⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-13 更新
HunyuanVideo-HOMA: Generic Human-Object Interaction in Multimodal Driven Human Animation
Authors:Ziyao Huang, Zixiang Zhou, Juan Cao, Yifeng Ma, Yi Chen, Zejing Rao, Zhiyong Xu, Hongmei Wang, Qin Lin, Yuan Zhou, Qinglin Lu, Fan Tang
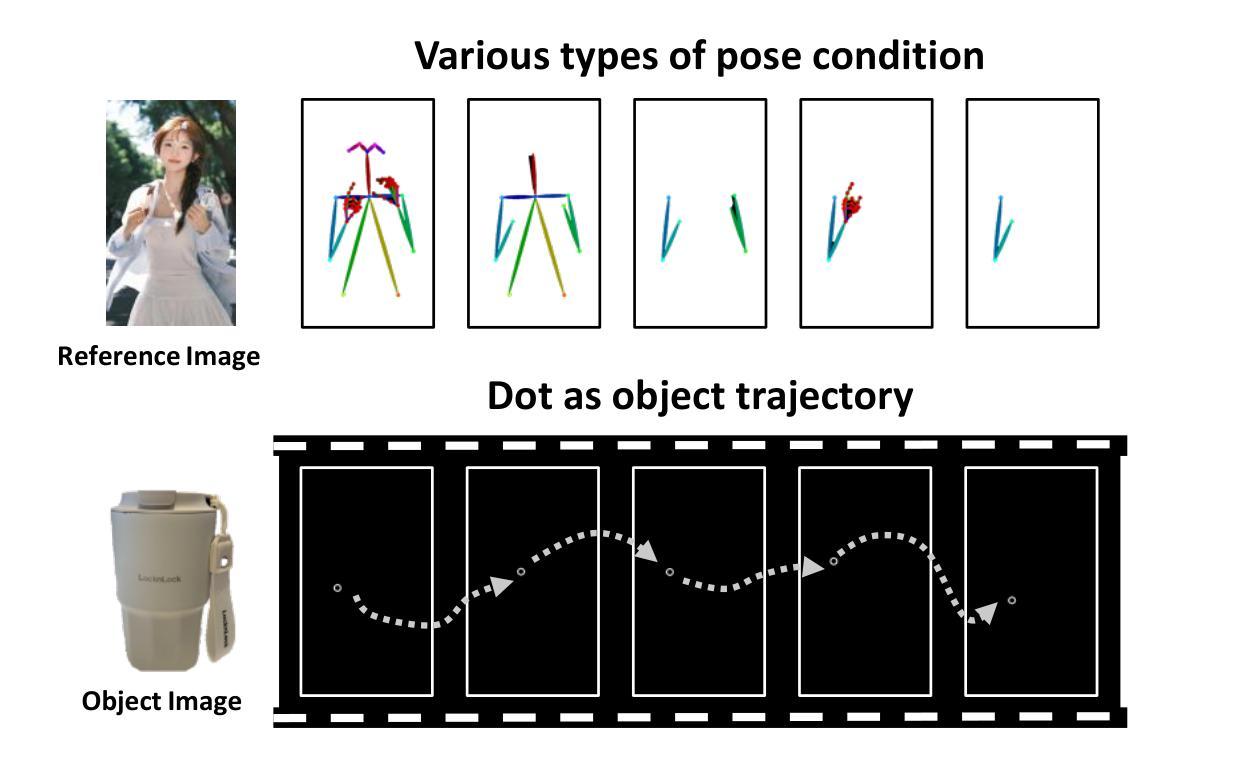
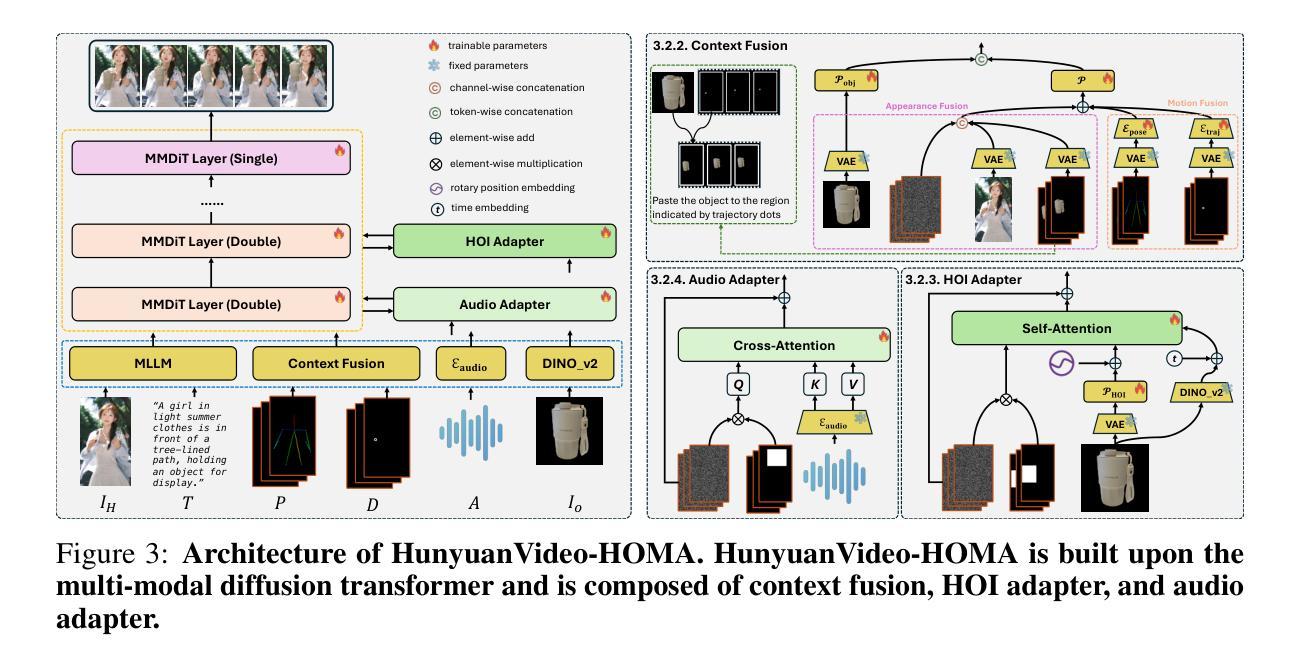
To address key limitations in human-object interaction (HOI) video generation – specifically the reliance on curated motion data, limited generalization to novel objects/scenarios, and restricted accessibility – we introduce HunyuanVideo-HOMA, a weakly conditioned multimodal-driven framework. HunyuanVideo-HOMA enhances controllability and reduces dependency on precise inputs through sparse, decoupled motion guidance. It encodes appearance and motion signals into the dual input space of a multimodal diffusion transformer (MMDiT), fusing them within a shared context space to synthesize temporally consistent and physically plausible interactions. To optimize training, we integrate a parameter-space HOI adapter initialized from pretrained MMDiT weights, preserving prior knowledge while enabling efficient adaptation, and a facial cross-attention adapter for anatomically accurate audio-driven lip synchronization. Extensive experiments confirm state-of-the-art performance in interaction naturalness and generalization under weak supervision. Finally, HunyuanVideo-HOMA demonstrates versatility in text-conditioned generation and interactive object manipulation, supported by a user-friendly demo interface. The project page is at https://anonymous.4open.science/w/homa-page-0FBE/.
为了克服人机交互(HOI)视频生成中的关键限制——特别是依赖于精心策划的运动数据、对新对象/场景的通用性有限以及访问受限——我们引入了HunyuanVideo-HOMA,这是一个弱条件多模态驱动框架。HunyuanVideo-HOMA通过稀疏的、解耦的运动指导增强了可控性,并减少了对精确输入的依赖。它将外观和运动信号编码到多模态扩散变压器(MMDiT)的双重输入空间中,将它们融合到一个共享上下文空间中,以合成时间上一致且物理上可行的交互。为了优化训练,我们整合了参数空间HOI适配器,该适配器从预训练的MMDiT权重进行初始化,既保留先验知识又实现高效适应,以及用于解剖准确的音频驱动唇同步的面部交叉注意适配器。大量实验证实,在弱监督下,我们的方法在交互自然性和泛化性方面达到了最新性能水平。最后,HunyuanVideo-HOMA展示了文本条件生成和交互式对象操作的通用性,并由用户友好的演示界面提供支持。项目页面位于:https://anonymous.4open.science/w/homa-page-0FBE/。
论文及项目相关链接
Summary
基于人类对象交互(HOI)视频生成中的关键限制,如依赖策划动作数据、对新物体或场景的通用性有限以及受限的可访问性,我们推出了HunyuanVideo-HOMA系统。该系统是一个弱条件的多模式驱动框架,增强了可控性并减少了对于精确输入的依赖。通过稀疏解耦运动指导来编码外观和运动信号进入双输入空间的多模式扩散变压器(MMDiT),并在共享语境空间中融合它们,合成时间连贯且物理上合理的交互。为了优化训练,我们整合了参数空间HOI适配器和面部交叉注意力适配器,分别用于从预训练的MMDiT权重中高效适应并保留先验知识,以及实现解剖准确的音频驱动唇同步。广泛的实验证明在弱监督下其交互自然性和通用性表现均为最新技术前沿。最后,胡源视频-HOMA通过用户友好的演示界面展示了其在文本驱动生成和交互式对象操作方面的通用性。该项目页面位于:匿名链接。
Key Takeaways
- HunyuanVideo-HOMA解决了人类对象交互视频生成中的关键限制问题。
- 该系统是一个弱条件的多模式驱动框架,旨在增强可控性并减少对精确输入的依赖。
- 通过稀疏解耦运动指导来编码外观和运动信号进入双输入空间的多模式扩散变压器(MMDiT)。
- 集成参数空间HOI适配器和面部交叉注意力适配器以提高效率和准确性。
- 在弱监督下表现出优秀的交互自然性和通用性表现。
- 提供用户友好的演示界面,展示其在文本驱动生成和交互式对象操作方面的通用性。
点此查看论文截图