⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-14 更新
VideoDeepResearch: Long Video Understanding With Agentic Tool Using
Authors:Huaying Yuan, Zheng Liu, Junjie Zhou, Ji-Rong Wen, Zhicheng Dou
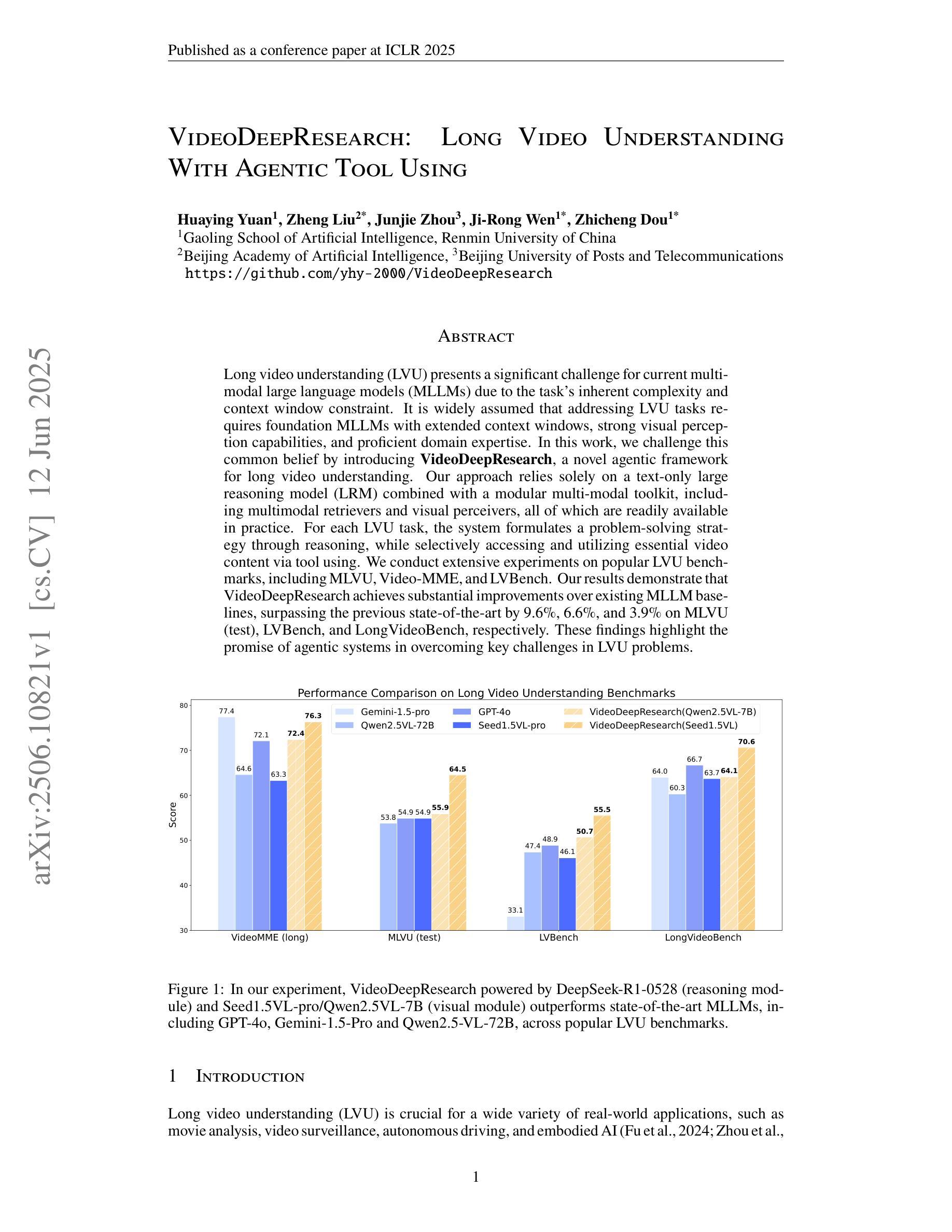
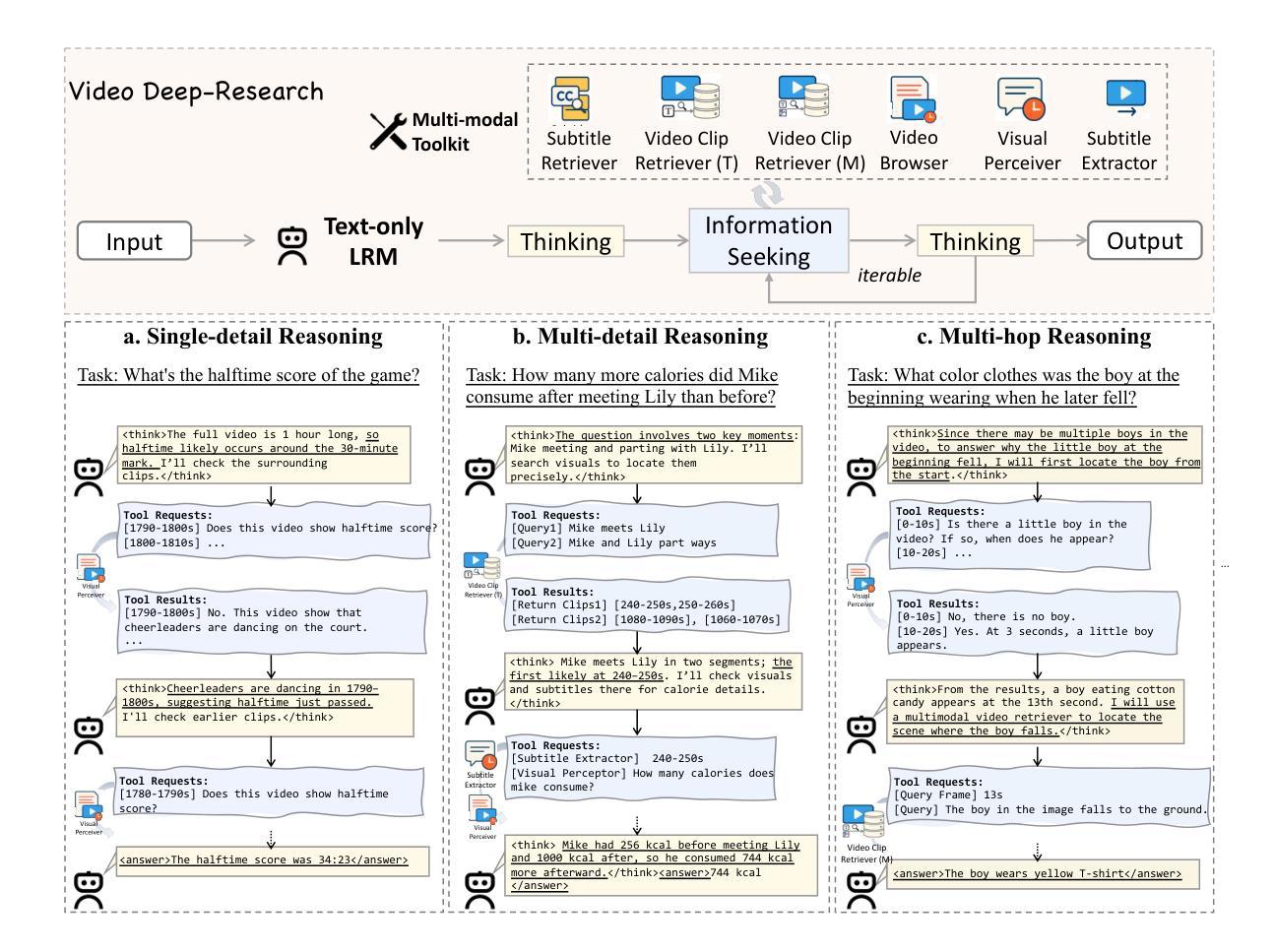
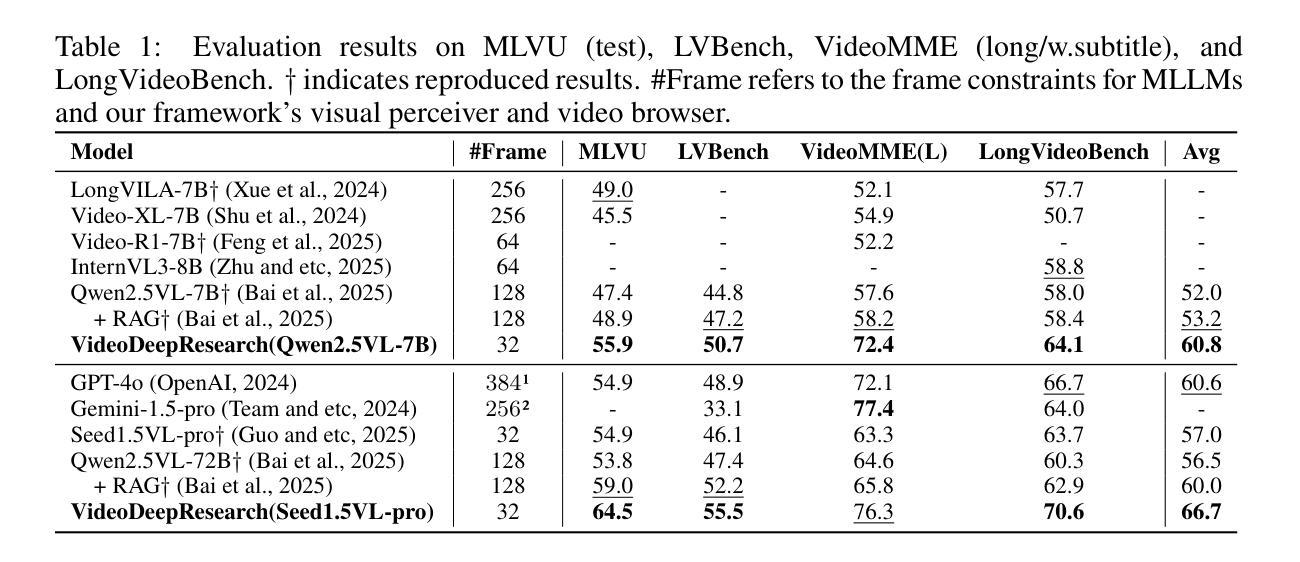
Long video understanding (LVU) presents a significant challenge for current multi-modal large language models (MLLMs) due to the task’s inherent complexity and context window constraint. It is widely assumed that addressing LVU tasks requires foundation MLLMs with extended context windows, strong visual perception capabilities, and proficient domain expertise. In this work, we challenge this common belief by introducing VideoDeepResearch, a novel agentic framework for long video understanding. Our approach relies solely on a text-only large reasoning model (LRM) combined with a modular multi-modal toolkit, including multimodal retrievers and visual perceivers, all of which are readily available in practice. For each LVU task, the system formulates a problem-solving strategy through reasoning, while selectively accessing and utilizing essential video content via tool using. We conduct extensive experiments on popular LVU benchmarks, including MLVU, Video-MME, and LVBench. Our results demonstrate that VideoDeepResearch achieves substantial improvements over existing MLLM baselines, surpassing the previous state-of-the-art by 9.6%, 6.6%, and 3.9% on MLVU (test), LVBench, and LongVideoBench, respectively. These findings highlight the promise of agentic systems in overcoming key challenges in LVU problems.
长视频理解(LVU)对当前的多模态大型语言模型(MLLMs)提出了重大挑战,这主要是由于该任务的固有复杂性和上下文窗口约束。普遍认为,解决LVU任务需要具有扩展上下文窗口、强大视觉感知能力和专业领域知识的基础MLLMs。在这项工作中,我们通过引入VideoDeepResearch,这是一个用于长视频理解的新型代理框架,来挑战这一普遍信念。我们的方法仅依赖于文本大型推理模型(LRM)和模块化多模态工具包,包括多模态检索器和视觉感知器,所有这些在实践中都可轻松使用。对于每个LVU任务,该系统通过推理制定问题解决策略,同时通过工具选择性访问和利用重要的视频内容。我们在流行的LVU基准测试上进行了大量实验,包括MLVU、Video-MME和LVBench。我们的结果表明,VideoDeepResearch在现有的MLLM基准测试上实现了显著改进,在MLVU(测试)、LVBench和LongVideoBench上的准确率分别提高了9.6%、6.6%和3.9%。这些发现突显了代理系统在克服LVU问题的关键挑战方面的潜力。
论文及项目相关链接
摘要
视频深度研究是一个新颖的针对长视频理解的框架,它通过采用模块化多模态工具集(包括多模态检索器和视觉感知器)和文本推理模型,无需特定的多模态大型语言模型即可应对长视频理解的挑战。该框架通过推理制定问题解决方案,并通过工具选择性访问和利用视频内容。实验结果表明,VideoDeepResearch在MLVU、Video-MME和LVBench等流行长视频理解基准测试上取得了显著的改进,超越了之前最好的成绩。这表明代理系统可能在解决长视频理解问题上展现出巨大的潜力。这一新发现颠覆了目前认为解决长视频理解任务需要基础多模态大型语言模型的普遍假设。这一框架不仅展示了技术上的突破,也为未来的研究提供了新的视角和方向。该框架提供了一种创新的解决方案,将现有的视频理解技术提升到了一个全新的水平。尽管无需大型语言模型也能取得良好效果,但在未来研究中对更多技术的集成和改进仍然值得期待。这一发现对于推动视频理解领域的发展具有重要意义。
关键见解
- VideoDeepResearch框架通过结合文本推理模型和模块化多模态工具集应对长视频理解的挑战。
点此查看论文截图
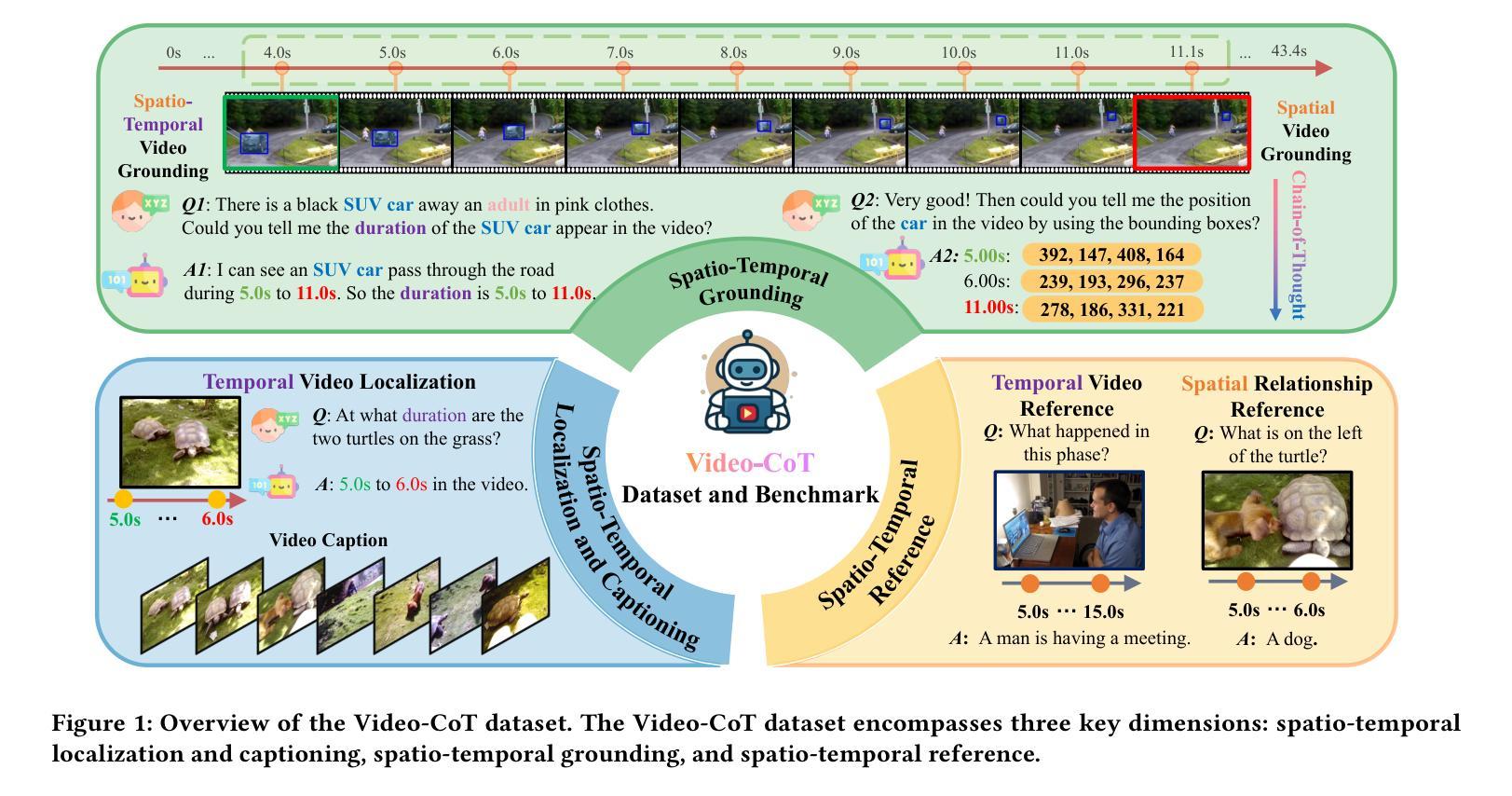
Video-CoT: A Comprehensive Dataset for Spatiotemporal Understanding of Videos Based on Chain-of-Thought
Authors:Shuyi Zhang, Xiaoshuai Hao, Yingbo Tang, Lingfeng Zhang, Pengwei Wang, Zhongyuan Wang, Hongxuan Ma, Shanghang Zhang
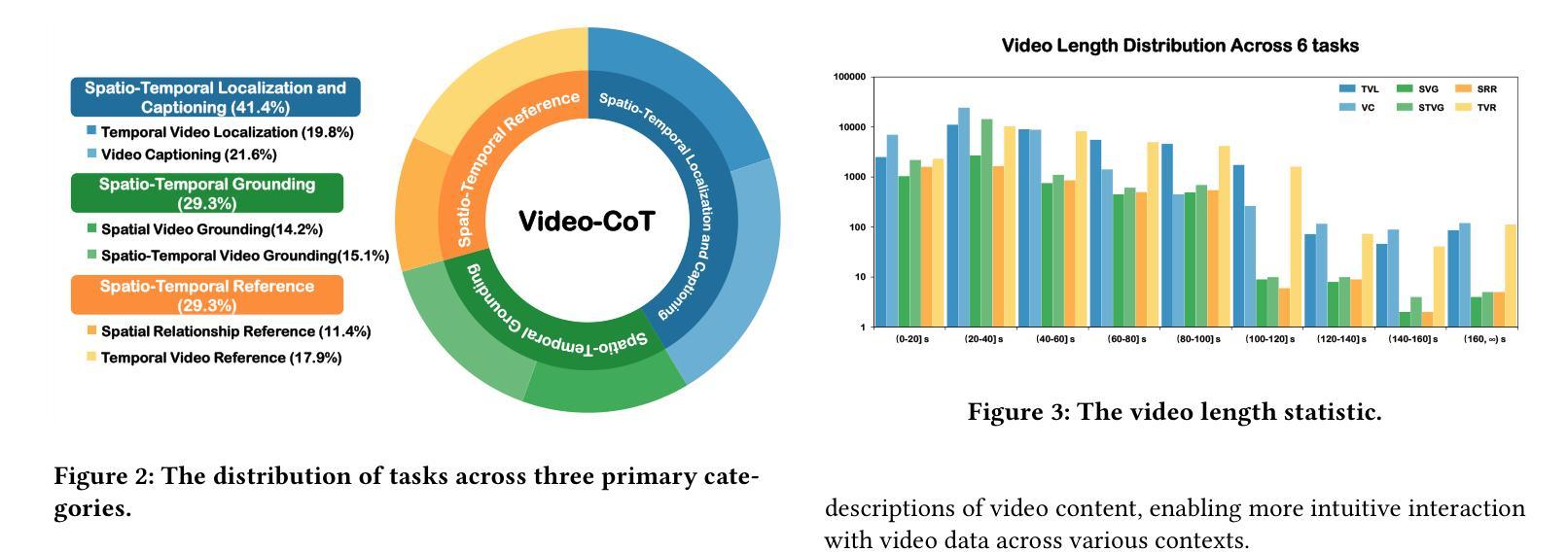
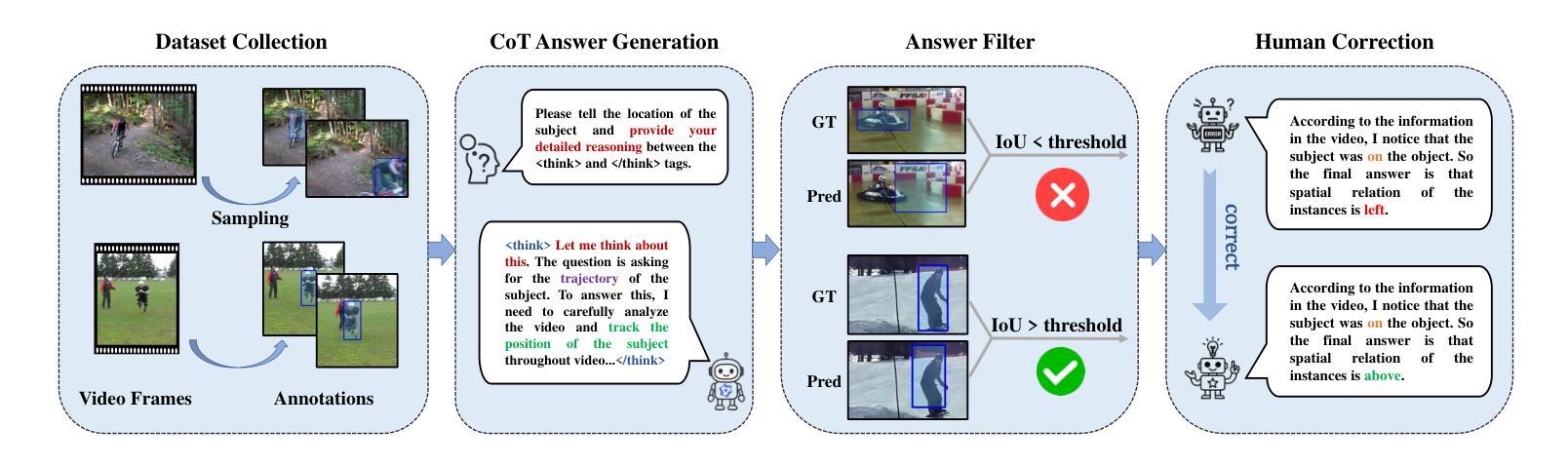
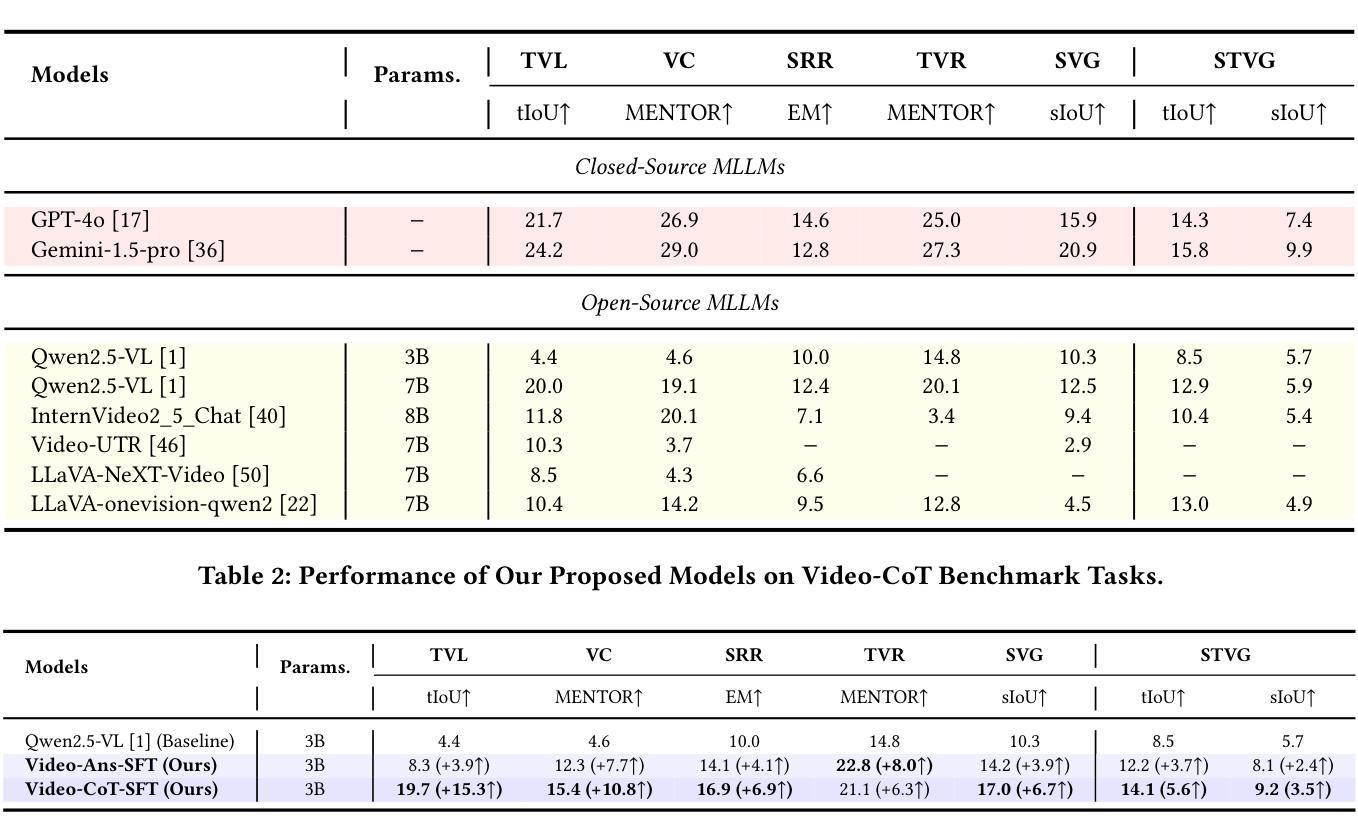
Video content comprehension is essential for various applications, ranging from video analysis to interactive systems. Despite advancements in large-scale vision-language models (VLMs), these models often struggle to capture the nuanced, spatiotemporal details essential for thorough video analysis. To address this gap, we introduce Video-CoT, a groundbreaking dataset designed to enhance spatiotemporal understanding using Chain-of-Thought (CoT) methodologies. Video-CoT contains 192,000 fine-grained spa-tiotemporal question-answer pairs and 23,000 high-quality CoT-annotated samples, providing a solid foundation for evaluating spatiotemporal understanding in video comprehension. Additionally, we provide a comprehensive benchmark for assessing these tasks, with each task featuring 750 images and tailored evaluation metrics. Our extensive experiments reveal that current VLMs face significant challenges in achieving satisfactory performance, high-lighting the difficulties of effective spatiotemporal understanding. Overall, the Video-CoT dataset and benchmark open new avenues for research in multimedia understanding and support future innovations in intelligent systems requiring advanced video analysis capabilities. By making these resources publicly available, we aim to encourage further exploration in this critical area. Project website:https://video-cot.github.io/ .
视频内容理解对于从视频分析到交互系统的各种应用至关重要。尽管大规模视觉语言模型(VLMs)取得了进展,但这些模型在捕捉对于全面视频分析至关重要的细微时空细节方面往往面临困难。为了弥补这一差距,我们引入了Video-CoT,这是一个突破性的数据集,旨在利用思维链(CoT)方法增强时空理解。Video-CoT包含19.2万个精细的时空问答对和2.3万个高质量的CoT注释样本,为评估视频理解中的时空理解提供了坚实的基础。此外,我们还为评估这些任务提供了一个综合基准测试,每个任务包含750张图像和定制的评估指标。我们的大量实验表明,目前的VLMs在实现令人满意的性能方面面临巨大挑战,突显了有效时空理解的困难。总的来说,Video-CoT数据集和基准测试为多媒体理解的研究开辟了新的途径,并支持未来需要高级视频分析能力的智能系统的创新。我们公开提供这些资源,旨在鼓励在这一关键领域的进一步探索。项目网站:https://video-cot.github.io/。
论文及项目相关链接
Summary
本文介绍了视频内容理解的重要性,并指出尽管大规模视觉语言模型(VLMs)有所发展,但在细微的时空细节捕捉方面仍存在挑战。为解决此问题,本文引入了Video-CoT数据集,采用Chain-of-Thought(CoT)方法增强时空理解。Video-CoT包含19.2万精细时空问答对和2.3万高质量的CoT注释样本,为视频理解中的时空理解评估提供了坚实基础。此外,本文还提供了一项综合基准测试,以评估这些任务,每个任务包含750张图像和定制评估指标。实验表明,当前VLMs在实现满意性能方面面临重大挑战,强调有效时空理解的困难。总体而言,Video-CoT数据集和基准测试为多媒体理解研究开辟了新途径,并支持未来需要先进视频分析能力的智能系统的创新。
Key Takeaways
- 视频内容理解对于从视频分析到交互系统等各种应用至关重要。
- 尽管有大规模视觉语言模型(VLMs)的发展,但它们在捕捉视频的细微时空细节方面仍面临挑战。
- Video-CoT数据集采用Chain-of-Thought(CoT)方法,旨在增强时空理解。
- Video-CoT包含192,000个精细的时空问答对和23,000个高质量的CoT注释样本,为视频理解中的时空理解评估提供了基础。
- 提供了一项综合基准测试,以评估视频理解任务,包含750张图像和定制评估指标。
- 实验显示,当前VLMs在视频理解方面性能有限,需要更有效的时空理解方法。
点此查看论文截图