⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-14 更新
Self-Adapting Language Models
Authors:Adam Zweiger, Jyothish Pari, Han Guo, Ekin Akyürek, Yoon Kim, Pulkit Agrawal
Large language models (LLMs) are powerful but static; they lack mechanisms to adapt their weights in response to new tasks, knowledge, or examples. We introduce Self-Adapting LLMs (SEAL), a framework that enables LLMs to self-adapt by generating their own finetuning data and update directives. Given a new input, the model produces a self-edit-a generation that may restructure the information in different ways, specify optimization hyperparameters, or invoke tools for data augmentation and gradient-based updates. Through supervised finetuning (SFT), these self-edits result in persistent weight updates, enabling lasting adaptation. To train the model to produce effective self-edits, we use a reinforcement learning loop with the downstream performance of the updated model as the reward signal. Unlike prior approaches that rely on separate adaptation modules or auxiliary networks, SEAL directly uses the model’s own generation to control its adaptation process. Experiments on knowledge incorporation and few-shot generalization show that SEAL is a promising step toward language models capable of self-directed adaptation. Our website and code is available at https://jyopari.github.io/posts/seal.
大型语言模型(LLM)虽然强大但相对静态,它们缺乏适应新任务、知识或示例的机制来调整其权重。我们引入了自适应大型语言模型(SEAL)框架,该框架使LLM能够通过生成自己的微调数据和更新指令进行自我适应。对于新的输入,模型会产生自我编辑的一代产品,这可能会以不同的方式重组信息,指定优化超参数,或调用数据增强工具和基于梯度的更新工具。通过监督微调(SFT),这些自我编辑会导致持久的权重更新,从而实现持久的适应。为了训练模型以产生有效的自我编辑,我们使用强化学习循环,以更新模型的下游性能作为奖励信号。不同于依赖单独适应模块或辅助网络的先前方法,SEAL直接使用模型本身的生成来控制其适应过程。在知识融入和少量场景下的通用化实验表明,SEAL是朝着能够自我指导适应的语言模型方向迈出的一步。我们的网站和代码可在 https://jyopari.github.io/posts/seal 中找到。
论文及项目相关链接
Summary
大型语言模型强大但静态,无法适应新任务、知识或示例。我们提出Self-Adapting LLMs(SEAL)框架,使LLMs能够通过生成自己的微调数据和更新指令进行自我适应。给定新输入,模型产生自我编辑,通过监督微调(SFT)实现持久权重更新和长期适应。我们使用强化学习循环训练模型产生有效的自我编辑,以更新模型的下游性能作为奖励信号。不同于依赖额外适应模块或辅助网络的先前方法,SEAL直接使用模型自身的生成来控制其适应过程。
Key Takeaways
- LLMs缺乏适应新任务、知识或示例的机制。
- Self-Adapting LLMs(SEAL)框架使LLMs能够自我适应。
- 模型通过生成自我编辑实现自我适应,包括信息重组、优化超参数、数据增强和基于梯度的更新。
- 监督微调(SFT)使自我编辑导致持久的权重更新和长期适应。
- 使用强化学习循环训练模型产生有效的自我编辑。
- 下游性能作为奖励信号来评估更新模型的性能。
- SEAL不同于先前方法,它直接使用模型自身的生成控制适应过程。
点此查看论文截图


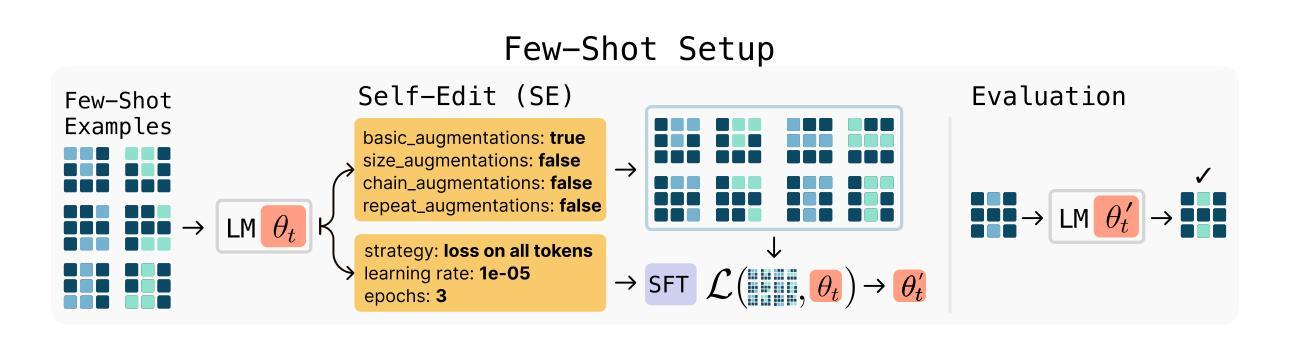

The Diffusion Duality
Authors:Subham Sekhar Sahoo, Justin Deschenaux, Aaron Gokaslan, Guanghan Wang, Justin Chiu, Volodymyr Kuleshov
Uniform-state discrete diffusion models hold the promise of fast text generation due to their inherent ability to self-correct. However, they are typically outperformed by autoregressive models and masked diffusion models. In this work, we narrow this performance gap by leveraging a key insight: Uniform-state diffusion processes naturally emerge from an underlying Gaussian diffusion. Our method, Duo, transfers powerful techniques from Gaussian diffusion to improve both training and sampling. First, we introduce a curriculum learning strategy guided by the Gaussian process, doubling training speed by reducing variance. Models trained with curriculum learning surpass autoregressive models in zero-shot perplexity on 3 of 7 benchmarks. Second, we present Discrete Consistency Distillation, which adapts consistency distillation from the continuous to the discrete setting. This algorithm unlocks few-step generation in diffusion language models by accelerating sampling by two orders of magnitude. We provide the code and model checkpoints on the project page: http://s-sahoo.github.io/duo
均匀状态离散扩散模型因其固有的自我校正能力而具有快速文本生成的潜力。然而,它们通常被自回归模型和掩码扩散模型所超越。在这项工作中,我们通过利用一个关键见解来缩小性能差距:均匀状态扩散过程自然来自于基础的高斯扩散。我们的方法Duo,从高斯扩散转移强大技术,提高了训练和采样的性能。首先,我们引入了一种由高斯过程引导的课程学习策略,通过减少方差使训练速度翻倍。用课程学习策略训练的模型在7个基准测试中的3个上实现了零射击困惑度超过自回归模型。其次,我们提出了离散一致性蒸馏,该算法将一致性蒸馏从连续环境适应到离散环境。该算法通过加速采样速度两个数量级,实现了扩散语言模型中的少步骤生成。我们已在项目页面上提供了代码和模型检查点:http://s-sahoo.github.io/duo。
论文及项目相关链接
PDF ICML 2025. We provide the code at: https://github.com/s-sahoo/duo
Summary
本文介绍了基于均匀态离散扩散模型的文本生成方法,通过借鉴高斯扩散过程中的关键技术来提升其性能。文章提出了两种改进策略:一是引入高斯过程引导的课程体系学习策略,通过减少方差来加倍训练速度;二是在离散环境中适配一致性蒸馏技术,实现了离散一致性蒸馏。这些技术使得扩散语言模型的零样本困惑度在多个基准测试中超越自回归模型,并实现了快速采样。
Key Takeaways
- 基于均匀态离散扩散模型的文本生成方法具有自我校正的潜力,但之前被自回归模型和掩模扩散模型所超越。
- 文章提出了借鉴高斯扩散过程中的技术来提升均匀态离散扩散模型的性能。
- 引入高斯过程引导的课程体系学习策略,通过减少方差来加倍训练速度,并在某些基准测试中超越自回归模型。
- 提出了离散一致性蒸馏技术,该技术使得扩散语言模型能够实现快速采样,并解锁了少步生成的能力。
- 文章强调了将连续设置中的技术适配到离散环境中的重要性。
- 文章提供了代码和模型检查点以供研究使用。
点此查看论文截图

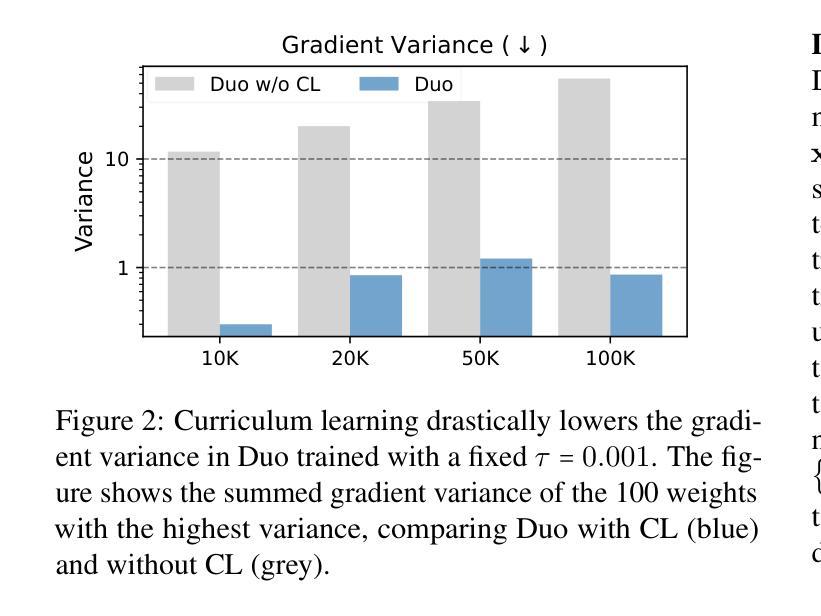
OmniFluids: Unified Physics Pre-trained Modeling of Fluid Dynamics
Authors:Rui Zhang, Qi Meng, Han Wan, Yang Liu, Zhi-Ming Ma, Hao Sun
High-fidelity and efficient simulation of fluid dynamics drive progress in various scientific and engineering applications. Traditional computational fluid dynamics methods offer strong interpretability and guaranteed convergence, but rely on fine spatial and temporal meshes, incurring prohibitive computational costs. Physics-informed neural networks (PINNs) and neural operators aim to accelerate PDE solvers using deep learning techniques. However, PINNs require extensive retraining and careful tuning, and purely data-driven operators demand large labeled datasets. Hybrid physics-aware methods embed numerical discretizations into network architectures or loss functions, but achieve marginal speed gains and become unstable when balancing coarse priors against high-fidelity measurements. To this end, we introduce OmniFluids, a unified physics pre-trained operator learning framework that integrates physics-only pre-training, coarse-grid operator distillation, and few-shot fine-tuning, which enables fast inference and accurate prediction under limited or zero data supervision. For architectural design, the key components of OmniFluids include a mixture of operators, a multi-frame decoder, and factorized Fourier layers, which enable efficient and scalable modeling of diverse physical tasks while maintaining seamless integration with physics-based supervision. Across a broad range of two- and three-dimensional benchmarks, OmniFluids significantly outperforms state-of-the-art AI-driven methods in flow field reconstruction and turbulence statistics accuracy, delivering 10-100x speedups compared to classical solvers, and accurately recovers unknown physical parameters from sparse, noisy data. This work establishes a new paradigm for efficient and generalizable surrogate modeling in complex fluid systems under limited data availability.
流体动力学的高精度和高效模拟推动了各种科学和工程应用的进步。传统的计算流体动力学方法虽然具有良好的可解释性和保证收敛性,但它们依赖于精细的空间和时间网格,计算成本高昂。物理信息神经网络(PINNs)和神经算子旨在使用深度学习技术加速偏微分方程求解器。然而,PINNs需要大量的重新训练和精细调整,而纯粹的数据驱动算子则需要大量标记数据集。混合物理感知方法将数值离散化嵌入网络架构或损失函数中,但在平衡粗略先验和高精度测量时,只实现了有限的加速,并且变得不稳定。为此,我们引入了OmniFluids,这是一个统一的物理预训练算子学习框架,它集成了仅物理预训练、粗网格算子蒸馏和少量微调,能够在有限或无数据监督的情况下实现快速推理和准确预测。在架构设计方面,OmniFluids的关键组件包括混合算子、多帧解码器和因子化傅里叶层,这些组件能够在维持与基于物理的监督无缝集成的同时,实现各种物理任务的高效和可扩展建模。在广泛的二维和三维基准测试中,OmniFluids在流场重建和湍流统计准确性方面显著优于最新的人工智能驱动方法,与经典求解器相比实现了10-100倍的加速,并能从稀疏、嘈杂的数据中准确恢复未知的物理参数。这项工作为在有限数据可用性的情况下,复杂流体系统中高效且可推广的替代建模建立了新范式。
论文及项目相关链接
Summary
本文介绍了OmniFluids,一个统一物理预训练算子学习框架,融合了物理预训练、粗网格算子蒸馏和少量精细调整技术。该框架实现了快速推断和有限或零数据监督下的准确预测。OmniFluids的关键组件包括混合算子、多帧解码器和分解傅里叶层,能高效且规模化地模拟多种物理任务,同时无缝集成物理基础监督。在广泛的二维和三维基准测试中,OmniFluids在流场重建和湍流统计准确性方面显著优于最新的人工智能驱动方法,与经典求解器相比实现了10-100倍的速度提升,并能从稀疏、嘈杂的数据中准确恢复未知的物理参数。这一工作建立了在有限数据下复杂流体系统中高效且可通用的替代建模的新范式。
Key Takeaways
- OmniFluids是一个统一物理预训练算子学习框架,融合了物理预训练技术。
- 该框架集成了粗网格算子蒸馏和少量精细调整技术,实现快速推断和有限数据监督下的准确预测。
- OmniFluids包括混合算子、多帧解码器和分解傅里叶层等关键组件。
- OmniFluids能高效且规模化地模拟多种物理任务,同时无缝集成物理基础监督。
- 在基准测试中,OmniFluids显著优于最新的人工智能驱动方法,实现了流场重建和湍流统计的高准确性。
- 与传统计算方法相比,OmniFluids提供了10-100倍的速度提升。
点此查看论文截图

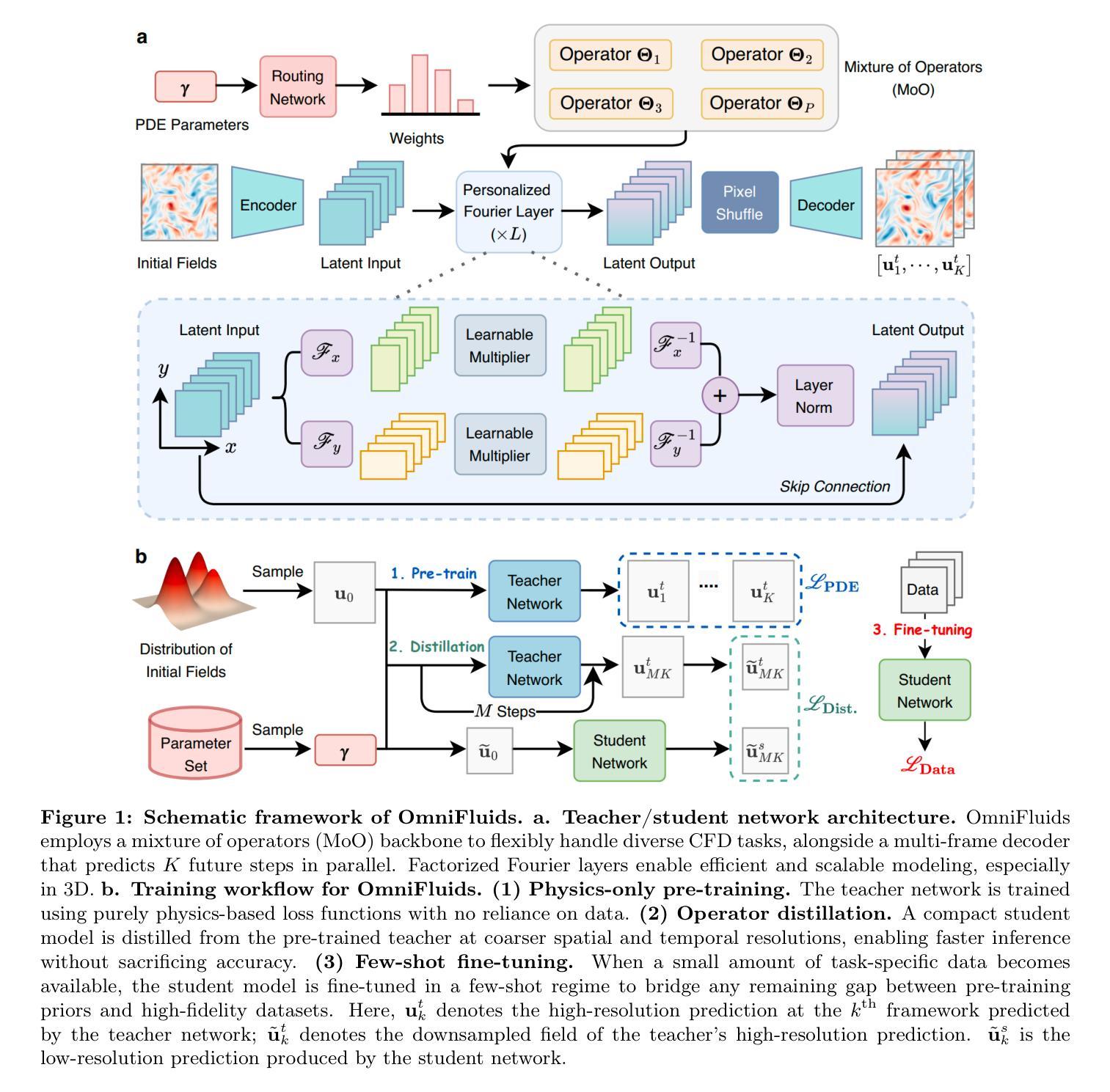
LLM-Driven Personalized Answer Generation and Evaluation
Authors:Mohammadreza Molavi, Mohammadreza Tavakoli, Mohammad Moein, Abdolali Faraji, Gábor Kismihók
Online learning has experienced rapid growth due to its flexibility and accessibility. Personalization, adapted to the needs of individual learners, is crucial for enhancing the learning experience, particularly in online settings. A key aspect of personalization is providing learners with answers customized to their specific questions. This paper therefore explores the potential of Large Language Models (LLMs) to generate personalized answers to learners’ questions, thereby enhancing engagement and reducing the workload on educators. To evaluate the effectiveness of LLMs in this context, we conducted a comprehensive study using the StackExchange platform in two distinct areas: language learning and programming. We developed a framework and a dataset for validating automatically generated personalized answers. Subsequently, we generated personalized answers using different strategies, including 0-shot, 1-shot, and few-shot scenarios. The generated answers were evaluated using three methods: 1. BERTScore, 2. LLM evaluation, and 3. human evaluation. Our findings indicated that providing LLMs with examples of desired answers (from the learner or similar learners) can significantly enhance the LLMs’ ability to tailor responses to individual learners’ needs.
在线学习因其灵活性和可访问性而经历了快速增长。个性化适应个别学习者的需求,对于增强学习体验,特别是在在线环境中,至关重要。个性化的关键方面是为学习者提供针对其特定问题的定制答案。因此,本文探讨了大型语言模型(LLM)为学习者的问题生成个性化答案的潜力,从而提高参与度,减轻教育工作者的负担。为了评估LLM在此背景下的有效性,我们使用了StackExchange平台在语言学习和编程两个不同的领域进行了全面的研究。我们开发了一个框架和数据集来验证自动生成的个性化答案。随后,我们采用不同的策略生成了个性化答案,包括零样本、一个样例和几个样例场景。生成的答案通过三种方法进行评估:1. BERTScore、2. LLM评估和3.人工评估。我们的研究结果表明,向LLM提供期望答案的示例(来自学习者或类似的学习者)可以显著提高LLM适应个别学习者需求的能力。
论文及项目相关链接
PDF This is the preprint version of a paper accepted at AIED 2025. The final version will be published by Springer
Summary
在线学习因其灵活性和可访问性而迅速增长。个性化适应个别学习者的需求对于提升学习体验尤为重要,特别是在在线环境中。本文探索了大型语言模型(LLMs)为学习者生成个性化答案的潜力,从而提高参与度和减轻教育工作者的负担。为了评估LLMs在此背景下的有效性,我们利用StackExchange平台在语言学习和编程两个领域进行了全面的研究。我们开发了一个框架和数据集来验证自动生成的个人化答案。通过不同的策略(如零样本、单样本和少样本场景)生成个性化答案,并使用三种方法进行评估:BERTScore、LLM评估和人工评估。我们发现为LLMs提供期望答案的示例(来自学习者或类似学习者)可以显著提高LLMs适应个别学习者需求的能力。
Key Takeaways
- 在线学习的增长得益于其灵活性和可访问性。
- 个性化对于提升在线学习体验至关重要。
- 大型语言模型(LLMs)有潜力为学习者生成个性化答案,从而提高参与度和减轻教育者的工作负担。
- 在语言学习和编程领域进行了LLMs的研究评估。
- 开发了一个框架和数据集来验证自动生成的个人化答案的有效性。
- 通过不同的策略(如零样本、单样本和少样本场景)生成个性化答案。
点此查看论文截图


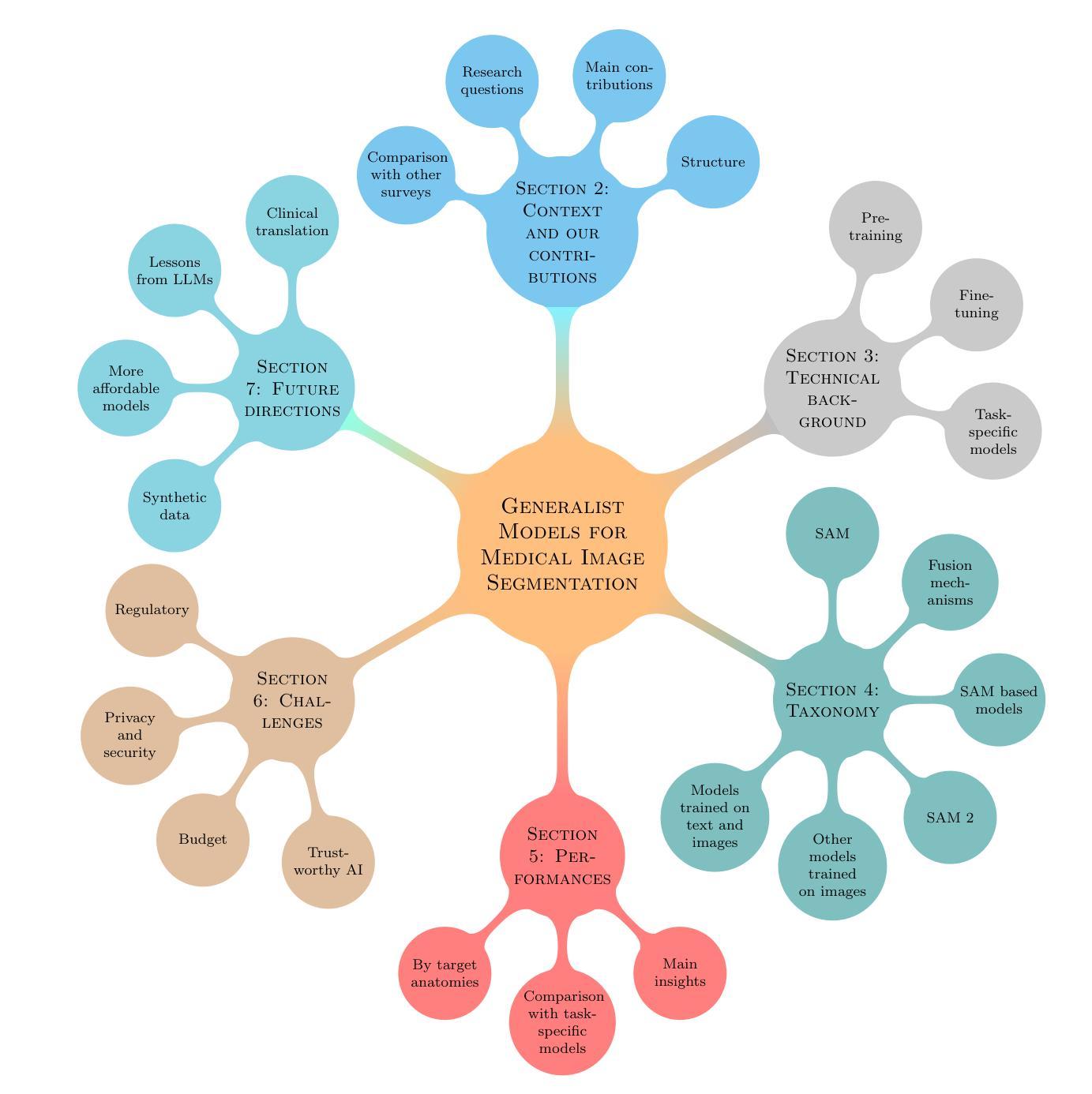
Generalist Models in Medical Image Segmentation: A Survey and Performance Comparison with Task-Specific Approaches
Authors:Andrea Moglia, Matteo Leccardi, Matteo Cavicchioli, Alice Maccarini, Marco Marcon, Luca Mainardi, Pietro Cerveri
Following the successful paradigm shift of large language models, leveraging pre-training on a massive corpus of data and fine-tuning on different downstream tasks, generalist models have made their foray into computer vision. The introduction of Segment Anything Model (SAM) set a milestone on segmentation of natural images, inspiring the design of a multitude of architectures for medical image segmentation. In this survey we offer a comprehensive and in-depth investigation on generalist models for medical image segmentation. We start with an introduction on the fundamentals concepts underpinning their development. Then, we provide a taxonomy on the different declinations of SAM in terms of zero-shot, few-shot, fine-tuning, adapters, on the recent SAM 2, on other innovative models trained on images alone, and others trained on both text and images. We thoroughly analyze their performances at the level of both primary research and best-in-literature, followed by a rigorous comparison with the state-of-the-art task-specific models. We emphasize the need to address challenges in terms of compliance with regulatory frameworks, privacy and security laws, budget, and trustworthy artificial intelligence (AI). Finally, we share our perspective on future directions concerning synthetic data, early fusion, lessons learnt from generalist models in natural language processing, agentic AI and physical AI, and clinical translation.
在大型语言模型成功实现范式转变之后,通过预训练大量数据语料库并在不同下游任务上进行微调,通用模型已经涉足计算机视觉领域。Segment Anything Model(SAM)的引入为自然图像分割树立了里程碑,激发了多种医疗图像分割架构的设计灵感。在这篇综述中,我们对医疗图像分割的通用模型进行了全面深入的研究。首先介绍了支撑它们发展的基本概念。然后,我们根据零样本、少样本、微调、适配器等方面对SAM的不同发展方向进行了分类,并介绍了最近的SAM 2以及其他单独在图像上训练的创新模型,还有其他同时训练文本和图像模型。我们全面分析了它们在初级研究和文献最佳水平上的表现,并与最新的特定任务模型进行了严格比较。我们强调了需要解决合规性框架、隐私和安全法律、预算和可信人工智能等方面的挑战。最后,我们分享了我们对合成数据、早期融合、从自然语言处理通用模型中学到的教训、智能体AI和物理AI以及临床翻译的未来方向的看法。
论文及项目相关链接
PDF 132 pages, 26 figures, 23 tables. Andrea Moglia and Matteo Leccardi are equally contributing authors
Summary
大型语言模型成功范式转移后,通用模型已涉足计算机视觉领域。Segment Anything Model(SAM)的引入为自然图像分割树立了里程碑,激发了多种医疗图像分割架构的设计。本文全面深入地调查了医疗图像分割的通用模型,从基本概念入手,提供SAM的不同变种分类,如零样本、少样本、微调、适配器等,并分析其与最新任务特定模型的性能对比。强调需要解决合规性、隐私和安全性、预算及可信人工智能等挑战。展望未来方向,包括合成数据、早期融合、自然语言处理中的通用模型教训、代理人工智能及物理人工智能和临床翻译等。
Key Takeaways
- 大型语言模型的范式转移推动了通用模型在医疗图像分割领域的应用。
- Segment Anything Model (SAM) 为自然图像分割树立了里程碑。
- SAM的多种变种如零样本、少样本、微调、适配器等在医疗图像分割领域有广泛应用。
- 通用模型在医疗图像分割方面的性能与最新任务特定模型进行了对比分析。
- 面临合规性、隐私和安全性、预算等方面的挑战。
- 需要从自然语言处理的通用模型中吸取教训,将其应用于医疗图像分割。
点此查看论文截图

IQE-CLIP: Instance-aware Query Embedding for Zero-/Few-shot Anomaly Detection in Medical Domain
Authors:Hong Huang, Weixiang Sun, Zhijian Wu, Jingwen Niu, Donghuan Lu, Xian Wu, Yefeng Zheng
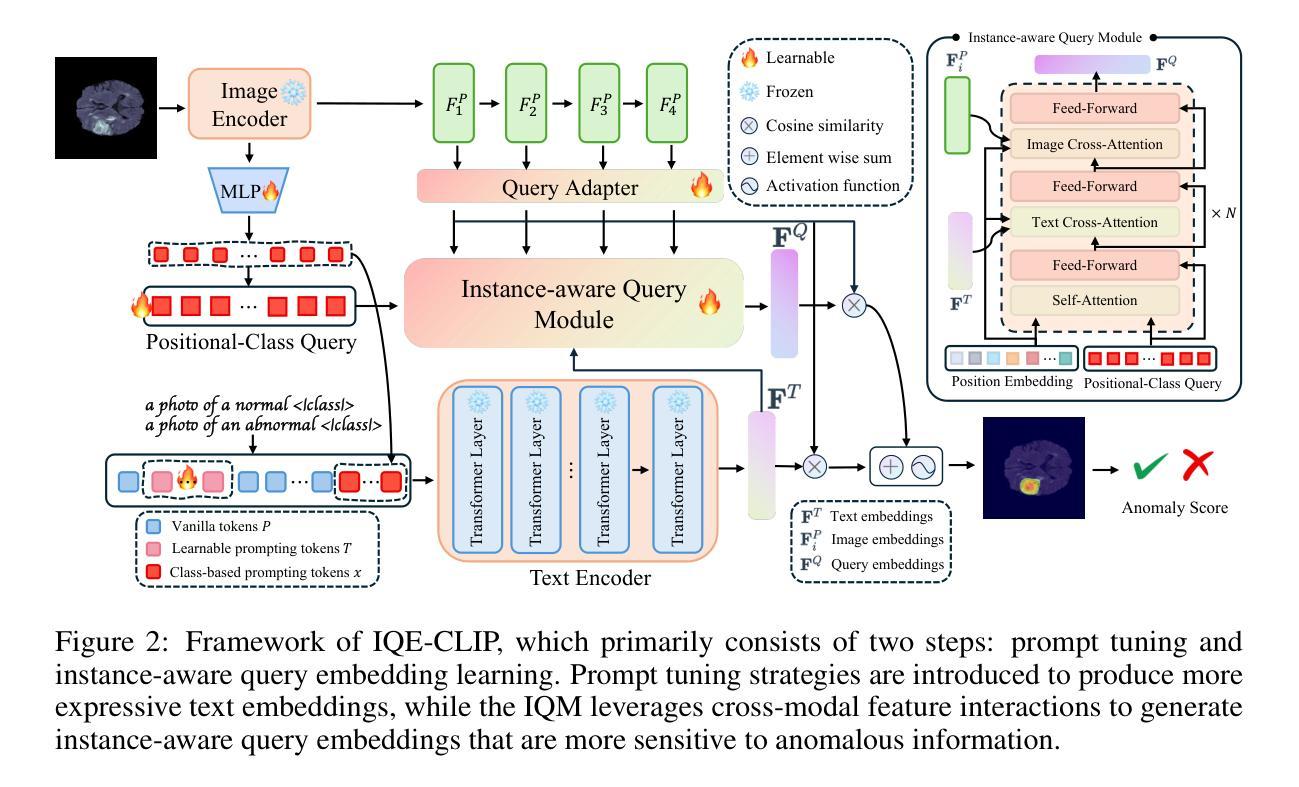
Recent advances in vision-language models, such as CLIP, have significantly improved performance in zero- and few-shot anomaly detection (ZFSAD) tasks. However, most existing CLIP-based methods assume prior knowledge of categories and rely on carefully designed prompts tailored to specific scenarios. While these text prompts capture semantic information in the textual space, they often fail to distinguish normal and anomalous instances in the joint embedding space. Moreover, most ZFSAD approaches focus on industrial domains, with limited exploration in medical tasks. To address these limitations, we propose IQE-CLIP, a novel framework for ZFSAD in the medical domain. We show that query embeddings integrating both textual and instance-aware visual information serve as more effective indicators of anomalies. Specifically, we introduce class-based and learnable prompting tokens to better adapt CLIP to the medical setting. Furthermore, we design an instance-aware query module that extracts region-level contextual information from both modalities, enabling the generation of anomaly-sensitive embeddings. Extensive experiments on six medical datasets demonstrate that IQE-CLIP achieves state-of-the-art performance in both zero-shot and few-shot settings. Code and data are available at \href{https://github.com/hongh0/IQE-CLIP/}{this https URL}.
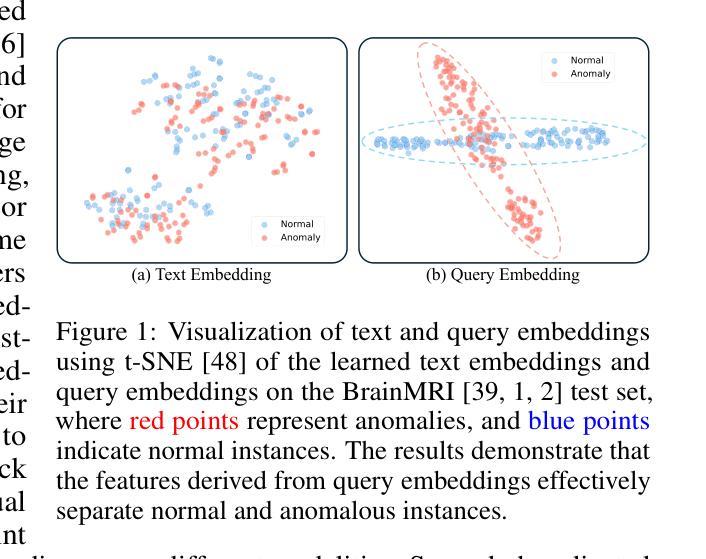
最近,诸如CLIP之类的视觉语言模型取得了重大进展,已在零样本和少样本异常检测(ZFSAD)任务中显著提高了性能。然而,大多数现有的基于CLIP的方法假设对类别有先验知识,并依赖于针对特定场景精心设计的提示。虽然这些文本提示捕获了文本空间中的语义信息,但它们通常在联合嵌入空间中无法区分正常和异常的实例。此外,大多数ZFSAD方法都集中在工业领域,在医疗任务方面的探索有限。为了解决这些局限性,我们提出了IQE-CLIP,这是一个用于医疗领域的ZFSAD的新型框架。我们表明,融合了文本和实例感知视觉信息的查询嵌入作为异常的更有效指标。具体来说,我们引入了基于类别的和可学习的提示令牌,以更好地适应CLIP在医疗环境中的使用。此外,我们设计了一个实例感知查询模块,可以从两种模态中提取区域级别的上下文信息,从而生成对异常敏感的嵌入。在六个医疗数据集上的广泛实验表明,IQE-CLIP在零样本和少样本设置中均达到了最新技术水平。代码和数据可在[https://github.com/hongh0/IQE-CLIP/]这个链接中找到。
论文及项目相关链接
Summary
最近,CLIP等视觉语言模型在零样本和少样本异常检测任务上的性能有了显著提升。然而,现有的CLIP方法大多假定有类别先验知识并依赖针对特定场景的精心设计的文本提示。本文提出IQE-CLIP框架,将文本和实例感知的视觉信息集成到查询嵌入中,以更有效地检测医学领域的异常。通过引入基于类别的可学习提示令牌和实例感知查询模块,IQE-CLIP在六个医学数据集上实现了零样本和少样本设置中的最佳性能。
Key Takeaways
- CLIP等视觉语言模型在零样本和少样本异常检测任务上表现优异。
- 现有方法依赖类别先验知识和针对特定场景的文本提示。
- IQE-CLIP框架集成文本和实例感知的视觉信息到查询嵌入中,有效提高异常检测效果。
- IQE-CLIP引入基于类别的可学习提示令牌,更好地适应医学领域。
- 实例感知查询模块能提取两种模态的区域级上下文信息,生成对异常敏感的嵌入。
- IQE-CLIP在六个医学数据集上实现了最佳性能。
点此查看论文截图

NeuralNexus at BEA 2025 Shared Task: Retrieval-Augmented Prompting for Mistake Identification in AI Tutors
Authors:Numaan Naeem, Sarfraz Ahmad, Momina Ahsan, Hasan Iqbal
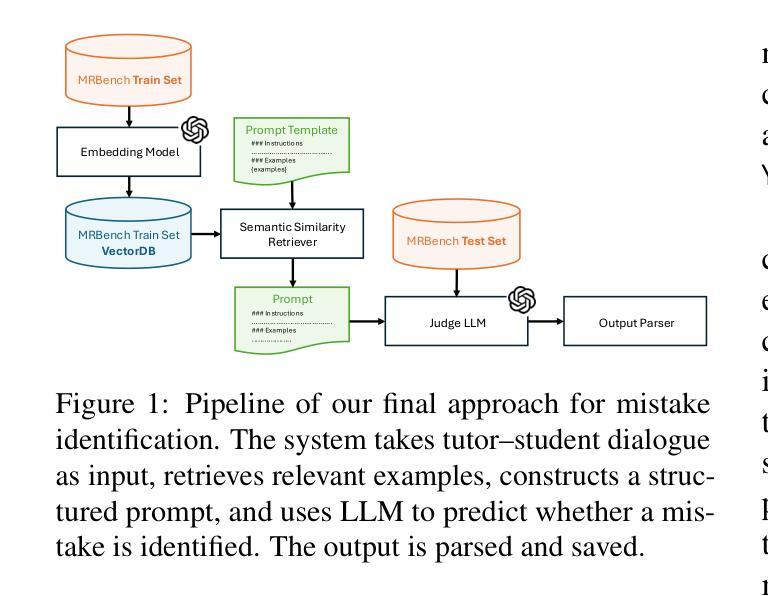
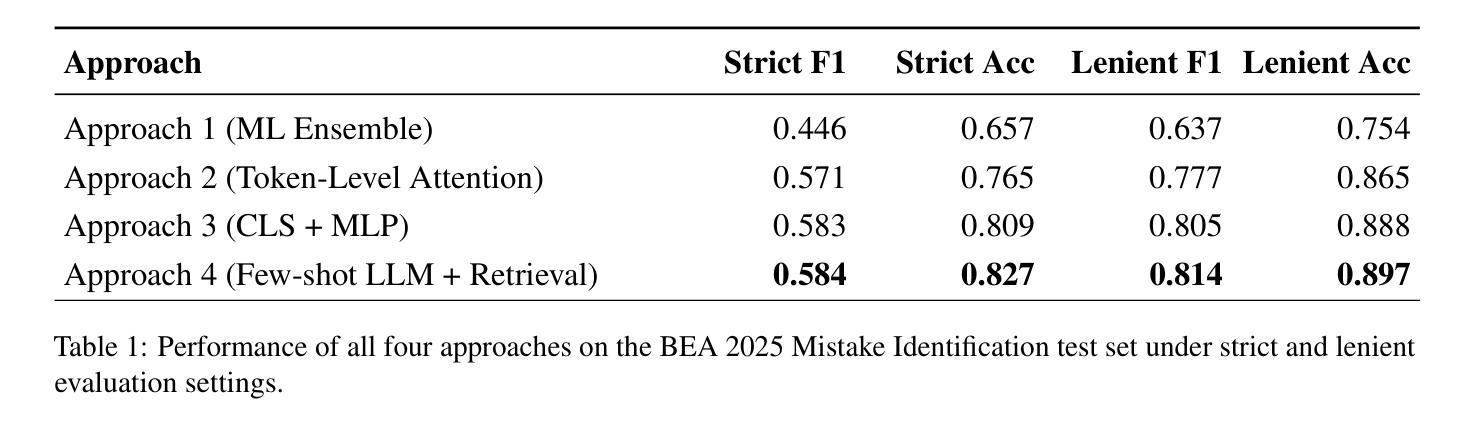
This paper presents our system for Track 1: Mistake Identification in the BEA 2025 Shared Task on Pedagogical Ability Assessment of AI-powered Tutors. The task involves evaluating whether a tutor’s response correctly identifies a mistake in a student’s mathematical reasoning. We explore four approaches: (1) an ensemble of machine learning models over pooled token embeddings from multiple pretrained language models (LMs); (2) a frozen sentence-transformer using [CLS] embeddings with an MLP classifier; (3) a history-aware model with multi-head attention between token-level history and response embeddings; and (4) a retrieval-augmented few-shot prompting system with a large language model (LLM) i.e. GPT 4o. Our final system retrieves semantically similar examples, constructs structured prompts, and uses schema-guided output parsing to produce interpretable predictions. It outperforms all baselines, demonstrating the effectiveness of combining example-driven prompting with LLM reasoning for pedagogical feedback assessment. Our code is available at https://github.com/NaumanNaeem/BEA_2025.
本文介绍了我们在Track 1:AI辅导老师教学技能评估的BEA 2025共享任务中的错误识别系统。该任务涉及评估辅导老师的回应是否能正确识别学生数学推理中的错误。我们探索了四种方法:(1)使用来自多个预训练语言模型的合并令牌嵌入的机器学习模型集合;(2)使用[CLS]嵌入与MLP分类器的冻结句子转换器;(3)在令牌级别历史与响应嵌入之间具有多头注意力的历史感知模型;(4)带有大型语言模型(LLM)即GPT 4o的增强检索提示系统。我们的最终系统检索语义相似的示例,构建结构化提示,并使用模式引导的输出解析来产生可解释的预测。它超越了所有基线,证明了结合示例驱动的提示和LLM推理进行教学反馈评估的有效性。我们的代码可在https://github.com/NaumanNaeem/BEA_2025找到。
论文及项目相关链接
PDF 6 pages, 2 figures, 1 table
Summary
本文介绍了针对BEA 2025共享任务中的轨道1:人工智能辅导老师的教学能力评估中的错误识别系统。任务旨在评估辅导老师的回应是否能正确识别学生数学推理中的错误。本文探索了四种方法,包括基于多个预训练语言模型的集成机器学习模型、使用冻结的句子变换器和多层感知器分类器的[CLS]嵌入、具有令牌级别历史与响应嵌入之间多头注意力的历史感知模型,以及结合大型语言模型(LLM)的检索增强型少样本提示系统(如GPT 4o)。最终系统通过检索相似示例、构建结构化提示和模式引导的输出解析来生成可解释的预测,超越了所有基线,证明了结合示例驱动的提示和LLM推理进行教学法反馈评估的有效性。
Key Takeaways
- 本文介绍了针对人工智能辅导老师教学评估的任务——错误识别系统。
- 四种方法的探索包括基于集成机器学习模型的响应错误识别系统。
- 采用冻结的句子变换器和多层感知器分类器来处理响应与令牌之间的关系。
- 历史感知模型结合了令牌级别历史和响应嵌入的多头注意力机制。
- 采用检索增强型少样本提示系统结合了大型语言模型(LLM)技术。
点此查看论文截图

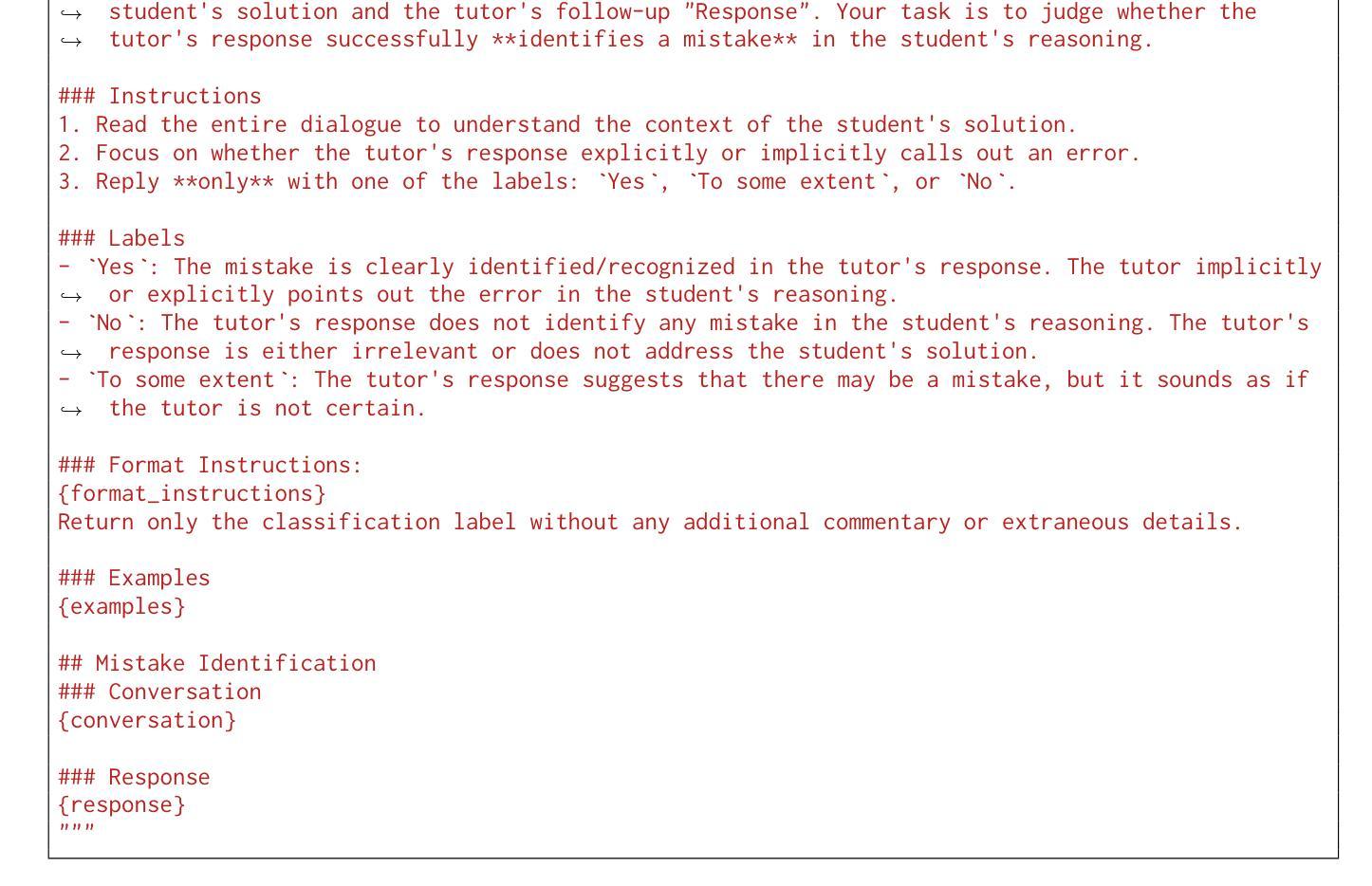
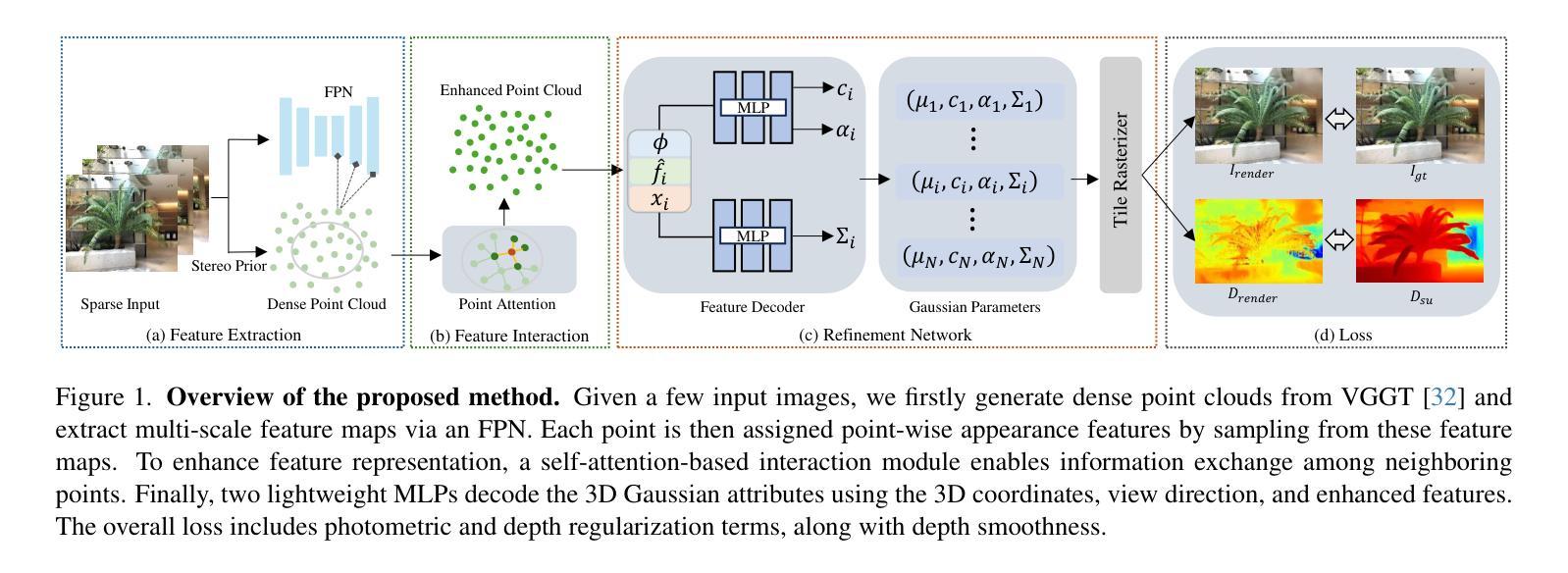
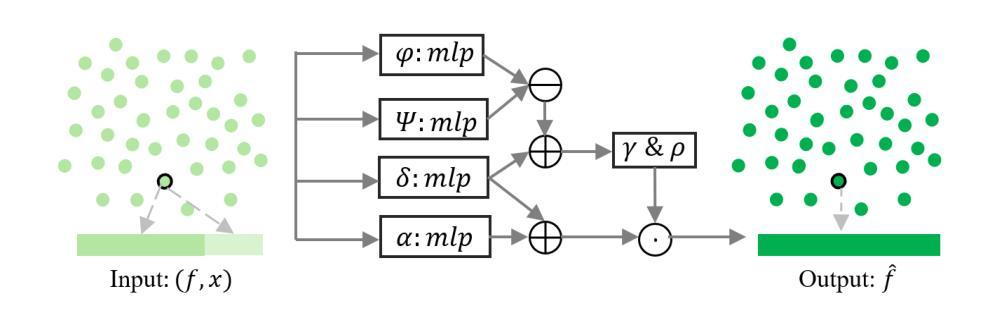
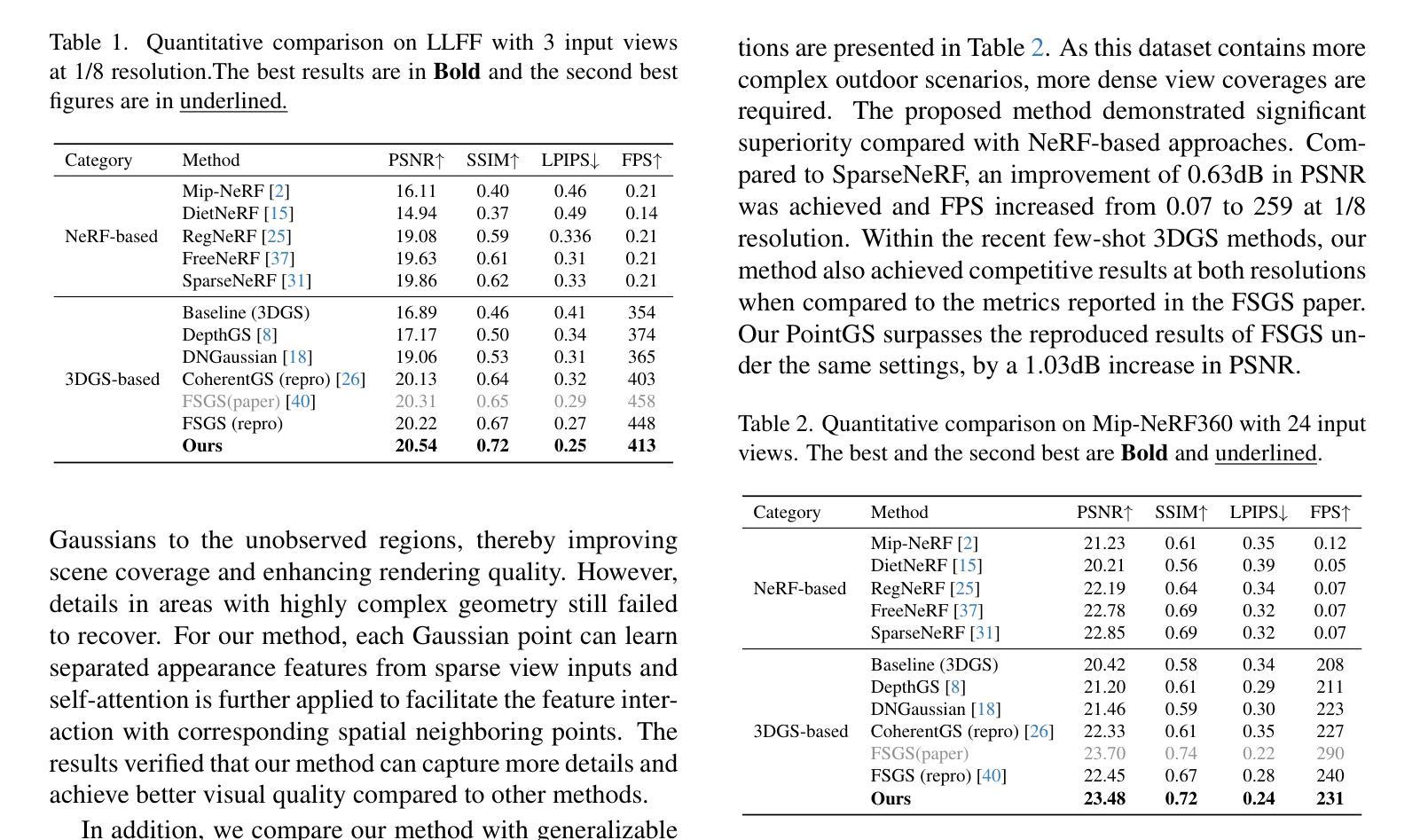
PointGS: Point Attention-Aware Sparse View Synthesis with Gaussian Splatting
Authors:Lintao Xiang, Hongpei Zheng, Yating Huang, Qijun Yang, Hujun Yin
3D Gaussian splatting (3DGS) is an innovative rendering technique that surpasses the neural radiance field (NeRF) in both rendering speed and visual quality by leveraging an explicit 3D scene representation. Existing 3DGS approaches require a large number of calibrated views to generate a consistent and complete scene representation. When input views are limited, 3DGS tends to overfit the training views, leading to noticeable degradation in rendering quality. To address this limitation, we propose a Point-wise Feature-Aware Gaussian Splatting framework that enables real-time, high-quality rendering from sparse training views. Specifically, we first employ the latest stereo foundation model to estimate accurate camera poses and reconstruct a dense point cloud for Gaussian initialization. We then encode the colour attributes of each 3D Gaussian by sampling and aggregating multiscale 2D appearance features from sparse inputs. To enhance point-wise appearance representation, we design a point interaction network based on a self-attention mechanism, allowing each Gaussian point to interact with its nearest neighbors. These enriched features are subsequently decoded into Gaussian parameters through two lightweight multi-layer perceptrons (MLPs) for final rendering. Extensive experiments on diverse benchmarks demonstrate that our method significantly outperforms NeRF-based approaches and achieves competitive performance under few-shot settings compared to the state-of-the-art 3DGS methods.
3D高斯涂抹(3DGS)是一种创新的渲染技术,它通过利用明确的3D场景表示在渲染速度和视觉质量上都超越了神经辐射场(NeRF)。现有的3DGS方法需要大量校准的视图来生成一致和完整的场景表示。当输入视图有限时,3DGS容易过度拟合训练视图,导致渲染质量明显下降。为了解决这一局限性,我们提出了一种点特征感知的高斯涂抹框架,能够实现从稀疏训练视图的实时高质量渲染。具体来说,我们首先采用最新的立体基础模型来估计准确的相机姿态并重建用于高斯初始化的密集点云。然后,我们通过从稀疏输入中采样和聚合多尺度2D外观特征来编码每个3D高斯的颜色属性。为了增强点级外观表示,我们设计了一个基于自注意力机制的点交互网络,允许每个高斯点与最近的邻居进行交互。这些丰富的特征随后通过两个轻量级的多层感知器(MLP)解码为高斯参数,用于最终渲染。在多种基准测试上的广泛实验表明,我们的方法显著优于基于NeRF的方法,并在小样本设置下实现了与最新3DGS方法相当的性能。
论文及项目相关链接
Summary
基于显式三维场景表示的高效渲染技术三维高斯插片方法能够有效提高渲染速度并提升视觉质量。当面临稀疏训练视图时,提出了一种点特征感知高斯插片框架以实现实时高质量渲染。该框架采用最新的立体基础模型估计摄像机姿态并重建用于高斯初始化的密集点云。此外,框架对三维高斯编码色彩属性并增强点对特征的代表性进行设计网络基于自注意力机制构建模型交互网并丰富每个高斯点的特征表现以改进最后的渲染结果。在基准测试实验中验证了方法表现远超NeRF所达成实现全面优越性相比于其它领先的高斯插片方法具有竞争力。实验表明,该方法在多种基准测试上表现优异,显著优于基于NeRF的方法,并在少样本设置下实现了与最新3DGS方法相当的竞争力。
Key Takeaways
- 3DGS方法在渲染速度和视觉质量方面超越神经网络辐射场方法(NeRF)。但其现有局限包括面对有限输入视图时表现出的过度拟合和渲染质量下降问题。为了解决这个问题,研究人员提出了一个名为Point-wise Feature-Aware Gaussian Splatting的新框架,该框架实现了从稀疏训练视图进行实时高质量渲染。该框架采用最新的立体基础模型进行相机姿态估计和密集点云重建;
- Point-wise Feature-Aware Gaussian Splatting利用多点视角数据和不同维度的信息融合来提升点特征的代表性,采用基于自注意力机制的网络设计模型来增强每个高斯点的特征表达;最后进行关键编码及参数化的Gaussian数据处理以便用于最终的渲染效果实现强化整体展示水平及优点强调无实物和无素材的渲染技术;
点此查看论文截图


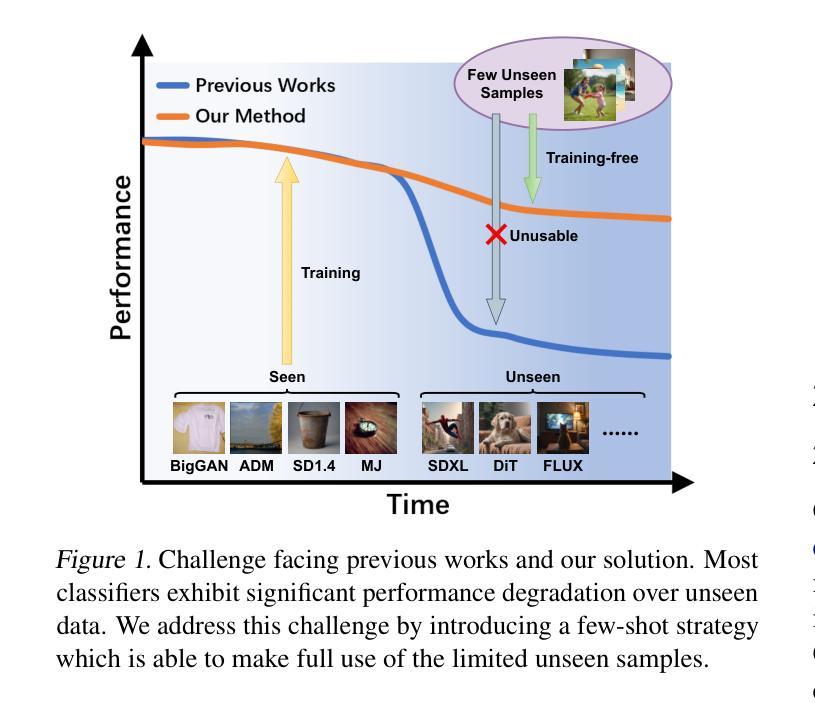
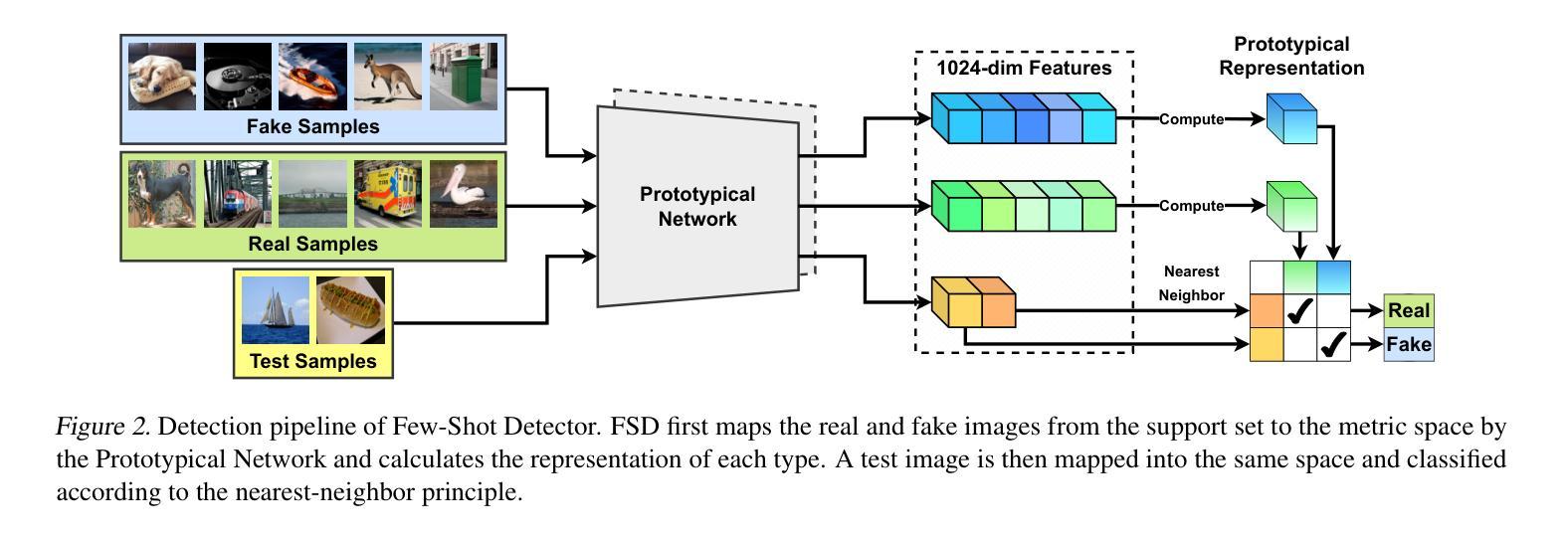
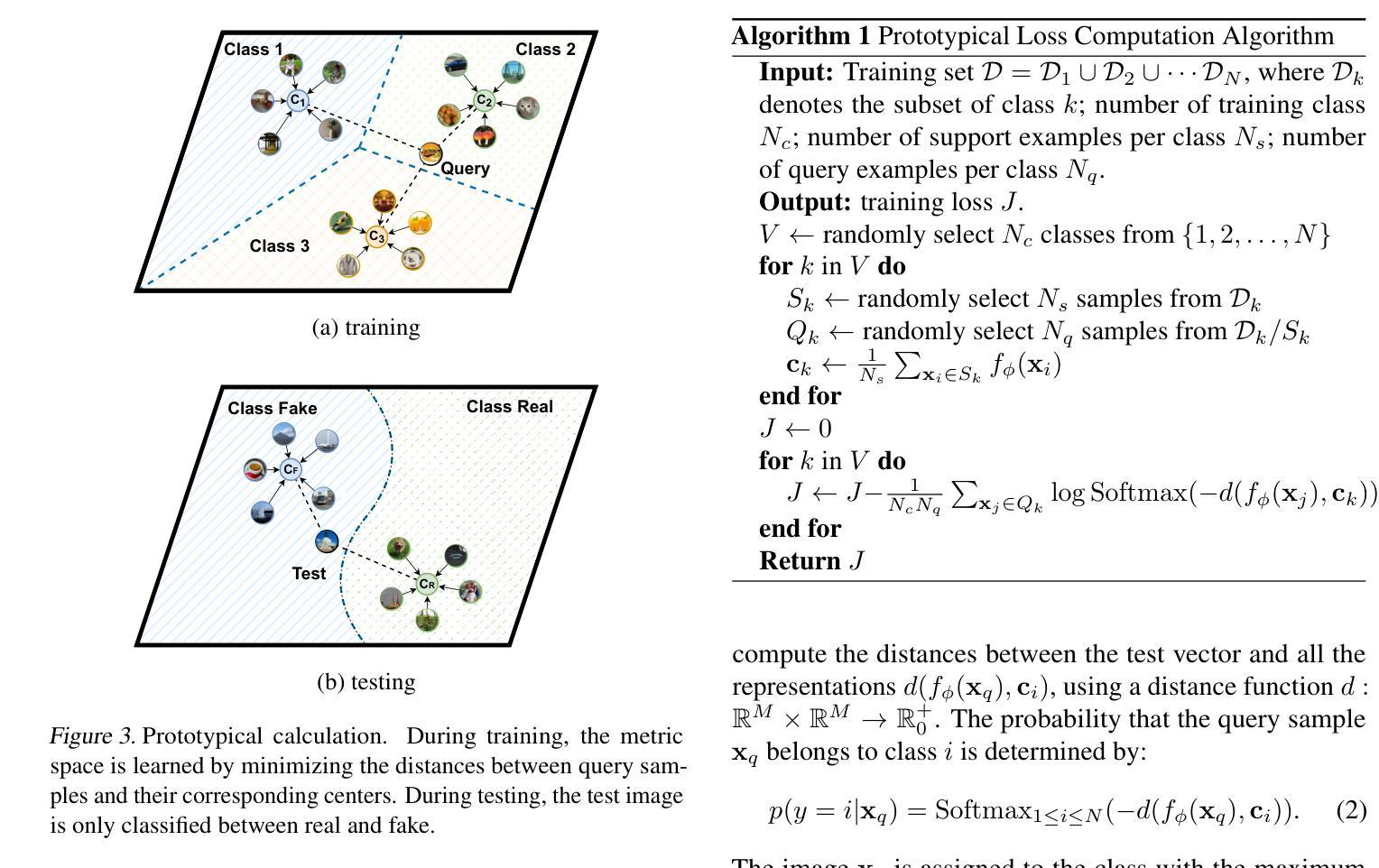
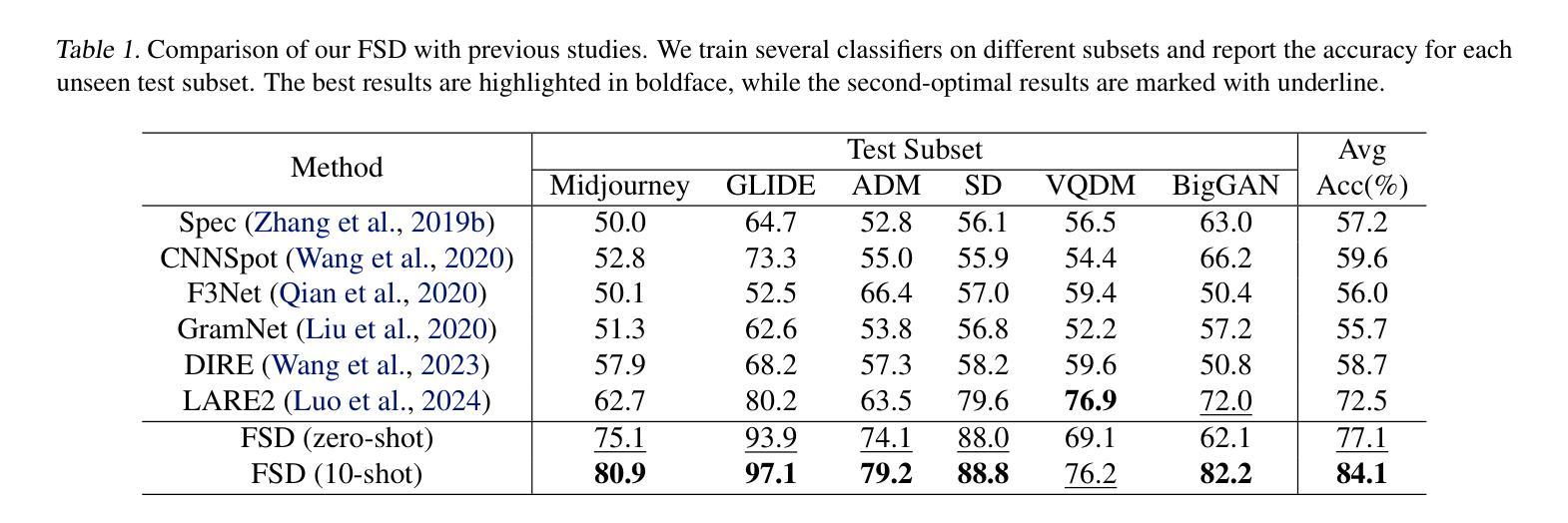
Few-Shot Learner Generalizes Across AI-Generated Image Detection
Authors:Shiyu Wu, Jing Liu, Jing Li, Yequan Wang
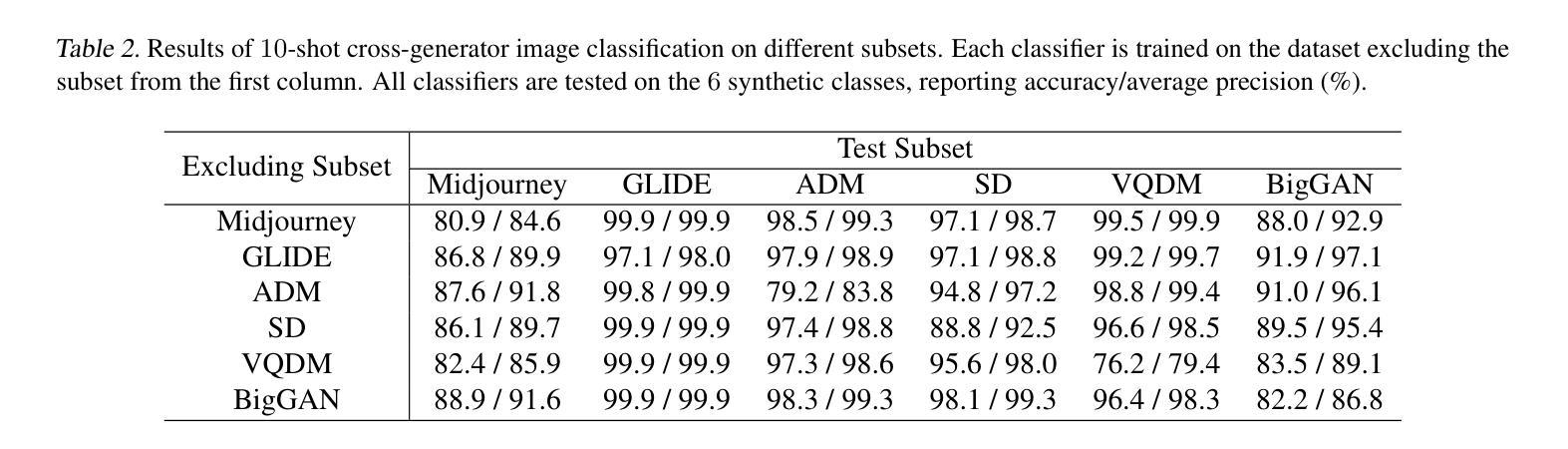
Current fake image detectors trained on large synthetic image datasets perform satisfactorily on limited studied generative models. However, these detectors suffer a notable performance decline over unseen models. Besides, collecting adequate training data from online generative models is often expensive or infeasible. To overcome these issues, we propose Few-Shot Detector (FSD), a novel AI-generated image detector which learns a specialized metric space for effectively distinguishing unseen fake images using very few samples. Experiments show that FSD achieves state-of-the-art performance by $+11.6%$ average accuracy on the GenImage dataset with only $10$ additional samples. More importantly, our method is better capable of capturing the intra-category commonality in unseen images without further training. Our code is available at https://github.com/teheperinko541/Few-Shot-AIGI-Detector.
当前基于大型合成图像数据集训练的假冒图像检测器在有限的生成模型研究上表现满意。然而,这些检测器在面对未知模型时性能会显著下降。此外,从在线生成模型中收集足够的训练数据通常成本高昂或不可行。为了克服这些问题,我们提出了Few-Shot Detector(FSD),这是一种新型的人工智能图像检测器,它通过非常有限的样本学习专门的度量空间,以有效区分未知的假冒图像。实验表明,FSD在GenImage数据集上通过仅增加10个样本就达到了最先进的性能,平均准确率提高了+11.6%。更重要的是,我们的方法能够更好地捕获未知图像中的类别内共性,而无需进一步训练。我们的代码可在https://github.com/teheperinko541/Few-Shot-AIGI-Detector上找到。
论文及项目相关链接
PDF 12 pages, 6 figures, Accepted at ICML 2025
Summary
基于当前假图像检测器在特定合成图像数据集上的训练表现,本文提出了一种全新的AI生成图像检测器——Few-Shot Detector(FSD)。该检测器能够在非常有限的样本下,通过学习专门的度量空间来有效区分未见过的假图像。实验表明,在GenImage数据集上,FSD通过使用仅10个额外样本达到了行业领先的水平,平均准确度提高了11.6%。并且FSD能更好的捕捉未见图像中的类别共性而无需进一步的训练。代码已公开在GitHub上。
Key Takeaways
- 当前假图像检测器在特定合成图像数据集上的表现良好,但在未见模型上的性能显著下降。
- 提出了全新的AI生成图像检测器——Few-Shot Detector(FSD)。
- FSD能够在非常有限的样本下有效区分未见过的假图像。
- 在GenImage数据集上,FSD通过使用仅10个额外样本达到了行业领先的水平,平均准确度提高了11.6%。
- FSD能够更好地捕捉未见图像中的类别共性。
- FSD无需进一步的训练就能实现这一功能。
- 代码已公开在GitHub上,便于其他研究者使用与进一步开发。
点此查看论文截图

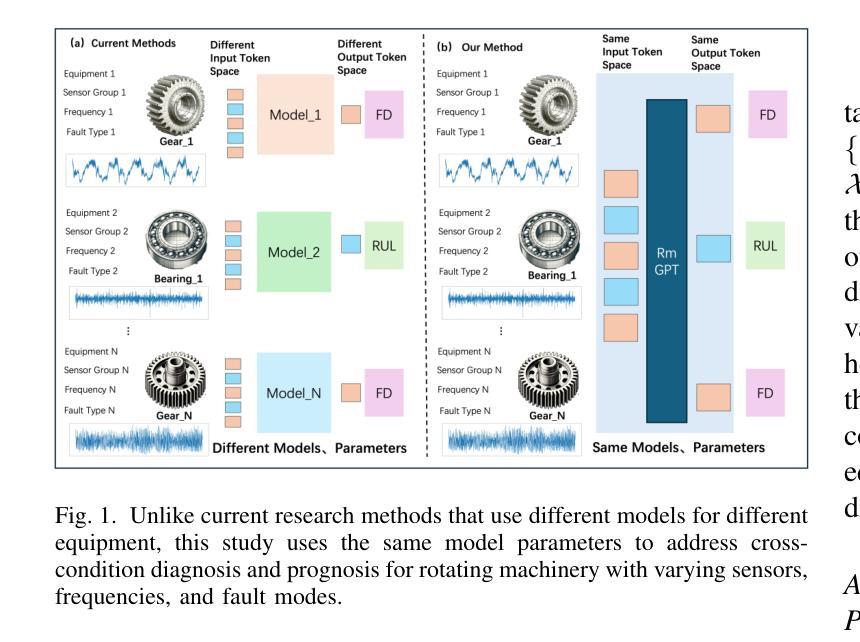
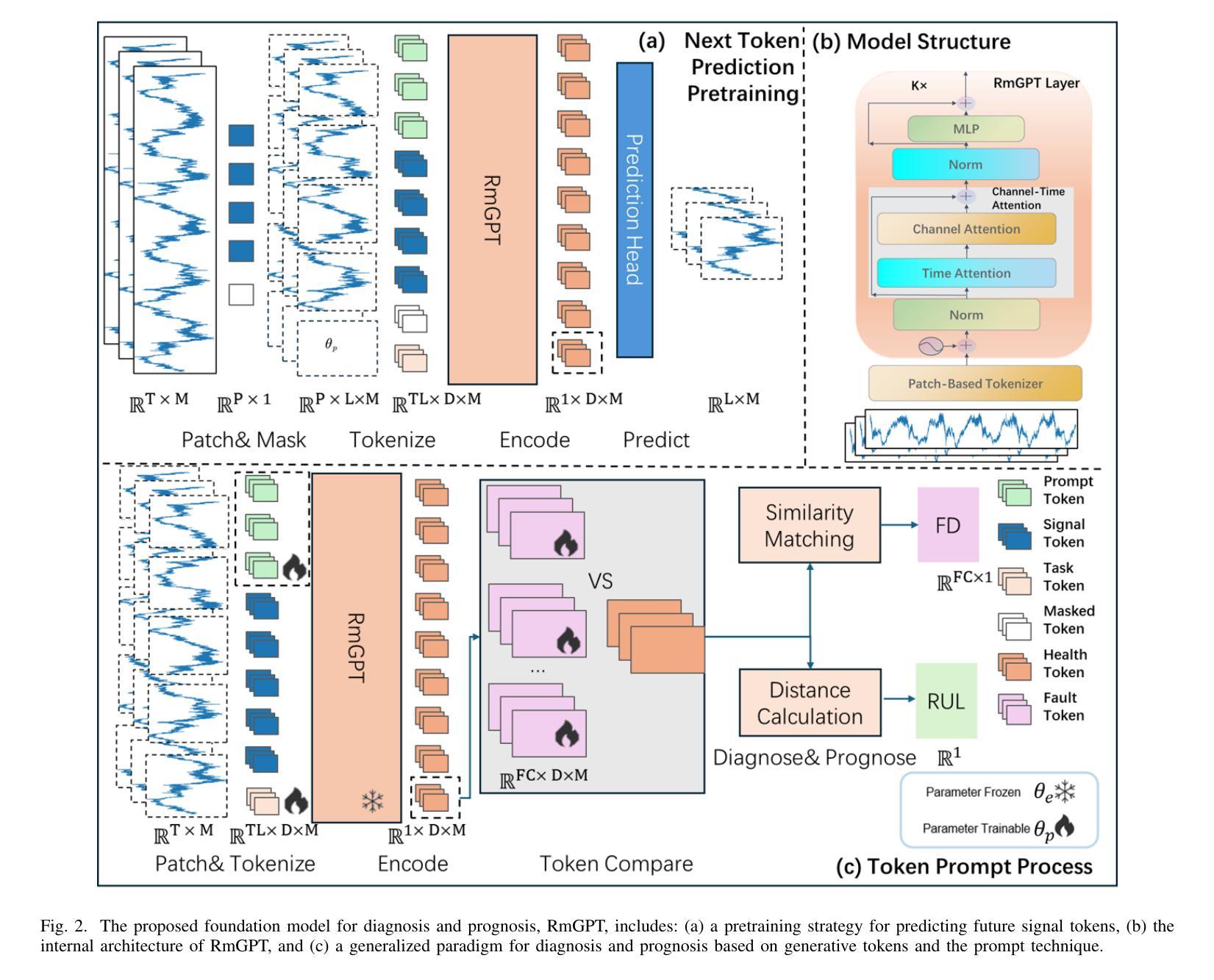
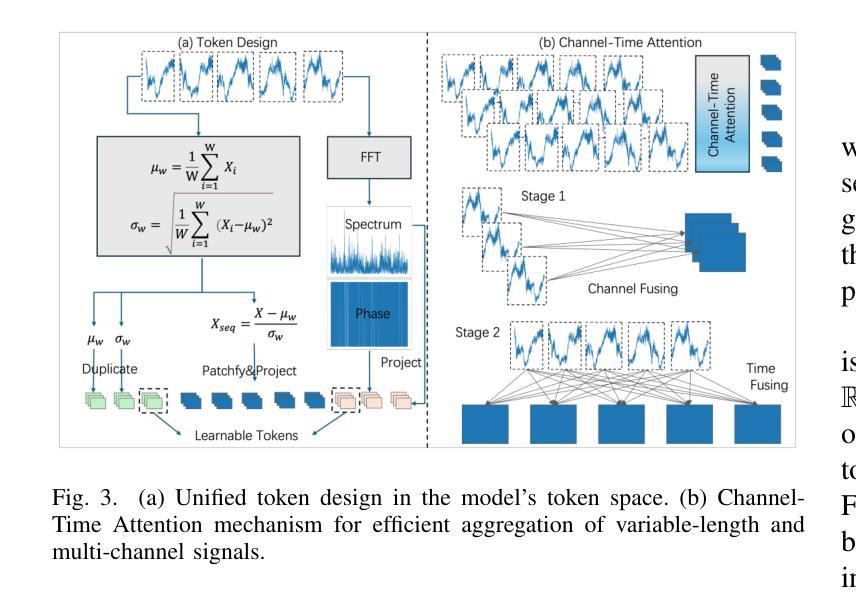
RmGPT: A Foundation Model with Generative Pre-trained Transformer for Fault Diagnosis and Prognosis in Rotating Machinery
Authors:Yilin Wang, Yifei Yu, Kong Sun, Peixuan Lei, Yuxuan Zhang, Enrico Zio, Aiguo Xia, Yuanxiang Li
In industry, the reliability of rotating machinery is critical for production efficiency and safety. Current methods of Prognostics and Health Management (PHM) often rely on task-specific models, which face significant challenges in handling diverse datasets with varying signal characteristics, fault modes and operating conditions. Inspired by advancements in generative pretrained models, we propose RmGPT, a unified model for diagnosis and prognosis tasks. RmGPT introduces a novel generative token-based framework, incorporating Signal Tokens, Prompt Tokens, Time-Frequency Task Tokens and Fault Tokens to handle heterogeneous data within a unified model architecture. We leverage self-supervised learning for robust feature extraction and introduce a next signal token prediction pretraining strategy, alongside efficient prompt learning for task-specific adaptation. Extensive experiments demonstrate that RmGPT significantly outperforms state-of-the-art algorithms, achieving near-perfect accuracy in diagnosis tasks and exceptionally low errors in prognosis tasks. Notably, RmGPT excels in few-shot learning scenarios, achieving 82% accuracy in 16-class one-shot experiments, highlighting its adaptability and robustness. This work establishes RmGPT as a powerful PHM foundation model for rotating machinery, advancing the scalability and generalizability of PHM solutions. \textbf{Code is available at: https://github.com/Pandalin98/RmGPT.
在工业领域,旋转机械的可靠性对生产效率和安全至关重要。目前的状态监测与健康管理(PHM)方法往往依赖于特定任务的模型,这些模型在处理具有不同信号特征、故障模式和工作条件的多样化数据集时面临巨大挑战。受生成式预训练模型发展的启发,我们提出了用于诊断和预后任务的统一模型RmGPT。RmGPT引入了一种新型基于标记的生成式框架,该框架结合了信号标记、提示标记、时间频率任务标记和故障标记,在一个统一的模型架构中处理异构数据。我们利用自监督学习进行稳健的特征提取,并引入下一个信号标记预测预训练策略,以及高效提示学习进行特定任务的适应。大量实验表明,RmGPT显著优于最新算法,在诊断任务中实现了近乎完美的准确率,在预后任务中错误率极低。值得一提的是,RmGPT在少样本学习场景中表现出色,在16类一次性实验中实现了8notifyAll年的准确率,突显了其适应性和稳健性。该工作确立了RmGPT作为旋转机械强大的PHM基础模型,提高了PHM解决方案的可扩展性和通用性。**代码可通过以下网址获取:https://github.com/Pandalin98/RmGPT。
论文及项目相关链接
PDF This paper has been accepted for publication in the IEEE Internet of Things Journal (IoT-J). The final version may differ slightly due to editorial revisions. Please cite the journal version when available
Summary
本文提出一种名为RmGPT的统一模型,用于旋转机械的故障诊断和预测。该模型采用基于生成式令牌的新框架,可处理不同数据集和复杂环境下的信号特征。模型利用自监督学习进行特征提取,并引入新的预训练策略进行信号令牌预测。实验表明,RmGPT在诊断任务中表现出极高的准确性,在预测任务中误差极低,尤其在少样本学习场景下表现优异。此模型是旋转机械领域强大的PHM基础模型,具有广泛的应用前景。
Key Takeaways
- RmGPT是一个用于旋转机械故障诊断和预测的统一模型。
- 该模型采用生成式令牌框架,包括信号令牌、提示令牌、时间频率任务令牌和故障令牌,以处理不同类型的数据。
- RmGPT利用自监督学习进行特征提取,提高模型的性能和泛化能力。
- 模型引入信号令牌预测预训练策略,以及高效的任务特定提示学习。
- 实验结果显示RmGPT在诊断任务中具有极高的准确性,预测任务中的误差很低。
- 在少样本学习场景下,RmGPT表现尤为出色,实现了高准确率。
点此查看论文截图