⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-13 更新
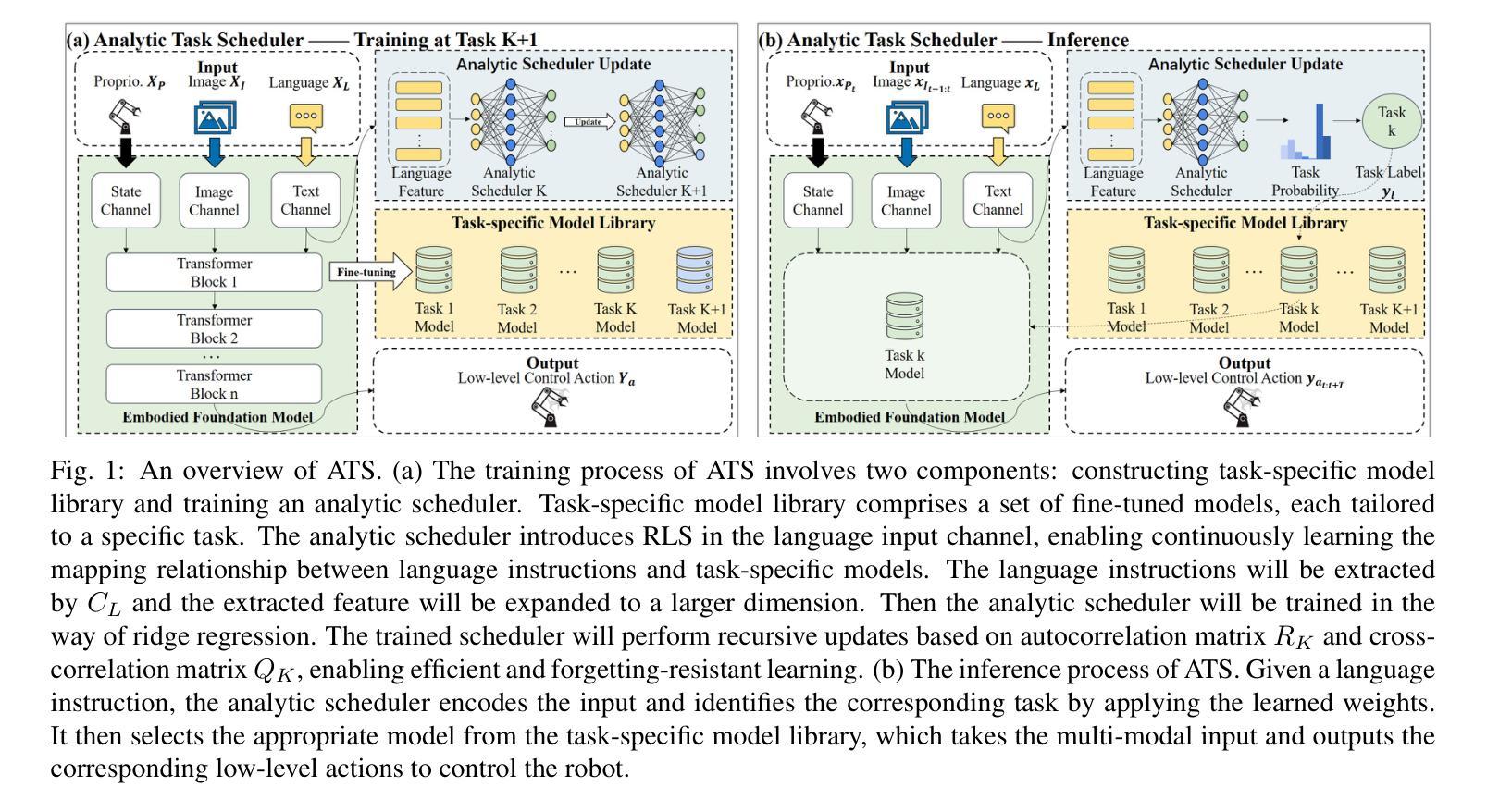
Analytic Task Scheduler: Recursive Least Squares Based Method for Continual Learning in Embodied Foundation Models
Authors:Lipei Xie, Yingxin Li, Huiping Zhuang
Embodied foundation models are crucial for Artificial Intelligence (AI) interacting with the physical world by integrating multi-modal inputs, such as proprioception, vision and language, to understand human intentions and generate actions to control robots. While these models demonstrate strong generalization and few-shot learning capabilities, they face significant challenges in continually acquiring new skills without forgetting previously learned skills, a problem known as catastrophic forgetting. To address this issue, we propose the Analytic Task Scheduler (ATS), a novel framework for continual learning in embodied foundation models. ATS consists of a task-specific model library, where each model is fine-tuned independently on a single task, and an analytic scheduler trained using recursive least squares (RLS) to learn the mapping between language instructions and task-specific models. This architecture enables accurate task recognition and dynamic model selection while fundamentally avoiding parameter interference across tasks. The scheduler updates its parameters incrementally using only statistics (autocorrelation and cross-correlation matrices), enabling forgetting-resistant learning without the need to revisit historical data. We validate ATS on a real-world robot platform (RM65B), demonstrating superior resistance to forgetting and strong adaptability to task variations. The results highlight ATS as an effective, scalable, and deployable solution for continual learning in embodied foundation models operating in complex, dynamic environments. Our code will be available at https://github.com/MIAA-Embodied-AI/AnalyticTaskScheduler
嵌入式的基础模型通过整合多种模式输入(如本体感受、视觉和语言),理解人类意图并生成控制机器人的动作,对人工智能(AI)与物理世界的交互至关重要。这些模型展现出强大的泛化和少样本学习能力,但在持续获取新技能时面临重大挑战,即遗忘先前学到的技能,这个问题被称为灾难性遗忘。为了解决这个问题,我们提出了分析任务调度器(ATS),这是一个嵌入式基础模型中持续学习的全新框架。ATS包括一个特定任务模型库,其中的每个模型都是针对单一任务独立精细调整的。此外,我们利用递归最小二乘法(RLS)训练了一个分析调度器,学习语言指令和任务特定模型之间的映射。这种架构能够实现精确的任务识别和动态模型选择,从根本上避免任务间的参数干扰。调度器仅使用统计信息(自相关和互相关矩阵)来增量更新其参数,从而实现抗遗忘学习,无需回顾历史数据。我们在实际机器人平台RM65B上验证了ATS,显示出其出色的抗遗忘性和对任务变化的强大适应性。结果强调ATS是嵌入式基础模型在复杂动态环境中持续学习的有效、可扩展和可部署的解决方案。我们的代码将在https://github.com/MIAA-Embodied-AI/AnalyticTaskScheduler上提供。
论文及项目相关链接
Summary
体貌基础模型在人工智能与物理世界交互中起到关键作用,通过整合多模式输入如身体感觉、视觉和语言,来理解人类意图并生成控制机器人的动作。面临持续学习新技能时遗忘旧技能的问题,我们提出解析任务调度器(ATS)这一新型框架,用于体貌基础模型的持续学习。ATS包括任务特定模型库,每个模型独立微调单一任务,解析调度器通过递归最小二乘法(RLS)学习语言指令与任务特定模型之间的映射。此架构实现了精确的任务识别和动态模型选择,从根本上避免了任务间的参数干扰。调度器仅通过统计信息(自相关和互相关矩阵)逐步更新参数,实现了遗忘抵抗性学习,无需回顾历史数据。我们在真实机器人平台RM65B上验证了ATS,表现出强大的抗遗忘性和任务适应性。
Key Takeaways
- 体貌基础模型在AI与物理世界交互中起关键作用,集成多模式输入如身体感觉、视觉和语言。
- 体貌基础模型面临持续学习新技能时的遗忘问题。
- 解析任务调度器(ATS)框架用于体貌基础模型的持续学习。
- ATS包括任务特定模型库和解析调度器,通过递归最小二乘法(RLS)学习语言指令与任务特定模型之间的映射。
- ATS架构避免任务间的参数干扰,实现精确任务识别和动态模型选择。
- 调度器通过统计信息逐步更新参数,实现遗忘抵抗性学习。
- 在真实机器人平台上验证了ATS的有效性、可伸缩性和部署性。
点此查看论文截图


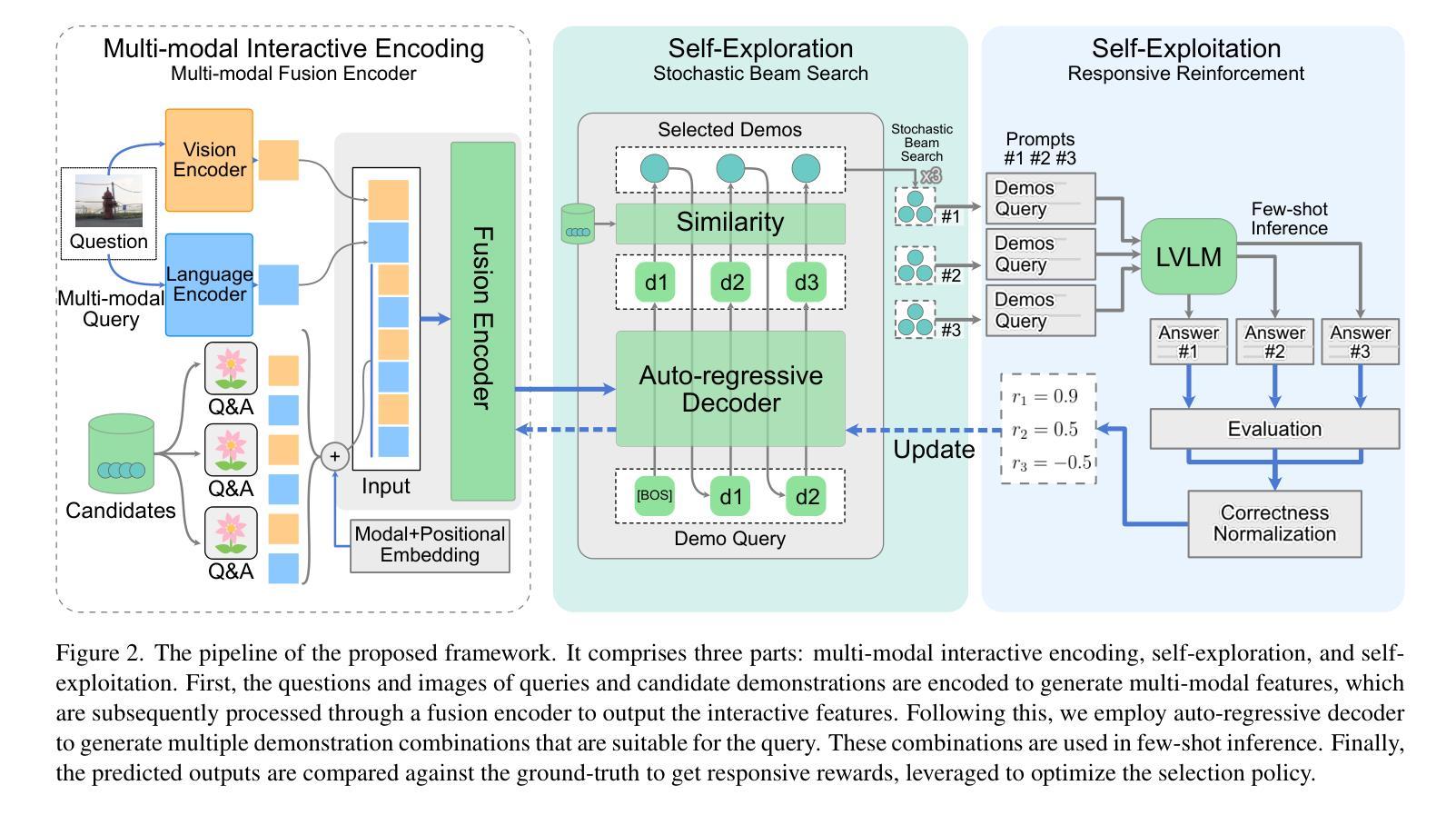
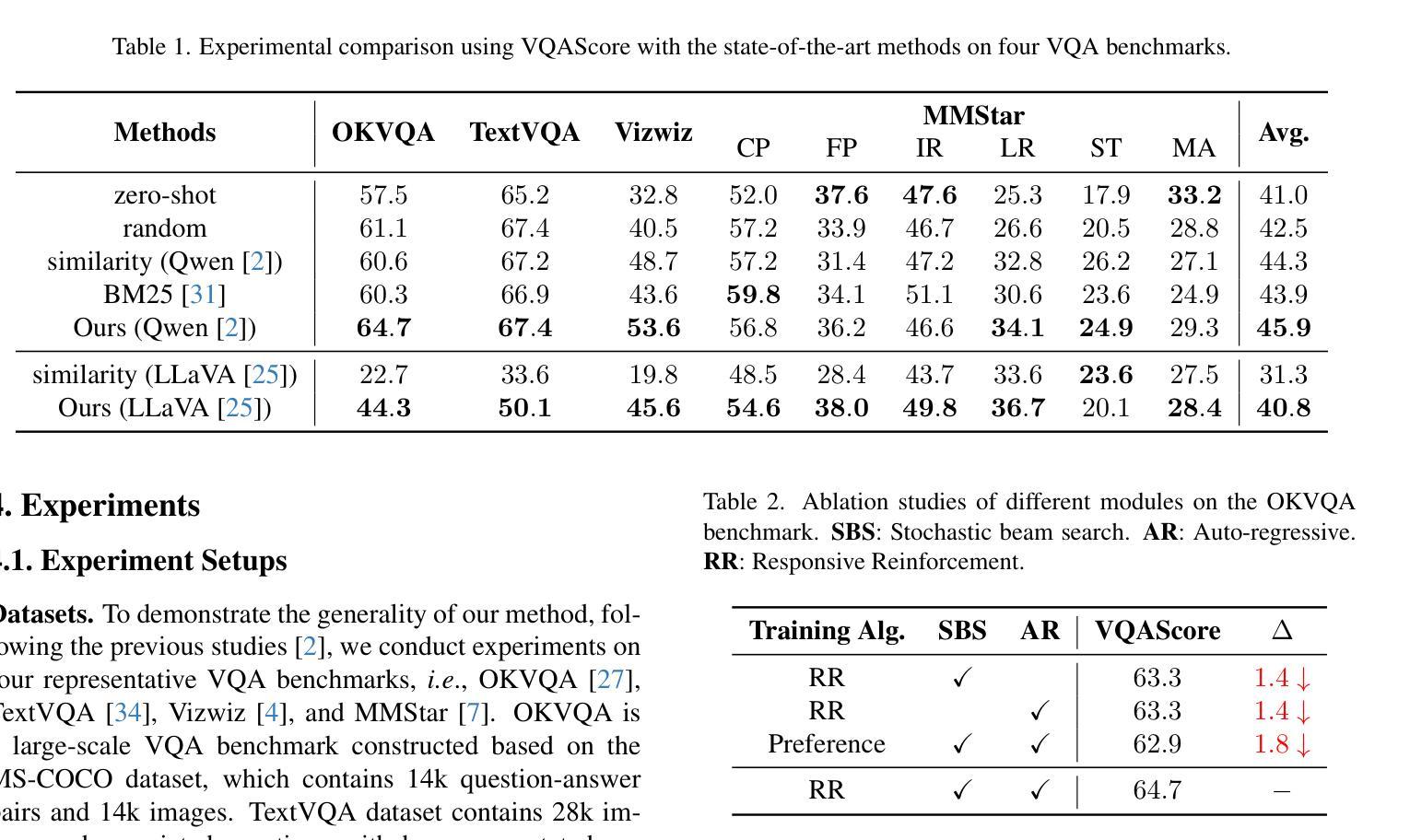
Provoking Multi-modal Few-Shot LVLM via Exploration-Exploitation In-Context Learning
Authors:Cheng Chen, Yunpeng Zhai, Yifan Zhao, Jinyang Gao, Bolin Ding, Jia Li
In-context learning (ICL), a predominant trend in instruction learning, aims at enhancing the performance of large language models by providing clear task guidance and examples, improving their capability in task understanding and execution. This paper investigates ICL on Large Vision-Language Models (LVLMs) and explores the policies of multi-modal demonstration selection. Existing research efforts in ICL face significant challenges: First, they rely on pre-defined demonstrations or heuristic selecting strategies based on human intuition, which are usually inadequate for covering diverse task requirements, leading to sub-optimal solutions; Second, individually selecting each demonstration fails in modeling the interactions between them, resulting in information redundancy. Unlike these prevailing efforts, we propose a new exploration-exploitation reinforcement learning framework, which explores policies to fuse multi-modal information and adaptively select adequate demonstrations as an integrated whole. The framework allows LVLMs to optimize themselves by continually refining their demonstrations through self-exploration, enabling the ability to autonomously identify and generate the most effective selection policies for in-context learning. Experimental results verify the superior performance of our approach on four Visual Question-Answering (VQA) datasets, demonstrating its effectiveness in enhancing the generalization capability of few-shot LVLMs.
上下文学习(ICL)是指示学习中的一种主要趋势,旨在通过提供明确的任务指导和示例来提高大型语言模型的性能,增强其在任务理解和执行方面的能力。本文针对大型视觉语言模型(LVLMs)上的ICL进行了调查,并探讨了多模态演示选择的策略。现有的ICL研究面临着重大挑战:首先,它们依赖于预先定义的演示或基于人类直觉的启发式选择策略,通常无法覆盖各种任务需求,导致次优解决方案;其次,个别选择每个演示忽略了它们之间的交互,导致信息冗余。不同于这些普遍的方法,我们提出了一种新的探索-利用强化学习框架,该框架探索了融合多模态信息和自适应选择充足演示品的策略,将其作为一个整体。该框架允许LVLMs通过不断自我探索优化其演示,具备自主识别和生成最有效的选择策略来进行上下文学习的能力。实验结果在四个视觉问答(VQA)数据集上验证了我们的方法性能优越,证明了其在提高少数LVLMs的泛化能力方面的有效性。
论文及项目相关链接
PDF 10 pages, 6 figures, CVPR 2025
Summary
在语境学习(ICL)中,针对大型视觉语言模型(LVLMs)的研究正在探索多模态演示选择策略。现有研究面临依赖预定义演示或基于人类直觉的启发式选择策略的挑战,无法覆盖多样化的任务需求,导致次优解决方案。本文提出一个新的探索-利用强化学习框架,该框架融合了多模态信息,并自适应地选择适当的演示作为一个整体。该框架使LVLMs能够通过自我探索不断优化演示,自主识别和生成最有效的选择策略,从而提高少样本LVLMs的泛化能力。
Key Takeaways
- ICL旨在提高大型语言模型的性能,通过提供明确的任务指导和示例来增强其在任务理解和执行方面的能力。
- 当前ICL在LVLMs上的研究面临挑战,如依赖预定义演示和启发式选择策略,以及无法建模演示之间的交互。
- 强化学习框架被用来探索多模态信息融合和自适应演示选择策略。
- 该框架允许LVLMs通过自我探索优化演示,提高了泛化能力。
- 实验结果表明,该框架在四个视觉问答(VQA)数据集上的性能优于传统方法。
- 该方法能有效提高少样本LVLMs的泛化能力。
点此查看论文截图


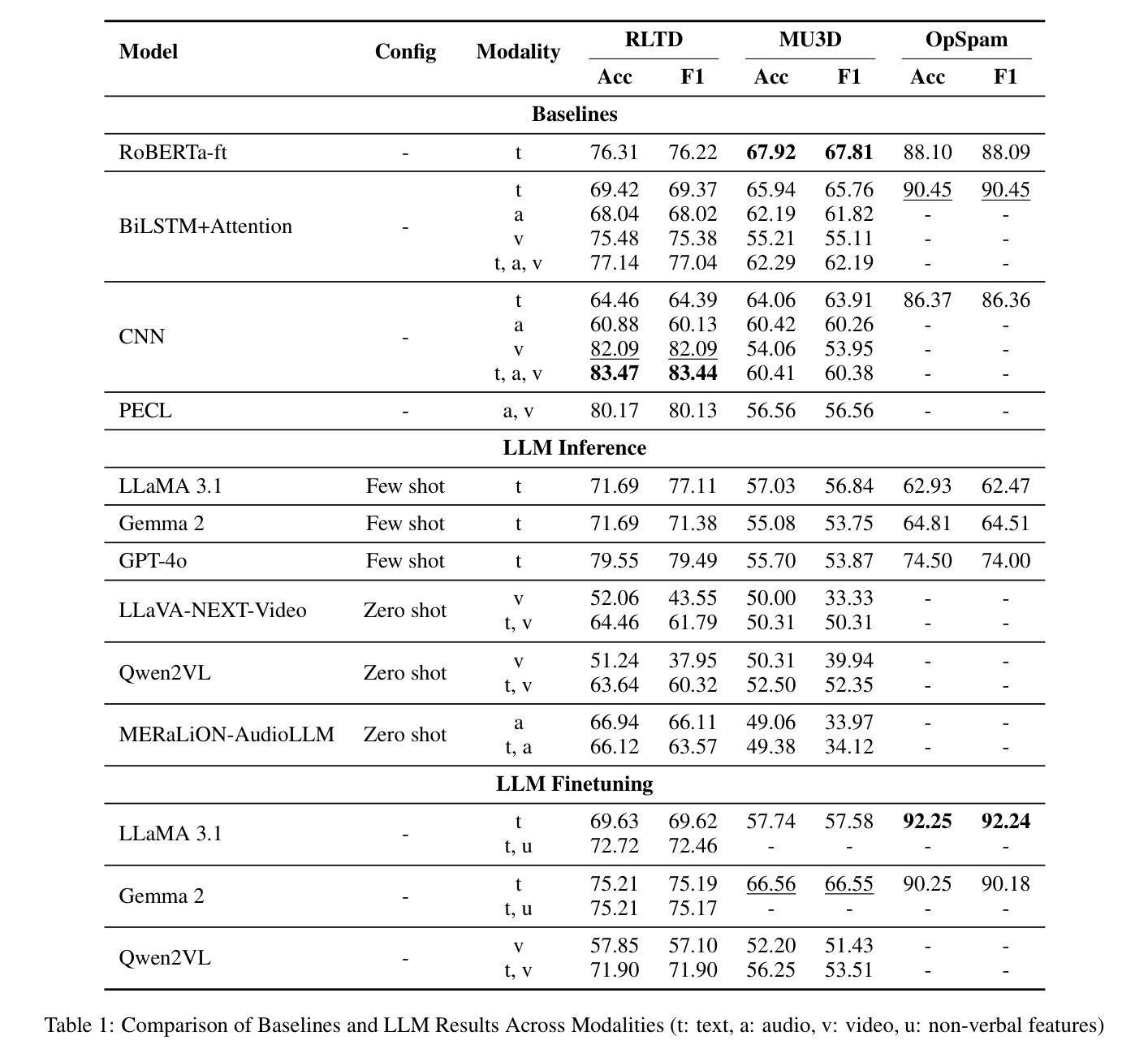
Hidden in Plain Sight: Evaluation of the Deception Detection Capabilities of LLMs in Multimodal Settings
Authors:Md Messal Monem Miah, Adrita Anika, Xi Shi, Ruihong Huang
Detecting deception in an increasingly digital world is both a critical and challenging task. In this study, we present a comprehensive evaluation of the automated deception detection capabilities of Large Language Models (LLMs) and Large Multimodal Models (LMMs) across diverse domains. We assess the performance of both open-source and commercial LLMs on three distinct datasets: real life trial interviews (RLTD), instructed deception in interpersonal scenarios (MU3D), and deceptive reviews (OpSpam). We systematically analyze the effectiveness of different experimental setups for deception detection, including zero-shot and few-shot approaches with random or similarity-based in-context example selection. Our results show that fine-tuned LLMs achieve state-of-the-art performance on textual deception detection tasks, while LMMs struggle to fully leverage cross-modal cues. Additionally, we analyze the impact of auxiliary features, such as non-verbal gestures and video summaries, and examine the effectiveness of different prompting strategies, including direct label generation and chain-of-thought reasoning. Our findings provide key insights into how LLMs process and interpret deceptive cues across modalities, highlighting their potential and limitations in real-world deception detection applications.
在日益数字化的世界中检测欺骗是一项既关键又具挑战性的任务。在这项研究中,我们对大型语言模型(LLM)和大型多模态模型(LMM)在各个领域中的自动化欺骗检测能力进行了全面评估。我们评估了开源和商业LLM在三个不同数据集上的表现:现实生活审判访谈(RLTD)、人际场景中的指令性欺骗(MU3D)和欺骗性评论(OpSpam)。我们系统分析了不同实验设置在欺骗检测中的有效性,包括零样本和少样本方法,这些方法采用随机或基于相似性的上下文示例选择。我们的结果表明,经过微调的大型语言模型在文本欺骗检测任务上达到了最新技术水平,而多模态模型在充分利用跨模态线索方面存在困难。此外,我们还分析了辅助特征(如非语言手势和视频摘要)的影响,并探讨了不同的提示策略的有效性,包括直接标签生成和链式思维推理。我们的研究为大型语言模型如何处理和解释跨模态的欺骗线索提供了关键见解,突出了它们在现实世界欺骗检测应用中的潜力和局限性。
论文及项目相关链接
PDF Accepted to ACL 2025 Main Conference
Summary
本文研究了大型语言模型(LLMs)和多模态模型(LMMs)在自动化欺骗检测方面的能力。通过对真实生活审判访谈、人际场景中的指令性欺骗和欺骗性评论等三个数据集进行评估,系统分析了不同实验设置在欺骗检测中的有效性,包括零样本和少样本方法,以及基于随机或相似性的上下文示例选择。研究结果表明,精细调整过的LLMs在文本欺骗检测任务上达到了最新技术水平,而LMMs在充分利用跨模态线索方面遇到了困难。此外,还分析了辅助特征(如非语言手势和视频摘要)和不同提示策略(如直接标签生成和链式思维推理)的有效性。研究为LLMs在跨模态中处理和解读欺骗线索提供了关键见解,突出了其在真实世界欺骗检测应用中的潜力和局限性。
Key Takeaways
- 大型语言模型(LLMs)在自动化欺骗检测方面表现出强大的能力,特别是在文本欺骗检测任务上达到了最新技术水平。
- 多模态模型(LMMs)在利用跨模态线索方面存在挑战,难以完全融合非语言信息和视频摘要等辅助特征。
- 零样本和少样本方法在欺骗检测实验中表现出不同的有效性,基于随机或相似性的上下文示例选择策略是关键因素之一。
- 直接标签生成和链式思维推理等不同的提示策略对欺骗检测有影响。
- LLMs在处理和分析欺骗线索方面具有很强的潜力,但也存在局限性,特别是在处理复杂的多模态信息时。
- 研究结果提供了关于LLMs如何解读欺骗线索的深入见解,有助于进一步改进和优化自动化欺骗检测技术。
点此查看论文截图

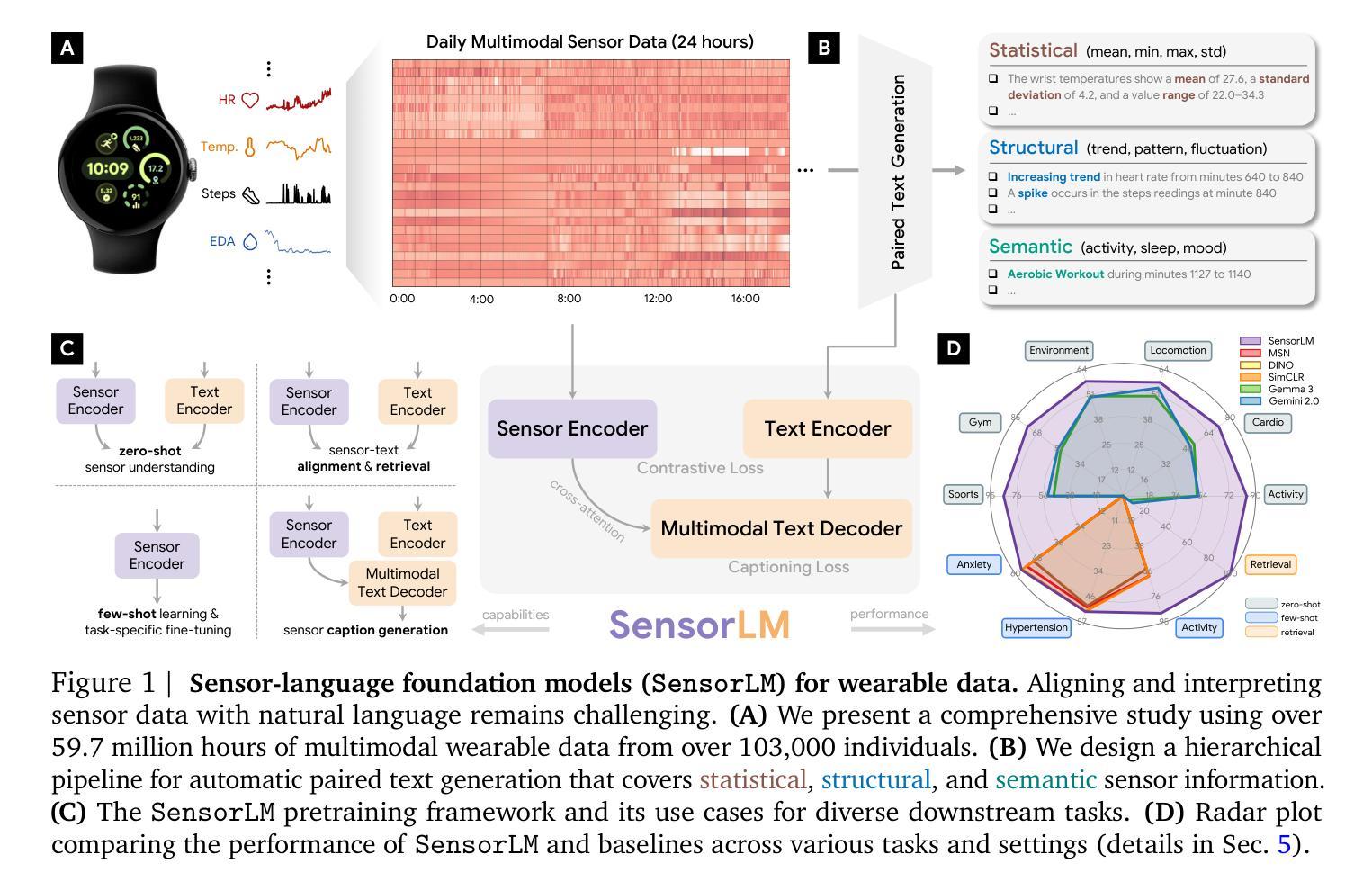
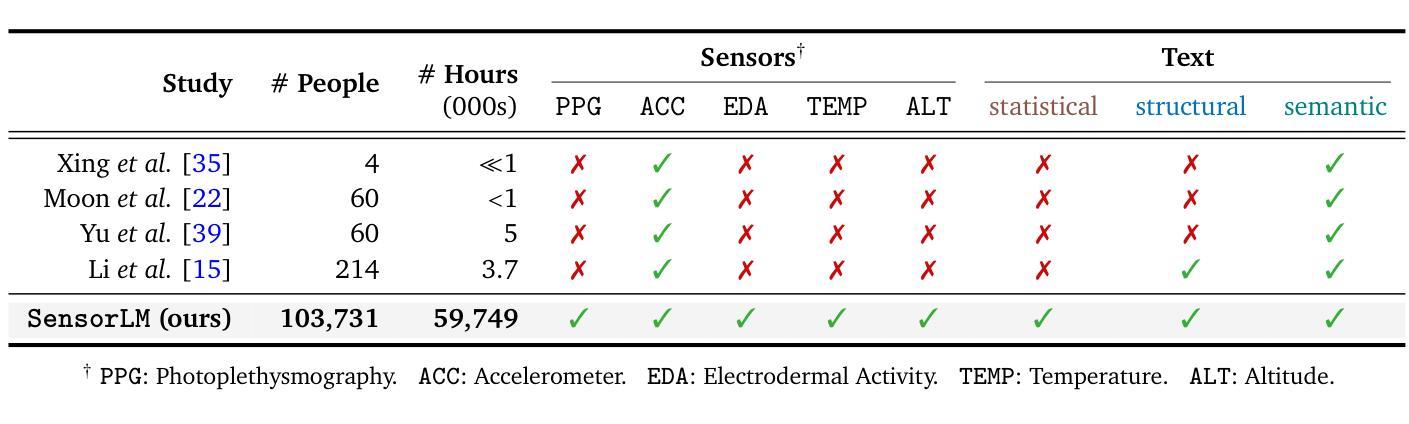
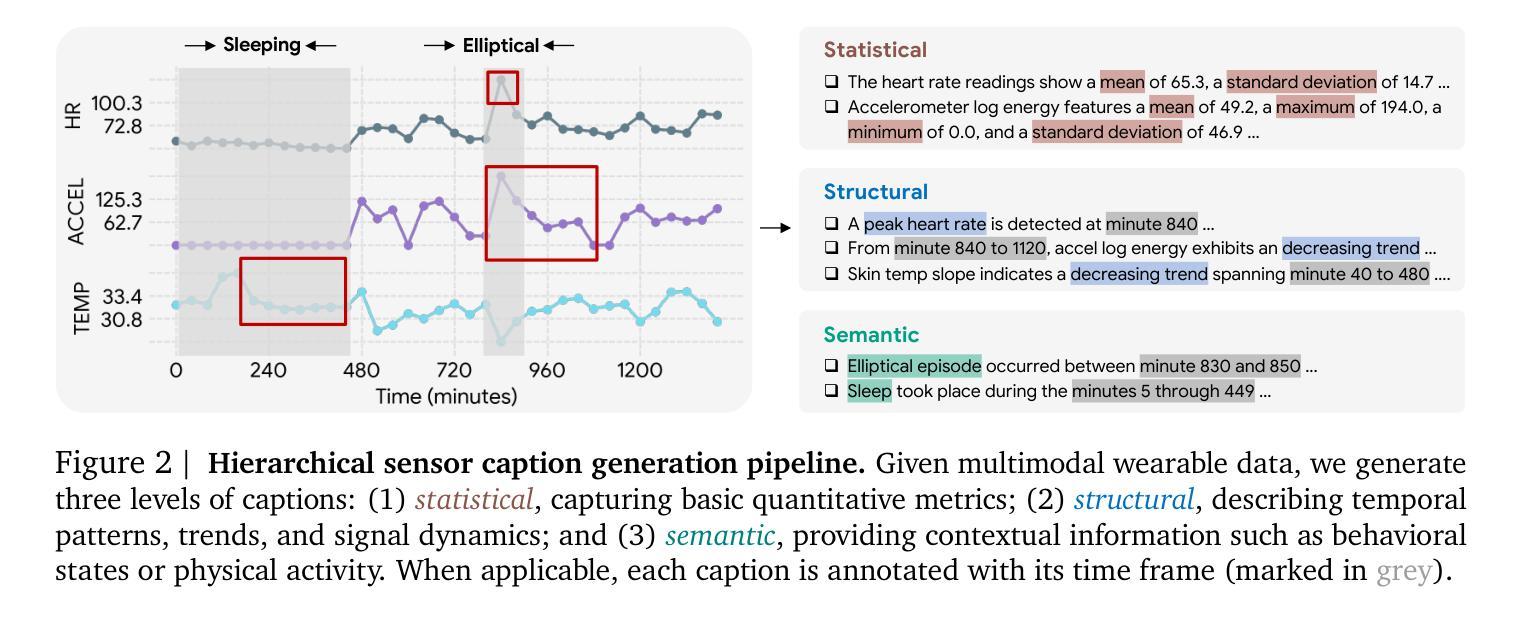
SensorLM: Learning the Language of Wearable Sensors
Authors:Yuwei Zhang, Kumar Ayush, Siyuan Qiao, A. Ali Heydari, Girish Narayanswamy, Maxwell A. Xu, Ahmed A. Metwally, Shawn Xu, Jake Garrison, Xuhai Xu, Tim Althoff, Yun Liu, Pushmeet Kohli, Jiening Zhan, Mark Malhotra, Shwetak Patel, Cecilia Mascolo, Xin Liu, Daniel McDuff, Yuzhe Yang
We present SensorLM, a family of sensor-language foundation models that enable wearable sensor data understanding with natural language. Despite its pervasive nature, aligning and interpreting sensor data with language remains challenging due to the lack of paired, richly annotated sensor-text descriptions in uncurated, real-world wearable data. We introduce a hierarchical caption generation pipeline designed to capture statistical, structural, and semantic information from sensor data. This approach enabled the curation of the largest sensor-language dataset to date, comprising over 59.7 million hours of data from more than 103,000 people. Furthermore, SensorLM extends prominent multimodal pretraining architectures (e.g., CLIP, CoCa) and recovers them as specific variants within a generic architecture. Extensive experiments on real-world tasks in human activity analysis and healthcare verify the superior performance of SensorLM over state-of-the-art in zero-shot recognition, few-shot learning, and cross-modal retrieval. SensorLM also demonstrates intriguing capabilities including scaling behaviors, label efficiency, sensor captioning, and zero-shot generalization to unseen tasks.
我们推出了SensorLM,这是一系列传感器语言基础模型,能够通过自然语言理解可穿戴传感器数据。尽管其普及性很高,但由于未整理的真实世界可穿戴数据中缺乏配对的丰富注释的传感器文本描述,将传感器数据与语言进行对齐和解释仍然具有挑战性。我们引入了一种分层标题生成管道,旨在从传感器数据中捕获统计、结构和语义信息。这种方法使得我们能够整理迄今为止最大的传感器语言数据集,包含超过5970万小时的数据,来自超过10万3千人的数据。此外,SensorLM扩展了著名的多模态预训练架构(例如CLIP,CoCa),将它们作为通用架构内的特定变体进行恢复。在人类活动分析和医疗保健领域的真实任务上进行的大量实验验证了SensorLM在零样本识别、小样学习本和跨模态检索方面的卓越性能优于最新技术。SensorLM还展示了令人感兴趣的功能,包括缩放行为、标签效率、传感器标题和零样本推广到未见任务的能力。
论文及项目相关链接
Summary:
提出一种名为SensorLM的传感器语言基础模型家族,该模型能够利用自然语言理解可穿戴传感器数据。研究解决了由于缺乏未加工真实世界可穿戴数据的丰富注释传感器文本描述,导致传感器数据与语言的对齐和解释具有挑战性。研究团队设计了一种分层标题生成管道,能够捕获传感器数据的统计、结构和语义信息。此方法成功构建了迄今为止最大的传感器语言数据集,包含超过5970万小时的数据,来自超过10万3千人。SensorLM扩展了著名的多模式预训练架构(如CLIP、CoCa),并在通用架构内将其回收为特定变体。在人类活动分析和医疗保健方面的实际任务上的大量实验表明,SensorLM在零样本识别、小样学习以及跨模态检索方面均优于现有技术。SensorLM还展示了有趣的特性,包括规模化行为、标签效率、传感器描述和零样本概括未见任务的能力。
Key Takeaways:
- SensorLM是一种传感器语言基础模型,能够利用自然语言理解可穿戴传感器数据。
- 缺乏丰富的注释传感器文本描述是解释传感器数据与语言的挑战之一。
- 提出了一个分层标题生成管道,用于捕获传感器数据的统计、结构和语义信息。
- 成功构建了迄今为止最大的传感器语言数据集,包含大量真实世界的可穿戴数据。
- SensorLM扩展了多模式预训练架构,并在通用架构内具有特定变体。
- 在实际任务上的实验表明,SensorLM在多个方面优于现有技术,包括零样本识别、小样学习以及跨模态检索。
点此查看论文截图

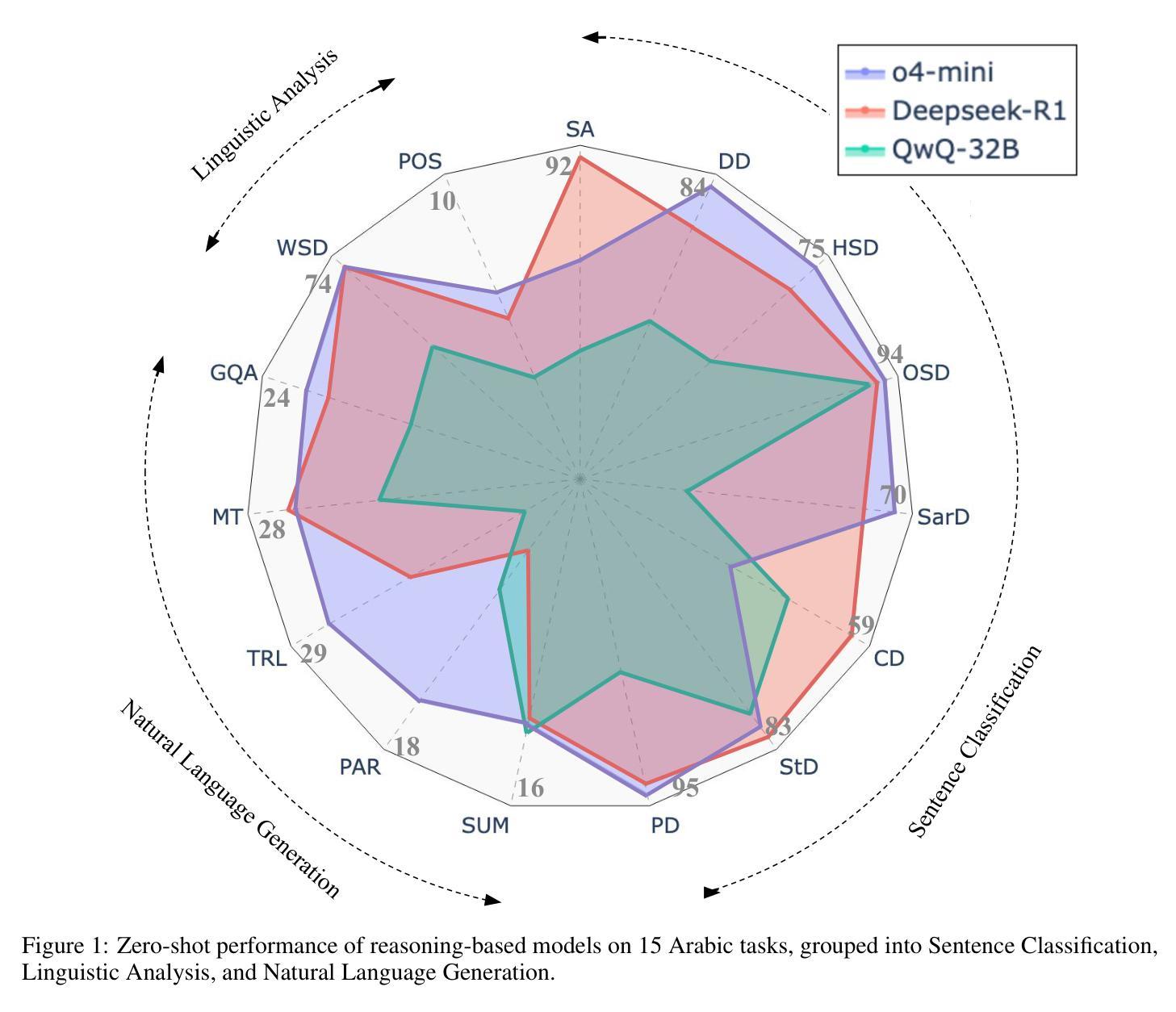
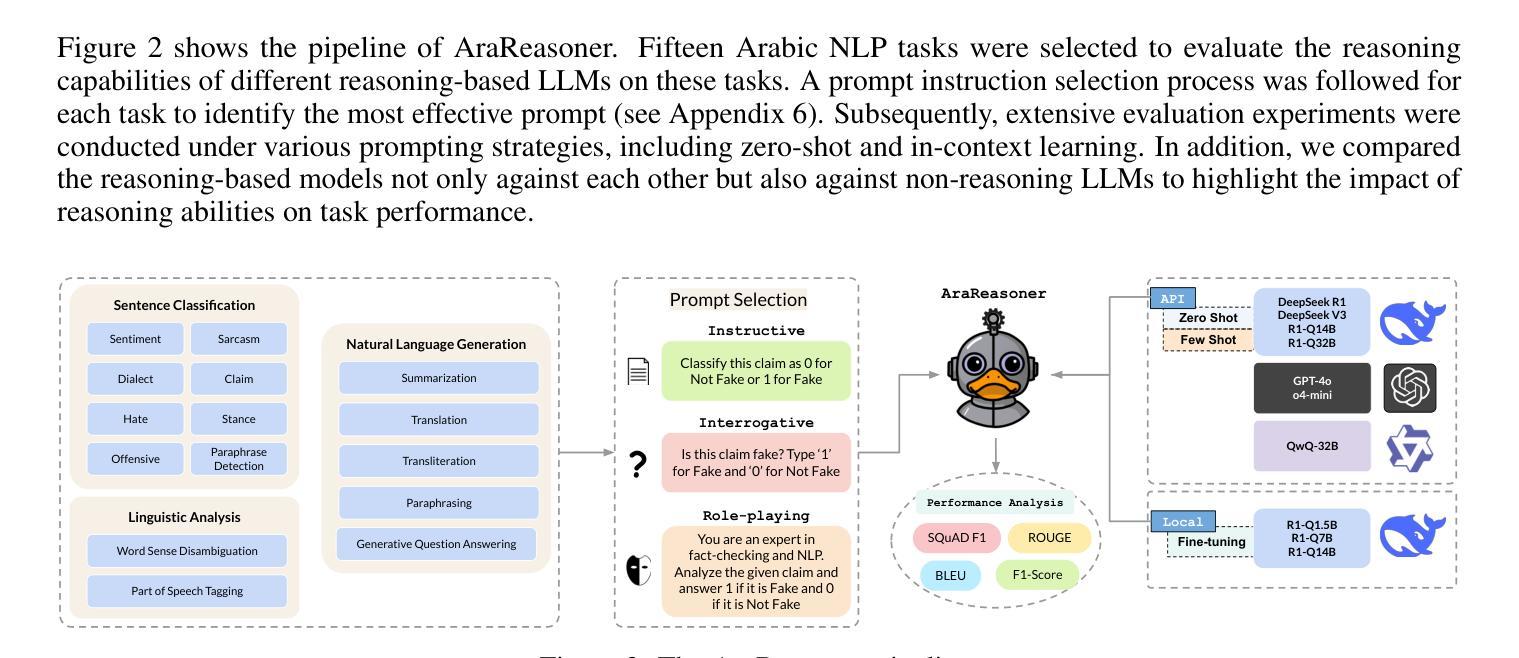
AraReasoner: Evaluating Reasoning-Based LLMs for Arabic NLP
Authors:Ahmed Hasanaath, Aisha Alansari, Ahmed Ashraf, Chafik Salmane, Hamzah Luqman, Saad Ezzini
Large language models (LLMs) have shown remarkable progress in reasoning abilities and general natural language processing (NLP) tasks, yet their performance on Arabic data, characterized by rich morphology, diverse dialects, and complex script, remains underexplored. This paper presents a comprehensive benchmarking study of multiple reasoning-focused LLMs, with a special emphasis on the newly introduced DeepSeek models, across a suite of fifteen Arabic NLP tasks. We experiment with various strategies, including zero-shot, few-shot, and fine-tuning. This allows us to systematically evaluate performance on datasets covering a range of applications to examine their capacity for linguistic reasoning under different levels of complexity. Our experiments reveal several key findings. First, carefully selecting just three in-context examples delivers an average uplift of over 13 F1 points on classification tasks-boosting sentiment analysis from 35.3% to 87.5% and paraphrase detection from 56.1% to 87.0%. Second, reasoning-focused DeepSeek architectures outperform a strong GPT o4-mini baseline by an average of 12 F1 points on complex inference tasks in the zero-shot setting. Third, LoRA-based fine-tuning yields up to an additional 8 points in F1 and BLEU compared to equivalent increases in model scale. The code is available at https://anonymous.4open.science/r/AraReasoner41299
大型语言模型(LLM)在推理能力和自然语言处理(NLP)的一般任务上取得了显著的进步,然而,它们在处理以丰富的形态、多样的方言和复杂的脚本为特点的阿拉伯数据方面的性能仍然被低估。本文全面评估了多个以推理为重点的大型语言模型,特别关注新推出的DeepSeek模型,在十五个阿拉伯NLP任务上的表现。我们尝试了各种策略,包括零样本、少样本和微调。这使我们能够系统地评估在覆盖各种应用的数据集上的性能,以检验它们在不同复杂程度下的语言推理能力。我们的实验揭示了几个关键发现。首先,精心选择仅三个上下文实例,可以在分类任务上平均提高超过13个F1点——情感分析从35.3%提高到87.5%,同义替换检测从56.1%提高到87.0%。其次,以推理为重点的DeepSeek架构在零样本设置下的复杂推理任务上平均比强大的GPT o4-mini基线高出12个F1点。第三,与模型规模的等效增加相比,基于LoRA的微调在F1和BLEU上产生了额外的高达8个点。代码可通过匿名访问:[链接在此处](https://anonymous.4open.science/r/AraReasoner41299)。
论文及项目相关链接
Summary
大型语言模型(LLM)在应对阿拉伯语数据上展现出卓越进步,涉及丰富的形态、多样的方言和复杂的脚本。本文全面评估了多个以推理为重点的LLM模型,特别是在新推出的DeepSeek模型上,跨越十五项阿拉伯语NLP任务。实验结果显示,在分类任务中,仅选择三个上下文实例进行微调平均提升了超过13个F1点;DeepSeek架构在零样本情况下平均优于GPT o4-mini基线12个F1点;基于LoRA的微调技术相比增加模型规模提高了额外的8个F1点和BLEU分数。
Key Takeaways
- 大型语言模型在阿拉伯语NLP任务中展现出显著进步,但仍需更多探索。
- 精心选择的三个上下文实例能显著提高分类任务的性能。
- DeepSeek模型在推理任务上表现出优越性能,特别是在零样本设置下。
- LoRA-based微调技术能有效提升模型性能。
- 论文提供了详细的实验方法和结果,包括在多个阿拉伯语NLP任务上的性能评估。
- 论文强调了阿拉伯语数据的独特性,包括丰富的形态、多样的方言和复杂的脚本,对LLM的挑战性。
点此查看论文截图

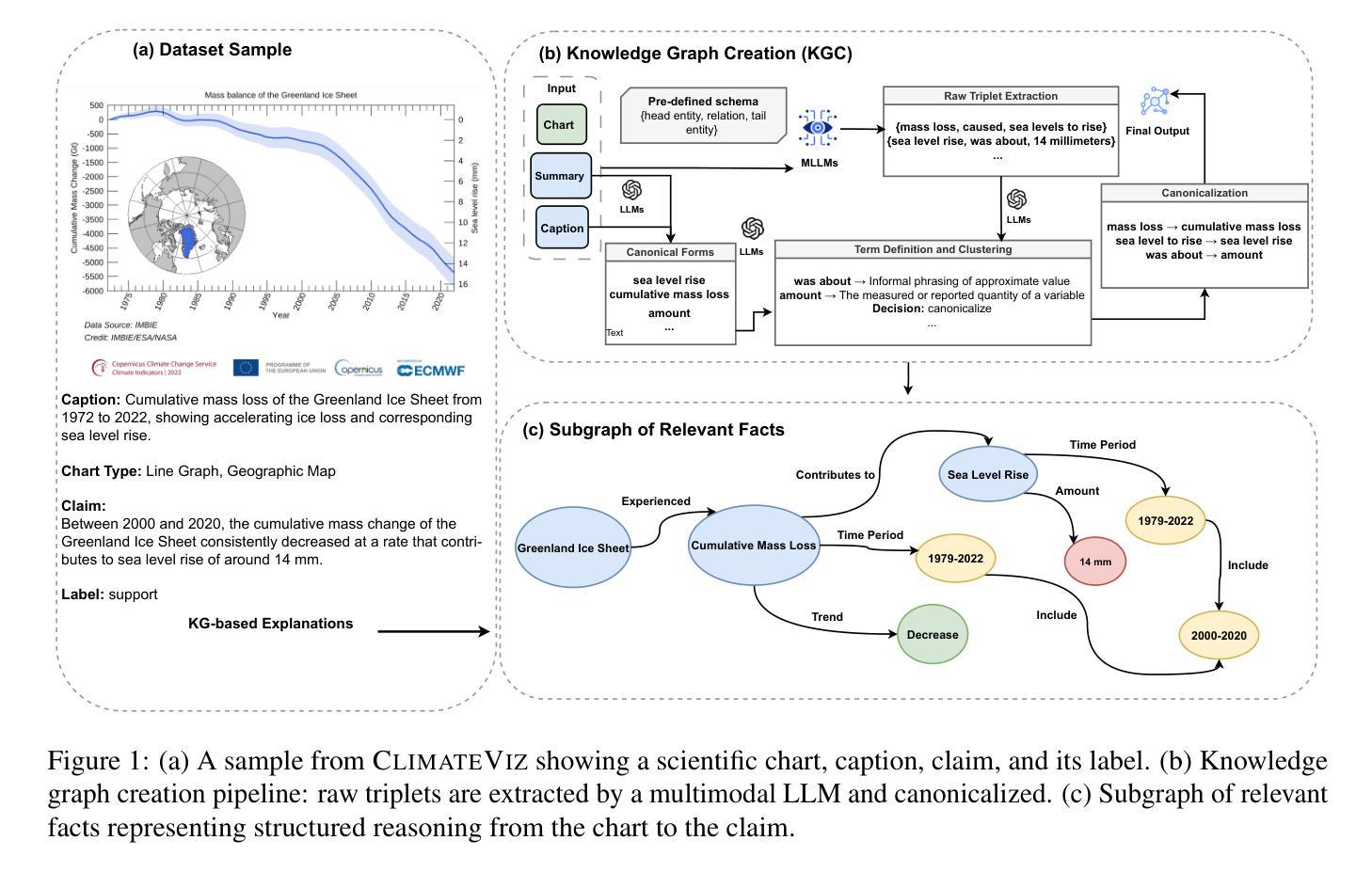
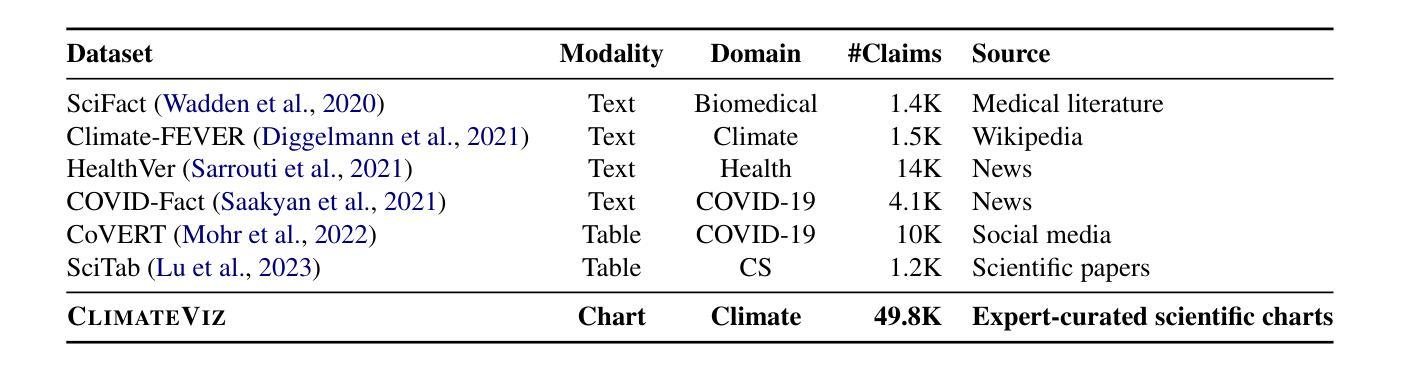
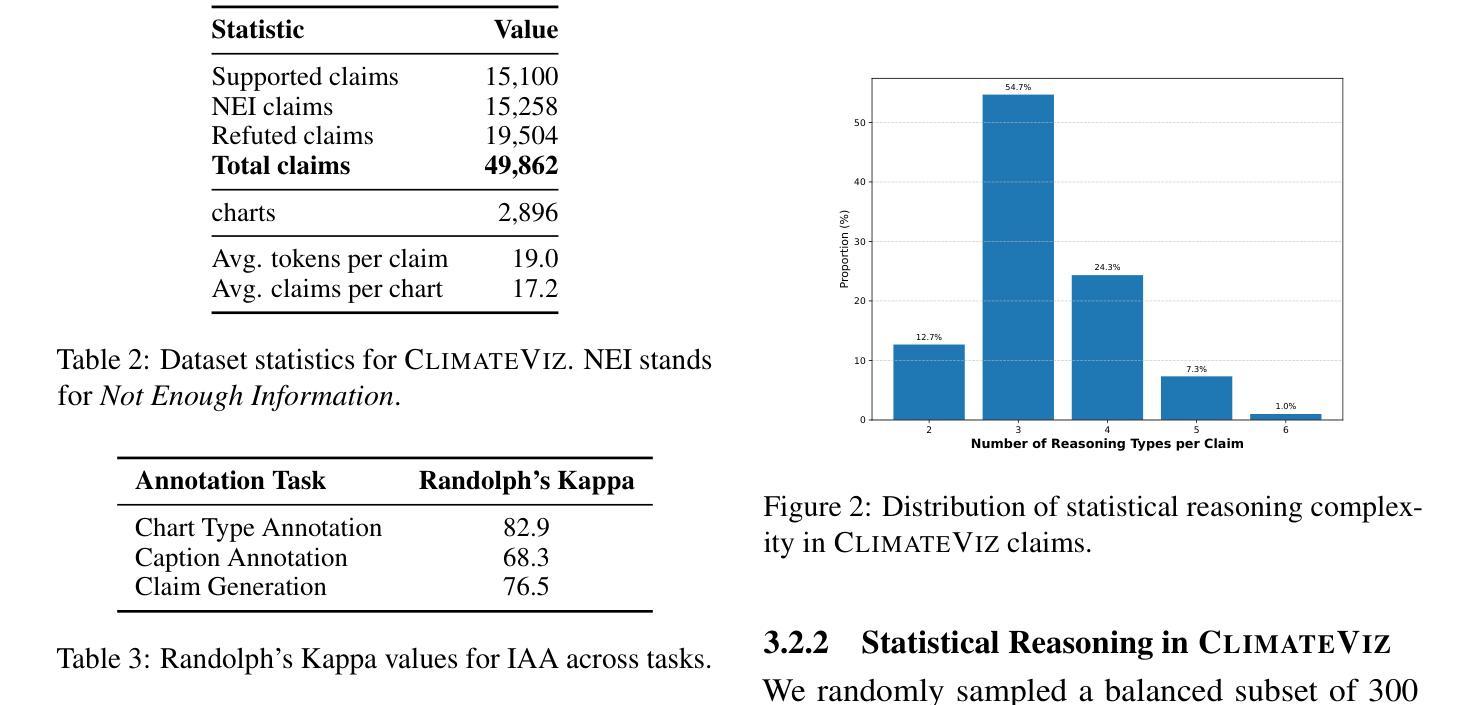
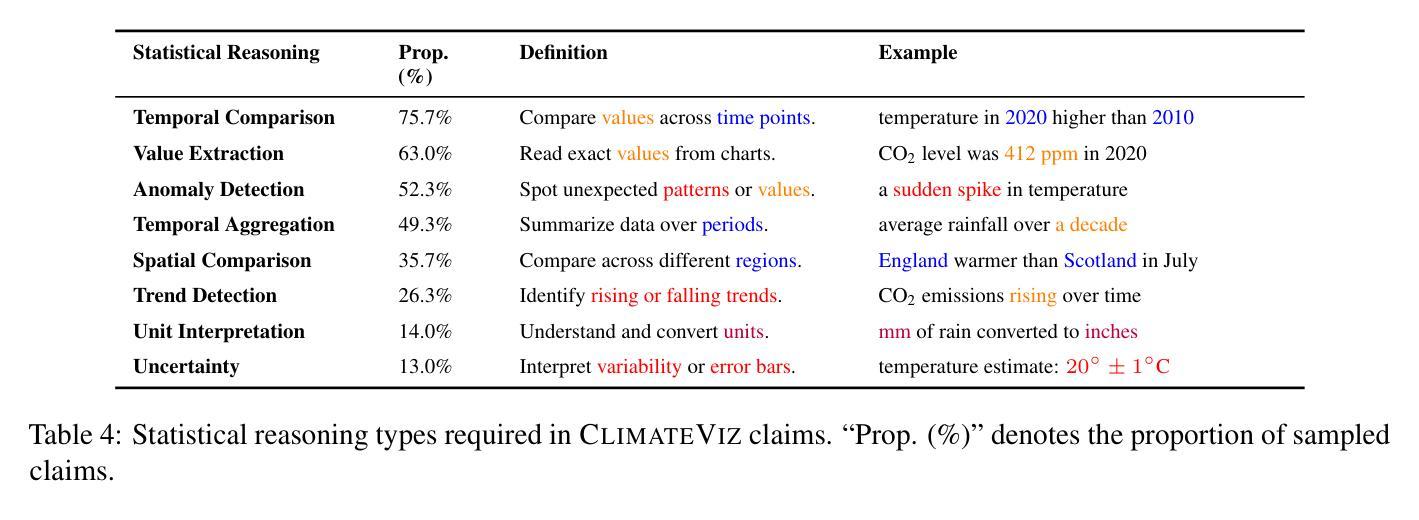
ClimateViz: A Benchmark for Statistical Reasoning and Fact Verification on Scientific Charts
Authors:Ruiran Su, Jiasheng Si, Zhijiang Guo, Janet B. Pierrehumbert
Scientific fact-checking has mostly focused on text and tables, overlooking scientific charts, which are key for presenting quantitative evidence and statistical reasoning. We introduce ClimateViz, the first large-scale benchmark for scientific fact-checking using expert-curated scientific charts. ClimateViz contains 49,862 claims linked to 2,896 visualizations, each labeled as support, refute, or not enough information. To improve interpretability, each example includes structured knowledge graph explanations covering trends, comparisons, and causal relations. We evaluate state-of-the-art multimodal language models, including both proprietary and open-source systems, in zero-shot and few-shot settings. Results show that current models struggle with chart-based reasoning: even the best systems, such as Gemini 2.5 and InternVL 2.5, reach only 76.2 to 77.8 percent accuracy in label-only settings, far below human performance (89.3 and 92.7 percent). Explanation-augmented outputs improve performance in some models. We released our dataset and code alongside the paper.
科学事实核查主要集中在文本和表格上,却忽视了科学图表这一呈现定量证据和统计推理的关键要素。我们推出了ClimateViz,这是使用专家制作的科学图表进行事实核查的首个大规模基准测试。ClimateViz包含与可视化内容相关的声明数量达49,862条,涉及可视化图表数量为2,896个,每个声明都被标记为支持、反驳或信息不足。为提高可解释性,每个示例都包含结构化知识图谱解释,涵盖趋势、比较和因果关系。我们评估了最先进的跨模态语言模型,包括专有和开源系统,在无预设情况和少量预设情况的环境中进行了评估。结果表明当前模型在基于图表的推理方面存在困难:即使是最先进的系统如Gemini 2.5和InternVL 2.5在仅标签的环境中准确率也只有76.2至77.8%,远低于人类的表现(分别为89.3%和92.7%)。通过增加解释性的输出能提高部分模型的性能。我们同时发布了数据集和代码以供公众参考。
论文及项目相关链接
Summary
本文主要介绍了针对科学图表的事实核查研究。由于科学事实核查主要关注文本和表格,忽略了科学图表在呈现定量证据和统计推理中的重要性,因此引入了ClimateViz这一大规模基准测试集。ClimateViz包含专家编制的科学图表,涉及气候变化领域的事实核查。评估了多种模态的语言模型,发现当前模型在图表推理方面存在困难,即使最好的系统也仅达到约77%的准确率,远低于人类的表现。通过解释增强的输出可提高某些模型的性能。数据集和代码已随论文发布。
Key Takeaways
- 科学事实核查通常忽视科学图表的重要性,这些图表对于呈现定量证据和统计推理至关重要。
- 引入ClimateViz作为大规模基准测试集,包含专家编制的科学图表与气候变化领域的事实核查信息。
- 评估了多种语言模型在零样本和小样本情境下的性能。
- 当前模型在基于图表的事实核查方面存在困难,即使最好的系统准确率也只有约77%。
- 人类表现优于现有模型,准确率达到约90%。
- 通过增加解释增强输出可提高某些模型的性能。
点此查看论文截图

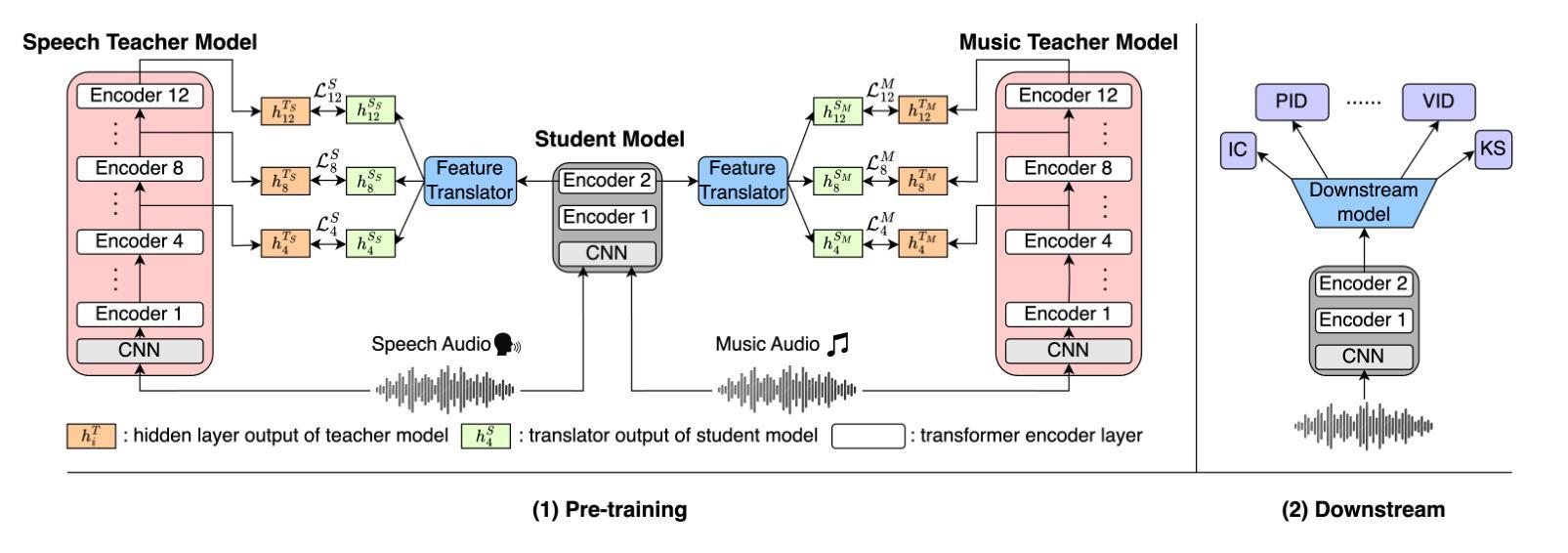
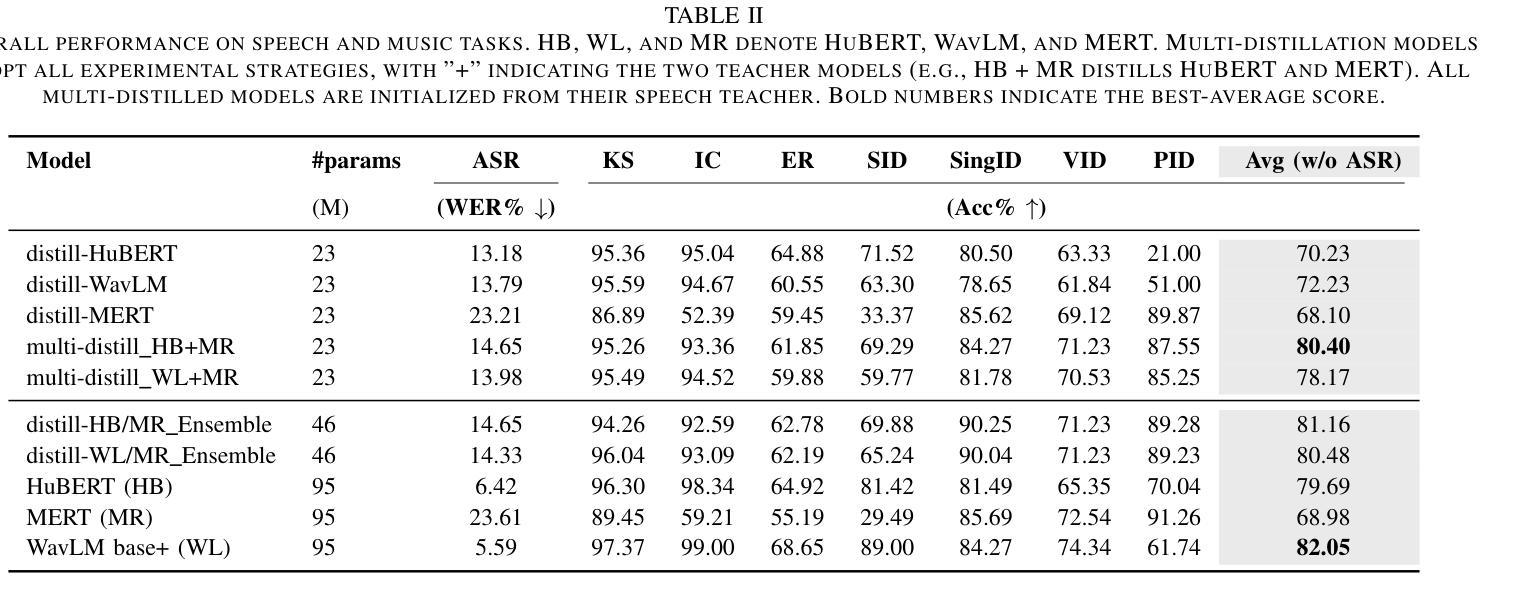
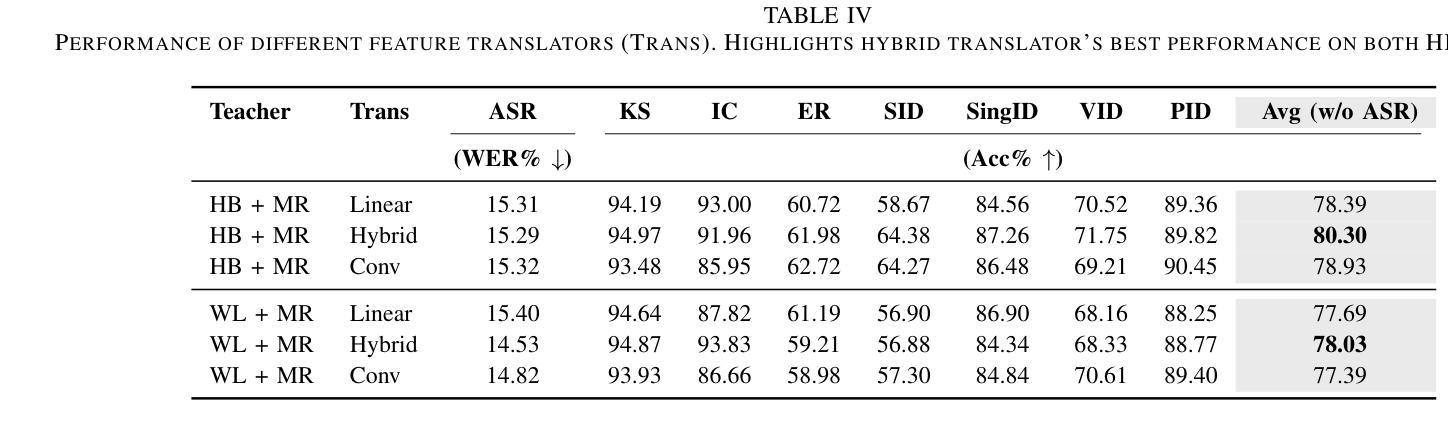
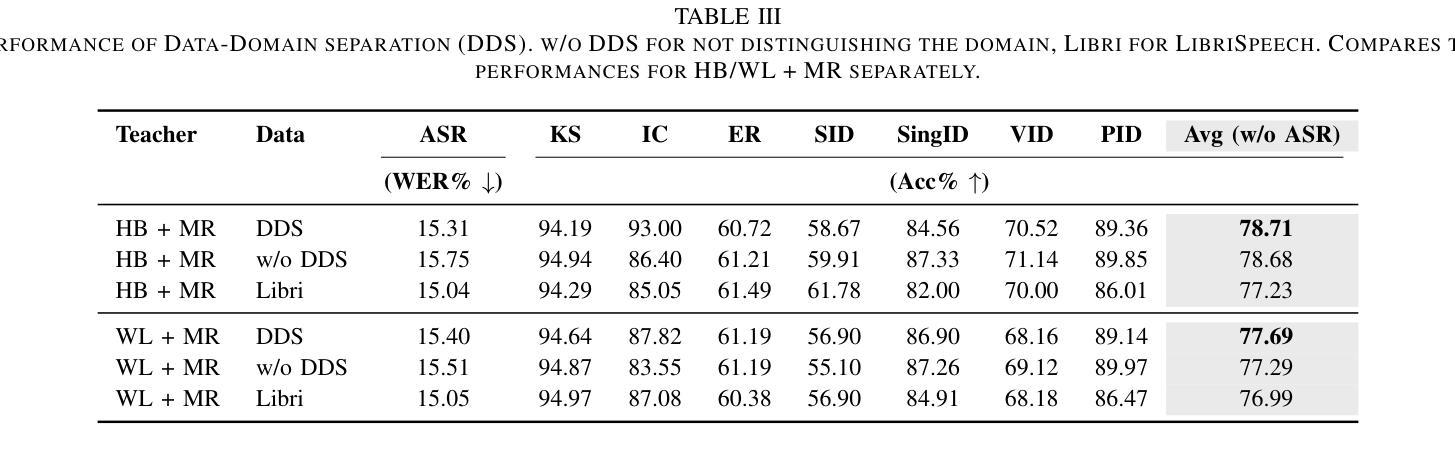
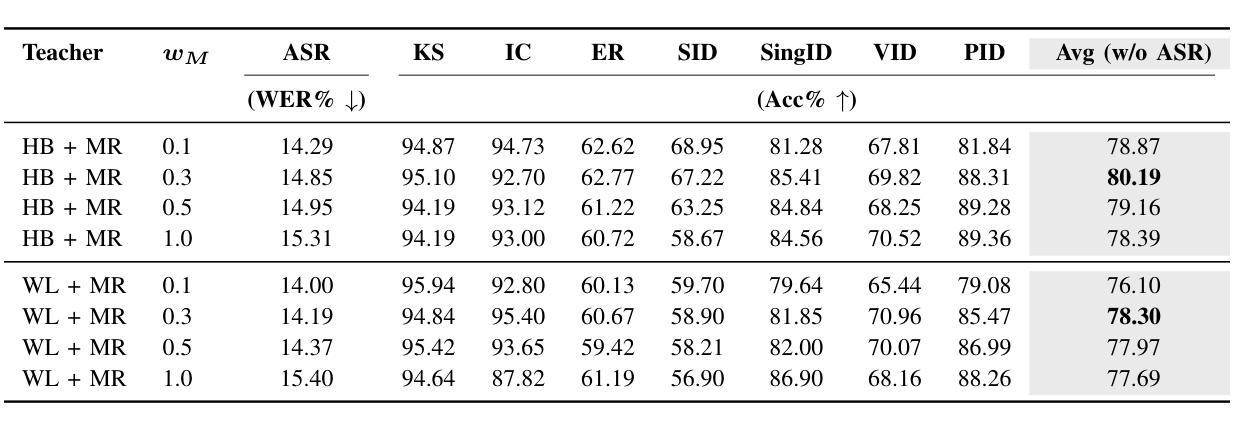
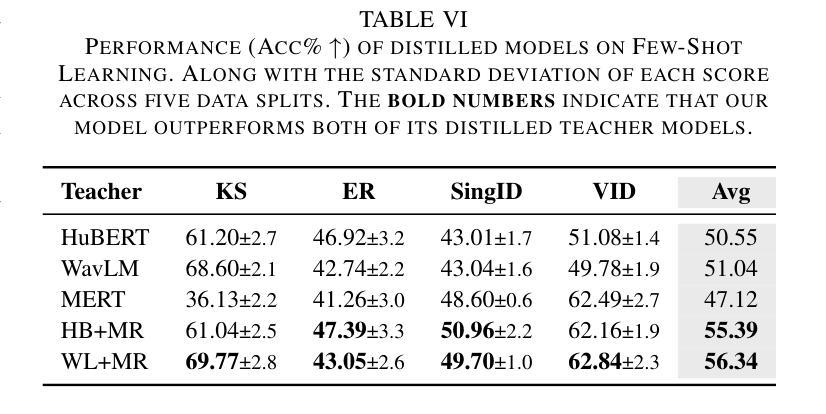
Multi-Distillation from Speech and Music Representation Models
Authors:Jui-Chiang Wei, Yi-Cheng Lin, Fabian Ritter-Gutierrez, Hung-yi Lee
Real-world audio often mixes speech and music, yet models typically handle only one domain. This paper introduces a multi-teacher distillation framework that unifies speech and music models into a single one while significantly reducing model size. Our approach leverages the strengths of domain-specific teacher models, such as HuBERT for speech and MERT for music, and explores various strategies to balance both domains. Experiments across diverse tasks demonstrate that our model matches the performance of domain-specific models, showing the effectiveness of cross-domain distillation. Additionally, we conduct few-shot learning experiments, highlighting the need for general models in real-world scenarios where labeled data is limited. Our results show that our model not only performs on par with specialized models but also outperforms them in few-shot scenarios, proving that a cross-domain approach is essential and effective for diverse tasks with limited data.
现实世界中的音频经常混合了语音和音乐,但模型通常只处理其中一个领域。本文引入了一个多教师蒸馏框架,该框架将语音和音乐模型统一到一个单一模型中,并显著减小了模型大小。我们的方法利用特定领域的教师模型的优点,如用于语音的HuBERT和用于音乐的MERT,并探索了各种策略来平衡这两个领域。在不同任务上的实验表明,我们的模型的性能与特定领域的模型相匹配,证明了跨域蒸馏的有效性。此外,我们进行了小样本学习实验,强调在现实世界场景中需要通用模型,因为这些场景中标注数据有限。我们的结果表明,我们的模型不仅在性能上与专用模型相当,而且在小样本来自不同领域的数据场景中表现更好,证明了跨域方法对于有限数据的多样任务的重要性和有效性。
论文及项目相关链接
PDF 8 pages, 1 figures
Summary
本文介绍了一种多教师蒸馏框架,该框架统一了语音和音乐模型,能够在减少模型大小的同时,保持甚至提升性能。该框架利用特定领域的教师模型(如用于语音的HuBERT和用于音乐的MERT)的优势,并通过各种策略平衡两个领域。实验表明,该模型在多样任务上的性能与特定领域的模型相匹配,并且在有限标签数据的真实场景中表现出强大的泛化能力。特别是在少样本场景下,该模型的性能甚至超越了专门领域的模型,证明了跨域策略对有限数据多样化任务的必要性和有效性。
Key Takeaways
- 引入多教师蒸馏框架,整合语音和音乐模型。
- 通过策略平衡不同领域,利用特定领域的教师模型优势。
- 模型大小显著减少,同时保持或提升性能。
- 在多样任务上,模型性能与特定领域模型相匹配。
- 在有限标签数据的真实场景中,模型展现出强大的泛化能力。
- 少样本场景下,模型性能超越专门领域模型。
点此查看论文截图


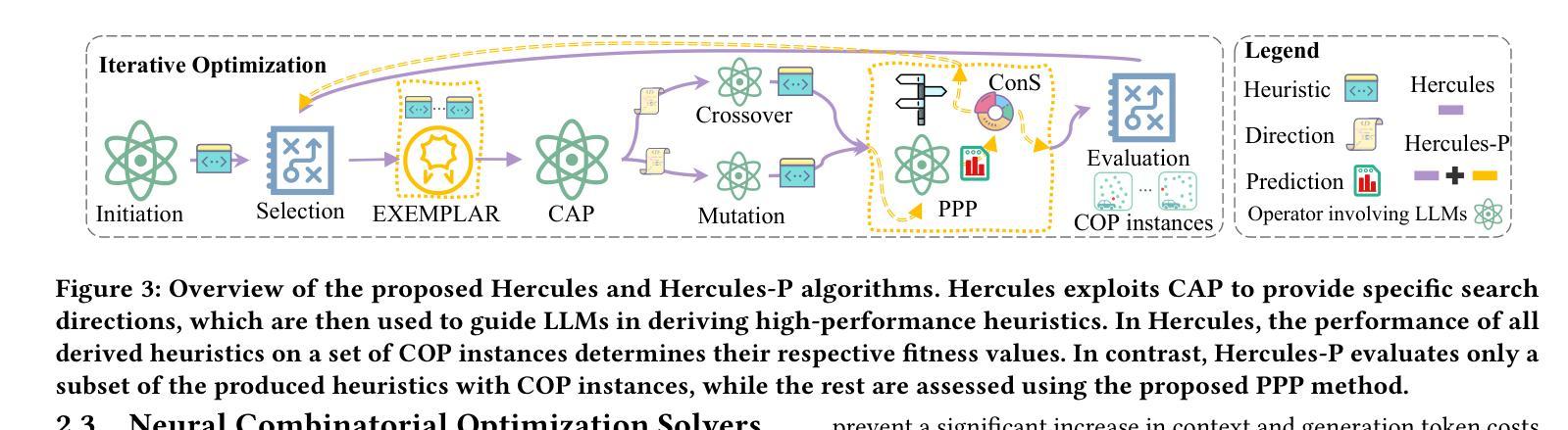
Efficient Heuristics Generation for Solving Combinatorial Optimization Problems Using Large Language Models
Authors:Xuan Wu, Di Wang, Chunguo Wu, Lijie Wen, Chunyan Miao, Yubin Xiao, You Zhou
Recent studies exploited Large Language Models (LLMs) to autonomously generate heuristics for solving Combinatorial Optimization Problems (COPs), by prompting LLMs to first provide search directions and then derive heuristics accordingly. However, the absence of task-specific knowledge in prompts often leads LLMs to provide unspecific search directions, obstructing the derivation of well-performing heuristics. Moreover, evaluating the derived heuristics remains resource-intensive, especially for those semantically equivalent ones, often requiring omissible resource expenditure. To enable LLMs to provide specific search directions, we propose the Hercules algorithm, which leverages our designed Core Abstraction Prompting (CAP) method to abstract the core components from elite heuristics and incorporate them as prior knowledge in prompts. We theoretically prove the effectiveness of CAP in reducing unspecificity and provide empirical results in this work. To reduce computing resources required for evaluating the derived heuristics, we propose few-shot Performance Prediction Prompting (PPP), a first-of-its-kind method for the Heuristic Generation (HG) task. PPP leverages LLMs to predict the fitness values of newly derived heuristics by analyzing their semantic similarity to previously evaluated ones. We further develop two tailored mechanisms for PPP to enhance predictive accuracy and determine unreliable predictions, respectively. The use of PPP makes Hercules more resource-efficient and we name this variant Hercules-P. Extensive experiments across four HG tasks, five COPs, and eight LLMs demonstrate that Hercules outperforms the state-of-the-art LLM-based HG algorithms, while Hercules-P excels at minimizing required computing resources. In addition, we illustrate the effectiveness of CAP, PPP, and the other proposed mechanisms by conducting relevant ablation studies.
最近的研究利用大型语言模型(LLM)自主生成解决组合优化问题(COP)的启发式方法,通过提示LLM首先提供搜索方向,然后据此推导启发式。然而,提示中缺乏特定任务的知识往往导致LLM提供非特定的搜索方向,阻碍高性能启发式的推导。此外,评估派生启发式仍然需要大量资源,特别是那些语义等效的启发式,通常需要大量资源消耗。为了能够让LLM提供具体的搜索方向,我们提出了Hercules算法,该算法利用我们设计的核心抽象提示(CAP)方法从精英启发式方法中抽象出核心组件,并将它们作为先验知识融入提示中。我们从理论上证明了CAP在减少非特异性方面的有效性,并在本文中提供了实证结果。为了降低评估派生启发式所需的计算资源,我们提出了首创的少镜头性能预测提示(PPP),这是一种用于启发式生成(HG)任务的方法。PPP利用LLM通过分析新派生启发式和已评估启发式之间的语义相似性来预测新启发式的适应度值。我们还针对PPP开发了两个定制机制,分别用于提高预测精度和确定不可靠的预测。PPP的使用使Hercules更加资源高效,我们将这种变体命名为Hercules-P。在四个HG任务、五个COP和八个LLM上的广泛实验表明,Hercules优于最新的LLM基于HG的算法,而Hercules-P在最小化所需计算资源方面表现出色。此外,我们通过进行相关的消融研究,说明了CAP、PPP和其他提议机制的有效性。
论文及项目相关链接
PDF Accepted by SIGKDD 2025
Summary
大型语言模型(LLMs)被用来自主生成解决组合优化问题(COPs)的启发式方法。然而,由于缺乏特定任务的提示知识,LLMs经常提供不具体的搜索方向。为解决这个问题,提出了Hercules算法,通过核心抽象提示法(CAP)融入精英启发式方法的先验知识。为减少评估派生启发式所需的计算资源,进一步提出了性能预测提示法(PPP)。实验证明,Hercules及其变体Hercules-P在效率和资源利用上表现出优异性能。
Key Takeaways
- LLMs被用于自主生成解决COPs的启发式方法,但缺乏特定任务提示知识导致搜索方向不明确。
- Hercules算法通过引入CAP方法,融入精英启发式方法的先验知识,提高LLMs提供具体搜索方向的能力。
- PPP方法用于减少评估派生启发式所需的计算资源,通过分析语义相似性进行性能预测。
- Hercules算法及其变体Hercules-P在效率和资源利用上表现出色,通过广泛实验得到验证。
- CAP、PPP等方法的有效性通过相关消融研究得到证实。
- Hercules算法可以应用于多个启发式生成任务和多种组合优化问题。
点此查看论文截图



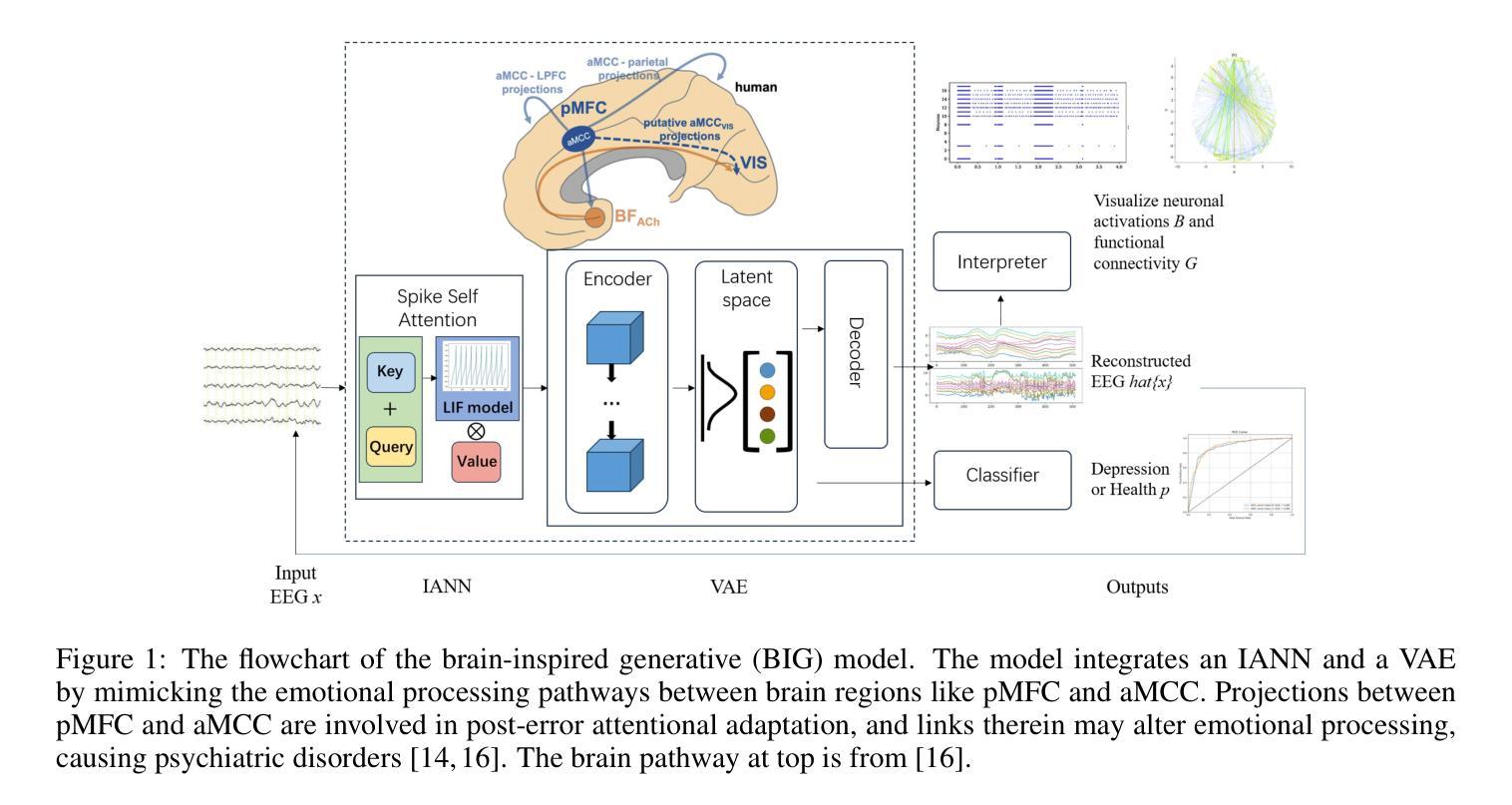
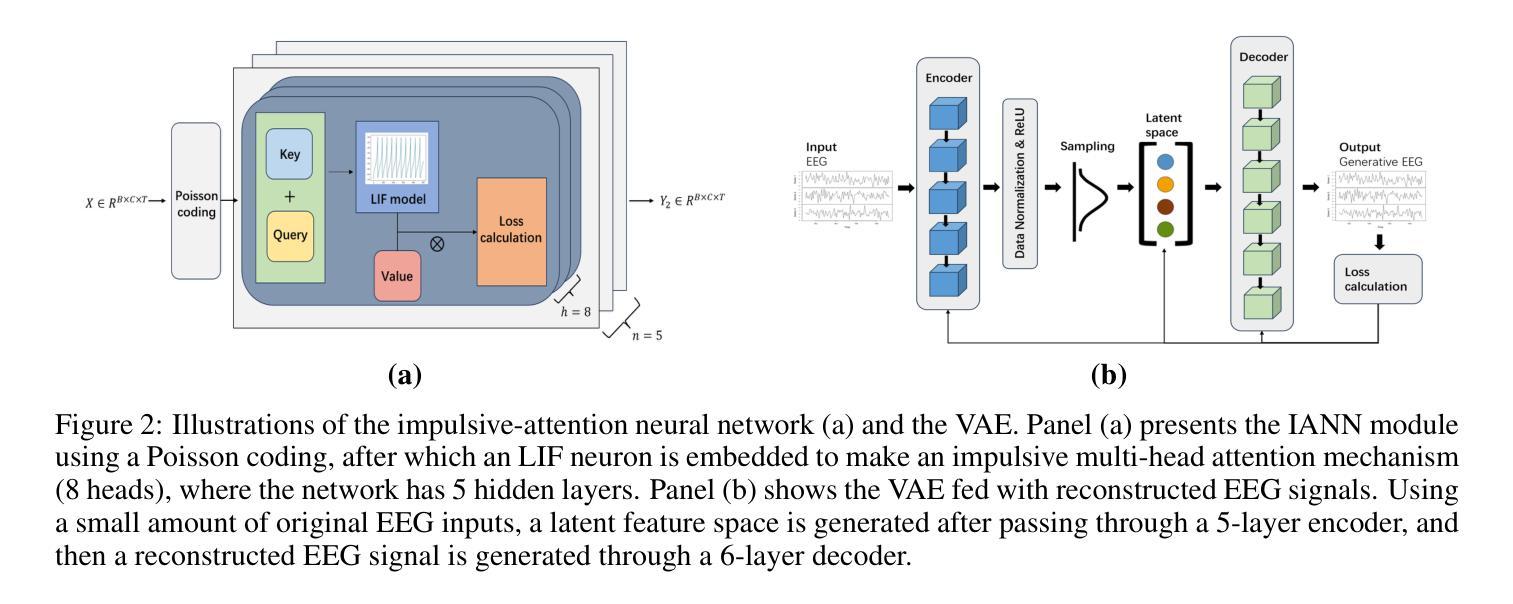
A brain-inspired generative model for EEG-based cognitive state identification
Authors:Bin Hu, Zhi-Hong Guan
This article proposes a brain-inspired generative (BIG) model that merges an impulsive-attention neural network and a variational autoencoder (VAE) for identifying cognitive states based on electroencephalography (EEG) data. A hybrid learning method is presented for training the model by integrating gradient-based learning and heteroassociative memory. The BIG model is capable of achieving multi-task objectives: EEG classification, generating new EEG, and brain network interpretation, alleviating the limitations of excessive data training and high computational cost in conventional approaches. Experimental results on two public EEG datasets with different sampling rates demonstrate that the BIG model achieves a classification accuracy above 89%, comparable with state-of-the-art methods, while reducing computational cost by nearly 11% over the baseline EEGNet. Incorporating the generated EEG data for training, the BIG model exhibits comparative performance in a few-shot pattern. Ablation studies justify the poised brain-inspired characteristic regarding the impulsive-attention module and the hybrid learning method. Thanks to the performance advantages with interpretable outputs, this BIG model has application potential for building digital twins of the brain.
本文提出了一种受大脑启发的生成(BIG)模型,该模型结合了冲动注意力神经网络和变分自编码器(VAE),用于根据脑电图(EEG)数据识别认知状态。文章介绍了一种混合学习方法来训练模型,该方法结合了基于梯度的学习和异联想记忆。BIG模型能够完成多任务目标:EEG分类、生成新EEG以及解释脑网络,从而缓解了传统方法中过度数据训练和计算成本过高的局限性。在两个具有不同采样率的公开EEG数据集上的实验结果表明,BIG模型的分类准确率高于89%,与最新技术方法相当,同时较基线EEGNet降低了近11%的计算成本。通过利用生成的EEG数据进行训练,BIG模型在少量样本情况下展现出相当的性能表现。消融研究证实了冲动注意力模块和混合学习方法在受大脑启发方面的特点。由于具有性能优势和可解释的输出结果,这一BIG模型在构建脑的数字双胞胎方面具有应用潜力。
论文及项目相关链接
Summary
本文提出一种受大脑启发的生成(BIG)模型,它将冲动注意力神经网络和变分自编码器(VAE)相结合,基于脑电图(EEG)数据识别认知状态。文章介绍了一种混合学习方法,通过结合梯度学习和异联想记忆来训练模型。BIG模型能够完成多任务目标:EEG分类、生成新的EEG以及解释脑网络,缓解了传统方法中过度数据训练和计算成本高的局限性。实验结果表明,在具有不同采样率的两个公共EEG数据集上,BIG模型的分类准确率高于89%,与最新技术相当,同时计算成本比基线EEGNet降低了近11%。此外,利用生成的EEG数据进行训练,BIG模型在少数样本情况下展现出比较优秀的性能。对冲动注意力模块和混合学习方法的剖析研究证实了其作为受大脑启发的模型的潜力。由于其在性能方面的优势以及可解释的输出结果,该BIG模型在构建大脑的数字化双胞胎方面具有应用潜力。
Key Takeaways
- 提出了一种新的脑启发生成(BIG)模型,融合了冲动注意力神经网络和变分自编码器(VAE)。
- 该模型通过混合学习方法进行训练,结合了梯度学习和异联想记忆。
- BIG模型可实现多任务目标:EEG分类、生成新EEG以及解释脑网络。
- 实验结果显示,在公共EEG数据集上,BIG模型分类准确率高且计算成本低。
- 在少数样本情况下,BIG模型表现优秀。
- 冲动注意力模块和混合学习方法的剖析研究证明了该模型的潜力。
点此查看论文截图

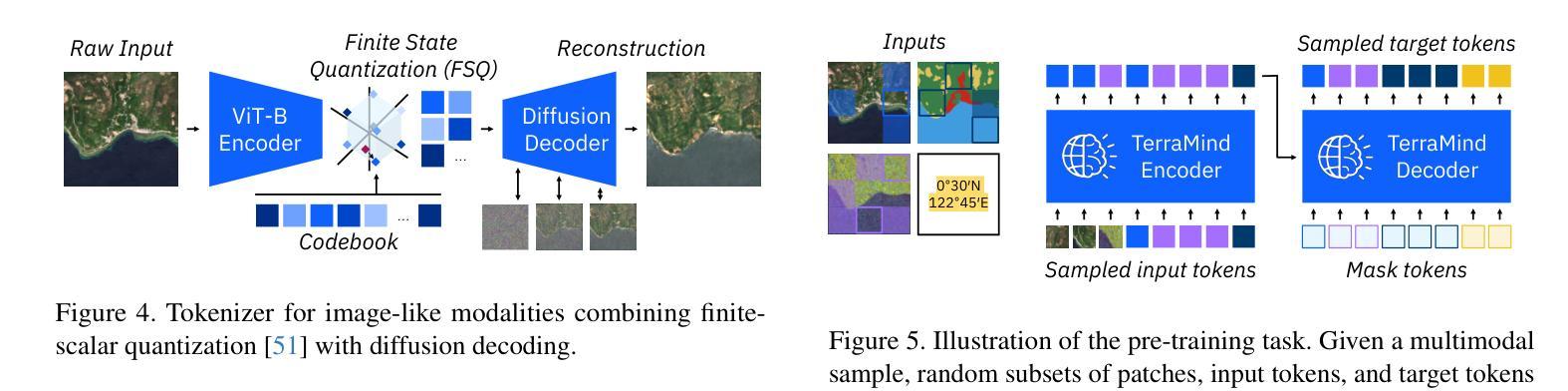
TerraMind: Large-Scale Generative Multimodality for Earth Observation
Authors:Johannes Jakubik, Felix Yang, Benedikt Blumenstiel, Erik Scheurer, Rocco Sedona, Stefano Maurogiovanni, Jente Bosmans, Nikolaos Dionelis, Valerio Marsocci, Niklas Kopp, Rahul Ramachandran, Paolo Fraccaro, Thomas Brunschwiler, Gabriele Cavallaro, Juan Bernabe-Moreno, Nicolas Longépé
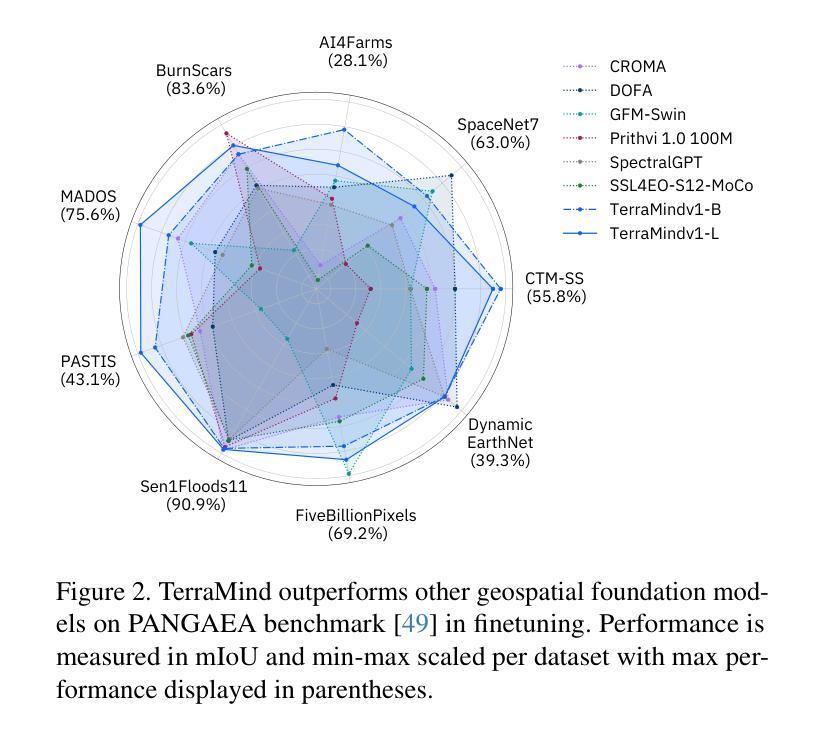
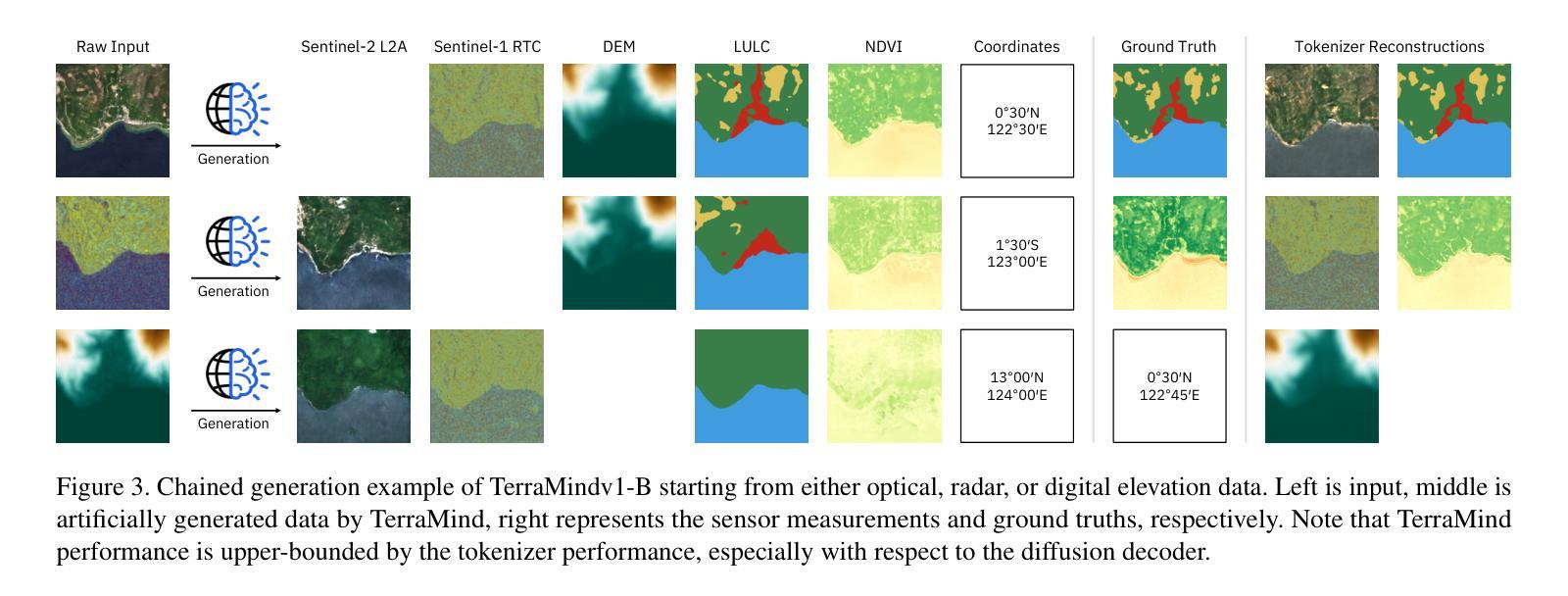
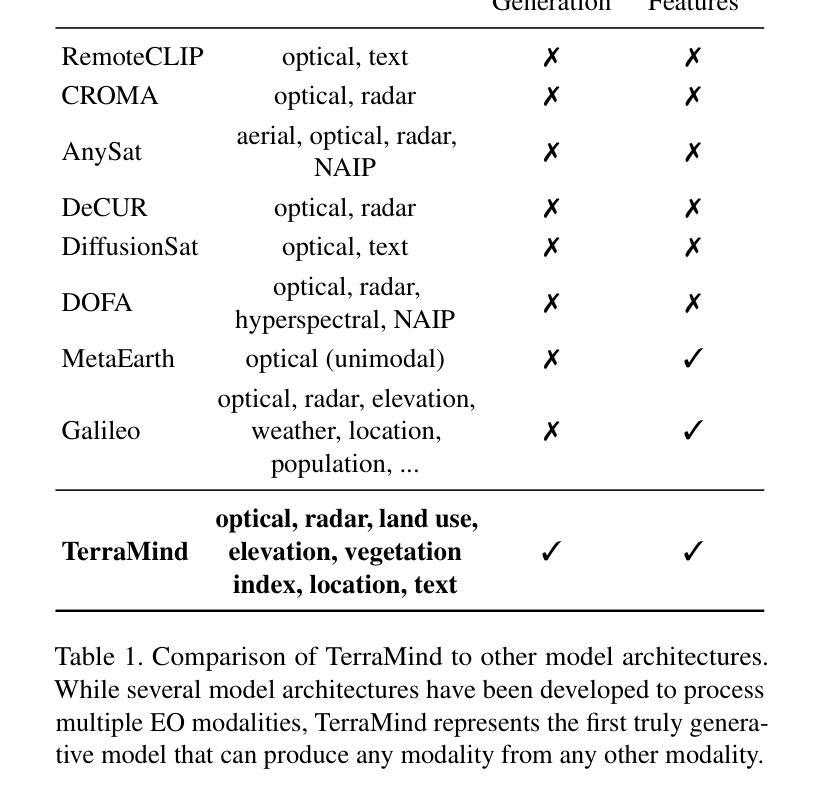
We present TerraMind, the first any-to-any generative, multimodal foundation model for Earth observation (EO). Unlike other multimodal models, TerraMind is pretrained on dual-scale representations combining both token-level and pixel-level data across modalities. On a token level, TerraMind encodes high-level contextual information to learn cross-modal relationships, while on a pixel level, TerraMind leverages fine-grained representations to capture critical spatial nuances. We pretrained TerraMind on nine geospatial modalities of a global, large-scale dataset. In this paper, we demonstrate that (i) TerraMind’s dual-scale early fusion approach unlocks a range of zero-shot and few-shot applications for Earth observation, (ii) TerraMind introduces “Thinking-in-Modalities” (TiM) – the capability of generating additional artificial data during finetuning and inference to improve the model output – and (iii) TerraMind achieves beyond state-of-the-art performance in community-standard benchmarks for EO like PANGAEA. The pretraining dataset, the model weights, and our code are open-sourced under a permissive license.
我们推出TerraMind,这是首个面向地球观测(EO)的任意到任意生成、多模式基础模型。与其他多模式模型不同,TerraMind是在双尺度表示上预训练的,结合了跨模式的令牌级别和像素级别数据。在令牌级别上,TerraMind编码高级上下文信息以学习跨模式关系,而在像素级别上,TerraMind利用精细表示来捕捉关键的空间细微差别。我们在全球大规模数据集的九个地理空间模式上预训练了TerraMind。在本文中,我们证明了(i)TerraMind的双尺度早期融合方法解锁了一系列零样本和少样本地球观测应用,(ii)TerraMind引入了“思考模式”(Thinking-in-Modalities,简称TiM)——在微调(finetuning)和推断过程中生成额外的模拟数据的能力,以提高模型输出的质量——以及(iii)TerraMind在像泛地球(PANGAEA)这样的地球观测社区标准基准测试中实现了超越最新技术的性能。预训练数据集、模型权重和我们的代码都是在许可下开源的。
论文及项目相关链接
Summary
TerraMind是首个面向地球观测的任意输入任意输出的生成式、多模态基础模型。它采用双尺度表示法,结合标记级别和像素级别的数据跨模态进行预训练。TerraMind的预训练数据集和模型权重都是开源的。
Key Takeaways
- TerraMind是首个地球观测领域的任意至任意生成式多模态基础模型。
- TerraMind采用双尺度预训练方法,结合标记级别和像素级别的数据跨模态进行训练。
- TerraMind能在零样本和少样本情况下应用在各种地球观测任务中。
- TerraMind引入“模态思考”(Thinking-in-Modalities,TiM)能力,在微调及推断过程中生成额外的模拟数据以提高模型输出质量。
- TerraMind在像PANGAEA这样的社区标准基准测试中表现超越了现有技术。
- TerraMind的预训练数据集和模型权重都是开源的。
点此查看论文截图

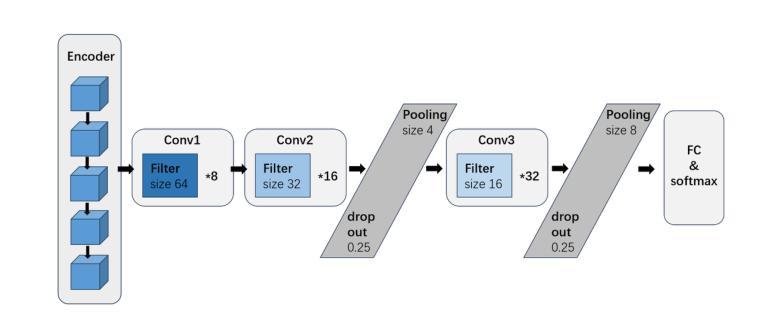
7B Fully Open Source Moxin-LLM/VLM – From Pretraining to GRPO-based Reinforcement Learning Enhancement
Authors:Pu Zhao, Xuan Shen, Zhenglun Kong, Yixin Shen, Sung-En Chang, Timothy Rupprecht, Lei Lu, Enfu Nan, Changdi Yang, Yumei He, Weiyan Shi, Xingchen Xu, Yu Huang, Wei Jiang, Wei Wang, Yue Chen, Yong He, Yanzhi Wang
Recently, Large Language Models (LLMs) have undergone a significant transformation, marked by a rapid rise in both their popularity and capabilities. Leading this evolution are proprietary LLMs like GPT-4 and GPT-o1, which have captured widespread attention in the AI community due to their remarkable performance and versatility. Simultaneously, open-source LLMs, such as LLaMA, have made great contributions to the ever-increasing popularity of LLMs due to the ease to customize and deploy the models across diverse applications. Although open-source LLMs present unprecedented opportunities for innovation and research, the commercialization of LLMs has raised concerns about transparency, reproducibility, and safety. Many open-source LLMs fail to meet fundamental transparency requirements by withholding essential components like training code and data, which may hinder further innovations on LLMs. To mitigate this issue, we introduce Moxin 7B, a fully open-source LLM developed, adhering to principles of open science, open source, open data, and open access. We release the pre-training code and configurations, training and fine-tuning datasets, and intermediate and final checkpoints, aiming to make continuous commitments to fully open-source LLMs. After pre-training the base model, we finetune the Moxin Base model with SOTA post-training framework and instruction data to obtain Moxin Instruct model. To improve the reasoning capability, we further finetune our Instruct model with chain-of-thought data distilled from DeepSeek R1, and then use Group Relative Policy Optimization (GRPO) following DeepSeek R1 to finetune our model, leading to the Moxin Reasoning model. Moreover, we develop our vision language model based on our Moxin model. Experiments show that our models achieve superior performance in various evaluations such as zero-shot evaluation, few-shot evaluation, and CoT evaluation.
最近,大型语言模型(LLM)经历了一次重大变革,其受欢迎程度和能力都迅速上升。引领这一变革的是像GPT-4和GPT-o1这样的专有大型语言模型,它们凭借出色的性能和多功能性在人工智能领域引起了广泛关注。同时,开源的大型语言模型,如LLaMA,由于其易于定制和部署在各种应用程序中,为大型语言模型日益普及做出了巨大贡献。尽管开源的大型语言模型为创新和研发提供了前所未有的机会,但大型语言模型的商业化引发了关于透明度、可重复性和安全的担忧。许多开源的大型语言模型未能满足基本的透明度要求,隐瞒了关键组件,如训练代码和数据,这可能阻碍大型语言模型的进一步创新。为了缓解这个问题,我们推出了Moxin 7B,这是一个完全开源的大型语言模型,遵循公开科学、开放源代码、开放数据和开放访问的原则。我们发布了预训练代码和配置、训练和微调数据集以及中间和最终检查点,致力于完全开源的大型语言模型的持续承诺。在预训练基础模型后,我们使用最新的后训练框架和指令数据对Moxin基础模型进行微调,以获得Moxin指令模型。为了提高推理能力,我们进一步使用来自DeepSeek R1的蒸馏思维链数据对指令模型进行微调,然后遵循DeepSeek R1使用组相对策略优化(GRPO)再次微调我们的模型,得到Moxin推理模型。此外,我们基于Moxin模型开发了我们的视觉语言模型。实验表明,我们的模型在零样本评估、小样例评估和思维链评估等各种评估中均取得了优越的性能。
论文及项目相关链接
Summary
大型语言模型(LLM)领域正经历快速的发展与变革,其中以GPT-4和GPT-o1等专有LLM以及LLaMA等开源LLM为代表。然而,商业化的LLM在透明度、可复制性和安全性方面引发关注。为解决这一问题,我们推出Moxin 7B这一遵循公开科学、开源、开放数据和开放访问原则的全开源LLM。其性能通过预训练基础模型、使用最佳实践的后训练框架和指令数据微调、结合通过DeepSeek R1提炼的思维链数据进行进一步微调,并采用Group Relative Policy Optimization (GRPO)进行优化。实验表明,该模型在零样本、少样本和思维链评估中表现卓越。
Key Takeaways
- 大型语言模型(LLM)领域正经历快速发展,专有和开源LLM均受到关注。
- 商业化LLM的透明度、可复制性和安全性引发关注。
- Moxin 7B是一个全开源的LLM,遵循公开科学、开源、开放数据和开放访问原则。
- Moxin 7B性能通过预训练基础模型,使用指令数据和思维链数据微调来提升。
- Group Relative Policy Optimization (GRPO)用于进一步优化模型性能。
- Moxin 7B模型在零样本、少样本和思维链评估中表现卓越。
点此查看论文截图


PEFTGuard: Detecting Backdoor Attacks Against Parameter-Efficient Fine-Tuning
Authors:Zhen Sun, Tianshuo Cong, Yule Liu, Chenhao Lin, Xinlei He, Rongmao Chen, Xingshuo Han, Xinyi Huang
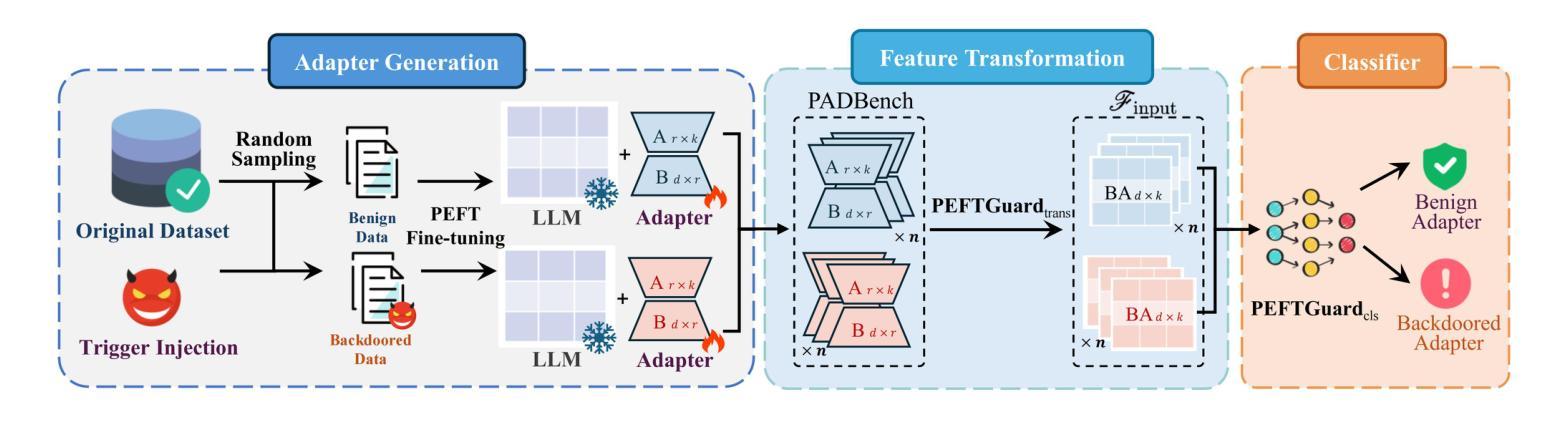
Fine-tuning is an essential process to improve the performance of Large Language Models (LLMs) in specific domains, with Parameter-Efficient Fine-Tuning (PEFT) gaining popularity due to its capacity to reduce computational demands through the integration of low-rank adapters. These lightweight adapters, such as LoRA, can be shared and utilized on open-source platforms. However, adversaries could exploit this mechanism to inject backdoors into these adapters, resulting in malicious behaviors like incorrect or harmful outputs, which pose serious security risks to the community. Unfortunately, few current efforts concentrate on analyzing the backdoor patterns or detecting the backdoors in the adapters. To fill this gap, we first construct and release PADBench, a comprehensive benchmark that contains 13,300 benign and backdoored adapters fine-tuned with various datasets, attack strategies, PEFT methods, and LLMs. Moreover, we propose PEFTGuard, the first backdoor detection framework against PEFT-based adapters. Extensive evaluation upon PADBench shows that PEFTGuard outperforms existing detection methods, achieving nearly perfect detection accuracy (100%) in most cases. Notably, PEFTGuard exhibits zero-shot transferability on three aspects, including different attacks, PEFT methods, and adapter ranks. In addition, we consider various adaptive attacks to demonstrate the high robustness of PEFTGuard. We further explore several possible backdoor mitigation defenses, finding fine-mixing to be the most effective method. We envision that our benchmark and method can shed light on future LLM backdoor detection research.
微调是提高大型语言模型(LLM)在特定领域性能的关键过程。由于参数高效微调(PEFT)能够通过集成低阶适配器降低计算需求,因此越来越受欢迎。这些轻量级适配器如LoRA可共享并在开源平台上使用。然而,对手可能会利用这一机制在这些适配器中注入后门,导致错误或有害输出等恶意行为,给社区带来严重的安全风险。遗憾的是,目前很少有工作关注分析后门模式或检测适配器中的后门。为了填补这一空白,我们首先构建并发布了PADBench,这是一个全面的基准测试平台,包含用各种数据集、攻击策略、PEFT方法和LLM微调得到的13,300个良性及被后门攻击的适配器。此外,我们提出了针对基于PEFT的适配器的首个后门检测框架PEFTGuard。在PADBench上的广泛评估显示,PEFTGuard在大多数情况下超过了现有的检测方法,几乎达到了完美的检测精度(100%)。值得注意的是,PEFTGuard在攻击、PEFT方法和适配器等级方面均展现出零射击转移能力。此外,我们考虑了各种自适应攻击来展示PEFTGuard的高稳健性。我们进一步探索了几种可能的后门缓解防御措施,发现fine-mixing是最有效的方法。我们期望我们的基准和方法能为未来的LLM后门检测研究提供启示。
论文及项目相关链接
PDF 21 pages, 7 figures
Summary
大型语言模型(LLM)的微调是提升其在特定领域表现的关键流程,参数效率高的微调(PEFT)因其能够借助低阶适配器减少计算需求而受到欢迎。然而,这些轻量级适配器存在安全风险,可能会被对手利用注入后门,导致模型输出错误或有害信息。针对这一问题,本文构建了PADBench基准测试平台,并推出了PEFTGuard后门检测框架。评价显示,PEFTGuard在多数情况下表现出近完美的检测精度,并且具有零样本迁移能力,能应对不同攻击、PEFT方法和适配器等级。同时,研究还探索了几种可能的后门缓解防御措施,发现fine-mixing是最有效的方法。
Key Takeaways
- PEFT成为提升LLM在特定领域表现的关键流程,并因减少计算需求而受到欢迎。
- LoRA等轻量级适配器存在安全风险,可能被对手利用注入后门。
- 构建了PADBench基准测试平台,包含良性及被后门的适配器。
- 推出了PEFTGuard后门检测框架,表现出高检测精度和零样本迁移能力。
- PEFTGuard能有效应对不同攻击、PEFT方法和适配器等级。
- 研究探索了多种后门缓解措施,发现fine-mixing是最有效的防御方法。
点此查看论文截图