⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-13 更新
The Less You Depend, The More You Learn: Synthesizing Novel Views from Sparse, Unposed Images without Any 3D Knowledge
Authors:Haoru Wang, Kai Ye, Yangyan Li, Wenzheng Chen, Baoquan Chen
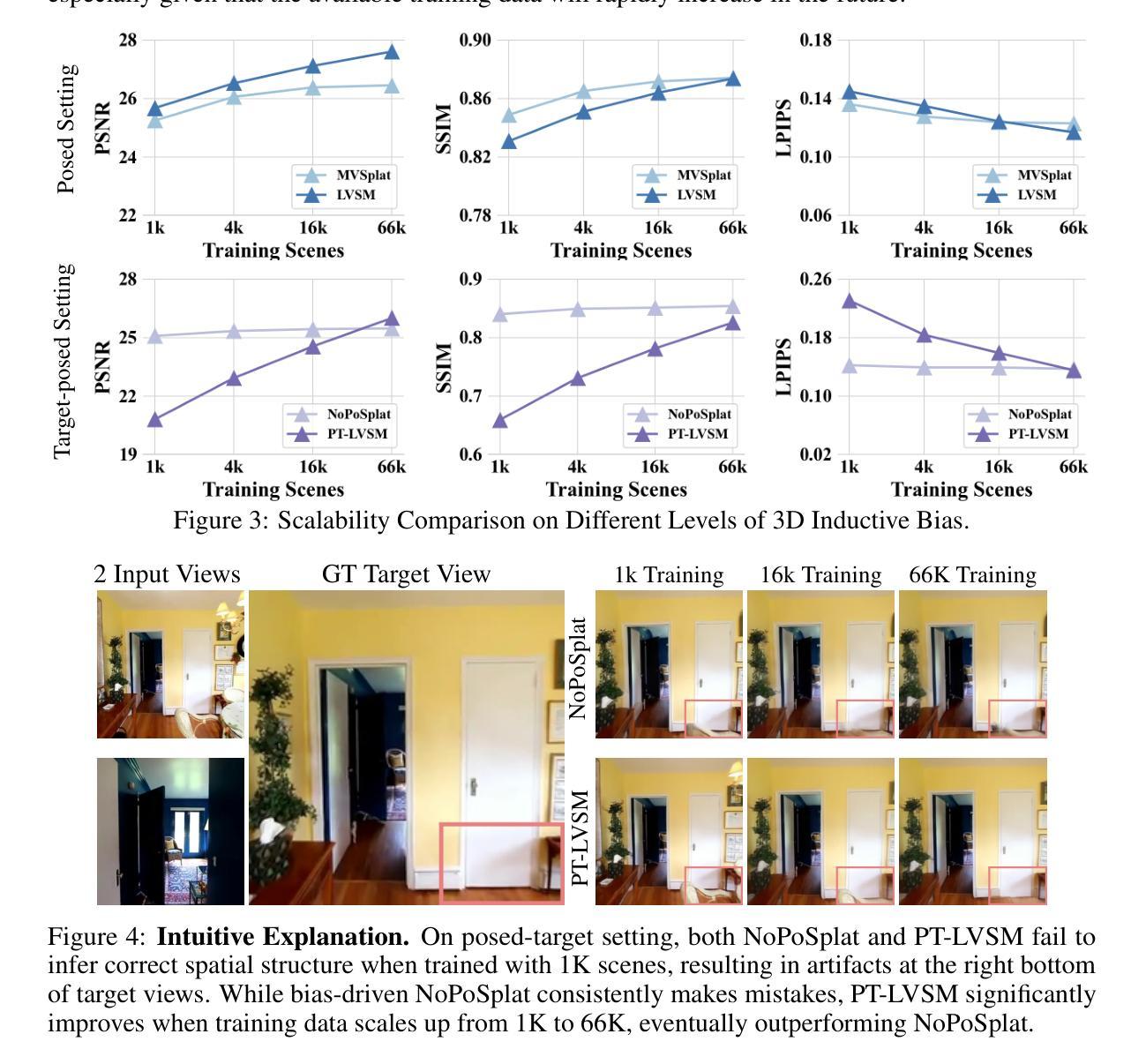
We consider the problem of generalizable novel view synthesis (NVS), which aims to generate photorealistic novel views from sparse or even unposed 2D images without per-scene optimization. This task remains fundamentally challenging, as it requires inferring 3D structure from incomplete and ambiguous 2D observations. Early approaches typically rely on strong 3D knowledge, including architectural 3D inductive biases (e.g., embedding explicit 3D representations, such as NeRF or 3DGS, into network design) and ground-truth camera poses for both input and target views. While recent efforts have sought to reduce the 3D inductive bias or the dependence on known camera poses of input views, critical questions regarding the role of 3D knowledge and the necessity of circumventing its use remain under-explored. In this work, we conduct a systematic analysis on the 3D knowledge and uncover a critical trend: the performance of methods that requires less 3D knowledge accelerates more as data scales, eventually achieving performance on par with their 3D knowledge-driven counterparts, which highlights the increasing importance of reducing dependence on 3D knowledge in the era of large-scale data. Motivated by and following this trend, we propose a novel NVS framework that minimizes 3D inductive bias and pose dependence for both input and target views. By eliminating this 3D knowledge, our method fully leverages data scaling and learns implicit 3D awareness directly from sparse 2D images, without any 3D inductive bias or pose annotation during training. Extensive experiments demonstrate that our model generates photorealistic and 3D-consistent novel views, achieving even comparable performance with methods that rely on posed inputs, thereby validating the feasibility and effectiveness of our data-centric paradigm. Project page: https://pku-vcl-geometry.github.io/Less3Depend/ .
我们考虑通用化新视角合成(NVS)的问题,其目标是从稀疏甚至未布置的2D图像生成真实感强的新视角图像,而无需针对每个场景进行优化。此任务仍然具有根本挑战性,因为它需要从不完整和模糊的2D观察结果中推断出3D结构。早期的方法通常依赖于强大的3D知识,包括建筑结构的3D归纳偏见(例如,将显式NeRF或3DGS等3D表示嵌入网络设计)以及针对输入和目标视角的真实相机姿态。尽管最近有努力试图减少3D归纳偏见或对输入视角已知相机姿态的依赖,但关于3D知识的作用以及避免使用它的必要性的关键问题仍然缺乏探索。在这项工作中,我们对3D知识进行了系统分析,并发现了一个关键趋势:需要较少3D知识的方法的性能随着数据规模的扩大而加速提高,最终与受3D知识驱动的方法的性能持平。这凸显了在大数据时代减少对3D知识的依赖的日益重要性。受此趋势的启发,我们提出了一种新型NVS框架,该框架最小化了对输入和目标视角的3D归纳偏见和姿态依赖。通过消除这种3D知识,我们的方法充分利用数据规模,直接从稀疏的2D图像学习隐含的3D意识,在训练过程中无需任何3D归纳偏见或姿态注释。大量实验表明,我们的模型生成了真实感强且与3D一致的全新视角图像,甚至实现了与依赖定位输入的方法相当的性能,从而验证了以数据为中心的模式可行性及有效性。项目页面:https://pku-vcl-geometry.github.io/Less3Depend/。
论文及项目相关链接
Summary
本文探讨了可推广的新视角合成(NVS)问题,旨在从稀疏或未摆放的2D图像生成真实感的新视角,而无需针对每个场景进行优化。文章指出,随着数据规模的增加,减少对3D知识的依赖的方法性能提升更快,最终与依赖3D知识的方法达到相当的性能。基于此趋势,提出了一种新型NVS框架,最小化了3D归纳偏见和姿势依赖。通过消除3D知识,该方法充分利用数据规模,直接从稀疏的2D图像学习隐式的3D意识,无需在训练期间提供任何3D归纳偏见或姿势注释。实验证明,该模型可以生成真实感且3D一致的全新视角,实现了与依赖定位输入的方法相当的性能。
Key Takeaways
- 文章探讨了新视角合成(NVS)问题,旨在从有限的2D图像生成真实感的新视角图像。
- 指出随着数据规模的增加,减少对3D知识依赖的方法性能提升更快。
- 提出了一种新型NVS框架,最小化了对3D归纳偏见和姿势依赖。
- 该框架消除了对3D知识的需求,通过数据规模学习隐式的3D意识。
- 实验证明,该模型可以生成真实感且3D一致的全新视角图像。
- 模型性能与依赖定位输入的方法相当,验证了数据中心范式的可行性。
点此查看论文截图


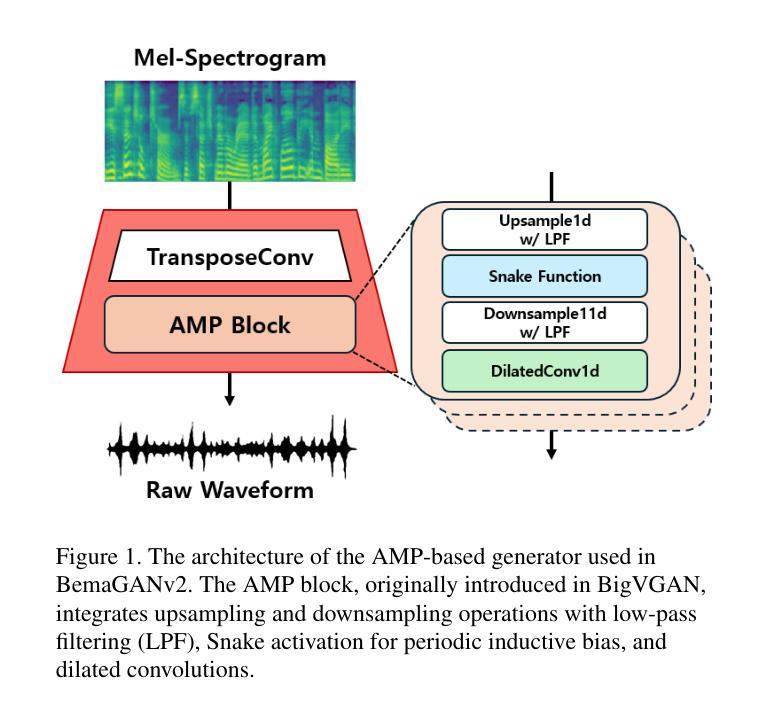
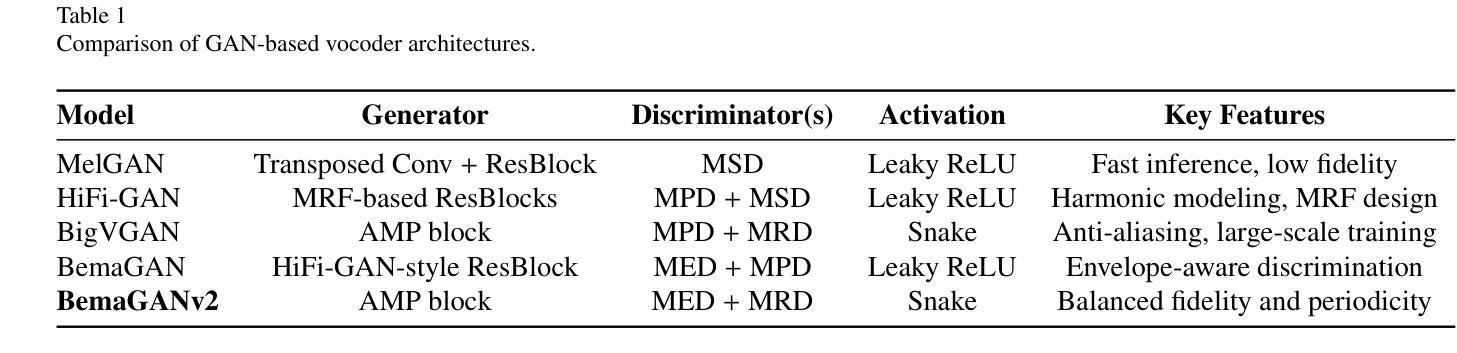
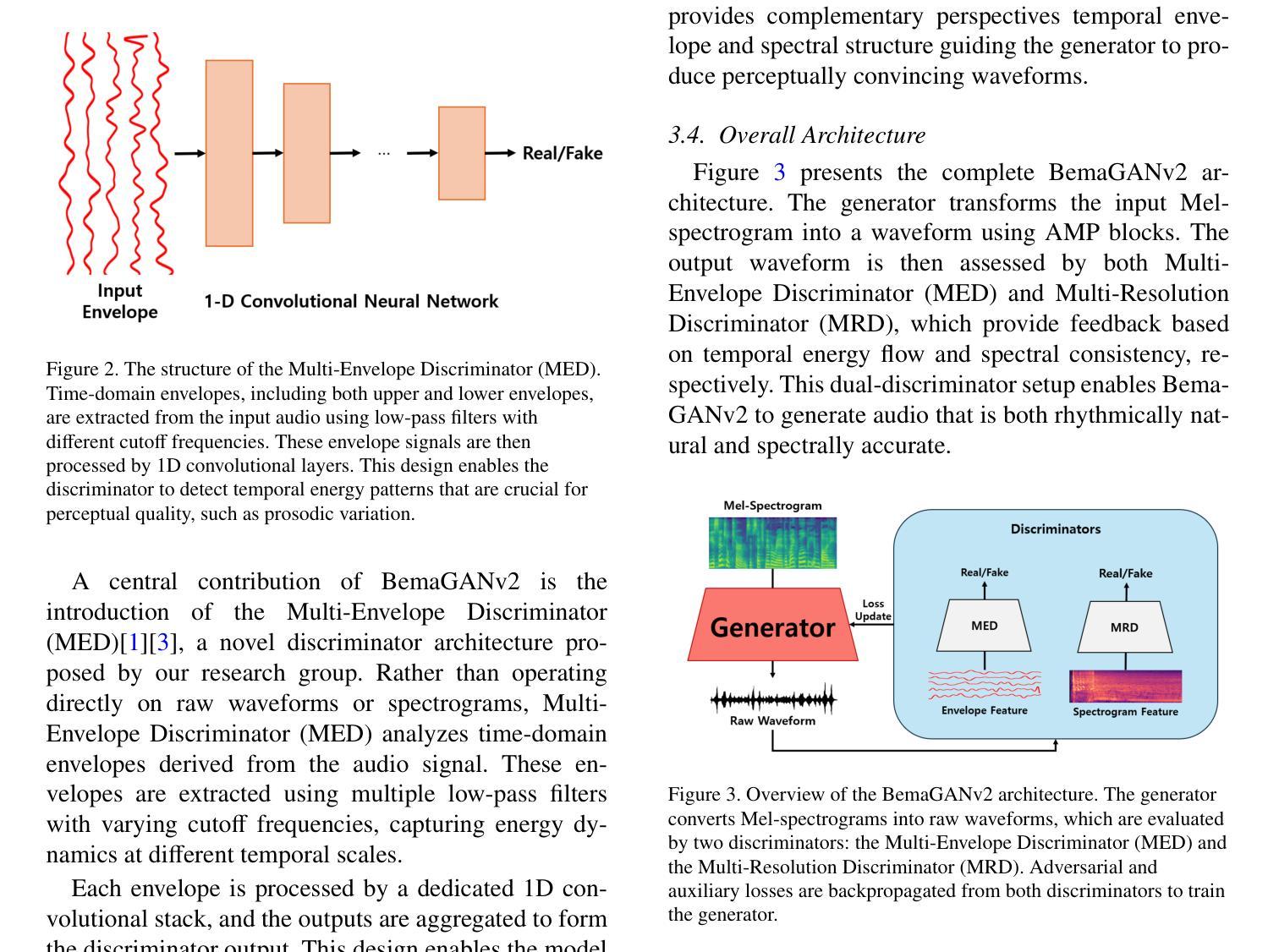
BemaGANv2: A Tutorial and Comparative Survey of GAN-based Vocoders for Long-Term Audio Generation
Authors:Taesoo Park, Mungwi Jeong, Mingyu Park, Narae Kim, Junyoung Kim, Mujung Kim, Jisang Yoo, Hoyun Lee, Sanghoon Kim, Soonchul Kwon
This paper presents a tutorial-style survey and implementation guide of BemaGANv2, an advanced GAN-based vocoder designed for high-fidelity and long-term audio generation. Built upon the original BemaGAN architecture, BemaGANv2 incorporates major architectural innovations by replacing traditional ResBlocks in the generator with the Anti-aliased Multi-Periodicity composition (AMP) module, which internally applies the Snake activation function to better model periodic structures. In the discriminator framework, we integrate the Multi-Envelope Discriminator (MED), a novel architecture we originally proposed, to extract rich temporal envelope features crucial for periodicity detection. Coupled with the Multi-Resolution Discriminator (MRD), this combination enables more accurate modeling of long-range dependencies in audio. We systematically evaluate various discriminator configurations, including MSD + MED, MSD + MRD, and MPD + MED + MRD, using objective metrics (FAD, SSIM, PLCC, MCD) and subjective evaluations (MOS, SMOS). This paper also provides a comprehensive tutorial on the model architecture, training methodology, and implementation to promote reproducibility. The code and pre-trained models are available at: https://github.com/dinhoitt/BemaGANv2.
本文是一篇教程式的调查与实现指南,介绍了BemaGANv2这一先进的基于GAN的编码器,旨在实现高保真和长期音频生成。BemaGANv2建立在原始BemaGAN架构之上,通过替换生成器中的传统ResBlocks,引入了重要的架构创新,采用了防混叠多周期组合(AMP)模块,该模块内部应用了Snake激活函数,以更好地模拟周期性结构。在判别器框架中,我们集成了我们最初提出的多包络判别器(MED),以提取丰富的时序包络特征,这对于周期性检测至关重要。与多分辨率判别器(MRD)相结合,这种组合能够实现音频中长距离依赖关系的更精确建模。我们系统地评估了各种判别器配置,包括MSD+MED、MSD+MRD和MPD+MED+MRD,采用客观度量(FAD、SSIM、PLCC、MCD)和主观评估(MOS、SMOS)。本文还提供了模型架构、训练方法和实现的全面教程,以促进可重复性。代码和预训练模型可在:https://github.com/dinhoitt/BemaGANv2找到。
论文及项目相关链接
PDF 11 pages, 7 figures. Survey and tutorial paper. Currently under review at ICT Express as an extended version of our ICAIIC 2025 paper
Summary
本文介绍了BemaGANv2的教程式综述与实现指南。作为基于GAN的高级音频生成器,BemaGANv2采用创新的架构,采用反锯齿多周期组成模块替代传统ResBlock,更好地模拟周期性结构。同时引入多信封鉴别器(MED)和多分辨率鉴别器(MRD),提高音频长期依赖关系的建模准确性。通过客观指标和主观评估对鉴别器配置进行系统评价,并提供模型架构、训练方法和实现的全面教程,促进可重复性。代码和预训练模型可在GitHub上找到。
Key Takeaways
- BemaGANv2是基于GAN的高级音频生成器。
- BemaGANv2引入创新的架构,使用反锯齿多周期组成(AMP)模块替代传统ResBlock。
- 多信封鉴别器(MED)用于提取音频周期性检测的关键时间包络特征。
- 结合多分辨率鉴别器(MRD),提高了对音频长期依赖关系的建模准确性。
- 对不同鉴别器配置进行客观指标和主观评估的系统评价。
- 论文提供了模型架构、训练方法和实现的全面教程。
点此查看论文截图

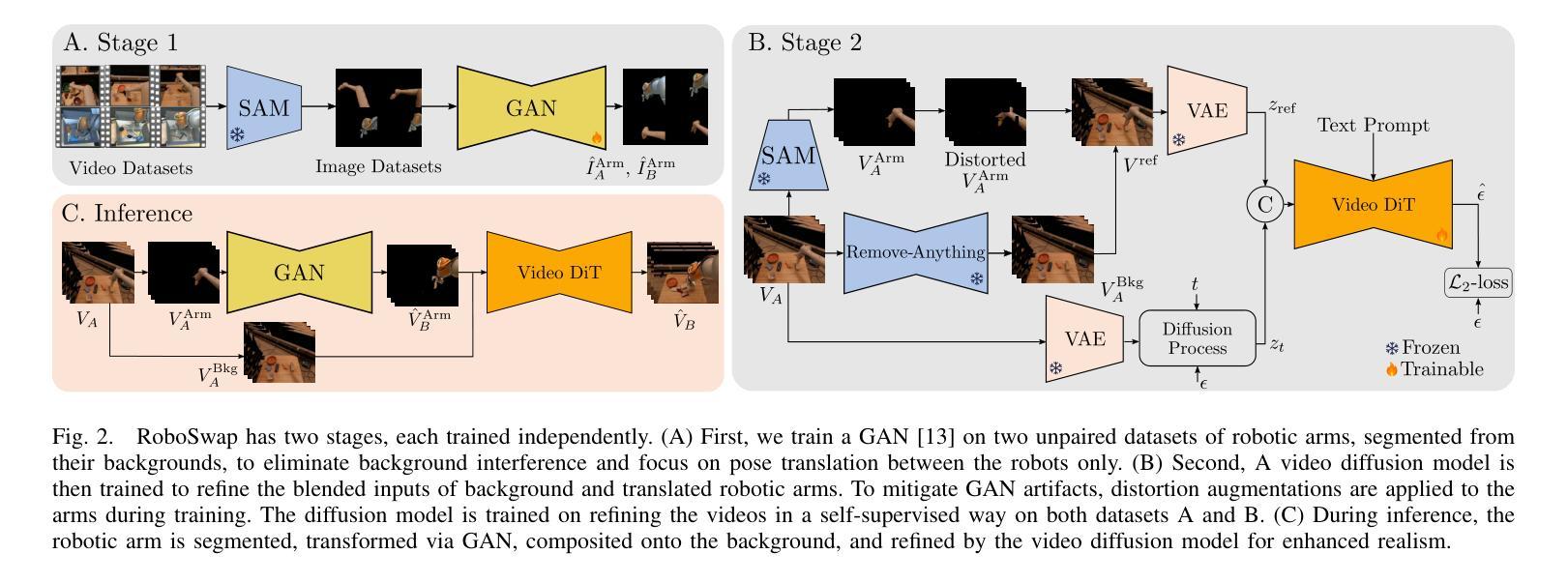
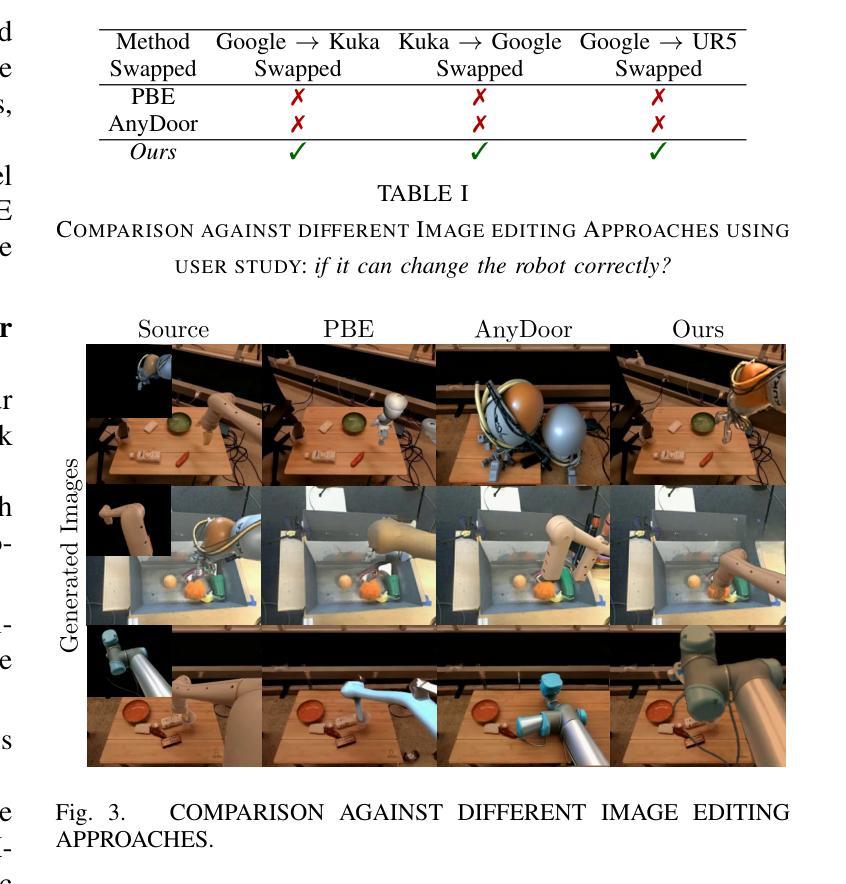
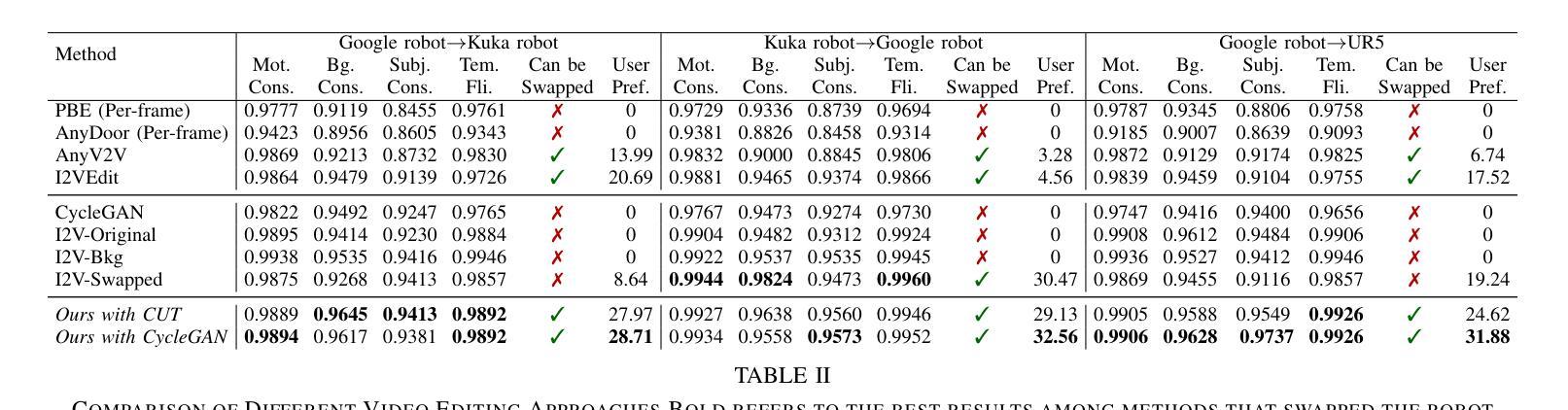
RoboSwap: A GAN-driven Video Diffusion Framework For Unsupervised Robot Arm Swapping
Authors:Yang Bai, Liudi Yang, George Eskandar, Fengyi Shen, Dong Chen, Mohammad Altillawi, Ziyuan Liu, Gitta Kutyniok
Recent advancements in generative models have revolutionized video synthesis and editing. However, the scarcity of diverse, high-quality datasets continues to hinder video-conditioned robotic learning, limiting cross-platform generalization. In this work, we address the challenge of swapping a robotic arm in one video with another: a key step for crossembodiment learning. Unlike previous methods that depend on paired video demonstrations in the same environmental settings, our proposed framework, RoboSwap, operates on unpaired data from diverse environments, alleviating the data collection needs. RoboSwap introduces a novel video editing pipeline integrating both GANs and diffusion models, combining their isolated advantages. Specifically, we segment robotic arms from their backgrounds and train an unpaired GAN model to translate one robotic arm to another. The translated arm is blended with the original video background and refined with a diffusion model to enhance coherence, motion realism and object interaction. The GAN and diffusion stages are trained independently. Our experiments demonstrate that RoboSwap outperforms state-of-the-art video and image editing models on three benchmarks in terms of both structural coherence and motion consistency, thereby offering a robust solution for generating reliable, cross-embodiment data in robotic learning.
最近生成模型的进展已经彻底改变了视频合成和编辑。然而,多样且高质量数据集的稀缺继续阻碍着视频条件下的机器人学习,并限制了跨平台的泛化。在这项工作中,我们解决了在一个视频中用另一个机器人手臂替换机器人手臂的挑战,这是跨体态学习的关键步骤。不同于以前依赖于相同环境设置中配对视频演示的方法,我们提出的RoboSwap框架使用来自不同环境的非配对数据,减轻了数据收集的需求。RoboSwap引入了一种新的视频编辑管道,融合了生成对抗网络(GANs)和扩散模型,结合了它们的独立优势。具体来说,我们从背景中提取机器人手臂,训练一个非配对GAN模型将一个机器人手臂翻译成另一个。翻译的机器人手臂与原始视频背景混合,并使用扩散模型进行精炼,以提高连贯性、运动真实性和物体交互性。GAN和扩散阶段是独立训练的。我们的实验表明,RoboSwap在三项基准测试上的结构连贯性和运动一致性方面都优于最新的视频和图像编辑模型,从而为机器人学习中的可靠跨体态数据生成提供了稳健的解决方案。
论文及项目相关链接
Summary
近期生成模型进展推动了视频合成与编辑的革新。然而,缺乏多样化高质量数据集仍是视频条件机器人学习的瓶颈,限制了跨平台泛化。本研究解决视频内替换机器人手臂这一关键跨体态学习步骤的挑战。不同于依赖相同环境设定下配对视频示范的以往方法,本研究所提框架RoboSwap采用不同环境下的非配对数据,缓解数据采集需求。RoboSwap推出新型视频编辑管道整合GANs与扩散模型,结合各自优势。具体而言,我们从背景中分割出机器人手臂,训练非配对GAN模型将一机器人手臂转换为另一手臂。翻译后的手臂与原始视频背景融合,并用扩散模型增强连贯性、动作现实感和物体交互。GAN和扩散阶段独立训练。实验显示,RoboSwap在结构连贯性和动作一致性方面,于三个基准测试上表现优于现有视频与图像编辑模型,为机器人学习中生成可靠跨体态数据提供了稳健解决方案。
Key Takeaways
- 生成模型的最新进展已经推动了视频合成和编辑的变革。
- 缺乏多样化高质量数据集仍然是视频条件机器人学习的主要挑战。
- 本研究提出了一个名为RoboSwap的新型框架,用于解决替换视频中机器人手臂的跨体态学习问题。
- RoboSwap采用非配对数据,可应对不同环境的数据采集挑战。
- 该框架结合了生成对抗网络(GANs)和扩散模型的优点,形成了一个创新的视频编辑管道。
- 实验证明,RoboSwap在结构连贯性和动作一致性方面显著优于当前先进的视频和图像编辑模型。
点此查看论文截图



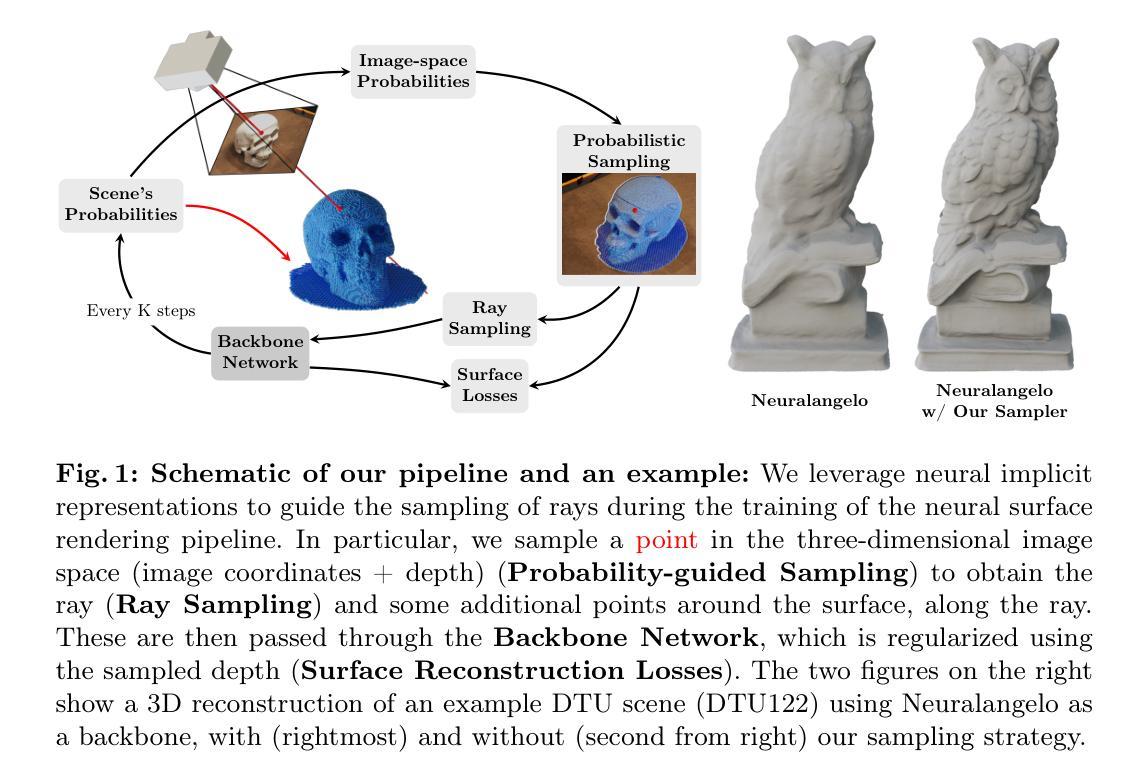
A Probability-guided Sampler for Neural Implicit Surface Rendering
Authors:Gonçalo Dias Pais, Valter Piedade, Moitreya Chatterjee, Marcus Greiff, Pedro Miraldo
Several variants of Neural Radiance Fields (NeRFs) have significantly improved the accuracy of synthesized images and surface reconstruction of 3D scenes/objects. In all of these methods, a key characteristic is that none can train the neural network with every possible input data, specifically, every pixel and potential 3D point along the projection rays due to scalability issues. While vanilla NeRFs uniformly sample both the image pixels and 3D points along the projection rays, some variants focus only on guiding the sampling of the 3D points along the projection rays. In this paper, we leverage the implicit surface representation of the foreground scene and model a probability density function in a 3D image projection space to achieve a more targeted sampling of the rays toward regions of interest, resulting in improved rendering. Additionally, a new surface reconstruction loss is proposed for improved performance. This new loss fully explores the proposed 3D image projection space model and incorporates near-to-surface and empty space components. By integrating our novel sampling strategy and novel loss into current state-of-the-art neural implicit surface renderers, we achieve more accurate and detailed 3D reconstructions and improved image rendering, especially for the regions of interest in any given scene.
神经辐射场(NeRF)的几个变体已经显著提高了合成图像的准确性和3D场景/对象的表面重建效果。在这些方法中,一个关键特点是都无法使用每一种可能输入数据来训练神经网络,特别是由于可扩展性问题,无法对投影射线上的每一个像素和潜在的3D点进行训练。虽然原始的NeRF会均匀采样图像像素和投影射线上的3D点,但一些变体只专注于引导投影射线上的3D点采样。在本文中,我们利用前景场景的隐式表面表示,并在3D图像投影空间中建立概率密度函数,实现更有针对性的射线采样,从而改进渲染效果。此外,还提出了一种新的表面重建损失以提高性能。这种新损失充分利用了所提出的3D图像投影空间模型,并包含了近表面和空旷空间组件。通过将我们的新型采样策略和新型损失集成到当前最先进的神经隐式表面渲染器中,我们实现了更准确、更精细的3D重建和改进的图像渲染,尤其对于给定场景中的重点区域。
论文及项目相关链接
PDF Accepted in ECCV 2024
Summary
神经网络辐射场(NeRF)的几个变体已经显著提高了合成图像的准确性和3D场景/对象的表面重建能力。这些方法的关键特征在于,由于可扩展性问题,它们都无法使用每一种可能的输入数据来训练神经网络,特别是每一个像素和投影射线上的潜在3D点。本文利用前景场景的隐式表面表示,在3D图像投影空间中建立概率密度函数,实现更有针对性的射线采样,从而改进渲染。此外,还提出了一种新的表面重建损失,以提高性能。通过将其新颖的采样策略和损失集成到当前最先进的神经隐式表面渲染器中,实现了更准确、更精细的3D重建和改进的图像渲染,特别是对于任何给定场景中的重点区域。
Key Takeaways
- NeRF及其变体在合成图像准确性和3D场景表面重建方面取得了显著进步。
- 由于可扩展性问题,现有方法无法处理所有可能的输入数据,尤其是像素和投影射线上的每个潜在3D点。
- 本文采用前景场景的隐式表面表示方法,对重点区域进行更有针对性的射线采样。
- 引入了一个新的概率密度函数模型,在3D图像投影空间中指导采样策略。
- 提出了一种新的表面重建损失函数,以改进渲染性能。
- 结合新的采样策略和损失函数,显著提高了3D重建的准确性和细节,特别是在场景的重点区域。
点此查看论文截图

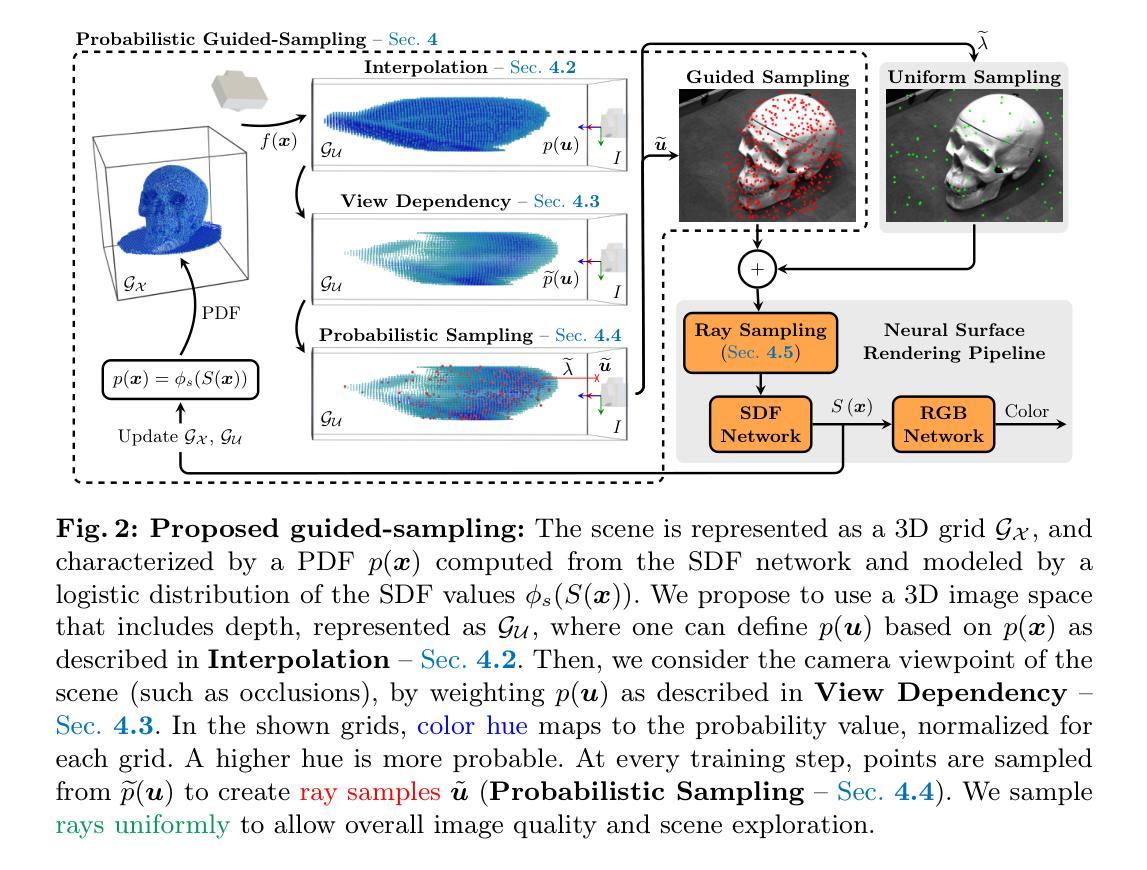
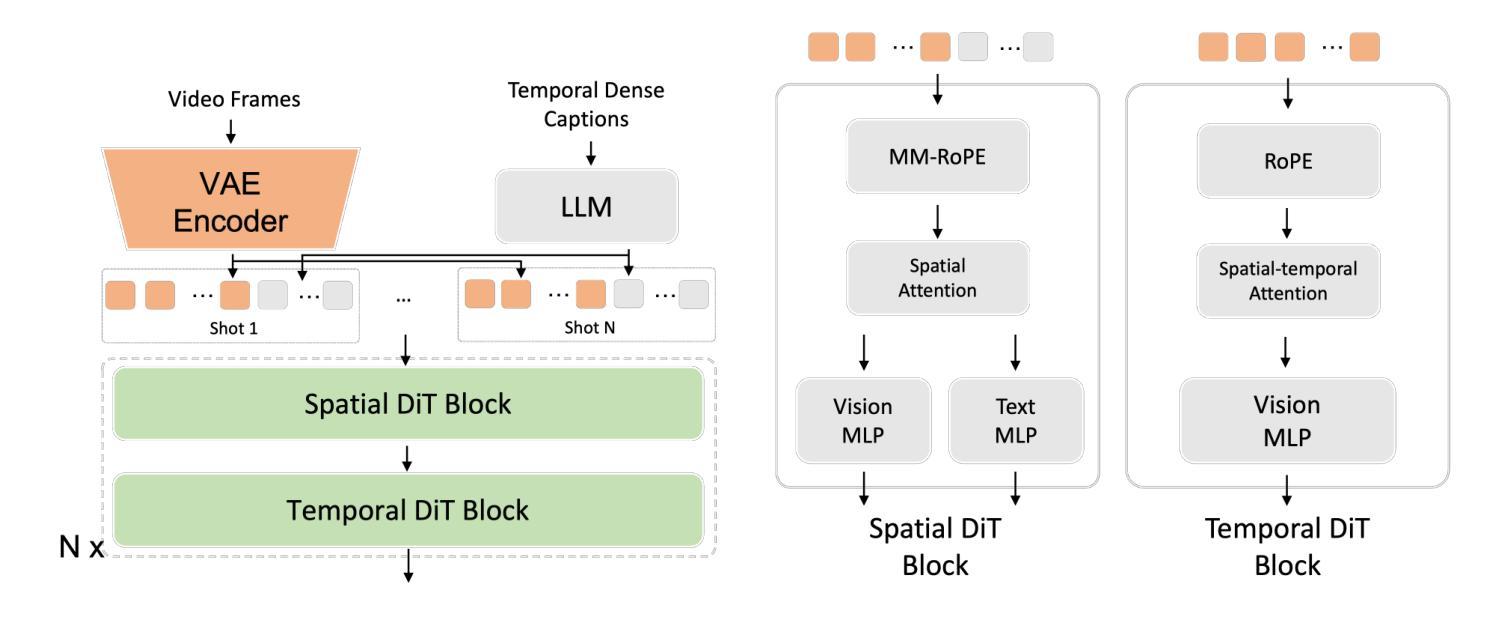
Genesis: Multimodal Driving Scene Generation with Spatio-Temporal and Cross-Modal Consistency
Authors:Xiangyu Guo, Zhanqian Wu, Kaixin Xiong, Ziyang Xu, Lijun Zhou, Gangwei Xu, Shaoqing Xu, Haiyang Sun, Bing Wang, Guang Chen, Hangjun Ye, Wenyu Liu, Xinggang Wang
We present Genesis, a unified framework for joint generation of multi-view driving videos and LiDAR sequences with spatio-temporal and cross-modal consistency. Genesis employs a two-stage architecture that integrates a DiT-based video diffusion model with 3D-VAE encoding, and a BEV-aware LiDAR generator with NeRF-based rendering and adaptive sampling. Both modalities are directly coupled through a shared latent space, enabling coherent evolution across visual and geometric domains. To guide the generation with structured semantics, we introduce DataCrafter, a captioning module built on vision-language models that provides scene-level and instance-level supervision. Extensive experiments on the nuScenes benchmark demonstrate that Genesis achieves state-of-the-art performance across video and LiDAR metrics (FVD 16.95, FID 4.24, Chamfer 0.611), and benefits downstream tasks including segmentation and 3D detection, validating the semantic fidelity and practical utility of the generated data.
我们提出了Genesis,这是一个统一框架,用于联合生成具有时空和跨模态一致性的多视图驾驶视频和激光雷达序列。Genesis采用两阶段架构,集成了基于DiT的视频扩散模型与3D-VAE编码,以及带有基于NeRF的渲染和自适应采样的BEV感知激光雷达生成器。两种模式通过共享潜在空间直接耦合,实现了视觉和几何领域之间的连贯演变。为了通过结构化语义引导生成,我们引入了DataCrafter,这是一个基于视觉语言模型的描述模块,提供场景级和实例级监督。在nuScenes基准测试上的广泛实验表明,Genesis在视频和激光雷达指标上达到了最新技术水平(FVD 16.95,FID 4.24,Chamfer 0.611),并有利于包括分割和3D检测在内的下游任务,验证了生成数据的语义保真度和实用性。
论文及项目相关链接
摘要
本文提出Genesis,一个统一框架,用于联合生成多视角驾驶视频和LiDAR序列,具有时空和跨模态一致性。Genesis采用两阶段架构,集成了基于DiT的视频扩散模型与3D-VAE编码,以及带有NeRF渲染和自适应采样的BEV感知LiDAR生成器。两种模态通过共享潜在空间直接耦合,实现视觉和几何域之间的连贯演变。为指导生成提供结构化语义,我们引入了DataCrafter,一个基于视觉语言模型的字幕模块,提供场景级和实例级监督。在nuScenes基准测试上的广泛实验表明,Genesis在视频和LiDAR指标上达到领先水平(FVD 16.95,FID 4.24,Chamfer 0.611),并有利于下游任务,包括分割和3D检测,验证了生成数据的语义保真度和实用性。
要点
- Genesis是一个联合生成多视角驾驶视频和LiDAR序列的统一框架,具有时空和跨模态一致性。
- 采用两阶段架构,集成DiT视频扩散模型与3D-VAE编码以及BEV感知LiDAR生成器。
- 通过共享潜在空间直接耦合两种模态,实现视觉和几何域的连贯演变。
- 引入DataCrafter模块,提供场景级和实例级监督,指导生成过程的结构化语义。
- 在nuScenes基准测试上表现优异,达到领先水平。
- 生成数据对下游任务如分割和3D检测有益,验证了其语义保真度和实用性。
点此查看论文截图

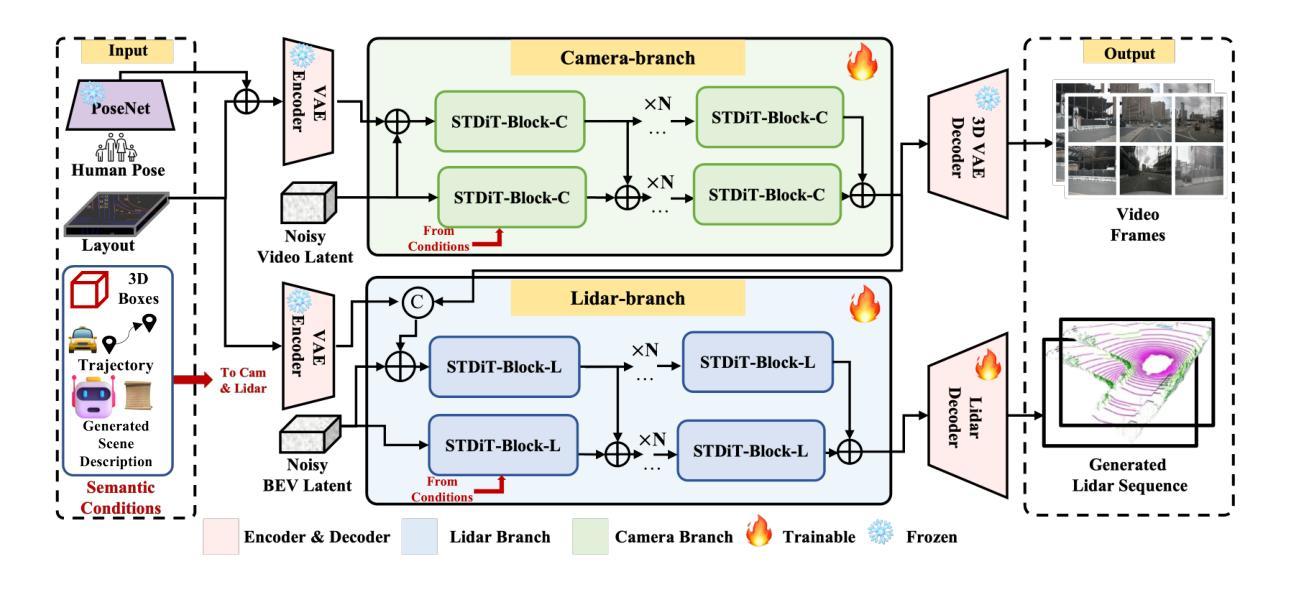
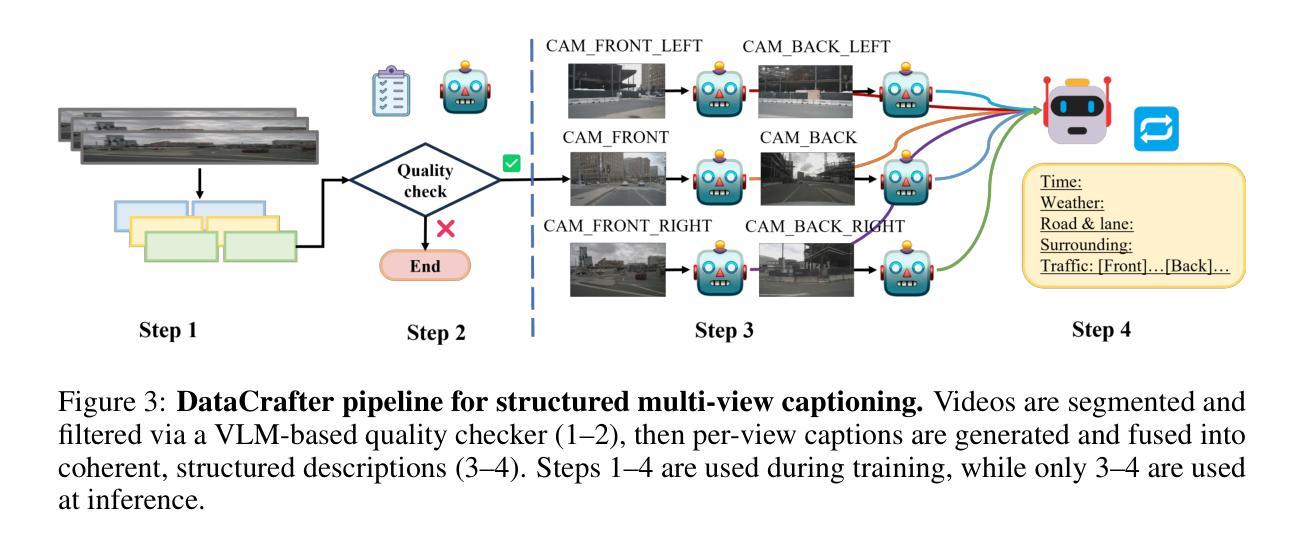
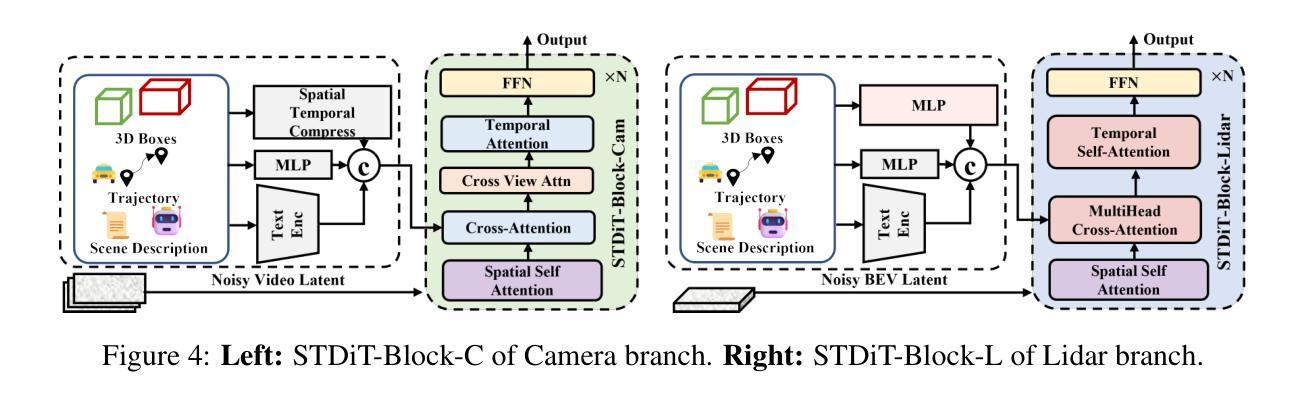
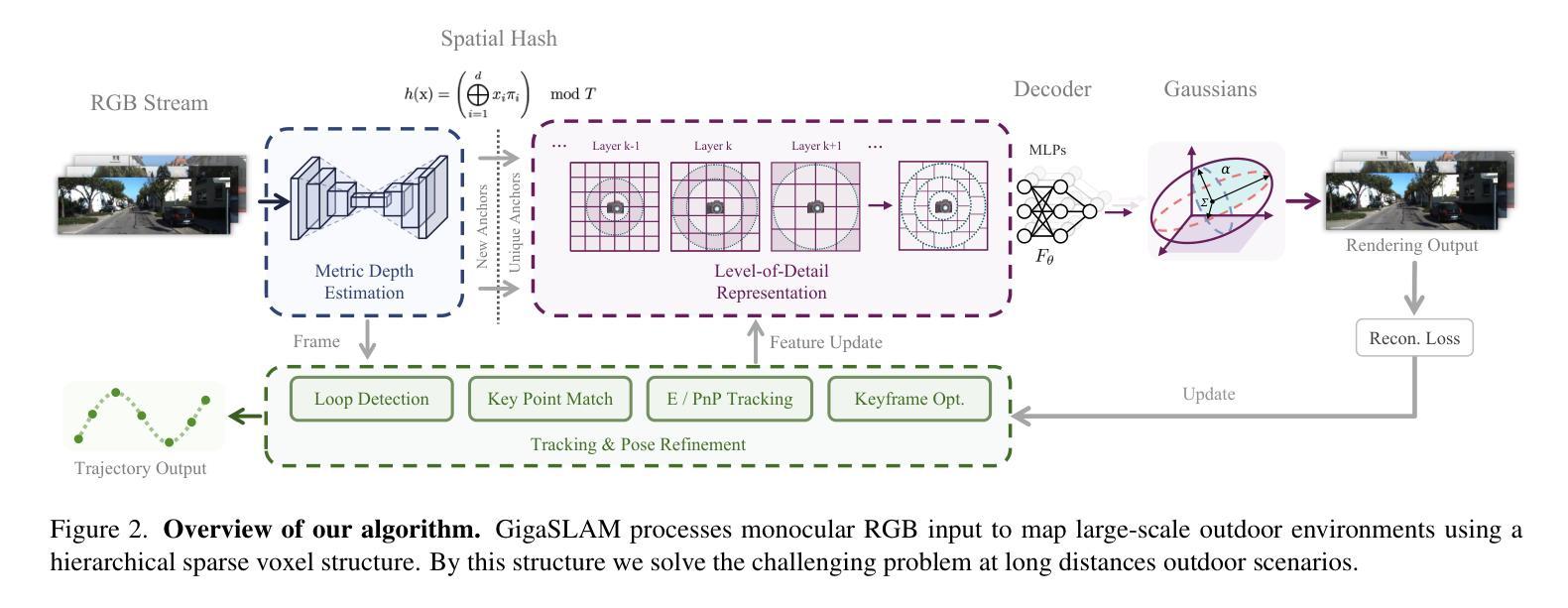
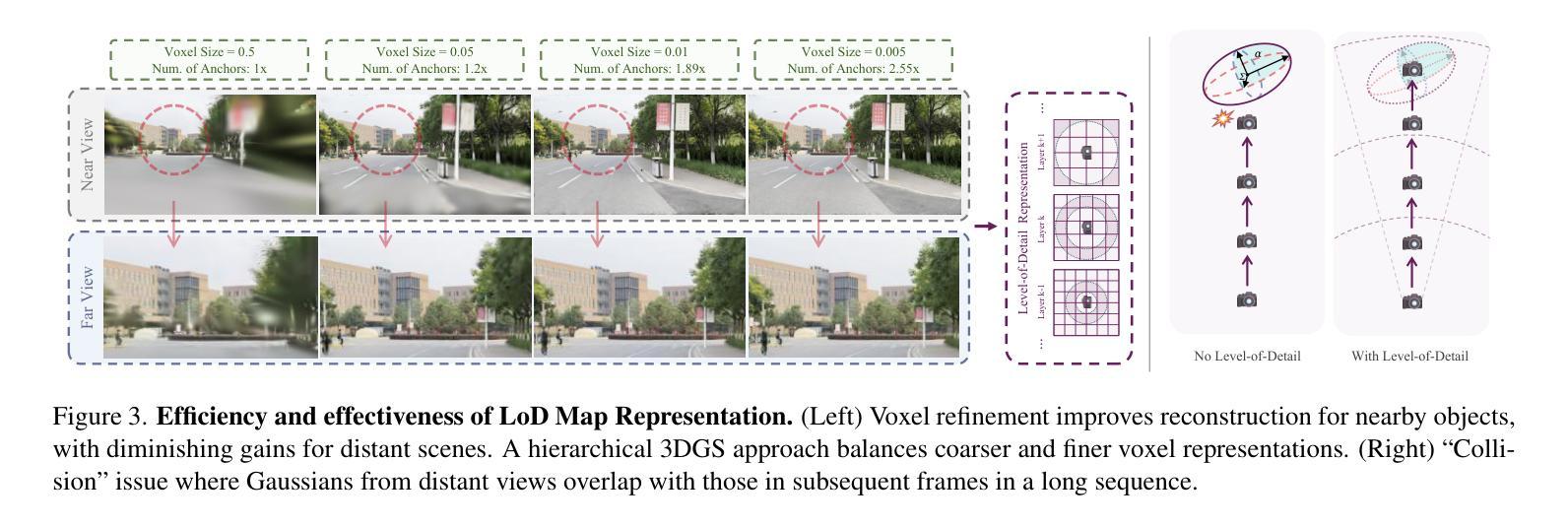
GigaSLAM: Large-Scale Monocular SLAM with Hierarchical Gaussian Splats
Authors:Kai Deng, Yigong Zhang, Jian Yang, Jin Xie
Tracking and mapping in large-scale, unbounded outdoor environments using only monocular RGB input presents substantial challenges for existing SLAM systems. Traditional Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) SLAM methods are typically limited to small, bounded indoor settings. To overcome these challenges, we introduce GigaSLAM, the first RGB NeRF / 3DGS-based SLAM framework for kilometer-scale outdoor environments, as demonstrated on the KITTI, KITTI 360, 4 Seasons and A2D2 datasets. Our approach employs a hierarchical sparse voxel map representation, where Gaussians are decoded by neural networks at multiple levels of detail. This design enables efficient, scalable mapping and high-fidelity viewpoint rendering across expansive, unbounded scenes. For front-end tracking, GigaSLAM utilizes a metric depth model combined with epipolar geometry and PnP algorithms to accurately estimate poses, while incorporating a Bag-of-Words-based loop closure mechanism to maintain robust alignment over long trajectories. Consequently, GigaSLAM delivers high-precision tracking and visually faithful rendering on urban outdoor benchmarks, establishing a robust SLAM solution for large-scale, long-term scenarios, and significantly extending the applicability of Gaussian Splatting SLAM systems to unbounded outdoor environments. GitHub: https://github.com/DengKaiCQ/GigaSLAM.
使用单目RGB输入在大规模、无边界的室外环境中进行追踪和映射,为现有的SLAM系统带来了巨大的挑战。传统的神经辐射场(NeRF)和3D高斯拼贴(3DGS)SLAM方法通常仅限于小型、有界的室内环境。为了克服这些挑战,我们引入了GigaSLAM,这是第一个基于RGB NeRF/3DGS的适用于公里级室外环境的SLAM框架,已在KITTI、KITTI 360、四季和A2D2数据集上得到了验证。我们的方法采用分层稀疏体素图表示,高斯数据通过多级神经网络进行解码。这种设计实现了高效、可扩展的映射和高保真视角渲染,适用于广阔的无界场景。对于前端跟踪,GigaSLAM采用度量深度模型结合极几何和PnP算法来精确估计姿态,同时采用基于词袋的回路关闭机制,以在长期轨迹中保持稳健的对齐。因此,GigaSLAM在城市室外基准测试上实现了高精度跟踪和视觉真实渲染,为大规模、长期场景建立了稳健的SLAM解决方案,并将高斯拼贴SLAM系统的应用范围显著扩展到了无边界的室外环境。GitHub:https://github.com/DengKaiCQ/GigaSLAM。
论文及项目相关链接
Summary
针对大规模、无边界的室外环境,仅使用单目RGB输入进行追踪和映射给现有SLAM系统带来了诸多挑战。传统Neural Radiance Fields(NeRF)和3D高斯贴图(3DGS)SLAM方法通常局限于小规模的室内环境。为应对这些挑战,我们推出GigaSLAM,这是首个基于RGB NeRF/3DGS的SLAM框架,适用于公里级室外环境,已在KITTI、KITTI 360、四季和A2D2数据集上得到验证。
Key Takeaways
- GigaSLAM是首个针对大规模、无边界室外环境的RGB NeRF/3DGS-based SLAM框架。
- 利用层次化稀疏体素图表现方法,结合神经网络解码高斯分布,实现高效、可扩展的映射和高保真视角渲染。
- 前端追踪采用度量深度模型,结合极线几何和PnP算法,准确估计姿态。
- 融入基于词袋的回路关闭机制,长期轨迹保持稳健对齐。
- GigaSLAM在高精度追踪和视觉真实渲染方面表现优异,为大规模、长期场景提供稳健SLAM解决方案。
- 该系统显著扩展了高斯贴图SLAM系统在无边界室外环境中的应用性。
- GitHub地址:https://github.com/DengKaiCQ/GigaSLAM。
点此查看论文截图

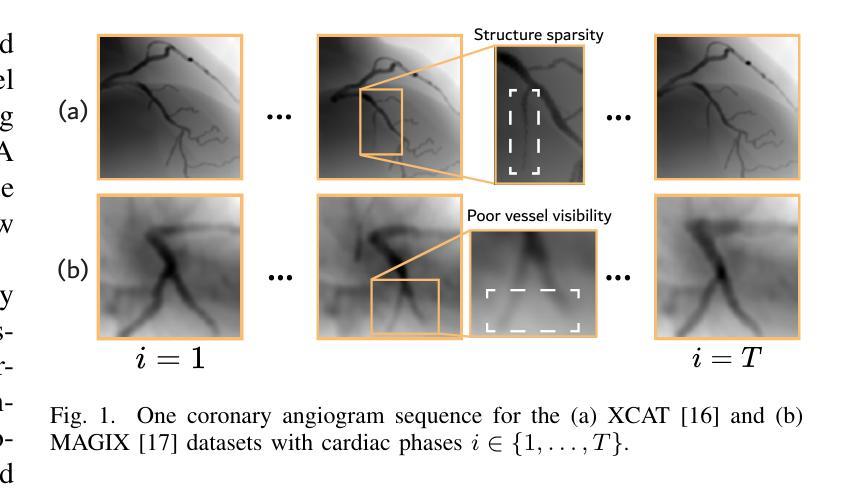
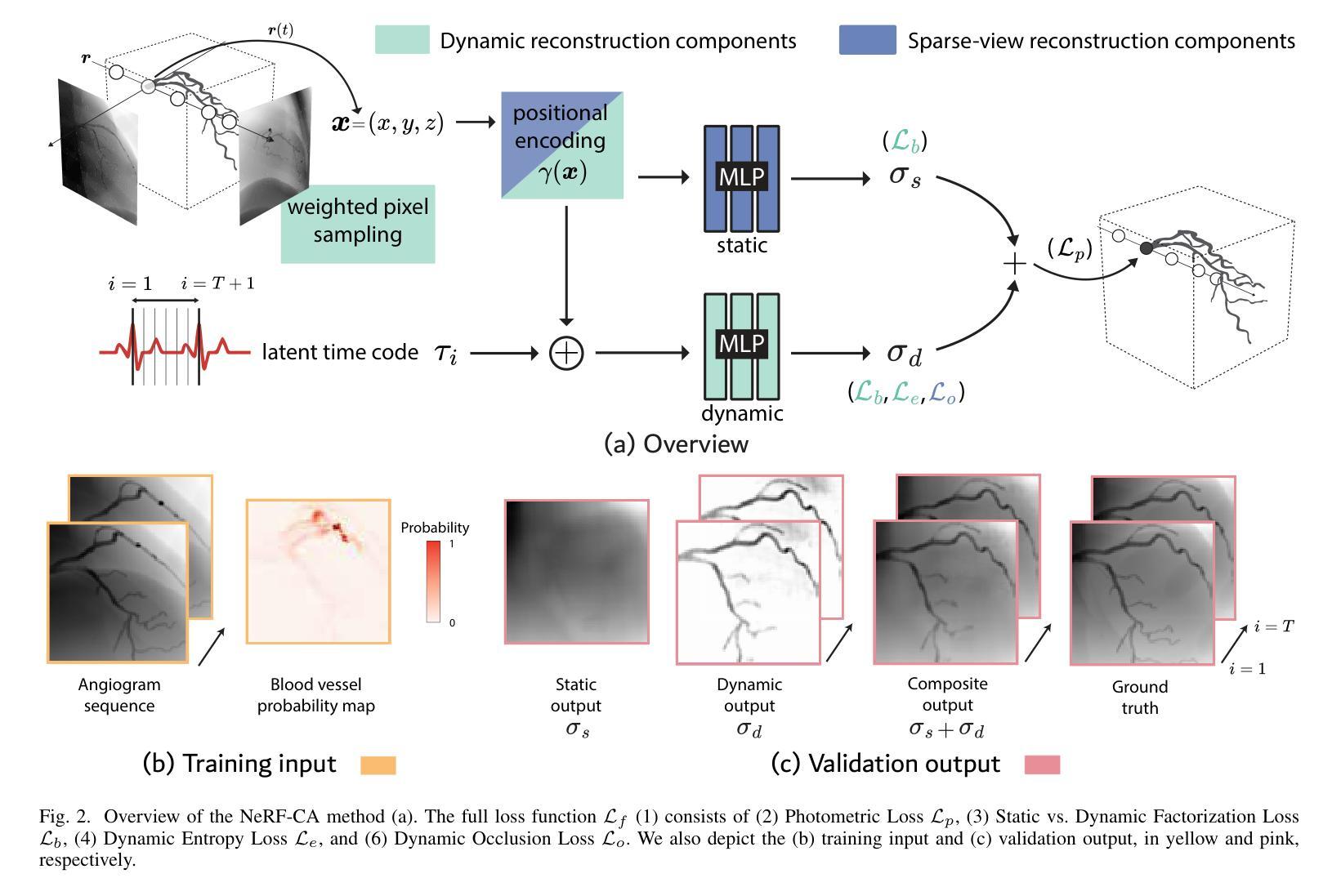
NeRF-CA: Dynamic Reconstruction of X-ray Coronary Angiography with Extremely Sparse-views
Authors:Kirsten W. H. Maas, Danny Ruijters, Anna Vilanova, Nicola Pezzotti
Dynamic three-dimensional (4D) reconstruction from two-dimensional X-ray coronary angiography (CA) remains a significant clinical problem. Existing CA reconstruction methods often require extensive user interaction or large training datasets. Recently, Neural Radiance Field (NeRF) has successfully reconstructed high-fidelity scenes in natural and medical contexts without these requirements. However, challenges such as sparse-views, intra-scan motion, and complex vessel morphology hinder its direct application to CA data. We introduce NeRF-CA, a first step toward a fully automatic 4D CA reconstruction that achieves reconstructions from sparse coronary angiograms. To the best of our knowledge, we are the first to address the challenges of sparse-views and cardiac motion by decoupling the scene into the moving coronary artery and the static background, effectively translating the problem of motion into a strength. NeRF-CA serves as a first stepping stone for solving the 4D CA reconstruction problem, achieving adequate 4D reconstructions from as few as four angiograms, as required by clinical practice, while significantly outperforming state-of-the-art sparse-view X-ray NeRF. We validate our approach quantitatively and qualitatively using representative 4D phantom datasets and ablation studies. To accelerate research in this domain, we made our codebase public: https://github.com/kirstenmaas/NeRF-CA.
从二维X射线冠状动脉造影(CA)进行动态三维(4D)重建仍然是临床上的一个重大问题。现有的CA重建方法通常需要大量用户交互或大量的训练数据集。最近,神经辐射场(NeRF)成功地重建了自然和医学背景下的高保真场景,而无需这些要求。然而,稀疏视图、扫描内运动以及复杂的血管形态等挑战阻碍了其直接应用于CA数据。我们引入了NeRF-CA,这是朝着全自动4D CA重建的第一步,实现了从稀疏冠状动脉造影图像进行重建。据我们所知,我们是第一个通过解耦场景为移动冠状动脉和静态背景来应对稀疏视图和心脏运动带来的挑战,有效地将运动问题转化为优势。NeRF-CA作为解决4D CA重建问题的第一步,能够从临床实践中所需的最少四张造影图像实现足够的4D重建,并且显著优于最新的稀疏视图X射线NeRF。我们使用有代表性的4D幻影数据集和消融研究从定量和定性两个方面验证了我们的方法。为了加速该领域的研究,我们公开了我们的代码库:https://github.com/kirstenmaas/NeRF-CA。
论文及项目相关链接
Summary
NeRF-CA方法基于神经辐射场技术解决了冠状动脉造影的三维重建问题,尤其解决了稀疏视角和心脏运动带来的挑战。通过分离动态冠状动脉和静态背景,实现了从少量造影图像(符合临床实践需求)进行高质量的四维重建。该方法已得到定量和定性验证,其研究代码已公开共享。
Key Takeaways
- NeRF-CA利用神经辐射场技术实现了从二维冠状动脉造影图像的三维重建。
- 该方法解决了稀疏视角和心脏运动带来的挑战。
- 通过分离动态冠状动脉和静态背景,解决了心脏运动问题,转化为优势。
- NeRF-CA能够从仅四个造影图像实现四维重建,符合临床实践需求。
- 与现有稀疏视角X射线神经辐射场方法相比,NeRF-CA表现更优。
- 研究已进行定量和定性验证,使用具有代表性的四维幻影数据集和消融研究。
点此查看论文截图

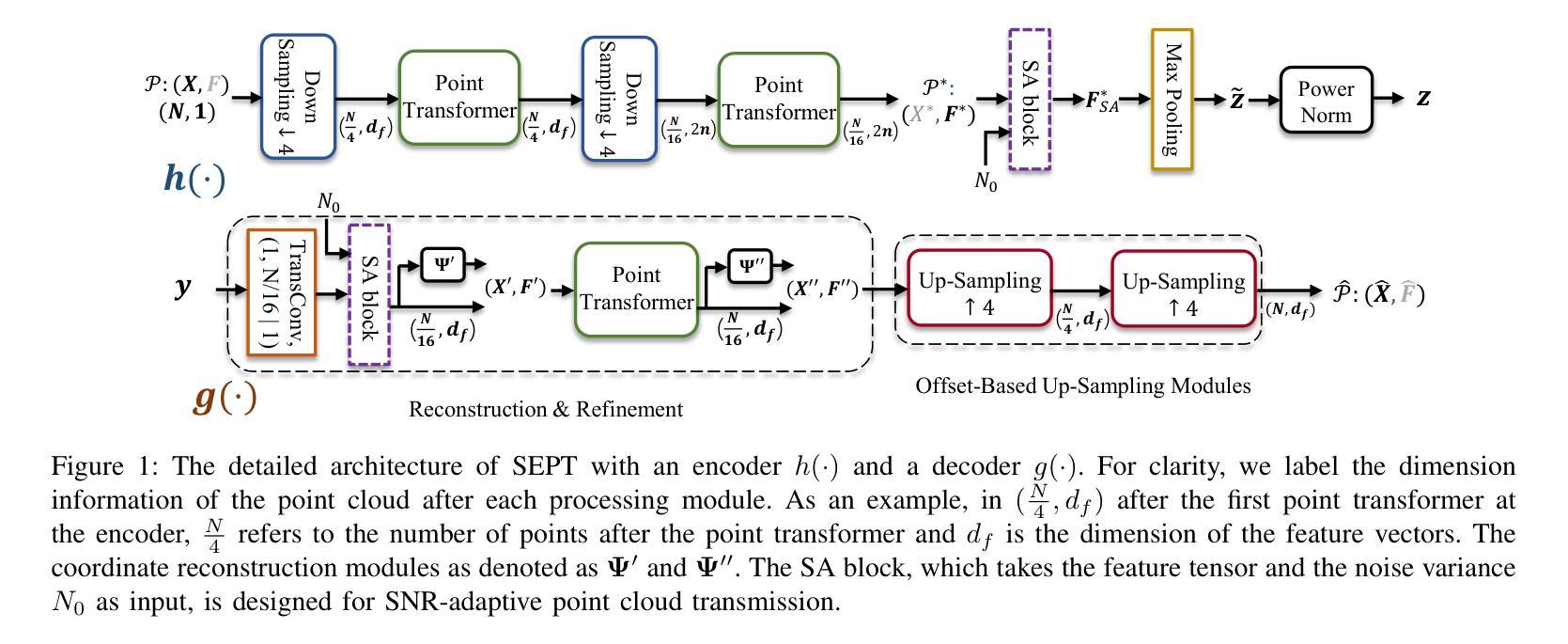
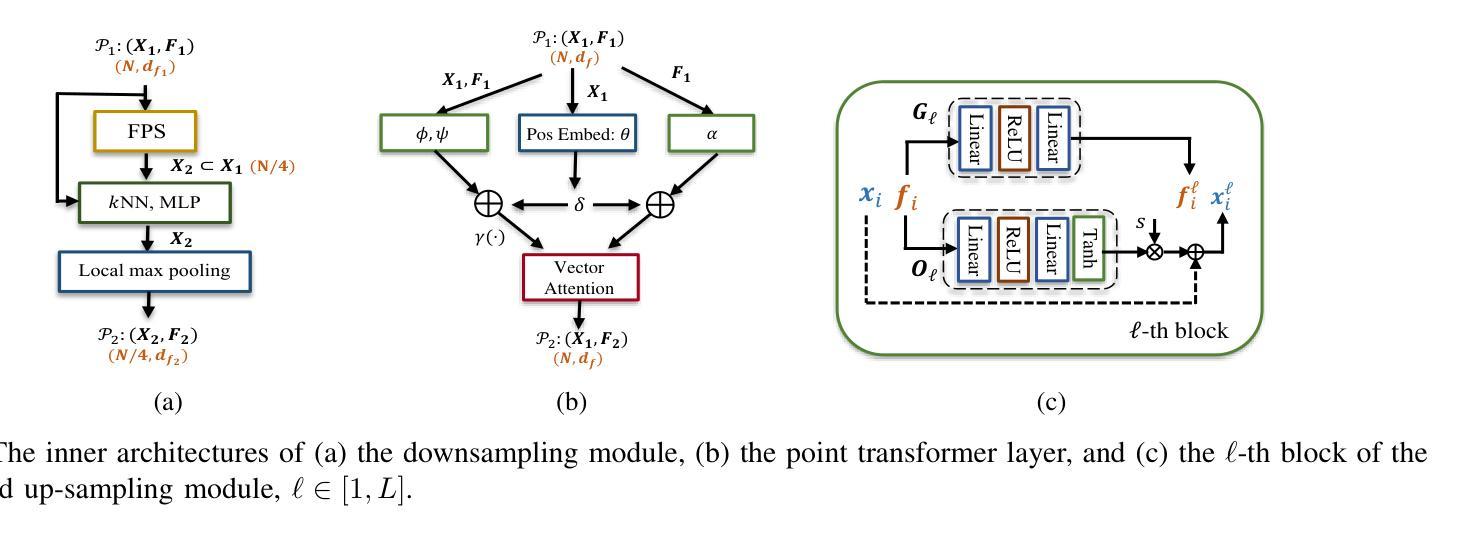
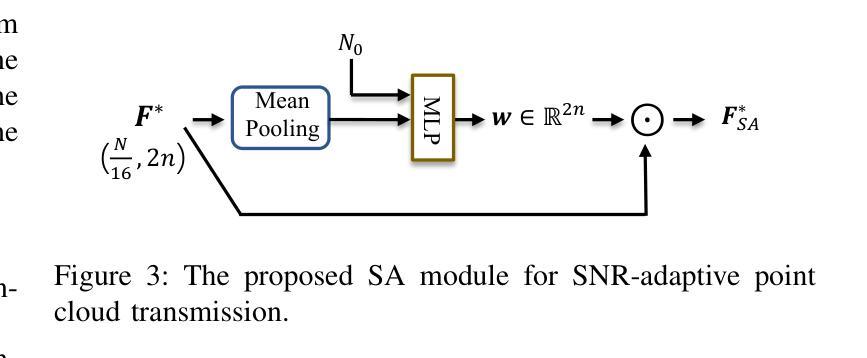
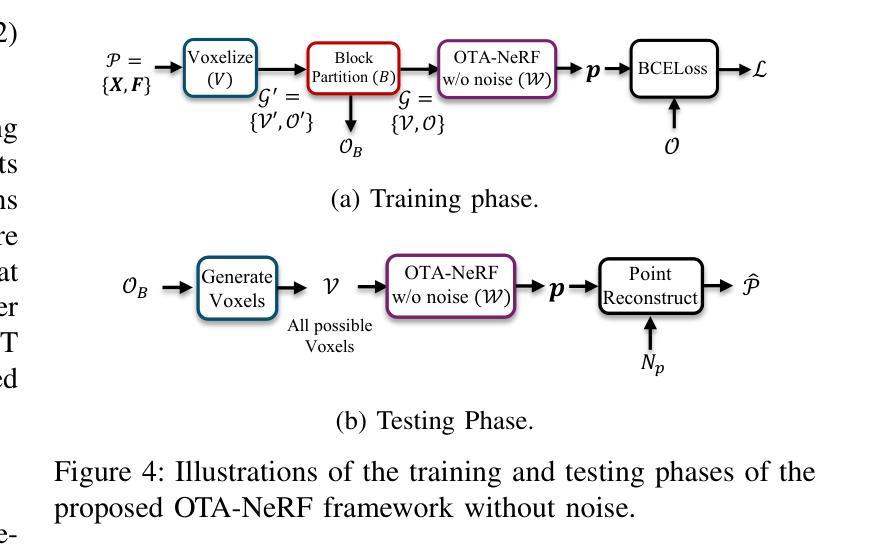
Over-the-Air Learning-based Geometry Point Cloud Transmission
Authors:Chenghong Bian, Yulin Shao, Deniz Gunduz
This paper presents novel solutions for the efficient and reliable transmission of point clouds over wireless channels for real-time applications. We first propose SEmatic Point cloud Transmission (SEPT) for small-scale point clouds, which encodes the point cloud via an iterative downsampling and feature extraction process. At the receiver, SEPT decoder reconstructs the point cloud with latent reconstruction and offset-based upsampling. A novel channel-adaptive module is proposed to allow SEPT to operate effectively over a wide range of channel conditions. Next, we propose OTA-NeRF, a scheme inspired by neural radiance fields. OTA-NeRF performs voxelization to the point cloud input and learns to encode the voxelized point cloud into a neural network. Instead of transmitting the extracted feature vectors as in SEPT, it transmits the learned neural network weights in an analog fashion along with few hyperparameters that are transmitted digitally. At the receiver, the OTA-NeRF decoder reconstructs the original point cloud using the received noisy neural network weights. To further increase the bandwidth efficiency of the OTA-NeRF scheme, a fine-tuning algorithm is developed, where only a fraction of the neural network weights are retrained and transmitted. Noticing the poor generality of the OTA-NeRF schemes, we propose an alternative approach, termed OTA-MetaNeRF, which encodes different input point clouds into the latent vectors with shared neural network weights. Extensive numerical experiments confirm that the proposed SEPT, OTA-NeRF and OTA-MetaNeRF schemes achieve superior or comparable performance over the conventional approaches, where an octree-based or a learning-based point cloud compression scheme is concatenated with a channel code. Finally, the run-time complexities are evaluated to verify the capability of the proposed schemes for real-time communications.
本文提出了针对实时应用中的点云在无线信道上的高效可靠传输的新解决方案。首先,我们针对小规模点云提出了语义点云传输(SEPT)方案。该方案通过迭代下采样和特征提取过程对点云进行编码。在接收器端,SEPT解码器通过潜在重建和基于偏移的上采样来重建点云。我们提出了一个新型的自适应信道模块,使SEPT能够在各种信道条件下有效地工作。接下来,我们提出了受神经辐射场启发的OTA-NeRF方案。OTA-NeRF对点云进行体素化,并学习将体素化点云编码到神经网络中。与SEPT传输提取的特征向量不同,它模拟传输了学习到的神经网络权重,并同时数字传输了一些超参数。在接收器端,OTA-NeRF解码器使用接收到的带噪声的神经网络权重重建原始点云。为了进一步提高OTA-NeRF方案的带宽效率,开发了一种微调算法,其中只有一小部分神经网络权重进行了重新训练并传输。我们注意到OTA-NeRF方案的普遍性较差,因此提出了一种替代方法,称为OTA-MetaNeRF,该方法使用共享神经网络权重将不同的输入点云编码为潜在向量。大量的数值实验证实,所提出的SEPT、OTA-NeRF和OTA-MetaNeRF方案在性能上优于或相当于传统方案,其中基于八叉树或基于学习的点云压缩方案与信道编码相结合。最后,评估了运行时间复杂度,以验证所提出方案在实时通信方面的能力。
论文及项目相关链接
PDF 17 pages, accepted to IEEE JSAC SI on Intelligent Communications for Real-Time Computer Vision (Comm4CV)
Summary
本文提出了针对实时应用中的点云在无线信道上的高效可靠传输的新解决方案。首先,针对小规模点云,提出了语义点云传输(SEPT)方案,通过迭代下采样和特征提取进行点云编码。接收端通过潜在重建和偏移上采样来重建点云。此外,还提出了一种新型信道自适应模块,使SEPT能够在广泛的信道条件下有效运行。其次,受到神经辐射场启发的OTA-NeRF方案对点云进行体素化,并学习将体素化点云编码到神经网络中。它传输学习到的神经网络权重和少量数字传输的超参数。接收端使用接收到的有噪声的神经网络权重重建原始点云。为了提高OTA-NeRF方案的带宽效率,开发了一种微调算法,其中仅重新训练并传输神经网络权重的一部分。考虑到OTA-NeRF方案的一般性较差,提出了另一种方法OTA-MetaNeRF,使用共享神经网络权重将不同的输入点云编码为潜在向量。实验证实,SEPT、OTA-NeRF和OTA-MetaNeRF方案在性能上优于或相当于传统方法,并评估了运行时间复杂度以验证其实时通信能力。
Key Takeaways
- 提出了SEPT方案,通过迭代下采样和特征提取进行小规模点云的编码传输,接收端能够重建点云。
- OTA-NeRF方案受到神经辐射场的启发,将点云体素化后学习编码到神经网络中,并传输神经网络权重。
- OTA-NeRF方案通过微调算法提高带宽效率,仅重新训练并传输神经网络权重的一部分。
- 注意到OTA-NeRF方案的一般性较差,提出了OTA-MetaNeRF方案,使用共享神经网络权重编码不同的输入点云。
- SEPT、OTA-NeRF和OTA-MetaNeRF方案在性能上优于或相当于传统方法,如基于八叉树或基于学习的点云压缩方案与信道编码的组合。
- 进行了广泛的数值实验来验证所提出方案的有效性。
点此查看论文截图