⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-13 更新
EmoNet-Voice: A Fine-Grained, Expert-Verified Benchmark for Speech Emotion Detection
Authors:Christoph Schuhmann, Robert Kaczmarczyk, Gollam Rabby, Felix Friedrich, Maurice Kraus, Kourosh Nadi, Huu Nguyen, Kristian Kersting, Sören Auer
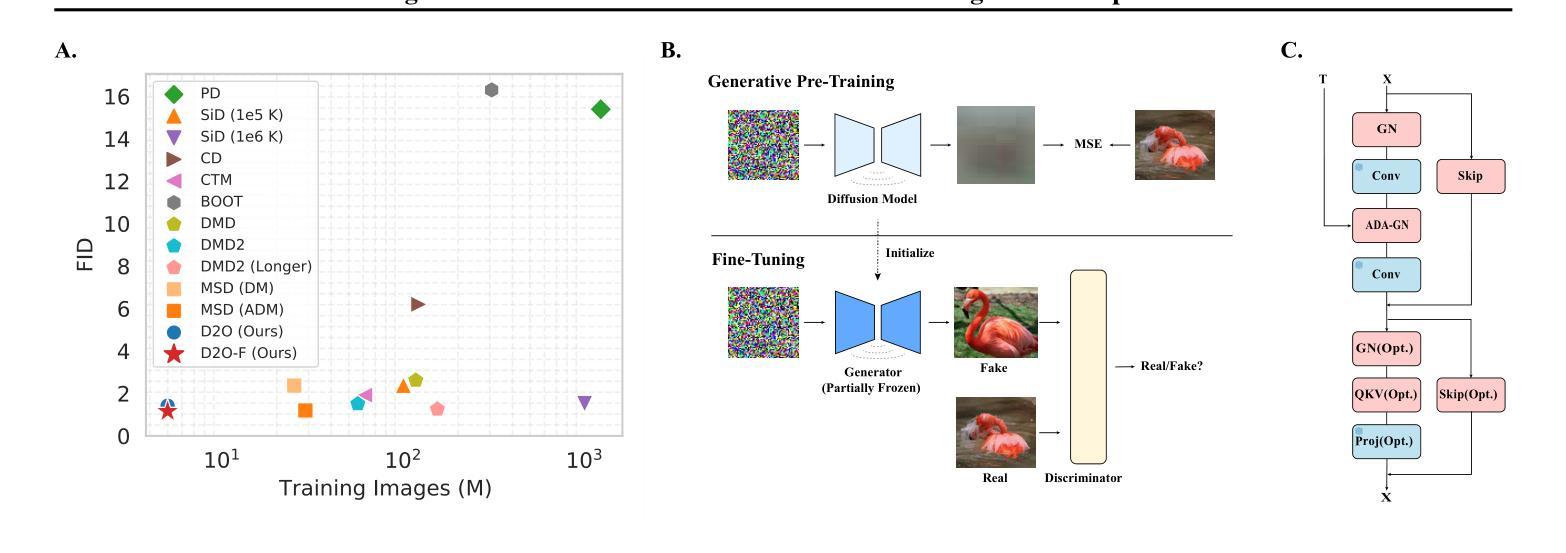
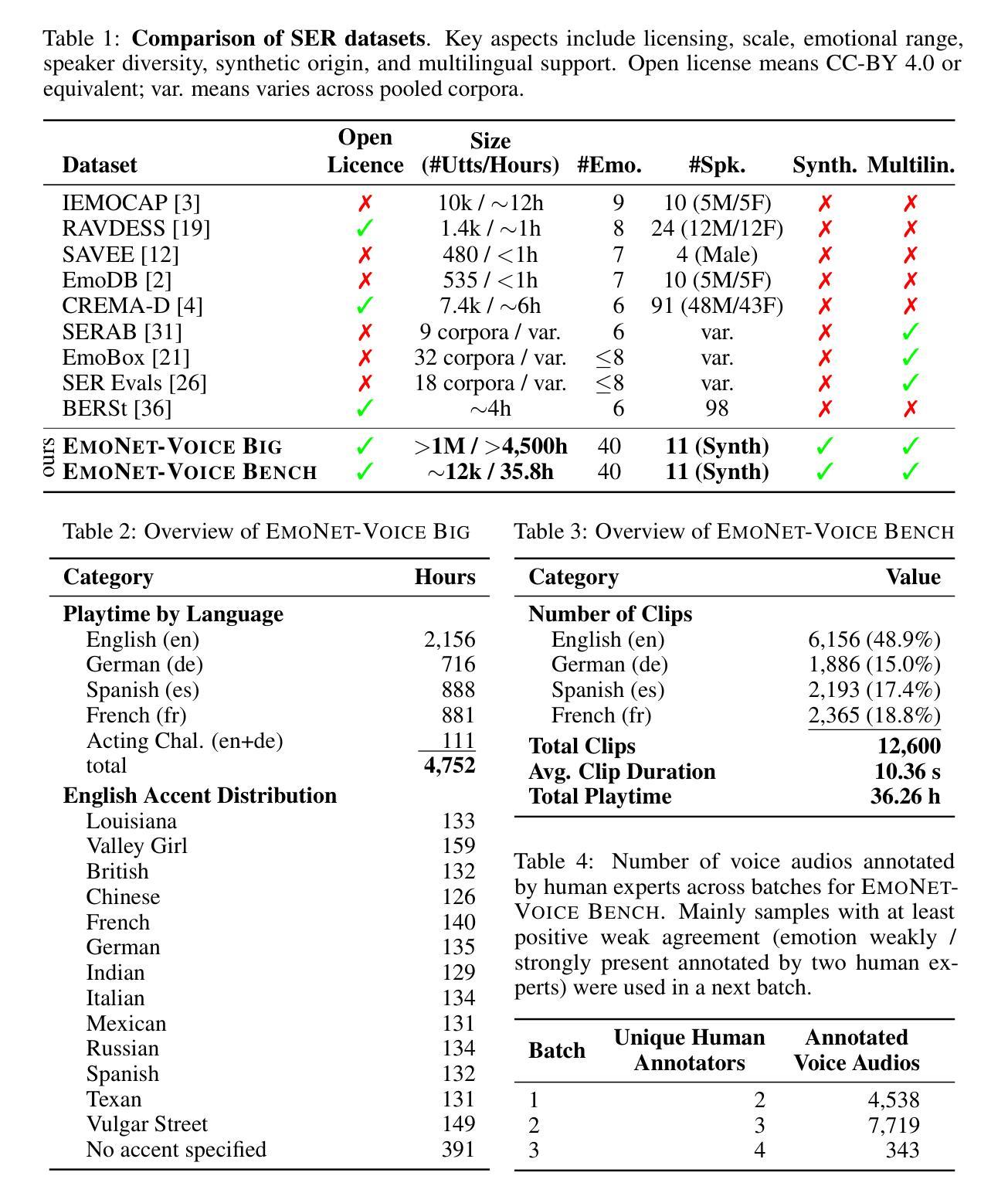
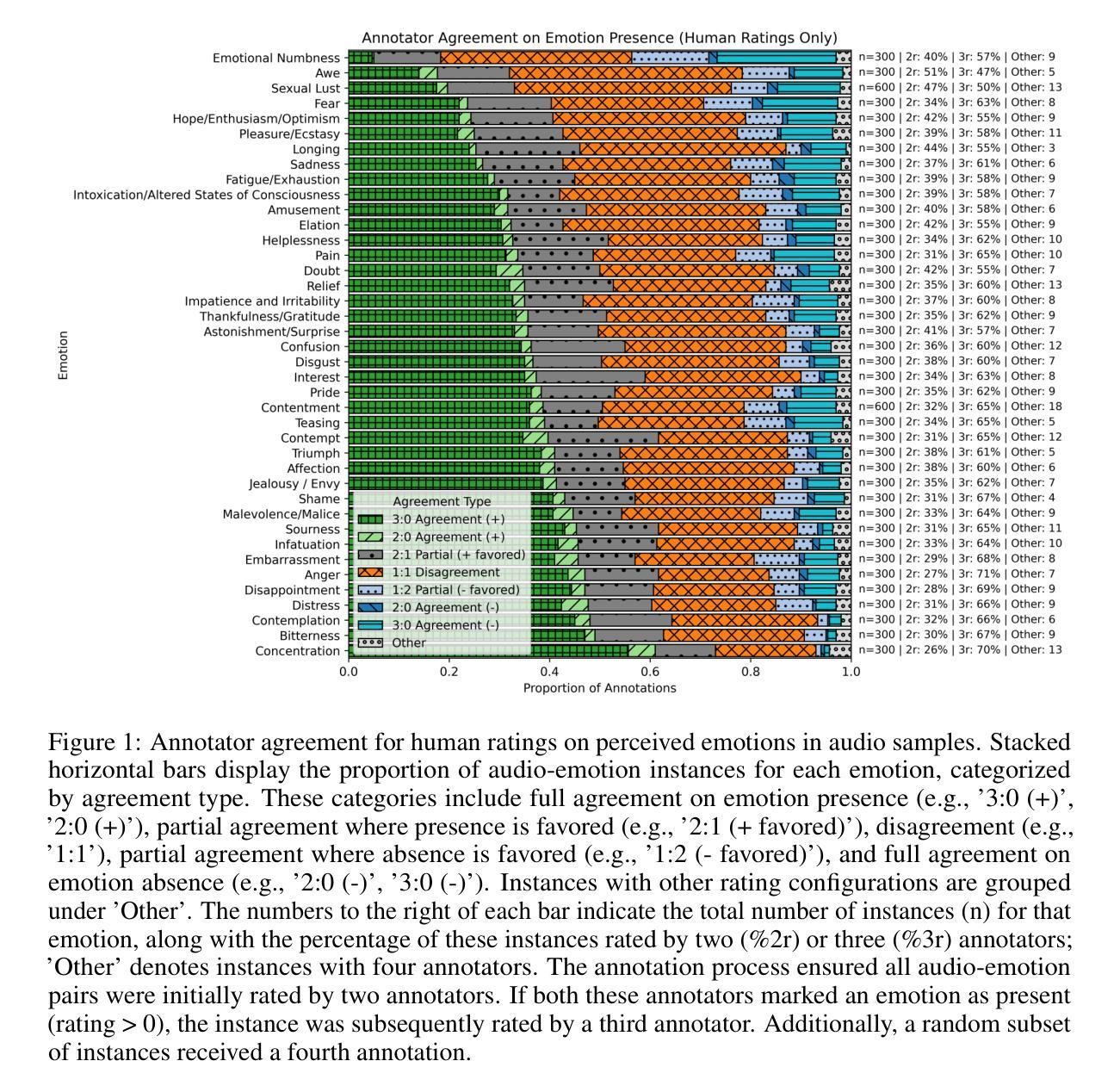
The advancement of text-to-speech and audio generation models necessitates robust benchmarks for evaluating the emotional understanding capabilities of AI systems. Current speech emotion recognition (SER) datasets often exhibit limitations in emotional granularity, privacy concerns, or reliance on acted portrayals. This paper introduces EmoNet-Voice, a new resource for speech emotion detection, which includes EmoNet-Voice Big, a large-scale pre-training dataset (featuring over 4,500 hours of speech across 11 voices, 40 emotions, and 4 languages), and EmoNet-Voice Bench, a novel benchmark dataset with human expert annotations. EmoNet-Voice is designed to evaluate SER models on a fine-grained spectrum of 40 emotion categories with different levels of intensities. Leveraging state-of-the-art voice generation, we curated synthetic audio snippets simulating actors portraying scenes designed to evoke specific emotions. Crucially, we conducted rigorous validation by psychology experts who assigned perceived intensity labels. This synthetic, privacy-preserving approach allows for the inclusion of sensitive emotional states often absent in existing datasets. Lastly, we introduce Empathic Insight Voice models that set a new standard in speech emotion recognition with high agreement with human experts. Our evaluations across the current model landscape exhibit valuable findings, such as high-arousal emotions like anger being much easier to detect than low-arousal states like concentration.
文本转语音和音频生成模型的进步为评估人工智能系统的情感理解能力提供了强大的基准。当前语音情感识别(SER)数据集在情感粒度、隐私担忧或依赖表演表现方面存在局限性。本文介绍了用于语音情感检测的新资源EmoNet-Voice,包括EmoNet-Voice Big,这是一个大规模预训练数据集(跨越11种声音、40种情感和4种语言,包含超过4500小时的语音),以及带有专家注释的新型基准数据集EmoNet-Voice Bench。EmoNet-Voice旨在评估SER模型在40个情感类别的精细粒度光谱上的表现,具有不同的强度级别。我们利用最先进的语音生成技术,精心制作了模拟演员表现特定情绪场景的合成音频片段。关键的是,我们由心理学专家进行了严格验证,他们分配了感知强度标签。这种合成、保护隐私的方法可以包含现有数据集中通常不存在的敏感情感状态。最后,我们推出了Empathic Insight Voice模型,该模型在语音情感识别方面树立了新的标准,与人类专家的契合度极高。我们在当前模型景观中的评估展现了有价值的发现,例如高唤醒情感(如愤怒)比低唤醒状态(如专注)更容易检测。
论文及项目相关链接
Summary
本文介绍了一个新型的语音情感识别数据集EmoNet-Voice,包括大规模预训练数据集EmoNet-Voice Big和新基准数据集EmoNet-Voice Bench。该数据集涵盖了40种情感类别的精细粒度,并利用先进的语音生成技术模拟演员演绎特定情感的场景。通过心理学专家进行的严格验证,确保情感强度的准确性。此外,采用合成和隐私保护的方法,可以包含现有数据集中缺失的敏感情感状态。最后,引入了Empathic Insight Voice模型,为语音情感识别设立了新的标准,并揭示了如愤怒等高唤起的情绪更容易被检测。
Key Takeaways
- 引入新型语音情感识别数据集EmoNet-Voice,包含大规模预训练数据集和新基准数据集。
- 涵盖40种情感类别的精细粒度,满足不同强度的情感检测需求。
- 利用先进的语音生成技术模拟真实情感场景。
- 通过心理学专家验证情感强度的准确性。
- 采用合成和隐私保护方法,包含敏感情感状态。
- 引入Empathic Insight Voice模型,为语音情感识别设立新标准。
点此查看论文截图

A Study on Speech Assessment with Visual Cues
Authors:Shafique Ahmed, Ryandhimas E. Zezario, Nasir Saleem, Amir Hussain, Hsin-Min Wang, Yu Tsao
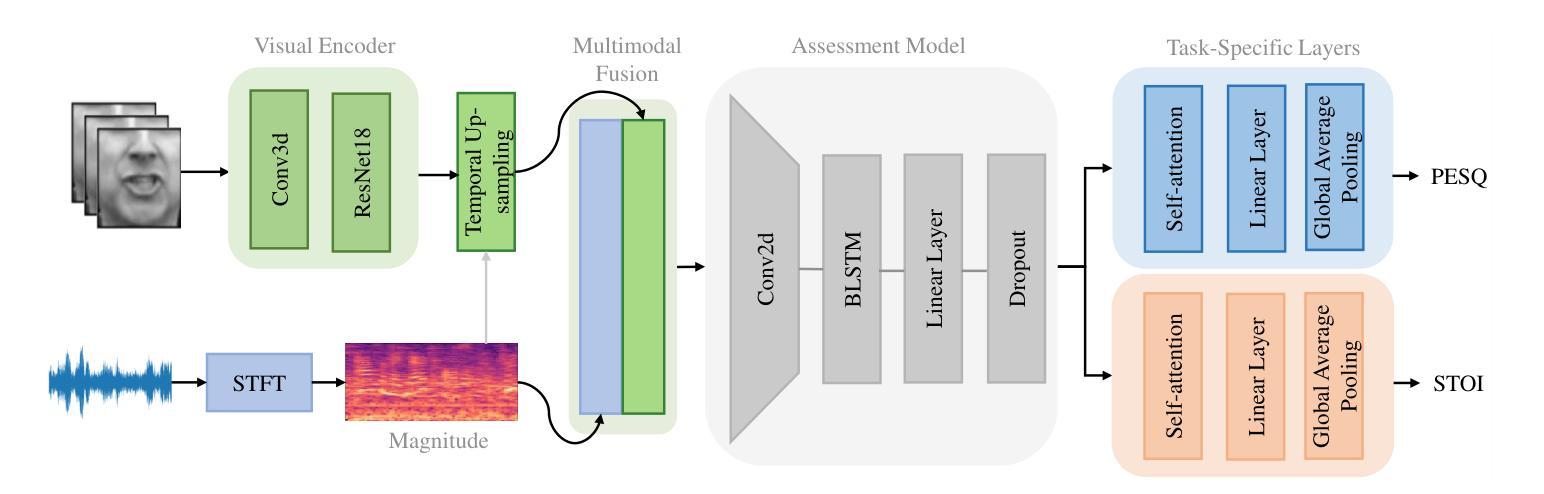
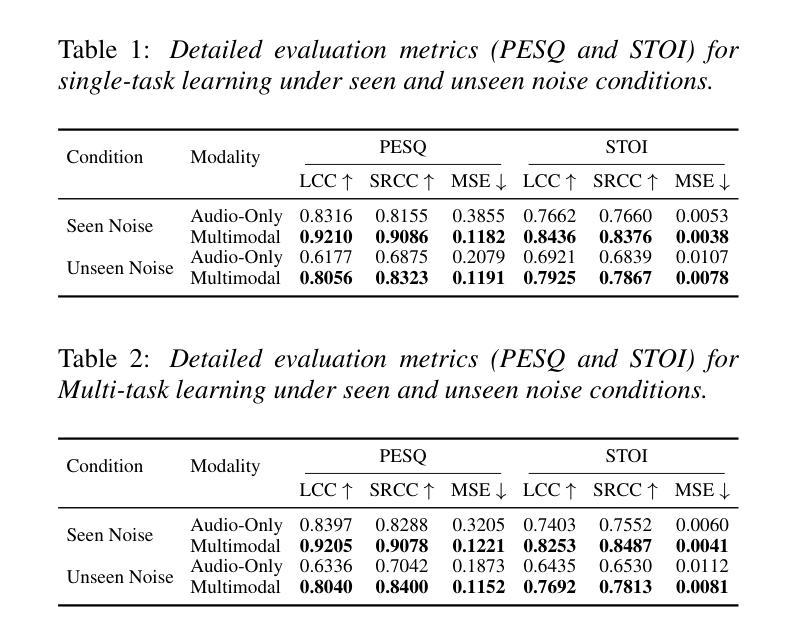
Non-intrusive assessment of speech quality and intelligibility is essential when clean reference signals are unavailable. In this work, we propose a multimodal framework that integrates audio features and visual cues to predict PESQ and STOI scores. It employs a dual-branch architecture, where spectral features are extracted using STFT, and visual embeddings are obtained via a visual encoder. These features are then fused and processed by a CNN-BLSTM with attention, followed by multi-task learning to simultaneously predict PESQ and STOI. Evaluations on the LRS3-TED dataset, augmented with noise from the DEMAND corpus, show that our model outperforms the audio-only baseline. Under seen noise conditions, it improves LCC by 9.61% (0.8397->0.9205) for PESQ and 11.47% (0.7403->0.8253) for STOI. These results highlight the effectiveness of incorporating visual cues in enhancing the accuracy of non-intrusive speech assessment.
在无干净参考信号的情况下,进行非侵入性的语音质量和清晰度评估至关重要。在这项工作中,我们提出了一个多模态框架,该框架融合了音频特征和视觉线索来预测PESQ和STOI分数。它采用双分支架构,其中通过STFT提取光谱特征,并通过视觉编码器获得视觉嵌入。然后,这些特征通过带有注意力的CNN-BLSTM进行融合和处理,随后进行多任务学习,以同时预测PESQ和STOI。在LRS3-TED数据集上的评估,辅以来自DEMAND语料库的噪声增强,表明我们的模型优于仅使用音频的基线模型。在未见过的噪声条件下,PESQ的LCC提高了9.61%(从0.8397提高到0.9205),STOI的LCC提高了11.47%(从0.7403提高到0.8253)。这些结果凸显了结合视觉线索在提高非侵入性语音评估的准确性方面的有效性。
论文及项目相关链接
PDF Accepted to Interspeech 2025
Summary
本研究提出一种非侵入性的多模态评估框架,该框架在无法获取干净参考信号的情况下,通过整合音频特征和视觉线索来预测PESQ和STOI分数。该框架采用双分支架构,从音频信号提取光谱特征,并通过视觉编码器获取视觉嵌入。这些特征经过融合后,通过结合卷积神经网络和双向长短时记忆网络的模型进行处理,并引入注意力机制。通过多任务学习,该模型能同时预测PESQ和STOI分数。在LRS3-TED数据集上的实验表明,与仅使用音频的基线模型相比,该模型表现出更好的性能。在面对未见过的噪声条件下,PESQ的LCC提高了9.61%,STOI的LCC提高了11.47%。结果证明了结合视觉线索能有效提高非侵入性语音评估的准确性。
Key Takeaways
- 非侵入性地评估语音质量和可懂度在缺乏干净参考信号时尤为重要。
- 研究提出了一种多模态评估框架,融合音频和视觉信息来预测语音质量指数(PESQ)和短时光信号可懂度指数(STOI)。
- 框架采用双分支架构,分别处理音频和视觉信息,通过卷积神经网络和双向长短时记忆网络(CNN-BLSTM)结合注意力机制进行特征融合和处理。
- 该框架采用了多任务学习以同时预测PESQ和STOI分数。
- 在LRS3-TED数据集上的实验表明,该模型在未见噪声条件下性能优异,相较于基线模型有显著提升。
- 模型的性能提升体现在对语音质量和可懂度的准确评估上。
点此查看论文截图

OmniDRCA: Parallel Speech-Text Foundation Model via Dual-Resolution Speech Representations and Contrastive Alignment
Authors:Chao-Hong Tan, Qian Chen, Wen Wang, Chong Deng, Qinglin Zhang, Luyao Cheng, Hai Yu, Xin Zhang, Xiang Lv, Tianyu Zhao, Chong Zhang, Yukun Ma, Yafeng Chen, Hui Wang, Jiaqing Liu, Jieping Ye
Recent studies on end-to-end speech generation with large language models (LLMs) have attracted significant community attention, with multiple works extending text-based LLMs to generate discrete speech tokens. Existing approaches primarily fall into two categories: (1) Methods that generate discrete speech tokens independently without incorporating them into the LLM’s autoregressive process, resulting in text generation being unaware of concurrent speech synthesis. (2) Models that generate interleaved or parallel speech-text tokens through joint autoregressive modeling, enabling mutual modality awareness during generation. This paper presents OmniDRCA, a parallel speech-text foundation model based on joint autoregressive modeling, featuring dual-resolution speech representations and contrastive cross-modal alignment. Our approach processes speech and text representations in parallel while enhancing audio comprehension through contrastive alignment. Experimental results on Spoken Question Answering benchmarks demonstrate that OmniDRCA establishes new state-of-the-art (SOTA) performance among parallel joint speech-text modeling based foundation models, and achieves competitive performance compared to interleaved models. Additionally, we explore the potential of extending the framework to full-duplex conversational scenarios.
关于使用大型语言模型(LLM)进行端到端语音生成的最新研究已经引起了社区的关注,多项工作将基于文本的LLM扩展到生成离散语音标记。现有方法主要可分为两类:(1)独立生成离散语音标记的方法,这些方法不会将其纳入LLM的自回归过程中,导致文本生成不知道当前的语音合成。(2)通过联合自回归建模生成交错或并行语音文本标记的模型,从而在生成过程中实现跨模态感知。本文介绍了OmniDRCA,一种基于联合自回归建模的并行语音文本基础模型,具有双分辨率语音表示和对比跨模态对齐功能。我们的方法并行处理语音和文本表示,同时通过对比对齐提高音频理解。在口语问答基准测试上的实验结果表明,OmniDRCA在基于并行联合语音文本建模的基础模型中建立了新的最先进的性能,并在与交错模型的比较中取得了具有竞争力的性能。此外,我们还探讨了将框架扩展到全双工对话场景的可能性。
论文及项目相关链接
总结
近期关于利用大型语言模型(LLMs)进行端到端语音生成的研究引起了社区的关注,多项工作将文本基础的LLMs扩展至生成离散语音标记。现有方法主要分为两类:(1)独立生成离散语音标记的方法,不将其纳入LLM的自回归过程,导致文本生成无法意识到并发的语音合成。(2)通过联合自回归建模生成交织或并行语音文本标记的模型,在生成过程中实现模态间的相互感知。本文提出了基于联合自回归建模的OmniDRCA并行语音文本基础模型,具有双分辨率语音表示和对比跨模态对齐的特点。该方法在并行处理语音和文本表示的同时,通过对齐对比增强音频理解。在口语问答基准测试上的实验结果表明,OmniDRCA在基于并行联合语音文本建模的基础模型中建立了新的最先进的性能,并在交织模型中实现了具有竞争力的性能。此外,我们还探讨了将框架扩展到全双工对话场景的可能性。
关键见解
- 端到端语音生成研究正吸引社区关注,大型语言模型(LLMs)被应用于生成离散语音标记。
- 现有方法分为独立生成和联合自回归建模两类。
- OmniDRCA模型采用基于联合自回归建模的并行语音文本基础架构。
- OmniDRCA具有双分辨率语音表示和对比跨模态对齐特点。
- 模型能并行处理语音和文本表示,增强音频理解。
- 在口语问答基准测试上,OmniDRCA表现出先进性能。
点此查看论文截图


Advancing STT for Low-Resource Real-World Speech
Authors:Flavio D’Intino, Hans-Peter Hutter
Swiss German is a low-resource language represented by diverse dialects that differ significantly from Standard German and from each other, lacking a standardized written form. As a result, transcribing Swiss German involves translating into Standard German. Existing datasets have been collected in controlled environments, yielding effective speech-to-text (STT) models, but these models struggle with spontaneous conversational speech. This paper, therefore, introduces the new SRB-300 dataset, a 300-hour annotated speech corpus featuring real-world long-audio recordings from 39 Swiss German radio and TV stations. It captures spontaneous speech across all major Swiss dialects recorded in various realistic environments and overcomes the limitation of prior sentence-level corpora. We fine-tuned multiple OpenAI Whisper models on the SRB-300 dataset, achieving notable enhancements over previous zero-shot performance metrics. Improvements in word error rate (WER) ranged from 19% to 33%, while BLEU scores increased between 8% and 40%. The best fine-tuned model, large-v3, achieved a WER of 17.1% and a BLEU score of 74.8. This advancement is crucial for developing effective and robust STT systems for Swiss German and other low-resource languages in real-world contexts.
瑞士德语是一种资源匮乏的语言,由多种方言组成,这些方言与标准德语以及彼此之间存在显著差异,并且没有标准化的书面形式。因此,转录瑞士德语需要将其翻译为标准德语。现有的数据集已在受控环境中收集,产生了有效的语音识别(STT)模型,但这些模型在处理日常会话语音时遇到困难。因此,本文介绍了新的SRB-300数据集,这是一个包含来自瑞士德语广播电台和电视台的300小时注释语音语料库的真实世界长音频录音。它捕捉了来自各种现实环境的所有主要瑞士方言的即兴演讲,克服了以前句子层面语料库的局限性。我们在SRB-300数据集上微调了多个OpenAIwhisper模型,相较于之前的零样本性能评价指标取得了显著的提升。单词错误率(WER)的改进范围在19%至33%之间,而BLEU分数提高了8%至40%。最佳的微调模型“大型v3”实现了单词错误率为17.1%,BLEU分数为74.8%。这一进展对于开发适用于瑞士德语和其他资源匮乏的语言的有效和稳健的STT系统在现实世界中具有重要意义。
论文及项目相关链接
PDF Conference: HCI International 2025, 20 pages, 4 figures
Summary
本文主要介绍了针对瑞士德语——一种缺乏标准化书面形式且表现为多样方言的语言——所创建的新数据集SRB-300。该数据集包含来自瑞士各大方言区的真实长音频记录,能反映出自发的口语表达。此外,文章还介绍了使用OpenAI Whisper模型在该数据集上进行微调所取得的显著成果,显著提高了语音转文本的性能。
Key Takeaways
- 瑞士德语缺乏标准化书面形式,表现为多样的方言,且各方言间差异显著。
- 现有数据集主要在受控环境下收集,对于自然口语表达的识别效果有限。
- 本文引入了新的SRB-300数据集,包含来自瑞士各大方言区的真实长音频记录,旨在解决这一难题。
- 使用OpenAI Whisper模型在SRB-300数据集上进行微调,显著提高了语音转文本的准确率。
- 在微调过程中,字错误率(WER)降低了19%至33%,BLEU分数提高了8%至40%。
- 最佳微调模型(large-v3)在WER和BLEU分数方面达到了显著成果,分别为17.1%和74.8%。
点此查看论文截图


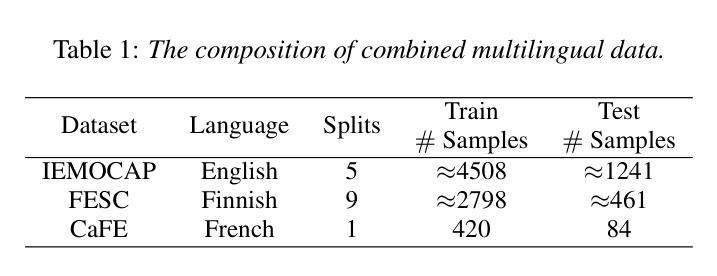
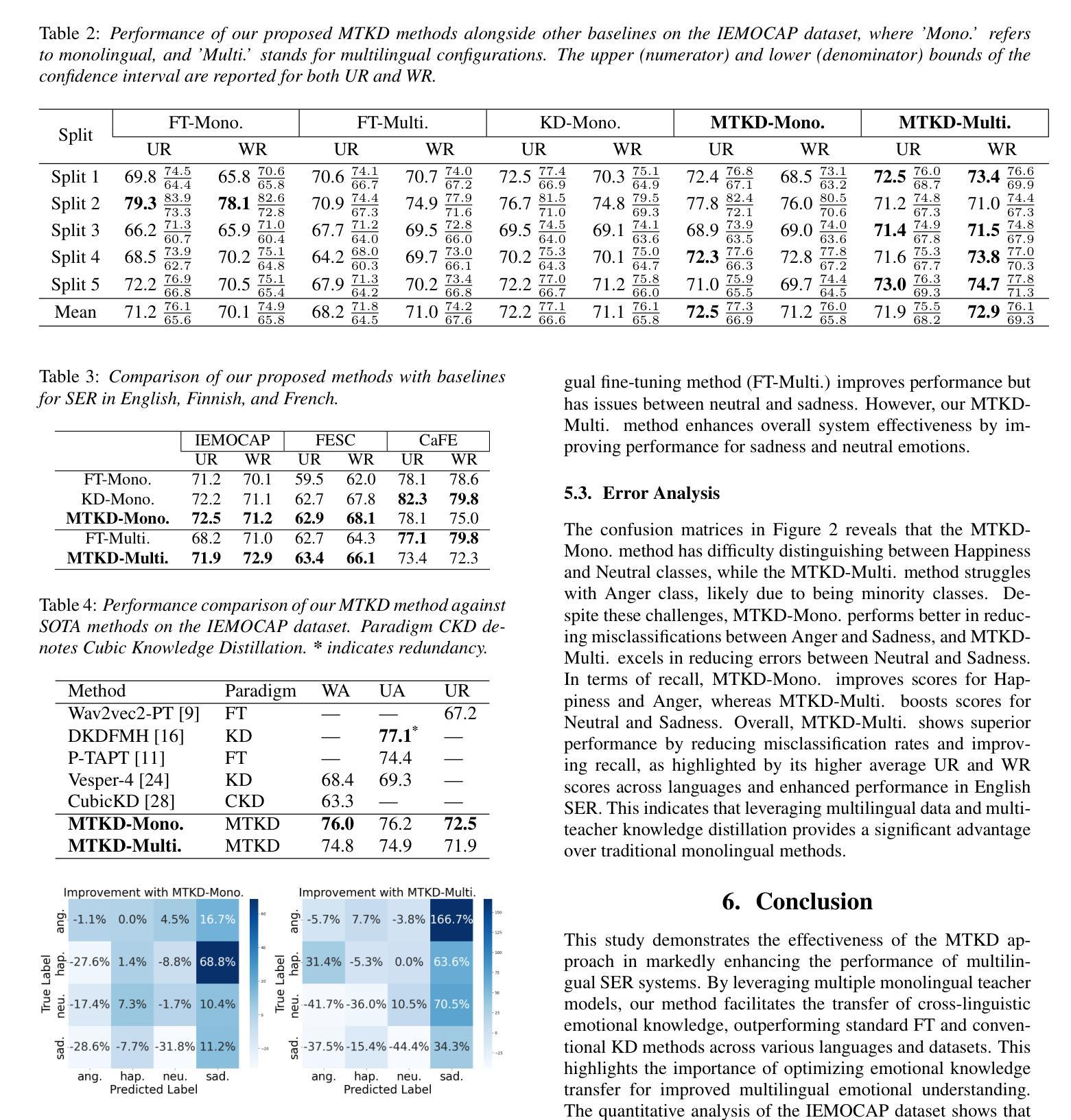
Multi-Teacher Language-Aware Knowledge Distillation for Multilingual Speech Emotion Recognition
Authors:Mehedi Hasan Bijoy, Dejan Porjazovski, Tamás Grósz, Mikko Kurimo
Speech Emotion Recognition (SER) is crucial for improving human-computer interaction. Despite strides in monolingual SER, extending them to build a multilingual system remains challenging. Our goal is to train a single model capable of multilingual SER by distilling knowledge from multiple teacher models. To address this, we introduce a novel language-aware multi-teacher knowledge distillation method to advance SER in English, Finnish, and French. It leverages Wav2Vec2.0 as the foundation of monolingual teacher models and then distills their knowledge into a single multilingual student model. The student model demonstrates state-of-the-art performance, with a weighted recall of 72.9 on the English dataset and an unweighted recall of 63.4 on the Finnish dataset, surpassing fine-tuning and knowledge distillation baselines. Our method excels in improving recall for sad and neutral emotions, although it still faces challenges in recognizing anger and happiness.
语音情绪识别(SER)对于改善人机交互至关重要。尽管单语SER取得了进展,但将其扩展到构建多语言系统仍然具有挑战性。我们的目标是通过从多个教师模型中提炼知识,训练一个能够进行多语言SER的单一模型。为解决这一问题,我们引入了一种新型的语言感知多教师知识提炼方法,以推进英语、芬兰语和法语中的SER。它利用Wav2Vec2.0作为单语教师模型的基础,然后将知识提炼到一个单一的多语言学生模型中。学生模型表现出卓越的性能,在英语数据集上的加权召回率为72.9,芬兰数据集上的未加权召回率为63.4,超过了微调和知识提炼的基线。我们的方法在改进悲伤和中性情绪的召回方面表现出色,尽管在识别愤怒和快乐情绪方面仍然面临挑战。
论文及项目相关链接
PDF Accepted to INTERSPEECH 2025 conference
Summary
基于情感识别在提升人机交互中的重要性,当前对于跨多语种情感识别的挑战正在加大。研究目标是通过多教师模型知识蒸馏的方式训练出一个单语种情感识别模型,并扩展到多语种情感识别领域。该研究引入了一种新型的语言感知多教师知识蒸馏方法,以推进英语、芬兰语和法语的情感识别。该研究以Wav2Vec2.0为基础构建单语种教师模型,并将其知识蒸馏到单一的多语种学生模型中。该学生模型表现出卓越的性能,在英语数据集上的加权召回率为72.9%,芬兰数据集上的非加权召回率为63.4%,超越了微调与知识蒸馏基线。该研究尤其擅长提高悲伤和中性情感的识别能力,但在愤怒和快乐情感的识别上仍面临挑战。
Key Takeaways
- 研究目标是利用多教师模型知识蒸馏训练单语种情感识别模型并扩展为多语种。
- 提出一种语言感知的多教师知识蒸馏新方法以提升多语种情感识别。
- 使用Wav2Vec2.0作为基础构建教师模型,然后将其蒸馏至学生模型。
- 学生模型展现出优异性能,包括英语数据集上的加权召回率和芬兰数据集上的非加权召回率均达到较高水平。
- 该方法擅长识别悲伤和中性情感,但在愤怒和快乐情感的识别上仍有提升空间。
- 研究实现了知识蒸馏和模型训练的有效结合,提升了模型的性能。
点此查看论文截图

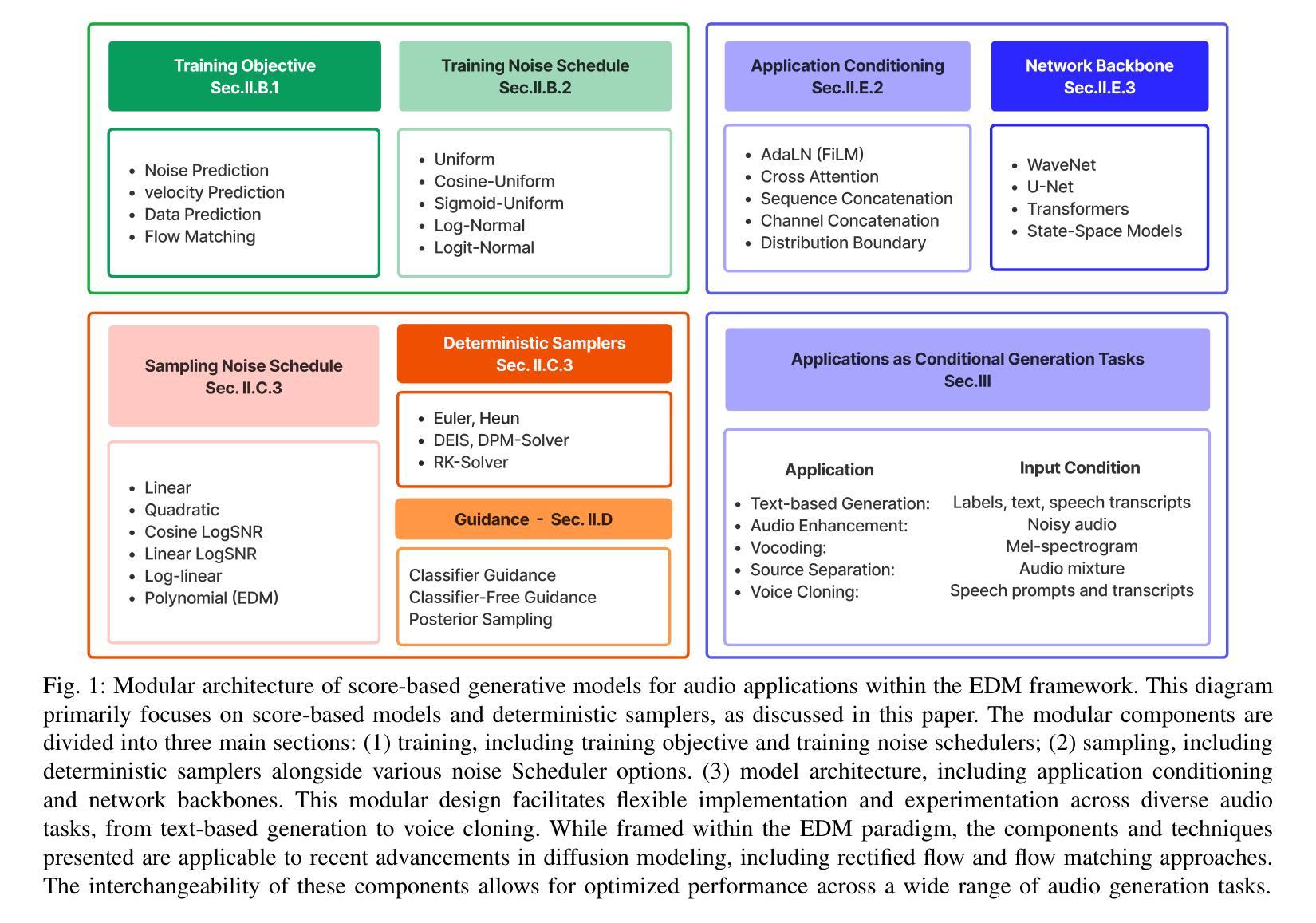
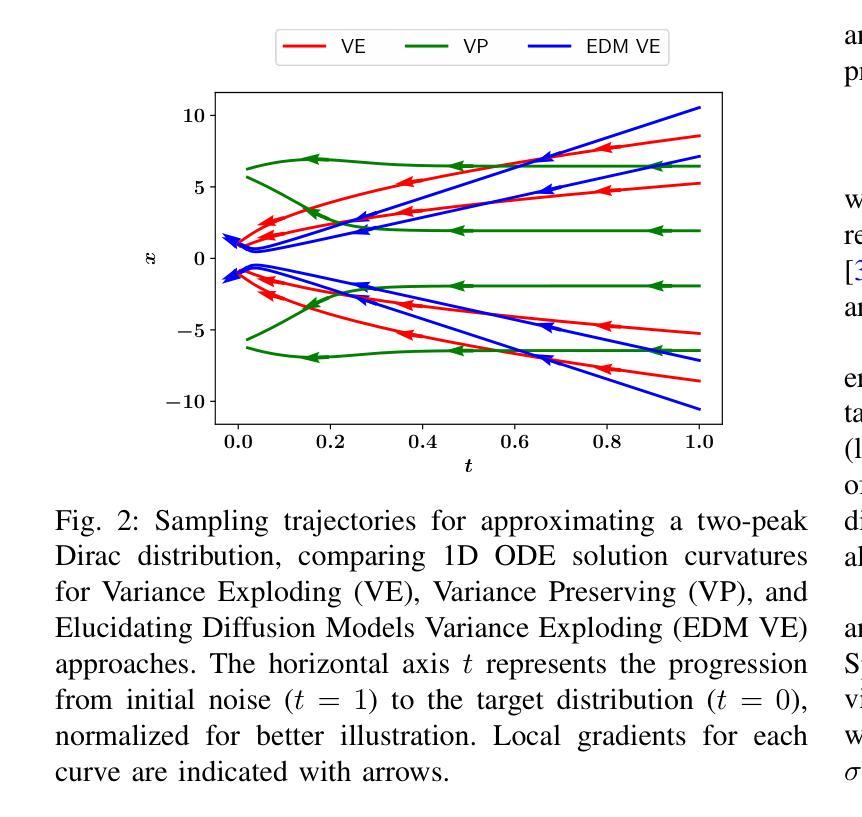
A Review on Score-based Generative Models for Audio Applications
Authors:Ge Zhu, Yutong Wen, Zhiyao Duan
Diffusion models have emerged as powerful deep generative techniques, producing high-quality and diverse samples in applications in various domains including audio. These models have many different design choices suitable for different applications, however, existing reviews lack in-depth discussions of these design choices. The audio diffusion model literature also lacks principled guidance for the implementation of these design choices and their comparisons for different applications. This survey provides a comprehensive review of diffusion model design with an emphasis on design principles for quality improvement and conditioning for audio applications. We adopt the score modeling perspective as a unifying framework that accommodates various interpretations, including recent approaches like flow matching. We systematically examine the training and sampling procedures of diffusion models, and audio applications through different conditioning mechanisms. To address the lack of audio diffusion model codebases and to promote reproducible research and rapid prototyping, we introduce an open-source codebase at https://github.com/gzhu06/AudioDiffuser that implements our reviewed framework for various audio applications. We demonstrate its capabilities through three case studies: audio generation, speech enhancement, and text-to-speech synthesis, with benchmark evaluations on standard datasets.
扩散模型已经作为强大的深度生成技术出现,在各种领域的应用中产生了高质量和多样化的样本,包括音频。这些模型有许多不同的设计选择,适合不同的应用,然而,现有的评论缺乏对这些设计选择的深入讨论。音频扩散模型文献也缺乏这些设计选择实施的原则性指导以及它们在不同应用中的比较。这篇综述对扩散模型设计进行了全面回顾,重点介绍了改进质量和音频应用条件的设计原则。我们采用评分建模视角作为统一框架,可以容纳各种解释,包括最新的方法如流匹配。我们系统地研究了扩散模型的训练和采样程序,以及通过不同条件机制进行的音频应用程序。为了解决音频扩散模型代码库缺乏的问题,并推动可重复的研究和快速原型设计,我们在https://github.com/gzhu06/AudioDiffuser上推出了一个开源代码库,为各种音频应用实现了我们回顾过的框架。我们通过三个案例研究展示了其能力:音频生成、语音增强和文本到语音的合成,并在标准数据集上进行了基准评估。
论文及项目相关链接
总结
扩散模型作为强大的深度生成技术,已广泛应用于包括音频在内的多个领域的应用中,并能产生高质量和多样化的样本。本文为扩散模型设计提供了全面的综述,重点介绍了提高质量和音频应用的条件设计原则。本文从得分建模的角度出发,统一框架接纳了各种解读,包括流程匹配等最新方法。系统地探讨了扩散模型的训练和采样过程以及通过不同条件机制在音频应用中的应用。为解决音频扩散模型代码库缺乏的问题,促进可重复研究和快速原型设计,本文引入了开源代码库,并展示了其在音频生成、语音增强和文本到语音合成三个案例研究中的能力,同时在标准数据集上进行基准评估。
关键见解
- 扩散模型已成为强大的深度生成技术,广泛应用于多个领域,包括音频。
- 现有文献缺乏对扩散模型设计的深入探讨,特别是在音频应用方面的原则性指导。
- 本文提供扩散模型设计的全面综述,重点介绍设计原则以提高质量和音频应用的条件。
- 采用得分建模的角度作为统一框架,接纳各种解读,包括流程匹配等最新方法。
- 系统地探讨扩散模型的训练和采样过程。
- 介绍开源代码库,解决音频扩散模型代码库缺乏的问题,促进可重复研究和快速原型设计。
- 通过音频生成、语音增强和文本到语音合成三个案例研究展示其能力,并在标准数据集上进行基准评估。
点此查看论文截图

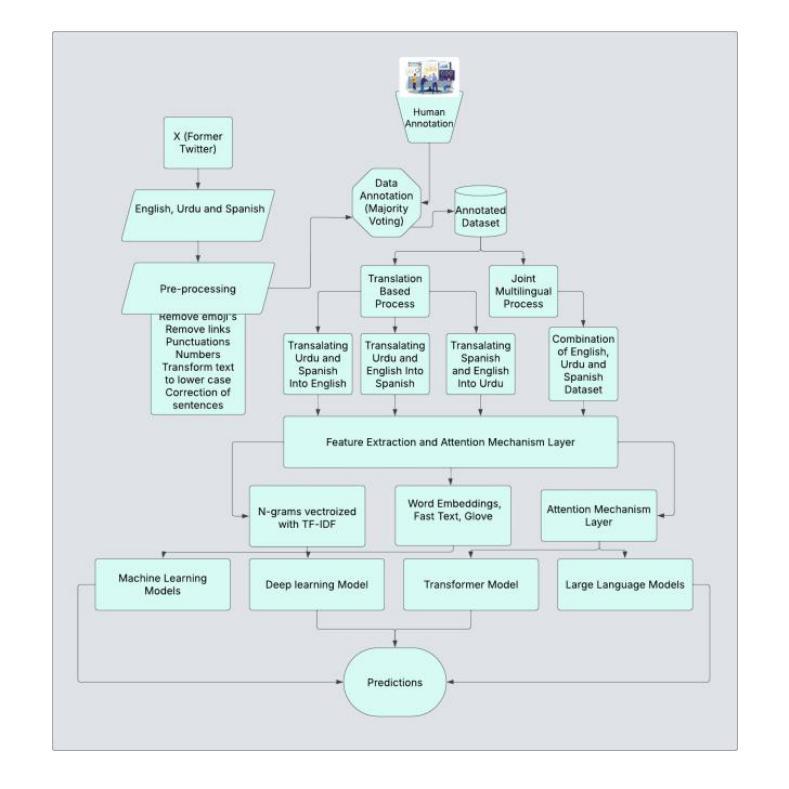
Multilingual Hate Speech Detection in Social Media Using Translation-Based Approaches with Large Language Models
Authors:Muhammad Usman, Muhammad Ahmad, M. Shahiki Tash, Irina Gelbukh, Rolando Quintero Tellez, Grigori Sidorov
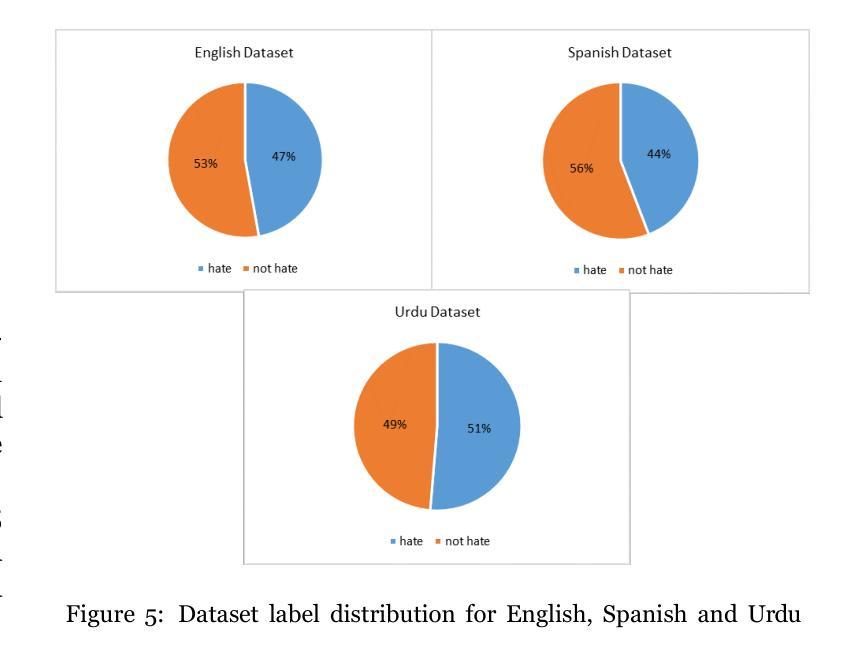
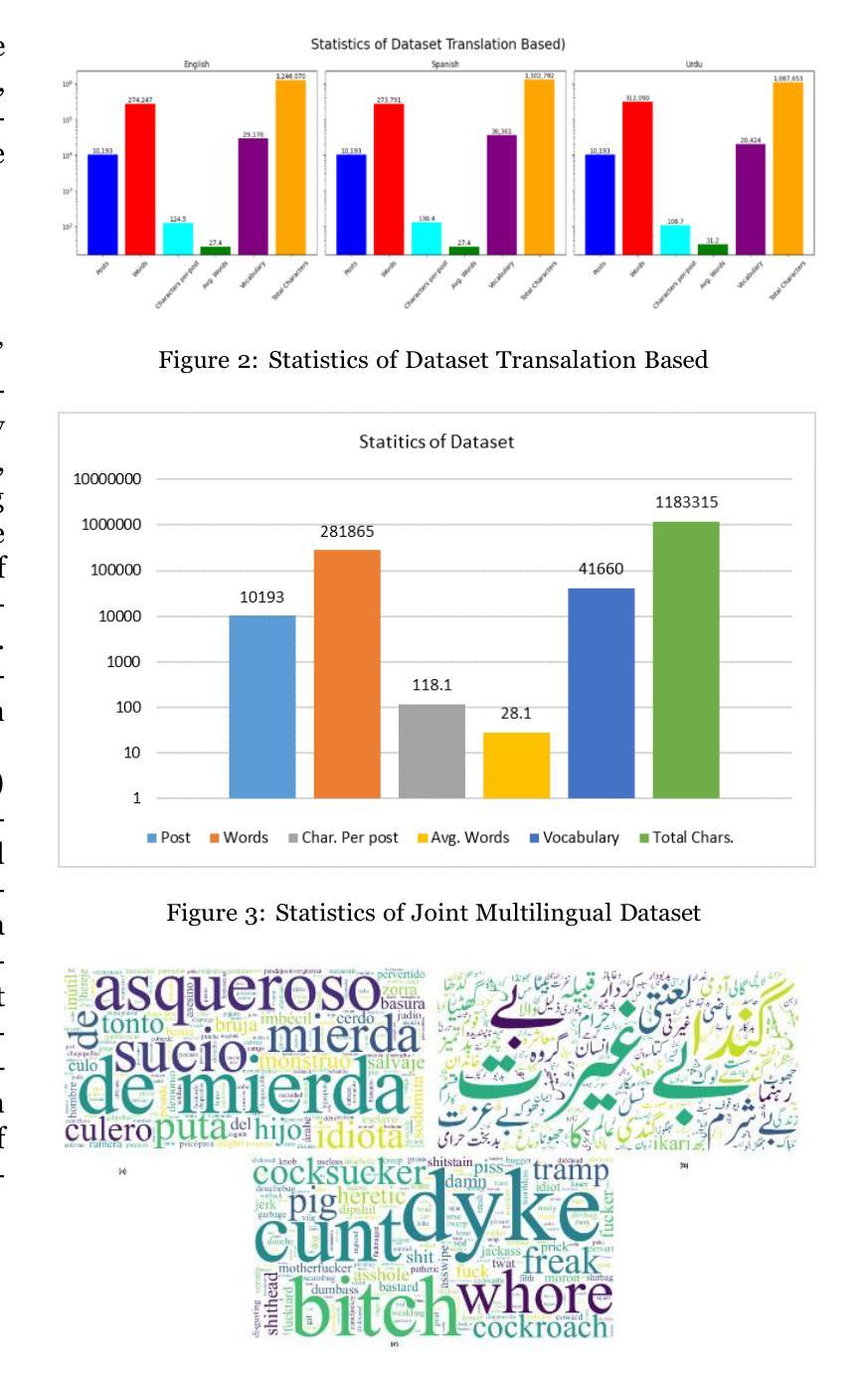
Social media platforms are critical spaces for public discourse, shaping opinions and community dynamics, yet their widespread use has amplified harmful content, particularly hate speech, threatening online safety and inclusivity. While hate speech detection has been extensively studied in languages like English and Spanish, Urdu remains underexplored, especially using translation-based approaches. To address this gap, we introduce a trilingual dataset of 10,193 tweets in English (3,834 samples), Urdu (3,197 samples), and Spanish (3,162 samples), collected via keyword filtering, with a balanced distribution of 4,849 Hateful and 5,344 Not-Hateful labels. Our methodology leverages attention layers as a precursor to transformer-based models and large language models (LLMs), enhancing feature extraction for multilingual hate speech detection. For non-transformer models, we use TF-IDF for feature extraction. The dataset is benchmarked using state-of-the-art models, including GPT-3.5 Turbo and Qwen 2.5 72B, alongside traditional machine learning models like SVM and other transformers (e.g., BERT, RoBERTa). Three annotators, following rigorous guidelines, ensured high dataset quality, achieving a Fleiss’ Kappa of 0.821. Our approach, integrating attention layers with GPT-3.5 Turbo and Qwen 2.5 72B, achieves strong performance, with macro F1 scores of 0.87 for English (GPT-3.5 Turbo), 0.85 for Spanish (GPT-3.5 Turbo), 0.81 for Urdu (Qwen 2.5 72B), and 0.88 for the joint multilingual model (Qwen 2.5 72B). These results reflect improvements of 8.75% in English (over SVM baseline 0.80), 8.97% in Spanish (over SVM baseline 0.78), 5.19% in Urdu (over SVM baseline 0.77), and 7.32% in the joint multilingual model (over SVM baseline 0.82). Our framework offers a robust solution for multilingual hate speech detection, fostering safer digital communities worldwide.
社交媒体平台是公众话语的重要空间,塑造意见和社区动态,然而它们的广泛使用也放大了有害内容,特别是仇恨言论,威胁网络安全和包容性。虽然英语和西班牙语的仇恨言论检测已经得到了广泛研究,但乌尔都语仍然被探索得不够深入,尤其是使用基于翻译的方法。为了弥补这一空白,我们引入了一个包含英语(3834个样本)、乌尔都语(3197个样本)和西班牙语(3162个样本)的三种语言数据集,通过关键词过滤收集,包含4849个仇恨标签和5344个非仇恨标签的平衡分布。我们的方法利用注意力层作为基于Transformer模型和大语言模型(LLM)的先决条件,增强特征提取能力,用于多语言仇恨言论检测。对于非Transformer模型,我们使用TF-IDF进行特征提取。该数据集采用最先进的模型进行基准测试,包括GPT-3.5 Turbo和Qwen 2.5 72B,以及传统的机器学习模型如SVM和其他Transformer(如BERT、RoBERTa)。三个注释者遵循严格的指导方针,确保数据集的高质量,达到Fleiss Kappa值为0.821。我们的方法将注意力层与GPT-3.5 Turbo和Qwen 2.5 72B相结合,取得了强大的性能表现。英语宏F1分数为0.87(GPT-3.5 Turbo),西班牙语为0.85(GPT-3.5 Turbo),乌尔都语为0.81(Qwen 2.5 72B),多语言联合模型为0.88(Qwen 2.5 72B)。这些结果反映了相对于SVM基准线的改进:英语提高8.75%(从0.80提高到0.87),西班牙语提高8.97%(从0.78提高到0.87),乌尔都语提高5.19%(从0.77提高到0.82),多语言联合模型提高7.32%(从0.82提高到0.88)。我们的框架为多语言仇恨言论检测提供了稳健的解决方案,促进了全球更安全的数字社区建设。
论文及项目相关链接
Summary:社交媒体平台是公众话语的重要空间,塑造意见和社区动态,但其广泛使用也放大了有害内容,特别是仇恨言论,威胁网络安全和包容性。针对多语言仇恨言论检测的研究尚存空白,本研究引入了一个包含英语、乌尔都语和西班牙语的三语数据集,并利用注意力层作为基于Transformer的大型语言模型的预处理步骤,以提高特征提取能力。该研究使用了前沿模型如GPT-3.5 Turbo和Qwen 2.5 72B以及传统的机器学习方法进行基准测试。最终研究表明该研究实现了在多语言环境下的高效仇恨言论检测,有助于提高全球数字社区的安全性。研究基于文本创建的分类模型能够为有效检测多语言环境下的仇恨言论提供坚实基础。总体而言,此数据集旨在实现更高效的多语言仇恨言论检测以促进网络安全发展,造福人类社会。这是一项具有重要意义的工作,对整个社交媒体发展也至关重要。它的数据集和创新方法可以推广到相关领域为更多的任务提供帮助。希望这项工作能够促进网络安全的发展,进一步保护用户的在线安全和个人隐私。这将是一项重大的贡献,具有广阔的应用前景。我们相信该工作将对未来的社交媒体平台产生积极影响。同时,该研究对于理解社交媒体平台上的仇恨言论传播机制以及制定有效的应对策略具有重要意义。研究团队的工作值得赞赏和支持。尽管挑战重重,他们仍取得了令人瞩目的成果。我们将密切关注该研究的后续进展和实际应用情况。
Key Takeaways:
点此查看论文截图



LID Models are Actually Accent Classifiers: Implications and Solutions for LID on Accented Speech
Authors:Niyati Bafna, Matthew Wiesner
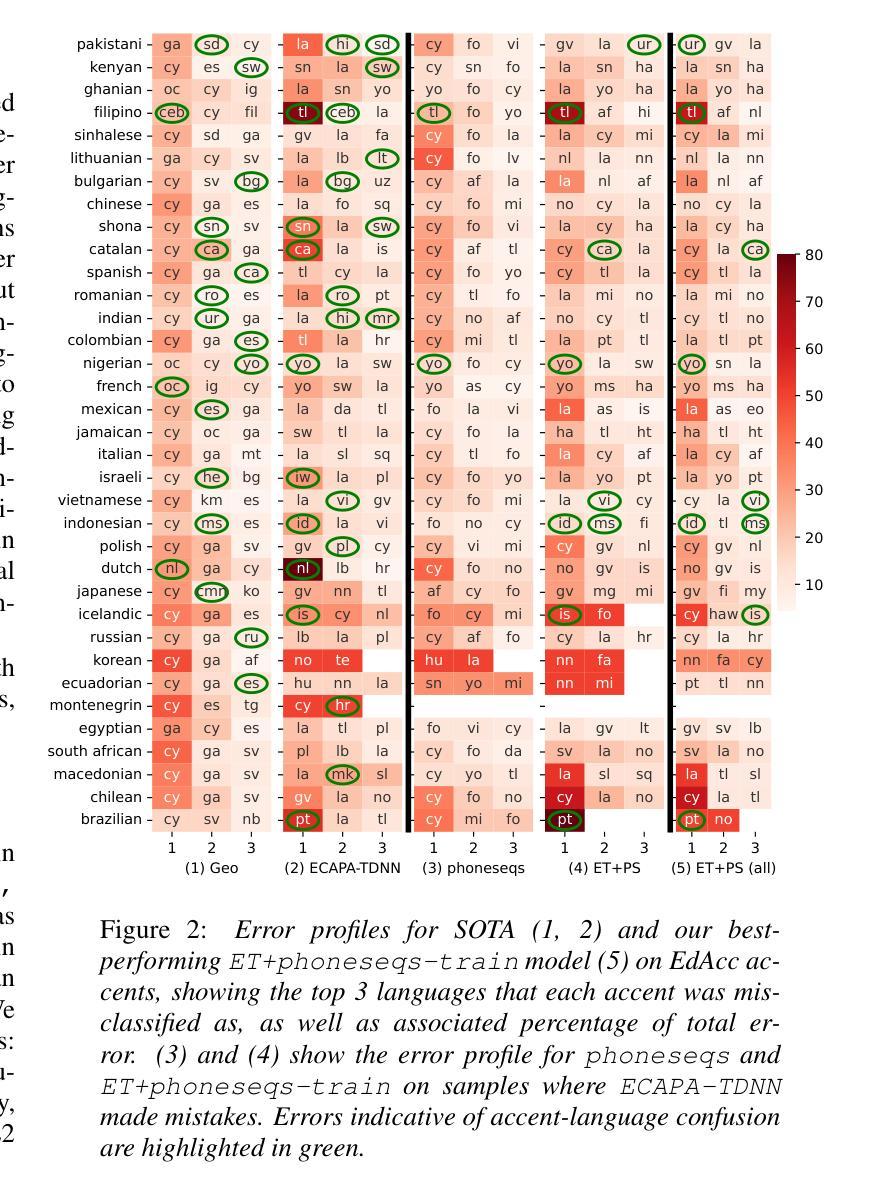
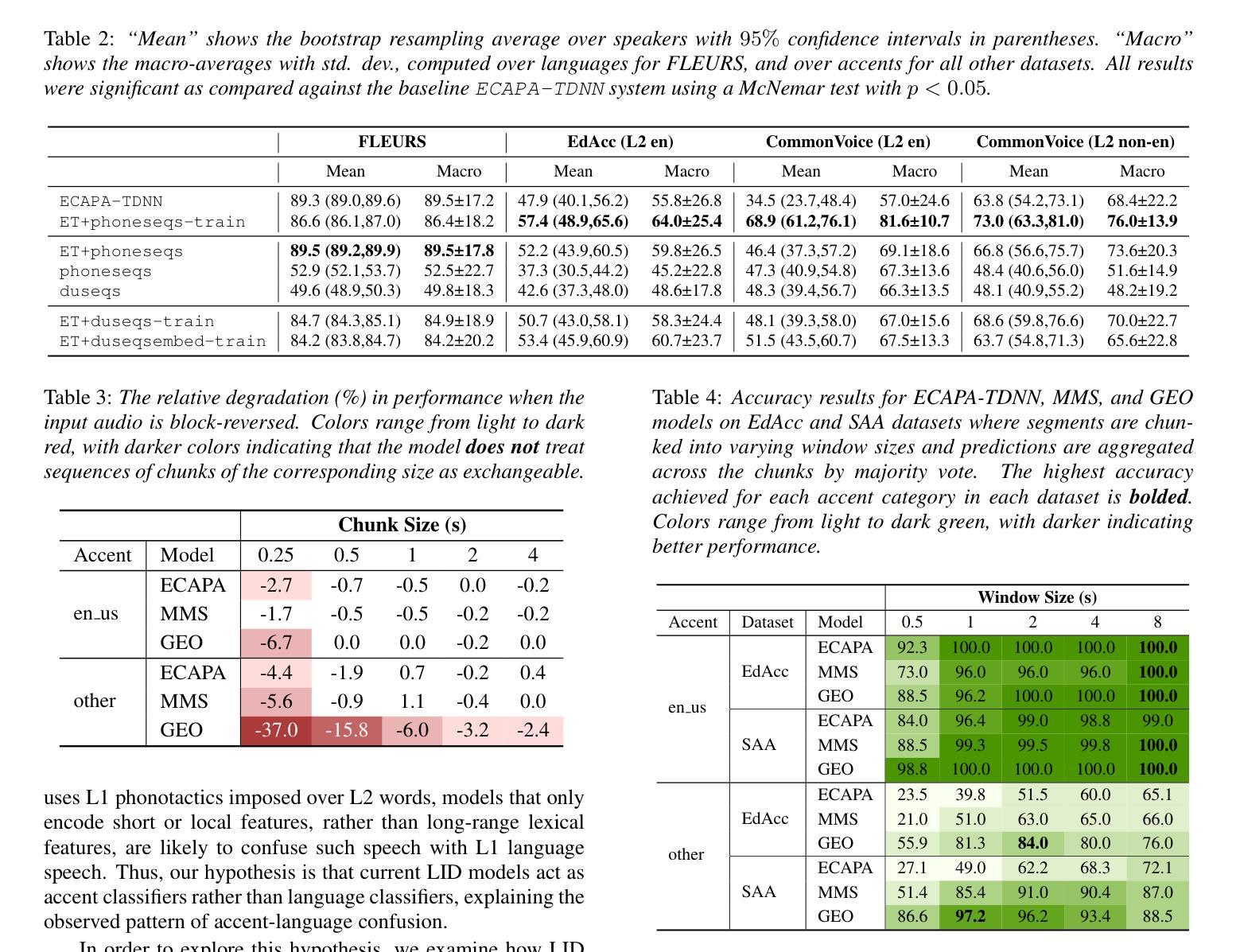
Prior research indicates that LID model performance significantly declines on accented speech; however, the specific causes, extent, and characterization of these errors remain under-explored. (i) We identify a common failure mode on accented speech whereby LID systems often misclassify L2 accented speech as the speaker’s native language or a related language. (ii) We present evidence suggesting that state-of-the-art models are invariant to permutations of short spans of speech, implying they classify on the basis of short phonotactic features indicative of accent rather than language. Our analysis reveals a simple method to enhance model robustness to accents through input chunking. (iii) We present an approach that integrates sequence-level information into our model without relying on monolingual ASR systems; this reduces accent-language confusion and significantly enhances performance on accented speech while maintaining comparable results on standard LID.
先前的研究表明,LID模型在有口音的语音上的表现会显著下降;然而,这些错误的具体原因、程度和特征仍然缺乏深入探索。(i)我们确定了在有口音的语音上的一种常见失效模式,即LID系统经常将带有口音的第二语言误分类为说话人的母语或相关语言。(ii)我们提供了证据表明,最先进的模型对于短语音段的排列具有不变性,这意味着它们是基于指示口音而非语言的短音系特征进行分类的。我们的分析揭示了一种通过输入分块来提高模型对口音的稳健性的简单方法。(iii)我们提出了一种将序列级别的信息集成到模型中的方法,无需依赖单语种自动语音识别系统;这减少了口音语言混淆,并显著提高了在有口音的语音上的性能,同时保持了标准LID的相当结果。
论文及项目相关链接
PDF Accepted at Interspeech 2025
Summary:
本文探讨了语言身份识别(LID)模型在带有口音的语音上的性能问题。研究发现,LID模型在处理带有口音的语音时会出现误分类的情况,即将非母语带有口音的语音错误地识别为说话者的母语或相关语言。文章分析了当前模型的局限性,并提出了一种通过输入分块增强模型对口音的鲁棒性的方法。此外,还介绍了一种不依赖单语自动语音识别系统的方法,将序列级别的信息融入模型中,从而减少口音引起的语言混淆,同时保持对标准LID的性能。
Key Takeaways:
- LID模型在处理带口音语音时性能显著下降,存在将L2口音语音误分类为母语或相关语言的常见失败模式。
- 当前先进模型对短语音片段的排列顺序具有不变性,暗示它们基于短语的音韵特征而非语言进行分类。
- 通过输入分块可以提高模型对口音的鲁棒性。
- 提出了一种集成序列级别信息的方法,无需依赖单语自动语音识别系统。
- 该方法能减少因口音导致的语言混淆,显著提高带口音语音的识别性能。
- 该方法在标准LID上的性能维持不变。
- 这些发现对于改进LID模型的性能和适应性具有重要意义。
点此查看论文截图

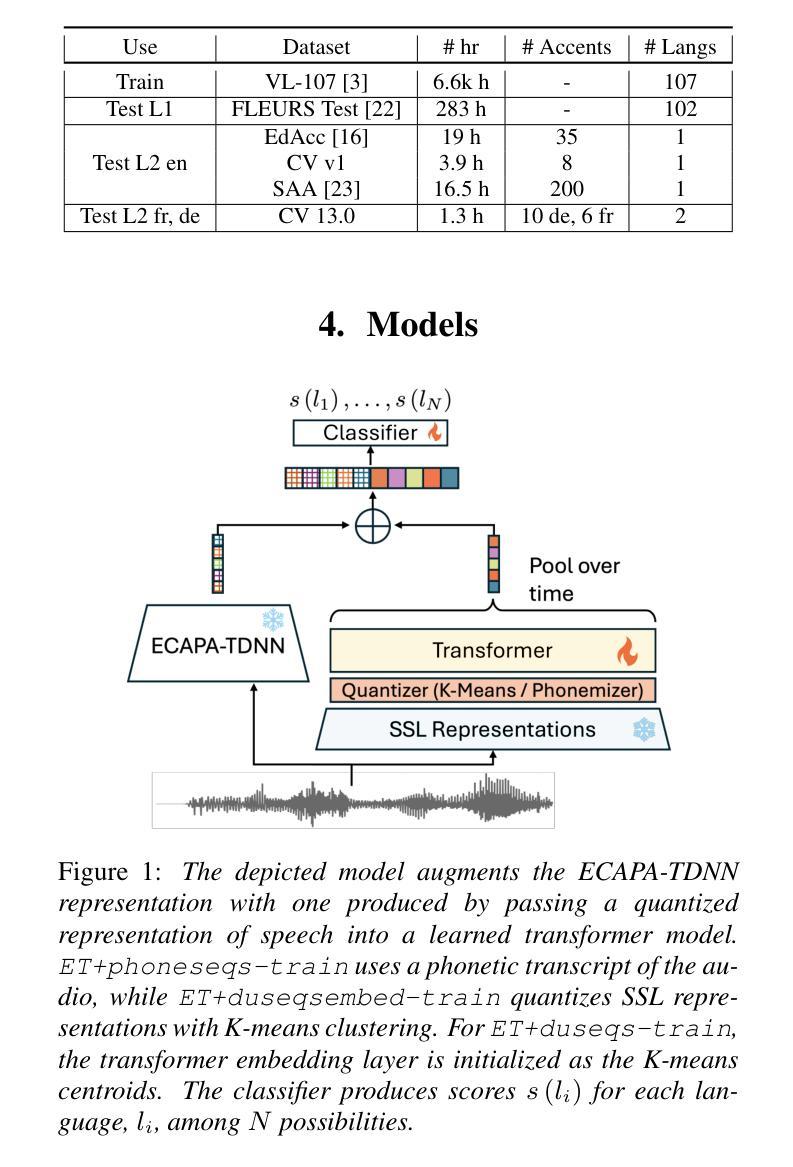
LLaSE-G1: Incentivizing Generalization Capability for LLaMA-based Speech Enhancement
Authors:Boyi Kang, Xinfa Zhu, Zihan Zhang, Zhen Ye, Mingshuai Liu, Ziqian Wang, Yike Zhu, Guobin Ma, Jun Chen, Longshuai Xiao, Chao Weng, Wei Xue, Lei Xie
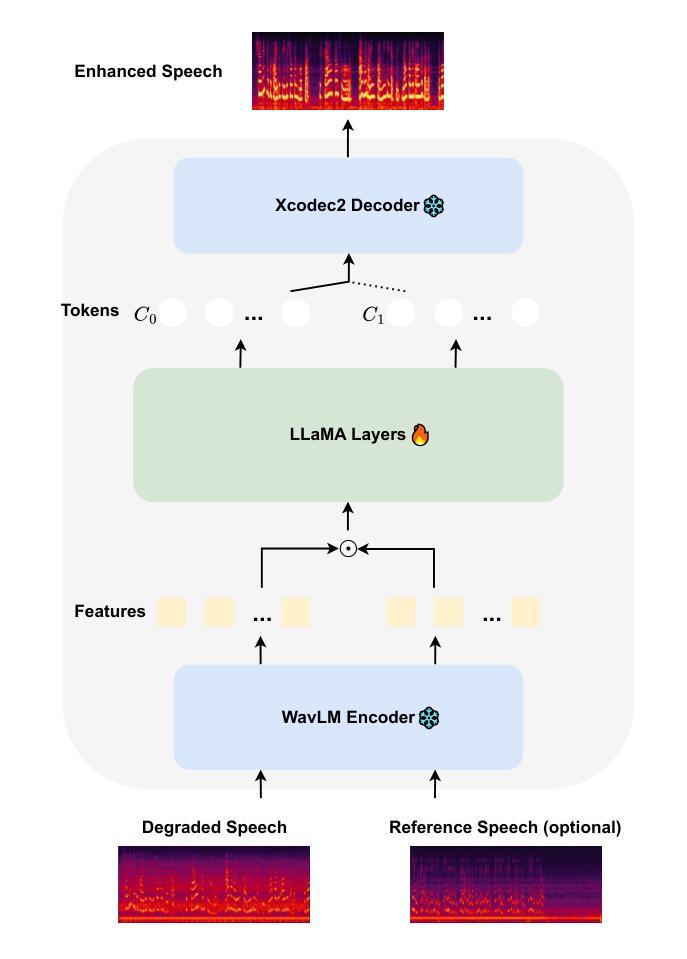
Recent advancements in language models (LMs) have demonstrated strong capabilities in semantic understanding and contextual modeling, which have flourished in generative speech enhancement (SE). However, many LM-based SE approaches primarily focus on semantic information, often neglecting the critical role of acoustic information, which leads to acoustic inconsistency after enhancement and limited generalization across diverse SE tasks. In this paper, we introduce LLaSE-G1, a LLaMA-based language model that incentivizes generalization capabilities for speech enhancement. LLaSE-G1 offers the following key contributions: First, to mitigate acoustic inconsistency, LLaSE-G1 employs continuous representations from WavLM as input and predicts speech tokens from X-Codec2, maximizing acoustic preservation. Second, to promote generalization capability, LLaSE-G1 introduces dual-channel inputs and outputs, unifying multiple SE tasks without requiring task-specific IDs. Third, LLaSE-G1 outperforms prior task-specific discriminative and generative SE models, demonstrating scaling effects at test time and emerging capabilities for unseen SE tasks. Additionally, we release our code and models to support further research in this area.
最近的语言模型(LM)进展表明,其在语义理解和上下文建模方面展现出强大的能力,并在生成性语音增强(SE)中繁荣发展。然而,许多基于LM的SE方法主要关注语义信息,往往忽视了声音信息的关键作用,这导致增强后的语音出现声音不一致,以及在各种SE任务中的泛化能力受限。在本文中,我们介绍了LLaSE-G1,这是一个基于LLaMA的语言模型,旨在激励其在语音增强方面的泛化能力。LLaSE-G1有以下关键贡献:首先,为了缓解声音不一致的问题,LLaSE-G1采用WavLM的连续表示作为输入,并通过X-Codec2预测语音令牌,最大限度地保留声音。其次,为了提升泛化能力,LLaSE-G1引入了双通道输入和输出,可以统一多种SE任务而无需特定任务标识。第三,LLaSE-G1在测试时间展现出规模化效果,优于之前的特定任务判别式和生成式SE模型,并具有处理未见过的SE任务的能力。此外,我们公开了代码和模型以支持该领域的进一步研究。
论文及项目相关链接
PDF ACL2025 main, Codes available at https://github.com/Kevin-naticl/LLaSE-G1
摘要
本文介绍了基于LLaMA的LLaSE-G1语言模型在语音增强中的表现。该模型旨在解决现有模型在语义理解和上下文建模方面的不足,并引入了一系列创新技术来增强模型的性能。LLaSE-G1通过采用WavLM的连续表示作为输入并预测X-Codec2的语音令牌来减轻声学不一致的问题,同时采用双通道输入和输出以统一多种语音增强任务,无需特定任务标识。此外,该模型还表现出卓越的性能,超越了现有的任务特定判别和生成式语音增强模型,具有出色的泛化能力和测试时间扩展效应。本文还公开了相关代码和模型,以支持该领域的进一步研究。
关键见解
LLaSE-G1语言模型旨在解决现有语言模型在语音增强中忽略声学信息的问题,通过采用WavLM的连续表示来减轻声学不一致性。
LLaSE-G1使用X-Codec2预测语音令牌以最大化声学保留效果。
该模型引入双频道输入和输出以促进泛化能力,统一多种语音增强任务,无需特定任务标识。
LLaSE-G1的性能超越了现有的任务特定判别和生成式语音增强模型。
LLaSE-G1模型在测试时展现出扩展效应,并能应对未见过的语音增强任务。
公开的代码和模型将支持该领域的进一步研究。
点此查看论文截图

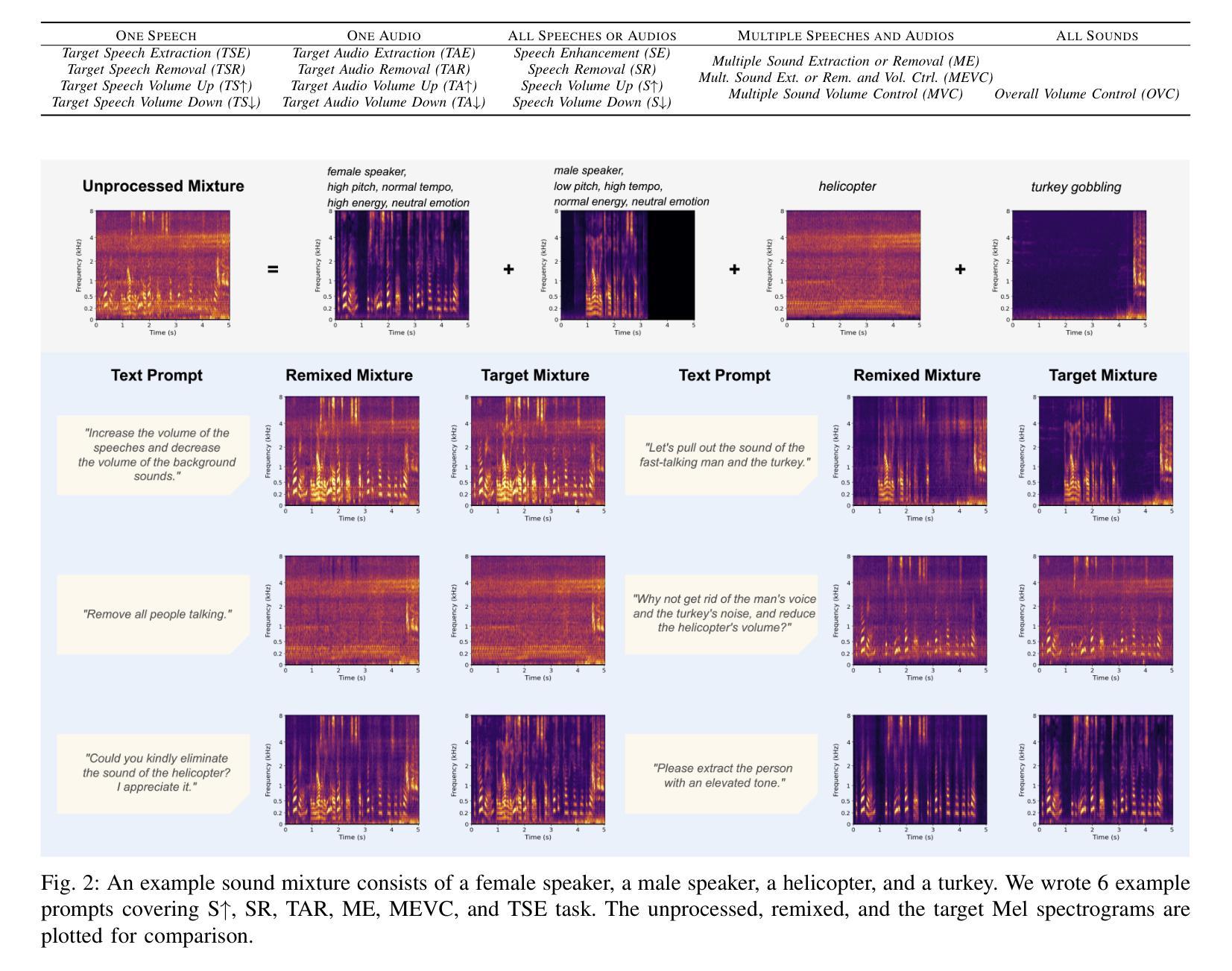
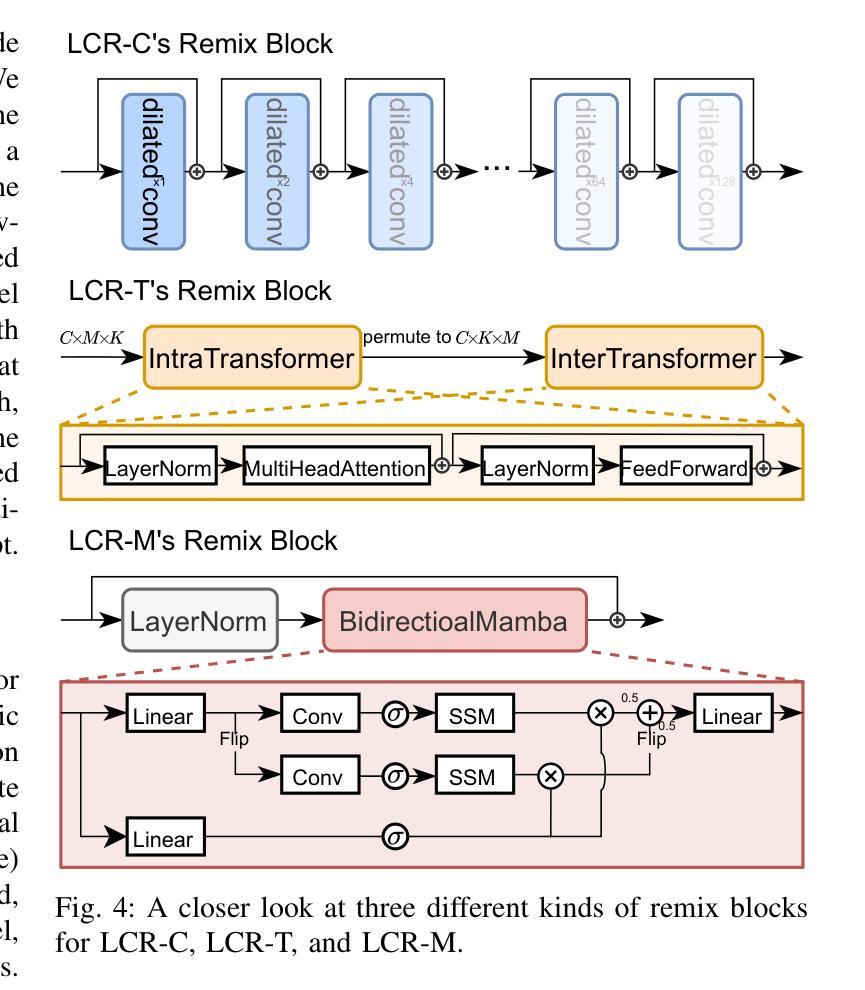
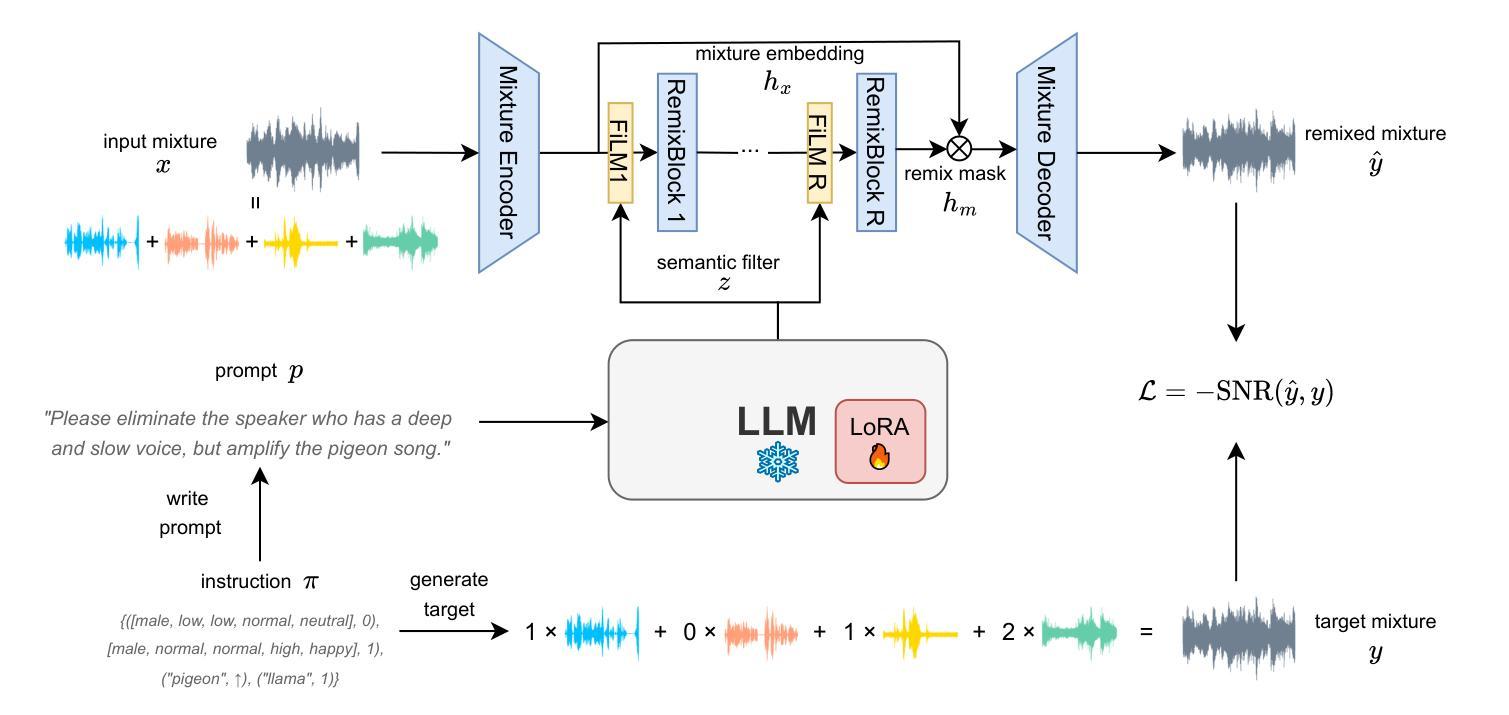
Listen, Chat, and Remix: Text-Guided Soundscape Remixing for Enhanced Auditory Experience
Authors:Xilin Jiang, Cong Han, Yinghao Aaron Li, Nima Mesgarani
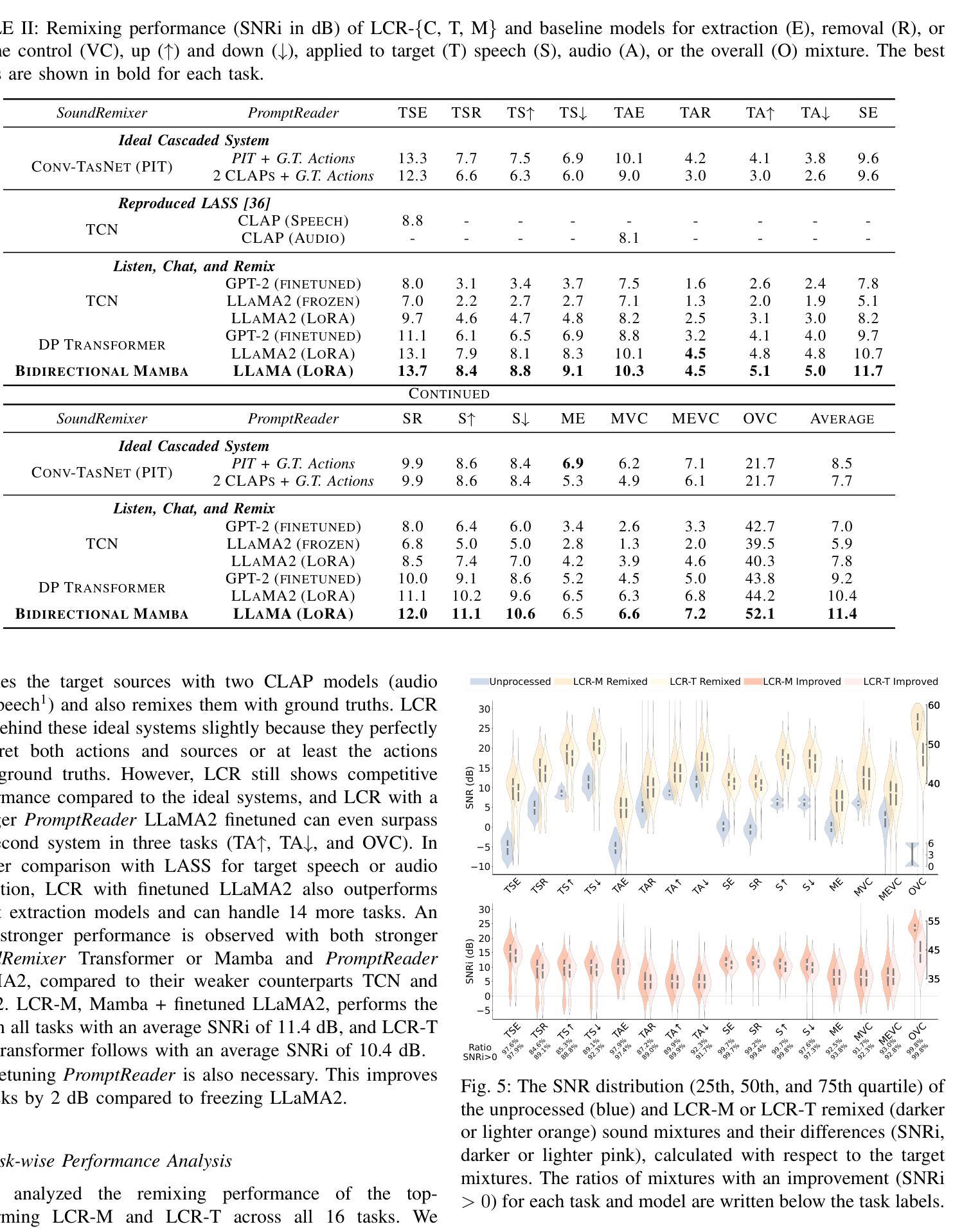
In daily life, we encounter a variety of sounds, both desirable and undesirable, with limited control over their presence and volume. Our work introduces “Listen, Chat, and Remix” (LCR), a novel multimodal sound remixer that controls each sound source in a mixture based on user-provided text instructions. LCR distinguishes itself with a user-friendly text interface and its unique ability to remix multiple sound sources simultaneously within a mixture, without needing to separate them. Users input open-vocabulary text prompts, which are interpreted by a large language model to create a semantic filter for remixing the sound mixture. The system then decomposes the mixture into its components, applies the semantic filter, and reassembles filtered components back to the desired output. We developed a 160-hour dataset with over 100k mixtures, including speech and various audio sources, along with text prompts for diverse remixing tasks including extraction, removal, and volume control of single or multiple sources. Our experiments demonstrate significant improvements in signal quality across all remixing tasks and robust performance in zero-shot scenarios with varying numbers and types of sound sources. An audio demo is available at: https://listenchatremix.github.io/demo.
在日常生活中,我们会遇到各种声音,包括想要的和不想听到的,但对它们的存在和音量只有有限的控制能力。我们的工作引入了“Listen, Chat, and Remix”(LCR)这一新颖的多模式声音混音器,它可以根据用户提供的文本指令控制混合中的每个声音源。LCR通过用户友好的文本接口和其在混合中同时混音多个声音源而无需分离的独有能力来区分自己。用户输入开放式词汇文本提示,由大型语言模型进行解释,为混音声音混合物创建语义过滤器。然后该系统将混合物分解成其组成部分,应用语义过滤器,并将过滤后的组件重新组装成所需的输出。我们开发了一个包含超过10万混合物的160小时数据集,包括语音和各种音频源以及用于各种混音任务的文本提示,包括提取、删除和控制单个或多个源的音量。我们的实验表明在所有混音任务中信号质量都有显著提高,并且在不同数量和类型的音源场景中零样本情景下的性能稳健。音频演示作品可在:https://listenchatremix.github.io/demo 访问。
论文及项目相关链接
PDF Accepted by IEEE Journal of Selected Topics in Signal Processing (JSTSP)
Summary
该文本介绍了一种名为“Listen, Chat, and Remix”(LCR)的新型多模式声音混音器。LCR通过用户提供的文本指令控制混合声音中的每个声音源。其特点为用户友好的文本界面,以及同时混音多个声音源的能力,无需单独分离。系统通过大型语言模型解释用户输入的开放词汇文本提示,创建语义过滤器来混音声音混合物。实验表明,LCR在所有的混音任务中都显著提高信号质量,并在不同数量和类型的音源场景中表现稳健。
Key Takeaways
- LCR是一种新型多模式声音混音器,可以通过用户提供的文本指令控制混合声音中的每个声音源。
- LCR具有用户友好的文本界面,可创建语义过滤器来混音声音混合物,无需单独分离多个声音源。
- 系统通过大型语言模型解释用户输入的开放词汇文本提示。
- LCR能处理包括语音和各种音频源在内的混合声音,并可以进行提取、删除、控制单一或多个源的音量等多样化的混音任务。
- LCR拥有160小时的数据集,包含超过10万个混合物。
- 实验表明,LCR在所有的混音任务中都显著提高信号质量,表现稳健。
点此查看论文截图