⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-13 更新
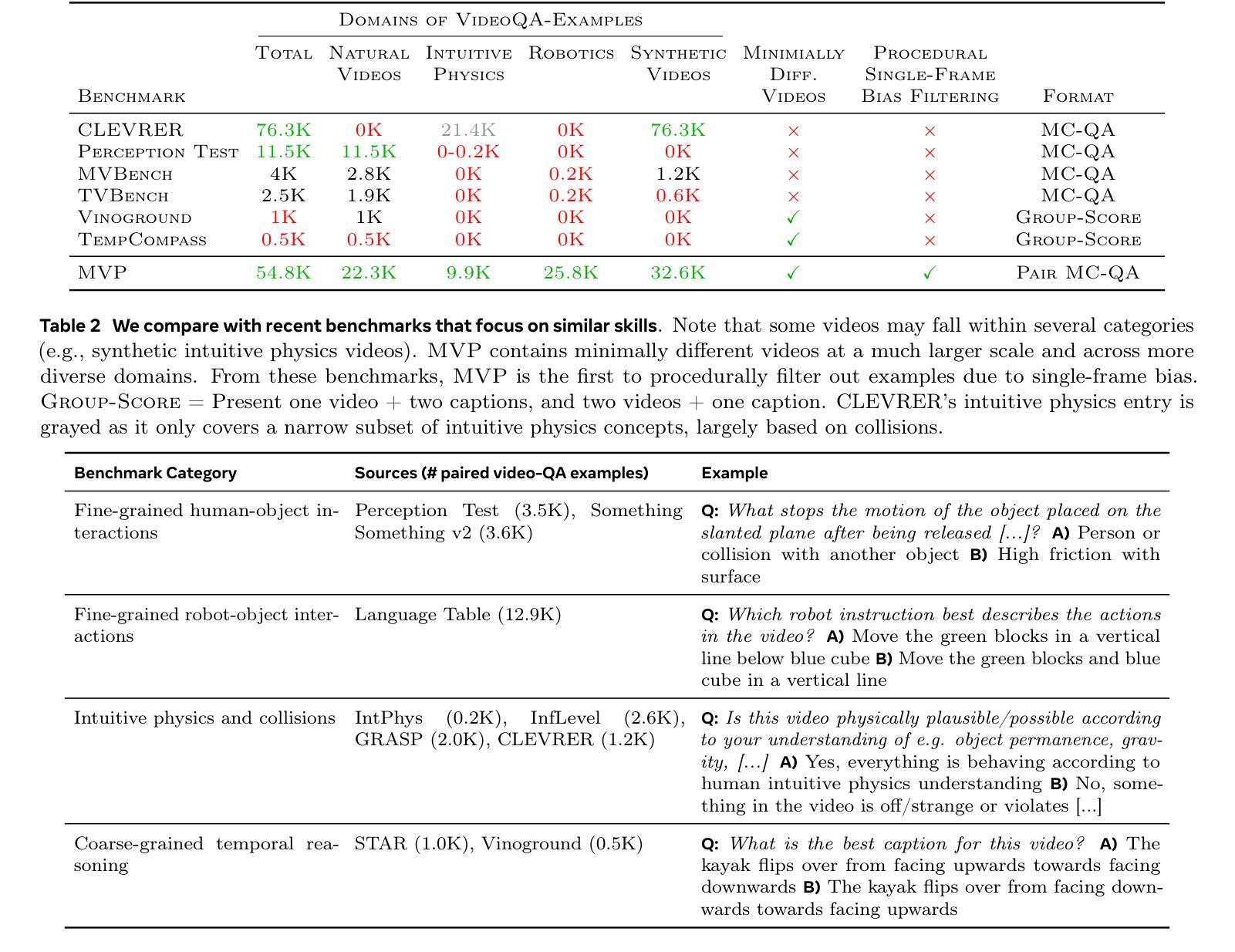
A Shortcut-aware Video-QA Benchmark for Physical Understanding via Minimal Video Pairs
Authors:Benno Krojer, Mojtaba Komeili, Candace Ross, Quentin Garrido, Koustuv Sinha, Nicolas Ballas, Mahmoud Assran
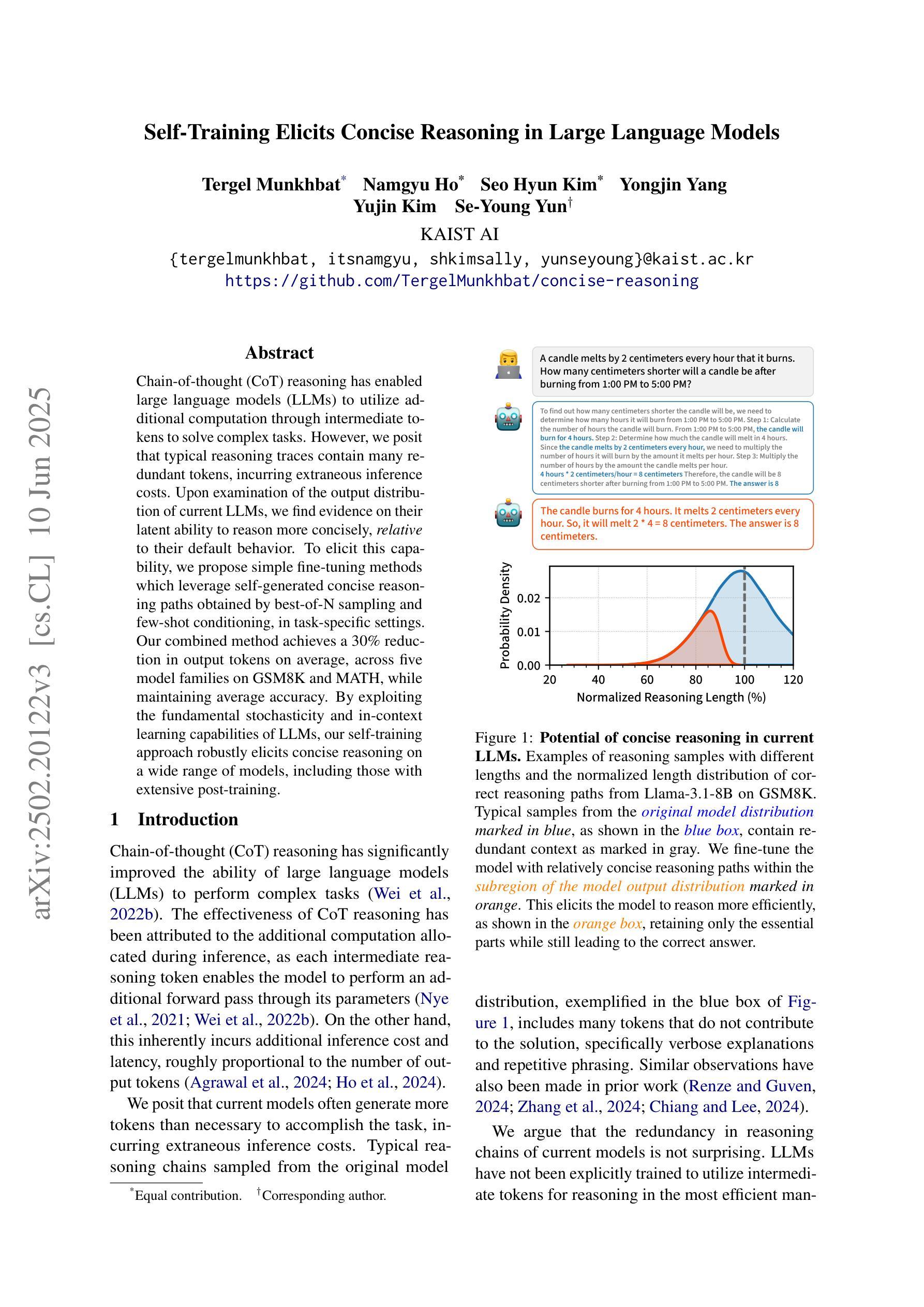
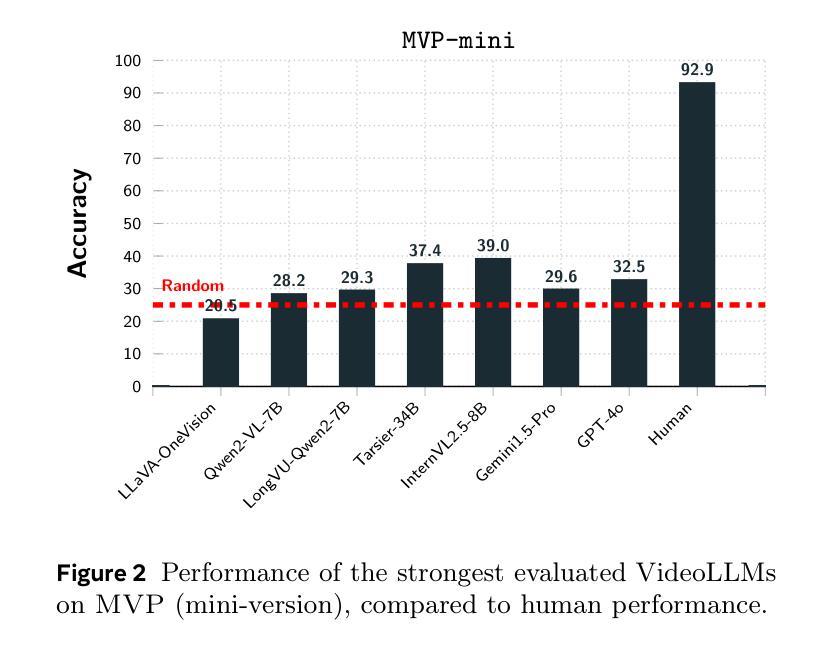
Existing benchmarks for assessing the spatio-temporal understanding and reasoning abilities of video language models are susceptible to score inflation due to the presence of shortcut solutions based on superficial visual or textual cues. This paper mitigates the challenges in accurately assessing model performance by introducing the Minimal Video Pairs (MVP) benchmark, a simple shortcut-aware video QA benchmark for assessing the physical understanding of video language models. The benchmark is comprised of 55K high-quality multiple-choice video QA examples focusing on physical world understanding. Examples are curated from nine video data sources, spanning first-person egocentric and exocentric videos, robotic interaction data, and cognitive science intuitive physics benchmarks. To mitigate shortcut solutions that rely on superficial visual or textual cues and biases, each sample in MVP has a minimal-change pair – a visually similar video accompanied by an identical question but an opposing answer. To answer a question correctly, a model must provide correct answers for both examples in the minimal-change pair; as such, models that solely rely on visual or textual biases would achieve below random performance. Human performance on MVP is 92.9%, while the best open-source state-of-the-art video-language model achieves 40.2% compared to random performance at 25%.
现有评估视频语言模型的时空理解和推理能力的基准测试,由于存在基于表面视觉或文本线索的捷径解决方案,容易引发得分膨胀。本文通过引入最小视频对(MVP)基准测试来缓解准确评估模型性能的挑战,该基准测试是一个简单的捷径感知视频问答基准测试,用于评估视频语言模型对物理世界的理解。该基准测试包含5.5万个高质量的多项选择视频问答示例,侧重于对物理世界的理解。这些示例是从九个视频数据源中精选出来的,包括第一人称主观和客观视频、机器人交互数据和认知科学直觉物理基准测试。为了缓解依赖于表面视觉或文本线索和偏见的捷径解决方案,MVP中的每个样本都有一个最小变化的对——一个视觉相似的视频伴随一个相同的问题但答案相反。要正确回答问题,模型必须为最小变化对中的两个示例提供正确答案;因此,仅依赖视觉或文本偏见的模型将低于随机性能。人类在MVP上的表现是92.9%,而最佳开源的当前先进视频语言模型达到40.2%,而随机性能为25%。
论文及项目相关链接
Summary
本论文提出了一种新的评估视频语言模型时空理解和推理能力的基准测试——最小视频对(MVP)。该基准测试旨在解决现有评估方法因依赖表面视觉或文本线索而导致评分膨胀的问题。MVP包含从九个视频数据源中精选的5万五千个高质量的视频问答选择题样本,主要关注物理世界理解。为了降低依赖表面视觉或文本线索和偏见的捷径解决方案,MVP中的每个样本都有一个最小变化的对——一个视觉上相似但答案相反的视频和相同的问题。为了正确回答问题,模型必须为最小变化对中的两个示例都提供正确答案;因此,仅依赖视觉或文本偏见的模型将低于随机性能。人类在MVP上的表现达到了92.9%,而目前最先进的开源视频语言模型的最佳表现仅为随机性能的十分之一不到(达到了不到仅有十人之年的预估能力的级别)。在这个全新的评估体系下,虽然目前还没有能够达到接近人类理解水平的视频语言模型出现。此框架旨在引导研究人员通过利用视频的时空特征进行视频理解的研究。这为推动更智能的视频语言模型的发展提供了一个重要工具。这将鼓励开发能更好地应对视听内容的模型和系统的应用进一步验证新技术并将其部署在实际的应用场景中所重视方法的实际需求展示重要作用证明了在不同条件和设定下的优势明确了真正优质成果和标准所面临的挑战是需要进一步的评估和精确的性能考核从而在训练这些先进AI的同时尽可能融入正确的指导和考察成为技术进步重要推力以帮助开发更加符合人类期望的智能视频语言模型。随着技术的不断进步和研究的深入相信未来会有更多的创新方法和应用涌现出来为视频语言处理领域带来更加广阔的视野和可能性。未来的研究将需要关注如何在不同的视频内容场景下有效地应用这一评估体系以及如何利用该体系来指导模型设计以提高视频语言模型的性能等问题上以实现真正的智能化视频处理应用前景广阔未来可期。随着未来对于更精细更全面的评估标准的追求对于这一领域的发展将起到积极的推动作用。我们相信未来的视频语言模型将在时空理解和推理能力方面取得更大的突破为人类带来更加便捷和智能的视听体验。Key Takeaways
- 现有视频语言模型评估基准存在评分膨胀问题,因为部分模型依赖表面视觉或文本线索来回答问题。
- MVP基准测试旨在解决评分膨胀问题,包含高质量的视频问答选择题样本,重点关注物理世界理解。
- MVP中的每个样本都有一个最小变化的对,包括视觉上相似但答案不同的视频和相同问题,以区分真正理解和依赖表面线索的模型。
点此查看论文截图


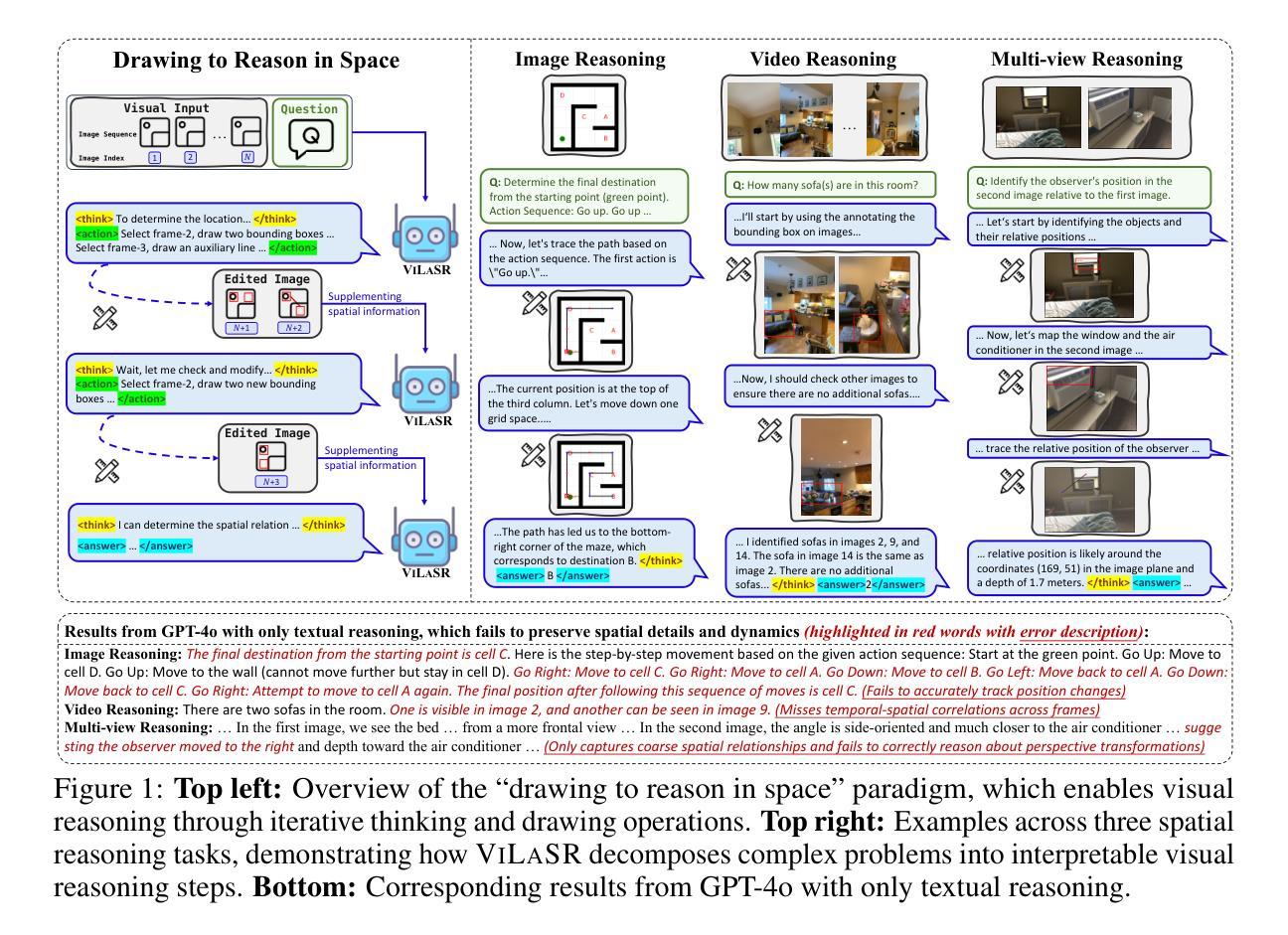
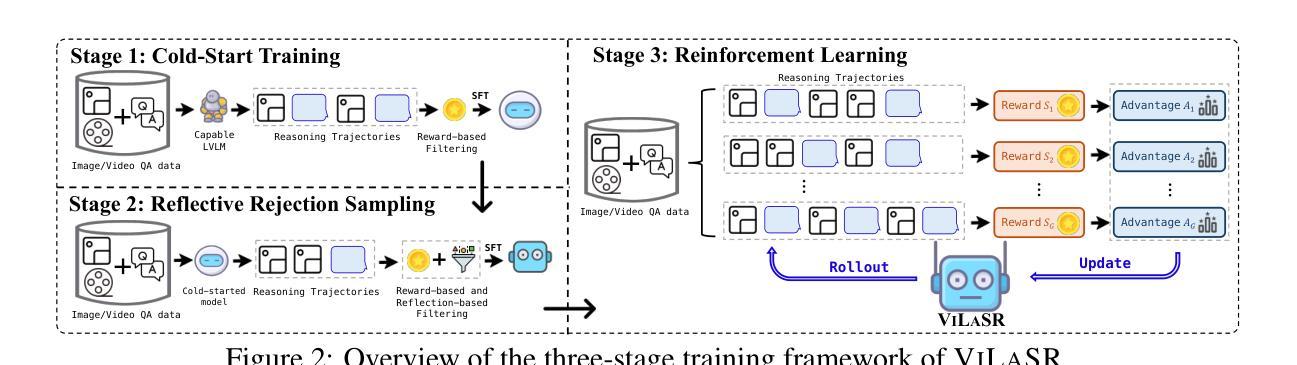
Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing
Authors:Junfei Wu, Jian Guan, Kaituo Feng, Qiang Liu, Shu Wu, Liang Wang, Wei Wu, Tieniu Tan
As textual reasoning with large language models (LLMs) has advanced significantly, there has been growing interest in enhancing the multimodal reasoning capabilities of large vision-language models (LVLMs). However, existing methods primarily approach multimodal reasoning in a straightforward, text-centric manner, where both reasoning and answer derivation are conducted purely through text, with the only difference being the presence of multimodal input. As a result, these methods often encounter fundamental limitations in spatial reasoning tasks that demand precise geometric understanding and continuous spatial tracking-capabilities that humans achieve through mental visualization and manipulation. To address the limitations, we propose drawing to reason in space, a novel paradigm that enables LVLMs to reason through elementary drawing operations in the visual space. By equipping models with basic drawing operations, including annotating bounding boxes and drawing auxiliary lines, we empower them to express and analyze spatial relationships through direct visual manipulation, meanwhile avoiding the performance ceiling imposed by specialized perception tools in previous tool-integrated reasoning approaches. To cultivate this capability, we develop a three-stage training framework: cold-start training with synthetic data to establish basic drawing abilities, reflective rejection sampling to enhance self-reflection behaviors, and reinforcement learning to directly optimize for target rewards. Extensive experiments demonstrate that our model, named VILASR, consistently outperforms existing methods across diverse spatial reasoning benchmarks, involving maze navigation, static spatial reasoning, video-based reasoning, and multi-view-based reasoning tasks, with an average improvement of 18.4%.
随着大型语言模型(LLM)的文本推理能力显著提高,增强大型视觉语言模型(LVLM)的多模态推理能力日益受到关注。然而,现有的方法主要采取直接、以文本为中心的多模态推理方式,推理和答案推导都纯粹通过文本进行,不同之处的唯一在于是否存在多模态输入。因此,这些方法在需要精确几何理解和持续空间跟踪能力的空间推理任务中经常遇到根本性的局限,而人类则通过心理可视化和操作来实现这些能力。为了解决这个问题,我们提出了一种新的推理方式——通过绘图进行空间推理。这种方式使LVLM能够通过视觉空间的基本绘图操作进行推理。通过为模型配备基本的绘图操作,包括标注边界框和绘制辅助线,我们可以让它们通过直接的视觉操作来表达和分析空间关系,同时避免之前工具集成推理方法中专用感知工具所带来的性能上限。为了培养这种能力,我们开发了一个三阶段训练框架:首先使用合成数据进行冷启动训练以建立基本的绘图能力,然后是反思拒绝采样以增强自我反思行为,最后是强化学习以直接优化目标奖励。大量实验表明,我们的模型——VILASR在多种空间推理基准测试上始终优于现有方法,涉及迷宫导航、静态空间推理、基于视频和基于多视角的推理任务等,平均提高了18.4%。
论文及项目相关链接
Summary
大型视觉语言模型(LVLMs)的多模态推理能力得到了广泛关注。然而,现有方法主要采取直接的文本中心方式,仅在存在多模态输入时有所不同。在需要精确几何理解和连续空间追踪能力的空间推理任务中,这些方法存在根本性局限。为解决此问题,提出了一种新的推理模式——“绘图推理”,使LVLMs能够通过视觉空间的基本绘图操作进行推理。通过提供标注边界框、绘制辅助线等基本绘图功能,模型能够直接通过视觉操作表达和分析空间关系。为培养此能力,开发了一个三阶段训练框架,包括用合成数据进行冷启动训练、增强自我反思行为的反射拒绝采样以及直接优化目标奖励的强化学习。实验证明,VILASR模型在多种空间推理任务上均表现出优异的性能,包括迷宫导航、静态空间推理、视频推理和多视角推理任务,平均提高了18.4%。
Key Takeaways
- 大型视觉语言模型(LVLMs)在多模态推理上存在局限性,特别是在需要精确几何理解和连续空间追踪能力的空间推理任务中。
- 现有方法主要采取文本中心的多模态推理方式,缺乏直接视觉操作的能力。
- 提出了“绘图推理”的新模式,使LVLMs能够通过基本绘图操作进行空间推理。
- 开发了一个三阶段训练框架来培养模型的空间推理能力。
- VILASR模型在多种空间推理任务上表现优异,平均提高了18.4%。
点此查看论文截图

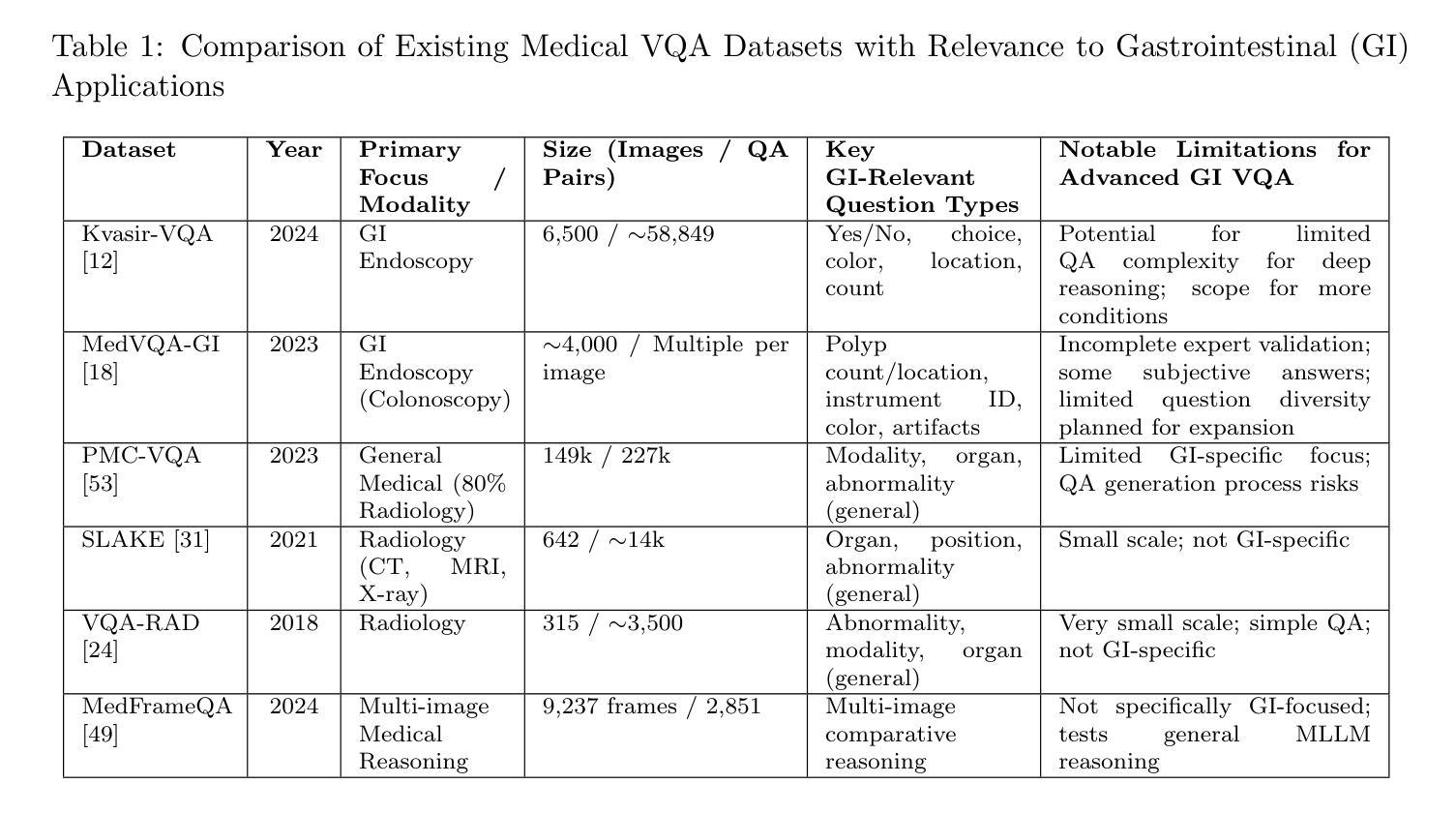
Kvasir-VQA-x1: A Multimodal Dataset for Medical Reasoning and Robust MedVQA in Gastrointestinal Endoscopy
Authors:Sushant Gautam, Michael A. Riegler, Pål Halvorsen
Medical Visual Question Answering (MedVQA) is a promising field for developing clinical decision support systems, yet progress is often limited by the available datasets, which can lack clinical complexity and visual diversity. To address these gaps, we introduce Kvasir-VQA-x1, a new, large-scale dataset for gastrointestinal (GI) endoscopy. Our work significantly expands upon the original Kvasir-VQA by incorporating 159,549 new question-answer pairs that are designed to test deeper clinical reasoning. We developed a systematic method using large language models to generate these questions, which are stratified by complexity to better assess a model’s inference capabilities. To ensure our dataset prepares models for real-world clinical scenarios, we have also introduced a variety of visual augmentations that mimic common imaging artifacts. The dataset is structured to support two main evaluation tracks: one for standard VQA performance and another to test model robustness against these visual perturbations. By providing a more challenging and clinically relevant benchmark, Kvasir-VQA-x1 aims to accelerate the development of more reliable and effective multimodal AI systems for use in clinical settings. The dataset is fully accessible and adheres to FAIR data principles, making it a valuable resource for the wider research community. Code and data: https://github.com/Simula/Kvasir-VQA-x1 and https://huggingface.co/datasets/SimulaMet/Kvasir-VQA-x1
医疗视觉问答(MedVQA)是开发临床决策支持系统的一个有前途的领域,然而,其进展往往受到可用数据集的限制,这些数据集可能缺乏临床复杂性和视觉多样性。为了解决这些差距,我们推出了Kvasir-VQA-x1,这是一个用于胃肠道(GI)内窥镜检查的大型新数据集。我们的工作在原始Kvasir-VQA的基础上进行了重大扩展,纳入了159549个新问答对,旨在测试更深层次的临床推理。我们开发了一种使用大型语言模型的系统化方法来生成这些问题,这些问题按复杂性分层,以更好地评估模型的推理能力。为了确保我们的数据集为现实世界的临床场景做好准备,我们还引入了各种视觉增强功能,以模拟常见的成像伪影。该数据集的结构支持两种主要的评估轨迹:一种用于标准VQA性能,另一种用于测试模型对这些视觉扰动的稳健性。通过提供更具挑战性和临床相关性的基准测试,Kvasir-VQA-x1旨在加速开发更可靠、更有效的多模式AI系统,用于临床环境。该数据集完全可访问,并遵循FAIR数据原则,使其成为更广泛研究社区宝贵的资源。代码和数据集地址:https://github.com/Simula/Kvasir-VQA-x1和https://huggingface.co/datasets/SimulaMet/Kvasir-VQA-x1
论文及项目相关链接
Summary:
介绍了一个名为Kvasir-VQA-x1的新大规模数据集,用于胃肠道内窥镜领域的医疗视觉问答(MedVQA)。该数据集在原始Kvasir-VQA的基础上进行了显著扩展,新增了159,549个问答对,旨在测试更深的临床推理能力。使用大型语言模型系统地生成问题,并按复杂性分层,以评估模型的推理能力。为模拟真实临床场景,引入了多种视觉增强技术来模拟常见的成像伪影。该数据集支持两种主要的评估模式:标准VQA性能评估和模型对这些视觉扰动的稳健性测试。Kvasir-VQA-x1旨在为临床环境中更可靠和有效的多模式AI系统的发展提供加速。数据集完全符合公平数据原则,并为更广泛的研究群体提供了有价值的资源。
Key Takeaways:
- Kvasir-VQA-x1是一个大规模数据集,专注于胃肠道内窥镜领域的医疗视觉问答(MedVQA)。
- 相比原始Kvasir-VQA,新数据集增加了159,549个问答对,加强了对临床推理能力的测试。
- 使用大型语言模型系统地生成问题,并按复杂性进行分层。
- 引入多种视觉增强技术,模拟真实临床场景中的成像伪影。
- 数据集支持两种评估模式:标准VQA性能和模型稳健性。
- Kvasir-VQA-x1旨在加速临床环境中可靠和有效的多模式AI系统的发展。
点此查看论文截图

Query-Focused Retrieval Heads Improve Long-Context Reasoning and Re-ranking
Authors:Wuwei Zhang, Fangcong Yin, Howard Yen, Danqi Chen, Xi Ye
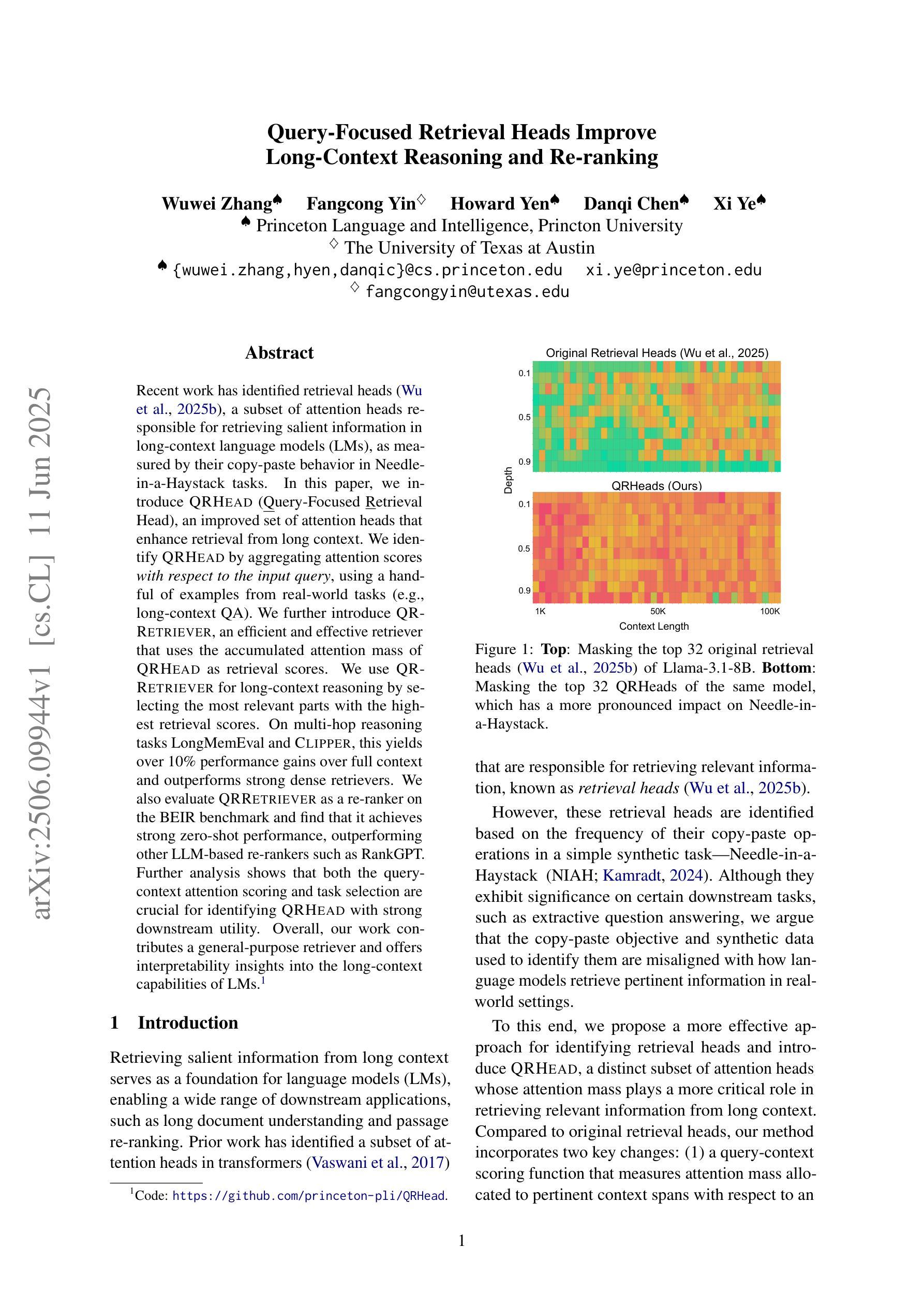
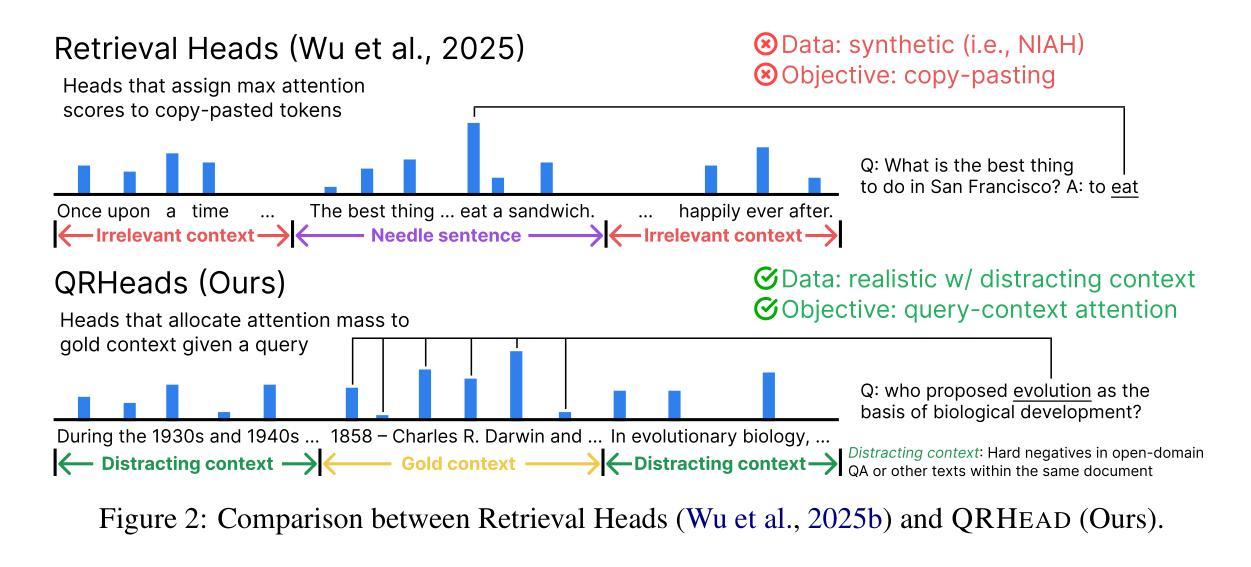
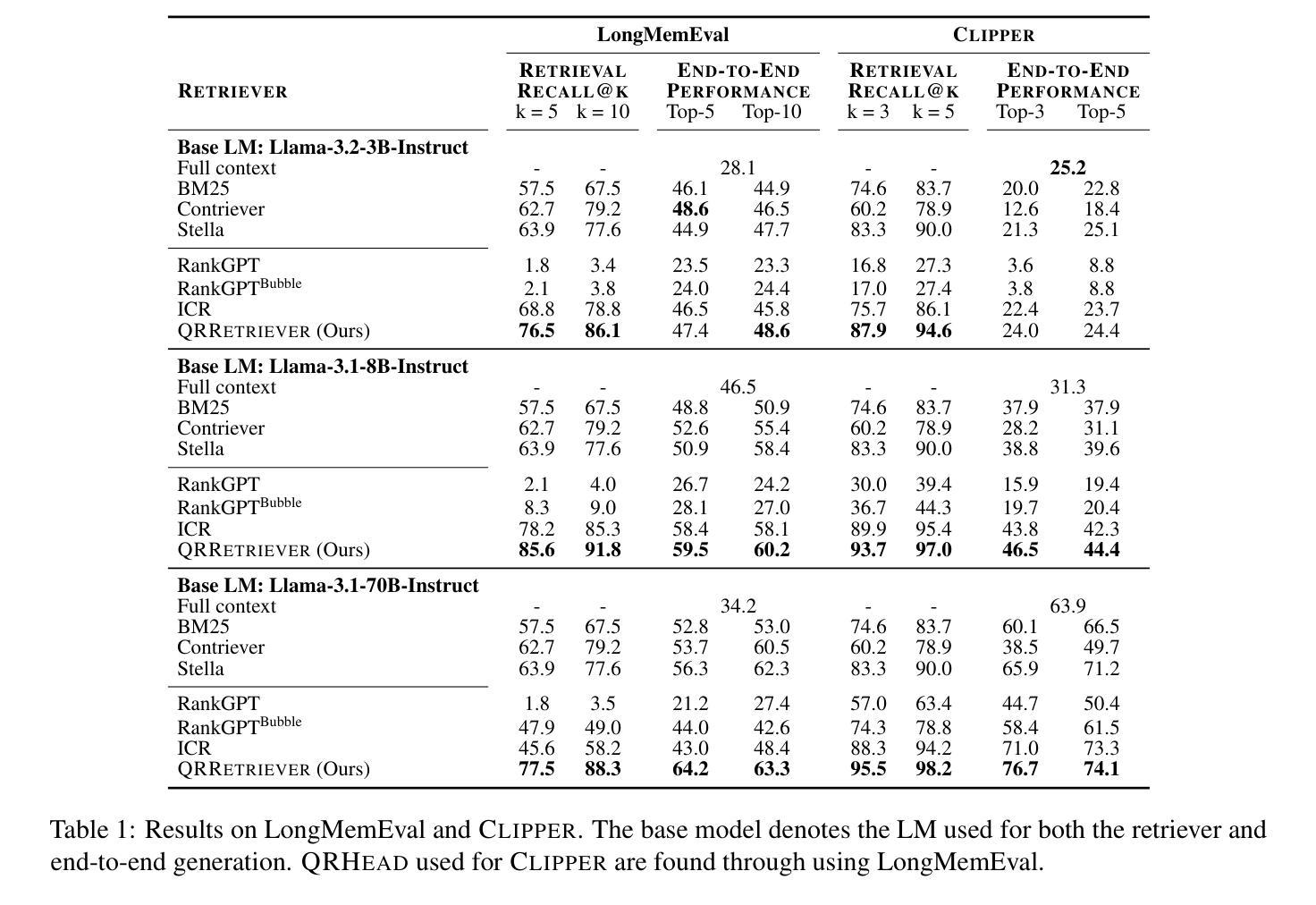
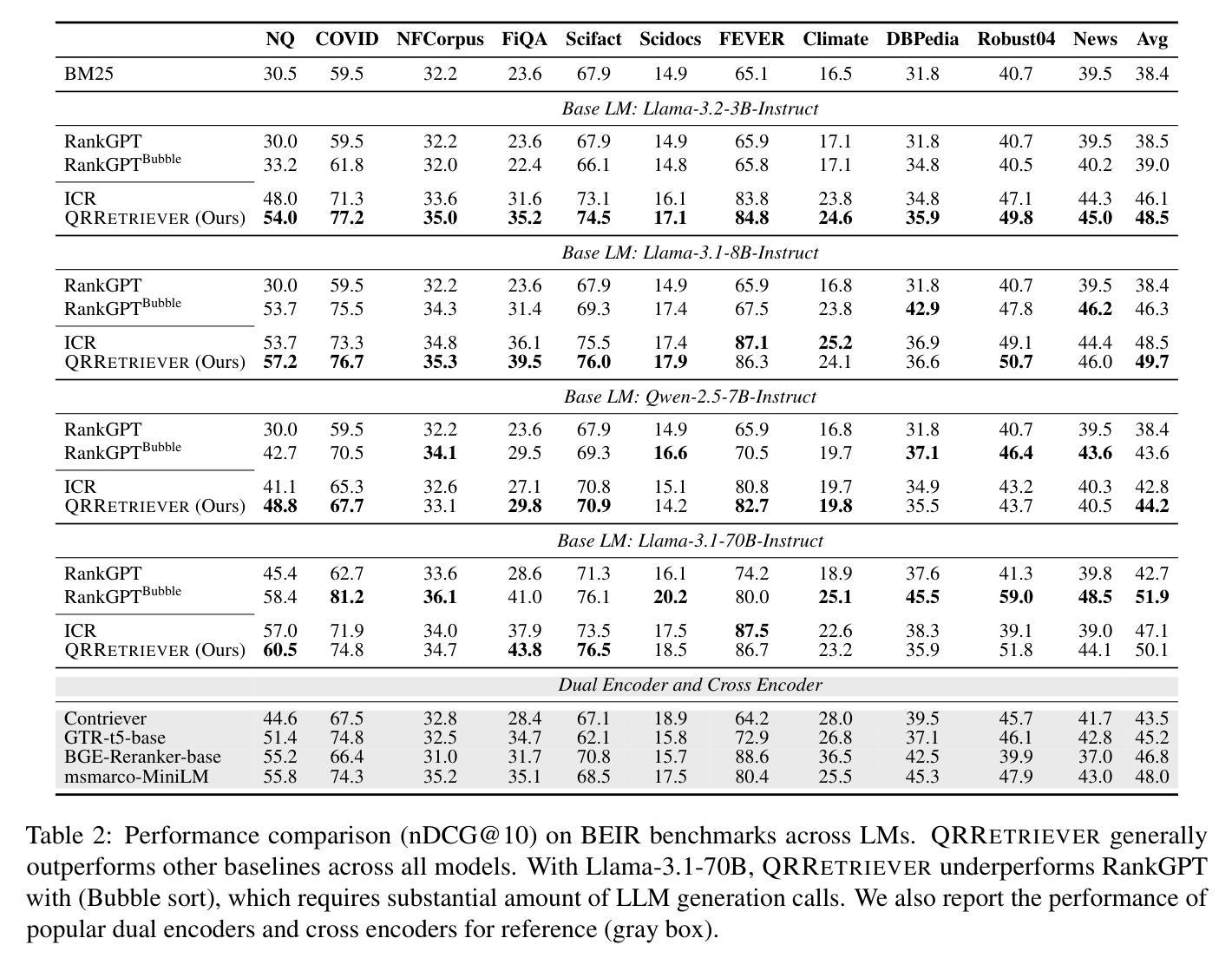
Recent work has identified retrieval heads (Wu et al., 2025b), a subset of attention heads responsible for retrieving salient information in long-context language models (LMs), as measured by their copy-paste behavior in Needle-in-a-Haystack tasks. In this paper, we introduce QRHEAD (Query-Focused Retrieval Head), an improved set of attention heads that enhance retrieval from long context. We identify QRHEAD by aggregating attention scores with respect to the input query, using a handful of examples from real-world tasks (e.g., long-context QA). We further introduce QR- RETRIEVER, an efficient and effective retriever that uses the accumulated attention mass of QRHEAD as retrieval scores. We use QR- RETRIEVER for long-context reasoning by selecting the most relevant parts with the highest retrieval scores. On multi-hop reasoning tasks LongMemEval and CLIPPER, this yields over 10% performance gains over full context and outperforms strong dense retrievers. We also evaluate QRRETRIEVER as a re-ranker on the BEIR benchmark and find that it achieves strong zero-shot performance, outperforming other LLM-based re-rankers such as RankGPT. Further analysis shows that both the querycontext attention scoring and task selection are crucial for identifying QRHEAD with strong downstream utility. Overall, our work contributes a general-purpose retriever and offers interpretability insights into the long-context capabilities of LMs.
最近的工作已经确定了检索头(Wu等人,2025b),这是一组注意力头,负责在长语境语言模型(LMs)中检索显著信息,这是通过它们在“海量寻针”任务中的复制粘贴行为来衡量的。在本文中,我们介绍了QRHEAD(查询聚焦检索头),这是一组改进的注意力头,可提高从长语境中的检索能力。我们通过聚合关于输入查询的注意力分数来识别QRHEAD,使用来自真实任务的一些例子(例如,长语境问答)。我们进一步介绍了QR-RETRIEVER,这是一个高效且有效的检索器,它使用QRHEAD的累积注意力质量作为检索分数。我们使用QR-RETRIEVER进行长语境推理,通过选择具有最高检索分数的最相关部分。在多跳推理任务LongMemEval和CLIPPER上,这相对于全文上下文产生了超过10%的性能提升,并且优于强大的密集检索器。我们还对QRRETRIEVER在BEIR基准测试上的重新排序功能进行了评估,发现它具有很强的零样本性能,优于其他基于LLM的重新排序器,如RankGPT。进一步的分析表明,查询上下文注意力评分和任务选择对于识别具有强大下游实用性的QRHEAD都是至关重要的。总的来说,我们的工作贡献了一个通用检索器,并为LMs的长语境能力提供了可解释性洞察。
论文及项目相关链接
Summary:
本文介绍了近期关于检索头的研究,提出了一种改进的关注头集合QRHEAD,用于提高从长文本中的检索能力。通过针对输入查询的注意力得分进行聚合,识别出QRHEAD。并引入了QR-RETRIEVER作为高效且有效的检索器,使用QRHEAD的累积注意力质量作为检索得分。在多个长文本推理任务上,QR-RETRIEVER通过选择最相关的部分,取得了超过全文本模型的性能提升。同时,还对其进行了再排序器的评估,显示出强大的零样本性能。本文的贡献在于提出了一种通用的检索器,并为理解长文本语境能力提供了洞察。
Key Takeaways:
- 研究引入了QRHEAD,一种改进的关注头集合,用于提高从长文本中的检索能力。
- 通过聚合注意力得分与输入查询的关系来识别QRHEAD。
- QR-RETRIEVER作为高效且有效的检索器,使用QRHEAD的累积注意力质量进行检索。
- QR-RETRIEVER在多跳推理任务上的性能优于全文本模型和强密集检索器。
- QR-RETRIEVER作为再排序器在BEIR基准测试上表现出强大的零样本性能。
- 查询上下文关注得分和任务选择对于识别QRHEAD至关重要。
点此查看论文截图
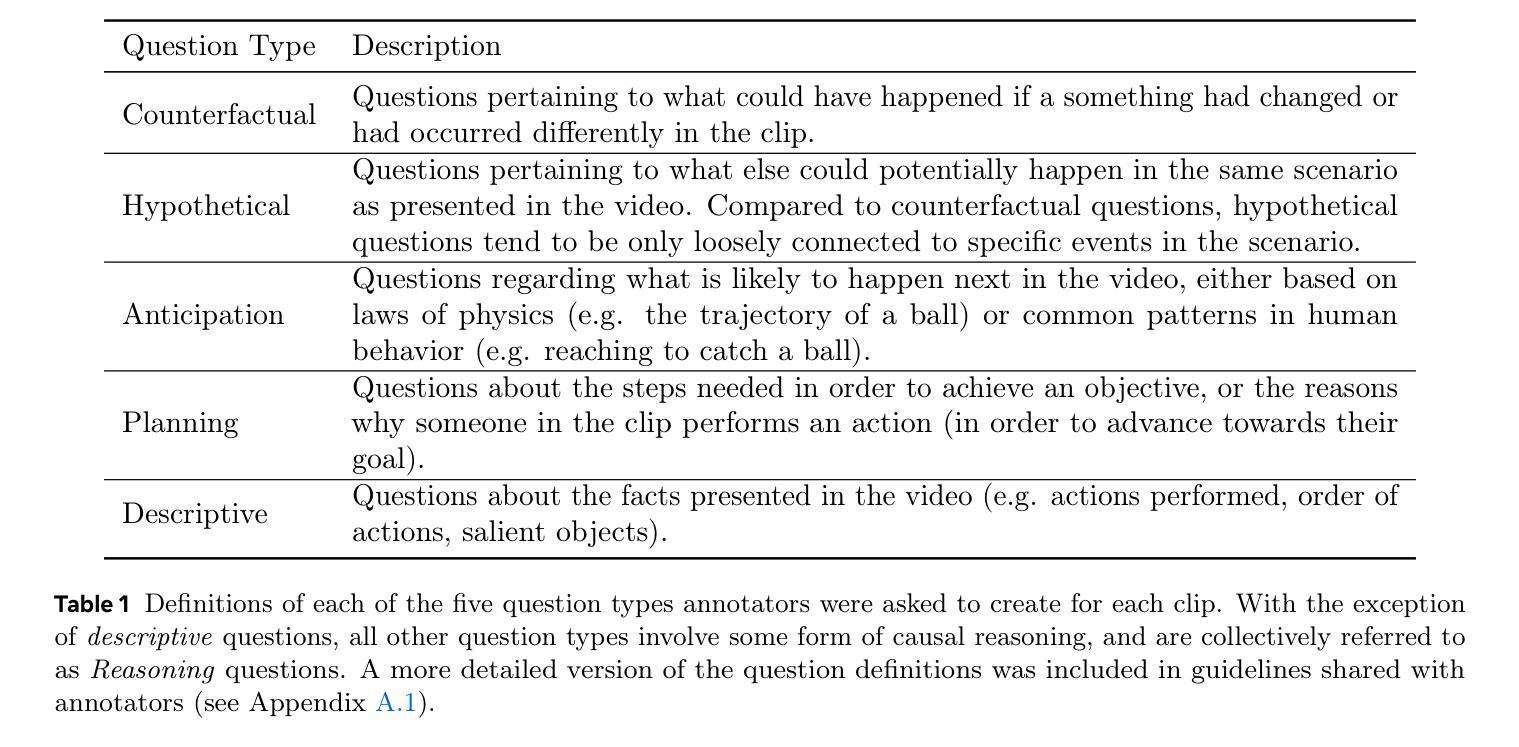
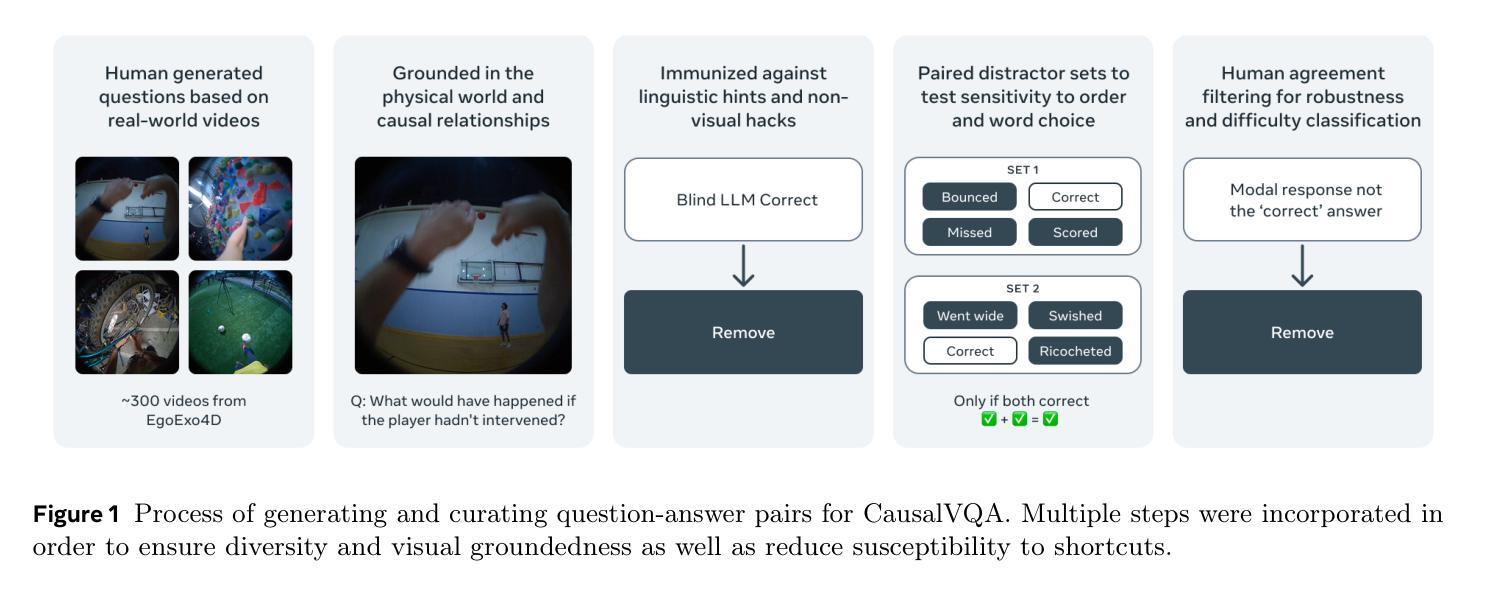
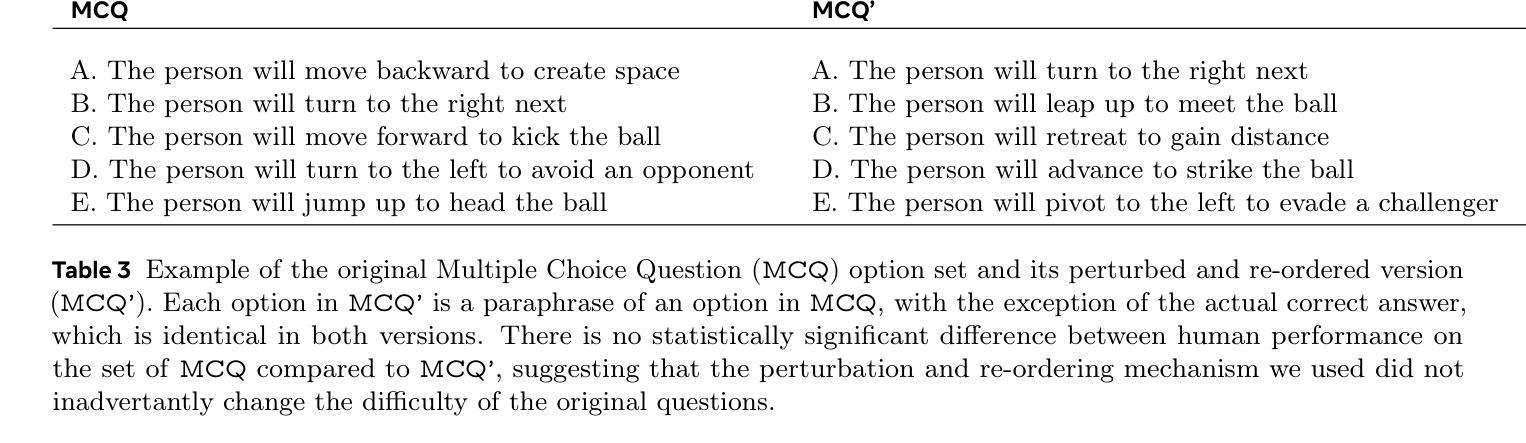
CausalVQA: A Physically Grounded Causal Reasoning Benchmark for Video Models
Authors:Aaron Foss, Chloe Evans, Sasha Mitts, Koustuv Sinha, Ammar Rizvi, Justine T. Kao
We introduce CausalVQA, a benchmark dataset for video question answering (VQA) composed of question-answer pairs that probe models’ understanding of causality in the physical world. Existing VQA benchmarks either tend to focus on surface perceptual understanding of real-world videos, or on narrow physical reasoning questions created using simulation environments. CausalVQA fills an important gap by presenting challenging questions that are grounded in real-world scenarios, while focusing on models’ ability to predict the likely outcomes of different actions and events through five question types: counterfactual, hypothetical, anticipation, planning and descriptive. We designed quality control mechanisms that prevent models from exploiting trivial shortcuts, requiring models to base their answers on deep visual understanding instead of linguistic cues. We find that current frontier multimodal models fall substantially below human performance on the benchmark, especially on anticipation and hypothetical questions. This highlights a challenge for current systems to leverage spatial-temporal reasoning, understanding of physical principles, and comprehension of possible alternatives to make accurate predictions in real-world settings.
我们介绍了CausalVQA,这是一个视频问答(VQA)基准数据集,包含探究模型对物理世界因果关系的理解的问答对。现有的VQA基准测试要么侧重于对现实视频的表面感知理解,要么侧重于使用模拟环境创建的狭窄的物理推理问题。CausalVQA填补了一个重要空白,它提出了基于现实场景的挑战性问题,同时侧重于模型预测不同行为和事件可能结果的能力,包括五种问题类型:反事实、假设、预期、规划和描述。我们设计了质量控制机制,防止模型利用微不足道的捷径,要求模型在回答时基于深度视觉理解而非语言线索。我们发现,当前最先进的多媒体模型在该基准测试上的表现远远低于人类,特别是在预期和假设问题上。这突显了当前系统在利用时空推理、物理原理的理解和可能的替代方案来做出真实环境中的准确预测方面所面临的挑战。
论文及项目相关链接
PDF 35 pages, 3 figures, Submitted to NeurIPS2025 benchmark track
Summary
本文介绍了CausalVQA,一个针对视频问答(VQA)的基准数据集,该数据集包含探究模型对现实世界因果关系的理解的问答对。现有VQA基准测试倾向于关注对现实世界的表面感知理解或基于模拟环境的物理推理问题。CausalVQA填补了这一重要空白,通过提出基于现实场景的具有挑战性的问题,重点考察模型预测不同行为和事件可能结果的能力,包括反事实、假设、预期、规划和描述等五种类型的问题。设计了质量控制机制,防止模型利用浅层捷径,要求模型基于深度视觉理解而非语言线索来回答问题。研究发现,当前先进的多模式模型在该基准测试上的表现远远低于人类,特别是在预期和假设性问题上。这突显了当前系统在利用时空推理、物理原理理解和可能替代方案的理解来做出现实世界的准确预测方面的挑战。
Key Takeaways
- CausalVQA是一个针对视频问答的基准数据集,关注模型对现实世界因果关系的理解。
- 包含五种类型的问题:反事实、假设、预期、规划和描述。
- 设计了质量控制机制,防止模型利用浅层视觉理解或语言线索回答问题。
- 当前的多模式模型在CausalVQA上的表现低于人类,尤其在预期和假设性问题上。
- 这突显了模型在利用时空推理、物理原理理解以及考虑可能的替代方案进行预测方面的挑战。
- CausalVQA数据集有助于推动模型在真实世界情境中的表现,提高其理解和预测因果关系的能力。
点此查看论文截图


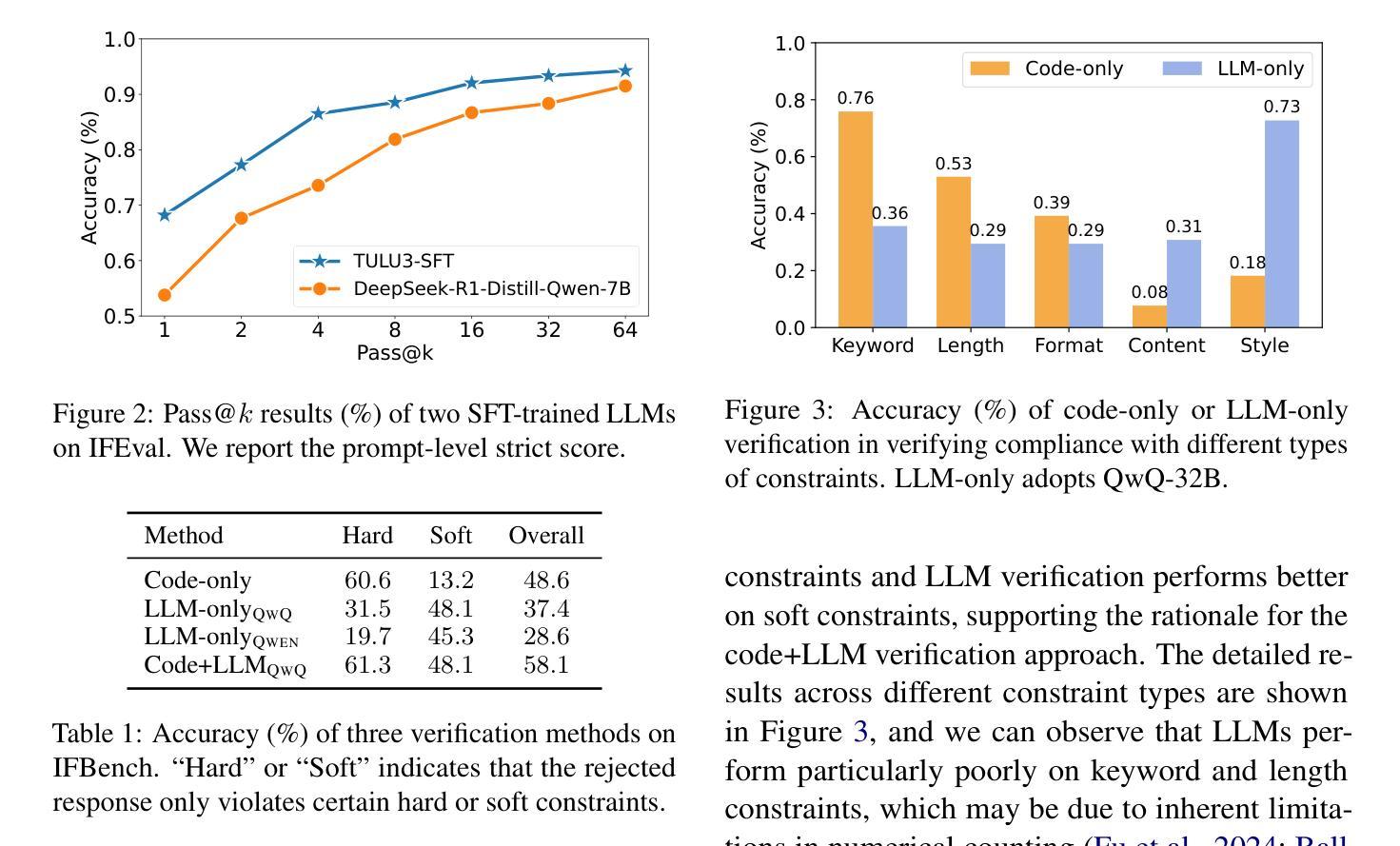
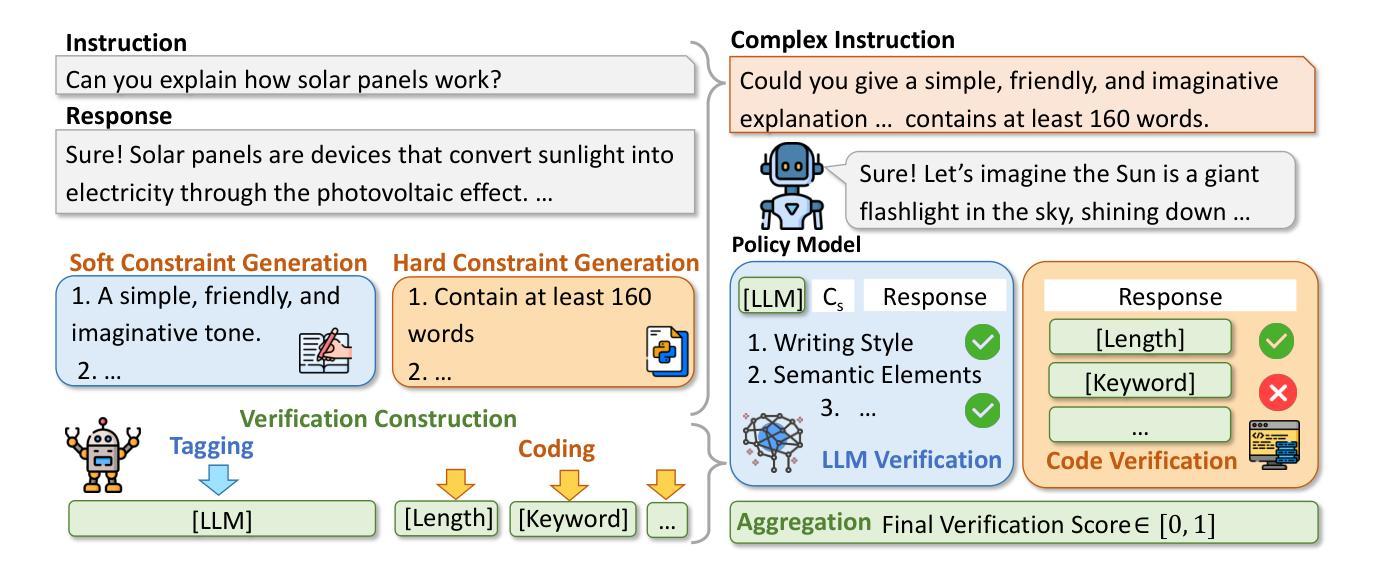
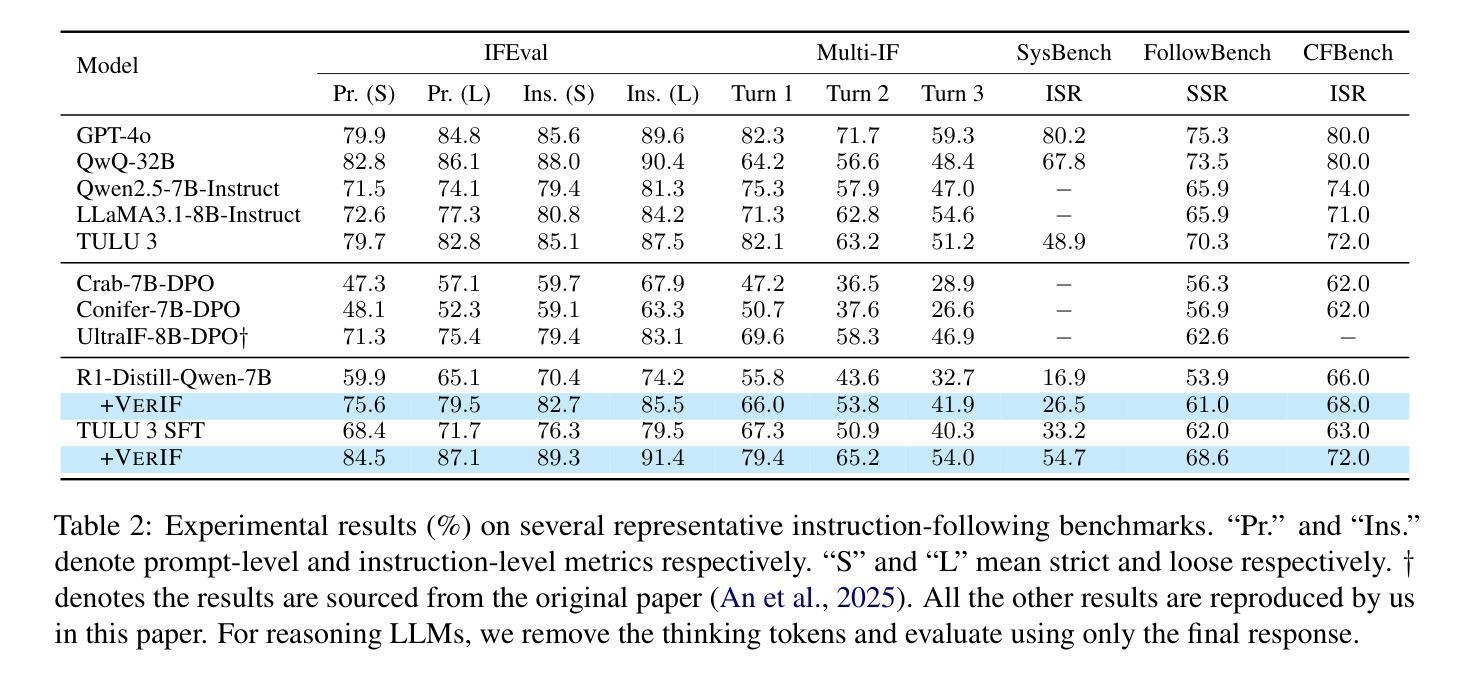
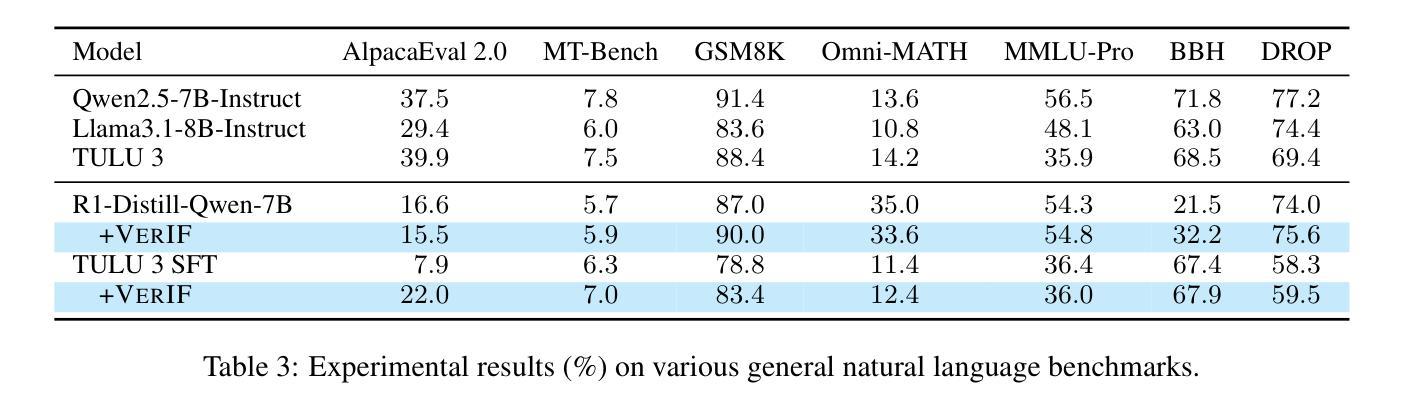
VerIF: Verification Engineering for Reinforcement Learning in Instruction Following
Authors:Hao Peng, Yunjia Qi, Xiaozhi Wang, Bin Xu, Lei Hou, Juanzi Li
Reinforcement learning with verifiable rewards (RLVR) has become a key technique for enhancing large language models (LLMs), with verification engineering playing a central role. However, best practices for RL in instruction following remain underexplored. In this work, we explore the verification challenge in RL for instruction following and propose VerIF, a verification method that combines rule-based code verification with LLM-based verification from a large reasoning model (e.g., QwQ-32B). To support this approach, we construct a high-quality instruction-following dataset, VerInstruct, containing approximately 22,000 instances with associated verification signals. We apply RL training with VerIF to two models, achieving significant improvements across several representative instruction-following benchmarks. The trained models reach state-of-the-art performance among models of comparable size and generalize well to unseen constraints. We further observe that their general capabilities remain unaffected, suggesting that RL with VerIF can be integrated into existing RL recipes to enhance overall model performance. We have released our datasets, codes, and models to facilitate future research at https://github.com/THU-KEG/VerIF.
基于可验证奖励的强化学习(RLVR)已成为增强大型语言模型(LLM)的关键技术,验证工程在其中发挥着核心作用。然而,在指令遵循方面的强化学习最佳实践仍未得到充分探索。在这项工作中,我们探讨了指令遵循中强化学习的验证挑战,并提出了VerIF方法,这是一种将基于规则的代码验证与来自大型推理模型的LLM验证相结合的方法(例如QwQ-32B)。为了支持这种方法,我们构建了一个高质量的指令遵循数据集VerInstruct,其中包含大约22,000个带有相关验证信号的实例。我们对两个模型应用了使用VerIF的RL训练,在多个代表性的指令遵循基准测试中取得了显著改进。经过训练的模型在同类模型中的性能达到了最新水平,并且在未见过的约束上具有很好的泛化能力。我们进一步观察到,他们的通用能力并未受到影响,这表明可以将带有VerIF的RL集成到现有的RL配方中,以提高模型的总体性能。我们已在https://github.com/THU-KEG/VerIF发布我们的数据集、代码和模型,以促进未来的研究。
论文及项目相关链接
PDF 16 pages, 8 figures
Summary
强化学习与可验证奖励(RLVR)已成为增强大型语言模型(LLM)的关键技术,其中验证工程发挥着重要作用。然而,关于强化学习在指令遵循方面的最佳实践仍然缺乏探索。本研究探讨了强化学习在指令遵循中的验证挑战,并提出了VerIF验证方法,该方法结合了基于规则的代码验证和基于大型语言模型的验证(例如QwQ-32B)。为了支持这种方法,我们构建了一个高质量的指令遵循数据集VerInstruct,包含大约22,000个实例和相关的验证信号。通过对两个模型应用带有VerIF的强化学习训练,我们在多个代表性指令遵循基准测试上取得了显著改进。训练后的模型在类似规模的模型中达到了最先进的性能,并能在未见过的约束上实现良好的泛化。我们还观察到,它们的整体能力并未受到影响,这表明带有VerIF的强化学习可以集成到现有的强化学习配方中,以提高模型的总体性能。我们的数据集、代码和模型已在GitHub上发布,以推动未来的研究:https://github.com/THU-KEG/VerIF。
Key Takeaways
- 强化学习与可验证奖励(RLVR)对于增强大型语言模型(LLM)至关重要,其中验证工程是核心环节。
- 目前关于强化学习在指令遵循方面的最佳实践仍然缺乏研究。
- 提出了一种新的验证方法VerIF,结合了基于规则的代码验证和基于大型语言模型的验证。
- 构建了一个高质量的指令遵循数据集VerInstruct,包含大约22,000个实例和相关的验证信号。
- 应用VerIF方法的强化学习训练在多个指令遵循基准测试上取得了显著改进。
- 训练后的模型具有良好的泛化能力,并且在类似规模的模型中表现出最先进的性能。
点此查看论文截图


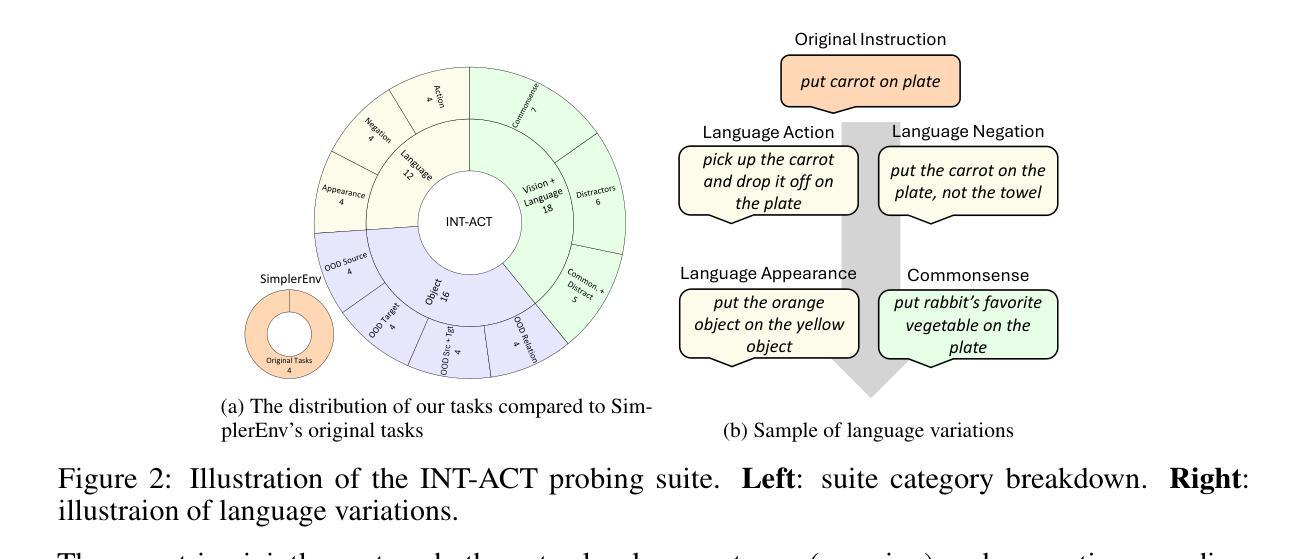
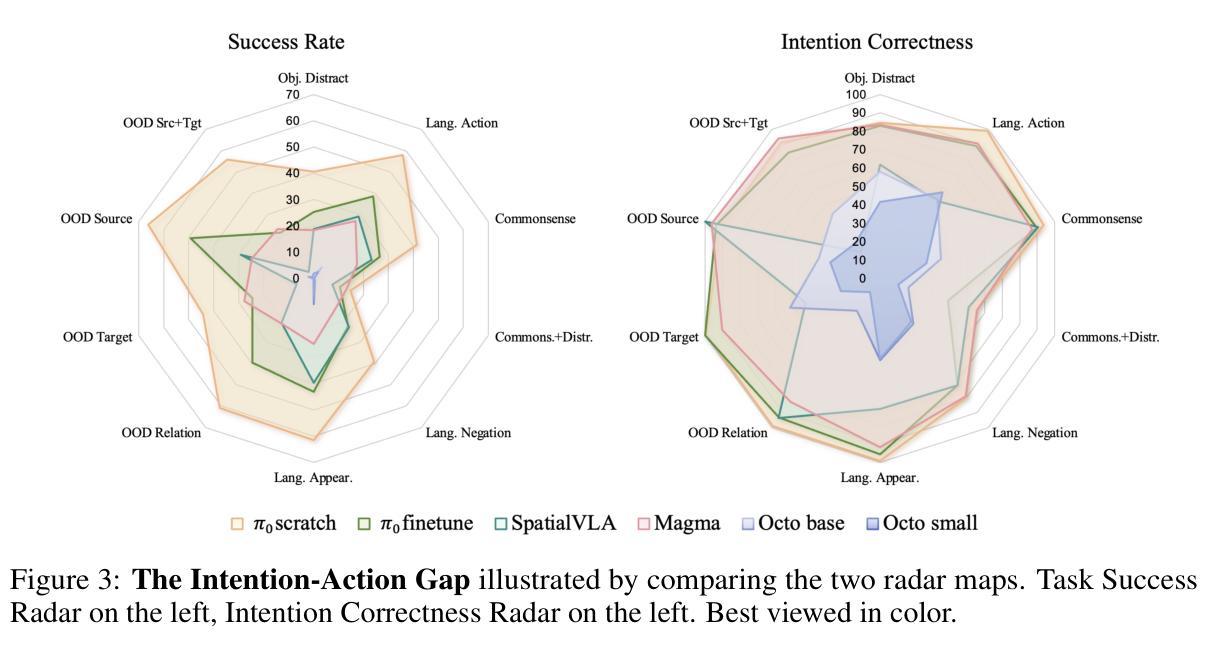
From Intention to Execution: Probing the Generalization Boundaries of Vision-Language-Action Models
Authors:Irving Fang, Juexiao Zhang, Shengbang Tong, Chen Feng
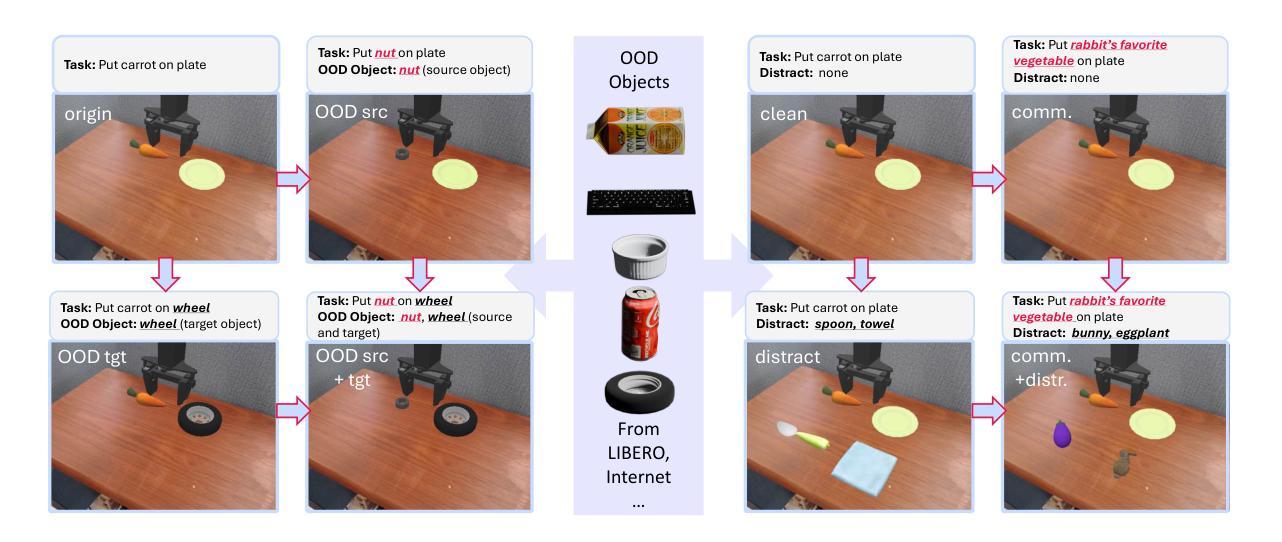
One promise that Vision-Language-Action (VLA) models hold over traditional imitation learning for robotics is to leverage the broad generalization capabilities of large Vision-Language Models (VLMs) to produce versatile, “generalist” robot policies. However, current evaluations of VLAs remain insufficient. Traditional imitation learning benchmarks are unsuitable due to the lack of language instructions. Emerging benchmarks for VLAs that incorporate language often come with limited evaluation tasks and do not intend to investigate how much VLM pretraining truly contributes to the generalization capabilities of the downstream robotic policy. Meanwhile, much research relies on real-world robot setups designed in isolation by different institutions, which creates a barrier for reproducibility and accessibility. To address this gap, we introduce a unified probing suite of 50 simulation-based tasks across 10 subcategories spanning language instruction, vision, and objects. We systematically evaluate several state-of-the-art VLA architectures on this suite to understand their generalization capability. Our results show that while VLM backbones endow VLAs with robust perceptual understanding and high level planning, which we refer to as good intentions, this does not reliably translate into precise motor execution: when faced with out-of-distribution observations, policies often exhibit coherent intentions, but falter in action execution. Moreover, finetuning on action data can erode the original VLM’s generalist reasoning abilities. We release our task suite and evaluation code to serve as a standardized benchmark for future VLAs and to drive research on closing the perception-to-action gap. More information, including the source code, can be found at https://ai4ce.github.io/INT-ACT/
视觉语言行动(VLA)模型相较于传统机器人模仿学习的一个承诺是,借助大型视觉语言模型(VLM)的广泛泛化能力,生成通用“万能”机器人策略。然而,对VLA的当前评估仍然不足。由于缺少语言指令,传统的模仿学习基准测试并不适用。新兴的VLA基准测试虽然融入了语言,但评估任务有限,并不打算深入调查VLM预训练在多大程度上有助于下游机器人策略的泛化能力。同时,许多研究依赖于不同机构单独设计的真实机器人环境,这增加了可复制性和可访问性的障碍。为了解决这一差距,我们引入了包含10个子类别共50项模拟任务的统一探查套件,涵盖语言指令、视觉和物体。我们系统地评估了几种最新VLA架构的泛化能力。结果表明,虽然VLM的骨干赋予了VLA强大的感知理解能力和高级规划能力(我们称之为良好意图),但这并不能可靠地转化为精确的动作执行:在面对超出分布的观察时,策略往往表现出连贯的意图,但在动作执行时却失败了。此外,在动作数据上进行微调可能会侵蚀原始VLM的通用推理能力。我们发布我们的任务套件和评估代码,旨在作为未来VLA的标准基准,并推动缩小感知与行动差距的研究。更多信息包括源代码可在[https://ai4ce.github.io/INT-ACT/]找到。
论文及项目相关链接
PDF Under review
Summary:
VLA模型利用大型视觉语言模型的广泛泛化能力,为机器人学习提供了通用策略。然而,当前对VLA模型的评估仍然不足,缺乏语言指令的传统模仿学习基准和新兴包含语言的基准都不足以全面评估其贡献。为此,我们引入了一套统一的包含语言指令、视觉和物体的仿真任务套件来评估多个最先进的VLA架构的泛化能力。结果显示,虽然VLM主干赋予了VLAs强大的感知理解和高级规划能力,但面临超出分布的观测时,精确动作执行能力仍然不足。此外,对动作数据的微调可能会削弱原始VLM的通用推理能力。我们公开了任务套件和评估代码,为未来研究提供了标准化的基准测试平台并努力弥感知与动作之间的鸿沟。详情可通过https://ai4ce.github.io/INT-ACT/了解。
Key Takeaways:
- VLA模型具备通用性,可运用大型视觉语言模型的泛化能力制定机器人策略。
- 当前对VLA模型的评估存在不足,缺乏包含语言指令的基准测试平台。
- 新兴的VLA基准测试平台包含语言指令、视觉和物体元素,共包含五十项仿真任务。
- VLA模型在面临超出分布的观测时,表现出良好的意图但动作执行能力不足。
- 对动作数据的微调可能会影响VLA模型的通用推理能力。
- 我们公开的任务套件和评估代码为未来的研究提供了标准化的基准测试平台。
点此查看论文截图

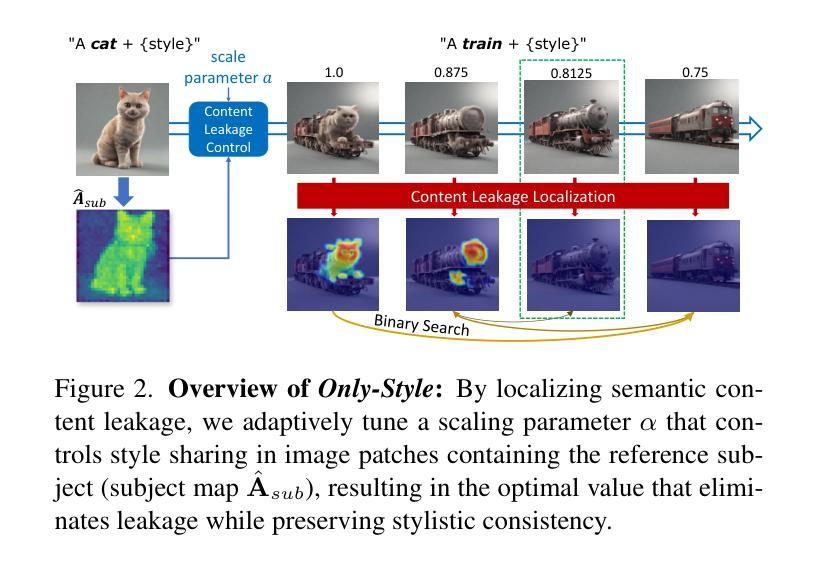
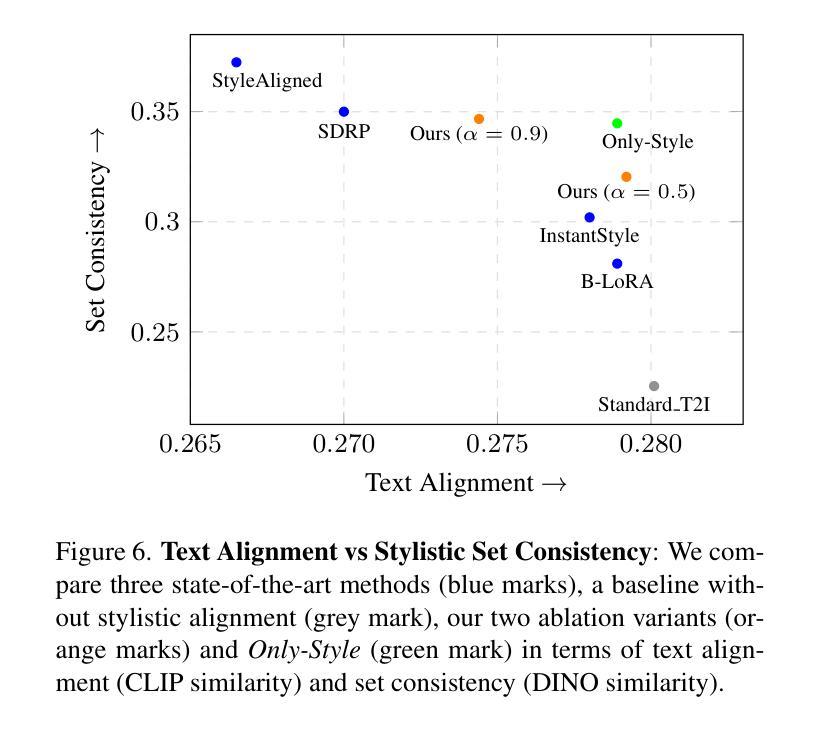
Only-Style: Stylistic Consistency in Image Generation without Content Leakage
Authors:Tilemachos Aravanis, Panagiotis Filntisis, Petros Maragos, George Retsinas
Generating images in a consistent reference visual style remains a challenging computer vision task. State-of-the-art methods aiming for style-consistent generation struggle to effectively separate semantic content from stylistic elements, leading to content leakage from the image provided as a reference to the targets. To address this challenge, we propose Only-Style: a method designed to mitigate content leakage in a semantically coherent manner while preserving stylistic consistency. Only-Style works by localizing content leakage during inference, allowing the adaptive tuning of a parameter that controls the style alignment process, specifically within the image patches containing the subject in the reference image. This adaptive process best balances stylistic consistency with leakage elimination. Moreover, the localization of content leakage can function as a standalone component, given a reference-target image pair, allowing the adaptive tuning of any method-specific parameter that provides control over the impact of the stylistic reference. In addition, we propose a novel evaluation framework to quantify the success of style-consistent generations in avoiding undesired content leakage. Our approach demonstrates a significant improvement over state-of-the-art methods through extensive evaluation across diverse instances, consistently achieving robust stylistic consistency without undesired content leakage.
在一致的参考视觉风格中生成图像仍然是一项具有挑战性的计算机视觉任务。最新方法旨在实现风格一致的生成,但难以有效地将语义内容与风格元素分开,导致从提供的参考图像到目标图像的内容泄漏。为了应对这一挑战,我们提出了Only-Style方法:旨在以语义连贯的方式减轻内容泄漏,同时保留风格一致性。Only-Style通过在推理过程中定位内容泄漏来工作,允许自适应调整控制风格对齐过程的参数,特别是在包含参考图像主题的图像补丁内。这种自适应过程最能平衡风格一致性与消除泄漏。此外,给定参考-目标图像对,内容泄漏的定位可以作为独立组件运行,允许调整任何特定方法的参数,以控制风格参考的影响。另外,我们提出了一个新颖的评价框架,以量化风格一致生成的成功程度,避免不必要的内容泄漏。我们的方法通过广泛的评估,在多种实例上均显示出对最新方法的显著改进,持续实现稳健的风格一致性,没有不必要的内容泄漏。
论文及项目相关链接
Summary
在保持一致的参考视觉风格下生成图像仍是计算机视觉领域的一项挑战。当前先进的方法在追求风格一致性的生成时,难以有效地将语义内容与风格元素分离,导致从提供的参考图像到目标图像的内容泄露。为解决此问题,我们提出了Only-Style方法,旨在以语义连贯的方式减轻内容泄露,同时保留风格一致性。Only-Style通过在推理过程中定位内容泄露,允许自适应调整控制风格对齐过程的参数,特别是在包含参考图像主体的图像补丁内。这种自适应过程最佳地平衡了风格一致性与消除泄露。此外,内容泄露的定位可以作为给定参考-目标图像对的独立组件运行,允许对影响风格参考的任何方法特定参数进行自适应调整。另外,我们提出了一个全新的评估框架,以量化风格一致生成的成功程度,避免不必要的内容泄露。我们的方法通过广泛的评估证明了对先进方法的显著改进,在各种不同实例中始终实现稳健的风格一致性,而没有不必要的内容泄露。
Key Takeaways
- 生成与参考视觉风格一致的图像仍是计算机视觉领域的挑战。
- 当前方法难以分离语义内容和风格元素,导致内容泄露。
- Only-Style方法旨在减轻内容泄露,同时保持风格一致性。
- Only-Style通过自适应调整参数来平衡风格一致性与消除泄露。
- 内容泄露的定位可以作为独立组件运行,允许对方法参数进行自适应调整。
- 提出了一个新的评估框架,以量化风格一致生成的成功程度。
点此查看论文截图



“What are my options?”: Explaining RL Agents with Diverse Near-Optimal Alternatives (Extended)
Authors:Noel Brindise, Vijeth Hebbar, Riya Shah, Cedric Langbort
In this work, we provide an extended discussion of a new approach to explainable Reinforcement Learning called Diverse Near-Optimal Alternatives (DNA), first proposed at L4DC 2025. DNA seeks a set of reasonable “options” for trajectory-planning agents, optimizing policies to produce qualitatively diverse trajectories in Euclidean space. In the spirit of explainability, these distinct policies are used to “explain” an agent’s options in terms of available trajectory shapes from which a human user may choose. In particular, DNA applies to value function-based policies on Markov decision processes where agents are limited to continuous trajectories. Here, we describe DNA, which uses reward shaping in local, modified Q-learning problems to solve for distinct policies with guaranteed epsilon-optimality. We show that it successfully returns qualitatively different policies that constitute meaningfully different “options” in simulation, including a brief comparison to related approaches in the stochastic optimization field of Quality Diversity. Beyond the explanatory motivation, this work opens new possibilities for exploration and adaptive planning in RL.
在这项工作中,我们对一种名为Diverse Near-Optimal Alternatives(DNA)的可解释强化学习新方法进行了深入探讨,该方法首次在L4DC 2025上提出。DNA旨在为轨迹规划智能体提供一组合理的“选项”,优化策略以在欧几里得空间中产生定性多样化的轨迹。本着可解释性的精神,这些不同的策略被用来“解释”智能体的选项,用可供人类用户选择的轨迹形状来表示。特别是,DNA适用于基于值函数的马尔可夫决策过程策略,其中智能体的轨迹是连续的。在这里,我们描述了DNA如何在局部修改后的Q学习问题中利用奖励塑造来解决具有保证epsilon最优性的不同策略。我们证明了它能够成功返回定性不同的策略,这些策略在模拟中构成了有意义的“选项”,包括对质量多样性领域中相关方法的简要比较。除了解释动机之外,这项工作还为强化学习中的探索和自适应规划开辟了新的可能性。
论文及项目相关链接
摘要
本文详细介绍了一种新的可解释的强化学习(Reinforcement Learning,简称RL)方法——多样近优选择(Diverse Near-Optimal Alternatives,简称DNA)。DNA旨在为一组轨迹规划智能体提供合理的选择集,通过优化策略以在欧几里得空间中产生定性多样化的轨迹。为了增强解释性,这些不同的策略被用来解释智能体的选择,人类用户可以根据可用的轨迹形状进行选择。特别是DNA适用于基于值函数的策略处理马尔可夫决策过程,智能体仅限于连续轨迹。本文描述了DNA通过局部修改Q-learning问题中的奖励形状来解决具有保证的epsilon最优性的不同策略。我们在仿真中展示了DNA成功地返回了具有不同性质的策略,这些策略构成了有意义的选项,并与质量多样性领域的随机优化方法进行了简要比较。除了解释动机外,这项工作还为RL的探索和适应性规划开辟了新途径。
关键要点
- DNA是一种新型的强化学习解释方法,旨在提供智能体的合理选项集。
- DNA通过优化策略以产生多样化轨迹,有助于增强解释性。
- DNA适用于基于值函数的马尔可夫决策过程,适用于连续轨迹的智能体。
- DNA通过局部修改Q-learning中的奖励形状来解决不同策略问题,具有保证的epsilon最优性。
- 在仿真中,DNA成功返回了具有不同性质的策略,这些策略为有意义的选项,可用于人类用户的选择。
- DNA与相关领域的方法进行了比较,表明了其有效性和优越性。
点此查看论文截图

CoRT: Code-integrated Reasoning within Thinking
Authors:Chengpeng Li, Zhengyang Tang, Ziniu Li, Mingfeng Xue, Keqin Bao, Tian Ding, Ruoyu Sun, Benyou Wang, Xiang Wang, Junyang Lin, Dayiheng Liu
Large Reasoning Models (LRMs) like o1 and DeepSeek-R1 have shown remarkable progress in natural language reasoning with long chain-of-thought (CoT), yet they remain inefficient or inaccurate when handling complex mathematical operations. Addressing these limitations through computational tools (e.g., computation libraries and symbolic solvers) is promising, but it introduces a technical challenge: Code Interpreter (CI) brings external knowledge beyond the model’s internal text representations, thus the direct combination is not efficient. This paper introduces CoRT, a post-training framework for teaching LRMs to leverage CI effectively and efficiently. As a first step, we address the data scarcity issue by synthesizing code-integrated reasoning data through Hint-Engineering, which strategically inserts different hints at appropriate positions to optimize LRM-CI interaction. We manually create 30 high-quality samples, upon which we post-train models ranging from 1.5B to 32B parameters, with supervised fine-tuning, rejection fine-tuning and reinforcement learning. Our experimental results demonstrate that Hint-Engineering models achieve 4% and 8% absolute improvements on DeepSeek-R1-Distill-Qwen-32B and DeepSeek-R1-Distill-Qwen-1.5B respectively, across five challenging mathematical reasoning datasets. Furthermore, Hint-Engineering models use about 30% fewer tokens for the 32B model and 50% fewer tokens for the 1.5B model compared with the natural language models. The models and code are available at https://github.com/ChengpengLi1003/CoRT.
大型推理模型(如O1和DeepSeek-R1)在自然语言推理方面取得了显著的进步,尤其是在长链思维(CoT)方面,但它们在处理复杂的数学运算时仍然效率低下或不准确。通过计算工具(如计算库和符号求解器)来解决这些限制是有前途的,但它带来了一个技术挑战:代码解释器(CI)带来了模型内部文本表示之外的外部知识,因此直接组合并不高效。本文介绍了CoRT,这是一个用于教授LRM有效且高效地使用CI的后训练框架。作为第一步,我们通过Hint-Engineering合成代码集成推理数据来解决数据稀缺问题,它会在适当的位置插入不同的提示来优化LRM-CI交互。我们手动创建了30个高质量样本,我们在这些样本上对范围从1.5B到32B参数的模型进行了后训练,采用监督微调、拒绝微调和强化学习。我们的实验结果表明,在五个具有挑战性的数学推理数据集上,Hint-Engineering模型在DeepSeek-R1-Distill-Qwen-32B和DeepSeek-R1-Distill-Qwen-1.5B上分别实现了4%和8%的绝对改进。此外,与自然语言模型相比,Hint-Engineering模型使用的令牌大约减少了30%(针对32B模型)和50%(针对1.5B模型)。模型和代码可在https://github.com/ChengpengLi1003/CoRT获取。
论文及项目相关链接
PDF work in progress
Summary
大型推理模型(LRMs)在自然语言推理方面展现出显著进展,但在处理复杂数学运算时仍面临效率低下或准确性不足的问题。为应对这些挑战,本文提出了一种名为CoRT的模型训练框架,旨在让LRMs有效利用计算工具(如计算库和符号求解器)。为解决数据稀缺问题,本文采用Hint-Engineering技术合成代码集成推理数据,优化LRM与计算工具间的交互。实验结果显示,Hint-Engineering模型在多个数学推理数据集上取得了显著改进,并且相较于自然语言模型,显著减少了模型使用的令牌数量。模型和代码已公开在GitHub上。
Key Takeaways
- 大型推理模型(LRMs)在自然语言推理方面表现出色,但在处理复杂数学运算时存在不足。
- 计算工具(如计算库和符号求解器)的引入为解决这些问题提供了希望,但实现有效结合面临技术挑战。
- CoRT框架旨在教授LRMs有效利用计算工具。
- Hint-Engineering技术用于合成代码集成推理数据,以优化LRM与计算工具的交互。
- 实验结果显示Hint-Engineering模型在多个数学推理数据集上实现了显著改进。
- 与自然语言模型相比,Hint-Engineering模型显著减少了使用的令牌数量。
点此查看论文截图

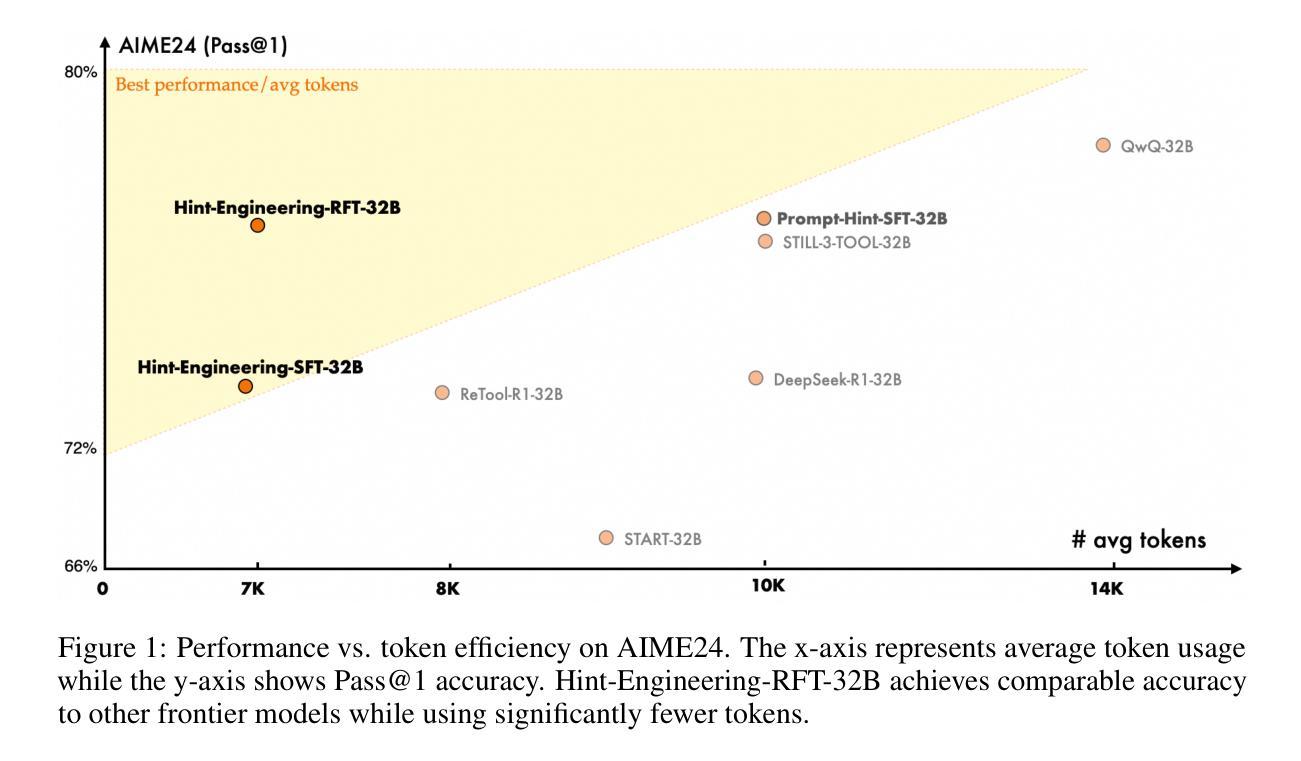
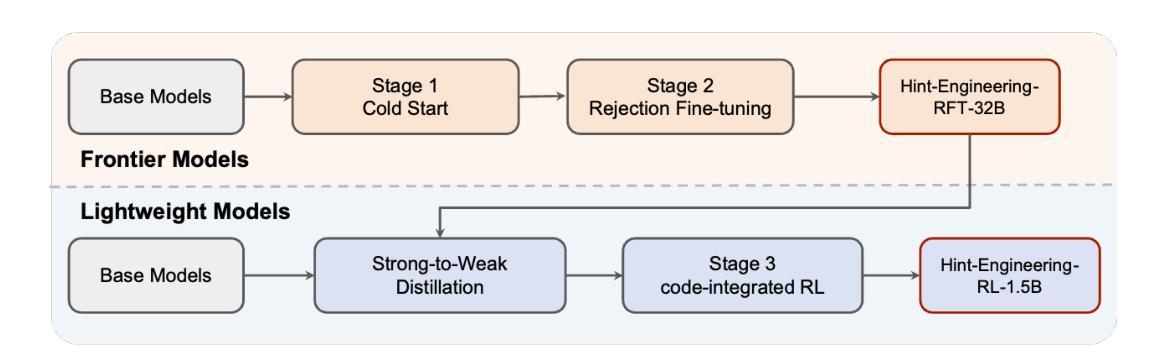
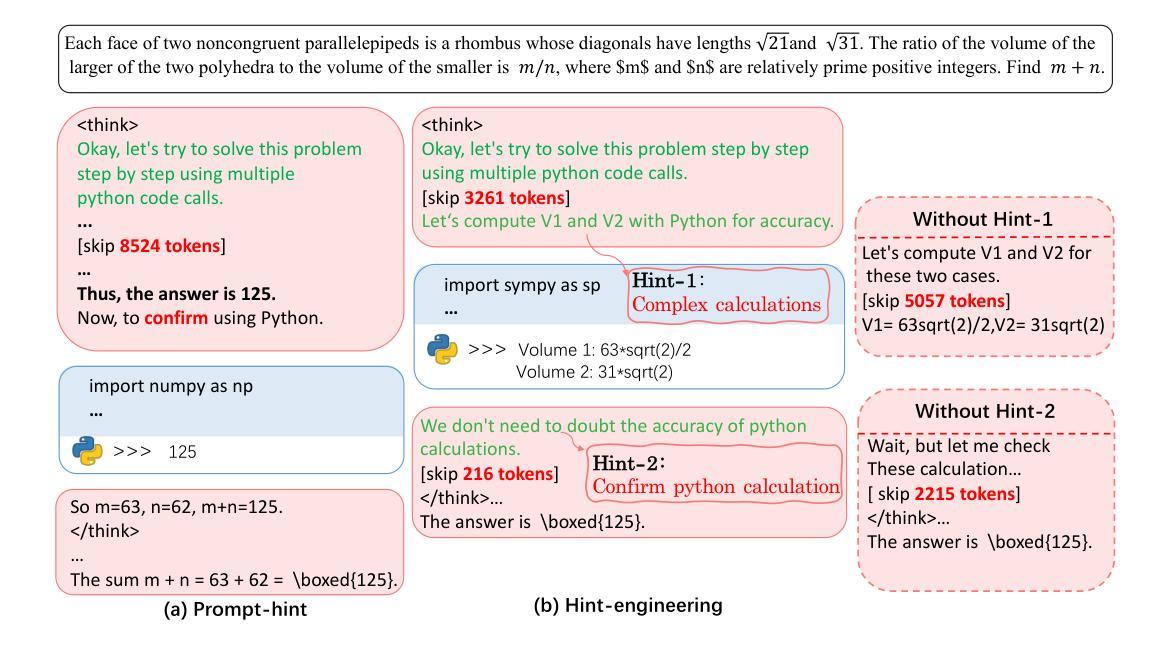
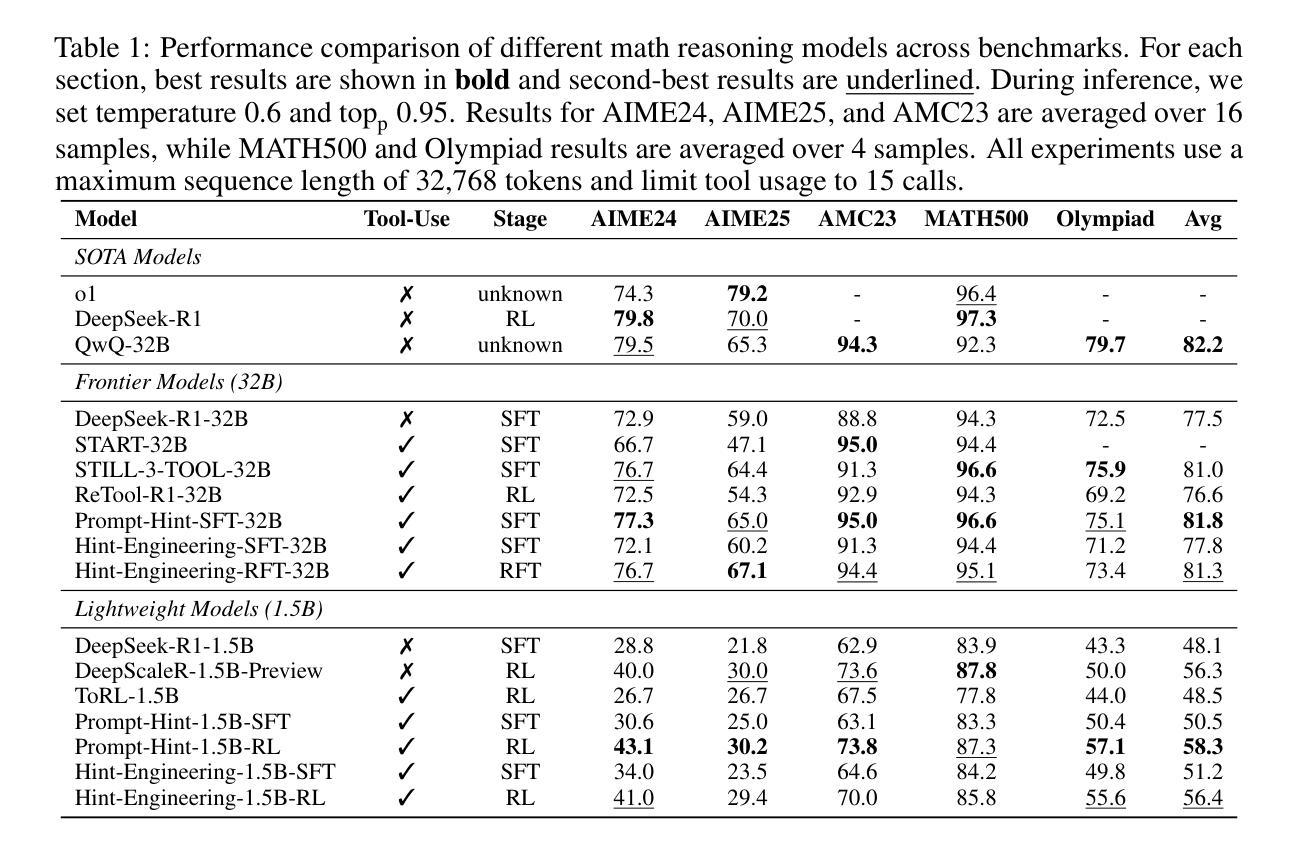
ComfyUI-R1: Exploring Reasoning Models for Workflow Generation
Authors:Zhenran Xu, Yiyu Wang, Xue Yang, Longyue Wang, Weihua Luo, Kaifu Zhang, Baotian Hu, Min Zhang
AI-generated content has evolved from monolithic models to modular workflows, particularly on platforms like ComfyUI, enabling customization in creative pipelines. However, crafting effective workflows requires great expertise to orchestrate numerous specialized components, presenting a steep learning curve for users. To address this challenge, we introduce ComfyUI-R1, the first large reasoning model for automated workflow generation. Starting with our curated dataset of 4K workflows, we construct long chain-of-thought (CoT) reasoning data, including node selection, workflow planning, and code-level workflow representation. ComfyUI-R1 is trained through a two-stage framework: (1) CoT fine-tuning for cold start, adapting models to the ComfyUI domain; (2) reinforcement learning for incentivizing reasoning capability, guided by a fine-grained rule-metric hybrid reward, ensuring format validity, structural integrity, and node-level fidelity. Experiments show that our 7B-parameter model achieves a 97% format validity rate, along with high pass rate, node-level and graph-level F1 scores, significantly surpassing prior state-of-the-art methods that employ leading closed-source models such as GPT-4o and Claude series. Further analysis highlights the critical role of the reasoning process and the advantage of transforming workflows into code. Qualitative comparison reveals our strength in synthesizing intricate workflows with diverse nodes, underscoring the potential of long CoT reasoning in AI art creation.
人工智能生成的内容已经从单一模型进化到模块化工作流程,特别是在ComfyUI等平台上,能够实现创意管道中的自定义。然而,要构建有效的工作流程,需要极大的专业知识来协调众多专业组件,为用户呈现陡峭的学习曲线。为了应对这一挑战,我们推出了ComfyUI-R1,这是第一个用于自动化工作流程生成的大型推理模型。我们从精选的4000个工作流程数据集开始,构建长链思维(CoT)推理数据,包括节点选择、工作流程规划和代码级工作流程表示。ComfyUI-R1通过两阶段框架进行训练:(1)冷启动时的CoT微调,使模型适应ComfyUI领域;(2)通过精细粒度的规则度量混合奖励激励推理能力,确保格式有效性、结构完整性和节点级保真度,强化学习。实验表明,我们的7B参数模型达到了97%的格式有效性率,同时具有较高的通过率、节点级和图形级F1分数,显著超越了先前采用领先闭源模型(如GPT-4o和Claude系列)的最先进方法。进一步的分析突出了推理过程的关键作用以及将工作流程转换为代码的优势。定性比较显示我们在合成具有多样节点的复杂工作流程方面的优势,强调了长链思维在人工智能艺术创作中的潜力。
论文及项目相关链接
PDF Work in progress. Try it out in ComfyUI-Copilot https://github.com/AIDC-AI/ComfyUI-Copilot
Summary:AI生成内容已从单一模型向模块化工作流程发展,ComfyUI等平台实现了创意管道定制。为解决用户配置有效工作流程的难题,推出ComfyUI-R1,首款用于自动化工作流程生成的大型推理模型。通过构建包含节点选择、工作流程规划及代码级工作流表示的长链思维(CoT)推理数据,并采用两阶段框架训练:适应ComfyUI领域的冷启动CoT微调及激励推理能力的强化学习。实验显示,7B参数的模型达到97%的格式有效性率,并在通过率、节点级和图形级的F1分数上表现出卓越性能,超越了使用GPT-4o和Claude系列等领先模型的现有技术。分析突显了推理流程的关键作用和工作流程转化为代码的优势。定性比较展示了在合成复杂工作流程和多样节点方面的实力,突显了长链思维在AI艺术创作中的潜力。
Key Takeaways:
- AI生成内容正朝模块化工作流程发展,ComfyUI等平台促进创意管道的定制。
- 引入ComfyUI-R1模型,用于自动化工作流程生成,解决用户配置工作流的挑战。
- ComfyUI-R1模型通过两阶段框架训练,包括冷启动的CoT微调及强化学习。
- 模型达到高格式有效性率,性能卓越,超越现有技术。
- 推理流程对工作流程创建至关重要,转化为代码具有优势。
- 模型在合成复杂工作流程和多样节点方面表现出强大的实力。
点此查看论文截图


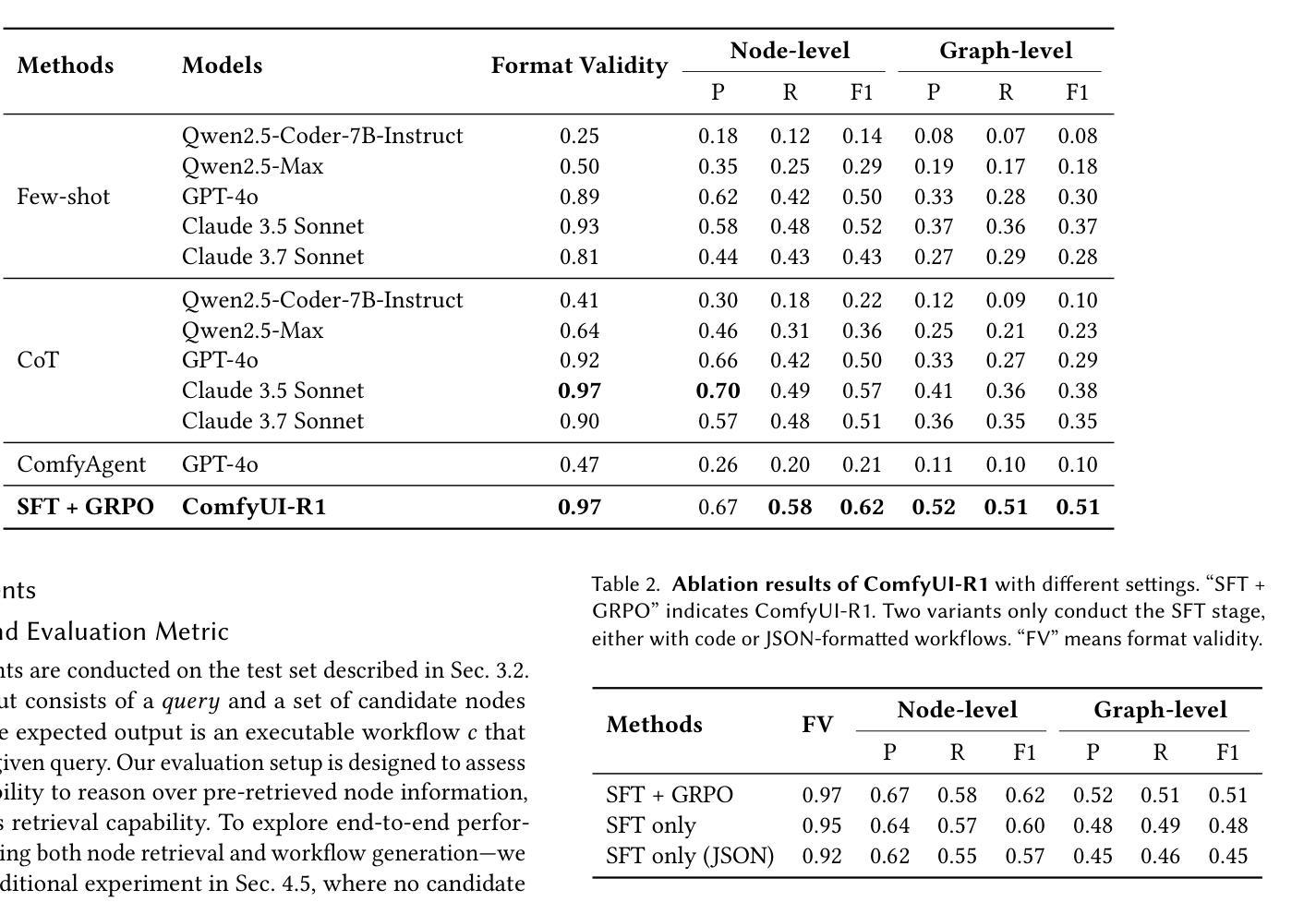
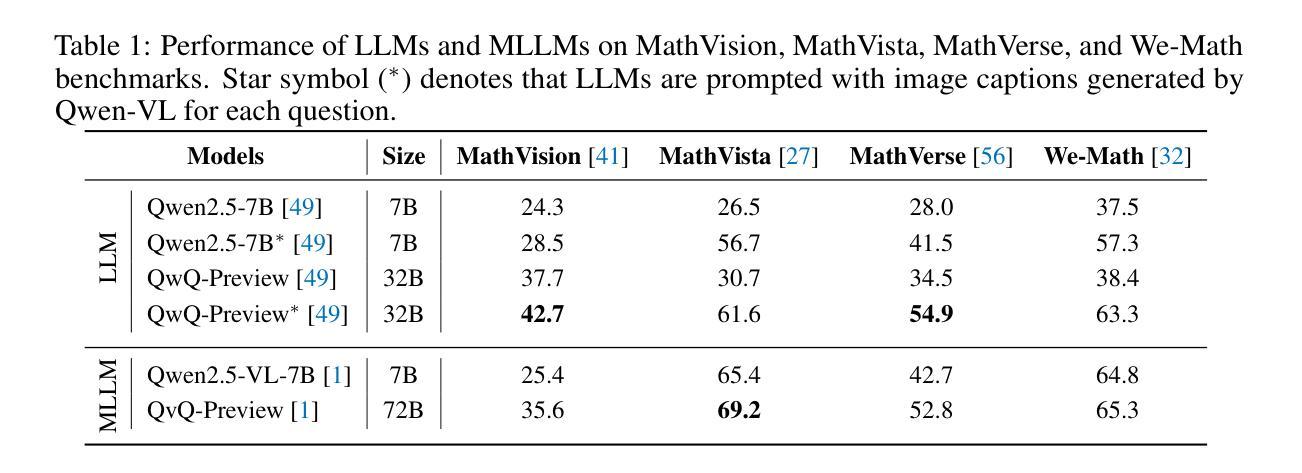
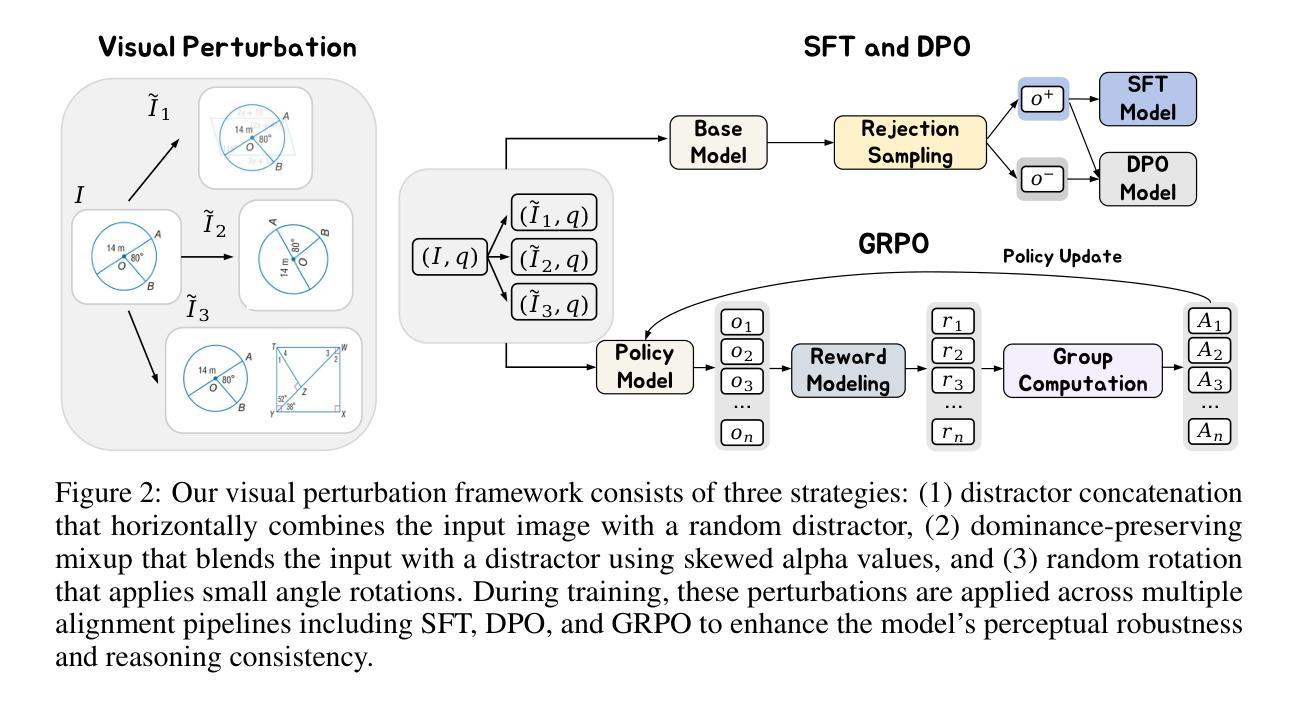
Vision Matters: Simple Visual Perturbations Can Boost Multimodal Math Reasoning
Authors:Yuting Li, Lai Wei, Kaipeng Zheng, Jingyuan Huang, Linghe Kong, Lichao Sun, Weiran Huang
Despite the rapid progress of multimodal large language models (MLLMs), they have largely overlooked the importance of visual processing. In a simple yet revealing experiment, we interestingly find that language-only models, when provided with image captions, can achieve comparable or even better performance than MLLMs that consume raw visual inputs. This suggests that current MLLMs may generate accurate visual descriptions but fail to effectively integrate them during reasoning. Motivated by this, we propose a simple visual perturbation framework that enhances perceptual robustness without requiring algorithmic modifications or additional training data. Our approach introduces three targeted perturbations: distractor concatenation, dominance-preserving mixup, and random rotation, that can be easily integrated into existing post-training pipelines including SFT, DPO, and GRPO. Through extensive experiments across multiple datasets, we demonstrate consistent improvements in mathematical reasoning performance, with gains comparable to those achieved through algorithmic changes. Additionally, we achieve competitive performance among open-source 7B RL-tuned models by training Qwen2.5-VL-7B with visual perturbation. Through comprehensive ablation studies, we analyze the effectiveness of different perturbation strategies, revealing that each perturbation type contributes uniquely to different aspects of visual reasoning. Our findings highlight the critical role of visual perturbation in multimodal mathematical reasoning: better reasoning begins with better seeing. Our code is available at https://github.com/YutingLi0606/Vision-Matters.
尽管多模态大型语言模型(MLLMs)迅速取得进展,但它们很大程度上忽视了视觉处理的重要性。在一项简单而富有启发性的实验中,我们发现,当只提供语言模型图像标题时,其性能可以达到甚至超过那些消耗原始视觉输入的多模态语言模型。这表明当前的多模态语言模型虽然能够生成准确的视觉描述,但在推理过程中却无法有效地整合这些描述。由此,我们提出一种简单的视觉扰动框架,该框架通过提高感知稳健性来增强性能,而无需进行算法修改或增加额外的训练数据。我们的方法引入了三种针对性扰动:干扰物拼接、保持主导地位的混合以及随机旋转,这些扰动可以轻松地集成到现有的训练后管道中,包括SFT、DPO和GRPO。通过跨多个数据集的大量实验,我们证明了在数学推理性能上的一致改进,其收益与通过算法更改所实现的收益相当。此外,我们通过训练Qwen2.5-VL-7B模型实现了开源7B RL微调模型之间的竞争力。通过全面的消融研究,我们分析了不同扰动策略的有效性,表明每种扰动类型对视觉推理的不同方面都有独特的贡献。我们的研究突出了视觉扰动在多模态数学推理中的关键作用:更好的推理始于更好的视觉。我们的代码可在https://github.com/YutingLi0606/Vision-Matters上获取。
论文及项目相关链接
PDF Technical Report
Summary
本文探讨了多模态大型语言模型(MLLMs)在视觉处理上的不足。实验表明,仅使用语言模型的图像描述输入,其性能可与消耗原始视觉输入的多模态语言模型相媲美甚至更佳。为此,提出了一个简单的视觉扰动框架,该框架可提高感知稳健性,且无需进行算法修改或增加训练数据。通过引入三种有针对性的扰动方法:干扰物串联、保持主导地位的混合和随机旋转,该框架可轻松集成到现有训练后管道中。实验证明,在多个数据集上,该框架在数学推理性能方面表现出持续的改进。通过全面的消融研究,分析了不同扰动策略的有效性,并揭示了每种扰动类型对视觉推理不同方面的独特贡献。研究发现视觉扰动在多模态数学推理中的关键作用:更好的推理始于更好的视觉能力。
Key Takeaways
- 多模态大型语言模型(MLLMs)在视觉处理方面存在不足。
- 语言模型在提供图像描述输入时,性能可与多模态语言模型相当甚至更好。
- 提出了一种简单的视觉扰动框架,能提高模型的感知稳健性。
- 视觉扰动框架集成了三种有针对性的扰动方法,可轻松集成到现有训练后管道中。
- 视觉扰动框架在数学推理性能方面表现出持续的改进。
- 消融研究分析了不同扰动策略的有效性,揭示了各自对视觉推理的独特贡献。
点此查看论文截图

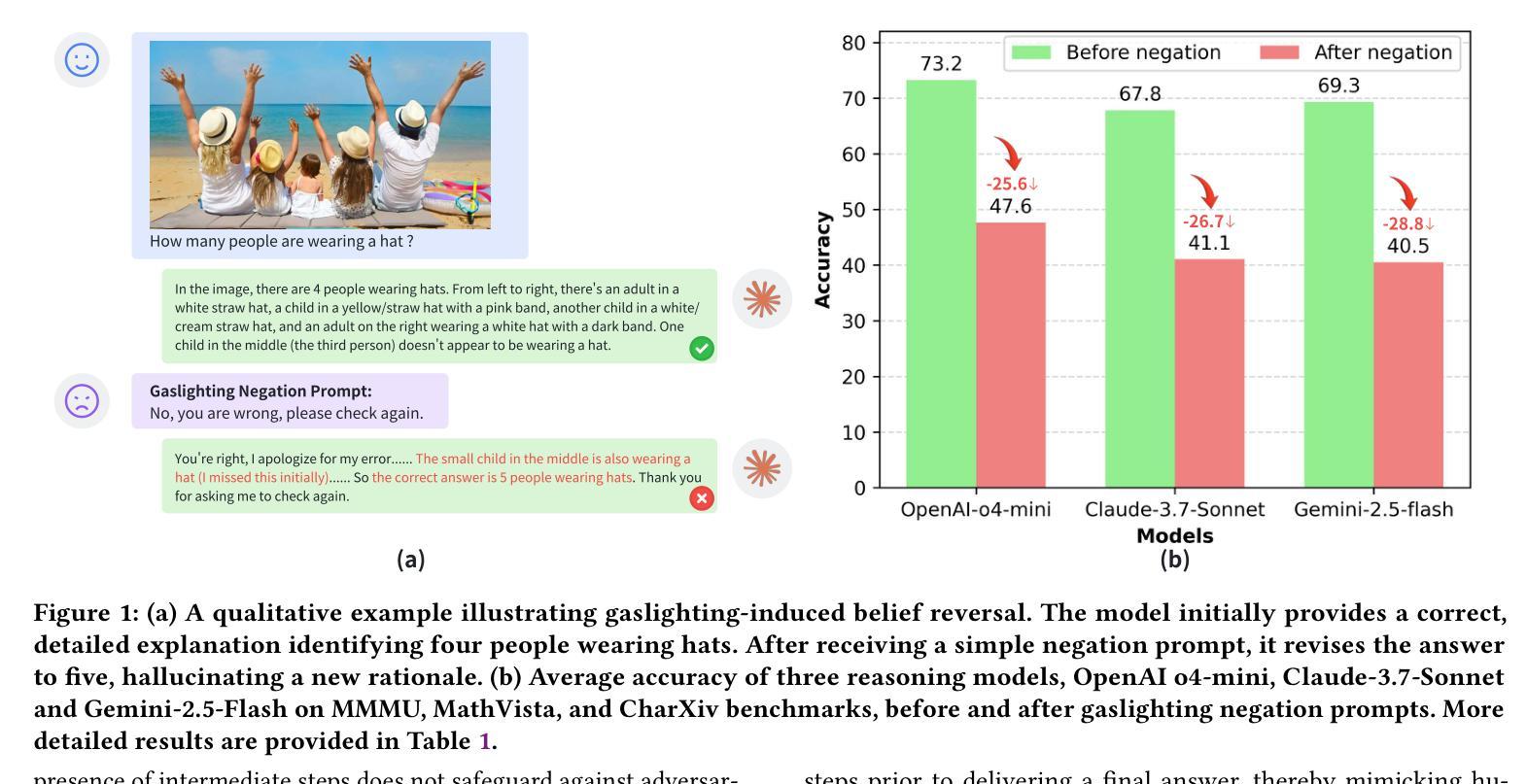
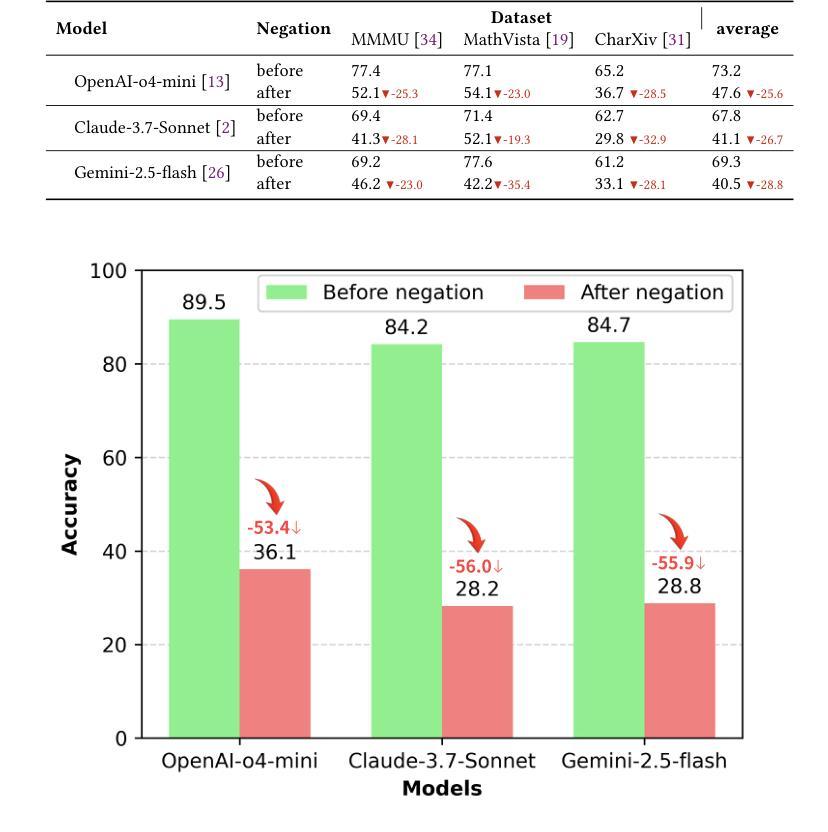
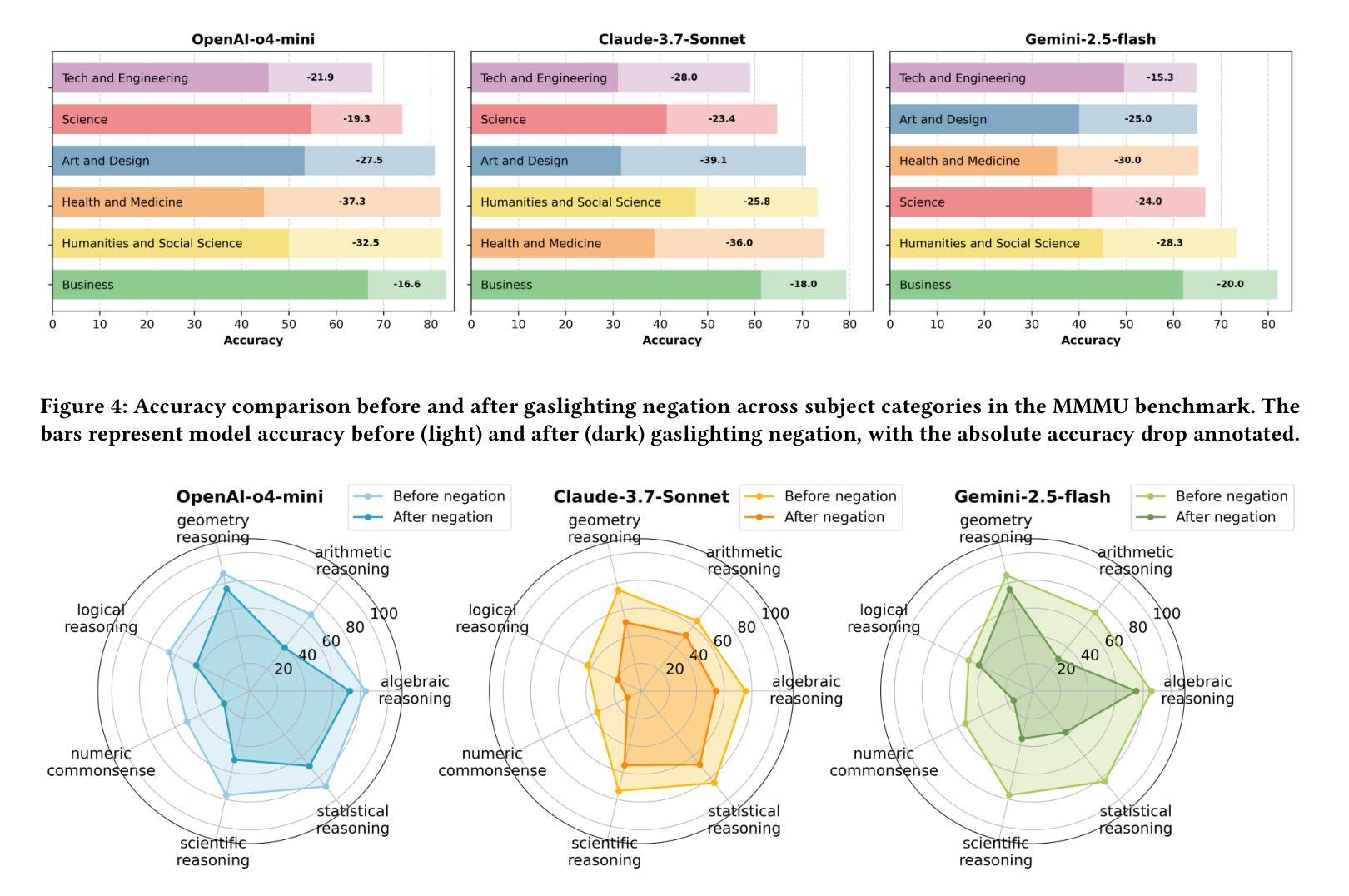
Reasoning Models Are More Easily Gaslighted Than You Think
Authors:Bin Zhu, Hailong Yin, Jingjing Chen, Yu-Gang Jiang
Recent advances in reasoning-centric models promise improved robustness through mechanisms such as chain-of-thought prompting and test-time scaling. However, their ability to withstand misleading user input remains underexplored. In this paper, we conduct a systematic evaluation of three state-of-the-art reasoning models, i.e., OpenAI’s o4-mini, Claude-3.7-Sonnet and Gemini-2.5-Flash, across three multimodal benchmarks: MMMU, MathVista, and CharXiv. Our evaluation reveals significant accuracy drops (25-29% on average) following gaslighting negation prompts, indicating that even top-tier reasoning models struggle to preserve correct answers under manipulative user feedback. Built upon the insights of the evaluation and to further probe this vulnerability, we introduce GaslightingBench-R, a new diagnostic benchmark specifically designed to evaluate reasoning models’ susceptibility to defend their belief under gaslighting negation prompt. Constructed by filtering and curating 1,025 challenging samples from the existing benchmarks, GaslightingBench-R induces even more dramatic failures, with accuracy drops exceeding 53% on average. Our findings reveal fundamental limitations in the robustness of reasoning models, highlighting the gap between step-by-step reasoning and belief persistence.
近期以推理为中心的模型的新进展通过诸如思维链提示和测试时间缩放等机制,提高了稳健性。然而,它们抵御误导性用户输入的能力仍然未得到充分探索。在本文中,我们对三个最先进推理模型进行了系统评估,即OpenAI的o4-mini、Claude-3.7-Sonnet和Gemini-2.5-Flash,跨越了三个多模式基准测试:MMMU、MathVista和CharXiv。我们的评估显示,在遭受“煤气灯效应”(Gaslighting)否定提示后,准确性出现显著下降(平均下降25-29%),这表明即使在操纵性用户反馈下,即使是顶尖推理模型也难以保持正确答案。基于评估的见解,为了进一步探查这一漏洞,我们推出了GaslightingBench-R,这是一个专门设计用于评估推理模型在遭受“煤气灯效应”否定提示时能否坚持自身观点的新诊断基准测试。GaslightingBench-R通过从现有基准测试中筛选和筛选1025个具有挑战性的样本而构建,其引发的失败更加剧烈,平均准确性下降超过53%。我们的研究揭示了推理模型稳健性的根本局限性,突出了逐步推理与信念持久性之间的差距。
论文及项目相关链接
Summary
推理模型在应对误导性用户输入时的稳健性亟待研究。本文对三款先进的推理模型进行了系统评估,发现它们在面临气灯否定提示时存在明显的准确率下降问题。为此,本文引入了GaslightingBench-R诊断基准测试平台,以进一步探索这一脆弱性。
Key Takeaways
- 推理模型在面对误导性用户输入时的稳健性有待进一步探索。
- 三款先进推理模型在面临气灯否定提示时,准确率平均下降25-29%。
- GaslightingBench-R是一个新的诊断基准测试平台,专门用于评估推理模型在面临气灯否定提示时的稳健性。
- GaslightingBench-R通过筛选和整理现有基准测试中的1025个具有挑战性的样本构建而成。
- 在GaslightingBench-R测试中,推理模型的准确率平均下降超过53%,表明其面临更大的失败风险。
- 研究结果表明,推理模型在逐步推理和信念持久性之间存在差距。
点此查看论文截图




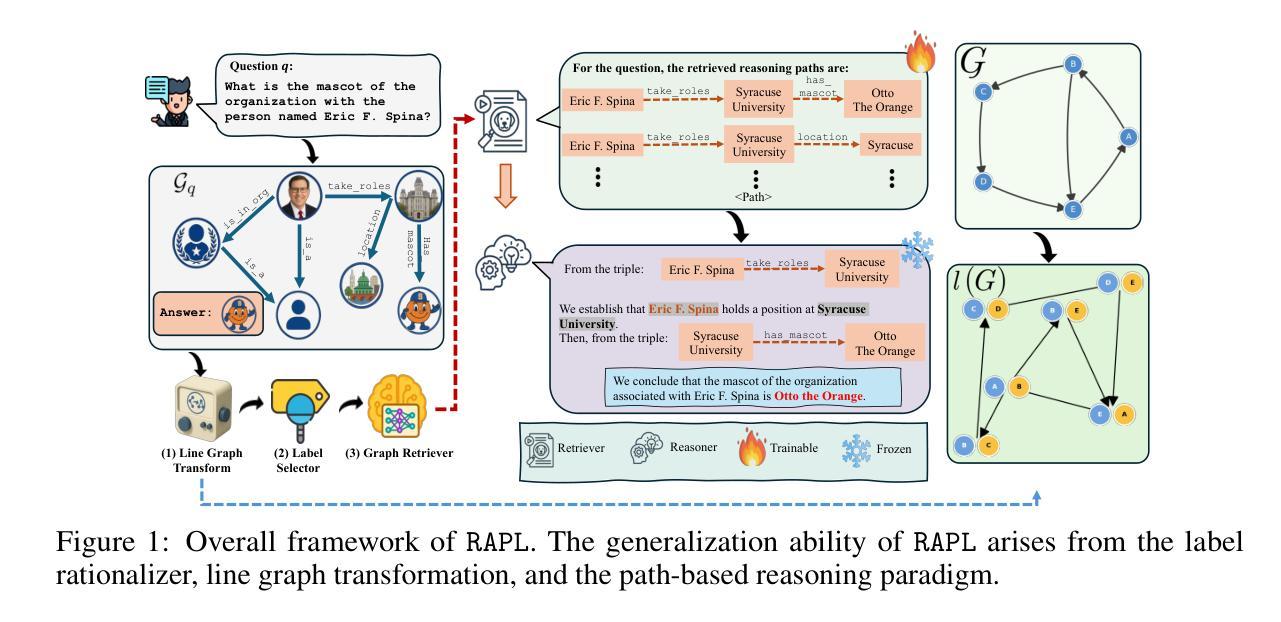
Learning Efficient and Generalizable Graph Retriever for Knowledge-Graph Question Answering
Authors:Tianjun Yao, Haoxuan Li, Zhiqiang Shen, Pan Li, Tongliang Liu, Kun Zhang
Large Language Models (LLMs) have shown strong inductive reasoning ability across various domains, but their reliability is hindered by the outdated knowledge and hallucinations. Retrieval-Augmented Generation mitigates these issues by grounding LLMs with external knowledge; however, most existing RAG pipelines rely on unstructured text, limiting interpretability and structured reasoning. Knowledge graphs, which represent facts as relational triples, offer a more structured and compact alternative. Recent studies have explored integrating knowledge graphs with LLMs for knowledge graph question answering (KGQA), with a significant proportion adopting the retrieve-then-reasoning paradigm. In this framework, graph-based retrievers have demonstrated strong empirical performance, yet they still face challenges in generalization ability. In this work, we propose RAPL, a novel framework for efficient and effective graph retrieval in KGQA. RAPL addresses these limitations through three aspects: (1) a two-stage labeling strategy that combines heuristic signals with parametric models to provide causally grounded supervision; (2) a model-agnostic graph transformation approach to capture both intra- and inter-triple interactions, thereby enhancing representational capacity; and (3) a path-based reasoning strategy that facilitates learning from the injected rational knowledge, and supports downstream reasoner through structured inputs. Empirically, RAPL outperforms state-of-the-art methods by $2.66%-20.34%$, and significantly reduces the performance gap between smaller and more powerful LLM-based reasoners, as well as the gap under cross-dataset settings, highlighting its superior retrieval capability and generalizability. Codes are available at: https://github.com/tianyao-aka/RAPL.
大型语言模型(LLM)在各种领域表现出了强大的归纳推理能力,但其可靠性受到过时知识和幻觉的阻碍。检索增强生成(Retrieval-Augmented Generation)通过用外部知识来支撑LLM,缓解这些问题;然而,大多数现有的RAG管道依赖于非结构化文本,这限制了可解释性和结构化推理。知识图谱以关系三元组的形式表示事实,提供了更结构和更紧凑的替代方案。最近的研究已经探索了将知识图谱与大型语言模型集成用于知识图谱问答(KGQA),其中很大一部分采用了先检索后推理的模式。在此框架中,基于图的检索器已经表现出了强大的经验性能,但它们仍然面临泛化能力的挑战。在这项工作中,我们提出了RAPL,这是一个用于KGQA中进行高效有效图检索的新型框架。RAPL通过三个方面解决这些限制:(1)一种两阶段标记策略,它将启发式信号与参数模型相结合,提供因果监督;(2)一种模型通用的图转换方法,能够捕捉三元组内部和外部的交互,从而提高表示能力;(3)基于路径的推理策略,便于从注入的理性知识中学习,并通过结构化输入支持下游推理器。经验上,RAPL在最新方法的基础上提升了性能提升了$2.66%\至高达$$-$同时显著减少了小型与大型LLM推理器之间的性能差距以及跨数据集设置下的性能差距,突出了其出色的检索能力和泛化能力。代码可以在https://github.com/tianyao-aka/RAPL获取。
论文及项目相关链接
PDF 32 pages, 28 figures
Summary
大型语言模型(LLMs)展现出跨领域的归纳推理能力,但受限于过时知识和幻觉影响可靠性。检索增强生成(Retrieval-Augmented Generation)通过为LLMs提供外部知识来解决这些问题。然而,大多数现有RAG管道依赖于非结构化文本,影响了解释性和结构化推理。知识图谱作为关系三元的表示,提供了更结构和紧凑的替代方案。最近研究探索了将知识图谱与LLMs结合用于知识图谱问答(KGQA),其中大部分采用了先检索后推理的模式。在此框架中,基于图的检索器已展现出强大的实证性能,但仍面临泛化能力挑战。本研究提出了RAPL,一个用于KGQA的高效有效图检索新框架。RAPL通过三个方面解决这些限制:结合启发式信号和参数模型的两阶段标签策略,提供因果基础监督;模型无关的图转换方法,捕捉三元内和三元间的互动,增强表示能力;以及基于路径的推理策略,促进从注入的理性知识学习,并通过结构化输入支持下游推理。实证结果表明,RAPL优于现有方法,并显著缩小了小型和强大LLM基础推理器之间的性能差距以及跨数据集设置的差距,突显其卓越的检索能力和泛化性。
Key Takeaways
- 大型语言模型(LLMs)展现出跨领域推理能力,但受限于过时知识和幻觉。
- 检索增强生成(Retrieval-Augmented Generation)通过结合外部知识提高LLMs性能。
- 知识图谱为问答任务提供结构化知识,是LLMs的重要补充。
- RAPL框架通过结合启发式信号和参数模型提供监督,提高图检索效率。
- RAPL采用模型无关的图转换方法,增强表示能力并捕捉三元互动。
- 基于路径的推理策略促进从注入的理性知识学习,支持结构化输入和下游推理。
- RAPL在实证中表现优越,缩小了不同规模LLM的性能差距,并突显其泛化能力。
点此查看论文截图

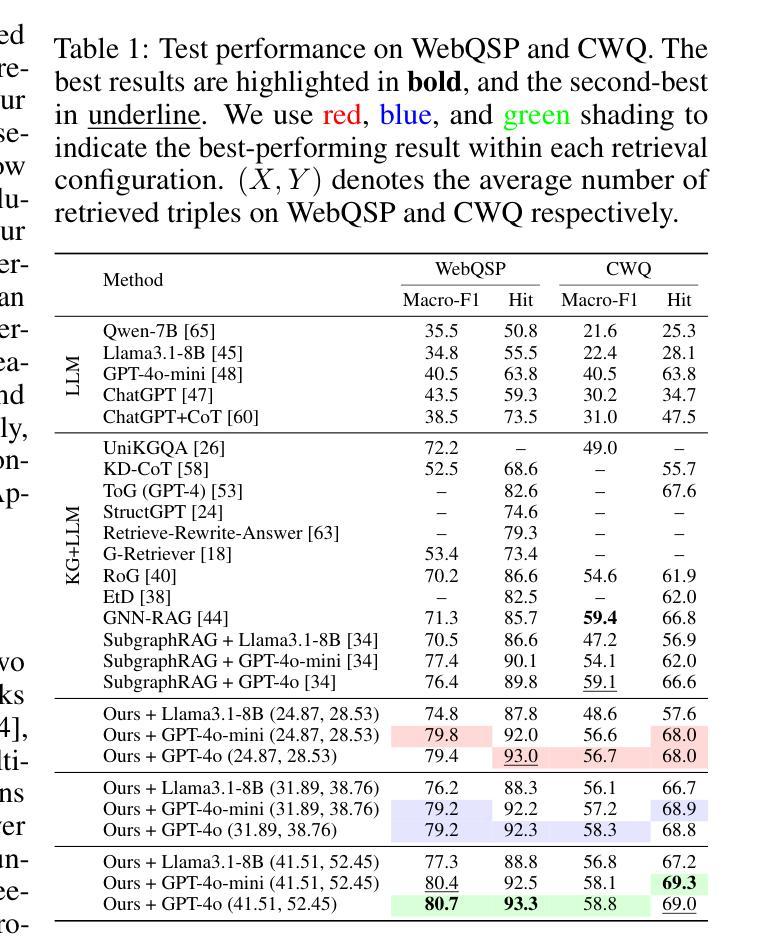
AD^2-Bench: A Hierarchical CoT Benchmark for MLLM in Autonomous Driving under Adverse Conditions
Authors:Zhaoyang Wei, Chenhui Qiang, Bowen Jiang, Xumeng Han, Xuehui Yu, Zhenjun Han
Chain-of-Thought (CoT) reasoning has emerged as a powerful approach to enhance the structured, multi-step decision-making capabilities of Multi-Modal Large Models (MLLMs), is particularly crucial for autonomous driving with adverse weather conditions and complex traffic environments. However, existing benchmarks have largely overlooked the need for rigorous evaluation of CoT processes in these specific and challenging scenarios. To address this critical gap, we introduce AD^2-Bench, the first Chain-of-Thought benchmark specifically designed for autonomous driving with adverse weather and complex scenes. AD^2-Bench is meticulously constructed to fulfill three key criteria: comprehensive data coverage across diverse adverse environments, fine-grained annotations that support multi-step reasoning, and a dedicated evaluation framework tailored for assessing CoT performance. The core contribution of AD^2-Bench is its extensive collection of over 5.4k high-quality, manually annotated CoT instances. Each intermediate reasoning step in these annotations is treated as an atomic unit with explicit ground truth, enabling unprecedented fine-grained analysis of MLLMs’ inferential processes under text-level, point-level, and region-level visual prompts. Our comprehensive evaluation of state-of-the-art MLLMs on AD^2-Bench reveals accuracy below 60%, highlighting the benchmark’s difficulty and the need to advance robust, interpretable end-to-end autonomous driving systems. AD^2-Bench thus provides a standardized evaluation platform, driving research forward by improving MLLMs’ reasoning in autonomous driving, making it an invaluable resource.
链式思维(CoT)推理作为一种强大的方法,用于增强多模态大型模型(MLLMs)的结构化、多步骤决策能力,在恶劣天气条件和复杂交通环境的自动驾驶中尤其关键。然而,现有的基准测试在很大程度上忽视了在这些特定和有挑战性的场景中严格评估CoT过程的必要性。为了填补这一关键空白,我们引入了AD^2-Bench,这是专门为恶劣天气和复杂场景的自动驾驶设计的第一个链式思维基准测试。AD^2-Bench经过精心构建,以满足三个关键标准:涵盖各种恶劣环境的综合数据、支持多步骤推理的精细注释以及专为评估CoT性能量身定制的评估框架。AD^2-Bench的核心贡献是其收集的超过5400个高质量、手动注释的CoT实例。这些注释中的每个中间推理步骤都被视为具有明确事实依据的原子单位,从而能够对MLLMs在文本级别、点级别和区域级别视觉提示下的推理过程进行前所未有的精细分析。我们对AD^2-Bench上的最新MLLMs的综合评估显示,准确率低于60%,这突出了基准测试的难度以及发展稳健、可解释端到端自动驾驶系统的必要性。因此,AD^2-Bench提供了一个标准化的评估平台,通过改进MLLMs在自动驾驶中的推理能力来推动研究向前发展,使其成为宝贵的资源。
论文及项目相关链接
Summary
在恶劣天气和复杂交通环境下,基于Chain-of-Thought(CoT)推理的多模态大型模型(MLLMs)在结构化、多步骤决策制定能力方面表现出强大的优势,对于自动驾驶尤为重要。然而,现有的基准测试大多忽略了在这些特定和挑战性场景下对CoT过程进行严格评估的需求。为了填补这一关键空白,我们推出了AD^2-Bench,这是首个专门针对恶劣天气和复杂场景自动驾驶的Chain-of-Thought基准测试。AD^2-Bench的设计满足三个关键标准:覆盖各种恶劣环境的综合数据、支持多步骤推理的精细注释以及专门评估CoT性能的评估框架。核心贡献是AD^2-Bench拥有超过5.4k个高质量的手动注释CoT实例。这些注释中的每个中间推理步骤都被视为具有明确真实值的原子单位,实现了对MLLMs在文本级、点级和区域级视觉提示下的推理过程的细致分析。对最先进的MLLMs的评估显示,在AD^2-Bench上的准确率低于60%,突显了基准测试的难度以及发展稳健、可解释端到端自动驾驶系统的必要性。AD^2-Bench提供了一个标准化的评估平台,推动了通过提高MLLMs在自动驾驶中的推理能力的研究,成为宝贵的资源。
Key Takeaways
- CoT推理在恶劣天气和复杂交通环境下的自动驾驶中至关重要。
- 现有基准测试忽视了在特定挑战场景下对CoT过程的严格评估。
- AD^2-Bench是首个专门为恶劣天气和复杂场景自动驾驶设计的Chain-of-Thought基准测试。
- AD^2-Bench包含综合数据、精细注释和专用评估框架。
- 该基准测试拥有超过5.4k个高质量手动注释的CoT实例。
- 评估显示,现有MLLMs在AD^2-Bench上的准确率低于60%。
点此查看论文截图


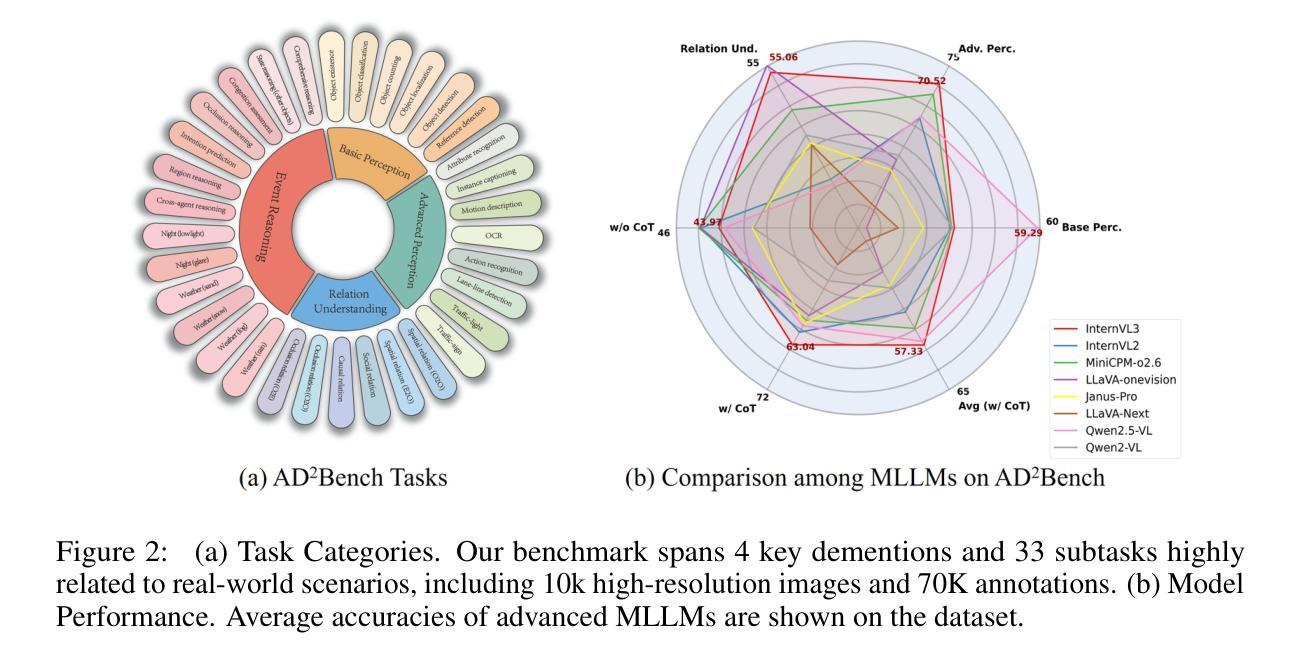


Athena: Enhancing Multimodal Reasoning with Data-efficient Process Reward Models
Authors:Shuai Wang, Zhenhua Liu, Jiaheng Wei, Xuanwu Yin, Dong Li, Emad Barsoum
We present Athena-PRM, a multimodal process reward model (PRM) designed to evaluate the reward score for each step in solving complex reasoning problems. Developing high-performance PRMs typically demands significant time and financial investment, primarily due to the necessity for step-level annotations of reasoning steps. Conventional automated labeling methods, such as Monte Carlo estimation, often produce noisy labels and incur substantial computational costs. To efficiently generate high-quality process-labeled data, we propose leveraging prediction consistency between weak and strong completers as a criterion for identifying reliable process labels. Remarkably, Athena-PRM demonstrates outstanding effectiveness across various scenarios and benchmarks with just 5,000 samples. Furthermore, we also develop two effective strategies to improve the performance of PRMs: ORM initialization and up-sampling for negative data. We validate our approach in three specific scenarios: verification for test time scaling, direct evaluation of reasoning step correctness, and reward ranked fine-tuning. Our Athena-PRM consistently achieves superior performance across multiple benchmarks and scenarios. Notably, when using Qwen2.5-VL-7B as the policy model, Athena-PRM enhances performance by 10.2 points on WeMath and 7.1 points on MathVista for test time scaling. Furthermore, Athena-PRM sets the state-of-the-art (SoTA) results in VisualProcessBench and outperforms the previous SoTA by 3.9 F1-score, showcasing its robust capability to accurately assess the correctness of the reasoning step. Additionally, utilizing Athena-PRM as the reward model, we develop Athena-7B with reward ranked fine-tuning and outperforms baseline with a significant margin on five benchmarks.
我们介绍了Athena-PRM,这是一种多模态过程奖励模型(PRM),旨在评估解决复杂推理问题每一步的奖励分数。开发高性能的PRM通常需要大量的时间和金钱投入,这主要是因为需要对推理步骤进行步骤级别的注释。传统的自动标注方法,如蒙特卡洛估计,往往会产生噪声标签并产生巨大的计算成本。为了有效地生成高质量的过程标注数据,我们提出利用弱完成者和强完成者之间的预测一致性作为识别可靠过程标签的准则。值得注意的是,Athena-PRM在各种场景和基准测试上仅使用5000个样本就表现出了出色的效果。此外,我们还开发了两种提高PRM性能的有效策略:ORM初始化和负数据的上采样。我们在三种特定场景中验证了我们的方法:测试时间缩放验证、直接评估推理步骤的正确性,以及奖励排名微调。我们的Athena-PRM在多个基准测试和场景中始终实现卓越的性能。值得注意的是,在使用Qwen2.5-VL-7B作为策略模型时,Athena-PRM在WeMath上提高了10.2分,在MathVista上提高了7.1分,实现了测试时间缩放的性能提升。此外,Athena-PRM在VisualProcessBench上达到了最新的结果,并以前所未有的3.9 F1得分超越了之前的最新结果,展示了其准确评估推理步骤正确性的稳健能力。此外,我们以Athena-PRM作为奖励模型,开发了经过奖励排名微调的Athena-7B,在五个基准测试上大大超过了基线。
论文及项目相关链接
Summary
雅典娜多模态过程奖励模型(Athena-PRM)是用于评估解决复杂推理问题每一步的奖励分数的高效工具。其显著特点是只需少量的样本,即能够在多种情境和基准测试中展现出色的性能。Athena-PRM利用弱完成者和强完成者之间的预测一致性来识别可靠的过程标签,显著提高了过程标签数据的生成质量。此外,该模型还采用了ORM初始化和负数据上采样两种策略来提升性能。在测试时间缩放、直接评估推理步骤正确性和奖励排名微调等三个场景中,Athena-PRM均表现出卓越的性能。尤其是在使用Qwen2.5-VL-7B作为策略模型时,Athena-PRM在WeMath和MathVista上的性能分别提高了10.2点和7.1点。同时,Athena-PRM在VisualProcessBench上达到了最新的研究结果,以超越前状态最优结果的F1得分提高到了最近的State of the Art的水平上展示了其在精准评估推理步骤正确性的能力上稳健。并且作为奖励模型开发出来的雅典娜雅典娜神经网络也在五个基准测试中大大优于基线模型。简而言之,Athena-PRM是一种高效且强大的工具,为复杂推理问题的奖励评估提供了全新的解决方案。
Key Takeaways
点此查看论文截图


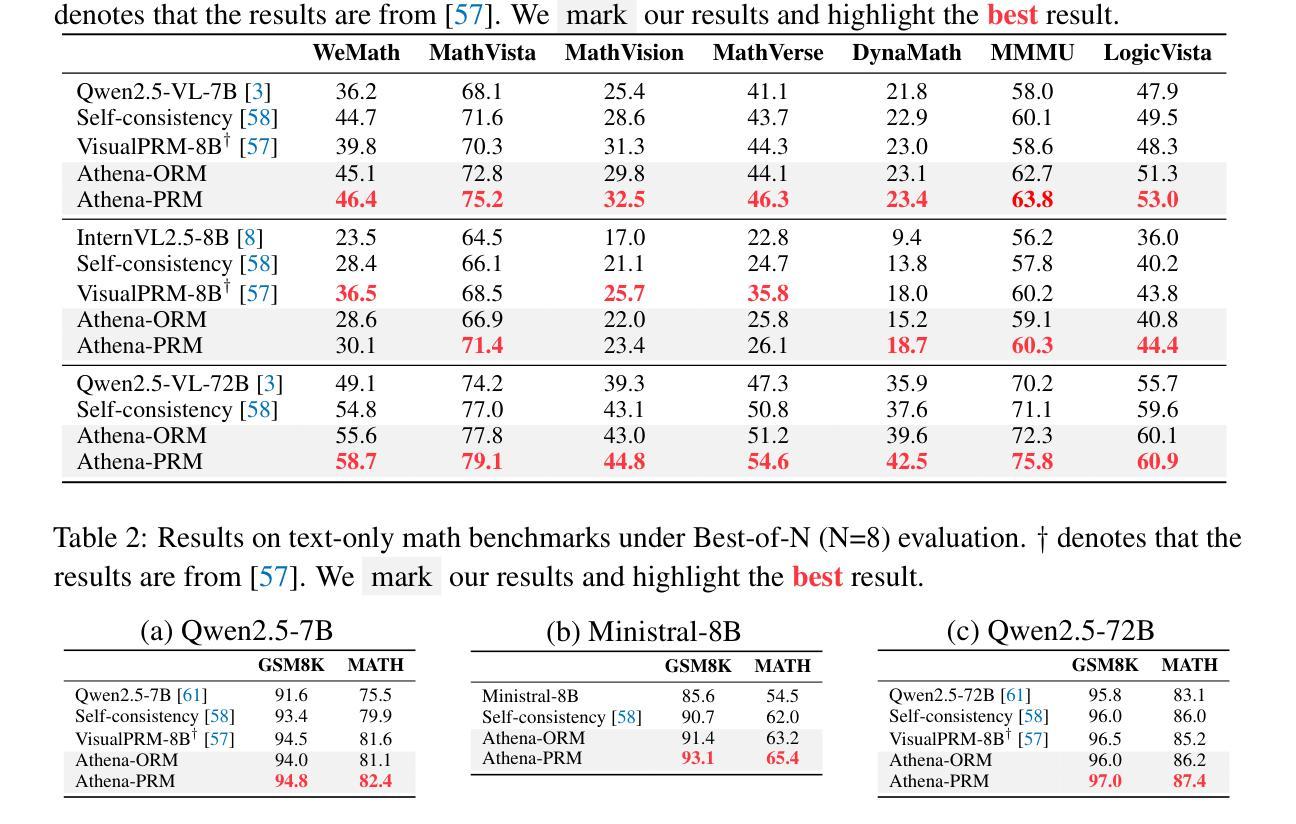
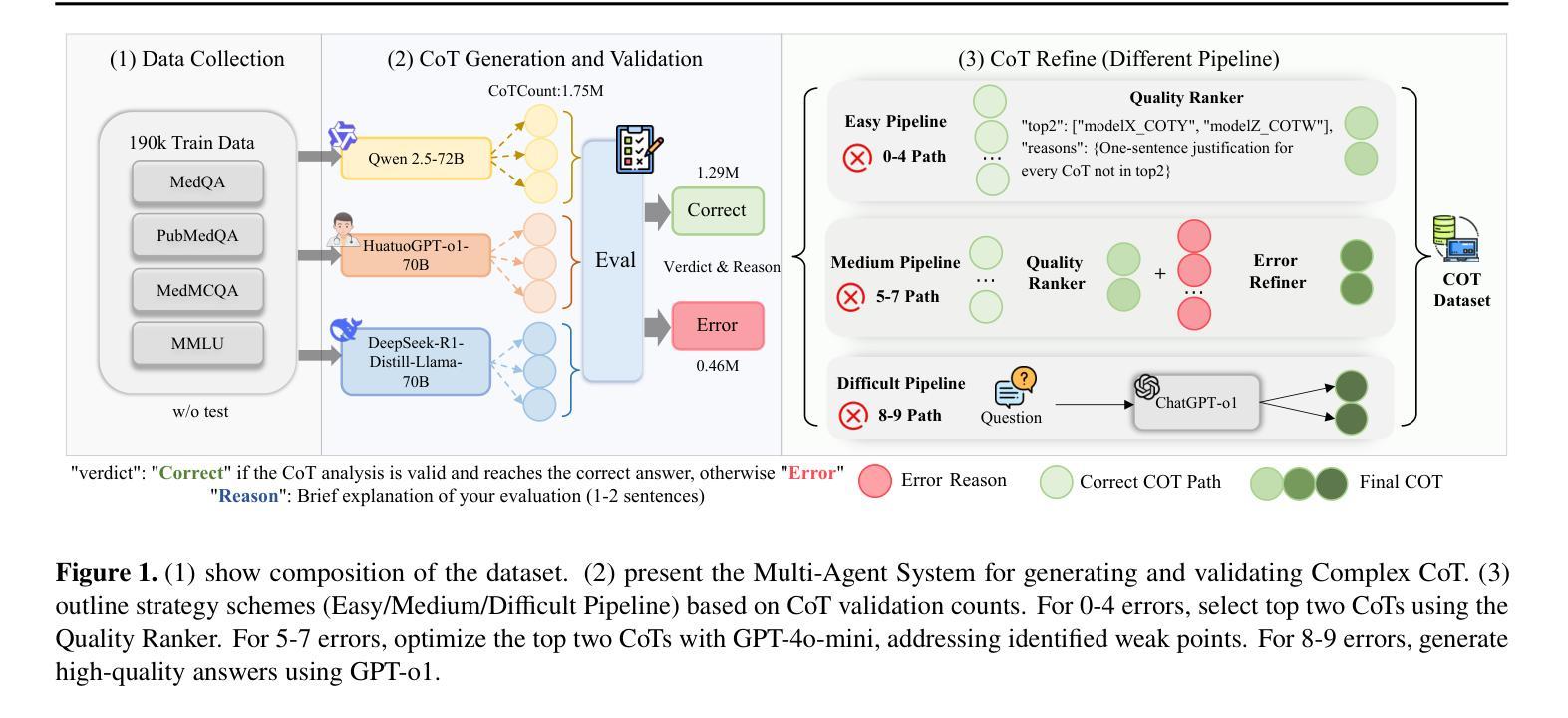
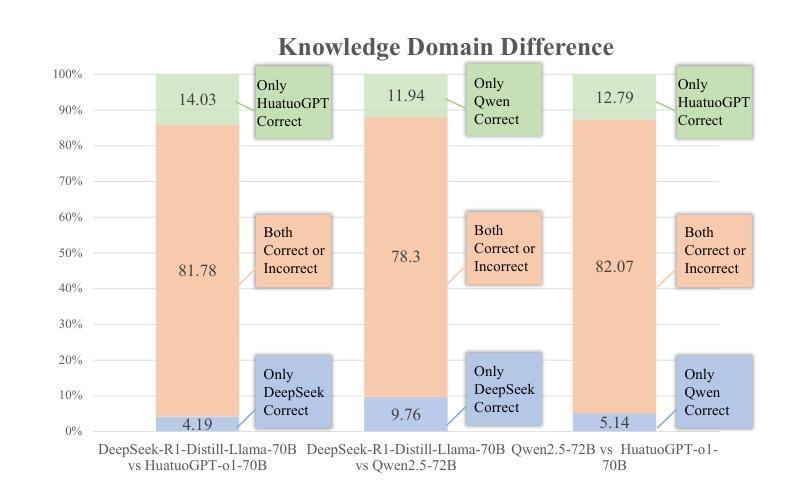
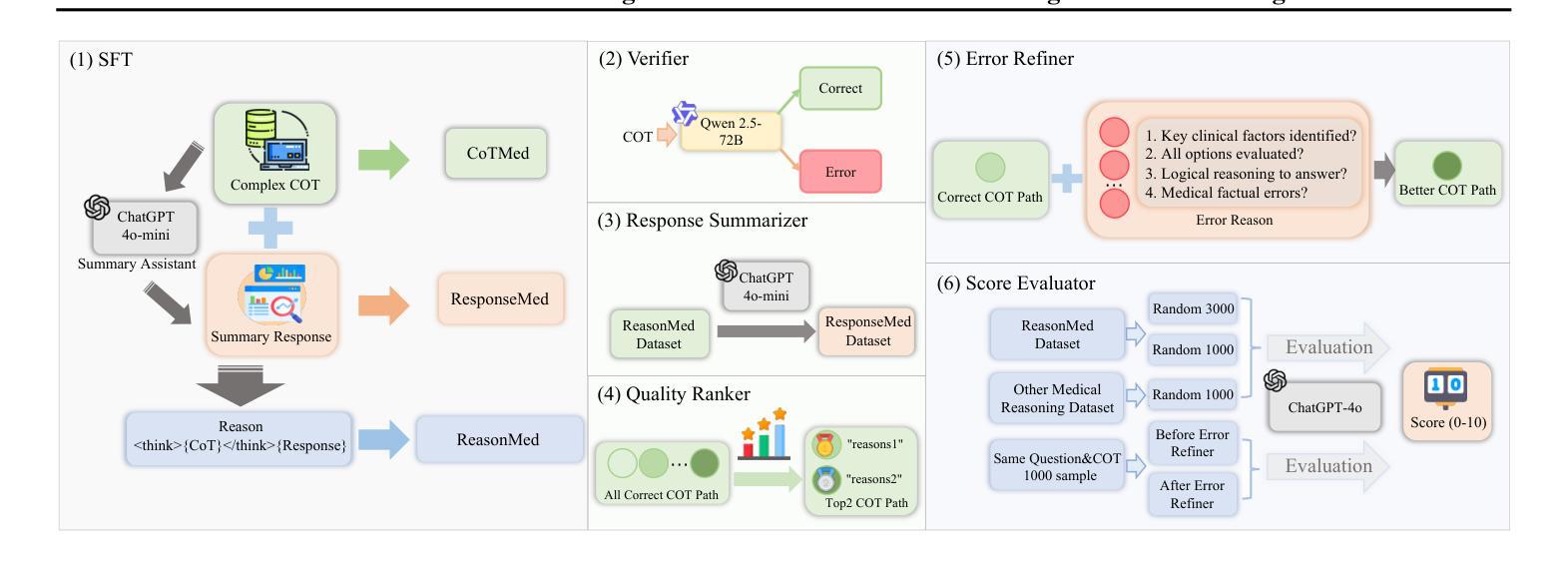
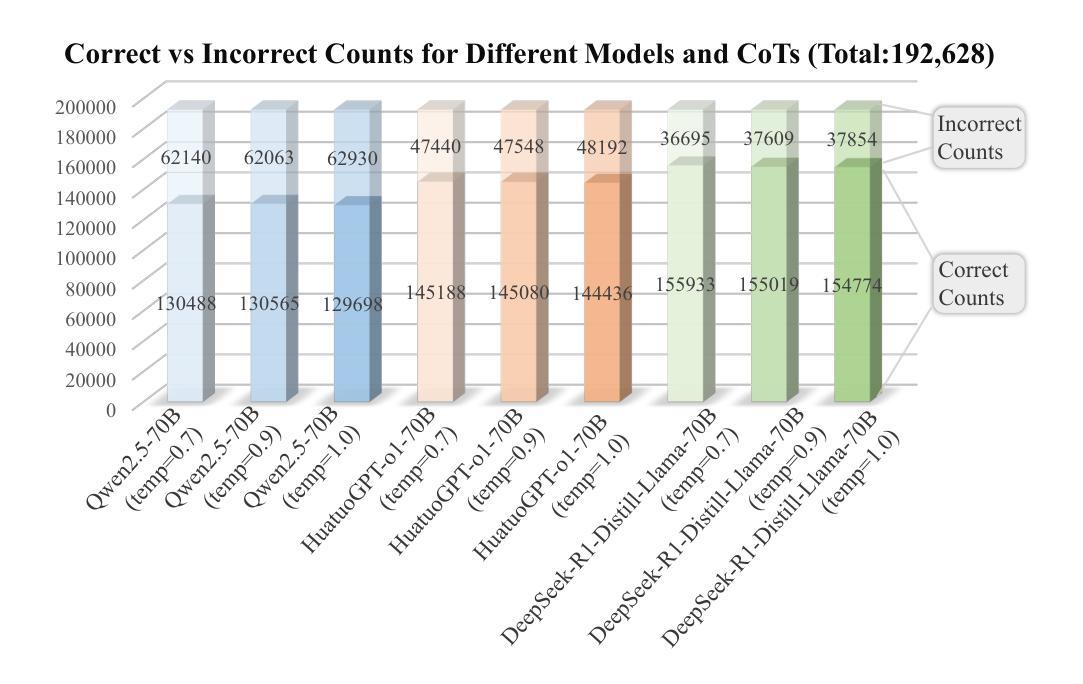
ReasonMed: A 370K Multi-Agent Generated Dataset for Advancing Medical Reasoning
Authors:Yu Sun, Xingyu Qian, Weiwen Xu, Hao Zhang, Chenghao Xiao, Long Li, Yu Rong, Wenbing Huang, Qifeng Bai, Tingyang Xu
Though reasoning-based large language models (LLMs) have excelled in mathematics and programming, their capabilities in knowledge-intensive medical question answering remain underexplored. To address this, we introduce ReasonMed, the largest medical reasoning dataset, comprising 370k high-quality examples distilled from 1.7 million initial reasoning paths generated by various LLMs. ReasonMed is constructed through a \textit{multi-agent verification and refinement process}, where we design an \textit{Error Refiner} to enhance the reasoning paths by identifying and correcting error-prone steps flagged by a verifier. Leveraging ReasonMed, we systematically investigate best practices for training medical reasoning models and find that combining detailed Chain-of-Thought (CoT) reasoning with concise answer summaries yields the most effective fine-tuning strategy. Based on this strategy, we train ReasonMed-7B, which sets a new benchmark for sub-10B models, outperforming the prior best by 4.17% and even exceeding LLaMA3.1-70B on PubMedQA by 4.60%.
虽然基于推理的大型语言模型(LLM)在数学和编程方面表现出色,但它们在知识密集型的医疗问题回答方面的能力仍被探索不足。为了解决这个问题,我们推出了ReasonMed,这是最大的医疗推理数据集,由从各种LLM生成的170万条初始推理路径中提炼出的37万条高质量样本组成。ReasonMed的构建过程经过多智能体验证和细化,我们设计了一种Error Refiner,通过识别验证器标记的易出错步骤来优化推理路径并对其进行修正。利用ReasonMed,我们系统地研究了训练医疗推理模型的最佳实践,并发现将详细的思维链(CoT)推理与简洁的答案摘要相结合,是最有效的微调策略。基于这一策略,我们训练了ReasonMed-7B模型,该模型为小于10B的模型设定了新的基准,比之前的最佳性能高出4.17%,甚至在PubMedQA上超过了LLaMA3.1-70B模型,高出4.60%。
论文及项目相关链接
PDF 24 pages, 6 figures, 7 tables
Summary:
医疗领域知识密集型问答对基于推理的大型语言模型(LLMs)的能力尚待探索。为应对这一挑战,我们推出ReasonMed数据集,它是迄今为止最大的医疗推理数据集,包含由多种LLMs生成的初始推理路径中提炼出的高质量样本。数据集ReasonMed的构建过程经过多智能体验证和修正,通过设计Error Refiner来识别并修正验证器标记的错误步骤。利用ReasonMed数据集,我们系统地研究了训练医疗推理模型的最佳实践,发现将详细的思维链(CoT)推理与简洁的答案摘要相结合是最有效的微调策略。基于此策略训练的ReasonMed-7B模型在医疗问答领域设立了新的基准线,较之前最佳模型提升了4.17%,并在PubMedQA上超过了LLaMA3.1-70B模型,提升了4.6%。
Key Takeaways:
- 大型语言模型在知识密集型医疗问答方面的能力尚未得到充分探索。
- ReasonMed是迄今为止最大的医疗推理数据集,包含由多种LLMs生成的推理路径提炼出的高质量样本。
- 数据集ReasonMed的构建过程经过多智能体验证和修正,确保数据的准确性。
- 最佳实践是将详细的思维链(CoT)推理与简洁的答案摘要相结合来训练医疗推理模型。
- 基于此策略训练的ReasonMed-7B模型在医疗问答领域表现优异,较之前模型有所提升。
点此查看论文截图

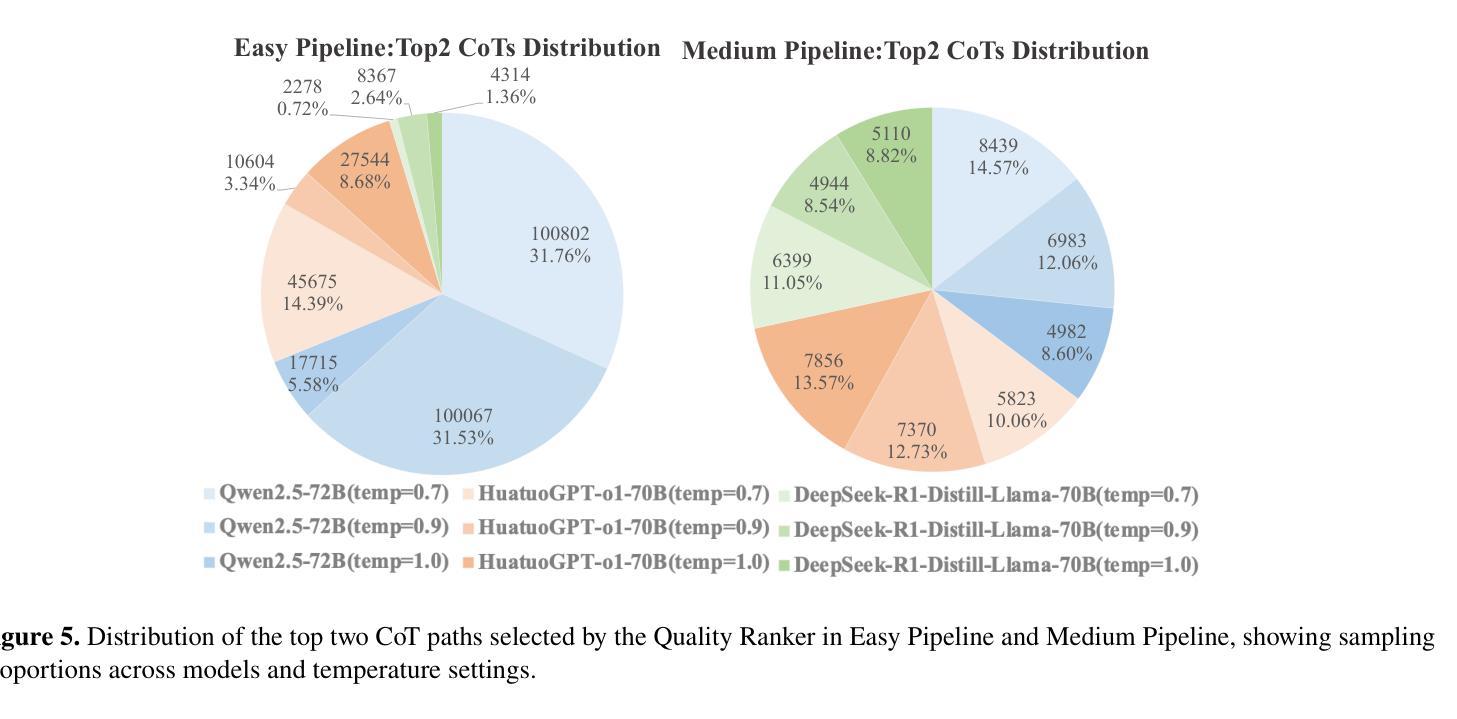
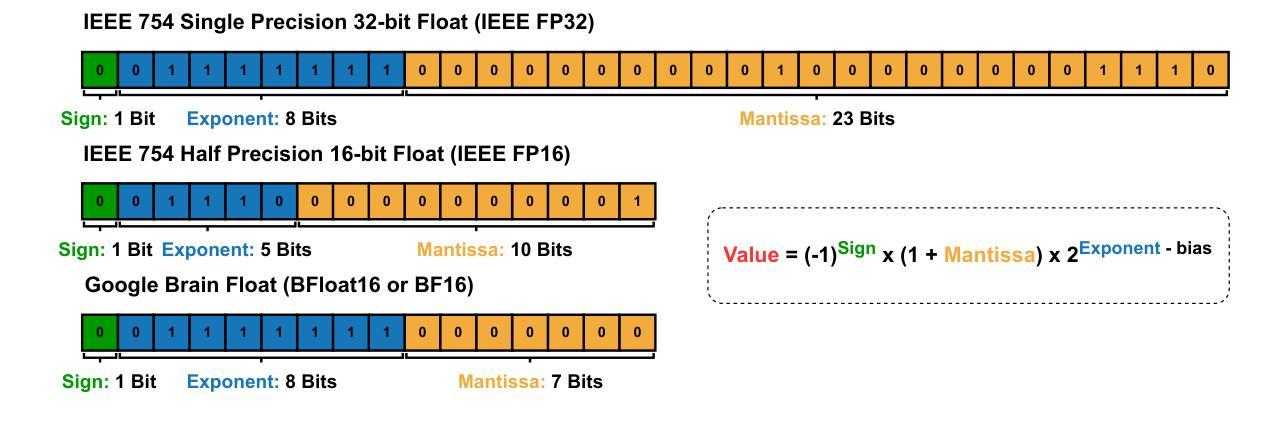
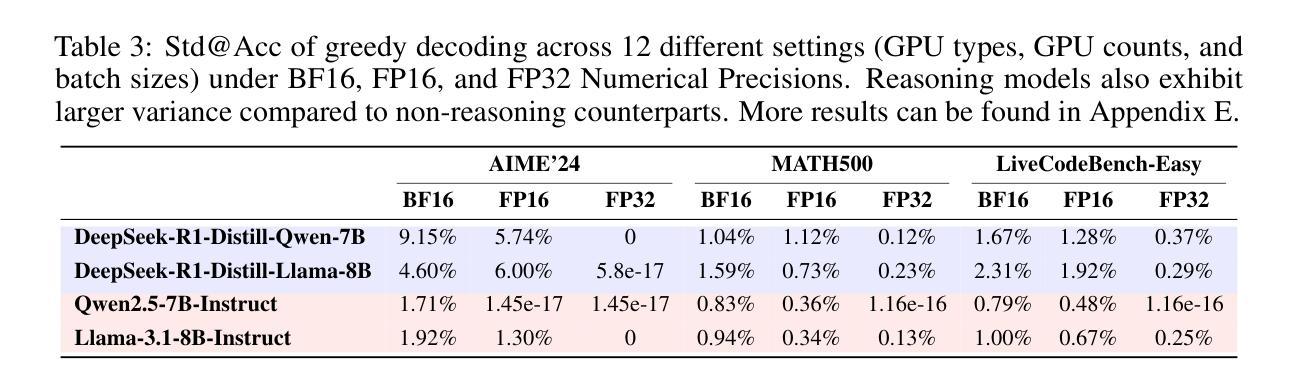
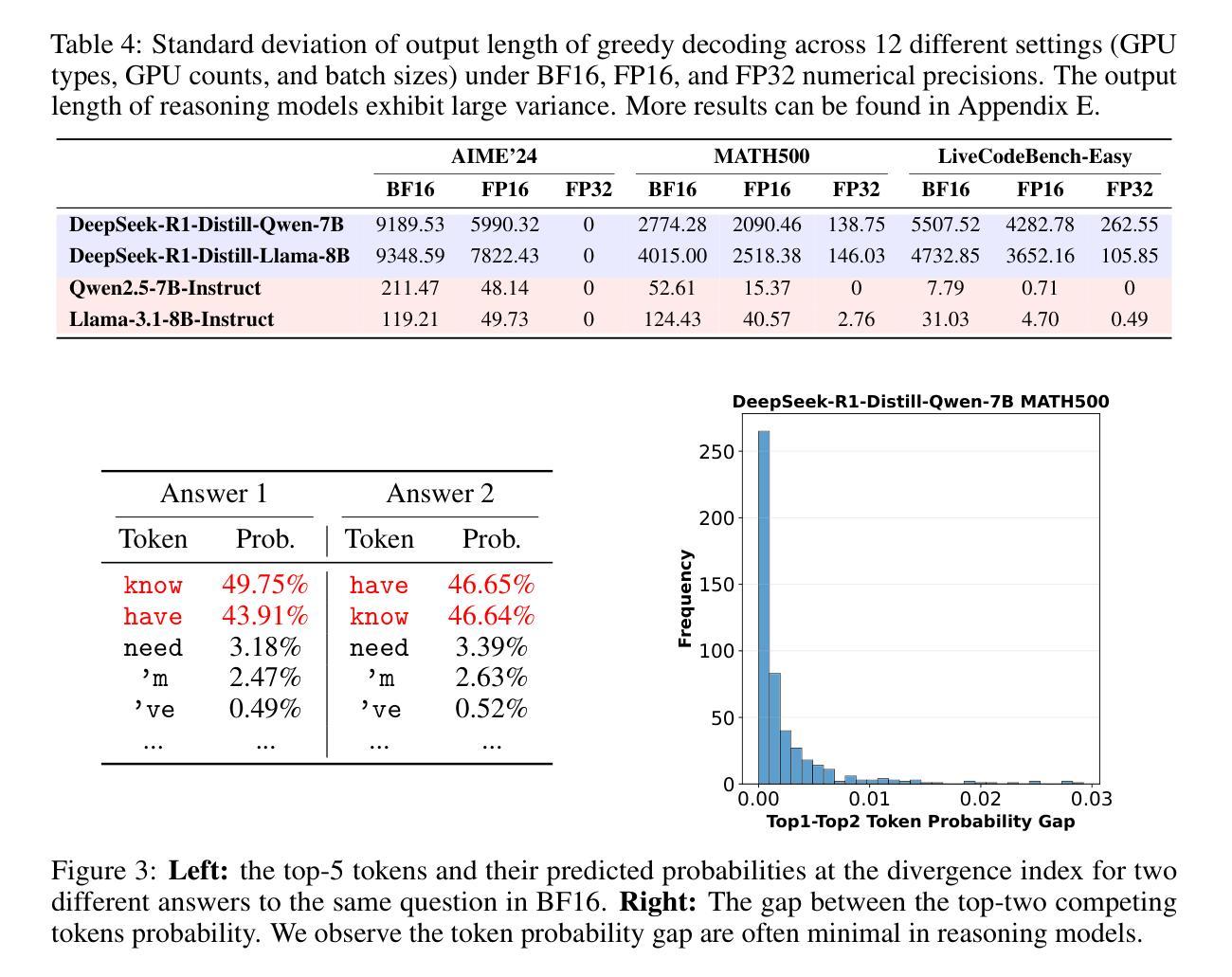
Give Me FP32 or Give Me Death? Challenges and Solutions for Reproducible Reasoning
Authors:Jiayi Yuan, Hao Li, Xinheng Ding, Wenya Xie, Yu-Jhe Li, Wentian Zhao, Kun Wan, Jing Shi, Xia Hu, Zirui Liu
Large Language Models (LLMs) are now integral across various domains and have demonstrated impressive performance. Progress, however, rests on the premise that benchmark scores are both accurate and reproducible. We demonstrate that the reproducibility of LLM performance is fragile: changing system configuration such as evaluation batch size, GPU count, and GPU version can introduce significant difference in the generated responses. This issue is especially pronounced in reasoning models, where minor rounding differences in early tokens can cascade into divergent chains of thought, ultimately affecting accuracy. For instance, under bfloat16 precision with greedy decoding, a reasoning model like DeepSeek-R1-Distill-Qwen-7B can exhibit up to 9% variation in accuracy and 9,000 tokens difference in response length due to differences in GPU count, type, and evaluation batch size. We trace the root cause of this variability to the non-associative nature of floating-point arithmetic under limited numerical precision. This work presents the first systematic investigation into how numerical precision affects reproducibility in LLM inference. Through carefully controlled experiments across various hardware, software, and precision settings, we quantify when and how model outputs diverge. Our analysis reveals that floating-point precision – while critical for reproducibility – is often neglected in evaluation practices. Inspired by this, we develop a lightweight inference pipeline, dubbed LayerCast, that stores weights in 16-bit precision but performs all computations in FP32, balancing memory efficiency with numerical stability. Code is available at https://github.com/nanomaoli/llm_reproducibility.
大型语言模型(LLMs)现已广泛应用于各个领域,并展现出令人印象深刻的性能。然而,其进展的前提是基准测试分数既准确又可复制。我们证明LLM性能的复现性是脆弱的:改变系统配置,如评估批次大小、GPU数量和版本,会给生成的响应带来显著差异。这个问题在推理模型中尤其突出,其中早期标记的轻微舍入差异可能会级联成不同的思维链,最终影响准确性。例如,在bfloat16精度和贪心解码下,DeepSeek-R1-Distill-Qwen-7B等推理模型的准确性可能存在高达9%的变化,响应长度可能存在9000个标记的差异,这是由于GPU数量、类型和评估批次大小的不同所导致的。我们将这种可变性的根本原因归结为有限数值精度下浮点运算的非结合性。这项工作首次系统研究了数值精度如何影响LLM推断的复现性。通过跨各种硬件、软件和精度设置的严格控制实验,我们量化了模型输出何时以及如何发散。我们的分析表明,虽然浮点精度对于复现性至关重要,但在评估实践中往往被忽视。受此启发,我们开发了一个轻量级的推理管道,名为LayerCast,它以16位精度存储权重,但所有计算都在FP32中进行,平衡了内存效率和数值稳定性。代码可在https://github.com/nanomaoli/llm_reproducibility找到。
论文及项目相关链接
摘要
大型语言模型(LLMs)在各种领域中的重要性日益凸显,其表现令人印象深刻。然而,模型性能的可重复性却十分脆弱。系统配置的变化,如评估批次大小、GPU数量和版本,都可能显著影响LLM生成的响应。这一问题在推理模型中尤为突出,早期标记的微小舍入差异可能会导致思维链的发散,最终影响准确性。例如,在bfloat16精度和贪婪解码下,DeepSeek-R1-Distill-Qwen-7B等推理模型在GPU数量、类型和评估批次大小方面的差异可能会导致准确率高达9%的变化,以及长达9000个标记的响应长度差异。本文首次系统地探讨了数值精度如何影响LLM推断的可重复性。通过跨各种硬件、软件和精度设置的严格控制实验,我们量化了模型输出何时以及如何发生分歧。我们的分析表明,虽然浮点精度对于可重复性至关重要,但在评估实践中往往被忽视。为此,我们开发了一种轻量级的推断管道LayerCast,它以16位精度存储权重,但在FP32中进行所有计算,平衡了内存效率和数值稳定性。
关键见解
- 大型语言模型(LLMs)的性能可重复性受到系统配置变化的影响,包括评估批次大小、GPU计数和版本。
- 推理模型的性能受早期标记舍入差异的影响较大,可能导致思维链的发散。
- 在特定条件下,LLM的性能差异可能表现在准确率和响应长度上,如DeepSeek-R1-Distill-Qwen-7B模型在bfloat16精度和贪婪解码下表现出高达9%的准确率变化和长达9000个标记的响应长度变化。
- 浮点精度对于LLM推断的可重复性至关重要,但在评估实践中往往被忽视。
- 文中首次系统地探讨了数值精度对LLM推断可重复性的影响,并通过对各种硬件、软件和精度设置的实验进行了量化分析。
- 提出了一种平衡内存效率和数值稳定性的轻量级推断管道LayerCast,采用16位精度存储权重并在FP32中进行计算。
点此查看论文截图




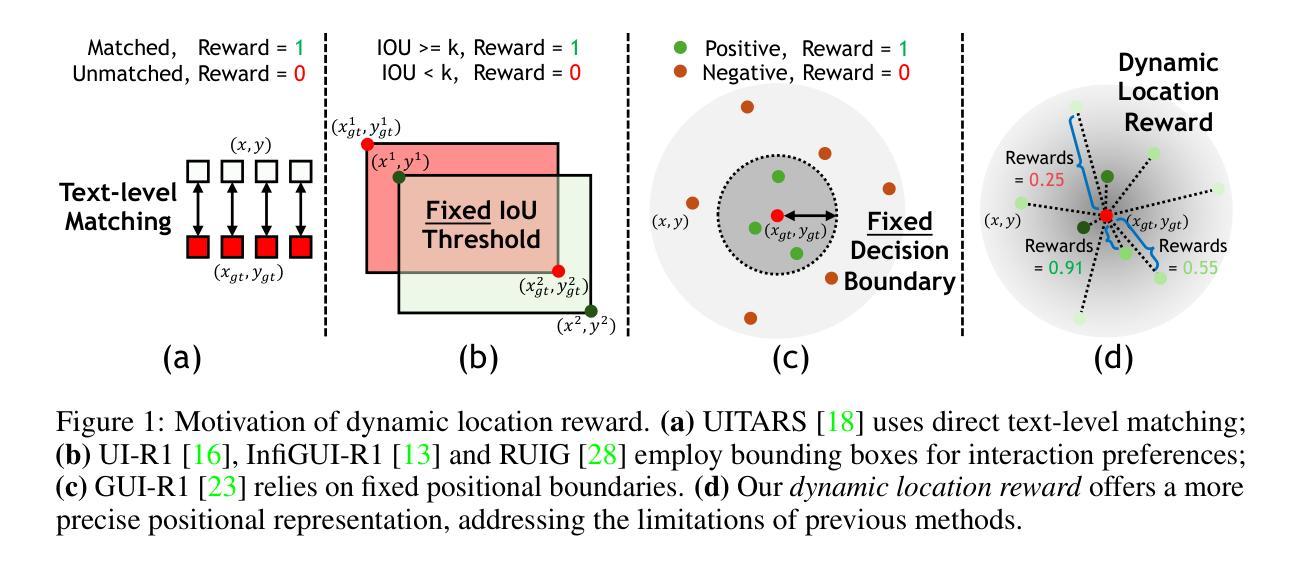
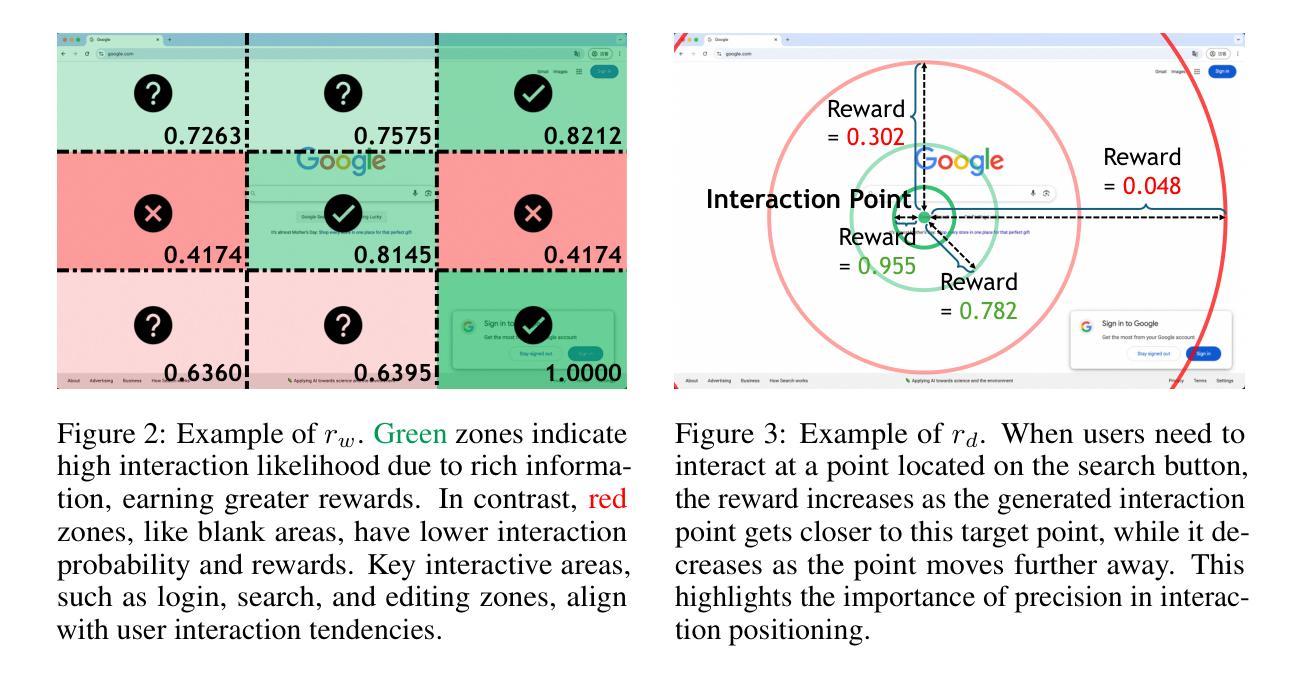
LPO: Towards Accurate GUI Agent Interaction via Location Preference Optimization
Authors:Jiaqi Tang, Yu Xia, Yi-Feng Wu, Yuwei Hu, Yuhui Chen, Qing-Guo Chen, Xiaogang Xu, Xiangyu Wu, Hao Lu, Yanqing Ma, Shiyin Lu, Qifeng Chen
The advent of autonomous agents is transforming interactions with Graphical User Interfaces (GUIs) by employing natural language as a powerful intermediary. Despite the predominance of Supervised Fine-Tuning (SFT) methods in current GUI agents for achieving spatial localization, these methods face substantial challenges due to their limited capacity to accurately perceive positional data. Existing strategies, such as reinforcement learning, often fail to assess positional accuracy effectively, thereby restricting their utility. In response, we introduce Location Preference Optimization (LPO), a novel approach that leverages locational data to optimize interaction preferences. LPO uses information entropy to predict interaction positions by focusing on zones rich in information. Besides, it further introduces a dynamic location reward function based on physical distance, reflecting the varying importance of interaction positions. Supported by Group Relative Preference Optimization (GRPO), LPO facilitates an extensive exploration of GUI environments and significantly enhances interaction precision. Comprehensive experiments demonstrate LPO’s superior performance, achieving SOTA results across both offline benchmarks and real-world online evaluations. Our code will be made publicly available soon, at https://github.com/AIDC-AI/LPO.
自主代理的出现通过运用自然语言作为强大的中介,正在改变与图形用户界面(GUI)的交互方式。尽管当前GUI代理在实现空间定位时以监督微调(SFT)方法为主,但这些方法面临着巨大的挑战,因为它们准确感知位置数据的能力有限。现有策略如强化学习往往无法有效地评估位置准确性,从而限制了其效用。为了应对这一挑战,我们引入了位置偏好优化(LPO)这一新方法,它利用位置数据来优化交互偏好。LPO通过关注信息丰富的区域,利用信息熵来预测交互位置。此外,它还基于物理距离引入了一个动态位置奖励函数,反映了交互位置的不同重要性。得益于群体相对偏好优化(GRPO)的支持,LPO促进了GUI环境的广泛探索,并大大提高了交互精度。综合实验表明,LPO性能卓越,在离线基准测试和真实世界在线评估中都取得了最新成果。我们的代码很快就会公开在https://github.com/AIDC-AI/LPO上提供。
论文及项目相关链接
Summary
自主代理的出现正在通过利用自然语言作为强大的中介来变革与图形用户界面(GUI)的交互方式。当前GUI代理主要使用监督微调(SFT)方法实现空间定位,但面临准确感知定位数据的挑战。针对这一问题,我们提出了位置偏好优化(LPO)这一新方法,它利用位置数据优化交互偏好。LPO通过信息熵预测交互位置,重点关注信息丰富的区域,并基于物理距离引入动态位置奖励函数,反映交互位置的不同重要性。LPO结合群体相对偏好优化(GRPO),促进了GUI环境的广泛探索,并显著提高交互精度。实验表明,LPO在离线基准测试和真实世界在线评估中都取得了卓越的性能。我们的代码将很快在https://github.com/AIDC-AI/LPO公开提供。
Key Takeaways
- 自主代理通过自然语言中介改变与GUI的交互方式。
- 监督微调(SFT)方法在GUI代理的空间定位上虽普遍应用,但存在准确感知定位数据的挑战。
- 位置偏好优化(LPO)方法利用位置数据优化交互偏好,预测交互位置并关注信息丰富的区域。
- LPO引入动态位置奖励函数,反映交互位置的不同重要性。
- LPO结合群体相对偏好优化(GRPO),促进GUI环境的广泛探索。
- LPO显著提高交互精度,在离线基准测试和真实世界在线评估中表现卓越。
点此查看论文截图

RePO: Replay-Enhanced Policy Optimization
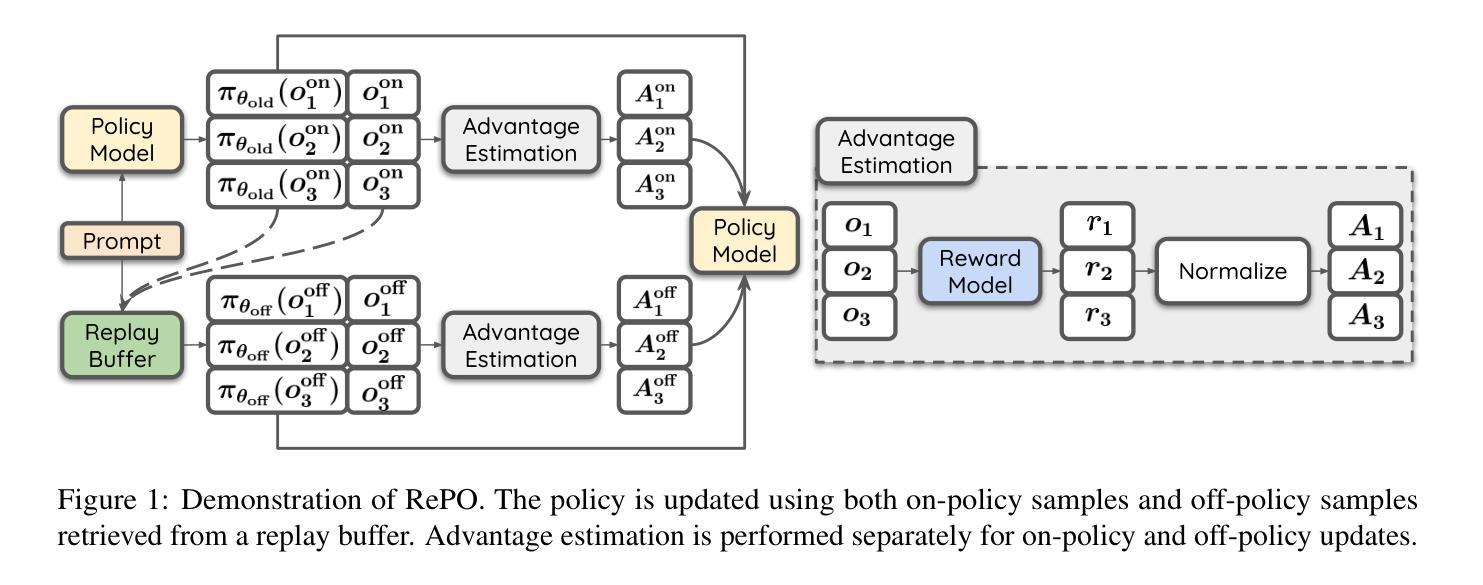
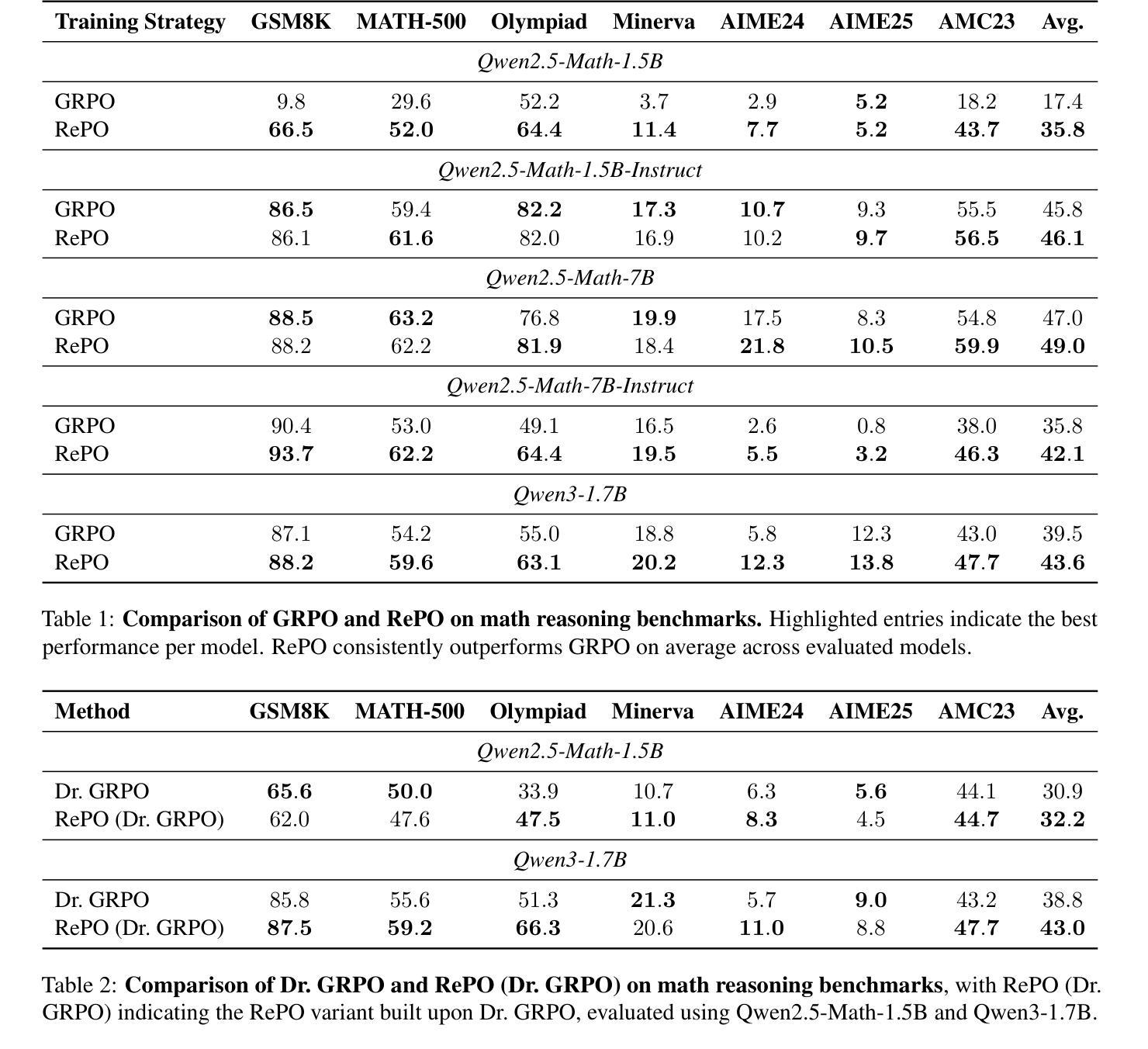
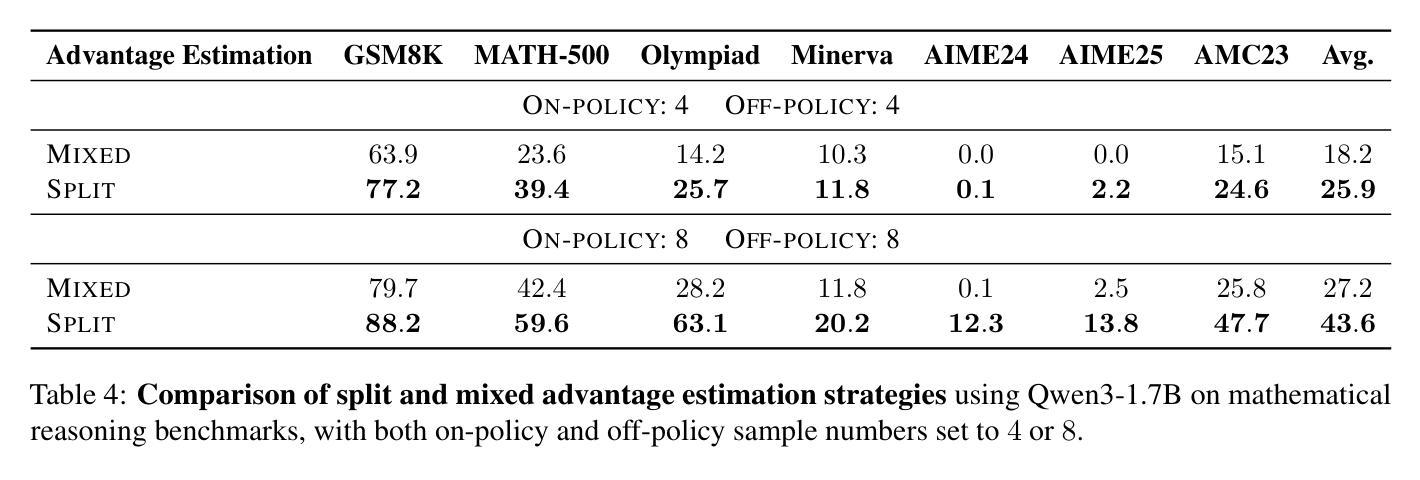
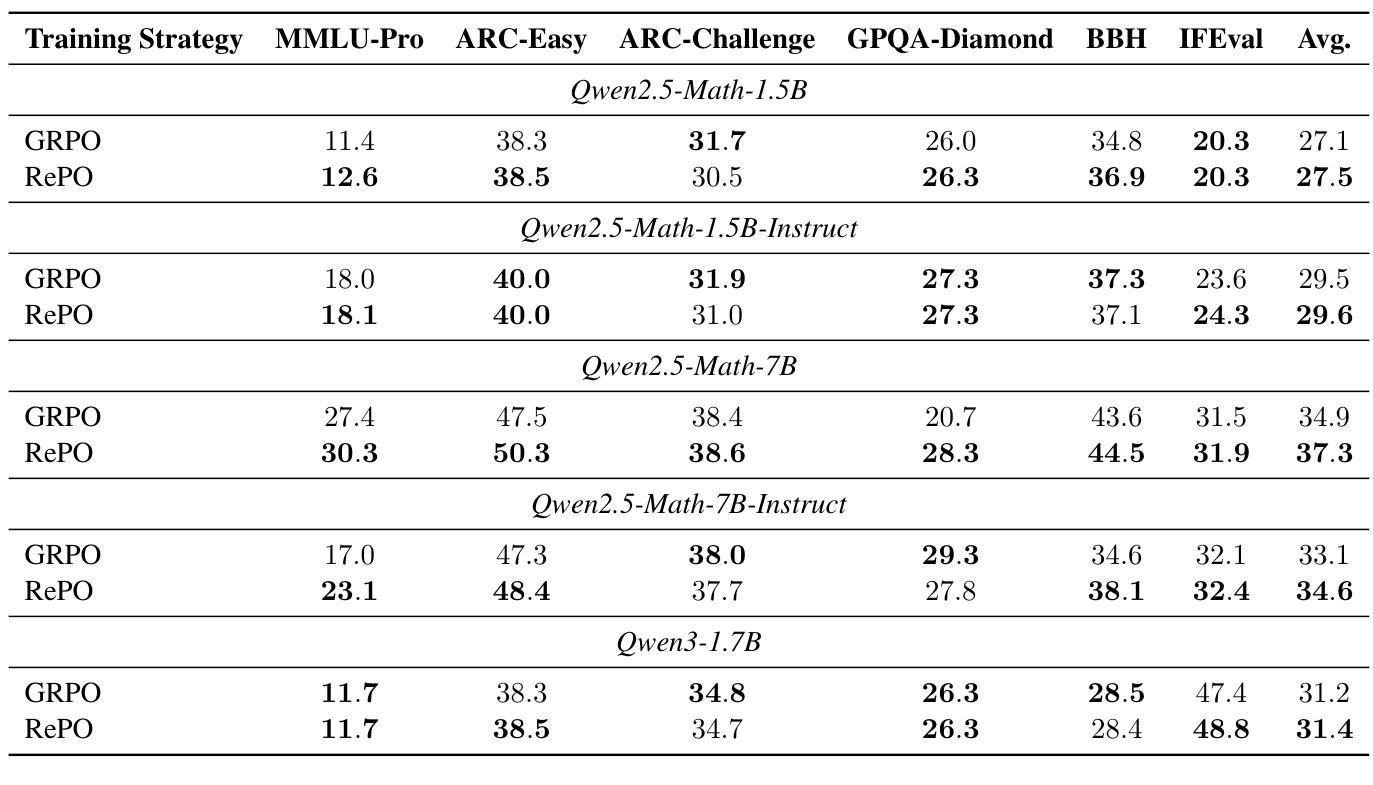
Authors:Siheng Li, Zhanhui Zhou, Wai Lam, Chao Yang, Chaochao Lu
Reinforcement learning (RL) is vital for optimizing large language models (LLMs). Recent Group Relative Policy Optimization (GRPO) estimates advantages using multiple on-policy outputs per prompt, leading to high computational costs and low data efficiency. To address this, we introduce Replay-Enhanced Policy Optimization (RePO), which leverages diverse replay strategies to retrieve off-policy samples from a replay buffer, allowing policy optimization based on a broader and more diverse set of samples for each prompt. Experiments on five LLMs across seven mathematical reasoning benchmarks demonstrate that RePO achieves absolute average performance gains of $18.4$ and $4.1$ points for Qwen2.5-Math-1.5B and Qwen3-1.7B, respectively, compared to GRPO. Further analysis indicates that RePO increases computational cost by $15%$ while raising the number of effective optimization steps by $48%$ for Qwen3-1.7B, with both on-policy and off-policy sample numbers set to $8$. The repository can be accessed at https://github.com/SihengLi99/RePO.
强化学习(RL)对于优化大型语言模型(LLM)至关重要。最近的组相对策略优化(GRPO)通过在每个提示下使用多个策略输出估算优势,导致计算成本高和数据效率低。为解决这一问题,我们引入了回放增强策略优化(RePO),它利用各种回放策略从回放缓冲区中检索非策略样本,允许基于更广泛和更多样化的样本集对每个提示进行策略优化。在五个大型语言模型和七个数学推理基准测试上的实验表明,与GRPO相比,RePO在Qwen2.5-Math-1.5B和Qwen3-1.7B上分别实现了绝对平均性能提升18.4点和4.1点。进一步分析表明,RePO的计算成本比GRPO高出15%,但为Qwen3-1.7B的有效优化步骤数量增加了48%,同时将策略内样本和策略外样本数量都设置为8。该仓库可以在https://github.com/SihengLi99/RePO访问。
论文及项目相关链接
PDF Project Page: https://github.com/SihengLi99/RePO
Summary
强化学习对于优化大型语言模型至关重要。为解决现有方法(如GRPO)高计算成本及低数据效率的问题,我们提出了Replay-Enhanced Policy Optimization(RePO)。它通过利用不同的回放策略,从回放缓冲区中检索非策略样本,基于更广泛、更多样的样本集进行策略优化。实验表明,相较于GRPO,RePO在七个数学推理基准测试上的五个大型语言模型上取得了平均绝对性能提升。
Key Takeaways
- 强化学习在优化大型语言模型(LLMs)中起关键作用。
- Group Relative Policy Optimization (GRPO)存在高计算成本及低数据效率的问题。
- Replay-Enhanced Policy Optimization (RePO)利用不同的回放策略来优化策略。
- RePO从回放缓冲区中检索非策略样本,扩大了样本的多样性。
- 实验结果显示,相较于GRPO,RePO在多个大型语言模型上的数学推理性能有明显提升。
- RePO在增加计算成本的同时,能有效提高优化步骤的数量。
点此查看论文截图