⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-14 更新
A Unit Enhancement and Guidance Framework for Audio-Driven Avatar Video Generation
Authors:S. Z. Zhou, Y. B. Wang, J. F. Wu, T. Hu, J. N. Zhang
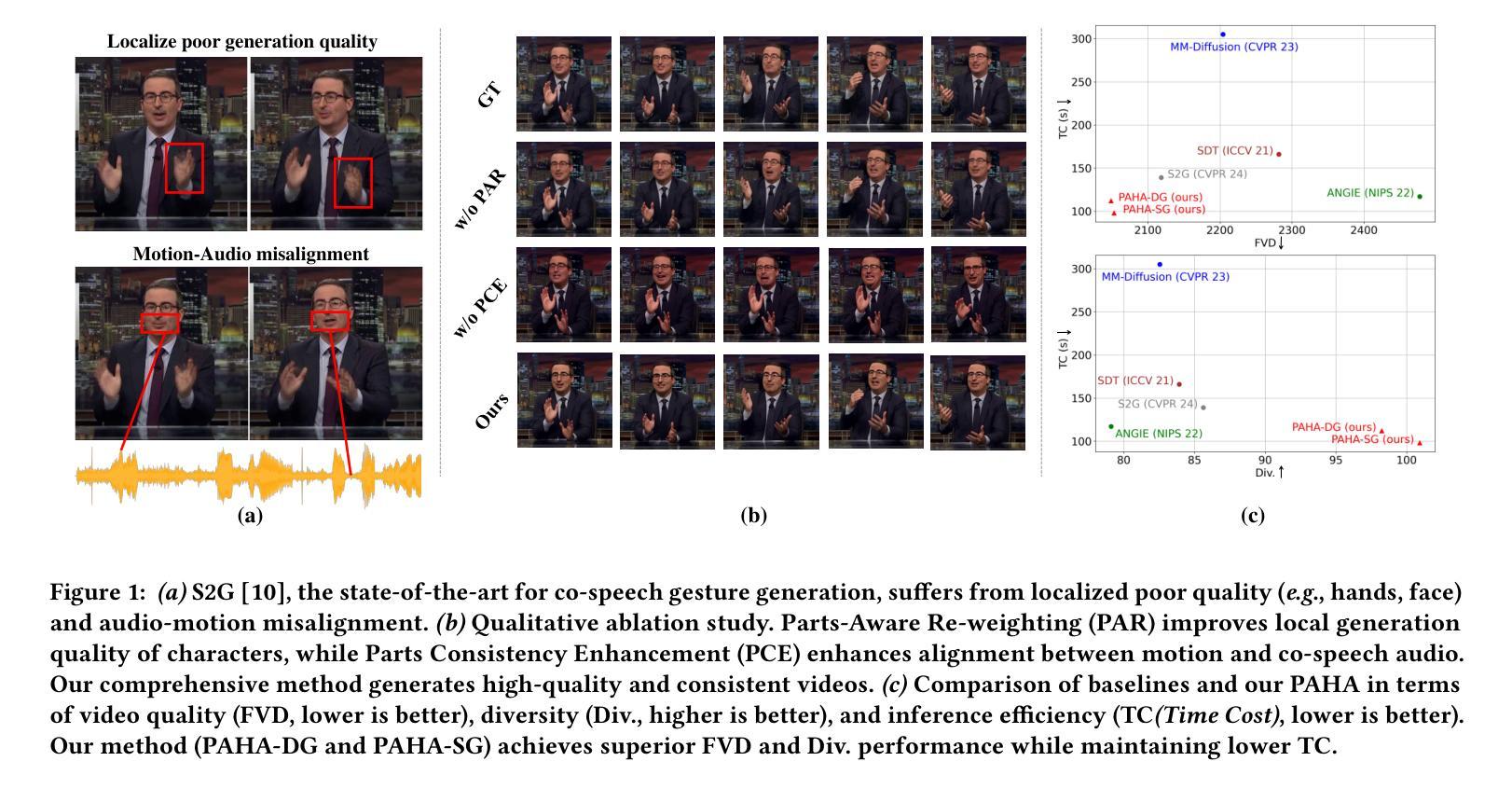
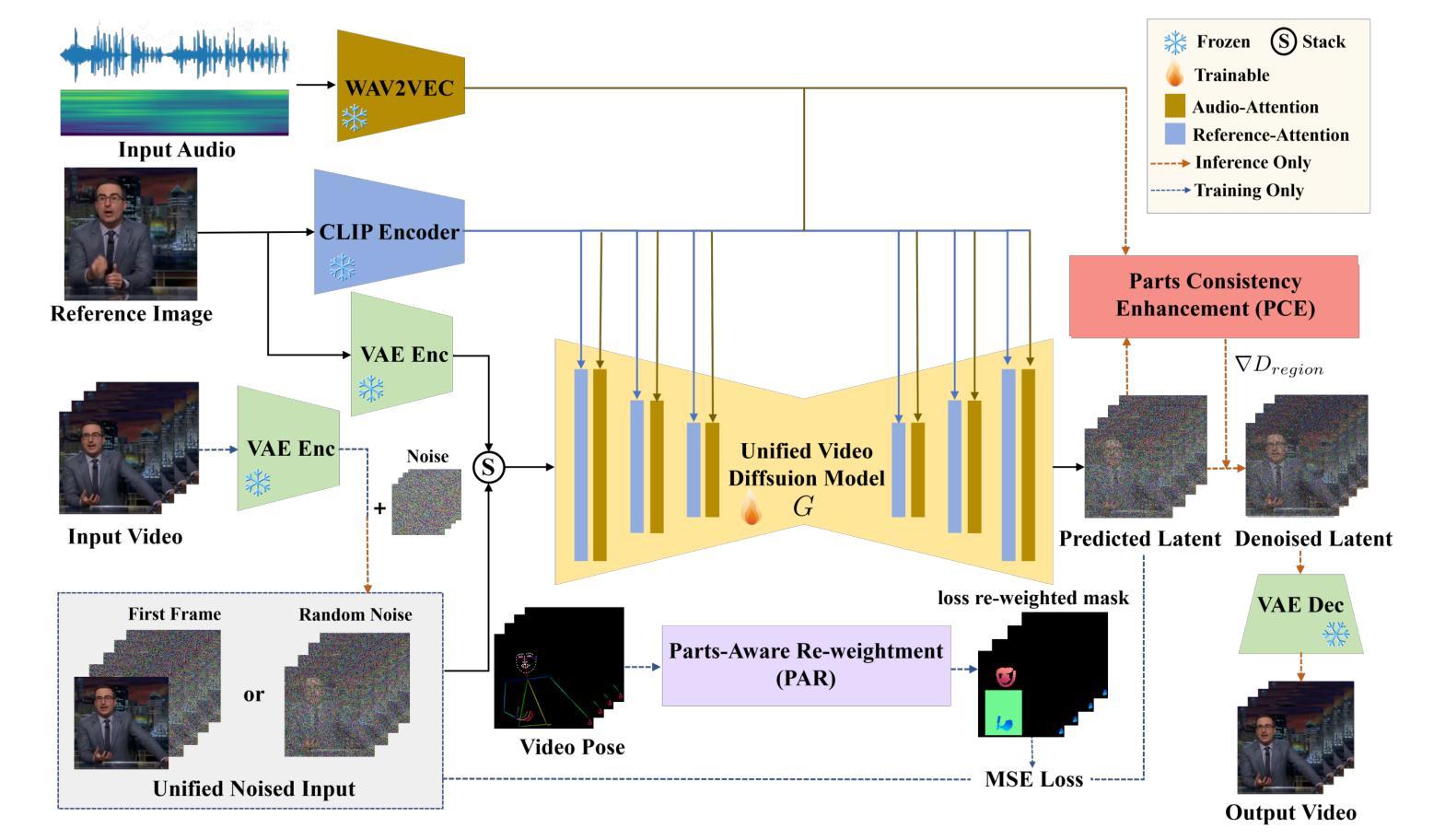
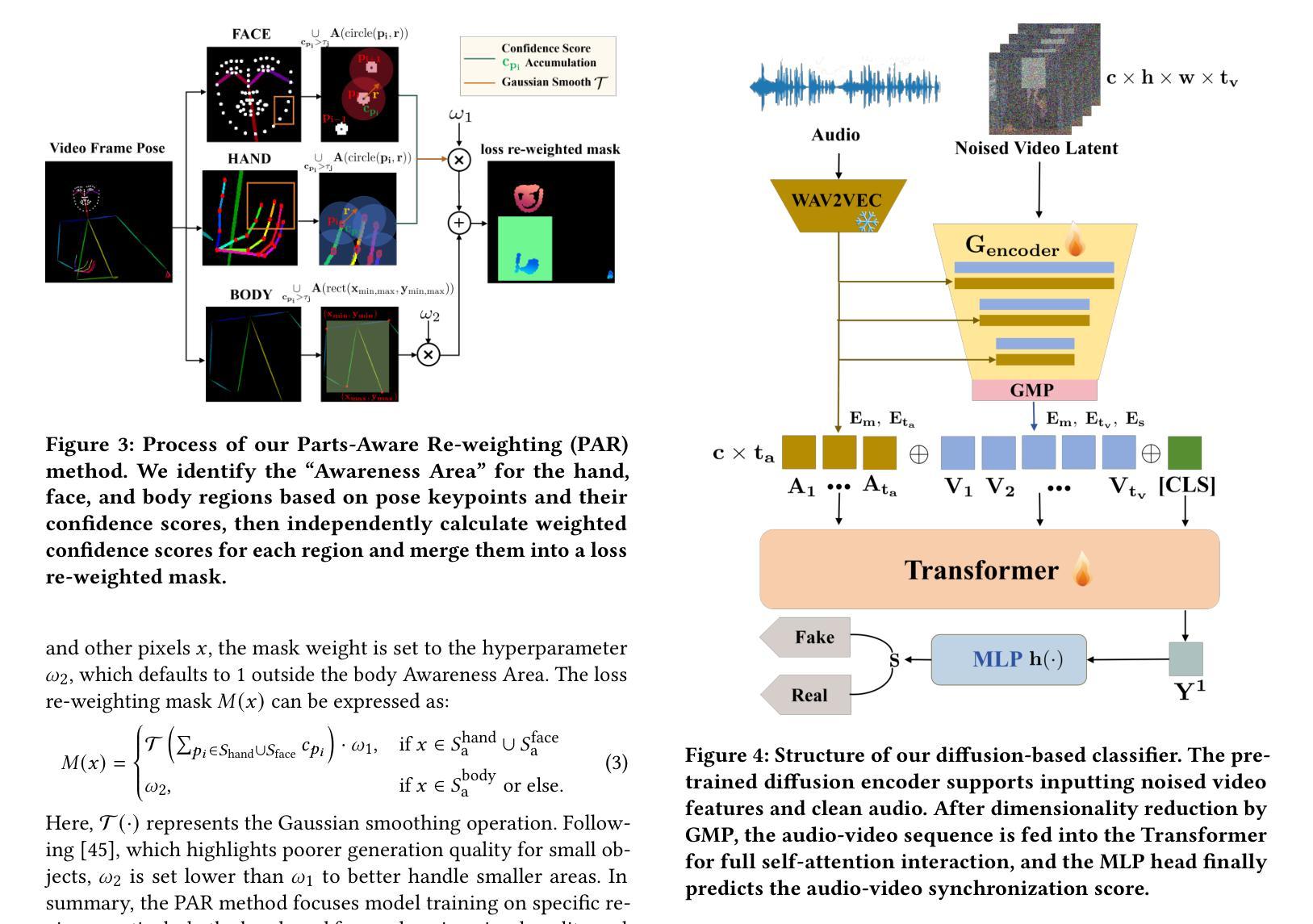
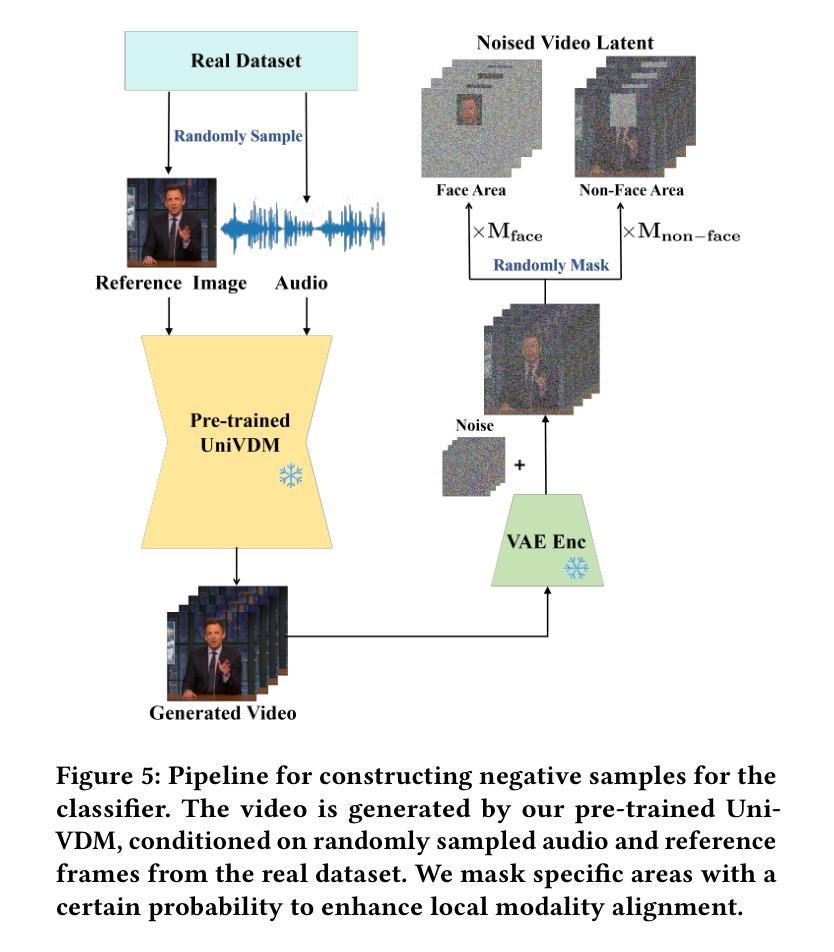
Audio-driven human animation technology is widely used in human-computer interaction, and the emergence of diffusion models has further advanced its development. Currently, most methods rely on multi-stage generation and intermediate representations, resulting in long inference time and issues with generation quality in specific foreground regions and audio-motion consistency. These shortcomings are primarily due to the lack of localized fine-grained supervised guidance. To address above challenges, we propose Parts-aware Audio-driven Human Animation, PAHA, a unit enhancement and guidance framework for audio-driven upper-body animation. We introduce two key methods: Parts-Aware Re-weighting (PAR) and Parts Consistency Enhancement (PCE). PAR dynamically adjusts regional training loss weights based on pose confidence scores, effectively improving visual quality. PCE constructs and trains diffusion-based regional audio-visual classifiers to improve the consistency of motion and co-speech audio. Afterwards, we design two novel inference guidance methods for the foregoing classifiers, Sequential Guidance (SG) and Differential Guidance (DG), to balance efficiency and quality respectively. Additionally, we build CNAS, the first public Chinese News Anchor Speech dataset, to advance research and validation in this field. Extensive experimental results and user studies demonstrate that PAHA significantly outperforms existing methods in audio-motion alignment and video-related evaluations. The codes and CNAS dataset will be released upon acceptance.
音频驱动的人形动画技术广泛应用于人机交互领域,扩散模型的出现进一步推动了其发展。目前,大多数方法依赖于多阶段生成和中间表示,导致推理时间长,特定前景区域生成质量和音画同步问题。这些缺点主要是由于缺乏局部精细监督指导。为了应对上述挑战,我们提出了Parts-aware Audio-driven Human Animation(PAHA),这是一个用于音频驱动的上半身动画的单位增强和指导框架。我们引入了两种关键方法:Parts-Aware Re-weighting(PAR)和Parts Consistency Enhancement(PCE)。PAR根据姿态置信度分数动态调整区域训练损失权重,有效提高视觉质量。PCE构建并训练基于扩散的区域音视频分类器,提高动作和语音的同步性。之后,我们为上述分类器设计了两种新型推理指导方法:Sequential Guidance(SG)和Differential Guidance(DG),以平衡效率和质量。此外,我们构建了首个公共中文新闻主播语音数据集CNAS,以推动该领域的研究和验证。大量的实验结果和用户研究表明,PAHA在音频动作对齐和视频相关评估方面显著优于现有方法。代码和CNAS数据集将在接受后发布。
论文及项目相关链接
PDF revised
Summary
基于音频驱动的人形动画技术在人机交互中的广泛应用,针对当前方法存在的推理时间长、前景区域生成质量问题和音频运动一致性等问题,提出了Parts-aware Audio-driven Human Animation(PAHA)框架。该框架包括Parts-Aware Re-weighting(PAR)和Parts Consistency Enhancement(PCE)两个关键方法,并设计了两种新型推理指导方法,实现了效率和质量的平衡。同时,建立了首个中文新闻主播语音数据集CNAS,以推动该领域的研究和验证。
Key Takeaways
- 音频驱动的人形动画技术在人机交互中广泛应用,但存在推理时间长、生成质量问题和音频运动一致性挑战。
- Parts-aware Audio-driven Human Animation(PAHA)框架被提出,以解决上述问题。
- PAHA包括Parts-Aware Re-weighting(PAR)和Parts Consistency Enhancement(PCE)两个关键方法,分别用于提高视觉质量和运动一致性。
- 设计了两种新型推理指导方法,实现了效率和质量的平衡。
- 建立了首个中文新闻主播语音数据集CNAS,用于研究和验证该领域的技术。
- 实验和用户研究结果表明,PAHA在音频运动对齐和视频相关评估方面显著优于现有方法。
点此查看论文截图