⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-13 更新
Large Language Models for Toxic Language Detection in Low-Resource Balkan Languages
Authors:Amel Muminovic, Amela Kadric Muminovic
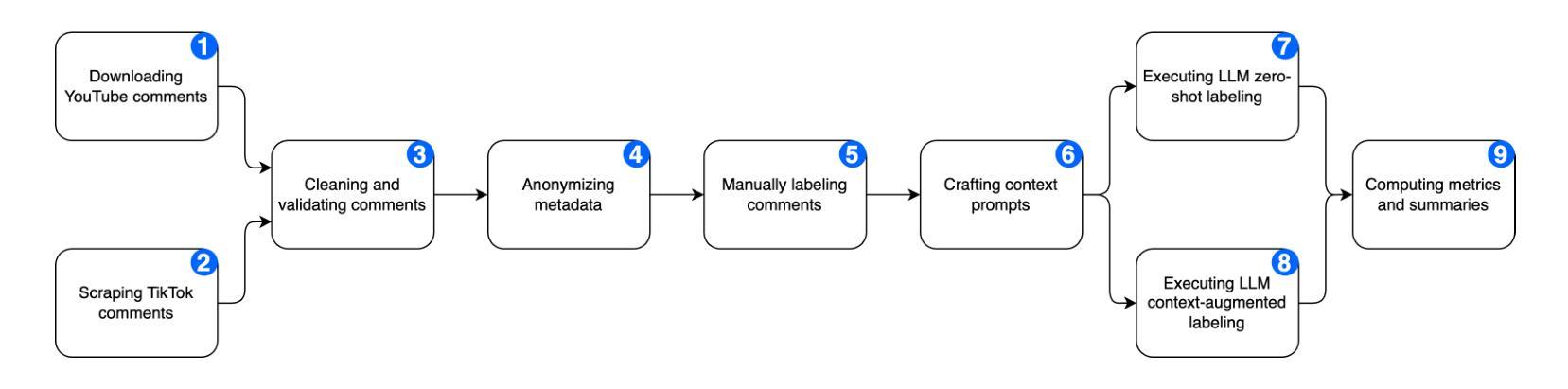
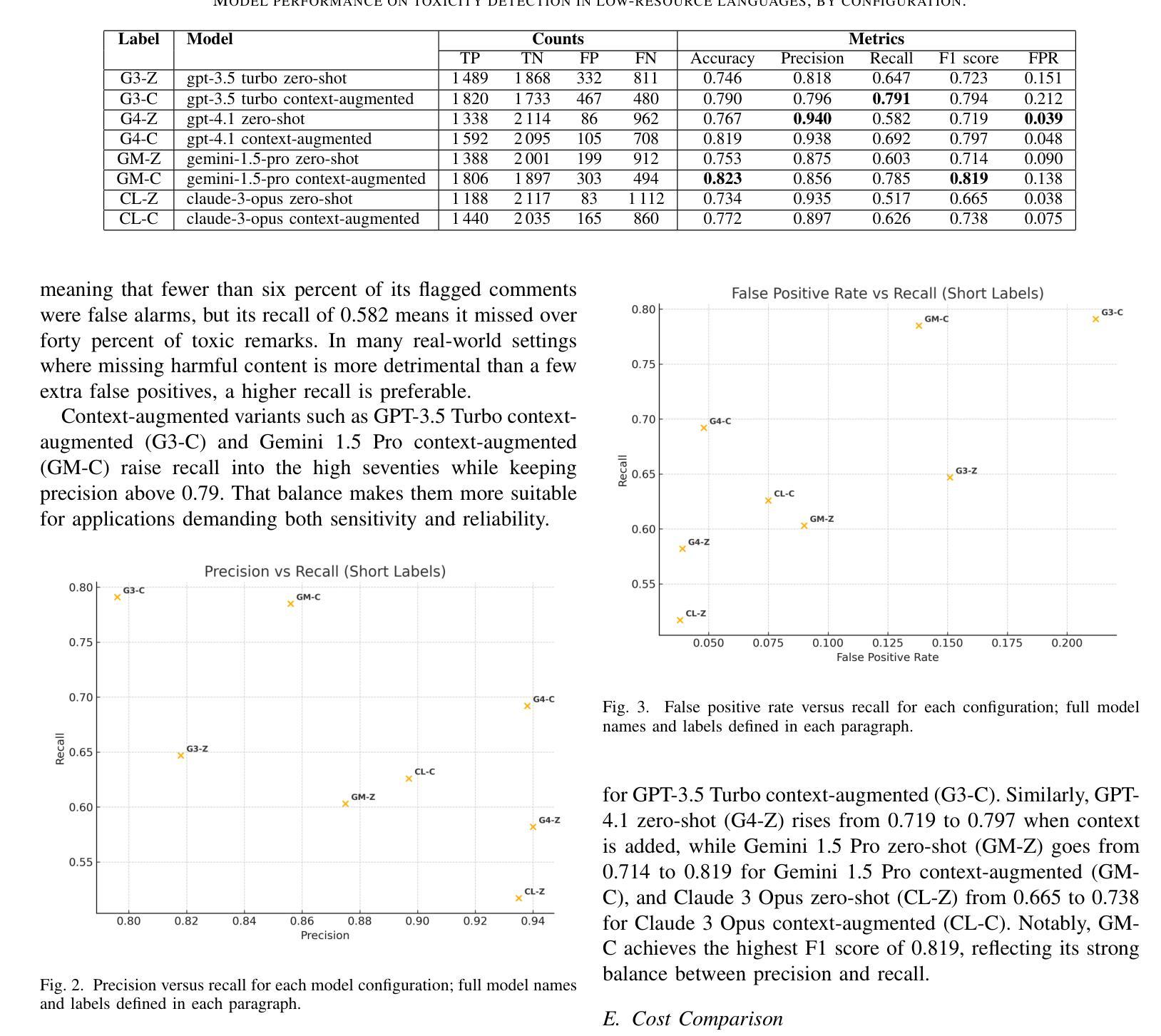
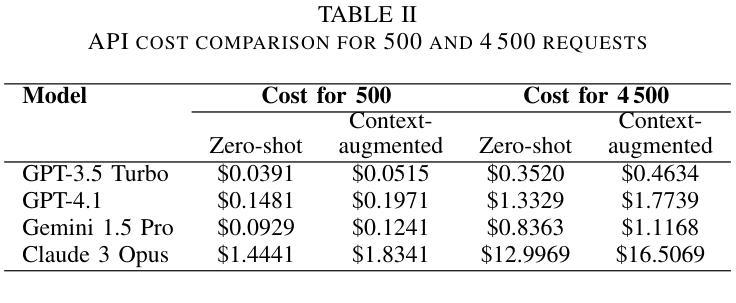
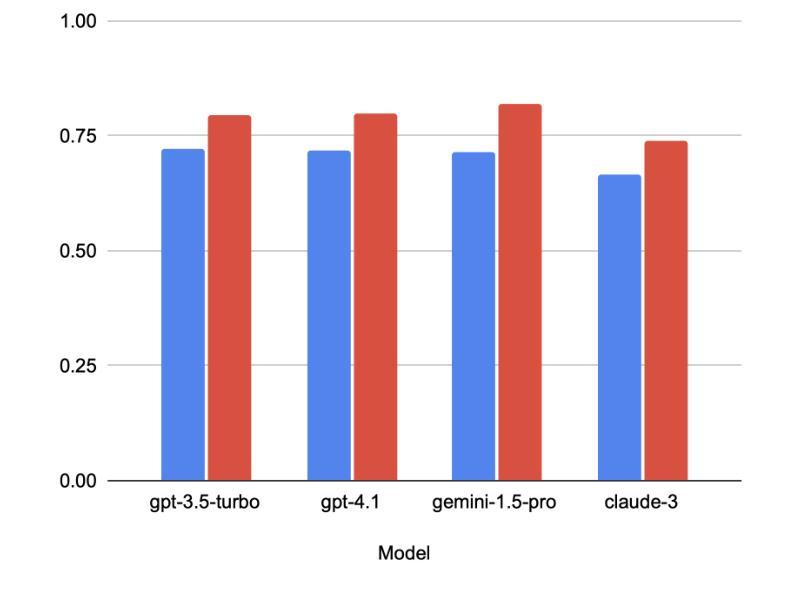
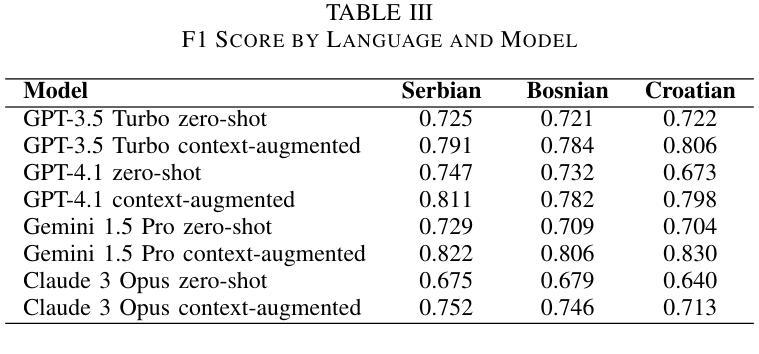
Online toxic language causes real harm, especially in regions with limited moderation tools. In this study, we evaluate how large language models handle toxic comments in Serbian, Croatian, and Bosnian, languages with limited labeled data. We built and manually labeled a dataset of 4,500 YouTube and TikTok comments drawn from videos across diverse categories, including music, politics, sports, modeling, influencer content, discussions of sexism, and general topics. Four models (GPT-3.5 Turbo, GPT-4.1, Gemini 1.5 Pro, and Claude 3 Opus) were tested in two modes: zero-shot and context-augmented. We measured precision, recall, F1 score, accuracy and false positive rates. Including a short context snippet raised recall by about 0.12 on average and improved F1 score by up to 0.10, though it sometimes increased false positives. The best balance came from Gemini in context-augmented mode, reaching an F1 score of 0.82 and accuracy of 0.82, while zero-shot GPT-4.1 led on precision and had the lowest false alarms. We show how adding minimal context can improve toxic language detection in low-resource settings and suggest practical strategies such as improved prompt design and threshold calibration. These results show that prompt design alone can yield meaningful gains in toxicity detection for underserved Balkan language communities.
网络有毒语言会导致真实伤害,特别是在缺乏管理工具的地区。在这项研究中,我们评估大型语言模型如何处理塞尔维亚语、克罗地亚语和波斯尼亚语的有毒评论,这些语言的标记数据有限。我们构建并手动标记了一个包含4500条YouTube和TikTok评论的数据集,这些评论来自音乐、政治、体育、模特、网红内容、性别主义讨论和一般话题等各类视频。我们测试了四种模型(GPT-3.5 Turbo、GPT-4.1、Gemini 1.5 Pro和Claude 3 Opus)在零射模式和增强上下文模式下的表现。我们测量了精确度、召回率、F1分数、准确率和误报率。包含简短上下文片段平均提高了约0.12的召回率,并使F1分数提高了高达0.10,但有时也会增加误报。最佳的平衡来自于增强上下文模式下的Gemini,其F1分数和准确率均达到0.82,而零射模式下的GPT-4.1在精确度上领先,并且误报率最低。我们展示了如何在资源有限的环境中通过添加最少的上下文来改善有毒语言检测,并提出了一些实用策略,如改进提示设计和阈值校准。这些结果表明,仅凭提示设计就可以在检测对巴尔干地区服务不足的语言社区的有毒性方面取得有意义的效果。
论文及项目相关链接
PDF 8 pages
Summary:
本研究评估了大型语言模型在处理塞尔维亚语、克罗地亚语和波斯尼亚语的毒性评论时的表现。研究者手动标注了一个包含4500条YouTube和TikTok评论的数据集,测试了四种模型在零样本和上下文增强模式下的性能。结果显示,添加上下文片段可以提高召回率和F1分数,但也会增加误报。Gemini在上下文增强模式下表现最佳,F1分数和准确率均达到0.82。研究结果表明,添加最小量的上下文可以改善低资源环境下的有毒语言检测,提示设计良好的提示和阈值校准等实用策略可以带来有意义的有毒性检测增益,对巴尔干语族的社区尤为关键。
Key Takeaways:
- 大型语言模型在处理低资源环境的毒性语言时的挑战。
- 手动标注的数据集用于评估模型性能。
- 上下文片段的添加可以提高模型的召回率和F1分数。
- Gemini在上下文增强模式下表现最佳。
- 添加最小量的上下文能显著提升有毒语言检测的准确性。
- 良好的提示设计和阈值校准能提高毒性检测的增益。
点此查看论文截图

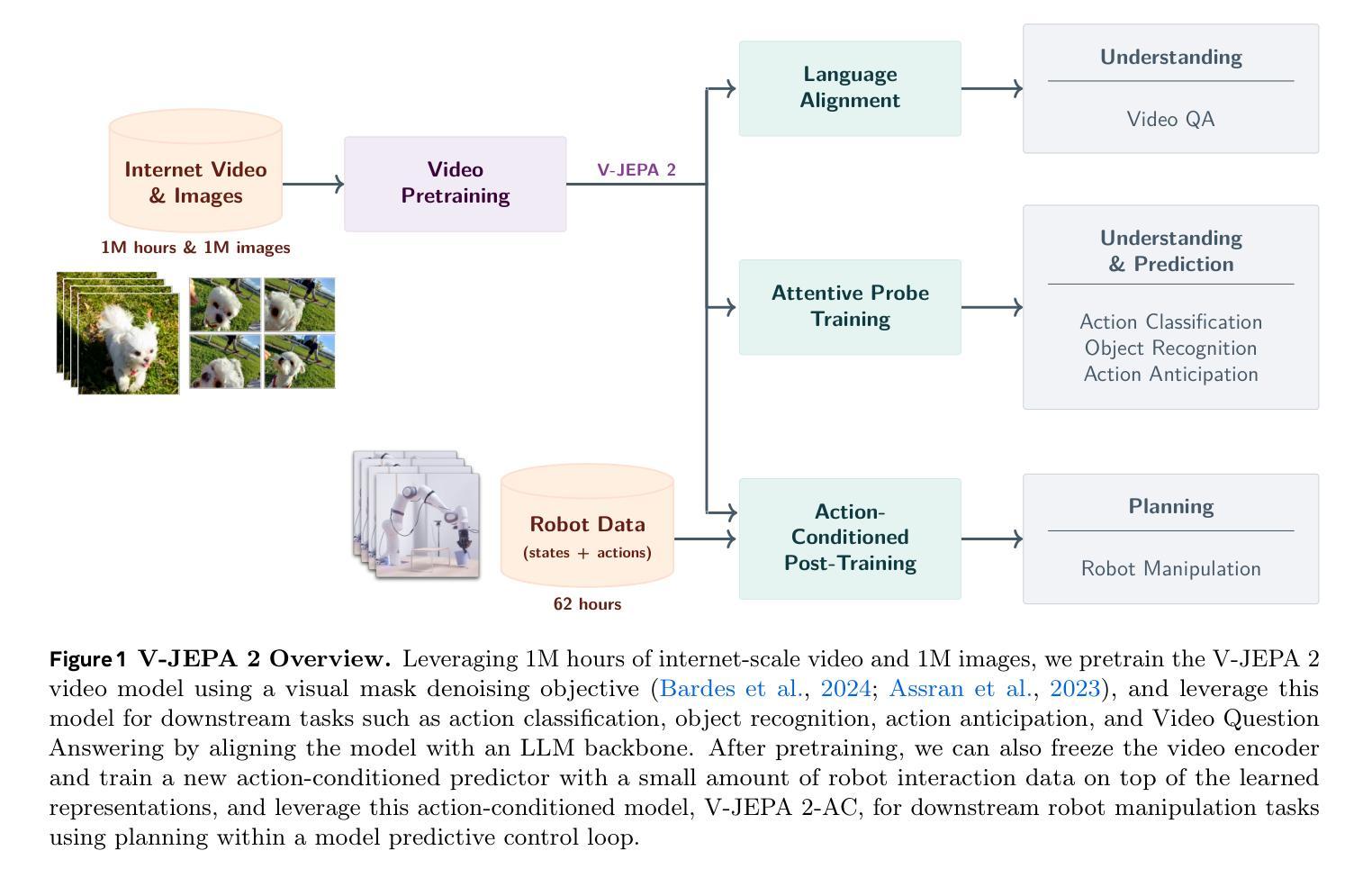
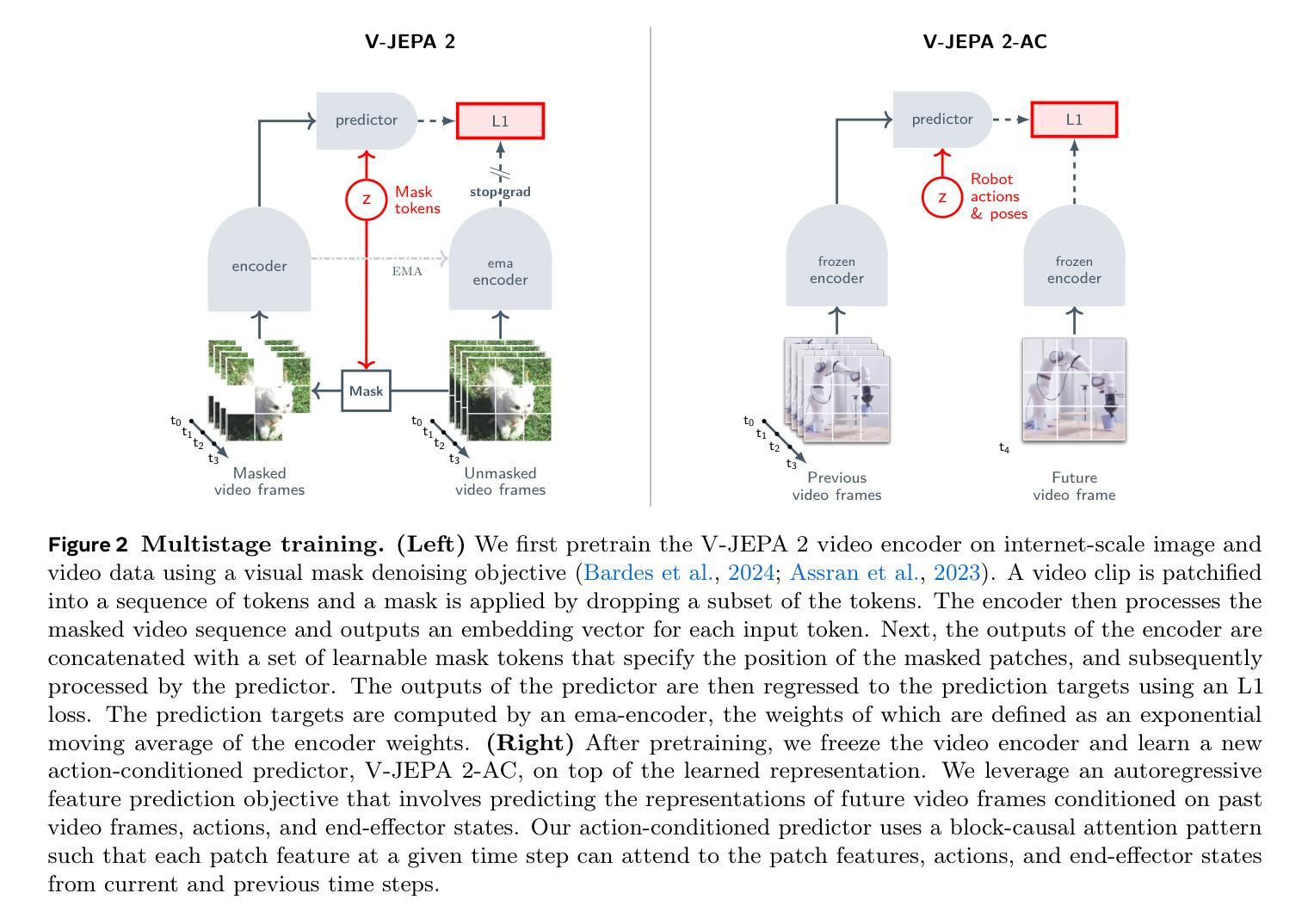
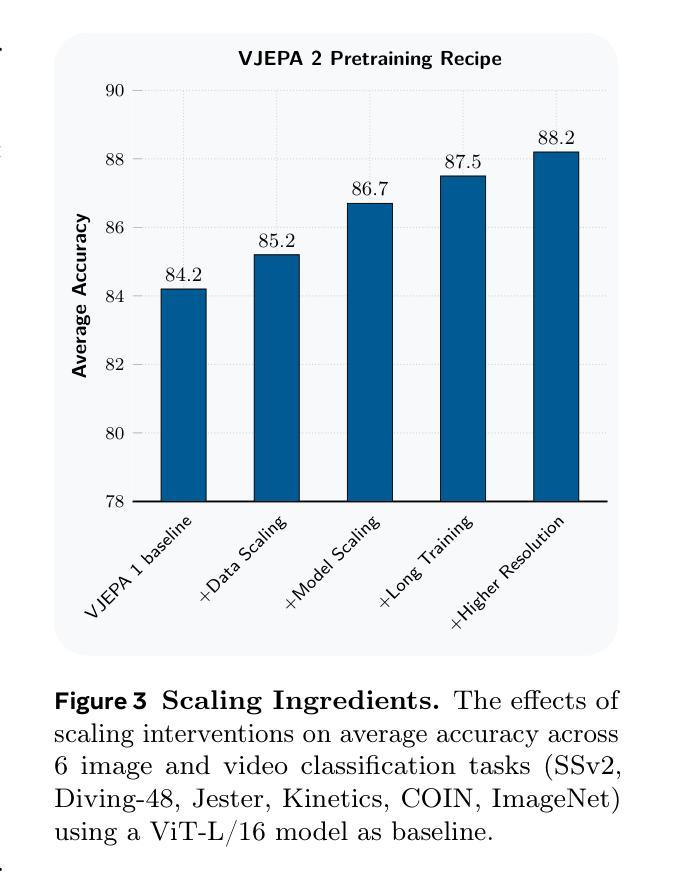
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Authors:Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba, Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, Sergio Arnaud, Abha Gejji, Ada Martin, Francois Robert Hogan, Daniel Dugas, Piotr Bojanowski, Vasil Khalidov, Patrick Labatut, Francisco Massa, Marc Szafraniec, Kapil Krishnakumar, Yong Li, Xiaodong Ma, Sarath Chandar, Franziska Meier, Yann LeCun, Michael Rabbat, Nicolas Ballas
A major challenge for modern AI is to learn to understand the world and learn to act largely by observation. This paper explores a self-supervised approach that combines internet-scale video data with a small amount of interaction data (robot trajectories), to develop models capable of understanding, predicting, and planning in the physical world. We first pre-train an action-free joint-embedding-predictive architecture, V-JEPA 2, on a video and image dataset comprising over 1 million hours of internet video. V-JEPA 2 achieves strong performance on motion understanding (77.3 top-1 accuracy on Something-Something v2) and state-of-the-art performance on human action anticipation (39.7 recall-at-5 on Epic-Kitchens-100) surpassing previous task-specific models. Additionally, after aligning V-JEPA 2 with a large language model, we demonstrate state-of-the-art performance on multiple video question-answering tasks at the 8 billion parameter scale (e.g., 84.0 on PerceptionTest, 76.9 on TempCompass). Finally, we show how self-supervised learning can be applied to robotic planning tasks by post-training a latent action-conditioned world model, V-JEPA 2-AC, using less than 62 hours of unlabeled robot videos from the Droid dataset. We deploy V-JEPA 2-AC zero-shot on Franka arms in two different labs and enable picking and placing of objects using planning with image goals. Notably, this is achieved without collecting any data from the robots in these environments, and without any task-specific training or reward. This work demonstrates how self-supervised learning from web-scale data and a small amount of robot interaction data can yield a world model capable of planning in the physical world.
现代人工智能面临的一个主要挑战是学会通过大量的观察理解世界并采取行动。本文探索了一种自监督方法,它结合了互联网规模的视频数据和小量的交互数据(机器人轨迹),以开发能够在物理世界中理解、预测和规划模型。我们首先在一个包含超过一百万小时互联网视频的视频和图像数据集上,对无动作联合嵌入预测架构V-JEPA 2进行预训练。V-JEPA 2在运动理解方面表现出强大的性能(在Something-Something v2上达到77.3%的top-1准确率),并在人类行为预测方面达到了最先进的性能(在Epic-Kitchens-100上的召回率为39.7%)。此外,在与大型语言模型对齐后,我们在参数规模为8亿的多个视频问答任务上表现出了最先进的性能(例如,PerceptionTest上为84.0%,TempCompass上为76.9%)。最后,我们展示了如何通过事后训练潜在的动作条件世界模型V-JEPA 2-AC,将自监督学习应用于机器人规划任务。我们使用来自Droid数据集的不到62小时的无标签机器人视频对V-JEPA 2-AC进行训练,然后将其零射击部署在Franka机械臂上,在两个不同的实验室环境中实现了基于图像目标的物体抓取和放置。值得注意的是,这无需从环境中的机器人收集任何数据,也无需任何特定任务的训练或奖励。这项工作展示了如何从互联网规模的数据和少量的机器人交互数据中通过自监督学习获得能够在物理世界中规划的世界模型。
论文及项目相关链接
PDF 48 pages, 19 figures
摘要
利用互联网规模视频数据和小量交互数据(机器人轨迹),通过自监督学习方法,发展出能够理解和预测物理世界的模型。预训练的V-JEPA 2模型在动作理解和人类行动预期方面表现出强大性能,与大型语言模型对齐后,在视频问答任务上表现出最新技术水平。此外,通过在后训练中使用机器人视频数据,我们展示了自监督学习在机器人规划任务中的应用。这项工作展示了如何从互联网规模数据和少量机器人交互数据中学习世界模型,并能够在物理世界中规划行动。
关键见解
- 现代AI面临的主要挑战是通过观察学习理解世界和采取行动。
- 研究采用自监督方法,结合互联网规模视频数据与少量交互数据(机器人轨迹)。
- V-JEPA 2模型在动作理解和人类行动预期方面表现出强大的性能。
- 与大型语言模型对齐后,V-JEPA 2在视频问答任务上达到最新技术水平。
- 通过使用机器人视频数据的后训练,展示了自监督学习在机器人规划任务中的应用。
- V-JEPA 2模型能够在不同的物理环境中实现零样本物体抓取和放置。
点此查看论文截图

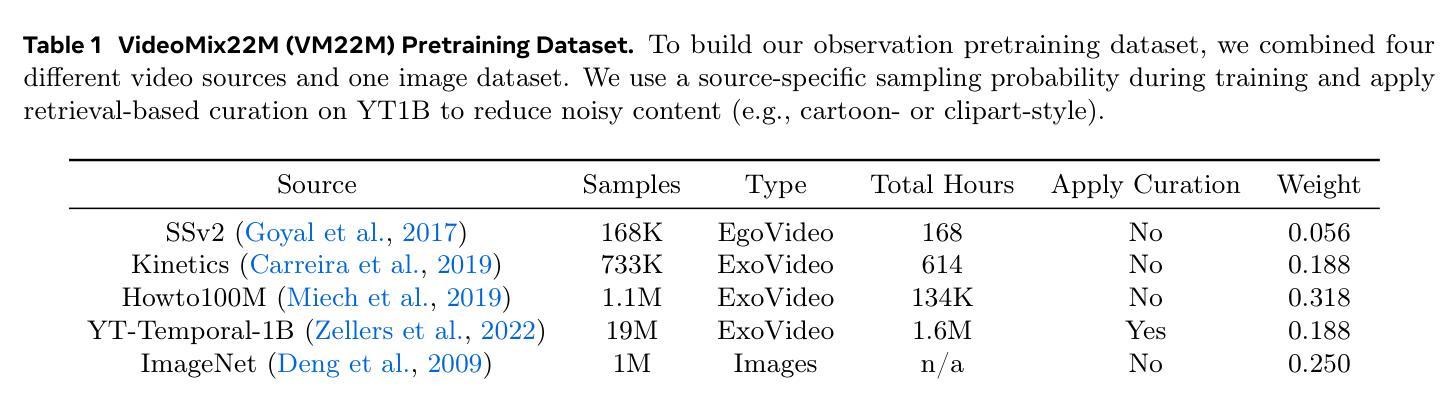
TOGA: Temporally Grounded Open-Ended Video QA with Weak Supervision
Authors:Ayush Gupta, Anirban Roy, Rama Chellappa, Nathaniel D. Bastian, Alvaro Velasquez, Susmit Jha
We address the problem of video question answering (video QA) with temporal grounding in a weakly supervised setup, without any temporal annotations. Given a video and a question, we generate an open-ended answer grounded with the start and end time. For this task, we propose TOGA: a vision-language model for Temporally Grounded Open-Ended Video QA with Weak Supervision. We instruct-tune TOGA to jointly generate the answer and the temporal grounding. We operate in a weakly supervised setup where the temporal grounding annotations are not available. We generate pseudo labels for temporal grounding and ensure the validity of these labels by imposing a consistency constraint between the question of a grounding response and the response generated by a question referring to the same temporal segment. We notice that jointly generating the answers with the grounding improves performance on question answering as well as grounding. We evaluate TOGA on grounded QA and open-ended QA tasks. For grounded QA, we consider the NExT-GQA benchmark which is designed to evaluate weakly supervised grounded question answering. For open-ended QA, we consider the MSVD-QA and ActivityNet-QA benchmarks. We achieve state-of-the-art performance for both tasks on these benchmarks.
我们解决了在弱监督设置下带有时间定位的视频问答(Video QA)问题,而无需任何时间注释。给定一个视频和一个问题,我们生成一个基于开始和结束时间的开放式答案。为此任务,我们提出了TOGA:一个用于带有时间定位的开放式视频问答的视听语言模型,该模型在弱监督下进行训练。我们指导并调整TOGA以联合生成答案和时间定位。我们在没有时间定位注释的弱监督设置中进行操作。我们为时间定位生成伪标签,并通过在定位响应的问题和针对同一时间段的响应之间施加一致性约束来确保这些标签的有效性。我们发现联合生成答案和定位可以提高问答和定位的性能。我们在定位问答和开放式问答任务上评估了TOGA。对于定位问答,我们考虑了NExT-GQA基准测试,该测试旨在评估弱监督下的定位问答。对于开放式问答,我们考虑了MSVD-QA和活动网QA基准测试。我们在这些基准测试上的这两项任务中都达到了最先进的性能。
论文及项目相关链接
Summary
视频问答中的时序定位问题可在无时序标注的弱监督设置下解决。给定视频和问题,我们生成基于起始和结束时间的开放答案。为此任务,我们提出TOGA模型,该模型在弱监督下联合生成答案和时序定位。通过生成时序定位伪标签并确保标签与问题的一致性约束来提高标签的有效性。联合生成答案和定位提高了问答和定位性能。我们在基准测试上评估了TOGA的性能,包括有依据的QA和开放式的QA任务,取得了显著的成绩。
Key Takeaways
- 该研究解决了视频问答中的时序定位问题,在无时序标注的弱监督环境下进行。
- 提出TOGA模型,用于在弱监督环境下联合生成答案和时序定位。
- 生成时序定位的伪标签并通过一致性约束来保证标签的有效性。
- 联合生成答案和定位提高了问答和定位的性能。
- 在基准测试上评估了TOGA模型在有依据的QA和开放式的QA任务上的性能。
- 在NExT-GQA、MSVD-QA和ActivityNet-QA等基准测试上取得了显著的成绩。
点此查看论文截图

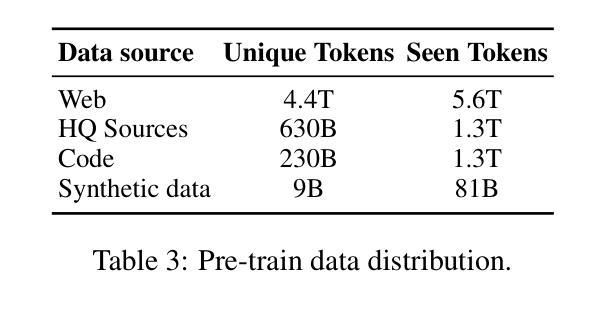
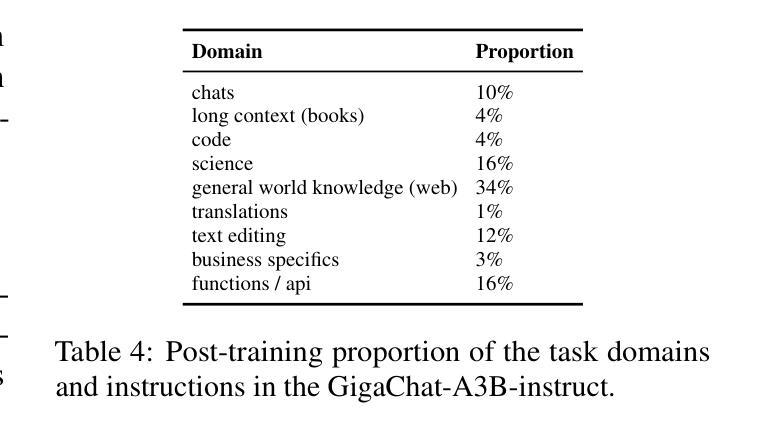
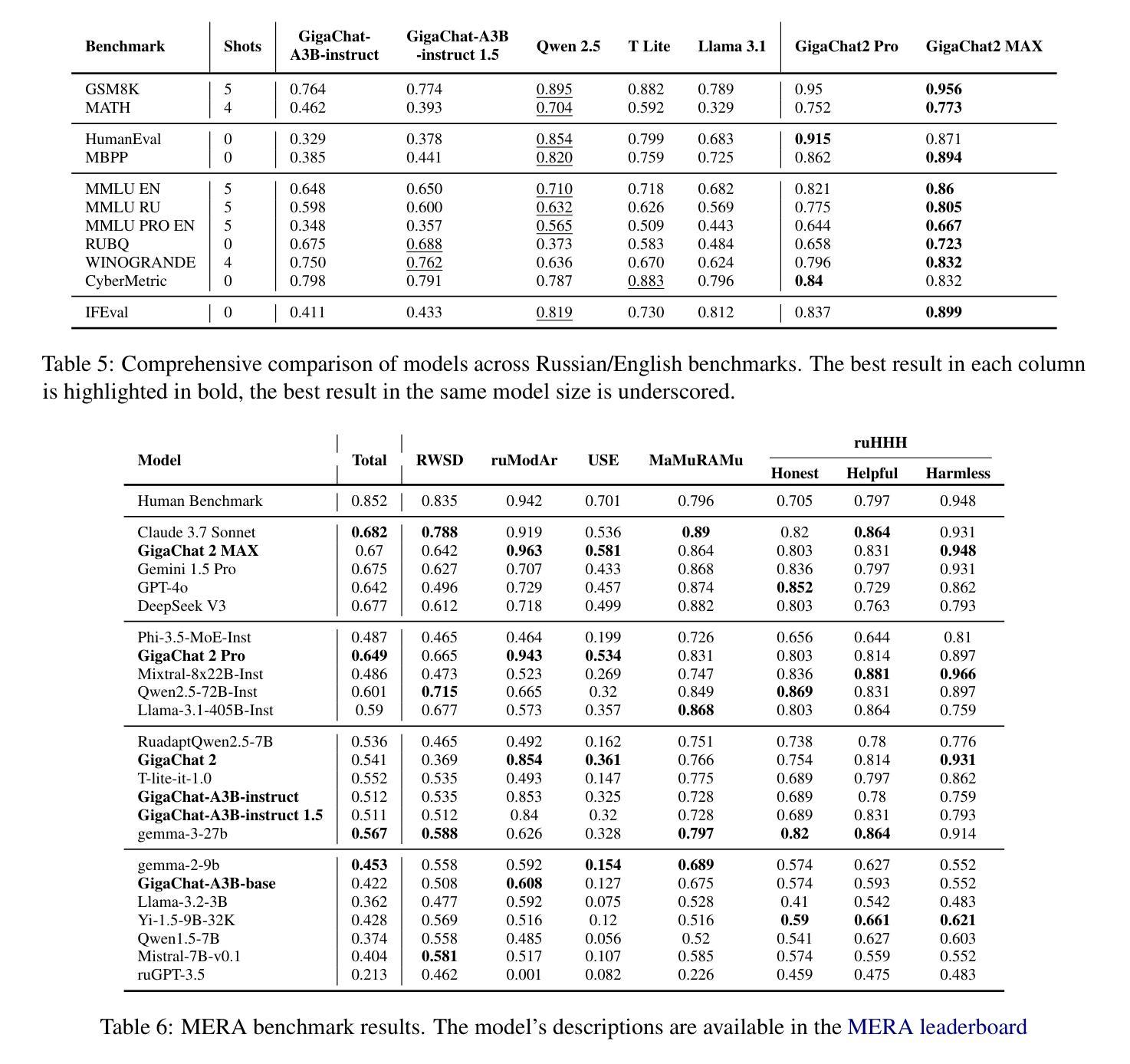
GigaChat Family: Efficient Russian Language Modeling Through Mixture of Experts Architecture
Authors: GigaChat team, Mamedov Valentin, Evgenii Kosarev, Gregory Leleytner, Ilya Shchuckin, Valeriy Berezovskiy, Daniil Smirnov, Dmitry Kozlov, Sergei Averkiev, Lukyanenko Ivan, Aleksandr Proshunin, Ainur Israfilova, Ivan Baskov, Artem Chervyakov, Emil Shakirov, Mikhail Kolesov, Daria Khomich, Darya Latortseva, Sergei Porkhun, Yury Fedorov, Oleg Kutuzov, Polina Kudriavtseva, Sofiia Soldatova, Kolodin Egor, Stanislav Pyatkin, Dzmitry Menshykh, Grafov Sergei, Eldar Damirov, Karlov Vladimir, Ruslan Gaitukiev, Arkadiy Shatenov, Alena Fenogenova, Nikita Savushkin, Fedor Minkin
Generative large language models (LLMs) have become crucial for modern NLP research and applications across various languages. However, the development of foundational models specifically tailored to the Russian language has been limited, primarily due to the significant computational resources required. This paper introduces the GigaChat family of Russian LLMs, available in various sizes, including base models and instruction-tuned versions. We provide a detailed report on the model architecture, pre-training process, and experiments to guide design choices. In addition, we evaluate their performance on Russian and English benchmarks and compare GigaChat with multilingual analogs. The paper presents a system demonstration of the top-performing models accessible via an API, a Telegram bot, and a Web interface. Furthermore, we have released three open GigaChat models in open-source (https://huggingface.co/ai-sage), aiming to expand NLP research opportunities and support the development of industrial solutions for the Russian language.
生成式大型语言模型(LLM)已成为现代多语言NLP研究与应用的核心。然而,针对俄语特别定制的基础模型开发受到限制,主要是由于所需的大量计算资源。本文介绍了GigaChat系列俄语LLM,该系列模型有基本模型和指令调整版本,提供多种大小可选。我们详细报告了模型架构、预训练过程和实验,以指导设计选择。此外,我们评估了它们在俄语和英语基准测试上的表现,并将GigaChat与多语种类似模型进行了比较。本文展示了通过API、Telegram机器人和Web界面访问的最佳模型的系统演示。此外,我们在开源平台(https://huggingface.co/ai-sage)上发布了三个开源GigaChat模型,旨在扩大NLP研究机会并支持俄语工业解决方案的开发。
论文及项目相关链接
PDF ACL-2025 System Demo
Summary
本文介绍了针对俄语开发的GigaChat系列大型生成式语言模型(LLM)。文章详细描述了模型架构、预训练过程和实验设计选择,并评估了其在俄语和英语基准测试上的性能表现。此外,还展示了GigaChat模型的高级表现并通过API、Telegram bot和Web界面进行演示。本文还公布了三个开源的GigaChat模型,旨在扩展NLP研究机会并支持俄语工业解决方案的开发。
Key Takeaways
- GigaChat系列是专门为俄语设计的大型生成式语言模型(LLM)。
- 文章详细阐述了GigaChat的模型架构、预训练过程以及实验设计选择。
- GigaChat模型在俄语和英语基准测试上表现出良好性能。
- GigaChat模型可以通过API、Telegram bot和Web界面进行访问和使用。
- 公开了三个开源的GigaChat模型,旨在支持NLP研究及俄语工业解决方案开发。
- GigaChat系列模型包括基础模型和指令微调版本,可满足不同的应用需求。
点此查看论文截图



Towards Efficient and Effective Alignment of Large Language Models
Authors:Yuxin Jiang
Large language models (LLMs) exhibit remarkable capabilities across diverse tasks, yet aligning them efficiently and effectively with human expectations remains a critical challenge. This thesis advances LLM alignment by introducing novel methodologies in data collection, training, and evaluation. We first address alignment data collection. Existing approaches rely heavily on manually curated datasets or proprietary models. To overcome these limitations, we propose Lion, an adversarial distillation framework that iteratively refines training data by identifying and generating challenging instructions, enabling state-of-the-art zero-shot reasoning. Additionally, we introduce Web Reconstruction (WebR), a fully automated framework that synthesizes instruction-tuning data directly from raw web documents, significantly improving data diversity and scalability over existing synthetic data methods. Next, we enhance alignment training through novel optimization techniques. We develop Learning to Edit (LTE), a framework that enables LLMs to efficiently integrate new knowledge while preserving existing information. LTE leverages meta-learning to improve both real-time and batch knowledge updates. Furthermore, we introduce Bridging and Modeling Correlations (BMC), a refinement of Direct Preference Optimization (DPO) that explicitly captures token-level correlations in preference data, leading to superior alignment across QA and mathematical reasoning tasks. Finally, we tackle the challenge of evaluating alignment. Existing benchmarks emphasize response quality but overlook adherence to specific constraints. To bridge this gap, we introduce FollowBench, a multi-level, fine-grained benchmark assessing LLMs’ ability to follow complex constraints across diverse instruction types. Our results expose key weaknesses in current models’ constraint adherence, offering insights for future improvements.
大型语言模型(LLM)在多种任务中展现出显著的能力,然而,如何有效且高效地将它们与人类期望对齐仍然是一个关键挑战。本论文通过引入数据收集、训练和评估的新方法,推动了LLM的对齐性。我们首先解决对齐数据的收集问题。现有方法严重依赖于人工编制的数据集或专有模型。为了克服这些局限性,我们提出了Lion,一个对抗蒸馏框架,通过识别和生成具有挑战性的指令来迭代地优化训练数据,从而实现最先进的零样本推理。此外,我们还介绍了WebR(网络重建),一个完全自动化的框架,直接从原始网络文档合成指令调整数据,显著提高了数据的多样性和可扩展性,超越了现有的合成数据方法。接下来,我们通过新型优化技术增强对齐训练。我们开发了Learning to Edit(LTE),一个框架,使LLM能够高效地整合新知识,同时保留现有信息。LTE利用元学习改进实时和批量知识更新。此外,我们对直接偏好优化(DPO)进行了改进,引入了Bridging and Modeling Correlations(BMC),它能够显式捕获偏好数据中的令牌级相关性,从而在问答和数学推理任务中实现对齐的优越性。最后,我们解决了对齐评估的挑战。现有基准测试侧重于响应质量,但忽视了特定约束的遵守情况。为了填补这一空白,我们推出了FollowBench,这是一个多层次、精细的基准测试,评估LLM遵循多种指令类型的复杂约束的能力。我们的结果揭示了当前模型在约束遵守方面的关键弱点,为未来的改进提供了见解。
论文及项目相关链接
PDF PhD thesis
Summary
大型语言模型(LLM)在各项任务中展现出卓越的能力,但如何有效地与人类期望对齐仍是关键挑战。本论文通过引入数据收集、训练和评估的新方法,推进了LLM的对齐研究。通过解决数据收集问题,提出对抗蒸馏框架Lion,能够迭代优化训练数据,实现最先进的零样本推理能力。同时,介绍全自动合成指令调整数据的WebR框架,提高了数据的多样性和可扩展性。在训练方面,通过新型优化技术提高对齐效果,开发LTE框架使LLM能够高效集成新知识同时保留现有信息。此外,改进DPO方法,提出BMC,更好地捕捉偏好数据的token级关联,在问答和数学推理任务中实现对齐的优越性。最后,针对评估问题,现有基准测试主要关注响应质量,忽视了特定约束的遵守。为此,引入多级别精细基准测试FollowBench,评估LLM遵循复杂指令的能力,揭示当前模型的弱点,为改进提供方向。
Key Takeaways
- 引入对抗蒸馏框架Lion解决LLM对齐中的数据收集问题,提高零样本推理能力。
- 提出WebR框架,从原始网页文档中直接合成指令调整数据,增强数据的多样性和可扩展性。
- 通过新型优化技术增强LLM的对齐训练效果,如LTE框架集成新知识和保留现有信息。
- 改进DPO方法,提出BMC以更好地捕捉偏好数据的token级关联,提升QA和数学推理任务的对齐效果。
- 强调现有LLM评估基准测试的不足,需要同时关注响应质量和特定约束的遵守。
- 引入多级别精细基准测试FollowBench来评估LLM遵循复杂指令的能力。
点此查看论文截图

On-the-Fly Adaptive Distillation of Transformer to Dual-State Linear Attention
Authors:Yeonju Ro, Zhenyu Zhang, Souvik Kundu, Zhangyang Wang, Aditya Akella
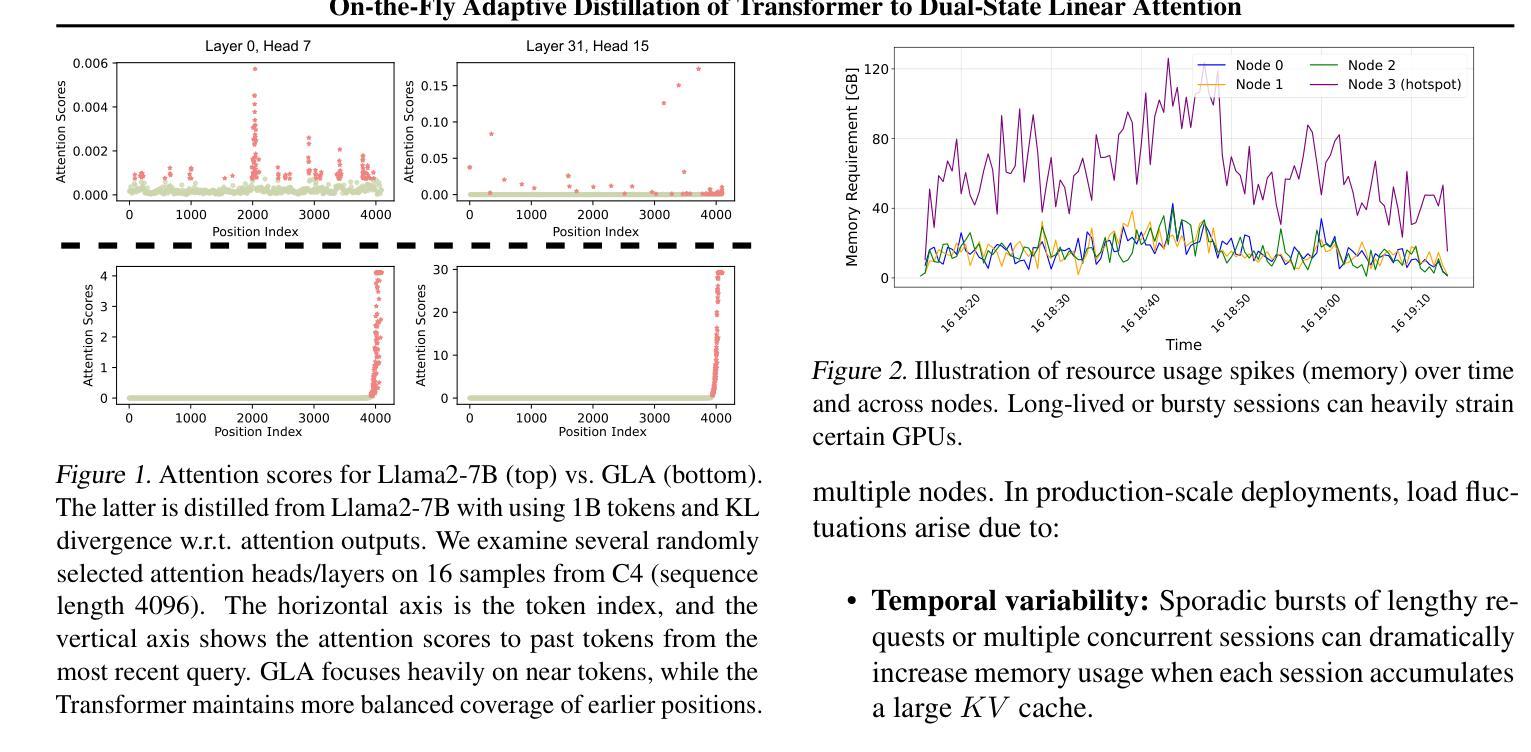
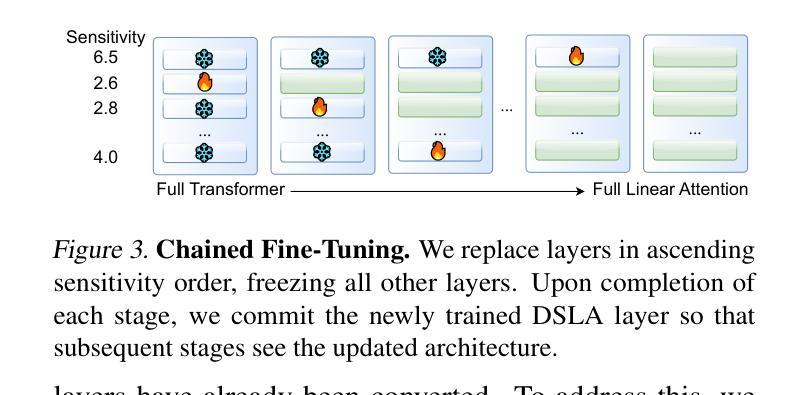
Large language models (LLMs) excel at capturing global token dependencies via self-attention but face prohibitive compute and memory costs on lengthy inputs. While sub-quadratic methods (e.g., linear attention) can reduce these costs, they often degrade accuracy due to overemphasizing recent tokens. In this work, we first propose \textit{dual-state linear attention} (\textbf{\dsla}), a novel design that maintains two specialized hidden states-one for preserving historical context and one for tracking recency-thereby mitigating the short-range bias typical of linear-attention architectures. To further balance efficiency and accuracy under dynamic workload conditions, we introduce \textbf{\serve}, an online \textit{adaptive distillation} framework that progressively replaces Transformer layers with DSLA layers at inference time, guided by a sensitivity-based layer ordering. \serve\ uses a chained fine-tuning strategy to ensure that each newly converted DSLA layer remains consistent with previously replaced layers, preserving the overall quality. Extensive evaluations on commonsense reasoning, long-context QA, and text summarization demonstrate that \serve\ yields \textbf{2.3x} faster inference than Llama2-7B and \textbf{3.0x} faster than the hybrid Zamba-7B, while retaining comparable performance across downstream tasks. Our ablation studies show that DSLA’s dual states capture both global and local dependencies, addressing the historical-token underrepresentation seen in prior linear attentions. Codes are available at https://github.com/utnslab/DSLA-Serve.
大型语言模型(LLM)擅长通过自注意力捕捉全局令牌依赖关系,但在处理长输入时面临着计算量大和内存成本高的挑战。虽然次二次方法(如线性注意力)可以降低这些成本,但它们往往会因为过度强调最近的令牌而降低准确性。在这项工作中,我们首先提出了\textit{双态线性注意力}(\textbf{DSLA}),这是一种新型设计,它维护了两个专门的隐藏状态——一个用于保留历史上下文,另一个用于跟踪近期信息——从而减轻了线性注意力架构通常存在的短程偏差。为了进一步提高动态工作负载条件下的效率和准确性之间的平衡,我们引入了\textbf{SERVE}——一种在线自适应蒸馏框架。在推理阶段,它会根据基于敏感性的层排序逐步用DSLA层替换Transformer层。SERVE使用级联微调策略确保新转换的DSLA层与先前替换的层保持一致,保持整体质量。在常识推理、长上下文问答和文本摘要方面的广泛评估表明,与Llama2-7B相比,SERVE提高了\textbf{2.3倍}的推理速度;与混合模型Zamba-7B相比,提高了\textbf{3.0倍},同时在下游任务上保持了相当的性能。我们的消融研究表明,DSLA的双状态能够捕捉全局和局部依赖关系,解决了先前线性注意力中出现的历史令牌欠表征问题。相关代码可在https://github.com/utnslab/DSLA-Serve找到。
论文及项目相关链接
Summary
本文提出了双状态线性注意力(DSLA)机制,旨在解决大型语言模型在处理长输入时面临的计算与内存成本问题。通过维护两个专门化的隐藏状态来平衡历史上下文与近期信息的追踪,从而减轻线性注意力架构的短程偏见。此外,还介绍了在线自适应蒸馏框架\serve,根据敏感层排序在推理过程中逐步替换Transformer层,旨在平衡效率和准确性。实验表明,\serve在保持性能的同时,推理速度比现有模型更快。
Key Takeaways
- 双状态线性注意力(DSLA)机制通过维护两个隐藏状态,分别用于保留历史上下文和追踪近期信息,解决了大型语言模型处理长输入时的计算与内存成本问题。
- \serve是一个在线自适应蒸馏框架,可以根据动态工作量条件逐步替换Transformer层,以提高效率并维持准确性。
- \serve通过敏感度导向的层序进行推理,逐步替换Transformer层,并采用链式微调策略确保新替换的DSLA层与之前替换的层保持一致。
- 实验表明,\serve在常识推理、长文本问答和文本摘要等多个任务上保持了与现有模型相当的性能,同时推理速度更快。
- DSLA机制能够捕捉全局和局部依赖关系,解决了先前线性注意力模型中历史令牌表示不足的问题。
- 提供的代码可在https://github.com/utnslab/DSLA-Serve上获取。
点此查看论文截图

Unifying Block-wise PTQ and Distillation-based QAT for Progressive Quantization toward 2-bit Instruction-Tuned LLMs
Authors:Jung Hyun Lee, Seungjae Shin, Vinnam Kim, Jaeseong You, An Chen
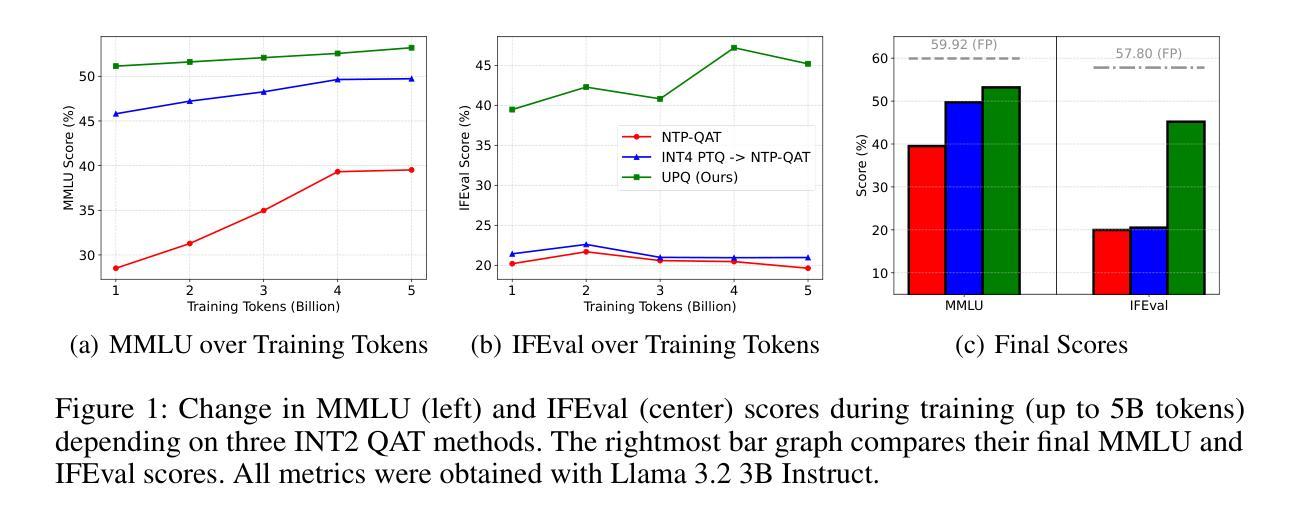
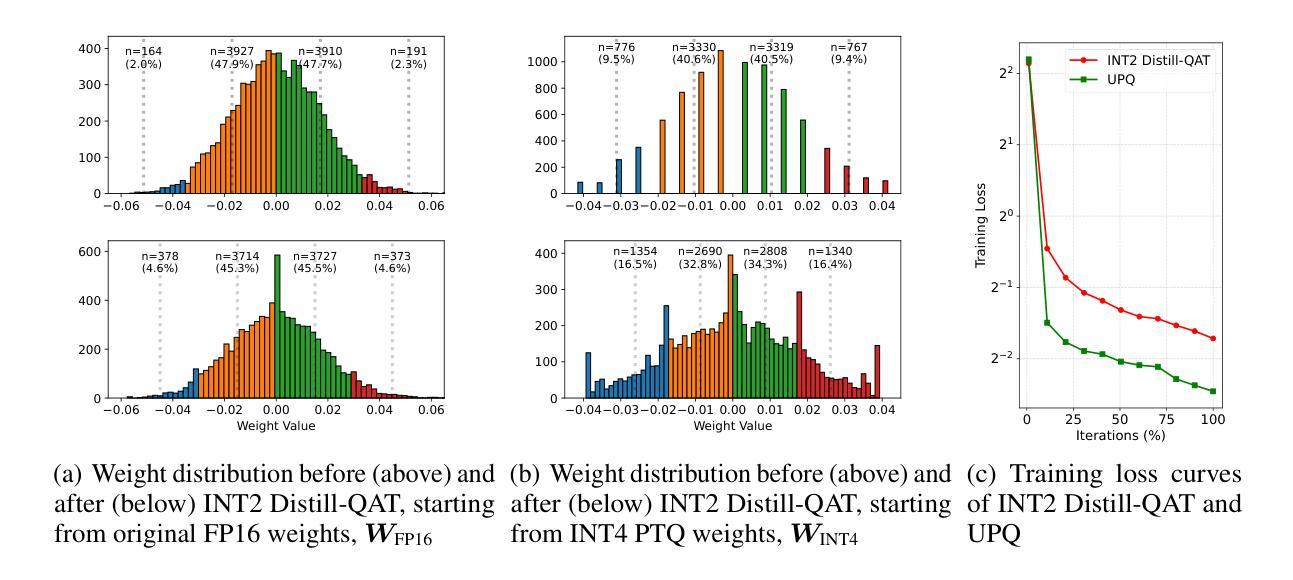
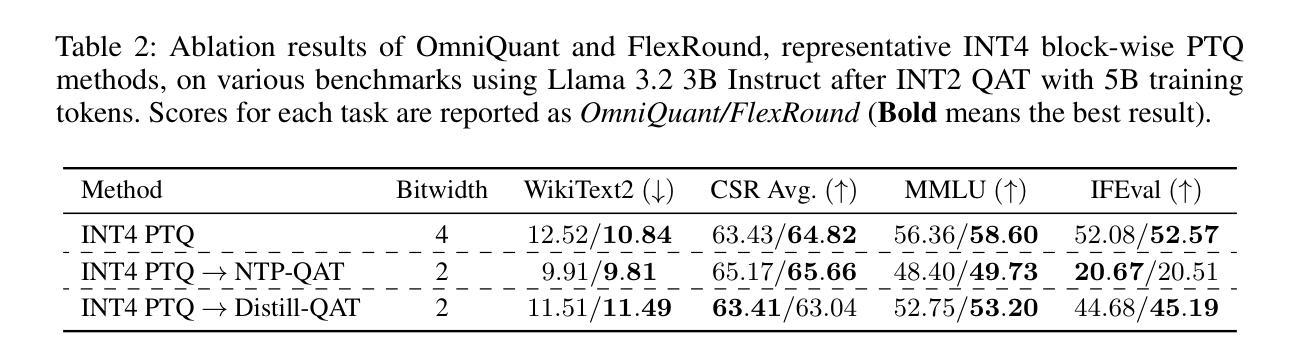
As the rapid scaling of large language models (LLMs) poses significant challenges for deployment on resource-constrained devices, there is growing interest in extremely low-bit quantization, such as 2-bit. Although prior works have shown that 2-bit large models are pareto-optimal over their 4-bit smaller counterparts in both accuracy and latency, these advancements have been limited to pre-trained LLMs and have not yet been extended to instruction-tuned models. To bridge this gap, we propose Unified Progressive Quantization (UPQ)$-$a novel progressive quantization framework (FP16$\rightarrow$INT4$\rightarrow$INT2) that unifies block-wise post-training quantization (PTQ) with distillation-based quantization-aware training (Distill-QAT) for INT2 instruction-tuned LLM quantization. UPQ first quantizes FP16 instruction-tuned models to INT4 using block-wise PTQ to significantly reduce the quantization error introduced by subsequent INT2 quantization. Next, UPQ applies Distill-QAT to enable INT2 instruction-tuned LLMs to generate responses consistent with their original FP16 counterparts by minimizing the generalized Jensen-Shannon divergence (JSD) between the two. To the best of our knowledge, we are the first to demonstrate that UPQ can quantize open-source instruction-tuned LLMs to INT2 without relying on proprietary post-training data, while achieving state-of-the-art performances on MMLU and IFEval$-$two of the most representative benchmarks for evaluating instruction-tuned LLMs.
随着大型语言模型(LLM)的快速扩展对资源受限设备上的部署带来重大挑战,人们对极低比特量化(如2比特)的兴趣日益增长。尽管之前的研究已经表明,在准确度和延迟方面,2比特大型模型比其4比特小型模型具有帕累托最优性能,但这些进展仅限于预训练LLM,尚未扩展到指令调优模型。为了弥补这一差距,我们提出了统一渐进量化(UPQ)——一种新颖的渐进量化框架(FP16→INT4→INT2),它将块级后训练量化(PTQ)与基于蒸馏的量化感知训练(Distill-QAT)相结合,用于INT2指令调优LLM量化。UPQ首先使用块级PTQ将FP16指令调优模型量化为INT4,以显著减少后续INT2量化引入的量化误差。接下来,UPQ应用Distill-QAT,使INT2指令调优LLM生成的响应与其原始FP16版本一致,通过最小化两者之间的广义Jensen-Shannon散度(JSD)来实现。据我们所知,我们首次证明UPQ可以在不依赖专有后训练数据的情况下将开源指令调优LLM量化为INT2,同时在MMLU和IFEval——两个评估指令调优LLM的最具代表性的基准测试上取得了最新性能表现。
论文及项目相关链接
PDF Preprint
Summary
随着大型语言模型(LLM)的快速扩展,在资源受限的设备上进行部署面临重大挑战。对于极低位量化(如2位)的需求日益增长。本文提出一种新型渐进量化框架——统一渐进量化(UPQ),它将块级后训练量化(PTQ)与基于蒸馏的量化感知训练(Distill-QAT)结合起来,用于INT2指令调优的LLM量化。UPQ使用FP16指令调优模型进行块级PTQ量化,以减少后续INT2量化的量化误差,然后通过应用Distill-QAT实现INT2指令调优的LLM生成响应与其原始的FP16模型响应的一致性。研究表明,UPQ可在不依赖专有后训练数据的情况下,将开源指令调优的LLM量化至INT2位,同时在MMLU和IFeval这两个最具代表性的指令调优LLM评估基准测试中取得最佳性能。
Key Takeaways
- 大型语言模型(LLM)在资源受限设备上的部署具有挑战,极低位量化(如2位)成为解决方案。
- 提出一种新型渐进量化框架——统一渐进量化(UPQ)。
- UPQ结合了块级后训练量化(PTQ)与基于蒸馏的量化感知训练(Distill-QAT)。
- UPQ首先使用FP16指令调优模型进行块级PTQ量化,以减少后续INT2量化的误差。
- Distill-QAT使INT2指令调优的LLM生成的响应与原始的FP16模型响应一致。
- UPQ在不依赖专有后训练数据的情况下,成功将开源指令调优的LLM量化至INT2位。
- 在最具代表性的指令调优LLM评估基准测试中,UPQ取得最佳性能。
点此查看论文截图


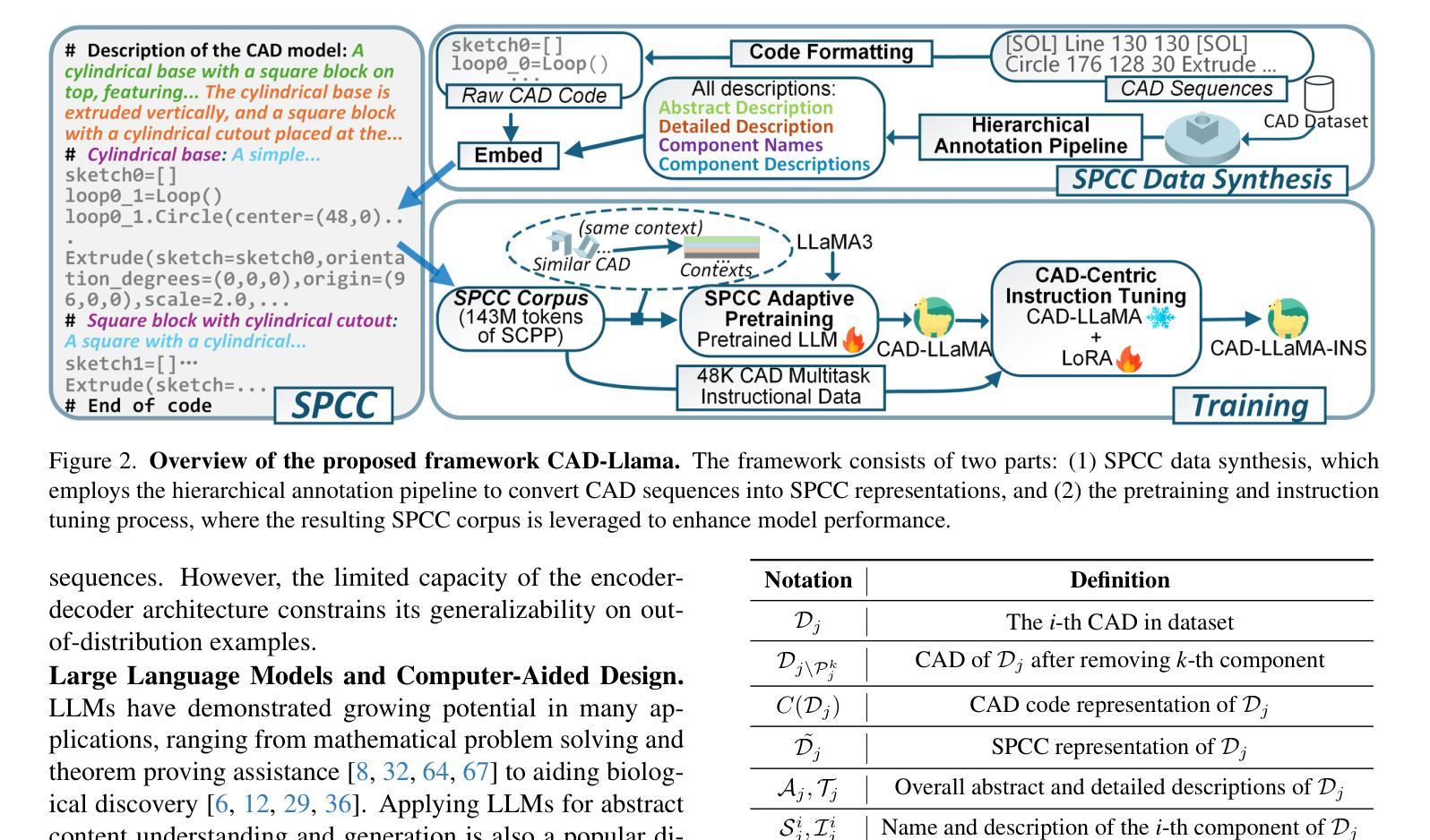
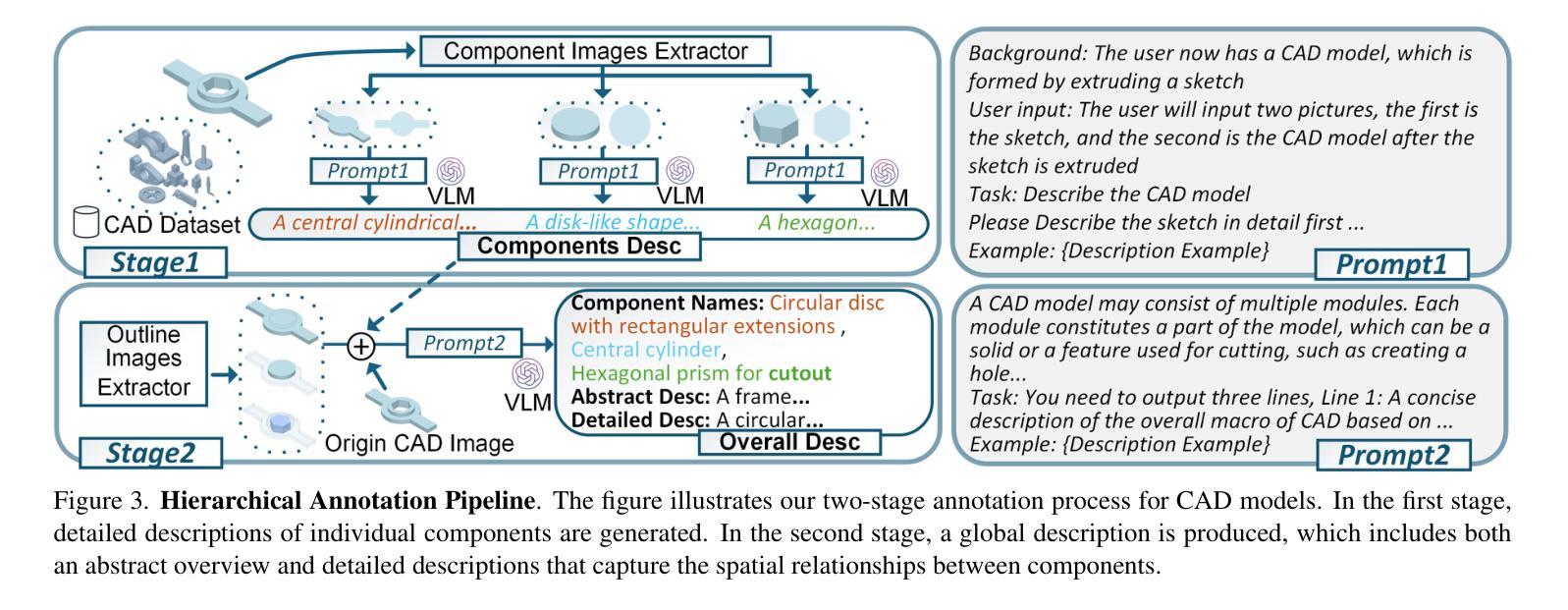
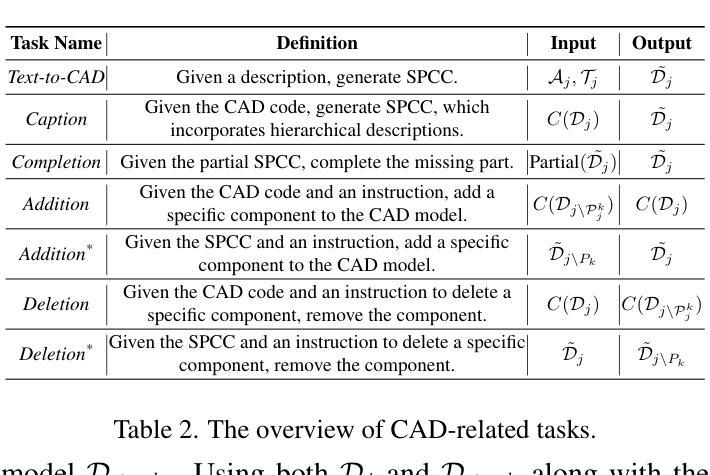
CAD-Llama: Leveraging Large Language Models for Computer-Aided Design Parametric 3D Model Generation
Authors:Jiahao Li, Weijian Ma, Xueyang Li, Yunzhong Lou, Guichun Zhou, Xiangdong Zhou
Recently, Large Language Models (LLMs) have achieved significant success, prompting increased interest in expanding their generative capabilities beyond general text into domain-specific areas. This study investigates the generation of parametric sequences for computer-aided design (CAD) models using LLMs. This endeavor represents an initial step towards creating parametric 3D shapes with LLMs, as CAD model parameters directly correlate with shapes in three-dimensional space. Despite the formidable generative capacities of LLMs, this task remains challenging, as these models neither encounter parametric sequences during their pretraining phase nor possess direct awareness of 3D structures. To address this, we present CAD-Llama, a framework designed to enhance pretrained LLMs for generating parametric 3D CAD models. Specifically, we develop a hierarchical annotation pipeline and a code-like format to translate parametric 3D CAD command sequences into Structured Parametric CAD Code (SPCC), incorporating hierarchical semantic descriptions. Furthermore, we propose an adaptive pretraining approach utilizing SPCC, followed by an instruction tuning process aligned with CAD-specific guidelines. This methodology aims to equip LLMs with the spatial knowledge inherent in parametric sequences. Experimental results demonstrate that our framework significantly outperforms prior autoregressive methods and existing LLM baselines.
最近,大型语言模型(LLM)取得了巨大成功,激发了人们将其生成能力扩展到通用文本之外的特定领域的兴趣。本研究探讨了使用LLM为计算机辅助设计(CAD)模型生成参数序列。这一努力是朝着使用LLM创建参数化3D形状迈出的初步一步,因为CAD模型参数直接与三维空间中的形状相关联。尽管LLM具有强大的生成能力,但这一任务仍然具有挑战性,因为这些模型在预训练阶段并未遇到参数序列,也不直接了解三维结构。为了解决这一问题,我们推出了CAD-Llama框架,旨在增强预训练的LLM生成参数化三维CAD模型的能力。具体而言,我们开发了一种分层注释管道和一种类似于代码的格式,将参数化的三维CAD命令序列翻译成结构化参数化CAD代码(SPCC),并融入分层语义描述。此外,我们提出了一种使用SPCC的自适应预训练方法,随后是符合CAD特定指南的指令调整过程。该方法旨在让LLM具备参数序列中的空间知识。实验结果表明,我们的框架显著优于先前的自回归方法和现有的LLM基线。
论文及项目相关链接
Summary
大型语言模型(LLM)在生成通用文本方面取得了显著成功,并正逐渐向特定领域扩展其生成能力。本研究探讨了利用LLM生成计算机辅助设计(CAD)模型的参数序列。此研究为利用LLM创建参数化三维形状迈出了初步的一步,CAD模型参数与三维空间中的形状直接相关。尽管LLM具有强大的生成能力,但生成参数序列的任务仍然具有挑战性,因为这些模型在预训练阶段并未遇到参数序列,并且缺乏对三维结构的直接了解。为此,我们提出了CAD-Llama框架,旨在增强预训练的LLM生成参数化三维CAD模型的能力。通过开发层次化注释管道和类似代码的格式,将参数化三维CAD命令序列翻译成结构化参数化CAD代码(SPCC),并结合层次语义描述。我们还提出了一种利用SPCC的适应性预训练方法和与CAD特定指南对齐的指令调整过程。此方法旨在赋予LLM参数序列中的空间知识。实验结果表明,我们的框架显著优于先前的自动回归方法和现有的LLM基准。
Key Takeaways
- 大型语言模型(LLM)在生成领域特定内容(如计算机辅助设计(CAD)模型的参数序列)方面展现出潜力。
- CAD-Llama框架旨在增强LLM在生成参数化三维CAD模型方面的能力。
- 通过层次化注释管道和类似代码的格式,将三维CAD模型的参数序列转化为结构化参数化CAD代码(SPCC)。
- 提出了一种适应性预训练方法和指令调整过程,以赋予LLM空间知识和对CAD特定指南的理解。
- 实验结果显示,CAD-Llama框架在生成参数化三维CAD模型方面显著优于其他方法。
- LLM在生成参数序列时面临挑战,如对三维结构的了解不足和在预训练阶段未接触参数序列。
点此查看论文截图

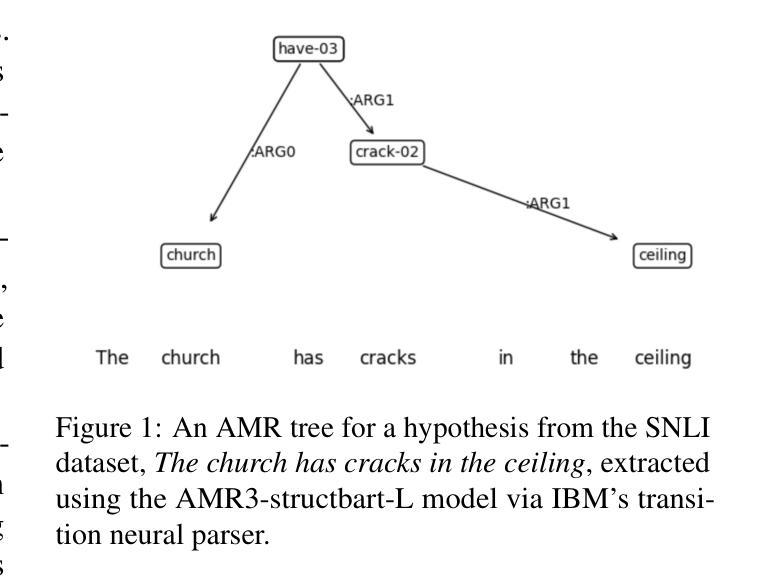
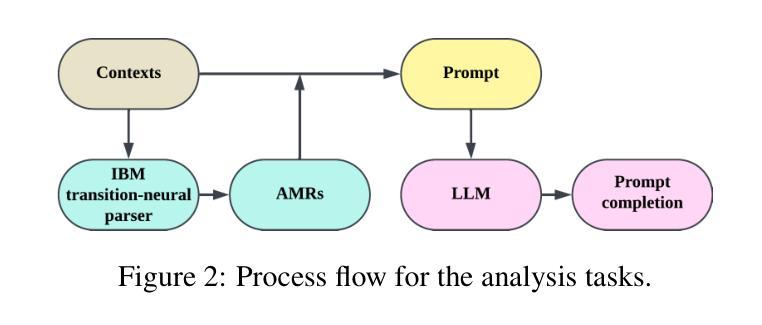
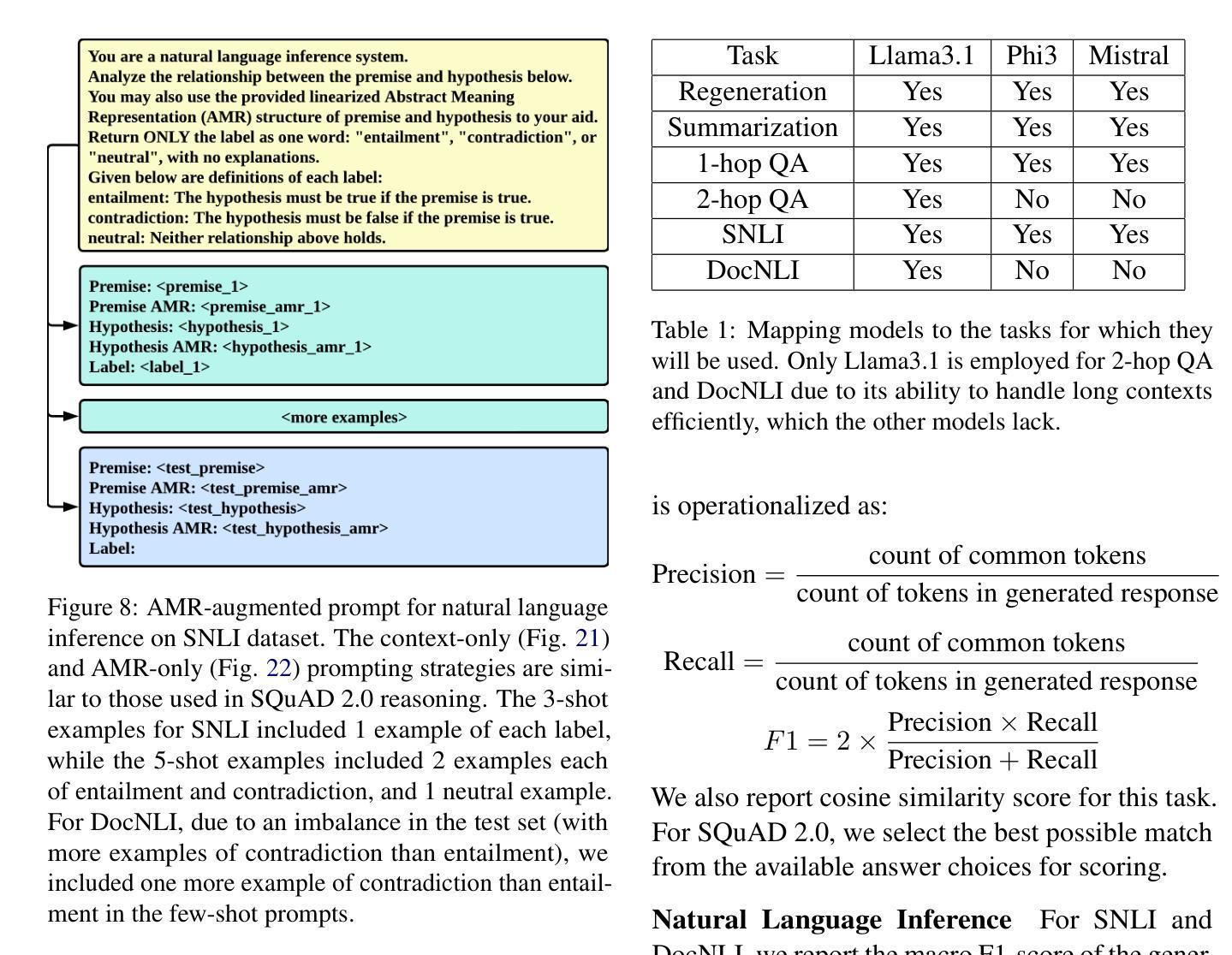
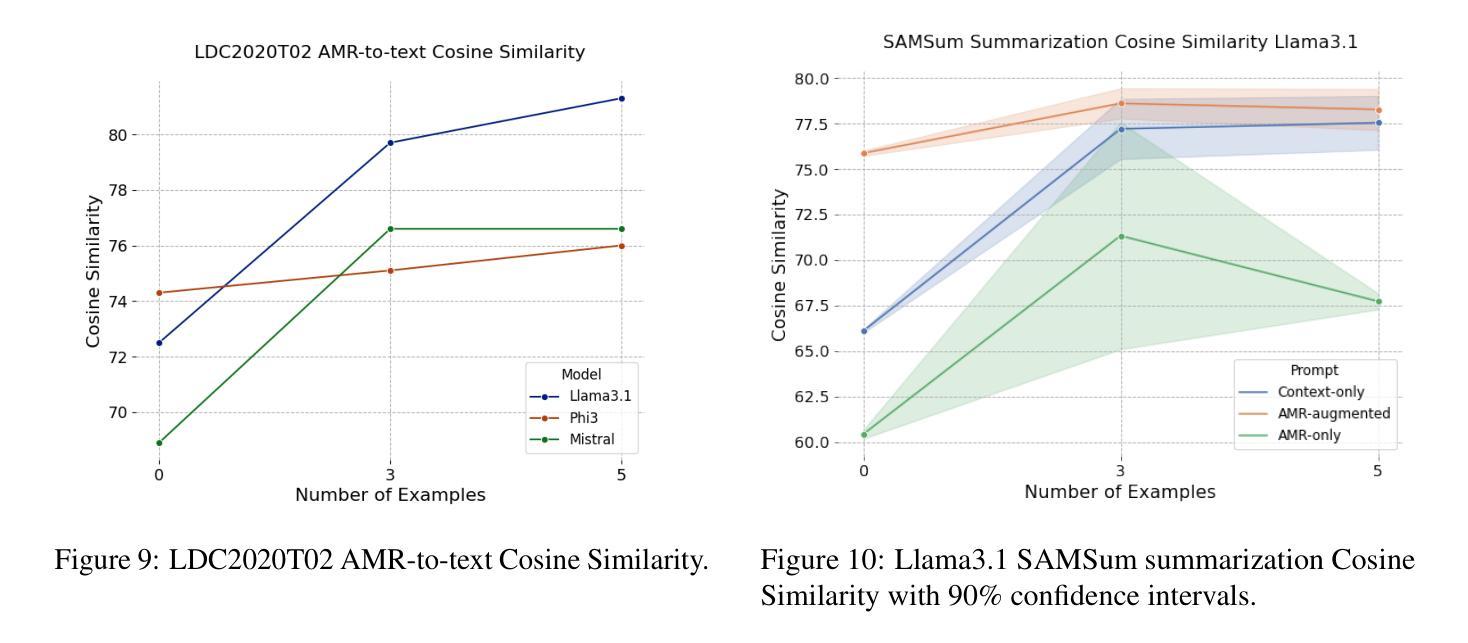
Can LLMs Interpret and Leverage Structured Linguistic Representations? A Case Study with AMRs
Authors:Ankush Raut, Xiaofeng Zhu, Maria Leonor Pacheco
This paper evaluates the ability of Large Language Models (LLMs) to leverage contextual information in the form of structured linguistic representations. Specifically, we examine the impact of encoding both short and long contexts using Abstract Meaning Representation (AMR) structures across a diverse set of language tasks. We perform our analysis using 8-bit quantized and instruction-tuned versions of Llama 3.1 (8B), Phi-3, and Mistral 7B. Our results indicate that, for tasks involving short contexts, augmenting the prompt with the AMR of the original language context often degrades the performance of the underlying LLM. However, for tasks that involve long contexts, such as dialogue summarization in the SAMSum dataset, this enhancement improves LLM performance, for example, by increasing the zero-shot cosine similarity score of Llama 3.1 from 66% to 76%. This improvement is more evident in the newer and larger LLMs, but does not extend to the older or smaller ones. In addition, we observe that LLMs can effectively reconstruct the original text from a linearized AMR, achieving a cosine similarity of 81% in the best-case scenario.
本文评估了大语言模型(LLM)利用结构化的语言表示形式中的上下文信息的能力。具体来说,我们研究了使用抽象意义表示(AMR)结构对短长和两种上下文进行编码对一系列语言任务的影响。我们使用8位量化和指令调整的Llama 3.1(8B)、Phi-3和Mistral 7B版本进行分析。我们的结果表明,对于涉及短上下文的任务,通过提示增强原始语言上下文的AMR往往会降低基础LLM的性能。然而,对于涉及长上下文的任务,如在SAMSum数据集中的对话摘要,这种增强会提高LLM的性能,例如,将Llama 3.1的零样本余弦相似度得分从66%提高到76%。这种改进在更新和更大的LLM中更为明显,但并不适用于旧或较小的LLM。此外,我们观察到LLM可以有效地从线性化的AMR中重建原始文本,在最佳情况下达到81%的余弦相似度。
论文及项目相关链接
PDF 13 pages, 23 figures. Accepted at XLLM @ ACL 2025
Summary:
本文探讨了大型语言模型(LLM)在利用结构化语言表示形式进行上下文信息方面的能力。研究通过抽象意义表示(AMR)结构编码短长和不同语境,对一系列语言任务进行了评估。分析表明,对于短语境任务,添加原始语境的AMR往往会降低LLM性能;而对于长语境任务,如对话摘要,这种增强则能提高LLM性能,特别是在新且大型的LLM中表现更为明显。此外,LLM还能有效地从线性化的AMR中重建原始文本。
Key Takeaways:
- 大型语言模型(LLM)能够利用抽象意义表示(AMR)结构进行上下文信息编码。
- 在短语境任务中,添加AMR会降低LLM性能。
- 对于长语境任务,如对话摘要,使用AMR结构增强能提高LLM性能。
- 新且大型的LLM在利用AMR结构方面的性能提升更为显著。
- LLM能从线性化的AMR有效地重建原始文本。
- LLM在处理语境信息时,不同语境(短或长)需要不同的处理策略。
点此查看论文截图


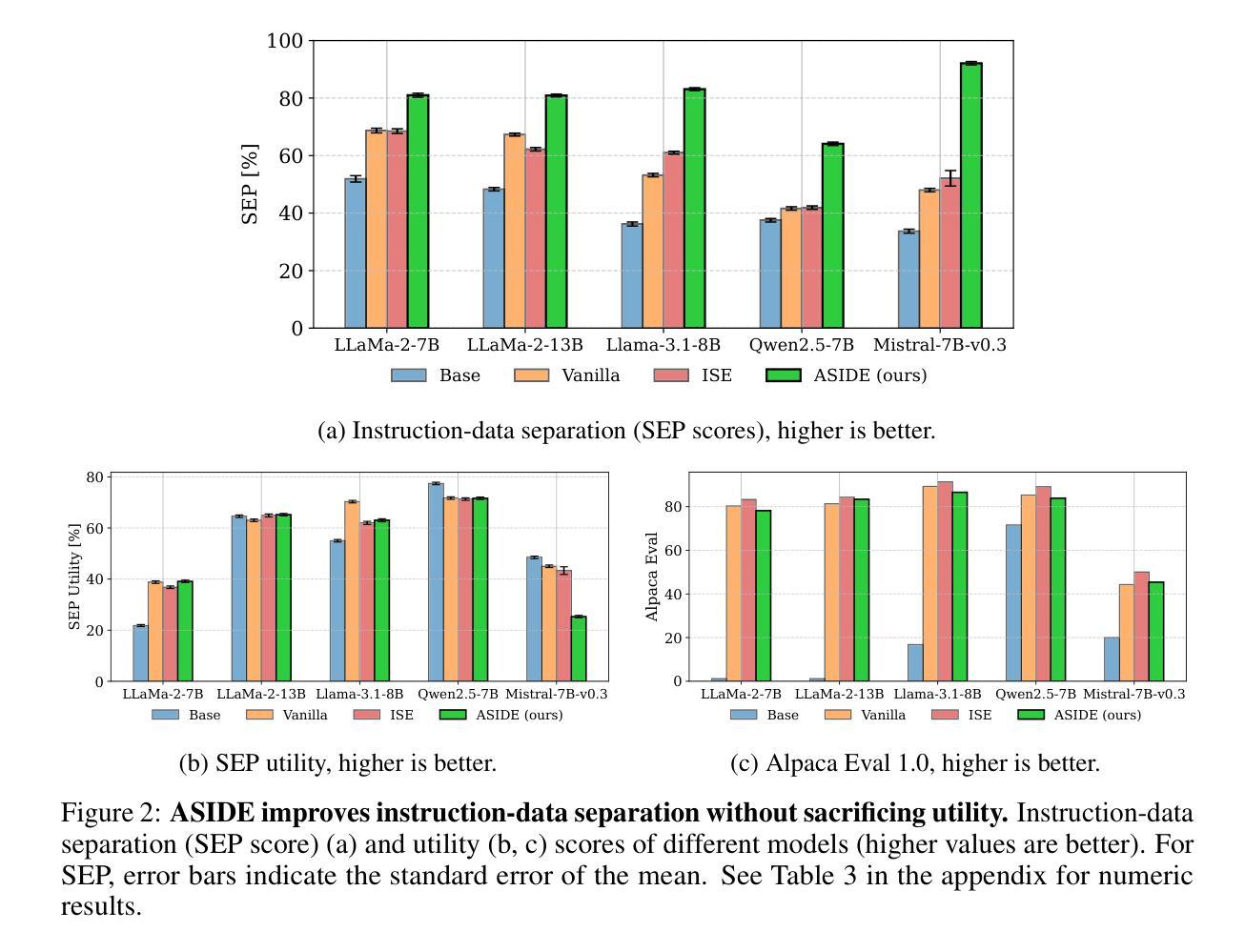
ASIDE: Architectural Separation of Instructions and Data in Language Models
Authors:Egor Zverev, Evgenii Kortukov, Alexander Panfilov, Alexandra Volkova, Soroush Tabesh, Sebastian Lapuschkin, Wojciech Samek, Christoph H. Lampert
Despite their remarkable performance, large language models lack elementary safety features, making them susceptible to numerous malicious attacks. In particular, previous work has identified the absence of an intrinsic separation between instructions and data as a root cause of the success of prompt injection attacks. In this work, we propose a new architectural element, ASIDE, that allows language models to clearly separate instructions and data at the level of embeddings. ASIDE applies an orthogonal rotation to the embeddings of data tokens, thus creating clearly distinct representations of instructions and data tokens without introducing any additional parameters. As we demonstrate experimentally across a range of models, instruction-tuning LLMs with ASIDE (1) leads to highly increased instruction-data separation without a loss in model utility and (2) makes the models more robust to prompt injection benchmarks, even without dedicated safety training. Additionally, we provide insights into the mechanism underlying our method through an analysis of the model representations. The source code and training scripts are openly accessible at https://github.com/egozverev/aside.
尽管大型语言模型表现出色,但它们缺乏基本的安全功能,使其容易受到众多恶意攻击。特别是,先前的工作已经确定指令和数据之间缺乏内在分离是提示注入攻击成功的根本原因。在这项工作中,我们提出了一种新的架构元素ASIDE,它允许语言模型在嵌入层面上清晰地分离指令和数据。ASIDE通过对数据嵌入进行正交旋转,从而创建指令和数据的清晰表示,且无需引入任何额外的参数。我们在一系列模型上进行的实验表明,使用ASIDE进行指令微调的大型语言模型(1)能够在不损失模型效用的前提下,实现高度增强的指令数据分离;(2)即使不经过专门的安全训练,也能使模型对提示注入基准测试更具鲁棒性。此外,我们还通过对模型表示的分析,深入了解了我们的方法背后的机制。源代码和培训脚本可在https://github.com/egozverev/aside公开访问。
论文及项目相关链接
PDF Preliminary version accepted to ICLR 2025 Workshop on Building Trust in Language Models and Applications
Summary
大型语言模型虽然表现优异,但缺乏基本的安全特性,容易受到多种恶意攻击。本文提出一种新型架构元素ASIDE,能在嵌入层面将指令和数据明确分离。通过应用数据标记嵌入的正交旋转,创造出指令和数据的清晰不同表示,无需引入额外参数。实验证明,在大型语言模型中采用ASIDE指令调优,不仅提高了指令与数据的分离度,且提升了模型对提示注入基准测试的鲁棒性,即使没有专门的安全训练也是如此。
Key Takeaways
- 大型语言模型存在安全漏洞,易受到恶意攻击。
- 缺乏指令和数据的内在分离是提示注入攻击成功的原因。
- ASIDE架构能够在嵌入层面分离指令和数据。
- ASIDE通过正交旋转数据标记嵌入来创建指令和数据的不同表示。
- ASIDE提高了指令与数据的分离度,同时不损失模型的实用性。
- 采用ASIDE的大型语言模型对提示注入基准测试更具鲁棒性。
点此查看论文截图


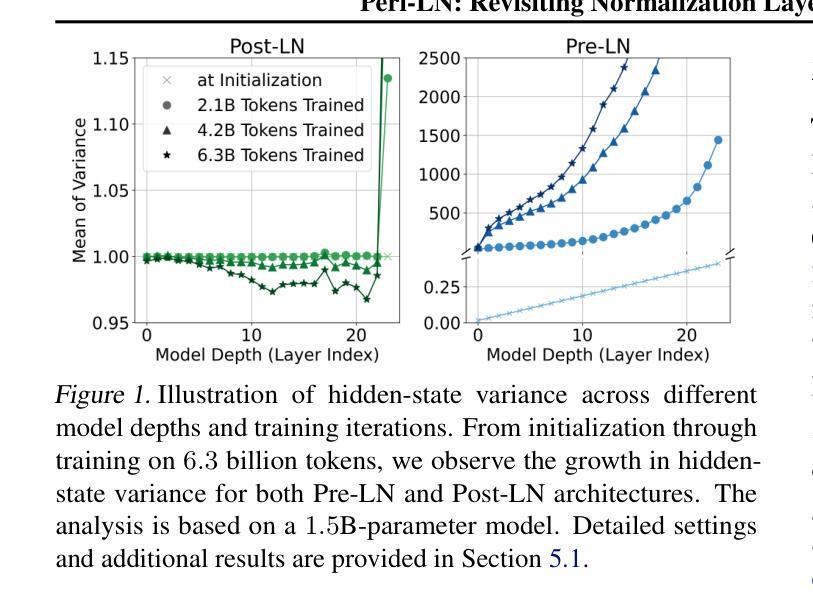
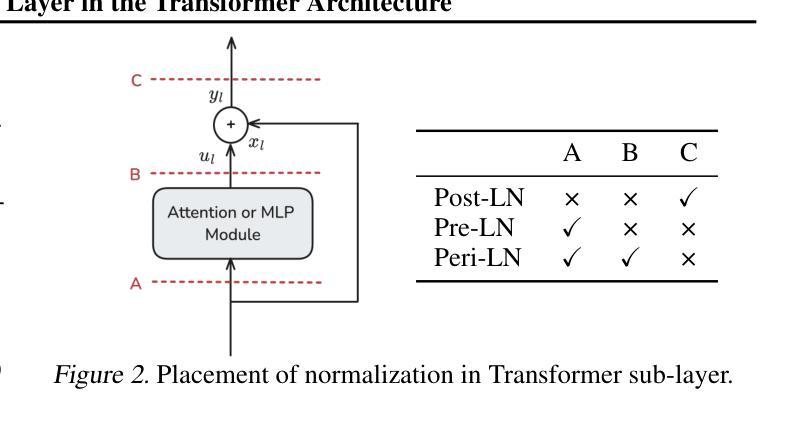
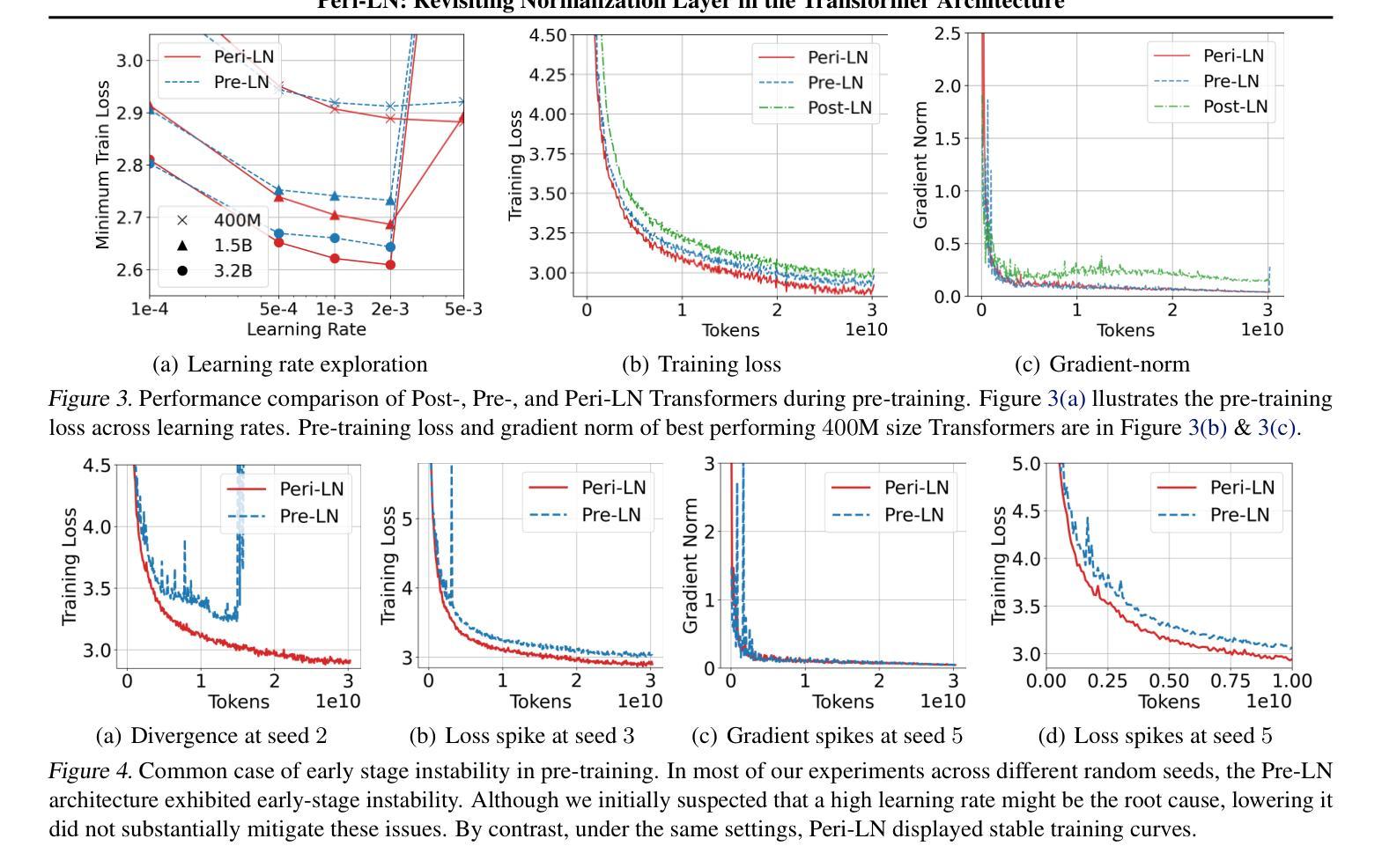
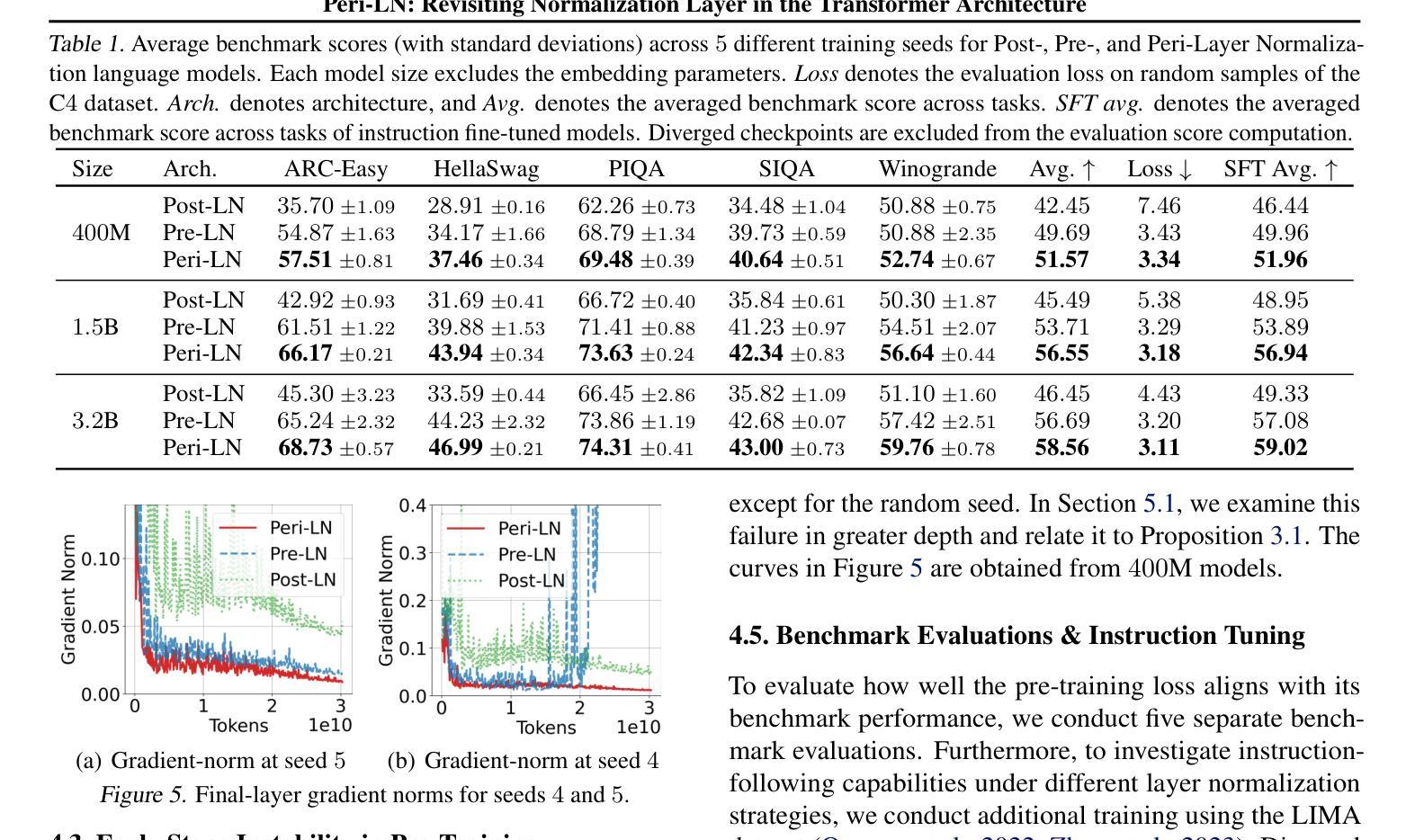
Peri-LN: Revisiting Normalization Layer in the Transformer Architecture
Authors:Jeonghoon Kim, Byeongchan Lee, Cheonbok Park, Yeontaek Oh, Beomjun Kim, Taehwan Yoo, Seongjin Shin, Dongyoon Han, Jinwoo Shin, Kang Min Yoo
Selecting a layer normalization (LN) strategy that stabilizes training and speeds convergence in Transformers remains difficult, even for today’s large language models (LLM). We present a comprehensive analytical foundation for understanding how different LN strategies influence training dynamics in large-scale Transformers. Until recently, Pre-LN and Post-LN have long dominated practices despite their limitations in large-scale training. However, several open-source models have recently begun silently adopting a third strategy without much explanation. This strategy places normalization layer peripherally around sublayers, a design we term Peri-LN. While Peri-LN has demonstrated promising performance, its precise mechanisms and benefits remain almost unexplored. Our in-depth analysis delineates the distinct behaviors of LN strategies, showing how each placement shapes activation variance and gradient propagation. To validate our theoretical insight, we conduct extensive experiments on Transformers up to $3.2$B parameters, showing that Peri-LN consistently achieves more balanced variance growth, steadier gradient flow, and convergence stability. Our results suggest that Peri-LN warrants broader consideration for large-scale Transformer architectures, providing renewed insights into the optimal placement of LN.
选择一种层归一化(LN)策略,以稳定训练并加速转换器中的收敛,即使在今天的大型语言模型(LLM)中仍然是一项艰巨的任务。我们提供了全面的分析基础,以了解不同的LN策略如何影响大规模转换器的训练动态。直到最近,尽管在大型训练中存在局限性,但Pre-LN和Post-LN的实践一直占据主导地位。然而,最近有几个开源模型开始默默地采用第三种策略,但没有太多解释。该策略将归一化层放置在子层周围,我们将其称为Peri-LN。虽然Peri-LN已显示出有前途的性能,但其精确机制和好处几乎尚未被探索。我们的深入分析阐明了LN策略的不同行为,展示了每种放置方式如何影响激活方差和梯度传播。为了验证我们的理论洞察力,我们在高达3.2B参数的转换器上进行了大量实验,结果显示Peri-LN始终实现了更平衡的方差增长、更稳定的梯度流动和收敛稳定性。我们的结果表明,对于大规模转换器架构,Peri-LN值得更广泛的考虑,为LN的最佳放置位置提供了新的见解。
论文及项目相关链接
PDF ICML2025 Camera-ready version
Summary
不同层归一化(LN)策略对大型Transformer训练的影响仍然难以确定,即使对于现今的大型语言模型(LLM)。研究者们提供了深入理解不同LN策略如何影响大规模Transformer训练动力的综合分析基础。直到最近,Pre-LN和Post-LN一直主导着实践,尽管它们在大型训练中存在局限性。然而,一些开源模型最近开始悄悄地采用第三种策略,即周边层归一化(Peri-LN),但很少解释。Peri-LN将归一化层置于子层周围,虽然已显示出有前景的性能,但其精确机制和好处几乎尚未被探索。本文深入分析勾勒出LN策略的不同行为,展示每种放置方式如何影响激活方差和梯度传播。为了验证理论见解,我们对高达3.2B参数的Transformer进行了大量实验,结果显示Peri-LN在方差增长、梯度流动的稳定性和收敛稳定性方面表现更稳定。我们的结果建议,对于大规模Transformer架构,应更广泛地考虑Peri-LN,并为LN的最佳放置位置提供新的见解。
Key Takeaways
- 不同层归一化(LN)策略在大型Transformer模型训练中具有重要影响。
- Pre-LN和Post-LN是实践中常见的两种策略,但在大型训练中存在局限性。
- 最近开源模型开始采用一种新兴的周边层归一化(Peri-LN)策略,但缺乏解释。
- Peri-LN通过将归一化层置于子层周围进行设计,显示出有前景的性能。
- LN策略的不同放置方式会影响激活方差和梯度传播。
- 实验结果表明,Peri-LN在方差增长、梯度稳定性及模型收敛等方面表现优异。
点此查看论文截图

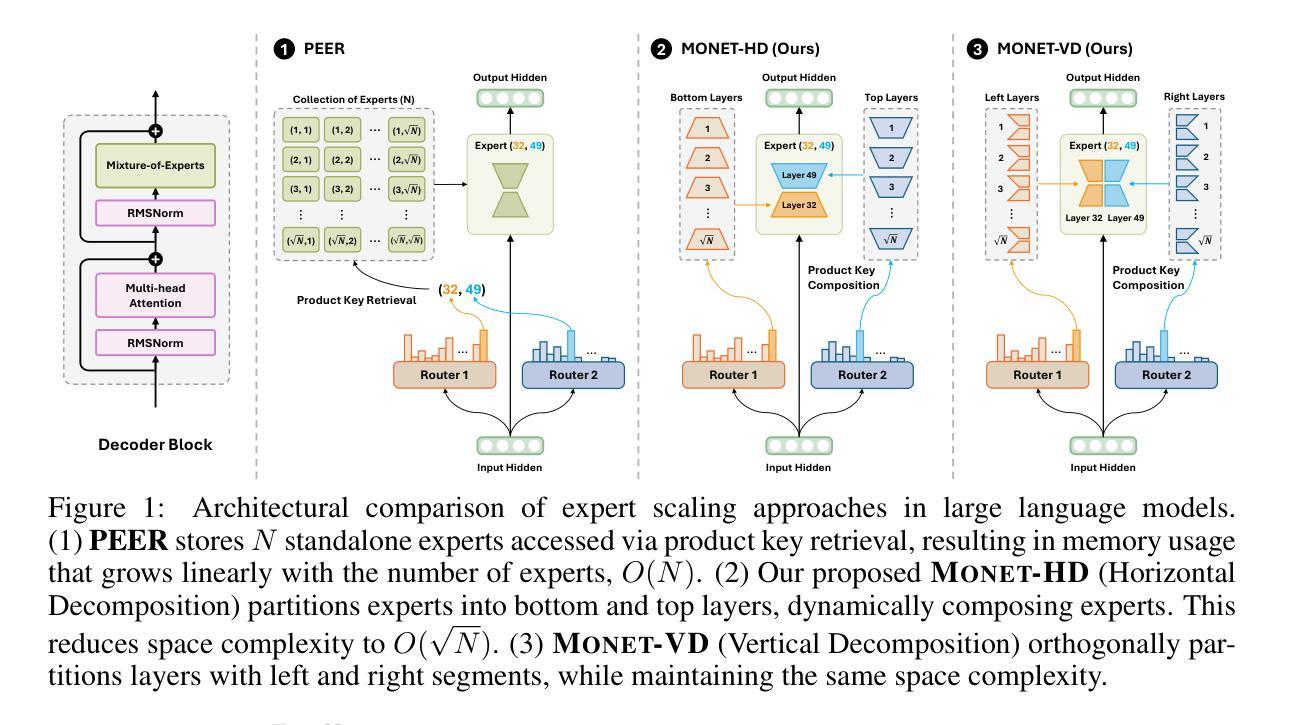
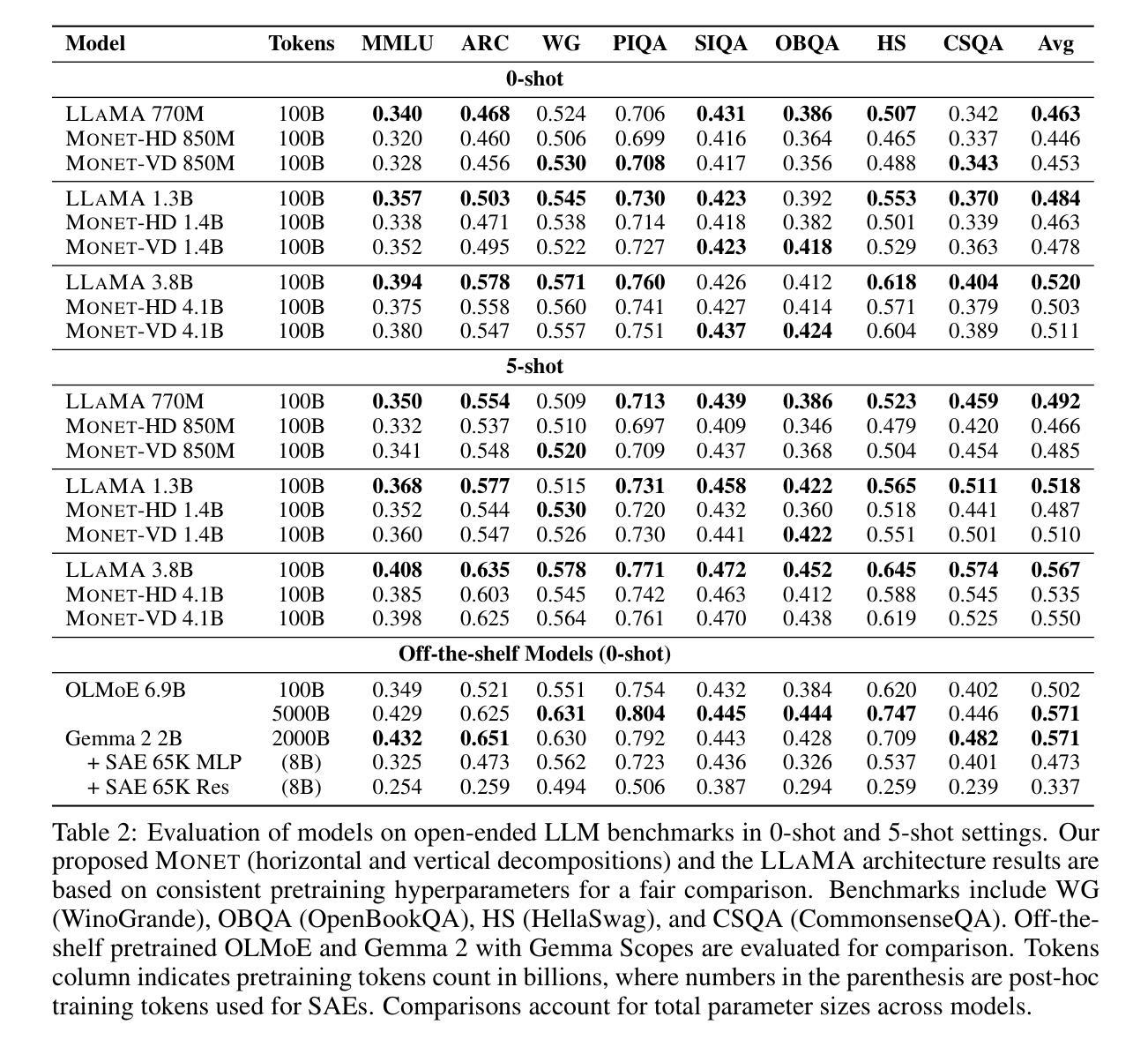
Monet: Mixture of Monosemantic Experts for Transformers
Authors:Jungwoo Park, Young Jin Ahn, Kee-Eung Kim, Jaewoo Kang
Understanding the internal computations of large language models (LLMs) is crucial for aligning them with human values and preventing undesirable behaviors like toxic content generation. However, mechanistic interpretability is hindered by polysemanticity – where individual neurons respond to multiple, unrelated concepts. While Sparse Autoencoders (SAEs) have attempted to disentangle these features through sparse dictionary learning, they have compromised LLM performance due to reliance on post-hoc reconstruction loss. To address this issue, we introduce Mixture of Monosemantic Experts for Transformers (Monet) architecture, which incorporates sparse dictionary learning directly into end-to-end Mixture-of-Experts pretraining. Our novel expert decomposition method enables scaling the expert count to 262,144 per layer while total parameters scale proportionally to the square root of the number of experts. Our analyses demonstrate mutual exclusivity of knowledge across experts and showcase the parametric knowledge encapsulated within individual experts. Moreover, Monet allows knowledge manipulation over domains, languages, and toxicity mitigation without degrading general performance. Our pursuit of transparent LLMs highlights the potential of scaling expert counts to enhance mechanistic interpretability and directly resect the internal knowledge to fundamentally adjust model behavior. The source code and pretrained checkpoints are available at https://github.com/dmis-lab/Monet.
理解大型语言模型(LLM)的内部计算对于将其与人类价值观对齐并防止生成有毒内容等不当行为至关重要。然而,多义性(即单个神经元对多个不相关概念的响应)阻碍了机械解释性。虽然稀疏自动编码器(SAE)试图通过稀疏字典学习来解开这些特征,但它们依赖于事后重建损失,从而损害了LLM的性能。为了解决这一问题,我们引入了“混合单义专家转换器”(Monet)架构,它将稀疏字典学习直接融入端到端的混合专家预训练。我们新颖的专家分解方法使专家数量按层增加到每层262,144个,同时总参数按专家数量的平方根成比例增长。我们的分析证明了专家之间知识的相互独立性,并展示了单个专家所包含的参数知识。此外,Monet允许在领域、语言和毒性减轻方面进行操作知识,而不会降低整体性能。我们对透明LLM的追求突显了增加专家数量以提高机械解释性的潜力,并可以直接切除内部知识来根本性地调整模型行为。源代码和预先训练的检查点可在https://github.com/dmis-lab/Monet获得。
论文及项目相关链接
Summary
大型语言模型(LLM)的内部计算理解对于与人类价值观对齐及防止生成有毒内容等不可取行为至关重要。然而,由于单词的多义性,即单个神经元会对多个不相关概念作出反应,导致机制性解释性受阻。尽管稀疏自动编码器(SAE)试图通过稀疏字典学习来解决这些特征的分解问题,但它们依赖于事后重建损失,从而损害了LLM的性能。为解决这一问题,我们引入了Mixture of Monosemantic Experts for Transformers(Monet)架构,该架构将稀疏字典学习直接纳入端到端的专家混合预训练。我们的新型专家分解方法使每层的专家数量能够扩展到262,144个,同时总参数与专家数量的平方根成比例扩展。分析表明,各专家之间的知识储备相互独立,展示了单个专家所封装的知识参数。此外,Monet能够在不降低整体性能的情况下,实现跨领域、跨语言的知识操纵和毒性缓解。我们对透明LLM的追求突显了增加专家数量以提高机制解释性的潜力,并可以直接调整内部知识以根本改变模型行为。
Key Takeaways
- 大型语言模型(LLM)的内部计算理解对于与人类价值观对齐及避免不良行为至关重要。
- 单词的多义性阻碍了对LLM机制性解释的理解。
- 稀疏自动编码器(SAE)虽然试图解决特征分解问题,但会因为依赖事后重建损失而损害LLM性能。
- Mixture of Monosemantic Experts for Transformers(Monet)架构直接纳入稀疏字典学习至端到端的专家混合预训练,以提高机制解释性。
- Monet通过新型专家分解方法使每层的专家数量能够大幅扩展。
- 专家之间的知识储备相互独立,且可以实现跨领域、跨语言的知识操纵和毒性缓解。
点此查看论文截图

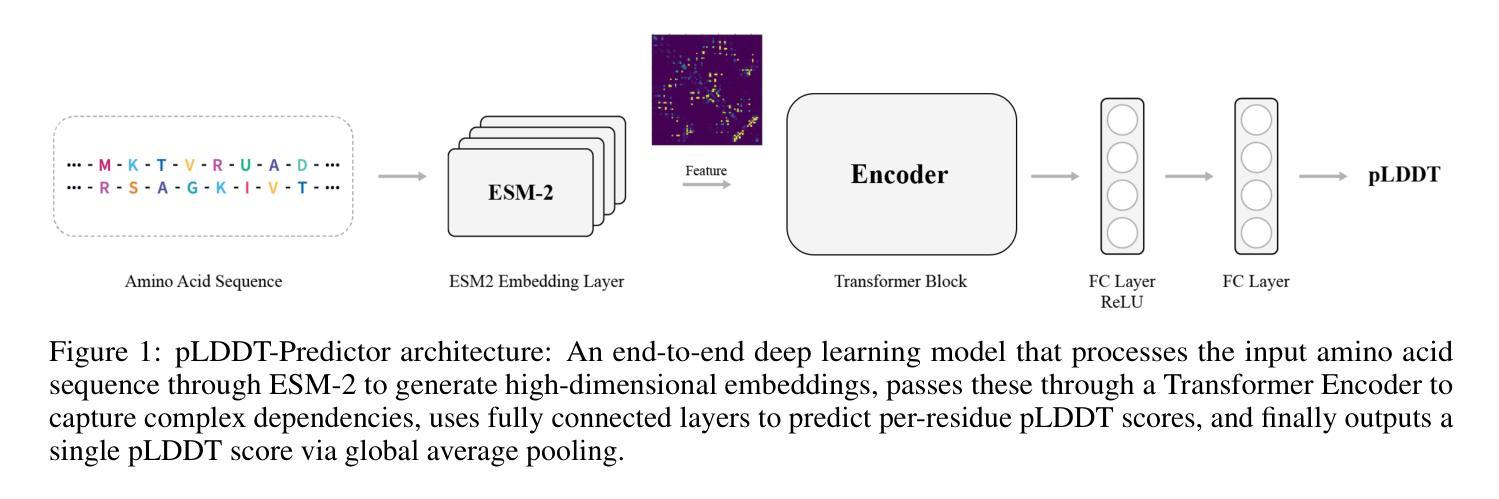
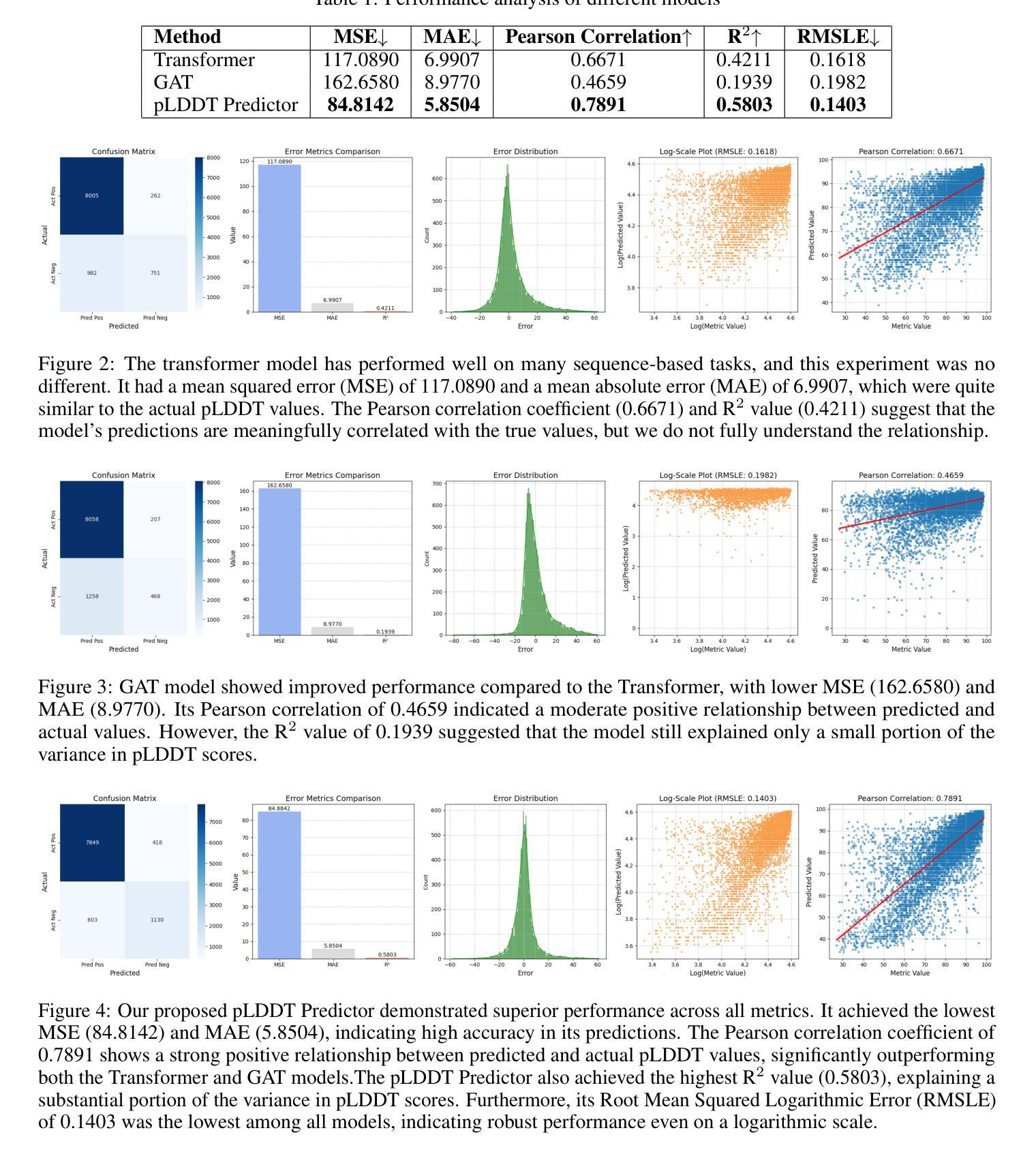
pLDDT-Predictor: High-speed Protein Screening Using Transformer and ESM2
Authors:Joongwon Chae, Zhenyu Wang, Ijaz Gul, Jiansong Ji, Zhenglin Chen, Peiwu Qin
Recent advancements in protein structure prediction, particularly AlphaFold2, have revolutionized structural biology by achieving near-experimental accuracy ($\text{average RMSD} < 1.5\text{\AA}$). However, the computational demands of these models (approximately 30 minutes per protein on an RTX 4090) significantly limit their application in high-throughput protein screening. While large language models like ESM (Evolutionary Scale Modeling) have shown promise in extracting structural information directly from protein sequences, rapid assessment of protein structure quality for large-scale analyses remains a major challenge. We introduce pLDDT-Predictor, a high-speed protein screening tool that achieves a $250,000\times$ speedup compared to AlphaFold2 by leveraging pre-trained ESM2 protein embeddings and a Transformer architecture. Our model predicts AlphaFold2’s pLDDT (predicted Local Distance Difference Test) scores with a Pearson correlation of 0.7891 and processes proteins in just 0.007 seconds on average. Using a comprehensive dataset of 1.5 million diverse protein sequences (ranging from 50 to 2048 amino acids), we demonstrate that pLDDT-Predictor accurately classifies high-confidence structures (pLDDT $>$ 70) with 91.2% accuracy and achieves an MSE of 84.8142 compared to AlphaFold2’s predictions. The source code and pre-trained models are freely available at https://github.com/jw-chae/pLDDT_Predictor, enabling the research community to perform rapid, large-scale protein structure quality assessments.
近期蛋白质结构预测方面的进展,特别是AlphaFold2,已经通过实现接近实验精度(平均RMSD < 1.5Å)的方式,彻底改变了结构生物学。然而,这些模型的计算需求(在RTX 4090上每个蛋白大约需要30分钟)显著限制了它们在高通量蛋白质筛选中的应用。虽然像ESM(进化规模建模)这样的大规模语言模型在直接从蛋白质序列中提取结构信息方面显示出希望,但对于大规模分析的蛋白质结构质量快速评估仍然是一个主要挑战。
我们引入了pLDDT-Predictor,这是一个高速蛋白质筛选工具,它通过利用预训练的ESM2蛋白质嵌入和Transformer架构,实现了相对于AlphaFold2的速度提升250,000倍。我们的模型预测AlphaFold2的pLDDT(预测局部距离差异测试)分数,Pearson相关系数为0.7891,平均每个蛋白质的处理时间仅为0.007秒。我们使用包含150万个不同蛋白质序列的综合数据集(从50到2048个氨基酸),证明了pLDDT-Predictor能够准确分类高可信度的结构(pLDDT > 70),准确率为91.2%,与AlphaFold2的预测相比,MSE为84.8142。
源代码和预训练模型可在https://github.com/jw-chae/pLDDT_Predictor免费获得,使研究社区能够进行快速的大规模蛋白质结构质量评估。
论文及项目相关链接
PDF Further experiments confirmed overfitting, and we are retracting the paper
摘要
AlphaFold2等蛋白质结构预测技术的最新进展对结构生物学产生革命性影响,但计算需求大限制了其高通量蛋白质筛选的应用。ESM等大型语言模型在直接从蛋白质序列中提取结构信息方面显示出潜力,但对大规模分析中蛋白质结构质量的快速评估仍是挑战。本研究引入pLDDT-Predictor,利用预训练的ESM2蛋白质嵌入和Transformer架构,实现了与AlphaFold2相比高达$250,000\times$的加速。该模型预测AlphaFold2的pLDDT分数与真实值高度相关,并对蛋白质进行快速处理。使用包含150万多种蛋白质序列的综合性数据集,展示pLDDT-Predictor准确分类高置信度结构,并接近AlphaFold2的预测精度。源代码和预训练模型可免费获取。
关键见解
- AlphaFold2等蛋白质结构预测技术取得了显著进展,但在高通量蛋白质筛选方面存在计算需求大的限制。
- ESM等大型语言模型在提取蛋白质序列的结构信息方面展现出潜力。
- pLDDT-Predictor是一个快速的蛋白质筛选工具,利用预训练的ESM2蛋白质嵌入和Transformer架构实现了高速处理。
- pLDDT-Predictor能预测AlphaFold2的pLDDT分数,与真实值高度相关,并具备高准确性。
- pLDDT-Predictor可在综合性数据集上准确分类高置信度结构。
- pLDDT-Predictor的源代码和预训练模型已公开发布,供研究社区使用。
点此查看论文截图


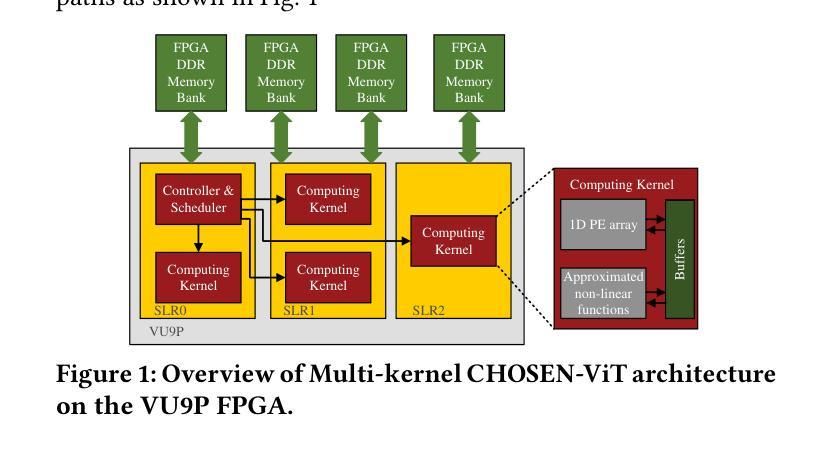
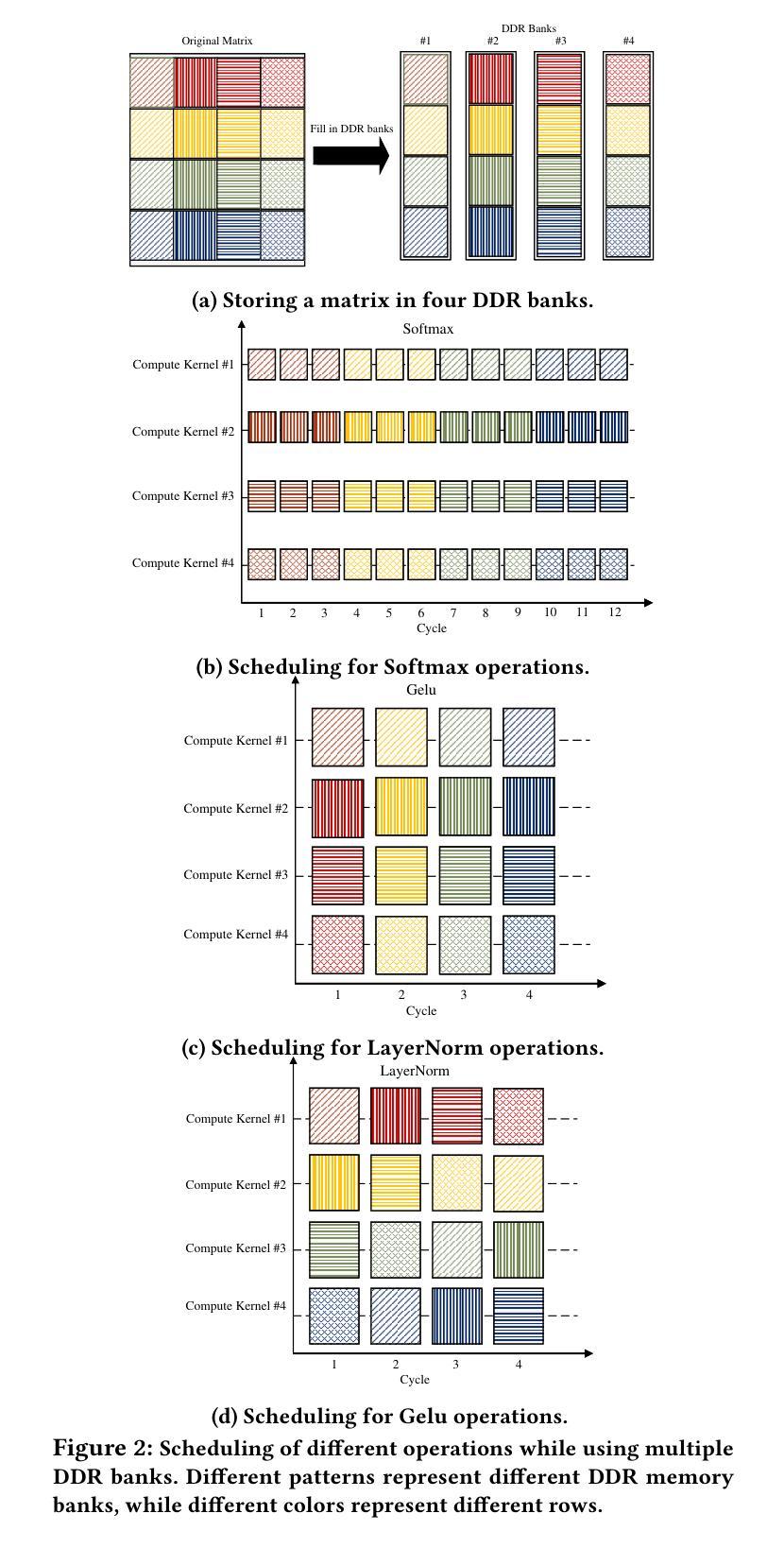
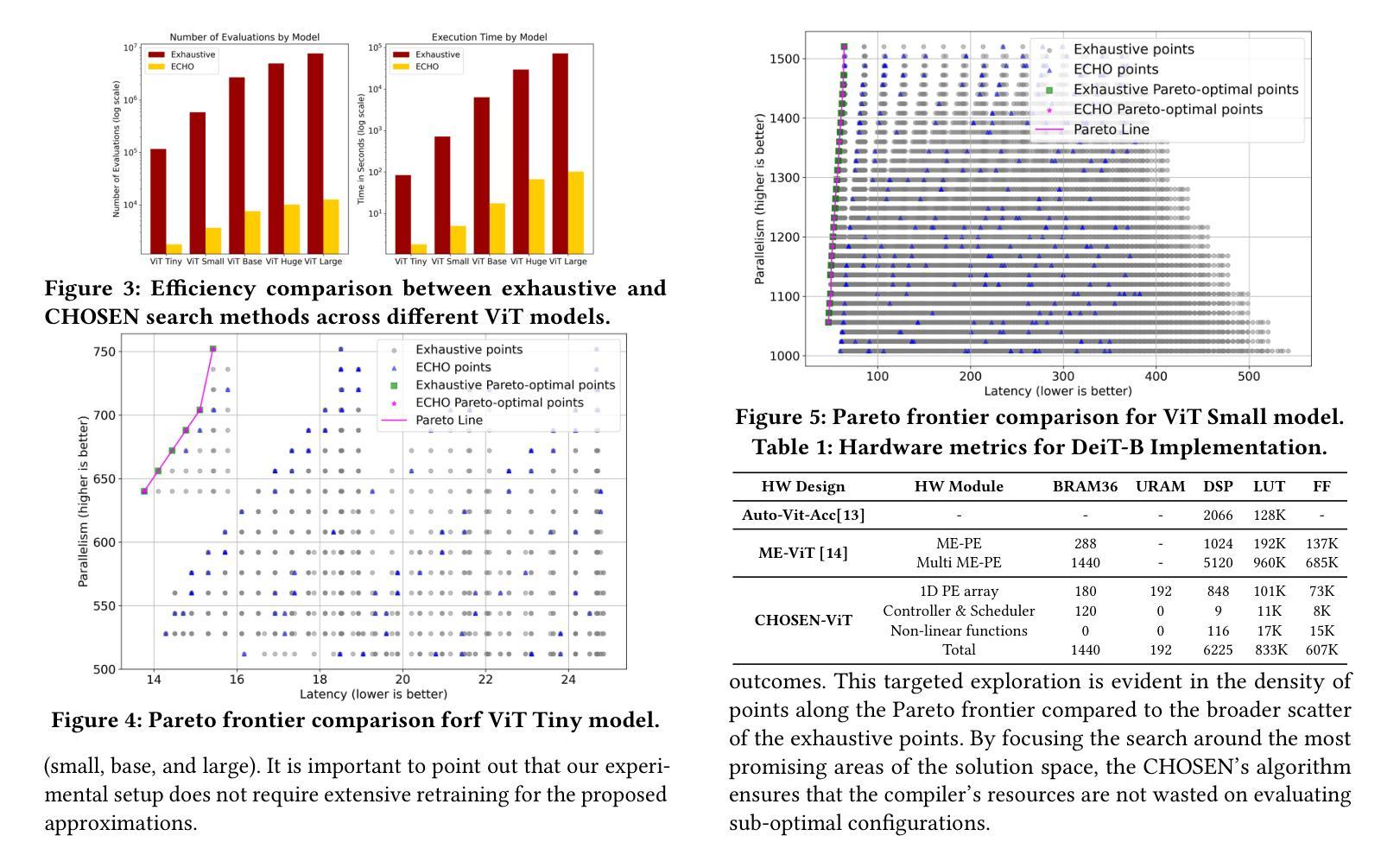
CHOSEN: Compilation to Hardware Optimization Stack for Efficient Vision Transformer Inference
Authors:Mohammad Erfan Sadeghi, Arash Fayyazi, Suhas Somashekar, Armin Abdollahi, Massoud Pedram
Vision Transformers (ViTs) represent a groundbreaking shift in machine learning approaches to computer vision. Unlike traditional approaches, ViTs employ the self-attention mechanism, which has been widely used in natural language processing, to analyze image patches. Despite their advantages in modeling visual tasks, deploying ViTs on hardware platforms, notably Field-Programmable Gate Arrays (FPGAs), introduces considerable challenges. These challenges stem primarily from the non-linear calculations and high computational and memory demands of ViTs. This paper introduces CHOSEN, a software-hardware co-design framework to address these challenges and offer an automated framework for ViT deployment on the FPGAs in order to maximize performance. Our framework is built upon three fundamental contributions: multi-kernel design to maximize the bandwidth, mainly targeting benefits of multi DDR memory banks, approximate non-linear functions that exhibit minimal accuracy degradation, and efficient use of available logic blocks on the FPGA, and efficient compiler to maximize the performance and memory-efficiency of the computing kernels by presenting a novel algorithm for design space exploration to find optimal hardware configuration that achieves optimal throughput and latency. Compared to the state-of-the-art ViT accelerators, CHOSEN achieves a 1.5x and 1.42x improvement in the throughput on the DeiT-S and DeiT-B models.
视觉转换器(ViTs)代表了计算机视觉机器学习方法的突破性转变。与传统的计算机视觉方法不同,ViTs采用自注意力机制(已在自然语言处理中广泛使用)来分析图像块。尽管ViTs在建模视觉任务方面具有优势,但在硬件平台(特别是现场可编程门阵列(FPGA))上部署ViTs仍存在相当大的挑战。这些挑战主要源于ViTs的非线性计算以及其对计算和内存的高需求。本文介绍了CHOSEN,这是一个软硬件协同设计框架,旨在解决这些挑战,并为FPGA上的ViT部署提供自动化框架,以最大化性能。我们的框架建立在三个基本贡献之上:多核设计以最大化带宽(主要针对多DDR内存银行的优势)、近似非线性函数以展现最小的精度损失以及高效使用FPGA上的可用逻辑块,以及高效的编译器。编译器通过提供一种新型算法来进行设计空间探索,以找到实现最佳吞吐量和延迟的最佳硬件配置,从而最大限度地提高计算内核的性能和内存效率。与最先进的ViT加速器相比,CHOSEN在DeiT-S和DeiT-B模型上的吞吐量提高了1.5倍和1.42倍。
论文及项目相关链接
Summary:
ViTs在机器视觉领域掀起革命性变革,但其在FPGA等硬件平台上的部署面临巨大挑战。本文提出CHOSEN软硬件协同设计框架,通过多核设计、近似非线性函数和高效编译器等技术,优化ViT在FPGA上的性能。相较于现有ViT加速器,CHOSEN在DeiT-S和DeiT-B模型上分别实现了1.5倍和1.42倍的吞吐性能提升。
Key Takeaways:
- Vision Transformers (ViTs) 引入自注意力机制,为计算机视觉领域带来革新。
- ViTs在FPGA硬件平台部署面临挑战,主要源于其非线性计算和高计算内存需求。
- CHOSEN框架通过多核设计最大化带宽,主要面向多DDR内存银行的优点。
- CHOSEN采用近似非线性函数,在极小准确性损失下优化性能。
- 该框架有效利用FPGA的逻辑块,实现高效运行。
- CHOSEN的编译器通过新型算法进行设计时域探索,找到实现最佳吞吐量和延迟的硬件配置。
点此查看论文截图


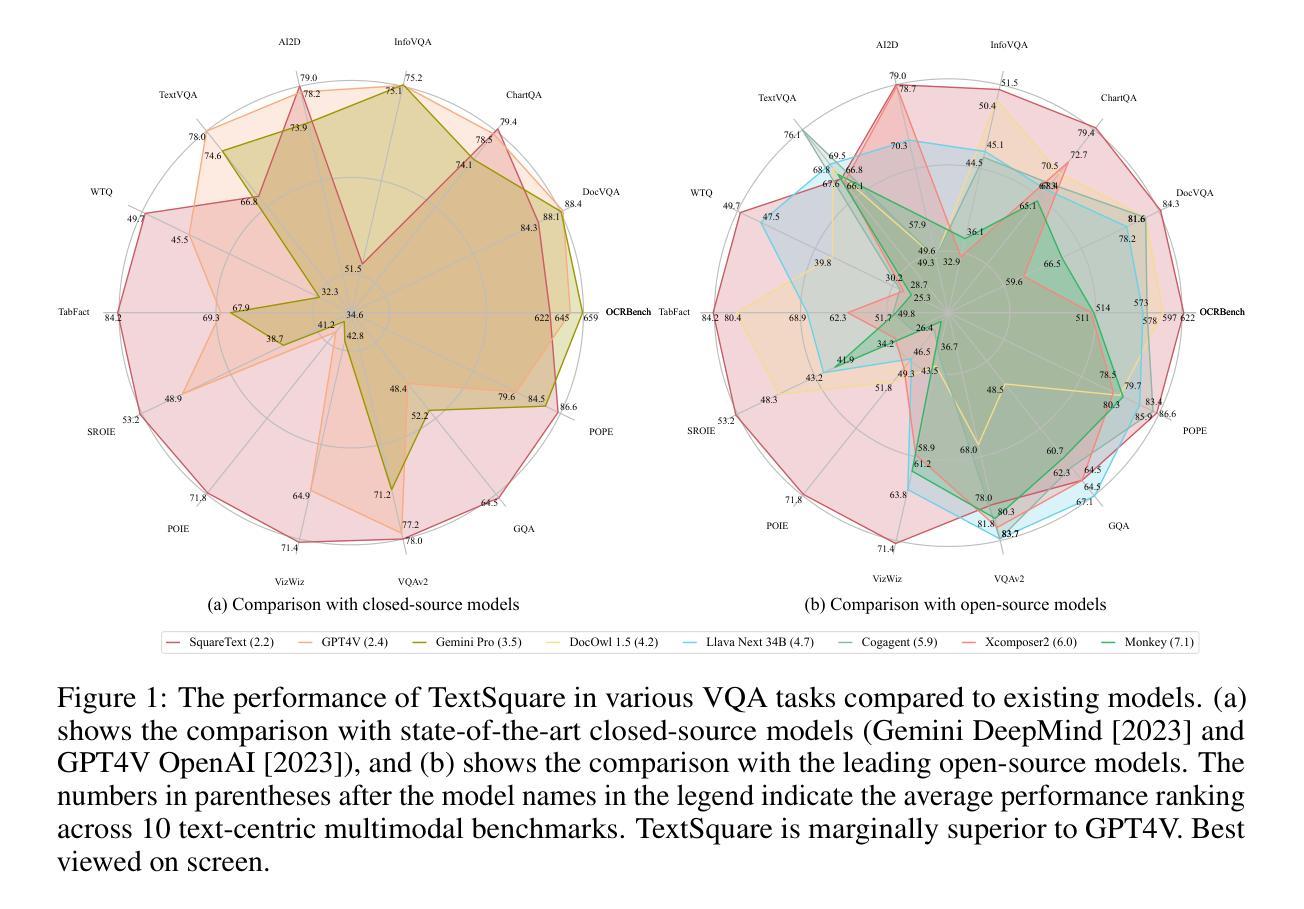
TextSquare: Scaling up Text-Centric Visual Instruction Tuning
Authors:Jingqun Tang, Chunhui Lin, Zhen Zhao, Shu Wei, Binghong Wu, Qi Liu, Yangfan He, Kuan Lu, Hao Feng, Yang Li, Siqi Wang, Lei Liao, Wei Shi, Yuliang Liu, Hao Liu, Yuan Xie, Xiang Bai, Can Huang
Text-centric visual question answering (VQA) has made great strides with the development of Multimodal Large Language Models (MLLMs), yet open-source models still fall short of leading models like GPT4V and Gemini, partly due to a lack of extensive, high-quality instruction tuning data. To this end, we introduce a new approach for creating a massive, high-quality instruction-tuning dataset, Square-10M, which is generated using closed-source MLLMs. The data construction process, termed Square, consists of four steps: Self-Questioning, Answering, Reasoning, and Evaluation. Our experiments with Square-10M led to three key findings: 1) Our model, TextSquare, considerably surpasses open-source previous state-of-the-art Text-centric MLLMs and sets a new standard on OCRBench(62.2%). It even outperforms top-tier models like GPT4V and Gemini in 6 of 10 text-centric benchmarks. 2) Additionally, we demonstrate the critical role of VQA reasoning data in offering comprehensive contextual insights for specific questions. This not only improves accuracy but also significantly mitigates hallucinations. Specifically, TextSquare scores an average of 75.1% across four general VQA and hallucination evaluation datasets, outperforming previous state-of-the-art models. 3) Notably, the phenomenon observed in scaling text-centric VQA datasets reveals a vivid pattern: the exponential increase of instruction tuning data volume is directly proportional to the improvement in model performance, thereby validating the necessity of the dataset scale and the high quality of Square-10M.
文本聚焦的视觉问答(VQA)随着多模态大型语言模型(MLLMs)的发展而取得了巨大进步。然而,开源模型仍然无法赶超如GPT4V和Gemini等领先模型,部分原因在于缺乏广泛的高质量指令调整数据。为此,我们介绍了一种创建大规模高质量指令调整数据集Square-10M的新方法,该方法使用封闭源代码的MLLMs生成。数据构建过程名为Square,分为四个步骤:自问、回答、推理和评价。我们使用Square-10M进行的实验得到了三个关键发现:
- 我们的模型TextSquare显著超越了之前开源的先进文本聚焦型MLLMs,并在OCRBench上设定了新标准(62.2%)。它甚至在10个文本聚焦的基准测试中中有6个超越了顶尖模型如GPT4V和Gemini。
- 此外,我们证明了VQA推理数据在提供特定问题的全面背景信息方面的关键作用。这不仅提高了准确性,而且有效减轻了幻觉现象。具体来说,TextSquare在四个通用VQA和幻觉评估数据集上的平均得分为75.1%,超过了之前的先进模型。
- 值得注意的是,在扩大文本聚焦的VQA数据集时观察到的现象呈现出一个清晰的模式:指令调整数据量的指数增长与模型性能的提高直接相关,从而验证了数据集规模和Square-10M高质量数据的必要性。
论文及项目相关链接
摘要
基于多模态大型语言模型(MLLMs)的文本中心视觉问答(VQA)已取得显著进展,但仍落后于GPT4V和Gemini等领先模型,部分原因在于缺乏大量高质量指令调整数据。为此,我们引入了一种创建大规模高质量指令调整数据集Square-10M的新方法,该方法利用闭源MLLMs生成。数据构建过程包括自我提问、回答、推理和评估四个步骤。使用Square-10M的实验表明:1)我们的TextSquare模型超越了之前开源的文本中心型MLLMs的先进水平,在OCRBench上设定了新标准(62.2%),并在10个文本中心型基准测试中6项超过GPT4V和Gemini。2)我们还证明了VQA推理数据在提供特定问题的全面上下文洞察中的关键作用。这不仅提高了准确性,而且显著减轻了虚构现象。TextSquare在四个一般VQA和虚构现象评估数据集上的平均得分为75.1%,优于之前的最佳模型。3)文本中心型VQA数据集扩展现象显示,指令调整数据量的指数增长与模型性能的提高直接相关,验证了数据集规模和Square-10M高质量数据的必要性。
关键见解
- 利用闭源MLLMs,推出了新的大规模高质量指令调整数据集Square-10M。
- TextSquare模型在多个文本中心型基准测试中表现出卓越性能,超越了现有开源模型及GPT4V和Gemini等顶尖模型。
- VQA推理数据对于提供问题的全面上下文洞察至关重要,不仅能提高准确性,还能有效抑制虚构现象。
- TextSquare在VQA评估中的表现优异,证明了其在处理复杂问题时的有效性。
- 数据集扩展现象显示,指令调整数据的数量与模型性能的提高呈正相关,凸显了大规模高质量数据集的重要性。
- Square-10M的推出对于推动文本中心型VQA领域的进步具有重大意义。
点此查看论文截图