⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-14 更新
Enhancing Medical Dialogue Generation through Knowledge Refinement and Dynamic Prompt Adjustment
Authors:Hongda Sun, Jiaren Peng, Wenzhong Yang, Liang He, Bo Du, Rui Yan
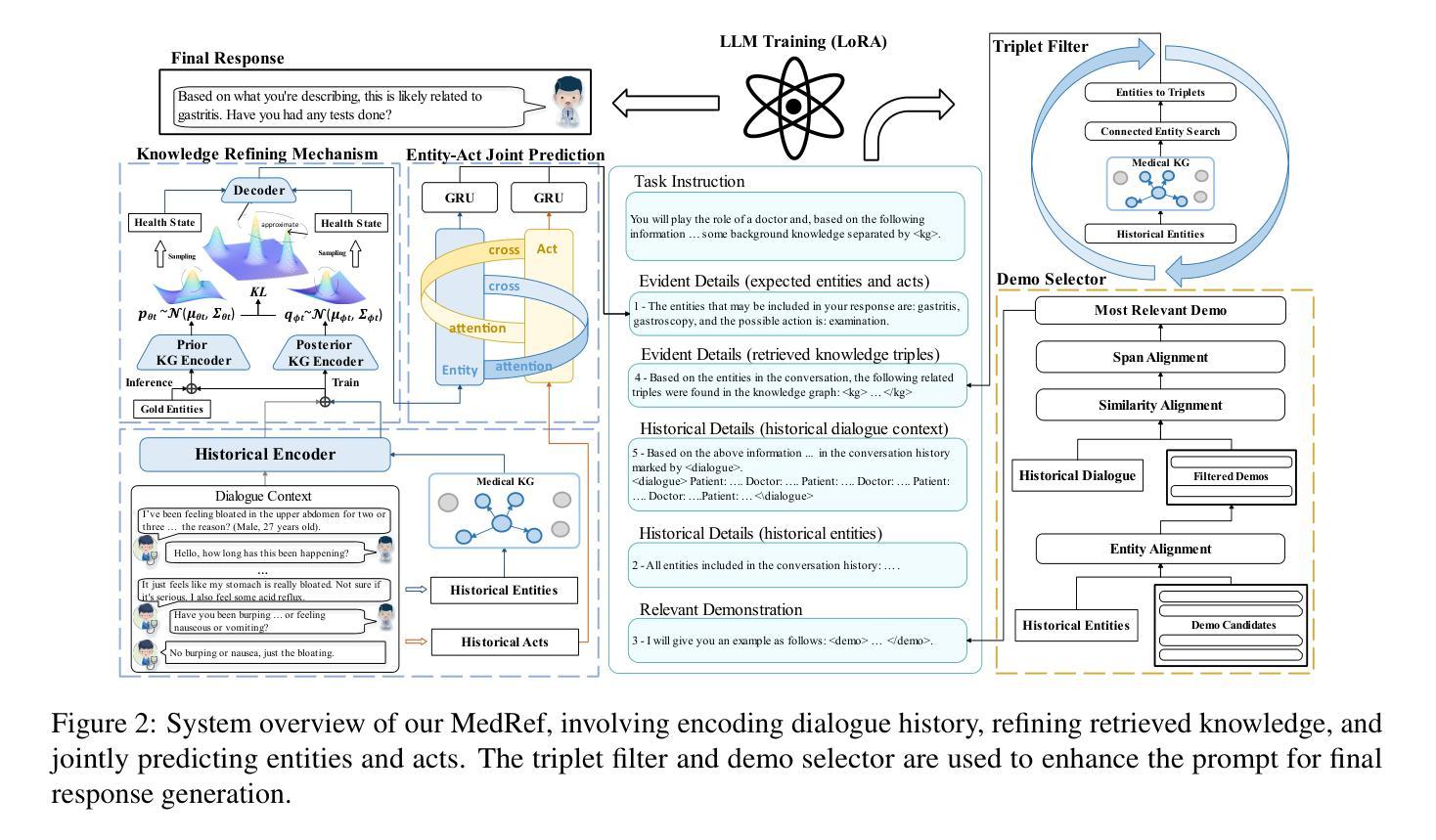
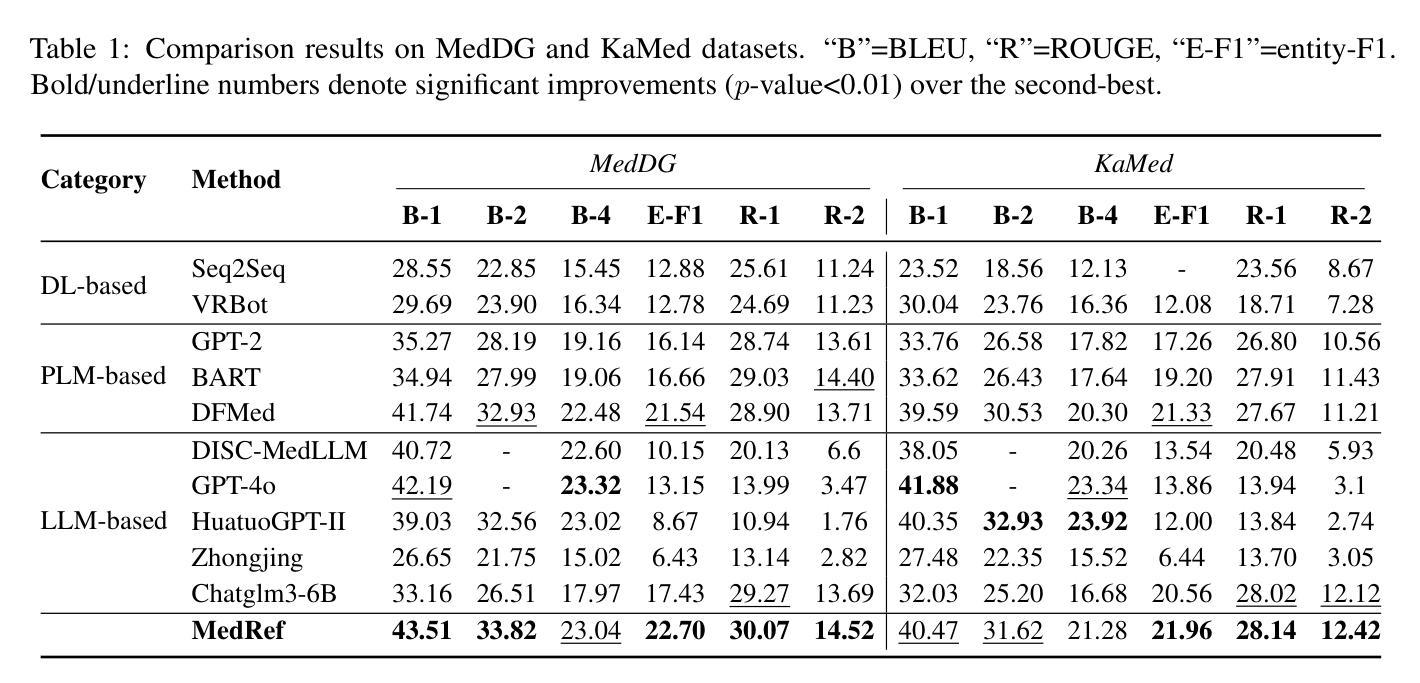
Medical dialogue systems (MDS) have emerged as crucial online platforms for enabling multi-turn, context-aware conversations with patients. However, existing MDS often struggle to (1) identify relevant medical knowledge and (2) generate personalized, medically accurate responses. To address these challenges, we propose MedRef, a novel MDS that incorporates knowledge refining and dynamic prompt adjustment. First, we employ a knowledge refining mechanism to filter out irrelevant medical data, improving predictions of critical medical entities in responses. Additionally, we design a comprehensive prompt structure that incorporates historical details and evident details. To enable real-time adaptability to diverse patient conditions, we implement two key modules, Triplet Filter and Demo Selector, providing appropriate knowledge and demonstrations equipped in the system prompt. Extensive experiments on MedDG and KaMed benchmarks show that MedRef outperforms state-of-the-art baselines in both generation quality and medical entity accuracy, underscoring its effectiveness and reliability for real-world healthcare applications.
医疗对话系统(MDS)已经成为重要的在线平台,可实现与患者的多轮、上下文感知的对话。然而,现有的MDS通常难以(1)识别相关的医学知识并(2)生成个性化且医学准确的回应。为了应对这些挑战,我们提出了MedRef这一新型MDS,它结合了知识精炼和动态提示调整。首先,我们采用知识精炼机制来过滤掉不相关的医疗数据,提高响应中关键医疗实体的预测能力。此外,我们设计了一种包含历史细节和明显细节的提示结构。为了实现实时适应各种患者状况的能力,我们实现了两个关键模块,即三元组过滤器和演示选择器,为系统提示提供适当的知识和演示。在MedDG和KaMed基准测试上的大量实验表明,MedRef在生成质量和医学实体准确性方面都优于最新基线,这突显了其在现实世界的医疗保健应用中的有效性和可靠性。
论文及项目相关链接
PDF ACL 2025 Findings
总结
医疗对话系统(MDS)已成为与患者进行有效沟通的关键在线平台,可实现多轮对话并了解患者背景。然而,现有MDS往往难以(1)识别相关医学知识并(2)生成个性化且准确的医学回应。为解决这些挑战,我们提出MedRef这一新型MDS,其融入了知识精炼和动态提示调整机制。首先,我们采用知识精炼机制过滤掉不相关的医学数据,提高关键医疗实体回应的预测能力。此外,我们设计了一种包含历史细节和显著特征的全面提示结构。为实现对不同患者状况的实时适应,我们引入了两个关键模块:三元组过滤器和演示选择器,为患者提供系统提示中的适当知识和演示。在MedDG和KaMed基准测试上的广泛实验表明,MedRef在生成质量和医学实体准确性方面均优于最新基线,凸显其在现实医疗应用中的有效性和可靠性。
要点摘要
- 医疗对话系统(MDS)已成为在线医疗交流的关键平台,支持多轮对话和背景理解。
- 现有MDS在识别医学知识和生成个性化回应方面存在挑战。
- MedRef是一种新型MDS,通过知识精炼机制提高医疗实体回应的预测能力。
- MedRef采用全面的提示结构,融入历史细节和显著特征。
- MedRef通过两个关键模块——三元组过滤器和演示选择器,实现实时适应不同的患者状况。
- 在基准测试上,MedRef在生成质量和医学实体准确性方面表现出优异性能。
点此查看论文截图

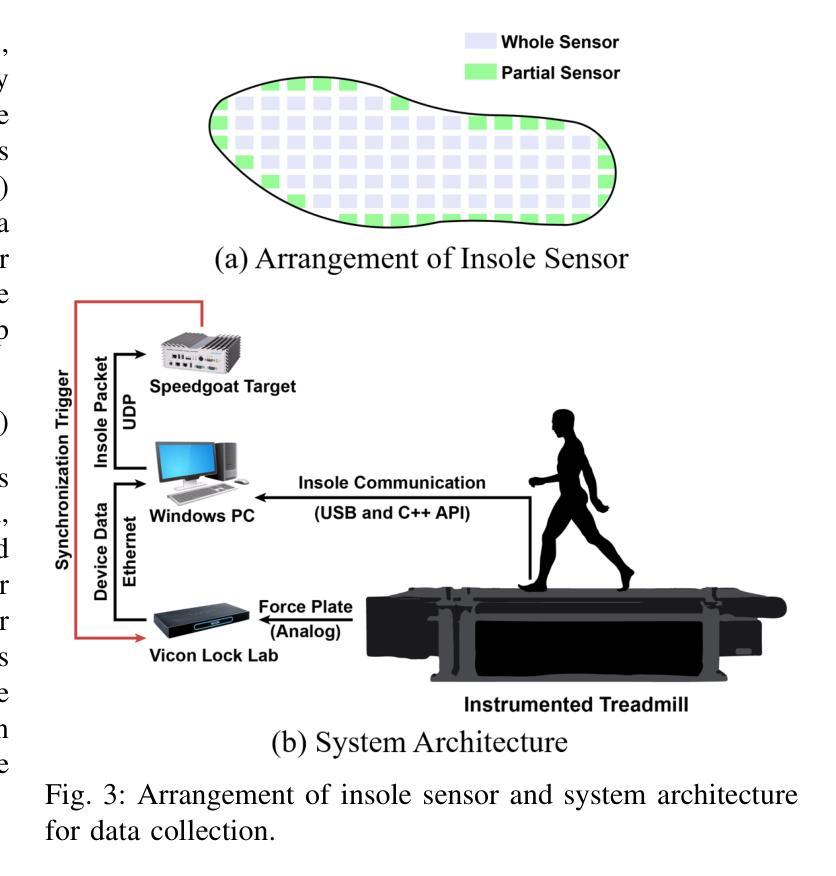
Ground Reaction Force Estimation via Time-aware Knowledge Distillation
Authors:Eun Som Jeon, Sinjini Mitra, Jisoo Lee, Omik M. Save, Ankita Shukla, Hyunglae Lee, Pavan Turaga
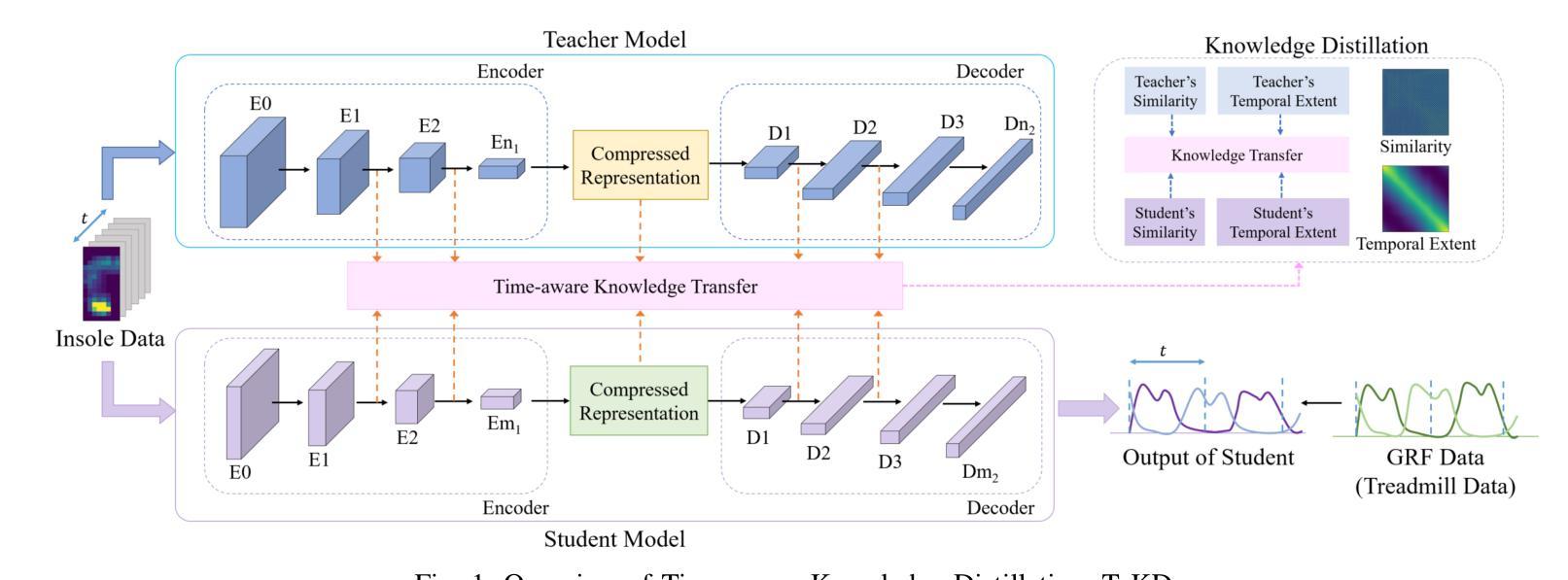
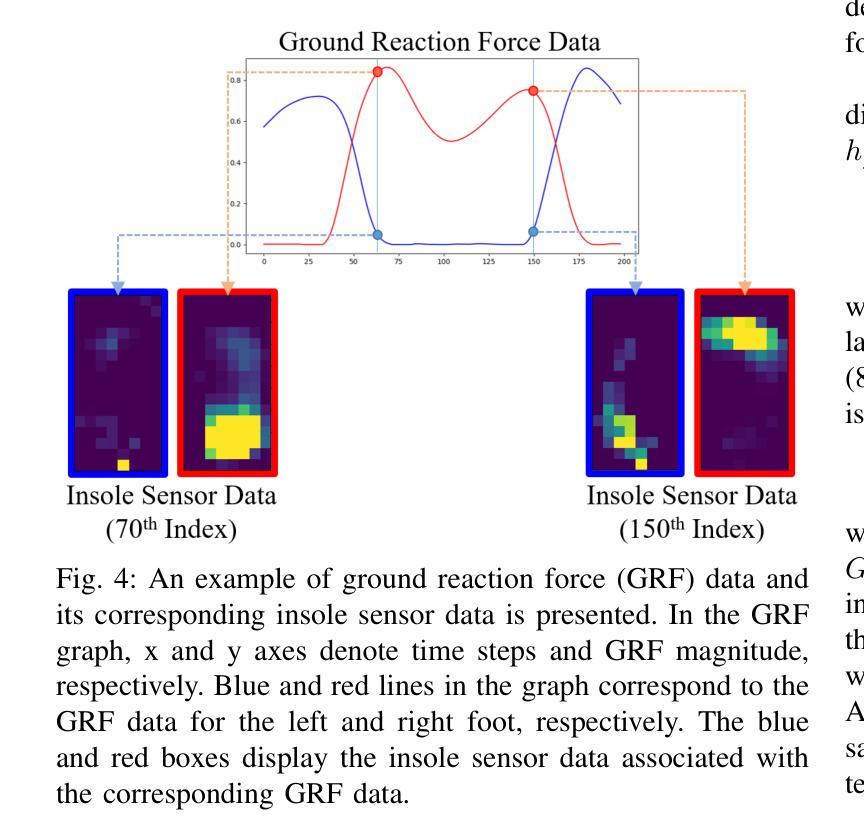
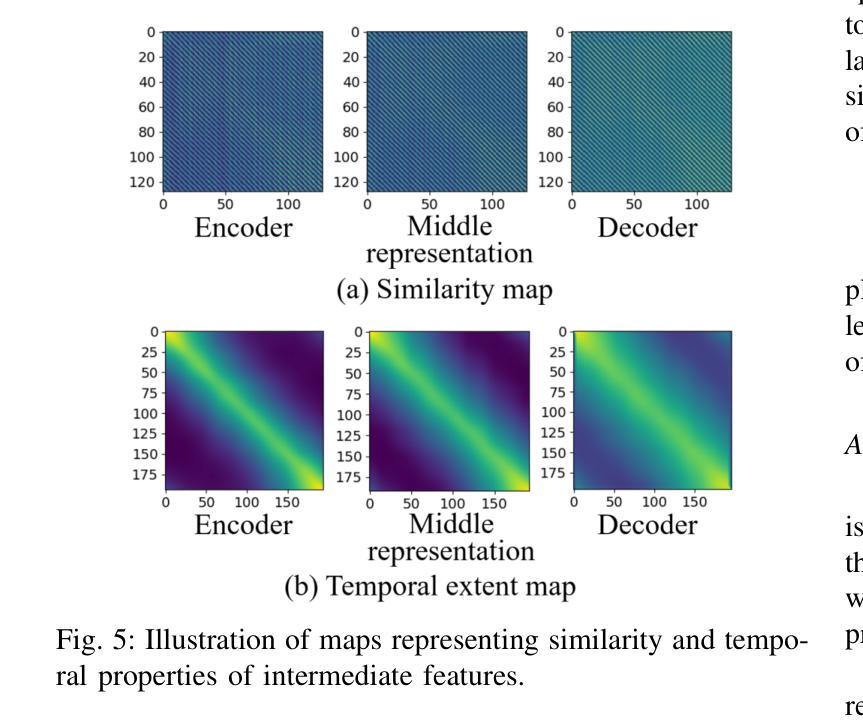
Human gait analysis with wearable sensors has been widely used in various applications, such as daily life healthcare, rehabilitation, physical therapy, and clinical diagnostics and monitoring. In particular, ground reaction force (GRF) provides critical information about how the body interacts with the ground during locomotion. Although instrumented treadmills have been widely used as the gold standard for measuring GRF during walking, their lack of portability and high cost make them impractical for many applications. As an alternative, low-cost, portable, wearable insole sensors have been utilized to measure GRF; however, these sensors are susceptible to noise and disturbance and are less accurate than treadmill measurements. To address these challenges, we propose a Time-aware Knowledge Distillation framework for GRF estimation from insole sensor data. This framework leverages similarity and temporal features within a mini-batch during the knowledge distillation process, effectively capturing the complementary relationships between features and the sequential properties of the target and input data. The performance of the lightweight models distilled through this framework was evaluated by comparing GRF estimations from insole sensor data against measurements from an instrumented treadmill. Empirical results demonstrated that Time-aware Knowledge Distillation outperforms current baselines in GRF estimation from wearable sensor data.
利用可穿戴传感器进行人体步态分析已广泛应用于日常生活健康护理、康复、物理治疗和临床诊疗与监测等多种应用。特别是地面反作用力(GRF)提供了关键信息,了解人体在行走过程中如何与地面相互作用。虽然仪器化跑步机被广泛用作测量行走过程中GRF的金标准,但由于其便携性差和成本高,对于许多应用来说并不实用。作为替代方案,人们使用低成本、便携式的可穿戴鞋垫传感器来测量GRF;然而,这些传感器容易受到噪声和干扰的影响,其准确性不如跑步机测量。为了解决这些挑战,我们提出了一种用于从鞋垫传感器数据中估算GRF的时间感知知识蒸馏框架。该框架在知识蒸馏过程中利用小批量内的相似性和时间特征,有效地捕捉特征和目标数据以及输入数据之间的互补关系和序列属性。通过将此框架中提炼的轻量级模型与从鞋垫传感器数据中估算的GRF与仪器化跑步机的测量结果进行比较,评估了这些模型的表现。实证结果表明,在可穿戴传感器数据的GRF估算方面,时间感知知识蒸馏的性能优于当前基线。
论文及项目相关链接
Summary
穿戴式传感器在人类步态分析中的应用广泛,如日常健康护理、康复、物理治疗和临床诊断监测等。地面反应力(GRF)是了解人体在行走过程中与地面相互作用的关键信息。虽然仪器化跑步机是测量行走过程中GRF的金标准,但其不便于携带和成本高昂的特点使其在实际应用中受到局限。可穿戴鞋垫传感器可作为替代方案来测量GRF,但其易受噪声干扰和准确性较低。为此,我们提出了基于时间感知知识蒸馏框架的GRF估算方法,该框架在知识蒸馏过程中利用小型批次内的相似性和时间特征,有效捕捉特征之间的互补关系以及目标和输入数据的顺序属性。通过比较来自鞋垫传感器数据的GRF估算值与仪器化跑步机的测量结果,评估了通过此框架提炼的轻量级模型性能。实验结果表明,基于时间感知知识蒸馏在穿戴式传感器数据的GRF估算方面优于当前基线方法。
Key Takeaways
- 穿戴式传感器用于步态分析广泛应用于日常健康护理、康复、物理治疗和临床诊断监测等领域。
- 地面反应力(GRF)是理解人体行走过程中与地面相互作用的关键信息。
- 仪器化跑步机是测量GRF的金标准,但其不便携带和成本高昂限制了应用。
- 可穿戴鞋垫传感器可替代仪器化跑步机测量GRF,但准确性较低且易受噪声干扰。
- 提出了基于时间感知知识蒸馏的GRF估算方法,结合特征相似性和时间特征,提高了估算准确性。
- 知识蒸馏框架有效捕捉特征间的互补关系以及数据的顺序属性。
点此查看论文截图


Multimodal Emotion Coupling via Speech-to-Facial and Bodily Gestures in Dyadic Interaction
Authors:Von Ralph Dane Marquez Herbuela, Yukie Nagai
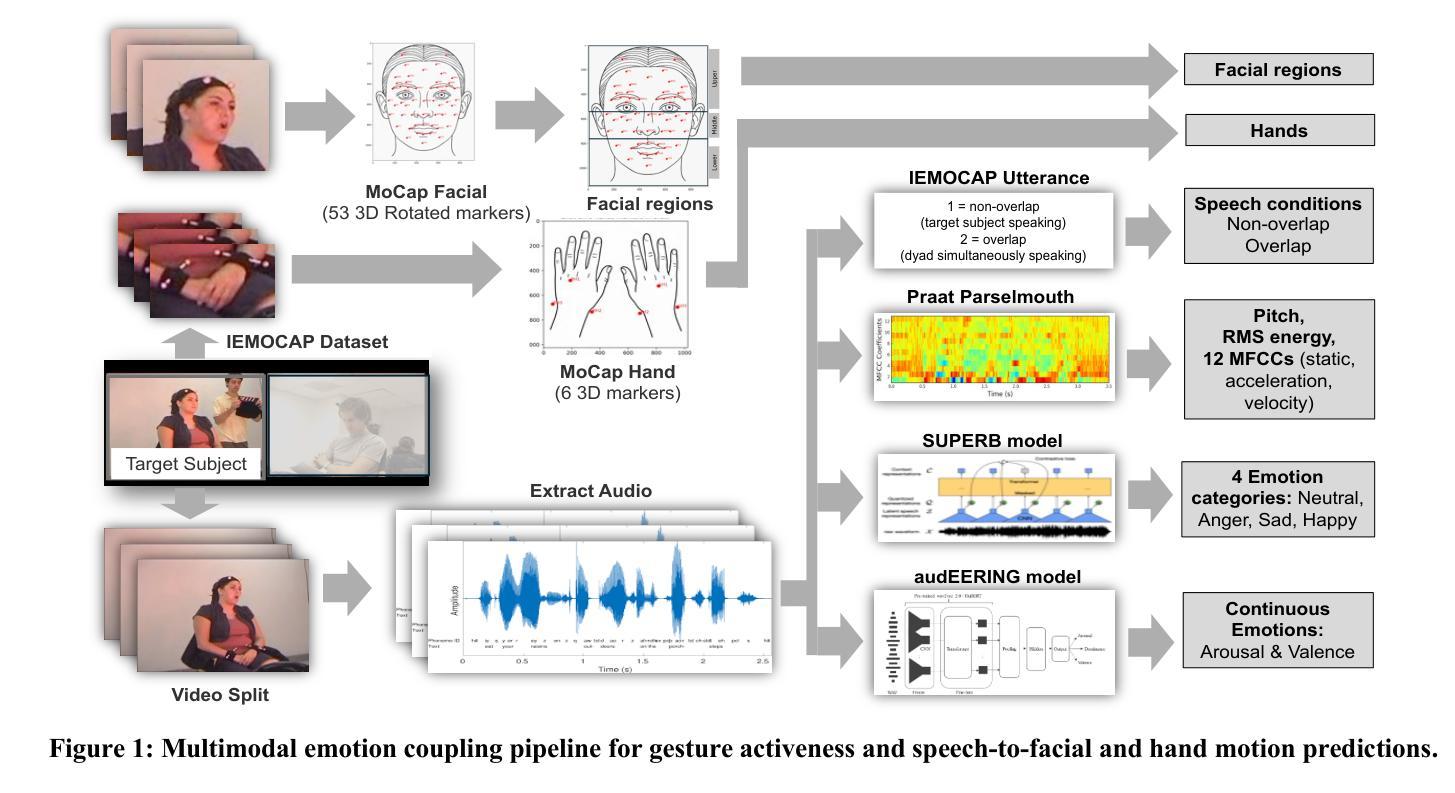
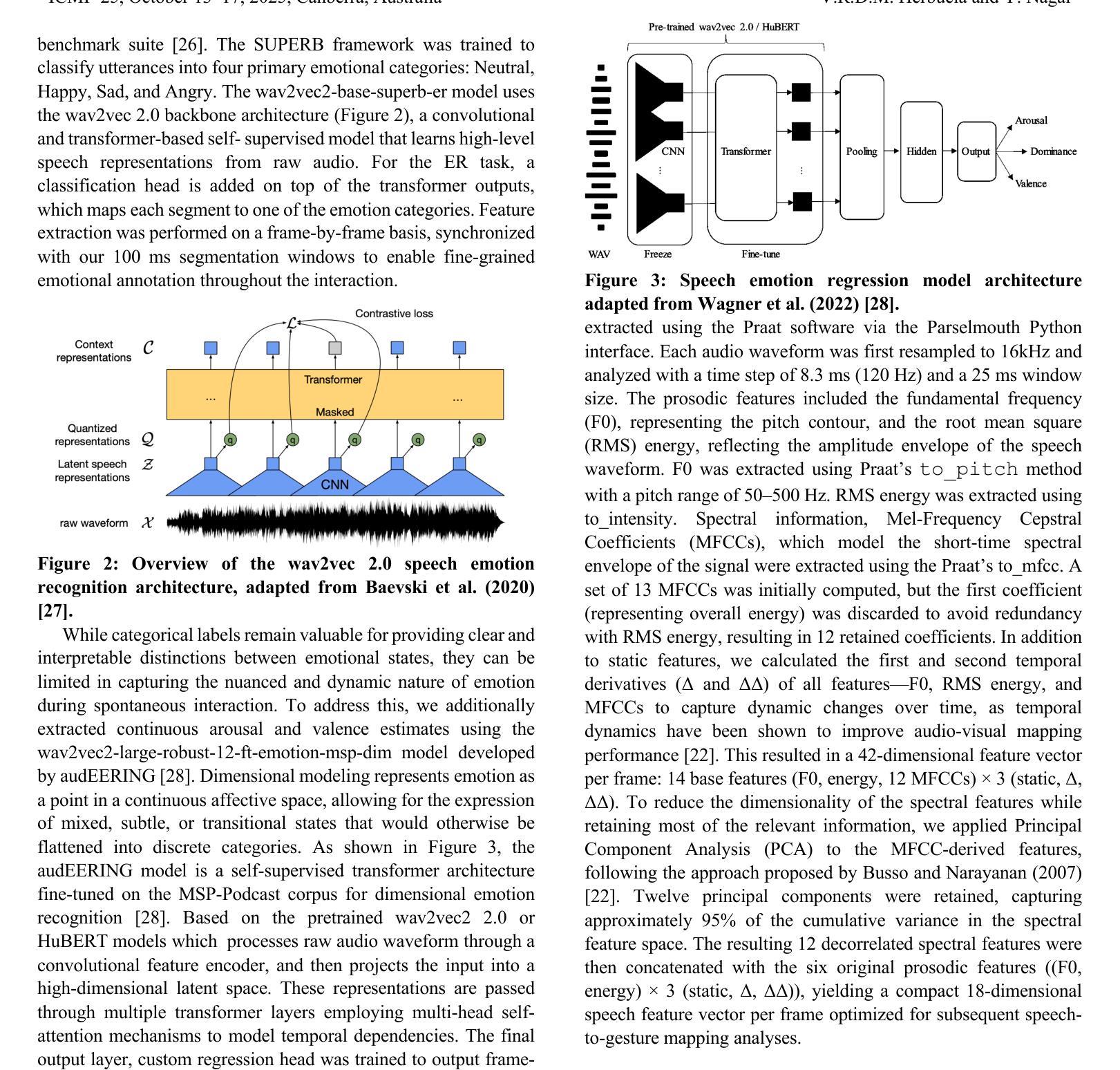
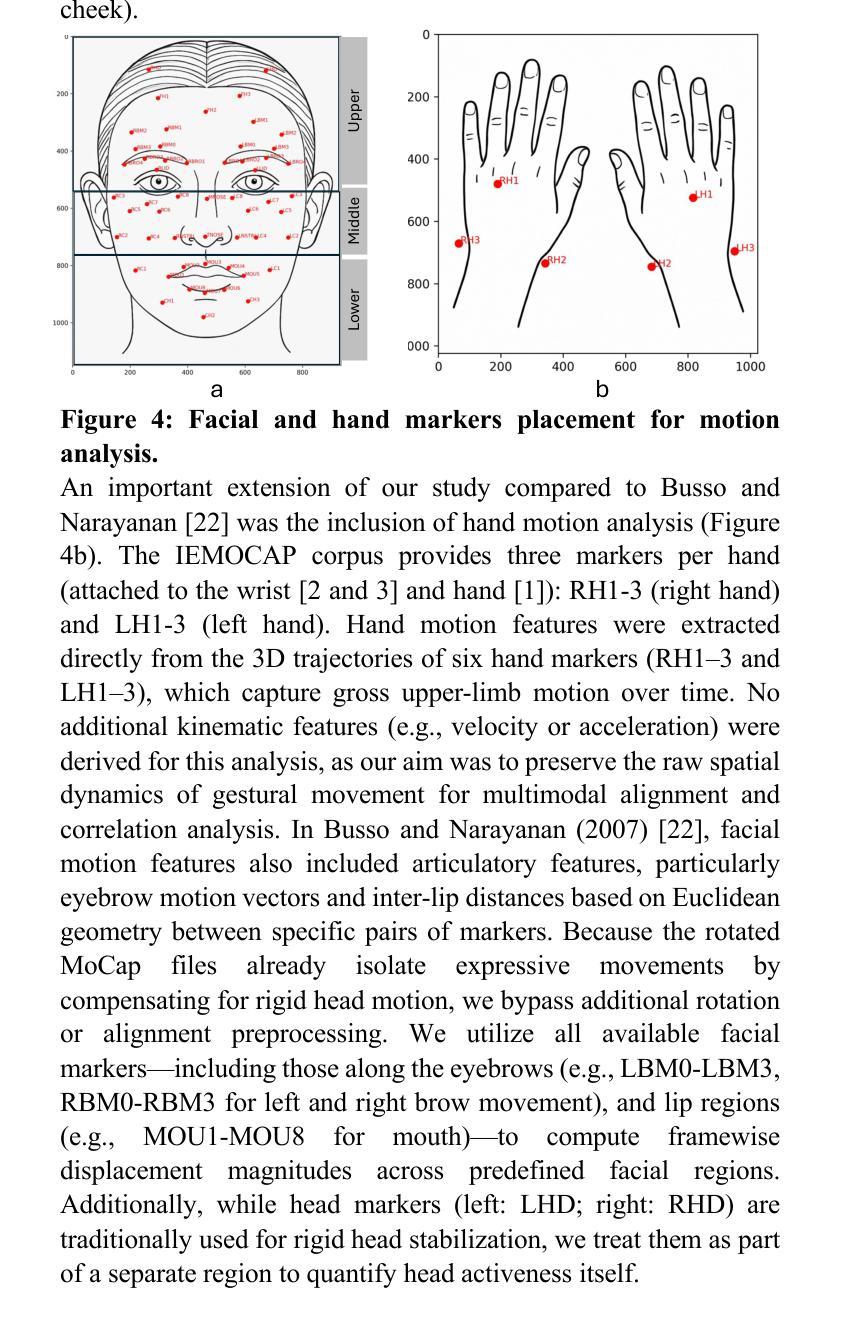
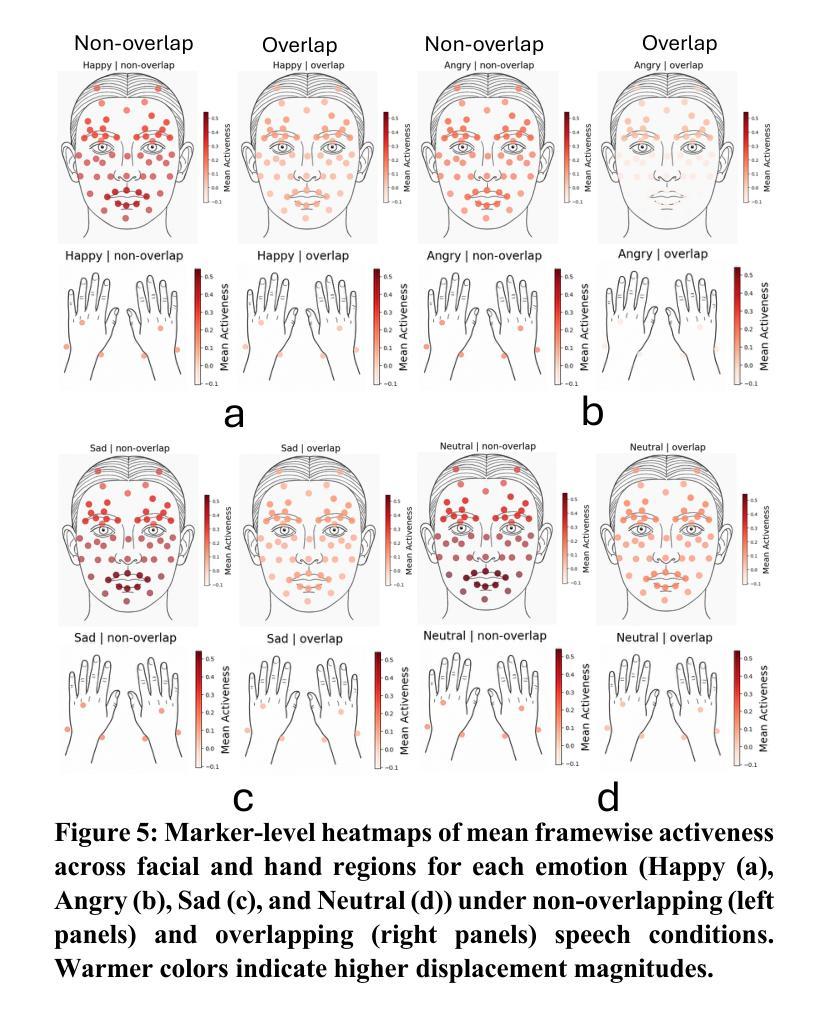
Human emotional expression emerges through coordinated vocal, facial, and gestural signals. While speech face alignment is well established, the broader dynamics linking emotionally expressive speech to regional facial and hand motion remains critical for gaining a deeper insight into how emotional and behavior cues are communicated in real interactions. Further modulating the coordination is the structure of conversational exchange like sequential turn taking, which creates stable temporal windows for multimodal synchrony, and simultaneous speech, often indicative of high arousal moments, disrupts this alignment and impacts emotional clarity. Understanding these dynamics enhances realtime emotion detection by improving the accuracy of timing and synchrony across modalities in both human interactions and AI systems. This study examines multimodal emotion coupling using region specific motion capture from dyadic interactions in the IEMOCAP corpus. Speech features included low level prosody, MFCCs, and model derived arousal, valence, and categorical emotions (Happy, Sad, Angry, Neutral), aligned with 3D facial and hand marker displacements. Expressive activeness was quantified through framewise displacement magnitudes, and speech to gesture prediction mapped speech features to facial and hand movements. Nonoverlapping speech consistently elicited greater activeness particularly in the lower face and mouth. Sadness showed increased expressivity during nonoverlap, while anger suppressed gestures during overlaps. Predictive mapping revealed highest accuracy for prosody and MFCCs in articulatory regions while arousal and valence had lower and more context sensitive correlations. Notably, hand speech synchrony was enhanced under low arousal and overlapping speech, but not for valence.
人类的情绪表达是通过协调的语音、面部表情和体态信号来实现的。虽然语音面部对齐已经确立,但将情绪表达性语音与面部和手部动作区域更广泛联系起来的动态关系对于深入了解真实互动中情绪和行为线索的传递方式仍然至关重要。对话交流的结构会进一步调节协调,如按顺序轮流发言,这为多模式同步创造了稳定的时间窗口,同时进行的语音通常表示高唤起时刻,会破坏这种对齐并影响情绪的清晰度。理解这些动态关系,可以通过提高人类互动和AI系统中跨模式的时间和同步精度,增强实时情感检测的准确性。本研究使用IEMOCAP语料库中的二元互动中的特定区域运动捕获来研究多模式情感耦合。语音特征包括低层声韵、MFCCs以及模型派生的唤起、效价和分类情绪(快乐、悲伤、愤怒、中性),与3D面部和手部标记位移相对应。表达活跃度是通过帧位移幅度来量化的,语音到手势预测将语音特征映射到面部和手部动作。非重叠语音持续激发更大的活跃度,特别是在面部下半部和嘴巴。悲伤在非重叠期间表现出更高的表达力,而愤怒在重叠期间抑制手势。预测映射显示,在发音区域的韵律和MFCCs准确性最高,而效价和唤起具有较低且更敏感的上下文相关性。值得注意的是,在手部与语音同步方面,在低唤起和重叠语音的情况下会增强,但效价并不适用此规律。
论文及项目相关链接
Summary
本文研究了人类情绪表达的多模态耦合现象,涉及语音、面部表情和手势信号的协调。文章深入探讨了情感表达语音与面部和手部运动的联系,并指出在对话交互中,会话结构如交替发言对多模态同步的影响。此外,文章还利用IEMOCAP语料库中的二元互动数据,探讨了语音特征(如语调、MFCCs及情绪模型衍生的兴奋度、效价和分类情绪)与面部和手部动作之间的联系。该研究量化了表达活跃度,并建立了语音与手势预测模型。发现非重叠语音更易激发强烈的情感表达,尤其是下半脸和嘴巴区域。悲伤情绪在非重叠期间表达更为显著,而愤怒情绪则在重叠期间抑制手势。预测映射显示语调及MFCCs在发音区域的准确性最高,而兴奋度和效价的相关性较低且更受上下文影响。值得注意的是,手语同步在低声和重叠语音情况下增强,但效价并不如此。
Key Takeaways
- 人类情绪表达涉及语音、面部表情和手势信号的协调。
- 情感表达语音与面部和手部运动之间存在紧密联系。
- 对话结构如交替发言对多模态同步有影响。
- IEMOCAP语料库用于研究语音特征(如语调、MFCCs及情绪模型)与面部和手部动作之间的关系。
- 表达活跃度通过框架位移幅度量化。
- 非重叠语音激发更强烈的情感表达,特别是下半脸和嘴巴区域。悲伤和愤怒情绪在表达上有显著区别。
点此查看论文截图