⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-14 更新
PointGS: Point Attention-Aware Sparse View Synthesis with Gaussian Splatting
Authors:Lintao Xiang, Hongpei Zheng, Yating Huang, Qijun Yang, Hujun Yin
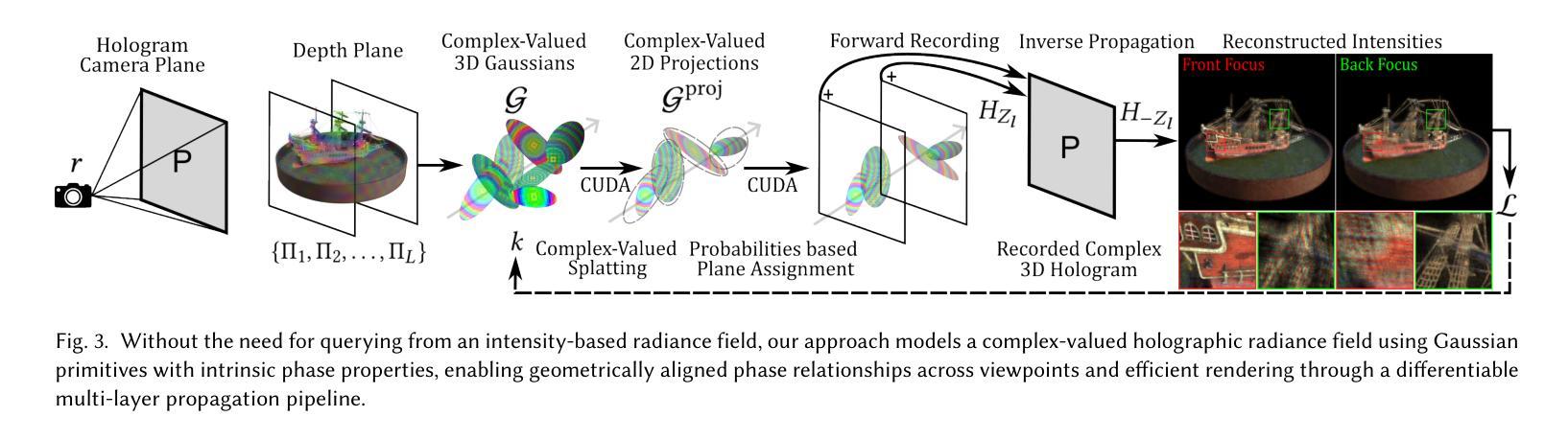
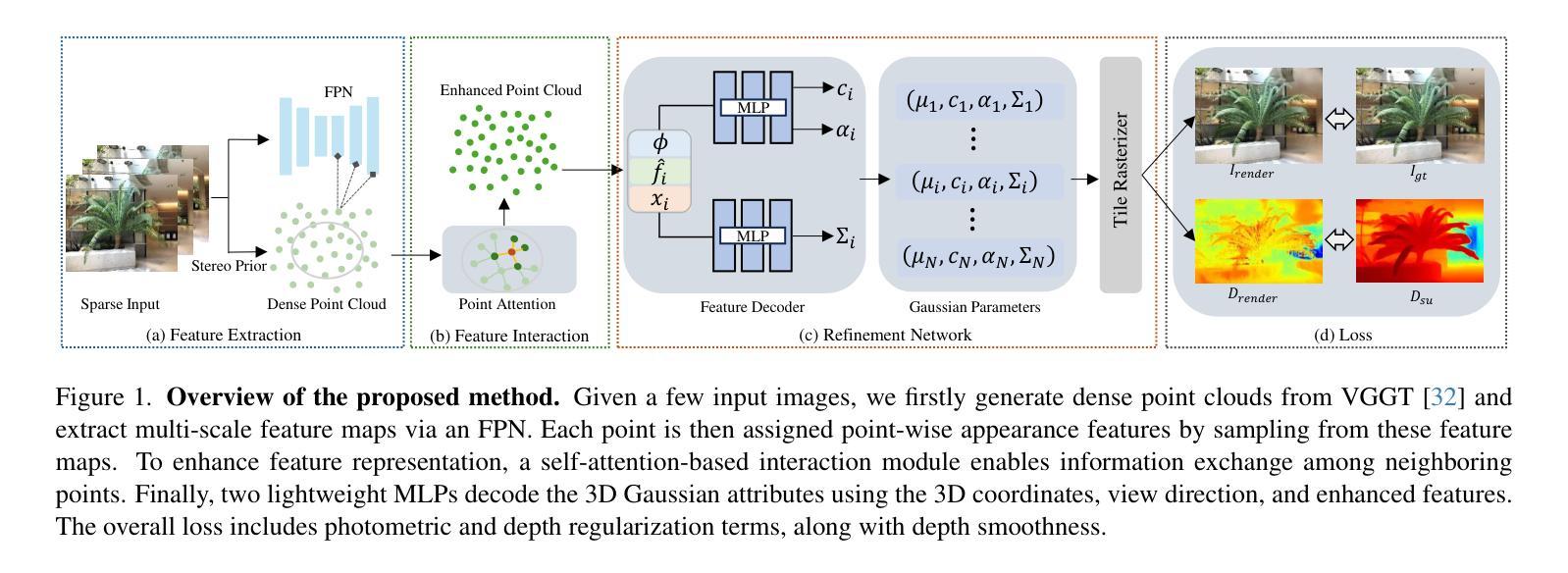
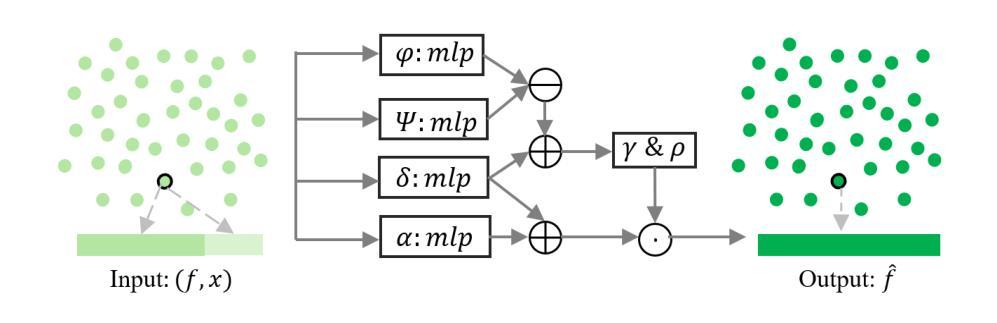
3D Gaussian splatting (3DGS) is an innovative rendering technique that surpasses the neural radiance field (NeRF) in both rendering speed and visual quality by leveraging an explicit 3D scene representation. Existing 3DGS approaches require a large number of calibrated views to generate a consistent and complete scene representation. When input views are limited, 3DGS tends to overfit the training views, leading to noticeable degradation in rendering quality. To address this limitation, we propose a Point-wise Feature-Aware Gaussian Splatting framework that enables real-time, high-quality rendering from sparse training views. Specifically, we first employ the latest stereo foundation model to estimate accurate camera poses and reconstruct a dense point cloud for Gaussian initialization. We then encode the colour attributes of each 3D Gaussian by sampling and aggregating multiscale 2D appearance features from sparse inputs. To enhance point-wise appearance representation, we design a point interaction network based on a self-attention mechanism, allowing each Gaussian point to interact with its nearest neighbors. These enriched features are subsequently decoded into Gaussian parameters through two lightweight multi-layer perceptrons (MLPs) for final rendering. Extensive experiments on diverse benchmarks demonstrate that our method significantly outperforms NeRF-based approaches and achieves competitive performance under few-shot settings compared to the state-of-the-art 3DGS methods.
3D高斯映射(3DGS)是一种创新的渲染技术,它通过利用明确的3D场景表示,在渲染速度与视觉质量上都超越了神经辐射场(NeRF)。现有的3DGS方法需要大量的校准视图来生成一致且完整的场景表示。当输入视图有限时,3DGS往往会对训练视图过度拟合,导致渲染质量明显下降。为了解决这个问题,我们提出了一种基于点特征感知的高斯映射框架,实现了从稀疏训练视图的实时高质量渲染。具体来说,我们首先采用最新的立体基础模型估计精确的相机姿态,并对高斯初始化重建密集点云。然后,我们通过从稀疏输入中采样和聚合多尺度2D外观特征,对每个3D高斯的颜色属性进行编码。为了增强点级的外观表示,我们设计了一个基于自注意力机制的点交互网络,允许每个高斯点与最近的邻居进行交互。这些丰富的特征随后通过两个轻量级的多层感知器(MLP)解码为高斯参数,用于最终渲染。在多种基准测试上的大量实验表明,我们的方法显著优于基于NeRF的方法,并在小样本设置下实现了与最先进的3DGS方法相当的性能。
论文及项目相关链接
Summary
本文介绍了基于点特征的3D高斯融合技术,该技术通过利用稀疏训练视图实现实时高质量渲染。通过采用最新的立体基础模型估计相机姿态并重建密集点云进行高斯初始化,采样并聚合多尺度二维外观特征,增强点特征表示,设计基于自注意力机制的点交互网络,实现高质量渲染。实验证明该方法在NeRF方法基础上显著提高渲染速度和视觉质量。
Key Takeaways
- 3D高斯融合技术(3DGS)是一种利用稀疏训练视图实现实时高质量渲染的创新渲染技术。
- 该技术利用最新的立体基础模型估计相机姿态并重建密集点云进行高斯初始化。
- 通过采样和聚合多尺度二维外观特征来增强点特征表示。
- 设计了一种基于自注意力机制的点交互网络,允许每个高斯点与最近的邻居进行交互。
- 该方法显著提高了渲染速度和视觉质量,超越了神经辐射场(NeRF)技术。
点此查看论文截图


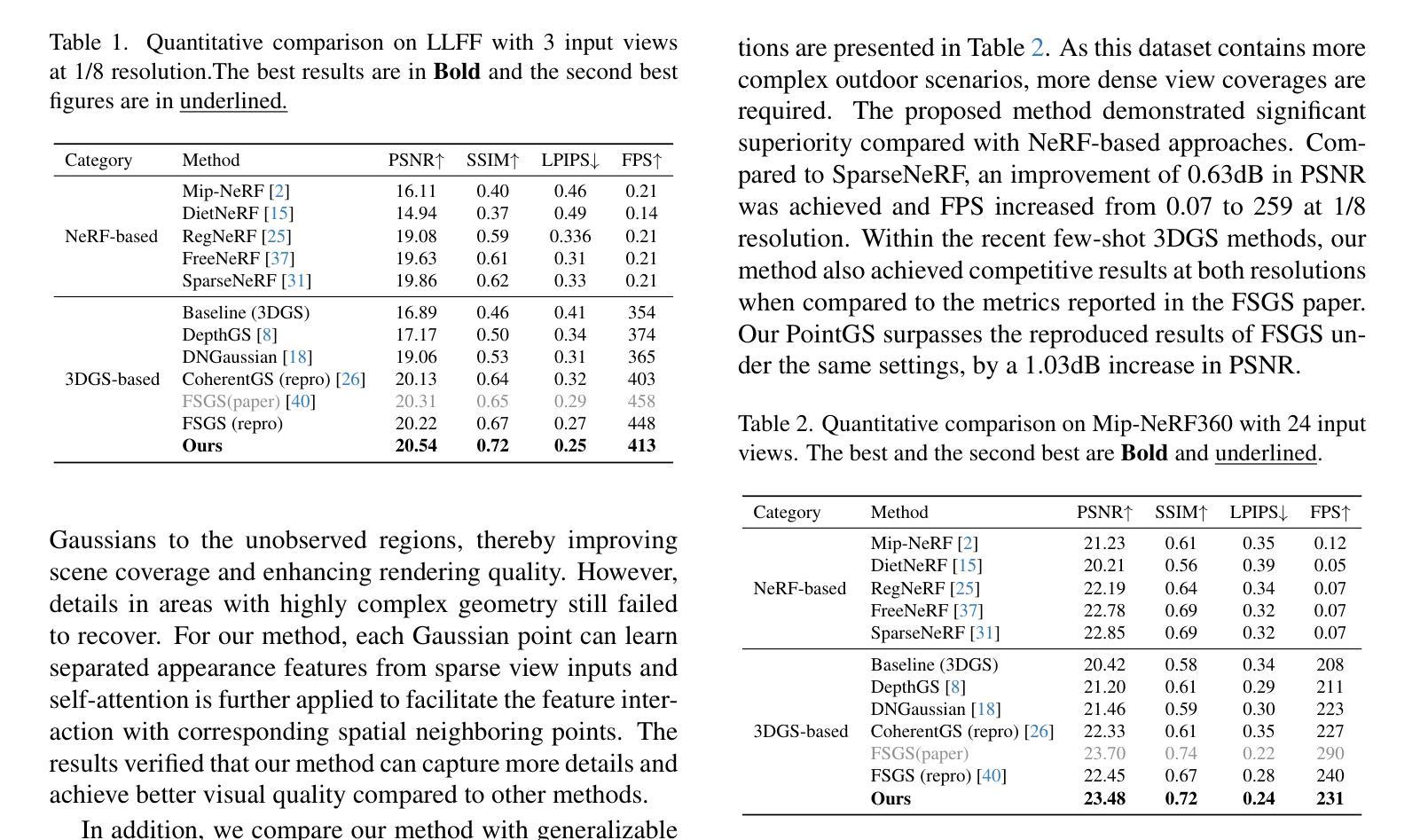
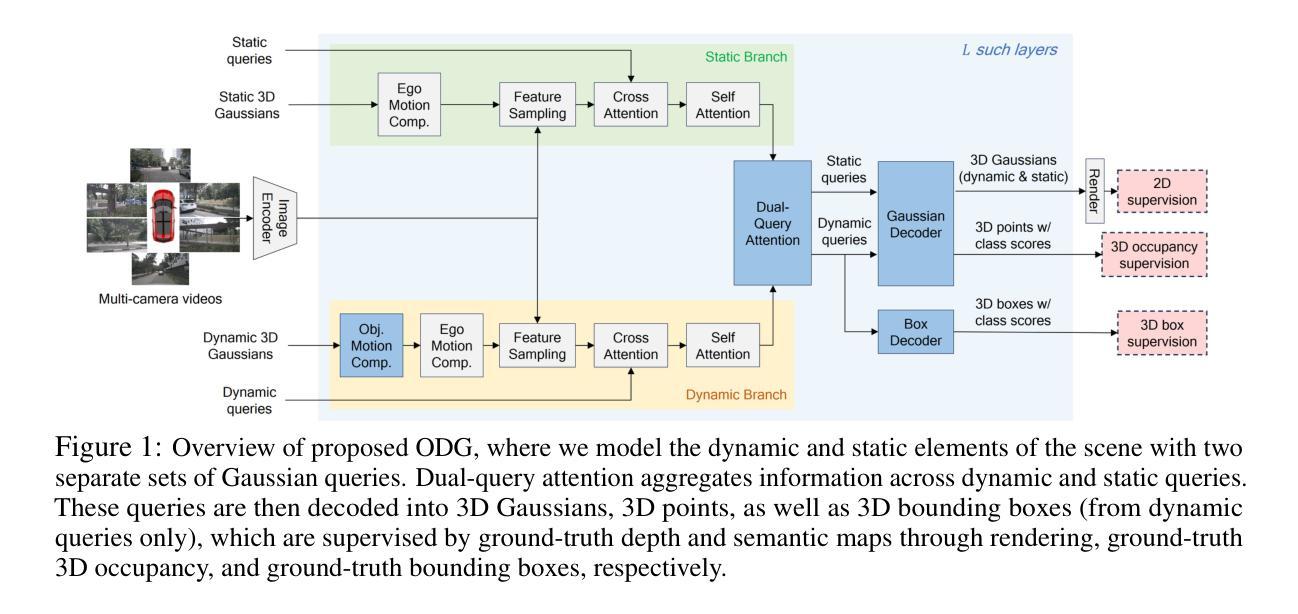
ODG: Occupancy Prediction Using Dual Gaussians
Authors:Yunxiao Shi, Yinhao Zhu, Shizhong Han, Jisoo Jeong, Amin Ansari, Hong Cai, Fatih Porikli
Occupancy prediction infers fine-grained 3D geometry and semantics from camera images of the surrounding environment, making it a critical perception task for autonomous driving. Existing methods either adopt dense grids as scene representation, which is difficult to scale to high resolution, or learn the entire scene using a single set of sparse queries, which is insufficient to handle the various object characteristics. In this paper, we present ODG, a hierarchical dual sparse Gaussian representation to effectively capture complex scene dynamics. Building upon the observation that driving scenes can be universally decomposed into static and dynamic counterparts, we define dual Gaussian queries to better model the diverse scene objects. We utilize a hierarchical Gaussian transformer to predict the occupied voxel centers and semantic classes along with the Gaussian parameters. Leveraging the real-time rendering capability of 3D Gaussian Splatting, we also impose rendering supervision with available depth and semantic map annotations injecting pixel-level alignment to boost occupancy learning. Extensive experiments on the Occ3D-nuScenes and Occ3D-Waymo benchmarks demonstrate our proposed method sets new state-of-the-art results while maintaining low inference cost.
环境占用预测通过从周围环境的相机图像推断精细的3D几何结构和语义,成为自动驾驶中的关键感知任务。现有方法要么采用密集网格作为场景表示,难以扩展到高分辨率,要么使用一组稀疏查询来学习整个场景,这不足以处理各种对象特征。在本文中,我们提出了ODG,一种分层双稀疏高斯表示法,以有效地捕捉复杂的场景动态。我们观察到驾驶场景可以普遍地分解为静态和动态两部分,在此基础上,我们定义双高斯查询以更好地模拟各种场景对象。我们利用分层高斯变换器预测占用的体素中心、语义类别以及高斯参数。利用3D高斯喷绘的实时渲染能力,我们还通过可用的深度语义图注释施加渲染监督,注入像素级对齐以促进占用学习。在Occ3D-nuScenes和Occ3D-Waymo基准测试上的广泛实验表明,我们提出的方法在保持较低推理成本的同时,创造了新的最佳结果。
论文及项目相关链接
Summary
本文提出了一种用于自主驾驶中占用预测的精细三维几何与语义推断方法。文章通过构建分层双稀疏高斯表示(ODG),有效地捕捉复杂的场景动态。通过对驾驶场景进行静态与动态分解,采用双高斯查询进行场景对象的建模。结合高斯参数,利用层次高斯变换器预测占据体素中心和语义类别。通过利用三维高斯贴图的实时渲染能力,通过深度与语义地图注释进行渲染监督,实现了占用学习的提升。在Occ3D-nuScenes和Occ3D-Waymo基准测试上的实验表明,该方法在保持低推理成本的同时,取得了最新的最佳结果。
Key Takeaways
- 本文提出了一种新的占用预测方法,结合了精细的三维几何和语义信息。
- 采用分层双稀疏高斯表示(ODG)有效捕捉复杂场景动态。
- 通过将驾驶场景分解为静态和动态部分,采用双高斯查询进行建模。
- 利用层次高斯变换器预测占据体素中心和语义类别。
- 通过实时渲染能力和深度与语义地图注释的渲染监督提升占用学习。
- 在多个基准测试上取得了最新的最佳结果。
点此查看论文截图

Complex-Valued Holographic Radiance Fields
Authors:Yicheng Zhan, Dong-Ha Shin, Seung-Hwan Baek, Kaan Akşit
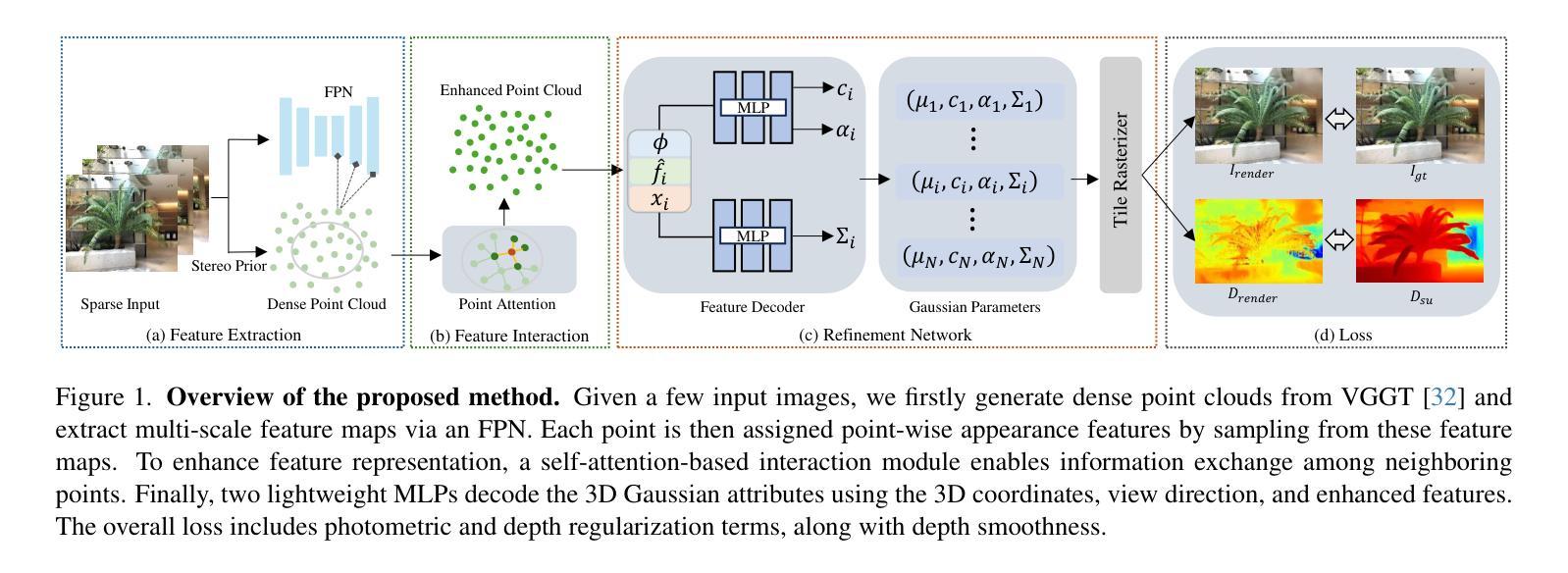
Modeling the full properties of light, including both amplitude and phase, in 3D representations is crucial for advancing physically plausible rendering, particularly in holographic displays. To support these features, we propose a novel representation that optimizes 3D scenes without relying on intensity-based intermediaries. We reformulate 3D Gaussian splatting with complex-valued Gaussian primitives, expanding support for rendering with light waves. By leveraging RGBD multi-view images, our method directly optimizes complex-valued Gaussians as a 3D holographic scene representation. This eliminates the need for computationally expensive hologram re-optimization. Compared with state-of-the-art methods, our method achieves 30x-10,000x speed improvements while maintaining on-par image quality, representing a first step towards geometrically aligned, physically plausible holographic scene representations.
在三维表示中对光的全属性进行建模,包括振幅和相位,对于推进物理可信渲染至关重要,特别是在全息显示中。为了支持这些特性,我们提出了一种新的表示方法,它优化了三维场景,且不依赖于基于强度的中介。我们以复值高斯原始数据重新制定了三维高斯拼贴,扩大了对光波渲染的支持。通过利用RGBD多视角图像,我们的方法直接优化复值高斯值作为三维全息场景表示。这消除了计算昂贵全息图重新优化的必要性。与最先进的方法相比,我们的方法在实现图像质量相当的同时,实现了30倍至1万倍的速度提升,朝着几何对齐、物理可信全息场景表示迈出了第一步。
论文及项目相关链接
PDF 28 pages, 21 figures
Summary
采用全光属性(包括振幅和相位)的建模对于推动物理真实渲染至关重要,特别是在全息显示领域。我们提出了一种新型的三维场景表示方法,优化三维高斯描图法并直接使用复数高斯的原生形态来渲染光线,同时RGBD多视角图像的运用直接优化了全息场景的复数高斯表示法,无需进行昂贵的全息优化计算。相较于当前主流方法,我们的方法实现了从30倍至最高达一万倍的速度提升,同时保持图像质量相当。这是朝着几何对齐的物理全息场景表示迈出的第一步。
Key Takeaways
- 利用全光属性(振幅和相位)建模对于推进物理真实渲染极为重要。特别是在全息显示领域,渲染光波的复杂性对建模提出高要求。
- 提出了一种新的三维场景表示方法,基于高斯波进行拓展支持光波的渲染,以复数高斯的原生形态进行优化处理。相较于传统的中间处理模式更加高效直接。
- 通过RGBD多视角图像的运用,直接优化了全息场景的复数高斯表示法,无需进行昂贵的全息优化计算,提高了效率。
- 该方法相较于当前主流技术有显著提高速度(达到高达一万倍)且图像质量保持稳定。这是一个革命性的突破,为后续技术改进奠定了基础。
点此查看论文截图