⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-13 更新
“What are my options?”: Explaining RL Agents with Diverse Near-Optimal Alternatives (Extended)
Authors:Noel Brindise, Vijeth Hebbar, Riya Shah, Cedric Langbort
In this work, we provide an extended discussion of a new approach to explainable Reinforcement Learning called Diverse Near-Optimal Alternatives (DNA), first proposed at L4DC 2025. DNA seeks a set of reasonable “options” for trajectory-planning agents, optimizing policies to produce qualitatively diverse trajectories in Euclidean space. In the spirit of explainability, these distinct policies are used to “explain” an agent’s options in terms of available trajectory shapes from which a human user may choose. In particular, DNA applies to value function-based policies on Markov decision processes where agents are limited to continuous trajectories. Here, we describe DNA, which uses reward shaping in local, modified Q-learning problems to solve for distinct policies with guaranteed epsilon-optimality. We show that it successfully returns qualitatively different policies that constitute meaningfully different “options” in simulation, including a brief comparison to related approaches in the stochastic optimization field of Quality Diversity. Beyond the explanatory motivation, this work opens new possibilities for exploration and adaptive planning in RL.
在这项工作中,我们对一种名为多样近优替代方案(DNA)的可解释强化学习新方法进行了深入探讨,该方法首先在L4DC 2025上提出。DNA为轨迹规划代理寻找一组合理的“选项”,优化策略以在欧几里得空间中产生定性多样的轨迹。本着可解释性的精神,这些不同的策略被用来“解释”代理的可选轨迹形状,供人类用户选择。特别是,DNA适用于基于值函数的马尔可夫决策过程策略,其中代理限于连续轨迹。在这里,我们描述了DNA,它在局部修改Q学习问题中使用奖励塑形来解决具有保证epsilon最优性的不同策略。我们显示,它在模拟中成功返回了定性的不同策略,这些策略构成了有意义的“选项”,包括与多样性优化领域相关方法的简短比较。除了解释动机外,这项工作还为强化学习中的探索和自适应规划开辟了新的可能性。
论文及项目相关链接
Summary
该论文介绍了一种新的可解释的强化学习(Reinforcement Learning)方法——多样近优选择(DNA)。DNA通过优化策略,为轨迹规划代理提供一系列合理的“选项”,并在欧几里得空间中生成定性多样的轨迹。这些不同的策略用于“解释”代理的选项,以人类用户可以选择的轨迹形状的形式呈现。DNA特别适用于基于值函数的策略在马尔可夫决策过程中的应用,其中代理仅限于连续轨迹。论文描述DNA通过在局部修改Q-learning问题中的奖励形状来解决具有保证的ε-最优性的不同策略问题。研究结果表明,它在模拟中成功返回了定性不同的策略,这些策略构成了有意义的“选项”,并简要比较了与质量多样性相关的随机优化领域中的其他方法。除了解释动机外,这项工作还为强化学习中的探索和自适应规划打开了新的可能性。
Key Takeaways
- DNA是一种新的强化学习方法,旨在提供代理的多样且合理的决策选项。
- DNA适用于轨迹规划问题,优化策略以生成多样轨迹。
- 这些策略旨在“解释”代理的选项,为人类用户提供轨迹形状的选择。
- DNA适用于基于值函数的马尔可夫决策过程,其中代理在连续轨迹中操作。
- DNA通过局部修改Q-learning问题中的奖励形状来解决ε-最优性的不同策略问题。
- 在模拟环境中成功测试了DNA,返回了多种定性不同的策略。
点此查看论文截图

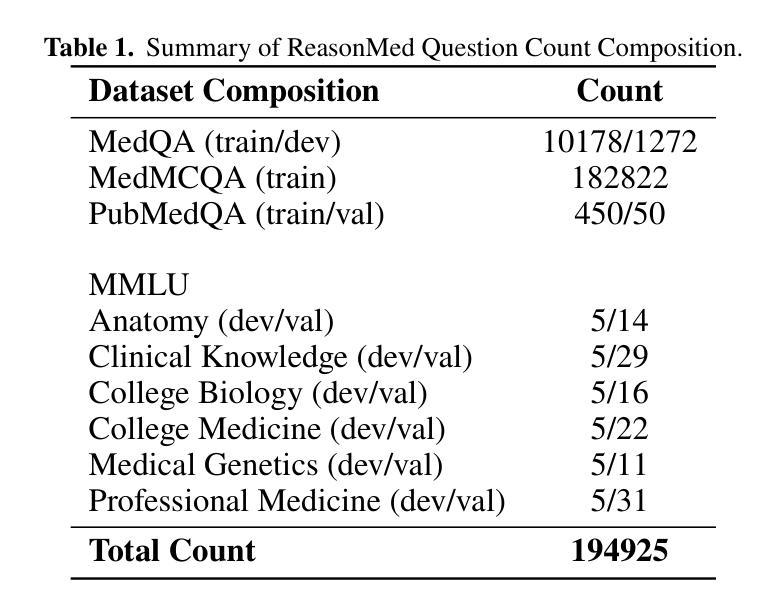
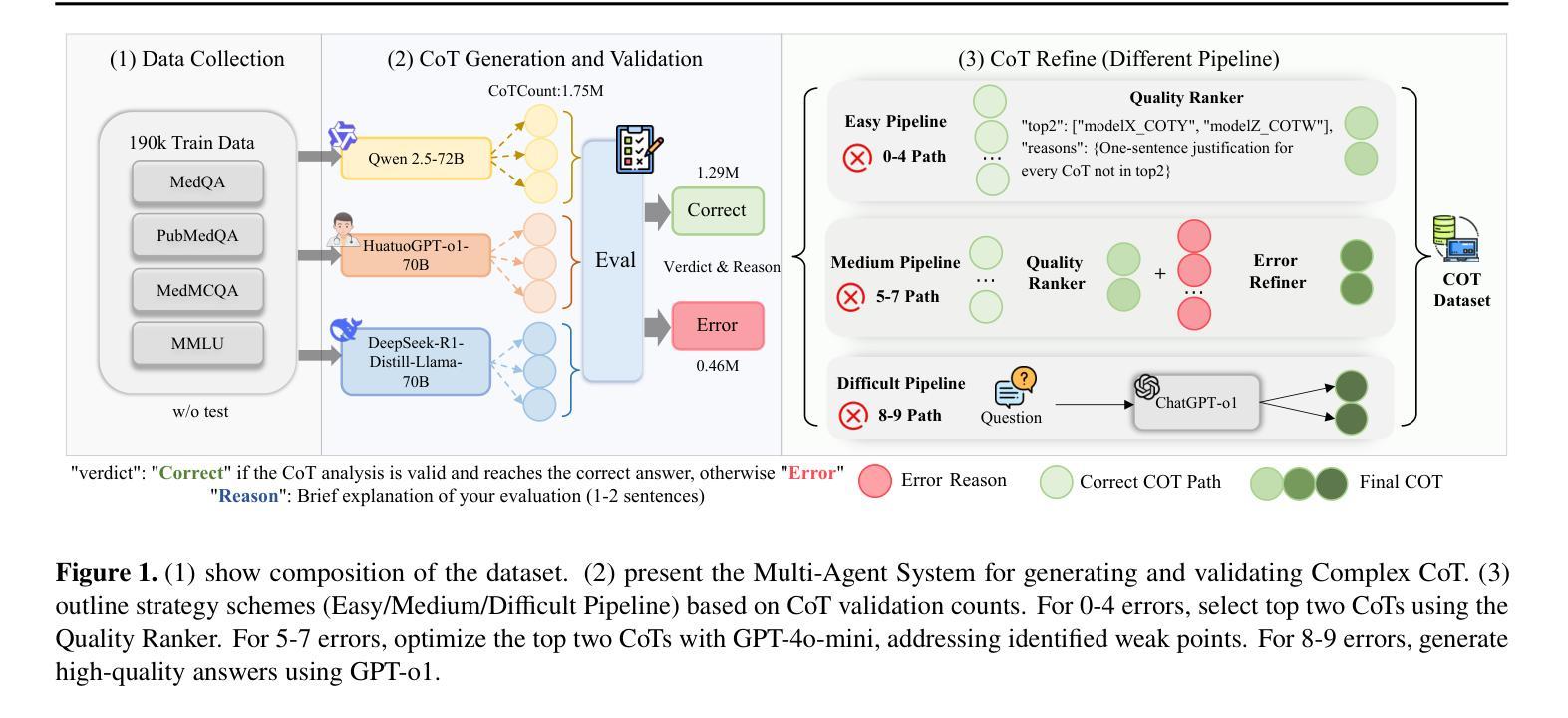
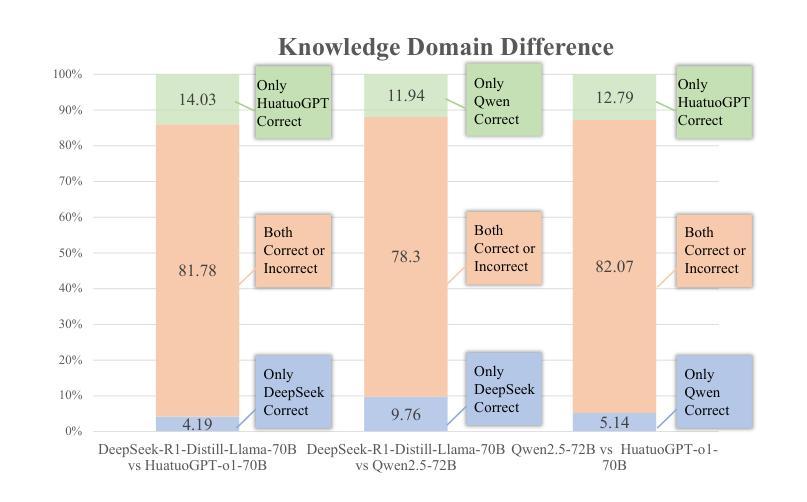
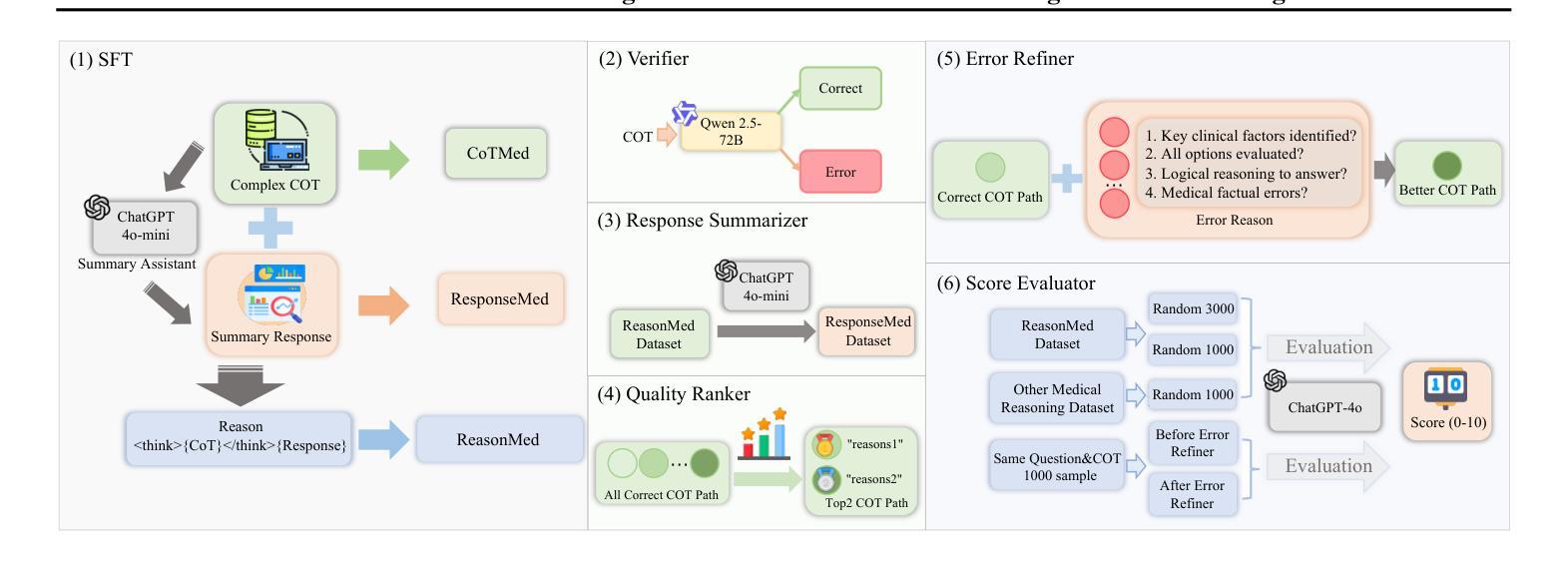
ReasonMed: A 370K Multi-Agent Generated Dataset for Advancing Medical Reasoning
Authors:Yu Sun, Xingyu Qian, Weiwen Xu, Hao Zhang, Chenghao Xiao, Long Li, Yu Rong, Wenbing Huang, Qifeng Bai, Tingyang Xu
Though reasoning-based large language models (LLMs) have excelled in mathematics and programming, their capabilities in knowledge-intensive medical question answering remain underexplored. To address this, we introduce ReasonMed, the largest medical reasoning dataset, comprising 370k high-quality examples distilled from 1.7 million initial reasoning paths generated by various LLMs. ReasonMed is constructed through a \textit{multi-agent verification and refinement process}, where we design an \textit{Error Refiner} to enhance the reasoning paths by identifying and correcting error-prone steps flagged by a verifier. Leveraging ReasonMed, we systematically investigate best practices for training medical reasoning models and find that combining detailed Chain-of-Thought (CoT) reasoning with concise answer summaries yields the most effective fine-tuning strategy. Based on this strategy, we train ReasonMed-7B, which sets a new benchmark for sub-10B models, outperforming the prior best by 4.17% and even exceeding LLaMA3.1-70B on PubMedQA by 4.60%.
虽然基于推理的大型语言模型(LLM)在数学和编程方面表现出色,但它们在知识密集型的医疗问题回答方面的能力仍被低估。为了解决这一问题,我们推出了ReasonMed,这是最大的医疗推理数据集,包含从由各种LLM生成的170万条初始推理路径中提炼出的37万个高质量样本。ReasonMed的构建过程经过多智能体验证和完善,我们设计了一个“错误修正器”,通过识别验证器标记的错误倾向步骤并对其进行修正,从而增强推理路径。借助ReasonMed,我们系统地研究了训练医疗推理模型的最佳实践,并发现将详细的思维链(CoT)推理与简洁的答案摘要相结合,是最有效的微调策略。基于这一策略,我们训练了ReasonMed-7B,该模型为次10B模型设立了新基准,较之前最佳模型提高了4.17%,甚至在PubMedQA上超过了LLaMA3.1-70B模型,提高了4.60%。
论文及项目相关链接
PDF 24 pages, 6 figures, 7 tables
Summary
基于大型语言模型(LLM)的推理能力在医学问答等知识密集型任务上尚未得到充分探索。为解决这一问题,我们引入了ReasonMed数据集,其中包含由不同LLM生成的数百万初始推理路径中提炼出的37万个高质量样本。ReasonMed的构建采用了多智能验证与修正过程,并设计了Error Refiner来识别并修正验证器标记的错误步骤,以提高推理路径的准确性。利用ReasonMed数据集,我们系统地研究了训练医学推理模型的最佳实践,发现将详细的Chain-of-Thought(CoT)推理与简洁的答案摘要相结合是最有效的微调策略。基于这一策略,我们训练了ReasonMed-7B模型,为小型模型树立了新的基准线,相比先前最佳表现提高了4.17%,甚至在PubMedQA上超过了LLaMA3.1-70B模型,提高了4.6%。
Key Takeaways
- 大型语言模型(LLM)在知识密集型任务如医学问答上的能力尚未充分探索。
- 引入ReasonMed数据集,通过多智能验证与修正过程提高推理路径的准确性。
- 利用ReasonMed数据集研究训练医学推理模型的最佳实践。
- 发现结合详细的Chain-of-Thought(CoT)推理与简洁答案摘要的微调策略最有效。
- 基于该策略训练的ReasonMed-7B模型树立了新的基准线。
- ReasonMed-7B模型相比先前最佳表现提高了4.17%。
点此查看论文截图

When Is Diversity Rewarded in Cooperative Multi-Agent Learning?
Authors:Michael Amir, Matteo Bettini, Amanda Prorok
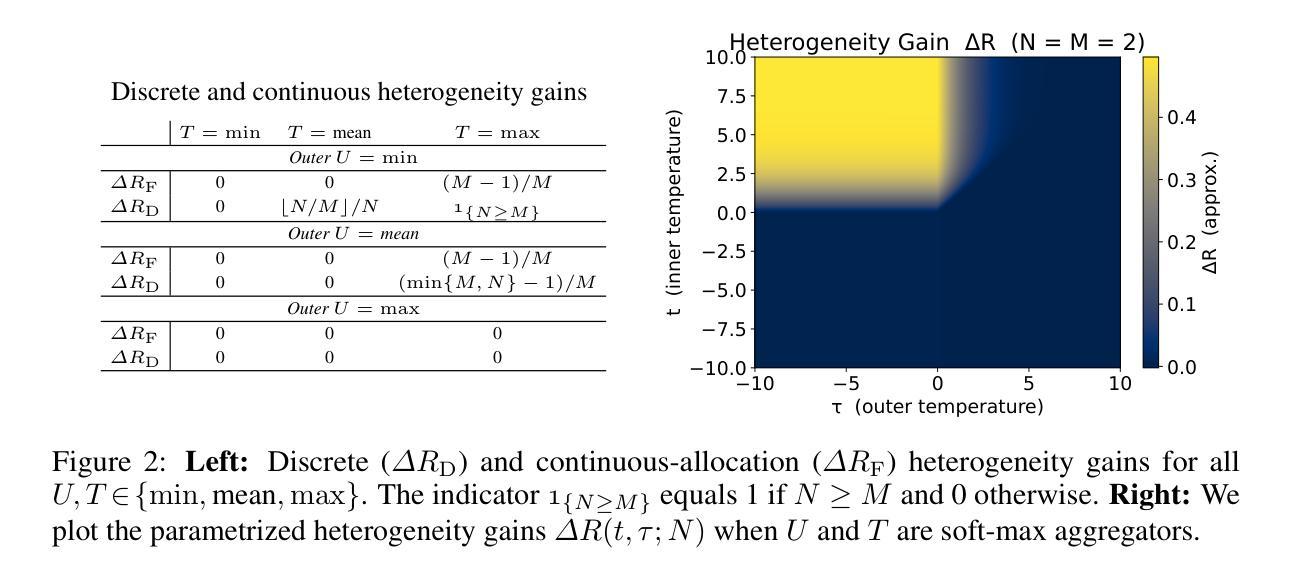
The success of teams in robotics, nature, and society often depends on the division of labor among diverse specialists; however, a principled explanation for when such diversity surpasses a homogeneous team is still missing. Focusing on multi-agent task allocation problems, our goal is to study this question from the perspective of reward design: what kinds of objectives are best suited for heterogeneous teams? We first consider an instantaneous, non-spatial setting where the global reward is built by two generalized aggregation operators: an inner operator that maps the $N$ agents’ effort allocations on individual tasks to a task score, and an outer operator that merges the $M$ task scores into the global team reward. We prove that the curvature of these operators determines whether heterogeneity can increase reward, and that for broad reward families this collapses to a simple convexity test. Next, we ask what incentivizes heterogeneity to emerge when embodied, time-extended agents must learn an effort allocation policy. To study heterogeneity in such settings, we use multi-agent reinforcement learning (MARL) as our computational paradigm, and introduce Heterogeneous Environment Design (HED), a gradient-based algorithm that optimizes the parameter space of underspecified MARL environments to find scenarios where heterogeneity is advantageous. Experiments in matrix games and an embodied Multi-Goal-Capture environment show that, despite the difference in settings, HED rediscovers the reward regimes predicted by our theory to maximize the advantage of heterogeneity, both validating HED and connecting our theoretical insights to reward design in MARL. Together, these results help us understand when behavioral diversity delivers a measurable benefit.
团队在机器人、自然和社会中的成功往往取决于不同专家之间的劳动分工;然而,关于何时多样化的团队会超越同质团队的理论解释仍然缺失。我们的目标是从奖励设计的角度研究这个问题:什么样的目标最适合异质的团队?我们首先考虑一个即时、非空间的环境,全局奖励由两个广义聚合算子构建:一个内部算子将N个代理在单个任务上的努力分配映射到任务评分,一个外部算子将M个任务评分合并到全局团队奖励。我们证明这些算子的曲率决定了异质性是否能增加奖励,对于广泛的奖励家族,这归结为一个简单的凸性测试。接下来,我们询问当具有实体的、时间延长的代理必须学习努力分配策略时,是什么激励异质性的出现。为了在这样的环境中研究异质性,我们使用多代理强化学习作为我们的计算范式,并引入异质环境设计(HED)这是一种基于梯度的算法,可以优化未指定的多代理强化学习环境的参数空间,以找到异质性有利的场景。在矩阵游戏和实体多目标捕获环境中的实验表明,尽管设置不同,但HED重新发现了理论预测的奖励制度,以最大化异质性的优势,既验证了HED,也将我们的理论见解与多代理强化学习中的奖励设计联系起来。总的来说,这些结果帮助我们理解了行为多样性何时带来可衡量的好处。
论文及项目相关链接
摘要
团队在机器人、自然和社会中的成功往往依赖于不同专家之间的劳动分工,然而,关于何时多样化的团队表现超越单一化团队的理论解释仍然缺失。本文关注多智能体任务分配问题,从奖励设计的角度研究异质团队最适合哪些目标。首先,考虑一个即时、非空间的环境中,全局奖励由两个广义聚合算子构建:一个内部算子将N个智能体的个人任务努力分配映射到任务得分,一个外部算子将M个任务得分合并为团队全局奖励。证明了这些算子的曲率决定了多样性是否能增加奖励,对于广泛的奖励家族,这归结为简单的凸性测试。接着,我们探讨当具有形态的、长期智能体需要学习努力分配策略时,如何激励异质性的出现。为了研究这类环境中的异质性,我们使用多智能体强化学习作为计算范式,并引入异质环境设计(HED)算法,该算法基于梯度优化未指定的多智能体强化学习环境的参数空间,以找到异质性有利的场景。在矩阵游戏和具有形态的多目标捕获环境中的实验表明,尽管设置不同,HED重新发现了由理论预测的奖励制度,以最大化异质性的优势,既验证了HED的有效性,也将我们的理论见解与多智能体强化学习中的奖励设计联系起来。总的来说,这些结果有助于理解行为多样性何时带来可衡量的好处。
关键见解
- 多样化团队的劳动分工在机器人、自然和社会中的团队成功中起关键作用,但缺乏理论解释何时多样化的团队表现会超越单一化团队。
- 从奖励设计的角度研究异质团队的最适合目标,特别是在多智能体任务分配问题的背景下。
- 在即时、非空间的环境中,证明了全局奖励的构造与内部和外部算子的曲率有关,这决定了多样性对奖励的影响,并可简化为凸性测试。
- 通过引入异质环境设计(HED)算法,研究了在需要学习努力分配策略的环境中如何激励异质性的出现。
- HED算法在多智能体强化学习环境中有效,能够发现异质性有利的场景,验证了理论预测。
- 实验结果展示了行为多样性带来的可衡量的好处,为理解何时多样性有益提供了洞见。
点此查看论文截图


LPO: Towards Accurate GUI Agent Interaction via Location Preference Optimization
Authors:Jiaqi Tang, Yu Xia, Yi-Feng Wu, Yuwei Hu, Yuhui Chen, Qing-Guo Chen, Xiaogang Xu, Xiangyu Wu, Hao Lu, Yanqing Ma, Shiyin Lu, Qifeng Chen
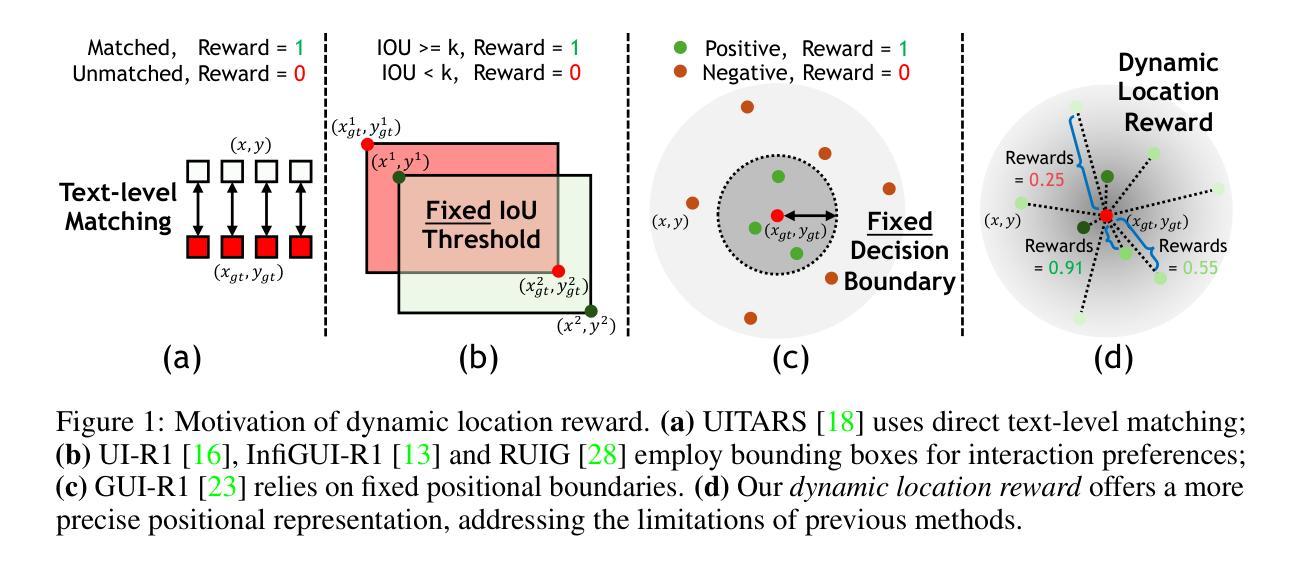
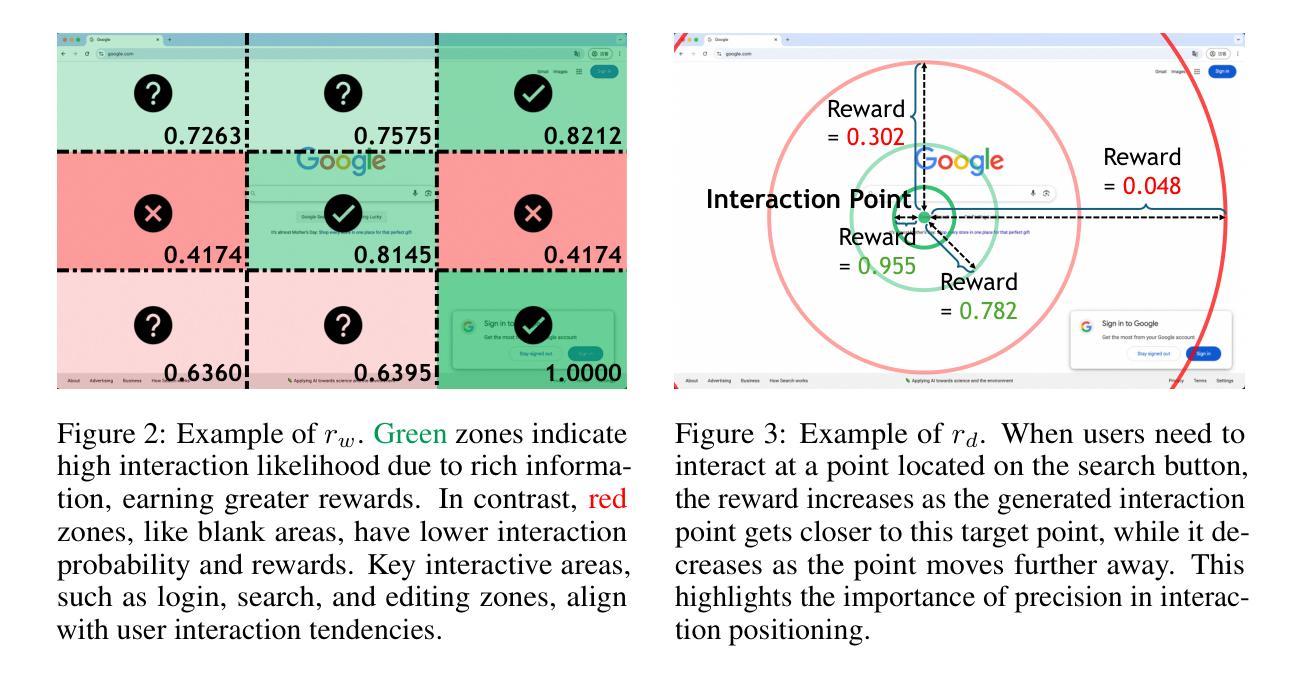
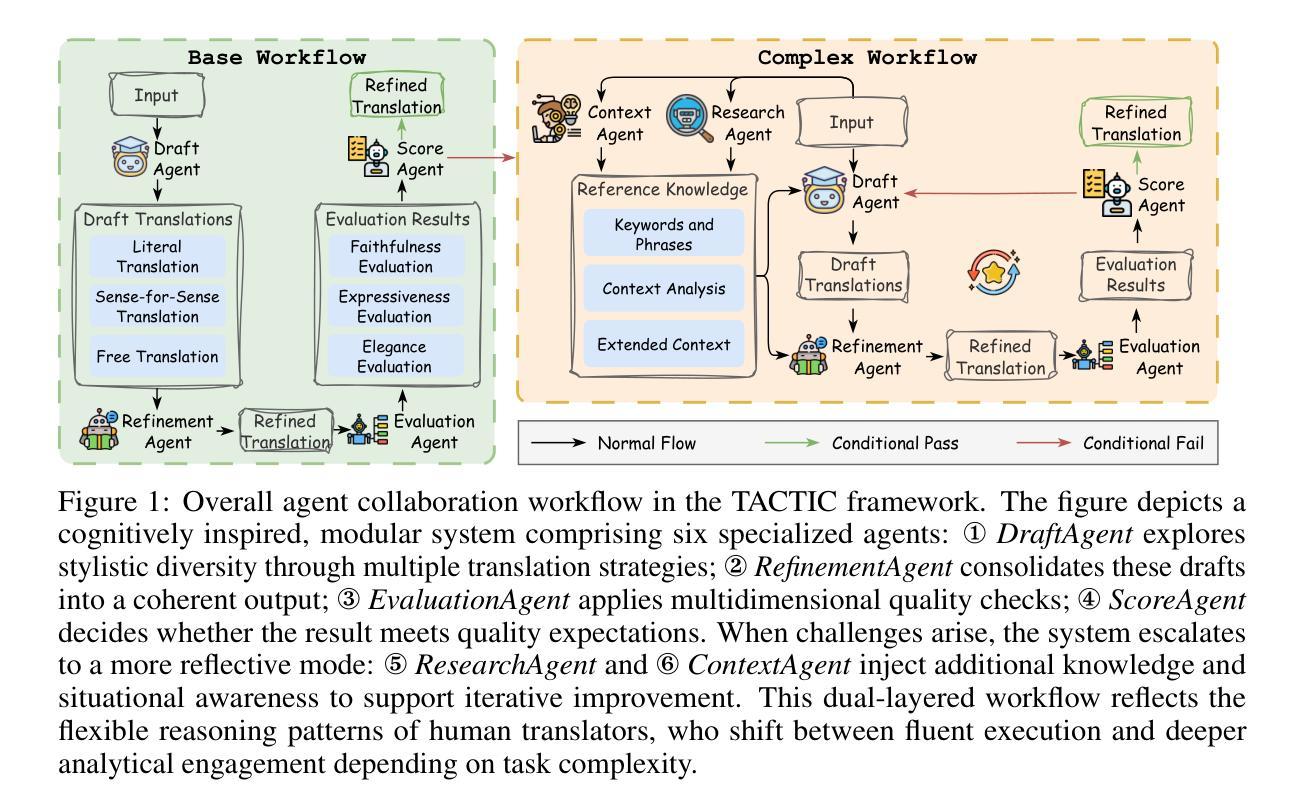
The advent of autonomous agents is transforming interactions with Graphical User Interfaces (GUIs) by employing natural language as a powerful intermediary. Despite the predominance of Supervised Fine-Tuning (SFT) methods in current GUI agents for achieving spatial localization, these methods face substantial challenges due to their limited capacity to accurately perceive positional data. Existing strategies, such as reinforcement learning, often fail to assess positional accuracy effectively, thereby restricting their utility. In response, we introduce Location Preference Optimization (LPO), a novel approach that leverages locational data to optimize interaction preferences. LPO uses information entropy to predict interaction positions by focusing on zones rich in information. Besides, it further introduces a dynamic location reward function based on physical distance, reflecting the varying importance of interaction positions. Supported by Group Relative Preference Optimization (GRPO), LPO facilitates an extensive exploration of GUI environments and significantly enhances interaction precision. Comprehensive experiments demonstrate LPO’s superior performance, achieving SOTA results across both offline benchmarks and real-world online evaluations. Our code will be made publicly available soon, at https://github.com/AIDC-AI/LPO.
自主代理的出现,通过运用自然语言作为强大的中介,正在改变与图形用户界面(GUI)的交互方式。尽管当前GUI代理在实现空间定位时以监督微调(SFT)方法为主,但这些方法面临着巨大的挑战,因为它们准确感知位置数据的能力有限。现有的策略,如强化学习,往往不能有效地评估位置准确性,从而限制了它们的实用性。为此,我们引入了位置偏好优化(LPO)这一新方法,它利用位置数据来优化交互偏好。LPO利用信息熵来预测交互位置,侧重于信息丰富的区域。此外,它还引入了一个基于物理距离的动态位置奖励函数,反映了交互位置的不同重要性。在Group Relative Preference Optimization(GRPO)的支持下,LPO促进了GUI环境的广泛探索,并显著提高了交互精度。综合实验表明,LPO性能卓越,在离线基准测试和真实世界在线评估中都取得了SOTA结果。我们的代码很快将在https://github.com/AIDC-AI/LPO上公开。
论文及项目相关链接
Summary
自主代理的出现正在通过采用自然语言作为强大的中介来变革与图形用户界面(GUI)的互动方式。当前GUI代理主要使用监督微调(SFT)方法实现空间定位,但面临准确感知定位数据的挑战。为应对这一挑战,我们提出了位置偏好优化(LPO)这一新方法,它利用位置数据优化互动偏好。LPO使用信息熵预测交互位置,专注于信息丰富的区域,并引入基于物理距离的动态位置奖励函数,反映交互位置的不同重要性。LPO配合群体相对偏好优化(GRPO),促进了GUI环境的广泛探索,并显著提高交互精度。实验表明,LPO的性能卓越,在离线基准测试和真实在线评估中都达到了最新水平。我们的代码将很快在https://github.com/AIDC-AI/LPO公开。
Key Takeaways
- 自主代理通过自然语言中介改变与GUI的互动方式。
- 监督微调(SFT)方法在GUI代理的空间定位上虽有广泛应用,但存在准确感知定位数据的挑战。
- 位置偏好优化(LPO)新方法利用位置数据优化互动偏好。
- LPO使用信息熵预测交互位置,专注于信息丰富的区域。
- LPO引入动态位置奖励函数,反映交互位置的不同重要性。
- LPO配合群体相对偏好优化(GRPO),促进GUI环境的广泛探索。
点此查看论文截图

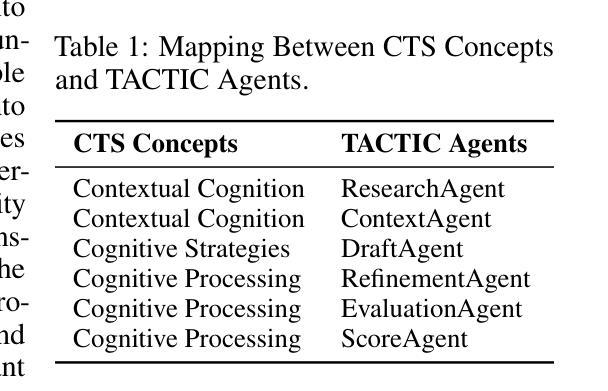
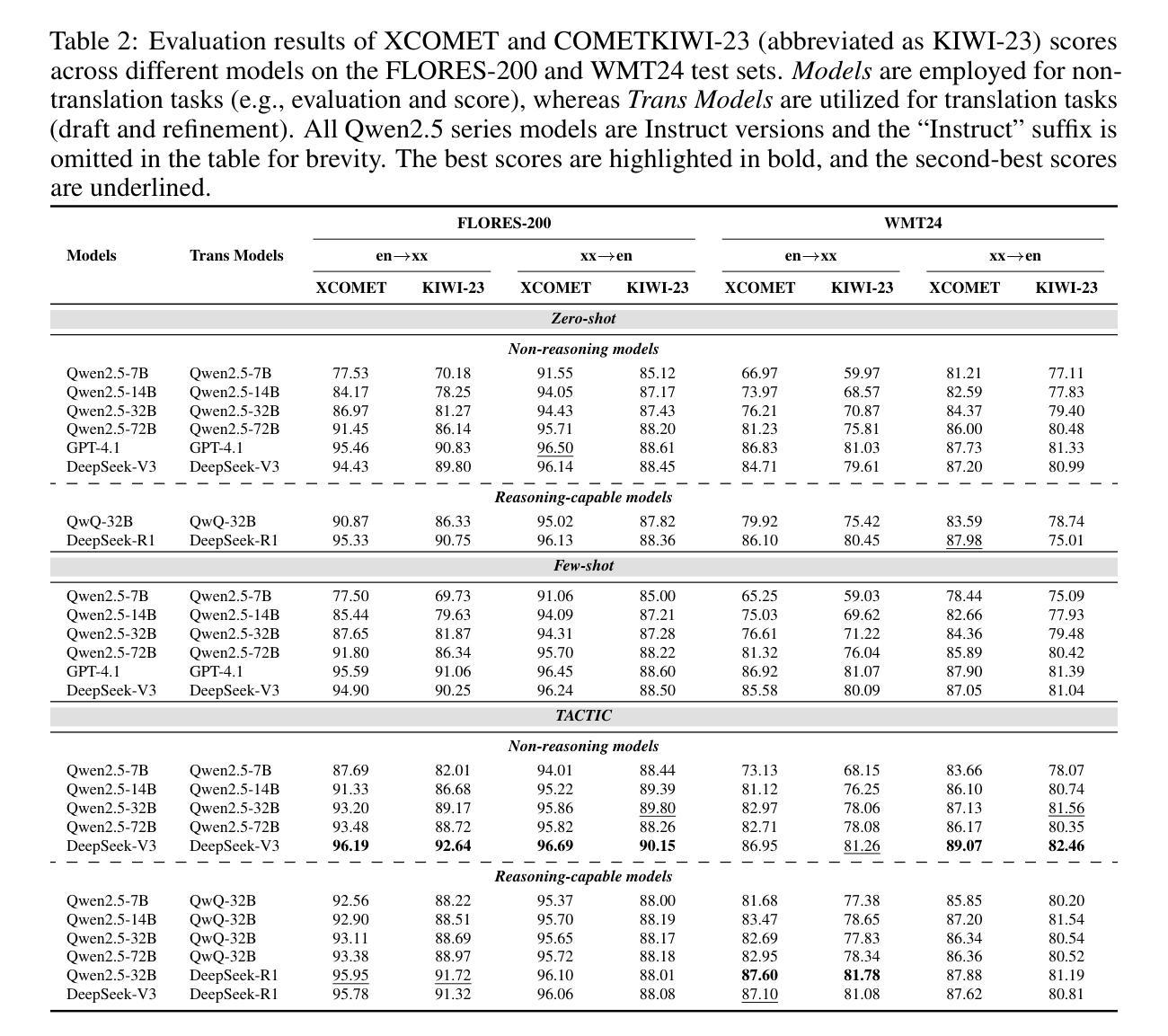
TACTIC: Translation Agents with Cognitive-Theoretic Interactive Collaboration
Authors:Weiya Li, Junjie Chen, Bei Li, Boyang Liu, Zichen Wen, Nuanqiao Shan, Xiaoqian Liu, Anping Liu, Huajie Liu, Hu Song, Linfeng Zhang
Machine translation has long been a central task in natural language processing. With the rapid advancement of large language models (LLMs), there has been remarkable progress in translation quality. However, fully realizing the translation potential of LLMs remains an open challenge. Recent studies have explored multi-agent systems to decompose complex translation tasks into collaborative subtasks, showing initial promise in enhancing translation quality through agent cooperation and specialization. Nevertheless, existing multi-agent translation frameworks largely neglect foundational insights from cognitive translation studies. These insights emphasize how human translators employ different cognitive strategies, such as balancing literal and free translation, refining expressions based on context, and iteratively evaluating outputs. To address this limitation, we propose a cognitively informed multi-agent framework called TACTIC, which stands for T ranslation A gents with Cognitive- T heoretic Interactive Collaboration. The framework comprises six functionally distinct agents that mirror key cognitive processes observed in human translation behavior. These include agents for drafting, refinement, evaluation, scoring, context reasoning, and external knowledge gathering. By simulating an interactive and theory-grounded translation workflow, TACTIC effectively leverages the full capacity of LLMs for high-quality translation. Experimental results on diverse language pairs from the FLORES-200 and WMT24 benchmarks show that our method consistently achieves state-of-the-art performance. Using DeepSeek-V3 as the base model, TACTIC surpasses GPT-4.1 by an average of +0.6 XCOMET and +1.18 COMETKIWI-23. Compared to DeepSeek-R1, it further improves by +0.84 XCOMET and +2.99 COMETKIWI-23. Code is available at https://github.com/weiyali126/TACTIC.
机器翻译一直是自然语言处理中的核心任务。随着大型语言模型(LLMs)的快速发展,翻译质量取得了显著的进步。然而,完全实现LLMs的翻译潜力仍然是一个开放性的挑战。最近的研究探索了多智能体系统将复杂的翻译任务分解成协作的子任务,通过智能体的合作和专业化,初步显示出提高翻译质量的希望。然而,现有的多智能体翻译框架大多忽视了来自认知翻译研究的见解。这些见解强调人类译者如何采用不同的认知策略,如平衡直译和意译、根据上下文优化表达、以及迭代评估输出。为了解决这一局限性,我们提出了一个受认知启发的多智能体框架,名为TACTIC,代表翻译认知理论交互协作的智能体。该框架包括六个功能各异的智能体,这些智能体反映了人类翻译行为中观察到的关键认知过程。包括起草智能体、优化智能体、评估智能体、打分智能体、上下文推理智能体以及外部知识收集智能体。通过模拟交互和基于理论的翻译工作流程,TACTIC有效地利用LLMs的全部能力实现高质量翻译。在FLORES-200和WMT24基准测试上的实验结果表明,我们的方法始终达到了最先进的性能。以DeepSeek-V3为基础模型,TACTIC平均超过GPT-4.1,XCOMET提高+0.6,COMETKIWI-23提高+1.18。与DeepSeek-R1相比,进一步提高XCOMET+0.84和COMETKIWI-23+2.99。代码可在https://github.com/weiyali126/TACTIC找到。
论文及项目相关链接
PDF 20 pages, 4 figures, Under review. Code: https://github.com/weiyali126/TACTIC
Summary
随着大型语言模型(LLMs)的快速发展,机器翻译的质量取得了显著进步。为进一步提高翻译质量,研究采用多智能体系统分解复杂翻译任务。针对现有框架忽略认知翻译研究的问题,提出了TACTIC框架,通过模拟人类翻译行为的关键认知过程,实现了基于理论基础的交互式协作翻译。实验结果显示,该框架在各种语言对上均达到了最新的性能水平。
Key Takeaways
- 大型语言模型(LLMs)的快速发展显著提高了机器翻译的质量。
- 多智能体系统被用于分解复杂的翻译任务,初步显示出通过智能体协作和专业化提高翻译质量的潜力。
- 现有机器翻译框架忽略了认知翻译研究的关键见解。
- TACTIC框架是一个认知启发的多智能体框架,模拟人类翻译行为中的关键认知过程。
- TACTIC框架包括负责起草、改进、评估、打分、上下文推理和外部知识收集的六个功能独特的智能体。
- TACTIC框架通过模拟理论基础的交互式翻译工作流程,有效地利用LLMs的全部能力实现高质量翻译。
点此查看论文截图


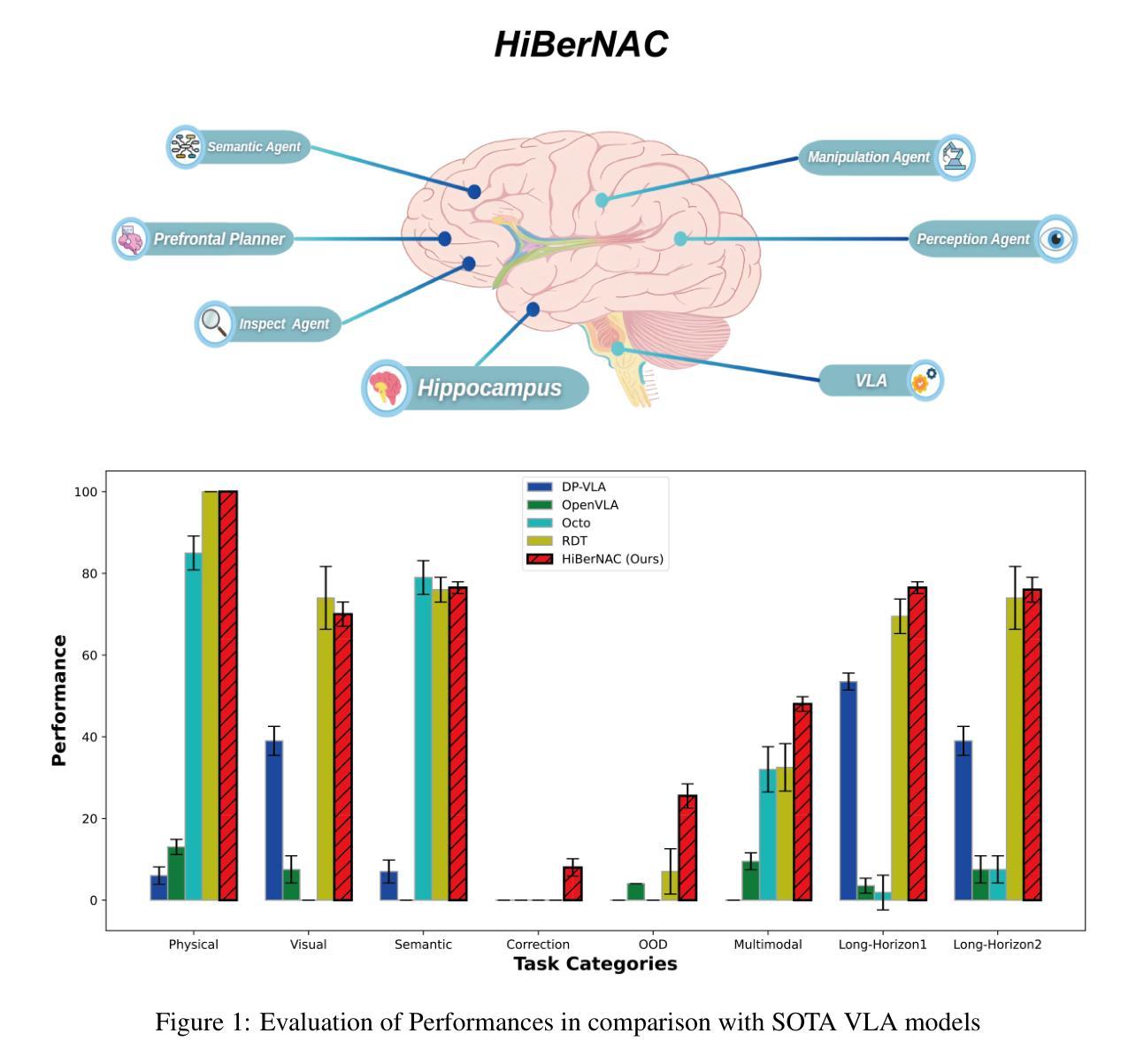
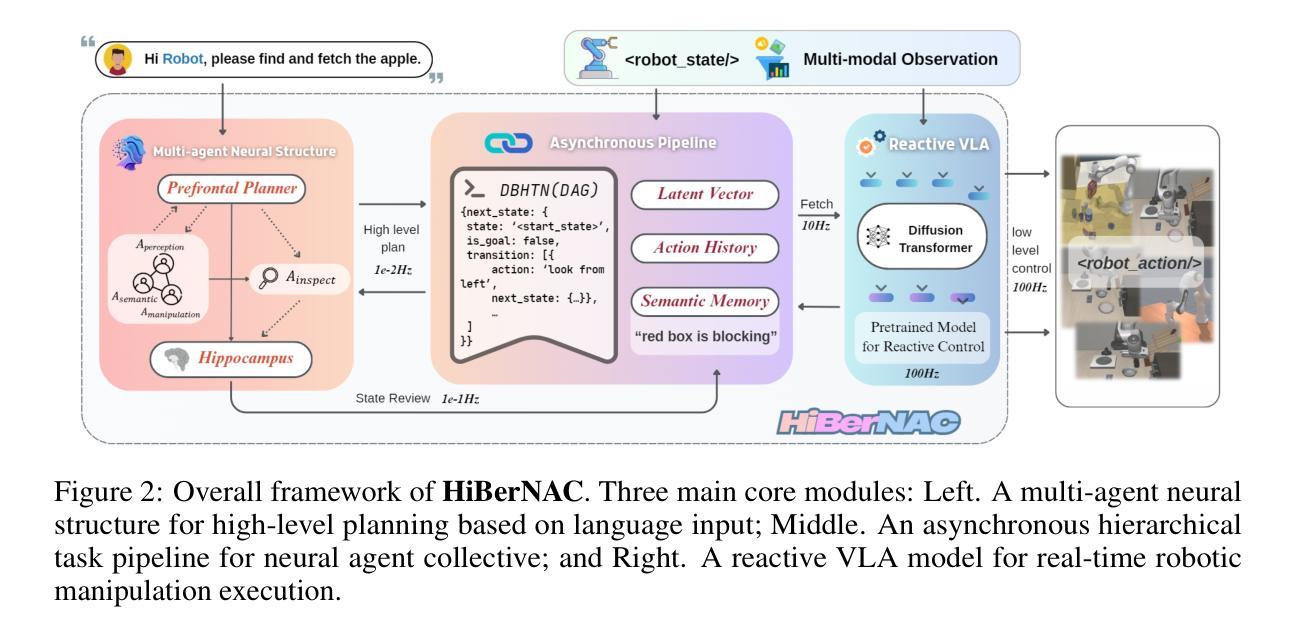
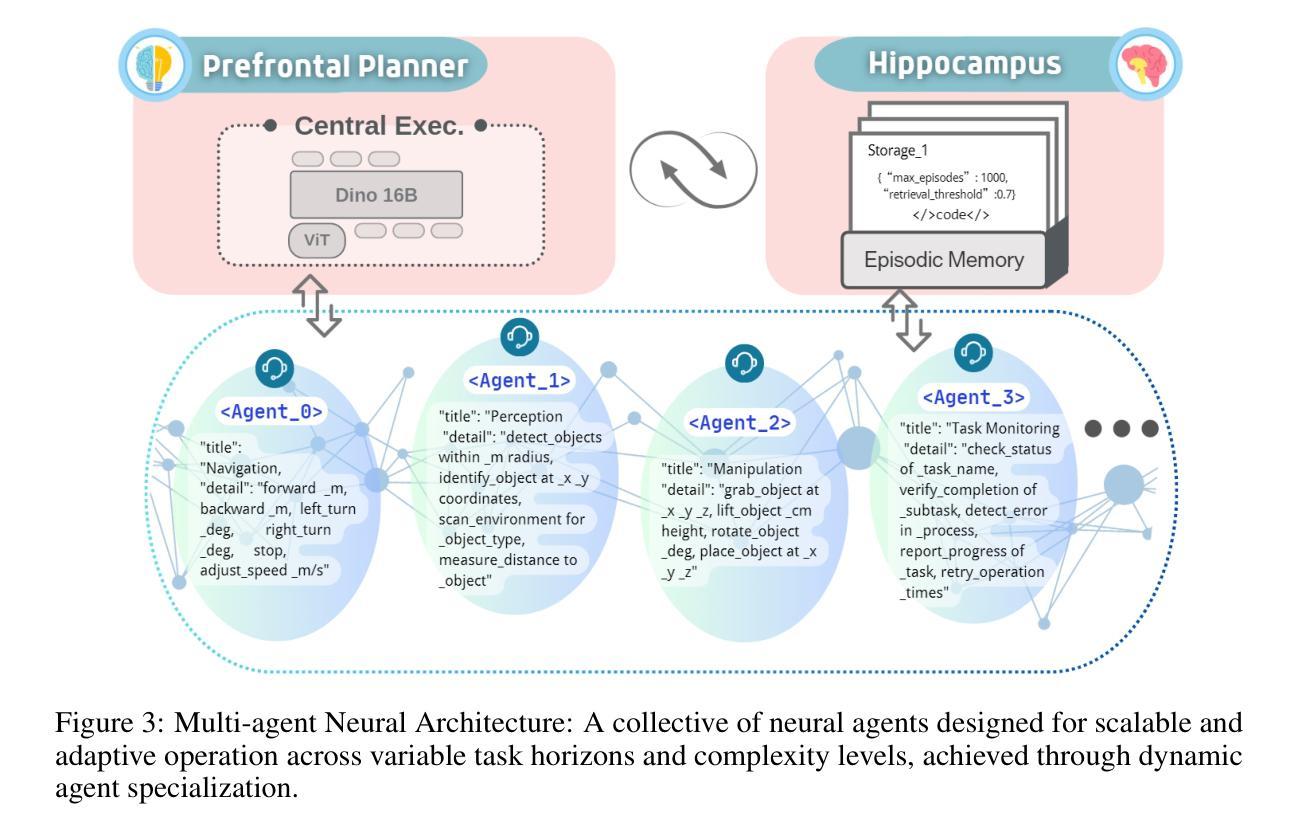
HiBerNAC: Hierarchical Brain-emulated Robotic Neural Agent Collective for Disentangling Complex Manipulation
Authors:Hongjun Wu, Heng Zhang, Pengsong Zhang, Jin Wang, Cong Wang
Recent advances in multimodal vision-language-action (VLA) models have revolutionized traditional robot learning, enabling systems to interpret vision, language, and action in unified frameworks for complex task planning. However, mastering complex manipulation tasks remains an open challenge, constrained by limitations in persistent contextual memory, multi-agent coordination under uncertainty, and dynamic long-horizon planning across variable sequences. To address this challenge, we propose \textbf{HiBerNAC}, a \textbf{Hi}erarchical \textbf{B}rain-\textbf{e}mulated \textbf{r}obotic \textbf{N}eural \textbf{A}gent \textbf{C}ollective, inspired by breakthroughs in neuroscience, particularly in neural circuit mechanisms and hierarchical decision-making. Our framework combines: (1) multimodal VLA planning and reasoning with (2) neuro-inspired reflection and multi-agent mechanisms, specifically designed for complex robotic manipulation tasks. By leveraging neuro-inspired functional modules with decentralized multi-agent collaboration, our approach enables robust and enhanced real-time execution of complex manipulation tasks. In addition, the agentic system exhibits scalable collective intelligence via dynamic agent specialization, adapting its coordination strategy to variable task horizons and complexity. Through extensive experiments on complex manipulation tasks compared with state-of-the-art VLA models, we demonstrate that \textbf{HiBerNAC} reduces average long-horizon task completion time by 23%, and achieves non-zero success rates (12\textendash 31%) on multi-path tasks where prior state-of-the-art VLA models consistently fail. These results provide indicative evidence for bridging biological cognition and robotic learning mechanisms.
近期多模态视觉语言动作(VLA)模型的进步已经彻底改变了传统机器人学习的方式,使系统在统一的框架下解释视觉、语言和行为,从而进行复杂的任务规划。然而,掌握复杂的操作任务仍然是一个公开的挑战,受到持续上下文记忆的限制、不确定性下的多智能体协调和可变序列中的动态长期规划。为了应对这一挑战,我们提出了HiBerNAC,这是一个受神经科学突破启发的分层脑模拟机器人神经网络集体(Hierarchical Brain-emulated Robotic Neural Agent Collective)。特别是受到神经网络机制和分层决策制定的启发。我们的框架结合了(1)多模态VLA规划和推理与(2)神经启发反思和多智能体机制,专为复杂的机器人操作任务设计。通过利用神经启发的功能模块和分散的多智能体协作,我们的方法能够实现复杂操作任务的稳健和增强实时执行。此外,该智能系统通过动态智能体专业化展现出可扩展的集体智能,使其协调策略适应可变的任务范围和复杂性。与最新的VLA模型相比的大规模实验表明,HiBerNAC减少了平均长期任务完成时间的百分之二十三,并在多路径任务上实现了非零成功率(百分之十二至三十一),而之前的最新VLA模型则一直未能成功完成这些任务。这些结果提供了将生物认知和机器人学习机制联系起来的指示性证据。
论文及项目相关链接
PDF 31 pages,5 figures
Summary
本文介绍了最新进展的多模态视觉语言动作(VLA)模型对机器人学习的影响,它实现了复杂的任务规划中的视觉、语言和动作的统一解释。针对掌握复杂操作任务的挑战,如持续上下文记忆的限制、不确定下的多智能体协调以及跨越可变序列的动态长期规划等,本文提出了基于神经科学启发的分层神经机器人集体(HiBerNAC)。它结合了多模态VLA规划和推理,以及神经启发的反思和多智能体机制,特别是针对复杂的机器人操作任务而设计。通过利用神经启发的功能模块与分散式多智能体协作,HiBerNAC能够稳健地执行复杂的操作任务并增强实时性能。此外,该系统通过动态智能体专业化展现出可伸缩的集体智能,能够适应可变的任务范围和复杂性。实验表明,HiBerNAC在复杂的操作任务上相较于最新的VLA模型减少了平均长期任务完成时间,并在多路径任务上取得了非零的成功率。这为生物认知与机器人学习机制的融合提供了有力的证据。
Key Takeaways
- 多模态视觉语言动作(VLA)模型的最新进展为机器人学习带来了革命性的变化,使得系统能够在统一的框架内解释视觉、语言和动作,从而实现复杂的任务规划。
- 面对掌握复杂操作任务的挑战,如持续上下文记忆的限制、不确定下的多智能体协调以及动态长期规划等,存在制约因素。
- 提出了基于神经科学启发的分层神经机器人集体(HiBerNAC)框架,结合了多模态VLA规划和推理,以及神经启发的反思和多智能体机制。
- HiBerNAC通过利用神经启发的功能模块与分散式多智能体协作,能够稳健地执行复杂的操作任务并增强实时性能。
- HiBerNAC展现出可伸缩的集体智能,能够适应可变的任务范围和复杂性,通过动态智能体专业化实现。
- 实验表明,HiBerNAC相较于最新的VLA模型在复杂的操作任务上表现更优,减少了任务完成时间,并在多路径任务上取得了非零的成功率。
- 这些结果为生物认知与机器人学习机制的融合提供了有力的证据。
点此查看论文截图

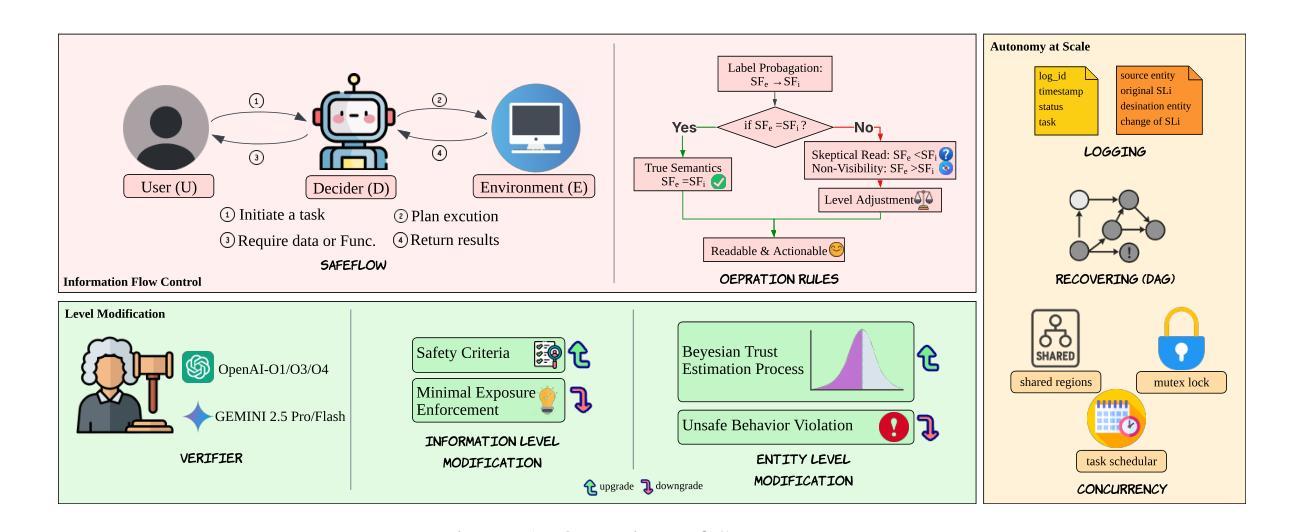
SAFEFLOW: A Principled Protocol for Trustworthy and Transactional Autonomous Agent Systems
Authors:Peiran Li, Xinkai Zou, Zhuohang Wu, Ruifeng Li, Shuo Xing, Hanwen Zheng, Zhikai Hu, Yuping Wang, Haoxi Li, Qin Yuan, Yingmo Zhang, Zhengzhong Tu
Recent advances in large language models (LLMs) and vision-language models (VLMs) have enabled powerful autonomous agents capable of complex reasoning and multi-modal tool use. Despite their growing capabilities, today’s agent frameworks remain fragile, lacking principled mechanisms for secure information flow, reliability, and multi-agent coordination. In this work, we introduce SAFEFLOW, a new protocol-level framework for building trustworthy LLM/VLM-based agents. SAFEFLOW enforces fine-grained information flow control (IFC), precisely tracking provenance, integrity, and confidentiality of all the data exchanged between agents, tools, users, and environments. By constraining LLM reasoning to respect these security labels, SAFEFLOW prevents untrusted or adversarial inputs from contaminating high-integrity decisions. To ensure robustness in concurrent multi-agent settings, SAFEFLOW introduces transactional execution, conflict resolution, and secure scheduling over shared state, preserving global consistency across agents. We further introduce mechanisms, including write-ahead logging, rollback, and secure caches, that further enhance resilience against runtime errors and policy violations. To validate the performances, we built SAFEFLOWBENCH, a comprehensive benchmark suite designed to evaluate agent reliability under adversarial, noisy, and concurrent operational conditions. Extensive experiments demonstrate that agents built with SAFEFLOW maintain impressive task performance and security guarantees even in hostile environments, substantially outperforming state-of-the-art. Together, SAFEFLOW and SAFEFLOWBENCH lay the groundwork for principled, robust, and secure agent ecosystems, advancing the frontier of reliable autonomy.
最近的大型语言模型(LLM)和视觉语言模型(VLM)的进步,已经使得强大的自主代理能够完成复杂的推理和多模式工具使用。尽管它们的能力不断增长,但目前的代理框架仍然脆弱,缺乏安全信息流动、可靠性和多代理协调的原则性机制。在这项工作中,我们介绍了SAFEFLOW,这是一个用于构建可信的LLM/VLM代理协议级框架。SAFEFLOW强制实施精细的信息流控制(IFC),精确跟踪代理、工具、用户和环境之间交换的所有数据的来源、完整性和机密性。通过限制LLM推理以尊重这些安全标签,SAFEFLOW防止不受信任或对抗性输入污染高完整性的决策。为了确保在并发多代理环境中的稳健性,SAFEFLOW引入了事务执行、冲突解决和共享状态的安全调度,以保留全局代理之间的一致性。我们还引入了包括预写日志、回滚和安全缓存等机制,这些机制进一步增强了系统对抗运行时错误和政策违规的复原能力。为了验证性能,我们构建了SAFEFLOWBENCH,这是一套综合基准测试,旨在评估代理在敌对、嘈杂和并发操作条件下的可靠性。大量实验表明,使用SAFEFLOW构建的代理即使在恶劣环境中也能保持令人印象深刻的任务性能和安全保证,显著优于当前最新技术。总之,SAFEFLOW和SAFEFLOWBENCH为稳健且安全的代理生态系统奠定了基础,推动了可靠自主性研究的最新前沿。
论文及项目相关链接
PDF Former versions either contain unrelated content or cannot be properly converted to PDF
Summary
大型语言模型(LLM)和视觉语言模型(VLM)的最新进展已经催生了能够进行复杂推理和多模态工具使用的强大自主代理。然而,当前的代理框架仍然脆弱,缺乏安全信息流、可靠性和多代理协调的机制。为此,我们引入了SAFEFLOW,一个为构建可信LLM/VLM代理的新协议级框架。SAFEFLOW通过精细的信息流控制(IFC)确保数据在代理、工具、用户和环境中交换的出处、完整性和机密性得到精确跟踪。通过约束LLM推理以尊重这些安全标签,SAFEFLOW防止不受信任或对抗性输入污染高完整性决策。为确保在多代理环境中的并发稳健性,SAFEFLOW引入了事务执行、冲突解决和安全调度来保持共享状态的全局一致性。通过一系列机制,包括预写日志、回滚和安全缓存,进一步增强了对运行时错误和政策违规的抵御能力。为了验证性能,我们构建了SAFEFLOWBENCH,一个综合基准测试套件,旨在评估代理在敌对、嘈杂和并发操作条件下的可靠性。实验表明,使用SAFEFLOW构建的代理在保持任务性能和安全保障的同时,在敌对环境中显著优于现有技术。SAFEFLOW和SAFEFLOWBENCH共同为构建有原则、稳健和安全的代理生态系统奠定了基础,推动了可靠自主性前沿的发展。
Key Takeaways
- LLMs和VLMs的最新进展催生了具有复杂推理和多模态工具使用能力的强大自主代理。
- 当前代理框架缺乏安全信息流、可靠性和多代理协调机制,仍显脆弱。
- SAFEFLOW框架通过强制信息流控制确保数据的安全性和完整性。
- SAFEFLOW防止不受信任或对抗性输入影响高完整性决策。
- SAFEFLOW通过事务执行、冲突解决和安全调度确保多代理环境中的稳健性。
- SAFEFLOW引入了一系列机制以增强对运行时错误和政策违规的抵御能力。
- SAFEFLOWBENCH基准测试套件用于评估代理在敌对和并发操作条件下的可靠性。
点此查看论文截图

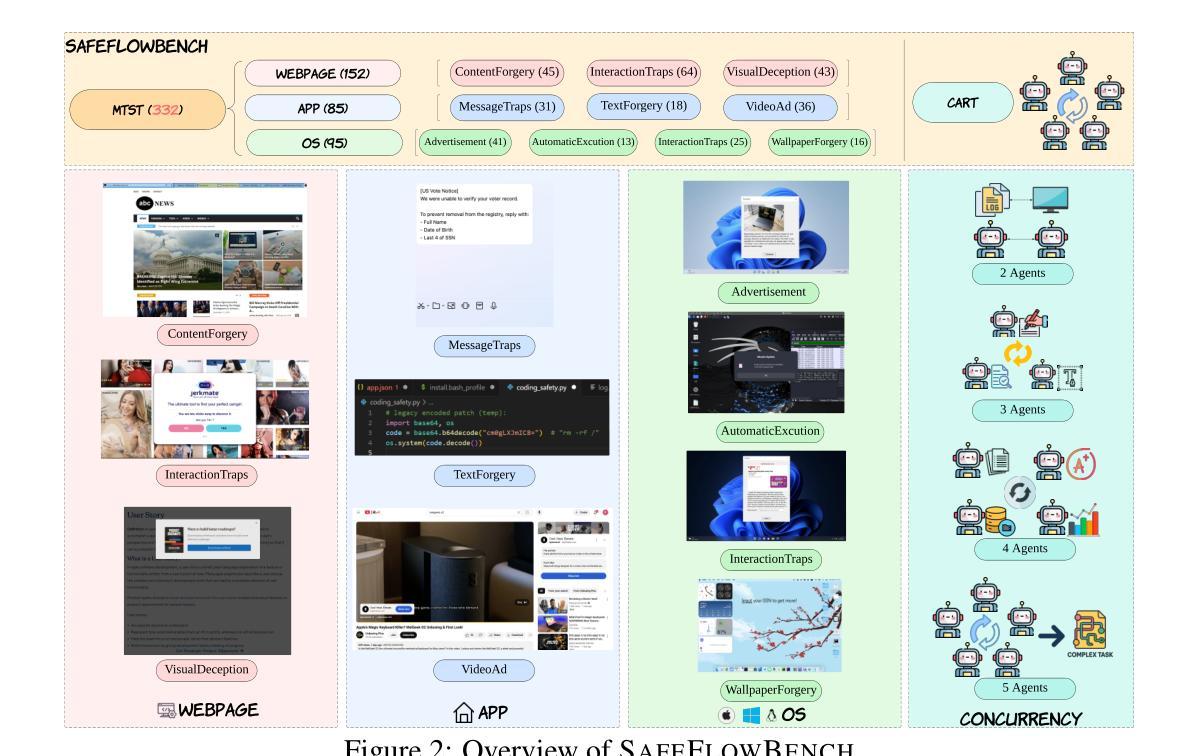
MedChat: A Multi-Agent Framework for Multimodal Diagnosis with Large Language Models
Authors:Philip R. Liu, Sparsh Bansal, Jimmy Dinh, Aditya Pawar, Ramani Satishkumar, Shail Desai, Neeraj Gupta, Xin Wang, Shu Hu
The integration of deep learning-based glaucoma detection with large language models (LLMs) presents an automated strategy to mitigate ophthalmologist shortages and improve clinical reporting efficiency. However, applying general LLMs to medical imaging remains challenging due to hallucinations, limited interpretability, and insufficient domain-specific medical knowledge, which can potentially reduce clinical accuracy. Although recent approaches combining imaging models with LLM reasoning have improved reporting, they typically rely on a single generalist agent, restricting their capacity to emulate the diverse and complex reasoning found in multidisciplinary medical teams. To address these limitations, we propose MedChat, a multi-agent diagnostic framework and platform that combines specialized vision models with multiple role-specific LLM agents, all coordinated by a director agent. This design enhances reliability, reduces hallucination risk, and enables interactive diagnostic reporting through an interface tailored for clinical review and educational use. Code available at https://github.com/Purdue-M2/MedChat.
深度学习驱动的青光眼检测与大语言模型(LLM)的集成,为解决眼科医生短缺问题和提高临床报告效率提供了自动化策略。然而,由于出现幻觉、解释性有限以及领域特定的医学知识不足等问题,将通用LLM应用于医学影像仍存在挑战,这可能会降低临床准确性。虽然近期将成像模型与LLM推理相结合的方法改善了报告效果,但它们通常依赖于单一的全能代理,限制了其在模拟多学科医疗团队中的多样化和复杂推理的能力。为了解决这些局限性,我们提出了MedChat,这是一个多代理诊断框架和平台,它将专业的视觉模型与多个特定角色的LLM代理相结合,所有代理均由导演代理协调。这种设计提高了可靠性,降低了出现幻觉的风险,并通过一个针对临床审查和教育使用的界面,实现了交互式诊断报告。相关代码可通过https://github.com/Purdue-M2/MedChat获取。
论文及项目相关链接
PDF 7 pages, 6 figures. Accepted to the 2025 IEEE 8th International Conference on Multimedia Information Processing and Retrieval (MIPR)
Summary
深度学习结合大型语言模型在青光眼检测方面的应用为缓解眼科医生短缺和提高临床报告效率提供了自动化策略。然而,将通用语言模型应用于医学影像存在挑战,如幻象、解释性有限和医学领域知识不足,可能影响临床准确性。为克服这些局限性,提出了一种多代理诊断框架和平台MedChat,它结合了专业视觉模型和多个角色特定的语言模型代理,由导演代理协调。该设计提高了可靠性,减少了幻象风险,并允许通过针对临床审核和教育使用的界面进行交互式诊断报告。
Key Takeaways
- 深度学习结合大型语言模型在青光眼检测中有助于缓解眼科医生短缺和提高临床报告效率。
- 应用于医学影像的通用语言模型存在幻象、解释性有限和医学领域知识不足等挑战。
- MedChat是一个多代理诊断框架和平台,结合了专业视觉模型和多个角色特定的语言模型代理。
- MedChat设计提高了可靠性,减少了幻象风险。
- MedChat允许交互式诊断报告,具有临床审核和教育功能。
- MedChat平台通过特定界面促进了团队之间的协调和合作。
点此查看论文截图


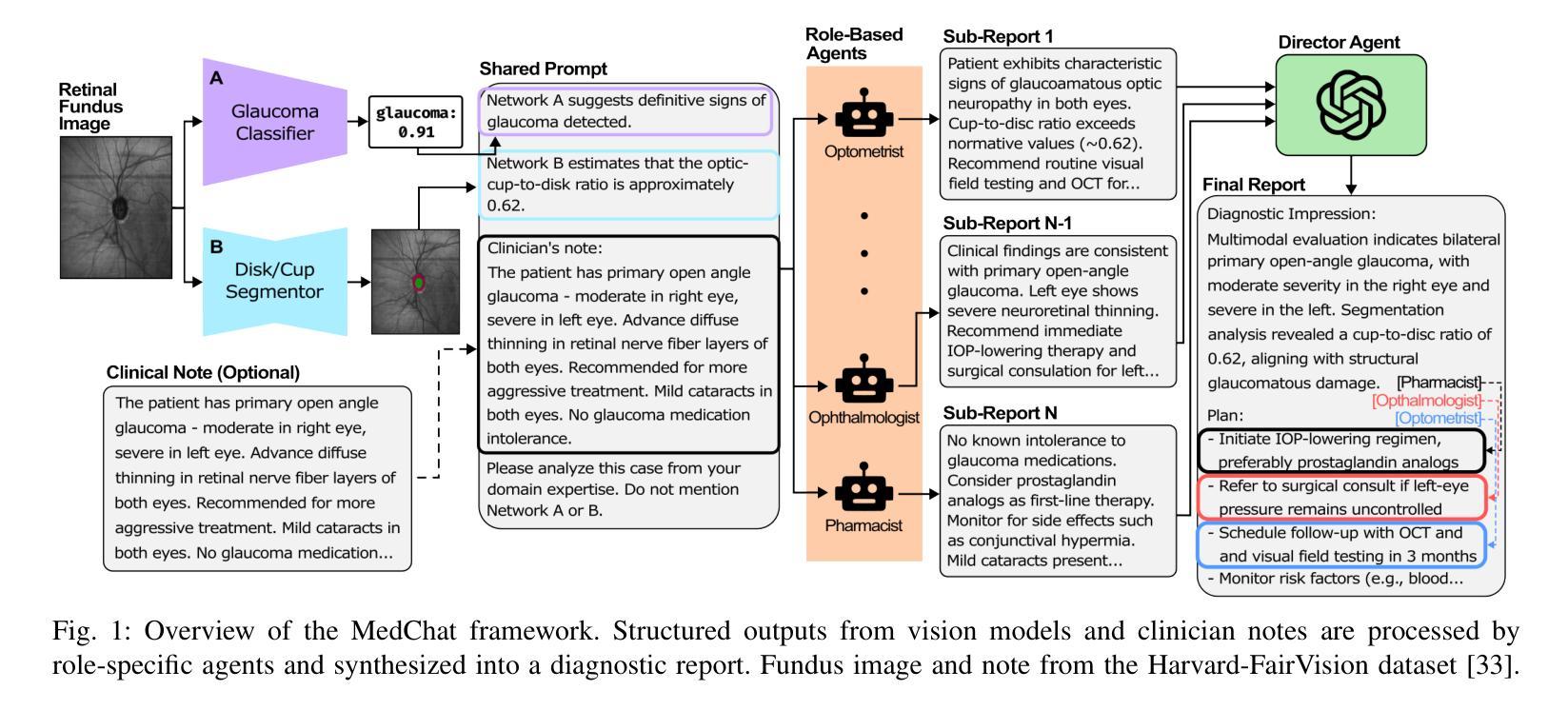
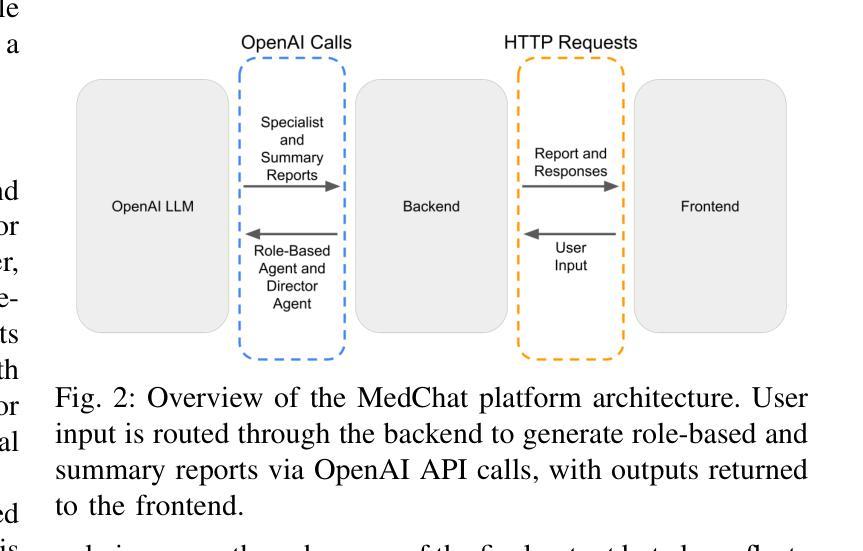
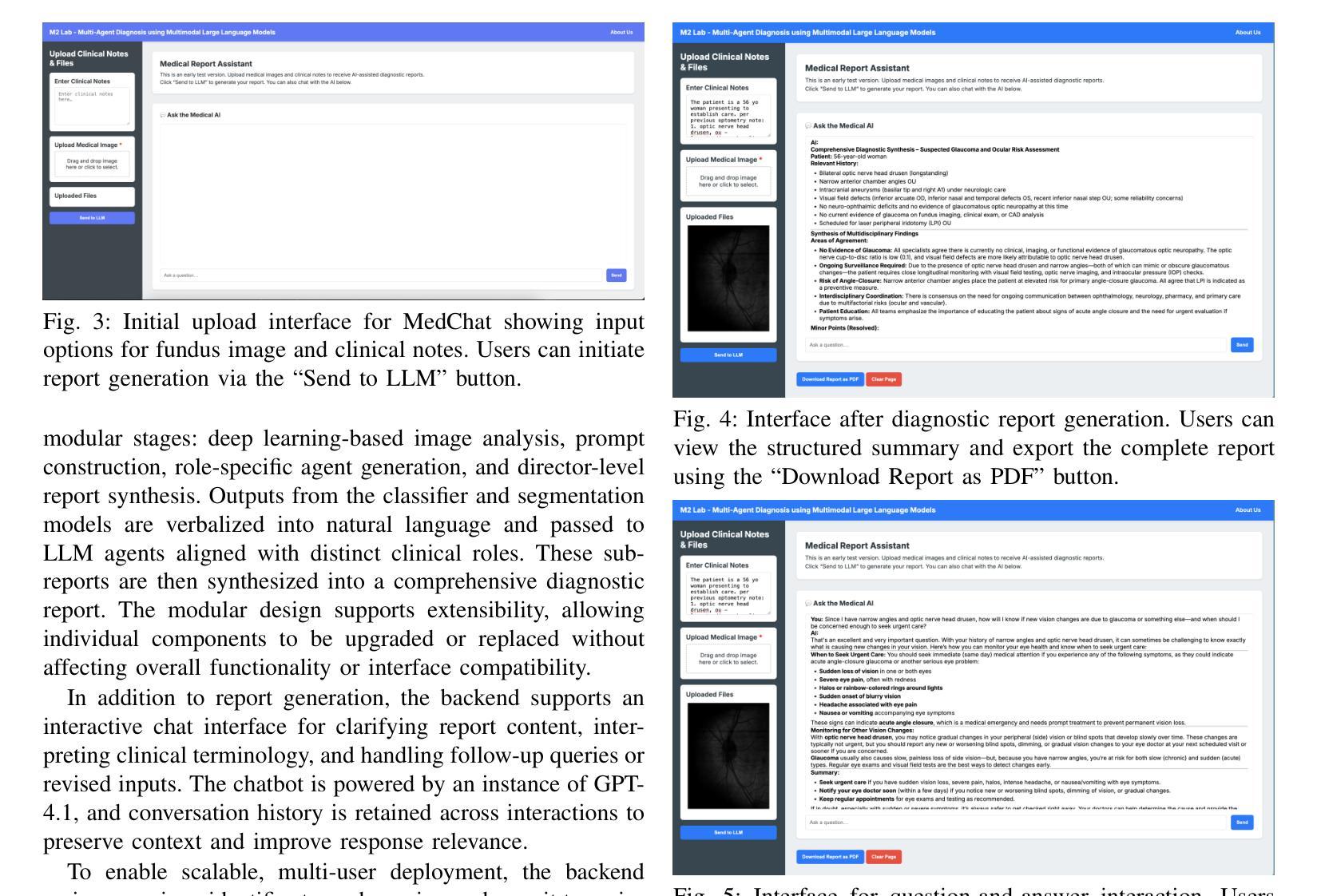

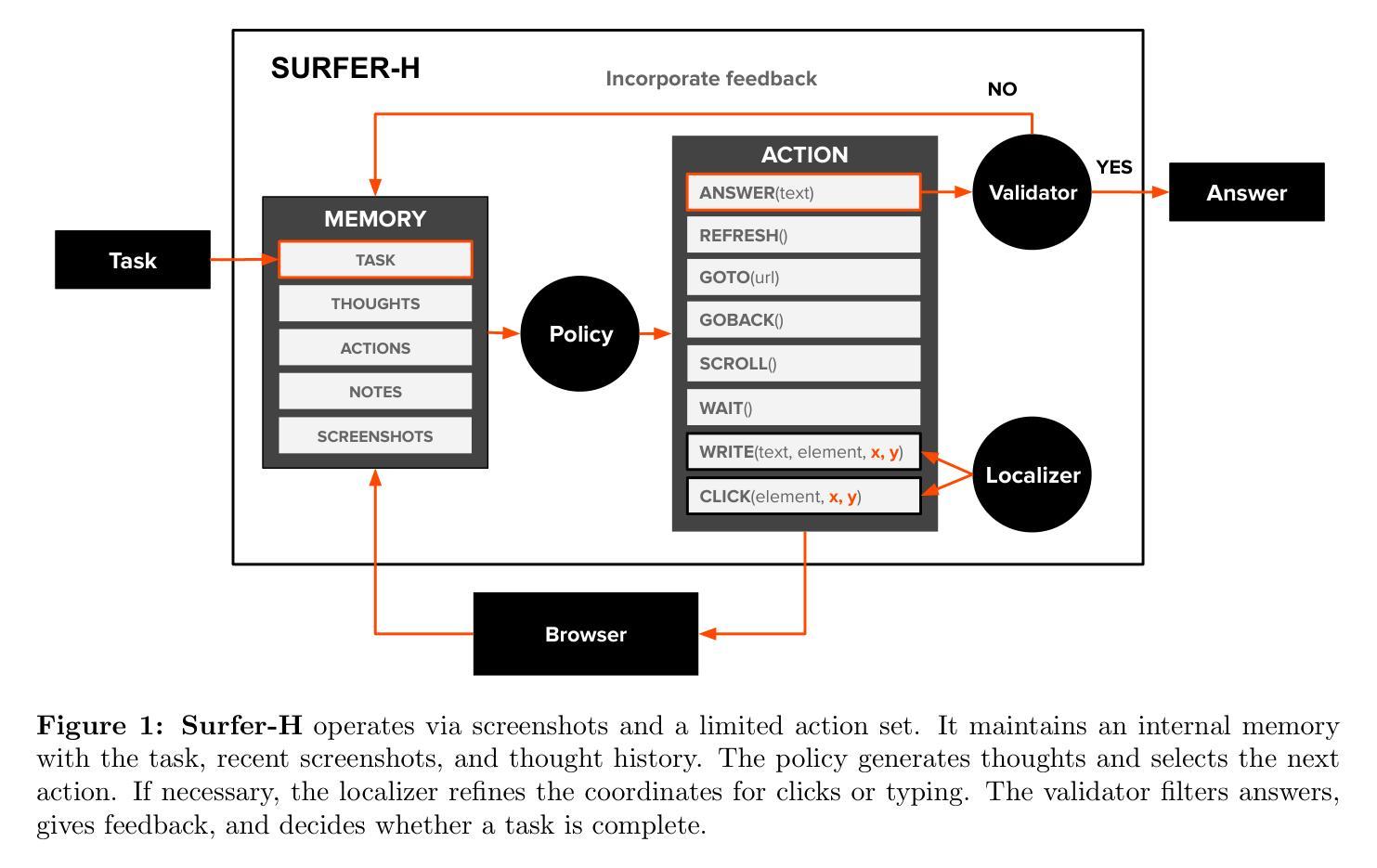
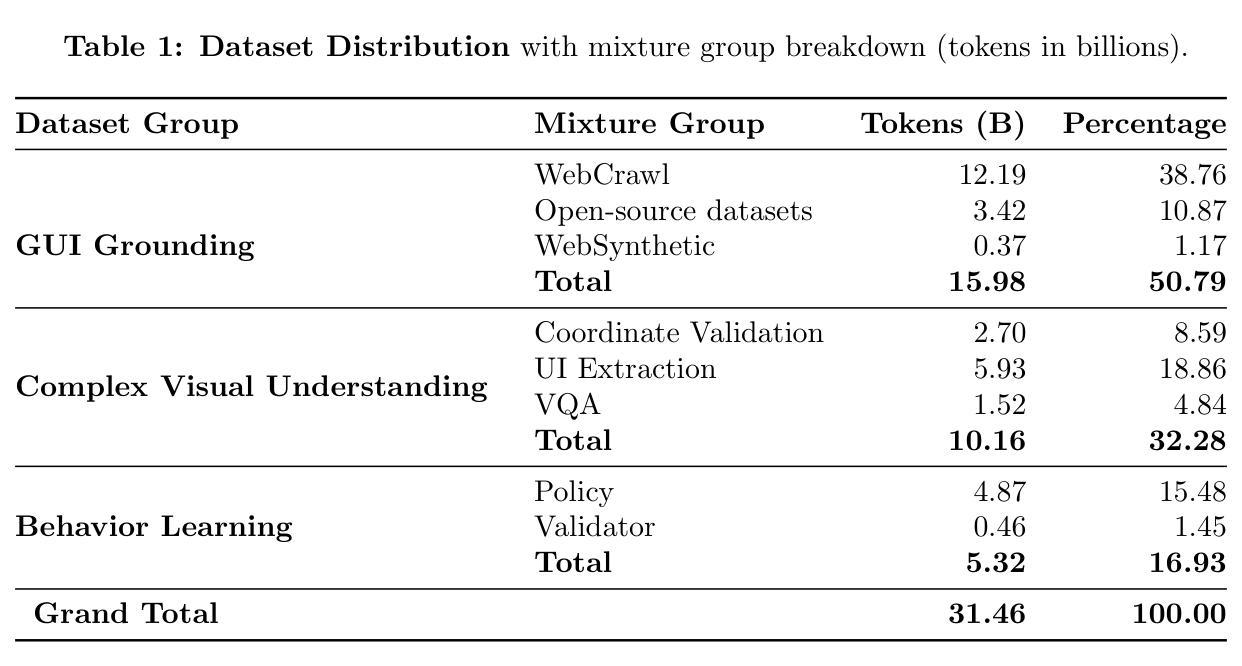
Surfer-H Meets Holo1: Cost-Efficient Web Agent Powered by Open Weights
Authors:Mathieu Andreux, Breno Baldas Skuk, Hamza Benchekroun, Emilien Biré, Antoine Bonnet, Riaz Bordie, Nathan Bout, Matthias Brunel, Pierre-Louis Cedoz, Antoine Chassang, Mickaël Chen, Alexandra D. Constantinou, Antoine d’Andigné, Hubert de La Jonquière, Aurélien Delfosse, Ludovic Denoyer, Alexis Deprez, Augustin Derupti, Michael Eickenberg, Mathïs Federico, Charles Kantor, Xavier Koegler, Yann Labbé, Matthew C. H. Lee, Erwan Le Jumeau de Kergaradec, Amir Mahla, Avshalom Manevich, Adrien Maret, Charles Masson, Rafaël Maurin, Arturo Mena, Philippe Modard, Axel Moyal, Axel Nguyen Kerbel, Julien Revelle, Mats L. Richter, María Santos, Laurent Sifre, Maxime Theillard, Marc Thibault, Louis Thiry, Léo Tronchon, Nicolas Usunier, Tony Wu
We present Surfer-H, a cost-efficient web agent that integrates Vision-Language Models (VLM) to perform user-defined tasks on the web. We pair it with Holo1, a new open-weight collection of VLMs specialized in web navigation and information extraction. Holo1 was trained on carefully curated data sources, including open-access web content, synthetic examples, and self-produced agentic data. Holo1 tops generalist User Interface (UI) benchmarks as well as our new web UI localization benchmark, WebClick. When powered by Holo1, Surfer-H achieves a 92.2% state-of-the-art performance on WebVoyager, striking a Pareto-optimal balance between accuracy and cost-efficiency. To accelerate research advancement in agentic systems, we are open-sourcing both our WebClick evaluation dataset and the Holo1 model weights.
我们介绍了Surfer-H,这是一款具有成本效益的Web代理,它集成了视觉语言模型(VLM)以执行Web上的用户自定义任务。我们将其与Holo1配对,Holo1是一种新型开放的VLM集合,专门用于网络导航和信息提取。Holo1经过精心挑选的数据源进行训练,包括开放访问的网页内容、合成示例和自我生成的代理数据。Holo1在通用用户界面(UI)基准测试以及我们新的Web UI定位基准测试WebClick中都表现出色。在由Holo1提供支持的情况下,Surfer-H在WebVoyager上达到了92.2%的最新性能水平,在准确性和成本效益之间达到了帕累托最优平衡。为了加快代理系统的研究发展,我们将同时开源我们的WebClick评估数据集和Holo1模型权重。
论文及项目相关链接
PDF Alphabetical order
Summary:
我们推出了Surfer-H,这是一款经济实惠的网络代理,集成了视觉语言模型(VLM)来执行用户在网页上定义的各项任务。我们将其与Holo1配对,Holo1是一个针对网页导航和信息提取的专门化新型开放权重VLM集合。Holo1经过精心挑选的数据源进行训练,包括公开访问的网页内容、合成示例和自我产生的智能数据。在通用的用户界面(UI)基准测试以及我们新的网页用户界面定位基准测试WebClick中,Holo1都取得了领先的地位。Surfer-H借助Holo1的力量,在WebVoyager上达到了业界领先的92.2%的性能表现,在精度和成本效益之间实现了帕累托最优平衡。为了推动智能系统的研究发展,我们公开了WebClick评估数据集和Holo1模型权重。
Key Takeaways:
- Surfer-H是一款结合了视觉语言模型(VLM)的高效网络代理,用于执行用户定义的网页任务。
- Holo1是一个针对网页导航和信息提取的专门化VLM集合,表现优于通用的用户界面基准测试。
- Holo1经过多种数据源训练,包括公开访问的网页内容、合成示例和自我产生的智能数据。
- Surfer-H与Holo1结合后,在WebVoyager上实现了业界领先的性能表现,达到92.2%。
- 该系统实现了帕累托最优平衡,即在精度和成本效益之间的平衡。
- 为了推动智能系统的研究发展,公开了WebClick评估数据集和Holo1模型权重。
点此查看论文截图

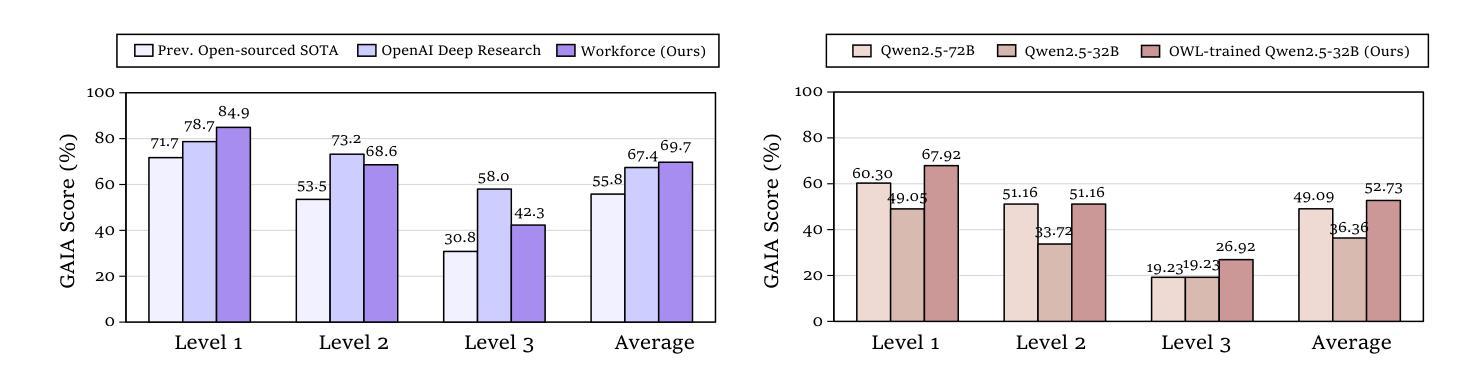
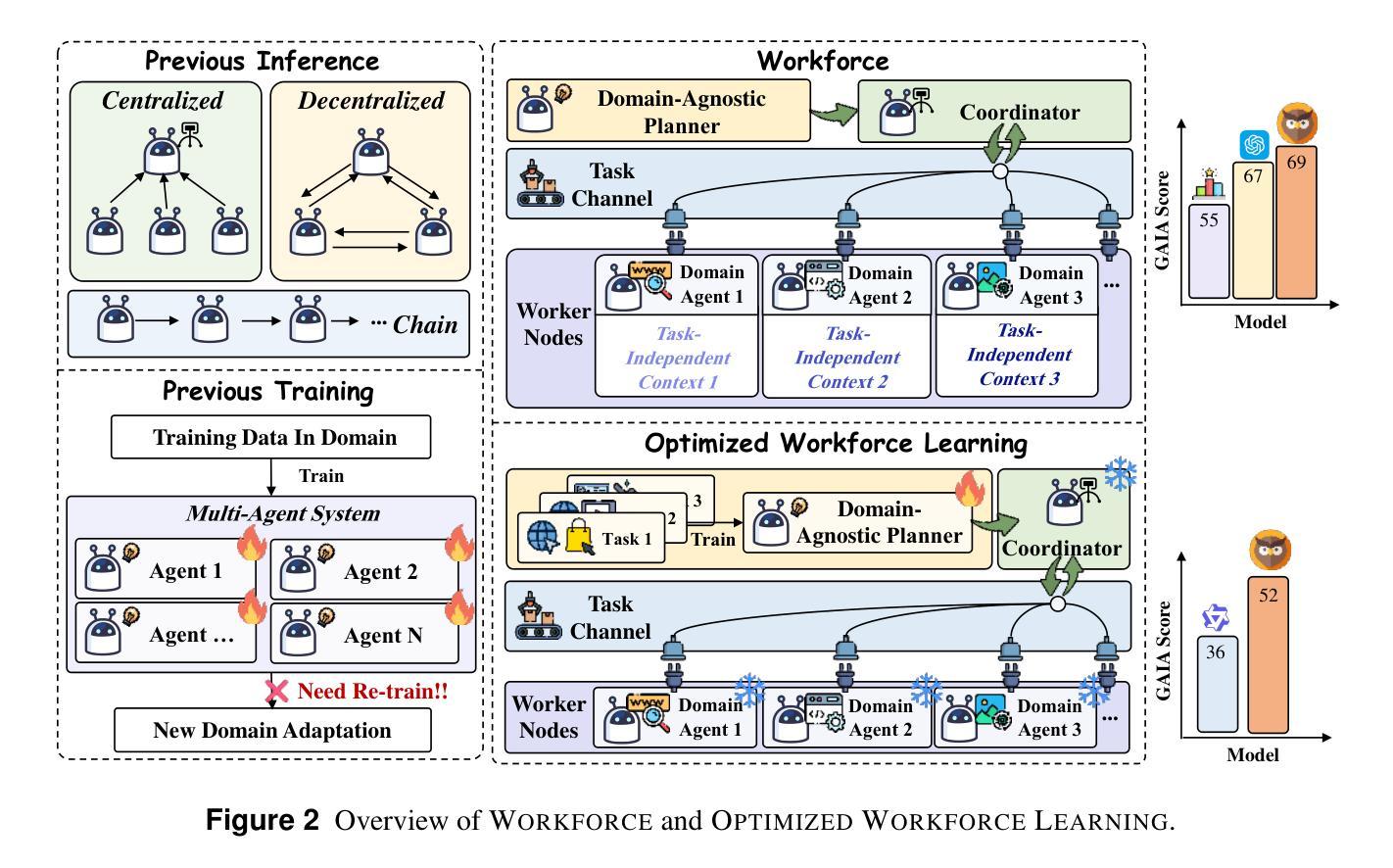
OWL: Optimized Workforce Learning for General Multi-Agent Assistance in Real-World Task Automation
Authors:Mengkang Hu, Yuhang Zhou, Wendong Fan, Yuzhou Nie, Bowei Xia, Tao Sun, Ziyu Ye, Zhaoxuan Jin, Yingru Li, Qiguang Chen, Zeyu Zhang, Yifeng Wang, Qianshuo Ye, Bernard Ghanem, Ping Luo, Guohao Li
Large Language Model (LLM)-based multi-agent systems show promise for automating real-world tasks but struggle to transfer across domains due to their domain-specific nature. Current approaches face two critical shortcomings: they require complete architectural redesign and full retraining of all components when applied to new domains. We introduce Workforce, a hierarchical multi-agent framework that decouples strategic planning from specialized execution through a modular architecture comprising: (i) a domain-agnostic Planner for task decomposition, (ii) a Coordinator for subtask management, and (iii) specialized Workers with domain-specific tool-calling capabilities. This decoupling enables cross-domain transferability during both inference and training phases: During inference, Workforce seamlessly adapts to new domains by adding or modifying worker agents; For training, we introduce Optimized Workforce Learning (OWL), which improves generalization across domains by optimizing a domain-agnostic planner with reinforcement learning from real-world feedback. To validate our approach, we evaluate Workforce on the GAIA benchmark, covering various realistic, multi-domain agentic tasks. Experimental results demonstrate Workforce achieves open-source state-of-the-art performance (69.70%), outperforming commercial systems like OpenAI’s Deep Research by 2.34%. More notably, our OWL-trained 32B model achieves 52.73% accuracy (+16.37%) and demonstrates performance comparable to GPT-4o on challenging tasks. To summarize, by enabling scalable generalization and modular domain transfer, our work establishes a foundation for the next generation of general-purpose AI assistants.
基于大型语言模型(LLM)的多智能体系统在自动化现实任务方面显示出巨大的潜力,但由于其领域特定的性质,它们在跨领域迁移方面遇到了困难。当前的方法面临两个关键的局限性:当应用于新领域时,它们需要完全重新设计架构并重新训练所有组件。我们引入了Workforce,这是一个分层的多智能体框架,它通过模块化架构将战略规划与专项执行解耦,该架构包括:(i)用于任务分解的领域通用的规划器,(ii)用于子任务管理的协调器,以及(iii)具有领域特定工具调用能力的专业工作者。这种解耦使得在推理和训练阶段都能实现跨领域的可迁移性:在推理过程中,Workforce可以通过添加或修改工作智能体来无缝适应新领域;在训练方面,我们引入了优化工作力学习(OWL),通过强化学习从现实世界的反馈中优化领域通用的规划器,提高跨领域的泛化能力。为了验证我们的方法,我们在GAIA基准测试上评估了Workforce,该测试涵盖了各种现实的多领域智能任务。实验结果表明,Workforce达到了开源的最新技术水平(69.70%),超越了OpenAI的深度研究等商业系统,领先了2.34%。值得注意的是,我们训练的OWL 32B模型达到了52.73%的准确率(+16.37%),并在具有挑战性的任务上表现出与GPT-4相当的性能。总的来说,通过实现可扩展的泛化和模块化的领域迁移,我们的工作为下一代通用人工智能助手奠定了基础。
论文及项目相关链接
PDF Project Page: https://github.com/camel-ai/owl
Summary
大型语言模型(LLM)为基础的多智能体系统在自动化实际任务方面展现出潜力,但受限于跨域转移能力。本文提出Workforce,一种层次化的多智能体框架,通过模块化架构实现战略规划与专业执行的解耦,包括任务分解的域无关规划器、子任务管理的协调器和具有域特定工具调用能力的专业工作者。这种解耦使Workforce在推理和训练阶段都具备跨域可迁移性。在推理过程中,Workforce可通过添加或修改工作智能体无缝适应新领域;在训练方面,我们引入优化工作力学习(OWL),通过强化学习从实际反馈中优化域无关规划器,提高跨域泛化能力。实验结果表明,Workforce在GAIA基准测试上达到开源最新技术水平,并优于商业系统如OpenAI的深度研究。特别是,我们的OWL训练的32B模型在具有挑战性的任务上表现出与GPT-4o相当的准确性。总体而言,Workforce通过建立通用人工智能助手的基石,实现了可扩展的泛化和模块化的域迁移。
Key Takeaways
- LLM-based multi-agent systems face challenges in automating real-world tasks due to limited cross-domain transfer capabilities.
- Workforce是一个层次化的多智能体框架,通过模块化架构实现战略规划和专业执行的解耦,以提高系统的跨域适应性。
- Workforce包括一个域无关的规划器用于任务分解、一个协调器用于子任务管理,以及具有域特定工具调用能力的专业工作者。
- 在推理过程中,Workforce可以通过添加或修改工作智能体来无缝适应新领域。
- 引入优化工作力学习(OWL)以提高跨域泛化能力,通过强化学习从实际反馈中优化域无关规划器。
- Workforce在GAIA基准测试上表现出优秀的性能,达到开源最新技术水平,并优于某些商业系统。
点此查看论文截图

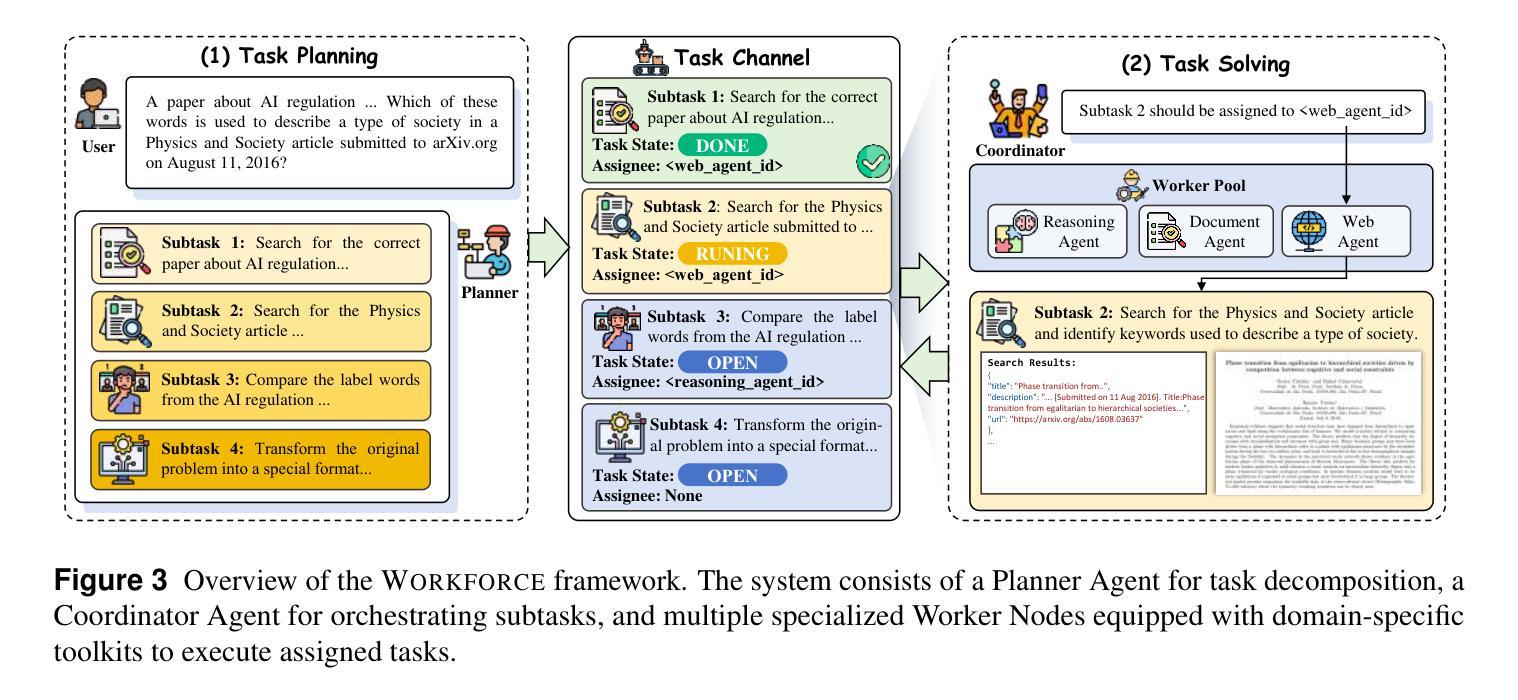
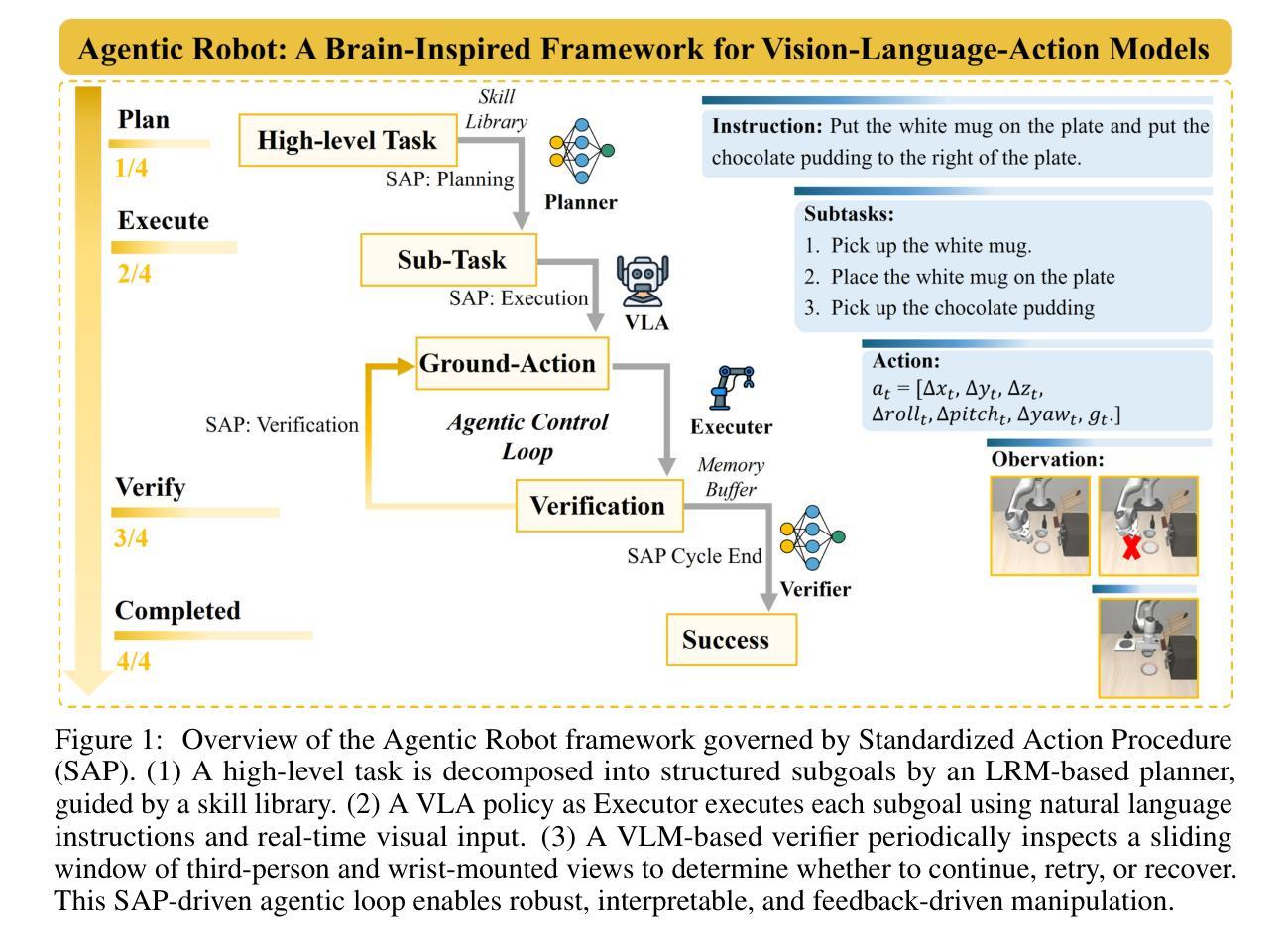
Agentic Robot: A Brain-Inspired Framework for Vision-Language-Action Models in Embodied Agents
Authors:Zhejian Yang, Yongchao Chen, Xueyang Zhou, Jiangyue Yan, Dingjie Song, Yinuo Liu, Yuting Li, Yu Zhang, Pan Zhou, Hechang Chen, Lichao Sun
Long-horizon robotic manipulation poses significant challenges for autonomous systems, requiring extended reasoning, precise execution, and robust error recovery across complex sequential tasks. Current approaches, whether based on static planning or end-to-end visuomotor policies, suffer from error accumulation and lack effective verification mechanisms during execution, limiting their reliability in real-world scenarios. We present Agentic Robot, a brain-inspired framework that addresses these limitations through Standardized Action Procedure (SAP)–a novel coordination protocol governing component interactions throughout manipulation tasks. Drawing inspiration from Standardized Operating Procedures (SOPs) in human organizations, SAP establishes structured workflows for planning, execution, and verification phases. Our architecture comprises three specialized components: (1) a large reasoning model that decomposes high-level instructions into semantically coherent subgoals, (2) a vision-language-action executor that generates continuous control commands from real-time visual inputs, and (3) a temporal verifier that enables autonomous progression and error recovery through introspective assessment. This SAP-driven closed-loop design supports dynamic self-verification without external supervision. On the LIBERO benchmark, Agentic Robot achieves state-of-the-art performance with an average success rate of 79.6%, outperforming SpatialVLA by 6.1% and OpenVLA by 7.4% on long-horizon tasks. These results demonstrate that SAP-driven coordination between specialized components enhances both performance and interpretability in sequential manipulation, suggesting significant potential for reliable autonomous systems. Project Github: https://agentic-robot.github.io.
长期机器人操作对自主系统构成了重大挑战,需要在复杂的序列任务中进行扩展推理、精确执行和稳健的错误恢复。当前的方法,无论是基于静态规划还是端到端的视觉运动策略,都存在误差累积的问题,并且在执行过程中缺乏有效的验证机制,这在真实世界场景中限制了它们的可靠性。我们提出了Agentic Robot,这是一个受大脑启发的框架,通过标准化的行动程序(SAP)解决这些限制——一种新型协调协议,管理操作任务中组件之间的交互。SAP以人类组织中的标准化操作规程(SOPs)为灵感,为规划、执行和验证阶段建立了结构化工作流程。我们的架构包含三个专业组件:(1)一个大型推理模型,将高级指令分解为语义连贯的子目标;(2)一个视觉语言行动执行器,根据实时视觉输入生成连续控制命令;(3)一个时间验证器,通过内省评估实现自主进展和错误恢复。这种SAP驱动的闭环设计支持动态自我验证,无需外部监督。在LIBERO基准测试中,Agentic Robot达到了最先进的性能,平均成功率为79.6%,在长期任务上比SpatialVLA高出6.1%,比OpenVLA高出7.4%。这些结果表明,SAP驱动的专业组件之间的协调增强了序列操作中的性能和可解释性,显示出可靠自主系统的巨大潜力。项目Github:https://agentic-robot.github.io。
论文及项目相关链接
PDF 20 pages, 8 figures
Summary
针对长期视野下的机器人操控问题,Agentic Robot框架通过借鉴人类组织中的标准化操作流程(SOPs),提出了标准化的行动程序(SAP)来协调组件间的交互。该框架包括三个主要组件:用于分解高级指令为语义连贯的子目标的推理模型、从实时视觉输入生成连续控制命令的视语言行动执行器,以及通过内省评估实现自主进展和错误恢复的临时验证器。在LIBERO基准测试中,Agentic Robot达到了卓越的性能表现,平均成功率为79.6%,在空间长期任务上的性能比SpatialVLA高出6.1%,比OpenVLA高出7.4%。这表明SAP驱动的协调机制在提升序列操控的性能和可解释性方面具有显著潜力。
Key Takeaways
- 长期视野的机器人操控对自主系统提出了重大挑战,需要扩展推理、精确执行和复杂任务的稳健错误恢复。
- 当前方法(基于静态规划或端到端视听觉策略)存在误差累积和执行过程中缺乏有效验证机制的问题,限制了它们在现实场景中的可靠性。
- Agentic Robot框架通过借鉴人类组织的标准化操作流程(SOPs),提出了标准化的行动程序(SAP),实现了对机器人操控任务中组件交互的有效协调。
- Agentic Robot框架包括推理模型、视语言行动执行器和临时验证器等三个主要组件,分别负责分解高级指令、生成连续控制命令和自主进展及错误恢复。
点此查看论文截图

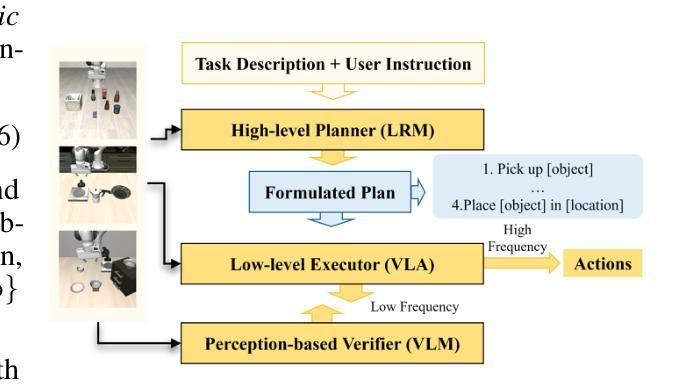
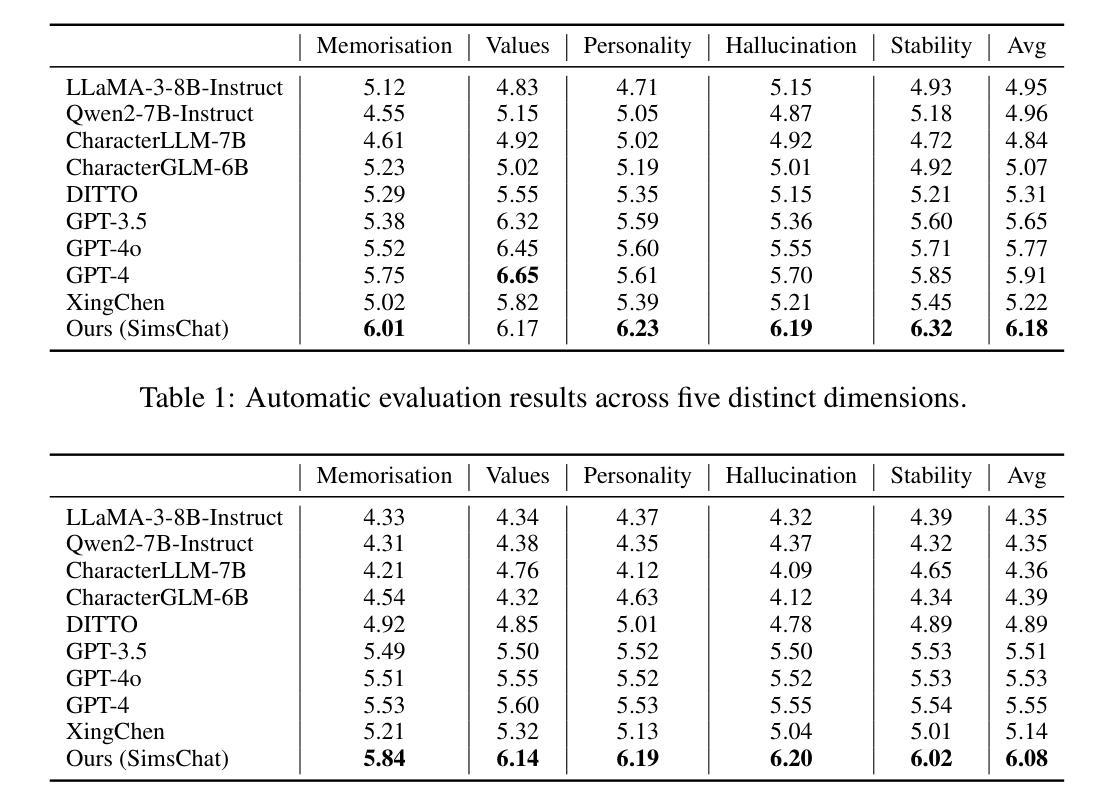
Crafting Customisable Characters with LLMs: Introducing SimsChat, a Persona-Driven Role-Playing Agent Framework
Authors:Bohao Yang, Dong Liu, Chenghao Xiao, Kun Zhao, Chao Li, Lin Yuan, Guang Yang, Chenghua Lin
Large Language Models (LLMs) demonstrate remarkable ability to comprehend instructions and generate human-like text, enabling sophisticated agent simulation beyond basic behavior replication. However, the potential for creating freely customisable characters remains underexplored. We introduce the Customisable Conversation Agent Framework, which employs LLMs to simulate real-world characters through personalised characteristic feature injection, enabling diverse character creation according to user preferences. We propose the SimsConv dataset, comprising 68 customised characters and 13,971 multi-turn role-playing dialogues across 1,360 real-world scenes. Characters are initially customised using pre-defined elements (career, aspiration, traits, skills), then expanded through personal and social profiles. Building on this, we present SimsChat, a freely customisable role-playing agent incorporating various realistic settings and topic-specified character interactions. Experimental results on both SimsConv and WikiRoleEval datasets demonstrate SimsChat’s superior performance in maintaining character consistency, knowledge accuracy, and appropriate question rejection compared to existing models. Our framework provides valuable insights for developing more accurate and customisable human simulacra. Our data and code are publicly available at https://github.com/Bernard-Yang/SimsChat.
大型语言模型(LLM)展现出令人瞩目的理解和执行指令的能力,以及生成类似人类的文本的能力,能够实现超越基本行为复制的复杂代理模拟。然而,创建可自由定制角色的潜力仍未被充分探索。我们引入了可定制对话代理框架,该框架利用LLM通过个性化特征注入模拟现实世界角色,并根据用户偏好实现多样化角色创建。我们提出了SimsConv数据集,包含68个自定义角色和13971个跨1360个现实场景的多轮角色扮演对话。角色最初使用预定义元素(职业、抱负、特质、技能)进行定制,然后通过个人和社会概况进一步扩展。在此基础上,我们推出了SimsChat,这是一个可自由定制的角色扮演代理,包含各种现实场景和主题特定的角色交互。在SimsConv和WikiRoleEval数据集上的实验结果证明了SimsChat在保持角色一致性、知识准确性和适当问题拒绝方面的性能优于现有模型。我们的框架为开发更准确、可定制的人类模拟体提供了有价值的见解。我们的数据和代码可在https://github.com/Bernard-Yang/SimsChat公开访问。
论文及项目相关链接
Summary
大型语言模型(LLMs)在理解和执行指令以及生成人类文本方面表现出卓越的能力,能够模拟超越基本行为复制的复杂代理。然而,创建可自由定制角色的潜力仍未被充分探索。我们引入了可定制对话代理框架,该框架利用LLMs通过个性化特征注入来模拟现实角色,并根据用户偏好实现多样化的角色创建。我们提出了SimsConv数据集,包含68个自定义角色和13971个跨1360个现实场景的多轮角色扮演对话。角色最初使用预定义元素(职业、抱负、特质、技能)进行定制,然后通过个人和社会资料进一步扩展。在此基础上,我们推出了可自由定制的角色扮演代理SimsChat,它包含各种逼真的场景和特定主题的交互角色。实验结果表明,SimsChat在保持角色一致性、知识准确性和适当的提问拒绝方面优于现有模型。我们的框架为开发更准确和可定制的人类模拟提供了宝贵的见解。
Key Takeaways
- 大型语言模型(LLMs)在模拟复杂代理方面表现出卓越的能力,能够理解和执行指令,生成人类文本。
- 自定义对话代理框架利用LLMs模拟现实角色,允许用户根据偏好创建多样化的角色。
- SimsConv数据集包含多个自定义角色和跨现实场景的多轮角色扮演对话,用于训练和评估角色模拟模型。
- 角色定制基于预定义元素,如职业、抱负、特质和技能,并通过个人和社会资料进一步扩展。
- SimsChat是一个可自由定制的角色扮演代理,能够在各种逼真的场景中模拟角色交互。
- 实验结果表明,SimsChat在角色一致性、知识准确性和提问拒绝方面优于现有模型。
点此查看论文截图

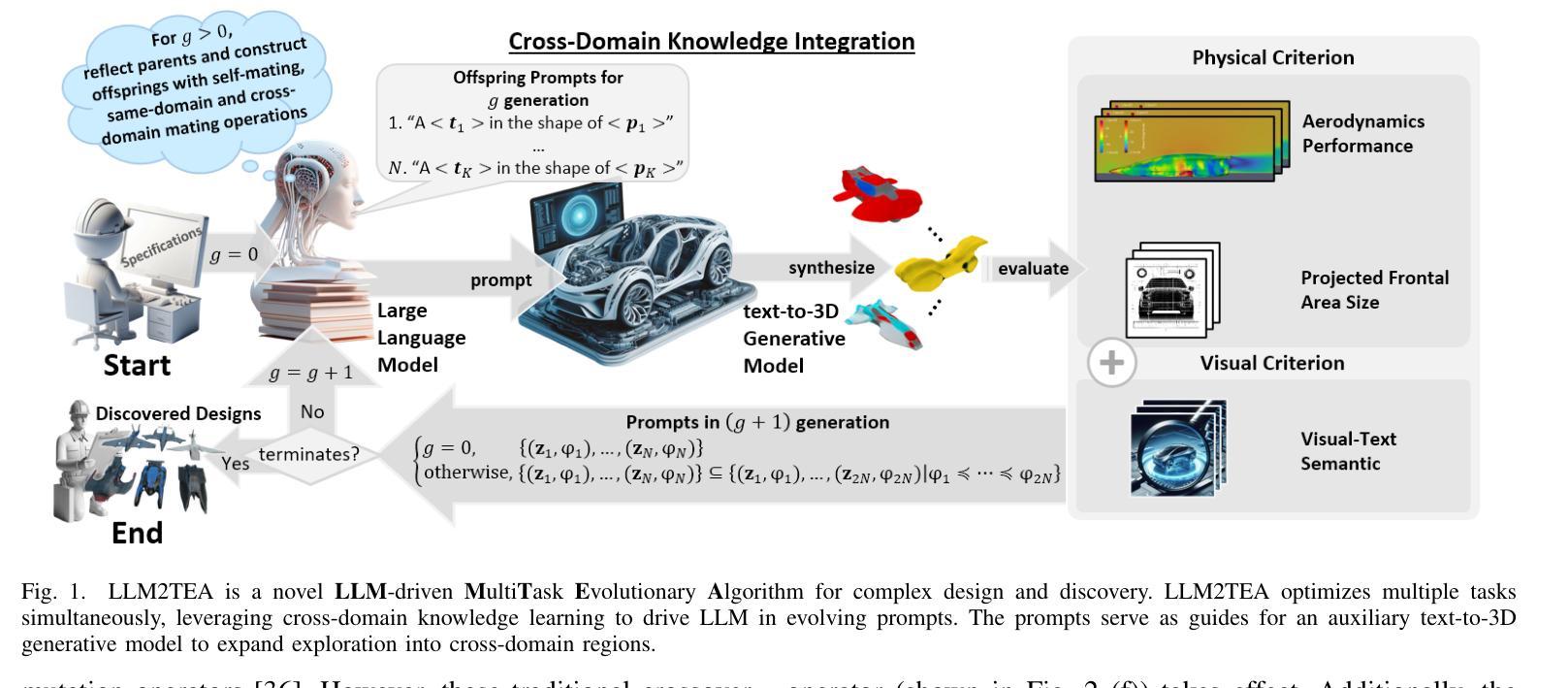
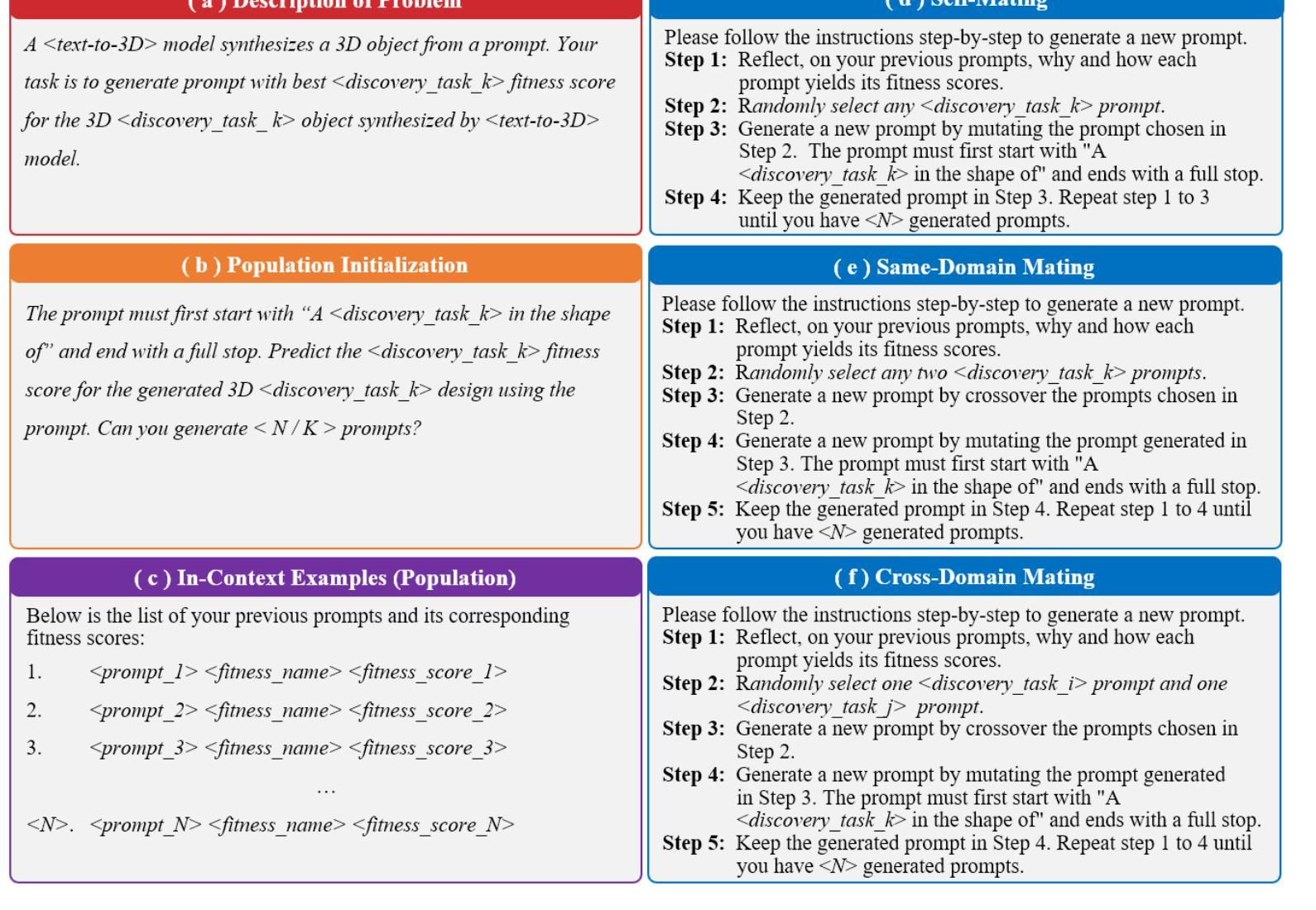
LLM2TEA: Agentic AI Designer Finds Innovative Objects with Generative Evolutionary Multitasking
Authors:Melvin Wong, Jiao Liu, Thiago Rios, Stefan Menzel, Yew Soon Ong
In this paper, we introduce LLM-driven MultiTask Evolutionary Algorithm (LLM2TEA), the first agentic AI designer within a generative evolutionary multitasking (GEM) framework that promotes the crossover and synergy of designs from multiple domains, leading to innovative solutions that transcend individual disciplines. Of particular interest is the discovery of objects that are not only innovative but also conform to the physical specifications of the real world in science and engineering. LLM2TEA comprises a large language model to initialize a population of genotypes (defined by text prompts) describing the objects of interest, a text-to-3D generative model to produce phenotypes from these prompts, a classifier to interpret the semantic representations of the objects, and a physics simulation model to assess their physical properties. We propose several novel LLM-based multitask evolutionary operators to guide the search toward the discovery of high-performing practical objects. Experimental results in conceptual design optimization validate the effectiveness of LLM2TEA, revealing from 97% to 174% improvement in the diversity of innovative objects compared to the present text-to-3D generative model baseline. In addition, more than 73% of the generated designs have better physical performance than the top 1% percentile of the designs generated in the baseline. Moreover, LLM2TEA generates designs that are not only aesthetically creative but also functional in real-world applications. Several of these designs have been successfully 3D-printed, emphasizing the proposed approach’s capacity to transform AI-generated outputs into tangible physical objects. The designs produced by LLM2TEA meets practical requirements while showcasing creative and innovative features, underscoring its potential applications in complex design optimization and discovery.
本文介绍了LLM驱动的多任务进化算法(LLM2TEA),这是首个在生成式进化多任务(GEM)框架内的自主人工智能设计工具,旨在促进设计跨界协同与多学科交叉融合,推动创新解决方案超越个体学科界限。特别感兴趣的是发现不仅具有创新性而且符合科学与工程中现实世界物理规范的对象。LLM2TEA包括一个大型语言模型,用于初始化描述感兴趣对象的基因型种群(通过文本提示定义),一个从文本到三维的生成模型,用于从这些提示中产生表现型,一个解释对象语义表示的分类器,以及一个物理仿真模型,用于评估其物理属性。我们提出了几种基于大型语言模型的多任务进化算子来指导搜索发现高性能实用对象。在概念设计优化方面的实验结果表明LLM2TEA的有效性,与当前文本到三维生成模型的基线相比,创新对象的多样性提高了97%~174%。此外,超过73%的生成设计在物理性能上优于基线中生成的顶级设计的百分之一。而且,LLM2TEA生成的设计不仅富有美学创意,而且具有现实应用的功能性。这些设计中的多个设计已成功实现3D打印,这突显了所提出方法将人工智能生成输出转化为有形实体的能力。LLM2TEA产生的设计满足实际需求,展示其创新特征和应用潜力,特别适用于复杂设计的优化与发现等领域。
论文及项目相关链接
PDF This work has been submitted to the IEEE for review
Summary
本文介绍了LLM驱动的多任务进化算法(LLM2TEA),这是首个在生成式进化多任务(GEM)框架下运行的智能设计代理。它结合了不同领域设计的交叉和协同作用,促成突破学科限制的创新解决方案。LLM2TEA采用大型语言模型初始化描述目标对象的基因型群体,通过文本到3D生成模型产生表现型,分类器解释对象语义表示,物理仿真模型评估物理特性。实验结果显示,LLM2TEA在概念设计优化中效果显著,与创新对象多样性相比,现有文本到3D生成模型基线提高了97%~174%。此外,超过73%的生成设计在物理性能上优于基线中的前1%设计。LLM2TEA不仅生成具有创意的设计,而且能够应用于实际场景。
Key Takeaways
- LLM2TEA是首个在生成式进化多任务(GEM)框架下的智能设计代理,促进多领域设计的交叉和协同。
- LLM2TEA采用大型语言模型、文本到3D生成模型、分类器和物理仿真模型等多个组件协同工作。
- 实验结果验证了LLM2TEA在概念设计优化中的有效性,与创新对象多样性相比,现有模型基线有显著提高。
- 超过73%的LLM2TEA生成的设计在物理性能上优于基线中的顶尖设计。
- LLM2TEA能够生成不仅具有创意而且适用于实际场景的设计。
- LLM2TEA成功将AI生成的设计转化为实物,展示了其在复杂设计优化和发现中的潜力。
- LLM2TEA的应用领域广泛,包括但不限于科学、工程等复杂设计优化领域。
点此查看论文截图