting to dynamic scenes by integrating dynamic-static separation and hierarchical motion modeling. First, we classify scene elements as static or dynamic through a novel fusion of deformation offset statistics and 2D motion flow consistency, refining our spatial representation to focus precisely where motion matters. We then introduce a hierarchical motion modeling strategy that captures both coarse global transformations and fine-grained local movements, enabling accurate handling of intricate, non-rigid motions. Finally, we integrate physically-based opacity estimation to ensure visually coherent reconstructions, even under challenging occlusions and perspective shifts. Extensive experiments on challenging datasets reveal that DynaSplat not only surpasses state-of-the-art alternatives in accuracy and realism but also provides a more intuitive, compact, and efficient route to dynamic scene reconstruction.
重建复杂且不断变化的环境仍是计算机视觉的核心目标,但现有解决方案往往难以应对现实世界中动态的复杂性。我们提出了DynaSplat方法,它通过整合动静分离和分层运动建模,将高斯Splatting扩展到动态场景。首先,我们通过变形偏移统计和2D运动流一致性融合的新方法,将场景元素分类为静态或动态,从而精确聚焦在运动关键区域来优化我们的空间表示。然后,我们引入了一种分层运动建模策略,既能捕捉粗糙的全局变换,又能捕捉精细的局部运动,从而实现复杂非刚性运动的精确处理。最后,我们结合了基于物理的透明度估计,以确保在具有挑战性的遮挡和透视变化下也能实现视觉连贯的重建。在具有挑战性的数据集上的广泛实验表明,DynaSplat不仅在准确性和逼真度上超越了最先进的替代方案,而且还为动态场景重建提供了更直观、更紧凑、更高效的途径。
论文及项目相关链接
Summary
本文提出了一个名为DynaSplat的新方法,用于动态场景的重建。该方法结合了动态静态分离和层次化运动建模,通过变形偏移统计和二维运动流一致性融合对场景元素进行分类,并对运动进行精准建模,从而实现了对复杂动态场景的精确重建。
Key Takeaways
- DynaSplat扩展了高斯Splatting技术,适用于动态场景的重建。
- 通过结合动态静态分离技术,DynaSplat能够区分场景中的静态和动态元素。
- 采用了层次化运动建模策略,能捕捉粗略的全局变换和精细的局部运动。
- 引入基于物理的透明度估计,确保在遮挡和透视变化下的视觉连贯性重建。
- DynaSplat在具有挑战性的数据集上的实验表现优于现有技术,具有更高的准确性和现实感。
- DynaSplat为动态场景重建提供了更直观、紧凑和高效的途径。
点此查看论文截图


Self-Supervised Multi-Part Articulated Objects Modeling via Deformable Gaussian Splatting and Progressive Primitive Segmentation
Authors:Haowen Wang, Xiaoping Yuan, Zhao Jin, Zhen Zhao, Zhengping Che, Yousong Xue, Jin Tian, Yakun Huang, Jian Tang
Articulated objects are ubiquitous in everyday life, and accurate 3D representations of their geometry and motion are critical for numerous applications. However, in the absence of human annotation, existing approaches still struggle to build a unified representation for objects that contain multiple movable parts. We introduce DeGSS, a unified framework that encodes articulated objects as deformable 3D Gaussian fields, embedding geometry, appearance, and motion in one compact representation. Each interaction state is modeled as a smooth deformation of a shared field, and the resulting deformation trajectories guide a progressive coarse-to-fine part segmentation that identifies distinct rigid components, all in an unsupervised manner. The refined field provides a spatially continuous, fully decoupled description of every part, supporting part-level reconstruction and precise modeling of their kinematic relationships. To evaluate generalization and realism, we enlarge the synthetic PartNet-Mobility benchmark and release RS-Art, a real-to-sim dataset that pairs RGB captures with accurately reverse-engineered 3D models. Extensive experiments demonstrate that our method outperforms existing methods in both accuracy and stability.
日常生活中的可动物体无处不在,对其几何形状和运动的精确三维表示对许多应用至关重要。然而,在没有人工标注的情况下,现有方法仍然难以对包含多个可动部件的物体构建统一表示。我们引入了DeGSS统一框架,它将可动物体编码为可变形三维高斯场,将几何形状、外观和运动嵌入到一个紧凑的表示中。每个交互状态都被建模为共享字段的平滑变形,得到的变形轨迹引导渐进的粗细部件分割,以识别不同的刚性组件,所有这些都以无监督的方式进行。优化后的字段提供了每个部件的空间连续、完全解耦的描述,支持部件级别的重建和他们运动学关系的精确建模。为了评估通用性和真实性,我们扩大了合成PartNet-Mobility基准测试,并发布了RS-Art,这是一个真实到模拟的数据集,它将RGB捕获与精确的逆向工程三维模型配对。大量实验表明,我们的方法在准确性和稳定性方面优于现有方法。
论文及项目相关链接
Summary
本文介绍了DeGSS框架,该框架将可移动物体编码为可变形三维高斯场,将几何形状、外观和运动嵌入一个紧凑的表示中。框架在无监督情况下模拟对象的交互状态作为共享场的平滑变形,并提供精细化字段以支持部件级重建和精确的刚体动力学关系建模。提出的数据集PartNet-Mobility和运动学测试显示其方法的准确性和稳定性超越了现有方法。
Key Takeaways
- DeGSS框架采用可变形三维高斯场表示物体几何和运动。
- 通过模拟共享场的平滑变形来建模对象的交互状态。
- 利用精细化场实现部件级别的重建和精确的刚体动力学关系建模。
- 通过无监督学习进行物体分割和识别。
- 提出新的数据集PartNet-Mobility和RS-Art以评估模型的泛化能力和现实性。
点此查看论文截图

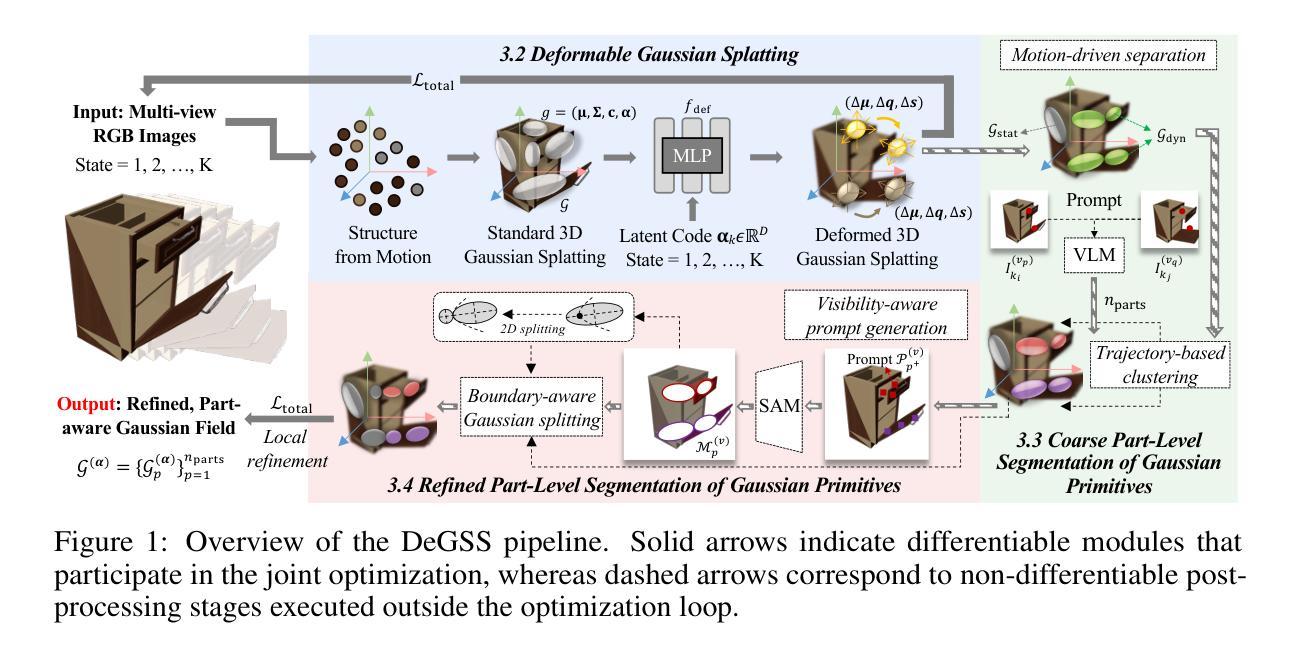
SemanticSplat: Feed-Forward 3D Scene Understanding with Language-Aware Gaussian Fields
Authors:Qijing Li, Jingxiang Sun, Liang An, Zhaoqi Su, Hongwen Zhang, Yebin Liu
Holistic 3D scene understanding, which jointly models geometry, appearance, and semantics, is crucial for applications like augmented reality and robotic interaction. Existing feed-forward 3D scene understanding methods (e.g., LSM) are limited to extracting language-based semantics from scenes, failing to achieve holistic scene comprehension. Additionally, they suffer from low-quality geometry reconstruction and noisy artifacts. In contrast, per-scene optimization methods rely on dense input views, which reduces practicality and increases complexity during deployment. In this paper, we propose SemanticSplat, a feed-forward semantic-aware 3D reconstruction method, which unifies 3D Gaussians with latent semantic attributes for joint geometry-appearance-semantics modeling. To predict the semantic anisotropic Gaussians, SemanticSplat fuses diverse feature fields (e.g., LSeg, SAM) with a cost volume representation that stores cross-view feature similarities, enhancing coherent and accurate scene comprehension. Leveraging a two-stage distillation framework, SemanticSplat reconstructs a holistic multi-modal semantic feature field from sparse-view images. Experiments demonstrate the effectiveness of our method for 3D scene understanding tasks like promptable and open-vocabulary segmentation. Video results are available at https://semanticsplat.github.io.
全景3D场景理解,即对几何、外观和语义进行联合建模,对于增强现实和机器人交互等应用至关重要。现有的前馈3D场景理解方法(例如LSM)仅限于从场景中提取基于语言的语义,无法实现全景场景理解。此外,它们还面临几何重建质量低和噪声干扰等问题。相比之下,基于场景的优化方法依赖于密集的输入视图,这降低了实用性,并增加了部署期间的复杂性。在本文中,我们提出了SemanticSplat,一种前馈的语义感知3D重建方法,它将3D高斯与潜在语义属性相结合,进行联合几何-外观-语义建模。为了预测语义各向异性高斯,SemanticSplat融合了不同的特征场(例如LSeg、SAM)与成本体积表示,该表示存储跨视图特征相似性,增强了连贯和准确的场景理解。利用两阶段蒸馏框架,SemanticSplat从稀疏视图图像重建全景多模态语义特征场。实验证明了我们方法在可提示和开放词汇分割等3D场景理解任务上的有效性。视频结果可在https://semanticsplat.github.io查看。
论文及项目相关链接
Summary
本文提出一种名为SemanticSplat的语义感知的3D重建方法,用于全息3D场景理解。该方法结合了3D高斯潜语义属性,实现了几何、外观和语义的联合建模。通过融合多种特征场和成本体积表示,SemanticSplat能够预测语义各向异性高斯,提高场景理解的连贯性和准确性。实验证明,该方法在稀疏视角图像上能有效重建全息多模态语义特征场,适用于可提示和开放词汇表的分割等3D场景理解任务。
Key Takeaways
- 强调了全息3D场景理解的重要性,特别是对于增强现实和机器人交互等应用。
- 指出现有方法的局限性:无法同时实现几何、外观和语义的全面建模,且存在几何重建质量低和噪声干扰问题。
- 介绍了SemanticSplat方法的特点:结合了语义感知的3D重建和全息场景理解,实现了几何、外观和语义的联合建模。
- 采用了多种特征场的融合技术和成本体积表示方法,提高了场景理解的连贯性和准确性。
- 通过两阶段蒸馏框架从稀疏视角图像中重建全息多模态语义特征场。
点此查看论文截图


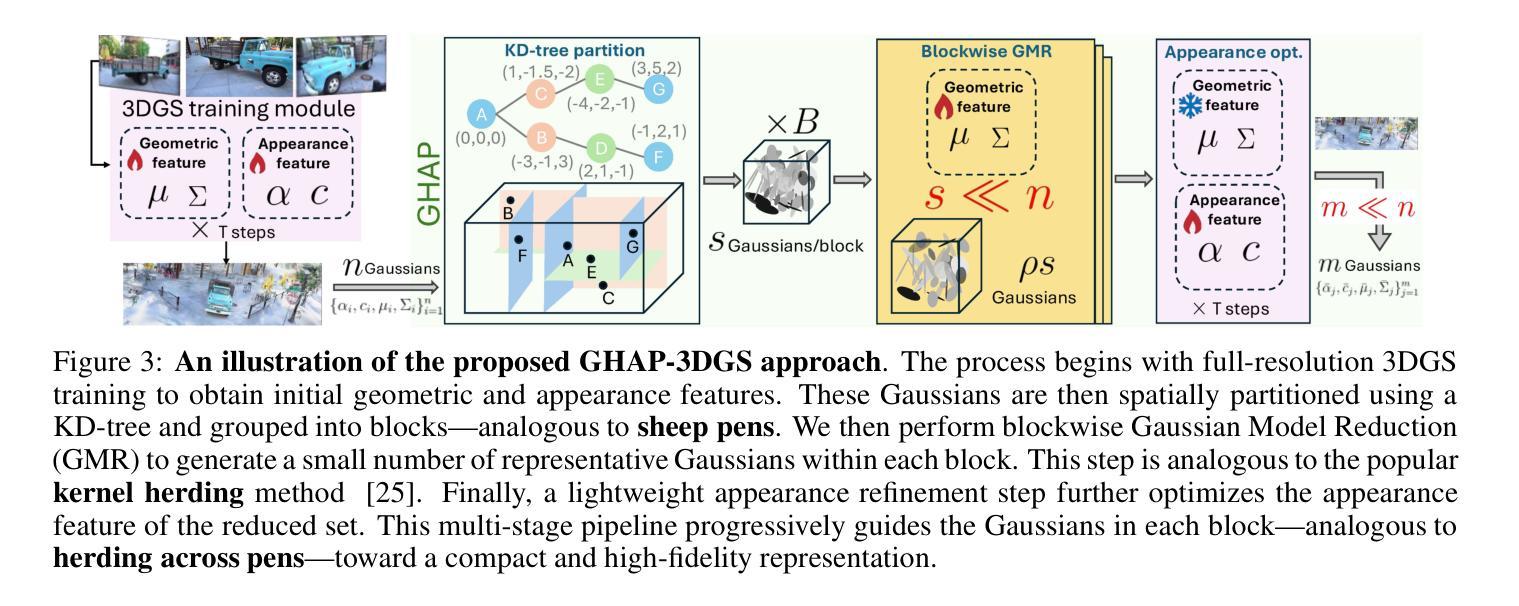
Gaussian Herding across Pens: An Optimal Transport Perspective on Global Gaussian Reduction for 3DGS
Authors:Tao Wang, Mengyu Li, Geduo Zeng, Cheng Meng, Qiong Zhang
3D Gaussian Splatting (3DGS) has emerged as a powerful technique for radiance field rendering, but it typically requires millions of redundant Gaussian primitives, overwhelming memory and rendering budgets. Existing compaction approaches address this by pruning Gaussians based on heuristic importance scores, without global fidelity guarantee. To bridge this gap, we propose a novel optimal transport perspective that casts 3DGS compaction as global Gaussian mixture reduction. Specifically, we first minimize the composite transport divergence over a KD-tree partition to produce a compact geometric representation, and then decouple appearance from geometry by fine-tuning color and opacity attributes with far fewer Gaussian primitives. Experiments on benchmark datasets show that our method (i) yields negligible loss in rendering quality (PSNR, SSIM, LPIPS) compared to vanilla 3DGS with only 10% Gaussians; and (ii) consistently outperforms state-of-the-art 3DGS compaction techniques. Notably, our method is applicable to any stage of vanilla or accelerated 3DGS pipelines, providing an efficient and agnostic pathway to lightweight neural rendering.
3D高斯贴图(3DGS)已成为辐射场渲染的强大技术,但它通常需要数以百万计的多余高斯基本体,从而消耗大量内存和渲染预算。现有的压缩方法通过基于启发式重要性分数的高斯修剪来解决这个问题,但没有全局保真度保证。为了弥补这一差距,我们从全新的最优传输角度提出将3DGS压缩视为全局高斯混合减少。具体来说,我们首先通过KD树分区最小化复合传输散度,以产生紧凑的几何表示,然后通过微调颜色和透明度属性来将外观与几何分离,所需的高斯基本体更少。在基准数据集上的实验表明,我们的方法(i)与使用仅10%的高斯相比,在渲染质量(PSNR、SSIM、LPIPS)方面几乎没有损失;(ii)始终优于最先进的3DGS压缩技术。值得注意的是,我们的方法适用于任何阶段的普通或加速3DGS管道,为轻量级神经渲染提供了高效且通用的途径。
论文及项目相关链接
PDF 18 pages, 8 figures
Summary
3DGS技术用于辐射场渲染效果显著,但存在大量冗余的高斯基本体,占用大量内存和渲染预算。现有压缩方法基于启发式重要性评分进行高斯剪枝,无法保证全局保真度。本研究从最优传输角度提出新的全球高斯混合减少方法,以缩小这一差距。首先,通过KD树分区最小化复合传输散度,产生紧凑的几何表示;然后,通过微调颜色和透明度属性,实现外观与几何的解耦,使用更少的高斯基本体。实验表明,该方法在保持渲染质量的同时,大大减少了高斯基本体的数量,优于其他先进的3DGS压缩技术。
Key Takeaways
- 3DGS技术在辐射场渲染中效果显著,但存在大量冗余高斯基本体问题。
- 现有压缩方法主要基于启发式重要性评分进行高斯剪枝,缺乏全局保真度保障。
- 提出一种基于最优传输角度的全球高斯混合减少新方法,实现紧凑的几何表示。
- 方法首先通过KD树分区最小化复合传输散度。
- 通过微调颜色和透明度属性,实现外观与几何的解耦,使用更少的高斯基本体。
- 实验表明,该方法在保持渲染质量的同时,显著减少了高斯基本体的数量。
点此查看论文截图


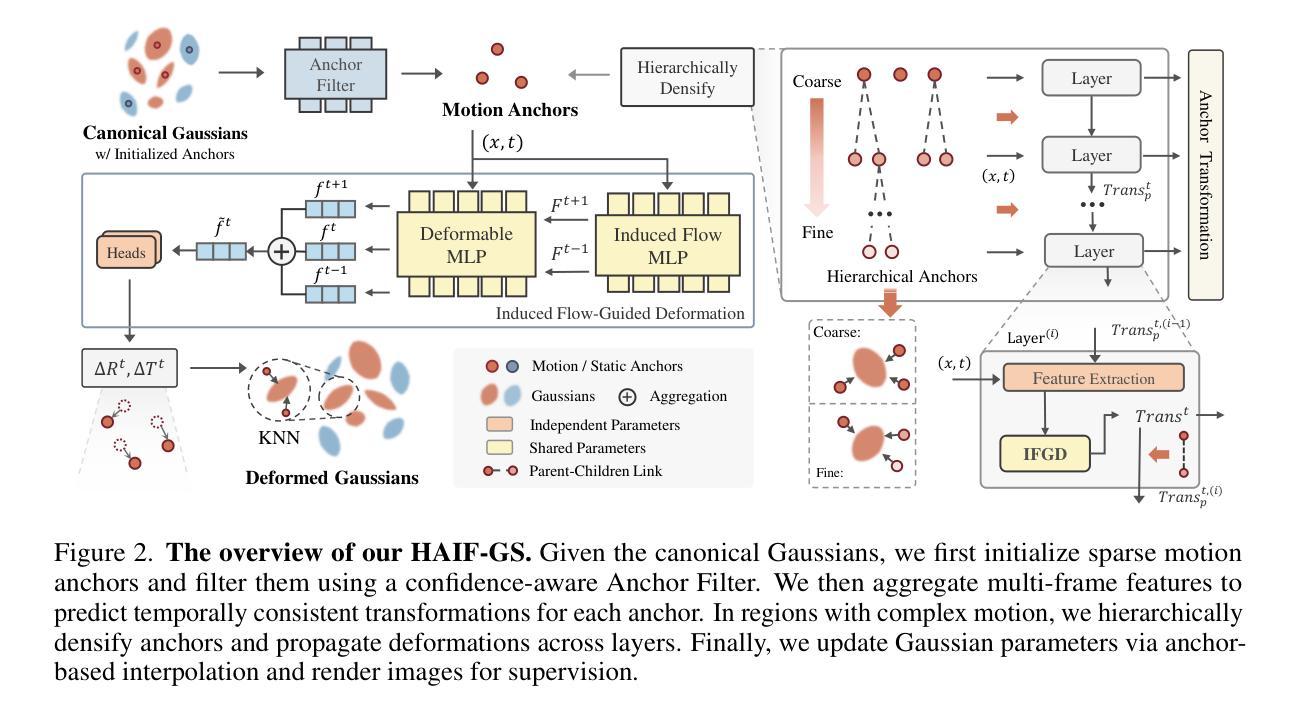
HAIF-GS: Hierarchical and Induced Flow-Guided Gaussian Splatting for Dynamic Scene
Authors:Jianing Chen, Zehao Li, Yujun Cai, Hao Jiang, Chengxuan Qian, Juyuan Kang, Shuqin Gao, Honglong Zhao, Tianlu Mao, Yucheng Zhang
Reconstructing dynamic 3D scenes from monocular videos remains a fundamental challenge in 3D vision. While 3D Gaussian Splatting (3DGS) achieves real-time rendering in static settings, extending it to dynamic scenes is challenging due to the difficulty of learning structured and temporally consistent motion representations. This challenge often manifests as three limitations in existing methods: redundant Gaussian updates, insufficient motion supervision, and weak modeling of complex non-rigid deformations. These issues collectively hinder coherent and efficient dynamic reconstruction. To address these limitations, we propose HAIF-GS, a unified framework that enables structured and consistent dynamic modeling through sparse anchor-driven deformation. It first identifies motion-relevant regions via an Anchor Filter to suppresses redundant updates in static areas. A self-supervised Induced Flow-Guided Deformation module induces anchor motion using multi-frame feature aggregation, eliminating the need for explicit flow labels. To further handle fine-grained deformations, a Hierarchical Anchor Propagation mechanism increases anchor resolution based on motion complexity and propagates multi-level transformations. Extensive experiments on synthetic and real-world benchmarks validate that HAIF-GS significantly outperforms prior dynamic 3DGS methods in rendering quality, temporal coherence, and reconstruction efficiency.
从单目视频中重建动态三维场景仍然是三维视觉领域的一个基本挑战。虽然三维高斯贴图(3DGS)在静态场景中实现了实时渲染,但由于学习结构化且时间上一致的动态表示的难度,将其扩展到动态场景是一个挑战。这一挑战在现有方法中通常表现为三个局限性:冗余的高斯更新、运动监督不足以及复杂非刚性变形的弱建模。这些问题共同阻碍了连贯和高效的动态重建。为了解决这些局限性,我们提出了HAIF-GS,这是一个通过稀疏锚驱动变形实现结构化且一致动态建模的统一框架。它首先通过锚点过滤器识别运动相关区域,从而抑制静态区域的冗余更新。自监督的诱导流引导变形模块利用多帧特征聚合诱导锚点运动,无需明确的流标签。为了进一步处理精细的变形,分层锚点传播机制根据运动复杂性提高锚点分辨率并传播多级变换。在合成和真实世界基准测试上的大量实验验证,HAIF-GS在渲染质量、时间连贯性和重建效率方面显著优于先前的动态3DGS方法。
论文及项目相关链接
Summary
动态三维场景从单目视频中重建仍是三维视觉中的基本挑战。针对现有方法在动态场景重建中面临的挑战,如冗余高斯更新、运动监督不足以及复杂非刚性变形的弱建模等,提出了HAIF-GS统一框架。该框架通过稀疏锚点驱动变形,实现结构化一致性动态建模。实验证明,HAIF-GS在渲染质量、时间连贯性和重建效率方面显著优于先前的动态3DGS方法。
Key Takeaways
- 动态三维场景从单目视频中重建是三维视觉领域的核心挑战。
- 现有方法在动态场景重建中面临冗余高斯更新、运动监督不足以及复杂非刚性变形的弱建模等问题。
- HAIF-GS框架通过稀疏锚点驱动变形,实现结构化一致性动态建模。
- Anchor Filter用于识别运动相关区域,抑制静态区域的冗余更新。
- 提出了自监督的Induced Flow-Guided Deformation模块,利用多帧特征聚合诱导锚点运动,无需明确流标签。
- Hierarchical Anchor Propagation机制根据运动复杂性提高锚点分辨率,并传播多级变换,以处理细微变形。
点此查看论文截图


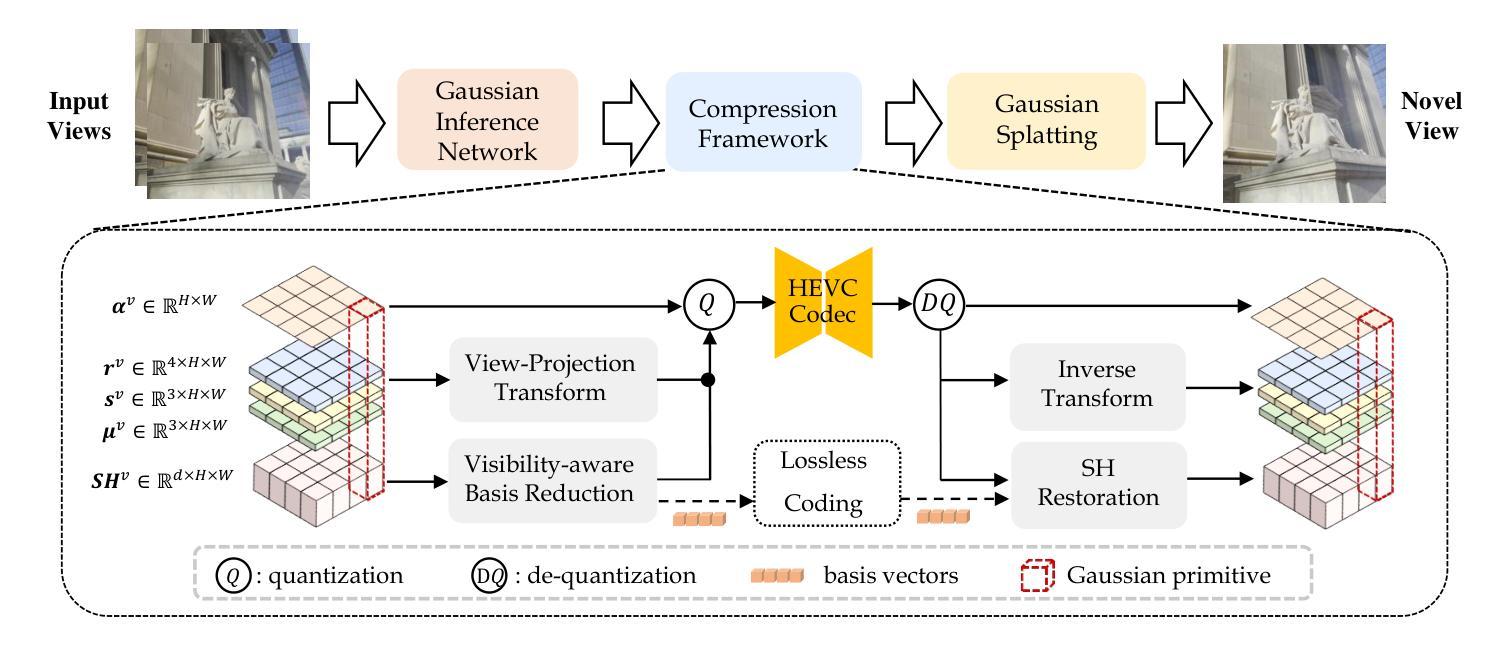
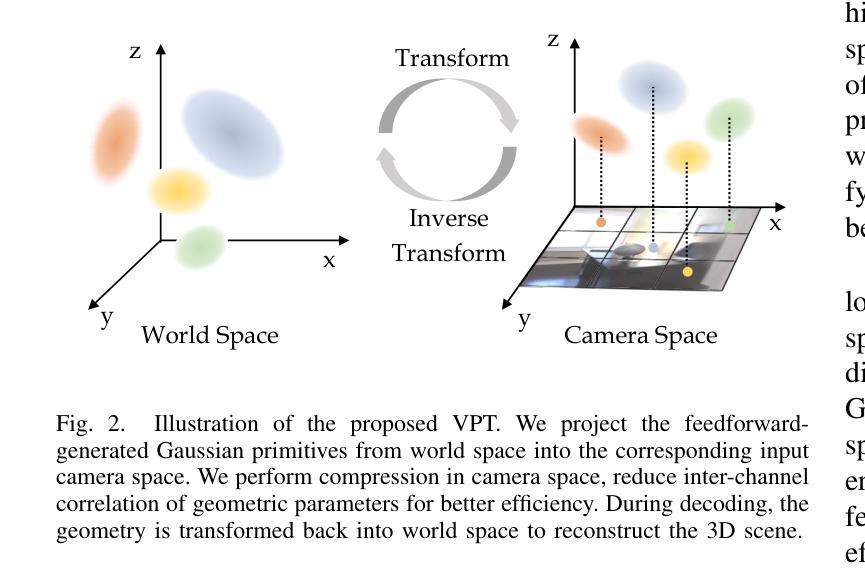
TinySplat: Feedforward Approach for Generating Compact 3D Scene Representation
Authors:Zetian Song, Jiaye Fu, Jiaqi Zhang, Xiaohan Lu, Chuanmin Jia, Siwei Ma, Wen Gao
The recent development of feedforward 3D Gaussian Splatting (3DGS) presents a new paradigm to reconstruct 3D scenes. Using neural networks trained on large-scale multi-view datasets, it can directly infer 3DGS representations from sparse input views. Although the feedforward approach achieves high reconstruction speed, it still suffers from the substantial storage cost of 3D Gaussians. Existing 3DGS compression methods relying on scene-wise optimization are not applicable due to architectural incompatibilities. To overcome this limitation, we propose TinySplat, a complete feedforward approach for generating compact 3D scene representations. Built upon standard feedforward 3DGS methods, TinySplat integrates a training-free compression framework that systematically eliminates key sources of redundancy. Specifically, we introduce View-Projection Transformation (VPT) to reduce geometric redundancy by projecting geometric parameters into a more compact space. We further present Visibility-Aware Basis Reduction (VABR), which mitigates perceptual redundancy by aligning feature energy along dominant viewing directions via basis transformation. Lastly, spatial redundancy is addressed through an off-the-shelf video codec. Comprehensive experimental results on multiple benchmark datasets demonstrate that TinySplat achieves over 100x compression for 3D Gaussian data generated by feedforward methods. Compared to the state-of-the-art compression approach, we achieve comparable quality with only 6% of the storage size. Meanwhile, our compression framework requires only 25% of the encoding time and 1% of the decoding time.
近期发展的前馈三维高斯拼贴(3DGS)为重建三维场景提供了新的范式。它使用在大规模多视角数据集上训练的神经网络,可以直接从稀疏的输入视角推断出3DGS表示。虽然前馈方法实现了高速重建,但它仍然面临着三维高斯存储成本高昂的问题。现有的依赖于场景优化的3DGS压缩方法由于架构不兼容而不可用。为了克服这一限制,我们提出了TinySplat,这是一种基于前馈生成紧凑三维场景表示的方法。TinySplat建立在标准前馈3DGS方法的基础上,集成了一个无需训练即可使用的压缩框架,该框架系统地消除了关键来源的冗余信息。具体来说,我们引入了视角投影变换(VPT),通过将几何参数投影到更紧凑的空间来减少几何冗余。我们进一步提出了基于可见性的基元减少(VABR),通过对主要观看方向上的特征能量进行基元变换来减轻感知冗余。最后,通过现成的视频编解码器解决空间冗余问题。在多个基准数据集上的综合实验结果表明,TinySplat对前馈方法生成的三维高斯数据实现了超过100倍的压缩。与最先进的压缩方法相比,我们在保持相当质量的同时,仅使用其6%的存储空间。同时,我们的压缩框架仅需要其编码时间的25%和解码时间的1%。
论文及项目相关链接
Summary
本文介绍了基于前馈的3D高斯混合(3DGS)技术的新发展。通过使用大规模多视角数据集训练的神经网络,该技术可以直接从稀疏输入视角推断出3DGS表示。然而,前馈方法虽然实现了较高的重建速度,但仍然存在大量存储成本的挑战。文章提出了一种全新的方法TinySplat,旨在解决这一局限性。TinySplat是基于标准前馈3DGS方法的压缩框架,能够系统地消除关键冗余信息来源。通过引入视图投影变换(VPT)减少几何冗余,通过可见性感知基础减少(VABR)减轻感知冗余,并通过现成的视频编码器解决空间冗余问题。实验结果表明,TinySplat对前馈方法生成的3D高斯数据实现了超过100倍的压缩比,相较于最新的压缩方法达到了相当的压缩效果,并且大幅度提升了编码和解码时间效率。总的来说,TinySplat提供了一个高效、紧凑的3D场景表示方法。
Key Takeaways
- 3DGS技术可以直接从稀疏视角推断出三维场景表示。
- 前馈方法虽然重建速度快,但存储成本高。
点此查看论文截图

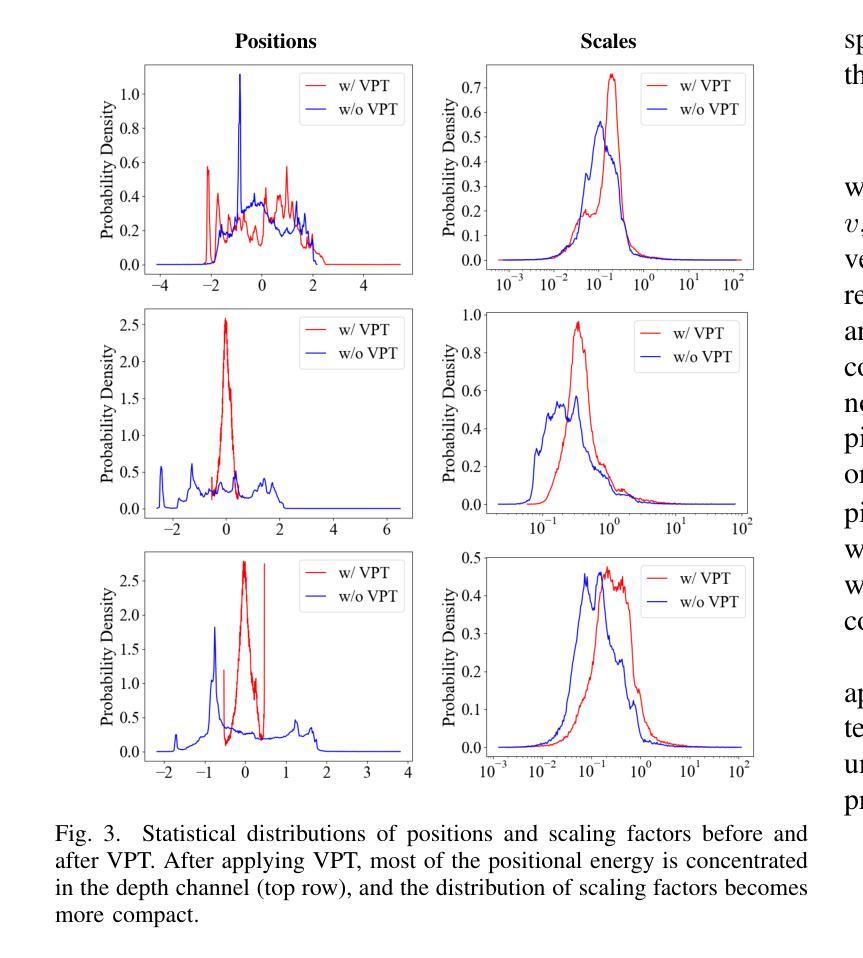
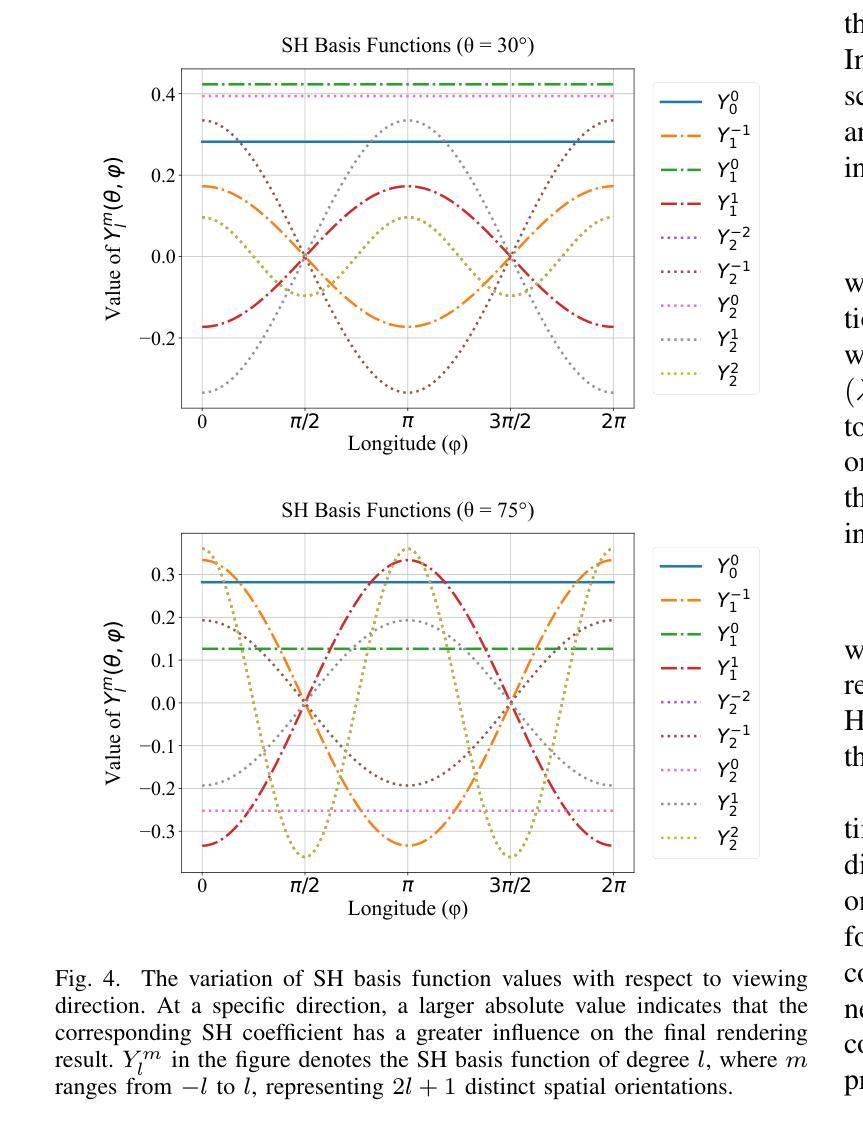
UniForward: Unified 3D Scene and Semantic Field Reconstruction via Feed-Forward Gaussian Splatting from Only Sparse-View Images
Authors:Qijian Tian, Xin Tan, Jingyu Gong, Yuan Xie, Lizhuang Ma
We propose a feed-forward Gaussian Splatting model that unifies 3D scene and semantic field reconstruction. Combining 3D scenes with semantic fields facilitates the perception and understanding of the surrounding environment. However, key challenges include embedding semantics into 3D representations, achieving generalizable real-time reconstruction, and ensuring practical applicability by using only images as input without camera parameters or ground truth depth. To this end, we propose UniForward, a feed-forward model to predict 3D Gaussians with anisotropic semantic features from only uncalibrated and unposed sparse-view images. To enable the unified representation of the 3D scene and semantic field, we embed semantic features into 3D Gaussians and predict them through a dual-branch decoupled decoder. During training, we propose a loss-guided view sampler to sample views from easy to hard, eliminating the need for ground truth depth or masks required by previous methods and stabilizing the training process. The whole model can be trained end-to-end using a photometric loss and a distillation loss that leverages semantic features from a pre-trained 2D semantic model. At the inference stage, our UniForward can reconstruct 3D scenes and the corresponding semantic fields in real time from only sparse-view images. The reconstructed 3D scenes achieve high-quality rendering, and the reconstructed 3D semantic field enables the rendering of view-consistent semantic features from arbitrary views, which can be further decoded into dense segmentation masks in an open-vocabulary manner. Experiments on novel view synthesis and novel view segmentation demonstrate that our method achieves state-of-the-art performances for unifying 3D scene and semantic field reconstruction.
我们提出了一种前馈高斯平铺模型,该模型统一了三维场景和语义场的重建。将三维场景与语义场相结合,有助于感知和理解周围环境。然而,关键挑战包括将语义嵌入到三维表示中,实现可泛化的实时重建,以及确保仅使用图像作为输入,而不使用相机参数或真实深度信息的实际可行性。为此,我们提出了UniForward,一种前馈模型,仅从未校准且未定位稀疏视角的图像中预测具有各向异性语义特征的三维高斯分布。为了统一表示三维场景和语义场,我们将语义特征嵌入到三维高斯分布中,并通过双分支解耦解码器进行预测。在训练过程中,我们提出了一种损失引导视图采样器,用于从易到难地采样视图,从而消除了以前方法所需的真实深度或掩码的需求,并稳定了训练过程。整个模型可以使用光度损失和蒸馏损失进行端到端的训练,该损失利用预训练的二维语义模型的语义特征。在推理阶段,我们的UniForward可以仅从稀疏视角图像中实时重建三维场景和相应的语义场。重建的三维场景实现了高质量渲染,重建的三维语义场可以从任意视角呈现一致的语义特征,并且可以进一步以开放词汇表的方式解码为密集分割掩码。在新型视图合成和新型视图分割方面的实验表明,我们的方法在统一三维场景和语义场重建方面达到了最先进的性能。
论文及项目相关链接
Summary
该文提出了一种前馈高斯点云模型(UniForward),该模型实现了三维场景和语义场的统一重建,仅使用未校准、未经姿态设定的稀疏视角图像作为输入。模型通过将语义特征嵌入三维高斯分布中进行预测,实现了场景和语义场的统一表示。训练过程中采用损失引导视图采样器,并采用光度损失和蒸馏损失进行端到端训练。在推理阶段,该模型能够实时从稀疏视角图像重建三维场景和对应的语义场,实现高质量渲染和任意视角的语义特征渲染。
Key Takeaways
- 提出了前馈高斯点云模型(UniForward),实现了三维场景和语义场的统一重建。
- 仅使用未校准、未经姿态设定的稀疏视角图像作为输入。
- 通过将语义特征嵌入三维高斯分布进行预测,实现场景和语义场的统一表示。
- 采用损失引导视图采样器,稳定训练过程,无需使用地面真实深度或掩码。
- 使用光度损失和蒸馏损失进行端到端训练。
- 能够在推理阶段实时从稀疏视角图像重建三维场景和对应的语义场。
- 实现了高质量渲染,并能从任意视角渲染语义特征,进一步解码为开放词汇表的密集分割掩码。
点此查看论文截图

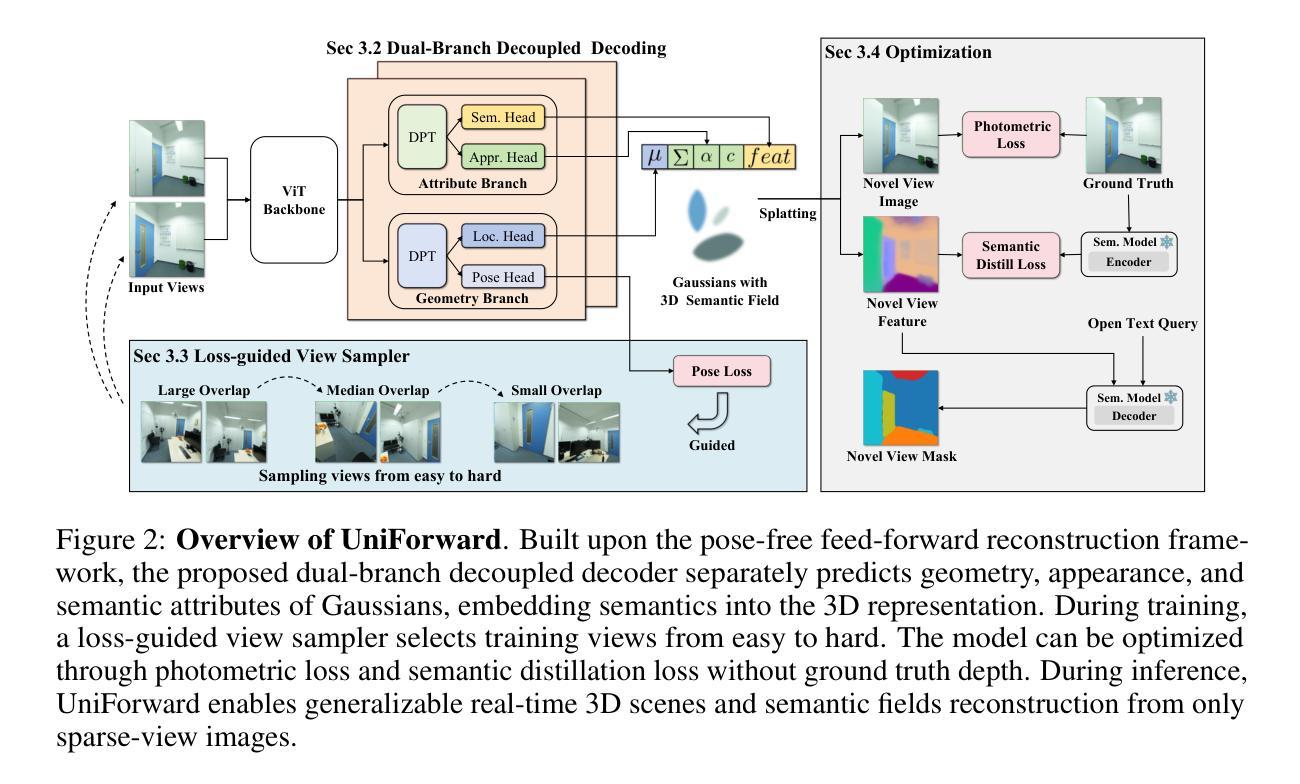
StreamSplat: Towards Online Dynamic 3D Reconstruction from Uncalibrated Video Streams
Authors:Zike Wu, Qi Yan, Xuanyu Yi, Lele Wang, Renjie Liao
Real-time reconstruction of dynamic 3D scenes from uncalibrated video streams is crucial for numerous real-world applications. However, existing methods struggle to jointly address three key challenges: 1) processing uncalibrated inputs in real time, 2) accurately modeling dynamic scene evolution, and 3) maintaining long-term stability and computational efficiency. To this end, we introduce StreamSplat, the first fully feed-forward framework that transforms uncalibrated video streams of arbitrary length into dynamic 3D Gaussian Splatting (3DGS) representations in an online manner, capable of recovering scene dynamics from temporally local observations. We propose two key technical innovations: a probabilistic sampling mechanism in the static encoder for 3DGS position prediction, and a bidirectional deformation field in the dynamic decoder that enables robust and efficient dynamic modeling. Extensive experiments on static and dynamic benchmarks demonstrate that StreamSplat consistently outperforms prior works in both reconstruction quality and dynamic scene modeling, while uniquely supporting online reconstruction of arbitrarily long video streams. Code and models are available at https://github.com/nickwzk/StreamSplat.
实时从未校准的视频流中重建动态的3D场景对于众多现实世界应用至关重要。然而,现有方法难以同时解决三个关键挑战:1)实时处理未校准的输入,2)准确模拟动态场景演变,以及3)保持长期稳定性和计算效率。为此,我们引入了StreamSplat,这是一个完全前馈的框架,能够以在线方式将任意长度的未校准视频流转换为动态的3D高斯喷绘(3DGS)表示,能够从时间局部观察中恢复场景动态。我们提出了两项关键技术创新:静态编码器中的概率采样机制用于3DGS位置预测,以及动态解码器中的双向变形场,能够实现稳健和高效的动态建模。在静态和动态基准测试上的广泛实验表明,StreamSplat在重建质量和动态场景建模方面均始终优于先前的工作,同时独特地支持任意长度视频流的在线重建。代码和模型可在https://github.com/nickwzk/StreamSplat找到。
论文及项目相关链接
摘要
实时从未校准的视频流重建动态三维场景对许多实际应用至关重要。然而,现有方法难以同时解决三个关键挑战:1)处理实时未校准输入;2)准确模拟动态场景演变;以及3)保持长期稳定性和计算效率。为此,我们推出了StreamSplat,这是一个全新的前馈框架,能够实时将任意长度的未校准视频流转换为动态三维高斯喷涂(3DGS)表示,从时间上局部观测恢复场景动态。我们提出了两项关键技术创新:静态编码器中的概率采样机制用于预测3DGS位置,以及动态解码器中的双向变形场,可实现稳健高效的动力学建模。在静态和动态基准测试上的广泛实验表明,StreamSplat在重建质量和动态场景建模方面均优于先前的工作,并且唯一支持任意长视频流的在线重建。相关代码和模型可在https://github.com/nickwzk/StreamSplat找到。
要点
- StreamSplat是首个全前馈框架,能够从任意长度的未校准视频流实时重建动态三维场景。
- 通过两项关键技术创新解决动态三维场景重建的三个主要挑战。
- 静态编码器中的概率采样机制用于预测3DGS位置。
- 动态解码器中的双向变形场实现稳健高效的动态建模。
- 在多项基准测试中表现优越,重建质量和动态场景建模均优于先前方法。
- 支持任意长视频流的在线重建。
点此查看论文截图

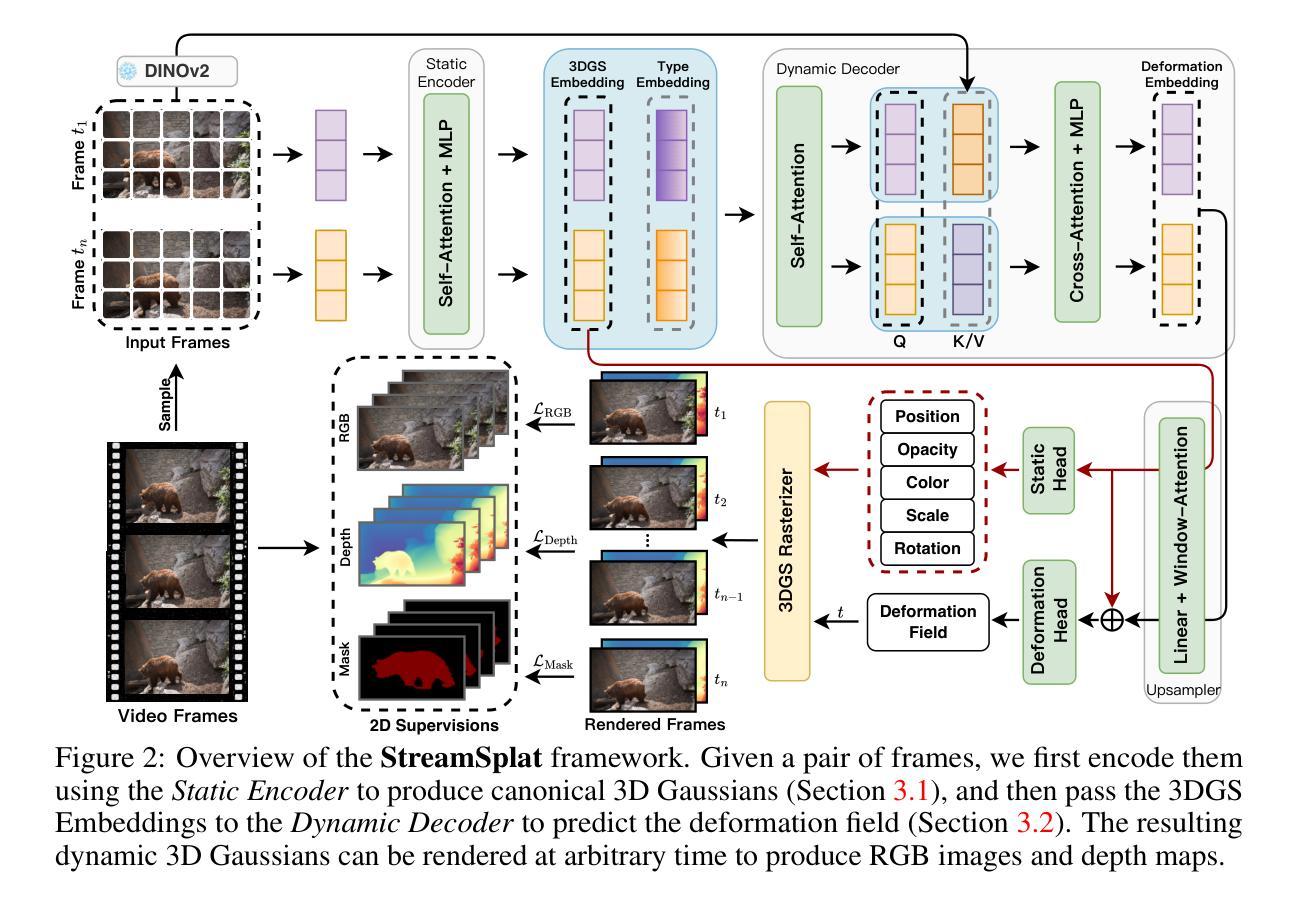

TraGraph-GS: Trajectory Graph-based Gaussian Splatting for Arbitrary Large-Scale Scene Rendering
Authors:Xiaohan Zhang, Sitong Wang, Yushen Yan, Yi Yang, Mingda Xu, Qi Liu
High-quality novel view synthesis for large-scale scenes presents a challenging dilemma in 3D computer vision. Existing methods typically partition large scenes into multiple regions, reconstruct a 3D representation using Gaussian splatting for each region, and eventually merge them for novel view rendering. They can accurately render specific scenes, yet they do not generalize effectively for two reasons: (1) rigid spatial partition techniques struggle with arbitrary camera trajectories, and (2) the merging of regions results in Gaussian overlap to distort texture details. To address these challenges, we propose TraGraph-GS, leveraging a trajectory graph to enable high-precision rendering for arbitrarily large-scale scenes. We present a spatial partitioning method for large-scale scenes based on graphs, which incorporates a regularization constraint to enhance the rendering of textures and distant objects, as well as a progressive rendering strategy to mitigate artifacts caused by Gaussian overlap. Experimental results demonstrate its superior performance both on four aerial and four ground datasets and highlight its remarkable efficiency: our method achieves an average improvement of 1.86 dB in PSNR on aerial datasets and 1.62 dB on ground datasets compared to state-of-the-art approaches.
高质量的大规模场景新视图合成是三维计算机视觉领域中的一个具有挑战性的难题。现有方法通常将大规模场景分割成多个区域,使用高斯飞溅技术为每个区域重建三维表示,并最终将它们合并以呈现新视图。它们可以准确地呈现特定场景,但由于两个原因,它们并不能够有效地推广: (1)刚性的空间分割技术难以处理任意的相机轨迹;(2)区域的合并导致高斯重叠,从而扭曲纹理细节。为了解决这些挑战,我们提出TraGraph-GS,利用轨迹图实现任意大规模场景的高精度渲染。我们提出了一种基于图的大型场景空间分割方法,该方法采用正则化约束以增强纹理和远距离物体的渲染,以及采用渐进渲染策略来缓解因高斯重叠而产生的伪影。实验结果表明,该方法在四个航空和四个地面数据集上的性能卓越,并且效率显著:我们的方法在航空数据集上平均提高了1.86 dB的PSNR,在地面数据集上平均提高了1.62 dB,与最新方法相比具有显著优势。
论文及项目相关链接
Summary
本文介绍了针对大规模场景的高质量新型视图合成在3D计算机视觉中的挑战。现有方法通常将大型场景分割成多个区域,为每个区域使用高斯贴图构建3D表示,并最终合并它们以进行新型视图渲染。然而,这些方法存在两个主要问题:一是刚性空间分割技术难以处理任意的相机轨迹,二是区域合并导致高斯重叠,从而扭曲纹理细节。为解决这些问题,本文提出了TraGraph-GS方法,利用轨迹图实现大规模场景的高精度渲染。该方法基于图进行空间分割,并引入正则化约束以提高纹理和远距离物体的渲染效果,同时采用渐进渲染策略来减轻高斯重叠引起的伪影。实验结果表明,该方法在四组航空和四组地面数据集上表现优异,且在效率上实现了显著的提升。
Key Takeaways
- 高质量的新型视图合成对于大规模场景在3D计算机视觉中是一项具有挑战的任务。
- 现有方法通常通过分割场景、构建3D表示和合并区域来进行渲染,但存在处理任意相机轨迹和纹理细节失真问题。
- TraGraph-GS方法利用轨迹图实现大规模场景的高精度渲染。
- 该方法基于图进行空间分割,并引入正则化约束提高纹理和远距离物体的渲染。
- 渐进渲染策略用于减轻高斯重叠引起的伪影。
- 实验结果表明,TraGraph-GS在多个数据集上表现优异,相较于现有方法平均提高了PSNR值。
点此查看论文截图

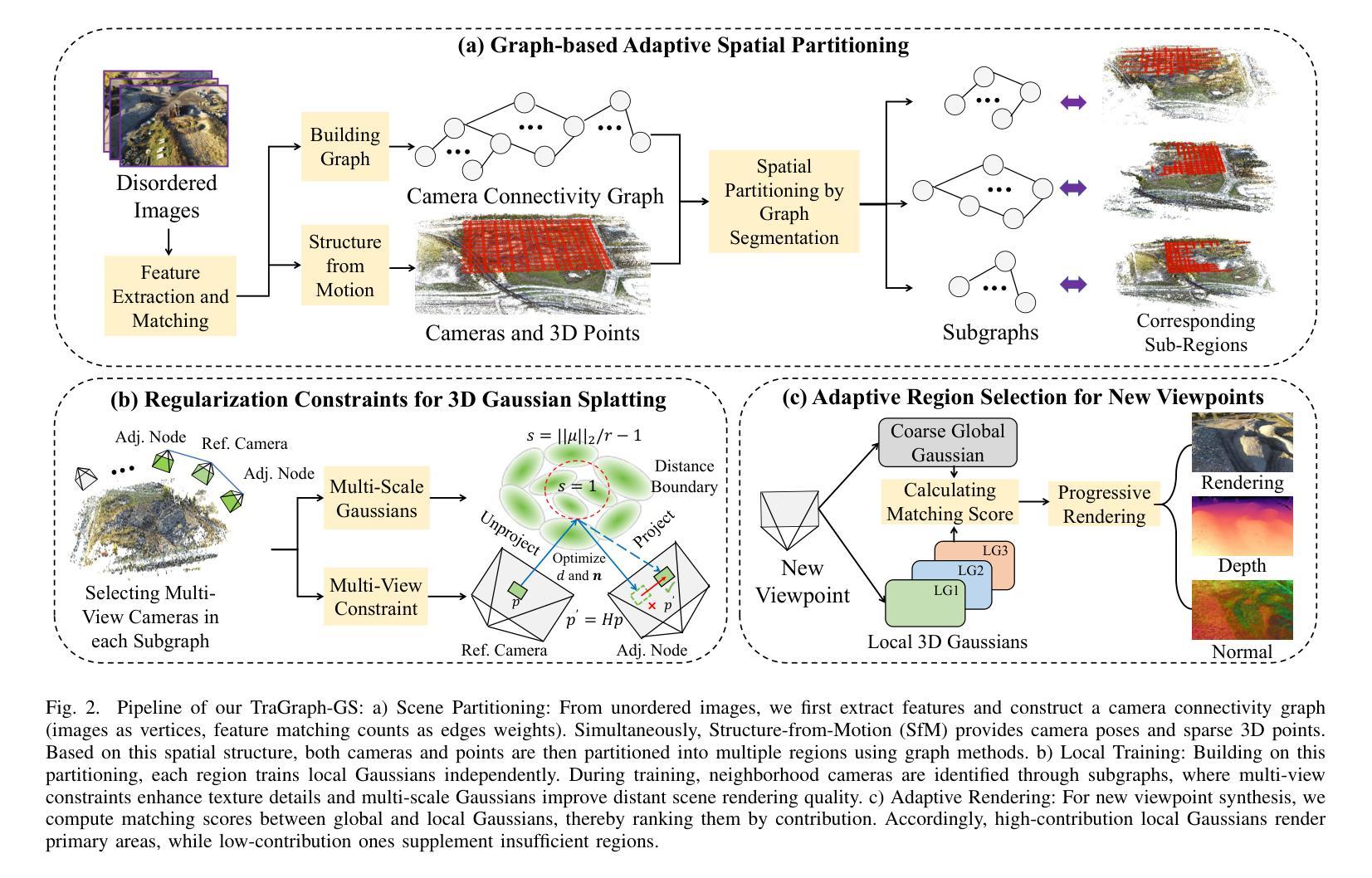


GigaSLAM: Large-Scale Monocular SLAM with Hierarchical Gaussian Splats
Authors:Kai Deng, Yigong Zhang, Jian Yang, Jin Xie
Tracking and mapping in large-scale, unbounded outdoor environments using only monocular RGB input presents substantial challenges for existing SLAM systems. Traditional Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) SLAM methods are typically limited to small, bounded indoor settings. To overcome these challenges, we introduce GigaSLAM, the first RGB NeRF / 3DGS-based SLAM framework for kilometer-scale outdoor environments, as demonstrated on the KITTI, KITTI 360, 4 Seasons and A2D2 datasets. Our approach employs a hierarchical sparse voxel map representation, where Gaussians are decoded by neural networks at multiple levels of detail. This design enables efficient, scalable mapping and high-fidelity viewpoint rendering across expansive, unbounded scenes. For front-end tracking, GigaSLAM utilizes a metric depth model combined with epipolar geometry and PnP algorithms to accurately estimate poses, while incorporating a Bag-of-Words-based loop closure mechanism to maintain robust alignment over long trajectories. Consequently, GigaSLAM delivers high-precision tracking and visually faithful rendering on urban outdoor benchmarks, establishing a robust SLAM solution for large-scale, long-term scenarios, and significantly extending the applicability of Gaussian Splatting SLAM systems to unbounded outdoor environments. GitHub: https://github.com/DengKaiCQ/GigaSLAM.
仅使用单目RGB输入在大规模、无边界的室外环境中进行追踪和映射,给现有的SLAM系统带来了巨大的挑战。传统的神经辐射场(NeRF)和3D高斯喷绘(3DGS)SLAM方法通常局限于小规模的室内环境。为了克服这些挑战,我们推出了GigaSLAM,这是第一个基于RGB NeRF/3DGS的SLAM框架,适用于公里级室外环境,如在KITTI、KITTI 360、四季和A2D2数据集上所示。我们的方法采用分层稀疏体素图表示,其中高斯数据通过多级细节神经网络进行解码。这种设计实现了高效、可扩展的映射和高保真视角渲染,适用于广阔的无界场景。对于前端跟踪,GigaSLAM结合度量深度模型、极线几何和PnP算法来准确估计姿态,同时采用基于词袋的环路闭合机制,以在长期轨迹中保持稳健的对齐。因此,GigaSLAM在城市室外基准测试上实现了高精度追踪和高保真渲染,为大规模、长期场景建立了稳健的SLAM解决方案,并将高斯喷绘SLAM系统的应用范围大大扩展到了无界室外环境。GitHub:https://github.com/DengKaiCQ/GigaSLAM。
论文及项目相关链接
摘要
该文本介绍了一种针对大范围户外环境的RGB NeRF/ 3DGS-基于SLAM框架的技术挑战,其结合了多种技术的优点以实现大范围环境中的地图创建与路径跟踪。作者采用神经网络和层次化的稀疏体素图表示方法,通过不同层次的细节解码高斯信息,实现了高效、可伸缩的映射和高保真度的视点渲染。同时,该框架结合了深度模型、极几何和PnP算法进行前端跟踪,并利用基于Bag-of-Words的闭环机制维持长期轨迹的稳健对齐。因此,GigaSLAM为大规模户外环境提供了稳健的SLAM解决方案,显著扩展了高斯Splatting SLAM系统的应用范围。其GitHub链接为:链接地址。整体来说,该研究在大规模室外环境定位与地图构建方面实现了显著的突破和进展。
关键见解
- GigaSLAM是首个针对大范围户外环境的RGB NeRF / 3DGS-基于SLAM框架。首次在大型室外场景如KITTI、KITTI 360、四季和A2D2数据集上展示了其性能。
- 采用层次化的稀疏体素图表示方法,结合神经网络解码高斯信息,实现高效映射和高保真度渲染。
- 前端跟踪结合了深度模型、极几何和PnP算法,提高了姿态估计的准确性。
- 利用基于Bag-of-Words的闭环机制来保持长期轨迹的稳健对齐。
- GigaSLAM在高精度跟踪和视觉真实渲染方面表现出色,为大规模、长期场景提供了稳健的SLAM解决方案。
- 该技术显著扩展了高斯Splatting SLAM系统的应用范围,使其适用于大范围户外环境。
点此查看论文截图

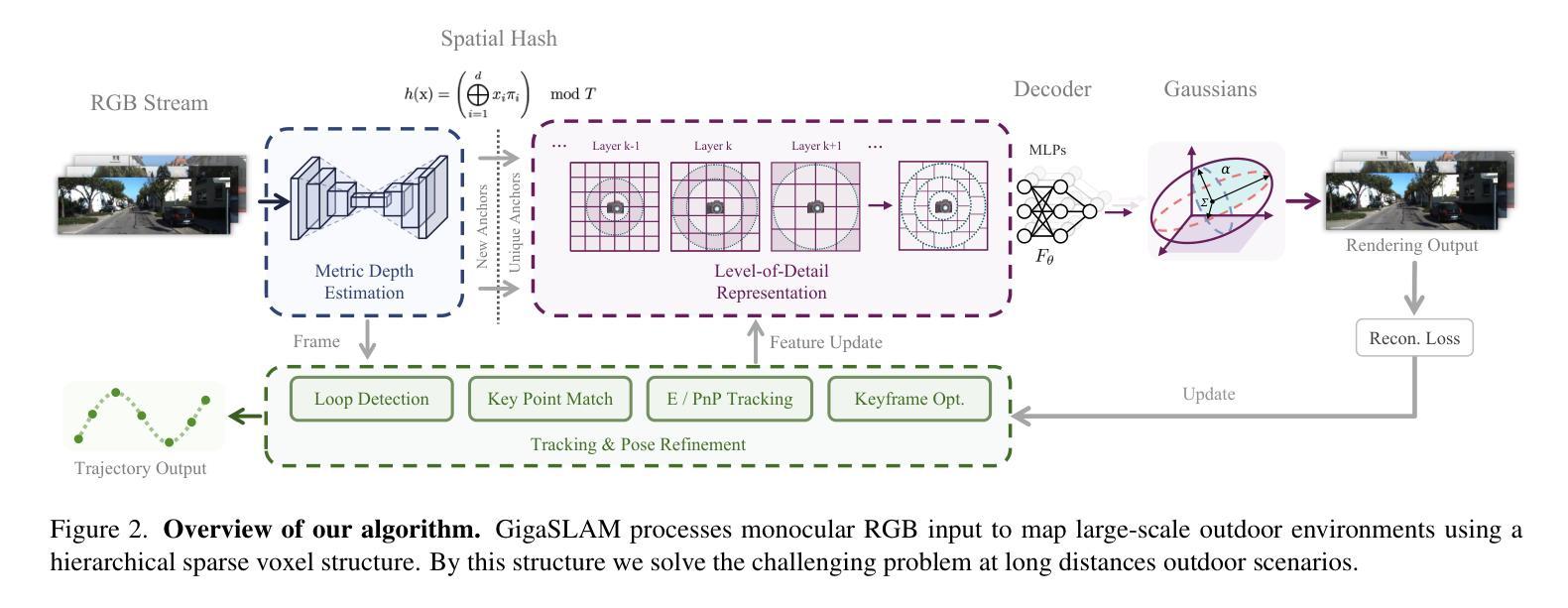
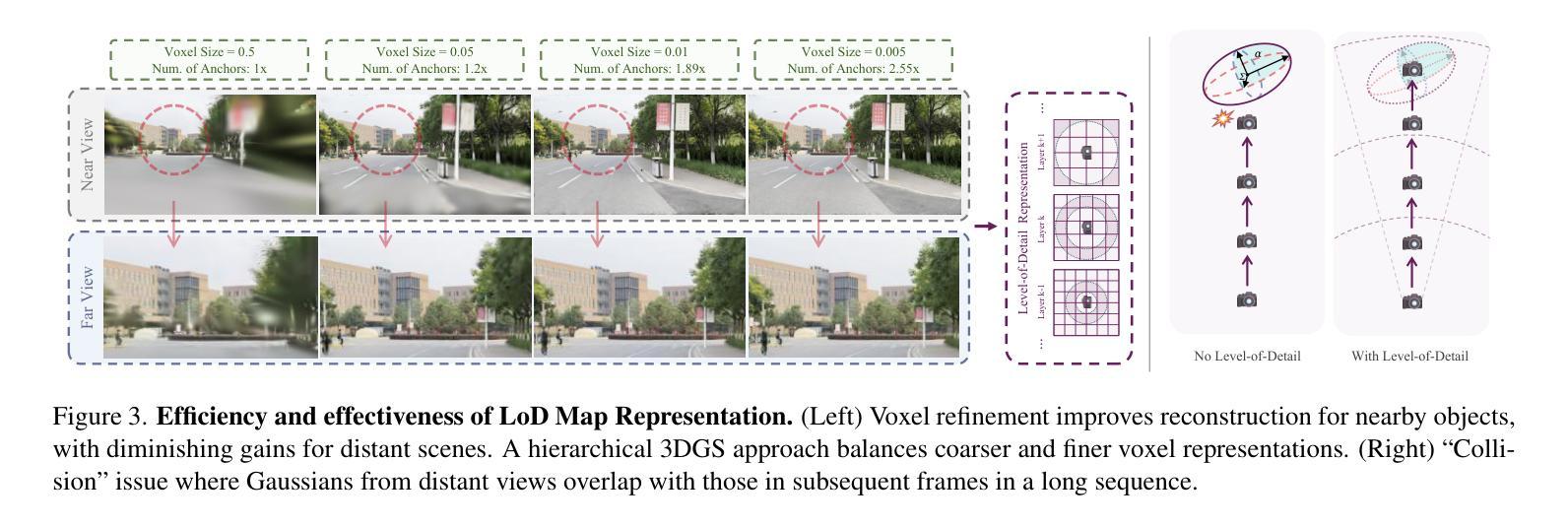
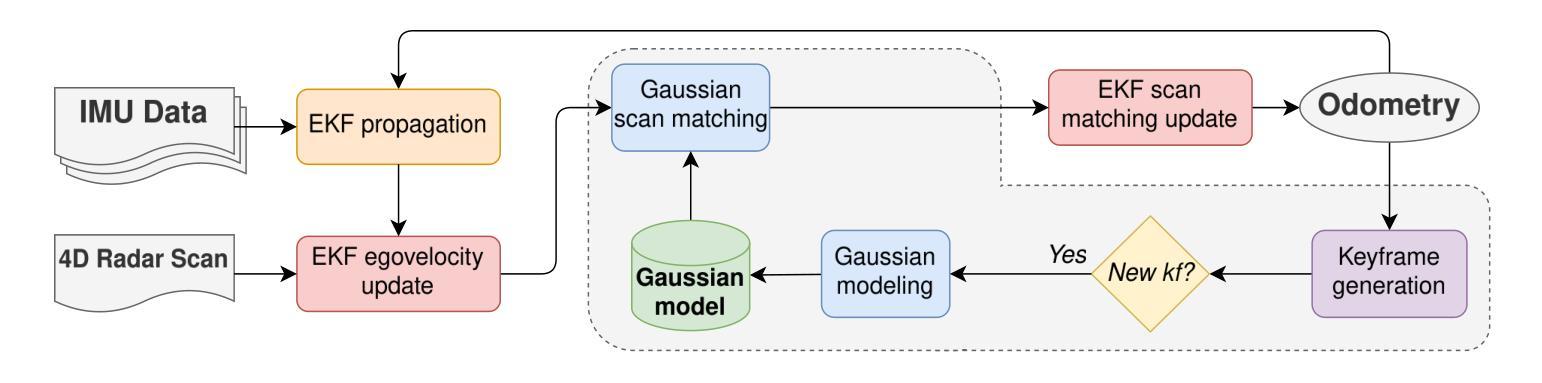
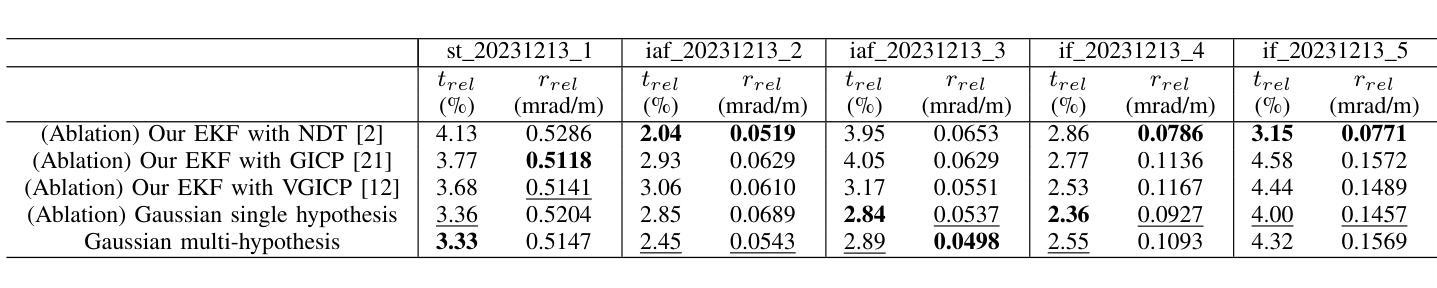
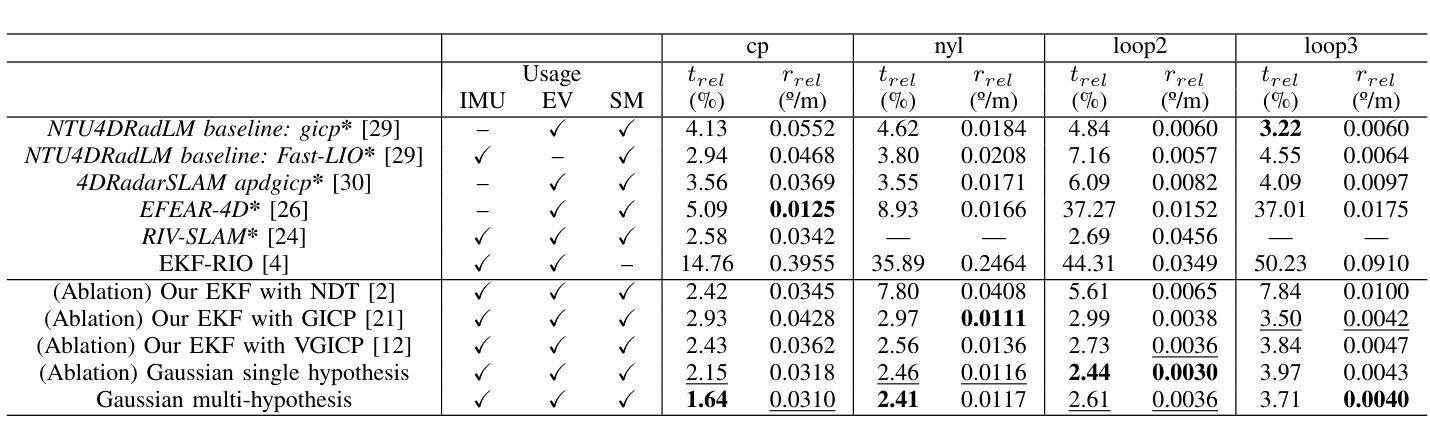
4D Radar-Inertial Odometry based on Gaussian Modeling and Multi-Hypothesis Scan Matching
Authors:Fernando Amodeo, Luis Merino, Fernando Caballero
4D millimeter-wave (mmWave) radars are sensors that provide robustness against adverse weather conditions (rain, snow, fog, etc.), and as such they are increasingly being used for odometry and SLAM applications. However, the noisy and sparse nature of the returned scan data proves to be a challenging obstacle for existing point cloud matching based solutions, especially those originally intended for more accurate sensors such as LiDAR. Inspired by visual odometry research around 3D Gaussian Splatting, in this paper we propose using freely positioned 3D Gaussians to create a summarized representation of a radar point cloud tolerant to sensor noise, and subsequently leverage its inherent probability distribution function for registration (similar to NDT). Moreover, we propose simultaneously optimizing multiple scan matching hypotheses in order to further increase the robustness of the system against local optima of the function. Finally, we fuse our Gaussian modeling and scan matching algorithms into an EKF radar-inertial odometry system designed after current best practices. Experiments using publicly available 4D radar datasets show that our Gaussian-based odometry is comparable to existing registration algorithms, outperforming them in several sequences.
四维毫米波雷达对恶劣天气(如雨、雪、雾等)具有稳健性,因此越来越多地用于测距和SLAM应用。然而,返回扫描数据具有噪声大和稀疏性特点,证明对于现有的基于点云匹配的解决方案构成了挑战,尤其是那些原本为激光雷达等更精确传感器设计的解决方案。本文受围绕三维高斯扩散的视觉测距研究启发,提出使用自由定位的3D高斯来创建耐受传感器噪声的雷达点云摘要表示,并利用其固有的概率分布函数进行注册(类似于NDT)。此外,我们提出同时优化多个扫描匹配假设,以进一步提高系统对函数局部最优解的稳健性。最后,我们将高斯建模和扫描匹配算法融合到根据当前最佳实践设计的扩展卡尔曼滤波器雷达惯性测距系统中。使用公开可用的四维雷达数据集进行的实验表明,我们的基于高斯测距与现有注册算法相当,并在多个序列中表现更佳。
论文及项目相关链接
PDF Our code and results can be publicly accessed at: https://github.com/robotics-upo/gaussian-rio-cpp
Summary
本文提出利用自由定位的3D高斯来创建雷达点云的简化表示,该表示对传感器噪声具有容忍性,并利用其内在的概率分布函数进行注册。通过优化多个扫描匹配假设,提高了系统对函数局部最优解的鲁棒性。最后,将高斯建模和扫描匹配算法融合到基于扩展卡尔曼滤波的雷达惯性里程计系统中。实验表明,基于高斯的方法与现有注册算法相当,并在多个序列上表现更好。
Key Takeaways
- 4D毫米波雷达在恶劣天气条件下具有稳健性,并越来越多地用于测距和SLAM应用。
- 雷达返回的扫描数据具有噪声和稀疏性,给现有的点云匹配解决方案带来了挑战。
- 提出的解决方案是利用3D高斯创建雷达点云的简化表示,该方法对传感器噪声具有容忍性。
- 使用高斯概率分布函数进行注册,类似于NDT(网格地图配准技术)。
- 通过优化多个扫描匹配假设,提高了系统的鲁棒性,以应对函数局部最优解的问题。
- 将高斯建模和扫描匹配算法融合到基于扩展卡尔曼滤波的雷达惯性里程计系统中。
点此查看论文截图



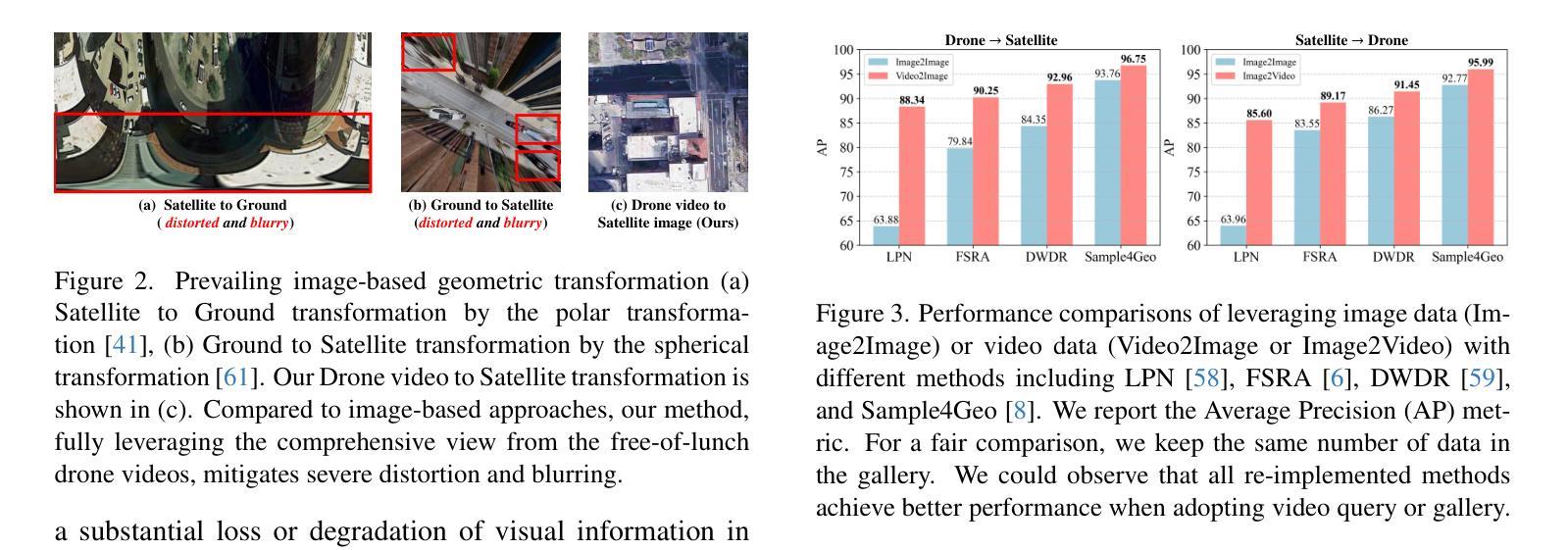
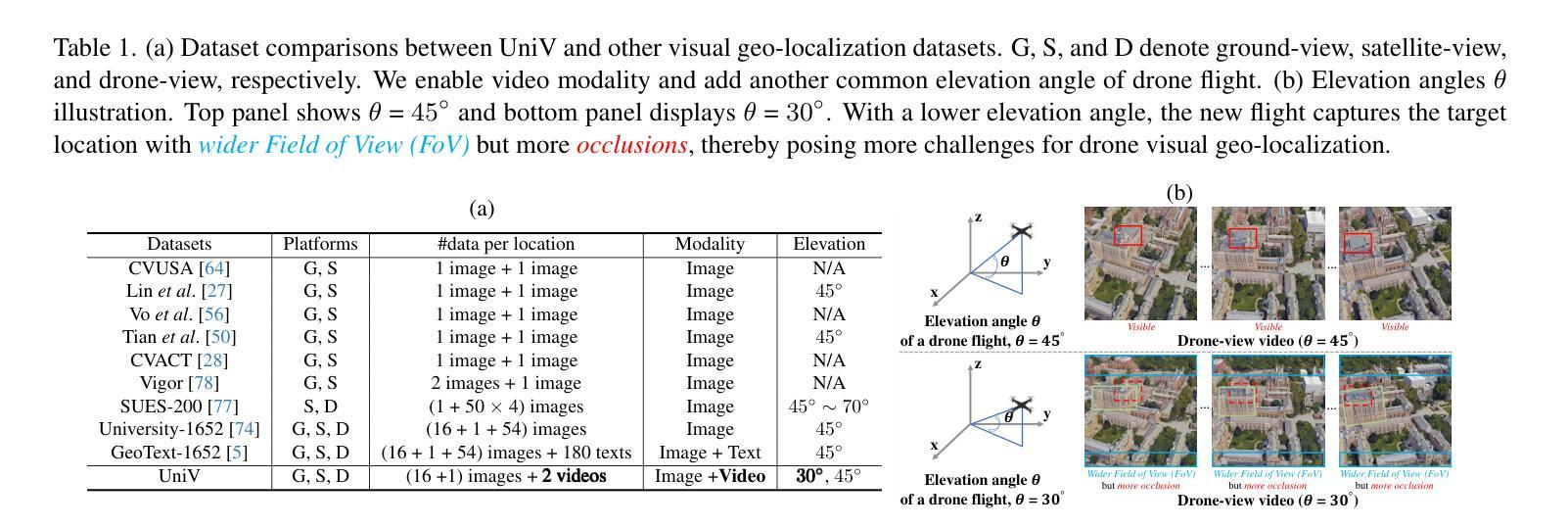
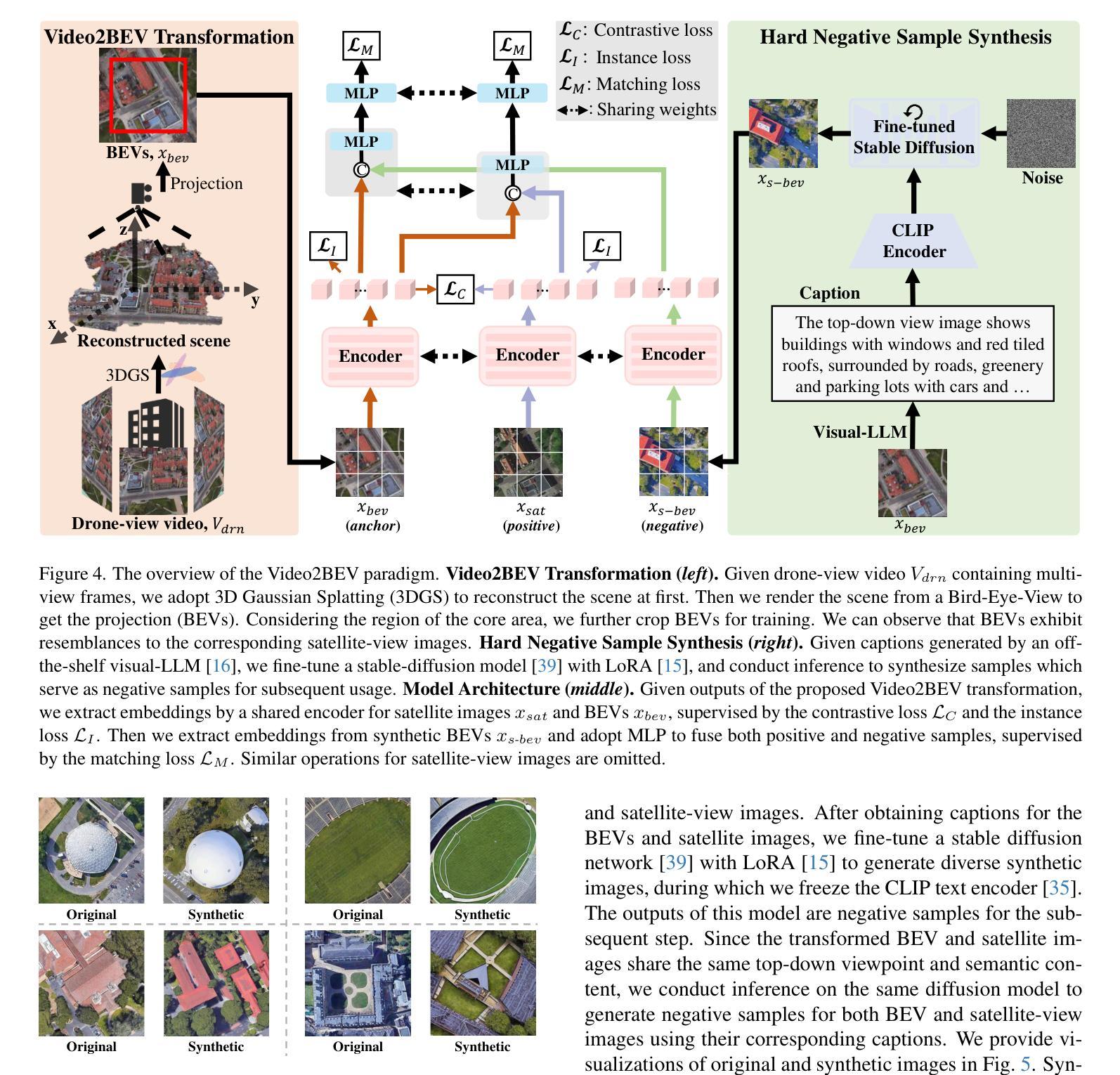
Video2BEV: Transforming Drone Videos to BEVs for Video-based Geo-localization
Authors:Hao Ju, Shaofei Huang, Si Liu, Zhedong Zheng
Existing approaches to drone visual geo-localization predominantly adopt the image-based setting, where a single drone-view snapshot is matched with images from other platforms. Such task formulation, however, underutilizes the inherent video output of the drone and is sensitive to occlusions and viewpoint disparity. To address these limitations, we formulate a new video-based drone geo-localization task and propose the Video2BEV paradigm. This paradigm transforms the video into a Bird’s Eye View (BEV), simplifying the subsequent \textbf{inter-platform} matching process. In particular, we employ Gaussian Splatting to reconstruct a 3D scene and obtain the BEV projection. Different from the existing transform methods, \eg, polar transform, our BEVs preserve more fine-grained details without significant distortion. To facilitate the discriminative \textbf{intra-platform} representation learning, our Video2BEV paradigm also incorporates a diffusion-based module for generating hard negative samples. To validate our approach, we introduce UniV, a new video-based geo-localization dataset that extends the image-based University-1652 dataset. UniV features flight paths at $30^\circ$ and $45^\circ$ elevation angles with increased frame rates of up to 10 frames per second (FPS). Extensive experiments on the UniV dataset show that our Video2BEV paradigm achieves competitive recall rates and outperforms conventional video-based methods. Compared to other competitive methods, our proposed approach exhibits robustness at lower elevations with more occlusions.
现有的无人机视觉地理定位方法主要采用基于图像的设置,其中单个无人机视角的快照与其他平台的图像进行匹配。然而,这种任务制定方式没有充分利用无人机固有的视频输出,并且对遮挡和视点差异很敏感。为了解决这些局限性,我们制定了基于视频的新型无人机地理定位任务,并提出了Video2BEV范式。该范式将视频转换为鸟瞰图(BEV),简化了随后的跨平台匹配过程。具体来说,我们采用高斯拼接技术重建了三维场景并获得了BEV投影。与现有的转换方法(例如极坐标变换)不同,我们的BEV在保留更多精细细节的同时,避免了显著的失真。为了促进平台内部判别表示的学习,我们的Video2BEV范式还引入了一个基于扩散的模块来生成硬负样本。为了验证我们的方法,我们引入了UniV,这是一个基于视频的新型地理定位数据集,扩展了基于图像的University-1652数据集。UniV以$30^\circ$和$45^\circ$的飞行路径为特色,帧率最高可达每秒10帧(FPS)。在UniV数据集上的大量实验表明,我们的Video2BEV范式具有竞争力的召回率,并且优于传统的视频方法。与其他有竞争力的方法相比,我们提出的方法在低海拔、有更多遮挡的情况下表现出稳健性。
论文及项目相关链接
摘要
本文主要研究无人机视觉地理定位方法,针对现有图像定位方法的不足,提出了基于视频的无人机地理定位任务和视频转鸟瞰视图(Video2BEV)的模式。该模式通过高斯摊涂技术重建3D场景,获得鸟瞰视图,简化了跨平台匹配过程。与现有转换方法相比,其鸟瞰图保留了更多的细节且不失真。为提升平台内特征学习的辨别力,Video2BEV模式还结合了基于扩散的模块生成硬负样本。为验证方法有效性,研究引入了新的视频地理定位数据集UniV,其在图像数据集University-1652基础上扩展,包含不同飞行高度和帧率的视频路径。实验表明,Video2BEV模式具有竞争力的召回率,且在低海拔和遮挡条件下表现稳健。
关键见解
- 现有无人机视觉地理定位方法主要基于图像匹配,未能充分利用无人机的视频输出,且易受遮挡和视角差异的影响。
- 提出了Video2BEV模式,将视频转换为鸟瞰图(BEV),简化了跨平台匹配过程。
- 采用高斯摊涂技术重建3D场景并获得BEV投影,相比其他转换方法,其保留了更多细节且避免失真。
- Video2BEV模式结合了基于扩散的模块生成硬负样本,提高了平台内特征学习的辨别力。
- 引入了新的视频地理定位数据集UniV,扩展了基于图像的数据集University-1652,包含不同飞行高度和帧率的视频路径。
- 实验表明Video2BEV模式具有竞争力的召回率,且在低海拔和遮挡条件下表现稳健。
点此查看论文截图

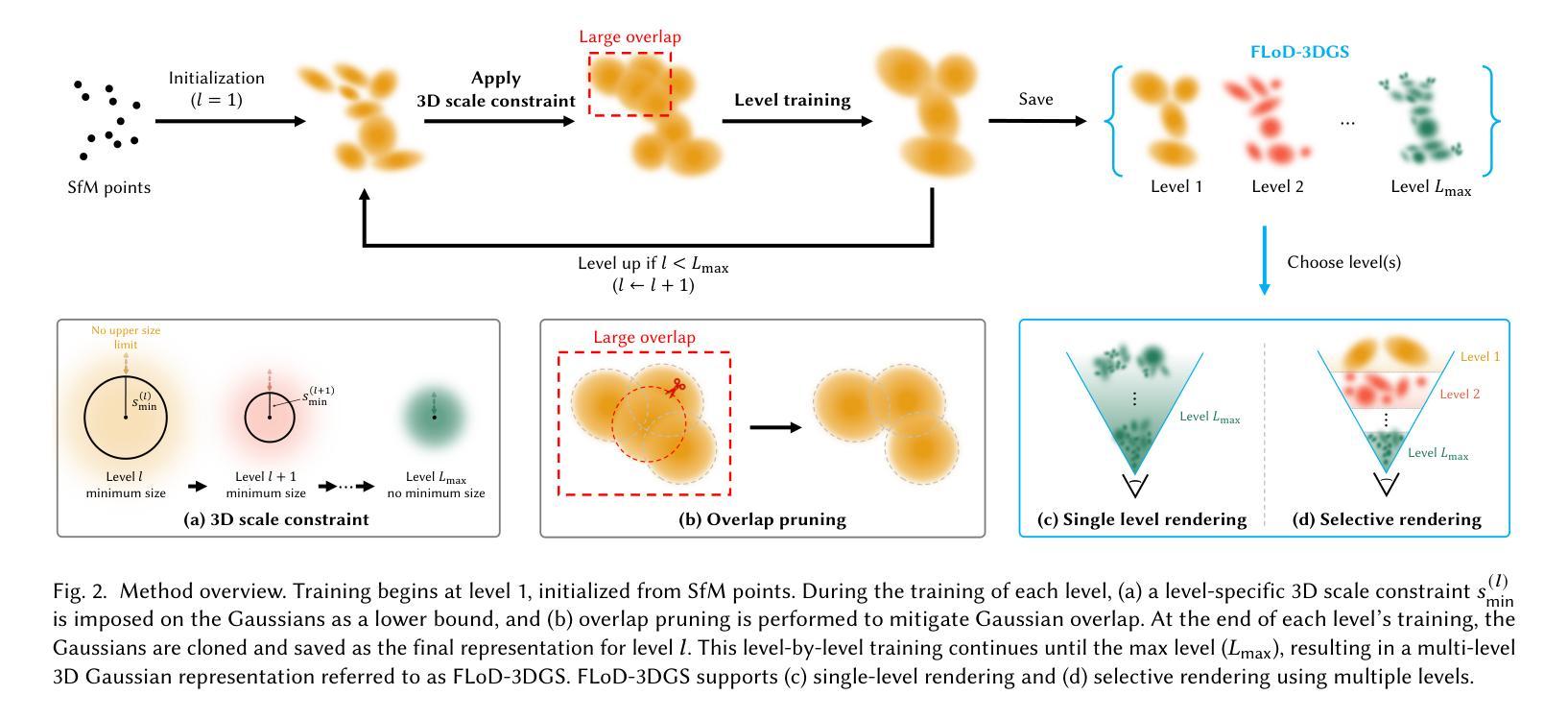
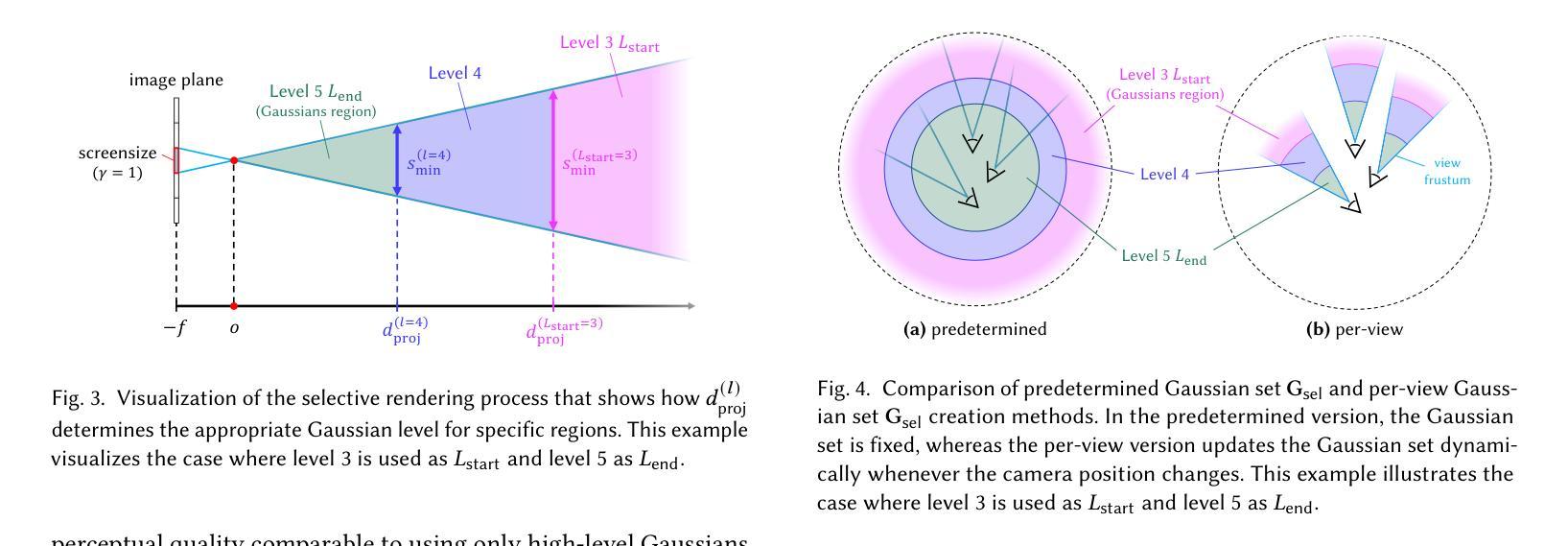
FLoD: Integrating Flexible Level of Detail into 3D Gaussian Splatting for Customizable Rendering
Authors:Yunji Seo, Young Sun Choi, Hyun Seung Son, Youngjung Uh
3D Gaussian Splatting (3DGS) and its subsequent works are restricted to specific hardware setups, either on only low-cost or on only high-end configurations. Approaches aimed at reducing 3DGS memory usage enable rendering on low-cost GPU but compromise rendering quality, which fails to leverage the hardware capabilities in the case of higher-end GPU. Conversely, methods that enhance rendering quality require high-end GPU with large VRAM, making such methods impractical for lower-end devices with limited memory capacity. Consequently, 3DGS-based works generally assume a single hardware setup and lack the flexibility to adapt to varying hardware constraints. To overcome this limitation, we propose Flexible Level of Detail (FLoD) for 3DGS. FLoD constructs a multi-level 3DGS representation through level-specific 3D scale constraints, where each level independently reconstructs the entire scene with varying detail and GPU memory usage. A level-by-level training strategy is introduced to ensure structural consistency across levels. Furthermore, the multi-level structure of FLoD allows selective rendering of image regions at different detail levels, providing additional memory-efficient rendering options. To our knowledge, among prior works which incorporate the concept of Level of Detail (LoD) with 3DGS, FLoD is the first to follow the core principle of LoD by offering adjustable options for a broad range of GPU settings. Experiments demonstrate that FLoD provides various rendering options with trade-offs between quality and memory usage, enabling real-time rendering under diverse memory constraints. Furthermore, we show that FLoD generalizes to different 3DGS frameworks, indicating its potential for integration into future state-of-the-art developments.
3D高斯贴图(3DGS)及其后续作品受限于特定的硬件配置,只能在低端或高端配置上运行。旨在减少3DGS内存使用的方法可以在低端GPU上进行渲染,但牺牲了渲染质量,在高端GPU的情况下未能充分利用硬件功能。相反,提高渲染质量的方法需要具有大VRAM的高端GPU,这使得此类方法对于内存有限的低端设备不切实际。因此,基于3DGS的作品通常假设单一的硬件配置,并且缺乏适应不同硬件约束的灵活性。为了克服这一局限性,我们为3DGS提出了灵活细节层次(FLoD)的方法。FLoD通过特定的三维尺度约束构建多层次的三维高斯贴图表示,每个层次都能独立地以不同细节和GPU内存使用重建整个场景。引入分层训练策略以确保各层次之间的结构一致性。此外,FLoD的多层次结构允许有选择地以不同细节层次渲染图像区域,提供更节省内存的渲染选项。据我们所知,在结合细节层次(LoD)概念的先前工作中,FLoD首次遵循LoD的核心原则,为广泛的GPU设置提供了可调选项。实验表明,FLoD提供了各种渲染选项,在质量和内存使用之间进行权衡,能够在各种内存约束下进行实时渲染。此外,我们证明了FLoD可以应用于不同的3DGS框架,显示出其未来融入最新发展的潜力。
论文及项目相关链接
PDF Project page: https://3dgs-flod.github.io/flod/
Summary
本文讨论了当前3D Gaussian Splatting(3DGS)技术面临的挑战及其限制,特别是在硬件适应性方面。针对这一问题,提出了Flexible Level of Detail(FLoD)方案,通过构建多层次的3DGS表示,实现不同硬件约束下的灵活适应。FLoD采用层级特定的3D尺度约束,独立重建场景并调整细节和GPU内存使用。实验证明,FLoD提供多种渲染选项,能在保证实时渲染的同时,有效平衡质量和内存使用,且可应用于不同的3DGS框架。
Key Takeaways
- 现有3DGS技术在硬件适应性方面存在局限,难以满足各种硬件约束。
- FLoD方案通过构建多层次3DGS表示,实现灵活适应不同硬件。
- FLoD采用层级特定的3D尺度约束,独立重建场景并调整细节和GPU内存使用。
- FLoD提供多种渲染选项,能在保证实时渲染的同时,有效平衡质量和内存使用。
- FLoD可应用于不同的3DGS框架,具有广泛的应用前景。
- FLoD通过层级训练策略确保结构一致性。
点此查看论文截图