⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-13 更新
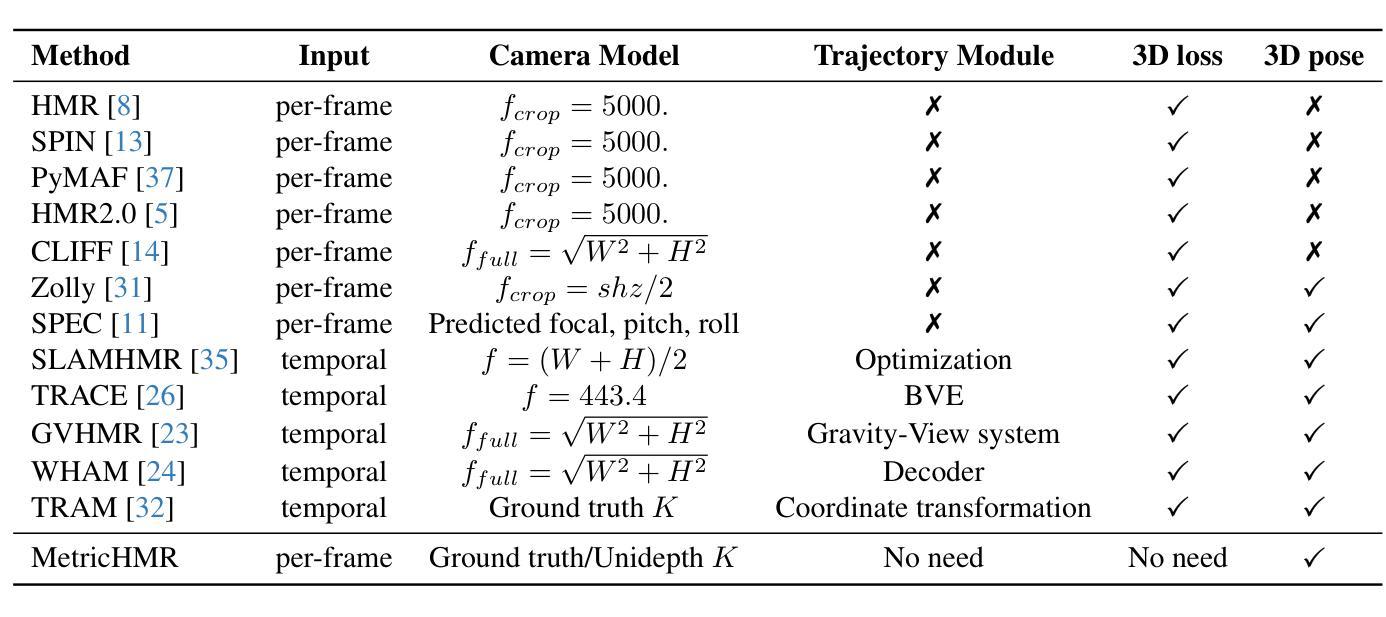
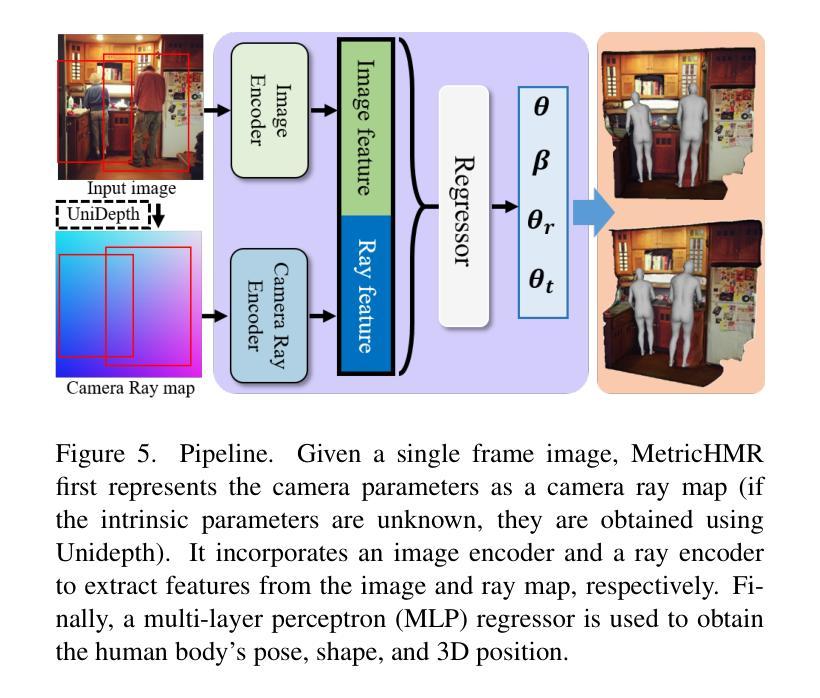
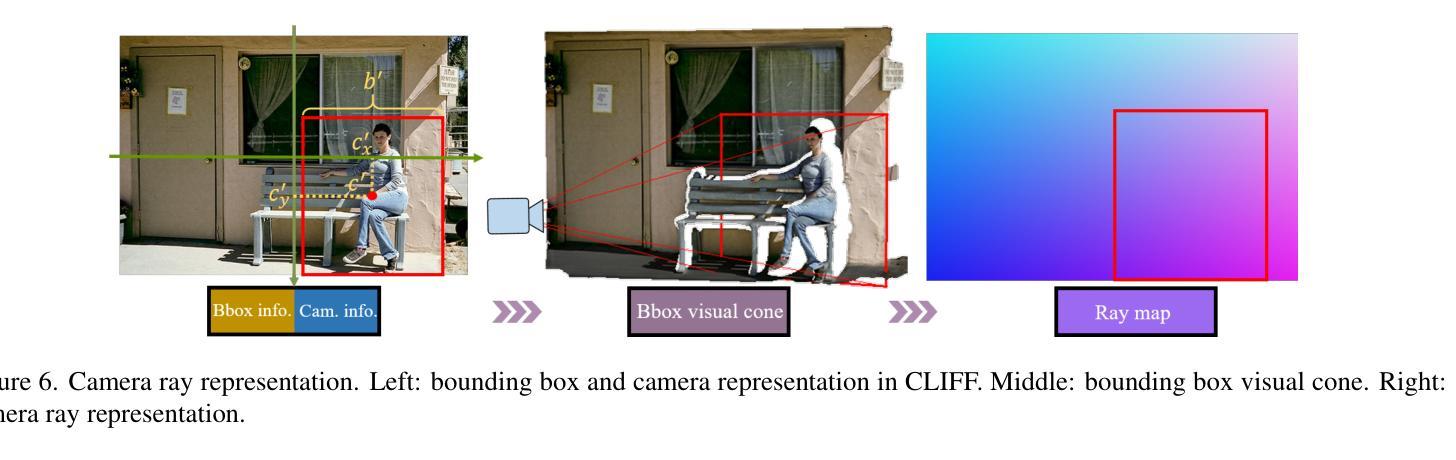
MetricHMR: Metric Human Mesh Recovery from Monocular Images
Authors:He Zhang, Chentao Song, Hongwen Zhang, Tao Yu
We introduce MetricHMR (Metric Human Mesh Recovery), an approach for metric human mesh recovery with accurate global translation from monocular images. In contrast to existing HMR methods that suffer from severe scale and depth ambiguity, MetricHMR is able to produce geometrically reasonable body shape and global translation in the reconstruction results. To this end, we first systematically analyze previous HMR methods on camera models to emphasize the critical role of the standard perspective projection model in enabling metric-scale HMR. We then validate the acceptable ambiguity range of metric HMR under the standard perspective projection model. Finally, we contribute a novel approach that introduces a ray map based on the standard perspective projection to jointly encode bounding-box information, camera parameters, and geometric cues for End2End metric HMR without any additional metric-regularization modules. Extensive experiments demonstrate that our method achieves state-of-the-art performance, even compared with sequential HMR methods, in metric pose, shape, and global translation estimation across both indoor and in-the-wild scenarios.
我们介绍了MetricHMR(度量人体网格恢复)方法,这是一种从单目图像进行精确全局翻译的度量人体网格恢复方法。与现有的受到严重尺度和深度歧义困扰的HMR方法不同,MetricHMR能够在重建结果中产生几何上合理的身体形态和全局平移。为此,我们首先系统地分析了相机模型下的先前HMR方法,以强调标准透视投影模型在启用度量尺度HMR中的关键作用。然后,我们在标准透视投影模型下验证了度量HMR的可接受歧义范围。最后,我们提出了一种基于标准透视投影的射线图方法,该方法可以联合编码边界框信息、相机参数和几何线索,以进行无需任何额外度量正则化模块的端到端度量HMR。大量实验表明,我们的方法在姿态、形状和全局平移估计方面达到了最新性能水平,即使在室内和野外场景中,与序贯HMR方法相比也表现出色。
论文及项目相关链接
Summary
MetricHMR方法是一种从单目图像中进行精确全局翻译的人体网格恢复方法。与现有存在尺度和深度模糊性的HMR方法不同,MetricHMR能够产生几何上合理的人体形状和全局翻译结果。它通过系统分析以前的HMR方法在相机模型上的不足,强调标准透视投影模型在实现Metric-scale HMR中的关键作用。此外,它还引入了一种基于标准透视投影的射线图方法,以联合编码边界框信息、相机参数和几何线索,从而实现端到端的Metric HMR,无需任何额外的度量正则化模块。实验表明,该方法在度量和全球翻译估计方面达到了最先进的技术水平,适用于室内和野外场景。
Key Takeaways
- MetricHMR是一种从单目图像进行人体网格恢复的方法,具有精确的全局翻译能力。
- 与其他HMR方法相比,MetricHMR能够产生几何上合理的结果。
- 标准透视投影模型在实现Metric-scale HMR中起到关键作用。
- MetricHMR通过引入基于标准透视投影的射线图方法,实现了端到端的HMR。
- 该方法不需要额外的度量正则化模块。
- MetricHMR在度量和全球翻译估计方面达到了最先进的技术水平。
- 该方法适用于室内和野外场景。
点此查看论文截图



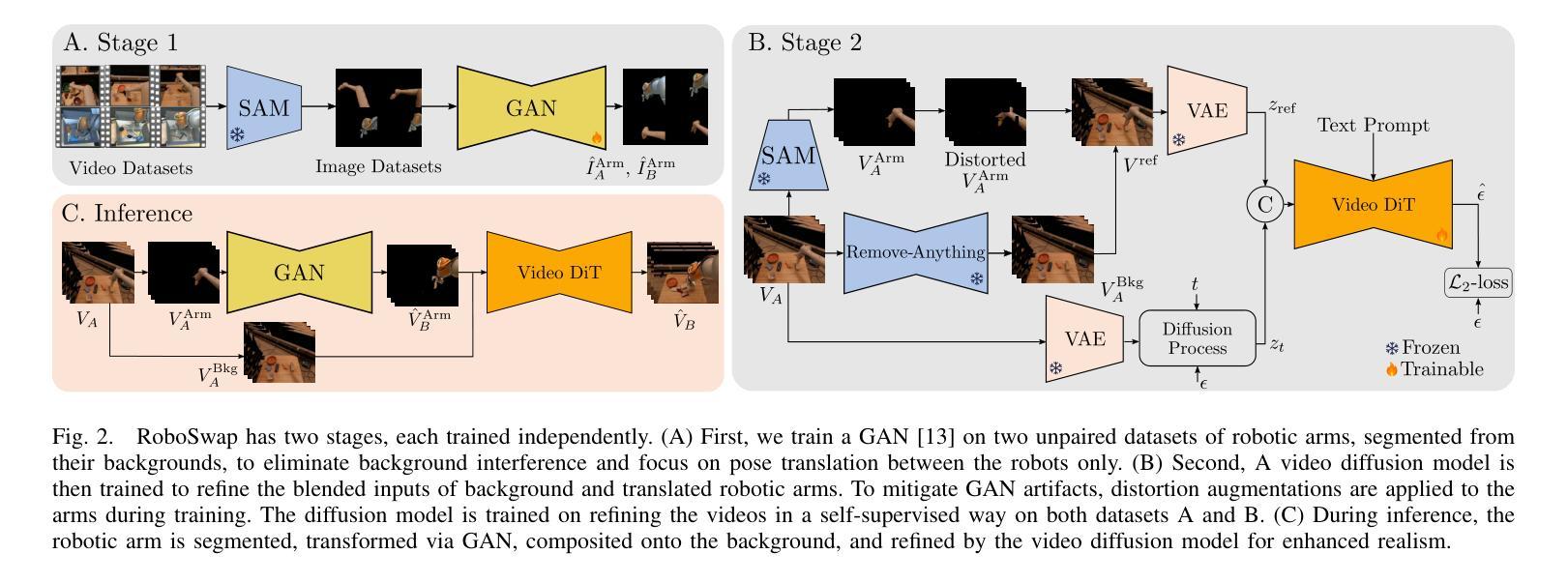
RoboSwap: A GAN-driven Video Diffusion Framework For Unsupervised Robot Arm Swapping
Authors:Yang Bai, Liudi Yang, George Eskandar, Fengyi Shen, Dong Chen, Mohammad Altillawi, Ziyuan Liu, Gitta Kutyniok
Recent advancements in generative models have revolutionized video synthesis and editing. However, the scarcity of diverse, high-quality datasets continues to hinder video-conditioned robotic learning, limiting cross-platform generalization. In this work, we address the challenge of swapping a robotic arm in one video with another: a key step for crossembodiment learning. Unlike previous methods that depend on paired video demonstrations in the same environmental settings, our proposed framework, RoboSwap, operates on unpaired data from diverse environments, alleviating the data collection needs. RoboSwap introduces a novel video editing pipeline integrating both GANs and diffusion models, combining their isolated advantages. Specifically, we segment robotic arms from their backgrounds and train an unpaired GAN model to translate one robotic arm to another. The translated arm is blended with the original video background and refined with a diffusion model to enhance coherence, motion realism and object interaction. The GAN and diffusion stages are trained independently. Our experiments demonstrate that RoboSwap outperforms state-of-the-art video and image editing models on three benchmarks in terms of both structural coherence and motion consistency, thereby offering a robust solution for generating reliable, cross-embodiment data in robotic learning.
近期生成模型的发展为视频合成和编辑带来了革命性的变革。然而,多样且高质量数据集的匮乏仍然阻碍了视频控制下的机器人学习,并限制了跨平台的泛化能力。在这项工作中,我们解决了在一个视频中交换一个机械臂与另一个机械臂的挑战,这是跨机器人学习中的关键步骤。不同于之前依赖于相同环境设置下的配对视频演示的方法,我们提出的RoboSwap框架能从各种环境中处理未配对的数据,减轻了数据收集的需求。RoboSwap引入了一种新型的视频编辑管道,集成了GANs和扩散模型,结合了它们的独立优势。具体来说,我们从背景中分割出机械臂,并训练一个未配对的GAN模型来将一个机械臂转换为另一个机械臂。翻译后的机械臂会与原始视频背景混合,并使用扩散模型进行精炼,以提高连贯性、运动真实性和物体交互性。GAN和扩散阶段是独立训练的。我们的实验表明,RoboSwap在三个基准测试上的表现优于最先进视频和图像编辑模型,在结构连贯性和运动一致性方面都表现出色,从而为机器人学习中的可靠跨机器人数据生成提供了稳健的解决方案。
论文及项目相关链接
Summary
本文介绍了RoboSwap框架在视频合成和编辑领域的创新应用,特别是解决机器人换臂的技术挑战。该框架能够在不同的环境中对未配对数据进行操作,从而减轻了数据收集的负担。通过结合GANs和扩散模型的优势,RoboSwap能够实现对机器人臂的分割、翻译和混合,提高视频的结构连贯性和运动一致性。
Key Takeaways
- RoboSwap框架解决了视频条件下机器人学习的数据瓶颈问题,特别是在多样化和高质量数据集稀缺的情况下。
- 该框架能够在不同的环境中处理未配对数据,降低了数据收集的需求和难度。
- 通过结合生成对抗网络(GANs)和扩散模型的优势,RoboSwap实现了视频编辑的先进功能。
- RoboSwap能够分割机器人臂并翻译到另一个臂,然后将其混合到原始视频背景中。
- 扩散模型的引入提高了视频内容的连贯性、运动真实性和物体交互效果。
- GAN和扩散阶段被独立训练,使得模型更加灵活和可扩展。
点此查看论文截图

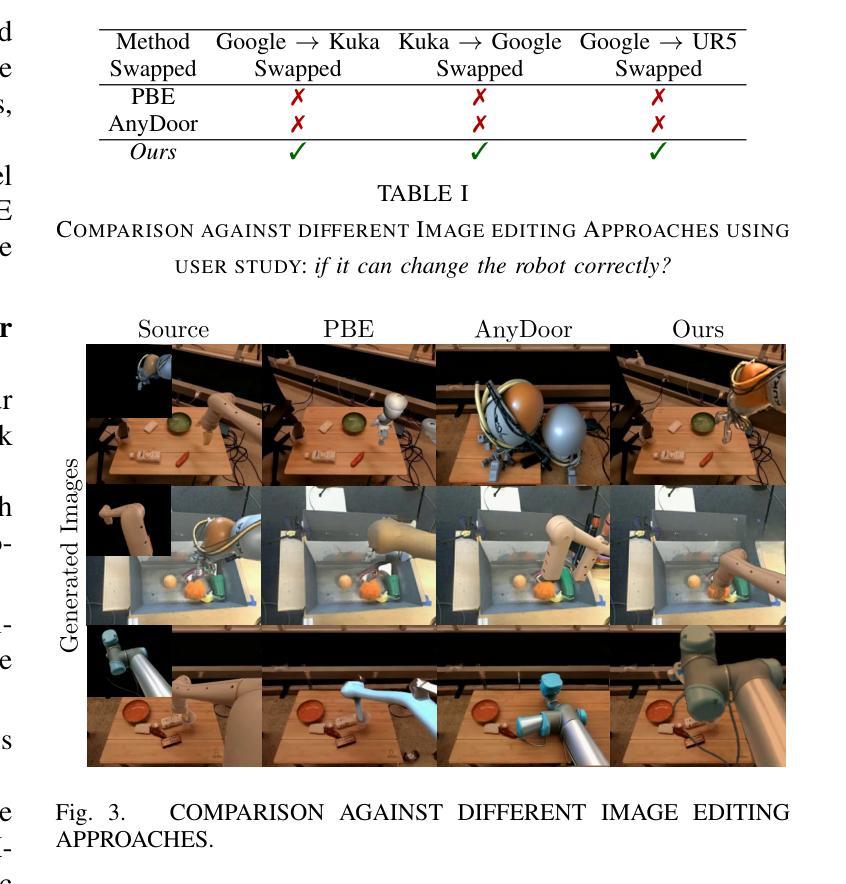


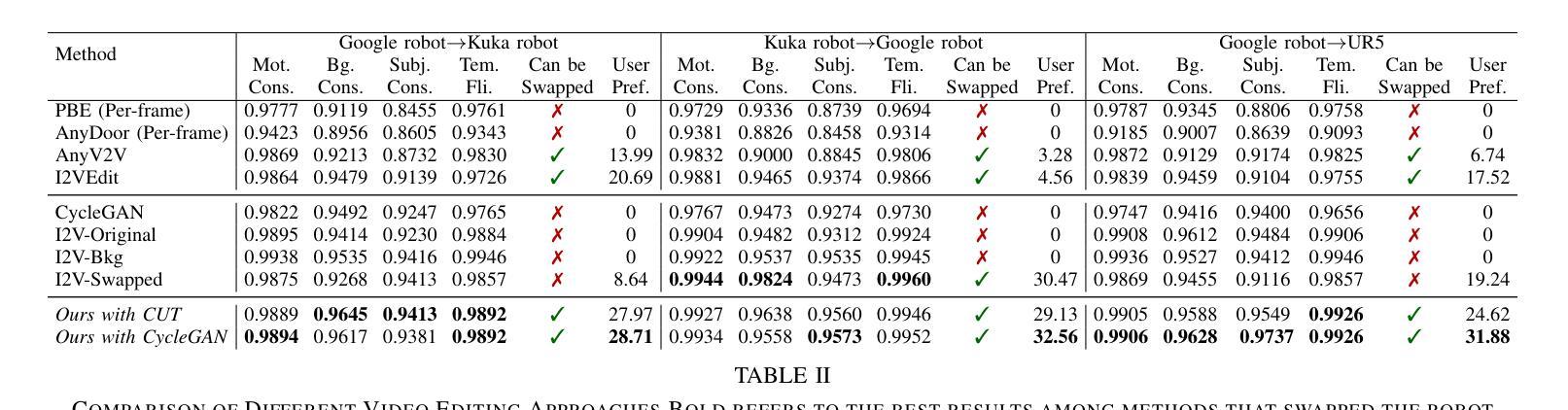
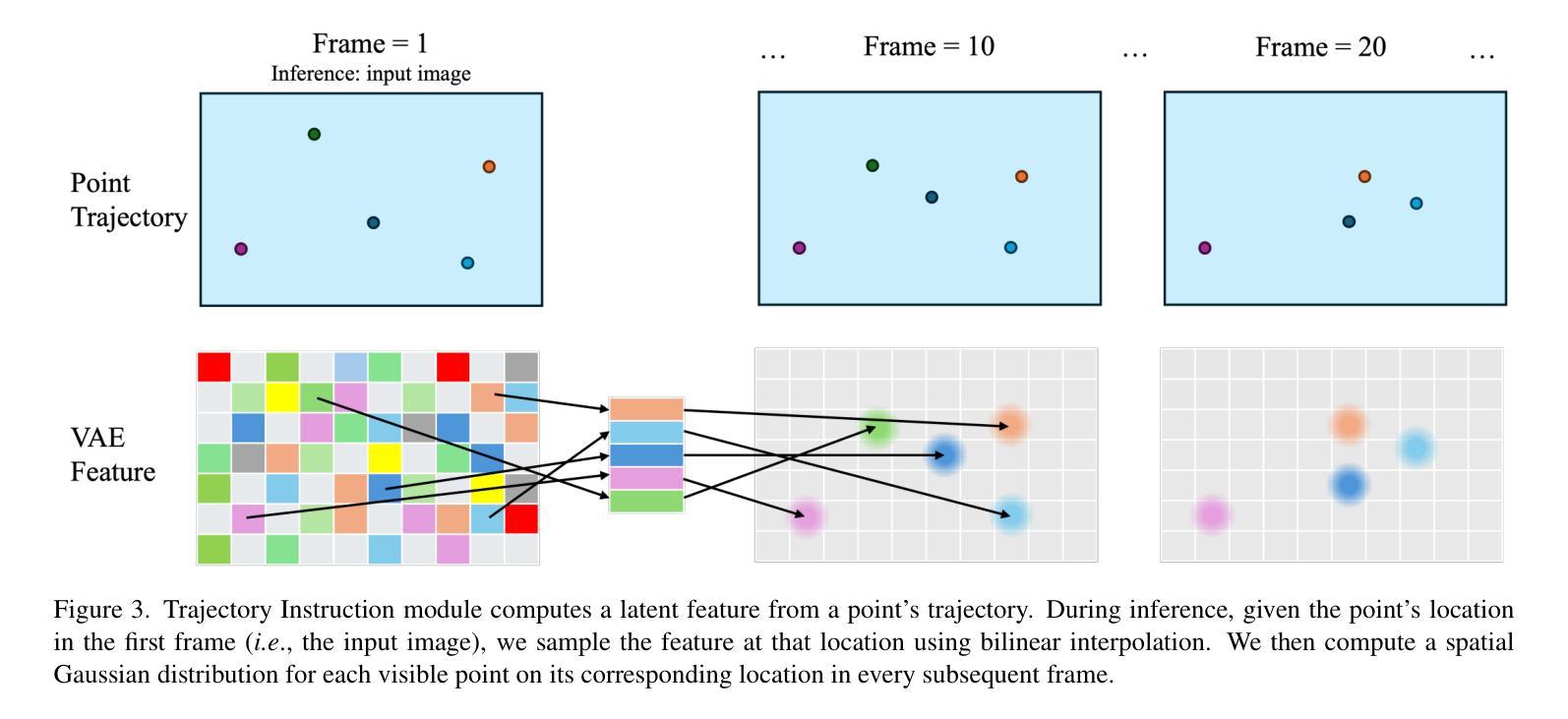
ATI: Any Trajectory Instruction for Controllable Video Generation
Authors:Angtian Wang, Haibin Huang, Jacob Zhiyuan Fang, Yiding Yang, Chongyang Ma
We propose a unified framework for motion control in video generation that seamlessly integrates camera movement, object-level translation, and fine-grained local motion using trajectory-based inputs. In contrast to prior methods that address these motion types through separate modules or task-specific designs, our approach offers a cohesive solution by projecting user-defined trajectories into the latent space of pre-trained image-to-video generation models via a lightweight motion injector. Users can specify keypoints and their motion paths to control localized deformations, entire object motion, virtual camera dynamics, or combinations of these. The injected trajectory signals guide the generative process to produce temporally consistent and semantically aligned motion sequences. Our framework demonstrates superior performance across multiple video motion control tasks, including stylized motion effects (e.g., motion brushes), dynamic viewpoint changes, and precise local motion manipulation. Experiments show that our method provides significantly better controllability and visual quality compared to prior approaches and commercial solutions, while remaining broadly compatible with various state-of-the-art video generation backbones. Project page: https://anytraj.github.io/.
我们提出一种视频生成中的运动控制统一框架,它通过基于轨迹的输入无缝地集成了相机移动、对象级别的翻译和精细的局部运动。与之前通过单独模块或针对特定任务的设计来解决这些运动类型的方法相比,我们的方法通过将一个轻量级的运动注入器投影到预训练图像到视频生成模型的潜在空间中,提供了一个连贯的解决方案。用户可以指定关键点及其运动路径来控制局部变形、整个对象的运动、虚拟相机的动态,或这些的组合。注入的轨迹信号引导生成过程,以产生时间上一致且语义上对齐的运动序列。我们的框架在多个视频运动控制任务中表现出卓越的性能,包括风格化的运动效果(例如,运动刷)、动态视点变化和精确的局部运动操作。实验表明,我们的方法与先前的方法和商业解决方案相比,在可控性和视觉质量方面提供了显著的优势,同时与各种最先进的视频生成主干广泛兼容。项目页面:https://anytraj.github.io/。
论文及项目相关链接
Summary
该文本介绍了一个统一框架,用于视频生成中的运动控制,该框架通过基于轨迹的输入无缝集成摄像机移动、对象级翻译和精细局部运动。与通过单独模块或特定任务设计解决这些运动类型的方法相比,我们的方法提供了一个紧凑的解决方案,通过轻量级运动注入器将用户定义的轨迹投影到预训练图像到视频生成模型的潜在空间中。用户可以通过指定关键点及其运动路径来控制局部变形、整个对象的运动、虚拟相机的动态或这些的组合。注入的轨迹信号引导生成过程,以产生时间上一致且语义上对齐的运动序列。我们的框架在多个视频运动控制任务中表现出卓越的性能,包括风格化的运动效果(如运动刷)、动态视点变化和精确局部运动操纵。实验表明,我们的方法与先前的方法和商业解决方案相比,在可控性和视觉质量方面提供了显著改善,同时与各种最先进的视频生成主干广泛兼容。
Key Takeaways
- 提出了一种统一框架用于视频生成中的运动控制。
- 通过轨迹基于的输入无缝集成了摄像机移动、对象级翻译和精细局部运动。
- 通过轻量级运动注入器,用户定义的轨迹被投影到预训练模型的潜在空间。
- 用户可以控制局部变形、整个对象运动、虚拟相机动态或这些的组合。
- 注入的轨迹信号产生时间上一致且语义上对齐的运动序列。
- 框架在多个视频运动控制任务中表现出卓越性能。
点此查看论文截图


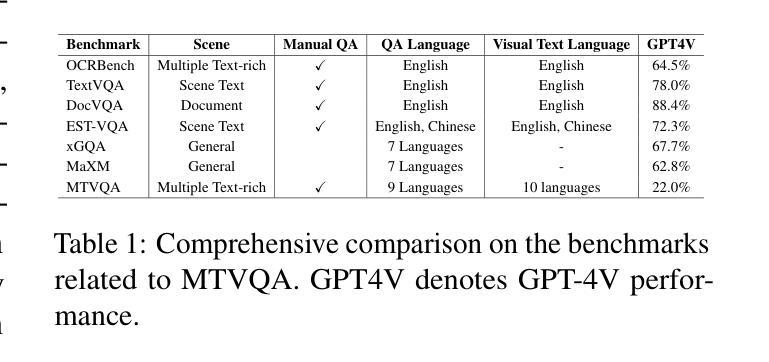
MTVQA: Benchmarking Multilingual Text-Centric Visual Question Answering
Authors:Jingqun Tang, Qi Liu, Yongjie Ye, Jinghui Lu, Shu Wei, Chunhui Lin, Wanqing Li, Mohamad Fitri Faiz Bin Mahmood, Hao Feng, Zhen Zhao, Yangfan He, Kuan Lu, Yanjie Wang, Yuliang Liu, Hao Liu, Xiang Bai, Can Huang
Text-Centric Visual Question Answering (TEC-VQA) in its proper format not only facilitates human-machine interaction in text-centric visual environments but also serves as a de facto gold proxy to evaluate AI models in the domain of text-centric scene understanding. Nonetheless, most existing TEC-VQA benchmarks have focused on high-resource languages like English and Chinese. Despite pioneering works to expand multilingual QA pairs in non-text-centric VQA datasets through translation engines, the translation-based protocol encounters a substantial “visual-textual misalignment” problem when applied to TEC-VQA. Specifically, it prioritizes the text in question-answer pairs while disregarding the visual text present in images. Moreover, it fails to address complexities related to nuanced meaning, contextual distortion, language bias, and question-type diversity. In this work, we tackle multilingual TEC-VQA by introducing MTVQA, the first benchmark featuring high-quality human expert annotations across 9 diverse languages, consisting of 6,778 question-answer pairs across 2,116 images. Further, by comprehensively evaluating numerous state-of-the-art Multimodal Large Language Models~(MLLMs), including Qwen2-VL, GPT-4o, GPT-4V, Claude3, and Gemini, on the MTVQA benchmark, it is evident that there is still a large room for performance improvement (Qwen2-VL scoring 30.9 versus 79.7 for human performance), underscoring the value of MTVQA. Additionally, we supply multilingual training data within the MTVQA dataset, demonstrating that straightforward fine-tuning with this data can substantially enhance multilingual TEC-VQA performance. We aspire that MTVQA will offer the research community fresh insights and stimulate further exploration in multilingual visual text comprehension. The project homepage is available at https://bytedance.github.io/MTVQA/.
文本为中心的视觉问答(TEC-VQA)在适当的形式下,不仅促进了文本为中心的视觉环境中的人机交互,而且还作为评估文本为中心的场景理解领域中AI模型的黄金标准代理。然而,现有的TEC-VQA基准测试主要集中在英语和中文等资源丰富语言上。尽管有开创性的工作通过翻译引擎在非文本为中心的VQA数据集中扩展了多种语言的问答对,但基于翻译的方法在应用于TEC-VQA时遇到了重大的“视觉文本不对齐”问题。具体来说,它优先考虑问答对中的文本,而忽视图像中呈现的视觉文本。此外,它无法解决与细微意义、上下文失真、语言偏见和问题类型多样性相关的复杂性。在这项工作中,我们通过引入MTVQA来解决多种语言的TEC-VQA问题,MTVQA是第一个具有9种不同语言的高质量人类专家注释的基准测试,包含6778个问答对,涉及2116张图像。此外,通过全面评估许多最新的多模态大型语言模型(MLLMs),包括Qwen2-VL、GPT-4o、GPT-4V、Claude3和Gemini在MTVQA基准上的表现,显然还有很大的性能提升空间(Qwen2-VL得分为30.9,而人类性能得分为79.7),这凸显了MTVQA的价值。另外,我们在MTVQA数据集中提供了多语言训练数据,证明使用此数据进行微调可以显著提高多语言TEC-VQA的性能。我们期望MTVQA能为研究社区提供新的见解,并激发多语言视觉文本理解领域的进一步探索。项目主页可在[https://bytedance.github.io/MTVQA/]找到。
论文及项目相关链接
PDF Accepted by ACL 2025 findings
Summary
文本为中心的多语言视觉问答(TEC-VQA)不仅促进了人机在文本为中心视觉环境中的交互,而且作为评估文本为中心场景理解领域AI模型的黄金标准。然而,现有的TEC-VQA基准测试主要集中在英语和中文等高资源语言上。通过引入MTVQA基准测试,我们解决了多语言TEC-VQA中的视觉文本不匹配问题,该基准测试包含9种不同语言的6778个问答对和2116张图像的高质量人类专家注释。评估显示,顶级的多模态大型语言模型仍有待提升(人类性能得分远高于现有模型)。同时,我们的数据支持通过微调提高多语言TEC-VQA性能,并期望为学术界提供新视角和更多探索机会。更多信息请访问我们的项目主页。
Key Takeaways
- 文本为中心视觉问答的重要性: TEC-VQA在促进人机交互和评估AI模型方面扮演重要角色。它不仅需要识别图像中的文字信息,还需理解和解答相关的文本问题。尽管它集中在一些高资源语言上,但对于更广泛的语言和文化交流至关重要。
点此查看论文截图