⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-14 更新
Semantic Localization Guiding Segment Anything Model For Reference Remote Sensing Image Segmentation
Authors:Shuyang Li, Shuang Wang, Zhuangzhuang Sun, Jing Xiao
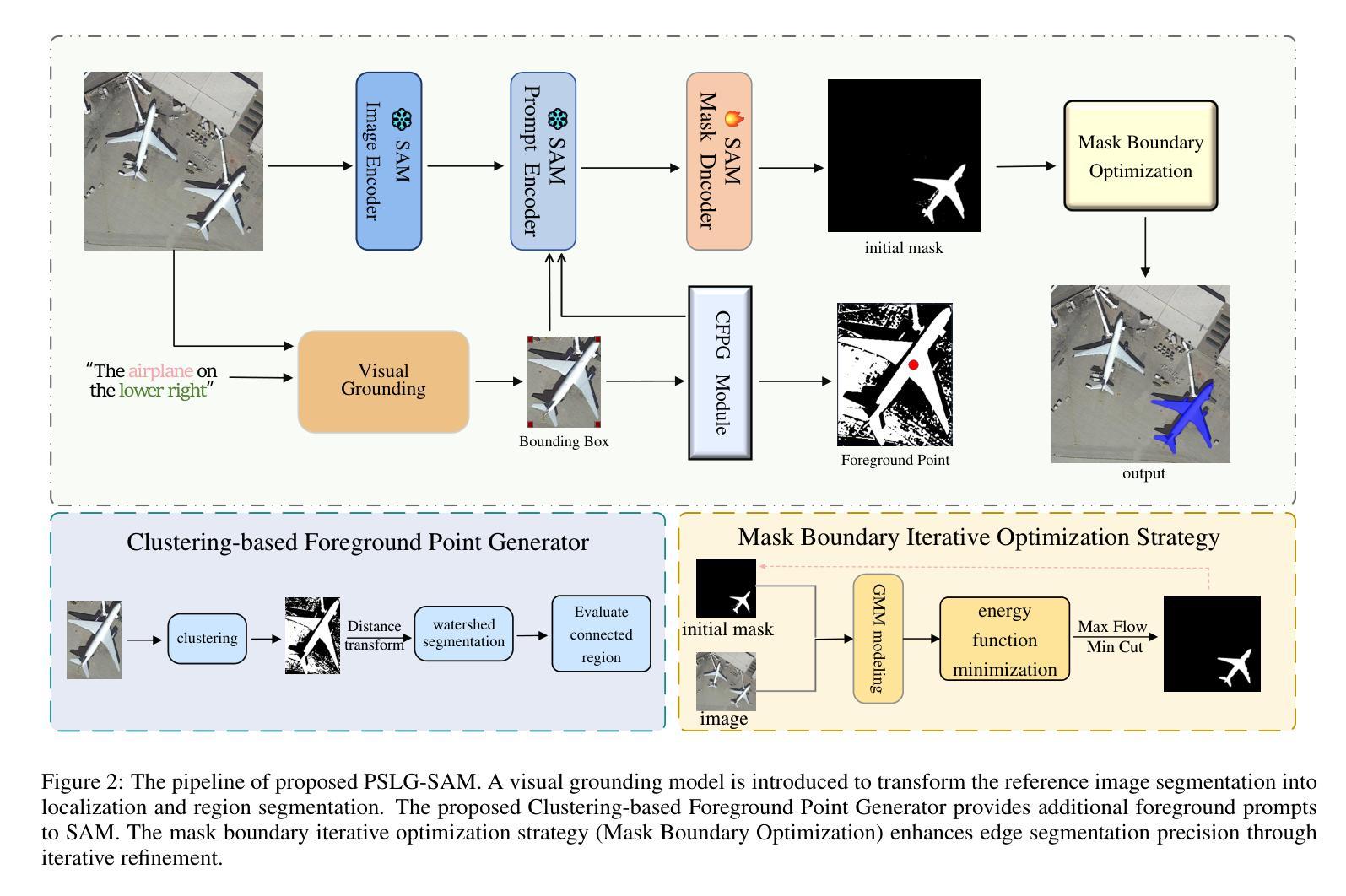
The Reference Remote Sensing Image Segmentation (RRSIS) task generates segmentation masks for specified objects in images based on textual descriptions, which has attracted widespread attention and research interest. Current RRSIS methods rely on multi-modal fusion backbones and semantic segmentation heads but face challenges like dense annotation requirements and complex scene interpretation. To address these issues, we propose a framework named \textit{prompt-generated semantic localization guiding Segment Anything Model}(PSLG-SAM), which decomposes the RRSIS task into two stages: coarse localization and fine segmentation. In coarse localization stage, a visual grounding network roughly locates the text-described object. In fine segmentation stage, the coordinates from the first stage guide the Segment Anything Model (SAM), enhanced by a clustering-based foreground point generator and a mask boundary iterative optimization strategy for precise segmentation. Notably, the second stage can be train-free, significantly reducing the annotation data burden for the RRSIS task. Additionally, decomposing the RRSIS task into two stages allows for focusing on specific region segmentation, avoiding interference from complex scenes.We further contribute a high-quality, multi-category manually annotated dataset. Experimental validation on two datasets (RRSIS-D and RRSIS-M) demonstrates that PSLG-SAM achieves significant performance improvements and surpasses existing state-of-the-art models.Our code will be made publicly available.
遥感图像参考分割(RRSIS)任务基于文本描述为图像中的指定对象生成分割掩膜,这已引起广泛的关注和研究的兴趣。目前的RRSIS方法依赖于多模态融合主干和语义分割头,但面临着密集标注要求和复杂场景解释等挑战。为了解决这些问题,我们提出了一种名为”基于提示生成的语义定位引导任何事物分割模型”(PSLG-SAM)的框架,将RRSIS任务分解为两个阶段:粗略定位和精细分割。在粗略定位阶段,视觉定位网络大致定位文本描述的对象。在精细分割阶段,第一阶段的坐标引导任何事物分割模型(SAM),通过基于聚类的前景点生成器和掩膜边界迭代优化策略进行精确分割。值得注意的是,第二阶段可以无训练地实现,显著减少了RRSIS任务的标注数据负担。此外,将RRSIS任务分解成两个阶段,可以专注于特定区域的分割,避免复杂场景的干扰。我们还贡献了一个高质量、多类别的手动标注数据集。在两个数据集(RRSIS-D和RRSIS-M)上的实验验证表明,PSLG-SAM实现了显著的性能改进,并超越了现有的最先进的模型。我们的代码将公开可用。
论文及项目相关链接
Summary:
本文介绍了远程遥感图像分割任务(RRSIS)的挑战和解决方案。为了解决这个问题,提出了一种名为PSLG-SAM的框架,该框架将RRSIS任务分解为粗定位和精细分割两个阶段。通过视觉定位网络粗略定位文本描述的对象,然后通过坐标指导精细分割模型进行精确分割。这种方法可以减少标注数据负担,避免复杂场景的干扰。实验验证显示,PSLG-SAM在RRSIS任务上取得了显著的性能提升,超过了现有最先进的模型。
Key Takeaways:
- RRSIS任务是基于文本描述生成遥感图像指定对象的分割掩模。
- 当前RRSIS方法面临密集标注需求和复杂场景解读的挑战。
- PSLG-SAM框架被提出以解决这些问题,分为粗定位和精细分割两个阶段。
- 粗定位阶段通过视觉定位网络粗略定位文本描述的对象。
- 精细分割阶段利用第一阶段坐标指导精细分割模型进行精确分割。
- 第二阶段可以无训练状态下进行,显著减少了RRSIS任务的标注数据负担。
点此查看论文截图