⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-13 更新
DGAE: Diffusion-Guided Autoencoder for Efficient Latent Representation Learning
Authors:Dongxu Liu, Yuang Peng, Haomiao Tang, Yuwei Chen, Chunrui Han, Zheng Ge, Daxin Jiang, Mingxue Liao
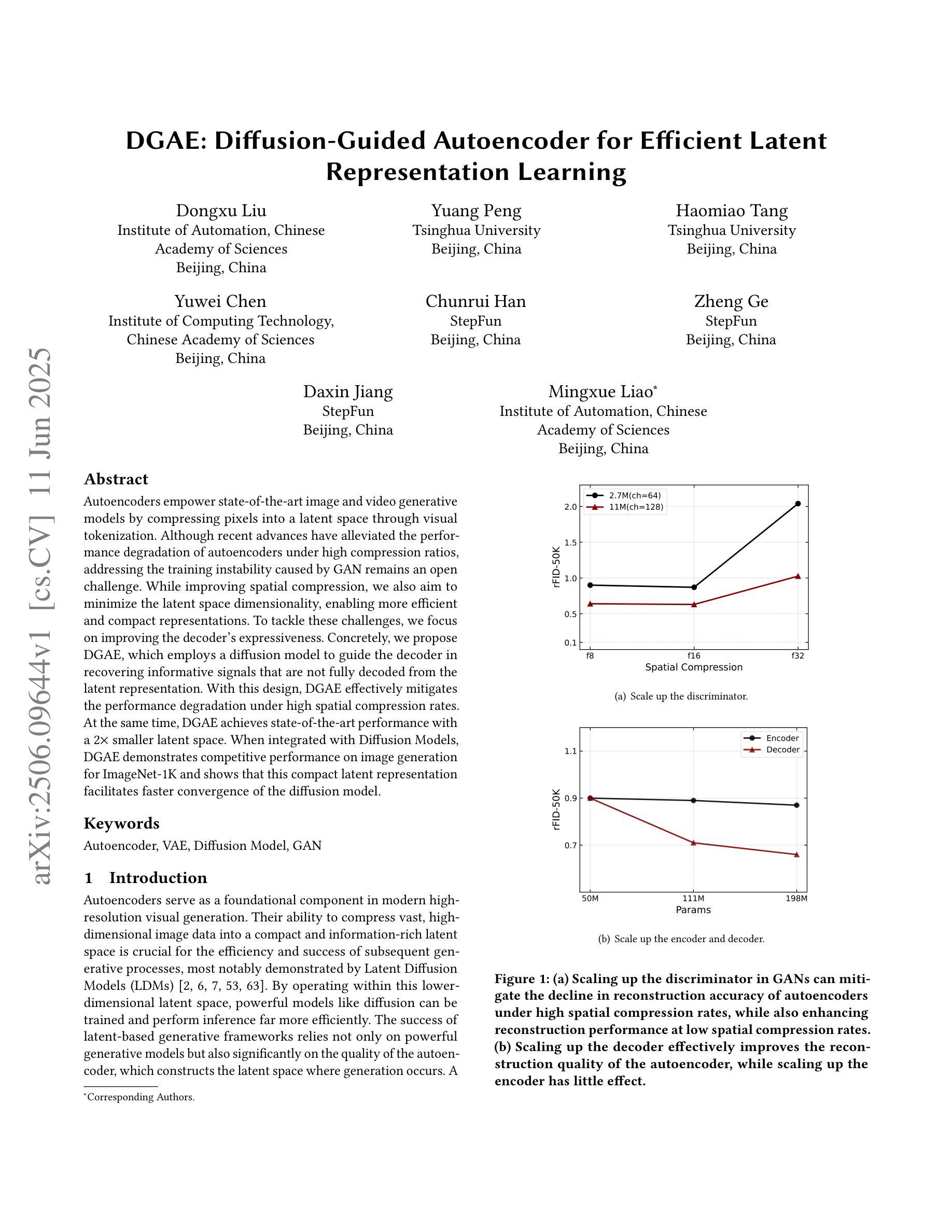
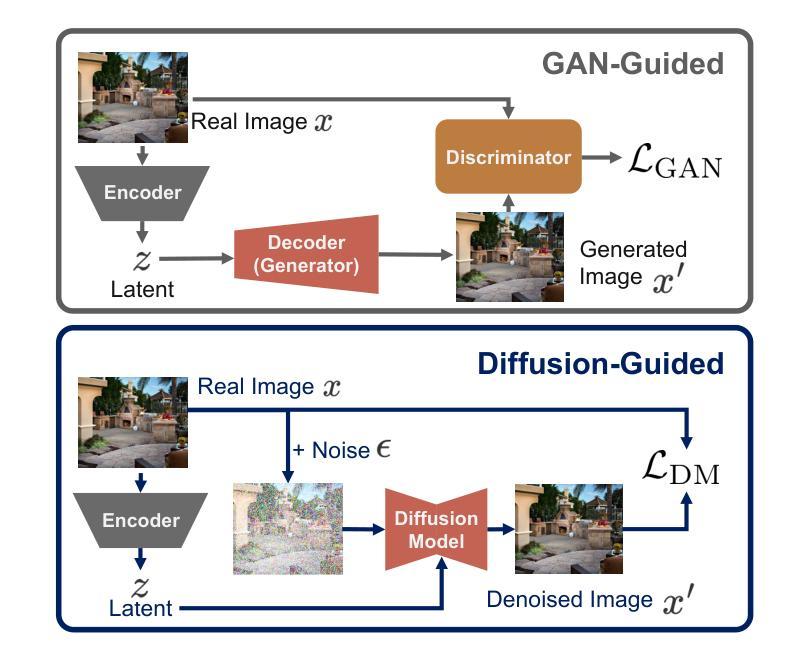
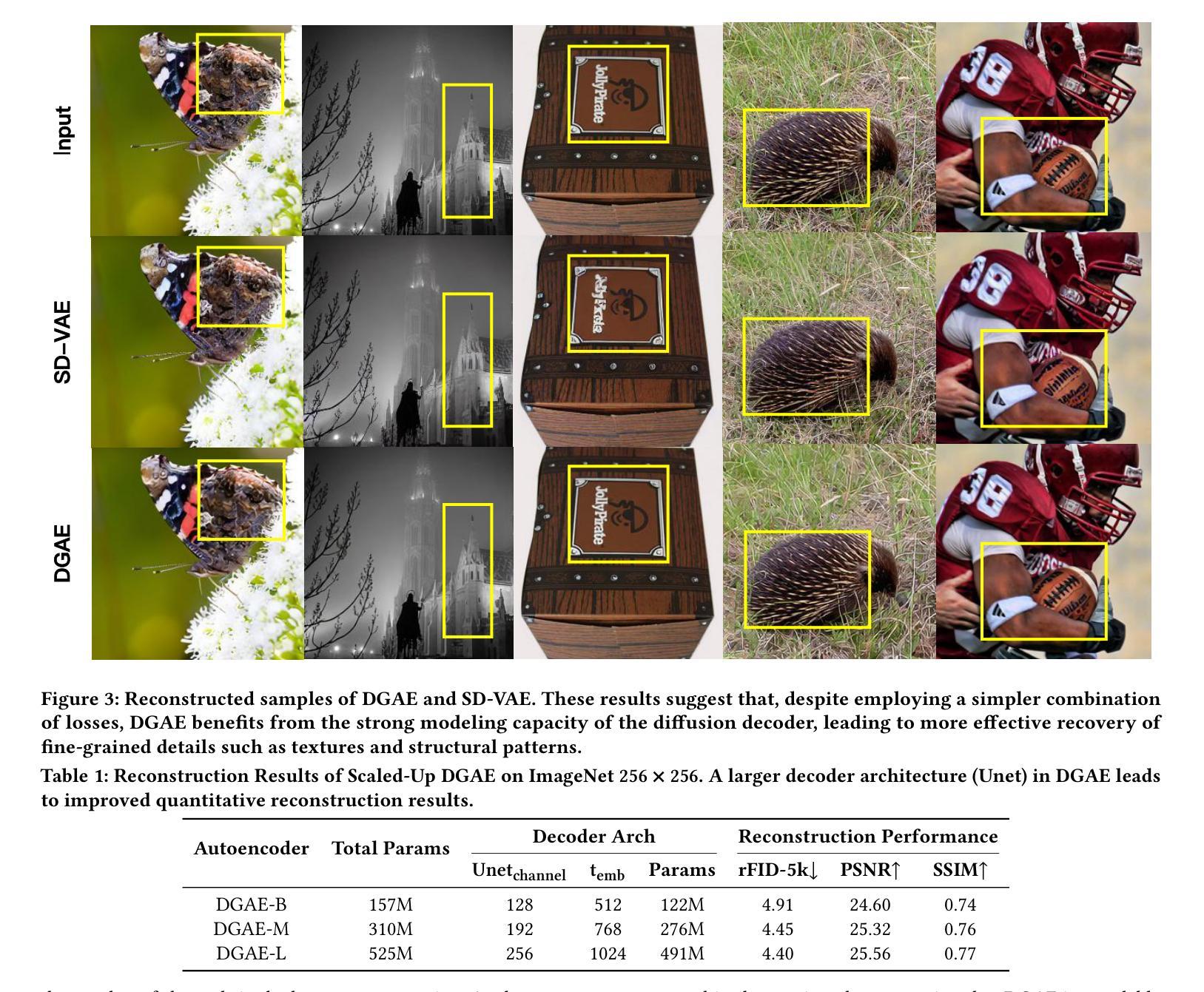
Autoencoders empower state-of-the-art image and video generative models by compressing pixels into a latent space through visual tokenization. Although recent advances have alleviated the performance degradation of autoencoders under high compression ratios, addressing the training instability caused by GAN remains an open challenge. While improving spatial compression, we also aim to minimize the latent space dimensionality, enabling more efficient and compact representations. To tackle these challenges, we focus on improving the decoder’s expressiveness. Concretely, we propose DGAE, which employs a diffusion model to guide the decoder in recovering informative signals that are not fully decoded from the latent representation. With this design, DGAE effectively mitigates the performance degradation under high spatial compression rates. At the same time, DGAE achieves state-of-the-art performance with a 2x smaller latent space. When integrated with Diffusion Models, DGAE demonstrates competitive performance on image generation for ImageNet-1K and shows that this compact latent representation facilitates faster convergence of the diffusion model.
自编码器通过视觉令牌化将像素压缩到潜在空间,为最先进的图像和视频生成模型提供了赋能。尽管最近的进展已经减轻了自编码器在高压缩比下的性能下降问题,但解决由GAN引起的训练不稳定仍然是一个公开的挑战。在提升空间压缩的同时,我们还致力于最小化潜在空间的维度,以实现更高效、更紧凑的表示。为了应对这些挑战,我们专注于提高解码器的表达能力。具体来说,我们提出了DGAE,它采用扩散模型来指导解码器恢复从潜在表示中未完全解码的信息信号。通过这种设计,DGAE在高空间压缩率下有效地缓解了性能下降的问题。同时,DGAE在具有更小两倍潜在空间的情况下实现了最先进的性能。当与扩散模型集成时,DGAE在ImageNet-1K的图像生成方面表现出竞争力,证明这种紧凑的潜在表示有助于扩散模型的快速收敛。
论文及项目相关链接
Summary
自动编码器通过视觉令牌化将像素压缩到潜在空间,为图像和视频生成模型提供技术支持。尽管近期发展缓解了高压缩比下自动编码器的性能下降问题,但解决由生成对抗网络引起的训练不稳定问题仍是挑战。在提高空间压缩的同时,我们的目标是减小潜在空间的维度,以实现更高效和紧凑的表示。为解决这些挑战,我们重点关注提高解码器的表达能力。具体地,我们提出了采用扩散模型引导解码器恢复从潜在表示中未完全解码的信号的DGAE。此设计使DGAE在高空间压缩率下有效缓解性能下降问题,同时实现更小两倍的潜在空间并达到领先水平。与扩散模型集成后,DGAE在ImageNet-1K的图像生成上表现出竞争力,并证明这种紧凑的潜在表示有助于扩散模型的快速收敛。
Key Takeaways
- 自动编码器通过视觉令牌化技术压缩图像和视频数据到潜在空间,这是现代生成模型的核心技术。
- 虽然存在高压缩比下的性能下降问题,但训练不稳定仍是生成对抗网络的一大挑战。
- 提高解码器的表达能力是解决上述挑战的关键,而DGAE方法通过采用扩散模型来引导解码器恢复未完全解码的信号。
- DGAE在高空间压缩率下能有效缓解性能下降,同时减小了潜在空间维度,实现更高效的数据表示。
- DGAE在ImageNet-1K的图像生成任务上表现出竞争力,证明了其有效性。
- 紧凑的潜在表示有助于扩散模型的快速收敛,表明DGAE具有广泛的应用前景。
点此查看论文截图

Revisiting Diffusion Models: From Generative Pre-training to One-Step Generation
Authors:Bowen Zheng, Tianming Yang
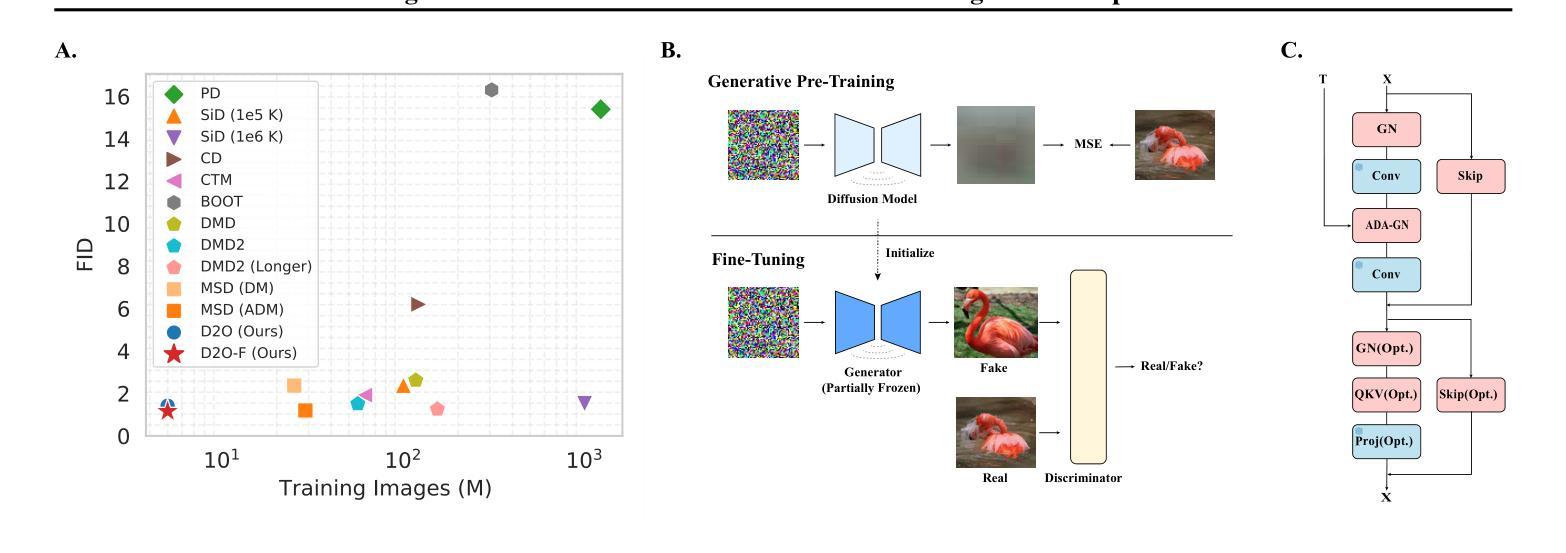
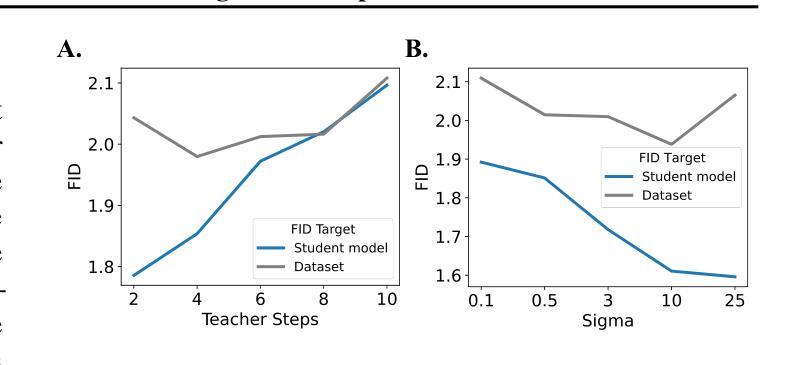
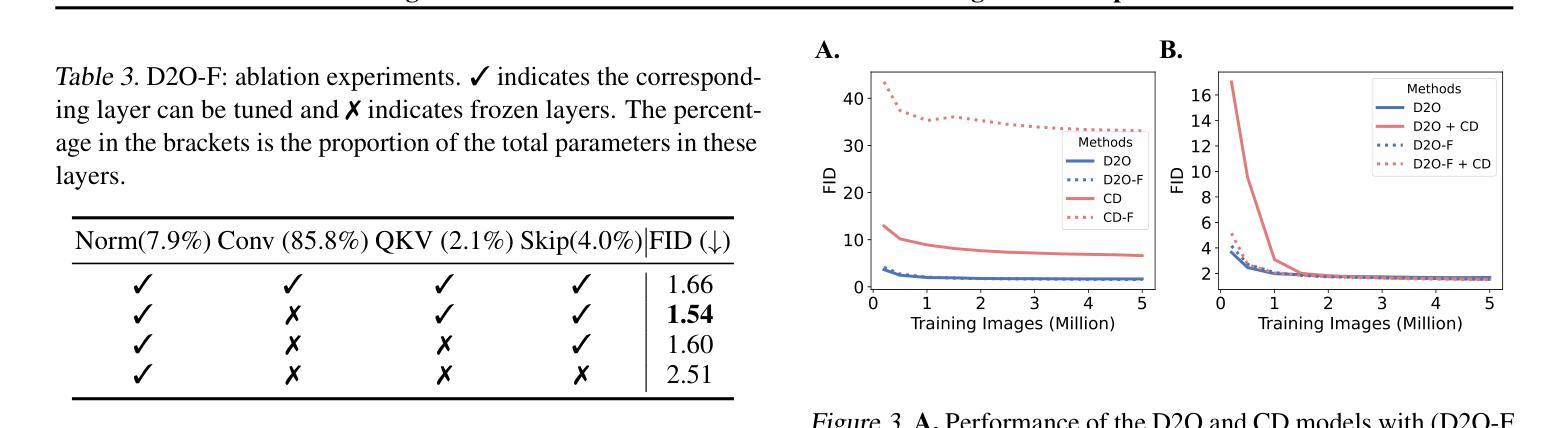
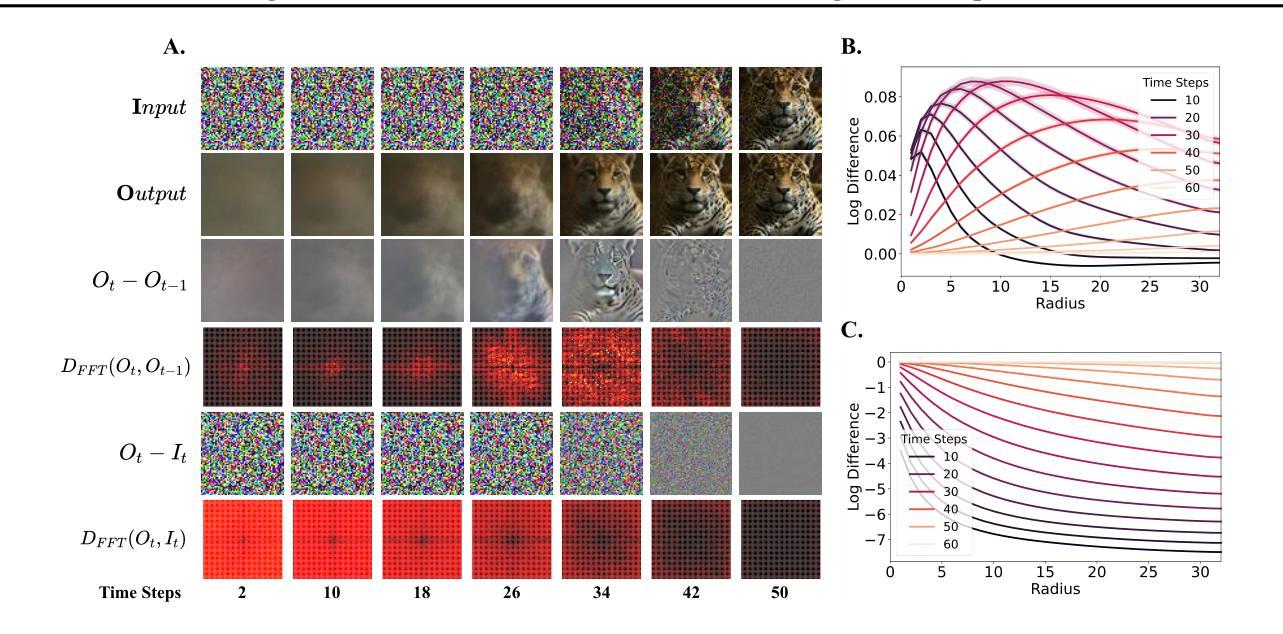
Diffusion distillation is a widely used technique to reduce the sampling cost of diffusion models, yet it often requires extensive training, and the student performance tends to be degraded. Recent studies show that incorporating a GAN objective may alleviate these issues, yet the underlying mechanism remains unclear. In this work, we first identify a key limitation of distillation: mismatched step sizes and parameter numbers between the teacher and the student model lead them to converge to different local minima, rendering direct imitation suboptimal. We further demonstrate that a standalone GAN objective, without relying a distillation loss, overcomes this limitation and is sufficient to convert diffusion models into efficient one-step generators. Based on this finding, we propose that diffusion training may be viewed as a form of generative pre-training, equipping models with capabilities that can be unlocked through lightweight GAN fine-tuning. Supporting this view, we create a one-step generation model by fine-tuning a pre-trained model with 85% of parameters frozen, achieving strong performance with only 0.2M images and near-SOTA results with 5M images. We further present a frequency-domain analysis that may explain the one-step generative capability gained in diffusion training. Overall, our work provides a new perspective for diffusion training, highlighting its role as a powerful generative pre-training process, which can be the basis for building efficient one-step generation models.
扩散蒸馏技术是降低扩散模型采样成本的一种常用技术,但它通常需要大量的训练,且学生模型的性能往往会下降。最近的研究表明,结合GAN目标可以缓解这些问题,但其潜在机制仍不清楚。在这项工作中,我们首先识别了蒸馏的一个关键局限性:教师和学生模型之间的步长不匹配以及参数数量不同导致它们收敛到不同的局部最小值,使得直接模仿变得不优。我们进一步证明,一个独立的GAN目标,在不依赖蒸馏损失的情况下,能够克服这一局限性,并且足以将扩散模型转化为高效的一步生成器。基于这一发现,我们建议将扩散训练视为一种生成预训练的形式,为模型提供能力,这些能力可以通过轻量级的GAN微调来解锁。为了支持这一观点,我们通过冻结预训练模型的85%参数,仅使用微调进行微调来创建一步生成模型,在仅使用0.2M图像的情况下取得了强大的性能,并在使用5M图像时接近SOTA结果。我们还提供了一项频率域分析来解释在扩散训练中获得的单步生成能力。总的来说,我们的工作为扩散训练提供了新的视角,强调了其作为强大的生成预训练过程的作用,这可以成为构建高效一步生成模型的基础。
论文及项目相关链接
PDF ICML 2025
Summary
本文探讨了在扩散模型中使用扩散蒸馏技术降低采样成本时遇到的问题,如训练量大和学生模型性能下降。研究指出,蒸馏技术的关键局限在于教师模型和学生模型在步骤大小和参数数量上的不匹配,导致它们收敛到不同的局部最小值,直接模仿并不理想。研究还发现,仅使用GAN目标而无需依赖蒸馏损失可克服这一局限,足以将扩散模型转化为高效的一步生成器。基于此,本文提出将扩散训练视为一种生成预训练方法,通过轻量级的GAN微调解锁模型能力。通过冻结预训练模型的85%参数进行微调,仅在0.2M图像上即可实现强劲性能,在5M图像上接近最佳结果。同时,还进行了频域分析,以解释在扩散训练中获得的一步生成能力。
Key Takeaways
- 扩散蒸馏在扩散模型中广泛应用,但存在训练量大和学生模型性能下降的问题。
- 蒸馏技术的关键局限在于教师模型和学生模型在步骤大小和参数数量上的不匹配。
- 仅使用GAN目标可克服这一局限,将扩散模型转化为高效的一步生成器。
- 扩散训练可视为一种生成预训练方法,通过轻量级的GAN微调解锁模型能力。
- 通过冻结大部分参数进行微调,可在少量图像上实现强劲性能。
- 提出了频域分析来解释一步生成能力的获得。
点此查看论文截图


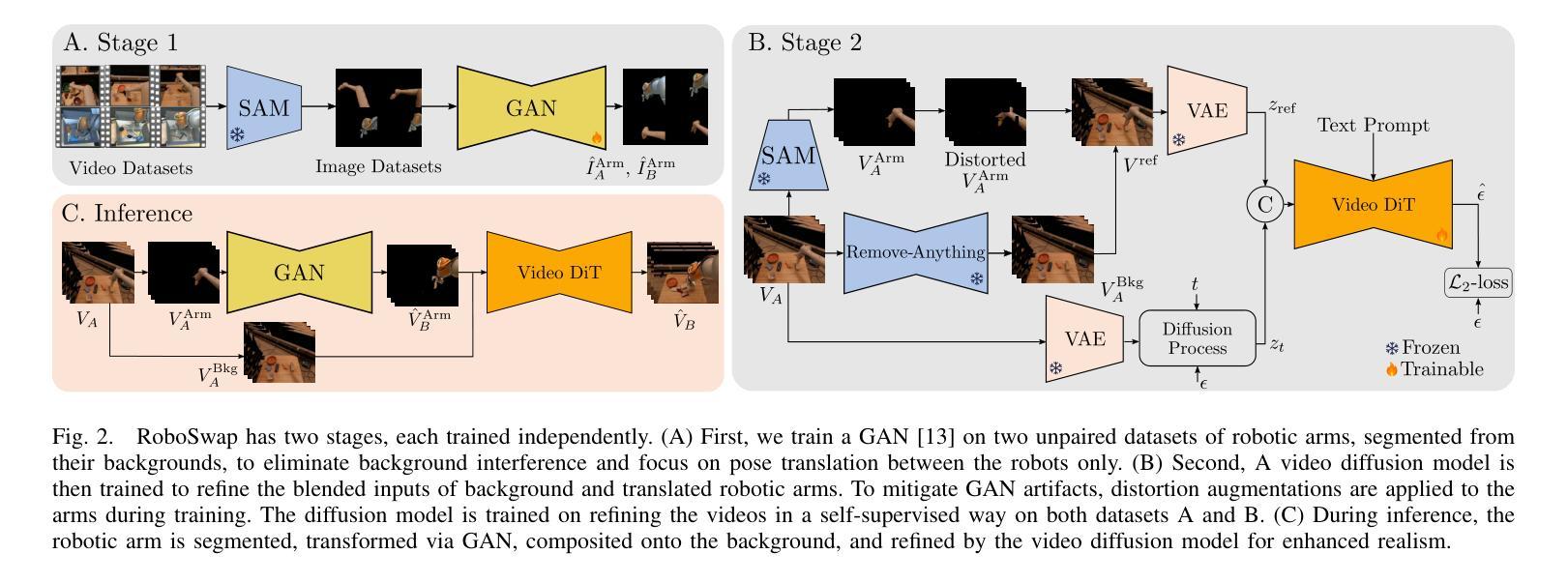
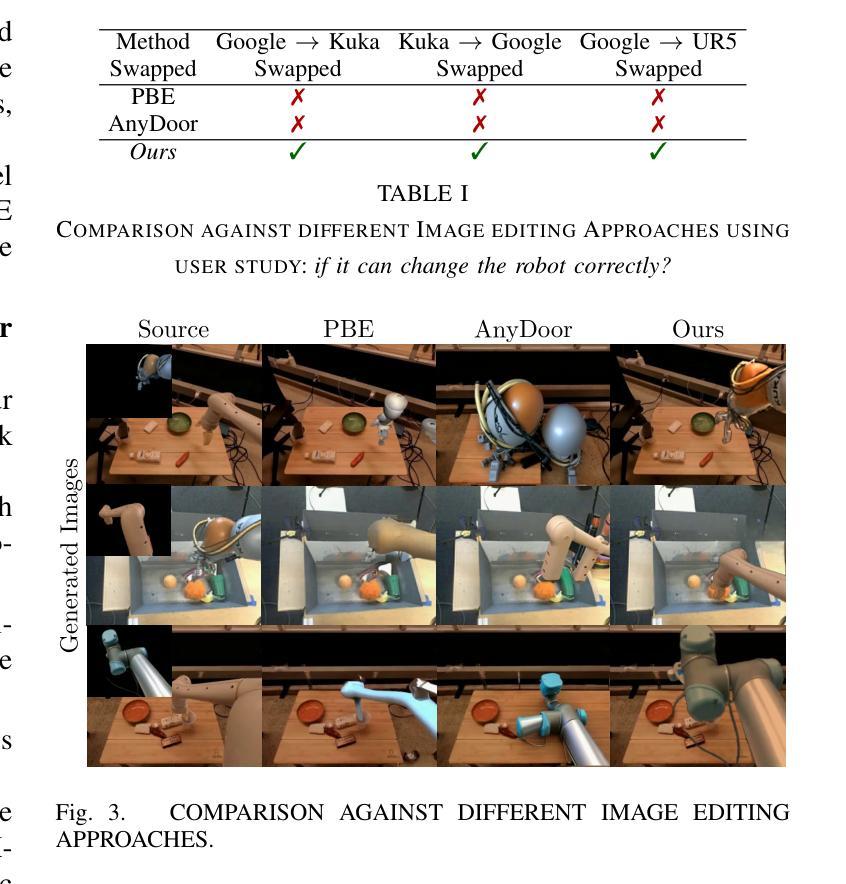
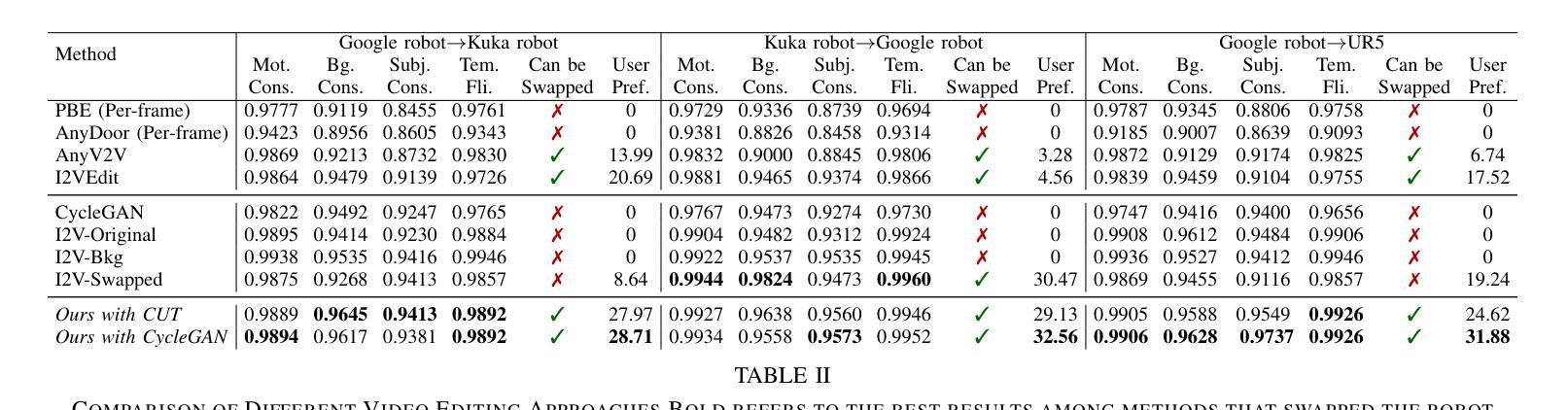
RoboSwap: A GAN-driven Video Diffusion Framework For Unsupervised Robot Arm Swapping
Authors:Yang Bai, Liudi Yang, George Eskandar, Fengyi Shen, Dong Chen, Mohammad Altillawi, Ziyuan Liu, Gitta Kutyniok
Recent advancements in generative models have revolutionized video synthesis and editing. However, the scarcity of diverse, high-quality datasets continues to hinder video-conditioned robotic learning, limiting cross-platform generalization. In this work, we address the challenge of swapping a robotic arm in one video with another: a key step for crossembodiment learning. Unlike previous methods that depend on paired video demonstrations in the same environmental settings, our proposed framework, RoboSwap, operates on unpaired data from diverse environments, alleviating the data collection needs. RoboSwap introduces a novel video editing pipeline integrating both GANs and diffusion models, combining their isolated advantages. Specifically, we segment robotic arms from their backgrounds and train an unpaired GAN model to translate one robotic arm to another. The translated arm is blended with the original video background and refined with a diffusion model to enhance coherence, motion realism and object interaction. The GAN and diffusion stages are trained independently. Our experiments demonstrate that RoboSwap outperforms state-of-the-art video and image editing models on three benchmarks in terms of both structural coherence and motion consistency, thereby offering a robust solution for generating reliable, cross-embodiment data in robotic learning.
近期生成模型的进展为视频合成和编辑带来了革命性的变革。然而,多样且高质量数据集的稀缺仍然阻碍了基于视频条件的机器人学习,限制了跨平台的泛化。在这项工作中,我们解决了在一个视频中用一个机械臂替换另一个机械臂的挑战,这是跨实体学习的重要步骤。不同于以前依赖于相同环境设置中的配对视频演示的方法,我们提出的RoboSwap框架利用来自不同环境的非配对数据,减轻了数据收集的需求。RoboSwap引入了一种新的视频编辑管道,结合了生成对抗网络(GAN)和扩散模型,结合了它们的独立优势。具体来说,我们从背景中分割出机械臂,训练一个非配对GAN模型将一个机械臂转换为另一个机械臂。翻译后的机械臂与原始视频背景混合,并使用扩散模型进行细化,以提高连贯性、运动真实性和对象交互。GAN和扩散阶段是独立训练的。我们的实验表明,RoboSwap在结构连贯性和运动一致性方面优于最先进的视频和图像编辑模型,在三个基准测试上都表现出色,从而为机器人学习中的可靠跨实体数据生成提供了稳健的解决方案。
论文及项目相关链接
Summary
近期生成模型的发展在视频合成和编辑方面带来了革新。然而,缺乏多样、高质量的数据集仍然阻碍着视频条件下的机器人学习,限制了跨平台的通用性。本研究致力于解决在一个视频中将一个机械臂替换为另一个机械臂的挑战,这是跨体态学习的关键步骤。不同于以往依赖于相同环境设置下配对视频示范的方法,我们提出的RoboSwap框架能够在来自不同环境的不配对数据上进行操作,减轻了数据收集的需求。RoboSwap引入了一种新的视频编辑管道,融合了生成对抗网络(GANs)和扩散模型,结合了它们的优势。我们具体分割了机械臂和其背景,训练了一种非配对GAN模型来转换一个机械臂为另一个。翻译的机械臂与原始视频背景混合,并用扩散模型进行精炼,提高了连贯性、运动现实性和物体交互性。GAN和扩散阶段是独立训练的。实验证明,RoboSwap在结构连贯性和运动一致性方面优于现有的视频和图像编辑模型,在三个基准测试中表现突出,为机器人学习中的可靠、跨体态数据生成提供了稳健的解决方案。
Key Takeaways
- 生成模型的新进展已革新视频合成和编辑技术。
- 数据集的多样性和高质量对视频条件下的机器人学习至关重要。
- RoboSwap框架能解决跨体态学习中机械臂替换的挑战。
- RoboSwap采用新型视频编辑管道,结合GANs和扩散模型的优点。
- RoboSwap通过分割机械臂和背景,训练非配对GAN模型实现机械臂转换。
- RoboSwap在结构连贯性和运动一致性方面优于其他模型。
点此查看论文截图